
最新刊期
卷 26 , 期 4 , 2021
-
 摘要:Image captioning and description belong to high-level visual understanding. They translate an image into natural language with decent words, appropriate sentence patterns, and correct grammars. The task is interesting and has wide application prospects on early education, visually impaired aid, automatic explanation, auto-reminding, development of intelligent interactive environment, and even designing of intelligent robots. They also provide support for studying image retrieval, object detection, visual semantic reasoning, and personalized description. At present, the task has attracted the attention of several researchers, and a large number of effective models have been proposed and developed. However, the task is difficult and challenging because the model has to bridge the visual information and natural language and close the semantic gap between the data with different modalities. In this work, the development timeline, popular frameworks and models, frequently used datasets, and corresponding performance of image captioning and description are surveyed comprehensively. Additionally, the remaining questions and limitations of current works are investigated and analyzed in depth. Overall, there are four parts for image captioning and description illustration in this study: 1) the image simple captioning and description (one sentence is generated for an image generally), including handcraft feature-based methods and deep feature-based approaches; 2) image dense captioning (multiple but relatively independent sentences are generated in general) and refined paragraph description (paragraph with a certain structure and logic is generated generally); 3) image personalized and sentimental captioning and description (sentence with personalized style and sentimental words is generated in general); and 4) corresponding evaluation datasets, metrics, and performances of the popular models. For the first part, the research history of image captioning and description is first introduced, including template-based framework and visual semantic retrieval-based framework based on handcraft visual feature. The classical and significant works such as semantic space sharing model and visual semantic component reorganization model are described in detail. Then, the current popular works based on deep learning techniques are sorted out carefully and elaborated in great detail. According to the usage of visual information, the models for image captioning and description based on deep feature can be mainly classified into three categories: 1) global visual feature-based model, 2) visual feature selection and optimization-based model, and 3) optimization strategy-oriented model. For each kind of model, the current popular works including the proposed models, superiority, and possible problems are analyzed and discussed. The models based on selected or optimized visual features such as visual attention region, attributes, and concepts as prior knowledge are usually more intuitive and show better performance, especially when advanced optimization strategies such as reinforcement learning are employed and the quality of generated sentences frequently possesses more accurate words and richer semantics, although a few methods based on global visual feature perform as good as them. Besides the models for image simple captioning and description, popular works on dense captioning and refinement description for images are presented and sorted out in the second part. The models for dense captioning generate more sentences for images and offer more detailed description. However, the semantic relevance among different visual objects, scenes, and actions is usually ignored and not embedded into the sentences although a few approaches take advantage of the possible visual relation to predict more accurate words. With regard to refined paragraph description for images, the hierarchical architecture with multiple recurrent neural network layers is the most employed basic framework, where hierarchical attention mechanism, visual attributes, and reinforcement learning strategy are also introduced into the related models to further improve the performance. However, the semantic relevance and logic among different visual objects remain to be further explored and represented, and the coherence and logicality of the generated description paragraph for images need to be further polished and refined. Additionally, in consideration of human habit of describing an image, personal experience is usually embedded into the description, and then the generated sentences often contain personalized and sentimental information. Therefore, a few significant works for personalized image captioning and sentimental description are also introduced and discussed in this paper. In particular, the discovery, representation, and embedding of personalized information and sentiment in the models are surveyed and analyzed in depth. Moreover, the limitations and problems about the task including the granularity and intensity of sentiments, the evaluation metrics of personalized and sentimental description, are worthy of further research and exploration. In addition to classical frameworks and popular models, the related public evaluation datasets and metrics are also summarized and presented. First of all, the image simple captioning and description datasets, including Microsoft common objects in context(MS COCO 2014), Flickr30K, and Flickr8K, and the performances of a few popular models on these datasets are briefly introduced. Afterward, the datasets, including Visual Genome and VG-P(Paragraph) for image dense captioning and paragraph description, and the performances of certain current works on the datasets are described and provided. Next, the datasets for the task of image description with personalized and sentimental expression, including SentiCap and FlickrStyle10K, are briefly introduced. Moreover, the performances of the main models are reported and discussed. Additionally, the frequently used evaluation methods, including traditional metrics and special targeted metrics, are described and compared. In conclusion, breakthrough has been made on image captioning and description in recent years, and the quality of generated sentences has been greatly improved. However, more efforts are still needed to generate more coherent and accurate sentences with richer semantics for images. The possible trends and solutions about image captioning and description are reconsidered and put forward in this study. To further promote the task to practical applications, the semantic gap between visual dataset and natural language should be narrowed by generating a structured paragraph with sentiment and logical semantics for images. However, several problems, including visual feature refinement and usage, sentiment and logic mining and embedding, corresponding training dataset collecting and metric designing for personalization, and sentiment and paragraph description evaluation, remain to be addressed.关键词:image captioning;the depth feature;visual description;paragraph generation;image sentiment;logical semantic125|296|2更新时间:2024-05-07
摘要:Image captioning and description belong to high-level visual understanding. They translate an image into natural language with decent words, appropriate sentence patterns, and correct grammars. The task is interesting and has wide application prospects on early education, visually impaired aid, automatic explanation, auto-reminding, development of intelligent interactive environment, and even designing of intelligent robots. They also provide support for studying image retrieval, object detection, visual semantic reasoning, and personalized description. At present, the task has attracted the attention of several researchers, and a large number of effective models have been proposed and developed. However, the task is difficult and challenging because the model has to bridge the visual information and natural language and close the semantic gap between the data with different modalities. In this work, the development timeline, popular frameworks and models, frequently used datasets, and corresponding performance of image captioning and description are surveyed comprehensively. Additionally, the remaining questions and limitations of current works are investigated and analyzed in depth. Overall, there are four parts for image captioning and description illustration in this study: 1) the image simple captioning and description (one sentence is generated for an image generally), including handcraft feature-based methods and deep feature-based approaches; 2) image dense captioning (multiple but relatively independent sentences are generated in general) and refined paragraph description (paragraph with a certain structure and logic is generated generally); 3) image personalized and sentimental captioning and description (sentence with personalized style and sentimental words is generated in general); and 4) corresponding evaluation datasets, metrics, and performances of the popular models. For the first part, the research history of image captioning and description is first introduced, including template-based framework and visual semantic retrieval-based framework based on handcraft visual feature. The classical and significant works such as semantic space sharing model and visual semantic component reorganization model are described in detail. Then, the current popular works based on deep learning techniques are sorted out carefully and elaborated in great detail. According to the usage of visual information, the models for image captioning and description based on deep feature can be mainly classified into three categories: 1) global visual feature-based model, 2) visual feature selection and optimization-based model, and 3) optimization strategy-oriented model. For each kind of model, the current popular works including the proposed models, superiority, and possible problems are analyzed and discussed. The models based on selected or optimized visual features such as visual attention region, attributes, and concepts as prior knowledge are usually more intuitive and show better performance, especially when advanced optimization strategies such as reinforcement learning are employed and the quality of generated sentences frequently possesses more accurate words and richer semantics, although a few methods based on global visual feature perform as good as them. Besides the models for image simple captioning and description, popular works on dense captioning and refinement description for images are presented and sorted out in the second part. The models for dense captioning generate more sentences for images and offer more detailed description. However, the semantic relevance among different visual objects, scenes, and actions is usually ignored and not embedded into the sentences although a few approaches take advantage of the possible visual relation to predict more accurate words. With regard to refined paragraph description for images, the hierarchical architecture with multiple recurrent neural network layers is the most employed basic framework, where hierarchical attention mechanism, visual attributes, and reinforcement learning strategy are also introduced into the related models to further improve the performance. However, the semantic relevance and logic among different visual objects remain to be further explored and represented, and the coherence and logicality of the generated description paragraph for images need to be further polished and refined. Additionally, in consideration of human habit of describing an image, personal experience is usually embedded into the description, and then the generated sentences often contain personalized and sentimental information. Therefore, a few significant works for personalized image captioning and sentimental description are also introduced and discussed in this paper. In particular, the discovery, representation, and embedding of personalized information and sentiment in the models are surveyed and analyzed in depth. Moreover, the limitations and problems about the task including the granularity and intensity of sentiments, the evaluation metrics of personalized and sentimental description, are worthy of further research and exploration. In addition to classical frameworks and popular models, the related public evaluation datasets and metrics are also summarized and presented. First of all, the image simple captioning and description datasets, including Microsoft common objects in context(MS COCO 2014), Flickr30K, and Flickr8K, and the performances of a few popular models on these datasets are briefly introduced. Afterward, the datasets, including Visual Genome and VG-P(Paragraph) for image dense captioning and paragraph description, and the performances of certain current works on the datasets are described and provided. Next, the datasets for the task of image description with personalized and sentimental expression, including SentiCap and FlickrStyle10K, are briefly introduced. Moreover, the performances of the main models are reported and discussed. Additionally, the frequently used evaluation methods, including traditional metrics and special targeted metrics, are described and compared. In conclusion, breakthrough has been made on image captioning and description in recent years, and the quality of generated sentences has been greatly improved. However, more efforts are still needed to generate more coherent and accurate sentences with richer semantics for images. The possible trends and solutions about image captioning and description are reconsidered and put forward in this study. To further promote the task to practical applications, the semantic gap between visual dataset and natural language should be narrowed by generating a structured paragraph with sentiment and logical semantics for images. However, several problems, including visual feature refinement and usage, sentiment and logic mining and embedding, corresponding training dataset collecting and metric designing for personalization, and sentiment and paragraph description evaluation, remain to be addressed.关键词:image captioning;the depth feature;visual description;paragraph generation;image sentiment;logical semantic125|296|2更新时间:2024-05-07 -
 摘要:Accurate segmentation of lung nodules is of great significance in the clinic. A computed tomography (CT) scan can detect lung cancer tissues with a diameter larger than 5 mm, and its fast imaging and high resolution make it the first choice for screening early stage lung cancer. At present, CT images of the lung have been widely used in pulmonary nodule segmentation and functional evaluation. However, a single lung scan will generate a large number of CT images, and it is very difficult for doctors to manually segment all images. Although the manual segmentation of lung nodules has extremely high accuracy, it is highly subjective, inefficient, and poorly repeatable. In addition, the lung nodules in CT images have different shapes and uneven density, and some adhere to surrounding tissues. Thus, few segmentation algorithms can adapt to all types of nodules. How to segment lung nodules accurately, efficiently, universally, and automatically has become a research hotspot. In recent years, the research on lung nodule segmentation methods has made great achievements. In order to assist more scholars to explore the segmentation method of lung nodules based on CT images, this article reviewed the research progress in this field. In this study, the lung nodule segmentation methods were divided into two categories: traditional segmentation methods and deep learning segmentation methods. The traditional segmentation methods for segmenting lung nodules are expressed based on mathematical knowledge; that is, theoretical information and logical rules are used to infer boundary information to achieve segmentation. According to different principles, the traditional segmentation principles were roughly divided into segmentation methods based on threshold and regional growth, clustering, active contour model (ACM), and mathematical model optimization. First, the traditional principles and their advantages and disadvantages are summarized and compared in this study. Then, new methods, including deep learning and deep learning with traditional methods, are focused. With the development of artificial intelligence, deep learning technology represented by convolutional neural networks (CNNs) has attracted considerable attention due to its superior lung nodule segmentation effect. Distinct from traditional segmentation methods, CNNs can use hidden layers such as convolution layers and pooling layers to actively learn the low-level features of nodules and form them into higher-level abstract features. By using a large amount of data for training and validation, we obtained the bias and weight of the model with the smallest loss rate in the validation set and used them to perform prediction on the testing set, wherein nodule segmentation will be conducted automatically. Because of the particularity, the study of CNN-based lung nodule segmentation is mainly concentrated on the design of the network structure. Fully convolutional networks and encoding-decoding symmetric networks such as U-Net obtained better performance on lung nodule segmentation. In particular, U-Net is commonly used in medical image segmentation due to its small amount of data required and superior segmentation effect. U-Net achieved remarkable success in the segmentation of lung nodules. In addition, the improved network based on U-Net structure also promoted the segmentation effect of nodules. After a brief introduction of the process of extracting lung nodule features by CNNs, this article presented two aspects of using deep learning methods alone and deep learning combined with traditional methods to segment nodules. It concentrated on the application of deep learning in lung nodule segmentation. At the same time, various optimization strategies for accelerating the model's convergence speed and improving the performance of the model on nodule segmentation were summarized. Finally, the commonly used evaluation indicators of lung nodule segmentation methods were briefly introduced. Furthermore, combined with the performance of the indicators presented in some literature, we looked forward to future development trends of the pulmonary nodule segmentation method. Researchers have focused on how to improve the accuracy of the segmentation results, the robustness of the model, and the universality of the method. To achieve this goal, the advantages and disadvantages of various methods were summarized and compared. In pulmonary CT images, traditional methods were more robust, but almost all of them were highly dependent on user intervention, such as region growing and dynamic planning algorithm involving low computational complexity. Moreover, they were sensitive to image quality, and their ability to integrate with prior knowledge was limited. In addition, these methods tend to experience over-segmentation and under-segmentation. Although ACM could improve the accuracy of the segmentation results by merging with prior knowledge such as nodule shape and texture to generate models, it increased the computational complexity. In recent years, with the continuous improvement of medical standards, traditional segmentation methods have failed to meet clinical needs. The development of computer vision, artificial intelligence, and other technologies has promoted the development of deep learning, which has been successfully used for lung nodule segmentation. The lung nodule segmentation method based on deep learning is universal, and the network optimizes the model through operations such as regularization, weight attenuation, dropout, improved activation function, and loss function, which can reduce the training time of the model under big data. Even in the case of a limited amount of training data, the accuracy of the model and the speed of segmentation can also be promoted by using data augmentation, preprocessing, adjusting the network structure, and using different optimizers to obtain better segmentation results. Therefore, deep learning methods have been gradually applied to segment lung nodules. The CT image-based lung nodule segmentation method has achieved great success, but the gray value of the lung nodule in the CT image is not much different from that of the surrounding tissues. Moreover, anatomical structures such as adhered blood vessels and pleura added more difficulties to segment the nodules. Thus, there is still much room for improvement in the effect of segmentation. From the current lung nodule segmentation methods, the segmentation method based on deep learning has high accuracy and fast speed. However, problems such as massive data requirements and super parameter determination still need to be solved in deep learning.关键词:lung nodules;computed tomography(CT) image;lung nodules segmentation method;deep learning;review422|124|4更新时间:2024-05-07
摘要:Accurate segmentation of lung nodules is of great significance in the clinic. A computed tomography (CT) scan can detect lung cancer tissues with a diameter larger than 5 mm, and its fast imaging and high resolution make it the first choice for screening early stage lung cancer. At present, CT images of the lung have been widely used in pulmonary nodule segmentation and functional evaluation. However, a single lung scan will generate a large number of CT images, and it is very difficult for doctors to manually segment all images. Although the manual segmentation of lung nodules has extremely high accuracy, it is highly subjective, inefficient, and poorly repeatable. In addition, the lung nodules in CT images have different shapes and uneven density, and some adhere to surrounding tissues. Thus, few segmentation algorithms can adapt to all types of nodules. How to segment lung nodules accurately, efficiently, universally, and automatically has become a research hotspot. In recent years, the research on lung nodule segmentation methods has made great achievements. In order to assist more scholars to explore the segmentation method of lung nodules based on CT images, this article reviewed the research progress in this field. In this study, the lung nodule segmentation methods were divided into two categories: traditional segmentation methods and deep learning segmentation methods. The traditional segmentation methods for segmenting lung nodules are expressed based on mathematical knowledge; that is, theoretical information and logical rules are used to infer boundary information to achieve segmentation. According to different principles, the traditional segmentation principles were roughly divided into segmentation methods based on threshold and regional growth, clustering, active contour model (ACM), and mathematical model optimization. First, the traditional principles and their advantages and disadvantages are summarized and compared in this study. Then, new methods, including deep learning and deep learning with traditional methods, are focused. With the development of artificial intelligence, deep learning technology represented by convolutional neural networks (CNNs) has attracted considerable attention due to its superior lung nodule segmentation effect. Distinct from traditional segmentation methods, CNNs can use hidden layers such as convolution layers and pooling layers to actively learn the low-level features of nodules and form them into higher-level abstract features. By using a large amount of data for training and validation, we obtained the bias and weight of the model with the smallest loss rate in the validation set and used them to perform prediction on the testing set, wherein nodule segmentation will be conducted automatically. Because of the particularity, the study of CNN-based lung nodule segmentation is mainly concentrated on the design of the network structure. Fully convolutional networks and encoding-decoding symmetric networks such as U-Net obtained better performance on lung nodule segmentation. In particular, U-Net is commonly used in medical image segmentation due to its small amount of data required and superior segmentation effect. U-Net achieved remarkable success in the segmentation of lung nodules. In addition, the improved network based on U-Net structure also promoted the segmentation effect of nodules. After a brief introduction of the process of extracting lung nodule features by CNNs, this article presented two aspects of using deep learning methods alone and deep learning combined with traditional methods to segment nodules. It concentrated on the application of deep learning in lung nodule segmentation. At the same time, various optimization strategies for accelerating the model's convergence speed and improving the performance of the model on nodule segmentation were summarized. Finally, the commonly used evaluation indicators of lung nodule segmentation methods were briefly introduced. Furthermore, combined with the performance of the indicators presented in some literature, we looked forward to future development trends of the pulmonary nodule segmentation method. Researchers have focused on how to improve the accuracy of the segmentation results, the robustness of the model, and the universality of the method. To achieve this goal, the advantages and disadvantages of various methods were summarized and compared. In pulmonary CT images, traditional methods were more robust, but almost all of them were highly dependent on user intervention, such as region growing and dynamic planning algorithm involving low computational complexity. Moreover, they were sensitive to image quality, and their ability to integrate with prior knowledge was limited. In addition, these methods tend to experience over-segmentation and under-segmentation. Although ACM could improve the accuracy of the segmentation results by merging with prior knowledge such as nodule shape and texture to generate models, it increased the computational complexity. In recent years, with the continuous improvement of medical standards, traditional segmentation methods have failed to meet clinical needs. The development of computer vision, artificial intelligence, and other technologies has promoted the development of deep learning, which has been successfully used for lung nodule segmentation. The lung nodule segmentation method based on deep learning is universal, and the network optimizes the model through operations such as regularization, weight attenuation, dropout, improved activation function, and loss function, which can reduce the training time of the model under big data. Even in the case of a limited amount of training data, the accuracy of the model and the speed of segmentation can also be promoted by using data augmentation, preprocessing, adjusting the network structure, and using different optimizers to obtain better segmentation results. Therefore, deep learning methods have been gradually applied to segment lung nodules. The CT image-based lung nodule segmentation method has achieved great success, but the gray value of the lung nodule in the CT image is not much different from that of the surrounding tissues. Moreover, anatomical structures such as adhered blood vessels and pleura added more difficulties to segment the nodules. Thus, there is still much room for improvement in the effect of segmentation. From the current lung nodule segmentation methods, the segmentation method based on deep learning has high accuracy and fast speed. However, problems such as massive data requirements and super parameter determination still need to be solved in deep learning.关键词:lung nodules;computed tomography(CT) image;lung nodules segmentation method;deep learning;review422|124|4更新时间:2024-05-07
Review

-
 摘要:ObjectiveWith the rapid development of deep convolutional neural networks (CNNs), great progress has been made in the research of single-image super-resolution (SISR) in terms of accuracy and efficiency. However, existing methods often resort to deeper CNNs that are not only difficult to train, but also have limited feature resolutions to capture the rich high-frequency detail information that is essential for accurate SR prediction. To address these issues, this letter presents a global attention-gated multi-scale memory network (GAMMNet) for SISR.MethodGAMMNet mainly consists of three key components: feature extraction, nonlinear mapping (NM), and high-resolution (HR) reconstruction. In the feature extraction part, the input low-resolution (LR) image passes through a 3×3 convolution layer to learn the low-level features. Then, we utilize a recursive structure to perform NM to learn the deeper-layer features. At the end of the network, we arrange four kernels with different sizes followed by a global attention gate (GAG) to achieve the HR reconstruction. Specifically, the NM module consists of four recursive residual memory blocks (RMBs). Each RMB outputs a multi-level representation by fusing the output of the top multi-scale residual unit (MRU) and the ones from the previous MRUs, followed by a GAG module, which serves as a gate to control how much of the previous states should be memorized and decides how much of the current state should be kept. The details of how to design the two novel modules (MRU and GAG) will be explained as follows. MRU takes advantage of the wide activation architecture inspired by the wide activation super-resolution(WDSR) method. As the nonlinear ReLU(rectified linear units) layers in residual blocks hinder the transmission of information flow from shallow layers to deeper layers, the wide activation architecture increases the channels of feature map before ReLU layers to help transmit information flows. Moreover, as the depth of the network increases, problems such as underutilization of features and gradual disappearance of features during transmission occur. Making full use of features is the key to network reconstruction of high-quality images. We parallelly stack two different convolution kernels with sizes of 3×3 and 5×5 to extract multi-scale features, which are further enhanced by the proposed GAG module, yielding the residual output. Finally, the output of MRU is the addition of the input and the residual output. GAG serves as a gate to enhance the input feature channels with different weights. First, different from the residual channel attention network(RCAN) that mainly considers the correlation between feature channels, our GAG takes into account the useful spatial holistic statistic information of the feature maps. We utilize a special spatial pooling operation to improve the global average pooling used in the original channel attention to obtain global context features, and take a weighted average of all location features to establish a more efficient long-range dependency. Then, we aggregate the global context information on each location feature. We first leverage a 1×1 convolution to reduce the feature channel number to 1. Then, we use a Softmax function to capture the global context information for each pixel, yielding the pixel-wise attention weight map. Afterward, we introduce a learning parameter λ1 to adaptively rescale the weight map. Now the weight map is correlated with the input feature maps, outputting the channel-wise weight vector that encodes the global holistic statistic information of the feature maps. Second, in order to reduce the amount of calculations under the premise of establishing effective long-distance dependencies, we learn to use a bottleneck layer used in SE block to implement feature transform, which not only significantly reduces the amount of calculations but also captures the correlation between feature channels. We feed the channel-wise attention weight vector into a feature transform module that consists of one 1×1 convolution layer, one normalization layer, one ReLU layer, and one 1×1 convolution layer and multiply an adaptively learning parameter λ2, yielding the enhanced channel-wise attention weights that capture channel-wise dependencies. Finally, we channel-wisely multiply the input feature maps and the enhanced channel-wise attention weights to aggregate the global context information onto each local feature. In the image magnification stage, we design an efficient reconstruction structure to combine local multi-scale features and global features to achieve image magnification. We first leverage three different convolutions followed by a GAG to adaptively adjust the reconstruction feature weights, which make full use of the local multi-scale features of the reconstructed part. Then, a pixel-shuffle module is added behind each branch to perform image magnification. At last, all the reconstructed outputs are added together with the top network branch to combine local and global feature information, outputting the final SR image.ResultWe adopt the DIV2K(DIVerse 2K resolution image) dataset, the most widely used training dataset for deep CNN-based SISR, to train our model. This dataset contains 1 000 HR images, 800 of which are used for training. We preprocess the HR images by bicubic down-sampling to obtain the LR images. Then, we use several commonly used benchmark datasets, including Set5, Set14, B100, Urban100, and Manga100 to test our model. The evaluation metrics are the peak signal-to-noise ratio (PSNR) and the structural similarity index measurement (SSIM) on the Y channel of the transformed YCbCr space. The input image patches are cropped with a size of 48×48 pixels, and the mini training batch size is set to 16. The hyperparameters of input, internal, and output channel numbers are set to 32, 128, and 32 for the MRUs, respectively. We arrange four RMBs in the non-linear mapping module, among which each block has four MRUs. For the upscale module, we use four different kernel sizes (3×3, 5×5, 7×7, and 9×9), followed by a GAG to generate the HR outputs. We compare our GAMMNet with several state-of-the-art deep CNN-based SISR methods, including super-resolution convolutional neural network(SRCNN), deeply-recursive convolutional network(DRCN), deep recursive residual network(DRRN), memory network(MemNet), cascading residual network(CARN), multi-scale residual network(MSRN), and adaptive weighted super-resolution network(AWSRN). Obviously, our GAMMNet achieves the best performance in terms of both PSNR and SSIM among all compared methods in almost all benchmark datasets, except for the SSIM on the Urban 100, where our GAMMNet achieves the second best performing SSIM of 0.792 6, which is slightly lower than the best AWSRN with SSIM of 0.793 0. Finally, we conduct ablation experiments on the important components of GAMMNet. We use 2×Set5 as the test set. The experiment first replaces the MRUs in GAMMNet with the smallest residual unit in WDSR and removes the GAG as the benchmark. Then, it adds the MRU and GAG and finally trains GAMMNet(simultaneously using the two proposed modules). The results show that the MRU and GAG modules improve PSNR by 0.1 and 0.08 points, respectively, and GAMMNet achieves the best performance on PSNR and SSIM, demonstrating the effectiveness of both module designs.ConclusionIn this study, the shallow features of the network are first extracted by the feature extraction module. Then, a nested recursive structure is used to realize the NM and learn the deeper features. This structure combines the features of different scales to effectively learn the context information of the feature maps at each level, and solves the problem of feature disappearing during information transmission by fusing the output of different levels. Finally, in the reconstruction part, the features of different scales are parallelized, and pixel shuffle is used to achieve high-quality magnification of images.关键词:single-image super-resolution(SISR);deep convolutional neural networks(DCNN);attention gate mechanism;multi-scale residual units(MRUs);recursive learning26|42|2更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of deep convolutional neural networks (CNNs), great progress has been made in the research of single-image super-resolution (SISR) in terms of accuracy and efficiency. However, existing methods often resort to deeper CNNs that are not only difficult to train, but also have limited feature resolutions to capture the rich high-frequency detail information that is essential for accurate SR prediction. To address these issues, this letter presents a global attention-gated multi-scale memory network (GAMMNet) for SISR.MethodGAMMNet mainly consists of three key components: feature extraction, nonlinear mapping (NM), and high-resolution (HR) reconstruction. In the feature extraction part, the input low-resolution (LR) image passes through a 3×3 convolution layer to learn the low-level features. Then, we utilize a recursive structure to perform NM to learn the deeper-layer features. At the end of the network, we arrange four kernels with different sizes followed by a global attention gate (GAG) to achieve the HR reconstruction. Specifically, the NM module consists of four recursive residual memory blocks (RMBs). Each RMB outputs a multi-level representation by fusing the output of the top multi-scale residual unit (MRU) and the ones from the previous MRUs, followed by a GAG module, which serves as a gate to control how much of the previous states should be memorized and decides how much of the current state should be kept. The details of how to design the two novel modules (MRU and GAG) will be explained as follows. MRU takes advantage of the wide activation architecture inspired by the wide activation super-resolution(WDSR) method. As the nonlinear ReLU(rectified linear units) layers in residual blocks hinder the transmission of information flow from shallow layers to deeper layers, the wide activation architecture increases the channels of feature map before ReLU layers to help transmit information flows. Moreover, as the depth of the network increases, problems such as underutilization of features and gradual disappearance of features during transmission occur. Making full use of features is the key to network reconstruction of high-quality images. We parallelly stack two different convolution kernels with sizes of 3×3 and 5×5 to extract multi-scale features, which are further enhanced by the proposed GAG module, yielding the residual output. Finally, the output of MRU is the addition of the input and the residual output. GAG serves as a gate to enhance the input feature channels with different weights. First, different from the residual channel attention network(RCAN) that mainly considers the correlation between feature channels, our GAG takes into account the useful spatial holistic statistic information of the feature maps. We utilize a special spatial pooling operation to improve the global average pooling used in the original channel attention to obtain global context features, and take a weighted average of all location features to establish a more efficient long-range dependency. Then, we aggregate the global context information on each location feature. We first leverage a 1×1 convolution to reduce the feature channel number to 1. Then, we use a Softmax function to capture the global context information for each pixel, yielding the pixel-wise attention weight map. Afterward, we introduce a learning parameter λ1 to adaptively rescale the weight map. Now the weight map is correlated with the input feature maps, outputting the channel-wise weight vector that encodes the global holistic statistic information of the feature maps. Second, in order to reduce the amount of calculations under the premise of establishing effective long-distance dependencies, we learn to use a bottleneck layer used in SE block to implement feature transform, which not only significantly reduces the amount of calculations but also captures the correlation between feature channels. We feed the channel-wise attention weight vector into a feature transform module that consists of one 1×1 convolution layer, one normalization layer, one ReLU layer, and one 1×1 convolution layer and multiply an adaptively learning parameter λ2, yielding the enhanced channel-wise attention weights that capture channel-wise dependencies. Finally, we channel-wisely multiply the input feature maps and the enhanced channel-wise attention weights to aggregate the global context information onto each local feature. In the image magnification stage, we design an efficient reconstruction structure to combine local multi-scale features and global features to achieve image magnification. We first leverage three different convolutions followed by a GAG to adaptively adjust the reconstruction feature weights, which make full use of the local multi-scale features of the reconstructed part. Then, a pixel-shuffle module is added behind each branch to perform image magnification. At last, all the reconstructed outputs are added together with the top network branch to combine local and global feature information, outputting the final SR image.ResultWe adopt the DIV2K(DIVerse 2K resolution image) dataset, the most widely used training dataset for deep CNN-based SISR, to train our model. This dataset contains 1 000 HR images, 800 of which are used for training. We preprocess the HR images by bicubic down-sampling to obtain the LR images. Then, we use several commonly used benchmark datasets, including Set5, Set14, B100, Urban100, and Manga100 to test our model. The evaluation metrics are the peak signal-to-noise ratio (PSNR) and the structural similarity index measurement (SSIM) on the Y channel of the transformed YCbCr space. The input image patches are cropped with a size of 48×48 pixels, and the mini training batch size is set to 16. The hyperparameters of input, internal, and output channel numbers are set to 32, 128, and 32 for the MRUs, respectively. We arrange four RMBs in the non-linear mapping module, among which each block has four MRUs. For the upscale module, we use four different kernel sizes (3×3, 5×5, 7×7, and 9×9), followed by a GAG to generate the HR outputs. We compare our GAMMNet with several state-of-the-art deep CNN-based SISR methods, including super-resolution convolutional neural network(SRCNN), deeply-recursive convolutional network(DRCN), deep recursive residual network(DRRN), memory network(MemNet), cascading residual network(CARN), multi-scale residual network(MSRN), and adaptive weighted super-resolution network(AWSRN). Obviously, our GAMMNet achieves the best performance in terms of both PSNR and SSIM among all compared methods in almost all benchmark datasets, except for the SSIM on the Urban 100, where our GAMMNet achieves the second best performing SSIM of 0.792 6, which is slightly lower than the best AWSRN with SSIM of 0.793 0. Finally, we conduct ablation experiments on the important components of GAMMNet. We use 2×Set5 as the test set. The experiment first replaces the MRUs in GAMMNet with the smallest residual unit in WDSR and removes the GAG as the benchmark. Then, it adds the MRU and GAG and finally trains GAMMNet(simultaneously using the two proposed modules). The results show that the MRU and GAG modules improve PSNR by 0.1 and 0.08 points, respectively, and GAMMNet achieves the best performance on PSNR and SSIM, demonstrating the effectiveness of both module designs.ConclusionIn this study, the shallow features of the network are first extracted by the feature extraction module. Then, a nested recursive structure is used to realize the NM and learn the deeper features. This structure combines the features of different scales to effectively learn the context information of the feature maps at each level, and solves the problem of feature disappearing during information transmission by fusing the output of different levels. Finally, in the reconstruction part, the features of different scales are parallelized, and pixel shuffle is used to achieve high-quality magnification of images.关键词:single-image super-resolution(SISR);deep convolutional neural networks(DCNN);attention gate mechanism;multi-scale residual units(MRUs);recursive learning26|42|2更新时间:2024-05-07 -
 摘要:ObjectiveSingle image super-resolution reconstruction (SISR) is a classic problem in computer vision. SISR aims to reconstruct one high-resolution image from single or many low-resolution (LR) images. Currently, image super-resolution (SR) technology is widely used in medical imaging, satellite remote sensing, video surveillance, and other fields. However, the SR problem is an essentially complex and morbid problem. To solve this problem, many SISR methods have been proposed, including interpolation-based methods and reconstruction-based methods. Due to large amplification factors, the repair performance will drop sharply, and the reconstructed results are very poor. With the rise of deep learning, deep convolutional neural networks have also been used to solve this problem. Researchers have proposed a series of models and made significant progress. With the gradual understanding of deep learning techniques, researchers have found that deep network brings better results than shallow network, and too deep network can cause gradient explosion or disappearance. In addition, the gradient explosion or disappearance can cause the model to be untrainable and thus unable to achieve the best results through training. In recent years, most networks based on deep learning for single-image SR reconstruction adopt single-scale convolution kernels. Generally, a 3×3 convolution kernel is used for feature extraction. Although single-scale convolution kernels can also extract a lot of detailed information, these algorithms usually ignore the problem of different receptive field sizes caused by different convolution kernel sizes. Receptive fields of different sizes will make the network pay attention to different features; therefore, only using a 3×3 convolution kernel will cause the network to ignore the macroscopic relation between different feature images. Considering these problems, this study proposes a multi-level perception network based on GoogLeNet, residual network, and dense convolutional network.MethodFirst, the feature extraction module is used as the input, which can extract low-frequency image features. The feature extraction module consists of two 3×3 convolution layers, which is input to multiple densely connected multi-level perception modules. The multi-level perception module is composed of 3×3 and 5×5 convolution kernels. The 3×3 convolution kernel is responsible for extracting detailed feature information, and the 5×5 convolution kernel is responsible for extracting global feature information. Second, the multi-level perception module is divided into shallow multi-level feature extraction, deep multi-level feature extraction, and tandem compression unit. The shallow multi-level feature extraction is composed of 3×3 chain convolution and 5×5 chain convolution. The former is responsible for extracting fine local feature information in shallow features, whereas the latter is responsible for extracting global features in shallow features. The deep multi-level feature extraction is also composed of 3×3 chain convolution and 5×5 chain convolution. The former extracts fine local feature information in deep features, whereas the latter extracts global feature information in deep features. In the tandem compression unit, the global feature information in shallow features, the fine local feature information in deep features, the global information in deep features, and the initial input are concatenated together and then compressed into the same dimension as the input image. In this way, not only low-level and high-level features of the image can be ensured, but also the macro relationship between the features can be guaranteed. Finally, the reconstruction module is used to obtain the final output by combining the upscaling image with the residual image. This study adopts the DIV2K dataset, which consists of 800 high-definition images, and each image has probably 2 million pixels. In order to make full use of these data, the picture is randomly rotated by 90°, 180°, and 270° and horizontally flipped.ResultThe reconstructed results are evaluated by using the peak signal-to-noise ratio (PSNR) and structural similarity index and compared with some state-of-the-art SR reconstruction methods. The reconstructed results with 2 scaling factor show that the PSNRs of the proposed algorithm in four benchmark test sets (Set5, Set14, Berkeley Segmentation Dataset(BSD100), and Urban100) are 37.851 1 dB, 33.933 8 dB, 32.219 1 dB, and 32.148 9 dB, respectively, which are all higher than those of the other methods.ConclusionCompared with other algorithms, the proposed convolutional network model in this study can better take into account the problem of the receptive field and fully extracts different levels of hierarchical features through multi-scale convolution. At the same time, the model uses the structural feature information of the LR image itself to complete the reconstruction, and good reconstructed results can be obtained by using this model.关键词:deep learning;convolutional neural network(CNN);single image super-resolution(SISR);multi-level perception;residual network;dense connection;DIV2K67|27|1更新时间:2024-05-07
摘要:ObjectiveSingle image super-resolution reconstruction (SISR) is a classic problem in computer vision. SISR aims to reconstruct one high-resolution image from single or many low-resolution (LR) images. Currently, image super-resolution (SR) technology is widely used in medical imaging, satellite remote sensing, video surveillance, and other fields. However, the SR problem is an essentially complex and morbid problem. To solve this problem, many SISR methods have been proposed, including interpolation-based methods and reconstruction-based methods. Due to large amplification factors, the repair performance will drop sharply, and the reconstructed results are very poor. With the rise of deep learning, deep convolutional neural networks have also been used to solve this problem. Researchers have proposed a series of models and made significant progress. With the gradual understanding of deep learning techniques, researchers have found that deep network brings better results than shallow network, and too deep network can cause gradient explosion or disappearance. In addition, the gradient explosion or disappearance can cause the model to be untrainable and thus unable to achieve the best results through training. In recent years, most networks based on deep learning for single-image SR reconstruction adopt single-scale convolution kernels. Generally, a 3×3 convolution kernel is used for feature extraction. Although single-scale convolution kernels can also extract a lot of detailed information, these algorithms usually ignore the problem of different receptive field sizes caused by different convolution kernel sizes. Receptive fields of different sizes will make the network pay attention to different features; therefore, only using a 3×3 convolution kernel will cause the network to ignore the macroscopic relation between different feature images. Considering these problems, this study proposes a multi-level perception network based on GoogLeNet, residual network, and dense convolutional network.MethodFirst, the feature extraction module is used as the input, which can extract low-frequency image features. The feature extraction module consists of two 3×3 convolution layers, which is input to multiple densely connected multi-level perception modules. The multi-level perception module is composed of 3×3 and 5×5 convolution kernels. The 3×3 convolution kernel is responsible for extracting detailed feature information, and the 5×5 convolution kernel is responsible for extracting global feature information. Second, the multi-level perception module is divided into shallow multi-level feature extraction, deep multi-level feature extraction, and tandem compression unit. The shallow multi-level feature extraction is composed of 3×3 chain convolution and 5×5 chain convolution. The former is responsible for extracting fine local feature information in shallow features, whereas the latter is responsible for extracting global features in shallow features. The deep multi-level feature extraction is also composed of 3×3 chain convolution and 5×5 chain convolution. The former extracts fine local feature information in deep features, whereas the latter extracts global feature information in deep features. In the tandem compression unit, the global feature information in shallow features, the fine local feature information in deep features, the global information in deep features, and the initial input are concatenated together and then compressed into the same dimension as the input image. In this way, not only low-level and high-level features of the image can be ensured, but also the macro relationship between the features can be guaranteed. Finally, the reconstruction module is used to obtain the final output by combining the upscaling image with the residual image. This study adopts the DIV2K dataset, which consists of 800 high-definition images, and each image has probably 2 million pixels. In order to make full use of these data, the picture is randomly rotated by 90°, 180°, and 270° and horizontally flipped.ResultThe reconstructed results are evaluated by using the peak signal-to-noise ratio (PSNR) and structural similarity index and compared with some state-of-the-art SR reconstruction methods. The reconstructed results with 2 scaling factor show that the PSNRs of the proposed algorithm in four benchmark test sets (Set5, Set14, Berkeley Segmentation Dataset(BSD100), and Urban100) are 37.851 1 dB, 33.933 8 dB, 32.219 1 dB, and 32.148 9 dB, respectively, which are all higher than those of the other methods.ConclusionCompared with other algorithms, the proposed convolutional network model in this study can better take into account the problem of the receptive field and fully extracts different levels of hierarchical features through multi-scale convolution. At the same time, the model uses the structural feature information of the LR image itself to complete the reconstruction, and good reconstructed results can be obtained by using this model.关键词:deep learning;convolutional neural network(CNN);single image super-resolution(SISR);multi-level perception;residual network;dense connection;DIV2K67|27|1更新时间:2024-05-07 -
 摘要:ObjectiveDue to the complex and changeable underwater environment, when light enters a water body, it is affected by absorption and scattering, which leads to color cast, blur, and low contrast of underwater images. Water has different absorption capabilities for different light rays. As a result, the red channel information of the image is poorly preserved, making underwater imaging difficult. In order to solve the problems caused by light absorption in underwater images, existing scientific research has found that compared with the red and blue channels, the obtained green channel details of the underwater channel are best preserved, whereas the red channel details are poorly preserved. According to the characteristics of underwater imaging, the present study proposes an underwater color image enhancement method based on two-scale image decomposition. The method can effectively solve the problems of color cast and low contrast of the image and reduce the introduction of red shadow to obtain high-resolution underwater images.MethodFirst, a contrast stretching method based on the gray world hypothesis is used. The method calculates the mean and mean square error of each channel independently and then uses a new normalization method using the mean and mean square error of each channel. In order to reduce the color cast problem of the image, a median filter is used to reduce the noise problem introduced by the red channel contrast stretch. Then, the two-scale image decomposition method is used to apply a large-scale mean filter to the red channel of the median filtered image and the green channel of the image after the contrast is stretched. Subsequently, the channel is divided into a large-scale base layer and a small-scale detail layer. While retaining the large-scale base layer of the red channel of the image, the small-scale detail layer of the green channel is introduced. Because the color and details of the red channel of the original image are equally important, the true details and colors of the red channel of the original image are introduced into the red channel of the processed image to achieve a better restoration of the red channel colors and details of the image. Different underwater images are selected as the experimental dataset, and the proposed method is compared with the dark channel prior method, fusion-based method, automatic red channel recovery method, and deep learning method based on convolutional neural network. First, subjective analysis of the visual effects is conducted, and then objective analysis is performed through different underwater evaluation indicators.ResultThe results of different experimental images are compared. The dark channel prior method cannot solve the problem of color cast and low contrast of underwater images. The red channel recovery method solves the problem of image color cast or low contrast, but the image results obtained are poorer than those of the proposed method. The fusion-based method is better than the proposed method in improving image contrast. This is maintained by the edge of the image fusion algorithm, but an obvious red shadow problem will be observed in the resulting image. The proposed method can better solve the red shadow problem in the image. Deep learning method can improve the brightness and clarity of the image, but the result still has a certain color cast problem. Compared with the four methods, the proposed method can better solve the problem of color cast of underwater images, and no red shadow is generated, which is more in line with the visual perception of human eyes. Three methods, namely, natural image quality evaluation method (NIQE), information entropy (IE), and underwater image quality measurement method (UIQM) inspired by the human visual system, are used in the experiment for comparative analysis. NIQE compares the test image with the default model calculated from the natural scene image. The lower the index, the better the image perception quality and the higher the clarity. At the same time, NIQE and human eye subjective quality evaluation have better consistency, are similar to the human visual system, and can effectively perform real-time image quality evaluation. IE is an index to measure the information richness of a pair of images. The larger the IE value, the richer the detailed information contained in the image. Finally, UIQM is a better existing underwater image quality evaluation method, which can solve the evaluation of three important indicators of underwater images (i.e., color, clarity, and contrast). The larger the value of UIQM, the higher the clarity and the better the quality of the image. Compared with fusion-based methods and deep learning methods, NIQE and IE in quantitative analysis are improved by 1.8% and 13.6%, respectively. The value of UIQM is 1.542, which is the best result compared with other methods. The experimental results show that the proposed method can better solve the problem of image color cast and red shadow compared with other methods.ConclusionFirst, through the contrast-based stretching method, the green channel image with good detail retention is used to compensate for the red channel image detail. We propose an underwater color image enhancement method based on two-scale image decomposition in this study. The proposed method can better reflect the detail of the red channel and does not lose the color information of the red channel itself. Subjective qualitative analysis and quantitative analysis are used to evaluate the algorithm in this study. According to the experimental results, the proposed method has poor performance on underwater color images with poor red and blue channel information because the method focuses on restoring the details and colors of the red channel. The method is suitable for underwater color images with poor red channel information performance and relatively good green channel and blue channel information performance. Therefore, considering only the red channel may be too restrictive. Next work, we consider the influence of the blue and green channels of the image on the red channel, and improve image clarity through image fusion.关键词:underwater image;two-scale decomposition;mean filtering;detail compensation;color cast;red shadow101|158|2更新时间:2024-05-07
摘要:ObjectiveDue to the complex and changeable underwater environment, when light enters a water body, it is affected by absorption and scattering, which leads to color cast, blur, and low contrast of underwater images. Water has different absorption capabilities for different light rays. As a result, the red channel information of the image is poorly preserved, making underwater imaging difficult. In order to solve the problems caused by light absorption in underwater images, existing scientific research has found that compared with the red and blue channels, the obtained green channel details of the underwater channel are best preserved, whereas the red channel details are poorly preserved. According to the characteristics of underwater imaging, the present study proposes an underwater color image enhancement method based on two-scale image decomposition. The method can effectively solve the problems of color cast and low contrast of the image and reduce the introduction of red shadow to obtain high-resolution underwater images.MethodFirst, a contrast stretching method based on the gray world hypothesis is used. The method calculates the mean and mean square error of each channel independently and then uses a new normalization method using the mean and mean square error of each channel. In order to reduce the color cast problem of the image, a median filter is used to reduce the noise problem introduced by the red channel contrast stretch. Then, the two-scale image decomposition method is used to apply a large-scale mean filter to the red channel of the median filtered image and the green channel of the image after the contrast is stretched. Subsequently, the channel is divided into a large-scale base layer and a small-scale detail layer. While retaining the large-scale base layer of the red channel of the image, the small-scale detail layer of the green channel is introduced. Because the color and details of the red channel of the original image are equally important, the true details and colors of the red channel of the original image are introduced into the red channel of the processed image to achieve a better restoration of the red channel colors and details of the image. Different underwater images are selected as the experimental dataset, and the proposed method is compared with the dark channel prior method, fusion-based method, automatic red channel recovery method, and deep learning method based on convolutional neural network. First, subjective analysis of the visual effects is conducted, and then objective analysis is performed through different underwater evaluation indicators.ResultThe results of different experimental images are compared. The dark channel prior method cannot solve the problem of color cast and low contrast of underwater images. The red channel recovery method solves the problem of image color cast or low contrast, but the image results obtained are poorer than those of the proposed method. The fusion-based method is better than the proposed method in improving image contrast. This is maintained by the edge of the image fusion algorithm, but an obvious red shadow problem will be observed in the resulting image. The proposed method can better solve the red shadow problem in the image. Deep learning method can improve the brightness and clarity of the image, but the result still has a certain color cast problem. Compared with the four methods, the proposed method can better solve the problem of color cast of underwater images, and no red shadow is generated, which is more in line with the visual perception of human eyes. Three methods, namely, natural image quality evaluation method (NIQE), information entropy (IE), and underwater image quality measurement method (UIQM) inspired by the human visual system, are used in the experiment for comparative analysis. NIQE compares the test image with the default model calculated from the natural scene image. The lower the index, the better the image perception quality and the higher the clarity. At the same time, NIQE and human eye subjective quality evaluation have better consistency, are similar to the human visual system, and can effectively perform real-time image quality evaluation. IE is an index to measure the information richness of a pair of images. The larger the IE value, the richer the detailed information contained in the image. Finally, UIQM is a better existing underwater image quality evaluation method, which can solve the evaluation of three important indicators of underwater images (i.e., color, clarity, and contrast). The larger the value of UIQM, the higher the clarity and the better the quality of the image. Compared with fusion-based methods and deep learning methods, NIQE and IE in quantitative analysis are improved by 1.8% and 13.6%, respectively. The value of UIQM is 1.542, which is the best result compared with other methods. The experimental results show that the proposed method can better solve the problem of image color cast and red shadow compared with other methods.ConclusionFirst, through the contrast-based stretching method, the green channel image with good detail retention is used to compensate for the red channel image detail. We propose an underwater color image enhancement method based on two-scale image decomposition in this study. The proposed method can better reflect the detail of the red channel and does not lose the color information of the red channel itself. Subjective qualitative analysis and quantitative analysis are used to evaluate the algorithm in this study. According to the experimental results, the proposed method has poor performance on underwater color images with poor red and blue channel information because the method focuses on restoring the details and colors of the red channel. The method is suitable for underwater color images with poor red channel information performance and relatively good green channel and blue channel information performance. Therefore, considering only the red channel may be too restrictive. Next work, we consider the influence of the blue and green channels of the image on the red channel, and improve image clarity through image fusion.关键词:underwater image;two-scale decomposition;mean filtering;detail compensation;color cast;red shadow101|158|2更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveGait recognition aims to identify and verify individuals on the basis of walking postures. The performance of existing gait recognition methods is easily influenced by factors such as viewing variances, clothing changes, and types of objects carried by a person. Furthermore, none of these methods consider that the coordination and periodicity of human walking are also important features for gait recognition. Therefore, we propose the pose energy map without considering shoulders (PEMoS) to reduce the effect of clothing changes and 2D Fourier transform magnitude spectrum of gait parameters (2DFoMS) to enhance the effect of the coordination and periodicity of human movements. As these features have a close relationship with the human pose, we call them pose features. Moreover, the proposed pose features are fused together with other excellent features such as GaitSet to improve the overall performance of gait recognition.MethodClothing changes can affect the detected positions of body joints, especially the shoulder joints. Therefore, we propose PEMoS, which ignores the shoulder width, to reduce the effect of clothing changes. The construction process of PEMoS is as follows: First, body joints in each frame are detected by pose estimation methods. Second, six upper limb joints, namely, RShoulder(right shoulder), RElbow(right elbow), RWrist(right wrist), LShoulder(loft shoulder), LElbow(left elbow), and LWrist(left wrist), are horizontally shifted with the displacement between the neck joint and the right or left shoulder joint, whereas the rest remain unchanged. Third, the pose binary map is formatted by connecting the corrected joints in a predefined order and width. Then, it is resized to 128×88 pixels centering on the MidHip joint. Fourth, PEMoS is computed by averaging pose binary maps within a period that include at least one complete gait cycle. Finally, PEMoS is activated by gamma transformation to improve the performance. 2DFoMS uses the coordination between human movements and the periodicity of one single movement to enhance the gait recognition performance. As the lower limbs are less affected by clothing or bags, three new gait parameters computed from the lower limbs are proposed, which include the area of the triangle formed by MidHip(middle hip), LKnee(left knee), and RKnee(right knee); the area of the triangle formed by MidHip, LAnkle(left ankle), and RAnkle(right ankle); and the area of the polygon enclosed by all the lower limb joints. Unlike the existing gait parameters that only consider the relationship between two joints, the proposed area parameters consider the local structural relationship of more than three points, which can enhance the effect of lower limb joints to the gait. The proposed three parameters are concatenated with the other 16 gait parameters extracted by regular methods to form a gait parameter column vector in each frame. The gait parameter column vectors of successive frames over time form a two-dimensional gait parameter matrix. As the gait parameters vary with time, they should be aligned to facilitate training and matching. On the basis of the observation that the width between two ankles varies with time much more regularly than other gait parameters, we propose to use the peak value position of the ankle width curve as base points to align all other gait parameters. 2DFoMS is computed by applying 2D Fourier transform on the registered gait parameter matrix. To fully utilize the advantages of the proposed features and the state-of-the-art features, such as GaitSet, two-level score fusion based on weighted average-max pooling is proposed to compute the matching score. The first level is the weighted average scores of multiple features. At this level, three groups of weights applicable to three different scenarios are proposed to compute the scores. At the second level, the max pooling of the first level scores is used as the final matching score.ResultWe evaluate the proposed method in terms of four aspects: overall performance, performance under different walking conditions, performance under cross-view conditions, and ablation study. In CASIA Gait Database B, the first 62 subjects are used for training, and the remaining 62 subjects are used for testing. The experimental results show that the proposed method achieves average accuracies of 99.56%, 99.23%, and 94.25% under walking normally, walking with a bag, and walking with a different coat, respectively, when the views of the probe sequence and its counterpart in the gallery set are the same. For cross-view recognition, the proposed method achieves average accuracies of 91.32%, 85.34%, and 69.51% under walking normally, walking with a bag, and walking with a different coat, respectively. Compared with the state-of-the-art methods, the average accuracy of the proposed method increases by about 6.98% under clothing changing conditions. Ablation study shows that PEMoS and 2DFoMS are effective in improving the gait recognition accuracy.ConclusionThe proposed PEMoS, which ignores the shoulder width, can increase the robustness and accuracy of gait recognition under clothing changing conditions. The proposed local structure gait parameters can enhance the effect of lower limb points to the gait, which are more robust to clothing or bag changes than the upper limb parameters. 2DFoMS can emphasize the effect of coordination between human movements and the periodicity of one single moment on the performance of gait recognition. The experimental results show that the proposed algorithm has achieved state-of-the-art performance, especially under clothing or bag changing conditions.关键词:gait recognition;pose feature;pose energy map without considering shoulders;coordination and periodicity of human movement;local structure gait parameters;2D Fourier transform on gait parameters;two level score fusion84|33|3更新时间:2024-05-07
摘要:ObjectiveGait recognition aims to identify and verify individuals on the basis of walking postures. The performance of existing gait recognition methods is easily influenced by factors such as viewing variances, clothing changes, and types of objects carried by a person. Furthermore, none of these methods consider that the coordination and periodicity of human walking are also important features for gait recognition. Therefore, we propose the pose energy map without considering shoulders (PEMoS) to reduce the effect of clothing changes and 2D Fourier transform magnitude spectrum of gait parameters (2DFoMS) to enhance the effect of the coordination and periodicity of human movements. As these features have a close relationship with the human pose, we call them pose features. Moreover, the proposed pose features are fused together with other excellent features such as GaitSet to improve the overall performance of gait recognition.MethodClothing changes can affect the detected positions of body joints, especially the shoulder joints. Therefore, we propose PEMoS, which ignores the shoulder width, to reduce the effect of clothing changes. The construction process of PEMoS is as follows: First, body joints in each frame are detected by pose estimation methods. Second, six upper limb joints, namely, RShoulder(right shoulder), RElbow(right elbow), RWrist(right wrist), LShoulder(loft shoulder), LElbow(left elbow), and LWrist(left wrist), are horizontally shifted with the displacement between the neck joint and the right or left shoulder joint, whereas the rest remain unchanged. Third, the pose binary map is formatted by connecting the corrected joints in a predefined order and width. Then, it is resized to 128×88 pixels centering on the MidHip joint. Fourth, PEMoS is computed by averaging pose binary maps within a period that include at least one complete gait cycle. Finally, PEMoS is activated by gamma transformation to improve the performance. 2DFoMS uses the coordination between human movements and the periodicity of one single movement to enhance the gait recognition performance. As the lower limbs are less affected by clothing or bags, three new gait parameters computed from the lower limbs are proposed, which include the area of the triangle formed by MidHip(middle hip), LKnee(left knee), and RKnee(right knee); the area of the triangle formed by MidHip, LAnkle(left ankle), and RAnkle(right ankle); and the area of the polygon enclosed by all the lower limb joints. Unlike the existing gait parameters that only consider the relationship between two joints, the proposed area parameters consider the local structural relationship of more than three points, which can enhance the effect of lower limb joints to the gait. The proposed three parameters are concatenated with the other 16 gait parameters extracted by regular methods to form a gait parameter column vector in each frame. The gait parameter column vectors of successive frames over time form a two-dimensional gait parameter matrix. As the gait parameters vary with time, they should be aligned to facilitate training and matching. On the basis of the observation that the width between two ankles varies with time much more regularly than other gait parameters, we propose to use the peak value position of the ankle width curve as base points to align all other gait parameters. 2DFoMS is computed by applying 2D Fourier transform on the registered gait parameter matrix. To fully utilize the advantages of the proposed features and the state-of-the-art features, such as GaitSet, two-level score fusion based on weighted average-max pooling is proposed to compute the matching score. The first level is the weighted average scores of multiple features. At this level, three groups of weights applicable to three different scenarios are proposed to compute the scores. At the second level, the max pooling of the first level scores is used as the final matching score.ResultWe evaluate the proposed method in terms of four aspects: overall performance, performance under different walking conditions, performance under cross-view conditions, and ablation study. In CASIA Gait Database B, the first 62 subjects are used for training, and the remaining 62 subjects are used for testing. The experimental results show that the proposed method achieves average accuracies of 99.56%, 99.23%, and 94.25% under walking normally, walking with a bag, and walking with a different coat, respectively, when the views of the probe sequence and its counterpart in the gallery set are the same. For cross-view recognition, the proposed method achieves average accuracies of 91.32%, 85.34%, and 69.51% under walking normally, walking with a bag, and walking with a different coat, respectively. Compared with the state-of-the-art methods, the average accuracy of the proposed method increases by about 6.98% under clothing changing conditions. Ablation study shows that PEMoS and 2DFoMS are effective in improving the gait recognition accuracy.ConclusionThe proposed PEMoS, which ignores the shoulder width, can increase the robustness and accuracy of gait recognition under clothing changing conditions. The proposed local structure gait parameters can enhance the effect of lower limb points to the gait, which are more robust to clothing or bag changes than the upper limb parameters. 2DFoMS can emphasize the effect of coordination between human movements and the periodicity of one single moment on the performance of gait recognition. The experimental results show that the proposed algorithm has achieved state-of-the-art performance, especially under clothing or bag changing conditions.关键词:gait recognition;pose feature;pose energy map without considering shoulders;coordination and periodicity of human movement;local structure gait parameters;2D Fourier transform on gait parameters;two level score fusion84|33|3更新时间:2024-05-07 -
 摘要:ObjectiveThe rapid development of artificial intelligence and target detection technology has accelerated the iteration of intelligent devices and also promoted the development of related technologies in the field of human-computer interaction. As an important body language and an important means to realize human-computer interaction, gesture recognition has attracted considerable attention. It has the characteristics of simplicity, high efficiency, directness, and rich content. This interaction mode is more in line with people's daily behavior and easier to understand. Gesture recognition has a wide application prospect in smart homes, virtual reality, sign language recognition, and other fields. Gesture recognition involves a wide range of disciplines such as image processing, ergonomics, machine vision, and deep learning. In addition, due to the variety of gestures and the complexity of practical application environment, gesture recognition has become a very challenging research topic.MethodThe traditional vision-based gesture recognition method mainly uses the skin color or skeleton model of the human body to partially segment gestures and realizes gesture classification through manual design and extraction of effective features. However, the collected RGB images are greatly affected by light conditions, skin color, clothing, and background. In the case of backlight, dark light, and dark skin color, the effects of segmentation and gesture recognition are poor. Features such as texture and edge are extracted manually, feature omission and misjudgment are easily generated during the extraction process. The recognition rate is low, and the robustness is poor under complex background. In recent years, deep learning technology has attracted more and more attention due to its robustness and high accuracy. The convolutional neural network model based on deep learning has gradually replaced the traditional manual feature extraction method and gradually become the mainstream method of gesture recognition. Although existing mainstream deep learning methods such as you only look once (YOLO) and single shot multibox detector (SSD) have achieved high accuracy in gesture recognition under complex backgrounds, their models are generally large, which is a difficult requirement to meet. It is difficult to achieve real-time detection effect with embedded devices and detection time. Therefore, how to reduce the complexity of the model and algorithms while ensuring the detection accuracy and meeting the requirements of real-time detection in practical applications has become an urgent problem that needs to be solved. The TinyYOLOv3 algorithm has the advantages of fast detection speed and small model, but its recognition accuracy is far from meeting the requirements of practical application. Therefore, to solve the above problems, this study proposes a gesture recognition method based on the improved TinyYOLOv3 algorithm. In this study, the TinyYOLOv3 backbone network is redesigned. The convolution operation with stride of 2 is used to replace the original maximum pooling layer, and the number of network layers is increased to ensure that the network extracts richer semantic information. At the same time, the depthwise separable convolution is used to replace the traditional convolution, and the characteristics of different network layers are integrated to reduce the size of the network model, ensure the recognition accuracy, and avoid the loss of feature information due to the deepening of the network structure. In the improvement of the loss function, the CIoU(complete intersection over union) loss is used to replace the original bounding box coordinate to predict loss. The experimental results show that CIoU is helpful to speed up the convergence of the model, reduce the training time, and improve the accuracy to a certain extent. The channel attention module is integrated into the feature extraction network, and the information of different channels is recalibrated to reduce the increase of parameters and improve the recognition accuracy. The data enhancement method is used to avoid overfitting training, and super parameter optimization, dynamic learning rate setting, prior frame clustering, and other methods are used to accelerate network convergence.ResultThis study uses the NUS-Ⅱ(National University of Singapore) gesture dataset for verification experiments. The experimental results show that the accuracy rate of the improved network recognition reaches 99.1%, which is 8.5% higher than that of the original network (TinyYOLOv3, 90.6%), and the size of the network model is reduced from 33.2 MB to 27.6 MB. Compared with YOLOv3, the recognition accuracy of the improved algorithm is slightly reduced; however, the detection speed is nearly doubled, the model size is about one-eighth that of YOLOv3, and the number of parameters is also reduced by nearly 10 times, verifying the feasibility of the algorithm. At the same time, ablation experiments were carried out on different improved modules, and the results showed that the improvement of each module helped to improve the accuracy of the algorithm. By comparing and analyzing the accuracy and loss rate changes of Tiny YOLOv3, improved Tiny YOLOv3 by CIoU and the algorithm in this paper, the advantages of the algorithm in this paper in training time and convergence speed are verified. The advantages of this algorithm in terms of training time and convergence speed are verified. This study also compared the improved algorithm with some classical traditional and deep learning gesture recognition algorithms. In terms of model size, detection time, and accuracy, the algorithm in this study achieved better results.ConclusionGesture recognition in complex background is a key and difficult problem in the field of gesture recognition. To solve the problems of low gesture recognition rate of traditional gesture recognition methods in complex background and long detection time of existing gesture recognition methods based on deep learning, a gesture recognition method based on improved TinyYOLOv3 algorithm is proposed in this study. The network structure, loss function, feature channel optimization, and prior frame clustering are improved. The use of depthwise separable convolution makes it possible to deepen the network while reducing the number of parameters. The deepening of the network structure and the optimization of the feature channel enable the network to extract more effective semantic information and improve the detection effect. The improved network not only ensures the accuracy, but also takes into account the balance between the network model size and detection time, which can meet the use requirements of embedded equipment.关键词:gesture recognition;TinyYOLOv3;depthwise separable convolution;CIoU loss76|75|3更新时间:2024-05-07
摘要:ObjectiveThe rapid development of artificial intelligence and target detection technology has accelerated the iteration of intelligent devices and also promoted the development of related technologies in the field of human-computer interaction. As an important body language and an important means to realize human-computer interaction, gesture recognition has attracted considerable attention. It has the characteristics of simplicity, high efficiency, directness, and rich content. This interaction mode is more in line with people's daily behavior and easier to understand. Gesture recognition has a wide application prospect in smart homes, virtual reality, sign language recognition, and other fields. Gesture recognition involves a wide range of disciplines such as image processing, ergonomics, machine vision, and deep learning. In addition, due to the variety of gestures and the complexity of practical application environment, gesture recognition has become a very challenging research topic.MethodThe traditional vision-based gesture recognition method mainly uses the skin color or skeleton model of the human body to partially segment gestures and realizes gesture classification through manual design and extraction of effective features. However, the collected RGB images are greatly affected by light conditions, skin color, clothing, and background. In the case of backlight, dark light, and dark skin color, the effects of segmentation and gesture recognition are poor. Features such as texture and edge are extracted manually, feature omission and misjudgment are easily generated during the extraction process. The recognition rate is low, and the robustness is poor under complex background. In recent years, deep learning technology has attracted more and more attention due to its robustness and high accuracy. The convolutional neural network model based on deep learning has gradually replaced the traditional manual feature extraction method and gradually become the mainstream method of gesture recognition. Although existing mainstream deep learning methods such as you only look once (YOLO) and single shot multibox detector (SSD) have achieved high accuracy in gesture recognition under complex backgrounds, their models are generally large, which is a difficult requirement to meet. It is difficult to achieve real-time detection effect with embedded devices and detection time. Therefore, how to reduce the complexity of the model and algorithms while ensuring the detection accuracy and meeting the requirements of real-time detection in practical applications has become an urgent problem that needs to be solved. The TinyYOLOv3 algorithm has the advantages of fast detection speed and small model, but its recognition accuracy is far from meeting the requirements of practical application. Therefore, to solve the above problems, this study proposes a gesture recognition method based on the improved TinyYOLOv3 algorithm. In this study, the TinyYOLOv3 backbone network is redesigned. The convolution operation with stride of 2 is used to replace the original maximum pooling layer, and the number of network layers is increased to ensure that the network extracts richer semantic information. At the same time, the depthwise separable convolution is used to replace the traditional convolution, and the characteristics of different network layers are integrated to reduce the size of the network model, ensure the recognition accuracy, and avoid the loss of feature information due to the deepening of the network structure. In the improvement of the loss function, the CIoU(complete intersection over union) loss is used to replace the original bounding box coordinate to predict loss. The experimental results show that CIoU is helpful to speed up the convergence of the model, reduce the training time, and improve the accuracy to a certain extent. The channel attention module is integrated into the feature extraction network, and the information of different channels is recalibrated to reduce the increase of parameters and improve the recognition accuracy. The data enhancement method is used to avoid overfitting training, and super parameter optimization, dynamic learning rate setting, prior frame clustering, and other methods are used to accelerate network convergence.ResultThis study uses the NUS-Ⅱ(National University of Singapore) gesture dataset for verification experiments. The experimental results show that the accuracy rate of the improved network recognition reaches 99.1%, which is 8.5% higher than that of the original network (TinyYOLOv3, 90.6%), and the size of the network model is reduced from 33.2 MB to 27.6 MB. Compared with YOLOv3, the recognition accuracy of the improved algorithm is slightly reduced; however, the detection speed is nearly doubled, the model size is about one-eighth that of YOLOv3, and the number of parameters is also reduced by nearly 10 times, verifying the feasibility of the algorithm. At the same time, ablation experiments were carried out on different improved modules, and the results showed that the improvement of each module helped to improve the accuracy of the algorithm. By comparing and analyzing the accuracy and loss rate changes of Tiny YOLOv3, improved Tiny YOLOv3 by CIoU and the algorithm in this paper, the advantages of the algorithm in this paper in training time and convergence speed are verified. The advantages of this algorithm in terms of training time and convergence speed are verified. This study also compared the improved algorithm with some classical traditional and deep learning gesture recognition algorithms. In terms of model size, detection time, and accuracy, the algorithm in this study achieved better results.ConclusionGesture recognition in complex background is a key and difficult problem in the field of gesture recognition. To solve the problems of low gesture recognition rate of traditional gesture recognition methods in complex background and long detection time of existing gesture recognition methods based on deep learning, a gesture recognition method based on improved TinyYOLOv3 algorithm is proposed in this study. The network structure, loss function, feature channel optimization, and prior frame clustering are improved. The use of depthwise separable convolution makes it possible to deepen the network while reducing the number of parameters. The deepening of the network structure and the optimization of the feature channel enable the network to extract more effective semantic information and improve the detection effect. The improved network not only ensures the accuracy, but also takes into account the balance between the network model size and detection time, which can meet the use requirements of embedded equipment.关键词:gesture recognition;TinyYOLOv3;depthwise separable convolution;CIoU loss76|75|3更新时间:2024-05-07 -
 摘要:ObjectiveFace recognition has been a widely studied topic in the field of computer vision for a long time. In the past few decades, great progress in face recognition has been achieved due to the capacity and wide application of convolutional neural networks. However, pose variations still remain a great challenge and warrant further studies. To the best of our knowledge, the existing methods that address this problem can be generally categorized into two classes: feature-based methods and deep learning-based methods. Feature-based methods attempt to obtain pose-invariant representations directly from non-frontal faces or design handcrafted local feature descriptors, which are robust to face poses. However, it is often too difficult to obtain robust representation of the face pose using these handcrafted local feature descriptors. Thus, these methods cannot produce satisfactory results, especially when the face pose is too large. In recent years, convolutional neural networks have been introduced in face recognition problems due to their outstanding performance in image classification tasks. Different from traditional methods, convolutional neural networks do not require the manual extraction of local feature descriptors. They try to directly rotate the face image of arbitrary pose and illuminate into the target pose, which maintains the face identity feature well. In addition, due to the powerful ability of image generation, generative adversarial network is also used in frontal face image synthesis and has achieved great progress. Compared with traditional methods, deep learning-based methods can obtain a higher face recognition rate. However, the disadvantage of deep learning-based methods is that the face images synthesized from the large face pose have low credibility, which lead to poor face recognition accuracy. To deal with the limitations of these two kinds of methods, we present a face pose correction algorithm based on 3D morphable model (3DMM) and image inpainting.MethodIn this study, we propose a face frontalization method by combining deep learning model and a 3DMM, which can generate a photorealistic frontal view of the face image. In detail, we first detect facial landmarks by using a well-known facial landmark detector, which is robust to large pose variations. We detect a total of 68 facial landmarks to fit the face image more accurately. Then, we perform accurate 3DMM fitting for face image with facial landmark weighting. Next, we estimate the depth information of the face image and rotate the 3D face model into frontal view using 3D transformation. Finally, we employ image inpainting for the irregular facial invisible region caused by self-occlusion by utilizing deep learning model. We fine-tune the pre-trained model to train our image inpainting model. In the training process, all of the convolutional layers are replaced with partial convolutional layers. Our training set consists of 13 223 face images that are selected from the labeled faces in the wild (LFW) dataset. Our image inpainting network is implemented in Keras. The batch size is set to 4, the learning rate is set to 10-4, and the weight decay is 0.000 5. The network training procedure is accelerated using NVIDIA GTX 1080 Ti GPU devices, which takes approximately 10 days in total.ResultWe compare our method with state-of-the-art methods, including the traditional method and deep learning method, on two public face datasets, namely, LFW dataset and StirlingESRC 3D face dataset. The quantitative evaluation metric is face recognition rate under different face poses, and we provide several synthesized frontal face images by our method. The synthesized frontal face images show that our method can produce more photorealistic results than other methods in the LFW dataset. We achieve 96.57% face recognition accuracy on the LFW face dataset. In addition, the quantitative experiment results show that our method outperforms all other methods in StirlingESRC 3D face dataset. The experimental results show that the face recognition accuracy of our method is improved under different face poses. Compared with the other two methods in the StirlingESRC 3D face dataset, the face recognition accuracy increased by 5.195% and 2.265% under the face pose of 22° and by 5.875% and 11.095% under the face pose of 45°, respectively. Moreover, the average face recognition rate increased by 5.53% and 7.13%, respectively. The experimental results show that the proposed multi-pose face recognition algorithm improves the accuracy of face recognition.ConclusionIn this study, we propose a face pose correction algorithm for multi-pose face recognition by combining 3DMM with deep learning model. The qualitative and quantitative experiment results show that our method can synthesize a more photorealistic frontal face image than other methods and can improve the accuracy performance of multi-pose face recognition.关键词:multi-pose face recognition;3D morphable model (3DMM);convolutional neural network(CNN);image inpainting;deep learning89|104|1更新时间:2024-05-07
摘要:ObjectiveFace recognition has been a widely studied topic in the field of computer vision for a long time. In the past few decades, great progress in face recognition has been achieved due to the capacity and wide application of convolutional neural networks. However, pose variations still remain a great challenge and warrant further studies. To the best of our knowledge, the existing methods that address this problem can be generally categorized into two classes: feature-based methods and deep learning-based methods. Feature-based methods attempt to obtain pose-invariant representations directly from non-frontal faces or design handcrafted local feature descriptors, which are robust to face poses. However, it is often too difficult to obtain robust representation of the face pose using these handcrafted local feature descriptors. Thus, these methods cannot produce satisfactory results, especially when the face pose is too large. In recent years, convolutional neural networks have been introduced in face recognition problems due to their outstanding performance in image classification tasks. Different from traditional methods, convolutional neural networks do not require the manual extraction of local feature descriptors. They try to directly rotate the face image of arbitrary pose and illuminate into the target pose, which maintains the face identity feature well. In addition, due to the powerful ability of image generation, generative adversarial network is also used in frontal face image synthesis and has achieved great progress. Compared with traditional methods, deep learning-based methods can obtain a higher face recognition rate. However, the disadvantage of deep learning-based methods is that the face images synthesized from the large face pose have low credibility, which lead to poor face recognition accuracy. To deal with the limitations of these two kinds of methods, we present a face pose correction algorithm based on 3D morphable model (3DMM) and image inpainting.MethodIn this study, we propose a face frontalization method by combining deep learning model and a 3DMM, which can generate a photorealistic frontal view of the face image. In detail, we first detect facial landmarks by using a well-known facial landmark detector, which is robust to large pose variations. We detect a total of 68 facial landmarks to fit the face image more accurately. Then, we perform accurate 3DMM fitting for face image with facial landmark weighting. Next, we estimate the depth information of the face image and rotate the 3D face model into frontal view using 3D transformation. Finally, we employ image inpainting for the irregular facial invisible region caused by self-occlusion by utilizing deep learning model. We fine-tune the pre-trained model to train our image inpainting model. In the training process, all of the convolutional layers are replaced with partial convolutional layers. Our training set consists of 13 223 face images that are selected from the labeled faces in the wild (LFW) dataset. Our image inpainting network is implemented in Keras. The batch size is set to 4, the learning rate is set to 10-4, and the weight decay is 0.000 5. The network training procedure is accelerated using NVIDIA GTX 1080 Ti GPU devices, which takes approximately 10 days in total.ResultWe compare our method with state-of-the-art methods, including the traditional method and deep learning method, on two public face datasets, namely, LFW dataset and StirlingESRC 3D face dataset. The quantitative evaluation metric is face recognition rate under different face poses, and we provide several synthesized frontal face images by our method. The synthesized frontal face images show that our method can produce more photorealistic results than other methods in the LFW dataset. We achieve 96.57% face recognition accuracy on the LFW face dataset. In addition, the quantitative experiment results show that our method outperforms all other methods in StirlingESRC 3D face dataset. The experimental results show that the face recognition accuracy of our method is improved under different face poses. Compared with the other two methods in the StirlingESRC 3D face dataset, the face recognition accuracy increased by 5.195% and 2.265% under the face pose of 22° and by 5.875% and 11.095% under the face pose of 45°, respectively. Moreover, the average face recognition rate increased by 5.53% and 7.13%, respectively. The experimental results show that the proposed multi-pose face recognition algorithm improves the accuracy of face recognition.ConclusionIn this study, we propose a face pose correction algorithm for multi-pose face recognition by combining 3DMM with deep learning model. The qualitative and quantitative experiment results show that our method can synthesize a more photorealistic frontal face image than other methods and can improve the accuracy performance of multi-pose face recognition.关键词:multi-pose face recognition;3D morphable model (3DMM);convolutional neural network(CNN);image inpainting;deep learning89|104|1更新时间:2024-05-07 -
 摘要:ObjectiveEstimation of human body posture has always been one of the engaging research directions in computer vision. Attitude estimation in a multiperson complex background is much more difficult than single-person pose estimation (SPPE) in a simple background. Negative factors such as complex background, multiperson recognition, and human occlusion add a large amount of difficulty to the accurate implementation of multiperson pose estimation algorithms. Multiperson pose estimation algorithms can be mainly divided into "top-down"and "bottom-up" frameworks. The essence of the "top-down" framework is from the holistic-local-to-integral process, by detecting the bounding box of the human body and then independently estimating the pose within each frame to complete multiperson pose estimation. The process of the "bottom-up" framework is from the local-to-integral process by first detecting the body parts independently and then assembling the detected body parts into a human body posture. Both frameworks have their own advantages and disadvantages. The use of a "top-down" framework is susceptible to redundant bounding boxes. The accuracy of pose estimation depends mainly on the quality of the human bounding box. With the "bottom-up" framework, when two or more people are very close together, the gestures that are detected and combined will become very blurred because the framework is localbased and lacks globality. Control is more prone to pose combination errors when applied to multiperson pose estimation in complex environments. We want to complete a more accurate multiperson pose estimation while grasping the overall situation. Therefore, a multiperson pose estimation method combining the YOLOv3 pruning model and SPPE is proposed to solve the problem of positioning and identification of multi-person pose estimation in complex environments, and improve the accuracy of multi-person pose estimation. The YOLOv3 algorithm is a type of end-to-end target detection algorithm proposed in 2018. It uses multiple residual networks for feature extraction and feature pyramid network to achieve feature fusion. Therefore, the YOLOv3 algorithm greatly improves the accuracy of target detection based on maintaining real-time performance. Moreover, the YOLOv3 model has many redundant parameters that greatly affect network operation rate and overall performance. The role of model pruning is to filter the importance of discriminative parameters and remove redundant parameters to reduce the overall model complexity and increase the operating rate. The stacked hourglass network introduced in 2016 consists of multiple hourglass subnets and is extremely malleable. The hourglass subnetwork consists of a residual network that exploits the excellent combining capabilities and feature extraction capabilities of the residual network to extract features of the picture or video. The idea of the primary network-subnetwork provides extremely flexible plasticity for the stacked hourglass network. Multiple subnetwork stacks can help subsequent subnetworks utilize the information extracted by the previous subnetwork, improving the accuracy of the overall network prediction of the human joint points.MethodThe algorithm is based on the target detection algorithm YOLOv3 and the stacked hourglass algorithm. The YOLOv3 network anchor box is modified by the overlap K-means algorithm to adapt to pedestrian target detection better, and the Trimming-YOLOv3 network is trained. In batch normalization, the scaling factor of the layer performs cyclic iterative channel pruning on the Trimming-YOLOv3 network, sets the pruning threshold and scaling factor, achieves a more effective model pruning effect, and trains to obtain the Trim-Prune-YOLOv3 network. To combine the SPPE network, the picture size is redefined to 256×256 pixels (nonsquare pictures are implemented by zero padding), then the four hourglass subnetworks are cascaded to obtain a stacked hourglass network, improving the overall attitude estimation accuracy.ResultThis method has been verified by the MPⅡ human pose dataset (MPⅡ dataset) of Stanford University, which is one of the most authoritative datasets in the field of human pose estimation. The MPⅡ is a very challenging multiperson pose dataset, which contains 3 844 training combinations and 1 758 test groups, including occluded people and overlapping people. The MPⅡ dataset contains 16 personal markers, which are the head, shoulders, elbows, wrists, hips, knees, and ankles. On the MPⅡ dataset, the accuracy of the multiperson pose estimation algorithm reaches 83.9%, the time complexity is O(n2), and the model parameter amount decreases by 42.9% compared with the unpruned original YOLOv3.ConclusionThe multiperson pose estimation method combined with the YOLOv3 pruning algorithm can effectively reduce the negative effect of complex environments on human pose estimation, achieve multiperson pose estimation, and improve estimation accuracy in complex environments, while using model pruning methods can effectively reduce model redundancy parameters to improve the overall speed of the algorithm. Experimental results show that the method can achieve a more accurate multiperson pose estimation and has better robustness and generalization ability compared with other methods.关键词:object detection;multi-person pose estimation;model pruning;YOLOv3;stacked hourglass network;MPII dataset86|122|7更新时间:2024-05-07
摘要:ObjectiveEstimation of human body posture has always been one of the engaging research directions in computer vision. Attitude estimation in a multiperson complex background is much more difficult than single-person pose estimation (SPPE) in a simple background. Negative factors such as complex background, multiperson recognition, and human occlusion add a large amount of difficulty to the accurate implementation of multiperson pose estimation algorithms. Multiperson pose estimation algorithms can be mainly divided into "top-down"and "bottom-up" frameworks. The essence of the "top-down" framework is from the holistic-local-to-integral process, by detecting the bounding box of the human body and then independently estimating the pose within each frame to complete multiperson pose estimation. The process of the "bottom-up" framework is from the local-to-integral process by first detecting the body parts independently and then assembling the detected body parts into a human body posture. Both frameworks have their own advantages and disadvantages. The use of a "top-down" framework is susceptible to redundant bounding boxes. The accuracy of pose estimation depends mainly on the quality of the human bounding box. With the "bottom-up" framework, when two or more people are very close together, the gestures that are detected and combined will become very blurred because the framework is localbased and lacks globality. Control is more prone to pose combination errors when applied to multiperson pose estimation in complex environments. We want to complete a more accurate multiperson pose estimation while grasping the overall situation. Therefore, a multiperson pose estimation method combining the YOLOv3 pruning model and SPPE is proposed to solve the problem of positioning and identification of multi-person pose estimation in complex environments, and improve the accuracy of multi-person pose estimation. The YOLOv3 algorithm is a type of end-to-end target detection algorithm proposed in 2018. It uses multiple residual networks for feature extraction and feature pyramid network to achieve feature fusion. Therefore, the YOLOv3 algorithm greatly improves the accuracy of target detection based on maintaining real-time performance. Moreover, the YOLOv3 model has many redundant parameters that greatly affect network operation rate and overall performance. The role of model pruning is to filter the importance of discriminative parameters and remove redundant parameters to reduce the overall model complexity and increase the operating rate. The stacked hourglass network introduced in 2016 consists of multiple hourglass subnets and is extremely malleable. The hourglass subnetwork consists of a residual network that exploits the excellent combining capabilities and feature extraction capabilities of the residual network to extract features of the picture or video. The idea of the primary network-subnetwork provides extremely flexible plasticity for the stacked hourglass network. Multiple subnetwork stacks can help subsequent subnetworks utilize the information extracted by the previous subnetwork, improving the accuracy of the overall network prediction of the human joint points.MethodThe algorithm is based on the target detection algorithm YOLOv3 and the stacked hourglass algorithm. The YOLOv3 network anchor box is modified by the overlap K-means algorithm to adapt to pedestrian target detection better, and the Trimming-YOLOv3 network is trained. In batch normalization, the scaling factor of the layer performs cyclic iterative channel pruning on the Trimming-YOLOv3 network, sets the pruning threshold and scaling factor, achieves a more effective model pruning effect, and trains to obtain the Trim-Prune-YOLOv3 network. To combine the SPPE network, the picture size is redefined to 256×256 pixels (nonsquare pictures are implemented by zero padding), then the four hourglass subnetworks are cascaded to obtain a stacked hourglass network, improving the overall attitude estimation accuracy.ResultThis method has been verified by the MPⅡ human pose dataset (MPⅡ dataset) of Stanford University, which is one of the most authoritative datasets in the field of human pose estimation. The MPⅡ is a very challenging multiperson pose dataset, which contains 3 844 training combinations and 1 758 test groups, including occluded people and overlapping people. The MPⅡ dataset contains 16 personal markers, which are the head, shoulders, elbows, wrists, hips, knees, and ankles. On the MPⅡ dataset, the accuracy of the multiperson pose estimation algorithm reaches 83.9%, the time complexity is O(n2), and the model parameter amount decreases by 42.9% compared with the unpruned original YOLOv3.ConclusionThe multiperson pose estimation method combined with the YOLOv3 pruning algorithm can effectively reduce the negative effect of complex environments on human pose estimation, achieve multiperson pose estimation, and improve estimation accuracy in complex environments, while using model pruning methods can effectively reduce model redundancy parameters to improve the overall speed of the algorithm. Experimental results show that the method can achieve a more accurate multiperson pose estimation and has better robustness and generalization ability compared with other methods.关键词:object detection;multi-person pose estimation;model pruning;YOLOv3;stacked hourglass network;MPII dataset86|122|7更新时间:2024-05-07 -
 摘要:ObjectiveImage classification is a classic topic in the field of computer vision. It can be divided into coarse-grained classification and fine-grained classification. The purpose of coarse-grained classification is to identify objects of different categories, whereas that of fine-grained image classification is to subdivide larger categories into more fine-grained categories, which in many cases have greater use value. Fine-grained image classification is a challenging research topic in computer vision. There are extensive research needs and application scenarios of fine-grained image classification in the industry and academia. Due to background interference and difficulty in extracting effective classification features, problems still exist in fine-grained classification. Compared with general image classification, fine-grained classification experiences background interference. This problem can be addressed by object detection methods. The task of object detection is to find the objects of interest in the image and determine their position and size. At present, more and more target detection methods are based on deep learning. These methods can be divided into two categories: one-stage detection method and two-stage detection method. One-stage detection method has fast detection speed, but its accuracy is slightly lower. Examples of one-stage detection method mainly include you only look once(YOLO) and single shot multibox detector(SSD). Two-stage detection method first uses region recommendation to generate candidate targets, and then it uses a convolutional neural network (CNN) to process this condition. Some of the examples of this method include R-CNN (region CNN), SPP-NET (spatial pyramid pooling convolutional network), and Faster R-CNN. Among them, YOLOv3 of the YOLO series has achieved a better balance in detection accuracy and speed compared with other commonly used target detection frameworks.MethodTo improve the accuracy of these detection methods, a fine-grained classification algorithm based on the fusion of YOLOv3 and bilinear features is proposed in this study. The algorithm first uses the retrained target detection algorithm YOLOv3 to coarsely locate the target. Then, a background suppression method is used to remove irrelevant background interference. Finally, the feature fusion method is used to bilinear convolutional neural networks in the classic fine-grained classification algorithm. It can find that the convolutional neural network (referred to as B-CNN (bilinear CNN)) is greatly improved. By merging the features of different convolutional layers, more abundant complementary information is obtained. We use this method to improve the accuracy. The specific operation steps are as follows: 1) enter the image; 2) use YOLOv3 pre-trained model to generate discriminative regions; 3) the background suppression method removes irrelevant background interference outside the discrimination box; 4) construct a bilinear fine classification network of feature fusion, and use deep convolutional neural networks to extract features at the multi-layer convolution stage on the image; 5) the outer product operation is used to fuse the features of the convolution layers at different stages, and the obtained fusion features of the three different levels of features are connected by the concat method to obtain the final bilinear vector. Finally, the Softmax layer is used to achieve fine-grained classification.ResultAfter adding the YOLOv3 algorithm with background suppression, the classification accuracy rates on the three datasets are 0.7%, 0.5%, and 3.1% higher than those of B-CNN, respectively, indicating that removing background interference using the YOLOv3 algorithm can effectively improve classification. After using feature fusion to optimize the B-CNN network structure, we use three datasets (namely, CUB-200-2011 (Caltech-UCSD Birds-200- 2011), Stanford Cars, and fine-grained visual categorization(FGVC) Aircraft) to test the performance. The results are 1.4% and 1.2% higher than B-CNN, which indicates that the fusion of the features of different convolutional layers and the strengthening of the spatial relationship of the features can effectively improve the classification accuracy rate. After using YOLOv3 for background suppression and fusion of B-CNN, the accuracy rates reach 86.3%, 92.8%, and 89.0% in the three datasets, respectively. Compared with B-CNN algorithm, the proposed algorithm improves the accuracy by 2.2%, 1.5%, and 4.9% in the three datasets, respectively, indicating its effectiveness. For the purpose of analyzing the classification performance of the algorithm, the improved algorithm classification results also have certain advantages compared with the mainstream algorithms.ConclusionThe fine-grained classification algorithm based on YOLOv3 and bilinear feature fusion proposed in this study not only uses YOLOv3 to effectively filter out several irrelevant backgrounds to obtain discriminative regions on the image, but also improves the bilinear fine-grainedness by means of feature fusion. Classification network, so as to extract richer fine-grained features, and make the results of fine-grained image classification more accurate. This study proposes a fine-grained classification algorithm based on YOLOv3 and bilinear feature fusion, which can remove interference from irrelevant backgrounds. At the same time, the improved feature fusion B-CNN can learn richer features, which improves to a certain extent the accuracy of fine-grained classification. Compared with the classic B-CNN algorithm, the three fine-grained datasets are better than some mainstream algorithms. On the other hand, some new fine-grained classification algorithms are constantly changing. They use a host of different deep learning models to perform fine classification in fine-grained classification, but do not use background suppression and feature fusion to extract richer fine-grained features. In the future, we will apply fusion to the new network and use different types of fusion to further improve the accuracy of fine-grained classification in this study.关键词:fine-grained image classification;target detection;background suppression;feature fusion;bilinear convolutional neural network (B-CNN)223|177|6更新时间:2024-05-07
摘要:ObjectiveImage classification is a classic topic in the field of computer vision. It can be divided into coarse-grained classification and fine-grained classification. The purpose of coarse-grained classification is to identify objects of different categories, whereas that of fine-grained image classification is to subdivide larger categories into more fine-grained categories, which in many cases have greater use value. Fine-grained image classification is a challenging research topic in computer vision. There are extensive research needs and application scenarios of fine-grained image classification in the industry and academia. Due to background interference and difficulty in extracting effective classification features, problems still exist in fine-grained classification. Compared with general image classification, fine-grained classification experiences background interference. This problem can be addressed by object detection methods. The task of object detection is to find the objects of interest in the image and determine their position and size. At present, more and more target detection methods are based on deep learning. These methods can be divided into two categories: one-stage detection method and two-stage detection method. One-stage detection method has fast detection speed, but its accuracy is slightly lower. Examples of one-stage detection method mainly include you only look once(YOLO) and single shot multibox detector(SSD). Two-stage detection method first uses region recommendation to generate candidate targets, and then it uses a convolutional neural network (CNN) to process this condition. Some of the examples of this method include R-CNN (region CNN), SPP-NET (spatial pyramid pooling convolutional network), and Faster R-CNN. Among them, YOLOv3 of the YOLO series has achieved a better balance in detection accuracy and speed compared with other commonly used target detection frameworks.MethodTo improve the accuracy of these detection methods, a fine-grained classification algorithm based on the fusion of YOLOv3 and bilinear features is proposed in this study. The algorithm first uses the retrained target detection algorithm YOLOv3 to coarsely locate the target. Then, a background suppression method is used to remove irrelevant background interference. Finally, the feature fusion method is used to bilinear convolutional neural networks in the classic fine-grained classification algorithm. It can find that the convolutional neural network (referred to as B-CNN (bilinear CNN)) is greatly improved. By merging the features of different convolutional layers, more abundant complementary information is obtained. We use this method to improve the accuracy. The specific operation steps are as follows: 1) enter the image; 2) use YOLOv3 pre-trained model to generate discriminative regions; 3) the background suppression method removes irrelevant background interference outside the discrimination box; 4) construct a bilinear fine classification network of feature fusion, and use deep convolutional neural networks to extract features at the multi-layer convolution stage on the image; 5) the outer product operation is used to fuse the features of the convolution layers at different stages, and the obtained fusion features of the three different levels of features are connected by the concat method to obtain the final bilinear vector. Finally, the Softmax layer is used to achieve fine-grained classification.ResultAfter adding the YOLOv3 algorithm with background suppression, the classification accuracy rates on the three datasets are 0.7%, 0.5%, and 3.1% higher than those of B-CNN, respectively, indicating that removing background interference using the YOLOv3 algorithm can effectively improve classification. After using feature fusion to optimize the B-CNN network structure, we use three datasets (namely, CUB-200-2011 (Caltech-UCSD Birds-200- 2011), Stanford Cars, and fine-grained visual categorization(FGVC) Aircraft) to test the performance. The results are 1.4% and 1.2% higher than B-CNN, which indicates that the fusion of the features of different convolutional layers and the strengthening of the spatial relationship of the features can effectively improve the classification accuracy rate. After using YOLOv3 for background suppression and fusion of B-CNN, the accuracy rates reach 86.3%, 92.8%, and 89.0% in the three datasets, respectively. Compared with B-CNN algorithm, the proposed algorithm improves the accuracy by 2.2%, 1.5%, and 4.9% in the three datasets, respectively, indicating its effectiveness. For the purpose of analyzing the classification performance of the algorithm, the improved algorithm classification results also have certain advantages compared with the mainstream algorithms.ConclusionThe fine-grained classification algorithm based on YOLOv3 and bilinear feature fusion proposed in this study not only uses YOLOv3 to effectively filter out several irrelevant backgrounds to obtain discriminative regions on the image, but also improves the bilinear fine-grainedness by means of feature fusion. Classification network, so as to extract richer fine-grained features, and make the results of fine-grained image classification more accurate. This study proposes a fine-grained classification algorithm based on YOLOv3 and bilinear feature fusion, which can remove interference from irrelevant backgrounds. At the same time, the improved feature fusion B-CNN can learn richer features, which improves to a certain extent the accuracy of fine-grained classification. Compared with the classic B-CNN algorithm, the three fine-grained datasets are better than some mainstream algorithms. On the other hand, some new fine-grained classification algorithms are constantly changing. They use a host of different deep learning models to perform fine classification in fine-grained classification, but do not use background suppression and feature fusion to extract richer fine-grained features. In the future, we will apply fusion to the new network and use different types of fusion to further improve the accuracy of fine-grained classification in this study.关键词:fine-grained image classification;target detection;background suppression;feature fusion;bilinear convolutional neural network (B-CNN)223|177|6更新时间:2024-05-07 -
 摘要:ObjectiveFashion retrieval method is a research hotspot in the field of computer vision and natural language processing. It aims to help users easily and quickly retrieve clothes that meet the query conditions from a large number of clothing. To make the retrieval method more diverse and convenient, the retrieval method researched in recent years usually includes the image query mode for intuitive retrieval and the text query mode for supplementary retrieval, that is, content-based image retrieval and text-based image retrieval. However, most of them pay attention to the precise matching in vision, and few pay attention to the similarity in style of clothing. In addition, the extracted feature dimensions are usually high, which leads to low retrieval efficiency. To solve these problems, we propose a fashion style retrieval method based on deep multimodal fusion.MethodTo solve the problem of low efficiency of image query mode, a hierarchical deep hash retrieval model is first proposed in this study. Its image deep feature extraction network is based on the pre-trained residual network ResNet for migration learning, which can learn the image deep features at a lower cost. The network classification layer is transformed into a hash coding layer, which can generate simple hash features. In this study, hash features are used for coarse retrieval, while in the fine retrieval stage, the preliminary results are rearranged based on the deep features of the image. To solve the problem of low efficiency of text query mode and to improve the scalability of the search engine, a text classification semantic retrieval model is proposed in this study, which designs a text classification network based on long short-term memory(LSTM) to classify query text in advance. Then, we construct a text embedding feature extraction model based on doc2vec, which can retrieve the text embedding feature in the pre-classified categories. At the same time, to capture the similarity of clothing style, a similar style context retrieval model is proposed, which measures the similarity of clothing style by referring to the similarity of part of speech and collocation level of words, references the training form of word2vec model in text words, and trains clothing as words and outfit as sentences. Finally, we use the probability driven method to quantify fashion style similarity without manual style annotation; compare different multimodal hybrid methods to maximize the similarity as the final return of search engine, that is, based on the text retrieval modal results to retrieve style context similar clothing; and rearrange all modal results and style context results based on image features.ResultChoosing Polyvore as the dataset, we use the test set data as the query and retrieve the returned training set data as the result, so as to evaluate the results for different indicators. For the image retrieval mode, compared with the original ResNet model, the average retrieval accuracy of top 5 of the hierarchical deep hash retrieval framework is improved by 11.6%, and the retrieval speed is increased by 2.57 s/query. The average retrieval accuracy of the two feature retrieval strategies from coarse to fine is comparable to that of the direct image deep feature retrieval. For the text retrieval mode, compared with the traditional text embedding model, the top 5 precision of the text classification semantic retrieval framework is increased by 29.96%, and the retrieval speed is increased by 16.53 s/query. Finally, for the multimodal fusion results, we retrieve the context style similar clothing based on the text modal results and rearrange the final results in the image feature space. The average style similarity of the final results is 24%.ConclusionWe propose a fashion style retrieval method based on deep multimodal fusion, whose hierarchical deep hash retrieval model is used as the image retrieval mode. Compared with most other modes and retrieval methods, the method of fine-tuning based on pre-training network with the goal of generating hash code and retrieval strategy from coarse to fine can improve the retrieval accuracy and speed. As the text retrieval mode, the text classification semantic retrieval model uses the text classification network to narrow the scope of retrieval and then uses the text features extracted from the text feature extraction model combined with the output of different models for retrieval. Compared with other text semantic retrieval methods, this mode can also improve the retrieval speed and accuracy. At the same time, in order to capture the similarity of fashion style, a similar style context retrieval model is proposed to find the results similar to the query clothing style and make the results more diverse.关键词:multimodal fashion search;hash feature;text embedding;style similarity;deep Hashing63|52|1更新时间:2024-05-07
摘要:ObjectiveFashion retrieval method is a research hotspot in the field of computer vision and natural language processing. It aims to help users easily and quickly retrieve clothes that meet the query conditions from a large number of clothing. To make the retrieval method more diverse and convenient, the retrieval method researched in recent years usually includes the image query mode for intuitive retrieval and the text query mode for supplementary retrieval, that is, content-based image retrieval and text-based image retrieval. However, most of them pay attention to the precise matching in vision, and few pay attention to the similarity in style of clothing. In addition, the extracted feature dimensions are usually high, which leads to low retrieval efficiency. To solve these problems, we propose a fashion style retrieval method based on deep multimodal fusion.MethodTo solve the problem of low efficiency of image query mode, a hierarchical deep hash retrieval model is first proposed in this study. Its image deep feature extraction network is based on the pre-trained residual network ResNet for migration learning, which can learn the image deep features at a lower cost. The network classification layer is transformed into a hash coding layer, which can generate simple hash features. In this study, hash features are used for coarse retrieval, while in the fine retrieval stage, the preliminary results are rearranged based on the deep features of the image. To solve the problem of low efficiency of text query mode and to improve the scalability of the search engine, a text classification semantic retrieval model is proposed in this study, which designs a text classification network based on long short-term memory(LSTM) to classify query text in advance. Then, we construct a text embedding feature extraction model based on doc2vec, which can retrieve the text embedding feature in the pre-classified categories. At the same time, to capture the similarity of clothing style, a similar style context retrieval model is proposed, which measures the similarity of clothing style by referring to the similarity of part of speech and collocation level of words, references the training form of word2vec model in text words, and trains clothing as words and outfit as sentences. Finally, we use the probability driven method to quantify fashion style similarity without manual style annotation; compare different multimodal hybrid methods to maximize the similarity as the final return of search engine, that is, based on the text retrieval modal results to retrieve style context similar clothing; and rearrange all modal results and style context results based on image features.ResultChoosing Polyvore as the dataset, we use the test set data as the query and retrieve the returned training set data as the result, so as to evaluate the results for different indicators. For the image retrieval mode, compared with the original ResNet model, the average retrieval accuracy of top 5 of the hierarchical deep hash retrieval framework is improved by 11.6%, and the retrieval speed is increased by 2.57 s/query. The average retrieval accuracy of the two feature retrieval strategies from coarse to fine is comparable to that of the direct image deep feature retrieval. For the text retrieval mode, compared with the traditional text embedding model, the top 5 precision of the text classification semantic retrieval framework is increased by 29.96%, and the retrieval speed is increased by 16.53 s/query. Finally, for the multimodal fusion results, we retrieve the context style similar clothing based on the text modal results and rearrange the final results in the image feature space. The average style similarity of the final results is 24%.ConclusionWe propose a fashion style retrieval method based on deep multimodal fusion, whose hierarchical deep hash retrieval model is used as the image retrieval mode. Compared with most other modes and retrieval methods, the method of fine-tuning based on pre-training network with the goal of generating hash code and retrieval strategy from coarse to fine can improve the retrieval accuracy and speed. As the text retrieval mode, the text classification semantic retrieval model uses the text classification network to narrow the scope of retrieval and then uses the text features extracted from the text feature extraction model combined with the output of different models for retrieval. Compared with other text semantic retrieval methods, this mode can also improve the retrieval speed and accuracy. At the same time, in order to capture the similarity of fashion style, a similar style context retrieval model is proposed to find the results similar to the query clothing style and make the results more diverse.关键词:multimodal fashion search;hash feature;text embedding;style similarity;deep Hashing63|52|1更新时间:2024-05-07 -
 摘要:ObjectiveVisual saliency detection aims to identify the most attractive objects or regions in an image and acts a fundamental role in many vision-based applications, such as target detection and tracking, visual content analysis, scene classification, image/video compression, image quality evaluation, and pedestrian detection. In recent years, the new paradigm shifts from 2D to 3D vision have triggered many interesting functionalities for those vision applications, but the traditional RGB saliency detection models cannot produce satisfactory results in these applications. Thus, visual saliency detection models based on RGB-D data, which involve different modality visual cues, have attracted a large amount of research interest. Existing RGB-D saliency detection models usually consist of two stages. In the first stage, multimodality visual cues, including spatial, depth, and motion cues, are extracted from the color map and the depth map. In the second stage, these cues are fused to obtain the final saliency map via various fusion methods, such as linear weighted summation, Bayesian framework, and conditional random field (CRF). In recent years, learning-based fusion methods, such as support vector machines, AdaBoost, random forest, and deep neural networks, have been widely studied. Several of the above fusion methods have achieved good results in the RGB saliency model. However, different from the traditional RGB saliency detection models, in most of the cases, the involved multimodality visual cues, especially the saliency results, are mutually substantially different from one another. The difference reveals the rivalry in multimodality saliency cues and brings difficulties to the fusion stage in RGB-D saliency models. Therefore, under the two-stage framework, a new challenge arises from design suitable features that can be designed for saliency maps of corresponding multimodality visual cues to increase the probability of mutual fusion in the first stage and how these saliency maps can be fused to obtain the final RGB-D visual saliency map in the second stage.MethodAn RGB-D saliency detection model is proposed based on superpixel-level CRF, and 3D scenes are represented by the video format of RGB maps and corresponding depth maps. The predicted saliency map is obtained in two stages for multimodality saliency cues and final fusion. Multimodality saliency cues, including spatial, depth, and motion cues, are considered, and three independent saliency maps for these cues are computed. A saliency fusion algorithm is proposed based on the superpixel-level CRF model. The graph structure of the CRF model is constructed by taking the superpixels as graph nodes, and each superpixel is connected to its adjacent superpixels. Based on the graph, a global energy function is designed to consider the influence of the involved multimodality saliency cues and the smoothing constraint between neighboring superpixels jointly. The global energy function consists of a data term and a smooth term. The data term describes the effects of the multimodality saliency maps on the final fused saliency maps. Three weighting maps of the multimodality saliency cues are learned via a convolutional neural network (CNN)and added to the data term because multimodality saliency maps play different roles in various scenarios. The smooth term adds constraints to the difference of the saliency values of adjacent superpixels, and the constraint intensity is controlled by the RGB and depth differences between them. When the difference values of RGB and depth vectors between two adjacent superpixels are smaller, these two adjacent pixels are more likely to have similar saliency values. The final predicted saliency map is obtained by optimizing the global energy function.ResultIn experiments, the proposed model is compared with six state-of-the-art saliency detection models on two public RGB-D video saliency datasets, namely, IRCCyN and DML-iTrack-3D. Five popular quantitative metrics are used to evaluate the proposed model, including area under curve (AUC), shuffled AUC (sAUC), similarity (SIM), Pearson correlation coefficient (PCC), and normalized scanpath saliency (NSS). Experimental results show that the proposed model outperforms state-of-the-art models on all involved datasets and evaluation metrics. Compared with the second highest scores, the AUC, sAUC, SIM, PCC, and NSS of our model increase by 2.3%, 2.3%, 18.9%, 21.6%, and 56.2%, respectively, on IRCCyN datasets, and increase by 2.0%, 1.4%, 29.1%, 10.6%, and 23.3%, respectively, on DML-iTrack-3D datasets. Moreover, the saliency maps of different visual cues and traditional fusion methods show that the proposed model achieves the best performance, and the proposed fusion method effectively takes advantage of different visual cues. To verify the benefit of the proposed CNN-based weight-learning network, the weights of multimodality saliency maps are set to same value. The experimental results show that performance decreases after removing the weight-learning network.ConclusionIn this study, an RGB-D saliency detection model based on superpixel-level CRF is proposed. The multimodality visual cues are first extracted and then fused by utilizing the CRF model with a global energy function. The fusion stage jointly considers the effects of the multimodality visual cues and the smoothing constraint of the saliency values of adjacent superpixels. Therefore, the proposed model makes full use of the advantages of multimodality visual cues and avoids the conflict caused by the competition among them, thus achieving better fusion results. The experimental results show that the five evaluation metrics of the proposed model are better than those of other start-of-the-art models in two RGB-D video saliency datasets. Thus, the proposed model can use the correlation among multimodality visual cues to detect the saliency objects or regions in 3D dynamic scenes effectively, which is believed helpful for 3D vision-based applications. In addition, the proposed model is a simple, intuitive combination of the traditional method and the deep learning method, and the combination of these two methods can still be improved greatly. The future study will further focus on how to combine traditional methods and deep learning methods more effectively.关键词:RGB-D saliency;saliency fusion;conditional random field(CRF);global energy function;convolutional neural network(CNN)136|209|2更新时间:2024-05-07
摘要:ObjectiveVisual saliency detection aims to identify the most attractive objects or regions in an image and acts a fundamental role in many vision-based applications, such as target detection and tracking, visual content analysis, scene classification, image/video compression, image quality evaluation, and pedestrian detection. In recent years, the new paradigm shifts from 2D to 3D vision have triggered many interesting functionalities for those vision applications, but the traditional RGB saliency detection models cannot produce satisfactory results in these applications. Thus, visual saliency detection models based on RGB-D data, which involve different modality visual cues, have attracted a large amount of research interest. Existing RGB-D saliency detection models usually consist of two stages. In the first stage, multimodality visual cues, including spatial, depth, and motion cues, are extracted from the color map and the depth map. In the second stage, these cues are fused to obtain the final saliency map via various fusion methods, such as linear weighted summation, Bayesian framework, and conditional random field (CRF). In recent years, learning-based fusion methods, such as support vector machines, AdaBoost, random forest, and deep neural networks, have been widely studied. Several of the above fusion methods have achieved good results in the RGB saliency model. However, different from the traditional RGB saliency detection models, in most of the cases, the involved multimodality visual cues, especially the saliency results, are mutually substantially different from one another. The difference reveals the rivalry in multimodality saliency cues and brings difficulties to the fusion stage in RGB-D saliency models. Therefore, under the two-stage framework, a new challenge arises from design suitable features that can be designed for saliency maps of corresponding multimodality visual cues to increase the probability of mutual fusion in the first stage and how these saliency maps can be fused to obtain the final RGB-D visual saliency map in the second stage.MethodAn RGB-D saliency detection model is proposed based on superpixel-level CRF, and 3D scenes are represented by the video format of RGB maps and corresponding depth maps. The predicted saliency map is obtained in two stages for multimodality saliency cues and final fusion. Multimodality saliency cues, including spatial, depth, and motion cues, are considered, and three independent saliency maps for these cues are computed. A saliency fusion algorithm is proposed based on the superpixel-level CRF model. The graph structure of the CRF model is constructed by taking the superpixels as graph nodes, and each superpixel is connected to its adjacent superpixels. Based on the graph, a global energy function is designed to consider the influence of the involved multimodality saliency cues and the smoothing constraint between neighboring superpixels jointly. The global energy function consists of a data term and a smooth term. The data term describes the effects of the multimodality saliency maps on the final fused saliency maps. Three weighting maps of the multimodality saliency cues are learned via a convolutional neural network (CNN)and added to the data term because multimodality saliency maps play different roles in various scenarios. The smooth term adds constraints to the difference of the saliency values of adjacent superpixels, and the constraint intensity is controlled by the RGB and depth differences between them. When the difference values of RGB and depth vectors between two adjacent superpixels are smaller, these two adjacent pixels are more likely to have similar saliency values. The final predicted saliency map is obtained by optimizing the global energy function.ResultIn experiments, the proposed model is compared with six state-of-the-art saliency detection models on two public RGB-D video saliency datasets, namely, IRCCyN and DML-iTrack-3D. Five popular quantitative metrics are used to evaluate the proposed model, including area under curve (AUC), shuffled AUC (sAUC), similarity (SIM), Pearson correlation coefficient (PCC), and normalized scanpath saliency (NSS). Experimental results show that the proposed model outperforms state-of-the-art models on all involved datasets and evaluation metrics. Compared with the second highest scores, the AUC, sAUC, SIM, PCC, and NSS of our model increase by 2.3%, 2.3%, 18.9%, 21.6%, and 56.2%, respectively, on IRCCyN datasets, and increase by 2.0%, 1.4%, 29.1%, 10.6%, and 23.3%, respectively, on DML-iTrack-3D datasets. Moreover, the saliency maps of different visual cues and traditional fusion methods show that the proposed model achieves the best performance, and the proposed fusion method effectively takes advantage of different visual cues. To verify the benefit of the proposed CNN-based weight-learning network, the weights of multimodality saliency maps are set to same value. The experimental results show that performance decreases after removing the weight-learning network.ConclusionIn this study, an RGB-D saliency detection model based on superpixel-level CRF is proposed. The multimodality visual cues are first extracted and then fused by utilizing the CRF model with a global energy function. The fusion stage jointly considers the effects of the multimodality visual cues and the smoothing constraint of the saliency values of adjacent superpixels. Therefore, the proposed model makes full use of the advantages of multimodality visual cues and avoids the conflict caused by the competition among them, thus achieving better fusion results. The experimental results show that the five evaluation metrics of the proposed model are better than those of other start-of-the-art models in two RGB-D video saliency datasets. Thus, the proposed model can use the correlation among multimodality visual cues to detect the saliency objects or regions in 3D dynamic scenes effectively, which is believed helpful for 3D vision-based applications. In addition, the proposed model is a simple, intuitive combination of the traditional method and the deep learning method, and the combination of these two methods can still be improved greatly. The future study will further focus on how to combine traditional methods and deep learning methods more effectively.关键词:RGB-D saliency;saliency fusion;conditional random field(CRF);global energy function;convolutional neural network(CNN)136|209|2更新时间:2024-05-07 -
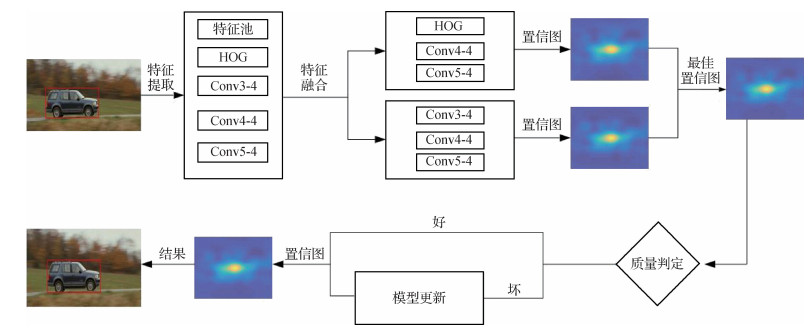 摘要:ObjectiveTarget tracking has become a hot research topic in the field of computer vision. It aims to use the target labeled in the first frame of the video sequence as training data so that the target can be tracked in real time throughout the subsequent video sequence. Target tracking has broad application prospects in the fields of intelligent video surveillance systems, human-computer interaction, and intelligent transportation systems. Thanks to the rapid development of artificial intelligence technology in the current era, target tracking has also been improved. However, video sequences obtained in the real world often have various complex situations. Thus, the motion state of the tracking target in the video sequence becomes more complicated. The current mainstream target tracking algorithms are mainly divided into target tracking algorithms based on deep learning and tracking algorithms based on correlation filter, but none of them can well solve various challenges in target tracking. In order to solve the problem that the target tracking algorithm will encounter occlusion, illumination variation, and scale variation in real scenes, we propose an adaptive model update target tracking algorithm that incorporates multi-feature fusion of time information and speed information to improve the performance of the target tracking algorithm in these situations.MethodIn the field of computer vision, the recognition of a target is often to construct a model of the target by extracting its features. The current commonly used features include deep features and handcrafted features. Deep features contain more semantic information, and handcrafted features have higher resolution. For deep features, the features extracted from the deeper network layers in the convolutional neural network have more semantic information but have lower resolution, and the features extracted from the shallower network layers have higher resolution but have less semantic information. Semantic information helps to improve the success rate of target tracking, and high resolution helps to improve the accuracy of target tracking. Considering this factor, we need to make a comprehensive selection of features. Our method aims to fuse different types of features in order to make the best combination between the semantic information and resolution of the features, so as to obtain the best tracking accuracy and success rate. Visual Geometry Group (VGG19) is an excellent deep neural network in the field of computer vision. It is used initially for image recognition. Because it has enough network layers, it has a good effect on the representation of objects. Thus, we extract three depth features of the target through the three different network layers of the pre-trained VGG19 convolutional neural network and extract the handcrafted histogram of oriented gradients (HOG) features of the target at the same time. The HOG feature is a feature descriptor used for object detection in computer vision and image processing. It is constructed by calculating and counting the gradient direction histogram of the local area of the image, and it maintains good invariance to image geometric and optical deformations. The three deep features are then fused to obtain a fusion feature of full depth features. Subsequently, two of the depth features are fused with the handcrafted HOG feature to obtain a fusion feature that combines the depth feature and the handcrafted feature. Then, we use these two fusion features to track the target independently, calculate the reliability of the two tracking results, and select the tracking result of the most reliable fusion feature as the final tracking result of the current frame. When the overall tracking results of the current frame cannot meet the requirements, we update the target model in time, add time context information and current robust characterization information to build a new tracking model, and use the updated model to re-track the current frame target. Then, the response map of re-tracking is determined by multi-peak determination and motion speed determination to select the best predicted position as the final result of the current frame.ResultA large number of tests have been performed on the object tracking benchmark (OTB) 2013 and OTB2015 benchmarks. Both benchmarks are the mainstream test datasets in the field of target tracking. The OTB2013 benchmark contains 50 video sequences, whereas the OTB2015 benchmark contains 100 video sequences. All video sequences cover 11 different challenges and include color and grayscale video sequences. We selected seven more mainstream tracking algorithms this year for comparison. The experimental results show that our algorithm achieved the best overall effect compared with the comparison algorithm and obtained excellent tracking results in different complex environments. The tracking accuracy and success rate of our algorithm in the OTB2013 benchmark reached 89.3% and 87%, respectively. The accuracy is 4.5% higher than that of the second-ranked long-term correlation tracking (LCT), and the success rate is 8.1% higher than that of the second-ranked spatially regularized discriminative correlation filters (SRDCF). The tracking accuracy and success rate of our algorithm in the OTB2015 benchmark reached 83.3% and 78.3%, respectively. The accuracy is 4.5% higher than that of the second-ranked SRDCF, and the success rate is 5.3% higher than that of the second-ranked SRDCF. Similarly, in the 11 different challenges of the OTB benchmark, the accuracy and success rate of our algorithm are almost always optimal or suboptimal.ConclusionOur algorithm combines depth features and handcrafted features, performs multi-peak analysis and motion speed determination on the tracking results, and adaptively updates features for re-tracking when the tracking results are poor. The experimental results show that our algorithm can effectively deal with the interference of complex factors such as illumination variation, background clutter, and occlusion and achieved a good tracking accuracy and success rate, which effectively improves the tracking quality.关键词:object tracking;hierarchical deep feature;time context information;multi-peak determination;model updating92|96|1更新时间:2024-05-07
摘要:ObjectiveTarget tracking has become a hot research topic in the field of computer vision. It aims to use the target labeled in the first frame of the video sequence as training data so that the target can be tracked in real time throughout the subsequent video sequence. Target tracking has broad application prospects in the fields of intelligent video surveillance systems, human-computer interaction, and intelligent transportation systems. Thanks to the rapid development of artificial intelligence technology in the current era, target tracking has also been improved. However, video sequences obtained in the real world often have various complex situations. Thus, the motion state of the tracking target in the video sequence becomes more complicated. The current mainstream target tracking algorithms are mainly divided into target tracking algorithms based on deep learning and tracking algorithms based on correlation filter, but none of them can well solve various challenges in target tracking. In order to solve the problem that the target tracking algorithm will encounter occlusion, illumination variation, and scale variation in real scenes, we propose an adaptive model update target tracking algorithm that incorporates multi-feature fusion of time information and speed information to improve the performance of the target tracking algorithm in these situations.MethodIn the field of computer vision, the recognition of a target is often to construct a model of the target by extracting its features. The current commonly used features include deep features and handcrafted features. Deep features contain more semantic information, and handcrafted features have higher resolution. For deep features, the features extracted from the deeper network layers in the convolutional neural network have more semantic information but have lower resolution, and the features extracted from the shallower network layers have higher resolution but have less semantic information. Semantic information helps to improve the success rate of target tracking, and high resolution helps to improve the accuracy of target tracking. Considering this factor, we need to make a comprehensive selection of features. Our method aims to fuse different types of features in order to make the best combination between the semantic information and resolution of the features, so as to obtain the best tracking accuracy and success rate. Visual Geometry Group (VGG19) is an excellent deep neural network in the field of computer vision. It is used initially for image recognition. Because it has enough network layers, it has a good effect on the representation of objects. Thus, we extract three depth features of the target through the three different network layers of the pre-trained VGG19 convolutional neural network and extract the handcrafted histogram of oriented gradients (HOG) features of the target at the same time. The HOG feature is a feature descriptor used for object detection in computer vision and image processing. It is constructed by calculating and counting the gradient direction histogram of the local area of the image, and it maintains good invariance to image geometric and optical deformations. The three deep features are then fused to obtain a fusion feature of full depth features. Subsequently, two of the depth features are fused with the handcrafted HOG feature to obtain a fusion feature that combines the depth feature and the handcrafted feature. Then, we use these two fusion features to track the target independently, calculate the reliability of the two tracking results, and select the tracking result of the most reliable fusion feature as the final tracking result of the current frame. When the overall tracking results of the current frame cannot meet the requirements, we update the target model in time, add time context information and current robust characterization information to build a new tracking model, and use the updated model to re-track the current frame target. Then, the response map of re-tracking is determined by multi-peak determination and motion speed determination to select the best predicted position as the final result of the current frame.ResultA large number of tests have been performed on the object tracking benchmark (OTB) 2013 and OTB2015 benchmarks. Both benchmarks are the mainstream test datasets in the field of target tracking. The OTB2013 benchmark contains 50 video sequences, whereas the OTB2015 benchmark contains 100 video sequences. All video sequences cover 11 different challenges and include color and grayscale video sequences. We selected seven more mainstream tracking algorithms this year for comparison. The experimental results show that our algorithm achieved the best overall effect compared with the comparison algorithm and obtained excellent tracking results in different complex environments. The tracking accuracy and success rate of our algorithm in the OTB2013 benchmark reached 89.3% and 87%, respectively. The accuracy is 4.5% higher than that of the second-ranked long-term correlation tracking (LCT), and the success rate is 8.1% higher than that of the second-ranked spatially regularized discriminative correlation filters (SRDCF). The tracking accuracy and success rate of our algorithm in the OTB2015 benchmark reached 83.3% and 78.3%, respectively. The accuracy is 4.5% higher than that of the second-ranked SRDCF, and the success rate is 5.3% higher than that of the second-ranked SRDCF. Similarly, in the 11 different challenges of the OTB benchmark, the accuracy and success rate of our algorithm are almost always optimal or suboptimal.ConclusionOur algorithm combines depth features and handcrafted features, performs multi-peak analysis and motion speed determination on the tracking results, and adaptively updates features for re-tracking when the tracking results are poor. The experimental results show that our algorithm can effectively deal with the interference of complex factors such as illumination variation, background clutter, and occlusion and achieved a good tracking accuracy and success rate, which effectively improves the tracking quality.关键词:object tracking;hierarchical deep feature;time context information;multi-peak determination;model updating92|96|1更新时间:2024-05-07 -
 摘要:Objective3D point clouds have received widespread attention for their wide range of applications, such as robotics, autonomous driving, and virtual reality applications. However, due to the characteristics of input and output size and order differences, uneven density, and differences in shape and scaling, point cloud processing is very challenging, and because of this, various shapes formed by irregular points are often difficult to distinguish. For this problem, sufficient contextual semantic information must be captured to thoroughly grasp the elusive shapes. In 2D images, convolutional neural networks (CNN) have fundamentally changed the landscape of computer vision by greatly improving the results of almost all vision tasks. CNN succeeds by using translation invariance, so the same set of convolution filters can be applied to all positions in the image, thereby reducing the number of parameters and improving the generalization ability. We hope to transfer these successes to 3D point cloud analysis. However, a 3D point cloud is an unordered set of 3D points, each with or without additional features (such as RGB), which does not conform to the regular lattice grid in a 2D image. Applying conventional CNNs to such unordered inputs is difficult. Some works convert point clouds into regular voxels or multi-view images. However, these conversions usually cause a large amount of inherent geometric information to be lost, and the amount of data in the 3D point cloud is huge, increasing the complexity of the conversion. Another solution is to learn directly from an irregular point cloud. PointNet learns each point independently, and then applies a symmetric function to accumulate features. This direction can realize the invariance of point replacement. Although impressive, it ignores local patterns that have proven to be important for advanced visual semantics in abstract image CNNs. To correct this, KCNet mines local patterns by creating KNN (K-nearest neighbor) graphs at each point of PointNet. However, it does not have a pooling layer that can explicitly increase the semantic level. PointNet++ hierarchical groups point clouds into local subsets and learn them through PointNet. This design does work similar to CNN, but the basic operation of PointNet requires high complexity to achieve sufficient effectiveness, which usually results in huge computational costs.MethodTo solve this problem, some works divide the point cloud into several subsets by sampling. Then, a hierarchical structure is constructed to learn the context representation from local to global. However, this greatly depends on effective inductive learning of local subsets, which is difficult to achieve for point clouds with uneven density and irregular shape. Inspired by inverse density function in point cloud networks, we propose a relational shape CNN (RSCNN) fused with inverse density function. The key of the network is to learn from the relationship, that is, to learn from the geometric topology constraints between the points, which encode meaningful shape information in the 3D point cloud, and the convolution kernel is regarded as a nonlinear function of the local coordinates of 3D points composed of 3D points. For a given point, predefined geometric prior convolution weights are used in advanced relational expressions, and kernel density estimation is used to study inverse density functions. The introduction of the inverse density function is further applied to non-uniformly sampled point clouds. In addition, for the segmentation task, we propose a deconvolution operator. Relation-shape deconvolution layer(RSDeconv) consists of two parts: interpolation and Relation-shape convolution layer(RSConv). The feature is propagated from the sampling point cloud to the original resolution through convolution. The spatial layout of the points can be used to calculate the induction through convolution, and it can reflect the potential shape formed by irregular points differently, so as to realize the context shape awareness learning of point cloud analysis. Benefit from the geometric prioris, the invariance to point displacement and the robustness to rigid transformations (such as translation and rotation) are realized.ResultClassification, partial segmentation, and semantic scene segmentation experiments were conducted on ModelNet40, ShapeNet, and ScanNet datasets to verify the classification and segmentation performance of the model. In the classification experiment of ModelNet40, its overall accuracy is improved by 3.1% compared with PointNet++. Even when PointNet++ takes normal as input, its accuracy is improved by 1.9% compared with PointNet++. In the ShapeNet partially segmented dataset, the mean intersection-over-union (mIoU) is 6.0% higher than that of PointNet++, and the instance mIoU is 1.4% higher than that of PointNet++. In the ScanNet indoor scene dataset, the mIoU is 13.7% higher than that of PointNet++. A comparison experiment is conducted on the ScanNet dataset to compare the unsynchronized length with and without density function. The experiment proves that the inverse density function improves the segmentation accuracy by about 0.8% and effectively improves the model performance.ConclusionThe experimental results show that the heterogeneous sampling of point clouds can be realized by introducing the inverse density function into the relational CNN. In addition, the deconvolution layer further propagates the feature from the subsampling point cloud back to the original resolution, which improves the segmentation accuracy. In general, the proposed network model can effectively obtain the global and local characteristics of point cloud data, achieving better classification and segmentation effect.关键词:relation-shape convolutional neural network(RSCNN);inverse density function;non-uniform sampling;deconvolution layer;classification and segmentation of point cloud51|57|1更新时间:2024-05-07
摘要:Objective3D point clouds have received widespread attention for their wide range of applications, such as robotics, autonomous driving, and virtual reality applications. However, due to the characteristics of input and output size and order differences, uneven density, and differences in shape and scaling, point cloud processing is very challenging, and because of this, various shapes formed by irregular points are often difficult to distinguish. For this problem, sufficient contextual semantic information must be captured to thoroughly grasp the elusive shapes. In 2D images, convolutional neural networks (CNN) have fundamentally changed the landscape of computer vision by greatly improving the results of almost all vision tasks. CNN succeeds by using translation invariance, so the same set of convolution filters can be applied to all positions in the image, thereby reducing the number of parameters and improving the generalization ability. We hope to transfer these successes to 3D point cloud analysis. However, a 3D point cloud is an unordered set of 3D points, each with or without additional features (such as RGB), which does not conform to the regular lattice grid in a 2D image. Applying conventional CNNs to such unordered inputs is difficult. Some works convert point clouds into regular voxels or multi-view images. However, these conversions usually cause a large amount of inherent geometric information to be lost, and the amount of data in the 3D point cloud is huge, increasing the complexity of the conversion. Another solution is to learn directly from an irregular point cloud. PointNet learns each point independently, and then applies a symmetric function to accumulate features. This direction can realize the invariance of point replacement. Although impressive, it ignores local patterns that have proven to be important for advanced visual semantics in abstract image CNNs. To correct this, KCNet mines local patterns by creating KNN (K-nearest neighbor) graphs at each point of PointNet. However, it does not have a pooling layer that can explicitly increase the semantic level. PointNet++ hierarchical groups point clouds into local subsets and learn them through PointNet. This design does work similar to CNN, but the basic operation of PointNet requires high complexity to achieve sufficient effectiveness, which usually results in huge computational costs.MethodTo solve this problem, some works divide the point cloud into several subsets by sampling. Then, a hierarchical structure is constructed to learn the context representation from local to global. However, this greatly depends on effective inductive learning of local subsets, which is difficult to achieve for point clouds with uneven density and irregular shape. Inspired by inverse density function in point cloud networks, we propose a relational shape CNN (RSCNN) fused with inverse density function. The key of the network is to learn from the relationship, that is, to learn from the geometric topology constraints between the points, which encode meaningful shape information in the 3D point cloud, and the convolution kernel is regarded as a nonlinear function of the local coordinates of 3D points composed of 3D points. For a given point, predefined geometric prior convolution weights are used in advanced relational expressions, and kernel density estimation is used to study inverse density functions. The introduction of the inverse density function is further applied to non-uniformly sampled point clouds. In addition, for the segmentation task, we propose a deconvolution operator. Relation-shape deconvolution layer(RSDeconv) consists of two parts: interpolation and Relation-shape convolution layer(RSConv). The feature is propagated from the sampling point cloud to the original resolution through convolution. The spatial layout of the points can be used to calculate the induction through convolution, and it can reflect the potential shape formed by irregular points differently, so as to realize the context shape awareness learning of point cloud analysis. Benefit from the geometric prioris, the invariance to point displacement and the robustness to rigid transformations (such as translation and rotation) are realized.ResultClassification, partial segmentation, and semantic scene segmentation experiments were conducted on ModelNet40, ShapeNet, and ScanNet datasets to verify the classification and segmentation performance of the model. In the classification experiment of ModelNet40, its overall accuracy is improved by 3.1% compared with PointNet++. Even when PointNet++ takes normal as input, its accuracy is improved by 1.9% compared with PointNet++. In the ShapeNet partially segmented dataset, the mean intersection-over-union (mIoU) is 6.0% higher than that of PointNet++, and the instance mIoU is 1.4% higher than that of PointNet++. In the ScanNet indoor scene dataset, the mIoU is 13.7% higher than that of PointNet++. A comparison experiment is conducted on the ScanNet dataset to compare the unsynchronized length with and without density function. The experiment proves that the inverse density function improves the segmentation accuracy by about 0.8% and effectively improves the model performance.ConclusionThe experimental results show that the heterogeneous sampling of point clouds can be realized by introducing the inverse density function into the relational CNN. In addition, the deconvolution layer further propagates the feature from the subsampling point cloud back to the original resolution, which improves the segmentation accuracy. In general, the proposed network model can effectively obtain the global and local characteristics of point cloud data, achieving better classification and segmentation effect.关键词:relation-shape convolutional neural network(RSCNN);inverse density function;non-uniform sampling;deconvolution layer;classification and segmentation of point cloud51|57|1更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveBuildings are major spatial elements in urban areas, and 3D building models are significant for construction of intelligent cities. Airborne light detection and ranging (LiDAR) has the advantages of low operation cost, fast acquisition, and all-weather access to the point cloud with high accuracy. As a high-quality data source, the airborne LiDAR point cloud provides convenience for building extraction, feature recognition, and 3D model reconstruction. Extracting accurate and complete building contours from the point cloud is important. However, due to the dispersion and randomness of scanning point, it is hard to balance the contour accuracy and completeness by using conventional fixed radius Alpha Shapes (A-Shapes) algorithm in extracting point cloud building contours. Moreover, in the case of large amount of data, the computational efficiency is relatively low, and the detection is time-consuming. The boundary extraction algorithm of variable rolling circle radius based on 2D grids is proposed to extract the rooftop contour of airborne LiDAR data of buildings.MethodThe proposed method consists of several steps. First, the origin point cloud is projected to the 2D plane, and a 2D grid structure is obtained by dividing the entire point cloud into the regular grid net. Boundary grids that contain LiDAR points can be selected by conducting 8-neighborhood detection. Then, the smoothness of each boundary grid can be calculated by using the connect line of the gravity center of discrete points in each grid. On the basis of the smoothness of the boundary grid, the multi-level radius value of the rolling circle can be determined adaptively. The 3×3 grid detection window should be generated according to the boundary grid. Moreover, all points in the detection window can be detected by using the rolling circle principle of Alpha Shapes algorithm, and the boundary points in the detection windows can be extracted according to the moving track of the rolling circle. The detection window is iteratively moving one by one along the boundary grids to extract the boundary of the point cloud until all boundary grids are detected. Finally, all boundary points can be extracted.ResultWe select the airborne LiDAR point cloud data in the urban area, which contains diverse types of buildings, to analyze the accuracy and efficiency of the proposed method. Several methods, including the proposed method, the fixed radius A-Shapes method, the adaptive radius variable Alpha Shapes (VA-Shapes) method, and the pack circle method, are implemented in the same platform to compare the reliability and efficiency of extracting contour from point clouds. In the contrast experiment, the proposed method can rapidly extract the contour of the point cloud for T-shaped building. However, if the target building is straight and the edge point cloud is irregular, the contour extracted by the proposed method is not ideal. The boundary points extracted by the pack circle method are usually redundant, and the fixed radius A-Shapes method needs to adjust parameters manually many times to obtain a suitable result. For back-shaped building, the fixed radius A-Shapes method and adaptive radius VA-Shapes method easily ignore the corner and other details, whereas the proposed method has the ability to extract small features, including corners and bulges, of the building. For annular sector-shaped building, the proposed method, fixed radius A-Shapes method, and adaptive radius VA-Shapes method can extract the inner and outer contour of the point cloud effectively; however, the pack circle method cannot easily detect the inner contour. In summary, the pack circle method is the most efficient, followed by the proposed method. The fixed radius Alpha Shapes method takes the most time. If the radius of the rolling circle in the fixed radius A-Shapes method is too large, the rectangular feature of the contour can be easily smoothed. When the radius of the rolling circle is too small, the extracted contour is incomplete or even wrong. For the pack circle method, the boundary points can be extracted correctly and effectively only when the detection radius and the number threshold of points are both suitable. For overall consideration, compared with the fixed radius A-Shapes method, adaptive radius VA-Shapes method, and pack circle method, the proposed method can reduce the calculation time effectively on the basis of ensuring the effect of boundary extraction and has better robustness and accuracy.ConclusionIn this study, we proposed the variable radius Alpha Shapes algorithm, which combines the advantages of grid generation and rolling circle detection. The experiment shows that our method can extract the complete contour of the building point cloud, with low complexity, high accuracy, and good robustness.关键词:airborne LiDAR;point cloud;building contour;Alpha Shapes algorithm;grid150|133|5更新时间:2024-05-07
摘要:ObjectiveBuildings are major spatial elements in urban areas, and 3D building models are significant for construction of intelligent cities. Airborne light detection and ranging (LiDAR) has the advantages of low operation cost, fast acquisition, and all-weather access to the point cloud with high accuracy. As a high-quality data source, the airborne LiDAR point cloud provides convenience for building extraction, feature recognition, and 3D model reconstruction. Extracting accurate and complete building contours from the point cloud is important. However, due to the dispersion and randomness of scanning point, it is hard to balance the contour accuracy and completeness by using conventional fixed radius Alpha Shapes (A-Shapes) algorithm in extracting point cloud building contours. Moreover, in the case of large amount of data, the computational efficiency is relatively low, and the detection is time-consuming. The boundary extraction algorithm of variable rolling circle radius based on 2D grids is proposed to extract the rooftop contour of airborne LiDAR data of buildings.MethodThe proposed method consists of several steps. First, the origin point cloud is projected to the 2D plane, and a 2D grid structure is obtained by dividing the entire point cloud into the regular grid net. Boundary grids that contain LiDAR points can be selected by conducting 8-neighborhood detection. Then, the smoothness of each boundary grid can be calculated by using the connect line of the gravity center of discrete points in each grid. On the basis of the smoothness of the boundary grid, the multi-level radius value of the rolling circle can be determined adaptively. The 3×3 grid detection window should be generated according to the boundary grid. Moreover, all points in the detection window can be detected by using the rolling circle principle of Alpha Shapes algorithm, and the boundary points in the detection windows can be extracted according to the moving track of the rolling circle. The detection window is iteratively moving one by one along the boundary grids to extract the boundary of the point cloud until all boundary grids are detected. Finally, all boundary points can be extracted.ResultWe select the airborne LiDAR point cloud data in the urban area, which contains diverse types of buildings, to analyze the accuracy and efficiency of the proposed method. Several methods, including the proposed method, the fixed radius A-Shapes method, the adaptive radius variable Alpha Shapes (VA-Shapes) method, and the pack circle method, are implemented in the same platform to compare the reliability and efficiency of extracting contour from point clouds. In the contrast experiment, the proposed method can rapidly extract the contour of the point cloud for T-shaped building. However, if the target building is straight and the edge point cloud is irregular, the contour extracted by the proposed method is not ideal. The boundary points extracted by the pack circle method are usually redundant, and the fixed radius A-Shapes method needs to adjust parameters manually many times to obtain a suitable result. For back-shaped building, the fixed radius A-Shapes method and adaptive radius VA-Shapes method easily ignore the corner and other details, whereas the proposed method has the ability to extract small features, including corners and bulges, of the building. For annular sector-shaped building, the proposed method, fixed radius A-Shapes method, and adaptive radius VA-Shapes method can extract the inner and outer contour of the point cloud effectively; however, the pack circle method cannot easily detect the inner contour. In summary, the pack circle method is the most efficient, followed by the proposed method. The fixed radius Alpha Shapes method takes the most time. If the radius of the rolling circle in the fixed radius A-Shapes method is too large, the rectangular feature of the contour can be easily smoothed. When the radius of the rolling circle is too small, the extracted contour is incomplete or even wrong. For the pack circle method, the boundary points can be extracted correctly and effectively only when the detection radius and the number threshold of points are both suitable. For overall consideration, compared with the fixed radius A-Shapes method, adaptive radius VA-Shapes method, and pack circle method, the proposed method can reduce the calculation time effectively on the basis of ensuring the effect of boundary extraction and has better robustness and accuracy.ConclusionIn this study, we proposed the variable radius Alpha Shapes algorithm, which combines the advantages of grid generation and rolling circle detection. The experiment shows that our method can extract the complete contour of the building point cloud, with low complexity, high accuracy, and good robustness.关键词:airborne LiDAR;point cloud;building contour;Alpha Shapes algorithm;grid150|133|5更新时间:2024-05-07 -
 摘要:ObjectiveDepth estimation from multiple images is a central task in computer vision. Reliable depth information provides an effective source for visual tasks, such as target detection, image segmentation, and special effects for movies. As one of the new multi-view image acquisition devices, the light field camera makes it more convenient to acquire multiple image data. A light field camera can simultaneously sample a scene from multiple viewpoints with a single exposure, which has unique advantages in portability and depth accuracy over other depth sensors. Occlusion is a challenging issue for light field depth estimation. For a non-occluded pixel on Lambertian surfaces, the angular patch corresponding to this pixel exhibits photo-consistency when refocused to its correct depth. However, the occluder will prevent viewpoints from sampling the same point. Thus, the photo-consistency fails to hold at occluded pixels. If the occluded viewpoints are accurately excluded, the photo-consistency of the remaining viewpoints can still be guaranteed. Therefore, how to identify the occluded viewpoints in the angular patch is crucial for accurate depth estimation. Previous works detected occlusion on the basis of the 2D model (RGB image) of the scene. However, occlusion is determined by the scene's 3D model, and it cannot be accurately detected using only the 2D model. Inaccurate occlusion detection will lead to low quality of depth estimation. In this study, we present a light field depth estimation algorithm that is robust to occlusion.MethodFirst, we reconstruct the 3D scene model by adding the foreground-background relation and depth difference between different objects in the 2D model. On the basis of the 3D model, we directly calculate the occlusion state of each view and record it in the occlusion map. Further analysis demonstrates that the generated occlusion map can exclude all occluded viewpoints. Thanks to the occlusion map, the scene is able to be divided into occluded and non-occluded regions, so that more appropriate cost function can be adopted in different regions. In this study, if a spatial point is visible in a subset of viewpoints, this spatial point will be included in the occluded region. The remaining spatial points will be included in the non-occluded regions. In the occluded regions, we exclude the occluded viewpoints by the occlusion map and build the cost volume on the basis of the photo-consistency of the remaining viewpoints. In the non-occluded regions, on the basis of the depth continuity of these regions, we design a defocus grid matching cost function that captures textures over a wider area than traditional methods. A wider capture range means that our cost function is capable of collecting more information to increase its robustness. To propagate the effective information of higher confidence points to low confidence points, every slice in the final data cost volume is filtered using the edge-preserving filter. Compared with graph-based optimization, the filter-based method is more efficient and easy to parallelize. Moreover, because our occlusion map has excluded the possible occlusions, the filter-based method is enough for most examples. The initial disparity label is generated from the filtered cost volume using the winner-takes-all method. Finally, we exploit the dependence between the occlusion map and the depth map to further improve the accuracy of depth estimation. That is, the depth map can help the reconstruction of the 3D model required for occlusion detection, and the occlusion map can help the cost function exclude the occluded viewpoints. On the basis of this dependence, we integrate occlusion detection and depth estimation into an expectation-maximization-based optimization framework to alternatively improve the accuracy of the occlusion map and the depth map.ResultExperiments are conducted on the HCI (Heidelberg Collaboratory for Image Processing) synthetic dataset and Stanford Lytro Illum dataset for real scenes. To ensure fairness, the number of depth labels of all cost-volume-based algorithms is uniformly set to 75. For quantitative evaluation, we use the percentage of bad pixels and the mean square error to measure the pros and cons of every algorithm. We also compare our occlusion detection method with state-of-the-art methods. Instead of evaluating the occlusion map of a single angular patch, we evaluate the occlusion map of all angular patches around the occlusion boundary. This evaluation method requires the algorithm to respond correctly to all degrees of occlusion. The experimental results show that the proposed method achieves better performance than other state-of-the-art methods in terms of both occlusion detection and depth estimation for single occlusion, multi-occlusion, and low-contrast occlusion. Compared with the suboptimal method, our mean square error is reduced by about 19.75% on average.ConclusionFor the depth estimation of scenes with occlusion, the superiority of the proposed 3D occlusion model is demonstrated through theoretical analysis and experimental verification. The proposed depth estimation algorithm is more suitable for scenes with complex occlusion.关键词:light field;depth estimation;3D occlusion model;anti-occlusion;exception maximization(EM)147|215|0更新时间:2024-05-07
摘要:ObjectiveDepth estimation from multiple images is a central task in computer vision. Reliable depth information provides an effective source for visual tasks, such as target detection, image segmentation, and special effects for movies. As one of the new multi-view image acquisition devices, the light field camera makes it more convenient to acquire multiple image data. A light field camera can simultaneously sample a scene from multiple viewpoints with a single exposure, which has unique advantages in portability and depth accuracy over other depth sensors. Occlusion is a challenging issue for light field depth estimation. For a non-occluded pixel on Lambertian surfaces, the angular patch corresponding to this pixel exhibits photo-consistency when refocused to its correct depth. However, the occluder will prevent viewpoints from sampling the same point. Thus, the photo-consistency fails to hold at occluded pixels. If the occluded viewpoints are accurately excluded, the photo-consistency of the remaining viewpoints can still be guaranteed. Therefore, how to identify the occluded viewpoints in the angular patch is crucial for accurate depth estimation. Previous works detected occlusion on the basis of the 2D model (RGB image) of the scene. However, occlusion is determined by the scene's 3D model, and it cannot be accurately detected using only the 2D model. Inaccurate occlusion detection will lead to low quality of depth estimation. In this study, we present a light field depth estimation algorithm that is robust to occlusion.MethodFirst, we reconstruct the 3D scene model by adding the foreground-background relation and depth difference between different objects in the 2D model. On the basis of the 3D model, we directly calculate the occlusion state of each view and record it in the occlusion map. Further analysis demonstrates that the generated occlusion map can exclude all occluded viewpoints. Thanks to the occlusion map, the scene is able to be divided into occluded and non-occluded regions, so that more appropriate cost function can be adopted in different regions. In this study, if a spatial point is visible in a subset of viewpoints, this spatial point will be included in the occluded region. The remaining spatial points will be included in the non-occluded regions. In the occluded regions, we exclude the occluded viewpoints by the occlusion map and build the cost volume on the basis of the photo-consistency of the remaining viewpoints. In the non-occluded regions, on the basis of the depth continuity of these regions, we design a defocus grid matching cost function that captures textures over a wider area than traditional methods. A wider capture range means that our cost function is capable of collecting more information to increase its robustness. To propagate the effective information of higher confidence points to low confidence points, every slice in the final data cost volume is filtered using the edge-preserving filter. Compared with graph-based optimization, the filter-based method is more efficient and easy to parallelize. Moreover, because our occlusion map has excluded the possible occlusions, the filter-based method is enough for most examples. The initial disparity label is generated from the filtered cost volume using the winner-takes-all method. Finally, we exploit the dependence between the occlusion map and the depth map to further improve the accuracy of depth estimation. That is, the depth map can help the reconstruction of the 3D model required for occlusion detection, and the occlusion map can help the cost function exclude the occluded viewpoints. On the basis of this dependence, we integrate occlusion detection and depth estimation into an expectation-maximization-based optimization framework to alternatively improve the accuracy of the occlusion map and the depth map.ResultExperiments are conducted on the HCI (Heidelberg Collaboratory for Image Processing) synthetic dataset and Stanford Lytro Illum dataset for real scenes. To ensure fairness, the number of depth labels of all cost-volume-based algorithms is uniformly set to 75. For quantitative evaluation, we use the percentage of bad pixels and the mean square error to measure the pros and cons of every algorithm. We also compare our occlusion detection method with state-of-the-art methods. Instead of evaluating the occlusion map of a single angular patch, we evaluate the occlusion map of all angular patches around the occlusion boundary. This evaluation method requires the algorithm to respond correctly to all degrees of occlusion. The experimental results show that the proposed method achieves better performance than other state-of-the-art methods in terms of both occlusion detection and depth estimation for single occlusion, multi-occlusion, and low-contrast occlusion. Compared with the suboptimal method, our mean square error is reduced by about 19.75% on average.ConclusionFor the depth estimation of scenes with occlusion, the superiority of the proposed 3D occlusion model is demonstrated through theoretical analysis and experimental verification. The proposed depth estimation algorithm is more suitable for scenes with complex occlusion.关键词:light field;depth estimation;3D occlusion model;anti-occlusion;exception maximization(EM)147|215|0更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveThe construction of B-spline basis functions has always been the focus of computer-aided design. The purpose of its research is mainly to solve the problem that the curve generated by the traditional method is fixed relative to the control vertices. The transformation form mainly incorporates the shape into the constructed basis function parameters to increase the flexibility of the curve,that is,to introduce free parameters to the expression of the classic Bernstein basis function or the extended Bernstein basis function,and adjusts the value of the parameter to adjust the shape of the curve. In recent years,researchers have proposed a large number of B-spline improvements,and they are mainly focused on two function spaces,namely,polynomial function space and trigonometric function space. The spline basis functions constructed in these two function spaces have their own advantages in addition to local adjustments to the corresponding curves. The spline curve constructed in the polynomial function space can be degenerated into a classic B-spline curve and has the advantages of simple calculation. Conversely,the basis function constructed in the trigonometric function space has the advantage of the derivation and cyclability of the trigonometric function. Both have high-order continuity,enabling the accurate representation of circle,ellipse,parabola,sine,cosine,cylindrical spiral,etc. The main purpose of this study is to combine the advantages of constructing spline basis functions in these two function spaces and use the weighting method to integrate the basis functions constructed in the two function spaces. The newly introduced weighting factors can be used as global parameters to make new extensions,and the flexibility of the curve is further enhanced. However,from the above two perspectives,some defects still exist. The reason is that the curve is edited and processed through the control vertices of the model,similar to the traditional method. When the control vertices are given,the curve is relatively fixed.MethodFirst,construct a set of cubic rational basis functions in the polynomial function space and prove that they are fully positive. Then,use the weighting idea to weigh the newly constructed cubic rational basis functions and the cubic triangular basis functions constructed and new Bernstein basis and prove that it retains all the good properties of the classic Bernstein basis functions. Subsequently,the new extended basis is linearly combined to obtain the non-uniform cubic weighted B-spline basis,and its properties are studied. Finally,the definition and properties of the corresponding cubic spline curve are given,and the application of the new curve is given based on it.ResultExperiments show that the curve constructed by the weighting method in this study retains the respective advantages of the polynomial function space and the trigonometric function space and also has local adjustment. At the same time,the introduced weighting factor also strengthens its global adjustment and further enhances the flexibility of the generated curve. It can improve the shortcomings of changing the curve shape only by adjusting the control vertices.ConclusionIn this study,the new λαβ-B-spline curve constructed by the weighting method has a structure similar to the classic B-spline curve while retaining the same properties as the classic B-spline curve,such as convex hull,symmetry,geometric invariance,and change. In addition,the curve constructed by the weighting method in this paper has some unique advantages: first,it has two local shape parameters that can be adjusted locally; second,the weighting factor introduced can be used as a global parameter,and the generated λαβ-B-spline curve can perform global adjustment; third,the λαβ-B-spline curve constructed by the weighting method retains the respective advantages of the polynomial function space and the trigonometric function space. The results show that the shape parameter selection scheme of the constructed curve is correct and effective,which reflects the superiority of the method in this study over other similar methods in the literature. In addition,the construction method with parameter expansion base given in this study and the selection method of shape parameters are general,which can be extended to construct B-spline and triangle surfaces with shape parameters.关键词:λαβ-Bernstein basis;weighted λαβ-B-spline;non-uniform;total positive;local adjustment property57|30|1更新时间:2024-05-07
摘要:ObjectiveThe construction of B-spline basis functions has always been the focus of computer-aided design. The purpose of its research is mainly to solve the problem that the curve generated by the traditional method is fixed relative to the control vertices. The transformation form mainly incorporates the shape into the constructed basis function parameters to increase the flexibility of the curve,that is,to introduce free parameters to the expression of the classic Bernstein basis function or the extended Bernstein basis function,and adjusts the value of the parameter to adjust the shape of the curve. In recent years,researchers have proposed a large number of B-spline improvements,and they are mainly focused on two function spaces,namely,polynomial function space and trigonometric function space. The spline basis functions constructed in these two function spaces have their own advantages in addition to local adjustments to the corresponding curves. The spline curve constructed in the polynomial function space can be degenerated into a classic B-spline curve and has the advantages of simple calculation. Conversely,the basis function constructed in the trigonometric function space has the advantage of the derivation and cyclability of the trigonometric function. Both have high-order continuity,enabling the accurate representation of circle,ellipse,parabola,sine,cosine,cylindrical spiral,etc. The main purpose of this study is to combine the advantages of constructing spline basis functions in these two function spaces and use the weighting method to integrate the basis functions constructed in the two function spaces. The newly introduced weighting factors can be used as global parameters to make new extensions,and the flexibility of the curve is further enhanced. However,from the above two perspectives,some defects still exist. The reason is that the curve is edited and processed through the control vertices of the model,similar to the traditional method. When the control vertices are given,the curve is relatively fixed.MethodFirst,construct a set of cubic rational basis functions in the polynomial function space and prove that they are fully positive. Then,use the weighting idea to weigh the newly constructed cubic rational basis functions and the cubic triangular basis functions constructed and new Bernstein basis and prove that it retains all the good properties of the classic Bernstein basis functions. Subsequently,the new extended basis is linearly combined to obtain the non-uniform cubic weighted B-spline basis,and its properties are studied. Finally,the definition and properties of the corresponding cubic spline curve are given,and the application of the new curve is given based on it.ResultExperiments show that the curve constructed by the weighting method in this study retains the respective advantages of the polynomial function space and the trigonometric function space and also has local adjustment. At the same time,the introduced weighting factor also strengthens its global adjustment and further enhances the flexibility of the generated curve. It can improve the shortcomings of changing the curve shape only by adjusting the control vertices.ConclusionIn this study,the new λαβ-B-spline curve constructed by the weighting method has a structure similar to the classic B-spline curve while retaining the same properties as the classic B-spline curve,such as convex hull,symmetry,geometric invariance,and change. In addition,the curve constructed by the weighting method in this paper has some unique advantages: first,it has two local shape parameters that can be adjusted locally; second,the weighting factor introduced can be used as a global parameter,and the generated λαβ-B-spline curve can perform global adjustment; third,the λαβ-B-spline curve constructed by the weighting method retains the respective advantages of the polynomial function space and the trigonometric function space. The results show that the shape parameter selection scheme of the constructed curve is correct and effective,which reflects the superiority of the method in this study over other similar methods in the literature. In addition,the construction method with parameter expansion base given in this study and the selection method of shape parameters are general,which can be extended to construct B-spline and triangle surfaces with shape parameters.关键词:λαβ-Bernstein basis;weighted λαβ-B-spline;non-uniform;total positive;local adjustment property57|30|1更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveStraight or parallel lines are commonly used as a typical feature in airport runway detection and identification for polarimetric synthetic aperture radar (PolSAR) images. However, some ground targets, such as rivers and roads, have line features similar to airport runways. Thus, they are likely to interfere with detection results. That is, the line features used in detection may result in wrong detection, increasing the false alarm rate and resulting in other problems. To address this issue, this study designs a novel detection method that combines support vector machine (SVM) classification with local binary pattern (LBP) feature in airport runway detection. LBP feature describes the local texture information of an image. It is widely used in the fields of face recognition and target detection and classification. Compared with other features, LBP feature exhibits the beneficial characteristics of rotation invariance and grayscale invariance, making its use easy and effective in distinguishing among different ground objects.MethodIn this study, airport runway detection is performed on the basis of a classification method in which polarization characteristics are used to extract the region of interest (ROI) and LBP characteristics are used to train the SVM classifier. The proposed algorithm has two parts: the training and detection parts. In the training part, training samples are selected from the original PolSAR image data. We divide the training samples into two types. That is, the samples from the airport runway area are regarded as one type and the samples from the non-airport runway area, such as forests, roads, oceans, and buildings, are regarded as another type. After constructing the sample sets, the LBP operator is applied to these sets to obtain the LBP features. Then, LBP feature histograms are counted to a form feature vector that is sent to the SVM for training. In the testing part, the suspected airport runway area, referred to as the ROI, is first segmented from the image. Then, LBP features are extracted from the ROI and sent to the trained SVM classifier for classification to obtain the initial detection result. Further identification processing is required to generate the final detection result. In extracting the suspected airport runway area, the polarimetric scattering entropy and power value of PolSAR images are calculated separately to construct a new scattering feature, namely, the alienated scattering power. The alienated scattering value of the suspected airport runway area is less than the average alienated scattering power of the entire image. Thus, extraction of the suspected airport runway area is achieved through this characteristic by setting a threshold. In the detection part, the images are classified using LBP features and SVM. First, LBP features are extracted by sliding an n×n window in the power image of the ROI. Then, the extracted features are translated into histograms to generate feature vectors, which are sent to the trained SVM classifier for classification. The classification results are represented as a binary image in which the airport runway area is denoted as "1" and other areas are denoted as "0". In the final identification process of the airport runway area, the binary image is masked to obtain the mask map, and operation is performed between the mask map and the extracted suspected runway area. The number of changed pixels in the suspected runway area is calculated. If the number of changed pixels is less than 50% of the area, then the area is considered the final real airport runway area; otherwise, it is a non-airport runway area.ResultPolSAR data collected by an uninhabited aerial vehicle SAR(UAVSAR) system are used to test the proposed method. The experimental results show that the method can detect airport runways with a complete structure and clear edges, and it has low false alarm and missed alarm rates.ConclusionCompared with existing methods, the method proposed in this study can more effectively detect airport runway areas and exhibits better detection effect and lower computation cost.关键词:polarimetric SAR(PolSAR) image;airport runway detection;local binary patterns(LBP) feature;support vector machine(SVM) classification;threshold segmentation92|760|0更新时间:2024-05-07
摘要:ObjectiveStraight or parallel lines are commonly used as a typical feature in airport runway detection and identification for polarimetric synthetic aperture radar (PolSAR) images. However, some ground targets, such as rivers and roads, have line features similar to airport runways. Thus, they are likely to interfere with detection results. That is, the line features used in detection may result in wrong detection, increasing the false alarm rate and resulting in other problems. To address this issue, this study designs a novel detection method that combines support vector machine (SVM) classification with local binary pattern (LBP) feature in airport runway detection. LBP feature describes the local texture information of an image. It is widely used in the fields of face recognition and target detection and classification. Compared with other features, LBP feature exhibits the beneficial characteristics of rotation invariance and grayscale invariance, making its use easy and effective in distinguishing among different ground objects.MethodIn this study, airport runway detection is performed on the basis of a classification method in which polarization characteristics are used to extract the region of interest (ROI) and LBP characteristics are used to train the SVM classifier. The proposed algorithm has two parts: the training and detection parts. In the training part, training samples are selected from the original PolSAR image data. We divide the training samples into two types. That is, the samples from the airport runway area are regarded as one type and the samples from the non-airport runway area, such as forests, roads, oceans, and buildings, are regarded as another type. After constructing the sample sets, the LBP operator is applied to these sets to obtain the LBP features. Then, LBP feature histograms are counted to a form feature vector that is sent to the SVM for training. In the testing part, the suspected airport runway area, referred to as the ROI, is first segmented from the image. Then, LBP features are extracted from the ROI and sent to the trained SVM classifier for classification to obtain the initial detection result. Further identification processing is required to generate the final detection result. In extracting the suspected airport runway area, the polarimetric scattering entropy and power value of PolSAR images are calculated separately to construct a new scattering feature, namely, the alienated scattering power. The alienated scattering value of the suspected airport runway area is less than the average alienated scattering power of the entire image. Thus, extraction of the suspected airport runway area is achieved through this characteristic by setting a threshold. In the detection part, the images are classified using LBP features and SVM. First, LBP features are extracted by sliding an n×n window in the power image of the ROI. Then, the extracted features are translated into histograms to generate feature vectors, which are sent to the trained SVM classifier for classification. The classification results are represented as a binary image in which the airport runway area is denoted as "1" and other areas are denoted as "0". In the final identification process of the airport runway area, the binary image is masked to obtain the mask map, and operation is performed between the mask map and the extracted suspected runway area. The number of changed pixels in the suspected runway area is calculated. If the number of changed pixels is less than 50% of the area, then the area is considered the final real airport runway area; otherwise, it is a non-airport runway area.ResultPolSAR data collected by an uninhabited aerial vehicle SAR(UAVSAR) system are used to test the proposed method. The experimental results show that the method can detect airport runways with a complete structure and clear edges, and it has low false alarm and missed alarm rates.ConclusionCompared with existing methods, the method proposed in this study can more effectively detect airport runway areas and exhibits better detection effect and lower computation cost.关键词:polarimetric SAR(PolSAR) image;airport runway detection;local binary patterns(LBP) feature;support vector machine(SVM) classification;threshold segmentation92|760|0更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0