
最新刊期
卷 31 , 期 1 , 2026
Scholar View

- “#论文摘要#,介绍了其在人工智能领域的研究进展,xx专家探索了智能算法优化课题,为提升算法效率提供解决方案。”
- “介绍了其在人工智能安全与治理领域的研究进展,相关专家从多种维度对现有生成图像检测方法进行分类与分析,为解决生成图像检测难题提供了新思路。”
 摘要:In the era of rapid advancements in generative artificial intelligence, the explosive growth of artificial intelligence-generated content (AIGC), propelled by the widespread use of models such as ChatGPT and diffusion models, has given rise to significant challenges. The proliferation of false information, fraudulent content, and inappropriate remarks has severely undermined the authenticity and credibility of information dissemination, highlighting the urgent need for effective artificial intelligence-generated images (AIGI) detection. The detection of AIGI, which aims to determine whether an image is generated by a generative model, is a crucial research direction in the field of AI security and governance. Early detection methods focused on detecting the content generated by generative adversarial networks. In recent years, images generated by diffusion models have received extensive attention, and related detection methods have emerged, demonstrating superior performance. However, current detection methods still encounter difficulties in achieving high-generalization and robust detection performance due to the diversity of generative model structures, the complexity of generated images, and the uncertainty of post-processing operations on generated images. This comprehensive review aims to provide a thorough understanding of the research landscape in AIGI detection. The paper first commences with an in-depth exploration of mainstream image-generation models. Generative adversarial networks, with their adversarial training mechanism between generators and discriminators, have evolved through various architectures such as conditional GAN (CGAN), CycleGAN, and StyleGAN, each enhancing the controllability and quality of generated images. Autoregressive models, inspired by the success of GPT-series in natural language processing, such as Image GPT and DALL-E, leverage powerful attention mechanisms for image generation. Based on the principles of diffusion and reverse diffusion processes, diffusion models have demonstrated remarkable capabilities in generating high-quality images, leading to the emergence of numerous models such as Stable Diffusion and its variants in recent years. Understanding these models is fundamental because their unique characteristics leave identifiable patterns in the generated images, which detection methods aim to identify. Subsequently, existing AIGI detection methods are systematically categorized from multiple perspectives, including supervision paradigm, learning methods, detection basis, backbone network, technical means, and interpretability. In terms of the supervision paradigm, most methods are based on supervised detection, with some incorporating additional contrastive learning losses or regularization terms to improve performance. Though less common, semi-supervised and unsupervised detection methods also contribute to the field. Regarding learning methods, eager learning-based approaches, especially those that using binary classifiers, are dominant, while lazy learning-based methods, such as those relying on the K-nearest neighbors algorithm, offer an alternative without requiring extensive training. When categorized by detection basis, methods based on pixel-domain features use characteristics such as texture, color, and reconstruction error. Frequency domain-based methods detect AIGI through the analysis of unique frequency patterns of generated images, such as the spectrum replication caused by upsampling in GAN models. Methods based on pre-trained model features leverage the powerful feature extraction capabilities of large pre-trained models such as contrastive language-image pre-training(CLIP) and Vision Transformer. Fusion feature-based methods combine different types of features, either from single-modality (e.g., fusing pixel and frequency domain features) or multi-modality (e.g., integrating image and text features), to improve detection accuracy. In contrast, rule-based methods rely on differences in the sensitivity of real and generated images to certain operations for detection. According to backbone network, early studies rely on traditional machine learning models such as random forest, support vector machine, and logistic regression. Convolutional neural networks such as ResNet have later become increasingly popular due to their powerful capabilities on local features. With the advent of pre-trained large models, visual language models such as CLIP, masked autoencoder(MAE), and large language and vision assistant(LLaVa) are increasingly being used as backbone networks, often fine-tuned with techniques such as LoRA to adapt to the detection task. Aiming to enhance the efficiency and effectiveness of detection algorithms, various technical means are employed, including incremental learning, knowledge distillation, transfer learning, ensemble learning, and few-shot learning. Additionally, data augmentation methods such as JPEG compression, Gaussian blurring, and random flipping are used to increase the diversity of training samples and improve the generalization capability of the detection model. In terms of interpretability of detection methods, several techniques have been developed. Layer-wise relevance propagation analyzes the contribution of each layer in the neural network to the final decision, helping to understand model prediction. Genetic programming optimizes the model structure to improve interpretability. Local interpretable model-agnostic explanations clarifies model’s predictions at the local level without relying on the specific model structure. Grad-CAM generates visual explanations by highlighting the important regions in the image for the model’s decision-making. Using the detection basis as the main classification criterion, a detailed introduction and analysis of the research status are presented. A detailed summary of benchmark datasets for general AIGI detection is then provided. These datasets substantially vary in structure, scale, image content, and the types of generators they cover. Some datasets are designed for specific types of images or generators. For example, several datasets (such as Forensic Synthetics) are dedicated to GAN-generated image detection, while others (such as Synthbuster) focus on detecting images generated by diffusion models. Comprehensive datasets can also be used for detecting images generated by multiple types of generators. The diversity in datasets reflects the complexity of the AIGI detection task and the need for a standardized evaluation environment. Moreover, the evaluation dimensions of detection methods, namely in-domain accuracy, out-of-domain generalization, and robustness, are introduced in detail. In-domain accuracy is measured using metrics such as accuracy, precision, recall, and average precision, which measure the performance of detection methods on images generated by generative models included in the training set. In contrast, out-of-domain generalization evaluates the performance of detection methods on unknown generative models and categories outside the training set, which is crucial with the constant emergence of new generative models. This dimension is evaluated through cross-generator, cross-category, and other types of generalization tests. Robustness assesses the capability of detection methods to resist various image post-processing operations, including JPEG compression, Gaussian blurring, and adversarial sample attacks. Furthermore, a horizontal comparison of representative detection methods is conducted, and the results show that different methods exhibit diverse generalization capabilities. The choice of backbone network and training set substantially impacts detection results. For example, some methods perform better on specific generative models, while others demonstrate higher accuracy across multiple generative models. Detection methods based on fusion features generally exhibit superior performance in terms of detection accuracy and generalization. Finally, the paper highlights the challenges and open problems in the current AIGI detection field. These challenges include the construction of large-scale unbiased datasets, because the bias in existing training data can reduce the robustness and generalization of detection models. Designing robust detection methods against physical-level attacks, such as printing and social network-based image processing in real-world scenarios, is also necessary. Moreover, creating comprehensive detection methods that can effectively handle a variety of generative models is crucial to keep up with their rapid advancements. Additionally, research on anti-forensics attacks against detection methods is essential because it can help improve the resilience of detection techniques. Future research directions are outlined to address these challenges and drive the continuous development of AIGI detection technologies.关键词:artificial intelligence security;artificial intelligence-generated image(AIGI) detection;digital forensics;image forensics;DeepFake detection;image generative model;deep learning1144|512|0更新时间:2026-02-02
摘要:In the era of rapid advancements in generative artificial intelligence, the explosive growth of artificial intelligence-generated content (AIGC), propelled by the widespread use of models such as ChatGPT and diffusion models, has given rise to significant challenges. The proliferation of false information, fraudulent content, and inappropriate remarks has severely undermined the authenticity and credibility of information dissemination, highlighting the urgent need for effective artificial intelligence-generated images (AIGI) detection. The detection of AIGI, which aims to determine whether an image is generated by a generative model, is a crucial research direction in the field of AI security and governance. Early detection methods focused on detecting the content generated by generative adversarial networks. In recent years, images generated by diffusion models have received extensive attention, and related detection methods have emerged, demonstrating superior performance. However, current detection methods still encounter difficulties in achieving high-generalization and robust detection performance due to the diversity of generative model structures, the complexity of generated images, and the uncertainty of post-processing operations on generated images. This comprehensive review aims to provide a thorough understanding of the research landscape in AIGI detection. The paper first commences with an in-depth exploration of mainstream image-generation models. Generative adversarial networks, with their adversarial training mechanism between generators and discriminators, have evolved through various architectures such as conditional GAN (CGAN), CycleGAN, and StyleGAN, each enhancing the controllability and quality of generated images. Autoregressive models, inspired by the success of GPT-series in natural language processing, such as Image GPT and DALL-E, leverage powerful attention mechanisms for image generation. Based on the principles of diffusion and reverse diffusion processes, diffusion models have demonstrated remarkable capabilities in generating high-quality images, leading to the emergence of numerous models such as Stable Diffusion and its variants in recent years. Understanding these models is fundamental because their unique characteristics leave identifiable patterns in the generated images, which detection methods aim to identify. Subsequently, existing AIGI detection methods are systematically categorized from multiple perspectives, including supervision paradigm, learning methods, detection basis, backbone network, technical means, and interpretability. In terms of the supervision paradigm, most methods are based on supervised detection, with some incorporating additional contrastive learning losses or regularization terms to improve performance. Though less common, semi-supervised and unsupervised detection methods also contribute to the field. Regarding learning methods, eager learning-based approaches, especially those that using binary classifiers, are dominant, while lazy learning-based methods, such as those relying on the K-nearest neighbors algorithm, offer an alternative without requiring extensive training. When categorized by detection basis, methods based on pixel-domain features use characteristics such as texture, color, and reconstruction error. Frequency domain-based methods detect AIGI through the analysis of unique frequency patterns of generated images, such as the spectrum replication caused by upsampling in GAN models. Methods based on pre-trained model features leverage the powerful feature extraction capabilities of large pre-trained models such as contrastive language-image pre-training(CLIP) and Vision Transformer. Fusion feature-based methods combine different types of features, either from single-modality (e.g., fusing pixel and frequency domain features) or multi-modality (e.g., integrating image and text features), to improve detection accuracy. In contrast, rule-based methods rely on differences in the sensitivity of real and generated images to certain operations for detection. According to backbone network, early studies rely on traditional machine learning models such as random forest, support vector machine, and logistic regression. Convolutional neural networks such as ResNet have later become increasingly popular due to their powerful capabilities on local features. With the advent of pre-trained large models, visual language models such as CLIP, masked autoencoder(MAE), and large language and vision assistant(LLaVa) are increasingly being used as backbone networks, often fine-tuned with techniques such as LoRA to adapt to the detection task. Aiming to enhance the efficiency and effectiveness of detection algorithms, various technical means are employed, including incremental learning, knowledge distillation, transfer learning, ensemble learning, and few-shot learning. Additionally, data augmentation methods such as JPEG compression, Gaussian blurring, and random flipping are used to increase the diversity of training samples and improve the generalization capability of the detection model. In terms of interpretability of detection methods, several techniques have been developed. Layer-wise relevance propagation analyzes the contribution of each layer in the neural network to the final decision, helping to understand model prediction. Genetic programming optimizes the model structure to improve interpretability. Local interpretable model-agnostic explanations clarifies model’s predictions at the local level without relying on the specific model structure. Grad-CAM generates visual explanations by highlighting the important regions in the image for the model’s decision-making. Using the detection basis as the main classification criterion, a detailed introduction and analysis of the research status are presented. A detailed summary of benchmark datasets for general AIGI detection is then provided. These datasets substantially vary in structure, scale, image content, and the types of generators they cover. Some datasets are designed for specific types of images or generators. For example, several datasets (such as Forensic Synthetics) are dedicated to GAN-generated image detection, while others (such as Synthbuster) focus on detecting images generated by diffusion models. Comprehensive datasets can also be used for detecting images generated by multiple types of generators. The diversity in datasets reflects the complexity of the AIGI detection task and the need for a standardized evaluation environment. Moreover, the evaluation dimensions of detection methods, namely in-domain accuracy, out-of-domain generalization, and robustness, are introduced in detail. In-domain accuracy is measured using metrics such as accuracy, precision, recall, and average precision, which measure the performance of detection methods on images generated by generative models included in the training set. In contrast, out-of-domain generalization evaluates the performance of detection methods on unknown generative models and categories outside the training set, which is crucial with the constant emergence of new generative models. This dimension is evaluated through cross-generator, cross-category, and other types of generalization tests. Robustness assesses the capability of detection methods to resist various image post-processing operations, including JPEG compression, Gaussian blurring, and adversarial sample attacks. Furthermore, a horizontal comparison of representative detection methods is conducted, and the results show that different methods exhibit diverse generalization capabilities. The choice of backbone network and training set substantially impacts detection results. For example, some methods perform better on specific generative models, while others demonstrate higher accuracy across multiple generative models. Detection methods based on fusion features generally exhibit superior performance in terms of detection accuracy and generalization. Finally, the paper highlights the challenges and open problems in the current AIGI detection field. These challenges include the construction of large-scale unbiased datasets, because the bias in existing training data can reduce the robustness and generalization of detection models. Designing robust detection methods against physical-level attacks, such as printing and social network-based image processing in real-world scenarios, is also necessary. Moreover, creating comprehensive detection methods that can effectively handle a variety of generative models is crucial to keep up with their rapid advancements. Additionally, research on anti-forensics attacks against detection methods is essential because it can help improve the resilience of detection techniques. Future research directions are outlined to address these challenges and drive the continuous development of AIGI detection technologies.关键词:artificial intelligence security;artificial intelligence-generated image(AIGI) detection;digital forensics;image forensics;DeepFake detection;image generative model;deep learning1144|512|0更新时间:2026-02-02 -
 摘要:In recent years, the number of neural network models has increased rapidly, and artificial intelligence technology represented by neural networks has achieved great success in many application fields. Neural network models inherently contain considerable redundant information. This redundancy creates favorable conditions for hiding confidential data. Therefore, neural network models can be used as covers for covert communication. This new paradigm is called neural network model steganography (model steganography). The steganographer chooses the location where confidential information is embedded in the model and uses a key to embed the confidential information into the model for transmission. The receiver uses the shared key to extract the confidential information in the location where it is embedded. Model steganography is used for covert communication without detection. In recent years, neural network model steganography technology has made great progress. In practice, it can be applied in some scenarios, such as military defense or secret communication between intelligence agencies, embedding confidential information in the model training process or hiding secret tasks in the model. In command distribution, the commander intends to send different commands to multiple officers, or multiple officers send different messages to the commander. Using model steganography allows transferring confidential information without being detected. Meanwhile, by modifying model parameters, malicious developers can embed malicious software into the benign model, resulting in the loss of model users. Using neural network backdoor technology to poison the target model enables performing different tasks defined by the attackers without the users’ knowledge. Technologies related to model steganography include model watermarking and multimedia steganography based on a neural network model. The model watermark takes the neural network as the protection object and embeds the digital watermark in the model to protect the intellectual property rights of the model owner. The watermark information embedded in the model can be extracted correctly without affecting the normal use of the cover model and without deliberately concealing the existence of the watermark information. In addition, the embedding capacity can accommodate the watermark information, so there is no need to pursue large capacity. Multimedia steganography based on a neural network model takes multimedia data as covers and the neural network model as a tool for information embedding and extraction and uses the neural network in each stage of embedding and extraction to embed confidential information in multimedia data. In terms of concealment, model steganography has unique advantages compared with its related technologies. The steganography of the model is naturally hidden. The model itself is a complex set of high-dimensional parameters, so a small number of parameter disturbances in the model are difficult to detect. Model steganography is usually achieved by modifying redundant parameters, which will not affect the function of the model. Regarding embedding capacity, model steganography has the potential of supercapacity compared with its related technologies. Model steganography can use parameter redundancy to embed data, and the neural network has a large number of parameters, so it can embed substantial information even if the minimum proportion parameters are modified. In accordance with the different strategies of model steganography, the existing methods can be divided into three categories: model steganography based on training, modification, and backdoor technology. Most of the results of model steganography are training-based model steganography. The main idea of training-based model steganography is to embed confidential information in the process of the training model. In the hidden layer of the model, the sender first selects the weight used to embed the confidential information and then embeds the confidential information into the model under the key function through the training model. In the output layer, the model output is required to be as similar as the confidential information as possible, and the model weight is constantly updated under the guidance of the confidential information. The basic idea of model steganography based on modification is to modify the model parameters to match the confidential information to achieve the purpose of embedding confidential information. Malicious payloads can be embedded without significantly affecting the model performance by replacing malware bytes or mapping model parameters to hide malware in the model. At the sending end, malicious developers choose to modify the location of model parameters to embed malicious software into the model. At the receiving end, they determine the location where the malicious software is embedded in the model parameters, extract the malicious software, check the integrity, and run the malicious software. Model steganography based on backdoor technology uses backdoor technology. Attackers bury backdoors in the model, making the infected model behave normally in general. However, when the backdoor trigger is activated, the output of the model will become the malicious target set by the attacker in advance. This method poisons the target model and can extract additional information from the output of the model. For the analysis method of model steganalysis, on the basis of whether the steganalyzer needs to master the internal details of the neural network model, current model steganalysis algorithms can be classified as white and black box model steganalysis. White box model steganalysis means that the analyst has knowledge and access rights to the internal structure and parameters of the model to detect and analyze the confidential information hidden in the model. Black box model steganalysis treats the target model as a “black box”, without accessing its internal structure and weight parameter details, to detect and analyze whether the model contains secret. To review the latest developments and trends, this study analyzes advanced methodologies in model steganography as follows: 1) it introduces the purpose and goal of model steganography, as well as its basic concepts, evaluation indicators, and technology classification. 2) The development status of model steganography is summarized and analyzed. 3) The advantages and disadvantages are compared and evaluated. 4) The development trend of model steganography is explored.关键词:steganography;model steganography;steganalysis;neural network;information hiding232|163|0更新时间:2026-02-02
摘要:In recent years, the number of neural network models has increased rapidly, and artificial intelligence technology represented by neural networks has achieved great success in many application fields. Neural network models inherently contain considerable redundant information. This redundancy creates favorable conditions for hiding confidential data. Therefore, neural network models can be used as covers for covert communication. This new paradigm is called neural network model steganography (model steganography). The steganographer chooses the location where confidential information is embedded in the model and uses a key to embed the confidential information into the model for transmission. The receiver uses the shared key to extract the confidential information in the location where it is embedded. Model steganography is used for covert communication without detection. In recent years, neural network model steganography technology has made great progress. In practice, it can be applied in some scenarios, such as military defense or secret communication between intelligence agencies, embedding confidential information in the model training process or hiding secret tasks in the model. In command distribution, the commander intends to send different commands to multiple officers, or multiple officers send different messages to the commander. Using model steganography allows transferring confidential information without being detected. Meanwhile, by modifying model parameters, malicious developers can embed malicious software into the benign model, resulting in the loss of model users. Using neural network backdoor technology to poison the target model enables performing different tasks defined by the attackers without the users’ knowledge. Technologies related to model steganography include model watermarking and multimedia steganography based on a neural network model. The model watermark takes the neural network as the protection object and embeds the digital watermark in the model to protect the intellectual property rights of the model owner. The watermark information embedded in the model can be extracted correctly without affecting the normal use of the cover model and without deliberately concealing the existence of the watermark information. In addition, the embedding capacity can accommodate the watermark information, so there is no need to pursue large capacity. Multimedia steganography based on a neural network model takes multimedia data as covers and the neural network model as a tool for information embedding and extraction and uses the neural network in each stage of embedding and extraction to embed confidential information in multimedia data. In terms of concealment, model steganography has unique advantages compared with its related technologies. The steganography of the model is naturally hidden. The model itself is a complex set of high-dimensional parameters, so a small number of parameter disturbances in the model are difficult to detect. Model steganography is usually achieved by modifying redundant parameters, which will not affect the function of the model. Regarding embedding capacity, model steganography has the potential of supercapacity compared with its related technologies. Model steganography can use parameter redundancy to embed data, and the neural network has a large number of parameters, so it can embed substantial information even if the minimum proportion parameters are modified. In accordance with the different strategies of model steganography, the existing methods can be divided into three categories: model steganography based on training, modification, and backdoor technology. Most of the results of model steganography are training-based model steganography. The main idea of training-based model steganography is to embed confidential information in the process of the training model. In the hidden layer of the model, the sender first selects the weight used to embed the confidential information and then embeds the confidential information into the model under the key function through the training model. In the output layer, the model output is required to be as similar as the confidential information as possible, and the model weight is constantly updated under the guidance of the confidential information. The basic idea of model steganography based on modification is to modify the model parameters to match the confidential information to achieve the purpose of embedding confidential information. Malicious payloads can be embedded without significantly affecting the model performance by replacing malware bytes or mapping model parameters to hide malware in the model. At the sending end, malicious developers choose to modify the location of model parameters to embed malicious software into the model. At the receiving end, they determine the location where the malicious software is embedded in the model parameters, extract the malicious software, check the integrity, and run the malicious software. Model steganography based on backdoor technology uses backdoor technology. Attackers bury backdoors in the model, making the infected model behave normally in general. However, when the backdoor trigger is activated, the output of the model will become the malicious target set by the attacker in advance. This method poisons the target model and can extract additional information from the output of the model. For the analysis method of model steganalysis, on the basis of whether the steganalyzer needs to master the internal details of the neural network model, current model steganalysis algorithms can be classified as white and black box model steganalysis. White box model steganalysis means that the analyst has knowledge and access rights to the internal structure and parameters of the model to detect and analyze the confidential information hidden in the model. Black box model steganalysis treats the target model as a “black box”, without accessing its internal structure and weight parameter details, to detect and analyze whether the model contains secret. To review the latest developments and trends, this study analyzes advanced methodologies in model steganography as follows: 1) it introduces the purpose and goal of model steganography, as well as its basic concepts, evaluation indicators, and technology classification. 2) The development status of model steganography is summarized and analyzed. 3) The advantages and disadvantages are compared and evaluated. 4) The development trend of model steganography is explored.关键词:steganography;model steganography;steganalysis;neural network;information hiding232|163|0更新时间:2026-02-02 - “深度神经网络在各领域广泛应用,但对抗样本威胁其可靠性和安全性。专家将对抗攻击技术分为白盒和黑盒攻击,详细介绍了对抗防御策略,为提升深度神经网络安全性提供解决方案。”
 摘要:Due to their excellent performance, deep neural networks are increasingly utilized in various aspects of daily life, playing a crucial role in decision-making and providing assistance across various fields. However, the discovery of adversarial example poses a considerable threat to the reliability and security of deep neural networks, markedly limiting their application in safety-critical areas. Therefore, in recent years, researchers have conducted extensive studies on adversarial examples. This paper first introduces the research background and definitions related to adversarial examples, and categorizes existing adversarial attack techniques into white-box and black-box attacks. White-box attacks assume full transparency of the target model during the generation of adversarial examples, where the attack algorithm has access to the model’s architecture, parameters, loss function, and gradients to craft adversarial examples. Black-box attacks refer to scenarios where the target model is treated as opaque during the generation of adversarial examples. The attack algorithm has no access to internal information, such as the model’s architecture or parameters, and can only interact with the model through input-output queries. In contrast, white-box attacks can be categorized into three types based on their approach: optimization-based, gradient-based, and generation-based attacks. Specifically, optimization-based attacks formulate the generation of adversarial examples as a constrained optimization problem, which is approximately solved using optimization algorithms. Their main advantage lies in realizing high attack success rates with relatively small perturbations; however, they often incur substantial computational and time costs. Gradient-based attacks generate adversarial examples by computing perturbations in the direction of the loss function’s gradient, scaled by a predefined step size. These methods notably improve the efficiency of adversarial example generation but require continuous access to the model’s gradients. Meanwhile, generation-based attacks aim to produce adversarial examples by designing and training a generative model to attack the target model. Once trained, the generative model can efficiently generate adversarial examples without requiring access to the gradients or internal parameters of the target model, making it highly suitable for large-scale adversarial example generation. Black-box attacks can be categorized into two types: transfer-based and query-based attacks. Specifically, transfer-based attacks exploit the transferability of adversarial examples across different models by generating adversarial inputs against a surrogate model, which are then used to attack the target black-box model. The main advantage of this approach is that it does not require access to the target model or its internal information, resulting in low computational cost. However, differences between the surrogate and target models can lead to instability in attack performance. Query-based attacks work by gradually refining adversarial examples through repeated interactions with the target model. By submitting inputs and analyzing the corresponding outputs, these attacks aim to mislead the model without requiring any knowledge of its internal architecture. While they often achieve high success rates, their efficiency is hindered by the substantial number of queries required. With the continuous development of adversarial example generation algorithms, an increasing number of defense methods have emerged. The most widely adopted defense techniques can generally be categorized into three groups: adversarial training, adversarial detection, and adversarial denoising. Specifically, adversarial training is considered one of the most effective defense strategies against adversarial attacks. This training involves incorporating adversarial examples into the training process of the target model to enhance its robustness against adversarial perturbations. This approach is generally applicable and does not rely on specific attack methods; however, it suffers from high computational cost. In contrast to adversarial training, adversarial detection does not adjust the parameters of the target model. Instead, this detection introduces an auxiliary classifier to determine whether an input is an adversarial example. This approach offers good integrability with existing models; however, its generalization capability is often limited. Unlike adversarial training and adversarial detection, adversarial denoising focuses on eliminating adversarial perturbations from input data to prevent them from misleading the target model. The main advantage of adversarial denoising lies in the potential to restore adversarial examples to their original form; however, this process can occasionally degrade the quality of clean, unaltered inputs. Adversarial example techniques not only reveal the vulnerabilities of deep learning models but also inspire innovative applications in security-sensitive tasks. For instance, adversarial perturbations have been utilized to enhance system resilience in scenarios such as adversarial steganography, adversarial watermarking, model protection, and multimedia authentication. These cross-task explorations introduce new directions for adversarial example research and contribute to improving the practical deployment of artificial intelligence (AI) systems in complex environments. Therefore, this paper reviews various applications of adversarial examples within the fields of steganography and digital watermarking. Furthermore, a diverse set of adversarial example generation methods is selected and systematically evaluated in terms of attack success rate, robustness, and transferability across different target network architectures and benchmark datasets, including Caltech-256 and ImageNet. Finally, the study identifies current limitations in existing adversarial example research and highlights promising directions for future exploration, such as cross-domain adversarial attacks, robustness evaluation, real-world attack scenarios, and the development of systematic defense frameworks.关键词:adversarial example(AE);adversarial attack;adversarial defense;adversarial steganography;adversarial watermark600|270|0更新时间:2026-02-02
摘要:Due to their excellent performance, deep neural networks are increasingly utilized in various aspects of daily life, playing a crucial role in decision-making and providing assistance across various fields. However, the discovery of adversarial example poses a considerable threat to the reliability and security of deep neural networks, markedly limiting their application in safety-critical areas. Therefore, in recent years, researchers have conducted extensive studies on adversarial examples. This paper first introduces the research background and definitions related to adversarial examples, and categorizes existing adversarial attack techniques into white-box and black-box attacks. White-box attacks assume full transparency of the target model during the generation of adversarial examples, where the attack algorithm has access to the model’s architecture, parameters, loss function, and gradients to craft adversarial examples. Black-box attacks refer to scenarios where the target model is treated as opaque during the generation of adversarial examples. The attack algorithm has no access to internal information, such as the model’s architecture or parameters, and can only interact with the model through input-output queries. In contrast, white-box attacks can be categorized into three types based on their approach: optimization-based, gradient-based, and generation-based attacks. Specifically, optimization-based attacks formulate the generation of adversarial examples as a constrained optimization problem, which is approximately solved using optimization algorithms. Their main advantage lies in realizing high attack success rates with relatively small perturbations; however, they often incur substantial computational and time costs. Gradient-based attacks generate adversarial examples by computing perturbations in the direction of the loss function’s gradient, scaled by a predefined step size. These methods notably improve the efficiency of adversarial example generation but require continuous access to the model’s gradients. Meanwhile, generation-based attacks aim to produce adversarial examples by designing and training a generative model to attack the target model. Once trained, the generative model can efficiently generate adversarial examples without requiring access to the gradients or internal parameters of the target model, making it highly suitable for large-scale adversarial example generation. Black-box attacks can be categorized into two types: transfer-based and query-based attacks. Specifically, transfer-based attacks exploit the transferability of adversarial examples across different models by generating adversarial inputs against a surrogate model, which are then used to attack the target black-box model. The main advantage of this approach is that it does not require access to the target model or its internal information, resulting in low computational cost. However, differences between the surrogate and target models can lead to instability in attack performance. Query-based attacks work by gradually refining adversarial examples through repeated interactions with the target model. By submitting inputs and analyzing the corresponding outputs, these attacks aim to mislead the model without requiring any knowledge of its internal architecture. While they often achieve high success rates, their efficiency is hindered by the substantial number of queries required. With the continuous development of adversarial example generation algorithms, an increasing number of defense methods have emerged. The most widely adopted defense techniques can generally be categorized into three groups: adversarial training, adversarial detection, and adversarial denoising. Specifically, adversarial training is considered one of the most effective defense strategies against adversarial attacks. This training involves incorporating adversarial examples into the training process of the target model to enhance its robustness against adversarial perturbations. This approach is generally applicable and does not rely on specific attack methods; however, it suffers from high computational cost. In contrast to adversarial training, adversarial detection does not adjust the parameters of the target model. Instead, this detection introduces an auxiliary classifier to determine whether an input is an adversarial example. This approach offers good integrability with existing models; however, its generalization capability is often limited. Unlike adversarial training and adversarial detection, adversarial denoising focuses on eliminating adversarial perturbations from input data to prevent them from misleading the target model. The main advantage of adversarial denoising lies in the potential to restore adversarial examples to their original form; however, this process can occasionally degrade the quality of clean, unaltered inputs. Adversarial example techniques not only reveal the vulnerabilities of deep learning models but also inspire innovative applications in security-sensitive tasks. For instance, adversarial perturbations have been utilized to enhance system resilience in scenarios such as adversarial steganography, adversarial watermarking, model protection, and multimedia authentication. These cross-task explorations introduce new directions for adversarial example research and contribute to improving the practical deployment of artificial intelligence (AI) systems in complex environments. Therefore, this paper reviews various applications of adversarial examples within the fields of steganography and digital watermarking. Furthermore, a diverse set of adversarial example generation methods is selected and systematically evaluated in terms of attack success rate, robustness, and transferability across different target network architectures and benchmark datasets, including Caltech-256 and ImageNet. Finally, the study identifies current limitations in existing adversarial example research and highlights promising directions for future exploration, such as cross-domain adversarial attacks, robustness evaluation, real-world attack scenarios, and the development of systematic defense frameworks.关键词:adversarial example(AE);adversarial attack;adversarial defense;adversarial steganography;adversarial watermark600|270|0更新时间:2026-02-02 - “相关专家针对AIGC技术生成的高逼真伪造人脸视频问题,构建了面向中文场景的量化评估基准,建立了CHN-DF数据集,为推动防伪检测技术迭代发展提供数据支撑与实践指导。”
 摘要:ObjectiveThe rapid advancement of AI-generated content (AIGC) technologies has enabled the creation of hyper-realistic synthetic face videos, posing unprecedented challenges to human visual perception systems. While existing face anti-spoofing detection algorithms demonstrate promising performance on Western-centric datasets, their effectiveness and applicability remain unverified in Chinese-specific contexts due to the lack of standardized evaluation benchmarks. This study aims to establish a quantitative assessment framework tailored for Chinese scenarios, driving the iterative development of anti-spoofing technologies.MethodAiming to address this issue, the CHN-DF dataset, the first large-scale benchmark dedicated to Chinese face video forgery detection, is proposed. The dataset construction process involves several critical stages, including data collection, fake sample generation, and quality assessment. Data collection was conducted in complex environmental settings, such as varying lighting conditions and occlusions, ensuring the diverse and challenging nature of the dataset. Over 190 000 dialogue clips from 2 540 real Chinese identity videos were collected across multiple sources, ensuring rich dataset variability. Twelve advanced AIGC tools that incorporate mainstream and cutting-edge methods based on diffusion, generative adversarial networks(GANs), and hybrid architectures are employed to generate the forged samples. These tools produced 434 727 mixed fake samples, covering seven types of manipulation techniques, such as expression transfer, lip-sync tampering, and audiovisual dissonance. Aiming to ensure data quality and integrity, human perception and automated detection techniques were employed in a dual-layer quality control process. This approach included an assessment framework that considers visual and auditory modalities to create a comprehensive evaluation standard that reflects the challenges encountered by anti-spoofing models in real-world applications. A system-level evaluation benchmark based on deep learning detection models was developed to further enhance the effectiveness of the dataset. This benchmark spans a variety of deepfake detection models, including state-of-the-art (SOTA) and widely used algorithms, to test the robustness and generalization capabilities of these models across different environmental and contextual factors. The goal was to test the adaptability of the detection algorithms to the complexities presented by the CHN-DF dataset.ResultThe CHN-DF dataset, which represents the world’s first Chinese language-based face video anti-spoofing dataset, contains a total of 434 727 samples. This dataset is designed to be diverse and complex, posing substantial challenges for current deepfake detection algorithms. In experimental evaluations using 16 different models, including SOTA and mainstream anti-spoofing models, the accuracy of detecting deepfake faces in this dataset was found to be lower than expected, thereby highlighting task complexity. Specifically, the accuracy for visual and audiovisual combined tests was below 85% and 70%, respectively. These results indicate the increased difficulty in accurately detecting deepfake faces in the CHN-DF dataset, demonstrating that current models are still far from perfect. Further analysis revealed the effectiveness of the evaluation benchmark in highlighting the limitations of existing algorithms. In cross-domain generalization tests, the performance of models fluctuated by an average of 19.6%, indicating substantial variations in model accuracy across different scenarios. This variability emphasizes the need for robust and adaptable algorithms that can handle diverse environmental conditions and complex manipulations in the CHN-DF dataset. Moreover, the evaluation benchmark demonstrated the need for integrating visual and auditory modalities for face video anti-spoofing detection. In numerous cases, models that relied solely on visual features failed to accurately detect fake videos, highlighting the importance of incorporating multimodal features for improved detection accuracy.ConclusionThe CHN-DF dataset and its associated evaluation benchmark effectively fill a critical gap in the field of face video anti-spoofing detection for Chinese language scenarios. Using systematic experimentation, this research clarifies the relationship between dataset characteristics and algorithm performance, elucidating the underlying mechanisms that contribute to the challenges faced by current models. Based on these findings, a roadmap for future improvements in the field is proposed, focusing on key directions such as enhancing model robustness and improving cross-modal generalization capabilities. These insights are crucial for the practical deployment of face video anti-spoofing detection technologies, offering theoretical support and practical guidance for future development. The CHN-DF dataset and evaluation protocol have been made publicly available on GitHub at https://github.com/HengruiLou/CHN-DF, serving as a valuable resource for researchers and practitioners in the field. This dataset serves not only as a technical reference but also as a catalyst for global collaboration in the fight against sophisticated, culturally specific deepfake threats. Future work will extend the dataset to include minority dialects. The dataset is linked at https://doi.org/10.57760/sciencedb.j00240.00067 and https://github.com/HengruiLou/CHN-DF.关键词:deepfake;deepfake face videos;face forgery evaluation benchmark;chinese dataset;multimodal186|199|0更新时间:2026-02-02
摘要:ObjectiveThe rapid advancement of AI-generated content (AIGC) technologies has enabled the creation of hyper-realistic synthetic face videos, posing unprecedented challenges to human visual perception systems. While existing face anti-spoofing detection algorithms demonstrate promising performance on Western-centric datasets, their effectiveness and applicability remain unverified in Chinese-specific contexts due to the lack of standardized evaluation benchmarks. This study aims to establish a quantitative assessment framework tailored for Chinese scenarios, driving the iterative development of anti-spoofing technologies.MethodAiming to address this issue, the CHN-DF dataset, the first large-scale benchmark dedicated to Chinese face video forgery detection, is proposed. The dataset construction process involves several critical stages, including data collection, fake sample generation, and quality assessment. Data collection was conducted in complex environmental settings, such as varying lighting conditions and occlusions, ensuring the diverse and challenging nature of the dataset. Over 190 000 dialogue clips from 2 540 real Chinese identity videos were collected across multiple sources, ensuring rich dataset variability. Twelve advanced AIGC tools that incorporate mainstream and cutting-edge methods based on diffusion, generative adversarial networks(GANs), and hybrid architectures are employed to generate the forged samples. These tools produced 434 727 mixed fake samples, covering seven types of manipulation techniques, such as expression transfer, lip-sync tampering, and audiovisual dissonance. Aiming to ensure data quality and integrity, human perception and automated detection techniques were employed in a dual-layer quality control process. This approach included an assessment framework that considers visual and auditory modalities to create a comprehensive evaluation standard that reflects the challenges encountered by anti-spoofing models in real-world applications. A system-level evaluation benchmark based on deep learning detection models was developed to further enhance the effectiveness of the dataset. This benchmark spans a variety of deepfake detection models, including state-of-the-art (SOTA) and widely used algorithms, to test the robustness and generalization capabilities of these models across different environmental and contextual factors. The goal was to test the adaptability of the detection algorithms to the complexities presented by the CHN-DF dataset.ResultThe CHN-DF dataset, which represents the world’s first Chinese language-based face video anti-spoofing dataset, contains a total of 434 727 samples. This dataset is designed to be diverse and complex, posing substantial challenges for current deepfake detection algorithms. In experimental evaluations using 16 different models, including SOTA and mainstream anti-spoofing models, the accuracy of detecting deepfake faces in this dataset was found to be lower than expected, thereby highlighting task complexity. Specifically, the accuracy for visual and audiovisual combined tests was below 85% and 70%, respectively. These results indicate the increased difficulty in accurately detecting deepfake faces in the CHN-DF dataset, demonstrating that current models are still far from perfect. Further analysis revealed the effectiveness of the evaluation benchmark in highlighting the limitations of existing algorithms. In cross-domain generalization tests, the performance of models fluctuated by an average of 19.6%, indicating substantial variations in model accuracy across different scenarios. This variability emphasizes the need for robust and adaptable algorithms that can handle diverse environmental conditions and complex manipulations in the CHN-DF dataset. Moreover, the evaluation benchmark demonstrated the need for integrating visual and auditory modalities for face video anti-spoofing detection. In numerous cases, models that relied solely on visual features failed to accurately detect fake videos, highlighting the importance of incorporating multimodal features for improved detection accuracy.ConclusionThe CHN-DF dataset and its associated evaluation benchmark effectively fill a critical gap in the field of face video anti-spoofing detection for Chinese language scenarios. Using systematic experimentation, this research clarifies the relationship between dataset characteristics and algorithm performance, elucidating the underlying mechanisms that contribute to the challenges faced by current models. Based on these findings, a roadmap for future improvements in the field is proposed, focusing on key directions such as enhancing model robustness and improving cross-modal generalization capabilities. These insights are crucial for the practical deployment of face video anti-spoofing detection technologies, offering theoretical support and practical guidance for future development. The CHN-DF dataset and evaluation protocol have been made publicly available on GitHub at https://github.com/HengruiLou/CHN-DF, serving as a valuable resource for researchers and practitioners in the field. This dataset serves not only as a technical reference but also as a catalyst for global collaboration in the fight against sophisticated, culturally specific deepfake threats. Future work will extend the dataset to include minority dialects. The dataset is linked at https://doi.org/10.57760/sciencedb.j00240.00067 and https://github.com/HengruiLou/CHN-DF.关键词:deepfake;deepfake face videos;face forgery evaluation benchmark;chinese dataset;multimodal186|199|0更新时间:2026-02-02 - “相关专家在图像和视频合成检测领域取得新进展,提出融合物理与深度学习的检测方法,创新结合光照和阴影一致性分析,有效提升检测精度和适应性,为合成内容检测提供新思路。”
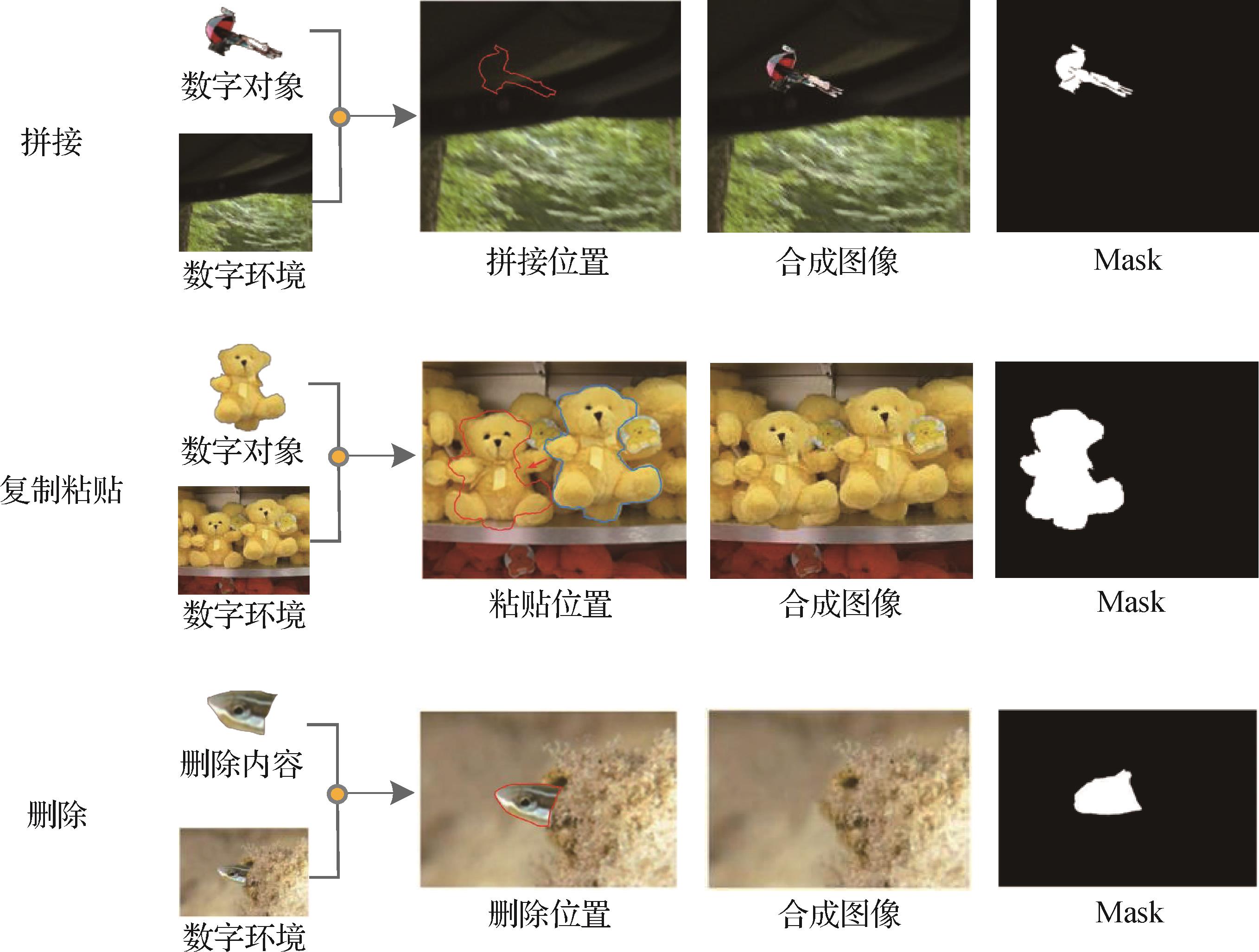 摘要:ObjectiveSynthesis and forgery of media content such as images and videos have become common methods in media post-production. As the technical barriers gradually decrease, the Internet is disseminated with a large amount of synthetic materials. This situation introduces great challenges to the integrity and security of digital media, which affects the authenticity and safety of audiovisual content. In the realm of synthetic media detection, research has greatly increased in recent years. Most commonly used detection methods focus on physical attributes or directly utilize deep neural networks for detection. Image forgery detection methods based on physical attributes can be broadly divided into those that utilize physical features and those that employ deep neural networks. Methods relying on physical features identify visual inconsistencies in images. These methods leverage the fact that synthetic images are often composed of multiple stitched images, which can result in irregularities in lighting, shadows, depth of field, and object distance. Inconsistency detection involves examining inherent physical properties such as lighting and shadows to assess their coherence. Lighting detection methods primarily analyze factors such as light source position, chromatic deviation, object reflectivity, light source color, and local light sources. Shadow detection methods focus on properties such as planar homology, shadow constraints, vanishing point positions for light and shadow, and consistency in geometric relationships. However, due to the diverse and complex environments in which images are acquired, the high precision required by these physical detection methods causes difficulty in relying solely on a single approach for forgery detection in real-world scenarios. In image forgery detection methods based on deep neural networks, some approaches use long short-term memory (LSTM), dual stream parallel network, pyramid architectures, and Transformers to conduct synthesis detection by identifying anomalies in local regions between image blocks while locating synthesized areas. While these methods have demonstrated certain levels of success in experimental settings, the relentless advancement in synthesis technology has resulted in synthetic images that are increasingly indistinguishable from authentic ones. As a result, detection methods relying solely on visual anomalies or signs of synthesis can no longer meet the growing demands for accuracy in detection.MethodWe present a novel approach called the lighting and shadow fusion network (LSFNet) to image forgery detection based on the consistency of lighting and shadows. It combines highly sensitive physical attribute detection with robust deep neural network techniques, which improves the capability to identify even the most meticulously crafted synthetic images. LSFNet comprises key modules, including illumination maps, object and shadow estimation, illumination analysis, and homogeneity analysis. Its goal is to integrate physical detection methods including illumination and shadow with deep neural network techniques for effective detection of well-crafted synthetic images. The method begins by creating an illumination map that labels the object and shadow areas, which results in a boundary illumination map formed by overlapping the illumination map with the object area. This study employs a feature extraction network to derive features from the boundary illumination map and the original image. As a result, a feature fusion network for consistency analysis of the illumination map and light intensity is established to determine the shooting environment of objects within the image. It estimates distances for objects and shadows using cross-ratio for homogeneous vertex estimation to ensure consistent detection of lighting direction in images. Finally, this study utilizes result fusion methods to comprehensively evaluate lighting analysis results and homogeneity analysis results to predict outcomes for synthetic images. Recognizing that existing datasets for synthetic image detection often lack detailed information regarding physical attributes, we introduce a new dataset designed to assist in detecting synthetic images by incorporating essential characteristics such as lighting conditions and object distances crucial for accurately identifying forgery in the complex digital media landscape at present.ResultExperiments conducted on the NIST 16 (National Institute of Standards and Technology Database 16), Coverage, and CASIA (Chinese Academy of Sciences Institute of Automation Database) datasets demonstrate that our method achieves AUC (area under the curve) scores of 94.2%, 93.6%, and 90.3%, respectively, and F1 scores of 80.2%, 79.3%, and 58.1%, outperforming the compared methods. In noise attack experiments, our method exhibits stronger adaptability to size variation, Gaussian blur, Gaussian noise, and JPEG (Joint Photographic Experts Group) compression, with an average AUC of 84.03%.ConclusionThe contributions of this study are summarized as follows: 1) we propose a versatile image forgery detection framework for high-fidelity synthetic images, which is called LSFNet. This framework integrates deep neural networks with physical detection methods and combines boundary lighting map detection and physical attribute consistency analysis. Experimental results show that our method outperforms mainstream techniques in accuracy and demonstrates robustness, which makes it suitable for various synthetic image detection tasks; 2) We present a shadow extraction and consistency analysis method tailored for image forgery detection. This approach, which utilizes Mask R-CNN as the backbone network for shadow prediction, models the relationship between shadow regions and real object areas. By assessing consistency through intersection over union, it significantly enhances the accuracy of image forgery detection; 3) We introduce a synthetic image detection dataset featuring physical attributes such as light source position, color temperature, camera position, object distance, depth of field, and complex backgrounds. The dataset is called the synthetic image physical properties detection dataset. This dataset comprises 22 203 images——15 012 collected images and 7 191 synthetically generated ones——all meticulously crafted by professionals to ensure high realism. The dataset maintains a training-validation-testing split of 7∶2∶1. It includes various synthesis methods such as stitching, copy-pasting, and deletion to effectively support training testing and optimization upgrades for image forgery detection models. The dataset is linked at: https://doi.org/10.57760/sciencedb.j00240.00069.关键词:Synthetic image detection;Illumination detection;shadow detection;detection dataset;artificial intelligence security241|283|0更新时间:2026-02-02
摘要:ObjectiveSynthesis and forgery of media content such as images and videos have become common methods in media post-production. As the technical barriers gradually decrease, the Internet is disseminated with a large amount of synthetic materials. This situation introduces great challenges to the integrity and security of digital media, which affects the authenticity and safety of audiovisual content. In the realm of synthetic media detection, research has greatly increased in recent years. Most commonly used detection methods focus on physical attributes or directly utilize deep neural networks for detection. Image forgery detection methods based on physical attributes can be broadly divided into those that utilize physical features and those that employ deep neural networks. Methods relying on physical features identify visual inconsistencies in images. These methods leverage the fact that synthetic images are often composed of multiple stitched images, which can result in irregularities in lighting, shadows, depth of field, and object distance. Inconsistency detection involves examining inherent physical properties such as lighting and shadows to assess their coherence. Lighting detection methods primarily analyze factors such as light source position, chromatic deviation, object reflectivity, light source color, and local light sources. Shadow detection methods focus on properties such as planar homology, shadow constraints, vanishing point positions for light and shadow, and consistency in geometric relationships. However, due to the diverse and complex environments in which images are acquired, the high precision required by these physical detection methods causes difficulty in relying solely on a single approach for forgery detection in real-world scenarios. In image forgery detection methods based on deep neural networks, some approaches use long short-term memory (LSTM), dual stream parallel network, pyramid architectures, and Transformers to conduct synthesis detection by identifying anomalies in local regions between image blocks while locating synthesized areas. While these methods have demonstrated certain levels of success in experimental settings, the relentless advancement in synthesis technology has resulted in synthetic images that are increasingly indistinguishable from authentic ones. As a result, detection methods relying solely on visual anomalies or signs of synthesis can no longer meet the growing demands for accuracy in detection.MethodWe present a novel approach called the lighting and shadow fusion network (LSFNet) to image forgery detection based on the consistency of lighting and shadows. It combines highly sensitive physical attribute detection with robust deep neural network techniques, which improves the capability to identify even the most meticulously crafted synthetic images. LSFNet comprises key modules, including illumination maps, object and shadow estimation, illumination analysis, and homogeneity analysis. Its goal is to integrate physical detection methods including illumination and shadow with deep neural network techniques for effective detection of well-crafted synthetic images. The method begins by creating an illumination map that labels the object and shadow areas, which results in a boundary illumination map formed by overlapping the illumination map with the object area. This study employs a feature extraction network to derive features from the boundary illumination map and the original image. As a result, a feature fusion network for consistency analysis of the illumination map and light intensity is established to determine the shooting environment of objects within the image. It estimates distances for objects and shadows using cross-ratio for homogeneous vertex estimation to ensure consistent detection of lighting direction in images. Finally, this study utilizes result fusion methods to comprehensively evaluate lighting analysis results and homogeneity analysis results to predict outcomes for synthetic images. Recognizing that existing datasets for synthetic image detection often lack detailed information regarding physical attributes, we introduce a new dataset designed to assist in detecting synthetic images by incorporating essential characteristics such as lighting conditions and object distances crucial for accurately identifying forgery in the complex digital media landscape at present.ResultExperiments conducted on the NIST 16 (National Institute of Standards and Technology Database 16), Coverage, and CASIA (Chinese Academy of Sciences Institute of Automation Database) datasets demonstrate that our method achieves AUC (area under the curve) scores of 94.2%, 93.6%, and 90.3%, respectively, and F1 scores of 80.2%, 79.3%, and 58.1%, outperforming the compared methods. In noise attack experiments, our method exhibits stronger adaptability to size variation, Gaussian blur, Gaussian noise, and JPEG (Joint Photographic Experts Group) compression, with an average AUC of 84.03%.ConclusionThe contributions of this study are summarized as follows: 1) we propose a versatile image forgery detection framework for high-fidelity synthetic images, which is called LSFNet. This framework integrates deep neural networks with physical detection methods and combines boundary lighting map detection and physical attribute consistency analysis. Experimental results show that our method outperforms mainstream techniques in accuracy and demonstrates robustness, which makes it suitable for various synthetic image detection tasks; 2) We present a shadow extraction and consistency analysis method tailored for image forgery detection. This approach, which utilizes Mask R-CNN as the backbone network for shadow prediction, models the relationship between shadow regions and real object areas. By assessing consistency through intersection over union, it significantly enhances the accuracy of image forgery detection; 3) We introduce a synthetic image detection dataset featuring physical attributes such as light source position, color temperature, camera position, object distance, depth of field, and complex backgrounds. The dataset is called the synthetic image physical properties detection dataset. This dataset comprises 22 203 images——15 012 collected images and 7 191 synthetically generated ones——all meticulously crafted by professionals to ensure high realism. The dataset maintains a training-validation-testing split of 7∶2∶1. It includes various synthesis methods such as stitching, copy-pasting, and deletion to effectively support training testing and optimization upgrades for image forgery detection models. The dataset is linked at: https://doi.org/10.57760/sciencedb.j00240.00069.关键词:Synthetic image detection;Illumination detection;shadow detection;detection dataset;artificial intelligence security241|283|0更新时间:2026-02-02 - “相关领域专家构建了基于多域特征融合的多分支网络框架MBMD,为解决现有检测方法泛化能力受限问题提供了新方案。”
 摘要:ObjectiveIn recent years, the rapid development of deepfake technology has led to the proliferation of realistic manipulated videos on social media. Even non-expert users can easily manipulate facial content using various applications and open-source tools. Given the sensitivity of personal identity information, false content tends to spread rapidly on the internet, which raises public concerns regarding video authenticity and personal privacy security. Although existing deepfake detection methods perform well in specific scenarios, their performance often degrades considerably when confronted with the ever-changing conditions of real-world scenarios. In other words, detection performance degrades when the forgery technique is unknown, which severely affects the performance of most deepfake detection methods in real-world applications. Furthermore, given that the existing deepfake detection methods based on convolutional neural networks often focus on either global or local spatiotemporal features, they still exhibit complexity in capturing global features and temporal information. The difficulty in capturing comprehensive forgery clues limits the generalization capability of detection methods. To address these issues, a multi-branch network based on multi-domain feature fusion is proposed in this study. This network comprehensively utilizes frequency, spatial, and spatiotemporal domain information to mine more detailed and comprehensive forgery clues.MethodIn the frequency stream, the discrete cosine transform is applied to the images, the low-frequency components that introduce additional noise and information redundancy are removed, and the high-frequency components are retained to capture frequency features of subtle structural changes in the images. In the spatial stream, a spatial feature enhancement block is designed to enhance the shallow features of CNN at multiple scales, and local abnormal regions in the images are captured. In the spatiotemporal stream, the Vision Transformer is used to process the frame sequence, and the global high-level features are obtained to perceive global spatiotemporal information. An information supplement block is developed to combine local features from the spatial stream with global high-level features captured by the Vision Transformer. As a result, the network can comprehensively capture global and local spatiotemporal inconsistencies. Finally, an interactive fusion module is used to enhance and fuse information from the frequency, spatial, and spatiotemporal domains to extract more detailed and comprehensive features for deepfake detection.ResultA systematic comparison was conducted between the proposed method and the state-of-the-art approaches across multiple datasets. In cross-dataset generalization experiments, the advantages of the proposed method were even more pronounced: on the Celeb-DF-v2 dataset, compared to the second-best performing detection model, the proposed method improved ACC by 2.63% and AUC by 3.01%; on the more challenging DFDC dataset, compared to the latest detection model, the proposed method achieved a notable improvement of 4.43% in AUC, highlighting its superior cross-domain adaptability. To further investigate the contribution of the model design to generalization performance, a systematic ablation study was conducted, which thoroughly analyzed the impact of different modules in cross-dataset scenarios. The experimental results clearly validate the effectiveness of each key component and explain the mechanism through which the proposed method enhances generalization capability from a quantitative perspective. This comprehensively confirms the innovativeness and practical utility of the proposed approach.ConclusionThe proposed method has been validated through systematic comparison with state-of-the-art approaches on multiple datasets. It not only achieves advanced performance levels but also demonstrates excellent cross-domain adaptability and interpretability, providing an effective solution for research in related fields.关键词:Deepfake detection;digital image forensics;multi-domain feature fusion;multi-branch;local-global role200|251|0更新时间:2026-02-02
摘要:ObjectiveIn recent years, the rapid development of deepfake technology has led to the proliferation of realistic manipulated videos on social media. Even non-expert users can easily manipulate facial content using various applications and open-source tools. Given the sensitivity of personal identity information, false content tends to spread rapidly on the internet, which raises public concerns regarding video authenticity and personal privacy security. Although existing deepfake detection methods perform well in specific scenarios, their performance often degrades considerably when confronted with the ever-changing conditions of real-world scenarios. In other words, detection performance degrades when the forgery technique is unknown, which severely affects the performance of most deepfake detection methods in real-world applications. Furthermore, given that the existing deepfake detection methods based on convolutional neural networks often focus on either global or local spatiotemporal features, they still exhibit complexity in capturing global features and temporal information. The difficulty in capturing comprehensive forgery clues limits the generalization capability of detection methods. To address these issues, a multi-branch network based on multi-domain feature fusion is proposed in this study. This network comprehensively utilizes frequency, spatial, and spatiotemporal domain information to mine more detailed and comprehensive forgery clues.MethodIn the frequency stream, the discrete cosine transform is applied to the images, the low-frequency components that introduce additional noise and information redundancy are removed, and the high-frequency components are retained to capture frequency features of subtle structural changes in the images. In the spatial stream, a spatial feature enhancement block is designed to enhance the shallow features of CNN at multiple scales, and local abnormal regions in the images are captured. In the spatiotemporal stream, the Vision Transformer is used to process the frame sequence, and the global high-level features are obtained to perceive global spatiotemporal information. An information supplement block is developed to combine local features from the spatial stream with global high-level features captured by the Vision Transformer. As a result, the network can comprehensively capture global and local spatiotemporal inconsistencies. Finally, an interactive fusion module is used to enhance and fuse information from the frequency, spatial, and spatiotemporal domains to extract more detailed and comprehensive features for deepfake detection.ResultA systematic comparison was conducted between the proposed method and the state-of-the-art approaches across multiple datasets. In cross-dataset generalization experiments, the advantages of the proposed method were even more pronounced: on the Celeb-DF-v2 dataset, compared to the second-best performing detection model, the proposed method improved ACC by 2.63% and AUC by 3.01%; on the more challenging DFDC dataset, compared to the latest detection model, the proposed method achieved a notable improvement of 4.43% in AUC, highlighting its superior cross-domain adaptability. To further investigate the contribution of the model design to generalization performance, a systematic ablation study was conducted, which thoroughly analyzed the impact of different modules in cross-dataset scenarios. The experimental results clearly validate the effectiveness of each key component and explain the mechanism through which the proposed method enhances generalization capability from a quantitative perspective. This comprehensively confirms the innovativeness and practical utility of the proposed approach.ConclusionThe proposed method has been validated through systematic comparison with state-of-the-art approaches on multiple datasets. It not only achieves advanced performance levels but also demonstrates excellent cross-domain adaptability and interpretability, providing an effective solution for research in related fields.关键词:Deepfake detection;digital image forensics;multi-domain feature fusion;multi-branch;local-global role200|251|0更新时间:2026-02-02 - “虹膜呈现攻击检测领域迎来新突破,相关专家构建了基于空间域与频域特征融合的虹膜PAD模型,为提升虹膜识别系统在跨域场景下的安全性和合成虹膜检测能力提供了有效方案。”
 摘要:ObjectiveIris recognition is a popular biometric recognition technology known for its uniqueness, stability, non-contact nature, and accuracy. By leveraging the complex and unique texture patterns of the human iris, iris recognition systems can accurately identify individuals and are widely used in critical sensors such as border control, prisons, banks, and coal mines. However, with the wide application of iris recognition systems, the threat of presentation attacks (PAs) has become increasingly prominent. Attackers attempt to deceive these systems using fake irises, such as printed irises, textured contact lenses, or artificial eyes, thereby enabling impersonation of others or evasion of identification. Aiming to ensure the security and reliability of iris recognition systems, iris presentation attack detection (PAD) is typically implemented as a preliminary step to distinguish between bona fide and fake inputs. Despite notable progress in iris PAD methodologies, current solutions face persistent challenges.One major issue is their sensitivity to environmental variations during image acquisition—factors such as lighting conditions, camera types, and subject-specific attributes can substantially influence detection accuracy. Another major limitation is the difficulty of effectively detecting synthetic irises, which are becoming increasingly sophisticated. This study introduces an innovative framework for iris PAD, designed to overcome these limitations through the integration of spatial-domain and frequency-domain features. Spatial-domain features capture local textures and structural information, key elements commonly exploited in PAs, while frequency-domain features exhibit improved robustness to environmental variability and can magnify differences between real and synthetic images. By leveraging the complementary advantages of both domains, the proposed method aims to enhance the detection accuracy and generalization capability.MethodThe proposed framework adopts a multifaceted approach to leverage spatial and frequency information from iris images. Initially, spatial-domain representations are generated using the local binary pattern (LBP) algorithm, which encodes texture characteristics by analyzing pixel intensity variations. The application of LBP enhances the fine-grained texture details in the spatial-domain images, emphasizing critical patterns while suppressing irrelevant noise, thereby facilitating effective feature extraction in subsequent stages. This preprocessing step ensures that the subsequent network can effectively capture distinguishing characteristics between bona fide and fake samples. Concurrently, the spatial-domain images are transformed into the frequency domain using the discrete cosine transform (DCT). The spatial and frequency domain representations are processed through two independent EfficientNet-B0 backbone networks for feature extraction. Aiming to integrate the spatial and frequency features, the framework employs spatial-channel fusion attention (SCFA) modules, which comprise parallel spatial attention and channel attention branches. These modules optimize feature fusion. SCFA modules integrate mid- and high-level representations from both domains, ensuring that their complementary information contributes effectively to the final classification. A low-frequency semantic guided attention (LSGA) module further refines the model’s focus, leveraging low-frequency information to emphasize the iris region while suppressing irrelevant background details, thereby improving discrimination capability. The model is trained using a combination of triplet loss and binary cross-entropy loss (BCE loss) functions. While BCE loss helps the model learn a separation boundary in the feature space, triplet loss increases inter-class distance by encouraging the network to maximize the distance between bona fide and fake samples. This dual-loss strategy strengthens the model’s capability to distinguish between the samples effectively. Overall, these components create a holistic framework designed to deliver robust performance across diverse PAD scenarios.ResultThe effectiveness of the proposed method was evaluated on the LivDet-Iris 2023 dataset, a benchmark dataset introduced by the latest LivDet-Iris 2023 competition, which features diverse and challenging PAs, including synthetic iris images. Comparative experiments were conducted against the competition’s winner method and several state-of-the-art (SOTA) approaches. The proposed method resulted in a notable reduction in the classification error rate ACER1 and ACER2 by 9.32% and 3.71%, respectively, demonstrating superior performance in distinguishing bona fide and fake samples. Notably, for synthetic iris attacks, the attack presentation classification error rate (APCER) was substantially reduced by 22.78%. Compared with a recent SOTA method which only utilizes spatial information, the proposed method achieved a reduction of 10.48% and 6.22% in terms of ACER1 and ACER2, respectively, and a reduction of 24.78% on the APCER during detection of synthetic iris samples. Ablation studies were performed on the LivDet-Iris 2023 dataset to validate the contributions of individual components. Results from these experiments confirmed the effectiveness of integrating frequency-domain information, which consistently improved model accuracy in classifying bona fide and fake iris images. The SCFA and LSGA modules were also shown to further boost model performance.ConclusionThis study introduces a novel iris PAD framework that effectively combines spatial-domain and frequency-domain information. By leveraging the complementary strengths of the two domains, the proposed method enhances the robustness and accuracy of iris PAD models. The integration of attention mechanisms, specifically spatial-channel fusion and low-frequency semantic guidance, ensures that the model focuses on relevant regions, thereby improving its capacity to distinguish between bona fide and fake samples. Experimental results on the LivDet-Iris 2023 dataset demonstrate the superior performance of the proposed approach. This study highlights the importance of incorporating frequency-domain features into PAD models to mitigate the effects of environmental variations and improve generalizability. The code is linked at: https://github.com/xianyunsun/fre-iris-pad.关键词:presentation attack detection(PAD);iris recognition;multi-domain feature fusion;attention mechanism;synthetic iris284|349|0更新时间:2026-02-02
摘要:ObjectiveIris recognition is a popular biometric recognition technology known for its uniqueness, stability, non-contact nature, and accuracy. By leveraging the complex and unique texture patterns of the human iris, iris recognition systems can accurately identify individuals and are widely used in critical sensors such as border control, prisons, banks, and coal mines. However, with the wide application of iris recognition systems, the threat of presentation attacks (PAs) has become increasingly prominent. Attackers attempt to deceive these systems using fake irises, such as printed irises, textured contact lenses, or artificial eyes, thereby enabling impersonation of others or evasion of identification. Aiming to ensure the security and reliability of iris recognition systems, iris presentation attack detection (PAD) is typically implemented as a preliminary step to distinguish between bona fide and fake inputs. Despite notable progress in iris PAD methodologies, current solutions face persistent challenges.One major issue is their sensitivity to environmental variations during image acquisition—factors such as lighting conditions, camera types, and subject-specific attributes can substantially influence detection accuracy. Another major limitation is the difficulty of effectively detecting synthetic irises, which are becoming increasingly sophisticated. This study introduces an innovative framework for iris PAD, designed to overcome these limitations through the integration of spatial-domain and frequency-domain features. Spatial-domain features capture local textures and structural information, key elements commonly exploited in PAs, while frequency-domain features exhibit improved robustness to environmental variability and can magnify differences between real and synthetic images. By leveraging the complementary advantages of both domains, the proposed method aims to enhance the detection accuracy and generalization capability.MethodThe proposed framework adopts a multifaceted approach to leverage spatial and frequency information from iris images. Initially, spatial-domain representations are generated using the local binary pattern (LBP) algorithm, which encodes texture characteristics by analyzing pixel intensity variations. The application of LBP enhances the fine-grained texture details in the spatial-domain images, emphasizing critical patterns while suppressing irrelevant noise, thereby facilitating effective feature extraction in subsequent stages. This preprocessing step ensures that the subsequent network can effectively capture distinguishing characteristics between bona fide and fake samples. Concurrently, the spatial-domain images are transformed into the frequency domain using the discrete cosine transform (DCT). The spatial and frequency domain representations are processed through two independent EfficientNet-B0 backbone networks for feature extraction. Aiming to integrate the spatial and frequency features, the framework employs spatial-channel fusion attention (SCFA) modules, which comprise parallel spatial attention and channel attention branches. These modules optimize feature fusion. SCFA modules integrate mid- and high-level representations from both domains, ensuring that their complementary information contributes effectively to the final classification. A low-frequency semantic guided attention (LSGA) module further refines the model’s focus, leveraging low-frequency information to emphasize the iris region while suppressing irrelevant background details, thereby improving discrimination capability. The model is trained using a combination of triplet loss and binary cross-entropy loss (BCE loss) functions. While BCE loss helps the model learn a separation boundary in the feature space, triplet loss increases inter-class distance by encouraging the network to maximize the distance between bona fide and fake samples. This dual-loss strategy strengthens the model’s capability to distinguish between the samples effectively. Overall, these components create a holistic framework designed to deliver robust performance across diverse PAD scenarios.ResultThe effectiveness of the proposed method was evaluated on the LivDet-Iris 2023 dataset, a benchmark dataset introduced by the latest LivDet-Iris 2023 competition, which features diverse and challenging PAs, including synthetic iris images. Comparative experiments were conducted against the competition’s winner method and several state-of-the-art (SOTA) approaches. The proposed method resulted in a notable reduction in the classification error rate ACER1 and ACER2 by 9.32% and 3.71%, respectively, demonstrating superior performance in distinguishing bona fide and fake samples. Notably, for synthetic iris attacks, the attack presentation classification error rate (APCER) was substantially reduced by 22.78%. Compared with a recent SOTA method which only utilizes spatial information, the proposed method achieved a reduction of 10.48% and 6.22% in terms of ACER1 and ACER2, respectively, and a reduction of 24.78% on the APCER during detection of synthetic iris samples. Ablation studies were performed on the LivDet-Iris 2023 dataset to validate the contributions of individual components. Results from these experiments confirmed the effectiveness of integrating frequency-domain information, which consistently improved model accuracy in classifying bona fide and fake iris images. The SCFA and LSGA modules were also shown to further boost model performance.ConclusionThis study introduces a novel iris PAD framework that effectively combines spatial-domain and frequency-domain information. By leveraging the complementary strengths of the two domains, the proposed method enhances the robustness and accuracy of iris PAD models. The integration of attention mechanisms, specifically spatial-channel fusion and low-frequency semantic guidance, ensures that the model focuses on relevant regions, thereby improving its capacity to distinguish between bona fide and fake samples. Experimental results on the LivDet-Iris 2023 dataset demonstrate the superior performance of the proposed approach. This study highlights the importance of incorporating frequency-domain features into PAD models to mitigate the effects of environmental variations and improve generalizability. The code is linked at: https://github.com/xianyunsun/fre-iris-pad.关键词:presentation attack detection(PAD);iris recognition;multi-domain feature fusion;attention mechanism;synthetic iris284|349|0更新时间:2026-02-02 - “介绍了其在人工智能安全领域的研究进展,专家提出了一种基于生成器架构的频率域对抗样本生成方法,为解决对抗样本的迁移性与生成效率问题提供了新的解决方案。”
 摘要:ObjectiveThe goal of digital image adversarial examples is to add subtle, nearly imperceptible noise to an image to deceive computer vision systems into making incorrect decisions. Most existing adversarial example generation methods aim to maximize the loss function, pushing the image away from the true label. These methods typically involve multiple searches across the input space to find possible adversarial perturbations. However, this approach often leads to overfitting to the source model, reducing the transferability of adversarial examples, making them minimally effective in attacking other models. Furthermore, performing iterative searches across the entire input space increases the computational cost of generating adversarial samples. To address the above issues, we propose a novel adversarial example generation method based on a generative architecture, which selectively interferes with the frequency components that are crucial for the decision-making process of the model. This method significantly improves the transferability of adversarial attacks. Once the generator is trained, it can rapidly generate adversarial examples by simply feeding in the input, thus enhancing the efficiency of adversarial example generation. Our method not only addresses the challenges of transferability and overfitting but also reduces the computational cost by eliminating the need for exhaustive searches in the input space, enabling fast and effective adversarial attacks.MethodSpecifically, our method begins by feeding the input into a generator architecture, which produces two outputs: Branch 1 generates the initial adversarial noise, and Output 2 provides the initial mask information. The purpose of the initial mask is to retain the feature information that is beneficial for classification in the original image. After obtaining the initial adversarial noise, we add it to the original sample to create the preliminary adversarial example. The next step involves applying a discrete cosine transform (DCT) to the adversarial example, followed by multiplying the DCT-transformed adversarial sample with the mask information to isolate the crucial frequency components that affect the decision-making process. Afterward, an inverse DCT (IDCT) is applied to recover the image in the spatial domain. This processed adversarial image is then fed into an image classifier, and the generator is optimized by maximizing the loss function, which drives the adversarial example to produce the desired misclassification results. The incorporation of the mask ensures that only the most influential frequency components, which directly influence the model’s classification, are preserved. This approach not only guides the generator to focus on the critical parts of the image but also enhances the transferability of the adversarial example to different models, given that the manipulated frequency components are less likely to be overfitted to a specific model. By strategically targeting and preserving important frequency information, our method improves the effectiveness and efficiency of generating adversarial examples.ResultOur method outperforms baseline attack methods in terms of attack effectiveness when applied to convolutional neural networks, vision Transformer models, and adversarially trained models. We also employed our approach to attack Google’s commercial API, and the results demonstrated that our method effectively compromised their classifier, causing it to produce incorrect detection outcomes. To further understand the underlying reasons for the success of our method, we conducted a heatmap visualization analysis. This analysis revealed that our method successfully shifted the model’s attention away from the foreground and toward the background, thereby manipulating the model’s decision-making process. Furthermore, leveraging the generative architecture, we used the trained generator to generate adversarial examples on the Animal dataset and the Microsoft common objects in context dataset. These adversarial samples were then applied to attack the cross-dataset image classification tasks and the downstream object detection tasks. The experimental results indicate that our method maintains its attack effectiveness in cross-dataset image classification tasks and downstream tasks, highlighting its transferability and versatility. Hence, our attack method is not only effective for image classification models but also exhibits strong attack capabilities for more complex tasks such as object detection. These results validate the broad applicability and robustness of our adversarial attack strategy across different types of computer vision models and tasks.ConclusionThe generator architecture proposed in this paper targets frequency components that are beneficial for classification decisions, significantly improving the transferability of adversarial attacks.关键词:deep learning;artificial intelligence security;computer vision;adversarial example in image classification;generative attack algorithm149|150|0更新时间:2026-02-02
摘要:ObjectiveThe goal of digital image adversarial examples is to add subtle, nearly imperceptible noise to an image to deceive computer vision systems into making incorrect decisions. Most existing adversarial example generation methods aim to maximize the loss function, pushing the image away from the true label. These methods typically involve multiple searches across the input space to find possible adversarial perturbations. However, this approach often leads to overfitting to the source model, reducing the transferability of adversarial examples, making them minimally effective in attacking other models. Furthermore, performing iterative searches across the entire input space increases the computational cost of generating adversarial samples. To address the above issues, we propose a novel adversarial example generation method based on a generative architecture, which selectively interferes with the frequency components that are crucial for the decision-making process of the model. This method significantly improves the transferability of adversarial attacks. Once the generator is trained, it can rapidly generate adversarial examples by simply feeding in the input, thus enhancing the efficiency of adversarial example generation. Our method not only addresses the challenges of transferability and overfitting but also reduces the computational cost by eliminating the need for exhaustive searches in the input space, enabling fast and effective adversarial attacks.MethodSpecifically, our method begins by feeding the input into a generator architecture, which produces two outputs: Branch 1 generates the initial adversarial noise, and Output 2 provides the initial mask information. The purpose of the initial mask is to retain the feature information that is beneficial for classification in the original image. After obtaining the initial adversarial noise, we add it to the original sample to create the preliminary adversarial example. The next step involves applying a discrete cosine transform (DCT) to the adversarial example, followed by multiplying the DCT-transformed adversarial sample with the mask information to isolate the crucial frequency components that affect the decision-making process. Afterward, an inverse DCT (IDCT) is applied to recover the image in the spatial domain. This processed adversarial image is then fed into an image classifier, and the generator is optimized by maximizing the loss function, which drives the adversarial example to produce the desired misclassification results. The incorporation of the mask ensures that only the most influential frequency components, which directly influence the model’s classification, are preserved. This approach not only guides the generator to focus on the critical parts of the image but also enhances the transferability of the adversarial example to different models, given that the manipulated frequency components are less likely to be overfitted to a specific model. By strategically targeting and preserving important frequency information, our method improves the effectiveness and efficiency of generating adversarial examples.ResultOur method outperforms baseline attack methods in terms of attack effectiveness when applied to convolutional neural networks, vision Transformer models, and adversarially trained models. We also employed our approach to attack Google’s commercial API, and the results demonstrated that our method effectively compromised their classifier, causing it to produce incorrect detection outcomes. To further understand the underlying reasons for the success of our method, we conducted a heatmap visualization analysis. This analysis revealed that our method successfully shifted the model’s attention away from the foreground and toward the background, thereby manipulating the model’s decision-making process. Furthermore, leveraging the generative architecture, we used the trained generator to generate adversarial examples on the Animal dataset and the Microsoft common objects in context dataset. These adversarial samples were then applied to attack the cross-dataset image classification tasks and the downstream object detection tasks. The experimental results indicate that our method maintains its attack effectiveness in cross-dataset image classification tasks and downstream tasks, highlighting its transferability and versatility. Hence, our attack method is not only effective for image classification models but also exhibits strong attack capabilities for more complex tasks such as object detection. These results validate the broad applicability and robustness of our adversarial attack strategy across different types of computer vision models and tasks.ConclusionThe generator architecture proposed in this paper targets frequency components that are beneficial for classification decisions, significantly improving the transferability of adversarial attacks.关键词:deep learning;artificial intelligence security;computer vision;adversarial example in image classification;generative attack algorithm149|150|0更新时间:2026-02-02 - “随着克隆语音技术发展,准确识别克隆语音成难题。专家提出一种面向克隆语音的目标说话人鉴别方法,通过设计组渐进信道融合模块、动态全局滤波器等,有效提取目标说话人特征,实验结果表明该方法在声纹认定任务中更具优势,为克隆语音声纹认定提供新方法。”
 摘要:ObjectiveThe rapid development of artificial intelligence technology, especially the revolutionary progress in the field of deep learning, has boosted voice cloning technologies such as text to speech (TTS) and voice conversion (VC) beyond traditional limitations. This innovation enables the rapid generation of digital voices that “sound like one’s own voice”, which offers users unprecedented convenience and enjoyment. However, malicious attackers may use their cloned voices to commit unlawful activities such as fraud, forgery, dissemination of false information, targeted harassment, and illegal access to personal sensitive information. These behaviors will undoubtedly pose an unprecedented challenge and threat to personal voice rights. Therefore, under the clear guidance of the law, the protection of voice rights as an important part of personal identity has become the focus of attention from various sectors of society. Accurately determining the sound source of the cloned speech in judicial practice, that is, ascertaining whether the cloned speech originates from the characteristics of the target speaker, has become a challenging dilemma. Although the existing speaker identification technology can confirm the speaker identity of human speech through voiceprint feature comparison, the cloned speech is not only similar to the timbre of the target speaker but also contains the characteristics of the source speaker. Therefore, the interference of the timbre of the source speaker makes the traditional speaker recognition technology difficult to be directly applied to the cloned speech. Against this backdrop, the target speaker verification method for cloned speech is proposed in this study.MethodSpecifically, the group progressive channel fusion (GPCF) module is first designed based on Res2Block to extract the common effective voiceprint features between human speech and cloned speech. This module is critical for distinguishing subtle differences between human speech and cloned speech that are generally indistinguishable to the human ear alone. Subsequently, the K-independent dynamic global filter (DGF) module is adopted to suppress the influence of the source speaker, which improves the representation and generalization capability of the model. The DGF plays a key role in filtering out the unwanted features of the source speaker, which ensures that the voiceprint of the target speaker remains the focus of the analysis. Thereafter, a feature aggregation mechanism is presented based on multi-scale layer attention to fuse deep and shallow features from different levels of the GPCF and DGF modules. This mechanism is designed to capture the intricate details of the voiceprint that may be missed by traditional methods, which provides a more comprehensive analysis of the speech features. Finally, the attentive statistics pooling (ASP) layer is used to further enhance the target speaker information in the representation feature tensor. The ASP layer is instrumental in refining the feature set. This refinement ensures that the most relevant and discriminative features are emphasized, which improves the accuracy of the voiceprint identification results.ResultExperiments on the AISHELL3 human speech dataset and the cloned speech dataset, which are created based on four speech synthesis and conversion algorithms——FastSpeech2, TriAANVC, FreeVC, and KnnVC——how that the equal error rates are reduced by 1.38%, 0.92%, and 0.61%, while the values for the minimum detection cost function are decreased by 0.012 5, 0.006 7, and 0.044 5, compared with the three advanced methods.ConclusionThese comparative experimental results show that the proposed method can significantly reduce the error rate associated with voiceprint identification, which leads to more reliable and accurate results. They also show the advantages of the proposed method in solving the task of cloned speech voiceprint identification. The proposed method effectively extracts the features of the target speaker from cloned speech, which offers a methodological guide for the voiceprint identification of cloned speech.关键词:Cloned speech;Voiceprint identification;group progressive channel fusion (GPCF);dynamic global filter (DGF);Multi-scale layer attention176|366|0更新时间:2026-02-02
摘要:ObjectiveThe rapid development of artificial intelligence technology, especially the revolutionary progress in the field of deep learning, has boosted voice cloning technologies such as text to speech (TTS) and voice conversion (VC) beyond traditional limitations. This innovation enables the rapid generation of digital voices that “sound like one’s own voice”, which offers users unprecedented convenience and enjoyment. However, malicious attackers may use their cloned voices to commit unlawful activities such as fraud, forgery, dissemination of false information, targeted harassment, and illegal access to personal sensitive information. These behaviors will undoubtedly pose an unprecedented challenge and threat to personal voice rights. Therefore, under the clear guidance of the law, the protection of voice rights as an important part of personal identity has become the focus of attention from various sectors of society. Accurately determining the sound source of the cloned speech in judicial practice, that is, ascertaining whether the cloned speech originates from the characteristics of the target speaker, has become a challenging dilemma. Although the existing speaker identification technology can confirm the speaker identity of human speech through voiceprint feature comparison, the cloned speech is not only similar to the timbre of the target speaker but also contains the characteristics of the source speaker. Therefore, the interference of the timbre of the source speaker makes the traditional speaker recognition technology difficult to be directly applied to the cloned speech. Against this backdrop, the target speaker verification method for cloned speech is proposed in this study.MethodSpecifically, the group progressive channel fusion (GPCF) module is first designed based on Res2Block to extract the common effective voiceprint features between human speech and cloned speech. This module is critical for distinguishing subtle differences between human speech and cloned speech that are generally indistinguishable to the human ear alone. Subsequently, the K-independent dynamic global filter (DGF) module is adopted to suppress the influence of the source speaker, which improves the representation and generalization capability of the model. The DGF plays a key role in filtering out the unwanted features of the source speaker, which ensures that the voiceprint of the target speaker remains the focus of the analysis. Thereafter, a feature aggregation mechanism is presented based on multi-scale layer attention to fuse deep and shallow features from different levels of the GPCF and DGF modules. This mechanism is designed to capture the intricate details of the voiceprint that may be missed by traditional methods, which provides a more comprehensive analysis of the speech features. Finally, the attentive statistics pooling (ASP) layer is used to further enhance the target speaker information in the representation feature tensor. The ASP layer is instrumental in refining the feature set. This refinement ensures that the most relevant and discriminative features are emphasized, which improves the accuracy of the voiceprint identification results.ResultExperiments on the AISHELL3 human speech dataset and the cloned speech dataset, which are created based on four speech synthesis and conversion algorithms——FastSpeech2, TriAANVC, FreeVC, and KnnVC——how that the equal error rates are reduced by 1.38%, 0.92%, and 0.61%, while the values for the minimum detection cost function are decreased by 0.012 5, 0.006 7, and 0.044 5, compared with the three advanced methods.ConclusionThese comparative experimental results show that the proposed method can significantly reduce the error rate associated with voiceprint identification, which leads to more reliable and accurate results. They also show the advantages of the proposed method in solving the task of cloned speech voiceprint identification. The proposed method effectively extracts the features of the target speaker from cloned speech, which offers a methodological guide for the voiceprint identification of cloned speech.关键词:Cloned speech;Voiceprint identification;group progressive channel fusion (GPCF);dynamic global filter (DGF);Multi-scale layer attention176|366|0更新时间:2026-02-02 - ““”这段话,介绍了其在数据浓缩后门攻击领域的研究进展,相关专家提出了分离触发器和多重对比的数据浓缩后门攻击方法,为解决现有数据浓缩后门攻击方法存在的问题提供了有效解决方案。”
 摘要:ObjectiveExisting backdoor attacks against dataset condensation condense poisoned data containing trigger and clean real data into a small dataset. However, the strong signal of real data in the poisoned data masks the weak signal of triggers (e.g., square, noises, or warping) in the poisoned data, leading to the failure of the triggers embedded within the condensed data, which subsequently prevents the embedding of hidden backdoors into the model. Meanwhile, these methods only consider decreasing the distance between the gradients of target class condensed data and poisoned data and fail to consider increasing the distance between the gradients of nontarget class condensed data and poisoned data. Consequently, the nontarget condensed data contaminate trigger information, thereby reducing the attack success rate. To address the above issues, this study proposes a backdoor attack against dataset condensation based on separated triggers and multiple comparisons. The proposed method optimizes the separated triggers to minimize the interference from real data during the embedding process. The poisoned condensed data generated by the method exhibit a high attack success rate while making it difficult to detect the embedded triggers.MethodTo help the model focus on the trigger, this study separates the trigger from real data. The separated trigger is embedded as a sample into the condensed data in parallel with real data to mitigate the interference of real data on the trigger. This study optimizes the separated trigger through a gradient matching method to bring the trigger close to the feature of target class real data. When partitioned amplification preprocessing is applied to the trigger, the number of trigger pixels is increased, enabling the acquisition of abundant gradients during the optimization process to guide learning. In the data condensation phase, while the distance between the gradients of target class condensed data and the trigger is minimized, the distance between the gradients of nontarget class condensed data and the trigger is considered to be maximized, eliminating the trigger information contaminated in the condensed data of nontarget classes. To fully exploit trigger information and embed it into the target class condensed data, this study aims to reduce the distance between the error gradients of the trigger and the target class condensed data, further enhancing the success rate of the backdoor attack.ResultFor validating the effectiveness of the method proposed in this paper, it was compared with four other methods on four datasets: Fashion Modified National Institute of Standards and Technology database(FashionMNIST), Canadian Institute for Advances Research’s ten categories dataset(CIFAR10), Stanford letter-10(STL10), and street view house numbers(SVHN). The proposed method achieves significant improvement in poisoned accuracy compared with the existing methods, with respective increases of 20%, 47.7%, 30%, and 6.5% over NaiveAttack, DoorPing, DoorPing-1, and DoorPing-2, respectively, while maintaining the accuracy of the model on clean samples without degradation. The poisoned condensation data synthesized by our proposed method maintain remarkably consistent poisoned accuracy when applied to train models with different architectures. To validate the stealthiness of our approach, this study synthesizes clean and poisoned condensation data across ConvNet and AlexNet architectures. Owing to the traces left by the backpropagation process, the poisoned and clean condensed data become indistinguishable blurred images. These traces cover the trigger, making it difficult for people to determine which set of condensed data contains the embedded trigger. To verify the effectiveness of the proposed method on complex datasets and models, this study synthesizes a set of poisoned condensation data using the CIFAR100 dataset and VGG11 architecture and evaluates poisoned accuracy. Experimental results demonstrate that the poisoned accuracy remains 100% even under complex datasets and model frameworks. Notably, when the poisoned condensed data trained on VGG11 are used to train models with other architectures, the poisoned accuracy rate degrades. Complex models typically possess powerful feature extraction capabilities, which embed substantial noise captured during training into the condensed data, leading to a decline in poisoned accuracy.ConclusionThe data condensation backdoor attack method proposed in this paper significantly improves the attack success rate, while the embedded triggers are difficult to detect. This method possesses good cross-model generalization ability and can be effectively extended to complex datasets. Compared with traditional backdoor attack methods, the backdoor attack based on condensed data has unique advantages. By treating a trigger as an independent sample alongside real data to match the gradient of condensed data, the proposed method mitigates the interference caused by strong signals from real data. Through aligning the trigger’s feature representation with that of target class real data, we reduce the difficulty of coembedding triggers and real data into condensed data. Furthermore, this study conducts gradient separation between the trigger and condensed data of nontarget classes via multiple comparisons, removing residual trigger features embedded in the nontarget condensed data and thereby significantly improving the success rate of backdoor attacks. The code is linked at https://github.com/tfuy/STMC.关键词:backdoor attack;dataset condensation;Separation;gradient matching;partitioned amplification preprocessing;maximize110|149|0更新时间:2026-02-02
摘要:ObjectiveExisting backdoor attacks against dataset condensation condense poisoned data containing trigger and clean real data into a small dataset. However, the strong signal of real data in the poisoned data masks the weak signal of triggers (e.g., square, noises, or warping) in the poisoned data, leading to the failure of the triggers embedded within the condensed data, which subsequently prevents the embedding of hidden backdoors into the model. Meanwhile, these methods only consider decreasing the distance between the gradients of target class condensed data and poisoned data and fail to consider increasing the distance between the gradients of nontarget class condensed data and poisoned data. Consequently, the nontarget condensed data contaminate trigger information, thereby reducing the attack success rate. To address the above issues, this study proposes a backdoor attack against dataset condensation based on separated triggers and multiple comparisons. The proposed method optimizes the separated triggers to minimize the interference from real data during the embedding process. The poisoned condensed data generated by the method exhibit a high attack success rate while making it difficult to detect the embedded triggers.MethodTo help the model focus on the trigger, this study separates the trigger from real data. The separated trigger is embedded as a sample into the condensed data in parallel with real data to mitigate the interference of real data on the trigger. This study optimizes the separated trigger through a gradient matching method to bring the trigger close to the feature of target class real data. When partitioned amplification preprocessing is applied to the trigger, the number of trigger pixels is increased, enabling the acquisition of abundant gradients during the optimization process to guide learning. In the data condensation phase, while the distance between the gradients of target class condensed data and the trigger is minimized, the distance between the gradients of nontarget class condensed data and the trigger is considered to be maximized, eliminating the trigger information contaminated in the condensed data of nontarget classes. To fully exploit trigger information and embed it into the target class condensed data, this study aims to reduce the distance between the error gradients of the trigger and the target class condensed data, further enhancing the success rate of the backdoor attack.ResultFor validating the effectiveness of the method proposed in this paper, it was compared with four other methods on four datasets: Fashion Modified National Institute of Standards and Technology database(FashionMNIST), Canadian Institute for Advances Research’s ten categories dataset(CIFAR10), Stanford letter-10(STL10), and street view house numbers(SVHN). The proposed method achieves significant improvement in poisoned accuracy compared with the existing methods, with respective increases of 20%, 47.7%, 30%, and 6.5% over NaiveAttack, DoorPing, DoorPing-1, and DoorPing-2, respectively, while maintaining the accuracy of the model on clean samples without degradation. The poisoned condensation data synthesized by our proposed method maintain remarkably consistent poisoned accuracy when applied to train models with different architectures. To validate the stealthiness of our approach, this study synthesizes clean and poisoned condensation data across ConvNet and AlexNet architectures. Owing to the traces left by the backpropagation process, the poisoned and clean condensed data become indistinguishable blurred images. These traces cover the trigger, making it difficult for people to determine which set of condensed data contains the embedded trigger. To verify the effectiveness of the proposed method on complex datasets and models, this study synthesizes a set of poisoned condensation data using the CIFAR100 dataset and VGG11 architecture and evaluates poisoned accuracy. Experimental results demonstrate that the poisoned accuracy remains 100% even under complex datasets and model frameworks. Notably, when the poisoned condensed data trained on VGG11 are used to train models with other architectures, the poisoned accuracy rate degrades. Complex models typically possess powerful feature extraction capabilities, which embed substantial noise captured during training into the condensed data, leading to a decline in poisoned accuracy.ConclusionThe data condensation backdoor attack method proposed in this paper significantly improves the attack success rate, while the embedded triggers are difficult to detect. This method possesses good cross-model generalization ability and can be effectively extended to complex datasets. Compared with traditional backdoor attack methods, the backdoor attack based on condensed data has unique advantages. By treating a trigger as an independent sample alongside real data to match the gradient of condensed data, the proposed method mitigates the interference caused by strong signals from real data. Through aligning the trigger’s feature representation with that of target class real data, we reduce the difficulty of coembedding triggers and real data into condensed data. Furthermore, this study conducts gradient separation between the trigger and condensed data of nontarget classes via multiple comparisons, removing residual trigger features embedded in the nontarget condensed data and thereby significantly improving the success rate of backdoor attacks. The code is linked at https://github.com/tfuy/STMC.关键词:backdoor attack;dataset condensation;Separation;gradient matching;partitioned amplification preprocessing;maximize110|149|0更新时间:2026-02-02 - “相关研究在图像水印领域取得新进展,专家提出频率感知驱动的深度鲁棒图像水印技术,通过差异化处理低频和高频成分,显著增强水印的不可见性和鲁棒性,为应对多样化攻击提供有效方案。”
 摘要:ObjectiveWith the rapid advancement of digital technology and the extensive use of the internet, the creation and dissemination of image content have undergone remarkable changes. Social media platforms, such as Douyin and WeChat Moments, have provided users with vast stages for showcasing and sharing visual works. These platforms have not only motivated the flourishing development of image creation but have also injected strong momentum into the “visual economy”. However, with the widespread distribution of image works, copyright issues have become increasingly prominent. Numerous malicious actors use technical means to steal, alter, or even commercialize the works of others without authorization, severely damaging the rights of original creators. This phenomenon not only disturbs the creative ecosystem but also threatens the sustainable development of digital content. Therefore, effectively protecting the copyright of image works in an open network environment has become a crucial issue in technical research and industrial practice. Digital image watermarking technology is one of the effective methods to address this problem. The earliest studies in digital watermarking encoded secret information in the least significant bit of image pixels; however, this method is easily detected by statistical measures. Researchers then shifted their attention to frequency domains, determining that encoding information in the discrete cosine transform and discrete wavelet transform domains was highly robust. However, all these traditional methods heavily relied on shallow, manually crafted image features, indicating that they did not fully use the carrier image, resulting in substantial limitations in robustness. In recent years, with the development of deep learning, numerous deep learning-based models have been applied to digital image watermarking to enhance robustness. However, most of these approaches treat the low-frequency and high-frequency components of feature maps equally, overlooking the considerable differences between different frequencies. This uniform treatment limits the model’s adaptability to diverse attacks, making it difficult to achieve high fidelity and strong robustness in watermarking. Various attacks affect image frequency bands differently. For example, median filtering primarily impacts the distortion of high-frequency regions, whereas JPEG compression has a greater impact on low-frequency distortion. The low-frequency part of an image typically conveys the smooth appearance of the global area, while the high-frequency part captures the rich details of local regions, such as edges, textures, and other complex features. Ignoring the differences between frequency components hinders effective feature learning, making it difficult to achieve robustness and invisibility in watermarking, which also limits the flexibility of the model in handling diverse information. In robust image watermarking models, fidelity and robustness are crucial evaluation metrics. Effectively capturing image features plays a key role in enhancing the fidelity and robustness of the watermarking model.MethodThe proposed method enhances watermarking performance by processing low-frequency and high-frequency components through differentiated mechanisms. Specifically, low-frequency components are modeled using a wavelet convolutional neural network of cascaded wavelet decomposition, deep convolution, and inverse wavelet reconstruction. This approach leverages wide receptive field convolutions to efficiently capture global structures and contextual information at a coarse granularity, enhancing the capability of the model to learn low-frequency information while maintaining computational efficiency. In contrast, high-frequency components are refined using a feature distillation block comprising depthwise separable convolutions and attention mechanisms. This design strengthens image details and enables efficient extraction of high-frequency information at a fine granularity. The Haar wavelet is used for decomposition due to its computational efficiency and simplicity, increasing its suitability for integration into convolutional neural networks. Additionally, a multifrequency wavelet loss function is employed to guide the model’s focus on feature distribution across different frequency bands, further improving generated image quality. Multifrequency wavelet transforms allow image representation at different scales. By decomposing the image into multiple levels, details from low-frequency to high-frequency are captured, which is crucial for image reconstruction, preserving additional details and reducing distortion. Subsequent wavelet decompositions are performed only on the low-frequency components after applying the first-level wavelet transform to the image.ResultExperimental results demonstrate that the proposed deep robust image watermarking driven by frequency awareness (RIWFP) achieves superior performance across multiple datasets. On the COCO dataset, RIWFP attains an accuracy of 91.4% under dropout attacks. Under salt and pepper noise and median blur attacks, RIWFP achieves a maximum accuracy of 100% and 99.5%, respectively, highlighting its effective learning of high-frequency information. On the ImageNet dataset, RIWFP records an accuracy of 93.4% and 99.6% under crop and JPEG attacks, respectively, notably outperforming other methods. Overall, RIWFP achieves average accuracies of 96.7% and 96.9% on the COCO and ImageNet datasets, respectively, surpassing existing methods. Ablation experiments further confirm that RIWFP enhances watermark invisibility and robustness by integrating wavelet convolution with a distillation mechanism, showing particular resilience to high-frequency-related noise and filtering attacks.ConclusionThe proposed method substantially improves watermark invisibility and robustness through a frequency-aware, coarse-to-fine processing strategy. This method demonstrates superior performance against various attacks, providing an effective solution for digital image watermarking.关键词:robust image watermarking;wavelet convolutional neural network;depthwise separable convolution;attention mechanism;multi-frequency wavelet loss143|273|0更新时间:2026-02-02
摘要:ObjectiveWith the rapid advancement of digital technology and the extensive use of the internet, the creation and dissemination of image content have undergone remarkable changes. Social media platforms, such as Douyin and WeChat Moments, have provided users with vast stages for showcasing and sharing visual works. These platforms have not only motivated the flourishing development of image creation but have also injected strong momentum into the “visual economy”. However, with the widespread distribution of image works, copyright issues have become increasingly prominent. Numerous malicious actors use technical means to steal, alter, or even commercialize the works of others without authorization, severely damaging the rights of original creators. This phenomenon not only disturbs the creative ecosystem but also threatens the sustainable development of digital content. Therefore, effectively protecting the copyright of image works in an open network environment has become a crucial issue in technical research and industrial practice. Digital image watermarking technology is one of the effective methods to address this problem. The earliest studies in digital watermarking encoded secret information in the least significant bit of image pixels; however, this method is easily detected by statistical measures. Researchers then shifted their attention to frequency domains, determining that encoding information in the discrete cosine transform and discrete wavelet transform domains was highly robust. However, all these traditional methods heavily relied on shallow, manually crafted image features, indicating that they did not fully use the carrier image, resulting in substantial limitations in robustness. In recent years, with the development of deep learning, numerous deep learning-based models have been applied to digital image watermarking to enhance robustness. However, most of these approaches treat the low-frequency and high-frequency components of feature maps equally, overlooking the considerable differences between different frequencies. This uniform treatment limits the model’s adaptability to diverse attacks, making it difficult to achieve high fidelity and strong robustness in watermarking. Various attacks affect image frequency bands differently. For example, median filtering primarily impacts the distortion of high-frequency regions, whereas JPEG compression has a greater impact on low-frequency distortion. The low-frequency part of an image typically conveys the smooth appearance of the global area, while the high-frequency part captures the rich details of local regions, such as edges, textures, and other complex features. Ignoring the differences between frequency components hinders effective feature learning, making it difficult to achieve robustness and invisibility in watermarking, which also limits the flexibility of the model in handling diverse information. In robust image watermarking models, fidelity and robustness are crucial evaluation metrics. Effectively capturing image features plays a key role in enhancing the fidelity and robustness of the watermarking model.MethodThe proposed method enhances watermarking performance by processing low-frequency and high-frequency components through differentiated mechanisms. Specifically, low-frequency components are modeled using a wavelet convolutional neural network of cascaded wavelet decomposition, deep convolution, and inverse wavelet reconstruction. This approach leverages wide receptive field convolutions to efficiently capture global structures and contextual information at a coarse granularity, enhancing the capability of the model to learn low-frequency information while maintaining computational efficiency. In contrast, high-frequency components are refined using a feature distillation block comprising depthwise separable convolutions and attention mechanisms. This design strengthens image details and enables efficient extraction of high-frequency information at a fine granularity. The Haar wavelet is used for decomposition due to its computational efficiency and simplicity, increasing its suitability for integration into convolutional neural networks. Additionally, a multifrequency wavelet loss function is employed to guide the model’s focus on feature distribution across different frequency bands, further improving generated image quality. Multifrequency wavelet transforms allow image representation at different scales. By decomposing the image into multiple levels, details from low-frequency to high-frequency are captured, which is crucial for image reconstruction, preserving additional details and reducing distortion. Subsequent wavelet decompositions are performed only on the low-frequency components after applying the first-level wavelet transform to the image.ResultExperimental results demonstrate that the proposed deep robust image watermarking driven by frequency awareness (RIWFP) achieves superior performance across multiple datasets. On the COCO dataset, RIWFP attains an accuracy of 91.4% under dropout attacks. Under salt and pepper noise and median blur attacks, RIWFP achieves a maximum accuracy of 100% and 99.5%, respectively, highlighting its effective learning of high-frequency information. On the ImageNet dataset, RIWFP records an accuracy of 93.4% and 99.6% under crop and JPEG attacks, respectively, notably outperforming other methods. Overall, RIWFP achieves average accuracies of 96.7% and 96.9% on the COCO and ImageNet datasets, respectively, surpassing existing methods. Ablation experiments further confirm that RIWFP enhances watermark invisibility and robustness by integrating wavelet convolution with a distillation mechanism, showing particular resilience to high-frequency-related noise and filtering attacks.ConclusionThe proposed method substantially improves watermark invisibility and robustness through a frequency-aware, coarse-to-fine processing strategy. This method demonstrates superior performance against various attacks, providing an effective solution for digital image watermarking.关键词:robust image watermarking;wavelet convolutional neural network;depthwise separable convolution;attention mechanism;multi-frequency wavelet loss143|273|0更新时间:2026-02-02
AI Security for Digital Images
- “海量遥感数据与AI大模型推动智能化遥感图像解译落地,“预训练 + 微调”成经典范式。专家调研提示词微调、适配器微调和低秩自适应微调三大类方法,总结性能,为“AI + 遥感”应用生态提供理论参考与研究思路。”
 摘要:Vision language model (VLM) currently plays a fundamental role in the research field located at the fusion of computer vision and natural language processing, demonstrating its application potential in various downstream vision tasks. With the continuous development of remote sensing data acquisition and processing technologies, the substantial amount of accumulated remote sensing images offers a solid data support for downstream remote sensing task. Remote sensing information extraction, fusion, and intelligent interpretation are crucial in various fields, such as high-resolution earth observation, land resources and energy exploration, environmental investigation, and military reconnaissance. Imperatively, using the generalization, versatility, and high-precision advantages of AI models can elevate the intelligence and automation level of remote sensing image interpretation. However, the performance of the state-of-the-art VLMs is highly related to its expanded billions or even trillions training parameters, the conventional pretraining and full fine-tuning from scratch paradigm become untenable due to its excessive computational costs and high storage requirements. As a cost-effective tuning method, the recent emergence of new paradigms based on parameter-efficient fine-tuning (PEFT) offers a practical solution through the adaptation of large VLM models to specialized domain or task without introducing additional parameters. A meaningful research direction focuses on reducing the cost of fine-tuning the foundational models for downstream remote sensing tasks while still maintaining excellent performance. The constructed interpretation models should possess efficient training and downstream task adaptation capabilities under low-resource conditions to address the increasingly refined application demands and reduce the computational burden of full-parameter fine-tuning. Existing reviews mainly concentrate on the basic large vision-language models in remote sensing and provide limited attention on the parameter-efficient fine-tuning of remote sensing pre-trained models, thereby neglecting the systematic summary of the corresponding mainstream methods. With the rapid development of intelligent interpretation models for remote sensing images, systematically elaborating and analyzing parameter-efficient fine-tuning methods for remote sensing image interpretation is of considerable importance to fully leverage the dominant advantages of remote sensing large models, lower the barrier for applying remote sensing large models, and promote low-cost training, low-latency inference, and lightweight deployment applications of large models. Aiming to mitigate this gap, this survey systematically analyzes and reveals the potential of PEFT in remote sensing image interpretation to surpass the performance of full fine-tuning through minimal parameter modifications. First, the formal definition of PEFT is introduced, and its mainstream algorithms are explored. Prompt tuning, adapter tuning, and low-rank adaption tuning are the most prevalently used PEFT methods in the field of visual domain. Therefore, this survey divides existing methods into three categories and meticulously analyzes the advancements in their applications. Furthermore, this survey discusses some basic theoretical knowledge on influential large pretrained vision and vision-language models. The survey also analyzes and summarizes the challenges of remote sensing downstream applications in terms of parameter-efficient fine-tuning methods from the perspective of dense prediction tasks, feature utilization, and training efficiency. A comprehensive investigation of relevant PEFT methods for diverse interpretation tasks, such as scene recognition, object classification, semantic segmentation, change detection, and object detection, is then provided. The contribution of each method, as well as the connections, similarities and differences among various methods on each downstream task, are comprehensively summarized and analyzed. Furthermore, existing remote sensing datasets suitable for each downstream task are collected and organized. All the datasets are provided with detailed information such as category number, data quantity, image size, and corresponding reference. Particularly, the prevailing evaluation criterion for each task is also provided for fair comparison. The collection, organization, and analysis of experimental results are performed considering datasets such as UC-Merced, AID, NWPU-RESISC45, UCAS-AOD, FAIR1M, LoveDA, and LEVIR-CD. Experimental results on several typical remote sensing datasets validate the superior performance of PEFT methods compared to full fine-tuning methods in terms of training parameters and memory cost. Building upon an extensive survey of the current state-of-the-art PEFT methods in remote sensing field, the related challenges are also discussed, and development trends are suggested for further research. Future research should include the following: 1) PEFT methods for generative tasks and multimodal data: PEFT techniques are conducive to empowering downstream applications of remote sensing generative foundation models that integrate multimodal content such as text, image, audio, and video. Exploring the application of PEFT methods in generative tasks within the multimodal remote sensing domain holds notable potential. 2) Research on the interpretability of PEFT methods: aiming to enhance the decision-making and cognitive capabilities of remote sensing large models, integrating prior information or multisource knowledge is necessary to guide the models. The robustness and trustworthiness of models can be largely improved by revealing the internal mechanisms of how models process multimodal information. 3) Research on the deployment and application of PEFT methods: designing large-scale foundational model architectures for efficient computation, combined with breakthrough in technologies such as model pruning, quantization, and inference acceleration, can help ultimately achieve low-cost training, low memory consumption, efficient real-time inference, and lightweight deployment applications for remote sensing large models. The authors hope that this survey can help establish a methodological framework for benchmarking PEFT algorithms in remote sensing image interpretation, providing researchers in this field with detailed and valuable perceptions for further investigation.关键词:vision-language large model;parameter-efficient fine-tuning(PEFT);remote sensing image interpretation;prompt;adapter;low rank adaptation179|205|0更新时间:2026-02-02
摘要:Vision language model (VLM) currently plays a fundamental role in the research field located at the fusion of computer vision and natural language processing, demonstrating its application potential in various downstream vision tasks. With the continuous development of remote sensing data acquisition and processing technologies, the substantial amount of accumulated remote sensing images offers a solid data support for downstream remote sensing task. Remote sensing information extraction, fusion, and intelligent interpretation are crucial in various fields, such as high-resolution earth observation, land resources and energy exploration, environmental investigation, and military reconnaissance. Imperatively, using the generalization, versatility, and high-precision advantages of AI models can elevate the intelligence and automation level of remote sensing image interpretation. However, the performance of the state-of-the-art VLMs is highly related to its expanded billions or even trillions training parameters, the conventional pretraining and full fine-tuning from scratch paradigm become untenable due to its excessive computational costs and high storage requirements. As a cost-effective tuning method, the recent emergence of new paradigms based on parameter-efficient fine-tuning (PEFT) offers a practical solution through the adaptation of large VLM models to specialized domain or task without introducing additional parameters. A meaningful research direction focuses on reducing the cost of fine-tuning the foundational models for downstream remote sensing tasks while still maintaining excellent performance. The constructed interpretation models should possess efficient training and downstream task adaptation capabilities under low-resource conditions to address the increasingly refined application demands and reduce the computational burden of full-parameter fine-tuning. Existing reviews mainly concentrate on the basic large vision-language models in remote sensing and provide limited attention on the parameter-efficient fine-tuning of remote sensing pre-trained models, thereby neglecting the systematic summary of the corresponding mainstream methods. With the rapid development of intelligent interpretation models for remote sensing images, systematically elaborating and analyzing parameter-efficient fine-tuning methods for remote sensing image interpretation is of considerable importance to fully leverage the dominant advantages of remote sensing large models, lower the barrier for applying remote sensing large models, and promote low-cost training, low-latency inference, and lightweight deployment applications of large models. Aiming to mitigate this gap, this survey systematically analyzes and reveals the potential of PEFT in remote sensing image interpretation to surpass the performance of full fine-tuning through minimal parameter modifications. First, the formal definition of PEFT is introduced, and its mainstream algorithms are explored. Prompt tuning, adapter tuning, and low-rank adaption tuning are the most prevalently used PEFT methods in the field of visual domain. Therefore, this survey divides existing methods into three categories and meticulously analyzes the advancements in their applications. Furthermore, this survey discusses some basic theoretical knowledge on influential large pretrained vision and vision-language models. The survey also analyzes and summarizes the challenges of remote sensing downstream applications in terms of parameter-efficient fine-tuning methods from the perspective of dense prediction tasks, feature utilization, and training efficiency. A comprehensive investigation of relevant PEFT methods for diverse interpretation tasks, such as scene recognition, object classification, semantic segmentation, change detection, and object detection, is then provided. The contribution of each method, as well as the connections, similarities and differences among various methods on each downstream task, are comprehensively summarized and analyzed. Furthermore, existing remote sensing datasets suitable for each downstream task are collected and organized. All the datasets are provided with detailed information such as category number, data quantity, image size, and corresponding reference. Particularly, the prevailing evaluation criterion for each task is also provided for fair comparison. The collection, organization, and analysis of experimental results are performed considering datasets such as UC-Merced, AID, NWPU-RESISC45, UCAS-AOD, FAIR1M, LoveDA, and LEVIR-CD. Experimental results on several typical remote sensing datasets validate the superior performance of PEFT methods compared to full fine-tuning methods in terms of training parameters and memory cost. Building upon an extensive survey of the current state-of-the-art PEFT methods in remote sensing field, the related challenges are also discussed, and development trends are suggested for further research. Future research should include the following: 1) PEFT methods for generative tasks and multimodal data: PEFT techniques are conducive to empowering downstream applications of remote sensing generative foundation models that integrate multimodal content such as text, image, audio, and video. Exploring the application of PEFT methods in generative tasks within the multimodal remote sensing domain holds notable potential. 2) Research on the interpretability of PEFT methods: aiming to enhance the decision-making and cognitive capabilities of remote sensing large models, integrating prior information or multisource knowledge is necessary to guide the models. The robustness and trustworthiness of models can be largely improved by revealing the internal mechanisms of how models process multimodal information. 3) Research on the deployment and application of PEFT methods: designing large-scale foundational model architectures for efficient computation, combined with breakthrough in technologies such as model pruning, quantization, and inference acceleration, can help ultimately achieve low-cost training, low memory consumption, efficient real-time inference, and lightweight deployment applications for remote sensing large models. The authors hope that this survey can help establish a methodological framework for benchmarking PEFT algorithms in remote sensing image interpretation, providing researchers in this field with detailed and valuable perceptions for further investigation.关键词:vision-language large model;parameter-efficient fine-tuning(PEFT);remote sensing image interpretation;prompt;adapter;low rank adaptation179|205|0更新时间:2026-02-02
Review
- ““目的高时间分辨率的事件相机为传统运动图像去模糊任务提供新的发展思路,但是当前基于事件驱动的运动图像去模糊方法中存在跨模态补偿机制不足、深度特征计算复杂度较高以及缺乏多尺度时空信息关注的问题,在复杂场景中的去模糊泛化性能受限。针对以上挑战,提出一种双通道Mamba去模糊网络(dual channel Mamba network,DCM-Net)。方法使用一种双通道跨模态Mamba模块(dual channel cross-modal Mamba,DCCM),通过线性复杂度的状态空间模型(state space model,SSM)隐状态映射,将事件与模糊图像投影至共享的潜在特征空间中,再通过非线性交叉门控结构,利用低噪声的模糊图像信息抑制事件噪声,并提取事件的清晰边缘特征,将其嵌入到图像特征中,实现事件和模糊图像的跨模态特征互补融合,达到去模糊的效果。此外,提出一种金字塔通道注意力模块(pyramid channel attention,PyCA)对特征的多尺度时空信息进行提取,引导网络聚焦关键时间通道,增强对空间内局部模糊的细节重建,进一步提高潜在清晰图像序列的复原精度。结果实验在合成的REDS(realistic and diverse scenes)数据集与半合成的HQF(high quality frames)数据集上进行,与11种方法进行了比较。与DeMo-IVF方法相比,本文方法在REDS数据集重建序列的峰值信噪比(peak signal-to-noise ratio,PSNR)平均提升了0.16 dB,结构相似性指数(structural similarity,SSIM)平均提升了0.003;在HQF数据集上,PSNR和SSIM分别平均提升约0.11 dB和0.002;在两个数据集上的序列重建结果的学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)达到最优。在与其中5种较先进方法进行比较的主观对比实验中,本文方法取得最佳评分。结论本文方法可以结合模糊图像和事件数据,重建出清晰潜在图像序列,证明了所提网络框架的有效性。””
 摘要:ObjectiveMotion deblurring is an ill-posed problem, because real-world blurred images result from the temporal integration of continuous scene dynamics and often lack information on intraframe motion and texture. Aiming to address the above challenge, recent work has leveraged event cameras, which are bio-inspired vision sensors with extremely high temporal resolution and provide intra-frame clues about motions and intensity textures, to perform the motion deblurring tasks. Despite efforts to enhance deblurring performance, most event-based methods depend on the simple concatenation of primary features, overlooking the substantial modal discrepancy between the spatial sparsity and temporal density of event data and the dense spatial characteristics of blurred images. This oversight restricts effective cross-modal feature interaction and ultimately leads to only marginal improvements in deblurring outcomes. Aiming to facilitate cross-modal fusion of events and blurred images, several methodologies that use Transformer-based cross-modal fusion architectures have been developed. However, the effectiveness of feature extraction and fusion processes within these cross-modal mechanisms depends on the quantity of structural components employed and the associated computational expenses. A limited number of structures may lead to insufficient deblurring performance, while extensive feature extraction often necessitates considerable computational resources. Furthermore, previous methods typically rely on convolutional layers or Transformer-based architectures that model global or windowed contexts within a singular receptive field along the channel dimension. This oversight regarding the integration of multiscale spatiotemporal information in the context of intricate motion scenarios leads to suboptimal reconstruction of local detail textures and a deterioration in generalization performance. Therefore, this study proposes a novel event-based motion deblurring framework called dual-channel Mamba network (DCM-Net) to address the above-mentioned issues. DCM-Net constructs a dual-channel module based on the Mamba model, efficiently achieving feature complementarity between the blurred image and events. Pyramid channel attention is also introduced to supplement multiscale spatiotemporal information in the features, ultimately achieving high-quality reconstruction of sharp latent image sequences.MethodIn this study, a module called dual-channel cross-modal Mamba (DCCM) is established. Specifically, DCCM employs state space model (SSM) with linear complexity to project the blurred image and events into a shared latent feature space. Subsequently, these representations are subjected to processing via nonlinear cross-gating architectures. DCCM integrates the features from both modalities using a nonlinear cross-gate structure that facilitates the learning of complementary features while mitigating redundancy. Aiming to minimize the influence of event noise, DCCM implements event gating thresholds that enable the selective extraction of features from blurred images that are relatively free of noise, which are then incorporated into the event features. Additionally, image features frequently suffer from texture loss due to the degradation caused by blurring. Given that event features retain clear texture information, they can be selectively integrated through the application of blurred image gating thresholds, thereby compensating for the loss and achieving a deblurring effect. Furthermore, to enhance the detailed reconstruction of networks in complex scenarios with non-uniform blur and non-linear motion, this research introduces a pyramid channel attention (PyCA) module based on the channel attention mechanism. Different from traditional channel attention techniques that depend exclusively on global pooling, PyCA not only extracts temporal feature information from vertical channels but also improves the acquisition of local blurred feature information within these channels by integrating multiscale pooling results. This approach enhances the network’s focus on intricate details within the local spatiotemporal context of features, thereby facilitating the extraction and enhancement of detailed texture features in that specific region. Consequently, this refinement contributes to the overall improvement of the sequence reconstruction performance of the deblurring network.ResultComparative experiments on two public datasets, realistic and diverse scenes(REDS) and high quality frames(HQF), are conducted to validate the effectiveness of the proposed DCM-Net. The original REDS dataset comprises high frame rate videos recorded using the GoPro action camera. This study employs frame interpolation algorithms and event simulators to produce blurred images and simulated event streams. Conversely, the original HQF dataset comprises real events and high-resolution video frames that were captured concurrently using the DAVIS240 event camera. In this study, blurred images are synthesized from the clear video frames. This model is compared with 11 state-of-the-art motion deblurring models, including the frame-based and event-based methods. Three widely recognized metrics in the domain of image processing are employed to evaluate reconstruction quality: peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS). The proposed method demonstrates superior performance on the REDS dataset, achieving an average PSNR of 30.166 dB and an average SSIM of 0.909 6, which demonstrates its superiority to other existing methods. Specifically, the proposed approach yields average PSNR and SSIM enhancements of 0.5% and 0.3%, respectively, compared to the leading state-of-the-art technique. Furthermore, on the HQF dataset, the method maintains exceptional performance, exhibiting average improvements of approximately 0.3% in PSNR and SSIM, thereby further confirming its effectiveness in handling real-world events. The proposed method also achieves state-of-the-art performance in average LPIPS for sequence reconstruction on REDS and HQF datasets. Additionally, visual comparisons and subjective experiments (user study) conducted on the two datasets further validate the effectiveness of the proposed method in this study. Considering the effective feature extraction capabilities inherent in the Mamba architecture, DCM-Net attains superior deblurring results while simultaneously exhibiting reduced computational complexity. Specifically, DCM-Net reduces computational overhead by over 40% in comparison to the leading state-of-the-art method that use the Swin-Transformer architecture and 27% compared to its own Transformer variant. Ablation studies on the sequence reconstruction of REDS dataset further validated the contributions of the key modules of DCM-Net. The removal of the DCCM module leads to a notable decline in PSNR and SSIM for DCM-Net. In contrast, the incorporation of PyCA in conjunction with DCCM still yields performance improvements (0.17 dB and 0.003 in PSNR and SSIM, respectively).ConclusionThe DCM-Net introduced in this study enables effective cross-modal interaction and fusion between blurred image and event data while enhancing the model’s focus on multiscale spatiotemporal information. DCM-Net outperforms existing methods, producing reconstructed latent image sequences with clear edge textures and minimal distortion. Furthermore, DCM-Net achieves an improved equilibrium among the number of model parameters, computational complexity, and overall performance.关键词:motion deblurring;event camera;mamba model;pyramid channel attention;cross-modal fusion210|218|0更新时间:2026-02-02
摘要:ObjectiveMotion deblurring is an ill-posed problem, because real-world blurred images result from the temporal integration of continuous scene dynamics and often lack information on intraframe motion and texture. Aiming to address the above challenge, recent work has leveraged event cameras, which are bio-inspired vision sensors with extremely high temporal resolution and provide intra-frame clues about motions and intensity textures, to perform the motion deblurring tasks. Despite efforts to enhance deblurring performance, most event-based methods depend on the simple concatenation of primary features, overlooking the substantial modal discrepancy between the spatial sparsity and temporal density of event data and the dense spatial characteristics of blurred images. This oversight restricts effective cross-modal feature interaction and ultimately leads to only marginal improvements in deblurring outcomes. Aiming to facilitate cross-modal fusion of events and blurred images, several methodologies that use Transformer-based cross-modal fusion architectures have been developed. However, the effectiveness of feature extraction and fusion processes within these cross-modal mechanisms depends on the quantity of structural components employed and the associated computational expenses. A limited number of structures may lead to insufficient deblurring performance, while extensive feature extraction often necessitates considerable computational resources. Furthermore, previous methods typically rely on convolutional layers or Transformer-based architectures that model global or windowed contexts within a singular receptive field along the channel dimension. This oversight regarding the integration of multiscale spatiotemporal information in the context of intricate motion scenarios leads to suboptimal reconstruction of local detail textures and a deterioration in generalization performance. Therefore, this study proposes a novel event-based motion deblurring framework called dual-channel Mamba network (DCM-Net) to address the above-mentioned issues. DCM-Net constructs a dual-channel module based on the Mamba model, efficiently achieving feature complementarity between the blurred image and events. Pyramid channel attention is also introduced to supplement multiscale spatiotemporal information in the features, ultimately achieving high-quality reconstruction of sharp latent image sequences.MethodIn this study, a module called dual-channel cross-modal Mamba (DCCM) is established. Specifically, DCCM employs state space model (SSM) with linear complexity to project the blurred image and events into a shared latent feature space. Subsequently, these representations are subjected to processing via nonlinear cross-gating architectures. DCCM integrates the features from both modalities using a nonlinear cross-gate structure that facilitates the learning of complementary features while mitigating redundancy. Aiming to minimize the influence of event noise, DCCM implements event gating thresholds that enable the selective extraction of features from blurred images that are relatively free of noise, which are then incorporated into the event features. Additionally, image features frequently suffer from texture loss due to the degradation caused by blurring. Given that event features retain clear texture information, they can be selectively integrated through the application of blurred image gating thresholds, thereby compensating for the loss and achieving a deblurring effect. Furthermore, to enhance the detailed reconstruction of networks in complex scenarios with non-uniform blur and non-linear motion, this research introduces a pyramid channel attention (PyCA) module based on the channel attention mechanism. Different from traditional channel attention techniques that depend exclusively on global pooling, PyCA not only extracts temporal feature information from vertical channels but also improves the acquisition of local blurred feature information within these channels by integrating multiscale pooling results. This approach enhances the network’s focus on intricate details within the local spatiotemporal context of features, thereby facilitating the extraction and enhancement of detailed texture features in that specific region. Consequently, this refinement contributes to the overall improvement of the sequence reconstruction performance of the deblurring network.ResultComparative experiments on two public datasets, realistic and diverse scenes(REDS) and high quality frames(HQF), are conducted to validate the effectiveness of the proposed DCM-Net. The original REDS dataset comprises high frame rate videos recorded using the GoPro action camera. This study employs frame interpolation algorithms and event simulators to produce blurred images and simulated event streams. Conversely, the original HQF dataset comprises real events and high-resolution video frames that were captured concurrently using the DAVIS240 event camera. In this study, blurred images are synthesized from the clear video frames. This model is compared with 11 state-of-the-art motion deblurring models, including the frame-based and event-based methods. Three widely recognized metrics in the domain of image processing are employed to evaluate reconstruction quality: peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS). The proposed method demonstrates superior performance on the REDS dataset, achieving an average PSNR of 30.166 dB and an average SSIM of 0.909 6, which demonstrates its superiority to other existing methods. Specifically, the proposed approach yields average PSNR and SSIM enhancements of 0.5% and 0.3%, respectively, compared to the leading state-of-the-art technique. Furthermore, on the HQF dataset, the method maintains exceptional performance, exhibiting average improvements of approximately 0.3% in PSNR and SSIM, thereby further confirming its effectiveness in handling real-world events. The proposed method also achieves state-of-the-art performance in average LPIPS for sequence reconstruction on REDS and HQF datasets. Additionally, visual comparisons and subjective experiments (user study) conducted on the two datasets further validate the effectiveness of the proposed method in this study. Considering the effective feature extraction capabilities inherent in the Mamba architecture, DCM-Net attains superior deblurring results while simultaneously exhibiting reduced computational complexity. Specifically, DCM-Net reduces computational overhead by over 40% in comparison to the leading state-of-the-art method that use the Swin-Transformer architecture and 27% compared to its own Transformer variant. Ablation studies on the sequence reconstruction of REDS dataset further validated the contributions of the key modules of DCM-Net. The removal of the DCCM module leads to a notable decline in PSNR and SSIM for DCM-Net. In contrast, the incorporation of PyCA in conjunction with DCCM still yields performance improvements (0.17 dB and 0.003 in PSNR and SSIM, respectively).ConclusionThe DCM-Net introduced in this study enables effective cross-modal interaction and fusion between blurred image and event data while enhancing the model’s focus on multiscale spatiotemporal information. DCM-Net outperforms existing methods, producing reconstructed latent image sequences with clear edge textures and minimal distortion. Furthermore, DCM-Net achieves an improved equilibrium among the number of model parameters, computational complexity, and overall performance.关键词:motion deblurring;event camera;mamba model;pyramid channel attention;cross-modal fusion210|218|0更新时间:2026-02-02
Image Processing and Coding
- “相关研究在三维点云去噪领域取得新进展,专家提出双阶段双分支模型,有效解决点云数据局部与全局特征提取融合难题,显著提升去噪效果,为相关应用提供有力支持。”
 摘要:ObjectiveThree-dimensional point cloud data has become an vital component in various modern technological applications, including autonomous navigation systems and the rapidly evolving realm of virtual reality. In these domains, the demand for precise and high-quality point cloud data is critical to ensuring that operational tasks are performed efficiently and accurately. However, generating accurate and clean point cloud data presents considerable challenges. Numerous factors, such as limitations in sensor technologies, varying environmental conditions, and errors during data processing, can introduce noise into the point cloud data, drastically compromising its quality and precision. Noise within point cloud data represents a significant hurdle to obtaining reliable information about the environment. This noise presents a major obstacle to acquiring reliable environmental information. Noise in point cloud data can obscure important spatial details, leading to uncertainties in applications that rely on accurate spatial data. For instance, in autonomous navigation, noise may result in incorrect obstacle detection, while in virtual reality, it can diminish the realism and immersion o virtual environments. Recognizing these challenges, researchers have invested considerable efforts in devising denoising techniques aimed at removing noise and enhancing data reliability. Among these strategies developed, deep learning methods have attracted substantial attention. These advanced approaches leverage neural networks to learn intricate mappings from noisy inputs to clean outputs. By capturing complex relationships between noisy and clean point cloud features, deep learning approaches offer promising improvements in denoising performance.MethodAiming to address the persistent challenge of noise in point cloud data, a novel method has been introduced. This method employs a network architecture comprising two primary stages, each augmented with distinct and complementary components. The first stage features a dual-branch encoder-decoder framework. Within this stage, the encoder is divided into two branches: a local encoder dedicated to learning local point cloud features, and a patch-based encoder that captures overall block features. An innovative aspect of this design lies in the integration of a cross-attention module. This module is designed to facilitate information exchange between local and block features, thus fostering a robust and comprehensive representation of point cloud data. During the feature extraction process in the first stage, the local encoder performs calculations to combine point distribution features. Meanwhile, the patch encoder computes and integrates patch shape features. This dual approach ensures that local micro-level details and global macro-level characteristics are preserved during the learning phase. Following feature extraction, the decoder plays a crucial role by estimating an initial displacement vector. This vector is subsequently added to the original noisy point cloud data, producing an intermediate output. This output is then channeled into the second stage, shifting the focus to feature enhancement. The second stage is designed to further refine and update the feature sets extracted during the first stage. A key characteristic of this two-stage model lies in its iterative learning process. The output features from the feature enhancement module in the second stage are recursively fed back into the decoder of the first stage. This recursive feedback loop enables an additional round of displacement decoding, allowing the newly generated displacement to interact synergistically with the previously updated point cloud data, thereby ensuring progressive refinement. In this stage, the decoder processes this feedback information to regress a refined displacement vector. The final vector emerges from a weighted summation of the displacement vectors generated by both stages. Consequently, an optimized displacement vector is achieved, adeptly guiding the denoising process of the noisy point clouds.ResultAiming to evaluate the effectiveness of the proposed methodology, extensive experiments were conducted on three renowned point cloud denoising datasets: point cloud upsampling network(PUNet), point clean network(PCNet), and Kinect_v1. These experiments were accompanied by comparative analyses with six leading denoising techniques. The results demonstrated the superior performance of the proposed model. For instance, on the PUNet dataset, while Pointfilter achieved three best performances and two second-best performances, the dual-branch dual-encoder model achieved six best and three second-best performances. Similarly, on the PCNet dataset, IterativePFN recorded two best and six second-best performances, whereas the dual-branch dual-encoder model achieved seven best and three second-best performances. On the Kinect_v1 dataset, although the proposed model delivered suboptimal performance in certain individual metrics compared to the best-performing methods, it achieved the highest overall performance.ConclusionThe successful implementation of the two-stage dual-branch model effectively addresses the complex challenge of extracting and integrating local and global features within point cloud data blocks. By incorporating advanced attention mechanisms, the proposed method achieves considerable improvements in denoising performing while maintaining the geometric integrity and structural characteristics of the data. The notable gains across multiple benchmark datasets highlight the method’s potential to advancing point cloud processing, with promising applications in areas such as 3D reconstruction, autonomous navigation, and immersive virtual reality.关键词:deep learning;3D point cloud denoising;dual-branch encoder;feature fusion;attention mechanism170|245|0更新时间:2026-02-02
摘要:ObjectiveThree-dimensional point cloud data has become an vital component in various modern technological applications, including autonomous navigation systems and the rapidly evolving realm of virtual reality. In these domains, the demand for precise and high-quality point cloud data is critical to ensuring that operational tasks are performed efficiently and accurately. However, generating accurate and clean point cloud data presents considerable challenges. Numerous factors, such as limitations in sensor technologies, varying environmental conditions, and errors during data processing, can introduce noise into the point cloud data, drastically compromising its quality and precision. Noise within point cloud data represents a significant hurdle to obtaining reliable information about the environment. This noise presents a major obstacle to acquiring reliable environmental information. Noise in point cloud data can obscure important spatial details, leading to uncertainties in applications that rely on accurate spatial data. For instance, in autonomous navigation, noise may result in incorrect obstacle detection, while in virtual reality, it can diminish the realism and immersion o virtual environments. Recognizing these challenges, researchers have invested considerable efforts in devising denoising techniques aimed at removing noise and enhancing data reliability. Among these strategies developed, deep learning methods have attracted substantial attention. These advanced approaches leverage neural networks to learn intricate mappings from noisy inputs to clean outputs. By capturing complex relationships between noisy and clean point cloud features, deep learning approaches offer promising improvements in denoising performance.MethodAiming to address the persistent challenge of noise in point cloud data, a novel method has been introduced. This method employs a network architecture comprising two primary stages, each augmented with distinct and complementary components. The first stage features a dual-branch encoder-decoder framework. Within this stage, the encoder is divided into two branches: a local encoder dedicated to learning local point cloud features, and a patch-based encoder that captures overall block features. An innovative aspect of this design lies in the integration of a cross-attention module. This module is designed to facilitate information exchange between local and block features, thus fostering a robust and comprehensive representation of point cloud data. During the feature extraction process in the first stage, the local encoder performs calculations to combine point distribution features. Meanwhile, the patch encoder computes and integrates patch shape features. This dual approach ensures that local micro-level details and global macro-level characteristics are preserved during the learning phase. Following feature extraction, the decoder plays a crucial role by estimating an initial displacement vector. This vector is subsequently added to the original noisy point cloud data, producing an intermediate output. This output is then channeled into the second stage, shifting the focus to feature enhancement. The second stage is designed to further refine and update the feature sets extracted during the first stage. A key characteristic of this two-stage model lies in its iterative learning process. The output features from the feature enhancement module in the second stage are recursively fed back into the decoder of the first stage. This recursive feedback loop enables an additional round of displacement decoding, allowing the newly generated displacement to interact synergistically with the previously updated point cloud data, thereby ensuring progressive refinement. In this stage, the decoder processes this feedback information to regress a refined displacement vector. The final vector emerges from a weighted summation of the displacement vectors generated by both stages. Consequently, an optimized displacement vector is achieved, adeptly guiding the denoising process of the noisy point clouds.ResultAiming to evaluate the effectiveness of the proposed methodology, extensive experiments were conducted on three renowned point cloud denoising datasets: point cloud upsampling network(PUNet), point clean network(PCNet), and Kinect_v1. These experiments were accompanied by comparative analyses with six leading denoising techniques. The results demonstrated the superior performance of the proposed model. For instance, on the PUNet dataset, while Pointfilter achieved three best performances and two second-best performances, the dual-branch dual-encoder model achieved six best and three second-best performances. Similarly, on the PCNet dataset, IterativePFN recorded two best and six second-best performances, whereas the dual-branch dual-encoder model achieved seven best and three second-best performances. On the Kinect_v1 dataset, although the proposed model delivered suboptimal performance in certain individual metrics compared to the best-performing methods, it achieved the highest overall performance.ConclusionThe successful implementation of the two-stage dual-branch model effectively addresses the complex challenge of extracting and integrating local and global features within point cloud data blocks. By incorporating advanced attention mechanisms, the proposed method achieves considerable improvements in denoising performing while maintaining the geometric integrity and structural characteristics of the data. The notable gains across multiple benchmark datasets highlight the method’s potential to advancing point cloud processing, with promising applications in areas such as 3D reconstruction, autonomous navigation, and immersive virtual reality.关键词:deep learning;3D point cloud denoising;dual-branch encoder;feature fusion;attention mechanism170|245|0更新时间:2026-02-02 - “相关研究在电影场景分割领域取得新进展,专家提出HASSNet混合架构方法,通过预训练与微调策略,结合状态空间模型和自注意力机制,显著提升场景分割精度,为电影内容理解和多媒体应用提供有力支持。”
 摘要:ObjectiveWith the rapid advancement of the film industry and the increasing complexity of movie content, automatic movie scene segmentation has emerged as a critical task for understanding film narrative structure and supporting various multimedia applications. Traditional scene segmentation methods often struggle with effectively extracting shot features and modeling the contextual relationships between shots in long video sequences. To address these challenges, this study proposes a novel hybrid architecture for movie scene segmentation called hybrid architecture scene segmentation network (HASSNet), which aims to enhance the effectiveness of shot feature extraction and intershot feature association while improving the contextual awareness capabilities of shot sequences.MethodThe proposed HASSNet consists of two coordinated modules and a two-stage training strategy. At the architectural level, we design 1) a Shot Mamba module for shot feature extraction and 2) a Scene Transformer module for intershot association. Shot Mamba adapts the Mamba state-space model to images by adopting a ViT style patching scheme on key frames, adding positional embeddings and a class token, and then modeling the patch sequence with stacked state-space blocks. Given a sequence composed of a center shot and its temporal neighbors, Scene Transformer takes the shot embeddings as input and applies multihead self-attention to explicitly model global dependencies among shots, yielding context-enriched “shot context embeddings” that capture short- and long-range relations needed for boundary reasoning. At the training level, we adopt a two-stage pipeline that leverages unlabeled and labeled movie data. In pretraining, we use all available movies without scene labels and drive learning with three unsupervised losses built upon a pseudoboundary generator. The pseudoboundary is obtained by scanning candidate split positions and selecting the one that maximizes the combined cosine similarity of the left-side shots to the left endpoint and the right-side shots to the right endpoint. On the basis of this proxy, we introduce 1) a shot-scene matching loss (SSMLoss) that uses an InfoNCE objective to maximize the similarity between the endpoint shots and the mean features of their respective sides while minimizing cross-side similarity; 2) a scene semantic consistency (SSC) loss that, for an anchor shot, treats a randomly chosen shot from the same side of the pseudoboundary as positive and one from the opposite side as negative, again optimized with InfoNCE; and 3) a boundary prediction (BP) loss that encourages the model to discriminate the pseudoboundary shot from nonboundary shots via binary cross entropy. Together, these losses guide the model to learn representations that increase intrascene coherence and interscene separability without requiring annotations. In fine-tuning, we transfer the pretrained parameters to the labeled subset of MovieNet, freeze the Shot Mamba parameters to avoid overfitting on limited labels, and train only the Scene Transformer with Focal Loss. This choice addresses the severe class imbalance in which true boundaries are sparse relative to nonboundary positions and empirically improves boundary sensitivity.ResultWe evaluate on MovieNet and test cross-dataset generalization on BBC and OVSD. On MovieNet, HASSNet outperforms recent approaches, including methods that also employ state-space models. In particular, relative to a state space-based baseline, HASSNet improves AP by 1.66%, mIoU by 10.54%, AUC-ROC by 0.21%, and F1 by 16.83%, demonstrating more accurate boundary localization and better scene grouping. Without any additional fine-tuning, the pretrained model also yields consistent gains on BBC and OVSD, indicating robust transferability. Among the unsupervised losses, tSSMLoss contributes most to boundary discrimination, while jointly optimizing SSMLoss, SSC, and BP yields the best performance. In fine-tuning, Focal Loss consistently outperforms the weighted cross entropy under severe class imbalance.ConclusionThis study proposes HASSNet, a hybrid architecture for movie scene segmentation trained with a pretraining and fine-tuning strategy. Shot Mamba learns strong, position-aware shot embeddings efficiently from unlabeled data, while Scene Transformer explicitly captures global intershot dependencies for boundary decisions. The pseudoboundary mechanism and the three unsupervised losses enable effective representation learning without labels, and the fine-tuning regimen with Focal Loss mitigates class imbalance in supervised adaptation. Extensive experiments on MovieNet, together with cross dataset and ablations, verify that HASSNet enhances contextual awareness across shots and delivers accurate scene boundary detection. Results indicate that hybrid architectures with pretraining are promising for long-form video understanding.关键词:movie scene segmentation;pre-trained model;state space model(SSM);self-attention mechanism;unsupervised similarity measurement93|168|0更新时间:2026-02-02
摘要:ObjectiveWith the rapid advancement of the film industry and the increasing complexity of movie content, automatic movie scene segmentation has emerged as a critical task for understanding film narrative structure and supporting various multimedia applications. Traditional scene segmentation methods often struggle with effectively extracting shot features and modeling the contextual relationships between shots in long video sequences. To address these challenges, this study proposes a novel hybrid architecture for movie scene segmentation called hybrid architecture scene segmentation network (HASSNet), which aims to enhance the effectiveness of shot feature extraction and intershot feature association while improving the contextual awareness capabilities of shot sequences.MethodThe proposed HASSNet consists of two coordinated modules and a two-stage training strategy. At the architectural level, we design 1) a Shot Mamba module for shot feature extraction and 2) a Scene Transformer module for intershot association. Shot Mamba adapts the Mamba state-space model to images by adopting a ViT style patching scheme on key frames, adding positional embeddings and a class token, and then modeling the patch sequence with stacked state-space blocks. Given a sequence composed of a center shot and its temporal neighbors, Scene Transformer takes the shot embeddings as input and applies multihead self-attention to explicitly model global dependencies among shots, yielding context-enriched “shot context embeddings” that capture short- and long-range relations needed for boundary reasoning. At the training level, we adopt a two-stage pipeline that leverages unlabeled and labeled movie data. In pretraining, we use all available movies without scene labels and drive learning with three unsupervised losses built upon a pseudoboundary generator. The pseudoboundary is obtained by scanning candidate split positions and selecting the one that maximizes the combined cosine similarity of the left-side shots to the left endpoint and the right-side shots to the right endpoint. On the basis of this proxy, we introduce 1) a shot-scene matching loss (SSMLoss) that uses an InfoNCE objective to maximize the similarity between the endpoint shots and the mean features of their respective sides while minimizing cross-side similarity; 2) a scene semantic consistency (SSC) loss that, for an anchor shot, treats a randomly chosen shot from the same side of the pseudoboundary as positive and one from the opposite side as negative, again optimized with InfoNCE; and 3) a boundary prediction (BP) loss that encourages the model to discriminate the pseudoboundary shot from nonboundary shots via binary cross entropy. Together, these losses guide the model to learn representations that increase intrascene coherence and interscene separability without requiring annotations. In fine-tuning, we transfer the pretrained parameters to the labeled subset of MovieNet, freeze the Shot Mamba parameters to avoid overfitting on limited labels, and train only the Scene Transformer with Focal Loss. This choice addresses the severe class imbalance in which true boundaries are sparse relative to nonboundary positions and empirically improves boundary sensitivity.ResultWe evaluate on MovieNet and test cross-dataset generalization on BBC and OVSD. On MovieNet, HASSNet outperforms recent approaches, including methods that also employ state-space models. In particular, relative to a state space-based baseline, HASSNet improves AP by 1.66%, mIoU by 10.54%, AUC-ROC by 0.21%, and F1 by 16.83%, demonstrating more accurate boundary localization and better scene grouping. Without any additional fine-tuning, the pretrained model also yields consistent gains on BBC and OVSD, indicating robust transferability. Among the unsupervised losses, tSSMLoss contributes most to boundary discrimination, while jointly optimizing SSMLoss, SSC, and BP yields the best performance. In fine-tuning, Focal Loss consistently outperforms the weighted cross entropy under severe class imbalance.ConclusionThis study proposes HASSNet, a hybrid architecture for movie scene segmentation trained with a pretraining and fine-tuning strategy. Shot Mamba learns strong, position-aware shot embeddings efficiently from unlabeled data, while Scene Transformer explicitly captures global intershot dependencies for boundary decisions. The pseudoboundary mechanism and the three unsupervised losses enable effective representation learning without labels, and the fine-tuning regimen with Focal Loss mitigates class imbalance in supervised adaptation. Extensive experiments on MovieNet, together with cross dataset and ablations, verify that HASSNet enhances contextual awareness across shots and delivers accurate scene boundary detection. Results indicate that hybrid architectures with pretraining are promising for long-form video understanding.关键词:movie scene segmentation;pre-trained model;state space model(SSM);self-attention mechanism;unsupervised similarity measurement93|168|0更新时间:2026-02-02 - “大型视觉语言模型在目标计数领域取得进展,但面临类别语义错位与解码器架构局限两大挑战。专家提出跨分支协作对齐网络(CANet),采用双分支解码器架构与视觉—文本类别对齐损失,有效解决上述问题,在多个基准数据集上取得优异性能,为复杂场景下的计数鲁棒性提升提供新思路。”
 摘要:ObjectiveIn recent years, pre-trained large vision-language models (VLMs) have been widely used in numerous vision-language tasks. These models typically incorporate a vision encoder and a text encoder to facilitate image alignment with their corresponding text prompts in the embedding space. Inspired by their success, interest in solving the class-agnostic counting problem based on VLMs has surged, leveraging text prompts instead of exemplars to specify the target category of interest. However, existing methods still encounter two critical challenges: category semantic misalignment and decoder architecture limitations. The former leads to false detections, where models often mistakenly identify background regions or irrelevant categories as targets. The latter arises from the over-reliance on single-CNN architectures for local feature extraction, resulting in a lack of understanding of global semantic information, which severely compromises the capability of the model to accurately estimate object counts in complex scenes. This limitation also compromises the robustness of counting performance in complex real-world scenarios, such as scenes with dense occlusions, perspective distortions, or heterogeneous object scales.MethodAiming to address these issues, a cross-branch cooperative alignment network (CANet) is proposed. This study introduces a dual-branch decoder architecture: The Transformer branch employs self-attention mechanisms to model global contextual dependencies (e.g., spatial relationships and density distribution), while the CNN branch uses convolutional operations to extract fine-grained local features (e.g., edges and textures of small). A bidirectional information mutual feedback module dynamically bridges the two branches, facilitating cross-scale feature interaction. This module transfers global priors from the Transformer branch to realize refined local predictions in the CNN branch, while injecting local details from the CNN branch into the Transformer branch to enhance spatial coherence. Moreover, a vision-text category alignment loss is proposed: this loss enforces cross-modal alignment between global image embeddings and text prompts via contrastive learning. Specifically, visual embeddings are pulled closer to their corresponding text embeddings (anchor text prompts) while being pushed away from unrelated text embeddings using counterfactual prompts (shift text prompts). By optimizing semantic consistency between the visual and textual modalities, the model learns to distinguish target semantics from interfering information, substantially reducing false detections caused by category ambiguity.ResultCANet is compared with four state-of-the-art text-promptable object counting methods on five benchmark datasets. On the FSC-147 dataset, CANet surpassed the second-best model, reducing the MAE and RMSE on the test set by 1.22 and 8.45, respectively. In cross-dataset evaluations, CANet achieved MAE reductions of 0.08 and 3.58 on CARPK and PUCPR+, respectively, compared to the second-best model. On the SHA and SHB datasets, CANet reduced the MAE by 47.0 and 9.8, respectively. Additionally, comprehensive ablation studies on the FSC-147 dataset demonstrated the effectiveness of the proposed method. For instance, the performance of two single-branch and dual-branch variants was compared using only CNN or Transformer to validate the effectiveness of the dual-branch decoder. The results showed that homogeneous dual-branch variants substantially outperform their corresponding single-branch counterparts, but none surpass the proposed dual-branch decoder. This finding indicates that single-architecture decoders have inherent limitations, and leveraging the complementary characteristics of both architectures can help simultaneously focus on global- and local-scale predictions, thereby improving overall performance. Aiming to verify the effectiveness of the information mutual feedback module, ablation studies were conducted, identifying a performance drop with the removal of the module. Visualization results were provided to validate the effectiveness of the vision-text category alignment loss, revealing that this loss substantially reduces false detections. Furthermore, this study demonstrated the effectiveness of CANet using different encoders and training strategies.ConclusionThe proposed CANet effectively addresses the challenges of category semantic misalignment and limitations in decoder architecture commonly encountered in text-prompted object counting. By leveraging global-local feature interaction and precise cross-modal alignment, CANet achieves state-of-the-art performance in cross-dataset evaluations, demonstrating strong generalization capabilities in zero-shot counting tasks. This work presents a robust and scalable framework for open-world scenarios, where objects notably vary in scale, density, and contextual complexity.关键词:Object counting;visual-language model (VLM);text-promptable;dual-branch decoder;information mutual feedback134|203|0更新时间:2026-02-02
摘要:ObjectiveIn recent years, pre-trained large vision-language models (VLMs) have been widely used in numerous vision-language tasks. These models typically incorporate a vision encoder and a text encoder to facilitate image alignment with their corresponding text prompts in the embedding space. Inspired by their success, interest in solving the class-agnostic counting problem based on VLMs has surged, leveraging text prompts instead of exemplars to specify the target category of interest. However, existing methods still encounter two critical challenges: category semantic misalignment and decoder architecture limitations. The former leads to false detections, where models often mistakenly identify background regions or irrelevant categories as targets. The latter arises from the over-reliance on single-CNN architectures for local feature extraction, resulting in a lack of understanding of global semantic information, which severely compromises the capability of the model to accurately estimate object counts in complex scenes. This limitation also compromises the robustness of counting performance in complex real-world scenarios, such as scenes with dense occlusions, perspective distortions, or heterogeneous object scales.MethodAiming to address these issues, a cross-branch cooperative alignment network (CANet) is proposed. This study introduces a dual-branch decoder architecture: The Transformer branch employs self-attention mechanisms to model global contextual dependencies (e.g., spatial relationships and density distribution), while the CNN branch uses convolutional operations to extract fine-grained local features (e.g., edges and textures of small). A bidirectional information mutual feedback module dynamically bridges the two branches, facilitating cross-scale feature interaction. This module transfers global priors from the Transformer branch to realize refined local predictions in the CNN branch, while injecting local details from the CNN branch into the Transformer branch to enhance spatial coherence. Moreover, a vision-text category alignment loss is proposed: this loss enforces cross-modal alignment between global image embeddings and text prompts via contrastive learning. Specifically, visual embeddings are pulled closer to their corresponding text embeddings (anchor text prompts) while being pushed away from unrelated text embeddings using counterfactual prompts (shift text prompts). By optimizing semantic consistency between the visual and textual modalities, the model learns to distinguish target semantics from interfering information, substantially reducing false detections caused by category ambiguity.ResultCANet is compared with four state-of-the-art text-promptable object counting methods on five benchmark datasets. On the FSC-147 dataset, CANet surpassed the second-best model, reducing the MAE and RMSE on the test set by 1.22 and 8.45, respectively. In cross-dataset evaluations, CANet achieved MAE reductions of 0.08 and 3.58 on CARPK and PUCPR+, respectively, compared to the second-best model. On the SHA and SHB datasets, CANet reduced the MAE by 47.0 and 9.8, respectively. Additionally, comprehensive ablation studies on the FSC-147 dataset demonstrated the effectiveness of the proposed method. For instance, the performance of two single-branch and dual-branch variants was compared using only CNN or Transformer to validate the effectiveness of the dual-branch decoder. The results showed that homogeneous dual-branch variants substantially outperform their corresponding single-branch counterparts, but none surpass the proposed dual-branch decoder. This finding indicates that single-architecture decoders have inherent limitations, and leveraging the complementary characteristics of both architectures can help simultaneously focus on global- and local-scale predictions, thereby improving overall performance. Aiming to verify the effectiveness of the information mutual feedback module, ablation studies were conducted, identifying a performance drop with the removal of the module. Visualization results were provided to validate the effectiveness of the vision-text category alignment loss, revealing that this loss substantially reduces false detections. Furthermore, this study demonstrated the effectiveness of CANet using different encoders and training strategies.ConclusionThe proposed CANet effectively addresses the challenges of category semantic misalignment and limitations in decoder architecture commonly encountered in text-prompted object counting. By leveraging global-local feature interaction and precise cross-modal alignment, CANet achieves state-of-the-art performance in cross-dataset evaluations, demonstrating strong generalization capabilities in zero-shot counting tasks. This work presents a robust and scalable framework for open-world scenarios, where objects notably vary in scale, density, and contextual complexity.关键词:Object counting;visual-language model (VLM);text-promptable;dual-branch decoder;information mutual feedback134|203|0更新时间:2026-02-02
Image Understanding and Computer Vision
- “医学图像病灶分割领域迎来新突破,相关专家构建了融合频率自适应与特征变换的分割网络,该网络通过动态平衡高低频分量并优化下采样策略,显著提升了分割准确性,为精准临床诊断和治疗制定提供了有力支持。”
 摘要:ObjectivePrecise segmentation of lesions in medical images is of great significance for clinical diagnosis and treatment planning. The development of automated, accurate, and robust medical image segmentation methods is critical for the advancement of computer-aided diagnosis. In recent years, the U-Net architecture based on convolutional neural networks (CNNs) has become a mainstream approach for medical image segmentation. However, the limited receptive fields of CNNs constrain their ability to capture widely distributed low-frequency features in images, including background information and large-scale structures. Inspired by the attention mechanism in natural language processing, Transformer, a method that can focus on global context information, was introduced into the medical image segmentation task. Medical image segmentation methods based on CNNs and Transformer have achieved good segmentation performance, but they mainly focus on extracting global semantic features and ignore low-frequency features such as background information and large-scale structures, as well as high-frequency detailed features widely distributed in images. This study proposes a medical image segmentation network (i.e., FAFTNet) that integrates frequency adaptation and feature transformation, aiming to achieve accurate segmentation through the dynamic balance of high- and low-frequency components and the optimization of downsampling strategies.MethodThis method is implemented on the basis of the U-Net encoder-decoder architecture and mainly consists of frequency adaptation encoding (FAE), feature decomposition transformation (FDT) module, and spatial-channel information reconstruction (SCIR) modules. The FAE module is used to balance high- and low-frequency components in feature representation learning and adopts adaptive dilation rates and kernel strategies in the feature encoding process. During the downsampling process, the FDT module is utilized to perform parallel max pooling and discrete wavelet transform balancing operations, aiming to restore and enhance the preservation of fine-grained details. Features processed through the downsampling stage are passed to the decoder stage, in which the first three stages are symmetrically aligned with the encoder. In the last three stages, the SCIR module is adopted, using a separation-based reconstruction strategy and separate transformation fusion operations to achieve cross reconstruction of information features while suppressing redundant spatial-channel dimension features. In the decoding phase, implicit features containing local and global information are decoded through multiple upsampling steps, gradually generating full-resolution segmentation maps.ResultThe proposed method was trained and validated on three public datasets: international skin imaging collaboration (ISIC) 2017, ISIC 2018, and data science bowl (DSB) 2018. Four evaluation metrics, namely, Dice coefficient, accuracy (ACC), specificity, and sensitivity (SE), were used to evaluate the effectiveness of the proposed method. On the ISIC 2017 and 2018 datasets, the proposed method indicated Dice scores of 89.42% and 89.84%, respectively, outperforming other comparison methods by 0.04%~7.83% and 0.13%~5.95%, respectively. Additionally, the proposed method achieved an SE score of 91.19 on the ISIC 2018 benchmark, demonstrating clear advantages. On the DSB dataset, the model achieved Dice coefficient, ACC, and SE scores of 91.52%, 97.65%, and 91.88%, respectively, presenting improvements of 2.59%, 2.29%, and 2.86%, respectively, over state-of-the-art methods. The proposed method also demonstrated superior performance in the visualization results, i.e., it effectively predicted the target segmentation area in images. Furthermore, under various interference factors, the proposed method still obtained better segmentation results than other methods, and the results closely matched the ground truth. Ablation experiments verified the effectiveness of the proposed model and its individual modules.ConclusionThe segmentation model proposed in this paper fully utilizes the high- and low-frequency information in images and effectively improves the segmentation performance. In future work, the focus will be on enhancing model adaptability across datasets and domains through transfer and multitask learning. The performance and application value of the network will be further improved by combining multitask learning with other tasks such as image classification and feature detection.关键词:deep learning;medical image segmentation;convolutional neural network (CNN);frequency adaptation;feature decomposition transformation256|163|0更新时间:2026-02-02
摘要:ObjectivePrecise segmentation of lesions in medical images is of great significance for clinical diagnosis and treatment planning. The development of automated, accurate, and robust medical image segmentation methods is critical for the advancement of computer-aided diagnosis. In recent years, the U-Net architecture based on convolutional neural networks (CNNs) has become a mainstream approach for medical image segmentation. However, the limited receptive fields of CNNs constrain their ability to capture widely distributed low-frequency features in images, including background information and large-scale structures. Inspired by the attention mechanism in natural language processing, Transformer, a method that can focus on global context information, was introduced into the medical image segmentation task. Medical image segmentation methods based on CNNs and Transformer have achieved good segmentation performance, but they mainly focus on extracting global semantic features and ignore low-frequency features such as background information and large-scale structures, as well as high-frequency detailed features widely distributed in images. This study proposes a medical image segmentation network (i.e., FAFTNet) that integrates frequency adaptation and feature transformation, aiming to achieve accurate segmentation through the dynamic balance of high- and low-frequency components and the optimization of downsampling strategies.MethodThis method is implemented on the basis of the U-Net encoder-decoder architecture and mainly consists of frequency adaptation encoding (FAE), feature decomposition transformation (FDT) module, and spatial-channel information reconstruction (SCIR) modules. The FAE module is used to balance high- and low-frequency components in feature representation learning and adopts adaptive dilation rates and kernel strategies in the feature encoding process. During the downsampling process, the FDT module is utilized to perform parallel max pooling and discrete wavelet transform balancing operations, aiming to restore and enhance the preservation of fine-grained details. Features processed through the downsampling stage are passed to the decoder stage, in which the first three stages are symmetrically aligned with the encoder. In the last three stages, the SCIR module is adopted, using a separation-based reconstruction strategy and separate transformation fusion operations to achieve cross reconstruction of information features while suppressing redundant spatial-channel dimension features. In the decoding phase, implicit features containing local and global information are decoded through multiple upsampling steps, gradually generating full-resolution segmentation maps.ResultThe proposed method was trained and validated on three public datasets: international skin imaging collaboration (ISIC) 2017, ISIC 2018, and data science bowl (DSB) 2018. Four evaluation metrics, namely, Dice coefficient, accuracy (ACC), specificity, and sensitivity (SE), were used to evaluate the effectiveness of the proposed method. On the ISIC 2017 and 2018 datasets, the proposed method indicated Dice scores of 89.42% and 89.84%, respectively, outperforming other comparison methods by 0.04%~7.83% and 0.13%~5.95%, respectively. Additionally, the proposed method achieved an SE score of 91.19 on the ISIC 2018 benchmark, demonstrating clear advantages. On the DSB dataset, the model achieved Dice coefficient, ACC, and SE scores of 91.52%, 97.65%, and 91.88%, respectively, presenting improvements of 2.59%, 2.29%, and 2.86%, respectively, over state-of-the-art methods. The proposed method also demonstrated superior performance in the visualization results, i.e., it effectively predicted the target segmentation area in images. Furthermore, under various interference factors, the proposed method still obtained better segmentation results than other methods, and the results closely matched the ground truth. Ablation experiments verified the effectiveness of the proposed model and its individual modules.ConclusionThe segmentation model proposed in this paper fully utilizes the high- and low-frequency information in images and effectively improves the segmentation performance. In future work, the focus will be on enhancing model adaptability across datasets and domains through transfer and multitask learning. The performance and application value of the network will be further improved by combining multitask learning with other tasks such as image classification and feature detection.关键词:deep learning;medical image segmentation;convolutional neural network (CNN);frequency adaptation;feature decomposition transformation256|163|0更新时间:2026-02-02 - “专家提出端到端医学图像分割框架,融合卷积神经网络与Transformer优势,解决全局—局部特征融合及卷积核参数固化问题,提升分割精度。”
 摘要:ObjectiveWith the rapid advancement of medical imaging technologies, medical image segmentation has become a critical and extensively researched topic in the field of medical image processing. By enabling precise pixel-level classification and accurate identification of regions of interest——such as organs, structural tissues, and pathological areas——this technique holds substantial value in medical research and clinical practice. Medical image segmentation plays a pivotal role in enhancing diagnostic accuracy, supporting personalized treatment planning, and ultimately improving patient outcomes. In recent years, the U-Net architecture, based on convolutional neural network (CNN), has emerged as a foundational model for medical image segmentation. However, due to the intrinsic limitations of CNN’s local receptive fields, they struggle to effectively capture long-range dependencies. This shortcoming hinders the accurate segmentation of anatomical structures with diverse morphologies. Although the Transformer architecture was designed to address the limitations of CNN in modeling long-range dependencies, it often struggles to capture fine-grained local details effectively. Consequently, hybrid networks that integrate CNN and Transformers within the U-Net framework have garnered increasing attention. Existing approaches typically integrate Transformer modules into specific components of the convolutional architecture——such as the encoder, decoder, or skip connections——to address this issue. However, these fragmented integration strategies can only establish limited local-global associations at discrete hierarchical levels, making it difficult to model the complex dependencies introduced by anatomical heterogeneity in medical images, ultimately compromising segmentation accuracy. Furthermore, traditional CNN used fixed convolutional kernel parameters once training is complete, rendering them incapable of adapting to geometric deformations of anatomical structures. This limitation notably constrains the capability of the model to represent dynamically deformable targets in medical imaging.MethodAiming to address the aforementioned challenges, this study proposes an end-to-end medical image segmentation framework, DPAR-Net, which enhances global-local feature integration through a synergistic dual-path encoding design and an adaptive receptive field mechanism. Specifically, a dual-path encoding architecture is constructed, wherein the CNN path captures fine-grained local textures, while the Transformer path extracts high-level global semantics. A correlation-based fusion mechanism is employed at corresponding hierarchical levels to dynamically adjust feature weights based on local-global semantic associations, replacing traditional fusion paradigms. This strategy maximizes the complementarity between CNN and Transformer representations, enabling a progressive fusion of local detail and global context. Additionally, a multilevel encoder fusion strategy is introduced to integrate shallow texture features with deep semantic features through cross-scale information interaction, thereby enhancing the multi-resolution analytical capability of the model for target structures. Finally, an adaptive receptive field mechanism is proposed to dynamically adjust the perceptive range of the convolutional kernel based on pixel-level semantic discrepancies. This approach overcomes the limitations of static convolutions in modeling deformable anatomical structures.ResultExperiments conducted on two publicly available datasets——Synapse (abdominal CT) and ACDC (cardiac MRI) ——demonstrate that the proposed method achieves a Dice score of 84.57% on the Synapse dataset, along with a substantial reduction in the HD95 metric to 12.23, outperforming existing state-of-the-art approaches. On the ACDC dataset, the method surpasses the classical U-Net by 1.19% and the latest CNN-Transformer hybrid models by 1.2% in average Dice score. Ablation studies further validate the synergistic effectiveness of the dual-path encoding and adaptive receptive field mechanisms. Comparative visualizations also highlight the method’s distinctive advantage in segmenting small targets, effectively addressing the issue of feature omission prevalent in existing techniques.ConclusionThe proposed method effectively overcomes the limitations of inadequate global-local feature integration and the static convolutional kernel parameters in current medical image segmentation models. By deeply integrating the complementary strengths of CNNs for local feature perception and Transformers for global context modeling, augmented with an adaptive receptive field mechanism, this approach notably enhances segmentation accuracy and presents a novel solution for processing complex medical images. The code is available at:https://github.com/Swq308/DPAR-Net.关键词:convolutional neural network(CNN);Transformer;Dual-Path Encoding;Adaptive Receptive Field;Multi-Level Fusion299|238|0更新时间:2026-02-02
摘要:ObjectiveWith the rapid advancement of medical imaging technologies, medical image segmentation has become a critical and extensively researched topic in the field of medical image processing. By enabling precise pixel-level classification and accurate identification of regions of interest——such as organs, structural tissues, and pathological areas——this technique holds substantial value in medical research and clinical practice. Medical image segmentation plays a pivotal role in enhancing diagnostic accuracy, supporting personalized treatment planning, and ultimately improving patient outcomes. In recent years, the U-Net architecture, based on convolutional neural network (CNN), has emerged as a foundational model for medical image segmentation. However, due to the intrinsic limitations of CNN’s local receptive fields, they struggle to effectively capture long-range dependencies. This shortcoming hinders the accurate segmentation of anatomical structures with diverse morphologies. Although the Transformer architecture was designed to address the limitations of CNN in modeling long-range dependencies, it often struggles to capture fine-grained local details effectively. Consequently, hybrid networks that integrate CNN and Transformers within the U-Net framework have garnered increasing attention. Existing approaches typically integrate Transformer modules into specific components of the convolutional architecture——such as the encoder, decoder, or skip connections——to address this issue. However, these fragmented integration strategies can only establish limited local-global associations at discrete hierarchical levels, making it difficult to model the complex dependencies introduced by anatomical heterogeneity in medical images, ultimately compromising segmentation accuracy. Furthermore, traditional CNN used fixed convolutional kernel parameters once training is complete, rendering them incapable of adapting to geometric deformations of anatomical structures. This limitation notably constrains the capability of the model to represent dynamically deformable targets in medical imaging.MethodAiming to address the aforementioned challenges, this study proposes an end-to-end medical image segmentation framework, DPAR-Net, which enhances global-local feature integration through a synergistic dual-path encoding design and an adaptive receptive field mechanism. Specifically, a dual-path encoding architecture is constructed, wherein the CNN path captures fine-grained local textures, while the Transformer path extracts high-level global semantics. A correlation-based fusion mechanism is employed at corresponding hierarchical levels to dynamically adjust feature weights based on local-global semantic associations, replacing traditional fusion paradigms. This strategy maximizes the complementarity between CNN and Transformer representations, enabling a progressive fusion of local detail and global context. Additionally, a multilevel encoder fusion strategy is introduced to integrate shallow texture features with deep semantic features through cross-scale information interaction, thereby enhancing the multi-resolution analytical capability of the model for target structures. Finally, an adaptive receptive field mechanism is proposed to dynamically adjust the perceptive range of the convolutional kernel based on pixel-level semantic discrepancies. This approach overcomes the limitations of static convolutions in modeling deformable anatomical structures.ResultExperiments conducted on two publicly available datasets——Synapse (abdominal CT) and ACDC (cardiac MRI) ——demonstrate that the proposed method achieves a Dice score of 84.57% on the Synapse dataset, along with a substantial reduction in the HD95 metric to 12.23, outperforming existing state-of-the-art approaches. On the ACDC dataset, the method surpasses the classical U-Net by 1.19% and the latest CNN-Transformer hybrid models by 1.2% in average Dice score. Ablation studies further validate the synergistic effectiveness of the dual-path encoding and adaptive receptive field mechanisms. Comparative visualizations also highlight the method’s distinctive advantage in segmenting small targets, effectively addressing the issue of feature omission prevalent in existing techniques.ConclusionThe proposed method effectively overcomes the limitations of inadequate global-local feature integration and the static convolutional kernel parameters in current medical image segmentation models. By deeply integrating the complementary strengths of CNNs for local feature perception and Transformers for global context modeling, augmented with an adaptive receptive field mechanism, this approach notably enhances segmentation accuracy and presents a novel solution for processing complex medical images. The code is available at:https://github.com/Swq308/DPAR-Net.关键词:convolutional neural network(CNN);Transformer;Dual-Path Encoding;Adaptive Receptive Field;Multi-Level Fusion299|238|0更新时间:2026-02-02 -
 摘要:ObjectiveMedical image segmentation is crucial for identifying anatomical structures and regions of interest in medical images, playing a critical role in diagnosis and treatment planning. Although traditional convolutional neural network (CNN)-based models have shown notable success, they often struggle to capture long-range dependencies, resulting in suboptimal feature extraction and segmentation performance. This limitation is particularly problematic in medical imaging, where accurate and detailed segmentation is necessary for reliable diagnoses. Transformer-based models that use the self-attention mechanism excel in global context modeling but demonstrate quadratic computational complexity with image size, increasing their computational cost for dense medical image segmentation tasks and hindering efficient real-world applications. Recent studies indicate that state-space models such as Mamba can simulate long-range dependencies with linear complexity. Furthermore, Kolmogorov-Arnold networks (KAN) possess powerful nonlinear modeling capabilities suitable for complex medical image features. However, traditional static weighting strategies ineffectively adapt to the dynamic nature of medical image data. Aiming to address these challenges, VMAML-UNet, a novel medical image segmentation framework combining KAN, is proposed to regulate multiscale weighted losses and visual Mamba for efficient long-range dependency modeling.MethodThe VMAML-UNet method adopts an encoder-decoder architecture, a widely used and effective design in deep learning for image segmentation tasks. In the encoding stage, a novel visual Mamba block (WCVM block) is introduced, incorporating wavelet convolutions to extract precise and localized features from lesion regions with linear computational complexity. The use of wavelet convolutions enables the model to expand its receptive field, which is critical for capturing long-range dependencies within the image. The visual Mamba block enhances feature extraction by improving the representation of critical areas within the image, thereby addressing the issue of insufficient feature capture. Furthermore, the encoding stage incorporates downsampling through block merging, which effectively reduces data dimensionality while retaining important features. In the decoding phase, WCVM blocks are reused, and block expansion is employed to perform upsampling. This approach aids in accurately reconstructing the segmentation mask with high accuracy, ensuring that fine details are preserved throughout the process. The skip connections between the encoder and decoder are designed to transfer critical information from low to high layers of the network. This study introduces a new component: the wavelet convolution attention aggregation (WCAA) module. The WCAA module is designed to fuse and refine features from multiple scales, both spatially and across channels, which allows the model to capture more complex, multidimensional patterns within the image. This module is particularly useful for improving the quality of segmentation in images where the regions of interest are surrounded by similar tissue, making them harder to differentiate. Additionally, a KAN-regulated multiscale weighted loss module is introduced to dynamically capture the nonlinear features and inter-layer dependencies among outputs from different stages of the model. This module addresses the limitations of traditional static weighting strategies, which fail to adapt to the dynamic nature of feature representations extracted at different layers. Specifically, the KAN module applies KAN convolutions to the final three decoder layers to generate multiscale segmentation masks, which are then used to compute hierarchical losses. These losses are then combined with the corresponding encoder outputs to form the multiscale weighted loss. Finally, this loss is integrated with the loss computed from the true labels and predicted masks, enabling effective backpropagation and model training.ResultAiming to evaluate the performance of the proposed VMAML-UNet model, experiments on three diverse and heterogeneous medical image datasets were conducted: the BUSI dataset, the GlaS dataset, and the CVC dataset. These datasets were selected because they represent different types of medical images with varying complexity and noise levels. Experimental results show that the VMAML-UNet outperforms other segmentation methods, such as VM-UNet, which also employs VSS blocks for segmentation. Specifically, on the BUSI dataset, the VMAML-UNet model achieved an improvement in intersection over union (IoU) and an improvement in F1 score by 2.72% and 2.02%, respectively, compared to VM-UNet. The BUSI dataset, which contains breast ultrasound images, presents challenges due to the noise and variability in image quality. However, the proposed model showed notable improvements in addressing these issues. On the GlaS dataset, which contains eye fundus images for glaucoma detection, the VMAML-UNet model achieved 3.38% and 1.89% improvements in IoU and F1 score, respectively. Glaucoma is a leading cause of blindness, and accurate segmentation of the optic nerve head is crucial for effective diagnosis. The strong performance of the VMAML-UNet model on this dataset highlights its capability to capture fine details in medical images. Similarly, on the CVC dataset, which comprises colonoscopy images, the model demonstrated improvements of 2.51% in IoU and 1.42% in F1 score. These results further confirm that the proposed VMAML-UNet model substantially improves segmentation performance across different types of medical images.ConclusionThrough the integration of wavelet convolution-enhanced visual state-space (VSS) blocks, the proposed VMAML-UNet notably reduces computational costs and effectively addresses the limitations of CNN and Transformer-based models in medical image segmentation. The superior performance of this model across three datasets highlights its broad applicability and efficiency in various medical imaging scenarios, offering valuable insights into the development of highly efficient and robust medical image segmentation methods.关键词:state space model (SSM);Kolmogorov-Arnold network (KAN);wavelet convolution;Multi-scale weighted loss;continuous flow384|240|0更新时间:2026-02-02
摘要:ObjectiveMedical image segmentation is crucial for identifying anatomical structures and regions of interest in medical images, playing a critical role in diagnosis and treatment planning. Although traditional convolutional neural network (CNN)-based models have shown notable success, they often struggle to capture long-range dependencies, resulting in suboptimal feature extraction and segmentation performance. This limitation is particularly problematic in medical imaging, where accurate and detailed segmentation is necessary for reliable diagnoses. Transformer-based models that use the self-attention mechanism excel in global context modeling but demonstrate quadratic computational complexity with image size, increasing their computational cost for dense medical image segmentation tasks and hindering efficient real-world applications. Recent studies indicate that state-space models such as Mamba can simulate long-range dependencies with linear complexity. Furthermore, Kolmogorov-Arnold networks (KAN) possess powerful nonlinear modeling capabilities suitable for complex medical image features. However, traditional static weighting strategies ineffectively adapt to the dynamic nature of medical image data. Aiming to address these challenges, VMAML-UNet, a novel medical image segmentation framework combining KAN, is proposed to regulate multiscale weighted losses and visual Mamba for efficient long-range dependency modeling.MethodThe VMAML-UNet method adopts an encoder-decoder architecture, a widely used and effective design in deep learning for image segmentation tasks. In the encoding stage, a novel visual Mamba block (WCVM block) is introduced, incorporating wavelet convolutions to extract precise and localized features from lesion regions with linear computational complexity. The use of wavelet convolutions enables the model to expand its receptive field, which is critical for capturing long-range dependencies within the image. The visual Mamba block enhances feature extraction by improving the representation of critical areas within the image, thereby addressing the issue of insufficient feature capture. Furthermore, the encoding stage incorporates downsampling through block merging, which effectively reduces data dimensionality while retaining important features. In the decoding phase, WCVM blocks are reused, and block expansion is employed to perform upsampling. This approach aids in accurately reconstructing the segmentation mask with high accuracy, ensuring that fine details are preserved throughout the process. The skip connections between the encoder and decoder are designed to transfer critical information from low to high layers of the network. This study introduces a new component: the wavelet convolution attention aggregation (WCAA) module. The WCAA module is designed to fuse and refine features from multiple scales, both spatially and across channels, which allows the model to capture more complex, multidimensional patterns within the image. This module is particularly useful for improving the quality of segmentation in images where the regions of interest are surrounded by similar tissue, making them harder to differentiate. Additionally, a KAN-regulated multiscale weighted loss module is introduced to dynamically capture the nonlinear features and inter-layer dependencies among outputs from different stages of the model. This module addresses the limitations of traditional static weighting strategies, which fail to adapt to the dynamic nature of feature representations extracted at different layers. Specifically, the KAN module applies KAN convolutions to the final three decoder layers to generate multiscale segmentation masks, which are then used to compute hierarchical losses. These losses are then combined with the corresponding encoder outputs to form the multiscale weighted loss. Finally, this loss is integrated with the loss computed from the true labels and predicted masks, enabling effective backpropagation and model training.ResultAiming to evaluate the performance of the proposed VMAML-UNet model, experiments on three diverse and heterogeneous medical image datasets were conducted: the BUSI dataset, the GlaS dataset, and the CVC dataset. These datasets were selected because they represent different types of medical images with varying complexity and noise levels. Experimental results show that the VMAML-UNet outperforms other segmentation methods, such as VM-UNet, which also employs VSS blocks for segmentation. Specifically, on the BUSI dataset, the VMAML-UNet model achieved an improvement in intersection over union (IoU) and an improvement in F1 score by 2.72% and 2.02%, respectively, compared to VM-UNet. The BUSI dataset, which contains breast ultrasound images, presents challenges due to the noise and variability in image quality. However, the proposed model showed notable improvements in addressing these issues. On the GlaS dataset, which contains eye fundus images for glaucoma detection, the VMAML-UNet model achieved 3.38% and 1.89% improvements in IoU and F1 score, respectively. Glaucoma is a leading cause of blindness, and accurate segmentation of the optic nerve head is crucial for effective diagnosis. The strong performance of the VMAML-UNet model on this dataset highlights its capability to capture fine details in medical images. Similarly, on the CVC dataset, which comprises colonoscopy images, the model demonstrated improvements of 2.51% in IoU and 1.42% in F1 score. These results further confirm that the proposed VMAML-UNet model substantially improves segmentation performance across different types of medical images.ConclusionThrough the integration of wavelet convolution-enhanced visual state-space (VSS) blocks, the proposed VMAML-UNet notably reduces computational costs and effectively addresses the limitations of CNN and Transformer-based models in medical image segmentation. The superior performance of this model across three datasets highlights its broad applicability and efficiency in various medical imaging scenarios, offering valuable insights into the development of highly efficient and robust medical image segmentation methods.关键词:state space model (SSM);Kolmogorov-Arnold network (KAN);wavelet convolution;Multi-scale weighted loss;continuous flow384|240|0更新时间:2026-02-02
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0