
最新刊期
卷 29 , 期 9 , 2024
数字人建模、生成与渲染技术
-
 摘要:As the breakthrough technology of artificial intelligence (AI) in the big data era, deep learning (DL) has prompted the renewed upsurge of face technology. Powered by rapid developments of new technologies, such as three-dimensional (3D) vision measurement, image processing chips, and DL models, 3D vision transformed into a key supporting technology in AI, visual reality, etc. The studies and applications of 3D facial imaging and reconstruction technologies have achieved important breakthroughs. 3D face data represent exact multidimensional facial attributes on account of rich visual information, such as texture, shape, space, etc. Moreover, 3D face data shows robust changes in large occlusions, expressions, and poses and increases the difficulty of forgery attack. Therefore, 3D face imaging and reconstruction effectively promote realistic “virtual digital human” reconstruction and rendering. In addition, these processes contribute to the improved security of the face system. In this paper, we comprehensively study the 3D face imaging technology and reconstruction models. The 3D face reconstruction methods based on DL are systematically and deeply analyzed. First, the development and innovation of 3D face imaging devices and capturing systems are discussed through a summary of public 3D face datasets. The devices and systems include consumer imaging devices (such as Kinect) and complex hybrid systems that fuse active and passive 3D imaging technologies to achieve precise geometry and appearance. Moreover, 3D face imaging based on new sensing technologies are introduced. Then, from the perspective of input resources, 3D face reconstruction methods based on DL are categorized into monocular, multiview, video and audio reconstruction methods. 3D face imaging technology introduces public classic 3D face datasets, popular 3D face imaging devices, and capturing systems. Most high-quality 3D face datasets, such as BU-3DFE, FaceScape and FaceVerse, are captured through a large imaging volume with a certain number of high-resolution cameras and controlled lighting conditions. They play key roles in applications of realistic rendering, driven animation, retargeting, etc. On the other hand, novel optical devices and imaging modules with small size and lightweight algorithm must be innovated for tiny AI as intelligent mobile devices. For 3D face reconstruction based on DL, monocular reconstruction has become the most popular technology. The state-of-the-art 3D face reconstruction method is generally self-supervised training on large-scale 2D face databases. The difficulties encountered in 3D face reconstruction include the lack of large-scale 3D face datasets, occlusions and poses of in-the-wild 2D face images, continuous expression deformations, etc. The DL network structure is categorized into general deep convolutional neural network (such as ResNet, U-Net, and Autoencoder), generative adversarial networks (GANs), implicit neural representation (INR) (such as neural radiance field (NeRF) and signed distance functions (SDF)), and Transformer. 3DMM and FLAME are widely used 3D face representation models. The StyleGAN model gives excellent performance in recovering high-quality face texture. INR has achieved remarkable results in 3D scene reconstruction, and the NeRF model plays an important role in the reconstruction of accurate head avatars. The combination of NeRF with GAN shows great potential in the reconstruction of high-fidelity 3D face geometry and realistic rendering appearances. Moreover, the Transformer model, which greatly improves the breakthrough of accuracy and speed, is mainly used in audio-driven 3D face reconstruction. Through in-depth analyses, the research difficulties accompanying 3D face are summarized, and future developments are actively being discussed and explored. Although recent research has made amazing progresses, challenges on how to improve the robustness and generalization to real-world lighting, extreme expressions/poses, and how to effectively disentangle facial attributes (such as identity, expression, albedo, and specular reflectance) and recover accurate detailed geometry of facial motions (such as wrinkles). In this study, we proposed a comprehensive and systematic review and covered classical technologies and studies on 3D face imaging and reconstruction in the last five years to provide a good reference for face studies, developments, and applications.关键词:3D face imaging;3D face reconstruction;deep learning (DL);generative adversarial network (GAN);implicit neural representation (INR)907|1010|0更新时间:2024-09-18
摘要:As the breakthrough technology of artificial intelligence (AI) in the big data era, deep learning (DL) has prompted the renewed upsurge of face technology. Powered by rapid developments of new technologies, such as three-dimensional (3D) vision measurement, image processing chips, and DL models, 3D vision transformed into a key supporting technology in AI, visual reality, etc. The studies and applications of 3D facial imaging and reconstruction technologies have achieved important breakthroughs. 3D face data represent exact multidimensional facial attributes on account of rich visual information, such as texture, shape, space, etc. Moreover, 3D face data shows robust changes in large occlusions, expressions, and poses and increases the difficulty of forgery attack. Therefore, 3D face imaging and reconstruction effectively promote realistic “virtual digital human” reconstruction and rendering. In addition, these processes contribute to the improved security of the face system. In this paper, we comprehensively study the 3D face imaging technology and reconstruction models. The 3D face reconstruction methods based on DL are systematically and deeply analyzed. First, the development and innovation of 3D face imaging devices and capturing systems are discussed through a summary of public 3D face datasets. The devices and systems include consumer imaging devices (such as Kinect) and complex hybrid systems that fuse active and passive 3D imaging technologies to achieve precise geometry and appearance. Moreover, 3D face imaging based on new sensing technologies are introduced. Then, from the perspective of input resources, 3D face reconstruction methods based on DL are categorized into monocular, multiview, video and audio reconstruction methods. 3D face imaging technology introduces public classic 3D face datasets, popular 3D face imaging devices, and capturing systems. Most high-quality 3D face datasets, such as BU-3DFE, FaceScape and FaceVerse, are captured through a large imaging volume with a certain number of high-resolution cameras and controlled lighting conditions. They play key roles in applications of realistic rendering, driven animation, retargeting, etc. On the other hand, novel optical devices and imaging modules with small size and lightweight algorithm must be innovated for tiny AI as intelligent mobile devices. For 3D face reconstruction based on DL, monocular reconstruction has become the most popular technology. The state-of-the-art 3D face reconstruction method is generally self-supervised training on large-scale 2D face databases. The difficulties encountered in 3D face reconstruction include the lack of large-scale 3D face datasets, occlusions and poses of in-the-wild 2D face images, continuous expression deformations, etc. The DL network structure is categorized into general deep convolutional neural network (such as ResNet, U-Net, and Autoencoder), generative adversarial networks (GANs), implicit neural representation (INR) (such as neural radiance field (NeRF) and signed distance functions (SDF)), and Transformer. 3DMM and FLAME are widely used 3D face representation models. The StyleGAN model gives excellent performance in recovering high-quality face texture. INR has achieved remarkable results in 3D scene reconstruction, and the NeRF model plays an important role in the reconstruction of accurate head avatars. The combination of NeRF with GAN shows great potential in the reconstruction of high-fidelity 3D face geometry and realistic rendering appearances. Moreover, the Transformer model, which greatly improves the breakthrough of accuracy and speed, is mainly used in audio-driven 3D face reconstruction. Through in-depth analyses, the research difficulties accompanying 3D face are summarized, and future developments are actively being discussed and explored. Although recent research has made amazing progresses, challenges on how to improve the robustness and generalization to real-world lighting, extreme expressions/poses, and how to effectively disentangle facial attributes (such as identity, expression, albedo, and specular reflectance) and recover accurate detailed geometry of facial motions (such as wrinkles). In this study, we proposed a comprehensive and systematic review and covered classical technologies and studies on 3D face imaging and reconstruction in the last five years to provide a good reference for face studies, developments, and applications.关键词:3D face imaging;3D face reconstruction;deep learning (DL);generative adversarial network (GAN);implicit neural representation (INR)907|1010|0更新时间:2024-09-18 -
 摘要:During continuous development of computer graphics and human-computer interaction, digital three-dimensional (3D) scenes have played a vital role in the academy and industry. 3D scenes show graphical rendering results, supply the environment for applications, and provide a foundation for interaction. Despite being common occurrences, indoor scenes are important. To increase players’ gaming experience, indoor game designers require all kinds of aesthetic digital 3D scenes. In online scene decoration, designers also need to predesign the decoration and furniture layout preview by interacting with 3D scenes. In studies of virtual reality, we can synthesize virtual space from a digital 3D scene, such as the synthesis of training data for wheelchair users. However, a number of difficulties still need to be overcome to obtain ideal digital 3D scenes for the applications mentioned above. First, manually synthesized 3D scenes are usually time consuming and require considerable experience. Designers must add objects to a scene and adjust their location and orientation one by one. These trivialities but heavy works cause difficulty in focusing on core ideas. Second, digital 3D scene is a data structure with extremely complex structure, and no unified consensus has been given to its data structure. Thus, digital 3D scenes are difficult to obtain and apply in large quantities compared with traditional data structures, such as image, audio or text. To solve the problems mentioned above, some existing work attempted to allow computers to automatically synthesize 3D scenes or interactively help synthesize scenes. This survey summarizes these works. This survey also investigates and summarizes 3D digital scene synthesis methodologies from three aspects: automatic scene synthesis, scene synthesis with multichannel and rich input, and interactive scene synthesis. The automatic synthesis allows the computer to directly build an indoor layout based on few inputs, such as the contour of the room or the list of objects. Initially, the scene is synthesized by manually setting rules and applying optimizers in an attempt to satisfy these rules. However, the situation increases in complexity during the synthesis practice, and thus, listing all the rules becomes impossible. As the amount of digital indoor scene increases, more works are introducing machine learning methods to study priors from the digital scenes of the 3D indoor scene dataset. Most of these works organize the furniture with graph to apply algorithms on the graph to process with the information. The results outperform those of former works. Researchers have been applying deep learning (DL) technology, such as convolutional neural network and generative adversarial network, to indoor scene synthesis, which strongly improves the synthetic effect. The synthesis with multichannel and rich input aims to synthesize a digital indoor 3D scene with unformatted information, such as image, text, RGBD scan, point cloud, etc. These algorithms enable the convenient formation of digital copies of scenes in the real world because they are mainly recorded by photos or literal description. Compared with the works on automatic synthesis, the scene syntheses with multichannel and rich input do not require diversity or aesthetics. However, this type of synthesis needs an algorithm for the accurate reconstruction of the indoor scene in the digital world. The interactive synthesis aims to let users control the process of computer-aided scene synthesis. The related works can mainly be divided into two parts: active and passive interactive syntheses. Active interactive synthesis simultaneously provides designers with suggestions while they synthesizing a scene. If the scene syntheses program can analyze the designers’ interaction and recommend the options with higher possibility to be chosen, considerable workload can be saved. During passive interactive synthesis, the system learns the user’s personal preferences from aspects, such as their behavior trajectory, personal abilities, work habits, and height information and automatically synthesize scenes that match the user’s preferences as much as possible. Eventually, this survey will also summarize the application scenario and core technology of the papers and introduce other typical application scenarios and future challenges. We summarized and classified the recent studies on applications of digital 3D scene synthesis to form this survey. Digital 3D indoor scene synthesis has attained great progress and has a wide prospect. The automatic scene synthesis has generally achieved its goal, and more attention should focused on the proposal and resolution of sub-problems and related issues afterward. For scene synthesis with rich input, existing work has explored inputs, such as image, RGBD-scan, text, and sketches. In the future, more potential input forms, such as music and symbols, should be explored. For scene interactive synthesis, current interactions are still limited to mouse and keyboard inputs, and methods based on interactive scenes, such as virtual reality, augmented reality, and hybrid reality, still need to be explored. Scene synthesis algorithm has continuously broadened its application. Industries normally require the automatic synthesis of a large amount of indoor scenes. The synthetic efficiency can be strongly increased if a computer can provide suggestions regarding an object and its layout. In academic studies, 3D scenes are usually applied to form all kinds of dataset. By rendering a scene’s photos from various perspectives and channels, researchers can easily obtain images. However, the study on indoor scene synthesis is still facing a number of limitations. The dissimilarity of data structure causes difficulty in extending the work of others. Copyright issues prevent a scene dataset from being freely used by researchers and coders. In the future, indoor scene datasets with additional furniture model and room contour will serve as the basis of indoor scene synthesis studies. Numerous related fields, such as style consistency and automatic photography, are also showing progress.关键词:indoor scene;3D scene synthesis;3D scene interaction;3D scene intelligent editing;computer graphics602|1160|0更新时间:2024-09-18
摘要:During continuous development of computer graphics and human-computer interaction, digital three-dimensional (3D) scenes have played a vital role in the academy and industry. 3D scenes show graphical rendering results, supply the environment for applications, and provide a foundation for interaction. Despite being common occurrences, indoor scenes are important. To increase players’ gaming experience, indoor game designers require all kinds of aesthetic digital 3D scenes. In online scene decoration, designers also need to predesign the decoration and furniture layout preview by interacting with 3D scenes. In studies of virtual reality, we can synthesize virtual space from a digital 3D scene, such as the synthesis of training data for wheelchair users. However, a number of difficulties still need to be overcome to obtain ideal digital 3D scenes for the applications mentioned above. First, manually synthesized 3D scenes are usually time consuming and require considerable experience. Designers must add objects to a scene and adjust their location and orientation one by one. These trivialities but heavy works cause difficulty in focusing on core ideas. Second, digital 3D scene is a data structure with extremely complex structure, and no unified consensus has been given to its data structure. Thus, digital 3D scenes are difficult to obtain and apply in large quantities compared with traditional data structures, such as image, audio or text. To solve the problems mentioned above, some existing work attempted to allow computers to automatically synthesize 3D scenes or interactively help synthesize scenes. This survey summarizes these works. This survey also investigates and summarizes 3D digital scene synthesis methodologies from three aspects: automatic scene synthesis, scene synthesis with multichannel and rich input, and interactive scene synthesis. The automatic synthesis allows the computer to directly build an indoor layout based on few inputs, such as the contour of the room or the list of objects. Initially, the scene is synthesized by manually setting rules and applying optimizers in an attempt to satisfy these rules. However, the situation increases in complexity during the synthesis practice, and thus, listing all the rules becomes impossible. As the amount of digital indoor scene increases, more works are introducing machine learning methods to study priors from the digital scenes of the 3D indoor scene dataset. Most of these works organize the furniture with graph to apply algorithms on the graph to process with the information. The results outperform those of former works. Researchers have been applying deep learning (DL) technology, such as convolutional neural network and generative adversarial network, to indoor scene synthesis, which strongly improves the synthetic effect. The synthesis with multichannel and rich input aims to synthesize a digital indoor 3D scene with unformatted information, such as image, text, RGBD scan, point cloud, etc. These algorithms enable the convenient formation of digital copies of scenes in the real world because they are mainly recorded by photos or literal description. Compared with the works on automatic synthesis, the scene syntheses with multichannel and rich input do not require diversity or aesthetics. However, this type of synthesis needs an algorithm for the accurate reconstruction of the indoor scene in the digital world. The interactive synthesis aims to let users control the process of computer-aided scene synthesis. The related works can mainly be divided into two parts: active and passive interactive syntheses. Active interactive synthesis simultaneously provides designers with suggestions while they synthesizing a scene. If the scene syntheses program can analyze the designers’ interaction and recommend the options with higher possibility to be chosen, considerable workload can be saved. During passive interactive synthesis, the system learns the user’s personal preferences from aspects, such as their behavior trajectory, personal abilities, work habits, and height information and automatically synthesize scenes that match the user’s preferences as much as possible. Eventually, this survey will also summarize the application scenario and core technology of the papers and introduce other typical application scenarios and future challenges. We summarized and classified the recent studies on applications of digital 3D scene synthesis to form this survey. Digital 3D indoor scene synthesis has attained great progress and has a wide prospect. The automatic scene synthesis has generally achieved its goal, and more attention should focused on the proposal and resolution of sub-problems and related issues afterward. For scene synthesis with rich input, existing work has explored inputs, such as image, RGBD-scan, text, and sketches. In the future, more potential input forms, such as music and symbols, should be explored. For scene interactive synthesis, current interactions are still limited to mouse and keyboard inputs, and methods based on interactive scenes, such as virtual reality, augmented reality, and hybrid reality, still need to be explored. Scene synthesis algorithm has continuously broadened its application. Industries normally require the automatic synthesis of a large amount of indoor scenes. The synthetic efficiency can be strongly increased if a computer can provide suggestions regarding an object and its layout. In academic studies, 3D scenes are usually applied to form all kinds of dataset. By rendering a scene’s photos from various perspectives and channels, researchers can easily obtain images. However, the study on indoor scene synthesis is still facing a number of limitations. The dissimilarity of data structure causes difficulty in extending the work of others. Copyright issues prevent a scene dataset from being freely used by researchers and coders. In the future, indoor scene datasets with additional furniture model and room contour will serve as the basis of indoor scene synthesis studies. Numerous related fields, such as style consistency and automatic photography, are also showing progress.关键词:indoor scene;3D scene synthesis;3D scene interaction;3D scene intelligent editing;computer graphics602|1160|0更新时间:2024-09-18 -
 摘要:A multimodal digital human refers to a digital avatar that can perform multimodal cognition and interaction and should be able to think and behave like a human being. Substantial progress has been made in related technologies due to cross-fertilization and vibrant development in various fields, such as computer vision and natural language processing. This article discusses three major themes in the areas of computer graphics and computer vision: multimodal head animation, multimodal body animation, and multimodal portrait creation. The methodologies and representative works in these areas are also introduced. Under the theme of multimodal head animation, this work presents the research on speech- and expression-driven head models. Under the theme of multimodal body animation, the paper explores techniques involving recurrent neural network (RNN)-, Transformer-, and denoising diffusion probabilistic model (DDPM)-based body animation. The discussion of multimodal portrait creation covers portrait creation guided by visual-linguistic similarity, portrait creation guided by multimodal denoising diffusion model, and three-dimensional (3D) multimodal generative models on digital portraits. Further, this article provides an overview and classification of representative works in these research directions, summarizes existing methods, and points out potential future research directions. This article delves into key directions in the field of multimodal digital humans and covers multimodal head animation, multimodal body animation, and the construction of multimodal digital human representations. In the realm of multimodal head animation, we extensively explore two major tasks: expression- and speech-driven animation. For explicit and implicit parameterized models for expression-driven head animation, mesh surfaces and neural radiance fields (NeRF) are used to improve the rendering effects. Explicit models employ 3D morphable and linear models but encounter challenges, such as weak expressive capacity, nondifferentiable rendering, and difficult modeling of personalized features. By contrast, implicit models, especially those based on NeRF, demonstrate superior expressive capacity and realism. In the domain of speech-driven head animation, we review 2D and 3D methods, with a particular focus on the important advantages of NeRF technology in enhancing realism. 2D speech-driven head video generation utilizes techniques, such as generative adversarial networks and image transfer, but depends on 3D prior knowledge and structural characteristics. On the other hand, methods using NeRF, such as audio driven NeRF for talking head synthesis (AD-NeRF) and semantic-aware implicit neural audio-driven video portrait generation (SSP-NeRF), achieve end-to-end training with differentiable NeRF. This condition substantially improves rendering realism while still addressing challenges associated with slow training and inference speeds. Multimodal body animation focuses on speech-driven body animation, music-driven dance, and text-driven body animation. We focus on the importance of learning speech semantics and melody and discuss the applications of RNN, Transformer, and denoising diffusion models in this field. Transformer gradually replaces RNN as the mainstream model, which gains notable advantages in sequence signal learning through attention mechanisms. We also highlight the body animation generation based on denoising diffusion models, such as free-form language-based motion synthesis and editing (FLAME), motion diffusion model (MDM), and text-driven human motion generation with diffusion model (MotionDiffuse), and multimodal denoising networks under music and text conditions. In the realm of the construction of multimodal digital human representations, the article emphasizes virtual-image construction guided by visual-language similarity and denoising of diffusion models. In addition, the demand for large-scale, diverse datasets in digital human representation construction is addressed to foster powerful and universal generative models. The three key aspects of multimodal digital humans are systematically explored: head animation, body animation, and digital human representation construction. In summary, explicit head models, although simple, editable, and computationally efficient, lack expressive capacity, and face challenges in rendering, especially in modeling facial personalization and nonfacial regions. By contrast, implicit models, especially those using NeRF, demonstrate stronger modeling capabilities and realistic rendering effects. In the realm of speech-driven animation, NeRF-based solutions for head animation overcome the limitations of 2D speaker and 3D digital head animation and achieve more natural and realistic speaker videos. Regarding body animation models, Transformer gradually replaces RNN, whereas denoising diffusion models can be used to potentially address mapping challenges in multimodal body animation. Finally, digital human representation construction faces challenges, with visual-language similarity and denoising diffusion model guidance showing promising results. However, the difficulty lies in the direct construction of 3D multimodal virtual humans due to the lack of sufficient 3D virtual human datasets. This study comprehensively analyzes various issues and provides clear directions and challenges for future research. In conclusion, should focus on future developments in multimodal digital humans. Key directions include improvement of 3D modeling and real-time rendering accuracy, integration of speech-driven and facial expression synthesis, construction of large and diverse datasets, exploration of multimodal information fusion and cross-modal learning, and addressing ethical and social impacts. Implicit representation methods, such as neural volume rendering, are crucial for improved 3D modeling. Simultaneously, the construction of larger datasets poses a formidable challenge in the development of robust and universal generative models. Exploration of multimodal information fusion and cross-modal learning allows models to learn from diverse data sources and present a range of behaviors and expressions. Attention to ethical and social impacts, including digital identity and privacy, is crucial. Such research directions should serve as guide the field toward a comprehensive, realistic, and universal future, with profound influence on interactions in virtual spaces.关键词:virtual human modeling;multimodal character animation;multimodal generation and editing;neural rendering;generative models;neural implicit representation1014|2480|0更新时间:2024-09-18
摘要:A multimodal digital human refers to a digital avatar that can perform multimodal cognition and interaction and should be able to think and behave like a human being. Substantial progress has been made in related technologies due to cross-fertilization and vibrant development in various fields, such as computer vision and natural language processing. This article discusses three major themes in the areas of computer graphics and computer vision: multimodal head animation, multimodal body animation, and multimodal portrait creation. The methodologies and representative works in these areas are also introduced. Under the theme of multimodal head animation, this work presents the research on speech- and expression-driven head models. Under the theme of multimodal body animation, the paper explores techniques involving recurrent neural network (RNN)-, Transformer-, and denoising diffusion probabilistic model (DDPM)-based body animation. The discussion of multimodal portrait creation covers portrait creation guided by visual-linguistic similarity, portrait creation guided by multimodal denoising diffusion model, and three-dimensional (3D) multimodal generative models on digital portraits. Further, this article provides an overview and classification of representative works in these research directions, summarizes existing methods, and points out potential future research directions. This article delves into key directions in the field of multimodal digital humans and covers multimodal head animation, multimodal body animation, and the construction of multimodal digital human representations. In the realm of multimodal head animation, we extensively explore two major tasks: expression- and speech-driven animation. For explicit and implicit parameterized models for expression-driven head animation, mesh surfaces and neural radiance fields (NeRF) are used to improve the rendering effects. Explicit models employ 3D morphable and linear models but encounter challenges, such as weak expressive capacity, nondifferentiable rendering, and difficult modeling of personalized features. By contrast, implicit models, especially those based on NeRF, demonstrate superior expressive capacity and realism. In the domain of speech-driven head animation, we review 2D and 3D methods, with a particular focus on the important advantages of NeRF technology in enhancing realism. 2D speech-driven head video generation utilizes techniques, such as generative adversarial networks and image transfer, but depends on 3D prior knowledge and structural characteristics. On the other hand, methods using NeRF, such as audio driven NeRF for talking head synthesis (AD-NeRF) and semantic-aware implicit neural audio-driven video portrait generation (SSP-NeRF), achieve end-to-end training with differentiable NeRF. This condition substantially improves rendering realism while still addressing challenges associated with slow training and inference speeds. Multimodal body animation focuses on speech-driven body animation, music-driven dance, and text-driven body animation. We focus on the importance of learning speech semantics and melody and discuss the applications of RNN, Transformer, and denoising diffusion models in this field. Transformer gradually replaces RNN as the mainstream model, which gains notable advantages in sequence signal learning through attention mechanisms. We also highlight the body animation generation based on denoising diffusion models, such as free-form language-based motion synthesis and editing (FLAME), motion diffusion model (MDM), and text-driven human motion generation with diffusion model (MotionDiffuse), and multimodal denoising networks under music and text conditions. In the realm of the construction of multimodal digital human representations, the article emphasizes virtual-image construction guided by visual-language similarity and denoising of diffusion models. In addition, the demand for large-scale, diverse datasets in digital human representation construction is addressed to foster powerful and universal generative models. The three key aspects of multimodal digital humans are systematically explored: head animation, body animation, and digital human representation construction. In summary, explicit head models, although simple, editable, and computationally efficient, lack expressive capacity, and face challenges in rendering, especially in modeling facial personalization and nonfacial regions. By contrast, implicit models, especially those using NeRF, demonstrate stronger modeling capabilities and realistic rendering effects. In the realm of speech-driven animation, NeRF-based solutions for head animation overcome the limitations of 2D speaker and 3D digital head animation and achieve more natural and realistic speaker videos. Regarding body animation models, Transformer gradually replaces RNN, whereas denoising diffusion models can be used to potentially address mapping challenges in multimodal body animation. Finally, digital human representation construction faces challenges, with visual-language similarity and denoising diffusion model guidance showing promising results. However, the difficulty lies in the direct construction of 3D multimodal virtual humans due to the lack of sufficient 3D virtual human datasets. This study comprehensively analyzes various issues and provides clear directions and challenges for future research. In conclusion, should focus on future developments in multimodal digital humans. Key directions include improvement of 3D modeling and real-time rendering accuracy, integration of speech-driven and facial expression synthesis, construction of large and diverse datasets, exploration of multimodal information fusion and cross-modal learning, and addressing ethical and social impacts. Implicit representation methods, such as neural volume rendering, are crucial for improved 3D modeling. Simultaneously, the construction of larger datasets poses a formidable challenge in the development of robust and universal generative models. Exploration of multimodal information fusion and cross-modal learning allows models to learn from diverse data sources and present a range of behaviors and expressions. Attention to ethical and social impacts, including digital identity and privacy, is crucial. Such research directions should serve as guide the field toward a comprehensive, realistic, and universal future, with profound influence on interactions in virtual spaces.关键词:virtual human modeling;multimodal character animation;multimodal generation and editing;neural rendering;generative models;neural implicit representation1014|2480|0更新时间:2024-09-18 -
 摘要:Digital human technology has attracted widespread attention in digital twins and metaverse fields. As an integral part of digital humans, people have started focusing on facial digitization and presentation. Consequently, the associated techniques find extensive applications in film, gaming, and virtual reality. A growing demand for facial realism rendering and high-quality facial inverse recovery has been observed. However, given the complex and multilayered material structure of the face, facial realism rendering presents a challenge. Furthermore, the composition of internal skin chemicals, such as melanin and hemoglobin, highly influences skin rendering. Factors, such as temperature and blood flow rate, may influence the skin’s appearance. The semitransparency of the skin introduces difficulties in the simulation of subsurface scattering effects, in addition to the wide presence of microscopic geometric features, such as pores and wrinkles on the face. All the issues mentioned above cause problems in the rendering domain and raise the demand for the quality of facial recovery. In addition, as a result of people’s exposure to real human faces in daily life, a heightened sensitivity to the texture and details of digital human faces has been observed, and this condition places greater demands on their realism and accuracy. Meanwhile, recovery of facial geometry and appearance is a crucial method for the construction of facial datasets. However, the high costs of acquisition equipment often constrain high-quality facial recovery, and most studies are limited by the acquisition speed for facial data, which result in the challenging capture of dynamic facial appearance. Lightweight recovery methods also encounter challenges related to the lack of facial material datasets. This paper presents an overview of recent advances in rendering and recovery of digital human faces. First, we introduce methods for realistic facial rendering and categorize them based on diffusion approximation and Monte Carlo approaches. Methods based on diffusion approximation, which focus on the efficient achievement of the semitransparency effect of the skin, are constrained by strict assumptions and suffer from certain limitations in precision. However, their simplified subsurface scattering models can render satisfactory images relatively quickly. Dynamic and interactive applications, such as games, often apply these methods. On the other hand, methods based on the Monte Carlo approach yield high precision and robust results via the meticulous and comprehensive simulation of the complex interactions between light and skin but require long computation times to converge. In applications, such as movies, where highly realistic visual effects are needed, they often become the preferred choice. We emphasized the development and challenges of methods based on diffusion approximation and divided them into improvements in the diffusion profiles, with real-time implementation of subsurface scattering, and hybrid methods combined with Monte Carlo techniques for detailed discussion. A recent Monte Carlo research aimed at improving the convergence rate for applications in facial rendering, including zero-variance random walks, next-event estimation, and path guiding. Second, we divided facial recovery work into two categories: high-precision recovery based on specialized acquisition equipment and low-precision recovery based on deep learning. This paper further categorizes the former based on the use of specialized lighting equipment, which distinguishes between active illumination and passive capture techniques, with provided detailed explanations for each category. Active illumination relies on professional lighting equipment, such as the application of gradient lighting to recover high-precision normal maps, to improve recovery quality. Conversely, passive capture methods are independent of professional lighting equipment, and any artificially provided lighting is limited to uniform illumination to reduce the interference of scene lighting on recovery and similar auxiliary roles. The exploration also focuses on low-precision facial recovery methods incorporating deep learning and classifies them into three categories, namely, geometric detail, texture mapping, and facial material information recoveries, to provide in-depth insights into each approach. We discuss a strategy for overcoming the limitations of geometric recovery based on parametric models, introduced refined parametric expressions of models, and predicted a range of maps, including displacement maps, that represent the model surface’s geometric details. For texture recovery, we explored the application of deep neural networks in generative tasks in the prediction of high-fidelity and personalized facial skin textures. Comprehensive reviews the various attempts to mitigate the ill-posed problem of separating reflectance information. In addition, we introduce the facial recovery work using multiview images and video sequences. These low-precision facial recovery methods can gain a wide application space given their flexibility and achieve improved recovery results with the rapid development of deep learning technology. Finally, the future trends in facial realism rendering and recovery methods based on the current state of research our outlined. In the realm of facial realism, existing works often represent the material properties of faces using texture maps and neglect the unique principles of skin coloration as a biological material. Furthermore, the rapid development of deep learning technology increases the importance of exploring of its integration with currently rendering techniques. In terms of inverse recovery, the lack of high-quality open-source datasets often poses limitations on data-based facial recovery methods. In addition, substantial improvement is needed in modeling and recovering details at the skin pore level. Combination of inverse recovery with text-based generative work also holds enormous potential and application scenarios. Hopefully, this paper can provide novice researchers in facial rendering and appearance recovery with valuable background knowledge and inspiration from harmony and ideas.关键词:facial realism rendering;subsurface scattering;facial inverse recovery;active illumination;passive capture;deep learning501|1074|1更新时间:2024-09-18
摘要:Digital human technology has attracted widespread attention in digital twins and metaverse fields. As an integral part of digital humans, people have started focusing on facial digitization and presentation. Consequently, the associated techniques find extensive applications in film, gaming, and virtual reality. A growing demand for facial realism rendering and high-quality facial inverse recovery has been observed. However, given the complex and multilayered material structure of the face, facial realism rendering presents a challenge. Furthermore, the composition of internal skin chemicals, such as melanin and hemoglobin, highly influences skin rendering. Factors, such as temperature and blood flow rate, may influence the skin’s appearance. The semitransparency of the skin introduces difficulties in the simulation of subsurface scattering effects, in addition to the wide presence of microscopic geometric features, such as pores and wrinkles on the face. All the issues mentioned above cause problems in the rendering domain and raise the demand for the quality of facial recovery. In addition, as a result of people’s exposure to real human faces in daily life, a heightened sensitivity to the texture and details of digital human faces has been observed, and this condition places greater demands on their realism and accuracy. Meanwhile, recovery of facial geometry and appearance is a crucial method for the construction of facial datasets. However, the high costs of acquisition equipment often constrain high-quality facial recovery, and most studies are limited by the acquisition speed for facial data, which result in the challenging capture of dynamic facial appearance. Lightweight recovery methods also encounter challenges related to the lack of facial material datasets. This paper presents an overview of recent advances in rendering and recovery of digital human faces. First, we introduce methods for realistic facial rendering and categorize them based on diffusion approximation and Monte Carlo approaches. Methods based on diffusion approximation, which focus on the efficient achievement of the semitransparency effect of the skin, are constrained by strict assumptions and suffer from certain limitations in precision. However, their simplified subsurface scattering models can render satisfactory images relatively quickly. Dynamic and interactive applications, such as games, often apply these methods. On the other hand, methods based on the Monte Carlo approach yield high precision and robust results via the meticulous and comprehensive simulation of the complex interactions between light and skin but require long computation times to converge. In applications, such as movies, where highly realistic visual effects are needed, they often become the preferred choice. We emphasized the development and challenges of methods based on diffusion approximation and divided them into improvements in the diffusion profiles, with real-time implementation of subsurface scattering, and hybrid methods combined with Monte Carlo techniques for detailed discussion. A recent Monte Carlo research aimed at improving the convergence rate for applications in facial rendering, including zero-variance random walks, next-event estimation, and path guiding. Second, we divided facial recovery work into two categories: high-precision recovery based on specialized acquisition equipment and low-precision recovery based on deep learning. This paper further categorizes the former based on the use of specialized lighting equipment, which distinguishes between active illumination and passive capture techniques, with provided detailed explanations for each category. Active illumination relies on professional lighting equipment, such as the application of gradient lighting to recover high-precision normal maps, to improve recovery quality. Conversely, passive capture methods are independent of professional lighting equipment, and any artificially provided lighting is limited to uniform illumination to reduce the interference of scene lighting on recovery and similar auxiliary roles. The exploration also focuses on low-precision facial recovery methods incorporating deep learning and classifies them into three categories, namely, geometric detail, texture mapping, and facial material information recoveries, to provide in-depth insights into each approach. We discuss a strategy for overcoming the limitations of geometric recovery based on parametric models, introduced refined parametric expressions of models, and predicted a range of maps, including displacement maps, that represent the model surface’s geometric details. For texture recovery, we explored the application of deep neural networks in generative tasks in the prediction of high-fidelity and personalized facial skin textures. Comprehensive reviews the various attempts to mitigate the ill-posed problem of separating reflectance information. In addition, we introduce the facial recovery work using multiview images and video sequences. These low-precision facial recovery methods can gain a wide application space given their flexibility and achieve improved recovery results with the rapid development of deep learning technology. Finally, the future trends in facial realism rendering and recovery methods based on the current state of research our outlined. In the realm of facial realism, existing works often represent the material properties of faces using texture maps and neglect the unique principles of skin coloration as a biological material. Furthermore, the rapid development of deep learning technology increases the importance of exploring of its integration with currently rendering techniques. In terms of inverse recovery, the lack of high-quality open-source datasets often poses limitations on data-based facial recovery methods. In addition, substantial improvement is needed in modeling and recovering details at the skin pore level. Combination of inverse recovery with text-based generative work also holds enormous potential and application scenarios. Hopefully, this paper can provide novice researchers in facial rendering and appearance recovery with valuable background knowledge and inspiration from harmony and ideas.关键词:facial realism rendering;subsurface scattering;facial inverse recovery;active illumination;passive capture;deep learning501|1074|1更新时间:2024-09-18 -
 摘要:Three-dimensional (3D) digital human motion generation guided by multimodal information generates human motion under specific input conditions through data, such as text, audio, image, and video. This technology has a wide spectrum of applications and extensive economic and social benefits in the fields of film, animation, game production, metaverse, etc., and is one of the research hotspots in the fields of computer graphics and computer vision. However, such a task faces grand challenges, including the difficult representation and fusion of multimodal information, lack of high-quality datasets, poor quality of generated motion (such as jitter, penetration, and foot sliding), and low generation efficiency. Although various solutions have been proposed to address the aforementioned challenges, a mechanism for achieving efficient and high-quality 3D digital human motion generation based on the characteristics of distinct modal data remains an open problem to be solved. This paper comprehensively reviews 3D digital human motion generation and elaborates on related recent advances from the perspectives of parametrized 3D human models, human motion representation, motion generation techniques, motion analysis and editing, existing human motion datasets and evaluation metrics. Parametrized human models facilitate digital human modeling and motion generation through the provision of parameters associated with body shapes and postures and serve as key pillars of current digital human research and applications. This survey begins with an introduction to widely used parametrized 3D human body models, including shape completion and animation of people (SCAPE), skinned multi-person linear model (SMPL), SMPL-X, and SMPL-H, and their detailed comparison in terms of model representations and the parameters used to control body shapes, poses, and facial expressions. Human motion representation is a core issue in digital human motion generation. This work highlights the musculoskeletal model and classic skinning algorithms, including linear blending skinning and dual quaternion skinning, and their application in physics-based and data-driven methods to control human movements. We have also extensively studied approaches to existing multimodal information-guided human motion generation and categorized them into four major branches, i.e., generative adversarial network-, autoencoder-, variational autoencoder-, and diffusion model-based methods. Other works, such as generative motion matching, have also been mentioned and compared with data-driven methods. The survey summarizes existing schemes of human motion generation from the perspectives of methods and model architectures and presents a unified framework for the generation of digital human motion. A motion encoder extracts motion features from an original motion sequence and fuses them with the conditional characteristics extracted by the conditional encoder into latent variables or maps them to the latent space. This condition enables generative adversarial networks, autoencoders, variational autoencoders, or diffusion models to generate qualified human movements through a motion decoder. In addition, this paper surveys the current work on digital human motion analysis and editing, including motion clustering, motion prediction, motion in-betweening, and motion in-filling. Data-driven human motion generation and evaluation requires the use of a high-quality dataset. We collected publicly available human motion databases and classified them into various types based on two criteria. From the perspective of data type, existing databases can be classified into motion capture and video reconstruction datasets. Motion capture data sets rely on devices, such as motion capture systems, cameras, and inertial measurement units, to obtain real human movement data (i.e., ground truth). Meanwhile, the video reconstruction dataset was used to reconstruct a 3D human body model through estimation of body joints from motion videos and fitting them to a parametric human body model. From the perspective of task type, commonly used databases can be classified into text-, action-, and audio-motion datasets. The new datasets are usually obtained by processing motion capture and video reconstruction datasets based on specific tasks. A comprehensive briefing on the evaluation metrics of 3D human motion generation, including motion quality, motion diversity, and multimodality, consistency between inputs and outputs, and inference efficiency, is also provided. Apart from objective evaluation metrics, user study was employed to generate human motion quality and was discussed in this paper. To compare the performances of various generation methods used in digital human motion on public datasets, we selected a collection of the most representative work and carried out extensive experiments for comprehensive evaluation. Finally, the well-addressed and underexplored issues in this field were summarized, and several potential further research directions regarding datasets, the quality and diversity of generated motions, cross-modal information fusion, and generation efficiency were discussed. Specifically, existing datasets generally fail to meet the expectations concerning motion diversity and descriptions associated with motions, data distribution, and length of motion sequence. Future work should consider the development of a large-scale 3D human motion database to boost the efficacy and robustness of motion generation models. In addition, the quality of generated human motions, especially those with complex movement patterns, remains dissatisfactory. Physical constraints and postprocessing show promise in the integration into human motion generation frameworks to tackle issues. In addition, although human-motion generation methods can generate various motion sequences from multimodal information, such as text, audio, music, actions and keyframes, work on cross-modal human motion generation (e.g., generating a motion from a text description and a piece of background music) is scarcely reported. Investigation of such a task is worthy, especially in unlocking new opportunities in this area. In terms of the diversity of generated content, some researchers have explored harvesting rich, diverse, and stylized motions using variational autoencoders, diffusion models, and contrastive language-image pretraining neural networks. However, current studies mainly focus on the motion generation of a single human represented by an SMPL-like naked parameterized 3D model. Meanwhile, the generation and interaction of multiple dressed humans have huge untapped application potential but have not received sufficient attention. Finally, another nonnegligible issue is a mechanism for boosting motion generation efficiency and achieving a good balance between quality and inference overhead. Possible solutions to such a problem include lightweight parameterized human models, information-intensive training datasets, and improved or more advanced generative frameworks.关键词:3D avatar;motion generation;multimodal information;parametric human model;generative adversarial network (GAN);autoencoder (AE);variational autoencoder (VAE);diffusion model776|1293|1更新时间:2024-09-18
摘要:Three-dimensional (3D) digital human motion generation guided by multimodal information generates human motion under specific input conditions through data, such as text, audio, image, and video. This technology has a wide spectrum of applications and extensive economic and social benefits in the fields of film, animation, game production, metaverse, etc., and is one of the research hotspots in the fields of computer graphics and computer vision. However, such a task faces grand challenges, including the difficult representation and fusion of multimodal information, lack of high-quality datasets, poor quality of generated motion (such as jitter, penetration, and foot sliding), and low generation efficiency. Although various solutions have been proposed to address the aforementioned challenges, a mechanism for achieving efficient and high-quality 3D digital human motion generation based on the characteristics of distinct modal data remains an open problem to be solved. This paper comprehensively reviews 3D digital human motion generation and elaborates on related recent advances from the perspectives of parametrized 3D human models, human motion representation, motion generation techniques, motion analysis and editing, existing human motion datasets and evaluation metrics. Parametrized human models facilitate digital human modeling and motion generation through the provision of parameters associated with body shapes and postures and serve as key pillars of current digital human research and applications. This survey begins with an introduction to widely used parametrized 3D human body models, including shape completion and animation of people (SCAPE), skinned multi-person linear model (SMPL), SMPL-X, and SMPL-H, and their detailed comparison in terms of model representations and the parameters used to control body shapes, poses, and facial expressions. Human motion representation is a core issue in digital human motion generation. This work highlights the musculoskeletal model and classic skinning algorithms, including linear blending skinning and dual quaternion skinning, and their application in physics-based and data-driven methods to control human movements. We have also extensively studied approaches to existing multimodal information-guided human motion generation and categorized them into four major branches, i.e., generative adversarial network-, autoencoder-, variational autoencoder-, and diffusion model-based methods. Other works, such as generative motion matching, have also been mentioned and compared with data-driven methods. The survey summarizes existing schemes of human motion generation from the perspectives of methods and model architectures and presents a unified framework for the generation of digital human motion. A motion encoder extracts motion features from an original motion sequence and fuses them with the conditional characteristics extracted by the conditional encoder into latent variables or maps them to the latent space. This condition enables generative adversarial networks, autoencoders, variational autoencoders, or diffusion models to generate qualified human movements through a motion decoder. In addition, this paper surveys the current work on digital human motion analysis and editing, including motion clustering, motion prediction, motion in-betweening, and motion in-filling. Data-driven human motion generation and evaluation requires the use of a high-quality dataset. We collected publicly available human motion databases and classified them into various types based on two criteria. From the perspective of data type, existing databases can be classified into motion capture and video reconstruction datasets. Motion capture data sets rely on devices, such as motion capture systems, cameras, and inertial measurement units, to obtain real human movement data (i.e., ground truth). Meanwhile, the video reconstruction dataset was used to reconstruct a 3D human body model through estimation of body joints from motion videos and fitting them to a parametric human body model. From the perspective of task type, commonly used databases can be classified into text-, action-, and audio-motion datasets. The new datasets are usually obtained by processing motion capture and video reconstruction datasets based on specific tasks. A comprehensive briefing on the evaluation metrics of 3D human motion generation, including motion quality, motion diversity, and multimodality, consistency between inputs and outputs, and inference efficiency, is also provided. Apart from objective evaluation metrics, user study was employed to generate human motion quality and was discussed in this paper. To compare the performances of various generation methods used in digital human motion on public datasets, we selected a collection of the most representative work and carried out extensive experiments for comprehensive evaluation. Finally, the well-addressed and underexplored issues in this field were summarized, and several potential further research directions regarding datasets, the quality and diversity of generated motions, cross-modal information fusion, and generation efficiency were discussed. Specifically, existing datasets generally fail to meet the expectations concerning motion diversity and descriptions associated with motions, data distribution, and length of motion sequence. Future work should consider the development of a large-scale 3D human motion database to boost the efficacy and robustness of motion generation models. In addition, the quality of generated human motions, especially those with complex movement patterns, remains dissatisfactory. Physical constraints and postprocessing show promise in the integration into human motion generation frameworks to tackle issues. In addition, although human-motion generation methods can generate various motion sequences from multimodal information, such as text, audio, music, actions and keyframes, work on cross-modal human motion generation (e.g., generating a motion from a text description and a piece of background music) is scarcely reported. Investigation of such a task is worthy, especially in unlocking new opportunities in this area. In terms of the diversity of generated content, some researchers have explored harvesting rich, diverse, and stylized motions using variational autoencoders, diffusion models, and contrastive language-image pretraining neural networks. However, current studies mainly focus on the motion generation of a single human represented by an SMPL-like naked parameterized 3D model. Meanwhile, the generation and interaction of multiple dressed humans have huge untapped application potential but have not received sufficient attention. Finally, another nonnegligible issue is a mechanism for boosting motion generation efficiency and achieving a good balance between quality and inference overhead. Possible solutions to such a problem include lightweight parameterized human models, information-intensive training datasets, and improved or more advanced generative frameworks.关键词:3D avatar;motion generation;multimodal information;parametric human model;generative adversarial network (GAN);autoencoder (AE);variational autoencoder (VAE);diffusion model776|1293|1更新时间:2024-09-18 -
 摘要:Three-dimensional human body reconstruction is a fundamental task in computer graphics and computer vision, with wide-ranging applications in virtual reality, human-computer interaction, motion analysis, and many other fields. This process is aimed at the accurate recovery of a three-dimensional model of the human body from given input data for further analysis and applications. However, high-fidelity reconstruction of clothed human bodies still presents difficulty given the diversity of human body shapes, variations in clothing, and complex human motion. Considerable progress has been attained in the field of three-dimensional human body reconstruction owing to the rapid development of deep learning methods. In deep learning techniques, multilayer neural network models are leveraged for the effective extraction of features from input data and learning of discriminative representations. In human body reconstruction, deep learning methods achieved remarkable advancements through revolutionized data feature extraction, implicit geometric representation, and neural rendering. This article aims to provide a comprehensive and accessible overview of three-dimensional human body reconstruction and elucidate the underlying methodologies, techniques, and algorithms used in this complex process. The article introduces first the classical framework of human body reconstruction, which comprises several key modules that collectively contribute to the reconstruction pipeline. These modules encompass various types of input data, including images, videos, and three-dimensional scans, that serve as fundamental building blocks in the reconstruction process. The representation of human body geometry is a vital aspect of human body reconstruction. Capturing the nuanced contours and shapes that define the human form presents a challenge. The article also explores various techniques for geometric representation, from mesh-based approaches to implicit representations and voxel grids. These techniques capture intricate details of the human body while ensuring that body shapes and poses remain realistic. The article also delves into the challenges associated with the reconstruction of clothed human bodies and examines the efficacy of parametric models in encapsulating the complexities of clothing deformations. Representation of human body motion is another crucial component of human body reconstruction. Realistic reconstructions require accurate modeling and capture of the dynamic nature of human movements. The article comprehensively explores various approaches to modeling human body motions, including articulated and non-rigid ones. Techniques, such as skeletal animation, motion capture, and spatiotemporal analysis, are discussed for the accurate and lifelike representations of human body motion. Parametric models also contribute to human body reconstruction because they provide a concise and expressive representation of the complete human body. The article further examines optimization-based methods, regression-based approaches, and popular parametric models, such as skinned multi-person linear (SMPL) and SMPL plus offsets, for human body reconstruction. These models allow the capture of realistic body shapes, poses, and clothing deformations. The article also discusses the advantages and limitations of these models and their applications in various domains. Deep learning techniques have had a transformative influence on three-dimensional human body reconstruction. The article explores the application of deep learning methodologies in data feature extraction, implicit geometric representation, and neural rendering and highlights the advancements achieved in leveraging convolutional neural networks, recurrent neural networks, and generative adversarial networks for various aspects of the reconstruction pipeline. These deep learning techniques considerably improve the accuracy and realism of reconstructed human bodies. Furthermore, publicly available datasets have been specifically curated for clothed human body reconstruction. These datasets serve as invaluable resources for benchmarking and evaluation of the performance of various reconstruction algorithms and enable researchers to compare and analyze the effectiveness of different techniques to foster advancements in the field. Then, a comprehensive survey of the rapid advancements in human body reconstruction algorithms over the past decade is presented. The survey highlights breakthroughs in dense view reconstruction, non-rigid structure from motion (NRSFM) methods, pixel-aligned implicit geometry reconstruction, generative models, and parameterized models. The discussion is also focused on the strengths, limitations, and potential applications of each approach to provide readers with holistic insights into the current state-of-the-art techniques. In conclusion, this article offers an in-depth and accessible exploration of three-dimensional human body reconstruction and covers a wide range of topics, such as data acquisition, geometry representation, motion modeling, and rendering of modules. The article not only summarizes existing methods but also provides insights into future research directions, such as the pursuit of high-fidelity reconstructions at reduced costs, accelerated reconstruction speeds, editable reconstruction outcomes, and the capability to reconstruct human bodies in natural environments. These research endeavors increase the accuracy, realism, and practicality of three-dimensional human body reconstruction systems and unlock new possibilities for various applications in the academia and industry.关键词:three-dimensional human body reconstruction;deep learning;parameterized model;implicit geometric representation;non-rigid structure-from-motion method;generative model451|1523|0更新时间:2024-09-18
摘要:Three-dimensional human body reconstruction is a fundamental task in computer graphics and computer vision, with wide-ranging applications in virtual reality, human-computer interaction, motion analysis, and many other fields. This process is aimed at the accurate recovery of a three-dimensional model of the human body from given input data for further analysis and applications. However, high-fidelity reconstruction of clothed human bodies still presents difficulty given the diversity of human body shapes, variations in clothing, and complex human motion. Considerable progress has been attained in the field of three-dimensional human body reconstruction owing to the rapid development of deep learning methods. In deep learning techniques, multilayer neural network models are leveraged for the effective extraction of features from input data and learning of discriminative representations. In human body reconstruction, deep learning methods achieved remarkable advancements through revolutionized data feature extraction, implicit geometric representation, and neural rendering. This article aims to provide a comprehensive and accessible overview of three-dimensional human body reconstruction and elucidate the underlying methodologies, techniques, and algorithms used in this complex process. The article introduces first the classical framework of human body reconstruction, which comprises several key modules that collectively contribute to the reconstruction pipeline. These modules encompass various types of input data, including images, videos, and three-dimensional scans, that serve as fundamental building blocks in the reconstruction process. The representation of human body geometry is a vital aspect of human body reconstruction. Capturing the nuanced contours and shapes that define the human form presents a challenge. The article also explores various techniques for geometric representation, from mesh-based approaches to implicit representations and voxel grids. These techniques capture intricate details of the human body while ensuring that body shapes and poses remain realistic. The article also delves into the challenges associated with the reconstruction of clothed human bodies and examines the efficacy of parametric models in encapsulating the complexities of clothing deformations. Representation of human body motion is another crucial component of human body reconstruction. Realistic reconstructions require accurate modeling and capture of the dynamic nature of human movements. The article comprehensively explores various approaches to modeling human body motions, including articulated and non-rigid ones. Techniques, such as skeletal animation, motion capture, and spatiotemporal analysis, are discussed for the accurate and lifelike representations of human body motion. Parametric models also contribute to human body reconstruction because they provide a concise and expressive representation of the complete human body. The article further examines optimization-based methods, regression-based approaches, and popular parametric models, such as skinned multi-person linear (SMPL) and SMPL plus offsets, for human body reconstruction. These models allow the capture of realistic body shapes, poses, and clothing deformations. The article also discusses the advantages and limitations of these models and their applications in various domains. Deep learning techniques have had a transformative influence on three-dimensional human body reconstruction. The article explores the application of deep learning methodologies in data feature extraction, implicit geometric representation, and neural rendering and highlights the advancements achieved in leveraging convolutional neural networks, recurrent neural networks, and generative adversarial networks for various aspects of the reconstruction pipeline. These deep learning techniques considerably improve the accuracy and realism of reconstructed human bodies. Furthermore, publicly available datasets have been specifically curated for clothed human body reconstruction. These datasets serve as invaluable resources for benchmarking and evaluation of the performance of various reconstruction algorithms and enable researchers to compare and analyze the effectiveness of different techniques to foster advancements in the field. Then, a comprehensive survey of the rapid advancements in human body reconstruction algorithms over the past decade is presented. The survey highlights breakthroughs in dense view reconstruction, non-rigid structure from motion (NRSFM) methods, pixel-aligned implicit geometry reconstruction, generative models, and parameterized models. The discussion is also focused on the strengths, limitations, and potential applications of each approach to provide readers with holistic insights into the current state-of-the-art techniques. In conclusion, this article offers an in-depth and accessible exploration of three-dimensional human body reconstruction and covers a wide range of topics, such as data acquisition, geometry representation, motion modeling, and rendering of modules. The article not only summarizes existing methods but also provides insights into future research directions, such as the pursuit of high-fidelity reconstructions at reduced costs, accelerated reconstruction speeds, editable reconstruction outcomes, and the capability to reconstruct human bodies in natural environments. These research endeavors increase the accuracy, realism, and practicality of three-dimensional human body reconstruction systems and unlock new possibilities for various applications in the academia and industry.关键词:three-dimensional human body reconstruction;deep learning;parameterized model;implicit geometric representation;non-rigid structure-from-motion method;generative model451|1523|0更新时间:2024-09-18 -
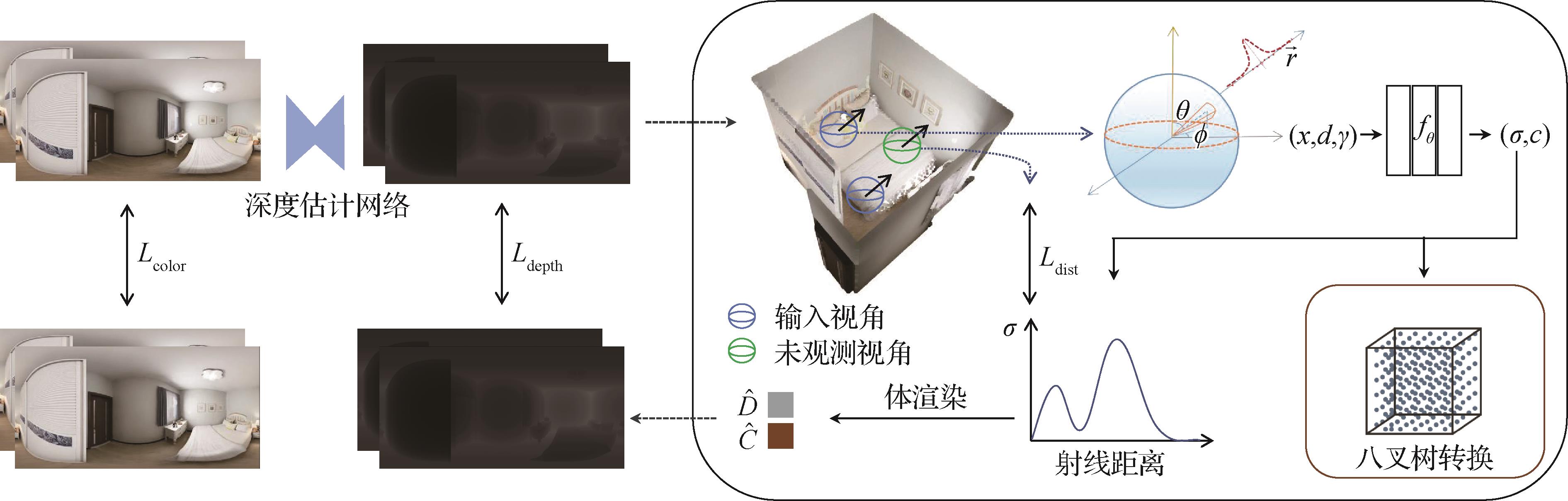 摘要:ObjectiveNeural radiance field (NeRF) account for a crucial technology used in the creation of immersive environments in various applications, including digital human simulations, interactive gaming, and virtual-reality property tours. These applications benefit considerably from the highly realistic rendering capabilities of NeRF, which can generate detailed and interactive 3D spaces. However, the reconstruction of NeRF typically necessitates to a dense set of multiview images of indoor scenes, which can be difficult to obtain. Current algorithms that address sparse image inputs often perform poorly in the accurate reconstruction of indoor scenes, which leads to less than optimal results. To overcome these challenges, we introduced a novel NeRF reconstruction algorithm specifically designed for sparse indoor panoramas. This algorithm enhances the reconstruction process via the improved allocation of sampling points and refinement of the geometric structure regardless of limited image data. In this manner, high-quality, realistic virtual environments can be synthesized from sparsely available indoor panoramas, which advances the potential applications of NeRF in various fields.MethodInitially, our algorithm, which is specifically designed to focused on regions of lower latitude, implements a distortion-aware sampling strategy during the ray sampling phase. This strategic approach ensures the sampling of more rays from the central areas of the panorama, which are typically richer in terms of visual information and less distorted compared with the peripheral regions. Concentration on these areas we can attain a marked improvement in rendering quality because the algorithm can better capture the essential features and details of the scene. For the further improvement of the reconstruction process, especially in the case sparse image inputs, a panoramic depth estimation network was employed. This network generates a depth map that provides crucial information on the spatial arrangement of objects within a scene. With the estimated depth map, our algorithm incorporates a depth sampling auxiliary strategy and a depth loss supervision strategy. These strategies work in tandem to guide the learning process of the network. The depth sampling strategy allocated a considerable portion of the sampling points in a Gaussian distribution around the estimated depth. This targeted approach enables the network to further comprehension of nuanced understanding of object surfaces, which is essential for accurate scene reconstruction. During the testing phase, our algorithm adopted a coarse-to-fine sampling strategy that aligns with the principles of NeRF. This methodical approach ensures that the network can progressively refine its understanding of the scene, starting with a broad overview and gradually through zooming in on finer details. To maintain the color and depth accuracy throughout the training process, we integrated a depth loss function during the training phase. This function effectively limits the variance of sampling point distribution, which results in a focused and accurate rendering of the scene. In addition, we tackled the issue involving artifacts and improved geometry through the introduction of distortion loss for unobserved viewpoints. This loss function effectively constrains the distribution of unobserved rays in space, which results in realistic and visually pleasing renderings. Moreover, to address the low rendering speed in neural rendering, we developed a real-time neural rendering algorithm with two distinct stages. The first stage involves partitions the bounding box of the scene into a series of octree grids, with each grid’s density determined via its spatial location. This process enables the efficient management of the complexity of the scene, which ensures that the rendering process is optimized for speed and quality. Further screening these grids leads to the identification of octree leaf nodes, which are essential for reducing memory consumption and improving the performance. In the second stage, our algorithm leverages the network to predict the color values of leaf nodes from various viewing directions. Spherical harmonics are employed to accurately fit the colors, which guaranteed that the rendered scene is vibrant and true to life. By caching the network model as an octree structure, we enable real-time rendering, which is crucial for applications that demand a seamless and immersive experience. This approach not only substantially improves the rendering speed but also maintains high-quality results, which are essential for the creation of realistic virtual environments.ResultWe evaluated the effectiveness of our proposed algorithm on three panoramic datasets, including two synthetic datasets (i.e., Replica and PNVS datasets) and one real dataset (i.e., WanHuaTong dataset). This diverse selection of datasets allowed for a thorough assessment of the algorithm’s performance under various conditions and complexities. Our evaluation outcomes illustrate the effectiveness of our algorithm and its superiority over existing reconstruction methods. Specifically, when tested on a Replica dataset with two panoramic images as input, our algorithm exhibited a considerable leap over the current state-of-the-art dense depth priors for NeRF (DDP-NeRF) algorithm. In addition, it achieved a 6% improvement in peak signal-to-noise ratio (PSNR) and an 8% reduction in root mean square error, which reflect improvements in image quality and accuracy. Moreover, our algorithm demonstrated an impressive rendering speed of 70 frames per second on the WanHuaTong dataset, which underscores its capability to handle real depth data with equal proficiency. The algorithm’s adaptability is further highlighted in scenarios with challenging panoramic images, such as top cropping and partial depth occlusion. Despite these obstacles, our method effectively recovered complete depth information, which showcases its robustness and reliability in practical applications.ConclusionWe proposed a NeRF reconstruction algorithm for sparse indoor panoramas, which enables highly realistic rendering from any viewpoints within the scene. Through the implementation of a panoramic-based ray sampling strategy and depth supervision, the algorithm improved the geometric reconstruction quality by focusing on object surfaces. In addition, it incorporated a deformation loss for unobserved viewpoints, which strengthened ray constraints and elevated the reconstruction quality under sparse input conditions. Experimental validation of different panoramic datasets demonstrated that our algorithm outperforms current techniques in terms of color and geometry metrics. This condition leads to the creation of highly realistic novel views and supports of real-time rendering, with potential applications in indoor navigation, virtual reality house viewing, mixed-reality games, and digital human scene synthesis.关键词:neural radiance field (NeRF) reconstruction;sparse input;panorama;novel view synthesis;virtual reality;digital human266|212|0更新时间:2024-09-18
摘要:ObjectiveNeural radiance field (NeRF) account for a crucial technology used in the creation of immersive environments in various applications, including digital human simulations, interactive gaming, and virtual-reality property tours. These applications benefit considerably from the highly realistic rendering capabilities of NeRF, which can generate detailed and interactive 3D spaces. However, the reconstruction of NeRF typically necessitates to a dense set of multiview images of indoor scenes, which can be difficult to obtain. Current algorithms that address sparse image inputs often perform poorly in the accurate reconstruction of indoor scenes, which leads to less than optimal results. To overcome these challenges, we introduced a novel NeRF reconstruction algorithm specifically designed for sparse indoor panoramas. This algorithm enhances the reconstruction process via the improved allocation of sampling points and refinement of the geometric structure regardless of limited image data. In this manner, high-quality, realistic virtual environments can be synthesized from sparsely available indoor panoramas, which advances the potential applications of NeRF in various fields.MethodInitially, our algorithm, which is specifically designed to focused on regions of lower latitude, implements a distortion-aware sampling strategy during the ray sampling phase. This strategic approach ensures the sampling of more rays from the central areas of the panorama, which are typically richer in terms of visual information and less distorted compared with the peripheral regions. Concentration on these areas we can attain a marked improvement in rendering quality because the algorithm can better capture the essential features and details of the scene. For the further improvement of the reconstruction process, especially in the case sparse image inputs, a panoramic depth estimation network was employed. This network generates a depth map that provides crucial information on the spatial arrangement of objects within a scene. With the estimated depth map, our algorithm incorporates a depth sampling auxiliary strategy and a depth loss supervision strategy. These strategies work in tandem to guide the learning process of the network. The depth sampling strategy allocated a considerable portion of the sampling points in a Gaussian distribution around the estimated depth. This targeted approach enables the network to further comprehension of nuanced understanding of object surfaces, which is essential for accurate scene reconstruction. During the testing phase, our algorithm adopted a coarse-to-fine sampling strategy that aligns with the principles of NeRF. This methodical approach ensures that the network can progressively refine its understanding of the scene, starting with a broad overview and gradually through zooming in on finer details. To maintain the color and depth accuracy throughout the training process, we integrated a depth loss function during the training phase. This function effectively limits the variance of sampling point distribution, which results in a focused and accurate rendering of the scene. In addition, we tackled the issue involving artifacts and improved geometry through the introduction of distortion loss for unobserved viewpoints. This loss function effectively constrains the distribution of unobserved rays in space, which results in realistic and visually pleasing renderings. Moreover, to address the low rendering speed in neural rendering, we developed a real-time neural rendering algorithm with two distinct stages. The first stage involves partitions the bounding box of the scene into a series of octree grids, with each grid’s density determined via its spatial location. This process enables the efficient management of the complexity of the scene, which ensures that the rendering process is optimized for speed and quality. Further screening these grids leads to the identification of octree leaf nodes, which are essential for reducing memory consumption and improving the performance. In the second stage, our algorithm leverages the network to predict the color values of leaf nodes from various viewing directions. Spherical harmonics are employed to accurately fit the colors, which guaranteed that the rendered scene is vibrant and true to life. By caching the network model as an octree structure, we enable real-time rendering, which is crucial for applications that demand a seamless and immersive experience. This approach not only substantially improves the rendering speed but also maintains high-quality results, which are essential for the creation of realistic virtual environments.ResultWe evaluated the effectiveness of our proposed algorithm on three panoramic datasets, including two synthetic datasets (i.e., Replica and PNVS datasets) and one real dataset (i.e., WanHuaTong dataset). This diverse selection of datasets allowed for a thorough assessment of the algorithm’s performance under various conditions and complexities. Our evaluation outcomes illustrate the effectiveness of our algorithm and its superiority over existing reconstruction methods. Specifically, when tested on a Replica dataset with two panoramic images as input, our algorithm exhibited a considerable leap over the current state-of-the-art dense depth priors for NeRF (DDP-NeRF) algorithm. In addition, it achieved a 6% improvement in peak signal-to-noise ratio (PSNR) and an 8% reduction in root mean square error, which reflect improvements in image quality and accuracy. Moreover, our algorithm demonstrated an impressive rendering speed of 70 frames per second on the WanHuaTong dataset, which underscores its capability to handle real depth data with equal proficiency. The algorithm’s adaptability is further highlighted in scenarios with challenging panoramic images, such as top cropping and partial depth occlusion. Despite these obstacles, our method effectively recovered complete depth information, which showcases its robustness and reliability in practical applications.ConclusionWe proposed a NeRF reconstruction algorithm for sparse indoor panoramas, which enables highly realistic rendering from any viewpoints within the scene. Through the implementation of a panoramic-based ray sampling strategy and depth supervision, the algorithm improved the geometric reconstruction quality by focusing on object surfaces. In addition, it incorporated a deformation loss for unobserved viewpoints, which strengthened ray constraints and elevated the reconstruction quality under sparse input conditions. Experimental validation of different panoramic datasets demonstrated that our algorithm outperforms current techniques in terms of color and geometry metrics. This condition leads to the creation of highly realistic novel views and supports of real-time rendering, with potential applications in indoor navigation, virtual reality house viewing, mixed-reality games, and digital human scene synthesis.关键词:neural radiance field (NeRF) reconstruction;sparse input;panorama;novel view synthesis;virtual reality;digital human266|212|0更新时间:2024-09-18 -
 摘要:ObjectiveClothed human reconstruction is an important problem in the field of computer vision and computer graphics. This process aims to generate three-dimensional (3D) human body models, including clothes and accessories, through computer technology, and is widely used in virtual reality, digital human body, 3D clothing assistant design, film and television special effects production, and other scenes. Compared with a large number of single-view images available on the internet, multiview images are more difficult to obtain. Considering that single-view images are easier to obtain on the internet, which can greatly reduce the use conditions and hardware cost of reconstruction, we consider single-view images as input to establish a complete mapping between single-view human image and human shape and restore the 3D shape and geometric details of the human body. Most methods based on parametric models can only predict the shape and posture of the human body with a smooth surface, whereas nonparametric model methods lack a fixed grid topology when generating fine geometric shapes. High-precision 3D human model extraction can be realized through the combination of parametric human model and implicit function. Given that clothing can produce dynamic flexible deformation with the change in human posture, most methods focus on obtaining the fold details of a clothed human model from 3D mesh deformation. The clothing can be separated from the human body with the assistance of a clothed template, and flexible deformation of the clothing caused by human body posture can be directly obtained via the learning-based method. Given the overlapping of limbs, occlusion, and complex clothed posture of clothed human body in single-view 3D human body reconstruction, obtaining geometric shape representation under various clothed postures and angles is difficult. Moreover, existing methods can only accurately extract and represent visual features from clothed human body images without considering the dynamic detail expression caused by complex clothed posture. Difficulties are encountered regarding the representation and learning of the clothed features related to the posture of single-view clothed human and generation of a clothed mesh with complex posture and dynamic folds. In this paper, we propose a single-perspective 3D human reconstruction clothed feature learning method.MethodWe propose a feature learning approach to reconstruct clothed human with a single-view image. The experimental hardware platform in this paper used two NVIDIA GeForce RTX 1080Ti GPU. We utilized the clothing co-parsing fashion street photography dataset, which includes 2 098 human images, to analyze the physical features of clothing. Human3.6M dataset was used to learn posture features of the human body, with the test set at 3DPW capture from the field environment. For fold feature learning, we used objects 00096 and 00159 in the CAPE dataset. For better training effects of the clothed mesh, we selected 150 meshes close to the dressed posture from the THuman2.0 dataset as the training set for use in shape feature learning. First, we represented the limb features of the single-view image and extracted the clothed human pose features through 2D node prediction and deep regression of pose features. Then, based on the pose features of the clothing, the sampling space of clothing fold centered on the flexible deformation joint and flexible deformation loss function were defined. In addition, flexible clothing deformation was learned through the introduction of a clothing template to the input ground truth model of the clothing body to obtain fold features. We only focused on crucial details inside the space to acquire the fold features. Afterward, the human shape features learning module was constructed via the combination of posture parameter regression, feature map sampling feature, and codec. The pixel and voxel alignment features were learned from the corresponding image and grid in the 3D human mesh dataset, and the shape features of the human body were decoded. Finally, through the combination of fold features, shape features of a clothed human, and calculated 3D sampling space, the 3D human mesh was reconstructed by defining the signed distance field, and the final clothed human model was outputted.ResultAiming at the results of posture feature and single-view 3D clothed human reconstruction, we used 3DPW and THuman2.0 datasets. Our experimental results findings compared with those of the three methods on the 3DPW dataset. The mean per joint position error (MPJPE) and MPJPE of Platts alignment (PA-MPJPE) were used to evaluate the differences between the predicted 3D joints and ground truth. The mean per vertex position error (MPVPE) was used to evaluate the predicted SMPL 3D human shape and the ground truth grid. Compared with that of the second-best model, the error was decreased by 1.28 on MPJPE, 1.66 on PA-MPJPE and 2.38 on MPVPE, and the average error was reduced by 2.4%. For the 3D reconstruction of the clothed human body, we conducted experiments to compare the four methods on the THuman2.0 dataset. We used the Chamfer distance (CD/Chamfer) and point-to-surface distance (P2S) of the 3D space to evaluate the gap between the two 3D mesh groups. Notably, the P2S of the reconstructed result can be reduced by 4.4% compared with the second-best model, and CD can be reduced by 2.6%. Experimental results reveal that the posture feature learning module contributed to the reconstruction of the complete limb and correct posture, and fold feature learning for optimized learned shape features can be used to obtain high-precision reconstruction results.ConclusionIn this paper, the clothed feature learning method for single-view 3D human-body reconstruction enables the effective learning of the clothed feature of single-view 3D human reconstruction and generates clothed human reconstruction results with complex posture and dynamic folds.关键词:single-view 3D human reconstruction;clothed feature learning;sampling space;flexible deformation;signed distance field275|889|1更新时间:2024-09-18
摘要:ObjectiveClothed human reconstruction is an important problem in the field of computer vision and computer graphics. This process aims to generate three-dimensional (3D) human body models, including clothes and accessories, through computer technology, and is widely used in virtual reality, digital human body, 3D clothing assistant design, film and television special effects production, and other scenes. Compared with a large number of single-view images available on the internet, multiview images are more difficult to obtain. Considering that single-view images are easier to obtain on the internet, which can greatly reduce the use conditions and hardware cost of reconstruction, we consider single-view images as input to establish a complete mapping between single-view human image and human shape and restore the 3D shape and geometric details of the human body. Most methods based on parametric models can only predict the shape and posture of the human body with a smooth surface, whereas nonparametric model methods lack a fixed grid topology when generating fine geometric shapes. High-precision 3D human model extraction can be realized through the combination of parametric human model and implicit function. Given that clothing can produce dynamic flexible deformation with the change in human posture, most methods focus on obtaining the fold details of a clothed human model from 3D mesh deformation. The clothing can be separated from the human body with the assistance of a clothed template, and flexible deformation of the clothing caused by human body posture can be directly obtained via the learning-based method. Given the overlapping of limbs, occlusion, and complex clothed posture of clothed human body in single-view 3D human body reconstruction, obtaining geometric shape representation under various clothed postures and angles is difficult. Moreover, existing methods can only accurately extract and represent visual features from clothed human body images without considering the dynamic detail expression caused by complex clothed posture. Difficulties are encountered regarding the representation and learning of the clothed features related to the posture of single-view clothed human and generation of a clothed mesh with complex posture and dynamic folds. In this paper, we propose a single-perspective 3D human reconstruction clothed feature learning method.MethodWe propose a feature learning approach to reconstruct clothed human with a single-view image. The experimental hardware platform in this paper used two NVIDIA GeForce RTX 1080Ti GPU. We utilized the clothing co-parsing fashion street photography dataset, which includes 2 098 human images, to analyze the physical features of clothing. Human3.6M dataset was used to learn posture features of the human body, with the test set at 3DPW capture from the field environment. For fold feature learning, we used objects 00096 and 00159 in the CAPE dataset. For better training effects of the clothed mesh, we selected 150 meshes close to the dressed posture from the THuman2.0 dataset as the training set for use in shape feature learning. First, we represented the limb features of the single-view image and extracted the clothed human pose features through 2D node prediction and deep regression of pose features. Then, based on the pose features of the clothing, the sampling space of clothing fold centered on the flexible deformation joint and flexible deformation loss function were defined. In addition, flexible clothing deformation was learned through the introduction of a clothing template to the input ground truth model of the clothing body to obtain fold features. We only focused on crucial details inside the space to acquire the fold features. Afterward, the human shape features learning module was constructed via the combination of posture parameter regression, feature map sampling feature, and codec. The pixel and voxel alignment features were learned from the corresponding image and grid in the 3D human mesh dataset, and the shape features of the human body were decoded. Finally, through the combination of fold features, shape features of a clothed human, and calculated 3D sampling space, the 3D human mesh was reconstructed by defining the signed distance field, and the final clothed human model was outputted.ResultAiming at the results of posture feature and single-view 3D clothed human reconstruction, we used 3DPW and THuman2.0 datasets. Our experimental results findings compared with those of the three methods on the 3DPW dataset. The mean per joint position error (MPJPE) and MPJPE of Platts alignment (PA-MPJPE) were used to evaluate the differences between the predicted 3D joints and ground truth. The mean per vertex position error (MPVPE) was used to evaluate the predicted SMPL 3D human shape and the ground truth grid. Compared with that of the second-best model, the error was decreased by 1.28 on MPJPE, 1.66 on PA-MPJPE and 2.38 on MPVPE, and the average error was reduced by 2.4%. For the 3D reconstruction of the clothed human body, we conducted experiments to compare the four methods on the THuman2.0 dataset. We used the Chamfer distance (CD/Chamfer) and point-to-surface distance (P2S) of the 3D space to evaluate the gap between the two 3D mesh groups. Notably, the P2S of the reconstructed result can be reduced by 4.4% compared with the second-best model, and CD can be reduced by 2.6%. Experimental results reveal that the posture feature learning module contributed to the reconstruction of the complete limb and correct posture, and fold feature learning for optimized learned shape features can be used to obtain high-precision reconstruction results.ConclusionIn this paper, the clothed feature learning method for single-view 3D human-body reconstruction enables the effective learning of the clothed feature of single-view 3D human reconstruction and generates clothed human reconstruction results with complex posture and dynamic folds.关键词:single-view 3D human reconstruction;clothed feature learning;sampling space;flexible deformation;signed distance field275|889|1更新时间:2024-09-18
Modeling, Generation and Rendering of Digital Human

-
 摘要:Traditional radar detection is almost ineffective in complex and strong electromagnetic interference environments, especially in the case of stealth targets with an extremely low-radar cross-section. In such scenarios, the infrared search and track (IRST) system, with its strong anti-interference capability and all-weather and all-airspace passive detection, emerges as a viable alternative to radar in target detection. Therefore, this system is widely used, such as reconnaissance and early warning, maritime surveillance, and precision guidance. However, the efficient and accurate use of the IRST system when identifying noncooperative small targets with minimal features, low intensity, scale variations, and unknown motion states in complex backgrounds and amidst noise interference remains a challenging task, which draws attention from scholars globally. To date, the research on infrared (IR) small-target detection technology mainly focuses on long-distance weak and small (point source) targets. However, when the scene and target scale change considerably, false alarms or missed detections easily occur. Therefore, this review focuses on the problem of IR multiscale small-target detection technology. To provide a comprehensive understanding of the current research status in this domain, this review summarizes the field from the perspectives of algorithm principles, literature, datasets, evaluation metrics, experiments, and development directions. First, the research motivation is clarified. In practical application background, with the change in the motion state of noncooperative small targets, the scale also vary greatly, from point-like targets to small targets with fuzzy boundaries to small targets with clear outlines, which is usually difficult to distinguish properly. Therefore, to be more in line with practical application background, this review is comprehensively analyzed from the perspective of IR multiscale small-target detection technology. Second, the imaging characteristics of IR multiscale small targets and backgrounds are analyzed. The targets are characterized by various types, scale changes (from point sources to small surface sources), low intensity, fuzzy boundaries, lack of texture and color information, and unknown motion status. The background also exhibits characterization of by complex and variable scenes and serious noise interference. Then, the algorithm principles, related literature, and advantages and disadvantages of different algorithms for single-frame IR image using multiscale small-target detection techniques are summarized. In this review, we classify IR multiscale small-target single-frame detection techniques into two main categories: classical and deep learning algorithms. The former are classified into background estimation, morphological, directional derivative/gradient/entropy, local contrast, frequency-domain, overcomplete sparse representation, and sparse low-rank decomposition methods based on various modeling ideas. The latter are divided into convolutional neural networks (CNNs), classical algorithm + CNN, and CNN + Transformer based on network structure. In these network structures, for the adequate extraction of the IR multiscale small-target feature information, design strategies, such as contextual feature fusion, multi-scale feature fusion, dense nesting, and generative adversarial networks, have been introduced. To reduce the computational complexity or the limitation of data sample size, scholars introduced strategies, such as lightweight design and weak supervision. Classical algorithms and deep learning algorithms feature their on advantages and disadvantages, and thus, appropriate algorithms should be selected depending on specific problems and needs. In addition, the combination of the two types of algorithms to maximize their advantages is a current research hotspot. Finally, 10 existing public datasets and 17 evaluation metrics are organized, and 7 classical algorithms and 15 deep learning algorithms are selected for qualitative and quantitative comparative analysis. In addition, in the research process in this field, we have integrated 20 existing classical algorithms, 15 deep learning algorithms and 9 evaluation metrics in a human-computer interaction system, and the video introduction of the relevant system is published in kourenke/GUI-system-for-IR-small-target-detection (github.com). A comprehensive review of multiscale small-target detection techniques in single frame IR images resulted in 9 specific suggestions for subsequent research directions in this field. This review cannot only help beginners in rapidly comprehending the research status and development trends in this field but also serve as a reference material for other researchers.关键词:infrared image;multi-scale small target;target detection;classical algorithm;deep learning algorithm1588|981|2更新时间:2024-09-18
摘要:Traditional radar detection is almost ineffective in complex and strong electromagnetic interference environments, especially in the case of stealth targets with an extremely low-radar cross-section. In such scenarios, the infrared search and track (IRST) system, with its strong anti-interference capability and all-weather and all-airspace passive detection, emerges as a viable alternative to radar in target detection. Therefore, this system is widely used, such as reconnaissance and early warning, maritime surveillance, and precision guidance. However, the efficient and accurate use of the IRST system when identifying noncooperative small targets with minimal features, low intensity, scale variations, and unknown motion states in complex backgrounds and amidst noise interference remains a challenging task, which draws attention from scholars globally. To date, the research on infrared (IR) small-target detection technology mainly focuses on long-distance weak and small (point source) targets. However, when the scene and target scale change considerably, false alarms or missed detections easily occur. Therefore, this review focuses on the problem of IR multiscale small-target detection technology. To provide a comprehensive understanding of the current research status in this domain, this review summarizes the field from the perspectives of algorithm principles, literature, datasets, evaluation metrics, experiments, and development directions. First, the research motivation is clarified. In practical application background, with the change in the motion state of noncooperative small targets, the scale also vary greatly, from point-like targets to small targets with fuzzy boundaries to small targets with clear outlines, which is usually difficult to distinguish properly. Therefore, to be more in line with practical application background, this review is comprehensively analyzed from the perspective of IR multiscale small-target detection technology. Second, the imaging characteristics of IR multiscale small targets and backgrounds are analyzed. The targets are characterized by various types, scale changes (from point sources to small surface sources), low intensity, fuzzy boundaries, lack of texture and color information, and unknown motion status. The background also exhibits characterization of by complex and variable scenes and serious noise interference. Then, the algorithm principles, related literature, and advantages and disadvantages of different algorithms for single-frame IR image using multiscale small-target detection techniques are summarized. In this review, we classify IR multiscale small-target single-frame detection techniques into two main categories: classical and deep learning algorithms. The former are classified into background estimation, morphological, directional derivative/gradient/entropy, local contrast, frequency-domain, overcomplete sparse representation, and sparse low-rank decomposition methods based on various modeling ideas. The latter are divided into convolutional neural networks (CNNs), classical algorithm + CNN, and CNN + Transformer based on network structure. In these network structures, for the adequate extraction of the IR multiscale small-target feature information, design strategies, such as contextual feature fusion, multi-scale feature fusion, dense nesting, and generative adversarial networks, have been introduced. To reduce the computational complexity or the limitation of data sample size, scholars introduced strategies, such as lightweight design and weak supervision. Classical algorithms and deep learning algorithms feature their on advantages and disadvantages, and thus, appropriate algorithms should be selected depending on specific problems and needs. In addition, the combination of the two types of algorithms to maximize their advantages is a current research hotspot. Finally, 10 existing public datasets and 17 evaluation metrics are organized, and 7 classical algorithms and 15 deep learning algorithms are selected for qualitative and quantitative comparative analysis. In addition, in the research process in this field, we have integrated 20 existing classical algorithms, 15 deep learning algorithms and 9 evaluation metrics in a human-computer interaction system, and the video introduction of the relevant system is published in kourenke/GUI-system-for-IR-small-target-detection (github.com). A comprehensive review of multiscale small-target detection techniques in single frame IR images resulted in 9 specific suggestions for subsequent research directions in this field. This review cannot only help beginners in rapidly comprehending the research status and development trends in this field but also serve as a reference material for other researchers.关键词:infrared image;multi-scale small target;target detection;classical algorithm;deep learning algorithm1588|981|2更新时间:2024-09-18 -
 摘要:In intelligent transportation systems (ITSs), vehicles are the most popular means of transportation. However, they become a security risk due to the frequent use by lawless elements. Thus, vehicle identification with use of monitoring equipment has become a research hotspot. Vehicle logo is the special identity of the vehicle, and it contains basic information of a vehicle brand manufacturer. Compared with the license plate, model, and color of the vehicle, the vehicle logo is relatively independent and reliable. The recognition of vehicle logos rapidly and accurately narrows down the scope of vehicle search, which makes it important in vehicle identification. This paper presents a systematic overview of the mainstream methods of vehicle logo recognition from the last decade to provide a reference for researchers in the field. The initial discussion focuses on vehicle logo recognition, which is continuously under construction and development. Vehicle identification provides a strong support to the development and maturity of ITSs. Vehicle identity comprises four parts: vehicle logos, license plates, vehicle models, and vehicle colors. For the reduced algorithmic costs and increased accuracy of vehicle identity recognition, vehicle logo recognition is the most suitable to be implemented for current needs. Second, the current international mainstream methods for vehicle logo recognition fall under classical and deep learning-based approaches, depending on their reliance on manual feature extraction. This section summarizes the advantages, disadvantages, and main ideas of both types of methods. Classical methods for the recognition of vehicle logos can design proprietary solutions for problems specific to vehicle logo recognition. Such methods show minimal dependence on the number of training samples and had low hardware requirements. However, they require manual feature extraction and cannot learn vehicle logo features independently for automatic recognition. The classical method for vehicle logo recognition involves the following steps: inputting of the image, preprocessing operations, feature extraction, recognition of vehicle logos, and outputting of the final result with accuracy. Vehicle logo recognition based on deep learning methods circumvents the laborious manual feature extraction process and exhibits an improved performance when sufficient samples are available. However, this step incurs high computational costs and demands the use of advanced hardware. The main approach of this method entails the creation of a vehicle logo recognition module and a model training module via deep learning techniques. The logo recognition module requires inputting the logo image, followed by preprocessing operations. Logo recognition is then accomplished through the application of deep learning methods, and the final performance refers to the accurate output of recognition findings. The model training module requires the preparation of a substantial dataset, application of preprocessing operations, connection of the neural network structure for independent learning and feature extraction from vehicle logo images, and utilization of a classification network for the recognition and classification of vehicle logos. These methods are further subdivided into contemporary international mainstream techniques. Classical vehicle logo recognition methods fall under four types: those based on scale-invariant feature transform feature extraction, histogram-of-oriented-gradient feature extraction, invariant moments, and other classical recognition methods. In addition, vehicle logo recognition based on deep learning methods come in three types: those based on you-only-look-once series of algorithms, deep residual network algorithms, and other algorithms based on convolutional neural networks (CNNs). This paper systematically sorted out the characteristics, advantages, and disadvantages of various algorithms and the datasets used in these methods. To reiterate, addressing the problem brought about by the scarcity of datasets on vehicle logos causes difficulty in the evaluation of the effectiveness of various algorithms and hinders the research on vehicle logos recognition. We explained in detail three publicly available vehicle logo datasets. Xiamen University Vehicle Logo Dataset (XMU), Vehicle Logo Dataset from Hefei University of Technology (HFUT-VL), and Vehicle Logo Dataset-45 (VLD-45) are available for researchers to conduct experiments and tests via the provided download addresses. In addition, we described four commonly used evaluation metrics and perform experiments on vehicle logo recognition methods based on these evaluation metrics using a publicly available dataset. Then, the results were compared and analyzed. Finally, regardless of excellent performance of conventional methods of vehicle logo recognition in small-sample environments and the numerous solutions proposed for certain complex environments, limitations were still encountered in complex and variable traffic situations. Although the use of a deep learning-based vehicle logo recognition method improved the recognition and robustness of the model after training, such an improvement came at the cost of training on a large-scale vehicle logo dataset and constantly updating hardware. By synthesizing the challenges faced by classical vehicle logo recognition methods in ITSs and vehicle logo recognition based on deep learning methods, this paper presents the following predictions and future development directions: 1) new algorithms can be developed for low-cost, highly robust, and efficient vehicle logo recognition for practical applications. Vehicle logo recognition represents a common image classification problem in complex traffic environments. This task inevitably faces severe challenges from various factors, such as lighting effects, inclination changes, occlusion, wear and tear, and extreme weather. The development of new algorithms that balance recognition accuracy and speed while reducing costs and complexity, which will expand the deployment scenarios of a model, remains a research direction worthy of continuous exploration. 2) Dynamic video research broadens the scope of applications in vehicle logo recognition. Vehicle logo recognition currently relies on static images, which presents challenges in data acquisition and expansion, consumes time and resources, and limits scalability and efficiency. Added complexity is encountered when dealing with multivehicle scenarios and continuous dynamic scenes. Dynamic video-based methods take advantage of easily collected video data and the capture of vehicle logos from diverse angles and environments. Consequently, video-based vehicle logo recognition opens avenues for future research with new opportunities and challenges. 3) Integration of the Transformer visual model improves the network structure to boost performance. Transformer neural networks, which show promise in recognition tasks, have gained attention for their exceptional representational capability and efficient processing of global information,. In contrast to CNNs, transformer visual models show excellent performance in image comprehension, global attention, and mitigation of feature loss. Thus, the incorporation of Transformer visual models in vehicle logo recognition research is of substantial value. 4) The combination of large artificial intelligence (AI) models improves cross-modal open-domain vehicle logo recognition via the integration of multimodal data for increased model robustness and accuracy. This approach assimilates vehicle logo features with associated textual data, such as manufacturer and model number, into a unified model to address limited multimodal information challenges. Large AI models effectively tackle data scarcity in the recognition of cross-modal open-domain decals and extract richer patterns from limited data to enhance the identification of unknown categories. Despite their powerful capabilities, deploying these models for vehicle logo recognition in open-domain scenarios poses financial challenges, which render their application a complex and cutting-edge task.关键词:intelligent transportation systems (ITSs);vehicle logo recognition;feature extraction;image classification;deep learning;review489|288|0更新时间:2024-09-18
摘要:In intelligent transportation systems (ITSs), vehicles are the most popular means of transportation. However, they become a security risk due to the frequent use by lawless elements. Thus, vehicle identification with use of monitoring equipment has become a research hotspot. Vehicle logo is the special identity of the vehicle, and it contains basic information of a vehicle brand manufacturer. Compared with the license plate, model, and color of the vehicle, the vehicle logo is relatively independent and reliable. The recognition of vehicle logos rapidly and accurately narrows down the scope of vehicle search, which makes it important in vehicle identification. This paper presents a systematic overview of the mainstream methods of vehicle logo recognition from the last decade to provide a reference for researchers in the field. The initial discussion focuses on vehicle logo recognition, which is continuously under construction and development. Vehicle identification provides a strong support to the development and maturity of ITSs. Vehicle identity comprises four parts: vehicle logos, license plates, vehicle models, and vehicle colors. For the reduced algorithmic costs and increased accuracy of vehicle identity recognition, vehicle logo recognition is the most suitable to be implemented for current needs. Second, the current international mainstream methods for vehicle logo recognition fall under classical and deep learning-based approaches, depending on their reliance on manual feature extraction. This section summarizes the advantages, disadvantages, and main ideas of both types of methods. Classical methods for the recognition of vehicle logos can design proprietary solutions for problems specific to vehicle logo recognition. Such methods show minimal dependence on the number of training samples and had low hardware requirements. However, they require manual feature extraction and cannot learn vehicle logo features independently for automatic recognition. The classical method for vehicle logo recognition involves the following steps: inputting of the image, preprocessing operations, feature extraction, recognition of vehicle logos, and outputting of the final result with accuracy. Vehicle logo recognition based on deep learning methods circumvents the laborious manual feature extraction process and exhibits an improved performance when sufficient samples are available. However, this step incurs high computational costs and demands the use of advanced hardware. The main approach of this method entails the creation of a vehicle logo recognition module and a model training module via deep learning techniques. The logo recognition module requires inputting the logo image, followed by preprocessing operations. Logo recognition is then accomplished through the application of deep learning methods, and the final performance refers to the accurate output of recognition findings. The model training module requires the preparation of a substantial dataset, application of preprocessing operations, connection of the neural network structure for independent learning and feature extraction from vehicle logo images, and utilization of a classification network for the recognition and classification of vehicle logos. These methods are further subdivided into contemporary international mainstream techniques. Classical vehicle logo recognition methods fall under four types: those based on scale-invariant feature transform feature extraction, histogram-of-oriented-gradient feature extraction, invariant moments, and other classical recognition methods. In addition, vehicle logo recognition based on deep learning methods come in three types: those based on you-only-look-once series of algorithms, deep residual network algorithms, and other algorithms based on convolutional neural networks (CNNs). This paper systematically sorted out the characteristics, advantages, and disadvantages of various algorithms and the datasets used in these methods. To reiterate, addressing the problem brought about by the scarcity of datasets on vehicle logos causes difficulty in the evaluation of the effectiveness of various algorithms and hinders the research on vehicle logos recognition. We explained in detail three publicly available vehicle logo datasets. Xiamen University Vehicle Logo Dataset (XMU), Vehicle Logo Dataset from Hefei University of Technology (HFUT-VL), and Vehicle Logo Dataset-45 (VLD-45) are available for researchers to conduct experiments and tests via the provided download addresses. In addition, we described four commonly used evaluation metrics and perform experiments on vehicle logo recognition methods based on these evaluation metrics using a publicly available dataset. Then, the results were compared and analyzed. Finally, regardless of excellent performance of conventional methods of vehicle logo recognition in small-sample environments and the numerous solutions proposed for certain complex environments, limitations were still encountered in complex and variable traffic situations. Although the use of a deep learning-based vehicle logo recognition method improved the recognition and robustness of the model after training, such an improvement came at the cost of training on a large-scale vehicle logo dataset and constantly updating hardware. By synthesizing the challenges faced by classical vehicle logo recognition methods in ITSs and vehicle logo recognition based on deep learning methods, this paper presents the following predictions and future development directions: 1) new algorithms can be developed for low-cost, highly robust, and efficient vehicle logo recognition for practical applications. Vehicle logo recognition represents a common image classification problem in complex traffic environments. This task inevitably faces severe challenges from various factors, such as lighting effects, inclination changes, occlusion, wear and tear, and extreme weather. The development of new algorithms that balance recognition accuracy and speed while reducing costs and complexity, which will expand the deployment scenarios of a model, remains a research direction worthy of continuous exploration. 2) Dynamic video research broadens the scope of applications in vehicle logo recognition. Vehicle logo recognition currently relies on static images, which presents challenges in data acquisition and expansion, consumes time and resources, and limits scalability and efficiency. Added complexity is encountered when dealing with multivehicle scenarios and continuous dynamic scenes. Dynamic video-based methods take advantage of easily collected video data and the capture of vehicle logos from diverse angles and environments. Consequently, video-based vehicle logo recognition opens avenues for future research with new opportunities and challenges. 3) Integration of the Transformer visual model improves the network structure to boost performance. Transformer neural networks, which show promise in recognition tasks, have gained attention for their exceptional representational capability and efficient processing of global information,. In contrast to CNNs, transformer visual models show excellent performance in image comprehension, global attention, and mitigation of feature loss. Thus, the incorporation of Transformer visual models in vehicle logo recognition research is of substantial value. 4) The combination of large artificial intelligence (AI) models improves cross-modal open-domain vehicle logo recognition via the integration of multimodal data for increased model robustness and accuracy. This approach assimilates vehicle logo features with associated textual data, such as manufacturer and model number, into a unified model to address limited multimodal information challenges. Large AI models effectively tackle data scarcity in the recognition of cross-modal open-domain decals and extract richer patterns from limited data to enhance the identification of unknown categories. Despite their powerful capabilities, deploying these models for vehicle logo recognition in open-domain scenarios poses financial challenges, which render their application a complex and cutting-edge task.关键词:intelligent transportation systems (ITSs);vehicle logo recognition;feature extraction;image classification;deep learning;review489|288|0更新时间:2024-09-18 -
 摘要:In the context of deep learning, an increasing number of fields are adopting deep and recurrent neural networks to construct high-performance data-driven models. Text recognition is widely applied in daily life fields, such as autonomous driving, product retrieval, text translation, document recognition, and logistics sorting. The detection and recognition of text from scene images can considerably reduce labor costs, improve work efficiency, and promote the development of information intelligence. Therefore, the research on text detection and recognition technology has practical and scientific value. The field of text recognition has resulted in the use of methods from recognition and sequence networks, which led to evolving technologies, such as methods based on connectionist temporal classification (CTC) loss, those based on attention mechanisms, and end-to-end recognition. CTC- and attention-based approaches perceive the task of matching text images with the corresponding character sequences as a sequence-to-sequence recognition issue by employing an encoder for the process. End-to-end text recognition methods meld text detection and recognition modules into a unified model, which facilitates the simultaneous training of both modules. Although the advancement of deep learning has driven the development of optical character recognition (OCR) technology, some researchers have discovered serious vulnerabilities in deep models: The addition of minute disturbances to images can cause the model to make incorrect judgments. In applications demanding a high performance, this phenomenon greatly hinders the application process of deep models. Therefore, an increasing number of researchers are beginning to focus on strategies for understanding the deep model’s response to this anomaly. Before understanding how the model resists this disturbance’s performance, a key task is discovering a mechanism for better disturbance generate, i.e., how to attack the model. Thus, most current research focuses on the development of algorithms that can generate disturbances efficiently. This article reviews and summarizes various adversarial examples of attack methods proposed in the field of text recognition. Approaches to adversarial attacks are divided into three types: gradient-, optimization-, and generative model-based types. These categories are further delineated into white- and black-box techniques, which are contingent upon the level of access to model parameters. In the field of text recognition, prevalent attack strategies involve watermark tactics and cleverly embed disturbances within the watermark. This approach maintains the attack success rate whilst rendering the adversarial image perceptibly natural to the human observer. Common attack methods also include additive and erosion disturbances and minimal pixel attack methods. Generative adversarial network-based attacks have contributed to the research on English and Chinese font-style generation. They deceive machine learning models by producing examples similar to the original data and thereby improve the robustness and reliability of OCR models. The research on Chinese font-style conversion can be attributed to three categories: 1) Stroke trajectory-based Chinese character generation methods generate novel characters by scrutinizing the stroke trajectory inherent to Chinese script. These techniques harness the unique stroke traits of Chinese characters to engender properties with similar stylistic attributes to accomplish style transference; 2) Style-based Chinese character generation methods generate new Chinese characters of specific style by learning the style features of various fonts; 3) Methods based on content and style features generate Chinese characters with specific style and content by learning the representation of content and style features. The attack of OCR adversarial examples provoked reflections on the security of neural networks. Some defense methods include data preprocessing, text tampering detection, and traditional adversarial sample defense methods. Finally, this review summarizes the challenges faced by adversarial sample attacks and defenses in text recognition. In the future, the transition from a white-box environment to a black-box environment requires extreme amount of attraction. In classification models, the content of black-box queries is relatively direct object, with only the unnormalized logical output of the last layer of the model needed to be obtained. However, sequence tasks are incapable of performing single-step output, which makes more effective attacks in fewer query environments a challenging problem. Considerable advancements have been attained in response generation during the advent of substantial vision-language models, such GPT-4. Regardless, the associated privacy and security concerns warrant attention, and thus, the adversarial robustness of large models needs further research. This review aims to provide a comprehensive perspective for the comprehension and resolution of adversarial problems in recognition to find the right balance between practicality and security and promote the continuous progress of the field.关键词:optical character recognition (OCR);scene text recognition (STR);adversarial examples;generative adversarial network (GAN);deep learning;sequence model494|287|1更新时间:2024-09-18
摘要:In the context of deep learning, an increasing number of fields are adopting deep and recurrent neural networks to construct high-performance data-driven models. Text recognition is widely applied in daily life fields, such as autonomous driving, product retrieval, text translation, document recognition, and logistics sorting. The detection and recognition of text from scene images can considerably reduce labor costs, improve work efficiency, and promote the development of information intelligence. Therefore, the research on text detection and recognition technology has practical and scientific value. The field of text recognition has resulted in the use of methods from recognition and sequence networks, which led to evolving technologies, such as methods based on connectionist temporal classification (CTC) loss, those based on attention mechanisms, and end-to-end recognition. CTC- and attention-based approaches perceive the task of matching text images with the corresponding character sequences as a sequence-to-sequence recognition issue by employing an encoder for the process. End-to-end text recognition methods meld text detection and recognition modules into a unified model, which facilitates the simultaneous training of both modules. Although the advancement of deep learning has driven the development of optical character recognition (OCR) technology, some researchers have discovered serious vulnerabilities in deep models: The addition of minute disturbances to images can cause the model to make incorrect judgments. In applications demanding a high performance, this phenomenon greatly hinders the application process of deep models. Therefore, an increasing number of researchers are beginning to focus on strategies for understanding the deep model’s response to this anomaly. Before understanding how the model resists this disturbance’s performance, a key task is discovering a mechanism for better disturbance generate, i.e., how to attack the model. Thus, most current research focuses on the development of algorithms that can generate disturbances efficiently. This article reviews and summarizes various adversarial examples of attack methods proposed in the field of text recognition. Approaches to adversarial attacks are divided into three types: gradient-, optimization-, and generative model-based types. These categories are further delineated into white- and black-box techniques, which are contingent upon the level of access to model parameters. In the field of text recognition, prevalent attack strategies involve watermark tactics and cleverly embed disturbances within the watermark. This approach maintains the attack success rate whilst rendering the adversarial image perceptibly natural to the human observer. Common attack methods also include additive and erosion disturbances and minimal pixel attack methods. Generative adversarial network-based attacks have contributed to the research on English and Chinese font-style generation. They deceive machine learning models by producing examples similar to the original data and thereby improve the robustness and reliability of OCR models. The research on Chinese font-style conversion can be attributed to three categories: 1) Stroke trajectory-based Chinese character generation methods generate novel characters by scrutinizing the stroke trajectory inherent to Chinese script. These techniques harness the unique stroke traits of Chinese characters to engender properties with similar stylistic attributes to accomplish style transference; 2) Style-based Chinese character generation methods generate new Chinese characters of specific style by learning the style features of various fonts; 3) Methods based on content and style features generate Chinese characters with specific style and content by learning the representation of content and style features. The attack of OCR adversarial examples provoked reflections on the security of neural networks. Some defense methods include data preprocessing, text tampering detection, and traditional adversarial sample defense methods. Finally, this review summarizes the challenges faced by adversarial sample attacks and defenses in text recognition. In the future, the transition from a white-box environment to a black-box environment requires extreme amount of attraction. In classification models, the content of black-box queries is relatively direct object, with only the unnormalized logical output of the last layer of the model needed to be obtained. However, sequence tasks are incapable of performing single-step output, which makes more effective attacks in fewer query environments a challenging problem. Considerable advancements have been attained in response generation during the advent of substantial vision-language models, such GPT-4. Regardless, the associated privacy and security concerns warrant attention, and thus, the adversarial robustness of large models needs further research. This review aims to provide a comprehensive perspective for the comprehension and resolution of adversarial problems in recognition to find the right balance between practicality and security and promote the continuous progress of the field.关键词:optical character recognition (OCR);scene text recognition (STR);adversarial examples;generative adversarial network (GAN);deep learning;sequence model494|287|1更新时间:2024-09-18 -
 摘要:Vessel and airway segmentation are arouse considerable interest in medical image analysis. Vessel and airway abnormalities, such as thickening and sclerosis of arterial walls, bleeding due to cerebrovascular rupture, and tumors in lungs or airways, must be evaluated for the corresponding early diagnosis and clinical treatment guidance. The development of medical imaging technology made image segmentation techniques important in the evaluation and diagnosis of such structural abnormalities. However, the accurate segmentation of vessels and airways presents a challenge due to their complex structural and pathological variations. Most studies have focused on specific types of vessels or airway segmentation, and comprehensive reviews of various vessel types and airway segmentation methods are relatively lacking. Medical experts and researchers can benefit from a comprehensive review of all types of vessels and airways, which can serve as a comprehensive clinical reference. In addition, various types of vessels and airways show morphological similarities, and certain algorithms and techniques can be simultaneously applied in their segmentation, with a comprehensive review expanding the breadth of discussion. Therefore, this paper summarizes four types of representative research on retinal vessel segmentation, cerebral vessel segmentation, coronary artery segmentation, and airway segmentation in the past two decades and reviews each type of research from three aspects: traditional, machine learning, and deep learning methods, In addition, this review summarizes the advantages and disadvantages of these various methods to provide theoretical references for subsequent studies. Moreover, this paper introduces loss functions, evaluation metrics that apply to vessel and airway segmentation in medical images, and collates currently publicly available datasets on various types of vessel and airway segmentation. Finally, this paper discusses the limitations of the current methods for medical image vessel and airway segmentation and future research directions. In our research, we have identified DRIVE and STARE datasets as prevailing public benchmarks for retinal vessel segmentation tasks and established a standardized system for evaluation metrics. Such development offers valuable insights and guidance in the advancement of this field. However, in regard to cerebrovascular and coronary artery segmentation tasks, various research endeavor utilized datasets that s exhibit substantial heterogeneity and are seldom publicly accessible. Furthermore, various studies apply inconsistent evaluation metrics, which underscores the imperative need for increased attention and progress in this domain. In addition, in the context of airway segmentation tasks, numerous research have adopted custom metrics, such as Branch Detected and Tree-length Detected, which enable precise assessment based on airway-specific attributes and are highly relevant to other types of segmentation tasks. The various subtypes of vessel and airway segmentation tasks share commonalities while also displaying distinctive features. On one hand, conventional techniques, such as threshold segmentation and morphological transformations, are widely applied in each segmentation task, with a focus on the processing of raw and grayscale image data. Traditional machine learning methods predominantly depend on the application of mathematical techniques and stochastic models to improve segmentation outcomes and focus on feature enhancement and noise reduction. Conversely, deep learning methods address specific challenges unique to each domain in various tasks while adapting to particular issues encountered. In the case of retinal vessel segmentation, most research initiatives concentrate on overcoming the challenges posed by capillaries. Cerebrovascular and coronary artery segmentation face the challenges associated with data scarcity and compromised image quality due to the limited number of datasets. In addition, airway segmentation is a relatively well-explored area, with ongoing research endeavors concentrating on the improvement and completeness of segmentation coherence to augment its clinical applicability. Deep learning methods have prevailed in current research due to their capacity for multilevel feature learning. Although notable progress has been achieved in the field of medical imaging for vessels and airway segmentation via deep learning, certain limitations persist, and pressing issues warrant attention. First, vessels and airway datasets have limited sizes, which constrains the generalizability of deep-learning models and renders them susceptible to overfitting during training. Second, the application of inconsistent evaluation metrics and undisclosed datasets in most studies hampers objective comparisons among algorithms in the same field and research progress. Third, supervised methods continually dominate the vessel and airway segmentation landscape. Notably, current endeavors are aimed at addressing the shortage of adequately labeled vessel image datasets through the use of unsupervised or semisupervised deep-learning techniques. Although these methods, which include approaches such as reinforcement learning, generative networks, and recurrent networks, may not be directly applicable to clinical vessel segmentation, they are garnering increased research interest. Furthermore, evaluation of vessels and airway segmentation models solely based on metrics, such as accuracy, intersection over union, and Dice coefficient, falls short. A comprehensive and standardized evaluation framework specific to vessels and airway segmentation, which necessitates systematic and meticulous research and formulation, must be developed. In addition, the evolution of imaging technology has resulted in production of high-resolution vessel and airway images but at the cost of increased computational demands. Nonetheless, numerous clinical applications demand real-time processing, but limited attention has been devoted to addressing this issue. Consequently, future research endeavors should focus on the reduction of the computational burden of segmentation algorithms. The research on medical imaging vessels and tracheal segmentation can be directed toward several key areas. First, with the continual advancement of medical imaging technology, the integration of medical image data from various modalities has been expanding. Consequently, medical imaging vessels and airway segmentation will increasingly focus on the exploration of the segmentation of multimodal images and effective strategies for the fusion of multiple image information. Second, the precise assessment of segmentation algorithm performance and guide model improvement can be attained through the development of specialized metrics tailored to distinguishing the characteristics of vessels and airway segmentation, such as the clDice metric emphasizing connectivity. Third, the research focus will pivot toward real-time vessel and airway segmentation in medical imaging, which will facilitate immediate analysis and diagnosis, which is critical for intraoperative navigation and emergency medicine, during image acquisition. Finally, despite the high number of methods developed for medical imaging vessels and airway segmentation, a universal macromodel suitable for all applications is lacking. Another crucial direction is the development of a versatile macromodel for medical imaging vessels and airway segmentation, which will leverage powerful computational capabilities and large-scale data training to construct accurate, efficient, and broadly applicable medical-image segmentation models. This direction holds promise in the context of the complex and diverse nature of medical imaging data.关键词:deep learning;medical image segmentation;retinal vessel segmentation;cerebrovascular segmentation;coronary artery segmentation;airway segmentation;image processing595|1393|0更新时间:2024-09-18
摘要:Vessel and airway segmentation are arouse considerable interest in medical image analysis. Vessel and airway abnormalities, such as thickening and sclerosis of arterial walls, bleeding due to cerebrovascular rupture, and tumors in lungs or airways, must be evaluated for the corresponding early diagnosis and clinical treatment guidance. The development of medical imaging technology made image segmentation techniques important in the evaluation and diagnosis of such structural abnormalities. However, the accurate segmentation of vessels and airways presents a challenge due to their complex structural and pathological variations. Most studies have focused on specific types of vessels or airway segmentation, and comprehensive reviews of various vessel types and airway segmentation methods are relatively lacking. Medical experts and researchers can benefit from a comprehensive review of all types of vessels and airways, which can serve as a comprehensive clinical reference. In addition, various types of vessels and airways show morphological similarities, and certain algorithms and techniques can be simultaneously applied in their segmentation, with a comprehensive review expanding the breadth of discussion. Therefore, this paper summarizes four types of representative research on retinal vessel segmentation, cerebral vessel segmentation, coronary artery segmentation, and airway segmentation in the past two decades and reviews each type of research from three aspects: traditional, machine learning, and deep learning methods, In addition, this review summarizes the advantages and disadvantages of these various methods to provide theoretical references for subsequent studies. Moreover, this paper introduces loss functions, evaluation metrics that apply to vessel and airway segmentation in medical images, and collates currently publicly available datasets on various types of vessel and airway segmentation. Finally, this paper discusses the limitations of the current methods for medical image vessel and airway segmentation and future research directions. In our research, we have identified DRIVE and STARE datasets as prevailing public benchmarks for retinal vessel segmentation tasks and established a standardized system for evaluation metrics. Such development offers valuable insights and guidance in the advancement of this field. However, in regard to cerebrovascular and coronary artery segmentation tasks, various research endeavor utilized datasets that s exhibit substantial heterogeneity and are seldom publicly accessible. Furthermore, various studies apply inconsistent evaluation metrics, which underscores the imperative need for increased attention and progress in this domain. In addition, in the context of airway segmentation tasks, numerous research have adopted custom metrics, such as Branch Detected and Tree-length Detected, which enable precise assessment based on airway-specific attributes and are highly relevant to other types of segmentation tasks. The various subtypes of vessel and airway segmentation tasks share commonalities while also displaying distinctive features. On one hand, conventional techniques, such as threshold segmentation and morphological transformations, are widely applied in each segmentation task, with a focus on the processing of raw and grayscale image data. Traditional machine learning methods predominantly depend on the application of mathematical techniques and stochastic models to improve segmentation outcomes and focus on feature enhancement and noise reduction. Conversely, deep learning methods address specific challenges unique to each domain in various tasks while adapting to particular issues encountered. In the case of retinal vessel segmentation, most research initiatives concentrate on overcoming the challenges posed by capillaries. Cerebrovascular and coronary artery segmentation face the challenges associated with data scarcity and compromised image quality due to the limited number of datasets. In addition, airway segmentation is a relatively well-explored area, with ongoing research endeavors concentrating on the improvement and completeness of segmentation coherence to augment its clinical applicability. Deep learning methods have prevailed in current research due to their capacity for multilevel feature learning. Although notable progress has been achieved in the field of medical imaging for vessels and airway segmentation via deep learning, certain limitations persist, and pressing issues warrant attention. First, vessels and airway datasets have limited sizes, which constrains the generalizability of deep-learning models and renders them susceptible to overfitting during training. Second, the application of inconsistent evaluation metrics and undisclosed datasets in most studies hampers objective comparisons among algorithms in the same field and research progress. Third, supervised methods continually dominate the vessel and airway segmentation landscape. Notably, current endeavors are aimed at addressing the shortage of adequately labeled vessel image datasets through the use of unsupervised or semisupervised deep-learning techniques. Although these methods, which include approaches such as reinforcement learning, generative networks, and recurrent networks, may not be directly applicable to clinical vessel segmentation, they are garnering increased research interest. Furthermore, evaluation of vessels and airway segmentation models solely based on metrics, such as accuracy, intersection over union, and Dice coefficient, falls short. A comprehensive and standardized evaluation framework specific to vessels and airway segmentation, which necessitates systematic and meticulous research and formulation, must be developed. In addition, the evolution of imaging technology has resulted in production of high-resolution vessel and airway images but at the cost of increased computational demands. Nonetheless, numerous clinical applications demand real-time processing, but limited attention has been devoted to addressing this issue. Consequently, future research endeavors should focus on the reduction of the computational burden of segmentation algorithms. The research on medical imaging vessels and tracheal segmentation can be directed toward several key areas. First, with the continual advancement of medical imaging technology, the integration of medical image data from various modalities has been expanding. Consequently, medical imaging vessels and airway segmentation will increasingly focus on the exploration of the segmentation of multimodal images and effective strategies for the fusion of multiple image information. Second, the precise assessment of segmentation algorithm performance and guide model improvement can be attained through the development of specialized metrics tailored to distinguishing the characteristics of vessels and airway segmentation, such as the clDice metric emphasizing connectivity. Third, the research focus will pivot toward real-time vessel and airway segmentation in medical imaging, which will facilitate immediate analysis and diagnosis, which is critical for intraoperative navigation and emergency medicine, during image acquisition. Finally, despite the high number of methods developed for medical imaging vessels and airway segmentation, a universal macromodel suitable for all applications is lacking. Another crucial direction is the development of a versatile macromodel for medical imaging vessels and airway segmentation, which will leverage powerful computational capabilities and large-scale data training to construct accurate, efficient, and broadly applicable medical-image segmentation models. This direction holds promise in the context of the complex and diverse nature of medical imaging data.关键词:deep learning;medical image segmentation;retinal vessel segmentation;cerebrovascular segmentation;coronary artery segmentation;airway segmentation;image processing595|1393|0更新时间:2024-09-18 -
 摘要:The research field of cross-view image geolocalization aims to determine the geographic location of images obtained from various viewpoints or perspectives to provide technical support for subsequent tasks, such as automatic driving, robot navigation, and three-dimensional reconstruction. This field involves matching images captured from different views, such as satellite and ground-level images, to accurately estimate their geographical coordinates. Cross-view image geolocalization presents difficulty due to differences in viewpoint, scale, illumination, and appearance among images. This process requires addressing the problems of viewpoint variation, geometric transformations, and handling the large search space of possible matching locations. Early studies on image geolocalization were mainly based on single-view images. Single-view image geolocalization can obtain the geolocation information of a given image by searching for the same-view reference image with prelabeled geolocation information from the image database. However, the traditional single-view image geolocalization method is usually limited by the quality and scale of the dataset, and thus, the positioning accuracy is usually low. To overcome these limitations, the researchers have proposed a series of cross-view image geolocalization methods that utilize image data from multiple perspectives to increase the positioning accuracy through the comparison and matching various perspectives. Given the complexity of geolocalization tasks and solutions, existing methods of cross-view image geolocalization can be classified in multiple ways. This review introduces various classification methods of cross-view image geolocalization and representative methods for each type, and compares their advantages and disadvantages. On the one hand, the diversification of platforms and the increase in multisource data provide more source data choices for cross-view image geolocalization. Based on the differences in matching image sources, cross-view image geolocalization methods can be classified into ground-satellite image- and drone-satellite image-oriented methods. Ground-satellite image-oriented geolocalization conducts image geolocalization on a satellite image based on a ground-view image to be queried. Although ground-satellite geolocalization has various application prospects, a huge visual difference exists between ground- and satellite-view images due to the large angle change, and thus, the matching task encounters difficulty. The drone-satellite geolocalization task, despite being a relatively new method of cross-view image geolocalization, is receiving increasing attention. Unlike the ground image, the drone experiences less occlusion, covers more scenes, and is found near the satellite perspective. The release of University-1652, a geolocalization dataset containing drone, ground, and satellite images, provides data support for related research. On the other hand, feature extraction can be used to solve the geographic location problem of horizontal images. Based on the diverse methods of image feature extraction and expression, cross-view image geolocation methods can be classified into those that are based on artificially designed features and those based on self-learning features of deep neural networks. The former mainly comprise methods based on hand-crafted feature descriptors, such as scale-invariant feature transform, speeded-up robust features, and oriented FAST and rotated BRIEF, which can often be used for similarity measurement using Euclidean or cosine distance or be directly inputted into machine learning models, such as support vector machines and random forest models. Nevertheless, methods belonging to this category exhibit a weak robustness, cannot be finetuned for specific tasks, and have limited accuracy. With the rise of deep learning and the release of large annotated datasets, such as CVUSA and CVACT, deep neural networks have been applied to cross-view image geolocation. Based on whether view alignment is incorporated and the manner of its implementation, methods based on self-learning features of deep neural networks can be subdivided into three categories, namely, those without view alignment processing, those with a view alignment based on traditional image transformations, and those with a view alignment based on image generation. Methods without a view alignment processing focus on end-to-end learning of image feature representation with sufficient discriminative capability, and deep neural networks are mainly based on convolutional neural networks and attention mechanisms. This kind of method is dedicated to making full use of content information in images but often ignores the spatial relationship between images of different views (such as ground and aerial views). This defect is compensated by methods with view alignment based on traditional image transformations. Traditional image-transforming methods were used to explicitly provide additional spatial information for input images, which narrows the domain gap between cross-view images. This kind of method includes polar coordinate transformation and perspective image transformation. Methods with view alignment based on image generation usually utilize generative neural networks first to generate image samples with realistic view angles and match these generated images with real ones to infer their corresponding geographical positions. The generative adversarial network is a representative method in this category. Apart from the description and categorization of methods, the commonly used datasets, including CVUSA, CVACT, and VIGOR for street view-satellite image matching, University-1652 for ground-drone-satellite image matching, and SUES-200 for drone-satellite image matching, and their characteristics for cross-view image geolocalization are summarized. In addition, this paper summarizes the commonly used metrics for model performance evaluation, including Recall@K, average precision (AP), and Hit Rate-K. The evaluation was based on the performances of CVUSA, CVACT, and University-1625. Finally, this review offers an view on the application areas and future development directions of cross-view image geolocalization. Although this research field has achieved considerable breakthroughs and progress, it still faces certain obstacles and challenges, such as the lack of multimodal datasets, challenges in nonrigid scenarios, and the need for real-time and online geolocation. Possible solutions and future research priorities have been proposed to further promote the development and innovation shown in this field. Such solutions include the creation of multimode geolocalization datasets, combination of multiscale and multiview information to solve the geo-location problem in nonrigid scenes, and fusion of other sensor data to achieve real-time geolocation.关键词:image geolocalization;cross-view;image matching;deep learning;representation learning;perspective transformation627|1233|0更新时间:2024-09-18
摘要:The research field of cross-view image geolocalization aims to determine the geographic location of images obtained from various viewpoints or perspectives to provide technical support for subsequent tasks, such as automatic driving, robot navigation, and three-dimensional reconstruction. This field involves matching images captured from different views, such as satellite and ground-level images, to accurately estimate their geographical coordinates. Cross-view image geolocalization presents difficulty due to differences in viewpoint, scale, illumination, and appearance among images. This process requires addressing the problems of viewpoint variation, geometric transformations, and handling the large search space of possible matching locations. Early studies on image geolocalization were mainly based on single-view images. Single-view image geolocalization can obtain the geolocation information of a given image by searching for the same-view reference image with prelabeled geolocation information from the image database. However, the traditional single-view image geolocalization method is usually limited by the quality and scale of the dataset, and thus, the positioning accuracy is usually low. To overcome these limitations, the researchers have proposed a series of cross-view image geolocalization methods that utilize image data from multiple perspectives to increase the positioning accuracy through the comparison and matching various perspectives. Given the complexity of geolocalization tasks and solutions, existing methods of cross-view image geolocalization can be classified in multiple ways. This review introduces various classification methods of cross-view image geolocalization and representative methods for each type, and compares their advantages and disadvantages. On the one hand, the diversification of platforms and the increase in multisource data provide more source data choices for cross-view image geolocalization. Based on the differences in matching image sources, cross-view image geolocalization methods can be classified into ground-satellite image- and drone-satellite image-oriented methods. Ground-satellite image-oriented geolocalization conducts image geolocalization on a satellite image based on a ground-view image to be queried. Although ground-satellite geolocalization has various application prospects, a huge visual difference exists between ground- and satellite-view images due to the large angle change, and thus, the matching task encounters difficulty. The drone-satellite geolocalization task, despite being a relatively new method of cross-view image geolocalization, is receiving increasing attention. Unlike the ground image, the drone experiences less occlusion, covers more scenes, and is found near the satellite perspective. The release of University-1652, a geolocalization dataset containing drone, ground, and satellite images, provides data support for related research. On the other hand, feature extraction can be used to solve the geographic location problem of horizontal images. Based on the diverse methods of image feature extraction and expression, cross-view image geolocation methods can be classified into those that are based on artificially designed features and those based on self-learning features of deep neural networks. The former mainly comprise methods based on hand-crafted feature descriptors, such as scale-invariant feature transform, speeded-up robust features, and oriented FAST and rotated BRIEF, which can often be used for similarity measurement using Euclidean or cosine distance or be directly inputted into machine learning models, such as support vector machines and random forest models. Nevertheless, methods belonging to this category exhibit a weak robustness, cannot be finetuned for specific tasks, and have limited accuracy. With the rise of deep learning and the release of large annotated datasets, such as CVUSA and CVACT, deep neural networks have been applied to cross-view image geolocation. Based on whether view alignment is incorporated and the manner of its implementation, methods based on self-learning features of deep neural networks can be subdivided into three categories, namely, those without view alignment processing, those with a view alignment based on traditional image transformations, and those with a view alignment based on image generation. Methods without a view alignment processing focus on end-to-end learning of image feature representation with sufficient discriminative capability, and deep neural networks are mainly based on convolutional neural networks and attention mechanisms. This kind of method is dedicated to making full use of content information in images but often ignores the spatial relationship between images of different views (such as ground and aerial views). This defect is compensated by methods with view alignment based on traditional image transformations. Traditional image-transforming methods were used to explicitly provide additional spatial information for input images, which narrows the domain gap between cross-view images. This kind of method includes polar coordinate transformation and perspective image transformation. Methods with view alignment based on image generation usually utilize generative neural networks first to generate image samples with realistic view angles and match these generated images with real ones to infer their corresponding geographical positions. The generative adversarial network is a representative method in this category. Apart from the description and categorization of methods, the commonly used datasets, including CVUSA, CVACT, and VIGOR for street view-satellite image matching, University-1652 for ground-drone-satellite image matching, and SUES-200 for drone-satellite image matching, and their characteristics for cross-view image geolocalization are summarized. In addition, this paper summarizes the commonly used metrics for model performance evaluation, including Recall@K, average precision (AP), and Hit Rate-K. The evaluation was based on the performances of CVUSA, CVACT, and University-1625. Finally, this review offers an view on the application areas and future development directions of cross-view image geolocalization. Although this research field has achieved considerable breakthroughs and progress, it still faces certain obstacles and challenges, such as the lack of multimodal datasets, challenges in nonrigid scenarios, and the need for real-time and online geolocation. Possible solutions and future research priorities have been proposed to further promote the development and innovation shown in this field. Such solutions include the creation of multimode geolocalization datasets, combination of multiscale and multiview information to solve the geo-location problem in nonrigid scenes, and fusion of other sensor data to achieve real-time geolocation.关键词:image geolocalization;cross-view;image matching;deep learning;representation learning;perspective transformation627|1233|0更新时间:2024-09-18
Review
-
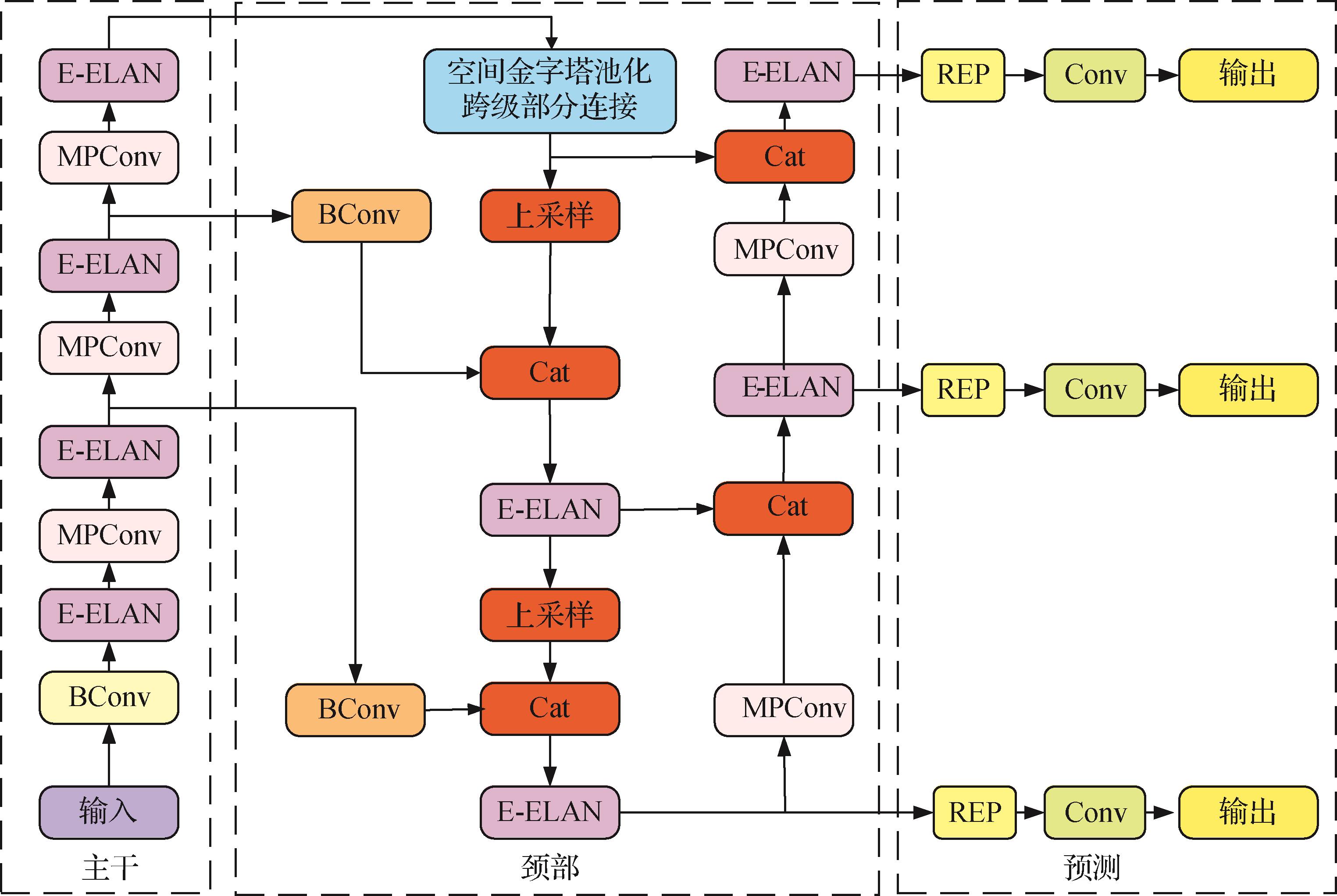 摘要:ObjectiveTraffic sign recognition has become an important research direction given the rapid development of driverless and assisted driving. To date, driverless and assisted driving pose additional requirements for accurate traffic sign recognition, especially in a real driving environment. The correct recognition rate of traffic signs is easily interfered by the external environment. In the identification of small-target traffic signs, most algorithms still present a very low accuracy, which easily results in erroneous and missed detection. Such a condition has a great impact on the driver’s accurate judgment of the state of road traffic signs. Given the hidden dangers of traffic, for the improved accuracy of traffic sign detection, the occurrence of accidents must be reduced and the driver’s driving safety be improved. On the basis of YOLOv7 model, this paper proposes a traffic sign recognition method to improve the YOLOv7 algorithm.MethodFirst, drawing on the idea of spacelab payload processing facility, on the basis of the spatial pyramid pooling cross stage partial cat (SPPCSPC) module of the original YOLOv7 model, the input feature map was reblocked, and pooling operations of different sizes are implemented in each block. Then, the pooled results were spliced based on the position of the original block. Finally, convolution operation was performed to obtain a new spatial pyramid pooling structure called spatial pyramid pooling fast cross stage partial concat (SPPFCSPC). Instead of the spatial pyramid pooling cross stage partial cat, the SPPFCSPC in the original model was used to pool the input feature map at multiple scales to optimize the training model, improve the accuracy of the algorithm, and identify targets more accurately. On the basis of this algorithm, given that the ordinary feature fusion method often adds characteristics of different resolutions after resizing without discrimination, to solve this problem, we used bidirectional feature pyramid network in the neck part to add a more weight to each input during feature fusion. Each input was allowed to learn the importance of each feature during fusion of features to effectively merge the multiscale features of the target and improve the detection capability for small targets. Then, aiming at the issue of small-target detection tasks requiring a high positioning performance, a normalized Wasserstein distance (NWD) method of interframe distance measurement was adopted to solve the high-sensitivity problem of the traditional intersection over union (IoU) metric in regard to small targets, which is used in anchor frame detectors to enhance the performance of nonmaximum suppression module and loss function. Specifically, bbox was remodeled as a two-dimensional Gaussian distribution for additional consistency with the characteristics of small targets, and the IoU of the prediction and truth boxes were converted into similarity between the two distributions. In addition, NWD was designed as a new evaluation indicator and used to measure the similarity of both distributions. The NWD metric can be applied to detectors that use the IoU metric, with the IoU being directly replaced with NWD. This metric can improve the capability to recognize traffic signs with less features in real traffic scenarios. Finally, through the lightweight upsampling content-aware reassembly of features operator, the output size of the input feature map was matched with the original image, and as a result, the input features were adapted to generate an upsampling kernel, realize the feature fusion of various scales, effectively increase the sensitivity domain of the model, improve the use of information around the target, increase the target detection capability, and reduce cases of missing detection.ResultThe experimental results show that the mAP@0.5 and mAP@0.5∶0.9 values of the model trained on the Tsinghua-Tencent 100K traffic sign dataset of the improved YOLOv7 algorithm reached 92.5% and 72.21%, respectively. In addition, the original YOLOv7 algorithm had mAP@0.5 and mAP@0.5∶0.9 values of 89.26% and 70.38%, respectively. Thus, its accuracy improved by 3.24% and 1.83%, respectively. Furthermore, the feasibility of improving the algorithm was verified on the CSUST Chinese traffic sign detection benchmark traffic sign dataset with small targets and the collated foreign traffic sign dataset. After experimental verification, compared with the original algorithm, the improved algorithm showed increased accuracies of 3.15% and 2.24% on the CSUST Chinese traffic sign detection benchmark dataset. In the collected foreign traffic sign dataset, after comparison with the original algorithm, the improved algorithm showed increased accuracies of 2.28% and 1.25%. Experiments revealed that the improved algorithm increased the recognition accuracy on the three traffic sign datasets.ConclusionExperimental verification and subjective and objective evaluation prove the feasibility and effectiveness of the improved YOLOv7 traffic sign recognition model in this paper. In addition, the improved model can effectively increase the recognition rate of ordinary and small-target traffic signs in various harsh environments under the premise of reducing the number of algorithm parameters. Thus, the improved model meets the recognition accuracy requirements of unmanned driving and assisted driving systems to a certain extent.关键词:traffic sign recognition;spatial pyramid pooling fast cross stage partial concat(SPPFCSPC);bi-directional feature pyramid network(BiFPN);normalized Wasserstein distance(NWD);content-aware reassembly of feature(CARAFE);small goals561|712|1更新时间:2024-09-18
摘要:ObjectiveTraffic sign recognition has become an important research direction given the rapid development of driverless and assisted driving. To date, driverless and assisted driving pose additional requirements for accurate traffic sign recognition, especially in a real driving environment. The correct recognition rate of traffic signs is easily interfered by the external environment. In the identification of small-target traffic signs, most algorithms still present a very low accuracy, which easily results in erroneous and missed detection. Such a condition has a great impact on the driver’s accurate judgment of the state of road traffic signs. Given the hidden dangers of traffic, for the improved accuracy of traffic sign detection, the occurrence of accidents must be reduced and the driver’s driving safety be improved. On the basis of YOLOv7 model, this paper proposes a traffic sign recognition method to improve the YOLOv7 algorithm.MethodFirst, drawing on the idea of spacelab payload processing facility, on the basis of the spatial pyramid pooling cross stage partial cat (SPPCSPC) module of the original YOLOv7 model, the input feature map was reblocked, and pooling operations of different sizes are implemented in each block. Then, the pooled results were spliced based on the position of the original block. Finally, convolution operation was performed to obtain a new spatial pyramid pooling structure called spatial pyramid pooling fast cross stage partial concat (SPPFCSPC). Instead of the spatial pyramid pooling cross stage partial cat, the SPPFCSPC in the original model was used to pool the input feature map at multiple scales to optimize the training model, improve the accuracy of the algorithm, and identify targets more accurately. On the basis of this algorithm, given that the ordinary feature fusion method often adds characteristics of different resolutions after resizing without discrimination, to solve this problem, we used bidirectional feature pyramid network in the neck part to add a more weight to each input during feature fusion. Each input was allowed to learn the importance of each feature during fusion of features to effectively merge the multiscale features of the target and improve the detection capability for small targets. Then, aiming at the issue of small-target detection tasks requiring a high positioning performance, a normalized Wasserstein distance (NWD) method of interframe distance measurement was adopted to solve the high-sensitivity problem of the traditional intersection over union (IoU) metric in regard to small targets, which is used in anchor frame detectors to enhance the performance of nonmaximum suppression module and loss function. Specifically, bbox was remodeled as a two-dimensional Gaussian distribution for additional consistency with the characteristics of small targets, and the IoU of the prediction and truth boxes were converted into similarity between the two distributions. In addition, NWD was designed as a new evaluation indicator and used to measure the similarity of both distributions. The NWD metric can be applied to detectors that use the IoU metric, with the IoU being directly replaced with NWD. This metric can improve the capability to recognize traffic signs with less features in real traffic scenarios. Finally, through the lightweight upsampling content-aware reassembly of features operator, the output size of the input feature map was matched with the original image, and as a result, the input features were adapted to generate an upsampling kernel, realize the feature fusion of various scales, effectively increase the sensitivity domain of the model, improve the use of information around the target, increase the target detection capability, and reduce cases of missing detection.ResultThe experimental results show that the mAP@0.5 and mAP@0.5∶0.9 values of the model trained on the Tsinghua-Tencent 100K traffic sign dataset of the improved YOLOv7 algorithm reached 92.5% and 72.21%, respectively. In addition, the original YOLOv7 algorithm had mAP@0.5 and mAP@0.5∶0.9 values of 89.26% and 70.38%, respectively. Thus, its accuracy improved by 3.24% and 1.83%, respectively. Furthermore, the feasibility of improving the algorithm was verified on the CSUST Chinese traffic sign detection benchmark traffic sign dataset with small targets and the collated foreign traffic sign dataset. After experimental verification, compared with the original algorithm, the improved algorithm showed increased accuracies of 3.15% and 2.24% on the CSUST Chinese traffic sign detection benchmark dataset. In the collected foreign traffic sign dataset, after comparison with the original algorithm, the improved algorithm showed increased accuracies of 2.28% and 1.25%. Experiments revealed that the improved algorithm increased the recognition accuracy on the three traffic sign datasets.ConclusionExperimental verification and subjective and objective evaluation prove the feasibility and effectiveness of the improved YOLOv7 traffic sign recognition model in this paper. In addition, the improved model can effectively increase the recognition rate of ordinary and small-target traffic signs in various harsh environments under the premise of reducing the number of algorithm parameters. Thus, the improved model meets the recognition accuracy requirements of unmanned driving and assisted driving systems to a certain extent.关键词:traffic sign recognition;spatial pyramid pooling fast cross stage partial concat(SPPFCSPC);bi-directional feature pyramid network(BiFPN);normalized Wasserstein distance(NWD);content-aware reassembly of feature(CARAFE);small goals561|712|1更新时间:2024-09-18 -
 摘要:ObjectivePalm vein recognition takes advantage the stability and uniqueness of human palm vein distribution for identification. The palm vein is hidden under the epidermis and cannot be photographed under visible light, and the replication of its complex structure presents difficulty. A severed palm or corpse fails certification because blood has stopped flowing, which makes palm vein recognition suitable for high-security applications. The noncontact collection in an open environment is more popular than the traditional collection method of placing the palm on a fixed bolt in the collection box. However, the opacity, inhomogeneity, and anisotropy of the skin tissue covering the palm vein cause scattering of near-infrared light. The visible light in open environments aggravates scattering and increases noise, which result in vague palm vein imaging in some people. The noncontact acquisition method increases the intraclass difference of the same sample increase due to rotation, translation, scaling, and illumination in multiple shots. The above difficulties make recognition challenging. A method based on unsupervised convolutional neural network was studied with aim of addressing such difficulties.MethodGiven that this paper requires a benchmark library to train the self-built network, a palm vein image library containing 600 images from 100 volunteers was established. Then, the program parameters were trained and adjusted using the self-built library. After several training adjustments, the optimal \and the trained network parameters were acquired. In image preprocessing, the region of interest (ROI) was extracted from all the palm vein images collected. First, the original palm vein image was denoised and binarized via low-pass filtering. Then, the palm contour was extracted via the dilation method in binary morphology. The obtained palm contour was refined into a single pixel, and the palm vein ROI was extracted using a method mentioned in literature. The extracted palm-vein ROI was adjusted based on the corresponding pixel size, and the mean was subtracted for normalization. A local region was extracted for each pixel in the processed ROI of the palm vein to ensure that it covers the entire ROI of the palm vein. In addition, all local regions are converted into vector forms. A filter of the principal component analysis was used to extract principal component information in the convolution layer to reduce the noise caused by visible light. The fixed-size Gabor filter was used to obtain prior knowledge on the multiscale adaptive Gabor filter to overcome the interferences resulting from image rotation, translation, scaling, and illumination changes on recognition and improve palm-vein stability features and recognition performance. Then, the amount of data was reduced by binarization. Finally, the adaptive K-nearest neighbors (Ada-KNN) variant classifier was used for classification and recognition. The Ada-KNN2 classifier uses heuristic learning method instead of neural network. With the use of density and distribution of the test point neighborhood, the specific k value suitable for the test point was determined using an artificial neural network to achieve efficient and accurate distinction between samples and solve the problem of the increased difference in the same sample image. In addition, unbalanced sample data are avoided, which a great influence on the results.ResultExperimental findings show that this method can effectively increase the recognition accuracy compared with traditional and classical network methods. The equal error rates (EERs) of the three libraries were 0.289 9%, 0.211 3%, and 0.158 6%, respectively. Compared with the traditional method that had the best effect on the three libraries during comparison, EER was reduced by 0.176 8%, 2.466 5%, and 1.468 1% compared with the classical network method that had the best effect. EER decreased by 0.033 3%, 0.233 3%, and 0.248 7%. The false rejection rate/false accept rate were 0.002 7/2.318 8, 0.002 3/1.282 1, and 0.000 0/1.596 2. In addition, from the generated receiver operating characteristic curve, the advantages of the method in recognition performance can be observed more intuitively. It can distinguish and recognize similar images to a great extent and improve the overall recognition performance. The proposed method also effectively solves the problem of increased differences in similar images due to alterations in rotation, translation, scaling, and illumination during noncontact acquisition, which led to a decrease in the recognition performance.ConclusionThe experimental findings underscore the effectiveness of the proposed method in addressing the aforementioned challenges. Nevertheless, the operational efficiency of this approach exhibits relative insufficiency. Consequently, further investigation and in-depth studies should be aimed at addressing this efficiency gap. Future research endeavors should cover strategies for the systematic enhancement of the operational efficiency without compromising the robustness and precision of the recognition process. One pivotal area of exploration pertains to sample size expansion, which warrants a meticulous examination of methodologies to ensure the scalability of the proposed approach. Concurrently, optimization measures should be meticulously devised to fine tune operational aspects to achieve an optimal balance between efficiency and accuracy.关键词:biometric identification;palm vein recognition;non-contact;near-infrared light image;convolutional neural network(CNN)159|272|0更新时间:2024-09-18
摘要:ObjectivePalm vein recognition takes advantage the stability and uniqueness of human palm vein distribution for identification. The palm vein is hidden under the epidermis and cannot be photographed under visible light, and the replication of its complex structure presents difficulty. A severed palm or corpse fails certification because blood has stopped flowing, which makes palm vein recognition suitable for high-security applications. The noncontact collection in an open environment is more popular than the traditional collection method of placing the palm on a fixed bolt in the collection box. However, the opacity, inhomogeneity, and anisotropy of the skin tissue covering the palm vein cause scattering of near-infrared light. The visible light in open environments aggravates scattering and increases noise, which result in vague palm vein imaging in some people. The noncontact acquisition method increases the intraclass difference of the same sample increase due to rotation, translation, scaling, and illumination in multiple shots. The above difficulties make recognition challenging. A method based on unsupervised convolutional neural network was studied with aim of addressing such difficulties.MethodGiven that this paper requires a benchmark library to train the self-built network, a palm vein image library containing 600 images from 100 volunteers was established. Then, the program parameters were trained and adjusted using the self-built library. After several training adjustments, the optimal \and the trained network parameters were acquired. In image preprocessing, the region of interest (ROI) was extracted from all the palm vein images collected. First, the original palm vein image was denoised and binarized via low-pass filtering. Then, the palm contour was extracted via the dilation method in binary morphology. The obtained palm contour was refined into a single pixel, and the palm vein ROI was extracted using a method mentioned in literature. The extracted palm-vein ROI was adjusted based on the corresponding pixel size, and the mean was subtracted for normalization. A local region was extracted for each pixel in the processed ROI of the palm vein to ensure that it covers the entire ROI of the palm vein. In addition, all local regions are converted into vector forms. A filter of the principal component analysis was used to extract principal component information in the convolution layer to reduce the noise caused by visible light. The fixed-size Gabor filter was used to obtain prior knowledge on the multiscale adaptive Gabor filter to overcome the interferences resulting from image rotation, translation, scaling, and illumination changes on recognition and improve palm-vein stability features and recognition performance. Then, the amount of data was reduced by binarization. Finally, the adaptive K-nearest neighbors (Ada-KNN) variant classifier was used for classification and recognition. The Ada-KNN2 classifier uses heuristic learning method instead of neural network. With the use of density and distribution of the test point neighborhood, the specific k value suitable for the test point was determined using an artificial neural network to achieve efficient and accurate distinction between samples and solve the problem of the increased difference in the same sample image. In addition, unbalanced sample data are avoided, which a great influence on the results.ResultExperimental findings show that this method can effectively increase the recognition accuracy compared with traditional and classical network methods. The equal error rates (EERs) of the three libraries were 0.289 9%, 0.211 3%, and 0.158 6%, respectively. Compared with the traditional method that had the best effect on the three libraries during comparison, EER was reduced by 0.176 8%, 2.466 5%, and 1.468 1% compared with the classical network method that had the best effect. EER decreased by 0.033 3%, 0.233 3%, and 0.248 7%. The false rejection rate/false accept rate were 0.002 7/2.318 8, 0.002 3/1.282 1, and 0.000 0/1.596 2. In addition, from the generated receiver operating characteristic curve, the advantages of the method in recognition performance can be observed more intuitively. It can distinguish and recognize similar images to a great extent and improve the overall recognition performance. The proposed method also effectively solves the problem of increased differences in similar images due to alterations in rotation, translation, scaling, and illumination during noncontact acquisition, which led to a decrease in the recognition performance.ConclusionThe experimental findings underscore the effectiveness of the proposed method in addressing the aforementioned challenges. Nevertheless, the operational efficiency of this approach exhibits relative insufficiency. Consequently, further investigation and in-depth studies should be aimed at addressing this efficiency gap. Future research endeavors should cover strategies for the systematic enhancement of the operational efficiency without compromising the robustness and precision of the recognition process. One pivotal area of exploration pertains to sample size expansion, which warrants a meticulous examination of methodologies to ensure the scalability of the proposed approach. Concurrently, optimization measures should be meticulously devised to fine tune operational aspects to achieve an optimal balance between efficiency and accuracy.关键词:biometric identification;palm vein recognition;non-contact;near-infrared light image;convolutional neural network(CNN)159|272|0更新时间:2024-09-18 -
An iris feature-encoding method by fusion of graph neural networks and convolutional neural networks
 摘要:ObjectiveIris recognition is a prevalent biometric feature in identity recognition technology owing to its inherent advantages, including stability, uniqueness, noncontact modality, and live-body authentication. The complete iris recognition workflow comprises four main steps: iris image acquisition, image preprocessing, feature encoding, and feature matching. Feature encoding serves as the core component of iris recognition algorithms. The improvement in interpretable iris feature encoding methods have become a pivotal concern in the field of iris recognition. Moreover, the recognition of low-quality iris samples, which often relies on specific parameter-dependent feature encoders, results in a poor generalization performance. The graph structure represents a data form with an irregular topological arrangement. Graph neural networks (GNNs) effectively update and aggregate features within such graph structures. The advancement of GNN led to the development of new approaches for feature encoding of these types of iris images. In this paper, a pioneering iris feature-fusion encoding network called IrisFusionNet, which integrates GNN with a convolutional neural network (CNN), is proposed. This network eradicates the need to implement complex parameter tuning steps and exhibits excellent generalization performance across various iris datasets.MethodIn the backbone network, the previously inserted pixel-level enhancement module alleviates local uncertainty in the input image through median filtering. In addition, global uncertainty was mitigated via Gaussian normalization. A dual-branch backbone network was proposed, where the head of the backbone network comprised a shared stack of CONV modules, and the neck was divided into two branches. The primary branch constructed a graph structure from an image using graph converter. We designed a hard graph attention network that introduces an efficient channel attention mechanism to aggregate and update features through utilization of edge-associated information within the graph structure. This step led to the extraction of microfeatures of iris textures. The auxiliary branch, on the other hand, used conventional CNN pipeline components, such as simple convolutional layers, pooling layers, and fully connected layers, to capture the macrostructural information on the iris. During the training phase, the fused features from the primary and auxiliary branches were optimized using a unique unified loss function graph triplet and additive angular margin unified loss (GTAU-Loss). The primary branch mapped iris images into a graph feature space, with the use of cosine similarity to measure semantic information in node feature vectors, L2 norm to measure the spatial relationship information within the adjacency matrix, and graph triplet loss to constrain feature distances within the feature space. The auxiliary branch applied an additional angular margin loss, which normalized the input image feature vectors and introduced an additional angular margin to constrain feature angle intervals, which improved intraclass feature compactness and interclass separation. Ultimately, a dynamic learning method based on an exponential model was used to fuse the features extracted from the primary and auxiliary branches and obtain the GTAU-Loss. The hyperparameter settings during training included the following: The optimization of network parameters involved the use of stochastic gradient descent (SGD) with a Nesterov momentum set to 0.9, an initial learning rate of 0.001, and a warm-up strategy adjusting the learning rate with a warm-up rate set to 0.1, conducted over 200 epochs. The iteration process of SGD was accelerated using NVIDIA RTX 3060 12 GB GPU devices, with 100 iterations lasting approximately one day. For feature matching concerning two distinct graph structures, the auxiliary branch calculated the cosine similarity between the output node features. Meanwhile, the primary branch applied a gate-based method and initially calculated the mean cosine similarity of all node pairs as the threshold for the gate, removed node pairs below this threshold, and retained node features above it to compute their cosine similarity. The similarity between these graph structures was represented as the weighted sum of cosine similarities from the primary and auxiliary branches. The similarity weights of the feature pairs computed using the primary and auxiliary branches were both set to 0.5. All experiments were conducted on a Windows 11 operating system, with PyTorch as the deep learning framework.ResultTo validate the effectiveness of integrating GNNs into the framework, this study conducted iris recognition experiments using a single-branch CNN framework and a dual-branch framework. The experimental outcomes substantiated the superior recognition performance involved in the structural design incorporating the GNN branch. Furthermore, to determine the optimal values for two crucial parameters, namely, the number of nearest neighbors (k) and the global feature dimension within the IrisFusionNet framework, we conducted detailed parameter experiments to determine their most favorable values. k was set to 8, and the optimal global feature dimension was 256. We compared the present method with several state-of-art (SOTA) methods in iris recognition, including CNN-based methods, such as ResNet, MobileNet, EfficientNet, ConvNext, etc., and GNN-based methods, such as dynamic graph representation. Comparative experimental results indicate that the feature extractor trained using IrisFusionNet, which was tested on three publicly, available low-quality iris datasets — CASIA-Iris-V4-Distance, CASIA-Iris-V4-Lamp, CASIA-Iris-Mobile-V1.0-S2—to achieve equal error rates of 1.06%, 0.71%, and 0.27% and false rejection rates at a false acceptance rate of 0.01% (FRR@FAR = 0.01%) of 7.49%, 4.21%, and 0.84%, respectively. In addition, the discriminant index reached 6.102, 6.574, and 8.451, which denote an improvement of over 30% compared with the baseline algorithm. The accuracy and clustering capability of iris recognition tasks using the feature extractor derived from IrisFusionNet substantially outperformed SOTA iris recognition algorithms based on convolutional neural networks and other GNN models. Furthermore, the graph structures derived from the graph transformer were visually displayed. The generated graph structures of similar iris images exhibited a high similarity, and those of dissimilar iris images presented remarkable differences. This intuitive visualization explained the excellent performance achieved in iris recognition by constructing graph structures and utilizing GNN methods.ConclusionIn this paper, we proposed a feature fusion coding a method based on GNN (IrisFusionNet). The macro features of iris images were extracted using the CNN and the micro features of iris images were extracted using GNNs to obtain fusion features encompassing comprehensive texture characteristics. The experimental results indicate that our method considerably improved the accuracy and clustering of iris recognition and obtained a high feasibility and generalizability without necessitating complex parameter tuning specific to particular datasets.关键词:iris feature coding;graph neural network (GNN);hard graph attention operators;feature fusion;unified loss function203|447|0更新时间:2024-09-18
摘要:ObjectiveIris recognition is a prevalent biometric feature in identity recognition technology owing to its inherent advantages, including stability, uniqueness, noncontact modality, and live-body authentication. The complete iris recognition workflow comprises four main steps: iris image acquisition, image preprocessing, feature encoding, and feature matching. Feature encoding serves as the core component of iris recognition algorithms. The improvement in interpretable iris feature encoding methods have become a pivotal concern in the field of iris recognition. Moreover, the recognition of low-quality iris samples, which often relies on specific parameter-dependent feature encoders, results in a poor generalization performance. The graph structure represents a data form with an irregular topological arrangement. Graph neural networks (GNNs) effectively update and aggregate features within such graph structures. The advancement of GNN led to the development of new approaches for feature encoding of these types of iris images. In this paper, a pioneering iris feature-fusion encoding network called IrisFusionNet, which integrates GNN with a convolutional neural network (CNN), is proposed. This network eradicates the need to implement complex parameter tuning steps and exhibits excellent generalization performance across various iris datasets.MethodIn the backbone network, the previously inserted pixel-level enhancement module alleviates local uncertainty in the input image through median filtering. In addition, global uncertainty was mitigated via Gaussian normalization. A dual-branch backbone network was proposed, where the head of the backbone network comprised a shared stack of CONV modules, and the neck was divided into two branches. The primary branch constructed a graph structure from an image using graph converter. We designed a hard graph attention network that introduces an efficient channel attention mechanism to aggregate and update features through utilization of edge-associated information within the graph structure. This step led to the extraction of microfeatures of iris textures. The auxiliary branch, on the other hand, used conventional CNN pipeline components, such as simple convolutional layers, pooling layers, and fully connected layers, to capture the macrostructural information on the iris. During the training phase, the fused features from the primary and auxiliary branches were optimized using a unique unified loss function graph triplet and additive angular margin unified loss (GTAU-Loss). The primary branch mapped iris images into a graph feature space, with the use of cosine similarity to measure semantic information in node feature vectors, L2 norm to measure the spatial relationship information within the adjacency matrix, and graph triplet loss to constrain feature distances within the feature space. The auxiliary branch applied an additional angular margin loss, which normalized the input image feature vectors and introduced an additional angular margin to constrain feature angle intervals, which improved intraclass feature compactness and interclass separation. Ultimately, a dynamic learning method based on an exponential model was used to fuse the features extracted from the primary and auxiliary branches and obtain the GTAU-Loss. The hyperparameter settings during training included the following: The optimization of network parameters involved the use of stochastic gradient descent (SGD) with a Nesterov momentum set to 0.9, an initial learning rate of 0.001, and a warm-up strategy adjusting the learning rate with a warm-up rate set to 0.1, conducted over 200 epochs. The iteration process of SGD was accelerated using NVIDIA RTX 3060 12 GB GPU devices, with 100 iterations lasting approximately one day. For feature matching concerning two distinct graph structures, the auxiliary branch calculated the cosine similarity between the output node features. Meanwhile, the primary branch applied a gate-based method and initially calculated the mean cosine similarity of all node pairs as the threshold for the gate, removed node pairs below this threshold, and retained node features above it to compute their cosine similarity. The similarity between these graph structures was represented as the weighted sum of cosine similarities from the primary and auxiliary branches. The similarity weights of the feature pairs computed using the primary and auxiliary branches were both set to 0.5. All experiments were conducted on a Windows 11 operating system, with PyTorch as the deep learning framework.ResultTo validate the effectiveness of integrating GNNs into the framework, this study conducted iris recognition experiments using a single-branch CNN framework and a dual-branch framework. The experimental outcomes substantiated the superior recognition performance involved in the structural design incorporating the GNN branch. Furthermore, to determine the optimal values for two crucial parameters, namely, the number of nearest neighbors (k) and the global feature dimension within the IrisFusionNet framework, we conducted detailed parameter experiments to determine their most favorable values. k was set to 8, and the optimal global feature dimension was 256. We compared the present method with several state-of-art (SOTA) methods in iris recognition, including CNN-based methods, such as ResNet, MobileNet, EfficientNet, ConvNext, etc., and GNN-based methods, such as dynamic graph representation. Comparative experimental results indicate that the feature extractor trained using IrisFusionNet, which was tested on three publicly, available low-quality iris datasets — CASIA-Iris-V4-Distance, CASIA-Iris-V4-Lamp, CASIA-Iris-Mobile-V1.0-S2—to achieve equal error rates of 1.06%, 0.71%, and 0.27% and false rejection rates at a false acceptance rate of 0.01% (FRR@FAR = 0.01%) of 7.49%, 4.21%, and 0.84%, respectively. In addition, the discriminant index reached 6.102, 6.574, and 8.451, which denote an improvement of over 30% compared with the baseline algorithm. The accuracy and clustering capability of iris recognition tasks using the feature extractor derived from IrisFusionNet substantially outperformed SOTA iris recognition algorithms based on convolutional neural networks and other GNN models. Furthermore, the graph structures derived from the graph transformer were visually displayed. The generated graph structures of similar iris images exhibited a high similarity, and those of dissimilar iris images presented remarkable differences. This intuitive visualization explained the excellent performance achieved in iris recognition by constructing graph structures and utilizing GNN methods.ConclusionIn this paper, we proposed a feature fusion coding a method based on GNN (IrisFusionNet). The macro features of iris images were extracted using the CNN and the micro features of iris images were extracted using GNNs to obtain fusion features encompassing comprehensive texture characteristics. The experimental results indicate that our method considerably improved the accuracy and clustering of iris recognition and obtained a high feasibility and generalizability without necessitating complex parameter tuning specific to particular datasets.关键词:iris feature coding;graph neural network (GNN);hard graph attention operators;feature fusion;unified loss function203|447|0更新时间:2024-09-18 -
 摘要:ObjectiveThe realm of our daily lives has witnessed the ubiquitous integration of fingerprint recognition technology in domains, such as authorized identification, fingerprint-based payments, and access control systems. However, recent studies have revealed the vulnerability of these systems to spoofing fingerprint attacks. Attackers can deceive authentication systems by imitating fingerprints using artificial materials. Thus, the authenticity of fingerprint under scrutiny must be ascertained prior to its use to authenticate the user's identity. The development of a spoofing fingerprint detection technology has attracted extensive attention from the academia and industry. The creation of spoofing fingerprints involve the use of diverse materials. The present research disregards the correlation of data distribution among spoofing fingerprints crafted from various materials, which consequently leads to limited generalization in cross-material detection. Hence, a high-generalization spoofing fingerprint detection method based on commonality feature learning is proposed through the analysis of the distribution correlation among counterfeit fingerprint data originating from diverse materials and the exploration of invariant forgery features within the material domain of distinct counterfeit fingerprints.MethodFirst, to characterize and learn the features of spoofing fingerprints obtained using various materials, a multiscale spoofing feature extractor (MFSE) is designed, and it includes a multiscale spatial-channel attention module to allow the MFSE to pay more attention to fine-grained differences between live and fake fingerprints and improve the capability of the network to learn spoofing features. Then, a common spoofing feature extractor (CSFE) is constructed for further analysis of the distribution correlation between spoofing fingerprint data of different materials and extraction of common spoofing features between spoofing fingerprints made from various materials. Under the guidance of prior knowledge on MFSE, CSFE calculates the distance of the feature distribution extracted by MFSE and CSFE in the regenerated Hilbert space through the feature distance measurement module and minimizes the maximum mean difference (MMD) of data distributions to reduce the distance between them. The multitask material domain invariant spoofing feature learning is implemented, and a material discriminator is designed to constrain the learned common spoofing features and remove specific material information from the spoofing fingerprint. CSFE involves the calculation of multiple loss functions. Manually setting the weight ratio of these loss functions may prevent the improvement of model performance. Therefore, an adaptive joint-optimization loss function is used to balance the loss values of each module and further expand the generalization capability of the network in the presence of unknown material spoofing fingerprints. The training process involves the use of a fingerprint image containing two kinds of labels, which include the authenticity label of the fingerprint and material label of the forged fingerprint. The true fingerprint lacks material properties and is marked as 0. Forged fingerprints are numbered from 1 based on the material category, and the authenticity of fingerprints and type of forged materials are assessed based on the authenticity and material labels, respectively. The random gradient descent method is used for optimization, and the learning rate setting is from 0.001, which is reduced by 0.1 time per 10 epoch.ResultThe experimental results on two public datasets revealed that the algorithm proposed in this paper achieved the best comprehensive performance in the cross-material detection of forged fingerprints. On the GreenBit sensor of LivDet2017 dataset, average classification error (ACE) reduced the rate by 0.16% compared with the second-ranked spoofing fingerprint detection model and increased true detection rate (TDR) by 2.4%. On the Digital persona sensor of LivDet2017 dataset, ACE reduced the rate by 0.26% compared with the second-ranked forgery fingerprint detection model and increased TDR by 0.7%. On LivDet2019 dataset, ACE reduces the rate by 1.34% on average compared with the second-ranked spoofing fingerprint detection model and increases TDR by 1.43% on average. These findings indicate a an increase in the corresponding generalization. A comparative experiment was performed to verify the superiority of the multi-scale spatial-channel (MSC) attention module to the convolutional block attention module (CBAM) module in spoofing fingerprint detection. To better evaluate our method, we conducted a series of ablation experiments to verify each module involved in common feature extraction training to aid in the cross-material spoofing fingerprint detection task. To reveal the improved generalization performance of CSFE compared with MFSE in cross-material spoofing fingerprint detection, this paper visualized the distribution of the proposed features using the t-distributed stochastic neighbor embedding algorithm.ConclusionThe method proposed in this paper achieved better detection results than other methods and exhibited a higher generalization performance in the detection of spoofing fingerprints made of unknown materials. Compared with spoofing fingerprint detection using the same material, the extant spoofing fingerprint detection technique harbors substantial scope for the refinement of its generalization capabilities for cross-material detection. Cross-material spoofing fingerprint detection aptly aligns with practical requirements and bears immense importance in the realm of research pursuits.关键词:spoofing fingerprint detection;material domain invariant spoofing feature;attention;commonality feature learning;generalization356|191|0更新时间:2024-09-18
摘要:ObjectiveThe realm of our daily lives has witnessed the ubiquitous integration of fingerprint recognition technology in domains, such as authorized identification, fingerprint-based payments, and access control systems. However, recent studies have revealed the vulnerability of these systems to spoofing fingerprint attacks. Attackers can deceive authentication systems by imitating fingerprints using artificial materials. Thus, the authenticity of fingerprint under scrutiny must be ascertained prior to its use to authenticate the user's identity. The development of a spoofing fingerprint detection technology has attracted extensive attention from the academia and industry. The creation of spoofing fingerprints involve the use of diverse materials. The present research disregards the correlation of data distribution among spoofing fingerprints crafted from various materials, which consequently leads to limited generalization in cross-material detection. Hence, a high-generalization spoofing fingerprint detection method based on commonality feature learning is proposed through the analysis of the distribution correlation among counterfeit fingerprint data originating from diverse materials and the exploration of invariant forgery features within the material domain of distinct counterfeit fingerprints.MethodFirst, to characterize and learn the features of spoofing fingerprints obtained using various materials, a multiscale spoofing feature extractor (MFSE) is designed, and it includes a multiscale spatial-channel attention module to allow the MFSE to pay more attention to fine-grained differences between live and fake fingerprints and improve the capability of the network to learn spoofing features. Then, a common spoofing feature extractor (CSFE) is constructed for further analysis of the distribution correlation between spoofing fingerprint data of different materials and extraction of common spoofing features between spoofing fingerprints made from various materials. Under the guidance of prior knowledge on MFSE, CSFE calculates the distance of the feature distribution extracted by MFSE and CSFE in the regenerated Hilbert space through the feature distance measurement module and minimizes the maximum mean difference (MMD) of data distributions to reduce the distance between them. The multitask material domain invariant spoofing feature learning is implemented, and a material discriminator is designed to constrain the learned common spoofing features and remove specific material information from the spoofing fingerprint. CSFE involves the calculation of multiple loss functions. Manually setting the weight ratio of these loss functions may prevent the improvement of model performance. Therefore, an adaptive joint-optimization loss function is used to balance the loss values of each module and further expand the generalization capability of the network in the presence of unknown material spoofing fingerprints. The training process involves the use of a fingerprint image containing two kinds of labels, which include the authenticity label of the fingerprint and material label of the forged fingerprint. The true fingerprint lacks material properties and is marked as 0. Forged fingerprints are numbered from 1 based on the material category, and the authenticity of fingerprints and type of forged materials are assessed based on the authenticity and material labels, respectively. The random gradient descent method is used for optimization, and the learning rate setting is from 0.001, which is reduced by 0.1 time per 10 epoch.ResultThe experimental results on two public datasets revealed that the algorithm proposed in this paper achieved the best comprehensive performance in the cross-material detection of forged fingerprints. On the GreenBit sensor of LivDet2017 dataset, average classification error (ACE) reduced the rate by 0.16% compared with the second-ranked spoofing fingerprint detection model and increased true detection rate (TDR) by 2.4%. On the Digital persona sensor of LivDet2017 dataset, ACE reduced the rate by 0.26% compared with the second-ranked forgery fingerprint detection model and increased TDR by 0.7%. On LivDet2019 dataset, ACE reduces the rate by 1.34% on average compared with the second-ranked spoofing fingerprint detection model and increases TDR by 1.43% on average. These findings indicate a an increase in the corresponding generalization. A comparative experiment was performed to verify the superiority of the multi-scale spatial-channel (MSC) attention module to the convolutional block attention module (CBAM) module in spoofing fingerprint detection. To better evaluate our method, we conducted a series of ablation experiments to verify each module involved in common feature extraction training to aid in the cross-material spoofing fingerprint detection task. To reveal the improved generalization performance of CSFE compared with MFSE in cross-material spoofing fingerprint detection, this paper visualized the distribution of the proposed features using the t-distributed stochastic neighbor embedding algorithm.ConclusionThe method proposed in this paper achieved better detection results than other methods and exhibited a higher generalization performance in the detection of spoofing fingerprints made of unknown materials. Compared with spoofing fingerprint detection using the same material, the extant spoofing fingerprint detection technique harbors substantial scope for the refinement of its generalization capabilities for cross-material detection. Cross-material spoofing fingerprint detection aptly aligns with practical requirements and bears immense importance in the realm of research pursuits.关键词:spoofing fingerprint detection;material domain invariant spoofing feature;attention;commonality feature learning;generalization356|191|0更新时间:2024-09-18 -
 摘要:ObjectiveThe rapid development of multimedia technology enables emerging video services, such as bullet chatting video and virtual idol. Technical parameters from network and application layers affect user’s quality of experience (QoE). In addition, the QoE changes when various adjustable functional parameters of these video services are modified, which we call QoE influenced by functional parameters (functional QoE, fQoE). Changes in functional parameters influence human cognition and emotion, and thus, fQoE is almost entirely decided by human subjective perceptions. Inferring directly from parameter design, which is difficult, makes fQoE modeling challenging. The success of the video services depends entirely on user ratings, and understanding fQoE and the reason behind its generation is crucial for service providers. Studies using questionnaire and interview methods have been conducted to understand users’ perceptions of functional parameters. However, subjects may be influenced by external criteria and social desirability, which potentially result in bias of the collected results. The above methods cannot perform the quantitative assessment of fQoE nor provide scientific evidence with interpretability. Electroencephalography (EEG) signals contain a wealth of information about brain activity, and EEG features can reveal brain network patterns during complex brain activity. Studies have used EEG as a powerful tool to assess the QoE influenced by technical parameters (tQoE) and uncovered relevant EEG single-electrode features, which revealed the correlation between tQoE and basic human perceptual functions and demonstrated the strong potential of EEG for fQoE assessment. However, fQoE may involve higher-order human cognitive functions that require interactions between multiple brain regions, such as social communication and emotion, whose complex relationships are difficult to be represented by single-electrode features. To address the limitations of the above studies, this paper presents an fQoE assessment model based on the EEG technology and investigates the neural mechanisms behind fQoE.MethodFirst, an EEG dataset for fQoE assessment was constructed. To reduce the influence of subjects’ personal preferences on the experimental results, we ensured that the stimulus materials contained five types of videos (auto-tune, technology, dance, film, and music). Different levels of fQoE were induced by changing the functional parameters, and the EEG data of subjects were collected simultaneously. Second, on top of single-electrode features, we additionally extracted multielectrode features (i.e., functional connectivity features) and fused both types in the form of graph. The EEG electrodes were represented as nodes on the graph, the single-electrode features as node features, and the functional connectivity as edges of the graph. The weights of edges represent the strength of functional connectivity, and were used in the comprehensive characterization of the user’s brain state when using video service. Finally, self-attention graph pooling mechanism was introduced to construct a brain-network construction model to identify fQoE levels. The graph pooling layer can enlarge the field of view to the whole graph structure during the training process, retain key nodes, and compose new graphs to render the model with the capability to capture key brain networks. We further explored the neurophysiological principles behind it and provided theoretical support for the improvement of emerging video services.ResultWith the bullet chatting video, a new type of video service, as an example, this paper explored the fQoE affected by the functional parameter of bullet chatting coverage and the neurophysiological principles behind it. The finding verified the scientific validity and feasibility of the method. Experiments revealed that the assessment method proposed in this paper achieved satisfactory results in the fQoE evaluation of multiple video types, with the best recognition accuracy of 86% (auto-tune), 80% (technology), 80% (dance), 82% (film), and 84% (music). Compared with existing machine learning and deep learning models, our method achieves the best recognition accuracy. The results on fQoE-related brain network analysis reveal that the number of brain connections in the frontal, parietal, and temporal lobes decreased, which indicates a attained fQoE for viewing bullet chat videos, i.e., a better viewing experience. This result also implies that functional parameters further lead to changes in the fQoE by affecting the human brain state. Specifically, the brain connection between the frontal and temporal lobes is related to speech information processing, the parietal lobe brain connection to visual information processing, the strength of frontal lobe brain connection to cognitive load levels, and its asymmetry to emotions and motivation.ConclusionIn this study, we initially presented an EEG-based fQoE assessment model to evaluate the fQoE levels using a brain-network construction model based on a self-attention graph pooling mechanism and analyzed the neurophysiological rationale behind it. The assessment method introduced in this paper serves as a quantitative tool and theoretical basis from neurophysiology for the accurate assessment of fQoE and optimization of functional parameters of video services.关键词:emerging video services;functional quality of experience(fQoE);electroencephalogram(EEG);brain network construction171|315|0更新时间:2024-09-18
摘要:ObjectiveThe rapid development of multimedia technology enables emerging video services, such as bullet chatting video and virtual idol. Technical parameters from network and application layers affect user’s quality of experience (QoE). In addition, the QoE changes when various adjustable functional parameters of these video services are modified, which we call QoE influenced by functional parameters (functional QoE, fQoE). Changes in functional parameters influence human cognition and emotion, and thus, fQoE is almost entirely decided by human subjective perceptions. Inferring directly from parameter design, which is difficult, makes fQoE modeling challenging. The success of the video services depends entirely on user ratings, and understanding fQoE and the reason behind its generation is crucial for service providers. Studies using questionnaire and interview methods have been conducted to understand users’ perceptions of functional parameters. However, subjects may be influenced by external criteria and social desirability, which potentially result in bias of the collected results. The above methods cannot perform the quantitative assessment of fQoE nor provide scientific evidence with interpretability. Electroencephalography (EEG) signals contain a wealth of information about brain activity, and EEG features can reveal brain network patterns during complex brain activity. Studies have used EEG as a powerful tool to assess the QoE influenced by technical parameters (tQoE) and uncovered relevant EEG single-electrode features, which revealed the correlation between tQoE and basic human perceptual functions and demonstrated the strong potential of EEG for fQoE assessment. However, fQoE may involve higher-order human cognitive functions that require interactions between multiple brain regions, such as social communication and emotion, whose complex relationships are difficult to be represented by single-electrode features. To address the limitations of the above studies, this paper presents an fQoE assessment model based on the EEG technology and investigates the neural mechanisms behind fQoE.MethodFirst, an EEG dataset for fQoE assessment was constructed. To reduce the influence of subjects’ personal preferences on the experimental results, we ensured that the stimulus materials contained five types of videos (auto-tune, technology, dance, film, and music). Different levels of fQoE were induced by changing the functional parameters, and the EEG data of subjects were collected simultaneously. Second, on top of single-electrode features, we additionally extracted multielectrode features (i.e., functional connectivity features) and fused both types in the form of graph. The EEG electrodes were represented as nodes on the graph, the single-electrode features as node features, and the functional connectivity as edges of the graph. The weights of edges represent the strength of functional connectivity, and were used in the comprehensive characterization of the user’s brain state when using video service. Finally, self-attention graph pooling mechanism was introduced to construct a brain-network construction model to identify fQoE levels. The graph pooling layer can enlarge the field of view to the whole graph structure during the training process, retain key nodes, and compose new graphs to render the model with the capability to capture key brain networks. We further explored the neurophysiological principles behind it and provided theoretical support for the improvement of emerging video services.ResultWith the bullet chatting video, a new type of video service, as an example, this paper explored the fQoE affected by the functional parameter of bullet chatting coverage and the neurophysiological principles behind it. The finding verified the scientific validity and feasibility of the method. Experiments revealed that the assessment method proposed in this paper achieved satisfactory results in the fQoE evaluation of multiple video types, with the best recognition accuracy of 86% (auto-tune), 80% (technology), 80% (dance), 82% (film), and 84% (music). Compared with existing machine learning and deep learning models, our method achieves the best recognition accuracy. The results on fQoE-related brain network analysis reveal that the number of brain connections in the frontal, parietal, and temporal lobes decreased, which indicates a attained fQoE for viewing bullet chat videos, i.e., a better viewing experience. This result also implies that functional parameters further lead to changes in the fQoE by affecting the human brain state. Specifically, the brain connection between the frontal and temporal lobes is related to speech information processing, the parietal lobe brain connection to visual information processing, the strength of frontal lobe brain connection to cognitive load levels, and its asymmetry to emotions and motivation.ConclusionIn this study, we initially presented an EEG-based fQoE assessment model to evaluate the fQoE levels using a brain-network construction model based on a self-attention graph pooling mechanism and analyzed the neurophysiological rationale behind it. The assessment method introduced in this paper serves as a quantitative tool and theoretical basis from neurophysiology for the accurate assessment of fQoE and optimization of functional parameters of video services.关键词:emerging video services;functional quality of experience(fQoE);electroencephalogram(EEG);brain network construction171|315|0更新时间:2024-09-18
Image Analysis and Recognition
-
 摘要:ObjectiveChromosome karyotype analysis separates and categorizes chromosomes in midcell division images, and it is widely used for the diagnosis of genetic diseases, in which overlapping chromosome segmentation is one of the key steps. Based on image analysis of overlapping chromosomes, the morphologically diverse chromosome clusters depend on detailed features, such as accurate boundaries during segmentation, in addition to obtaining the basic contour, texture, and semantic information. For this reason, in this paper, a two-stage overlapping chromosome segmentation model SC-Net was constructed through fusion of the contextual information of the target to improve the segmentation performance of the network.MethodFirst, the model SC-UNet++ added the hybrid pooling module (HPM) to the baseline model U-Net++ for semantic segmentation to capture the local context information of overlapping chromosomes and complemented the detailed features of chromosomes, such as color, thickness, and stripes, based on the superposition operation of empty space pyramid pooling and stripe pooling. The context fusion module (CFM) was connected in parallel to a decoder network, i.e., the channel correlation of input features was extracted using the efficient channel attention module, and the features obtained via the multiplication of the output with the input were subsequently fed to the HPM and the spatial attention module (SAM), which explored the correlation of the region around the pixel to obtain the local context and extract the global context through global pooling operation, respectively. In addition, context prior auxiliary branch (CPAB) was introduced after CFM to improve the global context information on channel and space. Second, the category a priori information of labeled training samples, which serves as an additional source of supervisory information during training and effectively distinguishes confusing spatial features in overlapping chromosome images, was used to generate the true affinity matrix. Finally, the elements of overlapping and non-overlapping regions were iteratively paired by the chromosome instance reconstruction algorithm to splice and form a single chromosome. In this paper, experimental analysis were based on ChromSeg dataset, and the hardware resources used included a desktop server with 32 GB RAM, a 3.3 GHz Intel Xeon CPU, and an NVIDIA RTX 3070 GPU. The model was used based on the semantic segmentation toolkit MMSegmentation version 0.30.0 and implemented under the Ubuntu 18.04 operating system, with PyTorch 1.10.0 serving as a deep learning framework. The following sections describe relevant hyperparameter settings and initialization methods for network training and the loss function selection strategy.ResultSC-Net fully extracted and utilized the contextual and category prior information of overlapping chromosome images and showed good performance in segmentation scenarios with various numbers of overlapping chromosomes. The effect of each improvement on the algorithm performance was investigated through ablation experiments, where various combinations of CFM, HPM, CPAB, and segmentation loss were designed on the baseline model U-Net++. The results proved the better performance of SC-UNet++ compared with models in all evaluation metrics. This condition confirms the effectiveness of the method proposed in this paper, i.e., SC-UNet++ attained better performance in the segmentation of overlapping chromosomes. Through comparative experiments, the SC-Net proposed in this paper caused improvements on the ChromSeg dataset, which outperformed several models in terms of all metrics, and the model achieved an overlapping chromosome region intersection and merger ratio of 83.5%. The overall accuracy obtained after the reconstruction of chromosome instances was 92.3%, which is higher than the best and the same two-stage ChromSeg segmentation methods by 2.7% and 1.8%. The SC-Net outperformed these models mainly due to its capability to extract contextual information and category relevance of the target, and it enables the model to further gain insights into overlapping regions.ConclusionThe overlapping chromosome segmentation model constructed in this paper can effectively solve the segmentation problem of morphologically diverse overlapping chromosome clusters by fusing contextual information and obtaining finer and more accurate results compared with the existing methods.关键词:overlapping chromosome segmentation;hybrid pooling module (HPM);contextual fusion module (CFM);contextual prior aided branch (CPAB);real affinity matrix142|423|0更新时间:2024-09-18
摘要:ObjectiveChromosome karyotype analysis separates and categorizes chromosomes in midcell division images, and it is widely used for the diagnosis of genetic diseases, in which overlapping chromosome segmentation is one of the key steps. Based on image analysis of overlapping chromosomes, the morphologically diverse chromosome clusters depend on detailed features, such as accurate boundaries during segmentation, in addition to obtaining the basic contour, texture, and semantic information. For this reason, in this paper, a two-stage overlapping chromosome segmentation model SC-Net was constructed through fusion of the contextual information of the target to improve the segmentation performance of the network.MethodFirst, the model SC-UNet++ added the hybrid pooling module (HPM) to the baseline model U-Net++ for semantic segmentation to capture the local context information of overlapping chromosomes and complemented the detailed features of chromosomes, such as color, thickness, and stripes, based on the superposition operation of empty space pyramid pooling and stripe pooling. The context fusion module (CFM) was connected in parallel to a decoder network, i.e., the channel correlation of input features was extracted using the efficient channel attention module, and the features obtained via the multiplication of the output with the input were subsequently fed to the HPM and the spatial attention module (SAM), which explored the correlation of the region around the pixel to obtain the local context and extract the global context through global pooling operation, respectively. In addition, context prior auxiliary branch (CPAB) was introduced after CFM to improve the global context information on channel and space. Second, the category a priori information of labeled training samples, which serves as an additional source of supervisory information during training and effectively distinguishes confusing spatial features in overlapping chromosome images, was used to generate the true affinity matrix. Finally, the elements of overlapping and non-overlapping regions were iteratively paired by the chromosome instance reconstruction algorithm to splice and form a single chromosome. In this paper, experimental analysis were based on ChromSeg dataset, and the hardware resources used included a desktop server with 32 GB RAM, a 3.3 GHz Intel Xeon CPU, and an NVIDIA RTX 3070 GPU. The model was used based on the semantic segmentation toolkit MMSegmentation version 0.30.0 and implemented under the Ubuntu 18.04 operating system, with PyTorch 1.10.0 serving as a deep learning framework. The following sections describe relevant hyperparameter settings and initialization methods for network training and the loss function selection strategy.ResultSC-Net fully extracted and utilized the contextual and category prior information of overlapping chromosome images and showed good performance in segmentation scenarios with various numbers of overlapping chromosomes. The effect of each improvement on the algorithm performance was investigated through ablation experiments, where various combinations of CFM, HPM, CPAB, and segmentation loss were designed on the baseline model U-Net++. The results proved the better performance of SC-UNet++ compared with models in all evaluation metrics. This condition confirms the effectiveness of the method proposed in this paper, i.e., SC-UNet++ attained better performance in the segmentation of overlapping chromosomes. Through comparative experiments, the SC-Net proposed in this paper caused improvements on the ChromSeg dataset, which outperformed several models in terms of all metrics, and the model achieved an overlapping chromosome region intersection and merger ratio of 83.5%. The overall accuracy obtained after the reconstruction of chromosome instances was 92.3%, which is higher than the best and the same two-stage ChromSeg segmentation methods by 2.7% and 1.8%. The SC-Net outperformed these models mainly due to its capability to extract contextual information and category relevance of the target, and it enables the model to further gain insights into overlapping regions.ConclusionThe overlapping chromosome segmentation model constructed in this paper can effectively solve the segmentation problem of morphologically diverse overlapping chromosome clusters by fusing contextual information and obtaining finer and more accurate results compared with the existing methods.关键词:overlapping chromosome segmentation;hybrid pooling module (HPM);contextual fusion module (CFM);contextual prior aided branch (CPAB);real affinity matrix142|423|0更新时间:2024-09-18 -
 摘要:ObjectiveBreast cancer belongs to the most common malignant tumors among women, and its early diagnosis and accurate classification bear great importance. Breast cancer whole slide pathological images serve as important auxiliary diagnostic means, and their classification can assist doctors in the accurate identification of tumor types. However, given the complexity and huge data volume of breast cancer whole slide pathological images, manual annotation of the label of each image becomes time consuming and labor intensive. Therefore, researchers have proposed various automated methods to address the issue encountered in the classification of breast cancer whole slide pathological images. Self- and weakly supervised learning effectively tackling the challenge of breast cancer whole slide pathological image classification. Self-supervised learning is a type of machine learning method that skips the manual annotation of labels. This method design tasks that enable the model to learn feature representations from unlabeled data. Self-supervised learning has achieved remarkable progress in the field of computer vision, but it still faces certain challenges in breast cancer whole slide pathological image classification. Given the complexity and diversity of pathological images, relying solely on the pseudo labels generated by self-supervised learning may fail to accurately reflect the true classification information, which affects the classification performance. On the other hand, weakly supervised learning leverages information from unlabeled image data through various methods, such as multiple instance learning or label propagation. However, the associated models encounter challenges, such as limited label information and noise, which affect the model’s stability during the learning process and thus the stability of prediction results. To overcome the limitations of self- and weakly supervised learning, this paper proposes a mixed supervised learning method for breast cancer whole slide pathological image classification. The integration of MoBY self-supervised contrastive learning with weakly supervised multi-instance learning combines the advantages of these learning architectures and makes full use of unlabeled and noisy labeled data. In addition, such combination improves the classification performance through feature selection and spatial correlation enhancement, which results in increased robustness.MethodFirst, the self-supervised MoBY was used to train the model on unlabeled pathological image data. MoBY, can learn key feature representations from images, is a self-supervised learning method based on self-reconstruction and contrastive learning. This process enables the model to extract useful feature information from unlabeled data and provide better initialization parameters for subsequent classification tasks. Then, a weakly supervised learning approach based on multiple instance learning was used for further model optimization. Multiple instance learning utilizes information from unlabeled image data for model training. In breast cancer whole slide pathological image classification, the accurate annotation of each image category often presents a challenge. This type of learning divides images into positive and negative instances based on instance-level labels to train the model. This approach partially contributes to solving the problem of limited label information and improves a model’s robustness and generalization capability. For the feature selection stage, representative feature vectors were selected from each whole slide image to reduce redundancy and noise, extract the most informative features, and improve the model’s focus and discriminative capability toward key regions. In addition, the paper leverages a Transformer encoder to improve the correlation among various image patches. The Transformer encoder is a powerful tool for modeling global contextual information in images, and it captures semantic relationships between different regions of an image to further increase the classification accuracy. The introduction of the Transformer encoder into breast cancer whole slide pathological image classification enables the improved utilization of global image information and further understanding of a model’s image structure and context. Comprehensive application of methods, such as self- and weakly supervised learning, resulted in the high accuracy and robustness of the proposed mixed supervised learning approach for the classification of breast cancer whole slide pathological images in this paper. In experiments, this method achieved excellent classification results on a dataset of breast cancer whole slide pathological images. This approach serves as a powerful tool and technical support for the early diagnosis and accurate classification of breast cancer.ResultThe effectiveness of the mixed supervised model was validated through evaluation experiments conducted on the publicly available Camelyon-16 breast-cancer pathological image dataset. Compared with the state-of-the-art weakly and self-supervised models of this dataset, the proposed model achieved evident improvements of 2.34% and 2.74% in the area under the receiver operating characteristic, respectively. This finding indicates that the proposed method outperformed the other models in terms of breast cancer whole slide pathological image classification tasks. To further validate its generalization capability, we performed experiments on an external validation dataset of MSK. The proposed model for this validation dataset demonstrated a great performance improvement of 6.26%, which further confirms its strong generalization capability and practicality.ConclusionThe proposed breast cancer whole slide pathological image classification method based on mixed supervision achieved remarkable results in addressing the related challenge By leveraging the advantages of self-supervised learning, weakly supervised learning, and spatial correlation enhancement, the given model demonstrated improved classification performance on public and external validation datasets. This method exhibits a good generalization capability and offers a viable solution for the early diagnosis and treatment of breast cancer. Future research should further refine and optimize the proposed method to increase its accuracy and robustness in breast cancer whole slide pathology image classification. This paper will address the challenges in breast cancer pathological image classification and contribute to the development of early breast cancer diagnosis and treatment.关键词:breast cancer whole slide pathology image;classification;mixed supervised learning;feature fusion;Transformer324|779|0更新时间:2024-09-18
摘要:ObjectiveBreast cancer belongs to the most common malignant tumors among women, and its early diagnosis and accurate classification bear great importance. Breast cancer whole slide pathological images serve as important auxiliary diagnostic means, and their classification can assist doctors in the accurate identification of tumor types. However, given the complexity and huge data volume of breast cancer whole slide pathological images, manual annotation of the label of each image becomes time consuming and labor intensive. Therefore, researchers have proposed various automated methods to address the issue encountered in the classification of breast cancer whole slide pathological images. Self- and weakly supervised learning effectively tackling the challenge of breast cancer whole slide pathological image classification. Self-supervised learning is a type of machine learning method that skips the manual annotation of labels. This method design tasks that enable the model to learn feature representations from unlabeled data. Self-supervised learning has achieved remarkable progress in the field of computer vision, but it still faces certain challenges in breast cancer whole slide pathological image classification. Given the complexity and diversity of pathological images, relying solely on the pseudo labels generated by self-supervised learning may fail to accurately reflect the true classification information, which affects the classification performance. On the other hand, weakly supervised learning leverages information from unlabeled image data through various methods, such as multiple instance learning or label propagation. However, the associated models encounter challenges, such as limited label information and noise, which affect the model’s stability during the learning process and thus the stability of prediction results. To overcome the limitations of self- and weakly supervised learning, this paper proposes a mixed supervised learning method for breast cancer whole slide pathological image classification. The integration of MoBY self-supervised contrastive learning with weakly supervised multi-instance learning combines the advantages of these learning architectures and makes full use of unlabeled and noisy labeled data. In addition, such combination improves the classification performance through feature selection and spatial correlation enhancement, which results in increased robustness.MethodFirst, the self-supervised MoBY was used to train the model on unlabeled pathological image data. MoBY, can learn key feature representations from images, is a self-supervised learning method based on self-reconstruction and contrastive learning. This process enables the model to extract useful feature information from unlabeled data and provide better initialization parameters for subsequent classification tasks. Then, a weakly supervised learning approach based on multiple instance learning was used for further model optimization. Multiple instance learning utilizes information from unlabeled image data for model training. In breast cancer whole slide pathological image classification, the accurate annotation of each image category often presents a challenge. This type of learning divides images into positive and negative instances based on instance-level labels to train the model. This approach partially contributes to solving the problem of limited label information and improves a model’s robustness and generalization capability. For the feature selection stage, representative feature vectors were selected from each whole slide image to reduce redundancy and noise, extract the most informative features, and improve the model’s focus and discriminative capability toward key regions. In addition, the paper leverages a Transformer encoder to improve the correlation among various image patches. The Transformer encoder is a powerful tool for modeling global contextual information in images, and it captures semantic relationships between different regions of an image to further increase the classification accuracy. The introduction of the Transformer encoder into breast cancer whole slide pathological image classification enables the improved utilization of global image information and further understanding of a model’s image structure and context. Comprehensive application of methods, such as self- and weakly supervised learning, resulted in the high accuracy and robustness of the proposed mixed supervised learning approach for the classification of breast cancer whole slide pathological images in this paper. In experiments, this method achieved excellent classification results on a dataset of breast cancer whole slide pathological images. This approach serves as a powerful tool and technical support for the early diagnosis and accurate classification of breast cancer.ResultThe effectiveness of the mixed supervised model was validated through evaluation experiments conducted on the publicly available Camelyon-16 breast-cancer pathological image dataset. Compared with the state-of-the-art weakly and self-supervised models of this dataset, the proposed model achieved evident improvements of 2.34% and 2.74% in the area under the receiver operating characteristic, respectively. This finding indicates that the proposed method outperformed the other models in terms of breast cancer whole slide pathological image classification tasks. To further validate its generalization capability, we performed experiments on an external validation dataset of MSK. The proposed model for this validation dataset demonstrated a great performance improvement of 6.26%, which further confirms its strong generalization capability and practicality.ConclusionThe proposed breast cancer whole slide pathological image classification method based on mixed supervision achieved remarkable results in addressing the related challenge By leveraging the advantages of self-supervised learning, weakly supervised learning, and spatial correlation enhancement, the given model demonstrated improved classification performance on public and external validation datasets. This method exhibits a good generalization capability and offers a viable solution for the early diagnosis and treatment of breast cancer. Future research should further refine and optimize the proposed method to increase its accuracy and robustness in breast cancer whole slide pathology image classification. This paper will address the challenges in breast cancer pathological image classification and contribute to the development of early breast cancer diagnosis and treatment.关键词:breast cancer whole slide pathology image;classification;mixed supervised learning;feature fusion;Transformer324|779|0更新时间:2024-09-18
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0