
最新刊期
2022 年 第 27 卷 第 4 期

-
 摘要:本文是关于中国图像工程的年度文献综述系列之二十七。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,对2021年度图像工程相关文献进行了统计和分析。具体从国内15种有关图像工程重要中文期刊在2021年发行的所有154期上所发表的学术研究和技术应用文献(共2 958篇)中,选取出所有属于图像工程领域的文献(共833篇),并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前16年相同),并在此基础上分别进行了各期刊各类文献的统计和分析。根据对2021年统计数据的分析可以看出:图像分析方向当前得到了最多的关注,其中目标检测和识别、图像分割和边缘检测、人体生物特征提取和验证等都是研究的焦点。另外,遥感、雷达、声呐、测绘以及生物、医学等领域的图像技术开发和应用最为活跃。总的来说,中国图像工程在2021年的研究深度和广度还在继续提高和扩大,仍保持了快速发展的势头。综合27年的统计数据还为读者提供了更全面和更可信的各个研究方向发展趋势的信息。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学130|104|3更新时间:2024-05-07
摘要:本文是关于中国图像工程的年度文献综述系列之二十七。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,对2021年度图像工程相关文献进行了统计和分析。具体从国内15种有关图像工程重要中文期刊在2021年发行的所有154期上所发表的学术研究和技术应用文献(共2 958篇)中,选取出所有属于图像工程领域的文献(共833篇),并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前16年相同),并在此基础上分别进行了各期刊各类文献的统计和分析。根据对2021年统计数据的分析可以看出:图像分析方向当前得到了最多的关注,其中目标检测和识别、图像分割和边缘检测、人体生物特征提取和验证等都是研究的焦点。另外,遥感、雷达、声呐、测绘以及生物、医学等领域的图像技术开发和应用最为活跃。总的来说,中国图像工程在2021年的研究深度和广度还在继续提高和扩大,仍保持了快速发展的势头。综合27年的统计数据还为读者提供了更全面和更可信的各个研究方向发展趋势的信息。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学130|104|3更新时间:2024-05-07 -
 摘要:人脸伪造技术的恶意使用,不仅损害公民的肖像权和名誉权,而且会危害国家政治和经济安全。因此,针对伪造人脸图像和视频的检测技术研究具有重要的现实意义和实践价值。本文在总结人脸伪造和伪造人脸检测的关键技术与研究进展的基础上,分析现有伪造和检测技术的局限。在人脸伪造方面,主要包括利用生成对抗技术的全新人脸生成技术和基于现有人脸的人脸编辑技术,介绍生成对抗网络在人脸图像生成的发展进程,重点介绍人脸编辑技术中的人脸交换技术和人脸重现技术,从网络结构、通用性和生成效果真实性等角度对现有的研究进展进行深入阐述。在伪造人脸检测方面,根据媒体载体的差异,分为伪造人脸图像检测和伪造人脸视频检测,首先介绍利用统计分布差异、拼接残留痕迹和局部瑕疵等特征的伪造人脸图像检测技术,然后根据提取伪造特征的差异,将伪造人脸视频检测技术分为基于帧间信息、帧内信息和生理信号的伪造视频检测技术,并从特征提取方式、网络结构设计特点和使用场景类型等方面进行详细阐述。最后,分析了当前人脸伪造技术和伪造人脸检测技术的不足,提出可行的改进意见,并对未来发展方向进行展望。关键词:人脸伪造;伪造人脸检测;生成对抗网络(GAN);人脸交换;人脸重现383|668|7更新时间:2024-05-07
摘要:人脸伪造技术的恶意使用,不仅损害公民的肖像权和名誉权,而且会危害国家政治和经济安全。因此,针对伪造人脸图像和视频的检测技术研究具有重要的现实意义和实践价值。本文在总结人脸伪造和伪造人脸检测的关键技术与研究进展的基础上,分析现有伪造和检测技术的局限。在人脸伪造方面,主要包括利用生成对抗技术的全新人脸生成技术和基于现有人脸的人脸编辑技术,介绍生成对抗网络在人脸图像生成的发展进程,重点介绍人脸编辑技术中的人脸交换技术和人脸重现技术,从网络结构、通用性和生成效果真实性等角度对现有的研究进展进行深入阐述。在伪造人脸检测方面,根据媒体载体的差异,分为伪造人脸图像检测和伪造人脸视频检测,首先介绍利用统计分布差异、拼接残留痕迹和局部瑕疵等特征的伪造人脸图像检测技术,然后根据提取伪造特征的差异,将伪造人脸视频检测技术分为基于帧间信息、帧内信息和生理信号的伪造视频检测技术,并从特征提取方式、网络结构设计特点和使用场景类型等方面进行详细阐述。最后,分析了当前人脸伪造技术和伪造人脸检测技术的不足,提出可行的改进意见,并对未来发展方向进行展望。关键词:人脸伪造;伪造人脸检测;生成对抗网络(GAN);人脸交换;人脸重现383|668|7更新时间:2024-05-07
综述
-
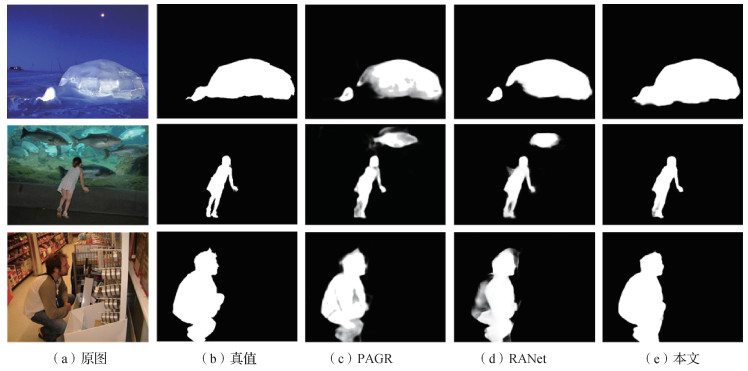
 摘要:目的在显著物体检测算法发展过程中,基准数据集发挥了重要作用。然而,现有基准数据集普遍存在数据集偏差,难以充分体现不同算法的性能,不能完全反映某些典型应用的技术特点。针对这一问题,本文对基准数据集的偏差和统计特性展开定量分析,提出针对特定任务的新基准数据集。方法首先,讨论设计和评价数据集时常用的度量指标;然后, 定量分析基准数据集的统计学差异,设计新的基准数据集MTMS300(multiple targets and multiple scales);接着,使用基准数据集对典型视觉显著性算法展开性能评估;最后,从公开基准数据集中找出对多数非深度学习算法而言都较为困难(指标得分低)的图像,构成另一个基准数据集DSC(difficult scenes in common)。结果采用平均注释图、超像素数目等6种度量指标对11个基准数据集进行定量分析,MTMS300数据集具有中心偏差小、目标面积比分布均衡、图像分辨率多样和目标数量较多等特点,DSC数据集具有前景/背景差异小、超像素数量多和图像熵值高的特点。使用11个基准数据集对18种视觉显著性算法进行定量评估,揭示了算法得分和数据集复杂度之间的相关性,并在MTMS300数据集上发现了现有算法的不足。结论提出的两个基准数据集具有不同的特点,有助于更为全面地评估视觉显著性算法,推动视觉显著性算法向特定任务方向发展。关键词:视觉显著性;显著物体检测;基准数据集;多目标;多尺度;小目标146|179|1更新时间:2024-05-07
摘要:目的在显著物体检测算法发展过程中,基准数据集发挥了重要作用。然而,现有基准数据集普遍存在数据集偏差,难以充分体现不同算法的性能,不能完全反映某些典型应用的技术特点。针对这一问题,本文对基准数据集的偏差和统计特性展开定量分析,提出针对特定任务的新基准数据集。方法首先,讨论设计和评价数据集时常用的度量指标;然后, 定量分析基准数据集的统计学差异,设计新的基准数据集MTMS300(multiple targets and multiple scales);接着,使用基准数据集对典型视觉显著性算法展开性能评估;最后,从公开基准数据集中找出对多数非深度学习算法而言都较为困难(指标得分低)的图像,构成另一个基准数据集DSC(difficult scenes in common)。结果采用平均注释图、超像素数目等6种度量指标对11个基准数据集进行定量分析,MTMS300数据集具有中心偏差小、目标面积比分布均衡、图像分辨率多样和目标数量较多等特点,DSC数据集具有前景/背景差异小、超像素数量多和图像熵值高的特点。使用11个基准数据集对18种视觉显著性算法进行定量评估,揭示了算法得分和数据集复杂度之间的相关性,并在MTMS300数据集上发现了现有算法的不足。结论提出的两个基准数据集具有不同的特点,有助于更为全面地评估视觉显著性算法,推动视觉显著性算法向特定任务方向发展。关键词:视觉显著性;显著物体检测;基准数据集;多目标;多尺度;小目标146|179|1更新时间:2024-05-07
数据集论文
-
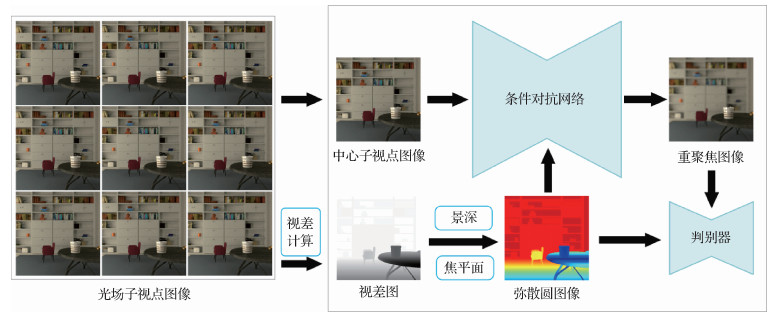 摘要:目的传统的基于子视点叠加的重聚焦算法混叠现象严重,基于光场图像重构的重聚焦方法计算量太大,性能提升困难。为此,本文借助深度神经网络设计和实现了一种基于条件生成对抗网络的新颖高效的端到端光场图像重聚焦算法。方法首先以光场图像为输入计算视差图,并从视差图中计算出所需的弥散圆(circle of confusion,COC)图像,然后根据COC图像对光场中心子视点图像进行散焦渲染,最终生成对焦平面和景深与COC图像相对应的重聚焦图像。结果所提算法在提出的仿真数据集和真实数据集上与相关算法进行评价比较,证明了所提算法能够生成高质量的重聚焦图像。使用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)进行定量分析的结果显示,本文算法比传统重聚焦算法平均PSNR提升了1.82 dB,平均SSIM提升了0.02,比同样使用COC图像并借助各向异性滤波的算法平均PSNR提升了7.92 dB, 平均SSIM提升了0.08。结论本文算法能够依据图像重聚焦和景深控制要求,生成输入光场图像的视差图,进而生成对应的COC图像。所提条件生成对抗神经网络模型能够依据得到的不同COC图像对输入的中心子视点进行散焦渲染,得到与之对应的重聚焦图像,与之前的算法相比,本文算法解决了混叠问题,优化了散焦效果,并显著降低了计算成本。关键词:光场;图像重聚焦;条件生成对抗网络;弥散圆(COC);散焦渲染145|266|1更新时间:2024-05-07
摘要:目的传统的基于子视点叠加的重聚焦算法混叠现象严重,基于光场图像重构的重聚焦方法计算量太大,性能提升困难。为此,本文借助深度神经网络设计和实现了一种基于条件生成对抗网络的新颖高效的端到端光场图像重聚焦算法。方法首先以光场图像为输入计算视差图,并从视差图中计算出所需的弥散圆(circle of confusion,COC)图像,然后根据COC图像对光场中心子视点图像进行散焦渲染,最终生成对焦平面和景深与COC图像相对应的重聚焦图像。结果所提算法在提出的仿真数据集和真实数据集上与相关算法进行评价比较,证明了所提算法能够生成高质量的重聚焦图像。使用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)进行定量分析的结果显示,本文算法比传统重聚焦算法平均PSNR提升了1.82 dB,平均SSIM提升了0.02,比同样使用COC图像并借助各向异性滤波的算法平均PSNR提升了7.92 dB, 平均SSIM提升了0.08。结论本文算法能够依据图像重聚焦和景深控制要求,生成输入光场图像的视差图,进而生成对应的COC图像。所提条件生成对抗神经网络模型能够依据得到的不同COC图像对输入的中心子视点进行散焦渲染,得到与之对应的重聚焦图像,与之前的算法相比,本文算法解决了混叠问题,优化了散焦效果,并显著降低了计算成本。关键词:光场;图像重聚焦;条件生成对抗网络;弥散圆(COC);散焦渲染145|266|1更新时间:2024-05-07 -
 摘要:目的基于二阶导数的图像恢复变分模型可以同时保持图像边缘与光滑特征,但其规则项的非线性、非光滑性,甚至非凸性制约着其快速算法的设计。针对总拉普拉斯(total Laplacian,TL)与欧拉弹性能(Euler’s elastica,EE)两种图像恢复变分模型,在设计快速交替方向乘子法(fast alternating direction methods of multipliers,fast ADMM)的基础上引入重启动策略,以有效消除解的振荡,从而大幅提高该类模型计算效率,并为其他相近模型的快速算法设计提供借鉴。方法基于原始ADMM方法设计反映能量泛函变化的残差公式,在设计的快速ADMM方法中根据残差的变化重新设置快速算法的相关参数,以避免计算过程中的能量振荡,达到算法加速目的。结果通过大量实验发现,采用原始ADMM、快速ADMM和重启动快速ADMM算法恢复图像的峰值信噪比(peak signal-to-noise ratio,PSNR)基本一致,但计算效率有不同程度的提高。与原始ADMM算法相比,在消除高斯白噪声和椒盐噪声中,对TL模型,其快速ADMM算法分别提高6%~50%和13%~240%;重启动快速ADMM算法提高100%~433%和100%~466%;对EE模型,其快速ADMM算法分别提高14%~54%和10%~83%;重启动快速ADMM算法分别提高100%~900%和66%~800%。此外,对于不同的惩罚参数组合,相同模型的快速ADMM算法的计算效率基本相同。结论对于两种典型的二阶变分图像恢复模型,本文提出的快速重启动ADMM算法比原始ADMM算法及快速ADMM算法在计算效率方面有较大提高,计算效率对不同惩罚参数组合具有鲁棒性。本文设计的算法对于含其他形式二阶导数规则项的变分图像分析模型的重启动快速算法的设计可提供有益借鉴。关键词:图像恢复;二阶变分模型;快速交替方向乘子方法(fast ADMM);重启动;总拉普拉斯模型;欧拉弹性能模型148|448|0更新时间:2024-05-07
摘要:目的基于二阶导数的图像恢复变分模型可以同时保持图像边缘与光滑特征,但其规则项的非线性、非光滑性,甚至非凸性制约着其快速算法的设计。针对总拉普拉斯(total Laplacian,TL)与欧拉弹性能(Euler’s elastica,EE)两种图像恢复变分模型,在设计快速交替方向乘子法(fast alternating direction methods of multipliers,fast ADMM)的基础上引入重启动策略,以有效消除解的振荡,从而大幅提高该类模型计算效率,并为其他相近模型的快速算法设计提供借鉴。方法基于原始ADMM方法设计反映能量泛函变化的残差公式,在设计的快速ADMM方法中根据残差的变化重新设置快速算法的相关参数,以避免计算过程中的能量振荡,达到算法加速目的。结果通过大量实验发现,采用原始ADMM、快速ADMM和重启动快速ADMM算法恢复图像的峰值信噪比(peak signal-to-noise ratio,PSNR)基本一致,但计算效率有不同程度的提高。与原始ADMM算法相比,在消除高斯白噪声和椒盐噪声中,对TL模型,其快速ADMM算法分别提高6%~50%和13%~240%;重启动快速ADMM算法提高100%~433%和100%~466%;对EE模型,其快速ADMM算法分别提高14%~54%和10%~83%;重启动快速ADMM算法分别提高100%~900%和66%~800%。此外,对于不同的惩罚参数组合,相同模型的快速ADMM算法的计算效率基本相同。结论对于两种典型的二阶变分图像恢复模型,本文提出的快速重启动ADMM算法比原始ADMM算法及快速ADMM算法在计算效率方面有较大提高,计算效率对不同惩罚参数组合具有鲁棒性。本文设计的算法对于含其他形式二阶导数规则项的变分图像分析模型的重启动快速算法的设计可提供有益借鉴。关键词:图像恢复;二阶变分模型;快速交替方向乘子方法(fast ADMM);重启动;总拉普拉斯模型;欧拉弹性能模型148|448|0更新时间:2024-05-07 -
 摘要:目的东巴画具有内容丰富、线条疏密相间、色彩多样的独特艺术风格,将现有针对自然图像的超分辨率算法直接应用于低分辨率东巴画时,对东巴画线条、色块以及材质的重建效果不理想。为了有效提高东巴画数字图像分辨率,本文针对东巴画提出超分辨率重建方法。方法首先,针对东巴画图像包含丰富高频信息的特点搭建重建网络,网络整体结构采用多级子网络级联方式渐进地重建出高分辨率东巴画,多级子网络标签共同指导重建,减少了东巴画图像在上采样过程中高频细节的丢失,每一级子网络内部均包含浅层特征提取模块和以残差密集结构为核心的深层特征提取模块,分别提取东巴画不同层次的特征进行融合,改善了卷积层简单的链式堆叠造成的特征丢失。其次,为了进一步提升重建东巴画的视觉质量,在像素损失的基础上引入感知损失和对抗损失进行对抗训练。最后,为了使网络对东巴画图像特征的学习更具针对性,本文自建东巴画数据集用于网络训练。结果实验结果表明,在本文东巴画测试集set20上,当上采样因子为8时,相较于Bicubic(bicubic interpolation)、SRCNN(super-resolution convolutional neural network)、Srresnet(super-resolution residual network)和IMDN(information multi-distillation network)方法,本文算法的峰值信噪比分别增加了3.28 dB、1.80 dB、0.23 dB和0.36 dB,重建东巴画的主观视觉质量也得到了更好的结果。结论本文提出的超分辨率网络模型能有效提高低分辨率东巴画的分辨率和清晰度,并且具有普适性,亦可采用其他数据集进行训练以拓展应用范围。关键词:东巴画;超分辨率;渐进式重建;残差密集;对抗训练146|170|2更新时间:2024-05-07
摘要:目的东巴画具有内容丰富、线条疏密相间、色彩多样的独特艺术风格,将现有针对自然图像的超分辨率算法直接应用于低分辨率东巴画时,对东巴画线条、色块以及材质的重建效果不理想。为了有效提高东巴画数字图像分辨率,本文针对东巴画提出超分辨率重建方法。方法首先,针对东巴画图像包含丰富高频信息的特点搭建重建网络,网络整体结构采用多级子网络级联方式渐进地重建出高分辨率东巴画,多级子网络标签共同指导重建,减少了东巴画图像在上采样过程中高频细节的丢失,每一级子网络内部均包含浅层特征提取模块和以残差密集结构为核心的深层特征提取模块,分别提取东巴画不同层次的特征进行融合,改善了卷积层简单的链式堆叠造成的特征丢失。其次,为了进一步提升重建东巴画的视觉质量,在像素损失的基础上引入感知损失和对抗损失进行对抗训练。最后,为了使网络对东巴画图像特征的学习更具针对性,本文自建东巴画数据集用于网络训练。结果实验结果表明,在本文东巴画测试集set20上,当上采样因子为8时,相较于Bicubic(bicubic interpolation)、SRCNN(super-resolution convolutional neural network)、Srresnet(super-resolution residual network)和IMDN(information multi-distillation network)方法,本文算法的峰值信噪比分别增加了3.28 dB、1.80 dB、0.23 dB和0.36 dB,重建东巴画的主观视觉质量也得到了更好的结果。结论本文提出的超分辨率网络模型能有效提高低分辨率东巴画的分辨率和清晰度,并且具有普适性,亦可采用其他数据集进行训练以拓展应用范围。关键词:东巴画;超分辨率;渐进式重建;残差密集;对抗训练146|170|2更新时间:2024-05-07
图像处理和编码
-
 摘要:目的针对目前基于生成式的步态识别方法采用特定视角的步态模板转换、识别率随视角跨度增大而不断下降的问题,本文提出融合自注意力机制的生成对抗网络的跨视角步态识别方法。方法该方法的网络结构由生成器、视角判别器和身份保持器构成,建立可实现任意视角间步态转换的网络模型。生成网络采用编码器—解码器结构将输入的步态特征和视角指示器连接,进而实现不同视角域的转换,并通过对抗训练和像素级损失使生成的目标视角步态模板与真实的步态模板相似。在判别网络中,利用视角判别器来约束生成视角与目标视角相一致,并使用联合困难三元组损失的身份保持器以最大化保留输入模板的身份信息。同时,在生成网络和判别网络中加入自注意力机制,以捕捉特征的全局依赖关系,从而提高生成图像的质量,并引入谱规范化使网络稳定训练。结果在CASIA-B(Chinese Academy of Sciences' Institute of Automation gait database——dataset B)和OU-MVLP(OU-ISIR gait database-multi-view large population dataset)数据集上进行实验,当引入自注意力模块和身份保留损失训练网络时,在CASIA-B数据集上的识别率有显著提升,平均rank-1准确率比GaitGAN(gait generative adversarial network)方法高15%。所提方法在OU-MVLP大规模的跨视角步态数据库中仍具有较好的适用性,可以达到65.9%的平均识别精度。结论本文方法提升了生成步态模板的质量,提取的视角不变特征更具判别力,识别精度较现有方法有一定提升,能较好地解决跨视角步态识别问题。关键词:机器视觉;步态识别;跨视角;自注意力;生成对抗网络(GANs)82|155|6更新时间:2024-05-07
摘要:目的针对目前基于生成式的步态识别方法采用特定视角的步态模板转换、识别率随视角跨度增大而不断下降的问题,本文提出融合自注意力机制的生成对抗网络的跨视角步态识别方法。方法该方法的网络结构由生成器、视角判别器和身份保持器构成,建立可实现任意视角间步态转换的网络模型。生成网络采用编码器—解码器结构将输入的步态特征和视角指示器连接,进而实现不同视角域的转换,并通过对抗训练和像素级损失使生成的目标视角步态模板与真实的步态模板相似。在判别网络中,利用视角判别器来约束生成视角与目标视角相一致,并使用联合困难三元组损失的身份保持器以最大化保留输入模板的身份信息。同时,在生成网络和判别网络中加入自注意力机制,以捕捉特征的全局依赖关系,从而提高生成图像的质量,并引入谱规范化使网络稳定训练。结果在CASIA-B(Chinese Academy of Sciences' Institute of Automation gait database——dataset B)和OU-MVLP(OU-ISIR gait database-multi-view large population dataset)数据集上进行实验,当引入自注意力模块和身份保留损失训练网络时,在CASIA-B数据集上的识别率有显著提升,平均rank-1准确率比GaitGAN(gait generative adversarial network)方法高15%。所提方法在OU-MVLP大规模的跨视角步态数据库中仍具有较好的适用性,可以达到65.9%的平均识别精度。结论本文方法提升了生成步态模板的质量,提取的视角不变特征更具判别力,识别精度较现有方法有一定提升,能较好地解决跨视角步态识别问题。关键词:机器视觉;步态识别;跨视角;自注意力;生成对抗网络(GANs)82|155|6更新时间:2024-05-07 -
 摘要:目的人体姿态估计旨在识别和定位不同场景图像中的人体关节点并优化关节点定位精度。针对由于服装款式多样、背景干扰和着装姿态多变导致人体姿态估计精度较低的问题,本文以着装场景下时尚街拍图像为例,提出一种着装场景下双分支网络的人体姿态估计方法。方法对输入图像进行人体检测,得到着装人体区域并分别输入姿态表示分支和着装部位分割分支。姿态表示分支通过在堆叠沙漏网络基础上增加多尺度损失和特征融合输出关节点得分图,解决服装款式多样以及复杂背景对关节点特征提取干扰问题,并基于姿态聚类定义姿态类别损失函数,解决着装姿态视角多变问题;着装部位分割分支通过连接残差网络的浅层特征与深层特征进行特征融合得到着装部位得分图。然后使用着装部位分割结果约束人体关节点定位,解决服装对关节点遮挡问题。最后通过姿态优化得到最终的人体姿态估计结果。结果在构建的着装图像数据集上验证了本文方法。实验结果表明,姿态表示分支有效提高了人体关节点定位准确率,着装部位分割分支能有效避免着装场景中人体关节点误定位。在结合着装部位分割优化后,人体姿态估计精度提高至92.5%。结论本文提出的人体姿态估计方法能够有效提高着装场景下的人体姿态估计精度,较好地满足虚拟试穿等实际应用需求。关键词:着装场景;人体检测;姿态估计;语义分割;姿态优化54|202|1更新时间:2024-05-07
摘要:目的人体姿态估计旨在识别和定位不同场景图像中的人体关节点并优化关节点定位精度。针对由于服装款式多样、背景干扰和着装姿态多变导致人体姿态估计精度较低的问题,本文以着装场景下时尚街拍图像为例,提出一种着装场景下双分支网络的人体姿态估计方法。方法对输入图像进行人体检测,得到着装人体区域并分别输入姿态表示分支和着装部位分割分支。姿态表示分支通过在堆叠沙漏网络基础上增加多尺度损失和特征融合输出关节点得分图,解决服装款式多样以及复杂背景对关节点特征提取干扰问题,并基于姿态聚类定义姿态类别损失函数,解决着装姿态视角多变问题;着装部位分割分支通过连接残差网络的浅层特征与深层特征进行特征融合得到着装部位得分图。然后使用着装部位分割结果约束人体关节点定位,解决服装对关节点遮挡问题。最后通过姿态优化得到最终的人体姿态估计结果。结果在构建的着装图像数据集上验证了本文方法。实验结果表明,姿态表示分支有效提高了人体关节点定位准确率,着装部位分割分支能有效避免着装场景中人体关节点误定位。在结合着装部位分割优化后,人体姿态估计精度提高至92.5%。结论本文提出的人体姿态估计方法能够有效提高着装场景下的人体姿态估计精度,较好地满足虚拟试穿等实际应用需求。关键词:着装场景;人体检测;姿态估计;语义分割;姿态优化54|202|1更新时间:2024-05-07 -
 摘要:目的针对口罩遮挡的人脸姿态分类新需求,为了提高基于卷积神经网络的人脸姿态分类效率和准确率,提出了一个轻量级卷积神经网络用于口罩人脸姿态分类。方法本文设计的轻量级卷积神经网络的核心为双尺度可分离注意力卷积单元。该卷积单元由3 × 3和5 × 5两个尺度的深度可分离卷积并联而成,并且将卷积块注意力模块(convolutional block attention module,CBAM)的空间注意力模块(spatial attention module,SAM)和通道注意力模块(channel attention module,CAM)分别嵌入深度(depthwise,DW)卷积和点(pointwise,PW)卷积中,针对性地对DW卷积及PW卷积的特征图进行调整。同时对SAM模块补充1 × 1的点卷积挤压结果增强其对空间信息的利用,形成更加有效的注意力图。在保证模型性能的前提下,控制构建网络的卷积单元通道数和单元数,并丢弃全连接层,采用卷积层替代,进一步轻量化网络模型。结果实验结果表明,本文模型的准确率较未改进SAM模块分离嵌入CBAM的模型、标准方式嵌入CBAM的模型和未嵌入注意力模块的模型分别提升了2.86%、6.41% 和12.16%。采用双尺度卷积核丰富特征,在有限的卷积单元内增强特征提取能力。与经典卷积神经网络对比,本文设计的模型仅有1.02 MB的参数量和24.18 MB的每秒浮点运算次数(floating-point operations per second,FLOPs),大幅轻量化了模型并能达到98.57%的准确率。结论本文设计了一个轻量高效的卷积单元构建网络模型,该模型具有较高的准确率和较低的参数量及计算复杂度,提高了口罩人脸姿态分类模型的效率和准确率。关键词:轻量级卷积神经网络;口罩人脸姿态分类;深度可分离卷积;卷积块注意力模块(CBAM);深度学习;新冠肺炎(COVID-19)80|150|0更新时间:2024-05-07
摘要:目的针对口罩遮挡的人脸姿态分类新需求,为了提高基于卷积神经网络的人脸姿态分类效率和准确率,提出了一个轻量级卷积神经网络用于口罩人脸姿态分类。方法本文设计的轻量级卷积神经网络的核心为双尺度可分离注意力卷积单元。该卷积单元由3 × 3和5 × 5两个尺度的深度可分离卷积并联而成,并且将卷积块注意力模块(convolutional block attention module,CBAM)的空间注意力模块(spatial attention module,SAM)和通道注意力模块(channel attention module,CAM)分别嵌入深度(depthwise,DW)卷积和点(pointwise,PW)卷积中,针对性地对DW卷积及PW卷积的特征图进行调整。同时对SAM模块补充1 × 1的点卷积挤压结果增强其对空间信息的利用,形成更加有效的注意力图。在保证模型性能的前提下,控制构建网络的卷积单元通道数和单元数,并丢弃全连接层,采用卷积层替代,进一步轻量化网络模型。结果实验结果表明,本文模型的准确率较未改进SAM模块分离嵌入CBAM的模型、标准方式嵌入CBAM的模型和未嵌入注意力模块的模型分别提升了2.86%、6.41% 和12.16%。采用双尺度卷积核丰富特征,在有限的卷积单元内增强特征提取能力。与经典卷积神经网络对比,本文设计的模型仅有1.02 MB的参数量和24.18 MB的每秒浮点运算次数(floating-point operations per second,FLOPs),大幅轻量化了模型并能达到98.57%的准确率。结论本文设计了一个轻量高效的卷积单元构建网络模型,该模型具有较高的准确率和较低的参数量及计算复杂度,提高了口罩人脸姿态分类模型的效率和准确率。关键词:轻量级卷积神经网络;口罩人脸姿态分类;深度可分离卷积;卷积块注意力模块(CBAM);深度学习;新冠肺炎(COVID-19)80|150|0更新时间:2024-05-07 -
 摘要:目的动物个体身份识别一直是智慧畜牧业的主要难题之一,由于动物个体本身与人类在图像识别上需要的数据特征不同以及各个特征作为个体属性之间的关系不明确,对动物个体识别领域的研究较少,针对具有高相似度的奶山羊个体身份识别问题,提出了基于深度学习的高相似度的奶山羊识别方法。方法采集了26只萨能奶山羊的全身图像,利用SSD(single shot MultiBox detection)网络进行数据集预处理,并随机选取1 040幅图像作为训练集,260幅图像作为测试集。其次采用ResNet18(residual neural network)预训练模型并进行迁移学习,最后联合三元组损失函数与交叉熵损失函数进行参数调整。研究表明,采用联合损失函数并结合Adam优化器算法时,可获得较好的识别效果。此外,在实验部分针对奶山羊的特征选取问题上,对奶山羊的羊脸区域与奶山羊的全身区域分别采用了三元组损失函数与孪生网络,验证了对奶山羊的识别仅靠羊脸区域的特征时准确率较低;此外,针对网络的训练,本文不仅通过YOLOv3(you only look once)以及孪生网络(siamese network)验证了奶山羊本身属于高相似度的数据集,而且针对奶山羊数据集分别采用三元组损失函数与交叉熵损失函数作为唯一的损失函数,并验证了该方法的有效性。结果奶山羊识别的最高精准度为93.077%,相较于Triplet-Loss损失函数74.615%的准确率以及CrossEntropy-Loss 89.615%准确率有了较大提升。结论本文提出的基于深度学习的高相似度的奶山羊识别方法不仅具有较高的准确率,而且在奶山羊个体身份识别方面具有极大的应用价值,有助于准确识别羊的身份,为相似度高的动物个体身份识别提供了思路。关键词:深度学习;奶山羊个体身份识别;Triplet-Loss;联合损失函数;迁移学习116|146|2更新时间:2024-05-07
摘要:目的动物个体身份识别一直是智慧畜牧业的主要难题之一,由于动物个体本身与人类在图像识别上需要的数据特征不同以及各个特征作为个体属性之间的关系不明确,对动物个体识别领域的研究较少,针对具有高相似度的奶山羊个体身份识别问题,提出了基于深度学习的高相似度的奶山羊识别方法。方法采集了26只萨能奶山羊的全身图像,利用SSD(single shot MultiBox detection)网络进行数据集预处理,并随机选取1 040幅图像作为训练集,260幅图像作为测试集。其次采用ResNet18(residual neural network)预训练模型并进行迁移学习,最后联合三元组损失函数与交叉熵损失函数进行参数调整。研究表明,采用联合损失函数并结合Adam优化器算法时,可获得较好的识别效果。此外,在实验部分针对奶山羊的特征选取问题上,对奶山羊的羊脸区域与奶山羊的全身区域分别采用了三元组损失函数与孪生网络,验证了对奶山羊的识别仅靠羊脸区域的特征时准确率较低;此外,针对网络的训练,本文不仅通过YOLOv3(you only look once)以及孪生网络(siamese network)验证了奶山羊本身属于高相似度的数据集,而且针对奶山羊数据集分别采用三元组损失函数与交叉熵损失函数作为唯一的损失函数,并验证了该方法的有效性。结果奶山羊识别的最高精准度为93.077%,相较于Triplet-Loss损失函数74.615%的准确率以及CrossEntropy-Loss 89.615%准确率有了较大提升。结论本文提出的基于深度学习的高相似度的奶山羊识别方法不仅具有较高的准确率,而且在奶山羊个体身份识别方面具有极大的应用价值,有助于准确识别羊的身份,为相似度高的动物个体身份识别提供了思路。关键词:深度学习;奶山羊个体身份识别;Triplet-Loss;联合损失函数;迁移学习116|146|2更新时间:2024-05-07 -
 摘要:目的绝缘子检测是输电线路智能巡维工作的重要组成部分,然而大多数情况仅能获得单一类型的绝缘子样本。将单一类型的绝缘子样本训练得到的模型直接用于其他类型的绝缘子检测,会由于训练数据与目标数据之间存在的域偏移导致其检测性能急剧下降。因此,提高模型的泛化能力以保持良好的检测性能显得尤为必要。为此,提出一种新颖的对抗一致性约束的无监督域自适应绝缘子检测算法。方法对源域样本与目标域样本分别设计了两个不同的分类器,并将网络的预测结果与对应的绝缘子进行类别约束,使模型能够提取到不同类型绝缘子独有的特征。此外,在对抗学习过程中引入一个额外的分类器用于将源域中绝缘子特征与从目标域中预测到的目标物特征分到同一类别下,从而使模型能提取不同类型绝缘子共有的鲁棒性特征。结果实验表明本文方法显著提高了模型的跨域检测性能。在glass → composite和composite → glass任务上的平均精度均值(mean average precision, mAP)分别达到55.1%和23.4%,优于主流的无监督域自适应目标检测方法。在公开数据集COCO(common objects in context)上的实验结果也较为优异,平均精度均值(mean average precision,mAP)达到61.5%。消融实验中,在glass → composite和composite → glass任务上,本文方法在基准性能上分别提升了11.5%和6.4%,表明了所提方法的有效性。结论本文方法减少了不同类型绝缘子间的差异带来的域偏移,提升了模型在跨域绝缘子检测任务中的泛化能力,提高了输电线路巡维工作的绝缘子检测效率。同时,在COCO数据集上的普适性实验表明本文方法同样适用于其他不同类物体的检测并且性能优异。关键词:无监督域自适应;域偏移;绝缘子检测;对抗一致性;鲁棒性特征75|122|2更新时间:2024-05-07
摘要:目的绝缘子检测是输电线路智能巡维工作的重要组成部分,然而大多数情况仅能获得单一类型的绝缘子样本。将单一类型的绝缘子样本训练得到的模型直接用于其他类型的绝缘子检测,会由于训练数据与目标数据之间存在的域偏移导致其检测性能急剧下降。因此,提高模型的泛化能力以保持良好的检测性能显得尤为必要。为此,提出一种新颖的对抗一致性约束的无监督域自适应绝缘子检测算法。方法对源域样本与目标域样本分别设计了两个不同的分类器,并将网络的预测结果与对应的绝缘子进行类别约束,使模型能够提取到不同类型绝缘子独有的特征。此外,在对抗学习过程中引入一个额外的分类器用于将源域中绝缘子特征与从目标域中预测到的目标物特征分到同一类别下,从而使模型能提取不同类型绝缘子共有的鲁棒性特征。结果实验表明本文方法显著提高了模型的跨域检测性能。在glass → composite和composite → glass任务上的平均精度均值(mean average precision, mAP)分别达到55.1%和23.4%,优于主流的无监督域自适应目标检测方法。在公开数据集COCO(common objects in context)上的实验结果也较为优异,平均精度均值(mean average precision,mAP)达到61.5%。消融实验中,在glass → composite和composite → glass任务上,本文方法在基准性能上分别提升了11.5%和6.4%,表明了所提方法的有效性。结论本文方法减少了不同类型绝缘子间的差异带来的域偏移,提升了模型在跨域绝缘子检测任务中的泛化能力,提高了输电线路巡维工作的绝缘子检测效率。同时,在COCO数据集上的普适性实验表明本文方法同样适用于其他不同类物体的检测并且性能优异。关键词:无监督域自适应;域偏移;绝缘子检测;对抗一致性;鲁棒性特征75|122|2更新时间:2024-05-07 -
 摘要:目的海面目标检测图像中的小目标数量居多,而基于深度学习的目标检测方法通常针对通用目标数据集设计检测模型,对图像中的小目标检测效果并不理想。使用一般目标检测模型检测海面目标图像的特征时,通常会出现小目标漏检情况,而一些特定的小目标检测模型对海面目标的检测效果还有待验证。为此,在标准的SSD(single shot multiBox detector)目标检测模型基础上,结合Xception深度可分卷积,提出一种轻量SSD模型用于海面目标检测。方法在标准的SSD目标检测模型基础上,使用基于Xception网络的深度可分卷积特征提取网络替换VGG-16(Visual Geometry Group network-16)骨干网络,通过控制变量来对比不同网络的检测效果;在特征提取网络中的exit flow层和Conv1层引入轻量级注意力机制模块来提高检测精度,并与在其他层引入轻量级注意力机制模块的模型进行检测效果对比;使用注意力机制改进的轻量SSD目标检测模型和其他几种模型分别对海面目标检测数据集中的小目标和正常目标进行测试。结果为证明本文模型的有效性,进行了多组对比实验。实验结果表明,模型轻量化导致特征表达能力降低,从而影响检测精度。相对于标准的SSD目标检测模型,本文模型在参数量降低16.26%、浮点运算量降低15.65%的情况下,浮标的平均检测精度提高了1.1%,漏检率减小了3%,平均精度均值(mean average precision,mAP)提高了0.51%,同时,保证了船的平均检测精度,并保证其漏检率不升高,在对数据集中的小目标进行测试时,本文模型也表现出较好的检测效果。结论本文提出的海面小目标检测模型,能够在压缩模型的同时,保证模型的检测速度和检测精度,达到网络轻量化的效果,并且降低了小目标的漏检率,可以有效实现对海面小目标的检测。关键词:深度学习;目标检测;注意力机制;深度可分卷积;SSD;海面小目标检测223|1175|9更新时间:2024-05-07
摘要:目的海面目标检测图像中的小目标数量居多,而基于深度学习的目标检测方法通常针对通用目标数据集设计检测模型,对图像中的小目标检测效果并不理想。使用一般目标检测模型检测海面目标图像的特征时,通常会出现小目标漏检情况,而一些特定的小目标检测模型对海面目标的检测效果还有待验证。为此,在标准的SSD(single shot multiBox detector)目标检测模型基础上,结合Xception深度可分卷积,提出一种轻量SSD模型用于海面目标检测。方法在标准的SSD目标检测模型基础上,使用基于Xception网络的深度可分卷积特征提取网络替换VGG-16(Visual Geometry Group network-16)骨干网络,通过控制变量来对比不同网络的检测效果;在特征提取网络中的exit flow层和Conv1层引入轻量级注意力机制模块来提高检测精度,并与在其他层引入轻量级注意力机制模块的模型进行检测效果对比;使用注意力机制改进的轻量SSD目标检测模型和其他几种模型分别对海面目标检测数据集中的小目标和正常目标进行测试。结果为证明本文模型的有效性,进行了多组对比实验。实验结果表明,模型轻量化导致特征表达能力降低,从而影响检测精度。相对于标准的SSD目标检测模型,本文模型在参数量降低16.26%、浮点运算量降低15.65%的情况下,浮标的平均检测精度提高了1.1%,漏检率减小了3%,平均精度均值(mean average precision,mAP)提高了0.51%,同时,保证了船的平均检测精度,并保证其漏检率不升高,在对数据集中的小目标进行测试时,本文模型也表现出较好的检测效果。结论本文提出的海面小目标检测模型,能够在压缩模型的同时,保证模型的检测速度和检测精度,达到网络轻量化的效果,并且降低了小目标的漏检率,可以有效实现对海面小目标的检测。关键词:深度学习;目标检测;注意力机制;深度可分卷积;SSD;海面小目标检测223|1175|9更新时间:2024-05-07 -
 摘要:目的全卷积模型的显著性目标检测大多通过不同层次特征的聚合实现检测,如何更好地提取和聚合特征是一个研究难点。常用的多层次特征融合策略有加法和级联法,但是这些方法忽略了不同卷积层的感受野大小以及产生的特征图对最后显著图的贡献差异等问题。为此,本文结合通道注意力机制和空间注意力机制有选择地逐步聚合深层和浅层的特征信息,更好地处理不同层次特征的传递和聚合,提出了新的显著性检测模型AGNet(attention-guided network),综合利用几种注意力机制对不同特征信息加权解决上述问题。方法该网络主要由特征提取模块(feature extraction module, FEM)、通道—空间注意力融合模块(channel-spatial attention aggregation module, C-SAAM)和注意力残差细化模块(attention residual refinement module,ARRM)组成,并且通过最小化像素位置感知(pixel position aware, PPA)损失训练网络。其中,C-SAAM旨在有选择地聚合浅层的边缘信息以及深层抽象的语义特征,利用通道注意力和空间注意力避免融合冗余的背景信息对显著性映射造成影响;ARRM进一步细化融合后的输出,并增强下一个阶段的输入。结果在5个公开数据集上的实验表明,AGNet在多个评价指标上达到最优性能。尤其在DUT-OMRON(Dalian University of Technology-OMRON)数据集上,F-measure指标相比于排名第2的显著性检测模型提高了1.9%,MAE(mean absolute error)指标降低了1.9%。同时,网络具有不错的速度表现,达到实时效果。结论本文提出的显著性检测模型能够准确地分割出显著目标区域,并提供清晰的局部细节。关键词:显著性检测;深度学习;通道注意力;空间注意力;特征融合;卷积神经网络(CNN)110|352|11更新时间:2024-05-07
摘要:目的全卷积模型的显著性目标检测大多通过不同层次特征的聚合实现检测,如何更好地提取和聚合特征是一个研究难点。常用的多层次特征融合策略有加法和级联法,但是这些方法忽略了不同卷积层的感受野大小以及产生的特征图对最后显著图的贡献差异等问题。为此,本文结合通道注意力机制和空间注意力机制有选择地逐步聚合深层和浅层的特征信息,更好地处理不同层次特征的传递和聚合,提出了新的显著性检测模型AGNet(attention-guided network),综合利用几种注意力机制对不同特征信息加权解决上述问题。方法该网络主要由特征提取模块(feature extraction module, FEM)、通道—空间注意力融合模块(channel-spatial attention aggregation module, C-SAAM)和注意力残差细化模块(attention residual refinement module,ARRM)组成,并且通过最小化像素位置感知(pixel position aware, PPA)损失训练网络。其中,C-SAAM旨在有选择地聚合浅层的边缘信息以及深层抽象的语义特征,利用通道注意力和空间注意力避免融合冗余的背景信息对显著性映射造成影响;ARRM进一步细化融合后的输出,并增强下一个阶段的输入。结果在5个公开数据集上的实验表明,AGNet在多个评价指标上达到最优性能。尤其在DUT-OMRON(Dalian University of Technology-OMRON)数据集上,F-measure指标相比于排名第2的显著性检测模型提高了1.9%,MAE(mean absolute error)指标降低了1.9%。同时,网络具有不错的速度表现,达到实时效果。结论本文提出的显著性检测模型能够准确地分割出显著目标区域,并提供清晰的局部细节。关键词:显著性检测;深度学习;通道注意力;空间注意力;特征融合;卷积神经网络(CNN)110|352|11更新时间:2024-05-07 -
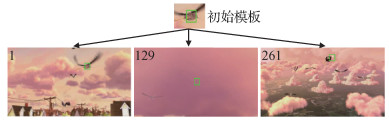 摘要:目的视觉目标跟踪算法主要包括基于相关滤波和基于孪生网络两大类。前者虽然精度较高但运行速度较慢,无法满足实时要求。后者在速度和精度方面取得了出色的跟踪性能,然而,绝大多数基于孪生网络的目标跟踪算法仍然使用单一固定的模板,导致算法难以有效处理目标遮挡、外观变化和相似干扰物等情形。针对当前孪生网络跟踪算法的不足,提出了一种高效、鲁棒的双模板融合目标跟踪方法(siamese tracker with double template fusion,Siam-DTF)。方法使用第1帧的标注框作为初始模板,然后通过外观模板分支借助外观模板搜索模块在跟踪过程中为目标获取合适、高质量的外观模板,最后通过双模板融合模块,进行响应图融合和特征融合。融合模块结合了初始模板和外观模板各自的优点,提升了算法的鲁棒性。结果实验在3个主流的目标跟踪公开数据集上与最新的9种方法进行比较,在OTB2015(object tracking benchmark 2015)数据集中,本文方法的AUC(area under curve)得分和精准度分别为0.701和0.918,相比于性能第2的SiamRPN++(siamese region proposal network++)算法分别提高了0.6%和1.3%;在VOT2016(visual object tracking 2016)数据集中,本文方法取得了最高的期望平均重叠(expected average overlap,EAO)和最少的失败次数,分别为0.477和0.172,而且EAO得分比基准算法SiamRPN++提高了1.6%,比性能第2的SiamMask_E算法提高了1.1%;在VOT2018数据集中,本文方法的期望平均重叠和精确度分别为0.403和0.608,在所有算法中分别排在第2位和第1位。本文方法的平均运行速度达到47帧/s,显著超出跟踪问题实时性标准要求。结论本文提出的双模板融合目标跟踪方法有效克服了当前基于孪生网络的目标跟踪算法的不足,在保证算法速度的同时有效提高了跟踪的精确度和鲁棒性,适用于工程部署与应用。关键词:视觉目标跟踪(VOT);孪生网络;特征融合;双模板机制;深度学习85|131|3更新时间:2024-05-07
摘要:目的视觉目标跟踪算法主要包括基于相关滤波和基于孪生网络两大类。前者虽然精度较高但运行速度较慢,无法满足实时要求。后者在速度和精度方面取得了出色的跟踪性能,然而,绝大多数基于孪生网络的目标跟踪算法仍然使用单一固定的模板,导致算法难以有效处理目标遮挡、外观变化和相似干扰物等情形。针对当前孪生网络跟踪算法的不足,提出了一种高效、鲁棒的双模板融合目标跟踪方法(siamese tracker with double template fusion,Siam-DTF)。方法使用第1帧的标注框作为初始模板,然后通过外观模板分支借助外观模板搜索模块在跟踪过程中为目标获取合适、高质量的外观模板,最后通过双模板融合模块,进行响应图融合和特征融合。融合模块结合了初始模板和外观模板各自的优点,提升了算法的鲁棒性。结果实验在3个主流的目标跟踪公开数据集上与最新的9种方法进行比较,在OTB2015(object tracking benchmark 2015)数据集中,本文方法的AUC(area under curve)得分和精准度分别为0.701和0.918,相比于性能第2的SiamRPN++(siamese region proposal network++)算法分别提高了0.6%和1.3%;在VOT2016(visual object tracking 2016)数据集中,本文方法取得了最高的期望平均重叠(expected average overlap,EAO)和最少的失败次数,分别为0.477和0.172,而且EAO得分比基准算法SiamRPN++提高了1.6%,比性能第2的SiamMask_E算法提高了1.1%;在VOT2018数据集中,本文方法的期望平均重叠和精确度分别为0.403和0.608,在所有算法中分别排在第2位和第1位。本文方法的平均运行速度达到47帧/s,显著超出跟踪问题实时性标准要求。结论本文提出的双模板融合目标跟踪方法有效克服了当前基于孪生网络的目标跟踪算法的不足,在保证算法速度的同时有效提高了跟踪的精确度和鲁棒性,适用于工程部署与应用。关键词:视觉目标跟踪(VOT);孪生网络;特征融合;双模板机制;深度学习85|131|3更新时间:2024-05-07 -
 摘要:目的在基于深度学习的图像语义分割方法中,损失函数通常只考虑单个像素点的预测值与真实值之间的交叉熵并对其进行简单求和,而引入图像像素间的上下文信息能够有效提高图像的语义分割的精度,但目前引入上下文信息的方法如注意力机制、条件随机场等算法需要高昂的计算成本和空间成本,不能广泛使用。针对这一问题,提出一种流形正则化约束的图像语义分割算法。方法以经过数据集ImageNet预训练的残差网络(residual network, ResNet)为基础,采用DeepLabV3作为骨架网络,通过骨架网络获得预测分割图像。进行子图像块的划分,将原始图像和分割图像分为若干大小相同的图像块。通过原始图像和分割图像的子图像块,计算输入数据与预测结果所处流形曲面上的潜在几何约束关系。利用流形约束的结果优化分割网络中的参数。结果通过加入流形正则化约束,捕获图像中上下文信息,降低了网络前向计算过程中造成的本征结构的损失,提高了算法精度。为验证所提方法的有效性,实验在Cityscapes和PASCAL VOC 2012(pattern analysis, statistical modeling and computational learning visual object classes)两个数据集上进行。在Cityscapes数据集中,精度值为78.0%,相比原始网络提高了0.5%;在PASCAL VOC 2012数据集中,精度值为69.5%,相比原始网络提高了2.1%。同时,在Cityscapes数据集中进行对比实验,验证了算法的有效性,对比实验结果证明提出的算法改善了语义分割的效果。结论本文提出的语义分割算法在不提高推理网络计算复杂度的前提下,取得了较好的分割精度,具有极大的实用价值。关键词:深度学习;语义分割;残差网络(ResNet);上下文信息捕捉;流形正则化82|147|1更新时间:2024-05-07
摘要:目的在基于深度学习的图像语义分割方法中,损失函数通常只考虑单个像素点的预测值与真实值之间的交叉熵并对其进行简单求和,而引入图像像素间的上下文信息能够有效提高图像的语义分割的精度,但目前引入上下文信息的方法如注意力机制、条件随机场等算法需要高昂的计算成本和空间成本,不能广泛使用。针对这一问题,提出一种流形正则化约束的图像语义分割算法。方法以经过数据集ImageNet预训练的残差网络(residual network, ResNet)为基础,采用DeepLabV3作为骨架网络,通过骨架网络获得预测分割图像。进行子图像块的划分,将原始图像和分割图像分为若干大小相同的图像块。通过原始图像和分割图像的子图像块,计算输入数据与预测结果所处流形曲面上的潜在几何约束关系。利用流形约束的结果优化分割网络中的参数。结果通过加入流形正则化约束,捕获图像中上下文信息,降低了网络前向计算过程中造成的本征结构的损失,提高了算法精度。为验证所提方法的有效性,实验在Cityscapes和PASCAL VOC 2012(pattern analysis, statistical modeling and computational learning visual object classes)两个数据集上进行。在Cityscapes数据集中,精度值为78.0%,相比原始网络提高了0.5%;在PASCAL VOC 2012数据集中,精度值为69.5%,相比原始网络提高了2.1%。同时,在Cityscapes数据集中进行对比实验,验证了算法的有效性,对比实验结果证明提出的算法改善了语义分割的效果。结论本文提出的语义分割算法在不提高推理网络计算复杂度的前提下,取得了较好的分割精度,具有极大的实用价值。关键词:深度学习;语义分割;残差网络(ResNet);上下文信息捕捉;流形正则化82|147|1更新时间:2024-05-07 -
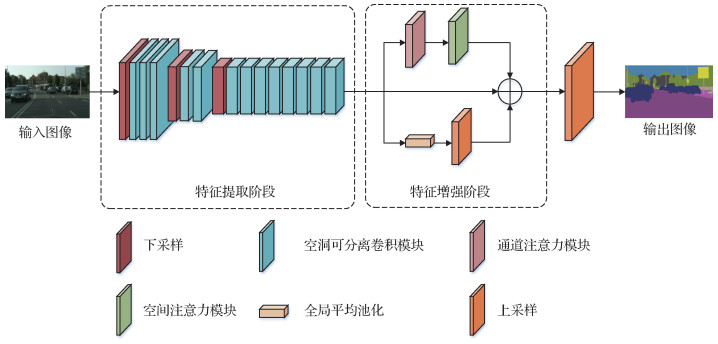 摘要:目的为满足语义分割算法准确度和实时性的要求,提出了一种基于空洞可分离卷积模块和注意力机制的实时语义分割方法。方法将深度可分离卷积与不同空洞率的空洞卷积相结合,设计了一个空洞可分离卷积模块,在减少模型计算量的同时,能够更高效地提取特征;在网络输出端加入了通道注意力模块和空间注意力模块,增强对特征的通道信息和空间信息的表达并与原始特征融合,以进一步提高特征的表达能力;将融合的特征上采样到原图大小,预测像素类别,实现语义分割。结果在Cityscapes数据集和CamVid数据集上进行了实验验证,分别取得70.4%和67.8%的分割精度,速度达到71帧/s,而模型参数量仅为0.66 M。在不影响速度的情况下,分割精度比原始方法分别提高了1.2%和1.2%,验证了该方法的有效性。同时,与近年来的实时语义分割方法相比也表现出一定优势。结论本文方法采用空洞可分离卷积模块和注意力模块,在减少模型计算量的同时,能够更高效地提取特征,且在保证实时分割的情况下提升分割精度,在准确度和实时性之间达到了有效的平衡。关键词:实时语义分割;深度可分离卷积;空洞卷积;通道注意力;空间注意力106|157|7更新时间:2024-05-07
摘要:目的为满足语义分割算法准确度和实时性的要求,提出了一种基于空洞可分离卷积模块和注意力机制的实时语义分割方法。方法将深度可分离卷积与不同空洞率的空洞卷积相结合,设计了一个空洞可分离卷积模块,在减少模型计算量的同时,能够更高效地提取特征;在网络输出端加入了通道注意力模块和空间注意力模块,增强对特征的通道信息和空间信息的表达并与原始特征融合,以进一步提高特征的表达能力;将融合的特征上采样到原图大小,预测像素类别,实现语义分割。结果在Cityscapes数据集和CamVid数据集上进行了实验验证,分别取得70.4%和67.8%的分割精度,速度达到71帧/s,而模型参数量仅为0.66 M。在不影响速度的情况下,分割精度比原始方法分别提高了1.2%和1.2%,验证了该方法的有效性。同时,与近年来的实时语义分割方法相比也表现出一定优势。结论本文方法采用空洞可分离卷积模块和注意力模块,在减少模型计算量的同时,能够更高效地提取特征,且在保证实时分割的情况下提升分割精度,在准确度和实时性之间达到了有效的平衡。关键词:实时语义分割;深度可分离卷积;空洞卷积;通道注意力;空间注意力106|157|7更新时间:2024-05-07 -
 摘要:目的艺术品数字化为从计算机视觉角度对艺术品研究提供了巨大机会。为更好地为数字艺术品博物馆提供艺术作品分类和艺术检索功能,使人们深入理解艺术品内涵,弘扬传统文化,促进文化遗产保护,本文将多任务学习引入自动艺术分析任务,基于贝叶斯理论提出一种原创性的自适应多任务学习方法。方法基于层次贝叶斯理论利用各任务之间的相关性引入任务簇约束损失函数模型。依据贝叶斯建模方法,通过最大化不确定性的高斯似然构造多任务损失函数,最终构建了一种自适应多任务学习模型。这种自适应多任务学习模型能够很便利地扩展至任意同类学习任务,相比其他最新模型能够更好地提升学习的性能,取得更佳的分析效果。结果本文方法解决了多任务学习中每个任务损失之间相对权重难以决策这一难题,能够自动决策损失函数的权重。为了评估本文方法的性能,在多模态艺术语义理解SemArt数据库上进行艺术作品分类以及跨模态艺术检索实验。艺术作品分类实验结果表明,本文方法相比于固定权重的多任务学习方法,在“时间范围”属性上提升了4.43%,同时本文方法的效果也优于自动确定损失权重的现有方法。跨模态艺术检索实验结果也表明,与使用“作者”属性的最新的基于知识图谱模型相比较,本文方法的改进幅度为9.91%,性能与分类的结果一致。结论本文方法可以在多任务学习框架内自适应地学习每个任务的权重,与目前流行的方法相比能显著提高自动艺术分析任务的性能。关键词:自动艺术分析;自适应多任务学习;贝叶斯理论;艺术分类;跨模态艺术检索122|79|0更新时间:2024-05-07
摘要:目的艺术品数字化为从计算机视觉角度对艺术品研究提供了巨大机会。为更好地为数字艺术品博物馆提供艺术作品分类和艺术检索功能,使人们深入理解艺术品内涵,弘扬传统文化,促进文化遗产保护,本文将多任务学习引入自动艺术分析任务,基于贝叶斯理论提出一种原创性的自适应多任务学习方法。方法基于层次贝叶斯理论利用各任务之间的相关性引入任务簇约束损失函数模型。依据贝叶斯建模方法,通过最大化不确定性的高斯似然构造多任务损失函数,最终构建了一种自适应多任务学习模型。这种自适应多任务学习模型能够很便利地扩展至任意同类学习任务,相比其他最新模型能够更好地提升学习的性能,取得更佳的分析效果。结果本文方法解决了多任务学习中每个任务损失之间相对权重难以决策这一难题,能够自动决策损失函数的权重。为了评估本文方法的性能,在多模态艺术语义理解SemArt数据库上进行艺术作品分类以及跨模态艺术检索实验。艺术作品分类实验结果表明,本文方法相比于固定权重的多任务学习方法,在“时间范围”属性上提升了4.43%,同时本文方法的效果也优于自动确定损失权重的现有方法。跨模态艺术检索实验结果也表明,与使用“作者”属性的最新的基于知识图谱模型相比较,本文方法的改进幅度为9.91%,性能与分类的结果一致。结论本文方法可以在多任务学习框架内自适应地学习每个任务的权重,与目前流行的方法相比能显著提高自动艺术分析任务的性能。关键词:自动艺术分析;自适应多任务学习;贝叶斯理论;艺术分类;跨模态艺术检索122|79|0更新时间:2024-05-07
图像分析和识别
-
 摘要:目的沉浸式投影系统已广泛运用于虚拟现实系统之中,然而沉浸式投影系统中的互反射现象严重影响着虚拟现实系统的落地使用。沉浸式投影系统的互反射是指由于投影机光线和屏幕反射光线相互叠加造成的亮度冗余现象,严重影响了投影系统的成像质量和人眼的视觉感受。为此,本文提出一种新的基于互反射通道(inter-reflection channel,IRC)先验和注意力机制的神经网络。方法IRC先验基于这样一个事实,即大多数受到互反射影响的投影图像都包含一些亮度较高的区域。高亮度区域往往受互反射影响更为严重,而低亮度区域受互反射影响程度较低。根据这一规律,采用IRC先验作为注意力图的监督样本,获取补偿图像的亮度区域信息。同时,为了对投影图像不同区域按影响程度进行差异化补偿,提出一种新的由两个相同子网络构成的补偿网络结构Pair-Net。结果实验对比了4种现有方法,Pair-Net在ROI(region of interesting)指标分析上取得了明显优势,在人眼感受上有显著的效果提升。结论本文提出的基于注意力机制的网络模型能够针对不同区域进行差异化补偿,很大程度上消除了互反射影响,提升了沉浸式投影系统的成像质量。关键词:沉浸式投影系统;互反射补偿;深度学习;注意力机制;虚拟现实106|1302|1更新时间:2024-05-07
摘要:目的沉浸式投影系统已广泛运用于虚拟现实系统之中,然而沉浸式投影系统中的互反射现象严重影响着虚拟现实系统的落地使用。沉浸式投影系统的互反射是指由于投影机光线和屏幕反射光线相互叠加造成的亮度冗余现象,严重影响了投影系统的成像质量和人眼的视觉感受。为此,本文提出一种新的基于互反射通道(inter-reflection channel,IRC)先验和注意力机制的神经网络。方法IRC先验基于这样一个事实,即大多数受到互反射影响的投影图像都包含一些亮度较高的区域。高亮度区域往往受互反射影响更为严重,而低亮度区域受互反射影响程度较低。根据这一规律,采用IRC先验作为注意力图的监督样本,获取补偿图像的亮度区域信息。同时,为了对投影图像不同区域按影响程度进行差异化补偿,提出一种新的由两个相同子网络构成的补偿网络结构Pair-Net。结果实验对比了4种现有方法,Pair-Net在ROI(region of interesting)指标分析上取得了明显优势,在人眼感受上有显著的效果提升。结论本文提出的基于注意力机制的网络模型能够针对不同区域进行差异化补偿,很大程度上消除了互反射影响,提升了沉浸式投影系统的成像质量。关键词:沉浸式投影系统;互反射补偿;深度学习;注意力机制;虚拟现实106|1302|1更新时间:2024-05-07
虚拟现实与增强现实
-
 摘要:目的图像匹配是遥感图像镶嵌拼接的重要环节,图像匹配技术通常采用两步法,首先利用高维描述子的最近和次近距离比建立初始匹配,然后通过迭代拟合几何模型消除错误匹配。尽管外点过滤算法大幅提高了时间效率,但其采用传统的两步法,构建初始匹配的方法仍然非常耗时,导致整个遥感图像拼接的速度提升仍然有限。为了提高遥感图像匹配的效率,本文提出了一种基于空间分治思想的快速匹配方法。方法首先,通过提取图像的大尺度特征生成少量的初始匹配,并基于初始匹配在两幅图像之间构建成对的分治空间中心点;然后,基于范围树搜索分治空间中心点一定范围内的相邻特征点,构造成对分治空间点集;最后,在各个分治空间点集内分别进行遥感图像特征的匹配。结果通过大量不同图像尺寸和相对旋转的遥感图像的实验表明,与传统的和其他先进方法相比,本文方法在保证较高精度的同时将匹配时间缩短到1/100~1/10。结论利用初始种子匹配构建分治匹配中心以将图像匹配分解在多个子区间进行的方法有助于提高遥感影像匹配的效率,该算法良好的时间性能对实时遥感应用具有实际价值。关键词:图像匹配;遥感影像;空间分治;区域树;空间结构71|206|1更新时间:2024-05-07
摘要:目的图像匹配是遥感图像镶嵌拼接的重要环节,图像匹配技术通常采用两步法,首先利用高维描述子的最近和次近距离比建立初始匹配,然后通过迭代拟合几何模型消除错误匹配。尽管外点过滤算法大幅提高了时间效率,但其采用传统的两步法,构建初始匹配的方法仍然非常耗时,导致整个遥感图像拼接的速度提升仍然有限。为了提高遥感图像匹配的效率,本文提出了一种基于空间分治思想的快速匹配方法。方法首先,通过提取图像的大尺度特征生成少量的初始匹配,并基于初始匹配在两幅图像之间构建成对的分治空间中心点;然后,基于范围树搜索分治空间中心点一定范围内的相邻特征点,构造成对分治空间点集;最后,在各个分治空间点集内分别进行遥感图像特征的匹配。结果通过大量不同图像尺寸和相对旋转的遥感图像的实验表明,与传统的和其他先进方法相比,本文方法在保证较高精度的同时将匹配时间缩短到1/100~1/10。结论利用初始种子匹配构建分治匹配中心以将图像匹配分解在多个子区间进行的方法有助于提高遥感影像匹配的效率,该算法良好的时间性能对实时遥感应用具有实际价值。关键词:图像匹配;遥感影像;空间分治;区域树;空间结构71|206|1更新时间:2024-05-07
遥感图像处理
-
 摘要:目的图像文本信息在日常生活中无处不在,其在传递信息的同时,也带来了信息泄露问题,而图像文字去除算法很好地解决了这个问题,但存在文字去除不干净以及文字去除后的区域填充结果视觉感受不佳等问题。为此,本文提出了一种基于门循环单元(gate recurrent unit,GRU)的图像文字去除模型,可以高质量和高效地去除图像中的文字。方法通过由门循环单元组成的笔画级二值掩膜检测模块精确地获得输入图像的笔画级二值掩膜;将得到的笔画级二值掩膜作为辅助信息,输入到基于生成对抗网络的文字去除模块中进行文字的去除和背景颜色的回填,并使用本文提出的文字损失函数和亮度损失函数提升文字去除的效果,以实现对文字高质量去除,同时使用逆残差块代替普通卷积,以实现高效率的文字去除。结果在1 080组通过人工处理得到的真实数据集和使用文字合成方法合成的1 000组合成数据集上,与其他3种文字去除方法进行了对比实验,实验结果表明,在峰值信噪比和结构相似性等图像质量指标以及视觉效果上,本文方法均取得了更好的性能。结论本文提出的基于门循环单元的图像文字去除模型,与对比方法相比,不仅能够有效解决图像文字去除不干净以及文字去除后的区域与背景不一致问题,并能有效地减少模型的参数量和计算量,最终整体计算量降低了72.0 %。关键词:文字去除;门循环单元(GRU);生成对抗网络(GAN);逆残差块;图像修复70|166|0更新时间:2024-05-07
摘要:目的图像文本信息在日常生活中无处不在,其在传递信息的同时,也带来了信息泄露问题,而图像文字去除算法很好地解决了这个问题,但存在文字去除不干净以及文字去除后的区域填充结果视觉感受不佳等问题。为此,本文提出了一种基于门循环单元(gate recurrent unit,GRU)的图像文字去除模型,可以高质量和高效地去除图像中的文字。方法通过由门循环单元组成的笔画级二值掩膜检测模块精确地获得输入图像的笔画级二值掩膜;将得到的笔画级二值掩膜作为辅助信息,输入到基于生成对抗网络的文字去除模块中进行文字的去除和背景颜色的回填,并使用本文提出的文字损失函数和亮度损失函数提升文字去除的效果,以实现对文字高质量去除,同时使用逆残差块代替普通卷积,以实现高效率的文字去除。结果在1 080组通过人工处理得到的真实数据集和使用文字合成方法合成的1 000组合成数据集上,与其他3种文字去除方法进行了对比实验,实验结果表明,在峰值信噪比和结构相似性等图像质量指标以及视觉效果上,本文方法均取得了更好的性能。结论本文提出的基于门循环单元的图像文字去除模型,与对比方法相比,不仅能够有效解决图像文字去除不干净以及文字去除后的区域与背景不一致问题,并能有效地减少模型的参数量和计算量,最终整体计算量降低了72.0 %。关键词:文字去除;门循环单元(GRU);生成对抗网络(GAN);逆残差块;图像修复70|166|0更新时间:2024-05-07 -
 摘要:目的针对包含混合噪声的3维坐标形式的骨骼运动数据优化问题,提出一种由双向循环自编码器和卷积自编码器串联构成的优化网络,其中双向循环自编码器用于使网络输出的优化数据具有更高的位置精度,卷积自编码器用于使优化数据具有更好的平滑性。方法首先,利用高精度动捕数据库预训练一个感知自编码器; 然后,用“噪声—高精度”数据对训练双自编码器,并在训练过程中添加隐变量约束。其中隐变量约束由预训练的感知自编码器返回,其作用在于能够使网络输出保持较高的精度并具有合理骨骼结构,使算法适用于提升运动数据的细节层次。结果实验分别在合成噪声数据集和真实噪声数据集上进行,与最新的卷积自编码器(convolutional auto-encoder,CAE)、双向循环自编码器(bidirectional recurrent auto-encoder,BRA)以及双向循环自编码器加感知约束(BRA with perceptual constraint, BRA-P)3种深度学习方法进行比较,在位置误差、骨骼长度误差和平滑性误差3项量化指标上,本文方法的优化结果与最新的3种方法在合成噪声数据集上相比,分别提高了33.1 %、25.5 %、12.2 %; 在真实噪声数据集上分别提高了27.2 %、39.2 %、16.8 %。结论本文提出的双自编码器优化网络综合了两种自编码器的优点, 使网络输出的优化数据具有更高的数据精度和更好的平滑性,且能够较好地保持运动数据的骨骼结构。关键词:深度学习;骨骼运动数据优化;双自编码器;隐变量约束;Kinect运动数据128|204|0更新时间:2024-05-07
摘要:目的针对包含混合噪声的3维坐标形式的骨骼运动数据优化问题,提出一种由双向循环自编码器和卷积自编码器串联构成的优化网络,其中双向循环自编码器用于使网络输出的优化数据具有更高的位置精度,卷积自编码器用于使优化数据具有更好的平滑性。方法首先,利用高精度动捕数据库预训练一个感知自编码器; 然后,用“噪声—高精度”数据对训练双自编码器,并在训练过程中添加隐变量约束。其中隐变量约束由预训练的感知自编码器返回,其作用在于能够使网络输出保持较高的精度并具有合理骨骼结构,使算法适用于提升运动数据的细节层次。结果实验分别在合成噪声数据集和真实噪声数据集上进行,与最新的卷积自编码器(convolutional auto-encoder,CAE)、双向循环自编码器(bidirectional recurrent auto-encoder,BRA)以及双向循环自编码器加感知约束(BRA with perceptual constraint, BRA-P)3种深度学习方法进行比较,在位置误差、骨骼长度误差和平滑性误差3项量化指标上,本文方法的优化结果与最新的3种方法在合成噪声数据集上相比,分别提高了33.1 %、25.5 %、12.2 %; 在真实噪声数据集上分别提高了27.2 %、39.2 %、16.8 %。结论本文提出的双自编码器优化网络综合了两种自编码器的优点, 使网络输出的优化数据具有更高的数据精度和更好的平滑性,且能够较好地保持运动数据的骨骼结构。关键词:深度学习;骨骼运动数据优化;双自编码器;隐变量约束;Kinect运动数据128|204|0更新时间:2024-05-07 -
 摘要:目的基于深度学习的动作识别方法识别准确率显著提升,但仍然存在很多挑战和困难。现行方法在一些训练数据大、分类类别多的数据集以及实际应用中鲁棒性较差,而且许多方法使用的模型参数量较大、计算复杂,提高模型准确度和鲁棒性的同时对模型进行轻量化仍然是一个重要的研究方向。为此,提出了一种基于知识蒸馏的轻量化时空图卷积动作识别融合模型。方法改进最新的时空卷积网络,利用分组卷积等设计参数量较少的时空卷积子模型; 为了训练该模型,选取两个现有的基于全卷积的模型作为教师模型在数据集上训练,在得到训练好的教师模型后,再利用知识蒸馏的方法结合数据增强技术训练参数量较少的时空卷积子模型; 利用线性融合的方法将知识蒸馏训练得到的子模型融合得到最终的融合模型。结果在广泛使用的NTU RGB + D数据集上与前沿的多种方法进行了比较,在CS(cross-subject)和CV(cross-view)两种评估标准下, 本文模型的准确率分别为90.9 %和96.5 %,与教师模型2s-AGCN(two-stream adaptive graph convolutional networks for skeleton-based action)相比,分别提高了2.4 %和1.4 %; 与教师模型DGNN(directed graph neural network)相比,分别提高了1.0 %和0.4 %; 与MS-AAGCN(multi-stream attention-enhanced adaptive graph convolutional neural network)模型相比,分别提高了0.9 %和0.3 %。结论本文提出的融合模型,综合了知识蒸馏、数据增强技术和模型融合的优点,使动作识别更加准确和鲁棒。关键词:动作识别;知识蒸馏;深度学习;融合模型;图卷积101|183|3更新时间:2024-05-07
摘要:目的基于深度学习的动作识别方法识别准确率显著提升,但仍然存在很多挑战和困难。现行方法在一些训练数据大、分类类别多的数据集以及实际应用中鲁棒性较差,而且许多方法使用的模型参数量较大、计算复杂,提高模型准确度和鲁棒性的同时对模型进行轻量化仍然是一个重要的研究方向。为此,提出了一种基于知识蒸馏的轻量化时空图卷积动作识别融合模型。方法改进最新的时空卷积网络,利用分组卷积等设计参数量较少的时空卷积子模型; 为了训练该模型,选取两个现有的基于全卷积的模型作为教师模型在数据集上训练,在得到训练好的教师模型后,再利用知识蒸馏的方法结合数据增强技术训练参数量较少的时空卷积子模型; 利用线性融合的方法将知识蒸馏训练得到的子模型融合得到最终的融合模型。结果在广泛使用的NTU RGB + D数据集上与前沿的多种方法进行了比较,在CS(cross-subject)和CV(cross-view)两种评估标准下, 本文模型的准确率分别为90.9 %和96.5 %,与教师模型2s-AGCN(two-stream adaptive graph convolutional networks for skeleton-based action)相比,分别提高了2.4 %和1.4 %; 与教师模型DGNN(directed graph neural network)相比,分别提高了1.0 %和0.4 %; 与MS-AAGCN(multi-stream attention-enhanced adaptive graph convolutional neural network)模型相比,分别提高了0.9 %和0.3 %。结论本文提出的融合模型,综合了知识蒸馏、数据增强技术和模型融合的优点,使动作识别更加准确和鲁棒。关键词:动作识别;知识蒸馏;深度学习;融合模型;图卷积101|183|3更新时间:2024-05-07 -
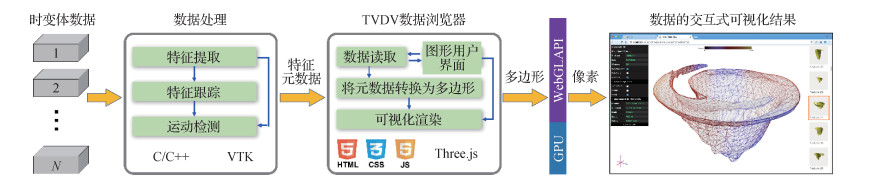 摘要:目的自然界中的大部分现象本质上都是在空间上随时间的流逝不断发展变化的物理或化学过程,可以表述为含有时间变量的数据场,这些数据场称为时变体数据。随着科学计算技术、计算机仿真技术以及现代观测技术的发展,能够以前所未有的精度对自然现象进行仿真或者观测,但同时也面临时变体数据体积大、时间长以及变量数目多的难题。为了更有效地显示时变体数据并挖掘数据中的关键信息,针对时变体数据的可视化,本文提出一种基于数据特征的方法,用于探索时变体数据中感兴趣区域(即特征)的特点与变化。方法通过将特征提取、特征跟踪、运动检测和提出的3种特征可视化方法(数据帧特征可视化、单个运动过程特征可视化和空间多运动过程特征可视化)置于同一个框架之中,提供一种从时间域和空间域探索多变量时变体数据的一站式解决方案,并突出时变体数据的动力学特性。结果本文方法在4组不同的时变体数据上应用,对数据中特征各变量的变化以及感兴趣的运动进行了特征可视化。结论实验结果显示本文方法能以较小的时间成本有效显示数据中的特征以及用户定义的运动,方法的有效性与实用性得到了验证。关键词:时变体数据;特征可视化;特征跟踪;运动检测;交互式可视化154|234|2更新时间:2024-05-07
摘要:目的自然界中的大部分现象本质上都是在空间上随时间的流逝不断发展变化的物理或化学过程,可以表述为含有时间变量的数据场,这些数据场称为时变体数据。随着科学计算技术、计算机仿真技术以及现代观测技术的发展,能够以前所未有的精度对自然现象进行仿真或者观测,但同时也面临时变体数据体积大、时间长以及变量数目多的难题。为了更有效地显示时变体数据并挖掘数据中的关键信息,针对时变体数据的可视化,本文提出一种基于数据特征的方法,用于探索时变体数据中感兴趣区域(即特征)的特点与变化。方法通过将特征提取、特征跟踪、运动检测和提出的3种特征可视化方法(数据帧特征可视化、单个运动过程特征可视化和空间多运动过程特征可视化)置于同一个框架之中,提供一种从时间域和空间域探索多变量时变体数据的一站式解决方案,并突出时变体数据的动力学特性。结果本文方法在4组不同的时变体数据上应用,对数据中特征各变量的变化以及感兴趣的运动进行了特征可视化。结论实验结果显示本文方法能以较小的时间成本有效显示数据中的特征以及用户定义的运动,方法的有效性与实用性得到了验证。关键词:时变体数据;特征可视化;特征跟踪;运动检测;交互式可视化154|234|2更新时间:2024-05-07
Chinagraph 2020
-
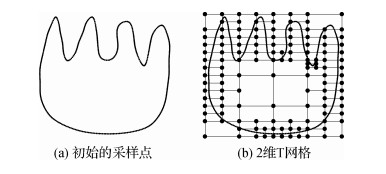 摘要:目的隐式曲线能够描述复杂的几何形状和拓扑结构,而传统的隐式B样条曲线的控制网格需要大量多余的控制点满足拓扑约束。有些情况下,获取的数据点不仅包含坐标信息,还包含相应的法向约束条件。针对这个问题,提出了一种带法向约束的隐式T样条曲线重建算法。方法结合曲率自适应地调整采样点的疏密,利用二叉树及其细分过程从散乱数据点集构造2维T网格; 基于隐式T样条函数提出了一种有效的曲线拟合模型。通过加入偏移数据点和光滑项消除额外零水平集,同时加入法向项减小曲线的法向误差,并依据最优化原理将问题转化为线性方程组求解得到控制系数,从而实现隐式曲线的重构。在误差较大的区域进行T网格局部细分,提高重建隐式曲线的精度。结果实验在3个数据集上与两种方法进行比较,实验结果表明,本文算法的法向误差显著减小,法向平均误差由10-3数量级缩小为10-4数量级,法向最大误差由10-2数量级缩小为10-3数量级。在重构曲线质量上,消除了额外零水平集。与隐式B样条控制网格相比,3个数据集的T网格的控制点数量只有B样条网格的55.88 %、39.80 %和47.06 %。结论本文算法能在保证数据点精度的前提下,有效降低法向误差,消除了额外的零水平集。与隐式B样条曲线相比,本文方法减少了控制系数的数量,提高了运算速度。关键词:离散数据;隐式曲线;T样条;曲线重建;法向约束58|117|2更新时间:2024-05-07
摘要:目的隐式曲线能够描述复杂的几何形状和拓扑结构,而传统的隐式B样条曲线的控制网格需要大量多余的控制点满足拓扑约束。有些情况下,获取的数据点不仅包含坐标信息,还包含相应的法向约束条件。针对这个问题,提出了一种带法向约束的隐式T样条曲线重建算法。方法结合曲率自适应地调整采样点的疏密,利用二叉树及其细分过程从散乱数据点集构造2维T网格; 基于隐式T样条函数提出了一种有效的曲线拟合模型。通过加入偏移数据点和光滑项消除额外零水平集,同时加入法向项减小曲线的法向误差,并依据最优化原理将问题转化为线性方程组求解得到控制系数,从而实现隐式曲线的重构。在误差较大的区域进行T网格局部细分,提高重建隐式曲线的精度。结果实验在3个数据集上与两种方法进行比较,实验结果表明,本文算法的法向误差显著减小,法向平均误差由10-3数量级缩小为10-4数量级,法向最大误差由10-2数量级缩小为10-3数量级。在重构曲线质量上,消除了额外零水平集。与隐式B样条控制网格相比,3个数据集的T网格的控制点数量只有B样条网格的55.88 %、39.80 %和47.06 %。结论本文算法能在保证数据点精度的前提下,有效降低法向误差,消除了额外的零水平集。与隐式B样条曲线相比,本文方法减少了控制系数的数量,提高了运算速度。关键词:离散数据;隐式曲线;T样条;曲线重建;法向约束58|117|2更新时间:2024-05-07 -
 摘要:目的目前针对全景图显著性检测的研究已经取得了一定成果,但在全景图像的位置特性问题中,大都仅探讨了纬度对全景图显著性检测的影响。而人们观看全景图像时,因视角有限,不同经度位置的显著性也有很大差异,从而导致预测的显著区域往往不够精确。为此本文以全景图的经度位置特性为出发点,提出基于观看经度联合加权的全景图显著性检测算法。方法使用空间显著性预测网络得到初步的显著性图像,使用赤道偏倚进行预处理以改善不同纬度位置的显著性检测效果。接着对显著性图像进行注视点经度加权,将观察者观看全景图的行为习惯与显著性图像相结合。之后对全景图进行双立方体投影与分割,提取全景图的亮度与深度特征,进而计算不同视口经度权重。经过两次加权,得到最终的显著性图像。结果在Salient360!挑战大赛提供的数据集上与其他几种算法进行了实验比较。结果显示,本文算法能得到很好的显著性检测结果。在对本文算法的通用性能的测试中,在标准化扫描路径显著性、相关系数、相似度与相对熵指标上分别达到了1.979 3、0.806 2、0.709 5和0.323 9,均优于其他算法。结论提出的全景图显著性检测算法解决了以往全景图显著性检测中不同经度位置检测结果不够准确的问题。关键词:显著性检测;全景图;注视点经度加权;双立方体投影;不同视口经度加权75|115|0更新时间:2024-05-07
摘要:目的目前针对全景图显著性检测的研究已经取得了一定成果,但在全景图像的位置特性问题中,大都仅探讨了纬度对全景图显著性检测的影响。而人们观看全景图像时,因视角有限,不同经度位置的显著性也有很大差异,从而导致预测的显著区域往往不够精确。为此本文以全景图的经度位置特性为出发点,提出基于观看经度联合加权的全景图显著性检测算法。方法使用空间显著性预测网络得到初步的显著性图像,使用赤道偏倚进行预处理以改善不同纬度位置的显著性检测效果。接着对显著性图像进行注视点经度加权,将观察者观看全景图的行为习惯与显著性图像相结合。之后对全景图进行双立方体投影与分割,提取全景图的亮度与深度特征,进而计算不同视口经度权重。经过两次加权,得到最终的显著性图像。结果在Salient360!挑战大赛提供的数据集上与其他几种算法进行了实验比较。结果显示,本文算法能得到很好的显著性检测结果。在对本文算法的通用性能的测试中,在标准化扫描路径显著性、相关系数、相似度与相对熵指标上分别达到了1.979 3、0.806 2、0.709 5和0.323 9,均优于其他算法。结论提出的全景图显著性检测算法解决了以往全景图显著性检测中不同经度位置检测结果不够准确的问题。关键词:显著性检测;全景图;注视点经度加权;双立方体投影;不同视口经度加权75|115|0更新时间:2024-05-07
ChinaVR 2020
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0