
最新刊期
2025 年 第 30 卷 第 7 期
-
三维点云场景语义分割研究进展 AI导读
“在自动驾驶、机器人技术等领域,点云场景分割技术取得重要进展,专家综述了研究方法和挑战,为未来发展提供方向。”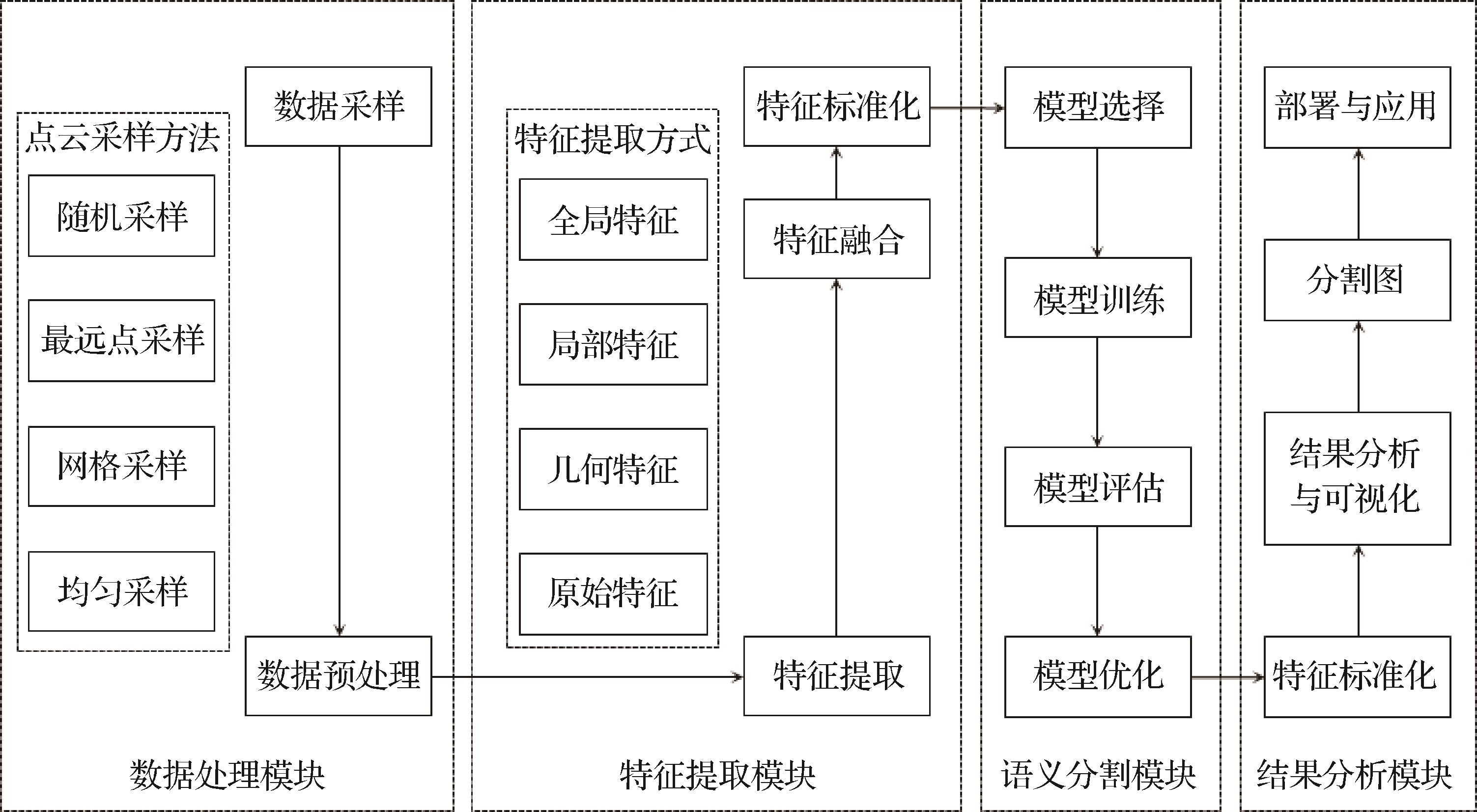 摘要:随着深度传感器技术的迅速发展和激光扫描仪的广泛应用,三维点云数据在自动驾驶、机器人技术、地理信息系统以及制造业等多个领域发挥着关键作用。本文从多个视角出发,对点云场景分割技术进行详尽的综述。1)介绍本领域的常用数据集、采样方法及点云特征提取技术;2)系统性地概述点云场景的语义分割研究方法,涵盖基于点的方法,分为基于MLP(multilayer perceptron)的方法、基于Transformer的方法、基于图卷积的方法和其他方法;基于体素的方法,基于视图的方法以及基于多模态融合方法。3)对上述各种方法的研究成果进行汇总与比较;4)指出当前面临的主要挑战,并探讨未来可能的研究方向。关键词:三维点云;点云场景语义分割;深度学习;采样方法;特征提取1060|2426|0更新时间:2025-07-14
摘要:随着深度传感器技术的迅速发展和激光扫描仪的广泛应用,三维点云数据在自动驾驶、机器人技术、地理信息系统以及制造业等多个领域发挥着关键作用。本文从多个视角出发,对点云场景分割技术进行详尽的综述。1)介绍本领域的常用数据集、采样方法及点云特征提取技术;2)系统性地概述点云场景的语义分割研究方法,涵盖基于点的方法,分为基于MLP(multilayer perceptron)的方法、基于Transformer的方法、基于图卷积的方法和其他方法;基于体素的方法,基于视图的方法以及基于多模态融合方法。3)对上述各种方法的研究成果进行汇总与比较;4)指出当前面临的主要挑战,并探讨未来可能的研究方向。关键词:三维点云;点云场景语义分割;深度学习;采样方法;特征提取1060|2426|0更新时间:2025-07-14 -
人脸深度伪造检测方法研究综述 AI导读
“深度伪造技术研究进展,专家系统归纳检测方法,为识别伪造人脸提供解决方案。”摘要:深度伪造技术是一种基于深度学习的合成技术,旨在生成高度逼真的合成图像、音频或视频,包括人脸伪造、声音模仿和人体姿态合成等内容。其中,人脸深度伪造可以实现非常逼真的换脸效果,广泛应用于电影、动画制作等领域。然而,该技术的滥用导致不雅视频与虚假新闻的传播,带来了恶劣的社会影响。为应对这些负面影响,众多学者提出一系列检测方法,以有效识别伪造人脸图像或视频。然而,当前的检测方法类型多样、优缺点各异,且应用场景各不相同,鉴于此,本文对相关研究进行了系统的归纳与整理。首先,整理了人脸深度伪造检测常用数据集与评价指标;其次,从图像级伪造人脸检测与视频级伪造人脸检测两个领域出发,根据特征选择的不同,将前者划分为基于空间域和基于频率域的检测方法,将后者划分为基于时空不一致、基于生物特征和基于多模态的检测方法,并详细总结了各类方法的原理、优缺点及发展趋势,特别地,考虑到文本生成图像/视频的流行以及生成式人工智能在多模态创作上的显著进步,综述了针对文本生成图像/视频的检测方法和基于多模态的检测方法;最后,梳理了人脸深度伪造检测领域的研究现状及瓶颈,并对未来的研究与发展方向进行了探讨。关键词:深度伪造检测;人脸伪造检测;人脸图像;人脸视频;空间域特征;频率域特征;时序特征;多模态特征1326|2408|0更新时间:2025-07-14
综述

-
外部迭代分数模型点云去噪方法 AI导读
“在3D视觉领域,研究者提出了基于外部迭代分数模型的点云去噪方法,有效提高了去噪精度和速度。” 摘要:目的由于传感器质量和环境因素的影响,点云数据可能受到噪声的干扰。而这些噪声会对后续的点云应用产生不利影响。因此,去除噪声成为一项基本的3D视觉任务。目前,基于深度学习的方法通常是通过训练神经网络来预测点的位移,然后将有噪声的点移到下面的干净表面上。然而这类算法或者迭代时间较长,或者在将点位移到干净表面上时会出现收敛过度或位移较大偏差的问题,影响了去噪的性能。为了提高去噪精度和去噪速度,本文提出基于外部迭代分数模型的点云去噪。方法首先将输入的噪声点云进行切块,然后输入到特征提取模块。之后,通过分数估计单元计算点的分数(即预测点云去噪过程中的梯度),在这里加入动量梯度上升动态修正梯度,减少更新步长,加快去噪速度。最后,将去噪好的部分拼接在一起,组成一个完整点云,再将去噪一次后的点云重新作为噪声点云进行输入,重复上述操作构成外部迭代。结果在实验中,将所提模型与先进的7种方法在3个数据集上进行对比。在PU(point cloud upsampling)数据集(10 K和50 K点云)中,针对1%、2%、3%噪声,所提模型在CD(chamfer distance)和P2M(point-to-mesh distance)指标上均优于性能排名第2的模型,表现为指标值的降低。在PC(PCNet)数据集(10 K和50 K点云)中,针对3%噪声的实验表明,所提模型在泛化性上表现突出,与性能排名第2的模型相比,CD和P2M指标值显著降低。在RueMadame数据集中进行场景去噪对比实验,从视觉效果可以直观观察到所提方法具有较强的去噪性能。此外,比较了去噪时间,与性能排名第3的模型相比,去噪时间减少了近30%,与性能排名第2的模型接近。结论本文所提出的点云去噪模型,相比于其他方法有更好的去噪精度和更快的去噪速度。关键词:点云去噪;外部迭代;分数模型;动量梯度上升;深度学习370|426|0更新时间:2025-07-14
摘要:目的由于传感器质量和环境因素的影响,点云数据可能受到噪声的干扰。而这些噪声会对后续的点云应用产生不利影响。因此,去除噪声成为一项基本的3D视觉任务。目前,基于深度学习的方法通常是通过训练神经网络来预测点的位移,然后将有噪声的点移到下面的干净表面上。然而这类算法或者迭代时间较长,或者在将点位移到干净表面上时会出现收敛过度或位移较大偏差的问题,影响了去噪的性能。为了提高去噪精度和去噪速度,本文提出基于外部迭代分数模型的点云去噪。方法首先将输入的噪声点云进行切块,然后输入到特征提取模块。之后,通过分数估计单元计算点的分数(即预测点云去噪过程中的梯度),在这里加入动量梯度上升动态修正梯度,减少更新步长,加快去噪速度。最后,将去噪好的部分拼接在一起,组成一个完整点云,再将去噪一次后的点云重新作为噪声点云进行输入,重复上述操作构成外部迭代。结果在实验中,将所提模型与先进的7种方法在3个数据集上进行对比。在PU(point cloud upsampling)数据集(10 K和50 K点云)中,针对1%、2%、3%噪声,所提模型在CD(chamfer distance)和P2M(point-to-mesh distance)指标上均优于性能排名第2的模型,表现为指标值的降低。在PC(PCNet)数据集(10 K和50 K点云)中,针对3%噪声的实验表明,所提模型在泛化性上表现突出,与性能排名第2的模型相比,CD和P2M指标值显著降低。在RueMadame数据集中进行场景去噪对比实验,从视觉效果可以直观观察到所提方法具有较强的去噪性能。此外,比较了去噪时间,与性能排名第3的模型相比,去噪时间减少了近30%,与性能排名第2的模型接近。结论本文所提出的点云去噪模型,相比于其他方法有更好的去噪精度和更快的去噪速度。关键词:点云去噪;外部迭代;分数模型;动量梯度上升;深度学习370|426|0更新时间:2025-07-14 - “在软件图形用户界面设计领域,研究者提出了基于Transformer的图标生成方法IconFormer,有效提升了图标设计的效率和创新性。”
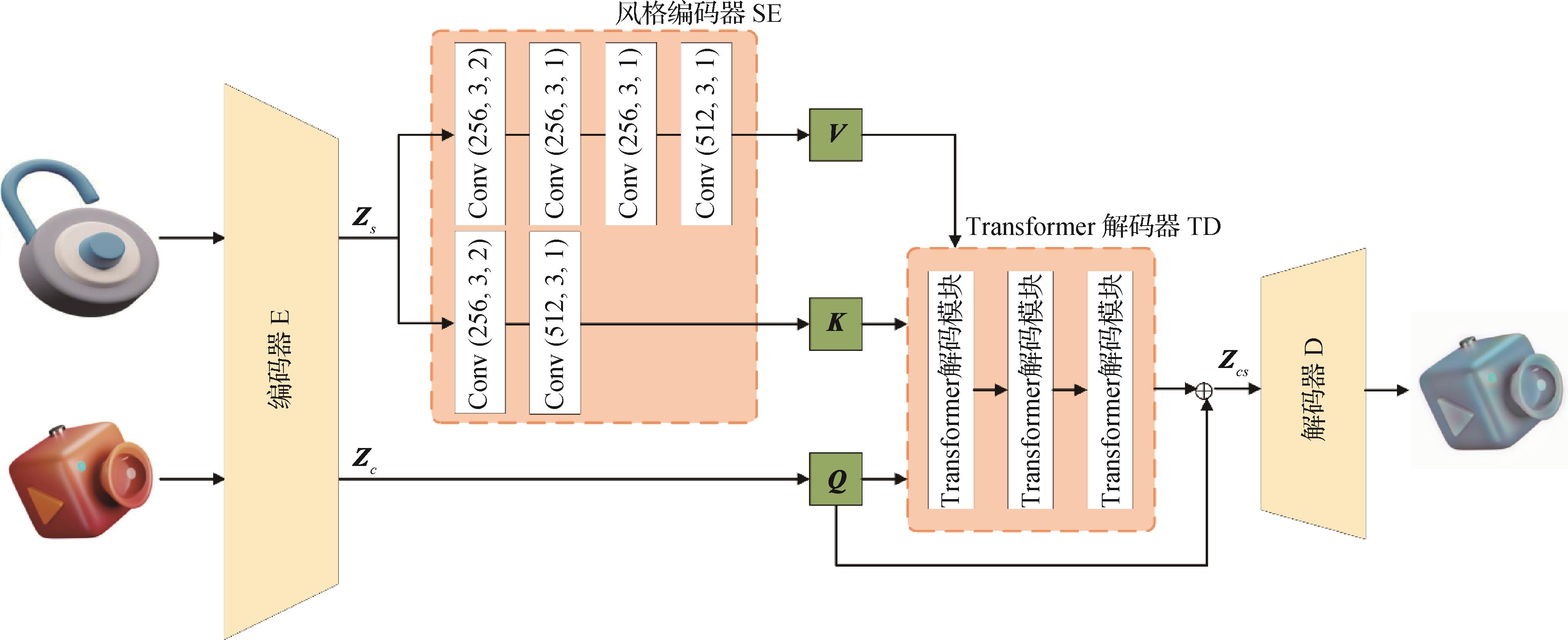 摘要:目的图标自动生成可以提高软件图形用户界面设计的效率,现有的图标自动生成方法存在多样性不足、生成过程复杂以及输入要求较高等问题,限制了生成结果的自由度和创新性。本文提出一种基于Transformer的高效且灵活的图标生成方法,该方法只需提供任意一对内容图标和风格图标,即可生成一幅新的具有特定风格的图标图像。方法提出一个图标生成模型IconFormer,网络结构中包括一个VGG(Visual Geometry Group)特征编码器、一个基于卷积神经网络(convolutional neural network,CNN)的风格编码器、一个Transformer多层解码器和一个CNN解码器,并用内容损失、风格损失、一致性损失和梯度损失组成的综合损失来优化网络模型。结果为了评估所提出的图标生成模型,构建了包含43 741个图标样本的数据集,在该数据集上对IconFormer模型进行训练和评估,并在相同条件下与先进的相关方法进行对比和分析。评估结果表明,本文的IconFormer生成的图标在颜色和结构上更为完整,而其他相关方法则一定程度出现了内容缺失、风格化不足和背景着色的情况,IconFormer在内容差异和梯度分数等量化指标上也明显优于其他模型。消融实验进一步表明了本文所构建的IconFormer模型各个创新点对图标生成过程所起的正向作用。结论所提出的图标生成模型IconFormer,结合了卷积神经网络和Transformer模型的优点,可以快速高效地生成具有不同风格的高质量图标。关键词:图标生成;图像风格迁移;卷积神经网络(CNN);Transformer;自注意力机制418|376|0更新时间:2025-07-14
摘要:目的图标自动生成可以提高软件图形用户界面设计的效率,现有的图标自动生成方法存在多样性不足、生成过程复杂以及输入要求较高等问题,限制了生成结果的自由度和创新性。本文提出一种基于Transformer的高效且灵活的图标生成方法,该方法只需提供任意一对内容图标和风格图标,即可生成一幅新的具有特定风格的图标图像。方法提出一个图标生成模型IconFormer,网络结构中包括一个VGG(Visual Geometry Group)特征编码器、一个基于卷积神经网络(convolutional neural network,CNN)的风格编码器、一个Transformer多层解码器和一个CNN解码器,并用内容损失、风格损失、一致性损失和梯度损失组成的综合损失来优化网络模型。结果为了评估所提出的图标生成模型,构建了包含43 741个图标样本的数据集,在该数据集上对IconFormer模型进行训练和评估,并在相同条件下与先进的相关方法进行对比和分析。评估结果表明,本文的IconFormer生成的图标在颜色和结构上更为完整,而其他相关方法则一定程度出现了内容缺失、风格化不足和背景着色的情况,IconFormer在内容差异和梯度分数等量化指标上也明显优于其他模型。消融实验进一步表明了本文所构建的IconFormer模型各个创新点对图标生成过程所起的正向作用。结论所提出的图标生成模型IconFormer,结合了卷积神经网络和Transformer模型的优点,可以快速高效地生成具有不同风格的高质量图标。关键词:图标生成;图像风格迁移;卷积神经网络(CNN);Transformer;自注意力机制418|376|0更新时间:2025-07-14
图像处理和编码
-
自适应切片辅助增强的小物体目标检测 AI导读
“在目标检测领域,ASAHI算法针对高分辨率图像中小目标检测难题,通过自适应调整切片数量减少冗余计算,提高检测精度和速度。” 摘要:目的在目标检测领域,深度学习模型已经取得巨大成功。但是已有的基于深度学习的目标检测算法在小物体目标检测中仍然困难重重,原因在于航拍图像多是更复杂的高分辨率场景,其中一些常见问题,如稠密度高、不固定的拍摄角度、目标物体尺寸小和高变异性等给现有目标检测方法带来巨大挑战。切片策略是近年来用于高分辨率图像小目标检测任务的众多优秀方法之一,然而现有的切片方法存在冗余计算问题,因此提出一种新的自适应切片方法,称为自适应切片辅助超推断(adaptive slicing-assisted hyper inference,ASAHI)。方法该方法关注切片数量而非传统的切片大小,可以根据图像分辨率自适应调整切片数量以消除冗余计算带来的性能损耗。在推理阶段,首先根据ASAHI算法将输入图像分割为6或12个重叠的块;之后对每个图像块进行插值处理以保持长宽比;接下来考虑到小块切片在检测大物体时的明显缺陷,分别对切片图像块和完整输入图像进行目标检测前向计算;最后为了提高高密度场景下推理的准确性和检测速度,后处理阶段集成了一种更快和更高效的Cluster-NMS(non-maximum suppression)方法和DIoU(distance- intersection over union)惩罚项,即Cluster-DIoU-NMS(CDN),将ASAHI推理和全图推理结果进行合并,再转回原始图像尺寸。为了支持切片图像块的推理,本文在训练阶段构建的数据集也包括切片图像块。结果在广泛的实验中,ASAHI在VisDrone(vision meets drones)和xView数据集上表现出具有竞争力的性能。结果显示,与现有切片方法相比,本文方法将IoU值为0.5时的平均精确率均值(mean average precision,mAP)mAP50提高1.7%,计算时间减少20%~25%;在VisDrone2019-DET-val(vision meets drones 2019 for detection for validation)数据集上,mAP50的结果提高到56.8%。结论本文方法可以有效处理高分辨率场景下小物体稠密度高、拍摄角度不同以及变异性高等复杂的因素,实现高质量的小物体目标检测。关键词:目标检测;小物体目标检测;切片推理;VisDrone;xView213|505|0更新时间:2025-07-14
摘要:目的在目标检测领域,深度学习模型已经取得巨大成功。但是已有的基于深度学习的目标检测算法在小物体目标检测中仍然困难重重,原因在于航拍图像多是更复杂的高分辨率场景,其中一些常见问题,如稠密度高、不固定的拍摄角度、目标物体尺寸小和高变异性等给现有目标检测方法带来巨大挑战。切片策略是近年来用于高分辨率图像小目标检测任务的众多优秀方法之一,然而现有的切片方法存在冗余计算问题,因此提出一种新的自适应切片方法,称为自适应切片辅助超推断(adaptive slicing-assisted hyper inference,ASAHI)。方法该方法关注切片数量而非传统的切片大小,可以根据图像分辨率自适应调整切片数量以消除冗余计算带来的性能损耗。在推理阶段,首先根据ASAHI算法将输入图像分割为6或12个重叠的块;之后对每个图像块进行插值处理以保持长宽比;接下来考虑到小块切片在检测大物体时的明显缺陷,分别对切片图像块和完整输入图像进行目标检测前向计算;最后为了提高高密度场景下推理的准确性和检测速度,后处理阶段集成了一种更快和更高效的Cluster-NMS(non-maximum suppression)方法和DIoU(distance- intersection over union)惩罚项,即Cluster-DIoU-NMS(CDN),将ASAHI推理和全图推理结果进行合并,再转回原始图像尺寸。为了支持切片图像块的推理,本文在训练阶段构建的数据集也包括切片图像块。结果在广泛的实验中,ASAHI在VisDrone(vision meets drones)和xView数据集上表现出具有竞争力的性能。结果显示,与现有切片方法相比,本文方法将IoU值为0.5时的平均精确率均值(mean average precision,mAP)mAP50提高1.7%,计算时间减少20%~25%;在VisDrone2019-DET-val(vision meets drones 2019 for detection for validation)数据集上,mAP50的结果提高到56.8%。结论本文方法可以有效处理高分辨率场景下小物体稠密度高、拍摄角度不同以及变异性高等复杂的因素,实现高质量的小物体目标检测。关键词:目标检测;小物体目标检测;切片推理;VisDrone;xView213|505|0更新时间:2025-07-14 -
引导集扩散模型在户型平面图重建中的应用 AI导读
“最新研究突破了传统户型平面图矢量化技术,通过引导集扩散模型提升墙体矢量化精度,为建筑与家居设计提供可靠技术支持。”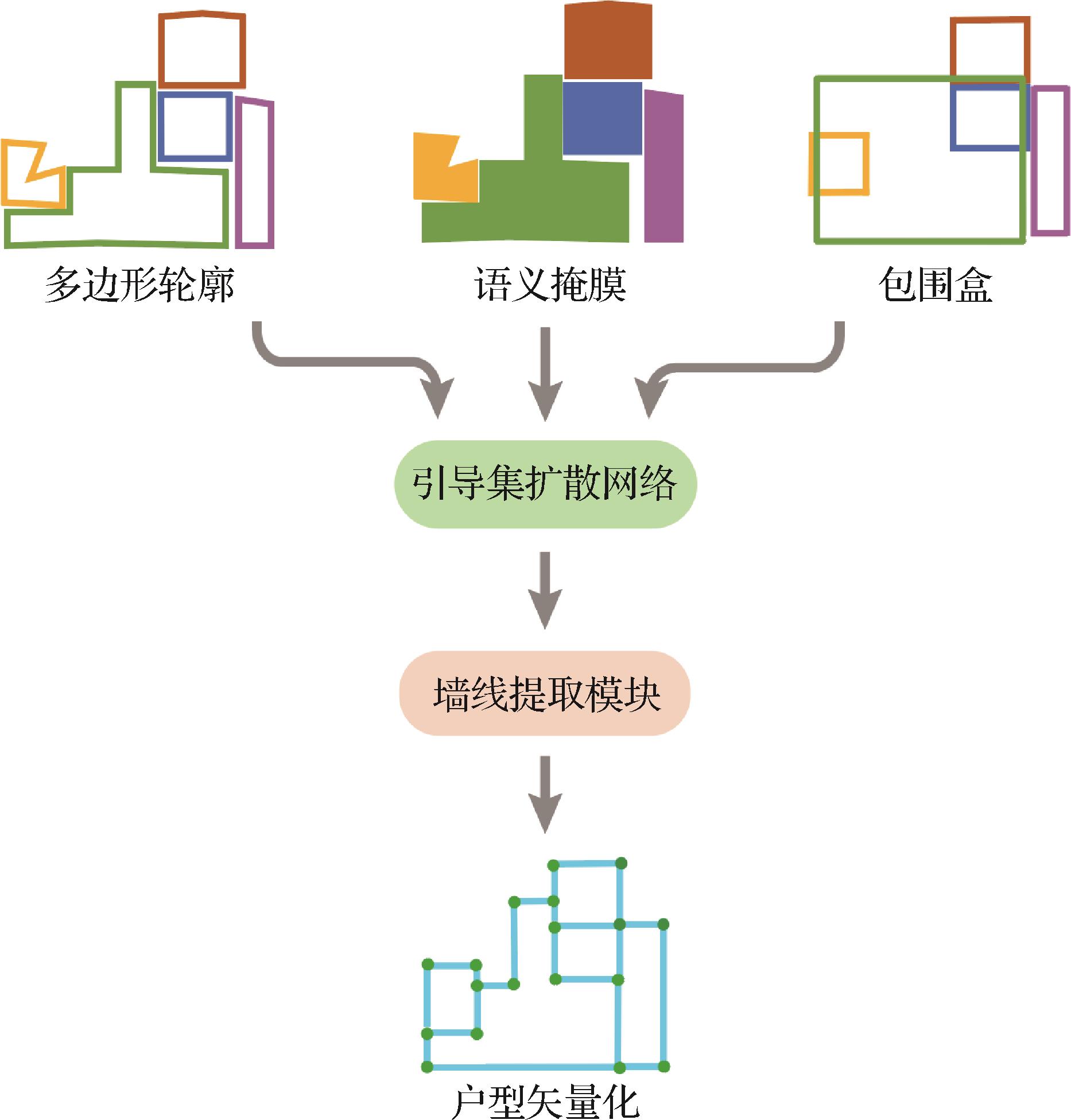 摘要:目的户型平面图的矢量化是一项关键技术,用于从户型平面点阵图中提取精确的结构信息,广泛应用于建筑装修、家居设计以及场景理解等领域。现有方法通常采用两阶段流程:第1阶段利用深度神经网络提取户型区域的掩膜,第2阶段通过后处理步骤从掩膜轮廓中提取墙体的矢量信息。然而,这种方法存在误差累积问题,后处理算法难以保证鲁棒性。为了解决上述问题,提出一种基于引导集扩散模型的户型平面图矢量重建算法。方法该算法通过将目标检测或实例分割方法中获得的粗糙轮廓输入扩散模型,逐步迭代轮廓点进行重建。此外,还引入了一种轮廓倾斜度损失函数,以帮助网络生成更规整的房间布局,从而进一步提升矢量化结果的准确性。结果在公开的CubiCase5K数据集上,对提出的算法进行广泛测试。实验结果表明,在不同的输入条件下,该算法均能有效优化房间轮廓的精度,显著提高墙线矢量化的提取精度。结论所提出的基于引导集扩散模型的矢量重建算法,通过解决传统方法中的误差累积问题,实现了室内户型平面图中墙体矢量化的精度提升。这一改进为建筑与家居设计等领域的应用提供了更为可靠的技术支持。关键词:深度学习;室内户型图;生成式重建;扩散模型;户型图矢量技术321|737|0更新时间:2025-07-14
摘要:目的户型平面图的矢量化是一项关键技术,用于从户型平面点阵图中提取精确的结构信息,广泛应用于建筑装修、家居设计以及场景理解等领域。现有方法通常采用两阶段流程:第1阶段利用深度神经网络提取户型区域的掩膜,第2阶段通过后处理步骤从掩膜轮廓中提取墙体的矢量信息。然而,这种方法存在误差累积问题,后处理算法难以保证鲁棒性。为了解决上述问题,提出一种基于引导集扩散模型的户型平面图矢量重建算法。方法该算法通过将目标检测或实例分割方法中获得的粗糙轮廓输入扩散模型,逐步迭代轮廓点进行重建。此外,还引入了一种轮廓倾斜度损失函数,以帮助网络生成更规整的房间布局,从而进一步提升矢量化结果的准确性。结果在公开的CubiCase5K数据集上,对提出的算法进行广泛测试。实验结果表明,在不同的输入条件下,该算法均能有效优化房间轮廓的精度,显著提高墙线矢量化的提取精度。结论所提出的基于引导集扩散模型的矢量重建算法,通过解决传统方法中的误差累积问题,实现了室内户型平面图中墙体矢量化的精度提升。这一改进为建筑与家居设计等领域的应用提供了更为可靠的技术支持。关键词:深度学习;室内户型图;生成式重建;扩散模型;户型图矢量技术321|737|0更新时间:2025-07-14 - “在微表情识别领域,专家提出了深度卷积神经网络与浅层3DCNN组成的三分支网络,显著提高了识别精确度,有效解决了样本不足、难以学习多类型特征的问题。”
 摘要:目的针对微表情样本不足、难以学习到多类型特征、识别精度低的问题,提出一个由深度卷积神经网络与浅层3DCNN(3D convolutional neural network)组成的、融入多个注意力模块的三分支网络。方法该网络在深度卷积神经网络中引入深度增强通道注意力模块ECANet(efficient channel attention network),在浅层3DCNN中提出新的面部特征增强注意力模块,通过3个分支分别提取和处理人脸特征、光流特征和光应变特征并逐层融合,从而能够充分利用各层特征中隐含的不同信息,减少识别过程中人脸细微特征的丢失,显著提高了微表情识别的精确度。此外,本文首次将IM Loss(information maximizing loss)函数引入微表情识别模型,并与Focal Loss函数结合,使模型能够更有效地处理难以分类的样本,有效提高了模型对于难样本的识别能力。结果在CASME Ⅱ(Chinese Academy of Sciences micro-expression database Ⅱ)、SMIC(spontaneous micro-expression corpus)、SAMM(spontaneous actions and micro-movements)微表情数据集和MEGC2019(micro-expression grand challenge 2019 composite database)复合微表情数据集上的实验表明,所提方法在微表情识别方面优于传统方法和现有的深度学习方法。结论本文提出的三分支网络显著提高了微表情识别的精确度,有效解决了微表情样本不足、难以学习到多类型特征的问题。关键词:微表情识别;特征融合;注意力机制;光流;深度学习322|517|0更新时间:2025-07-14
摘要:目的针对微表情样本不足、难以学习到多类型特征、识别精度低的问题,提出一个由深度卷积神经网络与浅层3DCNN(3D convolutional neural network)组成的、融入多个注意力模块的三分支网络。方法该网络在深度卷积神经网络中引入深度增强通道注意力模块ECANet(efficient channel attention network),在浅层3DCNN中提出新的面部特征增强注意力模块,通过3个分支分别提取和处理人脸特征、光流特征和光应变特征并逐层融合,从而能够充分利用各层特征中隐含的不同信息,减少识别过程中人脸细微特征的丢失,显著提高了微表情识别的精确度。此外,本文首次将IM Loss(information maximizing loss)函数引入微表情识别模型,并与Focal Loss函数结合,使模型能够更有效地处理难以分类的样本,有效提高了模型对于难样本的识别能力。结果在CASME Ⅱ(Chinese Academy of Sciences micro-expression database Ⅱ)、SMIC(spontaneous micro-expression corpus)、SAMM(spontaneous actions and micro-movements)微表情数据集和MEGC2019(micro-expression grand challenge 2019 composite database)复合微表情数据集上的实验表明,所提方法在微表情识别方面优于传统方法和现有的深度学习方法。结论本文提出的三分支网络显著提高了微表情识别的精确度,有效解决了微表情样本不足、难以学习到多类型特征的问题。关键词:微表情识别;特征融合;注意力机制;光流;深度学习322|517|0更新时间:2025-07-14
图像分析和识别
- “在语义分割领域,LCTNet结合轻量级CNN和Transformer,有效提取局部和全局信息,提高城市街景分割性能。”
 摘要:目的在语义分割领域,基于CNN的分割模型虽然在获取局部信息方面表现优越,但往往无法有效提取全局语义信息;相比之下,Transformer在提取全局语义信息方面明显优于CNN,为了更好地利用局部信息和全局语义信息,提出一种轻量级CNN-Transformer相结合的实时语义分割网络(lightweight CNN-Transformer combined network, LCTNet),以适应城市街景下的自动驾驶场景分割。方法首先,设计了轻量级的小波增强卷积块(wavelet-enhanced convolution block, WECB)用于下采样,该模块将传统卷积和小波变换相结合,加强了对边缘纹理细节的提取能力;其次,为提取多尺度上下文信息,设计了一个轻量级的多尺度融合模块(multi-scale fusion module, MFM),该模块能高效地提取并融合多尺度上下文信息;最后,为了捕捉长距离依赖关系和全局上下文信息,设计了轻量级的Transformer(lightweight Transformer, LWT),通过自注意力机制直接关注输入序列的任意位置,捕捉长距离依赖关系,从而改善城市街景分割效果。结果所提算法在Cityscapes和CamVid数据集上进行实验,平均交并比(mean intersection over union,mIoU)分别达到75.9%和69.7%,速度分别为63帧/s和84帧/s,参数量仅有1.06 M。结论所提算法在Cityscapes和CamVid数据集上与近年优秀的方法进行了比较,LCTNet有效地提高了分割性能,同时在分割精度、推理速度和参数量方面取得了较好的平衡。关键词:轻量级;实时语义分割;小波变换;Transformer;多尺度上下文信息388|446|0更新时间:2025-07-14
摘要:目的在语义分割领域,基于CNN的分割模型虽然在获取局部信息方面表现优越,但往往无法有效提取全局语义信息;相比之下,Transformer在提取全局语义信息方面明显优于CNN,为了更好地利用局部信息和全局语义信息,提出一种轻量级CNN-Transformer相结合的实时语义分割网络(lightweight CNN-Transformer combined network, LCTNet),以适应城市街景下的自动驾驶场景分割。方法首先,设计了轻量级的小波增强卷积块(wavelet-enhanced convolution block, WECB)用于下采样,该模块将传统卷积和小波变换相结合,加强了对边缘纹理细节的提取能力;其次,为提取多尺度上下文信息,设计了一个轻量级的多尺度融合模块(multi-scale fusion module, MFM),该模块能高效地提取并融合多尺度上下文信息;最后,为了捕捉长距离依赖关系和全局上下文信息,设计了轻量级的Transformer(lightweight Transformer, LWT),通过自注意力机制直接关注输入序列的任意位置,捕捉长距离依赖关系,从而改善城市街景分割效果。结果所提算法在Cityscapes和CamVid数据集上进行实验,平均交并比(mean intersection over union,mIoU)分别达到75.9%和69.7%,速度分别为63帧/s和84帧/s,参数量仅有1.06 M。结论所提算法在Cityscapes和CamVid数据集上与近年优秀的方法进行了比较,LCTNet有效地提高了分割性能,同时在分割精度、推理速度和参数量方面取得了较好的平衡。关键词:轻量级;实时语义分割;小波变换;Transformer;多尺度上下文信息388|446|0更新时间:2025-07-14 - “在360°全景图像处理领域,提出了畸变自适应语义聚合网络DSANet,有效提升了显著目标检测性能,为解决几何畸变和大视野问题提供解决方案。”
 摘要:目的为了有效应对360°全景图像的几何畸变和大视野特性带来的挑战,提出一种畸变自适应语义聚合网络 (distortion semantic aggregation network,DSANet)。该网络能够提升360°全景图像显著目标检测性能。方法DSANet由3个模块组成:畸变自适应校正模块(distortion aware calibration module,DACM)、多尺度语义注意力聚合模块(multiscale semantic attention aggregation module,MSAAM)以及渐进式细化模块(progressive refinement module, PRM)。DACM模块利用不同扩张率的可变形卷积来学习自适应权重矩阵,校正360°全景图像中的几何畸变;MSAAM模块结合注意力机制和可变形卷积,提取并融合全局语义特征与局部细节特征,生成多尺度语义特征;PRM模块逐层融合多尺度语义特征,进一步提升检测精度。MSAAM模块与PRM模块相配合,解决360°全景图像的大视野问题。结果在两个公开数据集360-SOD 和360-SSOD (共计1 605幅图像) 上进行的实验表明,DSANet在6种主流评价指标(Max F-measure、Mean F-measure、MAE(mean absolute error)、Max E-measure、Mean E-measure、Structure-measure)上均优于其他方法。结论本文方法在多个客观评价指标上表现突出,同时生成的显著目标图像在边缘轮廓性和空间结构细节信息上更为清晰。关键词:深度学习;显著目标检测(SOD);360°全景图像;几何畸变;大视野204|477|0更新时间:2025-07-14
摘要:目的为了有效应对360°全景图像的几何畸变和大视野特性带来的挑战,提出一种畸变自适应语义聚合网络 (distortion semantic aggregation network,DSANet)。该网络能够提升360°全景图像显著目标检测性能。方法DSANet由3个模块组成:畸变自适应校正模块(distortion aware calibration module,DACM)、多尺度语义注意力聚合模块(multiscale semantic attention aggregation module,MSAAM)以及渐进式细化模块(progressive refinement module, PRM)。DACM模块利用不同扩张率的可变形卷积来学习自适应权重矩阵,校正360°全景图像中的几何畸变;MSAAM模块结合注意力机制和可变形卷积,提取并融合全局语义特征与局部细节特征,生成多尺度语义特征;PRM模块逐层融合多尺度语义特征,进一步提升检测精度。MSAAM模块与PRM模块相配合,解决360°全景图像的大视野问题。结果在两个公开数据集360-SOD 和360-SSOD (共计1 605幅图像) 上进行的实验表明,DSANet在6种主流评价指标(Max F-measure、Mean F-measure、MAE(mean absolute error)、Max E-measure、Mean E-measure、Structure-measure)上均优于其他方法。结论本文方法在多个客观评价指标上表现突出,同时生成的显著目标图像在边缘轮廓性和空间结构细节信息上更为清晰。关键词:深度学习;显著目标检测(SOD);360°全景图像;几何畸变;大视野204|477|0更新时间:2025-07-14 -
多层混合注意力机制的类激活图可解释性方法 AI导读
“SAMLCAM方法通过多层混合注意力机制优化类激活图,提升深度卷积神经网络在视觉任务中的可解释性。”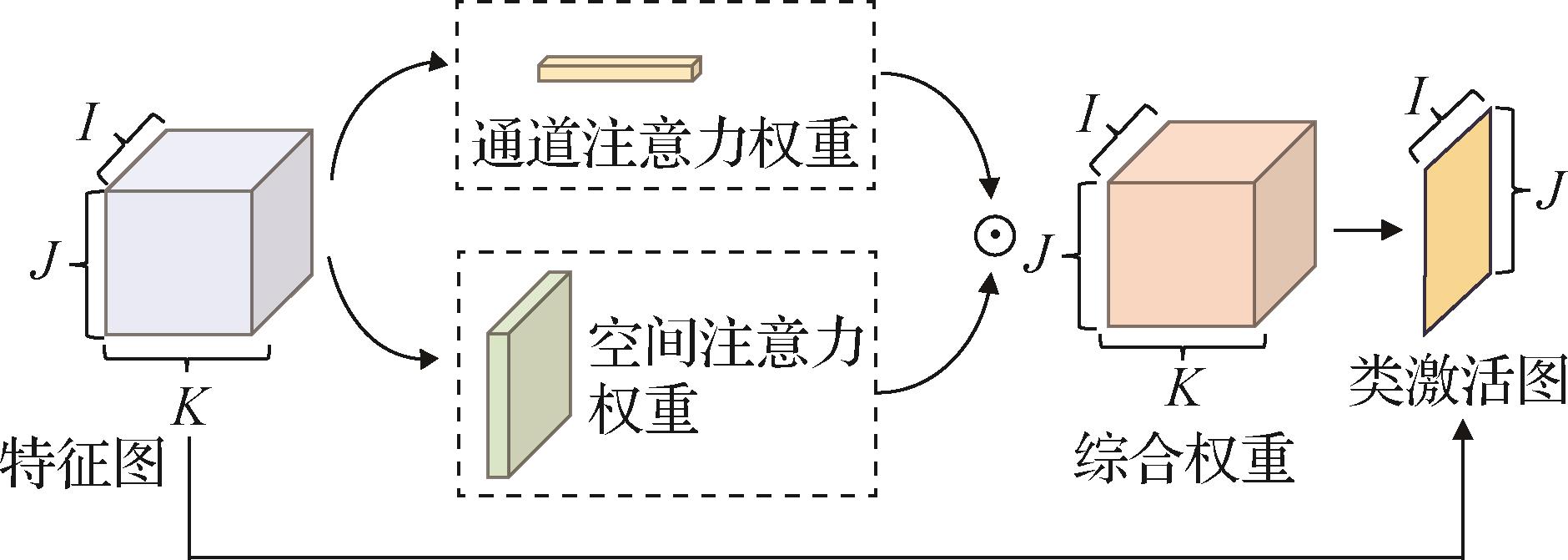 摘要:目的深度卷积神经网络在视觉任务中的广泛应用,使得其作为黑盒模型的复杂性和不透明性引发了对决策机制的关注。类激活图已被证明能有效提升图像分类的可解释性从而提高决策机制的理解程度,但现有方法在高亮目标区域时,常存在边界模糊、范围过大和细粒度不足的问题。为此,提出一种多层混合注意力机制的类激活图方法(spatial attention-based multi-layer fusion for high-quality class activation maps,SAMLCAM),以优化这些局限性。方法在以往的类激活图方法忽略了空间位置信息只关注通道级权重,降低了目标物体的定位性能,SAMLCAM方法提出一种结合了通道注意力机制和空间注意力机制的混合注意力机制,实现增强目标物体定位减少无效位置信息的效果。在得到有效物体定位结果后,根据神经网络多层卷积层的特点,改进多层特征图融合的方式提出多层加权融合机制,改善类激活图的边界效果范围过大和细粒度不足的问题,从而增强类激活图的视觉解释性。结果引用广泛用于计算机视觉模型的基准测试ILSVRC 2012(ImageNet Large-scale Visual Recognition Challenge 2012)数据集和MS COCO2017(Microsoft common objects in context 2017)数据集,对提出方法在多种待解释卷积网络模型下进行评估,包括消融实验、定性评估和定量评估。消融实验证明了各模块的有效性;定性评估对其可解释性效果进行视觉直观展示,验证效果的提升;定量评估中数据表明,SAMLCAM在Loc1和Loc5指标性能相较于最低数据均有大于8%的提升,在能量定位决策指标相较于最低数据均有大于7%的提升。由于改进方法减少了目标样本区域的上下文背景区域,使其对结果置信度存在负影响,但在可信度指标中,与其他方法比较仍可以保持比较小的差距并维持较高性能。结论本文方法在多种卷积神经网络架构上均展现出优异的解释性能,通过扩大目标样本区域的响应覆盖度并有效抑制背景或无关区域的响应,提升了可解释性结果的精确性与可靠性。关键词:类激活图(CAM);可解释性;注意力机制;图像分类;卷积神经网络(CNN)174|756|0更新时间:2025-07-14
摘要:目的深度卷积神经网络在视觉任务中的广泛应用,使得其作为黑盒模型的复杂性和不透明性引发了对决策机制的关注。类激活图已被证明能有效提升图像分类的可解释性从而提高决策机制的理解程度,但现有方法在高亮目标区域时,常存在边界模糊、范围过大和细粒度不足的问题。为此,提出一种多层混合注意力机制的类激活图方法(spatial attention-based multi-layer fusion for high-quality class activation maps,SAMLCAM),以优化这些局限性。方法在以往的类激活图方法忽略了空间位置信息只关注通道级权重,降低了目标物体的定位性能,SAMLCAM方法提出一种结合了通道注意力机制和空间注意力机制的混合注意力机制,实现增强目标物体定位减少无效位置信息的效果。在得到有效物体定位结果后,根据神经网络多层卷积层的特点,改进多层特征图融合的方式提出多层加权融合机制,改善类激活图的边界效果范围过大和细粒度不足的问题,从而增强类激活图的视觉解释性。结果引用广泛用于计算机视觉模型的基准测试ILSVRC 2012(ImageNet Large-scale Visual Recognition Challenge 2012)数据集和MS COCO2017(Microsoft common objects in context 2017)数据集,对提出方法在多种待解释卷积网络模型下进行评估,包括消融实验、定性评估和定量评估。消融实验证明了各模块的有效性;定性评估对其可解释性效果进行视觉直观展示,验证效果的提升;定量评估中数据表明,SAMLCAM在Loc1和Loc5指标性能相较于最低数据均有大于8%的提升,在能量定位决策指标相较于最低数据均有大于7%的提升。由于改进方法减少了目标样本区域的上下文背景区域,使其对结果置信度存在负影响,但在可信度指标中,与其他方法比较仍可以保持比较小的差距并维持较高性能。结论本文方法在多种卷积神经网络架构上均展现出优异的解释性能,通过扩大目标样本区域的响应覆盖度并有效抑制背景或无关区域的响应,提升了可解释性结果的精确性与可靠性。关键词:类激活图(CAM);可解释性;注意力机制;图像分类;卷积神经网络(CNN)174|756|0更新时间:2025-07-14 - “ERA-Net在三维点云地点识别领域取得突破,有效提取旋转特性的几何特征,展现出良好的鲁棒性和泛化能力。”
 摘要:目的地点识别是机器人利用实时扫描到的点云数据进行定位和自主导航的核心。现有的针对大规模点云的地点识别方法往往忽略了真实驾驶中存在的旋转问题。当查询场景发生旋转时,这些方法的识别性能会显著下降,这严重阻碍了它们在复杂现实场景中的应用。因此,本文提出一种有效的面向三维点云的具有旋转感知的地点识别网络(efficient rotation-aware network for point cloud based place recognition,ERA-Net)。方法首先,利用自注意机制与邻域注意力机制,在捕获点与点之间全局依赖关系的同时,捕获每个点与其邻域点之间的局部依赖关系,充分提取点间的语义特征。同时,利用点与其k邻近点的坐标信息,计算距离、角度以及角度差等低维几何特征,并设计基于特征距离的注意力池化模块,通过在高维空间分析特征之间的相关性,提取具有较强区分性且具有旋转特性的几何特征。最后,将提取的语义特征以及几何特征进行有效融合,通过NetVLAD模块,产生更具判别性的全局描述符。结果将提出的ERA-Net在公共数据集Oxford Robotcar上进行验证并与当前先进的方法(state-of-the-art method,SOTA)进行比较。在Oxford数据集中,ERA-Net的前1%平均召回率(average recall@1%,AR@1%)指标可以达到96.48%,在U.S.(university sector)、R.A.(residential area)以及B.D.(business district)数据集上的识别效果均优于其他方法。特别地,当查询场景进行旋转时,ERA-Net的识别效果优于已有方法。结论ERA-Net能够充分考虑点间的上下文信息,以及特征间的相关性,提取具有较强独特性的场景特征,在面对旋转问题时能够展现出较好的鲁棒性,具有较强的泛化能力。关键词:点云场景;地点识别;旋转感知;注意力机制;特征距离232|250|0更新时间:2025-07-14
摘要:目的地点识别是机器人利用实时扫描到的点云数据进行定位和自主导航的核心。现有的针对大规模点云的地点识别方法往往忽略了真实驾驶中存在的旋转问题。当查询场景发生旋转时,这些方法的识别性能会显著下降,这严重阻碍了它们在复杂现实场景中的应用。因此,本文提出一种有效的面向三维点云的具有旋转感知的地点识别网络(efficient rotation-aware network for point cloud based place recognition,ERA-Net)。方法首先,利用自注意机制与邻域注意力机制,在捕获点与点之间全局依赖关系的同时,捕获每个点与其邻域点之间的局部依赖关系,充分提取点间的语义特征。同时,利用点与其k邻近点的坐标信息,计算距离、角度以及角度差等低维几何特征,并设计基于特征距离的注意力池化模块,通过在高维空间分析特征之间的相关性,提取具有较强区分性且具有旋转特性的几何特征。最后,将提取的语义特征以及几何特征进行有效融合,通过NetVLAD模块,产生更具判别性的全局描述符。结果将提出的ERA-Net在公共数据集Oxford Robotcar上进行验证并与当前先进的方法(state-of-the-art method,SOTA)进行比较。在Oxford数据集中,ERA-Net的前1%平均召回率(average recall@1%,AR@1%)指标可以达到96.48%,在U.S.(university sector)、R.A.(residential area)以及B.D.(business district)数据集上的识别效果均优于其他方法。特别地,当查询场景进行旋转时,ERA-Net的识别效果优于已有方法。结论ERA-Net能够充分考虑点间的上下文信息,以及特征间的相关性,提取具有较强独特性的场景特征,在面对旋转问题时能够展现出较好的鲁棒性,具有较强的泛化能力。关键词:点云场景;地点识别;旋转感知;注意力机制;特征距离232|250|0更新时间:2025-07-14 - “在红外与可见光图像融合领域,研究者提出了基于信息交互线性Transformer的新型融合算法,有效提升了视觉效果和计算效率。”
 摘要:目的基于Transformer的深度学习技术在红外与可见光图像融合任务中表现出优异性能。然而基于Transformer的图像融合网络架构计算效率较低,训练过程中需要消耗大量计算资源和储存空间。此外,现有大多数融合方法忽略了编码阶段的跨模态信息交互。方法针对这两个问题,提出一种新型的红外与可见光图像融合算法,采用基于信息交互线性Transformer的网络结构,包括双分支编码器和解码器。双分支编码器首先利用卷积层提取源图像浅层特征,随后通过全局信息快速交互模块中信息交互快速 Transformer实现跨模态信息的深度整合,解码器利用多层级联卷积模块得到高质量重建图像。此外,设计傅里叶变换损失引导模型训练,以保留源图像重要频域信息。结果对比实验在MSRS(multi-spectral road scenarios)和TNO(the Netherlands organization)数据集上与13种传统以及深度学习融合方法进行比较。主观评价方面,本文方法在复杂场景下融合效果优势明显,能够产生人物目标轮廓清晰、高视觉质量的融合结果;客观指标方面,在MSRS数据集上本文算法在信息熵、视觉保真度、平均梯度、边缘强度和基于梯度的相似性度量5项指标上取得最优值,相比于对比方法最优值分别提升0.75%、0.15%、1.56%、1.52%和1.27%。在TNO数据集上本文算法在的信息熵、视觉保真度、平均梯度和基于梯度相似性度量4项指标上取得最优值,相比于对比方法最优值分别提升1.53%、3.79%、0.17%和6.94%。消融实验验证了本文融合网络各组件的有效性,并对本文方法计算复杂度进行分析。结论本文提出基于信息交互线性Transformer的融合网络,在提升视觉效果、保留复杂场景下纹理细节信息以及提高计算效率等方面均具有优越性。关键词:图像融合;信息交互;线性Transformer;傅里叶变换损失;深度学习254|212|0更新时间:2025-07-14
摘要:目的基于Transformer的深度学习技术在红外与可见光图像融合任务中表现出优异性能。然而基于Transformer的图像融合网络架构计算效率较低,训练过程中需要消耗大量计算资源和储存空间。此外,现有大多数融合方法忽略了编码阶段的跨模态信息交互。方法针对这两个问题,提出一种新型的红外与可见光图像融合算法,采用基于信息交互线性Transformer的网络结构,包括双分支编码器和解码器。双分支编码器首先利用卷积层提取源图像浅层特征,随后通过全局信息快速交互模块中信息交互快速 Transformer实现跨模态信息的深度整合,解码器利用多层级联卷积模块得到高质量重建图像。此外,设计傅里叶变换损失引导模型训练,以保留源图像重要频域信息。结果对比实验在MSRS(multi-spectral road scenarios)和TNO(the Netherlands organization)数据集上与13种传统以及深度学习融合方法进行比较。主观评价方面,本文方法在复杂场景下融合效果优势明显,能够产生人物目标轮廓清晰、高视觉质量的融合结果;客观指标方面,在MSRS数据集上本文算法在信息熵、视觉保真度、平均梯度、边缘强度和基于梯度的相似性度量5项指标上取得最优值,相比于对比方法最优值分别提升0.75%、0.15%、1.56%、1.52%和1.27%。在TNO数据集上本文算法在的信息熵、视觉保真度、平均梯度和基于梯度相似性度量4项指标上取得最优值,相比于对比方法最优值分别提升1.53%、3.79%、0.17%和6.94%。消融实验验证了本文融合网络各组件的有效性,并对本文方法计算复杂度进行分析。结论本文提出基于信息交互线性Transformer的融合网络,在提升视觉效果、保留复杂场景下纹理细节信息以及提高计算效率等方面均具有优越性。关键词:图像融合;信息交互;线性Transformer;傅里叶变换损失;深度学习254|212|0更新时间:2025-07-14
图像理解和计算机视觉
- “最新研究在三维场景本征分解领域取得突破,专家提出新算法,有效提升室内场景分解精度和效率,为虚拟物体插入等任务提供支持。”
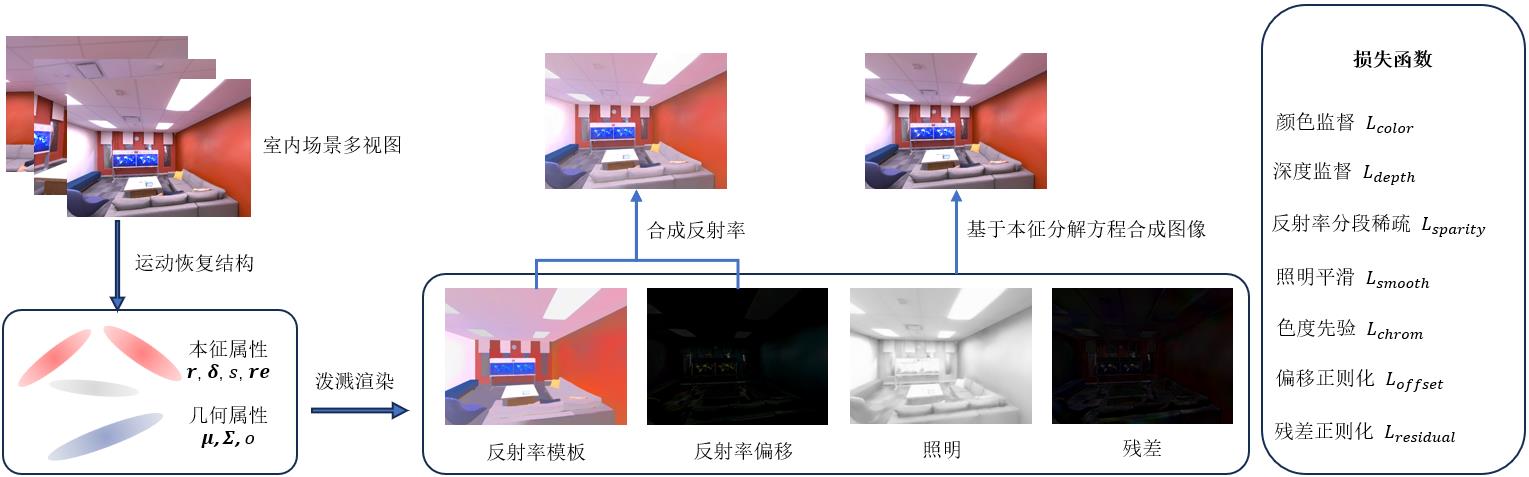 摘要:目的三维场景本征分解尝试将场景分解为反射率与照明的乘积,其分解结果可用于虚拟物体插入、图像材质编辑、重光照等任务,受到广泛关注与研究。但是,分解规模较大且布局复杂的室内场景是一个高度病态的问题,获得正确的分解结果具有较高的挑战性。本文基于当前最先进的辐射场表示技术三维高斯泼溅,提出一种针对室内场景的本征分解算法,大大提高了室内场景本征分解的精度和效率。方法为了更好地解耦本征属性,本文基于三维高斯泼溅技术设计了一种针对室内场景的本征分解模型,将场景分解为反射率及偏移、照明和残差项,并引入新的反射率分段稀疏、照明平滑与色度先验约束,以减少分解过程中的歧义,保证分解结果的合理性。同时还利用捕获的深度数据增强场景的几何信息,有利于反射率和照明能够更好的解耦,提高合成图像的质量。结果对来自合成数据集Replica的8个场景和真实数据集ScanNet++的5个场景进行实验,并对分解结果进行可视化;同时测试了新视角下合成图像的峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity index,SSIM)和学习感知图像块相似度(learned perceptural image patch similarity,LPIPS)指标。结果显示,本文方法不仅可以得到在视觉上更加合理的分解结果,并且合成图像的上述指标在Replica数据集上平均达到34.695 5 dB、0.965 4和0.086 1,在ScanNet++数据集上平均达到27.949 6 dB、0.895 0和0.144 4,优于对比的三维场景本征分解算法。结论与以往工作相比,本文方法能够快速分解室内场景,并支持在新视角下推理场景属性和合成高保真的图像,具有较高的应用价值。关键词:本征分解;三维高斯泼溅(3DGS);室内场景分解;Retinex理论;辐射场607|572|0更新时间:2025-07-14
摘要:目的三维场景本征分解尝试将场景分解为反射率与照明的乘积,其分解结果可用于虚拟物体插入、图像材质编辑、重光照等任务,受到广泛关注与研究。但是,分解规模较大且布局复杂的室内场景是一个高度病态的问题,获得正确的分解结果具有较高的挑战性。本文基于当前最先进的辐射场表示技术三维高斯泼溅,提出一种针对室内场景的本征分解算法,大大提高了室内场景本征分解的精度和效率。方法为了更好地解耦本征属性,本文基于三维高斯泼溅技术设计了一种针对室内场景的本征分解模型,将场景分解为反射率及偏移、照明和残差项,并引入新的反射率分段稀疏、照明平滑与色度先验约束,以减少分解过程中的歧义,保证分解结果的合理性。同时还利用捕获的深度数据增强场景的几何信息,有利于反射率和照明能够更好的解耦,提高合成图像的质量。结果对来自合成数据集Replica的8个场景和真实数据集ScanNet++的5个场景进行实验,并对分解结果进行可视化;同时测试了新视角下合成图像的峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity index,SSIM)和学习感知图像块相似度(learned perceptural image patch similarity,LPIPS)指标。结果显示,本文方法不仅可以得到在视觉上更加合理的分解结果,并且合成图像的上述指标在Replica数据集上平均达到34.695 5 dB、0.965 4和0.086 1,在ScanNet++数据集上平均达到27.949 6 dB、0.895 0和0.144 4,优于对比的三维场景本征分解算法。结论与以往工作相比,本文方法能够快速分解室内场景,并支持在新视角下推理场景属性和合成高保真的图像,具有较高的应用价值。关键词:本征分解;三维高斯泼溅(3DGS);室内场景分解;Retinex理论;辐射场607|572|0更新时间:2025-07-14 -
轻量级实时渲染参数优化方法 AI导读
“在图形应用领域,专家提出了一种轻量级实时渲染自动参数优化方法,有效减少渲染时间,同时保持高画质。” 摘要:目的随着数字孪生、虚拟现实等技术的普及,人们对画质和流畅性的需求不断提高。然而,受到关键性能硬件的制约,个人电脑或移动设备往往需要通过调整游戏或渲染引擎中的各项参数来提高帧率,而这必然会造成渲染质量损失。如何设置合理的渲染参数,在降低时间开销的同时,实现更高的渲染质量,成为图形应用领域广泛关注的问题。方法提出一种通用的轻量级实时渲染自动参数优化方法,使用极致梯度提升(extreme gradient boosting,XGBoost)对虚拟场景渲染时不同参数的渲染时间和图像质量进行建模,在预计算后,模型被简化为查找表(look up table,LUT)。在实际渲染时根据硬件状态、场景信息等条件使用LUT自动调整渲染参数,在减少渲染时间的同时保证渲染质量。结果该方法能够应用于游戏、渲染引擎中的各类渲染技术。本文分别在次表面散射和环境光遮蔽效果进行应用和测试。结果表明,与最佳的渲染参数相比,使用本文方法的次表面散射渲染时间缩短40%左右,环境光遮蔽渲染时间减低70%左右,而图像误差均仅增加2%左右。结论本文方法在减少渲染时间的同时,能够保持较高的渲染质量,具有良好的实用性,适用于游戏和渲染引擎中的各类渲染技术。代码仓库:https://github.com/LightweightRenderParamOptimization/LightweightRenderParamOptimization。关键词:实时渲染;渲染优化;极致梯度提升(XGBoost);查找表(LUT);虚幻引擎(UE)263|350|0更新时间:2025-07-14
摘要:目的随着数字孪生、虚拟现实等技术的普及,人们对画质和流畅性的需求不断提高。然而,受到关键性能硬件的制约,个人电脑或移动设备往往需要通过调整游戏或渲染引擎中的各项参数来提高帧率,而这必然会造成渲染质量损失。如何设置合理的渲染参数,在降低时间开销的同时,实现更高的渲染质量,成为图形应用领域广泛关注的问题。方法提出一种通用的轻量级实时渲染自动参数优化方法,使用极致梯度提升(extreme gradient boosting,XGBoost)对虚拟场景渲染时不同参数的渲染时间和图像质量进行建模,在预计算后,模型被简化为查找表(look up table,LUT)。在实际渲染时根据硬件状态、场景信息等条件使用LUT自动调整渲染参数,在减少渲染时间的同时保证渲染质量。结果该方法能够应用于游戏、渲染引擎中的各类渲染技术。本文分别在次表面散射和环境光遮蔽效果进行应用和测试。结果表明,与最佳的渲染参数相比,使用本文方法的次表面散射渲染时间缩短40%左右,环境光遮蔽渲染时间减低70%左右,而图像误差均仅增加2%左右。结论本文方法在减少渲染时间的同时,能够保持较高的渲染质量,具有良好的实用性,适用于游戏和渲染引擎中的各类渲染技术。代码仓库:https://github.com/LightweightRenderParamOptimization/LightweightRenderParamOptimization。关键词:实时渲染;渲染优化;极致梯度提升(XGBoost);查找表(LUT);虚幻引擎(UE)263|350|0更新时间:2025-07-14
计算机图形学
-
多尺度动态视觉网络的手术机器人场景分割 AI导读
“在机器人辅助腹腔镜手术领域,专家提出了多尺度动态视觉网络MDVNet,为提高手术精度提供新方案。” 摘要:目的机器人辅助腹腔镜手术指的是临床医生借助腔镜手术机器人完成外科手术。然而,腔镜手术在密闭的人体腔道完成,且分割目标的特征复杂多变,对医生的手术技能有较高要求。为辅助医生完成腔镜手术,提出一种高精度的腔镜手术场景分割方法,并搭建分体式腔镜手术机器人对所提出的方法进行了验证。方法首先,提出了多尺度动态视觉网络(multi-scale dynamic visual network, MDVNet)。该网络采用编码器—解码器结构。在编码器部分,动态大核卷积注意力模块(dynamic large kernel attention module, DLKA)可以通过多尺度大核注意力提取不同分割目标的多尺度特征,并动态选择机制进行自适应的特征融合。在解码器部分,低秩矩阵分解模块(low-rank matrix decomposition module, LMD)引导不同分辨率的特征图进行融合,可以有效滤除特征图中的噪声;边界引导模块(boundary guided module, BGM)可以引导模型学习手术场景的边界特征。最后,展示了基于Lap Game腹腔镜模拟器搭建的分体式腔镜手术机器人,网络模型的分割结果可以映射在手术机器人的视野中,辅助医生进行腔镜手术。结果MDVNet在3个手术场景数据集上取得了最先进的结果,平均交并比分别为51.19%、71.28%和52.47%。结论本文提出了适用于腔镜手术场景分割的多尺度动态视觉网络MDVNet,并在搭建的分体式腔镜手术机器人上对所提出方法进行了验证。代码开源地址为:https://github.com/YubinHan73/MDVNet。关键词:腔镜手术机器人;语义分割;大核卷积;低秩矩阵分解(LMD);边界分割315|584|0更新时间:2025-07-14
摘要:目的机器人辅助腹腔镜手术指的是临床医生借助腔镜手术机器人完成外科手术。然而,腔镜手术在密闭的人体腔道完成,且分割目标的特征复杂多变,对医生的手术技能有较高要求。为辅助医生完成腔镜手术,提出一种高精度的腔镜手术场景分割方法,并搭建分体式腔镜手术机器人对所提出的方法进行了验证。方法首先,提出了多尺度动态视觉网络(multi-scale dynamic visual network, MDVNet)。该网络采用编码器—解码器结构。在编码器部分,动态大核卷积注意力模块(dynamic large kernel attention module, DLKA)可以通过多尺度大核注意力提取不同分割目标的多尺度特征,并动态选择机制进行自适应的特征融合。在解码器部分,低秩矩阵分解模块(low-rank matrix decomposition module, LMD)引导不同分辨率的特征图进行融合,可以有效滤除特征图中的噪声;边界引导模块(boundary guided module, BGM)可以引导模型学习手术场景的边界特征。最后,展示了基于Lap Game腹腔镜模拟器搭建的分体式腔镜手术机器人,网络模型的分割结果可以映射在手术机器人的视野中,辅助医生进行腔镜手术。结果MDVNet在3个手术场景数据集上取得了最先进的结果,平均交并比分别为51.19%、71.28%和52.47%。结论本文提出了适用于腔镜手术场景分割的多尺度动态视觉网络MDVNet,并在搭建的分体式腔镜手术机器人上对所提出方法进行了验证。代码开源地址为:https://github.com/YubinHan73/MDVNet。关键词:腔镜手术机器人;语义分割;大核卷积;低秩矩阵分解(LMD);边界分割315|584|0更新时间:2025-07-14 - “在医学影像领域,专家提出了一种融合图像增强和自注意力机制的数据生成方法,有效提升了活动性肺结核影像数据的生成质量。”
 摘要:目的CT(computed tomography)影像数据是基于深度学习模型辅助医生进行活动性肺结核预防和诊断的重要基础,然而,隐私保护和获取成本等因素制约了大规模数据集的制作。而且,现有数据生成技术在处理低质量和来源多样化数据时存在局限,难以有效提升生成影像的质量,导致细微病灶难以有效生成,且生成影像清晰度不佳。因此,提出一种融合图像增强和自注意力机制的数据生成方法,提升活动性肺结核影像数据的生成质量。方法首先基于循环一致性对抗网络CycleGAN(cycle-consistent adversarial network)对低质量的源数据进行图像增强处理,然后再基于图像到图像的条件生成对抗网络Pix2Pix(image-to-image translation with conditional adversarial network)进行数据生成。在生成器设计上,采用U-Net架构,并融入含自注意力机制的残差模块,增强模型对图像中不同上、下文信息与细节特征的学习能力。同时,对于判别器,采用PatchGAN(patch-based generative adversarial network)架构,聚焦于分析图像的局部特征,并采用PReLU(parametric rectified linear unit)激活函数,其可自适应调整负斜率的特性有助于提升判别器的图像判别性能。结果在自建和公开的混合数据集上与主流方法进行比较的实验结果显示,在未经过图像增强的数据生成实验中,本文方法的数据生成效果与性能第2的方法相比较,峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity index measure,SSIM)分别提高1.38%和2.15%,FID(Fréchet inception distance)降低10.70%。在经过图像增强后的数据生成实验中,PSNR和SSIM分别提高0.52%和1.05%,FID降低2.01%。结论本文提出的数据生成方法,通过融合图像增强技术和自注意力机制有效提升了生成数据的整体质量。关键词:数据生成;图像增强;活动性肺结核;自注意力机制;CT影像;CycleGAN;Pix2Pix201|391|0更新时间:2025-07-14
摘要:目的CT(computed tomography)影像数据是基于深度学习模型辅助医生进行活动性肺结核预防和诊断的重要基础,然而,隐私保护和获取成本等因素制约了大规模数据集的制作。而且,现有数据生成技术在处理低质量和来源多样化数据时存在局限,难以有效提升生成影像的质量,导致细微病灶难以有效生成,且生成影像清晰度不佳。因此,提出一种融合图像增强和自注意力机制的数据生成方法,提升活动性肺结核影像数据的生成质量。方法首先基于循环一致性对抗网络CycleGAN(cycle-consistent adversarial network)对低质量的源数据进行图像增强处理,然后再基于图像到图像的条件生成对抗网络Pix2Pix(image-to-image translation with conditional adversarial network)进行数据生成。在生成器设计上,采用U-Net架构,并融入含自注意力机制的残差模块,增强模型对图像中不同上、下文信息与细节特征的学习能力。同时,对于判别器,采用PatchGAN(patch-based generative adversarial network)架构,聚焦于分析图像的局部特征,并采用PReLU(parametric rectified linear unit)激活函数,其可自适应调整负斜率的特性有助于提升判别器的图像判别性能。结果在自建和公开的混合数据集上与主流方法进行比较的实验结果显示,在未经过图像增强的数据生成实验中,本文方法的数据生成效果与性能第2的方法相比较,峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity index measure,SSIM)分别提高1.38%和2.15%,FID(Fréchet inception distance)降低10.70%。在经过图像增强后的数据生成实验中,PSNR和SSIM分别提高0.52%和1.05%,FID降低2.01%。结论本文提出的数据生成方法,通过融合图像增强技术和自注意力机制有效提升了生成数据的整体质量。关键词:数据生成;图像增强;活动性肺结核;自注意力机制;CT影像;CycleGAN;Pix2Pix201|391|0更新时间:2025-07-14
医学图像处理
- “在遥感图像检测领域,专家提出了一种新方法,有效提升了目标定位能力,改善了复杂背景下的漏检和误检问题。”
 摘要:目的针对遥感图像(remote sensing image,RSI)检测中目标尺寸小且密集、尺度变化大,尤其在复杂背景信息下容易出现漏检和误检问题,提出一种上下文信息和多尺度特征序列引导的遥感图像检测方法,以提升遥感图像的检测精度。方法首先,设计自适应大感受野机制(adaptive large receptive field,ALRF)用于特征提取。该机制通过级联不同扩张率的深度卷积进行分层特征提取,并利用通道和空间注意力对提取的特征进行通道加权和空间融合,使模型能够自适应地调整感受野大小,从而实现遥感图像上下文信息的有效利用。其次,为解决颈部网络特征融合过程中小目标语义信息丢失问题,设计多尺度特征序列融合架构(multi-scale feature fusion,MFF)。该架构通过构建多尺度特征序列,并结合浅层语义特征信息,实现复杂背景下多尺度全局信息的有效融合,从而减轻深层网络中特征模糊性对小目标局部细节捕捉的影响。最后,因传统交并比(intersection over union,IoU)对小目标位置偏差过于敏感,引入归一化Wasserstein距离(normalized Wasserstein distance,NWD)。NWD将边界框建模为二维高斯分布,计算这些分布间的Wasserstein距离来衡量边界框的相似性,从而降低小目标位置偏差敏感性。结果在NWPU VHR-10(Northwestern Polytechnical University very high resolution 10)和DIOR(dataset for object detection in aerial images)数据集上与10种方法进行综合比较,结果表明,提出的方法优于对比方法,平均精度(average precision,AP)分别达到93.15%和80.89%,相较于基准模型YOLOv8n(you only look once version 8 nano),提升了5.48%和2.97%,同时参数量下降6.96%。结论提出一种上下文信息和多尺度特征序列引导的遥感图像检测方法,该方法提升目标的定位能力,改善复杂背景下遥感图像检测中的漏检和误检问题。关键词:遥感图像(RSI);目标检测;感受野(RF);特征融合;归一化Wasserstein距离(NWD)242|440|0更新时间:2025-07-14
摘要:目的针对遥感图像(remote sensing image,RSI)检测中目标尺寸小且密集、尺度变化大,尤其在复杂背景信息下容易出现漏检和误检问题,提出一种上下文信息和多尺度特征序列引导的遥感图像检测方法,以提升遥感图像的检测精度。方法首先,设计自适应大感受野机制(adaptive large receptive field,ALRF)用于特征提取。该机制通过级联不同扩张率的深度卷积进行分层特征提取,并利用通道和空间注意力对提取的特征进行通道加权和空间融合,使模型能够自适应地调整感受野大小,从而实现遥感图像上下文信息的有效利用。其次,为解决颈部网络特征融合过程中小目标语义信息丢失问题,设计多尺度特征序列融合架构(multi-scale feature fusion,MFF)。该架构通过构建多尺度特征序列,并结合浅层语义特征信息,实现复杂背景下多尺度全局信息的有效融合,从而减轻深层网络中特征模糊性对小目标局部细节捕捉的影响。最后,因传统交并比(intersection over union,IoU)对小目标位置偏差过于敏感,引入归一化Wasserstein距离(normalized Wasserstein distance,NWD)。NWD将边界框建模为二维高斯分布,计算这些分布间的Wasserstein距离来衡量边界框的相似性,从而降低小目标位置偏差敏感性。结果在NWPU VHR-10(Northwestern Polytechnical University very high resolution 10)和DIOR(dataset for object detection in aerial images)数据集上与10种方法进行综合比较,结果表明,提出的方法优于对比方法,平均精度(average precision,AP)分别达到93.15%和80.89%,相较于基准模型YOLOv8n(you only look once version 8 nano),提升了5.48%和2.97%,同时参数量下降6.96%。结论提出一种上下文信息和多尺度特征序列引导的遥感图像检测方法,该方法提升目标的定位能力,改善复杂背景下遥感图像检测中的漏检和误检问题。关键词:遥感图像(RSI);目标检测;感受野(RF);特征融合;归一化Wasserstein距离(NWD)242|440|0更新时间:2025-07-14 - “在计算机视觉和遥感领域,专家提出了一种快速高精度的城市地区遥感神经辐射场三维重建算法,有效提高了复杂建筑群重建精度和训练效率。”
 摘要:目的利用卫星遥感影像对地球表面进行三维重建是计算机视觉和遥感领域的研究热点。一些大尺度的三维重建方法都期望在城市地区能有更好的效果。为了使复杂结构渲染更加精细、人造建筑的平面更加平整、训练速度更快,提出一种快速高精度的城市地区遥感神经辐射场(neural radiance field,NeRF)三维重建算法。方法根据城市地区相对于其他自然场景呈现的结构性规律,即城市建筑物通常具有较强的几何特征和规整性,采用Manhattan坐标系的几何结构约束三维重建过程,从而确保重建结果的几何准确性和细节保真度。此外,多分辨率哈希编码模块通过引入哈希表和可学习的位置编码减少原始神经辐射场的多层神经网络,显著减少了辐射场的训练时间。结果实验使用DFC2019(data fusion contest)数据集测试,与当前先进算法进行测试对比。实验结果表明,本文提出的方法在城市建筑物地区图像上具有高效训练速度的同时取得了更好的渲染质量与高程信息,有效地实现了复杂建筑群的重建。与现有方法相比,在图像质量与高程重建误差等指标上均有明显提升。结论该方法在提高城市复杂建筑群三维重建精度和训练效率方面表现更加优秀,为城市遥感影像三维重建提供了一种有效的解决方案。关键词:遥感影像;三维重建;神经辐射场(NeRF);曼哈顿框架(MF);哈希编码158|415|0更新时间:2025-07-14
摘要:目的利用卫星遥感影像对地球表面进行三维重建是计算机视觉和遥感领域的研究热点。一些大尺度的三维重建方法都期望在城市地区能有更好的效果。为了使复杂结构渲染更加精细、人造建筑的平面更加平整、训练速度更快,提出一种快速高精度的城市地区遥感神经辐射场(neural radiance field,NeRF)三维重建算法。方法根据城市地区相对于其他自然场景呈现的结构性规律,即城市建筑物通常具有较强的几何特征和规整性,采用Manhattan坐标系的几何结构约束三维重建过程,从而确保重建结果的几何准确性和细节保真度。此外,多分辨率哈希编码模块通过引入哈希表和可学习的位置编码减少原始神经辐射场的多层神经网络,显著减少了辐射场的训练时间。结果实验使用DFC2019(data fusion contest)数据集测试,与当前先进算法进行测试对比。实验结果表明,本文提出的方法在城市建筑物地区图像上具有高效训练速度的同时取得了更好的渲染质量与高程信息,有效地实现了复杂建筑群的重建。与现有方法相比,在图像质量与高程重建误差等指标上均有明显提升。结论该方法在提高城市复杂建筑群三维重建精度和训练效率方面表现更加优秀,为城市遥感影像三维重建提供了一种有效的解决方案。关键词:遥感影像;三维重建;神经辐射场(NeRF);曼哈顿框架(MF);哈希编码158|415|0更新时间:2025-07-14
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0