
最新刊期
2025 年 第 30 卷 第 10 期
- “在人工智能领域,专家建立了深度学习体系,为智能技术发展提供新方向。”
-
面向图像复原的非因果选择性状态空间模型 AI导读
“在计算机视觉领域,研究者提出了非因果选择性状态空间模型,有效提升了图像复原性能,为图像复原研究开辟了新方向。” 摘要:目的图像复原是计算机视觉领域的经典研究问题。选择性状态空间模型(selective state space model, selective SSM)因其高效的序列建模能力,广泛应用于各类图像复原任务。另外,非局部图像块之间存在依赖关系,能够辅助提升复原性能。而传统SSM采用确定性的令牌(token)扫描方式,仅能提取令牌序列的单向依赖关系。此时,令牌间的关系建模因在序列中的先后顺序受到因果性制约,这与图像块之间的非因果相互关系形成冲突,限制了复原性能的进一步提升。针对此问题,提出一种面向图像复原的非因果选择性状态空间模型,旨在赋予SSM建模令牌之间非因果依赖关系的能力。方法为解决SSM在因果性建模与图像内容非因果关系之间的矛盾,提出随机扫描策略,突破了传统扫描方式在因果性和空间限制上的局限,实现了令牌序列之间的非因果建模。具体而言,构建了随机重排和逆重排函数,实现了非固定次序下的令牌扫描,有效建模了不同令牌之间的非因果依赖关系。此外,针对图像退化干扰存在空间尺度变化和形态结构复杂的特点,融合多尺度先验构建了具有局部与全局信息互补性的非因果Mamba模型(non-causal Mamba, NCMamba),实现了对于各类图像复原任务的有效适配。结果实验分别在图像去噪、去模糊和去阴影任务上进行,验证了所提非因果建模和局部—全局互补策略的有效性。与现有方法相比,所提模型在图像去阴影数据集SRD(shadow removal dataset)上的峰值信噪比提升0.86 dB。结论面向图像复原任务,构建了非因果选择性状态空间模型,建模了令牌之间的非因果依赖关系,实现了局部与全局信息的有效互补,显著提升了复原性能。所提方法在主客观评价指标上均取得优异性能,为图像复原领域提供了新的解决方案。关键词:图像复原;选择性状态空间模型;非因果建模;多尺度建模;图像处理439|569|0更新时间:2025-10-16
摘要:目的图像复原是计算机视觉领域的经典研究问题。选择性状态空间模型(selective state space model, selective SSM)因其高效的序列建模能力,广泛应用于各类图像复原任务。另外,非局部图像块之间存在依赖关系,能够辅助提升复原性能。而传统SSM采用确定性的令牌(token)扫描方式,仅能提取令牌序列的单向依赖关系。此时,令牌间的关系建模因在序列中的先后顺序受到因果性制约,这与图像块之间的非因果相互关系形成冲突,限制了复原性能的进一步提升。针对此问题,提出一种面向图像复原的非因果选择性状态空间模型,旨在赋予SSM建模令牌之间非因果依赖关系的能力。方法为解决SSM在因果性建模与图像内容非因果关系之间的矛盾,提出随机扫描策略,突破了传统扫描方式在因果性和空间限制上的局限,实现了令牌序列之间的非因果建模。具体而言,构建了随机重排和逆重排函数,实现了非固定次序下的令牌扫描,有效建模了不同令牌之间的非因果依赖关系。此外,针对图像退化干扰存在空间尺度变化和形态结构复杂的特点,融合多尺度先验构建了具有局部与全局信息互补性的非因果Mamba模型(non-causal Mamba, NCMamba),实现了对于各类图像复原任务的有效适配。结果实验分别在图像去噪、去模糊和去阴影任务上进行,验证了所提非因果建模和局部—全局互补策略的有效性。与现有方法相比,所提模型在图像去阴影数据集SRD(shadow removal dataset)上的峰值信噪比提升0.86 dB。结论面向图像复原任务,构建了非因果选择性状态空间模型,建模了令牌之间的非因果依赖关系,实现了局部与全局信息的有效互补,显著提升了复原性能。所提方法在主客观评价指标上均取得优异性能,为图像复原领域提供了新的解决方案。关键词:图像复原;选择性状态空间模型;非因果建模;多尺度建模;图像处理439|569|0更新时间:2025-10-16 -
融合Mamba与蛇形卷积的图像去模糊网络 AI导读
“在图像去模糊领域,研究者提出了结合Mamba模型与蛇形卷积技术的MSNet,有效提升了图像细节恢复能力。” 摘要:目的针对Transformer在图像去模糊过程中难以精确恢复图像细节的问题,提出一种结合Mamba模型与蛇形卷积技术的图像去模糊网络MSNet(Mamba snake convolution network)。方法首先,结合Mamba框架与蛇形卷积,提出蛇形状态空间模块(snake state-space module,SSSM)。SSSM通过调整卷积核的形状和路径,动态适应图像局部特征并调整卷积方向,以对齐不同的模糊条纹模式;其次,使用多方向扫描模块(direction scan module,DSM)进行多个方向的扫描,捕捉图像中的长期依赖。再利用离散状态空间方程合并多方向的结构信息,增强模型对全局结构的捕捉能力;最后,引入蛇形通道注意力(snake channel attention,SCA),利用门控设计筛选和调整模糊信息的权重,确保在去除模糊的同时保留关键细节。结果实验在GoPro和HIDE数据集上,与主流的卷积神经网络(convolutional neural network,CNN)和Transformer去模糊方法相比,MSNet的峰值信噪比(peak signal to noise ratio,PSNR)分别提升1.2%和1.9%,结构相似性(structural similarity,SSIM)分别提升0.6%和0.7%。结论本文方法可以有效去除复杂场景下产生的图像模糊,并复原细节。关键词:图像去模糊;Mamba模型;方向扫描模块 (DSM);蛇形卷积;蛇形通道注意力 (SCA)581|511|0更新时间:2025-10-16
摘要:目的针对Transformer在图像去模糊过程中难以精确恢复图像细节的问题,提出一种结合Mamba模型与蛇形卷积技术的图像去模糊网络MSNet(Mamba snake convolution network)。方法首先,结合Mamba框架与蛇形卷积,提出蛇形状态空间模块(snake state-space module,SSSM)。SSSM通过调整卷积核的形状和路径,动态适应图像局部特征并调整卷积方向,以对齐不同的模糊条纹模式;其次,使用多方向扫描模块(direction scan module,DSM)进行多个方向的扫描,捕捉图像中的长期依赖。再利用离散状态空间方程合并多方向的结构信息,增强模型对全局结构的捕捉能力;最后,引入蛇形通道注意力(snake channel attention,SCA),利用门控设计筛选和调整模糊信息的权重,确保在去除模糊的同时保留关键细节。结果实验在GoPro和HIDE数据集上,与主流的卷积神经网络(convolutional neural network,CNN)和Transformer去模糊方法相比,MSNet的峰值信噪比(peak signal to noise ratio,PSNR)分别提升1.2%和1.9%,结构相似性(structural similarity,SSIM)分别提升0.6%和0.7%。结论本文方法可以有效去除复杂场景下产生的图像模糊,并复原细节。关键词:图像去模糊;Mamba模型;方向扫描模块 (DSM);蛇形卷积;蛇形通道注意力 (SCA)581|511|0更新时间:2025-10-16 - “在目标跟踪领域,研究者提出了基于视觉状态空间的TMamba算法,有效降低了计算量和显存占用,为序列级训练提供新思路。”
 摘要:目的Transformer的出现显著提升了目标跟踪模型的精度和鲁棒性,但其二次计算复杂度使得这些模型计算量较大,难以在实际场景中应用。且基于Transformer的模型还会导致较高的显存消耗,限制了跟踪模型的序列级训练。为了解决这些问题,提出一种基于视觉状态空间的目标跟踪模型。方法基于视觉Mamba框架提出TMamba算法。与基于Transformer的目标跟踪模型相比,TMamba在实现优越性能的同时显著降低了计算量和显存占用,为跟踪模型的序列级训练提供了新的思路。TMamba的核心模块是特征融合模块,该模块将深层特征的语义信息与浅层特征的细节信息相结合,为预测头提供更精确的特征,从而提高预测的准确性。此外,本文还提出双图像扫描策略来弥补视觉状态空间模型与追踪领域之间的差距。双图像扫描策略联合扫描模板和搜索区域图像,使视觉状态空间模型更适配跟踪模型。结果基于所提出的特征融合模块以及双图像扫描策略开发了一系列基于状态空间模型的目标跟踪模型。而且在7个数据集上对所提出的模型进行了全面评测,结果显示,TMamba在降低计算量和参数量的同时,在各数据集上均取得显著性能。TMamba-B在LaSOT数据集上取得了66%的成功率,超越了大多数基于Transformer的模型,同时仅有50.7 M的参数量和14.2 G的计算量。结论提出的TMamba算法探索了使用状态空间模型进行目标跟踪的可能性。TMamba在多个数据集上以更少的参数量和计算量实现了与基于Transformer的目标跟踪模型相当的性能。TMamba的低参数量、低计算量以及低显存占用的特点,有望进一步促进目标跟踪模型的实际应用,并推动跟踪模型序列级训练的发展。关键词:单目标跟踪;状态空间模型(SSM);多尺度特征融合;序列训练;高效存储模型873|582|0更新时间:2025-10-16
摘要:目的Transformer的出现显著提升了目标跟踪模型的精度和鲁棒性,但其二次计算复杂度使得这些模型计算量较大,难以在实际场景中应用。且基于Transformer的模型还会导致较高的显存消耗,限制了跟踪模型的序列级训练。为了解决这些问题,提出一种基于视觉状态空间的目标跟踪模型。方法基于视觉Mamba框架提出TMamba算法。与基于Transformer的目标跟踪模型相比,TMamba在实现优越性能的同时显著降低了计算量和显存占用,为跟踪模型的序列级训练提供了新的思路。TMamba的核心模块是特征融合模块,该模块将深层特征的语义信息与浅层特征的细节信息相结合,为预测头提供更精确的特征,从而提高预测的准确性。此外,本文还提出双图像扫描策略来弥补视觉状态空间模型与追踪领域之间的差距。双图像扫描策略联合扫描模板和搜索区域图像,使视觉状态空间模型更适配跟踪模型。结果基于所提出的特征融合模块以及双图像扫描策略开发了一系列基于状态空间模型的目标跟踪模型。而且在7个数据集上对所提出的模型进行了全面评测,结果显示,TMamba在降低计算量和参数量的同时,在各数据集上均取得显著性能。TMamba-B在LaSOT数据集上取得了66%的成功率,超越了大多数基于Transformer的模型,同时仅有50.7 M的参数量和14.2 G的计算量。结论提出的TMamba算法探索了使用状态空间模型进行目标跟踪的可能性。TMamba在多个数据集上以更少的参数量和计算量实现了与基于Transformer的目标跟踪模型相当的性能。TMamba的低参数量、低计算量以及低显存占用的特点,有望进一步促进目标跟踪模型的实际应用,并推动跟踪模型序列级训练的发展。关键词:单目标跟踪;状态空间模型(SSM);多尺度特征融合;序列训练;高效存储模型873|582|0更新时间:2025-10-16 - “最新研究提出了一种结合视觉Mamba和块特征分布的无监督工业异常检测模型,有效提升了检测效果,为工业异常检测领域提供新解决方案。”
 摘要:目的工业异常检测在现代工业生产中具有至关重要的作用,现有的工业异常检测方法主要是基于卷积神经网络(convolutional neural network,CNN) 或视觉变换器(vision Transformer,ViT)网络来实现。然而,CNN 存在难以处理长距离依赖关系的不足,而ViT又面临时间复杂度高的问题。基于此,提出一种结合视觉Mamba和块特征分布的无监督工业异常检测模型。方法该模型包含两个互补分支网络:块特征分布估计网络和基于视觉Mamba的自编码重建网络。块特征分布估计网络主要依赖局部块特征进行异常检测,通过融合高效的预训练块特征描述网络以及视觉Mamba编码器提取的正常样本的块特征,学习一个高斯混合密度网络来估计正常样本局部块特征的分布。在测试阶段利用高斯混合密度网络估计异常图像的各个位置的异常得分,从而得到一个局部异常得分图(local anomaly map,LAM);基于视觉Mamba的自编码重构网络则利用视觉Mamba编码器来捕捉长距离关联特征,增强对跨不同类别和形态的复杂异常图像的全局建模能力,在测试阶段利用重建误差估计异常图像的全局异常得分图(global anomaly map,GAM);最后,合并LAM和GAM得到最终检测结果。结果在MvTec AD(MvTec anomay detection dataset)、VisA和BTAD(bean tech anomaly detection)等公开数据集上与其他先进算法进行了比较,取得了有竞争力的结果。在MvTec AD数据集上所提模型相比性能第2的模型在像素级上 AU-ROC(area under the receiver operating characteristic curve)指标提升了0.9%,在图像级上 AU-ROC指标提升了2.4%。在BTAD数据集所提模型相比性能第2的模型在图像级上 AU-ROC 提升 0.4%。在VisA数据集上模型相比性能第2的模型在像素级上 AU-ROC指标提升了0.6%。结论将视觉状态空间用于图像重建检测图像异常是可行的,检测效果具有竞争力。关键词:异常检测;异常分割;视觉状态空间模型(SSM);高斯密度混合网络;异常数据集460|758|0更新时间:2025-10-16
摘要:目的工业异常检测在现代工业生产中具有至关重要的作用,现有的工业异常检测方法主要是基于卷积神经网络(convolutional neural network,CNN) 或视觉变换器(vision Transformer,ViT)网络来实现。然而,CNN 存在难以处理长距离依赖关系的不足,而ViT又面临时间复杂度高的问题。基于此,提出一种结合视觉Mamba和块特征分布的无监督工业异常检测模型。方法该模型包含两个互补分支网络:块特征分布估计网络和基于视觉Mamba的自编码重建网络。块特征分布估计网络主要依赖局部块特征进行异常检测,通过融合高效的预训练块特征描述网络以及视觉Mamba编码器提取的正常样本的块特征,学习一个高斯混合密度网络来估计正常样本局部块特征的分布。在测试阶段利用高斯混合密度网络估计异常图像的各个位置的异常得分,从而得到一个局部异常得分图(local anomaly map,LAM);基于视觉Mamba的自编码重构网络则利用视觉Mamba编码器来捕捉长距离关联特征,增强对跨不同类别和形态的复杂异常图像的全局建模能力,在测试阶段利用重建误差估计异常图像的全局异常得分图(global anomaly map,GAM);最后,合并LAM和GAM得到最终检测结果。结果在MvTec AD(MvTec anomay detection dataset)、VisA和BTAD(bean tech anomaly detection)等公开数据集上与其他先进算法进行了比较,取得了有竞争力的结果。在MvTec AD数据集上所提模型相比性能第2的模型在像素级上 AU-ROC(area under the receiver operating characteristic curve)指标提升了0.9%,在图像级上 AU-ROC指标提升了2.4%。在BTAD数据集所提模型相比性能第2的模型在图像级上 AU-ROC 提升 0.4%。在VisA数据集上模型相比性能第2的模型在像素级上 AU-ROC指标提升了0.6%。结论将视觉状态空间用于图像重建检测图像异常是可行的,检测效果具有竞争力。关键词:异常检测;异常分割;视觉状态空间模型(SSM);高斯密度混合网络;异常数据集460|758|0更新时间:2025-10-16 - “最新研究进展显示,专家建立了DenseMamba体系,为阿尔茨海默症早期诊断提供精准支持。”
 摘要:目的阿尔茨海默症(Alzheimer’s disease, AD)作为一种常见的老年性痴呆疾病,近年来已成为全球公共卫生面临的重大挑战,设计一种有效且精确的阿尔茨海默症早期诊断模型具有重要的临床意义和迫切需求。目前,阿尔茨海默症的临床诊断通常依赖于正电子发射断层扫描(positron emission tomography, PET)和核磁共振成像(magnetic resonance imaging, MRI)两种医学影像数据。然而,由于这两种模态间存在信息差异大、未精确配准等问题,现有的基于人工智能(artificial intelligence, AI)的诊断模型大多仅使用单一的MRI数据。这在一定程度上限制了多模态影像信息的充分利用和分类性能的进一步提升,制约了其临床实用性。针对上述问题,提出一种结合DenseNet和Mamba的多模态医学脑影像阿尔茨海默症早期诊断模型DenseMamba。方法该方法以经过标准预处理流程后的PET和MRI数据为输入,预处理流程包括:颅骨剥离、配准、偏置场校正和归一化。MRI和PET级联后首先经过卷积层和激活层进行初步特征提取,提取到的特征再依次经过若干个交替的Denseblock和TransMamba模块分别进行局部和全局的特征提取。Denseblock内的密集连接结构,增强了局部特征的提取和传播,从而能够捕捉影像中的细节信息;而TransMamba模块则基于状态空间模型,高效地建模全局依赖关系。交替的Denseblock和TransMamba使得模型能够更全面地理解多模态数据信息,充分挖掘多模态数据在临床诊断任务上的潜力。最后,将提取到的特征送入分类器得到疾病预测结果。结果为验证方法的有效性,在公开的ADNI(Alzheimer’s disease neuroimaging initiative)数据集上进行了评估。最终模型的准确率(accuracy)、精确度(precision)、召回率(recall)和F1值分别为92.42%、92.5%、92.42%和92.21%。DenseMamba在阿尔茨海默症分类任务中较对比算法表现优异,比次优算法准确率提升0.42%。结论实验结果表明,DenseMamba能够充分发挥PET和MRI数据的潜力,显著提升分类性能,为阿尔茨海默症的早期诊断提供更精准的支持。关键词:阿尔茨海默症 (AD);多模态医学图像;状态空间模型;Mamba;密集连接神经网络411|428|0更新时间:2025-10-16
摘要:目的阿尔茨海默症(Alzheimer’s disease, AD)作为一种常见的老年性痴呆疾病,近年来已成为全球公共卫生面临的重大挑战,设计一种有效且精确的阿尔茨海默症早期诊断模型具有重要的临床意义和迫切需求。目前,阿尔茨海默症的临床诊断通常依赖于正电子发射断层扫描(positron emission tomography, PET)和核磁共振成像(magnetic resonance imaging, MRI)两种医学影像数据。然而,由于这两种模态间存在信息差异大、未精确配准等问题,现有的基于人工智能(artificial intelligence, AI)的诊断模型大多仅使用单一的MRI数据。这在一定程度上限制了多模态影像信息的充分利用和分类性能的进一步提升,制约了其临床实用性。针对上述问题,提出一种结合DenseNet和Mamba的多模态医学脑影像阿尔茨海默症早期诊断模型DenseMamba。方法该方法以经过标准预处理流程后的PET和MRI数据为输入,预处理流程包括:颅骨剥离、配准、偏置场校正和归一化。MRI和PET级联后首先经过卷积层和激活层进行初步特征提取,提取到的特征再依次经过若干个交替的Denseblock和TransMamba模块分别进行局部和全局的特征提取。Denseblock内的密集连接结构,增强了局部特征的提取和传播,从而能够捕捉影像中的细节信息;而TransMamba模块则基于状态空间模型,高效地建模全局依赖关系。交替的Denseblock和TransMamba使得模型能够更全面地理解多模态数据信息,充分挖掘多模态数据在临床诊断任务上的潜力。最后,将提取到的特征送入分类器得到疾病预测结果。结果为验证方法的有效性,在公开的ADNI(Alzheimer’s disease neuroimaging initiative)数据集上进行了评估。最终模型的准确率(accuracy)、精确度(precision)、召回率(recall)和F1值分别为92.42%、92.5%、92.42%和92.21%。DenseMamba在阿尔茨海默症分类任务中较对比算法表现优异,比次优算法准确率提升0.42%。结论实验结果表明,DenseMamba能够充分发挥PET和MRI数据的潜力,显著提升分类性能,为阿尔茨海默症的早期诊断提供更精准的支持。关键词:阿尔茨海默症 (AD);多模态医学图像;状态空间模型;Mamba;密集连接神经网络411|428|0更新时间:2025-10-16 - “在医学影像领域,研究者提出了一种基于多方向蛇形卷积和视觉残差Mamba的两阶段冠状动脉分割方法,有效捕捉血管结构特征,实现低资源环境下更准确的冠状动脉分割。”
 摘要:目的基于计算机断层扫描血管造影(computed tomography angiography, CTA)图像的冠状动脉分割具有重要的临床应用价值。冠状动脉具有多分支和细分支的管状结构特点,同时面临前景与背景类别严重不平衡的问题。传统基于卷积神经网络(convolutional neural network, CNN)的冠状动脉分割网络难以建模血管间的长依赖关系,而基于视觉转换器(vision Transformer, ViT)的模型由于复杂度过高,在资源有限的现实环境中难以部署。最新研究表明,以Mamba为代表的状态空间模型(state space model)能够在保持线性复杂度的情况下有效建模长依赖关系。方法提出一种采用多方向蛇形卷积和视觉残差Mamba的两阶段冠状动脉分割方法——MDSVM-UNet++。采用传统的编码—解码架构:在编码阶段,为了准确捕捉血管细长而曲折的管状结构特征,提出新的多方向蛇形卷积模块,从矢状面、冠状面、水平面3个视角进行多视角融合学习,使模型能够更全面地自适应专注于冠状动脉细长局部结构;在解码阶段,为了建模血管切片间的长依赖关系同时保持线性复杂度,设计基于残差视觉Mamba的上采样解码器块,解码器块首先使用加法运算执行特征融合,随后将结果输入到残差视觉Mamba层中进行长依赖关系建模,最后通过三线性插值操作对特征图进行上采样。为了更准确地分割细分支血管,进一步提出两阶段分割模型:在第1阶段,采用MDSVM-UNet++对整幅CT图像进行直接分割,结果用于指导原图像的分块;随后,将分块后的数据重新输入MDSVM-UNet++进行第2阶段分割,最终合并所有分块的分割结果。在保证分割结果连续性的情况下,进一步减少了分割结果中的假阳性点,同时提高冠脉的连续性和平滑度。结果实验结果表明,提出的两阶段MDSVM-UNet++方法在IMAGECAS数据集上的Dice相似系数、豪斯多夫距离和平均豪斯多夫距离分别优于基准网络ImageCAS 5.41%、8.545 6和0.809 3。结论本文提出一种采用多方向蛇形卷积和视觉残差Mamba的两阶段冠状动脉分割方法:提出的多方向蛇形卷积可以更全面更准确地捕捉血管结构特征;设计的基于残差视觉Mamba的解码器模块,在线性复杂度下实现了血管切片间的长依赖关系的建模,最终实现低资源环境下更准确的冠状动脉分割。关键词:计算机断层扫描血管造影(CTA);冠状动脉分割;两阶段分割方法;动态蛇形卷积;状态空间模型(SSM)312|523|0更新时间:2025-10-16
摘要:目的基于计算机断层扫描血管造影(computed tomography angiography, CTA)图像的冠状动脉分割具有重要的临床应用价值。冠状动脉具有多分支和细分支的管状结构特点,同时面临前景与背景类别严重不平衡的问题。传统基于卷积神经网络(convolutional neural network, CNN)的冠状动脉分割网络难以建模血管间的长依赖关系,而基于视觉转换器(vision Transformer, ViT)的模型由于复杂度过高,在资源有限的现实环境中难以部署。最新研究表明,以Mamba为代表的状态空间模型(state space model)能够在保持线性复杂度的情况下有效建模长依赖关系。方法提出一种采用多方向蛇形卷积和视觉残差Mamba的两阶段冠状动脉分割方法——MDSVM-UNet++。采用传统的编码—解码架构:在编码阶段,为了准确捕捉血管细长而曲折的管状结构特征,提出新的多方向蛇形卷积模块,从矢状面、冠状面、水平面3个视角进行多视角融合学习,使模型能够更全面地自适应专注于冠状动脉细长局部结构;在解码阶段,为了建模血管切片间的长依赖关系同时保持线性复杂度,设计基于残差视觉Mamba的上采样解码器块,解码器块首先使用加法运算执行特征融合,随后将结果输入到残差视觉Mamba层中进行长依赖关系建模,最后通过三线性插值操作对特征图进行上采样。为了更准确地分割细分支血管,进一步提出两阶段分割模型:在第1阶段,采用MDSVM-UNet++对整幅CT图像进行直接分割,结果用于指导原图像的分块;随后,将分块后的数据重新输入MDSVM-UNet++进行第2阶段分割,最终合并所有分块的分割结果。在保证分割结果连续性的情况下,进一步减少了分割结果中的假阳性点,同时提高冠脉的连续性和平滑度。结果实验结果表明,提出的两阶段MDSVM-UNet++方法在IMAGECAS数据集上的Dice相似系数、豪斯多夫距离和平均豪斯多夫距离分别优于基准网络ImageCAS 5.41%、8.545 6和0.809 3。结论本文提出一种采用多方向蛇形卷积和视觉残差Mamba的两阶段冠状动脉分割方法:提出的多方向蛇形卷积可以更全面更准确地捕捉血管结构特征;设计的基于残差视觉Mamba的解码器模块,在线性复杂度下实现了血管切片间的长依赖关系的建模,最终实现低资源环境下更准确的冠状动脉分割。关键词:计算机断层扫描血管造影(CTA);冠状动脉分割;两阶段分割方法;动态蛇形卷积;状态空间模型(SSM)312|523|0更新时间:2025-10-16
视觉状态空间模型及应用

-
三维点云的配准方法综述 AI导读
“在三维点云配准领域,专家梳理了点云配准方法,为精确高效处理提供解决方案。” 摘要:三维点云是空间中的一组数据点,主要包括刚性点云和非刚性点云,是表达物体或场景几何信息的重要数据形式,广泛应用于计算机视觉、机器人导航、自动驾驶和增强现实等领域。但是由于传感器移动、噪声遮挡等原因导致数据产生偏移、不完整和不准确等问题,给后续处理带来挑战,因此,如何实现精确、高效和鲁棒的三维点云配准显得尤为重要。点云配准是对从同一场景的不同位置采集的两个或多个三维点云进行配准的过程,需要找到源点云和目标点云之间的对应关系,然后求解它们之间的变换矩阵。经过配准后点云数据能够在同一个坐标系下进行对齐,方便进行处理。本文将点云配准方法进行梳理并按照求解对应关系和求解变换矩阵进行分类,更直观地对点云配准方法进行介绍与对比。分别介绍刚性点云配准方法和非刚性点云配准方法,总结了目前基于优化的学习方法与基于深度学习方法的概况,介绍一些代表性的点云配准方法,为进一步的研究提供帮助。此外,本综述总结了基准数据集。最后,提出今后在这一领域上可能产生的问题及研究建议。关键词:三维点云;配准;刚性点云;非刚性点云;优化方法;深度学习799|467|0更新时间:2025-10-16
摘要:三维点云是空间中的一组数据点,主要包括刚性点云和非刚性点云,是表达物体或场景几何信息的重要数据形式,广泛应用于计算机视觉、机器人导航、自动驾驶和增强现实等领域。但是由于传感器移动、噪声遮挡等原因导致数据产生偏移、不完整和不准确等问题,给后续处理带来挑战,因此,如何实现精确、高效和鲁棒的三维点云配准显得尤为重要。点云配准是对从同一场景的不同位置采集的两个或多个三维点云进行配准的过程,需要找到源点云和目标点云之间的对应关系,然后求解它们之间的变换矩阵。经过配准后点云数据能够在同一个坐标系下进行对齐,方便进行处理。本文将点云配准方法进行梳理并按照求解对应关系和求解变换矩阵进行分类,更直观地对点云配准方法进行介绍与对比。分别介绍刚性点云配准方法和非刚性点云配准方法,总结了目前基于优化的学习方法与基于深度学习方法的概况,介绍一些代表性的点云配准方法,为进一步的研究提供帮助。此外,本综述总结了基准数据集。最后,提出今后在这一领域上可能产生的问题及研究建议。关键词:三维点云;配准;刚性点云;非刚性点云;优化方法;深度学习799|467|0更新时间:2025-10-16
综述
-
以分离噪声特征为引导的真实图像降噪 AI导读
“在图像降噪领域,研究者提出了一种特征分离—引导降噪模型,有效提升了图像降噪的稳定性和泛化性。” 摘要:目的基于合成噪声训练的去噪模型在实际应用中效果不佳。同时,许多真实图像去噪算法仅对图像进行端到端处理,未充分利用噪声信号的整体信息,不能有效去除噪声对图像结构信息的干扰。针对这些问题,提出一种以分离噪声特征为引导的真实图像降噪网络。方法采用特征分离的策略,设计噪声图像到无噪声图像映射和无噪声图像到噪声图像映射的对称网络约束噪声特征分离,从而将噪声特征从图像内容特征中分离开来。采用对比学习对噪声特征提取进行进一步的约束,提高模型对噪声特征的学习能力。然后将分离模块提取到的噪声特征作为图像降噪的先验,噪声特征引导网络在特征域进行噪声特征的抑制。最后,双向映射都通过相应的损失函数进行约束,该网络架构具有较强的适应性和稳定性。结果实验在SIDD(smartphone image denoising dataset),DND(darmstadt noise dataset)sRGB和PolyU(PolyU-real-world-noisy-images-dataset) 3个数据集上进行测试。在PolyU数据集上与其他算法相比,峰值信噪比(peak signal-to-noise ratio,PSNR)提高0.25%,结构相似性(structural similarity index measure,SSIM)提高0.72%;在SIDD数据集中进行消融实验以验证分离网络的有效性。结论本文提出的特征分离—引导降噪模型,综合特征分离和特征引导的思想,并融合对比学习的优点。该模型更好地利用了噪声信息,针对性地进行图像降噪,提升了图像降噪的稳定性和泛化性。关键词:图像降噪;真实噪声;特征分离;特征引导;对比学习89|115|0更新时间:2025-10-16
摘要:目的基于合成噪声训练的去噪模型在实际应用中效果不佳。同时,许多真实图像去噪算法仅对图像进行端到端处理,未充分利用噪声信号的整体信息,不能有效去除噪声对图像结构信息的干扰。针对这些问题,提出一种以分离噪声特征为引导的真实图像降噪网络。方法采用特征分离的策略,设计噪声图像到无噪声图像映射和无噪声图像到噪声图像映射的对称网络约束噪声特征分离,从而将噪声特征从图像内容特征中分离开来。采用对比学习对噪声特征提取进行进一步的约束,提高模型对噪声特征的学习能力。然后将分离模块提取到的噪声特征作为图像降噪的先验,噪声特征引导网络在特征域进行噪声特征的抑制。最后,双向映射都通过相应的损失函数进行约束,该网络架构具有较强的适应性和稳定性。结果实验在SIDD(smartphone image denoising dataset),DND(darmstadt noise dataset)sRGB和PolyU(PolyU-real-world-noisy-images-dataset) 3个数据集上进行测试。在PolyU数据集上与其他算法相比,峰值信噪比(peak signal-to-noise ratio,PSNR)提高0.25%,结构相似性(structural similarity index measure,SSIM)提高0.72%;在SIDD数据集中进行消融实验以验证分离网络的有效性。结论本文提出的特征分离—引导降噪模型,综合特征分离和特征引导的思想,并融合对比学习的优点。该模型更好地利用了噪声信息,针对性地进行图像降噪,提升了图像降噪的稳定性和泛化性。关键词:图像降噪;真实噪声;特征分离;特征引导;对比学习89|115|0更新时间:2025-10-16 -
面向低光增强的三维高斯泼溅模型 AI导读
“在图像处理领域,专家提出了一种低光增强方法,有效提升了图像质量与渲染速度,为低光照图像处理提供了新方案。” 摘要:目的使用低光图像训练神经渲染模型时,无法合成正常光照条件下的新视角图像。且低光照条件下处理目标检测、语义分割等任务时,模型性能会明显下降,面临较大的挑战。此外,现有方法在渲染速度和图像高频细节方面存在不定。针对现有问题,本文提出一种对三维高斯泼溅模型进行低光增强的方法。方法首先利用一个轻量化的光照预测网络将三维高斯泼溅模型中三维高斯分布的颜色属性分解为物体本征颜色和光照两个部分,利用本征颜色渲染得到正常光照场景图像,同时使用多种损失函数从结构和颜色上改善图像质量;为了提高图像中高频细节的清晰度,采用固定几何的优化方案。结果实验在低光场景的新视角合成数据集LOM(low-light & normal-light & over-exposure multi-view dataset)上与主流方法进行了比较,与对比结果中最佳方法相比,峰值信噪比(peak signal-to-noise ratio,PSNR)指标平均提升0.12 dB,结构相似性(structural similarity index, SSIM)指标平均提升1.3%,学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)指标平均提高5.5%,训练时间仅有以往方法的1/5,渲染速度则达到以往方法的1 000倍以上。结论本文方法能够更快地进行训练和渲染,同时也具有更高的图像质量,图像的高频细节和结构更加清晰,并通过全面的对比实验验证了方法的有效性与先进性。关键词:低光增强;新视角合成 (NVS);机器学习;神经渲染;三维高斯泼溅 (3D GS)473|593|0更新时间:2025-10-16
摘要:目的使用低光图像训练神经渲染模型时,无法合成正常光照条件下的新视角图像。且低光照条件下处理目标检测、语义分割等任务时,模型性能会明显下降,面临较大的挑战。此外,现有方法在渲染速度和图像高频细节方面存在不定。针对现有问题,本文提出一种对三维高斯泼溅模型进行低光增强的方法。方法首先利用一个轻量化的光照预测网络将三维高斯泼溅模型中三维高斯分布的颜色属性分解为物体本征颜色和光照两个部分,利用本征颜色渲染得到正常光照场景图像,同时使用多种损失函数从结构和颜色上改善图像质量;为了提高图像中高频细节的清晰度,采用固定几何的优化方案。结果实验在低光场景的新视角合成数据集LOM(low-light & normal-light & over-exposure multi-view dataset)上与主流方法进行了比较,与对比结果中最佳方法相比,峰值信噪比(peak signal-to-noise ratio,PSNR)指标平均提升0.12 dB,结构相似性(structural similarity index, SSIM)指标平均提升1.3%,学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)指标平均提高5.5%,训练时间仅有以往方法的1/5,渲染速度则达到以往方法的1 000倍以上。结论本文方法能够更快地进行训练和渲染,同时也具有更高的图像质量,图像的高频细节和结构更加清晰,并通过全面的对比实验验证了方法的有效性与先进性。关键词:低光增强;新视角合成 (NVS);机器学习;神经渲染;三维高斯泼溅 (3D GS)473|593|0更新时间:2025-10-16
图像处理和编码
- “在无人机航拍领域,专家提出了融合图像增强的正则化目标跟踪算法,有效提升了光照不足场景下的跟踪性能,为无人机稳定工作提供支持。”
 摘要:目的在无人机航拍场景中,光照变化、图像模糊以及低分辨率等因素对跟踪性能影响较大,以往的目标跟踪算法主要研究充足光照和高分辨率下的鲁棒跟踪,对光线不足场景中目标跟踪能力不足。现有的弱光场景跟踪算法往往通过添加独立前置增强模块实现“先增强后跟踪”的架构,隔离了相关滤波中正则化模块对场景的感知,从而限制了跟踪算法对场景的适应能力。方法针对以上问题,提出一种融合图像增强的正则化无人机相关滤波目标跟踪算法,实现了在光线变化和光照不足的情况下对航拍目标的鲁棒跟踪。构建自适应图像增强模块用以处理光线不足问题,便于获取更多信息;将光照质量因子引入时间正则化来约束跟踪响应的差异,融合光照信息实现对时间正则化的动态约束。结果在两个公开无人机数据集上进行实验,在UAVdark70数据集上,提出的跟踪模型在跟踪精度、跟踪成功率上均排名第1,与基准算法AutoTrack相比,所提模型跟踪准确率和跟踪成功率分别提高5.7%和4.3%;在UAV123@10fps数据集中,本模型在跟踪精度、跟踪成功率上均排名第1。与基准算法相比,跟踪准确率和跟踪成功率分别提高1.8%和1.3%。结论实验结果表明,所提算法能有效适应光照不足场景,同时对光线充足的场景也能提升性能,使得算法能有效适应不同场景,为无人机稳定、长效工作提供有力支持。本文算法更多细节发布于https://gitee.com/simplechl/FIERCF。关键词:计算机视觉;目标跟踪;无人机(UAV);相关滤波(CF);图像增强216|335|0更新时间:2025-10-16
摘要:目的在无人机航拍场景中,光照变化、图像模糊以及低分辨率等因素对跟踪性能影响较大,以往的目标跟踪算法主要研究充足光照和高分辨率下的鲁棒跟踪,对光线不足场景中目标跟踪能力不足。现有的弱光场景跟踪算法往往通过添加独立前置增强模块实现“先增强后跟踪”的架构,隔离了相关滤波中正则化模块对场景的感知,从而限制了跟踪算法对场景的适应能力。方法针对以上问题,提出一种融合图像增强的正则化无人机相关滤波目标跟踪算法,实现了在光线变化和光照不足的情况下对航拍目标的鲁棒跟踪。构建自适应图像增强模块用以处理光线不足问题,便于获取更多信息;将光照质量因子引入时间正则化来约束跟踪响应的差异,融合光照信息实现对时间正则化的动态约束。结果在两个公开无人机数据集上进行实验,在UAVdark70数据集上,提出的跟踪模型在跟踪精度、跟踪成功率上均排名第1,与基准算法AutoTrack相比,所提模型跟踪准确率和跟踪成功率分别提高5.7%和4.3%;在UAV123@10fps数据集中,本模型在跟踪精度、跟踪成功率上均排名第1。与基准算法相比,跟踪准确率和跟踪成功率分别提高1.8%和1.3%。结论实验结果表明,所提算法能有效适应光照不足场景,同时对光线充足的场景也能提升性能,使得算法能有效适应不同场景,为无人机稳定、长效工作提供有力支持。本文算法更多细节发布于https://gitee.com/simplechl/FIERCF。关键词:计算机视觉;目标跟踪;无人机(UAV);相关滤波(CF);图像增强216|335|0更新时间:2025-10-16 - “在计算机视觉领域,专家提出了一种暗光环境下行人识别的生成检测一体化方法,有效解决了图像增强与检测任务分离的问题,为低光环境下行人检测提供了新方案。”
 摘要:目的暗光环境下的行人检测是计算机视觉领域的一项重大挑战,其难点在于光照不充分会导致行人特征模糊不可辨识。传统方法一般通过图像增强或生成红外图像提供补充信息解决这一问题。但由于其增强过程与下游检测任务存在分离,限制其应用性能。针对这一问题,提出一种面向暗光条件下行人识别的生成检测一体化方法,旨在解决传统范式中暗光图像数据增强和下游检测任务间的割裂问题。方法提出一种端到端生成检测一体化架构,利用条件扩散模型从暗光图像生成辅助红外模态图像,并通过生成的多尺度特征提升目标检测性能。此外,为了避免梯度无法经过VAE(variational autoencoder) 解码器传递的问题,进一步提出生成检测端到端联合优化策略。结果在LLVIP(low-light visible-infrared paired dataset)和VTMOT(visible-thermal multiple object tracking dataset)数据集上的实验结果表明,本文方法在总体精度指标上显著优于传统方法和其他先进方法。在LLVIP数据集上,本文方法的F1值为85.75%,平均精度均值(mAP)为75.35%,优于传统方法中结果最佳的SCI(self-calibrated illumination)方法(F1值82.05%,mAP值72.30%)和其他先进方法中结果最佳的Faster_RCNN_hrnet(F1值82.91%,mAP值70.02%)。在VTMOT数据集上,本文方法同样表现优异,F1值为90.01%,mAP为73.44%,优于SCI方法(F1值85.91%,mAP值72.19%)和Faster_RCNN_hrnet(F1值84.48%,mAP值71.16%)。此外,消融实验验证了生成模块和联合优化策略在整体框架中的有效性。结论本文证明了生成检测一体化框架在复杂低光环境下的优越性,有效解决了生成过程与检测任务割裂的问题。未来研究将进一步优化生成效率,并扩展该方法至更多多模态应用领域。关键词:暗光行人识别;生成检测一体化;条件扩散模型;目标检测;红外图像生成;端到端联合优化;多模态融合221|292|0更新时间:2025-10-16
摘要:目的暗光环境下的行人检测是计算机视觉领域的一项重大挑战,其难点在于光照不充分会导致行人特征模糊不可辨识。传统方法一般通过图像增强或生成红外图像提供补充信息解决这一问题。但由于其增强过程与下游检测任务存在分离,限制其应用性能。针对这一问题,提出一种面向暗光条件下行人识别的生成检测一体化方法,旨在解决传统范式中暗光图像数据增强和下游检测任务间的割裂问题。方法提出一种端到端生成检测一体化架构,利用条件扩散模型从暗光图像生成辅助红外模态图像,并通过生成的多尺度特征提升目标检测性能。此外,为了避免梯度无法经过VAE(variational autoencoder) 解码器传递的问题,进一步提出生成检测端到端联合优化策略。结果在LLVIP(low-light visible-infrared paired dataset)和VTMOT(visible-thermal multiple object tracking dataset)数据集上的实验结果表明,本文方法在总体精度指标上显著优于传统方法和其他先进方法。在LLVIP数据集上,本文方法的F1值为85.75%,平均精度均值(mAP)为75.35%,优于传统方法中结果最佳的SCI(self-calibrated illumination)方法(F1值82.05%,mAP值72.30%)和其他先进方法中结果最佳的Faster_RCNN_hrnet(F1值82.91%,mAP值70.02%)。在VTMOT数据集上,本文方法同样表现优异,F1值为90.01%,mAP为73.44%,优于SCI方法(F1值85.91%,mAP值72.19%)和Faster_RCNN_hrnet(F1值84.48%,mAP值71.16%)。此外,消融实验验证了生成模块和联合优化策略在整体框架中的有效性。结论本文证明了生成检测一体化框架在复杂低光环境下的优越性,有效解决了生成过程与检测任务割裂的问题。未来研究将进一步优化生成效率,并扩展该方法至更多多模态应用领域。关键词:暗光行人识别;生成检测一体化;条件扩散模型;目标检测;红外图像生成;端到端联合优化;多模态融合221|292|0更新时间:2025-10-16 - “在可见光—红外行人重识别领域,本研究设计了一种融合结构与视觉特征的新算法,有效提升了跨模态行人重识别的识别精度,并在复杂场景中展现较高的鲁棒性和准确性。”
 摘要:目的可见光—红外行人重识别(visible-infrared person re-identification,VI-ReID)因可见光与红外图像间的模态差异而面临挑战,现有方法在特征分辨力方面存在不足。本研究旨在设计一种全新算法以获取高分辨力的行人特征,弥补跨模态识别任务中的不足。方法提出一种融合结构与视觉特征的VI-ReID算法,通过双流分支进行处理。首先,借助姿态估计提取骨骼关键点生成结构特征图,通过图卷积网络(graph convolutional network,GCN)学习骨骼的结构化信息,以构建结构特征提取分支;同时,以ResNet50(residual network)作为视觉提取分支获取图像视觉特征。在此基础上,提出结构—视觉跨模态注意力机制(structural-visual interactive attention mechanism,SVIAM),融合骨骼和视觉特征,得到高分辨力的联合特征表示。此外,为增强骨骼特征的一致性,提出结构内聚损失(structural cohesion loss,SCLoss)函数,持续优化骨骼特征,有效减少模态内差异,保证算法的稳定性与准确性。结果实验结果表明,所提算法在SYSU-MM01数据集上表现卓越,相较于基线DEEN(diverse embedding expansion network),在all search模式下,Rank-1准确率提高4.21%,mAP(mean average precision)提高3.52%;在indoor search模式下,Rank-1准确率提高7.39%,mAP提高2.56%。结论本研究提出融合结构与视觉特征的VI-ReID算法,有效提升了跨模态行人重识别的识别精度,并在复杂场景中展现较高的鲁棒性和准确性。关键词:可见光—红外行人重识别 (VI-ReID);层次化特征提取;骨骼结构特征;结构—视觉跨模态注意力机制 (SVIAM);结构内聚损失 (SCLoss)249|599|0更新时间:2025-10-16
摘要:目的可见光—红外行人重识别(visible-infrared person re-identification,VI-ReID)因可见光与红外图像间的模态差异而面临挑战,现有方法在特征分辨力方面存在不足。本研究旨在设计一种全新算法以获取高分辨力的行人特征,弥补跨模态识别任务中的不足。方法提出一种融合结构与视觉特征的VI-ReID算法,通过双流分支进行处理。首先,借助姿态估计提取骨骼关键点生成结构特征图,通过图卷积网络(graph convolutional network,GCN)学习骨骼的结构化信息,以构建结构特征提取分支;同时,以ResNet50(residual network)作为视觉提取分支获取图像视觉特征。在此基础上,提出结构—视觉跨模态注意力机制(structural-visual interactive attention mechanism,SVIAM),融合骨骼和视觉特征,得到高分辨力的联合特征表示。此外,为增强骨骼特征的一致性,提出结构内聚损失(structural cohesion loss,SCLoss)函数,持续优化骨骼特征,有效减少模态内差异,保证算法的稳定性与准确性。结果实验结果表明,所提算法在SYSU-MM01数据集上表现卓越,相较于基线DEEN(diverse embedding expansion network),在all search模式下,Rank-1准确率提高4.21%,mAP(mean average precision)提高3.52%;在indoor search模式下,Rank-1准确率提高7.39%,mAP提高2.56%。结论本研究提出融合结构与视觉特征的VI-ReID算法,有效提升了跨模态行人重识别的识别精度,并在复杂场景中展现较高的鲁棒性和准确性。关键词:可见光—红外行人重识别 (VI-ReID);层次化特征提取;骨骼结构特征;结构—视觉跨模态注意力机制 (SVIAM);结构内聚损失 (SCLoss)249|599|0更新时间:2025-10-16
图像分析和识别
-
融合局部空间信息的新视角合成方法 AI导读
“在神经渲染领域,专家提出了融合局部空间信息的新视角合成方法,有效改善了因点云质量和特征提取导致的渲染质量下降,为提升渲染效果提供了新方案。” 摘要:目的基于点云的神经渲染方法受点云质量及特征提取的影响,易导致新视角合成图像渲染质量下降,为此提出一种融合局部空间信息的新视角合成方法。方法针对点云质量及提取特征不足的问题,首先,设计一种神经点云特征对齐模块,将点云与图像匹配区域的特征进行对齐,融合后构成神经点云,提升其特征的局部表达能力;其次,提出一种神经点云Transformer模块,用于融合局部神经点云的上下文信息,在点云质量不佳的情况下仍能提取可靠的局部空间信息,有效增强了点云神经渲染方法的合成质量。结果实验结果表明,在真实场景数据集中,对于只包含单一物品的数据集Tanks and Temples,本文方法在峰值信噪比(peak signal to noise ratio, PSNR)指标上与NeRF(neural radiance field)方法相比提升19.2%,相较于使用点云输入的方法Tetra-NeRF和Point-NeRF分别提升了6.4%和3.8%,即使在场景更为复杂的ScanNet数据集中,与NeRF方法及Point-NeRF相比分别提升了34.6%和2.1%。结论本文方法能够更好地利用点云的局部空间信息,有效改善了稀疏视角图像输入下因点云质量和提取特征导致的渲染质量下降,实验结果验证了本文方法的有效性。关键词:神经辐射场 (NeRF);点云;神经渲染;三维重建;体积密度233|414|0更新时间:2025-10-16
摘要:目的基于点云的神经渲染方法受点云质量及特征提取的影响,易导致新视角合成图像渲染质量下降,为此提出一种融合局部空间信息的新视角合成方法。方法针对点云质量及提取特征不足的问题,首先,设计一种神经点云特征对齐模块,将点云与图像匹配区域的特征进行对齐,融合后构成神经点云,提升其特征的局部表达能力;其次,提出一种神经点云Transformer模块,用于融合局部神经点云的上下文信息,在点云质量不佳的情况下仍能提取可靠的局部空间信息,有效增强了点云神经渲染方法的合成质量。结果实验结果表明,在真实场景数据集中,对于只包含单一物品的数据集Tanks and Temples,本文方法在峰值信噪比(peak signal to noise ratio, PSNR)指标上与NeRF(neural radiance field)方法相比提升19.2%,相较于使用点云输入的方法Tetra-NeRF和Point-NeRF分别提升了6.4%和3.8%,即使在场景更为复杂的ScanNet数据集中,与NeRF方法及Point-NeRF相比分别提升了34.6%和2.1%。结论本文方法能够更好地利用点云的局部空间信息,有效改善了稀疏视角图像输入下因点云质量和提取特征导致的渲染质量下降,实验结果验证了本文方法的有效性。关键词:神经辐射场 (NeRF);点云;神经渲染;三维重建;体积密度233|414|0更新时间:2025-10-16 - “东巴画图像描述方法取得新进展,专家提出结合提示学习和视觉语义—生成融合的方法,有效提升了描述准确性和文化表达能力。”
 摘要:目的东巴画是纳西族传统艺术的瑰宝,其画面视觉元素丰富、色彩分明,具有鲜明的地域文化特色和民族特征。针对现有图像描述方法在东巴画描述中存在的领域偏移问题,提出一种结合提示学习和视觉语义—生成融合的东巴画图像描述方法。该方法引入内容提示模块和视觉语义—生成融合损失,旨在引导模型学习东巴画的主题信息,提升描述的准确性和文化表达能力。方法采用编码器—解码器(encoder-decoder)架构实现东巴画图像描述的生成。编码器采用卷积神经网络(convolutional neural network,CNN)捕获图像中关键的语义信息,并将这些特征整合到解码器编码层中的归一化层,控制文本描述的生成过程;解码器采用Transformer结构实现,利用自注意力机制有效地捕捉输入序列中的长距离依赖关系,使模型关注输入序列中的关键信息。此外,本文在解码器之前引入了内容提示模块。该模块通过图像特征向量得到图像的主体、动作等信息,并将其构建成提示信息作为描述文本的后置提示。通过后置提示信息,解码器能有效地关注描述文本中具体的文化场景和细节特征,增强对东巴画特定图案和场景的识别与理解能力。同时,引入了视觉语义—生成融合损失,通过优化该损失,引导模型提取东巴画中的关键信息,从而生成与图像保持高度一致的描述文本。结果实验结果表明,在东巴画测试集上,本文所提方法在BLEU_1(bilingual evaluation understudy)到BLEU_4、METEOR(metric for evaluation with explicit ordering)、ROUGE(recall-oriented understudy for gisting evaluation)和CIDEr(consensus-based image description evaluation)评价指标上分别达到0.603、0.426、0.317、0.246、0.256、0.403和0.599,东巴画图像描述文本在主观质量也得到了更好的效果。结论本文方法显著增强了模型对东巴画图像主题和民族文化特征的捕捉能力,有效提升了生成描述在准确性、语义关联性和表达流畅性方面的表现。关键词:东巴画;图像描述;提示学习;视觉语义—生成融合;领域偏移190|758|0更新时间:2025-10-16
摘要:目的东巴画是纳西族传统艺术的瑰宝,其画面视觉元素丰富、色彩分明,具有鲜明的地域文化特色和民族特征。针对现有图像描述方法在东巴画描述中存在的领域偏移问题,提出一种结合提示学习和视觉语义—生成融合的东巴画图像描述方法。该方法引入内容提示模块和视觉语义—生成融合损失,旨在引导模型学习东巴画的主题信息,提升描述的准确性和文化表达能力。方法采用编码器—解码器(encoder-decoder)架构实现东巴画图像描述的生成。编码器采用卷积神经网络(convolutional neural network,CNN)捕获图像中关键的语义信息,并将这些特征整合到解码器编码层中的归一化层,控制文本描述的生成过程;解码器采用Transformer结构实现,利用自注意力机制有效地捕捉输入序列中的长距离依赖关系,使模型关注输入序列中的关键信息。此外,本文在解码器之前引入了内容提示模块。该模块通过图像特征向量得到图像的主体、动作等信息,并将其构建成提示信息作为描述文本的后置提示。通过后置提示信息,解码器能有效地关注描述文本中具体的文化场景和细节特征,增强对东巴画特定图案和场景的识别与理解能力。同时,引入了视觉语义—生成融合损失,通过优化该损失,引导模型提取东巴画中的关键信息,从而生成与图像保持高度一致的描述文本。结果实验结果表明,在东巴画测试集上,本文所提方法在BLEU_1(bilingual evaluation understudy)到BLEU_4、METEOR(metric for evaluation with explicit ordering)、ROUGE(recall-oriented understudy for gisting evaluation)和CIDEr(consensus-based image description evaluation)评价指标上分别达到0.603、0.426、0.317、0.246、0.256、0.403和0.599,东巴画图像描述文本在主观质量也得到了更好的效果。结论本文方法显著增强了模型对东巴画图像主题和民族文化特征的捕捉能力,有效提升了生成描述在准确性、语义关联性和表达流畅性方面的表现。关键词:东巴画;图像描述;提示学习;视觉语义—生成融合;领域偏移190|758|0更新时间:2025-10-16 -
融合多关节特征的单目视觉三维人体姿态估计 AI导读
“在三维人体姿态估计领域,研究者提出了一种融合多关节特征的单目视觉三维人体姿态估计网络,有效提高了准确性和泛化性。” 摘要:目的针对目前三维人体姿态估计方法未能有效处理时间序列冗余,难以捕获人体关节上微小变化的问题,提出一种融合多关节特征的单目视觉三维人体姿态估计网络。方法在关节运动特征提取模块中,采用多分支操作提取关节在时间维度上的运动特征,并将不同特征融合形成具有高度表达力的特征表示。关节特征融合模块整合了不同关节组和中间帧的全局信息,通过矩阵内积的方式表达不同关节组在高纬度空间的相对位置及相互联系,得到中间3D姿态的初估值。关节约束模块引入中间帧的2D关节点空间位置关系作为隐式约束,与中间帧3D姿态初估值融合,减少不合理的姿态输出,提高最终3D姿态估计的准确性。结果实验结果表明,与MHFormer方法相比,本文方法在Human3.6M数据集上的平均关节位置误差(mean per joint position error,MPJPE)结果为29.0 mm,误差降低4.9%,对于复杂动作,如SittingDown和WalkDog,误差降低了7.7%和8.2%。在MPI-INF-3DHP数据集上,MPJPE指标降低36.2%,曲线下面积(area under the curve,AUC)指标提升12.9%,正确关节点百分比(percentage of correct keypoints,PCK)指标提升3%。实验结果体现出在面对复杂动作问题时,网络利用各分支提取了不同的关节时序运动特征,将不同关节组的位置信息进行融合交互,结合当前帧的关节姿态信息加以约束,取得更高的精度。在HumanEva数据集上的实验结果表明了本文方法适用不同数据集,消融实验进一步验证了各个模块的有效性。结论本文网络有效地融合了人体多关节特征,可以更好地提高单目视觉三维人体姿态估计的准确性,且具备较高的泛化性。关键词:三维人体姿态估计;人体拓扑结构;多分支网络;特征融合;姿态约束337|428|0更新时间:2025-10-16
摘要:目的针对目前三维人体姿态估计方法未能有效处理时间序列冗余,难以捕获人体关节上微小变化的问题,提出一种融合多关节特征的单目视觉三维人体姿态估计网络。方法在关节运动特征提取模块中,采用多分支操作提取关节在时间维度上的运动特征,并将不同特征融合形成具有高度表达力的特征表示。关节特征融合模块整合了不同关节组和中间帧的全局信息,通过矩阵内积的方式表达不同关节组在高纬度空间的相对位置及相互联系,得到中间3D姿态的初估值。关节约束模块引入中间帧的2D关节点空间位置关系作为隐式约束,与中间帧3D姿态初估值融合,减少不合理的姿态输出,提高最终3D姿态估计的准确性。结果实验结果表明,与MHFormer方法相比,本文方法在Human3.6M数据集上的平均关节位置误差(mean per joint position error,MPJPE)结果为29.0 mm,误差降低4.9%,对于复杂动作,如SittingDown和WalkDog,误差降低了7.7%和8.2%。在MPI-INF-3DHP数据集上,MPJPE指标降低36.2%,曲线下面积(area under the curve,AUC)指标提升12.9%,正确关节点百分比(percentage of correct keypoints,PCK)指标提升3%。实验结果体现出在面对复杂动作问题时,网络利用各分支提取了不同的关节时序运动特征,将不同关节组的位置信息进行融合交互,结合当前帧的关节姿态信息加以约束,取得更高的精度。在HumanEva数据集上的实验结果表明了本文方法适用不同数据集,消融实验进一步验证了各个模块的有效性。结论本文网络有效地融合了人体多关节特征,可以更好地提高单目视觉三维人体姿态估计的准确性,且具备较高的泛化性。关键词:三维人体姿态估计;人体拓扑结构;多分支网络;特征融合;姿态约束337|428|0更新时间:2025-10-16
图像理解和计算机视觉
-
聚焦全局与中间层的细节增强医学图像分割 AI导读
“在医学图像分割领域,研究者提出了DEMS-GIF网络模型,通过Transformer桥接特征融合和反向注意扩缩区域增强上采样策略,显著提升了分割准确性。”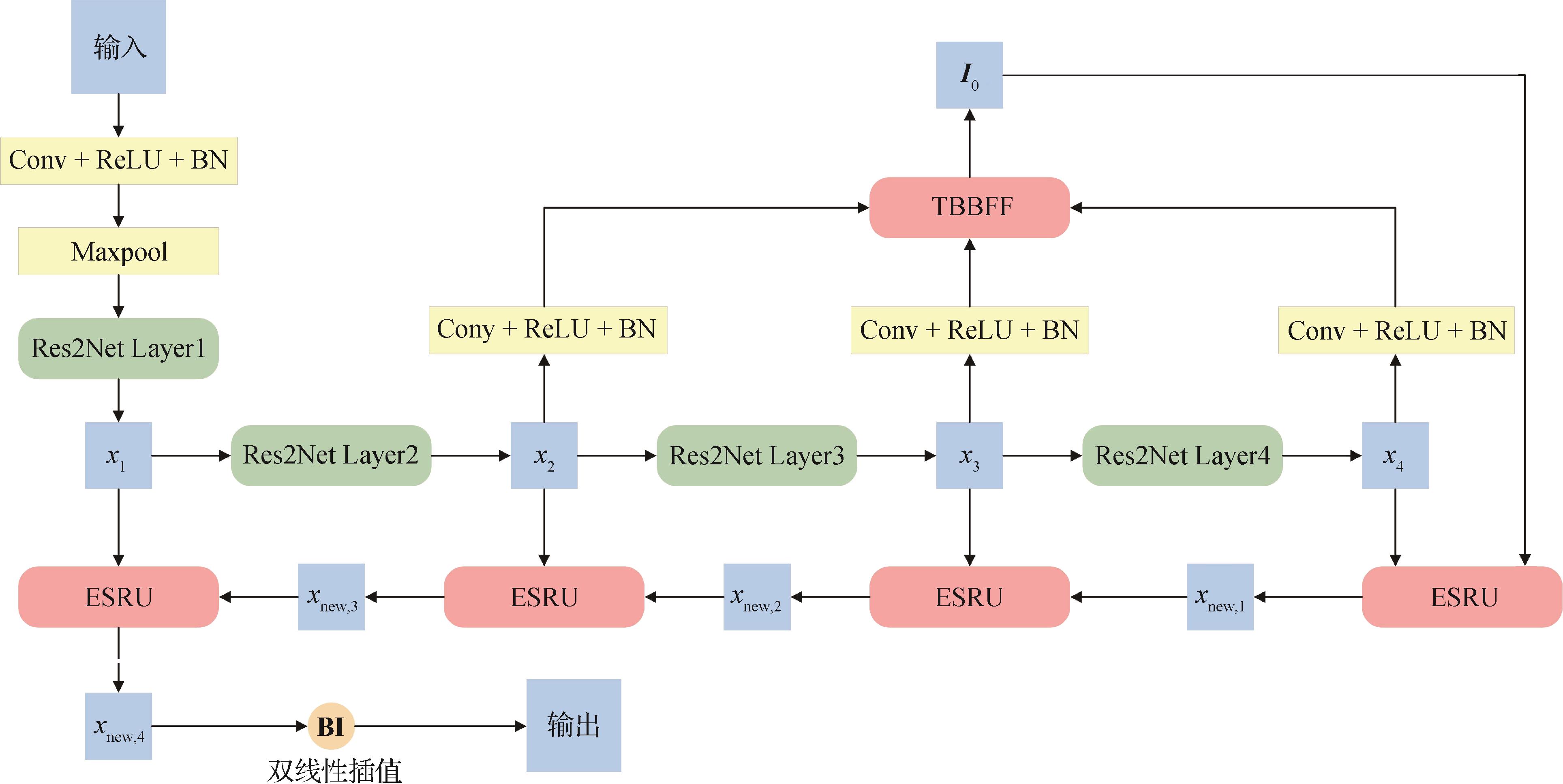 摘要:目的随着人工智能的发展,深度学习技术在医学图像分割中得到广泛应用。但现有方法往往采用自上而下或自下而上的方式进行特征融合,易忽略或丢失中间层特征信息。此外,现有方法对病灶区域分割边界不够精细。针对上述问题,本文提出一种聚焦全局与中间层特征的细节增强医学图像分割网络(detail-enhanced medical image segmentation network focusing on global and intermediate features,DEMS-GIF)。方法首先通过进一步关注中间层信息,并利用Transformer提取不同区域之间的长距离依赖关系的能力,设计了一种基于Transformer的桥接特征融合模块(Transformer-based bridge feature fusion module,TBBFF),以提升模型的特征提取能力。其次,通过引入反向注意力机制,并结合腐蚀和膨胀操作,提出一种反向注意下的扩缩区域增强上采样策略(expanded and scaled region enhanced upsampling strategy under reverse attention,ESRU),使得模型能够更好地捕捉边界和细节信息。DEMS-GIF模型通过结合TBBFF模块和ESRU策略,进一步提高了分割的准确性。结果在CVC-ClinicDB、DDTI(digital database thyroid image)和Kvasir-SEG 3个数据集上进行对比实验和模块消融实验,评估提出的DEMS-GIF模型,并在CVC-ClinicDB数据集上进行参数消融实验,以了解DEMS-GIF中每个模块和结构内部的有效性。实验结果表明,DEMS-GIF模型的mIoU值分别达到94.74%、84.56%和88.46%,Dice值分别达到94.82%、82.95%和87.44%。与原UNet型通道变换网络相比,mIoU值分别提升3.73%、3.4%和5.24%,Dice值分别提升4.84%、5.45%和6.82%。结论本文提出的DEMS-GIF网络模型较其他先进的分割方法的分割效果更优,表明了其在医学图像分割中的优越性。关键词:医学图像分割;特征融合;上采样;反向注意力;腐蚀;膨胀120|106|0更新时间:2025-10-16
摘要:目的随着人工智能的发展,深度学习技术在医学图像分割中得到广泛应用。但现有方法往往采用自上而下或自下而上的方式进行特征融合,易忽略或丢失中间层特征信息。此外,现有方法对病灶区域分割边界不够精细。针对上述问题,本文提出一种聚焦全局与中间层特征的细节增强医学图像分割网络(detail-enhanced medical image segmentation network focusing on global and intermediate features,DEMS-GIF)。方法首先通过进一步关注中间层信息,并利用Transformer提取不同区域之间的长距离依赖关系的能力,设计了一种基于Transformer的桥接特征融合模块(Transformer-based bridge feature fusion module,TBBFF),以提升模型的特征提取能力。其次,通过引入反向注意力机制,并结合腐蚀和膨胀操作,提出一种反向注意下的扩缩区域增强上采样策略(expanded and scaled region enhanced upsampling strategy under reverse attention,ESRU),使得模型能够更好地捕捉边界和细节信息。DEMS-GIF模型通过结合TBBFF模块和ESRU策略,进一步提高了分割的准确性。结果在CVC-ClinicDB、DDTI(digital database thyroid image)和Kvasir-SEG 3个数据集上进行对比实验和模块消融实验,评估提出的DEMS-GIF模型,并在CVC-ClinicDB数据集上进行参数消融实验,以了解DEMS-GIF中每个模块和结构内部的有效性。实验结果表明,DEMS-GIF模型的mIoU值分别达到94.74%、84.56%和88.46%,Dice值分别达到94.82%、82.95%和87.44%。与原UNet型通道变换网络相比,mIoU值分别提升3.73%、3.4%和5.24%,Dice值分别提升4.84%、5.45%和6.82%。结论本文提出的DEMS-GIF网络模型较其他先进的分割方法的分割效果更优,表明了其在医学图像分割中的优越性。关键词:医学图像分割;特征融合;上采样;反向注意力;腐蚀;膨胀120|106|0更新时间:2025-10-16
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0