
最新刊期
卷 29 , 期 10 , 2024
-
 摘要:Monocular visual-inertial simultaneous localization and mapping (VI-SLAM) is an important research topic in computer vision and robotics. It aims to estimate the pose (i.e., the position and orientation) of the device in real-time using a monocular camera with an inertial sensor while constructing the map of the environment. With the rapid development of various fields, such as augmented/virtual reality (AR/VR), robotics, and autonomous driving, monocular VI-SLAM has received widespread attention due to its advantages, including low hardware cost and no requirement for an external environment setup, among others. Over the past decade or so, monocular VI-SLAM has made significant progress and spawned many excellent methods and systems. However, because of the complexity of real-world scenarios, different methods have also shown distinct limitations. Although some works have reviewed and evaluated VI-SLAM methods, most of them only focus on classic methods, which cannot fully reflect the latest development status of VI-SLAM technology. Based on optimization type, VI-SLAM can be divided into filtering- and optimization-based methods. Filtering-based methods use filters to fuse observations from visual and inertial sensors, continuously updating the device’s state information for localization and mapping. Additionally, depending on whether visual data association (or feature matching) is performed separately, existing methods can be divided into indirect methods (or feature-based methods) and direct methods. Furthermore, with the development and widespread application of deep learning technology, researchers have started to incorporate deep learning methods into VI-SLAM to enhance robustness in extreme conditions or perform dense reconstruction. This paper first elaborates on the basic principles of monocular VI-SLAM methods and then classifies them analytically into direct and filtering-, optimization-, feature-, and deep learning-based methods. However, most of the existing datasets and benchmarks are focused on applications like autonomous driving and drones, mainly evaluating pose accuracy. Relatively few datasets have been specifically designed for AR.For a more comprehensive comparison of the advantages and disadvantages of different methods, we select three public datasets to quantitatively evaluate representative monocular VI-SLAM methods from multiple dimensions: the widely used EuRoC dataset, the ZJU-Sensetime dataset suitable for mobile platform AR applications, and the low cost and scalable frarnework to build localization benchmark(LSFB) dataset aimed at large-scale AR scenarios. Then, we supplemented the ZJU-Sensetime dataset with a more challenging set of sequences called sequences C to enhance the variety of data types and evaluation dimensions. This extended dataset is designed to evaluate the robustness of algorithms under extreme conditions such as pure rotation, planar motion, lighting changes, and dynamic scenes. Specifically, sequences C comprise eight sequences, labeled C0–C7. In the C0 sequence, the handheld device moves around a room, performing multiple pure rotational motions. The C1 sequence involves the device mounted on a stabilized gimbal and moves freely. In the C2 sequence, the device moves in a planar motion, maintaining a constant height. The C3 sequence includes turning lights on and off during recording. In the C4 sequence, the device overlooks the floor while moving. The C5 sequence captures the exterior wall with significant parallax and minimal co-visibility, while the C6 sequence involves viewing a monitor during recording, with slight movement and changing screen content. Finally, the C7 sequence involves long-distance recording. On the EuRoC dataset, both filtering- and optimization-based VI-SLAM methods achieved good accuracy. Multi-state constraint Kalman filter(MSCKF), an early filtering-based system, showed lower accuracy and struggled with some sequences. Some methods such OpenVINS and RNIN-VIO enhanced accuracy by adding new features and deep learning-based algorithms, respectively. OKVIS, an early optimization-based system, completed all sequences but with lower accuracy. Other methods such as VINS-Mono, RD-VIO, and ORB-SLAM3 achieved significant optimizations, improving initialization, robustness, and overall accuracy. Direct methods such as DM-VIO and SVO-Pro, which we extended from DSO and SVO, respectively, showed significant improvements in accuracy through techniques like delayed marginalization and efficient use of texture information. Adaptive VIO, which is based on deep learning, achieved high accuracy by continuously updating through online learning, demonstrating adaptability to new scenarios. Furthermore, on the ZJU-Sensetime dataset, the comparison results of different methods are largely similar to those in EuRoC. The main difference is that the accuracy of the direct method DM-VIO significantly decreases when using a rolling shutter camera, whereas the semidirect method SVO-Pro has a slightly better performance. Feature-based methods do not show a significant drop in accuracy, but the smaller field of view (FoV) found in phone cameras reduces the robustness of ORB-SLAM3, Kimera, and MSCKF. Additionally, ORB-SLAM3 has high tracking accuracy but a lower completeness, while Kimera and MSCKF show increased tracking errors. HybVIO, RNIN-VIO, and RD-VIO have the highest accuracy, while HybVIO slightly outperforms the two others. The deep learning-based Adaptive VIO also shows a significant drop in accuracy and struggles to complete sequences B and C, indicating generalization and robustness issues in complex scenarios. On the LSFB dataset, the comparison results are consistent with those in small-scale datasets. The methods with the highest accuracy in small scenes, such as RNIN-VIO, HybVIO, and RD-VIO, continue to show high accuracy in large scenes. In particular, RNIN-VIO demonstrates even more significant accuracy advantages in large scenes. In large-scale scenes, many feature points are distant and lack parallax, leading to rapid accumulation of errors, especially in methods that are heavily rely on visual constraints. The neural inertial network-based RNIN-VIO can better maximize IMU observations, reducing dependence on visual data. The VINS-Mono also shows significant advantages in large scenes, as its sliding window optimization facilitating the early inclusion of small-parallax feature points, effectively controlling error accumulation. In contrast, ORB-SLAM3, which relies on local maps, requires sufficient parallax before adding feature points to the local map, which can lead to insufficient visual constraints in distant environments and ultimately cause error accumulation and even tracking loss. The experimental results also show that optimization-based or combined filtering–optimization methods generally outperform filtering-based methods in terms of tracking accuracy and robustness. At the same time, direct/semidirect methods perform well when shooting with a global shutter camera, but are prone to error accumulation, especially in large scenes when affected by rolling shutter and light changes. Combining deep learning can improve robustness in extreme situations. Finally, the development trend of SLAM is discussed and prospected in this work based on three research hotspots: combining deep learning with V-SLAM/VI-SLAM, multisensor fusion, and end-cloud collaboration.关键词:visual-inertial SLAM(VI-SLAM);augmented reality(AR);visual-inertial dataset;multiple-view geometry;multi-sensor fusion886|1690|0更新时间:2024-10-23
摘要:Monocular visual-inertial simultaneous localization and mapping (VI-SLAM) is an important research topic in computer vision and robotics. It aims to estimate the pose (i.e., the position and orientation) of the device in real-time using a monocular camera with an inertial sensor while constructing the map of the environment. With the rapid development of various fields, such as augmented/virtual reality (AR/VR), robotics, and autonomous driving, monocular VI-SLAM has received widespread attention due to its advantages, including low hardware cost and no requirement for an external environment setup, among others. Over the past decade or so, monocular VI-SLAM has made significant progress and spawned many excellent methods and systems. However, because of the complexity of real-world scenarios, different methods have also shown distinct limitations. Although some works have reviewed and evaluated VI-SLAM methods, most of them only focus on classic methods, which cannot fully reflect the latest development status of VI-SLAM technology. Based on optimization type, VI-SLAM can be divided into filtering- and optimization-based methods. Filtering-based methods use filters to fuse observations from visual and inertial sensors, continuously updating the device’s state information for localization and mapping. Additionally, depending on whether visual data association (or feature matching) is performed separately, existing methods can be divided into indirect methods (or feature-based methods) and direct methods. Furthermore, with the development and widespread application of deep learning technology, researchers have started to incorporate deep learning methods into VI-SLAM to enhance robustness in extreme conditions or perform dense reconstruction. This paper first elaborates on the basic principles of monocular VI-SLAM methods and then classifies them analytically into direct and filtering-, optimization-, feature-, and deep learning-based methods. However, most of the existing datasets and benchmarks are focused on applications like autonomous driving and drones, mainly evaluating pose accuracy. Relatively few datasets have been specifically designed for AR.For a more comprehensive comparison of the advantages and disadvantages of different methods, we select three public datasets to quantitatively evaluate representative monocular VI-SLAM methods from multiple dimensions: the widely used EuRoC dataset, the ZJU-Sensetime dataset suitable for mobile platform AR applications, and the low cost and scalable frarnework to build localization benchmark(LSFB) dataset aimed at large-scale AR scenarios. Then, we supplemented the ZJU-Sensetime dataset with a more challenging set of sequences called sequences C to enhance the variety of data types and evaluation dimensions. This extended dataset is designed to evaluate the robustness of algorithms under extreme conditions such as pure rotation, planar motion, lighting changes, and dynamic scenes. Specifically, sequences C comprise eight sequences, labeled C0–C7. In the C0 sequence, the handheld device moves around a room, performing multiple pure rotational motions. The C1 sequence involves the device mounted on a stabilized gimbal and moves freely. In the C2 sequence, the device moves in a planar motion, maintaining a constant height. The C3 sequence includes turning lights on and off during recording. In the C4 sequence, the device overlooks the floor while moving. The C5 sequence captures the exterior wall with significant parallax and minimal co-visibility, while the C6 sequence involves viewing a monitor during recording, with slight movement and changing screen content. Finally, the C7 sequence involves long-distance recording. On the EuRoC dataset, both filtering- and optimization-based VI-SLAM methods achieved good accuracy. Multi-state constraint Kalman filter(MSCKF), an early filtering-based system, showed lower accuracy and struggled with some sequences. Some methods such OpenVINS and RNIN-VIO enhanced accuracy by adding new features and deep learning-based algorithms, respectively. OKVIS, an early optimization-based system, completed all sequences but with lower accuracy. Other methods such as VINS-Mono, RD-VIO, and ORB-SLAM3 achieved significant optimizations, improving initialization, robustness, and overall accuracy. Direct methods such as DM-VIO and SVO-Pro, which we extended from DSO and SVO, respectively, showed significant improvements in accuracy through techniques like delayed marginalization and efficient use of texture information. Adaptive VIO, which is based on deep learning, achieved high accuracy by continuously updating through online learning, demonstrating adaptability to new scenarios. Furthermore, on the ZJU-Sensetime dataset, the comparison results of different methods are largely similar to those in EuRoC. The main difference is that the accuracy of the direct method DM-VIO significantly decreases when using a rolling shutter camera, whereas the semidirect method SVO-Pro has a slightly better performance. Feature-based methods do not show a significant drop in accuracy, but the smaller field of view (FoV) found in phone cameras reduces the robustness of ORB-SLAM3, Kimera, and MSCKF. Additionally, ORB-SLAM3 has high tracking accuracy but a lower completeness, while Kimera and MSCKF show increased tracking errors. HybVIO, RNIN-VIO, and RD-VIO have the highest accuracy, while HybVIO slightly outperforms the two others. The deep learning-based Adaptive VIO also shows a significant drop in accuracy and struggles to complete sequences B and C, indicating generalization and robustness issues in complex scenarios. On the LSFB dataset, the comparison results are consistent with those in small-scale datasets. The methods with the highest accuracy in small scenes, such as RNIN-VIO, HybVIO, and RD-VIO, continue to show high accuracy in large scenes. In particular, RNIN-VIO demonstrates even more significant accuracy advantages in large scenes. In large-scale scenes, many feature points are distant and lack parallax, leading to rapid accumulation of errors, especially in methods that are heavily rely on visual constraints. The neural inertial network-based RNIN-VIO can better maximize IMU observations, reducing dependence on visual data. The VINS-Mono also shows significant advantages in large scenes, as its sliding window optimization facilitating the early inclusion of small-parallax feature points, effectively controlling error accumulation. In contrast, ORB-SLAM3, which relies on local maps, requires sufficient parallax before adding feature points to the local map, which can lead to insufficient visual constraints in distant environments and ultimately cause error accumulation and even tracking loss. The experimental results also show that optimization-based or combined filtering–optimization methods generally outperform filtering-based methods in terms of tracking accuracy and robustness. At the same time, direct/semidirect methods perform well when shooting with a global shutter camera, but are prone to error accumulation, especially in large scenes when affected by rolling shutter and light changes. Combining deep learning can improve robustness in extreme situations. Finally, the development trend of SLAM is discussed and prospected in this work based on three research hotspots: combining deep learning with V-SLAM/VI-SLAM, multisensor fusion, and end-cloud collaboration.关键词:visual-inertial SLAM(VI-SLAM);augmented reality(AR);visual-inertial dataset;multiple-view geometry;multi-sensor fusion886|1690|0更新时间:2024-10-23 -
 摘要:With the rapid development of software technology and the continuous updating of hardware devices, augmented reality technology has gradually matured and been widely used in various fields, such as military, medical, gaming, industry, and education. Accurate depth perception is crucial in augmented reality, and simply overlaying virtual objects onto video sequences no longer meets user demands. In many augmented reality scenarios, users need to interact with virtual objects constantly, and without accurate depth perception, augmented reality can hardly provide a seamless interactive experience. Virtual-real occlusion handling is one of the key factors to achieve this goal. It presents a realistic virtual-real fusion effect by establishing accurate occlusion relationship, so that the fusion scene can correctly reflect the spatial position relationship between virtual and real objects, thereby enhancing the user’s sense of immersion and realism. This paper first introduces the related background, concepts, and overall processing flow of virtual-real occlusion handling. Existing occlusion handling methods can be divided into three categories: depth based, image analysis based, and model based. By analyzing the distinct characteristics of rigid and nonrigid objects, we summarize the specific principles, representative research works, and the applicability to rigid and nonrigid objects of these three virtual-real occlusion handling methods. The shape and size of rigid objects remain unchanged after motion or force, and they mainly use two types virtual-real occlusion handling methods: depth based and model based. The depth-based methods have evolved from the early use of stereo vision algorithms to the use of depth sensors for indoor depth image acquisition and further to the prediction of moving objects’ depth by using outdoor map data, as well as the densification of sparse simultaneous localization and mapping depth in monocular mobile augmented reality. Further research should focus on the depth image restoration algorithms and the balance between real-time performance and accuracy of scene-dense depth computation algorithms in mobile augmented reality. The model-based methods have developed from constructing partial 3D models by segmenting object contours in video key frames or directly using modeling software to achieving dense reconstruction of indoor static scenes using depth images and constructing approximate 3D models of outdoor scenes by incorporating geographic spatial information. Model-based methods already have a relative well-established processing flow, but further exploration is still needed on how to enhance real-time performance while ensuring tracking and occlusion accuracy. In contrast to rigid objects, nonrigid objects are prone to irregular deformations during movement. Typical nonrigid objects in augmented reality are user’s hands or the bodies of other users. For nonrigid objects, related research has been conducted on all three types virtual-real occlusion handling methods. Depth-based methods focus on the depth image restoration algorithms. These algorithms aim to repair depth image noise while ensuring precise alignment between depth and RGB image, especially in extreme scenarios, such as when foreground and background have similar colors. Image analysis-based methods focus on foreground segmentation algorithms and occlusion relationship judgment means. Foreground segmentation algorithms have evolved from the early color models and background subtraction techniques to the deep learning-based segmentation networks. Moreover, the occlusion relationship judgment means have transitioned from user-specified to incorporating depth information to assist judgment. The key challenge in image analysis-based methods lies in overcoming the irregular deformations of nonrigid objects, obtaining accurate foreground segmentation masks and tracking continuously. Model-based methods initially used LeapMotion combined with customized hand parameters to fit hand model, but now using deep learning networks to reconstruct hand models has become mainstream. Model-based methods should improve the speed and accuracy of hand reconstruction. On the basis of summarizing the virtual-real occlusion handling methods for rigid and nonrigid objects, we also conduct a comparative analysis of existing methods from various perspectives including real-time performance, automation level, whether to support perspective or scene changes, and application scope. In addition, we summarize the specific workflows, difficulties and limitations of the three virtual-real occlusion handling methods. Finally, aiming at the problems existing in related research, we explore the challenges faced by current virtual-real occlusion technology and propose potential future research directions: 1) Occlusion handling for moving nonrigid objects. Obtaining accurate depth or 3D models of nonrigid objects is the key to solving this problem. The accuracy and robustness of hand segmentation must be further improved. Additionally, the use of simpler monocular depth estimation and rapid reconstruction of nonrigid objects other than user’s hands need to be further explored. 2) Occlusion handling for outdoor dynamic scenes. Existing depth cameras have limited working range, which makes them ineffective in outdoor scenes. Sparse 3D models obtained from geographic information systems have low precision and cannot be applied to dynamic objects, such as automobiles. Therefore, further research on dynamic objects’ virtual-real occlusion handling in large outdoor scenes is needed. 3) Registration algorithms for depth and RGB images. The accuracy of edge alignment between depth and color images must be improved without consuming too much computing resources.关键词:augmented reality;virtual-real occlusion handling;rigid and non-rigid bodies;depth image restoration;foreground extraction602|875|0更新时间:2024-10-23
摘要:With the rapid development of software technology and the continuous updating of hardware devices, augmented reality technology has gradually matured and been widely used in various fields, such as military, medical, gaming, industry, and education. Accurate depth perception is crucial in augmented reality, and simply overlaying virtual objects onto video sequences no longer meets user demands. In many augmented reality scenarios, users need to interact with virtual objects constantly, and without accurate depth perception, augmented reality can hardly provide a seamless interactive experience. Virtual-real occlusion handling is one of the key factors to achieve this goal. It presents a realistic virtual-real fusion effect by establishing accurate occlusion relationship, so that the fusion scene can correctly reflect the spatial position relationship between virtual and real objects, thereby enhancing the user’s sense of immersion and realism. This paper first introduces the related background, concepts, and overall processing flow of virtual-real occlusion handling. Existing occlusion handling methods can be divided into three categories: depth based, image analysis based, and model based. By analyzing the distinct characteristics of rigid and nonrigid objects, we summarize the specific principles, representative research works, and the applicability to rigid and nonrigid objects of these three virtual-real occlusion handling methods. The shape and size of rigid objects remain unchanged after motion or force, and they mainly use two types virtual-real occlusion handling methods: depth based and model based. The depth-based methods have evolved from the early use of stereo vision algorithms to the use of depth sensors for indoor depth image acquisition and further to the prediction of moving objects’ depth by using outdoor map data, as well as the densification of sparse simultaneous localization and mapping depth in monocular mobile augmented reality. Further research should focus on the depth image restoration algorithms and the balance between real-time performance and accuracy of scene-dense depth computation algorithms in mobile augmented reality. The model-based methods have developed from constructing partial 3D models by segmenting object contours in video key frames or directly using modeling software to achieving dense reconstruction of indoor static scenes using depth images and constructing approximate 3D models of outdoor scenes by incorporating geographic spatial information. Model-based methods already have a relative well-established processing flow, but further exploration is still needed on how to enhance real-time performance while ensuring tracking and occlusion accuracy. In contrast to rigid objects, nonrigid objects are prone to irregular deformations during movement. Typical nonrigid objects in augmented reality are user’s hands or the bodies of other users. For nonrigid objects, related research has been conducted on all three types virtual-real occlusion handling methods. Depth-based methods focus on the depth image restoration algorithms. These algorithms aim to repair depth image noise while ensuring precise alignment between depth and RGB image, especially in extreme scenarios, such as when foreground and background have similar colors. Image analysis-based methods focus on foreground segmentation algorithms and occlusion relationship judgment means. Foreground segmentation algorithms have evolved from the early color models and background subtraction techniques to the deep learning-based segmentation networks. Moreover, the occlusion relationship judgment means have transitioned from user-specified to incorporating depth information to assist judgment. The key challenge in image analysis-based methods lies in overcoming the irregular deformations of nonrigid objects, obtaining accurate foreground segmentation masks and tracking continuously. Model-based methods initially used LeapMotion combined with customized hand parameters to fit hand model, but now using deep learning networks to reconstruct hand models has become mainstream. Model-based methods should improve the speed and accuracy of hand reconstruction. On the basis of summarizing the virtual-real occlusion handling methods for rigid and nonrigid objects, we also conduct a comparative analysis of existing methods from various perspectives including real-time performance, automation level, whether to support perspective or scene changes, and application scope. In addition, we summarize the specific workflows, difficulties and limitations of the three virtual-real occlusion handling methods. Finally, aiming at the problems existing in related research, we explore the challenges faced by current virtual-real occlusion technology and propose potential future research directions: 1) Occlusion handling for moving nonrigid objects. Obtaining accurate depth or 3D models of nonrigid objects is the key to solving this problem. The accuracy and robustness of hand segmentation must be further improved. Additionally, the use of simpler monocular depth estimation and rapid reconstruction of nonrigid objects other than user’s hands need to be further explored. 2) Occlusion handling for outdoor dynamic scenes. Existing depth cameras have limited working range, which makes them ineffective in outdoor scenes. Sparse 3D models obtained from geographic information systems have low precision and cannot be applied to dynamic objects, such as automobiles. Therefore, further research on dynamic objects’ virtual-real occlusion handling in large outdoor scenes is needed. 3) Registration algorithms for depth and RGB images. The accuracy of edge alignment between depth and color images must be improved without consuming too much computing resources.关键词:augmented reality;virtual-real occlusion handling;rigid and non-rigid bodies;depth image restoration;foreground extraction602|875|0更新时间:2024-10-23 -
 摘要:Visual-based localization determines the camera translation and orientation of an image observation with respect to a prebuilt 3D-based representation of the environment. It is an essential technology that empowers the intelligent interactions between computing facilities and the real world. Compared with alternative positioning systems beyond, the capability to estimate the accurate 6DOF camera pose, along with the flexibility and frugality in deployment, positions visual-based localization technology as a cornerstone of many applications, ranging from autonomous vehicles to augmented and mixed reality. As a long-standing problem in computer vision, visual localization has made exceeding progress over the past decades. A primary branch of prior arts relies on a preconstructed 3D map obtained by structure-from-motion techniques. Such 3D maps, a.k.a. SfM point clouds, store 3D points and per-point visual features. To estimate the camera pose, these methods typically establish correspondences between 2D keypoints detected in the query image and 3D points of the SfM point cloud through descriptor matching. The 6DOF camera pose of the query image is then recovered from these 2D-3D matches by leveraging geometric principles introduced by photogrammetry. Despite delivering fairly sound and reliable performance, such a scheme often has to consume several gigabytes of storage for just a single scene, which would result in computationally expensive overhead and prohibitive memory footprint for large-scale applications and resource-intensive platforms. Furthermore, it suffers from other drawbacks, such as costly map maintenance and privacy vulnerability. The aforementioned issues pose a major bottleneck in real-world applications and have thus prompted researchers to shift their focus toward leaner solutions. Lightweight visual-based localization seeks to introduce improvements in scene representations and the associated localization methods, making the resulting framework computationally tractable and memory-efficient without incurring a notable performance expense. For the background, this literature review first introduces several flagship frameworks of the visual-based localization task as preliminaries. These frameworks can be broadly classified into three categories, including image-retrieval-based methods, structure-based methods, and hierarchical methods. 3D scene representations adopted in these conventional frameworks, such as reference image databases and SfM point clouds, generally exhibit a high degree of redundancy, which causes excessive memory usage and inefficiency in distinguishing scene features for descriptor matching. Next, this review provides a guided tour of recent advances that promote the brevity of the 3D scene representations and the efficiency of corresponding visual localization methods. From the perspective of scene representations, existing research efforts in lightweight visual localization can be classified into six categories. Within each category, this literature review analyzes its characteristics, application scenarios, and technical limitations while also surveying some of the representative works. First, several methods have been proposed to enhance memory efficiency by compressing the SfM point clouds. These methods reduce the size of SfM point clouds through the combination of techniques including feature quantization, keypoint subset sampling, and feature-free matching. Extreme compression rates, such as 1% and below, can be achieved with barely noticeable accuracy degradation. Employing line maps as scene representations has become a focus of research in the field of lightweight visual localization. In human-made scenes characterized by salient structural features, the substitution of line maps for point clouds offers two major merits: 1) the abundance and rich geometric properties of line segments make line maps a concise option for depicting the environment; 2) line features exhibit better robustness in weak-textured areas or under temporally varying lighting conditions. However, the lack of a unified line descriptor and the difficulty of establishing 2D-3D correspondences between 3D line segments and image observations remain as main challenges. In the field of autonomous driving, high-definition maps constructed from vectorized semantic features have unlocked a new wave of cost-effective and lightweight solutions to visual localization for self-driving vehicle. Recent trends involve the utilization of data-driven techniques to learn to localize. This end-to-end philosophy has given rise to two regression-based methods. Scene coordinate regression (SCR) methods eschew the explicit processes of feature extraction and matching. Instead, they establish a direct mapping between observations and scene coordinates through regression. While a grounding in geometry remains essential for camera pose estimation in SCR methods, pose regression methods employ deep neural networks to establish the mapping from image observations to camera poses without any explicit geometric reasoning. Absolute pose regression techniques are akin to image retrieval approaches with limited accuracy and generalization capability, while relative pose regression techniques typically serve as a postprocessing step following the coarse localization stage. Neural radiance fields and related volumetric-based approaches have emerged as a novel way for the neural implicit scene representation. While visual localization based solely on a learned volumetric-based implicit map is still in an exploratory phase, the progress made over the past year or two has already yielded an impressive performance in terms of the scene representation capability and precision of localization. Furthermore, this study quantitatively evaluates the performance of several representative lightweight visual localization methods on well-known indoor and outdoor datasets. Evaluation metrics, including offline mapping time usage, storage demand, and localization accuracy, are considered for making comparisons. Results reveal that SCR methods generally stand out among the existing work, boasting remarkably compact scene maps and high success rates of localization. Existing lightweight visual localization methods have dramatically pushed the performance boundary. However, challenges still remain in terms of scalability and robustness when enlarging the scene scale and taking considerable visual disparity between query and mapping images into consideration. Therefore, extensive efforts are still required to promote the compactness of scene representations and improving the robustness of localization methods. Finally, this review provides an outlook on developing trends in the hope of facilitating future research.关键词:visual localization;camera pose estimation;3D scene representation;lightweight map;feature matching;scene coordinate regression;pose regression715|1117|0更新时间:2024-10-23
摘要:Visual-based localization determines the camera translation and orientation of an image observation with respect to a prebuilt 3D-based representation of the environment. It is an essential technology that empowers the intelligent interactions between computing facilities and the real world. Compared with alternative positioning systems beyond, the capability to estimate the accurate 6DOF camera pose, along with the flexibility and frugality in deployment, positions visual-based localization technology as a cornerstone of many applications, ranging from autonomous vehicles to augmented and mixed reality. As a long-standing problem in computer vision, visual localization has made exceeding progress over the past decades. A primary branch of prior arts relies on a preconstructed 3D map obtained by structure-from-motion techniques. Such 3D maps, a.k.a. SfM point clouds, store 3D points and per-point visual features. To estimate the camera pose, these methods typically establish correspondences between 2D keypoints detected in the query image and 3D points of the SfM point cloud through descriptor matching. The 6DOF camera pose of the query image is then recovered from these 2D-3D matches by leveraging geometric principles introduced by photogrammetry. Despite delivering fairly sound and reliable performance, such a scheme often has to consume several gigabytes of storage for just a single scene, which would result in computationally expensive overhead and prohibitive memory footprint for large-scale applications and resource-intensive platforms. Furthermore, it suffers from other drawbacks, such as costly map maintenance and privacy vulnerability. The aforementioned issues pose a major bottleneck in real-world applications and have thus prompted researchers to shift their focus toward leaner solutions. Lightweight visual-based localization seeks to introduce improvements in scene representations and the associated localization methods, making the resulting framework computationally tractable and memory-efficient without incurring a notable performance expense. For the background, this literature review first introduces several flagship frameworks of the visual-based localization task as preliminaries. These frameworks can be broadly classified into three categories, including image-retrieval-based methods, structure-based methods, and hierarchical methods. 3D scene representations adopted in these conventional frameworks, such as reference image databases and SfM point clouds, generally exhibit a high degree of redundancy, which causes excessive memory usage and inefficiency in distinguishing scene features for descriptor matching. Next, this review provides a guided tour of recent advances that promote the brevity of the 3D scene representations and the efficiency of corresponding visual localization methods. From the perspective of scene representations, existing research efforts in lightweight visual localization can be classified into six categories. Within each category, this literature review analyzes its characteristics, application scenarios, and technical limitations while also surveying some of the representative works. First, several methods have been proposed to enhance memory efficiency by compressing the SfM point clouds. These methods reduce the size of SfM point clouds through the combination of techniques including feature quantization, keypoint subset sampling, and feature-free matching. Extreme compression rates, such as 1% and below, can be achieved with barely noticeable accuracy degradation. Employing line maps as scene representations has become a focus of research in the field of lightweight visual localization. In human-made scenes characterized by salient structural features, the substitution of line maps for point clouds offers two major merits: 1) the abundance and rich geometric properties of line segments make line maps a concise option for depicting the environment; 2) line features exhibit better robustness in weak-textured areas or under temporally varying lighting conditions. However, the lack of a unified line descriptor and the difficulty of establishing 2D-3D correspondences between 3D line segments and image observations remain as main challenges. In the field of autonomous driving, high-definition maps constructed from vectorized semantic features have unlocked a new wave of cost-effective and lightweight solutions to visual localization for self-driving vehicle. Recent trends involve the utilization of data-driven techniques to learn to localize. This end-to-end philosophy has given rise to two regression-based methods. Scene coordinate regression (SCR) methods eschew the explicit processes of feature extraction and matching. Instead, they establish a direct mapping between observations and scene coordinates through regression. While a grounding in geometry remains essential for camera pose estimation in SCR methods, pose regression methods employ deep neural networks to establish the mapping from image observations to camera poses without any explicit geometric reasoning. Absolute pose regression techniques are akin to image retrieval approaches with limited accuracy and generalization capability, while relative pose regression techniques typically serve as a postprocessing step following the coarse localization stage. Neural radiance fields and related volumetric-based approaches have emerged as a novel way for the neural implicit scene representation. While visual localization based solely on a learned volumetric-based implicit map is still in an exploratory phase, the progress made over the past year or two has already yielded an impressive performance in terms of the scene representation capability and precision of localization. Furthermore, this study quantitatively evaluates the performance of several representative lightweight visual localization methods on well-known indoor and outdoor datasets. Evaluation metrics, including offline mapping time usage, storage demand, and localization accuracy, are considered for making comparisons. Results reveal that SCR methods generally stand out among the existing work, boasting remarkably compact scene maps and high success rates of localization. Existing lightweight visual localization methods have dramatically pushed the performance boundary. However, challenges still remain in terms of scalability and robustness when enlarging the scene scale and taking considerable visual disparity between query and mapping images into consideration. Therefore, extensive efforts are still required to promote the compactness of scene representations and improving the robustness of localization methods. Finally, this review provides an outlook on developing trends in the hope of facilitating future research.关键词:visual localization;camera pose estimation;3D scene representation;lightweight map;feature matching;scene coordinate regression;pose regression715|1117|0更新时间:2024-10-23 -
 摘要:Rendering has been a prominent subject in the field of computer graphics for an extended period. It can be regarded as a function that accepts an abstract scene description as input and typically generates a 2D image as output. The theory and practice of rendering have remarkably advanced through years of research. In recent years, inverse rendering has emerged as a new research focus in the field of computer graphics due to the development of digital technology. The objective of inverse rendering is to reverse the rendering process and deduce scene parameters from the output image, which is equivalent to solving the inverse function of the rendering function. This process plays a crucial role in addressing perception problems in diverse advanced technological domains, including virtual reality, autonomous driving, and robotics. Numerous methods exist for implementing inverse rendering, with the current mainstream framework being optimization through “analysis by synthesis”. First, it estimates a set of initial scene parameters, then performs forward rendering on the scene, compares the rendered result with the target image, and then minimizes the difference (loss function) by optimizing the scene parameters using gradient descent-based method. This pipeline necessitates the ability to compute the derivatives of the output image in forward rendering with respect to the input parameters. Consequently, differentiable rendering has emerged to fulfill this requirement. Specifically, the research topic of differentiable rendering is to convert the forward rendering pipeline in computer graphics into a differentiable form, enabling the differentiation of the output image with respect to input parameters such as geometry, material, light source, and camera. Currently, forward rendering can be broadly categorized into three types: rasterization-based rendering, physically based rendering, and the emerging neural rendering. Rasterization-based rendering is a fundamental technique in computer graphics that converts geometric shapes into pixels for display. It involves projecting 3D objects onto a 2D screen, performing hidden surface removal, shading, and texturing to create realistic images efficiently. While rasterization is fast and suitable for real-time applications, it may lack physical accuracy in simulating light interactions. By contrast, physically based rendering aims to simulate real-world light behavior accurately by considering the physical properties of materials, light sources, and the environment. It calculates how light rays interact with surfaces, accounting for reflections, refractions, and scattering to produce photorealistic visual results. This method prioritizes realism and is widely used in industries, such as animation, gaming, and visual effects. Neural rendering is an emerging rendering technique in recent years, mainly used for image-based rendering tasks. In contrast to traditional graphics rendering, image-based rendering does not require any explicit 3D scene information (geometry, materials, lighting, etc.), but instead implicitly encodes scenes through a sequence of 2D images sampled from different viewpoints, enabling the generation of images of the scene from any viewpoint. Accordingly, differentiable rendering can also be categorized into three types: differentiable rasterization, physically based differentiable rendering, and differentiable neural rendering. In differentiable rasterization, many works employ approximate methods to compute approximate derivatives of the rasterization process for backpropagation of gradients or modify steps in the traditional rendering pipeline (usually rasterization and testing/blending steps) to make pixels differentiable with respect to vertices. Neural rendering is naturally differentiable because its rendering process is conducted through neural networks. For physically based differentiable rendering, accurately calculating the gradient of the image concerning scene parameters is challenging because of the intricate nature of geometry, material, and light transmission processes. Therefore, this study concentrates on recent research in the field of physically based differentiable rendering. The article is organized into the following sections: Section 1 introduces the computational methods of forward rendering and differentiable rendering from an abstract standpoint and two types of method for correctly computing boundary integral: edge sampling and reparameterization. Section 2 explores the attainment of differentiable rendering for distinct representations of geometry, such as volumetric representation, signed distance field, height field, and vectorized geometry; materials, such as volumetric material; parameterized bidirectional reflectance distribution function, bidirectional surface scattering reflectance distribution function, and continuously varying refractive index fields; and camera-related parameters, such as pixel reconstruction filter and time-of-flight camera. Section 3 focuses on enhancing the efficiency and robustness of differentiable rendering, including efficient sampling, high-efficiency system and framework, language for differentiable rendering and several techniques, to enhance the robustness of differentiable rendering. Section 4 showcases the application of differentiable rendering in practical tasks, which can be generally divided in three types: single-object reconstruction, object and environment light reconstruction, and scene reconstruction. Section 5 discusses the future development trends of differentiable rendering, including improving efficiency, robustness of differentiable rendering, and combining differentiable rendering with other methods.关键词:rendering;differentiable rendering;inverse rendering;ray tracing;3d reconstruction882|1288|0更新时间:2024-10-23
摘要:Rendering has been a prominent subject in the field of computer graphics for an extended period. It can be regarded as a function that accepts an abstract scene description as input and typically generates a 2D image as output. The theory and practice of rendering have remarkably advanced through years of research. In recent years, inverse rendering has emerged as a new research focus in the field of computer graphics due to the development of digital technology. The objective of inverse rendering is to reverse the rendering process and deduce scene parameters from the output image, which is equivalent to solving the inverse function of the rendering function. This process plays a crucial role in addressing perception problems in diverse advanced technological domains, including virtual reality, autonomous driving, and robotics. Numerous methods exist for implementing inverse rendering, with the current mainstream framework being optimization through “analysis by synthesis”. First, it estimates a set of initial scene parameters, then performs forward rendering on the scene, compares the rendered result with the target image, and then minimizes the difference (loss function) by optimizing the scene parameters using gradient descent-based method. This pipeline necessitates the ability to compute the derivatives of the output image in forward rendering with respect to the input parameters. Consequently, differentiable rendering has emerged to fulfill this requirement. Specifically, the research topic of differentiable rendering is to convert the forward rendering pipeline in computer graphics into a differentiable form, enabling the differentiation of the output image with respect to input parameters such as geometry, material, light source, and camera. Currently, forward rendering can be broadly categorized into three types: rasterization-based rendering, physically based rendering, and the emerging neural rendering. Rasterization-based rendering is a fundamental technique in computer graphics that converts geometric shapes into pixels for display. It involves projecting 3D objects onto a 2D screen, performing hidden surface removal, shading, and texturing to create realistic images efficiently. While rasterization is fast and suitable for real-time applications, it may lack physical accuracy in simulating light interactions. By contrast, physically based rendering aims to simulate real-world light behavior accurately by considering the physical properties of materials, light sources, and the environment. It calculates how light rays interact with surfaces, accounting for reflections, refractions, and scattering to produce photorealistic visual results. This method prioritizes realism and is widely used in industries, such as animation, gaming, and visual effects. Neural rendering is an emerging rendering technique in recent years, mainly used for image-based rendering tasks. In contrast to traditional graphics rendering, image-based rendering does not require any explicit 3D scene information (geometry, materials, lighting, etc.), but instead implicitly encodes scenes through a sequence of 2D images sampled from different viewpoints, enabling the generation of images of the scene from any viewpoint. Accordingly, differentiable rendering can also be categorized into three types: differentiable rasterization, physically based differentiable rendering, and differentiable neural rendering. In differentiable rasterization, many works employ approximate methods to compute approximate derivatives of the rasterization process for backpropagation of gradients or modify steps in the traditional rendering pipeline (usually rasterization and testing/blending steps) to make pixels differentiable with respect to vertices. Neural rendering is naturally differentiable because its rendering process is conducted through neural networks. For physically based differentiable rendering, accurately calculating the gradient of the image concerning scene parameters is challenging because of the intricate nature of geometry, material, and light transmission processes. Therefore, this study concentrates on recent research in the field of physically based differentiable rendering. The article is organized into the following sections: Section 1 introduces the computational methods of forward rendering and differentiable rendering from an abstract standpoint and two types of method for correctly computing boundary integral: edge sampling and reparameterization. Section 2 explores the attainment of differentiable rendering for distinct representations of geometry, such as volumetric representation, signed distance field, height field, and vectorized geometry; materials, such as volumetric material; parameterized bidirectional reflectance distribution function, bidirectional surface scattering reflectance distribution function, and continuously varying refractive index fields; and camera-related parameters, such as pixel reconstruction filter and time-of-flight camera. Section 3 focuses on enhancing the efficiency and robustness of differentiable rendering, including efficient sampling, high-efficiency system and framework, language for differentiable rendering and several techniques, to enhance the robustness of differentiable rendering. Section 4 showcases the application of differentiable rendering in practical tasks, which can be generally divided in three types: single-object reconstruction, object and environment light reconstruction, and scene reconstruction. Section 5 discusses the future development trends of differentiable rendering, including improving efficiency, robustness of differentiable rendering, and combining differentiable rendering with other methods.关键词:rendering;differentiable rendering;inverse rendering;ray tracing;3d reconstruction882|1288|0更新时间:2024-10-23 -
 摘要:With the development of natural human-computer interaction technologies, such as virtual reality(VR), metaverse, and artificial intelligence-generated content, human-computer interfaces based on interactive virtual contents are providing users with a new kind of task challenge——emotional challenge. Emotional challenge mainly examines the user’s ability to understand, explore, and deal with emotional issues in a virtual world. It is considered a core aspect of virtual interactive scenarios in the metaverse and an essential element in the future digital world. Moreover, users’ perceived emotional challenge has been proven to be a serious, profound, and reflective new type of user experience. Specifically, by resolving the tension within the narrative, identifying with virtual characters, and exploring emotional ambiguities, players encountering emotional challenge would be put in a more reflective state of mind and experience more diverse, impactful, and complex emotional experiences. Since the introduction of emotional challenge in 2015, it has attracted considerable attention in the field of human-computer interaction. With this background, researchers have conducted a series of research work on emotional challenge with respect to its definition, characteristics, interactive design, evaluation scales, and computational modeling. This study aims to systematically organize and introduce the related works of emotional challenge first and then elaborate its prospective applications in the metaverse. This paper starts by introducing the concept of challenge in digital games. Game challenge deals with the obstacles that players must overcome and the tasks that they must perform to make game progress. Game challenges generally have three different kinds. Physical challenge depends on players’ skills, such as speed, accuracy, endurance, dexterity, and strength, and cognitive challenge requires players to use their cognitive abilities, such as memory, observation, reasoning, planning, and problem solving. By contrast, emotional challenge deals with tension within the narrative or difficult material presented in the game and can only be overcome with a cognitive and affective effort from the player. Afterward, this paper introduces related works on emotional challenge, including how it differs from more traditional types of challenge, the diverse and relative negative emotional responses it evokes, the required game design characteristics, and the psychological theories relate to emotional challenge. This paper then introduces how emotional challenge affects player experience when separately from or jointly with traditional challenge in VR and PC conditions. Results showed that relatively exclusive emotional challenge induced a wider range of different emotions under VR and PC conditions, while the adding of emotional challenge broadened emotional responses only in VR condition. VR could also enhance players’ perceived experiences of emotional response, appreciation, immersion, and presence. This paper also reviewed the latest work on the potential of detecting perceived emotional challenge from physiological signals. Researchers collected physiological responses from a group of players who engaged in three typical game scenarios coving an entire spectrum of different game challenges. By collecting perceived challenge ratings from players and extracting basic physiological features, researchers applied multiple machine learning methods and metrics to detect challenge experiences. Results showed that most methods achieved a challenge detection accuracy of around 80%. Although emotional challenge has attracted considerable attention in the field of human-computer interaction, it has not been clearly defined at present. Additionally, current research on emotional challenge is primarily limited to the area of digital games. We believe that the concept of emotional challenge has the potential for application in various domains of human-computer interaction. Therefore, building upon previous works on emotional challenge, this paper provides a definition and description of emotional challenge from the perspective of human-computer interaction. Emotional challenge primarily examines users’ understanding, exploration, and processing abilities of emotions in virtual scenarios and the digital world. It often requires individuals to engage in meaningful choices and interactions within virtual interactive environments as they navigate emotional dilemmas and respond to the uncertainties arising from their interactions. For instance, in a virtual scenario, a sniper aims at an enemy soldier holding a rocket launcher, intending to destroy their own camp. However, the sniper suddenly realizes that the enemy soldier is a close friend with whom they have shared hardships. When faced with the decision of whether to pull the trigger, the sniper may experience an emotional challenge of “agonizing between friendship and protecting their own base”. With the proposed definition of emotional challenge, we also elaborate on how emotional challenge is understood from the perspectives of users and designers and highlight the main mediums through which emotional challenge exists. Finally, this paper summarizes the research importance of emotional challenge in the metaverse and provides an outlook on the application prospects of emotional challenge in the metaverse. The metaverse aims to create a comprehensive virtual digital living space that maps or transcends the real world. It includes a plethora of virtual content and virtual characters, with users being a part of it and interacting with these virtual characters or content. Through autonomous interactions with the virtual characters or content, users are likely to explore complex emotions and confront with emotional challenge. Hence, emotional challenge becomes the core content embedded in virtual interactive scenarios within the metaverse, making it an essential element in the future digital world. In the design of metaverse systems for application, the involvement of emotional challenge can equip the metaverse with the ability to evoke and generate complex but meaningful emotional experiences. It can assist in training users’ skills in understanding, exploring, and dealing with difficult emotional issues, promoting self-realization, self-expression, and self-management abilities and thus building correct life outlook and values.关键词:emotional challenge;narrative games;virtual reality(VR);metaverse;human-computer interaction356|620|0更新时间:2024-10-23
摘要:With the development of natural human-computer interaction technologies, such as virtual reality(VR), metaverse, and artificial intelligence-generated content, human-computer interfaces based on interactive virtual contents are providing users with a new kind of task challenge——emotional challenge. Emotional challenge mainly examines the user’s ability to understand, explore, and deal with emotional issues in a virtual world. It is considered a core aspect of virtual interactive scenarios in the metaverse and an essential element in the future digital world. Moreover, users’ perceived emotional challenge has been proven to be a serious, profound, and reflective new type of user experience. Specifically, by resolving the tension within the narrative, identifying with virtual characters, and exploring emotional ambiguities, players encountering emotional challenge would be put in a more reflective state of mind and experience more diverse, impactful, and complex emotional experiences. Since the introduction of emotional challenge in 2015, it has attracted considerable attention in the field of human-computer interaction. With this background, researchers have conducted a series of research work on emotional challenge with respect to its definition, characteristics, interactive design, evaluation scales, and computational modeling. This study aims to systematically organize and introduce the related works of emotional challenge first and then elaborate its prospective applications in the metaverse. This paper starts by introducing the concept of challenge in digital games. Game challenge deals with the obstacles that players must overcome and the tasks that they must perform to make game progress. Game challenges generally have three different kinds. Physical challenge depends on players’ skills, such as speed, accuracy, endurance, dexterity, and strength, and cognitive challenge requires players to use their cognitive abilities, such as memory, observation, reasoning, planning, and problem solving. By contrast, emotional challenge deals with tension within the narrative or difficult material presented in the game and can only be overcome with a cognitive and affective effort from the player. Afterward, this paper introduces related works on emotional challenge, including how it differs from more traditional types of challenge, the diverse and relative negative emotional responses it evokes, the required game design characteristics, and the psychological theories relate to emotional challenge. This paper then introduces how emotional challenge affects player experience when separately from or jointly with traditional challenge in VR and PC conditions. Results showed that relatively exclusive emotional challenge induced a wider range of different emotions under VR and PC conditions, while the adding of emotional challenge broadened emotional responses only in VR condition. VR could also enhance players’ perceived experiences of emotional response, appreciation, immersion, and presence. This paper also reviewed the latest work on the potential of detecting perceived emotional challenge from physiological signals. Researchers collected physiological responses from a group of players who engaged in three typical game scenarios coving an entire spectrum of different game challenges. By collecting perceived challenge ratings from players and extracting basic physiological features, researchers applied multiple machine learning methods and metrics to detect challenge experiences. Results showed that most methods achieved a challenge detection accuracy of around 80%. Although emotional challenge has attracted considerable attention in the field of human-computer interaction, it has not been clearly defined at present. Additionally, current research on emotional challenge is primarily limited to the area of digital games. We believe that the concept of emotional challenge has the potential for application in various domains of human-computer interaction. Therefore, building upon previous works on emotional challenge, this paper provides a definition and description of emotional challenge from the perspective of human-computer interaction. Emotional challenge primarily examines users’ understanding, exploration, and processing abilities of emotions in virtual scenarios and the digital world. It often requires individuals to engage in meaningful choices and interactions within virtual interactive environments as they navigate emotional dilemmas and respond to the uncertainties arising from their interactions. For instance, in a virtual scenario, a sniper aims at an enemy soldier holding a rocket launcher, intending to destroy their own camp. However, the sniper suddenly realizes that the enemy soldier is a close friend with whom they have shared hardships. When faced with the decision of whether to pull the trigger, the sniper may experience an emotional challenge of “agonizing between friendship and protecting their own base”. With the proposed definition of emotional challenge, we also elaborate on how emotional challenge is understood from the perspectives of users and designers and highlight the main mediums through which emotional challenge exists. Finally, this paper summarizes the research importance of emotional challenge in the metaverse and provides an outlook on the application prospects of emotional challenge in the metaverse. The metaverse aims to create a comprehensive virtual digital living space that maps or transcends the real world. It includes a plethora of virtual content and virtual characters, with users being a part of it and interacting with these virtual characters or content. Through autonomous interactions with the virtual characters or content, users are likely to explore complex emotions and confront with emotional challenge. Hence, emotional challenge becomes the core content embedded in virtual interactive scenarios within the metaverse, making it an essential element in the future digital world. In the design of metaverse systems for application, the involvement of emotional challenge can equip the metaverse with the ability to evoke and generate complex but meaningful emotional experiences. It can assist in training users’ skills in understanding, exploring, and dealing with difficult emotional issues, promoting self-realization, self-expression, and self-management abilities and thus building correct life outlook and values.关键词:emotional challenge;narrative games;virtual reality(VR);metaverse;human-computer interaction356|620|0更新时间:2024-10-23 -
 摘要:With the development of information technology, mixed reality (MR) technology has been applied in various fields, such as healthcare, education, and assisted guidance. MR scenes contain rich semantic information, and MR technology based on scene context information can improve users’ perception of the scene, optimize user interaction, and enhance the accuracy of interaction models. Therefore, they have quickly gained widespread attention. However, literature reviews specifically investigating context information in this field are limited, and organization and classification are lacking. This paper focuses on MR technology and systems that utilize context information. This study was conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines. First, keywords for the search were determined on the basis of three factors: research domain, study subjects, and research scenarios. Subsequently, searches were performed in two influential databases in the field of MR: ACM Digital Library and IEEE Xplore. A preliminary screening was then executed, considering the types of journals and conferences to eliminate irrelevant and unpublished literature. Subsequently, the titles and abstracts of the articles were reviewed sequentially, eliminating duplicates and irrelevant results. Finally, a total of 210 articles were individually screened to select 29 papers for the review. Additionally, four more articles were included on the basis of expertise, resulting in a total of 33 articles for the review. Through a comprehensive literature review of MR databases, three research questions were formulated, and a dataset of research articles was established. The three research questions addressed in this paper are as follows: 1) What are the different types of scene context? 2) How is scene context organized in various MR technologies and systems? 3) What are the application areas of empirical research? On the basis of the evolution of scene context and the refinement of MR technologies and systems, we analyze the empirical research papers spanning nearly 20 years. This analysis involves summarizing previous research and providing an overview of the latest developments in systems that leverage scene context. We also propose potential classification criteria, such as types of scene context, construction methods of knowledge bases for contextual information, fundamental technologies, and application domains. Among the various types of scene context, we categorize them into six classes: scene semantics, object semantics, spatial relationships, group relationships, dependence relationships, and motion relationships. Scene semantics is the semantic information encompassed by various elements in the scene environment, including objects, characters, and texture information. In the categorization of object semantics, we consider information about the individual object itself, such as user information, type, attributes, and special content. Spatial relationship refers to numerical information, such as the relative position, angle, or arrangement between various objects in the scene. We analyzed spatial relationships in three ways: base spatial relationships, microscene spatial information, and real-scene spatial information. We consider a certain number of closely neighboring objects of the same category as a group. Group relations focus on information about the overall perspective such as intergroup relations and the number of groups. Dependence relationship is concerned with the dependencies and affiliations that may exist between different objects in the scene at the functional and physical levels. Motion information is a new type of scene context, including basic motion information and special motion information, which describes the dynamic information of scene objects. Through an analysis of the utilization of various types of scene context, we establish the relationship between research objectives and contextual information, providing guidance on the selection of contextual information. The construction of knowledge bases is examined from user-intervention perspectives and types of fundamental technologies. Knowledge bases established with user intervention typically rely on researchers’ abstract analysis of scene objects rather than pre-existing databases. Conversely, knowledge bases built without user intervention rely on existing information, such as low-level raw data in databases or predefined scenarios. The underlying technologies in this context are categorized into virtual reality (VR) and augmented reality (AR). Conducting classification research from the dual perspectives of user intervention and fundamental technology facilitates a deeper understanding of how contextual information is organized in various MR systems. Application areas are investigated on the basis of the types of scenarios and whether they involve generative processes or not. The types of application scenarios are then categorized into six types: auxiliary guidance, AR annotation, scene reconstruction, medical treatment, object manipulation, and general purpose. Generative models can automatically generate target information, such as AR-annotated shadows based on the scene, whereas nongenerative models mainly focus on specific operations. Through analysis from these two perspectives, the advantages and disadvantages of MR systems and technologies in different application scenarios can be explored. Drawing upon the exploration and research in these three dimensions, we investigate the challenges associated with selecting, acquiring, and applying contextual information in MR scenarios. By classifying the research objects from different dimensions, we address the research questions and identify current shortcomings and future research directions. The aim of this review is to support researchers across diverse fields in designing, selecting, and evaluating scene context, ultimately fostering the advancement of future MR application technologies and systems.关键词:virtual reality(VR);augmented reality(AR);perception and interaction;context information;scene semantics385|603|0更新时间:2024-10-23
摘要:With the development of information technology, mixed reality (MR) technology has been applied in various fields, such as healthcare, education, and assisted guidance. MR scenes contain rich semantic information, and MR technology based on scene context information can improve users’ perception of the scene, optimize user interaction, and enhance the accuracy of interaction models. Therefore, they have quickly gained widespread attention. However, literature reviews specifically investigating context information in this field are limited, and organization and classification are lacking. This paper focuses on MR technology and systems that utilize context information. This study was conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines. First, keywords for the search were determined on the basis of three factors: research domain, study subjects, and research scenarios. Subsequently, searches were performed in two influential databases in the field of MR: ACM Digital Library and IEEE Xplore. A preliminary screening was then executed, considering the types of journals and conferences to eliminate irrelevant and unpublished literature. Subsequently, the titles and abstracts of the articles were reviewed sequentially, eliminating duplicates and irrelevant results. Finally, a total of 210 articles were individually screened to select 29 papers for the review. Additionally, four more articles were included on the basis of expertise, resulting in a total of 33 articles for the review. Through a comprehensive literature review of MR databases, three research questions were formulated, and a dataset of research articles was established. The three research questions addressed in this paper are as follows: 1) What are the different types of scene context? 2) How is scene context organized in various MR technologies and systems? 3) What are the application areas of empirical research? On the basis of the evolution of scene context and the refinement of MR technologies and systems, we analyze the empirical research papers spanning nearly 20 years. This analysis involves summarizing previous research and providing an overview of the latest developments in systems that leverage scene context. We also propose potential classification criteria, such as types of scene context, construction methods of knowledge bases for contextual information, fundamental technologies, and application domains. Among the various types of scene context, we categorize them into six classes: scene semantics, object semantics, spatial relationships, group relationships, dependence relationships, and motion relationships. Scene semantics is the semantic information encompassed by various elements in the scene environment, including objects, characters, and texture information. In the categorization of object semantics, we consider information about the individual object itself, such as user information, type, attributes, and special content. Spatial relationship refers to numerical information, such as the relative position, angle, or arrangement between various objects in the scene. We analyzed spatial relationships in three ways: base spatial relationships, microscene spatial information, and real-scene spatial information. We consider a certain number of closely neighboring objects of the same category as a group. Group relations focus on information about the overall perspective such as intergroup relations and the number of groups. Dependence relationship is concerned with the dependencies and affiliations that may exist between different objects in the scene at the functional and physical levels. Motion information is a new type of scene context, including basic motion information and special motion information, which describes the dynamic information of scene objects. Through an analysis of the utilization of various types of scene context, we establish the relationship between research objectives and contextual information, providing guidance on the selection of contextual information. The construction of knowledge bases is examined from user-intervention perspectives and types of fundamental technologies. Knowledge bases established with user intervention typically rely on researchers’ abstract analysis of scene objects rather than pre-existing databases. Conversely, knowledge bases built without user intervention rely on existing information, such as low-level raw data in databases or predefined scenarios. The underlying technologies in this context are categorized into virtual reality (VR) and augmented reality (AR). Conducting classification research from the dual perspectives of user intervention and fundamental technology facilitates a deeper understanding of how contextual information is organized in various MR systems. Application areas are investigated on the basis of the types of scenarios and whether they involve generative processes or not. The types of application scenarios are then categorized into six types: auxiliary guidance, AR annotation, scene reconstruction, medical treatment, object manipulation, and general purpose. Generative models can automatically generate target information, such as AR-annotated shadows based on the scene, whereas nongenerative models mainly focus on specific operations. Through analysis from these two perspectives, the advantages and disadvantages of MR systems and technologies in different application scenarios can be explored. Drawing upon the exploration and research in these three dimensions, we investigate the challenges associated with selecting, acquiring, and applying contextual information in MR scenarios. By classifying the research objects from different dimensions, we address the research questions and identify current shortcomings and future research directions. The aim of this review is to support researchers across diverse fields in designing, selecting, and evaluating scene context, ultimately fostering the advancement of future MR application technologies and systems.关键词:virtual reality(VR);augmented reality(AR);perception and interaction;context information;scene semantics385|603|0更新时间:2024-10-23 -
 摘要:The widespread adoption of virtual reality (VR) and augmented reality technologies across various sectors, including healthcare, education, military, and entertainment, has propelled head-mounted displays with high resolution and wide fields of view into the forefront of display devices. However, attaining a satisfactory level of immersion and interactivity poses a primary challenge in the realm of VR, with latency potentially leading to user discomfort in the form of dizziness and nausea. Multiple studies have underscored the necessity of achieving a highly realistic VR experience while maintaining user comfort, entailing the elevation of the screen’s image refresh rate to 1 800 Hz and keeping latency below 3~40 ms. Achieving real-time, photorealistic rendering at high resolution and low latency represents a formidable objective. Foveated rendering is an effective approach to address these issues by adjusting the rendering quality across the image based on gaze position, maintaining high quality in the fovea area while reducing quality in the periphery. This technique leads to substantial computational savings and improved rendering speed without a perceptible loss in visual quality. While previous reviews have examined technical approaches to foveated rendering, they focused more on categorizing the implementation techniques. A comprehensive review within the domain of machine learning still needs to be explored. With the ongoing advancements in machine learning within the rendering field, combining machine learning and foveated rendering is considered a promising research area, especially in postprocessing, where machine learning methods have great potential. Nonmachine learning methods inevitably introduce artifacts. By contrast, machine learning methods have a wide range of applications in the postprocessing domain of rendering to optimize and improve foveated rendering results and enhance the realism and immersion of foveated images in a manner unattainable through nonmachine learning approaches. Therefore, this work presents a comprehensive overview of foveated rendering from a machine-learning perspective. In this paper, we first provide an overview of the background knowledge of human visual perception, including aspects of the human visual system, contrast sensitivity functions, visual acuity models, and visual crowding. Subsequently, this paper briefly describes the most representative nonmachine learning methods for point-of-attention rendering, including adaptive resolution, geometric simplification, shading simplification, and hardware implementation, and summarizes these methods’ features, advantages, and disadvantages. Additionally, we describe the criteria employed for method evaluation in this review, including evaluation metrics for foveated images and gaze-point prediction. Next, we subdivide machine learning methods into super-resolution, denoise, image reconstruction, image synthesis, gaze prediction, and image application. We provide a detailed summary of them in terms of four aspects: results quality, network speed, user experience, and the ability to handle objects. Among them, super-resolution methods commonly use more neural blocks in the foveal region while fewer neural blocks in the periphery region, resulting in variable regional super-resolution quality. Similarly, foveated denoising usually performs fine denoising in the fovea and coarse denoising in the peripheral, but the denoising aspect has yet to receive extensive attention. The initial attempt to integrate image reconstruction with gaze utilized generative adversarial networks (GANs), yielding promising outcomes. Then, some researchers combined direct prediction and kernel prediction for image reconstruction, which is also the state of the art in this field. Gaze prediction is a key development direction for future VR rendering, which is mostly combined with saliency detection to predict the location of the viewpoint. Substantial work remains in the field, but unfortunately, only a tiny portion of the work can be achieved in real time. Finally, we present the current problems and challenges machine learning methods face. Our review of machine learning approaches in foveated rendering not only elucidates the research prospects and developmental direction but also provides insights for future researchers in choosing research direction and designing network architectures.关键词:foveated rendering;deep learning;real-time rendering;eye fixations prediction;image reconstruction;super-resolution;ray tracing denoising385|4230|0更新时间:2024-10-23
摘要:The widespread adoption of virtual reality (VR) and augmented reality technologies across various sectors, including healthcare, education, military, and entertainment, has propelled head-mounted displays with high resolution and wide fields of view into the forefront of display devices. However, attaining a satisfactory level of immersion and interactivity poses a primary challenge in the realm of VR, with latency potentially leading to user discomfort in the form of dizziness and nausea. Multiple studies have underscored the necessity of achieving a highly realistic VR experience while maintaining user comfort, entailing the elevation of the screen’s image refresh rate to 1 800 Hz and keeping latency below 3~40 ms. Achieving real-time, photorealistic rendering at high resolution and low latency represents a formidable objective. Foveated rendering is an effective approach to address these issues by adjusting the rendering quality across the image based on gaze position, maintaining high quality in the fovea area while reducing quality in the periphery. This technique leads to substantial computational savings and improved rendering speed without a perceptible loss in visual quality. While previous reviews have examined technical approaches to foveated rendering, they focused more on categorizing the implementation techniques. A comprehensive review within the domain of machine learning still needs to be explored. With the ongoing advancements in machine learning within the rendering field, combining machine learning and foveated rendering is considered a promising research area, especially in postprocessing, where machine learning methods have great potential. Nonmachine learning methods inevitably introduce artifacts. By contrast, machine learning methods have a wide range of applications in the postprocessing domain of rendering to optimize and improve foveated rendering results and enhance the realism and immersion of foveated images in a manner unattainable through nonmachine learning approaches. Therefore, this work presents a comprehensive overview of foveated rendering from a machine-learning perspective. In this paper, we first provide an overview of the background knowledge of human visual perception, including aspects of the human visual system, contrast sensitivity functions, visual acuity models, and visual crowding. Subsequently, this paper briefly describes the most representative nonmachine learning methods for point-of-attention rendering, including adaptive resolution, geometric simplification, shading simplification, and hardware implementation, and summarizes these methods’ features, advantages, and disadvantages. Additionally, we describe the criteria employed for method evaluation in this review, including evaluation metrics for foveated images and gaze-point prediction. Next, we subdivide machine learning methods into super-resolution, denoise, image reconstruction, image synthesis, gaze prediction, and image application. We provide a detailed summary of them in terms of four aspects: results quality, network speed, user experience, and the ability to handle objects. Among them, super-resolution methods commonly use more neural blocks in the foveal region while fewer neural blocks in the periphery region, resulting in variable regional super-resolution quality. Similarly, foveated denoising usually performs fine denoising in the fovea and coarse denoising in the peripheral, but the denoising aspect has yet to receive extensive attention. The initial attempt to integrate image reconstruction with gaze utilized generative adversarial networks (GANs), yielding promising outcomes. Then, some researchers combined direct prediction and kernel prediction for image reconstruction, which is also the state of the art in this field. Gaze prediction is a key development direction for future VR rendering, which is mostly combined with saliency detection to predict the location of the viewpoint. Substantial work remains in the field, but unfortunately, only a tiny portion of the work can be achieved in real time. Finally, we present the current problems and challenges machine learning methods face. Our review of machine learning approaches in foveated rendering not only elucidates the research prospects and developmental direction but also provides insights for future researchers in choosing research direction and designing network architectures.关键词:foveated rendering;deep learning;real-time rendering;eye fixations prediction;image reconstruction;super-resolution;ray tracing denoising385|4230|0更新时间:2024-10-23 -
 摘要:ObjectiveThis study introduces a novel method that aims to address the shortcomings of current no-reference point cloud quality assessment methods. Such methods necessitate the preprocessing of point clouds into 2D projections or other forms, which may introduce additional noise and limit the spatial contextual information of the data. The proposed approach overcomes these limitations. The approach comprises two crucial components, namely, the neighborhood information embedding transformation module and the point cloud cascading attention module. The former module is intended to capture the point cloud data’s local features and geometric structure without any extra preprocessing. This process preserves the point cloud’s original information and minimizes the potential for introducing additional noise, all while providing a more expansive spatial context. The latter module enhances the precision and flexibility of point cloud quality assessment by merging spatial and channel attention. The module dynamically learns weightings and applies them to features based on the aspects of various point cloud data, resulting in a more comprehensive understanding of multidimensional point cloud information.MethodThe proposed model employs innovative strategies to address challenges in assessing point cloud quality. In contrast to traditional approaches, it takes the original point cloud sample as input and eliminates the need for preprocessing. This process helps maintain the point cloud’s integrity and improve accuracy in assessment. Second, a U-shaped backbone network is constructed using sparse convolution to enable multiscale feature extraction, allowing the model to capture different scale features of the point cloud and understand point cloud data at local and overall levels more effectively. The module for transforming neighborhood information embedding is an essential part of the process because it extracts features through point-by-point learning. This process assists the model in thoroughly comprehending the local information present in the point cloud. Furthermore, the attention module for point cloud cascade bolsters small-scale features, elevating the recognizability of feature information. By progressively consolidating the multiscale feature information to construct a feature vector, the model can thoroughly represent the quality features of the point cloud. Ultimately, global adaptive pooling and regression functions are employed for regression prediction to finally obtain quality scores for distorted point clouds. The model’s architecture utilizes multiscale information to improve the representation and evaluation of features, resulting in increased progress and efficiency in the assessment of point cloud quality.ResultIn this study, a set of experiments was conducted to validate the efficacy of the proposed method for assessing the quality of point clouds. The results of the experiments demonstrate that the method shows substantial enhancements over 12 existing representative assessment methods for point cloud quality on two different datasets. The experiment specifically employs the SJTU-PCQA dataset, and the novel technique enhances the PLCC value by 8.7% and the SROCC value by 0.39% relative to the model with the second-highest performance. Thus, the new method more precisely evaluates the point cloud quality on the SJTU-PCQA dataset with improved correlation and performance. Similarly, the novel approach enhances the PLCC metric by 4.9% and the SROCC metric by 3.0% on the WPC dataset, surpassing the model with the second-best results. This result illustrates the efficiency and effectiveness of the new approach in point cloud quality assessment for various datasets. The results of these experiments highlight the effectiveness and superiority of the method proposed, providing substantial backing for subsequent research and applications in the arena of point cloud quality assessment. Furthermore, the method showcases its widely applicable nature.ConclusionThe no-reference method presented in this study enhances the precision of point cloud quality assessment. The technique employs a novel structure of embedding transformation for neighborhood information and cascading attention. Emphasis is placed on recognizable feature extraction to yield more accurate results in point cloud quality assessment.关键词:3D quality assessment;point cloud;no-reference;neighbor information;cascade attention328|617|0更新时间:2024-10-23
摘要:ObjectiveThis study introduces a novel method that aims to address the shortcomings of current no-reference point cloud quality assessment methods. Such methods necessitate the preprocessing of point clouds into 2D projections or other forms, which may introduce additional noise and limit the spatial contextual information of the data. The proposed approach overcomes these limitations. The approach comprises two crucial components, namely, the neighborhood information embedding transformation module and the point cloud cascading attention module. The former module is intended to capture the point cloud data’s local features and geometric structure without any extra preprocessing. This process preserves the point cloud’s original information and minimizes the potential for introducing additional noise, all while providing a more expansive spatial context. The latter module enhances the precision and flexibility of point cloud quality assessment by merging spatial and channel attention. The module dynamically learns weightings and applies them to features based on the aspects of various point cloud data, resulting in a more comprehensive understanding of multidimensional point cloud information.MethodThe proposed model employs innovative strategies to address challenges in assessing point cloud quality. In contrast to traditional approaches, it takes the original point cloud sample as input and eliminates the need for preprocessing. This process helps maintain the point cloud’s integrity and improve accuracy in assessment. Second, a U-shaped backbone network is constructed using sparse convolution to enable multiscale feature extraction, allowing the model to capture different scale features of the point cloud and understand point cloud data at local and overall levels more effectively. The module for transforming neighborhood information embedding is an essential part of the process because it extracts features through point-by-point learning. This process assists the model in thoroughly comprehending the local information present in the point cloud. Furthermore, the attention module for point cloud cascade bolsters small-scale features, elevating the recognizability of feature information. By progressively consolidating the multiscale feature information to construct a feature vector, the model can thoroughly represent the quality features of the point cloud. Ultimately, global adaptive pooling and regression functions are employed for regression prediction to finally obtain quality scores for distorted point clouds. The model’s architecture utilizes multiscale information to improve the representation and evaluation of features, resulting in increased progress and efficiency in the assessment of point cloud quality.ResultIn this study, a set of experiments was conducted to validate the efficacy of the proposed method for assessing the quality of point clouds. The results of the experiments demonstrate that the method shows substantial enhancements over 12 existing representative assessment methods for point cloud quality on two different datasets. The experiment specifically employs the SJTU-PCQA dataset, and the novel technique enhances the PLCC value by 8.7% and the SROCC value by 0.39% relative to the model with the second-highest performance. Thus, the new method more precisely evaluates the point cloud quality on the SJTU-PCQA dataset with improved correlation and performance. Similarly, the novel approach enhances the PLCC metric by 4.9% and the SROCC metric by 3.0% on the WPC dataset, surpassing the model with the second-best results. This result illustrates the efficiency and effectiveness of the new approach in point cloud quality assessment for various datasets. The results of these experiments highlight the effectiveness and superiority of the method proposed, providing substantial backing for subsequent research and applications in the arena of point cloud quality assessment. Furthermore, the method showcases its widely applicable nature.ConclusionThe no-reference method presented in this study enhances the precision of point cloud quality assessment. The technique employs a novel structure of embedding transformation for neighborhood information and cascading attention. Emphasis is placed on recognizable feature extraction to yield more accurate results in point cloud quality assessment.关键词:3D quality assessment;point cloud;no-reference;neighbor information;cascade attention328|617|0更新时间:2024-10-23 -
 摘要:ObjectiveThe structure from motion (SfM) technique serves as the fundamental step in the sparse reconstruction process, finding extensive applications in remote sensing mapping, indoor modeling, augmented reality, and ancient architecture preservation. SfM technology retrieves camera poses from images, encompassing two main categories: incremental and global approaches. The global SfM, in contrast to the iterative nature of incremental SfM, simultaneously estimates the absolute poses of all cameras through motion averaging, resulting in relatively high efficiency. However, it still encounters challenges regarding robustness and accuracy. Rotation averaging and translation averaging constitute crucial components within the motion averaging. Compared with rotation averaging, translation averaging is more difficult due to the following three reasons: 1) Only relative translation directions could be recovered by essential matrix estimation and decomposition, i.e., the produced relative translations are scale ambiguous. 2) Only cameras in the same parallel rigid component could their absolute locations be uniquely determined by translation averaging, while for rotation averaging, the requirement simply degenerates to the connected component. 3) Compared with relative rotation, the estimation accuracy of relative translation is more vulnerable to the feature point mismatches and more likely to be outlier contaminated. In traditional approaches, the translation averaging method based on scale separation (
摘要:ObjectiveThe structure from motion (SfM) technique serves as the fundamental step in the sparse reconstruction process, finding extensive applications in remote sensing mapping, indoor modeling, augmented reality, and ancient architecture preservation. SfM technology retrieves camera poses from images, encompassing two main categories: incremental and global approaches. The global SfM, in contrast to the iterative nature of incremental SfM, simultaneously estimates the absolute poses of all cameras through motion averaging, resulting in relatively high efficiency. However, it still encounters challenges regarding robustness and accuracy. Rotation averaging and translation averaging constitute crucial components within the motion averaging. Compared with rotation averaging, translation averaging is more difficult due to the following three reasons: 1) Only relative translation directions could be recovered by essential matrix estimation and decomposition, i.e., the produced relative translations are scale ambiguous. 2) Only cameras in the same parallel rigid component could their absolute locations be uniquely determined by translation averaging, while for rotation averaging, the requirement simply degenerates to the connected component. 3) Compared with relative rotation, the estimation accuracy of relative translation is more vulnerable to the feature point mismatches and more likely to be outlier contaminated. In traditional approaches, the translation averaging method based on scale separation ( -
 摘要:ObjectiveThe application of mixed reality (MR) in training environments, particularly in the field of aviation, marks a remarkable leap from traditional simulation models. This innovative technology overlays virtual elements onto the real world, creating a seamless interactive experience that is critical in simulating high-risk scenarios for pilots. Despite its advances, the integration of real and virtual elements often suffers from inconsistencies in lighting, which can disrupt the user’s sense of presence and diminish the effectiveness of training sessions. Prior attempts to reconcile these differences have involved static solutions that lack adaptability to the dynamic range of real-world lighting conditions encountered during flight. This study is informed by a comprehensive review of current methodologies, including photometric alignment techniques and the adaptation of CGI (computer-generated imagery) elements using standard graphics pipelines. Our analysis identified a gap in real-time dynamic relighting capabilities, which we address through a novel neural network-based approach.MethodThe methodological core of this research is the development of an advanced neural network architecture designed for the sophisticated task of image relighting. The neural network architecture proposed in this research is a convolutional neural network variant, specifically tailored to process high-fidelity images in a manner that retains critical details while adjusting to new lighting conditions. Meanwhile, an integral component of our methodology was the generation of a comprehensive dataset specifically tailored for the relighting of fighter jet cockpit environments. To ensure a high degree of realism, we synthesized photorealistic renderings of the cockpit interior under a wide array of atmospheric conditions, times of day, and geolocations across different latitudes and longitudes. This synthetic dataset was achieved by integrating our image capture process with an advanced weather simulation system, which allowed us to replicate the intricate effects of natural and artificial lighting as experienced within the cockpit. The resultant dataset presents a rich variety of lighting scenarios, ranging from the low-angle illumination of a sunrise to the diffused lighting of an overcast sky, providing our neural network with the nuanced training required to emulate real-world lighting dynamics accurately. The neural network is trained with this dataset to understand and dissect the complex interplay of lighting and material properties within a scene. The first step of the network involves a detailed decomposition of input images to separate and analyze the components affected by lighting, such as shadows, highlights, and color temperature. The geometry of the scene, the textures, and how objects occlude or reflect light must be deduced, extracting these elements into a format that can be manipulated independently of the original lighting conditions. To actualize the target lighting effect, the study leverages a concept adapted from the domain of precomputed radiance transfer——a technique traditionally used for rendering scenes with complex light interactions. By estimating radiance transfer functions at each pixel and representing these as coefficients over a series of spherical harmonic basis functions, the method facilitates a rapid and accurate recalculation of lighting across the scene. The environmental lighting conditions, captured through high dynamic range imaging techniques, are also projected onto these spherical harmonic functions. This approach allows for the real-time adjustment of lighting by simply recalculating the dot product of these coefficients, corresponding to the new lighting environment. This step is a computational breakthrough because it circumvents the need for extensive ray tracing or radiosity calculations, which are computationally expensive and often impractical for real-time applications. This method stands out for its low computational overhead, enabling near real-time relighting that can adjust dynamically as the simulated conditions change.ResultThe empirical results achieved through this method are substantiated through a series of rigorous tests and comparative analyses. The neural network’s performance was benchmarked against traditional and contemporary relighting methods across several scenarios reflecting diverse lighting conditions and complexities. The model consistently demonstrated superior performance, not only in the accuracy of light replication but also in maintaining the fidelity of the original textures and material properties. The visual quality of the relighting was assessed through objective performance metrics, including comparison of luminance distribution, color fidelity, and texture preservation against ground truth datasets. These metrics consistently indicated a remarkable improvement in visual coherence and a reduction in artifacts, ensuring a more immersive experience without the reliance on subjective user studies.ConclusionThe implemented method effectively resolves the challenge of inconsistent lighting conditions in MR flight simulators. It contributes to the field by enabling dynamic adaptation of real-world images to the lighting conditions of virtual environments. This research not only provides a valuable tool for enhancing the realism and immersion of flight simulators but also offers insights that could benefit future theoretical and practical advancements in MR technology. The study utilized spherical harmonic coefficients of environmental light maps to convey lighting condition information and pioneered the extraction of scene radiance lighting functions’ spherical harmonic coefficients from real image data. This validated the feasibility of predicting scene radiance transfer functions from real images using neural networks. The limitations and potential improvements of the current method are discussed, outlining directions for future research. For example, considering the temporal continuity present in the relighted images, future efforts could exploit this characteristic to optimize the neural network architecture, integrating modules that enhance the stability of the prediction results.关键词:relighting;neural rendering methods;radiance transfer functions;mixed reality(MR);flight simulator246|816|0更新时间:2024-10-23
摘要:ObjectiveThe application of mixed reality (MR) in training environments, particularly in the field of aviation, marks a remarkable leap from traditional simulation models. This innovative technology overlays virtual elements onto the real world, creating a seamless interactive experience that is critical in simulating high-risk scenarios for pilots. Despite its advances, the integration of real and virtual elements often suffers from inconsistencies in lighting, which can disrupt the user’s sense of presence and diminish the effectiveness of training sessions. Prior attempts to reconcile these differences have involved static solutions that lack adaptability to the dynamic range of real-world lighting conditions encountered during flight. This study is informed by a comprehensive review of current methodologies, including photometric alignment techniques and the adaptation of CGI (computer-generated imagery) elements using standard graphics pipelines. Our analysis identified a gap in real-time dynamic relighting capabilities, which we address through a novel neural network-based approach.MethodThe methodological core of this research is the development of an advanced neural network architecture designed for the sophisticated task of image relighting. The neural network architecture proposed in this research is a convolutional neural network variant, specifically tailored to process high-fidelity images in a manner that retains critical details while adjusting to new lighting conditions. Meanwhile, an integral component of our methodology was the generation of a comprehensive dataset specifically tailored for the relighting of fighter jet cockpit environments. To ensure a high degree of realism, we synthesized photorealistic renderings of the cockpit interior under a wide array of atmospheric conditions, times of day, and geolocations across different latitudes and longitudes. This synthetic dataset was achieved by integrating our image capture process with an advanced weather simulation system, which allowed us to replicate the intricate effects of natural and artificial lighting as experienced within the cockpit. The resultant dataset presents a rich variety of lighting scenarios, ranging from the low-angle illumination of a sunrise to the diffused lighting of an overcast sky, providing our neural network with the nuanced training required to emulate real-world lighting dynamics accurately. The neural network is trained with this dataset to understand and dissect the complex interplay of lighting and material properties within a scene. The first step of the network involves a detailed decomposition of input images to separate and analyze the components affected by lighting, such as shadows, highlights, and color temperature. The geometry of the scene, the textures, and how objects occlude or reflect light must be deduced, extracting these elements into a format that can be manipulated independently of the original lighting conditions. To actualize the target lighting effect, the study leverages a concept adapted from the domain of precomputed radiance transfer——a technique traditionally used for rendering scenes with complex light interactions. By estimating radiance transfer functions at each pixel and representing these as coefficients over a series of spherical harmonic basis functions, the method facilitates a rapid and accurate recalculation of lighting across the scene. The environmental lighting conditions, captured through high dynamic range imaging techniques, are also projected onto these spherical harmonic functions. This approach allows for the real-time adjustment of lighting by simply recalculating the dot product of these coefficients, corresponding to the new lighting environment. This step is a computational breakthrough because it circumvents the need for extensive ray tracing or radiosity calculations, which are computationally expensive and often impractical for real-time applications. This method stands out for its low computational overhead, enabling near real-time relighting that can adjust dynamically as the simulated conditions change.ResultThe empirical results achieved through this method are substantiated through a series of rigorous tests and comparative analyses. The neural network’s performance was benchmarked against traditional and contemporary relighting methods across several scenarios reflecting diverse lighting conditions and complexities. The model consistently demonstrated superior performance, not only in the accuracy of light replication but also in maintaining the fidelity of the original textures and material properties. The visual quality of the relighting was assessed through objective performance metrics, including comparison of luminance distribution, color fidelity, and texture preservation against ground truth datasets. These metrics consistently indicated a remarkable improvement in visual coherence and a reduction in artifacts, ensuring a more immersive experience without the reliance on subjective user studies.ConclusionThe implemented method effectively resolves the challenge of inconsistent lighting conditions in MR flight simulators. It contributes to the field by enabling dynamic adaptation of real-world images to the lighting conditions of virtual environments. This research not only provides a valuable tool for enhancing the realism and immersion of flight simulators but also offers insights that could benefit future theoretical and practical advancements in MR technology. The study utilized spherical harmonic coefficients of environmental light maps to convey lighting condition information and pioneered the extraction of scene radiance lighting functions’ spherical harmonic coefficients from real image data. This validated the feasibility of predicting scene radiance transfer functions from real images using neural networks. The limitations and potential improvements of the current method are discussed, outlining directions for future research. For example, considering the temporal continuity present in the relighted images, future efforts could exploit this characteristic to optimize the neural network architecture, integrating modules that enhance the stability of the prediction results.关键词:relighting;neural rendering methods;radiance transfer functions;mixed reality(MR);flight simulator246|816|0更新时间:2024-10-23 -
 摘要:ObjectiveWith the continuous development of computer vision, human-computer interaction, virtual reality, augmented reality, the visual and auditory interaction field has reached a commercialization level. Haptic interaction enables users to perceive the tactile characteristics of virtual graphics, and the integration with visual and audio makes virtual graphics have more physical attributes and enhances the user’s immersive experience. For example, purchasers can realistically feel the texture of online materials, drive a car without having to shift their eyes to distract themselves from some screen operations, shop at home, and experience different products, and doctors can remotely perform surgical simulations and planning. Furthermore, science and technology to the good, such as the blind, deaf, and dumb and other special groups through the sense of touch, can also fully enjoy the “era of map reading” to avoid not seeing and hearing is not capable of using the poor situation. The extensive use of haptic feedback technology brings the user a sense of immersion, greatly enhancing the sense of immersion and the sense of reality, virtual reality, augmented reality, mixed reality, and other areas of future research focus direction. Ultrasonic airborne haptic feedback technology provides noncontact and unconstrained haptic experience for virtual reality and mixed reality and is the main way of haptic presentation in the field of mixed reality. The current ultrasonic haptic feedback devices generally use the method of rapidly and repeatedly moving the ultrasonic focus on a given path when performing multipoint focusing to present an ideal pattern, and only single point focusing is performed in one modulation cycle, with low efficiency of array usage and large noise generated during the focusing process, which affects the user’s sense of experience. To solve the above problems, a novel ultrasonic haptic multipoint synchronous focusing method based on spatiotemporal modulation is proposed in this study; it can generate multiple focal points in each modulation period, reduce modulation noise, and enhance haptic synchronization effect while eliminating the directivity between focal points.MethodFirst, data are received for a plurality of focal points that must be focused, and the focusing information is sent to a calculation module via the top-level module. After receiving the coordinates of the focal points sent by the top-level module, the calculation module calculates the distance S from each ultrasound emitter to the focal point. Given that the ultrasonic emitters used are not omnidirectional, the ultrasonic emission angle has a limit. The maximum effective emission angle should be considered for calculating the path. A comparison can be made by calculating the longest emission distance L within the emission range. To achieve the focus of each transmitter transmitting signal at each focal point, the delay time of each transmitter driving signal must be controlled so that each signal is transmitted at different times, with the farthest emitter emitting ultrasonic waves first and the nearest emitter emitting ultrasonic waves last, thus ensuring that the ultrasonic waves emitted by each transmitter arrive at the same focus at the same time. The time delay required to focus each focal point is calculated and stored. Second, a modulation frequency f0 that can be perceived by the human body is chosen, and all focal points are emitted within the same modulation period T0. Under the assumption that there are I focal points, the modulation period T0 is divided into I equal parts of the time slice (T1~TI), and each focal point occupies a modulation period of T0/I, that is, each focusing time is T0/I. The required modulation frequency signal and rendering signal are generated, and the cycle time of the modulation signals is equally distributed according to the number of focusing points to obtain the final ultrasonic transmitter driving signal. Finally, the drive signal is sent to the delay module, which sends the delay data of the previous different focus points in different time slices of the modulation signal cycle to achieve the effect of multipoint focusing haptic synchronization.ResultTesting of the new modulation method through experiments showed that compared with traditional modulation methods, the modulation noise decreased by 8.4% and 13% when focusing on two points with duty cycles of 10% and 20%, respectively. However, the focusing power consumption increased by 80% and 86%. When focusing on four points with duty cycles of 10% and 20%, the new modulation method reduced modulation noise by 6.3% and 10.1%, while the focusing power consumption increased by 60% and 100%, respectively. In subjective graphic recognition experiments, the recognition rates for triangles, rectangles, and circles increased by 25%, 19%, and 35%, respectively. Comparative experimental results demonstrate that the new modulation method reduces focusing noise, enhances array utilization, and improves the recognition rates of presented graphics.ConclusionIn this study, we present a novel spatiotemporal modulation method for ultrasonic focused haptics. Experimental results show that this method can considerably reduce noise focusing noise and provide stronger feedback force.关键词:graphic presentation;spatiotemporal modulation;ultrasonic feedback;aerial tactile;multitouch270|922|0更新时间:2024-10-23
摘要:ObjectiveWith the continuous development of computer vision, human-computer interaction, virtual reality, augmented reality, the visual and auditory interaction field has reached a commercialization level. Haptic interaction enables users to perceive the tactile characteristics of virtual graphics, and the integration with visual and audio makes virtual graphics have more physical attributes and enhances the user’s immersive experience. For example, purchasers can realistically feel the texture of online materials, drive a car without having to shift their eyes to distract themselves from some screen operations, shop at home, and experience different products, and doctors can remotely perform surgical simulations and planning. Furthermore, science and technology to the good, such as the blind, deaf, and dumb and other special groups through the sense of touch, can also fully enjoy the “era of map reading” to avoid not seeing and hearing is not capable of using the poor situation. The extensive use of haptic feedback technology brings the user a sense of immersion, greatly enhancing the sense of immersion and the sense of reality, virtual reality, augmented reality, mixed reality, and other areas of future research focus direction. Ultrasonic airborne haptic feedback technology provides noncontact and unconstrained haptic experience for virtual reality and mixed reality and is the main way of haptic presentation in the field of mixed reality. The current ultrasonic haptic feedback devices generally use the method of rapidly and repeatedly moving the ultrasonic focus on a given path when performing multipoint focusing to present an ideal pattern, and only single point focusing is performed in one modulation cycle, with low efficiency of array usage and large noise generated during the focusing process, which affects the user’s sense of experience. To solve the above problems, a novel ultrasonic haptic multipoint synchronous focusing method based on spatiotemporal modulation is proposed in this study; it can generate multiple focal points in each modulation period, reduce modulation noise, and enhance haptic synchronization effect while eliminating the directivity between focal points.MethodFirst, data are received for a plurality of focal points that must be focused, and the focusing information is sent to a calculation module via the top-level module. After receiving the coordinates of the focal points sent by the top-level module, the calculation module calculates the distance S from each ultrasound emitter to the focal point. Given that the ultrasonic emitters used are not omnidirectional, the ultrasonic emission angle has a limit. The maximum effective emission angle should be considered for calculating the path. A comparison can be made by calculating the longest emission distance L within the emission range. To achieve the focus of each transmitter transmitting signal at each focal point, the delay time of each transmitter driving signal must be controlled so that each signal is transmitted at different times, with the farthest emitter emitting ultrasonic waves first and the nearest emitter emitting ultrasonic waves last, thus ensuring that the ultrasonic waves emitted by each transmitter arrive at the same focus at the same time. The time delay required to focus each focal point is calculated and stored. Second, a modulation frequency f0 that can be perceived by the human body is chosen, and all focal points are emitted within the same modulation period T0. Under the assumption that there are I focal points, the modulation period T0 is divided into I equal parts of the time slice (T1~TI), and each focal point occupies a modulation period of T0/I, that is, each focusing time is T0/I. The required modulation frequency signal and rendering signal are generated, and the cycle time of the modulation signals is equally distributed according to the number of focusing points to obtain the final ultrasonic transmitter driving signal. Finally, the drive signal is sent to the delay module, which sends the delay data of the previous different focus points in different time slices of the modulation signal cycle to achieve the effect of multipoint focusing haptic synchronization.ResultTesting of the new modulation method through experiments showed that compared with traditional modulation methods, the modulation noise decreased by 8.4% and 13% when focusing on two points with duty cycles of 10% and 20%, respectively. However, the focusing power consumption increased by 80% and 86%. When focusing on four points with duty cycles of 10% and 20%, the new modulation method reduced modulation noise by 6.3% and 10.1%, while the focusing power consumption increased by 60% and 100%, respectively. In subjective graphic recognition experiments, the recognition rates for triangles, rectangles, and circles increased by 25%, 19%, and 35%, respectively. Comparative experimental results demonstrate that the new modulation method reduces focusing noise, enhances array utilization, and improves the recognition rates of presented graphics.ConclusionIn this study, we present a novel spatiotemporal modulation method for ultrasonic focused haptics. Experimental results show that this method can considerably reduce noise focusing noise and provide stronger feedback force.关键词:graphic presentation;spatiotemporal modulation;ultrasonic feedback;aerial tactile;multitouch270|922|0更新时间:2024-10-23
Mixed Reality

-
 摘要:ObjectiveImage deblurring is a classic low-level computer vision problem that aims to restore a sharp image from a blurry image. In recent years, convolutional neural networks (CNNs) have boosted the advancement of computer vision considerably, and various CNN-based deblurring methods have been developed with remarkable results. Although convolution operation is powerful in capturing local information, the CNNs show a limitation in modeling long-range dependencies. By employing self-attention mechanisms, vision Transformers have shown a high ability to model long-range pixel relationships. However, most Transformer models designed for computer vision tasks involving high-resolution images use a local window self-attention mechanism. This is contradictory to the goal of employing Transformer structures to capture true long-range pixel dependencies. We review some deblurring models that are sufficient for processing high-resolution images; most CNN-based and vision Transformer-based approaches can only extract spatial local features. Some studies obtain the information with larger receptive field by directly increasing the window size, but this method not only has excessive computational overhead but also lacks flexibility in the process of feature extraction. To solve the above problems, we propose a method that can incorporate local and nonlocal information for the network.MethodWe employ the local feature representation (LFR) modules and nonlocal feature representation (NLFR) modules to extract enriched information. For the extraction of local information, most of the existing building blocks have this capability, and we can treat these blocks directly as LFR modules. In addition to obtaining local information, we also designed a generic NLFR module that can be easily combined with the LFR module for extracting nonlocal information. The NLFR module consists of a nonlocal feature extraction (NLFE) block and an interblock transmission (IBT) mechanism. The NLFE block applies a nonlocal self-attention mechanism, which avoids the interference of local information and texture details, captures purer nonlocal information, and considerably reduces the computational complexity. To reduce the effect of accumulating more local information in the NLFE block as the network depth increases, we introduce an IBT mechanism for successive NLFE blocks, which provides a direct data flow for the transfer of nonlocal information. This design has two advantages: 1) The NLFR module ignores local texture details in features when extracting information to ensure that information does not interfere with each other. 2) Instead of computing the self-similarity of all pixels within the receptive field, the NLFR module adaptively samples the salient pixels, considerably reducing computational complexity. We selected LeFF and ResBlock as the LFR module combined with the NLFR module and designed two models named NLCNet_L and NLCNet_R to deal with motion blur removal and defocus blur removal, respectively, based on the single-stage UNet as the model architecture.ResultWe verify the gains of each component of the NLFR module in the network; the network consisting of the NLFR module combined with the LFR module obtains peak signal-to-noise ratio(PSNR) gains of 0.89 dB compared with using only the LFR as the building block. Applying the IBT module over this, the performance is further improved by 0.09 dB on PSNR. For fair comparisons, we build a baseline model only using ResBlock as the building block with similar computational overhead and number of parameters to the proposed network. Results demonstrate that NLFR-combined ResBlock is more effective in constructing a deblurred network than directly using ResBlock as the building block. In scalability experiments, the experiment shows that the combination of NLFR modules with existing building blocks can remarkably improve the deblurring performance, including convolutional residual blocks and a Transformer block. In particular, two networks designed with NLFR-combination LeFF block and ResBlock as the building blocks achieve excellent results in single-image motion deblurring and dual-pixel defocus deblurring compared with other methods. In accordance with a popular training method, NLCNet_L was trained on the GoPro dataset with 3 000 epochs and tested on the GoPro test set. Our method achieves the best results on the GoPro test set with the lowest computational complexity. Compared with the previous method Uformer, our method improves PSNR by 0.29 dB. We trained NLCNet_R on the DPD dataset for 200 epochs for two-pixel defocus deblurring experiments. In the combined scene category, we achieved excellent performance in all four metrics. Compared with the previous method Uformer, our method improves the PSNR in indoor and outdoor scenes by 1.37 dB and 0.94 dB, respectively.ConclusionWe propose a generic NLFR module to represent the extraction of real nonlocal information from images, which can be coupled with local information within the block to improve the expressive ability of the model. Through rational design, the network composed of NLFR modules achieves excellent performance with low computational consumption, and the visual effect of the recovered image, especially the edge contours, is clearer and more complete.关键词:motion blur;defocus blur;self-attention;non-local features;fusion network634|961|0更新时间:2024-10-23
摘要:ObjectiveImage deblurring is a classic low-level computer vision problem that aims to restore a sharp image from a blurry image. In recent years, convolutional neural networks (CNNs) have boosted the advancement of computer vision considerably, and various CNN-based deblurring methods have been developed with remarkable results. Although convolution operation is powerful in capturing local information, the CNNs show a limitation in modeling long-range dependencies. By employing self-attention mechanisms, vision Transformers have shown a high ability to model long-range pixel relationships. However, most Transformer models designed for computer vision tasks involving high-resolution images use a local window self-attention mechanism. This is contradictory to the goal of employing Transformer structures to capture true long-range pixel dependencies. We review some deblurring models that are sufficient for processing high-resolution images; most CNN-based and vision Transformer-based approaches can only extract spatial local features. Some studies obtain the information with larger receptive field by directly increasing the window size, but this method not only has excessive computational overhead but also lacks flexibility in the process of feature extraction. To solve the above problems, we propose a method that can incorporate local and nonlocal information for the network.MethodWe employ the local feature representation (LFR) modules and nonlocal feature representation (NLFR) modules to extract enriched information. For the extraction of local information, most of the existing building blocks have this capability, and we can treat these blocks directly as LFR modules. In addition to obtaining local information, we also designed a generic NLFR module that can be easily combined with the LFR module for extracting nonlocal information. The NLFR module consists of a nonlocal feature extraction (NLFE) block and an interblock transmission (IBT) mechanism. The NLFE block applies a nonlocal self-attention mechanism, which avoids the interference of local information and texture details, captures purer nonlocal information, and considerably reduces the computational complexity. To reduce the effect of accumulating more local information in the NLFE block as the network depth increases, we introduce an IBT mechanism for successive NLFE blocks, which provides a direct data flow for the transfer of nonlocal information. This design has two advantages: 1) The NLFR module ignores local texture details in features when extracting information to ensure that information does not interfere with each other. 2) Instead of computing the self-similarity of all pixels within the receptive field, the NLFR module adaptively samples the salient pixels, considerably reducing computational complexity. We selected LeFF and ResBlock as the LFR module combined with the NLFR module and designed two models named NLCNet_L and NLCNet_R to deal with motion blur removal and defocus blur removal, respectively, based on the single-stage UNet as the model architecture.ResultWe verify the gains of each component of the NLFR module in the network; the network consisting of the NLFR module combined with the LFR module obtains peak signal-to-noise ratio(PSNR) gains of 0.89 dB compared with using only the LFR as the building block. Applying the IBT module over this, the performance is further improved by 0.09 dB on PSNR. For fair comparisons, we build a baseline model only using ResBlock as the building block with similar computational overhead and number of parameters to the proposed network. Results demonstrate that NLFR-combined ResBlock is more effective in constructing a deblurred network than directly using ResBlock as the building block. In scalability experiments, the experiment shows that the combination of NLFR modules with existing building blocks can remarkably improve the deblurring performance, including convolutional residual blocks and a Transformer block. In particular, two networks designed with NLFR-combination LeFF block and ResBlock as the building blocks achieve excellent results in single-image motion deblurring and dual-pixel defocus deblurring compared with other methods. In accordance with a popular training method, NLCNet_L was trained on the GoPro dataset with 3 000 epochs and tested on the GoPro test set. Our method achieves the best results on the GoPro test set with the lowest computational complexity. Compared with the previous method Uformer, our method improves PSNR by 0.29 dB. We trained NLCNet_R on the DPD dataset for 200 epochs for two-pixel defocus deblurring experiments. In the combined scene category, we achieved excellent performance in all four metrics. Compared with the previous method Uformer, our method improves the PSNR in indoor and outdoor scenes by 1.37 dB and 0.94 dB, respectively.ConclusionWe propose a generic NLFR module to represent the extraction of real nonlocal information from images, which can be coupled with local information within the block to improve the expressive ability of the model. Through rational design, the network composed of NLFR modules achieves excellent performance with low computational consumption, and the visual effect of the recovered image, especially the edge contours, is clearer and more complete.关键词:motion blur;defocus blur;self-attention;non-local features;fusion network634|961|0更新时间:2024-10-23 -
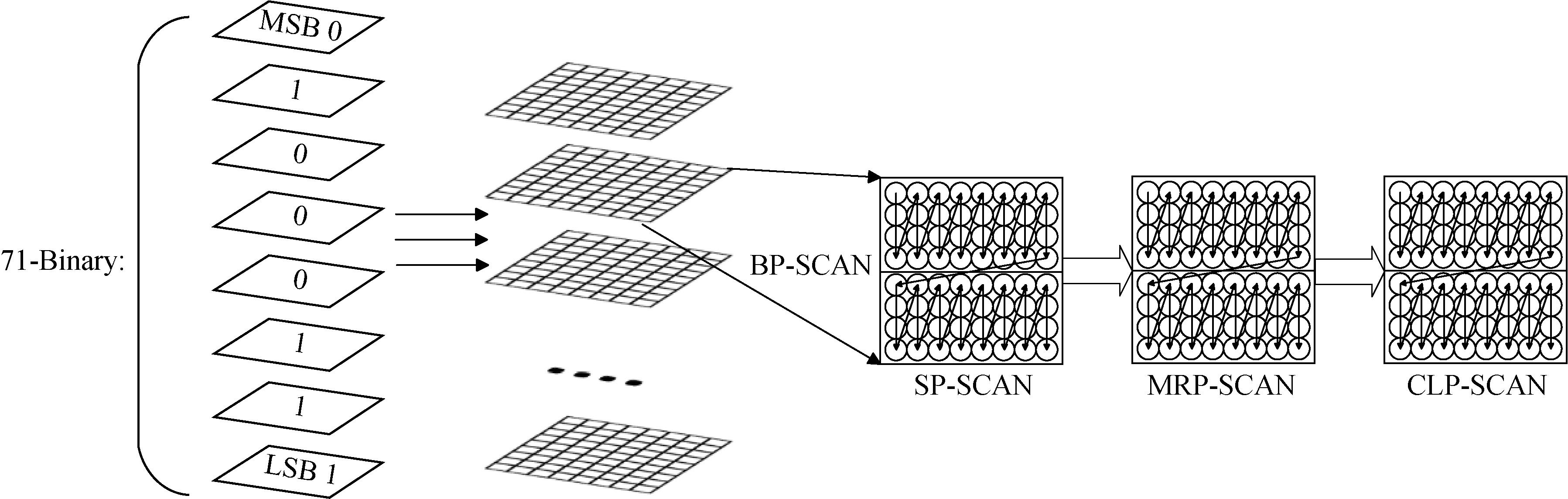 摘要:ObjectiveJPEG2000 is composed of multiple image encoding algorithms, with embedded block coding with optimized truncation (EBCOT) serving as the core encoding algorithm. EBCOT is a key algorithm in JPEG2000 image compression standard, and its coding results directly affect the compression quality of images. EBCOT encoding is internally composed of Tier1 encoding and Tier2 encoding. Tier1 encoding is responsible for encoding the quantized wavelet coefficients. This process is the core of EBCOT encoding to achieve compression effect; thus, it requires substantial resources in hardware implementation to ensure the efficiency and accuracy of data output. Tier2 encoding is responsible for truncating and packaging the encoding results of Tier1, and its encoding results affect the compression rate and compression effect of JPEG2000. Tier2 encoding takes less time, and the rate distortion calculation can be completed simultaneously with Tier1 encoding, shortening the compression time. At the same time, given the inherent intricacies of the algorithm, a diligent consideration of hardware resource utilization is imperative during its implementation in hardware. This cautious approach ensures the judicious employment of limited hardware resources toward the realization of an efficient EBCOT encoding tailored for JPEG2000 image compression. Therefore, to solve these problems, a parallel EBCOT coding very large scale integration circuit (VLSI) architecture with all pass multi bit plane cyclic coding is proposed.MethodThe EBCOT encoding process has two main parts: Tier1 encoding and Tier2 encoding. A novel encoding window structure, i.e., multi bit plane cyclic encoding (MBCE), is designed to address the encoding speed in the Tier1 encoding part. The encoding window consists of four encoding columns: completed encoding column, current encoding column, prediction column, and updated prediction column. The 5 × 4 encoding window in question exploits the encoding information of each bit plane layer to parallelize the encoding process, effectively breaking the interplane correlation and remarkably improving the encoding efficiency. Additionally, compared with traditional parallel encoding structures, this encoding window utilizes few encoding resources by reusing encoders. Furthermore, it supports encoding arbitrary-sized code blocks. With regard to the pass distortion calculation in the Tier2 encoding part, a pipeline calculation structure is designed to run in parallel with Tier1 encoding. By fetching the bit plane coding results in Tier1 encoding, the complex multiplication and addition operations are split into multiple stages of pipeline, enabling the structure to work at a higher frequency on FPGA and improving the overall encoding efficiency. Moreover, this structure can run in parallel with Tier1 encoding without compromising the throughput of Tier1 encoding. By designing an efficient Tier1 encoding structure and a multistage parallel encoding structure for Tier2, the parallel structure between them reduces the time required for EBCOT encoding and improves the overall encoding efficiency while ensuring the image compression quality. By optimizing the Tier1 and Tier2 encoding processes and utilizing parallel processing techniques, the proposed MBCE architecture aims to improve the efficiency of EBCOT encoding, reduce the encoding time, and enhance the overall image compression quality.ResultThe MBCE encoding structure proposed in Verilog is described at RTL level, and FPGA is selected as the experimental verification platform for this structure. The structural encoding rate, encoding compression effect, and the required resources of the encoding structure are compared with the existing EBCOT optimized structure. In terms of encoding efficiency, the proposed structure shows remarkable improvement compared with the bit plane parallel encoding structure. Moreover, the proposed MBCE structure considerably reduces the required encoding cycles in image compression compared with several existing EBCOT encoding VLSI structures. By implementing whole pass parallelism, the encoding efficiency is enhanced. Additionally, the hardware resource utilization and maximum operating frequency of the proposed structure are superior to several EBCOT structures mentioned in the literature. In the 1:8 lossless compression mode of the three-level 5/3 wavelet transform with a block size of 32 × 32, the MBCE structure is used to compress the same 512 × 512 pixels 8-bit standard grayscale image. Compared with the JPEG2000 standard image compression software Jasper, Openjpeg, and Kakadu, the peak signal-to-noise ratio error is less than 0.05 dB. On the xc4vlx25 model FPGA, its operating frequency can reach 193.1 MHz, and it can process 370 frames per second.ConclusionThe proposed MBCE structure in this study not only exhibits low resource utilization and high encoding throughput but also ensures short encoding cycles. The JPEG2000 compression system using the EBCOT structure proposed in this study has been tested and found to achieve a maximum image quality deviation compared with images encoded using standard JPEG2000 compression software. This remarkable deviation demonstrates the effectiveness of the proposed MBCE structure in preserving image quality during the compression process. The compressed images maintain a high level of fidelity comparable with those produced by established JPEG2000 compression software. This improvement in image quality is attributed to the optimized Tier1 and Tier2 encoding processes and the utilization of parallel processing techniques in the MBCE architecture. The resulting enhancement in image compression quality highlights the potential of the proposed MBCE structure for improving JPEG2000-based image compression.关键词:EBCOT encoding;multi-bitplanes cyclic encoding(MBCE);pass distortion calculation;passes parallelism;VLSI architecture243|456|0更新时间:2024-10-23
摘要:ObjectiveJPEG2000 is composed of multiple image encoding algorithms, with embedded block coding with optimized truncation (EBCOT) serving as the core encoding algorithm. EBCOT is a key algorithm in JPEG2000 image compression standard, and its coding results directly affect the compression quality of images. EBCOT encoding is internally composed of Tier1 encoding and Tier2 encoding. Tier1 encoding is responsible for encoding the quantized wavelet coefficients. This process is the core of EBCOT encoding to achieve compression effect; thus, it requires substantial resources in hardware implementation to ensure the efficiency and accuracy of data output. Tier2 encoding is responsible for truncating and packaging the encoding results of Tier1, and its encoding results affect the compression rate and compression effect of JPEG2000. Tier2 encoding takes less time, and the rate distortion calculation can be completed simultaneously with Tier1 encoding, shortening the compression time. At the same time, given the inherent intricacies of the algorithm, a diligent consideration of hardware resource utilization is imperative during its implementation in hardware. This cautious approach ensures the judicious employment of limited hardware resources toward the realization of an efficient EBCOT encoding tailored for JPEG2000 image compression. Therefore, to solve these problems, a parallel EBCOT coding very large scale integration circuit (VLSI) architecture with all pass multi bit plane cyclic coding is proposed.MethodThe EBCOT encoding process has two main parts: Tier1 encoding and Tier2 encoding. A novel encoding window structure, i.e., multi bit plane cyclic encoding (MBCE), is designed to address the encoding speed in the Tier1 encoding part. The encoding window consists of four encoding columns: completed encoding column, current encoding column, prediction column, and updated prediction column. The 5 × 4 encoding window in question exploits the encoding information of each bit plane layer to parallelize the encoding process, effectively breaking the interplane correlation and remarkably improving the encoding efficiency. Additionally, compared with traditional parallel encoding structures, this encoding window utilizes few encoding resources by reusing encoders. Furthermore, it supports encoding arbitrary-sized code blocks. With regard to the pass distortion calculation in the Tier2 encoding part, a pipeline calculation structure is designed to run in parallel with Tier1 encoding. By fetching the bit plane coding results in Tier1 encoding, the complex multiplication and addition operations are split into multiple stages of pipeline, enabling the structure to work at a higher frequency on FPGA and improving the overall encoding efficiency. Moreover, this structure can run in parallel with Tier1 encoding without compromising the throughput of Tier1 encoding. By designing an efficient Tier1 encoding structure and a multistage parallel encoding structure for Tier2, the parallel structure between them reduces the time required for EBCOT encoding and improves the overall encoding efficiency while ensuring the image compression quality. By optimizing the Tier1 and Tier2 encoding processes and utilizing parallel processing techniques, the proposed MBCE architecture aims to improve the efficiency of EBCOT encoding, reduce the encoding time, and enhance the overall image compression quality.ResultThe MBCE encoding structure proposed in Verilog is described at RTL level, and FPGA is selected as the experimental verification platform for this structure. The structural encoding rate, encoding compression effect, and the required resources of the encoding structure are compared with the existing EBCOT optimized structure. In terms of encoding efficiency, the proposed structure shows remarkable improvement compared with the bit plane parallel encoding structure. Moreover, the proposed MBCE structure considerably reduces the required encoding cycles in image compression compared with several existing EBCOT encoding VLSI structures. By implementing whole pass parallelism, the encoding efficiency is enhanced. Additionally, the hardware resource utilization and maximum operating frequency of the proposed structure are superior to several EBCOT structures mentioned in the literature. In the 1:8 lossless compression mode of the three-level 5/3 wavelet transform with a block size of 32 × 32, the MBCE structure is used to compress the same 512 × 512 pixels 8-bit standard grayscale image. Compared with the JPEG2000 standard image compression software Jasper, Openjpeg, and Kakadu, the peak signal-to-noise ratio error is less than 0.05 dB. On the xc4vlx25 model FPGA, its operating frequency can reach 193.1 MHz, and it can process 370 frames per second.ConclusionThe proposed MBCE structure in this study not only exhibits low resource utilization and high encoding throughput but also ensures short encoding cycles. The JPEG2000 compression system using the EBCOT structure proposed in this study has been tested and found to achieve a maximum image quality deviation compared with images encoded using standard JPEG2000 compression software. This remarkable deviation demonstrates the effectiveness of the proposed MBCE structure in preserving image quality during the compression process. The compressed images maintain a high level of fidelity comparable with those produced by established JPEG2000 compression software. This improvement in image quality is attributed to the optimized Tier1 and Tier2 encoding processes and the utilization of parallel processing techniques in the MBCE architecture. The resulting enhancement in image compression quality highlights the potential of the proposed MBCE structure for improving JPEG2000-based image compression.关键词:EBCOT encoding;multi-bitplanes cyclic encoding(MBCE);pass distortion calculation;passes parallelism;VLSI architecture243|456|0更新时间:2024-10-23
Image Processing and Coding
-
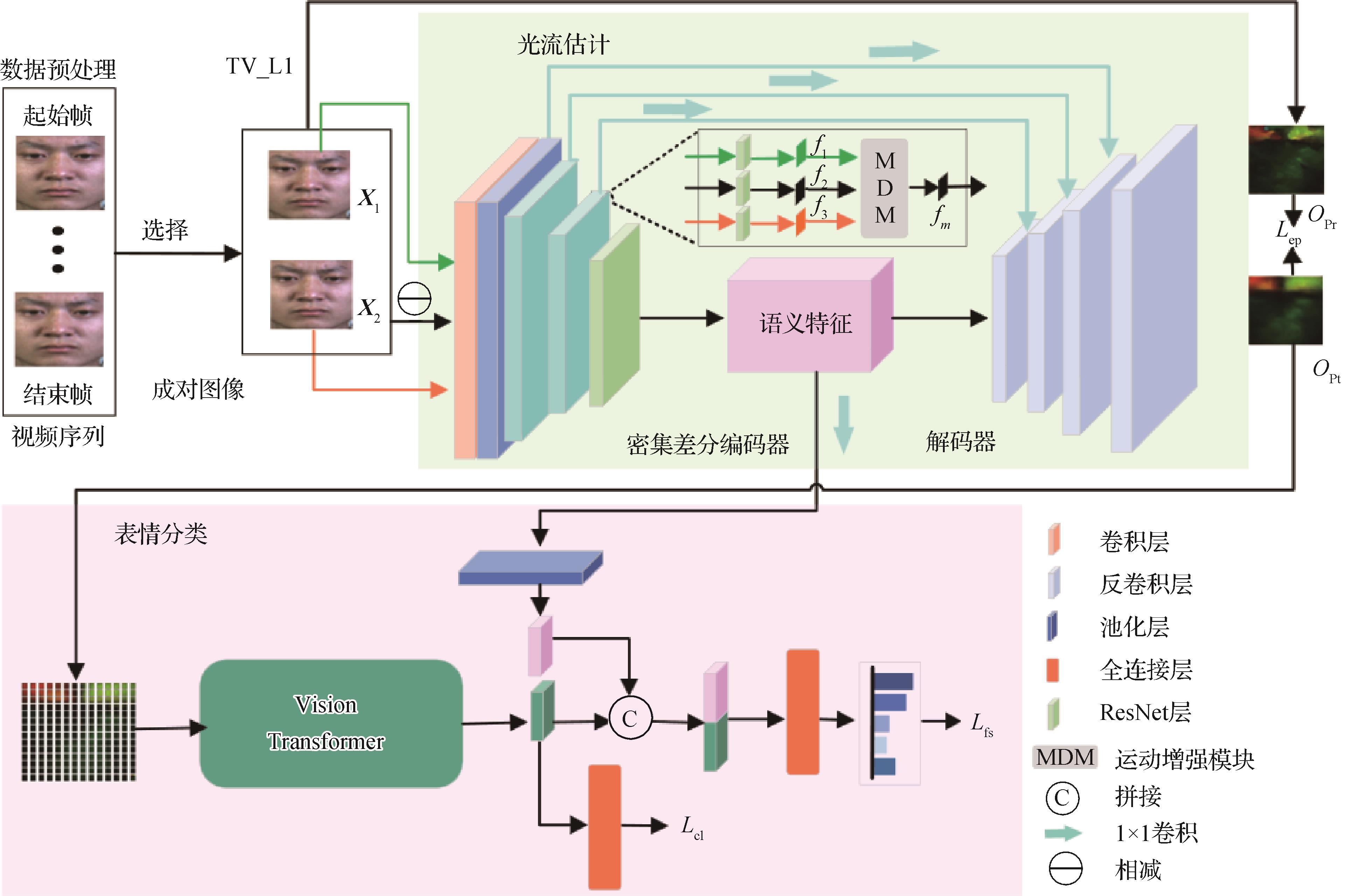 摘要:ObjectiveMicro-expressions are brief, subtle facial muscle movements that accidentally signal emotions when the person tries to hide their true inner feelings. Micro-expressions are more responsive to a person’s true feelings and motivations than macro-expressions. Micro-expression recognition aims to analyze and identify automatically the emotional category of the research object from the stressful movement of the facial muscles, which has an important application value in lie detection, psychological diagnosis, and other aspects. In the early development of micro-expression recognition, local binary patterns and optical flow were widely used as features for training traditional machine learning models. However, the traditional manual feature approach relies on manually designing rules, making it difficult to adapt to the differences in micro-expression data across different individuals and scenarios. Given that deep learning can automatically learn the optimal feature representation of an image, the recognition performance of micro-expression recognition studies based on deep learning far exceeds that of traditional methods. However, micro-expressions occur as subtle facial changes, which causes the micro-expression recognition task to remain challenging. By analyzing the pixel movement between consecutive frames, the optical flow can represent the dynamic information of micro-expressions. Deep learning-based micro-expression recognition methods perform facial muscle motion descriptions with optical flow information to improve micro-expression recognition performance. However, existing micro-expression recognition methods usually extract the optical flow information offline, which relies on existing optical flow estimation techniques and suffers from the insufficient description of subtle expressions and neglect of static facial expression information, which restricts the recognition effect of the model. Therefore, this study proposes a micro-expression recognition network based on adaptive optical flow estimation, which realizes optical flow estimation and micro-expression classification to learn micro-expression-related motion features through parallel association adaptively.MethodThe training samples of micro-expressions are limited, which makes it difficult to train complex network models. Therefore, this study selects the apex and their neighboring frames in the micro-expression video sequence as training data in the preprocessing stage. In addition, when loading the data, the original training data are replaced with image pairs containing motion information in the video sequence with a certain probability. Second, the deep learning network with a dense differential encoder-decoder implements the facial muscle motion adaptive optical flow estimation task to improve the characterization of subtle expressions. ResNet18 extracts features from the two-frame image and the difference map in a dense differential encoder. The branch processing the two frames shares the parameters. A motion enhancement module is added to the feature extraction branch of the differential image to accomplish the interlayer information interaction. In the motion enhancement module, the difference map features computed from the two frames need the spatial attention mechanism to focus on the micro-expression-related motion; the two frames are subtracted from each other to preserve and amplify the difference between the two frames, and using the two features provides valid information for subsequent networks. The decoder in this study maps the multilevel facial displacement information extracted by the dense differential encoder and the last layer of the two-frame image output features to reconstruct the optical flow features. Vision Transformer is a deep learning model based on the self-attention mechanism, which has global perception capability in comparison with the traditional convolutional neural network. Then, with the feature extraction capability of vision Transformer, the micro-expression discriminative information embedded in the reconstructed optical flow is mined. Finally, the semantic information of micro-expressions extracted from facial displacement information and the discriminative information of micro-expressions extracted from the vision Transformer model are fused to provide rich information for micro-expression classification. This study uses the Endpoint error loss constraint for the optical flow estimation task to achieve the learning purpose, which continuously reduces the Euclidean distance between the predicted and real optical flow. Cross entropy loss function constraints are used for the features extracted by vision Transformer and the fused features, which make the network learn micro-expression related information. At the same time, the image with low motion intensity in the two frames is equivalent to the neutral expression (without motion information), and the KL-divergence loss is applied to the output of the feature by the encoder to suppress irrelevant information. The loss functions interact to complete the network optimization.ResultThis study evaluates the model performance on a public dataset using the leave-one-subject-out cross-validation evaluation strategy. Face alignment and cropping are performed on the public dataset samples to unify the dataset. To demonstrate the state-of-the-art of the proposed method, we compare it with existing mainstream methods on composite datasets constructed by SMIC, SAMM, and CASME II. Our method achieves 82.89% and 85.59% UF1 and UAR on the whole dataset, 78.16% and 80.89% UF1 and UAR on the SMIC part, 94.52% and 96.02% UF1 and UAR on the CASME II part, and 73.24% and 75.83%. Our method achieves optimal results in the whole dataset, the SMIC part, and the CASME II part, and suboptimal results in the SAMM part. Compared to the latest proposed micro-expression method based on feature representation learning with adaptive displacement generation and Transformer fusion (FRL-DGT), our method demonstrates an improvement of 1.77% and 4.85%.ConclusionThe micro-expression recognition model based on adaptive optical flow estimation proposed in this study fuses the proposed two tasks of adaptive optical flow estimation and micro-expression categorization, which, on the one hand, senses the subtle facial movements in an end-to-end manner and improves the ability of subtle expression description, and on the other hand, fully exploits the micro-expression discriminative information and enhances the micro-expression performance.关键词:micro-expression recognition;adaptive optical flow estimation;motion features;differential encoder;feature fusion540|925|0更新时间:2024-10-23
摘要:ObjectiveMicro-expressions are brief, subtle facial muscle movements that accidentally signal emotions when the person tries to hide their true inner feelings. Micro-expressions are more responsive to a person’s true feelings and motivations than macro-expressions. Micro-expression recognition aims to analyze and identify automatically the emotional category of the research object from the stressful movement of the facial muscles, which has an important application value in lie detection, psychological diagnosis, and other aspects. In the early development of micro-expression recognition, local binary patterns and optical flow were widely used as features for training traditional machine learning models. However, the traditional manual feature approach relies on manually designing rules, making it difficult to adapt to the differences in micro-expression data across different individuals and scenarios. Given that deep learning can automatically learn the optimal feature representation of an image, the recognition performance of micro-expression recognition studies based on deep learning far exceeds that of traditional methods. However, micro-expressions occur as subtle facial changes, which causes the micro-expression recognition task to remain challenging. By analyzing the pixel movement between consecutive frames, the optical flow can represent the dynamic information of micro-expressions. Deep learning-based micro-expression recognition methods perform facial muscle motion descriptions with optical flow information to improve micro-expression recognition performance. However, existing micro-expression recognition methods usually extract the optical flow information offline, which relies on existing optical flow estimation techniques and suffers from the insufficient description of subtle expressions and neglect of static facial expression information, which restricts the recognition effect of the model. Therefore, this study proposes a micro-expression recognition network based on adaptive optical flow estimation, which realizes optical flow estimation and micro-expression classification to learn micro-expression-related motion features through parallel association adaptively.MethodThe training samples of micro-expressions are limited, which makes it difficult to train complex network models. Therefore, this study selects the apex and their neighboring frames in the micro-expression video sequence as training data in the preprocessing stage. In addition, when loading the data, the original training data are replaced with image pairs containing motion information in the video sequence with a certain probability. Second, the deep learning network with a dense differential encoder-decoder implements the facial muscle motion adaptive optical flow estimation task to improve the characterization of subtle expressions. ResNet18 extracts features from the two-frame image and the difference map in a dense differential encoder. The branch processing the two frames shares the parameters. A motion enhancement module is added to the feature extraction branch of the differential image to accomplish the interlayer information interaction. In the motion enhancement module, the difference map features computed from the two frames need the spatial attention mechanism to focus on the micro-expression-related motion; the two frames are subtracted from each other to preserve and amplify the difference between the two frames, and using the two features provides valid information for subsequent networks. The decoder in this study maps the multilevel facial displacement information extracted by the dense differential encoder and the last layer of the two-frame image output features to reconstruct the optical flow features. Vision Transformer is a deep learning model based on the self-attention mechanism, which has global perception capability in comparison with the traditional convolutional neural network. Then, with the feature extraction capability of vision Transformer, the micro-expression discriminative information embedded in the reconstructed optical flow is mined. Finally, the semantic information of micro-expressions extracted from facial displacement information and the discriminative information of micro-expressions extracted from the vision Transformer model are fused to provide rich information for micro-expression classification. This study uses the Endpoint error loss constraint for the optical flow estimation task to achieve the learning purpose, which continuously reduces the Euclidean distance between the predicted and real optical flow. Cross entropy loss function constraints are used for the features extracted by vision Transformer and the fused features, which make the network learn micro-expression related information. At the same time, the image with low motion intensity in the two frames is equivalent to the neutral expression (without motion information), and the KL-divergence loss is applied to the output of the feature by the encoder to suppress irrelevant information. The loss functions interact to complete the network optimization.ResultThis study evaluates the model performance on a public dataset using the leave-one-subject-out cross-validation evaluation strategy. Face alignment and cropping are performed on the public dataset samples to unify the dataset. To demonstrate the state-of-the-art of the proposed method, we compare it with existing mainstream methods on composite datasets constructed by SMIC, SAMM, and CASME II. Our method achieves 82.89% and 85.59% UF1 and UAR on the whole dataset, 78.16% and 80.89% UF1 and UAR on the SMIC part, 94.52% and 96.02% UF1 and UAR on the CASME II part, and 73.24% and 75.83%. Our method achieves optimal results in the whole dataset, the SMIC part, and the CASME II part, and suboptimal results in the SAMM part. Compared to the latest proposed micro-expression method based on feature representation learning with adaptive displacement generation and Transformer fusion (FRL-DGT), our method demonstrates an improvement of 1.77% and 4.85%.ConclusionThe micro-expression recognition model based on adaptive optical flow estimation proposed in this study fuses the proposed two tasks of adaptive optical flow estimation and micro-expression categorization, which, on the one hand, senses the subtle facial movements in an end-to-end manner and improves the ability of subtle expression description, and on the other hand, fully exploits the micro-expression discriminative information and enhances the micro-expression performance.关键词:micro-expression recognition;adaptive optical flow estimation;motion features;differential encoder;feature fusion540|925|0更新时间:2024-10-23 -
 摘要:ObjectiveIn industrial production, influenced by the complex environment during manufacturing and production processes, surface defects on products are difficult to avoid. These defects not only destroy the integrity of the products but also affect their quality, posing potential threats to the health and safety of individuals. Thus, defect detection on the surface of industrial products is an important part that cannot be ignored in production. In defect detection tasks, the targets must be accurately classified to determine whether they should be subjected to recycling treatment. At the same time, the detection results must be presented in the form of bounding boxes to assist enterprises in analyzing the causes of defects and improving the production process. The traditional method of surface defect detection is the manual inspection method. However, in practice, manual inspection often has large limitations. In recent years, the performance of computers has improved by leaps and bounds, and traditional machine vision technology has been widely tested in various production fields. These methods rely on image processing and feature engineering, and in specific scenarios, they can reach a level close to manual detection, truly realizing the productivity replacement of machines for some manual labor. However, the shortcoming is the difficulty in extracting features from complex backgrounds, often resulting in inaccurate detection. Therefore, it is hardly reused in other types of workpiece inspection tasks. Deep learning has played an increasingly important role in the field of computer vision in recent years. Deep learning-based defect detection methods learn the features of numerous defect samples and utilize the defect sample features to achieve classification and localization. With high detection accuracy and applicability, they have addressed the complexity and uncertainty associated with manual feature extraction in traditional image processing, achieving remarkable results in industrial product surface defect detection. However, given the complex background of some industrial product surfaces, the high similarity between some surface defects and the background, and the small difference between different defects, the existing methods could hardly detect surface defects with accuracy. In this study, we propose a differential detection network (YOLO-Differ) based on YOLOv5.MethodFirst, for cases where some defects are similar to background features on the surface of products, according to the studies of biology and psychology, predators use perceptual filters bound to specific features to separate target animals from the background during predation. In other words, they capture camouflaged targets by utilizing frequency domain features. The frequency signal strength of the target is lower than that of the background, and this difference helps us find targets similar to the background. Therefore, a novel method is proposed for the first time to integrate frequency cues in the object detection network, thus addressing the issue of inaccurate localization caused by defects that resemble the background, thereby enhancing the distinguishability between defects and the background. Second, a fine-grained classification branch is added after the detection module of the network to address the issue of small differences in defect features among different types. The vision Transformer(ViT) classification network is used as the corrective classifier in this branch to extract subtle distinguishing features of defects. Specifically, it divides the defective image into N blocks small enough to allow its inherent attention mechanism to capture important regions in the image. At the same time, Transformer performs global relationship modeling on different patches and gives each patch the importance of affecting classification results. This large range of relationship modeling and importance settings enable it to locate subtle differences in features and focus on important features of defects. Therefore, YOLO-Differ is divided into five parts: RGB feature extraction, frequency feature extraction, feature fusion, detection head, and fine-grained classification. First, RGB feature extraction, which consists of the backbone network and neck, is responsible for extracting the basic RGB feature information and fusing RGB features of different scales to obtain improved detection results. Next, RGB images are converted to YCbCr image space, and its results are processed through discrete cosine transform(DCT) and frequency enhancement to obtain their frequency features. The feature fusion module aligns and fuses the RGB features with frequency features. Then, the fused features are fed into the detection head to obtain defect localization information and preliminary classification results. Finally, the defect images are cropped in accordance with the location information and fed into the fine-grained classifier for secondary classification to obtain the final classification results of defects.ResultIn the experiment, YOLO-Differ models were compared with seven object detection models on three datasets, and YOLO-Differ consistently achieved optimal results. Compared with the current state-of-the-art models, the mean average precision(mAP) improved by 3.6%, 2.4%, and 0.4% on each respective dataset.ConclusionCompared with similar models, the YOLO-Differ model exhibits higher detection accuracy and stronger generality.关键词:surface defect detection;similarity;frequency features;fine-grained classification;generality377|2041|0更新时间:2024-10-23
摘要:ObjectiveIn industrial production, influenced by the complex environment during manufacturing and production processes, surface defects on products are difficult to avoid. These defects not only destroy the integrity of the products but also affect their quality, posing potential threats to the health and safety of individuals. Thus, defect detection on the surface of industrial products is an important part that cannot be ignored in production. In defect detection tasks, the targets must be accurately classified to determine whether they should be subjected to recycling treatment. At the same time, the detection results must be presented in the form of bounding boxes to assist enterprises in analyzing the causes of defects and improving the production process. The traditional method of surface defect detection is the manual inspection method. However, in practice, manual inspection often has large limitations. In recent years, the performance of computers has improved by leaps and bounds, and traditional machine vision technology has been widely tested in various production fields. These methods rely on image processing and feature engineering, and in specific scenarios, they can reach a level close to manual detection, truly realizing the productivity replacement of machines for some manual labor. However, the shortcoming is the difficulty in extracting features from complex backgrounds, often resulting in inaccurate detection. Therefore, it is hardly reused in other types of workpiece inspection tasks. Deep learning has played an increasingly important role in the field of computer vision in recent years. Deep learning-based defect detection methods learn the features of numerous defect samples and utilize the defect sample features to achieve classification and localization. With high detection accuracy and applicability, they have addressed the complexity and uncertainty associated with manual feature extraction in traditional image processing, achieving remarkable results in industrial product surface defect detection. However, given the complex background of some industrial product surfaces, the high similarity between some surface defects and the background, and the small difference between different defects, the existing methods could hardly detect surface defects with accuracy. In this study, we propose a differential detection network (YOLO-Differ) based on YOLOv5.MethodFirst, for cases where some defects are similar to background features on the surface of products, according to the studies of biology and psychology, predators use perceptual filters bound to specific features to separate target animals from the background during predation. In other words, they capture camouflaged targets by utilizing frequency domain features. The frequency signal strength of the target is lower than that of the background, and this difference helps us find targets similar to the background. Therefore, a novel method is proposed for the first time to integrate frequency cues in the object detection network, thus addressing the issue of inaccurate localization caused by defects that resemble the background, thereby enhancing the distinguishability between defects and the background. Second, a fine-grained classification branch is added after the detection module of the network to address the issue of small differences in defect features among different types. The vision Transformer(ViT) classification network is used as the corrective classifier in this branch to extract subtle distinguishing features of defects. Specifically, it divides the defective image into N blocks small enough to allow its inherent attention mechanism to capture important regions in the image. At the same time, Transformer performs global relationship modeling on different patches and gives each patch the importance of affecting classification results. This large range of relationship modeling and importance settings enable it to locate subtle differences in features and focus on important features of defects. Therefore, YOLO-Differ is divided into five parts: RGB feature extraction, frequency feature extraction, feature fusion, detection head, and fine-grained classification. First, RGB feature extraction, which consists of the backbone network and neck, is responsible for extracting the basic RGB feature information and fusing RGB features of different scales to obtain improved detection results. Next, RGB images are converted to YCbCr image space, and its results are processed through discrete cosine transform(DCT) and frequency enhancement to obtain their frequency features. The feature fusion module aligns and fuses the RGB features with frequency features. Then, the fused features are fed into the detection head to obtain defect localization information and preliminary classification results. Finally, the defect images are cropped in accordance with the location information and fed into the fine-grained classifier for secondary classification to obtain the final classification results of defects.ResultIn the experiment, YOLO-Differ models were compared with seven object detection models on three datasets, and YOLO-Differ consistently achieved optimal results. Compared with the current state-of-the-art models, the mean average precision(mAP) improved by 3.6%, 2.4%, and 0.4% on each respective dataset.ConclusionCompared with similar models, the YOLO-Differ model exhibits higher detection accuracy and stronger generality.关键词:surface defect detection;similarity;frequency features;fine-grained classification;generality377|2041|0更新时间:2024-10-23
Image Analysis and Recognition
-
Text self-training and adversarial learning-relevant domain adaptive industrial scene text detection
 摘要:ObjectiveThe surface of industrial equipment records important information, such as equipment model, specifications, and functions, which are crucial for equipment management and maintenance. Traditional information collection relies on workers taking photos and recording, which is inefficient and hardly meets the current high-efficiency and low-cost production requirements. By utilizing scene text detection technology to detect text in industrial scenarios automatically, production efficiency and cost effectiveness can be improved, which is crucial for industrial intelligence and automation. The success of scene text detection algorithms relies heavily on the availability of large-scale, high-quality annotation data. However, in industrial scenarios, data collection and annotation are time consuming and labor intensive, resulting in a small amount of data and no annotation information, severely limiting model performance. Furthermore, substantial domain gaps exist between the “source domain” (public data) and the “target domain” (industrial scene data), making it difficult for models trained on public datasets to generalize directly to industrial scene text detection tasks. Therefore, we focus on researching domain adaptive scene text detection algorithms. However, when applied to industrial scene text detection, these methods encounter the following problems: 1) Image translation methods achieve domain adaptation by generating similar target domain images, but this method focuses on adapting to low-frequency appearance information and are not effective in handling text detection tasks. 2) The quality of pseudo labels generated by self-training methods is low and cannot be adaptively improved during training, limiting the model’s domain adaptability. 3) The adversarial feature alignment method disregards the influence of background noise and cannot effectively mitigate domain gaps. To address these issues, we propose a domain adaptive industrial scene text detection method called DA-DB++, which stands for domain-adaptive differentiable binarization, based on text self-training and adversarial learning.MethodIn this study, we address the issues of low-quality pseudo labels and domain gaps. First, we introduce a teacher–student self-training framework. Applying data augmentation and mutual learning between teacher and student models, which enhances the robustness of the model, reduces domain bias and gradually generates high-quality pseudo labels during training. Specifically, the teacher model generates pseudo labels for data in the target domain, while the student model uses source domain data and pseudo labels for training. The exponential moving average of the student model is used to update the teacher model. Second, we propose image-level and instance-level adversarial learning modules in the student model to address the large domain gap. These modules align the feature distributions of the source and target domains, achieving domain-invariant learning within the network. Specifically, an image-level alignment module is added after the feature extraction network, and the coordinate attention mechanism is used to aggregate features along the horizontal and vertical spatial directions, improving the extraction of global-level features. This process helps reduce shifts caused by global image differences, such as image style and shape. The alignment of advanced semantic features can help the model better learn feature representations, effectively reduce domain gaps, and improve the model’s generalization ability. Instance-level alignment is implemented by using text labels for mask filtering. This process forces the network to focus on the text area and suppresses background noise interference. Finally, two adversarial learning modules are regularized to alleviate domain gaps and improve the model’s domain adaptability further.ResultWe conducted experiments and analysis with other domain adaptive text detection methods on the industrial nameplate dataset and public dataset to verify the effectiveness and robustness of our method. The experiments showed that each module of our proposed method contributes to the overall performance to varying degrees. When the ICDAR2013 and nameplate datasets were respectively used as the source and target domains, our method attained accuracy, recall, and F1 values of 96.2%, 95.0%, and 95.6%, respectively. These values were 10%, 15.3%, and 12.8% higher than the baseline model DBNet++. This result indicates that our method alleviates domain gaps and offsets, generates high-quality pseudo labels, and improves the model’s domain adaptability. Additionally, it demonstrates good performance on the ICDAR15 and MSRA-TD500 datasets, with F1 values increased by 0.9% and 3.1%, respectively, compared with state-of-the-art methods. In addition, applying our method to the efficient and accurate scene text detector (EAST) model results in a 5%, 11.8%, and 9.5% increase in the accuracy, recall, and F1 values, respectively, on the nameplate dataset.ConclusionIn this study, we propose a domain adaptive industrial scene text detection method to address the issue of low quality in pseudo labels and domain gaps between source and target, improving the model’s domain adaptability on the target dataset. The experimental results and analysis indicate that the method proposed in this study remarkably enhances the domain adaptability of the DBNet++ text detection model. It achieves state-of-the-art results in domain adaptation tasks for industrial nameplate and public text detection, thus verifying the effectiveness of the method proposed in this study. Additionally, experiments on the EAST model have demonstrated the universality of the proposed method. The model inference stage will not increase computational costs and time consumption.关键词:scene text detection;domain adaptation;text self-training;feature adversarial learning;consistency regularization328|618|0更新时间:2024-10-23
摘要:ObjectiveThe surface of industrial equipment records important information, such as equipment model, specifications, and functions, which are crucial for equipment management and maintenance. Traditional information collection relies on workers taking photos and recording, which is inefficient and hardly meets the current high-efficiency and low-cost production requirements. By utilizing scene text detection technology to detect text in industrial scenarios automatically, production efficiency and cost effectiveness can be improved, which is crucial for industrial intelligence and automation. The success of scene text detection algorithms relies heavily on the availability of large-scale, high-quality annotation data. However, in industrial scenarios, data collection and annotation are time consuming and labor intensive, resulting in a small amount of data and no annotation information, severely limiting model performance. Furthermore, substantial domain gaps exist between the “source domain” (public data) and the “target domain” (industrial scene data), making it difficult for models trained on public datasets to generalize directly to industrial scene text detection tasks. Therefore, we focus on researching domain adaptive scene text detection algorithms. However, when applied to industrial scene text detection, these methods encounter the following problems: 1) Image translation methods achieve domain adaptation by generating similar target domain images, but this method focuses on adapting to low-frequency appearance information and are not effective in handling text detection tasks. 2) The quality of pseudo labels generated by self-training methods is low and cannot be adaptively improved during training, limiting the model’s domain adaptability. 3) The adversarial feature alignment method disregards the influence of background noise and cannot effectively mitigate domain gaps. To address these issues, we propose a domain adaptive industrial scene text detection method called DA-DB++, which stands for domain-adaptive differentiable binarization, based on text self-training and adversarial learning.MethodIn this study, we address the issues of low-quality pseudo labels and domain gaps. First, we introduce a teacher–student self-training framework. Applying data augmentation and mutual learning between teacher and student models, which enhances the robustness of the model, reduces domain bias and gradually generates high-quality pseudo labels during training. Specifically, the teacher model generates pseudo labels for data in the target domain, while the student model uses source domain data and pseudo labels for training. The exponential moving average of the student model is used to update the teacher model. Second, we propose image-level and instance-level adversarial learning modules in the student model to address the large domain gap. These modules align the feature distributions of the source and target domains, achieving domain-invariant learning within the network. Specifically, an image-level alignment module is added after the feature extraction network, and the coordinate attention mechanism is used to aggregate features along the horizontal and vertical spatial directions, improving the extraction of global-level features. This process helps reduce shifts caused by global image differences, such as image style and shape. The alignment of advanced semantic features can help the model better learn feature representations, effectively reduce domain gaps, and improve the model’s generalization ability. Instance-level alignment is implemented by using text labels for mask filtering. This process forces the network to focus on the text area and suppresses background noise interference. Finally, two adversarial learning modules are regularized to alleviate domain gaps and improve the model’s domain adaptability further.ResultWe conducted experiments and analysis with other domain adaptive text detection methods on the industrial nameplate dataset and public dataset to verify the effectiveness and robustness of our method. The experiments showed that each module of our proposed method contributes to the overall performance to varying degrees. When the ICDAR2013 and nameplate datasets were respectively used as the source and target domains, our method attained accuracy, recall, and F1 values of 96.2%, 95.0%, and 95.6%, respectively. These values were 10%, 15.3%, and 12.8% higher than the baseline model DBNet++. This result indicates that our method alleviates domain gaps and offsets, generates high-quality pseudo labels, and improves the model’s domain adaptability. Additionally, it demonstrates good performance on the ICDAR15 and MSRA-TD500 datasets, with F1 values increased by 0.9% and 3.1%, respectively, compared with state-of-the-art methods. In addition, applying our method to the efficient and accurate scene text detector (EAST) model results in a 5%, 11.8%, and 9.5% increase in the accuracy, recall, and F1 values, respectively, on the nameplate dataset.ConclusionIn this study, we propose a domain adaptive industrial scene text detection method to address the issue of low quality in pseudo labels and domain gaps between source and target, improving the model’s domain adaptability on the target dataset. The experimental results and analysis indicate that the method proposed in this study remarkably enhances the domain adaptability of the DBNet++ text detection model. It achieves state-of-the-art results in domain adaptation tasks for industrial nameplate and public text detection, thus verifying the effectiveness of the method proposed in this study. Additionally, experiments on the EAST model have demonstrated the universality of the proposed method. The model inference stage will not increase computational costs and time consumption.关键词:scene text detection;domain adaptation;text self-training;feature adversarial learning;consistency regularization328|618|0更新时间:2024-10-23 -
 摘要:ObjectiveShips are the most important carriers of waterborne transportation, accounting for over two-thirds of global trade in goods transportation. Ship names, as one of the most crucial identification pieces of information for ships, possess uniqueness and distinctiveness, forming the core elements for intelligent ship identity recognition. Achieving ship name text detection is crucial in enhancing waterway traffic regulation and improving maritime transport safety. However, in real-world scenarios, given the variations in ship size and diverse ship types, the areas of ship name text regions differ, and the aspect ratio of ship name text varies greatly across different ship types, directly affecting the accuracy of ship name text detection and increasing the likelihood of missed detections. Additionally, during ship name text detection, various elements, such as background text and patterns in the scene, can introduce interference. Existing natural scene text detection algorithms do not completely eliminate these interference factors. Directly applying them to ship name text detection tasks may lead to poor algorithm robustness. Therefore, this study addresses the aforementioned issues and proposes a ship name detection method based on scene prior information.MethodFirst, given that ship name text regions are usually fixed at the bow and two sides of the ship, this study proposes a region supervision module based on prior loss, which utilizes the correlation between the bow and the ship name text target. Through the classification and regression branches on the shared feature maps, prior information of the bow region is obtained, constructing a scene prior loss with bow correlation. During training, the model simultaneously learns the ship name text detection main task and the bow object detection auxiliary task and updates the network parameters through joint losses to constrain the model’s attention to the ship name text region features and eliminate background interference. Then, a ship name region localization module based on asymmetric convolution is further proposed to improve the granularity of text region localization. It achieves lateral connections between deep semantic information and shallow localization information by fusing feature layers with different scales between networks. On the basis of the additive property of convolution, three convolution kernels with sizes of 3 × 3, 3 × 1, and 1 × 3 are used to enhance the fused feature maps, balancing the weights of the kernel region features to enrich the text edge information. Finally, a differentiable binarization optimization is introduced to generate text boundaries and realize ship name text region localization. Given that no ship name text detection dataset is publicly available, this study constructs the CBWLZ2023 dataset, comprising 1 659 images of various types of ships, such as fishing vessels, passenger ships, cargo ships, and warships, captured in real-world scenes such as waterways and ports, featuring differences in background, ship poses, lighting, text attributes, and character sizes.ResultTo validate the effectiveness of the proposed algorithm, this study collected, annotated, and publicly released a real-world ship name text detection dataset CBWLZ2023 for experimental verification and compared it with eight state-of-the-art general natural scene text detection methods. Quantitative analysis results show that the proposed algorithm achieves an F-value of 94.2% in the ship name text detection task, representing a 2.3% improvement over the second-best-performing model. Moreover, ablation experiments demonstrate that the model’s F-value increases by 2.3% and 0.7% after incorporating the region supervision module based on prior loss and the ship name region localization module based on asymmetric convolution, respectively. The fused model’s F-value increases by 2.8%, confirming the effectiveness of each algorithm module. Qualitative analysis results indicate that the proposed algorithm exhibits stronger robustness than other methods in dealing with text of varying scales and background interference, accurately capturing text regions with clear boundaries and effectively reducing false positives and missed detections. Experimental results demonstrate that the proposed algorithm enhances ship name text detection performance.ConclusionThis study proposes a ship name detection method based on scene prior information. The algorithm has two main advantages. First, it fully utilizes the strong correlation between the bow region of the ship and the ship name text region, suppressing the interference of background information in ship name detection tasks. Second, it integrates multiscale text feature information to enhance the robustness of multiscale text object detection. The proposed algorithm achieves higher detection accuracy than existing scene text detection algorithms on the CBWLZ2023 dataset, demonstrating its effectiveness and advancement. The CBWLZ2023 can be obtained from https://aistudio.baidu.com/aistudio/datasetdetail/224137.关键词:ship name text detection;scene priori loss;regional supervision;feature enhancement;asymmetric convolution463|997|0更新时间:2024-10-23
摘要:ObjectiveShips are the most important carriers of waterborne transportation, accounting for over two-thirds of global trade in goods transportation. Ship names, as one of the most crucial identification pieces of information for ships, possess uniqueness and distinctiveness, forming the core elements for intelligent ship identity recognition. Achieving ship name text detection is crucial in enhancing waterway traffic regulation and improving maritime transport safety. However, in real-world scenarios, given the variations in ship size and diverse ship types, the areas of ship name text regions differ, and the aspect ratio of ship name text varies greatly across different ship types, directly affecting the accuracy of ship name text detection and increasing the likelihood of missed detections. Additionally, during ship name text detection, various elements, such as background text and patterns in the scene, can introduce interference. Existing natural scene text detection algorithms do not completely eliminate these interference factors. Directly applying them to ship name text detection tasks may lead to poor algorithm robustness. Therefore, this study addresses the aforementioned issues and proposes a ship name detection method based on scene prior information.MethodFirst, given that ship name text regions are usually fixed at the bow and two sides of the ship, this study proposes a region supervision module based on prior loss, which utilizes the correlation between the bow and the ship name text target. Through the classification and regression branches on the shared feature maps, prior information of the bow region is obtained, constructing a scene prior loss with bow correlation. During training, the model simultaneously learns the ship name text detection main task and the bow object detection auxiliary task and updates the network parameters through joint losses to constrain the model’s attention to the ship name text region features and eliminate background interference. Then, a ship name region localization module based on asymmetric convolution is further proposed to improve the granularity of text region localization. It achieves lateral connections between deep semantic information and shallow localization information by fusing feature layers with different scales between networks. On the basis of the additive property of convolution, three convolution kernels with sizes of 3 × 3, 3 × 1, and 1 × 3 are used to enhance the fused feature maps, balancing the weights of the kernel region features to enrich the text edge information. Finally, a differentiable binarization optimization is introduced to generate text boundaries and realize ship name text region localization. Given that no ship name text detection dataset is publicly available, this study constructs the CBWLZ2023 dataset, comprising 1 659 images of various types of ships, such as fishing vessels, passenger ships, cargo ships, and warships, captured in real-world scenes such as waterways and ports, featuring differences in background, ship poses, lighting, text attributes, and character sizes.ResultTo validate the effectiveness of the proposed algorithm, this study collected, annotated, and publicly released a real-world ship name text detection dataset CBWLZ2023 for experimental verification and compared it with eight state-of-the-art general natural scene text detection methods. Quantitative analysis results show that the proposed algorithm achieves an F-value of 94.2% in the ship name text detection task, representing a 2.3% improvement over the second-best-performing model. Moreover, ablation experiments demonstrate that the model’s F-value increases by 2.3% and 0.7% after incorporating the region supervision module based on prior loss and the ship name region localization module based on asymmetric convolution, respectively. The fused model’s F-value increases by 2.8%, confirming the effectiveness of each algorithm module. Qualitative analysis results indicate that the proposed algorithm exhibits stronger robustness than other methods in dealing with text of varying scales and background interference, accurately capturing text regions with clear boundaries and effectively reducing false positives and missed detections. Experimental results demonstrate that the proposed algorithm enhances ship name text detection performance.ConclusionThis study proposes a ship name detection method based on scene prior information. The algorithm has two main advantages. First, it fully utilizes the strong correlation between the bow region of the ship and the ship name text region, suppressing the interference of background information in ship name detection tasks. Second, it integrates multiscale text feature information to enhance the robustness of multiscale text object detection. The proposed algorithm achieves higher detection accuracy than existing scene text detection algorithms on the CBWLZ2023 dataset, demonstrating its effectiveness and advancement. The CBWLZ2023 can be obtained from https://aistudio.baidu.com/aistudio/datasetdetail/224137.关键词:ship name text detection;scene priori loss;regional supervision;feature enhancement;asymmetric convolution463|997|0更新时间:2024-10-23 -
 摘要:ObjectiveThree-dimensional human pose estimation has always been a research hotspot in computer vision. Currently, most methods directly regress three-dimensional joint coordinates from videos or two-dimensional coordinate points, ignoring the estimation of joint rotation angles. However, joint rotation angles are crucial for certain applications, such as virtual reality and computer animation. To address this issue, we propose an attention fusion network for estimating three-dimensional human coordinates and rotation angles. Furthermore, many existing methods for video or motion sequence-based human pose estimation lack a dedicated network for handling the root joint separately. This limitation results in reduced overall coordinate accuracy, especially when the subject moves extensively within the scene, leading to drift and jitter phenomena. To tackle this problem, we also introduce a root joint processing approach, which ensures smoother and more stable motion of the root joint in the generated poses.MethodOur proposed attention fusion network for estimating three-dimensional human coordinates and rotation angles follows a two-step approach. First, we use a well-established 2D pose estimation algorithm to estimate the 2D motion sequence from video or image sequences. Then, we employ a skeleton length network and a skeleton direction network to estimate the bone lengths and bone directions of the human body from the 2D human motion sequence. Based on these estimates, we calculate the initial 3D human coordinates. Next, we input the initial 3D coordinates into a joint rotation angle estimation network to obtain the joint rotation angles. We then apply forward kinematics to compute the 3D human coordinates corresponding to the joint rotation angles. However, given network errors, the precision of the 3D coordinates corresponding to the joint rotation angles is slightly lower than that of the initial 3D coordinates. To address this issue, we propose a final step where we use an attention fusion module to integrate the initial 3D coordinates and the 3D coordinates corresponding to the joint rotation angles into the final 3D joint coordinates. This stepwise estimation algorithm for human pose estimation allows for constraints on the intermediate states of the estimation. Moreover, the attention fusion mechanism helps mitigate the accuracy loss caused by the errors in the joint rotation angle network, resulting in improved precision in the final results.ResultWe select several representative methods and conduct experiments on the Human3.6M dataset to compare their performance in terms of the mean per joint position error (MPJPE) metric. The Human3.6M dataset is one of the largest publicly available datasets in the field of human pose estimation. It consists of seven different subjects, each performing 15 different actions captured by four cameras. Each action is annotated with 2D and 3D pose annotations and camera intrinsic and extrinsic parameters. The actions in the dataset include walking, jumping, and fist-clenching, covering a wide range of human daily activities. Experimental results demonstrate that our proposed method achieves highly competitive results. The average MPJPE achieved by our method is 45.0 mm across all actions, and it achieves the best average MPJPE in some actions while obtaining the second-best average MPJPE in most of the other actions. The method that achieves the first-place result cannot estimate joint rotation angles while estimating 3D joint coordinates, which is precisely the strength of our proposed method. Below is an introduction to our model’s training method. We use the Adam optimizer for stochastic gradient descent and minimize the loss function. The batch size is set to 64, and the motion sequence length is set to 80. The learning rate is set to 0.001, and we train for 50 epochs. To prevent overfitting, we add dropout layers in each module with a parameter of 0.25.ConclusionTo address the issue of rotation ambiguity in traditional human pose estimation methods that estimate 3D joint coordinates, we propose an attention fusion network for estimating 3D human coordinates and rotation angles. This method decomposes the 3D coordinates into skeleton lengths, skeleton directions, and joint rotation angles. First, on the basis of the skeleton lengths and directions, we calculate the initial 3D joint coordinate sequence. Then, we input the 3D and 2D coordinates into the joint rotation module to compute the joint rotation angles corresponding to the joint coordinates. However, given factors such as network errors, the precision of the 3D joint coordinates may decrease during this process. Therefore, we employ an attention fusion network to mitigate these adverse effects and obtain more accurate 3D coordinates. Through comparative experiments, we demonstrate that our proposed method not only achieves more competitive results in terms of joint coordinate estimation accuracy but also estimates the corresponding joint rotation angles simultaneously with the 3D joint coordinates from the video.关键词:human pose estimation;joint coordinates;joint rotation angle;attention fusion;stepwise estimation405|696|0更新时间:2024-10-23
摘要:ObjectiveThree-dimensional human pose estimation has always been a research hotspot in computer vision. Currently, most methods directly regress three-dimensional joint coordinates from videos or two-dimensional coordinate points, ignoring the estimation of joint rotation angles. However, joint rotation angles are crucial for certain applications, such as virtual reality and computer animation. To address this issue, we propose an attention fusion network for estimating three-dimensional human coordinates and rotation angles. Furthermore, many existing methods for video or motion sequence-based human pose estimation lack a dedicated network for handling the root joint separately. This limitation results in reduced overall coordinate accuracy, especially when the subject moves extensively within the scene, leading to drift and jitter phenomena. To tackle this problem, we also introduce a root joint processing approach, which ensures smoother and more stable motion of the root joint in the generated poses.MethodOur proposed attention fusion network for estimating three-dimensional human coordinates and rotation angles follows a two-step approach. First, we use a well-established 2D pose estimation algorithm to estimate the 2D motion sequence from video or image sequences. Then, we employ a skeleton length network and a skeleton direction network to estimate the bone lengths and bone directions of the human body from the 2D human motion sequence. Based on these estimates, we calculate the initial 3D human coordinates. Next, we input the initial 3D coordinates into a joint rotation angle estimation network to obtain the joint rotation angles. We then apply forward kinematics to compute the 3D human coordinates corresponding to the joint rotation angles. However, given network errors, the precision of the 3D coordinates corresponding to the joint rotation angles is slightly lower than that of the initial 3D coordinates. To address this issue, we propose a final step where we use an attention fusion module to integrate the initial 3D coordinates and the 3D coordinates corresponding to the joint rotation angles into the final 3D joint coordinates. This stepwise estimation algorithm for human pose estimation allows for constraints on the intermediate states of the estimation. Moreover, the attention fusion mechanism helps mitigate the accuracy loss caused by the errors in the joint rotation angle network, resulting in improved precision in the final results.ResultWe select several representative methods and conduct experiments on the Human3.6M dataset to compare their performance in terms of the mean per joint position error (MPJPE) metric. The Human3.6M dataset is one of the largest publicly available datasets in the field of human pose estimation. It consists of seven different subjects, each performing 15 different actions captured by four cameras. Each action is annotated with 2D and 3D pose annotations and camera intrinsic and extrinsic parameters. The actions in the dataset include walking, jumping, and fist-clenching, covering a wide range of human daily activities. Experimental results demonstrate that our proposed method achieves highly competitive results. The average MPJPE achieved by our method is 45.0 mm across all actions, and it achieves the best average MPJPE in some actions while obtaining the second-best average MPJPE in most of the other actions. The method that achieves the first-place result cannot estimate joint rotation angles while estimating 3D joint coordinates, which is precisely the strength of our proposed method. Below is an introduction to our model’s training method. We use the Adam optimizer for stochastic gradient descent and minimize the loss function. The batch size is set to 64, and the motion sequence length is set to 80. The learning rate is set to 0.001, and we train for 50 epochs. To prevent overfitting, we add dropout layers in each module with a parameter of 0.25.ConclusionTo address the issue of rotation ambiguity in traditional human pose estimation methods that estimate 3D joint coordinates, we propose an attention fusion network for estimating 3D human coordinates and rotation angles. This method decomposes the 3D coordinates into skeleton lengths, skeleton directions, and joint rotation angles. First, on the basis of the skeleton lengths and directions, we calculate the initial 3D joint coordinate sequence. Then, we input the 3D and 2D coordinates into the joint rotation module to compute the joint rotation angles corresponding to the joint coordinates. However, given factors such as network errors, the precision of the 3D joint coordinates may decrease during this process. Therefore, we employ an attention fusion network to mitigate these adverse effects and obtain more accurate 3D coordinates. Through comparative experiments, we demonstrate that our proposed method not only achieves more competitive results in terms of joint coordinate estimation accuracy but also estimates the corresponding joint rotation angles simultaneously with the 3D joint coordinates from the video.关键词:human pose estimation;joint coordinates;joint rotation angle;attention fusion;stepwise estimation405|696|0更新时间:2024-10-23 -
 摘要:ObjectiveCitrus is one of the most common fruits in our country. At present, it is mostly picked by hand, but issues such as high cost and low efficiency severely restrict the scale of production. Therefore, automatic citrus picking has become a research hotspot in recent years. However, the growing environment of citrus is complex, its branch has different shapes, and the branches, leaves, and fruits are seriously shielded from each other. Accurate and real-time location of the picking point becomes the crucial aspect of automated picking. Currently, research on fruit picking point localization methods can be broadly categorized into two types: nondeep learning-based methods and deep learning-based methods. Nondeep learning-based methods mainly rely on digital image processing techniques, such as color space conversion, threshold segmentation, and watershed algorithm, to extract target contours and design corresponding algorithms for picking point localization. However, these methods often suffer from low accuracy and efficiency. Deep learning-based methods involve training deep learning models to perform tasks, such as detection or segmentation. The model’s output is then used as an intermediate result, and specific algorithms are designed on the basis of fruit growth characteristics and task requirements to achieve fruit picking point localization. These methods offer increased accuracy and real-time capabilities, making them a recent research focus. As a result, researchers are currently more focused on the application of deep learning methods in this area. However, most of the existing picking point localization methods have limitations in practical applications, often constrained by the design of end effectors and idealized application scenarios. Therefore, this study conducted a series of research to propose a universal and efficient method for locating fruit picking points, aiming to overcome the limitations of existing methods.MethodThis study proposes a framework for generating cluster bounding boxes and sparse instance segmentation of citrus branches and combines them in a cascade model to achieve real-time localization of citrus picking points. This method is mainly implemented in three steps. In the first step, the image within the picking field of view is input into a fruit object detector based on a feature extraction module (CSPDarknet) and a path aggregation network (PANnet). Multiple fruit object detection boxes are predicted through multilevel detection. These boxes are then clustered using a cluster box generator, and the cluster box with the most amount of citrus is selected, and its coordinates are calculated. In the second step, the image patches inside the cluster box are extracted and input to a branch sparse segmentation model. This step further focuses on segmenting the branch region, reducing background interference. Brightness priors are added to guide the weights of instance activation maps. The feature decoder learns the branch instance segmentation result. In the third step, on the basis of the branch segmentation result and the center points obtained in the first step for the cluster boxes, the branch instance masks are clustered to determine the relative position of branches to the cluster box center points. The final picking point coordinates are located by performing a pixel-wise search.ResultWe collected and created the citrus fruit detection dataset and citrus branch segmentation dataset through long-term outdoor collection. These two datasets consist of mature and immature citrus and include various challenges, such as sunny weather, cloudy weather, front light, and back light. The datasets have a total of 37 000 images. We conducted experimental validation on our proposed method using the separate datasets for citrus fruit detection and branch instance segmentation tasks. The fruit detection subtask based on the YOLOv5 model achieved an accuracy of 92.82%. Additionally, our proposed branch sparse instance segmentation method (BP-SparseInst) improved the performance of the branch segmentation task by 1.15%. Furthermore, our pick point localization method, based on the cascaded improvement model utilizing the cluster segmentation strategy and the DBSCAN fruit density algorithm, achieved a pick point localization accuracy of 95.77%. This result represents an improvement of approximately 4.1% compared with the previous method. Moreover, this method exhibited real-time performance with an FPS of 28.21 frame/s, which is an improvement of 8.07 frame/s compared with the previous method.ConclusionThrough these research efforts, we have made remarkable progress in the localization of fruit picking points in citrus. Moreover, it provides a matching robotic arm picking device for the practical application of the picking point positioning algorithm. This advancement provides strong support for the development of the citrus industry.关键词:picking robot;picking point positioning method;cluster box generator;brightness prior;branch sparse segmentation model368|1654|0更新时间:2024-10-23
摘要:ObjectiveCitrus is one of the most common fruits in our country. At present, it is mostly picked by hand, but issues such as high cost and low efficiency severely restrict the scale of production. Therefore, automatic citrus picking has become a research hotspot in recent years. However, the growing environment of citrus is complex, its branch has different shapes, and the branches, leaves, and fruits are seriously shielded from each other. Accurate and real-time location of the picking point becomes the crucial aspect of automated picking. Currently, research on fruit picking point localization methods can be broadly categorized into two types: nondeep learning-based methods and deep learning-based methods. Nondeep learning-based methods mainly rely on digital image processing techniques, such as color space conversion, threshold segmentation, and watershed algorithm, to extract target contours and design corresponding algorithms for picking point localization. However, these methods often suffer from low accuracy and efficiency. Deep learning-based methods involve training deep learning models to perform tasks, such as detection or segmentation. The model’s output is then used as an intermediate result, and specific algorithms are designed on the basis of fruit growth characteristics and task requirements to achieve fruit picking point localization. These methods offer increased accuracy and real-time capabilities, making them a recent research focus. As a result, researchers are currently more focused on the application of deep learning methods in this area. However, most of the existing picking point localization methods have limitations in practical applications, often constrained by the design of end effectors and idealized application scenarios. Therefore, this study conducted a series of research to propose a universal and efficient method for locating fruit picking points, aiming to overcome the limitations of existing methods.MethodThis study proposes a framework for generating cluster bounding boxes and sparse instance segmentation of citrus branches and combines them in a cascade model to achieve real-time localization of citrus picking points. This method is mainly implemented in three steps. In the first step, the image within the picking field of view is input into a fruit object detector based on a feature extraction module (CSPDarknet) and a path aggregation network (PANnet). Multiple fruit object detection boxes are predicted through multilevel detection. These boxes are then clustered using a cluster box generator, and the cluster box with the most amount of citrus is selected, and its coordinates are calculated. In the second step, the image patches inside the cluster box are extracted and input to a branch sparse segmentation model. This step further focuses on segmenting the branch region, reducing background interference. Brightness priors are added to guide the weights of instance activation maps. The feature decoder learns the branch instance segmentation result. In the third step, on the basis of the branch segmentation result and the center points obtained in the first step for the cluster boxes, the branch instance masks are clustered to determine the relative position of branches to the cluster box center points. The final picking point coordinates are located by performing a pixel-wise search.ResultWe collected and created the citrus fruit detection dataset and citrus branch segmentation dataset through long-term outdoor collection. These two datasets consist of mature and immature citrus and include various challenges, such as sunny weather, cloudy weather, front light, and back light. The datasets have a total of 37 000 images. We conducted experimental validation on our proposed method using the separate datasets for citrus fruit detection and branch instance segmentation tasks. The fruit detection subtask based on the YOLOv5 model achieved an accuracy of 92.82%. Additionally, our proposed branch sparse instance segmentation method (BP-SparseInst) improved the performance of the branch segmentation task by 1.15%. Furthermore, our pick point localization method, based on the cascaded improvement model utilizing the cluster segmentation strategy and the DBSCAN fruit density algorithm, achieved a pick point localization accuracy of 95.77%. This result represents an improvement of approximately 4.1% compared with the previous method. Moreover, this method exhibited real-time performance with an FPS of 28.21 frame/s, which is an improvement of 8.07 frame/s compared with the previous method.ConclusionThrough these research efforts, we have made remarkable progress in the localization of fruit picking points in citrus. Moreover, it provides a matching robotic arm picking device for the practical application of the picking point positioning algorithm. This advancement provides strong support for the development of the citrus industry.关键词:picking robot;picking point positioning method;cluster box generator;brightness prior;branch sparse segmentation model368|1654|0更新时间:2024-10-23
Image Understanding and Computer Vision
-
 摘要:ObjectiveCollision detection and collision processing are challenging problems and active research fields in computer graphics and virtual reality. The collision detection algorithm is a technical difficulty and the most important link in the entire simulation process. The quality of collision detection algorithms directly affects the authenticity of simulation situations. For collision detection between fabric and complex rigid body models, the softness and nonfixity of fabric pose great challenges to collision detection. When numerous particles that make up the fabric move, collisions inevitably occur. If collisions cannot be detected in a timely manner and the collision location cannot be repaired, penetration and distortion occur, considerably affecting subsequent simulations. Therefore, during the collision detection of fabric, higher requirements are placed on the authenticity and real-time performance of the system. To solve the problem of low detection rate and poor simulation authenticity when collision detection occurs between flexible fabric and complex rigid body models during interaction, this study analyzes the characteristics of flexible fabric and complex rigid body models and selects different suitable bounding boxes for collision detection of different detection objects. This study proposes a hybrid hierarchical bounding box method, a fast directed bounding box method, and a spatial grid method for detecting objects to improve the timeliness of collision detection.MethodIn response to the characteristics of flexible fabric that is soft and prone to deformation, a bounding box with fast construction speed and simple structure is selected for flexible fabric. The bounding box with a simple structure can be quickly updated to better cope with the deformation of flexible fabric during movement, making the bounding box better surrounded in the simulation of the fabric model and more rapid for subsequent collision detection. First, a hierarchical bounding box tree with a hybrid structure suitable for flexible fabric is constructed. The hierarchical bounding box tree structure is divided into three layers, with the upper, middle, and lower layers playing different roles in eliminating each other. The three layers of bounding boxes overlap with each other. The top layer uses a simple and fast spherical bounding box, the middle layer uses a spherical aixe align bounding box(AABB) mixed structure bounding box, and the bottom layer uses an AABB bounding box. A quickly constructed bounding box is used to eliminate irrelevant collision pairs quickly and efficiently, facilitating subsequent detection. The main reason for the slow speed and poor authenticity of collision detection for complex rigid body models is due to numerous points and surfaces contained in the complex surface, which leads to low detection efficiency and high system overhead. Moreover, the more complex the number of points and surfaces, the easier it is to cause penetration and distortion during simulation. In this situation, we use the method of triangle folding to simplify the complex rigid body model and combine it with quadratic error measurement to simplify and evaluate the model. This method enables the complex rigid body model to reduce the number of points and surfaces without losing the details of the model’s cause and allows the simplified model to replace the original complex model for rapid construction of the directed bounding box. This method accelerates the construction speed of bounding boxes and reduces system overhead, accelerating the process of collision detection. After collision detection of the bounding box structure, the collision pair information is obtained. The spatial grid method is used on the surface of the collision model to connect sequentially the model surface vertices between the detected models to construct a spatial grid. The area or volume of the spatial grid changes with the movement of the detected object. By detecting changes in the area or volume of the spatial grid, whether a collision has occurred is determined. The elements that make up the spatial grid must be constrained so that the area or volume of the spatial grid is within an acceptable range and is not zero. This process ensures that the simulation effect is not affected and prevents the collision simulation between the fabric and the rigid body model from penetrating.ResultCompared with traditional methods and other literature methods, this study conducted experiments to record collision detection data in multiple scenarios. The experimental results showed that in the same scenario, compared with other methods, the construction speed of the bounding box in this study was shortened by 10%~18%, and the tightness of the bounding box on the model was improved by 8%~15%. For the same collision model, the removal rate of irrelevant collision pairs by bounding boxes is improved by 8%~13% compared with traditional methods, and the overall collision detection time is reduced by 6%~13%. This method ensures the authenticity of the simulation while improving the collision detection rate and rejection rate.ConclusionThe improved bounding box method in this study has improved the detection speed in the rough detection stage and enhanced the rejection rate of incoherent collision pairs. In the precise detection stage, the use of spatial mesh methods can not only detect collisions but also prevent collision penetration between the fabric and the rigid body by imposing constraints on the model vertices. The algorithm in this study not only ensures the overall simulation authenticity but also improves the detection speed, reduces system overhead, and is more suitable for collision detection with flexible fabric and complex rigid body models.关键词:collision detection;fabric simulation;hybrid hierarchical bounding box;model simplification;space mesh338|791|0更新时间:2024-10-23
摘要:ObjectiveCollision detection and collision processing are challenging problems and active research fields in computer graphics and virtual reality. The collision detection algorithm is a technical difficulty and the most important link in the entire simulation process. The quality of collision detection algorithms directly affects the authenticity of simulation situations. For collision detection between fabric and complex rigid body models, the softness and nonfixity of fabric pose great challenges to collision detection. When numerous particles that make up the fabric move, collisions inevitably occur. If collisions cannot be detected in a timely manner and the collision location cannot be repaired, penetration and distortion occur, considerably affecting subsequent simulations. Therefore, during the collision detection of fabric, higher requirements are placed on the authenticity and real-time performance of the system. To solve the problem of low detection rate and poor simulation authenticity when collision detection occurs between flexible fabric and complex rigid body models during interaction, this study analyzes the characteristics of flexible fabric and complex rigid body models and selects different suitable bounding boxes for collision detection of different detection objects. This study proposes a hybrid hierarchical bounding box method, a fast directed bounding box method, and a spatial grid method for detecting objects to improve the timeliness of collision detection.MethodIn response to the characteristics of flexible fabric that is soft and prone to deformation, a bounding box with fast construction speed and simple structure is selected for flexible fabric. The bounding box with a simple structure can be quickly updated to better cope with the deformation of flexible fabric during movement, making the bounding box better surrounded in the simulation of the fabric model and more rapid for subsequent collision detection. First, a hierarchical bounding box tree with a hybrid structure suitable for flexible fabric is constructed. The hierarchical bounding box tree structure is divided into three layers, with the upper, middle, and lower layers playing different roles in eliminating each other. The three layers of bounding boxes overlap with each other. The top layer uses a simple and fast spherical bounding box, the middle layer uses a spherical aixe align bounding box(AABB) mixed structure bounding box, and the bottom layer uses an AABB bounding box. A quickly constructed bounding box is used to eliminate irrelevant collision pairs quickly and efficiently, facilitating subsequent detection. The main reason for the slow speed and poor authenticity of collision detection for complex rigid body models is due to numerous points and surfaces contained in the complex surface, which leads to low detection efficiency and high system overhead. Moreover, the more complex the number of points and surfaces, the easier it is to cause penetration and distortion during simulation. In this situation, we use the method of triangle folding to simplify the complex rigid body model and combine it with quadratic error measurement to simplify and evaluate the model. This method enables the complex rigid body model to reduce the number of points and surfaces without losing the details of the model’s cause and allows the simplified model to replace the original complex model for rapid construction of the directed bounding box. This method accelerates the construction speed of bounding boxes and reduces system overhead, accelerating the process of collision detection. After collision detection of the bounding box structure, the collision pair information is obtained. The spatial grid method is used on the surface of the collision model to connect sequentially the model surface vertices between the detected models to construct a spatial grid. The area or volume of the spatial grid changes with the movement of the detected object. By detecting changes in the area or volume of the spatial grid, whether a collision has occurred is determined. The elements that make up the spatial grid must be constrained so that the area or volume of the spatial grid is within an acceptable range and is not zero. This process ensures that the simulation effect is not affected and prevents the collision simulation between the fabric and the rigid body model from penetrating.ResultCompared with traditional methods and other literature methods, this study conducted experiments to record collision detection data in multiple scenarios. The experimental results showed that in the same scenario, compared with other methods, the construction speed of the bounding box in this study was shortened by 10%~18%, and the tightness of the bounding box on the model was improved by 8%~15%. For the same collision model, the removal rate of irrelevant collision pairs by bounding boxes is improved by 8%~13% compared with traditional methods, and the overall collision detection time is reduced by 6%~13%. This method ensures the authenticity of the simulation while improving the collision detection rate and rejection rate.ConclusionThe improved bounding box method in this study has improved the detection speed in the rough detection stage and enhanced the rejection rate of incoherent collision pairs. In the precise detection stage, the use of spatial mesh methods can not only detect collisions but also prevent collision penetration between the fabric and the rigid body by imposing constraints on the model vertices. The algorithm in this study not only ensures the overall simulation authenticity but also improves the detection speed, reduces system overhead, and is more suitable for collision detection with flexible fabric and complex rigid body models.关键词:collision detection;fabric simulation;hybrid hierarchical bounding box;model simplification;space mesh338|791|0更新时间:2024-10-23
Computer Graphics
-
 摘要:ObjectiveHigh-quality pathological slides are crucial for manual diagnosis and computer-aided diagnosis. However, pathology slides may contain artifacts that can affect their quality and consequently influence expert diagnostic judgment. Currently, the assessment of pathology slide quality often depends on manual sampling, which is time consuming and cannot encompass all slides. Additionally, despite relatively standardized detection criteria across different institutions, different quality control personnel may have varying interpretations, leading to subjective differences. These limitations restrict the traditional quality control process. Current methods typically involve analyzing image patches cropped at high magnifications, resulting in considerable consumption of computational resources. Moreover, certain artifacts, such as hole and tremor, often have larger dimensions and are better suited for learning on low-resolution images. However, cropping image blocks at high magnifications may exclude artifacts that coexist in tissue and background regions, such as ink and bubble, which compromise the integrity of artifact detection and analysis. To tackle these challenges, the process of assessing the quality of pathology slides must be digitized to enhance efficiency and accuracy. Therefore, this study introduces a novel algorithm, Window-Row-Col_Net (WRC_Net), designed for the detection of artifacts in digital pathology slides, specifically tailored for low-magnification pathological whole slide images.MethodThis study primarily consists of four components: pathological slide preprocessing, feature extraction module, feature fusion module, and single detection head. First, we tackle the problem of artifacts in pathological slides by performing preprocessing, which involves transforming the tissue pathological slides into lower-pixel-resolution versions of whole-slide images (thumbnails). This step helps reduce computational resource consumption and is well-suited for addressing larger-sized artifacts, such as holes and wrinkles. Afterward, these thumbnails are input into the feature extraction network to acquire the low-level feature representation of the slides. Moreover, to integrate effectively feature information from different levels, we devised a feature fusion module. This module plays a crucial role in the entire model, facilitating the aggregation of features from varying depths and directions. Additionally, we introduce the Window-Row-Col (WRC) module, which encompasses two vital components: the WRC attention module and the multiscale dilated module (MSDM). The WRC attention module dynamically aggregates features within square windows, spanning horizontal and vertical directions, capturing global and local contextual information, and establishing long-range dependencies. The MSDM incorporates dilated convolutions with varying dilation rates to extract multiscale information and enhance the model's perception of artifacts of different sizes. Through this feature fusion, we boost the expressive capability of features, thus giving the model with a competitive advantage in object detection tasks. Finally, the fused features are directed into a single detection head to produce the ultimate detection outcomes. The design of a single detection head structure streamlines the model's architecture, rendering it more succinct and efficient and also diminishing storage and computational burdens, thereby expediting the detection process.ResultWe created two new datasets for pathology slide artifacts, known as the Shanghai Pudong Department of Pathology slide dataset (SPDPSD) and the Ningbo Clinical Pathology Diagnosis Center slide dataset (NCPDCSD). The SPDPSD dataset originates from the Pathology Department of Pudong Hospital in Shanghai and comprises two types of tissue artifacts: ink and bubble. The NCPDCSD dataset is obtained from the Clinical Pathological Diagnosis Center in Ningbo and encompasses six types of tissue artifacts, including hole, tremor, incompleteness, ink, appearance, and bubble. Through comprehensive experiments on these two datasets, we conducted an extensive comparison between our proposed WRC_Net algorithm and the current state-of-the-art object detection methods. The WRC_Net algorithm demonstrated superior detection performance on the SPDPSD dataset, yielding remarkable improvements in metrics, such as mean average precision (mAP), mAP@IoU = 0.75 (mAP75), small object mAP (mAPs), medium object mAP (mAPm), and large object mAP (mAPl). Additionally, on the NCPDCSD dataset, our method displayed competitive performance. The results indicate that compared with other methods, WRC_Net achieved remarkable enhancements in multiple performance metrics while maintaining low computational complexity, striking a balance between speed and accuracy.ConclusionThe proposed algorithm for detecting pathology slide artifacts accurately identifies various types of artifacts in digital pathology slides, offering a more comprehensive and dependable quality assessment tool for the domain of medical image analysis. By striking a balance between efficiency and accuracy, our algorithm is anticipated to enhance the pathology diagnosis process and usher in a more efficient and precise workflow within pathology departments.关键词:digital pathology;whole slide images;artifact detection;multi-scale;feature fusion373|833|0更新时间:2024-10-23
摘要:ObjectiveHigh-quality pathological slides are crucial for manual diagnosis and computer-aided diagnosis. However, pathology slides may contain artifacts that can affect their quality and consequently influence expert diagnostic judgment. Currently, the assessment of pathology slide quality often depends on manual sampling, which is time consuming and cannot encompass all slides. Additionally, despite relatively standardized detection criteria across different institutions, different quality control personnel may have varying interpretations, leading to subjective differences. These limitations restrict the traditional quality control process. Current methods typically involve analyzing image patches cropped at high magnifications, resulting in considerable consumption of computational resources. Moreover, certain artifacts, such as hole and tremor, often have larger dimensions and are better suited for learning on low-resolution images. However, cropping image blocks at high magnifications may exclude artifacts that coexist in tissue and background regions, such as ink and bubble, which compromise the integrity of artifact detection and analysis. To tackle these challenges, the process of assessing the quality of pathology slides must be digitized to enhance efficiency and accuracy. Therefore, this study introduces a novel algorithm, Window-Row-Col_Net (WRC_Net), designed for the detection of artifacts in digital pathology slides, specifically tailored for low-magnification pathological whole slide images.MethodThis study primarily consists of four components: pathological slide preprocessing, feature extraction module, feature fusion module, and single detection head. First, we tackle the problem of artifacts in pathological slides by performing preprocessing, which involves transforming the tissue pathological slides into lower-pixel-resolution versions of whole-slide images (thumbnails). This step helps reduce computational resource consumption and is well-suited for addressing larger-sized artifacts, such as holes and wrinkles. Afterward, these thumbnails are input into the feature extraction network to acquire the low-level feature representation of the slides. Moreover, to integrate effectively feature information from different levels, we devised a feature fusion module. This module plays a crucial role in the entire model, facilitating the aggregation of features from varying depths and directions. Additionally, we introduce the Window-Row-Col (WRC) module, which encompasses two vital components: the WRC attention module and the multiscale dilated module (MSDM). The WRC attention module dynamically aggregates features within square windows, spanning horizontal and vertical directions, capturing global and local contextual information, and establishing long-range dependencies. The MSDM incorporates dilated convolutions with varying dilation rates to extract multiscale information and enhance the model's perception of artifacts of different sizes. Through this feature fusion, we boost the expressive capability of features, thus giving the model with a competitive advantage in object detection tasks. Finally, the fused features are directed into a single detection head to produce the ultimate detection outcomes. The design of a single detection head structure streamlines the model's architecture, rendering it more succinct and efficient and also diminishing storage and computational burdens, thereby expediting the detection process.ResultWe created two new datasets for pathology slide artifacts, known as the Shanghai Pudong Department of Pathology slide dataset (SPDPSD) and the Ningbo Clinical Pathology Diagnosis Center slide dataset (NCPDCSD). The SPDPSD dataset originates from the Pathology Department of Pudong Hospital in Shanghai and comprises two types of tissue artifacts: ink and bubble. The NCPDCSD dataset is obtained from the Clinical Pathological Diagnosis Center in Ningbo and encompasses six types of tissue artifacts, including hole, tremor, incompleteness, ink, appearance, and bubble. Through comprehensive experiments on these two datasets, we conducted an extensive comparison between our proposed WRC_Net algorithm and the current state-of-the-art object detection methods. The WRC_Net algorithm demonstrated superior detection performance on the SPDPSD dataset, yielding remarkable improvements in metrics, such as mean average precision (mAP), mAP@IoU = 0.75 (mAP75), small object mAP (mAPs), medium object mAP (mAPm), and large object mAP (mAPl). Additionally, on the NCPDCSD dataset, our method displayed competitive performance. The results indicate that compared with other methods, WRC_Net achieved remarkable enhancements in multiple performance metrics while maintaining low computational complexity, striking a balance between speed and accuracy.ConclusionThe proposed algorithm for detecting pathology slide artifacts accurately identifies various types of artifacts in digital pathology slides, offering a more comprehensive and dependable quality assessment tool for the domain of medical image analysis. By striking a balance between efficiency and accuracy, our algorithm is anticipated to enhance the pathology diagnosis process and usher in a more efficient and precise workflow within pathology departments.关键词:digital pathology;whole slide images;artifact detection;multi-scale;feature fusion373|833|0更新时间:2024-10-23
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0