
最新刊期
卷 28 , 期 10 , 2023
-
 摘要:Due to its ability to model long-distance dependencies, self-attention mechanism for adaptive computing, scalability for large models and big data, and better connection between vision and language, Transformer model is beneficial for natural language processing and computer vision apparently. To melt Transformer into vision tasks, such vision Transformer methods have been developing intensively. Current literatures can be summarized and analyzed for multiple applications-related methods. However, these different applications are often heterogeneous for various methods. In addition, comparative analysis is often focused on between Transformer and traditional convolution neural networks (CNNs), and multi-Transformer models are less involved in and linked mutually. We summarize and compare more than 100 popular methods of vision Transformer for various recognition tasks. Global recognition-based methods are reviewed for such classification of image and video contexts, and local recognition-based methods of object detection and vision segmentation. We summarize the methods in the context of face recognition, action recognition and pose estimation based on three specific recognition tasks mentioned above. Furthermore, solo task and independent domain methods are summarized, which can be used for image classification, object detection and other related vision tasks. The performance of these Transformer-based models are compared and analyzed on the public datasets as well. Image classification is mostly used to represent features in terms of visual and class tokens. The vision Transformer (ViT) and data-efficient image Transformers (DeiT)-illustrated models have its potentials for ImageNet datasets. Object detection tasks are required to detect targeted objects derived from input visual data, and the coordinates and labels of a series of bounding boxes are predictable as well. Object detection is illustrated by detection Transformer (DETR), which can alter the indirectness of previous classification and regression through proposals, anchors or windows. Subsequently, other related literatures are focused on improving the feature maps, computational complexity and convergence speed of DETR to a certain extent, such as conditional DETR, deformable DETR, unsupervised pre-training DETR (UP-DETR). Additionally, Transformer-based models have preferred relevant to such applications of salient object detection, point cloud 3D detection and few-shot object detection. Semantic segmentation tasks are required for an assignment from class label to each pixel in the image and the bounding box of the object like object detection can be predicted and optimized further. However, semantic segmentation can be used to determine pixel classes only, and it is still challenged to identify multiple instances-between similar pixels. Transformer is also paid attention to improve U-Net for medical image segmentation. It is possible to link the Transformer with pyramid network, or design different decoder structures for pixel-by-pixel segmentation, such as segmentation Transformer progressive upsampling (SETR-PUP) and segmentation Transformer multi-level feature aggregation (SETR-MLA). Mask classification methods are commonly used in instance segmentation and it can also be used for semantic segmentation via Transformer structure like a segmenter. Instance segmentation is similar to the combination of object detection and semantic segmentation. Compared to the bounding box of object detection, the output of instance segmentation is a mask, which can segment the edges of objects and distinguish different instances of similar objects. It can optimize the ability of semantic segmentation to some extent. Transformer can be used to melt more end-to-end methods into instance segmentation, and the quality of the masks can be used and improved during the segmentation process. Transformer can provide an alignment-free method for face recognition, and it can handle noises in related to facial expressions and racial bias. Action recognition tasks are required to classify videos-input human actions, which are similar to image classification tasks and additional processing of the temporal dimension is not avoidable. Transformer is developed for modeling long-term temporal and spatial dependencies for action recognition beyond two-stream network and three-dimensional convolution. Pose estimation is usually recognized as a human body keypoints-sorted problem and parts-between spatial relationship is identified. It consists of 2D pose estimation and 3D pose estimation. The former one is generally used to determine two-dimensional coordinates of body parts, while the latter one adds depth information on the basis of two-dimensional coordinates. Transformer is used to refine keypoint features for pose estimation, and the modeling of intra-frame node relationships and inter-frame temporal relationships are optimized as well. Multi-task models based Transformer research is focused on the integration of image classification, object detection and semantic segmentation tasks. Some other related popular models are also proposed that can be used in vision and language domains. Extensive research has shown the effectiveness of the vision Transformer in recognition tasks, and feature representation or network structure-relevant optimization is beneficial for its performance improvement. Future research direction are predicted in relevance to such effective and efficient methods for accuracy preservation in the context of positional encoding, self-supervised learning, multimodal integrating, and computational cost cutting.关键词:vision Transformer (ViT);self-attention;vision recognition;deep learning;image processing;video understanding307|2498|7更新时间:2024-05-07
摘要:Due to its ability to model long-distance dependencies, self-attention mechanism for adaptive computing, scalability for large models and big data, and better connection between vision and language, Transformer model is beneficial for natural language processing and computer vision apparently. To melt Transformer into vision tasks, such vision Transformer methods have been developing intensively. Current literatures can be summarized and analyzed for multiple applications-related methods. However, these different applications are often heterogeneous for various methods. In addition, comparative analysis is often focused on between Transformer and traditional convolution neural networks (CNNs), and multi-Transformer models are less involved in and linked mutually. We summarize and compare more than 100 popular methods of vision Transformer for various recognition tasks. Global recognition-based methods are reviewed for such classification of image and video contexts, and local recognition-based methods of object detection and vision segmentation. We summarize the methods in the context of face recognition, action recognition and pose estimation based on three specific recognition tasks mentioned above. Furthermore, solo task and independent domain methods are summarized, which can be used for image classification, object detection and other related vision tasks. The performance of these Transformer-based models are compared and analyzed on the public datasets as well. Image classification is mostly used to represent features in terms of visual and class tokens. The vision Transformer (ViT) and data-efficient image Transformers (DeiT)-illustrated models have its potentials for ImageNet datasets. Object detection tasks are required to detect targeted objects derived from input visual data, and the coordinates and labels of a series of bounding boxes are predictable as well. Object detection is illustrated by detection Transformer (DETR), which can alter the indirectness of previous classification and regression through proposals, anchors or windows. Subsequently, other related literatures are focused on improving the feature maps, computational complexity and convergence speed of DETR to a certain extent, such as conditional DETR, deformable DETR, unsupervised pre-training DETR (UP-DETR). Additionally, Transformer-based models have preferred relevant to such applications of salient object detection, point cloud 3D detection and few-shot object detection. Semantic segmentation tasks are required for an assignment from class label to each pixel in the image and the bounding box of the object like object detection can be predicted and optimized further. However, semantic segmentation can be used to determine pixel classes only, and it is still challenged to identify multiple instances-between similar pixels. Transformer is also paid attention to improve U-Net for medical image segmentation. It is possible to link the Transformer with pyramid network, or design different decoder structures for pixel-by-pixel segmentation, such as segmentation Transformer progressive upsampling (SETR-PUP) and segmentation Transformer multi-level feature aggregation (SETR-MLA). Mask classification methods are commonly used in instance segmentation and it can also be used for semantic segmentation via Transformer structure like a segmenter. Instance segmentation is similar to the combination of object detection and semantic segmentation. Compared to the bounding box of object detection, the output of instance segmentation is a mask, which can segment the edges of objects and distinguish different instances of similar objects. It can optimize the ability of semantic segmentation to some extent. Transformer can be used to melt more end-to-end methods into instance segmentation, and the quality of the masks can be used and improved during the segmentation process. Transformer can provide an alignment-free method for face recognition, and it can handle noises in related to facial expressions and racial bias. Action recognition tasks are required to classify videos-input human actions, which are similar to image classification tasks and additional processing of the temporal dimension is not avoidable. Transformer is developed for modeling long-term temporal and spatial dependencies for action recognition beyond two-stream network and three-dimensional convolution. Pose estimation is usually recognized as a human body keypoints-sorted problem and parts-between spatial relationship is identified. It consists of 2D pose estimation and 3D pose estimation. The former one is generally used to determine two-dimensional coordinates of body parts, while the latter one adds depth information on the basis of two-dimensional coordinates. Transformer is used to refine keypoint features for pose estimation, and the modeling of intra-frame node relationships and inter-frame temporal relationships are optimized as well. Multi-task models based Transformer research is focused on the integration of image classification, object detection and semantic segmentation tasks. Some other related popular models are also proposed that can be used in vision and language domains. Extensive research has shown the effectiveness of the vision Transformer in recognition tasks, and feature representation or network structure-relevant optimization is beneficial for its performance improvement. Future research direction are predicted in relevance to such effective and efficient methods for accuracy preservation in the context of positional encoding, self-supervised learning, multimodal integrating, and computational cost cutting.关键词:vision Transformer (ViT);self-attention;vision recognition;deep learning;image processing;video understanding307|2498|7更新时间:2024-05-07 -
 摘要:Human-biometric age information has been widely used for such domains like public security and digital entertainment. Such of human-facial-related age synthesis methods are mainly divided into traditional image processing methods and machine learning-based methods. Traditional image processing methods are divided into physics-based methods and prototype-based methods. Machine learning based method is focused on the model-based method, which can be divided into parametric linear model method, deep generative model method based on the time frame and generative adversarial network (GAN)-based method. The physics-based methods are focused on intuitive facial features only, for which some subtle changes are inevitably ignored, resulting in the irrationality of synthetic images. In addition, it requires a large number of facial samples for the same person at several of ages, which is costly and labor-intensive to be collected. The aging patterns generated by the prototype-based method are obtained by faces-related averaging value, and some important personalized features may be averaged, resulting in the loss of personal identity. Severe ghosting artifacts will be appeared in their synthetic images while some dictionary-based learning methods are used to preserve personalized features to some extent. Its related parametric linear model method and the deep generative model method based on the time frame are still challenged to find a general model suitable for a specific age group, and its following model established is still linear, so the quality of its synthetic image is deficient as well. The emerging GAN-based method can be used to train models using deep convolution network. Aging patterns-related age groups is learnt in terms of the generative adversarial learning mechanism, different types of loss functions are introduced for various problems appearing in the image, and the minimum value of the perceptual loss of the original image is sorted out. Aging mode can be realized in the input face image, and identity information can be preserved simultaneously. Recent GAN framework is derived of a series of variant models and has been optimizing consistently. GAN-based age synthesis methods can be segmented into four sorts of categories: GAN-classical, GAN-sequential, GAN-translational and GAN-conditional. For classical GAN method, it can be used to simulate face aging. However, the input information is not fully considered, which affects the identity retention, and all age maps and networks are limited under the control of age conditions, and the age accuracy of the generated image need to be optimized further. For sequential GAN method, it focuses on the sequential relationship of datasets, and there is a severe dependency. If the output of a certain model goes wrong, the performance of the whole model will be affected. Additionally, it requires consistent and completed images for each age group. The potentials of translational GAN is that a large number of photos of the same person are not required at different ages, and it needs sufficient images for each age group in the datasets only. Conditional GAN requires clear and correct labels for datasets. Compared to the methods based on translational GAN and sequential GAN, conditional GAN is extremely linked to the given limited tags in the datasets, and it is difficult to get refined control further. GAN-based methods can be used to improve the quality of generated images, but there are still some challenging problems to be resolved. Although various of face age synthesis methods based on generative adversarial network has achieved considerable progress, the generated face age image still has some problems, such as poor image quality, low realism, insufficient age transition effect and diversity. At present, the research of face age synthesis is still facing the following problems and challenges: 1) the limitations of existing face age synthesis datasets; 2) lack of prior knowledge of face age synthesis; 3) the ignored fine granularity of face age image; 4) face-related age synthesis at high resolution; and 5) current non-standardized evaluation of face age synthesis methods. Our literature review of the current face age synthesis technology is proposed, and current research situation is reviewed based on current facial age synthesis method as well. The methods of facial age synthesis can be classified, and generative adversarial network based method can be focused on as well. The commonly-used face age synthesis datasets and evaluation indicators are discussed, and the basic ideas, characteristics, and limitations of various face age synthesis methods are analyzed further. We also compare the performance of several representative methods on popular age synthesis datasets. We also predict some potential research directions and its in-depth development of related technologies.关键词:face age synthesis;image generation;face image database;face aging;deep generative approach;generative adversarial network (GAN)217|650|1更新时间:2024-05-07
摘要:Human-biometric age information has been widely used for such domains like public security and digital entertainment. Such of human-facial-related age synthesis methods are mainly divided into traditional image processing methods and machine learning-based methods. Traditional image processing methods are divided into physics-based methods and prototype-based methods. Machine learning based method is focused on the model-based method, which can be divided into parametric linear model method, deep generative model method based on the time frame and generative adversarial network (GAN)-based method. The physics-based methods are focused on intuitive facial features only, for which some subtle changes are inevitably ignored, resulting in the irrationality of synthetic images. In addition, it requires a large number of facial samples for the same person at several of ages, which is costly and labor-intensive to be collected. The aging patterns generated by the prototype-based method are obtained by faces-related averaging value, and some important personalized features may be averaged, resulting in the loss of personal identity. Severe ghosting artifacts will be appeared in their synthetic images while some dictionary-based learning methods are used to preserve personalized features to some extent. Its related parametric linear model method and the deep generative model method based on the time frame are still challenged to find a general model suitable for a specific age group, and its following model established is still linear, so the quality of its synthetic image is deficient as well. The emerging GAN-based method can be used to train models using deep convolution network. Aging patterns-related age groups is learnt in terms of the generative adversarial learning mechanism, different types of loss functions are introduced for various problems appearing in the image, and the minimum value of the perceptual loss of the original image is sorted out. Aging mode can be realized in the input face image, and identity information can be preserved simultaneously. Recent GAN framework is derived of a series of variant models and has been optimizing consistently. GAN-based age synthesis methods can be segmented into four sorts of categories: GAN-classical, GAN-sequential, GAN-translational and GAN-conditional. For classical GAN method, it can be used to simulate face aging. However, the input information is not fully considered, which affects the identity retention, and all age maps and networks are limited under the control of age conditions, and the age accuracy of the generated image need to be optimized further. For sequential GAN method, it focuses on the sequential relationship of datasets, and there is a severe dependency. If the output of a certain model goes wrong, the performance of the whole model will be affected. Additionally, it requires consistent and completed images for each age group. The potentials of translational GAN is that a large number of photos of the same person are not required at different ages, and it needs sufficient images for each age group in the datasets only. Conditional GAN requires clear and correct labels for datasets. Compared to the methods based on translational GAN and sequential GAN, conditional GAN is extremely linked to the given limited tags in the datasets, and it is difficult to get refined control further. GAN-based methods can be used to improve the quality of generated images, but there are still some challenging problems to be resolved. Although various of face age synthesis methods based on generative adversarial network has achieved considerable progress, the generated face age image still has some problems, such as poor image quality, low realism, insufficient age transition effect and diversity. At present, the research of face age synthesis is still facing the following problems and challenges: 1) the limitations of existing face age synthesis datasets; 2) lack of prior knowledge of face age synthesis; 3) the ignored fine granularity of face age image; 4) face-related age synthesis at high resolution; and 5) current non-standardized evaluation of face age synthesis methods. Our literature review of the current face age synthesis technology is proposed, and current research situation is reviewed based on current facial age synthesis method as well. The methods of facial age synthesis can be classified, and generative adversarial network based method can be focused on as well. The commonly-used face age synthesis datasets and evaluation indicators are discussed, and the basic ideas, characteristics, and limitations of various face age synthesis methods are analyzed further. We also compare the performance of several representative methods on popular age synthesis datasets. We also predict some potential research directions and its in-depth development of related technologies.关键词:face age synthesis;image generation;face image database;face aging;deep generative approach;generative adversarial network (GAN)217|650|1更新时间:2024-05-07 -
 摘要:Power grid is recognized as a key infrastructure for national energy security, and its surveillances and consistency of power lines can be used to facilitate nation’s capacity building. In recent years, the growth of electricity demand has been increasing intensively, and the distribution of power lines is much more wide-ranged, and its total mileage has also been extended dramatically. Due to the installation of power lines in a complicated natural environment in relevance to such factors like perennial exposure to wind, sun and rain, coupled with snow and ice coverage and other related extreme weather conditions, the loss or damage of power lines-related equipment is inevitable. Regular inspection has often been implemented to ensure the consistent supply of power and its security surveillances and power lines contexts. Existing methods of power lines-relevant inspection are often in the context of such domains of manual, robot, helicopter, remote sensing satellite, and unmanned aerial vehicle (UAV). The UAV inspection can be recognized as the key mode of power lines inspection in China to some extent. However, UAV-based inspection of power lines is still challenged for a large number of aerial images. Its manual detection is labor intensive, and missing detection or misjudgment is produced as well. Simultaneously, the preservation of power lines is also very challenged for UAV inspection. Such power lines detection plays an important role in autonomous navigation for UAV, low altitude obstacle avoidance flight and safe and stable operation of power grid. Therefore, UAV-captured aerial images analysis is used to detect power equipment, and machine vision is concerned for aerial images-based power lines detection, which can be as one of the potential direction for future research development. The literature is reviewed for decadal growth of machine vision based power lines detection using aerial images-captured source (main data source) and artificial intelligence algorithm (main implementation method). First, the geometric features of power lines in aerial images are briefly illustrated. Traditional image processing method based power lines detection is reviewed in terms of power lines detection, including image pre-processing, edge detection, power lines recognition, power lines fitting, and current challenges in power lines detection are listed below, e.g., image blurred, complex and changeable background, non-significant power line features, weather conditions and other related factors. Second, two sorts of conventional image processing and deep learning method based power lines detection mechanisms are involved in. In detail, traditional image processing methods for power lines detection are divided into such methods relevant to Hough transform, Radon transform, line segment detector (LSD), scan mark, and its contexts. The network structure of the deep convolutional neural network (DCNN) based deep learning methods are divided into its classification and semantic segmentation for power lines detection. The pros and cons of multiple methods are reviewed and analyzed further. Comparative analysis is carried out as follows: Hough and Radon transform based power lines detection are based on global feature extraction methods, which have some challenges to be resolved like high computational cost and large memory resources. The LSD and scan mark based detection methods have its potentials to optimize Hough and Radon transform. The LSD algorithm is preferred for high precision and short running time, but the algorithm is vulnerable to noise. The power lines-related feature extraction is incomplete based on scan mark, and they are prone to be distorted and fractured. In a word, to meet the requirement for automatic detection of power lines, traditional image processing methods mentioned above cannot be used to identify power lines effectively among many straight lines, and different thresholds are required to be set manually for different application scenarios and some threshold parameters need to be validated further. The deep learning methods for power lines detection can be used to learn and extract image features automatically, and end-to-end power lines detection can be realized without manual-based features design and adjustable threshold parameters. The power lines-related classification methods can be used to detect the coverage or non-coverage of power lines in aerial images only. But, the detailed location of power lines is still unclear while the power lines semantic segmentation methods can be used to extract location information of power lines automatically. Compared to the traditional image processing method, deep learning method is more effective in related to aerial images-derived detection of power lines, which is more accurate and faster than the traditional image processing method, and DCNN-based semantic segmentation method is essential for the intelligent recognition and analysis of power lines. Popular dataset and performance evaluation index of power lines detection are introduced as well. Finally, due to the problems of power lines detection methods based on deep learning is existed, future research work is predicted and focused on integrated dataset and dataset quality evaluation index, annotation of small sample dataset, fusion of multiple deep learning models, deep fusion of multiple learning, and fusion of multi-source data. To improve the stability and real-time performance of detection models, the application of machine vision technology can be greatly facilitated in power lines inspection, even for the whole smart grid further.关键词:machine vision;power lines detection;unmanned aerial vehicle (UAV) inspection;image processing;deep learning;semantic segmentation306|1495|1更新时间:2024-05-07
摘要:Power grid is recognized as a key infrastructure for national energy security, and its surveillances and consistency of power lines can be used to facilitate nation’s capacity building. In recent years, the growth of electricity demand has been increasing intensively, and the distribution of power lines is much more wide-ranged, and its total mileage has also been extended dramatically. Due to the installation of power lines in a complicated natural environment in relevance to such factors like perennial exposure to wind, sun and rain, coupled with snow and ice coverage and other related extreme weather conditions, the loss or damage of power lines-related equipment is inevitable. Regular inspection has often been implemented to ensure the consistent supply of power and its security surveillances and power lines contexts. Existing methods of power lines-relevant inspection are often in the context of such domains of manual, robot, helicopter, remote sensing satellite, and unmanned aerial vehicle (UAV). The UAV inspection can be recognized as the key mode of power lines inspection in China to some extent. However, UAV-based inspection of power lines is still challenged for a large number of aerial images. Its manual detection is labor intensive, and missing detection or misjudgment is produced as well. Simultaneously, the preservation of power lines is also very challenged for UAV inspection. Such power lines detection plays an important role in autonomous navigation for UAV, low altitude obstacle avoidance flight and safe and stable operation of power grid. Therefore, UAV-captured aerial images analysis is used to detect power equipment, and machine vision is concerned for aerial images-based power lines detection, which can be as one of the potential direction for future research development. The literature is reviewed for decadal growth of machine vision based power lines detection using aerial images-captured source (main data source) and artificial intelligence algorithm (main implementation method). First, the geometric features of power lines in aerial images are briefly illustrated. Traditional image processing method based power lines detection is reviewed in terms of power lines detection, including image pre-processing, edge detection, power lines recognition, power lines fitting, and current challenges in power lines detection are listed below, e.g., image blurred, complex and changeable background, non-significant power line features, weather conditions and other related factors. Second, two sorts of conventional image processing and deep learning method based power lines detection mechanisms are involved in. In detail, traditional image processing methods for power lines detection are divided into such methods relevant to Hough transform, Radon transform, line segment detector (LSD), scan mark, and its contexts. The network structure of the deep convolutional neural network (DCNN) based deep learning methods are divided into its classification and semantic segmentation for power lines detection. The pros and cons of multiple methods are reviewed and analyzed further. Comparative analysis is carried out as follows: Hough and Radon transform based power lines detection are based on global feature extraction methods, which have some challenges to be resolved like high computational cost and large memory resources. The LSD and scan mark based detection methods have its potentials to optimize Hough and Radon transform. The LSD algorithm is preferred for high precision and short running time, but the algorithm is vulnerable to noise. The power lines-related feature extraction is incomplete based on scan mark, and they are prone to be distorted and fractured. In a word, to meet the requirement for automatic detection of power lines, traditional image processing methods mentioned above cannot be used to identify power lines effectively among many straight lines, and different thresholds are required to be set manually for different application scenarios and some threshold parameters need to be validated further. The deep learning methods for power lines detection can be used to learn and extract image features automatically, and end-to-end power lines detection can be realized without manual-based features design and adjustable threshold parameters. The power lines-related classification methods can be used to detect the coverage or non-coverage of power lines in aerial images only. But, the detailed location of power lines is still unclear while the power lines semantic segmentation methods can be used to extract location information of power lines automatically. Compared to the traditional image processing method, deep learning method is more effective in related to aerial images-derived detection of power lines, which is more accurate and faster than the traditional image processing method, and DCNN-based semantic segmentation method is essential for the intelligent recognition and analysis of power lines. Popular dataset and performance evaluation index of power lines detection are introduced as well. Finally, due to the problems of power lines detection methods based on deep learning is existed, future research work is predicted and focused on integrated dataset and dataset quality evaluation index, annotation of small sample dataset, fusion of multiple deep learning models, deep fusion of multiple learning, and fusion of multi-source data. To improve the stability and real-time performance of detection models, the application of machine vision technology can be greatly facilitated in power lines inspection, even for the whole smart grid further.关键词:machine vision;power lines detection;unmanned aerial vehicle (UAV) inspection;image processing;deep learning;semantic segmentation306|1495|1更新时间:2024-05-07
Review

-
 摘要:ObjectiveComputer vision-related stereoscopic image quality assessment (SIQA) is focused on recently. It is essential for parameter setting and system optimizing for such domains of multiple stereoscopic image applications like image storage, compression, transmission, and display. Stereoscopic images can be segmented into two sorts of distorted images: symmetrically and asymmetrically distorted, in terms of the degree of degradation between the left and right views. For symmetric-based distorted stereoscopic images, the distortion type and degree occurred in the left and right views are basically in consistency. Early SIQA methods were effective in evaluating symmetrically distorted images by averaging scores or features derived from the two views. However, in practice, the stereoscopic images are often asymmetrically distorted, where the distortion type and level of the two views are different. Simply averaging the quality values of the two views cannot accurately simulate the binocular fusion process and the binocular rivalry phenomena in relevance to the human visual system. Consequently, the evaluation accuracy of these methods will be down to severe lower when the quality of asymmetrically distorted stereoscopic images is estimated. Previous studies have shown that when the left and right views of a stereoscopic image exhibit varying levels or types of distortion, binocular rivalry is primarily driven by one of the views. Specially, in the process of evaluating the quality of a stereoscopic image, the visual quality of one view has a greater impact on the stereopair quality evaluation than the other view. To address this issue, some methods have simulated the binocular rivalry phenomenon in human visual system, and used a weighted average method to fuse the visual information in the two views of stereo-pairs as well. However, existing methods are still challenged for its lower prediction accuracy of asymmetrically distorted images, and its feature extraction process is also time-consuming. To optimize the evaluation accuracy of asymmetrically distorted images, we develop a binocular rivalry-based no-reference SIQA method.MethodMultiple information-contained is used to generate image quality degradation coefficients in the two views, which can describe the degradation level of the distorted images accurately. According to the binocular rivalry phenomena in human visual system, the image quality degradation coefficients are used to generate fusion coefficients, which can be used to fuse the views-derived monocular features, including gray-scale features and HSV color space-extracted statistics. Since the human visual system is sensitive to structural information, the binocular structural similarity map (BSSIM) is constructed to measure the structural difference between the left and right views. As one part of the binocular difference features, structural difference features are extracted from the BSSIM. To quantify the differences between the left and right views, other related binocular difference features like entropy difference and degradation difference are obtained further. Finally, the binocular fusion features and the binocular difference features are concatenated into a more descriptive quality-aware feature vector, and a support vector regression model is trained to map the feature vector to the perception quality. In addition, to classify the symmetrically distorted stereoscopic images and the asymmetrically distorted stereoscopic images, a support vector classification model is also trained using the binocular difference features.ResultTo verify the performance of the proposed SIQA method, 4 sorts of publicly benchmark stereoscopic image databases are employed in relevance to the symmetrically and asymmetrically distorted stereoscopic images-involved LIVE 3D IQA Database Phase II (LIVE-II), Waterloo-IVC 3D IQA Database Phase I (IVC-I), and Waterloo-IVC 3D IQA Database Phase II (IVC-II). Symmetrically distorted stereoscopic images are only involved in the LIVE 3D IQA Database Phase I (LIVE-I). Comparative analysis is carried out in related to 10 state-of-the-art SIQA metrics. To measure the performance, three kinds of commonly-used performance indicators are involved in, including Spearman rank ordered correlation coefficient (SROCC), Pearson linear correlation coefficient (PLCC), and the root-mean-squared error (RMSE). The experimental results demonstrate that the SROCCs and the PLCCs (higher is better) of the proposed method are higher than 0.95. Furthermore, the RMSEs (lower is better) of the proposed method can be reached to a potential lower degree. Additionally, the proposed classifier is tested on LIVE-II, IVC-I, and IVC-II databases. For LIVE-II database, 95.46% of asymmetrically distorted stereoscopic images can be classified accurately. For IVC-I and IVC-II databases, each of classification accuracy of symmetrically distorted images can be reached to 94.76% and 98.97%, and each of the classification accuracy of asymmetrically distorted images can be reached to 92.64% and 96.22% as well.ConclusionThe degradation level can be quantified for the two views of asymmetrically distorted stereoscopic images. The image quality degradation coefficients are employed to fuse the monocular features, and it is beneficial to develop a more descriptive binocular perception feature vector and an improved prediction accuracy and robustness of asymmetrically distorted stereoscopic images. The proposed classifier can be used to clarify the symmetrically distorted stereoscopic images and the asymmetrically distorted stereoscopic images as well.关键词:stereoscopic image quality assessment (SIQA);asymmetric distortions;binocular rivalry;image quality degradation coefficients;binocular difference features95|216|1更新时间:2024-05-07
摘要:ObjectiveComputer vision-related stereoscopic image quality assessment (SIQA) is focused on recently. It is essential for parameter setting and system optimizing for such domains of multiple stereoscopic image applications like image storage, compression, transmission, and display. Stereoscopic images can be segmented into two sorts of distorted images: symmetrically and asymmetrically distorted, in terms of the degree of degradation between the left and right views. For symmetric-based distorted stereoscopic images, the distortion type and degree occurred in the left and right views are basically in consistency. Early SIQA methods were effective in evaluating symmetrically distorted images by averaging scores or features derived from the two views. However, in practice, the stereoscopic images are often asymmetrically distorted, where the distortion type and level of the two views are different. Simply averaging the quality values of the two views cannot accurately simulate the binocular fusion process and the binocular rivalry phenomena in relevance to the human visual system. Consequently, the evaluation accuracy of these methods will be down to severe lower when the quality of asymmetrically distorted stereoscopic images is estimated. Previous studies have shown that when the left and right views of a stereoscopic image exhibit varying levels or types of distortion, binocular rivalry is primarily driven by one of the views. Specially, in the process of evaluating the quality of a stereoscopic image, the visual quality of one view has a greater impact on the stereopair quality evaluation than the other view. To address this issue, some methods have simulated the binocular rivalry phenomenon in human visual system, and used a weighted average method to fuse the visual information in the two views of stereo-pairs as well. However, existing methods are still challenged for its lower prediction accuracy of asymmetrically distorted images, and its feature extraction process is also time-consuming. To optimize the evaluation accuracy of asymmetrically distorted images, we develop a binocular rivalry-based no-reference SIQA method.MethodMultiple information-contained is used to generate image quality degradation coefficients in the two views, which can describe the degradation level of the distorted images accurately. According to the binocular rivalry phenomena in human visual system, the image quality degradation coefficients are used to generate fusion coefficients, which can be used to fuse the views-derived monocular features, including gray-scale features and HSV color space-extracted statistics. Since the human visual system is sensitive to structural information, the binocular structural similarity map (BSSIM) is constructed to measure the structural difference between the left and right views. As one part of the binocular difference features, structural difference features are extracted from the BSSIM. To quantify the differences between the left and right views, other related binocular difference features like entropy difference and degradation difference are obtained further. Finally, the binocular fusion features and the binocular difference features are concatenated into a more descriptive quality-aware feature vector, and a support vector regression model is trained to map the feature vector to the perception quality. In addition, to classify the symmetrically distorted stereoscopic images and the asymmetrically distorted stereoscopic images, a support vector classification model is also trained using the binocular difference features.ResultTo verify the performance of the proposed SIQA method, 4 sorts of publicly benchmark stereoscopic image databases are employed in relevance to the symmetrically and asymmetrically distorted stereoscopic images-involved LIVE 3D IQA Database Phase II (LIVE-II), Waterloo-IVC 3D IQA Database Phase I (IVC-I), and Waterloo-IVC 3D IQA Database Phase II (IVC-II). Symmetrically distorted stereoscopic images are only involved in the LIVE 3D IQA Database Phase I (LIVE-I). Comparative analysis is carried out in related to 10 state-of-the-art SIQA metrics. To measure the performance, three kinds of commonly-used performance indicators are involved in, including Spearman rank ordered correlation coefficient (SROCC), Pearson linear correlation coefficient (PLCC), and the root-mean-squared error (RMSE). The experimental results demonstrate that the SROCCs and the PLCCs (higher is better) of the proposed method are higher than 0.95. Furthermore, the RMSEs (lower is better) of the proposed method can be reached to a potential lower degree. Additionally, the proposed classifier is tested on LIVE-II, IVC-I, and IVC-II databases. For LIVE-II database, 95.46% of asymmetrically distorted stereoscopic images can be classified accurately. For IVC-I and IVC-II databases, each of classification accuracy of symmetrically distorted images can be reached to 94.76% and 98.97%, and each of the classification accuracy of asymmetrically distorted images can be reached to 92.64% and 96.22% as well.ConclusionThe degradation level can be quantified for the two views of asymmetrically distorted stereoscopic images. The image quality degradation coefficients are employed to fuse the monocular features, and it is beneficial to develop a more descriptive binocular perception feature vector and an improved prediction accuracy and robustness of asymmetrically distorted stereoscopic images. The proposed classifier can be used to clarify the symmetrically distorted stereoscopic images and the asymmetrically distorted stereoscopic images as well.关键词:stereoscopic image quality assessment (SIQA);asymmetric distortions;binocular rivalry;image quality degradation coefficients;binocular difference features95|216|1更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveTransmission line is a key of infrastructure of power system. To keep the stability of the power system, it is required to preserve key components-based operation in the transmission line like fittings. Fittings are recognized as aluminum or iron-made metal accessories for multiple applications in relevant to such domains of protective fittings, connecting fittings, tension clamps and suspension clamps. Fittings can be mainly used to support, fix and connect bare conductors and insulators. Such components are erosional for such complicated natural environment year by year. They are likely to have displacement, deflection and damage, which will affect the stability of the transmission system structure. If the defects of fittings are not sorted out quickly, they will cause severe circuit-damaged accidents. To assess status of the fittings and realize fault diagnosis, it is required to locate and identify the target of the transmission line fittings accurately. The emerging deep learning and unmanned aerial vehicle inspection techniques have been developing to optimize conventional single manual inspection technology further. A maintenance mode is melted into gradually, which can use unmanned aerial vehicle to acquire images, and the deep learning method is then incorporated to process aerial photos automatically. Most of these methods are focused on supervised learning only, that is, model training-before artificial data annotation is required for. As more and more data on transmission line components are collected by unmanned aerial vehicle patrols, manual labeling requires a large amount of human resources, and such missing and incorrect labeling problems will be occurred after that. To resolve this problem, we develop a fitting detection model based on self-supervised Transformer. Self-supervised learning is focused on unlabeled data-related pretext task design to mine the feature representation of the data itself and improve the feature extraction ability of the model. Less supervised data is then used for fine-tuning training through detection or segmentation-related downstream tasks. To resolve the problem of large amount of the model calculation, Swin Transformer is improved and an efficient one-stage fitting detection model is built up based on self-supervised learning.MethodTransformer model has shown its great potentials for computer vision in recent years. Due to its global self-attention calculation, Transformer can be used to extract more effective image feature information than convolutional neural network (CNN) to some extent. In addition, self-supervised learning feature of Transformer in natural language processing (NLP) domain has been gradually developing in computer vision (CV) domain. The fitting detection method proposed is segmented into three main categories. First, Swin Transformer is used as the backbone network. The calculation of self-attention is improved to solve the problem of large amount of calculation, and a smaller and more efficient backbone E-Swin is generated further. Second, the self-supervised pretext task of image reconstruction is designed. The improved backbone network is pre-trained in terms of self-supervised learning, and feature extraction ability of the model is trained in related to a large number of unlabeled data. After the self-supervised training, the network will be used as the backbone of the detection model. Finally, to improve the detection accuracy and get the final model, an optimized detector head is used to establish a high-precision one-stage detection model, and a small amount of labeled data is used for fine-tuning training.ResultThe transmission line fittings dataset is used to train and evaluate the model. The samples of image data are cut out derived from the inspection of the transmission line unmanned aerial vehicle (UAV). The first dataset is a large number of unlabeled data for self-supervised learning. The aerial photos-related dataset is clipped directly to remove background redundancy and preserve valid target information. The second dataset is a kind of labeled dataset for fine-tuning with a total of 1 600 images. It is split into train samples and test samples according to the ratio of 4∶1. These samples consist of 12 types of fittings with a total labeled target of 10 178. The experimental results show that the average precision (AP50) of the model on the transmission line fittings dataset is 88.6%, which is 10% higher than the traditional detection models.ConclusionSelf-attention calculation of the backbone network is improved. Self-supervised learning can be used to extract efficient features and effective application of unlabeled data can be realized. A one-stage fitting detection model is facilitated for resolving the problem of data application in transmission line fittings detection further.关键词:deep learning;object detection;transmission line fitting;self-supervised learning;E-swin Transformer;one-stage detector188|170|1更新时间:2024-05-07
摘要:ObjectiveTransmission line is a key of infrastructure of power system. To keep the stability of the power system, it is required to preserve key components-based operation in the transmission line like fittings. Fittings are recognized as aluminum or iron-made metal accessories for multiple applications in relevant to such domains of protective fittings, connecting fittings, tension clamps and suspension clamps. Fittings can be mainly used to support, fix and connect bare conductors and insulators. Such components are erosional for such complicated natural environment year by year. They are likely to have displacement, deflection and damage, which will affect the stability of the transmission system structure. If the defects of fittings are not sorted out quickly, they will cause severe circuit-damaged accidents. To assess status of the fittings and realize fault diagnosis, it is required to locate and identify the target of the transmission line fittings accurately. The emerging deep learning and unmanned aerial vehicle inspection techniques have been developing to optimize conventional single manual inspection technology further. A maintenance mode is melted into gradually, which can use unmanned aerial vehicle to acquire images, and the deep learning method is then incorporated to process aerial photos automatically. Most of these methods are focused on supervised learning only, that is, model training-before artificial data annotation is required for. As more and more data on transmission line components are collected by unmanned aerial vehicle patrols, manual labeling requires a large amount of human resources, and such missing and incorrect labeling problems will be occurred after that. To resolve this problem, we develop a fitting detection model based on self-supervised Transformer. Self-supervised learning is focused on unlabeled data-related pretext task design to mine the feature representation of the data itself and improve the feature extraction ability of the model. Less supervised data is then used for fine-tuning training through detection or segmentation-related downstream tasks. To resolve the problem of large amount of the model calculation, Swin Transformer is improved and an efficient one-stage fitting detection model is built up based on self-supervised learning.MethodTransformer model has shown its great potentials for computer vision in recent years. Due to its global self-attention calculation, Transformer can be used to extract more effective image feature information than convolutional neural network (CNN) to some extent. In addition, self-supervised learning feature of Transformer in natural language processing (NLP) domain has been gradually developing in computer vision (CV) domain. The fitting detection method proposed is segmented into three main categories. First, Swin Transformer is used as the backbone network. The calculation of self-attention is improved to solve the problem of large amount of calculation, and a smaller and more efficient backbone E-Swin is generated further. Second, the self-supervised pretext task of image reconstruction is designed. The improved backbone network is pre-trained in terms of self-supervised learning, and feature extraction ability of the model is trained in related to a large number of unlabeled data. After the self-supervised training, the network will be used as the backbone of the detection model. Finally, to improve the detection accuracy and get the final model, an optimized detector head is used to establish a high-precision one-stage detection model, and a small amount of labeled data is used for fine-tuning training.ResultThe transmission line fittings dataset is used to train and evaluate the model. The samples of image data are cut out derived from the inspection of the transmission line unmanned aerial vehicle (UAV). The first dataset is a large number of unlabeled data for self-supervised learning. The aerial photos-related dataset is clipped directly to remove background redundancy and preserve valid target information. The second dataset is a kind of labeled dataset for fine-tuning with a total of 1 600 images. It is split into train samples and test samples according to the ratio of 4∶1. These samples consist of 12 types of fittings with a total labeled target of 10 178. The experimental results show that the average precision (AP50) of the model on the transmission line fittings dataset is 88.6%, which is 10% higher than the traditional detection models.ConclusionSelf-attention calculation of the backbone network is improved. Self-supervised learning can be used to extract efficient features and effective application of unlabeled data can be realized. A one-stage fitting detection model is facilitated for resolving the problem of data application in transmission line fittings detection further.关键词:deep learning;object detection;transmission line fitting;self-supervised learning;E-swin Transformer;one-stage detector188|170|1更新时间:2024-05-07 -
 摘要:ObjectiveVideo grounding is an essential and challenging task in relevance to video understanding nowadays. A natural language query can be used to describe a particular video segment in an untrimmed video. Given such a natural language query, the target of video grounding is focused on locating an action segment in the untrimmed video. As a high-level semantic understanding task in computer vision, video grounding faces many challenges, since it requires the joint modeling of visual modality and linguistic modality simultaneously. First, compared to static images, the content of videos in the real world usually contains more complicated scenes. Such a few-minute video is usually composed of several action scenarios, which can be as an integration status of actors, objectives, and motions. Second, natural language is inevitably ambiguous and subjective to some extent. The description of the same activity may diverse. Intuitively, there is a big semantic gap for visual and textual-between modality. Therefore, it needs to build an appropriate video-text multi-modal feature for accurate grounding further. To resolve the challenges mentioned above, we facilitate a novel proposal-free method to learn an appropriate multi-modal features with motion excitation. Specifically, the motion excitation is exploited to highlight motion clues of multi-modal features for accurate grounding.MethodThe proposed method consists of three key modules relevant to: 1) feature extraction, 2) feature optimization, and 3) boundary prediction. First, for the feature extraction module, the 3D convolutional neural network (CNN) networks and a bi-directional long short-term memory (Bi-LSTM) layer is used to get the video and query features. To get fine-grained semantic cues from a language query, we extract attention mechanism-based phrase-level feature of the query. The video-text multi-modal features can be focused on multiple semantic phrases via fusing the phrase-level and video features. Subsequently, we highlight the motion information in the above multi-modal features in the feature optimization module. The features contain contextual clues of motion on temporal dimension. Meanwhile, some channels of the features represent the dynamic motion pattern of the target moment; the other channels represent irrelevant redundant information. To optimize multi-modal feature representation utilizing motion information, the skip-connection convolution and the motion excitation are used in the feature optimization module. 1) For the skip-connection convolution, a 1D temporal convolution network is used to model the local context of motion and align it with the query on the temporal dimension. 2) For the motion excitation, the temporal adjacent multi-modal feature vectors-between differences is calculated, and the attention weight distribution of motion channel response is constructed, and the motion-sensitive channels are activated. Finally, we aggregate the multi-modal features focused on different semantic phrases. Non-local neural network is utilized to model the dependency among different semantic phrases. A temporal attentive pooling module is employed to aggregate the feature into a vector and a multilayer perceptron (MLP) layer to regress the temporal boundaries as well.ResultExtensive experiments are carried out to verify the effectiveness of our proposed method on two public datasets, e.g., the Charades-STA dataset and the ActivityNet Captions dataset. Comparative analysis can be reached to 52.36% and 42.97% in terms of the evaluation metric mean intersection over union (mIoU) on these two datasets. In addition, each of the evaluation metric R@1, IoU = {0.3, 0.5, 0.7} can reach to 73.79%, 61.16%, 52.36% and 60.54%, 43.68%, 25.43%. It is also compared with such two methods like local-global video-text interactions (LGI) and contextual pyramid network (CPNet). Experimental results show that our proposed method achieves significant improvement in performance compared to other methods.ConclusionTo optimize the complicated scenes of the video and bridge the gap between the video and the language, we enhance the motion patterns in related to video grounding. Accordingly, the usage of the skip-connection convolution and the motion excitation can be used optimize video-text multi-modal feature representation effectively. In this way, the model can be used to represent semantic matching information between video clips and text queries accurately to a certain extent.关键词:video grounding;motion excitation;multi-modal feature representation;proposal free;computer vision;video understanding109|454|0更新时间:2024-05-07
摘要:ObjectiveVideo grounding is an essential and challenging task in relevance to video understanding nowadays. A natural language query can be used to describe a particular video segment in an untrimmed video. Given such a natural language query, the target of video grounding is focused on locating an action segment in the untrimmed video. As a high-level semantic understanding task in computer vision, video grounding faces many challenges, since it requires the joint modeling of visual modality and linguistic modality simultaneously. First, compared to static images, the content of videos in the real world usually contains more complicated scenes. Such a few-minute video is usually composed of several action scenarios, which can be as an integration status of actors, objectives, and motions. Second, natural language is inevitably ambiguous and subjective to some extent. The description of the same activity may diverse. Intuitively, there is a big semantic gap for visual and textual-between modality. Therefore, it needs to build an appropriate video-text multi-modal feature for accurate grounding further. To resolve the challenges mentioned above, we facilitate a novel proposal-free method to learn an appropriate multi-modal features with motion excitation. Specifically, the motion excitation is exploited to highlight motion clues of multi-modal features for accurate grounding.MethodThe proposed method consists of three key modules relevant to: 1) feature extraction, 2) feature optimization, and 3) boundary prediction. First, for the feature extraction module, the 3D convolutional neural network (CNN) networks and a bi-directional long short-term memory (Bi-LSTM) layer is used to get the video and query features. To get fine-grained semantic cues from a language query, we extract attention mechanism-based phrase-level feature of the query. The video-text multi-modal features can be focused on multiple semantic phrases via fusing the phrase-level and video features. Subsequently, we highlight the motion information in the above multi-modal features in the feature optimization module. The features contain contextual clues of motion on temporal dimension. Meanwhile, some channels of the features represent the dynamic motion pattern of the target moment; the other channels represent irrelevant redundant information. To optimize multi-modal feature representation utilizing motion information, the skip-connection convolution and the motion excitation are used in the feature optimization module. 1) For the skip-connection convolution, a 1D temporal convolution network is used to model the local context of motion and align it with the query on the temporal dimension. 2) For the motion excitation, the temporal adjacent multi-modal feature vectors-between differences is calculated, and the attention weight distribution of motion channel response is constructed, and the motion-sensitive channels are activated. Finally, we aggregate the multi-modal features focused on different semantic phrases. Non-local neural network is utilized to model the dependency among different semantic phrases. A temporal attentive pooling module is employed to aggregate the feature into a vector and a multilayer perceptron (MLP) layer to regress the temporal boundaries as well.ResultExtensive experiments are carried out to verify the effectiveness of our proposed method on two public datasets, e.g., the Charades-STA dataset and the ActivityNet Captions dataset. Comparative analysis can be reached to 52.36% and 42.97% in terms of the evaluation metric mean intersection over union (mIoU) on these two datasets. In addition, each of the evaluation metric R@1, IoU = {0.3, 0.5, 0.7} can reach to 73.79%, 61.16%, 52.36% and 60.54%, 43.68%, 25.43%. It is also compared with such two methods like local-global video-text interactions (LGI) and contextual pyramid network (CPNet). Experimental results show that our proposed method achieves significant improvement in performance compared to other methods.ConclusionTo optimize the complicated scenes of the video and bridge the gap between the video and the language, we enhance the motion patterns in related to video grounding. Accordingly, the usage of the skip-connection convolution and the motion excitation can be used optimize video-text multi-modal feature representation effectively. In this way, the model can be used to represent semantic matching information between video clips and text queries accurately to a certain extent.关键词:video grounding;motion excitation;multi-modal feature representation;proposal free;computer vision;video understanding109|454|0更新时间:2024-05-07 -
 摘要:ObjectiveObject tracking has been concerned more as such a domain in relevance to computer vision. In the past decade, correlation filter has been recognized for object tracking due to its high accuracy and speed. For traditional correlation filter tracking algorithms, training sample set is generated using circulant shift operation on the underlying image patches, and the circulant matrix is used to compute in the Fourier domain as well, which can improve the learning efficiency further. However, due to Fourier transform is used periodically, the boundary of the image is not involved in computing. Consequently, the boundary of the object-tracking sample is discontinuous, resulting in the annoying boundary effect. The error and inquality of samples can be generated, which affects the filter ability severely. Two sorts of popular solutions are employed to resolve the boundary effects currently. The first one is oriented to draw real negative samples from the sampling area. But, all of the negative and positive samples are assigned equal weights, which cannot well suppress the boundary effect. The other one is focused on an integrated spatial regularization term relevant to the correlation filter framework. A defined spatial weight map is used to deal with boundary area-near spatial weights of the samples. However, spatial regularization weight map is defined in the first frame, and such related invariant can be kept during tracking, which is not melted into the variation of different object. Both of the two sorts of solutions are required to suppress boundary effects using cosine window. The introduction of cosine window is linked to the problem of sample contamination simultaneously. The generated samples are distorted by redundant pixels, for which the tracking performance is eroded. To resolve this problem, we develop a Gaussian mask-based correlation filter tracking algorithm.MethodGaussian shape mask is embedded into the spatially regularized correlation filter framework. It redefines the weight of the samples close to the object center and those next to the boundary of the sampling region, which strengthens the weight of the samples the object center and weakens the weight of the samples far away from the object center. Thus, the response of the samples close to the object center could be enhanced while those boundary area-near samples are suppressed. To improve the tracking performance, its related strategy can be implemented to suppress the boundary effect and shrink cosine window-caused sample contamination problem. The objective function of the proposed Gaussian mask correlation filter is configured out, and to obtain closed-form solutions of the filter and spatial weights, it is then solved using alternating direction of multiplier method. To deal with scale estimation problem, two sort of correlation filters are trained in terms of location and scale filters. The location filter is trained using histogram of gradient (HOG) feature and Visual Geometry Group (VGG) network-derived deep features, while the scale filter is trained using five-scale HOG features. The former one is mainly used for estimating the object location, while the latter one is used to determine the best scale of the target object.ResultTo evaluate the proposed Gaussian mask correlation filter, extensive experiments are carried out on several tracking benchmark datasets relevant to OTB2013, TC128, UAV123 and Got-10k, and comparative analysis is linked to such popular correlation filter based tracking methods like LADCF, ASRCF, RHCF and ECO. We use the general one-pass evaluation standard to evaluate all the tracking methods. For the evaluation metrics, the precision score and success rate are used and all the tracking methods are ranked according to the precision score in the precision plots and area under curve score in the success plots. The experimental results demonstrate that each of the OTB2013 dataset-relevant precision and success score is reached to 90.2% and 65.2%, in which the precision score is optimized by 0.5% over the baseline tracking method. For TC128 dataset, the values of the two metrics are 77.9% and 57.7%, where the success score is improved by 0.4 over the baseline tracking method. For UAV123 dataset, each of the two sorts of scores can be reached to 74.1% and 50.8%, where the precision score is improved by 0.3% compared to the baseline tracking method. For Got-10k dataset, the success rate is improved by 0.2% compared to the baseline tracking method. The qualitative results illustrate that our proposed method can be used to deal with such challenging issues like deformation, occlusion, out of view and fast motion. However, the limitation shows that computational cost of the proposed method is inevitable due to the introduction of the Gaussian mask. In addition, VGG network based deep features can increase the computational cost as well. For Got-10k dataset, the frame rate is about 5.2 frames per second, while the baseline tracking method is 5.43 frames per second, which realizes 0.23 frames per second higher.ConclusionThe Gaussian mask is melted into the correlation filter framework, which can suppress the boundary effect and resolve the sample contamination problem. The sample weights are redistributed to highlight the samples near the object center, while the weight of the samples far away from the object center are suppressed. Extensive experimental results demonstrate that the proposed strategy is effective to some extent. Compared to other related correlation filter based trackers, our proposed method has its potentials on four public benchmark datasets in terms of tracking precision and success rate, which can improves the tracking performance of the baseline tracking method further. Guassian mask can also be extended to other related correlation filter based tracking framework potentially. The introduction of the Gaussian mask can decrease the tracking speed. Our future work will focus on this problem.关键词:object tracking;correlation filter (CF);boundary effect;sample contamination;Gaussian shape mask119|378|1更新时间:2024-05-07
摘要:ObjectiveObject tracking has been concerned more as such a domain in relevance to computer vision. In the past decade, correlation filter has been recognized for object tracking due to its high accuracy and speed. For traditional correlation filter tracking algorithms, training sample set is generated using circulant shift operation on the underlying image patches, and the circulant matrix is used to compute in the Fourier domain as well, which can improve the learning efficiency further. However, due to Fourier transform is used periodically, the boundary of the image is not involved in computing. Consequently, the boundary of the object-tracking sample is discontinuous, resulting in the annoying boundary effect. The error and inquality of samples can be generated, which affects the filter ability severely. Two sorts of popular solutions are employed to resolve the boundary effects currently. The first one is oriented to draw real negative samples from the sampling area. But, all of the negative and positive samples are assigned equal weights, which cannot well suppress the boundary effect. The other one is focused on an integrated spatial regularization term relevant to the correlation filter framework. A defined spatial weight map is used to deal with boundary area-near spatial weights of the samples. However, spatial regularization weight map is defined in the first frame, and such related invariant can be kept during tracking, which is not melted into the variation of different object. Both of the two sorts of solutions are required to suppress boundary effects using cosine window. The introduction of cosine window is linked to the problem of sample contamination simultaneously. The generated samples are distorted by redundant pixels, for which the tracking performance is eroded. To resolve this problem, we develop a Gaussian mask-based correlation filter tracking algorithm.MethodGaussian shape mask is embedded into the spatially regularized correlation filter framework. It redefines the weight of the samples close to the object center and those next to the boundary of the sampling region, which strengthens the weight of the samples the object center and weakens the weight of the samples far away from the object center. Thus, the response of the samples close to the object center could be enhanced while those boundary area-near samples are suppressed. To improve the tracking performance, its related strategy can be implemented to suppress the boundary effect and shrink cosine window-caused sample contamination problem. The objective function of the proposed Gaussian mask correlation filter is configured out, and to obtain closed-form solutions of the filter and spatial weights, it is then solved using alternating direction of multiplier method. To deal with scale estimation problem, two sort of correlation filters are trained in terms of location and scale filters. The location filter is trained using histogram of gradient (HOG) feature and Visual Geometry Group (VGG) network-derived deep features, while the scale filter is trained using five-scale HOG features. The former one is mainly used for estimating the object location, while the latter one is used to determine the best scale of the target object.ResultTo evaluate the proposed Gaussian mask correlation filter, extensive experiments are carried out on several tracking benchmark datasets relevant to OTB2013, TC128, UAV123 and Got-10k, and comparative analysis is linked to such popular correlation filter based tracking methods like LADCF, ASRCF, RHCF and ECO. We use the general one-pass evaluation standard to evaluate all the tracking methods. For the evaluation metrics, the precision score and success rate are used and all the tracking methods are ranked according to the precision score in the precision plots and area under curve score in the success plots. The experimental results demonstrate that each of the OTB2013 dataset-relevant precision and success score is reached to 90.2% and 65.2%, in which the precision score is optimized by 0.5% over the baseline tracking method. For TC128 dataset, the values of the two metrics are 77.9% and 57.7%, where the success score is improved by 0.4 over the baseline tracking method. For UAV123 dataset, each of the two sorts of scores can be reached to 74.1% and 50.8%, where the precision score is improved by 0.3% compared to the baseline tracking method. For Got-10k dataset, the success rate is improved by 0.2% compared to the baseline tracking method. The qualitative results illustrate that our proposed method can be used to deal with such challenging issues like deformation, occlusion, out of view and fast motion. However, the limitation shows that computational cost of the proposed method is inevitable due to the introduction of the Gaussian mask. In addition, VGG network based deep features can increase the computational cost as well. For Got-10k dataset, the frame rate is about 5.2 frames per second, while the baseline tracking method is 5.43 frames per second, which realizes 0.23 frames per second higher.ConclusionThe Gaussian mask is melted into the correlation filter framework, which can suppress the boundary effect and resolve the sample contamination problem. The sample weights are redistributed to highlight the samples near the object center, while the weight of the samples far away from the object center are suppressed. Extensive experimental results demonstrate that the proposed strategy is effective to some extent. Compared to other related correlation filter based trackers, our proposed method has its potentials on four public benchmark datasets in terms of tracking precision and success rate, which can improves the tracking performance of the baseline tracking method further. Guassian mask can also be extended to other related correlation filter based tracking framework potentially. The introduction of the Gaussian mask can decrease the tracking speed. Our future work will focus on this problem.关键词:object tracking;correlation filter (CF);boundary effect;sample contamination;Gaussian shape mask119|378|1更新时间:2024-05-07 -
 摘要:ObjectiveThe task of multi-object tracking is often focused on estimating the number, location or other related properties of objects in the scene. Specifically, it is required to be estimated accurately and consistently over a period of time. Vehicle-related multi-target tracking can be as a key technique for such domain like intelligent transportation, and its performance has a significant impact on vehicle trajectory analysis and abnormal behavior identification to some extent. Vehicle-related multi-target tracking is also recognized as a key branch of multi-target tracking and a potential technique for autonomous driving and intelligent traffic surveillance systems. For vehicle-related multi-target tracking, temporal-based motion status of vehicles in traffic scenes can be automatically obtained, which is beneficial to analyze traffic conditions and implement decisions-making quickly for transportation administrations, as well as the automatic driving system. However, to resolve missed detection of distant vehicles or vehicle ID switch (IDs) problems, such factors are often to be dealt with in relevance to external illumination, road environment factors, changes in the scale of the vehicle near and far, and mutual occlusion. We develop an integrated short-term memory and CenterTrack ability to improve the vehicle multi-target tracking accuracy (multiple object tracking accuracy (MOTA)), and its adaptability of the algorithm can be optimized further.MethodFrom the analysis of a large number of traffic monitoring video data, it can be seen the reasons for the unbalanced samples in the training samples. On the one hand, due to the fast speed of the captured vehicle target, the identified distant small target vehicle can be preserved temperorily, and it lacks of more consistent frames. On the other hand, the amount of apparent feature information is lower derived from small target vehicle itself, and the amount of neural network-extracted feature information is disappeared quickly many times. The relative number of distant small targets in the field of view is relatively small. After downsampling as a training sample, the feature quantity is disappeared very fast, resulting in an extensive reduction in the number of effective training samples, which is actually penetrated into the network. The small target vehicles cannot be detected after that. The small sample expansion method is proposed and adopted to increase the number of training samples, especially for small target vehicles in the distance. The CenterTrack is retrained with the increased samples, and the position of the vehicle can be determined where the vehicle is near or far in the image sequence and the center displacement between adjacent frames that is learnt from the CenterTrack. Due to it is assumed that a uniform linear motion is performed when the trajectory fails in matching the new detection in the short time, location of the trajectory in the current frame can be predicted through memorizing the short-term historical motion information of the trajectory when the new detection target-associated trajectory is failed. However, for the short-term memory method, it is challenged that there may be multiple trajectories competing for the same new detection target and it made a degradation of MOTA. To resolve trajectory competition and matching-derived performance degradation, we classify the trajectories further according to the length of the loss times with detection, and less loss, higher priority. The higher-level trajectories are preferred to match all new detection. This method can be used to preserve the integrity of the vehicle trajectory through reducing the missed far small vehicle and the false match between the trajectories and the detection, It can reduce the number of tracked vehicle IDs as well.ResultTo verify the effectiveness of the proposed algorithm in multiple scenarios, we extract data from two different datasets for testing. First, five sort of test sequences are extracted from such of multi-target tracking dataset like University at Albany detection and tracking (UA-DETRAC), the traffic surveillance scenery. The results demonstrate that our method proposed can maintain the advantages of CenterTrack and achieve nearly 30% improvement compared with CenterTrack in the scenes where CenterTrack performs not well. Compared to you only look once—simple online and realtime tracking with deep association metric (YOLOv4-DeepSort), it has achieved nearly 10% significant improvement in all four scenarios. The experimental results in Sherbrooke, as another traffic monitoring dataset, illustrate that short-term memory module and the remote small target vehicle expansion module can be used well compared to the original CenterTrack, and the proposed MOTA has a large performance improvement as well.ConclusionWe analyze the challenges for detecting distant small target vehicles and vehicle tracking IDs in the vehicle multi-target tracking for the traffic monitoring scene. We resolve the imbalance in the number of samples between the distant small target vehicle and the nearby large target vehicle in the training sample in terms of expansion of the training samples of the small target vehicle in the distance as well, and the algorithm is improved for small target vehicle in the distance. At the same time, short-time trajectory memory module can be used to memorize the historical motion information of the failed trajectory to maintain the integrity of the trajectories when the losed detection appears again. Furthermore, the IDs can be reduced for tracking vehicles and the MOTA is improved in terms of the trajectories classification. Our CenterTrack-based algorithm proposed has been improving for such certain traffic video surveillance scene, and the experiments are carried out to validate the effectiveness of our algorithm proposed as well. Vehicle-related multi-target tracking technique has its potentials for developing the implementation for optimizing intelligent transportation and smart city strategies to a certain extent.关键词:multiple object tracking;target detection;trajectory memory;sample expansion;trajectory association157|422|0更新时间:2024-05-07
摘要:ObjectiveThe task of multi-object tracking is often focused on estimating the number, location or other related properties of objects in the scene. Specifically, it is required to be estimated accurately and consistently over a period of time. Vehicle-related multi-target tracking can be as a key technique for such domain like intelligent transportation, and its performance has a significant impact on vehicle trajectory analysis and abnormal behavior identification to some extent. Vehicle-related multi-target tracking is also recognized as a key branch of multi-target tracking and a potential technique for autonomous driving and intelligent traffic surveillance systems. For vehicle-related multi-target tracking, temporal-based motion status of vehicles in traffic scenes can be automatically obtained, which is beneficial to analyze traffic conditions and implement decisions-making quickly for transportation administrations, as well as the automatic driving system. However, to resolve missed detection of distant vehicles or vehicle ID switch (IDs) problems, such factors are often to be dealt with in relevance to external illumination, road environment factors, changes in the scale of the vehicle near and far, and mutual occlusion. We develop an integrated short-term memory and CenterTrack ability to improve the vehicle multi-target tracking accuracy (multiple object tracking accuracy (MOTA)), and its adaptability of the algorithm can be optimized further.MethodFrom the analysis of a large number of traffic monitoring video data, it can be seen the reasons for the unbalanced samples in the training samples. On the one hand, due to the fast speed of the captured vehicle target, the identified distant small target vehicle can be preserved temperorily, and it lacks of more consistent frames. On the other hand, the amount of apparent feature information is lower derived from small target vehicle itself, and the amount of neural network-extracted feature information is disappeared quickly many times. The relative number of distant small targets in the field of view is relatively small. After downsampling as a training sample, the feature quantity is disappeared very fast, resulting in an extensive reduction in the number of effective training samples, which is actually penetrated into the network. The small target vehicles cannot be detected after that. The small sample expansion method is proposed and adopted to increase the number of training samples, especially for small target vehicles in the distance. The CenterTrack is retrained with the increased samples, and the position of the vehicle can be determined where the vehicle is near or far in the image sequence and the center displacement between adjacent frames that is learnt from the CenterTrack. Due to it is assumed that a uniform linear motion is performed when the trajectory fails in matching the new detection in the short time, location of the trajectory in the current frame can be predicted through memorizing the short-term historical motion information of the trajectory when the new detection target-associated trajectory is failed. However, for the short-term memory method, it is challenged that there may be multiple trajectories competing for the same new detection target and it made a degradation of MOTA. To resolve trajectory competition and matching-derived performance degradation, we classify the trajectories further according to the length of the loss times with detection, and less loss, higher priority. The higher-level trajectories are preferred to match all new detection. This method can be used to preserve the integrity of the vehicle trajectory through reducing the missed far small vehicle and the false match between the trajectories and the detection, It can reduce the number of tracked vehicle IDs as well.ResultTo verify the effectiveness of the proposed algorithm in multiple scenarios, we extract data from two different datasets for testing. First, five sort of test sequences are extracted from such of multi-target tracking dataset like University at Albany detection and tracking (UA-DETRAC), the traffic surveillance scenery. The results demonstrate that our method proposed can maintain the advantages of CenterTrack and achieve nearly 30% improvement compared with CenterTrack in the scenes where CenterTrack performs not well. Compared to you only look once—simple online and realtime tracking with deep association metric (YOLOv4-DeepSort), it has achieved nearly 10% significant improvement in all four scenarios. The experimental results in Sherbrooke, as another traffic monitoring dataset, illustrate that short-term memory module and the remote small target vehicle expansion module can be used well compared to the original CenterTrack, and the proposed MOTA has a large performance improvement as well.ConclusionWe analyze the challenges for detecting distant small target vehicles and vehicle tracking IDs in the vehicle multi-target tracking for the traffic monitoring scene. We resolve the imbalance in the number of samples between the distant small target vehicle and the nearby large target vehicle in the training sample in terms of expansion of the training samples of the small target vehicle in the distance as well, and the algorithm is improved for small target vehicle in the distance. At the same time, short-time trajectory memory module can be used to memorize the historical motion information of the failed trajectory to maintain the integrity of the trajectories when the losed detection appears again. Furthermore, the IDs can be reduced for tracking vehicles and the MOTA is improved in terms of the trajectories classification. Our CenterTrack-based algorithm proposed has been improving for such certain traffic video surveillance scene, and the experiments are carried out to validate the effectiveness of our algorithm proposed as well. Vehicle-related multi-target tracking technique has its potentials for developing the implementation for optimizing intelligent transportation and smart city strategies to a certain extent.关键词:multiple object tracking;target detection;trajectory memory;sample expansion;trajectory association157|422|0更新时间:2024-05-07 -
 摘要:ObjectivePainting-specific layer thickness variation of oil painting can be used to reflect the shape, depth, and texture of the painted objects. Since the layer thickness is not be replicated easily, it is beneficial to identify the similarity between two sort of oil paintings. Thanks to its layer thickness, the surface of an oil painting will theoretically appear non-Lambertian feature, i.e., the reflectance light of a targeted point will have obvious variation at a different angle. This kind of non-Lambertian feature is beneficial for oil painting identification. However, since the thickness variation of the oil painting surface is often less than 1mm, this sort of non-Lambertian effect is illustrated as a stronger weakness and it is still challenging to be captured using a traditional camera, even though for its higher spatial resolution there. To identify the weak angular variation better, we develop a compact plenoptic camera-based acquisition system further for capturing the oil painting surface. We facilitate a surface light field of the target oil paintings using a micro-lens array, which amplifies the non-Lambertian feature. It can activate sensitive identification of the oil painting in a non-contactable measurement.MethodFirst, a surface light field is constructed via a micro-lens array in front of the oil painting surface at a distance of one focal length of the elemental micro-lens. In this case, the non-Lambertian effect of an oil painting can be significantly amplified based on the micro-lens array. Then, a compactable light field camera is used to capture a surface light field of the painting at 0.2 m away. A captured light field is composed of multiple angular samples (i.e., the sub-aperture images), which can refer to the speciality of the painting surfaces. For surface thickness variation, the angular samples of the captured light field are distributed deliberately, especially for some angular variation sensitive feature points. Therefore, this kind of non-Lambertian feature can be calculated to identify oil painting similarities. A theoretical analysis is used to demonstrate the optical path design of this amplification of angular differences. After capturing the surface light fields rather than applying the feature points matching, we try to measure the similarity of oil painting surfaces using a multiple angular views-derived polygonal similarity computation. The similarity metric is proposed, and the global distribution of those large angular variational feature points is concerned about simultaneously. The feature points are detected and gathered using the K-Means clustering. The K central points-related polygon can represent the spatial geometrical distribution for the surface-related undulation, which can be treated as a unique pattern for a given oil painting. Compared to feature point extraction and matching based schemes, the proposed similarity metric is more robust to image noises and feature point outliers.ResultIn the experiments, an oil painting surface light field generation and acquisition system is built up via such multiple tools like an Illum light field camera, a micro-lens array board, a step-motor translation stage, a positioner, a motion controller, and illumination devices. The surface light fields of some real world oil paintings are generated and captured using the proposed acquisition system. The proposed solution has its potential to clarify slight differences in the thickness of these samples to some extent. It is verified that the proposed solution can be used to detect the surface light field variation through multiple experiments, and micro-lens array and the target oil painting surface-between distance adjustment, in which surface undulation is greater than 0.5 mm. The proposed surface light field similarity metric is recognized to measure the region’s geometrical shape similarity. Comparative analysis is also carried out with scale-invariant feature transform (SIFT), light field features (LiFF), and Fourier disparity layer-based Harris-SIFT feature (FDL-HSIFT) feature extraction and its contexts. We also analyze the similarity of the computation results in terms of a different number of the K-Means centers. The results demonstrate that a feasible parameter K is essential for the distinguishability of the polygonal computation-based similarity metric. Since the surface light field capturing system is constructed based on a micro-lens array, the back-end capturing camera can be placed in front of the micro-lens array in a limited range only.ConclusionThe surface light field generation and acquisition system is illustrated and demonstrated in oil painting identification. The proposed solution of surface light field feature extraction and polygonal similarity computation can be optimized in terms of its distinguishability. Additionally, the surface light field capturing system can be further optimized through illumination optimization and more accurate fixtures-added application. It can be extended to detect the variations of other related types of non-Lambertian surfaces to a certain extent.关键词:surface light field;oil painting identification;light field feature;similarity computation;feature extraction121|222|1更新时间:2024-05-07
摘要:ObjectivePainting-specific layer thickness variation of oil painting can be used to reflect the shape, depth, and texture of the painted objects. Since the layer thickness is not be replicated easily, it is beneficial to identify the similarity between two sort of oil paintings. Thanks to its layer thickness, the surface of an oil painting will theoretically appear non-Lambertian feature, i.e., the reflectance light of a targeted point will have obvious variation at a different angle. This kind of non-Lambertian feature is beneficial for oil painting identification. However, since the thickness variation of the oil painting surface is often less than 1mm, this sort of non-Lambertian effect is illustrated as a stronger weakness and it is still challenging to be captured using a traditional camera, even though for its higher spatial resolution there. To identify the weak angular variation better, we develop a compact plenoptic camera-based acquisition system further for capturing the oil painting surface. We facilitate a surface light field of the target oil paintings using a micro-lens array, which amplifies the non-Lambertian feature. It can activate sensitive identification of the oil painting in a non-contactable measurement.MethodFirst, a surface light field is constructed via a micro-lens array in front of the oil painting surface at a distance of one focal length of the elemental micro-lens. In this case, the non-Lambertian effect of an oil painting can be significantly amplified based on the micro-lens array. Then, a compactable light field camera is used to capture a surface light field of the painting at 0.2 m away. A captured light field is composed of multiple angular samples (i.e., the sub-aperture images), which can refer to the speciality of the painting surfaces. For surface thickness variation, the angular samples of the captured light field are distributed deliberately, especially for some angular variation sensitive feature points. Therefore, this kind of non-Lambertian feature can be calculated to identify oil painting similarities. A theoretical analysis is used to demonstrate the optical path design of this amplification of angular differences. After capturing the surface light fields rather than applying the feature points matching, we try to measure the similarity of oil painting surfaces using a multiple angular views-derived polygonal similarity computation. The similarity metric is proposed, and the global distribution of those large angular variational feature points is concerned about simultaneously. The feature points are detected and gathered using the K-Means clustering. The K central points-related polygon can represent the spatial geometrical distribution for the surface-related undulation, which can be treated as a unique pattern for a given oil painting. Compared to feature point extraction and matching based schemes, the proposed similarity metric is more robust to image noises and feature point outliers.ResultIn the experiments, an oil painting surface light field generation and acquisition system is built up via such multiple tools like an Illum light field camera, a micro-lens array board, a step-motor translation stage, a positioner, a motion controller, and illumination devices. The surface light fields of some real world oil paintings are generated and captured using the proposed acquisition system. The proposed solution has its potential to clarify slight differences in the thickness of these samples to some extent. It is verified that the proposed solution can be used to detect the surface light field variation through multiple experiments, and micro-lens array and the target oil painting surface-between distance adjustment, in which surface undulation is greater than 0.5 mm. The proposed surface light field similarity metric is recognized to measure the region’s geometrical shape similarity. Comparative analysis is also carried out with scale-invariant feature transform (SIFT), light field features (LiFF), and Fourier disparity layer-based Harris-SIFT feature (FDL-HSIFT) feature extraction and its contexts. We also analyze the similarity of the computation results in terms of a different number of the K-Means centers. The results demonstrate that a feasible parameter K is essential for the distinguishability of the polygonal computation-based similarity metric. Since the surface light field capturing system is constructed based on a micro-lens array, the back-end capturing camera can be placed in front of the micro-lens array in a limited range only.ConclusionThe surface light field generation and acquisition system is illustrated and demonstrated in oil painting identification. The proposed solution of surface light field feature extraction and polygonal similarity computation can be optimized in terms of its distinguishability. Additionally, the surface light field capturing system can be further optimized through illumination optimization and more accurate fixtures-added application. It can be extended to detect the variations of other related types of non-Lambertian surfaces to a certain extent.关键词:surface light field;oil painting identification;light field feature;similarity computation;feature extraction121|222|1更新时间:2024-05-07 -
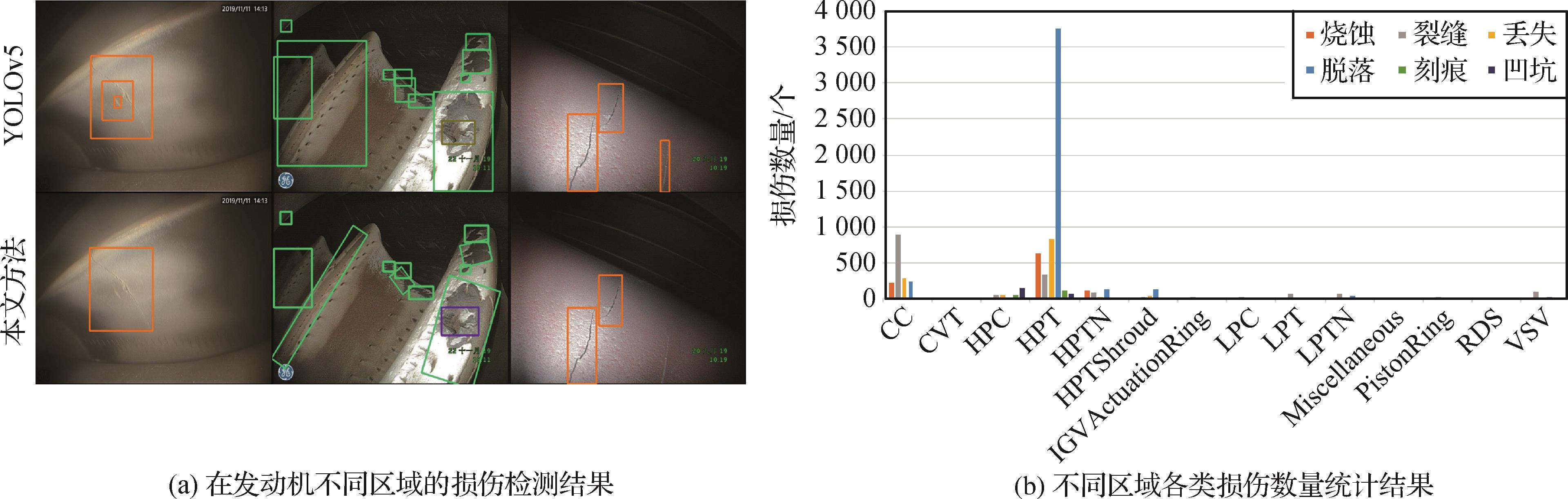 摘要:ObjectiveBorescope image-based damage detection of aeroengine is focused on its non-routine change, which can affect the flight safety and utilization rate of the aircraft straightforward. Current detection methods can be used to train a multifaceted off-the-shelf object detector-relevant damage using the same parameters for multiple areas. The detection accuracy of the existing detection methods is required to be optimized for resolving the problem of occurrence probabilities of the same type of damage in related to multiple areas of aeroengine. Furthermore, its detector may misclassify a seam or a scratch into a crack, or misidentify a nick into a dent, which affects the detection performance as well. To improve its accuracy of the damage detection, we develop an adaptive parameters-related aeroscope image damage detection method, which can detect such damages through borescope images-related multiple parameters for different areas. Furthermore, an independent detector is proposed and illustrated to detect single-class damage to avoid interference for a single detector from different types of damages, and a high miss-classification rate-relevant true and false identification is carried out for such damages detection. The final detection result can be obtained via the integrated detection results of different damage detectors.MethodThe proposed method is a based on the integration of a region recognizer, several object detectors, true and false identifiers, and a rotated bounding box generator. Specifically, to classify an aeroengine image into one of thirteen aeroengine parts, area-related recognizer is an image classifier in terms of Pytorch-Encoding. The YOLOv5 is selected as a benched single-damage detector for its high speed and precision. A single damage detector for each type of damage is trained for the expansion of a novel type of damage. The detectors are well-trained and tested on different areas of aeroengine in terms of the changeable super-parameters. The parameters are configured out according to the classification result of our recognizer in the inference process. A high miss-classification rate-related method is focused on true and false identifiers to damages analysis as well. The ResNet101 is chosen as the identifier to filter out fake cracks and identify nick and dent. We redraw the detected bounding boxes of missing-tbc into the rotated bounding boxes via segmentation of the damage areas. The rotated bounding box can be used to cover the key area of the missing-tbc tightly, and background image areas can be cut it out effectively.ResultComparative analysis is carried out with five sort of popular object detectors, called SSD, YOLACT, YOLOv5, YOLOX, and MaskRCNN. All the experiments are related to 2 654 borescope images from 13 aeroengine areas, which include six typical aeroengine damage types of burn, crack, missing material, missing-tbc, nick, and dent. The accuracy is used to evaluate the performance of our recognizer, and such of mean average precision (mAP), F-measure, accuracy, recall, and false positive is adopted for evaluating different objectors. Our detection method is employed relevant to region classification, damage detection, and several ablation studies as well. The average accuracy of recognizer on all detected areas is 95.35%. And, the accuracies of combustion chamber (CC), high pressure turbine (HPT), and high pressure turbine nozzle (HPTN) are higher than 99%. The mAP of our method on all types of damages is 56.3%, which is higher than the mAPs of YOLOv5 and SSD by 15.2% and 39.7%. The proposed damage detection method achieves 90.4% and 90.7% in terms of accuracy and recall, and YOLOv5 is optimized by 24.8% and 25.1%. The results demonstrate that the same super-parameters setting are still to be more optimal for borescope damage detection. For example, each of optimal confidence thresholds on HPT, high pressure compressor (HPC), and CC are 0.7, 0.2~0.6, and 0.6. We also compare the performance of our method of true and false identification excluded. The false-positive detection can be decreased using true and false identification.ConclusionTo improve its detection performance, an adaptive parameters set based borescope image damage detection of aeroengine is proposed for a damage detector at area-related scale. Furthermore, a high miss-classification rate-relevant true and false identification can be adopted for the damages as well.关键词:aeroengine;damage detection;object detection;borescope image;adaptive parameter115|325|0更新时间:2024-05-07
摘要:ObjectiveBorescope image-based damage detection of aeroengine is focused on its non-routine change, which can affect the flight safety and utilization rate of the aircraft straightforward. Current detection methods can be used to train a multifaceted off-the-shelf object detector-relevant damage using the same parameters for multiple areas. The detection accuracy of the existing detection methods is required to be optimized for resolving the problem of occurrence probabilities of the same type of damage in related to multiple areas of aeroengine. Furthermore, its detector may misclassify a seam or a scratch into a crack, or misidentify a nick into a dent, which affects the detection performance as well. To improve its accuracy of the damage detection, we develop an adaptive parameters-related aeroscope image damage detection method, which can detect such damages through borescope images-related multiple parameters for different areas. Furthermore, an independent detector is proposed and illustrated to detect single-class damage to avoid interference for a single detector from different types of damages, and a high miss-classification rate-relevant true and false identification is carried out for such damages detection. The final detection result can be obtained via the integrated detection results of different damage detectors.MethodThe proposed method is a based on the integration of a region recognizer, several object detectors, true and false identifiers, and a rotated bounding box generator. Specifically, to classify an aeroengine image into one of thirteen aeroengine parts, area-related recognizer is an image classifier in terms of Pytorch-Encoding. The YOLOv5 is selected as a benched single-damage detector for its high speed and precision. A single damage detector for each type of damage is trained for the expansion of a novel type of damage. The detectors are well-trained and tested on different areas of aeroengine in terms of the changeable super-parameters. The parameters are configured out according to the classification result of our recognizer in the inference process. A high miss-classification rate-related method is focused on true and false identifiers to damages analysis as well. The ResNet101 is chosen as the identifier to filter out fake cracks and identify nick and dent. We redraw the detected bounding boxes of missing-tbc into the rotated bounding boxes via segmentation of the damage areas. The rotated bounding box can be used to cover the key area of the missing-tbc tightly, and background image areas can be cut it out effectively.ResultComparative analysis is carried out with five sort of popular object detectors, called SSD, YOLACT, YOLOv5, YOLOX, and MaskRCNN. All the experiments are related to 2 654 borescope images from 13 aeroengine areas, which include six typical aeroengine damage types of burn, crack, missing material, missing-tbc, nick, and dent. The accuracy is used to evaluate the performance of our recognizer, and such of mean average precision (mAP), F-measure, accuracy, recall, and false positive is adopted for evaluating different objectors. Our detection method is employed relevant to region classification, damage detection, and several ablation studies as well. The average accuracy of recognizer on all detected areas is 95.35%. And, the accuracies of combustion chamber (CC), high pressure turbine (HPT), and high pressure turbine nozzle (HPTN) are higher than 99%. The mAP of our method on all types of damages is 56.3%, which is higher than the mAPs of YOLOv5 and SSD by 15.2% and 39.7%. The proposed damage detection method achieves 90.4% and 90.7% in terms of accuracy and recall, and YOLOv5 is optimized by 24.8% and 25.1%. The results demonstrate that the same super-parameters setting are still to be more optimal for borescope damage detection. For example, each of optimal confidence thresholds on HPT, high pressure compressor (HPC), and CC are 0.7, 0.2~0.6, and 0.6. We also compare the performance of our method of true and false identification excluded. The false-positive detection can be decreased using true and false identification.ConclusionTo improve its detection performance, an adaptive parameters set based borescope image damage detection of aeroengine is proposed for a damage detector at area-related scale. Furthermore, a high miss-classification rate-relevant true and false identification can be adopted for the damages as well.关键词:aeroengine;damage detection;object detection;borescope image;adaptive parameter115|325|0更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveVirtual reality technique has been focused on in relevance to such domains like intelligent robot, computer vision and artificial intelligence, and multiple scenes-oriented 3D reconstructions. Recent indoor scene reconstruction has been developing intensively in related to computer vision and robotics. The key task of 3D reconstruction is oriented to transform the point cloud data of indoor scene into a lightweight 3D scene model based on the spatial, geometric, semantic and other related features of point cloud. However, 3D indoor modeling is still challenged to reconstruct high quality 3D indoor scene straightforward because of complex structure, high occlusion and variability of indoor scenes. Current scene reconstruction methods are mainly segmented into such of methods relevant to model matching, machine learning, and deep learning. Model matching-based methods are linked to feature point selection in the matching process. Machine learning-based method is focused on scene segmentation, and its target can be relatively detected and replaced based on partial matching. However, when the indoor objects are severely missed, it is still challenged to deal with such narrow and cluttered indoor scene. Deep learning-based methods are required for training reliable and high-quality scene data, for which domain-specific and data-acquired are often costly for new scenes. To resolve these problems, we develop a semantic segmentation-based point cloud indoor scene reconstruction method, which can melt the point cloud data into a high-quality 3D scene model efficiently and accurately. The method proposed can be divided into three steps as listed below: fusion sampling, semantic segmentation and instance segmentation, and scene reconstruction.MethodWe demonstrate a semantic segmentation-based indoor scene reconstruction method. First, a down-sampling method is developed in terms of 3D scale-invariant feature transform (3D SIFT) feature points extraction and voxel filtering. It takes the local features of the scene as the guidance, and voxel filtering method is used to down-sample the point cloud and remove the noise outliers. The local feature points of the scene data are then obtained by 3D SIFT, which are used to optimize possible loss of key points in the sampling process under the voxel filtering. The local feature points are combined with voxel filtering to obtain the optimized sampling results. It can optimize a single voxel filter-derived critical points loss effectively, and efficient data representation can be offered for the semantic segmentation of subsequent indoor scenes. Second, we illustrate a plane feature-enhanced multi-level semantic segmentation method of PointNet. The plane feature is extracted based on the sampled scene of random sample consensus (RANSAC) algorithm, and planar features-related data is constructed as the dataset of training and testing network model, and the PointNet is then used for end-to-end scene semantic segmentation. The projection-based region growing optimization method is adopted to realize the fine segmentation of objects in indoor scene further. It can be used to optimize PointNet local feature representation and the accuracy of scene semantic segmentation to a certain extent. Finally, a model matching and plane fitting based 3D scene model reconstruction method is facilitated for both of internal and external scenarios-derived objects. The model library of the scene objects is built up in terms of the semantic segmentation analysis of the scene. To deal with the complex structure of each internal scenario-derived object, object and models-between similarities is calculated in the model library. Model matching method is melted in based on heuristic search and the semantic flags and local features of scene elements are used as indexes to carry out rough retrieval from model library, and the optimal matching model is used to match the objects in the scene to align and replace the objects in the scene. Therefore, the reconstruction work of internal scenario-derived objects can be completed further. The outdoor-related external environment objects are reconstructed via plane fitting method. After the axially-aligned bounding box (AABB) of each scene object is calculated, the plane model can be generated to complete the reconstruction of the external-related objects.ResultTo evaluate the performance of the proposed method, experiments are carried out in down-sampling, semantic segmentation, instance segmentation based on the Stanford large-scale 3D indoor space dataset (S3DIS). Experimental analyses demonstrate that the proposed fusion of plane feature enhancement and voxel filtering can get better plane extraction results in comparison with the non-sampled data. The running time of plane extraction algorithm is shrinked 85% significantly after down-sampling, and it can be optimized about 62% with down-sampling. Compared to PointNet, plane feature-enhanced semantic segmentation method is proposed and trained in Area-1-Area-5 scene and tested in Area-6 scene. The overall accuracy (OA) can be reached to 84.02% and mean intersection over union (mIoU) is reached to 60.65%, in which each of them are improved 2.3% and 4.2% than PointNet network.ConclusionThe S3DIS dataset-based experimental results have demonstrated that our method proposed can be dealt with semantic segmentation in related to large-scale indoor scenes. It can extract planar features better through the fusion of voxel filtering and the 3D SIFT. Furthermore, S3DIS area-6-related experiments have demonstrated that the performance of semantic segmentation is improved as well. The scene reconstruction method proposed can obtain more refined and accurate scene reconstruction results to some extent. Future research direction is predicted and focused on the completion of small objects with complex structures such as tables, chairs and bookshelves, which refers to little improvement in the accuracy of segmentation and reconstruction of such objects. To improve the accuracy of semantic segmentation, deep learning-based method can be probably used to deal with the features of small objects. It is required to develop potential reconstruction methods in the context of large and complex indoor scenes, especially for the scenes-related objects modeling.关键词:point cloud;indoor scene;semantic segmentation;instance segmentation;3d reconstruction187|758|2更新时间:2024-05-07
摘要:ObjectiveVirtual reality technique has been focused on in relevance to such domains like intelligent robot, computer vision and artificial intelligence, and multiple scenes-oriented 3D reconstructions. Recent indoor scene reconstruction has been developing intensively in related to computer vision and robotics. The key task of 3D reconstruction is oriented to transform the point cloud data of indoor scene into a lightweight 3D scene model based on the spatial, geometric, semantic and other related features of point cloud. However, 3D indoor modeling is still challenged to reconstruct high quality 3D indoor scene straightforward because of complex structure, high occlusion and variability of indoor scenes. Current scene reconstruction methods are mainly segmented into such of methods relevant to model matching, machine learning, and deep learning. Model matching-based methods are linked to feature point selection in the matching process. Machine learning-based method is focused on scene segmentation, and its target can be relatively detected and replaced based on partial matching. However, when the indoor objects are severely missed, it is still challenged to deal with such narrow and cluttered indoor scene. Deep learning-based methods are required for training reliable and high-quality scene data, for which domain-specific and data-acquired are often costly for new scenes. To resolve these problems, we develop a semantic segmentation-based point cloud indoor scene reconstruction method, which can melt the point cloud data into a high-quality 3D scene model efficiently and accurately. The method proposed can be divided into three steps as listed below: fusion sampling, semantic segmentation and instance segmentation, and scene reconstruction.MethodWe demonstrate a semantic segmentation-based indoor scene reconstruction method. First, a down-sampling method is developed in terms of 3D scale-invariant feature transform (3D SIFT) feature points extraction and voxel filtering. It takes the local features of the scene as the guidance, and voxel filtering method is used to down-sample the point cloud and remove the noise outliers. The local feature points of the scene data are then obtained by 3D SIFT, which are used to optimize possible loss of key points in the sampling process under the voxel filtering. The local feature points are combined with voxel filtering to obtain the optimized sampling results. It can optimize a single voxel filter-derived critical points loss effectively, and efficient data representation can be offered for the semantic segmentation of subsequent indoor scenes. Second, we illustrate a plane feature-enhanced multi-level semantic segmentation method of PointNet. The plane feature is extracted based on the sampled scene of random sample consensus (RANSAC) algorithm, and planar features-related data is constructed as the dataset of training and testing network model, and the PointNet is then used for end-to-end scene semantic segmentation. The projection-based region growing optimization method is adopted to realize the fine segmentation of objects in indoor scene further. It can be used to optimize PointNet local feature representation and the accuracy of scene semantic segmentation to a certain extent. Finally, a model matching and plane fitting based 3D scene model reconstruction method is facilitated for both of internal and external scenarios-derived objects. The model library of the scene objects is built up in terms of the semantic segmentation analysis of the scene. To deal with the complex structure of each internal scenario-derived object, object and models-between similarities is calculated in the model library. Model matching method is melted in based on heuristic search and the semantic flags and local features of scene elements are used as indexes to carry out rough retrieval from model library, and the optimal matching model is used to match the objects in the scene to align and replace the objects in the scene. Therefore, the reconstruction work of internal scenario-derived objects can be completed further. The outdoor-related external environment objects are reconstructed via plane fitting method. After the axially-aligned bounding box (AABB) of each scene object is calculated, the plane model can be generated to complete the reconstruction of the external-related objects.ResultTo evaluate the performance of the proposed method, experiments are carried out in down-sampling, semantic segmentation, instance segmentation based on the Stanford large-scale 3D indoor space dataset (S3DIS). Experimental analyses demonstrate that the proposed fusion of plane feature enhancement and voxel filtering can get better plane extraction results in comparison with the non-sampled data. The running time of plane extraction algorithm is shrinked 85% significantly after down-sampling, and it can be optimized about 62% with down-sampling. Compared to PointNet, plane feature-enhanced semantic segmentation method is proposed and trained in Area-1-Area-5 scene and tested in Area-6 scene. The overall accuracy (OA) can be reached to 84.02% and mean intersection over union (mIoU) is reached to 60.65%, in which each of them are improved 2.3% and 4.2% than PointNet network.ConclusionThe S3DIS dataset-based experimental results have demonstrated that our method proposed can be dealt with semantic segmentation in related to large-scale indoor scenes. It can extract planar features better through the fusion of voxel filtering and the 3D SIFT. Furthermore, S3DIS area-6-related experiments have demonstrated that the performance of semantic segmentation is improved as well. The scene reconstruction method proposed can obtain more refined and accurate scene reconstruction results to some extent. Future research direction is predicted and focused on the completion of small objects with complex structures such as tables, chairs and bookshelves, which refers to little improvement in the accuracy of segmentation and reconstruction of such objects. To improve the accuracy of semantic segmentation, deep learning-based method can be probably used to deal with the features of small objects. It is required to develop potential reconstruction methods in the context of large and complex indoor scenes, especially for the scenes-related objects modeling.关键词:point cloud;indoor scene;semantic segmentation;instance segmentation;3d reconstruction187|758|2更新时间:2024-05-07 -
 摘要:ObjectivePedestrian trajectory prediction is essential for such domains like unmanned vehicles, security surveillance, and social robotics nowadays. Trajectory prediction is beneficial for computer systems to perform better decision making and planning to some extent. Current methods are focused on pedestrian trajectory information, and scene elements-related spatial constraints on pedestrian motion in the same space are challenged to explain human-to-human social interactions further, in which future location of pedestrians cannot be located in building walls, and pedestrians at building corners undergo large velocity direction deflections due to cornering behavior. The pathways can be focused on the integrated scene information, for which the scene image is melted into a one-dimensional vector and merged with the trajectory information. Two-dimensional spatial signal of the scene will be distorted and it cannot be intuitively explained according to the modulating effect of the scene on pedestrian motion. To build a spatiotemporal graph representation of pedestrians, recent graph neural network (GNN) is used to develop a method based on graph attention network (GAT), in which pedestrians are as the graph nodes, trajectory features as the node attributes, and pedestrians-between spatial interactions are as the edges in the graph. These sorts of methods can be used to focus on pedestrians-between social interactions in the global scale. However, for crowded scenes, graph attention mechanism may not be able to assign appropriate weights to each pedestrian accurately, resulting in poor algorithm accuracy. To resolve the two problems mentioned above, we develop a scene constraints-based spatiotemporal graph convolutional network, called Scene-STGCNN, which aggregates pedestrian motion status with a graph convolutional neural network for local interactions, and it achieves accurate aggregation of pedestrian motion status with a small number of parameters. At the same time, we design a scene-based fine-tuning module to explicitly model the modulating effect of scenes on pedestrian motion with the information of neighboring scene changes as input.MethodScene-STGCNN consists of a motion module, a scene-based fine-tuning module, spatiotemporal convolution, and spatiotemporal extrapolation convolution. For the motion module, the graph convolution is a 1 × 1 core-sized convolutional neural network (CNN) layer for embedding pedestrian velocity information. The residual convolution is composed of CNN layer of 1 × 1 kernel size and BatchNorm (BN) layer. Temporal convolution is organized of BN layer, PReLU layer, 3 × 1 core-sized CNN layer, BN layer and Dropout layer as well. The motion module takes the pedestrian velocity spatiotemporal graph and the scene mask matrix as input, in which CNN-based pedestrian velocity spatiotemporal graph is encoded and the pedestrian spatiotemporal features of existing multiple frames are fused. For the scene-based fine-tuning module, temporal neighboring scene change information is first introduced to generate the scene-based pedestrian spatiotemporal map, and the embedding of the pedestrian spatiotemporal map by scene convolution is then performed to obtain the scene mask matrix, which is used to make Hadamard products with the intermediate motion features in the motion module. The real-time regulation role of the scene on pedestrians can be explicitly modeling further. Spatiotemporal convolution as a transition coding network consists of two temporal gating units and a spatial convolution, which is used to enhance the temporal correlation and contextual spatial dependence of pedestrian motion. A two-dimensional Gaussian distribution-related trajectory distribution is generated in terms of temporal extrapolation convolution. The kernel density estimation-based negative log-likelihood as the loss function will enhance the multimodality of the Scene-STGCNN prediction distribution while the prediction loss is optimized.ResultExperiments are carried out to compare with the other related seven popular methods on the publicly available datasets ETH (including ETH and HOTEL) and UCY (including UNIV, ZARA1, and ZARA2). The average displacement error (ADE) values are optimized by 12%, and the final displacement error (FDE) values are optimized by 9% in terms of average values. Ablation experiments are used to verify the effectiveness of the scene-based fine-tuning module, and the results demonstrate that the scene-based fine-tuning module can effectively model the modulation effect of the scene on pedestrian trajectory, and the prediction error of the algorithm is optimized as well. In addition, qualitative analysis is focused on the issues of Scene-STGCNN-captured inherent patterns of pedestrian motion and the involved prediction distribution. The visualization results show that Scene-STGCNN can be used to learn the pedestrian motion patterns effectively while maintaining accurate predictions.Conclusionwe facilitate a pedestrian trajectory prediction model, called Scene-STGCNN, which can fuse scene information with trajectory features effectively through a scene-based fine-tuning module. Furthermore, Scene-STGCNN potentials can be focused on scene information-related pedestrian trajectory prediction method to a certain extent via modeling the modulation effect of scene on pedestrian motion.关键词:pedestrian trajectory prediction;spatial constraints of scene;spatio-temporal feature extraction;spatio-temporal convolution;kernel density estimation164|525|2更新时间:2024-05-07
摘要:ObjectivePedestrian trajectory prediction is essential for such domains like unmanned vehicles, security surveillance, and social robotics nowadays. Trajectory prediction is beneficial for computer systems to perform better decision making and planning to some extent. Current methods are focused on pedestrian trajectory information, and scene elements-related spatial constraints on pedestrian motion in the same space are challenged to explain human-to-human social interactions further, in which future location of pedestrians cannot be located in building walls, and pedestrians at building corners undergo large velocity direction deflections due to cornering behavior. The pathways can be focused on the integrated scene information, for which the scene image is melted into a one-dimensional vector and merged with the trajectory information. Two-dimensional spatial signal of the scene will be distorted and it cannot be intuitively explained according to the modulating effect of the scene on pedestrian motion. To build a spatiotemporal graph representation of pedestrians, recent graph neural network (GNN) is used to develop a method based on graph attention network (GAT), in which pedestrians are as the graph nodes, trajectory features as the node attributes, and pedestrians-between spatial interactions are as the edges in the graph. These sorts of methods can be used to focus on pedestrians-between social interactions in the global scale. However, for crowded scenes, graph attention mechanism may not be able to assign appropriate weights to each pedestrian accurately, resulting in poor algorithm accuracy. To resolve the two problems mentioned above, we develop a scene constraints-based spatiotemporal graph convolutional network, called Scene-STGCNN, which aggregates pedestrian motion status with a graph convolutional neural network for local interactions, and it achieves accurate aggregation of pedestrian motion status with a small number of parameters. At the same time, we design a scene-based fine-tuning module to explicitly model the modulating effect of scenes on pedestrian motion with the information of neighboring scene changes as input.MethodScene-STGCNN consists of a motion module, a scene-based fine-tuning module, spatiotemporal convolution, and spatiotemporal extrapolation convolution. For the motion module, the graph convolution is a 1 × 1 core-sized convolutional neural network (CNN) layer for embedding pedestrian velocity information. The residual convolution is composed of CNN layer of 1 × 1 kernel size and BatchNorm (BN) layer. Temporal convolution is organized of BN layer, PReLU layer, 3 × 1 core-sized CNN layer, BN layer and Dropout layer as well. The motion module takes the pedestrian velocity spatiotemporal graph and the scene mask matrix as input, in which CNN-based pedestrian velocity spatiotemporal graph is encoded and the pedestrian spatiotemporal features of existing multiple frames are fused. For the scene-based fine-tuning module, temporal neighboring scene change information is first introduced to generate the scene-based pedestrian spatiotemporal map, and the embedding of the pedestrian spatiotemporal map by scene convolution is then performed to obtain the scene mask matrix, which is used to make Hadamard products with the intermediate motion features in the motion module. The real-time regulation role of the scene on pedestrians can be explicitly modeling further. Spatiotemporal convolution as a transition coding network consists of two temporal gating units and a spatial convolution, which is used to enhance the temporal correlation and contextual spatial dependence of pedestrian motion. A two-dimensional Gaussian distribution-related trajectory distribution is generated in terms of temporal extrapolation convolution. The kernel density estimation-based negative log-likelihood as the loss function will enhance the multimodality of the Scene-STGCNN prediction distribution while the prediction loss is optimized.ResultExperiments are carried out to compare with the other related seven popular methods on the publicly available datasets ETH (including ETH and HOTEL) and UCY (including UNIV, ZARA1, and ZARA2). The average displacement error (ADE) values are optimized by 12%, and the final displacement error (FDE) values are optimized by 9% in terms of average values. Ablation experiments are used to verify the effectiveness of the scene-based fine-tuning module, and the results demonstrate that the scene-based fine-tuning module can effectively model the modulation effect of the scene on pedestrian trajectory, and the prediction error of the algorithm is optimized as well. In addition, qualitative analysis is focused on the issues of Scene-STGCNN-captured inherent patterns of pedestrian motion and the involved prediction distribution. The visualization results show that Scene-STGCNN can be used to learn the pedestrian motion patterns effectively while maintaining accurate predictions.Conclusionwe facilitate a pedestrian trajectory prediction model, called Scene-STGCNN, which can fuse scene information with trajectory features effectively through a scene-based fine-tuning module. Furthermore, Scene-STGCNN potentials can be focused on scene information-related pedestrian trajectory prediction method to a certain extent via modeling the modulation effect of scene on pedestrian motion.关键词:pedestrian trajectory prediction;spatial constraints of scene;spatio-temporal feature extraction;spatio-temporal convolution;kernel density estimation164|525|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
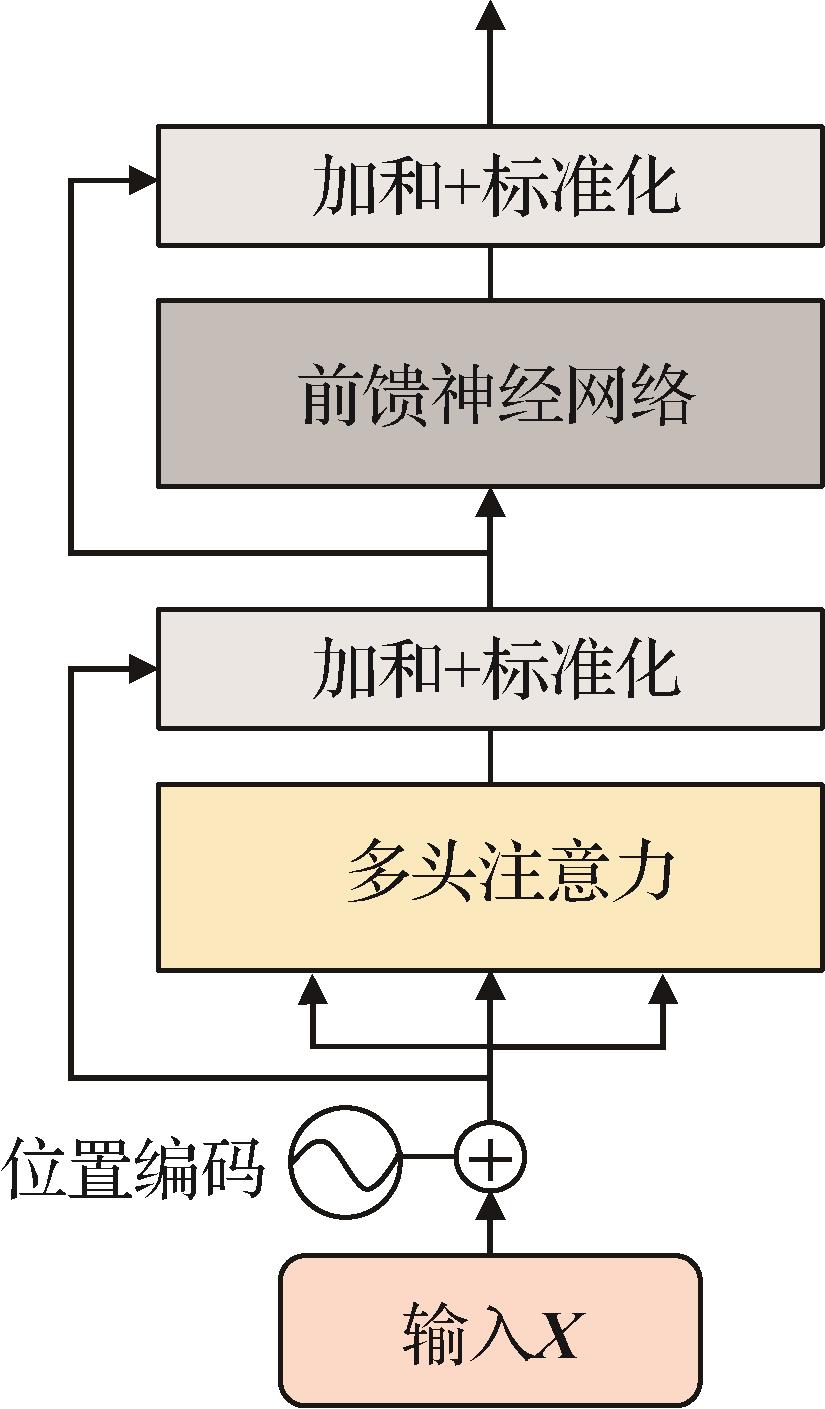 摘要:ObjectiveHigh performance-oriented robust tracking methods are often beneficial from its related depth model nowadays, which is deeply linked to the large-scale high quality annotations-related video datasets in the training phase. However, frame-manual annotating videos frame is labor-intensive and costly. In addition, existing video annotation methods are usually focused on interpolation operation relevant to sparse labeled datasets. An effective interpolation operation is mainly designed based on the geometric information or other related tracking methods. One potential of these methods is illustrated that they do not require any quality evaluation mechanism to filter out the noisy annotations, resulting in the annotations unreliable. Additionally, some interactive annotation tools have a high involvement of labor, which makes the annotating process more complex. An end-to-end deep model based video annotation via selection and refinement(VASR) can be used to generate reliable annotations via its selection and refinement. However, due to its training data consists of intermediate tracking results and object masks, it is highly associated with specific tracking methods. The process of generating annotations is complicated and time consuming. To meet the needs of visual tracking methods for large-scale annotated video datasets, simplify the annotation process, and optimize computing cost, we develop an efficient end-to-end model of Transformer-based label Net (TLNet) to automatically generate video annotations for sparse labeled tracking datasets further. Due to the Transformer model has its potentials to deal with sequential information, we melt it into our model to fuse the bidirectional and sequential input features.MethodIn this study, an efficient video annotation method is developed to generate reliable annotations quickly. The annotating strategy is implemented and it can be divided into three steps as follows: First, high-speed trackers are employed to perform forward and backward tracking. Second, these original annotations are evaluated in frame-level, and noisy frames are filtered out for manual annotation. Third, other related frames are optimized to generate more precise bounding boxes. To get its evaluation and optimization function mentioned above, a Transformer-based efficient model is illustrated, called TLNet. The proposed model consists of three sorts of modules, i.e., the feature extractor, feature fusion module, and prediction heads. To extract the vision features of the object, pixel-wise cross-correlation operation is used for the template and search region. A Transformer-based model is introduced to handle the sequential information after the vision and motion features are incorporated with, including the object appearance and motion cues. Furthermore, it is also used to fuse the bidirectional tracking results, i.e., forward tracking and backward tracking. The proposed model contains two sorts of sub-models in related to quality evaluation network and regression network. Among them, the former one is used to provide the confidence score of each frame’s original annotation, and then the failed frames will be filtered out and sent back to manual annotators. The latter one is used to optimize the original annotations of the remaining frames, and more precise bounding boxes can be output. Our method has its strong generalizability to some extent since video frames and bidirectional tracking results are used as input for the model training only, and no intermediate tracking results like confidence scores, response maps are used. Specifically, our method is decoupled from specific tracking algorithms, and it can integrate any existing high-speed tracking algorithms to perform the forward and backward tracking. In this way, efficient and reliable video annotations can be achieved further. The completed annotating process is designed simplified and easy-to-use as well.ResultOur method proposed is focused on generating annotations on two sort of large-scale tracking datasets like LaSOT, and TrackingNet. Two kind of evaluation protocols are set and matched for each of the two datasets. For LaSOT dataset, we apply the mean intersection over union (mIoU) to evaluate the annotations quality straightforward. The accuracy (Acc), recall, and true negative rate (TNR) are used to evaluate the filtering ability of the quality evaluation network as well. Compared to the VASR method costing about two weeks (336 hours totally), our method saves the time (43 hours totally) significantly in generating annotation. Specifically, 5.4% of frames are recognized as failed frames, where the Acc is 96.7%, and TNR is reached to 76.1%. After filtering out noisy frames and replacing with manual annotations, the mIoU of annotations are increased from 0.824 to 0.864. It is improved and reached to 0.871 further in terms of regression network. For the TrackingNet dataset, due to the noisy annotations are existed in its ground truth value, an indirect way is applied to evaluate the annotation quality. That is, we select out three sort of different tracking algorithms in related to ATOM, DiMP, and PrDiMP, and they are retrained using our annotations. The results are captured on three sort of tracking datasets relevant to LaSOT, TrackingNet, and GOT-10k, and it demonstrates that our annotations can be used to train a tracking model better than its original ground truth. It also can generate high quality annotations efficiently. Moreover, the ablation study also demonstrates the effectiveness of the Transformer model and its other related designs.ConclusionWe develop an efficient video annotation method, which can mine the sequential object appearance and motion information, and fuse the forward and backward tracking results. The reliable annotations can be generated, and more than 90% labor cost for manually annotating can be saved on the basis of the frame-level quality evaluation operation originated from our quality evaluation network, and bounding boxes optimization derived from our regression network. Due to decoupling with the specific tracking algorithms, our method has its strong generalizability, for which it applies any existing high-speed tracking algorithms to achieve efficient annotation. We predict that our annotation method proposed can make the annotating process more reliable, faster and simpler to a certain extent.关键词:video annotation;single object tracking;Transformer model;cross-correlation;sequential information fusion167|418|2更新时间:2024-05-07
摘要:ObjectiveHigh performance-oriented robust tracking methods are often beneficial from its related depth model nowadays, which is deeply linked to the large-scale high quality annotations-related video datasets in the training phase. However, frame-manual annotating videos frame is labor-intensive and costly. In addition, existing video annotation methods are usually focused on interpolation operation relevant to sparse labeled datasets. An effective interpolation operation is mainly designed based on the geometric information or other related tracking methods. One potential of these methods is illustrated that they do not require any quality evaluation mechanism to filter out the noisy annotations, resulting in the annotations unreliable. Additionally, some interactive annotation tools have a high involvement of labor, which makes the annotating process more complex. An end-to-end deep model based video annotation via selection and refinement(VASR) can be used to generate reliable annotations via its selection and refinement. However, due to its training data consists of intermediate tracking results and object masks, it is highly associated with specific tracking methods. The process of generating annotations is complicated and time consuming. To meet the needs of visual tracking methods for large-scale annotated video datasets, simplify the annotation process, and optimize computing cost, we develop an efficient end-to-end model of Transformer-based label Net (TLNet) to automatically generate video annotations for sparse labeled tracking datasets further. Due to the Transformer model has its potentials to deal with sequential information, we melt it into our model to fuse the bidirectional and sequential input features.MethodIn this study, an efficient video annotation method is developed to generate reliable annotations quickly. The annotating strategy is implemented and it can be divided into three steps as follows: First, high-speed trackers are employed to perform forward and backward tracking. Second, these original annotations are evaluated in frame-level, and noisy frames are filtered out for manual annotation. Third, other related frames are optimized to generate more precise bounding boxes. To get its evaluation and optimization function mentioned above, a Transformer-based efficient model is illustrated, called TLNet. The proposed model consists of three sorts of modules, i.e., the feature extractor, feature fusion module, and prediction heads. To extract the vision features of the object, pixel-wise cross-correlation operation is used for the template and search region. A Transformer-based model is introduced to handle the sequential information after the vision and motion features are incorporated with, including the object appearance and motion cues. Furthermore, it is also used to fuse the bidirectional tracking results, i.e., forward tracking and backward tracking. The proposed model contains two sorts of sub-models in related to quality evaluation network and regression network. Among them, the former one is used to provide the confidence score of each frame’s original annotation, and then the failed frames will be filtered out and sent back to manual annotators. The latter one is used to optimize the original annotations of the remaining frames, and more precise bounding boxes can be output. Our method has its strong generalizability to some extent since video frames and bidirectional tracking results are used as input for the model training only, and no intermediate tracking results like confidence scores, response maps are used. Specifically, our method is decoupled from specific tracking algorithms, and it can integrate any existing high-speed tracking algorithms to perform the forward and backward tracking. In this way, efficient and reliable video annotations can be achieved further. The completed annotating process is designed simplified and easy-to-use as well.ResultOur method proposed is focused on generating annotations on two sort of large-scale tracking datasets like LaSOT, and TrackingNet. Two kind of evaluation protocols are set and matched for each of the two datasets. For LaSOT dataset, we apply the mean intersection over union (mIoU) to evaluate the annotations quality straightforward. The accuracy (Acc), recall, and true negative rate (TNR) are used to evaluate the filtering ability of the quality evaluation network as well. Compared to the VASR method costing about two weeks (336 hours totally), our method saves the time (43 hours totally) significantly in generating annotation. Specifically, 5.4% of frames are recognized as failed frames, where the Acc is 96.7%, and TNR is reached to 76.1%. After filtering out noisy frames and replacing with manual annotations, the mIoU of annotations are increased from 0.824 to 0.864. It is improved and reached to 0.871 further in terms of regression network. For the TrackingNet dataset, due to the noisy annotations are existed in its ground truth value, an indirect way is applied to evaluate the annotation quality. That is, we select out three sort of different tracking algorithms in related to ATOM, DiMP, and PrDiMP, and they are retrained using our annotations. The results are captured on three sort of tracking datasets relevant to LaSOT, TrackingNet, and GOT-10k, and it demonstrates that our annotations can be used to train a tracking model better than its original ground truth. It also can generate high quality annotations efficiently. Moreover, the ablation study also demonstrates the effectiveness of the Transformer model and its other related designs.ConclusionWe develop an efficient video annotation method, which can mine the sequential object appearance and motion information, and fuse the forward and backward tracking results. The reliable annotations can be generated, and more than 90% labor cost for manually annotating can be saved on the basis of the frame-level quality evaluation operation originated from our quality evaluation network, and bounding boxes optimization derived from our regression network. Due to decoupling with the specific tracking algorithms, our method has its strong generalizability, for which it applies any existing high-speed tracking algorithms to achieve efficient annotation. We predict that our annotation method proposed can make the annotating process more reliable, faster and simpler to a certain extent.关键词:video annotation;single object tracking;Transformer model;cross-correlation;sequential information fusion167|418|2更新时间:2024-05-07 -
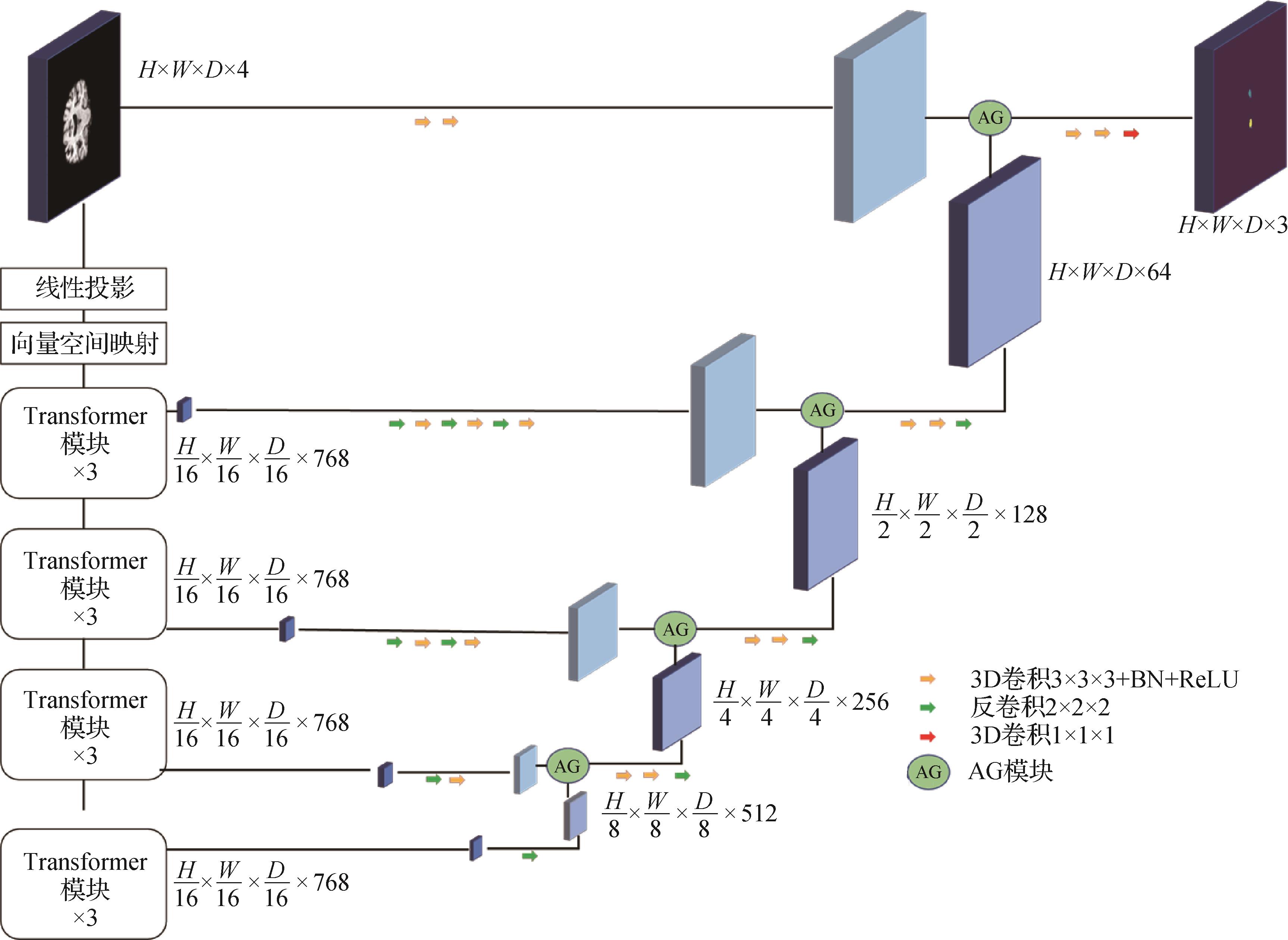 摘要:ObjectiveThe early intervention and diagnosis of Alzheimer’s disease (AD) have its high clinical and social value to a certain extent. Hippocampus is located and as one of the earliest affected brain regions in AD, and its dysfunction is recognized as such core features of the disease-memory impairment. It is labor-intensive and time inefficient to deal with AD contexts using magnetic resonance imaging (MRI).The emerging artificial intelligence (AI) technique is beneficial for high-accuracy hippocampus segmentation work on MRI scanning effectively and efficiently. When an AI-related algorithm is developed for AD diagnosis, convolutional neural networks (CNNs) based deep learning methods can be employed to carry out the task of hippocampus segmentation further. As the down-sampling steps are involved in the encoder, convolutions of various kernel sizes can be used to contract images and extract image features. To expand the generated feature map through encoding, upsampling it to the original spatial size of the input image, the decoders can be used to transpose convolutions and bilinear interpolation as well. First, convolutions can be used to integrate context information within the receptive field only. In this case, all pixels-out would be ignored for in-bound of the receptive field, even pixels are correlated with in-bound pixels, and redundant information is produced after that. To optimize task of hippocampus segmentation network, we focus on the natural characteristics of the hippocampus and clinical-based segmentation works. The characteristics of the hippocampus can be affected on the two aspects as mentioned below: the first one is oriented that the shape of the hippocampus is irregular, while its size of the second one is minimal, occupied by only 0.000 2 of the whole pixels of the MRI scans. For the first one, convolutions are difficult to extract features effectively from irregular shape objectives because they can extract local features only. An encoder in a neural network may contain many feature extraction layers, so the extracted information of the hippocampus will be lost because there are only limited pixels of the hippocampus in the original image. To sort the hippocampus-relevant region of interest out, it is required to segment small objects is a superposition of a detection network. The semantic segmentation network will only be oriented and applied inside the bounding box. However, it still has two identical features in the learning process, for which redundancy of computing resources are inevitable.MethodTo extract features from targets with irregular shapes effectively and highlight the target areas automatically, we adjust the segmentation in medical images and treat it as a sequence-to-sequence prediction task. We develop a U-shaped network based on self-attention and spatial attention mechanisms, called SA-TF-UNet. The SA-TF-UNet has an encoder-decoder architecture, where the encoder is based on pure Transformer blocks. Self-attention mechanisms in Transformer blocks can be used to enable global modeling as well. An attention gate (AG) is adopted to optimize the concatenation of the skip connections in U-Net, where the AGs can be learnt from depth layers of the Transformer and the weights on the target areas can be automatically set up more. To validate the effectiveness of AGs, we carried out experiments where one AG is only contained for the network. The comparative analysis is carried out the experiment as well, where we apply AG to all four layers. To determine the gating signals for each AG further, two sorts of structures are illustrated. The gating signals in these two sorts of structures are focused on the depth outputs of two Transformer blocks, and three Transformer blocks.ResultOur models proposed are tested on a dataset sample derived of 54 clinical MRI scans from AD patients. The dataset is divided into training data and testing data at a ratio of 8∶1 randomly. Three independent experiments are carried out, and an average result is used to reduce contingency simutaneously. The potential of SA-TF-UNet is demonstrated that the average dice of the left hippocampus and right hippocampus in three independent experiments are 0.900 1 and 0.909 1 relevant to an improvement of 2.82% and 3.37%. The other two related fine-tuned structures are linked that a dice coefficient of them is reached to more than 0.88 as well.ConclusionThe integrated self and spatial attention is beneifical for the precision of hippocampus segmentation. It is effective that the gating signal in AG is outputted in terms of one depth Transformer block only.关键词:hippocampus;medical image processing;Transformer;spatial attention;sementic segmentation186|397|0更新时间:2024-05-07
摘要:ObjectiveThe early intervention and diagnosis of Alzheimer’s disease (AD) have its high clinical and social value to a certain extent. Hippocampus is located and as one of the earliest affected brain regions in AD, and its dysfunction is recognized as such core features of the disease-memory impairment. It is labor-intensive and time inefficient to deal with AD contexts using magnetic resonance imaging (MRI).The emerging artificial intelligence (AI) technique is beneficial for high-accuracy hippocampus segmentation work on MRI scanning effectively and efficiently. When an AI-related algorithm is developed for AD diagnosis, convolutional neural networks (CNNs) based deep learning methods can be employed to carry out the task of hippocampus segmentation further. As the down-sampling steps are involved in the encoder, convolutions of various kernel sizes can be used to contract images and extract image features. To expand the generated feature map through encoding, upsampling it to the original spatial size of the input image, the decoders can be used to transpose convolutions and bilinear interpolation as well. First, convolutions can be used to integrate context information within the receptive field only. In this case, all pixels-out would be ignored for in-bound of the receptive field, even pixels are correlated with in-bound pixels, and redundant information is produced after that. To optimize task of hippocampus segmentation network, we focus on the natural characteristics of the hippocampus and clinical-based segmentation works. The characteristics of the hippocampus can be affected on the two aspects as mentioned below: the first one is oriented that the shape of the hippocampus is irregular, while its size of the second one is minimal, occupied by only 0.000 2 of the whole pixels of the MRI scans. For the first one, convolutions are difficult to extract features effectively from irregular shape objectives because they can extract local features only. An encoder in a neural network may contain many feature extraction layers, so the extracted information of the hippocampus will be lost because there are only limited pixels of the hippocampus in the original image. To sort the hippocampus-relevant region of interest out, it is required to segment small objects is a superposition of a detection network. The semantic segmentation network will only be oriented and applied inside the bounding box. However, it still has two identical features in the learning process, for which redundancy of computing resources are inevitable.MethodTo extract features from targets with irregular shapes effectively and highlight the target areas automatically, we adjust the segmentation in medical images and treat it as a sequence-to-sequence prediction task. We develop a U-shaped network based on self-attention and spatial attention mechanisms, called SA-TF-UNet. The SA-TF-UNet has an encoder-decoder architecture, where the encoder is based on pure Transformer blocks. Self-attention mechanisms in Transformer blocks can be used to enable global modeling as well. An attention gate (AG) is adopted to optimize the concatenation of the skip connections in U-Net, where the AGs can be learnt from depth layers of the Transformer and the weights on the target areas can be automatically set up more. To validate the effectiveness of AGs, we carried out experiments where one AG is only contained for the network. The comparative analysis is carried out the experiment as well, where we apply AG to all four layers. To determine the gating signals for each AG further, two sorts of structures are illustrated. The gating signals in these two sorts of structures are focused on the depth outputs of two Transformer blocks, and three Transformer blocks.ResultOur models proposed are tested on a dataset sample derived of 54 clinical MRI scans from AD patients. The dataset is divided into training data and testing data at a ratio of 8∶1 randomly. Three independent experiments are carried out, and an average result is used to reduce contingency simutaneously. The potential of SA-TF-UNet is demonstrated that the average dice of the left hippocampus and right hippocampus in three independent experiments are 0.900 1 and 0.909 1 relevant to an improvement of 2.82% and 3.37%. The other two related fine-tuned structures are linked that a dice coefficient of them is reached to more than 0.88 as well.ConclusionThe integrated self and spatial attention is beneifical for the precision of hippocampus segmentation. It is effective that the gating signal in AG is outputted in terms of one depth Transformer block only.关键词:hippocampus;medical image processing;Transformer;spatial attention;sementic segmentation186|397|0更新时间:2024-05-07 -
 摘要:ObjectiveThe corona virus disease 2019 (COVID-19) patients-oriented screening is mostly focused on reverse transcription-polymerase chain reaction (RT-PCR) nowadays. However, its challenges have been emerging in related to lower sensitivity and time-consuming. To optimize the related problem of diagnostic accuracy and labor intensive, chest X-ray (CXR) images and computed tomography (CT) images have been developing as two of key techniques for COVID-19 patients-oriented screening. However, these methods still have such limitations like clinicians-related experience factors in visual interpretation. In addition, inefficient diagnostic time span is challenged to be resolved for CT scanning technology as well. To get a rapid diagnosis of COVID-19 patients, emerging deep learning technique based CT scanning technology have been applied to segment and identify lesion regions in CT images of patients. Most of semantic segmentation methods are implemented in terms of convolutional neural networks (CNNs). The lesions of COVID-19 are multi-scale and irregular, and it is still difficult to capture completed information derived of the limited receptive field of CNN. Therefore, CNN-based semantic segmentation method does not pay enough attention to false negatives when such lesions are dealt with, and it still has the problem of low sensitivity and high specificity.MethodFirst, Swin Transformer is as the backbone and the output is extracted of the second, fourth, eighth, and twelfth Swin Transformer modules. Four sort of multi-scale feature maps are generated after that. Numerous of datasets are required to be used in terms of transfer learning method and its pre-training weight on ImageNet. Second, a residual connection and layer normalization (LN) based linear feed-forward module is developed to adjust the channel dimension of feature maps, and the axial attention module is applied to improve global information-related network’s attention as well. The linear feed-forward module-relevant fully connected layer can be carried out in the channel dimension only, and axial attention module-relevant self-attention is only computed locally, so computing cost has barely shrinked. Finally, for the decoder part, to improve the segmentation accuracy of edge information, a structure is developed to refine local information step by step, as well as multi-level prediction method is used for deep supervision. Furthermore, a multi-level prediction approach is also used for deep supervision. The Swin Transformer module is used to decode all levels of feature maps of the decoder part, which can optimize network learning and its related ability to refine local information gradually.ResultFor data augmentation-excluded data set of the COVID-19 CT segmentation, the Dice coefficient is 0.789, the sensitivity is 0.807; the specificity is 0.960, and the mean absolute error (MAE) is 0.055. Compared to the Semi-Inf-Net, each of it is increased by 5%, 8.2%, and 0.9%, and the MAE is decreased by 0.9%. For the ablation experiment, we have also verified the improvement of segmentation accuracy based on each module. The generalization ability is verified on 638 slices of the COVID-19 infection segmentation dataset, for which the Dice coefficient is 0.704, the sensitivity is 0.807, and the specificity is 0.960. Compared to the Semi-Inf-Net, each of it has increased by 10.7%, 0.1%, and 1.3% further.ConclusionSuch a Transformer is applied to segment COVID-19 CT images. Our network proposed can be dealt with both of local information and global information effectively through Transformer-purified network structure. The segmentation accuracy of COVID-19 lesions can be improved, and the problem of low sensitivity and high specificity of traditional CNN can be solved effectively to a certain extent. Experiments demonstrate that COVID-TransNet has its generalization performance and the ability of high accuracy segmentation. It is beneficial to assist clinicians efficiently in relevant to diagnosing COVID-19 patients.关键词:corona virus disease 2019 (COVID-19);computed tomography (CT) images segmentation;Swin Transformer;axial attention;multi-level prediction240|381|1更新时间:2024-05-07
摘要:ObjectiveThe corona virus disease 2019 (COVID-19) patients-oriented screening is mostly focused on reverse transcription-polymerase chain reaction (RT-PCR) nowadays. However, its challenges have been emerging in related to lower sensitivity and time-consuming. To optimize the related problem of diagnostic accuracy and labor intensive, chest X-ray (CXR) images and computed tomography (CT) images have been developing as two of key techniques for COVID-19 patients-oriented screening. However, these methods still have such limitations like clinicians-related experience factors in visual interpretation. In addition, inefficient diagnostic time span is challenged to be resolved for CT scanning technology as well. To get a rapid diagnosis of COVID-19 patients, emerging deep learning technique based CT scanning technology have been applied to segment and identify lesion regions in CT images of patients. Most of semantic segmentation methods are implemented in terms of convolutional neural networks (CNNs). The lesions of COVID-19 are multi-scale and irregular, and it is still difficult to capture completed information derived of the limited receptive field of CNN. Therefore, CNN-based semantic segmentation method does not pay enough attention to false negatives when such lesions are dealt with, and it still has the problem of low sensitivity and high specificity.MethodFirst, Swin Transformer is as the backbone and the output is extracted of the second, fourth, eighth, and twelfth Swin Transformer modules. Four sort of multi-scale feature maps are generated after that. Numerous of datasets are required to be used in terms of transfer learning method and its pre-training weight on ImageNet. Second, a residual connection and layer normalization (LN) based linear feed-forward module is developed to adjust the channel dimension of feature maps, and the axial attention module is applied to improve global information-related network’s attention as well. The linear feed-forward module-relevant fully connected layer can be carried out in the channel dimension only, and axial attention module-relevant self-attention is only computed locally, so computing cost has barely shrinked. Finally, for the decoder part, to improve the segmentation accuracy of edge information, a structure is developed to refine local information step by step, as well as multi-level prediction method is used for deep supervision. Furthermore, a multi-level prediction approach is also used for deep supervision. The Swin Transformer module is used to decode all levels of feature maps of the decoder part, which can optimize network learning and its related ability to refine local information gradually.ResultFor data augmentation-excluded data set of the COVID-19 CT segmentation, the Dice coefficient is 0.789, the sensitivity is 0.807; the specificity is 0.960, and the mean absolute error (MAE) is 0.055. Compared to the Semi-Inf-Net, each of it is increased by 5%, 8.2%, and 0.9%, and the MAE is decreased by 0.9%. For the ablation experiment, we have also verified the improvement of segmentation accuracy based on each module. The generalization ability is verified on 638 slices of the COVID-19 infection segmentation dataset, for which the Dice coefficient is 0.704, the sensitivity is 0.807, and the specificity is 0.960. Compared to the Semi-Inf-Net, each of it has increased by 10.7%, 0.1%, and 1.3% further.ConclusionSuch a Transformer is applied to segment COVID-19 CT images. Our network proposed can be dealt with both of local information and global information effectively through Transformer-purified network structure. The segmentation accuracy of COVID-19 lesions can be improved, and the problem of low sensitivity and high specificity of traditional CNN can be solved effectively to a certain extent. Experiments demonstrate that COVID-TransNet has its generalization performance and the ability of high accuracy segmentation. It is beneficial to assist clinicians efficiently in relevant to diagnosing COVID-19 patients.关键词:corona virus disease 2019 (COVID-19);computed tomography (CT) images segmentation;Swin Transformer;axial attention;multi-level prediction240|381|1更新时间:2024-05-07 -
 摘要:ObjectiveMedical instruments are recognized as indispensable tools to deal with surgerical tasks. Surgical trauma is still challenged to be optimized farther. The emerging surgical robots could shrink the harmful degree of derived of tsurgery operations, and it has higher stability and stronger learning ability in comparison with manual-based surgery. The precise segmentation of surgical instruments is a key link to the smooth operation of surgical robots. The existing segmentation methods can be used to locate the surgical instruments and segment the shape of the surgical instruments roughly. Due to these complex factors are required to be resolved in relevance to low contrast of surgical instruments, complex environment, mirror reflection, different sizes and shapes of surgical instruments, these segmentation methods are still challenged for a certain loss on boundary information and detailed features of surgical instruments, resulting in blurred boundaries and misclassification of details. To optimize its related surgical instrument segmentation, we develop a Transformer and convolutional neural network (CNN) based dual-encoder fusion segmentation network in terms of endoscopic images-relevant surgical instrument segmentation.MethodFor the encoder-decoder framework, a dual-encoder fusion segmentation network is facilitated to construct an end-to-end surgical instrument segmentation scheme. To optimize weak feature representation ability and get effective context features further,a Transformer and CNN fused dual-encoder block is built up to strengthen endoscopic images-related extraction ability of local details and global context information simultaneously. In addition, effective multi-scale feature extraction is also essential for the improvement of segmentation accuracy since heterogeneous surgical instruments are existed in sizes and shapes. To extract multi-scale attention feature maps, a multi-scale attention fusion module is embedded into the bottleneck layer for feature enhancement of local feature maps. To resolve its class imbalance issue-related surgical instrument segmentation task, an attention gated block is also introduced into the decoder unit to integrate the segmentation network into the surgical instruments better, and the attention to irrelevant features can be reduced as well.ResultTo verify the effectiveness and potentials of the dual-encoder fusion segmentation network proposed, two sort of publicity datasets on surgical instrument segmentation are adopted, including cataract surgery dataset (Kvasir-instrument dataset) and gastrointestinal surgery dataset (Endovis2017 dataset). Combined with the qualitative analysis and quantitative analysis, the segmentation performance is tested based on three sorts of experiments in related to ablation, comparison and visualization. The proposed dual-encoder fusion segmentation network has obtained a good segmentation results on both two datasets, which could achieve 96.46% of Dice score and 94.12% of mean intersection over union (mIOU) value on the Kvasir-instrument dataset, and 96.27% of Dice score and 92.55% of mIOU value on the Endovis2017 dataset. Compared to other related state-of-the-art comparison methods, the Dice score is improved by 1.51% and the mIOU value is improved by 2.52% compared to progressive alternating attention network(PAANet) model on the Kvasir-instrument dataset, and the Dice score is improved by 1.62% and the mIOU is improved by 2.22% compared to refined attention segmentation network(RASNet) model on the Endovis2017 dataset. Furthermore, to verify the effectiveness of each sub-module, quantitative and qualitative analysis based ablation experiments are also carried out. The dual-encoder module can be verified to improve its segmentation accuracy for Kvasir-instrument dataset and Endovis2017 dataset as well.ConclusionTo optimize surgical instrument segmentation task against such problems like mirror reflection, different shapes and size, and class imbalance, a CNN and Transformer based dual-encoder fusion segmentation network is developed to build up an end-to-end surgical instrument segmentation scheme. It is predicted that our method proposed can be used to segment the surgical instruments accurately based on endoscopic images in various shapes and sizes, which can provide a potential ability for robot-assisted surgery further.关键词:deep learning;surgical instrument segmentation;convolutional neural network (CNN);Transformer;dual encoder;feature attention mechanism190|307|0更新时间:2024-05-07
摘要:ObjectiveMedical instruments are recognized as indispensable tools to deal with surgerical tasks. Surgical trauma is still challenged to be optimized farther. The emerging surgical robots could shrink the harmful degree of derived of tsurgery operations, and it has higher stability and stronger learning ability in comparison with manual-based surgery. The precise segmentation of surgical instruments is a key link to the smooth operation of surgical robots. The existing segmentation methods can be used to locate the surgical instruments and segment the shape of the surgical instruments roughly. Due to these complex factors are required to be resolved in relevance to low contrast of surgical instruments, complex environment, mirror reflection, different sizes and shapes of surgical instruments, these segmentation methods are still challenged for a certain loss on boundary information and detailed features of surgical instruments, resulting in blurred boundaries and misclassification of details. To optimize its related surgical instrument segmentation, we develop a Transformer and convolutional neural network (CNN) based dual-encoder fusion segmentation network in terms of endoscopic images-relevant surgical instrument segmentation.MethodFor the encoder-decoder framework, a dual-encoder fusion segmentation network is facilitated to construct an end-to-end surgical instrument segmentation scheme. To optimize weak feature representation ability and get effective context features further,a Transformer and CNN fused dual-encoder block is built up to strengthen endoscopic images-related extraction ability of local details and global context information simultaneously. In addition, effective multi-scale feature extraction is also essential for the improvement of segmentation accuracy since heterogeneous surgical instruments are existed in sizes and shapes. To extract multi-scale attention feature maps, a multi-scale attention fusion module is embedded into the bottleneck layer for feature enhancement of local feature maps. To resolve its class imbalance issue-related surgical instrument segmentation task, an attention gated block is also introduced into the decoder unit to integrate the segmentation network into the surgical instruments better, and the attention to irrelevant features can be reduced as well.ResultTo verify the effectiveness and potentials of the dual-encoder fusion segmentation network proposed, two sort of publicity datasets on surgical instrument segmentation are adopted, including cataract surgery dataset (Kvasir-instrument dataset) and gastrointestinal surgery dataset (Endovis2017 dataset). Combined with the qualitative analysis and quantitative analysis, the segmentation performance is tested based on three sorts of experiments in related to ablation, comparison and visualization. The proposed dual-encoder fusion segmentation network has obtained a good segmentation results on both two datasets, which could achieve 96.46% of Dice score and 94.12% of mean intersection over union (mIOU) value on the Kvasir-instrument dataset, and 96.27% of Dice score and 92.55% of mIOU value on the Endovis2017 dataset. Compared to other related state-of-the-art comparison methods, the Dice score is improved by 1.51% and the mIOU value is improved by 2.52% compared to progressive alternating attention network(PAANet) model on the Kvasir-instrument dataset, and the Dice score is improved by 1.62% and the mIOU is improved by 2.22% compared to refined attention segmentation network(RASNet) model on the Endovis2017 dataset. Furthermore, to verify the effectiveness of each sub-module, quantitative and qualitative analysis based ablation experiments are also carried out. The dual-encoder module can be verified to improve its segmentation accuracy for Kvasir-instrument dataset and Endovis2017 dataset as well.ConclusionTo optimize surgical instrument segmentation task against such problems like mirror reflection, different shapes and size, and class imbalance, a CNN and Transformer based dual-encoder fusion segmentation network is developed to build up an end-to-end surgical instrument segmentation scheme. It is predicted that our method proposed can be used to segment the surgical instruments accurately based on endoscopic images in various shapes and sizes, which can provide a potential ability for robot-assisted surgery further.关键词:deep learning;surgical instrument segmentation;convolutional neural network (CNN);Transformer;dual encoder;feature attention mechanism190|307|0更新时间:2024-05-07 -
 摘要:ObjectiveThe end-to-end automatic medical image segmentation model has been concerned about recently. The emerging deep learning method has been widely used in various medical image processing tasks based on an integrated convolutional neural network (CNN) and U-Net architecture, especially for its potential ability of local feature extraction. Due to the inherent locality of the convolution operation itself, it is still challenged for global information acquisition further. The Transformer-based method is focused on global modeling capabilities, but it is still required to optimize CNNs-based local feature extraction farther. To fully integrate the potentials of two methods, we develop a group attention based medical image segmentation model, called GAU-Net.MethodFirst, to integrate the potentials of the convolutional neural network and the Swin Transformer, a dual of group attention module is designed that the Swin Transformer is linked to the convolutional neural network in parallel using the attention mechanism. To extract the global features of the image, a series of Swin Transformer modules are recognized as the sub-modules. The spatial and pixel channel attention modules are constructed using the convolutional neural network, and two of them are combined in series to develop the mixed attention in the group attention module. The sub-module can be used to extract key local features in the medical image on the spatial scale and pixel channel dimension, and two sub-modules-extracted features is spliced in the channel dimension, a residual unit is employed for feature fusion, and attention module-extracted key global and local features are grouped and fused, and the constructed group attention module is embedded in each layer of network encoder. Second, the attention calculation method is required to be focused on because of existing computational redundancy and efficient matching with the group attention module structure. To get simultaneous different attention calculations, encoder-extracted features are grouped proportionally in the feature channel dimension before it is input into the group attention module, and it can reduce the computational redundancy problem effectively and the diversity and richness of the network model-extracted semantic feature information are improved further. Finally, the extracted deep features are restored by layer-by-layer 2-fold upsampling to the original image size, and pixel classification is adopted to get the final segmentation result. At the same time, the class imbalance problem in the image is involved in, and the model training process is easily affected by irrelevant background pixels, and the linear combination of generalized dice loss and cross-entropy loss is used to solve the class imbalance problem and accelerate model convergence.ResultSuch of experimental verifications are carried out on the Synapse dataset and the ACDC dataset. The Synapse dataset consists of 30 cases with a total of 3 779 axial abdominal clinical computed tomography (CT) images. The data of 18 patient samples are used as the training set, and 12 patient samples are used as a test set. This dataset is labeled for 8 sort of abdominal organs in related to the aorta, gallbladder, spleen, left kidney, right kidney, liver, pancreas, and stomach. The ACDC dataset is collected from different patients using a magnetic resonance imaging (MRI) scanner. For each patient’s image, the left ventricle, right ventricle and myocardium are labeled as well. This dataset is composed of 70 training samples, 10 validation samples and 20 a test sample. Dice similarity coefficient and Hausdorff Distance95 are opted as the evaluation index to evaluate the accuracy of model segmentation results. Furthermore, ablation experiments are carried out to test the effectiveness of all modules and combinations. For the Synapse dataset, compared to the second-ranked method MISSFormer, the Dice value is increased by 0.97%, and the Hausdorff distance (HD) value is decreased by 5.88% and reached 82.93% (Dice) and 12.32 % (HD), respectively. For the ACDC dataset, compared to the second-ranked method MISSFormer, the Dice value is increased by 0.48% and reached to 91.34% (Dice).ConclusionOur medical image segmentation model proposed can be used to develop an integrated optimization for Swin Transformer and convolutional neural network effectively. The group attention module and group attention operation mode are melted into as well, which can improves the accuracy of medical image segmentation results further.关键词:deep learning;convolutional neural network(CNN);medical image segmentation;U-Net;group attention;Swin Transformer295|439|3更新时间:2024-05-07
摘要:ObjectiveThe end-to-end automatic medical image segmentation model has been concerned about recently. The emerging deep learning method has been widely used in various medical image processing tasks based on an integrated convolutional neural network (CNN) and U-Net architecture, especially for its potential ability of local feature extraction. Due to the inherent locality of the convolution operation itself, it is still challenged for global information acquisition further. The Transformer-based method is focused on global modeling capabilities, but it is still required to optimize CNNs-based local feature extraction farther. To fully integrate the potentials of two methods, we develop a group attention based medical image segmentation model, called GAU-Net.MethodFirst, to integrate the potentials of the convolutional neural network and the Swin Transformer, a dual of group attention module is designed that the Swin Transformer is linked to the convolutional neural network in parallel using the attention mechanism. To extract the global features of the image, a series of Swin Transformer modules are recognized as the sub-modules. The spatial and pixel channel attention modules are constructed using the convolutional neural network, and two of them are combined in series to develop the mixed attention in the group attention module. The sub-module can be used to extract key local features in the medical image on the spatial scale and pixel channel dimension, and two sub-modules-extracted features is spliced in the channel dimension, a residual unit is employed for feature fusion, and attention module-extracted key global and local features are grouped and fused, and the constructed group attention module is embedded in each layer of network encoder. Second, the attention calculation method is required to be focused on because of existing computational redundancy and efficient matching with the group attention module structure. To get simultaneous different attention calculations, encoder-extracted features are grouped proportionally in the feature channel dimension before it is input into the group attention module, and it can reduce the computational redundancy problem effectively and the diversity and richness of the network model-extracted semantic feature information are improved further. Finally, the extracted deep features are restored by layer-by-layer 2-fold upsampling to the original image size, and pixel classification is adopted to get the final segmentation result. At the same time, the class imbalance problem in the image is involved in, and the model training process is easily affected by irrelevant background pixels, and the linear combination of generalized dice loss and cross-entropy loss is used to solve the class imbalance problem and accelerate model convergence.ResultSuch of experimental verifications are carried out on the Synapse dataset and the ACDC dataset. The Synapse dataset consists of 30 cases with a total of 3 779 axial abdominal clinical computed tomography (CT) images. The data of 18 patient samples are used as the training set, and 12 patient samples are used as a test set. This dataset is labeled for 8 sort of abdominal organs in related to the aorta, gallbladder, spleen, left kidney, right kidney, liver, pancreas, and stomach. The ACDC dataset is collected from different patients using a magnetic resonance imaging (MRI) scanner. For each patient’s image, the left ventricle, right ventricle and myocardium are labeled as well. This dataset is composed of 70 training samples, 10 validation samples and 20 a test sample. Dice similarity coefficient and Hausdorff Distance95 are opted as the evaluation index to evaluate the accuracy of model segmentation results. Furthermore, ablation experiments are carried out to test the effectiveness of all modules and combinations. For the Synapse dataset, compared to the second-ranked method MISSFormer, the Dice value is increased by 0.97%, and the Hausdorff distance (HD) value is decreased by 5.88% and reached 82.93% (Dice) and 12.32 % (HD), respectively. For the ACDC dataset, compared to the second-ranked method MISSFormer, the Dice value is increased by 0.48% and reached to 91.34% (Dice).ConclusionOur medical image segmentation model proposed can be used to develop an integrated optimization for Swin Transformer and convolutional neural network effectively. The group attention module and group attention operation mode are melted into as well, which can improves the accuracy of medical image segmentation results further.关键词:deep learning;convolutional neural network(CNN);medical image segmentation;U-Net;group attention;Swin Transformer295|439|3更新时间:2024-05-07 -
 摘要:ObjectiveLung cancer-related early detection and intervention is beneficial for lowering mortality rates. Pleural effusion symptoms, and tumor cells and tumor cell masses can be sorted out in relevant to pleural effusion and its metastatic contexts. The detection of tumor cells in pleural effusion can be recognized as an emerging screening tool for lung cancer for early-stage intervention. One of the key preprocessing steps is focused on the precise segmentation of tumor cell masses in related to pleural fluid tumor cells. However, due to severe tumor cell masses-between overlapping and adhesion, unclear cell-to-cell spacing, and unstable staining results of tumor cells in pleural effusion are challenged to be resolved using conventional staining methods, manual micrographs of unstained pleural fluid tumor clumps for cell clump segmentation derived of experienced and well-trained pathologists. But, it still has such problems of inefficiency and the inevitable miss segmentation due to its labor-intensive work. In recent years, computer vision techniques have been developing intensively for optimizing the speed and accuracy of image analysis. Traditional methods for segmenting cellular microscopic images are carried out, including thresholding and such algorithms of clustering-based, graph-based, and active contouring. However, these methods are required for image downscaling, and they have the limitations of undeveloped graphical features. Convolutional neural network (CNN) based deep learning can be used to automatically find suitable features for image segmentation tasks nowadays. The UNet is derived from the end-to-end full convolutional network (FCN) structure, and it is widely used in medical image segmentation tasks due to its unique symmetric encoder and decoder network structure to get the segmentation result relevant to location information of the segmented target, in which arbitrary size image input and equal size output image can be yielded for arbitrary size image input and equal size output image. We develop a new CNN-based UNet network structure (DOCUNet) to perform tumor cell segmentation in pleural effusion, which can be focused on the integrated depthwise over-parameterized convolution (DO-conv) and channel and spatial attention convolutional block attention module (CBAM).MethodThe network is developed and divided into three sections: encoder, feature enhancer, and decoder. The encoder consists of a convolution operation and a down-sampler, and a hybrid of depthwise convolution and vanilla convolution is demonstrated in terms of depthwise over-parameterized convolution (DO-conv) based convolution operation rather than vanilla convolution. In practice, to get the final image features extraction, the first stage of feature extraction is obtained by depthwise convolution along the feature dimension of the input image and followed by a vanilla convolution operation. This design improves the network’s ability to extract features from cell clumps while keeping the output image size constant, and it addresses the issue of unclear features caused by severe intercellular adhesion. For the transition to the decoder, the CBAM attention module is inserted as a feature enhancer in the last layer of the encoder. The CBAM attention module is based on the channel attention mechanism, and the spatial attention mechanism is used to redistribute the weights of the encoder’s high-dimensional features through suppressing other related cells-interfered background features and enhancing the network’s utilization of the tumor cells’ internal features. For the purpose of feature redistribution, channel and spatial-generated attention maps are pointed multiplied with the input features. The use of jump connections in the decoder allows the network to learn features at multiple scales contextual information. Our research is affiliated to Tianjin Medical University’s microscopic images of tumor cell masses in pleural effusion. For the training sample set, 80 percent of the 117 images collection with completed labeling is chosen in random. After data enhancement, 20% of the images collection is chosen as the test sample set. The framework for building the model is chosen as Pytorch. The training is carried out on an NVIDIA RTX 3090 GPU. Each of loss function is binary cross entropy (BCE), the batch size is 4, and Adam is used as the optimizer based on an initial learning rate of 0.003, 1, and 2 of 0.9 and 0.999.ResultTo validate the proposed method’s effectiveness, the network models of all the five sort of semantic segmentation networks UNet, UNet++, ResUNet, Attention-UNet, UNet3+ and U2Net are involved for its comparative experiments using the same test sample set, and five sort of measurements of intersection over union (IoU), Dice coefficient, precision, recall and Hausdorff distance, as evaluation metrics, are used to evaluate its segmentation results. For each of the five evaluation metrics, the proposed network is valued and yielded of 0.858 0,0.920 4,0.928 2, 0.920 3 and 18.17. Compared to UNet, first of four measures are improved by 2.80, 1.65, 1.47 and 1.36 percent each. The Hausdorff distance is decreased by 41.16%. The proposed network’s segmentation results are visually closer to ground truth further, and the segmentation is clearer than other cell boundary-related models to a certain extent. The SEG-GradCAM-like activation heat maps-relevant ablation experiments is demonstrated that the proposed method can improve the network’s feature extraction ability, for which the network is allowed to focus on more on the internal features of tumor cells while suppressing irrelevant feature information in the image background.ConclusionTo achieve effective tumor cell cluster segmentation in pleural effusion, our DOCUNet is developed in terms of an attention mechanism and a UNet-integrated depthwise over-parameterized convolution. Comparative experiments demonstrate that the proposed method can be used to improve cell segmentation accuracy and its contexts further.关键词:pleural effusion tumor cell masses;UNet;attention mechanism;cell segmentation;over-parameter convolution123|303|0更新时间:2024-05-07
摘要:ObjectiveLung cancer-related early detection and intervention is beneficial for lowering mortality rates. Pleural effusion symptoms, and tumor cells and tumor cell masses can be sorted out in relevant to pleural effusion and its metastatic contexts. The detection of tumor cells in pleural effusion can be recognized as an emerging screening tool for lung cancer for early-stage intervention. One of the key preprocessing steps is focused on the precise segmentation of tumor cell masses in related to pleural fluid tumor cells. However, due to severe tumor cell masses-between overlapping and adhesion, unclear cell-to-cell spacing, and unstable staining results of tumor cells in pleural effusion are challenged to be resolved using conventional staining methods, manual micrographs of unstained pleural fluid tumor clumps for cell clump segmentation derived of experienced and well-trained pathologists. But, it still has such problems of inefficiency and the inevitable miss segmentation due to its labor-intensive work. In recent years, computer vision techniques have been developing intensively for optimizing the speed and accuracy of image analysis. Traditional methods for segmenting cellular microscopic images are carried out, including thresholding and such algorithms of clustering-based, graph-based, and active contouring. However, these methods are required for image downscaling, and they have the limitations of undeveloped graphical features. Convolutional neural network (CNN) based deep learning can be used to automatically find suitable features for image segmentation tasks nowadays. The UNet is derived from the end-to-end full convolutional network (FCN) structure, and it is widely used in medical image segmentation tasks due to its unique symmetric encoder and decoder network structure to get the segmentation result relevant to location information of the segmented target, in which arbitrary size image input and equal size output image can be yielded for arbitrary size image input and equal size output image. We develop a new CNN-based UNet network structure (DOCUNet) to perform tumor cell segmentation in pleural effusion, which can be focused on the integrated depthwise over-parameterized convolution (DO-conv) and channel and spatial attention convolutional block attention module (CBAM).MethodThe network is developed and divided into three sections: encoder, feature enhancer, and decoder. The encoder consists of a convolution operation and a down-sampler, and a hybrid of depthwise convolution and vanilla convolution is demonstrated in terms of depthwise over-parameterized convolution (DO-conv) based convolution operation rather than vanilla convolution. In practice, to get the final image features extraction, the first stage of feature extraction is obtained by depthwise convolution along the feature dimension of the input image and followed by a vanilla convolution operation. This design improves the network’s ability to extract features from cell clumps while keeping the output image size constant, and it addresses the issue of unclear features caused by severe intercellular adhesion. For the transition to the decoder, the CBAM attention module is inserted as a feature enhancer in the last layer of the encoder. The CBAM attention module is based on the channel attention mechanism, and the spatial attention mechanism is used to redistribute the weights of the encoder’s high-dimensional features through suppressing other related cells-interfered background features and enhancing the network’s utilization of the tumor cells’ internal features. For the purpose of feature redistribution, channel and spatial-generated attention maps are pointed multiplied with the input features. The use of jump connections in the decoder allows the network to learn features at multiple scales contextual information. Our research is affiliated to Tianjin Medical University’s microscopic images of tumor cell masses in pleural effusion. For the training sample set, 80 percent of the 117 images collection with completed labeling is chosen in random. After data enhancement, 20% of the images collection is chosen as the test sample set. The framework for building the model is chosen as Pytorch. The training is carried out on an NVIDIA RTX 3090 GPU. Each of loss function is binary cross entropy (BCE), the batch size is 4, and Adam is used as the optimizer based on an initial learning rate of 0.003, 1, and 2 of 0.9 and 0.999.ResultTo validate the proposed method’s effectiveness, the network models of all the five sort of semantic segmentation networks UNet, UNet++, ResUNet, Attention-UNet, UNet3+ and U2Net are involved for its comparative experiments using the same test sample set, and five sort of measurements of intersection over union (IoU), Dice coefficient, precision, recall and Hausdorff distance, as evaluation metrics, are used to evaluate its segmentation results. For each of the five evaluation metrics, the proposed network is valued and yielded of 0.858 0,0.920 4,0.928 2, 0.920 3 and 18.17. Compared to UNet, first of four measures are improved by 2.80, 1.65, 1.47 and 1.36 percent each. The Hausdorff distance is decreased by 41.16%. The proposed network’s segmentation results are visually closer to ground truth further, and the segmentation is clearer than other cell boundary-related models to a certain extent. The SEG-GradCAM-like activation heat maps-relevant ablation experiments is demonstrated that the proposed method can improve the network’s feature extraction ability, for which the network is allowed to focus on more on the internal features of tumor cells while suppressing irrelevant feature information in the image background.ConclusionTo achieve effective tumor cell cluster segmentation in pleural effusion, our DOCUNet is developed in terms of an attention mechanism and a UNet-integrated depthwise over-parameterized convolution. Comparative experiments demonstrate that the proposed method can be used to improve cell segmentation accuracy and its contexts further.关键词:pleural effusion tumor cell masses;UNet;attention mechanism;cell segmentation;over-parameter convolution123|303|0更新时间:2024-05-07
Medical Image Processing
-
Correlation subdomain alignment network based cross-domain hyperspectral image classification method
 摘要:ObjectiveHyperspectral image (HSI) classification method is focused on spectral and spatial information to recognize the category of each ground object pixel. Due to the large number of spectral bands and redundant information between spectral bands in hyperspectral data, it is challenged to extract the identifiable features. Deep learning technique has been widely used in HSI classification because of its potential feature extraction and generalization abilities. However, the classification performance of it often based on much more labeled training samples. Due to the relative high sensor and labor costs generated from collection to calibration of HSI, deep learning techniques are challenged for sufficient labeled his normally. It is feasible to classify a HSI (target domain) using another similar but not identical HSI (source domain) with rich labeling information to some extent. To complete the target-domain HSI classification, transfer learning technique can be used to transfer the domain-invariant knowledge learned from the labeled source domain to the target domain with a similar but different distribution. However, due to the lighting and sensor-derived constraints, the collected cross-domain HSIs have a large distribution difference frequently, and their distributions are challenged to be fully adapted. In addition, most transfer learning methods are rarely melted into in related to two-domain classifiers-between mismatched problems. Therefore, we develop a simple and effective deep transfer HSI classification method, called correlation subdomain alignment network (CSADN), which can be focused on distribution and classifier adaptations and the labeled source-domain knowledge can be transferred to an unlabeled target domain. The proposed method can use the labeled source-domain samples to complete the target domain HSI classification further.MethodThe CSADN is mainly composed of four aspects as mentioned below: 1) Data preprocessing: band selection is used to lower the dimension of the original HSIs. 2) Depth network-based feature learning: deep neural network is developed and used for feature learning. 3) Feature distribution adaptation: a covariance adaptation term is added to the loss function through minimizing the two-domain covariance to complete the global distribution adaptation. 4) Subdomain adaptation: a subdomain adaptation term is added to the loss function further, and the local features are aligned via minimizing the subdomain difference. 5) Classifier adaptation: the classifier difference is captured based on the classifier adaptation module, and the low-density separation criterion is utilized to yield the source-domain classifier to adapt the target-domain data better. To improve the classification accuracy of CSADN for the target-domain data further, joint domain adaptation is carried out between the feature level and classifier level.ResultThe classification performance and domain adaptation ability of CSADN are evaluated in experiments. For classification, ten sorts of cross-domain classification methods are selected for comparative experiments in the context of traditional transfer learning methods and deep transfer learning methods. For CSADN validation, four sets of real HSI data pairs are selected, including Botswana5-6 (BOT5-6), BOT6-7, BOT7-5, and Houston bright-shallow. It demonstrates that each of the accuracy of CSADN is optimized by 1.01%, 0.42%, 0.73%, and 0.64% for BOT5-6, BOT6-7, BOT7-5, and Houston bright-shallow data pairs. The Kappa coefficient of CSADN has its potentials apparently. For domain adaptation ability, the t-distributed stochastic neighbor embedding can be used to verify the effectiveness of CSADN via high-dimensional data visualization as well. The original features of HSIs and the domain adaptation after features of CSADN are visualized on four experimental data sets. Compared with the original features of HSIs, the CSADN-extracted features have their higher inter-class difference and lower intra-class difference simultaneously. Moreover, the feature distributions-between covariance differences can be reduced via the domain adaptation. It illustrates that the proposed method has its potential domain adaptation ability to a certain extent.ConclusionThe proposed CSADN is feasible to integrate the feature distribution adaptation and classifier adaptation into transfer knowledge from the source domain to the target domain. It can classify unlabeled samples in the target domain using labeled samples in the source domain only. Specifically, a domain adaptation layer is designed and embedded into as well. To complete the feature distribution adaptation, the difference between the first-order and second-order statistics of both domains is adapted through aligning the relevant subdomains and covariance. The classifier adaptation module is constructed and added to CSADN. The domain adaptation ability can be enhanced in terms of adapting the difference between classifiers, and the classification accuracy of the target domain data can be improved further. The target-domain pseudo label is used in CSADN, and the quality of the pseudo label can affect the domain adaptation effect of CSADN. To get better performance in cross-domain HSI classification tasks, future research direction is predicted that the pseudo label optimization technology can be introduced into CSADN further.关键词:hyperspectral image (HSI);classification;transfer learning;deep learning;cross-domain156|195|1更新时间:2024-05-07
摘要:ObjectiveHyperspectral image (HSI) classification method is focused on spectral and spatial information to recognize the category of each ground object pixel. Due to the large number of spectral bands and redundant information between spectral bands in hyperspectral data, it is challenged to extract the identifiable features. Deep learning technique has been widely used in HSI classification because of its potential feature extraction and generalization abilities. However, the classification performance of it often based on much more labeled training samples. Due to the relative high sensor and labor costs generated from collection to calibration of HSI, deep learning techniques are challenged for sufficient labeled his normally. It is feasible to classify a HSI (target domain) using another similar but not identical HSI (source domain) with rich labeling information to some extent. To complete the target-domain HSI classification, transfer learning technique can be used to transfer the domain-invariant knowledge learned from the labeled source domain to the target domain with a similar but different distribution. However, due to the lighting and sensor-derived constraints, the collected cross-domain HSIs have a large distribution difference frequently, and their distributions are challenged to be fully adapted. In addition, most transfer learning methods are rarely melted into in related to two-domain classifiers-between mismatched problems. Therefore, we develop a simple and effective deep transfer HSI classification method, called correlation subdomain alignment network (CSADN), which can be focused on distribution and classifier adaptations and the labeled source-domain knowledge can be transferred to an unlabeled target domain. The proposed method can use the labeled source-domain samples to complete the target domain HSI classification further.MethodThe CSADN is mainly composed of four aspects as mentioned below: 1) Data preprocessing: band selection is used to lower the dimension of the original HSIs. 2) Depth network-based feature learning: deep neural network is developed and used for feature learning. 3) Feature distribution adaptation: a covariance adaptation term is added to the loss function through minimizing the two-domain covariance to complete the global distribution adaptation. 4) Subdomain adaptation: a subdomain adaptation term is added to the loss function further, and the local features are aligned via minimizing the subdomain difference. 5) Classifier adaptation: the classifier difference is captured based on the classifier adaptation module, and the low-density separation criterion is utilized to yield the source-domain classifier to adapt the target-domain data better. To improve the classification accuracy of CSADN for the target-domain data further, joint domain adaptation is carried out between the feature level and classifier level.ResultThe classification performance and domain adaptation ability of CSADN are evaluated in experiments. For classification, ten sorts of cross-domain classification methods are selected for comparative experiments in the context of traditional transfer learning methods and deep transfer learning methods. For CSADN validation, four sets of real HSI data pairs are selected, including Botswana5-6 (BOT5-6), BOT6-7, BOT7-5, and Houston bright-shallow. It demonstrates that each of the accuracy of CSADN is optimized by 1.01%, 0.42%, 0.73%, and 0.64% for BOT5-6, BOT6-7, BOT7-5, and Houston bright-shallow data pairs. The Kappa coefficient of CSADN has its potentials apparently. For domain adaptation ability, the t-distributed stochastic neighbor embedding can be used to verify the effectiveness of CSADN via high-dimensional data visualization as well. The original features of HSIs and the domain adaptation after features of CSADN are visualized on four experimental data sets. Compared with the original features of HSIs, the CSADN-extracted features have their higher inter-class difference and lower intra-class difference simultaneously. Moreover, the feature distributions-between covariance differences can be reduced via the domain adaptation. It illustrates that the proposed method has its potential domain adaptation ability to a certain extent.ConclusionThe proposed CSADN is feasible to integrate the feature distribution adaptation and classifier adaptation into transfer knowledge from the source domain to the target domain. It can classify unlabeled samples in the target domain using labeled samples in the source domain only. Specifically, a domain adaptation layer is designed and embedded into as well. To complete the feature distribution adaptation, the difference between the first-order and second-order statistics of both domains is adapted through aligning the relevant subdomains and covariance. The classifier adaptation module is constructed and added to CSADN. The domain adaptation ability can be enhanced in terms of adapting the difference between classifiers, and the classification accuracy of the target domain data can be improved further. The target-domain pseudo label is used in CSADN, and the quality of the pseudo label can affect the domain adaptation effect of CSADN. To get better performance in cross-domain HSI classification tasks, future research direction is predicted that the pseudo label optimization technology can be introduced into CSADN further.关键词:hyperspectral image (HSI);classification;transfer learning;deep learning;cross-domain156|195|1更新时间:2024-05-07 -
 摘要:ObjectivePolarimetric synthetic aperture radar (PolSAR) is essential for high spatial resolution earth observation, and image classification can be as a key branch of PolSAR image interpretation. The emerging convolutional neural network (CNN) has its potentials in relevance to PolSAR image classification, but its accuracy and generalization ability is still challenged for its SAR labeling samples-derived constraints. We develop a multi-branch classification network model, which can integrate classification-refined location and semantic information of ground-based objects in polarimetric SAR images.MethodFirst, polarimetric SAR data are analyzed and interpreted in terms of scattering model-based Yamaguchi four-component decomposition method. To extract spatial features at different levels further, channels-related concatenation are conducted through 1) the decomposed surface scattering, 2) double scattering, 3) volume scattering and 4) helix scattering. Second, to optimize pixels features of PolSAR images as classification objects, a high-order conditional random field (CRF) energy function-guided multi-branch CNN feature extraction model is designed to extract 1) pixel feature information, 2) azimuth correction neighborhood information, and 3)position coordinate information, which is used to describe the relationship between global spatial features and local features. We design the direction correction pixel block as well, which is different from the traditional two-dimensional matrix. To optimize the effect of different types of pixels on the center pixel and the classification further, error points in the neighborhood information can be modified, especially for edge pixels. Finally, superpixel constraint module-related adaptive polarization linear iterative clustering (Pol-ASLIC) method is used to generate a superpixel segmentation image. For each pixel in the small superpixel interval, the average probability of the pre-classification results is calculated, and the most probable class is assigned to each pixel as the total class. It can reduce classification-derived interference of speckle noise and smooth adjacent pixels-between heterogeneity and homogeneity, and such of classification results can be more compactable. In the experiment, the simulation of ground truth-related uneven spatial distribution of samples are carried out, and the spatial sampling-decoupled method is adopted as the comparative experiment of random sampling method. The spatial sampling-decoupled method can generate mutually independent training samples and minimize the interference of the sampling position.ResultTo alleviate the impact of network instability on the classification results, each experiment is replicated for 10 times, and the average value is taken as the final display result. Two groups of NASA/JPL AIRSAR system-acquired real polarimetric SAR images are tested with a sampling rate of 1%. Extensive qualitative and quantitative experimental results demonstrate that the method proposed can generate feasible analysis in terms of a small number of labeled samples. It can extract more comprehensive and effective features under different sampling strategies in comparison with the machine learning method and traditional convolutional classification model. Compared to methods using pixel-level features or spatial features only, overall classification accuracy is improved by an average of 7%~10%. The classification accuracy of each category in the random sampling method is reached above 90% on both datasets. Furthermore, running speed is 2.5 times faster than support vector machine(SVM).ConclusionWe develop a multi-branch convolutional neural network to extract more effective and accurate eigenvalues through pixel feature-fused information, homogeneous region features, and geographic location information. To strengthen scale correlations between pixel-level and object-level data effectively, pixels-between spatial feature correlation can be further extended, in which the classification performance of the CNN model can be significantly improved in terms of a small number of labeled samples. The potential accuracy of remote sensing data terrain classification can be predicted to preserve the comprehensiveness and reliability of the characterization of ground-based object scattering models.关键词:SAR image classification;convolutional neural network (CNN);conditional random field (CRF);superpixel segmentation;sampling strategy;Yamaguchi decomposition244|291|1更新时间:2024-05-07
摘要:ObjectivePolarimetric synthetic aperture radar (PolSAR) is essential for high spatial resolution earth observation, and image classification can be as a key branch of PolSAR image interpretation. The emerging convolutional neural network (CNN) has its potentials in relevance to PolSAR image classification, but its accuracy and generalization ability is still challenged for its SAR labeling samples-derived constraints. We develop a multi-branch classification network model, which can integrate classification-refined location and semantic information of ground-based objects in polarimetric SAR images.MethodFirst, polarimetric SAR data are analyzed and interpreted in terms of scattering model-based Yamaguchi four-component decomposition method. To extract spatial features at different levels further, channels-related concatenation are conducted through 1) the decomposed surface scattering, 2) double scattering, 3) volume scattering and 4) helix scattering. Second, to optimize pixels features of PolSAR images as classification objects, a high-order conditional random field (CRF) energy function-guided multi-branch CNN feature extraction model is designed to extract 1) pixel feature information, 2) azimuth correction neighborhood information, and 3)position coordinate information, which is used to describe the relationship between global spatial features and local features. We design the direction correction pixel block as well, which is different from the traditional two-dimensional matrix. To optimize the effect of different types of pixels on the center pixel and the classification further, error points in the neighborhood information can be modified, especially for edge pixels. Finally, superpixel constraint module-related adaptive polarization linear iterative clustering (Pol-ASLIC) method is used to generate a superpixel segmentation image. For each pixel in the small superpixel interval, the average probability of the pre-classification results is calculated, and the most probable class is assigned to each pixel as the total class. It can reduce classification-derived interference of speckle noise and smooth adjacent pixels-between heterogeneity and homogeneity, and such of classification results can be more compactable. In the experiment, the simulation of ground truth-related uneven spatial distribution of samples are carried out, and the spatial sampling-decoupled method is adopted as the comparative experiment of random sampling method. The spatial sampling-decoupled method can generate mutually independent training samples and minimize the interference of the sampling position.ResultTo alleviate the impact of network instability on the classification results, each experiment is replicated for 10 times, and the average value is taken as the final display result. Two groups of NASA/JPL AIRSAR system-acquired real polarimetric SAR images are tested with a sampling rate of 1%. Extensive qualitative and quantitative experimental results demonstrate that the method proposed can generate feasible analysis in terms of a small number of labeled samples. It can extract more comprehensive and effective features under different sampling strategies in comparison with the machine learning method and traditional convolutional classification model. Compared to methods using pixel-level features or spatial features only, overall classification accuracy is improved by an average of 7%~10%. The classification accuracy of each category in the random sampling method is reached above 90% on both datasets. Furthermore, running speed is 2.5 times faster than support vector machine(SVM).ConclusionWe develop a multi-branch convolutional neural network to extract more effective and accurate eigenvalues through pixel feature-fused information, homogeneous region features, and geographic location information. To strengthen scale correlations between pixel-level and object-level data effectively, pixels-between spatial feature correlation can be further extended, in which the classification performance of the CNN model can be significantly improved in terms of a small number of labeled samples. The potential accuracy of remote sensing data terrain classification can be predicted to preserve the comprehensiveness and reliability of the characterization of ground-based object scattering models.关键词:SAR image classification;convolutional neural network (CNN);conditional random field (CRF);superpixel segmentation;sampling strategy;Yamaguchi decomposition244|291|1更新时间:2024-05-07
Remote Sensing Image Processing
-
 摘要:ObjectiveMap intelligent generation technique is focused on generating map images quickly and cost efficiently. For existing intelligent map generation technique, to get quick-responsed and low-cost map generation, remote sensing image is taken as the input, and its generative adversarial network (GAN) is used to generate the corresponding map image. Inevitably, it is challenged that the intra-class differences within geographical elements in remote sensing images and the differences of geographical elements between domains in the map generation task are still not involved in. The intra-class difference of geographical elements refers that similar geographical elements in remote sensing images have several of appearances, which are difficult to be interpreted. Geographical elements segmentation is required for map generation in relevance to melting obvious intra-class differences into corresponding categories. The difference of geographical elements between different domains means that the corresponding geographical elements in remote sensing images and map images are not exactly matched well. For example, the edges of vegetation elements in remote sensing images are irregular, while the edges of vegetation elements in map images are flat. Another challenge for map generation is to generate and keep consistency to the features of map elements. Aiming at the intra-class difference of geographical elements and the superposition of geographical elements, we develop a dual of map-intelligent generation method based on Transformer features.MethodThe model consists of three sorts of modules relevant to feature extraction, preliminary and refined generative adversarial contexts. First, feature extraction module is developed based on the latest Transformer network. It consists of a backbone and segmentation branch in terms of Swin-Transformer structure. Self-attention mechanism based Transformer can be used to construct the global relationship of the image, and it has a larger receptive field and it can extract feature information effectively. The segmentation branch is composed of a pyramid pooling module (PPM) and a feature pyramid network (FPN). To get more effective geographic element features, feature pyramid is employed to extract multi-level feature information, and the high-level geographic element semantic information can be integrated into the middle-level and low-level geographic element semantic information, and the PPM is used to introduce the global semantic information as well. Next, feature information is sent to the segmentation branch, which uses the actual segmentation results as a guidance to generate effective geographical element features. To guide map generation and resolve the problem of map generation caused by the differences in geographical elements, this module can be used to extract the features of geographical elements in remote sensing images. Third, the preliminary generative adversarial module has a preliminary generator and a discriminator. The preliminary generator is a multi-scale generator, consisting of a local generator and a global generator, and it is used to generate the high-resolution images. Both of local and global generators are linked to encoder/decoder structures. The input of the preliminary generator is derived of remote sensing image and geographical element features, and the output is originated from preliminary map image. The discriminator is also recognized as a multi-scale discriminator, which consists of three sorts of sub discriminators for the high-resolution images. The input of the discriminator is the generated map and the real map, and the output is the single channel confidence map. Finally, a refined generator is used for refined generative adversarial module, and a discriminator with the preliminary generative adversarial module is shared in as well. The structure of the refined generator is same as the preliminary generator, which is also as a multi-scale generator in terms of local and global generators. The input of the refinement generator is originated from a preliminary map image and the output is derived of a fine map image. A dual of generation framework is constructed in terms of refined and preliminary generative adversarial-related modules. In general, to obtain preliminary map images, the preliminary generative adversarial module is as inputs based on remote sensing images and geographical element features. The preliminary map image is rough, and there are incomplete geographical elements, such as uneven road edges and fractures. For the refined generative adversarial module, to learn the geometric characteristics of geographical elements in the real map, obtain high-quality fine map images, and alleviate the problem of inaccurate local map generation caused by the differences of geographical elements between domains, the generated primary map image is taken as the input, and the real map is taken as the guide as well.ResultExperiments are carried out on 9 regions on the aerial image dataset for online map generation (AIDOMG) dataset in comparison with 10 sort of popular methods. For the Haikou area, Frechet inception distance (FID) is reduced by 16.0%, Wasserstein distance (WD) is reduced by 4.2%, and the 1-nearest neighbor (1-NN) is reduced by 5.9% as well. For the Paris area, FID is decreased by 2.9%, WD is decreased by 1.0%, and 1-NN decreased by 2.1% simultaneously. Comparative analyses demonstrate that our method proposed can improve the results of map generation effectively. At the same time, ablation studies of the model can show the effectiveness of each module, and each module can be added and the model results is improved gradually as well.ConclusionTo solve the problem of poor map generation quality caused by the intra-class inconsistency of geographical elements effectively, a dual of Transformer features-related map-intelligent generation method is proposed, and the differences of geographical elements between domains can be illustrated via high-quality Transformer-guided feature and a dual of generation framework further.关键词:Transformer feature;remote sensing image;map image;intelligent map generation;generative adversarial network (GAN)125|315|0更新时间:2024-05-07
摘要:ObjectiveMap intelligent generation technique is focused on generating map images quickly and cost efficiently. For existing intelligent map generation technique, to get quick-responsed and low-cost map generation, remote sensing image is taken as the input, and its generative adversarial network (GAN) is used to generate the corresponding map image. Inevitably, it is challenged that the intra-class differences within geographical elements in remote sensing images and the differences of geographical elements between domains in the map generation task are still not involved in. The intra-class difference of geographical elements refers that similar geographical elements in remote sensing images have several of appearances, which are difficult to be interpreted. Geographical elements segmentation is required for map generation in relevance to melting obvious intra-class differences into corresponding categories. The difference of geographical elements between different domains means that the corresponding geographical elements in remote sensing images and map images are not exactly matched well. For example, the edges of vegetation elements in remote sensing images are irregular, while the edges of vegetation elements in map images are flat. Another challenge for map generation is to generate and keep consistency to the features of map elements. Aiming at the intra-class difference of geographical elements and the superposition of geographical elements, we develop a dual of map-intelligent generation method based on Transformer features.MethodThe model consists of three sorts of modules relevant to feature extraction, preliminary and refined generative adversarial contexts. First, feature extraction module is developed based on the latest Transformer network. It consists of a backbone and segmentation branch in terms of Swin-Transformer structure. Self-attention mechanism based Transformer can be used to construct the global relationship of the image, and it has a larger receptive field and it can extract feature information effectively. The segmentation branch is composed of a pyramid pooling module (PPM) and a feature pyramid network (FPN). To get more effective geographic element features, feature pyramid is employed to extract multi-level feature information, and the high-level geographic element semantic information can be integrated into the middle-level and low-level geographic element semantic information, and the PPM is used to introduce the global semantic information as well. Next, feature information is sent to the segmentation branch, which uses the actual segmentation results as a guidance to generate effective geographical element features. To guide map generation and resolve the problem of map generation caused by the differences in geographical elements, this module can be used to extract the features of geographical elements in remote sensing images. Third, the preliminary generative adversarial module has a preliminary generator and a discriminator. The preliminary generator is a multi-scale generator, consisting of a local generator and a global generator, and it is used to generate the high-resolution images. Both of local and global generators are linked to encoder/decoder structures. The input of the preliminary generator is derived of remote sensing image and geographical element features, and the output is originated from preliminary map image. The discriminator is also recognized as a multi-scale discriminator, which consists of three sorts of sub discriminators for the high-resolution images. The input of the discriminator is the generated map and the real map, and the output is the single channel confidence map. Finally, a refined generator is used for refined generative adversarial module, and a discriminator with the preliminary generative adversarial module is shared in as well. The structure of the refined generator is same as the preliminary generator, which is also as a multi-scale generator in terms of local and global generators. The input of the refinement generator is originated from a preliminary map image and the output is derived of a fine map image. A dual of generation framework is constructed in terms of refined and preliminary generative adversarial-related modules. In general, to obtain preliminary map images, the preliminary generative adversarial module is as inputs based on remote sensing images and geographical element features. The preliminary map image is rough, and there are incomplete geographical elements, such as uneven road edges and fractures. For the refined generative adversarial module, to learn the geometric characteristics of geographical elements in the real map, obtain high-quality fine map images, and alleviate the problem of inaccurate local map generation caused by the differences of geographical elements between domains, the generated primary map image is taken as the input, and the real map is taken as the guide as well.ResultExperiments are carried out on 9 regions on the aerial image dataset for online map generation (AIDOMG) dataset in comparison with 10 sort of popular methods. For the Haikou area, Frechet inception distance (FID) is reduced by 16.0%, Wasserstein distance (WD) is reduced by 4.2%, and the 1-nearest neighbor (1-NN) is reduced by 5.9% as well. For the Paris area, FID is decreased by 2.9%, WD is decreased by 1.0%, and 1-NN decreased by 2.1% simultaneously. Comparative analyses demonstrate that our method proposed can improve the results of map generation effectively. At the same time, ablation studies of the model can show the effectiveness of each module, and each module can be added and the model results is improved gradually as well.ConclusionTo solve the problem of poor map generation quality caused by the intra-class inconsistency of geographical elements effectively, a dual of Transformer features-related map-intelligent generation method is proposed, and the differences of geographical elements between domains can be illustrated via high-quality Transformer-guided feature and a dual of generation framework further.关键词:Transformer feature;remote sensing image;map image;intelligent map generation;generative adversarial network (GAN)125|315|0更新时间:2024-05-07
Geoinformatics
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0