
最新刊期
卷 28 , 期 4 , 2023
-
 摘要:This is the 28th annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for the editors of journals and potential authors of papers. Specifically, considering the wide distribution of related publications in China, all references (908) on image engineering research and technique are selected carefully from the research papers (3 096 in total) published in all issues (154) of a set of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have higher quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (same as the last 17 years). Analysis and discussions about the statistics of the results of classifications by journal and by category are also presented. Analysis on the statistics in 2022 shows that the direction of image analysis has received the most attention at present, among which object detection and recognition, image segmentation and primitive detection are the focus of research. Besides, the development and application of image technology in remote sensing, radar, sonar and mapping, as well as biology and medicine fields are the most active. In addition, image engineering technology is constantly expanding new application fields, new application categories may be increased in the future. In conclusion, this work shows a general and up-to-date picture of the various continuing progresses, either for depth or for width, of image engineering in China in 2022. The statistics for 28 years also provide readers with more comprehensive and credible information on the development trends of various research directions.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics96|226|1更新时间:2024-05-07
摘要:This is the 28th annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for the editors of journals and potential authors of papers. Specifically, considering the wide distribution of related publications in China, all references (908) on image engineering research and technique are selected carefully from the research papers (3 096 in total) published in all issues (154) of a set of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have higher quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (same as the last 17 years). Analysis and discussions about the statistics of the results of classifications by journal and by category are also presented. Analysis on the statistics in 2022 shows that the direction of image analysis has received the most attention at present, among which object detection and recognition, image segmentation and primitive detection are the focus of research. Besides, the development and application of image technology in remote sensing, radar, sonar and mapping, as well as biology and medicine fields are the most active. In addition, image engineering technology is constantly expanding new application fields, new application categories may be increased in the future. In conclusion, this work shows a general and up-to-date picture of the various continuing progresses, either for depth or for width, of image engineering in China in 2022. The statistics for 28 years also provide readers with more comprehensive and credible information on the development trends of various research directions.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics96|226|1更新时间:2024-05-07 -
 摘要:Artificial intelligence (AI) technology has been developing intensively, especially for such scenarios in relevance to its applications of 1) natural language processing, 2) computer vision, 3) recommendation systems, and 4) forecast analysis. AI technology has been challenging for human cognition over the past decade. In recent years, natural language processing techniques can be focused on more. ChatGPT, as a case of emerging generative AI technology, is launched in December of 2022. ChatGPT, as an advanced language model, is commonly used on the basis of its a) larger model sizes, b) advanced pre-training methods, c) faster computing resources, and d) more language processing tasks. This ChatGPT-related literature review is focused on its (1) public awareness and application status, (2) characteristics, (3) mechanisms, (4) scalability, (5) challenges and limitations, (6) future development and application prospects, and (7) improvements of GPT-4 relative to ChatGPT. Cognitive computing and AI-based ChatGPT can be as a sort of language model in terms of the Transformer architecture and Generative Pre-Training (GPT). This GPT-trained model can be related to natural language processing, which can predict the probability distribution of the next token using a multi-layer Transformer to generate natural language text. It can be outreached by training the learned language patterns on a large corpus of text. The OpenAI’s language model has shown a significant improvement in their level of intelligence from GPT-1(117 million parameters) in 2018 to GPT-3(175 billion parameters) in 2020. The language processing and generation capabilities of GPT have been improving dramatically in terms of consistent optimization like its 1) model size, 2) generative models, and 3) self-supervised learning. Thereafter, reinforcement learning-based InstructGPT is originated from Human Feedback and such probability of infeasible, untrue, and biased outputs can be significantly reduced in January 2022. In December 2022, ChatGPT is introduced as the sister model of InstructGPT. ChatGPT is not only add InstructGPT-based chat attributes, and a test version is opened to the public. The core technologies of ChatGPT can be linked to 1) reinforcement learning from human feedback(RLHF), 2) supervised fine-tuning(SFT), 3) instruction fine-tnning(IFT), and 4) chain-of-thought(CoT) as well. ChatGPT has attracked about 100 million active users per month after the launch of two months. In comparison, TikTok took nine months to achieve 100 million monthly active users, and Instagram took two and a half years. According to Similar Web, more than 13 million independent visitors use ChatGPT on average each day in January of 2023, which is more than twice in December of 2022. The leading US new media company Buzzfeed accurately seized the opportunity of ChatGPT and saw its stock price triple in two days. The ChatGPT-derived impact shows its potential preference for consumers. The ChatGPT can play mulitiple roles for such domain like clinics, translation, official administrations, and programming tasks. Such extensive application of ChatGPT is still to be developed. However, while ChatGPT has the potential for widespread application in various industries, it cannot be universally applied to all industries. For example, as certain industrial production processes typically rely on digitalization and do not necessitate the handling of human language, natural language processing techniques may not be required. Furthermore, various other factors, such as legal restrictions and data privacy concerns, may also impinge upon the application of natural language processing technologies within certain industries. For industries that require the processing of sensitive information, such as the healthcare industry, natural language processing technologies may need to comply with strict legal regulations to ensure data privacy and security. In addition to industry-specific reasons, it should be noted that ChatGPT has not yet achieved perfection in natural language processing tasks. In summary, as a phenomenal and technological product, AI-generated ChatGPT’s potentials are beneficial for textual and multi-modal AIGC applications to a certain extent, and it may have an impact on the a) survival of corporations, b) competition among countries, and c) entire social structure. However, the current various positive evaluations of ChatGPT can only be seen as a phenomenon of good rain after a long drought, and it cannot change the fact that ChatGPT is a questions and answers (Q&A) solution based on prior knowledge and models. It is required to be acknowledged that ChatGPT does not have its true recognition, intention, and creativity yet, and its true intelligence need to be tackled further.关键词:artificial intelligence(AI);deep learning;natural language processing;artificial intelligence generated content(AIGC);ChatGPT239|195|3更新时间:2024-05-07
摘要:Artificial intelligence (AI) technology has been developing intensively, especially for such scenarios in relevance to its applications of 1) natural language processing, 2) computer vision, 3) recommendation systems, and 4) forecast analysis. AI technology has been challenging for human cognition over the past decade. In recent years, natural language processing techniques can be focused on more. ChatGPT, as a case of emerging generative AI technology, is launched in December of 2022. ChatGPT, as an advanced language model, is commonly used on the basis of its a) larger model sizes, b) advanced pre-training methods, c) faster computing resources, and d) more language processing tasks. This ChatGPT-related literature review is focused on its (1) public awareness and application status, (2) characteristics, (3) mechanisms, (4) scalability, (5) challenges and limitations, (6) future development and application prospects, and (7) improvements of GPT-4 relative to ChatGPT. Cognitive computing and AI-based ChatGPT can be as a sort of language model in terms of the Transformer architecture and Generative Pre-Training (GPT). This GPT-trained model can be related to natural language processing, which can predict the probability distribution of the next token using a multi-layer Transformer to generate natural language text. It can be outreached by training the learned language patterns on a large corpus of text. The OpenAI’s language model has shown a significant improvement in their level of intelligence from GPT-1(117 million parameters) in 2018 to GPT-3(175 billion parameters) in 2020. The language processing and generation capabilities of GPT have been improving dramatically in terms of consistent optimization like its 1) model size, 2) generative models, and 3) self-supervised learning. Thereafter, reinforcement learning-based InstructGPT is originated from Human Feedback and such probability of infeasible, untrue, and biased outputs can be significantly reduced in January 2022. In December 2022, ChatGPT is introduced as the sister model of InstructGPT. ChatGPT is not only add InstructGPT-based chat attributes, and a test version is opened to the public. The core technologies of ChatGPT can be linked to 1) reinforcement learning from human feedback(RLHF), 2) supervised fine-tuning(SFT), 3) instruction fine-tnning(IFT), and 4) chain-of-thought(CoT) as well. ChatGPT has attracked about 100 million active users per month after the launch of two months. In comparison, TikTok took nine months to achieve 100 million monthly active users, and Instagram took two and a half years. According to Similar Web, more than 13 million independent visitors use ChatGPT on average each day in January of 2023, which is more than twice in December of 2022. The leading US new media company Buzzfeed accurately seized the opportunity of ChatGPT and saw its stock price triple in two days. The ChatGPT-derived impact shows its potential preference for consumers. The ChatGPT can play mulitiple roles for such domain like clinics, translation, official administrations, and programming tasks. Such extensive application of ChatGPT is still to be developed. However, while ChatGPT has the potential for widespread application in various industries, it cannot be universally applied to all industries. For example, as certain industrial production processes typically rely on digitalization and do not necessitate the handling of human language, natural language processing techniques may not be required. Furthermore, various other factors, such as legal restrictions and data privacy concerns, may also impinge upon the application of natural language processing technologies within certain industries. For industries that require the processing of sensitive information, such as the healthcare industry, natural language processing technologies may need to comply with strict legal regulations to ensure data privacy and security. In addition to industry-specific reasons, it should be noted that ChatGPT has not yet achieved perfection in natural language processing tasks. In summary, as a phenomenal and technological product, AI-generated ChatGPT’s potentials are beneficial for textual and multi-modal AIGC applications to a certain extent, and it may have an impact on the a) survival of corporations, b) competition among countries, and c) entire social structure. However, the current various positive evaluations of ChatGPT can only be seen as a phenomenon of good rain after a long drought, and it cannot change the fact that ChatGPT is a questions and answers (Q&A) solution based on prior knowledge and models. It is required to be acknowledged that ChatGPT does not have its true recognition, intention, and creativity yet, and its true intelligence need to be tackled further.关键词:artificial intelligence(AI);deep learning;natural language processing;artificial intelligence generated content(AIGC);ChatGPT239|195|3更新时间:2024-05-07 -
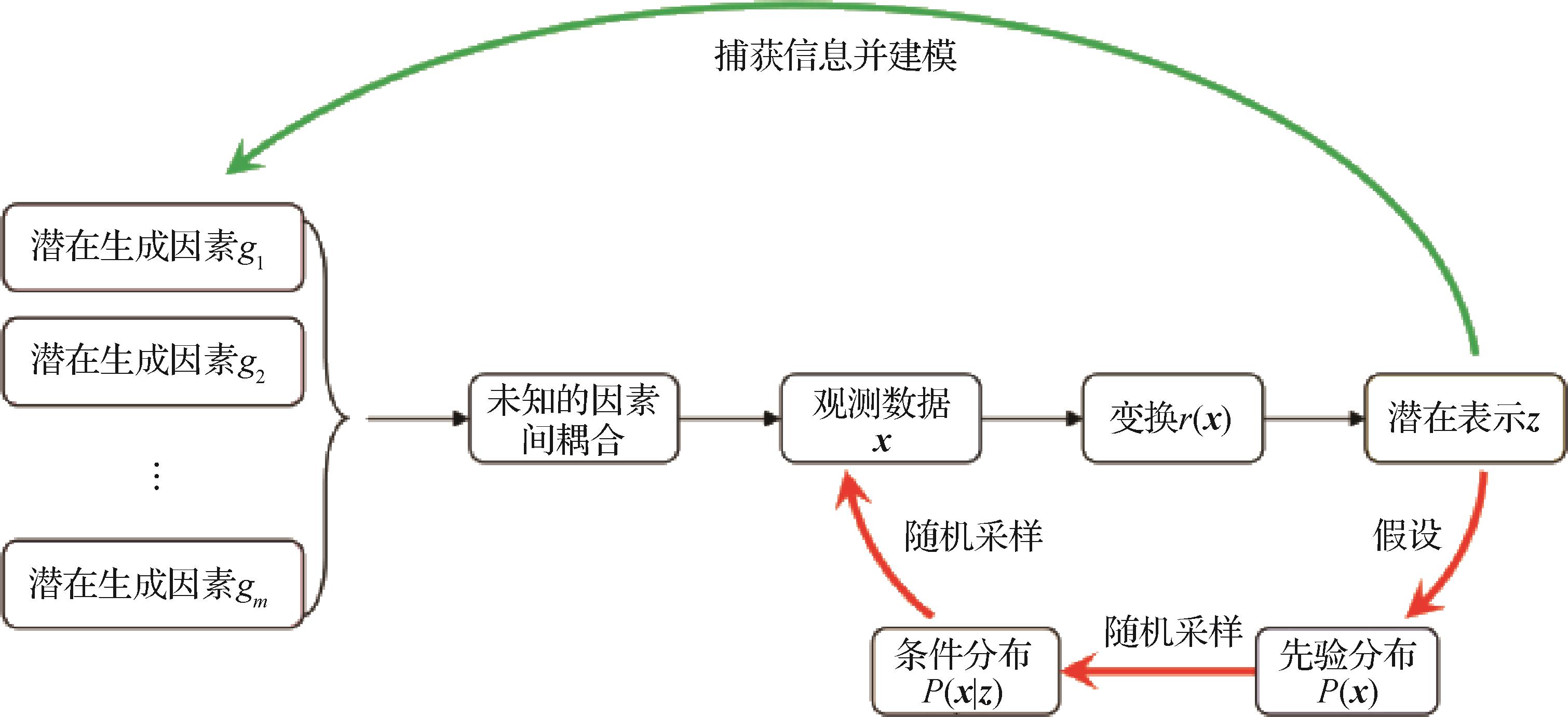 摘要:Representation learning is essential for machine learning technique nowadays. The transition of input representations have been developing intensively in algorithm performance benefited from the growth of hand-crafted features to the representation for multi-media data. However, the representations of visual data are often highly entangled. The interpretation challenges are to be faced because all information components are encoded into the same feature space. Disentangled representation learning (DRL) aims to learn a low-dimensional interpretable abstract representation that can sort the multiple factors of variation out in high-dimensional observations. In the disentangled representation, we can capture and manipulate the information of a single factor of variation through the corresponding latent subspace, which makes it more interpretable. DRL can improve sample efficiency and tolerance to the nuisance variables and offer robust representation of complex variations. Their semantic information is extracted and beneficial for artificial intelligence (AI) downstream tasks like recognition, classification and domain adaptation. Our summary is focused on brief introduction to the definition, research development and applications of DRL. Some of independent component analysis (ICA)-nonlinear DRL researches are covered as well since the DRL is similar to the identifiability issue of nonlinear independent component analysis (nonlinear ICA). The cause and effects mechanism of DRL as high-dimensional ground truth data is generated by a set of unobserved changing factors (generating factors). The DRL can be used to model the factors of variation in terms of latent representation, and the observed data generation process is restored. We summarize the key elements that a well-defined disentangled representation should be qualified into three aspects, which are 1) modularity, 2) compactness, and 3) explicitness. First, explicitness consists of the two sub-requirements of completeness and informativeness. Then, current DRL types are categorized into 1) dimension-wise disentanglement, 2) semantic-based disentanglement, 3) hierarchical disentanglement, and 4) nonlinear ICA four types in terms of its formulation, characteristics, and scope of application. Dimension-wise disentanglement is assumed that the generative factors are solely and each dimension of latent vector can be separated and mapped, which is suitable for learning the disentangled representation of simple synthetic visual data. Semantic-based disentanglement is hypnotized that some semantic information is solely as well. The generative factors are group-disentangled in terms of specific semantics and they are mapped to different latent spaces, which is suitable for complicated ground truth data. Hierarchical disentanglement is based on the assumption that there is a correlation between generative factors at different levels of abstraction. The generative factors are disentangled by group from the bottom up and they can be mapped to latent space of different semantic abstraction levels to form a hierarchical disentangled representation. Nonlinear ICA provides an identifiable method for observed data-mixed disentangling unknown generative factors through a nonlinear reversible generator. For the motivation of loss functions, the loss functions can be commonly used in disentangled representation learning, which are grouped into three categories: 1) modularity constraint: a single latent variable-constrained in the disentangled representation to capture only a single or a single group of factors of variation, and it promotes the separation of factors of variation mutually; 2) explicitness constraint: current latent variable of the latent representation is activated to encode the ground truth of the corresponding generating factor effectively, and the entire latent representation contains complete information about all generative factors; and 3) multi-purpose constraint: loss-related can optimize multiple disentangled representation, including modularity, compactness, and explicitness of the disentangled representation at the same time. The model-relevant can combine multiple loss constraint terms to form the final hybrid objective function. We compare the scope of application and limitations of each type of loss functions and summarize the classical disentangled representation works using the hybrid objective function further.关键词:disentangled representation learning;visual data;latent representation;factors of variation;latent space189|252|1更新时间:2024-05-07
摘要:Representation learning is essential for machine learning technique nowadays. The transition of input representations have been developing intensively in algorithm performance benefited from the growth of hand-crafted features to the representation for multi-media data. However, the representations of visual data are often highly entangled. The interpretation challenges are to be faced because all information components are encoded into the same feature space. Disentangled representation learning (DRL) aims to learn a low-dimensional interpretable abstract representation that can sort the multiple factors of variation out in high-dimensional observations. In the disentangled representation, we can capture and manipulate the information of a single factor of variation through the corresponding latent subspace, which makes it more interpretable. DRL can improve sample efficiency and tolerance to the nuisance variables and offer robust representation of complex variations. Their semantic information is extracted and beneficial for artificial intelligence (AI) downstream tasks like recognition, classification and domain adaptation. Our summary is focused on brief introduction to the definition, research development and applications of DRL. Some of independent component analysis (ICA)-nonlinear DRL researches are covered as well since the DRL is similar to the identifiability issue of nonlinear independent component analysis (nonlinear ICA). The cause and effects mechanism of DRL as high-dimensional ground truth data is generated by a set of unobserved changing factors (generating factors). The DRL can be used to model the factors of variation in terms of latent representation, and the observed data generation process is restored. We summarize the key elements that a well-defined disentangled representation should be qualified into three aspects, which are 1) modularity, 2) compactness, and 3) explicitness. First, explicitness consists of the two sub-requirements of completeness and informativeness. Then, current DRL types are categorized into 1) dimension-wise disentanglement, 2) semantic-based disentanglement, 3) hierarchical disentanglement, and 4) nonlinear ICA four types in terms of its formulation, characteristics, and scope of application. Dimension-wise disentanglement is assumed that the generative factors are solely and each dimension of latent vector can be separated and mapped, which is suitable for learning the disentangled representation of simple synthetic visual data. Semantic-based disentanglement is hypnotized that some semantic information is solely as well. The generative factors are group-disentangled in terms of specific semantics and they are mapped to different latent spaces, which is suitable for complicated ground truth data. Hierarchical disentanglement is based on the assumption that there is a correlation between generative factors at different levels of abstraction. The generative factors are disentangled by group from the bottom up and they can be mapped to latent space of different semantic abstraction levels to form a hierarchical disentangled representation. Nonlinear ICA provides an identifiable method for observed data-mixed disentangling unknown generative factors through a nonlinear reversible generator. For the motivation of loss functions, the loss functions can be commonly used in disentangled representation learning, which are grouped into three categories: 1) modularity constraint: a single latent variable-constrained in the disentangled representation to capture only a single or a single group of factors of variation, and it promotes the separation of factors of variation mutually; 2) explicitness constraint: current latent variable of the latent representation is activated to encode the ground truth of the corresponding generating factor effectively, and the entire latent representation contains complete information about all generative factors; and 3) multi-purpose constraint: loss-related can optimize multiple disentangled representation, including modularity, compactness, and explicitness of the disentangled representation at the same time. The model-relevant can combine multiple loss constraint terms to form the final hybrid objective function. We compare the scope of application and limitations of each type of loss functions and summarize the classical disentangled representation works using the hybrid objective function further.关键词:disentangled representation learning;visual data;latent representation;factors of variation;latent space189|252|1更新时间:2024-05-07 -
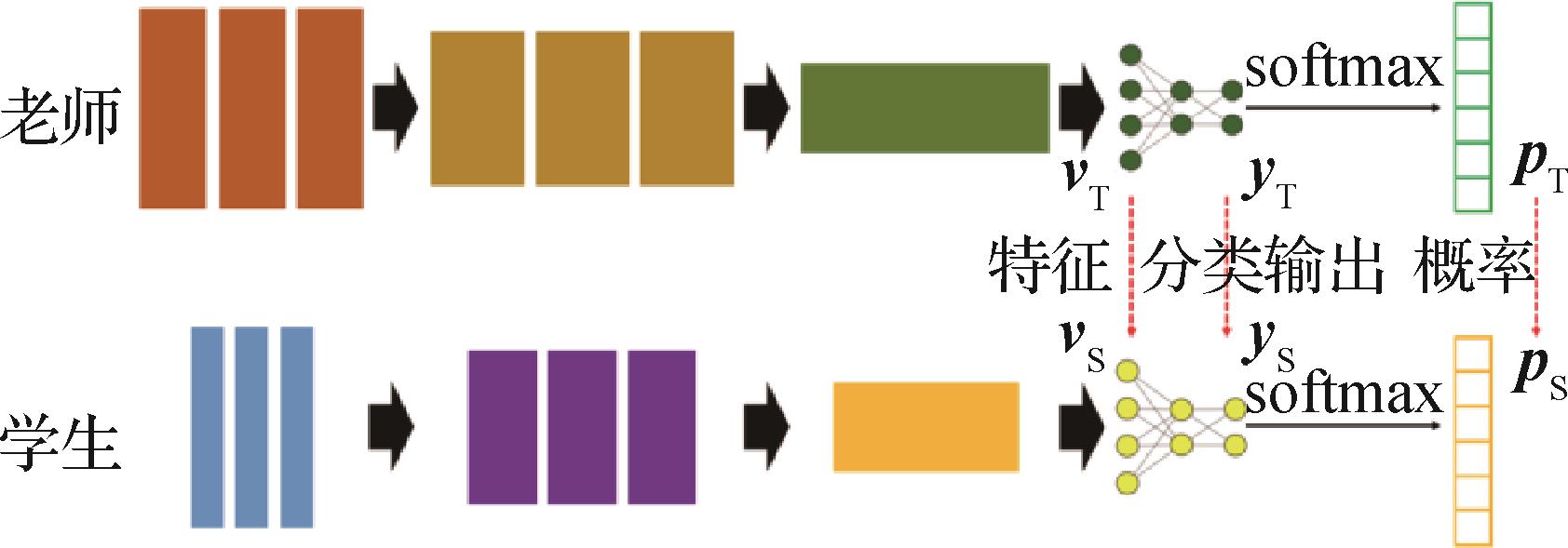 摘要:Computer vision tasks aim to construct computational models in relevant to functions-like of human visual systems. Current deep learning models are progressively improving upper bounds of performances in multiple computer vision tasks, especially for analysis and understanding of high-level semantics, i.e., multimedia-based descriptors for human recognition. Typical tasks to understand high-level semantics include image classification, object detection, instance segmentation, semantic segmentation, and video’s recognition and tracking. With the development of convolutional neural networks (CNNs), deep learning based high-level semantic understanding have all been benefiting from increasingly deeper and cumbersome models, which is also challenged for the problem of storages and computational costs. To obtain lighter structure and computation efficiency, many model compression strategies have been proposed, e.g., pruning, weight quantization, and low-rank factorization. But, such challenging issue is to be resolved for altered network structure or drop-severe of performance when deployed on computer vision tasks. Model distillation can be as one of the typical compression methods in terms of transfer learning to model compression. In general, model distillation utilizes a large and complicated pre-trained model as “teacher” and takes its effective representations, e.g., model outputs, features of hidden layers or feature maps-between similarities. These representations are treated as extra supervision signal together with the original ground truth for a lighter and faster model’s training, in which the lighter model is called “student”. As model distillation provides favorable balance between models’ performances and efficiency, it is being rapidly explored on different computer vision tasks. This paper investigates the progress of model distillation methods since its introduction in 2014 and introduces their different strategies in various applications. We review some popular distillation strategies and current model distillation algorithms deployed on image classification, object detection and semantic segmentation in this paper. First, we introduce distillation methods for image classification tasks, where model distillation has already achieved mature development. Fundamentals of model distillation starts from using teacher classifiers’ output logits as soft labels, bringing student with more inter-categories structural information, which is not available in conventional one-hot ground truths. Furthermore, hint learning can be used to utilize hierarchical structure of neural networks and take feature maps from hidden layers as another “teachers”-involved representations. Most of distillation strategies are designed and derived from similar approaches. In the aspects of frameworks’ design and application scenes, the paper respectively introduced some typical distillation strategies on classification models. Some methods mainly considered novel approaches on supervision signal design, i.e., ensembles that differs from conventional classification soft labels or feature maps. Newly developed features for student models to mimic are usually computed from attention or similarity maps of different layers, data augmentations or sampled images. Other methods consider adding noise or perturbation to teacher classifiers’ output or using probability inference to minimize the gap between teacher and student models. These specially designed features or logits are focused on a more appropriate representation of knowledge in teacher models than plain features from some layers’ outputs. Moreover, in other methods, the procedure of model distillation is altered, and more complicated schemes are introduced to transfer teacher’s knowledge instead of simply training the student with generated labels or features. Also, as generative adversarial networks (GANs) achieve promising performance in image synthesis, some model distillation methods also introduce adversarial mechanisms in classifiers’ distillation, where teacher models’ features are regarded as “real ones” and the students are expected to “generate” similar features. In many practical scenes such as model compression, self-training and parallel computing, classifiers’ distillation is utilized in coordinate to specific process as well, e.g., fine tuning networks with full-precision teachers, distilling student model with its previous versions during training, and using models from different nodes as teachers. We summarize some popular strategies performances and illustrate the data in a table after approaches of model distillation in image classification tasks are introduced. Distillation methods’ performances on improving classifiers’ top-1 accuracies are compared on several typical classification datasets. The second part of the paper focuses on specially developed distillation methods for computer vision tasks more complicated than classification, e.g., object detection, instance segmentation and semantic segmentation. Differentiated from classifiers, models of these tasks contain more redundant structures with heterogeneous outputs. Hence, recent works on detectors’ and segmentation models’ distillation is relatively less than those in classifiers’ distillation. The paper describes current challenges in designing of distillation frameworks on detection and segmentation tasks. Some of typical distillation methods for detectors and segmentation models are then introduced based on different tasks and their multifaceted structures. Since there were few works specified for instance segmentation models’ distillation, the papers simply introduce similar distillation methods for object detectors in the beginning of the second part. For detectors, requirements from localization demand special concentration on local information around foreground objects. Meanwhile, images from object detection datasets consists of more complicated scenes generally in which large amounts of different objects may occur. Hence, the solutions of distillation strategies-borrowing from for classifies may bring undesired performance decrease in object detection. Due to more complex structures in detectors, previous distillation methods may not be applicable. As “backbone with task heads” structure is widely used in modern computer vision models, researchers develop novel distillation methods mainly based on this typical framework. The introduced detectors’ distillation strategies investigate issues above and mainly focus on specific output logits acquirement and specially designed loss functions for different parts in detectors. To highlight foreground regions before distillation, backbones-derived feature maps are often selected through regions of interest (RoIs) using masking operations. Various of output logits are selected in different methods from teacher models’ task heads, affecting training of students’ task heads in terms of specific matching and imitation schemes. Semantic segmentation requires more global information than object detection or instance segmentation tasks, focusing on pixel-wise classification inside the total image. One of the critical factors of pixels’ correct classification is oriented to the analysis of inter-pixel relationships. Hence, model distillation methods for semantic segmentation also take advantages of pixels in both output masks and feature maps from hidden layers. Distillation strategies introduced in the paper are majorly on the application of hierarchical distillation on different part, e.g., the imitation of full output classification mask, imitation of full feature maps, computing of similarity matrices, and using conditional GANs (cGANs) for auxiliary imitation. The former two approaches are fundamental practices in model distillation. In contrast, to realize segmentation model’s pixel-wise knowledge to be more ‘compact’ after compression, some distillation methods utilize compressed features instead of original one to compute similarity with student. When cGANs is used to imitate student segmentation model to the teacher features, researchers introduce Wasserstein distance as a better metric for adversarial training. At the final part of this paper, previous works of model distillation for high-level semantic understanding are summarized. We review some obstacles and unsolved problems in current development of model distillation, and the future research direction is predicted as well.关键词:model distillation;deep learning;image classification;object detection;semantic segmentation;transfer learning188|450|1更新时间:2024-05-07
摘要:Computer vision tasks aim to construct computational models in relevant to functions-like of human visual systems. Current deep learning models are progressively improving upper bounds of performances in multiple computer vision tasks, especially for analysis and understanding of high-level semantics, i.e., multimedia-based descriptors for human recognition. Typical tasks to understand high-level semantics include image classification, object detection, instance segmentation, semantic segmentation, and video’s recognition and tracking. With the development of convolutional neural networks (CNNs), deep learning based high-level semantic understanding have all been benefiting from increasingly deeper and cumbersome models, which is also challenged for the problem of storages and computational costs. To obtain lighter structure and computation efficiency, many model compression strategies have been proposed, e.g., pruning, weight quantization, and low-rank factorization. But, such challenging issue is to be resolved for altered network structure or drop-severe of performance when deployed on computer vision tasks. Model distillation can be as one of the typical compression methods in terms of transfer learning to model compression. In general, model distillation utilizes a large and complicated pre-trained model as “teacher” and takes its effective representations, e.g., model outputs, features of hidden layers or feature maps-between similarities. These representations are treated as extra supervision signal together with the original ground truth for a lighter and faster model’s training, in which the lighter model is called “student”. As model distillation provides favorable balance between models’ performances and efficiency, it is being rapidly explored on different computer vision tasks. This paper investigates the progress of model distillation methods since its introduction in 2014 and introduces their different strategies in various applications. We review some popular distillation strategies and current model distillation algorithms deployed on image classification, object detection and semantic segmentation in this paper. First, we introduce distillation methods for image classification tasks, where model distillation has already achieved mature development. Fundamentals of model distillation starts from using teacher classifiers’ output logits as soft labels, bringing student with more inter-categories structural information, which is not available in conventional one-hot ground truths. Furthermore, hint learning can be used to utilize hierarchical structure of neural networks and take feature maps from hidden layers as another “teachers”-involved representations. Most of distillation strategies are designed and derived from similar approaches. In the aspects of frameworks’ design and application scenes, the paper respectively introduced some typical distillation strategies on classification models. Some methods mainly considered novel approaches on supervision signal design, i.e., ensembles that differs from conventional classification soft labels or feature maps. Newly developed features for student models to mimic are usually computed from attention or similarity maps of different layers, data augmentations or sampled images. Other methods consider adding noise or perturbation to teacher classifiers’ output or using probability inference to minimize the gap between teacher and student models. These specially designed features or logits are focused on a more appropriate representation of knowledge in teacher models than plain features from some layers’ outputs. Moreover, in other methods, the procedure of model distillation is altered, and more complicated schemes are introduced to transfer teacher’s knowledge instead of simply training the student with generated labels or features. Also, as generative adversarial networks (GANs) achieve promising performance in image synthesis, some model distillation methods also introduce adversarial mechanisms in classifiers’ distillation, where teacher models’ features are regarded as “real ones” and the students are expected to “generate” similar features. In many practical scenes such as model compression, self-training and parallel computing, classifiers’ distillation is utilized in coordinate to specific process as well, e.g., fine tuning networks with full-precision teachers, distilling student model with its previous versions during training, and using models from different nodes as teachers. We summarize some popular strategies performances and illustrate the data in a table after approaches of model distillation in image classification tasks are introduced. Distillation methods’ performances on improving classifiers’ top-1 accuracies are compared on several typical classification datasets. The second part of the paper focuses on specially developed distillation methods for computer vision tasks more complicated than classification, e.g., object detection, instance segmentation and semantic segmentation. Differentiated from classifiers, models of these tasks contain more redundant structures with heterogeneous outputs. Hence, recent works on detectors’ and segmentation models’ distillation is relatively less than those in classifiers’ distillation. The paper describes current challenges in designing of distillation frameworks on detection and segmentation tasks. Some of typical distillation methods for detectors and segmentation models are then introduced based on different tasks and their multifaceted structures. Since there were few works specified for instance segmentation models’ distillation, the papers simply introduce similar distillation methods for object detectors in the beginning of the second part. For detectors, requirements from localization demand special concentration on local information around foreground objects. Meanwhile, images from object detection datasets consists of more complicated scenes generally in which large amounts of different objects may occur. Hence, the solutions of distillation strategies-borrowing from for classifies may bring undesired performance decrease in object detection. Due to more complex structures in detectors, previous distillation methods may not be applicable. As “backbone with task heads” structure is widely used in modern computer vision models, researchers develop novel distillation methods mainly based on this typical framework. The introduced detectors’ distillation strategies investigate issues above and mainly focus on specific output logits acquirement and specially designed loss functions for different parts in detectors. To highlight foreground regions before distillation, backbones-derived feature maps are often selected through regions of interest (RoIs) using masking operations. Various of output logits are selected in different methods from teacher models’ task heads, affecting training of students’ task heads in terms of specific matching and imitation schemes. Semantic segmentation requires more global information than object detection or instance segmentation tasks, focusing on pixel-wise classification inside the total image. One of the critical factors of pixels’ correct classification is oriented to the analysis of inter-pixel relationships. Hence, model distillation methods for semantic segmentation also take advantages of pixels in both output masks and feature maps from hidden layers. Distillation strategies introduced in the paper are majorly on the application of hierarchical distillation on different part, e.g., the imitation of full output classification mask, imitation of full feature maps, computing of similarity matrices, and using conditional GANs (cGANs) for auxiliary imitation. The former two approaches are fundamental practices in model distillation. In contrast, to realize segmentation model’s pixel-wise knowledge to be more ‘compact’ after compression, some distillation methods utilize compressed features instead of original one to compute similarity with student. When cGANs is used to imitate student segmentation model to the teacher features, researchers introduce Wasserstein distance as a better metric for adversarial training. At the final part of this paper, previous works of model distillation for high-level semantic understanding are summarized. We review some obstacles and unsolved problems in current development of model distillation, and the future research direction is predicted as well.关键词:model distillation;deep learning;image classification;object detection;semantic segmentation;transfer learning188|450|1更新时间:2024-05-07 -
 摘要:Deep learning technique has been developing intensively in big data era. However, its capability is still challenged for the design of network structure and parameter setting. Therefore, it is essential to improve the performance of the model and optimize the complexity of the model. Machine learning can be segmented into five categories in terms of learning methods: 1) supervised learning, 2) unsupervised learning, 3) semi-supervised learning, 4) deep learning, and 5) reinforcement learning. These machine learning techniques are required to be incorporated in. To improve its fitting and generalization ability, we select supervised deep learning as a niche to summarize and analyze the optimization methods. First, the mechanism of optimization is demonstrated and its key elements are illustrated. Then, the optimization problem is decomposed into three directions in relevant to fitting ability: 1) convergence, 2) convergence speed, and 3) global-context quality. At the same time, we also summarize and analyze the specific methods and research results of these three optimization directions. Among them, convergence refers to running the algorithm and converging to a synthesis like a stationary point. The gradient exploding/vanishing problem is shown that small changes in a multi-layer network may amplify and stimuli or decline and disappear for each layer. The speed of convergence refers to the ability to assist the model to converge at a faster speed. After the convergence task of the model, the optimization algorithm to accelerate the model convergence should be considered to improve the performance of the model. The global-context quality problem is to ensure that the model converges to a lower solution (the global minimum). The first two problems are local-oriented and the last one is global-concerned. The boundary of these three problems is fuzzy, for example, some optimization methods to improve convergence can accelerate the convergence speed of the model as well. After the fitting optimization of the model, it is necessary to consider the large number of parameters in the deep learning model as well, which can cause poor generalization effect due to overfitting. Regularization can be regarded as an effective method for generalization. To improve the generalization ability of the model, current situation of regularization methods are categorized from two aspects: 1) data processing and 2) model parameters-constrained. Data processing refers to data processing during model training, such as dataset enhancement, noise injection and adversarial training. These optimization methods can improve the generalization ability of the model effectively. Model parameters constraints are oriented to parameters-constrained in the network, which can also improve the generalization ability of the model. We take generative adversarial network (GAN) as the application background and review the growth of its variant model because it can be as a commonly-used deep learning network. We analyze the application of relevant optimization methods in GAN domain from two aspects of fitting and generalization ability. Taking WGAN with gradient penalty (WGAN-GP) as the basic model, we design an experiment on MNIST-10 dataset to study the applicability of the six algorithms (stochastic gradient method(SGD), momentum SGD, Adagrad, Adadelta, root mean square propagation(RMSProp), and Adam) in the context of deep learning based GAN domain. The optimization effects are compared and analyzed in relevant to the experimental results of multiple optimization methods on variants of GAN model, and some GAN-based optimization strategies are required to be clarified further. At present, various optimization methods have been widely used in deep learning models. Various optimization methods to improve the fitting ability can improve the performance of the model. Furthermore, these regularized optimization methods are beneficial to alleviate the problem of model overfitting and improve the robustness of the model. But, there is still a lack of systematic theories and mechanisms for guidance. In addition, there are still some optimization problems to be further studied. The Lipschitz limitation of global gradients is not guaranteed in deep neural networks due to the gap between theory and practice. In the field of GAN, there is still a lack of theoretical breakthroughs to find the stable global optimal solution, that is, the optimal Nash equilibrium. Moreover, some of the existing optimization methods are empirical and its interpretability is lack of clear theoretical proof. There are many and complex optimization methods in deep learning. The use of various optimization methods should be focused on the integrated effect of multiple optimizations. Our critical analysis is potential to provide a reference for the optimization method selection in the design of deep neural network.关键词:machine learning;deep learning;deep learning optimization;regularization;generative adversarial network (GAN)225|389|1更新时间:2024-05-07
摘要:Deep learning technique has been developing intensively in big data era. However, its capability is still challenged for the design of network structure and parameter setting. Therefore, it is essential to improve the performance of the model and optimize the complexity of the model. Machine learning can be segmented into five categories in terms of learning methods: 1) supervised learning, 2) unsupervised learning, 3) semi-supervised learning, 4) deep learning, and 5) reinforcement learning. These machine learning techniques are required to be incorporated in. To improve its fitting and generalization ability, we select supervised deep learning as a niche to summarize and analyze the optimization methods. First, the mechanism of optimization is demonstrated and its key elements are illustrated. Then, the optimization problem is decomposed into three directions in relevant to fitting ability: 1) convergence, 2) convergence speed, and 3) global-context quality. At the same time, we also summarize and analyze the specific methods and research results of these three optimization directions. Among them, convergence refers to running the algorithm and converging to a synthesis like a stationary point. The gradient exploding/vanishing problem is shown that small changes in a multi-layer network may amplify and stimuli or decline and disappear for each layer. The speed of convergence refers to the ability to assist the model to converge at a faster speed. After the convergence task of the model, the optimization algorithm to accelerate the model convergence should be considered to improve the performance of the model. The global-context quality problem is to ensure that the model converges to a lower solution (the global minimum). The first two problems are local-oriented and the last one is global-concerned. The boundary of these three problems is fuzzy, for example, some optimization methods to improve convergence can accelerate the convergence speed of the model as well. After the fitting optimization of the model, it is necessary to consider the large number of parameters in the deep learning model as well, which can cause poor generalization effect due to overfitting. Regularization can be regarded as an effective method for generalization. To improve the generalization ability of the model, current situation of regularization methods are categorized from two aspects: 1) data processing and 2) model parameters-constrained. Data processing refers to data processing during model training, such as dataset enhancement, noise injection and adversarial training. These optimization methods can improve the generalization ability of the model effectively. Model parameters constraints are oriented to parameters-constrained in the network, which can also improve the generalization ability of the model. We take generative adversarial network (GAN) as the application background and review the growth of its variant model because it can be as a commonly-used deep learning network. We analyze the application of relevant optimization methods in GAN domain from two aspects of fitting and generalization ability. Taking WGAN with gradient penalty (WGAN-GP) as the basic model, we design an experiment on MNIST-10 dataset to study the applicability of the six algorithms (stochastic gradient method(SGD), momentum SGD, Adagrad, Adadelta, root mean square propagation(RMSProp), and Adam) in the context of deep learning based GAN domain. The optimization effects are compared and analyzed in relevant to the experimental results of multiple optimization methods on variants of GAN model, and some GAN-based optimization strategies are required to be clarified further. At present, various optimization methods have been widely used in deep learning models. Various optimization methods to improve the fitting ability can improve the performance of the model. Furthermore, these regularized optimization methods are beneficial to alleviate the problem of model overfitting and improve the robustness of the model. But, there is still a lack of systematic theories and mechanisms for guidance. In addition, there are still some optimization problems to be further studied. The Lipschitz limitation of global gradients is not guaranteed in deep neural networks due to the gap between theory and practice. In the field of GAN, there is still a lack of theoretical breakthroughs to find the stable global optimal solution, that is, the optimal Nash equilibrium. Moreover, some of the existing optimization methods are empirical and its interpretability is lack of clear theoretical proof. There are many and complex optimization methods in deep learning. The use of various optimization methods should be focused on the integrated effect of multiple optimizations. Our critical analysis is potential to provide a reference for the optimization method selection in the design of deep neural network.关键词:machine learning;deep learning;deep learning optimization;regularization;generative adversarial network (GAN)225|389|1更新时间:2024-05-07
Review

-
 摘要:ObjectiveShip hull number detection and recognition can be as the key technologies for marine awareness. It is essential for the preservation of maritime rights and interests. However, it is required to data-driven researches in support of ship hull number detection and recognition. Therefore, we develop a sparse ship hull number dataset in real scene (SSHN-RS), which contains 3 004 images with a total of 11 328 hull numbers. The challenging SSHN-RS dataset is featured of ship hull numbers of various countries, hull numbers of various types, horizontal hull numbers, inclined hull numbers, hull numbers with complex background, hull numbers with simple background, poorly illuminated hull numbers and partially occluded hull numbers. We carry out SSHN-RS-related research on ship hull number detection and recognition. The main challenges are required to be resolved on three aspects as following: 1) the hull number samples are sparse, which causes over-fitting of the network, 2) the features of hull number are densely distributed, which is challenged to learn some of the hull number characteristics fully, and 3) some hull number have its nested areas and a high degree of similarity, which is costly for large number of redundant results.MethodTo resolve these problems mentioned above, we demonstrate a ship hull number detection and recognition algorithm in terms of multi-view progressive context decoupling. First, a random perspective transformation technology with fixed center and maximized area is illustrated. To realize data augmentation and improve the generalization ability of the model, the hull number spatial attitude is extended without increasing the number of samples. Second, a progressive context decoupling technology is proposed. A series of new samples are first generated by sequentially erasing each character of the hull number, and the feature extraction network is then used to extract and fuse the multi-scale features of each sample. It can reduce the influence of feature-contextual information on feature learning and rich the data expansion. It can improve the feature expression ability effectively as well. Finally, in the testing stage, to generate new samples, and inputs the new samples into the testing network for prediction, an inter mask disturbance suppression technology is first focused on a method similar to the progressive context decoupling technology. At the same time, a one-dimensional non-maximum suppression technology is introduced that it can mainly process the hull number recognition results of each sample twice. To suppress the redundant mask in the detection and recognition results effectively, it can make each character of the hull number of all samples correspond to a recognition result. For the testing network, the output has only a set of optimal results. However, there is hull number noisy recognition in some samples. Therefore, the hull number recognition results of all samples are added on the original images, and the second one-dimensional non-maximum suppression technology is performed and processed on it. It can suppress the noises in some samples and outputs a set of optimal results. The post-processing module can optimize the detection and recognition performance further.ResultThe comparative experiment is mainly carried out on SSHN-RS. First, we conduct evaluation analysis on the general instance segmentation algorithms. Multi-view progressive context decoupling-based detection precision, recall, f-score and recognition rate of the ship number detection and recognition algorithm can reach 0.985 4, 0.957 6, 0.971 3 and 0.901 8, which are improved by 4.51%, 3.45%, 3.97% and 8.83% respectively compared to the second-ranked method. Second, the ablation experiments on the ship hull number detection and recognition algorithm are carried out in terms of multi-view progressive context decoupling. The experimental results show that the performance of ship hull number detection and recognition is improved whether each technology is used solely or mixed. Finally, to validate its effectiveness, we apply some popular modules of the ship hull number detection and recognition algorithm based on multi-view progressive context decoupling to other general instance segmentation algorithms. Taking the classic algorithm mask region based convolutional neural network(Mask RCNN) as an example, the indexes have been improved by 9.82%, 6.04%, 7.80% and 6.73% of each after our algorithm module is added.ConclusionOur SSHN-RS contains rich and effective ship hull number information, which can provide data support for ship hull number detection and recognition. The experimental results show that the multi-view progressive context decoupling-based ship hull number detection and recognition algorithm can optimize the detection and recognition performance of hull numbers due to sparse samples, dense character distribution, nested areas, and characters-between high similarity. This algorithm can be generalized to other deep learning based segmentation algorithms. The benchmarks-relevant are provided as a basis for future research on ship hull number detection and recognition. The dataset is available at https://github.com/Bingchuan897/SSHN-RS.关键词:sparse samples;public dataset;ship hull number detection and recognition;instance segmentation;data augmentation;progressive context decoupling336|1931|1更新时间:2024-05-07
摘要:ObjectiveShip hull number detection and recognition can be as the key technologies for marine awareness. It is essential for the preservation of maritime rights and interests. However, it is required to data-driven researches in support of ship hull number detection and recognition. Therefore, we develop a sparse ship hull number dataset in real scene (SSHN-RS), which contains 3 004 images with a total of 11 328 hull numbers. The challenging SSHN-RS dataset is featured of ship hull numbers of various countries, hull numbers of various types, horizontal hull numbers, inclined hull numbers, hull numbers with complex background, hull numbers with simple background, poorly illuminated hull numbers and partially occluded hull numbers. We carry out SSHN-RS-related research on ship hull number detection and recognition. The main challenges are required to be resolved on three aspects as following: 1) the hull number samples are sparse, which causes over-fitting of the network, 2) the features of hull number are densely distributed, which is challenged to learn some of the hull number characteristics fully, and 3) some hull number have its nested areas and a high degree of similarity, which is costly for large number of redundant results.MethodTo resolve these problems mentioned above, we demonstrate a ship hull number detection and recognition algorithm in terms of multi-view progressive context decoupling. First, a random perspective transformation technology with fixed center and maximized area is illustrated. To realize data augmentation and improve the generalization ability of the model, the hull number spatial attitude is extended without increasing the number of samples. Second, a progressive context decoupling technology is proposed. A series of new samples are first generated by sequentially erasing each character of the hull number, and the feature extraction network is then used to extract and fuse the multi-scale features of each sample. It can reduce the influence of feature-contextual information on feature learning and rich the data expansion. It can improve the feature expression ability effectively as well. Finally, in the testing stage, to generate new samples, and inputs the new samples into the testing network for prediction, an inter mask disturbance suppression technology is first focused on a method similar to the progressive context decoupling technology. At the same time, a one-dimensional non-maximum suppression technology is introduced that it can mainly process the hull number recognition results of each sample twice. To suppress the redundant mask in the detection and recognition results effectively, it can make each character of the hull number of all samples correspond to a recognition result. For the testing network, the output has only a set of optimal results. However, there is hull number noisy recognition in some samples. Therefore, the hull number recognition results of all samples are added on the original images, and the second one-dimensional non-maximum suppression technology is performed and processed on it. It can suppress the noises in some samples and outputs a set of optimal results. The post-processing module can optimize the detection and recognition performance further.ResultThe comparative experiment is mainly carried out on SSHN-RS. First, we conduct evaluation analysis on the general instance segmentation algorithms. Multi-view progressive context decoupling-based detection precision, recall, f-score and recognition rate of the ship number detection and recognition algorithm can reach 0.985 4, 0.957 6, 0.971 3 and 0.901 8, which are improved by 4.51%, 3.45%, 3.97% and 8.83% respectively compared to the second-ranked method. Second, the ablation experiments on the ship hull number detection and recognition algorithm are carried out in terms of multi-view progressive context decoupling. The experimental results show that the performance of ship hull number detection and recognition is improved whether each technology is used solely or mixed. Finally, to validate its effectiveness, we apply some popular modules of the ship hull number detection and recognition algorithm based on multi-view progressive context decoupling to other general instance segmentation algorithms. Taking the classic algorithm mask region based convolutional neural network(Mask RCNN) as an example, the indexes have been improved by 9.82%, 6.04%, 7.80% and 6.73% of each after our algorithm module is added.ConclusionOur SSHN-RS contains rich and effective ship hull number information, which can provide data support for ship hull number detection and recognition. The experimental results show that the multi-view progressive context decoupling-based ship hull number detection and recognition algorithm can optimize the detection and recognition performance of hull numbers due to sparse samples, dense character distribution, nested areas, and characters-between high similarity. This algorithm can be generalized to other deep learning based segmentation algorithms. The benchmarks-relevant are provided as a basis for future research on ship hull number detection and recognition. The dataset is available at https://github.com/Bingchuan897/SSHN-RS.关键词:sparse samples;public dataset;ship hull number detection and recognition;instance segmentation;data augmentation;progressive context decoupling336|1931|1更新时间:2024-05-07 -
 摘要:ObjectiveTo optimize the detection accuracy, lightweight target detection method is focused on the problem of cost efficiency of computation and storage. The Mobilenetv3 can extract feature effectively through the inverted residual structures-related bneck. However, features are connected with bneck-inner only excluded the bneck-between feature connection. The network accuracy is not optimized because more initial features are not involved in. To achieve a better balance between computation and detection accuracy, the neural architecture search-feature pyramid networks lite(NAS-FPNLite) can be as an effective target detection method based on deep learning technique. The NAS-FPNLite detector is focused on depth separation convolution in the feature pyramid part and the channel number of the intermediate feature layer can be compressed to a fixed 64-dimensional. A better balance can be achieved between the floating point operations and detection accuracy. The depth separation convolution can configure the parameters to 0 easily under this circumstance. To resolve these two problems, we develop a NAS-FPNLite lightweight object detection method in terms of the fusion of cross stage connection and inverted residual. First, an improved network model CSCMobileNetv3 is illustrated, which can obtain more multifaceted information and improves the efficiency of network feature extraction. Next, the inverted residual structure is applied to the feature pyramid part of NAS-FPNLite to obtain a higher number of channels during the depthwise separable convolutions, which can improve the detection accuracy on possibility-alleviated of those parameters become 0. Finally, the experiment for CSCMobilenetv3 model is validated on the Canadian Institute for Advanced Research(CIFAR)-100 and ImageNet 1000 datasets, as well as the inverted residual NAS-FPNLite detector in the COCO (common objects in context) dataset.MethodAt the beginning, to obtain different gradient information between network layers, a cross stage connection (CSC) structure is proposed in terms of DenseNet dense connection, which can combine the initial input with final output of the same level network block to obtain the gradient combination with the maximum difference, and get an improved CSCMobileNetv3 network model. The CSCMobileNetv3 network model is composed of 6 block structures, the first two blocks remain unchanged, and the last four block structures are combined with the CSC structure. Within the same block, the initial input is combined with the final output and as the input of the next block. At the same time, to obtain more different gradient information, the number of channels between the various blocks is changed from the original 16, 24, 40, 80, 112, 160 to 16, 24, 40, 80, 160, 320 in correspondent, It can surpress the intensity of the number of parameters and the amount of floating point operations effectively derived from the excessive expansion of channels. Then, in the detector part of NAS-FPNLite, the feature pyramid part is fused with the inverted residual structure, and the feature fusion method of element-by-element growth between different feature layers is replaced by the channel-concatenated. It is possible to maintain a higher number of channels via processing depthwise separable convolutions. To perform sufficient feature fusion, the situation where the parameters become 0 is avoided effectively, and a skip connection is realized between the input feature layer and the final output layer. A NAS-FPNLite object detection method fused with inverted residuals is demonstrated.ResultIn the training stage, our configuration is equipped with listed below: 1) the graphics card used is NVIDIA GeForce GTX 2070 Super, 2) 8 GB video memory, 3) CUDA version is CUDA10.0, and 4) the CPU is 8-core AMD Ryzen7 3700x. On CIFAR-100 dataset training, since the image resolution of the CIFAR-100 dataset is 32 × 32 pixels, and the CSCMobileNetv3 is required of the resolution of the input image to be set to 224 × 224 pixels, the first convolutional layer, and in the first and third bnecks, the convolution stride is set from 2 to 1, 200 epochs are trained, the learning rate is set to multi-stage adjustment, the initial learning rate lr is set to 0.1, and then at 100, 150 and 180 epochs, multiply the learning rate by a factor of 10. On ImageNet 1000 dataset training, the dataset needs to be preprocessed first, the image resolution is adjusted to 224 × 224 pixels as the input of the network, the number of training iterations is 150 epochs, the cosine annealing learning strategy is used, and the initial learning rate lr is 0.02. The experimental results show that the accuracy of the CSCMobileNetv3 network can be increased by 0.71% to 1.04% compared to MobileNetv3 when the scaling factors are 0.5, 0.75, and 1.0 on the CIFAR-100 dataset. Compared to MobileNetv3, CSCMobileNetv3 increases the number of parameters by 6% and the amount of floating point operations by about 11% when the scaling factor is 1.0, but the accuracy rate increases by 1.04%. Especially, when the CSCMobileNetv3 zoom factor is 0.75, the number of parameters is reduced by 30% compared to the MobileNetv3 zoom factor of 1.0 and the amount of floating point operations is reduced by 20%. The accuracy rate is still improved by 0.19%. On the ImageNet 1000 dataset, CSCMobileNetv3 has a 0.7% improvement in accuracy although the amount of parameters and floating point operations is slightly higher than that of MobileNetv3. To sum up, CSCMobileNetv3 has optimized relevant parameters, floating-point operations and accuracy. On the COCO dataset, compared to other lightweight object detection methods, the detection accuracy of CSCMobileNetv3 and NAS-FPNLite lightweight object detection method fused with inverted residuals can be improved by 0.7% to 4% based on equivalent computation.ConclusionThe CSCMobileNetv3 can obtain differential gradient information effectively, and achieve higher accuracy with a small calculation only. To improve detection accuracy, the NAS-FPNLite object detection method fused with inverted residuals can avoid the situation effectively where the parameters become 0. Our method has its balancing potentials between the amount of calculation and detection accuracy.关键词:lightweight object detection;image classification;depthwise separable convolution;multi-scale feature fusion139|267|1更新时间:2024-05-07
摘要:ObjectiveTo optimize the detection accuracy, lightweight target detection method is focused on the problem of cost efficiency of computation and storage. The Mobilenetv3 can extract feature effectively through the inverted residual structures-related bneck. However, features are connected with bneck-inner only excluded the bneck-between feature connection. The network accuracy is not optimized because more initial features are not involved in. To achieve a better balance between computation and detection accuracy, the neural architecture search-feature pyramid networks lite(NAS-FPNLite) can be as an effective target detection method based on deep learning technique. The NAS-FPNLite detector is focused on depth separation convolution in the feature pyramid part and the channel number of the intermediate feature layer can be compressed to a fixed 64-dimensional. A better balance can be achieved between the floating point operations and detection accuracy. The depth separation convolution can configure the parameters to 0 easily under this circumstance. To resolve these two problems, we develop a NAS-FPNLite lightweight object detection method in terms of the fusion of cross stage connection and inverted residual. First, an improved network model CSCMobileNetv3 is illustrated, which can obtain more multifaceted information and improves the efficiency of network feature extraction. Next, the inverted residual structure is applied to the feature pyramid part of NAS-FPNLite to obtain a higher number of channels during the depthwise separable convolutions, which can improve the detection accuracy on possibility-alleviated of those parameters become 0. Finally, the experiment for CSCMobilenetv3 model is validated on the Canadian Institute for Advanced Research(CIFAR)-100 and ImageNet 1000 datasets, as well as the inverted residual NAS-FPNLite detector in the COCO (common objects in context) dataset.MethodAt the beginning, to obtain different gradient information between network layers, a cross stage connection (CSC) structure is proposed in terms of DenseNet dense connection, which can combine the initial input with final output of the same level network block to obtain the gradient combination with the maximum difference, and get an improved CSCMobileNetv3 network model. The CSCMobileNetv3 network model is composed of 6 block structures, the first two blocks remain unchanged, and the last four block structures are combined with the CSC structure. Within the same block, the initial input is combined with the final output and as the input of the next block. At the same time, to obtain more different gradient information, the number of channels between the various blocks is changed from the original 16, 24, 40, 80, 112, 160 to 16, 24, 40, 80, 160, 320 in correspondent, It can surpress the intensity of the number of parameters and the amount of floating point operations effectively derived from the excessive expansion of channels. Then, in the detector part of NAS-FPNLite, the feature pyramid part is fused with the inverted residual structure, and the feature fusion method of element-by-element growth between different feature layers is replaced by the channel-concatenated. It is possible to maintain a higher number of channels via processing depthwise separable convolutions. To perform sufficient feature fusion, the situation where the parameters become 0 is avoided effectively, and a skip connection is realized between the input feature layer and the final output layer. A NAS-FPNLite object detection method fused with inverted residuals is demonstrated.ResultIn the training stage, our configuration is equipped with listed below: 1) the graphics card used is NVIDIA GeForce GTX 2070 Super, 2) 8 GB video memory, 3) CUDA version is CUDA10.0, and 4) the CPU is 8-core AMD Ryzen7 3700x. On CIFAR-100 dataset training, since the image resolution of the CIFAR-100 dataset is 32 × 32 pixels, and the CSCMobileNetv3 is required of the resolution of the input image to be set to 224 × 224 pixels, the first convolutional layer, and in the first and third bnecks, the convolution stride is set from 2 to 1, 200 epochs are trained, the learning rate is set to multi-stage adjustment, the initial learning rate lr is set to 0.1, and then at 100, 150 and 180 epochs, multiply the learning rate by a factor of 10. On ImageNet 1000 dataset training, the dataset needs to be preprocessed first, the image resolution is adjusted to 224 × 224 pixels as the input of the network, the number of training iterations is 150 epochs, the cosine annealing learning strategy is used, and the initial learning rate lr is 0.02. The experimental results show that the accuracy of the CSCMobileNetv3 network can be increased by 0.71% to 1.04% compared to MobileNetv3 when the scaling factors are 0.5, 0.75, and 1.0 on the CIFAR-100 dataset. Compared to MobileNetv3, CSCMobileNetv3 increases the number of parameters by 6% and the amount of floating point operations by about 11% when the scaling factor is 1.0, but the accuracy rate increases by 1.04%. Especially, when the CSCMobileNetv3 zoom factor is 0.75, the number of parameters is reduced by 30% compared to the MobileNetv3 zoom factor of 1.0 and the amount of floating point operations is reduced by 20%. The accuracy rate is still improved by 0.19%. On the ImageNet 1000 dataset, CSCMobileNetv3 has a 0.7% improvement in accuracy although the amount of parameters and floating point operations is slightly higher than that of MobileNetv3. To sum up, CSCMobileNetv3 has optimized relevant parameters, floating-point operations and accuracy. On the COCO dataset, compared to other lightweight object detection methods, the detection accuracy of CSCMobileNetv3 and NAS-FPNLite lightweight object detection method fused with inverted residuals can be improved by 0.7% to 4% based on equivalent computation.ConclusionThe CSCMobileNetv3 can obtain differential gradient information effectively, and achieve higher accuracy with a small calculation only. To improve detection accuracy, the NAS-FPNLite object detection method fused with inverted residuals can avoid the situation effectively where the parameters become 0. Our method has its balancing potentials between the amount of calculation and detection accuracy.关键词:lightweight object detection;image classification;depthwise separable convolution;multi-scale feature fusion139|267|1更新时间:2024-05-07 -
 摘要:ObjectiveThe pavement-relevant inspection is focused on the optimization for pavement cracks early-alarming detection and the preservation of pavement structure. However, conventional image processing-based techniques are labor-intensive and time-consuming, such as edge detection, threshold segmentation, template matching, and morphology operations. It is challenged to the geometric and spectral complexities of pavement crack and its contexts (e.g., illumination variation, oil or water stains, and shadows caused by trees and vehicles). The convolution neural network (CNN) based deep learning image processing techniques have been developing intensively. However, the CNN-based methods are less effective in long-range dependency modeling, which may cause insufficient detection results in complicated road surface scenarios. Some works are related to attention mechanisms like spatial or channel attention modules, and self-attention modules. However, these attention mechanism-based operations are still challenged for their sophistication and computational cost.MethodTo detect pavement cracks efficiently and effectively, we develop a novel Transformer-based encoder-decoder neural network, called CTNet, which consists of Transformer blocks, multi-scale local feature enhanced blocks, upsampling blocks, and skip connections. The CTNet can achieve more long-range dependency and global receptive field in terms of multi-head self-attention-based Transformer mechanism. Although Transformer is featured by high running efficiency and low computational overhead demand, it is infeasible to model local contextual information because Token generation can break the connections of neighboring regions. Thus, to capture more multi-scale local information, we design a multi-scale local feature-enhanced block in terms of a multiple dilation ratios-relevant dilation convolution block. Especially, the designed multi-scale local feature enhancement block is melted into each Transformer block for local information complement. Both of local and global low-level contextual features can be captured for feature enhancement. Afterwards, a novel decoder path is implemented to extract high-level features. The decoder consists of the Transformer blocks similar to the up-sampling blocks and the spatial details can be restored for end-to-end segmentation.ResultTo demonstrate the efficiency and effectiveness of our proposed CTNet, a series of comparative analyses and ablation studies are carried out on three datasets. First, the CTNet can optimize running efficiency, as well as comparable computation overhead and complexity compared to the current UNet, SegNet, DeepCrack, and SwinUnet. Second, CTNet is 6.78 times faster than the second-best DeepCrack model in terms of training speed. On CrackLS315 dataset, quantitative analyses are also showed that the optimal CTNet is obtained a precision of 91.38%, a recall of 80.38%, and a F1 measure of 85.53% of each; on CrackWH100 dataset, CTNet can obtain a precision of 92.70%, a recall of 90.52%, and a F1 measure 91.60% of each as well. However, it is still challenged to lack of local information when pure-Transformer-based Swin-UNet performed not well compared to fully convolution networks. Furthermore, the CTNet is insufficient to converge when the local blocks-enhanced are removed. In summary, the Transformer-based CTNet is beneficial to multi-scenario pavement cracks in terms of the global receptive field. The CTNet can get pavement crack detection results consistently.ConclusionThe proposed CTNet has its potentials to deal with noisy pavement images for pavement crack detection.关键词:road engineering;pavement crack detection;deep learning;semantic segmentation;self-attention;Transformer249|540|4更新时间:2024-05-07
摘要:ObjectiveThe pavement-relevant inspection is focused on the optimization for pavement cracks early-alarming detection and the preservation of pavement structure. However, conventional image processing-based techniques are labor-intensive and time-consuming, such as edge detection, threshold segmentation, template matching, and morphology operations. It is challenged to the geometric and spectral complexities of pavement crack and its contexts (e.g., illumination variation, oil or water stains, and shadows caused by trees and vehicles). The convolution neural network (CNN) based deep learning image processing techniques have been developing intensively. However, the CNN-based methods are less effective in long-range dependency modeling, which may cause insufficient detection results in complicated road surface scenarios. Some works are related to attention mechanisms like spatial or channel attention modules, and self-attention modules. However, these attention mechanism-based operations are still challenged for their sophistication and computational cost.MethodTo detect pavement cracks efficiently and effectively, we develop a novel Transformer-based encoder-decoder neural network, called CTNet, which consists of Transformer blocks, multi-scale local feature enhanced blocks, upsampling blocks, and skip connections. The CTNet can achieve more long-range dependency and global receptive field in terms of multi-head self-attention-based Transformer mechanism. Although Transformer is featured by high running efficiency and low computational overhead demand, it is infeasible to model local contextual information because Token generation can break the connections of neighboring regions. Thus, to capture more multi-scale local information, we design a multi-scale local feature-enhanced block in terms of a multiple dilation ratios-relevant dilation convolution block. Especially, the designed multi-scale local feature enhancement block is melted into each Transformer block for local information complement. Both of local and global low-level contextual features can be captured for feature enhancement. Afterwards, a novel decoder path is implemented to extract high-level features. The decoder consists of the Transformer blocks similar to the up-sampling blocks and the spatial details can be restored for end-to-end segmentation.ResultTo demonstrate the efficiency and effectiveness of our proposed CTNet, a series of comparative analyses and ablation studies are carried out on three datasets. First, the CTNet can optimize running efficiency, as well as comparable computation overhead and complexity compared to the current UNet, SegNet, DeepCrack, and SwinUnet. Second, CTNet is 6.78 times faster than the second-best DeepCrack model in terms of training speed. On CrackLS315 dataset, quantitative analyses are also showed that the optimal CTNet is obtained a precision of 91.38%, a recall of 80.38%, and a F1 measure of 85.53% of each; on CrackWH100 dataset, CTNet can obtain a precision of 92.70%, a recall of 90.52%, and a F1 measure 91.60% of each as well. However, it is still challenged to lack of local information when pure-Transformer-based Swin-UNet performed not well compared to fully convolution networks. Furthermore, the CTNet is insufficient to converge when the local blocks-enhanced are removed. In summary, the Transformer-based CTNet is beneficial to multi-scenario pavement cracks in terms of the global receptive field. The CTNet can get pavement crack detection results consistently.ConclusionThe proposed CTNet has its potentials to deal with noisy pavement images for pavement crack detection.关键词:road engineering;pavement crack detection;deep learning;semantic segmentation;self-attention;Transformer249|540|4更新时间:2024-05-07 -
 摘要:ObjectiveAnomaly detection has been developing in video surveillance domain. Video anomaly detection is focused on motions-irregular detection and extraction in relevant to long-distance rehabilitation motion analysis. But, it is challenged to obtain training samples that include all types of abnormal events. Therefore, existing anomaly detection methods in videos usually train a model on datasets, which contain normal samples only. In the testing phase, the events whose patterns are different from normal patterns are detected as abnormities. To represent the normal motion patterns in videos, early works are based on hand-crafted feature and concerned about low-level trajectory features. However, it is challenged to get effective trajectory features in complicated scenarios. Spatial-temporal features like the histogram of oriented flows (HOF) and the histogram of oriented gradients (HOG) are commonly used as representations of motion and content in anomaly detection. To model the motion and appearance patterns in anomaly detection, spatial-temporal features-based Markov random field (MRF), the mixture of probabilistic PCA (MPPCA), and the Gaussian mixture model are employed. Based on the assumption that normal patterns can be represented via linear combinations in dictionaries, sparse coding and dictionary learning can be used to encode normal patterns. Due to the insufficient descriptive power of hand-craft features, the robustness of these models is still poor in multiple scenarios. Currently, autoencoder-based deep learning methods are introduced in video anomaly detection. A 3D convolutional Auto-Encoder is designed to model normal patterns in regular frames. A convolutional long short term memory (LSTM) Auto-Encoder is developed to model normal appearance and motion patterns simultaneously in terms of the incorporation between convolutional neural network (CNN) and LSTM. To learn the sparse representation and dictionary of normal patterns, an adaptive iterative hard-thresholding algorithm is designed within an LSTM framework in according to the strong performance of sparse coding-based anomaly detection. Autoencoder-based prediction networks are introduced into anomaly detection in contrast to reconstruction-based models, which can detect anomalies through error computing between predicted frames and ground truth frames. Additionally, to process spatial-temporal information of different scales, a convolutional gate recurrent unit (ConvGRU) based multipath frame prediction network is demonstrated. Due to the blindness of self-supervised learning in anomaly detection, CNNs-based methods have their limitations in mining normal patterns. To improve the capability of feature expression, the vision transformer (ViT) model can used to extend the Transformer from natural language processing to the image domain. It can integrate CNN and Transformer to learn the global context information. Hence, we develop a Transformer and U-Net-based anomaly detection method as well.MethodIn this study, Transformer is embedded in a naive U-Net to learn local and global spatial-temporal information of normal events. First, an encoder is designed to extract spatial-temporal features from consecutive frames. To encode global information and learn the relevant information between feature pixels, final features of the encoder are fed into the Transformer. Then, a decoder is used to upsample the features of Transformer, and merges them with the low-level features of the encoder with the same resolution via skip connections. The whole network can combine the global spatial-temporal information with the local detail information. The size of the convolution kernel and deconvolution kernel is set to 3 × 3. The maximum pooling kernel size is 2 × 2. The encoder and decoder have four layers both. To make predicted frames close to their ground truth, we alleviate the intensity and gradient distances between predicted frames and their ground truth. To meet the requirements for anomaly detection of close-range rehabilitation movement, we collected an indoor motion dataset from published datasets based on hand movements for anomaly analysis because existing anomaly detection datasets are based on outdoor settings with long-distance attribution. For periodic hand movements, in addition to the traditional reconstruction loss, we introduce a dynamic image constraint to guide the network to focus on the periodic close-range motion area further.ResultWe compare the proposed approach to several anomaly detection methods on four outdoor public datasets and one indoor dataset. The improvements of the frame-level area under curve (AUC) performance on Avenue, Ped1, and Ped2 are 1.0%, 0.4%, and 1.1%, respectively. It can detect abnormal events on Ped1/Ped2 with the low-resolution attribute effectively. On the LV dataset, it achieves an AUC of 65.1%. Since the Transformer-based network can capture richer feature information in terms of the self-attention mechanism, the proposed network can mine various normal patterns in multiple scenes and improve detection performance effectively. On the collected indoor dataset, our performance of four actions, which are denoted as A1-1, A1-2, A1-3, and A1-4, reached 60.3%, 63.4%, 67.7%, and 64.4%, respectively. To verify the effectiveness of the Transformer module and dynamic image constraint, we conduct the ablation experiments in the training phase through removing the Transformer module and dynamic image constraint. Experimental results show that the Transformer module can improve the performance of anomaly detection. The performance of four actions of using the dynamic image constraint in the indoor dataset are improved by 0.6%, 2.4%, 1.1%, and 0.9%, respectively. It means the dynamic image loss can yield the network to pay attention to the foreground motion area.ConclusionWe develop a video anomaly detection method in relevant to Transformer and U-Net. A dataset of indoor motion is collected for the abnormal analysis of indoor close-up rehabilitation movement. Experimental results show that our method has its potentials to detect abnormal behaviors in indoor and outdoor videos effectively.关键词:anomaly detection;convolutional neural network(CNN);Transformer encoder;self-attention mechanism;self-supervised learning316|437|3更新时间:2024-05-07
摘要:ObjectiveAnomaly detection has been developing in video surveillance domain. Video anomaly detection is focused on motions-irregular detection and extraction in relevant to long-distance rehabilitation motion analysis. But, it is challenged to obtain training samples that include all types of abnormal events. Therefore, existing anomaly detection methods in videos usually train a model on datasets, which contain normal samples only. In the testing phase, the events whose patterns are different from normal patterns are detected as abnormities. To represent the normal motion patterns in videos, early works are based on hand-crafted feature and concerned about low-level trajectory features. However, it is challenged to get effective trajectory features in complicated scenarios. Spatial-temporal features like the histogram of oriented flows (HOF) and the histogram of oriented gradients (HOG) are commonly used as representations of motion and content in anomaly detection. To model the motion and appearance patterns in anomaly detection, spatial-temporal features-based Markov random field (MRF), the mixture of probabilistic PCA (MPPCA), and the Gaussian mixture model are employed. Based on the assumption that normal patterns can be represented via linear combinations in dictionaries, sparse coding and dictionary learning can be used to encode normal patterns. Due to the insufficient descriptive power of hand-craft features, the robustness of these models is still poor in multiple scenarios. Currently, autoencoder-based deep learning methods are introduced in video anomaly detection. A 3D convolutional Auto-Encoder is designed to model normal patterns in regular frames. A convolutional long short term memory (LSTM) Auto-Encoder is developed to model normal appearance and motion patterns simultaneously in terms of the incorporation between convolutional neural network (CNN) and LSTM. To learn the sparse representation and dictionary of normal patterns, an adaptive iterative hard-thresholding algorithm is designed within an LSTM framework in according to the strong performance of sparse coding-based anomaly detection. Autoencoder-based prediction networks are introduced into anomaly detection in contrast to reconstruction-based models, which can detect anomalies through error computing between predicted frames and ground truth frames. Additionally, to process spatial-temporal information of different scales, a convolutional gate recurrent unit (ConvGRU) based multipath frame prediction network is demonstrated. Due to the blindness of self-supervised learning in anomaly detection, CNNs-based methods have their limitations in mining normal patterns. To improve the capability of feature expression, the vision transformer (ViT) model can used to extend the Transformer from natural language processing to the image domain. It can integrate CNN and Transformer to learn the global context information. Hence, we develop a Transformer and U-Net-based anomaly detection method as well.MethodIn this study, Transformer is embedded in a naive U-Net to learn local and global spatial-temporal information of normal events. First, an encoder is designed to extract spatial-temporal features from consecutive frames. To encode global information and learn the relevant information between feature pixels, final features of the encoder are fed into the Transformer. Then, a decoder is used to upsample the features of Transformer, and merges them with the low-level features of the encoder with the same resolution via skip connections. The whole network can combine the global spatial-temporal information with the local detail information. The size of the convolution kernel and deconvolution kernel is set to 3 × 3. The maximum pooling kernel size is 2 × 2. The encoder and decoder have four layers both. To make predicted frames close to their ground truth, we alleviate the intensity and gradient distances between predicted frames and their ground truth. To meet the requirements for anomaly detection of close-range rehabilitation movement, we collected an indoor motion dataset from published datasets based on hand movements for anomaly analysis because existing anomaly detection datasets are based on outdoor settings with long-distance attribution. For periodic hand movements, in addition to the traditional reconstruction loss, we introduce a dynamic image constraint to guide the network to focus on the periodic close-range motion area further.ResultWe compare the proposed approach to several anomaly detection methods on four outdoor public datasets and one indoor dataset. The improvements of the frame-level area under curve (AUC) performance on Avenue, Ped1, and Ped2 are 1.0%, 0.4%, and 1.1%, respectively. It can detect abnormal events on Ped1/Ped2 with the low-resolution attribute effectively. On the LV dataset, it achieves an AUC of 65.1%. Since the Transformer-based network can capture richer feature information in terms of the self-attention mechanism, the proposed network can mine various normal patterns in multiple scenes and improve detection performance effectively. On the collected indoor dataset, our performance of four actions, which are denoted as A1-1, A1-2, A1-3, and A1-4, reached 60.3%, 63.4%, 67.7%, and 64.4%, respectively. To verify the effectiveness of the Transformer module and dynamic image constraint, we conduct the ablation experiments in the training phase through removing the Transformer module and dynamic image constraint. Experimental results show that the Transformer module can improve the performance of anomaly detection. The performance of four actions of using the dynamic image constraint in the indoor dataset are improved by 0.6%, 2.4%, 1.1%, and 0.9%, respectively. It means the dynamic image loss can yield the network to pay attention to the foreground motion area.ConclusionWe develop a video anomaly detection method in relevant to Transformer and U-Net. A dataset of indoor motion is collected for the abnormal analysis of indoor close-up rehabilitation movement. Experimental results show that our method has its potentials to detect abnormal behaviors in indoor and outdoor videos effectively.关键词:anomaly detection;convolutional neural network(CNN);Transformer encoder;self-attention mechanism;self-supervised learning316|437|3更新时间:2024-05-07 -
 摘要:ObjectiveHuman body motion-related recognition has been developing in the context of computer vision and pattern recognition like auxiliary human-computer interaction, motion analysis, intelligent monitoring, and virtual reality. To obtain two-dimensional information for its behavioral recognition, conventional motion behavior recognition is mainly used the RGB image sequence captured by RGB camera. To improve the ability to detect short-duration fragments, current feature descriptors for RGB image sequences are employed to characterize human behavior, such as histogram of oriented gradient (HOG), histogram of optical flow (HOF), and a three-dimensional feature pyramid. Some researchers are focused on the feature that image depth is insensitive to ambient light since RGB images are oriented to behavior image sequences of objects in terms of two-dimensional information. The depth information of the image is coordinated with the features of RGB image to describe the related behavior. Human behavior recognition-relevant multi-modal method can be used to fuse depth data and skeleton data, which can improve the recognition rate of action effectively. Recent depth map is widely used in relevant to human behavior recognition. But, the collection of depth information data is required to be optimized because of time complexity of feature extraction and space complexity of feature storage. To resolve the problems, we develop an algorithm to optimize frames of the depth map and resource consumption. At the same time, a new representation of motion features is facilitated as well according to the motion information of the centroid.MethodFirst, the temporal feature vector is used in terms of depth map sequence-extracted time sequence information. The centroid motion path relaxation algorithm is used to realize depth image de-duplication and de redundancy, and the skeleton map-extracted spatial structure feature vector from are spliced to form the spatio-temporal feature input. Next, spatial features are extracted in terms of the original skeleton points coordinates-spliced three-channel spatial feature map. Finally, the fusion probability of spatio-temporal features and spatial features is used for classification and recognition. Our centroid motion path relaxation algorithm is focused on the optimization of redundant information, the time complexity of feature extraction, and the space complexity of feature storage. For the skeleton data, the global feature of motion direction is proposed to fully reflect the integrity and coordination of limb movements. The extracted features are concatenated to obtain the spatio-temporal feature vector, and they can be fused and enhanced through the original coordinates of skeleton points-built three-channel spatial feature map. Its effectiveness is verified on the MSR-Action3D dataset.ResultThe experimental setting 1 demonstrate that it is 0.826 0% higher than the depth motion map(DMM)-local binary pattern (LBP) algorithm, 1.015 2% higher than DMM-CRC (collaborative representation classifier), 3.450 1% higher than gradient local auto correlation (DMM-GLAC) algorithm, 0.605 8% higher than EigenJoint algorithm, and 0.605 8% higher than space-time auto correlation of gradient (STACOG) algorithm is 10.624 5% higher. After removing redundancy, the result of experimental setting 1 is 0.126 1% higher as well. The cross-validation on experimental setting 2 show that the average classification and recognition rate in the three subsets is 95.743 2%, 2.443 2% higher than multi-fused method, 4.763 2% higher than CovP3DJ method, 0.343 2% higher than D3D-LSTM method, and 0.213 2% higher than joint subset selection method. For the overall data set, it is 2.030 3% higher than low latency method, 0.240 3% higher than combination of deep models method, and 2.340 3% higher than complex network coding method. The experimental setting 2 illustrates that the average classification recognition rate of cross-validation in three subsets is 95.743 2%, and the classification recognition rate of the complete dataset is 93.040 3%.ConclusionOur algorithm proposed can improve the recognition effect based on redundancy-optimized, and the features-extracted have lower correlation mutually, which can improve the accuracy of classification recognition effectively.关键词:action recognition;centroid motion;key temporal information;spatio-temporal feature representation;multimodal fusion186|460|4更新时间:2024-05-07
摘要:ObjectiveHuman body motion-related recognition has been developing in the context of computer vision and pattern recognition like auxiliary human-computer interaction, motion analysis, intelligent monitoring, and virtual reality. To obtain two-dimensional information for its behavioral recognition, conventional motion behavior recognition is mainly used the RGB image sequence captured by RGB camera. To improve the ability to detect short-duration fragments, current feature descriptors for RGB image sequences are employed to characterize human behavior, such as histogram of oriented gradient (HOG), histogram of optical flow (HOF), and a three-dimensional feature pyramid. Some researchers are focused on the feature that image depth is insensitive to ambient light since RGB images are oriented to behavior image sequences of objects in terms of two-dimensional information. The depth information of the image is coordinated with the features of RGB image to describe the related behavior. Human behavior recognition-relevant multi-modal method can be used to fuse depth data and skeleton data, which can improve the recognition rate of action effectively. Recent depth map is widely used in relevant to human behavior recognition. But, the collection of depth information data is required to be optimized because of time complexity of feature extraction and space complexity of feature storage. To resolve the problems, we develop an algorithm to optimize frames of the depth map and resource consumption. At the same time, a new representation of motion features is facilitated as well according to the motion information of the centroid.MethodFirst, the temporal feature vector is used in terms of depth map sequence-extracted time sequence information. The centroid motion path relaxation algorithm is used to realize depth image de-duplication and de redundancy, and the skeleton map-extracted spatial structure feature vector from are spliced to form the spatio-temporal feature input. Next, spatial features are extracted in terms of the original skeleton points coordinates-spliced three-channel spatial feature map. Finally, the fusion probability of spatio-temporal features and spatial features is used for classification and recognition. Our centroid motion path relaxation algorithm is focused on the optimization of redundant information, the time complexity of feature extraction, and the space complexity of feature storage. For the skeleton data, the global feature of motion direction is proposed to fully reflect the integrity and coordination of limb movements. The extracted features are concatenated to obtain the spatio-temporal feature vector, and they can be fused and enhanced through the original coordinates of skeleton points-built three-channel spatial feature map. Its effectiveness is verified on the MSR-Action3D dataset.ResultThe experimental setting 1 demonstrate that it is 0.826 0% higher than the depth motion map(DMM)-local binary pattern (LBP) algorithm, 1.015 2% higher than DMM-CRC (collaborative representation classifier), 3.450 1% higher than gradient local auto correlation (DMM-GLAC) algorithm, 0.605 8% higher than EigenJoint algorithm, and 0.605 8% higher than space-time auto correlation of gradient (STACOG) algorithm is 10.624 5% higher. After removing redundancy, the result of experimental setting 1 is 0.126 1% higher as well. The cross-validation on experimental setting 2 show that the average classification and recognition rate in the three subsets is 95.743 2%, 2.443 2% higher than multi-fused method, 4.763 2% higher than CovP3DJ method, 0.343 2% higher than D3D-LSTM method, and 0.213 2% higher than joint subset selection method. For the overall data set, it is 2.030 3% higher than low latency method, 0.240 3% higher than combination of deep models method, and 2.340 3% higher than complex network coding method. The experimental setting 2 illustrates that the average classification recognition rate of cross-validation in three subsets is 95.743 2%, and the classification recognition rate of the complete dataset is 93.040 3%.ConclusionOur algorithm proposed can improve the recognition effect based on redundancy-optimized, and the features-extracted have lower correlation mutually, which can improve the accuracy of classification recognition effectively.关键词:action recognition;centroid motion;key temporal information;spatio-temporal feature representation;multimodal fusion186|460|4更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveThe emerging deep learning technique has facilitated such artificial intelligence (AI)-related domains like image classification, natural language processing, speech recognition, and reinforcement learning. However, it is being challenged for the over-fitting problem of the models. Effective data is required to be obtained from mass, especially in the tasks of image classification. To tackle this problem, the concept of few-shot learning is developed, which aims at well-generalized knowledge learned from a large-scale dataset to handle downstream classification tasks with little training samples. Currently, most popular methods for few-shot image classification are based on meta-learning, which can be learnt to deal with few-shot tasks via similar classification tasks. The process of meta-learning is divided into two steps: 1) meta training, and 2) meta testing. For the meta training, an embedding network is trained by the meta-training set, and it is used to tackle a few training data-constructed downstream classification tasks from the meta-testing set. There is no intersection between meta-training set and meta-testing set, which means that no reliable prior knowledge is obtained by meta-learner in the meta-training process. Due to category differences between meta-training and meta-testing, some new challenges to meta-learning models are required to be resolved. If it focuses on training tasks only, the effectiveness of models will be affected when the meta-learner meets with the few-shot tasks with brand-new categories. To tackle this challenge with metric-based methods, we develop a multi-layer adaptive aggregation self-supervised few-shot classification model.MethodFirst, to reduce the parameters of the backbone and lower the training difficulty, a group of convolution blocks are used to replace the original convolution. Next, to improve the backbone, the multi-layer adaptive aggregation module is illustrated, which can refine the information of each network layer dynamically and balance the weights of each layer adaptively via the aggregated feature maps of those are the basis for subsequent downstream few-shot classification. Finally, to enhance the transferability of the learned model, the self-supervised contrastive learning is introduced to assist supervised learning to mine the potential information of the data themselves. It does not suffer from over-fitting because contrastive learning is not required to be supervised. It can be as an additional source of regularization as well, which is beneficial for the construction of feature space. The embedding networks can be paid more attention to learn the well-generalized knowledge in terms of the proposed self-supervised contrastive learning method, which makes the distribution of embedding feature maps smoother and the classification model is more suitable for the domain of downstream tasks.ResultTo validate the effectiveness of the proposed model, comparative analysis is carried out with some popular models, including 1) prototype network, 2) relation network, 3) cosine classifier, as well as the 4) mini-ImageNet dataset and 5) Caltech-UCSD birds-200-2011(CUB) dataset. For the mini-ImageNet dataset, each accuracy of the proposed model can be reached to 63.13% on 5-way 1-shot and 78.14% on 5-way 5-shot, it can be optimized by 13.71% and 9.94% each for the original Prototype network. For the fine-grained CUB dataset, the accuracies of the proposed model can be reached to 75.93% on 5-way 1-shot and 87.56% on 5-way 5-shot, which are 24.48% and 13.05% higher than the original Prototype network of each. Compared to the baseline on 5-way 1-shot and 5-way 5-shot, each of model accuracy is increased by 6.31%, 6.04% on mini-ImageNet, and they are increased by 8.95%, 8.77% of each as well on CUB. The comparative experiments demonstrate that the parameters of our backbone are optimized in comparison with the parameters of 5 backbones on Prototype network. A couple of ablation experiments are also conducted to verify the proposed model. Additionally, the heat maps-related contrastive experiment between baseline and the proposed model verifies that our model can prevent the embedding network from more background information of images and alleviate the interference of downstream classification tasks. Furthermore, the t-SNE method is used for visualization to sort the distribution of samples out in the feature space. The obtained feature distribution of t-SNE visualization experiment on CUB dataset can demonstrate that our model is capable of differentiating samples well from different categories, which can make the meta-testing set linearly separable.ConclusionTo resolve some problems in the field of few-shot learning, we develop a multi-layer adaptive aggregation self-supervised few-shot classification model. To alleviate the problem of training difficulty, the improved group convolution can be used to reduce the parameters of backbone. To optimize over-fitting and domain gap, the multi-layer adaptive aggregation method and the self-supervised contrastive learning method are used to adjust the distribution of embedding feature maps. In particular, the embedding networks are not be affected by the background-redundant of images based on our self-supervised contrastive learning method.关键词:few-shot learning;image classification;adaptive aggregation;self-supervised learning;contrastive learning197|339|2更新时间:2024-05-07
摘要:ObjectiveThe emerging deep learning technique has facilitated such artificial intelligence (AI)-related domains like image classification, natural language processing, speech recognition, and reinforcement learning. However, it is being challenged for the over-fitting problem of the models. Effective data is required to be obtained from mass, especially in the tasks of image classification. To tackle this problem, the concept of few-shot learning is developed, which aims at well-generalized knowledge learned from a large-scale dataset to handle downstream classification tasks with little training samples. Currently, most popular methods for few-shot image classification are based on meta-learning, which can be learnt to deal with few-shot tasks via similar classification tasks. The process of meta-learning is divided into two steps: 1) meta training, and 2) meta testing. For the meta training, an embedding network is trained by the meta-training set, and it is used to tackle a few training data-constructed downstream classification tasks from the meta-testing set. There is no intersection between meta-training set and meta-testing set, which means that no reliable prior knowledge is obtained by meta-learner in the meta-training process. Due to category differences between meta-training and meta-testing, some new challenges to meta-learning models are required to be resolved. If it focuses on training tasks only, the effectiveness of models will be affected when the meta-learner meets with the few-shot tasks with brand-new categories. To tackle this challenge with metric-based methods, we develop a multi-layer adaptive aggregation self-supervised few-shot classification model.MethodFirst, to reduce the parameters of the backbone and lower the training difficulty, a group of convolution blocks are used to replace the original convolution. Next, to improve the backbone, the multi-layer adaptive aggregation module is illustrated, which can refine the information of each network layer dynamically and balance the weights of each layer adaptively via the aggregated feature maps of those are the basis for subsequent downstream few-shot classification. Finally, to enhance the transferability of the learned model, the self-supervised contrastive learning is introduced to assist supervised learning to mine the potential information of the data themselves. It does not suffer from over-fitting because contrastive learning is not required to be supervised. It can be as an additional source of regularization as well, which is beneficial for the construction of feature space. The embedding networks can be paid more attention to learn the well-generalized knowledge in terms of the proposed self-supervised contrastive learning method, which makes the distribution of embedding feature maps smoother and the classification model is more suitable for the domain of downstream tasks.ResultTo validate the effectiveness of the proposed model, comparative analysis is carried out with some popular models, including 1) prototype network, 2) relation network, 3) cosine classifier, as well as the 4) mini-ImageNet dataset and 5) Caltech-UCSD birds-200-2011(CUB) dataset. For the mini-ImageNet dataset, each accuracy of the proposed model can be reached to 63.13% on 5-way 1-shot and 78.14% on 5-way 5-shot, it can be optimized by 13.71% and 9.94% each for the original Prototype network. For the fine-grained CUB dataset, the accuracies of the proposed model can be reached to 75.93% on 5-way 1-shot and 87.56% on 5-way 5-shot, which are 24.48% and 13.05% higher than the original Prototype network of each. Compared to the baseline on 5-way 1-shot and 5-way 5-shot, each of model accuracy is increased by 6.31%, 6.04% on mini-ImageNet, and they are increased by 8.95%, 8.77% of each as well on CUB. The comparative experiments demonstrate that the parameters of our backbone are optimized in comparison with the parameters of 5 backbones on Prototype network. A couple of ablation experiments are also conducted to verify the proposed model. Additionally, the heat maps-related contrastive experiment between baseline and the proposed model verifies that our model can prevent the embedding network from more background information of images and alleviate the interference of downstream classification tasks. Furthermore, the t-SNE method is used for visualization to sort the distribution of samples out in the feature space. The obtained feature distribution of t-SNE visualization experiment on CUB dataset can demonstrate that our model is capable of differentiating samples well from different categories, which can make the meta-testing set linearly separable.ConclusionTo resolve some problems in the field of few-shot learning, we develop a multi-layer adaptive aggregation self-supervised few-shot classification model. To alleviate the problem of training difficulty, the improved group convolution can be used to reduce the parameters of backbone. To optimize over-fitting and domain gap, the multi-layer adaptive aggregation method and the self-supervised contrastive learning method are used to adjust the distribution of embedding feature maps. In particular, the embedding networks are not be affected by the background-redundant of images based on our self-supervised contrastive learning method.关键词:few-shot learning;image classification;adaptive aggregation;self-supervised learning;contrastive learning197|339|2更新时间:2024-05-07 -
 摘要:ObjectiveClustering is focused on machine learning-related data segmentation for multiple datasets. Its applications are in relevant to such domains like image segmentation and anomaly detection. In addition, to simplify complex tasks optimize its performance, clustering is used in data preprocessing tasks of those are data sub-blocks segmentation, pseudo-labels generation, and abnormal points-removal. Self-supervised learning has become an essential technique for massive data analysis. However, it is challenged to extract effective supervision information and analyze the input data.MethodA consensus graph learning based self-supervised ensemble clustering (CGL-SEC) framework is developed. It consists of three main modules: 1) to construct the consensus graph based on several ensemble components (i.e., the basic clustering methods). 2) to extract the supervision information by learning the consensus graph representation, and 3) its node clustering results, where the subset of nodes with the high-confidence are selected as labeled samples. To optimize the ensemble components and the corresponding consensus graph, t basic clustering methods are re-trained in related the option of samples-labeled and other samples-unlabeled. The final clustering results can be optimized iteratively until the learning process converges.ResultA series of experiments are carried out on benchmarks, including both image and textual datasets. Especially, CGL-SEC is 3.85% over baseline in terms of clustering evaluation metric on themodified national institute of standards and technology database(MNIST-Test). First, to optimize data representation and cluster assignment at the same time, deep embedding clustering can be focused on data itself as the supervision information and auto-encoder with the reconstruction loss is pre-trained. The soft cluster assignment of features-embedded is then calculated, and the KL(Kullback-Leibler) divergence is minimized between the soft cluster assignment and the auxiliary target distribution. To improve the performance of the model further, following deep clustering network (DCN) can use hard clustering instead of soft allocation, and local constraints are applied by improved deep embedding clustering (IDEC). The pseudo-label strategy is implemented as a self-supervised learning method that uses the prediction results of the neural network as the label to simulate the supervision information compared to using data itself as the supervision information. Deep-cluster-based K-means clustering is used to generate pseudo-labels to guide the training of convolutional networks. However, the generated pseudo-labels have lower confidence and are prone to trivial solutions in the initial stage of network training. Deep embedding clustering with data augmentation (DEC-DA) and MixMatch-based prediction of data-enhanced samples are used as the supervision information of the original data, which improves the accuracy of the supervision information to a certain extent, but this method is difficult to extend to text and other fields. Deep adaptive clustering-based high-confidence pseudo-label subsets-selected are iteratively trained the network in the prediction results, but low-confidence samples-involved data distribution information is ignored. Pseudo-semi-supervised clustering votes are used to select a subset of high-confidence pseudo-labels, and all samples are used to train semi-supervised neural network. Although the ensemble strategy can improve the confidence of the pseudo-label, the voting strategy is concerned of category representation only without the feature representation of the sample itself, which can reduce the clustering performance in some cases. The ensemble learning is regarded as a representative machine learning method that reflects the ability of "group intelligence", whereas a learning method can improve the overall prediction performance via multiple base learners training and their coordinated prediction results. In pseudo-label-based clustering tasks, it can coordinate multiple base learners to obtain high-confidence pseudo-labels. However, the effectiveness of the supervision information acquisition is still to be resolved. The category information of the sample is considered for current pseudo-label-based ensemble clustering method only when the label is captured and some effective information are ignored like the feature representation of the sample itself and the clustering structure between samples.ConclusionGraph neural network is composed of content information of nodes and the structural information between nodes at the same time. To design a self-supervised ensemble clustering method based on consensus graph representation learning, it is required to make full use of sample features and relationships between samples in ensemble learning. To obtain higher confidence pseudo-labels as supervised information and improve the performance of self-supervised clustering, it is necessary to mine global and local information at the same time. We illustrate a learnable data ensemble representation through graph neural network. The confidence of pseudo-labels is improved, and the entire model is trained in self-supervision iteratively. To be summarized: 1) Commonly-used consensus graph learning-integrated clustering framework is developed, which can use multi-level information like clustering-integrated sample characteristics and category structure. 2) Self-supervision method is proposed, which uses graph neural network to mine the global and local information of the consensus graph, and high-confidence pseudo-labels are obtained as supervised information. 3) Experiments are demonstrated that the consensus graph learning ensemble clustering method has its potentials on image and text datasets.关键词:ensemble clustering;self-supervised clustering;graph representation learning;consensus graph;pseudo-label confidence126|141|0更新时间:2024-05-07
摘要:ObjectiveClustering is focused on machine learning-related data segmentation for multiple datasets. Its applications are in relevant to such domains like image segmentation and anomaly detection. In addition, to simplify complex tasks optimize its performance, clustering is used in data preprocessing tasks of those are data sub-blocks segmentation, pseudo-labels generation, and abnormal points-removal. Self-supervised learning has become an essential technique for massive data analysis. However, it is challenged to extract effective supervision information and analyze the input data.MethodA consensus graph learning based self-supervised ensemble clustering (CGL-SEC) framework is developed. It consists of three main modules: 1) to construct the consensus graph based on several ensemble components (i.e., the basic clustering methods). 2) to extract the supervision information by learning the consensus graph representation, and 3) its node clustering results, where the subset of nodes with the high-confidence are selected as labeled samples. To optimize the ensemble components and the corresponding consensus graph, t basic clustering methods are re-trained in related the option of samples-labeled and other samples-unlabeled. The final clustering results can be optimized iteratively until the learning process converges.ResultA series of experiments are carried out on benchmarks, including both image and textual datasets. Especially, CGL-SEC is 3.85% over baseline in terms of clustering evaluation metric on themodified national institute of standards and technology database(MNIST-Test). First, to optimize data representation and cluster assignment at the same time, deep embedding clustering can be focused on data itself as the supervision information and auto-encoder with the reconstruction loss is pre-trained. The soft cluster assignment of features-embedded is then calculated, and the KL(Kullback-Leibler) divergence is minimized between the soft cluster assignment and the auxiliary target distribution. To improve the performance of the model further, following deep clustering network (DCN) can use hard clustering instead of soft allocation, and local constraints are applied by improved deep embedding clustering (IDEC). The pseudo-label strategy is implemented as a self-supervised learning method that uses the prediction results of the neural network as the label to simulate the supervision information compared to using data itself as the supervision information. Deep-cluster-based K-means clustering is used to generate pseudo-labels to guide the training of convolutional networks. However, the generated pseudo-labels have lower confidence and are prone to trivial solutions in the initial stage of network training. Deep embedding clustering with data augmentation (DEC-DA) and MixMatch-based prediction of data-enhanced samples are used as the supervision information of the original data, which improves the accuracy of the supervision information to a certain extent, but this method is difficult to extend to text and other fields. Deep adaptive clustering-based high-confidence pseudo-label subsets-selected are iteratively trained the network in the prediction results, but low-confidence samples-involved data distribution information is ignored. Pseudo-semi-supervised clustering votes are used to select a subset of high-confidence pseudo-labels, and all samples are used to train semi-supervised neural network. Although the ensemble strategy can improve the confidence of the pseudo-label, the voting strategy is concerned of category representation only without the feature representation of the sample itself, which can reduce the clustering performance in some cases. The ensemble learning is regarded as a representative machine learning method that reflects the ability of "group intelligence", whereas a learning method can improve the overall prediction performance via multiple base learners training and their coordinated prediction results. In pseudo-label-based clustering tasks, it can coordinate multiple base learners to obtain high-confidence pseudo-labels. However, the effectiveness of the supervision information acquisition is still to be resolved. The category information of the sample is considered for current pseudo-label-based ensemble clustering method only when the label is captured and some effective information are ignored like the feature representation of the sample itself and the clustering structure between samples.ConclusionGraph neural network is composed of content information of nodes and the structural information between nodes at the same time. To design a self-supervised ensemble clustering method based on consensus graph representation learning, it is required to make full use of sample features and relationships between samples in ensemble learning. To obtain higher confidence pseudo-labels as supervised information and improve the performance of self-supervised clustering, it is necessary to mine global and local information at the same time. We illustrate a learnable data ensemble representation through graph neural network. The confidence of pseudo-labels is improved, and the entire model is trained in self-supervision iteratively. To be summarized: 1) Commonly-used consensus graph learning-integrated clustering framework is developed, which can use multi-level information like clustering-integrated sample characteristics and category structure. 2) Self-supervision method is proposed, which uses graph neural network to mine the global and local information of the consensus graph, and high-confidence pseudo-labels are obtained as supervised information. 3) Experiments are demonstrated that the consensus graph learning ensemble clustering method has its potentials on image and text datasets.关键词:ensemble clustering;self-supervised clustering;graph representation learning;consensus graph;pseudo-label confidence126|141|0更新时间:2024-05-07 -
 摘要:ObjectiveBinocular images-interrelated information fusion method has been developing intensively in terms of deep convolutional neural networks (DNNs) based binocular stereo image super-resolution tasks. However, current stereo image super-resolution algorithms are challenged for internal information learning of a single image. To resolve this problem, we develop a multi-level fusion attention network-relevant binocular image super-resolution reconstruction algorithm, which can learn stereo matching-related richer information-inner of the image.MethodOur network is demonstrated and composed of multiple modules in the context of 1) feature extraction, 2) mixed attention, 3) multi-level fusion, and 4) reconstruction. The feature extraction module consists of 1) convolutional layer, 2) residual unit, and 3) residual-intensive atrous space pyramid pooling module. Specifically, a convolutional layer is used to extract the shallow features of the low-resolution image, and the residual unit and the residual-intensive spatial pyramid pooling module is used to process the shallow features alternately. To form a spatial pyramid pooling group, the residual-intensive atrous space pyramid pooling module is interconnected of three hollow convolutions with expansion rates of 1, 4, and 8 in parallel. First, three spatial pyramid pooling groups of the same structure are cascaded, and the output features and input features of each group are transmitted back sequentially to the next group in terms of a densely connected manner. Then, to perform feature fusion and channel reduction, a convolution layer is utilized at the end of each spatial pyramid pooling group. At the end of the module, a dense feature fusion and global residual connection are performed and the output features of each spatial pyramid pooling group are fused together, and linear-superimposed is followed with the input features of the module. The mixed attention module is mainly organized of 1) the second-order channel non-local attention module, and 2) the parallax attention module. The second-order channel and non-local attention modules are divided into 1) second-order channels and spatial attention modules, and 2) high-efficiency non-local modules. To optimize effective information, the second-order channel and spatial attention module can be used to extract useful information of features in channel and spatial dimensions. The input features are transmitted in the channel and spatial dimensions at the same time, where the channel dimension first performs global covariance pooling on it, and the convolution is then used to increase and decrease the dimensionality of the channels to obtain the correlation between the channels, which is regarded as the channel attention map. Finally, the input features are adjusted using the channel attention map. In the spatial dimension, the module first performs global average pooling and global maximum pooling on the input feature map at the same time, and cascade the generated feature maps, the convolution and sigmoid function is then used to obtain the spatial attention map, and the spatial attention map is used to compare the input features make adjustments at the end. The high-efficiency non-local module uses non-local operation to learn the global correlation of features to expand the receptive field and capture contextual information. The parallax attention module first uses the convolutional layer and the residual unit to process the left and right feature maps, and the parallax attention mechanism is then used to capture the stereo correlation between the left and right images for stereo matching. The multi-level fusion module takes the dense residual block as the basic block, and the attention mechanism is then used to explore the interlinks between different depth features, assign different attention weights to different depth features, and improve the characterization ability of features. To obtain the reconstructed feature, sub-pixel convolution is used to up-sample the feature map and it is added to the enlarged feature of the low-resolution left image as well. Finally, a layer of convolution is used to obtain the reconstructed high-resolution image.ResultOur algorithm is developed and organized by 800 images of the Flickr1024 dataset and twice-downsampled 60 Middlebury images as the training set. Our research is focused on the bicubic interpolation down-samples the high-resolution images to generate low-resolution images, and a sum of 20 steps is used to crop these low-resolution images into image blocks, and the high-resolution images are also cropped after that. As the benchmark dataset, the test set is based on 5 images from the Middlebury dataset, 20 images from the KITTI2012 dataset, and 20 images from the KITTI2015 dataset. To evaluate the reconstruction effect of the model quantitatively and compare it to other methods, peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are used as evaluation indicators. We compare the results of the algorithm model to some single-image super-resolution methods, and the latest stereo image super-resolution methods like StereoSR, PASSRnet, SRResNet + SAM, SRResNet + DFAM, CVCnet on three benchmark test sets in terms of the scale and conditions. The KITTI2012 test set is as an example when the scale × 2, the PSNR and SSIM are 0.17 dB and 0.002 higher than the CVCnet network of each.ConclusionOur model is demonstrated and focused on fully learning for richer effective information, and it can guide the stereo matching of the left and right feature maps effectively. Furthermore, the fusion of high and low frequency information is in consistent, and a good reconstruction effect is achieved. Our algorithm model is still challenged to optimize richer information in a single image and the complementary information between the left and right images. The future research direction can be predicted that a single image feature extraction module is required to be designed and get a left and right image feature fusion module further.关键词:convolutional neural network(CNN);stereo image super-resolution;attention mechanism;stereo matching;information fusion137|287|3更新时间:2024-05-07
摘要:ObjectiveBinocular images-interrelated information fusion method has been developing intensively in terms of deep convolutional neural networks (DNNs) based binocular stereo image super-resolution tasks. However, current stereo image super-resolution algorithms are challenged for internal information learning of a single image. To resolve this problem, we develop a multi-level fusion attention network-relevant binocular image super-resolution reconstruction algorithm, which can learn stereo matching-related richer information-inner of the image.MethodOur network is demonstrated and composed of multiple modules in the context of 1) feature extraction, 2) mixed attention, 3) multi-level fusion, and 4) reconstruction. The feature extraction module consists of 1) convolutional layer, 2) residual unit, and 3) residual-intensive atrous space pyramid pooling module. Specifically, a convolutional layer is used to extract the shallow features of the low-resolution image, and the residual unit and the residual-intensive spatial pyramid pooling module is used to process the shallow features alternately. To form a spatial pyramid pooling group, the residual-intensive atrous space pyramid pooling module is interconnected of three hollow convolutions with expansion rates of 1, 4, and 8 in parallel. First, three spatial pyramid pooling groups of the same structure are cascaded, and the output features and input features of each group are transmitted back sequentially to the next group in terms of a densely connected manner. Then, to perform feature fusion and channel reduction, a convolution layer is utilized at the end of each spatial pyramid pooling group. At the end of the module, a dense feature fusion and global residual connection are performed and the output features of each spatial pyramid pooling group are fused together, and linear-superimposed is followed with the input features of the module. The mixed attention module is mainly organized of 1) the second-order channel non-local attention module, and 2) the parallax attention module. The second-order channel and non-local attention modules are divided into 1) second-order channels and spatial attention modules, and 2) high-efficiency non-local modules. To optimize effective information, the second-order channel and spatial attention module can be used to extract useful information of features in channel and spatial dimensions. The input features are transmitted in the channel and spatial dimensions at the same time, where the channel dimension first performs global covariance pooling on it, and the convolution is then used to increase and decrease the dimensionality of the channels to obtain the correlation between the channels, which is regarded as the channel attention map. Finally, the input features are adjusted using the channel attention map. In the spatial dimension, the module first performs global average pooling and global maximum pooling on the input feature map at the same time, and cascade the generated feature maps, the convolution and sigmoid function is then used to obtain the spatial attention map, and the spatial attention map is used to compare the input features make adjustments at the end. The high-efficiency non-local module uses non-local operation to learn the global correlation of features to expand the receptive field and capture contextual information. The parallax attention module first uses the convolutional layer and the residual unit to process the left and right feature maps, and the parallax attention mechanism is then used to capture the stereo correlation between the left and right images for stereo matching. The multi-level fusion module takes the dense residual block as the basic block, and the attention mechanism is then used to explore the interlinks between different depth features, assign different attention weights to different depth features, and improve the characterization ability of features. To obtain the reconstructed feature, sub-pixel convolution is used to up-sample the feature map and it is added to the enlarged feature of the low-resolution left image as well. Finally, a layer of convolution is used to obtain the reconstructed high-resolution image.ResultOur algorithm is developed and organized by 800 images of the Flickr1024 dataset and twice-downsampled 60 Middlebury images as the training set. Our research is focused on the bicubic interpolation down-samples the high-resolution images to generate low-resolution images, and a sum of 20 steps is used to crop these low-resolution images into image blocks, and the high-resolution images are also cropped after that. As the benchmark dataset, the test set is based on 5 images from the Middlebury dataset, 20 images from the KITTI2012 dataset, and 20 images from the KITTI2015 dataset. To evaluate the reconstruction effect of the model quantitatively and compare it to other methods, peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are used as evaluation indicators. We compare the results of the algorithm model to some single-image super-resolution methods, and the latest stereo image super-resolution methods like StereoSR, PASSRnet, SRResNet + SAM, SRResNet + DFAM, CVCnet on three benchmark test sets in terms of the scale and conditions. The KITTI2012 test set is as an example when the scale × 2, the PSNR and SSIM are 0.17 dB and 0.002 higher than the CVCnet network of each.ConclusionOur model is demonstrated and focused on fully learning for richer effective information, and it can guide the stereo matching of the left and right feature maps effectively. Furthermore, the fusion of high and low frequency information is in consistent, and a good reconstruction effect is achieved. Our algorithm model is still challenged to optimize richer information in a single image and the complementary information between the left and right images. The future research direction can be predicted that a single image feature extraction module is required to be designed and get a left and right image feature fusion module further.关键词:convolutional neural network(CNN);stereo image super-resolution;attention mechanism;stereo matching;information fusion137|287|3更新时间:2024-05-07 -
 摘要:ObjectiveThe 3D meshes are concerned of spatial information-demonstrated surface triangles, which can optimize surface information than other related representations like voxel or point cloud. The 3D shape analysis is still to be resolved in relevant to mesh representation on two aspects: 1) the irregular data structure of the mesh model is challenged for feature extraction using traditional 2D convolutional networks, and 2) the 3D rotation transformation is challenged for object recognition as well. The emerging convolutional neural networks (CNNs) have been developing dramatically in the context of 2D vision like classification, segmentation, detection, as well as 3D objects-oriented applications. Current CNN-based 3D mesh classification is developed from two aspects: 1) the 3D object is transferred to 2D images and the following 2D-based CNN methods are used, and 2) convolution methods are designed on 3D mesh data. However, it is still challenged to recognize rotated objects due to traditional CNN-equivariant-lacked pooling operation. The lack of rotation equivariance can be improved on the basis of two networks which are vectorized and equivariant networks. The vectorized network, known as capsule network, has shown its potentials in learning spatial transformation on 2D images, but convolution-constrained method is required to be applied on 3D mesh further. To apply the vectorized neural network to 3D mesh data and preserve rotation equivariance, we develop a vectorized spherical neural network-derived method for 3D mesh classification.MethodOur method can be segmented into three categories as mentioned below: First, the 3D mesh model is preprocessed to signals on the sphere. We normalize the 3D mesh into a unit sphere and get the spherical signals on the unit sphere using the ray casting scheme. The obtained spherical signals are nearly equivalent 3D shape representations and can be further processed by spherical convolution methods. The aims of processing 3D mesh to spherical signals are 1) to utilize the spherical signals-defined equivariant spherical convolution operators, and 2) to design vectorized neurons in a coordinated manner. Second, the autoencoder-structured model is used to learn the feature of the spherical signal. The model is composed of two sub-networks: i) a vectorized spherical convolutional neural network (VSCNN) to encode the equivariant feature and classify the 3D object, and ii) a multilayer perceptron decoder to decode the extracted feature back to sphere signal. The VSCNN is based on two kinds of spherical residual convolution block and the vector convolution layer. To train deeper networks and resist overfitting, we develop two spherical convolution modules which are
摘要:ObjectiveThe 3D meshes are concerned of spatial information-demonstrated surface triangles, which can optimize surface information than other related representations like voxel or point cloud. The 3D shape analysis is still to be resolved in relevant to mesh representation on two aspects: 1) the irregular data structure of the mesh model is challenged for feature extraction using traditional 2D convolutional networks, and 2) the 3D rotation transformation is challenged for object recognition as well. The emerging convolutional neural networks (CNNs) have been developing dramatically in the context of 2D vision like classification, segmentation, detection, as well as 3D objects-oriented applications. Current CNN-based 3D mesh classification is developed from two aspects: 1) the 3D object is transferred to 2D images and the following 2D-based CNN methods are used, and 2) convolution methods are designed on 3D mesh data. However, it is still challenged to recognize rotated objects due to traditional CNN-equivariant-lacked pooling operation. The lack of rotation equivariance can be improved on the basis of two networks which are vectorized and equivariant networks. The vectorized network, known as capsule network, has shown its potentials in learning spatial transformation on 2D images, but convolution-constrained method is required to be applied on 3D mesh further. To apply the vectorized neural network to 3D mesh data and preserve rotation equivariance, we develop a vectorized spherical neural network-derived method for 3D mesh classification.MethodOur method can be segmented into three categories as mentioned below: First, the 3D mesh model is preprocessed to signals on the sphere. We normalize the 3D mesh into a unit sphere and get the spherical signals on the unit sphere using the ray casting scheme. The obtained spherical signals are nearly equivalent 3D shape representations and can be further processed by spherical convolution methods. The aims of processing 3D mesh to spherical signals are 1) to utilize the spherical signals-defined equivariant spherical convolution operators, and 2) to design vectorized neurons in a coordinated manner. Second, the autoencoder-structured model is used to learn the feature of the spherical signal. The model is composed of two sub-networks: i) a vectorized spherical convolutional neural network (VSCNN) to encode the equivariant feature and classify the 3D object, and ii) a multilayer perceptron decoder to decode the extracted feature back to sphere signal. The VSCNN is based on two kinds of spherical residual convolution block and the vector convolution layer. To train deeper networks and resist overfitting, we develop two spherical convolution modules which are -
 摘要:ObjectiveFashion clothing matching has been developing for clothing-relevant fashion research nowadays. Fashion clothing matching studies are required to learn the complex matching relationship (i.e., fashion compatibility) among different fashion items in an representation-based outfit. Fashion items have rich partial designs and matching relationships among partial designs. To analyze their global compatibility learning, most of the existing researches are concerned of items’ global features (visual and textual features). But, local feature extraction is often ignored for local compatibility, which causes lower performance and accuracy of fashion style matching. Therefore, we develop a fashion style matching method in terms of global-local feature optimization and it is aimed to extract the local features of fashion images for local information representing, construct the local compatibility of fashion items, and improve the global and local compatibility-incorporated accuracy of fashion style matching.MethodFirst, we use two different convolutional neural networks (CNNs) to extract the global features of fashion items separately on the basis of the input fashion images and texts. To extract CNN-based local features of fashion images, a multiple branches-related local feature extraction network is designed. A branch of the local feature extraction network is composed of 1) a convolution layer, 2) a batch normalization (BN) layer, and 3) a rectified linear unit (ReLU) activation function. A branch can be used to extract a local feature in the fashion image, and different branches can be used to extract different local features of the fashion image. Second, a global-local compatibility learning module is constructed in terms of graph neural network (GNN) and self-attention mechanism (SAM), which can model both of the global and local compatibility. GNN is used to model interactions among global features and local features separately. The SAM-based weight information of different fashion items is defined and integrated into the modeling, and the item’s global and local compatibility are obtained both. Finally, a fashion clothing matching optimization model is built up to gain optimized matching results. The learned outfit global and local compatibility can be used to integrate all fashion items’ global compatibility and local compatibility separately in an outfit. To optimize matching results, the trade-off parameters are then defined to adjust the impact of the outfit global compatibility and local compatibility on fashion style matching. At the same time, the matching score is calculated as well. Different matching schemes have different matching scores, and the optimized fashion style matching result is generated according to the highest score.ResultThe proposed method is validated on the public Polyvore dataset that includes fashion item images and textual descriptions. The details are presented as follows. The local features of fashion items extracted by our local feature extraction network can represent the fashion items’ local information effectively without label-attributed supervision. Our global-local compatibility learning module can be used to learn the fashion item’s global compatibility and local compatibility at the same time, and the weights of different fashion items is involved, which can model the fashion global and local compatibility completely. The fill in the blank (FITB) accuracy ratio of fashion style matching is improved to 86.89%.ConclusionA fashion clothing matching method is developed in terms of global local feature optimization. First, we construct a local feature extraction network to extract local features of fashion images while the global features of fashion items are extracted. Next, the self-attention mechanism is introduced to weight different fashion items after the global matching relationships and local matching relationships of fashion items with graph network are analyzed, which constructs the global and local compatibilities of fashion items completely. Finally, to obtain the global and local compatibilities of the outfit, our fashion clothing matching optimization model is used to fuse the item’s global compatibility and local compatibility each in an outfit. To optimize matching results, the effectiveness of the two kinds of compatibilities on fashion clothing matching with parameters is adjusted as well. The convergence speed of our method is still slow. The optimization model is only used to combine the global and local compatibility of the outfit linearly. In practice, the relationship between the global compatibility and local compatibility is more complex. To improve the accuracy of fashion clothing matching, future work can be focused on the convergence speed and the clothing matching optimization further.关键词:fashion clothing matching;compatibility modeling;global feature;local feature;feature optimization111|234|0更新时间:2024-05-07
摘要:ObjectiveFashion clothing matching has been developing for clothing-relevant fashion research nowadays. Fashion clothing matching studies are required to learn the complex matching relationship (i.e., fashion compatibility) among different fashion items in an representation-based outfit. Fashion items have rich partial designs and matching relationships among partial designs. To analyze their global compatibility learning, most of the existing researches are concerned of items’ global features (visual and textual features). But, local feature extraction is often ignored for local compatibility, which causes lower performance and accuracy of fashion style matching. Therefore, we develop a fashion style matching method in terms of global-local feature optimization and it is aimed to extract the local features of fashion images for local information representing, construct the local compatibility of fashion items, and improve the global and local compatibility-incorporated accuracy of fashion style matching.MethodFirst, we use two different convolutional neural networks (CNNs) to extract the global features of fashion items separately on the basis of the input fashion images and texts. To extract CNN-based local features of fashion images, a multiple branches-related local feature extraction network is designed. A branch of the local feature extraction network is composed of 1) a convolution layer, 2) a batch normalization (BN) layer, and 3) a rectified linear unit (ReLU) activation function. A branch can be used to extract a local feature in the fashion image, and different branches can be used to extract different local features of the fashion image. Second, a global-local compatibility learning module is constructed in terms of graph neural network (GNN) and self-attention mechanism (SAM), which can model both of the global and local compatibility. GNN is used to model interactions among global features and local features separately. The SAM-based weight information of different fashion items is defined and integrated into the modeling, and the item’s global and local compatibility are obtained both. Finally, a fashion clothing matching optimization model is built up to gain optimized matching results. The learned outfit global and local compatibility can be used to integrate all fashion items’ global compatibility and local compatibility separately in an outfit. To optimize matching results, the trade-off parameters are then defined to adjust the impact of the outfit global compatibility and local compatibility on fashion style matching. At the same time, the matching score is calculated as well. Different matching schemes have different matching scores, and the optimized fashion style matching result is generated according to the highest score.ResultThe proposed method is validated on the public Polyvore dataset that includes fashion item images and textual descriptions. The details are presented as follows. The local features of fashion items extracted by our local feature extraction network can represent the fashion items’ local information effectively without label-attributed supervision. Our global-local compatibility learning module can be used to learn the fashion item’s global compatibility and local compatibility at the same time, and the weights of different fashion items is involved, which can model the fashion global and local compatibility completely. The fill in the blank (FITB) accuracy ratio of fashion style matching is improved to 86.89%.ConclusionA fashion clothing matching method is developed in terms of global local feature optimization. First, we construct a local feature extraction network to extract local features of fashion images while the global features of fashion items are extracted. Next, the self-attention mechanism is introduced to weight different fashion items after the global matching relationships and local matching relationships of fashion items with graph network are analyzed, which constructs the global and local compatibilities of fashion items completely. Finally, to obtain the global and local compatibilities of the outfit, our fashion clothing matching optimization model is used to fuse the item’s global compatibility and local compatibility each in an outfit. To optimize matching results, the effectiveness of the two kinds of compatibilities on fashion clothing matching with parameters is adjusted as well. The convergence speed of our method is still slow. The optimization model is only used to combine the global and local compatibility of the outfit linearly. In practice, the relationship between the global compatibility and local compatibility is more complex. To improve the accuracy of fashion clothing matching, future work can be focused on the convergence speed and the clothing matching optimization further.关键词:fashion clothing matching;compatibility modeling;global feature;local feature;feature optimization111|234|0更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveBreast cancer-prognostic Ki67 score can be as a key indicator for the proliferation rate of malignant (invasive) cells. Negative and positive nuclei detection is an essential part of Ki67 scoring. An automated algorithm for nuclei detection can alleviate the negative impact of intra/inter-observer variation and labor-intensive nuclei counting. In recent years, deep learning methods have been developing intensively in relevant to recognition tasks on pathology images in terms of their learning potentials. Deep learning-based model can learn features derived from the raw data and relieve labor-intensive annotation of training images for pathologists. To alleviate the labor cost of annotation, our research is focused on modeling Ki67 nuclei detection as the centroid detection problem. The existing centroid detection models are commonly used to convert the centroid annotation into a probability map with the same size as the input image, the centroid detection problem is thus converted to a semantic segmentation-like problem. However, a semantic segmentation model has restricted by huge computation cost due to its huge amount of convolutional layers-related decoder. Nevertheless, due to the non-deep-learning post processing on the output heatmap, the whole detection process is complicated and inefficient, and the quality of a deep learning model is required to be developed further. Our CentroidNet model is facilitated to optimize nucleus centroid detection.MethodThe CentroidNet consists of a fully convolutional centroid detector initiated by ResNeXt, along with the detector’s training and inference methods. The CentroidNet can place evenly spaced anchor points on the input image. Actually, the anchor points are the places where the center of the detector’s receptive field is sited on. Each anchor point-interconnected detector can predict the classification probabilities and the offset to the anchor point, which is called a candidate point as a whole. In this way, the anchor points are the niches of the candidate points. A candidate point has the highest probability and is higher than 0.9. It is treated as predicted point. To assign labels for anchor/candidate points, we implement the “nearest anchor” strategy. This strategy can assign any annotated point to its nearest anchor point literally. Those anchor points are not assigned via any background label-assigned annotated point, whereas those classified label is “background” and label-coordinated is the anchor’s coordinate. This strategy is mutual-benefited between annotated points and anchor/candidate points. The label jittering problem can be avoided, which is often seen in current one-to-one assignment strategies. The anchors-between spacing is concerned about more. We recommend that the anchor spacing approximate the First Percentile of the minimal distance between each annotated point in the training set to its neighboring annotated points. Such spacing can balance the ratio of foreground labels, regression-coordinated, and optimal efficiency. The CentroidNet’s detector can avoid the commonly adopted paradigm of U-Net or feature pyramid network(FPN), which involves shortcut connections and multiple upsampling layers. This lightweight detector can improve quality and efficiency.ResultWe evaluate the quality and efficiency of CentroidNet model on BCData, the largest publicly available dataset for centroid detection of Ki67 carcinoma nuclei in breast cancer. For quality analysis, the CentroidNet can achieve an averaged F1 score of 0.879 1 compared to the SOTA(state of the art) score. For efficiency evaluation, the CentroidNet can achieve SOTA with an inference speed of 12.96 ms/image and a GPU memory footprint of 138.8 MB/image.ConclusionThe CentroidNet is featured of light-weight, efficient and ease of use. It has the potentials for centroid detection of Ki67 carcinoma nuclei in breast cancer.关键词:breast cancer;Ki67 score;centroid detection;one-to-one label assignment;anchor point62|188|1更新时间:2024-05-07
摘要:ObjectiveBreast cancer-prognostic Ki67 score can be as a key indicator for the proliferation rate of malignant (invasive) cells. Negative and positive nuclei detection is an essential part of Ki67 scoring. An automated algorithm for nuclei detection can alleviate the negative impact of intra/inter-observer variation and labor-intensive nuclei counting. In recent years, deep learning methods have been developing intensively in relevant to recognition tasks on pathology images in terms of their learning potentials. Deep learning-based model can learn features derived from the raw data and relieve labor-intensive annotation of training images for pathologists. To alleviate the labor cost of annotation, our research is focused on modeling Ki67 nuclei detection as the centroid detection problem. The existing centroid detection models are commonly used to convert the centroid annotation into a probability map with the same size as the input image, the centroid detection problem is thus converted to a semantic segmentation-like problem. However, a semantic segmentation model has restricted by huge computation cost due to its huge amount of convolutional layers-related decoder. Nevertheless, due to the non-deep-learning post processing on the output heatmap, the whole detection process is complicated and inefficient, and the quality of a deep learning model is required to be developed further. Our CentroidNet model is facilitated to optimize nucleus centroid detection.MethodThe CentroidNet consists of a fully convolutional centroid detector initiated by ResNeXt, along with the detector’s training and inference methods. The CentroidNet can place evenly spaced anchor points on the input image. Actually, the anchor points are the places where the center of the detector’s receptive field is sited on. Each anchor point-interconnected detector can predict the classification probabilities and the offset to the anchor point, which is called a candidate point as a whole. In this way, the anchor points are the niches of the candidate points. A candidate point has the highest probability and is higher than 0.9. It is treated as predicted point. To assign labels for anchor/candidate points, we implement the “nearest anchor” strategy. This strategy can assign any annotated point to its nearest anchor point literally. Those anchor points are not assigned via any background label-assigned annotated point, whereas those classified label is “background” and label-coordinated is the anchor’s coordinate. This strategy is mutual-benefited between annotated points and anchor/candidate points. The label jittering problem can be avoided, which is often seen in current one-to-one assignment strategies. The anchors-between spacing is concerned about more. We recommend that the anchor spacing approximate the First Percentile of the minimal distance between each annotated point in the training set to its neighboring annotated points. Such spacing can balance the ratio of foreground labels, regression-coordinated, and optimal efficiency. The CentroidNet’s detector can avoid the commonly adopted paradigm of U-Net or feature pyramid network(FPN), which involves shortcut connections and multiple upsampling layers. This lightweight detector can improve quality and efficiency.ResultWe evaluate the quality and efficiency of CentroidNet model on BCData, the largest publicly available dataset for centroid detection of Ki67 carcinoma nuclei in breast cancer. For quality analysis, the CentroidNet can achieve an averaged F1 score of 0.879 1 compared to the SOTA(state of the art) score. For efficiency evaluation, the CentroidNet can achieve SOTA with an inference speed of 12.96 ms/image and a GPU memory footprint of 138.8 MB/image.ConclusionThe CentroidNet is featured of light-weight, efficient and ease of use. It has the potentials for centroid detection of Ki67 carcinoma nuclei in breast cancer.关键词:breast cancer;Ki67 score;centroid detection;one-to-one label assignment;anchor point62|188|1更新时间:2024-05-07 -
 摘要:ObjectivePathological examination can be as the “gold standard” to interpret breast cancer diagnosis and its tumor types. To improve the treatment effect of breast cancer, accurate interpretation is beneficial to clarify the type of the disease early and effectively. However, it is time-consuming to check the pathological whole slide images (WSIs) manually, and the diagnosis result is easily affected by personal experience. Due to computer vision-based convolutional neural networks (CNNs) are applied to the classification task of histopathological images computer-aided diagnostic (CAD) techniques for digital images of histopathology has been developing intensively. However, it is still challenged to split large-sized WSIs into small patches and each patch is processed individually without the spatial information between them. Also, the information-involved of the patches learned is not utilized in the small size patch feature aggregation process. To resolve these problems, we develop a spatial correlation-based classification method for breast histopathology images, which can re-identify the WSIs classification problem through deep learning feature fusion and recurrent neural network (RNN) based classification.MethodOur demonstration consists of four aspects: 1) pre-processing operation of WSIs, 2) CNN-based breast patch prediction, 3) image patch feature fusion, and 4) RNN-based WSIs classification. First, it is focused on a preprocessing operation on whole slide images of breast pathology, using a sliding window to cut the WSIs into patches of a suitable size in terms of a CNN. Second, CNN-based patch prediction is used to predict the possibility of cancer in each patch and each patch is encoded as a fixed-length feature. To reduce unpredictable class of cancerous patch being classified as non-cancerous patch, the ResNet34 is used as the patch classification model and penalty factors is added in Focal loss. Third, the feature fusion of image blocks can be recognized as a feature fusion niche that takes the entire grid of patches as input and the spatial correlation of patches and their surrounding patches are as feature fusion of all patches within the grid, thus block descriptors are formed. Feature fusion methods are involved in, including 1) Weight, 2) Max, 3) Avg, 4) Norm3, and 5) WeightNorm3. Finally, the RNN-based WSIs classification is used to pass the block feature descriptors with high probability of cancer in each WSIs to the RNN, and the RNN model is used to learn the sequence relationship between the image block feature sequences. It can expand the processing field of view of the classification model to multiple Blocks and optimize the classification accuracy of breast pathology WSIs. Additionally, we design and develop an online recognition system for assistance.ResultA detailed annotated whole slide images dataset of breast pathology is constructed, and benign/malignant dichotomous classification experiments are carried out on this dataset. The results are compared to three WSIs classification methods in the self-constructed dataset, and it shows that the classification accuracy of the method can be reached to 96.3%, which is 1.9% higher than non-spatial correlation method. The classification accuracy of each is 8.8% and 1.3% higher compared to heat map features-based methods and spatial correlation and random forest-related methods.ConclusionThe proposed breast pathology recognition method can improve image recognition accuracy and provide an efficient diagnostic aid for pathology image diagnosis work, which integrates feature fusion and RNN classification into a synthesized model.关键词:breast cancer;pathological whole slide images;classification;convolutional neural network(CNN);feature fusion;recurrent neural network(RNN)131|283|1更新时间:2024-05-07
摘要:ObjectivePathological examination can be as the “gold standard” to interpret breast cancer diagnosis and its tumor types. To improve the treatment effect of breast cancer, accurate interpretation is beneficial to clarify the type of the disease early and effectively. However, it is time-consuming to check the pathological whole slide images (WSIs) manually, and the diagnosis result is easily affected by personal experience. Due to computer vision-based convolutional neural networks (CNNs) are applied to the classification task of histopathological images computer-aided diagnostic (CAD) techniques for digital images of histopathology has been developing intensively. However, it is still challenged to split large-sized WSIs into small patches and each patch is processed individually without the spatial information between them. Also, the information-involved of the patches learned is not utilized in the small size patch feature aggregation process. To resolve these problems, we develop a spatial correlation-based classification method for breast histopathology images, which can re-identify the WSIs classification problem through deep learning feature fusion and recurrent neural network (RNN) based classification.MethodOur demonstration consists of four aspects: 1) pre-processing operation of WSIs, 2) CNN-based breast patch prediction, 3) image patch feature fusion, and 4) RNN-based WSIs classification. First, it is focused on a preprocessing operation on whole slide images of breast pathology, using a sliding window to cut the WSIs into patches of a suitable size in terms of a CNN. Second, CNN-based patch prediction is used to predict the possibility of cancer in each patch and each patch is encoded as a fixed-length feature. To reduce unpredictable class of cancerous patch being classified as non-cancerous patch, the ResNet34 is used as the patch classification model and penalty factors is added in Focal loss. Third, the feature fusion of image blocks can be recognized as a feature fusion niche that takes the entire grid of patches as input and the spatial correlation of patches and their surrounding patches are as feature fusion of all patches within the grid, thus block descriptors are formed. Feature fusion methods are involved in, including 1) Weight, 2) Max, 3) Avg, 4) Norm3, and 5) WeightNorm3. Finally, the RNN-based WSIs classification is used to pass the block feature descriptors with high probability of cancer in each WSIs to the RNN, and the RNN model is used to learn the sequence relationship between the image block feature sequences. It can expand the processing field of view of the classification model to multiple Blocks and optimize the classification accuracy of breast pathology WSIs. Additionally, we design and develop an online recognition system for assistance.ResultA detailed annotated whole slide images dataset of breast pathology is constructed, and benign/malignant dichotomous classification experiments are carried out on this dataset. The results are compared to three WSIs classification methods in the self-constructed dataset, and it shows that the classification accuracy of the method can be reached to 96.3%, which is 1.9% higher than non-spatial correlation method. The classification accuracy of each is 8.8% and 1.3% higher compared to heat map features-based methods and spatial correlation and random forest-related methods.ConclusionThe proposed breast pathology recognition method can improve image recognition accuracy and provide an efficient diagnostic aid for pathology image diagnosis work, which integrates feature fusion and RNN classification into a synthesized model.关键词:breast cancer;pathological whole slide images;classification;convolutional neural network(CNN);feature fusion;recurrent neural network(RNN)131|283|1更新时间:2024-05-07 -
 摘要:ObjectiveTo realize the Alzheimer’s disease (AD) prediction, most of methods are focused on magnetic resonance imaging (MRI) image baseline of the patient. Current 2D and 3D convolutional neural networks (CNNs) are commonly used for MRI feature extraction. But, the challenge issue is required to learn temperal feature of the image changing although CNN deep models can be used on image feature selection. To extract the changing features and get the early prediction of Alzheimer’s disease effectively, we develop a ConvLSTM (convolution long short term memory) based on temporal images series slice (CTISS) model further.MethodThe CTISS model consist of 1) ConvLSTM and 2) Attention, which can extract spatio-temporal features from MRI and locate the disease relative spatial position of each. After slicing 3D MRI into 2D slices, the CTISS model can extract features from corresponding channels of the slices, one slice for each channel. Parameter optimization of the CTISS model shows that Attention-incorporated Conv2D layer is more efficient than the attention-intergrated bi-directional convolutional long short-term memory (Bi-ConvLSTM) layer. Sequential MRI images are split into slices-consistent, which are categorized into the corresponding channels. Each channel is fed with 2 serial slices. This model can use two stages of brain image beyond one-stage MRI. A network structure of hierarchical and sequential convolution is established, and root mean square prop (RMSprop)is used as the adaptive learning rate for training. To extract temporal features from brain image slices, our algorithm is constructed in terms of Bi-ConvLSTM model with Attention.ResultThe experiments are equipped with 4 Titan GPU, 12 GB memory per GPU, selecting 691 patients, totally 1 765 samples in AD/MCI/NC classes, which have 751 AD, 500 MCI and 514 NC. CTISS model is created by Keras2.0 python library. First, MRI images are normalized into size 256 × 256 × 256. Second, each image is sliced into size 256 × 256 and grouped into time sequence according to the medical case ID. Finally, all those sequential slices are sent to 256 channels separately. Our CTISS model can capture long-term sequential image features related to the status of the disease, which is 0.89 in AD vs NC, 0.81 in MCI vs NC, 0.72 in AD vs MCI and 0.94 in AD vs MCI vs NC. Especially, the accuracy can be improved 12% in the 3-facets classification, which are 1) prediction performance, 2) feature extraction ability, and 3) comparative analysis with existing models. At the same time, the CTISS model-extracted image features like the cavity enlargement of the whole-brain atrophy and the regional fibrosis of the brain are consistent with the pathological anatomy of Alzheimer’s disease.ConclusionThe AUC (area under curve) of CTISS model has its better optimization in 3 facets-classified than 2 facets-classified. The potentials of the CTISS model is linked to 2 aspects: 1) its performance is stable in different size of classes; 2) it achieves better AUC in long term series data for the sequential feature learning.关键词:Alzheimer’s disease (AD);prediction;temporal sequential;magnetic resonance imaging (MRI);features extraction;long short term memory (LSTM)120|300|0更新时间:2024-05-07
摘要:ObjectiveTo realize the Alzheimer’s disease (AD) prediction, most of methods are focused on magnetic resonance imaging (MRI) image baseline of the patient. Current 2D and 3D convolutional neural networks (CNNs) are commonly used for MRI feature extraction. But, the challenge issue is required to learn temperal feature of the image changing although CNN deep models can be used on image feature selection. To extract the changing features and get the early prediction of Alzheimer’s disease effectively, we develop a ConvLSTM (convolution long short term memory) based on temporal images series slice (CTISS) model further.MethodThe CTISS model consist of 1) ConvLSTM and 2) Attention, which can extract spatio-temporal features from MRI and locate the disease relative spatial position of each. After slicing 3D MRI into 2D slices, the CTISS model can extract features from corresponding channels of the slices, one slice for each channel. Parameter optimization of the CTISS model shows that Attention-incorporated Conv2D layer is more efficient than the attention-intergrated bi-directional convolutional long short-term memory (Bi-ConvLSTM) layer. Sequential MRI images are split into slices-consistent, which are categorized into the corresponding channels. Each channel is fed with 2 serial slices. This model can use two stages of brain image beyond one-stage MRI. A network structure of hierarchical and sequential convolution is established, and root mean square prop (RMSprop)is used as the adaptive learning rate for training. To extract temporal features from brain image slices, our algorithm is constructed in terms of Bi-ConvLSTM model with Attention.ResultThe experiments are equipped with 4 Titan GPU, 12 GB memory per GPU, selecting 691 patients, totally 1 765 samples in AD/MCI/NC classes, which have 751 AD, 500 MCI and 514 NC. CTISS model is created by Keras2.0 python library. First, MRI images are normalized into size 256 × 256 × 256. Second, each image is sliced into size 256 × 256 and grouped into time sequence according to the medical case ID. Finally, all those sequential slices are sent to 256 channels separately. Our CTISS model can capture long-term sequential image features related to the status of the disease, which is 0.89 in AD vs NC, 0.81 in MCI vs NC, 0.72 in AD vs MCI and 0.94 in AD vs MCI vs NC. Especially, the accuracy can be improved 12% in the 3-facets classification, which are 1) prediction performance, 2) feature extraction ability, and 3) comparative analysis with existing models. At the same time, the CTISS model-extracted image features like the cavity enlargement of the whole-brain atrophy and the regional fibrosis of the brain are consistent with the pathological anatomy of Alzheimer’s disease.ConclusionThe AUC (area under curve) of CTISS model has its better optimization in 3 facets-classified than 2 facets-classified. The potentials of the CTISS model is linked to 2 aspects: 1) its performance is stable in different size of classes; 2) it achieves better AUC in long term series data for the sequential feature learning.关键词:Alzheimer’s disease (AD);prediction;temporal sequential;magnetic resonance imaging (MRI);features extraction;long short term memory (LSTM)120|300|0更新时间:2024-05-07 -
 摘要:ObjectiveU-Net can be as the basic network in medical image segmentation. For U-Net and its various augmented networks, the encoder can extract features from input images in terms of a series of convolution and down-sampling operations. With the convolution and down-sampling operations at each layer of the encoder, the feature map sizes are decreased and the receptive field sizes can be remained to increase. For the network training, each level of the encoder can learn discriminative feature information at the current scale. To improve its feature utilization, the augmented U-Net schemes can melt skip connections between the encoder features and the decoder features into feature information-reused of shallow layers. However, the same scale are concatenated the features only via the skip-connected channel, and the role of multi-scale features with complementary information can be ignored. In addition, encoder features are oriented at a relatively shallow position in the overall network structure, while decoder features are based on a relatively deep position. As a result, a semantic feature gap is required to be bridged between encoder features and decoder features when skip connections are made. To optimize the U-Net and its augmented networks model, a novel segmentation network model is developed.MethodWe construct a segmentation network in terms of multi-scale feature fusion and additive attention mechanism. First, the features are fused in relevant to multi-scale receptive fields at different levels of the encoder. To guide the encoder features and enhance their discrimination ability, additive attention is introduced between the fused features and the encoder features at each level of the encoder. Second, to bridge the gap between the two semantic features, encoder and decoder features-between additive attention is used to learn important feature information in skip connections features adaptively. Experiments are carried out based on five-fold cross-validation. Multimodal magnetic resonance(MR) images of 234 high-grade glioma (HGG) samples and 59 low-grade glioma (LGG) samples in the BraTS2020 training dataset are used as the training data. MR images of 59 HGG samples and 15 LGG samples from the BraTS2020 training dataset are regarded as the validation data. The validation dataset of BraTS2020 is used as the final test data. The images of each modality are normalized using the Z-Score approach on the basis of the original data. The loss function is used in terms of the categorical cross-entropy loss function. Our model proposed is equipped with Ubuntu 18.04 operating system using Pycharm based on Keras, and the network model is trained and predicted on a workstation with a 16 GB graphics memory NVIDIA Quadro P5000 GPU. An ADAM optimizer is used in terms of a learning rate of 0.000 1 and the parameters in the network are initialized using the he_normal parameter initialization method. Our batch size for training the network is set to 12 and the model took 3 days to train after 150 iterations.ResultTo evaluate the performance of the proposed model, the Dice coefficient and the 95% Hausdorff distance (HD95) are used as evaluation metrics for the segmented regions of whole tumor(WT), tumor core(TC) and enhancing tumor(ET). To obtain quantitative evaluation results for these evaluation metrics, network-based segmentation results are uploaded to the BraTS2020 online evaluation platform. First, the segmentation effectiveness of the proposed network is verified on the BraTS2020 validation dataset. The experimental results show that the average Dice of the proposed network in relevant to ET, WT and TC are 0.706 4, 0.887 5 and 0.719 4 of each. Then, the proposed network is investigated in ablation experiments to validate the effectiveness of the proposed multi-scale feature fusion module, the fused feature additive attention module, and the encoder-decoder additive attention concatenate module. The results of the ablation experiments show that the addition of the proposed multi-scale feature fusion module to the backbone network improves the average Dice of the network of ET, WT and TC by 2.23%, 2.13% and 0.97%, respectively. In addition, the average Dice values of the network about ET, WT and TC are increased by 1.54%, 0.58% and 1.45% more after adding the proposed multi-scale feature fusion and fused feature additive attention modules to the network. The average Dice values of the network related to ET, WT and TC are increased by 2.46%, 0.82% and 3.51% further after the proposed encoder-decoder additive attention concatenate module is added to the network. Finally, our optimal network is compared to U-Net and popular augmented networks, as well as other non-U-Net segmentation networks. The proposed network to the 2D network DR-Unet104 is optimized by 4.73%, 3.08% and 0.13% for TC, ET and WT. Furthermore, the visualization results show that the proposed network can segment the boundaries of different tumor regions more accurately and achieve a better overall segmentation effect.ConclusionTo segment brain tumor sub-regions in MR images more accurately, we develop a novel segmentation network model. It can fuse multi-scale features with complementary information in the encoder, and additive attention guidance can be applied to the features in the current scale. To reduce the gap between the two semantic features, additive attention mechanism is also used between the encoder features and the decoder features when skip connections are made.关键词:medical image segmentation;brain tumor;magnetic resonance (MR) images;U-Net;multi-scale feature fusion;additive attention196|443|1更新时间:2024-05-07
摘要:ObjectiveU-Net can be as the basic network in medical image segmentation. For U-Net and its various augmented networks, the encoder can extract features from input images in terms of a series of convolution and down-sampling operations. With the convolution and down-sampling operations at each layer of the encoder, the feature map sizes are decreased and the receptive field sizes can be remained to increase. For the network training, each level of the encoder can learn discriminative feature information at the current scale. To improve its feature utilization, the augmented U-Net schemes can melt skip connections between the encoder features and the decoder features into feature information-reused of shallow layers. However, the same scale are concatenated the features only via the skip-connected channel, and the role of multi-scale features with complementary information can be ignored. In addition, encoder features are oriented at a relatively shallow position in the overall network structure, while decoder features are based on a relatively deep position. As a result, a semantic feature gap is required to be bridged between encoder features and decoder features when skip connections are made. To optimize the U-Net and its augmented networks model, a novel segmentation network model is developed.MethodWe construct a segmentation network in terms of multi-scale feature fusion and additive attention mechanism. First, the features are fused in relevant to multi-scale receptive fields at different levels of the encoder. To guide the encoder features and enhance their discrimination ability, additive attention is introduced between the fused features and the encoder features at each level of the encoder. Second, to bridge the gap between the two semantic features, encoder and decoder features-between additive attention is used to learn important feature information in skip connections features adaptively. Experiments are carried out based on five-fold cross-validation. Multimodal magnetic resonance(MR) images of 234 high-grade glioma (HGG) samples and 59 low-grade glioma (LGG) samples in the BraTS2020 training dataset are used as the training data. MR images of 59 HGG samples and 15 LGG samples from the BraTS2020 training dataset are regarded as the validation data. The validation dataset of BraTS2020 is used as the final test data. The images of each modality are normalized using the Z-Score approach on the basis of the original data. The loss function is used in terms of the categorical cross-entropy loss function. Our model proposed is equipped with Ubuntu 18.04 operating system using Pycharm based on Keras, and the network model is trained and predicted on a workstation with a 16 GB graphics memory NVIDIA Quadro P5000 GPU. An ADAM optimizer is used in terms of a learning rate of 0.000 1 and the parameters in the network are initialized using the he_normal parameter initialization method. Our batch size for training the network is set to 12 and the model took 3 days to train after 150 iterations.ResultTo evaluate the performance of the proposed model, the Dice coefficient and the 95% Hausdorff distance (HD95) are used as evaluation metrics for the segmented regions of whole tumor(WT), tumor core(TC) and enhancing tumor(ET). To obtain quantitative evaluation results for these evaluation metrics, network-based segmentation results are uploaded to the BraTS2020 online evaluation platform. First, the segmentation effectiveness of the proposed network is verified on the BraTS2020 validation dataset. The experimental results show that the average Dice of the proposed network in relevant to ET, WT and TC are 0.706 4, 0.887 5 and 0.719 4 of each. Then, the proposed network is investigated in ablation experiments to validate the effectiveness of the proposed multi-scale feature fusion module, the fused feature additive attention module, and the encoder-decoder additive attention concatenate module. The results of the ablation experiments show that the addition of the proposed multi-scale feature fusion module to the backbone network improves the average Dice of the network of ET, WT and TC by 2.23%, 2.13% and 0.97%, respectively. In addition, the average Dice values of the network about ET, WT and TC are increased by 1.54%, 0.58% and 1.45% more after adding the proposed multi-scale feature fusion and fused feature additive attention modules to the network. The average Dice values of the network related to ET, WT and TC are increased by 2.46%, 0.82% and 3.51% further after the proposed encoder-decoder additive attention concatenate module is added to the network. Finally, our optimal network is compared to U-Net and popular augmented networks, as well as other non-U-Net segmentation networks. The proposed network to the 2D network DR-Unet104 is optimized by 4.73%, 3.08% and 0.13% for TC, ET and WT. Furthermore, the visualization results show that the proposed network can segment the boundaries of different tumor regions more accurately and achieve a better overall segmentation effect.ConclusionTo segment brain tumor sub-regions in MR images more accurately, we develop a novel segmentation network model. It can fuse multi-scale features with complementary information in the encoder, and additive attention guidance can be applied to the features in the current scale. To reduce the gap between the two semantic features, additive attention mechanism is also used between the encoder features and the decoder features when skip connections are made.关键词:medical image segmentation;brain tumor;magnetic resonance (MR) images;U-Net;multi-scale feature fusion;additive attention196|443|1更新时间:2024-05-07 -
 摘要:ObjectiveGallbladder carcinoma is recognized as one of the most malignant tumors in relevant to biliary system. Its prognosis is extremely poor, and only 6 months of overall average. It is challenged for missed diagnose because of the lack of typical clinical manifestations in early stage of gallbladder cancer. To clarify gallbladder lesions for early detection of gallbladder carcinoma accurately, current gallbladder cancer-related diagnosis is mainly focused on the interpretation of digital pathological section images (such as b-ultrasound, computed tomography (CT), magnetic resonance imaging (MRI), etc.) in terms of the computer-aided diagnosis (CAD). However, the accuracy is quite lower because the molecular level information of diseased organs cannot be obtained. Micro-hyperspectral technology can be incorporated the features of spectral analysis and optical imaging, and it can obtain the chemical composition and physical features for biological tissue samples at the same time. The changes of physical attributes of cancerous tissue may not be clear in the early stage, but the changes of chemical factors like its composition, structure and content can be reflected by spectral information. Therefore, micro hyperspectral imaging has its potentials to achieve the early diagnosis of cancer more accurately. Micro-hyperspectral technology, as a special optical diagnosis technology, can provide an effective auxiliary diagnosis method for clinical research. However, it can provide richer spectral information but large amount of data and information redundancy are increased. To develop an improved accuracy detection method and use the rich spatial and hyperspectral information effectively, we design a multi-scale fusion attention mechanism-relevant network model for gallbladder cancer-oriented classification accuracy optimization.MethodThe multiscale squeeze-and-excitation-residual (MSE-Res) can be used to realize the fusion of multiscale features between channel dimensions. First, an improved multi-scale feature extraction module is employed to extract features of different scales in channel dimension. To extract the salient features of the image a maximum pooled layer, an upper sampling layer is used beyond convolution layer of 1 × 1. To compensate for the missing local information in the pooled layer, a 1 × 1 convolution layer is added to the jump link. Next, the attention mechanism is introduced to learn the correlation of features between different channels, and the fusion of features is realized between channels. Finally, the residual link is used to alleviate over fitting problem while the deep features of the image are extracted. Our gallbladder cancer-based micro-hyperspectral images dataset is derived from the multidimensional common bile duct database produced by Professor Li Qingli’s team of East China Normal University. The database is composed of 880 multi-dimensional image scenes captured from common bile duct tissues of 174 patients. Each micro-hyperspectral image size is 1 280 × 1 024 × 60. The spectral resolution is 2~5 nm and the spectral range is 550~1 000 nm. All images are labeled by expertise. These micro-hyperspectral images of gallbladder carcinoma consists of three different samples: 1) background, 2) distorted region, and 3) normal region. The background part is organized of cells or blank areas-secreted fat mucus, which can be removed during model training and excluded in the training process. To facilitate the follow-up experiments, the image size is cut to 640 × 512 × 60, and four different hyperspectral image datasets are involved in. At the beginning, the spectral validation and principal component analysis (PCA) are used to preprocess the micro-hyperspectral images in order to reduce the interference of the stability of the light source and the noise in the micro-hyperspectral imaging system to the spectral curves of different tissues in the micro-hyperspectral imaging system. Then, the MSE-ResNet is used to classify the microscopic hyperspectral images of gallbladder carcinoma-relevant pathological sections. Our configuration is equipped with python3.5.6 and Keras2.1.6 on NVIDIA GeForce RTX 2080 Ti GPU, Intel (R) Xeon (R) CPU E5-2678 v3 CPU. The learning rate is 0.001, batch size is 16, and dropout rate is 0.3, as well as the optimization strategy is based on stochastic gradient descent (SGD). To alleviate over fitting problem of the network and improve the generalization ability of the model, three kind of regularization methods are used in MSE-ResNet, which are 1) batch normalization, 2) L2 regularization, and 3) dropout regularization.ResultThe comparison and ablation-related experiments on micro-hyperspectral datasets of gallbladder carcinoma are carried out. Initially, we use several evaluation metrics to evaluate the performance of the MSE-ResNet. The overall classification accuracy, average classification accuracy and kappa coefficient of this model are reached to 99.619%, 99.581% and 0.990 of each, which is better than SE-ResNet and Inception-SE-ResNet. Second, we compare the MSE-ResNet model to other related deep learning and machine learning methods, such as 1D-CNN, ResNet, DenseNet, support vector machine (SVM), and K-nearest neighbor (KNN). The results show that our MSE-Res module can extract the spatial and channel features of micro-hyperspectral images effectively, and classification results can be achieved with less computational cost and better robustness. Our MSE-ResNet model can be used to learn the features of hyperspectral images automatically and optimize the network parameters through back propagation in comparison with the traditional machine learning methods, which is more beneficial for the classification of micro-hyperspectral images. At last, we compare the micro-hyperspectral image to the traditional RGB image. The experimental results show that the richer band information of the micro-hyperspectral image can improve the model classification results effectively.ConclusionTo improve the accuracy of classification of gallbladder cancer, our MSE-ResNet can be focused on the spatial and spectral information of hyperspectral images effectively. It has its potentials for gallbladder cancer-oriented medical diagnosis.关键词:hyperspectral image of gallbladder carcinoma;multi-scale feature fusion;residual network;images classification;squeeze and excitation(SE) module187|286|6更新时间:2024-05-07
摘要:ObjectiveGallbladder carcinoma is recognized as one of the most malignant tumors in relevant to biliary system. Its prognosis is extremely poor, and only 6 months of overall average. It is challenged for missed diagnose because of the lack of typical clinical manifestations in early stage of gallbladder cancer. To clarify gallbladder lesions for early detection of gallbladder carcinoma accurately, current gallbladder cancer-related diagnosis is mainly focused on the interpretation of digital pathological section images (such as b-ultrasound, computed tomography (CT), magnetic resonance imaging (MRI), etc.) in terms of the computer-aided diagnosis (CAD). However, the accuracy is quite lower because the molecular level information of diseased organs cannot be obtained. Micro-hyperspectral technology can be incorporated the features of spectral analysis and optical imaging, and it can obtain the chemical composition and physical features for biological tissue samples at the same time. The changes of physical attributes of cancerous tissue may not be clear in the early stage, but the changes of chemical factors like its composition, structure and content can be reflected by spectral information. Therefore, micro hyperspectral imaging has its potentials to achieve the early diagnosis of cancer more accurately. Micro-hyperspectral technology, as a special optical diagnosis technology, can provide an effective auxiliary diagnosis method for clinical research. However, it can provide richer spectral information but large amount of data and information redundancy are increased. To develop an improved accuracy detection method and use the rich spatial and hyperspectral information effectively, we design a multi-scale fusion attention mechanism-relevant network model for gallbladder cancer-oriented classification accuracy optimization.MethodThe multiscale squeeze-and-excitation-residual (MSE-Res) can be used to realize the fusion of multiscale features between channel dimensions. First, an improved multi-scale feature extraction module is employed to extract features of different scales in channel dimension. To extract the salient features of the image a maximum pooled layer, an upper sampling layer is used beyond convolution layer of 1 × 1. To compensate for the missing local information in the pooled layer, a 1 × 1 convolution layer is added to the jump link. Next, the attention mechanism is introduced to learn the correlation of features between different channels, and the fusion of features is realized between channels. Finally, the residual link is used to alleviate over fitting problem while the deep features of the image are extracted. Our gallbladder cancer-based micro-hyperspectral images dataset is derived from the multidimensional common bile duct database produced by Professor Li Qingli’s team of East China Normal University. The database is composed of 880 multi-dimensional image scenes captured from common bile duct tissues of 174 patients. Each micro-hyperspectral image size is 1 280 × 1 024 × 60. The spectral resolution is 2~5 nm and the spectral range is 550~1 000 nm. All images are labeled by expertise. These micro-hyperspectral images of gallbladder carcinoma consists of three different samples: 1) background, 2) distorted region, and 3) normal region. The background part is organized of cells or blank areas-secreted fat mucus, which can be removed during model training and excluded in the training process. To facilitate the follow-up experiments, the image size is cut to 640 × 512 × 60, and four different hyperspectral image datasets are involved in. At the beginning, the spectral validation and principal component analysis (PCA) are used to preprocess the micro-hyperspectral images in order to reduce the interference of the stability of the light source and the noise in the micro-hyperspectral imaging system to the spectral curves of different tissues in the micro-hyperspectral imaging system. Then, the MSE-ResNet is used to classify the microscopic hyperspectral images of gallbladder carcinoma-relevant pathological sections. Our configuration is equipped with python3.5.6 and Keras2.1.6 on NVIDIA GeForce RTX 2080 Ti GPU, Intel (R) Xeon (R) CPU E5-2678 v3 CPU. The learning rate is 0.001, batch size is 16, and dropout rate is 0.3, as well as the optimization strategy is based on stochastic gradient descent (SGD). To alleviate over fitting problem of the network and improve the generalization ability of the model, three kind of regularization methods are used in MSE-ResNet, which are 1) batch normalization, 2) L2 regularization, and 3) dropout regularization.ResultThe comparison and ablation-related experiments on micro-hyperspectral datasets of gallbladder carcinoma are carried out. Initially, we use several evaluation metrics to evaluate the performance of the MSE-ResNet. The overall classification accuracy, average classification accuracy and kappa coefficient of this model are reached to 99.619%, 99.581% and 0.990 of each, which is better than SE-ResNet and Inception-SE-ResNet. Second, we compare the MSE-ResNet model to other related deep learning and machine learning methods, such as 1D-CNN, ResNet, DenseNet, support vector machine (SVM), and K-nearest neighbor (KNN). The results show that our MSE-Res module can extract the spatial and channel features of micro-hyperspectral images effectively, and classification results can be achieved with less computational cost and better robustness. Our MSE-ResNet model can be used to learn the features of hyperspectral images automatically and optimize the network parameters through back propagation in comparison with the traditional machine learning methods, which is more beneficial for the classification of micro-hyperspectral images. At last, we compare the micro-hyperspectral image to the traditional RGB image. The experimental results show that the richer band information of the micro-hyperspectral image can improve the model classification results effectively.ConclusionTo improve the accuracy of classification of gallbladder cancer, our MSE-ResNet can be focused on the spatial and spectral information of hyperspectral images effectively. It has its potentials for gallbladder cancer-oriented medical diagnosis.关键词:hyperspectral image of gallbladder carcinoma;multi-scale feature fusion;residual network;images classification;squeeze and excitation(SE) module187|286|6更新时间:2024-05-07 -
 摘要:ObjectiveThe chest X-ray-relevant screening and diagnostic method is essential for radiology nowadays. Most of chest X-ray images interpretation is still restricted by clinical experience and challenged for misdiagnose and missed diagnoses. To detect and identify one or more potential diseases in images automatically, it is beneficial for improving diagnostic efficiency and accuracy using computer-based technique. Compared to natural images, multiple lesions are challenged to be detected and distinguished accurately in a single image because abnormal areas have a small proportion and complex representations in chest X-ray images. Current convolutional neural network(CNN) based deep learning models have been widely used in the context of medical imaging. The structure of the CNN convolution kernel has sensitive to local detail information, and it is possible to extract richer image features. However, the convolution kernel cannot be used to get global information, and the features-extracted are restricted of redundant information like its relevance of background, muscles, and bones. The model’s performance in multi-label classification tasks are affected to a certain extent. At present, the vision Transformer (ViT) model has achieved its priorities in computer vision-related tasks. The ViT can be used to capture information simultaneously and effectively for multiple regions of the entire image. However, it is required to use large-scale dataset training to achieve good performance. Due to some factors like patient privacy and manual annotate costs, the size of the chest X-ray image data set has been limited. To reduce the model's dependence on data scale and improve the performance of multi-label classification, we develop the CNN-based ViT pre-training model in terms of the transfer learning method for diagnosis-assisted of chest X-ray image and multi-label classification.MethodThe CNN-based ViT model is pre-trained on a huge scale ground truth dataset, and it is used to obtain the initial parameters of the model. The model structure is fine-tuned according to the features of chest X-ray dataset. A 1 × 1 convolution layer is used to convert the chest X-ray images channels between 1 to 3. The number of output nodes of the linear layer in the classifier is balanced from 1 000 to the number of chest X-ray classification labels, and the Sigmoid is used as an activation function. The parameters of the backbone network are initialized in terms of the pre-trained ViT model parameters, and it is trained in the chest X-ray dataset after that to complete multi-label classification. The experiment is configured of Python3.7 and PyTorch1.8 to construct the model and RTX3090 GPU for training. Stochastic gradient descent(SGD) optimizer, binary cross-entropy(BCE) loss function, an initial learning rate of 1E-3, the cosine annealing learning rate decay are used. For training, each image is scaled to a size of 512 × 512 pixels, and a 224 × 224 pixels area and it is then cropped in random as the model input, and data augmentation is performed randomly by some of the flipping, perspective transformation, shearing, translation, zooming, and changing brightness. For testing, the chest X-ray image is scaled to 256 × 256 pixels and center crop a 224 ×224 area to input the trained model.ResultThe experiment is performed on the IU X-Ray, which is a small-scale chest X-ray dataset. This model is evaluated in quantitative using the average of area under ROC curve (AUC) scores across all classification labels. The results show that the average AUC score of the pre-trained ViT model is 0.774. The accuracy and training efficiency of the non-pre-trained ViT model is dropped significantly. The average AUC score is reached to 0.566 only, which is 0.208 lower. In addition, the attention mechanism heat map is generated based on the ViT model, which can strengthen the interpretability of the model. A series of ablation experiments are carried out for data augmentation, model structure, and batch size design. The fine-tuned ViT model is trained on the Chest-Ray14 and CheXpert dataset as well. The average AUC score is reached to 0.839 and 0.806, which is optimized by 0.014 and 0.031.ConclusionA pre-trained ViT model is used for the multi-label classification of chest X-ray images via transfer learning. The experimental results illustrate that the ViT has its stronger multi-label classification performance in chest X-ray images, and its attention mechanism is beneficial for lesions precision-focused like the interior of the chest cavity and the heart. Transfer learning is potential to improve the classification performance and model generalization of the ViT in small-scale datasets, and the training cost is reduced greatly. Ablation experiments demonstrate that the incorporated model of CNN and Transformer has its priority beyond single-structure model. Data enhancement and the batch size cutting can improve the performance of the model, but smaller scale of batch is still interlinked to longer training span. To improve the model's ability, we predict that future research direction can be focused on the extraction for complex disease and high-level semantic information, such as their small lesions, disease location, and severity.关键词:chest X-ray images;multi-label classification;convolutional neural network(CNN);vision Transformer(ViT);transfer learning263|443|1更新时间:2024-05-07
摘要:ObjectiveThe chest X-ray-relevant screening and diagnostic method is essential for radiology nowadays. Most of chest X-ray images interpretation is still restricted by clinical experience and challenged for misdiagnose and missed diagnoses. To detect and identify one or more potential diseases in images automatically, it is beneficial for improving diagnostic efficiency and accuracy using computer-based technique. Compared to natural images, multiple lesions are challenged to be detected and distinguished accurately in a single image because abnormal areas have a small proportion and complex representations in chest X-ray images. Current convolutional neural network(CNN) based deep learning models have been widely used in the context of medical imaging. The structure of the CNN convolution kernel has sensitive to local detail information, and it is possible to extract richer image features. However, the convolution kernel cannot be used to get global information, and the features-extracted are restricted of redundant information like its relevance of background, muscles, and bones. The model’s performance in multi-label classification tasks are affected to a certain extent. At present, the vision Transformer (ViT) model has achieved its priorities in computer vision-related tasks. The ViT can be used to capture information simultaneously and effectively for multiple regions of the entire image. However, it is required to use large-scale dataset training to achieve good performance. Due to some factors like patient privacy and manual annotate costs, the size of the chest X-ray image data set has been limited. To reduce the model's dependence on data scale and improve the performance of multi-label classification, we develop the CNN-based ViT pre-training model in terms of the transfer learning method for diagnosis-assisted of chest X-ray image and multi-label classification.MethodThe CNN-based ViT model is pre-trained on a huge scale ground truth dataset, and it is used to obtain the initial parameters of the model. The model structure is fine-tuned according to the features of chest X-ray dataset. A 1 × 1 convolution layer is used to convert the chest X-ray images channels between 1 to 3. The number of output nodes of the linear layer in the classifier is balanced from 1 000 to the number of chest X-ray classification labels, and the Sigmoid is used as an activation function. The parameters of the backbone network are initialized in terms of the pre-trained ViT model parameters, and it is trained in the chest X-ray dataset after that to complete multi-label classification. The experiment is configured of Python3.7 and PyTorch1.8 to construct the model and RTX3090 GPU for training. Stochastic gradient descent(SGD) optimizer, binary cross-entropy(BCE) loss function, an initial learning rate of 1E-3, the cosine annealing learning rate decay are used. For training, each image is scaled to a size of 512 × 512 pixels, and a 224 × 224 pixels area and it is then cropped in random as the model input, and data augmentation is performed randomly by some of the flipping, perspective transformation, shearing, translation, zooming, and changing brightness. For testing, the chest X-ray image is scaled to 256 × 256 pixels and center crop a 224 ×224 area to input the trained model.ResultThe experiment is performed on the IU X-Ray, which is a small-scale chest X-ray dataset. This model is evaluated in quantitative using the average of area under ROC curve (AUC) scores across all classification labels. The results show that the average AUC score of the pre-trained ViT model is 0.774. The accuracy and training efficiency of the non-pre-trained ViT model is dropped significantly. The average AUC score is reached to 0.566 only, which is 0.208 lower. In addition, the attention mechanism heat map is generated based on the ViT model, which can strengthen the interpretability of the model. A series of ablation experiments are carried out for data augmentation, model structure, and batch size design. The fine-tuned ViT model is trained on the Chest-Ray14 and CheXpert dataset as well. The average AUC score is reached to 0.839 and 0.806, which is optimized by 0.014 and 0.031.ConclusionA pre-trained ViT model is used for the multi-label classification of chest X-ray images via transfer learning. The experimental results illustrate that the ViT has its stronger multi-label classification performance in chest X-ray images, and its attention mechanism is beneficial for lesions precision-focused like the interior of the chest cavity and the heart. Transfer learning is potential to improve the classification performance and model generalization of the ViT in small-scale datasets, and the training cost is reduced greatly. Ablation experiments demonstrate that the incorporated model of CNN and Transformer has its priority beyond single-structure model. Data enhancement and the batch size cutting can improve the performance of the model, but smaller scale of batch is still interlinked to longer training span. To improve the model's ability, we predict that future research direction can be focused on the extraction for complex disease and high-level semantic information, such as their small lesions, disease location, and severity.关键词:chest X-ray images;multi-label classification;convolutional neural network(CNN);vision Transformer(ViT);transfer learning263|443|1更新时间:2024-05-07 -
 摘要:ObjectiveThree-dimensional (3D) image segmentation of human tissues, organs and lesion areas is projected for computer-aided diagnosis and medical images-related 3D visualization. Thanks to the emerging deep learning technique, fully-supervised network models have been developing intensively in relevant to medical image segmentation tasks. However, it is challenged for a large amount of annotated data and 3D image segmentation data-labeled is costly and inefficient. Semi-supervised learning is focused on a small size of data-labeled and sufficient data-unlabeled in terms of easy acquisition of unlabeled data, which can alleviate the cost and time-consuming problem of data labeling. Our research is focused on new consistency regular method for semi-supervised 3D medical image segmentation model. To improve the medical image segmentation effect, our model can use unlabeled data through the fusion of different consistency methods.MethodThe network model is demonstrated on the V-Net, which can remove the residual structure of encoding and decoding. To get efficient features of unlabeled data, the proposed shape-aware cross-consistency regular network is introduced via the V-Net network structure extension on the basis of an encoder and two independent decoders-involved dual tasks (shape-aware cross-consistency regular network based on dual tasks (SACC-Net)), which are divided into a main decoder a and an auxiliary decoder b. The output of encoder-shared is transmitted to the two decoders after noise disturbance. At the same time, the two decoders can output the prediction results after each iteration. To increase the generalization and anti-noise ability of the model, it can minimize the difference between the two parts of the results during the training process. Additionally, the proportion of labeled samples in the training samples is extremely small because the feature distributions between the pre-processed medical image samples are relatively similar. To improve the learning ability of the model to segmented samples further, geometric prior information constraints are melted into the segmentation target. A shape-aware regression layer is added at the end of each decoder as well. During the training phase, each decoder can output two parts of the prediction results at the same time. That is, the total output of each iteration-after network consists of four parts. It can be used to decode the segmentation map SA and the signed distance map output by the decoder A, and the segmentation map SB and the signed distance map output by the decoder B through the dual-task consistency of each decoding part. To enhance the model’s ability and learn the effective features of segmentation targets to a greater extent, constraints and cross constraints can be used to realize a consistent regular method that combines data-level and model-level disturbances with multi-task mechanisms, and make better use of unlabeled data.ResultOur algorithm is validated on the MRI data set published in Atrium Segmentation Challenge held by MICCAI (Medical Image Computing and Computer Assisted Intervention Society) in 2018. The experiment is divided into two test groups based on the amounts proportion of labeled data. In the training set, 10% annotated data is used only in the experimental group, the Dice coefficient, Jaccard index, HD (Hausdorff distance) distance, and average symmetric surface distance is reached to 88.01%, 78.89%, 8.19, and 2.09 of each. In the other group, 20% annotated data of the experiments are used only. The median Dice coefficient, Jaccard index, HD distance and average symmetric surface distance can be reached to 90.14%, 82.11%, 6.57, and 1.78 each as well. Furthermore, In respect of the shape perception method using the level set function for regression tasks, the Dice evaluation index can be improved by 0.69 and 0.60 in comparison with shape-aware semi-supervised net(SASS Net) in 10% and 20% of the marked training results. Each improvement is reached to 1.44% and 0.72% in terms of comparative results of dual-task consistency(DTC) trained with 10% and 20% labeled data.ConclusionThe semi-supervised segmentation model (SACC-Net) is illustrated for the criteria optimization for both of the region and boundary-based segmentation, which can incorporate the level-consistency of its data, model and task. The constrained method has its potential segmentation effect and generalization performance for semi-supervised methods.关键词:medical imaging;semi-supervised learning;three-dimensional image segmentation;consistency regularization;magnetic resonance imaging (MRI)128|315|1更新时间:2024-05-07
摘要:ObjectiveThree-dimensional (3D) image segmentation of human tissues, organs and lesion areas is projected for computer-aided diagnosis and medical images-related 3D visualization. Thanks to the emerging deep learning technique, fully-supervised network models have been developing intensively in relevant to medical image segmentation tasks. However, it is challenged for a large amount of annotated data and 3D image segmentation data-labeled is costly and inefficient. Semi-supervised learning is focused on a small size of data-labeled and sufficient data-unlabeled in terms of easy acquisition of unlabeled data, which can alleviate the cost and time-consuming problem of data labeling. Our research is focused on new consistency regular method for semi-supervised 3D medical image segmentation model. To improve the medical image segmentation effect, our model can use unlabeled data through the fusion of different consistency methods.MethodThe network model is demonstrated on the V-Net, which can remove the residual structure of encoding and decoding. To get efficient features of unlabeled data, the proposed shape-aware cross-consistency regular network is introduced via the V-Net network structure extension on the basis of an encoder and two independent decoders-involved dual tasks (shape-aware cross-consistency regular network based on dual tasks (SACC-Net)), which are divided into a main decoder a and an auxiliary decoder b. The output of encoder-shared is transmitted to the two decoders after noise disturbance. At the same time, the two decoders can output the prediction results after each iteration. To increase the generalization and anti-noise ability of the model, it can minimize the difference between the two parts of the results during the training process. Additionally, the proportion of labeled samples in the training samples is extremely small because the feature distributions between the pre-processed medical image samples are relatively similar. To improve the learning ability of the model to segmented samples further, geometric prior information constraints are melted into the segmentation target. A shape-aware regression layer is added at the end of each decoder as well. During the training phase, each decoder can output two parts of the prediction results at the same time. That is, the total output of each iteration-after network consists of four parts. It can be used to decode the segmentation map SA and the signed distance map output by the decoder A, and the segmentation map SB and the signed distance map output by the decoder B through the dual-task consistency of each decoding part. To enhance the model’s ability and learn the effective features of segmentation targets to a greater extent, constraints and cross constraints can be used to realize a consistent regular method that combines data-level and model-level disturbances with multi-task mechanisms, and make better use of unlabeled data.ResultOur algorithm is validated on the MRI data set published in Atrium Segmentation Challenge held by MICCAI (Medical Image Computing and Computer Assisted Intervention Society) in 2018. The experiment is divided into two test groups based on the amounts proportion of labeled data. In the training set, 10% annotated data is used only in the experimental group, the Dice coefficient, Jaccard index, HD (Hausdorff distance) distance, and average symmetric surface distance is reached to 88.01%, 78.89%, 8.19, and 2.09 of each. In the other group, 20% annotated data of the experiments are used only. The median Dice coefficient, Jaccard index, HD distance and average symmetric surface distance can be reached to 90.14%, 82.11%, 6.57, and 1.78 each as well. Furthermore, In respect of the shape perception method using the level set function for regression tasks, the Dice evaluation index can be improved by 0.69 and 0.60 in comparison with shape-aware semi-supervised net(SASS Net) in 10% and 20% of the marked training results. Each improvement is reached to 1.44% and 0.72% in terms of comparative results of dual-task consistency(DTC) trained with 10% and 20% labeled data.ConclusionThe semi-supervised segmentation model (SACC-Net) is illustrated for the criteria optimization for both of the region and boundary-based segmentation, which can incorporate the level-consistency of its data, model and task. The constrained method has its potential segmentation effect and generalization performance for semi-supervised methods.关键词:medical imaging;semi-supervised learning;three-dimensional image segmentation;consistency regularization;magnetic resonance imaging (MRI)128|315|1更新时间:2024-05-07 -
 摘要:ObjectiveReal-time tumor localization is essential for tumor tracking radiotherapy. Conventional tumor localization methods commonly estimate the tumor motion by measuring the similarity between the X-ray images and digitally reconstructed radiography (DRR) computed from computed tomography (CT). However, due to the scatter, beam hardening and quantum noise, there exists intensity inconsistency between the X-ray projections and DRR which may compromise the accuracy of tumor localization. Thus, it is crucial to calculate DRR similar with the X-ray images for precise tumor localization. Current DRR-relevant methods can be segmented into two categories: 1) statistical-based Monte Carlo (MC) simulation and 2) analysis-based ray tracing (RT). The MC methods simulate the interaction process between photons and human tissue and can generate DRRs of high similarity with the X-ray projections. But it suffers from low computational efficiency which hinders its clinical application. The RT methods calculate DRR by simulating the absorption and attenuation process of X-ray penetrating human tissue. Compared to MC methods, the RT methods have higher computational efficiency, but there is a big intensity gap between their results and the real X-ray images. To address the problems mentioned above, we develop an improved cycle consistency generative adversarial network (Cycle-GAN) based DRR generation algorithm (CG-DRR), which can efficiently generate DRR with high similarity to the X-ray images.MethodCG-DRR consists of two mapping functions Gy, Gx and associated adversarial discriminators Dy, Dx. The Gy is trained to generate DRRs indistinguishable from X-ray images based on DRR calculated by RT (DRRRT), while Dy aims to distinguish between generated DRRs and real X-ray images, and vice versa for Gx, Dx. The training loss for CG-DRR is composed of three elements: 1) adversarial loss for matching the distribution of generated DRR to the X-ray distribution in the target domain; 2) a cycle consistency L1-norm loss to prevent the learned mappings Gy, Gx from contradicting each other; and 3) gradient penalty configuration to stabilize network training. For validation, planning CT and CBCT (cone beam computed tomography) projections (X-ray images) for radiotherapy of 3 pelvic and 3 chest patients are collected. For the pelvic/chest data, the CG-DRR is trained on 1 077/588 CBCT projections randomly selected from two patients and tested on 100/50 unseen CBCT projections from the same patients, and 100/50 CBCT projections randomly selected from the third patient. The third patient data was only used for testing to evaluate the inter-patient generalization performance of the CG-DRR. The overall framework is composed of three stages. In the data preprocessing stage, FDK (Feldkamp-Davis-Kress) algorithm is first used to reconstruct the 3D CBCT image based on the CBCT projections. Rigid registration is then performed to align the CT with CBCT. The DRRRT can be generated according to the geometric parameters of CBCT projections. The CBCT projections and DRRRT are rescaled to 256 × 256 pixels and their intensity is normalized into [0, 1]. In the training stage, the parameters of CG-DRR are optimized using mini-batch (size = 4) stochastic gradient descent (SGD) and Adam solver (β1 = 0.5) through alternating gradient descent steps on the discriminators and generators. The learning rate is fixed at 0.001 in the first 100 epochs, and then decreased to 0 in the next 100 epochs linearly. In the application stage, the input of Gy is DRRRT, which is rescaled to 256 × 256 pixels and normalized into [0, 1]. The output of Gy is up-sampled and de-normalized to obtain a DRR with the same size and intensity range as the CBCT projections.ResultEvaluation is performed by comparing the generated DRR to ground-truth CBCT projections in terms of the peak signal-to-noise ratio (PSNR), the mean absolute error (MAE), the normalized root-mean-square error (NRMSE), and the structural similarity index (SSIM). To further evaluate the structural consistency, two additional indicators, feature similarity index measure (FSIM) and gradient magnitude similarity deviation (GMSD), are also evaluated. For RT, RealDRR and CG-DRR, 1)the average PSNR are 11.6 dB, 32.9 dB, 29.6 dB for pelvic data, 16.4 dB, 31.3 dB, 25.2 dB for chest data; 2) the average MAE are 0.21, 0.02, 0.03 for pelvic data and 0.12, 0.03, 0.05 for chest data; and 3) the average NRMSE are 0.27, 0.03, 0.04 for pelvic data and 0.16, 0.04, 0.06 for chest data; 4) the average SSIM are 0.745, 0.985, 0.980 for pelvic data and 0.840, 0.985, 0.975 for chest data. But, the results of RealDRR contain noticeable structural distortions, with faked or missed tissue structures compared with DRRRT. Especially for chest data, the position of the thoracic diaphragm is significantly shifted. Compared with the results of RealDRR, CG-DRR can keep a good consistency of tissue structure. For the average FSIM, the pelvic results are increased from 0.855 to 0.870, an improvement of 2%; the chest results are increased from 0.91 to 0.93, an improvement of 2.2%. For the average GMSD, the pelvic results decreased from 0.175 to 0.17, a reduction of 2.9%; the chest results decreased from 0.135 to 0.115, a reduction of 14.8%. For computational efficiency, the CG-DRR can render a highly realistic DRR in 0.31 s.ConclusionThe cycle-consistent generative adversarial mechanism is applied to DRR generation. The proposed algorithm can efficiently generate DRR that has good intensity similarity and structural consistency with X-ray projections.关键词:digital reconstructed radiograph (DRR);intensity correction;deep learning;cycle-consistent generative adversarial networks;gradient penalty265|223|0更新时间:2024-05-07
摘要:ObjectiveReal-time tumor localization is essential for tumor tracking radiotherapy. Conventional tumor localization methods commonly estimate the tumor motion by measuring the similarity between the X-ray images and digitally reconstructed radiography (DRR) computed from computed tomography (CT). However, due to the scatter, beam hardening and quantum noise, there exists intensity inconsistency between the X-ray projections and DRR which may compromise the accuracy of tumor localization. Thus, it is crucial to calculate DRR similar with the X-ray images for precise tumor localization. Current DRR-relevant methods can be segmented into two categories: 1) statistical-based Monte Carlo (MC) simulation and 2) analysis-based ray tracing (RT). The MC methods simulate the interaction process between photons and human tissue and can generate DRRs of high similarity with the X-ray projections. But it suffers from low computational efficiency which hinders its clinical application. The RT methods calculate DRR by simulating the absorption and attenuation process of X-ray penetrating human tissue. Compared to MC methods, the RT methods have higher computational efficiency, but there is a big intensity gap between their results and the real X-ray images. To address the problems mentioned above, we develop an improved cycle consistency generative adversarial network (Cycle-GAN) based DRR generation algorithm (CG-DRR), which can efficiently generate DRR with high similarity to the X-ray images.MethodCG-DRR consists of two mapping functions Gy, Gx and associated adversarial discriminators Dy, Dx. The Gy is trained to generate DRRs indistinguishable from X-ray images based on DRR calculated by RT (DRRRT), while Dy aims to distinguish between generated DRRs and real X-ray images, and vice versa for Gx, Dx. The training loss for CG-DRR is composed of three elements: 1) adversarial loss for matching the distribution of generated DRR to the X-ray distribution in the target domain; 2) a cycle consistency L1-norm loss to prevent the learned mappings Gy, Gx from contradicting each other; and 3) gradient penalty configuration to stabilize network training. For validation, planning CT and CBCT (cone beam computed tomography) projections (X-ray images) for radiotherapy of 3 pelvic and 3 chest patients are collected. For the pelvic/chest data, the CG-DRR is trained on 1 077/588 CBCT projections randomly selected from two patients and tested on 100/50 unseen CBCT projections from the same patients, and 100/50 CBCT projections randomly selected from the third patient. The third patient data was only used for testing to evaluate the inter-patient generalization performance of the CG-DRR. The overall framework is composed of three stages. In the data preprocessing stage, FDK (Feldkamp-Davis-Kress) algorithm is first used to reconstruct the 3D CBCT image based on the CBCT projections. Rigid registration is then performed to align the CT with CBCT. The DRRRT can be generated according to the geometric parameters of CBCT projections. The CBCT projections and DRRRT are rescaled to 256 × 256 pixels and their intensity is normalized into [0, 1]. In the training stage, the parameters of CG-DRR are optimized using mini-batch (size = 4) stochastic gradient descent (SGD) and Adam solver (β1 = 0.5) through alternating gradient descent steps on the discriminators and generators. The learning rate is fixed at 0.001 in the first 100 epochs, and then decreased to 0 in the next 100 epochs linearly. In the application stage, the input of Gy is DRRRT, which is rescaled to 256 × 256 pixels and normalized into [0, 1]. The output of Gy is up-sampled and de-normalized to obtain a DRR with the same size and intensity range as the CBCT projections.ResultEvaluation is performed by comparing the generated DRR to ground-truth CBCT projections in terms of the peak signal-to-noise ratio (PSNR), the mean absolute error (MAE), the normalized root-mean-square error (NRMSE), and the structural similarity index (SSIM). To further evaluate the structural consistency, two additional indicators, feature similarity index measure (FSIM) and gradient magnitude similarity deviation (GMSD), are also evaluated. For RT, RealDRR and CG-DRR, 1)the average PSNR are 11.6 dB, 32.9 dB, 29.6 dB for pelvic data, 16.4 dB, 31.3 dB, 25.2 dB for chest data; 2) the average MAE are 0.21, 0.02, 0.03 for pelvic data and 0.12, 0.03, 0.05 for chest data; and 3) the average NRMSE are 0.27, 0.03, 0.04 for pelvic data and 0.16, 0.04, 0.06 for chest data; 4) the average SSIM are 0.745, 0.985, 0.980 for pelvic data and 0.840, 0.985, 0.975 for chest data. But, the results of RealDRR contain noticeable structural distortions, with faked or missed tissue structures compared with DRRRT. Especially for chest data, the position of the thoracic diaphragm is significantly shifted. Compared with the results of RealDRR, CG-DRR can keep a good consistency of tissue structure. For the average FSIM, the pelvic results are increased from 0.855 to 0.870, an improvement of 2%; the chest results are increased from 0.91 to 0.93, an improvement of 2.2%. For the average GMSD, the pelvic results decreased from 0.175 to 0.17, a reduction of 2.9%; the chest results decreased from 0.135 to 0.115, a reduction of 14.8%. For computational efficiency, the CG-DRR can render a highly realistic DRR in 0.31 s.ConclusionThe cycle-consistent generative adversarial mechanism is applied to DRR generation. The proposed algorithm can efficiently generate DRR that has good intensity similarity and structural consistency with X-ray projections.关键词:digital reconstructed radiograph (DRR);intensity correction;deep learning;cycle-consistent generative adversarial networks;gradient penalty265|223|0更新时间:2024-05-07
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0