
最新刊期
卷 27 , 期 3 , 2022
-
 摘要:The development of medical imaging, artificial intelligence (AI) and clinical applications derived from AI-based medical imaging has been recognized in past two decades. The improvement and optimization of AI-based technologies have been significantly applied to various of clinical scenarios to strengthen the capability and accuracy of diagnosis and treatment. Nowadays, China has been playing a major role and making increasing contributions in the field of AI-based medical imaging. More worldwide researchers in the context of AI-based medical imaging have contributed to universities and institutions in China. The number of research papers published by Chinese scholars in top international journals and conferences like AI-based medical imaging has dramatically increased annually. Some AI-based medical imaging international conferences and summits have been successfully held in China. There is an increasing number of traditional medical, internet technology and AI enterprises contributing to the research and development of AI-based medical imaging products. More collaborative medical research projects have been implemented for AI-based medical imaging. The Chinese administrations have also planned relevant policies and issued strategic plans for AI-based medical imaging, and included the intelligent medical care as one of the key tasks for the development of new generation of AI in China in 2030. In order to review China's contribution for AI-based medical imaging, we conducted a 20 years review for AI-based medical imaging forecasting in China. Specifically, we summarized all papers published by Chinese scholars in the top AI-based medical imaging journals and conferences including Medical Image Analysis (MedIA), IEEE Transactions on Medical Imaging (TMI), and Medical Image Computing and Computer Assisted Intervention (MICCAI) in the past 20 years. The detailed quantitative metrics like the number of published papers, authorship, affiliations, author's cooperation network, keywords, and the number of citations were critically reviewed. Meanwhile, we briefly summarized some milestone events of AI-based medical imaging in China, including the renowned international and domestic conferences in AI-based medical imaging held in China, the release of the "The White Paper on Medical Imaging Artificial Intelligence in China", as well as China's contributions during the COVID-19(corona virus desease 2019) pandemic. For instance, the total number of published papers in the past 20 years and the proportion of published papers in 2021 by Chinese affiliations have reached to 333 and 37.29% in MedIA, 601 and 42.26% in TMI, and 985 and 44.26% in MICCAI. In those published papers by Chinese institutes, the proportion of the first and the corresponding Chinese authors is 71.97% in MedIA, 69.64% in TMI, and 77.4% in MICCAI in 2021. The average number of citations per paper by Chinese institutes is 22, 28, and 9 in MedIA, TMI, and MICCAI, respectively. In all published papers by Chinese institutes, the predominant research methods were transformed from conventional approaches to sparse representation in 2012, and to deep learning in 2017, which were close to the latest developmental trend of AI technologies. Besides conventional applications such as medical image registration, segmentation, reconstruction and computer-aided diagnosis, etc., the published papers also focused on healthcare quick response in terms of COVID-19 pandemic. The China-derived data and source codes have been sharing in the global context to facilitate worldwide AI-based medical imaging research and education. Our analysis could provide a reference for international scientific research and education for newly Chinese scholars and students based on the growth of the global AI-based medical imaging. Finally, we promoted technology forecasting on AI-based medical imaging as mentioned below. First, strengthen the capability of deep learning for AI-based medical imaging further, including optimal and efficient deep learning, generalizable deep learning, explainable deep learning, fair deep learning, and responsible and trustworthy deep learning.Next, improve the availability and sharing of high-quality and benchmarked medical imaging datasets in the context of AI-based medical imaging development, validation, and dissemination are harnessed to reveal the key challenges in both basic scientific research and clinical applications. Third, focus on the multi-center and multi-modal medical imaging data acquisition and fusion, as well as integration with natural language such as diagnosis report. Fourth, awake doctors' intervention further to realize the clinical applications of AI-based medical imaging. Finally, conduct talent training, international collaboration, as well as sharing of open source data and codes for worldwide development of AI-based medical imaging.关键词:medical imaging;artificial intelligence(AI);developmental history;international cooperation;quantitative statistics399|718|6更新时间:2024-05-07
摘要:The development of medical imaging, artificial intelligence (AI) and clinical applications derived from AI-based medical imaging has been recognized in past two decades. The improvement and optimization of AI-based technologies have been significantly applied to various of clinical scenarios to strengthen the capability and accuracy of diagnosis and treatment. Nowadays, China has been playing a major role and making increasing contributions in the field of AI-based medical imaging. More worldwide researchers in the context of AI-based medical imaging have contributed to universities and institutions in China. The number of research papers published by Chinese scholars in top international journals and conferences like AI-based medical imaging has dramatically increased annually. Some AI-based medical imaging international conferences and summits have been successfully held in China. There is an increasing number of traditional medical, internet technology and AI enterprises contributing to the research and development of AI-based medical imaging products. More collaborative medical research projects have been implemented for AI-based medical imaging. The Chinese administrations have also planned relevant policies and issued strategic plans for AI-based medical imaging, and included the intelligent medical care as one of the key tasks for the development of new generation of AI in China in 2030. In order to review China's contribution for AI-based medical imaging, we conducted a 20 years review for AI-based medical imaging forecasting in China. Specifically, we summarized all papers published by Chinese scholars in the top AI-based medical imaging journals and conferences including Medical Image Analysis (MedIA), IEEE Transactions on Medical Imaging (TMI), and Medical Image Computing and Computer Assisted Intervention (MICCAI) in the past 20 years. The detailed quantitative metrics like the number of published papers, authorship, affiliations, author's cooperation network, keywords, and the number of citations were critically reviewed. Meanwhile, we briefly summarized some milestone events of AI-based medical imaging in China, including the renowned international and domestic conferences in AI-based medical imaging held in China, the release of the "The White Paper on Medical Imaging Artificial Intelligence in China", as well as China's contributions during the COVID-19(corona virus desease 2019) pandemic. For instance, the total number of published papers in the past 20 years and the proportion of published papers in 2021 by Chinese affiliations have reached to 333 and 37.29% in MedIA, 601 and 42.26% in TMI, and 985 and 44.26% in MICCAI. In those published papers by Chinese institutes, the proportion of the first and the corresponding Chinese authors is 71.97% in MedIA, 69.64% in TMI, and 77.4% in MICCAI in 2021. The average number of citations per paper by Chinese institutes is 22, 28, and 9 in MedIA, TMI, and MICCAI, respectively. In all published papers by Chinese institutes, the predominant research methods were transformed from conventional approaches to sparse representation in 2012, and to deep learning in 2017, which were close to the latest developmental trend of AI technologies. Besides conventional applications such as medical image registration, segmentation, reconstruction and computer-aided diagnosis, etc., the published papers also focused on healthcare quick response in terms of COVID-19 pandemic. The China-derived data and source codes have been sharing in the global context to facilitate worldwide AI-based medical imaging research and education. Our analysis could provide a reference for international scientific research and education for newly Chinese scholars and students based on the growth of the global AI-based medical imaging. Finally, we promoted technology forecasting on AI-based medical imaging as mentioned below. First, strengthen the capability of deep learning for AI-based medical imaging further, including optimal and efficient deep learning, generalizable deep learning, explainable deep learning, fair deep learning, and responsible and trustworthy deep learning.Next, improve the availability and sharing of high-quality and benchmarked medical imaging datasets in the context of AI-based medical imaging development, validation, and dissemination are harnessed to reveal the key challenges in both basic scientific research and clinical applications. Third, focus on the multi-center and multi-modal medical imaging data acquisition and fusion, as well as integration with natural language such as diagnosis report. Fourth, awake doctors' intervention further to realize the clinical applications of AI-based medical imaging. Finally, conduct talent training, international collaboration, as well as sharing of open source data and codes for worldwide development of AI-based medical imaging.关键词:medical imaging;artificial intelligence(AI);developmental history;international cooperation;quantitative statistics399|718|6更新时间:2024-05-07 -
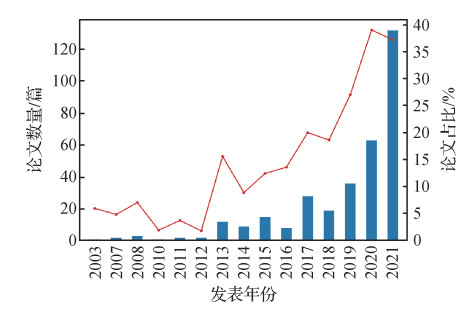
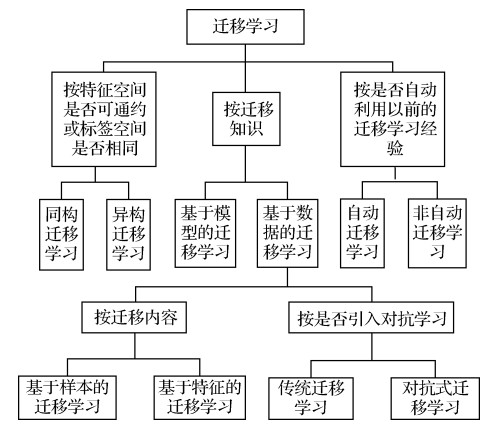 摘要:Medical image classification is a key element of medical image analysis. The method of medical image classification has been evolving in deep learning and transfer learning. A large number of important literatures of medical image classification are analyzed based on transfer learning. As a result, three transfer learning strategies and five modes of medical image classifying are summarized. The transfer learning modes are constructed based on general characteristics which extracted from designed transfer learning processes theoretically. The relevance of the transfer learning strategies and the modes is illustrated as well. These transfer strategies and modes illustrated the application of transfer learning in this field from a higher level of abstraction. The applications, advantages, limitations of these transfer learning strategies and modes are analyzed. The transfer learning in the context of medical image feature extraction and classification is the model-based transfer learning. Most of the migrated models are deep convolution neural network (DCNN). High classifying efficiency is obtained due to ImageNet (a large public image database) training results. To migrate model from the source domain to the target domain, the model needs to be adapted to the tasks of the targeted domain. From the important literature of medical image classification, three transfer model adaptive strategies were sorted out. They are structure fit, parameter option and migrated model based features extraction. The strategies of fitted structure are to modify the structure of the migrated model. Layers can be deleted or added as needed. These layers can be as convolution layer, full connection layer, feature smoothing layer, feature extracting layer, and batch normalizing layer, respectively. The optional strategies of parameter are to re-train the migrated model to adjust the model parameters via using the target domain data. Both the parameters of convolution layer and the parameters of full connection layer can be fitted. The migrated-model-based strategy of features extraction is only used for feature extraction. Image features can be extracted from the convolution layer and the full connection layer. Five transfer learning modes were sorted out based on the literature of medical image classification. They are the DCNN mode, the hybrid mode, the mode of fused feature and classification. The mode of multi-classifier fusing and the mode of transferring are conducted two times all. For instance, the fitting strategies of structure and parameters of convolution layer are used in the DCNN mode to get more accurate features. The transfer learning modes can basically cover all kinds of transfer learning processes in medical image classification researches. The DCNN mode is to use a DCNN to complete image feature extraction and classification. The hybrid model is composed of a DCNN and a traditional classifier. The former is used for feature extracting and the latter is used for classifying. It has the advantage of DCNN feature extraction and advantage of traditional classified classifier. The mode of integrated feature and classification is composed of feature extraction methods and a classifier. Feature extracting methods can be a DCNN or manual features. The mode of multi-classifier fusing is composed of multiple classifiers. The final classifying result is obtained based on multiple classified integrating results. The integrating result is more reliable than the result from single classifier mode (i.e., the DCNN mode and the hybrid mode). In the twice mode of transferring, the initial model is trained in the source domain, then it is migrated to the temporary targeted domain to be trained for the second time, and finally it is migrated to the final targeted domain to be trained for the third time. Compared to first transfer, this mode priority is that the triple migrated model accumulates more knowledge of training. The transfer-learning based issues and of medical image classification potentials are illustrated as below: 1) It is difficult to pick an efficient transfer learning algorithm. Due to the diversity and complexity of medical images, the generalization capability of transfer learning algorithm is to be strengthened. Manual option for a specific image classifying task is often based on continuous high computational cost tests. A low cost automatic transfer learning algorithm is a challenging issue. 2) The modification of transfer model and the setting of mega parameters are lack of theoretical mechanism. The structure and parameters of the migrated model can only be modified through the existing experiences and continuous experiments, and the setting of mega parameters is not different, which lead to the low efficiency of transfer learning. 3) It is challenged to classify rare disease images due to pathological image data samples of rare diseases. The antagonistic transfer learning can generate and enhance target domain data. The heterogeneous transfer learning yield to transfer the knowledge of different modalities or the source domain to target domain. Therefore, the two methods of transfer learning can be further developed in image classification of rare diseases.关键词:medical images;image classification;transfer learning;transfer learning strategies;transfer learning mode333|404|13更新时间:2024-05-07
摘要:Medical image classification is a key element of medical image analysis. The method of medical image classification has been evolving in deep learning and transfer learning. A large number of important literatures of medical image classification are analyzed based on transfer learning. As a result, three transfer learning strategies and five modes of medical image classifying are summarized. The transfer learning modes are constructed based on general characteristics which extracted from designed transfer learning processes theoretically. The relevance of the transfer learning strategies and the modes is illustrated as well. These transfer strategies and modes illustrated the application of transfer learning in this field from a higher level of abstraction. The applications, advantages, limitations of these transfer learning strategies and modes are analyzed. The transfer learning in the context of medical image feature extraction and classification is the model-based transfer learning. Most of the migrated models are deep convolution neural network (DCNN). High classifying efficiency is obtained due to ImageNet (a large public image database) training results. To migrate model from the source domain to the target domain, the model needs to be adapted to the tasks of the targeted domain. From the important literature of medical image classification, three transfer model adaptive strategies were sorted out. They are structure fit, parameter option and migrated model based features extraction. The strategies of fitted structure are to modify the structure of the migrated model. Layers can be deleted or added as needed. These layers can be as convolution layer, full connection layer, feature smoothing layer, feature extracting layer, and batch normalizing layer, respectively. The optional strategies of parameter are to re-train the migrated model to adjust the model parameters via using the target domain data. Both the parameters of convolution layer and the parameters of full connection layer can be fitted. The migrated-model-based strategy of features extraction is only used for feature extraction. Image features can be extracted from the convolution layer and the full connection layer. Five transfer learning modes were sorted out based on the literature of medical image classification. They are the DCNN mode, the hybrid mode, the mode of fused feature and classification. The mode of multi-classifier fusing and the mode of transferring are conducted two times all. For instance, the fitting strategies of structure and parameters of convolution layer are used in the DCNN mode to get more accurate features. The transfer learning modes can basically cover all kinds of transfer learning processes in medical image classification researches. The DCNN mode is to use a DCNN to complete image feature extraction and classification. The hybrid model is composed of a DCNN and a traditional classifier. The former is used for feature extracting and the latter is used for classifying. It has the advantage of DCNN feature extraction and advantage of traditional classified classifier. The mode of integrated feature and classification is composed of feature extraction methods and a classifier. Feature extracting methods can be a DCNN or manual features. The mode of multi-classifier fusing is composed of multiple classifiers. The final classifying result is obtained based on multiple classified integrating results. The integrating result is more reliable than the result from single classifier mode (i.e., the DCNN mode and the hybrid mode). In the twice mode of transferring, the initial model is trained in the source domain, then it is migrated to the temporary targeted domain to be trained for the second time, and finally it is migrated to the final targeted domain to be trained for the third time. Compared to first transfer, this mode priority is that the triple migrated model accumulates more knowledge of training. The transfer-learning based issues and of medical image classification potentials are illustrated as below: 1) It is difficult to pick an efficient transfer learning algorithm. Due to the diversity and complexity of medical images, the generalization capability of transfer learning algorithm is to be strengthened. Manual option for a specific image classifying task is often based on continuous high computational cost tests. A low cost automatic transfer learning algorithm is a challenging issue. 2) The modification of transfer model and the setting of mega parameters are lack of theoretical mechanism. The structure and parameters of the migrated model can only be modified through the existing experiences and continuous experiments, and the setting of mega parameters is not different, which lead to the low efficiency of transfer learning. 3) It is challenged to classify rare disease images due to pathological image data samples of rare diseases. The antagonistic transfer learning can generate and enhance target domain data. The heterogeneous transfer learning yield to transfer the knowledge of different modalities or the source domain to target domain. Therefore, the two methods of transfer learning can be further developed in image classification of rare diseases.关键词:medical images;image classification;transfer learning;transfer learning strategies;transfer learning mode333|404|13更新时间:2024-05-07 -
 摘要:The generative adversarial network (GAN) consists of a generator based on the data distribution learning and an identified sample's authenticity discriminator. They learn from each other gradually in the process of confrontation. The network enables the deep learning method to learn the loss function automatically and reduces expertise dependence. It has been widely used in natural image processing, and it is also a promising solution for related problems in medical image processing field. This paper aims to bridge the gap between GAN and specific medical field problems and point out the future improvement directions. First, the basic principle of GAN is issued. Secondly, we review the latest medical images research on data augmentation, modality migration, image segmentation, and denoising; analyze the advantage and disadvantage of each method and the scope of application. Next, the current quality assessment is summarized. At the end, the research development, issue, and future improvement direction of GAN on medical image are summarized. GAN theoretical study focus on three aspects of task splitting, introducing conditional constraints and image-to-image translation, which effectively improved the quality of the synthesized image, increased the resolution, and allowed more manipulation across the image synthesis process. However, there are some challenges as mentioned below: 1) Generate high-quality, high-resolution, and diverse images under large-scale complex data sets. 2) The manipulation of synthesized image attributes at different levels and different granularities. 3) The lack of paired training data and the guarantee of image translation quality and diversity. GAN application study in data augmentation, modality migration, image segmentation, and denoising of medical images has been widely analyzed. 1) The network model based on the Pix2pix basic framework can synthesize additional high-quality and high-resolution samples and improve the segmentation and classification performance based on data augmentation effectively. However, there are still problems such as insufficient synthetic sample diversity, basic biological structures maintenance difficulty, and limited 3D image synthesis capabilities. 2) The network model based on the CycleGAN basic framework does not require paired training images. It has been extensively analyzed in modality migration, but may lose the basic structure information. The current research on structure preservation in modality migration limits in the fusion of information, such as edges and segmentation. 3) Both the generator and the discriminator can be fused with the current segmentation model to improve the performance of the segmentation model. The generator can synthesize additional data, and the discriminator can guide model training from a high-level semantic level and make full use of unlabeled data. However, current research mainly focuses on single-modality image segmentation. 4) GAN application in image denoising can reconstruct normal-dose images from low-dose images, reducing the radiation impact suffered by patients. The critical issues of GAN in medical image processing are presented as follows: 1) Most medical image data is three-dimensional, such as MRI (magnetic resonance imaging) and CT (computed tomography), etc. The improvement of the synthesis quality and resolution of the three-dimensional data is a critical issue. 2) The difficulty in ensuring the diversity of synthesized data while keeping its basic geometric structure's rationality. 3) The question on how to make full use of unlabeled and unpaired data to generate high-quality, high-resolution, and diverse images. 4) The improvement of algorithms' cross-modality generalization performance, and the effective migration of different modality data. Future research should focus on the issues as following: 1) To optimize network architecture, objective function, and training methods for 3D data synthesis, improving model training stability, quality, resolution, and diversity of 3D synthesized images. 2) To further promote the prior geometric knowledge integration with GAN. 3) To take full advantage of the GAN's weak supervision characteristics. 4) To extract invariant features via attribute decoupling for good generalization performance and achieve attribute control at different levels, granularities, and needs in the process of modality migration. To conclude, ever since GAN was proposed, its theory has been continuously improved. A considerable evolution in medical image applications has been sorted out, such as data augmentation, modality migration, image segmentation, and denoising. Some challenging issues are still waiting to be resolved, including three-dimensional data synthesis, geometric structure rationality maintenance, unlabeled and unpaired data usage, and multi-modality data application.关键词:generative adversarial network (GAN);medical image;deep learning;data augmentation;modality migration;image segmentation;image denoising192|253|2更新时间:2024-05-07
摘要:The generative adversarial network (GAN) consists of a generator based on the data distribution learning and an identified sample's authenticity discriminator. They learn from each other gradually in the process of confrontation. The network enables the deep learning method to learn the loss function automatically and reduces expertise dependence. It has been widely used in natural image processing, and it is also a promising solution for related problems in medical image processing field. This paper aims to bridge the gap between GAN and specific medical field problems and point out the future improvement directions. First, the basic principle of GAN is issued. Secondly, we review the latest medical images research on data augmentation, modality migration, image segmentation, and denoising; analyze the advantage and disadvantage of each method and the scope of application. Next, the current quality assessment is summarized. At the end, the research development, issue, and future improvement direction of GAN on medical image are summarized. GAN theoretical study focus on three aspects of task splitting, introducing conditional constraints and image-to-image translation, which effectively improved the quality of the synthesized image, increased the resolution, and allowed more manipulation across the image synthesis process. However, there are some challenges as mentioned below: 1) Generate high-quality, high-resolution, and diverse images under large-scale complex data sets. 2) The manipulation of synthesized image attributes at different levels and different granularities. 3) The lack of paired training data and the guarantee of image translation quality and diversity. GAN application study in data augmentation, modality migration, image segmentation, and denoising of medical images has been widely analyzed. 1) The network model based on the Pix2pix basic framework can synthesize additional high-quality and high-resolution samples and improve the segmentation and classification performance based on data augmentation effectively. However, there are still problems such as insufficient synthetic sample diversity, basic biological structures maintenance difficulty, and limited 3D image synthesis capabilities. 2) The network model based on the CycleGAN basic framework does not require paired training images. It has been extensively analyzed in modality migration, but may lose the basic structure information. The current research on structure preservation in modality migration limits in the fusion of information, such as edges and segmentation. 3) Both the generator and the discriminator can be fused with the current segmentation model to improve the performance of the segmentation model. The generator can synthesize additional data, and the discriminator can guide model training from a high-level semantic level and make full use of unlabeled data. However, current research mainly focuses on single-modality image segmentation. 4) GAN application in image denoising can reconstruct normal-dose images from low-dose images, reducing the radiation impact suffered by patients. The critical issues of GAN in medical image processing are presented as follows: 1) Most medical image data is three-dimensional, such as MRI (magnetic resonance imaging) and CT (computed tomography), etc. The improvement of the synthesis quality and resolution of the three-dimensional data is a critical issue. 2) The difficulty in ensuring the diversity of synthesized data while keeping its basic geometric structure's rationality. 3) The question on how to make full use of unlabeled and unpaired data to generate high-quality, high-resolution, and diverse images. 4) The improvement of algorithms' cross-modality generalization performance, and the effective migration of different modality data. Future research should focus on the issues as following: 1) To optimize network architecture, objective function, and training methods for 3D data synthesis, improving model training stability, quality, resolution, and diversity of 3D synthesized images. 2) To further promote the prior geometric knowledge integration with GAN. 3) To take full advantage of the GAN's weak supervision characteristics. 4) To extract invariant features via attribute decoupling for good generalization performance and achieve attribute control at different levels, granularities, and needs in the process of modality migration. To conclude, ever since GAN was proposed, its theory has been continuously improved. A considerable evolution in medical image applications has been sorted out, such as data augmentation, modality migration, image segmentation, and denoising. Some challenging issues are still waiting to be resolved, including three-dimensional data synthesis, geometric structure rationality maintenance, unlabeled and unpaired data usage, and multi-modality data application.关键词:generative adversarial network (GAN);medical image;deep learning;data augmentation;modality migration;image segmentation;image denoising192|253|2更新时间:2024-05-07 -
 摘要:Heart diseases diagnosis and treatment has become one of the major public health issues for human beings where non-invasive cardiac imaging is of great significance. Unfortunately, imaging scan time and cardiac image resolution become an intensive contradiction due to the characteristics of living heartbeat. Super-resolution (SR) image reconstruction like low-resolution-images based high-resolution cardiac images reconstruction are obtained based on the determined tolerable error within a short imaging time. Deep learning methods have revealed great vitality in the field of medical image processing nowadays. In terms of its good learning ability and data-driven factors, deep-learning-based SR reconstruction is qualified based on deep residual networks, generative adversarial networks compared with traditional methods. Our research analysis reviews the field via analyzing characteristics of representative methods, summing up cardiac image resources and the scale, summarizing commonly used evaluation indicators, giving performance evaluation and application conclusions of the methods and discussing methods in other fields that can be adapted for SR reconstructing cardiac magnetic resonance (CMR) images. Our analysis is derived from 13 opted literature reviews from Google, database systems and logic programming (DBLP), and CNKI taking deep learning, cardiac and SR reconstruction as search keywords. This review first categorizes all methods by their evaluation datasets, which are open resource or not. Details on the datasets and links to the open-source datasets are also facilitated. By defining standard evaluation indicators based on the reconstructed SR images and their ground truth, namely high-resolution (HR) images, the performance of SR reconstruction methods can be evaluated quantitatively. This demonstration summarizes the 8 evaluation indicators in the cardiac SR reconstruction methods, including structural similarity, cardiovascular diameter measured value, dice coefficient. The evaluation indicators are divided into three categories with respect to the following aspects, those are evaluation of the quality of SR reconstructed images, evaluation of cardiac function and evaluation of the effectiveness of cardiac segmentation. Meanwhile, all 13 literature reviews are only used to increase the spatial resolution of the CMR images. Our research classifies the methods as CMR 2D SR reconstruction, CMR 3D SR reconstruction, and CMR SR reconstruction in other dimensions, depending on the dimension of the cardiac images processing based on the deep learning methods. In general, most CMR 2D SR reconstruction methods can reconstruct high resolution cardiac images in a relative short time span to assure SR reconstruction quality. In contrast, the CMR 3D SR reconstruction methods are involved 3D convolution, which take the spatial structure of the heart into account. The integrated information is analyzed amongst adjacent slices of CMR. Some of these methods achieve the SR reconstruction result qualified than CMR 2D SR reconstruction methods. However, a number of CMR data is small size and most of them are not open. The larger perceptual domain of the methods increases the computation complexity and reduces the temporal performance to some extent. As for CMR SR reconstruction in higher dimensions, corresponding methods meet the requirement of high-resolution image generation and image denoising in clinical analysis. All the selected CMR SR reconstruction methods can also be organized in accordance with network models and high-resolution image degradation methods, such as U-Net, generative adversarial network and long short-term memory network from the aspect of network models. Fourier degradation and different interpolation degradation methods are from the aspect of degradation methods. SR reconstructed high-resolution images can accurately facilitate heart anatomy, blood flow evaluation and heart tissue segmentation level. This research also reviewed the feasibility of adapting other SR reconstruction methods for CMR SR reconstruction as they are currently proposed and applied to images of other in vivo tissues and structures. Our research also tries to find some of the SR reconstruction methods from the field of natural images computer vision to discuss the feasibility that adapting them to CMR SR reconstruction, such as channel attention mechanisms, video SR methods and SR of real scenes. In summary, SR reconstruction of CMR images has its distinctive features than SR reconstruction of natural images like more diverse and purposeful evaluation metrics constraint of local reconstruction quality and to the difficulties of getting training data. It is found that deep-learning-based cardiac SR reconstruction has concerned more in motion artifact suppression, model simplification, and time performance further. In addition, current methods basically rely on the powerful expression ability of the CNN(convolutional neural network), and little clinical prior knowledge is melted to the network to guide its learning. Performance comparison between existing models is relatively less, and there is no representative image repository to evaluate performances of different cardiac SR reconstruction methods.关键词:deep learning;cardiac imaging;super-resolution reconstruction;magnetic resonance imaging;datasets of cardiac images;convolutional neural networks;high-resolution images242|1030|3更新时间:2024-05-07
摘要:Heart diseases diagnosis and treatment has become one of the major public health issues for human beings where non-invasive cardiac imaging is of great significance. Unfortunately, imaging scan time and cardiac image resolution become an intensive contradiction due to the characteristics of living heartbeat. Super-resolution (SR) image reconstruction like low-resolution-images based high-resolution cardiac images reconstruction are obtained based on the determined tolerable error within a short imaging time. Deep learning methods have revealed great vitality in the field of medical image processing nowadays. In terms of its good learning ability and data-driven factors, deep-learning-based SR reconstruction is qualified based on deep residual networks, generative adversarial networks compared with traditional methods. Our research analysis reviews the field via analyzing characteristics of representative methods, summing up cardiac image resources and the scale, summarizing commonly used evaluation indicators, giving performance evaluation and application conclusions of the methods and discussing methods in other fields that can be adapted for SR reconstructing cardiac magnetic resonance (CMR) images. Our analysis is derived from 13 opted literature reviews from Google, database systems and logic programming (DBLP), and CNKI taking deep learning, cardiac and SR reconstruction as search keywords. This review first categorizes all methods by their evaluation datasets, which are open resource or not. Details on the datasets and links to the open-source datasets are also facilitated. By defining standard evaluation indicators based on the reconstructed SR images and their ground truth, namely high-resolution (HR) images, the performance of SR reconstruction methods can be evaluated quantitatively. This demonstration summarizes the 8 evaluation indicators in the cardiac SR reconstruction methods, including structural similarity, cardiovascular diameter measured value, dice coefficient. The evaluation indicators are divided into three categories with respect to the following aspects, those are evaluation of the quality of SR reconstructed images, evaluation of cardiac function and evaluation of the effectiveness of cardiac segmentation. Meanwhile, all 13 literature reviews are only used to increase the spatial resolution of the CMR images. Our research classifies the methods as CMR 2D SR reconstruction, CMR 3D SR reconstruction, and CMR SR reconstruction in other dimensions, depending on the dimension of the cardiac images processing based on the deep learning methods. In general, most CMR 2D SR reconstruction methods can reconstruct high resolution cardiac images in a relative short time span to assure SR reconstruction quality. In contrast, the CMR 3D SR reconstruction methods are involved 3D convolution, which take the spatial structure of the heart into account. The integrated information is analyzed amongst adjacent slices of CMR. Some of these methods achieve the SR reconstruction result qualified than CMR 2D SR reconstruction methods. However, a number of CMR data is small size and most of them are not open. The larger perceptual domain of the methods increases the computation complexity and reduces the temporal performance to some extent. As for CMR SR reconstruction in higher dimensions, corresponding methods meet the requirement of high-resolution image generation and image denoising in clinical analysis. All the selected CMR SR reconstruction methods can also be organized in accordance with network models and high-resolution image degradation methods, such as U-Net, generative adversarial network and long short-term memory network from the aspect of network models. Fourier degradation and different interpolation degradation methods are from the aspect of degradation methods. SR reconstructed high-resolution images can accurately facilitate heart anatomy, blood flow evaluation and heart tissue segmentation level. This research also reviewed the feasibility of adapting other SR reconstruction methods for CMR SR reconstruction as they are currently proposed and applied to images of other in vivo tissues and structures. Our research also tries to find some of the SR reconstruction methods from the field of natural images computer vision to discuss the feasibility that adapting them to CMR SR reconstruction, such as channel attention mechanisms, video SR methods and SR of real scenes. In summary, SR reconstruction of CMR images has its distinctive features than SR reconstruction of natural images like more diverse and purposeful evaluation metrics constraint of local reconstruction quality and to the difficulties of getting training data. It is found that deep-learning-based cardiac SR reconstruction has concerned more in motion artifact suppression, model simplification, and time performance further. In addition, current methods basically rely on the powerful expression ability of the CNN(convolutional neural network), and little clinical prior knowledge is melted to the network to guide its learning. Performance comparison between existing models is relatively less, and there is no representative image repository to evaluate performances of different cardiac SR reconstruction methods.关键词:deep learning;cardiac imaging;super-resolution reconstruction;magnetic resonance imaging;datasets of cardiac images;convolutional neural networks;high-resolution images242|1030|3更新时间:2024-05-07 -
 摘要:Lung disease like corona virus disease 2019(COVID-19) and lung cancer endanger the health of human beings. Early screening and treatment can significantly decrease the mortality of lung diseases. Computed tomography (CT) technology can be an effective information collection method for the diagnosis and treatment of lung diseases. CT-based lung lesion region image segmentation is a key step in lung disease screening. High quality lung lesion region segmentation can effectively improve the level of early stage diagnosis and treatment of lung diseases. However, high-quality lung lesion region segmentation in lung CT images has become a challenging issue in computer-aided diagnosis due to the diversity and complexity of lung diseases. Our research reviews the relevant literature recently. First, it is compared and summarized the pros and cons of traditional segmentation methods of lung CT image based on region and active contour. The region-based method uses the similarity and difference of features to guide image segmentation, mainly including threshold method, region growth method, clustering method and random walk method. The active-contour-based method is to set an initial contour line with decreasing energy. The contour line deforms in the internal energy derived from its own characteristics and the external energy originated from image characteristics. Its movement is in accordance with the principle of minimum energy until the energy function is in minimization and the contour line stops next to the boundary of lung region. The active contour method is divided into parametric active contour method and geometric active contour method in terms of the contour curve analysis. Low segmentation accuracy lung CT image segmentation methods are widely used in the early stage diagnosis. Next, the improved model analysis of lung CT image segmentation network structure is based on convolutional neural networks (CNNs), fully convolutional networks (FCNs), and generative adversarial network (GAN). In respect of the CNN-based deep learning segmentation methods, the segmentation methods of lung and lung lesion region can be divided into two-dimensional and three-dimensional methods in terms of the dimension of convolution kernel, the segmentation methods of lung and lung lesion region can also be divided into two-dimensional and three-dimensional methods based on the dimension of convolution kernel for the FCN-based deep learning segmentation methods. In respect of the U-Net based lung CT image segmentation methods, it can be divided into solo network lung CT image segmentation method and multi network lung CT image segmentation method according to the form of U-Net architecture. Due to the CT image containing COVID-19 infection area is very different from the ordinary lung CT imageand the differentiated segmentation characteristics of the two in the same network, the solo network lung CT image segmentation method can be analyzed that whether the data-set contains COVID-19 or not. The multi-network lung CT image segmentation method can be divided into cascade U-Net and dual path U-Net based on the option of serial mode or parallel mode. For the GAN-based lung CT image segmentation methods, it can be divided into GAN models based on network architecture, generator and other methods according to the ways to improve the different architectures of GAN. Deep-learning-based segmentation method has the advantages of high segmentation accuracy, strong transfer learning ability and high robustness. In particular, the auxiliary diagnosis of COVID-19 cases analysis is significantly qualified based on deep learning. Next, the common datasets and evaluation indexes of lung and lung lesion region segmentation are illustrated, including almost 10 lung CT open datasets, such as national lung screening test(NLST) dataset, computer vision and image analysis international early lung cancer action plan database(VIA/I-ELCAP) dataset, lung image database consortium and image database resource initiative(LIDC-IDRI) dataset and Nederlands-Leuvens Longkanker Screenings Onderzoek(NELSON) dataset, and 7 COVID-19 lung CT datasets analysis. It also demonstrates that the related lung CT images datasets is provided based on five large-scale competitions, including TIANCHI dataset, lung nodule analysis 16(LUNA16) dataset, Lung Nodule Database(LNDb) dataset, Kaggle Data Science Bowl 2017(Kaggle DSB) 2017 dataset and Automatic Nodule Detection 2009(ANODE09) dataset, respectively. Our 8 evaluation index is commonly used to evaluate the quality of lung CT image segmentation model, including involved Dice similarity coefficient, Jaccard similarity coefficient, accuracy, precision, false positive rate, false negative rate, sensitivity and specificity, respectively. To increase the number and diversity of training samples, GAN is used to synthesize high-quality adversarial images to expand the dataset. At the end, the prospects, challenges and potentials of CT-based high-precision segmentation strategies are critical reviewed for lung and lung lesion regions. Because the special structure of U-Net can effectively extract target features and restore the information loss derived from down sampling, it does not need a large number of samples for training to achieve high segmentation effect. Therefore, it is necessary to segment lung and lung lesions based on U-Net. The integration of GAN and U-Net is to improve the segmentation accuracy of lung and lung lesion areas. GAN-based network architecture is to extend the dataset for good training quality. The further U-Net application has its priority for qualified segmentation consistently.关键词:computed tomography(CT);medical image segmentation;lung CT image segmentation;lung lesion region;deep learning;corona virus disease 2019(COVID-19)280|226|4更新时间:2024-05-07
摘要:Lung disease like corona virus disease 2019(COVID-19) and lung cancer endanger the health of human beings. Early screening and treatment can significantly decrease the mortality of lung diseases. Computed tomography (CT) technology can be an effective information collection method for the diagnosis and treatment of lung diseases. CT-based lung lesion region image segmentation is a key step in lung disease screening. High quality lung lesion region segmentation can effectively improve the level of early stage diagnosis and treatment of lung diseases. However, high-quality lung lesion region segmentation in lung CT images has become a challenging issue in computer-aided diagnosis due to the diversity and complexity of lung diseases. Our research reviews the relevant literature recently. First, it is compared and summarized the pros and cons of traditional segmentation methods of lung CT image based on region and active contour. The region-based method uses the similarity and difference of features to guide image segmentation, mainly including threshold method, region growth method, clustering method and random walk method. The active-contour-based method is to set an initial contour line with decreasing energy. The contour line deforms in the internal energy derived from its own characteristics and the external energy originated from image characteristics. Its movement is in accordance with the principle of minimum energy until the energy function is in minimization and the contour line stops next to the boundary of lung region. The active contour method is divided into parametric active contour method and geometric active contour method in terms of the contour curve analysis. Low segmentation accuracy lung CT image segmentation methods are widely used in the early stage diagnosis. Next, the improved model analysis of lung CT image segmentation network structure is based on convolutional neural networks (CNNs), fully convolutional networks (FCNs), and generative adversarial network (GAN). In respect of the CNN-based deep learning segmentation methods, the segmentation methods of lung and lung lesion region can be divided into two-dimensional and three-dimensional methods in terms of the dimension of convolution kernel, the segmentation methods of lung and lung lesion region can also be divided into two-dimensional and three-dimensional methods based on the dimension of convolution kernel for the FCN-based deep learning segmentation methods. In respect of the U-Net based lung CT image segmentation methods, it can be divided into solo network lung CT image segmentation method and multi network lung CT image segmentation method according to the form of U-Net architecture. Due to the CT image containing COVID-19 infection area is very different from the ordinary lung CT imageand the differentiated segmentation characteristics of the two in the same network, the solo network lung CT image segmentation method can be analyzed that whether the data-set contains COVID-19 or not. The multi-network lung CT image segmentation method can be divided into cascade U-Net and dual path U-Net based on the option of serial mode or parallel mode. For the GAN-based lung CT image segmentation methods, it can be divided into GAN models based on network architecture, generator and other methods according to the ways to improve the different architectures of GAN. Deep-learning-based segmentation method has the advantages of high segmentation accuracy, strong transfer learning ability and high robustness. In particular, the auxiliary diagnosis of COVID-19 cases analysis is significantly qualified based on deep learning. Next, the common datasets and evaluation indexes of lung and lung lesion region segmentation are illustrated, including almost 10 lung CT open datasets, such as national lung screening test(NLST) dataset, computer vision and image analysis international early lung cancer action plan database(VIA/I-ELCAP) dataset, lung image database consortium and image database resource initiative(LIDC-IDRI) dataset and Nederlands-Leuvens Longkanker Screenings Onderzoek(NELSON) dataset, and 7 COVID-19 lung CT datasets analysis. It also demonstrates that the related lung CT images datasets is provided based on five large-scale competitions, including TIANCHI dataset, lung nodule analysis 16(LUNA16) dataset, Lung Nodule Database(LNDb) dataset, Kaggle Data Science Bowl 2017(Kaggle DSB) 2017 dataset and Automatic Nodule Detection 2009(ANODE09) dataset, respectively. Our 8 evaluation index is commonly used to evaluate the quality of lung CT image segmentation model, including involved Dice similarity coefficient, Jaccard similarity coefficient, accuracy, precision, false positive rate, false negative rate, sensitivity and specificity, respectively. To increase the number and diversity of training samples, GAN is used to synthesize high-quality adversarial images to expand the dataset. At the end, the prospects, challenges and potentials of CT-based high-precision segmentation strategies are critical reviewed for lung and lung lesion regions. Because the special structure of U-Net can effectively extract target features and restore the information loss derived from down sampling, it does not need a large number of samples for training to achieve high segmentation effect. Therefore, it is necessary to segment lung and lung lesions based on U-Net. The integration of GAN and U-Net is to improve the segmentation accuracy of lung and lung lesion areas. GAN-based network architecture is to extend the dataset for good training quality. The further U-Net application has its priority for qualified segmentation consistently.关键词:computed tomography(CT);medical image segmentation;lung CT image segmentation;lung lesion region;deep learning;corona virus disease 2019(COVID-19)280|226|4更新时间:2024-05-07
Review

-
 摘要:ObjectiveThe primary routine clinical diagnosis of COVID-19(corona virus disease 2019) is usually conducted based on epidemiological history, clinical manifestations and various laboratory detection methods, including nucleic acid amplification test (NAAT), computed tomography (CT) scan and serological techniques. However, manual detection is costly, time-consuming and leads to the potential increase of the infection risk of clinicians. As a good alternative, artificial intelligence techniques on available data from laboratory tests play an important role in the confirmation of COVID-19 cases. Some studies have been designed for distinguishing between novel coronavirus pneumonia, community-acquired pneumonia and normal people by graph neural network. However, these studies leverage the relationships between features to build a topological structure graph (e.g., connecting the nodes with high similarity), while ignoring the inner relationships between different parts of the lung, and thus limiting the performance of their models. To address this issue, we propose a graph neural network with hierarchical information inherent to the physical structure of lungs for the improved diagnosis of COVID-19. Besides, an attention mechanism is introduced to capture the discriminative features of different severities of infection in the left and right lobes of different patients.MethodFirstly, the topological structure is constructed based on the lungs' physical structure, and different lung segments are regarded as different nodes. Each node in the graph contains three kinds of handcrafted features, such as volume, density and mass feature, which reflect the infection in each lung segment and can be extracted from chest CT images using VB-Net. Secondly, based on graph neural network (GNN) and attention mechanism, we propose a novel structural attention graph neural network (SAGNN), which can perform the graph classification task. The SAGNN first aggregates the features in a given sample graph, and then uses the attention mechanism to effectively fuse the different features to obtain the final graph representation. This representation is then fed into a linear layer with softmax activation function that performs graph classification, so that the corresponding sample graph can be finally classified as a mild case or a severe one. To alleviate the effect of category imbalance on the classification results, we use the focal loss function. We optimize the proposed model via back propagation and learn the representations of graphs.ResultTo verify the effectiveness of the proposed method, we compared SAGNN with several classical machine learning methods and graph classification methods on a real COVID-19 dataset, which includes 358 severe cases and 1 329 mild cases, provided by Shanghai Public Health Clinical Center. The result of comparative experiments was measured using three evaluation metrics including the sensitivity (SEN), the specificity (SPE) and the area under the receiver operating characteristic(ROC) curve (AUC). In the experiments, our model had a good performance, indicating the effectiveness of our model. Based on comparison with the classical machine learning methods and the graph neural network methods, SAGNN outperformed by 14.2%~42.0% and 3.6%~4.8% in terms of SEN, respectively. In terms of AUC, the performance of SAGNN increased by 8.9%~18.7% and 3.1%~3.6%, respectively. In addition, through the ablation experiments of SAGNN, we found that the SAGNN with attention mechanism outperformed by 2.4%, 1.4% and 1.1% in SPE, SEN and AUC than the SAGNN not with attention mechanism, respectively. The SAGNN with focal loss function outperformed by 2.1%, 1.1% and 0.9% in SPE, SEN and AUC than the SAGNN with cross-entropy loss function, respectively.ConclusionIn this work, we propose SAGNN, a new architecture for the diagnosis of severe and mild cases of COVID-19. Experimental results show the superior performance of SAGNN on classification task. Experimental results show that concatenating features of lung segments by their structure is effective. Moreover, we introduce an attention mechanism to distinguish the infection degree of right and left lungs. The focal loss is used to solve the issue of imbalanced group distribution, which further improves the overall network performance. We thus demonstrate the potential of SAGNN as clinical diagnosis support in this highly critical domain of medical intervention. We believe that our architecture provides a valuable case study for the early diagnosis of COVID-19, which is helpful for improvement in the field of computer-aided diagnosis and clinical practice.关键词:corona virus disease 2019(COVID-19) diagnosis;graph neural network(GNN);structural attention mechanism;topology diagram;graph classification109|229|2更新时间:2024-05-07
摘要:ObjectiveThe primary routine clinical diagnosis of COVID-19(corona virus disease 2019) is usually conducted based on epidemiological history, clinical manifestations and various laboratory detection methods, including nucleic acid amplification test (NAAT), computed tomography (CT) scan and serological techniques. However, manual detection is costly, time-consuming and leads to the potential increase of the infection risk of clinicians. As a good alternative, artificial intelligence techniques on available data from laboratory tests play an important role in the confirmation of COVID-19 cases. Some studies have been designed for distinguishing between novel coronavirus pneumonia, community-acquired pneumonia and normal people by graph neural network. However, these studies leverage the relationships between features to build a topological structure graph (e.g., connecting the nodes with high similarity), while ignoring the inner relationships between different parts of the lung, and thus limiting the performance of their models. To address this issue, we propose a graph neural network with hierarchical information inherent to the physical structure of lungs for the improved diagnosis of COVID-19. Besides, an attention mechanism is introduced to capture the discriminative features of different severities of infection in the left and right lobes of different patients.MethodFirstly, the topological structure is constructed based on the lungs' physical structure, and different lung segments are regarded as different nodes. Each node in the graph contains three kinds of handcrafted features, such as volume, density and mass feature, which reflect the infection in each lung segment and can be extracted from chest CT images using VB-Net. Secondly, based on graph neural network (GNN) and attention mechanism, we propose a novel structural attention graph neural network (SAGNN), which can perform the graph classification task. The SAGNN first aggregates the features in a given sample graph, and then uses the attention mechanism to effectively fuse the different features to obtain the final graph representation. This representation is then fed into a linear layer with softmax activation function that performs graph classification, so that the corresponding sample graph can be finally classified as a mild case or a severe one. To alleviate the effect of category imbalance on the classification results, we use the focal loss function. We optimize the proposed model via back propagation and learn the representations of graphs.ResultTo verify the effectiveness of the proposed method, we compared SAGNN with several classical machine learning methods and graph classification methods on a real COVID-19 dataset, which includes 358 severe cases and 1 329 mild cases, provided by Shanghai Public Health Clinical Center. The result of comparative experiments was measured using three evaluation metrics including the sensitivity (SEN), the specificity (SPE) and the area under the receiver operating characteristic(ROC) curve (AUC). In the experiments, our model had a good performance, indicating the effectiveness of our model. Based on comparison with the classical machine learning methods and the graph neural network methods, SAGNN outperformed by 14.2%~42.0% and 3.6%~4.8% in terms of SEN, respectively. In terms of AUC, the performance of SAGNN increased by 8.9%~18.7% and 3.1%~3.6%, respectively. In addition, through the ablation experiments of SAGNN, we found that the SAGNN with attention mechanism outperformed by 2.4%, 1.4% and 1.1% in SPE, SEN and AUC than the SAGNN not with attention mechanism, respectively. The SAGNN with focal loss function outperformed by 2.1%, 1.1% and 0.9% in SPE, SEN and AUC than the SAGNN with cross-entropy loss function, respectively.ConclusionIn this work, we propose SAGNN, a new architecture for the diagnosis of severe and mild cases of COVID-19. Experimental results show the superior performance of SAGNN on classification task. Experimental results show that concatenating features of lung segments by their structure is effective. Moreover, we introduce an attention mechanism to distinguish the infection degree of right and left lungs. The focal loss is used to solve the issue of imbalanced group distribution, which further improves the overall network performance. We thus demonstrate the potential of SAGNN as clinical diagnosis support in this highly critical domain of medical intervention. We believe that our architecture provides a valuable case study for the early diagnosis of COVID-19, which is helpful for improvement in the field of computer-aided diagnosis and clinical practice.关键词:corona virus disease 2019(COVID-19) diagnosis;graph neural network(GNN);structural attention mechanism;topology diagram;graph classification109|229|2更新时间:2024-05-07 -
Segmentation and quantitative analysis of intrapulmonary vasculature in CT images from COPD patients
 摘要:ObjectiveChronic obstructive pulmonary disease (COPD) is a worldwide prevalent pulmonary disease. In China, COPD is the third leading cause of death. Pulmonary function tests (PFTs) are widely used to assess COPD severity, but they cannot evaluate the contribution of each disease compartment. Pulmonary vascular remodeling is a remarkable characteristic of COPD. In the past, pulmonary vascular remodeling was regarded as an end-stage feature of COPD. However, more recent studies have found that vascular disease is present in patients with early COPD stage. Pulmonary vascular remodeling has been described as dilation of proximal vessels and pruning or narrowing of distal vessels, thereby increasing vascular resistance. The available tools for the assessment of pulmonary vascular disease remain limited. Computed tomography (CT) is the most widely used imaging modality in COPD patients; it may be utilized to assess the severity of pulmonary vascular diseases. This study aims to develop and validate an automatic method for extracting pulmonary vessels and quantifying pulmonary vascular morphology in CT images.MethodThe extraction of pulmonary vessels is important for automated quantitative analysis of pulmonary vascular morphology. We present an anisotropic variational approach, which incorporates appearance and orientation of pulmonary vessels as prior knowledge for extracting pulmonary vessels. The pipeline of segmentation procedure includes three stages as follows. First, because the lung segmentation can reduce the running time of subsequent stages, we apply a U-Net model, which is a convolution neural network (CNN) trained with high diversity clinical CT images to obtain the left and right lungs. Second, the response of conventional Hessian-based vesselness filters is low at the vessels' edges and bifurcations. To overcome this problem, motivated by the measurement of anisotropy of diffusion tensor, a multiscale Hessian-based vesselness filter is used to highlight pulmonary vessels and generate the axial orientation of tubular structures. This vesselness filter may mitigate the low response of branch points and maintain robust contrast of various images. Third, considering the long and thin characteristic of pulmonary vessels, we incorporate an anisotropic variational regularizer into a continuous maximal flow framework to improve the segmentation performance. This anisotropic regularizer was constructed from the orientation of pulmonary vessels in the form of matrix generated by Eigen vectors of Hessian matrix. The proposed segmentation framework was implemented with parallel computing library. For quantifying the extracted pulmonary vessels, a public clinical data set from the ArteryVein challenge and a simulated data set from the VascuSynth were used to evaluate the performance of pulmonary vessel segmentation. To verify the association between the small vessel volume and COPD, 614 patients with COPD and other pulmonary diseases were investigated with the proposed approach.ResultFor evaluating the pulmonary vessel segmentation method, we tested our segmentation method on simulated vessels with seven levels of Gaussian noise (σ=5, 10, 15, 20, 25, 30, 35) and 10 CT scans from a public clinical data set. The average dice coefficient for the simulated data set is 0.87 (σ=5), 0.80 (σ=10), 0.77 (σ=15), 0.75 (σ=20), 0.73 (σ=25), 0.71 (σ=30), and 0.69 (σ=35). The average dice coefficient for the clinical data set is 0.79. For investigating the pulmonary vessel remodeling in COPD patients, 614 CT scans from 352 patients with COPD and 262 patients with other diseases were used for quantitative analysis, where 281 cases in the COPD group contain GOLD classification information (GOLD 1:16 cases, GOLD 2:108 cases, GOLD 3:108 cases, and GOLD 4:49 cases). The average proportion of small pulmonary vessels (cross section areas < 10 mm2) in the non-COPD and the COPD group was 0.656±0.067 and 0.589±0.074, respectively. The proportions of small vessels in the GOLD1-4 group were 0.612±0.051, 0.600±0.078, 0.565±0.067, and 0.528±0.053.ConclusionWe proposed a pulmonary vessel segmentation method that incorporates the vessels' directions. It can be used in the study of pulmonary vascular remodeling. Experimental results have verified the difference in the proportion of small pulmonary vessel volume between the non-COPD and the COPD group, and the differences also exist in GOLD 1-4 groups.关键词:chronic obstructive pulmonary disease(COPD);pulmonary vasculature segmentation;anisotropic total variation;continuous max flow;quantitative analysis182|130|0更新时间:2024-05-07
摘要:ObjectiveChronic obstructive pulmonary disease (COPD) is a worldwide prevalent pulmonary disease. In China, COPD is the third leading cause of death. Pulmonary function tests (PFTs) are widely used to assess COPD severity, but they cannot evaluate the contribution of each disease compartment. Pulmonary vascular remodeling is a remarkable characteristic of COPD. In the past, pulmonary vascular remodeling was regarded as an end-stage feature of COPD. However, more recent studies have found that vascular disease is present in patients with early COPD stage. Pulmonary vascular remodeling has been described as dilation of proximal vessels and pruning or narrowing of distal vessels, thereby increasing vascular resistance. The available tools for the assessment of pulmonary vascular disease remain limited. Computed tomography (CT) is the most widely used imaging modality in COPD patients; it may be utilized to assess the severity of pulmonary vascular diseases. This study aims to develop and validate an automatic method for extracting pulmonary vessels and quantifying pulmonary vascular morphology in CT images.MethodThe extraction of pulmonary vessels is important for automated quantitative analysis of pulmonary vascular morphology. We present an anisotropic variational approach, which incorporates appearance and orientation of pulmonary vessels as prior knowledge for extracting pulmonary vessels. The pipeline of segmentation procedure includes three stages as follows. First, because the lung segmentation can reduce the running time of subsequent stages, we apply a U-Net model, which is a convolution neural network (CNN) trained with high diversity clinical CT images to obtain the left and right lungs. Second, the response of conventional Hessian-based vesselness filters is low at the vessels' edges and bifurcations. To overcome this problem, motivated by the measurement of anisotropy of diffusion tensor, a multiscale Hessian-based vesselness filter is used to highlight pulmonary vessels and generate the axial orientation of tubular structures. This vesselness filter may mitigate the low response of branch points and maintain robust contrast of various images. Third, considering the long and thin characteristic of pulmonary vessels, we incorporate an anisotropic variational regularizer into a continuous maximal flow framework to improve the segmentation performance. This anisotropic regularizer was constructed from the orientation of pulmonary vessels in the form of matrix generated by Eigen vectors of Hessian matrix. The proposed segmentation framework was implemented with parallel computing library. For quantifying the extracted pulmonary vessels, a public clinical data set from the ArteryVein challenge and a simulated data set from the VascuSynth were used to evaluate the performance of pulmonary vessel segmentation. To verify the association between the small vessel volume and COPD, 614 patients with COPD and other pulmonary diseases were investigated with the proposed approach.ResultFor evaluating the pulmonary vessel segmentation method, we tested our segmentation method on simulated vessels with seven levels of Gaussian noise (σ=5, 10, 15, 20, 25, 30, 35) and 10 CT scans from a public clinical data set. The average dice coefficient for the simulated data set is 0.87 (σ=5), 0.80 (σ=10), 0.77 (σ=15), 0.75 (σ=20), 0.73 (σ=25), 0.71 (σ=30), and 0.69 (σ=35). The average dice coefficient for the clinical data set is 0.79. For investigating the pulmonary vessel remodeling in COPD patients, 614 CT scans from 352 patients with COPD and 262 patients with other diseases were used for quantitative analysis, where 281 cases in the COPD group contain GOLD classification information (GOLD 1:16 cases, GOLD 2:108 cases, GOLD 3:108 cases, and GOLD 4:49 cases). The average proportion of small pulmonary vessels (cross section areas < 10 mm2) in the non-COPD and the COPD group was 0.656±0.067 and 0.589±0.074, respectively. The proportions of small vessels in the GOLD1-4 group were 0.612±0.051, 0.600±0.078, 0.565±0.067, and 0.528±0.053.ConclusionWe proposed a pulmonary vessel segmentation method that incorporates the vessels' directions. It can be used in the study of pulmonary vascular remodeling. Experimental results have verified the difference in the proportion of small pulmonary vessel volume between the non-COPD and the COPD group, and the differences also exist in GOLD 1-4 groups.关键词:chronic obstructive pulmonary disease(COPD);pulmonary vasculature segmentation;anisotropic total variation;continuous max flow;quantitative analysis182|130|0更新时间:2024-05-07 -
 摘要:ObjectiveHuman chest computed tomography (CT) image analysis is a key measure for diagnosing human lung diseases. However, the current scanned chest CT images might not meet the requirement of diagnosing lung diseases accurately. Medical image enhancement is an effective technique to improve the image quality and has been used in many clinical applications, such as knee joint disease detection, breast lesion segmentation and corona virus disease 2019(COVID-19) detection. Developing new enhancement algorithms is essential to improve the quality of chest CT images. A simple yet effective chest CT image enhancement algorithm is presented based on basic information preservation and detail enhancement.MethodA good chest CT image enhancement algorithm should well improve the clarity of edges or speckles in the image, while preserving much original structural information. Our human chest CT image enhancement algorithm is developed as follows. First, this algorithm exploits the advanced guided filter to decompose the CT image into multiple layers, including a base layer and multiple different scales of detail layers. Next, an entropy-based weight strategy is adopted to fuse the detail layers, which could well strengthen the informative details and suppress the texture-less layers. Afterwards, the fused detail layer is further strengthened based on an enhancement coefficient. In the end, the enhanced detail layer and the original base layer are integrated to generate the targeted chest CT image. The proposed algorithm could well enhance the details of the chest CT image, as well as transfer much original basic structural information to the enhanced image. Moreover, with the help of our algorithm, the surgeons can inspect more clear medical images without impacting their perception of the pathology information. In order to verify the effectiveness of our proposed algorithm, we have constructed a chest CT image dataset, which is composed of 20 sets/3 209 chest CT images, and then evaluated our algorithm and five state-of-the-art image enhancement algorithms on this large-scale dataset. In addition, the experiments are performed in both qualitative and quantitative ways.ResultTwo qualitative comparison cases demonstrate that our algorithm has mainly strengthened the useful details, while effectively suppressing the background information. As for the five comparison algorithms, histogram equalization(HE) and contrast limited adaptive histogram equalization(CLAHE) usually change the whole image intensities with large variation and degrade the image quality as compared to the original image. Alternative toggle operator(AO) could enhance the chest CT image with much better visual quality than HE and CLAHE, but it has excessively enhanced both image details and background noises. Low-light image enhancement(LIME) and robust retinex model(RRM) usually increase the intensities of the whole image and result in images of inappropriate contrast. The quantitative average standard deviation(STD), structural similarity metric(SSIM), peak signal to noise ratio(PSNR) values of our algorithm are significantly greater than those of the other five comparison algorithms (i.e., increased by 4.95, 0.16, 4.47, respectively) on our constructed chest CT image dataset. To be specific, greater average STD value of our algorithm indicates it has enhanced images with more clear details compared to the other five comparison algorithms. Larger average SSIM and PSNR values of our algorithm validate that it has preserved more basic structural information from the original image than the other five comparison algorithms. Meanwhile, the proposed algorithm only costs about 0.10 seconds to enhance a single CT image, which indicates the proposed algorithm has great potential to be efficiently applied in the real clinical scenarios. Overall, our algorithm achieves the best results amongst all the six image enhancement algorithms in terms of both visual quality and quantitative metrics.ConclusionIn this study, we have developed a simple yet effective human chest CT image enhancement algorithm, which can effectively enhance the textural details of chest CT images while preserving a large amount of original basic structural information. With the help of our enhanced human chest CT images, the surgeons could diagnose lung diseases more accurately. Moreover, the proposed algorithm owns good generalization ability, and is capable of well enhancing CT images scanned from other sites and even other modalities of images.关键词:diagnosis of lung diseases;chest CT image enhancement;image decomposition;basic information preservation;detail enhancement172|252|0更新时间:2024-05-07
摘要:ObjectiveHuman chest computed tomography (CT) image analysis is a key measure for diagnosing human lung diseases. However, the current scanned chest CT images might not meet the requirement of diagnosing lung diseases accurately. Medical image enhancement is an effective technique to improve the image quality and has been used in many clinical applications, such as knee joint disease detection, breast lesion segmentation and corona virus disease 2019(COVID-19) detection. Developing new enhancement algorithms is essential to improve the quality of chest CT images. A simple yet effective chest CT image enhancement algorithm is presented based on basic information preservation and detail enhancement.MethodA good chest CT image enhancement algorithm should well improve the clarity of edges or speckles in the image, while preserving much original structural information. Our human chest CT image enhancement algorithm is developed as follows. First, this algorithm exploits the advanced guided filter to decompose the CT image into multiple layers, including a base layer and multiple different scales of detail layers. Next, an entropy-based weight strategy is adopted to fuse the detail layers, which could well strengthen the informative details and suppress the texture-less layers. Afterwards, the fused detail layer is further strengthened based on an enhancement coefficient. In the end, the enhanced detail layer and the original base layer are integrated to generate the targeted chest CT image. The proposed algorithm could well enhance the details of the chest CT image, as well as transfer much original basic structural information to the enhanced image. Moreover, with the help of our algorithm, the surgeons can inspect more clear medical images without impacting their perception of the pathology information. In order to verify the effectiveness of our proposed algorithm, we have constructed a chest CT image dataset, which is composed of 20 sets/3 209 chest CT images, and then evaluated our algorithm and five state-of-the-art image enhancement algorithms on this large-scale dataset. In addition, the experiments are performed in both qualitative and quantitative ways.ResultTwo qualitative comparison cases demonstrate that our algorithm has mainly strengthened the useful details, while effectively suppressing the background information. As for the five comparison algorithms, histogram equalization(HE) and contrast limited adaptive histogram equalization(CLAHE) usually change the whole image intensities with large variation and degrade the image quality as compared to the original image. Alternative toggle operator(AO) could enhance the chest CT image with much better visual quality than HE and CLAHE, but it has excessively enhanced both image details and background noises. Low-light image enhancement(LIME) and robust retinex model(RRM) usually increase the intensities of the whole image and result in images of inappropriate contrast. The quantitative average standard deviation(STD), structural similarity metric(SSIM), peak signal to noise ratio(PSNR) values of our algorithm are significantly greater than those of the other five comparison algorithms (i.e., increased by 4.95, 0.16, 4.47, respectively) on our constructed chest CT image dataset. To be specific, greater average STD value of our algorithm indicates it has enhanced images with more clear details compared to the other five comparison algorithms. Larger average SSIM and PSNR values of our algorithm validate that it has preserved more basic structural information from the original image than the other five comparison algorithms. Meanwhile, the proposed algorithm only costs about 0.10 seconds to enhance a single CT image, which indicates the proposed algorithm has great potential to be efficiently applied in the real clinical scenarios. Overall, our algorithm achieves the best results amongst all the six image enhancement algorithms in terms of both visual quality and quantitative metrics.ConclusionIn this study, we have developed a simple yet effective human chest CT image enhancement algorithm, which can effectively enhance the textural details of chest CT images while preserving a large amount of original basic structural information. With the help of our enhanced human chest CT images, the surgeons could diagnose lung diseases more accurately. Moreover, the proposed algorithm owns good generalization ability, and is capable of well enhancing CT images scanned from other sites and even other modalities of images.关键词:diagnosis of lung diseases;chest CT image enhancement;image decomposition;basic information preservation;detail enhancement172|252|0更新时间:2024-05-07 -
 摘要:ObjectiveFemoral intertrochanteric fracture is the most common fracture in the elderly. Each type of fracture requires a specific treatment method. Computer imaging techniques, such as X-ray and computerized tomography (CT), are used to help doctors in clinical diagnosis. Considering the complex fracture types and the large number of patients, missed diagnosis or misdiagnosis is incurred. In recent years, the development of computer image recognition technology has helped doctors improve the diagnostic accuracy. Femoral fractures have two types, namely, Arbeitsgemeinschaftfür Osteosynthesefragen(AO)/Orthopaedic Trauma Association(OTA) and six-types. The classification methods can be divided into traditional machine learning methods and deep learning methods. In traditional machine learning methods, man-made features are used for learning to make classification. However, these methods usually cannot achieve fine-grained and high-precision classification, and only a few fracture classification methods can be used for three-dimensional images. The deep learning method usually needs a large number of samples to participate in training to obtain good performance. To solve the above problems, this paper proposes a fracture classification method for small samples and multiple classification.MethodAn attention-based multi-view fusion network is proposed, in which a data-fusion strategy is used to improve the feature-fusion performance. Firstly, the original CT layered scanning images are reconstructed to three-dimension, and then two-dimensional images are obtained from different viewpoints. Secondly, a multi-view depth learning network with attention mechanism is used to fuse the different features with different viewpoints. Max-pooling, fully connective layer (FC) and rectified linear unit (ReLU) layers are used for learning the weights of different viewpoints. These layers are used to learn the view attention. The max-pooling operator down-sample the H×W×M original samples' tensor to 1×1×M, which is then down-sampled to 1×1×M/r by the FC layer. The weighted parameters of each viewpoint are obtained using the ReLu and Sigmoid operations. Thirdly, the multiview images are multiplied by the view-weights and work as inputs of convolutional neural network (CNN). The probability that the sample falls into one class is learnt in the CNN. The attention mechanism helps network learning distinctive features. Moreover, the multi-view tensor reduces data dimension, thus improving CNN performance under small data sample size. With the consideration of CT scanning difference, pose changes are observed in 3D reconstructed models. These differences will result in uncertainty learning and reduce the classification performance. Then, a rotation network is used to obtain the view invariant features. RotationNet is defined as a differentiable multi-layer CNN, which has an additional viewpoint variable to learn how to compare with aforementioned multi-view network. The additional viewpoint variable functions to label incorrect view. The final layer of RotationNet is a concatenation of multi-view SoftMax layer, each of which outputs the category likelihood of each image. The category likelihood should be close to one when the estimated is correct. RotationNet only use partial set of multi-view images for classification, making it useful in typical scenarios, where only partial-view images are available. The RotationNet uses 2D CNN as backbone, in which large training sample size is needed. Then, in this paper, transfer learning is processed in the training step to improve the performance on multiple classification. The parameters of RotationNet are pre-trained on ModelNet40. A global parameter fine tuning process is employed on the fracture data in training step considering the difference of ModelNet40 and our fracture data.ResultThe proposed methods are compared with two three-dimensional deep learning network models, namely, 3D ResNet and original multi-view CNN. Two types of classification, namely, AO and six-type, are used. A total of 23 training samples and 10 testing samples are present in each category. Firstly, the number of viewpoints is analyzed. Experimental results illustrate that the classification performance is improved when the number of viewpoints is changed from 4 to 12. However, the performance fluctuated when viewpoint number is great than 16. The reason is because of similarity between samples, which can be considered as same sample and results to performance reduce. In the following experiments, the number of viewpoints is set to 12. Secondly, the attention mechanism is analyzed. The proposed attention multi-view CNN (MV_att) is compared with original multi-view CNN (MVCNN) on the data-fusion model. The area under curve of our proposed MV_att is improved by approximately 3% on AO classification, which is approximately 5% in average on six-type classification. Thirdly, the performance of the models is analyzed. The accuracy of MV_att is 25% higher than that of MVCNN on AO classification. The pre-training RotationNet is 8% higher than MV_att on the six-type classification. Comparative experiments show that the proposed multiview fusion depth learning method is much better than the traditional voxel-based method, and it is also conducive to the rapid convergence of the network.ConclusionIn fracture classification, the multi-view fusion classification method with attention mechanism proposed in this paper has higher accuracy than the traditional voxel depth learning method. The attention mechanism is useful in extracting distinct features. The multi-view data fusion model is useful in reducing the needs of sample size. The transfer learning is useful in improving the performance of the network.关键词:fracture classification;3D reconstruction;multi-view sampling;multi-view fusion;attention mechanism97|1464|0更新时间:2024-05-07
摘要:ObjectiveFemoral intertrochanteric fracture is the most common fracture in the elderly. Each type of fracture requires a specific treatment method. Computer imaging techniques, such as X-ray and computerized tomography (CT), are used to help doctors in clinical diagnosis. Considering the complex fracture types and the large number of patients, missed diagnosis or misdiagnosis is incurred. In recent years, the development of computer image recognition technology has helped doctors improve the diagnostic accuracy. Femoral fractures have two types, namely, Arbeitsgemeinschaftfür Osteosynthesefragen(AO)/Orthopaedic Trauma Association(OTA) and six-types. The classification methods can be divided into traditional machine learning methods and deep learning methods. In traditional machine learning methods, man-made features are used for learning to make classification. However, these methods usually cannot achieve fine-grained and high-precision classification, and only a few fracture classification methods can be used for three-dimensional images. The deep learning method usually needs a large number of samples to participate in training to obtain good performance. To solve the above problems, this paper proposes a fracture classification method for small samples and multiple classification.MethodAn attention-based multi-view fusion network is proposed, in which a data-fusion strategy is used to improve the feature-fusion performance. Firstly, the original CT layered scanning images are reconstructed to three-dimension, and then two-dimensional images are obtained from different viewpoints. Secondly, a multi-view depth learning network with attention mechanism is used to fuse the different features with different viewpoints. Max-pooling, fully connective layer (FC) and rectified linear unit (ReLU) layers are used for learning the weights of different viewpoints. These layers are used to learn the view attention. The max-pooling operator down-sample the H×W×M original samples' tensor to 1×1×M, which is then down-sampled to 1×1×M/r by the FC layer. The weighted parameters of each viewpoint are obtained using the ReLu and Sigmoid operations. Thirdly, the multiview images are multiplied by the view-weights and work as inputs of convolutional neural network (CNN). The probability that the sample falls into one class is learnt in the CNN. The attention mechanism helps network learning distinctive features. Moreover, the multi-view tensor reduces data dimension, thus improving CNN performance under small data sample size. With the consideration of CT scanning difference, pose changes are observed in 3D reconstructed models. These differences will result in uncertainty learning and reduce the classification performance. Then, a rotation network is used to obtain the view invariant features. RotationNet is defined as a differentiable multi-layer CNN, which has an additional viewpoint variable to learn how to compare with aforementioned multi-view network. The additional viewpoint variable functions to label incorrect view. The final layer of RotationNet is a concatenation of multi-view SoftMax layer, each of which outputs the category likelihood of each image. The category likelihood should be close to one when the estimated is correct. RotationNet only use partial set of multi-view images for classification, making it useful in typical scenarios, where only partial-view images are available. The RotationNet uses 2D CNN as backbone, in which large training sample size is needed. Then, in this paper, transfer learning is processed in the training step to improve the performance on multiple classification. The parameters of RotationNet are pre-trained on ModelNet40. A global parameter fine tuning process is employed on the fracture data in training step considering the difference of ModelNet40 and our fracture data.ResultThe proposed methods are compared with two three-dimensional deep learning network models, namely, 3D ResNet and original multi-view CNN. Two types of classification, namely, AO and six-type, are used. A total of 23 training samples and 10 testing samples are present in each category. Firstly, the number of viewpoints is analyzed. Experimental results illustrate that the classification performance is improved when the number of viewpoints is changed from 4 to 12. However, the performance fluctuated when viewpoint number is great than 16. The reason is because of similarity between samples, which can be considered as same sample and results to performance reduce. In the following experiments, the number of viewpoints is set to 12. Secondly, the attention mechanism is analyzed. The proposed attention multi-view CNN (MV_att) is compared with original multi-view CNN (MVCNN) on the data-fusion model. The area under curve of our proposed MV_att is improved by approximately 3% on AO classification, which is approximately 5% in average on six-type classification. Thirdly, the performance of the models is analyzed. The accuracy of MV_att is 25% higher than that of MVCNN on AO classification. The pre-training RotationNet is 8% higher than MV_att on the six-type classification. Comparative experiments show that the proposed multiview fusion depth learning method is much better than the traditional voxel-based method, and it is also conducive to the rapid convergence of the network.ConclusionIn fracture classification, the multi-view fusion classification method with attention mechanism proposed in this paper has higher accuracy than the traditional voxel depth learning method. The attention mechanism is useful in extracting distinct features. The multi-view data fusion model is useful in reducing the needs of sample size. The transfer learning is useful in improving the performance of the network.关键词:fracture classification;3D reconstruction;multi-view sampling;multi-view fusion;attention mechanism97|1464|0更新时间:2024-05-07 -
 摘要:ObjectiveLung cancer is one of the most common diseases in humans and mainly causes the rising mortality rate. Medical experts believe that the early diagnosis of lung cancer can reduce mortality by screening for lung nodules through computed tomography(CT). Checking a large number of CT images can reduce lung cancer risk. However, CT scan images contain a large volume of information about nodules, and as the number of images increases, accuracy becomes a very challenging task for radiologists. Therefore, an effective computer-aided diagnosis (CAD) system should be designed. However, the high false-positive rate remains a challenging problem. In response, this paper proposes a new lung nodule detection framework based on 3D ReSidualU-blocks (3D RSU) module and nested U structure.MethodThis paper trains an end-to-end lung nodule detection model for one stage. The whole system can shorten the processing time of pulmonary nodule detection without reducing the accuracy of early detection. The 3D deep convolutional neural network (CNN) proposed in this paper is based on the region proposal network (RPN) of the Faster R-CNN Network. The 3D CNN can make full use of the spatial information of CT images. The problem of missed detection by the nodule and the large number of false-positive nodules during detection of nodules with small diameter nodules can be solved by dividing the front background information and enhancing the ability to detect non-salient objects in the image. In this paper, the 3D RSU was designed to capture multi-scale features within the stage. The symmetrical codec structure can be used to learn how to extract and encode multi-scale context information. By using the different layers of 3D RSU, the network can allow feature maps of any spatial resolution as input elements to extract elements at multiple scales. This process reduces the loss of detail caused by large-scale direct up-sampling. The 3D RSU was embedded into the network to form a nested u-shaped structure. This structure allows the network to obtain larger resolution feature maps, thus providing multiple levels of deep features. High-level semantic features can be transitioned to supplement low-level conventional features. Improve the detection performance of non-important targets such as calcification and ground glass. If high-resolution feature maps only are used for prediction, a large amount of lung nodule position information contained in low-resolution feature maps will be lost. Therefore, a feature pyramid network was designed in the decoding structure to integrate low-level high-resolution features. In addition to the strong high-level semantic features, the location details and strong semantics of nodule detection are enriched, and the detection of small nodules is realized.ResultThe framework was evaluated on the public lung nodule analysis (LUNA16) challenge data set containing 888 patient lung nodule labels. A total of 10 folds were observed in the entire data set. This article used a 10-fold cross-validation method to compare performance indicators. Our network training uses a stochastic gradient descent optimizer. The initial learning rate is 0.01. After reaching 1/3 and 2/3 of the total number of iterations, the learning rate was adjusted to 0.001 and 0.000 1, respectively, and the weight attenuation is 1×10-4. The batch size is 8, the number of model iterations is 120, one round of training takes approximately 620 s, and the training of a model takes approximately 20 h. Through ablation and comparative experiments, this paper discusses the advantages of 3D RSU module in pulmonary nodule detection performance compared with Res18, and the structural advantages of nested U structure over traditional U structure. Fewer false-positives means more correct nodules are identified with fewer errors, and more immediate help for doctors. Compared with the 3D ResNet-18 module, the 3D RSU module proposed in this paper has a significant improvement in low false positives. It shows that the 3D RSU module reduces the detail loss caused by large-scale direct-up sampling through codec structure and cascade operation. The semantic features of pulmonary nodules were used to obtain the highest number of low-level features of pulmonary nodules, to allow the network to directly extract multiple proportion features from each residual block. Therefore, compared with 3D Resnet-18 block, 3D RSU block can obtain feature map with richer semantics and clearer location information. Notably, a low false-positive rate is important0 for the system to identify acceptable modules with less false-positive results. Therefore, the 3D RSU module has a more extensive clinical application value. In comparison with the traditional U-NET structure, the nested U structure proposed in this paper has a slightly higher parameter value than the Res18_FPN_RPN network, and the gap in the test time is almost negligible, indicating that although the structure of this article is more complex, the nested U structure does not remarkably. Increase the computational overhead. In comparison with benchmark experiments, our method can accurately detect lung nodules with a sensitivity of 97.1%, and the sensitivity increased by 2.5%. This method has high sensitivity and specificity. The average sensitivity of the seven false alarm rate points of 0.125, 0.25, 0.5, 1, 2 and 8 is 86.4%, especially when 0.25 false alarms are scanned per scan, in which the sensitivity reaches 80.9%, which is better than the result of 76.9%.ConclusionThe nodule detection model proposed in this paper has high sensitivity in the low false-positive rate, thus allowing this network to provide more reliable and clear reference information for early lung cancer diagnosis in routine clinical practice for doctors.关键词:pulmonary nodule detection;nested structure;feature pyramid network;insignificant target detection;10-fold cross-validation87|271|2更新时间:2024-05-07
摘要:ObjectiveLung cancer is one of the most common diseases in humans and mainly causes the rising mortality rate. Medical experts believe that the early diagnosis of lung cancer can reduce mortality by screening for lung nodules through computed tomography(CT). Checking a large number of CT images can reduce lung cancer risk. However, CT scan images contain a large volume of information about nodules, and as the number of images increases, accuracy becomes a very challenging task for radiologists. Therefore, an effective computer-aided diagnosis (CAD) system should be designed. However, the high false-positive rate remains a challenging problem. In response, this paper proposes a new lung nodule detection framework based on 3D ReSidualU-blocks (3D RSU) module and nested U structure.MethodThis paper trains an end-to-end lung nodule detection model for one stage. The whole system can shorten the processing time of pulmonary nodule detection without reducing the accuracy of early detection. The 3D deep convolutional neural network (CNN) proposed in this paper is based on the region proposal network (RPN) of the Faster R-CNN Network. The 3D CNN can make full use of the spatial information of CT images. The problem of missed detection by the nodule and the large number of false-positive nodules during detection of nodules with small diameter nodules can be solved by dividing the front background information and enhancing the ability to detect non-salient objects in the image. In this paper, the 3D RSU was designed to capture multi-scale features within the stage. The symmetrical codec structure can be used to learn how to extract and encode multi-scale context information. By using the different layers of 3D RSU, the network can allow feature maps of any spatial resolution as input elements to extract elements at multiple scales. This process reduces the loss of detail caused by large-scale direct up-sampling. The 3D RSU was embedded into the network to form a nested u-shaped structure. This structure allows the network to obtain larger resolution feature maps, thus providing multiple levels of deep features. High-level semantic features can be transitioned to supplement low-level conventional features. Improve the detection performance of non-important targets such as calcification and ground glass. If high-resolution feature maps only are used for prediction, a large amount of lung nodule position information contained in low-resolution feature maps will be lost. Therefore, a feature pyramid network was designed in the decoding structure to integrate low-level high-resolution features. In addition to the strong high-level semantic features, the location details and strong semantics of nodule detection are enriched, and the detection of small nodules is realized.ResultThe framework was evaluated on the public lung nodule analysis (LUNA16) challenge data set containing 888 patient lung nodule labels. A total of 10 folds were observed in the entire data set. This article used a 10-fold cross-validation method to compare performance indicators. Our network training uses a stochastic gradient descent optimizer. The initial learning rate is 0.01. After reaching 1/3 and 2/3 of the total number of iterations, the learning rate was adjusted to 0.001 and 0.000 1, respectively, and the weight attenuation is 1×10-4. The batch size is 8, the number of model iterations is 120, one round of training takes approximately 620 s, and the training of a model takes approximately 20 h. Through ablation and comparative experiments, this paper discusses the advantages of 3D RSU module in pulmonary nodule detection performance compared with Res18, and the structural advantages of nested U structure over traditional U structure. Fewer false-positives means more correct nodules are identified with fewer errors, and more immediate help for doctors. Compared with the 3D ResNet-18 module, the 3D RSU module proposed in this paper has a significant improvement in low false positives. It shows that the 3D RSU module reduces the detail loss caused by large-scale direct-up sampling through codec structure and cascade operation. The semantic features of pulmonary nodules were used to obtain the highest number of low-level features of pulmonary nodules, to allow the network to directly extract multiple proportion features from each residual block. Therefore, compared with 3D Resnet-18 block, 3D RSU block can obtain feature map with richer semantics and clearer location information. Notably, a low false-positive rate is important0 for the system to identify acceptable modules with less false-positive results. Therefore, the 3D RSU module has a more extensive clinical application value. In comparison with the traditional U-NET structure, the nested U structure proposed in this paper has a slightly higher parameter value than the Res18_FPN_RPN network, and the gap in the test time is almost negligible, indicating that although the structure of this article is more complex, the nested U structure does not remarkably. Increase the computational overhead. In comparison with benchmark experiments, our method can accurately detect lung nodules with a sensitivity of 97.1%, and the sensitivity increased by 2.5%. This method has high sensitivity and specificity. The average sensitivity of the seven false alarm rate points of 0.125, 0.25, 0.5, 1, 2 and 8 is 86.4%, especially when 0.25 false alarms are scanned per scan, in which the sensitivity reaches 80.9%, which is better than the result of 76.9%.ConclusionThe nodule detection model proposed in this paper has high sensitivity in the low false-positive rate, thus allowing this network to provide more reliable and clear reference information for early lung cancer diagnosis in routine clinical practice for doctors.关键词:pulmonary nodule detection;nested structure;feature pyramid network;insignificant target detection;10-fold cross-validation87|271|2更新时间:2024-05-07 -
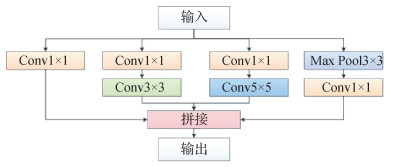 摘要:ObjectiveIdiopathic pulmonary fibrosis (IPF), which is characterized by progressive dyspnea and decreased pulmonary function, is a chronic lung disease with occult onset and unknown etiology, histological or imaging manifestations of common interstitial pneumonia. Considering the progressive development of IPF and limited diagnostic methods, it may eventually lead to complete pulmonary dysfunction, causing great difficulties to the prognosis of IPF. Currently, the existing methods for predicting the severity of pulmonary function decline still have the problem of low accuracy. Forced vital capacity (FVC) can be used as an important index to predict the decline of pulmonary function.MethodBy integrating multi-scale residual and attention mechanism, a prediction model for the progression of IPF was proposed, and this mechanism includes a computed tomography(CT) feature extraction network and a multimodal feature prediction network. The CT feature extraction network is responsible for CT feature extraction of pre-processed lung CT images, while the multimodal feature prediction network is responsible for extracting the multimodal features. The multimodal features fused the CT features and clinical features as input to predict the FVC of IPF patients in different weeks. The pulmonary fibrosis data set provided by the Open Source Imaging Consortium (OSIC) was used as benchmark data. First, the data were pre-processed. Unnecessary data were removed, and the lung CT image size was unified to 512×512 pixels. Feature engineering was performed, the clinical text data were normalized, and more effective data features for model training were generated. Secondly, a CT feature extraction network based on InceptionV1 as the backbone network was constructed. The residual module and the improved channel attention of convolutional block attention module (CBAM-ICA) were added to the multi-scale CT feature fusion module to expand the receptive field of the network to focus the attention to the effective features of the lung area and suppress unimportant information. A parallel dilated convolution module was added to the convolution layers to increase the receptive field, supplement the lost details and improve the network performance. The three improved multi-scale CT feature fusion modules were stacked in series twice to improve the ability of the network to obtain CT features. Finally, a multimodal prediction network composed of attention module and multi-layer perceptron was constructed. The multi-modal prediction network fused the multi-scale CT features extracted by the CT feature extraction network with some clinical features (e.g., age, gender and smoking) to form the first multimodal feature that predicts the linear change rate of FVC in IPF patients. Then, the FVC linear change rate was fused with other clinical features as a new feature to form the second multimodal feature that predicts the FVC values of IPF patients with different expected weeks to improve the prediction performance of the network.ResultBy using the prediction model for the progression of IPF on the pulmonary fibrosis test data set provided by the OSIC, a Laplace log likelihood score -6.810 7 was obtained. Experimental results show that the proposed method was better than the existing methods in predicting pulmonary function decline. The ablation experiments were conducted to show that the Laplace log likelihood scores of CT feature extraction network in the prediction model for the progression of IPF were improved by adding residual module, dilated convolution module and CBAM-ICA respectively, and the prediction score of the model was the best when the above three modules were added simultaneously. Comparison experiments were conducted to further verify the effectiveness of the model. First, the results of the quantile selection experiment show that taking[0.2, 0.5, 0.8] as the parameter of quantile loss function can improve the prediction results. Second, the attention module comparison experiment shows that the performance of CBAM-ICA is better than those of other attention modules. Third, the comparison results among different attention mechanism locations show that adding attention mechanism to the multi-scale CT feature fusion module A and C simultaneously can provide the best performance. Fourth, the comparison experiments on CT feature extraction network show that the Laplace log likelihood score of using InceptionV1 as the CT feature extraction network's backbone network is better than those of using most other networks. Finally, the prediction performance comparisons on different modal data show that multimodal data can effectively improve the accuracy of model prediction compared with monomodal data. These experiments further verify the accuracy and effectiveness of the proposed prediction model for the progression of IPF.ConclusionBy integrating multi-scale residual and attention mechanism, the proposed prediction model for the progression of IPF is effective in predicting FVC values of IPF patients with different weeks. The model can help doctors better understand the severity of pulmonary function decline in IPF patients, and it can provide guidance for the prognosis of patients with.关键词:idiopathic pulmonary fibrosis(IPF);prediction model;multi-scale residual;forced vital capacity(FVC);attention mechanism65|82|2更新时间:2024-05-07
摘要:ObjectiveIdiopathic pulmonary fibrosis (IPF), which is characterized by progressive dyspnea and decreased pulmonary function, is a chronic lung disease with occult onset and unknown etiology, histological or imaging manifestations of common interstitial pneumonia. Considering the progressive development of IPF and limited diagnostic methods, it may eventually lead to complete pulmonary dysfunction, causing great difficulties to the prognosis of IPF. Currently, the existing methods for predicting the severity of pulmonary function decline still have the problem of low accuracy. Forced vital capacity (FVC) can be used as an important index to predict the decline of pulmonary function.MethodBy integrating multi-scale residual and attention mechanism, a prediction model for the progression of IPF was proposed, and this mechanism includes a computed tomography(CT) feature extraction network and a multimodal feature prediction network. The CT feature extraction network is responsible for CT feature extraction of pre-processed lung CT images, while the multimodal feature prediction network is responsible for extracting the multimodal features. The multimodal features fused the CT features and clinical features as input to predict the FVC of IPF patients in different weeks. The pulmonary fibrosis data set provided by the Open Source Imaging Consortium (OSIC) was used as benchmark data. First, the data were pre-processed. Unnecessary data were removed, and the lung CT image size was unified to 512×512 pixels. Feature engineering was performed, the clinical text data were normalized, and more effective data features for model training were generated. Secondly, a CT feature extraction network based on InceptionV1 as the backbone network was constructed. The residual module and the improved channel attention of convolutional block attention module (CBAM-ICA) were added to the multi-scale CT feature fusion module to expand the receptive field of the network to focus the attention to the effective features of the lung area and suppress unimportant information. A parallel dilated convolution module was added to the convolution layers to increase the receptive field, supplement the lost details and improve the network performance. The three improved multi-scale CT feature fusion modules were stacked in series twice to improve the ability of the network to obtain CT features. Finally, a multimodal prediction network composed of attention module and multi-layer perceptron was constructed. The multi-modal prediction network fused the multi-scale CT features extracted by the CT feature extraction network with some clinical features (e.g., age, gender and smoking) to form the first multimodal feature that predicts the linear change rate of FVC in IPF patients. Then, the FVC linear change rate was fused with other clinical features as a new feature to form the second multimodal feature that predicts the FVC values of IPF patients with different expected weeks to improve the prediction performance of the network.ResultBy using the prediction model for the progression of IPF on the pulmonary fibrosis test data set provided by the OSIC, a Laplace log likelihood score -6.810 7 was obtained. Experimental results show that the proposed method was better than the existing methods in predicting pulmonary function decline. The ablation experiments were conducted to show that the Laplace log likelihood scores of CT feature extraction network in the prediction model for the progression of IPF were improved by adding residual module, dilated convolution module and CBAM-ICA respectively, and the prediction score of the model was the best when the above three modules were added simultaneously. Comparison experiments were conducted to further verify the effectiveness of the model. First, the results of the quantile selection experiment show that taking[0.2, 0.5, 0.8] as the parameter of quantile loss function can improve the prediction results. Second, the attention module comparison experiment shows that the performance of CBAM-ICA is better than those of other attention modules. Third, the comparison results among different attention mechanism locations show that adding attention mechanism to the multi-scale CT feature fusion module A and C simultaneously can provide the best performance. Fourth, the comparison experiments on CT feature extraction network show that the Laplace log likelihood score of using InceptionV1 as the CT feature extraction network's backbone network is better than those of using most other networks. Finally, the prediction performance comparisons on different modal data show that multimodal data can effectively improve the accuracy of model prediction compared with monomodal data. These experiments further verify the accuracy and effectiveness of the proposed prediction model for the progression of IPF.ConclusionBy integrating multi-scale residual and attention mechanism, the proposed prediction model for the progression of IPF is effective in predicting FVC values of IPF patients with different weeks. The model can help doctors better understand the severity of pulmonary function decline in IPF patients, and it can provide guidance for the prognosis of patients with.关键词:idiopathic pulmonary fibrosis(IPF);prediction model;multi-scale residual;forced vital capacity(FVC);attention mechanism65|82|2更新时间:2024-05-07 -
 摘要:ObjectiveThe corona virus disease 2019 (COVID-19), also known as severe acute respiratory syndrome coronavirus (SARS-CoV-2), has rapidly spread throughout the world as a result of the increased mobility of populations in a globalized world, wreaking havoc on people's daily lives, the global economy, and the global healthcare system. The novelty and dissemination speed of COVID-19 compelled researchers around the world to move quickly, using all resources and capabilities to analyse and characterize the novel coronavirus in terms of transmission routes and viral latency. Early and effective screening of COVID-19 patients and corresponding medical treatment, care and isolation to cut off the transmission route of the novel coronavirus are the key to prevent the spread of the epidemic. Due to the rapid infection of COVID-19, it is very important to screen COVID-19 threats based on precise segmenting lesions in lung CT images, which can be a low cost and quick response method nowadays. Rapid and accurate segmentation of coronavirus pneumonia CT images is of great significance for auxiliary diagnosis and patient monitoring. Currently, the main method for COVID-19 screening is the reverse transcription polymerase chain reaction like reverse transcription-polymerase chain reaction(RT-PCR) analysis. But, RT-PCR is time consuming to provide the diagnosis results, and the false negative rate is relatively high. Another effective method for COVID-19 screening is computed tomography (CT) technology. The CT scanning technology has high sensitivity and enhanced three-dimensional representation of infection visualization. Computed tomography (CT) has been used as an important method for the diagnosis and treatment of patients with COVID-19, the chest CT images of patients with COVID-19 mostly show multifocal, patchy, peripheral distribution, and ground glass opacity (GGO) which is mostly seen in the lower lobes of both lungs; a high degree of suspicion for novel coronavirus's infection can be obtained if more GGO than consolidation is found on CT images; therefore, detection of GGO in CT slices regions can provide clinicians with important information and help in the fight against COVID-19. The current analysis of COVID-19 pneumonia lesions has low segmentation accuracy and insufficient attention to false negatives.MethodOur accurate segmentation model based on small data set. In view of the complexity and variability of the targeted area of COVID-19 pneumonia, we improved Inf-Net and proposed a multi-scale encoding and decoding network (MED-Net) based on deep learning method. The computational cost may be caused by multi-scale encoding and decoding. The network extends the encoder-decoder structure in FC-Net, in which the decoder part is on the left column; The middle column is atrous spatial pyramid pooling (ASPP) structure; The right column is a multi-scale parallel decoder which is based on the improvement of parallel partial decoder. In this network structure, HarDNet68 is adopted as the backbone in terms of high resource utilization and fast computing speed, which can be as a simplified version of DenseNet, reduces DenseNet based hierarchical connections to get cascade loss deduction. HardNet68 is mainly composed of five harmonious dense blocks (HDB). Based on 5 different scales, We extract multiscale features from the first convolution layer and the 5 HDB sequential steps of HarDNet68 via a five atrous spatial pyramid pooling (ASPP). Meanwhile, as a new decoding component, a multiscale parallel partial decoder (MPPD) is based on the parallel decoder (PPD), which can aggregate the features between different levels in parallel. By decoding the branches of three different receptive fields, we have dealt with information loss issues in the encoder part and the difficulty of small lesions segmentation. Our deep supervision mechanism has melted the multi-scale decoder into the true positive and true negative samples analyses, for improving the sensitivity of the model.ResultCurrent COVID-19 CT Segmentation provides completed segmentation labels as a small data set. This research is improved based on Inf-Net, and the model structure is simple, the edge attention module(EA) is not introduced, and the reverse attention module(RA) is not quoted, only one MPPD is used to optimize the network stricture. The quantitative results show that MED-Net can effectively cope with the problems of fewer samples in the small dataset, the texture, size and position of the segmentation target vary greatly. On the data set with only 50 training images and 50 test images, the Dice coefficient is 73.8%, the sensitivity is 77.7%, and the specificity is 94.3%. Compared with the previous work, it has increased by 8.21%, 12.28% and 7.76% respectively. Among them, Dice coefficient and sensitivity have reached the most advanced level based on the same division mode of this data set. Simultaneously the qualitative results address that the segmentation result of the proposed model is closer to ground-truth in this experiment. We also conducted ablation experiments, that the use of MPPD has obvious effects to deal with small lesions area segmentation and improving segmentation accuracy.ConclusionOur analysis shows that the proposed method can effectively improve the segmentation accuracy of the lesions in the CT images of the COVID-19 derived lungs disease. Our segmentation accuracy of MED-Net is qualified. The quantitative and qualitative results demonstrate that MED-Net is relatively effective in controlling edges and details, which can capture rich context information, and improve sensitivity. MED-Net can also effectively resolve the small lesions segmentation issue. For COVID-19 CT Segmentation data set, it has several of qualified evaluation indicators based on end-to-end learning. The potential of automatic segmentation of COVID-19 pneumonia is further facilitated.关键词:corona virus disease 2019(COVID-19);CT image segmentation;multi-scale codec;depth monitoring mechanism;small lesions segmentation105|238|2更新时间:2024-05-07
摘要:ObjectiveThe corona virus disease 2019 (COVID-19), also known as severe acute respiratory syndrome coronavirus (SARS-CoV-2), has rapidly spread throughout the world as a result of the increased mobility of populations in a globalized world, wreaking havoc on people's daily lives, the global economy, and the global healthcare system. The novelty and dissemination speed of COVID-19 compelled researchers around the world to move quickly, using all resources and capabilities to analyse and characterize the novel coronavirus in terms of transmission routes and viral latency. Early and effective screening of COVID-19 patients and corresponding medical treatment, care and isolation to cut off the transmission route of the novel coronavirus are the key to prevent the spread of the epidemic. Due to the rapid infection of COVID-19, it is very important to screen COVID-19 threats based on precise segmenting lesions in lung CT images, which can be a low cost and quick response method nowadays. Rapid and accurate segmentation of coronavirus pneumonia CT images is of great significance for auxiliary diagnosis and patient monitoring. Currently, the main method for COVID-19 screening is the reverse transcription polymerase chain reaction like reverse transcription-polymerase chain reaction(RT-PCR) analysis. But, RT-PCR is time consuming to provide the diagnosis results, and the false negative rate is relatively high. Another effective method for COVID-19 screening is computed tomography (CT) technology. The CT scanning technology has high sensitivity and enhanced three-dimensional representation of infection visualization. Computed tomography (CT) has been used as an important method for the diagnosis and treatment of patients with COVID-19, the chest CT images of patients with COVID-19 mostly show multifocal, patchy, peripheral distribution, and ground glass opacity (GGO) which is mostly seen in the lower lobes of both lungs; a high degree of suspicion for novel coronavirus's infection can be obtained if more GGO than consolidation is found on CT images; therefore, detection of GGO in CT slices regions can provide clinicians with important information and help in the fight against COVID-19. The current analysis of COVID-19 pneumonia lesions has low segmentation accuracy and insufficient attention to false negatives.MethodOur accurate segmentation model based on small data set. In view of the complexity and variability of the targeted area of COVID-19 pneumonia, we improved Inf-Net and proposed a multi-scale encoding and decoding network (MED-Net) based on deep learning method. The computational cost may be caused by multi-scale encoding and decoding. The network extends the encoder-decoder structure in FC-Net, in which the decoder part is on the left column; The middle column is atrous spatial pyramid pooling (ASPP) structure; The right column is a multi-scale parallel decoder which is based on the improvement of parallel partial decoder. In this network structure, HarDNet68 is adopted as the backbone in terms of high resource utilization and fast computing speed, which can be as a simplified version of DenseNet, reduces DenseNet based hierarchical connections to get cascade loss deduction. HardNet68 is mainly composed of five harmonious dense blocks (HDB). Based on 5 different scales, We extract multiscale features from the first convolution layer and the 5 HDB sequential steps of HarDNet68 via a five atrous spatial pyramid pooling (ASPP). Meanwhile, as a new decoding component, a multiscale parallel partial decoder (MPPD) is based on the parallel decoder (PPD), which can aggregate the features between different levels in parallel. By decoding the branches of three different receptive fields, we have dealt with information loss issues in the encoder part and the difficulty of small lesions segmentation. Our deep supervision mechanism has melted the multi-scale decoder into the true positive and true negative samples analyses, for improving the sensitivity of the model.ResultCurrent COVID-19 CT Segmentation provides completed segmentation labels as a small data set. This research is improved based on Inf-Net, and the model structure is simple, the edge attention module(EA) is not introduced, and the reverse attention module(RA) is not quoted, only one MPPD is used to optimize the network stricture. The quantitative results show that MED-Net can effectively cope with the problems of fewer samples in the small dataset, the texture, size and position of the segmentation target vary greatly. On the data set with only 50 training images and 50 test images, the Dice coefficient is 73.8%, the sensitivity is 77.7%, and the specificity is 94.3%. Compared with the previous work, it has increased by 8.21%, 12.28% and 7.76% respectively. Among them, Dice coefficient and sensitivity have reached the most advanced level based on the same division mode of this data set. Simultaneously the qualitative results address that the segmentation result of the proposed model is closer to ground-truth in this experiment. We also conducted ablation experiments, that the use of MPPD has obvious effects to deal with small lesions area segmentation and improving segmentation accuracy.ConclusionOur analysis shows that the proposed method can effectively improve the segmentation accuracy of the lesions in the CT images of the COVID-19 derived lungs disease. Our segmentation accuracy of MED-Net is qualified. The quantitative and qualitative results demonstrate that MED-Net is relatively effective in controlling edges and details, which can capture rich context information, and improve sensitivity. MED-Net can also effectively resolve the small lesions segmentation issue. For COVID-19 CT Segmentation data set, it has several of qualified evaluation indicators based on end-to-end learning. The potential of automatic segmentation of COVID-19 pneumonia is further facilitated.关键词:corona virus disease 2019(COVID-19);CT image segmentation;multi-scale codec;depth monitoring mechanism;small lesions segmentation105|238|2更新时间:2024-05-07 -
 摘要:ObjectiveLiver cancer is currently one of the most common cancers with the highest mortality rate in the world. Computed tomography (CT) is a commonly used clinical tumor diagnosis method. It can aid to designate targeted treatment plans based on the shape and location of the tumor measurement. Manual segmentation of CT images has challenged issues, such as low efficiency and the influence of doctors' experience. Hence, an efficient automatic segmentation method is focused on in clinical practice. Liver treatment can benefit from accurate and fast automatic segmentation methods. Due to the low contrast of soft tissue in CT images, the shape and position of liver tumors are highly variable, and the boundaries of liver tumor regions are difficult to identify, most of the tumors area are relatively small, so automatic liver tumor segmentation is a challenging task in practice. The segmentation model is capable to discover the differences between each class accurately. Deep-learning-based models can be divided into three categories: 2D, 2.5D and 3D, respectively. The traditional channel attention module uses the global average pooling (GAP) to squeeze feature map. This operation calculates the average value of the feature map straightforward, resulting in the loss of spatial information on the feature map. The model can focus on the correlation amongst channels and ignore the spatial features of each channel, but segmentation task is related to the spatial information. This research illustrated a liver tumor 2D segmentation model with feature selection and residual fusion to improve the performance of low-complexity models.MethodThe attention-mechanism-based model optimizes U-Net bottleneck features and redesigned skip connections. In order to meet the characteristics of liver tumor segmentation tasks, we optimized the traditional attention module. Our demonstration facilates the global feature squeeze (GFS) substitute of the global average pooling (GAP) in the traditional attention module. A designed bottleneck feature selection module is based on this attention module. In terms of the diversity of liver and liver tumor segmentation tasks, the feature selection (FS) module and the neighboring feature selection (NFS) module are evolved. The spatial information with the least amount of parameters greatly improves the accuracy of the segmentation task. Both modules can calibrate the channels adaptively. The difference is that the global feature selection module focuses on the conditions of all channels. Each channel proposes a type of semantic feature. The operation of the channel feature is to compress all channels to determine the correlation of all channels. It is suitable for segmentation tasks such as liver segmentation tasks that need to melt all the semantic information into the graph. The adjacent feature association module is oriented adjacent groups of channels and aims to identify the connection of adjacent semantic features, which is suitable for segmentation division tasks, such as liver tumor segmentation tasks. The spatial feature residual fusion (SFRF) module in U-Net skip connection is designated to resolve the semantic gap issue of U-Net skip connection and make full use of the effectiveness of spatial features. The spatial feature residual fusion module fill the semantic gap in the early skip connections via introducing mid-to-late high-level features. In order to avoid excessively affecting the early feature expression, the residual link method is adopted. The module uses 1×1 convolution compression for deep features. The bilinear interpolation to upsample the feature map is conducted following the channel. The skip connections are introduced to implement feature recalibration based on the spatial attention module (SAM). The spatial feature residual fusion module is used to resolve semantic mis-match issue between the front and rear spatial features, so that the features can be sorted out efficiently.ResultOur research analysis performed component ablation tests on the LiTS public data set and compared it with the current method. Following the feature selection (FS/NFS) operation in U-Net bottleneck, the model is significantly improved compared to the baseline. The per Dice score of the liver segmentation prediction results is above 95%, which is about 37% better than the error prediction of the baseline. The tumor segmentation prediction scores were all above 65%. The baseline added spatial attention module (SAM) and spatial feature residual fusion (SFRF) module to the skip connection. The FS module and the NFS module achieved the highest per Dice score in liver segmentation and liver tumor segmentation tasks, respectively. In the liver and liver tumor segmentation tasks, per Dice score of 96.2% and 68.4% were obtained, respectively. This analysis result is comparable to 2.5D and 3D. The effect of the model is equivalent, 0.8% higher than the per Dice score of the current 2D liver tumor segmentation model.ConclusionOur demonstration delivered a liver tumor 2D segmentation model based on feature selection and residual fusion. The model realized the function of the channel degree via the bottleneck feature selection module, effectively inhibits the invalid features, and improves the accuracy of the prediction results. To optimize the skip connection and fill the semantic gap of U-Net, the spatial features can be facilitated. The segmentation effect of the model is further improved. The Experiments show that the proposed model has qualified on the LiTS dataset, especially in the 2D segmentation analysis.关键词:automatic liver tumor segmentation;attention mechanism;U-Net;feature selection;residual fusion83|218|0更新时间:2024-05-07
摘要:ObjectiveLiver cancer is currently one of the most common cancers with the highest mortality rate in the world. Computed tomography (CT) is a commonly used clinical tumor diagnosis method. It can aid to designate targeted treatment plans based on the shape and location of the tumor measurement. Manual segmentation of CT images has challenged issues, such as low efficiency and the influence of doctors' experience. Hence, an efficient automatic segmentation method is focused on in clinical practice. Liver treatment can benefit from accurate and fast automatic segmentation methods. Due to the low contrast of soft tissue in CT images, the shape and position of liver tumors are highly variable, and the boundaries of liver tumor regions are difficult to identify, most of the tumors area are relatively small, so automatic liver tumor segmentation is a challenging task in practice. The segmentation model is capable to discover the differences between each class accurately. Deep-learning-based models can be divided into three categories: 2D, 2.5D and 3D, respectively. The traditional channel attention module uses the global average pooling (GAP) to squeeze feature map. This operation calculates the average value of the feature map straightforward, resulting in the loss of spatial information on the feature map. The model can focus on the correlation amongst channels and ignore the spatial features of each channel, but segmentation task is related to the spatial information. This research illustrated a liver tumor 2D segmentation model with feature selection and residual fusion to improve the performance of low-complexity models.MethodThe attention-mechanism-based model optimizes U-Net bottleneck features and redesigned skip connections. In order to meet the characteristics of liver tumor segmentation tasks, we optimized the traditional attention module. Our demonstration facilates the global feature squeeze (GFS) substitute of the global average pooling (GAP) in the traditional attention module. A designed bottleneck feature selection module is based on this attention module. In terms of the diversity of liver and liver tumor segmentation tasks, the feature selection (FS) module and the neighboring feature selection (NFS) module are evolved. The spatial information with the least amount of parameters greatly improves the accuracy of the segmentation task. Both modules can calibrate the channels adaptively. The difference is that the global feature selection module focuses on the conditions of all channels. Each channel proposes a type of semantic feature. The operation of the channel feature is to compress all channels to determine the correlation of all channels. It is suitable for segmentation tasks such as liver segmentation tasks that need to melt all the semantic information into the graph. The adjacent feature association module is oriented adjacent groups of channels and aims to identify the connection of adjacent semantic features, which is suitable for segmentation division tasks, such as liver tumor segmentation tasks. The spatial feature residual fusion (SFRF) module in U-Net skip connection is designated to resolve the semantic gap issue of U-Net skip connection and make full use of the effectiveness of spatial features. The spatial feature residual fusion module fill the semantic gap in the early skip connections via introducing mid-to-late high-level features. In order to avoid excessively affecting the early feature expression, the residual link method is adopted. The module uses 1×1 convolution compression for deep features. The bilinear interpolation to upsample the feature map is conducted following the channel. The skip connections are introduced to implement feature recalibration based on the spatial attention module (SAM). The spatial feature residual fusion module is used to resolve semantic mis-match issue between the front and rear spatial features, so that the features can be sorted out efficiently.ResultOur research analysis performed component ablation tests on the LiTS public data set and compared it with the current method. Following the feature selection (FS/NFS) operation in U-Net bottleneck, the model is significantly improved compared to the baseline. The per Dice score of the liver segmentation prediction results is above 95%, which is about 37% better than the error prediction of the baseline. The tumor segmentation prediction scores were all above 65%. The baseline added spatial attention module (SAM) and spatial feature residual fusion (SFRF) module to the skip connection. The FS module and the NFS module achieved the highest per Dice score in liver segmentation and liver tumor segmentation tasks, respectively. In the liver and liver tumor segmentation tasks, per Dice score of 96.2% and 68.4% were obtained, respectively. This analysis result is comparable to 2.5D and 3D. The effect of the model is equivalent, 0.8% higher than the per Dice score of the current 2D liver tumor segmentation model.ConclusionOur demonstration delivered a liver tumor 2D segmentation model based on feature selection and residual fusion. The model realized the function of the channel degree via the bottleneck feature selection module, effectively inhibits the invalid features, and improves the accuracy of the prediction results. To optimize the skip connection and fill the semantic gap of U-Net, the spatial features can be facilitated. The segmentation effect of the model is further improved. The Experiments show that the proposed model has qualified on the LiTS dataset, especially in the 2D segmentation analysis.关键词:automatic liver tumor segmentation;attention mechanism;U-Net;feature selection;residual fusion83|218|0更新时间:2024-05-07
Computerd Tomography Image
-
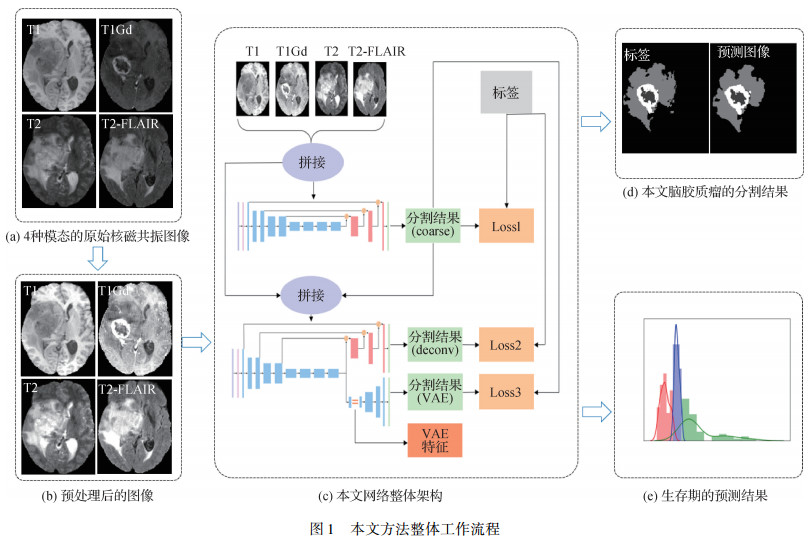 摘要:ObjectiveGlioma is the most common primary brain tumor with the highest mortality. The survival rate of different degrees of gliomas varies greatly. The magnetic resonance imaging based (MRI-based) scan imaging in the context of tumor substructure is composed of diversified intensity distributions, reflecting different tumor biological characteristics. Diagnosis grading and survival time prediction are conducted in terms of accurate detection and segmentation of abnormal tumor tissues. Radiomics aims to mine medical image data via a wide range of quantitative features extraction nowadays. The radiomics-based analyses are becoming essential for the medical prognosis. There is some constraints in designing and extracting features for traditional image omics. Deep learning methods are subjected of manual designing and extracting features. Deep learning convolutional neural networks (CNNs) has its priority in U-Net based image segmentation currently. Due to the time-consuming and labor-intensive labeling of gliomas and the lack of a large amount of supervision information, a U-Net based variational-auto-encoder (VAE) branch and the self-supervision information can deal with the over-fitting of the model effectively. The VAE branch can extract the potential robust features of images to resolve traditional image omics. A two-stage cascaded U-Net algorithm is demonstrated in context of VAE branch, which can realize the automatic segmentation of gliomas for diagnosis grading and the extraction of robust features derived from subsequent survival time prediction.MethodIn the first stage, the network predicts the coarse segmentation results in terms of the input of multi-modal MR images. The initial results and the multi-modal MR images are integrated as the input of the second stage for the network to improve the segmentation results. Moreover, a VAE branch is melted in the second stage of the network to obtain robust representative features and improve the generalization of the model. The representative features are used to predict the human life span based on the random forest algorithm. The traditional convolution gives the same weights to all channels of the input feature maps by default for feature fusion, while the squeeze-and-excitation (SE) module can learn the importance of different channels, so the SE module is evolved to the basic unit of this demonstrated algorithm. Furthermore, the prediction illustrates large differences in shape and size between patients, the cascaded network that detects and then segment can lead to the redundancy of model parameters. The proposed network adds an attention gate mechanism to the additive jump connection of the traditional U-Net, which achieves the same effect as the method that detects and then segment without increasing the amount of parameters. In addition, when the enhanced tumor area is small, this algorithm analysis is probably mislead the necrotic area and the non-enhanced tumor area as the enhanced tumor area. When the predicted enhanced tumor area is less than 500 voxels, the enhanced tumor area is substituted with necrotic and non-enhancing tumor area. This research method illustrates a random forest-based regressor for the prediction of the overall survival time and a random forest-based classifier for the prediction of category of the overall survival time at the end. The premise requires the use of low-dimensional potential features extracted by VAE and the clinical features of the patient's age, and feature option is implemented via the recursive feature elimination method based on random forest regression. When the prediction result of the regression model is inconsistent with the prediction category of the classification model, the final prediction result is divided into a fixed overall survival time according to the prediction category if the probability predicting the category exceeds 80% The short-term corresponds to 10 months, the mid-term corresponds to 12.5 months, and the long-term corresponds to 15 months.ResultOur research analysis implements a five-fold cross validation on BraTS2020 training set. The generated result is the average of 5 validation results. The method achieves Dice similarity coefficients of 90.66%, 85.09%, and 79.02% in the whole tumor area, tumor core area and enhanced tumor area in the validation set, respectively. In terms of the clinical feature of patient's age, the overall survival prediction accuracy rate reaches 41.4%, and the potential extracted features in the VAE branch, the accuracy rate could reach 55.2%. Although the accuracy rate is 3.5% lower than that of the first-ranked method, this proposed method has a slight advantage in terms of the mean square error.Conclusionthe research proposes a two-stage cascaded U-Net network with a VAE branch to resolve over-fitting issue. Simultaneously, the branch can also extract the potential features of the tumor to predict the survival time. The test results demonstrate that the network can segment brain tumors more accurately, and the potential extracted features can predict suitable patient survival time, which can provide a powerful reference for clinicians in the diagnosis of gliomas.关键词:automatic 3D segmentation of glioma;survival prediction;cascade neural network;variational auto-encoder(VAE);attention mechanism233|331|0更新时间:2024-05-07
摘要:ObjectiveGlioma is the most common primary brain tumor with the highest mortality. The survival rate of different degrees of gliomas varies greatly. The magnetic resonance imaging based (MRI-based) scan imaging in the context of tumor substructure is composed of diversified intensity distributions, reflecting different tumor biological characteristics. Diagnosis grading and survival time prediction are conducted in terms of accurate detection and segmentation of abnormal tumor tissues. Radiomics aims to mine medical image data via a wide range of quantitative features extraction nowadays. The radiomics-based analyses are becoming essential for the medical prognosis. There is some constraints in designing and extracting features for traditional image omics. Deep learning methods are subjected of manual designing and extracting features. Deep learning convolutional neural networks (CNNs) has its priority in U-Net based image segmentation currently. Due to the time-consuming and labor-intensive labeling of gliomas and the lack of a large amount of supervision information, a U-Net based variational-auto-encoder (VAE) branch and the self-supervision information can deal with the over-fitting of the model effectively. The VAE branch can extract the potential robust features of images to resolve traditional image omics. A two-stage cascaded U-Net algorithm is demonstrated in context of VAE branch, which can realize the automatic segmentation of gliomas for diagnosis grading and the extraction of robust features derived from subsequent survival time prediction.MethodIn the first stage, the network predicts the coarse segmentation results in terms of the input of multi-modal MR images. The initial results and the multi-modal MR images are integrated as the input of the second stage for the network to improve the segmentation results. Moreover, a VAE branch is melted in the second stage of the network to obtain robust representative features and improve the generalization of the model. The representative features are used to predict the human life span based on the random forest algorithm. The traditional convolution gives the same weights to all channels of the input feature maps by default for feature fusion, while the squeeze-and-excitation (SE) module can learn the importance of different channels, so the SE module is evolved to the basic unit of this demonstrated algorithm. Furthermore, the prediction illustrates large differences in shape and size between patients, the cascaded network that detects and then segment can lead to the redundancy of model parameters. The proposed network adds an attention gate mechanism to the additive jump connection of the traditional U-Net, which achieves the same effect as the method that detects and then segment without increasing the amount of parameters. In addition, when the enhanced tumor area is small, this algorithm analysis is probably mislead the necrotic area and the non-enhanced tumor area as the enhanced tumor area. When the predicted enhanced tumor area is less than 500 voxels, the enhanced tumor area is substituted with necrotic and non-enhancing tumor area. This research method illustrates a random forest-based regressor for the prediction of the overall survival time and a random forest-based classifier for the prediction of category of the overall survival time at the end. The premise requires the use of low-dimensional potential features extracted by VAE and the clinical features of the patient's age, and feature option is implemented via the recursive feature elimination method based on random forest regression. When the prediction result of the regression model is inconsistent with the prediction category of the classification model, the final prediction result is divided into a fixed overall survival time according to the prediction category if the probability predicting the category exceeds 80% The short-term corresponds to 10 months, the mid-term corresponds to 12.5 months, and the long-term corresponds to 15 months.ResultOur research analysis implements a five-fold cross validation on BraTS2020 training set. The generated result is the average of 5 validation results. The method achieves Dice similarity coefficients of 90.66%, 85.09%, and 79.02% in the whole tumor area, tumor core area and enhanced tumor area in the validation set, respectively. In terms of the clinical feature of patient's age, the overall survival prediction accuracy rate reaches 41.4%, and the potential extracted features in the VAE branch, the accuracy rate could reach 55.2%. Although the accuracy rate is 3.5% lower than that of the first-ranked method, this proposed method has a slight advantage in terms of the mean square error.Conclusionthe research proposes a two-stage cascaded U-Net network with a VAE branch to resolve over-fitting issue. Simultaneously, the branch can also extract the potential features of the tumor to predict the survival time. The test results demonstrate that the network can segment brain tumors more accurately, and the potential extracted features can predict suitable patient survival time, which can provide a powerful reference for clinicians in the diagnosis of gliomas.关键词:automatic 3D segmentation of glioma;survival prediction;cascade neural network;variational auto-encoder(VAE);attention mechanism233|331|0更新时间:2024-05-07 -
 摘要:ObjectiveThe segmentation of cardiac dynamic magnetic resonance imaging (MRI) is essential to evaluate cardiac functional parameters in clinical diagnosis. Based on the segmentation results, the qualified analysis can be obtained the myocardial mass and thickness, ejection fraction, ventricular volume and other diagnostic indicators effectively. Currently, the method of heart segmentation is still limited to manual segmentation. This method is time-consuming and human behavior-oriented. Therefore, the issue of automatic and accurate cardiac-MRI (CMRI) segmentation has been focused on. However, due to the non-uniform magnetic field intensity, artifacts resulted blurred boundaries in the process of imaging. Organs of different subjects vary greatly, especially the variable shape and size of the right ventricle, which tends to produce volume effect. In addition, dynamic magnetic resonance imaging is featured based on a small scale of short axis sections with thick slice, which results in low short axis resolution and sparse information of the image. As the existing data sets only including ground truth of dynamic MRI images at two sites in the end of systole and end of diastole, the existing networks usually only take the images at these two sites as segmentation objects, which ignores the information of dynamic MRI images timescale. Hence, automatic segmentation of dynamic cardiac MRI images is challenged of the issues of intra-class uncertainty and inter-class imbalance. This illustration demonstrates a spatio-temporal multi-scale UNet that makes use of time information to conduct feature enhancement and spatial information to get feature correction.MethodFirst, a new time-enhanced coding path is developed in order to fully obtain the time information of dynamic CMRI images, which consists of two branches are those of the target frame branch and the key sequence branch. The target frame is the image to be segmented, and the key sequence is the consistent time series containing the target frame. The key sequence is used to obtain richer time features, while the target frame provides more accurate edge features. Due to the beating frequency of the heart, the boundary information of the target organ would be in conflict with that of the time scaled images in the key sequence, and the edge information extracted from the target frame could make up for this problem. It is worth noting that the key sequence and target frame are cut or filled into 256×256 pixels due to the different sizes of images in the data set. Simultaneously, this analysis also makes the same data enhancement for the target frame and the key sequence and random affine changing and random rotation in order to extend the amount of data in the training set and improve the generalization ability and robustness of the model. Meanwhile, in order to aggregate more beneficial features and better integrate edge information and time features, this research illustrated a deformable global connection instead of the traditional long connection to provide more extensive multi-dimensional feature information for the decoding part of the network. Compared with the original network which only transfers the results of the encoding layer to the decoding layer, the features of the deformable global connection are the weighted sum of the global features. The deformable global connection is composed of the context modeling part, the feature transformation part and the deformable convolutional layer part. The part of modeling algorithm obtains the attention weight of the feature vector in the $x-y$ plane, which represents the global context feature. The feature transformation captures the dependencies between channels to reduce the optimization difficulty via layer normalization. The deformable convolutional layer captures the geometry of the heart. In the process of decoding, the decoding layer can perform targeted aggregation to improve the compact and semantic consistency within the class based on the obtained weights. At the end, the spatial directional field features are learned and the original segmentation results are calibrated by these features. The spatial direction field, generated by ground truth, provides each pixel with a unique path from the boundary to the central region. The orientation relationship is revealed amongst the pixels on the target organ. The feature of central region is used to correct the segmentation map based on the requirement of spatial direction field.ResultThe online test results of the Automated Cardiac Diagnosis Challenge(ACDC) cardiac segmentation challenge illustrated that the average dice for the segmentation of left ventricle, right ventricle and left ventricle in this research analyses were 95%, 91.5% and 91% each, which is 2%, 1.5% and 2.5% higher than the initial network analysis. The average Hausdorff distance of the segmentation results is 6.77, 11.39 and 8.54, respectively, which is 2.22, 2.07 and 3.64 lower than the initial network.ConclusionThis demonstrated experiments show that the proposed network can improve the segmentation effect of target organs effectively based on the spatio-temporal information of cardiac MRI images.关键词:medical image;cardiac magnetic resonance imaging(CMRI);feature enhancement;spatial directional field;UNet80|166|2更新时间:2024-05-07
摘要:ObjectiveThe segmentation of cardiac dynamic magnetic resonance imaging (MRI) is essential to evaluate cardiac functional parameters in clinical diagnosis. Based on the segmentation results, the qualified analysis can be obtained the myocardial mass and thickness, ejection fraction, ventricular volume and other diagnostic indicators effectively. Currently, the method of heart segmentation is still limited to manual segmentation. This method is time-consuming and human behavior-oriented. Therefore, the issue of automatic and accurate cardiac-MRI (CMRI) segmentation has been focused on. However, due to the non-uniform magnetic field intensity, artifacts resulted blurred boundaries in the process of imaging. Organs of different subjects vary greatly, especially the variable shape and size of the right ventricle, which tends to produce volume effect. In addition, dynamic magnetic resonance imaging is featured based on a small scale of short axis sections with thick slice, which results in low short axis resolution and sparse information of the image. As the existing data sets only including ground truth of dynamic MRI images at two sites in the end of systole and end of diastole, the existing networks usually only take the images at these two sites as segmentation objects, which ignores the information of dynamic MRI images timescale. Hence, automatic segmentation of dynamic cardiac MRI images is challenged of the issues of intra-class uncertainty and inter-class imbalance. This illustration demonstrates a spatio-temporal multi-scale UNet that makes use of time information to conduct feature enhancement and spatial information to get feature correction.MethodFirst, a new time-enhanced coding path is developed in order to fully obtain the time information of dynamic CMRI images, which consists of two branches are those of the target frame branch and the key sequence branch. The target frame is the image to be segmented, and the key sequence is the consistent time series containing the target frame. The key sequence is used to obtain richer time features, while the target frame provides more accurate edge features. Due to the beating frequency of the heart, the boundary information of the target organ would be in conflict with that of the time scaled images in the key sequence, and the edge information extracted from the target frame could make up for this problem. It is worth noting that the key sequence and target frame are cut or filled into 256×256 pixels due to the different sizes of images in the data set. Simultaneously, this analysis also makes the same data enhancement for the target frame and the key sequence and random affine changing and random rotation in order to extend the amount of data in the training set and improve the generalization ability and robustness of the model. Meanwhile, in order to aggregate more beneficial features and better integrate edge information and time features, this research illustrated a deformable global connection instead of the traditional long connection to provide more extensive multi-dimensional feature information for the decoding part of the network. Compared with the original network which only transfers the results of the encoding layer to the decoding layer, the features of the deformable global connection are the weighted sum of the global features. The deformable global connection is composed of the context modeling part, the feature transformation part and the deformable convolutional layer part. The part of modeling algorithm obtains the attention weight of the feature vector in the $x-y$ plane, which represents the global context feature. The feature transformation captures the dependencies between channels to reduce the optimization difficulty via layer normalization. The deformable convolutional layer captures the geometry of the heart. In the process of decoding, the decoding layer can perform targeted aggregation to improve the compact and semantic consistency within the class based on the obtained weights. At the end, the spatial directional field features are learned and the original segmentation results are calibrated by these features. The spatial direction field, generated by ground truth, provides each pixel with a unique path from the boundary to the central region. The orientation relationship is revealed amongst the pixels on the target organ. The feature of central region is used to correct the segmentation map based on the requirement of spatial direction field.ResultThe online test results of the Automated Cardiac Diagnosis Challenge(ACDC) cardiac segmentation challenge illustrated that the average dice for the segmentation of left ventricle, right ventricle and left ventricle in this research analyses were 95%, 91.5% and 91% each, which is 2%, 1.5% and 2.5% higher than the initial network analysis. The average Hausdorff distance of the segmentation results is 6.77, 11.39 and 8.54, respectively, which is 2.22, 2.07 and 3.64 lower than the initial network.ConclusionThis demonstrated experiments show that the proposed network can improve the segmentation effect of target organs effectively based on the spatio-temporal information of cardiac MRI images.关键词:medical image;cardiac magnetic resonance imaging(CMRI);feature enhancement;spatial directional field;UNet80|166|2更新时间:2024-05-07 -
 摘要:ObjectiveHuman brain tumors are a group of mutant cells in the brain or skull. These benign or malignant brain tumors can be classified based on their growth characteristics and influence on the human body. Gliomas are one of the most frequent forms of malignant brain tumors, accounting for approximately 40% to 50% of all brain tumors. Glioma is classified as high-grade glioma (HGG) or low-grade glioma (LGG) depending on the degree of invasion. Low-grade glioma (LGG) is a well-differentiated glioma with a prompt prognosis. High-grade glioma (HGG) is a poorly differentiated glioma with a in qualified prognosis. Gliomas with varying degrees of differentiation are appeared following the varied degrees of peritumoral edema, edema types, and necrosis. the boundary of gliomas and normal tissues is often blurred. It is difficult to identify the scope of lesions and surgical area, which has a significant impact on surgical quality and patient prognosis. As a non-invasive and clear soft tissue contrast imaging tool, magnetic resonance imaging (MRI) can provide vital information on the shape, size, and location of brain tumors. High-precision brain tumor MRI image segmentation is challenged due to the complicated and variable morphology, fuzzy borders, low contrast, and complicated sample gradients of brain tumors. Manual segmentation is time-consuming and inconsistent. The International Association for Medical Image Computing and Computer-Aided Intervention (MICCAI)'s Brain Tumor Segmentation (BraTS) is a global medical image segmentation challenge concentrating on the evaluation of automatic segmentation methods for human brain tumors. There are four types of automatic brain tumor segmentation algorithms as mentioned below: supervised learning, semi-supervised learning, unsupervised learning, and hybrid learning. Supervised-learning-based algorithm is currently the effective method. Various depth neural network models for computer vision problems, such as Visual Geometry Group Network (VGGNet), GoogLeNet, ResNet, and DenseNet, have been presented in recent years. The above deep neural network model proposes a novel approach to the problem of MRI brain image segmentation, and it significantly advances the development of deep learning-based brain tumor diagnosis methods. As a result, deep learning method is to develop the task of automatic segmentation of brain tumor MRI images.MethodOur research integrates low resolution information and high resolution information via the U-Net structure of the all convolutional neural network. An improved cross stage partial U-Net(CSPU-Net) brain tumor segmentation network derived from the U-Net network achieves high-precision brain tumor MRI image segmentation. The basic goal of the cross stage partial (CSP) module is to segment the grass-roots feature mapping into two sections as following: 1)Dividing the gradient flow to extend distinct network paths, and then 2) fusing the two portions based on horizontal hierarchy. The conveyed gradient information can have huge correlation discrepancies by alternating series and transition procedures. To extract image features, CSPU-Net adds two types of cross stage partial network structures to the up and down sampling of the U-Net network. The number of gradient routes is increased using the splitting and merging technique. The drawbacks of utilizing explicit feature map replication for connection are mitigated, enhancing the model's feature learning capabilities. To overcome the imbalance issue of sample class, two loss functions, general dice loss and weighted cross-entropy are combined. The cross stage partial structure is final compared to ResU-Net, which adds a residual block, to in identify the effectiveness of cross stage partial structure as ResU-Net in the brain tumor segmentation test.ResultOur experimental results of the CSPU-Net model in the context of the BraTS 2018 and BraTS 2019 datasets has its priority. The BraTS 2018 dataset yielded 87.9% accuracy in whole tumor segmentation, 80.6% accuracy in core tumor segmentation, and 77.3% accuracy in enhanced tumor segmentation, respectively. This method enhances the segmentation accuracy of brain tumor MRI images by 0.80%, 1.60%, and 2.20% each. In the BraTS 2019 dataset, the whole tumor segmentation accuracy is 87.8%, the core tumor segmentation accuracy is 77.9%, and the improved tumor segmentation accuracy is 70.7%, respectively. This method enhances the segmentation accuracy of brain tumor MRI images by 0.70%, 1.30%, and 1.40%, respectively in comparison of the traditional improved ResU-Net.ConclusionThis research provides a cross-stage deep learning-based 2D segmentation network for human brain tumor MRI images. Using cross stage partial network structure in U-Net up and down sampling, the model enhances the accuracy of brain tumor segmentation via gradient path expansion and information loss deduction. The demonstrated results illustrate that our model has its potentials on BraTS datasets on 2D segmentation models development and demonstrates the module's efficiency in the brain tumor segmentation task.关键词:brain tumor segmentation;deep learning;U-Net;cross stage partial network structure;residual module147|346|5更新时间:2024-05-07
摘要:ObjectiveHuman brain tumors are a group of mutant cells in the brain or skull. These benign or malignant brain tumors can be classified based on their growth characteristics and influence on the human body. Gliomas are one of the most frequent forms of malignant brain tumors, accounting for approximately 40% to 50% of all brain tumors. Glioma is classified as high-grade glioma (HGG) or low-grade glioma (LGG) depending on the degree of invasion. Low-grade glioma (LGG) is a well-differentiated glioma with a prompt prognosis. High-grade glioma (HGG) is a poorly differentiated glioma with a in qualified prognosis. Gliomas with varying degrees of differentiation are appeared following the varied degrees of peritumoral edema, edema types, and necrosis. the boundary of gliomas and normal tissues is often blurred. It is difficult to identify the scope of lesions and surgical area, which has a significant impact on surgical quality and patient prognosis. As a non-invasive and clear soft tissue contrast imaging tool, magnetic resonance imaging (MRI) can provide vital information on the shape, size, and location of brain tumors. High-precision brain tumor MRI image segmentation is challenged due to the complicated and variable morphology, fuzzy borders, low contrast, and complicated sample gradients of brain tumors. Manual segmentation is time-consuming and inconsistent. The International Association for Medical Image Computing and Computer-Aided Intervention (MICCAI)'s Brain Tumor Segmentation (BraTS) is a global medical image segmentation challenge concentrating on the evaluation of automatic segmentation methods for human brain tumors. There are four types of automatic brain tumor segmentation algorithms as mentioned below: supervised learning, semi-supervised learning, unsupervised learning, and hybrid learning. Supervised-learning-based algorithm is currently the effective method. Various depth neural network models for computer vision problems, such as Visual Geometry Group Network (VGGNet), GoogLeNet, ResNet, and DenseNet, have been presented in recent years. The above deep neural network model proposes a novel approach to the problem of MRI brain image segmentation, and it significantly advances the development of deep learning-based brain tumor diagnosis methods. As a result, deep learning method is to develop the task of automatic segmentation of brain tumor MRI images.MethodOur research integrates low resolution information and high resolution information via the U-Net structure of the all convolutional neural network. An improved cross stage partial U-Net(CSPU-Net) brain tumor segmentation network derived from the U-Net network achieves high-precision brain tumor MRI image segmentation. The basic goal of the cross stage partial (CSP) module is to segment the grass-roots feature mapping into two sections as following: 1)Dividing the gradient flow to extend distinct network paths, and then 2) fusing the two portions based on horizontal hierarchy. The conveyed gradient information can have huge correlation discrepancies by alternating series and transition procedures. To extract image features, CSPU-Net adds two types of cross stage partial network structures to the up and down sampling of the U-Net network. The number of gradient routes is increased using the splitting and merging technique. The drawbacks of utilizing explicit feature map replication for connection are mitigated, enhancing the model's feature learning capabilities. To overcome the imbalance issue of sample class, two loss functions, general dice loss and weighted cross-entropy are combined. The cross stage partial structure is final compared to ResU-Net, which adds a residual block, to in identify the effectiveness of cross stage partial structure as ResU-Net in the brain tumor segmentation test.ResultOur experimental results of the CSPU-Net model in the context of the BraTS 2018 and BraTS 2019 datasets has its priority. The BraTS 2018 dataset yielded 87.9% accuracy in whole tumor segmentation, 80.6% accuracy in core tumor segmentation, and 77.3% accuracy in enhanced tumor segmentation, respectively. This method enhances the segmentation accuracy of brain tumor MRI images by 0.80%, 1.60%, and 2.20% each. In the BraTS 2019 dataset, the whole tumor segmentation accuracy is 87.8%, the core tumor segmentation accuracy is 77.9%, and the improved tumor segmentation accuracy is 70.7%, respectively. This method enhances the segmentation accuracy of brain tumor MRI images by 0.70%, 1.30%, and 1.40%, respectively in comparison of the traditional improved ResU-Net.ConclusionThis research provides a cross-stage deep learning-based 2D segmentation network for human brain tumor MRI images. Using cross stage partial network structure in U-Net up and down sampling, the model enhances the accuracy of brain tumor segmentation via gradient path expansion and information loss deduction. The demonstrated results illustrate that our model has its potentials on BraTS datasets on 2D segmentation models development and demonstrates the module's efficiency in the brain tumor segmentation task.关键词:brain tumor segmentation;deep learning;U-Net;cross stage partial network structure;residual module147|346|5更新时间:2024-05-07 -
 摘要:ObjectiveAlzheimer's disease (AD) is one of the most common irreversible neurodegenerative diseases. The main clinical manifestation is cognitive impairment, which usually occurs in the middle-aged and elderly stage. The diagnosis and recognition of AD is constrained of the inefficient experience and mis-diagnosis of clinicians. If the onset stage of AD can be targeted in early diagnosis, it will yield relevant interference and treatment measures to the early stage of AD. A high accuracy automatic detection algorithm will help clinicians to prevent and treat AD.MethodStructured magnetic resonance imaging (S-MRI) is used to extract gray matter density characteristics of each subject after pre-treatment. A group L1/2 sparsity method based on smoothing function (${\rm{SGL}}$1/2) is illustrated. This smooth grouping sparsity method is based on the common group L1/2 (${\rm{GL}}$1/2) method. ${\rm{GL}}$1/2 method can aid Group Lasso method to select high correlation feature group without sparse the selected feature group, so it can remove some redundant features in redundant group and surviving group simultaneously. However, this group sparsity method has the difficulties of oscillation and convergence because it contains non-smooth absolute value function. The selected ${\rm{SGL}}$1/2 method uses a smooth function to approximate the non-smooth absolute value function of the traditional ${\rm{GL}}$1/2 method. The sparse model becomes a smooth model, which can quickly converge to the optimal value. Meanwhile, these regularization benchmark need to group features in advance at the group scale. In order to obtain scientific grouping of human brain features, a registered anatomical automatic labeling (AAL) template, which registers the original AAL template into the standard template, so that the obtained AAL template has the same spatial distribution as each pre-processed targeting image. Based on this grouping template, each region is regarded as a group. All voxels in each region are targeted as the features of each group for group sparing. In respect of classification method, a calibrated hinge is opted to substitute the hinge loss function in SVM (calibrated SVM, C-SVM). C-SVM can make the points near the classification plane more inclined to the correct side of the classification. We select four classification methods, which are support vector machine (SVM), calibrated support vector machine (C-SVM), linear classification and logistic regression. C-SVM uses a calibrated hinge loss function to replace the hinge loss function of traditional support vector machine, and then classifies the features of AD and cognitive normal (CN) control group via a simple classification function. The analyzed results illustrates that the classification accuracy of C-SVM reaches 91.06%. We select C-SVM as the benchmark, and the ${\rm{SGL}}$1/2 group sparse method is integrated based on registered AAL template to form the main classification method.ResultThe key demonstration is selected from the "ADNI1: Complete 2Yr 1.5T" dataset of Alzheimer's disease neuroimaging initiative (ADNI) for training and testing, and compared the classification performance with the classification model combined with ${\rm{GL}}$1/2 and ${\rm{SGL}}$1/2 group level regularization methods. The calibration support vector machine classification model has a good classification effect on the recognition of AD based on ${\rm{SGL}}$1/2 group sparsity method. In the control group of AD and CN control group, the classification accuracy reaches 94.70%. In order to show the generalization of the model, we also selected Cuingnet data sets from relevant for classification literatures. The results also confirmed that the illustrated model had qualified classification effect. In the control group of AD and CN, the accuracy rate reached 91.97%. In terms of the features of each group segmented by the registered AAL group template, the C-SVM model is used to classify, and the classification effect of each group region is obtained. We select six regions with the best classification effect, and compare the results of the targeted illustrated model.ConclusionThe demonstrated ${\rm{SGL}}$1/2 group sparse classification model is based on AAL grouping template proposed in this research. The priorities of inter group sparse and intra group sparse are evolved. The high correlation features of high correlation group are selected in all human brain regions, and realize the accurate location of high correlation brain regions with AD, which provides a benchmark for the automatic diagnosis of AD further.关键词:Alzheimer's disease (AD);smooth group L1/2;calibrated support vector machine (C-SVM);structured magnetic resonance imaging;inter group sparsity;intra group sparsity60|132|0更新时间:2024-05-07
摘要:ObjectiveAlzheimer's disease (AD) is one of the most common irreversible neurodegenerative diseases. The main clinical manifestation is cognitive impairment, which usually occurs in the middle-aged and elderly stage. The diagnosis and recognition of AD is constrained of the inefficient experience and mis-diagnosis of clinicians. If the onset stage of AD can be targeted in early diagnosis, it will yield relevant interference and treatment measures to the early stage of AD. A high accuracy automatic detection algorithm will help clinicians to prevent and treat AD.MethodStructured magnetic resonance imaging (S-MRI) is used to extract gray matter density characteristics of each subject after pre-treatment. A group L1/2 sparsity method based on smoothing function (${\rm{SGL}}$1/2) is illustrated. This smooth grouping sparsity method is based on the common group L1/2 (${\rm{GL}}$1/2) method. ${\rm{GL}}$1/2 method can aid Group Lasso method to select high correlation feature group without sparse the selected feature group, so it can remove some redundant features in redundant group and surviving group simultaneously. However, this group sparsity method has the difficulties of oscillation and convergence because it contains non-smooth absolute value function. The selected ${\rm{SGL}}$1/2 method uses a smooth function to approximate the non-smooth absolute value function of the traditional ${\rm{GL}}$1/2 method. The sparse model becomes a smooth model, which can quickly converge to the optimal value. Meanwhile, these regularization benchmark need to group features in advance at the group scale. In order to obtain scientific grouping of human brain features, a registered anatomical automatic labeling (AAL) template, which registers the original AAL template into the standard template, so that the obtained AAL template has the same spatial distribution as each pre-processed targeting image. Based on this grouping template, each region is regarded as a group. All voxels in each region are targeted as the features of each group for group sparing. In respect of classification method, a calibrated hinge is opted to substitute the hinge loss function in SVM (calibrated SVM, C-SVM). C-SVM can make the points near the classification plane more inclined to the correct side of the classification. We select four classification methods, which are support vector machine (SVM), calibrated support vector machine (C-SVM), linear classification and logistic regression. C-SVM uses a calibrated hinge loss function to replace the hinge loss function of traditional support vector machine, and then classifies the features of AD and cognitive normal (CN) control group via a simple classification function. The analyzed results illustrates that the classification accuracy of C-SVM reaches 91.06%. We select C-SVM as the benchmark, and the ${\rm{SGL}}$1/2 group sparse method is integrated based on registered AAL template to form the main classification method.ResultThe key demonstration is selected from the "ADNI1: Complete 2Yr 1.5T" dataset of Alzheimer's disease neuroimaging initiative (ADNI) for training and testing, and compared the classification performance with the classification model combined with ${\rm{GL}}$1/2 and ${\rm{SGL}}$1/2 group level regularization methods. The calibration support vector machine classification model has a good classification effect on the recognition of AD based on ${\rm{SGL}}$1/2 group sparsity method. In the control group of AD and CN control group, the classification accuracy reaches 94.70%. In order to show the generalization of the model, we also selected Cuingnet data sets from relevant for classification literatures. The results also confirmed that the illustrated model had qualified classification effect. In the control group of AD and CN, the accuracy rate reached 91.97%. In terms of the features of each group segmented by the registered AAL group template, the C-SVM model is used to classify, and the classification effect of each group region is obtained. We select six regions with the best classification effect, and compare the results of the targeted illustrated model.ConclusionThe demonstrated ${\rm{SGL}}$1/2 group sparse classification model is based on AAL grouping template proposed in this research. The priorities of inter group sparse and intra group sparse are evolved. The high correlation features of high correlation group are selected in all human brain regions, and realize the accurate location of high correlation brain regions with AD, which provides a benchmark for the automatic diagnosis of AD further.关键词:Alzheimer's disease (AD);smooth group L1/2;calibrated support vector machine (C-SVM);structured magnetic resonance imaging;inter group sparsity;intra group sparsity60|132|0更新时间:2024-05-07
Magnetic Resonance Image
-
 摘要:ObjectiveB-mode ultrasound (BUS) provides information about the structure and morphology information of human breast lesions, while elastography ultrasound (EUS) can provide additional bio-mechanical information. Dual-modal ultrasound imaging can effectively improve the accuracy of the human breast cancer diagnosis. The single-modal ultrasound-based computer-aided diagnosis (CAD) model has its potential applications. Deep transfer learning is a significant branch of transfer learning analysis. This technique can be utilized to guide the information transfer between EUS images and BUS images. However, clinical image samples are limited based on training deep learning models due to the high cost of data collection and annotation. Self-supervised learning (SSL) is an effective solution to demonstrate its potential in a variety of medical image analysis tasks. In respect of the SSL pipeline, the backbone network is trained based on a pretext task, where the supervision information is generated from the train samples without manual annotation. Based on the weight parameters of the trained backbone network, the obtained results are then transferred to the downstream network for further fine-tuning with small size annotated samples. A step-based correlation multi-modal deep convolution neural network (CorrMCNN) has been facilitated to conduct a self-supervised image reconstruction task currently. In the training process, the model transfers the effective information between two modalities to optimize the correlation loss through SSL-based deep transfer learning. Since each BUS and EUS scan the same lesion area for the targeted patient simultaneously, the analyzed results are demonstrated in pairs and share labels. Learning using privileged information (LUPI) is a supervised transfer learning paradigm for paired source domain (privileged information) and target domain data based on shared labels. It can exploit the intrinsic knowledge correlation between the paired data in the source domain and target domain with shared labels, which guides knowledge transfer to improve model capability. Since the label information is used to guide transfer learning in classifiers, the current LUPI algorithm focus on the classifier. Feature representation is also the key step for a qualified CAD system. A two-stage deep transfer learning (TSDTL) algorithm is demonstrated for human breast ultrasound CAD, which transfers the clear information from EUS images to the CAD model of BUS-based human breast cancer and further improves the performance of the CAD model.MethodIn the first stage of deep transfer learning, an SSL task is first designed based on dual-modal ultrasonic image reconstruction, which trains the CorrMCNN model to conduct the interactive transfer of information between the two modal images of BUS and EUS images. The bi-channel encoder networks are adopted to learn the feature representation derived from the dual-modal images, respectively. The high-level learned features are used following for concatenation to obtain the joint representation. The original BUS and EUS images are reconstructed from the joint feature representation through the bi-channel decoder networks. In the training process, the network implicitly implements deep transfer learning via the correlation loss optimization amongst high-level features derived from two channels. In the second stage of deep transfer learning, the pre-training backbone network is reused followed by a sub-network for classification. The BUS and EUS images are input into this new network for targeted breast cancer classification based on dual-modal ultrasound images. In this training process, the data of the source domain and target domain can be applied to supervised transfer learning with the shared labels, and this strategy belongs to the general LUPI paradigm. Consequently, it can be considered that this deep transfer learning stage implicitly conducts knowledge transfer under the LUPI paradigm, which is based on the dual-modal ultrasound breast cancer classification task. In the final stage, the corresponding channel sub-network is fine-tuned with single-modal ultrasound data, which obtains an accurate breast cancer B-mode image classification model. The obtained single-channel network is the final network model of BUS-based breast cancer CAD, which can be directly applied to the diagnostic tasks of the emerging BUS images.ResultThe performance of the algorithm is demonstrated on a breast tumor dual-modal ultrasound dataset. Our illustrated TSDTL achieves the mean classification accuracy of 87.84±2.08%, sensitivity of 88.89±3.70%, specificity of 86.71±2.21%, and Youden index of 75.60±4.07% respectively, which develops the classification model trained on single-modal BUS images and a variety of typical deep transfer learning algorithms.ConclusionOur TSDTL algorithm analysis can effectively transfer the information of EUS to the BUS-based human breast cancer CAD model through our illustrated two-stage deep transfer learning.关键词:B-mode ultrasound imaging;elastography ultrasound imaging;computer-aided diagnosis of breast cancer;learning using privileged information(LUPI);deep transfer learning;self-supervised learning(SSL)47|72|3更新时间:2024-05-07
摘要:ObjectiveB-mode ultrasound (BUS) provides information about the structure and morphology information of human breast lesions, while elastography ultrasound (EUS) can provide additional bio-mechanical information. Dual-modal ultrasound imaging can effectively improve the accuracy of the human breast cancer diagnosis. The single-modal ultrasound-based computer-aided diagnosis (CAD) model has its potential applications. Deep transfer learning is a significant branch of transfer learning analysis. This technique can be utilized to guide the information transfer between EUS images and BUS images. However, clinical image samples are limited based on training deep learning models due to the high cost of data collection and annotation. Self-supervised learning (SSL) is an effective solution to demonstrate its potential in a variety of medical image analysis tasks. In respect of the SSL pipeline, the backbone network is trained based on a pretext task, where the supervision information is generated from the train samples without manual annotation. Based on the weight parameters of the trained backbone network, the obtained results are then transferred to the downstream network for further fine-tuning with small size annotated samples. A step-based correlation multi-modal deep convolution neural network (CorrMCNN) has been facilitated to conduct a self-supervised image reconstruction task currently. In the training process, the model transfers the effective information between two modalities to optimize the correlation loss through SSL-based deep transfer learning. Since each BUS and EUS scan the same lesion area for the targeted patient simultaneously, the analyzed results are demonstrated in pairs and share labels. Learning using privileged information (LUPI) is a supervised transfer learning paradigm for paired source domain (privileged information) and target domain data based on shared labels. It can exploit the intrinsic knowledge correlation between the paired data in the source domain and target domain with shared labels, which guides knowledge transfer to improve model capability. Since the label information is used to guide transfer learning in classifiers, the current LUPI algorithm focus on the classifier. Feature representation is also the key step for a qualified CAD system. A two-stage deep transfer learning (TSDTL) algorithm is demonstrated for human breast ultrasound CAD, which transfers the clear information from EUS images to the CAD model of BUS-based human breast cancer and further improves the performance of the CAD model.MethodIn the first stage of deep transfer learning, an SSL task is first designed based on dual-modal ultrasonic image reconstruction, which trains the CorrMCNN model to conduct the interactive transfer of information between the two modal images of BUS and EUS images. The bi-channel encoder networks are adopted to learn the feature representation derived from the dual-modal images, respectively. The high-level learned features are used following for concatenation to obtain the joint representation. The original BUS and EUS images are reconstructed from the joint feature representation through the bi-channel decoder networks. In the training process, the network implicitly implements deep transfer learning via the correlation loss optimization amongst high-level features derived from two channels. In the second stage of deep transfer learning, the pre-training backbone network is reused followed by a sub-network for classification. The BUS and EUS images are input into this new network for targeted breast cancer classification based on dual-modal ultrasound images. In this training process, the data of the source domain and target domain can be applied to supervised transfer learning with the shared labels, and this strategy belongs to the general LUPI paradigm. Consequently, it can be considered that this deep transfer learning stage implicitly conducts knowledge transfer under the LUPI paradigm, which is based on the dual-modal ultrasound breast cancer classification task. In the final stage, the corresponding channel sub-network is fine-tuned with single-modal ultrasound data, which obtains an accurate breast cancer B-mode image classification model. The obtained single-channel network is the final network model of BUS-based breast cancer CAD, which can be directly applied to the diagnostic tasks of the emerging BUS images.ResultThe performance of the algorithm is demonstrated on a breast tumor dual-modal ultrasound dataset. Our illustrated TSDTL achieves the mean classification accuracy of 87.84±2.08%, sensitivity of 88.89±3.70%, specificity of 86.71±2.21%, and Youden index of 75.60±4.07% respectively, which develops the classification model trained on single-modal BUS images and a variety of typical deep transfer learning algorithms.ConclusionOur TSDTL algorithm analysis can effectively transfer the information of EUS to the BUS-based human breast cancer CAD model through our illustrated two-stage deep transfer learning.关键词:B-mode ultrasound imaging;elastography ultrasound imaging;computer-aided diagnosis of breast cancer;learning using privileged information(LUPI);deep transfer learning;self-supervised learning(SSL)47|72|3更新时间:2024-05-07 -
 摘要:ObjectiveBrightness-mode ultra-sound images are usually generated from the interface back to the probe by the echo of sound waves amongst different tissues. This method has its priority for no ionizing radiation and low price. It has been recognized as one of the most regular medical imaging by clinicians and radiologists. Imaging physicians usually diagnose tumors via breast ultrasound tumor regions observation. These features are fused with the corresponding contrast-enhanced ultrasound features to enhance visual information for further discrimination. Therefore, the lesion area can provide effective information for discriminating the shape and boundary. Machine learning, especially deep learning, can learn the middle-level and high-level abstract features from the original ultrasound, generating several applicable methods and playing an important role in the clinic, such as auxiliary diagnosis and image-guided treatment. Currently, it is widely used in tumor diagnosis, organ segmentation, and region of interest (ROI) detection and tracking. Due to the constrained information originated from B-model ultrasound and its overlapping phenomenon, the neural network cannot focus on the lesion area of the image with poor imaging quality during the feature extraction, resulting in classification errors. Therefore, in order to improve the accuracy of human breast ultrasound diagnosis, this research illustrates an end-to-end automatic benign and malignant classification model fused with bimodal data to realize an accurate diagnosis of human breast ultrasound.MethodFirst, a backbone networks, of ResNet34 is optioned based on experimental comparison. It can learn more clear features for classification, especially for breast ultrasound images with poor imaging effects. Hence, the ultrasound tumor segmentation mask is as a guide to strengthening the learning of the key features of classification based on the residual block. The model can concentrate on the targeting regions via reducing the interference of tumor overlapping phenomenon and lowering the influence of poor image quality. An attention guidance mechanism is facilitated to enhance key features, but the presence of noise samples in the sample, such as benign tumors exhibiting irregular morphology, edge burrs, and other malignant tumor features, will reduce the accuracy of model classification. The contrast-enhanced ultrasound morphological features can be used to distinguish the pathological results of tumors further. Therefore, we use the natural language analysis method to convert the text of the pathological results into a feature vector based on the effective contrast-enhanced ultrasound (CEUS) pathological notations simultaneously, our research analysis visualizes the spatial distribution of the converted vectors to verify the usability of the pathological results of CEUS in breast tumors classification. It is sorted out that the features are distributed in clusters and polarities, which demonstrates the effectiveness of the contrast features for classification. At the end, our research B-mode ultrasound extraction of deep image features fuses various feature vectors of CEUS to realize the classification of breast tumors.ResultThe adopted breast ultrasound images dataset(BM-Breast) dataset is of 1 093 breast ultrasound samples that have been desensitized and preprocessed (benign: malignant = 562 ∶531). To verify the algorithm's effectiveness, this paper uses several mainstream classification algorithms for comparison and compared them with the classification accuracy of algorithms for breast ultrasound classification. The classification accuracy of the proposed fusion algorithm reaches 87.45%, and the area under curve (AUC) reaches 0.905. In the attention guidance mechanism module, this paper also conduct experiments on both a public dataset and a private dataset. The experimental results on those two datasets show that the classification accuracy has been improved by 3%, so the algorithm application is effective and robust.ConclusionOur guided attention model demonstration can learn the effective features of breast ultrasound. The fusion diagnosis of bimodal data features improves the diagnosis accuracy. This algorithm analysis promotes cooperation further between medicine and engineering via the clinical diagnosis restoration. The illustrated specificity facilitates the model capability to recognize noise samples. More accurately distinguish cases that are difficult to distinguish in clinical diagnosis. The experimental results show that the classification model algorithm in this paper has practical value.关键词:attention mechanism;feature fusion and classification;breast ultrasound;bimodal data;intelligent diagnosis98|100|1更新时间:2024-05-07
摘要:ObjectiveBrightness-mode ultra-sound images are usually generated from the interface back to the probe by the echo of sound waves amongst different tissues. This method has its priority for no ionizing radiation and low price. It has been recognized as one of the most regular medical imaging by clinicians and radiologists. Imaging physicians usually diagnose tumors via breast ultrasound tumor regions observation. These features are fused with the corresponding contrast-enhanced ultrasound features to enhance visual information for further discrimination. Therefore, the lesion area can provide effective information for discriminating the shape and boundary. Machine learning, especially deep learning, can learn the middle-level and high-level abstract features from the original ultrasound, generating several applicable methods and playing an important role in the clinic, such as auxiliary diagnosis and image-guided treatment. Currently, it is widely used in tumor diagnosis, organ segmentation, and region of interest (ROI) detection and tracking. Due to the constrained information originated from B-model ultrasound and its overlapping phenomenon, the neural network cannot focus on the lesion area of the image with poor imaging quality during the feature extraction, resulting in classification errors. Therefore, in order to improve the accuracy of human breast ultrasound diagnosis, this research illustrates an end-to-end automatic benign and malignant classification model fused with bimodal data to realize an accurate diagnosis of human breast ultrasound.MethodFirst, a backbone networks, of ResNet34 is optioned based on experimental comparison. It can learn more clear features for classification, especially for breast ultrasound images with poor imaging effects. Hence, the ultrasound tumor segmentation mask is as a guide to strengthening the learning of the key features of classification based on the residual block. The model can concentrate on the targeting regions via reducing the interference of tumor overlapping phenomenon and lowering the influence of poor image quality. An attention guidance mechanism is facilitated to enhance key features, but the presence of noise samples in the sample, such as benign tumors exhibiting irregular morphology, edge burrs, and other malignant tumor features, will reduce the accuracy of model classification. The contrast-enhanced ultrasound morphological features can be used to distinguish the pathological results of tumors further. Therefore, we use the natural language analysis method to convert the text of the pathological results into a feature vector based on the effective contrast-enhanced ultrasound (CEUS) pathological notations simultaneously, our research analysis visualizes the spatial distribution of the converted vectors to verify the usability of the pathological results of CEUS in breast tumors classification. It is sorted out that the features are distributed in clusters and polarities, which demonstrates the effectiveness of the contrast features for classification. At the end, our research B-mode ultrasound extraction of deep image features fuses various feature vectors of CEUS to realize the classification of breast tumors.ResultThe adopted breast ultrasound images dataset(BM-Breast) dataset is of 1 093 breast ultrasound samples that have been desensitized and preprocessed (benign: malignant = 562 ∶531). To verify the algorithm's effectiveness, this paper uses several mainstream classification algorithms for comparison and compared them with the classification accuracy of algorithms for breast ultrasound classification. The classification accuracy of the proposed fusion algorithm reaches 87.45%, and the area under curve (AUC) reaches 0.905. In the attention guidance mechanism module, this paper also conduct experiments on both a public dataset and a private dataset. The experimental results on those two datasets show that the classification accuracy has been improved by 3%, so the algorithm application is effective and robust.ConclusionOur guided attention model demonstration can learn the effective features of breast ultrasound. The fusion diagnosis of bimodal data features improves the diagnosis accuracy. This algorithm analysis promotes cooperation further between medicine and engineering via the clinical diagnosis restoration. The illustrated specificity facilitates the model capability to recognize noise samples. More accurately distinguish cases that are difficult to distinguish in clinical diagnosis. The experimental results show that the classification model algorithm in this paper has practical value.关键词:attention mechanism;feature fusion and classification;breast ultrasound;bimodal data;intelligent diagnosis98|100|1更新时间:2024-05-07
Ultrasound Image
-
 摘要:ObjectiveCerebral ischemic stroke is the most common type of cerebral stroke, which is characterized by high morbidity, mortality and disability. The lack of obvious symptoms before the onset of the disease, the rapid onset of the disease, and the narrow time window for thrombolytic therapy have led to it being a high-risk disease in clinical practice. Although initial progress has been made in cerebral stroke prevention and treatment, it remains a significant cause of disability or death in adults. According to the survey, approximately 75% of stroke patients have varying degrees of functional impairment and loss of work, causing a heavy burden on families and society. With the accelerated aging and urbanization of society, the prevalence of unhealthy lifestyles among the population and the widespread exposure to cerebrovascular disease risk factors, in the disease burden of stroke has greatly increased, with a trend of rapid growth in low-income groups, marked gender and geographical differences and youthfulness. Therefore, effective ways to reduce disability and mortality rates should be developed. The early diagnosis of cerebral stroke is important. Many methods can be used to diagnose cerebral stroke in modern medicine, but the processes are relatively complex. In addition, some tests have certain drawbacks, and the presence of the disease is hard to detect in the early stages of illness, thus requiring advanced equipment and experienced clinicians. How to improve the accuracy of early diagnosis of cerebral stroke has become an important research hotspot for medical aid diagnosis. The characteristics and advantages of traditional Chinese medicine (TCM) are essential in the contemporary medical system of diseases, especially the inspection diagnosis of TCM, which is the most important in TCM diagnosis. Chinese medicine diagnosis is an objective and accurate empirical medicine, which has gradually formed and developed in long-term medical practice and clinically proven, with extremely rich connotations. Based on the basic principles of Chinese medicine diagnosis (the inspection diagnosis of TCM), and diagnosis can be improved by applying modern scientific knowledge and methods in practice. This method not only provides strong evidence for early diagnosis and treatment, but also has extremely important practical significance in saving medical resources, reducing the medical burden on patients and alleviating the harm caused by cerebral stroke disease.MethodFirst, feature extraction is performed on the images of the patient's face and hands. The color features are easily affected by light, and the chroma component in ${\rm{YCbCr}}$ color space is used to reduce the effect of luminance. The most important of the texture features are the features of texture length, depth and thickness in the images, and the gray level co-generation matrix (GLCM) was used to extract the image texture features effectively. Then, the higher-order spatial dimensional features further learned from the original image and the attentional features are learned from the different features by designing a reasonable dual Transformer joint classification model. Different transformer modules were cascaded, and multi-layer perception was used for image classification. This method not only considers color and texture features in the image, but also analyzes the spatial features of the image. Based on the differences arising from successive changes in color and texture between different regions in an image, this paper uses transformer to extract the attention features between different regions to improve the performance of the diagnostic model. In addition, the detection model is trained end-to-end. During the training process, the batch size is set to 4, the learning rate is set to 1E-5 and the maximum number of cycles is set to 100. The experiment uses NVIDIA TITAN XP GPU, and the data set was divided into five groups equally for five cross-validations. Finally, the average accuracy of all cross-validated results was taken as the final result of the experiment.ResultWhen detecting cerebral ischemic stroke, the models with color features (${\rm{YCbCr}}$) and texture features (GLCM) extracted separately achieved accuracies of 79.40% and 80.46% on the dataset, while the model with the fusion of color and texture features achieved an accuracy of 83.53% on the dataset, which was significantly better than the model without feature fusion. Color features and texture features can effectively improve the classification accuracy in classification by using a transformer model, and feature fusion can make the model further improve the detection accuracy. Under the premise of fusion of color and texture features, the accuracy of model classification using a transformer module has dropped by approximately 2%. This finding shows that features from different parts play different roles in the final detection, and the gaps between the same features from different parts can easily disappear in the process of feature fusion into one transformer module. The dual transformer joint classification model uses color, texture, spatial and attention features, and the combination of these features can effectively improve the performance of the model. In addition, the average accuracy of the proposed model on the dataset in this paper outperforms the experimental results of related classification models.ConclusionIn this paper, we proposed an end-to-end joint classification detection method based on the dual Transformer module. High-quality data were acquired using YCbCr color space and GLCM to accelerate the convergence process of the model. In addition, we extracted feature information from the patient's face and hand images. More importantly, the model learning capability was enhanced, and the model performance was improved using a self-attentive mechanism to learn the association between features and assign weights. The proposed model has a good diagnostic effect, and the automatic assisted diagnosis reduced the influence of subjective factors, which is valuable in the study of cerebral ischemic stroke auxiliary diagnosis, provides a reference for clinicians to make decisions on cerebral ischemic stroke disease diagnosis and provides a new method for patients to conduct effective self-screening.关键词:inspection diagnosis of traditional Chinese medicine;feature extraction;feature fusion;end-to-end;Transformer176|193|3更新时间:2024-05-07
摘要:ObjectiveCerebral ischemic stroke is the most common type of cerebral stroke, which is characterized by high morbidity, mortality and disability. The lack of obvious symptoms before the onset of the disease, the rapid onset of the disease, and the narrow time window for thrombolytic therapy have led to it being a high-risk disease in clinical practice. Although initial progress has been made in cerebral stroke prevention and treatment, it remains a significant cause of disability or death in adults. According to the survey, approximately 75% of stroke patients have varying degrees of functional impairment and loss of work, causing a heavy burden on families and society. With the accelerated aging and urbanization of society, the prevalence of unhealthy lifestyles among the population and the widespread exposure to cerebrovascular disease risk factors, in the disease burden of stroke has greatly increased, with a trend of rapid growth in low-income groups, marked gender and geographical differences and youthfulness. Therefore, effective ways to reduce disability and mortality rates should be developed. The early diagnosis of cerebral stroke is important. Many methods can be used to diagnose cerebral stroke in modern medicine, but the processes are relatively complex. In addition, some tests have certain drawbacks, and the presence of the disease is hard to detect in the early stages of illness, thus requiring advanced equipment and experienced clinicians. How to improve the accuracy of early diagnosis of cerebral stroke has become an important research hotspot for medical aid diagnosis. The characteristics and advantages of traditional Chinese medicine (TCM) are essential in the contemporary medical system of diseases, especially the inspection diagnosis of TCM, which is the most important in TCM diagnosis. Chinese medicine diagnosis is an objective and accurate empirical medicine, which has gradually formed and developed in long-term medical practice and clinically proven, with extremely rich connotations. Based on the basic principles of Chinese medicine diagnosis (the inspection diagnosis of TCM), and diagnosis can be improved by applying modern scientific knowledge and methods in practice. This method not only provides strong evidence for early diagnosis and treatment, but also has extremely important practical significance in saving medical resources, reducing the medical burden on patients and alleviating the harm caused by cerebral stroke disease.MethodFirst, feature extraction is performed on the images of the patient's face and hands. The color features are easily affected by light, and the chroma component in ${\rm{YCbCr}}$ color space is used to reduce the effect of luminance. The most important of the texture features are the features of texture length, depth and thickness in the images, and the gray level co-generation matrix (GLCM) was used to extract the image texture features effectively. Then, the higher-order spatial dimensional features further learned from the original image and the attentional features are learned from the different features by designing a reasonable dual Transformer joint classification model. Different transformer modules were cascaded, and multi-layer perception was used for image classification. This method not only considers color and texture features in the image, but also analyzes the spatial features of the image. Based on the differences arising from successive changes in color and texture between different regions in an image, this paper uses transformer to extract the attention features between different regions to improve the performance of the diagnostic model. In addition, the detection model is trained end-to-end. During the training process, the batch size is set to 4, the learning rate is set to 1E-5 and the maximum number of cycles is set to 100. The experiment uses NVIDIA TITAN XP GPU, and the data set was divided into five groups equally for five cross-validations. Finally, the average accuracy of all cross-validated results was taken as the final result of the experiment.ResultWhen detecting cerebral ischemic stroke, the models with color features (${\rm{YCbCr}}$) and texture features (GLCM) extracted separately achieved accuracies of 79.40% and 80.46% on the dataset, while the model with the fusion of color and texture features achieved an accuracy of 83.53% on the dataset, which was significantly better than the model without feature fusion. Color features and texture features can effectively improve the classification accuracy in classification by using a transformer model, and feature fusion can make the model further improve the detection accuracy. Under the premise of fusion of color and texture features, the accuracy of model classification using a transformer module has dropped by approximately 2%. This finding shows that features from different parts play different roles in the final detection, and the gaps between the same features from different parts can easily disappear in the process of feature fusion into one transformer module. The dual transformer joint classification model uses color, texture, spatial and attention features, and the combination of these features can effectively improve the performance of the model. In addition, the average accuracy of the proposed model on the dataset in this paper outperforms the experimental results of related classification models.ConclusionIn this paper, we proposed an end-to-end joint classification detection method based on the dual Transformer module. High-quality data were acquired using YCbCr color space and GLCM to accelerate the convergence process of the model. In addition, we extracted feature information from the patient's face and hand images. More importantly, the model learning capability was enhanced, and the model performance was improved using a self-attentive mechanism to learn the association between features and assign weights. The proposed model has a good diagnostic effect, and the automatic assisted diagnosis reduced the influence of subjective factors, which is valuable in the study of cerebral ischemic stroke auxiliary diagnosis, provides a reference for clinicians to make decisions on cerebral ischemic stroke disease diagnosis and provides a new method for patients to conduct effective self-screening.关键词:inspection diagnosis of traditional Chinese medicine;feature extraction;feature fusion;end-to-end;Transformer176|193|3更新时间:2024-05-07 -
 摘要:ObjectiveStroke is a severe human cerebrovascular disease that causes brain tissue damage due to sudden rupture of blood vessels or vascular obstruction originated blood flow inefficiency. The incidence of ischemic stroke is high frequency, high recurrence rate and high fatality rate. Traditional Chinese medicine (TCM) has its priority of stroke. In the four-diagnosis-inspection, listening, asking and feeling the pulse-(in Chinese) of Chinese medicine, the prime step of inspection shows that information extraction is one of the essential factors of TCM. But, TCM has its constraints of medical standardization and manual factor issues. A deep learning technology is benefit to further recognize the constraints of TCM.MethodOur research illustrates a dual-branch cross-attention feature fusion model (DCFFM) based on facial images and hand images. It can assists in predicting stroke disease well. The overall model is divided into three parts: facial feature extraction module, hand feature extraction module and feature fusion module. For the facial feature extraction module, we construct the subject branch and auxiliary information branch to extract facial features. In accordance with the guidance of Chinese medicine doctors, we pre-process the facial image and use the key diagnostic area of the stroke in the face as the input of the main branch. In addition, we also integrate the knowledge of inspection of TCM to cut out the image of the area around the eyebrows, and use the Sobel filter to extract the gradient image as the input of the auxiliary information branch. For the hand feature extraction module, this demonstration adopts the same double-branch structure to cut out the palm area as the input of the main branch. In order to more stably and accurately reflect the pathological condition of the hand and reflect the small changes in the characteristics of the hand, we convert the palm image from the RGB color space to the HSV color space and transfer it to the differentiated auxiliary information branch. The proposed branches are respectively input to their respective convolution blocks, and the depth characteristics of the input data are extracted based on the convolution operation. Max pooling is used on the feature maps and batch normalization is used to prevent the model from over-fitting. In addition, we use two loss functions to constrain the training of the two feature extraction modules, and use the total loss to constrain the entire model. Between the two branches of each feature extraction module, we built an information interaction module (IIM) for further information interaction amongst the branches to reveal the model extract distinctive features. It assigns a certain weight to the feature map of auxiliary information and then interconnected with the feature of the subject branch. We use 1 × 1 convolution fusion to reduce dimensionality. Under no special operations circumstances, the IIM can be trained in an end-to-end manipulation. For the feature fusion module, multiple convolutional layers are used for overall fusion dimensionality reduction to generate the prediction result via the multi-branch deep feature fusion based on fusing the depth features of the facial feature extraction module and the hand feature extraction module.ResultIn order to aid model training and improve the stability and robustness of the model, our demonstration screens and extends the collected 3 011 face and hand image data. We remove some scrambled images with scars and conduct the data extension by horizontal flipping. We remove some images of peeling, disability, background clutter and implement random option for the remaining images to expand the data by horizontal flipping. It is determined that 3 964 images of positive and negative samples are involved as the experimental data set. Our multiple sets of comparative experiments and ablation experiments have been facilitated based on a variety of evaluation indicators to verify the performance of the model, such as accuracy, specificity, sensitivity, and F1-score. First, we compare the overall performance of the proposed method with the current mainstream classification algorithms. Experimental results show that the accuracy of the method proposed reaches 83.36%, which is 3%—7% higher than the performance of other mainstream classification models. Based on ten-fold cross-validation, the specificity and sensitivity reached 82.47% and 85.10% respectively. The illustrated sensitivity shows a relatively large advantage, indicating that the method in this paper has a better performance for the detection of true positives. Next, we still verified the impact of facial feature extraction module, hand feature extraction module and IIM on the performance of the model. This analyzed results show that feature extraction of face data and hand data can effectively improve the performance of the model simultaneously. In addition, the IIM has targeted the sensitivity and specificity of the model.ConclusionOur method can use human facial features and human hand data to assist in stroke prediction, and has good stability and robustness. Meanwhile, the demonstrated IIM also promotes the information interaction between multi-branch tasks.关键词:inspection diagnosis of traditional Chinese medicine;stroke;image identification;feature extraction;feature fusion;convolutional neural network82|270|0更新时间:2024-05-07
摘要:ObjectiveStroke is a severe human cerebrovascular disease that causes brain tissue damage due to sudden rupture of blood vessels or vascular obstruction originated blood flow inefficiency. The incidence of ischemic stroke is high frequency, high recurrence rate and high fatality rate. Traditional Chinese medicine (TCM) has its priority of stroke. In the four-diagnosis-inspection, listening, asking and feeling the pulse-(in Chinese) of Chinese medicine, the prime step of inspection shows that information extraction is one of the essential factors of TCM. But, TCM has its constraints of medical standardization and manual factor issues. A deep learning technology is benefit to further recognize the constraints of TCM.MethodOur research illustrates a dual-branch cross-attention feature fusion model (DCFFM) based on facial images and hand images. It can assists in predicting stroke disease well. The overall model is divided into three parts: facial feature extraction module, hand feature extraction module and feature fusion module. For the facial feature extraction module, we construct the subject branch and auxiliary information branch to extract facial features. In accordance with the guidance of Chinese medicine doctors, we pre-process the facial image and use the key diagnostic area of the stroke in the face as the input of the main branch. In addition, we also integrate the knowledge of inspection of TCM to cut out the image of the area around the eyebrows, and use the Sobel filter to extract the gradient image as the input of the auxiliary information branch. For the hand feature extraction module, this demonstration adopts the same double-branch structure to cut out the palm area as the input of the main branch. In order to more stably and accurately reflect the pathological condition of the hand and reflect the small changes in the characteristics of the hand, we convert the palm image from the RGB color space to the HSV color space and transfer it to the differentiated auxiliary information branch. The proposed branches are respectively input to their respective convolution blocks, and the depth characteristics of the input data are extracted based on the convolution operation. Max pooling is used on the feature maps and batch normalization is used to prevent the model from over-fitting. In addition, we use two loss functions to constrain the training of the two feature extraction modules, and use the total loss to constrain the entire model. Between the two branches of each feature extraction module, we built an information interaction module (IIM) for further information interaction amongst the branches to reveal the model extract distinctive features. It assigns a certain weight to the feature map of auxiliary information and then interconnected with the feature of the subject branch. We use 1 × 1 convolution fusion to reduce dimensionality. Under no special operations circumstances, the IIM can be trained in an end-to-end manipulation. For the feature fusion module, multiple convolutional layers are used for overall fusion dimensionality reduction to generate the prediction result via the multi-branch deep feature fusion based on fusing the depth features of the facial feature extraction module and the hand feature extraction module.ResultIn order to aid model training and improve the stability and robustness of the model, our demonstration screens and extends the collected 3 011 face and hand image data. We remove some scrambled images with scars and conduct the data extension by horizontal flipping. We remove some images of peeling, disability, background clutter and implement random option for the remaining images to expand the data by horizontal flipping. It is determined that 3 964 images of positive and negative samples are involved as the experimental data set. Our multiple sets of comparative experiments and ablation experiments have been facilitated based on a variety of evaluation indicators to verify the performance of the model, such as accuracy, specificity, sensitivity, and F1-score. First, we compare the overall performance of the proposed method with the current mainstream classification algorithms. Experimental results show that the accuracy of the method proposed reaches 83.36%, which is 3%—7% higher than the performance of other mainstream classification models. Based on ten-fold cross-validation, the specificity and sensitivity reached 82.47% and 85.10% respectively. The illustrated sensitivity shows a relatively large advantage, indicating that the method in this paper has a better performance for the detection of true positives. Next, we still verified the impact of facial feature extraction module, hand feature extraction module and IIM on the performance of the model. This analyzed results show that feature extraction of face data and hand data can effectively improve the performance of the model simultaneously. In addition, the IIM has targeted the sensitivity and specificity of the model.ConclusionOur method can use human facial features and human hand data to assist in stroke prediction, and has good stability and robustness. Meanwhile, the demonstrated IIM also promotes the information interaction between multi-branch tasks.关键词:inspection diagnosis of traditional Chinese medicine;stroke;image identification;feature extraction;feature fusion;convolutional neural network82|270|0更新时间:2024-05-07
Traditional Chinese Medical Image
-
 摘要:ObjectiveCataracts are the primary inducement for human blindness and vision impairment. Early intervention and cataract surgery can effectively improve the vision and life quality of cataract patients. Anterior segment optical coherence tomography (AS-OCT) image can capture cataract opacity information through a non-contact, objective, and fast manner. Compared with other ophthalmic images like fundus images, AS-OCT images are capable of capturing the clear nucleus region, which is very significant for nuclear cataract (NC) diagnosis. Clinical studies have identified that a strong opacity correlation relationship and high repeatability between average density value of the nucleus region and NC severity levels in AS-OCT images. Moreover, the clinical works also have suggested that the correlation relationships between different nucleus regions and NC severity levels. These original research works provide the clinical reference for automatic AS-OCT image-based NC classification. However, automatic NC classification based on AS-OCT images has been rarely studied, and there is much improvement room for NC classification performance on AS-OCT images.MethodMotivated by the clinical research of NC, this paper proposes an efficient multi-region fusion attention network (MRA-Net) model by infusing clinical prior knowledge, aiming to classify nuclear cataract severity levels on AS-OCT images accurately. In the MRA-Net, we construct a multi-region fusion attention (MRA) block to fuse feature representation information from different nucleus regions to enhance the overall classification performance, in which we not only adopt the summation operation to fuse different region information but also apply the softmax function to focus on salient channel and suppress redundant channels. In respect of the residual connection can alleviate the gradient vanishing issue, the MRA block is plugged into a cluster of Residual-MRA modules to demonstrate MRA-Net. Moreover, we also test the impacts of two different dataset splitting methods on NC classification results: participant-based splitting method and eye-based splitting method, which is easily ignored by previous works. In the training, this paper resizes the original AS-OCT images into 224 × 224 pixels as the network inputs and set batch size to 16. Stochastic gradient descent (SGD) optimizer is used as the optimizer with default settings and we set training epochs to 100.ResultOur research analysis demonstrates that the proposed MRA-Net achieves 87.78% accuracy and obtains 1% improvement than squeeze and excitation network (SENet) based on a clinical AS-OCT image dataset. We also conduct comparable experiments to verify that the summation operation works better the concatenation on the MRA block by using ResNet as the backbone network. The results of two dataset splitting methods also that ten classification methods like MRA-Net and SENet obtain better classification results on the eye-based dataset than the participant-based dataset, e.g., the highest improvements on F1 and Kappa are 4.03% and 8% correspondingly.ConclusionOur MRA-Net considers the difference of feature distribution in different regions in a feature map and incorporates the clinical priors into network architecture design. MRA-Net obtains surpassing classification performance and outperforms advanced methods. The classification results of two dataset splitting methods on AS-OCT image dataset also indicated that given the similar nuclear cataract severity in the two eyes of the same participant. Thus, the AS-OCT image dataset is suggested to be split based on the participant level rather than the eye level, which ensures that each participant falls into the same training or testing datasets. Overall, our MRA-Net has the potential as a computer-aided diagnosis tool to assist clinicians in diagnosing cataract.关键词:nuclear cataract classification;anterior segment optical coherence tomography(AS-OCT) image;multi-region fusion attention block;deep learning;nucleus region103|232|2更新时间:2024-05-07
摘要:ObjectiveCataracts are the primary inducement for human blindness and vision impairment. Early intervention and cataract surgery can effectively improve the vision and life quality of cataract patients. Anterior segment optical coherence tomography (AS-OCT) image can capture cataract opacity information through a non-contact, objective, and fast manner. Compared with other ophthalmic images like fundus images, AS-OCT images are capable of capturing the clear nucleus region, which is very significant for nuclear cataract (NC) diagnosis. Clinical studies have identified that a strong opacity correlation relationship and high repeatability between average density value of the nucleus region and NC severity levels in AS-OCT images. Moreover, the clinical works also have suggested that the correlation relationships between different nucleus regions and NC severity levels. These original research works provide the clinical reference for automatic AS-OCT image-based NC classification. However, automatic NC classification based on AS-OCT images has been rarely studied, and there is much improvement room for NC classification performance on AS-OCT images.MethodMotivated by the clinical research of NC, this paper proposes an efficient multi-region fusion attention network (MRA-Net) model by infusing clinical prior knowledge, aiming to classify nuclear cataract severity levels on AS-OCT images accurately. In the MRA-Net, we construct a multi-region fusion attention (MRA) block to fuse feature representation information from different nucleus regions to enhance the overall classification performance, in which we not only adopt the summation operation to fuse different region information but also apply the softmax function to focus on salient channel and suppress redundant channels. In respect of the residual connection can alleviate the gradient vanishing issue, the MRA block is plugged into a cluster of Residual-MRA modules to demonstrate MRA-Net. Moreover, we also test the impacts of two different dataset splitting methods on NC classification results: participant-based splitting method and eye-based splitting method, which is easily ignored by previous works. In the training, this paper resizes the original AS-OCT images into 224 × 224 pixels as the network inputs and set batch size to 16. Stochastic gradient descent (SGD) optimizer is used as the optimizer with default settings and we set training epochs to 100.ResultOur research analysis demonstrates that the proposed MRA-Net achieves 87.78% accuracy and obtains 1% improvement than squeeze and excitation network (SENet) based on a clinical AS-OCT image dataset. We also conduct comparable experiments to verify that the summation operation works better the concatenation on the MRA block by using ResNet as the backbone network. The results of two dataset splitting methods also that ten classification methods like MRA-Net and SENet obtain better classification results on the eye-based dataset than the participant-based dataset, e.g., the highest improvements on F1 and Kappa are 4.03% and 8% correspondingly.ConclusionOur MRA-Net considers the difference of feature distribution in different regions in a feature map and incorporates the clinical priors into network architecture design. MRA-Net obtains surpassing classification performance and outperforms advanced methods. The classification results of two dataset splitting methods on AS-OCT image dataset also indicated that given the similar nuclear cataract severity in the two eyes of the same participant. Thus, the AS-OCT image dataset is suggested to be split based on the participant level rather than the eye level, which ensures that each participant falls into the same training or testing datasets. Overall, our MRA-Net has the potential as a computer-aided diagnosis tool to assist clinicians in diagnosing cataract.关键词:nuclear cataract classification;anterior segment optical coherence tomography(AS-OCT) image;multi-region fusion attention block;deep learning;nucleus region103|232|2更新时间:2024-05-07 -
 摘要:ObjectiveLinear lesion is an important symptom in the progressive development of high myopia to pathological myopia. Clinical studies have shown that linear lesion appears as retinal pigment epithelium-Bruch's membrane-choriocapillaris complex (RBCC) disruption in non-invasive retinal optical coherence tomography (OCT) images; it includes RBCC disorder and myopic stretch line. Recently, convolutional neural networks (CNNs) have demonstrated excellent performance on computer vision tasks, and many convolutional neural network based methods have been applied for medical segmentation tasks. However, the automatic segmentation of linear lesion is extremely challenging due to the small target attribution and blurred boundary problem. To tackle this issue, a novel deep-supervision and feature-aggregation based network (DSFA-Net) is proposed for the segmentation of linear lesion in OCT image with high myopia.MethodTo reduce the network parameters, the proposed DSFA-Net considers the U-Net with half channels the baseline. A novel feature aggregation pooling module (FAPM) is proposed and embedded in the encoder path to preserve more details for small targets. It can aggregate the contextual information and local spatial information during the downsampling operation. FAPM is performed using two steps. First, the input feature map is parallel fed into three pathways. The first two pathways contain a horizontal and vertical strip pooling layer followed by a 1D convolutional layer with kernel size of 1×3 and 3×1 and a reshape layer to capture contextual information. The third pathway contains a 2D convolutional layer with kernel size 7×7 followed by a sigmoid function to enable each pixel to obtain a normalized weight between 0 and 1. These weights are multiplied with the original input feature and fed into a reshape layer to capture the local spatial information. Second, the output features of these pathways are combined by the element-wise addition to obtain the aggregated output feature. A novel dense semantic flow supervision module (DSFSM) is proposed and embedded in the decoder path to aggregate the details and semantic information between features with different resolutions during the feature decoding. This approach combines the advantages of deep supervision and dense semantic flow supervision strategy and increases the effective feature maps in the hidden layers of the network. The proposed DSFA-Net is implemented and trained based on Python3.8 and Pytorch with NVDIA TITAN X GPU, Intel i7-9700KF CPU. The initial learning rate is set to 0.001, and the batch size is set to 2. Stochastic gradient descent (SGD) with a momentum of 0.9 and weight decay of 0.000 1 is adopted as the optimizer. Binary cross entropy (BCE) loss and Dice loss are combined as the total loss function for the proposed DSFA-Net because linear lesion has variant sizes, which cause data unbalance problem.ResultThe proposed DSFA-Net was evaluated on 751 2D retinal OCT B-scan images provided by the First People's Hospital Affiliated to Shanghai Jiao Tong University. The size of each OCT B-scan image is 256×512 pixels. The ground truth is manually annotated under the supervision of the experienced ophthalmologists. Compared with the original U-Net, the proposed DSFA-Net decreases the network parameter number by 53.19%, and the average Dice similarity coefficient (DSC), Jaccard, and sensitivity indicators increase by 4.30%, 4.60%, and 2.35%, respectively. Compared with the seven other existing image semantic segmentation networks, such as CE-Net, SegNet, and Attention-UNet, the proposed DSFA-Net has achieved state-of-the-art segmentation performance while maintaining the minimum amount of network parameters. Several ablation experiments have been designed and conducted to evaluate the performance of the proposed FAPM and DSFSM modules. With the embedding of FAPM into the encoder path of the baseline (baseline+FAPM), the average DSC, Jaccard, and sensitivity indicators increase by 1.05%, 1.35%, and 3.35%, respectively. With the embedding of DSFSM into the decoder path of the baseline (baseline+DSFSM), the average DSC, Jaccard, and sensitivity indicators increase by 4.90%, 5.35%, and 5.90%, respectively. With the embedding of FAPM and DSFSM into the baseline (the proposed DSFA-Net), the average DSC, Jaccard, and sensitivity indicators increase by 6.00%, 6.45%, and 5.50%, respectively. The results of the ablation experiment show that the proposed FAPM and DSFSM modules can effectively improve the segmentation performance of the network.ConclusionWe propose a novel deep-supervision and feature-aggregation based network for the segmentation of linear lesion in OCT image with high myopia. The proposed FAPM and DSFSM modules can be inserted into convolutional neural networks conveniently. The experimental results prove that the proposed DSFA-Net improves the accuracy of linear lesion segmentation in retinal OCT images, indicating the potential clinical application value.关键词:high myopia;linear lesion;optical coherence tomography(OCT);deep supervision;feature aggregation;convolutional neural network(CNN);medical image segmentation82|142|0更新时间:2024-05-07
摘要:ObjectiveLinear lesion is an important symptom in the progressive development of high myopia to pathological myopia. Clinical studies have shown that linear lesion appears as retinal pigment epithelium-Bruch's membrane-choriocapillaris complex (RBCC) disruption in non-invasive retinal optical coherence tomography (OCT) images; it includes RBCC disorder and myopic stretch line. Recently, convolutional neural networks (CNNs) have demonstrated excellent performance on computer vision tasks, and many convolutional neural network based methods have been applied for medical segmentation tasks. However, the automatic segmentation of linear lesion is extremely challenging due to the small target attribution and blurred boundary problem. To tackle this issue, a novel deep-supervision and feature-aggregation based network (DSFA-Net) is proposed for the segmentation of linear lesion in OCT image with high myopia.MethodTo reduce the network parameters, the proposed DSFA-Net considers the U-Net with half channels the baseline. A novel feature aggregation pooling module (FAPM) is proposed and embedded in the encoder path to preserve more details for small targets. It can aggregate the contextual information and local spatial information during the downsampling operation. FAPM is performed using two steps. First, the input feature map is parallel fed into three pathways. The first two pathways contain a horizontal and vertical strip pooling layer followed by a 1D convolutional layer with kernel size of 1×3 and 3×1 and a reshape layer to capture contextual information. The third pathway contains a 2D convolutional layer with kernel size 7×7 followed by a sigmoid function to enable each pixel to obtain a normalized weight between 0 and 1. These weights are multiplied with the original input feature and fed into a reshape layer to capture the local spatial information. Second, the output features of these pathways are combined by the element-wise addition to obtain the aggregated output feature. A novel dense semantic flow supervision module (DSFSM) is proposed and embedded in the decoder path to aggregate the details and semantic information between features with different resolutions during the feature decoding. This approach combines the advantages of deep supervision and dense semantic flow supervision strategy and increases the effective feature maps in the hidden layers of the network. The proposed DSFA-Net is implemented and trained based on Python3.8 and Pytorch with NVDIA TITAN X GPU, Intel i7-9700KF CPU. The initial learning rate is set to 0.001, and the batch size is set to 2. Stochastic gradient descent (SGD) with a momentum of 0.9 and weight decay of 0.000 1 is adopted as the optimizer. Binary cross entropy (BCE) loss and Dice loss are combined as the total loss function for the proposed DSFA-Net because linear lesion has variant sizes, which cause data unbalance problem.ResultThe proposed DSFA-Net was evaluated on 751 2D retinal OCT B-scan images provided by the First People's Hospital Affiliated to Shanghai Jiao Tong University. The size of each OCT B-scan image is 256×512 pixels. The ground truth is manually annotated under the supervision of the experienced ophthalmologists. Compared with the original U-Net, the proposed DSFA-Net decreases the network parameter number by 53.19%, and the average Dice similarity coefficient (DSC), Jaccard, and sensitivity indicators increase by 4.30%, 4.60%, and 2.35%, respectively. Compared with the seven other existing image semantic segmentation networks, such as CE-Net, SegNet, and Attention-UNet, the proposed DSFA-Net has achieved state-of-the-art segmentation performance while maintaining the minimum amount of network parameters. Several ablation experiments have been designed and conducted to evaluate the performance of the proposed FAPM and DSFSM modules. With the embedding of FAPM into the encoder path of the baseline (baseline+FAPM), the average DSC, Jaccard, and sensitivity indicators increase by 1.05%, 1.35%, and 3.35%, respectively. With the embedding of DSFSM into the decoder path of the baseline (baseline+DSFSM), the average DSC, Jaccard, and sensitivity indicators increase by 4.90%, 5.35%, and 5.90%, respectively. With the embedding of FAPM and DSFSM into the baseline (the proposed DSFA-Net), the average DSC, Jaccard, and sensitivity indicators increase by 6.00%, 6.45%, and 5.50%, respectively. The results of the ablation experiment show that the proposed FAPM and DSFSM modules can effectively improve the segmentation performance of the network.ConclusionWe propose a novel deep-supervision and feature-aggregation based network for the segmentation of linear lesion in OCT image with high myopia. The proposed FAPM and DSFSM modules can be inserted into convolutional neural networks conveniently. The experimental results prove that the proposed DSFA-Net improves the accuracy of linear lesion segmentation in retinal OCT images, indicating the potential clinical application value.关键词:high myopia;linear lesion;optical coherence tomography(OCT);deep supervision;feature aggregation;convolutional neural network(CNN);medical image segmentation82|142|0更新时间:2024-05-07 -
 摘要:ObjectiveThe regions of interest (ROI) extrancted correction in hand-wrist reference bones is the essential method to target accurate bone age. Current image processing methods have high time complexity and operation difficulty, which cannot meet the requirement of large-scale clinical use. Deep learning technology has its feature extraction priority but the missing and misjudgment of individual reference bones will lead to low average extraction accuracy when it is used to extract ROIs of hand-wrist reference bones. The intensive positioning and classification capability of object detection algorithms is analyzed to demonstrate an automatic reference bone matching and correction method for the purpose of extracting all hand-wrist ROIs accurately.MethodThe amount of reference bones in the human hand-wrist is clear in common. The identified illustration strict regularity and correlation for the time-scaled bone age. Based on this, a large quantity of human hand-wrist X-ray images have been collected as the benchmark in genders and age scales. As for the evaluation, the reference bone sample orientation can be easily identified to calibrate the reference bone ROI and improve the extraction accuracy further based on matching the position similarity between the sample and the standard atlas. This demonstration is mainly divided into 3 steps: 1) All reference bone candidate ROIs are extracted in preliminary based on the object detection algorithm. Due to the insufficient generalization capability of most deep learning models, the accuracy rate is low when extracting some complicated reference bones. Based on the results of the reference bone candidate ROIs generated, this research adds a series of post-processing procedures, including replicated ROIs of the same reference bone category deduction, and filter regions alteration with low confidence in terms of the threshold set by the algorithm; 2) In order to guarantee the overall capability of the reference bone ROI extraction, it is necessary to match automatically and refill the deducted regions of the sample. First, while the skeletal development process of different human hand-wrists is similar, the distribution of reference bones in the same skeletal region is also strictly regular. It is of great value to use the large data atlas of reference bones to evaluate the sample's ROI. Hence, the human hand-wrist is segmented into 4 individual skeletal regions in terms of the bone growth characteristics. Different skeletal regions are matched and corrected independently. Next, a location-point matching model sorted out the most similar changeable features, such as the shape and position of the deducted region based on the big data standardized atlas of reference bones and choose it as the reference bone ROI that is missing from the sample; 3) The generated ROI cannot guarantee high-coordinated accuracy, it is required to optimize the location coordinates for a higher extraction accuracy further based on the refilled ROI result. On the basis of the refilled ROI coordinates, all possible regions of the reference bone category in the hand-wrist are categorized via a multi-scale sliding window and construct the ROI classification model to generate the possibility of the current reference bone in the window region. The region with the highest confidence is altered as the revised reference bone ROI. The basic network structure of AlexNet is demonstrated in the ROI classification model, which includes five convolutional layers and three fully connected layers.Moreover, the image augmentation method is applied to generate all positive and negative samples of the reference bone ROIs for model training. At the end, the trained model is applied in to verify its classification effect in the testing set.ResultThe demonstrated results illustrated that the intergrated method of object detection and matching correction algorithms has its priority. The ROI classification model application can achieve a classification accuracy of more than 99% for all 14 reference bones. When the location-point matching model is used to correct a single reference bone ROI in different skeletal regions, it can reach an average of 92.56% accuracy. The integrated matching correction method combining with proposed models can improve the average accuracy of 1.42% based on the extraction results from the object detection algorithms. The average accuracy of faster region-convolutional neural network (Faster R-CNN), you only look once v3(YOLOv3), and single shot multibox detector(SSD) has increased by 0.54%, 2.48% and 1.23%, respectively. Based on the Faster R-CNN algorithm intergration, it can reach the highest 98.45% intersection-over-union (IoU) accuracy rate. The calculated IoU value is greater than or equal to 0.75, the currently predicted candidate region is assessed as the correct region.ConclusionIn terms of the location features of the hand-wrist reference bones, this method can re-match and correct the individual reference bone categories that are difficult to extract. Following sufficient data atlas of other reference bone categories, this method can be further applied to multiple bone age scoring methods including the TW3 and RUS-CHN method.关键词:region of interest(ROI);object detection;location matching;big data;sliding window64|207|0更新时间:2024-05-07
摘要:ObjectiveThe regions of interest (ROI) extrancted correction in hand-wrist reference bones is the essential method to target accurate bone age. Current image processing methods have high time complexity and operation difficulty, which cannot meet the requirement of large-scale clinical use. Deep learning technology has its feature extraction priority but the missing and misjudgment of individual reference bones will lead to low average extraction accuracy when it is used to extract ROIs of hand-wrist reference bones. The intensive positioning and classification capability of object detection algorithms is analyzed to demonstrate an automatic reference bone matching and correction method for the purpose of extracting all hand-wrist ROIs accurately.MethodThe amount of reference bones in the human hand-wrist is clear in common. The identified illustration strict regularity and correlation for the time-scaled bone age. Based on this, a large quantity of human hand-wrist X-ray images have been collected as the benchmark in genders and age scales. As for the evaluation, the reference bone sample orientation can be easily identified to calibrate the reference bone ROI and improve the extraction accuracy further based on matching the position similarity between the sample and the standard atlas. This demonstration is mainly divided into 3 steps: 1) All reference bone candidate ROIs are extracted in preliminary based on the object detection algorithm. Due to the insufficient generalization capability of most deep learning models, the accuracy rate is low when extracting some complicated reference bones. Based on the results of the reference bone candidate ROIs generated, this research adds a series of post-processing procedures, including replicated ROIs of the same reference bone category deduction, and filter regions alteration with low confidence in terms of the threshold set by the algorithm; 2) In order to guarantee the overall capability of the reference bone ROI extraction, it is necessary to match automatically and refill the deducted regions of the sample. First, while the skeletal development process of different human hand-wrists is similar, the distribution of reference bones in the same skeletal region is also strictly regular. It is of great value to use the large data atlas of reference bones to evaluate the sample's ROI. Hence, the human hand-wrist is segmented into 4 individual skeletal regions in terms of the bone growth characteristics. Different skeletal regions are matched and corrected independently. Next, a location-point matching model sorted out the most similar changeable features, such as the shape and position of the deducted region based on the big data standardized atlas of reference bones and choose it as the reference bone ROI that is missing from the sample; 3) The generated ROI cannot guarantee high-coordinated accuracy, it is required to optimize the location coordinates for a higher extraction accuracy further based on the refilled ROI result. On the basis of the refilled ROI coordinates, all possible regions of the reference bone category in the hand-wrist are categorized via a multi-scale sliding window and construct the ROI classification model to generate the possibility of the current reference bone in the window region. The region with the highest confidence is altered as the revised reference bone ROI. The basic network structure of AlexNet is demonstrated in the ROI classification model, which includes five convolutional layers and three fully connected layers.Moreover, the image augmentation method is applied to generate all positive and negative samples of the reference bone ROIs for model training. At the end, the trained model is applied in to verify its classification effect in the testing set.ResultThe demonstrated results illustrated that the intergrated method of object detection and matching correction algorithms has its priority. The ROI classification model application can achieve a classification accuracy of more than 99% for all 14 reference bones. When the location-point matching model is used to correct a single reference bone ROI in different skeletal regions, it can reach an average of 92.56% accuracy. The integrated matching correction method combining with proposed models can improve the average accuracy of 1.42% based on the extraction results from the object detection algorithms. The average accuracy of faster region-convolutional neural network (Faster R-CNN), you only look once v3(YOLOv3), and single shot multibox detector(SSD) has increased by 0.54%, 2.48% and 1.23%, respectively. Based on the Faster R-CNN algorithm intergration, it can reach the highest 98.45% intersection-over-union (IoU) accuracy rate. The calculated IoU value is greater than or equal to 0.75, the currently predicted candidate region is assessed as the correct region.ConclusionIn terms of the location features of the hand-wrist reference bones, this method can re-match and correct the individual reference bone categories that are difficult to extract. Following sufficient data atlas of other reference bone categories, this method can be further applied to multiple bone age scoring methods including the TW3 and RUS-CHN method.关键词:region of interest(ROI);object detection;location matching;big data;sliding window64|207|0更新时间:2024-05-07 -
 摘要:Objectiveopen field test (OFT) video classification is a wide spread method to assess locomotors activity and mice habits control in pharmacological experiments. One major goal of traditional OFT is to sort out distinguishable features between a testing group and a reference group. Researchers will analyze those video clips to find out animal behaviors differences for the two groups of mice based on digital OFT videos records. The manual inspection of OFT data is time consumed and high cost involved. A detailed analysis process relies heavily on professional experiences. Our research illustrates a learning-based classification through an OFT-videos-based quantitative feature extraction. We show that a spliced feature matrix learning method has its priority than current independent features. Hence, a convolutional neural network based solution sort out the oriented video clips of two groups of mice. Our analyzed results can be summarized as following: 1) a novel spliced feature matrix of OFT video is demonstrated based on 22-dimension quantitative behavioral features. 2) To analyze the influence of network structure on the classification, we design and test 8 different convolutional neural networks in the experiments.MethodOur research focuses on the varied characteristics between the two groups of mice macroscopic behavior. In the context of the spatial and temporal domain of OFT video data, 22 distinct types of features are extracted including average crawling speed and distance, the positional distribution of staying, resting time, turning frequencies and so on. These quantitative vector-based descriptions of the OFT video can be well distinguished based on traditional machine learning classifiers, such as K-means clustering, boosting classification, support vector machine (SVM), or convolutional neural network (CNN). Some quantitative feature vectors are proposed to separate the testing group from the reference group. Another critical factor is the mice crawling path, which cannot be vector-oriented. A novel regularization and fusion are employed to illustrate both the quantitative features and non-quantitative crawling path. By constructing the targeted self-correlation matrix of weighted feature vectors, a 484 × 484 quantitative feature matrix is spliced with a 484 × 484 crawling path image, and it leads a spliced feature matrix representation with a 2D dimension of 484 × 968. We introduce a CNN-based classification of spliced feature matrices from different network structures. Based on 4-layers CNN to 10-layers CNN, the quantitative feature matrix or the spliced feature matrices are learned via the basic network structures, which are we evaluate the impacts of different network structures and feature dimensions on the precision of OFT video classification further. In the experiments, we test the demonstrated feature extraction and classification on the real OFT dataset. The dataset is composed of OFT video of 32 mice, including 17 mice in the test group and 15 mice in the reference group. The testing animal group is injected with a kind of anti-depressants, and the reference group injected with only placebo. Each mouse is eye-captured independently using a video camera for a 24 hours timescale detection in the OFT experiment. These video data is cropped into targeted short duration video clips, each of which is 10 minutes long. We construct a dataset based on 3 080 testing samples and 1 034 reference samples. In the training analysis, the training dataset is based on 3 000 samples and the testing dataset is based on 1 114 samples.ResultOur demonstration indicates that the proposed algorithm is optimized to manual classification and supported-vector-machine solution. In respect of the experiment datasets, the classification precision of the proposed algorithm is up to 99.25%. The accurate classification of mouse OFT video can be achieved via a simplified network structure, such as a 9-layers CNN. The varied feature dimension to classification accuracy is not balanced. In terms of the ablation results among different quantitative features, the large angle turning, staying time and positional distribution are critical for identifying its grouping than other quantitative feature dimensions. Non-quantitative crawling path image has obvious contribution to classification, which improves 2%—3% precision in classification. The demonstration also verifies can achieve good classification via a sample network structure.ConclusionOverall, we propose a CNN-based solution to classify the testing group OFT videos from the reference group of OFT videos via the spliced feature matrix learning. Both the quantitative features and qualitative crawling path are melted into a novel regularization and fusion. The identified classification has optimized on manual classification and traditional SVM methods. Our classification precision can reach 99.25% on the experimental dataset. It demonstrates a great potential for the OFT analysis. The further research work can verify the relationship between distinguishable features and detailed mouse behavior. The learning network optimization can be further called to enhance the generalization of the OFT classification.关键词:open field test (OFT);behavioral analysis;video classification;spliced feature matrix;convolutional neural network (CNN)52|110|1更新时间:2024-05-07
摘要:Objectiveopen field test (OFT) video classification is a wide spread method to assess locomotors activity and mice habits control in pharmacological experiments. One major goal of traditional OFT is to sort out distinguishable features between a testing group and a reference group. Researchers will analyze those video clips to find out animal behaviors differences for the two groups of mice based on digital OFT videos records. The manual inspection of OFT data is time consumed and high cost involved. A detailed analysis process relies heavily on professional experiences. Our research illustrates a learning-based classification through an OFT-videos-based quantitative feature extraction. We show that a spliced feature matrix learning method has its priority than current independent features. Hence, a convolutional neural network based solution sort out the oriented video clips of two groups of mice. Our analyzed results can be summarized as following: 1) a novel spliced feature matrix of OFT video is demonstrated based on 22-dimension quantitative behavioral features. 2) To analyze the influence of network structure on the classification, we design and test 8 different convolutional neural networks in the experiments.MethodOur research focuses on the varied characteristics between the two groups of mice macroscopic behavior. In the context of the spatial and temporal domain of OFT video data, 22 distinct types of features are extracted including average crawling speed and distance, the positional distribution of staying, resting time, turning frequencies and so on. These quantitative vector-based descriptions of the OFT video can be well distinguished based on traditional machine learning classifiers, such as K-means clustering, boosting classification, support vector machine (SVM), or convolutional neural network (CNN). Some quantitative feature vectors are proposed to separate the testing group from the reference group. Another critical factor is the mice crawling path, which cannot be vector-oriented. A novel regularization and fusion are employed to illustrate both the quantitative features and non-quantitative crawling path. By constructing the targeted self-correlation matrix of weighted feature vectors, a 484 × 484 quantitative feature matrix is spliced with a 484 × 484 crawling path image, and it leads a spliced feature matrix representation with a 2D dimension of 484 × 968. We introduce a CNN-based classification of spliced feature matrices from different network structures. Based on 4-layers CNN to 10-layers CNN, the quantitative feature matrix or the spliced feature matrices are learned via the basic network structures, which are we evaluate the impacts of different network structures and feature dimensions on the precision of OFT video classification further. In the experiments, we test the demonstrated feature extraction and classification on the real OFT dataset. The dataset is composed of OFT video of 32 mice, including 17 mice in the test group and 15 mice in the reference group. The testing animal group is injected with a kind of anti-depressants, and the reference group injected with only placebo. Each mouse is eye-captured independently using a video camera for a 24 hours timescale detection in the OFT experiment. These video data is cropped into targeted short duration video clips, each of which is 10 minutes long. We construct a dataset based on 3 080 testing samples and 1 034 reference samples. In the training analysis, the training dataset is based on 3 000 samples and the testing dataset is based on 1 114 samples.ResultOur demonstration indicates that the proposed algorithm is optimized to manual classification and supported-vector-machine solution. In respect of the experiment datasets, the classification precision of the proposed algorithm is up to 99.25%. The accurate classification of mouse OFT video can be achieved via a simplified network structure, such as a 9-layers CNN. The varied feature dimension to classification accuracy is not balanced. In terms of the ablation results among different quantitative features, the large angle turning, staying time and positional distribution are critical for identifying its grouping than other quantitative feature dimensions. Non-quantitative crawling path image has obvious contribution to classification, which improves 2%—3% precision in classification. The demonstration also verifies can achieve good classification via a sample network structure.ConclusionOverall, we propose a CNN-based solution to classify the testing group OFT videos from the reference group of OFT videos via the spliced feature matrix learning. Both the quantitative features and qualitative crawling path are melted into a novel regularization and fusion. The identified classification has optimized on manual classification and traditional SVM methods. Our classification precision can reach 99.25% on the experimental dataset. It demonstrates a great potential for the OFT analysis. The further research work can verify the relationship between distinguishable features and detailed mouse behavior. The learning network optimization can be further called to enhance the generalization of the OFT classification.关键词:open field test (OFT);behavioral analysis;video classification;spliced feature matrix;convolutional neural network (CNN)52|110|1更新时间:2024-05-07 -
 摘要:ObjectiveAt present, the prevalence of cardiovascular disease continues to increase in China. Approximately 290 million people in China suffer from cardiovascular and cerebrovascular diseases. In 2016, the mortality rate of cardiovascular disease was the highest in China. Cardiovascular disease has caused a serious burden on the society; thus, the prevention and treatment of cardiovascular disease are urgent. Vascular interventional surgery is one of the main methods for the treatment of cardiovascular diseases, which has the advantages of less blood loss, less trauma, less complications, and rapid postoperative recovery. In the process of vascular interventional surgery, the contact force between the front end of the interventional instrument and the vascular wall is greatly important to the safety of the operation. If the contact force is extremely large, then the vascular wall becomes scratched and punctured or the plaque is moved, thereby leading to the failure of the operation and may cause danger to the lives of patients. Therefore, measuring the contact force of the front end of interventional instruments is a difficult problem in the process of vascular interventional surgery. To solve this problem, this paper creatively proposes a method to estimate the contact force between the instrument and the vascular wall by observing the deformation of the front end of the instrument.MethodTo solve this problem, different from the commonly used force feedback method, a method to predict the contact force of the front end of interventional instrument based on image acquisition is proposed. An experimental environment was built to simulate the process of vascular interventional surgery, a force sensor was used to measure the contact force of the front end of the interventional device, and a camera was used to obtain the image containing the deformation of the interventional device. For the image with deformed guide wire, multiframe background averaging method is used to model the background. Canny operator is used to detect the edge of the original image and the background. The edge in the background is removed from the edge of the original image, and then morphological filtering method is used to process the detected edge image to obtain the contour of the interventional device. The deformation of the front end of the interventional device is calculated by the contour of the interventional device. Here, the contact force and deformation of the front end of the interventional device are modeled. The contact force of the front end of the interventional device is divided into the force perpendicular to the contact surface and the force along the contact surface. A method is proposed to describe the deformation of the instrument by using the maximum curvature of the deformation section at the front end of the guide wire. We use the triangle composed of three points on the instrument to solve the maximum curvature, and its circumscribed circle curvature is calculated to represent the curvature of the segment, where the three points are located. Then, and it is traversed at the front end of the interventional instrument to obtain the maximum value, which is the maximum curvature. Subsequently, the relationship between the force and the maximum curvature of the interventional device is obtained by analyzing the experimental data.ResultThe results show some mappings between the front-end contact force and the maximum curvature of the interventional device. This relationship can be accurately expressed in functional expressions with an average error of less than 10% in predicting forces. At the same time, the force perpendicular to the contact surface is much greater than the force along the contact surface. The force perpendicular to the contact surface can be used to approximately replace the contact force between the front end of the interventional device and the vascular wall. In a certain range, the contact force of the front end of the interventional device increases with the increase in the maximum curvature. Beyond this range, the contact force of the front end of the interventional device reaches the maximum and does not continue to increase with the increase in the maximum curvature.ConclusionTherefore, we can estimate the contact force of the front end of the guide wire by obtaining the maximum curvature of the front end of the guide wire, and then judge the contact state between the interventional device and the vascular wall during vascular surgery. Through this method, adding sensors and other devices on the interventional device is unnecessary, and the contact force of the front end of the interventional device can be obtained to reduce the risk of vascular wall being scratched or punctured by the front end of the interventional device. In addition, the difficulty of operation is reduced, and the operation power is improved.关键词:vascular interventional surgery;contact force of interventional device;deformation of interventional device;guide wire image;maximum curvature79|148|1更新时间:2024-05-07
摘要:ObjectiveAt present, the prevalence of cardiovascular disease continues to increase in China. Approximately 290 million people in China suffer from cardiovascular and cerebrovascular diseases. In 2016, the mortality rate of cardiovascular disease was the highest in China. Cardiovascular disease has caused a serious burden on the society; thus, the prevention and treatment of cardiovascular disease are urgent. Vascular interventional surgery is one of the main methods for the treatment of cardiovascular diseases, which has the advantages of less blood loss, less trauma, less complications, and rapid postoperative recovery. In the process of vascular interventional surgery, the contact force between the front end of the interventional instrument and the vascular wall is greatly important to the safety of the operation. If the contact force is extremely large, then the vascular wall becomes scratched and punctured or the plaque is moved, thereby leading to the failure of the operation and may cause danger to the lives of patients. Therefore, measuring the contact force of the front end of interventional instruments is a difficult problem in the process of vascular interventional surgery. To solve this problem, this paper creatively proposes a method to estimate the contact force between the instrument and the vascular wall by observing the deformation of the front end of the instrument.MethodTo solve this problem, different from the commonly used force feedback method, a method to predict the contact force of the front end of interventional instrument based on image acquisition is proposed. An experimental environment was built to simulate the process of vascular interventional surgery, a force sensor was used to measure the contact force of the front end of the interventional device, and a camera was used to obtain the image containing the deformation of the interventional device. For the image with deformed guide wire, multiframe background averaging method is used to model the background. Canny operator is used to detect the edge of the original image and the background. The edge in the background is removed from the edge of the original image, and then morphological filtering method is used to process the detected edge image to obtain the contour of the interventional device. The deformation of the front end of the interventional device is calculated by the contour of the interventional device. Here, the contact force and deformation of the front end of the interventional device are modeled. The contact force of the front end of the interventional device is divided into the force perpendicular to the contact surface and the force along the contact surface. A method is proposed to describe the deformation of the instrument by using the maximum curvature of the deformation section at the front end of the guide wire. We use the triangle composed of three points on the instrument to solve the maximum curvature, and its circumscribed circle curvature is calculated to represent the curvature of the segment, where the three points are located. Then, and it is traversed at the front end of the interventional instrument to obtain the maximum value, which is the maximum curvature. Subsequently, the relationship between the force and the maximum curvature of the interventional device is obtained by analyzing the experimental data.ResultThe results show some mappings between the front-end contact force and the maximum curvature of the interventional device. This relationship can be accurately expressed in functional expressions with an average error of less than 10% in predicting forces. At the same time, the force perpendicular to the contact surface is much greater than the force along the contact surface. The force perpendicular to the contact surface can be used to approximately replace the contact force between the front end of the interventional device and the vascular wall. In a certain range, the contact force of the front end of the interventional device increases with the increase in the maximum curvature. Beyond this range, the contact force of the front end of the interventional device reaches the maximum and does not continue to increase with the increase in the maximum curvature.ConclusionTherefore, we can estimate the contact force of the front end of the guide wire by obtaining the maximum curvature of the front end of the guide wire, and then judge the contact state between the interventional device and the vascular wall during vascular surgery. Through this method, adding sensors and other devices on the interventional device is unnecessary, and the contact force of the front end of the interventional device can be obtained to reduce the risk of vascular wall being scratched or punctured by the front end of the interventional device. In addition, the difficulty of operation is reduced, and the operation power is improved.关键词:vascular interventional surgery;contact force of interventional device;deformation of interventional device;guide wire image;maximum curvature79|148|1更新时间:2024-05-07
Research and Application
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0