
最新刊期
2025 年 第 30 卷 第 9 期
- “在人工智能领域,专家建立了深度学习体系,为智能技术发展提供新方向。”
-
人工智能赋能地月空间感知技术现状及展望 AI导读
“在地月空间感知领域,人工智能技术展现出构建智能感知体系的能力,为地月空间开发智能化发展提供新方向。” 摘要:随着深空探测的不断推进,地月空间已成为探月和深空任务的关键战略区域。面对日益增多的航天器及太空碎片数量,亟需先进的空间态势感知技术以实现对地月空间目标的精准监测与持续跟踪。传统方法因复杂动力学环境和远距离探测精度限制,难以满足高精度轨迹预测和目标识别的需求,制约了地月空间感知技术进一步发展,人工智能技术的快速发展为解决这一瓶颈问题提供了新契机。本文系统梳理了人工智能技术在地月空间感知领域的应用进展,涵盖空间目标监视需求、传统机器学习在目标检测及轨道定轨中的应用,以及深度学习、强化学习等人工智能算法的初步应用。通过对国内外典型研究成果的对比分析,归纳了现有技术的优势和不足,提出在算法优化、模型开发等方面的发展展望。分析表明,人工智能方法在提升暗弱目标检测精度、智能轨道确定及复杂态势感知方面表现出显著潜力,尽管面临数据匮乏和专用场景未知等挑战,人工智能技术已初步展现出构建全天候、高自适应性地月空间智能感知体系的能力。未来需加强人工智能与地月空间目标检测、轨道定轨与预报等传统技术结合,持续拓展人工智能在地月空间感知领域的应用,推动地月空间开发迈向智能化发展新阶段。关键词:地月空间;态势感知;人工智能(AI);目标检测;轨道定轨658|357|0更新时间:2025-09-16
摘要:随着深空探测的不断推进,地月空间已成为探月和深空任务的关键战略区域。面对日益增多的航天器及太空碎片数量,亟需先进的空间态势感知技术以实现对地月空间目标的精准监测与持续跟踪。传统方法因复杂动力学环境和远距离探测精度限制,难以满足高精度轨迹预测和目标识别的需求,制约了地月空间感知技术进一步发展,人工智能技术的快速发展为解决这一瓶颈问题提供了新契机。本文系统梳理了人工智能技术在地月空间感知领域的应用进展,涵盖空间目标监视需求、传统机器学习在目标检测及轨道定轨中的应用,以及深度学习、强化学习等人工智能算法的初步应用。通过对国内外典型研究成果的对比分析,归纳了现有技术的优势和不足,提出在算法优化、模型开发等方面的发展展望。分析表明,人工智能方法在提升暗弱目标检测精度、智能轨道确定及复杂态势感知方面表现出显著潜力,尽管面临数据匮乏和专用场景未知等挑战,人工智能技术已初步展现出构建全天候、高自适应性地月空间智能感知体系的能力。未来需加强人工智能与地月空间目标检测、轨道定轨与预报等传统技术结合,持续拓展人工智能在地月空间感知领域的应用,推动地月空间开发迈向智能化发展新阶段。关键词:地月空间;态势感知;人工智能(AI);目标检测;轨道定轨658|357|0更新时间:2025-09-16 -
月球探测遥感影像匹配方法研究综述 AI导读
“在深空探测领域,国内外专家综述了月球影像匹配的研究进展,为行星表面测绘提供重要支持。” 摘要:随着深空探测技术的发展,月球探测器获取了不同类型的海量遥感影像,这些影像为行星表面测绘、地质分析及资源勘探提供了重要支持。然而,由于月球表面环境的独特性,如极端的地形起伏、光照变化及缺乏显著纹理,月球遥感影像匹配面临着辐射差异、几何畸变和尺度变化等严峻挑战。本文综述了自实施月球探测任务以来,国内外关于月球影像匹配的研究进展。首先对月球探测任务和获取的影像数据进行了介绍,然后阐述了不同类型的月球影像匹配方法,具体包括:1)在月球影像特征匹配方法研究进展方面,梳理了轨道器影像匹配、巡视器影像匹配和月球多模态影像匹配的相关研究发展过程; 2)针对月球影像密集匹配方法研究进展,围绕基于金字塔的匹配和半全局匹配(semi-global matching,SGM)算法等方面进行阐述;3)在月球影像深度学习匹配方法部分,剖析了基于深度学习的特征匹配和密集匹配代表性算法的核心思想,并总结分析了这些算法的参数量、推理速度及硬件需求等指标;4)通过实验对比了传统方法和深度学习方法的匹配性能。根据特征匹配实验结果,传统方法中HAPCG(histogram of absolute phase consistency gradients)精度表现总体最佳,深度学习方法中ALIKE(accurate and lightweight keypoint detection and descriptor extraction)的表现较为优秀。密集匹配方法中,SGBM(semi-global block matching)和DepthAnything均呈现出较好的性能。最后对月球遥感影像匹配的未来发展方向进行了展望和探讨。关键词:深空探测;遥感影像;特征匹配;密集匹配;深度学习560|665|0更新时间:2025-09-16
摘要:随着深空探测技术的发展,月球探测器获取了不同类型的海量遥感影像,这些影像为行星表面测绘、地质分析及资源勘探提供了重要支持。然而,由于月球表面环境的独特性,如极端的地形起伏、光照变化及缺乏显著纹理,月球遥感影像匹配面临着辐射差异、几何畸变和尺度变化等严峻挑战。本文综述了自实施月球探测任务以来,国内外关于月球影像匹配的研究进展。首先对月球探测任务和获取的影像数据进行了介绍,然后阐述了不同类型的月球影像匹配方法,具体包括:1)在月球影像特征匹配方法研究进展方面,梳理了轨道器影像匹配、巡视器影像匹配和月球多模态影像匹配的相关研究发展过程; 2)针对月球影像密集匹配方法研究进展,围绕基于金字塔的匹配和半全局匹配(semi-global matching,SGM)算法等方面进行阐述;3)在月球影像深度学习匹配方法部分,剖析了基于深度学习的特征匹配和密集匹配代表性算法的核心思想,并总结分析了这些算法的参数量、推理速度及硬件需求等指标;4)通过实验对比了传统方法和深度学习方法的匹配性能。根据特征匹配实验结果,传统方法中HAPCG(histogram of absolute phase consistency gradients)精度表现总体最佳,深度学习方法中ALIKE(accurate and lightweight keypoint detection and descriptor extraction)的表现较为优秀。密集匹配方法中,SGBM(semi-global block matching)和DepthAnything均呈现出较好的性能。最后对月球遥感影像匹配的未来发展方向进行了展望和探讨。关键词:深空探测;遥感影像;特征匹配;密集匹配;深度学习560|665|0更新时间:2025-09-16 - “在航天器监测领域,专家提出了基于无线电被动感知技术的近月空间航天器天地基联合监测方案,为近月空间航天器监测系统设计与实现提供技术参考。”
 摘要:目的针对地月距离上航天器监测手段地基光学与雷达作用限制,提出一种基于无线电被动感知技术的近月空间航天器天地基联合监测方案,无需主动发射无线电信号,仅利用在轨航天器发送的下行无线电信号实现目标监测。方法首先,介绍了无线电被动感知技术的理论方法;然后,设计了一种适用于近月空间航天器的天基、地基与天地基协同监测方案,包括系统架构、工作流程,分析了传感器布局、目标引导、信号接收、TDOA(time difference of arrival)/FDOA(frequency difference of arrival)处理、误差修正、目标定轨与预报等关键技术;最后,通过近月空间在轨航天器无线电被动感知监测实验进行初步验证。结果利用所提方案开展了基于地基测站的近月空间在轨航天器监测实验,有效监测到目标下行信号与多普勒变化运动规律,初步验证了监测方案可行性。结论提出的基于无线电被动感知的近月空间航天器天地基监测方案,可为后续近月空间航天器监测系统设计与实现提供有益的技术参考。关键词:近月空间;航天器;下行信号;无线电被动感知;监测实验266|230|0更新时间:2025-09-16
摘要:目的针对地月距离上航天器监测手段地基光学与雷达作用限制,提出一种基于无线电被动感知技术的近月空间航天器天地基联合监测方案,无需主动发射无线电信号,仅利用在轨航天器发送的下行无线电信号实现目标监测。方法首先,介绍了无线电被动感知技术的理论方法;然后,设计了一种适用于近月空间航天器的天基、地基与天地基协同监测方案,包括系统架构、工作流程,分析了传感器布局、目标引导、信号接收、TDOA(time difference of arrival)/FDOA(frequency difference of arrival)处理、误差修正、目标定轨与预报等关键技术;最后,通过近月空间在轨航天器无线电被动感知监测实验进行初步验证。结果利用所提方案开展了基于地基测站的近月空间在轨航天器监测实验,有效监测到目标下行信号与多普勒变化运动规律,初步验证了监测方案可行性。结论提出的基于无线电被动感知的近月空间航天器天地基监测方案,可为后续近月空间航天器监测系统设计与实现提供有益的技术参考。关键词:近月空间;航天器;下行信号;无线电被动感知;监测实验266|230|0更新时间:2025-09-16 - “在地月空间感知任务设计与分析领域,专家基于“容器云+微服务”设计了智能仿真系统架构,有效支持任务正向设计及方案优化,为地月空间任务研究提供新方向。”
 摘要:目的地月空间轨道普遍存在周期长、混沌性强、对各类扰动高度敏感等特征,地月空间感知任务呈现出显著的动态变化和不确定性,亟需借助虚拟仿真、仿真试验以及人工智能等先进技术手段开展科学研究与试验验证。方法本文以地月空间感知任务设计与分析为牵引,以服务化、标准化、国产化和工具化为理念,基于“容器云 + 微服务”设计了满足高性能计算、高并发访问、多样化应用需求的“基础支撑 + 服务支撑 + 典型应用”3层智能仿真系统架构。分析了地月空间轨道动力学模型库、基于Kuberneter的计算任务智能调度和全链路微服务集成框架等关键技术。结果研制了地月空间感知任务设计与分析仿真系统,阐述了场景设计模块、态势感知系统设计与分析模块、任务规划模块、体系仿真模块、试验设计模块以及试验评估模块的实现情况。结论通过应用案例说明,仿真系统能够有效支持用户开展地月空间任务的正向设计以及方案的选代优化,高精度星历模型下15年驻留轨道积分能够达到分钟级计算性能,具有高效性、智能性、稳定性和良好的扩展性。关键词:系统架构;容器技术;微服务技术;地月空间;三体轨道324|512|0更新时间:2025-09-16
摘要:目的地月空间轨道普遍存在周期长、混沌性强、对各类扰动高度敏感等特征,地月空间感知任务呈现出显著的动态变化和不确定性,亟需借助虚拟仿真、仿真试验以及人工智能等先进技术手段开展科学研究与试验验证。方法本文以地月空间感知任务设计与分析为牵引,以服务化、标准化、国产化和工具化为理念,基于“容器云 + 微服务”设计了满足高性能计算、高并发访问、多样化应用需求的“基础支撑 + 服务支撑 + 典型应用”3层智能仿真系统架构。分析了地月空间轨道动力学模型库、基于Kuberneter的计算任务智能调度和全链路微服务集成框架等关键技术。结果研制了地月空间感知任务设计与分析仿真系统,阐述了场景设计模块、态势感知系统设计与分析模块、任务规划模块、体系仿真模块、试验设计模块以及试验评估模块的实现情况。结论通过应用案例说明,仿真系统能够有效支持用户开展地月空间任务的正向设计以及方案的选代优化,高精度星历模型下15年驻留轨道积分能够达到分钟级计算性能,具有高效性、智能性、稳定性和良好的扩展性。关键词:系统架构;容器技术;微服务技术;地月空间;三体轨道324|512|0更新时间:2025-09-16 -
地月空间编目系统观测体制研究 AI导读
“在地月空间非合作目标编目定轨领域,专家提出了基于天基光学观测技术的编目定轨关键算法,为提高编目定轨精度和时效性提供解决方案。” 摘要:目的地月空间非合作目标因缺乏合作信号的高精度测量手段,同时深空探测地面测控资源有限,以及在地月空间多体摄动环境条件下运动轨迹复杂需考虑完备的动力学模型,其编目定轨精度与时效性受到一定的制约和独特的挑战。方法本文聚焦地月空间非合作目标的编目定轨,提出基于天基光学观测技术的三体轨道约束条件下的空间目标编目定轨关键算法,以远距逆行轨道(distant retrograde orbit,DRO)和近直线晕轨道(near rectilinear halo orbit,NRHO)组成的地月空间卫星星座,模拟天基平台与空间目标的光学观测数据,利用仿真数据,采取动力学统计定轨算法,探讨了不同平台轨道误差、不同平台数量和平台分布,以及不同观测数据条件下的DRO、NRHO目标的编目定轨精度。结果在天基平台轨道误差1 km、光学成像观测2″测量噪声水平、光压10%模型误差的仿真条件下,2DRO与2NRHO地月空间导航星座对DRO目标单站定轨精度为1~7 km,双站3天内每天观测3 h,定轨精度约1 km,预报1天轨道精度优于1.3 km;对于NRHO目标,单站观测3天定轨精度为1~3 km,双站每天观测3 h、6 h以及连续协同观测定轨精度分别优于1.2 km、1.1 km和1.0 km,这3种观测条件下预报1天轨道均方根误差(root mean square error, RMSE)分别优于3.0 km、2.5 km和1.9 km。结果表明,在天基测站误差1 km和3天定轨弧长的条件下,双站观测精度较单站观测有显著提高,双站每天观测3 h,针对DRO和NRHO目标的定轨精度均优于1.2 km,DRO轨道预报1天的精度优于1.3 km,NRHO轨道预报1天在连续观测3天的条件下精度最高,优于1.9 km。结论本文采用完备的三体动力学模型,通过对典型地月空间目标光学定轨的多种场景仿真,发现双站每天3 h观测的编目定轨能力优于单站每天连续观测的定轨精度。这一结论对地月空间编目定轨观测效率和观测体制的规划和布局,以及地月空间区域的态势感知能力论证和分析有重要的工程应用价值。关键词:地月空间;非合作目标;天基光学观测;编目定轨;远距离逆行轨道(DRO);近直线罩轨道(NRHO)303|236|0更新时间:2025-09-16
摘要:目的地月空间非合作目标因缺乏合作信号的高精度测量手段,同时深空探测地面测控资源有限,以及在地月空间多体摄动环境条件下运动轨迹复杂需考虑完备的动力学模型,其编目定轨精度与时效性受到一定的制约和独特的挑战。方法本文聚焦地月空间非合作目标的编目定轨,提出基于天基光学观测技术的三体轨道约束条件下的空间目标编目定轨关键算法,以远距逆行轨道(distant retrograde orbit,DRO)和近直线晕轨道(near rectilinear halo orbit,NRHO)组成的地月空间卫星星座,模拟天基平台与空间目标的光学观测数据,利用仿真数据,采取动力学统计定轨算法,探讨了不同平台轨道误差、不同平台数量和平台分布,以及不同观测数据条件下的DRO、NRHO目标的编目定轨精度。结果在天基平台轨道误差1 km、光学成像观测2″测量噪声水平、光压10%模型误差的仿真条件下,2DRO与2NRHO地月空间导航星座对DRO目标单站定轨精度为1~7 km,双站3天内每天观测3 h,定轨精度约1 km,预报1天轨道精度优于1.3 km;对于NRHO目标,单站观测3天定轨精度为1~3 km,双站每天观测3 h、6 h以及连续协同观测定轨精度分别优于1.2 km、1.1 km和1.0 km,这3种观测条件下预报1天轨道均方根误差(root mean square error, RMSE)分别优于3.0 km、2.5 km和1.9 km。结果表明,在天基测站误差1 km和3天定轨弧长的条件下,双站观测精度较单站观测有显著提高,双站每天观测3 h,针对DRO和NRHO目标的定轨精度均优于1.2 km,DRO轨道预报1天的精度优于1.3 km,NRHO轨道预报1天在连续观测3天的条件下精度最高,优于1.9 km。结论本文采用完备的三体动力学模型,通过对典型地月空间目标光学定轨的多种场景仿真,发现双站每天3 h观测的编目定轨能力优于单站每天连续观测的定轨精度。这一结论对地月空间编目定轨观测效率和观测体制的规划和布局,以及地月空间区域的态势感知能力论证和分析有重要的工程应用价值。关键词:地月空间;非合作目标;天基光学观测;编目定轨;远距离逆行轨道(DRO);近直线罩轨道(NRHO)303|236|0更新时间:2025-09-16 - “在空间态势感知领域,专家提出了基于KAN的高轨目标短弧初轨确定模型,有效解决了天基光学观测问题,为空间目标监测提供新手段。”
 摘要:目的作为空间态势感知的关键环节,高效且准确的初轨确定技术对于轨迹关联、卫星编目和异动感知等下游任务至关重要。传统方法通常依赖精确的动力学模型和充足的观测数据,但在短弧段条件下,物理约束不足易导致出现平凡解或方法不收敛的问题。尽管深度学习方法在数据拟合方面表现优异,但其对轨道动力学内在物理规律的建模能力仍存在不足。针对以上问题,提出一种基于KAN(Kolmogorov-Arnold network)的天基光学观测高轨目标短弧初轨确定模型,该模型兼具强大的物理规律捕捉能力和数学拟合能力,能够获得稳定且高精度的定轨结果。方法首先,构建了面向初轨确定任务的专用KAN模型架构,采用“先升维,后降维”的策略增强物理特征提取能力,并设计了融合运动状态约束的损失函数,以针对性优化初轨确定性能。此外建立了一个大规模的天基光学观测短弧段数据集,该数据集源自真实在轨卫星数据,每个观测弧段时长5 min,包含6个观测点,记录了目标卫星相对于观测卫星的方位角、俯仰角及其变化率。数据集涵盖多样化的目标卫星轨道,为模型的训练与性能验证提供了可靠的数据支持。结果与传统方法相比,所提方法预测结果的位置和速度误差分别为27.458 km和3.904 m/s,仅为传统方法的0.58%和1.14%。与基于多层感知机(multilayer perceptron,MLP)的深度学习方法相比,所提方法预测结果的位置和速度误差分别为前者的25.01%和19.58%,显示出更优的性能。结论提出的基于KAN的初轨确定模型有效解决了天基光学观测的高轨目标短弧初轨确定问题,在定轨精度、计算效率和结果稳定性等方面均展现出显著优势,为空间目标监测提供了新的技术手段。关键词:初轨确定;KAN;短弧段;天基光学观测;高轨目标;深度学习299|282|0更新时间:2025-09-16
摘要:目的作为空间态势感知的关键环节,高效且准确的初轨确定技术对于轨迹关联、卫星编目和异动感知等下游任务至关重要。传统方法通常依赖精确的动力学模型和充足的观测数据,但在短弧段条件下,物理约束不足易导致出现平凡解或方法不收敛的问题。尽管深度学习方法在数据拟合方面表现优异,但其对轨道动力学内在物理规律的建模能力仍存在不足。针对以上问题,提出一种基于KAN(Kolmogorov-Arnold network)的天基光学观测高轨目标短弧初轨确定模型,该模型兼具强大的物理规律捕捉能力和数学拟合能力,能够获得稳定且高精度的定轨结果。方法首先,构建了面向初轨确定任务的专用KAN模型架构,采用“先升维,后降维”的策略增强物理特征提取能力,并设计了融合运动状态约束的损失函数,以针对性优化初轨确定性能。此外建立了一个大规模的天基光学观测短弧段数据集,该数据集源自真实在轨卫星数据,每个观测弧段时长5 min,包含6个观测点,记录了目标卫星相对于观测卫星的方位角、俯仰角及其变化率。数据集涵盖多样化的目标卫星轨道,为模型的训练与性能验证提供了可靠的数据支持。结果与传统方法相比,所提方法预测结果的位置和速度误差分别为27.458 km和3.904 m/s,仅为传统方法的0.58%和1.14%。与基于多层感知机(multilayer perceptron,MLP)的深度学习方法相比,所提方法预测结果的位置和速度误差分别为前者的25.01%和19.58%,显示出更优的性能。结论提出的基于KAN的初轨确定模型有效解决了天基光学观测的高轨目标短弧初轨确定问题,在定轨精度、计算效率和结果稳定性等方面均展现出显著优势,为空间目标监测提供了新的技术手段。关键词:初轨确定;KAN;短弧段;天基光学观测;高轨目标;深度学习299|282|0更新时间:2025-09-16 -
基于频域图像的地月三角平动点轨道特征识别 AI导读
“在空间稳定轨道设计领域,专家提出了基于图像信息提取的频率数据处理方法,首次构造并得到地月三角平动点附近空间稳定轨道的半分析解,为轨道设计提供高效解决方案。” 摘要:目的地月三角平动点附近存在稳定的轨道,这对可能存在的自然天体的研究以及一些工程应用都有重要的意义。在实际工作中,现有的轨道设计方法普遍采用数值方法进行迭代,效率受限,需要进一步改进。方法在本工作中,提出基于图像信息提取的频率数据处理方法,对不同振幅轨道的相同频率进行了研究,从而实现了对轨道的不同组成频率项的数值拟合。不同于传统的半分析解构造方法,本文方法从频域分析结果出发,对拟周期轨道的主要频率项进行分析。与使用数值连续方法得到对应轨道的速度相比,本文方法所消耗时间仅为数值连续方法的1%。结果对地月三角平动点附近的空间稳定轨道进行了研究,验证频率数据处理算法的可靠性,并得到了相应稳定区域内稳定轨道的半分析解,验证解的可靠性。本文方法首次构造并得到了地月三角平动点附近空间稳定轨道的半分析解。结论本文方法适用于空间任务所需要的各种具有受迫和自由运动特征的拟周期轨道,可以较快获得相应轨道族的半分析解,从而加速轨道设计过程。该方法可以应用于未来的工程实践,使轨道设计过程更有效率。关键词:三角平动点(TLPs);拟周期轨道;频域分析;半分析解;轨道设计优化;数值拟合182|286|0更新时间:2025-09-16
摘要:目的地月三角平动点附近存在稳定的轨道,这对可能存在的自然天体的研究以及一些工程应用都有重要的意义。在实际工作中,现有的轨道设计方法普遍采用数值方法进行迭代,效率受限,需要进一步改进。方法在本工作中,提出基于图像信息提取的频率数据处理方法,对不同振幅轨道的相同频率进行了研究,从而实现了对轨道的不同组成频率项的数值拟合。不同于传统的半分析解构造方法,本文方法从频域分析结果出发,对拟周期轨道的主要频率项进行分析。与使用数值连续方法得到对应轨道的速度相比,本文方法所消耗时间仅为数值连续方法的1%。结果对地月三角平动点附近的空间稳定轨道进行了研究,验证频率数据处理算法的可靠性,并得到了相应稳定区域内稳定轨道的半分析解,验证解的可靠性。本文方法首次构造并得到了地月三角平动点附近空间稳定轨道的半分析解。结论本文方法适用于空间任务所需要的各种具有受迫和自由运动特征的拟周期轨道,可以较快获得相应轨道族的半分析解,从而加速轨道设计过程。该方法可以应用于未来的工程实践,使轨道设计过程更有效率。关键词:三角平动点(TLPs);拟周期轨道;频域分析;半分析解;轨道设计优化;数值拟合182|286|0更新时间:2025-09-16 - “在地月目标编目定轨领域,专家提出了结合CNN与CAR的短弧航迹智能轨道族分类方法,实现了高鲁棒性的航迹分类,为地月空间复杂轨道的智能识别提供有效参考。”
 摘要:目的地月空间距离遥远,对地月目标的观测弧段短、间隔长,导致观测的航迹难以判定其所属轨道族。如何根据短弧航迹对其轨道族快速、精准分类,是实现地月目标编目定轨的重要前提。然而,传统方法受限于地月系统复杂的三体动力学特性,且先验知识与统计信息不足,对航迹分类存在精度低、效率不足的缺陷。为解决该问题,提出一种结合卷积神经网络(convolutional neural network, CNN)与约束容许域(constraint admissible region, CAR)的短弧航迹智能轨道族分类方法。方法首先,利用不同轨道族的雅可比常数约束,构建各轨道族的CAR,表征假设轨道集合。其次,根据地月轨道数据库生成训练集,通过训练,CNN可实现依据假设轨道对其所属轨道族的快速、精准分辨。最后,将CNN方法与不同轨道族的CAR结合,建立轨道族的联合判别机制,实现目标航迹的智能归属分析。结果仿真结果表明,在使用DRO(distant retrograde orbit)卫星观测HaloL1、HaloL2等轨道的典型场景中,所提出的CNN-CAR方法可使CAR面积减少50%,且对未知航迹的分类成功率较单独使用CAR提升近一倍。结论所设计的算法实现了高鲁棒性的航迹分类。该方法可为地月空间复杂轨道的智能识别、航迹关联与编目维持等任务提供有效参考。关键词:态势感知;航迹分类;卷积神经网络(CNN);约束容许域(CAR);地月空间目标;融合算法330|231|0更新时间:2025-09-16
摘要:目的地月空间距离遥远,对地月目标的观测弧段短、间隔长,导致观测的航迹难以判定其所属轨道族。如何根据短弧航迹对其轨道族快速、精准分类,是实现地月目标编目定轨的重要前提。然而,传统方法受限于地月系统复杂的三体动力学特性,且先验知识与统计信息不足,对航迹分类存在精度低、效率不足的缺陷。为解决该问题,提出一种结合卷积神经网络(convolutional neural network, CNN)与约束容许域(constraint admissible region, CAR)的短弧航迹智能轨道族分类方法。方法首先,利用不同轨道族的雅可比常数约束,构建各轨道族的CAR,表征假设轨道集合。其次,根据地月轨道数据库生成训练集,通过训练,CNN可实现依据假设轨道对其所属轨道族的快速、精准分辨。最后,将CNN方法与不同轨道族的CAR结合,建立轨道族的联合判别机制,实现目标航迹的智能归属分析。结果仿真结果表明,在使用DRO(distant retrograde orbit)卫星观测HaloL1、HaloL2等轨道的典型场景中,所提出的CNN-CAR方法可使CAR面积减少50%,且对未知航迹的分类成功率较单独使用CAR提升近一倍。结论所设计的算法实现了高鲁棒性的航迹分类。该方法可为地月空间复杂轨道的智能识别、航迹关联与编目维持等任务提供有效参考。关键词:态势感知;航迹分类;卷积神经网络(CNN);约束容许域(CAR);地月空间目标;融合算法330|231|0更新时间:2025-09-16 -
地月空间物体雷达成像与智能认知方法 AI导读
“在地月空间探测领域,专家系统探索了雷达探测机制与信息获取方法,为实现地月空间物体高稳健探测提供核心路径。” 摘要:目的随着月球探索、深空探测任务的持续推进,地月空间物体的高稳健探测成为保障航天活动安全的核心需求。本研究旨在系统探索雷达对该类物体的探测机制与信息获取方法,重点解决其轨道动力学高度复杂导致的信号积累效率低与成像效果差等难题。方法首先,通过对地月空间典型轨道的分析,揭示了不同轨道目标相对于雷达的径向距离与速度变化规律;其次,针对目标姿态转动难以等效简化的关键问题,论述了融合轨道运动方程与电磁散射模型的必要性,阐明运动约束模型是实现复杂条件下雷达成像处理的理论基础;最后,基于雷达探测月面目标的典型场景,对比月面不同区域的雷达成像结果,实证分析了轨道特性差异对径向观测量变化规律的影响机制,进一步阐明运动约束模型对成像性能提升的意义。结果不同轨道类型目标的径向运动特征存在显著差异,这直接决定了雷达信号处理策略的选择;姿态与轨道的强耦合效应使传统成像模型失效,基于精确运动约束的补偿算法可有效抑制成像散焦,月面成像实验进一步验证了考虑运动约束模型的重要性。结论发展基于不同轨道及姿态变化模型约束下的目标成像与智能认知方法,是实现地月空间物体高稳健探测的核心路径,对构建深空探测体系具有重要意义。关键词:地月空间;雷达成像;轨道约束;电磁散射模型;智能认知203|604|0更新时间:2025-09-16
摘要:目的随着月球探索、深空探测任务的持续推进,地月空间物体的高稳健探测成为保障航天活动安全的核心需求。本研究旨在系统探索雷达对该类物体的探测机制与信息获取方法,重点解决其轨道动力学高度复杂导致的信号积累效率低与成像效果差等难题。方法首先,通过对地月空间典型轨道的分析,揭示了不同轨道目标相对于雷达的径向距离与速度变化规律;其次,针对目标姿态转动难以等效简化的关键问题,论述了融合轨道运动方程与电磁散射模型的必要性,阐明运动约束模型是实现复杂条件下雷达成像处理的理论基础;最后,基于雷达探测月面目标的典型场景,对比月面不同区域的雷达成像结果,实证分析了轨道特性差异对径向观测量变化规律的影响机制,进一步阐明运动约束模型对成像性能提升的意义。结果不同轨道类型目标的径向运动特征存在显著差异,这直接决定了雷达信号处理策略的选择;姿态与轨道的强耦合效应使传统成像模型失效,基于精确运动约束的补偿算法可有效抑制成像散焦,月面成像实验进一步验证了考虑运动约束模型的重要性。结论发展基于不同轨道及姿态变化模型约束下的目标成像与智能认知方法,是实现地月空间物体高稳健探测的核心路径,对构建深空探测体系具有重要意义。关键词:地月空间;雷达成像;轨道约束;电磁散射模型;智能认知203|604|0更新时间:2025-09-16 -
地月空间多目标高时效跟踪方法研究 AI导读
“在地月空间多目标自动跟踪领域,专家提出了基于DeepSORT的高效跟踪方法,显著提升了跟踪准确性和实时性,为解决复杂场景下的多目标跟踪问题提供解决方案。” 摘要:目的针对地月空间多目标运动状态复杂及高动态跟踪的挑战,为满足大视场光学探测中对多个运动速度和方向不一致目标的快速、准确跟踪需求,本文提出一种基于 DeepSORT(deep simple online and realtime tracking)的高效地月空间多目标自动跟踪方法。方法首先根据目标的形态特征生成自适应检测框,并针对不同类别目标配置差异化的检测框策略,同时结合特征提取技术计算运动目标的表观信息,将其融入DeepSORT算法框架,显著提升了多目标跟踪的准确性和实时性。结果仿真目标跟踪模式下的图像实验结果表明,该方法的多目标跟踪准确度达到95.0%,IDF1分数为96.2%。新疆天文台南山1 m大视场望远镜目标跟踪模式下的实测数据结果显示,该方法的多目标跟踪准确度达到91.5%,IDF1分数为91.7%,4 k × 4 k图像的处理时间约为0.53 s/帧,并且在目标消失和轨迹交叉等复杂场景下表现出较强的鲁棒性。结论该方法能够跟踪轨迹交叉的多目标,且在暗弱目标偶尔未提取或断续消失的复杂场景中,仍能准确跟踪多目标。关键词:地月空间;图像处理;多目标跟踪;空间目标;DeepSORT223|296|0更新时间:2025-09-16
摘要:目的针对地月空间多目标运动状态复杂及高动态跟踪的挑战,为满足大视场光学探测中对多个运动速度和方向不一致目标的快速、准确跟踪需求,本文提出一种基于 DeepSORT(deep simple online and realtime tracking)的高效地月空间多目标自动跟踪方法。方法首先根据目标的形态特征生成自适应检测框,并针对不同类别目标配置差异化的检测框策略,同时结合特征提取技术计算运动目标的表观信息,将其融入DeepSORT算法框架,显著提升了多目标跟踪的准确性和实时性。结果仿真目标跟踪模式下的图像实验结果表明,该方法的多目标跟踪准确度达到95.0%,IDF1分数为96.2%。新疆天文台南山1 m大视场望远镜目标跟踪模式下的实测数据结果显示,该方法的多目标跟踪准确度达到91.5%,IDF1分数为91.7%,4 k × 4 k图像的处理时间约为0.53 s/帧,并且在目标消失和轨迹交叉等复杂场景下表现出较强的鲁棒性。结论该方法能够跟踪轨迹交叉的多目标,且在暗弱目标偶尔未提取或断续消失的复杂场景中,仍能准确跟踪多目标。关键词:地月空间;图像处理;多目标跟踪;空间目标;DeepSORT223|296|0更新时间:2025-09-16 -
面向月球空间站的智能时序行为检测 AI导读
“在航天领域,专家提出了一种高效时序动作检测框架,为航天员动作监测提供轻量化、高精度解决方案,助力太空任务安全与效率。” 摘要:目的随着全球太空经济加速发展,我国航天事业已进入深空探测、空间站常态化运营与地月资源开发的新阶段。航天员在复杂太空环境中的动作规范性直接影响任务安全与效率。然而,现有视频动作检测方法因依赖密集光流计算,存在高计算成本与实时性不足的瓶颈,难以满足航天任务中长时间、高精度动作监测的需求。方法为解决上述问题,提出一种高效时序动作检测框架,旨在通过稀疏光流表征与知识蒸馏技术,提升航天员训练与工作视频的动作检测效率,为太空任务中实时操作反馈、虚拟训练系统优化提供技术支持。本文方法采用稀疏光流表征,规避密集光流的高内存开销,缩短光流提取时间。通过从密集光流中蒸馏时空特征知识,弥补稀疏表征的信息损失,确保检测精度。结果该方法输入相对稀疏的光流,将光流计算耗时缩减至传统密集光流的1/4,总处理时间从132.1 h显著降低至32.5 h,有效规避了密集光流计算的高内存和计算成本。在检测精度方面,通过设计知识蒸馏机制,将平均精度均值从60.7%提升至61.5%,超越了基准模型的性能指标,验证了稀疏采样策略的计算效率优势与蒸馏网络在特征增强方面的有效性,实现了精度与效能的同步提升。结论本文为航天员动作检测提供了一种轻量化、高精度的解决方案,可实现快速高效动作定位,有助于实现太空情景下的高效航天员动作检测。关键词:动作检测;时序动作定位(TAD);知识蒸馏;视频理解;太空任务安全监测203|277|0更新时间:2025-09-16
摘要:目的随着全球太空经济加速发展,我国航天事业已进入深空探测、空间站常态化运营与地月资源开发的新阶段。航天员在复杂太空环境中的动作规范性直接影响任务安全与效率。然而,现有视频动作检测方法因依赖密集光流计算,存在高计算成本与实时性不足的瓶颈,难以满足航天任务中长时间、高精度动作监测的需求。方法为解决上述问题,提出一种高效时序动作检测框架,旨在通过稀疏光流表征与知识蒸馏技术,提升航天员训练与工作视频的动作检测效率,为太空任务中实时操作反馈、虚拟训练系统优化提供技术支持。本文方法采用稀疏光流表征,规避密集光流的高内存开销,缩短光流提取时间。通过从密集光流中蒸馏时空特征知识,弥补稀疏表征的信息损失,确保检测精度。结果该方法输入相对稀疏的光流,将光流计算耗时缩减至传统密集光流的1/4,总处理时间从132.1 h显著降低至32.5 h,有效规避了密集光流计算的高内存和计算成本。在检测精度方面,通过设计知识蒸馏机制,将平均精度均值从60.7%提升至61.5%,超越了基准模型的性能指标,验证了稀疏采样策略的计算效率优势与蒸馏网络在特征增强方面的有效性,实现了精度与效能的同步提升。结论本文为航天员动作检测提供了一种轻量化、高精度的解决方案,可实现快速高效动作定位,有助于实现太空情景下的高效航天员动作检测。关键词:动作检测;时序动作定位(TAD);知识蒸馏;视频理解;太空任务安全监测203|277|0更新时间:2025-09-16 -
窄角相机月球影像自适应多尺度超分辨率重建 AI导读
“在月球科学探测领域,专家提出了多尺度超分辨率模型MSRT,有效恢复月球NAC影像精细地貌,为地质分析和着陆区评估提供高质量数据支持。” 摘要:目的针对月球南极窄角相机(narrow-angle camera, NAC)影像因“求和”模式导致空间分辨率显著下降、关键地貌模糊的问题,本文旨在通过超分辨率技术恢复其精细地貌,为月球科学与探测任务提供高质量数据。方法构建模拟NAC“求和”模式下多尺度退化的月球影像数据集,通过模拟“求和”模式得到包含2倍、3倍和4倍下采样的退化影像,用于模型训练和验证。进一步,提出融合卷积神经网络(convolutional neural network, CNN)与Transformer的多尺度超分辨率模型(multi-scale super resolution Transformer, MSRT)。其创新性在于采用共享Transformer骨干提取跨尺度深度特征,并为各尺度设计独立的轻量化上采样分支,实现“主干共享、分支特化”的高效重建,提升了对复杂退化的适应性与精度,兼顾模型复杂度。结果实验结果表明,MSRT在2倍、3倍及4倍超分任务中均显著优于对比方法。在最具挑战的4×任务(2 m/像素→0.5 m/像素)中,峰值信噪比(peak signal-to-noise ratio, PSNR)达28.73 dB,结构相似性指数(structural similarity index, SSIM)为0.923。消融研究验证了模型设计的有效性。可视化结果证实MSRT能有效抑制伪影,清晰重建小型陨石坑、岩块等精细月表地貌。结论本文提出的MSRT模型有效解决了月球NAC影像多尺度退化问题,可显著提升月表微小地貌特征的重建质量,为精细地质分析、着陆区评估和巡视器安全路径规划提供了高质量的数据支持和技术保障。关键词:超分辨率重建;月球窄角相机;Transformer;多尺度;深度学习245|225|0更新时间:2025-09-16
摘要:目的针对月球南极窄角相机(narrow-angle camera, NAC)影像因“求和”模式导致空间分辨率显著下降、关键地貌模糊的问题,本文旨在通过超分辨率技术恢复其精细地貌,为月球科学与探测任务提供高质量数据。方法构建模拟NAC“求和”模式下多尺度退化的月球影像数据集,通过模拟“求和”模式得到包含2倍、3倍和4倍下采样的退化影像,用于模型训练和验证。进一步,提出融合卷积神经网络(convolutional neural network, CNN)与Transformer的多尺度超分辨率模型(multi-scale super resolution Transformer, MSRT)。其创新性在于采用共享Transformer骨干提取跨尺度深度特征,并为各尺度设计独立的轻量化上采样分支,实现“主干共享、分支特化”的高效重建,提升了对复杂退化的适应性与精度,兼顾模型复杂度。结果实验结果表明,MSRT在2倍、3倍及4倍超分任务中均显著优于对比方法。在最具挑战的4×任务(2 m/像素→0.5 m/像素)中,峰值信噪比(peak signal-to-noise ratio, PSNR)达28.73 dB,结构相似性指数(structural similarity index, SSIM)为0.923。消融研究验证了模型设计的有效性。可视化结果证实MSRT能有效抑制伪影,清晰重建小型陨石坑、岩块等精细月表地貌。结论本文提出的MSRT模型有效解决了月球NAC影像多尺度退化问题,可显著提升月表微小地貌特征的重建质量,为精细地质分析、着陆区评估和巡视器安全路径规划提供了高质量的数据支持和技术保障。关键词:超分辨率重建;月球窄角相机;Transformer;多尺度;深度学习245|225|0更新时间:2025-09-16
人工智能赋能地月空间感知

- “在人工智能领域,专家建立了深度学习体系,为智能技术发展提供新方向。”
- “最新研究突破,提出了基于动态分辨率的文档多模态大模型TextLLM,无需OCR工具即可处理高分辨率文档图像,显著提升了文档理解性能。”
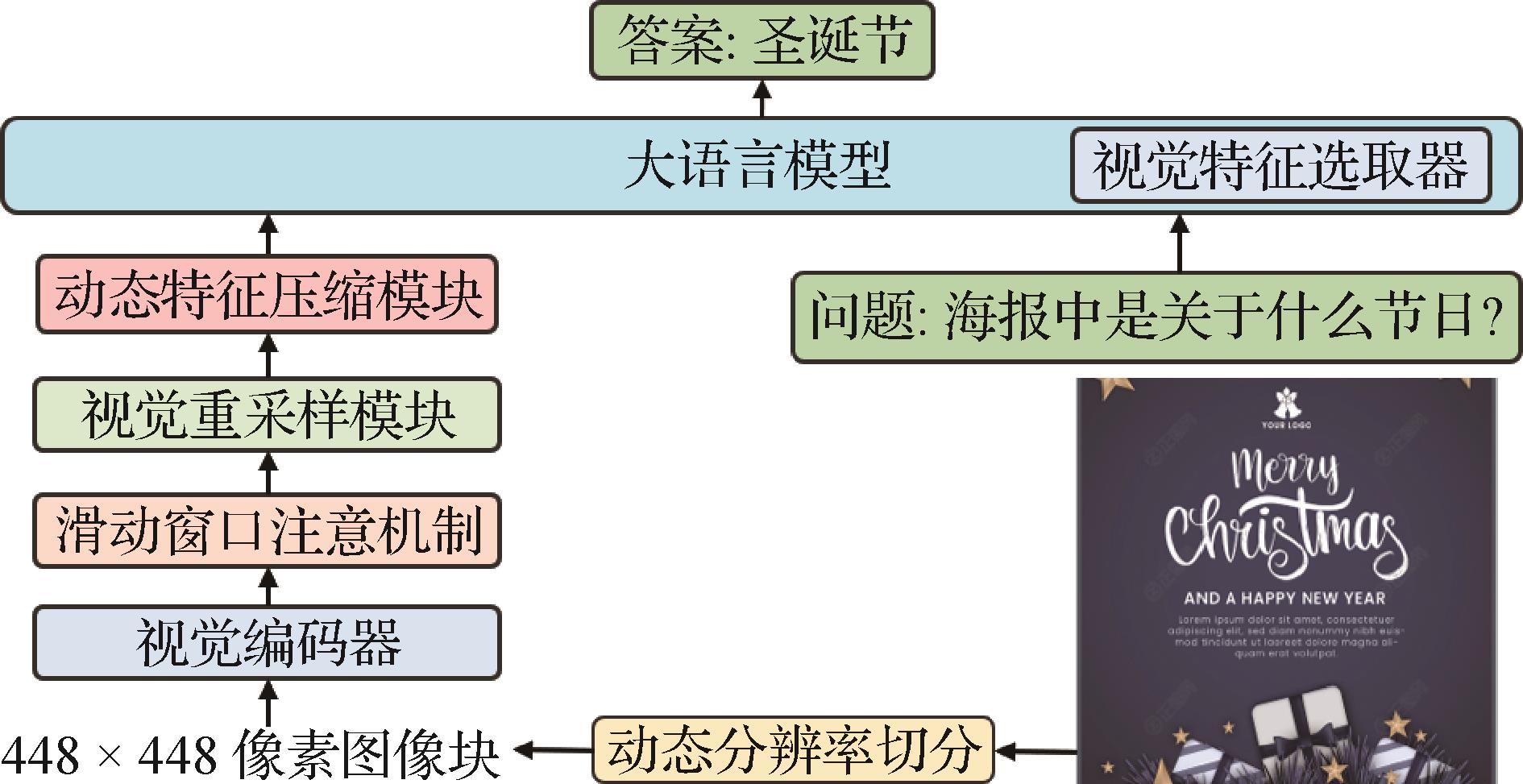 摘要:目的文档智能旨在自动和智能地处理纸质文本信息,包括但不限于表格、表单和发票等,极大便利了信息的电子化管理。然而,传统深度学习方法往往专注于单一任务的优化,限制了它们在处理复杂多变的文档场景时的效能。此外,这些方法需要额外的光学字符识别(optical character recognition,OCR)工具来提取文档中的文字信息,这不仅增加了处理步骤,也可能引入额外的错误。多模态大模型的出现为免去OCR工具统一处理文档信息带来了希望,但是在处理高分辨率的文档图像和应对逐渐增加的视觉标记时,仍然面临着不小的挑战。本文提出一种基于动态分辨率的文档多模态大模型TextLLM,能免OCR工具处理高分辨率的文档图像。方法基于最新的多模态大模型训练了一个能够处理动态分辨率的文档多模态大模型。在动态分辨率的基础上,提出一种动态特征压缩算法,设置动态的可学习压缩率来获得需要保留的特征长度,通过计算特征相似度来得到重要性特征,以此来聚合关键特征。更进一步,利用大语言模型的注意力机制捕捉与提示词相关的视觉特征部分,根据提示词的注意力分布图筛选出最相关的特征,并保留其周围相关特征。结果实验在多个数据集上与6种先进方法进行了比较,TextLLM在多个文档理解基准测试中取得了显著的性能提升。在DocVQA、WTQ、ChartQA和TextVQA等数据集上的表现均优于对比模型,分别获得了82.4、37.6、70.8和65.3的分数。此外,在综合评测数据集OCRBench中,模型得分高达601,证明了其在多样化文本相关任务中的适应能力和整体效果。同时也在多个数据集中进行了消融实验以验证算法的有效性,消融实验验证了提出的动态算法能够改善模型效果。结论本文提出基于动态分辨率的文档大模型TextLLM,并提出动态压缩特征和动态选择的算法来应对多场景的文档。实验结果表明,本文模型优于几种先进的文档大模型,兼具了高效性和准确性。关键词:多模态;文档大模型;文档智能;动态分辨率;动态压缩率303|523|0更新时间:2025-09-16
摘要:目的文档智能旨在自动和智能地处理纸质文本信息,包括但不限于表格、表单和发票等,极大便利了信息的电子化管理。然而,传统深度学习方法往往专注于单一任务的优化,限制了它们在处理复杂多变的文档场景时的效能。此外,这些方法需要额外的光学字符识别(optical character recognition,OCR)工具来提取文档中的文字信息,这不仅增加了处理步骤,也可能引入额外的错误。多模态大模型的出现为免去OCR工具统一处理文档信息带来了希望,但是在处理高分辨率的文档图像和应对逐渐增加的视觉标记时,仍然面临着不小的挑战。本文提出一种基于动态分辨率的文档多模态大模型TextLLM,能免OCR工具处理高分辨率的文档图像。方法基于最新的多模态大模型训练了一个能够处理动态分辨率的文档多模态大模型。在动态分辨率的基础上,提出一种动态特征压缩算法,设置动态的可学习压缩率来获得需要保留的特征长度,通过计算特征相似度来得到重要性特征,以此来聚合关键特征。更进一步,利用大语言模型的注意力机制捕捉与提示词相关的视觉特征部分,根据提示词的注意力分布图筛选出最相关的特征,并保留其周围相关特征。结果实验在多个数据集上与6种先进方法进行了比较,TextLLM在多个文档理解基准测试中取得了显著的性能提升。在DocVQA、WTQ、ChartQA和TextVQA等数据集上的表现均优于对比模型,分别获得了82.4、37.6、70.8和65.3的分数。此外,在综合评测数据集OCRBench中,模型得分高达601,证明了其在多样化文本相关任务中的适应能力和整体效果。同时也在多个数据集中进行了消融实验以验证算法的有效性,消融实验验证了提出的动态算法能够改善模型效果。结论本文提出基于动态分辨率的文档大模型TextLLM,并提出动态压缩特征和动态选择的算法来应对多场景的文档。实验结果表明,本文模型优于几种先进的文档大模型,兼具了高效性和准确性。关键词:多模态;文档大模型;文档智能;动态分辨率;动态压缩率303|523|0更新时间:2025-09-16 - “最新研究突破了电子文档视觉问答数据生成技术,显著提升了多模态大型语言模型的文档阅读性能。”
 摘要:目的电子文档视觉问答数据生成技术旨在结合电子文档图像的文字内容与视觉信息,以生成问题及其对应答案。利用高质量的视觉指令微调数据集,可以显著提升多模态大型语言模型的文档阅读性能。目前,人工或模板方法生成的数据集存在数量不足和质量不高的问题。因此,本文设计了一种基于多模态大语言模型的电子文档图像问答数据生成方法。方法提出一种基于多模态大型语言模型的大规模数据生成方法,包括4个关键步骤:自我提问与回答、数量与格式检查、数据过滤和一致性检验。通过输入电子文档图像及相应指令至多模态大型语言模型,初步生成多个问答对;进行数量与格式的检查;将合格的问答对及其对应图像和指令输入至多模态大型语言模型,以过滤掉与图像内容无关、回答错误或未使用外部知识的问答对;针对同一问答对,利用多模态大型语言模型生成多个不同表述的问题,并检查回答的一致性,以剔除回答不一致的问答对。结果本文构建了一个高质量的数据集,包含324 546幅图像和2 036 263个问答对。通过对问答对正确率的随机抽样统计,结果显示正确率为91.34%。此外,还在DocVQA等文档类问答数据集上测试了该数据集对多模态大语言模型性能的提升作用。微调实验结果表明,在LLaVA-OV和Deepseek-VL模型上,基于本数据集的微调能够提升DocVQA数据集上的平均归一化编辑相似度,分别提高了1.4%和2.6%。消融实验进一步表明,去除数据过滤步骤后,模型性能下降了1.3%。通过与人工标注数据DocVQA的互补性实验,结果表明,在DocVQA训练集基础上加入部分视觉问答数据集进行训练后,模型性能比仅使用DocVQA训练集微调时提升了1.3%。此外,与现有方法生成的数据集进行性能对比时,本文方法生成的数据集在模型性能提升方面表现最为显著。后续的后处理实验也进一步证明了所提出的数据集在生成问答对时仍具有一定的提升空间。结论本文提出的基于多模态大型语言模型的电子文档图像视觉问答数据生成方法,有效解决了现有数据集数量少、质量差的问题,显著提升了多模态大型语言模型的文档阅读理解能力。关键词:多模态大模型;电子文档图像;视觉指令微调数据集;视觉感知理解;视觉文字430|562|0更新时间:2025-09-16
摘要:目的电子文档视觉问答数据生成技术旨在结合电子文档图像的文字内容与视觉信息,以生成问题及其对应答案。利用高质量的视觉指令微调数据集,可以显著提升多模态大型语言模型的文档阅读性能。目前,人工或模板方法生成的数据集存在数量不足和质量不高的问题。因此,本文设计了一种基于多模态大语言模型的电子文档图像问答数据生成方法。方法提出一种基于多模态大型语言模型的大规模数据生成方法,包括4个关键步骤:自我提问与回答、数量与格式检查、数据过滤和一致性检验。通过输入电子文档图像及相应指令至多模态大型语言模型,初步生成多个问答对;进行数量与格式的检查;将合格的问答对及其对应图像和指令输入至多模态大型语言模型,以过滤掉与图像内容无关、回答错误或未使用外部知识的问答对;针对同一问答对,利用多模态大型语言模型生成多个不同表述的问题,并检查回答的一致性,以剔除回答不一致的问答对。结果本文构建了一个高质量的数据集,包含324 546幅图像和2 036 263个问答对。通过对问答对正确率的随机抽样统计,结果显示正确率为91.34%。此外,还在DocVQA等文档类问答数据集上测试了该数据集对多模态大语言模型性能的提升作用。微调实验结果表明,在LLaVA-OV和Deepseek-VL模型上,基于本数据集的微调能够提升DocVQA数据集上的平均归一化编辑相似度,分别提高了1.4%和2.6%。消融实验进一步表明,去除数据过滤步骤后,模型性能下降了1.3%。通过与人工标注数据DocVQA的互补性实验,结果表明,在DocVQA训练集基础上加入部分视觉问答数据集进行训练后,模型性能比仅使用DocVQA训练集微调时提升了1.3%。此外,与现有方法生成的数据集进行性能对比时,本文方法生成的数据集在模型性能提升方面表现最为显著。后续的后处理实验也进一步证明了所提出的数据集在生成问答对时仍具有一定的提升空间。结论本文提出的基于多模态大型语言模型的电子文档图像视觉问答数据生成方法,有效解决了现有数据集数量少、质量差的问题,显著提升了多模态大型语言模型的文档阅读理解能力。关键词:多模态大模型;电子文档图像;视觉指令微调数据集;视觉感知理解;视觉文字430|562|0更新时间:2025-09-16 -
图增强与多重神经网络优化的多维图对比学习 AI导读
“在无监督图表示学习领域,研究人员提出了LAST-MGCL模型,通过局部—全局图增强技术和多重神经网络协同建模,有效提升了节点表示质量,为无监督图表征学习提供了有效解决方案。” 摘要:目的图表示学习在社交网络、生物信息及推荐系统等领域应用广泛。无监督图对比学习因其无需大量标注数据即可获取高质量节点表示而备受关注,但现有方法普遍存在增强策略单一、对比粒度粗放等问题,影响嵌入表示质量。针对上述问题,提出一种结合局部—全局图增强技术与多重神经网络协同建模的多维度图对比学习模型(local and SVD-based global augmentation with triple network for multi-dimensional graph comparative learning, LAST-MGCL)。方法首先,构建局部增强图神经网络和奇异值分解增强模块,分别从节点邻域信息和整体拓扑模式出发,对原始图数据进行多粒度增强;其次,设计由多头注意力图神经网络构成的三重编码网络,分别处理原始图和增强图,通过跨网络信息交互强化多视图融合表示;最后,提出跨网络对比、跨视图对比与邻居对比相结合的多维度对比损失,协同优化图表示质量。结果在节点分类任务上,LAST-MGCL模型在Cora、Citeseer和PubMed数据集上的平均分类准确率分别达到83.1%、72.6%和81.8%,整体优于当前主流对比学习方法,表现出较好的分类性能与鲁棒性;同时,在可视化任务中,LAST-MGCL生成的节点嵌入表现出更紧密的类内聚合和更清晰的类间边界,进一步验证了模型在表征学习中的有效性。结论本文提出的LAST-MGCL面向无标签图数据场景,对现有图对比学习框架进行了系统性增强,为无监督图表征学习提供了一种有效解决方案。关键词:图表示学习;多重孪生网络;多维度对比学习;局部—全局图增强;图神经网络(GNN);大语言模型(LLM)271|214|0更新时间:2025-09-16
摘要:目的图表示学习在社交网络、生物信息及推荐系统等领域应用广泛。无监督图对比学习因其无需大量标注数据即可获取高质量节点表示而备受关注,但现有方法普遍存在增强策略单一、对比粒度粗放等问题,影响嵌入表示质量。针对上述问题,提出一种结合局部—全局图增强技术与多重神经网络协同建模的多维度图对比学习模型(local and SVD-based global augmentation with triple network for multi-dimensional graph comparative learning, LAST-MGCL)。方法首先,构建局部增强图神经网络和奇异值分解增强模块,分别从节点邻域信息和整体拓扑模式出发,对原始图数据进行多粒度增强;其次,设计由多头注意力图神经网络构成的三重编码网络,分别处理原始图和增强图,通过跨网络信息交互强化多视图融合表示;最后,提出跨网络对比、跨视图对比与邻居对比相结合的多维度对比损失,协同优化图表示质量。结果在节点分类任务上,LAST-MGCL模型在Cora、Citeseer和PubMed数据集上的平均分类准确率分别达到83.1%、72.6%和81.8%,整体优于当前主流对比学习方法,表现出较好的分类性能与鲁棒性;同时,在可视化任务中,LAST-MGCL生成的节点嵌入表现出更紧密的类内聚合和更清晰的类间边界,进一步验证了模型在表征学习中的有效性。结论本文提出的LAST-MGCL面向无标签图数据场景,对现有图对比学习框架进行了系统性增强,为无监督图表征学习提供了一种有效解决方案。关键词:图表示学习;多重孪生网络;多维度对比学习;局部—全局图增强;图神经网络(GNN);大语言模型(LLM)271|214|0更新时间:2025-09-16
文字多模态大模型
-
状态空间模型在医学图像处理方面的研究进展 AI导读
“最新研究显示,基于SSM的Mamba模型在医学图像处理领域取得突破,性能有望超越Transformer,为AI医学影像分析提供新思路。” 摘要:状态空间模型(state space model,SSM)在长序列计算效率方面表现优异。2024年基于SSM的具有选择机制和硬件感知状态扩展的Mamba模型问世,状态空间模型成为新的备受瞩目的人工智能架构,其性能可能超过Transformer。为了充分了解状态空间模型在医学图像处理领域的研究和应用,本文进行了全面的调查,首先对状态空间模型的发展历程和各种基于SSM的基础模型进行总结,然后按照图像分割、分类、配准和融合、重建,以及疾病预测、医学图像合成、放射治疗剂量预测任务进行分类研究,探讨了每种任务中SSM模型的改进和应用,最后讨论了状态空间模型面临的挑战和今后的研究方向。本文讨论的研究及其开源实现汇编在GitHub中,地址为https://github.com/wyl32123/ssm-medical-paper/tree/main。关键词:状态空间模型(SSM);Mamba;医学图像分割;医学图像分类;医学图像配准和融合;医学图像重建653|708|0更新时间:2025-09-16
摘要:状态空间模型(state space model,SSM)在长序列计算效率方面表现优异。2024年基于SSM的具有选择机制和硬件感知状态扩展的Mamba模型问世,状态空间模型成为新的备受瞩目的人工智能架构,其性能可能超过Transformer。为了充分了解状态空间模型在医学图像处理领域的研究和应用,本文进行了全面的调查,首先对状态空间模型的发展历程和各种基于SSM的基础模型进行总结,然后按照图像分割、分类、配准和融合、重建,以及疾病预测、医学图像合成、放射治疗剂量预测任务进行分类研究,探讨了每种任务中SSM模型的改进和应用,最后讨论了状态空间模型面临的挑战和今后的研究方向。本文讨论的研究及其开源实现汇编在GitHub中,地址为https://github.com/wyl32123/ssm-medical-paper/tree/main。关键词:状态空间模型(SSM);Mamba;医学图像分割;医学图像分类;医学图像配准和融合;医学图像重建653|708|0更新时间:2025-09-16
综述
-
融合多阶段差分特征的光场图像显著性检测 AI导读
“在光场图像显著性检测领域,研究者提出了一种融合多阶段差分特征的检测网络,有效提升了显著物体检测的准确性。” 摘要:目的光场图像因其能够捕捉不同深度的场景细节信息,可以有效提升显著性检测的效果。然而,焦点堆栈图像虽然富含深度信息,但不同焦平面中存在的模糊干扰会降低光场显著性检测的性能。此外,现有的大多数方法都仅在显著性预测阶段考虑不同图像特征的交互,导致不同特征的互补性利用不足。为了解决以上问题,提出一种融合多阶段差分特征的光场图像显著性检测网络,旨在提高光场图像中显著物体检测的准确性。方法提出一种基于多阶段自差分特征的焦点堆栈深度感知方法,以连续深度聚焦信息指导显著目标定位。提出一种多模态阶段融合方法,通过多模态差异约束捕获高精度的焦点堆栈聚焦区域,以实现焦点堆栈图像与全聚焦图像的多阶段特征融合,并利用焦点堆栈深度感知方法和多模态阶段融合方法的互补信息增强目标物体的可识别性。将两种方法引入编码阶段,实现特征的早期交互,缓解了特征利用率低的问题。结果实验在被广泛应用的DUTLF-FS(Dalian University of Technology Light Field Focal Stack)、HFUT-Lytro(Hefei University of Technology Lytro)和Lytro Illum数据集上与11种方法进行比较。在DUTLF-FS数据集中,相比FESNet模型,在不额外引入深度图线索的前提下,最大F指标相对提升0.2%;在HFUT-Lytro数据集中,相比FESNet模型,平均绝对误差相对降低12.9%;在Lytro Illum数据集中,相比LFTransNet模型,平均绝对误差相对降低22.2%。消融实验进一步证实了所设计的模块的有效性。结论本文提出的显著性检测模型能有效增强复杂场景中的显著区域特征,并抑制背景区域,能够准确地识别显著目标。关键词:显著性检测;光场图像;多阶段融合;差分特征;多模态特征融合300|389|0更新时间:2025-09-16
摘要:目的光场图像因其能够捕捉不同深度的场景细节信息,可以有效提升显著性检测的效果。然而,焦点堆栈图像虽然富含深度信息,但不同焦平面中存在的模糊干扰会降低光场显著性检测的性能。此外,现有的大多数方法都仅在显著性预测阶段考虑不同图像特征的交互,导致不同特征的互补性利用不足。为了解决以上问题,提出一种融合多阶段差分特征的光场图像显著性检测网络,旨在提高光场图像中显著物体检测的准确性。方法提出一种基于多阶段自差分特征的焦点堆栈深度感知方法,以连续深度聚焦信息指导显著目标定位。提出一种多模态阶段融合方法,通过多模态差异约束捕获高精度的焦点堆栈聚焦区域,以实现焦点堆栈图像与全聚焦图像的多阶段特征融合,并利用焦点堆栈深度感知方法和多模态阶段融合方法的互补信息增强目标物体的可识别性。将两种方法引入编码阶段,实现特征的早期交互,缓解了特征利用率低的问题。结果实验在被广泛应用的DUTLF-FS(Dalian University of Technology Light Field Focal Stack)、HFUT-Lytro(Hefei University of Technology Lytro)和Lytro Illum数据集上与11种方法进行比较。在DUTLF-FS数据集中,相比FESNet模型,在不额外引入深度图线索的前提下,最大F指标相对提升0.2%;在HFUT-Lytro数据集中,相比FESNet模型,平均绝对误差相对降低12.9%;在Lytro Illum数据集中,相比LFTransNet模型,平均绝对误差相对降低22.2%。消融实验进一步证实了所设计的模块的有效性。结论本文提出的显著性检测模型能有效增强复杂场景中的显著区域特征,并抑制背景区域,能够准确地识别显著目标。关键词:显著性检测;光场图像;多阶段融合;差分特征;多模态特征融合300|389|0更新时间:2025-09-16
图像处理和编码
-
基于交换注意力机制的任意图像风格迁移 AI导读
“在图像风格迁移领域,研究者提出了一种无需额外微调的高效风格迁移方法,能够处理丰富多样的视觉内容和艺术风格,输出高保真、风格一致的迁移结果。” 摘要:目的图像风格迁移旨在将一种艺术风格应用到一幅真实图像上,同时保持内容的完整性。传统的风格迁移方法存在伪影、风格模糊等问题。文字到图像生成扩散模型难以通过语言精确表达特定作品的创意。现有研究通过微调模型或文本嵌入技术提升风格准确度,但微调模型引入了额外计算成本,效率较低。针对这些挑战,本文提出一种无需额外微调模型的高效风格迁移方法。方法本文方法包含一种新颖的三线并行风格迁移框架,即图像生成路径、内容引导路径和风格引导路径。利用摄影和艺术图像作为视觉提示,通过一种新颖的注意力交换机制,将引导图像信息注入新图像生成路径,实现灵活、高效的任意图像风格迁移。结果通过定性和定量实验比较,本文方法能够在推理时间内生成高质量的风格迁移结果,定性实验表明本文方法适用于人像、风景和静物等多种题材,水墨、油画和素描等多种风格,且视觉效果优于对比的先进风格迁移方法;定量实验表明本文方法提升了风格准确性,取得了最优结果。结论所提方法在零微调设置下即可对任意输入图像完成风格迁移,无需针对特定风格或内容重新训练或微调模型。该方法能够同时处理丰富多样的视觉内容,涵盖人像、建筑、静物、自然风景等常见题材,以及广泛的艺术风格,包括但不限于水墨、油画、素描等主流风格。并在上述任意内容与风格的组合中,均稳定输出高保真、风格一致、语义保持完整的迁移结果。关键词:图像生成;生成式模型;扩散模型;风格迁移;注意力机制469|867|0更新时间:2025-09-16
摘要:目的图像风格迁移旨在将一种艺术风格应用到一幅真实图像上,同时保持内容的完整性。传统的风格迁移方法存在伪影、风格模糊等问题。文字到图像生成扩散模型难以通过语言精确表达特定作品的创意。现有研究通过微调模型或文本嵌入技术提升风格准确度,但微调模型引入了额外计算成本,效率较低。针对这些挑战,本文提出一种无需额外微调模型的高效风格迁移方法。方法本文方法包含一种新颖的三线并行风格迁移框架,即图像生成路径、内容引导路径和风格引导路径。利用摄影和艺术图像作为视觉提示,通过一种新颖的注意力交换机制,将引导图像信息注入新图像生成路径,实现灵活、高效的任意图像风格迁移。结果通过定性和定量实验比较,本文方法能够在推理时间内生成高质量的风格迁移结果,定性实验表明本文方法适用于人像、风景和静物等多种题材,水墨、油画和素描等多种风格,且视觉效果优于对比的先进风格迁移方法;定量实验表明本文方法提升了风格准确性,取得了最优结果。结论所提方法在零微调设置下即可对任意输入图像完成风格迁移,无需针对特定风格或内容重新训练或微调模型。该方法能够同时处理丰富多样的视觉内容,涵盖人像、建筑、静物、自然风景等常见题材,以及广泛的艺术风格,包括但不限于水墨、油画、素描等主流风格。并在上述任意内容与风格的组合中,均稳定输出高保真、风格一致、语义保持完整的迁移结果。关键词:图像生成;生成式模型;扩散模型;风格迁移;注意力机制469|867|0更新时间:2025-09-16
图像理解和计算机视觉
- “最新研究突破遥感影像领域自适应难题,提出语言文本引导的全局预训练—局部微调框架,显著提升跨时空领域迁移性能。”
 摘要:目的随着视觉大模型的发展,利用多源无标注遥感影像预训练学习全局视觉特征,并在局部目标任务上进行迁移微调,已成为遥感影像领域自适应的一种新范式。然而,现有的全局预训练策略主要聚焦于学习低级的通用视觉特征,难以捕捉复杂、高层次的语义关联。此外,微调过程中使用的少量标注样本往往只反映目标域的特定场景,无法充分激活全局模型中与目标域匹配的领域知识。因此,面对复杂多变的遥感影像跨时空领域偏移,现有方法得到的全局模型与目标任务之间仍然存在巨大的语义鸿沟。为应对这一挑战,本文提出一种语言文本引导的“全局模型预训练—局部模型微调”的领域自适应框架。方法提出框架针对遥感数据的时空异质性特点,借助大型视觉语言助手LLaVA(large language and vision assistant)生成包含季节、地理区域及地物分布等时空信息的遥感影像文本描述。通过语言文本引导的学习帮助全局模型挖掘地物的时空分布规律,增强局部任务微调时相关领域知识的激活。结果在对比判别式、掩码生成式和扩散生成式3种不同全局预训练策略上设置了3组“全局—局部”跨时空领域自适应语义分割实验来验证提出框架的有效性。以全局→局部(长沙)为例,使用语言文本引导相比于无文本引导在3种不同预训练策略上分别提升了8.7%、4.4%和2.9%。同样地,提出框架在全局→局部(湘潭)和全局→局部(武汉)上也都有性能提升。结论证明了语言文本对准确理解跨时空遥感影像中的语义内容具有积极影响。与无文本引导的学习方法相比,提出框架显著提升了模型的迁移性能。关键词:遥感影像;语义分割;领域自适应;视觉语言模型;时空异质性320|625|0更新时间:2025-09-16
摘要:目的随着视觉大模型的发展,利用多源无标注遥感影像预训练学习全局视觉特征,并在局部目标任务上进行迁移微调,已成为遥感影像领域自适应的一种新范式。然而,现有的全局预训练策略主要聚焦于学习低级的通用视觉特征,难以捕捉复杂、高层次的语义关联。此外,微调过程中使用的少量标注样本往往只反映目标域的特定场景,无法充分激活全局模型中与目标域匹配的领域知识。因此,面对复杂多变的遥感影像跨时空领域偏移,现有方法得到的全局模型与目标任务之间仍然存在巨大的语义鸿沟。为应对这一挑战,本文提出一种语言文本引导的“全局模型预训练—局部模型微调”的领域自适应框架。方法提出框架针对遥感数据的时空异质性特点,借助大型视觉语言助手LLaVA(large language and vision assistant)生成包含季节、地理区域及地物分布等时空信息的遥感影像文本描述。通过语言文本引导的学习帮助全局模型挖掘地物的时空分布规律,增强局部任务微调时相关领域知识的激活。结果在对比判别式、掩码生成式和扩散生成式3种不同全局预训练策略上设置了3组“全局—局部”跨时空领域自适应语义分割实验来验证提出框架的有效性。以全局→局部(长沙)为例,使用语言文本引导相比于无文本引导在3种不同预训练策略上分别提升了8.7%、4.4%和2.9%。同样地,提出框架在全局→局部(湘潭)和全局→局部(武汉)上也都有性能提升。结论证明了语言文本对准确理解跨时空遥感影像中的语义内容具有积极影响。与无文本引导的学习方法相比,提出框架显著提升了模型的迁移性能。关键词:遥感影像;语义分割;领域自适应;视觉语言模型;时空异质性320|625|0更新时间:2025-09-16
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0