
学术动态
加载中...
快捷入口
- 投稿
- 审稿
- 编辑
2026年第7期
更多2025年度三维视觉前沿趋势与十大进展 AI导读
音频驱动的数字人技术进展 AI导读
平行图像:从理论框架到多模态智能视觉应用 AI导读
遥感图像开放词汇感知进展 AI导读

排行榜  更多
更多
- 0 1 多模态遥感图像配准方法研究综述 1139
- 0 2 数字人风格化、多模态驱动与交互进展 1136
- 0 3 人工智能生成图像检测技术综述 921
- 0 4 面向地月空间感知任务设计与分析的智能仿真系统架构与实现 774
- 0 5 人工智能模型水印研究进展 565
- 0 6 机器人灵巧手:迈向通用操作的关键技术 510
- 0 7 图像去模糊研究综述 473
- 0 8 基于机器视觉的半导体晶圆缺陷检测方法综述 424
- 0 9 脉冲视觉研究进展 408
- 10 曲线笔触渲染的图像风格迁移 378
- 11 中国遥感软件研制进展与发展方向——以像素专家PIE为例 375
- 12 2025年度三维视觉前沿趋势与十大进展 355
- 13 深度伪造及其取证技术综述 354
- 14 大模型时代的光学文字识别:现状及展望 329
- 15 光学视觉传感器技术研究进展 322
- 16 人类面部重演方法综述 319
- 17 二维码掩膜下的稀疏对抗补丁攻击 306
- 18 持续学习研究进展 284
- 19 基于深度学习的图像融合方法综述 276
- 20 端到端自动驾驶系统研究综述 275
查看更多
在线出版
语义通信联合优化的电力图像监测 AI导读
融合光谱提示与混合注意力的高光谱 AI导读
频域知识引导的高光谱图像开集识别方法 AI导读
专刊专栏
更多-
视觉状态空间模型及应用
专栏编委:王兴刚, 张长青, 任文琦, 傅雪阳, 周涛, 赵峰, 石争浩 -
连续学习及图像处理应用
专栏编委:胡伏原, 周涛, 王亮, 李玺, 洪晓鹏, 郑伟诗, 王瑞平, 张彰, 吕凡 -
图像图形学发展年度报告
-
视觉及多模态大模型
专栏编委:方乐缘, 贾伟, 林倞, 谭明奎, 王耀威, 吴庆耀, -
无人系统的平行决策智能
专栏编委:舒振杰, 王飞跃, 鲍泓, 陈龙, 戴玉超, 贺威, 林懿伦, 鲁继文, 田大新
数据集共享
MORE > 更多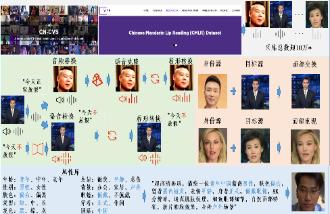
面向人脸视频防伪检测的大规模中文数据测评基准
2025年12月19日

合成图像物理属性检测数据集
2025年12月19日

夜间无人机航拍图像车辆检测数据集DroneVehicle-Night
2025年12月19日

面向数据抽取的中文条形图表数据集
2025年12月19日

多模态大模型面向电子文档的视觉问答数据
2025年12月19日
查看更多
虚拟专辑
更多




优秀论文
优秀编委
优秀审稿专家
年度会议
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0