
最新刊期
卷 30 , 期 7 , 2025
- “在自动驾驶、机器人技术等领域,点云场景分割技术取得重要进展,专家综述了研究方法和挑战,为未来发展提供方向。”
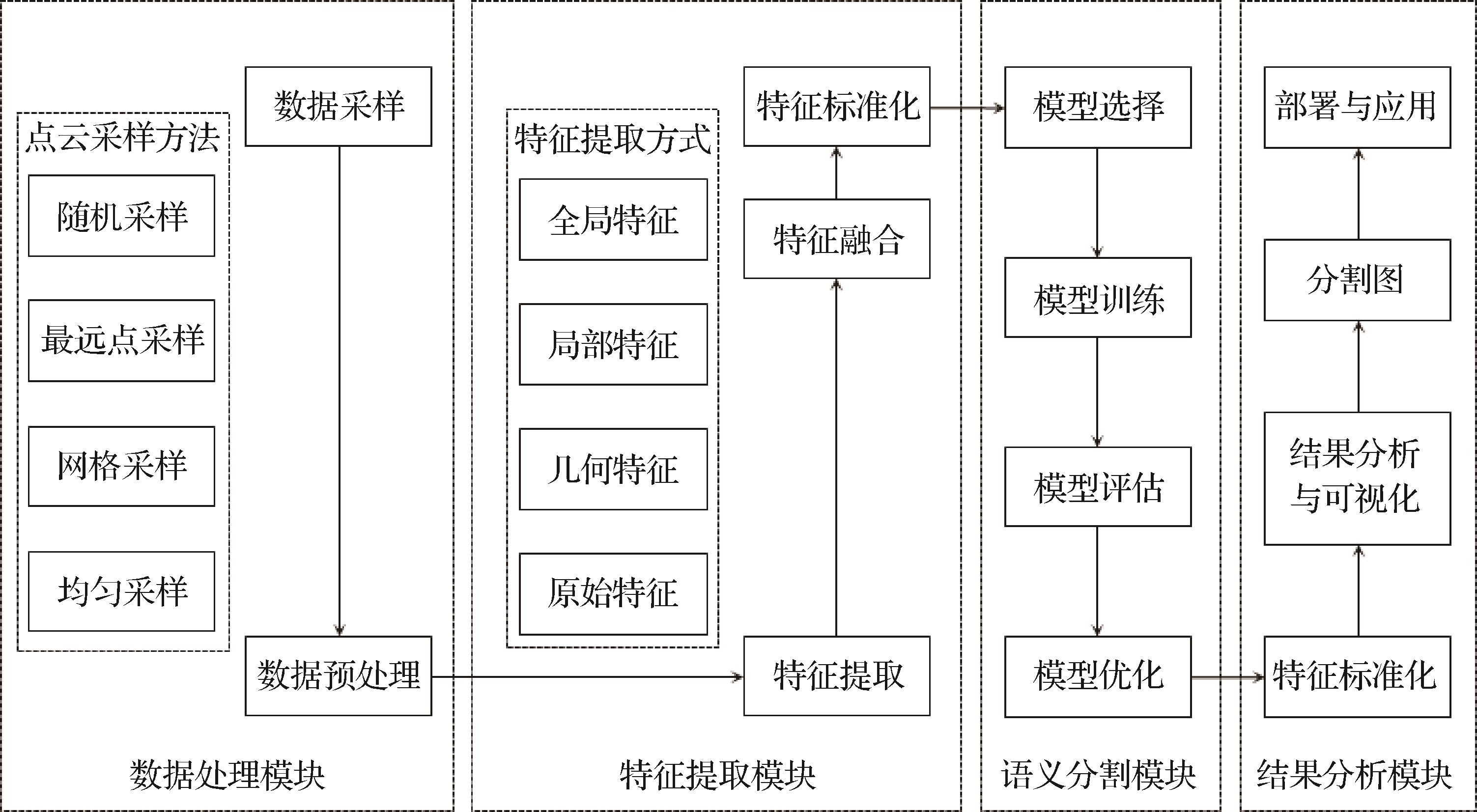 摘要:With the continuous advancement of depth sensing technology, particularly the widespread application of laser scanners across diverse scenarios, 3D point cloud technology is playing a pivotal role in an increasing number of fields. These fields include, but are not limited to, autonomous driving, robotics, geographic information systems, manufacturing, building information modeling, cultural heritage preservation, virtual reality, and augmented reality. As a high-precision, dense, and detailed form of spatial data representation, 3D point clouds can accurately capture various types of information, including the geometric shape, spatial structure, surface texture, and environmental layout of objects. Consequently, the processing, analysis, and comprehension of point cloud data are particularly significant in these applications, particularly point cloud segmentation technology, which serves as the foundation for advanced tasks, such as object recognition, scene understanding, map construction, and dynamic environment monitoring.This study aims to conduct a comprehensive review and in-depth exploration of current mainstream 3D point cloud segmentation methods from multiple perspectives, dissecting the latest advancements in this research domain. In particular, it begins with a detailed analysis and discussion of the fundamentals of 3D point cloud segmentation, covering aspects such as datasets, performance evaluation metrics, sampling methods, and feature extraction techniques. This study summarizes currently publicly available mainstream point cloud datasets, including ShapeNet, Semantic3D, S3DIS, and ScanNet, meticulously dissecting the characteristics, annotation forms, application scenarios, and technical challenges associated with each dataset. In addition, it delves into commonly utilized performance evaluation metrics in the semantic segmentation of point cloud scenes, including overall accuracy, mean class accuracy, and mean intersection over union. These metrics provide effective means for quantifying and comparing model performance, facilitating comprehensive evaluations and improvements across different tasks and scenarios.In the data preprocessing phase, this study systematically summarizes prevalent point cloud sampling strategies. Given that 3D point cloud data typically possess large scales and irregular distributions, a suitable sampling method is essential for reducing computational costs and enhancing model training efficiency. This study introduces strategies, such as farthest point sampling, random sampling, and grid sampling, analyzing their application scenarios, advantages, disadvantages, and specific implementation methods in various tasks. Furthermore, it discusses feature extraction techniques for 3D point clouds, encompassing various methods, including global feature extraction, local feature extraction, and the fusion of global and local features. Through effective feature extraction, more discriminative representations can be provided for subsequent segmentation tasks, aiding the model in improved object recognition and scene understanding.Building on this foundation, this study systematically reviews 3D point cloud segmentation methods from four distinct perspectives: point-based, voxel-based, view-based, and multi-modal fusion methods. First, point-based methods directly process each point within the point cloud, maintaining the high resolution and density of the data while avoiding information loss. Point-based methods are further subdivided into multilayer perceptron (MLP)-based methods, Transformer-based models, graph convolutional network-based methods, and other related approaches. Each category exhibits unique advantages in different application scenarios. For example, MLP is effective for capturing the local features of point clouds, while Transformer-based models excel in handling long-range dependencies and global relationships. Despite the strong performance of point-based methods, their direct processing of a large number of 3D points results in high computational complexity and relatively low efficiency when managing large-scale point cloud scenes.Second, this study presents voxel-based methods, which process point cloud data by partitioning them into regular 3D grids (voxels), effectively reducing data size and simplifying subsequent computations. This approach structures point cloud data, providing relatively stable performance in large-scale scenes. It is particularly applicable to scenarios with large scene sizes but low resolution requirements. However, the inevitable information loss and reduction in spatial resolution during voxelization limit performance in handling fine-grained tasks.Third, the view-based approach processes a 3D point cloud by projecting it onto a 2D plane, leveraging mature 2D image processing techniques and convolutional neural networks. This method transforms the point cloud segmentation task into a traditional image segmentation problem, enhancing processing efficiency, particularly in scenarios where point cloud density is high and rapid processing is required. However, projecting 3D information onto 2D space may lead to the loss of spatial geometric information, resulting in potentially lower accuracy compared with methods that directly handle 3D point clouds in certain applications.Lastly, this study explores multimodal fusion methods, which combine various forms of data, such as point clouds, voxels, and views, fully utilizing the complementarity of different modalities in scene understanding to enhance the accuracy, robustness, and generalization ability of point cloud segmentation.Subsequently, this study conducts a detailed analysis and comparison of the experimental results from different methods. Based on various datasets and performance evaluation metrics, it reveals the strengths and weaknesses of each method in diverse application scenarios. For example, point-based methods excel in fine segmentation tasks and can capture subtle geometric information, while voxel-based and view-based methods offer higher processing efficiency when dealing with large-scale point cloud scenes. Through the comparative analysis of experimental results, this study provides valuable references for point cloud segmentation tasks across different application scenarios.Finally, this study summarizes the major challenges that are currently experienced in the field of 3D point cloud segmentation, including the sparsity and irregularity of point cloud data, the influence of noise and missing points, insufficient generalization ability across diverse scenes, and the demand for real-time processing. This study also anticipates future research directions and proposes measures, such as a deeper understanding of the complex semantic structures of point cloud data through the integration of large language models, the introduction of semi-supervised and unsupervised learning methods to reduce reliance on labeled data, and enhancements in real-time performance and computational efficiency to further advance point cloud segmentation technology. We hope that this comprehensive review can provide a systematic reference for researchers and industrial applications in the field of point cloud technology, facilitating the implementation and development of 3D point cloud technology in a broader range of practical applications.关键词:3D point cloud;point cloud scene semantic segmentation;deep learning;sampling method;feature extraction1060|2426|0更新时间:2025-07-14
摘要:With the continuous advancement of depth sensing technology, particularly the widespread application of laser scanners across diverse scenarios, 3D point cloud technology is playing a pivotal role in an increasing number of fields. These fields include, but are not limited to, autonomous driving, robotics, geographic information systems, manufacturing, building information modeling, cultural heritage preservation, virtual reality, and augmented reality. As a high-precision, dense, and detailed form of spatial data representation, 3D point clouds can accurately capture various types of information, including the geometric shape, spatial structure, surface texture, and environmental layout of objects. Consequently, the processing, analysis, and comprehension of point cloud data are particularly significant in these applications, particularly point cloud segmentation technology, which serves as the foundation for advanced tasks, such as object recognition, scene understanding, map construction, and dynamic environment monitoring.This study aims to conduct a comprehensive review and in-depth exploration of current mainstream 3D point cloud segmentation methods from multiple perspectives, dissecting the latest advancements in this research domain. In particular, it begins with a detailed analysis and discussion of the fundamentals of 3D point cloud segmentation, covering aspects such as datasets, performance evaluation metrics, sampling methods, and feature extraction techniques. This study summarizes currently publicly available mainstream point cloud datasets, including ShapeNet, Semantic3D, S3DIS, and ScanNet, meticulously dissecting the characteristics, annotation forms, application scenarios, and technical challenges associated with each dataset. In addition, it delves into commonly utilized performance evaluation metrics in the semantic segmentation of point cloud scenes, including overall accuracy, mean class accuracy, and mean intersection over union. These metrics provide effective means for quantifying and comparing model performance, facilitating comprehensive evaluations and improvements across different tasks and scenarios.In the data preprocessing phase, this study systematically summarizes prevalent point cloud sampling strategies. Given that 3D point cloud data typically possess large scales and irregular distributions, a suitable sampling method is essential for reducing computational costs and enhancing model training efficiency. This study introduces strategies, such as farthest point sampling, random sampling, and grid sampling, analyzing their application scenarios, advantages, disadvantages, and specific implementation methods in various tasks. Furthermore, it discusses feature extraction techniques for 3D point clouds, encompassing various methods, including global feature extraction, local feature extraction, and the fusion of global and local features. Through effective feature extraction, more discriminative representations can be provided for subsequent segmentation tasks, aiding the model in improved object recognition and scene understanding.Building on this foundation, this study systematically reviews 3D point cloud segmentation methods from four distinct perspectives: point-based, voxel-based, view-based, and multi-modal fusion methods. First, point-based methods directly process each point within the point cloud, maintaining the high resolution and density of the data while avoiding information loss. Point-based methods are further subdivided into multilayer perceptron (MLP)-based methods, Transformer-based models, graph convolutional network-based methods, and other related approaches. Each category exhibits unique advantages in different application scenarios. For example, MLP is effective for capturing the local features of point clouds, while Transformer-based models excel in handling long-range dependencies and global relationships. Despite the strong performance of point-based methods, their direct processing of a large number of 3D points results in high computational complexity and relatively low efficiency when managing large-scale point cloud scenes.Second, this study presents voxel-based methods, which process point cloud data by partitioning them into regular 3D grids (voxels), effectively reducing data size and simplifying subsequent computations. This approach structures point cloud data, providing relatively stable performance in large-scale scenes. It is particularly applicable to scenarios with large scene sizes but low resolution requirements. However, the inevitable information loss and reduction in spatial resolution during voxelization limit performance in handling fine-grained tasks.Third, the view-based approach processes a 3D point cloud by projecting it onto a 2D plane, leveraging mature 2D image processing techniques and convolutional neural networks. This method transforms the point cloud segmentation task into a traditional image segmentation problem, enhancing processing efficiency, particularly in scenarios where point cloud density is high and rapid processing is required. However, projecting 3D information onto 2D space may lead to the loss of spatial geometric information, resulting in potentially lower accuracy compared with methods that directly handle 3D point clouds in certain applications.Lastly, this study explores multimodal fusion methods, which combine various forms of data, such as point clouds, voxels, and views, fully utilizing the complementarity of different modalities in scene understanding to enhance the accuracy, robustness, and generalization ability of point cloud segmentation.Subsequently, this study conducts a detailed analysis and comparison of the experimental results from different methods. Based on various datasets and performance evaluation metrics, it reveals the strengths and weaknesses of each method in diverse application scenarios. For example, point-based methods excel in fine segmentation tasks and can capture subtle geometric information, while voxel-based and view-based methods offer higher processing efficiency when dealing with large-scale point cloud scenes. Through the comparative analysis of experimental results, this study provides valuable references for point cloud segmentation tasks across different application scenarios.Finally, this study summarizes the major challenges that are currently experienced in the field of 3D point cloud segmentation, including the sparsity and irregularity of point cloud data, the influence of noise and missing points, insufficient generalization ability across diverse scenes, and the demand for real-time processing. This study also anticipates future research directions and proposes measures, such as a deeper understanding of the complex semantic structures of point cloud data through the integration of large language models, the introduction of semi-supervised and unsupervised learning methods to reduce reliance on labeled data, and enhancements in real-time performance and computational efficiency to further advance point cloud segmentation technology. We hope that this comprehensive review can provide a systematic reference for researchers and industrial applications in the field of point cloud technology, facilitating the implementation and development of 3D point cloud technology in a broader range of practical applications.关键词:3D point cloud;point cloud scene semantic segmentation;deep learning;sampling method;feature extraction1060|2426|0更新时间:2025-07-14 - “深度伪造技术研究进展,专家系统归纳检测方法,为识别伪造人脸提供解决方案。”
 摘要:Deepfake technology refers to the synthesis of images, audio, and videos by using deep learning algorithms. This technology enables the precise mapping of facial features or other physical characteristics from one person onto a subject in another video, achieving highly realistic face-swapping effects. With advancements in algorithms and the increased accessibility of computational resources, the threshold for utilizing deepfake technology has gradually lowered, bringing convenience and numerous social and legal challenges. For example, deepfake technology is used to bring deceased actors back to the screen, providing a novel experience to the audience. Meanwhile, it is frequently exploited to impersonate citizens or leaders for fraudulent activities, produce pornographic content, or create fake news to influence public opinion. Consequently, the importance of deepfake detection technology is increasing, making it a significant focus of current research. To detect images and videos synthesized via deepfake technology, researchers must design models that can uncover subtle traces of manipulation within these media. However, accurately identifying these traces remains challenging due to several factors that complicate the detection process. First, rapid advancements in deepfake technology have made differentiating fake images and videos from authentic content increasingly difficult. As techniques such as generative adversarial networks (GANs) and diffusion models continue to evolve and improve, the texture, lighting, and motion within synthesized media become more seamlessly realistic, imposing significant challenges on detection models that seek to recognize subtle cues of manipulation. Second, forgers can employ a variety of countermeasures to obscure traces of manipulation, such as applying compression, cropping, or noise addition. Furthermore, forgers may create adversarial samples that are specifically crafted to exploit and bypass the vulnerability of detection models, making the identification of deepfake even more complex. Thirdly, the generalizability of deepfake detection methods remains a significant hurdle, because different generative techniques leave behind distinct forensic traces. For example, GAN-generated images frequently exhibit prominent grid-like artifacts in the frequency domain, while images produced through diffusion models typically leave only subtle, less detectable traces in this domain. Therefore, detection models that do not exclusively rely on low-level, technique-specific features but instead focus on capturing deep, generalized features that ensure robustness and applicability across diverse forgery types and detection scenarios are crucial. To address these multifaceted challenges, numerous scholars have proposed a variety of detection methods that are designed to capture nuanced traces left by deepfake manipulations. For example, certain approaches focus on identifying subtle forgery artifacts within the frequency domain of images, capitalizing on the distinct spectral anomalies that forgeries frequently introduce. Other methods prioritize assessing temporal consistency across video frames, because unnatural transitions or frame-level inconsistencies can indicate synthesized content. In addition, some detection strategies focus on evaluating synchronization among different modalities within videos, such as audio and visual elements, to detect inconsistencies that may reveal forgery. At present, several review papers in academia have summarized key research and developments within this domain. However, given the rapid advancements in generative artificial intelligence (AI), fake faces created with diffusion models have recently gained popularity, with scarcely any review that addresses the detection of such forgeries. Furthermore, as generative AI progresses continues advancing toward multimodal integration, deepfake detection methods are similarly evolving to incorporate features from multiple modalities. Nonetheless, the majority of existing reviews lack sufficient focus on multimodal detection approaches, underscoring a gap in the literature that this review seeks to address. To provide an up-to-date overview of face deepfake detection, this review first organizes commonly used datasets and evaluation metrics in the field. Then, it divides detection methods into image-level and video-level face deepfake detection. Based on feature selection approaches, image-level methods are categorized into spatial-domain and frequency-domain methods, while video-level methods are categorized into approaches based on spatiotemporal inconsistencies, biological features, and multimodal features. Each category is thoroughly analyzed with regard to its principles, strengths, weaknesses, and developmental trends. Finally, current research status and challenges in face deepfake detection are summarized, and future research directions are discussed. Compared with other related reviews, the novelty of this review lies in its summary of detection methods that specifically targets text-to-image/video generation and multimodal detection methods. This review is aligned with the latest trends in generative AI, offering a comprehensive and up-to-date summary of recent advancements in face deepfake detection. By examining the latest methodologies, including those developed to address forgeries created through advanced techniques, such as diffusion models and multimodal integration, this review reflects the ongoing evolution of detection technology. It highlights the progress made and the challenges that remain, positioning itself as a valuable resource for researchers who aim to navigate and contribute to the cutting-edge developments in this rapidly advancing field. A comprehensive analysis of face deepfake detection methods reveals that current techniques achieve nearly 100% accuracy within the training datasets, particularly those leveraging advanced models, such as Transformers. However, their performance frequently declines significantly in cross-dataset testing, particularly for spatial-domain and frequency-domain detection methods. This decline suggests that these approaches may fail to capture essential, generalizable features that are robust across varying datasets. By contrast, biological feature-based methods demonstrate superior generalization capabilities, successfully adapting to different contexts. However, they require carefully tailored training data and specific application conditions to reach optimal performance. Meanwhile, multimodal detection methods, which integrate features across multiple modalities, offer enhanced robustness and adaptability due to their layered approach. However, this added complexity frequently results in higher computational costs and increased model intricacy. Given the diversity in feature selection, along with the unique advantages and limitations inherent to each detection approach, no single method has yet provided a fully comprehensive solution to the deepfake detection challenge. This reality underscores the critical need for continued research in this evolving field and highlights the importance of this review in mapping current advancements and identifying future research directions.关键词:DeepFake detection;face forgery detection;face image;face video;spatial domain feature;frequency domain feature;temporal features;multimodal features1326|2408|0更新时间:2025-07-14
摘要:Deepfake technology refers to the synthesis of images, audio, and videos by using deep learning algorithms. This technology enables the precise mapping of facial features or other physical characteristics from one person onto a subject in another video, achieving highly realistic face-swapping effects. With advancements in algorithms and the increased accessibility of computational resources, the threshold for utilizing deepfake technology has gradually lowered, bringing convenience and numerous social and legal challenges. For example, deepfake technology is used to bring deceased actors back to the screen, providing a novel experience to the audience. Meanwhile, it is frequently exploited to impersonate citizens or leaders for fraudulent activities, produce pornographic content, or create fake news to influence public opinion. Consequently, the importance of deepfake detection technology is increasing, making it a significant focus of current research. To detect images and videos synthesized via deepfake technology, researchers must design models that can uncover subtle traces of manipulation within these media. However, accurately identifying these traces remains challenging due to several factors that complicate the detection process. First, rapid advancements in deepfake technology have made differentiating fake images and videos from authentic content increasingly difficult. As techniques such as generative adversarial networks (GANs) and diffusion models continue to evolve and improve, the texture, lighting, and motion within synthesized media become more seamlessly realistic, imposing significant challenges on detection models that seek to recognize subtle cues of manipulation. Second, forgers can employ a variety of countermeasures to obscure traces of manipulation, such as applying compression, cropping, or noise addition. Furthermore, forgers may create adversarial samples that are specifically crafted to exploit and bypass the vulnerability of detection models, making the identification of deepfake even more complex. Thirdly, the generalizability of deepfake detection methods remains a significant hurdle, because different generative techniques leave behind distinct forensic traces. For example, GAN-generated images frequently exhibit prominent grid-like artifacts in the frequency domain, while images produced through diffusion models typically leave only subtle, less detectable traces in this domain. Therefore, detection models that do not exclusively rely on low-level, technique-specific features but instead focus on capturing deep, generalized features that ensure robustness and applicability across diverse forgery types and detection scenarios are crucial. To address these multifaceted challenges, numerous scholars have proposed a variety of detection methods that are designed to capture nuanced traces left by deepfake manipulations. For example, certain approaches focus on identifying subtle forgery artifacts within the frequency domain of images, capitalizing on the distinct spectral anomalies that forgeries frequently introduce. Other methods prioritize assessing temporal consistency across video frames, because unnatural transitions or frame-level inconsistencies can indicate synthesized content. In addition, some detection strategies focus on evaluating synchronization among different modalities within videos, such as audio and visual elements, to detect inconsistencies that may reveal forgery. At present, several review papers in academia have summarized key research and developments within this domain. However, given the rapid advancements in generative artificial intelligence (AI), fake faces created with diffusion models have recently gained popularity, with scarcely any review that addresses the detection of such forgeries. Furthermore, as generative AI progresses continues advancing toward multimodal integration, deepfake detection methods are similarly evolving to incorporate features from multiple modalities. Nonetheless, the majority of existing reviews lack sufficient focus on multimodal detection approaches, underscoring a gap in the literature that this review seeks to address. To provide an up-to-date overview of face deepfake detection, this review first organizes commonly used datasets and evaluation metrics in the field. Then, it divides detection methods into image-level and video-level face deepfake detection. Based on feature selection approaches, image-level methods are categorized into spatial-domain and frequency-domain methods, while video-level methods are categorized into approaches based on spatiotemporal inconsistencies, biological features, and multimodal features. Each category is thoroughly analyzed with regard to its principles, strengths, weaknesses, and developmental trends. Finally, current research status and challenges in face deepfake detection are summarized, and future research directions are discussed. Compared with other related reviews, the novelty of this review lies in its summary of detection methods that specifically targets text-to-image/video generation and multimodal detection methods. This review is aligned with the latest trends in generative AI, offering a comprehensive and up-to-date summary of recent advancements in face deepfake detection. By examining the latest methodologies, including those developed to address forgeries created through advanced techniques, such as diffusion models and multimodal integration, this review reflects the ongoing evolution of detection technology. It highlights the progress made and the challenges that remain, positioning itself as a valuable resource for researchers who aim to navigate and contribute to the cutting-edge developments in this rapidly advancing field. A comprehensive analysis of face deepfake detection methods reveals that current techniques achieve nearly 100% accuracy within the training datasets, particularly those leveraging advanced models, such as Transformers. However, their performance frequently declines significantly in cross-dataset testing, particularly for spatial-domain and frequency-domain detection methods. This decline suggests that these approaches may fail to capture essential, generalizable features that are robust across varying datasets. By contrast, biological feature-based methods demonstrate superior generalization capabilities, successfully adapting to different contexts. However, they require carefully tailored training data and specific application conditions to reach optimal performance. Meanwhile, multimodal detection methods, which integrate features across multiple modalities, offer enhanced robustness and adaptability due to their layered approach. However, this added complexity frequently results in higher computational costs and increased model intricacy. Given the diversity in feature selection, along with the unique advantages and limitations inherent to each detection approach, no single method has yet provided a fully comprehensive solution to the deepfake detection challenge. This reality underscores the critical need for continued research in this evolving field and highlights the importance of this review in mapping current advancements and identifying future research directions.关键词:DeepFake detection;face forgery detection;face image;face video;spatial domain feature;frequency domain feature;temporal features;multimodal features1326|2408|0更新时间:2025-07-14
Review

- “在3D视觉领域,研究者提出了基于外部迭代分数模型的点云去噪方法,有效提高了去噪精度和速度。”
 摘要:ObjectivePoint cloud data play an irreplaceable role as important means of environmental sensing and spatial representation in a variety of fields, such as autonomous driving, robotics, and 3D reconstruction. A point cloud is a form of data that represents a discrete set of points on the surface of an object in space by means of 3D coordinates. It is typically captured using 3D imaging sensors, such as LiDAR and depth cameras. These sensors can efficiently acquire spatial information in the environment, providing critical data support for applications, such as environment sensing for self-driving vehicles, autonomous navigation for robots, and 3D reconstruction of complex scenes. However, the process of acquiring point cloud data is frequently subject to multiple influences from the sensor’s performance, environmental conditions, and external disturbances. In such case, the acquired point cloud data may contain a large amount of noise, which is manifested as a deviation of discrete point positions, redundant points, or missing point information. This condition negatively affects subsequent tasks. Therefore, the effective denoising of noisy point cloud data has become a fundamental and extremely important research problem in the field of point clouds. Traditional denoising methods typically rely on geometric processing techniques to identify and remove noisy points by analyzing the geometric properties of the local neighborhood. However, in complex real-world scenarios, traditional methods frequently experience difficulty in achieving satisfactory results when dealing with large-scale data, nonuniformly distributed noise, and fast denoising in dynamic scenarios. For this reason, an increasing number of studies have begun to combine deep learning methods with design denoising algorithms that can efficiently deal with large-scale noisy point cloud data by taking advantage of the 3D structural properties of point clouds. These methods cannot only significantly improve denoising accuracy but also handle multiple types of noise and retain important structural information in a point cloud. At present, deep learning-based methods typically train neural networks to predict point displacements and then move noisy points to a clean surface below. However, such algorithms either have a long iteration time or suffer from over-convergence or a large deviation of displacement when moving points to a clean surface, affecting denoising performance. To improve denoising accuracy and speed, this study proposes point cloud denoising based on an external iterative fractional model.MethodFirst, the input noisy point cloud is chunked and divided into parts to be inputted into the network. Next, the part of the point cloud with noise is inputted into the feature extraction module, through which the features of a point cloud are extracted. Then, the features are inputted into the score estimation unit to obtain the score of the point cloud. Considering that the iteration time of the score model is too long, we add the method of momentum gradient ascent to accelerate the iteration of the point cloud. Finally, the denoised part of the point cloud is spliced together to form a complete denoised point cloud. After the denoised point cloud is obtained, it is used as the input for the next denoising, and the above operations are repeated. The model in this study is set with four external iterations as the total denoising process. Among them, the external iteration is a complete point cloud denoising process that includes a series of complete operations, such as point cloud chunking, feature extraction, and score estimation. By contrast, internal iteration refers to the multiple shifts of noise points by the estimated scores in the score estimation model. In this study, the operation that originally requires a large number of internal iterations is transformed into a limited number of external iterations, accelerating denoising speed.ResultThe experiments are compared with seven models, namely, point clean net(PCN), graph-convolutional point cloud denoising network(GPDNet), DMRDenoise, PDFlow, Pointfilter, Scoredenoise, and IterativePFN, in 1%, 2%, and 3% noise for the point cloud upsampling(PU) datasets 10 K and 50 K point clouds. The model is optimal in the evaluation metrics, Chamfer distance (CD) and point-to-mesh distance (P2M) (lower values are better). A comparison of scene denoising is performed on the RueMadame dataset, which contains only noisy scanned data, and thus, we only consider visual results. After denoising by using our method, the least noise is left in the scene. Thereafter, denoising time comparison is performed on this dataset, and our method reduces time by nearly 30% compared with the model with the third-place performance, which is similar to the time of the model with the second-place performance. We then perform a comparison of generalizability on the PC dataset of 10 K and 50 K point clouds with 3% noise. Our method also has the lowest CD and P2M values. Finally, we perform a series of ablation experiments to demonstrate the effectiveness of our model. All the aforementioned experiments are tested on NVIDIA GeForce RTX 4090 graphics processing unit to ensure their fairness and impartiality.ConclusionThe point cloud denoising model proposed in this study exhibits better denoising accuracy and faster denoising speed compared with other methods. In the future, we hope to apply our network architecture to other tasks, such as point cloud up-sampling and complementation.关键词:point cloud denoising;external iterative;score model;momentum gradient ascent;deep learning370|426|0更新时间:2025-07-14
摘要:ObjectivePoint cloud data play an irreplaceable role as important means of environmental sensing and spatial representation in a variety of fields, such as autonomous driving, robotics, and 3D reconstruction. A point cloud is a form of data that represents a discrete set of points on the surface of an object in space by means of 3D coordinates. It is typically captured using 3D imaging sensors, such as LiDAR and depth cameras. These sensors can efficiently acquire spatial information in the environment, providing critical data support for applications, such as environment sensing for self-driving vehicles, autonomous navigation for robots, and 3D reconstruction of complex scenes. However, the process of acquiring point cloud data is frequently subject to multiple influences from the sensor’s performance, environmental conditions, and external disturbances. In such case, the acquired point cloud data may contain a large amount of noise, which is manifested as a deviation of discrete point positions, redundant points, or missing point information. This condition negatively affects subsequent tasks. Therefore, the effective denoising of noisy point cloud data has become a fundamental and extremely important research problem in the field of point clouds. Traditional denoising methods typically rely on geometric processing techniques to identify and remove noisy points by analyzing the geometric properties of the local neighborhood. However, in complex real-world scenarios, traditional methods frequently experience difficulty in achieving satisfactory results when dealing with large-scale data, nonuniformly distributed noise, and fast denoising in dynamic scenarios. For this reason, an increasing number of studies have begun to combine deep learning methods with design denoising algorithms that can efficiently deal with large-scale noisy point cloud data by taking advantage of the 3D structural properties of point clouds. These methods cannot only significantly improve denoising accuracy but also handle multiple types of noise and retain important structural information in a point cloud. At present, deep learning-based methods typically train neural networks to predict point displacements and then move noisy points to a clean surface below. However, such algorithms either have a long iteration time or suffer from over-convergence or a large deviation of displacement when moving points to a clean surface, affecting denoising performance. To improve denoising accuracy and speed, this study proposes point cloud denoising based on an external iterative fractional model.MethodFirst, the input noisy point cloud is chunked and divided into parts to be inputted into the network. Next, the part of the point cloud with noise is inputted into the feature extraction module, through which the features of a point cloud are extracted. Then, the features are inputted into the score estimation unit to obtain the score of the point cloud. Considering that the iteration time of the score model is too long, we add the method of momentum gradient ascent to accelerate the iteration of the point cloud. Finally, the denoised part of the point cloud is spliced together to form a complete denoised point cloud. After the denoised point cloud is obtained, it is used as the input for the next denoising, and the above operations are repeated. The model in this study is set with four external iterations as the total denoising process. Among them, the external iteration is a complete point cloud denoising process that includes a series of complete operations, such as point cloud chunking, feature extraction, and score estimation. By contrast, internal iteration refers to the multiple shifts of noise points by the estimated scores in the score estimation model. In this study, the operation that originally requires a large number of internal iterations is transformed into a limited number of external iterations, accelerating denoising speed.ResultThe experiments are compared with seven models, namely, point clean net(PCN), graph-convolutional point cloud denoising network(GPDNet), DMRDenoise, PDFlow, Pointfilter, Scoredenoise, and IterativePFN, in 1%, 2%, and 3% noise for the point cloud upsampling(PU) datasets 10 K and 50 K point clouds. The model is optimal in the evaluation metrics, Chamfer distance (CD) and point-to-mesh distance (P2M) (lower values are better). A comparison of scene denoising is performed on the RueMadame dataset, which contains only noisy scanned data, and thus, we only consider visual results. After denoising by using our method, the least noise is left in the scene. Thereafter, denoising time comparison is performed on this dataset, and our method reduces time by nearly 30% compared with the model with the third-place performance, which is similar to the time of the model with the second-place performance. We then perform a comparison of generalizability on the PC dataset of 10 K and 50 K point clouds with 3% noise. Our method also has the lowest CD and P2M values. Finally, we perform a series of ablation experiments to demonstrate the effectiveness of our model. All the aforementioned experiments are tested on NVIDIA GeForce RTX 4090 graphics processing unit to ensure their fairness and impartiality.ConclusionThe point cloud denoising model proposed in this study exhibits better denoising accuracy and faster denoising speed compared with other methods. In the future, we hope to apply our network architecture to other tasks, such as point cloud up-sampling and complementation.关键词:point cloud denoising;external iterative;score model;momentum gradient ascent;deep learning370|426|0更新时间:2025-07-14 - “在软件图形用户界面设计领域,研究者提出了基于Transformer的图标生成方法IconFormer,有效提升了图标设计的效率和创新性。”
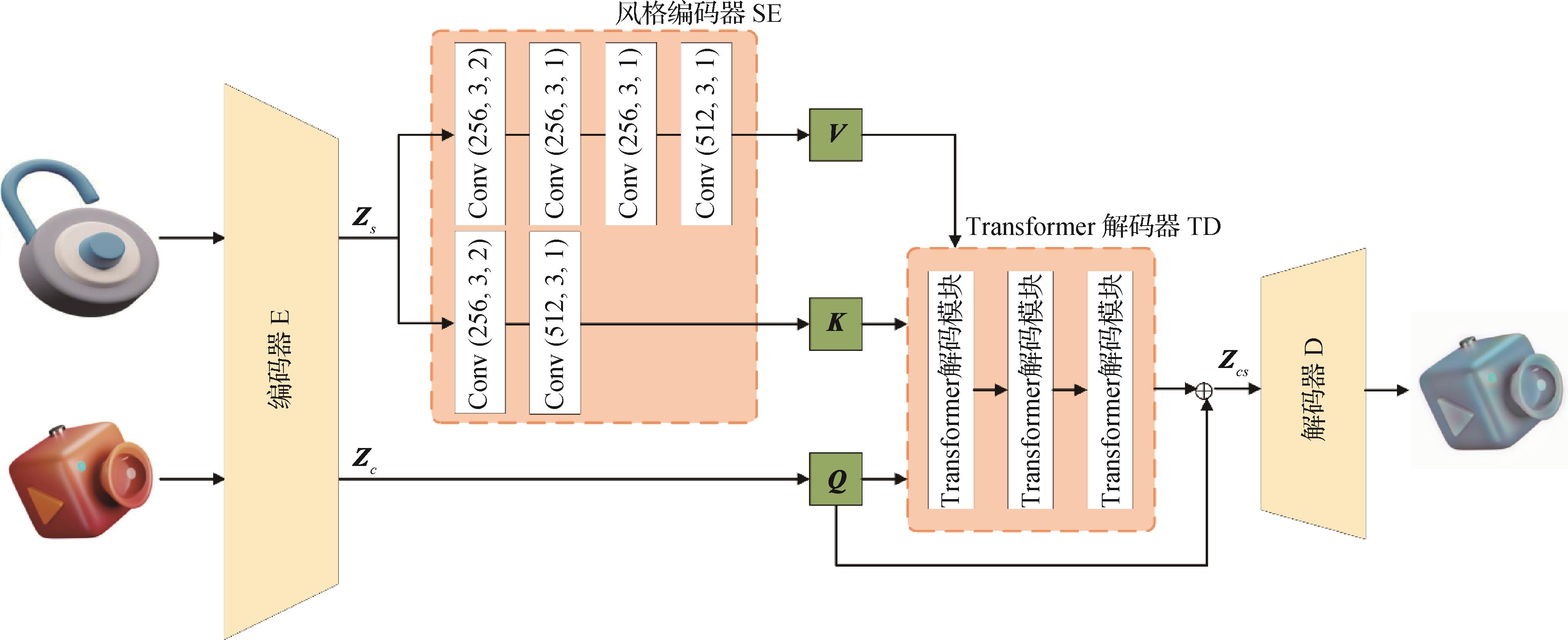 摘要:ObjectiveIcons are essential components for the graphical user interface (GUI) design of software or web sites because they can quickly and directly convey their meaning to users through visual information, improving the usability of software and websites. However, manually creating a large number of icon images with a consistent style and a harmonious color scheme is a labor-exhaustive and time-expensive procedure. Moreover, professional artists are required to do this job. Therefore, researchers have explored methods for automatically generating icons by using deep learning models to improve the efficiency of GUI design in software. Several state-of-the-art icon generation methods have been proposed in recent years. However, some of these methods based on generative adversarial networks suffer from the problem of insufficient diversity in the generated icons, while some of these methods require users to provide initial icon sketches or color prompts as auxiliary inputs, increasing the complexity of the generation process. Therefore, this study proposes a novel icon generation method based on Transformer and convolutional neural network (CNN), with which new icons can be generated based on given pair of content icon and style icon. In this manner, icons can be generated more efficiently and flexibly than in previous methods with better quality. The proposed model in this study, called IconFormer, can effectively establish the relationship between content and style through Transformer and avoid the problems of missing local detail information of the content and insufficient stylization.MethodThis study proposes an icon generation model, called IconFormer, based on deep neural networks. The network architecture is composed of a feature encoder based on VGG, a style encoder based on CNNs, a multilayer Transformer decoder, and a CNN decoder. The style encoder is designed to discover more style information from style features. The Transformer decoder achieves a high degree of integration between content encoding and style encoding. To train and test the proposed icon generation model, this study collects a high-quality dataset that contains 43 741 icon images, comprising icons of different styles, categories, and structures. The icon dataset is organized into pairs, with each pair containing a content icon and a style icon. The dataset is divided into a training set and a testing set, following a ratio of 9∶1. The content and style features are first extracted from the input content icon and style icon with the ImageNet pretrained VGG19 encoder, and then the style features are further encoded into style key K and style value V with the style encoder. Subsequently, the content features as Q, style key K, and style value V are inputted into the multilayer Transformer decoder for feature fusion. Finally, the fused features are decoded into a stylized new icon with the CNN decoder. A new loss function integrated by content loss, style loss, identity loss, and gradient loss is adopted to optimize network parameters.ResultThe proposed IconFormer is evaluated on the icon dataset and compared with previous state-of-the-art methods under the same configuration. These state-of-the-art methods include AdaIN(adaptive instance normalization), ArtFlow, StyleFormer, StyTr2(style transfer transformer), CAP-VSTNet(content affinity preserved versatile style transfer network), and S2WAT(strips window attention Transformer). The experimental results suggest that the icons generated by the proposed IconFormer are more complete in color and structure than those generated by the previous methods. The icons generated by AdaIN, ArtFlow, and StyleFormer demonstrate content loss and insufficient stylization in different extents. StyTr2 cannot effectively distinguish the primary structure from background information of an icon, and most of the background of its generated icons are colorized. The quantitative analysis results show that the proposed IconFormer outperforms previous methods in terms of content and gradient differences. AdaIN results in the highest content difference, indicating that this method exhibits content loss, while ArtFlow presents the highest style difference, indicating that this method cannot effectively stylize content icons. Several ablation experiments are conducted to verify the effectiveness of the feature encoder, style encoder, and loss function definition in the icon generation process. The result shows that the VGG feature extractor, style encoder, and integrated loss function with gradient loss have positive effects on the resulting icons. Additional experiments are conducted to generate a set of icons with a unified style, and the results show that IconFormer is extremely convenient to generate a set of icons with a consistent style, harmonious colors, and high quality.ConclusionThe icon generation model, IconFormer, based on CNNs and Transformer proposed in this study combines the advantages of CNNs and Transformers, and thus can generate new icons with high quality and efficiency, saving time and labor cost for the GUI design of software or websites.关键词:icon generation;image style transfer;convolutional neural network(CNN);Transformer;self-attention mechanism418|376|0更新时间:2025-07-14
摘要:ObjectiveIcons are essential components for the graphical user interface (GUI) design of software or web sites because they can quickly and directly convey their meaning to users through visual information, improving the usability of software and websites. However, manually creating a large number of icon images with a consistent style and a harmonious color scheme is a labor-exhaustive and time-expensive procedure. Moreover, professional artists are required to do this job. Therefore, researchers have explored methods for automatically generating icons by using deep learning models to improve the efficiency of GUI design in software. Several state-of-the-art icon generation methods have been proposed in recent years. However, some of these methods based on generative adversarial networks suffer from the problem of insufficient diversity in the generated icons, while some of these methods require users to provide initial icon sketches or color prompts as auxiliary inputs, increasing the complexity of the generation process. Therefore, this study proposes a novel icon generation method based on Transformer and convolutional neural network (CNN), with which new icons can be generated based on given pair of content icon and style icon. In this manner, icons can be generated more efficiently and flexibly than in previous methods with better quality. The proposed model in this study, called IconFormer, can effectively establish the relationship between content and style through Transformer and avoid the problems of missing local detail information of the content and insufficient stylization.MethodThis study proposes an icon generation model, called IconFormer, based on deep neural networks. The network architecture is composed of a feature encoder based on VGG, a style encoder based on CNNs, a multilayer Transformer decoder, and a CNN decoder. The style encoder is designed to discover more style information from style features. The Transformer decoder achieves a high degree of integration between content encoding and style encoding. To train and test the proposed icon generation model, this study collects a high-quality dataset that contains 43 741 icon images, comprising icons of different styles, categories, and structures. The icon dataset is organized into pairs, with each pair containing a content icon and a style icon. The dataset is divided into a training set and a testing set, following a ratio of 9∶1. The content and style features are first extracted from the input content icon and style icon with the ImageNet pretrained VGG19 encoder, and then the style features are further encoded into style key K and style value V with the style encoder. Subsequently, the content features as Q, style key K, and style value V are inputted into the multilayer Transformer decoder for feature fusion. Finally, the fused features are decoded into a stylized new icon with the CNN decoder. A new loss function integrated by content loss, style loss, identity loss, and gradient loss is adopted to optimize network parameters.ResultThe proposed IconFormer is evaluated on the icon dataset and compared with previous state-of-the-art methods under the same configuration. These state-of-the-art methods include AdaIN(adaptive instance normalization), ArtFlow, StyleFormer, StyTr2(style transfer transformer), CAP-VSTNet(content affinity preserved versatile style transfer network), and S2WAT(strips window attention Transformer). The experimental results suggest that the icons generated by the proposed IconFormer are more complete in color and structure than those generated by the previous methods. The icons generated by AdaIN, ArtFlow, and StyleFormer demonstrate content loss and insufficient stylization in different extents. StyTr2 cannot effectively distinguish the primary structure from background information of an icon, and most of the background of its generated icons are colorized. The quantitative analysis results show that the proposed IconFormer outperforms previous methods in terms of content and gradient differences. AdaIN results in the highest content difference, indicating that this method exhibits content loss, while ArtFlow presents the highest style difference, indicating that this method cannot effectively stylize content icons. Several ablation experiments are conducted to verify the effectiveness of the feature encoder, style encoder, and loss function definition in the icon generation process. The result shows that the VGG feature extractor, style encoder, and integrated loss function with gradient loss have positive effects on the resulting icons. Additional experiments are conducted to generate a set of icons with a unified style, and the results show that IconFormer is extremely convenient to generate a set of icons with a consistent style, harmonious colors, and high quality.ConclusionThe icon generation model, IconFormer, based on CNNs and Transformer proposed in this study combines the advantages of CNNs and Transformers, and thus can generate new icons with high quality and efficiency, saving time and labor cost for the GUI design of software or websites.关键词:icon generation;image style transfer;convolutional neural network(CNN);Transformer;self-attention mechanism418|376|0更新时间:2025-07-14
Image Processing and Coding
- “在目标检测领域,ASAHI算法针对高分辨率图像中小目标检测难题,通过自适应调整切片数量减少冗余计算,提高检测精度和速度。”
 摘要:ObjectiveObject detection has attracted considerable attention because of its wide application in various fields. In recent years, the progress of deep learning technology has facilitated the development of object detection algorithms combined with deep convolutional neural networks. In natural scenes, traditional object detectors have achieved excellent results. However, current object detection algorithms still encounter difficulties in small object detection. The reason is that most aerial images refer to complex high-resolution scenes, and some common problems, such as high density, unfixed shooting angle, small size, and high variability of targets, have introduced great challenges to existing object detection methods. Thus, small object detection has emerged as a key area in the field of object detection research. Its broad applications mainly include identification of early small lesions and masses in medical imaging, remote sensing exploration in military operations, and location analysis of small defects in industrial production. Some researchers have obtained high-resolution image features through multiple up-sampling operations, while another set of approaches effectively deals with problems such as high intensity by adding a penalty item in the post-processing stage. Among them, one excellent work is the use of slicing strategy, which slices the image into smaller image blocks to enlarge the receptive field. However, the existing slicing-based methods involve redundant computation that increases the calculation cost and reduces the detection speed.MethodTherefore, a new adaptive slicing method, which is called adaptive slicing-aided hyper inference (ASAHI), is proposed in this study. This approach focuses on the number of slices rather than the traditional slice size. The approach can adaptively adjust the number of slices according to the image resolution to reduce the performance loss caused by redundant calculation. Specifically, in the inference stage, the work first divides the input image into 6 or 12 overlapping patches using the ASAHI algorithm. Then, it interpolates each image patch to maintain the aspect ratio. Next, considering the obvious defects of the slicing strategy in detecting large objects, this method separately performs forward computation on the sliced image patches and the complete input image. Finally, the post-processing stage integrates a faster and efficient Cluster-NMS method and DIoU penalty term to improve accuracy and detection speed in high-density scenes. This method, which is called Cluster-DIoU-NMS(CDN), merges the ASAHI inference and full-image inference results and resizes them back to the original image size. Correspondingly, the dataset constructed in the training stage also includes slice image blocks to support the ASAHI inference. The dataset of slicing images and the pre-training dataset of the entire images together constitute the fine-tuning dataset for the training of this work. Notably, the slicing method used in the fine-tuning dataset can be either the ASAHI algorithm or the conventional sliding window method. In the ASAHI slicing process, this method sets a distinction threshold to control the number of slices . If the length or width of the image exceeds this threshold, then the image will be cut into total 12 slices; otherwise, it will be cut into total 6 slices. Thereafter, the width and height of the slice block are calculated according to the value of , and the coordinate position of the slice is determined. After the abovementioned calculation, the ASAHI algorithm realizes the adaptive adjustment of slice size within a limited range by controlling the number of slices.ResultBroad experiments demonstrate that ASAHI exhibits competitive performance on the VisDrone and xView datasets. The results show that the proposed method achieves the highest mAP50 scores (45.6% and 22.7%) and fast inference speeds (4.88 images per second and 3.58 images per second) on both datasets. In addition, the mAP and mAP75 increase by 1.7% and 1.1%, respectively, on the VisDrone2019-DET-test dataset. Meanwhile, the mAP and mAP75 improve by 1.43% and 0.9%, respectively, on the xView test set. On the VisDrone2019-dt-val dataset, the mAP50 of the experiment exceeds 56.8%. Compared with state of the art, the proposed method achieves the highest mAP (36.0%), mAP75 (28.2%), and mAP50 (56.8%) values, with a highest processing speed of 5.26 images per second, which suggests a better balance performance.ConclusionThe proposed algorithm can effectively handle complex factors, such as high density, different shooting angles, and high variability, in high-resolution scenes. It can also achieve high-quality detection of small objects.关键词:object detection;small object detection;sliced inference;VisDrone;xView213|505|0更新时间:2025-07-14
摘要:ObjectiveObject detection has attracted considerable attention because of its wide application in various fields. In recent years, the progress of deep learning technology has facilitated the development of object detection algorithms combined with deep convolutional neural networks. In natural scenes, traditional object detectors have achieved excellent results. However, current object detection algorithms still encounter difficulties in small object detection. The reason is that most aerial images refer to complex high-resolution scenes, and some common problems, such as high density, unfixed shooting angle, small size, and high variability of targets, have introduced great challenges to existing object detection methods. Thus, small object detection has emerged as a key area in the field of object detection research. Its broad applications mainly include identification of early small lesions and masses in medical imaging, remote sensing exploration in military operations, and location analysis of small defects in industrial production. Some researchers have obtained high-resolution image features through multiple up-sampling operations, while another set of approaches effectively deals with problems such as high intensity by adding a penalty item in the post-processing stage. Among them, one excellent work is the use of slicing strategy, which slices the image into smaller image blocks to enlarge the receptive field. However, the existing slicing-based methods involve redundant computation that increases the calculation cost and reduces the detection speed.MethodTherefore, a new adaptive slicing method, which is called adaptive slicing-aided hyper inference (ASAHI), is proposed in this study. This approach focuses on the number of slices rather than the traditional slice size. The approach can adaptively adjust the number of slices according to the image resolution to reduce the performance loss caused by redundant calculation. Specifically, in the inference stage, the work first divides the input image into 6 or 12 overlapping patches using the ASAHI algorithm. Then, it interpolates each image patch to maintain the aspect ratio. Next, considering the obvious defects of the slicing strategy in detecting large objects, this method separately performs forward computation on the sliced image patches and the complete input image. Finally, the post-processing stage integrates a faster and efficient Cluster-NMS method and DIoU penalty term to improve accuracy and detection speed in high-density scenes. This method, which is called Cluster-DIoU-NMS(CDN), merges the ASAHI inference and full-image inference results and resizes them back to the original image size. Correspondingly, the dataset constructed in the training stage also includes slice image blocks to support the ASAHI inference. The dataset of slicing images and the pre-training dataset of the entire images together constitute the fine-tuning dataset for the training of this work. Notably, the slicing method used in the fine-tuning dataset can be either the ASAHI algorithm or the conventional sliding window method. In the ASAHI slicing process, this method sets a distinction threshold to control the number of slices . If the length or width of the image exceeds this threshold, then the image will be cut into total 12 slices; otherwise, it will be cut into total 6 slices. Thereafter, the width and height of the slice block are calculated according to the value of , and the coordinate position of the slice is determined. After the abovementioned calculation, the ASAHI algorithm realizes the adaptive adjustment of slice size within a limited range by controlling the number of slices.ResultBroad experiments demonstrate that ASAHI exhibits competitive performance on the VisDrone and xView datasets. The results show that the proposed method achieves the highest mAP50 scores (45.6% and 22.7%) and fast inference speeds (4.88 images per second and 3.58 images per second) on both datasets. In addition, the mAP and mAP75 increase by 1.7% and 1.1%, respectively, on the VisDrone2019-DET-test dataset. Meanwhile, the mAP and mAP75 improve by 1.43% and 0.9%, respectively, on the xView test set. On the VisDrone2019-dt-val dataset, the mAP50 of the experiment exceeds 56.8%. Compared with state of the art, the proposed method achieves the highest mAP (36.0%), mAP75 (28.2%), and mAP50 (56.8%) values, with a highest processing speed of 5.26 images per second, which suggests a better balance performance.ConclusionThe proposed algorithm can effectively handle complex factors, such as high density, different shooting angles, and high variability, in high-resolution scenes. It can also achieve high-quality detection of small objects.关键词:object detection;small object detection;sliced inference;VisDrone;xView213|505|0更新时间:2025-07-14 - “最新研究突破了传统户型平面图矢量化技术,通过引导集扩散模型提升墙体矢量化精度,为建筑与家居设计提供可靠技术支持。”
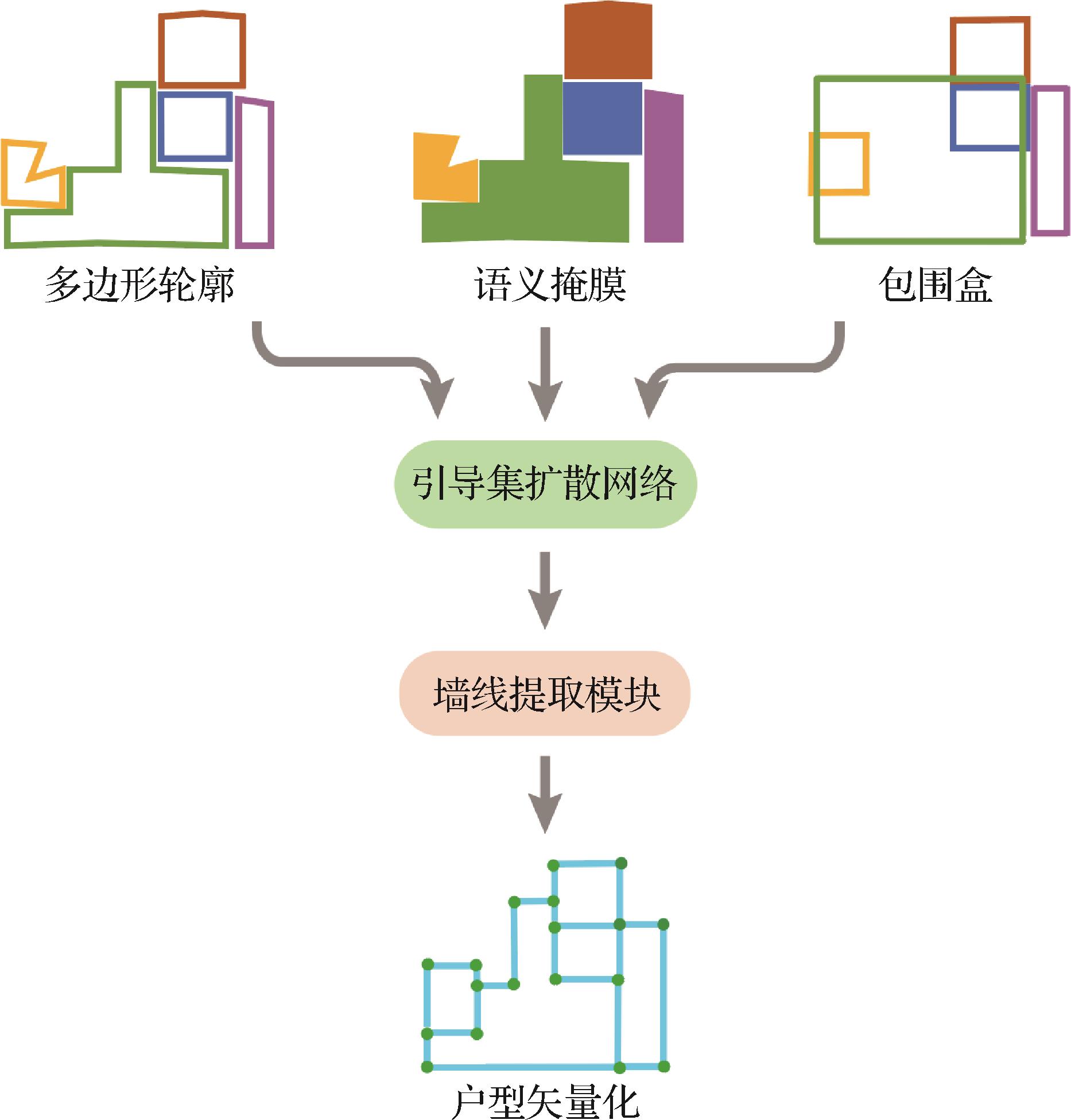 摘要:ObjectiveIndoor floor plan vectorization is a sophisticated technique that aims to extract precise structural information from raster images and convert them into vector representations. This process is essential in fields, such as architectural renovation, interior design, and scene understanding, where the accurate and efficient vectorization of floor plans can considerably enhance the quality and usability of spatial data. The vectorization process has been traditionally performed using a two-stage pipeline. In the first stage, deep neural networks are used to segment the raster image, producing masks that define room regions within the floor plan. These masks serve as the foundation for the subsequent vectorization process. In the second stage, post-processing algorithms are applied to these masks to extract vector information, with focus on elements, such as walls, doors, and other structural components. However, this process also poses challenges. One of the major issues is error accumulation. Inaccuracies in initial mask generation can lead to compounded errors during vectorization. Moreover, post-processing algorithms frequently lack robustness, particularly when dealing with complex or degraded input images, leading to suboptimal vectorization results.MethodTo address these challenges, we propose a novel approach based on diffusion models for the vector reconstruction of indoor floor plans. Diffusion models, which were originally developed for generative tasks, have exhibited considerable promise in producing high-quality output by iteratively refining input data. Our method leverages this capability to enhance the precision of floor plan vectorization. In particular, the algorithm starts with rough masks generated using object detection or instance segmentation models. Although these masks provide a basic outline of room regions, they may lack the accuracy required for precise vectorization. The diffusion model is then employed to iteratively refine the contour points of these rough masks, gradually reconstructing room contours with higher accuracy. This process involves multiple iterations, during which the model adjusts the contour points based on patterns learned from the training data, leading to a more accurate representation of room boundaries. A key innovation of our approach is the introduction of a contour inclination loss function. This loss function is specifically designed to guide the diffusion model in generating more reasonable and structurally sound room layouts. By penalizing unrealistic or impractical contour inclinations, the model is encouraged to produce output that closely resembles real-world room configurations. This process not only improves the visual accuracy of room contours but also enhances the overall quality of the vectorized floor plan. The benefits of our diffusion model-based approach are manifold. First, we can significantly reduce the error accumulation that plagues traditional methods by refining room contours before the vectorization stage. The more accurate the room contours, the more precise the subsequent wall vector extraction process. Second, the use of a diffusion model allows for a more robust handling of complex or noisy input images. In contrast with traditional post-processing algorithms, which may experience difficulty with irregularities in the input data, the diffusion model’s iterative refinement process is better equipped to address such challenges, leading to more reliable vectorization results.ResultWe have thoroughly validated our method on the public CubiCase5K dataset, which is a widely used benchmark in the field of floor plan vectorization. The results of our experiments demonstrate that our approach significantly outperforms existing methods in terms of accuracy and robustness. Notably, we observe a marked improvement in the precision of wall vector extraction, which is crucial for applications in architectural renovation and interior design. The diffusion model’s ability to produce more accurate room contours directly translates into better vectorized representations of floor plans, making our approach an invaluable tool for professionals in these fields.ConclusionIn conclusion, the vectorization of indoor floor plans is a critical task with far-reaching applications, and the limitations of traditional methods have highlighted the need for more advanced techniques. Our diffusion model-based algorithm represents a significant step forward, offering a more accurate and reliable solution for the vector reconstruction of indoor floor plans. By refining room contours through iterative adjustments and incorporating a contour inclination loss function, our method not only addresses the issue of error accumulation but also enhances the overall quality of the vectorized output. Furthermore, our method exhibits broad application prospects in the field of interior design. Modern interior designers increasingly rely on digital tools for design and planning, wherein accurate indoor space representation is essential. With our method, designers can quickly generate high-quality room outlines and apply them to various design scenarios, such as furniture placement, lighting design, and space optimization. This efficient and precise vectorization technology not only saves designers significant time but also improves the feasibility and practicality of design solutions. In the field of building renovation, our approach also offers significant advantages. During the renovation of old buildings, redrawing and optimizing the original floor plan are frequently necessary. This process is often constrained by the quality of the original drawings, particularly in older buildings, where the original plans may have already deteriorated or been lost. Through our diffusion model vectorization method, architects can quickly reconstruct digital versions of these old floor plans and use them as a foundation for renovation designs. This step not only improves the efficiency of the renovation process but also helps preserve the historical character of the building. Lastly, our method demonstrates important application potential in the field of architectural scene understanding. With the rise of smart homes and automated building management systems, accurate interior floor plan data are critical for enabling these intelligent features. Our vectorization method can generate highly accurate representations of indoor spaces, providing reliable foundational data for intelligent systems. Overall, our approach promises to significantly improve the efficiency and effectiveness of floor plan vectorization, paving the way for more accurate architectural designs and enhanced spatial understanding.关键词:deep learning;indoor floor plan;generated reconstruction;diffusion model;floorplan vector technology321|737|0更新时间:2025-07-14
摘要:ObjectiveIndoor floor plan vectorization is a sophisticated technique that aims to extract precise structural information from raster images and convert them into vector representations. This process is essential in fields, such as architectural renovation, interior design, and scene understanding, where the accurate and efficient vectorization of floor plans can considerably enhance the quality and usability of spatial data. The vectorization process has been traditionally performed using a two-stage pipeline. In the first stage, deep neural networks are used to segment the raster image, producing masks that define room regions within the floor plan. These masks serve as the foundation for the subsequent vectorization process. In the second stage, post-processing algorithms are applied to these masks to extract vector information, with focus on elements, such as walls, doors, and other structural components. However, this process also poses challenges. One of the major issues is error accumulation. Inaccuracies in initial mask generation can lead to compounded errors during vectorization. Moreover, post-processing algorithms frequently lack robustness, particularly when dealing with complex or degraded input images, leading to suboptimal vectorization results.MethodTo address these challenges, we propose a novel approach based on diffusion models for the vector reconstruction of indoor floor plans. Diffusion models, which were originally developed for generative tasks, have exhibited considerable promise in producing high-quality output by iteratively refining input data. Our method leverages this capability to enhance the precision of floor plan vectorization. In particular, the algorithm starts with rough masks generated using object detection or instance segmentation models. Although these masks provide a basic outline of room regions, they may lack the accuracy required for precise vectorization. The diffusion model is then employed to iteratively refine the contour points of these rough masks, gradually reconstructing room contours with higher accuracy. This process involves multiple iterations, during which the model adjusts the contour points based on patterns learned from the training data, leading to a more accurate representation of room boundaries. A key innovation of our approach is the introduction of a contour inclination loss function. This loss function is specifically designed to guide the diffusion model in generating more reasonable and structurally sound room layouts. By penalizing unrealistic or impractical contour inclinations, the model is encouraged to produce output that closely resembles real-world room configurations. This process not only improves the visual accuracy of room contours but also enhances the overall quality of the vectorized floor plan. The benefits of our diffusion model-based approach are manifold. First, we can significantly reduce the error accumulation that plagues traditional methods by refining room contours before the vectorization stage. The more accurate the room contours, the more precise the subsequent wall vector extraction process. Second, the use of a diffusion model allows for a more robust handling of complex or noisy input images. In contrast with traditional post-processing algorithms, which may experience difficulty with irregularities in the input data, the diffusion model’s iterative refinement process is better equipped to address such challenges, leading to more reliable vectorization results.ResultWe have thoroughly validated our method on the public CubiCase5K dataset, which is a widely used benchmark in the field of floor plan vectorization. The results of our experiments demonstrate that our approach significantly outperforms existing methods in terms of accuracy and robustness. Notably, we observe a marked improvement in the precision of wall vector extraction, which is crucial for applications in architectural renovation and interior design. The diffusion model’s ability to produce more accurate room contours directly translates into better vectorized representations of floor plans, making our approach an invaluable tool for professionals in these fields.ConclusionIn conclusion, the vectorization of indoor floor plans is a critical task with far-reaching applications, and the limitations of traditional methods have highlighted the need for more advanced techniques. Our diffusion model-based algorithm represents a significant step forward, offering a more accurate and reliable solution for the vector reconstruction of indoor floor plans. By refining room contours through iterative adjustments and incorporating a contour inclination loss function, our method not only addresses the issue of error accumulation but also enhances the overall quality of the vectorized output. Furthermore, our method exhibits broad application prospects in the field of interior design. Modern interior designers increasingly rely on digital tools for design and planning, wherein accurate indoor space representation is essential. With our method, designers can quickly generate high-quality room outlines and apply them to various design scenarios, such as furniture placement, lighting design, and space optimization. This efficient and precise vectorization technology not only saves designers significant time but also improves the feasibility and practicality of design solutions. In the field of building renovation, our approach also offers significant advantages. During the renovation of old buildings, redrawing and optimizing the original floor plan are frequently necessary. This process is often constrained by the quality of the original drawings, particularly in older buildings, where the original plans may have already deteriorated or been lost. Through our diffusion model vectorization method, architects can quickly reconstruct digital versions of these old floor plans and use them as a foundation for renovation designs. This step not only improves the efficiency of the renovation process but also helps preserve the historical character of the building. Lastly, our method demonstrates important application potential in the field of architectural scene understanding. With the rise of smart homes and automated building management systems, accurate interior floor plan data are critical for enabling these intelligent features. Our vectorization method can generate highly accurate representations of indoor spaces, providing reliable foundational data for intelligent systems. Overall, our approach promises to significantly improve the efficiency and effectiveness of floor plan vectorization, paving the way for more accurate architectural designs and enhanced spatial understanding.关键词:deep learning;indoor floor plan;generated reconstruction;diffusion model;floorplan vector technology321|737|0更新时间:2025-07-14 - “在微表情识别领域,专家提出了深度卷积神经网络与浅层3DCNN组成的三分支网络,显著提高了识别精确度,有效解决了样本不足、难以学习多类型特征的问题。”
 摘要:ObjectiveMicro-expressions are involuntary, brief facial movements that occur when individuals experience certain emotions, often revealing their genuine feelings despite effort to conceal them. Recognizing these expressions is valuable in a variety of real-world applications. Traditional methods for micro-expression recognition typically rely on handcrafted features combined with classical machine learning techniques, which extract feature descriptors from original images. However, these methods frequently struggle with subtle and fast spatiotemporal changes inherent in micro-expressions, leading to suboptimal recognition accuracy. Optical flow is a common technique used for micro-expression recognition because it captures small motion changes and focuses on spatiotemporal information. Despite their advantages, optical flow-based methods are computationally expensive, requiring substantial resources for video processing. In addition, issues such as unclear boundaries between expression categories and limited sample sizes in datasets challenge the performance of current deep learning models, such as the 3D convolutional neural network (3DCNN), which may struggle with feature learning, generalization, and model fitting. To address these issues, this study proposes a three-branch network that is designed to overcome the challenges posed by insufficient micro-expression data, the difficulty in learning multilevel features, and low recognition accuracy. The proposed network integrates a deep convolutional neural network (CNN) and shallow 3DCNN with multiple attention mechanisms.MethodThe network incorporates an enhanced channel attention module (ECANet) within deep CNN, allowing for a more effective selection of key feature channels while reducing interference from irrelevant data. In addition, a facial feature enhancement attention module is proposed for shallow 3DCNN, enhancing the model’s ability to detect subtle facial expression changes. The network uses three distinct branches to extract and process facial, optical flow, and optical strain features, which are progressively fused across layers. This approach maximizes the information captured at each layer, minimizing the loss of fine details and significantly improving recognition accuracy. Moreover, this study is the first to introduce the information maximizing loss function into micro-expression recognition in combination with the focal loss function. This weighted combination helps the model to better handle challenging samples, improving recognition accuracy for difficult cases. The proposed method consists of three major stages: preprocessing, feature extraction and fusion, and micro-expression classification. During the preprocessing stage, the apex frame of each video sequence is located to identify the peak of the expression. Optical flow and strain maps are extracted from the apex and onset frames. During the feature extraction and fusion stage, the first branch network utilizes ResNet-18 with ECANet to extract facial features, while the second and third branch networks, which are shallow 3DCNN models with the face-enhanced attention module, extract features from optical flow and strain maps. The features from the three branches are then fused layer-by-layer to enhance feature representation. During the final classification stage, the softmax function is applied to predict the probabilities of each feature that belongs to one of three micro-expression categories: negative, positive, or surprise. The class with the highest probability is chosen as the predicted result.ResultTo minimize biases during model training, this study uses leave-one-subject-out cross-validation on the Chinese Academy of Sciences Micro-expression (CASME) Ⅱ, SMIC, SAMM, and 2019 Micro-expression Grand Challenge datasets. In this approach, data from one subject are reserved for testing, while the remaining data are used for training, ensuring that no information from the test subject is included during training. The evaluation metrics used include unweighted average recall (UAR) and unweighted F1-score (UF1). The experimental results show that the proposed method achieves the highest UF1 and UAR scores on the CASME Ⅱ dataset, with scores of 0.984 3 and 0.985 7, respectively. On the SMIC dataset, the UF1 and UAR scores are 0.767 1 and 0.752 5, respectively, which also outperform existing methods. Ablation studies further confirm the effectiveness and robustness of the proposed approach.ConclusionThe proposed micro-expression recognition model effectively reduces the loss of subtle facial features, enhances recognition accuracy, and captures key facial features while minimizing redundant information. By introducing specialized loss functions, the model also improves its ability to accurately recognize difficult samples. Compared with other mainstream models, the proposed approach achieves state-of-the-art recognition performance, and the results of the ablation studies validate the robustness of the method. In conclusion, the proposed method significantly improves the efficiency and accuracy of micro-expression recognition.关键词:micro-expression recognition;feature fusion;attention mechanism;optical flow;deep learning322|517|0更新时间:2025-07-14
摘要:ObjectiveMicro-expressions are involuntary, brief facial movements that occur when individuals experience certain emotions, often revealing their genuine feelings despite effort to conceal them. Recognizing these expressions is valuable in a variety of real-world applications. Traditional methods for micro-expression recognition typically rely on handcrafted features combined with classical machine learning techniques, which extract feature descriptors from original images. However, these methods frequently struggle with subtle and fast spatiotemporal changes inherent in micro-expressions, leading to suboptimal recognition accuracy. Optical flow is a common technique used for micro-expression recognition because it captures small motion changes and focuses on spatiotemporal information. Despite their advantages, optical flow-based methods are computationally expensive, requiring substantial resources for video processing. In addition, issues such as unclear boundaries between expression categories and limited sample sizes in datasets challenge the performance of current deep learning models, such as the 3D convolutional neural network (3DCNN), which may struggle with feature learning, generalization, and model fitting. To address these issues, this study proposes a three-branch network that is designed to overcome the challenges posed by insufficient micro-expression data, the difficulty in learning multilevel features, and low recognition accuracy. The proposed network integrates a deep convolutional neural network (CNN) and shallow 3DCNN with multiple attention mechanisms.MethodThe network incorporates an enhanced channel attention module (ECANet) within deep CNN, allowing for a more effective selection of key feature channels while reducing interference from irrelevant data. In addition, a facial feature enhancement attention module is proposed for shallow 3DCNN, enhancing the model’s ability to detect subtle facial expression changes. The network uses three distinct branches to extract and process facial, optical flow, and optical strain features, which are progressively fused across layers. This approach maximizes the information captured at each layer, minimizing the loss of fine details and significantly improving recognition accuracy. Moreover, this study is the first to introduce the information maximizing loss function into micro-expression recognition in combination with the focal loss function. This weighted combination helps the model to better handle challenging samples, improving recognition accuracy for difficult cases. The proposed method consists of three major stages: preprocessing, feature extraction and fusion, and micro-expression classification. During the preprocessing stage, the apex frame of each video sequence is located to identify the peak of the expression. Optical flow and strain maps are extracted from the apex and onset frames. During the feature extraction and fusion stage, the first branch network utilizes ResNet-18 with ECANet to extract facial features, while the second and third branch networks, which are shallow 3DCNN models with the face-enhanced attention module, extract features from optical flow and strain maps. The features from the three branches are then fused layer-by-layer to enhance feature representation. During the final classification stage, the softmax function is applied to predict the probabilities of each feature that belongs to one of three micro-expression categories: negative, positive, or surprise. The class with the highest probability is chosen as the predicted result.ResultTo minimize biases during model training, this study uses leave-one-subject-out cross-validation on the Chinese Academy of Sciences Micro-expression (CASME) Ⅱ, SMIC, SAMM, and 2019 Micro-expression Grand Challenge datasets. In this approach, data from one subject are reserved for testing, while the remaining data are used for training, ensuring that no information from the test subject is included during training. The evaluation metrics used include unweighted average recall (UAR) and unweighted F1-score (UF1). The experimental results show that the proposed method achieves the highest UF1 and UAR scores on the CASME Ⅱ dataset, with scores of 0.984 3 and 0.985 7, respectively. On the SMIC dataset, the UF1 and UAR scores are 0.767 1 and 0.752 5, respectively, which also outperform existing methods. Ablation studies further confirm the effectiveness and robustness of the proposed approach.ConclusionThe proposed micro-expression recognition model effectively reduces the loss of subtle facial features, enhances recognition accuracy, and captures key facial features while minimizing redundant information. By introducing specialized loss functions, the model also improves its ability to accurately recognize difficult samples. Compared with other mainstream models, the proposed approach achieves state-of-the-art recognition performance, and the results of the ablation studies validate the robustness of the method. In conclusion, the proposed method significantly improves the efficiency and accuracy of micro-expression recognition.关键词:micro-expression recognition;feature fusion;attention mechanism;optical flow;deep learning322|517|0更新时间:2025-07-14
Image Analysis and Recognition
- “在语义分割领域,LCTNet结合轻量级CNN和Transformer,有效提取局部和全局信息,提高城市街景分割性能。”
 摘要:ObjectiveConvolutional neural networks (CNNs) have been widely used in the field of semantic segmentation due to their excellent ability to handle local information in images. However, they frequently struggle when capturing global semantic information, limiting their performance in complex scenes with long-range dependencies. By contrast, Transformer models have demonstrated superior performance in extracting global semantic information. The self-attention mechanism in Transformers allows them to capture information across an entire image. This capability is particularly important in the context of complex urban street scene segmentation.MethodTo better leverage local information and global semantic information, this study proposes a lightweight CNN-Transformer combined network for real-time semantic segmentation, referred to as LCTNet. By combining the advantages of traditional CNNs and Transformers, the objective is to maintain high segmentation accuracy while achieving model lightweighting and real-time processing capabilities. First, although highly effective in extracting local features, traditional convolution operations frequently lose some key details when dealing with complex edges and fine textures, especially during down-sampling. To enhance the model’s ability to extract edge and texture details, this study designs a lightweight wavelet-enhanced convolution block. This module innovatively combines traditional convolution operations with wavelet transform to enhance the extraction of detailed texture information. Second, the variation in object scale is highly significant in complex urban street scenes, such as small cars in the distance and pedestrians nearby, which vary considerably in their proportion within an image. To address this challenge, this study designs a lightweight multi-scale fusion module (MFM) for efficiently extracting and integrating multi-scale contextual information. By using pooling kernels with varying sizes, MFM can extract feature information at different scales, ensuring the capture of small-scale details and large-scale global features. During the fusion stage, MFM uses a dense connection strategy to efficiently integrate the features extracted from different-scale pooling. By directly connecting each scale’s feature layer with others, all scale information is fully shared and interacted with. This dense connection method effectively enhances feature representation capability, enabling the model to comprehensively understand a scene across multiple scales and improve the recognition and segmentation accuracy of objects of different scales. Through this design, MFM not only improves the model’s segmentation performance in complex urban street scenes but also maintains lightweight characteristics, achieving efficient multi-scale information fusion while maintaining low computational overhead. Finally, Transformer models excel in terms of capturing long-range dependencies and global contextual information, particularly when dealing with complex scenes, significantly improving model performance. To fully utilize the advantages of Transformers, this study designs a lightweight Transformer module (LWT). This module focuses on capturing long-range dependencies at any position in the input sequence, ensuring that the model can understand the semantic information of a scene on a global scale. LWT receives features from different layers of the network as input, encompassing local and global semantic information. By integrating multilayer features, LWT can comprehensively capture the multilevel semantic information of an image. This multilayer feature input allows the model to understand not only detailed information but also the overall semantic structure. Such ability is crucial for complex urban street scene segmentation.ResultThe proposed algorithm was tested on two standard datasets that are widely used for urban street scene segmentation, namely, Cityscapes and CamVid. The experimental results showed that the mean intersection over union reached 75.9% on the Cityscapes dataset and 69.7% on the CamVid dataset, with inference speeds of 63 frame/s and 84 frame/s, respectively. The model’s parameter count was only 1.06 M.ConclusionThe proposed algorithm was compared with several excellent methods from recent years on the Cityscapes and CamVid datasets. The results indicate that the proposed algorithm achieves lightweight and real-time processing while maintaining high segmentation accuracy. Compared with traditional CNN models and some of the latest segmentation algorithms, the proposed algorithm exhibits advantages in terms of parameter count and computational complexity, achieving a good balance between accuracy and speed.关键词:lightweight;real-time semantic segmentation;wavelet transform;Transformer;multi-scale contextual information388|446|0更新时间:2025-07-14
摘要:ObjectiveConvolutional neural networks (CNNs) have been widely used in the field of semantic segmentation due to their excellent ability to handle local information in images. However, they frequently struggle when capturing global semantic information, limiting their performance in complex scenes with long-range dependencies. By contrast, Transformer models have demonstrated superior performance in extracting global semantic information. The self-attention mechanism in Transformers allows them to capture information across an entire image. This capability is particularly important in the context of complex urban street scene segmentation.MethodTo better leverage local information and global semantic information, this study proposes a lightweight CNN-Transformer combined network for real-time semantic segmentation, referred to as LCTNet. By combining the advantages of traditional CNNs and Transformers, the objective is to maintain high segmentation accuracy while achieving model lightweighting and real-time processing capabilities. First, although highly effective in extracting local features, traditional convolution operations frequently lose some key details when dealing with complex edges and fine textures, especially during down-sampling. To enhance the model’s ability to extract edge and texture details, this study designs a lightweight wavelet-enhanced convolution block. This module innovatively combines traditional convolution operations with wavelet transform to enhance the extraction of detailed texture information. Second, the variation in object scale is highly significant in complex urban street scenes, such as small cars in the distance and pedestrians nearby, which vary considerably in their proportion within an image. To address this challenge, this study designs a lightweight multi-scale fusion module (MFM) for efficiently extracting and integrating multi-scale contextual information. By using pooling kernels with varying sizes, MFM can extract feature information at different scales, ensuring the capture of small-scale details and large-scale global features. During the fusion stage, MFM uses a dense connection strategy to efficiently integrate the features extracted from different-scale pooling. By directly connecting each scale’s feature layer with others, all scale information is fully shared and interacted with. This dense connection method effectively enhances feature representation capability, enabling the model to comprehensively understand a scene across multiple scales and improve the recognition and segmentation accuracy of objects of different scales. Through this design, MFM not only improves the model’s segmentation performance in complex urban street scenes but also maintains lightweight characteristics, achieving efficient multi-scale information fusion while maintaining low computational overhead. Finally, Transformer models excel in terms of capturing long-range dependencies and global contextual information, particularly when dealing with complex scenes, significantly improving model performance. To fully utilize the advantages of Transformers, this study designs a lightweight Transformer module (LWT). This module focuses on capturing long-range dependencies at any position in the input sequence, ensuring that the model can understand the semantic information of a scene on a global scale. LWT receives features from different layers of the network as input, encompassing local and global semantic information. By integrating multilayer features, LWT can comprehensively capture the multilevel semantic information of an image. This multilayer feature input allows the model to understand not only detailed information but also the overall semantic structure. Such ability is crucial for complex urban street scene segmentation.ResultThe proposed algorithm was tested on two standard datasets that are widely used for urban street scene segmentation, namely, Cityscapes and CamVid. The experimental results showed that the mean intersection over union reached 75.9% on the Cityscapes dataset and 69.7% on the CamVid dataset, with inference speeds of 63 frame/s and 84 frame/s, respectively. The model’s parameter count was only 1.06 M.ConclusionThe proposed algorithm was compared with several excellent methods from recent years on the Cityscapes and CamVid datasets. The results indicate that the proposed algorithm achieves lightweight and real-time processing while maintaining high segmentation accuracy. Compared with traditional CNN models and some of the latest segmentation algorithms, the proposed algorithm exhibits advantages in terms of parameter count and computational complexity, achieving a good balance between accuracy and speed.关键词:lightweight;real-time semantic segmentation;wavelet transform;Transformer;multi-scale contextual information388|446|0更新时间:2025-07-14 -
Distortion semantic aggregation network for salient object detection in 360° omnidirectional images AI导读
“在360°全景图像处理领域,提出了畸变自适应语义聚合网络DSANet,有效提升了显著目标检测性能,为解决几何畸变和大视野问题提供解决方案。” 摘要:ObjectiveBy integrating corrected images with spatial and semantic information, salient object detection (SOD) that uses omnidirectional image data significantly outperforms single-modality detection in terms of prediction accuracy. The emergence of deep learning techniques has further accelerated advancements in SOD for omnidirectional images. However, existing models in this area fundamentally disregard the challenges of image distortion and the distinct characteristics of different modalities. They commonly rely on simplistic fusion methods, such as element addition, multiplication, or concatenation, which fail to foster meaningful interactions among the modalities of omnidirectional images. This approach does not effectively utilize complementary information or the potential correlations among them. To rectify this deficiency, developing more robust methods that enhance information interaction across different modalities of omnidirectional images is imperative, leading to superior SOD results. Researchers have successfully designed a distortion semantic aggregation network (DSANet). This innovative method is applied for the first time to SOD in omnidirectional images, rigorously analyzes the correlations among various modalities, and leverages these relationships to optimize the fusion and interaction processes.MethodDSANet consists of three modules: the distortion adaptive correction module (DACM), the multi-scale semantic attention aggregation module (MSAAM), and the progressive refinement module (PRM). First, an aberration problem occurs in transforming omnidirectional images into equal rectangular projection (ERP) images, and the aberration partially affects the accuracy of target detection. Therefore, this study designs the DACM module to adaptively correct the distortion features of the input ERP image to improve detection accuracy. The mechanism of the DACM module learns the adaptive weight matrix by using deformable convolutions with different dilatation rates for the input ERP image to correct geometric distortions in 360°omnidirectional images. Second, the corrected ERP image is fed into the ResNet-50 encoder for feature extraction. Convolutional neural networks can obtain abstract semantic features through multiple convolution and pooling operations, but the diversity of input images results in significant target scale and location uncertainty, and the theoretical receptive field is frequently different from the actual receptive field to a certain extent, resulting in the network not being able to effectively extract global semantic features. Therefore, if single-scale deep features are used directly, then correct salient targets may not be obtained due to the lack of semantic features. Meanwhile, the combination of global semantic features after channel attention and local detailed features after spatial attention can solve the problem. Based on this idea, this study designs MSAAM, which is primarily composed of two sub-modules: global semantic features and local detail features. The mechanism of MSAAM is to input the features extracted by the encoder into the channel attention module to extract the channel weight values through convolutional processing and then multiply them by pixels with the input features to obtain the global semantic features. Subsequently, the global semantic features are inputted into the spatial attention module to obtain the spatial weight values and multiply them by the input feature elements to obtain the detailed features. Finally, the global semantic features are merged with the local detailed features to generate the multi-scale semantic features. The PRM module fuses the multi-scale semantic features layer by layer to further improve detection accuracy. The MSAAM module cooperates with the PRM module to solve the problem of a large field of view in 360°omnidirectional images. Finally, the saliency map generated by the MSAAM module is unclear and internally mutilated due to the contradiction among different feature layers in the fusion process. To obtain more accurate saliency maps, this study designs the PRM in the decoder, which fuses the multi-scale semantic feature maps from the encoder layer by layer from deep to shallow maps, to further refine and enhance the feature maps at each stage. The mechanism of action of PRM up-samples the high-level features and fuses them with the low-level features for elemental multiplication and then multiplies and sums them with each of the high-level and low-level features to obtain the coarse-level features. The coarse-level features are activated to obtain the weight values, inverted, multiplied with the coarse-level features, summed to obtain the fine-level features, and then aggregated from the high level to the low level to obtain the output features.ResultExperiments on two publicly available datasets, namely, 360-SOD and 360-SSOD (total of 1 605 images), show that DSANet outperforms the other methods in six mainstream evaluation metrics, i.e., max F-measure, mean F-measure, mean absolute error(MAE), max E-measure, mean E-measure, and structure-measure.ConclusionThe method proposed in this study excels in several objective evaluation metrics while generating salient object images that are clearer in terms of edge contouring and spatial structural detail information.关键词:deep learning;salient object detection(SOD);360° omnidirectional image;Geometric distortion;large-scale vision204|477|0更新时间:2025-07-14
摘要:ObjectiveBy integrating corrected images with spatial and semantic information, salient object detection (SOD) that uses omnidirectional image data significantly outperforms single-modality detection in terms of prediction accuracy. The emergence of deep learning techniques has further accelerated advancements in SOD for omnidirectional images. However, existing models in this area fundamentally disregard the challenges of image distortion and the distinct characteristics of different modalities. They commonly rely on simplistic fusion methods, such as element addition, multiplication, or concatenation, which fail to foster meaningful interactions among the modalities of omnidirectional images. This approach does not effectively utilize complementary information or the potential correlations among them. To rectify this deficiency, developing more robust methods that enhance information interaction across different modalities of omnidirectional images is imperative, leading to superior SOD results. Researchers have successfully designed a distortion semantic aggregation network (DSANet). This innovative method is applied for the first time to SOD in omnidirectional images, rigorously analyzes the correlations among various modalities, and leverages these relationships to optimize the fusion and interaction processes.MethodDSANet consists of three modules: the distortion adaptive correction module (DACM), the multi-scale semantic attention aggregation module (MSAAM), and the progressive refinement module (PRM). First, an aberration problem occurs in transforming omnidirectional images into equal rectangular projection (ERP) images, and the aberration partially affects the accuracy of target detection. Therefore, this study designs the DACM module to adaptively correct the distortion features of the input ERP image to improve detection accuracy. The mechanism of the DACM module learns the adaptive weight matrix by using deformable convolutions with different dilatation rates for the input ERP image to correct geometric distortions in 360°omnidirectional images. Second, the corrected ERP image is fed into the ResNet-50 encoder for feature extraction. Convolutional neural networks can obtain abstract semantic features through multiple convolution and pooling operations, but the diversity of input images results in significant target scale and location uncertainty, and the theoretical receptive field is frequently different from the actual receptive field to a certain extent, resulting in the network not being able to effectively extract global semantic features. Therefore, if single-scale deep features are used directly, then correct salient targets may not be obtained due to the lack of semantic features. Meanwhile, the combination of global semantic features after channel attention and local detailed features after spatial attention can solve the problem. Based on this idea, this study designs MSAAM, which is primarily composed of two sub-modules: global semantic features and local detail features. The mechanism of MSAAM is to input the features extracted by the encoder into the channel attention module to extract the channel weight values through convolutional processing and then multiply them by pixels with the input features to obtain the global semantic features. Subsequently, the global semantic features are inputted into the spatial attention module to obtain the spatial weight values and multiply them by the input feature elements to obtain the detailed features. Finally, the global semantic features are merged with the local detailed features to generate the multi-scale semantic features. The PRM module fuses the multi-scale semantic features layer by layer to further improve detection accuracy. The MSAAM module cooperates with the PRM module to solve the problem of a large field of view in 360°omnidirectional images. Finally, the saliency map generated by the MSAAM module is unclear and internally mutilated due to the contradiction among different feature layers in the fusion process. To obtain more accurate saliency maps, this study designs the PRM in the decoder, which fuses the multi-scale semantic feature maps from the encoder layer by layer from deep to shallow maps, to further refine and enhance the feature maps at each stage. The mechanism of action of PRM up-samples the high-level features and fuses them with the low-level features for elemental multiplication and then multiplies and sums them with each of the high-level and low-level features to obtain the coarse-level features. The coarse-level features are activated to obtain the weight values, inverted, multiplied with the coarse-level features, summed to obtain the fine-level features, and then aggregated from the high level to the low level to obtain the output features.ResultExperiments on two publicly available datasets, namely, 360-SOD and 360-SSOD (total of 1 605 images), show that DSANet outperforms the other methods in six mainstream evaluation metrics, i.e., max F-measure, mean F-measure, mean absolute error(MAE), max E-measure, mean E-measure, and structure-measure.ConclusionThe method proposed in this study excels in several objective evaluation metrics while generating salient object images that are clearer in terms of edge contouring and spatial structural detail information.关键词:deep learning;salient object detection(SOD);360° omnidirectional image;Geometric distortion;large-scale vision204|477|0更新时间:2025-07-14 - “SAMLCAM方法通过多层混合注意力机制优化类激活图,提升深度卷积神经网络在视觉任务中的可解释性。”
 摘要:ObjectiveThe success of deep convolutional neural networks (DCNNs) in image classification, object detection, and semantic segmentation has revolutionized the field of artificial intelligence (AI). Models based on DCNNs have demonstrated exceptional accuracy and have been deployed in various real-world applications. However, a major drawback of DCNNs is their lack of interpretability, which is frequently referred to as the “black-box” problem. When a DCNN makes a prediction, understanding how and why it arrived at that decision is a challenging task. This lack of transparency hinders our ability to trust and rely on these models’ output, particularly in critical domains, such as healthcare, autonomous driving, and finance. In medical diagnosis, for example, comprehending the reasoning behind a model’s diagnosis is crucial for healthcare professionals to make informed decisions about patient care. Explainable AI (XAI) aims to address this issue by providing human-interpretable explanations for decisions made by complex machine learning models. XAI seeks to bridge the gap between model performance and interpretability, allowing users to understand the inner workings of a model and have confidence in its output. Researchers have been actively developing techniques and methods for enhancing the interpretability of deep learning models. One approach is to generate visual explanations through techniques, such as class activation map (CAM), gradient-weighted CAM (Grad-CAM), and smooth Grad-CAM. These methods provide heat maps or attention maps that highlight the areas of an input image that influence the model’s decision the most. By visualizing this information, users can gain insights into the features and patterns that the model focuses on when making predictions. Experimental evidence shows that CAM methods can effectively enhance the interpretability of image classification. However, existing methods can only provide rough range explanations and suffer from the issues of excessively large boundary effects and insufficient granularity. To address these problems, spatial attention-based multilayer fusion for high-quality CAM (SAMLCAM) is proposed. SAMLCAM combines channel attention and spatial attention mechanisms based on Gra’d-CAM. SAMLCAM achieves more effective object localization and enhances visual interpretability by addressing the issues of excessively large activation map boundaries and lack of fine granularity through multilayer fusion.MethodIn existing CAM methods, only the channel weights are considered, while beneficial information from spatial position, which contributes to target localization, is frequently overlooked. In our study, a hybrid attention mechanism that combines channel attention and spatial attention is proposed to enhance the interpretability of target localization. The spatial attention mechanism focuses on the spatial relationship among different regions in feature maps. By assigning higher weights to regions that are more likely to contain the target object, SAMLCAM can enhance the precision of object localization while reducing false positives. This attention mechanism allows the model to allocate more attention to discriminative features, improving object localization. One key improvement of SAMLCAM lies in its multilayer attention mechanism. Previous methods frequently suffer from boundary effects, wherein activation maps tend to have excessively large boundaries that may include irrelevant regions. SAMLCAM addresses this issue by refining attention maps at multiple layers of a network. It not only relies on the results from the final convolutional layer but also considers multiple aspects, including attention to shallow layers. This feature enriches the reference information, resulting in a more comprehensive understanding of the semantic information of the target object while reducing unnecessary background information. This multilayer attention mechanism helps gradually refine boundaries and improve localization accuracy by reducing the influence of irrelevant regions. Moreover, SAMLCAM deals with the problem of insufficient granularity in CAM. In some cases, activation maps generated using previously available methods lack fine details, making precisely identifying the object of interest a challenging task. SAMLCAM overcomes this limitation by leveraging the multilayer attention mechanism to capture more detailed information in activation maps, resulting in high-quality CAM with enhanced visual interpretability. The ImageNet Large-scale Visual Recognition Challenge (ILSVRC) 2012 dataset is a large-scale image classification dataset that consists of over a million labeled images from 1 000 different categories. It is widely used in benchmarking computer vision models. The evaluation results on the ILSVRC 2012 validation dataset demonstrate the effectiveness of SAMLCAM in improving object localization and energy localization decision metrics. The proposed method contributes to the field by offering a more comprehensive understanding of how deep models make decisions in visual tasks and provides insights into improving the interpretability of these models. The proposed SAMLCAM method is evaluated on five backbone convolutional network models by using the ILSVRC 2012 validation dataset and compared with five state-of-the-art saliency models, namely, Grad-CAM, Grad-CAM++, XGradCAM, ScoreCAM, and LayerCAM. The results demonstrate the performance improvement of SAMLCAM compared with the lowest-performing methods in the Loc1 and Loc5 metrics, with an increase of over 8%. In addition, when comparing energy localization decision metrics, SAMLCAM exhibits an improvement of more than 7% over the lowest-performing methods. Notably, the improved method reduces the contextual background areas that surround the target sample region, negatively affecting the confidence metric. However, in terms of the credibility metric, SAMLCAM maintains relatively high performance with only a small gap compared with the other methods. In addition, we conduct a series of comparative experiments to clearly demonstrate the effectiveness of the fusion algorithm in the form of images.ResultIn conclusion, the SAMLCAM method presents a novel approach for enhancing the interpretability of DCNN models. By incorporating channel attention and spatial attention mechanisms, the proposed method improves object localization and overcomes the limitations of previous methods, such as excessive boundary effects and lack of fine granularity, in CAM. The evaluation results on the ILSVRC 2012 dataset highlight the performance improvement of SAMLCAM compared with other methods in terms of localization and energy localization decision metrics. The proposed method contributes to advancing the field of visual deep learning and offers valuable insights into understanding and improving the interpretability of black-box models.ConclusionThe proposed method demonstrates superior explanatory performance across various convolutional neural network architectures by expanding the response coverage of target sample regions while effectively suppressing responses in background or irrelevant areas, thereby enhancing the precision and reliability of the interpretability results.关键词:class activation map(CAM);explainability artificial intelligence;attention mechanism;image classification;convolutional neural network(CNN)174|756|0更新时间:2025-07-14
摘要:ObjectiveThe success of deep convolutional neural networks (DCNNs) in image classification, object detection, and semantic segmentation has revolutionized the field of artificial intelligence (AI). Models based on DCNNs have demonstrated exceptional accuracy and have been deployed in various real-world applications. However, a major drawback of DCNNs is their lack of interpretability, which is frequently referred to as the “black-box” problem. When a DCNN makes a prediction, understanding how and why it arrived at that decision is a challenging task. This lack of transparency hinders our ability to trust and rely on these models’ output, particularly in critical domains, such as healthcare, autonomous driving, and finance. In medical diagnosis, for example, comprehending the reasoning behind a model’s diagnosis is crucial for healthcare professionals to make informed decisions about patient care. Explainable AI (XAI) aims to address this issue by providing human-interpretable explanations for decisions made by complex machine learning models. XAI seeks to bridge the gap between model performance and interpretability, allowing users to understand the inner workings of a model and have confidence in its output. Researchers have been actively developing techniques and methods for enhancing the interpretability of deep learning models. One approach is to generate visual explanations through techniques, such as class activation map (CAM), gradient-weighted CAM (Grad-CAM), and smooth Grad-CAM. These methods provide heat maps or attention maps that highlight the areas of an input image that influence the model’s decision the most. By visualizing this information, users can gain insights into the features and patterns that the model focuses on when making predictions. Experimental evidence shows that CAM methods can effectively enhance the interpretability of image classification. However, existing methods can only provide rough range explanations and suffer from the issues of excessively large boundary effects and insufficient granularity. To address these problems, spatial attention-based multilayer fusion for high-quality CAM (SAMLCAM) is proposed. SAMLCAM combines channel attention and spatial attention mechanisms based on Gra’d-CAM. SAMLCAM achieves more effective object localization and enhances visual interpretability by addressing the issues of excessively large activation map boundaries and lack of fine granularity through multilayer fusion.MethodIn existing CAM methods, only the channel weights are considered, while beneficial information from spatial position, which contributes to target localization, is frequently overlooked. In our study, a hybrid attention mechanism that combines channel attention and spatial attention is proposed to enhance the interpretability of target localization. The spatial attention mechanism focuses on the spatial relationship among different regions in feature maps. By assigning higher weights to regions that are more likely to contain the target object, SAMLCAM can enhance the precision of object localization while reducing false positives. This attention mechanism allows the model to allocate more attention to discriminative features, improving object localization. One key improvement of SAMLCAM lies in its multilayer attention mechanism. Previous methods frequently suffer from boundary effects, wherein activation maps tend to have excessively large boundaries that may include irrelevant regions. SAMLCAM addresses this issue by refining attention maps at multiple layers of a network. It not only relies on the results from the final convolutional layer but also considers multiple aspects, including attention to shallow layers. This feature enriches the reference information, resulting in a more comprehensive understanding of the semantic information of the target object while reducing unnecessary background information. This multilayer attention mechanism helps gradually refine boundaries and improve localization accuracy by reducing the influence of irrelevant regions. Moreover, SAMLCAM deals with the problem of insufficient granularity in CAM. In some cases, activation maps generated using previously available methods lack fine details, making precisely identifying the object of interest a challenging task. SAMLCAM overcomes this limitation by leveraging the multilayer attention mechanism to capture more detailed information in activation maps, resulting in high-quality CAM with enhanced visual interpretability. The ImageNet Large-scale Visual Recognition Challenge (ILSVRC) 2012 dataset is a large-scale image classification dataset that consists of over a million labeled images from 1 000 different categories. It is widely used in benchmarking computer vision models. The evaluation results on the ILSVRC 2012 validation dataset demonstrate the effectiveness of SAMLCAM in improving object localization and energy localization decision metrics. The proposed method contributes to the field by offering a more comprehensive understanding of how deep models make decisions in visual tasks and provides insights into improving the interpretability of these models. The proposed SAMLCAM method is evaluated on five backbone convolutional network models by using the ILSVRC 2012 validation dataset and compared with five state-of-the-art saliency models, namely, Grad-CAM, Grad-CAM++, XGradCAM, ScoreCAM, and LayerCAM. The results demonstrate the performance improvement of SAMLCAM compared with the lowest-performing methods in the Loc1 and Loc5 metrics, with an increase of over 8%. In addition, when comparing energy localization decision metrics, SAMLCAM exhibits an improvement of more than 7% over the lowest-performing methods. Notably, the improved method reduces the contextual background areas that surround the target sample region, negatively affecting the confidence metric. However, in terms of the credibility metric, SAMLCAM maintains relatively high performance with only a small gap compared with the other methods. In addition, we conduct a series of comparative experiments to clearly demonstrate the effectiveness of the fusion algorithm in the form of images.ResultIn conclusion, the SAMLCAM method presents a novel approach for enhancing the interpretability of DCNN models. By incorporating channel attention and spatial attention mechanisms, the proposed method improves object localization and overcomes the limitations of previous methods, such as excessive boundary effects and lack of fine granularity, in CAM. The evaluation results on the ILSVRC 2012 dataset highlight the performance improvement of SAMLCAM compared with other methods in terms of localization and energy localization decision metrics. The proposed method contributes to advancing the field of visual deep learning and offers valuable insights into understanding and improving the interpretability of black-box models.ConclusionThe proposed method demonstrates superior explanatory performance across various convolutional neural network architectures by expanding the response coverage of target sample regions while effectively suppressing responses in background or irrelevant areas, thereby enhancing the precision and reliability of the interpretability results.关键词:class activation map(CAM);explainability artificial intelligence;attention mechanism;image classification;convolutional neural network(CNN)174|756|0更新时间:2025-07-14 - “ERA-Net在三维点云地点识别领域取得突破,有效提取旋转特性的几何特征,展现出良好的鲁棒性和泛化能力。”
 摘要:ObjectivePoint cloud-based place recognition involves identifying and matching a specific location within a pre-built map by comparing global descriptors generated from a scene. This process is crucial for robot localization and autonomous navigation, wherein real-time point clouds are continuously scanned. For example, autonomous vehicles and robots rely on robust place recognition to navigate safely and efficiently, ensuring that they can recognize and reidentify locations within a scene. The primary goal of place recognition is to enable a system to determine accurately whether it has previously encountered a location. This ability is essential for certain tasks, such as loop closure in simultaneous localization and mapping and re-localization in dynamic environments. Place recognition methods can be categorized into two approaches in accordance with data type: image-based and LiDAR-based methods. Image-based methods have achieved promising results by using 2D images in the place recognition task. However, the performance of image-based methods is easily degraded in real-world environments due to illumination changes and viewpoint variation. Point clouds can be captured easily by 3D sensors, and they provide high-precision geometry information of objects. Hence, misleading caused by lighting change and viewpoint variation can be avoided to a certain extent. Although many methods have been proposed for 3D place recognition, these methods typically perform well in prescribed travel routes. However, a significant challenge that is frequently overlooked is the effect of data rotation. In real-world scenarios, vehicles do not travel on fixed routes. When a vehicle deviates from a prescribed route in the same place, the acquired point clouds are rotated relative to the submaps. Existing location recognition methods for large-scale point clouds often ignore the rotation problem in real driving. When a query scene is rotated, the recognition performance of these methods degrades significantly, seriously hindering their application in complex real-world scenarios.MethodIn this study, we propose an efficient rotation-aware network for point cloud-based place recognition (ERA-Net) for point cloud-based place recognition that leverages semantic and geometric features to achieve better discriminative ability. ERA-Net employs an attention mechanism that thoroughly considers global dependencies among points and local correlations between a point and its neighboring points to extract semantic features. In addition, it utilizes the coordinate information of a point and its k-nearest neighbors to derive low-dimensional geometric features that exhibit rotational invariance, such as distance, angle, and angular difference. By calculating the associations of these features in high-dimensional space, ERA-Net extracts geometric characteristics that demonstrate strong uniqueness and rotational invariance. First, global dependencies among points are captured using a self-attention mechanism, while local dependencies between each point and its k-nearest neighbor points are modeled through neighboring attention mechanisms. These mechanisms ensure the comprehensive extraction of attention features among points. The self-attention mechanism computes self-coefficients by considering the geometric properties of individual points, while the neighboring attention mechanism focuses on local coefficients by considering the neighborhood structure. Simultaneously, several low-dimensional geometric features are calculated using the coordinates of points. The sampled points, their local center of mass, and k-nearest neighbors form a stable local triangular structure. Low-dimensional geometric features, such as distances, angles, and angular differences, are calculated. These geometric features remain invariant to point cloud rotations. Subsequently, a novel feature distance-based attention pooling module is designed to extract geometric features with high discrimination and rotational invariance by analyzing correlations among features in high-dimensional space. Feature distance measures the similarity among different points in high-dimensional feature space. Points may be geometrically distant from one another in terms of their spatial positions. However, they can share similar features semantically. The feature distance-based pooling method captures the relationships among these geometrically distant but semantically similar points. It can also effectively distinguish points with similar spatial coordinates but considerable semantic differences. Finally, the extracted semantic and geometric features are fused through the NetVLAD module, generating more discriminative global descriptors for point clouds.ResultThe proposed ERA-Net is validated on the public dataset Oxford Robotcar and compared with state-of-the-art (SOTA) methods. In the Oxford Robotcar dataset, the average recall (AR)@1% of ERA-Net reaches 96.48% and the AR@1 reaches 90.47%. ERA-Net outperforms other SOTA methods on the U.S. (university sector), R.A. (residential area), and B.D. (business district) datasets. We select three representative queries of the Oxford dataset to verify the retrieval capability of ERA-Net. Although the scene contains structurally unstable trees, slender poles, or a large number of planar points, ERA-Net can retrieve the correct place. In particular, ERA-Net outperforms existing methods in terms of recognition when the query scene is rotated. The recognition performance of most existing methods decreases significantly when the query scene is rotated. The results of AR@1% and AR@1 of ERA-Net and other SOTA methods under different rotation angles are tested separately. The tested rotation angles include 30°, 60°, 90°, 120°, 150°, and 180°, and these angles represent the maximum rotation range. The query point cloud is randomly rotated from 0° to the maximum rotation angle. The performance of ERA-Net is better than those of the other methods when the rotation angle of the query scene is increasing. The experimental results show that ERA-Net can still extract features with strong uniqueness and rotation invariance from the scene and correctly retrieve the corresponding scene even when facing the rotation of point cloud data.ConclusionIn this study, we propose a rotation-aware place recognition network, i.e., ERA-Net, which leverages semantic and geometric features. The experimental results show that the recognition performance of ERA-Net is better than those of SOTA methods. ERA-Net performs significantly better than other methods on the three in-house datasets. For AR@1%, ERA-Net reaches 91.04%, 87.37%, and 87.12% on the U.S., R.A., and B.D. datasets, respectively. Simultaneously, ERA-Net achieves better results in the rotation test. The extraction of low-dimensional geometric features can better improve the recognition effect of ERA-Net. The attention pooling module based on feature distance can capture the relationship among distant but semantically similar points and effectively distinguish points with similar coordinates but considerable semantic differences. ERA-Net can extract scene features with strong uniqueness by fully considering the contextual information among points and the correlation among features. It exhibits good robustness and strong generalization ability when facing the rotation problem.关键词:scene point clouds;place recognition;rotation-aware;attention mechanism;feature distance232|250|0更新时间:2025-07-14
摘要:ObjectivePoint cloud-based place recognition involves identifying and matching a specific location within a pre-built map by comparing global descriptors generated from a scene. This process is crucial for robot localization and autonomous navigation, wherein real-time point clouds are continuously scanned. For example, autonomous vehicles and robots rely on robust place recognition to navigate safely and efficiently, ensuring that they can recognize and reidentify locations within a scene. The primary goal of place recognition is to enable a system to determine accurately whether it has previously encountered a location. This ability is essential for certain tasks, such as loop closure in simultaneous localization and mapping and re-localization in dynamic environments. Place recognition methods can be categorized into two approaches in accordance with data type: image-based and LiDAR-based methods. Image-based methods have achieved promising results by using 2D images in the place recognition task. However, the performance of image-based methods is easily degraded in real-world environments due to illumination changes and viewpoint variation. Point clouds can be captured easily by 3D sensors, and they provide high-precision geometry information of objects. Hence, misleading caused by lighting change and viewpoint variation can be avoided to a certain extent. Although many methods have been proposed for 3D place recognition, these methods typically perform well in prescribed travel routes. However, a significant challenge that is frequently overlooked is the effect of data rotation. In real-world scenarios, vehicles do not travel on fixed routes. When a vehicle deviates from a prescribed route in the same place, the acquired point clouds are rotated relative to the submaps. Existing location recognition methods for large-scale point clouds often ignore the rotation problem in real driving. When a query scene is rotated, the recognition performance of these methods degrades significantly, seriously hindering their application in complex real-world scenarios.MethodIn this study, we propose an efficient rotation-aware network for point cloud-based place recognition (ERA-Net) for point cloud-based place recognition that leverages semantic and geometric features to achieve better discriminative ability. ERA-Net employs an attention mechanism that thoroughly considers global dependencies among points and local correlations between a point and its neighboring points to extract semantic features. In addition, it utilizes the coordinate information of a point and its k-nearest neighbors to derive low-dimensional geometric features that exhibit rotational invariance, such as distance, angle, and angular difference. By calculating the associations of these features in high-dimensional space, ERA-Net extracts geometric characteristics that demonstrate strong uniqueness and rotational invariance. First, global dependencies among points are captured using a self-attention mechanism, while local dependencies between each point and its k-nearest neighbor points are modeled through neighboring attention mechanisms. These mechanisms ensure the comprehensive extraction of attention features among points. The self-attention mechanism computes self-coefficients by considering the geometric properties of individual points, while the neighboring attention mechanism focuses on local coefficients by considering the neighborhood structure. Simultaneously, several low-dimensional geometric features are calculated using the coordinates of points. The sampled points, their local center of mass, and k-nearest neighbors form a stable local triangular structure. Low-dimensional geometric features, such as distances, angles, and angular differences, are calculated. These geometric features remain invariant to point cloud rotations. Subsequently, a novel feature distance-based attention pooling module is designed to extract geometric features with high discrimination and rotational invariance by analyzing correlations among features in high-dimensional space. Feature distance measures the similarity among different points in high-dimensional feature space. Points may be geometrically distant from one another in terms of their spatial positions. However, they can share similar features semantically. The feature distance-based pooling method captures the relationships among these geometrically distant but semantically similar points. It can also effectively distinguish points with similar spatial coordinates but considerable semantic differences. Finally, the extracted semantic and geometric features are fused through the NetVLAD module, generating more discriminative global descriptors for point clouds.ResultThe proposed ERA-Net is validated on the public dataset Oxford Robotcar and compared with state-of-the-art (SOTA) methods. In the Oxford Robotcar dataset, the average recall (AR)@1% of ERA-Net reaches 96.48% and the AR@1 reaches 90.47%. ERA-Net outperforms other SOTA methods on the U.S. (university sector), R.A. (residential area), and B.D. (business district) datasets. We select three representative queries of the Oxford dataset to verify the retrieval capability of ERA-Net. Although the scene contains structurally unstable trees, slender poles, or a large number of planar points, ERA-Net can retrieve the correct place. In particular, ERA-Net outperforms existing methods in terms of recognition when the query scene is rotated. The recognition performance of most existing methods decreases significantly when the query scene is rotated. The results of AR@1% and AR@1 of ERA-Net and other SOTA methods under different rotation angles are tested separately. The tested rotation angles include 30°, 60°, 90°, 120°, 150°, and 180°, and these angles represent the maximum rotation range. The query point cloud is randomly rotated from 0° to the maximum rotation angle. The performance of ERA-Net is better than those of the other methods when the rotation angle of the query scene is increasing. The experimental results show that ERA-Net can still extract features with strong uniqueness and rotation invariance from the scene and correctly retrieve the corresponding scene even when facing the rotation of point cloud data.ConclusionIn this study, we propose a rotation-aware place recognition network, i.e., ERA-Net, which leverages semantic and geometric features. The experimental results show that the recognition performance of ERA-Net is better than those of SOTA methods. ERA-Net performs significantly better than other methods on the three in-house datasets. For AR@1%, ERA-Net reaches 91.04%, 87.37%, and 87.12% on the U.S., R.A., and B.D. datasets, respectively. Simultaneously, ERA-Net achieves better results in the rotation test. The extraction of low-dimensional geometric features can better improve the recognition effect of ERA-Net. The attention pooling module based on feature distance can capture the relationship among distant but semantically similar points and effectively distinguish points with similar coordinates but considerable semantic differences. ERA-Net can extract scene features with strong uniqueness by fully considering the contextual information among points and the correlation among features. It exhibits good robustness and strong generalization ability when facing the rotation problem.关键词:scene point clouds;place recognition;rotation-aware;attention mechanism;feature distance232|250|0更新时间:2025-07-14 - “在红外与可见光图像融合领域,研究者提出了基于信息交互线性Transformer的新型融合算法,有效提升了视觉效果和计算效率。”
 摘要:ObjectiveTransformer-based deep learning techniques have demonstrated excellent performance in infrared and visible image fusion. However, Transformer-based image fusion networks suffer from low computational efficiency and require substantial computational resources and storage space during training. In addition, most existing fusion methods overlook cross-modal information interaction during the encoding phase, leading to the loss of complementary information, particularly in complex scenarios, such as low-light conditions or smoke occlusion, where highlighting target features is challenging. To address these challenges, we propose a fusion network based on an information interaction linear Transformer (I2F Transformer). The proposed I2F Transformer reduces computational costs while enhancing cross-modal information integration, producing fused images with a clear background and prominent targets.MethodIn this study, we propose a novel infrared and visible image fusion algorithm that employs a network structure based on an information interaction linear Transformer, including a dual-branch encoder and decoder. First, the encoder adopts a dual-branch structure to extract features separately from infrared and visible light images. The encoder extracts shallow features from the source images by using a 3 × 3 convolutional layer with a stride of 1. Then, these shallow features are input into three cascaded global information fast interaction modules, where complementary features from infrared and visible feature maps are further extracted and integrated through the I2F Transformer to achieve deep integration of cross-modal features. The decoder consists of five cascaded convolutional modules, with each containing a convolutional layer and an activation function layer, ultimately reconstructing the fused features into a high-quality fused image. To enhance the model’s training effectiveness, a Fourier transform loss function is designed to preserve critical frequency domain information from the source images, ensuring the detail and clarity of the fused images.ResultComparative experiments were conducted on the Multi-spectral Road Scenarios (MSRS) and TNO datasets, comparing 13 traditional and deep learning-based fusion methods. In the subjective evaluation, the proposed method demonstrated a clear advantage in complex scenarios. With regard to the objective evaluation, our method achieved optimal values in 5 objective metrics on the MSRS dataset: entropy (EN), visual information fidelity (VIF), average gradient (AG), edge intensity (EI), and gradient-based similarity measure (QAB/F). Compared with the best values in the 5 metrics of 13 existing fusion algorithms, an average increase of 0.75%, 0.15%, 1.56%, 1.52%, and 1.27% are reached. Our method achieved the best values in EN, VIF, AG, and QAB/F on the TNO dataset. Compared with the best values in the 4 aforementioned metrics of 13 existing fusion algorithms, an average increase of 1.53%, 3.79%, 0.17%, and 6.94% are reached. In addition, we validated the effectiveness of each component in the network through ablation experiments. To further validate the computational efficiency of the fusion model, we analyzed the algorithm’s computational complexity.ConclusionIn this study, we proposed a fusion network based on an information interaction linear Transformer, innovatively introduced a cross-modal information interaction mechanism, and achieved network lightweighting through linear modules in the I2F Transformer. The experimental results show that compared with 13 existing fusion methods, the proposed method demonstrates superiority in enhancing visual effects, preserving texture details in complex scenes, and improving computational efficiency.关键词:image fusion;information interaction;linear transformer;Fourier transform loss;deep learning254|212|0更新时间:2025-07-14
摘要:ObjectiveTransformer-based deep learning techniques have demonstrated excellent performance in infrared and visible image fusion. However, Transformer-based image fusion networks suffer from low computational efficiency and require substantial computational resources and storage space during training. In addition, most existing fusion methods overlook cross-modal information interaction during the encoding phase, leading to the loss of complementary information, particularly in complex scenarios, such as low-light conditions or smoke occlusion, where highlighting target features is challenging. To address these challenges, we propose a fusion network based on an information interaction linear Transformer (I2F Transformer). The proposed I2F Transformer reduces computational costs while enhancing cross-modal information integration, producing fused images with a clear background and prominent targets.MethodIn this study, we propose a novel infrared and visible image fusion algorithm that employs a network structure based on an information interaction linear Transformer, including a dual-branch encoder and decoder. First, the encoder adopts a dual-branch structure to extract features separately from infrared and visible light images. The encoder extracts shallow features from the source images by using a 3 × 3 convolutional layer with a stride of 1. Then, these shallow features are input into three cascaded global information fast interaction modules, where complementary features from infrared and visible feature maps are further extracted and integrated through the I2F Transformer to achieve deep integration of cross-modal features. The decoder consists of five cascaded convolutional modules, with each containing a convolutional layer and an activation function layer, ultimately reconstructing the fused features into a high-quality fused image. To enhance the model’s training effectiveness, a Fourier transform loss function is designed to preserve critical frequency domain information from the source images, ensuring the detail and clarity of the fused images.ResultComparative experiments were conducted on the Multi-spectral Road Scenarios (MSRS) and TNO datasets, comparing 13 traditional and deep learning-based fusion methods. In the subjective evaluation, the proposed method demonstrated a clear advantage in complex scenarios. With regard to the objective evaluation, our method achieved optimal values in 5 objective metrics on the MSRS dataset: entropy (EN), visual information fidelity (VIF), average gradient (AG), edge intensity (EI), and gradient-based similarity measure (QAB/F). Compared with the best values in the 5 metrics of 13 existing fusion algorithms, an average increase of 0.75%, 0.15%, 1.56%, 1.52%, and 1.27% are reached. Our method achieved the best values in EN, VIF, AG, and QAB/F on the TNO dataset. Compared with the best values in the 4 aforementioned metrics of 13 existing fusion algorithms, an average increase of 1.53%, 3.79%, 0.17%, and 6.94% are reached. In addition, we validated the effectiveness of each component in the network through ablation experiments. To further validate the computational efficiency of the fusion model, we analyzed the algorithm’s computational complexity.ConclusionIn this study, we proposed a fusion network based on an information interaction linear Transformer, innovatively introduced a cross-modal information interaction mechanism, and achieved network lightweighting through linear modules in the I2F Transformer. The experimental results show that compared with 13 existing fusion methods, the proposed method demonstrates superiority in enhancing visual effects, preserving texture details in complex scenes, and improving computational efficiency.关键词:image fusion;information interaction;linear transformer;Fourier transform loss;deep learning254|212|0更新时间:2025-07-14
Image Understanding and Computer Vision
- “最新研究在三维场景本征分解领域取得突破,专家提出新算法,有效提升室内场景分解精度和效率,为虚拟物体插入等任务提供支持。”
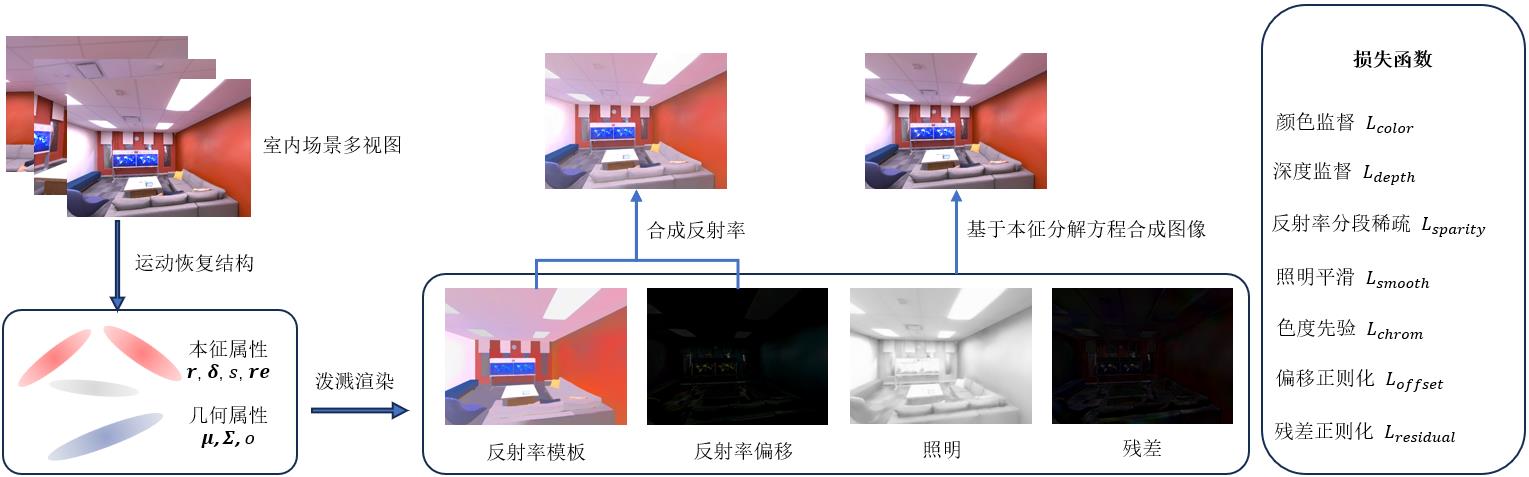 摘要:ObjectiveThe intrinsic decomposition of 3D scenes involves breaking down a scene into a product of reflectance and shading. Decomposition results can be applied to various tasks, such as virtual object insertion, image material replacement, and relighting, and thus, they have received widespread attention and have been the subject of numerous researches. However, decomposing large-scale and intricately structured indoor scenes presents a highly ill-posed problem due to the complexity of indoor environments, which contain various light sources, materials, and geometries. This complexity makes accurately disentangling reflectance and shading difficult because multiple possible combinations of these factors can explain the same observed image. Traditional methods frequently use prior constraints based on physical knowledge, human intuition, and visual perception to facilitate the reasonable separation of intrinsic attributes. Despite such effort, traditional methods still struggle in handling the complex interaction between reflectance and shading, resulting in poor decomposition results and limited applicability to different scenarios. Therefore, to achieve accurate and consistent decomposition results, addressing the inherent ambiguities and uncertainties involved is essential.MethodTo address these challenges, this study proposes an intrinsic decomposition algorithm that is specifically designed for indoor scenes, leveraging the state-of-the-art radiance field representation technique called 3D Gaussian splatting. This approach significantly improves the accuracy and efficiency of intrinsic decomposition for complex indoor environments. At present, many studies have further improved the rendering quality and efficiency of 3D Gaussian splatting and applied it to inverse rendering, dynamic scene modeling, and other tasks. Such development has inspired us to use 3D Gaussian splatting as a proxy for scene representation in this work. Building on this foundation, we develop an intrinsic decomposition model that is tailored for indoor scenes. This model is based on Retinex theory and aims to decompose a scene into reflectance, which represents the albedo of objects, and shading, which represents the interaction between lighting and object geometry. However, decomposing a scene into reflectance and shading is insufficient for representing all types of objects in indoor scenes. We use residual terms to fit specular reflections because indoor scenes have specular materials. To prevent loss of texture in reflectance during the optimization process, we use a reflectance offset to capture these details. The four aforementioned components effectively represent most objects in indoor scenes and facilitate the decomposition and optimization of intrinsic scene attributes. To better separate the above attributes, we introduce new reflectance piecewise sparsity, shading smoothness, and chromaticity prior constraints to reduce ambiguity in the decomposition process and ensure the rationality of the results. In accordance with the assumptions of Retinex theory, changes in gradient within a scene are attributed to illumination-independent reflectance and shading. Reflectance refers to the inherent color of an object and is the primary factor that is responsible for significant changes in appearance. Reflectance exhibits sparsity, because it tends to cluster in the RGB color space, forming distinct groups. By contrast, shading, which is influenced by the slow variation of light intensity in a scene, is generally assumed to be smooth. Directly separating reflectance from shading is challenging, and thus, we adopt methods from other computer vision fields. We segment a scene piecewise, apply sparsity constraints to each reflectance piece, constrain shading to be smoother in flat areas, and use chromaticity priors to ensure the color consistency of reflectance. These constraints effectively ensure the rationality of the decomposition results. In addition to these novel constraints, we enhance the geometric information of a scene by incorporating captured depth data, which provide valuable cues about a scene’s structure. This improved understanding allows for a more accurate decoupling of reflectance and shading, ultimately leading to higher-quality synthesized images.ResultWe conducted experiments on eight scenes from the synthetic dataset Replica and five scenes from the real-world dataset ScanNet++. The decomposition results were visualized in the main text, and we evaluated the quality of synthesized images from novel views by using common image quality metrics, including peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS). The results demonstrate that our method not only produces more visually plausible decomposition results but also outperforms previous 3D scene intrinsic decomposition algorithms in terms of quantitative metrics. In particular, our method achieved average PSNR, SSIM, and LPIPS values of 34.695 5 dB, 0.965 4, and 0.086 1, respectively, on the Replica dataset. On the ScanNet++ dataset, our method achieved average values of 27.949 6 dB, 0.895 0, and 0.144 4, respectively. These improvements highlight the effectiveness of our approach in handling complex indoor scenes and producing high-fidelity decomposition results. Our experiments also showcase the proposed method’s ability to synthesize realistic images from previously unseen views. This capability is particularly important for applications, such as augmented reality and virtual reality. The high quality of the synthesized images further demonstrates our method’s robustness in decoupling reflectance and illumination.ConclusionCompared with previous methods, our approach excels in rapidly and accurately decomposing indoor scenes. Its strong generalization across diverse indoor environments, ranging from synthetic setups to real-world datasets, makes it highly valuable for applications, such as virtual object insertion, scene relighting, and material editing. This versatility significantly enhances the practical utility of our method. We believe that this work lays a strong foundation for future research, paving the way for more advanced techniques in the field of intrinsic decomposition and beyond.关键词:intrinsic decomposition;3D Gaussian splatting(3DGS);indoor scenes decomposition;Retinex theory;radiance fields607|572|0更新时间:2025-07-14
摘要:ObjectiveThe intrinsic decomposition of 3D scenes involves breaking down a scene into a product of reflectance and shading. Decomposition results can be applied to various tasks, such as virtual object insertion, image material replacement, and relighting, and thus, they have received widespread attention and have been the subject of numerous researches. However, decomposing large-scale and intricately structured indoor scenes presents a highly ill-posed problem due to the complexity of indoor environments, which contain various light sources, materials, and geometries. This complexity makes accurately disentangling reflectance and shading difficult because multiple possible combinations of these factors can explain the same observed image. Traditional methods frequently use prior constraints based on physical knowledge, human intuition, and visual perception to facilitate the reasonable separation of intrinsic attributes. Despite such effort, traditional methods still struggle in handling the complex interaction between reflectance and shading, resulting in poor decomposition results and limited applicability to different scenarios. Therefore, to achieve accurate and consistent decomposition results, addressing the inherent ambiguities and uncertainties involved is essential.MethodTo address these challenges, this study proposes an intrinsic decomposition algorithm that is specifically designed for indoor scenes, leveraging the state-of-the-art radiance field representation technique called 3D Gaussian splatting. This approach significantly improves the accuracy and efficiency of intrinsic decomposition for complex indoor environments. At present, many studies have further improved the rendering quality and efficiency of 3D Gaussian splatting and applied it to inverse rendering, dynamic scene modeling, and other tasks. Such development has inspired us to use 3D Gaussian splatting as a proxy for scene representation in this work. Building on this foundation, we develop an intrinsic decomposition model that is tailored for indoor scenes. This model is based on Retinex theory and aims to decompose a scene into reflectance, which represents the albedo of objects, and shading, which represents the interaction between lighting and object geometry. However, decomposing a scene into reflectance and shading is insufficient for representing all types of objects in indoor scenes. We use residual terms to fit specular reflections because indoor scenes have specular materials. To prevent loss of texture in reflectance during the optimization process, we use a reflectance offset to capture these details. The four aforementioned components effectively represent most objects in indoor scenes and facilitate the decomposition and optimization of intrinsic scene attributes. To better separate the above attributes, we introduce new reflectance piecewise sparsity, shading smoothness, and chromaticity prior constraints to reduce ambiguity in the decomposition process and ensure the rationality of the results. In accordance with the assumptions of Retinex theory, changes in gradient within a scene are attributed to illumination-independent reflectance and shading. Reflectance refers to the inherent color of an object and is the primary factor that is responsible for significant changes in appearance. Reflectance exhibits sparsity, because it tends to cluster in the RGB color space, forming distinct groups. By contrast, shading, which is influenced by the slow variation of light intensity in a scene, is generally assumed to be smooth. Directly separating reflectance from shading is challenging, and thus, we adopt methods from other computer vision fields. We segment a scene piecewise, apply sparsity constraints to each reflectance piece, constrain shading to be smoother in flat areas, and use chromaticity priors to ensure the color consistency of reflectance. These constraints effectively ensure the rationality of the decomposition results. In addition to these novel constraints, we enhance the geometric information of a scene by incorporating captured depth data, which provide valuable cues about a scene’s structure. This improved understanding allows for a more accurate decoupling of reflectance and shading, ultimately leading to higher-quality synthesized images.ResultWe conducted experiments on eight scenes from the synthetic dataset Replica and five scenes from the real-world dataset ScanNet++. The decomposition results were visualized in the main text, and we evaluated the quality of synthesized images from novel views by using common image quality metrics, including peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS). The results demonstrate that our method not only produces more visually plausible decomposition results but also outperforms previous 3D scene intrinsic decomposition algorithms in terms of quantitative metrics. In particular, our method achieved average PSNR, SSIM, and LPIPS values of 34.695 5 dB, 0.965 4, and 0.086 1, respectively, on the Replica dataset. On the ScanNet++ dataset, our method achieved average values of 27.949 6 dB, 0.895 0, and 0.144 4, respectively. These improvements highlight the effectiveness of our approach in handling complex indoor scenes and producing high-fidelity decomposition results. Our experiments also showcase the proposed method’s ability to synthesize realistic images from previously unseen views. This capability is particularly important for applications, such as augmented reality and virtual reality. The high quality of the synthesized images further demonstrates our method’s robustness in decoupling reflectance and illumination.ConclusionCompared with previous methods, our approach excels in rapidly and accurately decomposing indoor scenes. Its strong generalization across diverse indoor environments, ranging from synthetic setups to real-world datasets, makes it highly valuable for applications, such as virtual object insertion, scene relighting, and material editing. This versatility significantly enhances the practical utility of our method. We believe that this work lays a strong foundation for future research, paving the way for more advanced techniques in the field of intrinsic decomposition and beyond.关键词:intrinsic decomposition;3D Gaussian splatting(3DGS);indoor scenes decomposition;Retinex theory;radiance fields607|572|0更新时间:2025-07-14 - “在图形应用领域,专家提出了一种轻量级实时渲染自动参数优化方法,有效减少渲染时间,同时保持高画质。”
 摘要:ObjectiveWith the rapid development of virtual reality, augmented reality, and digital twin technologies, these innovations have not only transformed the manner in which people perceive virtual worlds but have also considerably advanced graphics rendering techniques. In these emerging fields, the quality of user experience directly depends on the realism and interactivity of the virtual world, making high-quality graphics and smooth performance indispensable. Although high-quality rendering has made significant progress in personal computer (PC) and console games, applying these techniques to mobile devices, such as laptops, tablets, and smartphones, remains a significant challenge. Mobile devices are considerably limited in terms of processing power, graphics capabilities, and memory compared with high-end PCs and dedicated gaming consoles. In addition, mobile devices require long battery life and cannot afford the high power consumption typical to desktop systems. Consequently, achieving high-quality, low-latency rendering under constrained hardware conditions is a major challenge. In modern game and rendering engines, a variety of rendering techniques (e.g., subsurface scattering, ambient occlusion, screen space reflection, and normal mapping) are integrated into a complex rendering pipeline. These techniques frequently come with numerous adjustable parameters, such as number of scattering samples, shadow precision, reflection intensity, ambient occlusion level, texture resolution, and level of detail. These parameters significantly affect image quality but also directly influence rendering computation and time costs. Therefore, finding an optimal balance between image quality and rendering time is critical for optimizing rendering parameters. Typically, these parameters are manually configured by developers based on different hardware environments and scene requirements. Developers frequently rely on trial and error, adjustment, and visual feedback to optimize these parameters for ideal rendering performance and quality. This manual approach is inefficient, error-prone, and nearly impossible when dealing with complex 3D scenes and dynamic game environments. Moreover, as games and virtual reality technologies evolve, real-time rendering must complete large amounts of complex calculations for each frame. Any misconfiguration can lead to performance bottlenecks or distorted visual effects. For example, shadow rendering precision may be crucial for some scenes but can be reduced in others to save computational resources. If these parameters cannot be dynamically optimized in real time, then the rendering engine may overuse resources in certain frames, leading to frame rate drops or increased latency, which severely affect user experience. To address this issue, researchers have explored various methods for optimizing rendering parameters in recent years. These methods include sampling scene space by using octrees, leveraging Pareto frontiers to find locally optimal parameters, using regression analysis and linear functions to quickly fit low-power parameters, or employing neural networks to estimate performance bottlenecks in real time based on drawcall counts. Although these methods have achieved a certain level of success in rendering optimization, they still exhibit significant limitations. First, function-fitting methods are prone to errors across different scenes, making generalization difficult. Second, the complexity of neural network inference introduces substantial computational overhead. Each time a neural network is used for parameter prediction, it adds additional computational burden. In real-time rendering, any delay can negatively affect performance. Consequently, existing neural network-based optimization methods frequently perform parameter prediction for every few dozen frames instead of calculating the optimal parameters for every single frame. Non-real-time parameter updating is particularly problematic in dynamic scenes wherein the complexity of the scene and camera view may change drastically at any moment. Neural networks may fail to respond promptly to these changes, compromising rendering stability and image quality. For example, when the camera moves quickly, objects and lighting in the scene may undergo significant changes, rendering the previous parameter predictions obsolete and leading to visual artifacts or frame rate fluctuations, which, in turn, degrade user experience.MethodTo address these issues, this study proposes a lightweight, real-time automatic rendering parameter optimization method. The proposed method is computationally efficient and allows for adaptive per-frame rendering parameter updates, ensuring consistency in rendering after parameter adjustments. The method is divided into three stages: model training, pre-computation, and adaptive real-time rendering. During the model training stage, various rendering parameters, hardware configurations, and scene information are used within a virtual environment to collect data on rendering time and image quality. These data are then used to train the model, which is divided into two parts: one part for evaluating rendering time and the other part for evaluating image quality. This division enables the model to fully explore the intrinsic relationships among parameters, rendering time, and image quality. In addition, the specially designed virtual scenes provide sufficient sample information, allowing the model to be generalized to new scenes. During the pre-computation stage, the key step is to first assess the real-time hardware information of the device, including those of the processor, graphics card, and other performance parameters. This step is completed during scene loading to ensure that rendering parameter optimization can be customized based on the specific performance of the device. Subsequently, the system simplifies the optimization problem of rendering time and image quality from a 2D multi-objective optimization problem into two independent 1D linear search tasks. This simplification significantly accelerates pre-computation speed, because linear search is considerably simpler than complex optimization in 2D space. In particular, a trade-off typically exists between rendering time and image quality, and thus, optimizing these factors requires finding a balance among many parameter combinations. To simplify this process, the system decomposes it into two independent 1D linear search tasks. First, the system searches for the optimal rendering time settings achievable within the given rendering time threshold (set to the fastest 20% in this study) under the current hardware conditions. Second, the system searches along image quality dimensions, ensuring that rendering time does not increase significantly, to find rendering parameters that maximize image quality. By employing this two-step search strategy, the system effectively balances rendering time and image quality while ensuring that the optimization process is efficient and accurate. Once optimization is completed, the resulting model is simplified into a lookup table (LUT), which records the optimal rendering parameter combinations for different hardware configurations. This LUT is tailored in accordance with the device’s hardware parameters, ready for use in the subsequent real-time rendering phase. Before rendering each frame during the adaptive real-time rendering stage, the system quickly retrieves the optimal rendering parameter settings from the pre-generated LUT based on the current hardware status and scene information. The lookup speed of the LUT is extremely fast, significantly reducing computational overhead compared with real-time parameter calculation. This reduction allows the system to complete parameter selection within milliseconds and immediately apply these parameters for rendering. The process ensures efficiency and flexibility in rendering. By completing extensive pre-computation tasks in advance, the system is only required to perform simple lookup operations during actual rendering, achieving a balance between high-quality rendering and fast responsiveness. Ultimately, the selected parameters are applied directly to the rendering of the current frame, ensuring that each frame achieves the optimal result based on hardware performance and scene requirements.ResultThe experimental results show that compared with neural networks and light gradient boosting machine models applied to subsurface scattering and ambient occlusion rendering techniques, the proposed method demonstrates advantages across multiple dimensions, including image quality, scene dependency, rendering time, and model performance. In particular, the proposed method reduces subsurface scattering rendering time by approximately 40% in various scenes and ambient occlusion rendering time by about 70%, with an increase of only around 2% in image quality error. In addition, the real-time inference time per frame is less than 0.1 ms.ConclusionThe proposed method effectively reduces rendering time while maintaining high rendering quality, making it highly practical for the actual demands of modern games and rendering engines. The implementation can be accessed at the following link:https://github.com/LightweightRenderParamOptimization/LightweightRenderParamOptimization.关键词:real-time rendering;rendering optimization;extreme gradient boosting(XGBoost);look up table(LUT);unreal engine(UE)263|350|0更新时间:2025-07-14
摘要:ObjectiveWith the rapid development of virtual reality, augmented reality, and digital twin technologies, these innovations have not only transformed the manner in which people perceive virtual worlds but have also considerably advanced graphics rendering techniques. In these emerging fields, the quality of user experience directly depends on the realism and interactivity of the virtual world, making high-quality graphics and smooth performance indispensable. Although high-quality rendering has made significant progress in personal computer (PC) and console games, applying these techniques to mobile devices, such as laptops, tablets, and smartphones, remains a significant challenge. Mobile devices are considerably limited in terms of processing power, graphics capabilities, and memory compared with high-end PCs and dedicated gaming consoles. In addition, mobile devices require long battery life and cannot afford the high power consumption typical to desktop systems. Consequently, achieving high-quality, low-latency rendering under constrained hardware conditions is a major challenge. In modern game and rendering engines, a variety of rendering techniques (e.g., subsurface scattering, ambient occlusion, screen space reflection, and normal mapping) are integrated into a complex rendering pipeline. These techniques frequently come with numerous adjustable parameters, such as number of scattering samples, shadow precision, reflection intensity, ambient occlusion level, texture resolution, and level of detail. These parameters significantly affect image quality but also directly influence rendering computation and time costs. Therefore, finding an optimal balance between image quality and rendering time is critical for optimizing rendering parameters. Typically, these parameters are manually configured by developers based on different hardware environments and scene requirements. Developers frequently rely on trial and error, adjustment, and visual feedback to optimize these parameters for ideal rendering performance and quality. This manual approach is inefficient, error-prone, and nearly impossible when dealing with complex 3D scenes and dynamic game environments. Moreover, as games and virtual reality technologies evolve, real-time rendering must complete large amounts of complex calculations for each frame. Any misconfiguration can lead to performance bottlenecks or distorted visual effects. For example, shadow rendering precision may be crucial for some scenes but can be reduced in others to save computational resources. If these parameters cannot be dynamically optimized in real time, then the rendering engine may overuse resources in certain frames, leading to frame rate drops or increased latency, which severely affect user experience. To address this issue, researchers have explored various methods for optimizing rendering parameters in recent years. These methods include sampling scene space by using octrees, leveraging Pareto frontiers to find locally optimal parameters, using regression analysis and linear functions to quickly fit low-power parameters, or employing neural networks to estimate performance bottlenecks in real time based on drawcall counts. Although these methods have achieved a certain level of success in rendering optimization, they still exhibit significant limitations. First, function-fitting methods are prone to errors across different scenes, making generalization difficult. Second, the complexity of neural network inference introduces substantial computational overhead. Each time a neural network is used for parameter prediction, it adds additional computational burden. In real-time rendering, any delay can negatively affect performance. Consequently, existing neural network-based optimization methods frequently perform parameter prediction for every few dozen frames instead of calculating the optimal parameters for every single frame. Non-real-time parameter updating is particularly problematic in dynamic scenes wherein the complexity of the scene and camera view may change drastically at any moment. Neural networks may fail to respond promptly to these changes, compromising rendering stability and image quality. For example, when the camera moves quickly, objects and lighting in the scene may undergo significant changes, rendering the previous parameter predictions obsolete and leading to visual artifacts or frame rate fluctuations, which, in turn, degrade user experience.MethodTo address these issues, this study proposes a lightweight, real-time automatic rendering parameter optimization method. The proposed method is computationally efficient and allows for adaptive per-frame rendering parameter updates, ensuring consistency in rendering after parameter adjustments. The method is divided into three stages: model training, pre-computation, and adaptive real-time rendering. During the model training stage, various rendering parameters, hardware configurations, and scene information are used within a virtual environment to collect data on rendering time and image quality. These data are then used to train the model, which is divided into two parts: one part for evaluating rendering time and the other part for evaluating image quality. This division enables the model to fully explore the intrinsic relationships among parameters, rendering time, and image quality. In addition, the specially designed virtual scenes provide sufficient sample information, allowing the model to be generalized to new scenes. During the pre-computation stage, the key step is to first assess the real-time hardware information of the device, including those of the processor, graphics card, and other performance parameters. This step is completed during scene loading to ensure that rendering parameter optimization can be customized based on the specific performance of the device. Subsequently, the system simplifies the optimization problem of rendering time and image quality from a 2D multi-objective optimization problem into two independent 1D linear search tasks. This simplification significantly accelerates pre-computation speed, because linear search is considerably simpler than complex optimization in 2D space. In particular, a trade-off typically exists between rendering time and image quality, and thus, optimizing these factors requires finding a balance among many parameter combinations. To simplify this process, the system decomposes it into two independent 1D linear search tasks. First, the system searches for the optimal rendering time settings achievable within the given rendering time threshold (set to the fastest 20% in this study) under the current hardware conditions. Second, the system searches along image quality dimensions, ensuring that rendering time does not increase significantly, to find rendering parameters that maximize image quality. By employing this two-step search strategy, the system effectively balances rendering time and image quality while ensuring that the optimization process is efficient and accurate. Once optimization is completed, the resulting model is simplified into a lookup table (LUT), which records the optimal rendering parameter combinations for different hardware configurations. This LUT is tailored in accordance with the device’s hardware parameters, ready for use in the subsequent real-time rendering phase. Before rendering each frame during the adaptive real-time rendering stage, the system quickly retrieves the optimal rendering parameter settings from the pre-generated LUT based on the current hardware status and scene information. The lookup speed of the LUT is extremely fast, significantly reducing computational overhead compared with real-time parameter calculation. This reduction allows the system to complete parameter selection within milliseconds and immediately apply these parameters for rendering. The process ensures efficiency and flexibility in rendering. By completing extensive pre-computation tasks in advance, the system is only required to perform simple lookup operations during actual rendering, achieving a balance between high-quality rendering and fast responsiveness. Ultimately, the selected parameters are applied directly to the rendering of the current frame, ensuring that each frame achieves the optimal result based on hardware performance and scene requirements.ResultThe experimental results show that compared with neural networks and light gradient boosting machine models applied to subsurface scattering and ambient occlusion rendering techniques, the proposed method demonstrates advantages across multiple dimensions, including image quality, scene dependency, rendering time, and model performance. In particular, the proposed method reduces subsurface scattering rendering time by approximately 40% in various scenes and ambient occlusion rendering time by about 70%, with an increase of only around 2% in image quality error. In addition, the real-time inference time per frame is less than 0.1 ms.ConclusionThe proposed method effectively reduces rendering time while maintaining high rendering quality, making it highly practical for the actual demands of modern games and rendering engines. The implementation can be accessed at the following link:https://github.com/LightweightRenderParamOptimization/LightweightRenderParamOptimization.关键词:real-time rendering;rendering optimization;extreme gradient boosting(XGBoost);look up table(LUT);unreal engine(UE)263|350|0更新时间:2025-07-14
Computer Graphics
- “在机器人辅助腹腔镜手术领域,专家提出了多尺度动态视觉网络MDVNet,为提高手术精度提供新方案。”
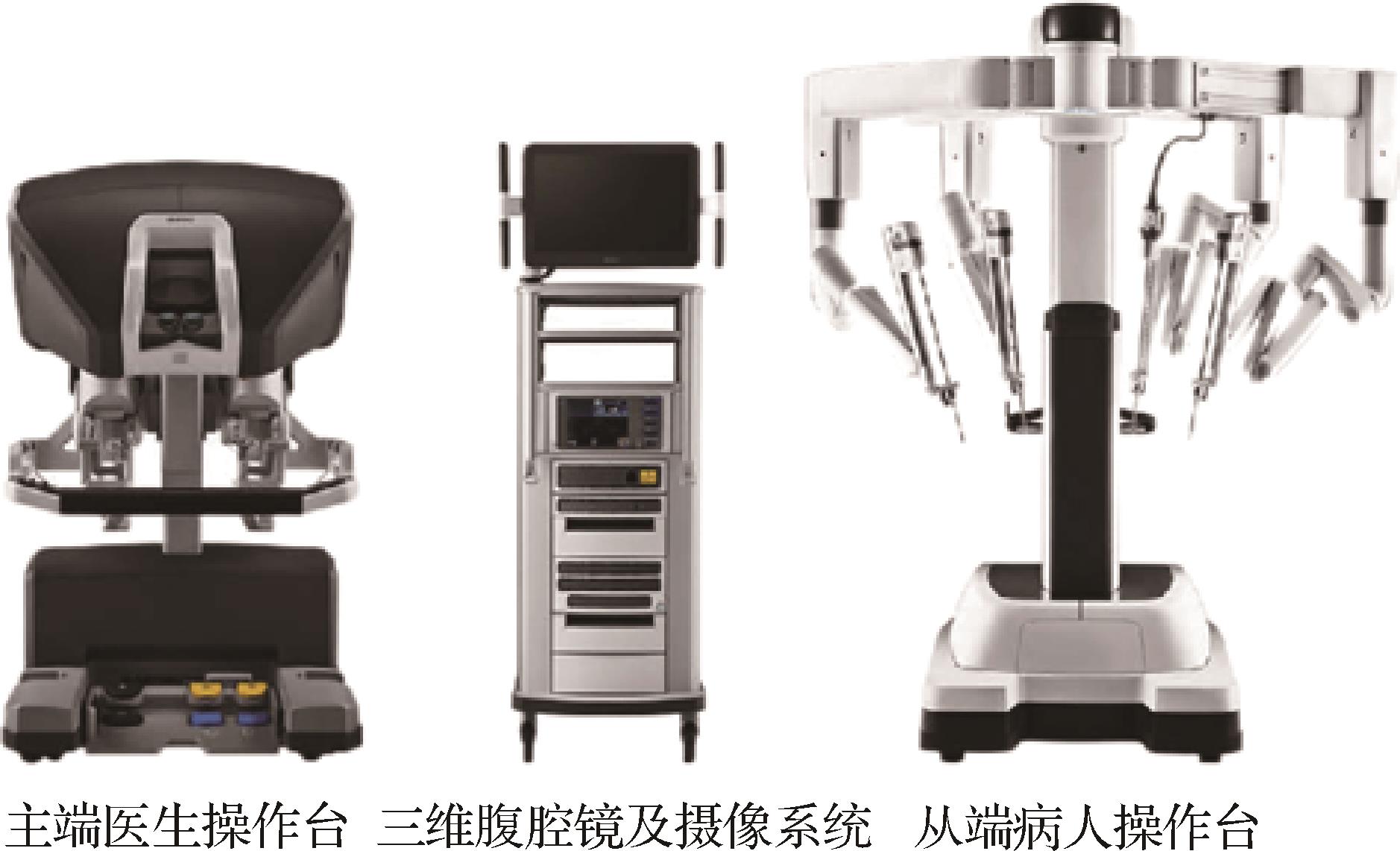 摘要:ObjectiveRobot-assisted endoscopic surgery is performed with the help of intelligent endoscopic surgical robots to effectively reduce trauma, shorten the recovery period, and improve surgical success rates. Endoscopic surgery scene segmentation means the use of deep learning techniques to accurately segment the entire surgical scene; the targets include anatomical areas and instruments. However, endoscopic surgery is completed in a closed human body cavity, and the whole process is accompanied by frequent cutting, traction, and other surgical operations, making the features of the segmentation targets complex and variable. In advancing robot-assisted surgery, developing high-precision surgical scene segmentation algorithms that can assist surgeons in performing surgeries is crucial. In this work, we propose an innovative surgical scene segmentation network named multiscale dynamic visual network (MDVNet), which aims to address three major challenges in endoscopic surgical scene segmentation: target size variation, intraoperative complex noises, and indistinguishable boundaries.MethodMDVNet adopts an encoder–decoder structure. For the encoder, a dynamic large kernel convolutional attention (DLKA) module can extract multiscale features of the surgical scene is applied. The DLKA module consists of multiple branches each equipped with large kernel convolutions of different sizes, allowing the network to capture details and a wide range of features of targets with different sizes (7, 11, and 21 in this work). The dynamic selection mechanism also helps to adaptively fuse features to meet the needs of different sized segmentation targets in endoscopic surgery scene. This newly designed module directly addresses the problem of target size variability, which is a major obstacle faced by previous surgical scene segmentation methods. For the decoder, the following two key modules are proposed: low-rank matrix decomposition module (LMD) and boundary guided module (BGM) to solve the intraoperative complex noises and indistinguishable boundaries challenges in endoscopic images. The core idea of LMD is to separate the noise components from the useful feature information in the feature map through the low-rank matrix decomposition technique. In endoscopic surgical scenes, noise is generated in surgical images due to motion blur, blood splash, and water mist on the tissue surface caused by surgical operations. These noises reduce the segmentation accuracy of the network. LMD decomposes the feature map into a low-rank matrix containing the main feature information of the image and a sparse matrix containing the noise and outliers through nonnegative matrix factorization. Through this process, LMD can effectively remove the noise and provide a high-quality feature map for subsequent segmentation tasks. In surgical scenes, the boundaries between different tissues and instruments are highly indistinguishable due to contact, occlusion, or similar texture features. To solve this problem, BGM uses a combination of boundary-sensitive Laplace convolutions and normal convolutions to compute the boundary maps of the ground truth and the highest resolution feature maps, respectively. In addition, BGM uses a combination of cross-entropy loss function and dice loss function to guide the network to learn the boundary features and pay attention to the boundary region during training, thus improving the ability to recognize the boundary. A split laparoscopic surgical robot platform was constructed with the practical operational needs of the surgical process, integrating the advanced Lap Game endoscopic simulator, the Franka robotic arms, and a high-precision endoscopic imaging system, to apply the proposed MDVNet to actual surgical scenarios and verify its effectiveness. Users can manipulate the robotic arm equipped with surgical instruments through the control handle and complete endoscopic surgical operations such as cutting, freeing, and suturing in the endoscopic simulator to simulate the process of surgery. The segmentation results of the network are displayed on the user console to assist the surgeon in performing endoscopic surgery.ResultTo fully validate the effectiveness and potential of the proposed MDVNet, we subjected it to comprehensive comparative analysis with other advanced surgical scene segmentation methods on three different surgical scene datasets, namely, the robotic surgical scene dataset (Endovis2018), cataract surgical scene dataset (CaDIS), and minimally invasive laparoscopic surgery dataset (MILS). Experimental results show that MDVNet achieves the best segmentation results on all three datasets, with the intersection over union (mIoU) of 51.19% on Endovis2018, 71.28% on CaDIS (Task III), and 52.47% on MILS. Visualization results on the three datasets also illustrate that MDVNet can effectively segment multiple targets such as surgical instruments and anatomical areas in surgical scenes. We also conducted ablation experiments on the Endovis2018 dataset with three different modules, DLKA, LMD, and BGM. The results demonstrate that the different modules in MDVNet complement each other and can be combined to produce a positive gain effect on the whole method. Finally, the proposed MDVNet was employed on the laparoscopic surgical robot, and the segmentation results of the network were superimposed with the original surgical images for output to assist the surgeon in performing laparoscopic surgery.ConclusionTo solve the three major challenges of endoscopic surgical scene segmentation, including target size variation, intraoperative complex noises, and indistinguishable boundaries, this work proposes an innovative surgical scene segmentation network named MDVNet. It is composed of three modules, DLKA, LMD, and BGM. For the encoder, DLKA can extract the multiscale features of different segmentation targets by applying multiscale large kernel attention and perform adaptive feature fusion by dynamic selection mechanism, effectively reducing the misidentification caused by the change of target sizes. For the decoder, LMD first filters out the noise in the feature maps and obtains high-quality feature maps. BGM guides the model to learn the boundary features of the surgical scene by calculating the loss between the boundary maps of the feature maps and the ground truth. MDVNet achieves state-of-the-art (SOTA) results on three different surgical scene datasets Endovis2018, CaDIS, and MILS. Code is available at https://github.com/YubinHan73/MDVNet.关键词:endoscopic surgical robot;semantic segmentation;large kernel convolution;low-rank matrix decomposition (LMD);boundary segmentation315|584|0更新时间:2025-07-14
摘要:ObjectiveRobot-assisted endoscopic surgery is performed with the help of intelligent endoscopic surgical robots to effectively reduce trauma, shorten the recovery period, and improve surgical success rates. Endoscopic surgery scene segmentation means the use of deep learning techniques to accurately segment the entire surgical scene; the targets include anatomical areas and instruments. However, endoscopic surgery is completed in a closed human body cavity, and the whole process is accompanied by frequent cutting, traction, and other surgical operations, making the features of the segmentation targets complex and variable. In advancing robot-assisted surgery, developing high-precision surgical scene segmentation algorithms that can assist surgeons in performing surgeries is crucial. In this work, we propose an innovative surgical scene segmentation network named multiscale dynamic visual network (MDVNet), which aims to address three major challenges in endoscopic surgical scene segmentation: target size variation, intraoperative complex noises, and indistinguishable boundaries.MethodMDVNet adopts an encoder–decoder structure. For the encoder, a dynamic large kernel convolutional attention (DLKA) module can extract multiscale features of the surgical scene is applied. The DLKA module consists of multiple branches each equipped with large kernel convolutions of different sizes, allowing the network to capture details and a wide range of features of targets with different sizes (7, 11, and 21 in this work). The dynamic selection mechanism also helps to adaptively fuse features to meet the needs of different sized segmentation targets in endoscopic surgery scene. This newly designed module directly addresses the problem of target size variability, which is a major obstacle faced by previous surgical scene segmentation methods. For the decoder, the following two key modules are proposed: low-rank matrix decomposition module (LMD) and boundary guided module (BGM) to solve the intraoperative complex noises and indistinguishable boundaries challenges in endoscopic images. The core idea of LMD is to separate the noise components from the useful feature information in the feature map through the low-rank matrix decomposition technique. In endoscopic surgical scenes, noise is generated in surgical images due to motion blur, blood splash, and water mist on the tissue surface caused by surgical operations. These noises reduce the segmentation accuracy of the network. LMD decomposes the feature map into a low-rank matrix containing the main feature information of the image and a sparse matrix containing the noise and outliers through nonnegative matrix factorization. Through this process, LMD can effectively remove the noise and provide a high-quality feature map for subsequent segmentation tasks. In surgical scenes, the boundaries between different tissues and instruments are highly indistinguishable due to contact, occlusion, or similar texture features. To solve this problem, BGM uses a combination of boundary-sensitive Laplace convolutions and normal convolutions to compute the boundary maps of the ground truth and the highest resolution feature maps, respectively. In addition, BGM uses a combination of cross-entropy loss function and dice loss function to guide the network to learn the boundary features and pay attention to the boundary region during training, thus improving the ability to recognize the boundary. A split laparoscopic surgical robot platform was constructed with the practical operational needs of the surgical process, integrating the advanced Lap Game endoscopic simulator, the Franka robotic arms, and a high-precision endoscopic imaging system, to apply the proposed MDVNet to actual surgical scenarios and verify its effectiveness. Users can manipulate the robotic arm equipped with surgical instruments through the control handle and complete endoscopic surgical operations such as cutting, freeing, and suturing in the endoscopic simulator to simulate the process of surgery. The segmentation results of the network are displayed on the user console to assist the surgeon in performing endoscopic surgery.ResultTo fully validate the effectiveness and potential of the proposed MDVNet, we subjected it to comprehensive comparative analysis with other advanced surgical scene segmentation methods on three different surgical scene datasets, namely, the robotic surgical scene dataset (Endovis2018), cataract surgical scene dataset (CaDIS), and minimally invasive laparoscopic surgery dataset (MILS). Experimental results show that MDVNet achieves the best segmentation results on all three datasets, with the intersection over union (mIoU) of 51.19% on Endovis2018, 71.28% on CaDIS (Task III), and 52.47% on MILS. Visualization results on the three datasets also illustrate that MDVNet can effectively segment multiple targets such as surgical instruments and anatomical areas in surgical scenes. We also conducted ablation experiments on the Endovis2018 dataset with three different modules, DLKA, LMD, and BGM. The results demonstrate that the different modules in MDVNet complement each other and can be combined to produce a positive gain effect on the whole method. Finally, the proposed MDVNet was employed on the laparoscopic surgical robot, and the segmentation results of the network were superimposed with the original surgical images for output to assist the surgeon in performing laparoscopic surgery.ConclusionTo solve the three major challenges of endoscopic surgical scene segmentation, including target size variation, intraoperative complex noises, and indistinguishable boundaries, this work proposes an innovative surgical scene segmentation network named MDVNet. It is composed of three modules, DLKA, LMD, and BGM. For the encoder, DLKA can extract the multiscale features of different segmentation targets by applying multiscale large kernel attention and perform adaptive feature fusion by dynamic selection mechanism, effectively reducing the misidentification caused by the change of target sizes. For the decoder, LMD first filters out the noise in the feature maps and obtains high-quality feature maps. BGM guides the model to learn the boundary features of the surgical scene by calculating the loss between the boundary maps of the feature maps and the ground truth. MDVNet achieves state-of-the-art (SOTA) results on three different surgical scene datasets Endovis2018, CaDIS, and MILS. Code is available at https://github.com/YubinHan73/MDVNet.关键词:endoscopic surgical robot;semantic segmentation;large kernel convolution;low-rank matrix decomposition (LMD);boundary segmentation315|584|0更新时间:2025-07-14 - “在医学影像领域,专家提出了一种融合图像增强和自注意力机制的数据生成方法,有效提升了活动性肺结核影像数据的生成质量。”
 摘要:ObjectiveComputed tomography (CT) image data provide an important basis for deep learning models to assist doctors in the prevention and diagnosis of active pulmonary tuberculosis. The accurate generation and processing of CT image data are crucial for the diagnosis level of doctors. Compared with traditional diagnostic methods, deep learning models can automatically identify and process large-scale image data, improving the efficiency and accuracy of diagnosis. However, forming large-scale and high-quality datasets still faces many challenges due to privacy protection regulations and high acquisition costs. These factors limit the amount of data required to train a deep learning model, affecting the performance of the model. Existing data generation techniques exhibit limitations when dealing with data from low-quality and diverse sources. In particular, these techniques experience difficulty in achieving ideal results in the quality of generated images, especially in generating subtle lesions and ensuring image clarity. This limitation not only affects the ability of the model to identify detailed lesions, but also limits the ability of doctors to use the generated images for accurate diagnosis. Therefore, this study proposes a data generation method that combines image enhancement and self-attention mechanism to improve the generation quality of active pulmonary tuberculosis image data. This method not only performs well in improving image clarity but can also effectively enhance the expression ability of the generated data for subtle lesions.MethodFirst, we use a cycle-consistent adversarial network (CycleGAN) to enhance the original low-quality source data. CycleGAN uses two generators and two discriminators to ensure transformation consistency between the source domain and target domain through the cycle consistency loss function, improving the quality of image data in an unsupervised manner. Then, image-to-image translation with a conditional adversarial network(Pix2Pix) was used for data generation. Pix2Pix gives more attention to image-to-image mapping and makes the generated image as close as possible to the real image through the cooperative work of the generator and the conditional discriminator. This scheme provides special attention to the matching of data samples and their detail processing, enhancing the accuracy and fineness of image data. At the generator design level, this study uses the U-Net architecture and integrates the residual module with a self-attention mechanism. The U-Net architecture enables the model to effectively use the information of each feature layer through a symmetric encoder-decoder path, enhancing the model’s ability to learn the features of images with different resolutions. Combined with the self-attention mechanism, the residual module significantly improves the model’s ability to perceive and process image context information and detail features. For the discriminator part, this study adopts the PatchGAN architecture, which focuses on analyzing the local features of an image. PatchGAN can finely detect the details of an image by dividing the image into multiple small blocks and discriminating authenticity separately. This study also uses the parametric rectified linear unit activation function, which can adaptively adjust the negative slope, endowing the model with better nonlinear expression ability in the process of backpropagation to improve the image discrimination performance of the discriminator.ResultTo verify the effectiveness of the proposed method, experiments are performed on the self-built and public mixed datasets, and the results are compared with those of mainstream methods. In the data generation experiment without image enhancement processing, the data generation effect of the proposed method is 1.38% and 2.15% higher than that of the second performing method in the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) indicators, respectively, while Fréchet inception distance (FID) is reduced by 10.70%. These results show that the proposed method exhibits significant advantage in terms of image quality. In the data generation experiment after image enhancement processing, the PSNR and SSIM of the proposed method are increased by 0.52% and 1.05%, respectively, while FID is reduced by 2.01% compared with the other methods. These experimental results further prove the effectiveness of the proposed method in improving the quality of image data generation, particularly in the generation of subtle lesions and the improvement of image clarity.ConclusionIn general, the data generation method that combines image enhancement technology and self-attention mechanism proposed in this study effectively improves the overall generation quality of CT image data of active pulmonary tuberculosis. By processing low-quality source data and extracting the fine features of the generated data, the proposed method not only improves the generation ability of subtle lesions, but also significantly enhances the definition of the generated image, overcoming the limitations of the existing generation technology in dealing with complex medical image data.关键词:data generation;image enhancement;active tuberculosis;self attention mechanism;CT images;CycleGAN;Pix2Pix201|391|0更新时间:2025-07-14
摘要:ObjectiveComputed tomography (CT) image data provide an important basis for deep learning models to assist doctors in the prevention and diagnosis of active pulmonary tuberculosis. The accurate generation and processing of CT image data are crucial for the diagnosis level of doctors. Compared with traditional diagnostic methods, deep learning models can automatically identify and process large-scale image data, improving the efficiency and accuracy of diagnosis. However, forming large-scale and high-quality datasets still faces many challenges due to privacy protection regulations and high acquisition costs. These factors limit the amount of data required to train a deep learning model, affecting the performance of the model. Existing data generation techniques exhibit limitations when dealing with data from low-quality and diverse sources. In particular, these techniques experience difficulty in achieving ideal results in the quality of generated images, especially in generating subtle lesions and ensuring image clarity. This limitation not only affects the ability of the model to identify detailed lesions, but also limits the ability of doctors to use the generated images for accurate diagnosis. Therefore, this study proposes a data generation method that combines image enhancement and self-attention mechanism to improve the generation quality of active pulmonary tuberculosis image data. This method not only performs well in improving image clarity but can also effectively enhance the expression ability of the generated data for subtle lesions.MethodFirst, we use a cycle-consistent adversarial network (CycleGAN) to enhance the original low-quality source data. CycleGAN uses two generators and two discriminators to ensure transformation consistency between the source domain and target domain through the cycle consistency loss function, improving the quality of image data in an unsupervised manner. Then, image-to-image translation with a conditional adversarial network(Pix2Pix) was used for data generation. Pix2Pix gives more attention to image-to-image mapping and makes the generated image as close as possible to the real image through the cooperative work of the generator and the conditional discriminator. This scheme provides special attention to the matching of data samples and their detail processing, enhancing the accuracy and fineness of image data. At the generator design level, this study uses the U-Net architecture and integrates the residual module with a self-attention mechanism. The U-Net architecture enables the model to effectively use the information of each feature layer through a symmetric encoder-decoder path, enhancing the model’s ability to learn the features of images with different resolutions. Combined with the self-attention mechanism, the residual module significantly improves the model’s ability to perceive and process image context information and detail features. For the discriminator part, this study adopts the PatchGAN architecture, which focuses on analyzing the local features of an image. PatchGAN can finely detect the details of an image by dividing the image into multiple small blocks and discriminating authenticity separately. This study also uses the parametric rectified linear unit activation function, which can adaptively adjust the negative slope, endowing the model with better nonlinear expression ability in the process of backpropagation to improve the image discrimination performance of the discriminator.ResultTo verify the effectiveness of the proposed method, experiments are performed on the self-built and public mixed datasets, and the results are compared with those of mainstream methods. In the data generation experiment without image enhancement processing, the data generation effect of the proposed method is 1.38% and 2.15% higher than that of the second performing method in the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) indicators, respectively, while Fréchet inception distance (FID) is reduced by 10.70%. These results show that the proposed method exhibits significant advantage in terms of image quality. In the data generation experiment after image enhancement processing, the PSNR and SSIM of the proposed method are increased by 0.52% and 1.05%, respectively, while FID is reduced by 2.01% compared with the other methods. These experimental results further prove the effectiveness of the proposed method in improving the quality of image data generation, particularly in the generation of subtle lesions and the improvement of image clarity.ConclusionIn general, the data generation method that combines image enhancement technology and self-attention mechanism proposed in this study effectively improves the overall generation quality of CT image data of active pulmonary tuberculosis. By processing low-quality source data and extracting the fine features of the generated data, the proposed method not only improves the generation ability of subtle lesions, but also significantly enhances the definition of the generated image, overcoming the limitations of the existing generation technology in dealing with complex medical image data.关键词:data generation;image enhancement;active tuberculosis;self attention mechanism;CT images;CycleGAN;Pix2Pix201|391|0更新时间:2025-07-14
Medical Image Processing
- “在遥感图像检测领域,专家提出了一种新方法,有效提升了目标定位能力,改善了复杂背景下的漏检和误检问题。”
 摘要:ObjectiveRemote sensing images (RSIs) have been widely used in environmental monitoring, resource management, and emergency response due to their wide coverage, rich information content, and high temporal and spatial resolution. However, in the actual process of object detection, the objects in RSIs are typically small in size, densely distributed, and exhibit large-scale variations, which can easily lead to missed and false detection problems, particularly in complex backgrounds. To address these challenges, we propose an RSI detection method guided by contextual information and multi-scale feature sequences.MethodFirst, we designed an adaptive large receptive field (ALRF) during the feature extraction stage. The design of a reasonable receptive field (RF) is crucial for RSI processing. A large RF cannot only effectively capture the global structure of large targets, but can also use contextual information to capture the details of small targets, improving detection performance. Large kernel convolution is a common method for expanding RF, but its computational cost is high. As the size of the convolution kernel increases, the number of parameters will also increase rapidly, affecting the inference speed and efficiency of a model. To solve this problem, ALRF adopts multilayer cascade dilated convolution to expand RF by gradually increasing the size and dilation rate of the convolution kernel while maintaining a low number of parameters, achieving an RF and context perception capability comparable with that of large kernel convolution. For the hierarchical features extracted via cascade dilated convolution, ALRF performs channel weighing through channel attention and then spatial fusion through spatial attention, adaptively adjusting RF size in accordance with the features of different targets, effectively capturing contextual information in RSIs, and realizing the extraction of multi-scale features. Secondly, we proposed a multi-scale feature fusion (MFF) architecture during the feature fusion stage. MFF is primarily composed of a focal scale fusion engine (FSFE) and a fine-scale feature encoder (FFE), and it fuses the multi-scale feature sequences extracted from the backbone network through a bidirectional feature pyramid network structure. FSFE constructs a multi-scale feature sequence by using Gaussian convolution kernels with increasing standard deviations. By contrast, FFE introduces detailed information from the shallow feature layer of P2 and uses hybrid coding to enhance semantic expression. MFF achieves effective fusion of multi-scale global information under complex background information through the collaborative work of FSFE and FFE, reducing the effect of feature ambiguity in deep networks on capturing small target details. Finally, we introduce the normalized Wasserstein distance (NWD) to replace the traditional intersection over union (IoU). NWD measures the similarity of bounding boxes by modeling them as 2D Gaussian distributions and calculating the Wasserstein distance between these distributions. As a robust similarity metric, NWD can accurately evaluate the alignment between the bounding box of a small object and the ground truth box, reducing sensitivity to positional deviations.ResultOur method is experimentally verified on two datasets, namely, the Northwestern Polytechnical University very-high resolution 10 (NWPU VHR-10) dataset and the dataset for object detection in aerial images (DIOR), and compared with 10 detection methods from the two-stage, one-stage, and DETR series. Experimental results show that the method exhibits significant advantages in small target detection and complex backgrounds. On the NWPU VHR-10 dataset, the average precision (AP) of the method is improved by 5.48% to 93.15% compared with the baseline model, You Only Look Once v8 Nano (YOLOv8n), while the number of parameters is reduced by 6.96%. In DIOR, the AP of the method is 80.89%, which is 2.97% higher than that of YOLOv8n. The effectiveness of ALRF, MFF, and NWD is verified through ablation experiments. ALRF achieves efficient use of contextual information through cascaded dilated convolutions. MFF enhances the ability to capture small target details by constructing multi-scale feature sequences and introducing shallow features. NWD improves the balance of positive and negative sample distribution by modeling the bounding box as a 2D Gaussian distribution. The simultaneous use of ALRF, MFF, and NWD can achieve the best effect on the model, with precision, recall, and AP increased by 2.76%, 4.61%, and 5.48%, respectively, compared with the baseline model. In addition, the precision–recall curve of this method is closer to the upper right and more stable, indicating that it is stable in the detection of different categories of targets. Simultaneously, this method is effective in reducing false and missed detections and exhibits stronger generalization and robustness compared with other methods.ConclusionAn RSI detection method guided by context information and multi-scale feature sequences is proposed to solve the problems of dense small targets, large target size variations, and complex background in RSI detection. This method first uses ALRF to effectively utilize context information. Then, MFF is used to reduce the semantic information loss of small targets. Finally, NWD is introduced to replace the traditional IoU to optimize the distribution of positive and negative samples. The experimental results show that the AP of this method on the NWPU VHR-10 dataset and DIOR reaches 93.15% and 80.89%, respectively. Meanwhile, the model parameters are only 2.94 M, which is significantly better than that of the comparison method. In our future work, the proposed method will be extended to target detection under multi-view imaging conditions, and a lightweight model suitable for real-time detection applications will be developed.关键词:remote sensing image(RSI);target detection;receptive field(RF);feature fusion;normalized Wasserstein distance(NWD)242|440|0更新时间:2025-07-14
摘要:ObjectiveRemote sensing images (RSIs) have been widely used in environmental monitoring, resource management, and emergency response due to their wide coverage, rich information content, and high temporal and spatial resolution. However, in the actual process of object detection, the objects in RSIs are typically small in size, densely distributed, and exhibit large-scale variations, which can easily lead to missed and false detection problems, particularly in complex backgrounds. To address these challenges, we propose an RSI detection method guided by contextual information and multi-scale feature sequences.MethodFirst, we designed an adaptive large receptive field (ALRF) during the feature extraction stage. The design of a reasonable receptive field (RF) is crucial for RSI processing. A large RF cannot only effectively capture the global structure of large targets, but can also use contextual information to capture the details of small targets, improving detection performance. Large kernel convolution is a common method for expanding RF, but its computational cost is high. As the size of the convolution kernel increases, the number of parameters will also increase rapidly, affecting the inference speed and efficiency of a model. To solve this problem, ALRF adopts multilayer cascade dilated convolution to expand RF by gradually increasing the size and dilation rate of the convolution kernel while maintaining a low number of parameters, achieving an RF and context perception capability comparable with that of large kernel convolution. For the hierarchical features extracted via cascade dilated convolution, ALRF performs channel weighing through channel attention and then spatial fusion through spatial attention, adaptively adjusting RF size in accordance with the features of different targets, effectively capturing contextual information in RSIs, and realizing the extraction of multi-scale features. Secondly, we proposed a multi-scale feature fusion (MFF) architecture during the feature fusion stage. MFF is primarily composed of a focal scale fusion engine (FSFE) and a fine-scale feature encoder (FFE), and it fuses the multi-scale feature sequences extracted from the backbone network through a bidirectional feature pyramid network structure. FSFE constructs a multi-scale feature sequence by using Gaussian convolution kernels with increasing standard deviations. By contrast, FFE introduces detailed information from the shallow feature layer of P2 and uses hybrid coding to enhance semantic expression. MFF achieves effective fusion of multi-scale global information under complex background information through the collaborative work of FSFE and FFE, reducing the effect of feature ambiguity in deep networks on capturing small target details. Finally, we introduce the normalized Wasserstein distance (NWD) to replace the traditional intersection over union (IoU). NWD measures the similarity of bounding boxes by modeling them as 2D Gaussian distributions and calculating the Wasserstein distance between these distributions. As a robust similarity metric, NWD can accurately evaluate the alignment between the bounding box of a small object and the ground truth box, reducing sensitivity to positional deviations.ResultOur method is experimentally verified on two datasets, namely, the Northwestern Polytechnical University very-high resolution 10 (NWPU VHR-10) dataset and the dataset for object detection in aerial images (DIOR), and compared with 10 detection methods from the two-stage, one-stage, and DETR series. Experimental results show that the method exhibits significant advantages in small target detection and complex backgrounds. On the NWPU VHR-10 dataset, the average precision (AP) of the method is improved by 5.48% to 93.15% compared with the baseline model, You Only Look Once v8 Nano (YOLOv8n), while the number of parameters is reduced by 6.96%. In DIOR, the AP of the method is 80.89%, which is 2.97% higher than that of YOLOv8n. The effectiveness of ALRF, MFF, and NWD is verified through ablation experiments. ALRF achieves efficient use of contextual information through cascaded dilated convolutions. MFF enhances the ability to capture small target details by constructing multi-scale feature sequences and introducing shallow features. NWD improves the balance of positive and negative sample distribution by modeling the bounding box as a 2D Gaussian distribution. The simultaneous use of ALRF, MFF, and NWD can achieve the best effect on the model, with precision, recall, and AP increased by 2.76%, 4.61%, and 5.48%, respectively, compared with the baseline model. In addition, the precision–recall curve of this method is closer to the upper right and more stable, indicating that it is stable in the detection of different categories of targets. Simultaneously, this method is effective in reducing false and missed detections and exhibits stronger generalization and robustness compared with other methods.ConclusionAn RSI detection method guided by context information and multi-scale feature sequences is proposed to solve the problems of dense small targets, large target size variations, and complex background in RSI detection. This method first uses ALRF to effectively utilize context information. Then, MFF is used to reduce the semantic information loss of small targets. Finally, NWD is introduced to replace the traditional IoU to optimize the distribution of positive and negative samples. The experimental results show that the AP of this method on the NWPU VHR-10 dataset and DIOR reaches 93.15% and 80.89%, respectively. Meanwhile, the model parameters are only 2.94 M, which is significantly better than that of the comparison method. In our future work, the proposed method will be extended to target detection under multi-view imaging conditions, and a lightweight model suitable for real-time detection applications will be developed.关键词:remote sensing image(RSI);target detection;receptive field(RF);feature fusion;normalized Wasserstein distance(NWD)242|440|0更新时间:2025-07-14 - “在计算机视觉和遥感领域,专家提出了一种快速高精度的城市地区遥感神经辐射场三维重建算法,有效提高了复杂建筑群重建精度和训练效率。”
 摘要:ObjectiveSatellite remote sensing images have high application value in urban planning and construction, natural resource management, surface change monitoring, and scientific research. The 3D reconstruction of Earth’s surface by using satellite remote sensing images has become a research hot spot in the fields of computer vision and remote sensing. As neural rendering implicit 3D reconstruction becomes more widely applied in the field of remote sensing, research on neural radiance field (NeRF) in remote sensing scenarios has expanded, and various neural rendering algorithms have emerged. Concepts and models, such as urban planning, communication infrastructure construction, digital maps, and smart cities, require large-scale 3D reconstruction methods to perform better in urban areas. Urban buildings frequently exhibit structural regularities, typically presenting geometric structures, such as cuboids, cubes, and prisms. This important prior knowledge has not been effectively utilized in previous remote sensing NeRF algorithms. Therefore, this study aims to introduce geometric structure constraints that are specific to urban areas into remote sensing NeRF 3D reconstruction algorithms. In addition, the rendering method of NeRF and excessive parameters lead to extremely slow training and rendering time. The number of sampling points is determined by the training data, which are responsible for the training and optimization of the entire target space. Reducing the number of sampling points may degrade rendering quality. Therefore, to achieve fast scene reconstruction, optimizing the network structure is necessary, along with reducing its layers and dimensions to accelerate training and rendering.MethodFor the 3D reconstruction of complex urban buildings, this study proposes an improved strategy for rendering complex structures more finely and ensuring flatter planes of artificial buildings. During preprocessing, the method adds two adjacent rays to each training ray that do not participate in backpropagation. After obtaining the density information of a scene through a multilayer network, the method inversely solves the depth points of the three rays and determines the surface points of the target. Based on the surface points, a set of surface normals is solved. By using the clustering information of these surface normals, the surface information of the scene and normals perpendicular to the surface is restored and clustered under Manhattan conditions. The three major orthogonal clusters within the Manhattan framework are solved based on the largest cluster, and backpropagation is performed in accordance with constraints, such as orthogonality and normalization, ensuring that the reconstruction target meets Manhattan framework conditions. Training speed is slow due to the extensive computations involved in rendering. To address this issue, the method uses multilayer encoding to reduce the complexity of the neural network. For coarse network sampling points, which must learn the entire scene’s 3D information, multi-resolution learnable positional encoding is used to map them into high-dimensional space. For fine network sampling points, which must learn detailed texture information, hash encoding is used. Hash encoding optimizes network input by interpolating sampling points through multi-resolution grids, finding the corresponding hash encoding data, and integrating multiple resolution hash encodings before feeding them into a smaller network for training. This improvement significantly reduces the training time of the radiance field, achieving fast and high-precision reconstruction of complex urban buildings. This method is implemented on Quadro RTX 8000 graphics processing unit by using the PyTorch Lightning framework. The initial learning rate is set to
摘要:ObjectiveSatellite remote sensing images have high application value in urban planning and construction, natural resource management, surface change monitoring, and scientific research. The 3D reconstruction of Earth’s surface by using satellite remote sensing images has become a research hot spot in the fields of computer vision and remote sensing. As neural rendering implicit 3D reconstruction becomes more widely applied in the field of remote sensing, research on neural radiance field (NeRF) in remote sensing scenarios has expanded, and various neural rendering algorithms have emerged. Concepts and models, such as urban planning, communication infrastructure construction, digital maps, and smart cities, require large-scale 3D reconstruction methods to perform better in urban areas. Urban buildings frequently exhibit structural regularities, typically presenting geometric structures, such as cuboids, cubes, and prisms. This important prior knowledge has not been effectively utilized in previous remote sensing NeRF algorithms. Therefore, this study aims to introduce geometric structure constraints that are specific to urban areas into remote sensing NeRF 3D reconstruction algorithms. In addition, the rendering method of NeRF and excessive parameters lead to extremely slow training and rendering time. The number of sampling points is determined by the training data, which are responsible for the training and optimization of the entire target space. Reducing the number of sampling points may degrade rendering quality. Therefore, to achieve fast scene reconstruction, optimizing the network structure is necessary, along with reducing its layers and dimensions to accelerate training and rendering.MethodFor the 3D reconstruction of complex urban buildings, this study proposes an improved strategy for rendering complex structures more finely and ensuring flatter planes of artificial buildings. During preprocessing, the method adds two adjacent rays to each training ray that do not participate in backpropagation. After obtaining the density information of a scene through a multilayer network, the method inversely solves the depth points of the three rays and determines the surface points of the target. Based on the surface points, a set of surface normals is solved. By using the clustering information of these surface normals, the surface information of the scene and normals perpendicular to the surface is restored and clustered under Manhattan conditions. The three major orthogonal clusters within the Manhattan framework are solved based on the largest cluster, and backpropagation is performed in accordance with constraints, such as orthogonality and normalization, ensuring that the reconstruction target meets Manhattan framework conditions. Training speed is slow due to the extensive computations involved in rendering. To address this issue, the method uses multilayer encoding to reduce the complexity of the neural network. For coarse network sampling points, which must learn the entire scene’s 3D information, multi-resolution learnable positional encoding is used to map them into high-dimensional space. For fine network sampling points, which must learn detailed texture information, hash encoding is used. Hash encoding optimizes network input by interpolating sampling points through multi-resolution grids, finding the corresponding hash encoding data, and integrating multiple resolution hash encodings before feeding them into a smaller network for training. This improvement significantly reduces the training time of the radiance field, achieving fast and high-precision reconstruction of complex urban buildings. This method is implemented on Quadro RTX 8000 graphics processing unit by using the PyTorch Lightning framework. The initial learning rate is set to
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0