
最新刊期
卷 28 , 期 5 , 2023
-
 摘要:Pedestrians-oriented group re-identification (GReID) analysis is focused on non-overlapped and multi-viewed small groups. To extract stable and robust feature representations, the challenge issue of GReID is to model the temporal changes and intra-group pedestrians. Our summary is reviewed on the growth of GReID critically. First, we review its research domain in related to its basic concepts, technologies and datasets in relevance. To optimize the surveillance in public security, the GReID can monitor and prevent group-based crimes accurately like women and children-oriented kidnapping and trafficking. Due to pedestrians-targeted are severely occluded or even disappeared, it can leverage the appearance features of pedestrians’ partners as additional prior information for recognition. Specifically, GReID-based groups are composed of 2 to 8 members. First, the same group can be identified when the identified intersection-over-union(IoU) ratio of member is greater than 60% in the two group images. Then, a variety of GReID algorithms are introduced and tested in detail. The existing works can be categorized from three perspectives: 1) data, 2) method, and 3) label. For data types, the existing methods can be segmented into: real image-based, synthetic images-based, and real video-based methods. The real images-based method is basically focused on the datasets collected from real surveillance scenarios, such as CUHK-SYSU Group (CSG), RoadGroup, iLIDS-MCTS, and etc. These datasets can be used to collect several group images from different camera views of different groups and provide the elements of location information and identification information of member. This supervision information can be used to design discriminative group feature representations. However, it is still more challenging to collect and label the real group datasets than the traditional pedestrian re-identification datasets because the consistent group identity is required to be judged between group images, including member variations and layout variations. The following datasets are proposed based on 3D synthetic images. This type of datasets can generate mass group images with high-quality labels efficiency and effectively. These methods can be used to improve the performances of the model in real datasets through massive synthetic data. The video-based datasets can provide several consecutive frames for each group from the surveillance videos. Researchers can extract the group features according to the potential patio-temporal or intra-group relationships. They can be mainly divided into: traditional methods and deep learning methods. The former one is to design group descriptors and extract group features derived of human experience. However, due to the high dependence on the prior knowledge of expertise, it is unable to describe and generalize all possible situations for group images. The model can construct the representations of group images automatically because the emerging deep learning based methods is beneficial for a large number of data samples, and the discrimination and robustness of the deep models have been significantly improved. Deep learning-based methods can be divided into 1) the feature learning-based, 2) metric learning based, and 3) generative adversarial network (GAN) based. The deep feature learning based methods aim to design a discriminative network structure or a discriminative feature learning strategy. The features-extracted can reflect the group identification of the input images accurately, and it can be robust enough to suppress occlusion, illumination, number and layout variations of intra-group members. Metric learning based methods can be focused on a similarity criterion evaluation between two groups of images. To get high similarity under the designed measurement criteria, even two group images from the same group class have great differences. To optimize small size of the dataset, GAN-based method attempts to expand the dataset scale of the GReID task by style transfer of samples from other related pedestrian re-identification datasets. For its label, the existing methods can be categorized into: supervised and unsupervised. Supervised learning based methods tend to be more competitive because the group labels or the member labels are participated in the entire training process. It often can learn the similarity only for the local area of the group images because labels are not be provided in the unsupervised learning, and cluster methods can be designed to extract the feature representations of the same group class. To sum up,1) the specific scenarios based GReID is required to be developed from the aspects of data collection and method design further; 2) GReID is still not interrelated to other related visual tasks mutually. Therefore, multiple tasks-collaborated are called to resolve more industry needs, and the implementation of the industry is required to be accelerated for the domain of academia and industry. Furthermore, the data privacy policy-relevant ethic issue needs to be utilized for virtual data and real data in the future.关键词:group re-identification(GReID);pedestrian re-identification;synthesis data;deep learning;feature learning;metric learning;Transformer238|359|1更新时间:2024-05-07
摘要:Pedestrians-oriented group re-identification (GReID) analysis is focused on non-overlapped and multi-viewed small groups. To extract stable and robust feature representations, the challenge issue of GReID is to model the temporal changes and intra-group pedestrians. Our summary is reviewed on the growth of GReID critically. First, we review its research domain in related to its basic concepts, technologies and datasets in relevance. To optimize the surveillance in public security, the GReID can monitor and prevent group-based crimes accurately like women and children-oriented kidnapping and trafficking. Due to pedestrians-targeted are severely occluded or even disappeared, it can leverage the appearance features of pedestrians’ partners as additional prior information for recognition. Specifically, GReID-based groups are composed of 2 to 8 members. First, the same group can be identified when the identified intersection-over-union(IoU) ratio of member is greater than 60% in the two group images. Then, a variety of GReID algorithms are introduced and tested in detail. The existing works can be categorized from three perspectives: 1) data, 2) method, and 3) label. For data types, the existing methods can be segmented into: real image-based, synthetic images-based, and real video-based methods. The real images-based method is basically focused on the datasets collected from real surveillance scenarios, such as CUHK-SYSU Group (CSG), RoadGroup, iLIDS-MCTS, and etc. These datasets can be used to collect several group images from different camera views of different groups and provide the elements of location information and identification information of member. This supervision information can be used to design discriminative group feature representations. However, it is still more challenging to collect and label the real group datasets than the traditional pedestrian re-identification datasets because the consistent group identity is required to be judged between group images, including member variations and layout variations. The following datasets are proposed based on 3D synthetic images. This type of datasets can generate mass group images with high-quality labels efficiency and effectively. These methods can be used to improve the performances of the model in real datasets through massive synthetic data. The video-based datasets can provide several consecutive frames for each group from the surveillance videos. Researchers can extract the group features according to the potential patio-temporal or intra-group relationships. They can be mainly divided into: traditional methods and deep learning methods. The former one is to design group descriptors and extract group features derived of human experience. However, due to the high dependence on the prior knowledge of expertise, it is unable to describe and generalize all possible situations for group images. The model can construct the representations of group images automatically because the emerging deep learning based methods is beneficial for a large number of data samples, and the discrimination and robustness of the deep models have been significantly improved. Deep learning-based methods can be divided into 1) the feature learning-based, 2) metric learning based, and 3) generative adversarial network (GAN) based. The deep feature learning based methods aim to design a discriminative network structure or a discriminative feature learning strategy. The features-extracted can reflect the group identification of the input images accurately, and it can be robust enough to suppress occlusion, illumination, number and layout variations of intra-group members. Metric learning based methods can be focused on a similarity criterion evaluation between two groups of images. To get high similarity under the designed measurement criteria, even two group images from the same group class have great differences. To optimize small size of the dataset, GAN-based method attempts to expand the dataset scale of the GReID task by style transfer of samples from other related pedestrian re-identification datasets. For its label, the existing methods can be categorized into: supervised and unsupervised. Supervised learning based methods tend to be more competitive because the group labels or the member labels are participated in the entire training process. It often can learn the similarity only for the local area of the group images because labels are not be provided in the unsupervised learning, and cluster methods can be designed to extract the feature representations of the same group class. To sum up,1) the specific scenarios based GReID is required to be developed from the aspects of data collection and method design further; 2) GReID is still not interrelated to other related visual tasks mutually. Therefore, multiple tasks-collaborated are called to resolve more industry needs, and the implementation of the industry is required to be accelerated for the domain of academia and industry. Furthermore, the data privacy policy-relevant ethic issue needs to be utilized for virtual data and real data in the future.关键词:group re-identification(GReID);pedestrian re-identification;synthesis data;deep learning;feature learning;metric learning;Transformer238|359|1更新时间:2024-05-07 -
 摘要:Person re-identification (Re-ID) aims to build identity correspondence of the target pedestrian among multiple non-overlap monitoring areas, which has significant application value in the fields such as smart city, criminal investigation and forensics, and surveillance security. Conventional Re-ID methods are often focused on short-term scenarios, which aim to tackle some challenges in related to illumination difference, view-angle change and occlusion. In these methods, the target pedestrian of interest (TPoI) is assumed as unchangeable dressing status while he re-appears under the surveillance circustmances. Such methods are restricted by the homology of appearance across different cameras, such as the same color and texture of pedestrians’ clothes. In contrast, cloth-changing person Re-ID aims at long-term scenarios, which determines that the TPoI re-appears after a long-time gap likes one week or more. In addition to the above challenges in classical person Re-ID, cloth-changing person Re-ID also suffers the difficulty of appearance difference caused by clothes changing. This makes it a research difficulty in recent years. Considering cloth-changing person Re-ID, this paper discusses its challenges and difficulties, and provides an indepth review on recent progress in terms of the analysis of datasets and methods. Based on the analysis, some potential research trends and solutions are proposed. First, we summary and compare the existing cloth-changing person Re-ID datasets in relevant to 1) RGBD-based pattern analysis and computer vision(PAVIS), BIWI, and IAS-Lab, 2) radio frequency-based radio frequency re-identification dataset-campus(RRD-Campus) and RRD-Home, 3) RGB image-based Celeb-ReID, person Re-ID under moderate clothing change(PRCC), long-term cloth-changing(LTCC), and DeepChange and 4) video-based train station dataset(TSD), Motion-ReID and CVID-ReID(cloth-varing video Re-ID), which can be oriented to their difficulties and limitations on the aspects of collecting methods, number of identities and images. Additionally, some popular person Re-ID evaluation metrics are summarized in the context of cumulative match characteristics (CMC), mean average precision (mAP) and mean inverse negative penalty (mINP). Second, we summary the existing cloth-changing person Re-ID methods and segment them into two major categories in terms of data collection: 1) non-visual sensor-based and 2) visual camera-based methods. Non-visual sensor based methods are used to alleviate the influence of clothes from the perspective of data collection manner. In this paper, non-visual sensors are configured into two aspects, i.e., RGBD sensor and radio frequency (RF). The RGBD sensor is used to produce depth information, which can boost the human shape information and eliminate the effect of cloth color. However, the depth information is still influenced by clothes’ contour. The RF-based method can be used for overcoming the weakness further. The wireless devices-derived RF signal emittion can penetrate cloths and reflect the shape information of human body. Unfortunately, the non-visual sensor based methods heavily rely on expensive snesors. It is hard to be applied to the existing surveillance systems. In contrast, visual camera based methods can be used to RGB monitoring cameras directly, and its problem can be tackled through cloth-invariant feature learning and representation from RGB images/videos. These methods can be divided into three categories: 1) explicit feature learning and extraction (EFLE), 2) feature decoupling (FD), and 3) implicit data adaption (IDA). The EFLE can extract cloth-invariant identity-relevant biometric features explicitly, such as face, gait, and body shape. And, these methods consist of two aspects, i.e., hand-crafted and learning-based. The hand-crafted methods can be used to design feature representation, e.g., body measurement and analysis. The learning-based methods guide deep neural network models to learn biometric features using some localization or regularization modules. The FD is used to decouple identity information and cloth-related appearance feature and produce pure identity information, e.g., CESD, DG-Net, IS-GAN, AFD-Net, etc. Differently, IDA adopts a data-driven manner, which can adapt intra-class diversity automatically using large volume of data with abundant intra-class variance, e.g., ReIDCaps, RCSANet. On the basis, the cons of current cloth-changing person Re-ID methods are analyzed, e.g., lack of large-scale and multi-view dataset, feature alignment problem, occlusion, weak feature discriminability and generalization problem. Aiming to these drawbacks, this paper further looks forward to six promising research directions as mentioned below: 1) to construct large-scale video-based datasets and explore spatio-temporal features from video clips or contexts. It is supposed that video footages include rich gait information and provide multi-view body characteristics for 3D human reconstruction; 2) to utilize 3D human reconstruction for learning view-invariant human geometric features from 3D space. The 3D body is assumed to be robust to shape deformation which highlights body structure information; 3) to weaken the effect of clothes-related attributes with the help of pedestrian attribute analysis. It is beneficial for the extraction of semantic-level cues; 4) to mine and integrate multiple features using multi-feature co-learning simultaneously, such as gaits, face and shape. These multi-modality features can yield Re-ID models to pay attention on different views of a walking human and thus help investigate more discriminative representation; 5) to overcome the limitation of limited labelled data with unsupervised learning. Notably, the integration of generative models and constrastive learning can be used to supervise the feature learning through minimizing the difference between raw image and synthesized image; and 6) multi-task learning pipeline can be as another feasible solution. It combines multiple correlated tasks, such as pedestrian attribute analysis, action analysis and body reconstruction. This resembles to the idea of recently popular universal models that regularizes the stem model to learn more generalized representations.关键词:video surveillance;cloth-changing person re-identification;deep learning;feature learning and representation;biometric;feature decoupling;data-driven learning331|610|2更新时间:2024-05-07
摘要:Person re-identification (Re-ID) aims to build identity correspondence of the target pedestrian among multiple non-overlap monitoring areas, which has significant application value in the fields such as smart city, criminal investigation and forensics, and surveillance security. Conventional Re-ID methods are often focused on short-term scenarios, which aim to tackle some challenges in related to illumination difference, view-angle change and occlusion. In these methods, the target pedestrian of interest (TPoI) is assumed as unchangeable dressing status while he re-appears under the surveillance circustmances. Such methods are restricted by the homology of appearance across different cameras, such as the same color and texture of pedestrians’ clothes. In contrast, cloth-changing person Re-ID aims at long-term scenarios, which determines that the TPoI re-appears after a long-time gap likes one week or more. In addition to the above challenges in classical person Re-ID, cloth-changing person Re-ID also suffers the difficulty of appearance difference caused by clothes changing. This makes it a research difficulty in recent years. Considering cloth-changing person Re-ID, this paper discusses its challenges and difficulties, and provides an indepth review on recent progress in terms of the analysis of datasets and methods. Based on the analysis, some potential research trends and solutions are proposed. First, we summary and compare the existing cloth-changing person Re-ID datasets in relevant to 1) RGBD-based pattern analysis and computer vision(PAVIS), BIWI, and IAS-Lab, 2) radio frequency-based radio frequency re-identification dataset-campus(RRD-Campus) and RRD-Home, 3) RGB image-based Celeb-ReID, person Re-ID under moderate clothing change(PRCC), long-term cloth-changing(LTCC), and DeepChange and 4) video-based train station dataset(TSD), Motion-ReID and CVID-ReID(cloth-varing video Re-ID), which can be oriented to their difficulties and limitations on the aspects of collecting methods, number of identities and images. Additionally, some popular person Re-ID evaluation metrics are summarized in the context of cumulative match characteristics (CMC), mean average precision (mAP) and mean inverse negative penalty (mINP). Second, we summary the existing cloth-changing person Re-ID methods and segment them into two major categories in terms of data collection: 1) non-visual sensor-based and 2) visual camera-based methods. Non-visual sensor based methods are used to alleviate the influence of clothes from the perspective of data collection manner. In this paper, non-visual sensors are configured into two aspects, i.e., RGBD sensor and radio frequency (RF). The RGBD sensor is used to produce depth information, which can boost the human shape information and eliminate the effect of cloth color. However, the depth information is still influenced by clothes’ contour. The RF-based method can be used for overcoming the weakness further. The wireless devices-derived RF signal emittion can penetrate cloths and reflect the shape information of human body. Unfortunately, the non-visual sensor based methods heavily rely on expensive snesors. It is hard to be applied to the existing surveillance systems. In contrast, visual camera based methods can be used to RGB monitoring cameras directly, and its problem can be tackled through cloth-invariant feature learning and representation from RGB images/videos. These methods can be divided into three categories: 1) explicit feature learning and extraction (EFLE), 2) feature decoupling (FD), and 3) implicit data adaption (IDA). The EFLE can extract cloth-invariant identity-relevant biometric features explicitly, such as face, gait, and body shape. And, these methods consist of two aspects, i.e., hand-crafted and learning-based. The hand-crafted methods can be used to design feature representation, e.g., body measurement and analysis. The learning-based methods guide deep neural network models to learn biometric features using some localization or regularization modules. The FD is used to decouple identity information and cloth-related appearance feature and produce pure identity information, e.g., CESD, DG-Net, IS-GAN, AFD-Net, etc. Differently, IDA adopts a data-driven manner, which can adapt intra-class diversity automatically using large volume of data with abundant intra-class variance, e.g., ReIDCaps, RCSANet. On the basis, the cons of current cloth-changing person Re-ID methods are analyzed, e.g., lack of large-scale and multi-view dataset, feature alignment problem, occlusion, weak feature discriminability and generalization problem. Aiming to these drawbacks, this paper further looks forward to six promising research directions as mentioned below: 1) to construct large-scale video-based datasets and explore spatio-temporal features from video clips or contexts. It is supposed that video footages include rich gait information and provide multi-view body characteristics for 3D human reconstruction; 2) to utilize 3D human reconstruction for learning view-invariant human geometric features from 3D space. The 3D body is assumed to be robust to shape deformation which highlights body structure information; 3) to weaken the effect of clothes-related attributes with the help of pedestrian attribute analysis. It is beneficial for the extraction of semantic-level cues; 4) to mine and integrate multiple features using multi-feature co-learning simultaneously, such as gaits, face and shape. These multi-modality features can yield Re-ID models to pay attention on different views of a walking human and thus help investigate more discriminative representation; 5) to overcome the limitation of limited labelled data with unsupervised learning. Notably, the integration of generative models and constrastive learning can be used to supervise the feature learning through minimizing the difference between raw image and synthesized image; and 6) multi-task learning pipeline can be as another feasible solution. It combines multiple correlated tasks, such as pedestrian attribute analysis, action analysis and body reconstruction. This resembles to the idea of recently popular universal models that regularizes the stem model to learn more generalized representations.关键词:video surveillance;cloth-changing person re-identification;deep learning;feature learning and representation;biometric;feature decoupling;data-driven learning331|610|2更新时间:2024-05-07 -
 摘要:Gait recognition is inter-related to pedestrians’ identity. Pedestrians’ gait recognition can be focused on at a distance and it cannot require special acquisition equipment, high image resolution, or explicit cooperation from the person in comparison with recognition methods relevant to the features of face, fingerprint, iris and other biometrics. Moreover, one’s gait is difficult to be hidden or disguised. Gait recognition has a wide range of applications in public surveillance, forensic collection, and daily attendance. In these practical applications, the performance of gait recognition is easily affected by covariates such as viewpoint variations, occlusions, and segmentation error, among which viewpoint variations are one of the main factors affecting the gait recognition performance. The intra-class differences of different viewpoints are often greater than the inter-class differences of the same viewpoint. Therefore, improving the robustness of cross-view gait recognition has become a hot topic. A review of existing cross-view gait recognition methods is critical analyzed. First, current situation is introduced in related to basic concepts, data acquisition methods, application scenarios, and its growing paths. Then, we review video-based cross-view gait recognition methods further. Cross-view gait databases are analyzed in the context of 1) data type, 2) sample size, 3) viewpoint number, 4) acquisition environment, 5) other related covariates, and 6) the characteristics of these databases in detail. Then, cross-view gait classification methods are presented in detail. Unlike most existing reviews that classify gait recognition methods by the basic steps such as data acquisition, feature representation, and classification, we focus on cross-view recognition problems. Specifically, four cross-view gait recognition methods are analyzed on the basis of feature representation and classification (i.e., 3D gait information construction, view transformation model (VTM), view-invariant feature extraction, and the deep learning-based methods). For 3D gait information methods, gait information is extracted from multi-view gait videos and it is used to construct 3D gait models. These methods have good robustness to large view changes, but they often require: complex configurations, expensive high-resolution multi-camera systems, and frame synchronization. All of them limit their application to real surveillance scenarios. For VTM methods, singular value decomposition (SVD) and regression-derived view transformation models are introduced to local and global features. The discriminative analysis can be ignored although the VTM may minimize the error between the transformed gait features and the original gait features. For view-invariant feature extraction methods, 1) manual feature extraction, 2) discriminative subspace learning, and 3) metric learning are compared. Among the discriminative subspace learning methods, the canonical correlation analysis (CCA) based methods are highlighted. Despite the advantages of these methods, it is still challenged to sort robust view-invariant subspace or metric for features out. Deep learning based methods for cross-view recognition is mainly composed of convolution neural network (CNN), recurrent neural network (RNN), auto encoder (AE), generative adversarial network (GAN), 3D convolutional neural network (3D CNN), and graph convolutional network (GCN). To summary the potentials of multiple cross-view gait recognition methods, some representative state-of-the-art methods are compared and analyzed further on CASIA-B(CASIA gait database, dataset B), OU-ISIR LP(OU-ISIR gait database, large population dataset) and OU-MVLP(OU-ISIR gait database multi-view large population dataset) databases. It is found that the methods using 3D CNN or multiple neural network architectures, which represent gait features with a sequence of silhouettes, achieve good performance. Additionally, deep neural network methods based on body model representation also show excellent performance under the condition with only view variations. Finally, future research directions are predicted for cross-view gait recognition, including 1) the establishment of large-scale gait databases containing complex covariates, 2) cross-database gait recognition, 3) self-supervised learning methods for gait features, 4) disentangled representation learning methods for gait features, 5) further developing model-based gait representation methods, 6) exploring new methods for temporal feature extraction, 7) multimodal fusion gait recognition, and 8) improving the security of gait recognition systems.关键词:computer vision;biometric recognition;gait recognition;cross-view;machine learning;deep learning;neural network252|2172|8更新时间:2024-05-07
摘要:Gait recognition is inter-related to pedestrians’ identity. Pedestrians’ gait recognition can be focused on at a distance and it cannot require special acquisition equipment, high image resolution, or explicit cooperation from the person in comparison with recognition methods relevant to the features of face, fingerprint, iris and other biometrics. Moreover, one’s gait is difficult to be hidden or disguised. Gait recognition has a wide range of applications in public surveillance, forensic collection, and daily attendance. In these practical applications, the performance of gait recognition is easily affected by covariates such as viewpoint variations, occlusions, and segmentation error, among which viewpoint variations are one of the main factors affecting the gait recognition performance. The intra-class differences of different viewpoints are often greater than the inter-class differences of the same viewpoint. Therefore, improving the robustness of cross-view gait recognition has become a hot topic. A review of existing cross-view gait recognition methods is critical analyzed. First, current situation is introduced in related to basic concepts, data acquisition methods, application scenarios, and its growing paths. Then, we review video-based cross-view gait recognition methods further. Cross-view gait databases are analyzed in the context of 1) data type, 2) sample size, 3) viewpoint number, 4) acquisition environment, 5) other related covariates, and 6) the characteristics of these databases in detail. Then, cross-view gait classification methods are presented in detail. Unlike most existing reviews that classify gait recognition methods by the basic steps such as data acquisition, feature representation, and classification, we focus on cross-view recognition problems. Specifically, four cross-view gait recognition methods are analyzed on the basis of feature representation and classification (i.e., 3D gait information construction, view transformation model (VTM), view-invariant feature extraction, and the deep learning-based methods). For 3D gait information methods, gait information is extracted from multi-view gait videos and it is used to construct 3D gait models. These methods have good robustness to large view changes, but they often require: complex configurations, expensive high-resolution multi-camera systems, and frame synchronization. All of them limit their application to real surveillance scenarios. For VTM methods, singular value decomposition (SVD) and regression-derived view transformation models are introduced to local and global features. The discriminative analysis can be ignored although the VTM may minimize the error between the transformed gait features and the original gait features. For view-invariant feature extraction methods, 1) manual feature extraction, 2) discriminative subspace learning, and 3) metric learning are compared. Among the discriminative subspace learning methods, the canonical correlation analysis (CCA) based methods are highlighted. Despite the advantages of these methods, it is still challenged to sort robust view-invariant subspace or metric for features out. Deep learning based methods for cross-view recognition is mainly composed of convolution neural network (CNN), recurrent neural network (RNN), auto encoder (AE), generative adversarial network (GAN), 3D convolutional neural network (3D CNN), and graph convolutional network (GCN). To summary the potentials of multiple cross-view gait recognition methods, some representative state-of-the-art methods are compared and analyzed further on CASIA-B(CASIA gait database, dataset B), OU-ISIR LP(OU-ISIR gait database, large population dataset) and OU-MVLP(OU-ISIR gait database multi-view large population dataset) databases. It is found that the methods using 3D CNN or multiple neural network architectures, which represent gait features with a sequence of silhouettes, achieve good performance. Additionally, deep neural network methods based on body model representation also show excellent performance under the condition with only view variations. Finally, future research directions are predicted for cross-view gait recognition, including 1) the establishment of large-scale gait databases containing complex covariates, 2) cross-database gait recognition, 3) self-supervised learning methods for gait features, 4) disentangled representation learning methods for gait features, 5) further developing model-based gait representation methods, 6) exploring new methods for temporal feature extraction, 7) multimodal fusion gait recognition, and 8) improving the security of gait recognition systems.关键词:computer vision;biometric recognition;gait recognition;cross-view;machine learning;deep learning;neural network252|2172|8更新时间:2024-05-07 -
 摘要:The precision of pedestrian detection is focused on instances-relevant location on given input images. However, due to the perception of visible images to light changes, visible images are challenged for lower visibility conditions like extreme weathers. Hence, visible images-based pedestrian detection is merely suitable for the development of temporal applications like autonomous driving and video surveillance. The infrared image can provide a clear pedestrian profile for such low-visibility scenes according to the temperature difference between the human body and the environment. Under the circumstances of sufficient light, visible images can also provide more information-lacked in infrared images like hair, face, and other related features. Visible and infrared images can provide visual information-added in common. However, the key challenges of visible and infrared images is to utilize the two modalities-between and their modality-specific noise mutually. To generate temperature information, the difference is leaked out that the visible image consists of color information in red, green, and blue (RGB) channels, while the infrared image has one channel only. And, imaging mechanism-based wavelength range of the two is different as well. The emerging deep learning technique based cross-modal pedestrian detection approaches have been developing dramatically. Our summary aims to review and analyze some popular researches on cross-modal pedestrian detection in recent years. It can be segmented into two categories: 1) the difference between two different modalities and 2) the cross-modal detectors application to the real scene. The application of cross-modal pedestrian detectors to the actual scene can be divided into three types: cost analysis-related data annotation, real-time detection, and cost-analysis of applications. The research aspects between two modalities can be divided into: the misalignment and the inadequate fusion. The misalignment of two modalities shows that the visible-infrared image pairs are required to be strictly aligned, and the features from different modalities are called to match at corresponding positions. The inadequate fusion of two modalities is required to maximize the mutual benefits between two modalities. The early research on the insufficient fusion of two-modality is related to the study of the fusion stage (when to fuse) of two-modality. The later studies on the insufficient fusion of two-modality data are focused on the study of the fusion methods (how to fuse) of two-modality. The fusion stage can be divided into three steps: image, feature, and decision. Similarly, the fusion methods can be segmented into three categories: image, feature, and detection. Subsequently, we introduce some commonly used cross-modal pedestrian detection datasets, including the Korea Advanced Institute of Science and Technology(KAIST), the forward looking infrared radiometer(FLIR), the computer vision center-14(CVC-14), and the low-light visible-infrared parred(LLVIP). Then, we introduce some evaluation metrics method for cross-modal pedestrian detectors, including missed rate (MR), mean average precision (mAP), and a pair of visible and thermal images in temporal (speed). Finally, we summarize the challenges to be resolved in the field of cross-modal pedestrian detection and our predictions are focused on the future direction analysis of cross-modal pedestrian detection. 1) In the real world, due to the different parallax and field of view of two different sensors, the problem of misalignment of visible-infrared modality feature modules is more concerned about. However, the problem of unaligned modality features is possible to sacrifice the performance of the detector and hinder the use of unaligned data in datasets, and is not feasible to the application of dual sensors in real life to some extent. Thus, the problem of two modalities’ position is to be resolved as a key research direction. 2) At present, the datasets of cross-modal pedestrian detection are all captured on sunny days, and current advanced cross-modal pedestrian detection methods are only based on all-day pedestrian detection on sunny days. However, to realize the cross-modal pedestrian detection system throughout all day and all weathers, it is required to optimize and beyond day and night data on sunny days. We also need to focus on the data under extreme weather conditions. 3) Recent studies on cross-modal pedestrian detection are focused on datasets captured by vehicle-mounted cameras. Compared to datasets captured from the monitoring perspective, the scenes of vehicle-mounted datasets are changeable, which can suppress over-fitting effectively. However, the nighttime images in the vehicle-mounted datasets may be brighter than those of the surveillance perspective datasets because of their headlight brightness at night. Therefore, we predict that multiple visual-angles datasets can be used to train the cross-modal pedestrian detector at the same time. It can not only increase the robustness of the model in darker scenes, but also suppress over-fitting at a certain scene. 4) Autonomous driving systems and robot systems are required to be quick responded for detection results. Although many models have fast inference ability on GPU(graphics processing unit), the inference speed on real devices need to be optimized, so real-time detection will be the continuous development direction of cross-modal pedestrian detection as well. 5) There is still a large gap in cross-modal pedestrian detection technology for small scale and partial or severe occluded pedestrians. However, driving systems-assisted detection and occlusion can be as a very common problem in life for small targets of pedestrians at a distance to alert drivers to slow down in advance. The cross-modal pedestrian detection technology can be forecasted and recognized for small scale targets and occlusion as the direction of future research.关键词:cross-modal pedestrian detection;visible image;infrared image;deep learning;pedestrian detection222|259|4更新时间:2024-05-07
摘要:The precision of pedestrian detection is focused on instances-relevant location on given input images. However, due to the perception of visible images to light changes, visible images are challenged for lower visibility conditions like extreme weathers. Hence, visible images-based pedestrian detection is merely suitable for the development of temporal applications like autonomous driving and video surveillance. The infrared image can provide a clear pedestrian profile for such low-visibility scenes according to the temperature difference between the human body and the environment. Under the circumstances of sufficient light, visible images can also provide more information-lacked in infrared images like hair, face, and other related features. Visible and infrared images can provide visual information-added in common. However, the key challenges of visible and infrared images is to utilize the two modalities-between and their modality-specific noise mutually. To generate temperature information, the difference is leaked out that the visible image consists of color information in red, green, and blue (RGB) channels, while the infrared image has one channel only. And, imaging mechanism-based wavelength range of the two is different as well. The emerging deep learning technique based cross-modal pedestrian detection approaches have been developing dramatically. Our summary aims to review and analyze some popular researches on cross-modal pedestrian detection in recent years. It can be segmented into two categories: 1) the difference between two different modalities and 2) the cross-modal detectors application to the real scene. The application of cross-modal pedestrian detectors to the actual scene can be divided into three types: cost analysis-related data annotation, real-time detection, and cost-analysis of applications. The research aspects between two modalities can be divided into: the misalignment and the inadequate fusion. The misalignment of two modalities shows that the visible-infrared image pairs are required to be strictly aligned, and the features from different modalities are called to match at corresponding positions. The inadequate fusion of two modalities is required to maximize the mutual benefits between two modalities. The early research on the insufficient fusion of two-modality is related to the study of the fusion stage (when to fuse) of two-modality. The later studies on the insufficient fusion of two-modality data are focused on the study of the fusion methods (how to fuse) of two-modality. The fusion stage can be divided into three steps: image, feature, and decision. Similarly, the fusion methods can be segmented into three categories: image, feature, and detection. Subsequently, we introduce some commonly used cross-modal pedestrian detection datasets, including the Korea Advanced Institute of Science and Technology(KAIST), the forward looking infrared radiometer(FLIR), the computer vision center-14(CVC-14), and the low-light visible-infrared parred(LLVIP). Then, we introduce some evaluation metrics method for cross-modal pedestrian detectors, including missed rate (MR), mean average precision (mAP), and a pair of visible and thermal images in temporal (speed). Finally, we summarize the challenges to be resolved in the field of cross-modal pedestrian detection and our predictions are focused on the future direction analysis of cross-modal pedestrian detection. 1) In the real world, due to the different parallax and field of view of two different sensors, the problem of misalignment of visible-infrared modality feature modules is more concerned about. However, the problem of unaligned modality features is possible to sacrifice the performance of the detector and hinder the use of unaligned data in datasets, and is not feasible to the application of dual sensors in real life to some extent. Thus, the problem of two modalities’ position is to be resolved as a key research direction. 2) At present, the datasets of cross-modal pedestrian detection are all captured on sunny days, and current advanced cross-modal pedestrian detection methods are only based on all-day pedestrian detection on sunny days. However, to realize the cross-modal pedestrian detection system throughout all day and all weathers, it is required to optimize and beyond day and night data on sunny days. We also need to focus on the data under extreme weather conditions. 3) Recent studies on cross-modal pedestrian detection are focused on datasets captured by vehicle-mounted cameras. Compared to datasets captured from the monitoring perspective, the scenes of vehicle-mounted datasets are changeable, which can suppress over-fitting effectively. However, the nighttime images in the vehicle-mounted datasets may be brighter than those of the surveillance perspective datasets because of their headlight brightness at night. Therefore, we predict that multiple visual-angles datasets can be used to train the cross-modal pedestrian detector at the same time. It can not only increase the robustness of the model in darker scenes, but also suppress over-fitting at a certain scene. 4) Autonomous driving systems and robot systems are required to be quick responded for detection results. Although many models have fast inference ability on GPU(graphics processing unit), the inference speed on real devices need to be optimized, so real-time detection will be the continuous development direction of cross-modal pedestrian detection as well. 5) There is still a large gap in cross-modal pedestrian detection technology for small scale and partial or severe occluded pedestrians. However, driving systems-assisted detection and occlusion can be as a very common problem in life for small targets of pedestrians at a distance to alert drivers to slow down in advance. The cross-modal pedestrian detection technology can be forecasted and recognized for small scale targets and occlusion as the direction of future research.关键词:cross-modal pedestrian detection;visible image;infrared image;deep learning;pedestrian detection222|259|4更新时间:2024-05-07 -
 摘要:As a subtask of visual grounding (VG), referring expression comprehension (REC) is focused on the input referring expression-defined object location in the given image. To optimize multimodal data-based artificial intelligence (AI) tasks, the REC has used to facilitate interaction ability between humans, machines, and the physical world. The REC can be used for such domains like navigation, autonomous driving, robotics, and early education in terms of visual understanding systems and dialogue systems. Additionally, it is beneficial for other related studies, including 1) image retrieval, 2) image captioning, and 3) visual question answering. In the past two decades, computer vision-oriented object detection has been developing dramatically, which can locate all predefined and fixed categories objects. To get the referring expression input-defined object, a challenging problem of the REC is required for multiple objects-related reasoning. The general process of REC can be divided into three modules: linguistic feature extraction, visual feature extraction, and visual-linguistic fusion. The most important one of three modules is visual-linguistic fusion, which can realize the interaction and screening between linguistic and visual features. Furthermore, current researches are oriented to the design of the visual feature extraction module, which is recognized as the basic module of one REC model to a certain extent. Visual input has richer information than text input and more redundant information interference are required to be alleviated. So, the potentials of object localization are linked to extracting effective visual features further. We segment existing REC methods into three categories.1) Regional convolution granularity visual representation method, it can be divided into five sub-categories in accordance with visual-linguistic fusion module based modeling: (1)early,(2) attention mechanism fusion,(3) expression decomposition fusion,(4)graph network fusion, and (5)Transformer-based fusion. It is still challenged for computational cost and lower speed because it is required to generate object proposals for the input image in advance. Moreover, the performance of the REC model is challenged for the quality of the object proposals as well. 2) Grid convolution granularity visual representation method: the multi-modal fusion module of it can be divided into two categories:(1)filtering-based fusion and (2)Transformer-based fusion. Its model inference speed can be accelerated to 10 times at least since the generation of object proposals is not required for that. 3) Image patch granularity visual representation method: as visual feature extractors, two methods mentioned above are based on pre-trained object detection networks or convolutional networks. The visual features are still challenged to match REC-required visual elements. Therefore, more researches are focused on the integration of visual feature extraction module and the visual-linguistic fusion module, in which image patches-derived pixel can be as the input. To be compatible with the requirements of the REC task, direct text input-guided visual features are generated beyond pre-trained convolutional neural network(CNN) visual feature extractor. The REC mission are introduced and clarified on the basis of four popular datasets and the evaluation methods. Furthermore, three sort of REC-contextual challenging problems are required to be resolved: 1) model’s reasoning speed, 2) interpretability of the model, and 3) reasoning ability of the model to expressions. The video and 3D domains-related future research direction of REC is predicted and analyzed further on the two aspects of its model design and domain development.关键词:visual grounding(VG);referring expression comprehension(REC);vision and language;visual representation granularity;multi-modal feature fusion340|1293|2更新时间:2024-05-07
摘要:As a subtask of visual grounding (VG), referring expression comprehension (REC) is focused on the input referring expression-defined object location in the given image. To optimize multimodal data-based artificial intelligence (AI) tasks, the REC has used to facilitate interaction ability between humans, machines, and the physical world. The REC can be used for such domains like navigation, autonomous driving, robotics, and early education in terms of visual understanding systems and dialogue systems. Additionally, it is beneficial for other related studies, including 1) image retrieval, 2) image captioning, and 3) visual question answering. In the past two decades, computer vision-oriented object detection has been developing dramatically, which can locate all predefined and fixed categories objects. To get the referring expression input-defined object, a challenging problem of the REC is required for multiple objects-related reasoning. The general process of REC can be divided into three modules: linguistic feature extraction, visual feature extraction, and visual-linguistic fusion. The most important one of three modules is visual-linguistic fusion, which can realize the interaction and screening between linguistic and visual features. Furthermore, current researches are oriented to the design of the visual feature extraction module, which is recognized as the basic module of one REC model to a certain extent. Visual input has richer information than text input and more redundant information interference are required to be alleviated. So, the potentials of object localization are linked to extracting effective visual features further. We segment existing REC methods into three categories.1) Regional convolution granularity visual representation method, it can be divided into five sub-categories in accordance with visual-linguistic fusion module based modeling: (1)early,(2) attention mechanism fusion,(3) expression decomposition fusion,(4)graph network fusion, and (5)Transformer-based fusion. It is still challenged for computational cost and lower speed because it is required to generate object proposals for the input image in advance. Moreover, the performance of the REC model is challenged for the quality of the object proposals as well. 2) Grid convolution granularity visual representation method: the multi-modal fusion module of it can be divided into two categories:(1)filtering-based fusion and (2)Transformer-based fusion. Its model inference speed can be accelerated to 10 times at least since the generation of object proposals is not required for that. 3) Image patch granularity visual representation method: as visual feature extractors, two methods mentioned above are based on pre-trained object detection networks or convolutional networks. The visual features are still challenged to match REC-required visual elements. Therefore, more researches are focused on the integration of visual feature extraction module and the visual-linguistic fusion module, in which image patches-derived pixel can be as the input. To be compatible with the requirements of the REC task, direct text input-guided visual features are generated beyond pre-trained convolutional neural network(CNN) visual feature extractor. The REC mission are introduced and clarified on the basis of four popular datasets and the evaluation methods. Furthermore, three sort of REC-contextual challenging problems are required to be resolved: 1) model’s reasoning speed, 2) interpretability of the model, and 3) reasoning ability of the model to expressions. The video and 3D domains-related future research direction of REC is predicted and analyzed further on the two aspects of its model design and domain development.关键词:visual grounding(VG);referring expression comprehension(REC);vision and language;visual representation granularity;multi-modal feature fusion340|1293|2更新时间:2024-05-07
Review

-
 摘要:Person re-identification (Person ReID) has been concerned more in computer vision nowadays. It can identify a pedestrian-targeted in the images and recognize its multiple spatio-temporal re-appearance. Person ReID can be used to retrieve pedestrians-specific from image or video databases as well. Person re-identification research has strong practical needs and has potential applications in the fields of public safety, new retailing, and human-computer interaction. Conventional forensic-based human-relevant face recognition can provide one of the most powerful technical means for identity checking. However, it is challenged that imaging-coordinated is restricted by its rigid angle and distance. The semi-coordinated face recognition is evolved in technically. Actually, there are a large number of scenarios-discreted to be dealt with for public surveillance, where the monitored objects do not need to cooperate with the camera to image, and they do not need to be aware that they are being filmed; in some extreme cases, Some suspects may even deliberately cover themselves key biometric features. To provide wide-ranged tracking spatiotemepally, the surveillance of public security is called for person re-identification urgently. It is possible to sort facial elements out from the back and interprete the facial features further in support of pedestrian re-identification technology. The potential of the person re-identification task is that the recognition object is a non-cooperative target. Pedestrian-oriented imaging has challenged for complicated changes in relevant to its posture, viewing angle, illumination, imaging quality, and certain occlusion-ranged. The key challenges are dealt with its learning-related issues of temporal-based image feature expression and spatial-based meta-image data to the distinctive feature. In addition, compared to the face recognition task, data collection and labeling are more challenging in the person re-identification task, and existing datasets gap are called to be bridged and richer intensively in comparison with face recognition datasets. The feature extractor-generated has a severe overfitting phenomenon in common. The heterogeneity of data set-cross model is still a big challenging issue. Interdisplinary research is calling for the breakthrough of person re-identification. Rank-1 and mean average precision (mAP) have been greatly improved on multiple datasets, and some of them have begun to be applied practically. Current person re-identification analysis is mainly focused on the elements of clothing appearance and lacks of explicit multivisual anglesi-view observation and description of pedestrian appearance, which is inconsistent with the mechanism of human observation. The human-relevant ability of comprehensive perception can generate an observation description of the target from the multi-visual surface information. For example, meet a familiar friend on the street: we will quick-responsed for the perception subconsciously even if we cannot see the face clearly. In addition to clothing information, we will perceive more information-contextual as well, including gender, age, body shape, posture, facial expression and mental state. This paper aims to break the existing setting of person re-identification task and form a comprehensive observation description of pedestrians.To facilitate person re-identification research further, we develop a portrait interpretation calculation (ReID2.0) on the basis of prior person re-identification. Its attributes and motion-like status are observed and described on four aspects as mentioned below: 1) appearance, 2) posture, 3) emotion, and 4) intention. Here, appearance information is used to describe the apparent information of the face and biological characteristics; posture information is focused on the description of static and sequential body shape characteristics of the human body; emotion information is oriented to the facial expression of the human face and emotional expression of a pedestrian; intention information is targeted on the behavioral description and intentional predictions of a pedestrian; these four types of information is based on multi-view observation and perception of pedestrians, and a human-centered representation is constructed to a certain extent. Due to the difficulty of labeling, there is still no dataset to be constructed in a description requirements according to the four aspects of behavior awareness.We demonstrate a benchmark dataset of Portrait250K for the portrait interpretation calculation. The Portrait250K is composed of 250 000 portraits of 51 movies and TV series from various countries. For each portrait, there are eight human-annotated labels corresponding to eight subtasks. The distribution of images and labels illustrates ground truth features, such as its a) long-tailed or unbalanced distributions, b) diversified occlusions, c) truncations, d) lighting, e) clothing, f) makeup, and g) changeable background scenarios. To advance Portrait250K-based portrait interpretation calculation further, the metrics are designed for each subtask and an integrated evaluation metric, called portrait interpretation quality (PIQ),is developed systematically, which can balance the weights for each subtask. Furthermore, we design a paradigm of multi-task learning-based baseline method. Multi-task representation learning is concerned about and a spatial scheme is demonstrated, named feature space separation. A simple learning loss is proposed as well.The proposed portrait interpretation calculation forms a comprehensive observational description of pedestrians, which provides a reference for further research on person re-identification and human-like agents.关键词:person re-identification(Person ReID);portrait interpretation;ReID2.0;representation learning;computer vision180|228|1更新时间:2024-05-07
摘要:Person re-identification (Person ReID) has been concerned more in computer vision nowadays. It can identify a pedestrian-targeted in the images and recognize its multiple spatio-temporal re-appearance. Person ReID can be used to retrieve pedestrians-specific from image or video databases as well. Person re-identification research has strong practical needs and has potential applications in the fields of public safety, new retailing, and human-computer interaction. Conventional forensic-based human-relevant face recognition can provide one of the most powerful technical means for identity checking. However, it is challenged that imaging-coordinated is restricted by its rigid angle and distance. The semi-coordinated face recognition is evolved in technically. Actually, there are a large number of scenarios-discreted to be dealt with for public surveillance, where the monitored objects do not need to cooperate with the camera to image, and they do not need to be aware that they are being filmed; in some extreme cases, Some suspects may even deliberately cover themselves key biometric features. To provide wide-ranged tracking spatiotemepally, the surveillance of public security is called for person re-identification urgently. It is possible to sort facial elements out from the back and interprete the facial features further in support of pedestrian re-identification technology. The potential of the person re-identification task is that the recognition object is a non-cooperative target. Pedestrian-oriented imaging has challenged for complicated changes in relevant to its posture, viewing angle, illumination, imaging quality, and certain occlusion-ranged. The key challenges are dealt with its learning-related issues of temporal-based image feature expression and spatial-based meta-image data to the distinctive feature. In addition, compared to the face recognition task, data collection and labeling are more challenging in the person re-identification task, and existing datasets gap are called to be bridged and richer intensively in comparison with face recognition datasets. The feature extractor-generated has a severe overfitting phenomenon in common. The heterogeneity of data set-cross model is still a big challenging issue. Interdisplinary research is calling for the breakthrough of person re-identification. Rank-1 and mean average precision (mAP) have been greatly improved on multiple datasets, and some of them have begun to be applied practically. Current person re-identification analysis is mainly focused on the elements of clothing appearance and lacks of explicit multivisual anglesi-view observation and description of pedestrian appearance, which is inconsistent with the mechanism of human observation. The human-relevant ability of comprehensive perception can generate an observation description of the target from the multi-visual surface information. For example, meet a familiar friend on the street: we will quick-responsed for the perception subconsciously even if we cannot see the face clearly. In addition to clothing information, we will perceive more information-contextual as well, including gender, age, body shape, posture, facial expression and mental state. This paper aims to break the existing setting of person re-identification task and form a comprehensive observation description of pedestrians.To facilitate person re-identification research further, we develop a portrait interpretation calculation (ReID2.0) on the basis of prior person re-identification. Its attributes and motion-like status are observed and described on four aspects as mentioned below: 1) appearance, 2) posture, 3) emotion, and 4) intention. Here, appearance information is used to describe the apparent information of the face and biological characteristics; posture information is focused on the description of static and sequential body shape characteristics of the human body; emotion information is oriented to the facial expression of the human face and emotional expression of a pedestrian; intention information is targeted on the behavioral description and intentional predictions of a pedestrian; these four types of information is based on multi-view observation and perception of pedestrians, and a human-centered representation is constructed to a certain extent. Due to the difficulty of labeling, there is still no dataset to be constructed in a description requirements according to the four aspects of behavior awareness.We demonstrate a benchmark dataset of Portrait250K for the portrait interpretation calculation. The Portrait250K is composed of 250 000 portraits of 51 movies and TV series from various countries. For each portrait, there are eight human-annotated labels corresponding to eight subtasks. The distribution of images and labels illustrates ground truth features, such as its a) long-tailed or unbalanced distributions, b) diversified occlusions, c) truncations, d) lighting, e) clothing, f) makeup, and g) changeable background scenarios. To advance Portrait250K-based portrait interpretation calculation further, the metrics are designed for each subtask and an integrated evaluation metric, called portrait interpretation quality (PIQ),is developed systematically, which can balance the weights for each subtask. Furthermore, we design a paradigm of multi-task learning-based baseline method. Multi-task representation learning is concerned about and a spatial scheme is demonstrated, named feature space separation. A simple learning loss is proposed as well.The proposed portrait interpretation calculation forms a comprehensive observational description of pedestrians, which provides a reference for further research on person re-identification and human-like agents.关键词:person re-identification(Person ReID);portrait interpretation;ReID2.0;representation learning;computer vision180|228|1更新时间:2024-05-07
Frontier
-
 摘要:ObjectivePedestrian re-identification is focused on multiview non-overlapping-derived problem of querying and identifying the same identity pedestrian. However, such real-world application scenarios are challenged to some camera-relevant factors like 1) hardware, 2) shooting distance, 3) angle of view, 4) background clutters, and 5) occlusions. Current surveillance camera-based images can be captured and it is still challenged for its low resolution (LR) as well. In real scenes, pedestrian re-identification (re-id) methods are required to resolve multiple pedestrians-oriented heterogeneous problem for low resolution image further. To deal with the mismatch problem between high resolution (HR) images and LR images, conventional re-id methods are mainly concerned of the cross-resolution matching problem. It is essential to richer mutual-benefited ability between low-resolution gallery images and query images. To improve the low-resolution pedestrian matching performance, we develop a novel of gun-ball camera-based pedestrian re-identification benchmark dataset and a low-resolution pedestrian re-identification benchmark model is designed as well.MethodThis data collection is acquired by the gun and ball system, which is deployed at three intersections. To capture LR images, two of three cameras are placed at each intersection, and the gun camera has a fixed direction and focal length. To obtain high-resolution images more, the other ball camera can be used to tune the focal length and the direction of view according to the target pedestrian position. And, a pedestrian re-identification dataset can be built and sampled by 200 pedestrians-identified categories (the same pedestrian is captured and identified at different locations), and a sample of 320 pedestrian-unidentified categories (pedestrians can be captured under a certain camera only). Each of these pedestrians-related images are all in related to the two aspects of high resolution and low resolution. A pedestrian-identified image can be captured by at least 2 different gun-ball cameras from different places, and a pedestrian-unidentified image can be captured by one gun-ball camera only and it is required to be searched and matched across cameras further. Pedestrian-unidentified images are in relevance to both of LR & HR as well. Some optimal factors are illustrated as mentioned below: 1) a richer and more diverse pedestrian dataset: the gun-ball camera-based pedestrian re-identification dataset can be used to acquire various pedestrian images from intersections. 2) The pedestrian dynamics: each pedestrian image has its temporal information because the gun-ball camera-based pedestrian dataset is captured and cropped from the video stream. Such temporal-based pedestrian images can be used for video-related pedestrian re-identification as well. 3) Other potentials: some pedestrians-unidentified images can be focused on, which can be used to study pedestrian re-identification algorithms in semi-supervised or unsupervised domains, as well as the ground truth of identification systems. That is, given an unknown identity of a pedestrian, its identification system can automatically detect the similar one in the surveillance screen or database. To strengthen the matching problem of LR images of pedestrians, we consider 1) image super-resolution, 2) pedestrian-related feature learning, and 3) discrimination as three key factors in our baseline. Specifically, to optimize each aspect of resolution, pedestrian feature-related learning and discrimination, the baseline is involved of a super-resolution module, a pedestrian re-identification module, and a pedestrian feature discriminator. Therefore, we design a baseline pedestrian re-identification model and it is benched on the 5 following aspects: generator G, image discriminator Ds, gradient discriminator Dg, pedestrian feature extractor F, and pedestrian feature discriminator Df. To resolve the problem of low-resolution pedestrian re-identification in real scenes, our proposed model can be used to optimize both of the resolution of pedestrian image and pedestrian discrimination features.ResultThe low-resolution pedestrian re-identification baseline model is demonstrated and experimentally validated on the gun-ball pedestrian re-identification dataset. The mean average precision (mAP) and Rank-1 metrics are improved by 3.1% and 6.1%.ConclusionLR-related pedestrian recognition in natural scenes can be facilitated, and its pixel misalignment-derived problem of low quality of generated super-resolved images can be resolved to a certain extent. The dataset and benchmark model are proposed and its potential is in related to pedestrian re-identification and image super-resolution. It provides a data source for the field of low-resolution pedestrian re-identification. Also, the proposed baseline model can be predicted to tackle the low-resolution pedestrian matching problem further.关键词:pedestrian re-identification;benchmark dataset;low-resolution(LR);super-resolution(SR);discriminator229|340|1更新时间:2024-05-07
摘要:ObjectivePedestrian re-identification is focused on multiview non-overlapping-derived problem of querying and identifying the same identity pedestrian. However, such real-world application scenarios are challenged to some camera-relevant factors like 1) hardware, 2) shooting distance, 3) angle of view, 4) background clutters, and 5) occlusions. Current surveillance camera-based images can be captured and it is still challenged for its low resolution (LR) as well. In real scenes, pedestrian re-identification (re-id) methods are required to resolve multiple pedestrians-oriented heterogeneous problem for low resolution image further. To deal with the mismatch problem between high resolution (HR) images and LR images, conventional re-id methods are mainly concerned of the cross-resolution matching problem. It is essential to richer mutual-benefited ability between low-resolution gallery images and query images. To improve the low-resolution pedestrian matching performance, we develop a novel of gun-ball camera-based pedestrian re-identification benchmark dataset and a low-resolution pedestrian re-identification benchmark model is designed as well.MethodThis data collection is acquired by the gun and ball system, which is deployed at three intersections. To capture LR images, two of three cameras are placed at each intersection, and the gun camera has a fixed direction and focal length. To obtain high-resolution images more, the other ball camera can be used to tune the focal length and the direction of view according to the target pedestrian position. And, a pedestrian re-identification dataset can be built and sampled by 200 pedestrians-identified categories (the same pedestrian is captured and identified at different locations), and a sample of 320 pedestrian-unidentified categories (pedestrians can be captured under a certain camera only). Each of these pedestrians-related images are all in related to the two aspects of high resolution and low resolution. A pedestrian-identified image can be captured by at least 2 different gun-ball cameras from different places, and a pedestrian-unidentified image can be captured by one gun-ball camera only and it is required to be searched and matched across cameras further. Pedestrian-unidentified images are in relevance to both of LR & HR as well. Some optimal factors are illustrated as mentioned below: 1) a richer and more diverse pedestrian dataset: the gun-ball camera-based pedestrian re-identification dataset can be used to acquire various pedestrian images from intersections. 2) The pedestrian dynamics: each pedestrian image has its temporal information because the gun-ball camera-based pedestrian dataset is captured and cropped from the video stream. Such temporal-based pedestrian images can be used for video-related pedestrian re-identification as well. 3) Other potentials: some pedestrians-unidentified images can be focused on, which can be used to study pedestrian re-identification algorithms in semi-supervised or unsupervised domains, as well as the ground truth of identification systems. That is, given an unknown identity of a pedestrian, its identification system can automatically detect the similar one in the surveillance screen or database. To strengthen the matching problem of LR images of pedestrians, we consider 1) image super-resolution, 2) pedestrian-related feature learning, and 3) discrimination as three key factors in our baseline. Specifically, to optimize each aspect of resolution, pedestrian feature-related learning and discrimination, the baseline is involved of a super-resolution module, a pedestrian re-identification module, and a pedestrian feature discriminator. Therefore, we design a baseline pedestrian re-identification model and it is benched on the 5 following aspects: generator G, image discriminator Ds, gradient discriminator Dg, pedestrian feature extractor F, and pedestrian feature discriminator Df. To resolve the problem of low-resolution pedestrian re-identification in real scenes, our proposed model can be used to optimize both of the resolution of pedestrian image and pedestrian discrimination features.ResultThe low-resolution pedestrian re-identification baseline model is demonstrated and experimentally validated on the gun-ball pedestrian re-identification dataset. The mean average precision (mAP) and Rank-1 metrics are improved by 3.1% and 6.1%.ConclusionLR-related pedestrian recognition in natural scenes can be facilitated, and its pixel misalignment-derived problem of low quality of generated super-resolved images can be resolved to a certain extent. The dataset and benchmark model are proposed and its potential is in related to pedestrian re-identification and image super-resolution. It provides a data source for the field of low-resolution pedestrian re-identification. Also, the proposed baseline model can be predicted to tackle the low-resolution pedestrian matching problem further.关键词:pedestrian re-identification;benchmark dataset;low-resolution(LR);super-resolution(SR);discriminator229|340|1更新时间:2024-05-07
Dataset
-
 摘要:ObjectivePerson re-identification (ReID) is a computer vision-based cross camera recognition technology to target a pedestrian-specific in an image or video sequence. To obtain more discriminative features and achieve high accuracy, the deep learning based method of ReID is focused on processing personal features in recent years. The whole pedestrian image is often as the sample for the ReID model and each pixel feature is as the basis for recognition in the image. However, ReID, as a cross-camera recognition task, is required to deploy a wide range and number of camera locations, which will inevitably lead to background variations in pedestrian images. In other words, the heterogeneity of images-captured is challenged for the interrelations between background similarity and its identity for both of single and multiple cameras. Therefore, it is necessary to rich background information to the pedestrian similarity metric in the ReID model. To resolve this problem, we develop a foreground segmentation-based multi-branch joint person re-identification method in terms of the residual network 50 (ResNet50).MethodAn integration of foreground segmentation and ReID method are employed. First, as the input for feature extraction, the foreground area of the pedestrian images is extracted by the foreground segmentation module. Then, to achieve mutual benefits between different features, the global features in the image are combined with local features and high-dimensional features with low-dimensional features using a multi-grain feature-guided branch and multi-scale feature fusion branch. For the foreground segmentation module, an attention mechanism is used to improve mask region-based convolutional neural network (Mask R-CNN). And, the foreground segmentation loss function is adopted to optimize the feature information loss derived of rough segmentation of the foreground. For multi-grain feature branch, the convolutional block attention module (CBAM) is improved initially in terms of a three-branch attention structure. The information-interacted between two dimensions is based on adding new branches between the spatial and channel dimensions. Furthermore, an attention-sharing strategy is implemented. To improve the effectiveness of feature extraction and avoid feature chunking-derived missing information, the attention information is shared in coarse-grained branches with fine-grained branches, which can yield global features to guide the extraction of local features simply. For multi-scale feature fusion branch, the features at different stages backbone network feature extraction are used as the input of multi-scale fusion straightforward. Additionally, the pyramid attention structure is used as well to get the feature information before fusion. Next, for the fusion module, to synthesize the global information and alleviate the loss of feature information, a non-local algorithm is illustrated in multiscale for feature fusion. Finally, as a joint loss function, the loss-incorporated is in relevance with foreground segmentation, TriHard, and Softmax. And, it is used to train the network for optimization further.ResultThe comparative analysis is based on 3 publicly available datasets (Market-1501, Duke multi-tracking multi-camera re-identification(DukeMTMC-reID) and multi-scene multi-time person ReID dataset(MSMT17)). The metrics-related evaluations consist of rank-n accuracy (Rank-n) and mean average precision (mAP). For the Market-1501 dataset, the Rank-1 and mAP can be reached 96.8% and 91.5% of each, which is a 0.6% improvement in Rank-1 and a 1% improvement in mAP compared to attention pyramid network (APNet-C); For the DukeMTMC-reID dataset, the Rank-1 and mAP can be reached to 91.5% and 82.3% of each, as well as an improvement of 1.1% in Rank-1 and an improvement of 0.8% in mAP compared to the model APNet-C; For the MSMT17 dataset, the Rank-1 and mAP can be reached to 83.9% and 63.8% of each, which is increased by 0.2% in Rank-1 and 0.3% in mAP compared to APNet-C;ConclusionWe facilitate a foreground segmentation based multi-branch joint model. It can be focused on foreground extraction-based in accordance with an integration of multiple scales and grains image features. At the same time, the foreground segmentation module can wipe out ineffective background and alleviate the background-differentiated false recognition more.关键词:foreground segmentation;semantic segmentation;person re-identification(ReID);feature fusion;attention mechanism136|216|1更新时间:2024-05-07
摘要:ObjectivePerson re-identification (ReID) is a computer vision-based cross camera recognition technology to target a pedestrian-specific in an image or video sequence. To obtain more discriminative features and achieve high accuracy, the deep learning based method of ReID is focused on processing personal features in recent years. The whole pedestrian image is often as the sample for the ReID model and each pixel feature is as the basis for recognition in the image. However, ReID, as a cross-camera recognition task, is required to deploy a wide range and number of camera locations, which will inevitably lead to background variations in pedestrian images. In other words, the heterogeneity of images-captured is challenged for the interrelations between background similarity and its identity for both of single and multiple cameras. Therefore, it is necessary to rich background information to the pedestrian similarity metric in the ReID model. To resolve this problem, we develop a foreground segmentation-based multi-branch joint person re-identification method in terms of the residual network 50 (ResNet50).MethodAn integration of foreground segmentation and ReID method are employed. First, as the input for feature extraction, the foreground area of the pedestrian images is extracted by the foreground segmentation module. Then, to achieve mutual benefits between different features, the global features in the image are combined with local features and high-dimensional features with low-dimensional features using a multi-grain feature-guided branch and multi-scale feature fusion branch. For the foreground segmentation module, an attention mechanism is used to improve mask region-based convolutional neural network (Mask R-CNN). And, the foreground segmentation loss function is adopted to optimize the feature information loss derived of rough segmentation of the foreground. For multi-grain feature branch, the convolutional block attention module (CBAM) is improved initially in terms of a three-branch attention structure. The information-interacted between two dimensions is based on adding new branches between the spatial and channel dimensions. Furthermore, an attention-sharing strategy is implemented. To improve the effectiveness of feature extraction and avoid feature chunking-derived missing information, the attention information is shared in coarse-grained branches with fine-grained branches, which can yield global features to guide the extraction of local features simply. For multi-scale feature fusion branch, the features at different stages backbone network feature extraction are used as the input of multi-scale fusion straightforward. Additionally, the pyramid attention structure is used as well to get the feature information before fusion. Next, for the fusion module, to synthesize the global information and alleviate the loss of feature information, a non-local algorithm is illustrated in multiscale for feature fusion. Finally, as a joint loss function, the loss-incorporated is in relevance with foreground segmentation, TriHard, and Softmax. And, it is used to train the network for optimization further.ResultThe comparative analysis is based on 3 publicly available datasets (Market-1501, Duke multi-tracking multi-camera re-identification(DukeMTMC-reID) and multi-scene multi-time person ReID dataset(MSMT17)). The metrics-related evaluations consist of rank-n accuracy (Rank-n) and mean average precision (mAP). For the Market-1501 dataset, the Rank-1 and mAP can be reached 96.8% and 91.5% of each, which is a 0.6% improvement in Rank-1 and a 1% improvement in mAP compared to attention pyramid network (APNet-C); For the DukeMTMC-reID dataset, the Rank-1 and mAP can be reached to 91.5% and 82.3% of each, as well as an improvement of 1.1% in Rank-1 and an improvement of 0.8% in mAP compared to the model APNet-C; For the MSMT17 dataset, the Rank-1 and mAP can be reached to 83.9% and 63.8% of each, which is increased by 0.2% in Rank-1 and 0.3% in mAP compared to APNet-C;ConclusionWe facilitate a foreground segmentation based multi-branch joint model. It can be focused on foreground extraction-based in accordance with an integration of multiple scales and grains image features. At the same time, the foreground segmentation module can wipe out ineffective background and alleviate the background-differentiated false recognition more.关键词:foreground segmentation;semantic segmentation;person re-identification(ReID);feature fusion;attention mechanism136|216|1更新时间:2024-05-07 -
 摘要:ObjectivePedestrians’ re-identification (Re-ID) can be as one of key techniques for multi-camera pedestrians’ retrieval in the video surveillance system. To achieve good performance, current Re-ID model is often trained on a scene based on a large number of annotations (source domain), but the performance will be dropped significantly when a new scene (target domain) is applied straightforward. However, re-labeling is time-consuming and labor-intensive for the new scene, which is beneficial for Re-ID-related optimization. The unsupervised domain adaptive pedestrians’ re-identification (UDA Re-ID) method is focused on a model training, which can be generalized on the target domain well using the existing source domain data-labeled and target domain data-unlabeled. But, these methods are still challenged for the instability of instance features and image heterogeneity of the intra-class distance-wider and the inter-class distance-narrowed. Furthermore, current cluster unlabeled target domain data can be melted into multiple clusters, and the encoded pseudo labels can be assigned for each cluster. However, due to the limited representation ability of the model, the clustering results are incredible, especially in the early stage of training. One pedestrian-related image is grouped into different clusters while some images of different pedestrian are merged into a cluster, called pseudo label noises. However, it is still challenged for the problem of pseudo label noises-over-fitted and the performance of the model-suppressed although pseudo labels are recognized as a supervision signal for the feature learning process (e.g., contrastive learning). To resolve these problems, we develop a multi-centroid representation network with consistency constraints method (MCRNCC) in terms of the popular multi-centroid representation network method (MCRN).MethodThe MCRNCC is designed on the basis of three MCRN-related modules to improve the stability of instance features and the robustness of pedestrian features, and the overfitting risk of the pseudo-label noise can be reduced. First, to optimize the instance feature stability and semantic information, an instance-consistent is demonstrated to suppress the feature distance of the same instance under different augmentation. The exponential moving average model is illustrated to output additional features based on recent self-supervised learning works. For each image of the training batch, it can be augmented twice in random, the features can be extracted in relevance to original model and exponential moving average model, and cosine distance is used to constrain the feature pairs. Second, to improve robustness of multiple variations-captured, its homogeneity is concerned for suppressing the distance between feature pairs of positive instances. Specifically, two instances are opted to construct a positive pair in the context of same labels-without identity label, and two instances is opted as well to construct a negative pair in related to same label-within multiple identity labels, and a triplet is built up to optimize the network as well. Finally, the label-ensemble-based optimization is carried out to convert one-hot encoded pseudo labels into more reliable soft labels, which improves the robustness of supervision signals. In detail, we add a target domain classifier to generate additional label predictions, followed by linearly weighting the predictions and one-hot encoded pseudo labels into refined soft labels.ResultTo verify the effectiveness of our method, adequate experiments are carried out on 4 popular UDA Re-ID tasks like 1) Duke→Market, 2) Market→Duke, 3) Duke→MSMT, and 4) Market→MSMT tasks. At the beginning, the ablation studies are carried out about the modules in MCRNCC. The four tasks-derived instance consistency constraints can be reached to 0.6%, 0.2%, 0.7% and 0.8% of each mean average precision (mAP), which demonstrates the effectiveness of the instance consistency constraint. The camera consistency constraint yields a general improvement for all of 4 tasks. For example, mAP/Rank-1 is increased by 3.5%/3.2% and 5.3%/4.7% on Duke→MSMT and Market→MSMT. In addition, we visualize the feature space of adding camera consistency constraint before and after. Furthermore, we compare the feature space of some pedestrian-focused close to the camera consistency constraint, and the visualization results show that the camera consistency can make the feature space more compactible. The label-ensemble-optimized can be improved to 0.6%, 0.6%, 1.4% and 0.4% of the mAP for each 4 tasks. Second, our proposed MCRNCC is compared to the existing methods. The comparative analysis shows that the MCRNCC can be reached to 85.0%/94.0%, 73.5%/85.6%, 41.3%/71.6% and 39.3%/69.5% for the optimization of mAP/Rank-1 performance, and the MCRN is surpassed by 1.2%/0.2%, 2.0%/1.1%, 5.6%/4.1%, and 6.5%/5.1% as well.Conclusionwe develop a method MCRNCC to resolve the UDA Re-ID problem further. The instance consistency constraint and camera consistency constraint proposed in MCRNCC can enable the model to learn more robust pedestrian-related feature representations, while the proposed label ensemble-based optimization can reduce the overfitting risks of pseudo label noises. Experiments show that the effectiveness of three-module based MCRNCC has its potentials for future works.关键词:computer vision;pedestrians’ re-identification(Re-ID);unsupervised domain adaption(UDA);consistency constraint;label refinery117|432|1更新时间:2024-05-07
摘要:ObjectivePedestrians’ re-identification (Re-ID) can be as one of key techniques for multi-camera pedestrians’ retrieval in the video surveillance system. To achieve good performance, current Re-ID model is often trained on a scene based on a large number of annotations (source domain), but the performance will be dropped significantly when a new scene (target domain) is applied straightforward. However, re-labeling is time-consuming and labor-intensive for the new scene, which is beneficial for Re-ID-related optimization. The unsupervised domain adaptive pedestrians’ re-identification (UDA Re-ID) method is focused on a model training, which can be generalized on the target domain well using the existing source domain data-labeled and target domain data-unlabeled. But, these methods are still challenged for the instability of instance features and image heterogeneity of the intra-class distance-wider and the inter-class distance-narrowed. Furthermore, current cluster unlabeled target domain data can be melted into multiple clusters, and the encoded pseudo labels can be assigned for each cluster. However, due to the limited representation ability of the model, the clustering results are incredible, especially in the early stage of training. One pedestrian-related image is grouped into different clusters while some images of different pedestrian are merged into a cluster, called pseudo label noises. However, it is still challenged for the problem of pseudo label noises-over-fitted and the performance of the model-suppressed although pseudo labels are recognized as a supervision signal for the feature learning process (e.g., contrastive learning). To resolve these problems, we develop a multi-centroid representation network with consistency constraints method (MCRNCC) in terms of the popular multi-centroid representation network method (MCRN).MethodThe MCRNCC is designed on the basis of three MCRN-related modules to improve the stability of instance features and the robustness of pedestrian features, and the overfitting risk of the pseudo-label noise can be reduced. First, to optimize the instance feature stability and semantic information, an instance-consistent is demonstrated to suppress the feature distance of the same instance under different augmentation. The exponential moving average model is illustrated to output additional features based on recent self-supervised learning works. For each image of the training batch, it can be augmented twice in random, the features can be extracted in relevance to original model and exponential moving average model, and cosine distance is used to constrain the feature pairs. Second, to improve robustness of multiple variations-captured, its homogeneity is concerned for suppressing the distance between feature pairs of positive instances. Specifically, two instances are opted to construct a positive pair in the context of same labels-without identity label, and two instances is opted as well to construct a negative pair in related to same label-within multiple identity labels, and a triplet is built up to optimize the network as well. Finally, the label-ensemble-based optimization is carried out to convert one-hot encoded pseudo labels into more reliable soft labels, which improves the robustness of supervision signals. In detail, we add a target domain classifier to generate additional label predictions, followed by linearly weighting the predictions and one-hot encoded pseudo labels into refined soft labels.ResultTo verify the effectiveness of our method, adequate experiments are carried out on 4 popular UDA Re-ID tasks like 1) Duke→Market, 2) Market→Duke, 3) Duke→MSMT, and 4) Market→MSMT tasks. At the beginning, the ablation studies are carried out about the modules in MCRNCC. The four tasks-derived instance consistency constraints can be reached to 0.6%, 0.2%, 0.7% and 0.8% of each mean average precision (mAP), which demonstrates the effectiveness of the instance consistency constraint. The camera consistency constraint yields a general improvement for all of 4 tasks. For example, mAP/Rank-1 is increased by 3.5%/3.2% and 5.3%/4.7% on Duke→MSMT and Market→MSMT. In addition, we visualize the feature space of adding camera consistency constraint before and after. Furthermore, we compare the feature space of some pedestrian-focused close to the camera consistency constraint, and the visualization results show that the camera consistency can make the feature space more compactible. The label-ensemble-optimized can be improved to 0.6%, 0.6%, 1.4% and 0.4% of the mAP for each 4 tasks. Second, our proposed MCRNCC is compared to the existing methods. The comparative analysis shows that the MCRNCC can be reached to 85.0%/94.0%, 73.5%/85.6%, 41.3%/71.6% and 39.3%/69.5% for the optimization of mAP/Rank-1 performance, and the MCRN is surpassed by 1.2%/0.2%, 2.0%/1.1%, 5.6%/4.1%, and 6.5%/5.1% as well.Conclusionwe develop a method MCRNCC to resolve the UDA Re-ID problem further. The instance consistency constraint and camera consistency constraint proposed in MCRNCC can enable the model to learn more robust pedestrian-related feature representations, while the proposed label ensemble-based optimization can reduce the overfitting risks of pseudo label noises. Experiments show that the effectiveness of three-module based MCRNCC has its potentials for future works.关键词:computer vision;pedestrians’ re-identification(Re-ID);unsupervised domain adaption(UDA);consistency constraint;label refinery117|432|1更新时间:2024-05-07 -
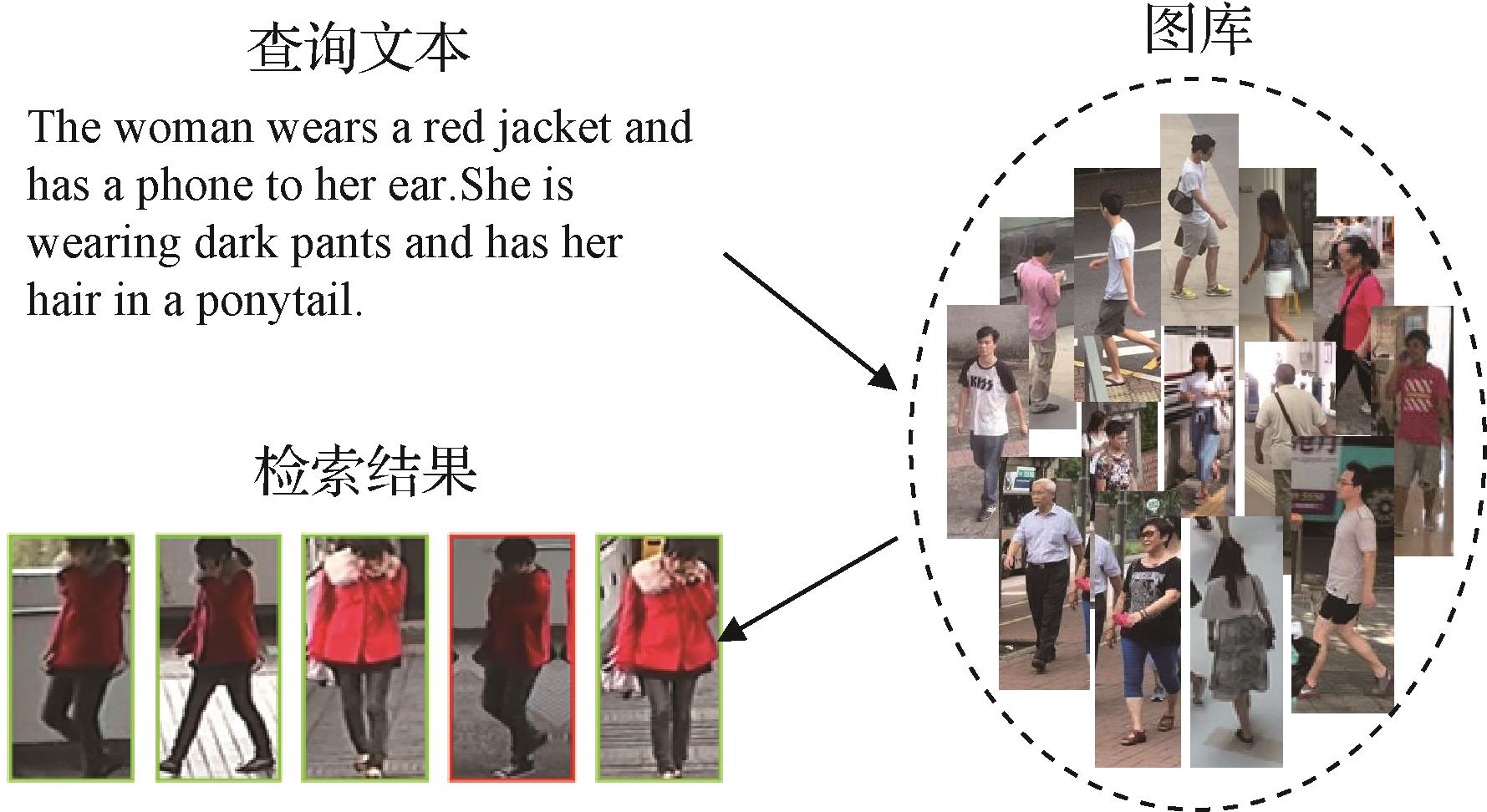 摘要:ObjectiveText-to-image person re-identification is a sub-task of image-text retrieval, which aims to retrieve the target person images corresponding to the given text description. The main challenge of the text-to-image person re-identification task is the significant feature gap between vision and language. The fine-grained matching between the semantic information of the two modalities is restricted by modal gap as well. The mixture of multiple local features and global feature are often adopted for cross-modal matching recently. These local-level matching methods are complicated and suppress the retrieval speed. Insufficient training data is still challenged for text-to-image person re-identification tasks as well. To alleviate this insufficiency, conventional methods are typically initialized their backbone models with weights pre-trained on single-modal large-scale datasets. However, this initialization method cannot be used to learn the information of fine-grained image-text cross-modal matching and its semantic alignment. Therefore, an easy-to-use method is required to optimize the cross-modal alignment for the text-to-image person re-identification model.MethodWe develop a transformer network with a temperature-scaled projection matching method and contrastive language-image pre-training (CLIP) for text-to-image person re-identification. The CLIP is a general multimodal foundation model pre-trained on large-scale image-text datasets. The vision transformer is used as the visual backbone network to preserve fine-grained information, which can resolve the convolutional neural network(CNN)-based constraint of long-range relationships and down-sampling. To optimize the cross-modal image-text alignment capability of the pre-trained CLIP model, our model is focused on fine-grained image-text semantic feature alignment using global features only. In addition, a temperature-scaled cross-modal projection matching (TCMPM) loss function is developed for image-text cross-modal feature matching as well. The TCMPM loss can be used to minimize the Kullback-Leibler(KL) divergence between temperature-scaled projection distributions and normalized true matching distributions in a mini-batch.ResultExtensive experiments are carried out on two datasets in comparison with the latest text-to-image person re-identification methods. We adopt the two popular public datasets, CUHK person discription(CUHK-PEDES) and identity-centric and fine-grained person discription(ICFG-PEDES), to validate the effectiveness of the proposed method. Rank-K (K = 1, 5, 10) are adopted as the retrieval evaluation metrics. On the CUHK-PEDES dataset, the Rank-1 value is improved by 5.92% compared to the best performing existing local-level matching method, and it is improved by 7.09% for existing global-level matching method. On the ICFG-PEDES dataset, the Rank-1 value is improved by 1.21% for local-level matching model. The ablation studies are also carried out on the CUHK-PEDES and ICFG-PEDES dataset. Compared to original CMPM loss, the Rank-1 value of the TCMPM loss is improved by 9.54% on the CUHK-PEDES dataset, and the Rank-1 value is improved by 4.67% on the ICFG-PEDES dataset. Compared to the InfoNCE loss, a commonly-used loss in cross-modal comparative learning, the Rank-1 value can be improved by 3.38% on the CUHK-PEDES dataset in terms of the TCMPM loss, and the Rank-1 value is improved by 0.42% on the ICFG-PEDES dataset.ConclusionAn end-to-end dual Transformer network is developed to learn representations of person images and descriptive texts in the text-to-image person re-identification. We demonstrate that the global-level matching method has its potential to outperform current state-of-the-art local-level matching methods. The transformer network can resolve the problem that CNN cannot model the long-range relationship and detailed information-loss for down-sampling. In addition, our proposed method can benefit from the powerful cross-modal alignment capability of CLIP, and together with our further designed TCMPM loss, our model can thus learn more discriminative image-text features.关键词:cross modal retrieval;person re-identification;person search;Transformer;text-image retrieval511|411|2更新时间:2024-05-07
摘要:ObjectiveText-to-image person re-identification is a sub-task of image-text retrieval, which aims to retrieve the target person images corresponding to the given text description. The main challenge of the text-to-image person re-identification task is the significant feature gap between vision and language. The fine-grained matching between the semantic information of the two modalities is restricted by modal gap as well. The mixture of multiple local features and global feature are often adopted for cross-modal matching recently. These local-level matching methods are complicated and suppress the retrieval speed. Insufficient training data is still challenged for text-to-image person re-identification tasks as well. To alleviate this insufficiency, conventional methods are typically initialized their backbone models with weights pre-trained on single-modal large-scale datasets. However, this initialization method cannot be used to learn the information of fine-grained image-text cross-modal matching and its semantic alignment. Therefore, an easy-to-use method is required to optimize the cross-modal alignment for the text-to-image person re-identification model.MethodWe develop a transformer network with a temperature-scaled projection matching method and contrastive language-image pre-training (CLIP) for text-to-image person re-identification. The CLIP is a general multimodal foundation model pre-trained on large-scale image-text datasets. The vision transformer is used as the visual backbone network to preserve fine-grained information, which can resolve the convolutional neural network(CNN)-based constraint of long-range relationships and down-sampling. To optimize the cross-modal image-text alignment capability of the pre-trained CLIP model, our model is focused on fine-grained image-text semantic feature alignment using global features only. In addition, a temperature-scaled cross-modal projection matching (TCMPM) loss function is developed for image-text cross-modal feature matching as well. The TCMPM loss can be used to minimize the Kullback-Leibler(KL) divergence between temperature-scaled projection distributions and normalized true matching distributions in a mini-batch.ResultExtensive experiments are carried out on two datasets in comparison with the latest text-to-image person re-identification methods. We adopt the two popular public datasets, CUHK person discription(CUHK-PEDES) and identity-centric and fine-grained person discription(ICFG-PEDES), to validate the effectiveness of the proposed method. Rank-K (K = 1, 5, 10) are adopted as the retrieval evaluation metrics. On the CUHK-PEDES dataset, the Rank-1 value is improved by 5.92% compared to the best performing existing local-level matching method, and it is improved by 7.09% for existing global-level matching method. On the ICFG-PEDES dataset, the Rank-1 value is improved by 1.21% for local-level matching model. The ablation studies are also carried out on the CUHK-PEDES and ICFG-PEDES dataset. Compared to original CMPM loss, the Rank-1 value of the TCMPM loss is improved by 9.54% on the CUHK-PEDES dataset, and the Rank-1 value is improved by 4.67% on the ICFG-PEDES dataset. Compared to the InfoNCE loss, a commonly-used loss in cross-modal comparative learning, the Rank-1 value can be improved by 3.38% on the CUHK-PEDES dataset in terms of the TCMPM loss, and the Rank-1 value is improved by 0.42% on the ICFG-PEDES dataset.ConclusionAn end-to-end dual Transformer network is developed to learn representations of person images and descriptive texts in the text-to-image person re-identification. We demonstrate that the global-level matching method has its potential to outperform current state-of-the-art local-level matching methods. The transformer network can resolve the problem that CNN cannot model the long-range relationship and detailed information-loss for down-sampling. In addition, our proposed method can benefit from the powerful cross-modal alignment capability of CLIP, and together with our further designed TCMPM loss, our model can thus learn more discriminative image-text features.关键词:cross modal retrieval;person re-identification;person search;Transformer;text-image retrieval511|411|2更新时间:2024-05-07 -
 摘要:ObjectiveVideo surveillance systems have been widely used for public security such as tracking the suspect and looking for missing person. It is really expensive and time-consuming to analyze videos manually. Person re-identification (ReID) aims to match the same person appearing at different times and places under non-overlapping cameras. With the development of deep learning, ReID has gained significant performance increment on the benchmark. It is known that in ReID, the retrieval mainly depends on apparent cues such as clothes information. However, if the surveillance video is captured in a long-time span, people may change their clothes when appearing in the surveillance system. Besides, criminals may also change their clothes to evade surveillance cameras. In such cases, existing methods are likely to fail because they extract unreliable clothes-relevant features. Clothes-changing problem is inevitable in the real-scene application of ReID. Recently, clothes-changing ReID receives a lot of attention. In clothes-changing ReID, every person wears multiple outfits. The key point to clothes-changing ReID is to extract discriminative clothes-irrelevant features from images with different clothes. Usually, body shape can be used to identify people. Some existing methods extract body shape information from contour images but suffer from low image quality and poor robustness. To resolve these problems, we propose a sketch images-guided method for clothes-changing person re-identification method. There are two main approaches in existing methods: 1) extracting clothes-irrelevant information such as key points, pose and gait and fuse clothes-irrelevant information into person features. 2) Decoupling clothes-irrelevant and clothes-relevant feature using an encoder-decoder architecture.MethodFirst, to improve the accuracy and robustness of body shape information, we propose to obtain more accurate and robust shape information from sketch images rather than contour images. Then we use an extra independently-trained network to extract the shape features of the person. Additionally, to reduce the clothes information in visual features and improve the discrimination of visual features, we propose a clothes-irrelevant weight guidance module based on sketch images. The module further uses the clothes position information in sketch images to guide the extraction process of visual features. With the guidance, the model can extract features with less clothes information. We use a two-stream network to fuse the shape feature and clothes-irrelevant apparent feature to get the complete person feature. We implement our method by using python and PyTorch. We train our network with one NVIDIA 3090 GPU device. We perform random horizontal flips and random erasing for augmentation. We use Adam optimizer and the learning rate is set to 0.000 35. The learning rate will decay per 20 batches.ResultThe performance of the proposed method is evaluated on two public clothes-changing dataset: long-term cloth changing (LTCC) and person re-identification under moderate clothing change (PRCC). Our method overperforms the state-of-the-art methods on both two datasets. The proposed method obtains 38.0% Rank-1 and 15.9% mean average precision (mAP) on LTCC dataset; 55.5% Rank-1 and 52.6% mAP on PRCC dataset. The results of the ablation experiment demonstrate that the sketch images have their priority in robustness and accuracy compared with contour images. Visible results show that our proposed method can effectively weaken the model’s attention on the clothes area.ConclusionWe propose a better way to extract body shape information and propose a sketch-based guidance module, which utilizes clothes-irrelevant information to wipe out clothing information in visual features. Experiments show that sketch images are superior to contour images in robustness and accuracy. Sketch images can provide more body shape information as a complement to visual features than contour images. The proposed clothes-irrelevant weight guidance module can effectively reduce clothing information in visual features. Our proposed sketch images-guided clothes-changing person re-identification method effectively extracts complete person features, which include clothing-irrelevant visual features and body shape features.关键词:computer vision;clothes-changing person re-identification;sketch images;appearance feature;shape feature;two-stream network137|327|0更新时间:2024-05-07
摘要:ObjectiveVideo surveillance systems have been widely used for public security such as tracking the suspect and looking for missing person. It is really expensive and time-consuming to analyze videos manually. Person re-identification (ReID) aims to match the same person appearing at different times and places under non-overlapping cameras. With the development of deep learning, ReID has gained significant performance increment on the benchmark. It is known that in ReID, the retrieval mainly depends on apparent cues such as clothes information. However, if the surveillance video is captured in a long-time span, people may change their clothes when appearing in the surveillance system. Besides, criminals may also change their clothes to evade surveillance cameras. In such cases, existing methods are likely to fail because they extract unreliable clothes-relevant features. Clothes-changing problem is inevitable in the real-scene application of ReID. Recently, clothes-changing ReID receives a lot of attention. In clothes-changing ReID, every person wears multiple outfits. The key point to clothes-changing ReID is to extract discriminative clothes-irrelevant features from images with different clothes. Usually, body shape can be used to identify people. Some existing methods extract body shape information from contour images but suffer from low image quality and poor robustness. To resolve these problems, we propose a sketch images-guided method for clothes-changing person re-identification method. There are two main approaches in existing methods: 1) extracting clothes-irrelevant information such as key points, pose and gait and fuse clothes-irrelevant information into person features. 2) Decoupling clothes-irrelevant and clothes-relevant feature using an encoder-decoder architecture.MethodFirst, to improve the accuracy and robustness of body shape information, we propose to obtain more accurate and robust shape information from sketch images rather than contour images. Then we use an extra independently-trained network to extract the shape features of the person. Additionally, to reduce the clothes information in visual features and improve the discrimination of visual features, we propose a clothes-irrelevant weight guidance module based on sketch images. The module further uses the clothes position information in sketch images to guide the extraction process of visual features. With the guidance, the model can extract features with less clothes information. We use a two-stream network to fuse the shape feature and clothes-irrelevant apparent feature to get the complete person feature. We implement our method by using python and PyTorch. We train our network with one NVIDIA 3090 GPU device. We perform random horizontal flips and random erasing for augmentation. We use Adam optimizer and the learning rate is set to 0.000 35. The learning rate will decay per 20 batches.ResultThe performance of the proposed method is evaluated on two public clothes-changing dataset: long-term cloth changing (LTCC) and person re-identification under moderate clothing change (PRCC). Our method overperforms the state-of-the-art methods on both two datasets. The proposed method obtains 38.0% Rank-1 and 15.9% mean average precision (mAP) on LTCC dataset; 55.5% Rank-1 and 52.6% mAP on PRCC dataset. The results of the ablation experiment demonstrate that the sketch images have their priority in robustness and accuracy compared with contour images. Visible results show that our proposed method can effectively weaken the model’s attention on the clothes area.ConclusionWe propose a better way to extract body shape information and propose a sketch-based guidance module, which utilizes clothes-irrelevant information to wipe out clothing information in visual features. Experiments show that sketch images are superior to contour images in robustness and accuracy. Sketch images can provide more body shape information as a complement to visual features than contour images. The proposed clothes-irrelevant weight guidance module can effectively reduce clothing information in visual features. Our proposed sketch images-guided clothes-changing person re-identification method effectively extracts complete person features, which include clothing-irrelevant visual features and body shape features.关键词:computer vision;clothes-changing person re-identification;sketch images;appearance feature;shape feature;two-stream network137|327|0更新时间:2024-05-07 -
 摘要:ObjectivePedestrian re-identification can be focused on real-time target detection and matching. Due to labor-intensive to annotate accurate labels,unsupervised domain adaptation has become a potential solution. To generate pseudo labels, this method is required for clustering accompany with noise. Experimental analysis is demonstrated that camera-cross is one of the key distorted factors for noise. Current eigenvector method is oriented to weaken the cross-domain and it is challenged for identifying camera ID-based information effectively. Hence, we design a camera module to resolve the problem of camera-cross. In addition, a single network is often used to extract features. Experimental analysis illustrate the single feature extraction ability of a single backbone network would also have more effective impact on the final performance. Therefore, learning-mutual is used to optimize the single network. For pedestrian searching, a good ranking algorithm is beneficial for a better recognition performance. We optimize traditional re-ranking algorithm using spatio-temporal information in the dataset because regular re-ranking optimization limits its application in real scenarios due to huge performance consumption. The time and space consumption close to the original ranking can reach the traditional re-ranking effect. To optimize the ranking, we develop a joint of spatio-temporal information-relevant multi-network and camera-splitting training framework.MethodFirst, to improve the initial recognition performance, the network is pre-trained on the source domain dataset, and two of loss functions in relevance with label smoothing cross-entropy and triplet are used to pre-train the source domain. Second, due to the unique features extracted from a single backbone network, the single network model cannot be used to preserve good generalization ability in the ever-changing real scenarios. Therefore, we design a learning-mutual model to enhance its robustness. The pedestrian re-identification-oriented camera-split strategy is implemented to deal with recognition interference derived from cross-camera. For the pseudo-label generation, the dataset is split according to the camera ID, and the output vector is averaged after different networks-toward input. Additionally, we make full use of spatial information to optimize the pedestrian re-identification algorithm in another dimension because prior recognition analyses are originated from the distribution factors of pedestrians. For example, since the same camera is relatively close under the same timestamp, we use the timestamp information in the image. The one-hot-coded time stamps are spliced into feature vectors and it is then clustered to obtain pseudo labels. For training, to transfer knowledge from one network model to another, we use the class prediction of each network model as a soft label for training other related network models. For learning-mutual module, a time-averaging model is added, which can be updated iteratively during the training process. To suppress error-amplified, a large amount of prior information can be preserved. Furthermore, the learning-mutual correlation loss function is designed as well. Traditional classification loss and triplet loss are modified, and the loss function is designed on the basis of the integration of pseudo-labels and multiple backbone networks-related features. The network model training-based feature distribution can be constrained by multiple network models at the same time. For features-sorting, to optimize the traditional sort algorithm, pedestrian re-identification characteristics and spatiotemporal information of the dataset can be used according to the cameras of the same pseudo label number. The distribution of timestamp and statistics is used to generate the time distribution between different cameras, and a spatiotemporal score of camera is defined to fine-tune distance-between characteristics. This method is focused on a re-ranking spatially and the efficient and effective method can achieve similar spatio-temporal results close to the original ranking.ResultThe comparative analysis is carried out and popular 10 methods are compared on two cross-domain experimental datasets. For source domain-relevant Duke multi-tracking multi-camera reidentification(DukeMTMC-ReID) data set and target domain-related market-1501 dataset, the mean average precision (mAP) value can be reached to 82.5%, and the Rank1 is increased by 3.1% and reached to 95.3%. For the dataset in relevant to source domain market-1501 and target domain DukeMTMC-ReID, mAP and Rank1 can be reached to 75.3% and 90.2% of each.ConclusionTo improve the accuracy of pseudo labels and optimize the matching ranking, the spatiotemporal distance ranking-coordinated learning-mutual model is developed in sub-camera network. Its computation is optimized more and pedestrian re-recognition performance is improved further.关键词:pedstrian re-ID;mutual learning;multiple cameras;cross domain;time and space distance89|226|0更新时间:2024-05-07
摘要:ObjectivePedestrian re-identification can be focused on real-time target detection and matching. Due to labor-intensive to annotate accurate labels,unsupervised domain adaptation has become a potential solution. To generate pseudo labels, this method is required for clustering accompany with noise. Experimental analysis is demonstrated that camera-cross is one of the key distorted factors for noise. Current eigenvector method is oriented to weaken the cross-domain and it is challenged for identifying camera ID-based information effectively. Hence, we design a camera module to resolve the problem of camera-cross. In addition, a single network is often used to extract features. Experimental analysis illustrate the single feature extraction ability of a single backbone network would also have more effective impact on the final performance. Therefore, learning-mutual is used to optimize the single network. For pedestrian searching, a good ranking algorithm is beneficial for a better recognition performance. We optimize traditional re-ranking algorithm using spatio-temporal information in the dataset because regular re-ranking optimization limits its application in real scenarios due to huge performance consumption. The time and space consumption close to the original ranking can reach the traditional re-ranking effect. To optimize the ranking, we develop a joint of spatio-temporal information-relevant multi-network and camera-splitting training framework.MethodFirst, to improve the initial recognition performance, the network is pre-trained on the source domain dataset, and two of loss functions in relevance with label smoothing cross-entropy and triplet are used to pre-train the source domain. Second, due to the unique features extracted from a single backbone network, the single network model cannot be used to preserve good generalization ability in the ever-changing real scenarios. Therefore, we design a learning-mutual model to enhance its robustness. The pedestrian re-identification-oriented camera-split strategy is implemented to deal with recognition interference derived from cross-camera. For the pseudo-label generation, the dataset is split according to the camera ID, and the output vector is averaged after different networks-toward input. Additionally, we make full use of spatial information to optimize the pedestrian re-identification algorithm in another dimension because prior recognition analyses are originated from the distribution factors of pedestrians. For example, since the same camera is relatively close under the same timestamp, we use the timestamp information in the image. The one-hot-coded time stamps are spliced into feature vectors and it is then clustered to obtain pseudo labels. For training, to transfer knowledge from one network model to another, we use the class prediction of each network model as a soft label for training other related network models. For learning-mutual module, a time-averaging model is added, which can be updated iteratively during the training process. To suppress error-amplified, a large amount of prior information can be preserved. Furthermore, the learning-mutual correlation loss function is designed as well. Traditional classification loss and triplet loss are modified, and the loss function is designed on the basis of the integration of pseudo-labels and multiple backbone networks-related features. The network model training-based feature distribution can be constrained by multiple network models at the same time. For features-sorting, to optimize the traditional sort algorithm, pedestrian re-identification characteristics and spatiotemporal information of the dataset can be used according to the cameras of the same pseudo label number. The distribution of timestamp and statistics is used to generate the time distribution between different cameras, and a spatiotemporal score of camera is defined to fine-tune distance-between characteristics. This method is focused on a re-ranking spatially and the efficient and effective method can achieve similar spatio-temporal results close to the original ranking.ResultThe comparative analysis is carried out and popular 10 methods are compared on two cross-domain experimental datasets. For source domain-relevant Duke multi-tracking multi-camera reidentification(DukeMTMC-ReID) data set and target domain-related market-1501 dataset, the mean average precision (mAP) value can be reached to 82.5%, and the Rank1 is increased by 3.1% and reached to 95.3%. For the dataset in relevant to source domain market-1501 and target domain DukeMTMC-ReID, mAP and Rank1 can be reached to 75.3% and 90.2% of each.ConclusionTo improve the accuracy of pseudo labels and optimize the matching ranking, the spatiotemporal distance ranking-coordinated learning-mutual model is developed in sub-camera network. Its computation is optimized more and pedestrian re-recognition performance is improved further.关键词:pedstrian re-ID;mutual learning;multiple cameras;cross domain;time and space distance89|226|0更新时间:2024-05-07 -
 摘要:ObjectiveVisible-infrared cross-modality pedestrianre-identification (VI-ReID) is focused on same identity-related images between the visible and infrared modality. As a popular technique of intelligent surveillance, it is still challenged for cross-modality. To optimize intra-class variations in RGB image-based pedestrian re-identification (RGB-ReID) task, one crucial challenge in VI-ReID is to bridge the modality gap between the RGB and infrared(IR) images of the same identity because current methods are mainly derived from modality-incorporated feature learning or modality transformation approaches. Specifically, modality-incorporated feature learning methods are used to map the inputs of RGB and IR images into a common embedding space for cross-modality feature alignment. A two-stream convolutional neural network (two-stream CNN) architecture has been recognized and some discriminative constraints are developed as well. However, each filter is constrained for a small region, convolutions is challenged to interlinked to spatial-ranged concepts. Quantitative tests illustrates that the CNNs are strongly biased toward textures rather than shapes. Moreover, existing methods in VI-ReID focus on the global or local feature representation only. Another path of modality transformation approaches can be used to generate cross-modality images-relevant pedestrain images or transform them into an intermediate modality. Generative adversarial network (GAN) and encoder-decoder structures are commonly used for these methods. However, due to the distorted IR-to-RGB translation and additional noises, image generation is incredible and GAN models are difficult to be converged. The RGB images consist of three-color channels, while IR images only contain a single channel reflecting the thermal radiation emitted from the human body and its contexts. Compared to the missing colors and textures in IR images, we review VI-ReID problem and the contour is realized in terms of a relative effective feature. Furthermore, contour is a modality-shared path as it keeps consistent for both of IR and RGB images, which is more accurate and reliable than generated intermediate modality. We implement VI-ReID-integrated contour strategy. To develop its optimization, we take the contour as an auxiliary modality to narrow the modality gap. Meanwhile, we tend to introduce local features into our model to collaborate with global ones further beyond part-based features.MethodA contour-guided dual-grained feature fusion network (CGDGFN) is developed for VI-ReID. It consists of two types of fusion. The first type is concerned of the image to contour fusion, which is called global-grained fusion (G-Fusion) at image-level. G-Fusion can output the augmented contour features. The other type can realize fusion between augmented contour features and local features, which is oriented at image and part mixed level. As the local feature is involved in, it called as local-grained fusion (L-Fusion) for simplicity. The proposed CGDGFN consists of four branches, which are 1) RGB images, 2) IR images, 3) RGB contour and 4) IR contour. First, the input of the network is a pair of RGB and IR images, while they are fed into RGB branch and IR branch, and a contour detector generates their contour images. Then, RGB and IR-relevant contour images of two modalities are fed into RGB-contour branch and IR-contour branch. The ResNet50 is used as the backbone architecture for each branch. The first convolutional layer in each branch has independent parameters to capture modality-specific information, while the remaining blocks are used to learn weight-shared modality-invariant features. In addition, RGB branch and IR branch average pooling layer structure is optimzed for part-based features extraction. G-Fusion is used to fuse an image to its corresponding contour image. After G-Fusion, the augmented contour features will be produced by the global average pooling layer of RGB-contour branch and IR-contour branch. Meanwhile, RGB branch and IR branch can output corresponding local features. RGB local feature as well as IR local feature is an array of feature vectors and its length is clarified by the partition setting. Two of local feature extraction methods are involved in: 1) uniform partition and 2) soft partition. L-Fusion is responsible for fusing the augmented contour features and corresponding local ones. The implementation of our method is based on the Pytorch framework. We adopt the ResNet50 pre-trained on ImageNet as the backbone network, and the stride of the last convolutional layer is set to 1 to obtain feature maps with higher spatial size. The batch size is set to 64. For each batch, we select 4 identities in random and each identity includes 8 visible images and 8 infrared images. The input images are resized to 288×144 pixels, random cropping and random horizontal flip are used for data augmentation. The stochastic gradient descent (SGD) optimizer is used for optimization and the momentum is set to 0.9. We train the model for 60 epochs at first. The initial learning rate is set as 0.01 and warmup strategy is applied to enhance performance. To realize its soft partition, we fine-tune our model for additional 20 epochs as well.ResultThe proposed CGDGFN method is compared with state-of-the-art (SOTA) VI-ReID approaches on two databases Sun Yat-sen University multiple modality 01(SYSU-MM01) and Dongguk body-based person recognition database(RegDB), which is composed of the methods of global-feature, local-feature, and image generation. The standard cumulated matching characteristics (CMC) and mean average precision (mAP) are employed to evaluate the performance. Our proposed method has obtained 62.42% rank-1 identification rate and 58.14% mAP score on SYSU-MM01, and the values of rank-1 and mAP on RegDB are reached to 84.42% and 77.82% each in comparison with popular SOTA approaches on both datasets.ConclusionWe introduce the contour clue to VI-ReID. To leverage contour information, we took the contour as an auxiliary modality, and a contour-guided dual-grained feature fusion network (CGDGFN) is developed for VI-ReID. Global-grained fusion (G-Fusion) can enhance the original contour representation and produce augmented contour features. Local-grained fusion (L-Fusion) can fuse the part-based local features and the augmented contour features to output its powerful image representation further.关键词:pedestrian re-identification;cross-modality;feature fusion;contour;feature learning151|211|0更新时间:2024-05-07
摘要:ObjectiveVisible-infrared cross-modality pedestrianre-identification (VI-ReID) is focused on same identity-related images between the visible and infrared modality. As a popular technique of intelligent surveillance, it is still challenged for cross-modality. To optimize intra-class variations in RGB image-based pedestrian re-identification (RGB-ReID) task, one crucial challenge in VI-ReID is to bridge the modality gap between the RGB and infrared(IR) images of the same identity because current methods are mainly derived from modality-incorporated feature learning or modality transformation approaches. Specifically, modality-incorporated feature learning methods are used to map the inputs of RGB and IR images into a common embedding space for cross-modality feature alignment. A two-stream convolutional neural network (two-stream CNN) architecture has been recognized and some discriminative constraints are developed as well. However, each filter is constrained for a small region, convolutions is challenged to interlinked to spatial-ranged concepts. Quantitative tests illustrates that the CNNs are strongly biased toward textures rather than shapes. Moreover, existing methods in VI-ReID focus on the global or local feature representation only. Another path of modality transformation approaches can be used to generate cross-modality images-relevant pedestrain images or transform them into an intermediate modality. Generative adversarial network (GAN) and encoder-decoder structures are commonly used for these methods. However, due to the distorted IR-to-RGB translation and additional noises, image generation is incredible and GAN models are difficult to be converged. The RGB images consist of three-color channels, while IR images only contain a single channel reflecting the thermal radiation emitted from the human body and its contexts. Compared to the missing colors and textures in IR images, we review VI-ReID problem and the contour is realized in terms of a relative effective feature. Furthermore, contour is a modality-shared path as it keeps consistent for both of IR and RGB images, which is more accurate and reliable than generated intermediate modality. We implement VI-ReID-integrated contour strategy. To develop its optimization, we take the contour as an auxiliary modality to narrow the modality gap. Meanwhile, we tend to introduce local features into our model to collaborate with global ones further beyond part-based features.MethodA contour-guided dual-grained feature fusion network (CGDGFN) is developed for VI-ReID. It consists of two types of fusion. The first type is concerned of the image to contour fusion, which is called global-grained fusion (G-Fusion) at image-level. G-Fusion can output the augmented contour features. The other type can realize fusion between augmented contour features and local features, which is oriented at image and part mixed level. As the local feature is involved in, it called as local-grained fusion (L-Fusion) for simplicity. The proposed CGDGFN consists of four branches, which are 1) RGB images, 2) IR images, 3) RGB contour and 4) IR contour. First, the input of the network is a pair of RGB and IR images, while they are fed into RGB branch and IR branch, and a contour detector generates their contour images. Then, RGB and IR-relevant contour images of two modalities are fed into RGB-contour branch and IR-contour branch. The ResNet50 is used as the backbone architecture for each branch. The first convolutional layer in each branch has independent parameters to capture modality-specific information, while the remaining blocks are used to learn weight-shared modality-invariant features. In addition, RGB branch and IR branch average pooling layer structure is optimzed for part-based features extraction. G-Fusion is used to fuse an image to its corresponding contour image. After G-Fusion, the augmented contour features will be produced by the global average pooling layer of RGB-contour branch and IR-contour branch. Meanwhile, RGB branch and IR branch can output corresponding local features. RGB local feature as well as IR local feature is an array of feature vectors and its length is clarified by the partition setting. Two of local feature extraction methods are involved in: 1) uniform partition and 2) soft partition. L-Fusion is responsible for fusing the augmented contour features and corresponding local ones. The implementation of our method is based on the Pytorch framework. We adopt the ResNet50 pre-trained on ImageNet as the backbone network, and the stride of the last convolutional layer is set to 1 to obtain feature maps with higher spatial size. The batch size is set to 64. For each batch, we select 4 identities in random and each identity includes 8 visible images and 8 infrared images. The input images are resized to 288×144 pixels, random cropping and random horizontal flip are used for data augmentation. The stochastic gradient descent (SGD) optimizer is used for optimization and the momentum is set to 0.9. We train the model for 60 epochs at first. The initial learning rate is set as 0.01 and warmup strategy is applied to enhance performance. To realize its soft partition, we fine-tune our model for additional 20 epochs as well.ResultThe proposed CGDGFN method is compared with state-of-the-art (SOTA) VI-ReID approaches on two databases Sun Yat-sen University multiple modality 01(SYSU-MM01) and Dongguk body-based person recognition database(RegDB), which is composed of the methods of global-feature, local-feature, and image generation. The standard cumulated matching characteristics (CMC) and mean average precision (mAP) are employed to evaluate the performance. Our proposed method has obtained 62.42% rank-1 identification rate and 58.14% mAP score on SYSU-MM01, and the values of rank-1 and mAP on RegDB are reached to 84.42% and 77.82% each in comparison with popular SOTA approaches on both datasets.ConclusionWe introduce the contour clue to VI-ReID. To leverage contour information, we took the contour as an auxiliary modality, and a contour-guided dual-grained feature fusion network (CGDGFN) is developed for VI-ReID. Global-grained fusion (G-Fusion) can enhance the original contour representation and produce augmented contour features. Local-grained fusion (L-Fusion) can fuse the part-based local features and the augmented contour features to output its powerful image representation further.关键词:pedestrian re-identification;cross-modality;feature fusion;contour;feature learning151|211|0更新时间:2024-05-07
Person Re-identification
-
 摘要:Objective3D sensors-portable are developed and focused on user-friendly 3D facial data. Its low-quality 3D face recognition is concerned about more in the context of pattern recognition in recent years. Low quality 3D face recognition is challenged of the problem of low quality and high noise. To suppress high noise in low-quality 3D face data and alleviate the difficulty of extracting effective features in terms of limited single-depth data, we develop a novel low-quality 3D face recognition method on the basis of soft threshold denoising and video data fusion.MethodFirst, a trainable soft threshold denoising module is developed to denoise the features in the process of feature extraction. To denoise the features in the process of network feature extraction, deep learning method is melted into the soft threshold denoising module designed using the neural network model beyond threshold-manual method. Then, to make the features extracted more distinctive, a joint gradient loss function is fed into softmax and Arcface(additive angular margin loss for deep face recognition) to extract more effective features. Finally, to make use of multiple frames of low-quality video data, a recurrent unit-gated video data fusion module is proposed to improve the quality of face-related data, which can optimize the mutual-benefited information between video frame data.ResultTo verify the effectiveness, comparative analysis is carried out in respect of two popular low-quality 3D face datasets, called the Lock3DFace(low-cost kinect 3D faces) and the Extended-Multi-Dim dataset. To be clarified, the experiments are followed by the prior training and testing protocol. Specifically, each of three protocols mentioned below are in comparison with the method of second-highest performance. For the Lock3DFace closed-set protocol, the average recognition rate is increased by 3.13%; For the Lock3DFace open-set protocol, the average recognition rate is optimized by 0.28%; For the Extended-Multi-Dim open-set protocol, the average recognition rate is improved by 1.03%. Furthermore, the ablation study demonstrates that the effectiveness and the feasibility of soft threshold denoising and video data fusion as well.ConclusionA trainable soft threshold denoising module is developed to denoise the low-quality 3D faces. The joint gradient loss function can be used to extract more distinctive features in relevant to softmax and Arcface. Furthermore, a video-based data fusion module is used to fuse information-added between video frames and the accuracy of low-quality 3D face recognition can be improved further. This low-quality 3D face recognition method can alleviate the degree of noise and integrate more effective information in terms of multiple frames of video data, which is potential to optimize low-quality 3D face recognition.关键词:3D face recognition;low-quality 3D face;soft threshold denoising;joint gradient loss function;video data fusion104|258|1更新时间:2024-05-07
摘要:Objective3D sensors-portable are developed and focused on user-friendly 3D facial data. Its low-quality 3D face recognition is concerned about more in the context of pattern recognition in recent years. Low quality 3D face recognition is challenged of the problem of low quality and high noise. To suppress high noise in low-quality 3D face data and alleviate the difficulty of extracting effective features in terms of limited single-depth data, we develop a novel low-quality 3D face recognition method on the basis of soft threshold denoising and video data fusion.MethodFirst, a trainable soft threshold denoising module is developed to denoise the features in the process of feature extraction. To denoise the features in the process of network feature extraction, deep learning method is melted into the soft threshold denoising module designed using the neural network model beyond threshold-manual method. Then, to make the features extracted more distinctive, a joint gradient loss function is fed into softmax and Arcface(additive angular margin loss for deep face recognition) to extract more effective features. Finally, to make use of multiple frames of low-quality video data, a recurrent unit-gated video data fusion module is proposed to improve the quality of face-related data, which can optimize the mutual-benefited information between video frame data.ResultTo verify the effectiveness, comparative analysis is carried out in respect of two popular low-quality 3D face datasets, called the Lock3DFace(low-cost kinect 3D faces) and the Extended-Multi-Dim dataset. To be clarified, the experiments are followed by the prior training and testing protocol. Specifically, each of three protocols mentioned below are in comparison with the method of second-highest performance. For the Lock3DFace closed-set protocol, the average recognition rate is increased by 3.13%; For the Lock3DFace open-set protocol, the average recognition rate is optimized by 0.28%; For the Extended-Multi-Dim open-set protocol, the average recognition rate is improved by 1.03%. Furthermore, the ablation study demonstrates that the effectiveness and the feasibility of soft threshold denoising and video data fusion as well.ConclusionA trainable soft threshold denoising module is developed to denoise the low-quality 3D faces. The joint gradient loss function can be used to extract more distinctive features in relevant to softmax and Arcface. Furthermore, a video-based data fusion module is used to fuse information-added between video frames and the accuracy of low-quality 3D face recognition can be improved further. This low-quality 3D face recognition method can alleviate the degree of noise and integrate more effective information in terms of multiple frames of video data, which is potential to optimize low-quality 3D face recognition.关键词:3D face recognition;low-quality 3D face;soft threshold denoising;joint gradient loss function;video data fusion104|258|1更新时间:2024-05-07 -
 摘要:ObjectiveOptical flow estimation is essential for computer vision and image processing, which is focused on pixel-wise motions between consecutive images. It is beneficial for multiple research domains like target tracking, crowd flow segmentation, and human behavior analysis. In addition, optical flow can be as an effective tool for video-based motion extraction. Hence, it was investigated to find out the face spoofing-relevant motion clues. It is still challenged for accurate optical flow estimation under complex illumination circumstances although optical flow estimation has attracted wide attention in the field of computer vision. Most of dense optical flow estimation methods are based on variational iteration in terms of Horn and Schunck’s framework. The variational framework consists of data and regularization terms in common. Due to the uncontrolled illumination conditions are required to be clarified, the gradient constancy hypothesis can be adopted as the data term for variational model. The brightness constancy assumption can be optimized to a certain extent. However, neither brightness constancy assumption nor gradient constancy hypothesis effective in representing the complex illumination variations. As a result, the calculation of optical flow is mutual-benefited to illumination changes. Optical flow estimations are required to be regularized because of the inherent ill-posedness. The Tikhonov regularization is often based on the L2 norm, and it is minimized in terms of small-amplitude coefficients-distributed preservation, which can capture global patterns well in optical flow calculation. And, the minimization of the L1 norm is focused on more zero- or small-amplitude coefficients, and less large-amplitude ones. For discrete signals, L1 norm can give out better results than L2. L1 norm-based optical flow computation can be more precisely for mathematical modeling. To deal with regularization problems, conventional L1 and L2 norm is still related to current variational optical flow models. Robust penalty function-relevant L1 or L2 norm regularization can be used to generate smooth flow field and preserve motion inconsistency. However, it could lose the fine-scale motion structures and produce excessive segmentation artifacts. The image pre-processing methods can also be carried out in estimation of optical flow while illumination changes cannot be ignored between two consecutive frames. Optical flow calculation can provide motion features in facial biometric systems as well, which is concerned for such domains like surveillance, access control and forensic investigations. However, one of the challenges of facial biometric systems is the high possibility of the systems being deceived or spoofed by non-real faces. Recent face anti-spoofing technique can be as an effective pathway for facial biometric systems.Methodto strengthen video-based targets motion in relevance with illumination changes, our research is focused on structure-texture-perceptive retinex model and optical flow-robust estimation for human-facial anti-spoofing application. For retinex theory, to improve robustness of optical flow against non-uniform illumination, the components of illumination and reflectance in the image are separated by decoupling. Reflection and illumination components are separated from the image base on a stronger reflectivity constancy assumption. After that, the illumination component is filtered through a low pass filter and it is then integrated into the new optical flow model. Additionally, a smooth-sparse regularization constraint is adopted to preserve edges and improve the accuracy of optical flow estimation. Furthermore, the numerical implementation of the model is demonstrated.ResultComparative analysis is carried out with some state-of-the-art optical flow estimation methods, including the variational based methods and deep learning based approaches on 3 publicity datasets of Middleburry, MPI Sintel and KITTI 2015. The quantitative analysis is carried out in terms of average angular error (AAE), average end-point error (EPE) and the Fl scores in comparison with other related optical flow computations. Moreover, to evaluate the robustness of optical flow with respect to variations of illumination using the datasets, we consider conducting simulations of illumination to the source images. To render synthetic images, illumination patterns of linear, sinusoidal, Gaussian and mixture of Gaussian are involved in. To simulate the regularity and variability of real-world illumination patterns, such parameters like additive factor, multiplicative factor and gamma correlation are used as well. The experimental results show that our model outperforms all other evaluated methods on the three public datasets and their synthetic versions with different illumination patterns. To verify the feasibility of illumination-invariant method, the calculation is applied to obtain human-facial optical flow motion features, and face liveness-detected experiments are conducted on the Institute of Automation, Chinese Academy of Sciences (CASIA) face anti-spoofing database. The proposed STARFlow method is compared to some popular anti-spoofing methods related to optical flow like weighted regularization transform (WRT) and ARFlow. The quantitative and comparative evaluation metrics is composed of the accuracy of face anti-spoofing classification and the half total error rate (HTER). Similarly, to validate the illumination robustness of the proposed method under challenging illumination changes, four synthetic illumination patterns are also appended to the dataset. Experiments are carried out on the basis of the completed CASIA database and the four illumination environments.ConclusionIn this study, a new variational optical flow estimation model is facilitated in terms of structure-texture aware retinex theory. Experimental results validate that the proposed model outperforms several state-of-the-art optical flow estimation approaches, including some variational based methods and deep learning based methods. Meanwhile, the proposed STARFlow method can achieve a potential illumination-invariance in terms of face anti-spoofing under different illumination changes circumstances. The source code of this project is available at:https://github.com/Xiaoxin-Liao/STARFlow.关键词:Retinex model;structure-texture awareness;varying illumination;L0 gradient regularization;optical flow;face anti-spoofing141|383|0更新时间:2024-05-07
摘要:ObjectiveOptical flow estimation is essential for computer vision and image processing, which is focused on pixel-wise motions between consecutive images. It is beneficial for multiple research domains like target tracking, crowd flow segmentation, and human behavior analysis. In addition, optical flow can be as an effective tool for video-based motion extraction. Hence, it was investigated to find out the face spoofing-relevant motion clues. It is still challenged for accurate optical flow estimation under complex illumination circumstances although optical flow estimation has attracted wide attention in the field of computer vision. Most of dense optical flow estimation methods are based on variational iteration in terms of Horn and Schunck’s framework. The variational framework consists of data and regularization terms in common. Due to the uncontrolled illumination conditions are required to be clarified, the gradient constancy hypothesis can be adopted as the data term for variational model. The brightness constancy assumption can be optimized to a certain extent. However, neither brightness constancy assumption nor gradient constancy hypothesis effective in representing the complex illumination variations. As a result, the calculation of optical flow is mutual-benefited to illumination changes. Optical flow estimations are required to be regularized because of the inherent ill-posedness. The Tikhonov regularization is often based on the L2 norm, and it is minimized in terms of small-amplitude coefficients-distributed preservation, which can capture global patterns well in optical flow calculation. And, the minimization of the L1 norm is focused on more zero- or small-amplitude coefficients, and less large-amplitude ones. For discrete signals, L1 norm can give out better results than L2. L1 norm-based optical flow computation can be more precisely for mathematical modeling. To deal with regularization problems, conventional L1 and L2 norm is still related to current variational optical flow models. Robust penalty function-relevant L1 or L2 norm regularization can be used to generate smooth flow field and preserve motion inconsistency. However, it could lose the fine-scale motion structures and produce excessive segmentation artifacts. The image pre-processing methods can also be carried out in estimation of optical flow while illumination changes cannot be ignored between two consecutive frames. Optical flow calculation can provide motion features in facial biometric systems as well, which is concerned for such domains like surveillance, access control and forensic investigations. However, one of the challenges of facial biometric systems is the high possibility of the systems being deceived or spoofed by non-real faces. Recent face anti-spoofing technique can be as an effective pathway for facial biometric systems.Methodto strengthen video-based targets motion in relevance with illumination changes, our research is focused on structure-texture-perceptive retinex model and optical flow-robust estimation for human-facial anti-spoofing application. For retinex theory, to improve robustness of optical flow against non-uniform illumination, the components of illumination and reflectance in the image are separated by decoupling. Reflection and illumination components are separated from the image base on a stronger reflectivity constancy assumption. After that, the illumination component is filtered through a low pass filter and it is then integrated into the new optical flow model. Additionally, a smooth-sparse regularization constraint is adopted to preserve edges and improve the accuracy of optical flow estimation. Furthermore, the numerical implementation of the model is demonstrated.ResultComparative analysis is carried out with some state-of-the-art optical flow estimation methods, including the variational based methods and deep learning based approaches on 3 publicity datasets of Middleburry, MPI Sintel and KITTI 2015. The quantitative analysis is carried out in terms of average angular error (AAE), average end-point error (EPE) and the Fl scores in comparison with other related optical flow computations. Moreover, to evaluate the robustness of optical flow with respect to variations of illumination using the datasets, we consider conducting simulations of illumination to the source images. To render synthetic images, illumination patterns of linear, sinusoidal, Gaussian and mixture of Gaussian are involved in. To simulate the regularity and variability of real-world illumination patterns, such parameters like additive factor, multiplicative factor and gamma correlation are used as well. The experimental results show that our model outperforms all other evaluated methods on the three public datasets and their synthetic versions with different illumination patterns. To verify the feasibility of illumination-invariant method, the calculation is applied to obtain human-facial optical flow motion features, and face liveness-detected experiments are conducted on the Institute of Automation, Chinese Academy of Sciences (CASIA) face anti-spoofing database. The proposed STARFlow method is compared to some popular anti-spoofing methods related to optical flow like weighted regularization transform (WRT) and ARFlow. The quantitative and comparative evaluation metrics is composed of the accuracy of face anti-spoofing classification and the half total error rate (HTER). Similarly, to validate the illumination robustness of the proposed method under challenging illumination changes, four synthetic illumination patterns are also appended to the dataset. Experiments are carried out on the basis of the completed CASIA database and the four illumination environments.ConclusionIn this study, a new variational optical flow estimation model is facilitated in terms of structure-texture aware retinex theory. Experimental results validate that the proposed model outperforms several state-of-the-art optical flow estimation approaches, including some variational based methods and deep learning based methods. Meanwhile, the proposed STARFlow method can achieve a potential illumination-invariance in terms of face anti-spoofing under different illumination changes circumstances. The source code of this project is available at:https://github.com/Xiaoxin-Liao/STARFlow.关键词:Retinex model;structure-texture awareness;varying illumination;L0 gradient regularization;optical flow;face anti-spoofing141|383|0更新时间:2024-05-07 -
 摘要:ObjectiveIdentity authentication method is in relevance with the biological characteristics of the human body, which is benefited from breakthrough of computer technology and consistent improvement of hardware computing ability in the past 20 years. The biometrics-relevant artificial intelligence (AI) technology has been developed intensively. Iris-related features analysis is crucial for biometric authentication method. Current iris recognition technique is used to optimize short-distance and specific scenarios, but it is still challenged for the applications in the context of long-distance and non-collaborative scenarios. There are two main constraints as mentioned below: first, the iris recognition process is required for a short distance-relevant sensor-based instruction in terms of matching-completed prompts. This acquisition process is challenged for large-scale application farther. Second, current sensor-based hardware acquisition is increased as the distance between target and acquisition device. The accuracy and reliability of recognition will be lower severely because the quality of iris image-gathered is not effective. The iris recognition performance is required to be improved for long-distance and low-quality images and non-prompted scenes. To get credible identity authentication, a variety of biometrics are focused on iris recognition-assisted. Multiple modal-fused biometric information is more effective compared to single modality based identification. First, due to the heterogeneity of biological characteristics, a variety of modes of biometric recognition needs to be mutual-benefited. Second, safe authentication methods will not be guaranteed effectively when the biometric information storage encounters information leakage. To meet the needs of iris recognition in real scenario, it is necessary to generate richer biometric information in the eye area of the human face, such as the iris and eye area. Eye area-related semantic information has good recognizability for identity identification, but the eye area recognition is disturbed easily by complex background information. The iris texture features are relatively stable and iris recognition is affected less. Therefore, to get accurate and stable authentication in non-prompted and long-distance scenarios, effective fusion of the eye circumference and iris can be optimized to achieve modalities-mutual benefits and enhance the reliability and security of biometric identity authentication.MethodSome of the existing methods pay more attention on the high-dimensional semantic feature layer. To fuse the feature vectors of different modes, addition, multiplication and other related ways are then used. Due to great limitations, lack of certain flexibility and adaptability, the differences and the semantic characteristics of each mode are ignored at different stages. It is ineffective to combine multimode information of different stages mutually. To extract more robusted and distinctive features, the spatial attention mechanism and feature- reused method are coordinated and the model-opted can be focused on the feasible iris texture area, and the problem of gradient disappearance is alleviated via propagation-forward. For fusion strategy, the introduction of intermediate fusion expression layer can be adaptively used to learn the corresponding weights according to the contribution value of low, medium and high-level feature information of different modes, and it can be fused to generate more robust and distinctive features in terms of the integrated weights, which can improve the recognition performance of iris recognition in long-distance and non-cooperative status.ResultTo verify the effectiveness of the proposed method, experiments are carried out and compared to three popular public datasets, called notre dame (ND)-IRIS-0405, Institute of Automation,Chinese Academy of Sciences (CASIA)-Iris-M1-S3, and CASIA-Iris-Distance. Comparative analysis is in comparison with other related state-of-the-arts methods, including false reject rate (FRR), true accept rate (TAR), and equal error rate (EER). Lower FRR and EER values can indicate better performance, while TAR is vice versa. The test results of the three publicly available datasets can demonstrate that each EER value can be optimized and reached to 0.19%, 0.48% and 1.33%.ConclusionWe develop a convolutional neural network (CNN) based model. The model is focused on the iris texture area in terms of the integration of efficient channel attention mechanism and feature-reused and the problem of model gradient disappearance can be alleviated to a certain extent, which is beneficial for the depth of the model and robust distinctive features. At the same time, the intermediate fusion joint expression layer is introduced and focused on characteristics of semantic features of different modes at different stages, and it can learn the corresponding weights adaptively according to the degree of contribution generated by the low, medium and high semantic features of different modes, and the iris and eye area features are fused into distinctive features more through weighted fusion, which can improve the iris recognition performance in long-distance and non-cooperative status. This method is easy to be trainable as well.关键词:iris recognition;periocular recognition;central fusion expression layer;adaptive weighting;biometric fusion;long-distance and non-cooperative113|244|1更新时间:2024-05-07
摘要:ObjectiveIdentity authentication method is in relevance with the biological characteristics of the human body, which is benefited from breakthrough of computer technology and consistent improvement of hardware computing ability in the past 20 years. The biometrics-relevant artificial intelligence (AI) technology has been developed intensively. Iris-related features analysis is crucial for biometric authentication method. Current iris recognition technique is used to optimize short-distance and specific scenarios, but it is still challenged for the applications in the context of long-distance and non-collaborative scenarios. There are two main constraints as mentioned below: first, the iris recognition process is required for a short distance-relevant sensor-based instruction in terms of matching-completed prompts. This acquisition process is challenged for large-scale application farther. Second, current sensor-based hardware acquisition is increased as the distance between target and acquisition device. The accuracy and reliability of recognition will be lower severely because the quality of iris image-gathered is not effective. The iris recognition performance is required to be improved for long-distance and low-quality images and non-prompted scenes. To get credible identity authentication, a variety of biometrics are focused on iris recognition-assisted. Multiple modal-fused biometric information is more effective compared to single modality based identification. First, due to the heterogeneity of biological characteristics, a variety of modes of biometric recognition needs to be mutual-benefited. Second, safe authentication methods will not be guaranteed effectively when the biometric information storage encounters information leakage. To meet the needs of iris recognition in real scenario, it is necessary to generate richer biometric information in the eye area of the human face, such as the iris and eye area. Eye area-related semantic information has good recognizability for identity identification, but the eye area recognition is disturbed easily by complex background information. The iris texture features are relatively stable and iris recognition is affected less. Therefore, to get accurate and stable authentication in non-prompted and long-distance scenarios, effective fusion of the eye circumference and iris can be optimized to achieve modalities-mutual benefits and enhance the reliability and security of biometric identity authentication.MethodSome of the existing methods pay more attention on the high-dimensional semantic feature layer. To fuse the feature vectors of different modes, addition, multiplication and other related ways are then used. Due to great limitations, lack of certain flexibility and adaptability, the differences and the semantic characteristics of each mode are ignored at different stages. It is ineffective to combine multimode information of different stages mutually. To extract more robusted and distinctive features, the spatial attention mechanism and feature- reused method are coordinated and the model-opted can be focused on the feasible iris texture area, and the problem of gradient disappearance is alleviated via propagation-forward. For fusion strategy, the introduction of intermediate fusion expression layer can be adaptively used to learn the corresponding weights according to the contribution value of low, medium and high-level feature information of different modes, and it can be fused to generate more robust and distinctive features in terms of the integrated weights, which can improve the recognition performance of iris recognition in long-distance and non-cooperative status.ResultTo verify the effectiveness of the proposed method, experiments are carried out and compared to three popular public datasets, called notre dame (ND)-IRIS-0405, Institute of Automation,Chinese Academy of Sciences (CASIA)-Iris-M1-S3, and CASIA-Iris-Distance. Comparative analysis is in comparison with other related state-of-the-arts methods, including false reject rate (FRR), true accept rate (TAR), and equal error rate (EER). Lower FRR and EER values can indicate better performance, while TAR is vice versa. The test results of the three publicly available datasets can demonstrate that each EER value can be optimized and reached to 0.19%, 0.48% and 1.33%.ConclusionWe develop a convolutional neural network (CNN) based model. The model is focused on the iris texture area in terms of the integration of efficient channel attention mechanism and feature-reused and the problem of model gradient disappearance can be alleviated to a certain extent, which is beneficial for the depth of the model and robust distinctive features. At the same time, the intermediate fusion joint expression layer is introduced and focused on characteristics of semantic features of different modes at different stages, and it can learn the corresponding weights adaptively according to the degree of contribution generated by the low, medium and high semantic features of different modes, and the iris and eye area features are fused into distinctive features more through weighted fusion, which can improve the iris recognition performance in long-distance and non-cooperative status. This method is easy to be trainable as well.关键词:iris recognition;periocular recognition;central fusion expression layer;adaptive weighting;biometric fusion;long-distance and non-cooperative113|244|1更新时间:2024-05-07 -
 摘要:ObjectiveGait recognition can be focused on the identity labels of pedestrians-relevant recognition according to its walking style. Since it can be manipulated without coordination-derived constraints on a long distance scale, more applications potentials are illustrated for such domains like crime prevention, forensic identification, and public security. However, the process of gait recognition is challenged for many factors like camera views, carrying conditions, and different clothes. Current gait recognition tasks can be divided into two categories: model-based and appearance-based. Specifically, the model-based methods can be used to extract the human body structures for gait analysis. Conventional deep learning and graph convolutional network (GCN) based pose estimation is taken to extract gait features from the pose sequences in terms of hand-crafted features to model the walking process in common. First, model-based methods are robust to carrying and clothing theoretically, which is often challenged for human pose-precise low-resolution problems. Second, the appearance-based methods are oriented to learn gait features in terms of human body structures-potential modeling. The silhouettes are mostly taken as the input, and these methods can be divided into three sub-categories further: template-based, sequence-based, and set-based. Specifically, template-based methods can be used to fuse the silhouettes of a gait circle into a template but the temporal information is sacrificed inevitably. The sequence-based methods can yield the silhouettes of a gait sequence as a video for spatio-temporal features extraction. And, the set-based methods can use the silhouettes of a gait sequence as an insequential set and the permutation invariant is added to the input order. Furthermore, multiple data for gait recognition are categorized into the appearance-based methods, including RGB frames, gray images, and optical flow. Compared to these data modalities and the pose sequences in the model-based methods, the silhouettes are easy to use, which are more suitable for the low-resolution scales. To be noticed, recent silhouettes-based methods for gait recognition can learn multi-part features through slicing the output of the backbone horizontally. However, multi features are extracted solely and the feature-interacted is lacked, which is likely to hinder the recognition accuracy. To resolve this prolbem, we design a new module to enhance the multifaceted feature learning for gait recognition.MethodSilhouette-based gait recognition model consists of two parts: backbone-based, and multi-component feature learning. First, we design the backbone in term of the network structures in GaitSet and GaitPart, which can be as two popular methods for silhouette-based gait recognition. For the backbone-relevant, the features are first extracted for each silhouette (regular 2D convolution and max pooling in relevance to spatial dimension), and a set pooling is taken to aggregate the silhouette-level features in a non-squential set (implemented by max pooling along the temporal dimension). Second, we design a new module for multiple-features learning and try to learn more robust and discriminative features for each motion. The independent-shared mechanism is introduced to learn motion-specific features, which is implemented by regional pooling and fully connected layers are sepearated. In particular, the interaction can be strengthened across various motions in terms of the coordinated mechanism, which consists of feature normalization and feature remapping. Feature normalization is parameter-free for weight balancing. And, feature remapping is implemented by a fully connected layer or element-wise multiple implecations.ResultThe experiments are carried out on Institute of Automation, Chinese Academy of Sciences(CASIA-B) and OUMVLP, and GaitSet GaitPart are as the baselines. The CASIA-B consists of 124 samples and collects the sequences of regular walking, such as walking with bags, and walking in different clothes for each object. The OUMVLP consists of 10 307 samples, which can collect the sequences of regular walking for each sample. Each sequence for CASIA-B and OUMVLP is recorded by 11 cameras and 14 cameras. GaitSet and GaitPart are commonly-used silhouettes methods as input for gait recognition. To learn the multifaceted features for gait recognition, GaitSet is regarded as an unseqential set and the features are sliced horizontally. To learn more specific features, GaitPart is focused on supressing the receptive field of convolutional layers and modeling the micro-motion features. To demonstrate its consistency, the identical-view cases-excluded rank-1 accuracy is taken as the main metric for performance comparison. For example, each of rank-1 accuracy for walking with bags on CASIA-B can be optimized by 1.62% and 1.17% based on GaitSet and GaitPart.ConclusionA new module is facilitated to enhance the multi-components learning for gait recognition, which is cost-effective and the accuracy is improved in consistency. To be summarized, 1) the lack of interaction to hinder the recognition accuracy is concerned. 2) The independent-shared mechanism is introducted into multifaceted feature learning for gait recognition, and a plug-and-play module is designed to learn more discriminative features for muliple motions. 3) This GaitSet and GaitPart-based method has its potentials for consistent optimization over the baselines under all walking circumstances.关键词:gait recognition;silhouette sequences;multi-part features;independent mechanism;shared mechanism193|129|0更新时间:2024-05-07
摘要:ObjectiveGait recognition can be focused on the identity labels of pedestrians-relevant recognition according to its walking style. Since it can be manipulated without coordination-derived constraints on a long distance scale, more applications potentials are illustrated for such domains like crime prevention, forensic identification, and public security. However, the process of gait recognition is challenged for many factors like camera views, carrying conditions, and different clothes. Current gait recognition tasks can be divided into two categories: model-based and appearance-based. Specifically, the model-based methods can be used to extract the human body structures for gait analysis. Conventional deep learning and graph convolutional network (GCN) based pose estimation is taken to extract gait features from the pose sequences in terms of hand-crafted features to model the walking process in common. First, model-based methods are robust to carrying and clothing theoretically, which is often challenged for human pose-precise low-resolution problems. Second, the appearance-based methods are oriented to learn gait features in terms of human body structures-potential modeling. The silhouettes are mostly taken as the input, and these methods can be divided into three sub-categories further: template-based, sequence-based, and set-based. Specifically, template-based methods can be used to fuse the silhouettes of a gait circle into a template but the temporal information is sacrificed inevitably. The sequence-based methods can yield the silhouettes of a gait sequence as a video for spatio-temporal features extraction. And, the set-based methods can use the silhouettes of a gait sequence as an insequential set and the permutation invariant is added to the input order. Furthermore, multiple data for gait recognition are categorized into the appearance-based methods, including RGB frames, gray images, and optical flow. Compared to these data modalities and the pose sequences in the model-based methods, the silhouettes are easy to use, which are more suitable for the low-resolution scales. To be noticed, recent silhouettes-based methods for gait recognition can learn multi-part features through slicing the output of the backbone horizontally. However, multi features are extracted solely and the feature-interacted is lacked, which is likely to hinder the recognition accuracy. To resolve this prolbem, we design a new module to enhance the multifaceted feature learning for gait recognition.MethodSilhouette-based gait recognition model consists of two parts: backbone-based, and multi-component feature learning. First, we design the backbone in term of the network structures in GaitSet and GaitPart, which can be as two popular methods for silhouette-based gait recognition. For the backbone-relevant, the features are first extracted for each silhouette (regular 2D convolution and max pooling in relevance to spatial dimension), and a set pooling is taken to aggregate the silhouette-level features in a non-squential set (implemented by max pooling along the temporal dimension). Second, we design a new module for multiple-features learning and try to learn more robust and discriminative features for each motion. The independent-shared mechanism is introduced to learn motion-specific features, which is implemented by regional pooling and fully connected layers are sepearated. In particular, the interaction can be strengthened across various motions in terms of the coordinated mechanism, which consists of feature normalization and feature remapping. Feature normalization is parameter-free for weight balancing. And, feature remapping is implemented by a fully connected layer or element-wise multiple implecations.ResultThe experiments are carried out on Institute of Automation, Chinese Academy of Sciences(CASIA-B) and OUMVLP, and GaitSet GaitPart are as the baselines. The CASIA-B consists of 124 samples and collects the sequences of regular walking, such as walking with bags, and walking in different clothes for each object. The OUMVLP consists of 10 307 samples, which can collect the sequences of regular walking for each sample. Each sequence for CASIA-B and OUMVLP is recorded by 11 cameras and 14 cameras. GaitSet and GaitPart are commonly-used silhouettes methods as input for gait recognition. To learn the multifaceted features for gait recognition, GaitSet is regarded as an unseqential set and the features are sliced horizontally. To learn more specific features, GaitPart is focused on supressing the receptive field of convolutional layers and modeling the micro-motion features. To demonstrate its consistency, the identical-view cases-excluded rank-1 accuracy is taken as the main metric for performance comparison. For example, each of rank-1 accuracy for walking with bags on CASIA-B can be optimized by 1.62% and 1.17% based on GaitSet and GaitPart.ConclusionA new module is facilitated to enhance the multi-components learning for gait recognition, which is cost-effective and the accuracy is improved in consistency. To be summarized, 1) the lack of interaction to hinder the recognition accuracy is concerned. 2) The independent-shared mechanism is introducted into multifaceted feature learning for gait recognition, and a plug-and-play module is designed to learn more discriminative features for muliple motions. 3) This GaitSet and GaitPart-based method has its potentials for consistent optimization over the baselines under all walking circumstances.关键词:gait recognition;silhouette sequences;multi-part features;independent mechanism;shared mechanism193|129|0更新时间:2024-05-07
Human Identification Based on Face,Iris and Gait
-
 摘要:ObjectiveThe pedestrian attribute recognition task is currently challenged for the sample distribution issue of some severe unbalanced attribute categories. To resolve the problems, we develop a method of progressive iteration optimization for pedestrian attribute recognition.MethodFirst, data generation model based on masked autoencoder is used for data extension of the unbalanced categories distribution, and general large model-derived can be oriented to the small task. The balanced attributes-data generation model (BA-DGM) relevant masked autoencoder can be utilized to mask the original pedestrian images in terms of a random masking ratio and such newly generated images can be obtained for small-amount categories. The potential information can be fully mined, such as the topological relationship of the visible area, and the latent features-derived pedestrian images can be more resilient. Furthermore, it demonstrates that the autoencoder model can effectively achieve the universal feature representation of the targeted pedestrian, including the consensus features like the relationship-interconnected between various key components of the pedestrian. Second, discrimination model is used for filtering-consistent for the newly generated sample data, and the heuristic attention mechanism is adopted and implemented to deal with generative adversarial networks (GANs). The newly attention features-data discrimination model (AF-DDM) can be utilized and the diversified sample can be achieved while the key features of the attributes are preserved, which can enhance the interpretability of the recognition model. At the same time, to learn effective features-related attributes, the filtered data is generated for training model. In the training process of the discrimination model, 50-layer residual network model is adopted as the backbone network to be trained on the original attribute recognition dataset, using a multi-label classification framework. And, in the reasoning process of the discrimination model, the whole attribute labels are divided into two categories: key attribute labels and other related attribute labels. For key attribute labels, to keep consistent with the original labels and preserve the relevant high confidence, the newly generated sample can be kept in consistency in terms of the predicted labels from discrimination model, but it cannot be vice versed. Finally, the pedestrian attribute recognition model and data-contextual can be optimized further based on the cyclical iteration of data generation and discrimination. To optimize generalization ability of the model, the knowledge distillation framework can be used to fuse the discrimination models of the balanced sample data as well. After multiple iterations, the progressive iterations-distillation fusion model (PI-DFM) based attribute discrimination models can be used as the teacher models and category balancing-afterward attribute recognition dataset is used as the training data. The above models are mutual-benefited in accordance with the datasets of different sample proportions. The network structure of the student model is consistent with the teacher model and the Kullback-Leibler (KL) divergence between the student output and the teacher output is calculated as the distillation loss function. In large-scale practical application scenarios, the sample proportion of test data and train data might be different. To improve the generalization ability of the model in an open uncertain scenario, teacher model can be trained by integrating different sample-proportion data in terms of the knowledge distillation framework.ResultExperimental results are demonstrated that the proposed optimization method can effectively improve the accuracy of the model on the four popular evaluation datasets. The proposed metrics for attributes and samples are calculated, including 1) the mean accuracy of all attributes and 2) the F1 score of all samples, representing the harmonic average of the mean accuracy and the mean recall. For example, in the richly annotated pedestrian v2 (RAPv2) dataset, the mean accuracy is increased by about 5.0% and the average F1 score is increased by about 1.7% as well on the hypothesis of an unchanged model complexity. After several loops of cyclic iteration, the number of unbalanced categories in the original data is reduced to zero, and the optimization can be thus realized for the dataset. In the ablation studies, new samples are randomly generated for each positive sample image, and then the discrimination model is used to filter inconsistent samples. The probability of spatial distribution of the preserved details is analyzed experimentally in terms of the masked region analysis of the filtered samples. The heuristic attention mechanism is introduced and data discrimination model can retain the relevant features of the key attributes of the targeted pedestrian better, which demonstrates that the interpretability of the discrimination model can be further improved by deeply mining the distribution of related features for different attributes.ConclusionThe progressive iterative optimization strategy proposed in this paper has good complementarity with the existing improvement methods, and is helpful to further improve the accuracy of the recognition model. To optimize the relationship modeling among multiple pedestrian attributes and improve the interpretability of the recognition model further, future research direction can be predicted and focused on universal feature representation-based masked autoencoder (MAE) model combined with such prior knowledge like human skeleton structure.关键词:pedestrian attribute recognition;unbalanced sample;progressive iteration;masked autoencoder;transfer learning;consistency filtering;knowledge distillation69|147|0更新时间:2024-05-07
摘要:ObjectiveThe pedestrian attribute recognition task is currently challenged for the sample distribution issue of some severe unbalanced attribute categories. To resolve the problems, we develop a method of progressive iteration optimization for pedestrian attribute recognition.MethodFirst, data generation model based on masked autoencoder is used for data extension of the unbalanced categories distribution, and general large model-derived can be oriented to the small task. The balanced attributes-data generation model (BA-DGM) relevant masked autoencoder can be utilized to mask the original pedestrian images in terms of a random masking ratio and such newly generated images can be obtained for small-amount categories. The potential information can be fully mined, such as the topological relationship of the visible area, and the latent features-derived pedestrian images can be more resilient. Furthermore, it demonstrates that the autoencoder model can effectively achieve the universal feature representation of the targeted pedestrian, including the consensus features like the relationship-interconnected between various key components of the pedestrian. Second, discrimination model is used for filtering-consistent for the newly generated sample data, and the heuristic attention mechanism is adopted and implemented to deal with generative adversarial networks (GANs). The newly attention features-data discrimination model (AF-DDM) can be utilized and the diversified sample can be achieved while the key features of the attributes are preserved, which can enhance the interpretability of the recognition model. At the same time, to learn effective features-related attributes, the filtered data is generated for training model. In the training process of the discrimination model, 50-layer residual network model is adopted as the backbone network to be trained on the original attribute recognition dataset, using a multi-label classification framework. And, in the reasoning process of the discrimination model, the whole attribute labels are divided into two categories: key attribute labels and other related attribute labels. For key attribute labels, to keep consistent with the original labels and preserve the relevant high confidence, the newly generated sample can be kept in consistency in terms of the predicted labels from discrimination model, but it cannot be vice versed. Finally, the pedestrian attribute recognition model and data-contextual can be optimized further based on the cyclical iteration of data generation and discrimination. To optimize generalization ability of the model, the knowledge distillation framework can be used to fuse the discrimination models of the balanced sample data as well. After multiple iterations, the progressive iterations-distillation fusion model (PI-DFM) based attribute discrimination models can be used as the teacher models and category balancing-afterward attribute recognition dataset is used as the training data. The above models are mutual-benefited in accordance with the datasets of different sample proportions. The network structure of the student model is consistent with the teacher model and the Kullback-Leibler (KL) divergence between the student output and the teacher output is calculated as the distillation loss function. In large-scale practical application scenarios, the sample proportion of test data and train data might be different. To improve the generalization ability of the model in an open uncertain scenario, teacher model can be trained by integrating different sample-proportion data in terms of the knowledge distillation framework.ResultExperimental results are demonstrated that the proposed optimization method can effectively improve the accuracy of the model on the four popular evaluation datasets. The proposed metrics for attributes and samples are calculated, including 1) the mean accuracy of all attributes and 2) the F1 score of all samples, representing the harmonic average of the mean accuracy and the mean recall. For example, in the richly annotated pedestrian v2 (RAPv2) dataset, the mean accuracy is increased by about 5.0% and the average F1 score is increased by about 1.7% as well on the hypothesis of an unchanged model complexity. After several loops of cyclic iteration, the number of unbalanced categories in the original data is reduced to zero, and the optimization can be thus realized for the dataset. In the ablation studies, new samples are randomly generated for each positive sample image, and then the discrimination model is used to filter inconsistent samples. The probability of spatial distribution of the preserved details is analyzed experimentally in terms of the masked region analysis of the filtered samples. The heuristic attention mechanism is introduced and data discrimination model can retain the relevant features of the key attributes of the targeted pedestrian better, which demonstrates that the interpretability of the discrimination model can be further improved by deeply mining the distribution of related features for different attributes.ConclusionThe progressive iterative optimization strategy proposed in this paper has good complementarity with the existing improvement methods, and is helpful to further improve the accuracy of the recognition model. To optimize the relationship modeling among multiple pedestrian attributes and improve the interpretability of the recognition model further, future research direction can be predicted and focused on universal feature representation-based masked autoencoder (MAE) model combined with such prior knowledge like human skeleton structure.关键词:pedestrian attribute recognition;unbalanced sample;progressive iteration;masked autoencoder;transfer learning;consistency filtering;knowledge distillation69|147|0更新时间:2024-05-07
Pedestrian Attributes Recognition
-
 摘要:ObjectiveVideo action detection is one of the challenging tasks in computer vision and video recognition, which aims to locate all actors and recognize their actions in video clips. However, two major problems are required to be resolved in the real world: First, there are pairwise interactions between actors in real scenes, so it is suboptimal to perform action recognition only in terms of their own regional features. Specifically, explicitly modeling interactions may be beneficial to the performance of action detection. Second, action detection is a multi-label classification task because an actor may perform multiple types of actions at the same time. We argue that it is beneficial to consider the inherent dependency between different classes. In this study, we propose a video action detection framework that simultaneously modeling interaction between actors and dependency between categories.MethodOur framework proposed consists of three main parts: actor feature extraction, long short-term interaction and classification. In detail, the actor feature extraction part first utilizes the Faster region based convolutional neural network (Faster R-CNN) as a person detector to detect the potential actors in the whole dataset. After this, we only keep the detected actors which have relatively high confidence score. Furthermore, we take the SlowFast network as backbone to extract features from the raw videos. For each actor, we apply the RoIAlign operation on the extracted feature map based on the location of the actor and the corresponding feature of the actor is generated. To include the geometric information, the coordinates of actors is embedded into their features. The actor-related features are as the input of following steps. The long short-term interaction part includes short-term interaction module (STIM) and long-term interaction module (LTIM). The STIM can leverage the graph attention network (GAT) to model short-term spatio-temporal interactions between actors, and LTIM can use long-term feature banks (LFB) to model long-term temporal dependency between actors. For short-term spatio-temporal interaction modeling, the intersection over union (IoU)-tracker is used to connect the bounding boxes of the same person in temporal. For optimization, we propose a decoupling mechanism to handle spatial and temporal interactions. The interaction between nodes of different actors at the same time step is defined as spatial interaction, and the interaction between nodes of the same actor at different time steps is recognized as temporal interaction. The graph attention network (GAT) is applied for each of them, where the nodes are the actor features, and their pairwise relationships are then represented via the edges. For long-term temporal dependency modeling, a sliding window mechanism is used to obtain a long-term feature bank, which can contain a large scale of temporal contexts. Current short-term features and the long-term feature bank can be transmitted into the non-local module, where the short-term features are used as queries, and the features in the long-term feature bank are used as key-value pairs to extract relevant long-term temporal context information. The classification part is based on a class relationship module (CRM), which first extracts class-specific feature for each class of each actor. The features of different classes of the same actor can be passed into the self-attention module to compute the semantic correlation between action classes. Finally, we propose a two-stage score fusion (TSSF) strategy to update the classification probability scores on the basis of the complementarity of different modules.ResultWe carry out quantitative and qualitative analysis on the public dataset atomic visual actions version 2.1(AVA v2.1). For the quantitative analysis, the evaluation metrics is the average precision (AP) with an IoU threshold of 0.5. For each class, we compute the average precision and report the average over all classes. The results of our method in all test sub-categories, Human Pose category, Human-Object Interaction category, and Human-Human Interaction category are 31.0%, 50.8%, 22.3%, and 32.5%, respectively. Compared to the baseline, it increases by 2.8%, 2.0%, 2.6% and 3.6% each. Compared to actor-centric relation network (ACRN), video action transformer network (VAT), actor-context-actor relation network (ACAR-Net) and other related algorithms, our method is optimized by 0.8% further. For the qualitative analysis, the visualization results demonstrate that our method can capture the interaction accurately between action performers, and the rationality and reliability of the class dependency modeling can be reflected as well. To verify the effectiveness of the proposed modules, a series of ablation experiments are conducted. Additionally, the methods proposed are all end-to-end training, but the method proposed in this paper uses a fixed backbone, which has a faster training speed and lower computing resource consumption.ConclusionTo fully interpret the interaction between actors and dependency between classes, a video action detection framework is illustrated. The effectiveness of our proposed method is validated according to the experimental results on AVA v2.1 dataset.关键词:video action detection;multi-label classification;interaction relationship modeling;two-stage fusion;deep learning;attention mechanism159|334|1更新时间:2024-05-07
摘要:ObjectiveVideo action detection is one of the challenging tasks in computer vision and video recognition, which aims to locate all actors and recognize their actions in video clips. However, two major problems are required to be resolved in the real world: First, there are pairwise interactions between actors in real scenes, so it is suboptimal to perform action recognition only in terms of their own regional features. Specifically, explicitly modeling interactions may be beneficial to the performance of action detection. Second, action detection is a multi-label classification task because an actor may perform multiple types of actions at the same time. We argue that it is beneficial to consider the inherent dependency between different classes. In this study, we propose a video action detection framework that simultaneously modeling interaction between actors and dependency between categories.MethodOur framework proposed consists of three main parts: actor feature extraction, long short-term interaction and classification. In detail, the actor feature extraction part first utilizes the Faster region based convolutional neural network (Faster R-CNN) as a person detector to detect the potential actors in the whole dataset. After this, we only keep the detected actors which have relatively high confidence score. Furthermore, we take the SlowFast network as backbone to extract features from the raw videos. For each actor, we apply the RoIAlign operation on the extracted feature map based on the location of the actor and the corresponding feature of the actor is generated. To include the geometric information, the coordinates of actors is embedded into their features. The actor-related features are as the input of following steps. The long short-term interaction part includes short-term interaction module (STIM) and long-term interaction module (LTIM). The STIM can leverage the graph attention network (GAT) to model short-term spatio-temporal interactions between actors, and LTIM can use long-term feature banks (LFB) to model long-term temporal dependency between actors. For short-term spatio-temporal interaction modeling, the intersection over union (IoU)-tracker is used to connect the bounding boxes of the same person in temporal. For optimization, we propose a decoupling mechanism to handle spatial and temporal interactions. The interaction between nodes of different actors at the same time step is defined as spatial interaction, and the interaction between nodes of the same actor at different time steps is recognized as temporal interaction. The graph attention network (GAT) is applied for each of them, where the nodes are the actor features, and their pairwise relationships are then represented via the edges. For long-term temporal dependency modeling, a sliding window mechanism is used to obtain a long-term feature bank, which can contain a large scale of temporal contexts. Current short-term features and the long-term feature bank can be transmitted into the non-local module, where the short-term features are used as queries, and the features in the long-term feature bank are used as key-value pairs to extract relevant long-term temporal context information. The classification part is based on a class relationship module (CRM), which first extracts class-specific feature for each class of each actor. The features of different classes of the same actor can be passed into the self-attention module to compute the semantic correlation between action classes. Finally, we propose a two-stage score fusion (TSSF) strategy to update the classification probability scores on the basis of the complementarity of different modules.ResultWe carry out quantitative and qualitative analysis on the public dataset atomic visual actions version 2.1(AVA v2.1). For the quantitative analysis, the evaluation metrics is the average precision (AP) with an IoU threshold of 0.5. For each class, we compute the average precision and report the average over all classes. The results of our method in all test sub-categories, Human Pose category, Human-Object Interaction category, and Human-Human Interaction category are 31.0%, 50.8%, 22.3%, and 32.5%, respectively. Compared to the baseline, it increases by 2.8%, 2.0%, 2.6% and 3.6% each. Compared to actor-centric relation network (ACRN), video action transformer network (VAT), actor-context-actor relation network (ACAR-Net) and other related algorithms, our method is optimized by 0.8% further. For the qualitative analysis, the visualization results demonstrate that our method can capture the interaction accurately between action performers, and the rationality and reliability of the class dependency modeling can be reflected as well. To verify the effectiveness of the proposed modules, a series of ablation experiments are conducted. Additionally, the methods proposed are all end-to-end training, but the method proposed in this paper uses a fixed backbone, which has a faster training speed and lower computing resource consumption.ConclusionTo fully interpret the interaction between actors and dependency between classes, a video action detection framework is illustrated. The effectiveness of our proposed method is validated according to the experimental results on AVA v2.1 dataset.关键词:video action detection;multi-label classification;interaction relationship modeling;two-stage fusion;deep learning;attention mechanism159|334|1更新时间:2024-05-07
Video Action Detection
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0