
最新刊期
卷 28 , 期 6 , 2023
-
 摘要:Virtual-real human-computer interaction (VR-HCI) is an interdisciplinary field that encompasses human and computer interactions to address human-related cognitive and emotional needs. This interdisciplinary knowledge integrates domains such as computer science, cognitive psychology, ergonomics, multimedia technology, and virtual reality. With the advancement of big data and artificial intelligence, VR-HCI benefits industries like education, healthcare, robotics, and entertainment, and is increasingly recognized as a key supporting technology for metaverse-related development. In recent years, machine learning-based human cognitive and emotional analysis has evolved, particularly in applications like robotics and wearable interaction devices. As a result, VR-HCI has focused on the challenging issue of creating “intelligent” and “anthropomorphic” interaction systems. This literature review examines the growth of VR-HCI from four aspects: perceptual computing, human-machine interaction and coordination, human-computer dialogue interaction, and data visualization. Perceptual computing aims to model human daily life behavior, cognitive processes, and emotional contexts for personalized and efficient human-computer interactions. This discussion covers three perceptual aspects related to pathways, objects, and scenes. Human-machine interaction scenarios involve virtual and real-world integration and perceptual pathways, which are divided into primary perception types: visual-based, sensor-based, and wireless non-contact. Object-based perception is subdivided into personal and group contexts, while scene-based perception is subdivided into physical behavior and cognitive contexts. Human-machine interaction primarily encompasses technical disciplines such as mechanical and electrical engineering, computer and control science, artificial intelligence, and other related arts or humanistic disciplines like psychology and design. Human-robot interaction can be categorized by functional mechanisms into 1) collaborative operation robots, 2) service and assistance robots, and 3) social, entertainment, and educational robots. Key modules in human-computer dialogue interaction systems include speech recognition, speaker recognition, dialogue system, and speech synthesis. The level of intelligence in these interaction systems can be further enhanced by considering users' inherent characteristics, such as speech pronunciation, preferences, emotions, and other attributes. For human-machine interaction, it mainly involves technical disciplines in relevant to mechanical and electrical engineering, computer and control science, and artificial intelligence, as well as other related arts or humanistic disciplines like psychology and design. Humans-robots interaction can be segmented into three categories in terms of its functional mechanism: 1) collaborative operation robots, 2) service and assistance robots, and 3) social, entertainment and educational robots. For human-computer dialogue interaction, the system consists of such key modules like speech recognition, speaker recognition, dialogue system, and speech synthesis. The microphone sensor can pick up the speech signal, which is then converted to text information through the speech recognition module. The dialogue system can process the text information, understand the user's intention, and generates a reply. Finally, the speech-synthesized module can convert the reply information into speech information, completing the interaction process. In recent years, the level of intelligence of the interaction system can be further improved by combining users' inherent characteristics such as speech pronunciation, preferences, emotions, and other characteristics, optimizing the various modules of the interaction system. For data transformation and visualization, it is benched for performing data cleaning tasks on tabular data, and various tools in R and Python can perform these tasks as well. Many software systems have developed graphical user interfaces to assist users in completing data transformation tasks, such as Microsoft Excel, Tableau Prep Builder, and OpenRefine. Current recommendation-based algorithms interactive systems are beneficial for users transform data easily. Researchers have also developed tools that can transform network structures. We analyze its four aspects of 1) interactive data transformation, 2) data transformation visualization, 3) data table visual comparison, and 4) code visualization in human-computer interaction systems. We identify several future research directions in VR-HCI, namely 1) designing generalized and personalized perceptual computing, 2) building human-machine cooperation with a deep understanding of user behavior, and 3) expanding user-adaptive dialogue systems. For perceptual computing, it still lacks joint perception of multiple devices and individual differences in human behavior perception. Furthermore, most perceptual research can use generalized models, neglecting individual differences, resulting in lower perceptual accuracy, making it difficult to apply in actual settings. Therefore, future perceptual computing research trends are required for multimodal, transferable, personalized, and scalable research. For human-machine interaction and coordination, a systematic approach is necessary for constructing a design for human-machine interaction and collaboration. This approach requires in-depth research on user understanding, construction of interaction datasets, and long-term user experience. For human-computer dialogue interaction, current research mostly focuses on open-domain systems, which use pre-trained models to improve modeling accuracy for emotions, intentions, and knowledge. Future research should be aimed at developing more intelligent human-machine conversations that cater to individual user needs. For data transformation and visualization in HCI, the future directions can be composed of two parts: 1) the intelligence level of data transformation can be improved through interaction for individual data workers on several aspects, e.g., appropriate algorithms for multiple types of data, recommendations for consistent user behavior and real-time analysis to support massive data. 2) The focus is on the integration of data transformation and visualization among multiple users, including designing collaborative mechanisms, resolving conflicts in data operation, visualizing complex data transformation codes, evaluating the effectiveness of various visualization methods, and recording and displaying multiple human behaviors. In summary, the development of VR-HCI can provide new opportunities and challenges for human-computer interaction towards Metaverse, which has the potential to seamlessly integrate virtual and real worlds.关键词:human-computer interaction(HCI);perceptual computing;human-machine cooperation;dialogue system;data visualization414|386|2更新时间:2024-05-07
摘要:Virtual-real human-computer interaction (VR-HCI) is an interdisciplinary field that encompasses human and computer interactions to address human-related cognitive and emotional needs. This interdisciplinary knowledge integrates domains such as computer science, cognitive psychology, ergonomics, multimedia technology, and virtual reality. With the advancement of big data and artificial intelligence, VR-HCI benefits industries like education, healthcare, robotics, and entertainment, and is increasingly recognized as a key supporting technology for metaverse-related development. In recent years, machine learning-based human cognitive and emotional analysis has evolved, particularly in applications like robotics and wearable interaction devices. As a result, VR-HCI has focused on the challenging issue of creating “intelligent” and “anthropomorphic” interaction systems. This literature review examines the growth of VR-HCI from four aspects: perceptual computing, human-machine interaction and coordination, human-computer dialogue interaction, and data visualization. Perceptual computing aims to model human daily life behavior, cognitive processes, and emotional contexts for personalized and efficient human-computer interactions. This discussion covers three perceptual aspects related to pathways, objects, and scenes. Human-machine interaction scenarios involve virtual and real-world integration and perceptual pathways, which are divided into primary perception types: visual-based, sensor-based, and wireless non-contact. Object-based perception is subdivided into personal and group contexts, while scene-based perception is subdivided into physical behavior and cognitive contexts. Human-machine interaction primarily encompasses technical disciplines such as mechanical and electrical engineering, computer and control science, artificial intelligence, and other related arts or humanistic disciplines like psychology and design. Human-robot interaction can be categorized by functional mechanisms into 1) collaborative operation robots, 2) service and assistance robots, and 3) social, entertainment, and educational robots. Key modules in human-computer dialogue interaction systems include speech recognition, speaker recognition, dialogue system, and speech synthesis. The level of intelligence in these interaction systems can be further enhanced by considering users' inherent characteristics, such as speech pronunciation, preferences, emotions, and other attributes. For human-machine interaction, it mainly involves technical disciplines in relevant to mechanical and electrical engineering, computer and control science, and artificial intelligence, as well as other related arts or humanistic disciplines like psychology and design. Humans-robots interaction can be segmented into three categories in terms of its functional mechanism: 1) collaborative operation robots, 2) service and assistance robots, and 3) social, entertainment and educational robots. For human-computer dialogue interaction, the system consists of such key modules like speech recognition, speaker recognition, dialogue system, and speech synthesis. The microphone sensor can pick up the speech signal, which is then converted to text information through the speech recognition module. The dialogue system can process the text information, understand the user's intention, and generates a reply. Finally, the speech-synthesized module can convert the reply information into speech information, completing the interaction process. In recent years, the level of intelligence of the interaction system can be further improved by combining users' inherent characteristics such as speech pronunciation, preferences, emotions, and other characteristics, optimizing the various modules of the interaction system. For data transformation and visualization, it is benched for performing data cleaning tasks on tabular data, and various tools in R and Python can perform these tasks as well. Many software systems have developed graphical user interfaces to assist users in completing data transformation tasks, such as Microsoft Excel, Tableau Prep Builder, and OpenRefine. Current recommendation-based algorithms interactive systems are beneficial for users transform data easily. Researchers have also developed tools that can transform network structures. We analyze its four aspects of 1) interactive data transformation, 2) data transformation visualization, 3) data table visual comparison, and 4) code visualization in human-computer interaction systems. We identify several future research directions in VR-HCI, namely 1) designing generalized and personalized perceptual computing, 2) building human-machine cooperation with a deep understanding of user behavior, and 3) expanding user-adaptive dialogue systems. For perceptual computing, it still lacks joint perception of multiple devices and individual differences in human behavior perception. Furthermore, most perceptual research can use generalized models, neglecting individual differences, resulting in lower perceptual accuracy, making it difficult to apply in actual settings. Therefore, future perceptual computing research trends are required for multimodal, transferable, personalized, and scalable research. For human-machine interaction and coordination, a systematic approach is necessary for constructing a design for human-machine interaction and collaboration. This approach requires in-depth research on user understanding, construction of interaction datasets, and long-term user experience. For human-computer dialogue interaction, current research mostly focuses on open-domain systems, which use pre-trained models to improve modeling accuracy for emotions, intentions, and knowledge. Future research should be aimed at developing more intelligent human-machine conversations that cater to individual user needs. For data transformation and visualization in HCI, the future directions can be composed of two parts: 1) the intelligence level of data transformation can be improved through interaction for individual data workers on several aspects, e.g., appropriate algorithms for multiple types of data, recommendations for consistent user behavior and real-time analysis to support massive data. 2) The focus is on the integration of data transformation and visualization among multiple users, including designing collaborative mechanisms, resolving conflicts in data operation, visualizing complex data transformation codes, evaluating the effectiveness of various visualization methods, and recording and displaying multiple human behaviors. In summary, the development of VR-HCI can provide new opportunities and challenges for human-computer interaction towards Metaverse, which has the potential to seamlessly integrate virtual and real worlds.关键词:human-computer interaction(HCI);perceptual computing;human-machine cooperation;dialogue system;data visualization414|386|2更新时间:2024-05-07 -
 摘要:A brain-computer interface (BCI) establishes a direct communication pathway between the living brain and an external device in terms of brain signals-acquiring and analysis and commands-converted output. It can be used to replace, repair, augment, supplement or improve the normal output of the central nervous system. The BCIs can be divided into invasive or noninvasive BCIs based on the placement of the acquisition electrode. An invasive BCI is linked to its records or brain neurons-relevant stimulation through surgical brain-implanted electrodes. But, it is just used for animal experiments or severe paralysis patients although invasive BCIs can be used to record a high signal-to-noise ratio-related brain signals. Non-invasive BCIs have its potentials of their credibility and portability in comparison with invasive BCIs. The electroencephalography (EEG) is commonly used for brain signal for BCIs now. The EEG-based BCI systems consist of two directions: coding methods used to generate brain signals and the decoding methods used to decode brain signals. In recent years, the growth of coding methods has extended the application scenarios and applicability of the system. Furthermore, to get high-performance BCIs, brain signal decoding methods has greatly developed and low signal-to-noise ratio of EEG signals is optimized as well. The BCI systems can be segmented into such categories of active, reactive or passive. For an active BCI, a user can consciously control mental activities of external stimuli excluded. The motor imagery based (MI-based) BCI system is an active BCI system in terms of EEG signals-within specific frequency changes, which can be balanced using non-motor output mental rehearsal of a motor action. For reactive BCI, brain activity is triggered by an external stimulus, and the user reacts to the stimulus from the external world. Most researches are focused on static-state visual evoked potential based (SSVEP-based) BCI and an event-related potential based (ERP-based) BCI. SSVEPs are brain responses that are elicited over the visual region when a user focuses on a flicker of a visual stimulus. An ERP-based BCI is usually based on a P300 component of ERP, which can be produced after the onset of the stimulus. For a passive BCI, it can provide the hidden state of the brain in the human-computer interaction process rather than temporal and humanized interaction, especially for affective BCIs and mental load BCIs. Our literature analysis is focused on BCI systems from four contexts of its MI-based, SSVEP-based, ERP-based, and affective BCI. Current situation and the application of BCI systems can be analyzed for coding and decoding technology as mentioned below: 1) MI-based BCI studies are mostly focused on the classification of EEG patterns during MI tasks from different limbs, such as the left hand, right hand, and both feet. However, small instruction sets are still challenged for the actual application requirements. Thus, fine MI tasks from the unilateral limb are developed to deal with that. We review fine MI paradigms of multiple unilateral limb contexts in relevance to its joints, directions, and tasks. Decoding methods consist of two procedures in common: feature extraction and feature classification. Feature extraction extracts task-related and recognizable features from brain signals, and feature classification uses features-extracted to clarify the intentions of users. For MI decoding technology, two-stage traditional decoding methods are first briefly introduced, e.g., common spatial pattern (CSP) and linear discriminant analysis (LDA). After that, we summarize the latest deep learning methods, which can improve the decoding accuracy, and some migration learning methods are summarized, which can alleviate its calibration data. Finally, recent applications of the MI-BCI system are introduced in related to control of the mechanical arm and stroke rehabilitation. 2) SSVEP-based BCI systems are concerned about in terms of their high information transmission rate, strong stability, and applicability. Recent researches to highlight of SSVEP-based BCI studies are reviewed literately as well. For example, some new coding strategies are implemented for instruction set or users’ preference and such emerging decoding methods are used to optimize its performance of SSVEP detection. Additionally, we summarize the main application directions of SSVEP-based BCI systems, including communication, control, and state monitoring, and the latest application progress are reviewed as well. 3) For ERP-based BCIs, the signal-to-noise ratio of the ERP response is required to be relatively higher, and a single target-related rapid serial visual presentation paradigm is challenged for the detection of multiple targets. To sum up, BCI-hybrid paradigms are developed in terms of the integration of the ERP and other related paradigms. Function-based ERP decoding methods are divided into four categories of signal de-noising, feature extraction, transfer learning, and zero calibration algorithms. Current status of decoding methods and ERP-based BCI applications are summarized as well. 4) Affective BCI can be adopted to recognize and balance human emotion. The emotion and new decoding methods are evolved in, including multimodal fusion and transfer learning. Additionally, the application of affective BCI in healthcare is reviewed and analyzed as well. Finally, future research direction of non-invasive BCI are predicted further.关键词:brain-computer interface(BCI);non-invasive;encoding method;decoding method;system application370|1916|1更新时间:2024-05-07
摘要:A brain-computer interface (BCI) establishes a direct communication pathway between the living brain and an external device in terms of brain signals-acquiring and analysis and commands-converted output. It can be used to replace, repair, augment, supplement or improve the normal output of the central nervous system. The BCIs can be divided into invasive or noninvasive BCIs based on the placement of the acquisition electrode. An invasive BCI is linked to its records or brain neurons-relevant stimulation through surgical brain-implanted electrodes. But, it is just used for animal experiments or severe paralysis patients although invasive BCIs can be used to record a high signal-to-noise ratio-related brain signals. Non-invasive BCIs have its potentials of their credibility and portability in comparison with invasive BCIs. The electroencephalography (EEG) is commonly used for brain signal for BCIs now. The EEG-based BCI systems consist of two directions: coding methods used to generate brain signals and the decoding methods used to decode brain signals. In recent years, the growth of coding methods has extended the application scenarios and applicability of the system. Furthermore, to get high-performance BCIs, brain signal decoding methods has greatly developed and low signal-to-noise ratio of EEG signals is optimized as well. The BCI systems can be segmented into such categories of active, reactive or passive. For an active BCI, a user can consciously control mental activities of external stimuli excluded. The motor imagery based (MI-based) BCI system is an active BCI system in terms of EEG signals-within specific frequency changes, which can be balanced using non-motor output mental rehearsal of a motor action. For reactive BCI, brain activity is triggered by an external stimulus, and the user reacts to the stimulus from the external world. Most researches are focused on static-state visual evoked potential based (SSVEP-based) BCI and an event-related potential based (ERP-based) BCI. SSVEPs are brain responses that are elicited over the visual region when a user focuses on a flicker of a visual stimulus. An ERP-based BCI is usually based on a P300 component of ERP, which can be produced after the onset of the stimulus. For a passive BCI, it can provide the hidden state of the brain in the human-computer interaction process rather than temporal and humanized interaction, especially for affective BCIs and mental load BCIs. Our literature analysis is focused on BCI systems from four contexts of its MI-based, SSVEP-based, ERP-based, and affective BCI. Current situation and the application of BCI systems can be analyzed for coding and decoding technology as mentioned below: 1) MI-based BCI studies are mostly focused on the classification of EEG patterns during MI tasks from different limbs, such as the left hand, right hand, and both feet. However, small instruction sets are still challenged for the actual application requirements. Thus, fine MI tasks from the unilateral limb are developed to deal with that. We review fine MI paradigms of multiple unilateral limb contexts in relevance to its joints, directions, and tasks. Decoding methods consist of two procedures in common: feature extraction and feature classification. Feature extraction extracts task-related and recognizable features from brain signals, and feature classification uses features-extracted to clarify the intentions of users. For MI decoding technology, two-stage traditional decoding methods are first briefly introduced, e.g., common spatial pattern (CSP) and linear discriminant analysis (LDA). After that, we summarize the latest deep learning methods, which can improve the decoding accuracy, and some migration learning methods are summarized, which can alleviate its calibration data. Finally, recent applications of the MI-BCI system are introduced in related to control of the mechanical arm and stroke rehabilitation. 2) SSVEP-based BCI systems are concerned about in terms of their high information transmission rate, strong stability, and applicability. Recent researches to highlight of SSVEP-based BCI studies are reviewed literately as well. For example, some new coding strategies are implemented for instruction set or users’ preference and such emerging decoding methods are used to optimize its performance of SSVEP detection. Additionally, we summarize the main application directions of SSVEP-based BCI systems, including communication, control, and state monitoring, and the latest application progress are reviewed as well. 3) For ERP-based BCIs, the signal-to-noise ratio of the ERP response is required to be relatively higher, and a single target-related rapid serial visual presentation paradigm is challenged for the detection of multiple targets. To sum up, BCI-hybrid paradigms are developed in terms of the integration of the ERP and other related paradigms. Function-based ERP decoding methods are divided into four categories of signal de-noising, feature extraction, transfer learning, and zero calibration algorithms. Current status of decoding methods and ERP-based BCI applications are summarized as well. 4) Affective BCI can be adopted to recognize and balance human emotion. The emotion and new decoding methods are evolved in, including multimodal fusion and transfer learning. Additionally, the application of affective BCI in healthcare is reviewed and analyzed as well. Finally, future research direction of non-invasive BCI are predicted further.关键词:brain-computer interface(BCI);non-invasive;encoding method;decoding method;system application370|1916|1更新时间:2024-05-07 -
 摘要:The preservation and exhibition of cultural relics have been concerned more nowadays, in which number of worldwide museums is even higher at about 55 097 and all the artefacts have been melted into. In China, total number of museums can be reached to 6 183, and it has involved 108 million state-owned movable cultural relics (sets) and 767 000 immovable cultural relics nationwide recently. Traditional museums are mainly focused on display cases, pictures, and other related audio-visual materials. Current digitization of cultural objects is beneficial to optimize traditional methods further. First, standard and consistent preservation can be introduced to alleviate natural-derived irreversible damage challenges to cultural objects. Next, it facilitates diverse ways of displaying cultural relics, which can enhance public awareness for appreciate heritage in a holistic, multi-angle, and three-dimensional manner. In recent years, the development of information technology has harnessed the emergence of many new conservation techniques and ways of displaying heritage, such as deep learning based 3D reconstruction and intelligent museums-oriented metaverse technologies of virtual reality. The digitization of museums has been launched globally in the context of digitization of collection resources since 1990s. But, the following digital museums are still challenged to deal with the problem of museum-across integrated resources. Such worldwide research projects for intelligent museums construction has been called for further. The goal of a smart museum is aimed to create a feasible intelligent ecosystem for museum-relevant domains. We review global-contextual technologies, in which four category of such key technologies in relevance to digital acquisition, heritage realism reconstruction, virtual-intelligent-integrated interaction, and smart platform construction. For digital acquisition of cultural relics, we illustrate and analyze the two most common types of methods in related to 3D scanning and close-up photogrammetry. For the realistic reconstruction technology of cultural relics, geometric processing and deep learning-based methods are focused on in terms of 3D reconstruction model analysis. For virtual-intelligent-integrated interaction, a variety of interaction methods are demonstrated in related to such aspects of multimodality, gesture, and handling. For the construction of smart platforms, we summarize some emerging technologies, and the final artistic results are described and achieved. The case study analysis is based on such famous multination museums of the Louvre Museum in France, the Hermitage Museum in Russia, the Palace Museum in Beijing and other related world-renowned museums. We sort out that the commonly-used construction process of smart museums for cultural relics through collection of digital information, three-dimensional reconstruction, and the integration of multiple virtual interaction. The consensus is focused on improving conservation measures and inherit culture. At the same time, potential metaverse technology can be used to build metaverse museum platforms further. Finally, modernizing museums analysis is focused on and its relevant tools and technologies has been focused on metaverse-related technologies. In the future, such emerging metaverse technologies can be used to predicted and integrated into the construction of smart museums as well like blockchain technology, computing and storage, artificial intelligence, and brain-computer Interface. It is focused on the integrated and intelligent construction of museums, and more ultimate and immersive experience can be melted into visitors experiences. To sum up, to promote the development and preservation of global civilization, metaverse technology-integrated intelligent museums are required for its integrated construction in relevance to human cognitive abilities and behavioral patterns.关键词:metaverse;wisdom museum;digital acquisition;3d reconstruction;virtual interaction306|434|1更新时间:2024-05-07
摘要:The preservation and exhibition of cultural relics have been concerned more nowadays, in which number of worldwide museums is even higher at about 55 097 and all the artefacts have been melted into. In China, total number of museums can be reached to 6 183, and it has involved 108 million state-owned movable cultural relics (sets) and 767 000 immovable cultural relics nationwide recently. Traditional museums are mainly focused on display cases, pictures, and other related audio-visual materials. Current digitization of cultural objects is beneficial to optimize traditional methods further. First, standard and consistent preservation can be introduced to alleviate natural-derived irreversible damage challenges to cultural objects. Next, it facilitates diverse ways of displaying cultural relics, which can enhance public awareness for appreciate heritage in a holistic, multi-angle, and three-dimensional manner. In recent years, the development of information technology has harnessed the emergence of many new conservation techniques and ways of displaying heritage, such as deep learning based 3D reconstruction and intelligent museums-oriented metaverse technologies of virtual reality. The digitization of museums has been launched globally in the context of digitization of collection resources since 1990s. But, the following digital museums are still challenged to deal with the problem of museum-across integrated resources. Such worldwide research projects for intelligent museums construction has been called for further. The goal of a smart museum is aimed to create a feasible intelligent ecosystem for museum-relevant domains. We review global-contextual technologies, in which four category of such key technologies in relevance to digital acquisition, heritage realism reconstruction, virtual-intelligent-integrated interaction, and smart platform construction. For digital acquisition of cultural relics, we illustrate and analyze the two most common types of methods in related to 3D scanning and close-up photogrammetry. For the realistic reconstruction technology of cultural relics, geometric processing and deep learning-based methods are focused on in terms of 3D reconstruction model analysis. For virtual-intelligent-integrated interaction, a variety of interaction methods are demonstrated in related to such aspects of multimodality, gesture, and handling. For the construction of smart platforms, we summarize some emerging technologies, and the final artistic results are described and achieved. The case study analysis is based on such famous multination museums of the Louvre Museum in France, the Hermitage Museum in Russia, the Palace Museum in Beijing and other related world-renowned museums. We sort out that the commonly-used construction process of smart museums for cultural relics through collection of digital information, three-dimensional reconstruction, and the integration of multiple virtual interaction. The consensus is focused on improving conservation measures and inherit culture. At the same time, potential metaverse technology can be used to build metaverse museum platforms further. Finally, modernizing museums analysis is focused on and its relevant tools and technologies has been focused on metaverse-related technologies. In the future, such emerging metaverse technologies can be used to predicted and integrated into the construction of smart museums as well like blockchain technology, computing and storage, artificial intelligence, and brain-computer Interface. It is focused on the integrated and intelligent construction of museums, and more ultimate and immersive experience can be melted into visitors experiences. To sum up, to promote the development and preservation of global civilization, metaverse technology-integrated intelligent museums are required for its integrated construction in relevance to human cognitive abilities and behavioral patterns.关键词:metaverse;wisdom museum;digital acquisition;3d reconstruction;virtual interaction306|434|1更新时间:2024-05-07 -
 摘要:Imitation learning(IL) is focused on the integration of reinforcement learning and supervised learning through observing demonstrations and learning expert strategies. The additional information related imitation learning can be used to optimize and implement its strategy, which can provide the possibility to alleviate low efficiency of sample problem. In recent years, imitation learning has become a popular framework for solving reinforcement learning problems, and a variety of algorithms and techniques have emerged to improve the performance of learning procedure. Combined with the latest research in the field of image processing, imitation learning has played an important role in such domains like game artificial intelligence (AI), robot control, autonomous driving. Traditional imitation learning methods are mainly composed of behavioral cloning (BC), inverse reinforcement learning (IRL), and adversarial imitation learning (AIL). Thanks to the computing ability and upstream graphics and image tasks (such as object recognition and scene understanding), imitation learning methods can be used to integrate a variety of technologies-emerged for complex tasks. We summarize and analyze imitation learning further, which is composed of imitation learning from observation (ILfO) and cross-domain imitation learning (CDIL). The ILfO can be used to optimize the requirements for expert demonstration, and information-observable can be learnt only without specific action information from experts. This setting makes imitation learning algorithms more practical, and it can be applied to real-life scenes. To alter the environment transition dynamics modeling, ILfO algorithms can be divided into two categories: model-based and model-free. For model-based methods, due to path-constructed of the model in the process of interaction between the agent and the environment, it can be assorted into forward dynamic model and inverse dynamic model further. The other related model-free methods are mainly composed of adversarial-based and function-rewarded engineering. Cross-domain imitation learning are mainly focused on the status of different domains for agents and experts, such as multiple Markov decision processes. Current CDIL research are mainly focused on the domain differences of three aspects of discrepancy in relevant to: transition dynamics, morphological, and view point. The technical solutions to CDIL problems can be mainly divided into such methods like: direct, mapping, adversarial, and optimal transport. The application of imitation learning is mainly on such aspects like game AI, robot control, and automatic driving. The recognition and perception capabilities of intelligent agents are optimized further in image processing, such as object detection, video understanding, video classification, and video recognition. Our critical analysis can be focused on the annual development of imitation learning from the five aspects: behavioral cloning, inverse reinforcement learning, adversarial imitation learning, imitation learning from observation, and cross-domain imitation learning.关键词:imitation learning (IL);reinforcement learning;imitation learning form observation (ILfO);cross domain imitation learning (CDIL);application of imitation learning518|1432|0更新时间:2024-05-07
摘要:Imitation learning(IL) is focused on the integration of reinforcement learning and supervised learning through observing demonstrations and learning expert strategies. The additional information related imitation learning can be used to optimize and implement its strategy, which can provide the possibility to alleviate low efficiency of sample problem. In recent years, imitation learning has become a popular framework for solving reinforcement learning problems, and a variety of algorithms and techniques have emerged to improve the performance of learning procedure. Combined with the latest research in the field of image processing, imitation learning has played an important role in such domains like game artificial intelligence (AI), robot control, autonomous driving. Traditional imitation learning methods are mainly composed of behavioral cloning (BC), inverse reinforcement learning (IRL), and adversarial imitation learning (AIL). Thanks to the computing ability and upstream graphics and image tasks (such as object recognition and scene understanding), imitation learning methods can be used to integrate a variety of technologies-emerged for complex tasks. We summarize and analyze imitation learning further, which is composed of imitation learning from observation (ILfO) and cross-domain imitation learning (CDIL). The ILfO can be used to optimize the requirements for expert demonstration, and information-observable can be learnt only without specific action information from experts. This setting makes imitation learning algorithms more practical, and it can be applied to real-life scenes. To alter the environment transition dynamics modeling, ILfO algorithms can be divided into two categories: model-based and model-free. For model-based methods, due to path-constructed of the model in the process of interaction between the agent and the environment, it can be assorted into forward dynamic model and inverse dynamic model further. The other related model-free methods are mainly composed of adversarial-based and function-rewarded engineering. Cross-domain imitation learning are mainly focused on the status of different domains for agents and experts, such as multiple Markov decision processes. Current CDIL research are mainly focused on the domain differences of three aspects of discrepancy in relevant to: transition dynamics, morphological, and view point. The technical solutions to CDIL problems can be mainly divided into such methods like: direct, mapping, adversarial, and optimal transport. The application of imitation learning is mainly on such aspects like game AI, robot control, and automatic driving. The recognition and perception capabilities of intelligent agents are optimized further in image processing, such as object detection, video understanding, video classification, and video recognition. Our critical analysis can be focused on the annual development of imitation learning from the five aspects: behavioral cloning, inverse reinforcement learning, adversarial imitation learning, imitation learning from observation, and cross-domain imitation learning.关键词:imitation learning (IL);reinforcement learning;imitation learning form observation (ILfO);cross domain imitation learning (CDIL);application of imitation learning518|1432|0更新时间:2024-05-07 - 摘要:Nowadays, with the booming of multimedia data, the character of multi-source and multi-modality of data has become a challenging problem in multimedia research. Its representation and generation can be as two key factors in cross-modal learning research. Cross-modal representation studies feature learning and information integration methods using multi-modal data. To get more effective feature representation, multimodality-between mutual benefits are required to be strengthened. Cross-modal generation is focused on the knowledge transfer mechanism across modalities. The modals-between semantic consistency can be used to realize data-interchangeable profiles of different modals. It is beneficial to improve modalities-between migrating ability. The literature review in cross-modal representation and generation are critically analyzed on the aspect of 1) traditional cross-modal representation learning, 2) big model for cross-modal representation learning, 3) image-to-text cross-modal conversion, joint representation, and 4) cross-modal image generation. Traditional cross-modal representation has two categories: joint representation and coordinated representation. Joint representation can yield multiple single-modal information to the joint representation space when each of single-modal information is processed through the coordinated representations, and cross-modal representations can be learnt mutually in terms of similarity constraints. Deep neural networks (DNNs) based self-supervised learning ability are activated to deal with large-scale unlabeled data, especially for the Transformer-based methods. To enrich the supervised learning paradigm, the pre-trained large models can yield large-scale unlabeled data to learn training, and a downstream tasks-derived small amount of labeled data is used for model fine-tuning. The pre-trained model has better versatility and transfering ability compared to the trained model for specific tasks, and the fine-tuned model can be used to optimize downstream tasks as well. The developmentof cross-modal synthesis (a.k.a. image caption or video caption) methods have been summarized, including end-to-end, semantic-based, and stylize-based methods. In addition, current situation of cross-modal conversion between image and text has beenanalyzed, including image caption, video caption, and visual question answering. The cross-modal generation methods are summarized as well in relevance to the joint representation of cross-modal information, image generation, text-image cross-modal generation, and cross-modal generation based on pre-trained models. In recent years, generative adversarial networks (GANs) and denoising diffusion probabilistic models (DDPMs) have been faciliating in cross-modal generation tasks. Thanks to the strong adaptability and generation ability of DDPM models, cross-modal generation research can be developed and the constraints of vulnerable textures are optimized to a certain extent. The growth of GAN-based and DDPM-based methods are summarized and analyzed further.关键词:multimedia technology;cross-modal learning;foundation model;cross-modal representation;cross-modal generation;deep learning618|1234|4更新时间:2024-05-07
Intelligent Interaction and Cross modal Learning

-
 摘要:Visual sensing technique is essential for human to perceive and understand the world around them. An “electronic eyeball” can be melted into outdoor-related visual information,and visual sensors are equipped with such domains like consumer electronics,machine vision,surveillance,and academic researches. Visual sensor technology-based multiple sensors can be used to richer multi-dimension visual data,which can enhance human-related perceptive and cognitive ability. This literature review is focused on the growth of optical visual sensor technology,including such image sensors in relevance to CCD,CMOS,intelligent-visual,and infrared-context. The CMOS image sensor chip is produced in terms of CMOS technology,in which image acquisition unit and signal processing unit can be integrated into the same chip. It can be mass-produced to a certain extent. Cost-effective applications can be oriented to such aspects in related to small size,light weight,low cost and low power consumption. With the rapid development of autonomous driving, intelligent transportation, machine vision and other fields, multi-functional and intelligent CMOS image sensors with small size will become the focus of research. The emerging CCD sensor technology and its applications have been facilitating as well. The potentials of CCD image sensor can be applied for such domains in related to remote sensing,astronomy,low light detection. In the future, the multi-spectral TDI CCD architecture based on CCD and CMOS fusion technology will be widely used. Infrared image sensor is configured and set that infrared radiation detection can be converted into physical quantity. The high-performance digital signal processing function can be integrated on the infrared focal plane. The newly infrared image sensor can be focused on larger array,higher resolution,wider spectrums,more flexible sensitivity,multi-band,and system-level chip further.关键词:optical visual sensor;CCD image sensor;CMOS image sensor;intelligent visual sensor;infrared image sensor224|216|1更新时间:2024-05-07
摘要:Visual sensing technique is essential for human to perceive and understand the world around them. An “electronic eyeball” can be melted into outdoor-related visual information,and visual sensors are equipped with such domains like consumer electronics,machine vision,surveillance,and academic researches. Visual sensor technology-based multiple sensors can be used to richer multi-dimension visual data,which can enhance human-related perceptive and cognitive ability. This literature review is focused on the growth of optical visual sensor technology,including such image sensors in relevance to CCD,CMOS,intelligent-visual,and infrared-context. The CMOS image sensor chip is produced in terms of CMOS technology,in which image acquisition unit and signal processing unit can be integrated into the same chip. It can be mass-produced to a certain extent. Cost-effective applications can be oriented to such aspects in related to small size,light weight,low cost and low power consumption. With the rapid development of autonomous driving, intelligent transportation, machine vision and other fields, multi-functional and intelligent CMOS image sensors with small size will become the focus of research. The emerging CCD sensor technology and its applications have been facilitating as well. The potentials of CCD image sensor can be applied for such domains in related to remote sensing,astronomy,low light detection. In the future, the multi-spectral TDI CCD architecture based on CCD and CMOS fusion technology will be widely used. Infrared image sensor is configured and set that infrared radiation detection can be converted into physical quantity. The high-performance digital signal processing function can be integrated on the infrared focal plane. The newly infrared image sensor can be focused on larger array,higher resolution,wider spectrums,more flexible sensitivity,multi-band,and system-level chip further.关键词:optical visual sensor;CCD image sensor;CMOS image sensor;intelligent visual sensor;infrared image sensor224|216|1更新时间:2024-05-07 -
 摘要:Remote sensing images are often captured from multiview and multiple altitudes, thereby comprising a mass of objects with limited sizes which significantly challenge current detection methods that can achieve outstanding performance on natural images. Moreover, how to precisely detect these small objects plays a crucial role in developing an intelligent interpretation system for remote sensing images. Focusing on the remote sensing images, this paper conducts a comprehensive survey for deep learning-based small object detection (SOD) can be reviewed and analyzed literately, including 1) features-represent bottlenecks, 2) background confusion, and 3) branching-regressed sensitivity. Specially, one of the major bottlenecks is for objective’s representation. It refers that the down-sample operations in the prevailing feature extractors can suppress the signals of small objects unavoidably, and the following detection is impaired further in terms of the weak representations. The detection of size-limited instances is also interference of the confusion between the objects and backgrounds and the sensitivity of regression branch. For the former, the representations of small objects tend to be contaminated in related to feature extraction-contextual factors, which may erase the discriminative information that plays a significant role in head network. And the sensitivity of regression branch in small object detection is derived from the low tolerance for bounding box perturbation, in which a slight deviation of a predicted box will cause a drastic drop on the intersection-over-union (IoU), which is generally adopted to evaluate the accuracy of localization. Furthermore, we review and analyze the literature of small object detection for remote sensing images in the deep-learning era. In detail, by systematically reviewing corresponding methods of three small object detection tasks, i.e., SOD for optical remote sensing images, SOD for synthetic aperture radar (SAR) images and SOD for infrared images, an understandable taxonomy of the reviewed algorithms for each task is given. Specifically, we rigorously split the representative methods into several categories according to the major techniques used. In addition to the algorithm survey, considering the deep learning-based methods are hungry for data and to provide a comprehensive survey about small object detection, we also retrospect several publicly available datasets which are commonly used in these three SOD tasks. For each concrete field, we list the prevailing benchmarks in accordance with the published papers, and a brief introduction and some example images about these datasets are illustrated: small size. What is more, other related features about small object detection are highlighted as well, such as image resolution, data source, the number of images and annotated instances, and some proper statistics of each task, etc. Additionally, to better investigate the performance of generic detection methods on small objects, we analyze an in-depth evaluation and comparison of main-stream detection algorithms and several SOD methods for remote sensing images, namely SODA-A(small object detection datasets), AIR-SARShip and NUAA-SIRST(Nanjing University of Aeronautics and Astronautics, single-frame infrared small target). Afterwards, current situation in applications of small object detection for remote sensing images are analyzed, including SOD-based intelligent transportation system and scene-related understanding. Such harbor-targeted recognition is based on SAR image analysis, the precision-guided weapons based on the detection and recognition techniques of infrared images, and the tracking of moving targets at sea on top of multimodal remote sensing data. In the end, to enlighten the further research of small object detection in remote sensing images, we discuss four promising directions in the future. Concretely, it is required that an efficient backbone network can avoid the information loss of small objects while capturing the discriminative features to optimize the down-stream tasks about small objects. Large-scale benchmarks with well annotated small instances play an irreplaceable role linked to small object detection in remote sensing images further. Moreover, a multimodal remote sensing data-collaborated SOD algorithm is also preferred. A proper evaluation metric can not only guide the training and inference of small object detection methods under some specific scenes, but also rich its domain-related development.关键词:small object detection(SOD);deep learning;optical remote sensing images;SAR images;infrared images;public datasets763|1544|5更新时间:2024-05-07
摘要:Remote sensing images are often captured from multiview and multiple altitudes, thereby comprising a mass of objects with limited sizes which significantly challenge current detection methods that can achieve outstanding performance on natural images. Moreover, how to precisely detect these small objects plays a crucial role in developing an intelligent interpretation system for remote sensing images. Focusing on the remote sensing images, this paper conducts a comprehensive survey for deep learning-based small object detection (SOD) can be reviewed and analyzed literately, including 1) features-represent bottlenecks, 2) background confusion, and 3) branching-regressed sensitivity. Specially, one of the major bottlenecks is for objective’s representation. It refers that the down-sample operations in the prevailing feature extractors can suppress the signals of small objects unavoidably, and the following detection is impaired further in terms of the weak representations. The detection of size-limited instances is also interference of the confusion between the objects and backgrounds and the sensitivity of regression branch. For the former, the representations of small objects tend to be contaminated in related to feature extraction-contextual factors, which may erase the discriminative information that plays a significant role in head network. And the sensitivity of regression branch in small object detection is derived from the low tolerance for bounding box perturbation, in which a slight deviation of a predicted box will cause a drastic drop on the intersection-over-union (IoU), which is generally adopted to evaluate the accuracy of localization. Furthermore, we review and analyze the literature of small object detection for remote sensing images in the deep-learning era. In detail, by systematically reviewing corresponding methods of three small object detection tasks, i.e., SOD for optical remote sensing images, SOD for synthetic aperture radar (SAR) images and SOD for infrared images, an understandable taxonomy of the reviewed algorithms for each task is given. Specifically, we rigorously split the representative methods into several categories according to the major techniques used. In addition to the algorithm survey, considering the deep learning-based methods are hungry for data and to provide a comprehensive survey about small object detection, we also retrospect several publicly available datasets which are commonly used in these three SOD tasks. For each concrete field, we list the prevailing benchmarks in accordance with the published papers, and a brief introduction and some example images about these datasets are illustrated: small size. What is more, other related features about small object detection are highlighted as well, such as image resolution, data source, the number of images and annotated instances, and some proper statistics of each task, etc. Additionally, to better investigate the performance of generic detection methods on small objects, we analyze an in-depth evaluation and comparison of main-stream detection algorithms and several SOD methods for remote sensing images, namely SODA-A(small object detection datasets), AIR-SARShip and NUAA-SIRST(Nanjing University of Aeronautics and Astronautics, single-frame infrared small target). Afterwards, current situation in applications of small object detection for remote sensing images are analyzed, including SOD-based intelligent transportation system and scene-related understanding. Such harbor-targeted recognition is based on SAR image analysis, the precision-guided weapons based on the detection and recognition techniques of infrared images, and the tracking of moving targets at sea on top of multimodal remote sensing data. In the end, to enlighten the further research of small object detection in remote sensing images, we discuss four promising directions in the future. Concretely, it is required that an efficient backbone network can avoid the information loss of small objects while capturing the discriminative features to optimize the down-stream tasks about small objects. Large-scale benchmarks with well annotated small instances play an irreplaceable role linked to small object detection in remote sensing images further. Moreover, a multimodal remote sensing data-collaborated SOD algorithm is also preferred. A proper evaluation metric can not only guide the training and inference of small object detection methods under some specific scenes, but also rich its domain-related development.关键词:small object detection(SOD);deep learning;optical remote sensing images;SAR images;infrared images;public datasets763|1544|5更新时间:2024-05-07 -
 摘要:Computer vision-oriented hyperspectral images (HSIs) are featured to enrich spatial and spectral information compared to gray and RGB images. It has been developing in such domains like target detection, scene classification, and tracking. However, the HSI imaging technique is challenged for its distortion problems (e.g., low spatial resolution, noise). HSI-related super-resolution (SR) methods are proposed to reconstruct high-quality HSIs in terms of a high spectral resolution and spatial resolution (HR). Current HSI SR methods can be segmented into two categories: spatial SR and spectral SR. The spatial SR method is oriented to reconstruct the target HR HSI via improving the spatial resolution of low-resolution (LR) HSI. It can be subdivided into single image SR and fusion based SR methods further. Single image based SR method can be used to reconstruct the target HSI via directly improving the spatial resolution of LR HSI. However, due to much more spatial information is sacrificed, single image based SR method is challenged to reconstruct effective HSIs. Therefore, to fuse these high quality spatial information into the LR HSIs, extra high spatial homogeneous information is introduced (e.g., multispectral image (MSI), RGB). In this way, the spatial resolution of LR HSI can be improved greatly (e.g., 8 times, 16 times, and 32 times SR). The other HSI SR method is focused on the spectral super-resolution method, which can improve the spectral resolution of high spatial resolution images (e.g., MSI, RGB) and generate the target hyperspectral image. The literature review is focused on the growth of HSI SR methods in relevance to three aspects single image-based, fusion-based, and spectral super-resolution contexts. Each of these three category for HSI SR methods can be further subdivided into two aspects of traditional optimization framework and deep learning based methods. For single image HSI SR, due to the SR problem being an illness inverse problem, traditional optimization framework based single image HSI SR methods is used to develop effective image priors to restrain the SR process. Image priors like low-rank, sparse representation, and non-local features are commonly used in single based HSI SR method, but it still challenged for such problems of manpower and restrictions. For the traditional fusion based method, the core element is to balance the spatial-spectral correlation between HR MSI and LR HSI. It is feasible to split these two images into key components and then re-combine the effective parts of each image. Therefore, multiple schemes are introduced (e.g., non-negative matrix factorization, coupled tensor factorization) to leverage the key information from HR MSI and LR HSI. In addition, to increase the effectiveness of these decomposition methods, some constraints are required to be introduced (e.g., sparse, low-rank). For the traditional spectral resolution method, it is essential to learn how to reconstruct the spectral characteristics from RGB/MSI images. When paired RGB and HSI exist, a promising way is feasible to construct a dictionary (e.g., sparse dictionary learning) that the mapping relation can be recorded between RGB/MSI images and HSIs. The dictionary learning based spectral super-resolution methods have been developing as well, but it is often challenged to realize more generalization ability for applications. In recent years, deep learning based methods have facilitated much more computer vision tasks, and is beneficial for exploiting the inherent spatial-spectral relations of HSIs. For the single image HSI SR methods, a deep convolution neural network (DCNN) is utilized to learn the mapping process from LR HSI to HR HSI. The DCNN is capable to learn deep image prior from plenty of training samples, which has better representation ability than the heuristic handcrafted image priors (e.g., low-rank, sparse) to some extent. However, the performance of this kind of method is often restricted by the amount and variety of training samples. Therefore, it is necessary to reconstruct HR HSI from LR HSI in an unsupervised manner, but the robustness of the unsupervised method is still a challenging problem to be resolved. For the deep learning based HSI fusion methods, to extract spatial-spectral information from MSIs and HSIs, an effective design of DCNN frameworks (e.g., multi-branch, multi-scale, 3D-CNN) are concerned about. However, such problems (e.g., noise, unknown degeneration, unregistered) are challenged for effective generalization ability of DCNN-based HSI fusion method. To resolve these problems, unsupervised and alternative learning methods are introduced to improve fusion-based generalization ability. The DCNN-unfolding is proposed and the optimal interpretability is demonstrated, and its registration strategy is introduced to improve the robustness further. For the spectral super resolution method, DCNN is demonstrated to model the mapping scheme between RGB/MSI and HR HSI. However, there still some barriers are required to be resolved for DCNN-based spectral super resolution method. For example, most existing spectral super resolution methods can generate HSI only according to its fixed spectral interval or spectrum range. A spectral super resolution framework is required to be linked with generalization ability well in the future. In this study, we will summarize the developing of the HSI SR scope from the perspective of new designs, new methods, and new application scenes.关键词:hyperspectral image(HSI);super-resolution reconstruction;single image super-resolution;fusion based super-resolution;spectral super-resolution752|1482|3更新时间:2024-05-07
摘要:Computer vision-oriented hyperspectral images (HSIs) are featured to enrich spatial and spectral information compared to gray and RGB images. It has been developing in such domains like target detection, scene classification, and tracking. However, the HSI imaging technique is challenged for its distortion problems (e.g., low spatial resolution, noise). HSI-related super-resolution (SR) methods are proposed to reconstruct high-quality HSIs in terms of a high spectral resolution and spatial resolution (HR). Current HSI SR methods can be segmented into two categories: spatial SR and spectral SR. The spatial SR method is oriented to reconstruct the target HR HSI via improving the spatial resolution of low-resolution (LR) HSI. It can be subdivided into single image SR and fusion based SR methods further. Single image based SR method can be used to reconstruct the target HSI via directly improving the spatial resolution of LR HSI. However, due to much more spatial information is sacrificed, single image based SR method is challenged to reconstruct effective HSIs. Therefore, to fuse these high quality spatial information into the LR HSIs, extra high spatial homogeneous information is introduced (e.g., multispectral image (MSI), RGB). In this way, the spatial resolution of LR HSI can be improved greatly (e.g., 8 times, 16 times, and 32 times SR). The other HSI SR method is focused on the spectral super-resolution method, which can improve the spectral resolution of high spatial resolution images (e.g., MSI, RGB) and generate the target hyperspectral image. The literature review is focused on the growth of HSI SR methods in relevance to three aspects single image-based, fusion-based, and spectral super-resolution contexts. Each of these three category for HSI SR methods can be further subdivided into two aspects of traditional optimization framework and deep learning based methods. For single image HSI SR, due to the SR problem being an illness inverse problem, traditional optimization framework based single image HSI SR methods is used to develop effective image priors to restrain the SR process. Image priors like low-rank, sparse representation, and non-local features are commonly used in single based HSI SR method, but it still challenged for such problems of manpower and restrictions. For the traditional fusion based method, the core element is to balance the spatial-spectral correlation between HR MSI and LR HSI. It is feasible to split these two images into key components and then re-combine the effective parts of each image. Therefore, multiple schemes are introduced (e.g., non-negative matrix factorization, coupled tensor factorization) to leverage the key information from HR MSI and LR HSI. In addition, to increase the effectiveness of these decomposition methods, some constraints are required to be introduced (e.g., sparse, low-rank). For the traditional spectral resolution method, it is essential to learn how to reconstruct the spectral characteristics from RGB/MSI images. When paired RGB and HSI exist, a promising way is feasible to construct a dictionary (e.g., sparse dictionary learning) that the mapping relation can be recorded between RGB/MSI images and HSIs. The dictionary learning based spectral super-resolution methods have been developing as well, but it is often challenged to realize more generalization ability for applications. In recent years, deep learning based methods have facilitated much more computer vision tasks, and is beneficial for exploiting the inherent spatial-spectral relations of HSIs. For the single image HSI SR methods, a deep convolution neural network (DCNN) is utilized to learn the mapping process from LR HSI to HR HSI. The DCNN is capable to learn deep image prior from plenty of training samples, which has better representation ability than the heuristic handcrafted image priors (e.g., low-rank, sparse) to some extent. However, the performance of this kind of method is often restricted by the amount and variety of training samples. Therefore, it is necessary to reconstruct HR HSI from LR HSI in an unsupervised manner, but the robustness of the unsupervised method is still a challenging problem to be resolved. For the deep learning based HSI fusion methods, to extract spatial-spectral information from MSIs and HSIs, an effective design of DCNN frameworks (e.g., multi-branch, multi-scale, 3D-CNN) are concerned about. However, such problems (e.g., noise, unknown degeneration, unregistered) are challenged for effective generalization ability of DCNN-based HSI fusion method. To resolve these problems, unsupervised and alternative learning methods are introduced to improve fusion-based generalization ability. The DCNN-unfolding is proposed and the optimal interpretability is demonstrated, and its registration strategy is introduced to improve the robustness further. For the spectral super resolution method, DCNN is demonstrated to model the mapping scheme between RGB/MSI and HR HSI. However, there still some barriers are required to be resolved for DCNN-based spectral super resolution method. For example, most existing spectral super resolution methods can generate HSI only according to its fixed spectral interval or spectrum range. A spectral super resolution framework is required to be linked with generalization ability well in the future. In this study, we will summarize the developing of the HSI SR scope from the perspective of new designs, new methods, and new application scenes.关键词:hyperspectral image(HSI);super-resolution reconstruction;single image super-resolution;fusion based super-resolution;spectral super-resolution752|1482|3更新时间:2024-05-07 -
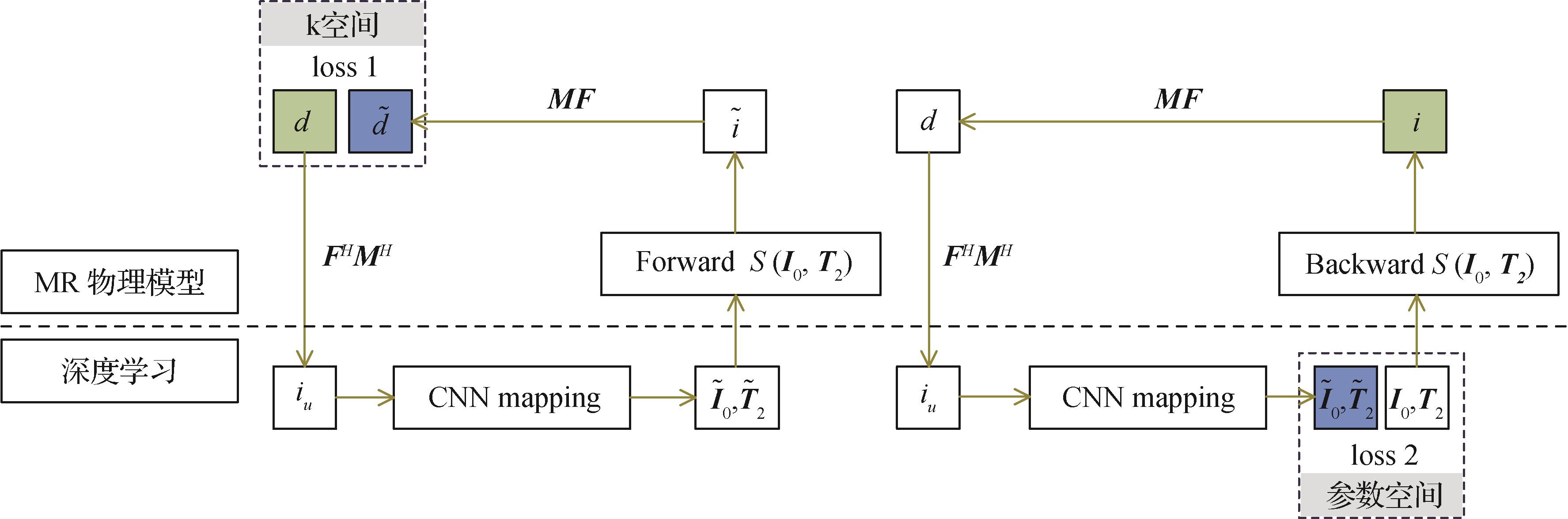 摘要:Magnetic resonance imaging (MRI) is a commonly-used non-invasive medical imaging method. Due to richable soft tissue-related contrast features of human body, medical imaging diagnosis is beneficial from more internal structures-contextual image in clinic, including its organs, bones, muscles, and blood vessels. However, two sorts of bottlenecks of MRI like slow scanning speed and labor-intensive scanning operation are required to be resolved beyond the constraints of hardware and existing techniques. Current MRI has been facilitating in terms of the emerging deep learning based medical imaging technique. To optimize its acquisition time, parallel imaging and compressed sensing combined with the use of multi-array coils, conventional MRI mainly depends on the hardware improvements and new compactable sequence design. First, literature review of deep learning-based MR reconstruction methods are analyzed, including such deep learning issues originated from 1) integration of parallel imaging and compressed sensing of MRI and 2) acceleration of multi-contrast images and dynamic images of single-contrast image. Deep learning-based reconstruction models is oriented to get their generalizability incorporated with multiple datasets, in which MRI data are challenged for multiple factors like its relevance of centers, models, and field strengths. Two decadal development of quantitative MRI technique can provide pixel-level characterization of intrinsic tissue quantitative parameters, such as T1, T2, and ADC. Generally, quantitative MRI is often required to get multiple weighted images under different parameters, and quantitative tissue parameters can be generated via signal model-required pixel-level nonlinear fitting. Compared to the acquisition of contrast images, acquisition and reconstruction duration has become more longer. To accelerate the acquisition and reconstruction or facilitate accurate mapping, extension ability of deep learning has been developing for the reconstruction of MRI fast imaging. Apart from conventional single parameter mapping method, simultaneous multi-parameter mapping techniques have leaked out, such as MR fingerprinting. Compared to single parameter mapping, multi-parameter mapping can be synchronized and accelerated, and more efficient acquisition and inherent coregistration can be used to deal with such complicated reconstruction. Deep learning technique can be as a multifaceted tool to simplify the reconstruction and speed up the acquisition. However, it is still challenged for such constraints like deep learning algorithms and large amounts of training data. Deep learning methods are required to be melted into magnetic resonance physical models and traditional reconstruction algorithms to a certain extent, and to improve the interpretability of the model and alleviate the impact on large datasets, such methods of data enhancement, weakly supervised learning, unsupervised learning, and transfer learning can be involved in as well. A quantitative MRI-relevant unsupervised network can be potentially used for training in terms of different parameter mapping sequences, which can greatly shrink the amount of data samples further.关键词:deep learning;magnetic resonance imaging(MRI);contrast weighted imaging;quantitative imaging276|918|1更新时间:2024-05-07
摘要:Magnetic resonance imaging (MRI) is a commonly-used non-invasive medical imaging method. Due to richable soft tissue-related contrast features of human body, medical imaging diagnosis is beneficial from more internal structures-contextual image in clinic, including its organs, bones, muscles, and blood vessels. However, two sorts of bottlenecks of MRI like slow scanning speed and labor-intensive scanning operation are required to be resolved beyond the constraints of hardware and existing techniques. Current MRI has been facilitating in terms of the emerging deep learning based medical imaging technique. To optimize its acquisition time, parallel imaging and compressed sensing combined with the use of multi-array coils, conventional MRI mainly depends on the hardware improvements and new compactable sequence design. First, literature review of deep learning-based MR reconstruction methods are analyzed, including such deep learning issues originated from 1) integration of parallel imaging and compressed sensing of MRI and 2) acceleration of multi-contrast images and dynamic images of single-contrast image. Deep learning-based reconstruction models is oriented to get their generalizability incorporated with multiple datasets, in which MRI data are challenged for multiple factors like its relevance of centers, models, and field strengths. Two decadal development of quantitative MRI technique can provide pixel-level characterization of intrinsic tissue quantitative parameters, such as T1, T2, and ADC. Generally, quantitative MRI is often required to get multiple weighted images under different parameters, and quantitative tissue parameters can be generated via signal model-required pixel-level nonlinear fitting. Compared to the acquisition of contrast images, acquisition and reconstruction duration has become more longer. To accelerate the acquisition and reconstruction or facilitate accurate mapping, extension ability of deep learning has been developing for the reconstruction of MRI fast imaging. Apart from conventional single parameter mapping method, simultaneous multi-parameter mapping techniques have leaked out, such as MR fingerprinting. Compared to single parameter mapping, multi-parameter mapping can be synchronized and accelerated, and more efficient acquisition and inherent coregistration can be used to deal with such complicated reconstruction. Deep learning technique can be as a multifaceted tool to simplify the reconstruction and speed up the acquisition. However, it is still challenged for such constraints like deep learning algorithms and large amounts of training data. Deep learning methods are required to be melted into magnetic resonance physical models and traditional reconstruction algorithms to a certain extent, and to improve the interpretability of the model and alleviate the impact on large datasets, such methods of data enhancement, weakly supervised learning, unsupervised learning, and transfer learning can be involved in as well. A quantitative MRI-relevant unsupervised network can be potentially used for training in terms of different parameter mapping sequences, which can greatly shrink the amount of data samples further.关键词:deep learning;magnetic resonance imaging(MRI);contrast weighted imaging;quantitative imaging276|918|1更新时间:2024-05-07 -
 摘要:Autonomous driving-oriented accurate perception and measurement of the three-dimensional (3D) spatial position and scale can be as the basis for realizing the control ability and decision-making level. Sensing technology-driven autonomous vehicles are equipped with high-resolution camera, light detection and ranging(LiDAR), radar, global positioning system(GPS)/inertial measurement unit(IMU) and other related sensors. Current LiDAR or multi-modal data-based 3D object detection algorithms are challenged for its deployment and application because of the shortcomings of LiDAR sensors like high price, limited sensing range, and sparse point clouds data. In contrast, such high-resolution cameras are commonly-used and featured by its lower price, and it can obtain high-resolution spatial information, richer shape, and appearance details as well. The emerging image-based 3D object detection is focused on further. At present, constraints of detection accuracy of the existing methods are still to be analyzed thoroughly and systematically. We summary the research results and industrial applications in relevance to such 1) perspectives of commonly used datasets and evaluation criteria, 2) data impact, 3) methodological constraints and prediction errors. First, a brief introduction is linked to perspective of academic domain and application of autonomous driving industry. We briefly review latest growths of Baidu Apollo, Google Waymo, Tesla and other related autonomous driving companies, and the thread of 3D object detection methods for autonomous driving. Then, we analyzed and summarized four popular datasets like KITTI, nuScenes, Waymo open dataset, and DAIR-V2X dataset from three aspects of: 1) data acquisition/sensors, data accuracy and data label information; 2) key evaluation standards proposed by these data sets, and 3) pros/cons and applicability of these evaluation standards. Third, main constraints of the image-based 3D object detection algorithm and the errors are derived from two sides of: data and methodology. Such main data constraints are originated from their data accuracy, sample difference, data volume, and data annotation. The data accuracy is mainly limited by equipment performance. The sample difference is mainly restricted by such image processing problems in related to object distance difference, angle difference, occlusion, and truncation. Data volume is affected by variety of 3D data types and high difficulty of labeling. The volume of 3D object detection data set is much smaller in comparison with the 2D object detection data set. Data annotation is mainly focused on 3D bounding box labeling, the labeling details, and quality of the dataset, especially for image annotation used in image-based 3D object detection. For non-rigid objects like pedestrians, the annotation error is larger, and there are some optimal for improving the labeling method. The general framework of image-based 3D object detection can be classified as one-stage methods and two-stage methods, and the limitations consists of 1) the prior geometric relationship, 2) depth prediction accuracy, and 3) data modality. The prior geometric relationship is focused on 2D-3D geometric constraints for 2D images-projected 3D objects and objects-between position relationships. The image-based 3D object detection methods face such problems as: prior 2D-3D geometric constraints and occluded and truncated objects. The prediction of depth information from 2D images is an ill conditioned problem, and dimension collapse will cause depth prediction error-relevant loss of depth information in the image. On the one hand, the depth prediction is often not accurate due to the influence of projection relationship. On the other hand, the performance of continuous depth prediction is often poor at the depth mutation of the image (such as edge of objects). When the prediction depth is discretized, there is a problem that the classification of depth is relatively rough, and the accuracy classification cannot be arbitrarily divided. The limitation of single image-based data modality is mainly reflected via large error of depth prediction. The detection performance of the algorithm can be optimized by 1) simulating the stereo signal and LiDAR point clouds, or 2) using stereo image as the aided input, or 3) leveraging point clouds data with accurate 3D information as supervision signal. In addition, video data can be adopted to improve the detection accuracy to a certain extent. Forth, current research situation is summarized and compared from academic and industrial domain. Finally, some future research directions are predicted in terms of such factors of datasets, evaluation indicators, and depth prediction.关键词:3D object detection;benchmark;constraint;error analysis;autonomous driving;image processing;computer vision502|874|5更新时间:2024-05-07
摘要:Autonomous driving-oriented accurate perception and measurement of the three-dimensional (3D) spatial position and scale can be as the basis for realizing the control ability and decision-making level. Sensing technology-driven autonomous vehicles are equipped with high-resolution camera, light detection and ranging(LiDAR), radar, global positioning system(GPS)/inertial measurement unit(IMU) and other related sensors. Current LiDAR or multi-modal data-based 3D object detection algorithms are challenged for its deployment and application because of the shortcomings of LiDAR sensors like high price, limited sensing range, and sparse point clouds data. In contrast, such high-resolution cameras are commonly-used and featured by its lower price, and it can obtain high-resolution spatial information, richer shape, and appearance details as well. The emerging image-based 3D object detection is focused on further. At present, constraints of detection accuracy of the existing methods are still to be analyzed thoroughly and systematically. We summary the research results and industrial applications in relevance to such 1) perspectives of commonly used datasets and evaluation criteria, 2) data impact, 3) methodological constraints and prediction errors. First, a brief introduction is linked to perspective of academic domain and application of autonomous driving industry. We briefly review latest growths of Baidu Apollo, Google Waymo, Tesla and other related autonomous driving companies, and the thread of 3D object detection methods for autonomous driving. Then, we analyzed and summarized four popular datasets like KITTI, nuScenes, Waymo open dataset, and DAIR-V2X dataset from three aspects of: 1) data acquisition/sensors, data accuracy and data label information; 2) key evaluation standards proposed by these data sets, and 3) pros/cons and applicability of these evaluation standards. Third, main constraints of the image-based 3D object detection algorithm and the errors are derived from two sides of: data and methodology. Such main data constraints are originated from their data accuracy, sample difference, data volume, and data annotation. The data accuracy is mainly limited by equipment performance. The sample difference is mainly restricted by such image processing problems in related to object distance difference, angle difference, occlusion, and truncation. Data volume is affected by variety of 3D data types and high difficulty of labeling. The volume of 3D object detection data set is much smaller in comparison with the 2D object detection data set. Data annotation is mainly focused on 3D bounding box labeling, the labeling details, and quality of the dataset, especially for image annotation used in image-based 3D object detection. For non-rigid objects like pedestrians, the annotation error is larger, and there are some optimal for improving the labeling method. The general framework of image-based 3D object detection can be classified as one-stage methods and two-stage methods, and the limitations consists of 1) the prior geometric relationship, 2) depth prediction accuracy, and 3) data modality. The prior geometric relationship is focused on 2D-3D geometric constraints for 2D images-projected 3D objects and objects-between position relationships. The image-based 3D object detection methods face such problems as: prior 2D-3D geometric constraints and occluded and truncated objects. The prediction of depth information from 2D images is an ill conditioned problem, and dimension collapse will cause depth prediction error-relevant loss of depth information in the image. On the one hand, the depth prediction is often not accurate due to the influence of projection relationship. On the other hand, the performance of continuous depth prediction is often poor at the depth mutation of the image (such as edge of objects). When the prediction depth is discretized, there is a problem that the classification of depth is relatively rough, and the accuracy classification cannot be arbitrarily divided. The limitation of single image-based data modality is mainly reflected via large error of depth prediction. The detection performance of the algorithm can be optimized by 1) simulating the stereo signal and LiDAR point clouds, or 2) using stereo image as the aided input, or 3) leveraging point clouds data with accurate 3D information as supervision signal. In addition, video data can be adopted to improve the detection accuracy to a certain extent. Forth, current research situation is summarized and compared from academic and industrial domain. Finally, some future research directions are predicted in terms of such factors of datasets, evaluation indicators, and depth prediction.关键词:3D object detection;benchmark;constraint;error analysis;autonomous driving;image processing;computer vision502|874|5更新时间:2024-05-07 -
 摘要:3D scene understanding and reconstruction are essential for machine vision and intelligence, which aim to reconstruct completed models of real scenes from multiple scene scans and understand the semantic meanings of each functional component in the scene. This technique is indispensable for real world digitalization and simulation, which can be widely used in related domains like robots, navigation system and virtual tourism. Its key challenges are required to be resolved on the three aspects: 1) to recognize the same area in multiple real scans and fuse all the scans into an integrated scene point cloud; 2) to make sense of the whole scene and recognize the semantics of multiple functional components; 3) to complete the missing region in the original point cloud caused by occlusion during scanning. It is necessary to extract point cloud feature in order to fuse multiple real scene scans into an integrated point cloud, which can be invariant to scanning position and rotation. Thus, intrinsic geometry features like point distance and singular value in neighborhood covariance matrix are often involved in rotation-invariant feature design. Contrastive learning scheme is usually taken to help the learned features from the same area to be close to each other, while extracted features from different areas to be far away. To get generalization ability better, data augmentation of scanned point cloud can also be used during feature learning process. Features-learnt pose estimation of scanning device can be configured to calculate the transformation matrix between point cloud pairs. After the transformation relationship is sorted out, the following point cloud fusion can be implemented using the raw point cloud scans. To further understand raw point cloud-based whole scene and segment the whole scene into functional parts on the basis of multiple semantics, an effective and efficient network with appropriate 3D convolution operation is required to parse entire points-based scene hierarchically, and specific learning schemes are necessary as well to adapt to various situation. The definition and formulation of basic convolution operation in 3D space is recognized as the core of pattern recognition for 3D scene point cloud. It is highly correlated to the approximated convolution kernel in 3D space where feature extraction can be developed in terms of appropriate point cloud grouping and down/up-sampling. The discrete approximation of 3D continuous convolution pursues being capable of recognizing various geometry pattern while keeping as few parameters as possible. Network design based on these elementary 3D convolution operations is also a fundamental part of outstanding scene parsing. Furthermore, point-level semantic segmentation of scanned scene can be linked mutually in relevance to such aspects of boundary detection, instance segmentation, and scene coloring, where network parameters are supervised through more auxiliary regularization. Semi-supervised methods and weak-supervised methods are required to overcome the lack of data annotation for real data. The segmentation results and semantic hints can be used to strengthen the fine-grained completion of object point cloud from scanned scene, in which the segmented objects can be handled separately, and semantics can be used to provide the structure and geometry prior when occlusion-derived missing region is completed. For the learning of object point cloud completion, it is crucial to learn a compact latent code space to represent all the complete shapes and design versatile decoder to reconstruct the structure and fine-grained geometry details of object point cloud. The learnt latent code space should contain complete shapes as much as possible, thus requiring large-scale synthetic model dataset for training to ensure the generalization ability. The encoder should be designed to recognize the structure of original point cloud and extract specific geometry pattern which preserves this information in latent code, while the decoder is used to recover the overall skeleton of original scanned objects and complete all the details according to the existing local geometry hints. For real scanned object completion, it is required to optimize the integration of latent code space further for synthetic models and real scanned point cloud. A cross-domain learning scheme is used to apply the knowledge of completion to real object scans, whereas the details of real scanned object can be preserved in the completed version. We analyze the current situation about scene understanding and reconstruction, including point cloud fusion, 3D convolution operation, entire scene segmentation, and fine-grained object completion. We analyze the frontier technologies and predict promising future research trends. It is significant for the following research to pay more attention on more open space with further challenges on computing efficiency, handling out-of-domain knowledge, and more complex situation with human-scene interaction. The 3D scene understanding and reconstruction technology will help the machine to understand the real world in a more natural way which can facilitate such various application domains like robots and navigation. It also potential to conduct plausible simulation of real world based on the reconstruction and parsing of real scenes, making it a useful tool in making various decisions.关键词:3D scenes;point could fusion;scene segmentation;object shape completion;deep learning376|1844|4更新时间:2024-05-07
摘要:3D scene understanding and reconstruction are essential for machine vision and intelligence, which aim to reconstruct completed models of real scenes from multiple scene scans and understand the semantic meanings of each functional component in the scene. This technique is indispensable for real world digitalization and simulation, which can be widely used in related domains like robots, navigation system and virtual tourism. Its key challenges are required to be resolved on the three aspects: 1) to recognize the same area in multiple real scans and fuse all the scans into an integrated scene point cloud; 2) to make sense of the whole scene and recognize the semantics of multiple functional components; 3) to complete the missing region in the original point cloud caused by occlusion during scanning. It is necessary to extract point cloud feature in order to fuse multiple real scene scans into an integrated point cloud, which can be invariant to scanning position and rotation. Thus, intrinsic geometry features like point distance and singular value in neighborhood covariance matrix are often involved in rotation-invariant feature design. Contrastive learning scheme is usually taken to help the learned features from the same area to be close to each other, while extracted features from different areas to be far away. To get generalization ability better, data augmentation of scanned point cloud can also be used during feature learning process. Features-learnt pose estimation of scanning device can be configured to calculate the transformation matrix between point cloud pairs. After the transformation relationship is sorted out, the following point cloud fusion can be implemented using the raw point cloud scans. To further understand raw point cloud-based whole scene and segment the whole scene into functional parts on the basis of multiple semantics, an effective and efficient network with appropriate 3D convolution operation is required to parse entire points-based scene hierarchically, and specific learning schemes are necessary as well to adapt to various situation. The definition and formulation of basic convolution operation in 3D space is recognized as the core of pattern recognition for 3D scene point cloud. It is highly correlated to the approximated convolution kernel in 3D space where feature extraction can be developed in terms of appropriate point cloud grouping and down/up-sampling. The discrete approximation of 3D continuous convolution pursues being capable of recognizing various geometry pattern while keeping as few parameters as possible. Network design based on these elementary 3D convolution operations is also a fundamental part of outstanding scene parsing. Furthermore, point-level semantic segmentation of scanned scene can be linked mutually in relevance to such aspects of boundary detection, instance segmentation, and scene coloring, where network parameters are supervised through more auxiliary regularization. Semi-supervised methods and weak-supervised methods are required to overcome the lack of data annotation for real data. The segmentation results and semantic hints can be used to strengthen the fine-grained completion of object point cloud from scanned scene, in which the segmented objects can be handled separately, and semantics can be used to provide the structure and geometry prior when occlusion-derived missing region is completed. For the learning of object point cloud completion, it is crucial to learn a compact latent code space to represent all the complete shapes and design versatile decoder to reconstruct the structure and fine-grained geometry details of object point cloud. The learnt latent code space should contain complete shapes as much as possible, thus requiring large-scale synthetic model dataset for training to ensure the generalization ability. The encoder should be designed to recognize the structure of original point cloud and extract specific geometry pattern which preserves this information in latent code, while the decoder is used to recover the overall skeleton of original scanned objects and complete all the details according to the existing local geometry hints. For real scanned object completion, it is required to optimize the integration of latent code space further for synthetic models and real scanned point cloud. A cross-domain learning scheme is used to apply the knowledge of completion to real object scans, whereas the details of real scanned object can be preserved in the completed version. We analyze the current situation about scene understanding and reconstruction, including point cloud fusion, 3D convolution operation, entire scene segmentation, and fine-grained object completion. We analyze the frontier technologies and predict promising future research trends. It is significant for the following research to pay more attention on more open space with further challenges on computing efficiency, handling out-of-domain knowledge, and more complex situation with human-scene interaction. The 3D scene understanding and reconstruction technology will help the machine to understand the real world in a more natural way which can facilitate such various application domains like robots and navigation. It also potential to conduct plausible simulation of real world based on the reconstruction and parsing of real scenes, making it a useful tool in making various decisions.关键词:3D scenes;point could fusion;scene segmentation;object shape completion;deep learning376|1844|4更新时间:2024-05-07
Object Detection and Image Reconstruction
-
 摘要:Text recognition is focused on text transcription-based image processing modeling in relevance to such domains like document digitization, content moderation, scene text translation, automation driving, scene understanding, and other related contexts. Conventional text recognition techniques are often concerned about characters-seen recognition more. However, two factors in the training set of these methods are yet to be well covered, which are novel character categories and out-of-vocabulary (OOV) samples. Newly characters-related samples are often linked with OOV-based samples. However, it may pay attention to seen characters without novel combinations or contexts. For novel character categories, internet-based environments can be mainly used to face unseen ligatures like 1) emoticons and unperceived languages, 2) scene-text recognition environments, and 3) characters from foreign and region-specific languages. For digitization profiling, the undiscovered characters may not be involved in as well. Since the heterogeneity of language format to be balanced, the linguistic statistic data (e.g., n-gram, context, etc.) can be biased the training data gradually, which is challenged for vocabulary-high-correlated text recognition methods. The two factors are required to yield three key scientific problems that affect the costs or efficiency in open-world applications. The novel characters are oriented for the novel spotting capability, whereas characters-unseen are rejected to replace silent seen characters. Furthermore, as the popular open-set recognition problem, three scientific problems can be leaked out as mentioned below. First, the emergence of novel characters is not efficient in many cases, in which re-training upon each occurrence is costly, and an incremental learning capability need to be strengthened after that. Second, an amount of attention is received as the generalized zero-shot learning text recognition task. Third, Linguistic bias robustness is yielded by the OOV samples. Due to the character-based nature prediction, more popular methods can be used to possess the capability to handle characters-seen OOV samples to some extent. However, such capabilities are constrained to demonstrate strong vocabulary reliance because of the capacity of language models, the open-set text recognition (OSTR) task is feasible since existing tasks like zero-shot text recognition and OOV recognition can be used to model individual aspects of the problems only. This task aims to spot and recognize the novel characters, which is robust to linguistic skews. As an extension of the conventional text recognition task, the OSTR task is used to retain a decent recognition capability on seen contents. In recent years, the OSTR task has been developing intensively in the context of character recognition. The literature review is carried out on the open-set text recognition task and its related domains. It consists of such five aspects of the background, genericity, the concept, implementation, and summary. For the background, we introduce the application background of the OSTR task and analyze the specific OSTR-derived cases. For genericity, the generic open-set recognition is introduced in brief as a preliminary of the OSTR task that is less familiar to some researchers in the text recognition field. For concept, the definition of the OSTR task is introduced, followed by a discussion on its relationship with existing text recognition tasks, e.g., conventional close-set text recognition task and the zero-shot text recognition task. Its implementation-wise, common text recognition frameworks are first introduced. For implementation, it can be recognized as derivations of such frameworks, where the derivation is based on the three key scientific problems as following: new category spotting, incremental recognition of novel classes, and linguistic bias robustness. Specifically, the new category spotting problem refers to rejecting samples that come from an absent class of a given label set. Slightly different from the generic open-set text recognition task, the given label-set is challenged in related to the training data straightfoward. Incremental recognition refers to new categories recognition in terms of the non-retrained side information of the corresponding categories. The definition is slightly different from the common zero-shot learning definition, it can be excluded some generative adversarial network (GAN)-based transductive approaches. The linguistic bias robustness holds its original definition beyond more stressed unseen characters. For each scientific problem, its solution can be covered in text recognition and other modeling-similar related fields. The evaluation is carried out and it can mainly cover the datasets and protocols used in the OSTR task and its contexts as listed: 1) multiple protocols based public available datasets, 2) commonly used metric to measure model performance, and 3) several of popular protocols, typical methods, and the performance. Here, a protocol refers to the compositions of training sets, testing sets, and evaluation metrics. For summary, the comparative analysis of the growth and technical preference are demonstrated. Finally, the potnetialss of the trends and future research directions are predicted further.关键词:character recognition;open set recognition;open-set text recognition (OSTR);close-set text recognition;zero-set text recognition208|567|2更新时间:2024-05-07
摘要:Text recognition is focused on text transcription-based image processing modeling in relevance to such domains like document digitization, content moderation, scene text translation, automation driving, scene understanding, and other related contexts. Conventional text recognition techniques are often concerned about characters-seen recognition more. However, two factors in the training set of these methods are yet to be well covered, which are novel character categories and out-of-vocabulary (OOV) samples. Newly characters-related samples are often linked with OOV-based samples. However, it may pay attention to seen characters without novel combinations or contexts. For novel character categories, internet-based environments can be mainly used to face unseen ligatures like 1) emoticons and unperceived languages, 2) scene-text recognition environments, and 3) characters from foreign and region-specific languages. For digitization profiling, the undiscovered characters may not be involved in as well. Since the heterogeneity of language format to be balanced, the linguistic statistic data (e.g., n-gram, context, etc.) can be biased the training data gradually, which is challenged for vocabulary-high-correlated text recognition methods. The two factors are required to yield three key scientific problems that affect the costs or efficiency in open-world applications. The novel characters are oriented for the novel spotting capability, whereas characters-unseen are rejected to replace silent seen characters. Furthermore, as the popular open-set recognition problem, three scientific problems can be leaked out as mentioned below. First, the emergence of novel characters is not efficient in many cases, in which re-training upon each occurrence is costly, and an incremental learning capability need to be strengthened after that. Second, an amount of attention is received as the generalized zero-shot learning text recognition task. Third, Linguistic bias robustness is yielded by the OOV samples. Due to the character-based nature prediction, more popular methods can be used to possess the capability to handle characters-seen OOV samples to some extent. However, such capabilities are constrained to demonstrate strong vocabulary reliance because of the capacity of language models, the open-set text recognition (OSTR) task is feasible since existing tasks like zero-shot text recognition and OOV recognition can be used to model individual aspects of the problems only. This task aims to spot and recognize the novel characters, which is robust to linguistic skews. As an extension of the conventional text recognition task, the OSTR task is used to retain a decent recognition capability on seen contents. In recent years, the OSTR task has been developing intensively in the context of character recognition. The literature review is carried out on the open-set text recognition task and its related domains. It consists of such five aspects of the background, genericity, the concept, implementation, and summary. For the background, we introduce the application background of the OSTR task and analyze the specific OSTR-derived cases. For genericity, the generic open-set recognition is introduced in brief as a preliminary of the OSTR task that is less familiar to some researchers in the text recognition field. For concept, the definition of the OSTR task is introduced, followed by a discussion on its relationship with existing text recognition tasks, e.g., conventional close-set text recognition task and the zero-shot text recognition task. Its implementation-wise, common text recognition frameworks are first introduced. For implementation, it can be recognized as derivations of such frameworks, where the derivation is based on the three key scientific problems as following: new category spotting, incremental recognition of novel classes, and linguistic bias robustness. Specifically, the new category spotting problem refers to rejecting samples that come from an absent class of a given label set. Slightly different from the generic open-set text recognition task, the given label-set is challenged in related to the training data straightfoward. Incremental recognition refers to new categories recognition in terms of the non-retrained side information of the corresponding categories. The definition is slightly different from the common zero-shot learning definition, it can be excluded some generative adversarial network (GAN)-based transductive approaches. The linguistic bias robustness holds its original definition beyond more stressed unseen characters. For each scientific problem, its solution can be covered in text recognition and other modeling-similar related fields. The evaluation is carried out and it can mainly cover the datasets and protocols used in the OSTR task and its contexts as listed: 1) multiple protocols based public available datasets, 2) commonly used metric to measure model performance, and 3) several of popular protocols, typical methods, and the performance. Here, a protocol refers to the compositions of training sets, testing sets, and evaluation metrics. For summary, the comparative analysis of the growth and technical preference are demonstrated. Finally, the potnetialss of the trends and future research directions are predicted further.关键词:character recognition;open set recognition;open-set text recognition (OSTR);close-set text recognition;zero-set text recognition208|567|2更新时间:2024-05-07 -
 摘要:The deep neural networks (DNNs)-relevant artificial intelligence (AI) technique has been developing intensively in the context of such domains like computer vision, pattern analysis, natural language processing, bioinformatics, and games. Especially, AI models have been widely deployed in the cloud by technology companies to provide smart and personalized services. However, creating state-of-the-art AI models requires a lot of high-quality data, powerful computing resources and expert knowledge of the architecture design. Furthermore, AI models are threatened to be copied, tampered and redistributed in an unauthorized manner. It indicates that it is necessary to protect the AI models against intellectual property infringement, which yields researchers to concern about the intellectual property protection. Current techniques are concerned of digital watermarking for intellectual property protection of AI models, which is referred to AI model watermarking. The core of AI model watermarking is to embed a secret watermark revealing the ownership of the AI model to be protected into the AI model through an imperceptible way. However, unlike many multimedia watermarking methods that treat media data as a static signal, AI model watermarking is required to embed information into an AI model with a specific task. We cannot directly apply conventional multimedia watermarking methods to AI models since simply modifying a given AI model may significantly impair the performance of the AI model on its original task. It motivates people to design watermarking methods specifically for AI models. For embedding a watermark, the performance of the watermarked AI model on its original task should not be degraded significantly and the embedded watermark concealed in the watermarked AI model should be able to be extracted to identify the ownership of the AI model when disputes arise. Considering whether the watermark extractor should know the internal details of the target AI model or not, we can divide existing methods into two categories, i.e., white-box AI model watermarking and black-box AI model watermarking. For white-box AI model watermarking, the watermark extractor should know the internal details of the target watermarked AI model so that he can extract the embedded watermark from model parameters or model structures. For black-box AI model watermarking, the watermark extractor does not know the internal details of the target watermarked AI model, but he has the ability to query the prediction results of the target model in correspondence to a set of trigger samples. The trigger samples are carefully crafted. By checking whether the prediction results are consistent with the pre-specific labels of the trigger samples, the watermark extractor is capable of determining the ownership of the target watermarked AI model. A special case of black-box AI model watermarking is box-free AI model watermarking, in which the watermark extractor has no access to the target model. It means that the watermark extractor cannot know the internal details of the model and interact with the model. However, the watermark extractor can extract the watermark from any sample generated by the target model. The ownership can be verified via extracting the watermark from the output. In addition, fragile AI model watermarking has also been investigated recently. Unlike many methods that focus on robust verification, fragile model watermarking enables us to detect whether the target model was modified or not, thereby achieving integrity verification of the target model. To review the latest developments and trends, advanced methodologies in AI model watermarking are analyzed as mentioned below: 1) the aims and objectives, basic concepts, evaluation metrics and technical classification of AI model watermarking are introduced. 2) Current development status of AI model watermarking is summarized and analyzed. 3) Such pros and cons are compared and analyzed as well. 4)The prospects for the development trend of AI model watermarking and the potentials of AI model watermarking in relevance to AI security are provided.关键词:model watermarking;digital watermarking;information hiding;artificial intelligence security;intellectual property protection607|263|7更新时间:2024-05-07
摘要:The deep neural networks (DNNs)-relevant artificial intelligence (AI) technique has been developing intensively in the context of such domains like computer vision, pattern analysis, natural language processing, bioinformatics, and games. Especially, AI models have been widely deployed in the cloud by technology companies to provide smart and personalized services. However, creating state-of-the-art AI models requires a lot of high-quality data, powerful computing resources and expert knowledge of the architecture design. Furthermore, AI models are threatened to be copied, tampered and redistributed in an unauthorized manner. It indicates that it is necessary to protect the AI models against intellectual property infringement, which yields researchers to concern about the intellectual property protection. Current techniques are concerned of digital watermarking for intellectual property protection of AI models, which is referred to AI model watermarking. The core of AI model watermarking is to embed a secret watermark revealing the ownership of the AI model to be protected into the AI model through an imperceptible way. However, unlike many multimedia watermarking methods that treat media data as a static signal, AI model watermarking is required to embed information into an AI model with a specific task. We cannot directly apply conventional multimedia watermarking methods to AI models since simply modifying a given AI model may significantly impair the performance of the AI model on its original task. It motivates people to design watermarking methods specifically for AI models. For embedding a watermark, the performance of the watermarked AI model on its original task should not be degraded significantly and the embedded watermark concealed in the watermarked AI model should be able to be extracted to identify the ownership of the AI model when disputes arise. Considering whether the watermark extractor should know the internal details of the target AI model or not, we can divide existing methods into two categories, i.e., white-box AI model watermarking and black-box AI model watermarking. For white-box AI model watermarking, the watermark extractor should know the internal details of the target watermarked AI model so that he can extract the embedded watermark from model parameters or model structures. For black-box AI model watermarking, the watermark extractor does not know the internal details of the target watermarked AI model, but he has the ability to query the prediction results of the target model in correspondence to a set of trigger samples. The trigger samples are carefully crafted. By checking whether the prediction results are consistent with the pre-specific labels of the trigger samples, the watermark extractor is capable of determining the ownership of the target watermarked AI model. A special case of black-box AI model watermarking is box-free AI model watermarking, in which the watermark extractor has no access to the target model. It means that the watermark extractor cannot know the internal details of the model and interact with the model. However, the watermark extractor can extract the watermark from any sample generated by the target model. The ownership can be verified via extracting the watermark from the output. In addition, fragile AI model watermarking has also been investigated recently. Unlike many methods that focus on robust verification, fragile model watermarking enables us to detect whether the target model was modified or not, thereby achieving integrity verification of the target model. To review the latest developments and trends, advanced methodologies in AI model watermarking are analyzed as mentioned below: 1) the aims and objectives, basic concepts, evaluation metrics and technical classification of AI model watermarking are introduced. 2) Current development status of AI model watermarking is summarized and analyzed. 3) Such pros and cons are compared and analyzed as well. 4)The prospects for the development trend of AI model watermarking and the potentials of AI model watermarking in relevance to AI security are provided.关键词:model watermarking;digital watermarking;information hiding;artificial intelligence security;intellectual property protection607|263|7更新时间:2024-05-07 -
 摘要:Human-cardiovascular disease is challenged for its high morbidity and severe sequelae nowadays. To meet the need of the medical industry, current medical image analysis is facilitated via the development of deep learning. Conventional image processing technology is processed basically in terms of thresholding. The emerging deep learning technique can be focused on reality-oriented function in terms of specific eigenvalues. Such deep residual network and generative confrontation network have its potentials for its effectiveness and robust originated from good learning ability and data-driven factors. Our critical analysis is based on 1) characteristics of representative methods, 2) resources and scale of cardiac images, 3) comparative study of the performance evaluation and application conclusions of different methods through popular evaluation indicators, and 4) clinical domains are discussed as well. The literature review is originated from IEEE, SPIE, and China National Knowledge Network, with image processing and heart as search keywords. The difference between image processing methods is evaluated in terms of Dice coefficient and Hausdorff distance, and the performance is evaluated in quantitative further. For chamber segmentation, several approaches for right ventricle segmentation are reviewed and analyzed. As far as the principle of the segmentation method is concerned, the single of threshold is still challenged for segmentation unless it is integrated into other related methods, so it cannot be used as a single zone in segmentation technique. A brief theoretical introduction is mentioned for each method. Then, its methodology, prior datasets, and the effectiveness of segmentation process are involved in evaluation. Finally, the pros and cons of each method are analyzed as well. For the domain of epicardium and pericardium tissue, we will briefly introduce the popular image processing techniques for segmenting epicardium and pericardium tissue. Four category of key methods are analyzed in relevance to its: traditional image processing methods, atlas-based methods, machine learning, and deep learning. Traditional image processing methods are composed of such techniques of thresholding, region growing, and active contouring. Finally, Dice coefficient-derived capabilities of each algorithm are compared horizontally. For the segmentation method of the epicardium, it is easier to segment the epicardium into pericardium-illustrated coordination. Epicardial and pericardial fatty tissue are unevenly distributed around the heart, resulting in large sections-between variability and the images-between for its computed tomography(CT) and magnetic resonance imaging(MRI). The heterogeneity in shape is required to demonstrate further. However, the pericardium is featured of more smoother, thinner and oval in CT and MRI images. Such methods of active contours or ellipse fitting are suitable for segmenting such shapes naturally. Once the pericardium is divided, the epicardium is more easily divided into all pericardium-within fatty tissue. The great challenge is focused on epicardium-thinner segmentation. The slice of thickness can be set at 2~3 mm when CT scans are collected for coronary artery calcification(CAC) scoring. The pericardium is usually less than 2 mm thick, and it will often appear blurred or blurred on CT images in accordance with partial volume averaging, especially for heart organ-moving consistency. Some methods are purely pericardial delineation methods, while others are part of a method to segment and quantify the epicardium. For the epicardium part, we will mainly introduce the method of epicardium segmentation by the first pericardium-segmented. Pericardial fat segmentation methods typically rely on traditional image processing methods, such as 1) thresholding and region growing, and 2) various preprogrammed heuristics can be used to identify common structures and segment pericardial fat. Recent atlas-based segmentation approaches are employed but its clinical ability is relatively weakened. After current situation of segmentation is introduced, we will introduce some real scenarios applied in clinical practice. We can see that cardiac image processing has a large number of clinical problems are required to be solved. At the same time, we will briefly introduce the market situation of image processing in domestic market, integration of industry, education and research, and the main relevant policy trends. the development of the main related industries is introduced and involve in like 1) the establishment of related imaging databases in China, 2) the development of related imaging technologies in China, and 3) the development of related hardware equipment in China. At the end, it is discussed that the development of cardiac image segmentation processing is increasingly inseparable in related to the development of deep learning. However, because deep learning itself is difficult to be explained, we called on medical knowledge-interpreted method models, and deep learning based constraints are called to be resolved further, such homogeneity data sets and its related of higher accuracy.关键词:image segementation;whole heart segmentation;epicardium;pericardial fat;auxiliary detection600|611|0更新时间:2024-05-07
摘要:Human-cardiovascular disease is challenged for its high morbidity and severe sequelae nowadays. To meet the need of the medical industry, current medical image analysis is facilitated via the development of deep learning. Conventional image processing technology is processed basically in terms of thresholding. The emerging deep learning technique can be focused on reality-oriented function in terms of specific eigenvalues. Such deep residual network and generative confrontation network have its potentials for its effectiveness and robust originated from good learning ability and data-driven factors. Our critical analysis is based on 1) characteristics of representative methods, 2) resources and scale of cardiac images, 3) comparative study of the performance evaluation and application conclusions of different methods through popular evaluation indicators, and 4) clinical domains are discussed as well. The literature review is originated from IEEE, SPIE, and China National Knowledge Network, with image processing and heart as search keywords. The difference between image processing methods is evaluated in terms of Dice coefficient and Hausdorff distance, and the performance is evaluated in quantitative further. For chamber segmentation, several approaches for right ventricle segmentation are reviewed and analyzed. As far as the principle of the segmentation method is concerned, the single of threshold is still challenged for segmentation unless it is integrated into other related methods, so it cannot be used as a single zone in segmentation technique. A brief theoretical introduction is mentioned for each method. Then, its methodology, prior datasets, and the effectiveness of segmentation process are involved in evaluation. Finally, the pros and cons of each method are analyzed as well. For the domain of epicardium and pericardium tissue, we will briefly introduce the popular image processing techniques for segmenting epicardium and pericardium tissue. Four category of key methods are analyzed in relevance to its: traditional image processing methods, atlas-based methods, machine learning, and deep learning. Traditional image processing methods are composed of such techniques of thresholding, region growing, and active contouring. Finally, Dice coefficient-derived capabilities of each algorithm are compared horizontally. For the segmentation method of the epicardium, it is easier to segment the epicardium into pericardium-illustrated coordination. Epicardial and pericardial fatty tissue are unevenly distributed around the heart, resulting in large sections-between variability and the images-between for its computed tomography(CT) and magnetic resonance imaging(MRI). The heterogeneity in shape is required to demonstrate further. However, the pericardium is featured of more smoother, thinner and oval in CT and MRI images. Such methods of active contours or ellipse fitting are suitable for segmenting such shapes naturally. Once the pericardium is divided, the epicardium is more easily divided into all pericardium-within fatty tissue. The great challenge is focused on epicardium-thinner segmentation. The slice of thickness can be set at 2~3 mm when CT scans are collected for coronary artery calcification(CAC) scoring. The pericardium is usually less than 2 mm thick, and it will often appear blurred or blurred on CT images in accordance with partial volume averaging, especially for heart organ-moving consistency. Some methods are purely pericardial delineation methods, while others are part of a method to segment and quantify the epicardium. For the epicardium part, we will mainly introduce the method of epicardium segmentation by the first pericardium-segmented. Pericardial fat segmentation methods typically rely on traditional image processing methods, such as 1) thresholding and region growing, and 2) various preprogrammed heuristics can be used to identify common structures and segment pericardial fat. Recent atlas-based segmentation approaches are employed but its clinical ability is relatively weakened. After current situation of segmentation is introduced, we will introduce some real scenarios applied in clinical practice. We can see that cardiac image processing has a large number of clinical problems are required to be solved. At the same time, we will briefly introduce the market situation of image processing in domestic market, integration of industry, education and research, and the main relevant policy trends. the development of the main related industries is introduced and involve in like 1) the establishment of related imaging databases in China, 2) the development of related imaging technologies in China, and 3) the development of related hardware equipment in China. At the end, it is discussed that the development of cardiac image segmentation processing is increasingly inseparable in related to the development of deep learning. However, because deep learning itself is difficult to be explained, we called on medical knowledge-interpreted method models, and deep learning based constraints are called to be resolved further, such homogeneity data sets and its related of higher accuracy.关键词:image segementation;whole heart segmentation;epicardium;pericardial fat;auxiliary detection600|611|0更新时间:2024-05-07 -
 摘要:Person re-Identification (person re-ID) technique aims to solve the problem of association and matching of target person images across multiple cameras within a camera network of a surveillance system, especially in the case of face, iris and other biometrics recognition failure under non-cooperative application scenarios, and has become one of the key component and supporting technique for intelligent video surveillance systems and applications in intelligent public security and smart cities. Recently, person re-ID has attracted more and more attention from both academia and industry, and has made rapid development and progress. To meet the requirement of its technical challenges and application needs of person re-ID in practical scenarios, this paper will first give a brief introduction to the development history, commonly used datasets and evaluation metrics. Then, the recent progress in hot research topics of person re-ID is extensively reviewed and analyzed, which includes: occluded person re-ID, unsupervised person re-ID, virtual data generation, domain generalization, cloth-changing person re-ID, cross-modal person re-ID and person search. First, to address the problem of impact of possible occlusions on the performance of person re-ID, recent progress in occluded person re-ID is first reviewed, in which the popular datasets for occluded person re-ID are briefly introduced, and the two major categories of occluded person re-ID models are then further reviewed. Second, facing the challenges of low-efficiency and high-cost data annotation and great impact of training data on the performance of person re-ID, unsupervised person re-ID and virtual data generation for person re-ID emerges as two hot topics in person re-ID. The paper elaborates the recent advances of unsupervised person re-ID, which can be classified into three major categories: pseudo label generation-based models, domain transfer-based models, and other related models, which take into consideration of the extra information like time-stamps, camera labels besides person image. Third, the-state-of-the-art works on virtual data generation for person re-ID are reviewed, with detailed introduction and performance comparisons of major virtual datasets. Fourth, recent researches on domain generalization person re-ID will be reviewed,which are classified into five categories: batch/instance normalization models, domain invariant feature learning models, deep-learning-based explicit image matching models, models based on mixture of experts and meta-learning-based models. Fifth, since most current person re-ID models largely depend on the color appearance of persons’ clothes, clothes-changing person re-ID becomes a challenging setting, in which person images can exhibit large intra-class variation and small inter-class variation. Typical cloth-changing person re-ID datasets are introduced and the recent researches will then be reviewed, in which models in the first category explicitly introduces extra cloth-appearance-independent features like contour and face while the second try to decouple the cloth features and person ID features. Sixth, to compensate the drawbacks of conventional person re-ID of visible light/RGB images in natural complex scenes like poor lighting conditions in the night, the-state-of-the-art of cross-modal person re-ID, which aims to resolve the problem through other visible RGB images-excluded heterogeneous data, are reviewed, with a brief introduction of commonly used cross-modal person re-ID datasets first and then four sub-categories models according to the different modalities employed, including: RGB-infrared image person re-ID, RGB image-text person re-ID, RGB image-sketch person re-ID, and RGB-depth image person re-ID, respectively. Seventh, since existing person re-ID benchmarks and methods mainly focus on matching cropped person images between queries and candidates and is different from practical scenarios where the bounding box annotations of persons are often unavailable, person search, which jointly considers person detection and person re-ID in a single framework, becomes a new hot research topic. The typical datasets and recent progress on person search are reviewed. Finally, the existing challenges and development trend of person re-ID techniques are discussed. It is hoped that the summary and analysis can provide reference for relevant researchers to carry out research on person re-ID and promote the progress of person re-ID techniques and applications.关键词:intelligent video surveillance;occluded person re-ID;unsupervised person re-ID;virtual data generation;domain generalization person re-ID;cloth-changing person re-ID;cross-modal person re-ID;person search291|1872|2更新时间:2024-05-07
摘要:Person re-Identification (person re-ID) technique aims to solve the problem of association and matching of target person images across multiple cameras within a camera network of a surveillance system, especially in the case of face, iris and other biometrics recognition failure under non-cooperative application scenarios, and has become one of the key component and supporting technique for intelligent video surveillance systems and applications in intelligent public security and smart cities. Recently, person re-ID has attracted more and more attention from both academia and industry, and has made rapid development and progress. To meet the requirement of its technical challenges and application needs of person re-ID in practical scenarios, this paper will first give a brief introduction to the development history, commonly used datasets and evaluation metrics. Then, the recent progress in hot research topics of person re-ID is extensively reviewed and analyzed, which includes: occluded person re-ID, unsupervised person re-ID, virtual data generation, domain generalization, cloth-changing person re-ID, cross-modal person re-ID and person search. First, to address the problem of impact of possible occlusions on the performance of person re-ID, recent progress in occluded person re-ID is first reviewed, in which the popular datasets for occluded person re-ID are briefly introduced, and the two major categories of occluded person re-ID models are then further reviewed. Second, facing the challenges of low-efficiency and high-cost data annotation and great impact of training data on the performance of person re-ID, unsupervised person re-ID and virtual data generation for person re-ID emerges as two hot topics in person re-ID. The paper elaborates the recent advances of unsupervised person re-ID, which can be classified into three major categories: pseudo label generation-based models, domain transfer-based models, and other related models, which take into consideration of the extra information like time-stamps, camera labels besides person image. Third, the-state-of-the-art works on virtual data generation for person re-ID are reviewed, with detailed introduction and performance comparisons of major virtual datasets. Fourth, recent researches on domain generalization person re-ID will be reviewed,which are classified into five categories: batch/instance normalization models, domain invariant feature learning models, deep-learning-based explicit image matching models, models based on mixture of experts and meta-learning-based models. Fifth, since most current person re-ID models largely depend on the color appearance of persons’ clothes, clothes-changing person re-ID becomes a challenging setting, in which person images can exhibit large intra-class variation and small inter-class variation. Typical cloth-changing person re-ID datasets are introduced and the recent researches will then be reviewed, in which models in the first category explicitly introduces extra cloth-appearance-independent features like contour and face while the second try to decouple the cloth features and person ID features. Sixth, to compensate the drawbacks of conventional person re-ID of visible light/RGB images in natural complex scenes like poor lighting conditions in the night, the-state-of-the-art of cross-modal person re-ID, which aims to resolve the problem through other visible RGB images-excluded heterogeneous data, are reviewed, with a brief introduction of commonly used cross-modal person re-ID datasets first and then four sub-categories models according to the different modalities employed, including: RGB-infrared image person re-ID, RGB image-text person re-ID, RGB image-sketch person re-ID, and RGB-depth image person re-ID, respectively. Seventh, since existing person re-ID benchmarks and methods mainly focus on matching cropped person images between queries and candidates and is different from practical scenarios where the bounding box annotations of persons are often unavailable, person search, which jointly considers person detection and person re-ID in a single framework, becomes a new hot research topic. The typical datasets and recent progress on person search are reviewed. Finally, the existing challenges and development trend of person re-ID techniques are discussed. It is hoped that the summary and analysis can provide reference for relevant researchers to carry out research on person re-ID and promote the progress of person re-ID techniques and applications.关键词:intelligent video surveillance;occluded person re-ID;unsupervised person re-ID;virtual data generation;domain generalization person re-ID;cloth-changing person re-ID;cross-modal person re-ID;person search291|1872|2更新时间:2024-05-07 -
 摘要:The six degree of freedom based (6DoF-based ) video technique is featured by interaction between video content and users, and it is focused on its 1) linear-derived multiple capacities, 2) horizontal straightness, 3) vertical straightness, 4) pitch, 5) yaw, and 6) roll motions of users. In this manner, users can change multiple audio-visual dimensions, including: viewing perspective, lighting condition or directions, focal length or spot, field of view through ground truth-compared computational or synthesized content reconstruction. The 6DoF video can be used to change conventional behavior of video watching, in which the user-video interaction is limited to different span of channels and the relations between video contents is restricted as well. The 6DoF-based technique can offer immersive experience for users because the homogeneity of video-watching receptive content can be in consistency per their motion. In this way, the 6DoF video can be recognized as an epoch-making type of video for academia and industries. At the same time, metaverse-driven 6DoF video has also been recognized as a new generation of interactive media technology, which is recognized as one of the key technologies for Metaversein related domains. All these features make users experience feel depth-immersive and diversified. This mutual-benefited status is in relevance to the metaverse-based perception, computing, reconstruction, collaboration, interaction, and other related technical features. Basically, 6DoF video is originated from the framework of typical multimedia communication system, where it can be suitable to meet the basic procedure requirement of video-contextual multimedia communication like its capturing, content process, video compression, transmission, decode and display. To realize intelligent human-terminal interaction, it brings a new look beyond traditional 3D video communication system, and the requirements for interaction range and intelligence are still acomplicated. Therefore, such newly techniques are in support of new type of video to a certain extent. Our proposed technical framework of 6DoF-relevant multimedia communication system is demonstrated on the three aspects of generation, distribution, and visualization. Forty scientific and technical challenges of this domain are illustrated and it can be categorized them into 10 different directions. We carry out literature review of its growth of per one of these 10 directions on the aspects of content acquisition and pre-processing, coding compression and transmission optimization, interaction, and presentation. For techniques analysis, it is focused on such aspects of 1) content generation-derived multiview video-captured content, 2) multiview video plus depth, and 3) point cloud. The data-acquired systems can be categorized by 2 types of multiview and multiview plus depth system, and different types of contents can be thus obtained via these systems. To describe the 3D structure of the spot scene initially, multiview color videos can be captured without any affiliated information, but it is a challenging issue for subsequent data processing techniques. After that, multiview plus depth system is proposed to handle this problem, while data can be classified into two types of i) color plus depth and ii) point cloud. Data-heteogenous volume is a big challenge for these kinds of data representation to some extent. The video compression techniques-after can be focused on in terms of the video contents. Popular compression techniques for multiview video, multiview video plus depth, light fields, and point clouds are discussed further, including their origination, mechanism, performance, and credible application standards. Subsequently, transmission techniques for 6DoF video are illustrated as well after the video bitstream is obtained. Such techniques like bit allocation, interaction oriented transmission, standards and protocols are all mentioned and discussed. Its quality evaluation and synthesized-view for user-terminal interaction are analyzed as well. It can be reached to user-friendly in terms of a “capture to display” based 6DoF video system. Pixel-based methods are still discussed and optimized but computational cost is challenged there. Recent learning based methods are more concerned about terminal-oriented applications, especially for its synthesized view. To meet the requirements from practical applications, 40 scientific and technical challenges mentioned above are still to be resolved further.关键词:metaverse;six degree of freedom (6DoF) video;content capturing;coding compression;view synthesis273|1112|4更新时间:2024-05-07
摘要:The six degree of freedom based (6DoF-based ) video technique is featured by interaction between video content and users, and it is focused on its 1) linear-derived multiple capacities, 2) horizontal straightness, 3) vertical straightness, 4) pitch, 5) yaw, and 6) roll motions of users. In this manner, users can change multiple audio-visual dimensions, including: viewing perspective, lighting condition or directions, focal length or spot, field of view through ground truth-compared computational or synthesized content reconstruction. The 6DoF video can be used to change conventional behavior of video watching, in which the user-video interaction is limited to different span of channels and the relations between video contents is restricted as well. The 6DoF-based technique can offer immersive experience for users because the homogeneity of video-watching receptive content can be in consistency per their motion. In this way, the 6DoF video can be recognized as an epoch-making type of video for academia and industries. At the same time, metaverse-driven 6DoF video has also been recognized as a new generation of interactive media technology, which is recognized as one of the key technologies for Metaversein related domains. All these features make users experience feel depth-immersive and diversified. This mutual-benefited status is in relevance to the metaverse-based perception, computing, reconstruction, collaboration, interaction, and other related technical features. Basically, 6DoF video is originated from the framework of typical multimedia communication system, where it can be suitable to meet the basic procedure requirement of video-contextual multimedia communication like its capturing, content process, video compression, transmission, decode and display. To realize intelligent human-terminal interaction, it brings a new look beyond traditional 3D video communication system, and the requirements for interaction range and intelligence are still acomplicated. Therefore, such newly techniques are in support of new type of video to a certain extent. Our proposed technical framework of 6DoF-relevant multimedia communication system is demonstrated on the three aspects of generation, distribution, and visualization. Forty scientific and technical challenges of this domain are illustrated and it can be categorized them into 10 different directions. We carry out literature review of its growth of per one of these 10 directions on the aspects of content acquisition and pre-processing, coding compression and transmission optimization, interaction, and presentation. For techniques analysis, it is focused on such aspects of 1) content generation-derived multiview video-captured content, 2) multiview video plus depth, and 3) point cloud. The data-acquired systems can be categorized by 2 types of multiview and multiview plus depth system, and different types of contents can be thus obtained via these systems. To describe the 3D structure of the spot scene initially, multiview color videos can be captured without any affiliated information, but it is a challenging issue for subsequent data processing techniques. After that, multiview plus depth system is proposed to handle this problem, while data can be classified into two types of i) color plus depth and ii) point cloud. Data-heteogenous volume is a big challenge for these kinds of data representation to some extent. The video compression techniques-after can be focused on in terms of the video contents. Popular compression techniques for multiview video, multiview video plus depth, light fields, and point clouds are discussed further, including their origination, mechanism, performance, and credible application standards. Subsequently, transmission techniques for 6DoF video are illustrated as well after the video bitstream is obtained. Such techniques like bit allocation, interaction oriented transmission, standards and protocols are all mentioned and discussed. Its quality evaluation and synthesized-view for user-terminal interaction are analyzed as well. It can be reached to user-friendly in terms of a “capture to display” based 6DoF video system. Pixel-based methods are still discussed and optimized but computational cost is challenged there. Recent learning based methods are more concerned about terminal-oriented applications, especially for its synthesized view. To meet the requirements from practical applications, 40 scientific and technical challenges mentioned above are still to be resolved further.关键词:metaverse;six degree of freedom (6DoF) video;content capturing;coding compression;view synthesis273|1112|4更新时间:2024-05-07 -
 摘要:Forest is a sort of highly complex and important ecosystem and it is still challenged by such severe forest fires. To strengthen the information-driven ability of forest fire emergency management decision-making, it is required to build a forest fire virtual simulation platform in terms of virtual reality and visualization technology. Therefore, our review analysis is focused on a virtual reality and visualization-based forest fire virtual simulation platform for exploring the forest scene visualization and forest fire simulation technology, and it seeks to trace forest scenes, multi-source forest fire simulation, and its fire scene further. In order to provide visual decision-making support for fire rescue command and fire disaster assessment, information-driven forest fire emergency management decision-making is improved further. First, we discuss and analyze the highly realistic 3D visualization reconstruction technology of real forest landscapes, which is beneficial for a forest model library and realize highly realistic 3D visualization reconstruction of forest landscape areas. To establish a forest fire spread model and reflect the forest fire combustion process and pyrolysis-physical characteristics accurately and its combustion process-oriented real-time visual simulation, it is essential to develop the application of forest fire simulation technology and explore the mechanism of forest fire spread. The related methods are categorized into forest scene visualization and forest fire simulation technology, and the research growth of it is summarized as well. Forest scene visualization methods can be divided into mechanism-based tree modeling methods, including L system-based and custom sketch-based or interactive modeling methods, and forest stand characteristics-based natural scene reconstruction methods. That is, real-world forest stands feature data like images and point clouds are used to reconstruct forest trees. The two types of methods mentioned above are mostly used to construct single tree models as the theoretical basis for large-scale forest scene reconstruction. The mechanism-based tree modeling method can be used to balance the tree structure intuitively and flexibly, and it is more suitable for plant growth design, immersive creation, and other related fields; the forest stand characteristics-based real scene reconstruction method has high fidelity, and it is suitable for vegetation quantification, small-scale ecosystem simulation, and its contexts. Forest fire simulation technology is divided into three categories: physical model, empirical model, and semi-empirical model. The physical model can be well used to illustrate the physical and chemical reactions in the burning process of the forest fire and show the changes in the flame. The empirical model is used for the relevant data obtained from the experiment for mathematical fitting, which can simulate the forest fire spreading status in some typical scenarios, and the accuracy of the direction and rate of forest fire spread is guaranteed. For the semi-empirical model, the physical and chemical reactions in the process of forest fire spread and the statistical analysis methods in specific experiments used are considered at the same time, which reduces the computing cost of physical simulation and enables real-time simulation further. In addition, forest fire simulation can be a key aspect of immersive forest fire simulation and interactive fire extinguishing simulation research, and real forest scene visualization is on the basis of other related research. Real-time generation of realistic forest scenes is beneficial for the simulation of the forest fire. The immersion of the corresponding senses can be improved by constructing real forest scenes to approach the real situation of forest fires, and complex terrain and meteorological conditions can be simulated and visualized as well. Experience and realistic scene roaming can be one of the application scenarios for forest scene visualization technology. We link researches of 1) the growth of forest scene visualization and the forest fire simulation technology, 2) an immersive three-dimensional visual simulation of forest fire scene, and various forest fire ignition methods related to forest fire spread, and 3) fire extinguishing simulation together. Furthermore, most researches are focused on the forest fire spread model coupled in relevance to atmospheric, ecological, and hydrological models since a real and credible forest fire cannot be completely simulated only by forest scene visualization and forest fire simulation technology. To aid fire departments to alleviate deployment decisions, both the forest scene visualization and forest fire simulation technologies can be applied in the field of forest firefighting, strategic planning, and resource allocation via simulation-based planning methods. Finally, we summarize the relevance of forest scene visualization and forest fire simulation technology. Three types of models of forest fire spreading, physical, empirical, and semi-empirical are introduced in detail, in which task-based forest scene visualization into tree modeling methods are related to forest stand characteristics-based reconstruction methods, and the theoretical basis, scope of application, pros and, cons of forest scene visualization and forest fire simulation technology are explained as well. At the same time, it is essential to resolve some application problems in terms of large-scale scene rendering technology and forest fire protection, and a virtual reality and visualization technology-driven basis are offered for future construction of forest fire virtual simulation. The development trend of forest scene visualization and forest fire simulation technology is predicted further.关键词:tree modeling;forest scene visualization;forest fire simulation;forest fire spread model;fire extinguishing simulation technology288|528|0更新时间:2024-05-07
摘要:Forest is a sort of highly complex and important ecosystem and it is still challenged by such severe forest fires. To strengthen the information-driven ability of forest fire emergency management decision-making, it is required to build a forest fire virtual simulation platform in terms of virtual reality and visualization technology. Therefore, our review analysis is focused on a virtual reality and visualization-based forest fire virtual simulation platform for exploring the forest scene visualization and forest fire simulation technology, and it seeks to trace forest scenes, multi-source forest fire simulation, and its fire scene further. In order to provide visual decision-making support for fire rescue command and fire disaster assessment, information-driven forest fire emergency management decision-making is improved further. First, we discuss and analyze the highly realistic 3D visualization reconstruction technology of real forest landscapes, which is beneficial for a forest model library and realize highly realistic 3D visualization reconstruction of forest landscape areas. To establish a forest fire spread model and reflect the forest fire combustion process and pyrolysis-physical characteristics accurately and its combustion process-oriented real-time visual simulation, it is essential to develop the application of forest fire simulation technology and explore the mechanism of forest fire spread. The related methods are categorized into forest scene visualization and forest fire simulation technology, and the research growth of it is summarized as well. Forest scene visualization methods can be divided into mechanism-based tree modeling methods, including L system-based and custom sketch-based or interactive modeling methods, and forest stand characteristics-based natural scene reconstruction methods. That is, real-world forest stands feature data like images and point clouds are used to reconstruct forest trees. The two types of methods mentioned above are mostly used to construct single tree models as the theoretical basis for large-scale forest scene reconstruction. The mechanism-based tree modeling method can be used to balance the tree structure intuitively and flexibly, and it is more suitable for plant growth design, immersive creation, and other related fields; the forest stand characteristics-based real scene reconstruction method has high fidelity, and it is suitable for vegetation quantification, small-scale ecosystem simulation, and its contexts. Forest fire simulation technology is divided into three categories: physical model, empirical model, and semi-empirical model. The physical model can be well used to illustrate the physical and chemical reactions in the burning process of the forest fire and show the changes in the flame. The empirical model is used for the relevant data obtained from the experiment for mathematical fitting, which can simulate the forest fire spreading status in some typical scenarios, and the accuracy of the direction and rate of forest fire spread is guaranteed. For the semi-empirical model, the physical and chemical reactions in the process of forest fire spread and the statistical analysis methods in specific experiments used are considered at the same time, which reduces the computing cost of physical simulation and enables real-time simulation further. In addition, forest fire simulation can be a key aspect of immersive forest fire simulation and interactive fire extinguishing simulation research, and real forest scene visualization is on the basis of other related research. Real-time generation of realistic forest scenes is beneficial for the simulation of the forest fire. The immersion of the corresponding senses can be improved by constructing real forest scenes to approach the real situation of forest fires, and complex terrain and meteorological conditions can be simulated and visualized as well. Experience and realistic scene roaming can be one of the application scenarios for forest scene visualization technology. We link researches of 1) the growth of forest scene visualization and the forest fire simulation technology, 2) an immersive three-dimensional visual simulation of forest fire scene, and various forest fire ignition methods related to forest fire spread, and 3) fire extinguishing simulation together. Furthermore, most researches are focused on the forest fire spread model coupled in relevance to atmospheric, ecological, and hydrological models since a real and credible forest fire cannot be completely simulated only by forest scene visualization and forest fire simulation technology. To aid fire departments to alleviate deployment decisions, both the forest scene visualization and forest fire simulation technologies can be applied in the field of forest firefighting, strategic planning, and resource allocation via simulation-based planning methods. Finally, we summarize the relevance of forest scene visualization and forest fire simulation technology. Three types of models of forest fire spreading, physical, empirical, and semi-empirical are introduced in detail, in which task-based forest scene visualization into tree modeling methods are related to forest stand characteristics-based reconstruction methods, and the theoretical basis, scope of application, pros and, cons of forest scene visualization and forest fire simulation technology are explained as well. At the same time, it is essential to resolve some application problems in terms of large-scale scene rendering technology and forest fire protection, and a virtual reality and visualization technology-driven basis are offered for future construction of forest fire virtual simulation. The development trend of forest scene visualization and forest fire simulation technology is predicted further.关键词:tree modeling;forest scene visualization;forest fire simulation;forest fire spread model;fire extinguishing simulation technology288|528|0更新时间:2024-05-07 -
 摘要:Visualization and visual analysis have become an key instrument in analyzing and understanding data in the era of big data. Visualization maps data to the visual channel through visual encoding, allowing users to quickly access multi-dimensional information from large amounts of data through the human perception, while visual analysis builds an interaction loop between data and users based on the visual representation, and promotes the user’s reasoning on complex data analysis through interactive visual interfaces. However, as the current data scale continues to grow and its structure becomes increasingly complex, the rich information exceeds the expression ability of the screen space and the processing ability of human visual perception. In this context, straightforward visual encoding cannot effectively convey all the information in data any longer. In addition, interactive exploration is challenged of large-scale complex data as well. It is unfeasible for users to determine the exploration direction based on experience or simple observation of data. Users may fall into time-consuming trial-and-error attempts without uncovering the insights hidden in the data. Therefore, it becomes natural to shift the effort from users to artificial intelligence. The most recent visualization and visual analytic approaches often rely on artificial intelligence (AI) methods to analyze, understand, and summarize data, extract key structures and relationships from data, simplify visualization content, optimize information transmission in visual performance forms, and provide guidance and direction for interactive exploration. With the advancement of AI methods (such as deep learning), machine intelligence is constantly increasing its ability to fit, analyze, and reason about complex data and transformations. This empowers artificial intelligence to overcome the heterogeneity across multi-modal data, such as the data elements, user intention, and visual representation. It further enables AI to establish complex connections among these heterogeneous factors involved in visual exploration. Accordingly, leveraging the power of AI to enhance visualization and visual analysis systems has attracted significant research attention from the visualization community in the past several years. This research direction inspires a wide diversity of research works. Some might focus on improving the performance of traditional computation tasks in visualization with AI methods, while other works even expands the boundaries of visualization methods and explores new research opportunities. For example, in visualization creation, by learning to accurately match data features and user intentions, the AI-powered approaches can automatically create visualizations showing the key information of users’ interest. These approaches effectively reduce the requirements of professional visualization skills and relieve the burden on users in manual operations. For scientific visualization, by observing a large number of simulation members, the AI-enabled techniques can quickly generate renderings of different simulation parameters and visualization parameters in interaction without the need for time-consuming simulations or complex rendering. For interactive exploration, by incorporating various kinds of interaction means, machine learning-based methods can reduce the learning and usage cost for users to use interactive systems, and, therefore attract a broader range of users to experience visualization systems. For visual analysis, by learning user behaviors and analyzing data, the intelligent approaches can suggest interaction operations during exploration, reducing trial-and-error costs and improving analysis efficiency. The literature review briefly introduces the AI-driven visualization researches, summarizes these approaches by categories, and discuss their applications and development. The survey covers four key tasks in visualization: data-oriented visualization management, visualization creation, interactive exploration, and visual analysis. Data management focuses on how to represent and manage large-scale integrated data to support subsequent high-precision rendering. Visualization creation focuses on how to map data to informative visual representations. Interactive exploration discusses how to enrich the interaction means during visual explorations. Visual analysis emphasizes how to combine visualization and interaction to facilitate intuitive and efficient data analysis. These four key tasks cover the entire visualization process from data to visual presentation and then to the human cognition. The survey further discusses the application of intelligent visualization and visual analysis using chart data as an example. Finally, the paper will discuss the development trend of intelligent visualization and visual analysis and point out the potential research directions in future. In terms of artificial intelligence methods, this survey focuses on the application of the new-generation of intelligence methods, with deep learning being one of the most prominent representative, in the field of visualization. It does not elaborate on the use traditional learning methods, such as linear optimization and cluster analysis, etc. Intelligent visualization becomes central to the entire discipline of visualization with many potential applications. Several key trends can be observed in its development. For data representation, the trend is to move from structured data on regular grids towards a more flexible and effective space using deep representation, commonly through networks based on multi-layer perceptrons. The improved computation space can open up possibilities of further researches, such as 1) generalizing the neural network to handle multiple variables, 2) multiple simulations (ensembles), and 3) multiple tasks. For intelligent creation of visualization, applications of AI include using natural language generation algorithms to enhance the connection between users and intelligent tools, using data-driven models to strengthen these tools, and making these tools more effective at recognizing and predicting the user’s design intent. For intelligent interaction, the research focus shifts to developing machine learning methods that enhance visualization expression and information transformation, moving away from rule-based processes with limited scalability and extensibility. For visual analysis, the trend moves towards using deep learning for content and interaction recommendation, interactive update to visual analysis models, and interpretation of user interactions. Overall, these trends demonstrate the potential for intelligent visualization to significantly improve the efficiency and accuracy of data analysis and communication.关键词:visualization;visual analytics;machine learning;deep learning;frontier report372|333|1更新时间:2024-05-07
摘要:Visualization and visual analysis have become an key instrument in analyzing and understanding data in the era of big data. Visualization maps data to the visual channel through visual encoding, allowing users to quickly access multi-dimensional information from large amounts of data through the human perception, while visual analysis builds an interaction loop between data and users based on the visual representation, and promotes the user’s reasoning on complex data analysis through interactive visual interfaces. However, as the current data scale continues to grow and its structure becomes increasingly complex, the rich information exceeds the expression ability of the screen space and the processing ability of human visual perception. In this context, straightforward visual encoding cannot effectively convey all the information in data any longer. In addition, interactive exploration is challenged of large-scale complex data as well. It is unfeasible for users to determine the exploration direction based on experience or simple observation of data. Users may fall into time-consuming trial-and-error attempts without uncovering the insights hidden in the data. Therefore, it becomes natural to shift the effort from users to artificial intelligence. The most recent visualization and visual analytic approaches often rely on artificial intelligence (AI) methods to analyze, understand, and summarize data, extract key structures and relationships from data, simplify visualization content, optimize information transmission in visual performance forms, and provide guidance and direction for interactive exploration. With the advancement of AI methods (such as deep learning), machine intelligence is constantly increasing its ability to fit, analyze, and reason about complex data and transformations. This empowers artificial intelligence to overcome the heterogeneity across multi-modal data, such as the data elements, user intention, and visual representation. It further enables AI to establish complex connections among these heterogeneous factors involved in visual exploration. Accordingly, leveraging the power of AI to enhance visualization and visual analysis systems has attracted significant research attention from the visualization community in the past several years. This research direction inspires a wide diversity of research works. Some might focus on improving the performance of traditional computation tasks in visualization with AI methods, while other works even expands the boundaries of visualization methods and explores new research opportunities. For example, in visualization creation, by learning to accurately match data features and user intentions, the AI-powered approaches can automatically create visualizations showing the key information of users’ interest. These approaches effectively reduce the requirements of professional visualization skills and relieve the burden on users in manual operations. For scientific visualization, by observing a large number of simulation members, the AI-enabled techniques can quickly generate renderings of different simulation parameters and visualization parameters in interaction without the need for time-consuming simulations or complex rendering. For interactive exploration, by incorporating various kinds of interaction means, machine learning-based methods can reduce the learning and usage cost for users to use interactive systems, and, therefore attract a broader range of users to experience visualization systems. For visual analysis, by learning user behaviors and analyzing data, the intelligent approaches can suggest interaction operations during exploration, reducing trial-and-error costs and improving analysis efficiency. The literature review briefly introduces the AI-driven visualization researches, summarizes these approaches by categories, and discuss their applications and development. The survey covers four key tasks in visualization: data-oriented visualization management, visualization creation, interactive exploration, and visual analysis. Data management focuses on how to represent and manage large-scale integrated data to support subsequent high-precision rendering. Visualization creation focuses on how to map data to informative visual representations. Interactive exploration discusses how to enrich the interaction means during visual explorations. Visual analysis emphasizes how to combine visualization and interaction to facilitate intuitive and efficient data analysis. These four key tasks cover the entire visualization process from data to visual presentation and then to the human cognition. The survey further discusses the application of intelligent visualization and visual analysis using chart data as an example. Finally, the paper will discuss the development trend of intelligent visualization and visual analysis and point out the potential research directions in future. In terms of artificial intelligence methods, this survey focuses on the application of the new-generation of intelligence methods, with deep learning being one of the most prominent representative, in the field of visualization. It does not elaborate on the use traditional learning methods, such as linear optimization and cluster analysis, etc. Intelligent visualization becomes central to the entire discipline of visualization with many potential applications. Several key trends can be observed in its development. For data representation, the trend is to move from structured data on regular grids towards a more flexible and effective space using deep representation, commonly through networks based on multi-layer perceptrons. The improved computation space can open up possibilities of further researches, such as 1) generalizing the neural network to handle multiple variables, 2) multiple simulations (ensembles), and 3) multiple tasks. For intelligent creation of visualization, applications of AI include using natural language generation algorithms to enhance the connection between users and intelligent tools, using data-driven models to strengthen these tools, and making these tools more effective at recognizing and predicting the user’s design intent. For intelligent interaction, the research focus shifts to developing machine learning methods that enhance visualization expression and information transformation, moving away from rule-based processes with limited scalability and extensibility. For visual analysis, the trend moves towards using deep learning for content and interaction recommendation, interactive update to visual analysis models, and interpretation of user interactions. Overall, these trends demonstrate the potential for intelligent visualization to significantly improve the efficiency and accuracy of data analysis and communication.关键词:visualization;visual analytics;machine learning;deep learning;frontier report372|333|1更新时间:2024-05-07
Pattern Recognition and Intelligent Visualization
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0