
最新刊期
卷 30 , 期 10 , 2025
- “在计算机视觉领域,研究者提出了非因果选择性状态空间模型,有效提升了图像复原性能,为图像复原研究开辟了新方向。”
 摘要:ObjectiveImage restoration plays a crucial role in enhancing the quality of degraded images and boosting the efficacy of downstream applications such as image segmentation, object detection, and autonomous driving. This problem centers on reconstructing a high-quality image from its compromised version, which tackles various distortions such as noise, blur, and compression artifacts. In the era of deep learning, the effectiveness of image restoration techniques has remarkably improved, which is largely due to the development of sophisticated models including convolutional neural networks (CNNs), graph models, and vision Transformers tailored for complex image degradation scenarios. A recently introduced selective state space model, which is known as Mamba, has propelled considerable progress across domains including natural language processing and computer vision. Mamba distinguishes itself with its robust expressive modeling capabilities, which enable it to adeptly capture and depict intricate data patterns. Moreover, Mamba offers enhanced computational efficiency and a reduced memory footprint, which surpass those of previous models. To utilize Mamba for image processing, tokens must be extracted from images. Following token acquisition, Mamba models the interactions and dependencies along the token sequence. Mamba leverages advanced state space modeling to decode the structure and semantics of an image by analyzing token interactions. In image restoration, tokens represent image patches, and their dependencies are typically considered non-causal, which allows interactions regardless of spatial distance. The existing deterministic token scanning in selective state space models, which imposes a causal relationship and one-way interactions, conflicts with this non-causal approach. This mismatch may constrain the potential of these models in image restoration, which affects their performance. To bridge this gap, we introduce NCMamba, which is a novel model that reconciles the causal bias of selective state space models with the non-causal nature of image patch interactions. Our research validates the effectiveness of NCMamba across diverse image restoration challenges.MethodTo mitigate the contradiction between the inherent causal relationships of the selective state space model and the non-causal relationships among spatial image patches, we introduce a stochastic scanning strategy for tokens. This innovative method deviates from traditional deterministic scanning techniques through effectively eliminating the intrinsic causal constraints. This approach facilitates a more comprehensive and nuanced modeling of the spatial relationships within image patches, which considerably boosts the capability of the model to perform high-quality image restoration. The strategy employs a random shuffle function to disrupt the linear arrangement of tokens. This function ensures that the interaction likelihood of each token pair is equalized, which enables the model to effectively capture non-causal dependencies. An inverse shuffle function complements this approach by reordering the tokens to their original sequence, which aids in precise image reconstruction. Specifically, the random shuffle function stochastically permutes the token sequence. As a result, the concept of “distance” between tokens is eradicated, and all tokens are treated equally post-shuffle. The relationship between every token pair then has the same probability of being processed directly by the selective state space model. Consequently, the inverse shuffle function restores the shuffled tokens to their original order, which facilitates the accurate reconstitution of the data structure of the image. Combining multi-scale, local relationship, and global relationship priors, our proposed model, which is dubbed NCMamba (non-causal Mamba), integrates local-global complementary modeling within a UNet structure, which showcases general modeling capability for diverse image restoration tasks.ResultNCMamba was tested across multiple datasets, particularly on image denoising, deblurring, and shadow removal. The experiments demonstrate that NCMamba consistently outperformed established models such as CNNs and vision Transformers. Notably, on the SRD dataset for image shadow removal, NCMamba achieved a PSNR improvement of 0.86 dB over the ShadowDiffusion method. Ablation studies further validated the effectiveness of our non-causal modeling and local-global complementary strategies.ConclusionThis study introduces NCMamba, which is a tailored selective state space model designed for image restoration. Our extensive testing confirms its superiority over traditional models, which establishes it as a robust solution for complex image restoration tasks. The empirical evidence underscores the capability of NCMamba to deliver significant improvements in image quality under various conditions.关键词:image restoration;selective state space model(selective SSM);Non-causal modeling;multi-scale modeling;image processing439|569|0更新时间:2025-10-16
摘要:ObjectiveImage restoration plays a crucial role in enhancing the quality of degraded images and boosting the efficacy of downstream applications such as image segmentation, object detection, and autonomous driving. This problem centers on reconstructing a high-quality image from its compromised version, which tackles various distortions such as noise, blur, and compression artifacts. In the era of deep learning, the effectiveness of image restoration techniques has remarkably improved, which is largely due to the development of sophisticated models including convolutional neural networks (CNNs), graph models, and vision Transformers tailored for complex image degradation scenarios. A recently introduced selective state space model, which is known as Mamba, has propelled considerable progress across domains including natural language processing and computer vision. Mamba distinguishes itself with its robust expressive modeling capabilities, which enable it to adeptly capture and depict intricate data patterns. Moreover, Mamba offers enhanced computational efficiency and a reduced memory footprint, which surpass those of previous models. To utilize Mamba for image processing, tokens must be extracted from images. Following token acquisition, Mamba models the interactions and dependencies along the token sequence. Mamba leverages advanced state space modeling to decode the structure and semantics of an image by analyzing token interactions. In image restoration, tokens represent image patches, and their dependencies are typically considered non-causal, which allows interactions regardless of spatial distance. The existing deterministic token scanning in selective state space models, which imposes a causal relationship and one-way interactions, conflicts with this non-causal approach. This mismatch may constrain the potential of these models in image restoration, which affects their performance. To bridge this gap, we introduce NCMamba, which is a novel model that reconciles the causal bias of selective state space models with the non-causal nature of image patch interactions. Our research validates the effectiveness of NCMamba across diverse image restoration challenges.MethodTo mitigate the contradiction between the inherent causal relationships of the selective state space model and the non-causal relationships among spatial image patches, we introduce a stochastic scanning strategy for tokens. This innovative method deviates from traditional deterministic scanning techniques through effectively eliminating the intrinsic causal constraints. This approach facilitates a more comprehensive and nuanced modeling of the spatial relationships within image patches, which considerably boosts the capability of the model to perform high-quality image restoration. The strategy employs a random shuffle function to disrupt the linear arrangement of tokens. This function ensures that the interaction likelihood of each token pair is equalized, which enables the model to effectively capture non-causal dependencies. An inverse shuffle function complements this approach by reordering the tokens to their original sequence, which aids in precise image reconstruction. Specifically, the random shuffle function stochastically permutes the token sequence. As a result, the concept of “distance” between tokens is eradicated, and all tokens are treated equally post-shuffle. The relationship between every token pair then has the same probability of being processed directly by the selective state space model. Consequently, the inverse shuffle function restores the shuffled tokens to their original order, which facilitates the accurate reconstitution of the data structure of the image. Combining multi-scale, local relationship, and global relationship priors, our proposed model, which is dubbed NCMamba (non-causal Mamba), integrates local-global complementary modeling within a UNet structure, which showcases general modeling capability for diverse image restoration tasks.ResultNCMamba was tested across multiple datasets, particularly on image denoising, deblurring, and shadow removal. The experiments demonstrate that NCMamba consistently outperformed established models such as CNNs and vision Transformers. Notably, on the SRD dataset for image shadow removal, NCMamba achieved a PSNR improvement of 0.86 dB over the ShadowDiffusion method. Ablation studies further validated the effectiveness of our non-causal modeling and local-global complementary strategies.ConclusionThis study introduces NCMamba, which is a tailored selective state space model designed for image restoration. Our extensive testing confirms its superiority over traditional models, which establishes it as a robust solution for complex image restoration tasks. The empirical evidence underscores the capability of NCMamba to deliver significant improvements in image quality under various conditions.关键词:image restoration;selective state space model(selective SSM);Non-causal modeling;multi-scale modeling;image processing439|569|0更新时间:2025-10-16 - “在图像去模糊领域,研究者提出了结合Mamba模型与蛇形卷积技术的MSNet,有效提升了图像细节恢复能力。”
 摘要:ObjectiveTraditional image deblurring methods, such as those based on convolutional neural networks (CNNs) and Transformers, have achieved substantial advancements in improving deblurring performance. Despite these achievements, these methods are still constrained by high computational demands and limitations in restoring intricate image details. In complex conditions involving motion blur or high-frequency details, existing approaches often rely on fixed convolution kernels or global self-attention mechanisms. Such static designs lack the adaptability to handle diverse types of blur effectively, which leads to suboptimal detail recovery and inadequate reconstruction of global image structures. Moreover, Transformer-based deblurring methods frequently require extensive computational resources, which significantly diminishes their feasibility for deployment on mobile devices or embedded systems. These resource constraints not only restrict their applicability in practical scenarios but also impede their broader adoption in real-world applications. To address these challenges, this study proposes a novel image deblurring method, which is termed MSNet. By integrating the efficient state space modeling capabilities of the Mamba framework with snake convolution techniques, MSNet leverages the complementary strengths of these innovations. This approach aims to reduce computational overhead while achieving high-fidelity recovery of fine image details and structural information. With its enhanced adaptability and efficiency, MSNet is better suited for practical applications. It offers robust performance in tackling complex deblurring tasks across diverse scenarios.MethodTo achieve the objective, the MSNet network integrates three key modules: the snake state space module (SSSM), the directional scanning module (DSM), and the snake channel attention module (SCA). Each module is designed for a specific purpose, and their combination effectively tackles local detail recovery and global structure restoration. The SSSM combines the Mamba framework with snake convolution technology, with the aim of enhancing the capability of the model to capture subtle blur features. Unlike traditional CNN-based methods relying on fixed convolution kernels, SSSM dynamically adjusts the shape and path of the convolutional kernels. This way allows them to adapt to local image features and blur stripe patterns. Snake convolution alters the convolution path to effectively capture local blur features. Moreover, the Mamba framework takes advantage of state space models through processing long-range dependencies with linear computational complexity. In contrast to the high computational complexity of Transformer-based models relying on self-attention, Mamba can more efficiently capture long-term dependencies in the image, which avoids the excessive computational burden associated with Transformer models. Simultaneously, snake convolution enhances the precision with which the network adapts to local image features. Thus, it offers notable advantages in capturing complex motion blur and fine detail blur. The DSM module transforms image features into a one-dimensional sequence and scans these features in multiple directions (diagonal, horizontal, and vertical) to capture long-range dependencies. This module effectively improves global structure restoration, particularly in scenes with objects moving simultaneously in multiple directions, which allows for better reconstruction of the overall image structure. The SCA module uses a gating mechanism to filter and adjust the weights of the blurred information. Through combining snake convolution with a channel attention mechanism, this module allows the model to dynamically adjust the weights of different features, which prioritizes key image details while removing irrelevant blur information. Through this selective focus, the SCA module significantly enhances detail recovery and optimizes the overall deblurring performance.ResultTo validate the effectiveness of MSNet, we conducted comparative and ablation experiments on two widely used image deblurring benchmark datasets: GoPro and HIDE. During the experiments, MSNet was compared against several commonly used deblurring methods. The results show that MSNet exhibited outstanding performance in addressing image blur artifacts and restoring fine details. On the GoPro dataset, MSNet achieved significant improvements in PSNR and SSIM compared with Transformer- and CNN-based methods. MSNet demonstrated superior accuracy in restoring blurred regions, which effectively addressed the limitations of existing methods in handling complex scenes. This performance highlights capability of MSNet to process images with intricate details and challenging blur conditions more effectively than its counterparts. On the HIDE dataset, MSNet also outperformed Transformer- and CNN-based methods through achieving higher PSNR and SSIM scores. It showed remarkable accuracy in deblurring fine textual and facial details in blurred images. By leveraging its adaptive convolution design and multi-directional scanning approach, MSNet exhibited strong robustness and generalization capabilities. Thus, it is well suited for complex and dynamic scenarios. Moreover, MSNet demonstrated exceptional computational efficiency. It achieved a computational complexity of 63.7 GFLOPs on the GoPro dataset, which was significantly lower than those of MIMO-UNet and other comparative methods. This balance of high deblurring performance and low computational cost makes MSNet an ideal solution for real-time deblurring tasks in resource-constrained environments. Ablation studies further validated the contributions of the key modules of MSNet. The removal of the SSSM or the SCA module led to a significant drop in PSNR, with the greatest decrease occurring when both modules were removed. These findings highlight the critical role of these modules in improving deblurring accuracy and restoring fine image details. In addition, network depth analysis revealed that MSNet-28 (28 layers) achieved the best performance, with a PSNR of 33.51 dB and an SSIM of 0.97. This result confirms the importance of optimizing network depth and module design to enhance overall performance.ConclusionMSNet demonstrates outstanding performance across multiple datasets. It not only showcases its exceptional deblurring accuracy and detail recovery capabilities but also achieves a good balance in computational efficiency. By incorporating the state space model of the Mamba framework and the flexibility of serpentine convolution, MSNet efficiently handles long-range dependencies, particularly exhibiting stronger adaptability in complex blur scenarios. The ablation experiments validate the importance of each module, with the SSSM and SCA modules playing key roles in detail recovery and global structure reconstruction. Overall, MSNet excels in deblurring tasks with its strong generalization capabilities, efficient computation, and superior performance in detail recovery.关键词:image deblurring;mamba model;direction scan module (DSM);snake convolution;snake channel attention (SCA)581|511|0更新时间:2025-10-16
摘要:ObjectiveTraditional image deblurring methods, such as those based on convolutional neural networks (CNNs) and Transformers, have achieved substantial advancements in improving deblurring performance. Despite these achievements, these methods are still constrained by high computational demands and limitations in restoring intricate image details. In complex conditions involving motion blur or high-frequency details, existing approaches often rely on fixed convolution kernels or global self-attention mechanisms. Such static designs lack the adaptability to handle diverse types of blur effectively, which leads to suboptimal detail recovery and inadequate reconstruction of global image structures. Moreover, Transformer-based deblurring methods frequently require extensive computational resources, which significantly diminishes their feasibility for deployment on mobile devices or embedded systems. These resource constraints not only restrict their applicability in practical scenarios but also impede their broader adoption in real-world applications. To address these challenges, this study proposes a novel image deblurring method, which is termed MSNet. By integrating the efficient state space modeling capabilities of the Mamba framework with snake convolution techniques, MSNet leverages the complementary strengths of these innovations. This approach aims to reduce computational overhead while achieving high-fidelity recovery of fine image details and structural information. With its enhanced adaptability and efficiency, MSNet is better suited for practical applications. It offers robust performance in tackling complex deblurring tasks across diverse scenarios.MethodTo achieve the objective, the MSNet network integrates three key modules: the snake state space module (SSSM), the directional scanning module (DSM), and the snake channel attention module (SCA). Each module is designed for a specific purpose, and their combination effectively tackles local detail recovery and global structure restoration. The SSSM combines the Mamba framework with snake convolution technology, with the aim of enhancing the capability of the model to capture subtle blur features. Unlike traditional CNN-based methods relying on fixed convolution kernels, SSSM dynamically adjusts the shape and path of the convolutional kernels. This way allows them to adapt to local image features and blur stripe patterns. Snake convolution alters the convolution path to effectively capture local blur features. Moreover, the Mamba framework takes advantage of state space models through processing long-range dependencies with linear computational complexity. In contrast to the high computational complexity of Transformer-based models relying on self-attention, Mamba can more efficiently capture long-term dependencies in the image, which avoids the excessive computational burden associated with Transformer models. Simultaneously, snake convolution enhances the precision with which the network adapts to local image features. Thus, it offers notable advantages in capturing complex motion blur and fine detail blur. The DSM module transforms image features into a one-dimensional sequence and scans these features in multiple directions (diagonal, horizontal, and vertical) to capture long-range dependencies. This module effectively improves global structure restoration, particularly in scenes with objects moving simultaneously in multiple directions, which allows for better reconstruction of the overall image structure. The SCA module uses a gating mechanism to filter and adjust the weights of the blurred information. Through combining snake convolution with a channel attention mechanism, this module allows the model to dynamically adjust the weights of different features, which prioritizes key image details while removing irrelevant blur information. Through this selective focus, the SCA module significantly enhances detail recovery and optimizes the overall deblurring performance.ResultTo validate the effectiveness of MSNet, we conducted comparative and ablation experiments on two widely used image deblurring benchmark datasets: GoPro and HIDE. During the experiments, MSNet was compared against several commonly used deblurring methods. The results show that MSNet exhibited outstanding performance in addressing image blur artifacts and restoring fine details. On the GoPro dataset, MSNet achieved significant improvements in PSNR and SSIM compared with Transformer- and CNN-based methods. MSNet demonstrated superior accuracy in restoring blurred regions, which effectively addressed the limitations of existing methods in handling complex scenes. This performance highlights capability of MSNet to process images with intricate details and challenging blur conditions more effectively than its counterparts. On the HIDE dataset, MSNet also outperformed Transformer- and CNN-based methods through achieving higher PSNR and SSIM scores. It showed remarkable accuracy in deblurring fine textual and facial details in blurred images. By leveraging its adaptive convolution design and multi-directional scanning approach, MSNet exhibited strong robustness and generalization capabilities. Thus, it is well suited for complex and dynamic scenarios. Moreover, MSNet demonstrated exceptional computational efficiency. It achieved a computational complexity of 63.7 GFLOPs on the GoPro dataset, which was significantly lower than those of MIMO-UNet and other comparative methods. This balance of high deblurring performance and low computational cost makes MSNet an ideal solution for real-time deblurring tasks in resource-constrained environments. Ablation studies further validated the contributions of the key modules of MSNet. The removal of the SSSM or the SCA module led to a significant drop in PSNR, with the greatest decrease occurring when both modules were removed. These findings highlight the critical role of these modules in improving deblurring accuracy and restoring fine image details. In addition, network depth analysis revealed that MSNet-28 (28 layers) achieved the best performance, with a PSNR of 33.51 dB and an SSIM of 0.97. This result confirms the importance of optimizing network depth and module design to enhance overall performance.ConclusionMSNet demonstrates outstanding performance across multiple datasets. It not only showcases its exceptional deblurring accuracy and detail recovery capabilities but also achieves a good balance in computational efficiency. By incorporating the state space model of the Mamba framework and the flexibility of serpentine convolution, MSNet efficiently handles long-range dependencies, particularly exhibiting stronger adaptability in complex blur scenarios. The ablation experiments validate the importance of each module, with the SSSM and SCA modules playing key roles in detail recovery and global structure reconstruction. Overall, MSNet excels in deblurring tasks with its strong generalization capabilities, efficient computation, and superior performance in detail recovery.关键词:image deblurring;mamba model;direction scan module (DSM);snake convolution;snake channel attention (SCA)581|511|0更新时间:2025-10-16 - “在目标跟踪领域,研究者提出了基于视觉状态空间的TMamba算法,有效降低了计算量和显存占用,为序列级训练提供新思路。”
 摘要:ObjectiveThe emergence of Transformer models has revolutionized the field of object tracking, significantly enhancing the accuracy and robustness of these models. Transformers, with their self-attention mechanisms, have been demonstrated to capture long-range dependencies and complex relationships within data, making them a powerful tool for various computer vision tasks, including object tracking. However, a critical drawback of Transformer-based object tracking models is their computational complexity, which scales quadratically with the length of the input sequence. This characteristic imposes a substantial computational burden, particularly in practical scenarios where efficiency is paramount. Real-world applications require models that not only perform well but also operate with minimal computational cost, fewer parameters, and fast response times. However, the high computational demands and parameter counts of Transformer-based models render them less suitable for these applications. Moreover, Transformer-based object tracking models typically exhibit high memory consumption, which poses an additional challenge to video-level object tracking tasks. High memory usage restricts the number of video frames that can be processed simultaneously, limiting the ability to capture sufficient temporal information required for effective tracking. This limitation hinders the development of video-level tracking models, because the inability to sample sufficient frames can lead to suboptimal performance and reduced tracking accuracy. To address these challenges, this study introduces a novel object tracking model based on visual state-space models.MethodBuilding upon the visual Mamba framework, we propose the TMamba algorithm, which leverages the strengths of state-space models for object tracking. The TMamba model offers a promising alternative to Transformer-based tracking models by achieving superior performance with significantly reduced computational load and memory usage. This reduction is crucial for enabling the deployment of object tracking models in resource-constrained environments, such as edge devices and real-time systems. The core component of TMamba is the feature fusion module, which is designed to integrate information from different feature hierarchies within the network. In particular, the feature fusion module combines the rich semantic information from deep features with the detailed, high-resolution information from shallow features. By fusing these features, the module produces a multilevel representation that provides the prediction head with more accurate and comprehensive information, leading to improved prediction accuracy. A key innovation of TMamba is the introduction of a dual image scanning strategy, which addresses the unique challenges of adapting visual state-space models to the tracking domain. In visual state-space models, the approach for scanning images is crucial, because it directly affects the model’s ability to process and interpret visual data. In contrast with classification and detection tasks, wherein a single image is inputted into the network, object tracking requires the simultaneous processing of multiple images, typically a template and a search region. How these images are scanned and fed into the network is a critical factor that determines the model’s performance. Our proposed dual image scanning strategy involves jointly scanning the template and search region images, allowing the visual state-space model to better accommodate the specific requirements of object tracking. This strategy enhances the model’s ability to learn spatial and temporal dependencies across frames, leading to more accurate and reliable tracking.ResultTo evaluate the effectiveness of the proposed TMamba algorithm, we developed a series of object tracking models based on state-space models and conducted extensive experiments on seven benchmark datasets. These datasets include LaSOT, TrackingNet, and GOT-10k, which are widely used in the object tracking community for performance evaluation. The results demonstrate that TMamba consistently achieves outstanding performance across all the datasets, with significant reductions in computational cost and parameter count compared with Transformer-based models. For example, TMamba-B, one of the configurations of our model, achieves a 66% area under the curve (AUC) score on the LaSOT dataset, an 82.3% AUC score on TrackingNet, and a 72% AUC score on GOT-10k. These results not only surpass those of many Transformer-based models but also highlight the efficiency of TMamba in terms of computational resources. TMamba-B contains only 50.7 million parameters and requires only 14.2 GFLOPs for processing, making it one of the most efficient models in its class. This efficiency is achieved without compromising accuracy, demonstrating the potential of state-space models in high-performance object tracking. Further analysis of the experimental results reveals several key insights. First, the feature fusion module plays a crucial role in enhancing the model’s performance by effectively combining information from different feature levels. This fusion allows TMamba to leverage the strength of deep and shallow features, resulting in a more robust representation that is well-suited for tracking diverse objects under various conditions. Second, the dual image scanning strategy proves to be highly effective in bridging the gap between visual state-space models and the tracking domain. By jointly scanning the template and search region images, this strategy enables TMamba to better capture spatial and temporal relationships, which are essential for accurate tracking.ConclusionThis study introduces the TMamba algorithm and investigates the feasibility of employing state-space models in the domain of object tracking. The results demonstrate that TMamba not only matches, but in some cases, even surpasses the performance of Transformer-based object tracking models across multiple datasets. Moreover, TMamba achieves these results with a significantly reduced parameter count and lower computational complexity, making it a more practical choice for real-world applications. The characteristics of TMamba, namely, its low parameter count, minimal computational demands, and reduced memory usage, suggest that it exhibits considerable potential to advance the practical application of object tracking models. By addressing the limitations of existing Transformer-based approaches, TMamba paves the way for the development of more efficient and scalable video-level object tracking solutions.关键词:single-object tracking;state space model(SSM);multi-scale feature fusion;sequential training;memory-efficient model873|582|0更新时间:2025-10-16
摘要:ObjectiveThe emergence of Transformer models has revolutionized the field of object tracking, significantly enhancing the accuracy and robustness of these models. Transformers, with their self-attention mechanisms, have been demonstrated to capture long-range dependencies and complex relationships within data, making them a powerful tool for various computer vision tasks, including object tracking. However, a critical drawback of Transformer-based object tracking models is their computational complexity, which scales quadratically with the length of the input sequence. This characteristic imposes a substantial computational burden, particularly in practical scenarios where efficiency is paramount. Real-world applications require models that not only perform well but also operate with minimal computational cost, fewer parameters, and fast response times. However, the high computational demands and parameter counts of Transformer-based models render them less suitable for these applications. Moreover, Transformer-based object tracking models typically exhibit high memory consumption, which poses an additional challenge to video-level object tracking tasks. High memory usage restricts the number of video frames that can be processed simultaneously, limiting the ability to capture sufficient temporal information required for effective tracking. This limitation hinders the development of video-level tracking models, because the inability to sample sufficient frames can lead to suboptimal performance and reduced tracking accuracy. To address these challenges, this study introduces a novel object tracking model based on visual state-space models.MethodBuilding upon the visual Mamba framework, we propose the TMamba algorithm, which leverages the strengths of state-space models for object tracking. The TMamba model offers a promising alternative to Transformer-based tracking models by achieving superior performance with significantly reduced computational load and memory usage. This reduction is crucial for enabling the deployment of object tracking models in resource-constrained environments, such as edge devices and real-time systems. The core component of TMamba is the feature fusion module, which is designed to integrate information from different feature hierarchies within the network. In particular, the feature fusion module combines the rich semantic information from deep features with the detailed, high-resolution information from shallow features. By fusing these features, the module produces a multilevel representation that provides the prediction head with more accurate and comprehensive information, leading to improved prediction accuracy. A key innovation of TMamba is the introduction of a dual image scanning strategy, which addresses the unique challenges of adapting visual state-space models to the tracking domain. In visual state-space models, the approach for scanning images is crucial, because it directly affects the model’s ability to process and interpret visual data. In contrast with classification and detection tasks, wherein a single image is inputted into the network, object tracking requires the simultaneous processing of multiple images, typically a template and a search region. How these images are scanned and fed into the network is a critical factor that determines the model’s performance. Our proposed dual image scanning strategy involves jointly scanning the template and search region images, allowing the visual state-space model to better accommodate the specific requirements of object tracking. This strategy enhances the model’s ability to learn spatial and temporal dependencies across frames, leading to more accurate and reliable tracking.ResultTo evaluate the effectiveness of the proposed TMamba algorithm, we developed a series of object tracking models based on state-space models and conducted extensive experiments on seven benchmark datasets. These datasets include LaSOT, TrackingNet, and GOT-10k, which are widely used in the object tracking community for performance evaluation. The results demonstrate that TMamba consistently achieves outstanding performance across all the datasets, with significant reductions in computational cost and parameter count compared with Transformer-based models. For example, TMamba-B, one of the configurations of our model, achieves a 66% area under the curve (AUC) score on the LaSOT dataset, an 82.3% AUC score on TrackingNet, and a 72% AUC score on GOT-10k. These results not only surpass those of many Transformer-based models but also highlight the efficiency of TMamba in terms of computational resources. TMamba-B contains only 50.7 million parameters and requires only 14.2 GFLOPs for processing, making it one of the most efficient models in its class. This efficiency is achieved without compromising accuracy, demonstrating the potential of state-space models in high-performance object tracking. Further analysis of the experimental results reveals several key insights. First, the feature fusion module plays a crucial role in enhancing the model’s performance by effectively combining information from different feature levels. This fusion allows TMamba to leverage the strength of deep and shallow features, resulting in a more robust representation that is well-suited for tracking diverse objects under various conditions. Second, the dual image scanning strategy proves to be highly effective in bridging the gap between visual state-space models and the tracking domain. By jointly scanning the template and search region images, this strategy enables TMamba to better capture spatial and temporal relationships, which are essential for accurate tracking.ConclusionThis study introduces the TMamba algorithm and investigates the feasibility of employing state-space models in the domain of object tracking. The results demonstrate that TMamba not only matches, but in some cases, even surpasses the performance of Transformer-based object tracking models across multiple datasets. Moreover, TMamba achieves these results with a significantly reduced parameter count and lower computational complexity, making it a more practical choice for real-world applications. The characteristics of TMamba, namely, its low parameter count, minimal computational demands, and reduced memory usage, suggest that it exhibits considerable potential to advance the practical application of object tracking models. By addressing the limitations of existing Transformer-based approaches, TMamba paves the way for the development of more efficient and scalable video-level object tracking solutions.关键词:single-object tracking;state space model(SSM);multi-scale feature fusion;sequential training;memory-efficient model873|582|0更新时间:2025-10-16 - “最新研究提出了一种结合视觉Mamba和块特征分布的无监督工业异常检测模型,有效提升了检测效果,为工业异常检测领域提供新解决方案。”
 摘要:ObjectiveIndustrial image anomaly detection plays a crucial role in modern industrial production because it can timely detect defects in products, effectively improve product qualification rate, enhance industrial productivity, and reduce production costs. Traditional anomaly detection algorithms often show certain limitations when dealing with new types of anomalies, especially complex issues such as logical anomalies. Thus, they have difficulty meeting the demand for high-precision and efficient detection in industrial production. Therefore, this study is committed to exploring the potential application of visual state space in the field of image processing and anomaly detection. The aim is to find a more effective method for addressing the shortcomings of traditional algorithms in detecting new types of anomalies, especially the limitations in handling logical anomalies. The reconstruction-based method is considered capable of addressing logical anomalies caused by factors such as object quantity, structure, position, and arrangement order because using only normal images to train the model will result in significant errors in the reconstructed output compared with images containing logical anomalies. Existing reconstruction-based anomaly detection methods are mainly based on convolutional neural networks (CNNs) or vision Transformer (ViT) networks. However, CNN exhibits difficulty in handling long-distance dependencies, while ViT presents high time complexity. The latest research shows that state space models represented by Mamba can effectively model long dependencies while maintaining linear complexity. We have explored the potential application of visual state space in anomaly detection and aspire to develop a more precise and efficient image anomaly detection technology by leveraging its advantages to meet strict quality control requirements in industrial production. This endeavor will drive industrial production toward intelligent automation direction while improving overall efficiency and competitiveness.MethodA novel unsupervised industrial anomaly detection model combining visual Mamba and patch feature distribution is proposed. This model consists of two complementary branch networks: a patch feature distribution estimation network and a self-encoding reconstruction network based on visual Mamba. The patch feature distribution estimation network primarily relies on local patch features for anomaly detection. It fuses local patch features of normal samples through the Vision Mamba encoder and pretrained efficient patch description network and learns a Gaussian mixture density network to estimate the distribution of these features. During the testing phase, this Gaussian mixture density network is used to estimate anomaly scores at various positions in the anomalous images, which produces a local anomaly map (LAM). Meanwhile, the self-encoding reconstruction network based on visual Mamba utilizes a visual Mamba encoder to capture long-range associated features, which enhances the global modeling capability for complex anomaly detection across different categories and forms. In the testing phase, reconstruction errors are used to estimate a global anomaly map (GAM) for the anomalous images. Finally, LAM and GAM are combined to obtain the final detection results. For the dataset, we conducted detailed preprocessing and clipped the images to appropriate sizes according to the requirements of different models. For example, the size of the input image was 256 × 256 pixels. We carefully adjusted the number of coding blocks in the encoder of the visual state space in the reconstruction method to achieve the best anomaly detection performance and maximize the overall performance of the model. The experiments in this study were conducted on a desktop computer equipped with an Intel Core i5, 2.5 GHz CPU, GeForce GTX 3060Ti GPU with 12 GB memory, 32 GB RAM, and Ubuntu18.04 as the operating system. According to our experimental observations, we set the learning rate to 0.001, configured the model to run for 200 epochs, and determined a batch size of 48. Regarding the selection of image blocks, in the PDN method combined with Patchsize, we chose a value of 32.ResultWe compared our model with other advanced algorithms on publicly available datasets such as MvTec AD, VisA, and BTAD, and our model demonstrated highly competitive performance. On the MvTec AD dataset, our model improved the pixel-level AU-ROC metric by 0.9% to reach 93.9%, and the image-level AU-ROC metric by 2.4% to reach 93.8%, compared with the second-best performing model. On the BTAD dataset, our model achieved a 0.4% improvement in image-level AU-ROC (reaching 92.6%) compared with the second-best performing model. On the VisA dataset, our model achieved a 0.6% improvement in pixel-level AU-ROC (reaching 96.6%) compared with the second-best performing model. According to visualizations of anomaly localization in our study on MvTec and VisA datasets, the anomaly localization of our model is more accurate than those of other models.ConclusionThe application of visual state space to image reconstruction for detecting image anomalies is a feasible and effective method, and its anomaly localization effect has significant competitiveness. This study believes that aggregating features in the middle of the extraction model will be more helpful for adapting to anomaly detection tasks. The setting of the number of image block vectors may be helpful for the localization and detection of anomalies because more image block descriptor vectors can represent more detailed information. The two points are worth further research in the future. This study organically combines two popular methods in the industrial anomaly detection field while integrating visual state space into the model, which supports its application in the field of anomaly detection.关键词:anomaly detection;Anomaly segmentation;vision state space model(SSM);Gaussian Density Approximation Network;Anomaly Dataset460|758|0更新时间:2025-10-16
摘要:ObjectiveIndustrial image anomaly detection plays a crucial role in modern industrial production because it can timely detect defects in products, effectively improve product qualification rate, enhance industrial productivity, and reduce production costs. Traditional anomaly detection algorithms often show certain limitations when dealing with new types of anomalies, especially complex issues such as logical anomalies. Thus, they have difficulty meeting the demand for high-precision and efficient detection in industrial production. Therefore, this study is committed to exploring the potential application of visual state space in the field of image processing and anomaly detection. The aim is to find a more effective method for addressing the shortcomings of traditional algorithms in detecting new types of anomalies, especially the limitations in handling logical anomalies. The reconstruction-based method is considered capable of addressing logical anomalies caused by factors such as object quantity, structure, position, and arrangement order because using only normal images to train the model will result in significant errors in the reconstructed output compared with images containing logical anomalies. Existing reconstruction-based anomaly detection methods are mainly based on convolutional neural networks (CNNs) or vision Transformer (ViT) networks. However, CNN exhibits difficulty in handling long-distance dependencies, while ViT presents high time complexity. The latest research shows that state space models represented by Mamba can effectively model long dependencies while maintaining linear complexity. We have explored the potential application of visual state space in anomaly detection and aspire to develop a more precise and efficient image anomaly detection technology by leveraging its advantages to meet strict quality control requirements in industrial production. This endeavor will drive industrial production toward intelligent automation direction while improving overall efficiency and competitiveness.MethodA novel unsupervised industrial anomaly detection model combining visual Mamba and patch feature distribution is proposed. This model consists of two complementary branch networks: a patch feature distribution estimation network and a self-encoding reconstruction network based on visual Mamba. The patch feature distribution estimation network primarily relies on local patch features for anomaly detection. It fuses local patch features of normal samples through the Vision Mamba encoder and pretrained efficient patch description network and learns a Gaussian mixture density network to estimate the distribution of these features. During the testing phase, this Gaussian mixture density network is used to estimate anomaly scores at various positions in the anomalous images, which produces a local anomaly map (LAM). Meanwhile, the self-encoding reconstruction network based on visual Mamba utilizes a visual Mamba encoder to capture long-range associated features, which enhances the global modeling capability for complex anomaly detection across different categories and forms. In the testing phase, reconstruction errors are used to estimate a global anomaly map (GAM) for the anomalous images. Finally, LAM and GAM are combined to obtain the final detection results. For the dataset, we conducted detailed preprocessing and clipped the images to appropriate sizes according to the requirements of different models. For example, the size of the input image was 256 × 256 pixels. We carefully adjusted the number of coding blocks in the encoder of the visual state space in the reconstruction method to achieve the best anomaly detection performance and maximize the overall performance of the model. The experiments in this study were conducted on a desktop computer equipped with an Intel Core i5, 2.5 GHz CPU, GeForce GTX 3060Ti GPU with 12 GB memory, 32 GB RAM, and Ubuntu18.04 as the operating system. According to our experimental observations, we set the learning rate to 0.001, configured the model to run for 200 epochs, and determined a batch size of 48. Regarding the selection of image blocks, in the PDN method combined with Patchsize, we chose a value of 32.ResultWe compared our model with other advanced algorithms on publicly available datasets such as MvTec AD, VisA, and BTAD, and our model demonstrated highly competitive performance. On the MvTec AD dataset, our model improved the pixel-level AU-ROC metric by 0.9% to reach 93.9%, and the image-level AU-ROC metric by 2.4% to reach 93.8%, compared with the second-best performing model. On the BTAD dataset, our model achieved a 0.4% improvement in image-level AU-ROC (reaching 92.6%) compared with the second-best performing model. On the VisA dataset, our model achieved a 0.6% improvement in pixel-level AU-ROC (reaching 96.6%) compared with the second-best performing model. According to visualizations of anomaly localization in our study on MvTec and VisA datasets, the anomaly localization of our model is more accurate than those of other models.ConclusionThe application of visual state space to image reconstruction for detecting image anomalies is a feasible and effective method, and its anomaly localization effect has significant competitiveness. This study believes that aggregating features in the middle of the extraction model will be more helpful for adapting to anomaly detection tasks. The setting of the number of image block vectors may be helpful for the localization and detection of anomalies because more image block descriptor vectors can represent more detailed information. The two points are worth further research in the future. This study organically combines two popular methods in the industrial anomaly detection field while integrating visual state space into the model, which supports its application in the field of anomaly detection.关键词:anomaly detection;Anomaly segmentation;vision state space model(SSM);Gaussian Density Approximation Network;Anomaly Dataset460|758|0更新时间:2025-10-16 - “最新研究进展显示,专家建立了DenseMamba体系,为阿尔茨海默症早期诊断提供精准支持。”
 摘要:ObjectiveAlzheimer’s disease (AD) is a common form of dementia in the elderly and has become a major challenge in global public health in recent years. With the acceleration of global aging, the incidence of AD continues to rise, which places tremendous pressure on medical treatment and caregiving. The main characteristic of AD is the gradual decline in cognitive functions, particularly memory, language, and decision-making abilities, which are often accompanied by irreversible neuronal loss and brain atrophy. As the disease progresses, it becomes increasingly difficult to differentiate AD from other types of dementia, which makes early diagnosis more challenging. Therefore, early diagnosis is crucial for timely intervention and personalized treatment plans, as it can effectively delay disease progression. Currently, clinical diagnosis of AD typically relies on neuropsychological assessments, biomarker detection, and neuroimaging techniques. Among these approaches, positron emission tomography (PET) and magnetic resonance imaging (MRI) are the most commonly used imaging methods to evaluate the brain structure and function of AD patients. PET provides information on brain metabolism and amyloid plaques, while MRI offers high-resolution structural images that can reveal brain atrophy and other neuroanatomical changes related to the disease. However, the two imaging methods significantly differ in various aspects, such as resolution, contrast, and spatial alignment issues. As a result, existing artificial intelligence (AI)-based diagnostic models often rely on single-modality data, particularly MRI images. This reliance limits the full utilization of multimodal information and restricts further improvements in classification performance. To address this issue, this study proposes an early diagnosis model for AD based on multimodal imaging data (PET and MRI)——DenseMamba. This model combines the advantages of both imaging modalities, which overcomes the limitations of traditional single-modality methods. The model adopts a state-space model-based framework (Mamba) to effectively extract and fuse heterogeneous modal features, which achieves more robust classification performance.MethodThe DenseMamba model uses multimodal PET and MRI imaging data as input. To effectively integrate the two types of imaging data, the model first performs initial feature extraction through a convolutional layer and an activation layer. The extracted features are then passed through several alternating Denseblock and TransMamba modules for further local and global feature extraction. The Denseblock module, with its dense connection design, enhances feature learning capability by facilitating feature reuse across layers, which effectively mitigates the vanishing gradient problem in deep neural networks. This dense connectivity helps capture complex patterns and dependencies within the data. By contrast, the TransMamba module focuses on capturing global feature representations, modeling long-range dependencies within the data, and effectively integrating cross-space and -time related information. After multiple rounds of local and global feature extraction, the final features are processed by a classification head (composed of fully connected layers and a softmax output layer) to perform the multi-class classification task. The final output is the predicted category for each input image, which indicates whether the patient is classified as healthy control, mild cognitive impairment, or AD.ResultTo validate the effectiveness of the DenseMamba model, extensive experiments were conducted using the publicly available Alzheimer’s disease neuroimaging initiative (ADNI) dataset. This dataset includes multimodal imaging data (PET and MRI), and the imaging data have been preprocessed to ensure alignment between PET and MRI images. Experimental results show that the DenseMamba model significantly outperforms traditional single-modality methods; specifically, it achieves an accuracy of 92.42%, precision of 92.5%, recall of 92.42%, and an F1 score of 92.21%.ConclusionDenseMamba provides an efficient and accurate solution for the early diagnosis of AD. By combining the complementary advantages of PET and MRI, DenseMamba overcomes some of the limitations of traditional single-modality methods, such as insufficient feature representation and data misalignment issues. Experimental results demonstrate that DenseMamba performs excellently on the ADNI dataset, which significantly improves classification performance and far surpasses existing single-modality imaging classification methods.This approach exhibits strong clinical application potential, which provides precise support for the early diagnosis of AD and facilitates earlier interventions and personalized treatments. In the future, further improvements to the DenseMamba model may include introducing advanced fusion techniques and expanding the dataset to include a broader patient population and additional imaging modalities. These enhancements will further improve the generalization ability and clinical applicability of the model, which offer more effective tools for the early diagnosis and treatment of AD and other neurodegenerative diseases.关键词:Alzheimer’s disease (AD);multimodal medical images;state-space model;Mamba;dense connectivity neural network411|428|0更新时间:2025-10-16
摘要:ObjectiveAlzheimer’s disease (AD) is a common form of dementia in the elderly and has become a major challenge in global public health in recent years. With the acceleration of global aging, the incidence of AD continues to rise, which places tremendous pressure on medical treatment and caregiving. The main characteristic of AD is the gradual decline in cognitive functions, particularly memory, language, and decision-making abilities, which are often accompanied by irreversible neuronal loss and brain atrophy. As the disease progresses, it becomes increasingly difficult to differentiate AD from other types of dementia, which makes early diagnosis more challenging. Therefore, early diagnosis is crucial for timely intervention and personalized treatment plans, as it can effectively delay disease progression. Currently, clinical diagnosis of AD typically relies on neuropsychological assessments, biomarker detection, and neuroimaging techniques. Among these approaches, positron emission tomography (PET) and magnetic resonance imaging (MRI) are the most commonly used imaging methods to evaluate the brain structure and function of AD patients. PET provides information on brain metabolism and amyloid plaques, while MRI offers high-resolution structural images that can reveal brain atrophy and other neuroanatomical changes related to the disease. However, the two imaging methods significantly differ in various aspects, such as resolution, contrast, and spatial alignment issues. As a result, existing artificial intelligence (AI)-based diagnostic models often rely on single-modality data, particularly MRI images. This reliance limits the full utilization of multimodal information and restricts further improvements in classification performance. To address this issue, this study proposes an early diagnosis model for AD based on multimodal imaging data (PET and MRI)——DenseMamba. This model combines the advantages of both imaging modalities, which overcomes the limitations of traditional single-modality methods. The model adopts a state-space model-based framework (Mamba) to effectively extract and fuse heterogeneous modal features, which achieves more robust classification performance.MethodThe DenseMamba model uses multimodal PET and MRI imaging data as input. To effectively integrate the two types of imaging data, the model first performs initial feature extraction through a convolutional layer and an activation layer. The extracted features are then passed through several alternating Denseblock and TransMamba modules for further local and global feature extraction. The Denseblock module, with its dense connection design, enhances feature learning capability by facilitating feature reuse across layers, which effectively mitigates the vanishing gradient problem in deep neural networks. This dense connectivity helps capture complex patterns and dependencies within the data. By contrast, the TransMamba module focuses on capturing global feature representations, modeling long-range dependencies within the data, and effectively integrating cross-space and -time related information. After multiple rounds of local and global feature extraction, the final features are processed by a classification head (composed of fully connected layers and a softmax output layer) to perform the multi-class classification task. The final output is the predicted category for each input image, which indicates whether the patient is classified as healthy control, mild cognitive impairment, or AD.ResultTo validate the effectiveness of the DenseMamba model, extensive experiments were conducted using the publicly available Alzheimer’s disease neuroimaging initiative (ADNI) dataset. This dataset includes multimodal imaging data (PET and MRI), and the imaging data have been preprocessed to ensure alignment between PET and MRI images. Experimental results show that the DenseMamba model significantly outperforms traditional single-modality methods; specifically, it achieves an accuracy of 92.42%, precision of 92.5%, recall of 92.42%, and an F1 score of 92.21%.ConclusionDenseMamba provides an efficient and accurate solution for the early diagnosis of AD. By combining the complementary advantages of PET and MRI, DenseMamba overcomes some of the limitations of traditional single-modality methods, such as insufficient feature representation and data misalignment issues. Experimental results demonstrate that DenseMamba performs excellently on the ADNI dataset, which significantly improves classification performance and far surpasses existing single-modality imaging classification methods.This approach exhibits strong clinical application potential, which provides precise support for the early diagnosis of AD and facilitates earlier interventions and personalized treatments. In the future, further improvements to the DenseMamba model may include introducing advanced fusion techniques and expanding the dataset to include a broader patient population and additional imaging modalities. These enhancements will further improve the generalization ability and clinical applicability of the model, which offer more effective tools for the early diagnosis and treatment of AD and other neurodegenerative diseases.关键词:Alzheimer’s disease (AD);multimodal medical images;state-space model;Mamba;dense connectivity neural network411|428|0更新时间:2025-10-16 - “在医学影像领域,研究者提出了一种基于多方向蛇形卷积和视觉残差Mamba的两阶段冠状动脉分割方法,有效捕捉血管结构特征,实现低资源环境下更准确的冠状动脉分割。”
 摘要:ObjectiveCardiovascular disease (CVD) accounts for approximately half of noncommunicable diseases. Coronary artery stenosis is considered a major risk factor for CVD. Computed tomography angiography (CTA) has become one of the widely used noninvasive imaging methods for coronary diagnosis due to its excellent image resolution. Clinically, coronary artery segmentation is crucial for the diagnosis and quantification of coronary artery diseases. Coronary arteries are characterized by their multibranching and tubular structures, with severe imbalance between foreground and background classes. Traditional coronary artery segmentation networks based on convolutional neural networks experience difficulty in modeling long-range dependencies between vessels, while Vision Transformer models are difficult to deploy in resource-constrained real-world environments due to their high complexity. Recent studies have shown that state space models, such as Mamba, can effectively model long-range dependencies while maintaining linear complexity.MethodGiven these reasons, this study applies visual Mamba to coronary artery segmentation for the first time and proposes a two-stage coronary artery segmentation method, called MDSVM-UNet++, based on multidirectional snake convolution (MDSConv) and visual residual Mamba. MDSVM-UNet++ adopts a traditional encoder–decoder architecture. During the encoding stage, dynamic snake convolution is used to replace traditional convolution to accurately capture the elongated and tortuous tubular structure features of the vessels, introducing deformable offsets into the convolution kernel and employing an iterative strategy to prevent the model from deviating from the target while learning the deformable offsets, ensuring the continuity of attention. In addition, an MDSConv layer is proposed to extract features from the three dimensions (x, y, z) of a 3D image, retaining attention from multiple directions and further improving segmentation accuracy, allowing the model to focus more on slender and complex tubular structures. During the decoding stage, an up-sampling decoder block based on residual visual Mamba is designed to model long-range dependencies between vascular slices while maintaining linear complexity. This block employs dense spatial pooling techniques to generate fine multi-scale contexts, first performing feature fusion by using addition and then inputting the results into the residual visual Mamba layer for long-range dependency modeling, followed by trilinear interpolation for up-sampling the feature maps. To achieve more accurate segmentation of small branch vessels, a two-stage segmentation model is further proposed. During the first stage, the original CTA images are scaled down to a size of 128 × 128 × 64, and then MDSVM-UNet++ is directly applied to segment the entire CTA image. The results are used to guide the partitioning of the original image into a set of 64 × 64 × 64 voxel blocks, allowing the data to contain more coronary artery information. Subsequently, the segmented data are re-inputted into the MDSVM-UNet++ network for the second stage of segmentation, with all the segmented results merged at the end. This approach reduces false positive points in the segmentation results while ensuring continuity and improving the smoothness of coronary arteries.ResultIn the experimental section, we implemented the model by using the PyTorch framework and trained it on NVIDIA GTX 3090. We selected 750 CTA images from the ImageCAS dataset as the training set, with the remaining 250 CTA images used as validation and test sets. The first-stage segmentation network was trained for 25 epochs by using the Adam optimizer with a learning rate of 0.001. The second-stage segmentation network underwent 50 iterations, with the learning rate decayed by a factor of 0.1 at the 30th and 40th iterations. The Dice similarity coefficient (DSC) was used as the evaluation metric, while the Hausdorff distance (HD) and average HD (AHD) served as auxiliary metrics. The experimental results indicated that the proposed MDSVM-UNet++ method outperformed the latest baseline network, ImageCas, on the ImageCAS dataset, achieving 5.41% improvement in DSC, an increase of 8.545 6 in HD, and an increase of 0.809 3 in AHD.ConclusionGiven the tubular structural characteristics of coronary arteries, this study applies visual Mamba to coronary artery segmentation for the first time, proposing a two-stage coronary artery segmentation method based on dynamic snake convolution and visual residual Mamba. On the one hand, dynamic snake convolution is utilized to more accurately capture vascular structural features. On the other hand, a decoding module based on visual residual Mamba is designed to model long-range dependencies between vascular slices while maintaining linear complexity, ultimately achieving more accurate coronary artery segmentation in resource-limited environments.关键词:computed tomography angiography(CTA);coronary artery segmentation;two-stage split method;dynamic snake convolution;state space model(SSM)312|523|0更新时间:2025-10-16
摘要:ObjectiveCardiovascular disease (CVD) accounts for approximately half of noncommunicable diseases. Coronary artery stenosis is considered a major risk factor for CVD. Computed tomography angiography (CTA) has become one of the widely used noninvasive imaging methods for coronary diagnosis due to its excellent image resolution. Clinically, coronary artery segmentation is crucial for the diagnosis and quantification of coronary artery diseases. Coronary arteries are characterized by their multibranching and tubular structures, with severe imbalance between foreground and background classes. Traditional coronary artery segmentation networks based on convolutional neural networks experience difficulty in modeling long-range dependencies between vessels, while Vision Transformer models are difficult to deploy in resource-constrained real-world environments due to their high complexity. Recent studies have shown that state space models, such as Mamba, can effectively model long-range dependencies while maintaining linear complexity.MethodGiven these reasons, this study applies visual Mamba to coronary artery segmentation for the first time and proposes a two-stage coronary artery segmentation method, called MDSVM-UNet++, based on multidirectional snake convolution (MDSConv) and visual residual Mamba. MDSVM-UNet++ adopts a traditional encoder–decoder architecture. During the encoding stage, dynamic snake convolution is used to replace traditional convolution to accurately capture the elongated and tortuous tubular structure features of the vessels, introducing deformable offsets into the convolution kernel and employing an iterative strategy to prevent the model from deviating from the target while learning the deformable offsets, ensuring the continuity of attention. In addition, an MDSConv layer is proposed to extract features from the three dimensions (x, y, z) of a 3D image, retaining attention from multiple directions and further improving segmentation accuracy, allowing the model to focus more on slender and complex tubular structures. During the decoding stage, an up-sampling decoder block based on residual visual Mamba is designed to model long-range dependencies between vascular slices while maintaining linear complexity. This block employs dense spatial pooling techniques to generate fine multi-scale contexts, first performing feature fusion by using addition and then inputting the results into the residual visual Mamba layer for long-range dependency modeling, followed by trilinear interpolation for up-sampling the feature maps. To achieve more accurate segmentation of small branch vessels, a two-stage segmentation model is further proposed. During the first stage, the original CTA images are scaled down to a size of 128 × 128 × 64, and then MDSVM-UNet++ is directly applied to segment the entire CTA image. The results are used to guide the partitioning of the original image into a set of 64 × 64 × 64 voxel blocks, allowing the data to contain more coronary artery information. Subsequently, the segmented data are re-inputted into the MDSVM-UNet++ network for the second stage of segmentation, with all the segmented results merged at the end. This approach reduces false positive points in the segmentation results while ensuring continuity and improving the smoothness of coronary arteries.ResultIn the experimental section, we implemented the model by using the PyTorch framework and trained it on NVIDIA GTX 3090. We selected 750 CTA images from the ImageCAS dataset as the training set, with the remaining 250 CTA images used as validation and test sets. The first-stage segmentation network was trained for 25 epochs by using the Adam optimizer with a learning rate of 0.001. The second-stage segmentation network underwent 50 iterations, with the learning rate decayed by a factor of 0.1 at the 30th and 40th iterations. The Dice similarity coefficient (DSC) was used as the evaluation metric, while the Hausdorff distance (HD) and average HD (AHD) served as auxiliary metrics. The experimental results indicated that the proposed MDSVM-UNet++ method outperformed the latest baseline network, ImageCas, on the ImageCAS dataset, achieving 5.41% improvement in DSC, an increase of 8.545 6 in HD, and an increase of 0.809 3 in AHD.ConclusionGiven the tubular structural characteristics of coronary arteries, this study applies visual Mamba to coronary artery segmentation for the first time, proposing a two-stage coronary artery segmentation method based on dynamic snake convolution and visual residual Mamba. On the one hand, dynamic snake convolution is utilized to more accurately capture vascular structural features. On the other hand, a decoding module based on visual residual Mamba is designed to model long-range dependencies between vascular slices while maintaining linear complexity, ultimately achieving more accurate coronary artery segmentation in resource-limited environments.关键词:computed tomography angiography(CTA);coronary artery segmentation;two-stage split method;dynamic snake convolution;state space model(SSM)312|523|0更新时间:2025-10-16
Visual State Space Model and Applications

- “在三维点云配准领域,专家梳理了点云配准方法,为精确高效处理提供解决方案。”
 摘要:A 3D point cloud is a set of data points in space, which is an important form of data to express the geometric information of an object or a scene. It is widely used in various fields, such as computer graphics, computer vision, robot navigation, automatic driving, and augmented reality. In practical applications, incomplete and inaccurate data due to different factors, including sensor movement and noise occlusion, bring challenges to the subsequent processing. Therefore, realizing accurate, efficient, and robust 3D point cloud registration is particularly important. The point cloud registration process involves aligning two or more 3D point clouds collected from different locations in the same scene, which generally requires two steps: finding the correspondence and solving the transformation. Specifically, finding the correspondence means determining the correspondence between the source and target point clouds and the connection between them. Solving the transformation refers to computing the correspondence between the source and target point clouds into a transformation matrix. After the alignment, the point cloud data can be aligned under the same coordinate system for easy processing. In this study, we organize and summarize the 3D point cloud registration methods to date. We also classify them according to the two modules of finding the correspondence and solving the transformation matrix. The relationship between each 3D point cloud registration method is also sorted out to conduct a more intuitive comparison of the point cloud registration methods. This study introduces rigid and non-rigid point cloud registration methods, summarizes the overview of the current optimization- and deep learning-based methods, and introduces some representative point cloud registration methods to provide assistance for further research. A rigid point cloud is a point cloud in which the relative distances and positions between points in the point cloud data remain unchanged when moving or rotating. In other words, the entire point cloud is transformed as a rigid body without deformation or distortion. Rigid point clouds are commonly used to represent the 3D form of solid objects or structures, such as buildings and machine parts. The task of rigid point cloud alignment involves aligning two or more rigid point clouds to ensure their consistent spatial positions in the same coordinate system. In this study, the rigid alignment methods are introduced in two major blocks: finding correspondences and solving rigid transformations. The methods for finding rigid correspondences are categorized into three parts: iterative solving, feature extraction, and matching correspondences. The methods of iterative solving mainly include iterative nearest point and its variants, normal distribution and its variants, and other traditional methods. These methods can realize high-precision alignment and do not require training, but they are too demanding and require complete data and a good initial pose. The feature extraction method extracts the salient features of the source and target point clouds and then compares these features to obtain the correspondence. This study comprehensively describes the 3D point cloud registration method using extracted point, line, surface, rotation invariant, and texture features. Matching correspondence methods, particularly nearest neighbor search and soft matching methods, are used to find the correct correspondence between the features of the source point cloud to compute the transformation matrix. In this study, rigid transform solving methods such as random sampling, singular value decomposition, and deep learning methods are described in detail. This study also introduces the non-rigid alignment method. Non-rigid point cloud means that the relative distance and position between points in the point cloud data can be changed, that is, non-rigid deformation such as deformation, stretching, and twisting may occur in the point cloud during the transformation process. Non-rigid point clouds are usually used to describe 3D forms with dynamic deformation characteristics such as human bodies, animals, fabrics, or flexible structures. Again, the task of non-rigid point cloud alignment involves aligning two or more non-rigid point clouds to guarantee their consistent spatial positions and shapes in the same coordinate system by estimating deformation fields or transformations. As mentioned earlier, the non-rigid alignment method introduced in this study is divided into two main blocks: finding the correspondence and solving the non-rigid transformation. The part of finding non-rigid correspondences mainly introduces some deformation field representations, such as point-by-point positional representation, point-by-point radial representation, deformation map representation, and a priori-based representation. The non-rigid deformation field describes how each point in the point cloud is displaced and deformed during the transformation process in the non-rigid point cloud alignment. It can be used to represent complex deformation relationships such as stretching, compression, and rotation of local shapes in a point cloud. The non-rigid deformation field is usually represented in the form of continuous mathematical function or discrete vector field, which is a key tool to realize accurate alignment and deformation reconstruction of point cloud. In introducing the part of solving non-rigid transformations, this study focuses on optimization- and deep learning-based solving methods. The deep learning-based solving methods are mainly introduced, such as mainstream convolutional neural network (CNN) methods, graph convolutional neural network (GCNN) methods, and Transformer methods. In addition, benchmark datasets and evaluation metrics are summarized in this survey. The commonly used datasets for point cloud alignment are comprehensively described, including the ModelNet, 7-Scenes, 3DMatch, KITTI, ETHdata, and 4DMatch datasets. The commonly used evaluation metrics, including root mean square error, alignment recall, and mean relative error, are explained in detail. Finally, the possible future problems facing this topic and suggestions for conducting research are presented.关键词:3D point cloud;registration;rigid point cloud;non-rigid point cloud;optimization method;deep learning799|467|0更新时间:2025-10-16
摘要:A 3D point cloud is a set of data points in space, which is an important form of data to express the geometric information of an object or a scene. It is widely used in various fields, such as computer graphics, computer vision, robot navigation, automatic driving, and augmented reality. In practical applications, incomplete and inaccurate data due to different factors, including sensor movement and noise occlusion, bring challenges to the subsequent processing. Therefore, realizing accurate, efficient, and robust 3D point cloud registration is particularly important. The point cloud registration process involves aligning two or more 3D point clouds collected from different locations in the same scene, which generally requires two steps: finding the correspondence and solving the transformation. Specifically, finding the correspondence means determining the correspondence between the source and target point clouds and the connection between them. Solving the transformation refers to computing the correspondence between the source and target point clouds into a transformation matrix. After the alignment, the point cloud data can be aligned under the same coordinate system for easy processing. In this study, we organize and summarize the 3D point cloud registration methods to date. We also classify them according to the two modules of finding the correspondence and solving the transformation matrix. The relationship between each 3D point cloud registration method is also sorted out to conduct a more intuitive comparison of the point cloud registration methods. This study introduces rigid and non-rigid point cloud registration methods, summarizes the overview of the current optimization- and deep learning-based methods, and introduces some representative point cloud registration methods to provide assistance for further research. A rigid point cloud is a point cloud in which the relative distances and positions between points in the point cloud data remain unchanged when moving or rotating. In other words, the entire point cloud is transformed as a rigid body without deformation or distortion. Rigid point clouds are commonly used to represent the 3D form of solid objects or structures, such as buildings and machine parts. The task of rigid point cloud alignment involves aligning two or more rigid point clouds to ensure their consistent spatial positions in the same coordinate system. In this study, the rigid alignment methods are introduced in two major blocks: finding correspondences and solving rigid transformations. The methods for finding rigid correspondences are categorized into three parts: iterative solving, feature extraction, and matching correspondences. The methods of iterative solving mainly include iterative nearest point and its variants, normal distribution and its variants, and other traditional methods. These methods can realize high-precision alignment and do not require training, but they are too demanding and require complete data and a good initial pose. The feature extraction method extracts the salient features of the source and target point clouds and then compares these features to obtain the correspondence. This study comprehensively describes the 3D point cloud registration method using extracted point, line, surface, rotation invariant, and texture features. Matching correspondence methods, particularly nearest neighbor search and soft matching methods, are used to find the correct correspondence between the features of the source point cloud to compute the transformation matrix. In this study, rigid transform solving methods such as random sampling, singular value decomposition, and deep learning methods are described in detail. This study also introduces the non-rigid alignment method. Non-rigid point cloud means that the relative distance and position between points in the point cloud data can be changed, that is, non-rigid deformation such as deformation, stretching, and twisting may occur in the point cloud during the transformation process. Non-rigid point clouds are usually used to describe 3D forms with dynamic deformation characteristics such as human bodies, animals, fabrics, or flexible structures. Again, the task of non-rigid point cloud alignment involves aligning two or more non-rigid point clouds to guarantee their consistent spatial positions and shapes in the same coordinate system by estimating deformation fields or transformations. As mentioned earlier, the non-rigid alignment method introduced in this study is divided into two main blocks: finding the correspondence and solving the non-rigid transformation. The part of finding non-rigid correspondences mainly introduces some deformation field representations, such as point-by-point positional representation, point-by-point radial representation, deformation map representation, and a priori-based representation. The non-rigid deformation field describes how each point in the point cloud is displaced and deformed during the transformation process in the non-rigid point cloud alignment. It can be used to represent complex deformation relationships such as stretching, compression, and rotation of local shapes in a point cloud. The non-rigid deformation field is usually represented in the form of continuous mathematical function or discrete vector field, which is a key tool to realize accurate alignment and deformation reconstruction of point cloud. In introducing the part of solving non-rigid transformations, this study focuses on optimization- and deep learning-based solving methods. The deep learning-based solving methods are mainly introduced, such as mainstream convolutional neural network (CNN) methods, graph convolutional neural network (GCNN) methods, and Transformer methods. In addition, benchmark datasets and evaluation metrics are summarized in this survey. The commonly used datasets for point cloud alignment are comprehensively described, including the ModelNet, 7-Scenes, 3DMatch, KITTI, ETHdata, and 4DMatch datasets. The commonly used evaluation metrics, including root mean square error, alignment recall, and mean relative error, are explained in detail. Finally, the possible future problems facing this topic and suggestions for conducting research are presented.关键词:3D point cloud;registration;rigid point cloud;non-rigid point cloud;optimization method;deep learning799|467|0更新时间:2025-10-16
Review
- “在图像降噪领域,研究者提出了一种特征分离—引导降噪模型,有效提升了图像降噪的稳定性和泛化性。”
 摘要:ObjectiveImage noise refers to the distortion phenomenon in visual signals caused by random variations or external interference. This phenomenon often leads to poor performance in various computational tasks. The core goal of image denoising is to restore clear, accurate, and high-quality images from those affected by noise interference, which makes them more consistent with human visual perception for subsequent image analysis, processing, or visual presentation. Currently, restoring damaged high-quality images has become a primary objective in the field of image processing. Many studies have achieved promising results in dealing with known distributions of noise (such as additive Gaussian white noise). However, real-world noise differs fundamentally from synthetic noise due to its origins from various factors, such as changes in lighting conditions, sensor stability, and environmental interference. This complexity leads to poor generalization capability of models trained on synthetic noise when faced with real noise, which results in suboptimal denoising effects. Some deep learning methods directly learn residual images through networks and use differences as constraints to realize image denoising. However, real noise exhibits high non-uniformity and complexity, while single-task networks for pixel-space noise separation often ignores the complexity of noise distribution and the correlation between noise and the overall structure of the image. Therefore, this approach easily mistakes non-noise information in the image for noise and removes it. This error leads to loss of image clarity and details, which disrupts the overall structure of the image. Meanwhile, some methods adopt a combination of traditional methods and deep learning, which utilizes prior information to separate image data. Compared with traditional direct mapping approaches, these methods are more flexible and can more accurately locate and process noise. Thus, they improve the adaptability to different types of noise to some extent. However, these techniques have certain limitations in that they tend to ignore the characteristics of the image itself, which may affect its overall structure during denoising. In addition, such means usually require additional computational and network steps, which may be limited in practical applications. We propose a noise feature separation network to mitigate the impact of noise learning bias on the image itself and better balance prior information and image characteristics.MethodIn this study, we draw inspiration from the concept of separation and employ a multi-module joint network, which is called the feature separation and guidance for real image denoising network, to realize feature separation and guidance. This network comprises a separation module, a guidance module, and a contrastive learning module. Considering that convolutional neural networks (CNNs) may overlook the global structural information of images when extracting deep semantic features, the basic architecture network of our network module is implemented using a cross-structure of CNN and Transformer. First, we designed a symmetric network to constrain the noise separation module without relying on any prior information. The symmetric network learns the bidirectional mapping relationship of images by mapping noise images to noise-free images, and vice versa. Subsequently, the separated noise features are used as guidance information for the image denoising module, which enables multi-scale guidance for removing noise signal features in the feature space. Finally, based on the idea of contrastive learning, we further constrain the separation module by leveraging the differences between positive and negative samples to realize noise feature separation. Given that our model learns the bidirectional mapping relationship between noisy and noise-free images, the noise separation module is constrained by structural and contrastive losses. This constraint provides more accurate noise signal features for the image denoising module and enhances the accuracy and generalization performance of the network denoising.ResultExperiments were conducted on the SIDD dataset for training and on three datasets (smartphone image denoising dataset(SIDD), darmstadt noise dataset(DND) sRGB, and PolyU-real-world-noisy-images-dataset(PolyU)) for testing. Compared with other real image denoising methods, our approach produces more consistent results in peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM). Specifically, on the PolyU dataset, PSNR improved by 0.25%, and SSIM enhanced by 0.72%. Several ablation experiments were also conducted, and the effectiveness of each algorithm module was verified through visual demonstrations. Experimental results demonstrate that our proposed algorithm significantly improves the effect of image denoising and enhances the generalization performance of the model to a certain extent.ConclusionThis study proposes a feature space separation-guided denoising model. Based on the concept of feature separation, this model effectively transforms between feature space and pixel space, which enables flexible learning of noise signal features and provides accurate guidance information for the denoising model. Further adoption of contrastive learning improves the learning of noise signal features. Leveraging the cross-structure of Transformer and CNN enhances the retention of image features during the denoising process, which reduces the loss of key information. This network architecture efficiently separates the noise features within the image from its intrinsic features. As a result, more accurate localization and processing of noise signals is realized while preserving the original details and structure of the image. By separating and reconstructing noise signals in the feature space, our method minimizes the loss of overall image information during the denoising process, which improves denoising effectiveness and maintains image quality. The proposed method exhibits competitive performance when compared with representative state-of-the-art methods for image denoising.关键词:image denoising;real noise;feature separation;feature guidance;contrastive learning89|115|0更新时间:2025-10-16
摘要:ObjectiveImage noise refers to the distortion phenomenon in visual signals caused by random variations or external interference. This phenomenon often leads to poor performance in various computational tasks. The core goal of image denoising is to restore clear, accurate, and high-quality images from those affected by noise interference, which makes them more consistent with human visual perception for subsequent image analysis, processing, or visual presentation. Currently, restoring damaged high-quality images has become a primary objective in the field of image processing. Many studies have achieved promising results in dealing with known distributions of noise (such as additive Gaussian white noise). However, real-world noise differs fundamentally from synthetic noise due to its origins from various factors, such as changes in lighting conditions, sensor stability, and environmental interference. This complexity leads to poor generalization capability of models trained on synthetic noise when faced with real noise, which results in suboptimal denoising effects. Some deep learning methods directly learn residual images through networks and use differences as constraints to realize image denoising. However, real noise exhibits high non-uniformity and complexity, while single-task networks for pixel-space noise separation often ignores the complexity of noise distribution and the correlation between noise and the overall structure of the image. Therefore, this approach easily mistakes non-noise information in the image for noise and removes it. This error leads to loss of image clarity and details, which disrupts the overall structure of the image. Meanwhile, some methods adopt a combination of traditional methods and deep learning, which utilizes prior information to separate image data. Compared with traditional direct mapping approaches, these methods are more flexible and can more accurately locate and process noise. Thus, they improve the adaptability to different types of noise to some extent. However, these techniques have certain limitations in that they tend to ignore the characteristics of the image itself, which may affect its overall structure during denoising. In addition, such means usually require additional computational and network steps, which may be limited in practical applications. We propose a noise feature separation network to mitigate the impact of noise learning bias on the image itself and better balance prior information and image characteristics.MethodIn this study, we draw inspiration from the concept of separation and employ a multi-module joint network, which is called the feature separation and guidance for real image denoising network, to realize feature separation and guidance. This network comprises a separation module, a guidance module, and a contrastive learning module. Considering that convolutional neural networks (CNNs) may overlook the global structural information of images when extracting deep semantic features, the basic architecture network of our network module is implemented using a cross-structure of CNN and Transformer. First, we designed a symmetric network to constrain the noise separation module without relying on any prior information. The symmetric network learns the bidirectional mapping relationship of images by mapping noise images to noise-free images, and vice versa. Subsequently, the separated noise features are used as guidance information for the image denoising module, which enables multi-scale guidance for removing noise signal features in the feature space. Finally, based on the idea of contrastive learning, we further constrain the separation module by leveraging the differences between positive and negative samples to realize noise feature separation. Given that our model learns the bidirectional mapping relationship between noisy and noise-free images, the noise separation module is constrained by structural and contrastive losses. This constraint provides more accurate noise signal features for the image denoising module and enhances the accuracy and generalization performance of the network denoising.ResultExperiments were conducted on the SIDD dataset for training and on three datasets (smartphone image denoising dataset(SIDD), darmstadt noise dataset(DND) sRGB, and PolyU-real-world-noisy-images-dataset(PolyU)) for testing. Compared with other real image denoising methods, our approach produces more consistent results in peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM). Specifically, on the PolyU dataset, PSNR improved by 0.25%, and SSIM enhanced by 0.72%. Several ablation experiments were also conducted, and the effectiveness of each algorithm module was verified through visual demonstrations. Experimental results demonstrate that our proposed algorithm significantly improves the effect of image denoising and enhances the generalization performance of the model to a certain extent.ConclusionThis study proposes a feature space separation-guided denoising model. Based on the concept of feature separation, this model effectively transforms between feature space and pixel space, which enables flexible learning of noise signal features and provides accurate guidance information for the denoising model. Further adoption of contrastive learning improves the learning of noise signal features. Leveraging the cross-structure of Transformer and CNN enhances the retention of image features during the denoising process, which reduces the loss of key information. This network architecture efficiently separates the noise features within the image from its intrinsic features. As a result, more accurate localization and processing of noise signals is realized while preserving the original details and structure of the image. By separating and reconstructing noise signals in the feature space, our method minimizes the loss of overall image information during the denoising process, which improves denoising effectiveness and maintains image quality. The proposed method exhibits competitive performance when compared with representative state-of-the-art methods for image denoising.关键词:image denoising;real noise;feature separation;feature guidance;contrastive learning89|115|0更新时间:2025-10-16 - “在图像处理领域,专家提出了一种低光增强方法,有效提升了图像质量与渲染速度,为低光照图像处理提供了新方案。”
 摘要:ObjectiveLow-light image enhancement for neural rendering is a critical challenge, especially in the domain of novel view synthesis (NVS), which aims to generate realistic images from new viewpoints based on a set of pre-captured images. When neural rendering models are trained under low-light conditions, they fail to produce high-quality results that resemble images captured under normal lighting. These low-light images introduce problems, particularly in downstream tasks such as object detection and semantic segmentation, due to their degraded quality. Traditional methods for addressing this issue usually struggle to balance rendering speed with the preservation of high-frequency details in the generated images. This research aims to address these limitations by proposing a new method for enhancing low-light images using a 3D Gaussian point cloud splatting model. The goal is to improve the quality of rendered images while significantly reducing the training and rendering times, which makes the approach suitable for practical applications in real-world scenarios where low-light conditions are common.MethodThe proposed method introduces a low-light enhancement framework based on the 3D Gaussian point cloud splatting model. The model is enhanced by decomposing the color attributes of the 3D Gaussian distributions into intrinsic object color and lighting components. A lightweight lighting prediction network is used to estimate the lighting conditions, which allows for the rendering of images that simulate normal lighting conditions, even when the training data consist solely of low-light images. To further improve image quality, a multi-stage gradient weighting strategy is employed. This implementation helps address noise issues commonly found in low-light images, where image noise is amplified due to insufficient lighting. The multi-stage gradient weighting technique ensures that the noise does not obscure important image details, which leads to clearer results. Moreover, the method uses a fixed geometry optimization scheme to retain high-frequency details in the rendered images. This utilization is crucial because low-light conditions can cause distortions in the image structure, and fixed geometry ensures that the overall image clarity and structure are preserved. The core of the methodology revolves around the combination of color decomposition and geometry optimization, which allows the system to maintain high accuracy in rendering while improving efficiency.ResultExperiments were conducted using the low-light & normal-light & over-exposure multi-view dataset(LOM) dataset, which consists of low-light scene images and their corresponding normal-light images, and the results were compared with several mainstream methods in the field of neural rendering and low-light enhancement. The evaluation metrics used in the comparison include peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS). The proposed method outperformed the current state-of-the-art approaches across all metrics. In terms of PSNR, the proposed method achieved a 0.12 dB improvement over the best existing method, which indicates a higher signal-to-noise ratio and thus clearer images. SSIM presented a 1.3% improvement. This result suggests that the structural similarity between the generated images and the ground truth was significantly better. LPIPS, which measures perceptual similarity, improved by 5.5%, which demonstrates that the generated images were closer to human perception of the original scenes. In addition to improvements in image quality, the method also delivered significant gains in computational efficiency. The proposed approach reduced training and rendering times by over tenfold compared with traditional methods. This substantial acceleration is due to the explicit point cloud rendering technique used in the 3D Gaussian point cloud splatting model, which eliminates the need for complex and time-consuming calculations typically required in other neural rendering methods.ConclusionThe proposed low-light enhancement method based on the 3D Gaussian point cloud splatting model offers a substantial advancement over existing techniques in image quality and computational efficiency. By decomposing the color attributes of the 3D Gaussian distributions into intrinsic object color and lighting components, the method enables the rendering of high-quality images under normal-light conditions, even when the training data consist solely of low-light images. The multi-stage gradient weighting strategy effectively addresses the noise amplification issue common in low-light image processing, while the fixed geometry optimization ensures the preservation of high-frequency details and overall image structure. These innovations contribute to the superior performance of the method in generating high-quality images for NVS under challenging low-light conditions. In terms of performance, the proposed method achieves notable improvements in PSNR, SSIM, and LPIPS compared with the state-of-the-art methods. The capability of the method to produce clearer images with better structural and perceptual quality, as well as its significantly faster training and rendering times, makes it a promising solution for real-time applications in fields such as autonomous driving, virtual reality, and 3D scene reconstruction, where image quality and computational efficiency are highly important. This work demonstrates the effectiveness and superiority of the proposed method in enhancing low-light images for neural rendering. The method is a valuable contribution to the fields of computer vision and image synthesis.关键词:low light enhancement;novel view synthesis (NVS);machine learning;neural rendering;3D Gaussian splatting (3D GS)473|593|0更新时间:2025-10-16
摘要:ObjectiveLow-light image enhancement for neural rendering is a critical challenge, especially in the domain of novel view synthesis (NVS), which aims to generate realistic images from new viewpoints based on a set of pre-captured images. When neural rendering models are trained under low-light conditions, they fail to produce high-quality results that resemble images captured under normal lighting. These low-light images introduce problems, particularly in downstream tasks such as object detection and semantic segmentation, due to their degraded quality. Traditional methods for addressing this issue usually struggle to balance rendering speed with the preservation of high-frequency details in the generated images. This research aims to address these limitations by proposing a new method for enhancing low-light images using a 3D Gaussian point cloud splatting model. The goal is to improve the quality of rendered images while significantly reducing the training and rendering times, which makes the approach suitable for practical applications in real-world scenarios where low-light conditions are common.MethodThe proposed method introduces a low-light enhancement framework based on the 3D Gaussian point cloud splatting model. The model is enhanced by decomposing the color attributes of the 3D Gaussian distributions into intrinsic object color and lighting components. A lightweight lighting prediction network is used to estimate the lighting conditions, which allows for the rendering of images that simulate normal lighting conditions, even when the training data consist solely of low-light images. To further improve image quality, a multi-stage gradient weighting strategy is employed. This implementation helps address noise issues commonly found in low-light images, where image noise is amplified due to insufficient lighting. The multi-stage gradient weighting technique ensures that the noise does not obscure important image details, which leads to clearer results. Moreover, the method uses a fixed geometry optimization scheme to retain high-frequency details in the rendered images. This utilization is crucial because low-light conditions can cause distortions in the image structure, and fixed geometry ensures that the overall image clarity and structure are preserved. The core of the methodology revolves around the combination of color decomposition and geometry optimization, which allows the system to maintain high accuracy in rendering while improving efficiency.ResultExperiments were conducted using the low-light & normal-light & over-exposure multi-view dataset(LOM) dataset, which consists of low-light scene images and their corresponding normal-light images, and the results were compared with several mainstream methods in the field of neural rendering and low-light enhancement. The evaluation metrics used in the comparison include peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS). The proposed method outperformed the current state-of-the-art approaches across all metrics. In terms of PSNR, the proposed method achieved a 0.12 dB improvement over the best existing method, which indicates a higher signal-to-noise ratio and thus clearer images. SSIM presented a 1.3% improvement. This result suggests that the structural similarity between the generated images and the ground truth was significantly better. LPIPS, which measures perceptual similarity, improved by 5.5%, which demonstrates that the generated images were closer to human perception of the original scenes. In addition to improvements in image quality, the method also delivered significant gains in computational efficiency. The proposed approach reduced training and rendering times by over tenfold compared with traditional methods. This substantial acceleration is due to the explicit point cloud rendering technique used in the 3D Gaussian point cloud splatting model, which eliminates the need for complex and time-consuming calculations typically required in other neural rendering methods.ConclusionThe proposed low-light enhancement method based on the 3D Gaussian point cloud splatting model offers a substantial advancement over existing techniques in image quality and computational efficiency. By decomposing the color attributes of the 3D Gaussian distributions into intrinsic object color and lighting components, the method enables the rendering of high-quality images under normal-light conditions, even when the training data consist solely of low-light images. The multi-stage gradient weighting strategy effectively addresses the noise amplification issue common in low-light image processing, while the fixed geometry optimization ensures the preservation of high-frequency details and overall image structure. These innovations contribute to the superior performance of the method in generating high-quality images for NVS under challenging low-light conditions. In terms of performance, the proposed method achieves notable improvements in PSNR, SSIM, and LPIPS compared with the state-of-the-art methods. The capability of the method to produce clearer images with better structural and perceptual quality, as well as its significantly faster training and rendering times, makes it a promising solution for real-time applications in fields such as autonomous driving, virtual reality, and 3D scene reconstruction, where image quality and computational efficiency are highly important. This work demonstrates the effectiveness and superiority of the proposed method in enhancing low-light images for neural rendering. The method is a valuable contribution to the fields of computer vision and image synthesis.关键词:low light enhancement;novel view synthesis (NVS);machine learning;neural rendering;3D Gaussian splatting (3D GS)473|593|0更新时间:2025-10-16
Image Processing and Coding
- “在无人机航拍领域,专家提出了融合图像增强的正则化目标跟踪算法,有效提升了光照不足场景下的跟踪性能,为无人机稳定工作提供支持。”
 摘要:ObjectiveThe tracking task of unmanned aerial vehicles (UAVs) often encounters various complex scenes. Factors such as illumination change, image blur, and low resolution greatly affect the tracking performance, which causes difficulty in achieving stable and long-term tracking tasks. The previous target tracking algorithms mainly focus on the robust tracking task of UAVs under sufficient light and high resolution. Less research is available on the tracking task in low-light scenes. The existing tracking algorithms for low-light scenes typically add an independent pre-image enhancement module to achieve an “enhancement-before-tracking” architecture, which can deal with low-light scenes. However, this architecture isolates the perception of scene information using the regularization module in the correlation filter, which limits the adaptability of the tracking algorithm to the tracking scene.MethodTo solve the two problems mentioned above, a target tracking algorithm based on image enhancement using a regularized correlation filter for UAVs is proposed to achieve robust tracking of UAV targets in the case of light changes and low resolution. First, an adaptive image enhancement module is constructed, and an illumination quality criterion composed of brightness and brightness difference is proposed. This criterion can flexibly determine whether to enhance the image according to the size of the illumination quality criterion, which avoids the large reduction in the running speed caused by image enhancement processing for all images and the excessive processing of some normal illumination images. In this way, the performance of the algorithm is not decreased but increased. The improved image enhancement module can improve the insufficient light of the image in certain cases and ensure clarity. As a result, the image can provide more effective feature information for subsequent processing, which effectively enhances the performance of the algorithm. Second, the illumination quality factor obtained in the image enhancement module is introduced into the temporal regularization to constrain the difference between the tracking response values of the two frames, and the illumination information in the scene is fused to realize the dynamic constraint of the temporal regularization. This fusion further enhances the adaptability of the algorithm to complex scenes and improves the robustness of the algorithm. Finally, the alternating direction method of multipliers is used to optimize the objective function of the proposed algorithm. The closed-form solution of each parameter can be obtained with fewer iterations, which further enhances the performance of the algorithm.ResultTo comprehensively evaluate the performance of the proposed algorithm, sufficient experiments are conducted on two public UAV datasets. The UAVdark70 dataset is mainly for dark-light and low-resolution scenes, with few categories but a large amount of data. The difficulty lies in accurately tracking the target in low-light and low-resolution situations. The UAV123@10fps dataset is a large and comprehensive dataset, with comprehensive tracking scenes, rich tracking objects, and many types of challenge attributes. It is used to test the comprehensive capability of the algorithm. On the UAVdark70 dark-light dataset, the proposed tracking model ranks first in tracking accuracy and tracking success rate. Compared with the benchmark algorithm AutoTrack, the tracking accuracy and tracking success rate of the proposed model are increased by 5.7% and 4.3%, respectively. The results show that the algorithm can run stably under dark-light conditions and has good adaptability to the environment. In the UAV123@10fps comprehensive dataset, this model ranks first in tracking accuracy and tracking success rate. Compared with the benchmark algorithm AutoTrack, the tracking accuracy and tracking success rate of the model are increased by 1.8% and 1.3%, respectively. Therefore, the proposed algorithm can effectively track the target with the temporal regularization fused with the illumination quality factor in various complex situations, which reflects robustness and scene adaptability. The data of challenge attributes reveal the overall excellent performance of the algorithm on the UAV123@10fps dataset. Specifically, in the face of camera motion, fast movement, out of view, occlusion, similar objects, and other challenge attributes, the proposed algorithm ranks first, which fully reflects the scene adaptability and robustness of the algorithm. It fully embodies the scene adaptability and robustness of the algorithm. To particularly test the effect of the algorithm, ablation experiments are conducted on the UAVdark70 dataset. The results show that the two proposed modules can improve the algorithm, and the combination of the two modules maximizes the comprehensive performance of the algorithm. Compared with the baseline algorithm, the tracking accuracy and tracking success rate are increased by 5.7% and 4.3%, respectively. However, given that the UAVdark70 dataset mainly contains dark-light images, image enhancement processing is required. Thus, the speed is 4.1 frame/s lower than that of AutoTrack, but the real-time requirement is still achieved.ConclusionFor the target tracking task of UAVs in low-light and low-resolution scenes, a target tracking algorithm based on image enhancement using a regularized correlation filter for UAVs is proposed to enhance adaptability to low-light scenes. In this way, the UAV can work in various scenes for a longer time. The comprehensive experimental results indicate that the proposed algorithm can effectively deal with insufficient light. It can also improve the tracking performance of UAVs in complex scenes with sufficient light. Therefore, the algorithm can effectively adapt to different scenes and provide strong support for stable and sustained operation of UAVs.关键词:computer vision;target tracking;unmanned aerial vehicle(UAV);correlation filtering(CF);image enhancement216|335|0更新时间:2025-10-16
摘要:ObjectiveThe tracking task of unmanned aerial vehicles (UAVs) often encounters various complex scenes. Factors such as illumination change, image blur, and low resolution greatly affect the tracking performance, which causes difficulty in achieving stable and long-term tracking tasks. The previous target tracking algorithms mainly focus on the robust tracking task of UAVs under sufficient light and high resolution. Less research is available on the tracking task in low-light scenes. The existing tracking algorithms for low-light scenes typically add an independent pre-image enhancement module to achieve an “enhancement-before-tracking” architecture, which can deal with low-light scenes. However, this architecture isolates the perception of scene information using the regularization module in the correlation filter, which limits the adaptability of the tracking algorithm to the tracking scene.MethodTo solve the two problems mentioned above, a target tracking algorithm based on image enhancement using a regularized correlation filter for UAVs is proposed to achieve robust tracking of UAV targets in the case of light changes and low resolution. First, an adaptive image enhancement module is constructed, and an illumination quality criterion composed of brightness and brightness difference is proposed. This criterion can flexibly determine whether to enhance the image according to the size of the illumination quality criterion, which avoids the large reduction in the running speed caused by image enhancement processing for all images and the excessive processing of some normal illumination images. In this way, the performance of the algorithm is not decreased but increased. The improved image enhancement module can improve the insufficient light of the image in certain cases and ensure clarity. As a result, the image can provide more effective feature information for subsequent processing, which effectively enhances the performance of the algorithm. Second, the illumination quality factor obtained in the image enhancement module is introduced into the temporal regularization to constrain the difference between the tracking response values of the two frames, and the illumination information in the scene is fused to realize the dynamic constraint of the temporal regularization. This fusion further enhances the adaptability of the algorithm to complex scenes and improves the robustness of the algorithm. Finally, the alternating direction method of multipliers is used to optimize the objective function of the proposed algorithm. The closed-form solution of each parameter can be obtained with fewer iterations, which further enhances the performance of the algorithm.ResultTo comprehensively evaluate the performance of the proposed algorithm, sufficient experiments are conducted on two public UAV datasets. The UAVdark70 dataset is mainly for dark-light and low-resolution scenes, with few categories but a large amount of data. The difficulty lies in accurately tracking the target in low-light and low-resolution situations. The UAV123@10fps dataset is a large and comprehensive dataset, with comprehensive tracking scenes, rich tracking objects, and many types of challenge attributes. It is used to test the comprehensive capability of the algorithm. On the UAVdark70 dark-light dataset, the proposed tracking model ranks first in tracking accuracy and tracking success rate. Compared with the benchmark algorithm AutoTrack, the tracking accuracy and tracking success rate of the proposed model are increased by 5.7% and 4.3%, respectively. The results show that the algorithm can run stably under dark-light conditions and has good adaptability to the environment. In the UAV123@10fps comprehensive dataset, this model ranks first in tracking accuracy and tracking success rate. Compared with the benchmark algorithm AutoTrack, the tracking accuracy and tracking success rate of the model are increased by 1.8% and 1.3%, respectively. Therefore, the proposed algorithm can effectively track the target with the temporal regularization fused with the illumination quality factor in various complex situations, which reflects robustness and scene adaptability. The data of challenge attributes reveal the overall excellent performance of the algorithm on the UAV123@10fps dataset. Specifically, in the face of camera motion, fast movement, out of view, occlusion, similar objects, and other challenge attributes, the proposed algorithm ranks first, which fully reflects the scene adaptability and robustness of the algorithm. It fully embodies the scene adaptability and robustness of the algorithm. To particularly test the effect of the algorithm, ablation experiments are conducted on the UAVdark70 dataset. The results show that the two proposed modules can improve the algorithm, and the combination of the two modules maximizes the comprehensive performance of the algorithm. Compared with the baseline algorithm, the tracking accuracy and tracking success rate are increased by 5.7% and 4.3%, respectively. However, given that the UAVdark70 dataset mainly contains dark-light images, image enhancement processing is required. Thus, the speed is 4.1 frame/s lower than that of AutoTrack, but the real-time requirement is still achieved.ConclusionFor the target tracking task of UAVs in low-light and low-resolution scenes, a target tracking algorithm based on image enhancement using a regularized correlation filter for UAVs is proposed to enhance adaptability to low-light scenes. In this way, the UAV can work in various scenes for a longer time. The comprehensive experimental results indicate that the proposed algorithm can effectively deal with insufficient light. It can also improve the tracking performance of UAVs in complex scenes with sufficient light. Therefore, the algorithm can effectively adapt to different scenes and provide strong support for stable and sustained operation of UAVs.关键词:computer vision;target tracking;unmanned aerial vehicle(UAV);correlation filtering(CF);image enhancement216|335|0更新时间:2025-10-16 - “在计算机视觉领域,专家提出了一种暗光环境下行人识别的生成检测一体化方法,有效解决了图像增强与检测任务分离的问题,为低光环境下行人检测提供了新方案。”
 摘要:ObjectivePedestrian detection in dark-light environments is a key challenge in the field of computer vision due to the lack of sufficient lighting, which results in blurry and low-contrast features of pedestrians. Traditional approaches to address this issue often focus on enhancing image quality through domain-specific visible light enhancement or generating infrared images to provide complementary information. However, these approaches are typically limited by the separation between the data enhancement process and the downstream detection tasks, which results in suboptimal performance. To overcome these limitations, this study proposes an integrated generation and detection framework tailored for pedestrian detection in dark-light conditions. The primary goal of the proposed framework is to bridge the gap between data enhancement and pedestrian detection by generating high-quality infrared images from dark-light images and jointly optimizing the generation and detection tasks in a unified architecture.MethodThe proposed framework is built upon a conditional diffusion model, which is used to generate auxiliary infrared modality images from dark-light RGB images. Unlike traditional approaches that first enhance or generate images and then input them into a detection network separately, this framework integrates the image generation and pedestrian detection tasks into a single end-to-end architecture. Inspired by ControlNet, the model leverages a conditional diffusion process to produce infrared images that provide enhanced pedestrian features. These infrared images are then used in conjunction with the original dark-light images to improve the detection performance. In addition, the framework extracts multi-scale features from the generated images through a UNet architecture, which replaces the traditional backbone network of the detection model. These multi-scale features are directly fed into the detection head, which allows the detection task to be optimized simultaneously with the image generation process. To ensure effective joint optimization, the framework incorporates a novel strategy to bypass the typical gradient flow limitations encountered when using variational autoencoders (VAEs). In standard designs, the VAE decoder is often a fixed module that prevents gradients from being propagated back during the training of the detection task. To address this limitation, the proposed framework allows the gradient to flow through the multi-scale feature maps generated by the UNet, which ensures that the generation and detection tasks benefit from the same optimization process. The detection task is supervised by a loss function that combines boundary box regression, classification, and confidence losses. This integration enables the model to learn object localization and classification.ResultExtensive experiments were conducted on the LLVIP and VTMOT datasets, which together contain 26 193 paired visible-light and infrared images (a total 52 386 images), all annotated with pedestrian detection labels. These datasets present significant challenges, particularly due to images captured under extreme low-light conditions. The proposed method was evaluated against several state-of-the-art techniques, including single-domain visible light enhancement methods and cross-domain infrared image generation approaches. Experimental results on the LLVIP and VTMOT datasets show that the method proposed in this study significantly outperforms traditional and state-of-the-art methods in terms of overall accuracy metrics. For example, on the LLVIP dataset, the F1 value of the proposed method is 85.75%, and the mAP is 75.35%. It outperforms the SCI method, which is the best of the traditional methods (an F1 value of 82.05% and a mean average precision(mAP) value of 72.30%), and Faster_RCNN_hrnet, which is the best of the state-of-the-art methods (an F1 value of 82.91% and a mAP value of 70.02%). On the VTMOT dataset, the proposed method also performs effectively with an F1 value of 90.01% and a mAP of 73.44%. It is superior to the best SCI method among the traditional methods (an F1 value of 85.91% and a mAP value of 72.19%) and the best Faster_RCNN_hrnet among the advanced methods (an F1 value of 84.48% and a mAP value of 71.16%). Moreover, the proposed method outperforms other methods overall in terms of precision, recall, and F1 score, which highlights its robustness and reliability in detecting pedestrians in dark-light conditions. In addition to the quantitative improvements, qualitative analysis reveals that the generated infrared images, when fused with the original dark-light images, provide clearer and more distinguishable pedestrian features. This fusion process helps reduce false positives and enhances the accuracy of pedestrian detection. The proposed framework could successfully detect pedestrians that were missed by other methods, especially in challenging scenes with low contrast between the pedestrians and their backgrounds. These results demonstrate the advantages of the joint infrared generation and pedestrian detection approach in overcoming the limitations of traditional methods, particularly in extreme lighting conditions. Ablation studies were conducted to evaluate the contribution of different components within the proposed framework. The results showed that the infrared image generation module and the joint optimization strategy are crucial for improving detection performance. Removing the infrared generation module led to a notable performance drop, as the model struggled to detect pedestrians in low-light conditions using only visible-light images. Similarly, excluding the joint optimization strategy caused a decrease in accuracy due to the lack of gradient propagation between the image generation and detection tasks.ConclusionThis study presents a novel integrated framework for pedestrian detection in dark-light environments, which combines the generation of infrared modality images with the detection task in a unified architecture. By leveraging a conditional diffusion model to generate auxiliary infrared images and extracting multi-scale features to assist pedestrian detection, the framework successfully addresses the limitations of traditional methods that separate the data enhancement and detection tasks. The proposed end-to-end architecture not only simplifies the detection pipeline but also ensures optimization of the generated images to improve detection accuracy. The experimental results confirm that the proposed framework significantly improves pedestrian detection performance under dark-light conditions compared with single-domain visible light enhancement methods, cross-domain infrared generation methods, and current generalized pedestrian detection methods. The framework achieves higher precision, recall, F1 scores, and mAP while reducing the number of false detections and missed pedestrians. Furthermore, the ablation studies validate the importance of the infrared generation module and the joint optimization strategy in achieving superior detection performance. In summary, the integrated generation and detection framework proposed in this study offers a powerful solution for pedestrian detection in dark-light conditions, which provides qualitative and quantitative improvements. Future research may focus on addressing the computational complexity and inference time associated with diffusion models by exploring accelerated sampling techniques and lightweight architectures to enhance the real-time capabilities of the framework. The flexibility of the proposed architecture allows for easy adaptation to various detection models, which makes it a versatile tool for future developments in multimodal pedestrian detection.关键词:dark light pedestrian detection;integrated generation and detection;conditional diffusion model;object detection;infrared image generation;end-to-end joint optimization;multimodal fusion221|292|0更新时间:2025-10-16
摘要:ObjectivePedestrian detection in dark-light environments is a key challenge in the field of computer vision due to the lack of sufficient lighting, which results in blurry and low-contrast features of pedestrians. Traditional approaches to address this issue often focus on enhancing image quality through domain-specific visible light enhancement or generating infrared images to provide complementary information. However, these approaches are typically limited by the separation between the data enhancement process and the downstream detection tasks, which results in suboptimal performance. To overcome these limitations, this study proposes an integrated generation and detection framework tailored for pedestrian detection in dark-light conditions. The primary goal of the proposed framework is to bridge the gap between data enhancement and pedestrian detection by generating high-quality infrared images from dark-light images and jointly optimizing the generation and detection tasks in a unified architecture.MethodThe proposed framework is built upon a conditional diffusion model, which is used to generate auxiliary infrared modality images from dark-light RGB images. Unlike traditional approaches that first enhance or generate images and then input them into a detection network separately, this framework integrates the image generation and pedestrian detection tasks into a single end-to-end architecture. Inspired by ControlNet, the model leverages a conditional diffusion process to produce infrared images that provide enhanced pedestrian features. These infrared images are then used in conjunction with the original dark-light images to improve the detection performance. In addition, the framework extracts multi-scale features from the generated images through a UNet architecture, which replaces the traditional backbone network of the detection model. These multi-scale features are directly fed into the detection head, which allows the detection task to be optimized simultaneously with the image generation process. To ensure effective joint optimization, the framework incorporates a novel strategy to bypass the typical gradient flow limitations encountered when using variational autoencoders (VAEs). In standard designs, the VAE decoder is often a fixed module that prevents gradients from being propagated back during the training of the detection task. To address this limitation, the proposed framework allows the gradient to flow through the multi-scale feature maps generated by the UNet, which ensures that the generation and detection tasks benefit from the same optimization process. The detection task is supervised by a loss function that combines boundary box regression, classification, and confidence losses. This integration enables the model to learn object localization and classification.ResultExtensive experiments were conducted on the LLVIP and VTMOT datasets, which together contain 26 193 paired visible-light and infrared images (a total 52 386 images), all annotated with pedestrian detection labels. These datasets present significant challenges, particularly due to images captured under extreme low-light conditions. The proposed method was evaluated against several state-of-the-art techniques, including single-domain visible light enhancement methods and cross-domain infrared image generation approaches. Experimental results on the LLVIP and VTMOT datasets show that the method proposed in this study significantly outperforms traditional and state-of-the-art methods in terms of overall accuracy metrics. For example, on the LLVIP dataset, the F1 value of the proposed method is 85.75%, and the mAP is 75.35%. It outperforms the SCI method, which is the best of the traditional methods (an F1 value of 82.05% and a mean average precision(mAP) value of 72.30%), and Faster_RCNN_hrnet, which is the best of the state-of-the-art methods (an F1 value of 82.91% and a mAP value of 70.02%). On the VTMOT dataset, the proposed method also performs effectively with an F1 value of 90.01% and a mAP of 73.44%. It is superior to the best SCI method among the traditional methods (an F1 value of 85.91% and a mAP value of 72.19%) and the best Faster_RCNN_hrnet among the advanced methods (an F1 value of 84.48% and a mAP value of 71.16%). Moreover, the proposed method outperforms other methods overall in terms of precision, recall, and F1 score, which highlights its robustness and reliability in detecting pedestrians in dark-light conditions. In addition to the quantitative improvements, qualitative analysis reveals that the generated infrared images, when fused with the original dark-light images, provide clearer and more distinguishable pedestrian features. This fusion process helps reduce false positives and enhances the accuracy of pedestrian detection. The proposed framework could successfully detect pedestrians that were missed by other methods, especially in challenging scenes with low contrast between the pedestrians and their backgrounds. These results demonstrate the advantages of the joint infrared generation and pedestrian detection approach in overcoming the limitations of traditional methods, particularly in extreme lighting conditions. Ablation studies were conducted to evaluate the contribution of different components within the proposed framework. The results showed that the infrared image generation module and the joint optimization strategy are crucial for improving detection performance. Removing the infrared generation module led to a notable performance drop, as the model struggled to detect pedestrians in low-light conditions using only visible-light images. Similarly, excluding the joint optimization strategy caused a decrease in accuracy due to the lack of gradient propagation between the image generation and detection tasks.ConclusionThis study presents a novel integrated framework for pedestrian detection in dark-light environments, which combines the generation of infrared modality images with the detection task in a unified architecture. By leveraging a conditional diffusion model to generate auxiliary infrared images and extracting multi-scale features to assist pedestrian detection, the framework successfully addresses the limitations of traditional methods that separate the data enhancement and detection tasks. The proposed end-to-end architecture not only simplifies the detection pipeline but also ensures optimization of the generated images to improve detection accuracy. The experimental results confirm that the proposed framework significantly improves pedestrian detection performance under dark-light conditions compared with single-domain visible light enhancement methods, cross-domain infrared generation methods, and current generalized pedestrian detection methods. The framework achieves higher precision, recall, F1 scores, and mAP while reducing the number of false detections and missed pedestrians. Furthermore, the ablation studies validate the importance of the infrared generation module and the joint optimization strategy in achieving superior detection performance. In summary, the integrated generation and detection framework proposed in this study offers a powerful solution for pedestrian detection in dark-light conditions, which provides qualitative and quantitative improvements. Future research may focus on addressing the computational complexity and inference time associated with diffusion models by exploring accelerated sampling techniques and lightweight architectures to enhance the real-time capabilities of the framework. The flexibility of the proposed architecture allows for easy adaptation to various detection models, which makes it a versatile tool for future developments in multimodal pedestrian detection.关键词:dark light pedestrian detection;integrated generation and detection;conditional diffusion model;object detection;infrared image generation;end-to-end joint optimization;multimodal fusion221|292|0更新时间:2025-10-16 - “在可见光—红外行人重识别领域,本研究设计了一种融合结构与视觉特征的新算法,有效提升了跨模态行人重识别的识别精度,并在复杂场景中展现较高的鲁棒性和准确性。”
 摘要:ObjectiveVisible-infrared person re-identification (VI-ReID) has emerged as a challenging task primarily due to the pronounced modal discrepancies between visible and infrared images. In the visible light spectrum, images are repleted with vivid colors and intricate textures, but they are highly susceptible to perturbations caused by varying illumination conditions. For instance, during dawn or dusk, the subdued light can distort the visual appearance of pedestrians, which causes difficulty in accurately discerning their unique features. By contrast, infrared images, which predominantly capture thermal radiation, offer a distinct advantage in low-light or obscured scenarios. However, they lack the detailed visual cues present in their visible counterparts, such as clothing patterns or facial features. These fundamental differences have led to great difficulties in achieving reliable person re-identification across modalities. Compounding this issue, existing methods lack sufficient feature discrimination. In numerous real-world datasets and scenarios, they struggle to distinguish between pedestrians with similar postures or occluded body parts, which compromises the overall accuracy and reliability of the recognition process.MethodTo directly address these challenges, this research designed an innovative algorithm capable of extracting high-resolution pedestrian features, with the ultimate aim of bridging the existing gaps in cross-modal recognition tasks. The methodological framework of this study centered around a novel VI-ReID algorithm that incorporated structural and visual features, which operated through a meticulously designed dual-stream branch architecture. The first step in this process involved the extraction of skeletal key points using advanced pose estimation techniques. By leveraging state-of-the-art algorithms, such as OpenPose or custom-developed variants with enhanced capabilities in some cases, we precisely localized the key joints of the human body even in the presence of partial occlusions or extreme postural variations. This accuracy was achieved through various complex computational steps, which started with the initial detection of body regions, followed by the refinement of joint positions based on anatomical constraints and probabilistic models. The extracted skeletal key points were then used to generate detailed structural feature maps, which served as the foundation for further analysis. Subsequently, a graph convolutional network (GCN) was employed to delve deep into the structured information encapsulated within the skeletal framework. The GCN architecture was meticulously designed, which comprised multiple layers, with each having a carefully calibrated node connection pattern. The choice of activation functions was optimized to enhance the propagation of relevant information while suppressing noise. Weighted processing was implemented to account for the varying importance of different joints in characterizing a person’s gait or posture, which ensured that the most discriminative features were emphasized. This comprehensive approach enabled the construction of a highly effective structural feature extraction branch. Simultaneously, ResNet50, which is a popular deep learning model renowned for its prowess in visual feature extraction, was adapted to serve as the visual extraction branch. In this context, several fine-tuning procedures were conducted to tailor the model to the unique characteristics of visible and infrared images. This optimization involved adjusting the parameters of the pretrained model based on the statistical properties of the target datasets, as well as devising innovative strategies for leveraging the outputs from different hierarchical levels of the network. For instance, by selectively combining features from the early and late layers, we captured low-level details and high-level semantic information. In certain cases, attention mechanisms were integrated to further focus on the most salient visual regions, which enhanced the overall discriminative power of the visual features. Based on the two parallel streams, a structure-visual inter-modal attention mechanism (SVIAM) was proposed to seamlessly fuse the skeletal and visual features. This mechanism was underpinned by a sophisticated computational process that involved the precise calculation of correlation weights between the two modalities. Through the use of detailed schematics and mathematical formulas, we illustrated the attention distribution, which highlighted the most relevant regions and features for recognition. Compared with simplistic concatenation or rudimentary fusion methods, SVIAM demonstrated a remarkable superiority in terms of feature integration, which led to a more cohesive and discriminative joint feature representation. Furthermore, to bolster the consistency of the skeletal features and mitigate intra-modal differences, a structure cohesion loss (SCLoss) function was devised. The mathematical formulation of SCLoss was derived with great care, with the geometric and topological properties of the skeletal data being considered. Each parameter within the function was meticulously calibrated to serve a specific purpose: whether to penalize deviations from the expected skeletal structure or encourage the alignment of related joints. Through extensive experimental validation and theoretical analysis, we demonstrated the mechanism by which SCLoss effectively optimized the skeletal features, which enhanced the overall stability and accuracy of the algorithm.ResultExperimental results provided unequivocal evidence of the superiority of the algorithm. On the widely recognized SYSU-MM01 dataset, our proposed algorithm outperformed the baseline DEEN by significant margins. In the all-search mode, the Rank-1 accuracy rate remarkably improved by 4.21%, while the mean average precision (mAP) soared by 3.52%. Similarly, in the indoor search mode, the Rank-1 accuracy rate achieved an even more impressive increase of 7.39%, which was accompanied by a 2.56% elevation in mAP. These results not only validated the effectiveness of our approach in enhancing cross-modal person re-identification accuracy but also showcased its robustness and reliability in complex scenarios.ConclusionThis research introduced a pioneering VI-ReID algorithm that integrated structural and visual features, which effectively addressed the challenges posed by modal differences and substantially elevated the recognition precision in cross-modal person re-identification. The performance of the algorithm in complex and dynamic environments further attested to its high level of robustness and accuracy, which lays the foundation for future advancements in this critical area of research.关键词:visible-infrared person re-identification (VI-ReID);hierarchical feature extraction;skeletal structure features;structural-visual interactive attention mechanism (SVIAM);structural cohesion loss (SCLoss)249|599|0更新时间:2025-10-16
摘要:ObjectiveVisible-infrared person re-identification (VI-ReID) has emerged as a challenging task primarily due to the pronounced modal discrepancies between visible and infrared images. In the visible light spectrum, images are repleted with vivid colors and intricate textures, but they are highly susceptible to perturbations caused by varying illumination conditions. For instance, during dawn or dusk, the subdued light can distort the visual appearance of pedestrians, which causes difficulty in accurately discerning their unique features. By contrast, infrared images, which predominantly capture thermal radiation, offer a distinct advantage in low-light or obscured scenarios. However, they lack the detailed visual cues present in their visible counterparts, such as clothing patterns or facial features. These fundamental differences have led to great difficulties in achieving reliable person re-identification across modalities. Compounding this issue, existing methods lack sufficient feature discrimination. In numerous real-world datasets and scenarios, they struggle to distinguish between pedestrians with similar postures or occluded body parts, which compromises the overall accuracy and reliability of the recognition process.MethodTo directly address these challenges, this research designed an innovative algorithm capable of extracting high-resolution pedestrian features, with the ultimate aim of bridging the existing gaps in cross-modal recognition tasks. The methodological framework of this study centered around a novel VI-ReID algorithm that incorporated structural and visual features, which operated through a meticulously designed dual-stream branch architecture. The first step in this process involved the extraction of skeletal key points using advanced pose estimation techniques. By leveraging state-of-the-art algorithms, such as OpenPose or custom-developed variants with enhanced capabilities in some cases, we precisely localized the key joints of the human body even in the presence of partial occlusions or extreme postural variations. This accuracy was achieved through various complex computational steps, which started with the initial detection of body regions, followed by the refinement of joint positions based on anatomical constraints and probabilistic models. The extracted skeletal key points were then used to generate detailed structural feature maps, which served as the foundation for further analysis. Subsequently, a graph convolutional network (GCN) was employed to delve deep into the structured information encapsulated within the skeletal framework. The GCN architecture was meticulously designed, which comprised multiple layers, with each having a carefully calibrated node connection pattern. The choice of activation functions was optimized to enhance the propagation of relevant information while suppressing noise. Weighted processing was implemented to account for the varying importance of different joints in characterizing a person’s gait or posture, which ensured that the most discriminative features were emphasized. This comprehensive approach enabled the construction of a highly effective structural feature extraction branch. Simultaneously, ResNet50, which is a popular deep learning model renowned for its prowess in visual feature extraction, was adapted to serve as the visual extraction branch. In this context, several fine-tuning procedures were conducted to tailor the model to the unique characteristics of visible and infrared images. This optimization involved adjusting the parameters of the pretrained model based on the statistical properties of the target datasets, as well as devising innovative strategies for leveraging the outputs from different hierarchical levels of the network. For instance, by selectively combining features from the early and late layers, we captured low-level details and high-level semantic information. In certain cases, attention mechanisms were integrated to further focus on the most salient visual regions, which enhanced the overall discriminative power of the visual features. Based on the two parallel streams, a structure-visual inter-modal attention mechanism (SVIAM) was proposed to seamlessly fuse the skeletal and visual features. This mechanism was underpinned by a sophisticated computational process that involved the precise calculation of correlation weights between the two modalities. Through the use of detailed schematics and mathematical formulas, we illustrated the attention distribution, which highlighted the most relevant regions and features for recognition. Compared with simplistic concatenation or rudimentary fusion methods, SVIAM demonstrated a remarkable superiority in terms of feature integration, which led to a more cohesive and discriminative joint feature representation. Furthermore, to bolster the consistency of the skeletal features and mitigate intra-modal differences, a structure cohesion loss (SCLoss) function was devised. The mathematical formulation of SCLoss was derived with great care, with the geometric and topological properties of the skeletal data being considered. Each parameter within the function was meticulously calibrated to serve a specific purpose: whether to penalize deviations from the expected skeletal structure or encourage the alignment of related joints. Through extensive experimental validation and theoretical analysis, we demonstrated the mechanism by which SCLoss effectively optimized the skeletal features, which enhanced the overall stability and accuracy of the algorithm.ResultExperimental results provided unequivocal evidence of the superiority of the algorithm. On the widely recognized SYSU-MM01 dataset, our proposed algorithm outperformed the baseline DEEN by significant margins. In the all-search mode, the Rank-1 accuracy rate remarkably improved by 4.21%, while the mean average precision (mAP) soared by 3.52%. Similarly, in the indoor search mode, the Rank-1 accuracy rate achieved an even more impressive increase of 7.39%, which was accompanied by a 2.56% elevation in mAP. These results not only validated the effectiveness of our approach in enhancing cross-modal person re-identification accuracy but also showcased its robustness and reliability in complex scenarios.ConclusionThis research introduced a pioneering VI-ReID algorithm that integrated structural and visual features, which effectively addressed the challenges posed by modal differences and substantially elevated the recognition precision in cross-modal person re-identification. The performance of the algorithm in complex and dynamic environments further attested to its high level of robustness and accuracy, which lays the foundation for future advancements in this critical area of research.关键词:visible-infrared person re-identification (VI-ReID);hierarchical feature extraction;skeletal structure features;structural-visual interactive attention mechanism (SVIAM);structural cohesion loss (SCLoss)249|599|0更新时间:2025-10-16
Image Analysis and Recognition
- “在神经渲染领域,专家提出了融合局部空间信息的新视角合成方法,有效改善了因点云质量和特征提取导致的渲染质量下降,为提升渲染效果提供了新方案。”
 摘要:ObjectiveModeling real-world scenes from image data and generating photorealistic novel views introduce great challenges within the fields of computer vision and graphics. Neural radiance field (NeRF) and its extensions have emerged as highly successful approaches for addressing this challenge by leveraging neural radiance fields. However, these methods frequently reconstruct radiance fields across the entire space using global multi-layer perceptions (MLPs) through ray marching, which results in prolonged reconstruction times. This delay is primarily attributed to the slow fitting of per-scene networks and the excessive sampling of extensive empty spaces. To solve these problems, neural radiance field representation based on point clouds is proposed, which uses 3D points to model the scene. Unlike NeRF, which relies purely on per-scene fitting, this method can be efficiently initialized by a feed-forward deep neural network pretrained across scenes. Furthermore, ray sampling in an empty scene space is avoided by utilizing a classical point cloud that approximates the actual scene geometry. However, the neural radiance field representation based on point clouds is affected by the quality of the point cloud, and the influence of extracted image features leads to a decrease in the rendering quality of new perspective images. To this end, a novel-view synthesis method integrating local spatial information is proposed from the two key points of aligning point cloud features and fusing local point cloud context information field.MethodThe network architecture in this study comprises neural networks for point cloud generation and neural radiance fields based on point clouds. The point cloud and confidence are produced by the depth prediction network in the neural network component for point cloud generation. The image is processed using the feature pyramid network to extract features at different scales. The neural alignment module for point cloud features is subsequently employed to integrate the feature derived from the point cloud and the image. The features are aligned to extract the semantic information of the image. This step enables the network to more effectively adjust to the structural and textural characteristics of various scene images. Neural point clouds are created by mixing points, confidence levels, and image features. In the neural radiance field network structure based on point clouds, the RGB value and volume density of the sampling point are predicted by aggregating the neural point cloud features near the sampling point. This experiment utilizes the Transformer layer combined with the contextual information of the local neural point cloud to better capture the spatial and geometric shape details, and it outputs high-quality synthetic images through volume rendering.ResultThis experiment establishes the environment on the Ubuntu18.04 system to assure the reliability of the training and testing procedure. The CPU is an Intel Core i9-10900, the memory capacity is 32 GB, and the graphics card is an RTX 3090. The experiment primarily uses the peak signal-to-noise ratio (PSNR) as the metric for evaluating the test results. It also utilizes the structural similarity index measure and the learned perceptual image patch similarity. Network training uses the Adam algorithm for adaptive learning rate optimization. By dynamically adjusting the learning rate, the network can more effectively balance the convergence speed and stability during the training process. The initial learning rate is set to 0.000 5, and the decay rate parameters are set to 0.9 and 0.99. Four widely utilized datasets(DTU, NeRF Synthetic, Tanks and Temples, and ScanNet)will be utilized in the experiment. DTU is a dataset comprising indoor scenes. Each scene is composed of 49 object photography angles, with 7 brightness levels per angle, and has a resolution of 512 pixels by 640 pixels. NeRF Synthetic is a synthetic dataset containing eight scenes, each with 100 training images and 200 test images. These images are fully rendered and synthesized by Blender. ScanNet is an interior scanning dataset. Scenes 241 and 101 will be applied to the evaluation. A total of 20% of the total image count will be allocated for training objectives (1 463 images for Scene-241 and 1 000 images for Scene-101), with the remaining images being utilized for evaluation purposes. The Tanks and Temples dataset is an extensive collection of indoor scene data and comprises 14 distinct scenes. Experimental results show that, for the Tanks and Temples datasets containing only a single object, the PSNR of this method is improved by 19.2% compared with the NeRF method. The ratios are enhanced by 6.4% and 3.8% compared with those obtained by Tetra-NeRF and Point-NeRF using point cloud input, respectively. Even in the ScanNet dataset with more complex scenes, the ratios are improved by 34.6% and 2.1% compared with the NeRF method and Point-NeRF, respectively.ConclusionThis study presents a novel-view synthesis method integrating local spatial information that, in conjunction with a neural alignment module for point cloud features, dynamically modifies the alignment characteristics of a neural point cloud. When the points correspond to aligned features, our approach can enhance the precision of this procedure through the extraction of features from images at various dimensions along with the semantic information they encompass. The neural Transformer module based on point clouds enhances the capability of the network to extract spatial position and geometry information from the neural point cloud by incorporating context information from nearby sampling points. This improved efficiency is particularly useful when dealing with points of different qualities and shapes. The experimental results for the Tanks and Temples, Synthetic Blender, and ScanNet datasets show that this method outperforms existing advanced neural radiation field representations based on point clouds in terms of visual effects and assessment indicators. Overall, the method outlined in this document improves the combination of point clouds and image characteristics. It utilizes the contextual information found in local point cloud features to assist the network in merging sparse point cloud features. This process leads to more lifelike and unique details in the resulting image. Moreover, high-quality scene images are produced from input images that contain only a small number of shots.关键词:neural radiance field (NeRF);point cloud;neural rendering;three dimensional reconstruction;volume density233|414|0更新时间:2025-10-16
摘要:ObjectiveModeling real-world scenes from image data and generating photorealistic novel views introduce great challenges within the fields of computer vision and graphics. Neural radiance field (NeRF) and its extensions have emerged as highly successful approaches for addressing this challenge by leveraging neural radiance fields. However, these methods frequently reconstruct radiance fields across the entire space using global multi-layer perceptions (MLPs) through ray marching, which results in prolonged reconstruction times. This delay is primarily attributed to the slow fitting of per-scene networks and the excessive sampling of extensive empty spaces. To solve these problems, neural radiance field representation based on point clouds is proposed, which uses 3D points to model the scene. Unlike NeRF, which relies purely on per-scene fitting, this method can be efficiently initialized by a feed-forward deep neural network pretrained across scenes. Furthermore, ray sampling in an empty scene space is avoided by utilizing a classical point cloud that approximates the actual scene geometry. However, the neural radiance field representation based on point clouds is affected by the quality of the point cloud, and the influence of extracted image features leads to a decrease in the rendering quality of new perspective images. To this end, a novel-view synthesis method integrating local spatial information is proposed from the two key points of aligning point cloud features and fusing local point cloud context information field.MethodThe network architecture in this study comprises neural networks for point cloud generation and neural radiance fields based on point clouds. The point cloud and confidence are produced by the depth prediction network in the neural network component for point cloud generation. The image is processed using the feature pyramid network to extract features at different scales. The neural alignment module for point cloud features is subsequently employed to integrate the feature derived from the point cloud and the image. The features are aligned to extract the semantic information of the image. This step enables the network to more effectively adjust to the structural and textural characteristics of various scene images. Neural point clouds are created by mixing points, confidence levels, and image features. In the neural radiance field network structure based on point clouds, the RGB value and volume density of the sampling point are predicted by aggregating the neural point cloud features near the sampling point. This experiment utilizes the Transformer layer combined with the contextual information of the local neural point cloud to better capture the spatial and geometric shape details, and it outputs high-quality synthetic images through volume rendering.ResultThis experiment establishes the environment on the Ubuntu18.04 system to assure the reliability of the training and testing procedure. The CPU is an Intel Core i9-10900, the memory capacity is 32 GB, and the graphics card is an RTX 3090. The experiment primarily uses the peak signal-to-noise ratio (PSNR) as the metric for evaluating the test results. It also utilizes the structural similarity index measure and the learned perceptual image patch similarity. Network training uses the Adam algorithm for adaptive learning rate optimization. By dynamically adjusting the learning rate, the network can more effectively balance the convergence speed and stability during the training process. The initial learning rate is set to 0.000 5, and the decay rate parameters are set to 0.9 and 0.99. Four widely utilized datasets(DTU, NeRF Synthetic, Tanks and Temples, and ScanNet)will be utilized in the experiment. DTU is a dataset comprising indoor scenes. Each scene is composed of 49 object photography angles, with 7 brightness levels per angle, and has a resolution of 512 pixels by 640 pixels. NeRF Synthetic is a synthetic dataset containing eight scenes, each with 100 training images and 200 test images. These images are fully rendered and synthesized by Blender. ScanNet is an interior scanning dataset. Scenes 241 and 101 will be applied to the evaluation. A total of 20% of the total image count will be allocated for training objectives (1 463 images for Scene-241 and 1 000 images for Scene-101), with the remaining images being utilized for evaluation purposes. The Tanks and Temples dataset is an extensive collection of indoor scene data and comprises 14 distinct scenes. Experimental results show that, for the Tanks and Temples datasets containing only a single object, the PSNR of this method is improved by 19.2% compared with the NeRF method. The ratios are enhanced by 6.4% and 3.8% compared with those obtained by Tetra-NeRF and Point-NeRF using point cloud input, respectively. Even in the ScanNet dataset with more complex scenes, the ratios are improved by 34.6% and 2.1% compared with the NeRF method and Point-NeRF, respectively.ConclusionThis study presents a novel-view synthesis method integrating local spatial information that, in conjunction with a neural alignment module for point cloud features, dynamically modifies the alignment characteristics of a neural point cloud. When the points correspond to aligned features, our approach can enhance the precision of this procedure through the extraction of features from images at various dimensions along with the semantic information they encompass. The neural Transformer module based on point clouds enhances the capability of the network to extract spatial position and geometry information from the neural point cloud by incorporating context information from nearby sampling points. This improved efficiency is particularly useful when dealing with points of different qualities and shapes. The experimental results for the Tanks and Temples, Synthetic Blender, and ScanNet datasets show that this method outperforms existing advanced neural radiation field representations based on point clouds in terms of visual effects and assessment indicators. Overall, the method outlined in this document improves the combination of point clouds and image characteristics. It utilizes the contextual information found in local point cloud features to assist the network in merging sparse point cloud features. This process leads to more lifelike and unique details in the resulting image. Moreover, high-quality scene images are produced from input images that contain only a small number of shots.关键词:neural radiance field (NeRF);point cloud;neural rendering;three dimensional reconstruction;volume density233|414|0更新时间:2025-10-16 -
Fusion of prompt learning and visual semantic generation for image captioning of Dongba paintings AI导读
“东巴画图像描述方法取得新进展,专家提出结合提示学习和视觉语义—生成融合的方法,有效提升了描述准确性和文化表达能力。” 摘要:ObjectiveDongba painting is a treasured form of Naxi traditional art. It is rich visual elements, distinct colors, and strong regional cultural and national characteristics. The application of existing image description methods to Dongba paintings is hindered by domain bias, with the model generating text features aligned with those of natural images. The conventional approaches to image description require the use of predefined sentence structures and depend on the quantity and quality of datasets. The descriptions generated by such methods are often repetitive and lack diversity. When these methods are directly applied to Dongba painting descriptions, they present certain limitations. Multi-task pretraining models jointly train multiple vision-language objectives, including image-text contrastive learning, image-text matching, and image-conditioned language modeling. However, these image captioning models tend to generate generic descriptions and cannot capture the distinctive style present in ethnic images. Most controlled image captioning models regulate the generation of image descriptions through analyzing textual data and extracting keywords or entities. However, keyword extraction relies on the explicit entity information present within the sentence. It cannot consider the implicit cultural connotations and semantic depth inherent to Dongba paintings. Consequently, the resulting descriptions are simple and one dimensional. To address these issues, this study proposes an image captioning method based on the fusion of prompt learning and visual semantic generation. This approach guides the model in acquiring the cultural background knowledge associated with Dongba paintings, which mitigates the domain bias challenge.MethodFirst, this study uses a codec architecture to realize image captioning for Dongba paintings. In the encoding stage, the encoder employs a convolutional neural network to extract the essential semantic information from the Dongba painting image. This information is then integrated into the normalization layer within the coding layer of the decoder, which enables the control of the process of generating textual descriptions. Therefore, the resulting descriptions are semantically aligned with the image content. In the decoding stage, a Transformer structure is employed to efficiently capture long-distance dependencies in the input sequence through a self-attention mechanism. This utilization facilitates the generation of accurate and coherent text output. To circumvent overfitting resulting from the stacking of decoder layers, the proposed model employs a decoder comprising 10 layers. In addition, pretrained BERT weights are employed for initialization, which enhances the performance and convergence speed of the model. Second, we introduce a visual semantic generative fusion loss, which is optimized to guide the model to extract the key information in the Dongba paintings. As a result, descriptive texts that are highly consistent with the images are generated. Meanwhile, the content prompt module is introduced before the decoder. Through a mapper, the cultural background information such as religious patterns, gods, spirits, and hell ghosts in Dongba paintings can be obtained. By combining prompt information and text information, the decoder can more effectively understand and use the content information of the image. This capability improves the relevance and accuracy of the generated description text and the image theme. Finally, to enhance the capacity of the model for targeted learning and description of painting image features, a bespoke dataset for image captioning of Dongba paintings caption is constructed. This dataset is based on the themes of Dongba paintings and the underlying Dongba culture, and it is used for model training.ResultSeveral experiments are conducted on the test dataset for Dongba paintings in this study to verify the effectiveness of the proposed method. The experiment includes contrast and ablation experiments. In the ablation experiments, the architectural configuration of the encoder and decoder is retained, and the ablation model is constructed in accordance with this configuration. Three kinds of comparison experiments are formed. In the first part, the effect of different model encoders on image feature extraction and image description text quality is compared. In the second part, the effect of the number of coding layers of model decoders on the quality of generated description text is discussed. In the third part, some advanced algorithms are selected for comparison to verify the superiority of the proposed algorithms. Experimental results show that the proposed method achieves 0.603, 0.426, 0.317, 0.246, 0.256, 0.403, and 0.599 in the evaluation indexes of BLEU-1 to BLEU-4, METEOR, ROUGE, and CIDEr, respectively. It also achieves better results in the subjective quality of image description text for Dongba paintings.ConclusionThe image captioning method based on the fusion of prompt learning and visual semantic generation for Dongba paintings proposed in this study effectively enhances the capability of the encoder to capture image features and the capability of the decoder to understand the input text. This improvement results in descriptions that are more relevant to the semantics of the images, as well as more accurate and fluid. Furthermore, the method preserves the national characteristics of Dongba paintings. In the future, the relationships between the elements in Dongba paintings will be comprehensively explored. Furthermore, the size and diversity of the dataset will be expanded. The model structure will be optimized to enhance its robustness. Other datasets will be also used for training purposes, which will expand the scope of application.关键词:Dongba painting;image caption;prompt learning;visual semantic-generation fusion;domain shift190|758|0更新时间:2025-10-16
摘要:ObjectiveDongba painting is a treasured form of Naxi traditional art. It is rich visual elements, distinct colors, and strong regional cultural and national characteristics. The application of existing image description methods to Dongba paintings is hindered by domain bias, with the model generating text features aligned with those of natural images. The conventional approaches to image description require the use of predefined sentence structures and depend on the quantity and quality of datasets. The descriptions generated by such methods are often repetitive and lack diversity. When these methods are directly applied to Dongba painting descriptions, they present certain limitations. Multi-task pretraining models jointly train multiple vision-language objectives, including image-text contrastive learning, image-text matching, and image-conditioned language modeling. However, these image captioning models tend to generate generic descriptions and cannot capture the distinctive style present in ethnic images. Most controlled image captioning models regulate the generation of image descriptions through analyzing textual data and extracting keywords or entities. However, keyword extraction relies on the explicit entity information present within the sentence. It cannot consider the implicit cultural connotations and semantic depth inherent to Dongba paintings. Consequently, the resulting descriptions are simple and one dimensional. To address these issues, this study proposes an image captioning method based on the fusion of prompt learning and visual semantic generation. This approach guides the model in acquiring the cultural background knowledge associated with Dongba paintings, which mitigates the domain bias challenge.MethodFirst, this study uses a codec architecture to realize image captioning for Dongba paintings. In the encoding stage, the encoder employs a convolutional neural network to extract the essential semantic information from the Dongba painting image. This information is then integrated into the normalization layer within the coding layer of the decoder, which enables the control of the process of generating textual descriptions. Therefore, the resulting descriptions are semantically aligned with the image content. In the decoding stage, a Transformer structure is employed to efficiently capture long-distance dependencies in the input sequence through a self-attention mechanism. This utilization facilitates the generation of accurate and coherent text output. To circumvent overfitting resulting from the stacking of decoder layers, the proposed model employs a decoder comprising 10 layers. In addition, pretrained BERT weights are employed for initialization, which enhances the performance and convergence speed of the model. Second, we introduce a visual semantic generative fusion loss, which is optimized to guide the model to extract the key information in the Dongba paintings. As a result, descriptive texts that are highly consistent with the images are generated. Meanwhile, the content prompt module is introduced before the decoder. Through a mapper, the cultural background information such as religious patterns, gods, spirits, and hell ghosts in Dongba paintings can be obtained. By combining prompt information and text information, the decoder can more effectively understand and use the content information of the image. This capability improves the relevance and accuracy of the generated description text and the image theme. Finally, to enhance the capacity of the model for targeted learning and description of painting image features, a bespoke dataset for image captioning of Dongba paintings caption is constructed. This dataset is based on the themes of Dongba paintings and the underlying Dongba culture, and it is used for model training.ResultSeveral experiments are conducted on the test dataset for Dongba paintings in this study to verify the effectiveness of the proposed method. The experiment includes contrast and ablation experiments. In the ablation experiments, the architectural configuration of the encoder and decoder is retained, and the ablation model is constructed in accordance with this configuration. Three kinds of comparison experiments are formed. In the first part, the effect of different model encoders on image feature extraction and image description text quality is compared. In the second part, the effect of the number of coding layers of model decoders on the quality of generated description text is discussed. In the third part, some advanced algorithms are selected for comparison to verify the superiority of the proposed algorithms. Experimental results show that the proposed method achieves 0.603, 0.426, 0.317, 0.246, 0.256, 0.403, and 0.599 in the evaluation indexes of BLEU-1 to BLEU-4, METEOR, ROUGE, and CIDEr, respectively. It also achieves better results in the subjective quality of image description text for Dongba paintings.ConclusionThe image captioning method based on the fusion of prompt learning and visual semantic generation for Dongba paintings proposed in this study effectively enhances the capability of the encoder to capture image features and the capability of the decoder to understand the input text. This improvement results in descriptions that are more relevant to the semantics of the images, as well as more accurate and fluid. Furthermore, the method preserves the national characteristics of Dongba paintings. In the future, the relationships between the elements in Dongba paintings will be comprehensively explored. Furthermore, the size and diversity of the dataset will be expanded. The model structure will be optimized to enhance its robustness. Other datasets will be also used for training purposes, which will expand the scope of application.关键词:Dongba painting;image caption;prompt learning;visual semantic-generation fusion;domain shift190|758|0更新时间:2025-10-16 - “在三维人体姿态估计领域,研究者提出了一种融合多关节特征的单目视觉三维人体姿态估计网络,有效提高了准确性和泛化性。”
 摘要:ObjectiveDespite the widespread use of monocular cameras for capturing photos and videos in various scenarios, they still encounter challenging issues such as human occlusion and loss of depth information. The goal is to achieve stability and accuracy in this process. Conventional approaches have attempted to estimate the 3D human position solely from images, and they rely on manual feature extraction to reconstruct the stance. However, these methods suffer from low accuracy because they lack depth information and encounter issues with occlusion. The lack of depth information and the presence of human occlusion in monocular camera images still hinder the accurate estimation of the 3D position of an individual. Owing to the improved accuracy of 2D joint point detectors, the work may be divided into two stages. Initially, the task entails employing human 2D joint point detectors on video or RGB images to estimate the location of 2D joint points in the image space. In the second phase, the 2D joint points are transformed into 3D space by leveraging their positions. This work focuses on the second stage of the research, which involves using 2D joint point data to rebuild the 3D position of the human body. Recurrent neural network (RNN) has been utilized for human posture estimation with the successful application of deep learning in various other fields. RNNs can extract human postural variables that change in space and time. Moreover, RNNs perform more efficiently than other approaches. Nevertheless, the high computational cost of RNNs makes them impractical for predicting extended sequences. Consequently, Temporal convolutional networks (TCNs) are employed to estimate human posture. The TCN model has a reduced number of parameters and achieves a lower level of inaccuracy. However, TCN faces limitations in effectively combining spatial and temporal features and not fully utilizing information from 2D joints. Consequently, this study presents an estimation network for 3D human poses that integrates multi-joint features.MethodThe joint motion feature extraction module comprises four parallel branches, each extracting distinct joint motion features in the temporal dimension. By fusing these diverse features, the module forms a highly expressive feature representation that enhances the capability of the network to capture subtle motion changes. In estimating 3D human poses, the joint feature fusion module independently extracts temporally significant features for each joint set and utilizes matrix inner products to describe the relative spatial relationships between different joint groups. This method establishes overall inter-group connections, which ensures the accuracy and coherence of the estimated poses. The joint restraint module enhances the accuracy of the final predicted 3D pose and avoids the occurrence of unrealistic poses by using the spatial information of the 2D joints in the intermediate frames as global information and applying 2D-3D implicit constraints.ResultIn this study, we assess the accuracy of three public datasets to compare the proposed method with state-of-the-art models. Metric evaluation is based on the capability of the model to reconstruct 3D bit-postures. To assess the suitability of the proposed method, we conducted experiments on three separate datasets using the same network structure. The experimental findings on the Human3.6M dataset indicate that the current method yields a mean per joint position error (MPJPE) value of 29.0 mm. This value represents a 4.9% reduction in error when compared with the MHFormer method, which demonstrates the capability of the method to attain noteworthy outcomes and substantiates its efficacy. For complex actions such as SittingDown and WalkDog, the errors are reduced by 7.7% and 8.2%. The proposed method exhibits substantial improvements over the MHFormer approach on the 3DHP dataset in terms of evaluation metrics. Specifically, it obtains a reduction of 36.2% in the MPJPE, an increase of 12.9% in the area under curve(AUC) metric, and a noteworthy uplift of 3% in the percentage of correct keypoints(PCK) score. The experimental results demonstrate that, for complex actions, the network utilizes different branches to extract diverse temporal motion features of joints. This step enables the inference of joint positions based on contextual information and enhances spatiotemporal information interaction between joint groups using the positional information of other joints. By integrating the joint information from the current frame, the network constrains the estimated poses to be more realistic, which achieves superior spatiotemporal modeling. Despite these advancements, when benchmarked against state-of-the-art methods on the HumanEva dataset, our method maintains a strong competitive edge in the estimation of 3D human poses. Across every dataset tested, the present method consistently yields favorable outcomes, which substantiates its superior generalizability and applicability to diverse human pose datasets. Moreover, this study conducts thorough ablation experiments to validate the effectiveness of each module. The experiments demonstrate that each component indeed contributes to enhancing the overall accuracy of the network. Ablative studies on the length of input time series reveal that a longer input sequence corresponds to better performance of our method, which leads to increasingly accurate estimates of 3D human poses.ConclusionIn this study, the experimental results and visual representations indicate that the proposed estimation model for human poses, which incorporates three integral modules, excels at building temporal and spatial dependencies between joints compared with other methodologies. This model facilitates a comprehensive representation of the joint space of the human body, particularly effective when addressing the issue of self-occlusion. In scenarios where body parts are occluded, our method effectively utilizes the interdependencies within the context to alleviate the impact of occlusions on human pose estimation, which boosts the precision of the predictions. Even in situations where depth information is lacking, our approach consistently estimates human poses accurately by leveraging the spatial positional relationships among various joints.关键词:3D human pose estimation;human topology structure;multi-branch network;feature fusion;pose constraints337|428|0更新时间:2025-10-16
摘要:ObjectiveDespite the widespread use of monocular cameras for capturing photos and videos in various scenarios, they still encounter challenging issues such as human occlusion and loss of depth information. The goal is to achieve stability and accuracy in this process. Conventional approaches have attempted to estimate the 3D human position solely from images, and they rely on manual feature extraction to reconstruct the stance. However, these methods suffer from low accuracy because they lack depth information and encounter issues with occlusion. The lack of depth information and the presence of human occlusion in monocular camera images still hinder the accurate estimation of the 3D position of an individual. Owing to the improved accuracy of 2D joint point detectors, the work may be divided into two stages. Initially, the task entails employing human 2D joint point detectors on video or RGB images to estimate the location of 2D joint points in the image space. In the second phase, the 2D joint points are transformed into 3D space by leveraging their positions. This work focuses on the second stage of the research, which involves using 2D joint point data to rebuild the 3D position of the human body. Recurrent neural network (RNN) has been utilized for human posture estimation with the successful application of deep learning in various other fields. RNNs can extract human postural variables that change in space and time. Moreover, RNNs perform more efficiently than other approaches. Nevertheless, the high computational cost of RNNs makes them impractical for predicting extended sequences. Consequently, Temporal convolutional networks (TCNs) are employed to estimate human posture. The TCN model has a reduced number of parameters and achieves a lower level of inaccuracy. However, TCN faces limitations in effectively combining spatial and temporal features and not fully utilizing information from 2D joints. Consequently, this study presents an estimation network for 3D human poses that integrates multi-joint features.MethodThe joint motion feature extraction module comprises four parallel branches, each extracting distinct joint motion features in the temporal dimension. By fusing these diverse features, the module forms a highly expressive feature representation that enhances the capability of the network to capture subtle motion changes. In estimating 3D human poses, the joint feature fusion module independently extracts temporally significant features for each joint set and utilizes matrix inner products to describe the relative spatial relationships between different joint groups. This method establishes overall inter-group connections, which ensures the accuracy and coherence of the estimated poses. The joint restraint module enhances the accuracy of the final predicted 3D pose and avoids the occurrence of unrealistic poses by using the spatial information of the 2D joints in the intermediate frames as global information and applying 2D-3D implicit constraints.ResultIn this study, we assess the accuracy of three public datasets to compare the proposed method with state-of-the-art models. Metric evaluation is based on the capability of the model to reconstruct 3D bit-postures. To assess the suitability of the proposed method, we conducted experiments on three separate datasets using the same network structure. The experimental findings on the Human3.6M dataset indicate that the current method yields a mean per joint position error (MPJPE) value of 29.0 mm. This value represents a 4.9% reduction in error when compared with the MHFormer method, which demonstrates the capability of the method to attain noteworthy outcomes and substantiates its efficacy. For complex actions such as SittingDown and WalkDog, the errors are reduced by 7.7% and 8.2%. The proposed method exhibits substantial improvements over the MHFormer approach on the 3DHP dataset in terms of evaluation metrics. Specifically, it obtains a reduction of 36.2% in the MPJPE, an increase of 12.9% in the area under curve(AUC) metric, and a noteworthy uplift of 3% in the percentage of correct keypoints(PCK) score. The experimental results demonstrate that, for complex actions, the network utilizes different branches to extract diverse temporal motion features of joints. This step enables the inference of joint positions based on contextual information and enhances spatiotemporal information interaction between joint groups using the positional information of other joints. By integrating the joint information from the current frame, the network constrains the estimated poses to be more realistic, which achieves superior spatiotemporal modeling. Despite these advancements, when benchmarked against state-of-the-art methods on the HumanEva dataset, our method maintains a strong competitive edge in the estimation of 3D human poses. Across every dataset tested, the present method consistently yields favorable outcomes, which substantiates its superior generalizability and applicability to diverse human pose datasets. Moreover, this study conducts thorough ablation experiments to validate the effectiveness of each module. The experiments demonstrate that each component indeed contributes to enhancing the overall accuracy of the network. Ablative studies on the length of input time series reveal that a longer input sequence corresponds to better performance of our method, which leads to increasingly accurate estimates of 3D human poses.ConclusionIn this study, the experimental results and visual representations indicate that the proposed estimation model for human poses, which incorporates three integral modules, excels at building temporal and spatial dependencies between joints compared with other methodologies. This model facilitates a comprehensive representation of the joint space of the human body, particularly effective when addressing the issue of self-occlusion. In scenarios where body parts are occluded, our method effectively utilizes the interdependencies within the context to alleviate the impact of occlusions on human pose estimation, which boosts the precision of the predictions. Even in situations where depth information is lacking, our approach consistently estimates human poses accurately by leveraging the spatial positional relationships among various joints.关键词:3D human pose estimation;human topology structure;multi-branch network;feature fusion;pose constraints337|428|0更新时间:2025-10-16
Image Understanding and Computer Vision
- “在医学图像分割领域,研究者提出了DEMS-GIF网络模型,通过Transformer桥接特征融合和反向注意扩缩区域增强上采样策略,显著提升了分割准确性。”
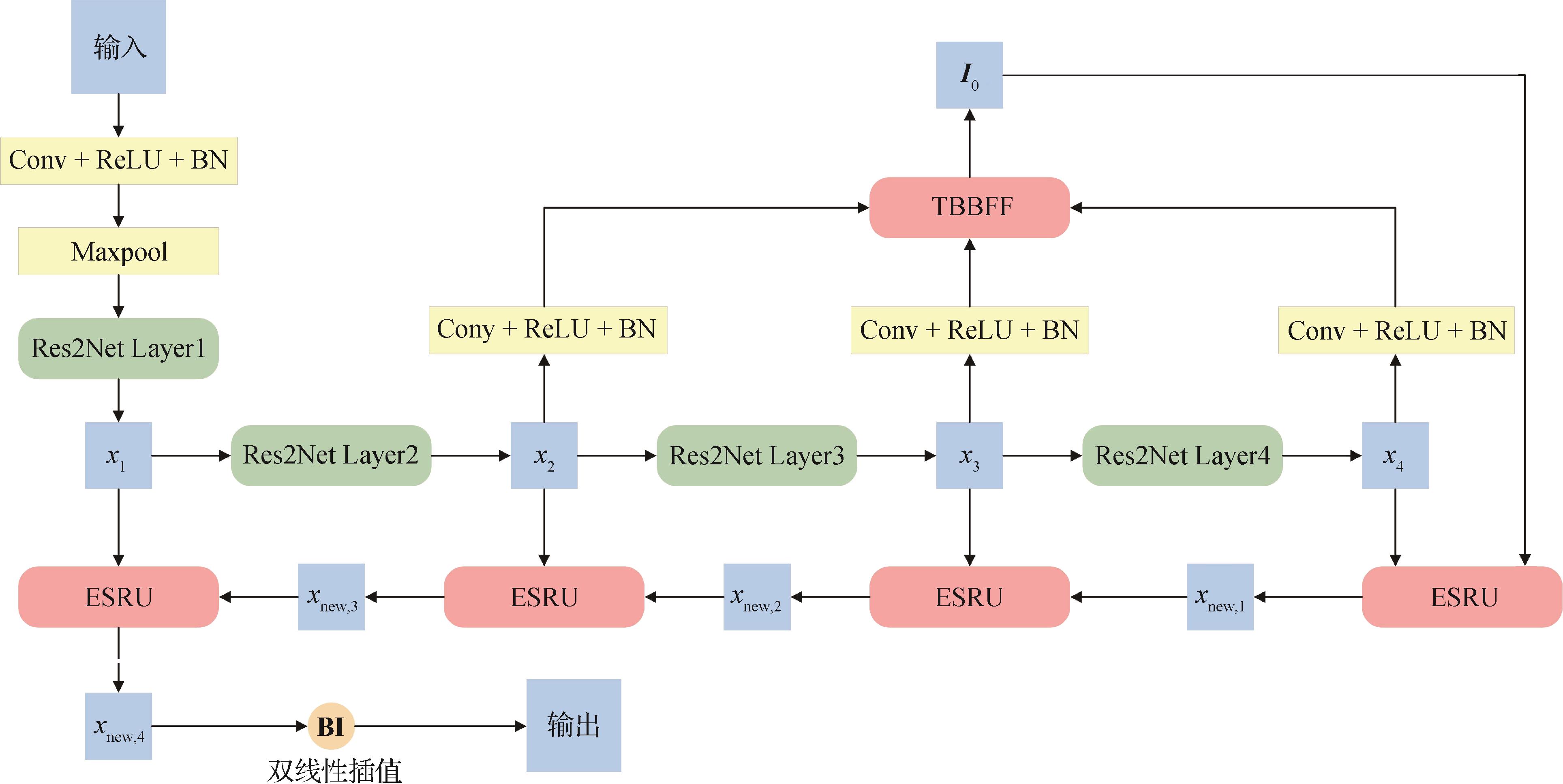 摘要:ObjectiveMedical image segmentation is a crucial and challenging task in the field of not only medical imaging but also modern medicine. Segmentation techniques can be used to precisely locate and measure tumors, blood vessels, and other structures, which facilitate the early diagnosis of the disease and the evaluation of treatment outcomes. In addition, accurate and reliable medical image segmentation can be utilized to monitor disease progression, assist physicians in formulating long-term treatment plans, lay a solid foundation for clinical diagnosis and pathological research, and provide valuable data support. Feature fusion in medical image segmentation can comprehensively capture detailed and global information by combining multi-level, multi-scale, and multimodal features, which improves segmentation accuracy and robustness. This method not only enhances the capability of automated medical image processing and reduces dependence on large amounts of annotated data but also increases the accuracy of clinical decisions. This approach helps doctors make highly reliable judgments in diagnosis and treatment, which promote the development of medical automation. In medical image segmentation, upsampling strategies can effectively restore high-resolution features and detailed information, which enhances the capability of the segmentation model to recognize small structures and boundaries. By adopting appropriate upsampling methods, the spatial information of the original image can be preserved and recovered, which improve the precision of segmentation. This enhancement not only aids in the precise localization of lesion areas and the extraction of biological features but also holds significant importance for clinical diagnosis and treatment decision making. The advancement of artificial intelligence has facilitated the wide application of deep learning techniques. However, these deep learning methods often employ top-down or bottom-up approaches for feature fusion, which can result in the neglect or loss of intermediate layer feature information. Moreover, existing methods still encounter issues with imprecise segmentation boundaries of lesion areas, which leads to the omission of critical information when dealing with fine structures and complex background information. To address these concerns, this study proposes a detail-enhanced medical image segmentation network focusing on global and intermediate features (DEMS-GIF).MethodFirst, to address the shortcomings of existing feature fusion methods in capturing complex structures and integrating intermediate features, this study proposes a Transformer-based bridge feature fusion (TBBFF) module. Compared with other feature fusion modules, the TBBFF module focuses more on intermediate feature information and leverages the capability of the Transformer to capture long-range dependencies between different regions. These features enable the network to better understand the overall structure and contextual information of the image, which further enhances the segmentation performance and robustness of the model. Second, to address the issues of excessive smoothness in generated images and the lack of precise boundary segmentation in the areas of lesion using existing methods, this study proposes an expanded and scale-region-enhanced upsampling strategy under reverse attention (ESRU strategy). By incorporating a reverse attention mechanism and combining erosion and dilation operations, the model can better capture boundary and detail information in the target regions of medical images, which enhances the integrity and continuity of the segmented regions. This enhancement, in turn, improves the accuracy and stability of segmentation. In conclusion, the DEMS-GIF model, which integrating the TBBFF module and the ESRU strategy, effectively extracts image details and global information. Thus, it ensures the integrity of the segmented regions and further enhances segmentation accuracy.ResultWe evaluated the superiority of the DEMS-GIF model by comparing it with recent and classic methods through applying them on three different datasets: CVC-ClinicDB, digital database thyroid image(DDTI), and Kvasir-SEG. The experimental results demonstrate that, on the CVC-ClinicDB dataset, the DEMS-GIF model achieved mIoU and Dice scores of 94.74% and 94.82%, respectively. Compared with recently proposed segmentation methods, the mIoU achieved by DEMS-GIF outperformed those of MSUNet, MBSNet, and SCSONet by 3.98%, 4.42%, and 20.13%, respectively. With an increase in training iterations, the train loss of DEMS-GIF decreased significantly and was notably lower than those of ResUNet++ and SCSONet. On the DDTI dataset, the DEMS-GIF model achieved a precision of 85.52% and an mIoU of 84.56%. Compared with traditional network models, DEMS-GIF showed the most significant differences with ResNet++, with precision and mIoU higher by 13.97% and 10.96%, respectively. In addition, the train loss of DEMS-GIF was noticeably lower than those of other models, with the most significant difference observed with MFSNet. On the Kvasir-SEG dataset, the DEMS-GIF model achieved mIoU and Dice scores of 87.44%. Its mIoU was 12.69% higher than that of ResUNet++, and its Dice was 6.82% higher than that of UNet, which demonstrates substantial superiority. Compared with those of other models such as MBSNet, DTA-UNet, and SCSONet, the mIoU of DEMS-GIF was higher by 6.77%, 3.84%, and 25.02%, respectively, which suggests the best performance. During training, the train loss of DEMS-GIF was significantly lower than those of other network models, except that of MFSNet. We also conducted ablation experiments to understand the effectiveness of each module and structure within DEMS-GIF. The ablation experiments were divided into module ablation and parameter ablation. The module ablation experiments were conducted on the CVC-ClinicDB, DDTI, and Kvasir-SEG datasets, and the parameter ablation experiments were performed on the CVC-ClinicDB dataset. Using Res2Net as the baseline network, the module ablation experiments thoroughly discussed the impact of the TBBFF module and ESRU strategy on model performance. The results demonstrated that the combination of the TBBFF module and ESRU strategy allows the network to focus more on lesion areas, which results in more accurate segmentation. Parameter ablation involved experiments on the threshold and adaptive parameters used in reweighting with erosion and dilation operations. The findings illustrated the contribution of each parameter in the DEMS-GIF model and identified the optimal parameter values. As a result, the model settings are optimized to further enhance the overall performance and reliability of the model.ConclusionIn this study, we propose DEMS-GIF, which integrates the TBBFF module and the ESRU strategy. The network effectively leverages intermediate layer feature information to integrate features across different scales and levels. It also enhances the focus on boundary and detail information of lesion areas, which realizes efficient extraction and refined processing of image features. This process results in more complete and accurate segmentation regions. Experimental results show that the proposed DEMS-GIF network model outperforms other advanced segmentation methods, which demonstrates its superiority in medical image segmentation.关键词:medical image segmentation;feature fusion;upsampling;reverse attention;erosion;dilation120|106|0更新时间:2025-10-16
摘要:ObjectiveMedical image segmentation is a crucial and challenging task in the field of not only medical imaging but also modern medicine. Segmentation techniques can be used to precisely locate and measure tumors, blood vessels, and other structures, which facilitate the early diagnosis of the disease and the evaluation of treatment outcomes. In addition, accurate and reliable medical image segmentation can be utilized to monitor disease progression, assist physicians in formulating long-term treatment plans, lay a solid foundation for clinical diagnosis and pathological research, and provide valuable data support. Feature fusion in medical image segmentation can comprehensively capture detailed and global information by combining multi-level, multi-scale, and multimodal features, which improves segmentation accuracy and robustness. This method not only enhances the capability of automated medical image processing and reduces dependence on large amounts of annotated data but also increases the accuracy of clinical decisions. This approach helps doctors make highly reliable judgments in diagnosis and treatment, which promote the development of medical automation. In medical image segmentation, upsampling strategies can effectively restore high-resolution features and detailed information, which enhances the capability of the segmentation model to recognize small structures and boundaries. By adopting appropriate upsampling methods, the spatial information of the original image can be preserved and recovered, which improve the precision of segmentation. This enhancement not only aids in the precise localization of lesion areas and the extraction of biological features but also holds significant importance for clinical diagnosis and treatment decision making. The advancement of artificial intelligence has facilitated the wide application of deep learning techniques. However, these deep learning methods often employ top-down or bottom-up approaches for feature fusion, which can result in the neglect or loss of intermediate layer feature information. Moreover, existing methods still encounter issues with imprecise segmentation boundaries of lesion areas, which leads to the omission of critical information when dealing with fine structures and complex background information. To address these concerns, this study proposes a detail-enhanced medical image segmentation network focusing on global and intermediate features (DEMS-GIF).MethodFirst, to address the shortcomings of existing feature fusion methods in capturing complex structures and integrating intermediate features, this study proposes a Transformer-based bridge feature fusion (TBBFF) module. Compared with other feature fusion modules, the TBBFF module focuses more on intermediate feature information and leverages the capability of the Transformer to capture long-range dependencies between different regions. These features enable the network to better understand the overall structure and contextual information of the image, which further enhances the segmentation performance and robustness of the model. Second, to address the issues of excessive smoothness in generated images and the lack of precise boundary segmentation in the areas of lesion using existing methods, this study proposes an expanded and scale-region-enhanced upsampling strategy under reverse attention (ESRU strategy). By incorporating a reverse attention mechanism and combining erosion and dilation operations, the model can better capture boundary and detail information in the target regions of medical images, which enhances the integrity and continuity of the segmented regions. This enhancement, in turn, improves the accuracy and stability of segmentation. In conclusion, the DEMS-GIF model, which integrating the TBBFF module and the ESRU strategy, effectively extracts image details and global information. Thus, it ensures the integrity of the segmented regions and further enhances segmentation accuracy.ResultWe evaluated the superiority of the DEMS-GIF model by comparing it with recent and classic methods through applying them on three different datasets: CVC-ClinicDB, digital database thyroid image(DDTI), and Kvasir-SEG. The experimental results demonstrate that, on the CVC-ClinicDB dataset, the DEMS-GIF model achieved mIoU and Dice scores of 94.74% and 94.82%, respectively. Compared with recently proposed segmentation methods, the mIoU achieved by DEMS-GIF outperformed those of MSUNet, MBSNet, and SCSONet by 3.98%, 4.42%, and 20.13%, respectively. With an increase in training iterations, the train loss of DEMS-GIF decreased significantly and was notably lower than those of ResUNet++ and SCSONet. On the DDTI dataset, the DEMS-GIF model achieved a precision of 85.52% and an mIoU of 84.56%. Compared with traditional network models, DEMS-GIF showed the most significant differences with ResNet++, with precision and mIoU higher by 13.97% and 10.96%, respectively. In addition, the train loss of DEMS-GIF was noticeably lower than those of other models, with the most significant difference observed with MFSNet. On the Kvasir-SEG dataset, the DEMS-GIF model achieved mIoU and Dice scores of 87.44%. Its mIoU was 12.69% higher than that of ResUNet++, and its Dice was 6.82% higher than that of UNet, which demonstrates substantial superiority. Compared with those of other models such as MBSNet, DTA-UNet, and SCSONet, the mIoU of DEMS-GIF was higher by 6.77%, 3.84%, and 25.02%, respectively, which suggests the best performance. During training, the train loss of DEMS-GIF was significantly lower than those of other network models, except that of MFSNet. We also conducted ablation experiments to understand the effectiveness of each module and structure within DEMS-GIF. The ablation experiments were divided into module ablation and parameter ablation. The module ablation experiments were conducted on the CVC-ClinicDB, DDTI, and Kvasir-SEG datasets, and the parameter ablation experiments were performed on the CVC-ClinicDB dataset. Using Res2Net as the baseline network, the module ablation experiments thoroughly discussed the impact of the TBBFF module and ESRU strategy on model performance. The results demonstrated that the combination of the TBBFF module and ESRU strategy allows the network to focus more on lesion areas, which results in more accurate segmentation. Parameter ablation involved experiments on the threshold and adaptive parameters used in reweighting with erosion and dilation operations. The findings illustrated the contribution of each parameter in the DEMS-GIF model and identified the optimal parameter values. As a result, the model settings are optimized to further enhance the overall performance and reliability of the model.ConclusionIn this study, we propose DEMS-GIF, which integrates the TBBFF module and the ESRU strategy. The network effectively leverages intermediate layer feature information to integrate features across different scales and levels. It also enhances the focus on boundary and detail information of lesion areas, which realizes efficient extraction and refined processing of image features. This process results in more complete and accurate segmentation regions. Experimental results show that the proposed DEMS-GIF network model outperforms other advanced segmentation methods, which demonstrates its superiority in medical image segmentation.关键词:medical image segmentation;feature fusion;upsampling;reverse attention;erosion;dilation120|106|0更新时间:2025-10-16
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0