|
|
|
发布时间: 2022-04-16 |
虚拟现实与增强现实 |
|
|
|


|
收稿日期: 2020-10-22; 修回日期: 2020-12-29; 预印本日期: 2021-01-05
基金项目: 国家自然科学基金项目(U183310179);四川省科技厅重点研发项目(2021YFG0300)
作者简介:
雷清桦,1996年生,男,硕士研究生,主要研究方向为图像处理和深度学习。E-mail: 2018223040021@stu.scu.edu.cn
杨婷,女,硕士研究生,主要研究方向为图像处理和深度学习。E-mail: 2018223045158@stu.scu.edu.cn 程鹏,通信作者,男,副教授,主要研究方向为图像配准、图像融合与计算机视觉。E-mail: scechina@163.com *通信作者: 程鹏 scechina@163.com
中图法分类号: TP391.41
文献标识码: A
文章编号: 1006-8961(2022)04-1238-13
|
摘要
目的 沉浸式投影系统已广泛运用于虚拟现实系统之中,然而沉浸式投影系统中的互反射现象严重影响着虚拟现实系统的落地使用。沉浸式投影系统的互反射是指由于投影机光线和屏幕反射光线相互叠加造成的亮度冗余现象,严重影响了投影系统的成像质量和人眼的视觉感受。为此,本文提出一种新的基于互反射通道(inter-reflection channel,IRC)先验和注意力机制的神经网络。方法 IRC先验基于这样一个事实,即大多数受到互反射影响的投影图像都包含一些亮度较高的区域。高亮度区域往往受互反射影响更为严重,而低亮度区域受互反射影响程度较低。根据这一规律,采用IRC先验作为注意力图的监督样本,获取补偿图像的亮度区域信息。同时,为了对投影图像不同区域按影响程度进行差异化补偿,提出一种新的由两个相同子网络构成的补偿网络结构Pair-Net。结果 实验对比了4种现有方法,Pair-Net在ROI(region of interesting)指标分析上取得了明显优势,在人眼感受上有显著的效果提升。结论 本文提出的基于注意力机制的网络模型能够针对不同区域进行差异化补偿,很大程度上消除了互反射影响,提升了沉浸式投影系统的成像质量。
关键词
沉浸式投影系统; 互反射补偿; 深度学习; 注意力机制; 虚拟现实
Abstract
Objective Immersive projection system is focused on for the aspects of virtual reality and augmented reality system nowadays. In the context of immersive projection system, the inner-reflection issue is essential to the projection images quality and the fidelity of reality scenes. Inter-reflection refers to brightness redundancy problems derived of overlapping of projector light and screen reflection light in immersive projection system, which severely affects the imaging quality of the projection system. Meanwhile, it is a challenging issue to eliminate optics-based inner-reflection due to the complexity of light transmission in immersive environment. Method A new and simple image prior like inner-reflection channel (IRC) prior and a new attention guide neural network like Pair-Net generate the high-quality inner-reflection compensated projection image in immersive projection system. The IRC prior is a kind of statistic of projection image in immersive projection system. The scenario of most inner-reflection effected projection images are composed of some high intensity pixels. Those high intensity local patches are affected through inner-reflection, which can be used as an attention map to train our compensation net, IRC prior based Pair-Net, a new compensation network, learns the complex reflection and compensation function of immersive projection environment. Result Our experiment demonstrated the improvement in region of interesting (ROI) analysis indicators and human visual perception compared the four existing methods. Pair-Net is capable to learn the complex inner-reflection information and pay attention to the high inner-reflection region. The result of Pair-Net is qualified to the end-to-end projection compensation methods qualitatively and quantitatively. Conclusion Our method illustrates its qualitative and quantitative effectiveness based on significant margin. Immersive projection system have been widely using in those large-scare virtual-reality scene. But, inner-reflection almost exits in all immersive projection system which can heavily decrease the quality of projection image and the fidelity of reality scenes. These challenges often create bottlenecks for generalization of projector system and block the implementation of virtual reality projects. Inner-reflection compensation aims to compensate the projector input image to enhance the projection images quality and lower the effect of inner-reflection. The typical compensation system consists of in-situ projector-camera (pro-cam) pair and a curved screen. The geometric modeling sorts the light transmission and reflection function out. First, light transmission and reflection function in immersive projection environment need to invert a potential large-scale matrix. Next, it is hard for traditional inner-reflection compensation solution to produce high visually quality result due to the mathematical error are inevitable. Finally, current solutions compensate the whole images more and ignore multi-regions based single image intensity issue. A new convolutional neural network (CNN) is prior to photometric compensation domain based photometric compensation algorithm. We facilitated IRC prior and a Pair-Net for inner-reflection compensation. Pair-Net intends to the different patches of image in multiple light intensity immersive projection scenario. The adopted attention mechanisms for different intensity region compensation and use IRC prior to get the attention map. We design Pair-Net as composed of two sub-nets for paying different attention to the higher intensity and lower intensity region in single image. Two auto-encoder sub-net encourages rich multi-level interaction between the camera captured projection image and the ground truth image, and thus capturing the reflection information of the projection screen. Then, the IRC prior yields two sub-net to pay different attention to variance intensity region in immersive projection scenario summary, we first harness an attention guide inner-reflection compensation Pair-Net model in immersive projection system. In addition, the IRC prior is generated the attention map initially.
Key words
immersive projection system; inter-reflection compensation; deep learning; attention mechanism; virtual reality
0 引言
随着沉浸式虚拟现实技术的发展,沉浸式投影系统在大型虚拟现实场景中得到了广泛应用,但存在一个重要且经常忽视的问题,就是光线互反射。
大多数沉浸式投影系统都存在互反射现象,互反射现象严重降低了投影图像质量和虚拟现实场景逼真度。该问题常常成为沉浸式系统推广的瓶颈,阻碍了虚拟现实项目的实施。同时,在沉浸式投影环境中,光的反射和折射非常复杂,特别是复杂的投影环境,使得利用光学方法解决这一问题变得困难。互反射补偿是指通过对投影机输入图像进行补偿,得到能够提高投影图像质量、消除互反射影响的图像。典型的沉浸式投影补偿系统包括投影仪—摄像机对和一个放置在适当距离和方向上的曲面屏幕,如图 1所示。


现行方法大多是先建立场景几何模型,然后再寻找光的反射函数,计算光线在屏幕间的互反射。虽然这些方法相对容易实现,但是主要存在3个问题。1)在沉浸式投影环境中,光的反射函数通常比较复杂,大多数方法都需要大矩阵进行求逆运算,而该矩阵的逆却可能是不存在的,无法进行求解。2)传统的互反射补偿方案由于不可避免的数学误差,难以产生高质量的视觉效果。3)以往的解决方案大多是对整幅图像进行补偿,忽略了图像亮度不同区域的补偿强度应该不同的问题。目前,还没有研究针对互反射问题的差异化提出补偿方案。Huang和Ling(2019a, b)提出了新的基于卷积神经网络(convolutional neural network, CNN)的光补偿算法CompenNet和CompenNet++,与传统方法相比,在光补偿方面具有更大优势。受此启发,本文提出一种新的基于互反射通道(inter-reflection channel,IRC)先验补偿网络Pair-Net,充分考虑了沉浸式投影环境下图像不同区域的补偿强度应该不同的特点,设计了两个结构相同的端到端的子网络分别负责对高亮度区域和低亮度区域进行补偿。通过使用注意力机制,使两个子网络能够分别学习到原图中两个区域的补偿函数。而注意力图的生成是通过IRC先验图的监督学习得到的,能够为两个网络划分出亮度不同区域。图 2展示了本文的解决方案,可以看出,经过补偿的投影结果(图 2(d))在视觉上明显比未经补偿的投影结果(图 2(b))更接近原图。

综上所述,本文方法主要有以下贡献:1)在沉浸或半沉浸式投影系统中,提出通过IRC先验获取投影图像不同区域的亮度信息;2)提出一种新型补偿网络Pair-Net,使用两个子网络分别补偿高亮区域和低亮区域,提升了补偿图像质量;3)在互反射补偿问题中使用注意力机制,可以对不同区域进行差别化补偿,提升了补偿图像视觉效果。
1 相关工作
1.1 互反射补偿
1.1.1 基于光传输矩阵的互反射补偿
基于光传输矩阵的补偿算法(Ashdown,2006; Ng等,2003;Grundhöfer,2013;Grundhöfer和Iwai,2015;Ng等,2012;Wang等,2009)建立在相机的像素点只受投影仪对应像素点影响的假设之上。这意味着投影仪和相机对之间的像素点存在一对一的映射关系。根据这一假设,Ng等人(2003)提出一种近似求解光传输矩阵的逆的方法,采用较小的矩阵初始值模拟计算,利用小矩阵求逆和分层矩阵求逆提高精度。由于采用子矩阵模拟光传输矩阵,在精度上存在不足。实际上对于多数基于光传输矩阵的方法来说,矩阵规模较大,计算量也较大。此外,投影光线和反射光线可以影响周围区域,这意味着像素级光传输矩阵在假设本身上就存在问题。
1.1.2 基于反射模型的互反射补偿
为了避免大规模矩阵计算,提出了越来越多的无矩阵方法,将投影仪作为光源,在真实投影场景中建立光的反射模型(Li等,2013;Bimber等,2006;Takeda等,2016;Habe等,2007;Zou等,2008)。Bimber等人(2006)提出一种直接互反射补偿方法,通过建立沉浸式投影环境下的真实反射模型,先计算环境中的互反射,然后将原图减去互反射得到补偿图像。Takeda等人(2016)提出一种投影仪—相机对的空间反射模型,用一种在光线照射下会改变颜色的化合物制作投影屏幕,光线照射可以通过屏幕后面的光感LED(light emitting diode)阵列控制,通过LED阵列改变最终投影图像的显示效果。由于该方法需要通过LED辅助设备进行投影图像矫正,因此实用性较低。
1.2 注意力机制
注意力机制已广泛用于神经网络(Ma等,2012;Mejjati等,2018)。Kuen等人(2016)提出一种递归注意力网络,可以自动学习输入图像中的一系列子区域,用于显著性检测,将这些局部估计区域合并成一个全局估计。Li等人(2017)提出一种通过全局上下文检测目标的注意引导方法,证明了注意力机制在计算机视觉和图像处理任务中应用的优越性。Chen等人(2016)提出一种生成图像中每个像素点的注意力权重的方法,称为像素级别的注意力机制。
本文首次在互反射补偿中运用注意力机制,由于相机捕获的图像是受到互反射影响形成的图像,因此图像上面存在互反射分布信息。利用IRC先验作为注意力图生成器的监督便可以获取不同亮度区域的注意力图。
2 互反射通道
2.1 互反射通道定义
本文提出的互反射通道先验是受著名的暗通道先验的启发,暗通道先验已广泛应用于图像去雾领域(Xu等,2012)。互反射通道(IRC)基于投影图像像素点的亮度值通常高于原始图像,并且原始图像中亮度较高的图像受互反射影响较大、亮度较低的图像受互反射影响相对较少这一事实。因此,获取相机拍摄图像三通道的高值区域,能够有效描述受互反射影响更大的区域。本文将这种情况定义为互反射通道。对于相机拍摄的投影图像Icam,互反射通道S可描述为
| $ {\boldsymbol{S}}({\boldsymbol{x}}) = \mathop {\max }\limits_{y \in {\boldsymbol{\varOmega }}(x)} \left({\mathop {\max }\limits_{c \in \{ r, g, b\} } \left({{\boldsymbol{I}}_{{\rm{cam}}}^c\left(y \right)} \right)} \right) $ | (1) |
式中,Icamc是Icam的RGB通道中的一个通道,Ω(x) 是某个局部区域,中心点为x。IRC通过如下两个取较大值操作求得:1)对图像中的每一个像素点计算RGB三个通道中的最大值,即
通过上述操作,能够获取到沉浸式投影系统的高亮度区域,这就是IRC的定义。IRC不仅包含反射信息,也包含原图的高亮信息,高亮区域反射越强,对周边区域影响越大。IRC的高亮区域主要由两个因素造成,一是互反射,互反射几乎存在于投影图像的所有区域,特别是在输入图像的高亮度区域。二是输入图像中的高亮度区域和物体,如天空、海洋、雪地或白羊,也将导致IRC中的高亮度值。利用IRC得到的沉浸式投影系统的反射信息,可以监督Pair-Net的注意图的生成,使高亮和低亮区域按合适的权重进行补偿。
2.2 IRC的优势
图 3是获取的投影图像的IRC先验图,可以看出,由于原图左上角的光晕影响以及互反射造成该区域的图像亮度较高。通过IRC先验,能够有效获取到原图的高光区域以及受到互反射影响的区域。在训练中,可以将IRC先验作为注意力掩膜来区分高亮度和低亮度区域,从而使用双网络进行差异化补偿。

传统暗通道图像先验方法主要对原始图像的特征区域进行区分,并计算区域最小值,这样的区域特征信息对于互反射补偿问题是无效的。这是由于在投影系统中的互反射补偿问题中,场景中的光污染是互反射造成的,图像中的高亮区域对投影结果影响更大,而非暗通道特征区域信息。此外,IRC先验是基于投影图像的特征进行计算的,除了能够获得原图的高亮区域外,受互反射影响形成的高亮区域也可以提取出来。因此,本文提出并采用IRC先验而非暗通道作为区域特征提取的监督先验。
3 Pair-Net网络设计
3.1 曲面投影系统的数学模型
本文提出的互反射补偿系统由一个未校准的相机—投影仪对和一个固定距离和方向的曲线投影屏幕组成,如图 1和图 4所示,其中,E为全局光照。整个曲面投影系统可以描述为
| $ \boldsymbol{I}_{\mathrm{cam}}=f_{\mathrm{c}}\left(f_{\mathrm{s}}\left(f_{\mathrm{p}}\left(\boldsymbol{I}_{\mathrm{in}}\right), E, s\right)\right) $ | (2) |
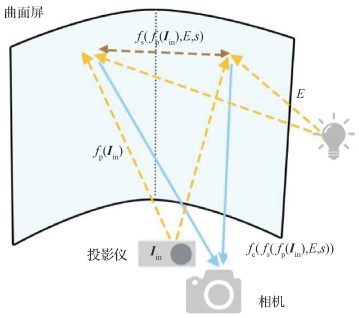
式中,Iin是投影仪输入图像,Icam是相机拍摄图像。fp和fc是投影仪和相机的转换函数,fs是光线在屏幕间的反射函数。由于不同屏幕材质具有不同的光线反射率,本文使用s表示屏幕的反射率。同时,由于本文专注解决沉浸式投影系统的互反射问题,因此控制环境光照为E = 0,避免环境光照的影响。为了简化公式,可以将投影仪—相机的转换函数合并成为一个函数T,式(2)可以重新表述为
| $ \boldsymbol{I}_{\mathrm{cam}}=T\left(\boldsymbol{I}_{\mathrm{in}}, s\right) $ | (3) |
互反射补偿是为了生成一幅由原图Iin补偿得到的投影仪输入图像Iin*,并且希望将Iin*投影仪之后得到的图像视觉效果与原图Iin尽量接近,这一过程可以描述为
| $ T\left(\boldsymbol{I}_{\mathrm{in}}^{*}, s\right)=\boldsymbol{I}_{\mathrm{in}} $ | (4) |
| $ \boldsymbol{I}_{\mathrm{in}}^{*}=T^{-1}\left(\boldsymbol{I}_{\mathrm{in}}, s\right) $ | (5) |
3.2 基于深度学习的公式
本文使用投影图像与相机拍摄图像作为训练集,由式(3)变形可得
| $ \boldsymbol{I}_{\mathrm{cam}}=T\left(\boldsymbol{I}_{\mathrm{in}}, s\right) \rightarrow \boldsymbol{I}_{\mathrm{in}}=T^{-1}\left(\boldsymbol{I}_{\mathrm{cam}}, s\right) $ | (6) |
然后,使用Tθ表示卷积神经网络,θ表示网络中可学习的参数,通过学习得到沉浸式投影环境中的投影仪与相机的转换函数。考虑到投影屏幕中不同区域的互反射强度不同,将网络模型划分成为两个相同的子网络Tθback和Tθpro,分别对原图的高亮区域和低亮区域进行学习和补偿。为了方便描述,将图像中的高亮区域称为背景,低亮区域称为前景。使用Ipred表示训练过程中将原图Icam输入网络得到的输出图像,θ={θpro, θback}表示网络中的可学习参数,使用maskback和maskpro分别表示将背景和前景分开的掩膜,掩膜采用IRC先验监督学习得到。因此,该深度学习模型可以表示为
| $ \boldsymbol{I}_{\text {pred }}=T_{\theta}\left(\boldsymbol{I}_{\mathrm{cam}}, s\right) $ | (7) |
| $ \begin{array}{c} {{\boldsymbol{I}}_{{\rm{pred }}}} = \boldsymbol{mas}{\boldsymbol{k}_{{\rm{back }}}} \times T_\theta ^{{\rm{back }}}\left({{{\boldsymbol{I}}_{{\rm{cam }}}}, s} \right) + \\ \boldsymbol{mas}{\boldsymbol{k}_{{\rm{pr}}{{\rm{o}}_{{\rm{pro}}}}}} \times T_\theta ^{{\rm{pro}}}\left({{{\boldsymbol{I}}_{{\rm{cam}}}}, s} \right) \end{array} $ | (8) |
实验中使用{Iin, Icam}作为训练集。由于曲面投影屏的投影图像会出现几何变形,因此对相机拍摄图像Icam进行几何矫正(Huang和Ling,2019a)。本实验拍摄了N=5 000幅图像作为训练集。数据集可以表示为D={(Iin(i), Icam(i))}i=1N,其中N=5 000。最后,使用损失函数Loss=l1+lssim进行训练,具体计算为
| $ \theta = {\mathop{\rm argmin}\nolimits} \sum\limits_i {\left({Loss\left({{{\bf{I}}_{{\mathop{\rm pred}\nolimits} (i)}}, {{\bf{I}}_{{\rm{in}}(i)}}} \right)} \right)} $ | (9) |
| $ \begin{aligned} \boldsymbol{I}_{\text {pred }(i)} &=\boldsymbol{mask}_{\mathrm{back}} \times T_{\theta}^{\mathrm{back}}\left(\boldsymbol{I}_{\mathrm{cam}(i)}, s\right)+\\ & \boldsymbol{mask}_{\text {pro }} \times T_{\theta}^{\mathrm{pro}}\left(\boldsymbol{I}_{\mathrm{cam}(i)}, s\right) \end{aligned} $ | (10) |
采用Loss=l1+lssim组合作为损失函数的原因在于,l1损失函数能够很好地对图像颜色进行优化,而结构相似性损失函数和l1损失函数能够优化生成图像的整体质量(Zhao等,2017)。
3.3 互反射补偿流程
根据上述公式,本文设计了由两个子网组成的补偿网络Pair-Net,分别用于校正图像中的低亮度区域和高亮度区域,同时设计了一个掩膜网学习投影环境中的互反射信息,生成对暗区域和高亮度区域具有不同权重的注意图,网络结构如图 5所示,其中,Iin是投影仪输入图像,Icam是相机拍摄图像,λ为掩膜的权重系数,Tθpro是前景补偿网络,Tθback是背景补偿网络,Ipred是补偿图像。
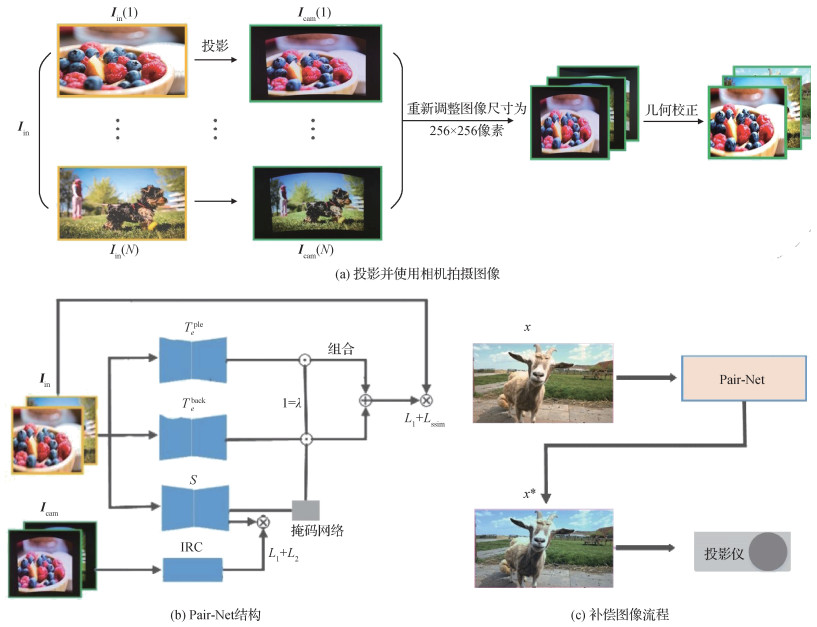
在训练过程中,前景网和背景网分别以两幅几何校正后的图像作为输入。子网的两个输入和输出都是256×256×3。然后,将两个子网的输出图像根据掩膜网生成的注意力图进行融合得到生成图像。
在训练过程中,将相机拍摄的投影图像Icam作为补偿子网络Tθpro和Tθback的输入,为了获取不同的补偿强度,对两个子网络的输入进行不同强度的伽玛矫正。Tθpro和Tθback的补偿输出图像最终通过掩膜网络输出的掩膜进行融合,得到最终的网络生成图像Ipred,并通过Ipred与投影仪输入图像Iin计算一个损失函数。训练完成后,只需输入图像Iin就可以得到相机补偿图像,达到互反射消除的目的。
3.3.1 前景网络和背景网络的设计
在前景和背景网络中,输入图像送入一个卷积层序列进行降采样。因为更深层的网络结构允许更为复杂的模型映射,从而有更大的潜力提高网络精度和生成高质量图像(Ronneberger等,2015)。因此,在降采样中间利用残差块序列加深网络,提高生成图像的质量。残差块通过将低层次特征与当前层特征相结合,可以有效训练更深层次的网络。同时,利用跳卷积将低层次特征信息传递给深层网络保证低层次特征不会丢失。然后,利用3个反向卷积层,逐步向上采样到256 × 256 × 3作为前景和背景网络的输出。具体子网络架构和残差块架构如表 1和表 2所示。
表 1
子网络架构
Table 1
The structure of sub network
| 类型 | 卷积尺寸/步长 | 输出尺寸 |
| 输入层 | - | 256×256×3 |
| 卷积层 | 3×3/2 | 128×128×32 |
| 卷积层 | 3×3/2 | 64×64×64 |
| 卷积层 | 3×3/2 | 32×32×128 |
| 残差块 | - | 32×32×128 |
| 残差块 | - | 32×32×128 |
| 残差块 | - | 32×32×128 |
| 反卷积层 | 2×2/2 | 64×64×64 |
| 反卷积层 | 2×2/2 | 128×128×32 |
| 反卷积层 | 2×2/2 | 256×256×3 |
| 注:“-”表示无相关数据。 | ||
表 2
残差块架构
Table 2
The structure of residual block
| 类型 | 卷积尺寸/步长 | 输出尺寸 |
| 卷积层 | 3×3/1 | 32×32×128 |
| 批归一化 | - | 32×32×128 |
| 卷积层 | 3×3/1 | 32×32×128 |
| 批归一化 | - | 32×32×128 |
| 注:“-”表示无相关数据。 | ||
3.3.2 掩膜网的设计
由于在未投影前不可能获取每幅投影图像的IRC,而且互反射强弱依赖于环境。为此,本研究采用一个掩膜网S(图 5(b))监督生成注意力图,该注意力图能够学习IRC的光照信息。掩膜网的架构非常简单,如表 3所示,由4个卷积层和1个残差块组成,对图像特征信息进行编码。同时利用两个卷积层对特征图进行上采样,得到256 × 256 × 1的输出。由于未经投影无法直接获得一幅投影图像的IRC,因此通过学习的方式获取待补偿图像的IRC。将掩膜网络的输出与训练集输入图像(相机拍摄的受互反射影响的图像)的IRC计算一个L1 + L2损失。经过训练,掩膜网络能够学习到图像中的高光部分以及可能受到投影互反射影响的部分,从而得到一个近似于IRC的掩膜。
表 3
掩膜网架构
Table 3
The structure of mask network
| 类型 | 卷积尺寸/步长 | 输出尺寸 |
| 输入层 | - | 256×256×3 |
| 卷积层 | 3×3/2 | 128×128×32 |
| 批归一化 | - | 128×128×32 |
| 卷积层 | 3×3/2 | 64×64×64 |
| 批归一化 | - | 64×64×64 |
| 卷积层 | 2×2/2 | 128×128×32 |
| 卷积层 | 2×2/2 | 256×256×3 |
| 注:“-”表示无相关数据。 | ||
3.4 基于注意力机制的互反射补偿
互反射补偿的目的是训练一个模型Tθ对输入图像进行补偿,以减弱甚至消除互反射。然而,不同区域互反射强度不同,许多情况互反射的全局补偿方案并不适用。本文对高亮度区域和低亮度区域进行不同关注,对不同区域进行差异化补偿。差异化补偿有两个关键点,一是高亮区域和低亮区域的定位,二是如何对背景和前景进行适当补偿。本文在IRC先验的基础上构建一个掩膜网S解决第1个问题。掩膜网生成高亮度区域和低亮度区域的掩膜。掩膜的生成过程为Mθ: Iin→ircback,ircpro=1-λ×ircback,其中,ircback是背景注意力图,ircpro是前景注意力图。注意力图中的像素点值进行了归一化处理,在0~1之间。将图像Iin输入到网络后,分别将前景的掩膜和背景的掩膜通过矩阵乘法运算获取前景网络和背景网络的相应部分,矩阵乘法运算用符号⊙表示。对于第2个问题,本文设置一个可学习的参数λ学习最优的补偿强度。
因此,将输入图像Iin输入掩膜网中,生成Iin对应的前景注意力图ircpro,将ircpro与前景网Tθpro生成图像Ipredpro作矩阵乘法得到前景部分。同样,对ircback和Ipredback作矩阵乘法得到背景部分。最后,将前景与背景部分相加得到最终的生成图像。由于自动学习的参数λ值不同,前景和背景会获得不同程度的补偿,具体为
| $ \begin{gathered} \boldsymbol{I}_{\text {pred }}=\lambda \times \boldsymbol{i r c}_{\mathrm{back}} \odot \boldsymbol{I}_{\text {pred }}^{\text {back }}+ \\ \left(1-\lambda \times \boldsymbol{i r c}_{\mathrm{back}}\right) \odot \boldsymbol{I}_{\text {pred }}^{\text {pro }} \end{gathered} $ | (11) |
| $ \boldsymbol{I}_{\text {pred }}^{\text {back }}=T_{\theta}^{\text {back }}\left(\boldsymbol{I}_{\text {cam }}\right) $ | (12) |
| $ \boldsymbol{I}_{\text {pred }}^{\text {pro }}=T_{\theta}^{\text {pro }}\left(\boldsymbol{I}_{\mathrm{cam}}\right) $ | (13) |
4 实验及评价指标
4.1 客观评价指标
采用传统的像素级别指标峰值信噪比(peak signal to noise ratio,PSNR)、结构相似性(structural similarity index,SSIM)和均方根误差(root mean square error,RMSE)等评价图像质量。由于曲面投影屏幕的几何变形不能得到准确校正,导致评价指标结果偏低,不能很好地反映光照的消除程度,因此在采用传统图像评价指标的同时,本文提出一种新的图像指标评价方式——感兴趣区域(region of interesting,ROI)分析。通过PSNR、SSIM、RMSE和ROI分析,共同说明方法的有效性。
ROI分析的基本思想是收集不同算法的投影图像,在每幅图像中选择几个相对平滑区域,计算区域均值和标准差。区域均值表示区域光照,标准方差描述区域质量。最后,将每个区域的方差绘制在图中与均值中点垂直的直线上。具体计算为
| $ \mu_{k}=\frac{1}{m n} \sum\limits_{i=1}^{m} \sum\limits_{j=1}^{n} x(i, j) $ | (14) |
| $ \delta_{k}=\sqrt{\frac{1}{m n} \sum\limits_{i=1}^{m} \sum\limits_{j=1}^{n}(x(i, j)-\mu)} $ | (15) |
式中,μk和δk为投影图像的第k个子区域的均值与方差,m和n是该子区域的高度和宽度。上述指标可以用来比较投影图像与原始图像的亮度差距和图像质量。
4.2 数据集
实验的投影仪—摄像系统由2 992 × 2 000像素分辨率的尼康DX VR相机和1 920 × 1 080像素分辨率的JMGO G7投影仪组成。相机与投影仪之间的距离为500 mm,投影仪前方有一个弧形屏幕,距离为800 mm。相机的白平衡模式、快门速度、感光度和对焦分别设置为自动、1/45、200和光圈值f = 5.6。为了模拟真实的沉浸式系统,排除全局光的影响,实验在黑暗环境中拍摄照片。
由于沉浸式投影系统的研究没有相应的公共数据集,本文使用相机拍摄图像,构建Cam-Pro数据集,包括5 000幅用于训练的256 × 256像素的RGB图像和800幅用于训练过程中进行网络拟合程度测试的图像。同时针对互反射补偿算法的特殊性,采集50幅色彩风格不同的图像用于算法最终补偿效果的客观指标测试。如图 5(a)所示,由于曲面屏上的投影图像总是伴有几何畸变,不能直接作为数据集,因此对上述数据中相机捕获的图像都进行几何校正(Huang等,2019a)。为了便于图像预处理,将采集的摄像机图像和原始图像统一下采样到1 920 × 1 080像素。如表 3,由于网络结构的输入层图像尺寸为256×256×3,因此需要将下采样图调整到256 × 256 × 3作为网络输入。
4.3 实现细节
实验在PyTorch框架下训练、20个epoch,batch-size为16,优化函数采用Adam函数,学习率由1E-3逐步提高到lE-4。
5 实验结果
5.1 对比现行方法
在ROI评价指标的基准上,与3种无注意力机制的方法,即Bimber等人(2006)方法、CompenNet方法和CompenNet++方法进行对比,视觉效果比较和ROI分析分别如图 6和图 7所示。


在比较方法中,Bimber等人(2006)的方法建立了真实投影环境的数学模型,将投影屏幕划分成n个子区域,并计算区域之间的互反射,该方法需要获得所有与环境有关的参数,如镜头畸变、表面反射和投影—相机对几何位置的细节信息,但在真实场景中,由于投影环境不同,这些参数很难保持不变,对实际使用会造成一些不便。本文提出的Pair-Net无论是视觉效果还是ROI分析,都比Bimber等人(2006)方法有明显改进。
为了说明互反射问题的难度和注意力机制的有效性,将Pair-Net与基于深度学习的端到端网络CompenNet和CompenNet++进行比较,3种模型在同一数据集上训练。CompenNet和Compennet++在不考虑不同区域不同光照强度情况下对投影图像进行全局补偿。观察这两个模型的结果,可以看到它们对输入图像进行了相同强度的补偿,可以很好地去除高亮区域的互反射,然而低亮区域太暗,图像色彩质量严重下降。从图 7的ROI分析可以看出,CompenNet与CompenNet++补偿图像的标准差异较大。而Pair-Net补偿的图像在区域均值和方差上都与原图更加接近,能够在很好地消除反射光的同时,得到更好的成像质量,在评价指标和视觉效果方面均优于CompenNet和CompenNet++。
不同方法的PSNR、SSIM和RMSE如表 4所示,计算方法为使用相机拍摄补偿图像的投影经几何矫正后与原图计算。从表 4可以看出,4种方法的PSNR和SSIM指标较原图均有比较显著的提升,说明互反射得到了消除,投影图像质量得到了增强。本文方法的PSNR和RMSE指标均优于其他方法,SSIM指标居于第3,未经补偿的图像投影和Bimber等人(2006)方法获得的SSIM指标较高,原因在于SSIM指标更注重考量图像的结构性和清晰程度,而本文方法以及基于深度学习的方法的图像都是经过网络生成的,在图像清晰度和结构相似性方面相较于原图有一定程度的失真,因此造成了SSIM指标偏低,但是在可接受范围内。
表 4
不同方法的质量评价
Table 4
The quantitative indexes of different methods
| 方法 | PSNR/dB | SSIM | RMSE |
| 未补偿 | 14.034 9 | 0.581 0 | 0.349 5 |
| CompenNet | 16.288 2 | 0.533 9 | 0.270 0 |
| CompenNet++ | 16.610 9 | 0.542 5 | 0.262 2 |
| Bimber等人(2006) | 15.511 4 | 0.596 6 | 0.297 9 |
| 本文 | 17.323 8 | 0.561 4 | 0.239 4 |
| 注:加粗字体表示各列最优结果。 | |||
5.2 单网络与双网络结构对比
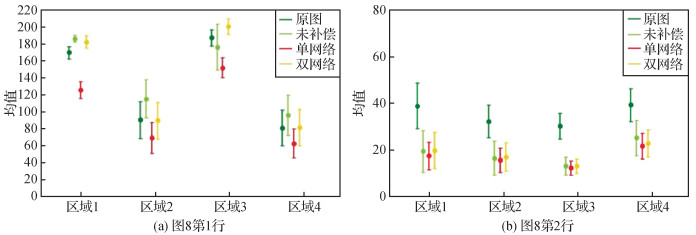
为了验证双子网络结构设计的有效性,设计了一个单补偿网模型进行对比,实验结果如图 8所示。可以看出,单网络模型无法在不同补偿强度下对高、低亮度区域进行自适应补偿,低亮度区域在投影图像中变得亮度极低,意味着不同亮度区域进行了同一强度的补偿,同时单网的色彩失真问题比较严重,这是由于单补偿网络的算法对全局采取一致性的补偿强度,造成不同区域间存在色差。而Pair-Net对不同区域采取不同补偿强度,能够得到正确的颜色。

图 8表明,双网络结构设计能有效消除沉浸式投影系统中的互反射,恢复投影图像的颜色和质量,相较于基于全局水平考虑的单网络设计,Pair-Net的双网络设计能够差异化对待不同亮度区域,提升图像质量,获得更加合适的色彩效果。单网络与双网络结构的ROI分析如图 9所示,可以看出,Pair-Net取得了与原始图像最接近的均值方差。
5.3 IRC先验的作用
注意力机制在Pair-Net中起着至关重要的作用,能够差异化补偿原图的高亮区域和低亮区域,提升最终补偿图像的质量。而IRC先验的作用是监督生成注意力图,提供有效的互反射分布信息。如果将注意力图ircback替换为全为1的掩膜,即将整幅图像标记为背景,则得到带有背景补偿强度的整幅图像补偿结果。如果ircback均为0,则Pair-Net将成为只考虑前景补偿强度的补偿结构。如果缺少IRC注意力图的监督,则暗区域会过度补偿,而高亮度区域补偿程度不够。
为了验证IRC先验监督和注意力机制的有效性,设计了一个明通道与IRC先验的对比实验。实验1采用原始投影图像的明通道作为注意力图的监督。明通道作为图像处理领域常用的算法,能够获取原始图像高亮度区域的掩膜。实验2采用IRC监督生成不同的前景和背景掩膜作为对照实验,IRC监督不仅考虑了原始图像的亮度信息,也学习沉浸式投影系统中的互反射信息。实验结果如图 10所示。可以看出,使用明通道不能很好地进行前景和背景的差异化补偿,导致投影图像颜色失真。观察图 10第2行可以发现,使用明通道作为监督的补偿图像的天空区域光照没有很好地消除。而Pair-Net针对高亮度的天空区域和低亮度的鹿区域进行了很好的差异化补偿,最终效果更加优秀。明通道与IRC先验的ROI分析如图 11所示,可以看出,IRC监督的互反射消除效果更好,图像质量优于明通道。


6 结论
本文基于注意力机制提出一种互反射补偿网络Pair-Net,解决了投影式虚拟现实系统中由于光照冗余反射造成图像质量下降问题。同时提出IRC先验,有效获取了投影图像中的高光区域以及原始图像的高光区域用于监督注意力图的生成,能够提升补偿效果。
Pair-Net基于IRC先验监督生成的注意力图,关注强互反射区域,对互反射较强的区域增强补偿效果,对较弱的互反射区或低亮区域在投影后使其光强保持在合适水平。实验数据集通过真实投影场景收集获得,测试数据在相同实验场景进行测试从而保证算法的有效性。与现有算法相比,本文算法的PSNR和RMSE指标获得最高分值,SSIM指标位居第二,ROI分析展示了本文算法在互反射消除上的优势。在人眼视觉感受上,本文提出的算法基本不存在严重色差,具有很好的人眼视觉感受。实验结果表明,本文方法在客观指标和视觉效果上均优于传统方法和基于CNN的光度补偿算法。
然而,本文算法存在一些局限,将在后续工作中进一步研究。首先,采用端到端的CNN网络进行补偿需要对齐的图像数据集。因此,对某些无法使用照相机收集到整个投影场景图像的虚拟现实设备,该方法需要进一步改进。其次,本文算法生成的图像一定程度上存在模糊问题,与传统算法相比,SSIM指标有所下降,因此,生成图像清晰度仍然有提升的空间。
参考文献
-
Ashdown M, Okabe T, Sato I and Sato Y. 2006. Robust content-dependent photometric projector compensation//Proceedings of 2006 Conference on Computer Vision and Pattern Recognition Workshop. New York, USA: IEEE: 4-6 [DOI: 10.1109/CVPRW.2006.172]
-
Bimber O, Grundhöfer A, Zeidler T, Danch D and Kapakos P. 2006. Compensating indirect scattering for immersive and semi-immersive projection displays//Proceedings of 2006 IEEE Virtual Reality Conference. Alexandria, USA: IEEE: 151-158 [DOI: 10.1109/VR.2006.34]
-
Chen L C, Yang Y, Wang J, Wei X and Yuille A L. 2016. Attention to scale: scale-aware semantic image segmentation//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE: 3640-3649 [DOI: 10.1109/CVPR.2016.396]
-
Grundhöfer A. 2013. Practical non-linear photometric projector compensation//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Portland, USA: IEEE: 924-929 [DOI: 10.1109/CVPRW.2013.136]
-
Grundhöfer A, Iwai D. 2015. Robust, error-tolerant photometric projector compensation. IEEE Transactions on Image Processing, 24(12): 5086-5099 [DOI:10.1109/TIP.2015.2478388]
-
Habe H, Saeki N and Matsuyama T. 2007. Inter-reflection compensation for immersive projection display//Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, USA: IEEE: 1-2 [DOI: 10.1109/CVPR.2007.383473]
-
Huang B Y and Ling H B. 2019a. CompenNet++: end-to-end full projector compensation//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE: 7164-7173 [DOI: 10.1109/ICCV.2019.00726]
-
Huang B Y and Ling H B. 2019b. End-to-end projector photometric compensation//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE: 6803-6812 [DOI: 10.1109/CVPR.2019.00697]
-
Kuen J, Wang Z H and Wang G. 2016. Recurrent attentional networks for saliency detection//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE: 3668-3677 [DOI: 10.1109/CVPR.2016.399]
-
Li J N, Wei Y C, Liang X D, Dong J, Xu T F, Feng J S, Yan S C. 2017. Attentive contexts for object detection. IEEE Transactions on Multimedia, 19(5): 944-954 [DOI:10.1109/TMM.2016.2642789]
-
Li Y Q, Yuan Q S and Lu D M. 2013. Perceptual radiometric compensation for inter-reflection in immersive projection environment//Proceedings of the 19th ACM Symposium on Virtual Reality Software and Technology. Singapore, Singapore: ACM: 201-208 [DOI: 10.1145/2503713.2503720]
-
Ma S L, Ma B K and Song M. 2012. Signal attenuation time series prediction method based on the chaos algorithm//Proceedings of 2012 International Symposium on Antennas, Propagation and EM Theory. Xi'an, China: IEEE: 802-806 [DOI: 10.1109/ISAPE.2012.6408893]
-
Mejjati Y A, Richardt C, Tompkin J, Cosker D and Kim K I. 2018. Unsupervised attention-guided image-to-image translation//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: ACM: 3697-3707
-
Ng R, Ramamoorthi R and Hanrahan P. 2003. All-frequency shadows using non-linear wavelet lighting approximation//ACM SIGGRAPH 2003 Papers. San Diego, USA: ACM: 376-381 [DOI: 10.1145/1201775.882280]
-
Ng T T, Pahwa R S, Bai J M, Tan K H, Ramamoorthi R. 2012. From the rendering equation to stratified light transport inversion. International Journal of Computer Vision, 96(2): 235-251 [DOI:10.1007/s11263-011-0467-6]
-
Ronneberger O, Fischer P and Brox T. 2015. U-Net: Convolutional networks for biomedical image segmentation//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich, Germany: Springer: 234-241 [DOI: 10.1007/978-3-319-24574-4_28]
-
Takeda S, Iwai D, Sato K. 2016. Inter-reflection compensation of immersive projection display by spatio-temporal screen reflectance modulation. IEEE Transactions on Visualization and Computer Graphics, 22(4): 1424-1431 [DOI:10.1109/TVCG.2016.2518136]
-
Wang J P, Dong Y, Tong X, Lin Z C, Guo B N. 2009. Kernel Nyström method for light transport. ACM Transactions on Graphics, 28(3): #29 [DOI:10.1145/1531326.1531335]
-
Xu H R, Guo J M, Liu Q and Ye L L. 2012. Fast image dehazing using improved dark channel prior//Proceedings of 2012 IEEE International Conference on Information Science and Technology. Wuhan, China: IEEE: 663-667 [DOI: 10.1109/ICIST.2012.6221729]
-
Zhao H, Gallo O, Frosio I, Kautz J. 2017. Loss functions for image restoration with neural networks. IEEE Transactions on Computational Imaging, 3(1): 47-57 [DOI:10.1109/tci.2016.2644865]
-
Zhu J Y, Park T and Isola P. 2010. Unpaired image-to-image translation using cycle-consistent adversarial networks//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 183-202 [DOI: 10.1109/ICCV.2017.244]
-
Zou W H, Xu H S, Han B, Park D. 2008. A novel methodology for photometric compensation of projection display on patterned screen. Chinese Optics Letters, 6(7): 499-501


