
最新刊期
2026 年 第 31 卷 第 1 期
学者观点

- “#论文摘要#,介绍了其在人工智能领域的研究进展,xx专家探索了智能算法优化课题,为提升算法效率提供解决方案。”
-
人工智能生成图像检测技术综述 AI导读
“介绍了其在人工智能安全与治理领域的研究进展,相关专家从多种维度对现有生成图像检测方法进行分类与分析,为解决生成图像检测难题提供了新思路。” 摘要:人工智能生成图像检测旨在判断图像是否由生成模型生成,是人工智能安全与治理领域一个重要研究方向。然而当前生成图像检测方法因生成模型结构的多样性、生成图像的复杂性以及对生成图像后处理操作的不确定性难以实现高效和鲁棒检测。早期的检测方法重点关注对生成对抗网络生成内容的检测。近年来,扩散模型生成图像的检测受到广泛关注,与之相关的检测方法涌现,并表现出优越性能。因此,首先对近年来的主流图像生成模型进行梳理,然后从监督范式、学习方式、检测依据、骨干网络、技术手段和可解释性多种维度对现有生成图像检测方法进行分类,并以检测依据(像素域特征、频域特征、预训练模型特征、融合特征和特定规则)作为主要划分标准,对各类研究工作的基本思想与特点进行详细阐述与综合分析。此外,列举了当前用于通用生成图像检测的基准数据集,从数据集结构和规模等方面进行综合比较,并对面向检测方法的综合评测基准进行汇总。关于评估维度,从域内准确性、域外泛化性和鲁棒性3个层面进行介绍。之后,对代表性检测方法进行横向比较,就检测结果进行分析。最后,对当前生成图像检测领域待解决的问题进行总结,并对未来的研究方向进行展望。关键词:人工智能安全;人工智能生成图像(AIGI)检测;数字取证;图像取证;深度伪造检测;图像生成模型;深度学习1144|512|0更新时间:2026-02-02
摘要:人工智能生成图像检测旨在判断图像是否由生成模型生成,是人工智能安全与治理领域一个重要研究方向。然而当前生成图像检测方法因生成模型结构的多样性、生成图像的复杂性以及对生成图像后处理操作的不确定性难以实现高效和鲁棒检测。早期的检测方法重点关注对生成对抗网络生成内容的检测。近年来,扩散模型生成图像的检测受到广泛关注,与之相关的检测方法涌现,并表现出优越性能。因此,首先对近年来的主流图像生成模型进行梳理,然后从监督范式、学习方式、检测依据、骨干网络、技术手段和可解释性多种维度对现有生成图像检测方法进行分类,并以检测依据(像素域特征、频域特征、预训练模型特征、融合特征和特定规则)作为主要划分标准,对各类研究工作的基本思想与特点进行详细阐述与综合分析。此外,列举了当前用于通用生成图像检测的基准数据集,从数据集结构和规模等方面进行综合比较,并对面向检测方法的综合评测基准进行汇总。关于评估维度,从域内准确性、域外泛化性和鲁棒性3个层面进行介绍。之后,对代表性检测方法进行横向比较,就检测结果进行分析。最后,对当前生成图像检测领域待解决的问题进行总结,并对未来的研究方向进行展望。关键词:人工智能安全;人工智能生成图像(AIGI)检测;数字取证;图像取证;深度伪造检测;图像生成模型;深度学习1144|512|0更新时间:2026-02-02 -
 摘要:神经网络模型数量增长迅猛,以神经网络为代表的人工智能技术在很多应用领域取得巨大成功。与此同时,神经网络模型含有大量冗余信息,可为隐藏机密信息提供便利条件,因此可以借助神经网络模型传递机密信息。在此背景下,本文介绍以神经网络为载体的隐写技术。通过与相关技术进行对比,首先概述了神经网络模型隐写的研究意义、基础概念和评价指标;之后依据模型隐写的不同策略,从基于训练的模型隐写、基于修改的模型隐写、基于后门等技术的模型隐写3个不同的角度分别梳理了研究现状,阐述各类方法的核心机制与适用场景,以及分析了各类方法在实际应用中的优缺点。同时也对模型隐写分析的成果进行了分析和讨论,总结白盒和黑盒模型隐写分析技术,揭示当前模型隐写攻防态势。最后对模型隐写技术发展趋势进行了展望,指出大模型隐写、高隐蔽—大容量协同优化、端到端安全传输等未来方向。本文提供了一个关于模型隐写技术的全面视角,旨在展示其在信息安全领域的重要性和潜力。关键词:隐写;模型隐写;隐写分析;神经网络;信息隐藏232|163|0更新时间:2026-02-02
摘要:神经网络模型数量增长迅猛,以神经网络为代表的人工智能技术在很多应用领域取得巨大成功。与此同时,神经网络模型含有大量冗余信息,可为隐藏机密信息提供便利条件,因此可以借助神经网络模型传递机密信息。在此背景下,本文介绍以神经网络为载体的隐写技术。通过与相关技术进行对比,首先概述了神经网络模型隐写的研究意义、基础概念和评价指标;之后依据模型隐写的不同策略,从基于训练的模型隐写、基于修改的模型隐写、基于后门等技术的模型隐写3个不同的角度分别梳理了研究现状,阐述各类方法的核心机制与适用场景,以及分析了各类方法在实际应用中的优缺点。同时也对模型隐写分析的成果进行了分析和讨论,总结白盒和黑盒模型隐写分析技术,揭示当前模型隐写攻防态势。最后对模型隐写技术发展趋势进行了展望,指出大模型隐写、高隐蔽—大容量协同优化、端到端安全传输等未来方向。本文提供了一个关于模型隐写技术的全面视角,旨在展示其在信息安全领域的重要性和潜力。关键词:隐写;模型隐写;隐写分析;神经网络;信息隐藏232|163|0更新时间:2026-02-02 -
对抗样本生成、防御与应用研究综述 AI导读
“深度神经网络在各领域广泛应用,但对抗样本威胁其可靠性和安全性。专家将对抗攻击技术分为白盒和黑盒攻击,详细介绍了对抗防御策略,为提升深度神经网络安全性提供解决方案。” 摘要:得益于愈发优异的性能,深度神经网络越来越多地应用在日常生活的各个方面,成为各领域中主导决策或辅助决策的重要角色。然而,对抗样本的发现对深度神经网络的可靠性和安全性构成重大威胁,极大限制了其在高度关注安全性的领域的应用。因此,研究者针对对抗样本展开了诸多研究。本文首先介绍对抗样本的研究背景及术语定义,并将现有的对抗攻击技术分成白盒攻击和黑盒攻击,其中白盒攻击包括基于优化、梯度和生成3种攻击,黑盒攻击包括基于迁移、查询两种攻击;其次,详细介绍现有的3种对抗防御策略,分别为对抗训练、对抗检测和对抗去噪;接着,列举对抗样本应用的两种典型技术,包括对抗隐写和对抗水印;最后,指出现有对抗样本在攻击、防御研究中存在的不足之处和值得进一步探索的领域。关键词:对抗样本(AE);对抗攻击;对抗防御;对抗隐写;对抗水印600|270|0更新时间:2026-02-02
摘要:得益于愈发优异的性能,深度神经网络越来越多地应用在日常生活的各个方面,成为各领域中主导决策或辅助决策的重要角色。然而,对抗样本的发现对深度神经网络的可靠性和安全性构成重大威胁,极大限制了其在高度关注安全性的领域的应用。因此,研究者针对对抗样本展开了诸多研究。本文首先介绍对抗样本的研究背景及术语定义,并将现有的对抗攻击技术分成白盒攻击和黑盒攻击,其中白盒攻击包括基于优化、梯度和生成3种攻击,黑盒攻击包括基于迁移、查询两种攻击;其次,详细介绍现有的3种对抗防御策略,分别为对抗训练、对抗检测和对抗去噪;接着,列举对抗样本应用的两种典型技术,包括对抗隐写和对抗水印;最后,指出现有对抗样本在攻击、防御研究中存在的不足之处和值得进一步探索的领域。关键词:对抗样本(AE);对抗攻击;对抗防御;对抗隐写;对抗水印600|270|0更新时间:2026-02-02 - “相关专家针对AIGC技术生成的高逼真伪造人脸视频问题,构建了面向中文场景的量化评估基准,建立了CHN-DF数据集,为推动防伪检测技术迭代发展提供数据支撑与实践指导。”
 摘要:目的针对生成式人工智能(artificial intelligence generated content,AIGC)技术生成的高逼真伪造人脸视频对人类视觉感知的欺骗性问题,以及当前人脸防伪检测算法评估体系在中文数据层面有效性和应用性验证方面的空白,旨在构建面向中文场景的量化评估基准以推动防伪检测技术迭代发展。方法提出面向大规模中文人脸伪造视频的CHN-DF(Chinese-deepfake)数据集,详细阐述数据采集、伪造样本生成及质量评估的全流程构建方法。通过多维度实验验证数据集复杂性,兼顾跨模态伪造技术覆盖、环境干扰因子完备性等复杂因素,并建立基于深度检测模型的系统性评测基准。结果发布全球首个包含434 727样本的中文人脸视频防伪数据集,实验显示该数据集鉴别难度高,在16种包含SOTA(state-of-the-art)与主流防伪模型的测评中视觉与视听结合的准确率分别控制在85%与70%以下。构建的评测基准覆盖了视觉与听觉模态场景,在跨域泛化性测试中显示模型准确率性能波动平均幅度达19.6%,显著揭示现有算法的应用局限性。结论构建的中文防伪评测基准有效填补领域空白,通过系统性实验阐明数据集特性与算法性能的关联机制,提出针对模型鲁棒性增强、跨模态泛化能力提升等关键发展方向,为面向中文场景的量化评估以及人脸视频防伪技术的实际部署提供数据支撑与实践指导。CHN-DF数据集在线发布地址为:https://doi.org/10.57760/sciencedb.j00240.00067和https://github.com/HengruiLou/CHN-DF。关键词:深度伪造;人脸伪造视频;人脸防伪评测基准;中文数据集;多模态186|199|0更新时间:2026-02-02
摘要:目的针对生成式人工智能(artificial intelligence generated content,AIGC)技术生成的高逼真伪造人脸视频对人类视觉感知的欺骗性问题,以及当前人脸防伪检测算法评估体系在中文数据层面有效性和应用性验证方面的空白,旨在构建面向中文场景的量化评估基准以推动防伪检测技术迭代发展。方法提出面向大规模中文人脸伪造视频的CHN-DF(Chinese-deepfake)数据集,详细阐述数据采集、伪造样本生成及质量评估的全流程构建方法。通过多维度实验验证数据集复杂性,兼顾跨模态伪造技术覆盖、环境干扰因子完备性等复杂因素,并建立基于深度检测模型的系统性评测基准。结果发布全球首个包含434 727样本的中文人脸视频防伪数据集,实验显示该数据集鉴别难度高,在16种包含SOTA(state-of-the-art)与主流防伪模型的测评中视觉与视听结合的准确率分别控制在85%与70%以下。构建的评测基准覆盖了视觉与听觉模态场景,在跨域泛化性测试中显示模型准确率性能波动平均幅度达19.6%,显著揭示现有算法的应用局限性。结论构建的中文防伪评测基准有效填补领域空白,通过系统性实验阐明数据集特性与算法性能的关联机制,提出针对模型鲁棒性增强、跨模态泛化能力提升等关键发展方向,为面向中文场景的量化评估以及人脸视频防伪技术的实际部署提供数据支撑与实践指导。CHN-DF数据集在线发布地址为:https://doi.org/10.57760/sciencedb.j00240.00067和https://github.com/HengruiLou/CHN-DF。关键词:深度伪造;人脸伪造视频;人脸防伪评测基准;中文数据集;多模态186|199|0更新时间:2026-02-02 - “相关专家在图像和视频合成检测领域取得新进展,提出融合物理与深度学习的检测方法,创新结合光照和阴影一致性分析,有效提升检测精度和适应性,为合成内容检测提供新思路。”
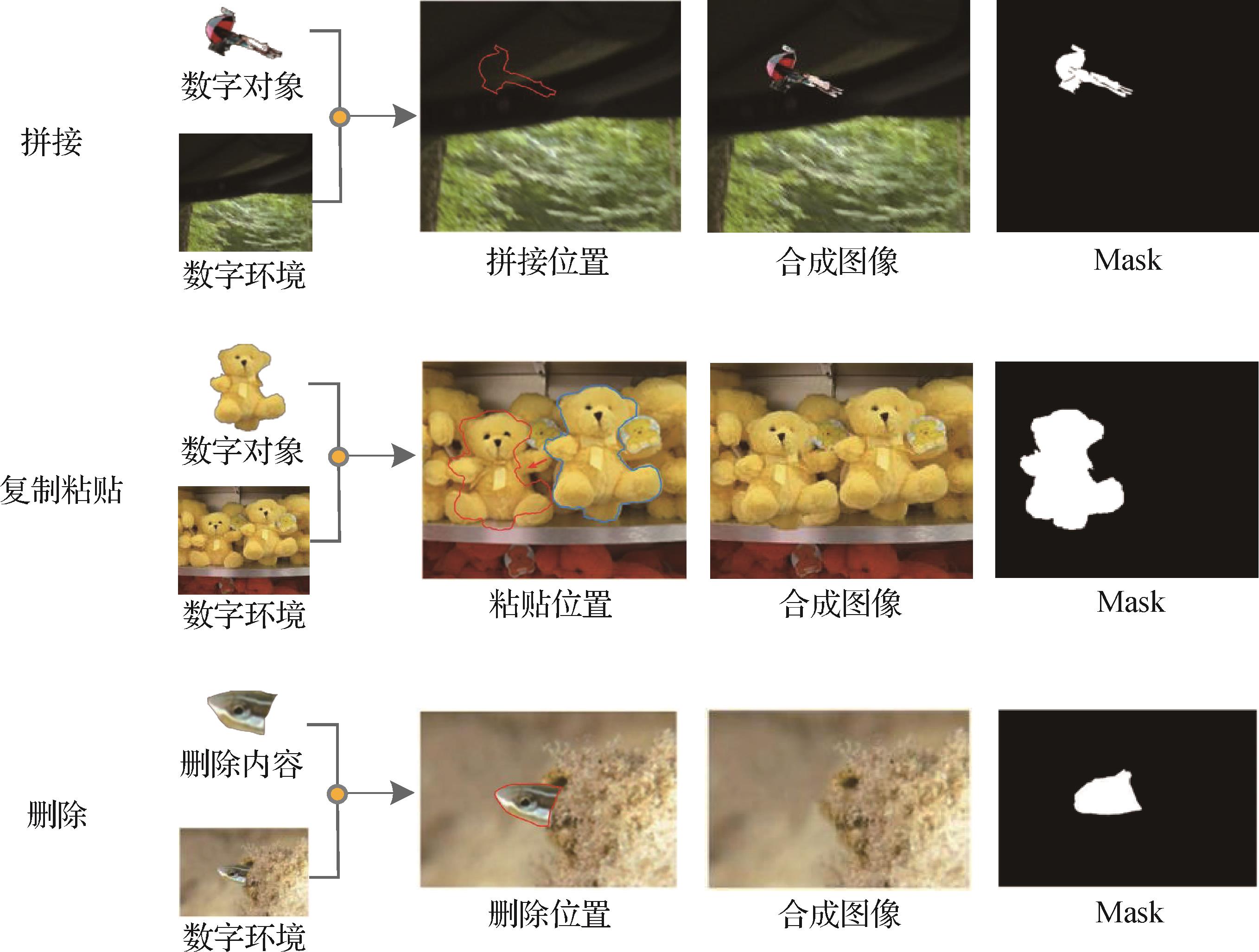 摘要:目的图像和视频合成技术在媒体后期处理领域广泛应用,随着技术门槛的降低,大量合成素材被发布并迅速传播。然而,部分合成内容可能含有误导性信息,威胁视听内容的真实性和安全性。传统合成检测方法主要依赖合成痕迹或画面异常检测,但随着合成技术的不断进步,现有方法在检测精度和适应性方面仍存在优化空间,需要改进以应对日益复杂的合成内容检测需求。方法本文提出一种融合物理与深度学习的合成图像检测方法,创新性地结合光照和阴影一致性分析。通过特征提取与融合网络,实现光照图与光照强度的一致性分析,判断物体采集环境;利用交比估计检测光照方向一致性,有效提升了检测精度和适应性。同时构建了具有物理属性的数据集,为合成图像检测提供数据支持。结果在NIST 16(National Institute of Standards and Technology Database 16)、Coverage和CASIA(Chinese Academy of Sciences Institute of Automation Database)数据集上的实验表明,本文方法在AUC(area under the curve)指标上分别达到94.2%、93.6%和90.3%,F1分数分别达到80.2%、79.3%和58.1%,优于对比方法。在噪声攻击实验中,本文方法对尺寸变化、高斯模糊、高斯噪声和JPEG(Joint Photographic Experts Group)压缩表现出更强的适应性,平均AUC为84.03%。此外,本文提出的数据集在训练过程中表现出高可用性,使用该数据集训练的模型AUC平均提升18.1%。结论本文方法在准确性和鲁棒性方面均优于对比方法,构建的数据集能够有效支持合成图像检测模型的训练、验证和测试,为该领域的研究提供了重要参考。数据集下载链接:https://doi.org/10.57760/sciencedb.j00240.00069。关键词:合成图像检测;光照检测;阴影检测;检测数据集;人工智能安全241|283|0更新时间:2026-02-02
摘要:目的图像和视频合成技术在媒体后期处理领域广泛应用,随着技术门槛的降低,大量合成素材被发布并迅速传播。然而,部分合成内容可能含有误导性信息,威胁视听内容的真实性和安全性。传统合成检测方法主要依赖合成痕迹或画面异常检测,但随着合成技术的不断进步,现有方法在检测精度和适应性方面仍存在优化空间,需要改进以应对日益复杂的合成内容检测需求。方法本文提出一种融合物理与深度学习的合成图像检测方法,创新性地结合光照和阴影一致性分析。通过特征提取与融合网络,实现光照图与光照强度的一致性分析,判断物体采集环境;利用交比估计检测光照方向一致性,有效提升了检测精度和适应性。同时构建了具有物理属性的数据集,为合成图像检测提供数据支持。结果在NIST 16(National Institute of Standards and Technology Database 16)、Coverage和CASIA(Chinese Academy of Sciences Institute of Automation Database)数据集上的实验表明,本文方法在AUC(area under the curve)指标上分别达到94.2%、93.6%和90.3%,F1分数分别达到80.2%、79.3%和58.1%,优于对比方法。在噪声攻击实验中,本文方法对尺寸变化、高斯模糊、高斯噪声和JPEG(Joint Photographic Experts Group)压缩表现出更强的适应性,平均AUC为84.03%。此外,本文提出的数据集在训练过程中表现出高可用性,使用该数据集训练的模型AUC平均提升18.1%。结论本文方法在准确性和鲁棒性方面均优于对比方法,构建的数据集能够有效支持合成图像检测模型的训练、验证和测试,为该领域的研究提供了重要参考。数据集下载链接:https://doi.org/10.57760/sciencedb.j00240.00069。关键词:合成图像检测;光照检测;阴影检测;检测数据集;人工智能安全241|283|0更新时间:2026-02-02 - “相关领域专家构建了基于多域特征融合的多分支网络框架MBMD,为解决现有检测方法泛化能力受限问题提供了新方案。”
 摘要:目的由于现有的基于卷积神经网络的检测方法往往局限于观察全局或局部时空特征,难以获取更全面的伪造线索,从而限制了检测方法的泛化能力。为了解决这一问题,本文提出一种基于多域特征融合的多分支网络框架(multi-branch multi-division,MBMD),综合利用频率域、空间域和时空域信息,以挖掘更全面细致的伪造线索。方法在频率流中对图像进行DCT(discrete cosine transform)变换,去除低频分量并保留高频分量,以捕捉图像细微结构变化的频率特征。在空间流中,设计了空间特征增强块(spatial feature enhancement block,SEB)对CNN(convolutional neural network)的浅层特征进行多尺度增强,以捕捉图像中的局部异常区域。此外,在时空流中设计了信息补充块(information supplement block,ISB),将空间流中的局部特征与视觉Transformer捕获的全局高层特征相结合,使网络能够更全面地捕捉全局和局部的时空不一致。最后,通过交互融合模块(interactive fusion module,IFM)将频率域、空间域和时空域信息进行增强融合,以提取更全面细致的特征。结果实验在不同数据集上与最新的方法进行了比较:在跨数据集实验中,相比于性能第2的检测模型,在Celeb-DF-v2数据集中ACC值提高2.63%,AUC值提高3.01%;在DFDC数据集中,相比于最新的检测模型,AUC值提高4.43%。同时通过消融实验分析了不同模块对泛化性能的影响,验证了提出方法的有效性。结论在不同数据集上的实验表明,提出的方法在未知数据集上具有更好的泛化能力。关键词:Deepfake检测;数字图像取证;多域特征融合;多分支;局部全局作用200|251|0更新时间:2026-02-02
摘要:目的由于现有的基于卷积神经网络的检测方法往往局限于观察全局或局部时空特征,难以获取更全面的伪造线索,从而限制了检测方法的泛化能力。为了解决这一问题,本文提出一种基于多域特征融合的多分支网络框架(multi-branch multi-division,MBMD),综合利用频率域、空间域和时空域信息,以挖掘更全面细致的伪造线索。方法在频率流中对图像进行DCT(discrete cosine transform)变换,去除低频分量并保留高频分量,以捕捉图像细微结构变化的频率特征。在空间流中,设计了空间特征增强块(spatial feature enhancement block,SEB)对CNN(convolutional neural network)的浅层特征进行多尺度增强,以捕捉图像中的局部异常区域。此外,在时空流中设计了信息补充块(information supplement block,ISB),将空间流中的局部特征与视觉Transformer捕获的全局高层特征相结合,使网络能够更全面地捕捉全局和局部的时空不一致。最后,通过交互融合模块(interactive fusion module,IFM)将频率域、空间域和时空域信息进行增强融合,以提取更全面细致的特征。结果实验在不同数据集上与最新的方法进行了比较:在跨数据集实验中,相比于性能第2的检测模型,在Celeb-DF-v2数据集中ACC值提高2.63%,AUC值提高3.01%;在DFDC数据集中,相比于最新的检测模型,AUC值提高4.43%。同时通过消融实验分析了不同模块对泛化性能的影响,验证了提出方法的有效性。结论在不同数据集上的实验表明,提出的方法在未知数据集上具有更好的泛化能力。关键词:Deepfake检测;数字图像取证;多域特征融合;多分支;局部全局作用200|251|0更新时间:2026-02-02 - “虹膜呈现攻击检测领域迎来新突破,相关专家构建了基于空间域与频域特征融合的虹膜PAD模型,为提升虹膜识别系统在跨域场景下的安全性和合成虹膜检测能力提供了有效方案。”
 摘要:目的虹膜呈现攻击检测(presentation attack detection, PAD)是确保虹膜识别系统安全可靠的关键技术之一。针对现有检测方法在跨域场景下泛化性不足、难以有效检测合成虹膜的问题,提出一种基于空间域与频域特征融合的虹膜PAD模型。利用频域信息对环境变化的鲁棒性和合成/真实图像的频域差异,促使模型结合虹膜图像在空间域和频域中的互补特征,提升其检测精度和合成虹膜识别能力。方法首先对输入图像使用局部二值模式(local binary pattern, LBP)算法进行处理,生成空间域图像,接着使用离散余弦变换(discrete cosine transform, DCT)将空间域图像转换为频域图像;然后利用两个EfficientNet_b0作为骨干网络,分别对空间域和频域图像进行特征提取;进一步,通过两个空间通道融合注意力模块分别融合骨干网络所提取的中、高层特征;最后,在使用二元交叉熵损失函数的基础上,引入三元组损失进行联合训练,以提升模型所提特征的区分度。此外,为了让模型重点关注图像中的虹膜区域,引入了低频语义信息引导的注意力模块。结果在最新的虹膜PAD比赛LivDet-Iris 2023数据集上,将本文方法与比赛中的冠军方法及多种现有方法进行比较。相比于冠军方法,本文方法的综合检测错误率ACER1和ACER2分别下降9.32%和3.71%,其中合成虹膜的平均检测错误率APCER下降22.78%,打印虹膜的检测错误率APCER下降6.32%。相比于其他先进的现有方法,本文方法的综合检测错误率ACER1和ACER2分别下降8.91%和3.58%。此外,在LivDet-Iris 2023数据集上进行消融实验以验证所提模块的有效性,结果显示加入频域信息有效提升了模型分类真假虹膜的准确率。结论本文提出的虹膜呈现攻击检测模型有效利用图像的空间域和频域信息,提高了模型检测各类型虹膜呈现攻击的能力,且表现出更好的泛化性。本文模型和代码在https://github.com/xianyunsun/fre-iris-pad开放。关键词:呈现攻击检测(PAD);虹膜识别;多域特征融合;注意力机制;合成虹膜284|349|0更新时间:2026-02-02
摘要:目的虹膜呈现攻击检测(presentation attack detection, PAD)是确保虹膜识别系统安全可靠的关键技术之一。针对现有检测方法在跨域场景下泛化性不足、难以有效检测合成虹膜的问题,提出一种基于空间域与频域特征融合的虹膜PAD模型。利用频域信息对环境变化的鲁棒性和合成/真实图像的频域差异,促使模型结合虹膜图像在空间域和频域中的互补特征,提升其检测精度和合成虹膜识别能力。方法首先对输入图像使用局部二值模式(local binary pattern, LBP)算法进行处理,生成空间域图像,接着使用离散余弦变换(discrete cosine transform, DCT)将空间域图像转换为频域图像;然后利用两个EfficientNet_b0作为骨干网络,分别对空间域和频域图像进行特征提取;进一步,通过两个空间通道融合注意力模块分别融合骨干网络所提取的中、高层特征;最后,在使用二元交叉熵损失函数的基础上,引入三元组损失进行联合训练,以提升模型所提特征的区分度。此外,为了让模型重点关注图像中的虹膜区域,引入了低频语义信息引导的注意力模块。结果在最新的虹膜PAD比赛LivDet-Iris 2023数据集上,将本文方法与比赛中的冠军方法及多种现有方法进行比较。相比于冠军方法,本文方法的综合检测错误率ACER1和ACER2分别下降9.32%和3.71%,其中合成虹膜的平均检测错误率APCER下降22.78%,打印虹膜的检测错误率APCER下降6.32%。相比于其他先进的现有方法,本文方法的综合检测错误率ACER1和ACER2分别下降8.91%和3.58%。此外,在LivDet-Iris 2023数据集上进行消融实验以验证所提模块的有效性,结果显示加入频域信息有效提升了模型分类真假虹膜的准确率。结论本文提出的虹膜呈现攻击检测模型有效利用图像的空间域和频域信息,提高了模型检测各类型虹膜呈现攻击的能力,且表现出更好的泛化性。本文模型和代码在https://github.com/xianyunsun/fre-iris-pad开放。关键词:呈现攻击检测(PAD);虹膜识别;多域特征融合;注意力机制;合成虹膜284|349|0更新时间:2026-02-02 - “介绍了其在人工智能安全领域的研究进展,专家提出了一种基于生成器架构的频率域对抗样本生成方法,为解决对抗样本的迁移性与生成效率问题提供了新的解决方案。”
 摘要:目的对抗样本作为人工智能安全领域的基础性问题,其生成方法的研究具有重要意义。当前的全局扰动优化策略生成的对抗样本存在源模型过拟合问题,这显著降低了跨模型迁移攻击的效果。为了解决这一问题,一种有效的思路是将图像转换到频率域,提取对决策相关的频率信息后进行针对性干扰以生成对抗样本。但现有频率域攻击方法过度依赖低频信息,导致对抗攻击的可迁移性受限。方法为了突破传统攻击方法在迁移性与生成效率方面的双重局限,本文提出一种基于生成器架构的频率域对抗样本生成方法。该方法能够在频率域中自适应地保留对分类决策有益的高频和低频信息,并通过干扰这些信息生成对抗样本。通过利用生成器架构,本文方法无需真实标签,一旦生成器训练完成,即可直接将输入图像送入生成器生成对抗样本,从而显著提高生成效率,同时保持了较高的迁移攻击性能。结果在ImageNet上进行的大量实验证明,本方法在卷积神经网络(convolutional neural network, CNN)和视觉变换器(vision Transformer, ViT)上均优于现有方法。此外,本文还利用了动物数据集以及微软通用物体检测数据集(Microsoft common objects in context, MS-COCO)分别在跨数据集图像分类任务以及目标检测任务上验证了攻击方法的有效性。结论本文提出的基于生成器架构的频率域对抗样本生成方法,通过自适应选择并干扰对分类决策有益的频率成分,显著提升了对抗样本的迁移攻击能力,在生成效率和攻击性能上均优于对比方法,为对抗样本生成领域提供了新的解决方案。关键词:深度学习;人工智能安全;计算机视觉;图像分类对抗样本;生成式攻击算法149|150|0更新时间:2026-02-02
摘要:目的对抗样本作为人工智能安全领域的基础性问题,其生成方法的研究具有重要意义。当前的全局扰动优化策略生成的对抗样本存在源模型过拟合问题,这显著降低了跨模型迁移攻击的效果。为了解决这一问题,一种有效的思路是将图像转换到频率域,提取对决策相关的频率信息后进行针对性干扰以生成对抗样本。但现有频率域攻击方法过度依赖低频信息,导致对抗攻击的可迁移性受限。方法为了突破传统攻击方法在迁移性与生成效率方面的双重局限,本文提出一种基于生成器架构的频率域对抗样本生成方法。该方法能够在频率域中自适应地保留对分类决策有益的高频和低频信息,并通过干扰这些信息生成对抗样本。通过利用生成器架构,本文方法无需真实标签,一旦生成器训练完成,即可直接将输入图像送入生成器生成对抗样本,从而显著提高生成效率,同时保持了较高的迁移攻击性能。结果在ImageNet上进行的大量实验证明,本方法在卷积神经网络(convolutional neural network, CNN)和视觉变换器(vision Transformer, ViT)上均优于现有方法。此外,本文还利用了动物数据集以及微软通用物体检测数据集(Microsoft common objects in context, MS-COCO)分别在跨数据集图像分类任务以及目标检测任务上验证了攻击方法的有效性。结论本文提出的基于生成器架构的频率域对抗样本生成方法,通过自适应选择并干扰对分类决策有益的频率成分,显著提升了对抗样本的迁移攻击能力,在生成效率和攻击性能上均优于对比方法,为对抗样本生成领域提供了新的解决方案。关键词:深度学习;人工智能安全;计算机视觉;图像分类对抗样本;生成式攻击算法149|150|0更新时间:2026-02-02 -
面向克隆语音的目标说话人鉴别方法 AI导读
“随着克隆语音技术发展,准确识别克隆语音成难题。专家提出一种面向克隆语音的目标说话人鉴别方法,通过设计组渐进信道融合模块、动态全局滤波器等,有效提取目标说话人特征,实验结果表明该方法在声纹认定任务中更具优势,为克隆语音声纹认定提供新方法。” 摘要:目的随着文本到语音(text to speech,TTS)、语音转换(voice conversion,VC)等克隆语音技术的快速发展,如何在司法实践中准确识别克隆语音,即克隆语音是否来源于目标说话人特征,成为一个极具挑战性的难题。虽然现有说话人识别技术可以通过声纹特征比对确认自然语音的说话人身份,但由于克隆语音不仅与目标说话人音色相似,且又包含源说话人的特点,使得传统说话人识别技术难以去除源说话人音色的干扰,难以直接应用于深度克隆语音。基于此,研究了一种面向克隆语音的目标说话人鉴别方法。方法基于Res2Block设计组渐进信道融合模块(group progressive channel fusion, GPCF),以有效提取自然语音与克隆语音之间的公共有效声纹特征信息;采用基于K独立的动态全局滤波器(dynamic global filter, DGF),以有效抑制源说话人的影响,提高模型表征和泛化能力;利用基于多尺度层注意力的特征融合机制,以有效融合不同层次GPCF模块和DGF模块的深浅层特征;使用注意力统计池(attentive statistics pooling,ASP)层,进一步增强表示特征张量中的目标说话人信息。结果在所设计的数据集上与3种较新的方法进行实验比较,相对于其他3种方法,本文方法等错误率(equal error rate,EER)分别降低了1.38%、0.92%和0.61%,最小检测代价函数(minimum detection cast function,minDCF)分别降低了0.012 5、0.006 7和0.044 5。结论在FastSpeech2(fast and high-quality end-to-end text to speech)、TriAANVC(triple adaptive attention normalization for any-to-any voice conversion)、FreeVC(high-quality text-free one-shot voice conversion)和KnnVC(nearest neighbors voice conversion)共4种语音克隆数据集上的对比实验结果表明,所提方法在处理面向克隆语音的声纹认定任务时更具有优势,可以有效提取克隆语音中的目标说话人特征,为克隆语音的声纹认定提供方法指导。关键词:克隆语音;声纹认定;组渐进信道融合 (GPCF);动态全局滤波器 (DGF);多尺度层注意力机制176|366|0更新时间:2026-02-02
摘要:目的随着文本到语音(text to speech,TTS)、语音转换(voice conversion,VC)等克隆语音技术的快速发展,如何在司法实践中准确识别克隆语音,即克隆语音是否来源于目标说话人特征,成为一个极具挑战性的难题。虽然现有说话人识别技术可以通过声纹特征比对确认自然语音的说话人身份,但由于克隆语音不仅与目标说话人音色相似,且又包含源说话人的特点,使得传统说话人识别技术难以去除源说话人音色的干扰,难以直接应用于深度克隆语音。基于此,研究了一种面向克隆语音的目标说话人鉴别方法。方法基于Res2Block设计组渐进信道融合模块(group progressive channel fusion, GPCF),以有效提取自然语音与克隆语音之间的公共有效声纹特征信息;采用基于K独立的动态全局滤波器(dynamic global filter, DGF),以有效抑制源说话人的影响,提高模型表征和泛化能力;利用基于多尺度层注意力的特征融合机制,以有效融合不同层次GPCF模块和DGF模块的深浅层特征;使用注意力统计池(attentive statistics pooling,ASP)层,进一步增强表示特征张量中的目标说话人信息。结果在所设计的数据集上与3种较新的方法进行实验比较,相对于其他3种方法,本文方法等错误率(equal error rate,EER)分别降低了1.38%、0.92%和0.61%,最小检测代价函数(minimum detection cast function,minDCF)分别降低了0.012 5、0.006 7和0.044 5。结论在FastSpeech2(fast and high-quality end-to-end text to speech)、TriAANVC(triple adaptive attention normalization for any-to-any voice conversion)、FreeVC(high-quality text-free one-shot voice conversion)和KnnVC(nearest neighbors voice conversion)共4种语音克隆数据集上的对比实验结果表明,所提方法在处理面向克隆语音的声纹认定任务时更具有优势,可以有效提取克隆语音中的目标说话人特征,为克隆语音的声纹认定提供方法指导。关键词:克隆语音;声纹认定;组渐进信道融合 (GPCF);动态全局滤波器 (DGF);多尺度层注意力机制176|366|0更新时间:2026-02-02 -
分离触发器和多重对比的数据浓缩后门攻击 AI导读
““”这段话,介绍了其在数据浓缩后门攻击领域的研究进展,相关专家提出了分离触发器和多重对比的数据浓缩后门攻击方法,为解决现有数据浓缩后门攻击方法存在的问题提供了有效解决方案。” 摘要:目的现有数据浓缩后门攻击方法将含有触发器的中毒样本和干净样本浓缩为小的数据集,中毒数据中真实数据的强信号掩盖触发器的弱信号,并且未考虑将非目标类浓缩数据与中毒数据特征分离,非目标类浓缩数据残留触发器特征。因此,提出分离触发器和多重对比的数据浓缩后门攻击。方法首先将触发器与真实数据进行分离。分离的触发器作为样本与真实数据并行嵌入浓缩数据,减少真实数据对触发器的干扰。然后,对分离的触发器进行优化,将触发器接近目标类真实数据的特征,提高触发器的嵌入效果,同时对触发器进行了分区放大预处理来增加触发器像素的数量,使其在优化过程获取大量的梯度用于指导学习。在数据浓缩阶段,通过多重对比将目标类浓缩数据与触发器特征投影在同一空间,将非目标类浓缩数据与触发器特征分离,进一步提高后门攻击的成功率。结果为了验证所提出方法的有效性,将所提出方法在 FashionMNIST(Fashion Modified National Institute of Standards and Technology database)、CIFAR10(Canadian Institute for Advances Research’s ten categories dataset)、STL10(Stanford letter-10)、SVHN(street view house numbers)与其他4种方法进行对比实验。所提出的方法在5个数据集和6个不同的模型上均达到100%的攻击成功率,同时未降低干净样本在模型上的准确率。结论所提出的方法通过解决现有方法存在的问题,实现了性能的显著提高。本文方法具体代码见:https://github.com/tfuy/STMC。关键词:后门攻击;数据浓缩;分离;梯度匹配;分区放大预处理;最大化110|149|0更新时间:2026-02-02
摘要:目的现有数据浓缩后门攻击方法将含有触发器的中毒样本和干净样本浓缩为小的数据集,中毒数据中真实数据的强信号掩盖触发器的弱信号,并且未考虑将非目标类浓缩数据与中毒数据特征分离,非目标类浓缩数据残留触发器特征。因此,提出分离触发器和多重对比的数据浓缩后门攻击。方法首先将触发器与真实数据进行分离。分离的触发器作为样本与真实数据并行嵌入浓缩数据,减少真实数据对触发器的干扰。然后,对分离的触发器进行优化,将触发器接近目标类真实数据的特征,提高触发器的嵌入效果,同时对触发器进行了分区放大预处理来增加触发器像素的数量,使其在优化过程获取大量的梯度用于指导学习。在数据浓缩阶段,通过多重对比将目标类浓缩数据与触发器特征投影在同一空间,将非目标类浓缩数据与触发器特征分离,进一步提高后门攻击的成功率。结果为了验证所提出方法的有效性,将所提出方法在 FashionMNIST(Fashion Modified National Institute of Standards and Technology database)、CIFAR10(Canadian Institute for Advances Research’s ten categories dataset)、STL10(Stanford letter-10)、SVHN(street view house numbers)与其他4种方法进行对比实验。所提出的方法在5个数据集和6个不同的模型上均达到100%的攻击成功率,同时未降低干净样本在模型上的准确率。结论所提出的方法通过解决现有方法存在的问题,实现了性能的显著提高。本文方法具体代码见:https://github.com/tfuy/STMC。关键词:后门攻击;数据浓缩;分离;梯度匹配;分区放大预处理;最大化110|149|0更新时间:2026-02-02 -
频率感知驱动的深度鲁棒图像水印 AI导读
“相关研究在图像水印领域取得新进展,专家提出频率感知驱动的深度鲁棒图像水印技术,通过差异化处理低频和高频成分,显著增强水印的不可见性和鲁棒性,为应对多样化攻击提供有效方案。” 摘要:目的近年来,基于深度学习的水印方法得到了广泛研究。现有方法通常对特征图的低频和高频部分同等对待,忽视了不同频率成分之间的重要差异,导致模型在处理多样化攻击时缺乏灵活性,难以同时实现水印的高保真性和强鲁棒性。为此,本文提出一种频率感知驱动的深度鲁棒图像水印技术(deep robust image watermarking driven by frequency awareness, RIWFP)。方法通过差异化机制处理低频和高频成分,提升水印性能。具体而言,低频成分通过小波卷积神经网络进行建模,利用宽感受野卷积在粗粒度层面高效学习全局结构和上下文信息;高频成分则采用深度可分离卷积和注意力机制组成的特征蒸馏块进行精炼,强化图像细节,在细粒度层面高效捕捉高频信息。此外,本文使用多频率小波损失函数,引导模型聚焦于不同频带的特征分布,进一步提升生成图像的质量。结果实验结果表明,提出的频率感知驱动的深度鲁棒图像水印技术在多个数据集上均表现出优越性能。在COCO(common objects in context)数据集上,RIWFP在随机丢弃攻击下的准确率达到91.4%;在椒盐噪声和中值滤波攻击下,RIWFP分别以100%和99.5%的准确率达到了最高水平,展现了其对高频信息的高效学习能力。在ImageNet数据集上,RIWFP在裁剪攻击下的准确率为93.4%;在JPEG压缩攻击下的准确率为99.6%,均显著优于其他对比方法。综合来看,RIWFP在COCO和ImageNet数据集上的平均准确率分别为96.7%和96.9%,均高于其他对比方法。结论本文所提方法通过频率感知的粗到细处理策略,显著增强了水印的不可见性和鲁棒性,在处理多种攻击时表现出优越性能。关键词:鲁棒图像水印;小波卷积神经网络;深度可分离卷积;注意力机制;多频率小波损失143|273|0更新时间:2026-02-02
摘要:目的近年来,基于深度学习的水印方法得到了广泛研究。现有方法通常对特征图的低频和高频部分同等对待,忽视了不同频率成分之间的重要差异,导致模型在处理多样化攻击时缺乏灵活性,难以同时实现水印的高保真性和强鲁棒性。为此,本文提出一种频率感知驱动的深度鲁棒图像水印技术(deep robust image watermarking driven by frequency awareness, RIWFP)。方法通过差异化机制处理低频和高频成分,提升水印性能。具体而言,低频成分通过小波卷积神经网络进行建模,利用宽感受野卷积在粗粒度层面高效学习全局结构和上下文信息;高频成分则采用深度可分离卷积和注意力机制组成的特征蒸馏块进行精炼,强化图像细节,在细粒度层面高效捕捉高频信息。此外,本文使用多频率小波损失函数,引导模型聚焦于不同频带的特征分布,进一步提升生成图像的质量。结果实验结果表明,提出的频率感知驱动的深度鲁棒图像水印技术在多个数据集上均表现出优越性能。在COCO(common objects in context)数据集上,RIWFP在随机丢弃攻击下的准确率达到91.4%;在椒盐噪声和中值滤波攻击下,RIWFP分别以100%和99.5%的准确率达到了最高水平,展现了其对高频信息的高效学习能力。在ImageNet数据集上,RIWFP在裁剪攻击下的准确率为93.4%;在JPEG压缩攻击下的准确率为99.6%,均显著优于其他对比方法。综合来看,RIWFP在COCO和ImageNet数据集上的平均准确率分别为96.7%和96.9%,均高于其他对比方法。结论本文所提方法通过频率感知的粗到细处理策略,显著增强了水印的不可见性和鲁棒性,在处理多种攻击时表现出优越性能。关键词:鲁棒图像水印;小波卷积神经网络;深度可分离卷积;注意力机制;多频率小波损失143|273|0更新时间:2026-02-02
面向数字图像的人工智能安全
-
面向遥感图像解译的参数高效微调研究综述 AI导读
“海量遥感数据与AI大模型推动智能化遥感图像解译落地,“预训练 + 微调”成经典范式。专家调研提示词微调、适配器微调和低秩自适应微调三大类方法,总结性能,为“AI + 遥感”应用生态提供理论参考与研究思路。”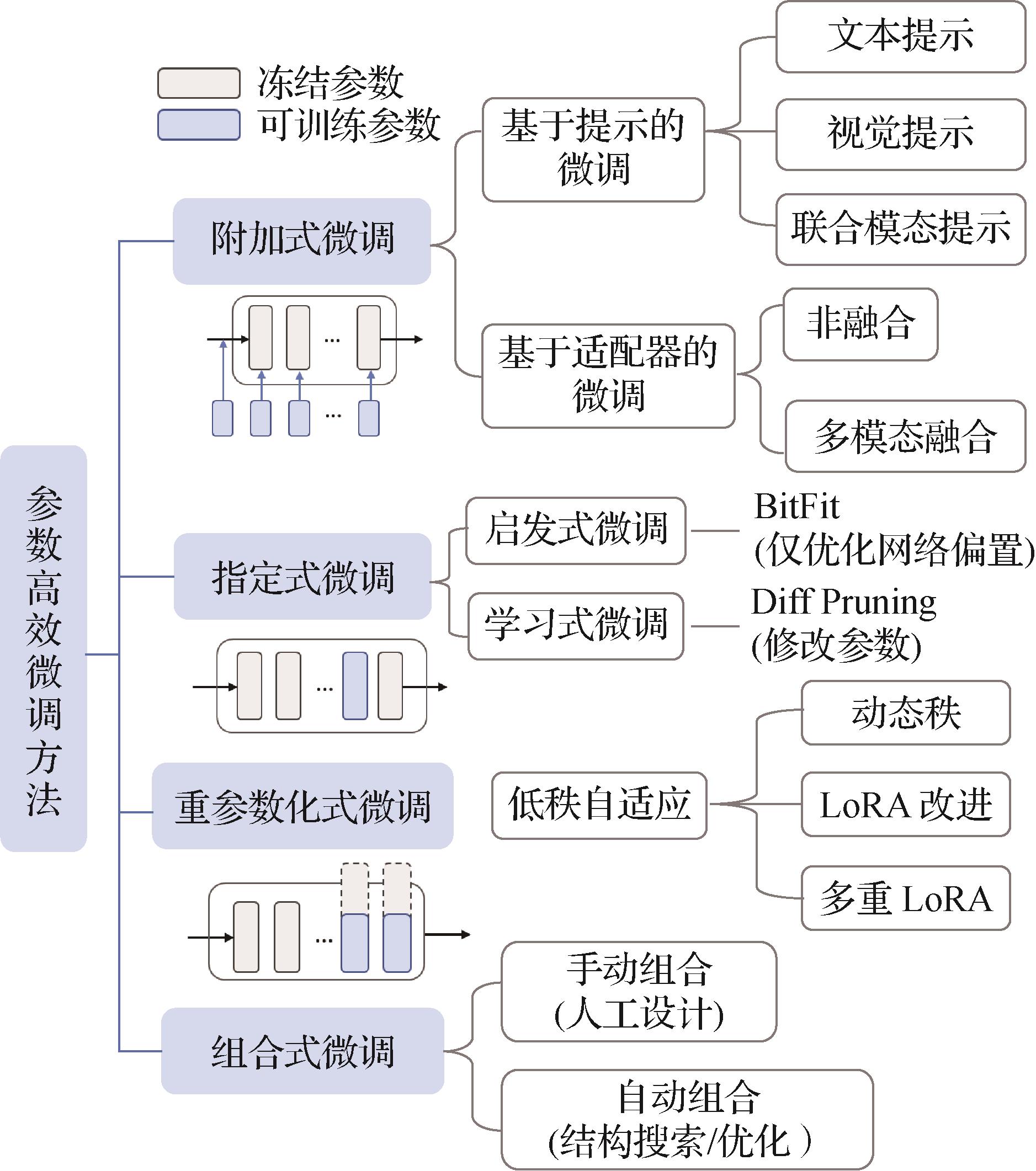 摘要:海量遥感数据的获取和AI大模型的发展极大程度地推动了智能化遥感图像解译的下游应用落地。“预训练 + 微调”是视觉语言基础大模型适配下游领域的经典范式,能有效将基础模型的知识迁移至新任务中。尽管遥感大模型发展如火如荼且在下游任务中表现突出,扩展的模型规模和高昂的训练成本使其难以适用于资源受限、标签不足、需求动态的实际应用场景。为使模型快速适应特定下游任务且有效避免额外训练资源消耗,参数高效微调方法得以广泛研究,并逐渐应用于遥感图像解译当中,成为当下的研究热点。本文面向不同类型的参数高效微调方法和解译任务,对提示词微调、适配器微调和低秩自适应微调三大类方法展开调研并梳理了现有研究工作。此外,本文收集归纳并总结了多个代表性数据集上30余种用于遥感图像解译任务的参数高效微调方法的性能,并从模型精度、训练参数量和推理耗时角度综合评估了方法性能,有助于启发研究者提出新方法并进行公平比较。最后,本文结合当前现状从多模态生成式任务、模型可解释性、边缘端部署应用的角度,展望并讨论了该交叉领域的未来研究方向,旨在为打造“AI + 遥感”的下游应用生态提供理论参考与研究思路。关键词:视觉语言大模型;参数高效微调(PEFT);遥感图像解译;提示词;适配器;低秩自适应179|205|0更新时间:2026-02-02
摘要:海量遥感数据的获取和AI大模型的发展极大程度地推动了智能化遥感图像解译的下游应用落地。“预训练 + 微调”是视觉语言基础大模型适配下游领域的经典范式,能有效将基础模型的知识迁移至新任务中。尽管遥感大模型发展如火如荼且在下游任务中表现突出,扩展的模型规模和高昂的训练成本使其难以适用于资源受限、标签不足、需求动态的实际应用场景。为使模型快速适应特定下游任务且有效避免额外训练资源消耗,参数高效微调方法得以广泛研究,并逐渐应用于遥感图像解译当中,成为当下的研究热点。本文面向不同类型的参数高效微调方法和解译任务,对提示词微调、适配器微调和低秩自适应微调三大类方法展开调研并梳理了现有研究工作。此外,本文收集归纳并总结了多个代表性数据集上30余种用于遥感图像解译任务的参数高效微调方法的性能,并从模型精度、训练参数量和推理耗时角度综合评估了方法性能,有助于启发研究者提出新方法并进行公平比较。最后,本文结合当前现状从多模态生成式任务、模型可解释性、边缘端部署应用的角度,展望并讨论了该交叉领域的未来研究方向,旨在为打造“AI + 遥感”的下游应用生态提供理论参考与研究思路。关键词:视觉语言大模型;参数高效微调(PEFT);遥感图像解译;提示词;适配器;低秩自适应179|205|0更新时间:2026-02-02
综述
- ““目的高时间分辨率的事件相机为传统运动图像去模糊任务提供新的发展思路,但是当前基于事件驱动的运动图像去模糊方法中存在跨模态补偿机制不足、深度特征计算复杂度较高以及缺乏多尺度时空信息关注的问题,在复杂场景中的去模糊泛化性能受限。针对以上挑战,提出一种双通道Mamba去模糊网络(dual channel Mamba network,DCM-Net)。方法使用一种双通道跨模态Mamba模块(dual channel cross-modal Mamba,DCCM),通过线性复杂度的状态空间模型(state space model,SSM)隐状态映射,将事件与模糊图像投影至共享的潜在特征空间中,再通过非线性交叉门控结构,利用低噪声的模糊图像信息抑制事件噪声,并提取事件的清晰边缘特征,将其嵌入到图像特征中,实现事件和模糊图像的跨模态特征互补融合,达到去模糊的效果。此外,提出一种金字塔通道注意力模块(pyramid channel attention,PyCA)对特征的多尺度时空信息进行提取,引导网络聚焦关键时间通道,增强对空间内局部模糊的细节重建,进一步提高潜在清晰图像序列的复原精度。结果实验在合成的REDS(realistic and diverse scenes)数据集与半合成的HQF(high quality frames)数据集上进行,与11种方法进行了比较。与DeMo-IVF方法相比,本文方法在REDS数据集重建序列的峰值信噪比(peak signal-to-noise ratio,PSNR)平均提升了0.16 dB,结构相似性指数(structural similarity,SSIM)平均提升了0.003;在HQF数据集上,PSNR和SSIM分别平均提升约0.11 dB和0.002;在两个数据集上的序列重建结果的学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)达到最优。在与其中5种较先进方法进行比较的主观对比实验中,本文方法取得最佳评分。结论本文方法可以结合模糊图像和事件数据,重建出清晰潜在图像序列,证明了所提网络框架的有效性。””
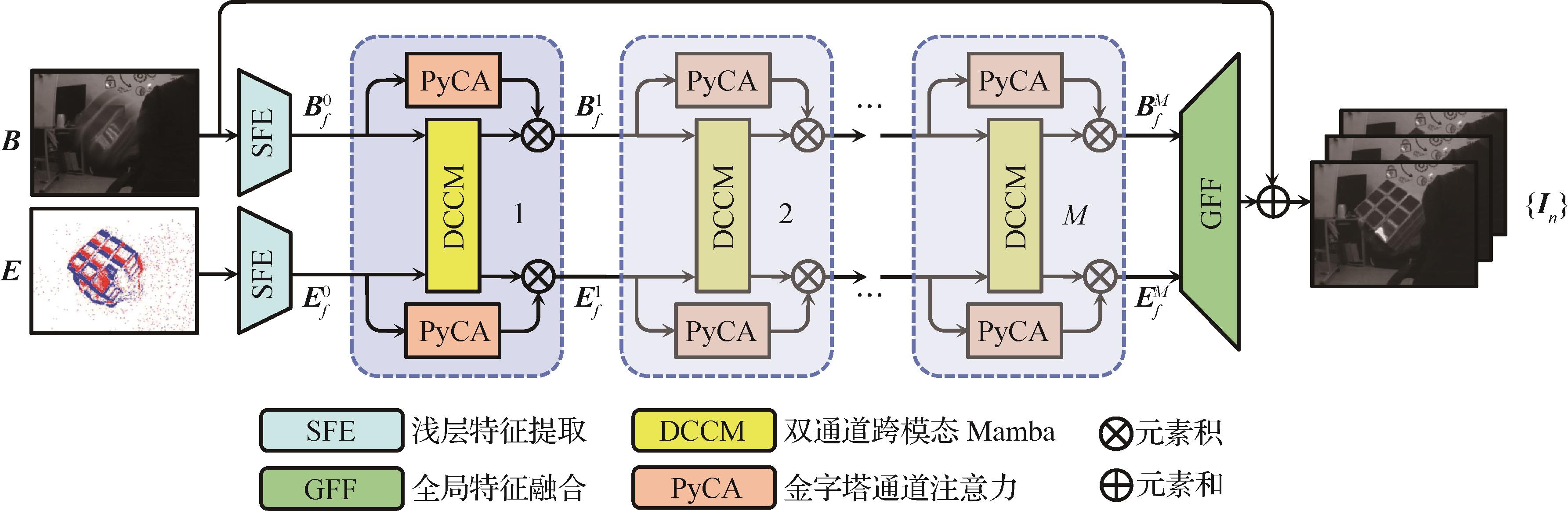 摘要:目的高时间分辨率的事件相机为传统运动图像去模糊任务提供新的发展思路,但是当前基于事件驱动的运动图像去模糊方法中存在跨模态补偿机制不足、深度特征计算复杂度较高以及缺乏多尺度时空信息关注的问题,在复杂场景中的去模糊泛化性能受限。针对以上挑战,提出一种双通道Mamba去模糊网络(dual channel Mamba network,DCM-Net)。方法使用一种双通道跨模态Mamba模块(dual channel cross-modal Mamba,DCCM),通过线性复杂度的状态空间模型(state space model,SSM)隐状态映射,将事件与模糊图像投影至共享的潜在特征空间中,再通过非线性交叉门控结构,利用低噪声的模糊图像信息抑制事件噪声,并提取事件的清晰边缘特征,将其嵌入到图像特征中,实现事件和模糊图像的跨模态特征互补融合,达到去模糊的效果。此外,提出一种金字塔通道注意力模块(pyramid channel attention,PyCA)对特征的多尺度时空信息进行提取,引导网络聚焦关键时间通道,增强对空间内局部模糊的细节重建,进一步提高潜在清晰图像序列的复原精度。结果实验在合成的REDS(realistic and diverse scenes)数据集与半合成的HQF(high quality frames)数据集上进行,与11种方法进行了比较。与DeMo-IVF方法相比,本文方法在REDS数据集重建序列的峰值信噪比(peak signal-to-noise ratio,PSNR)平均提升了0.16 dB,结构相似性指数(structural similarity,SSIM)平均提升了0.003;在HQF数据集上,PSNR和SSIM分别平均提升约0.11 dB和0.002;在两个数据集上的序列重建结果的学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)达到最优。在与其中5种较先进方法进行比较的主观对比实验中,本文方法取得最佳评分。结论本文方法可以结合模糊图像和事件数据,重建出清晰潜在图像序列,证明了所提网络框架的有效性。关键词:运动图像去模糊;事件相机;Mamba模型;金字塔通道注意力;跨模态融合210|218|0更新时间:2026-02-02
摘要:目的高时间分辨率的事件相机为传统运动图像去模糊任务提供新的发展思路,但是当前基于事件驱动的运动图像去模糊方法中存在跨模态补偿机制不足、深度特征计算复杂度较高以及缺乏多尺度时空信息关注的问题,在复杂场景中的去模糊泛化性能受限。针对以上挑战,提出一种双通道Mamba去模糊网络(dual channel Mamba network,DCM-Net)。方法使用一种双通道跨模态Mamba模块(dual channel cross-modal Mamba,DCCM),通过线性复杂度的状态空间模型(state space model,SSM)隐状态映射,将事件与模糊图像投影至共享的潜在特征空间中,再通过非线性交叉门控结构,利用低噪声的模糊图像信息抑制事件噪声,并提取事件的清晰边缘特征,将其嵌入到图像特征中,实现事件和模糊图像的跨模态特征互补融合,达到去模糊的效果。此外,提出一种金字塔通道注意力模块(pyramid channel attention,PyCA)对特征的多尺度时空信息进行提取,引导网络聚焦关键时间通道,增强对空间内局部模糊的细节重建,进一步提高潜在清晰图像序列的复原精度。结果实验在合成的REDS(realistic and diverse scenes)数据集与半合成的HQF(high quality frames)数据集上进行,与11种方法进行了比较。与DeMo-IVF方法相比,本文方法在REDS数据集重建序列的峰值信噪比(peak signal-to-noise ratio,PSNR)平均提升了0.16 dB,结构相似性指数(structural similarity,SSIM)平均提升了0.003;在HQF数据集上,PSNR和SSIM分别平均提升约0.11 dB和0.002;在两个数据集上的序列重建结果的学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)达到最优。在与其中5种较先进方法进行比较的主观对比实验中,本文方法取得最佳评分。结论本文方法可以结合模糊图像和事件数据,重建出清晰潜在图像序列,证明了所提网络框架的有效性。关键词:运动图像去模糊;事件相机;Mamba模型;金字塔通道注意力;跨模态融合210|218|0更新时间:2026-02-02
图像处理和编码
-
双阶段双分支模型的三维点云去噪 AI导读
“相关研究在三维点云去噪领域取得新进展,专家提出双阶段双分支模型,有效解决点云数据局部与全局特征提取融合难题,显著提升去噪效果,为相关应用提供有力支持。” 摘要:目的三维点云数据在三维重建、自动驾驶等领域有着广泛应用,然而由于传感器设备受限和环境因素,点云数据不可避免地受到噪声影响,降低了数据质量,进而影响了后续处理和分析的准确性。现有的基于深度学习的点云去噪主流方法大多采取单阶段单分支去噪流程,导致模型学习到的特征的表达能力有限,难以捕捉点云复杂的结构信息。因此,提出一种双阶段双分支模型用于三维点云去噪,旨在获得综合点云特征。方法阶段1:利用双分支编码器提取点云块局部和全局特征,并用交叉注意力融合;阶段2:利用注意力机制增强阶段1特征,聚焦强特征表达。最终,加权融合两阶段解码位移,指导点云去噪。结果在3个数据集上与较新的6种方法进行比较,在PUNet(point cloud upsampling network)数据集上,相比Pointfilter取得3个最佳性能、2个次佳性能,双分支双编码器模型取得6个最佳性能、3个次佳性能;在PCNet(point clean network)数据集上,相比于IterativePFN取得2个最佳性能、6个次佳性能,双分支双编码器模型取得7个最佳性能、3个次佳性能;在Kinect_v1数据集上,相比于同期最优模型,双阶段双分支模型在两种指标上取得次佳效果,整体达到最佳。结论本文所提出的双阶段双分支模型的三维点云去噪,解决了点云数据块局部特征和全局特征的提取和融合问题,实现了更好的去噪效果。关键词:深度学习;三维点云去噪;双分支编码器;特征融合;注意力机制170|245|0更新时间:2026-02-02
摘要:目的三维点云数据在三维重建、自动驾驶等领域有着广泛应用,然而由于传感器设备受限和环境因素,点云数据不可避免地受到噪声影响,降低了数据质量,进而影响了后续处理和分析的准确性。现有的基于深度学习的点云去噪主流方法大多采取单阶段单分支去噪流程,导致模型学习到的特征的表达能力有限,难以捕捉点云复杂的结构信息。因此,提出一种双阶段双分支模型用于三维点云去噪,旨在获得综合点云特征。方法阶段1:利用双分支编码器提取点云块局部和全局特征,并用交叉注意力融合;阶段2:利用注意力机制增强阶段1特征,聚焦强特征表达。最终,加权融合两阶段解码位移,指导点云去噪。结果在3个数据集上与较新的6种方法进行比较,在PUNet(point cloud upsampling network)数据集上,相比Pointfilter取得3个最佳性能、2个次佳性能,双分支双编码器模型取得6个最佳性能、3个次佳性能;在PCNet(point clean network)数据集上,相比于IterativePFN取得2个最佳性能、6个次佳性能,双分支双编码器模型取得7个最佳性能、3个次佳性能;在Kinect_v1数据集上,相比于同期最优模型,双阶段双分支模型在两种指标上取得次佳效果,整体达到最佳。结论本文所提出的双阶段双分支模型的三维点云去噪,解决了点云数据块局部特征和全局特征的提取和融合问题,实现了更好的去噪效果。关键词:深度学习;三维点云去噪;双分支编码器;特征融合;注意力机制170|245|0更新时间:2026-02-02 -
预训练混合架构模型的电影场景分割方法 AI导读
“相关研究在电影场景分割领域取得新进展,专家提出HASSNet混合架构方法,通过预训练与微调策略,结合状态空间模型和自注意力机制,显著提升场景分割精度,为电影内容理解和多媒体应用提供有力支持。” 摘要:目的随着电影内容的复杂化与多样化,电影场景分割成为理解影片结构和支持多媒体应用的重要任务。为提升镜头特征提取和特征关联的有效性,增强镜头序列的上下文感知能力,提出一种混合架构电影场景分割方法(hybrid architecture scene segmentation network, HASSNet)。方法首先,采用预训练结合微调策略,在大量无场景标签的电影数据上进行无监督预训练,使模型学习有效的镜头特征表示和关联特性,然后在有场景标签的数据上进行微调训练,进一步提升模型性能;其次,模型架构上混合了状态空间模型和自注意力机制模型,分别设计Shot Mamba镜头特征提取模块和Scene Transformer特征关联模块,Shot Mamba通过对镜头图像分块建模提取有效特征表示,Scene Transformer则通过注意力机制对不同镜头特征进行关联建模;最后,采用3种无监督损失函数进行预训练,提升模型在镜头特征提取和关联上的性能,并使用Focal Loss损失函数进行微调,以改善由于类别不平衡导致的精度不足问题。结果实验结果表明,HASSNet在3个数据集上显著提升了场景分割的精度,在典型电影场景分割数据集MovieNet中,与先进的场景分割方法相比,AP(average precision)、mIoU(mean intersection over union)、AUC-ROC(area under the receiver operating characteristic curve)和F1分别提升1.66%、10.54%、0.21%和16.83%,验证了本文提出的HASSNet方法可以有效提升场景边界定位的准确性。结论本文提出的HASSNet方法有效结合了预训练与微调策略,借助混合状态空间模型和自注意力机制模型的特点,增强了镜头的上下文感知能力,使电影场景分割的结果更加准确。关键词:电影场景分割;预训练模型;状态空间模型(SSM);自注意力机制;无监督相似性度量93|168|0更新时间:2026-02-02
摘要:目的随着电影内容的复杂化与多样化,电影场景分割成为理解影片结构和支持多媒体应用的重要任务。为提升镜头特征提取和特征关联的有效性,增强镜头序列的上下文感知能力,提出一种混合架构电影场景分割方法(hybrid architecture scene segmentation network, HASSNet)。方法首先,采用预训练结合微调策略,在大量无场景标签的电影数据上进行无监督预训练,使模型学习有效的镜头特征表示和关联特性,然后在有场景标签的数据上进行微调训练,进一步提升模型性能;其次,模型架构上混合了状态空间模型和自注意力机制模型,分别设计Shot Mamba镜头特征提取模块和Scene Transformer特征关联模块,Shot Mamba通过对镜头图像分块建模提取有效特征表示,Scene Transformer则通过注意力机制对不同镜头特征进行关联建模;最后,采用3种无监督损失函数进行预训练,提升模型在镜头特征提取和关联上的性能,并使用Focal Loss损失函数进行微调,以改善由于类别不平衡导致的精度不足问题。结果实验结果表明,HASSNet在3个数据集上显著提升了场景分割的精度,在典型电影场景分割数据集MovieNet中,与先进的场景分割方法相比,AP(average precision)、mIoU(mean intersection over union)、AUC-ROC(area under the receiver operating characteristic curve)和F1分别提升1.66%、10.54%、0.21%和16.83%,验证了本文提出的HASSNet方法可以有效提升场景边界定位的准确性。结论本文提出的HASSNet方法有效结合了预训练与微调策略,借助混合状态空间模型和自注意力机制模型的特点,增强了镜头的上下文感知能力,使电影场景分割的结果更加准确。关键词:电影场景分割;预训练模型;状态空间模型(SSM);自注意力机制;无监督相似性度量93|168|0更新时间:2026-02-02 -
视觉语言模型驱动的目标计数 AI导读
“大型视觉语言模型在目标计数领域取得进展,但面临类别语义错位与解码器架构局限两大挑战。专家提出跨分支协作对齐网络(CANet),采用双分支解码器架构与视觉—文本类别对齐损失,有效解决上述问题,在多个基准数据集上取得优异性能,为复杂场景下的计数鲁棒性提升提供新思路。” 摘要:目的大型视觉语言模型的进展给解决基于文本提示的目标计数问题带来新的思路。然而,现有方法仍面临类别语义错位与解码器架构局限两大挑战。前者导致模型易将相似背景或无关类别误检为目标,后者依赖单一卷积神经网络(convolutional neural network,CNN)架构的局部特征提取,可能引发全局语义与局部细节的割裂,严重制约复杂场景下的计数鲁棒性。针对上述问题,提出跨分支协作对齐网络(cross-branch cooperative alignment network,CANet)。方法其核心包括:1)双分支解码器架构:通过并行Transformer分支(建模全局上下文依赖)与CNN分支(提取细粒度局部特征),结合信息互馈模块实现跨分支的特征交互和密度图预测;2)视觉—文本类别对齐损失:通过约束图像与文本特征的跨模态对齐,迫使模型区分目标与干扰语义,实现对类别的准确检测。结果在5个基准数据集上与先进的4种基于文本的目标计数方法进行比较实验。在FSC-147(few-shot counting-147)数据集上, CANet相较于性能第2的模型,在测试集上的平均绝对误差(mean absolute error,MAE)和均方根误差(root mean squared error,RMSE)分别降低1.22和8.45;在CARPK(car parking lot dataset)和PUCPR+(Pontifical Catholic University of Parana+ dataset)数据集的交叉验证实验上,相较于性能第2的模型,MAE分别降低0.08和3.58;在SHA(ShanghaiTech part-A)和SHB(ShanghaiTech part-B)数据集的交叉验证实验上,相较于性能第2的模型,MAE分别降低了47.0和9.8。同时也在FSC-147数据集上进行丰富的消融实验以验证算法的有效性,消融实验结果表明提出的方法针对两个问题做出了有效改进。结论本文方法能够解决现有方法所面临的两个问题,使计数结果更加准确。本文方法在4个数据集的交叉验证实验均取得SOTA(state-of-the-art)的性能,表明了CANet在零样本目标计数任务中的强大泛化能力。关键词:目标计数;视觉语言模型(VLM);文本提示;双分支解码器;信息互馈134|203|0更新时间:2026-02-02
摘要:目的大型视觉语言模型的进展给解决基于文本提示的目标计数问题带来新的思路。然而,现有方法仍面临类别语义错位与解码器架构局限两大挑战。前者导致模型易将相似背景或无关类别误检为目标,后者依赖单一卷积神经网络(convolutional neural network,CNN)架构的局部特征提取,可能引发全局语义与局部细节的割裂,严重制约复杂场景下的计数鲁棒性。针对上述问题,提出跨分支协作对齐网络(cross-branch cooperative alignment network,CANet)。方法其核心包括:1)双分支解码器架构:通过并行Transformer分支(建模全局上下文依赖)与CNN分支(提取细粒度局部特征),结合信息互馈模块实现跨分支的特征交互和密度图预测;2)视觉—文本类别对齐损失:通过约束图像与文本特征的跨模态对齐,迫使模型区分目标与干扰语义,实现对类别的准确检测。结果在5个基准数据集上与先进的4种基于文本的目标计数方法进行比较实验。在FSC-147(few-shot counting-147)数据集上, CANet相较于性能第2的模型,在测试集上的平均绝对误差(mean absolute error,MAE)和均方根误差(root mean squared error,RMSE)分别降低1.22和8.45;在CARPK(car parking lot dataset)和PUCPR+(Pontifical Catholic University of Parana+ dataset)数据集的交叉验证实验上,相较于性能第2的模型,MAE分别降低0.08和3.58;在SHA(ShanghaiTech part-A)和SHB(ShanghaiTech part-B)数据集的交叉验证实验上,相较于性能第2的模型,MAE分别降低了47.0和9.8。同时也在FSC-147数据集上进行丰富的消融实验以验证算法的有效性,消融实验结果表明提出的方法针对两个问题做出了有效改进。结论本文方法能够解决现有方法所面临的两个问题,使计数结果更加准确。本文方法在4个数据集的交叉验证实验均取得SOTA(state-of-the-art)的性能,表明了CANet在零样本目标计数任务中的强大泛化能力。关键词:目标计数;视觉语言模型(VLM);文本提示;双分支解码器;信息互馈134|203|0更新时间:2026-02-02
图像理解和计算机视觉
-
融合频率自适应和特征变换的医学图像分割 AI导读
“医学图像病灶分割领域迎来新突破,相关专家构建了融合频率自适应与特征变换的分割网络,该网络通过动态平衡高低频分量并优化下采样策略,显著提升了分割准确性,为精准临床诊断和治疗制定提供了有力支持。” 摘要:目的医学图像中病灶的精准分割对临床诊断和治疗制定至关重要。虽然现有方法多利用深度特征、注意力机制或多尺度结构来提升性能,但对高低频特征的显式建模不足,下采样过程中易产生信息丢失。本文提出一种融合频率自适应与特征变换的分割网络(frequency adaptation and feaTNet),通过动态平衡高低频分量并优化下采样策略,以提升分割的准确性。方法该方法是基于编码器—解码器结构实现的,主要包括频率自适应编码模块(frequency adaptation encoding module,FAE)、特征分解变换模块(feature decomposition transformation module,FDT)和空间通道信息重构模块(spatial-channel information reconstruction module,SCIR)。频率自适应编码模块用于特征表示学习中的高低频分量平衡,在特征编码过程采用动态扩张率和自适应核策略;特征分解变换模块应用于下采样过程,通过并行最大池化和离散小波变换平衡操作,实现细节感知信息的恢复和保持;空间通道信息重构模块采用分离重构策略及分离变换融合操作实现解码过程的信息特征交叉重建并抑制空间通道维度特征冗余。结果在ISIC2017(international skin imaging collaboration 2017)、ISIC2018和DSB2018(data science bowl challenge 2018) 3个公开数据集中进行训练和验证。在ISIC2017和ISIC2018数据集上的Dice得分为89.42%和89.84%,分别优于其他对比方法0.04%~7.83%和0.13%~5.95%。在ISIC2018基准上的敏感性(sensitivity,SE)指标达到91.19%,具有明显优势。在DSB2018数据集上,本文模型的Dice系数(Dice coefficient)、准确度(accuracy,ACC)和敏感性(SE)指标分别为91.52%、97.65%和91.88%,相较于较先进的算法分别提升2.59%、2.29%和2.86%。结论本文提出的分割模型,充分利用了图像中的高频和低频信息,有效提升了分割性能。关键词:深度学习;医学图像分割;卷积神经网络(CNN);频率自适应;特征分解变换256|163|0更新时间:2026-02-02
摘要:目的医学图像中病灶的精准分割对临床诊断和治疗制定至关重要。虽然现有方法多利用深度特征、注意力机制或多尺度结构来提升性能,但对高低频特征的显式建模不足,下采样过程中易产生信息丢失。本文提出一种融合频率自适应与特征变换的分割网络(frequency adaptation and feaTNet),通过动态平衡高低频分量并优化下采样策略,以提升分割的准确性。方法该方法是基于编码器—解码器结构实现的,主要包括频率自适应编码模块(frequency adaptation encoding module,FAE)、特征分解变换模块(feature decomposition transformation module,FDT)和空间通道信息重构模块(spatial-channel information reconstruction module,SCIR)。频率自适应编码模块用于特征表示学习中的高低频分量平衡,在特征编码过程采用动态扩张率和自适应核策略;特征分解变换模块应用于下采样过程,通过并行最大池化和离散小波变换平衡操作,实现细节感知信息的恢复和保持;空间通道信息重构模块采用分离重构策略及分离变换融合操作实现解码过程的信息特征交叉重建并抑制空间通道维度特征冗余。结果在ISIC2017(international skin imaging collaboration 2017)、ISIC2018和DSB2018(data science bowl challenge 2018) 3个公开数据集中进行训练和验证。在ISIC2017和ISIC2018数据集上的Dice得分为89.42%和89.84%,分别优于其他对比方法0.04%~7.83%和0.13%~5.95%。在ISIC2018基准上的敏感性(sensitivity,SE)指标达到91.19%,具有明显优势。在DSB2018数据集上,本文模型的Dice系数(Dice coefficient)、准确度(accuracy,ACC)和敏感性(SE)指标分别为91.52%、97.65%和91.88%,相较于较先进的算法分别提升2.59%、2.29%和2.86%。结论本文提出的分割模型,充分利用了图像中的高频和低频信息,有效提升了分割性能。关键词:深度学习;医学图像分割;卷积神经网络(CNN);频率自适应;特征分解变换256|163|0更新时间:2026-02-02 - “专家提出端到端医学图像分割框架,融合卷积神经网络与Transformer优势,解决全局—局部特征融合及卷积核参数固化问题,提升分割精度。”
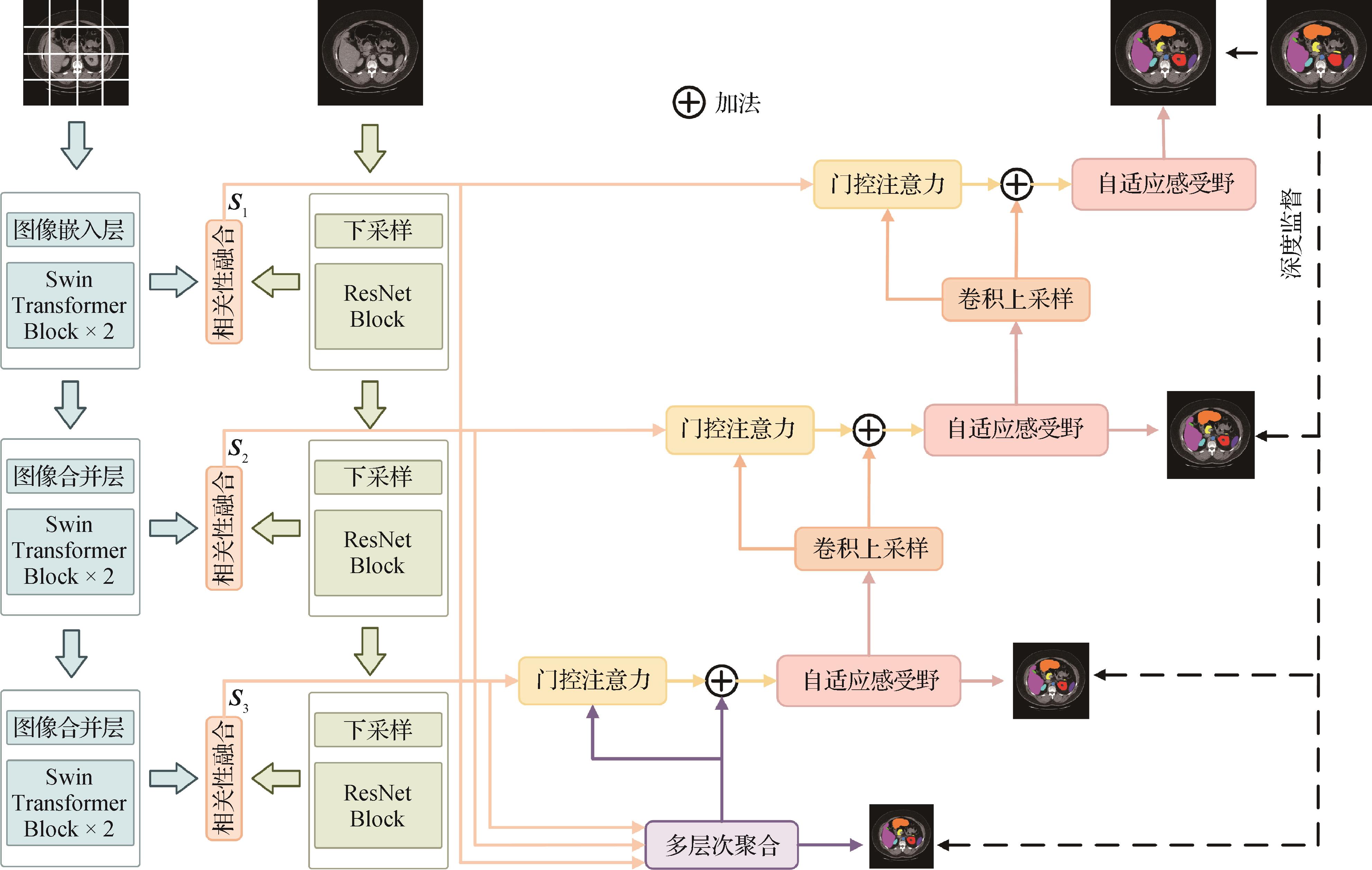 摘要:目的受限于局部感受野,卷积神经网络难以有效建模长程依赖。现有研究尝试将 Transformer模块引入编码器、解码器或跳跃连接以增强全局信息建模能力,但此类局部式嵌入仍不足以捕获器官在尺度与形态高度可变情况下所呈现的复杂依赖关系。此外,传统卷积在训练后趋于静态,难以适应器官的几何形变,从而在一定程度上限制了模型对动态形变结构的表征能力。方法针对上述问题,提出一种端到端的医学图像分割框架,通过双路径编码与自适应感受野机制的协同设计,增强模型对全局—局部特征融合能力。具体而言,首先,设计了双路径编码结构,在多个网络层级融合卷积神经网络与Transformer特征,实现局部细节与全局上下文的渐进式融合;其次,构建编码器多层次融合机制,通过跨尺度信息交互整合浅层纹理与深层语义特征,增强模型对目标结构的多分辨率解析能力;最后,提出自适应感受野机制,基于像素级语义差距动态调整卷积核感知范围,突破静态卷积在形变组织表征中的瓶颈。结果实验在两个公开数据集上与最新的方法进行比较,在Synapse数据集中,本文方法较次优模型在DSC(Dice similarity coefficient)和HD95(95% Hausdorff distance)评价指标上分别提升0.54%和0.44;在ACDC(automated cardiac diagnosis challenge)数据集上的DSC值提高0.34%;消融实验进一步验证了双路径编码与自适应感受野机制的协同有效性。结论本文方法通过深度融合卷积神经网络局部感知与Transformer全局建模的各自优势,结合自适应感受野机制,有效解决了当前医学图像分割模型中全局—局部特征融合不足及卷积核参数静态固化的问题,实现了SOTA(state-of-the-art)级别的分割精度,为复杂医学图像分割任务提供了新的方案。代码已开源:https://github.com/Swq308/DPAR-Net。关键词:卷积神经网络(CNN);Transformer;双路径编码;自适应感受野;多层次融合299|238|0更新时间:2026-02-02
摘要:目的受限于局部感受野,卷积神经网络难以有效建模长程依赖。现有研究尝试将 Transformer模块引入编码器、解码器或跳跃连接以增强全局信息建模能力,但此类局部式嵌入仍不足以捕获器官在尺度与形态高度可变情况下所呈现的复杂依赖关系。此外,传统卷积在训练后趋于静态,难以适应器官的几何形变,从而在一定程度上限制了模型对动态形变结构的表征能力。方法针对上述问题,提出一种端到端的医学图像分割框架,通过双路径编码与自适应感受野机制的协同设计,增强模型对全局—局部特征融合能力。具体而言,首先,设计了双路径编码结构,在多个网络层级融合卷积神经网络与Transformer特征,实现局部细节与全局上下文的渐进式融合;其次,构建编码器多层次融合机制,通过跨尺度信息交互整合浅层纹理与深层语义特征,增强模型对目标结构的多分辨率解析能力;最后,提出自适应感受野机制,基于像素级语义差距动态调整卷积核感知范围,突破静态卷积在形变组织表征中的瓶颈。结果实验在两个公开数据集上与最新的方法进行比较,在Synapse数据集中,本文方法较次优模型在DSC(Dice similarity coefficient)和HD95(95% Hausdorff distance)评价指标上分别提升0.54%和0.44;在ACDC(automated cardiac diagnosis challenge)数据集上的DSC值提高0.34%;消融实验进一步验证了双路径编码与自适应感受野机制的协同有效性。结论本文方法通过深度融合卷积神经网络局部感知与Transformer全局建模的各自优势,结合自适应感受野机制,有效解决了当前医学图像分割模型中全局—局部特征融合不足及卷积核参数静态固化的问题,实现了SOTA(state-of-the-art)级别的分割精度,为复杂医学图像分割任务提供了新的方案。代码已开源:https://github.com/Swq308/DPAR-Net。关键词:卷积神经网络(CNN);Transformer;双路径编码;自适应感受野;多层次融合299|238|0更新时间:2026-02-02 -
 摘要:目的在医学图像分割领域,传统基于卷积神经网络(convolutional neural network,CNN)的模型在捕捉长距离依赖信息方面存在固有局限,而基于视觉Transformer(vision Transformer, ViT)的模型其自注意力机制的计算复杂度与图像尺寸呈平方关系,在资源有限的现实环境中难以部署。为了解决这些问题,提出一种融合视觉 Mamba 和自适应多尺度损失的医学图像分割方法VMAML-UNet(medical image segmentation with vision Mamba and adaptive multi-scale loss)。方法VMAML-UNet采用编码器—解码器架构。在编码阶段,设计了融合小波卷积的视觉 Mamba 块,以线性复杂度提取病变区域的精确特征并扩大感受野,并通过块合并进行下采样。解码阶段同样引入融合小波卷积的视觉 Mamba 块并利用块扩展进行上采样。跳跃连接中,提出小波卷积注意力聚合模块,用于提取并融合不同尺度下的图像特征。此外,设计了柯尔莫哥洛夫—阿诺德网络(Kolmogorov-Arnold network, KAN)调控多尺度加权损失,动态调控各层级损失权重。结果在BUSI(breast ultrasound images dataset)、GlaS(gland segmentation in histology images challenge dataset)和CVC(CVC-ClinicDB dataset)3个异质性显著的医学图像数据集上的实验结果表明,与主流的VM-UNet(vision Mamba UNet)等采用Mamba的医学图像分割方法相比取得显著的性能提升。在BUSI数据集上,交并比(intersection over union,IoU)和F1分数分别提升2.72%和2.02%;在GlaS数据集上,IoU和F1分数分别提升3.38%和1.89%;在CVC数据集上,IoU和F1分数分别提升2.51%和1.42%。结论提出的VMAML-UNet采用基于视觉Mamba的线性复杂度的长距离依赖建模与基于KAN的动态损失优化机制,显著减少了计算成本,同时提升了模型对复杂医学图像的分割精度。该模型在3个数据集上的优异表现证明了其在不同医学图像场景下的广泛适用性和高效性。关键词:状态空间模型 (SSM);柯尔莫哥洛夫—阿诺德网络 (KAN);小波卷积;多尺度加权损失;连续流384|240|0更新时间:2026-02-02
摘要:目的在医学图像分割领域,传统基于卷积神经网络(convolutional neural network,CNN)的模型在捕捉长距离依赖信息方面存在固有局限,而基于视觉Transformer(vision Transformer, ViT)的模型其自注意力机制的计算复杂度与图像尺寸呈平方关系,在资源有限的现实环境中难以部署。为了解决这些问题,提出一种融合视觉 Mamba 和自适应多尺度损失的医学图像分割方法VMAML-UNet(medical image segmentation with vision Mamba and adaptive multi-scale loss)。方法VMAML-UNet采用编码器—解码器架构。在编码阶段,设计了融合小波卷积的视觉 Mamba 块,以线性复杂度提取病变区域的精确特征并扩大感受野,并通过块合并进行下采样。解码阶段同样引入融合小波卷积的视觉 Mamba 块并利用块扩展进行上采样。跳跃连接中,提出小波卷积注意力聚合模块,用于提取并融合不同尺度下的图像特征。此外,设计了柯尔莫哥洛夫—阿诺德网络(Kolmogorov-Arnold network, KAN)调控多尺度加权损失,动态调控各层级损失权重。结果在BUSI(breast ultrasound images dataset)、GlaS(gland segmentation in histology images challenge dataset)和CVC(CVC-ClinicDB dataset)3个异质性显著的医学图像数据集上的实验结果表明,与主流的VM-UNet(vision Mamba UNet)等采用Mamba的医学图像分割方法相比取得显著的性能提升。在BUSI数据集上,交并比(intersection over union,IoU)和F1分数分别提升2.72%和2.02%;在GlaS数据集上,IoU和F1分数分别提升3.38%和1.89%;在CVC数据集上,IoU和F1分数分别提升2.51%和1.42%。结论提出的VMAML-UNet采用基于视觉Mamba的线性复杂度的长距离依赖建模与基于KAN的动态损失优化机制,显著减少了计算成本,同时提升了模型对复杂医学图像的分割精度。该模型在3个数据集上的优异表现证明了其在不同医学图像场景下的广泛适用性和高效性。关键词:状态空间模型 (SSM);柯尔莫哥洛夫—阿诺德网络 (KAN);小波卷积;多尺度加权损失;连续流384|240|0更新时间:2026-02-02
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0