
最新刊期
卷 28 , 期 1 , 2023
-
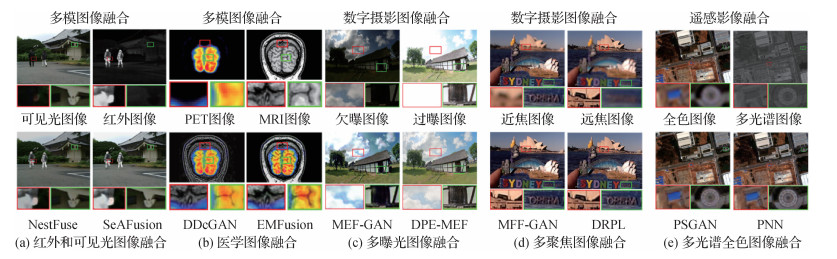 摘要:Image fusion aims to integrate complementary information from multi-source images into a single fused image to characterize the imaging scene and facilitate the subsequent vision tasks further. In recent years, it has been a concern in the field of image processing, especially in artificial intelligence-related industries like intelligent medical service, autonomous driving, smart photography, security surveillance, and military monitoring. Moreover, the growth of deep learning has been promoting deep learning-based image fusion algorithms. In particular, the emergence of advanced techniques, such as the auto-encoder, generative adversarial network, and Transformer, has led to a qualitative leap in image fusion performance. However, a comprehensive review and analysis of state-of-the-art deep learning-based image fusion algorithms for different fusion scenarios are required to be realized. Thus, we develop a systematic and critical review to explore the developments of image fusion in recent years. First, a comprehensive and systematic introduction of the image fusion field is presented from the following three aspects: 1) the development of image fusion technology, 2) the prevailing datasets, and 3) the common evaluation metrics. Then, more extensive qualitative experiments, quantitative experiments, and running efficiency evaluations of representative image fusion methods are conducted on the public datasets to compare their performance. Finally, the summary and challenges in the image fusion community are highlighted. In particular, some prospects are recommended further in the field of image fusion. First of all, from the perspective of fusion scenarios, the existing image fusion methods can be divided into three categories, i.e., multi-modal image fusion, digital photography image fusion, and remote sensing image fusion. Specifically, multi-modal image fusion is composed of infrared and visible image fusion as well as medical image fusion, and digital photography image fusion consists of multi-exposure image fusion as well as multi-focus image fusion. Multi-spectral and panchromatic image fusion can be as one of the key aspects for remote sensing image fusion. In addition, the domain of deep learning-based image fusion algorithms can be classified into the auto-encoder based (AE-based) fusion framework, convolutional neural network based (CNN-based) fusion framework, and generative adversarial network based (GAN-based) fusion framework from the aspect of network architectures. The AE-based fusion framework achieves the feature extraction and image reconstruction by a pre-trained auto-encoder, and accomplishes deep feature fusion via manual fusion strategies. To clarify feature extraction, fusion, and image reconstruction, the CNN-based fusion framework is originated from detailed network structures and loss functions. The GAN-based framework defines the image fusion problem as an adversarial game between the generators and discriminators. From the perspective of the supervision paradigm, the deep learning fusion methods can also be categorized into three classes, i.e., unsupervised, self-supervised, and supervised. The supervised methods leverage ground truth value to guide the training processes, and the unsupervised approaches construct loss function via constraining the similarity between the fusion result and source images. The self-supervised algorithms are associated with the AE-based framework in common. Our critical review is focused on the main concepts and discussions of the characteristics of each method for different fusion scenarios from the perspectives of the network architecture and supervision paradigm. Especially, we summarize the limitations of different fusion algorithms and provide some recommendations for further research. Secondly, we briefly introduce the popular public datasets and provide the interfaces-related to download them for each specific image fusion scenario. Then, we present the common evaluation metrics in the image fusion field from two aspects: regular-based evaluation metrics and specific-based metrics designed for pan-sharpening. The generic metrics can be utilized to evaluate multi-modal and digital photography image fusion algorithms of those are entropy-based, correlation-based, image feature-based, image structure-based, and human visual perception-based metrics in total. Some of the generic metrics, such as peak signal-to-noise ratio (PSNR), correlation coefficient (CC), structural similarity index measure (SSIM), and visual information fidelity (VIF), are also used for the quantitative assessment of pan-sharpening. The specific metrics designed for pan-sharpening consist of no-reference metrics and full-reference metrics that employ the full-resolution image as the reference image, i.e., ground truth. Thirdly, we present the qualitative/quantitative results, and average running times of representative alternatives for various fusion missions. Finally, this review has critically analyzed the conclusion, highlights the challenges in the image fusion community, and carried out forecasting analysis, such as non-registered image fusion, high-level vision task-driven image fusion, cross-resolution image fusion, real-time image fusion, color image fusion, image fusion based on physical imaging principles, image fusion under extreme conditions, and comprehensive evaluation metrics, etc. The methods, datasets, and evaluation metrics mentioned are linked at: https://github.com/Linfeng-Tang/Image-Fusion.关键词:image fusion;deep learning;multi-modal;digital photography;remote sensing imagery6357|7342|21更新时间:2024-05-08
摘要:Image fusion aims to integrate complementary information from multi-source images into a single fused image to characterize the imaging scene and facilitate the subsequent vision tasks further. In recent years, it has been a concern in the field of image processing, especially in artificial intelligence-related industries like intelligent medical service, autonomous driving, smart photography, security surveillance, and military monitoring. Moreover, the growth of deep learning has been promoting deep learning-based image fusion algorithms. In particular, the emergence of advanced techniques, such as the auto-encoder, generative adversarial network, and Transformer, has led to a qualitative leap in image fusion performance. However, a comprehensive review and analysis of state-of-the-art deep learning-based image fusion algorithms for different fusion scenarios are required to be realized. Thus, we develop a systematic and critical review to explore the developments of image fusion in recent years. First, a comprehensive and systematic introduction of the image fusion field is presented from the following three aspects: 1) the development of image fusion technology, 2) the prevailing datasets, and 3) the common evaluation metrics. Then, more extensive qualitative experiments, quantitative experiments, and running efficiency evaluations of representative image fusion methods are conducted on the public datasets to compare their performance. Finally, the summary and challenges in the image fusion community are highlighted. In particular, some prospects are recommended further in the field of image fusion. First of all, from the perspective of fusion scenarios, the existing image fusion methods can be divided into three categories, i.e., multi-modal image fusion, digital photography image fusion, and remote sensing image fusion. Specifically, multi-modal image fusion is composed of infrared and visible image fusion as well as medical image fusion, and digital photography image fusion consists of multi-exposure image fusion as well as multi-focus image fusion. Multi-spectral and panchromatic image fusion can be as one of the key aspects for remote sensing image fusion. In addition, the domain of deep learning-based image fusion algorithms can be classified into the auto-encoder based (AE-based) fusion framework, convolutional neural network based (CNN-based) fusion framework, and generative adversarial network based (GAN-based) fusion framework from the aspect of network architectures. The AE-based fusion framework achieves the feature extraction and image reconstruction by a pre-trained auto-encoder, and accomplishes deep feature fusion via manual fusion strategies. To clarify feature extraction, fusion, and image reconstruction, the CNN-based fusion framework is originated from detailed network structures and loss functions. The GAN-based framework defines the image fusion problem as an adversarial game between the generators and discriminators. From the perspective of the supervision paradigm, the deep learning fusion methods can also be categorized into three classes, i.e., unsupervised, self-supervised, and supervised. The supervised methods leverage ground truth value to guide the training processes, and the unsupervised approaches construct loss function via constraining the similarity between the fusion result and source images. The self-supervised algorithms are associated with the AE-based framework in common. Our critical review is focused on the main concepts and discussions of the characteristics of each method for different fusion scenarios from the perspectives of the network architecture and supervision paradigm. Especially, we summarize the limitations of different fusion algorithms and provide some recommendations for further research. Secondly, we briefly introduce the popular public datasets and provide the interfaces-related to download them for each specific image fusion scenario. Then, we present the common evaluation metrics in the image fusion field from two aspects: regular-based evaluation metrics and specific-based metrics designed for pan-sharpening. The generic metrics can be utilized to evaluate multi-modal and digital photography image fusion algorithms of those are entropy-based, correlation-based, image feature-based, image structure-based, and human visual perception-based metrics in total. Some of the generic metrics, such as peak signal-to-noise ratio (PSNR), correlation coefficient (CC), structural similarity index measure (SSIM), and visual information fidelity (VIF), are also used for the quantitative assessment of pan-sharpening. The specific metrics designed for pan-sharpening consist of no-reference metrics and full-reference metrics that employ the full-resolution image as the reference image, i.e., ground truth. Thirdly, we present the qualitative/quantitative results, and average running times of representative alternatives for various fusion missions. Finally, this review has critically analyzed the conclusion, highlights the challenges in the image fusion community, and carried out forecasting analysis, such as non-registered image fusion, high-level vision task-driven image fusion, cross-resolution image fusion, real-time image fusion, color image fusion, image fusion based on physical imaging principles, image fusion under extreme conditions, and comprehensive evaluation metrics, etc. The methods, datasets, and evaluation metrics mentioned are linked at: https://github.com/Linfeng-Tang/Image-Fusion.关键词:image fusion;deep learning;multi-modal;digital photography;remote sensing imagery6357|7342|21更新时间:2024-05-08 -
 摘要:Visual tracking can be as one of the key tasks in computer vision applications like surveillance, robotics and automatic driving in the past decades. The performance issue for visual tracking is still challenged of the quality of visible light data in adverse scenes, such as low illumination, background clutter, haze and smog. To deal with the imaging constraints of visible light data, current researches are focused on multiple modal data-introduced in common. The visible and modal data integration can be effective in tracking performance in terms of the manner of thermal infrared, depth, event and language. Benefiting from the integrated capability of visible and multi-modal data, multi-modal trackers have been developing intensively in such complicated scenarios of those are low illumination, occlusion, fast motion and semantic ambiguity. Nowadays, our executive summary is focused on reviewing the RGB and thermal infrared(RGBT) tracking algorithms, which is oriented for the popular visible-infrared visual tracking towards multi-modal visual tracking. Existing multi-modal visual tracking-based summaries are concerned of the segmentation of tracking algorithms in terms of multi-framework tracking or multi-level based fusions derived of pixel, feature, and decision. With respect of the information fusion plays a key role in multi-modal visual tracking, we divide and analyze existing RGBT tracking methods from the perspective of information fusion, including synthesized and specific-based fusions. Specifically, the fusion-integrated can be used to combine all multimodal information together via different fusion methods, including: 1) sparse representation fusion, 2) collaborative graph representation fusion, 3) modality-synthesized and modality-specific information fusion, and 4) attribute-based feature decoupling fusion. First, sparse representation fusion has a good ability to suppress feature noise, but most of these algorithms are restricted by the time-consuming online optimization of the sparse representation models. In addition, these methods can be used as target representation via pixel values, and thus have low robustness in complex scenes. Second, collaborative graph representation fusion can be used to suppress the effect of background clutter in terms of modality weights and local image patch weights. However, these methods are required for multi-variables optimization iteratively, and the tracking efficiency is quite lower. Furthermore, these models are required to use color and gradient features, which are better than pixel values but also hard to deal with challenging scenarios. Third, modality-synthesized and modality-specific information fusion can use be used to model modality-synthesized and modality-specific representations based on different sub-networks and provide an effective fusion strategy for tracking. However, these methods are lack of the information interaction in the learning of modality-specific representations, and thus introduce noises and redundancy easily. Fourth, attribute-based feature decoupling fusion can be applied to model the target representations under different attributes, and it alleviates the dependence on large-scale training data more. However, it is difficult to cover all challenging problems in practical applications. Although these fusion-synthesized methods have achieved good tracking performance, all multiple modalities information-synthesized have to introduce the information redundancy and feature noises inevitably. To resolve these problems, some researches have been concerned of fusion-specific methods in RGBT tracking. This sort of fusion is aimed to mine the specific features of multiple modalities for effective and efficient information fusion, including: 1) feature-selected fusion, 2) attention-mechanism-based adaptive fusion, 3)mutual-enhanced fusion, and 4)other fusion-specific methods. Feature selection fusion is employed to select specific features in regular. It can not only avoid the interference of data noises and is beneficial to improving tracking performance, but also eliminate data redundancy. However, the selection criteria are hard to be designed, and unsuitable criterion often removes useful information under low-quality data and thus limits tracking performance. Adaptive fusion is aimed to estimate the reliability of multi-modal data in term of attention mechanism, including the modality, spatial and channel reliabilities, and thus achieves the adaptive fusion of multi-modal information. However, there is no clear supervision to generate these weights-reliable, which is possible to mislead the estimated results in complex scenarios. Mutual enhancement fusion is focused on data noises-related suppression for low-quality modality and its features can be enhanced between the specific information and other modality. These methods can be implemented to mine the specific information of multiple modalities and improve target representations of low-quality modalities. However, these methods are complicated and have low tracking efficiency.The task of multi-modal vision tracking has three sub-tasks besides RGBT tracking, including: 1) visible-depth tracking (called RGB and depth(RGBD) tracking), 2) visible-event tracking (called RGBE(RGB and event) tracking), 3) visible-language tracking (called RGB and language(RGBL) tracking). We review these three multi-modal visual tracking issues in brief as well. Furthermore, we predict some academic challenges and future directions for multi-modal visual tracking.关键词:information fusion;visual tracking;multiple modalities;combinative fusion;discriminative fusion439|404|7更新时间:2024-05-08
摘要:Visual tracking can be as one of the key tasks in computer vision applications like surveillance, robotics and automatic driving in the past decades. The performance issue for visual tracking is still challenged of the quality of visible light data in adverse scenes, such as low illumination, background clutter, haze and smog. To deal with the imaging constraints of visible light data, current researches are focused on multiple modal data-introduced in common. The visible and modal data integration can be effective in tracking performance in terms of the manner of thermal infrared, depth, event and language. Benefiting from the integrated capability of visible and multi-modal data, multi-modal trackers have been developing intensively in such complicated scenarios of those are low illumination, occlusion, fast motion and semantic ambiguity. Nowadays, our executive summary is focused on reviewing the RGB and thermal infrared(RGBT) tracking algorithms, which is oriented for the popular visible-infrared visual tracking towards multi-modal visual tracking. Existing multi-modal visual tracking-based summaries are concerned of the segmentation of tracking algorithms in terms of multi-framework tracking or multi-level based fusions derived of pixel, feature, and decision. With respect of the information fusion plays a key role in multi-modal visual tracking, we divide and analyze existing RGBT tracking methods from the perspective of information fusion, including synthesized and specific-based fusions. Specifically, the fusion-integrated can be used to combine all multimodal information together via different fusion methods, including: 1) sparse representation fusion, 2) collaborative graph representation fusion, 3) modality-synthesized and modality-specific information fusion, and 4) attribute-based feature decoupling fusion. First, sparse representation fusion has a good ability to suppress feature noise, but most of these algorithms are restricted by the time-consuming online optimization of the sparse representation models. In addition, these methods can be used as target representation via pixel values, and thus have low robustness in complex scenes. Second, collaborative graph representation fusion can be used to suppress the effect of background clutter in terms of modality weights and local image patch weights. However, these methods are required for multi-variables optimization iteratively, and the tracking efficiency is quite lower. Furthermore, these models are required to use color and gradient features, which are better than pixel values but also hard to deal with challenging scenarios. Third, modality-synthesized and modality-specific information fusion can use be used to model modality-synthesized and modality-specific representations based on different sub-networks and provide an effective fusion strategy for tracking. However, these methods are lack of the information interaction in the learning of modality-specific representations, and thus introduce noises and redundancy easily. Fourth, attribute-based feature decoupling fusion can be applied to model the target representations under different attributes, and it alleviates the dependence on large-scale training data more. However, it is difficult to cover all challenging problems in practical applications. Although these fusion-synthesized methods have achieved good tracking performance, all multiple modalities information-synthesized have to introduce the information redundancy and feature noises inevitably. To resolve these problems, some researches have been concerned of fusion-specific methods in RGBT tracking. This sort of fusion is aimed to mine the specific features of multiple modalities for effective and efficient information fusion, including: 1) feature-selected fusion, 2) attention-mechanism-based adaptive fusion, 3)mutual-enhanced fusion, and 4)other fusion-specific methods. Feature selection fusion is employed to select specific features in regular. It can not only avoid the interference of data noises and is beneficial to improving tracking performance, but also eliminate data redundancy. However, the selection criteria are hard to be designed, and unsuitable criterion often removes useful information under low-quality data and thus limits tracking performance. Adaptive fusion is aimed to estimate the reliability of multi-modal data in term of attention mechanism, including the modality, spatial and channel reliabilities, and thus achieves the adaptive fusion of multi-modal information. However, there is no clear supervision to generate these weights-reliable, which is possible to mislead the estimated results in complex scenarios. Mutual enhancement fusion is focused on data noises-related suppression for low-quality modality and its features can be enhanced between the specific information and other modality. These methods can be implemented to mine the specific information of multiple modalities and improve target representations of low-quality modalities. However, these methods are complicated and have low tracking efficiency.The task of multi-modal vision tracking has three sub-tasks besides RGBT tracking, including: 1) visible-depth tracking (called RGB and depth(RGBD) tracking), 2) visible-event tracking (called RGBE(RGB and event) tracking), 3) visible-language tracking (called RGB and language(RGBL) tracking). We review these three multi-modal visual tracking issues in brief as well. Furthermore, we predict some academic challenges and future directions for multi-modal visual tracking.关键词:information fusion;visual tracking;multiple modalities;combinative fusion;discriminative fusion439|404|7更新时间:2024-05-08 -
 摘要:The aim of pan-sharpening is focused on data acquisition and processing captured from multiple remote sensing satellites in terms of machine learning and signal processing techniques. To produce a high-quality multispectral image, its objective is oriented to fuse a low spatial resolution-based multispectral (MS) image and a high spatial resolution-based panchromatic (PAN) image. Machine learning (ML) technique is being developed to deal with it. Pan-sharpening, a recent multispectral image-based image fusion technique, has been concerned about in terms of machine learning, which is featured by its medium/low spatial resolution. In recent years, remote sensing (RS) science, big data science and convolutional neural networks based (CNNs-based) techniques (a sub-category of ML), have promoted image processing, computer vision and its contexts. Thanks to the priority of RS images-based pan-sharpening of fusion, CNN-oriented researches have been developing dramatically, but some challenging issues are required to be handled, such as the detailed introduction to typical pan-sharpening CNNs, data simulation, feasible and open training-test datasets, simple and easy-to-understand unified code writing framework, etc. So, we mainly review the growth of CNNs for RS-based pan-sharpening from 5 aspects as following: 1) detailed introduction of 7 CNN-based pan-sharpening methods and comparative analysis are given out under the datasets-coordinated; 2) the simulation of training-test datasets is introduced in details. We intend to release the pan-sharpening datasets of related satellites (such as WorldView-3, QuickBird, GaoFen2, WorldView-2 satellites); 3) for all 7 CNN-based methods introduced, Python codes-based on Pytorch library is released in a framework-integrated to facilitate the completeness and feasibility further; 4) a pan-sharpening-unified MATLAB software package is demonstrated for the test of deep-learning and traditional approaches, which is beneficial to conduct balancing tests; and 5) future research direction is predicted as well. Please click the link for project details: https://liangjiandeng.github.io/PanCollection.html. First, CNN-based techniques have proven to have good performance under the similar situations. But, the performance has decreased when a complete different situation is employed (such as in contrast with existing contemporary methods), a limitation of these approaches are challenged. Next, the fine-tuning technique has demonstrated its effectiveness in resolving the problem mentioned above, ensuring better performance for these complicated test scenarios. Compared to the quickest speed conventional methods, the computing load of the studied CNN-based algorithms can be determined as an appropriate manner during the testing phase. Finally, we recommend that a novel design of CNN-based pan-sharpening methods. The skip connection operation can aid ML-based methods in achieving a faster convergence when it is focused on the analyzed CNN-based pan-sharpening approaches. Instead, a stronger feature extraction and learning can be supported by the design of multi-scaled architectures (including the bidirectional structure even). Furthermore, the capacity of the generalized networks can be improved using a fine-tuning technique and learning in a customized domain (instead of the original image domain). However, there are still some problems to be resolved. The computational weight problem is challenged to create networks with fewer parameters so as to guarantee network performance (even achieving a quick convergence). Furthermore, the recent advancements in CNN for pan-sharpening have a restricted capacity for generalization. A lower resolution-based initial vision is beneficial to provide labels for network training. As a result, loss functions-based techniques (unsupervised) have been developed in evaluating similarities at full resolution. The future research is potential to be developed for full resolution further.关键词:Pansharpening;convolutional neural network(CNN);comparison of typical CNN methods;datasets releasing;coding-framework releasing;pansharpening survey532|746|2更新时间:2024-05-08
摘要:The aim of pan-sharpening is focused on data acquisition and processing captured from multiple remote sensing satellites in terms of machine learning and signal processing techniques. To produce a high-quality multispectral image, its objective is oriented to fuse a low spatial resolution-based multispectral (MS) image and a high spatial resolution-based panchromatic (PAN) image. Machine learning (ML) technique is being developed to deal with it. Pan-sharpening, a recent multispectral image-based image fusion technique, has been concerned about in terms of machine learning, which is featured by its medium/low spatial resolution. In recent years, remote sensing (RS) science, big data science and convolutional neural networks based (CNNs-based) techniques (a sub-category of ML), have promoted image processing, computer vision and its contexts. Thanks to the priority of RS images-based pan-sharpening of fusion, CNN-oriented researches have been developing dramatically, but some challenging issues are required to be handled, such as the detailed introduction to typical pan-sharpening CNNs, data simulation, feasible and open training-test datasets, simple and easy-to-understand unified code writing framework, etc. So, we mainly review the growth of CNNs for RS-based pan-sharpening from 5 aspects as following: 1) detailed introduction of 7 CNN-based pan-sharpening methods and comparative analysis are given out under the datasets-coordinated; 2) the simulation of training-test datasets is introduced in details. We intend to release the pan-sharpening datasets of related satellites (such as WorldView-3, QuickBird, GaoFen2, WorldView-2 satellites); 3) for all 7 CNN-based methods introduced, Python codes-based on Pytorch library is released in a framework-integrated to facilitate the completeness and feasibility further; 4) a pan-sharpening-unified MATLAB software package is demonstrated for the test of deep-learning and traditional approaches, which is beneficial to conduct balancing tests; and 5) future research direction is predicted as well. Please click the link for project details: https://liangjiandeng.github.io/PanCollection.html. First, CNN-based techniques have proven to have good performance under the similar situations. But, the performance has decreased when a complete different situation is employed (such as in contrast with existing contemporary methods), a limitation of these approaches are challenged. Next, the fine-tuning technique has demonstrated its effectiveness in resolving the problem mentioned above, ensuring better performance for these complicated test scenarios. Compared to the quickest speed conventional methods, the computing load of the studied CNN-based algorithms can be determined as an appropriate manner during the testing phase. Finally, we recommend that a novel design of CNN-based pan-sharpening methods. The skip connection operation can aid ML-based methods in achieving a faster convergence when it is focused on the analyzed CNN-based pan-sharpening approaches. Instead, a stronger feature extraction and learning can be supported by the design of multi-scaled architectures (including the bidirectional structure even). Furthermore, the capacity of the generalized networks can be improved using a fine-tuning technique and learning in a customized domain (instead of the original image domain). However, there are still some problems to be resolved. The computational weight problem is challenged to create networks with fewer parameters so as to guarantee network performance (even achieving a quick convergence). Furthermore, the recent advancements in CNN for pan-sharpening have a restricted capacity for generalization. A lower resolution-based initial vision is beneficial to provide labels for network training. As a result, loss functions-based techniques (unsupervised) have been developed in evaluating similarities at full resolution. The future research is potential to be developed for full resolution further.关键词:Pansharpening;convolutional neural network(CNN);comparison of typical CNN methods;datasets releasing;coding-framework releasing;pansharpening survey532|746|2更新时间:2024-05-08 -
 摘要:Multi-focus image fusion technique can extend the depth-of-field (DOF) of optical lenses effectively via a software-based manner. It aims to fuse a set of partially focused source images of the same scene by generating an all-in-focus fused image, which will be more suitable for human or machine perception. As a result, multi-focus image fusion is of high practical significance in many areas including digital photography, microscopy imaging, integral imaging, thermal imaging, etc. Traditional multi-focus image fusion methods, which generally include transform domain methods (e.g., multi-scale transform-based methods and sparse representation-based methods) and spatial domain methods (e.g., block-based methods and pixel-based methods), are often based on manually designed transform models, activity level measures and fusion rules. To achieve high fusion performance, these key factors tend to become much more complicated in the fusion algorithm, which are usually at the cost of computational efficiency. In addition, these key factors are often independently designed with relatively weak association, which limits the fusion performance to a great extent. In the past few years, deep learning has been introduced into the study of multi-focus image fusion and has rapidly emerged as the current mainstream of this field, with a variety of deep learning-based fusion methods being proposed in the literature. Deep learning models like convolutional neural networks (CNNs) and generative adversarial networks (GANs) have been facilitating in the study of multi-focus image fusion. It is of high significance to conduct a comprehensive survey to review the recent advances achieved in deep learning-based multi-focus image fusion and put forward some future prospects for further improvement. Some survey papers related to image fusion including multi-focus image fusion have been recently published in the international journals around 2020. However, the survey works on multi-focus image fusion are rarely reported in Chinese journals. Moreover, considering that this field grows very rapidly with dozens of papers being published each year, a more timely survey is also highly expected. Based on the above considerations, we demonstrate a systematic review for the deep learning-based multi-focus image fusion methods. In this paper, the existing deep learning-based methods are classified into two main categories: 1) deep classification model-based methods and 2) deep regression model-based methods. Additionally, these two categories of methods are further divided into sub-categories. Specifically, the classification model-based methods are further divided into image block-based methods and image segmentation-based methods in terms of the pixel processing manner adopted. The regression model-based methods are further divided into supervised learning-based methods and unsupervised learning-based methods, according to the learning manner of network models. For each category, the representative fusion methods are introduced as well. In addition, we conduct a comparative study on the performance of 25 representative multi-focus image fusion methods, including 5 traditional transform domain methods, 5 traditional spatial domain methods and 15 deep learning-based methods. To this end, we use three commonly-used multi-focus image fusion datasets in the experiments including "Lytro", "MFFW" and "Classic". Additionally, eight objective evaluation metrics that are widely used in multi-focus image fusion are adopted for performance assessment, which are composed of include two information theory-based metrics, two image feature-based metrics, two structural similarity-based metrics and two human visual perception-based metrics. The experimental results verify that deep learning-based methods can achieve very promising fusion results. However, it is worth noting that the performance of most deep learning-based methods is not significantly better than that of the traditional fusion methods. One main reason for this phenomenon is the lack of large-scale and realistic datasets for training in multi-focus image fusion, and the way to create synthetic datasets for training is inevitability different from the real situation, leading to that the potential of deep learning-based methods cannot be fully tapped. Finally, we summarize some challenging problems in the study of deep learning-based multi-focus image fusion and put forward some future prospects accordingly, which mainly include the four aspects as following: 1) the fusion of focus boundary regions; 2) the fusion of mis-registered source images; 3) the construction of large-scale datasets with real labels for network training; and 4) the improvement of network architecture and model training approach.关键词:multi-focus image fusion(MFIF);image fusion;deep learning;convolutional neural network (CNN);generative adversarial network (GAN)503|872|0更新时间:2024-05-08
摘要:Multi-focus image fusion technique can extend the depth-of-field (DOF) of optical lenses effectively via a software-based manner. It aims to fuse a set of partially focused source images of the same scene by generating an all-in-focus fused image, which will be more suitable for human or machine perception. As a result, multi-focus image fusion is of high practical significance in many areas including digital photography, microscopy imaging, integral imaging, thermal imaging, etc. Traditional multi-focus image fusion methods, which generally include transform domain methods (e.g., multi-scale transform-based methods and sparse representation-based methods) and spatial domain methods (e.g., block-based methods and pixel-based methods), are often based on manually designed transform models, activity level measures and fusion rules. To achieve high fusion performance, these key factors tend to become much more complicated in the fusion algorithm, which are usually at the cost of computational efficiency. In addition, these key factors are often independently designed with relatively weak association, which limits the fusion performance to a great extent. In the past few years, deep learning has been introduced into the study of multi-focus image fusion and has rapidly emerged as the current mainstream of this field, with a variety of deep learning-based fusion methods being proposed in the literature. Deep learning models like convolutional neural networks (CNNs) and generative adversarial networks (GANs) have been facilitating in the study of multi-focus image fusion. It is of high significance to conduct a comprehensive survey to review the recent advances achieved in deep learning-based multi-focus image fusion and put forward some future prospects for further improvement. Some survey papers related to image fusion including multi-focus image fusion have been recently published in the international journals around 2020. However, the survey works on multi-focus image fusion are rarely reported in Chinese journals. Moreover, considering that this field grows very rapidly with dozens of papers being published each year, a more timely survey is also highly expected. Based on the above considerations, we demonstrate a systematic review for the deep learning-based multi-focus image fusion methods. In this paper, the existing deep learning-based methods are classified into two main categories: 1) deep classification model-based methods and 2) deep regression model-based methods. Additionally, these two categories of methods are further divided into sub-categories. Specifically, the classification model-based methods are further divided into image block-based methods and image segmentation-based methods in terms of the pixel processing manner adopted. The regression model-based methods are further divided into supervised learning-based methods and unsupervised learning-based methods, according to the learning manner of network models. For each category, the representative fusion methods are introduced as well. In addition, we conduct a comparative study on the performance of 25 representative multi-focus image fusion methods, including 5 traditional transform domain methods, 5 traditional spatial domain methods and 15 deep learning-based methods. To this end, we use three commonly-used multi-focus image fusion datasets in the experiments including "Lytro", "MFFW" and "Classic". Additionally, eight objective evaluation metrics that are widely used in multi-focus image fusion are adopted for performance assessment, which are composed of include two information theory-based metrics, two image feature-based metrics, two structural similarity-based metrics and two human visual perception-based metrics. The experimental results verify that deep learning-based methods can achieve very promising fusion results. However, it is worth noting that the performance of most deep learning-based methods is not significantly better than that of the traditional fusion methods. One main reason for this phenomenon is the lack of large-scale and realistic datasets for training in multi-focus image fusion, and the way to create synthetic datasets for training is inevitability different from the real situation, leading to that the potential of deep learning-based methods cannot be fully tapped. Finally, we summarize some challenging problems in the study of deep learning-based multi-focus image fusion and put forward some future prospects accordingly, which mainly include the four aspects as following: 1) the fusion of focus boundary regions; 2) the fusion of mis-registered source images; 3) the construction of large-scale datasets with real labels for network training; and 4) the improvement of network architecture and model training approach.关键词:multi-focus image fusion(MFIF);image fusion;deep learning;convolutional neural network (CNN);generative adversarial network (GAN)503|872|0更新时间:2024-05-08 -
 摘要:To capture more effective visual information of the natural scenes, multi-sensor imaging systems have been challenging in multiple configurations or modalities due to the hardware design constraints. It is required to fuse multiple source images into a single high-quality image in terms of rich and feasible perceptual information and few artifacts. To facilitate various image processing and computer vision tasks, image fusion technique can be used to generate a single and clarified image features. Traditional image fusion models are often constructed in accordance with label-manual features or unidentified feature-learned representations. The generalization ability of the models needs to be developed further.Deep learning technique is focused on progressive multi-layer features extraction via end-to-end model training. Most of demonstration-relevant can be learned for specific task automatically. Compared with the traditional methods, deep learning-based models can improve the fusion performance intensively in terms of image fusion. Current image fusion-related deep learning models are often beneficial based on convolutional neural networks (CNNs) and generative adversarial networks (GANs). In recent years, the newly network structures and training techniques have been incorporated for the growth of image fusion like vision transformers and meta-learning techniques. Most of image fusion-relevant literatures are analyzed from specific multi-fusion issues like exposure, focus, spectrum image, and modality issues. However, more deep learning-related model designs and training techniques is required to be incorporated between multi-fusion tasks. To draw a clear picture of deep learning-based image fusion techniques, we try to review the latest image fusion researches in terms of 1) dataset generation, 2) neural network construction, 3) loss function design, 4) model optimization, and 5) performance evaluation. For dataset generation, we emphasize two categories: a) supervised learning and b) unsupervised (or self-supervised) learning. For neural network construction, we distinguish the early or late stages of this construction process, and the issue of information fusion is implemented between multi-scale, coarse-to-fine and the adversarial networks-incorporated (i.e., discriminative networks) as well. For loss function design, the perceptual loss functions-specific method is essential for image fusion-related perceptual applications like multi-exposure and multi-focus image fusion. For model optimization, the generic first-order optimization techniques are covered (e.g., stochastic gradient descent(SGD), SGD+momentum, Adam, and AdamW) and the advanced alternation and bi-level optimization methods are both taken into consideration. For performance evaluation, a commonly-used quantitative metrics are reviewed for the manifested measurement of fusion performance. The relationship between the loss functions (also as a form of evaluation metrics) are used to drive the learning of CNN-based image fusion methods and the evaluation metrics. In addition, to illustrate the transfer feasibility of image fusion-consensus to a tailored image fusion application, a selection of image fusion methods is discussed (e.g., a high-quality texture image-fused depth map enhancement). Some popular computer vision tasks are involved in (such as image denoising, blind image deblurring, and image super-resolution), which can be resolved by image fusion innovatively. Finally, we review some potential challenging issues, including: 1) reliable and efficient ground-truth training data-constructed (i.e., the input image sequence and the predictable image-fused), 2) lightweight, interpretable, and generalizable CNN-based image fusion methods, 3) human or machine-related vision-perceptual calibrated loss functions, 4) convergence-accelerated image fusion models in related to adversarial training setting-specific and the bias-related of the test-time training, and 5) human-related ethical issues in relevant to fairness and unbiased performance evaluation.关键词:image fusion;deep neural networks;stochastic gradient descent(SGD);image quality assessment;deep learning407|539|2更新时间:2024-05-08
摘要:To capture more effective visual information of the natural scenes, multi-sensor imaging systems have been challenging in multiple configurations or modalities due to the hardware design constraints. It is required to fuse multiple source images into a single high-quality image in terms of rich and feasible perceptual information and few artifacts. To facilitate various image processing and computer vision tasks, image fusion technique can be used to generate a single and clarified image features. Traditional image fusion models are often constructed in accordance with label-manual features or unidentified feature-learned representations. The generalization ability of the models needs to be developed further.Deep learning technique is focused on progressive multi-layer features extraction via end-to-end model training. Most of demonstration-relevant can be learned for specific task automatically. Compared with the traditional methods, deep learning-based models can improve the fusion performance intensively in terms of image fusion. Current image fusion-related deep learning models are often beneficial based on convolutional neural networks (CNNs) and generative adversarial networks (GANs). In recent years, the newly network structures and training techniques have been incorporated for the growth of image fusion like vision transformers and meta-learning techniques. Most of image fusion-relevant literatures are analyzed from specific multi-fusion issues like exposure, focus, spectrum image, and modality issues. However, more deep learning-related model designs and training techniques is required to be incorporated between multi-fusion tasks. To draw a clear picture of deep learning-based image fusion techniques, we try to review the latest image fusion researches in terms of 1) dataset generation, 2) neural network construction, 3) loss function design, 4) model optimization, and 5) performance evaluation. For dataset generation, we emphasize two categories: a) supervised learning and b) unsupervised (or self-supervised) learning. For neural network construction, we distinguish the early or late stages of this construction process, and the issue of information fusion is implemented between multi-scale, coarse-to-fine and the adversarial networks-incorporated (i.e., discriminative networks) as well. For loss function design, the perceptual loss functions-specific method is essential for image fusion-related perceptual applications like multi-exposure and multi-focus image fusion. For model optimization, the generic first-order optimization techniques are covered (e.g., stochastic gradient descent(SGD), SGD+momentum, Adam, and AdamW) and the advanced alternation and bi-level optimization methods are both taken into consideration. For performance evaluation, a commonly-used quantitative metrics are reviewed for the manifested measurement of fusion performance. The relationship between the loss functions (also as a form of evaluation metrics) are used to drive the learning of CNN-based image fusion methods and the evaluation metrics. In addition, to illustrate the transfer feasibility of image fusion-consensus to a tailored image fusion application, a selection of image fusion methods is discussed (e.g., a high-quality texture image-fused depth map enhancement). Some popular computer vision tasks are involved in (such as image denoising, blind image deblurring, and image super-resolution), which can be resolved by image fusion innovatively. Finally, we review some potential challenging issues, including: 1) reliable and efficient ground-truth training data-constructed (i.e., the input image sequence and the predictable image-fused), 2) lightweight, interpretable, and generalizable CNN-based image fusion methods, 3) human or machine-related vision-perceptual calibrated loss functions, 4) convergence-accelerated image fusion models in related to adversarial training setting-specific and the bias-related of the test-time training, and 5) human-related ethical issues in relevant to fairness and unbiased performance evaluation.关键词:image fusion;deep neural networks;stochastic gradient descent(SGD);image quality assessment;deep learning407|539|2更新时间:2024-05-08 -
 摘要:Multimodal medical-fused images are essential to more comprehensive and accurate medical image descriptions for various clinical applications like medical diagnosis, treatment planning, and surgical navigation. However, single-modal medical images is challenged to deal with diagnose disease types and localize lesions due to its variety and complexity of disease types.As a result, multimodal medical image fusion methods are focused on obtaining medical images with rich information in clinical applications. Medical-based imaging techniques are mainly segmented into electromagnetic energy-based and acoustic energy-based. To achieve the effect of real-time imaging and provide dynamic images, the latter one uses the multiple propagation speed of ultrasound in different media. Current medical image fusion techniques are mainly concerned of static images in terms of electromagnetic energy imaging techniques. For example, it is related to some key issues like X-ray computed tomography imaging, single photon emission computed tomography, positron emission tomography and magnetic resonance imaging. We review recent literature-relevant based on the current status of medical image fusion methods. Our critical analysis can divide current medical image fusion techniques into two categories: 1) traditional methods and 2) deep learning methods. Nowadays, spatial domain and frequency domain-based algorithms are very proactive for traditional medical image fusion methods. The spatial domain techniques are implemented for the evaluation of image element values via prior pixel-level strategies, and the images-fused can realize less spatial distortion and a lower signal-to-noise ratio. The spatial domain-based methods are included some key aspects like 1) simple min/max, 2) independent component analysis, 3) principal component analysis, 4) weighted average, 5) simple average, 6) fuzzy logic, and 7) cloud model. The fusion process of spatial domain-based methods is quite simple, and its algorithm complexity can lower the computation cost. It also has a relatively good performance in alleviating the spectral distortion of fused images. However, the challenging issue is called for their fusion results better in terms of clarity, contrast and continuous lower spatial resolution. In the frequency domain, the input image is first converted from the null domain to the frequency domain via Fourier transform computation, and the fusion algorithm is then applied to the image-converted to obtain the final fused image, followed by the inversed Fourier transform. The commonly-used fusion algorithms in the frequency domain are composed of 1) pyramid transform, 2) wavelet transform and 3) multi-scale geometric transform fusion algorithms. This multi-level decomposition based methods can enhance the detail retention of the fused image. The output fusion results contain high spatial resolution and high quality spectral components. However, this type of algorithm is derived from a fine-grained fusion rule design as well. The deep learning-based methods are mainly related to convolutional neural networks (CNN) and generative adversarial networks (GAN), which can avoid fine-grained fusion rule design, reduce the manual involvement in the process, and their stronger feature extraction capability enables their fusion results to retain more source image information. The CNN can be used to process the spatial and structural information effectively in the neighborhood of the input image. It consists of a series of convolutional layers, pooling layers and fully connected layers. The convolution layer and pooling layer can extract the features in the source image, and the fully connected layer can complete the mapping from the features to the final output. In CNN, image fusion is regarded as a classification problem, corresponding to the process of feature extraction, feature option and output prediction. The fusion task is targeted on image transformation, activity level measurement and fusion rule design as well. Different from CNN, GAN network can be used to model saliency information in medical images through adversarial learning mechanism. GAN is a generative model with two multilayer networks, the first network mentioned is a generator-used to generate pseudo data, and the second following network is a discriminator-used to classify images into real data and pseudo data. The back-propagation-based training mode can improve the ability of GAN to distinguish between real data and generated data. Although GAN is not as widely used in multi-model medical image fusion (MMIF) as CNN, it has the potential for in-depth research. A completed overview of existing multimodal medical image databases and fusion quality evaluation metrics is developed further. Four open-source freely accessible medical image databases are involved in, such as the open access series of imaging studies (OASIS) dataset, the cancer immunome atlas (TCIA) dataset, the whole brain atlas (AANLIB) dataset, and the Alzheimer' s disease neuroimaging initiative (ANDI) dataset. And, a gene database for green fluorescent protein and phase contrast images are included as well, called the John Innes centre (JIC) dataset. Our critical review is based on the summary of 25 commonly-used medical image fusion result evaluation indicators in four types of metrics: 1) information theory-based; 2) image feature-based; 3) image structural similarity-based and 4) human visual perception-based, as well as 22 fusion algorithms for medical image datasets in recent years. The pros and cons of the algorithms are analyzed in terms of the technical-based comparison, fusion modes and evaluation indexes of each algorithm. In addition, our review is carried out on a large number of experiments to compare the performance of deep learning-based and traditional medical image fusion methods. Source images of three modal pairs are tested qualitatively and quantitatively via 22 multimodal medical image fusion algorithms. For qualitative analysis, the brightness, contrast and distortion of the fused image are observed based on the human vision system. For quantitative-based analysis, 15 objective evaluation indexes are used. By analyzing the qualitative and quantitative results, some critical analyses are discussed based on the current situation, challenging issues and future direction of medical image fusion techniques. Both of the traditional and deep learning methods have promoted fusion performance to a certain extent. More medical image fusion methods with good fusion effect and high model robustness are illustrated in the context of the algorithm optimization and the enrichment of medical image data sets. And, the two technical fields will continue to be developed towards the common research trends of expanding the multi-facet and multi-case medical images, proposing effective indicators suitable for medical image fusion, and deepening the research scope of image fusion.关键词:multimodel medical image;medical image fusion;deep learning;medical image database;quality evaluation metrics873|1380|3更新时间:2024-05-08
摘要:Multimodal medical-fused images are essential to more comprehensive and accurate medical image descriptions for various clinical applications like medical diagnosis, treatment planning, and surgical navigation. However, single-modal medical images is challenged to deal with diagnose disease types and localize lesions due to its variety and complexity of disease types.As a result, multimodal medical image fusion methods are focused on obtaining medical images with rich information in clinical applications. Medical-based imaging techniques are mainly segmented into electromagnetic energy-based and acoustic energy-based. To achieve the effect of real-time imaging and provide dynamic images, the latter one uses the multiple propagation speed of ultrasound in different media. Current medical image fusion techniques are mainly concerned of static images in terms of electromagnetic energy imaging techniques. For example, it is related to some key issues like X-ray computed tomography imaging, single photon emission computed tomography, positron emission tomography and magnetic resonance imaging. We review recent literature-relevant based on the current status of medical image fusion methods. Our critical analysis can divide current medical image fusion techniques into two categories: 1) traditional methods and 2) deep learning methods. Nowadays, spatial domain and frequency domain-based algorithms are very proactive for traditional medical image fusion methods. The spatial domain techniques are implemented for the evaluation of image element values via prior pixel-level strategies, and the images-fused can realize less spatial distortion and a lower signal-to-noise ratio. The spatial domain-based methods are included some key aspects like 1) simple min/max, 2) independent component analysis, 3) principal component analysis, 4) weighted average, 5) simple average, 6) fuzzy logic, and 7) cloud model. The fusion process of spatial domain-based methods is quite simple, and its algorithm complexity can lower the computation cost. It also has a relatively good performance in alleviating the spectral distortion of fused images. However, the challenging issue is called for their fusion results better in terms of clarity, contrast and continuous lower spatial resolution. In the frequency domain, the input image is first converted from the null domain to the frequency domain via Fourier transform computation, and the fusion algorithm is then applied to the image-converted to obtain the final fused image, followed by the inversed Fourier transform. The commonly-used fusion algorithms in the frequency domain are composed of 1) pyramid transform, 2) wavelet transform and 3) multi-scale geometric transform fusion algorithms. This multi-level decomposition based methods can enhance the detail retention of the fused image. The output fusion results contain high spatial resolution and high quality spectral components. However, this type of algorithm is derived from a fine-grained fusion rule design as well. The deep learning-based methods are mainly related to convolutional neural networks (CNN) and generative adversarial networks (GAN), which can avoid fine-grained fusion rule design, reduce the manual involvement in the process, and their stronger feature extraction capability enables their fusion results to retain more source image information. The CNN can be used to process the spatial and structural information effectively in the neighborhood of the input image. It consists of a series of convolutional layers, pooling layers and fully connected layers. The convolution layer and pooling layer can extract the features in the source image, and the fully connected layer can complete the mapping from the features to the final output. In CNN, image fusion is regarded as a classification problem, corresponding to the process of feature extraction, feature option and output prediction. The fusion task is targeted on image transformation, activity level measurement and fusion rule design as well. Different from CNN, GAN network can be used to model saliency information in medical images through adversarial learning mechanism. GAN is a generative model with two multilayer networks, the first network mentioned is a generator-used to generate pseudo data, and the second following network is a discriminator-used to classify images into real data and pseudo data. The back-propagation-based training mode can improve the ability of GAN to distinguish between real data and generated data. Although GAN is not as widely used in multi-model medical image fusion (MMIF) as CNN, it has the potential for in-depth research. A completed overview of existing multimodal medical image databases and fusion quality evaluation metrics is developed further. Four open-source freely accessible medical image databases are involved in, such as the open access series of imaging studies (OASIS) dataset, the cancer immunome atlas (TCIA) dataset, the whole brain atlas (AANLIB) dataset, and the Alzheimer' s disease neuroimaging initiative (ANDI) dataset. And, a gene database for green fluorescent protein and phase contrast images are included as well, called the John Innes centre (JIC) dataset. Our critical review is based on the summary of 25 commonly-used medical image fusion result evaluation indicators in four types of metrics: 1) information theory-based; 2) image feature-based; 3) image structural similarity-based and 4) human visual perception-based, as well as 22 fusion algorithms for medical image datasets in recent years. The pros and cons of the algorithms are analyzed in terms of the technical-based comparison, fusion modes and evaluation indexes of each algorithm. In addition, our review is carried out on a large number of experiments to compare the performance of deep learning-based and traditional medical image fusion methods. Source images of three modal pairs are tested qualitatively and quantitatively via 22 multimodal medical image fusion algorithms. For qualitative analysis, the brightness, contrast and distortion of the fused image are observed based on the human vision system. For quantitative-based analysis, 15 objective evaluation indexes are used. By analyzing the qualitative and quantitative results, some critical analyses are discussed based on the current situation, challenging issues and future direction of medical image fusion techniques. Both of the traditional and deep learning methods have promoted fusion performance to a certain extent. More medical image fusion methods with good fusion effect and high model robustness are illustrated in the context of the algorithm optimization and the enrichment of medical image data sets. And, the two technical fields will continue to be developed towards the common research trends of expanding the multi-facet and multi-case medical images, proposing effective indicators suitable for medical image fusion, and deepening the research scope of image fusion.关键词:multimodel medical image;medical image fusion;deep learning;medical image database;quality evaluation metrics873|1380|3更新时间:2024-05-08
Review

-
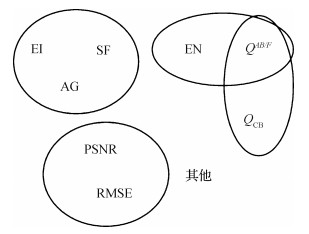 摘要:ObjectiveAs a research branch in the field of image fusion, objective assessment metrics can overcome these shortcomings of subjective evaluation methods that are easily affected by human psychological interference, surrounding environment, and visual characteristics. It can be utilized to evaluate algorithms and design parameters. Our algorithms advantages proposed can be demonstrated via objective assessment metrics. However, there is still a lack of benchmarks and metrics in various application fields like visible and infrared image fusion. A couple of objective assessment metrics can be selected based on prior experience. To facilitate the comparative analysis for different fusion algorithms, our research is focused on a general option method for objective assessment metrics and a set of recommended metrics for the fusion of visible and infrared images.MethodA new selecting method for objective assessment metrics is built. Our method consists of three parts: 1) correlation analysis, 2) consistency analysis and 3) discrete analysis. The Kendall correlation coefficient is utilized to perform correlation analysis for all objective assessment metrics. All the objective assessment metrics are clustered according to the value of the correlation coefficient: if the Kendall value of two metrics is higher than the threshold, the two metrics will be put into the same group. The Borda voting method is used in the consistency analysis. There is a ranking for all algorithms in terms of each metric value. An overall ranking is also generated by Borda voting method based on each single ranking of different metrics. The correlation coefficient is used to analyze the consistency between each single ranking and the overall ranking. The objective assessment metric has higher consistency if its correlation coefficient value is higher. Such experiments showed that the metric value will be fluctuated if the fusion quality is changed. A good metric should reflect the fusion quality of different algorithms clearly, so the metric value will cause a large fluctuation in terms of different fusion quality. The different fusion quality we illustrated is originated from multiple algorithms. The coefficient of variation is used to interpret the fluctuation because different objective assessment metrics match different measurement scales. The coefficient of variation reflects overall fluctuations under the influence of the measurement scale. Therefore, the final selected objective assessment metrics set has the following three characteristics: 1) high consistency, 2) high coefficient of variation and 3)non-same group.ResultThe experiments are conducted on the visible and infrared fusion benchmark (VIFB) dataset. The experiments are segmented into two groups in terms of the visible images in the dataset in related to grayscale images and RGB color images. The recommended objective assessment metric set is under the fusion of visible and infrared image, color visible and infrared image fusion: {standard deviation(SD),
摘要:ObjectiveAs a research branch in the field of image fusion, objective assessment metrics can overcome these shortcomings of subjective evaluation methods that are easily affected by human psychological interference, surrounding environment, and visual characteristics. It can be utilized to evaluate algorithms and design parameters. Our algorithms advantages proposed can be demonstrated via objective assessment metrics. However, there is still a lack of benchmarks and metrics in various application fields like visible and infrared image fusion. A couple of objective assessment metrics can be selected based on prior experience. To facilitate the comparative analysis for different fusion algorithms, our research is focused on a general option method for objective assessment metrics and a set of recommended metrics for the fusion of visible and infrared images.MethodA new selecting method for objective assessment metrics is built. Our method consists of three parts: 1) correlation analysis, 2) consistency analysis and 3) discrete analysis. The Kendall correlation coefficient is utilized to perform correlation analysis for all objective assessment metrics. All the objective assessment metrics are clustered according to the value of the correlation coefficient: if the Kendall value of two metrics is higher than the threshold, the two metrics will be put into the same group. The Borda voting method is used in the consistency analysis. There is a ranking for all algorithms in terms of each metric value. An overall ranking is also generated by Borda voting method based on each single ranking of different metrics. The correlation coefficient is used to analyze the consistency between each single ranking and the overall ranking. The objective assessment metric has higher consistency if its correlation coefficient value is higher. Such experiments showed that the metric value will be fluctuated if the fusion quality is changed. A good metric should reflect the fusion quality of different algorithms clearly, so the metric value will cause a large fluctuation in terms of different fusion quality. The different fusion quality we illustrated is originated from multiple algorithms. The coefficient of variation is used to interpret the fluctuation because different objective assessment metrics match different measurement scales. The coefficient of variation reflects overall fluctuations under the influence of the measurement scale. Therefore, the final selected objective assessment metrics set has the following three characteristics: 1) high consistency, 2) high coefficient of variation and 3)non-same group.ResultThe experiments are conducted on the visible and infrared fusion benchmark (VIFB) dataset. The experiments are segmented into two groups in terms of the visible images in the dataset in related to grayscale images and RGB color images. The recommended objective assessment metric set is under the fusion of visible and infrared image, color visible and infrared image fusion: {standard deviation(SD),$Q^{A B / F}$ $Q_{\mathrm{CB}}$ $Q^{A B / F}$ $Q_{\mathrm{CB}}$ $Q^{A B / F}$ $Q_{\mathrm{CB}}$ $Q^{A B / F}$ $Q^{A B / F}$ $Q^{A B / F}$ 关键词:image fusion;objective assessment metrics;correlation analysis;consistency analysis;coefficient of variation897|471|9更新时间:2024-05-08 -
 摘要:ObjectiveMulti-modal images have been developed based on multiple imaging techniques. The infrared image collects the radiation information of the target in the infrared band. The visible image is more suitable to human visual perception in terms of higher spatial resolution, richer effective information and lower noise. Infrared and visible image fusion (IVIF) can integrate the configurable information of multi-sensors to alleviate the limitations of hardware equipment and obtain more low-cost information for high-quality images. The IVIF can be used for a wide range of applications like surveillance, remote sensing and agriculture. However, there are several challenges to be solved in multi-modal image fusion. For instance, effective information extraction issue from different modalities and the problem-solving for fusion rule of the complementary information of different modalities. Current researches can be roughly divided into two categories: 1) traditional methods and 2) deep learning based methods. The traditional methods decompose the infrared image and the visible image into the transform domain to make the decomposed representation have special properties that are benefit to fusion, then perform fusion in the transform domain, which can depress information loss and avoid the artifacts caused by direct pixel manipulation, and finally reconstruct the fused image. Traditional methods are based on the assumptions on the source image pair and manual-based image decomposition methods to extract features. However, these hand-crafted features are not comprehensive and may cause the sensitivity to high-frequency or primary components and generate image distortion and artifacts. In recent years, data-driven deep learning-based image fusion methods have been developing. Most of the deep learning based fusion methods have been oriented for the infrared and visible image fusion in the deep feature space. Deep learning-based fusion methods can be divided into two categories: 1) convolutional neural network (CNN) for fusion, and 2) generative adversarial network (GAN) to generate fusion images. CNN-based information extraction is not fully utilized by the intermediate layers. The GAN-based methods are challenged to preserving image details in adequately.MethodWe develop a novel progressive infrared and visible image fusion framework (ProFuse), which extracts multi-scale features with U-Net as our backbone, merges the multi-scale features and reconstructs the fused image layer by layer. Our network has composed of three parts: 1) encoder; 2) fusion module; and 3) decoder. First, a series of multi-scale feature maps are generated from the infrared image and the visible image via the encoder. Next, the multi-scale features of the infrared and visible image pair are fused in the fusion layer to obtain fused features. At last, the fused features pass through the decoder to construct the fused image. The network architecture of the encoder and decoder is designed based on U-Net. The encoder consists of the replicable applications of recurrent residual convolutional unit (RRCU) and the max pooling operation. Each down-sampling step can be doubled the number of feature channels, so that more features can be extracted. The decoder aims to reconstruct the final fused image. Every step in the decoder consists of an up-sampling of the feature map followed by a 3 × 3 convolution that halves the number of feature channels, a concatenation with the corresponding feature maps from the encoder, and a RRCU. At the fusion layer, our spatial attention-based fusion method is used to deal with image fusion tasks. This method has the following two advantages. First, it can perform fusion on global information-contained high-level features (at bottleneck semantic layer), and details-related low-level features (at shallow layers). Second, our method not only perform fusion on the original scale (maintaining more details), but also perform fusion on other smaller scales (maintaining semantic information). Therefore, the design of progressive fusion is mainly specified in the following two aspects: 1) we conduct image fusion progressively from high-level to low-level and 2) from small-scale to large-scale progressively.ResultIn order to evaluate the fusion performance of our method, we conduct experiments on publicly available Toegepast Natuurwetenschappelijk Onderzoek (TNO) dataset and compare it with some state-of-the-art (SOTA) fusion methods including DenseFuse, discrete wavelet transform (DWT), Fusion-GAN, ratio of low-pass pyramid (RP), generative adversarial network with multiclassification constraints for infrared and visible image fusion (GANMcC), curvelet transform (CVT). All these competitors are implemented according to public code, and the parameters are set by referring to their original papers. Our method is evaluated with other methods in subjective evaluation, and some quality metrics are used to evaluate the fusion performance objectively. Generally speaking, the fusion results of our method obviously have higher contrast, more details and clearer targets. Compared with other methods, our method preserves the detailed information of visible and infrared radiation in maximization. At the same time, very little noise and artifacts are introduced in the results. We evaluate the performances of different fusion methods quantitatively via using six metrics, i.e., entropy (EN), structure similarity (SSIM), edge-based similarity measure (Qabf), mutual information (MI), standard deviation (STD), sum of the correlations of differences (SCD). Our method has achieved a larger value on EN, Qabf, MI and STD. The maximum EN value indicates that our method retains richer information than other competitors. The Qabf is a novel objective quality evaluation metric for fused images. The higher the value of Qabf is, the better the quality of the fusion images are. STD is an objective evaluation index that measures the richness of image information. The larger the value, the more scattered the gray-level distribution of the image, the more information the image carries, and the better the quality of the fused image. The larger the value of MI, the more information obtained from the source images, and the better the fusion effect. Our method has an improvement of 115.64% in the MI index compared with the generative adversarial network for infrared and visible image fusion (FusionGAN) method, 19.93% in the STD index compared with the GANMcC method, 1.91% in the edge preservation (Qabf) index compared with the DWT method and 1.30% in the EN index compared with the GANMcC method. This indicates that our method is effective for IVIF task.ConclusionExtensive experiments demonstrate the effectiveness and generalization of our method. It shows better results on the evaluations in qualitative and quantitative both.关键词:image fusion;deep learning;unsupervised learning;infrared image;visible image401|1|1更新时间:2024-05-08
摘要:ObjectiveMulti-modal images have been developed based on multiple imaging techniques. The infrared image collects the radiation information of the target in the infrared band. The visible image is more suitable to human visual perception in terms of higher spatial resolution, richer effective information and lower noise. Infrared and visible image fusion (IVIF) can integrate the configurable information of multi-sensors to alleviate the limitations of hardware equipment and obtain more low-cost information for high-quality images. The IVIF can be used for a wide range of applications like surveillance, remote sensing and agriculture. However, there are several challenges to be solved in multi-modal image fusion. For instance, effective information extraction issue from different modalities and the problem-solving for fusion rule of the complementary information of different modalities. Current researches can be roughly divided into two categories: 1) traditional methods and 2) deep learning based methods. The traditional methods decompose the infrared image and the visible image into the transform domain to make the decomposed representation have special properties that are benefit to fusion, then perform fusion in the transform domain, which can depress information loss and avoid the artifacts caused by direct pixel manipulation, and finally reconstruct the fused image. Traditional methods are based on the assumptions on the source image pair and manual-based image decomposition methods to extract features. However, these hand-crafted features are not comprehensive and may cause the sensitivity to high-frequency or primary components and generate image distortion and artifacts. In recent years, data-driven deep learning-based image fusion methods have been developing. Most of the deep learning based fusion methods have been oriented for the infrared and visible image fusion in the deep feature space. Deep learning-based fusion methods can be divided into two categories: 1) convolutional neural network (CNN) for fusion, and 2) generative adversarial network (GAN) to generate fusion images. CNN-based information extraction is not fully utilized by the intermediate layers. The GAN-based methods are challenged to preserving image details in adequately.MethodWe develop a novel progressive infrared and visible image fusion framework (ProFuse), which extracts multi-scale features with U-Net as our backbone, merges the multi-scale features and reconstructs the fused image layer by layer. Our network has composed of three parts: 1) encoder; 2) fusion module; and 3) decoder. First, a series of multi-scale feature maps are generated from the infrared image and the visible image via the encoder. Next, the multi-scale features of the infrared and visible image pair are fused in the fusion layer to obtain fused features. At last, the fused features pass through the decoder to construct the fused image. The network architecture of the encoder and decoder is designed based on U-Net. The encoder consists of the replicable applications of recurrent residual convolutional unit (RRCU) and the max pooling operation. Each down-sampling step can be doubled the number of feature channels, so that more features can be extracted. The decoder aims to reconstruct the final fused image. Every step in the decoder consists of an up-sampling of the feature map followed by a 3 × 3 convolution that halves the number of feature channels, a concatenation with the corresponding feature maps from the encoder, and a RRCU. At the fusion layer, our spatial attention-based fusion method is used to deal with image fusion tasks. This method has the following two advantages. First, it can perform fusion on global information-contained high-level features (at bottleneck semantic layer), and details-related low-level features (at shallow layers). Second, our method not only perform fusion on the original scale (maintaining more details), but also perform fusion on other smaller scales (maintaining semantic information). Therefore, the design of progressive fusion is mainly specified in the following two aspects: 1) we conduct image fusion progressively from high-level to low-level and 2) from small-scale to large-scale progressively.ResultIn order to evaluate the fusion performance of our method, we conduct experiments on publicly available Toegepast Natuurwetenschappelijk Onderzoek (TNO) dataset and compare it with some state-of-the-art (SOTA) fusion methods including DenseFuse, discrete wavelet transform (DWT), Fusion-GAN, ratio of low-pass pyramid (RP), generative adversarial network with multiclassification constraints for infrared and visible image fusion (GANMcC), curvelet transform (CVT). All these competitors are implemented according to public code, and the parameters are set by referring to their original papers. Our method is evaluated with other methods in subjective evaluation, and some quality metrics are used to evaluate the fusion performance objectively. Generally speaking, the fusion results of our method obviously have higher contrast, more details and clearer targets. Compared with other methods, our method preserves the detailed information of visible and infrared radiation in maximization. At the same time, very little noise and artifacts are introduced in the results. We evaluate the performances of different fusion methods quantitatively via using six metrics, i.e., entropy (EN), structure similarity (SSIM), edge-based similarity measure (Qabf), mutual information (MI), standard deviation (STD), sum of the correlations of differences (SCD). Our method has achieved a larger value on EN, Qabf, MI and STD. The maximum EN value indicates that our method retains richer information than other competitors. The Qabf is a novel objective quality evaluation metric for fused images. The higher the value of Qabf is, the better the quality of the fusion images are. STD is an objective evaluation index that measures the richness of image information. The larger the value, the more scattered the gray-level distribution of the image, the more information the image carries, and the better the quality of the fused image. The larger the value of MI, the more information obtained from the source images, and the better the fusion effect. Our method has an improvement of 115.64% in the MI index compared with the generative adversarial network for infrared and visible image fusion (FusionGAN) method, 19.93% in the STD index compared with the GANMcC method, 1.91% in the edge preservation (Qabf) index compared with the DWT method and 1.30% in the EN index compared with the GANMcC method. This indicates that our method is effective for IVIF task.ConclusionExtensive experiments demonstrate the effectiveness and generalization of our method. It shows better results on the evaluations in qualitative and quantitative both.关键词:image fusion;deep learning;unsupervised learning;infrared image;visible image401|1|1更新时间:2024-05-08 -
 摘要:ObjectiveCurrent image fusion can be as one the key branches of information fusion. Infrared and visible image fusion (IVF) is developed for image fusion dramatically. A visible light sensor-derived image can capture light-reflected. It is rich in texture detail information and fit to the human eye observation pattern. The image-fused can integrate rich detail information and thermal radiation information. Therefore, it is essential for such applications like object tracking, video surveillance, and autonomous driving. To resolve the constraints of manual-designed feature extraction and feature fusion in traditional infrared and visible image fusion methods, as well as the problems that convolutional neural network based (CNN-based) methods cannot effectively extract global contextual information in images and inadequate fusion during feature fusion, We develop an visual transformer-based end-to-end unsupervised fusion network via group-layered fusion strategies.MethodFirst, a channel attention-based transformer is designed, which enhances the features further through computing the self-attention in the channel dimension and using the channel attention in series as the feed-forward network of the transformer. After that, to extract features from the source image, the transformer module and CNN are used in parallel to form a local-global feature extraction module. The features-extracted have the generality of the features extracted by the CNN model to avoid manual design of extraction rules. The global nature of the features extracted by the transformer can be used to make up for the shortage of convolutional operations. In addition, to alleviate the loss of feature information, we design a newly layer-grouped fusion module to fuse the local-global features-extracted by grouping the features of multiple sources in the channel dimension, fusing the features of the corresponding groups initially, and then fusing the features of different groups via a hierarchical residual structure.ResultOur analysis is experimented on publicly available datasets TNO and RoadScene in comparison with six popular methods, which include traditional and deep learning-based methods both. Qualitative and quantitative evaluation methods are used to assess its effectiveness together. The qualitative analysis focuses on the clarity, contrast of the images perceived by the human eye. On the basis of qualitative evaluation, our method is capable to restore information-added in the infrared and visible images more effectively and maximize the useful information. At the same time, the fused images have contrast and definition and visual effects better. A quantitative-based comparison is carried out using six different metrics as well. On the TNO dataset, the proposed method achieved the best results in metrics normalized mutual information (NMI), nonlinear correlation information entropy (
摘要:ObjectiveCurrent image fusion can be as one the key branches of information fusion. Infrared and visible image fusion (IVF) is developed for image fusion dramatically. A visible light sensor-derived image can capture light-reflected. It is rich in texture detail information and fit to the human eye observation pattern. The image-fused can integrate rich detail information and thermal radiation information. Therefore, it is essential for such applications like object tracking, video surveillance, and autonomous driving. To resolve the constraints of manual-designed feature extraction and feature fusion in traditional infrared and visible image fusion methods, as well as the problems that convolutional neural network based (CNN-based) methods cannot effectively extract global contextual information in images and inadequate fusion during feature fusion, We develop an visual transformer-based end-to-end unsupervised fusion network via group-layered fusion strategies.MethodFirst, a channel attention-based transformer is designed, which enhances the features further through computing the self-attention in the channel dimension and using the channel attention in series as the feed-forward network of the transformer. After that, to extract features from the source image, the transformer module and CNN are used in parallel to form a local-global feature extraction module. The features-extracted have the generality of the features extracted by the CNN model to avoid manual design of extraction rules. The global nature of the features extracted by the transformer can be used to make up for the shortage of convolutional operations. In addition, to alleviate the loss of feature information, we design a newly layer-grouped fusion module to fuse the local-global features-extracted by grouping the features of multiple sources in the channel dimension, fusing the features of the corresponding groups initially, and then fusing the features of different groups via a hierarchical residual structure.ResultOur analysis is experimented on publicly available datasets TNO and RoadScene in comparison with six popular methods, which include traditional and deep learning-based methods both. Qualitative and quantitative evaluation methods are used to assess its effectiveness together. The qualitative analysis focuses on the clarity, contrast of the images perceived by the human eye. On the basis of qualitative evaluation, our method is capable to restore information-added in the infrared and visible images more effectively and maximize the useful information. At the same time, the fused images have contrast and definition and visual effects better. A quantitative-based comparison is carried out using six different metrics as well. On the TNO dataset, the proposed method achieved the best results in metrics normalized mutual information (NMI), nonlinear correlation information entropy ($Q_{\mathrm{NICE}}$ $Q_{\mathrm{NICE}}$ 关键词:infrared image;visible image;image fusion;visual transformer;convolutional neural network (CNN)220|801|5更新时间:2024-05-08 -
 摘要:ObjectiveImage fusion can be as one of the processing techniques in the context of computer vision, which aims to integrate the salient features from multiple input images into a complicated image. In recent years, image fusion approaches have been involved in applications-relevant like video clips analysis and medical-related interpretation. Generally, the existing fusion algorithms consist of two categories of methods: 1) traditional-based and 2) deep learning-based. Most traditional methods have introduced the signal processing operators for image fusion and the completed fusion task. However, the feature extraction and fusion rules are constrained of human-labeled methods. The feature extraction and fusion rule are quite complicated for realizing better fusion results. Thanks to the rapid development of deep learning, current image fusion methods have been facilitated based on this technique. Multi-scale decomposition can be as an effective method to extract the features for deep learning-based infrared image and visible image fusion. To alleviate the rough scale settings in the traditional multi-scale decomposition methods, we develop an improved octave convolution-based image fusion algorithm. Deep features can be divided in terms of octave convolution-based frequency.MethodOur fusion method is composed of four aspects as following: 1) encoder, 2) feature enhancement, 3) fusion strategy and 4) decoder. The encoder extracts deep features on four scales source image-derived through convolution and pooling. The deep features-extracted of each scale are subdivided into low-frequency, sub low-frequency and high-frequency features in terms of octave convolution. For enhancement phase, high-level features are added to low-level features for feature enhancement between different scales. High-level high-frequency features are utilized to enhance low-level sub low-frequency features, and high-level sub low-frequency features are utilized to enhance low-level low-frequency features. The low-frequency, sub low-frequency and high-frequency features of each scale are fused based on multiple fusion strategies. To produce the informative fused image, the features-fused are reconstructed via the designed decoder. In our experiment, all requirements are based on the Ubuntu system with NVIDIA GTX 1080Ti GPU. The Python version is 3.6.10 and the PyTorch is used for implementation. For training phase, the network does not use the fusion strategy. The pairs of infrared and visual images are not required for network training because it just needs deep features extraction and image reconstruction with these deep features. We choose 80 000 images from the dataset MS COCO(Microsoft common objects in context) as the training set of our auto-encoder network, which is converted to grayscale and then resized to 256×256 pixels. Adam optimizer is utilized to optimize our model. The learning rate, batch size and epochs are set as 1×10-4, 1 and 2 of each. After the training, the network can complete the image fusion task. First, the improved encoder is used to obtain the low-frequency, sub low-frequency and high-frequency features of the source image in multiple scales. These features can be enhanced between top and bottom levels. Second, these features are fused in terms of multiple fusion strategy. Finally, to obtain the informative fused image, the features-fused are reconstructed in terms of the designed decoder.ResultThe proposed fusion algorithm is compared to 9 sorts of existing image fusion algorithms on TNO and RoadScene datasets, and all image fusion algorithms are evaluated qualitatively and quantitatively. This algorithm can fully keep the effective natural-relevant information between the source image and the fused results. It is still challenged to evaluate some algorithms quantitatively, so we choose the 6 objective metrics to evaluate the fusion performance of these methods. Compared with other algorithms on TNO dataset, the proposed algorithm achieves the best performance in five indicators: 1) entropy, 2) standard deviation, 3) visual information fidelity, 4) mutual information and 5) wavelet transform-based feature mutual information. Compared with the best values in the above five metrics of nine existing fusion algorithms, an average increase of are outreached 0.54%, 4.14%, 5.01%, 0.55%, 0.68% of each further. The performance of our algorithm-developed on RoadScene dataset is consistent with that on TNO dataset basically. The best values are obtained in 4 kinds of quality metrics: a) entropy, b) standard deviation, c) visual information fidelity, and d) mutual information. Compared to the 9 sort of existing methods, the best values of the four metrics are increased by 0.45%, 6.13%, 7.43%, and 0.45%, respectively. The gap between the value of our algorithm and the best value is only 0.002 05 in wavelet transform-based feature mutual information.ConclusionA novel and effective deep learning architecture is developed for infrared and visible image fusion analysis based on convolutional neural network and octave convolution. This network structure can make full use of multi-scale deep features. The octave convolution makes a more detailed division of the extracted features and the appropriated fusion strategies can be selected for these deep features further. Because low-frequency, sub low-frequency and high-frequency features are divided in each scale, more appropriated features can be selected to enhance low-level features in the feature enhancement phase. The experimental results show that our algorithm has its potentials in image fusion according to qualitative and quantitative evaluation.关键词:image processing;image fusion;octave convolution;infrared image;visible image109|224|1更新时间:2024-05-08
摘要:ObjectiveImage fusion can be as one of the processing techniques in the context of computer vision, which aims to integrate the salient features from multiple input images into a complicated image. In recent years, image fusion approaches have been involved in applications-relevant like video clips analysis and medical-related interpretation. Generally, the existing fusion algorithms consist of two categories of methods: 1) traditional-based and 2) deep learning-based. Most traditional methods have introduced the signal processing operators for image fusion and the completed fusion task. However, the feature extraction and fusion rules are constrained of human-labeled methods. The feature extraction and fusion rule are quite complicated for realizing better fusion results. Thanks to the rapid development of deep learning, current image fusion methods have been facilitated based on this technique. Multi-scale decomposition can be as an effective method to extract the features for deep learning-based infrared image and visible image fusion. To alleviate the rough scale settings in the traditional multi-scale decomposition methods, we develop an improved octave convolution-based image fusion algorithm. Deep features can be divided in terms of octave convolution-based frequency.MethodOur fusion method is composed of four aspects as following: 1) encoder, 2) feature enhancement, 3) fusion strategy and 4) decoder. The encoder extracts deep features on four scales source image-derived through convolution and pooling. The deep features-extracted of each scale are subdivided into low-frequency, sub low-frequency and high-frequency features in terms of octave convolution. For enhancement phase, high-level features are added to low-level features for feature enhancement between different scales. High-level high-frequency features are utilized to enhance low-level sub low-frequency features, and high-level sub low-frequency features are utilized to enhance low-level low-frequency features. The low-frequency, sub low-frequency and high-frequency features of each scale are fused based on multiple fusion strategies. To produce the informative fused image, the features-fused are reconstructed via the designed decoder. In our experiment, all requirements are based on the Ubuntu system with NVIDIA GTX 1080Ti GPU. The Python version is 3.6.10 and the PyTorch is used for implementation. For training phase, the network does not use the fusion strategy. The pairs of infrared and visual images are not required for network training because it just needs deep features extraction and image reconstruction with these deep features. We choose 80 000 images from the dataset MS COCO(Microsoft common objects in context) as the training set of our auto-encoder network, which is converted to grayscale and then resized to 256×256 pixels. Adam optimizer is utilized to optimize our model. The learning rate, batch size and epochs are set as 1×10-4, 1 and 2 of each. After the training, the network can complete the image fusion task. First, the improved encoder is used to obtain the low-frequency, sub low-frequency and high-frequency features of the source image in multiple scales. These features can be enhanced between top and bottom levels. Second, these features are fused in terms of multiple fusion strategy. Finally, to obtain the informative fused image, the features-fused are reconstructed in terms of the designed decoder.ResultThe proposed fusion algorithm is compared to 9 sorts of existing image fusion algorithms on TNO and RoadScene datasets, and all image fusion algorithms are evaluated qualitatively and quantitatively. This algorithm can fully keep the effective natural-relevant information between the source image and the fused results. It is still challenged to evaluate some algorithms quantitatively, so we choose the 6 objective metrics to evaluate the fusion performance of these methods. Compared with other algorithms on TNO dataset, the proposed algorithm achieves the best performance in five indicators: 1) entropy, 2) standard deviation, 3) visual information fidelity, 4) mutual information and 5) wavelet transform-based feature mutual information. Compared with the best values in the above five metrics of nine existing fusion algorithms, an average increase of are outreached 0.54%, 4.14%, 5.01%, 0.55%, 0.68% of each further. The performance of our algorithm-developed on RoadScene dataset is consistent with that on TNO dataset basically. The best values are obtained in 4 kinds of quality metrics: a) entropy, b) standard deviation, c) visual information fidelity, and d) mutual information. Compared to the 9 sort of existing methods, the best values of the four metrics are increased by 0.45%, 6.13%, 7.43%, and 0.45%, respectively. The gap between the value of our algorithm and the best value is only 0.002 05 in wavelet transform-based feature mutual information.ConclusionA novel and effective deep learning architecture is developed for infrared and visible image fusion analysis based on convolutional neural network and octave convolution. This network structure can make full use of multi-scale deep features. The octave convolution makes a more detailed division of the extracted features and the appropriated fusion strategies can be selected for these deep features further. Because low-frequency, sub low-frequency and high-frequency features are divided in each scale, more appropriated features can be selected to enhance low-level features in the feature enhancement phase. The experimental results show that our algorithm has its potentials in image fusion according to qualitative and quantitative evaluation.关键词:image processing;image fusion;octave convolution;infrared image;visible image109|224|1更新时间:2024-05-08 -
 摘要:ObjectiveInfrared sensors can be dealt with poor visibility or extreme weather conditions like foggy or sleeting. However, the sensors-infrared imaging ability is constrained of poor spatial resolution compared to similar visible range RGB cameras. Therefore, the applicability of commonly-used infrared imaging systems is challenged for the spatial resolution constraints. To resolve the low-resolution infrared images, many infrared sensors are equipped with high-resolution visible range RGB cameras. Its mechanism is focused on the higher-resolution visible modality to guide the process of lower-resolution sensor-derived more detailed super resolution-optimized images in the visible images. The one challenging issue is the requirement to keep consistency for the target modality features and alleviate redundant artifacts or textures presented in the visible modality only. The other challenging problem is concerned about stereo-paired infrared and visible images and the problem-solving for the difference in their spectral range to pixel-wise align the two images, most of the guided-super resolution methods are bases on the aligned image pairs.MethodOur model is focused on guided transformer super-resolution network (GTSR) for the super resolution in infrared image. Those infrared and visible images are designed as queries and keys of each in a transformer. For image reconstruction tasks, it consists of two modules-optimized of those are 1) guided transformer module for transferring the accurate texture features, and 2) super resolution reconstruction module for generating the high resolution results. Due to the misaligned problem for infrared and visible image pairs, there is a certain parallax between them. A guided transformer for information guidance and fusion is used to search for texture information-relevant originated from high-resolution visible images, and the related texture information is fused to obtain synthetic features via low-resolution infrared images. There four aspects of the guided transformer module are: a) texture extractor, b) relevance calculation, c) hard-attention-based feature transfer, and d) soft-attention-based feature synthesis. First, to extract features between infrared and visible images, texture extractor is used. Second, to obtain a hard-attention map and a soft-attention map, features-extracted are formulated from the infrared and visible image as the query and key in a transformer for the relevance calculation. Finally, to transfer and fuse high resolution features from the visible image into the infrared features extraction, hard-attention map and the soft-attention map are employed. A set of synthetic features are obtained as well. To generate the final high resolution infrared image, the features are melted into the following super-resolution reconstruction module. Most of deep networks are focused on highly redundant features extraction due to the deeper nature of networks that similar features are extracted by different layers. In the super resolution reconstruction module, the channel-splitting strategy is implemented to eliminate the redundant features in the network. The residual groups extracted feature maps are segmented into two streamlines through each scale of
摘要:ObjectiveInfrared sensors can be dealt with poor visibility or extreme weather conditions like foggy or sleeting. However, the sensors-infrared imaging ability is constrained of poor spatial resolution compared to similar visible range RGB cameras. Therefore, the applicability of commonly-used infrared imaging systems is challenged for the spatial resolution constraints. To resolve the low-resolution infrared images, many infrared sensors are equipped with high-resolution visible range RGB cameras. Its mechanism is focused on the higher-resolution visible modality to guide the process of lower-resolution sensor-derived more detailed super resolution-optimized images in the visible images. The one challenging issue is the requirement to keep consistency for the target modality features and alleviate redundant artifacts or textures presented in the visible modality only. The other challenging problem is concerned about stereo-paired infrared and visible images and the problem-solving for the difference in their spectral range to pixel-wise align the two images, most of the guided-super resolution methods are bases on the aligned image pairs.MethodOur model is focused on guided transformer super-resolution network (GTSR) for the super resolution in infrared image. Those infrared and visible images are designed as queries and keys of each in a transformer. For image reconstruction tasks, it consists of two modules-optimized of those are 1) guided transformer module for transferring the accurate texture features, and 2) super resolution reconstruction module for generating the high resolution results. Due to the misaligned problem for infrared and visible image pairs, there is a certain parallax between them. A guided transformer for information guidance and fusion is used to search for texture information-relevant originated from high-resolution visible images, and the related texture information is fused to obtain synthetic features via low-resolution infrared images. There four aspects of the guided transformer module are: a) texture extractor, b) relevance calculation, c) hard-attention-based feature transfer, and d) soft-attention-based feature synthesis. First, to extract features between infrared and visible images, texture extractor is used. Second, to obtain a hard-attention map and a soft-attention map, features-extracted are formulated from the infrared and visible image as the query and key in a transformer for the relevance calculation. Finally, to transfer and fuse high resolution features from the visible image into the infrared features extraction, hard-attention map and the soft-attention map are employed. A set of synthetic features are obtained as well. To generate the final high resolution infrared image, the features are melted into the following super-resolution reconstruction module. Most of deep networks are focused on highly redundant features extraction due to the deeper nature of networks that similar features are extracted by different layers. In the super resolution reconstruction module, the channel-splitting strategy is implemented to eliminate the redundant features in the network. The residual groups extracted feature maps are segmented into two streamlines through each scale of$C$ 关键词:image super-resolution;image fusion;infrared image;Transformer;deep learning455|447|6更新时间:2024-05-08 -
 摘要:ObjectiveMulti-source image fusion is focused effective information extraction and integration for diversified images. It is beneficial to resolve the insufficient information-related problem for single image and improve the efficiency of data processing for multi-source images. The infrared and visible images are widely used in the context of image processing and have their mutual benefits for information ability. To obtain a clear and accurate description of the scene, the fusion-mutual can optimize the detailed texture information in the visible image and clarify the target information in the infrared image. So, we develop a fusion-mutual algorithm in terms of deep learning-relevant image processing method.MethodFirst, densed convolutional network is improved, and an end-to-end convolutional network fusion model is trained in relevant to encoding and decoding. To reconstruct the fusion results, the encoder is used to extract the features of the source image and guide the multilevel features into the decoder. Each layer-encoded has the feature-guided beyond regular decoding structure. The pooling-based size is narrowed down in the coding part. The upsampling can be enlarged in the decoding part to realize the multi-scale fusion and reconstruction. The training effectiveness can be improved further in the process of convolution layer stack but information loss is followed by. To train the network effectively, a hybrid loss function is designed. The weighted fidelity term will be used to constrain the pixel similarity between the fusion result and the source image when the structural tensor loss is activated in the fusion image to extract more structural features from the source image. The coding part is divided into three layers to ensure effective feature extraction in depth, and each layer is segmented by a pooling layer. The network-depth-via convolution blocks between each layer are down from 3 to 1 gradually. To bridge the extraction of effective network features, it can adapt more extraction of shallow network and less extraction of a deep network. To realize multi-scale information interaction, the features are efficient to be guided in the encoding part. It can be fused into the decoding layer at the same time. For decoding part of the design, the first layer is composed of five parts of the convolution blocks. Our fusion results are obtained after the fifth convolution block output. The second layer is composed of three convolution blocks, and the third layer is constructed based on a convolution block only. The sampling process is interconnected between layers. After the network structure is constructed, we proposed a loss fusion algorithm, which are included L2 saliency detection-based norm constraints; and the F norm constraint is based on structure tensor calculation for infrared and visible light. The image features are user-friendly. The fusion results are mutual-benefited under the control of the network structure and the loss algorithm.ResultA series of evaluation indicators are achieved compared to traditional fusion methods and deep learning fusion methods on the TNO dataset and RoadScene dataset. To demonstrate the feasibility of the fusion method, its experiment is carried out on TNO dataset and RoadScene dataset. Furthermore, to validate the effectiveness of our loss function-based algorithm, the network structure and loss are ablated both in terms of the principle of control variables.ConclusionTo obtain potential high-quality fusion images and achieve good fusion effects further, our fusion model has shown its priorities for models optimization.关键词:image fusion;multi-level feature guidance;hybrid loss;structure tensor;detection of significance;deep learning188|582|0更新时间:2024-05-08
摘要:ObjectiveMulti-source image fusion is focused effective information extraction and integration for diversified images. It is beneficial to resolve the insufficient information-related problem for single image and improve the efficiency of data processing for multi-source images. The infrared and visible images are widely used in the context of image processing and have their mutual benefits for information ability. To obtain a clear and accurate description of the scene, the fusion-mutual can optimize the detailed texture information in the visible image and clarify the target information in the infrared image. So, we develop a fusion-mutual algorithm in terms of deep learning-relevant image processing method.MethodFirst, densed convolutional network is improved, and an end-to-end convolutional network fusion model is trained in relevant to encoding and decoding. To reconstruct the fusion results, the encoder is used to extract the features of the source image and guide the multilevel features into the decoder. Each layer-encoded has the feature-guided beyond regular decoding structure. The pooling-based size is narrowed down in the coding part. The upsampling can be enlarged in the decoding part to realize the multi-scale fusion and reconstruction. The training effectiveness can be improved further in the process of convolution layer stack but information loss is followed by. To train the network effectively, a hybrid loss function is designed. The weighted fidelity term will be used to constrain the pixel similarity between the fusion result and the source image when the structural tensor loss is activated in the fusion image to extract more structural features from the source image. The coding part is divided into three layers to ensure effective feature extraction in depth, and each layer is segmented by a pooling layer. The network-depth-via convolution blocks between each layer are down from 3 to 1 gradually. To bridge the extraction of effective network features, it can adapt more extraction of shallow network and less extraction of a deep network. To realize multi-scale information interaction, the features are efficient to be guided in the encoding part. It can be fused into the decoding layer at the same time. For decoding part of the design, the first layer is composed of five parts of the convolution blocks. Our fusion results are obtained after the fifth convolution block output. The second layer is composed of three convolution blocks, and the third layer is constructed based on a convolution block only. The sampling process is interconnected between layers. After the network structure is constructed, we proposed a loss fusion algorithm, which are included L2 saliency detection-based norm constraints; and the F norm constraint is based on structure tensor calculation for infrared and visible light. The image features are user-friendly. The fusion results are mutual-benefited under the control of the network structure and the loss algorithm.ResultA series of evaluation indicators are achieved compared to traditional fusion methods and deep learning fusion methods on the TNO dataset and RoadScene dataset. To demonstrate the feasibility of the fusion method, its experiment is carried out on TNO dataset and RoadScene dataset. Furthermore, to validate the effectiveness of our loss function-based algorithm, the network structure and loss are ablated both in terms of the principle of control variables.ConclusionTo obtain potential high-quality fusion images and achieve good fusion effects further, our fusion model has shown its priorities for models optimization.关键词:image fusion;multi-level feature guidance;hybrid loss;structure tensor;detection of significance;deep learning188|582|0更新时间:2024-05-08
Infrared and Visible Image Fusion
-
 摘要:ObjectiveCross-modal medical image fusion has been developed as a key aspect for precision diagnosis. Thanks to the development of precision technology, positron emission tomography (PET) and computed tomography (CT) can be mainly used for lung tumors detection. The high-resolution of CT images are beneficial to bone tissues diagnosis, but the imaging effect of the lesions is poor, especially the information of tumors-infiltrated cannot be displayed clearly. The PET images can show soft tissues clearly, but the imaging effect of the bone tissues is weakened. Medical images fusion technology can integrate the anatomical and functional information of lesions region and locate lung tumors more accurately. To resolve the problem of low contrast and poor edge detail retention in traditional pixel-level image fusion, the paper develop a decomposition-paralleled adaptive fusion model.Method1) Use non-subsampled contourlet transform (NSCT) to extract multi-directional details information, 2) use latent low-rank representation (LatLRR) to extract key feature information. The following four aspects are taken into consideration in terms of low frequency sub-bands fusion: first, image fusion is a mapping process of gray value many-to-one, and there is uncertainty existing in the mapping process. Next, the noise in the image is caused by artificial respiration, blood flow, and the overlap between organs and tissues. The noise confuses the contour features in the image and magnifies the ambiguity of the image. Third, the original image is decomposed by NSCT to obtain low-frequency and high-frequency sub-bands. The low-frequency sub-band retains the main energy information like the contour and background of the original image, and the uncertain relationship of the mapping is also retained. Therefore, it is required to design reasonable fusion rules to deal with the mapping relationship. Fourth, fuzzy set theory based fusion rules represent the whole image with a fuzzy matrix and a certain algorithm is used to solve the fuzzy matrix, which solves the fuzzy problem effectively in the image fusion process. The Gaussian membership function can apparently describe the low-frequency sub-band contextual fuzzy information. Therefore, the Gaussian membership function is used as the adaptive weighting coefficient of the low-frequency sub-band, and the fuzzy logic-based adaptive weighting fusion rule is adopted. The fusion rules of the high-frequency sub-bands are considered in the following aspects as well. First, considering that the high-frequency sub-bands contain the contours and edge details of the tissues and organs of the original image, they have structural similarity, and there are strong coefficients between coefficients. Second, structural similarity index measure (SSIM) is a measure of the similarity between two images, which reflects the correlation better between high-frequency sub-band coefficients. Therefore, the averaged structural similarity index is used to measure the coefficient correlation between the two high-frequency sub-bands. Third, the range of the lesion region of lung tumors is no more than one hundred pixels in common. The region-based fusion rules can more complete the characteristics of the lesion region. The regional variance can represent the variation degree of gray value in local regions. The larger of the variance is, the richer of the information reflecting the details of the image are. Therefore, the region variance is selected as the basis for calculating the image activity. The high frequency sub-bands are composed of contour edge information of the image. Therefore, the high frequency sub-bands use the fusion in terms of the Piella framework. In this method, the averaged structure similarity is introduced as the matching method, and the regional variance is used as the activity method, and an adaptive weighting decision factor is designed to fuse the high frequency sub-bands. Finally, the effectiveness of our algorithm is verified via comparative experiments.ResultThe paper focus on five groups of CT pulmonary window/PET and the five groups of CT mediastinal window/PET are tested. The experiment of compressed sensing-integrated NSCT is carried out and six objective evaluation indexes are selected to evaluate the quality of fused images. The experimental results show that our average gradient, edge intensity and spatial frequency of fused images are improved by 66.6%, 64.4% and 80.3%, respectively.ConclusionTo assist quick-response clinical activity and accurate diagnosis and treatment more, our research method is potential to improve the contrastive result of fused images and retain edge details effectively.关键词:image fusion;Piella framework;non-subsampled contourlet transform (NSCT);latent low-rank representation (LatLRR);positron emission tomography/computed tomography (PET/CT)152|130|1更新时间:2024-05-08
摘要:ObjectiveCross-modal medical image fusion has been developed as a key aspect for precision diagnosis. Thanks to the development of precision technology, positron emission tomography (PET) and computed tomography (CT) can be mainly used for lung tumors detection. The high-resolution of CT images are beneficial to bone tissues diagnosis, but the imaging effect of the lesions is poor, especially the information of tumors-infiltrated cannot be displayed clearly. The PET images can show soft tissues clearly, but the imaging effect of the bone tissues is weakened. Medical images fusion technology can integrate the anatomical and functional information of lesions region and locate lung tumors more accurately. To resolve the problem of low contrast and poor edge detail retention in traditional pixel-level image fusion, the paper develop a decomposition-paralleled adaptive fusion model.Method1) Use non-subsampled contourlet transform (NSCT) to extract multi-directional details information, 2) use latent low-rank representation (LatLRR) to extract key feature information. The following four aspects are taken into consideration in terms of low frequency sub-bands fusion: first, image fusion is a mapping process of gray value many-to-one, and there is uncertainty existing in the mapping process. Next, the noise in the image is caused by artificial respiration, blood flow, and the overlap between organs and tissues. The noise confuses the contour features in the image and magnifies the ambiguity of the image. Third, the original image is decomposed by NSCT to obtain low-frequency and high-frequency sub-bands. The low-frequency sub-band retains the main energy information like the contour and background of the original image, and the uncertain relationship of the mapping is also retained. Therefore, it is required to design reasonable fusion rules to deal with the mapping relationship. Fourth, fuzzy set theory based fusion rules represent the whole image with a fuzzy matrix and a certain algorithm is used to solve the fuzzy matrix, which solves the fuzzy problem effectively in the image fusion process. The Gaussian membership function can apparently describe the low-frequency sub-band contextual fuzzy information. Therefore, the Gaussian membership function is used as the adaptive weighting coefficient of the low-frequency sub-band, and the fuzzy logic-based adaptive weighting fusion rule is adopted. The fusion rules of the high-frequency sub-bands are considered in the following aspects as well. First, considering that the high-frequency sub-bands contain the contours and edge details of the tissues and organs of the original image, they have structural similarity, and there are strong coefficients between coefficients. Second, structural similarity index measure (SSIM) is a measure of the similarity between two images, which reflects the correlation better between high-frequency sub-band coefficients. Therefore, the averaged structural similarity index is used to measure the coefficient correlation between the two high-frequency sub-bands. Third, the range of the lesion region of lung tumors is no more than one hundred pixels in common. The region-based fusion rules can more complete the characteristics of the lesion region. The regional variance can represent the variation degree of gray value in local regions. The larger of the variance is, the richer of the information reflecting the details of the image are. Therefore, the region variance is selected as the basis for calculating the image activity. The high frequency sub-bands are composed of contour edge information of the image. Therefore, the high frequency sub-bands use the fusion in terms of the Piella framework. In this method, the averaged structure similarity is introduced as the matching method, and the regional variance is used as the activity method, and an adaptive weighting decision factor is designed to fuse the high frequency sub-bands. Finally, the effectiveness of our algorithm is verified via comparative experiments.ResultThe paper focus on five groups of CT pulmonary window/PET and the five groups of CT mediastinal window/PET are tested. The experiment of compressed sensing-integrated NSCT is carried out and six objective evaluation indexes are selected to evaluate the quality of fused images. The experimental results show that our average gradient, edge intensity and spatial frequency of fused images are improved by 66.6%, 64.4% and 80.3%, respectively.ConclusionTo assist quick-response clinical activity and accurate diagnosis and treatment more, our research method is potential to improve the contrastive result of fused images and retain edge details effectively.关键词:image fusion;Piella framework;non-subsampled contourlet transform (NSCT);latent low-rank representation (LatLRR);positron emission tomography/computed tomography (PET/CT)152|130|1更新时间:2024-05-08 -
 摘要:ObjectiveArtificial intelligence based (AI-based) medical clinical diagnosis technique has been developing in recent years. It can alleviate the problems of medical image analysis in China via deep networks modeling and medical image data analysis, such as the shortage of expertises, the imbalance of urban and rural medical resources allocation, and the the imaging accuracy issues. However, clinical-aided are often linked to multi-model data with different characteristics distribution in different hospitals. Therefore, improving the generalization and stability of the cross-model medical diagnosis-consistent model is required for quick response intensively. In order to alleviate the domain shift existing in the ultrasound imaging field, the unsupervised domain adaptation method can be as the one of the most concerning methods at present. It can avoid the manual labeling of ultrasound image data of various models, a single model can be learnt to adapt to the target domain sample set with data deviation through the labeled source domain sample set, which improves the generalizability of convolutional neural network (CNN) to a certain extent. However, current unsupervised domain adaptation research has some challenging constraints, such as poor feature extraction and inconsistent optimization of domain fusion and sample classification. In view of the limitations in related to domain adaptation network, we develop an intergrated domain adaptation network, which focuses on the under-expressed feature of nodular region features in thyroid ultrasound images. This research is aimed to enhance the fusion of source domain features space and target domain features space.MethodIn this study, a new domain adaptation network is constructed called based on domain-adversarial training of neural networks (DANN), called multi-level adversarial domain adaptation network (MADAN). In the training process, we first build a three-layer generator and discriminator structure according to the transition from general to special features, which can obtain more semantic information in the image. To ensure the coordination of the two optimization processes, the sample classification task and the domain fusion task are both implemented via a meta-optimization strategy. Furthermore, to enhance the global geometric features of diseased tissue regions, we embed a self-attention module in the adversarial structure. Our dataset is composed of 6 849 images-selected from ultrasound images in 4 different models, namely P (Philips1), T(Toshiba), F (GE), and U (Philips2). Our domain adaptation network is carried out in the PyTorch toolbox. The input image is resized to 224 × 224 pixels for training, the momentum parameter is set to 0.9, and the learning rate is set to 0.001. The stochastic gradient descent (SGD)-related learning process is accelerated using an NVIDIA GTX TITAN RTX device, which takes approximately 10 hours in 50 000 iterations. It is possible to obtain more effective samples in the context to benign and malignant labels of the source domain, the target domain during the training process, and the labels of the target domain data are not required at all. The training process performs the supervised classification task of the source domain dataset and the domain alignment task. In the testing process, the feature extractor and classifier fitted are used to verify the classification accuracy of the target domain data. In addition, we use t-distributed stochastic neighbor embedding (t-SNE) to visualize the learned data features, which demonstrates the effectiveness of our network further on the feature-fused of different datasets.ResultWe compared our network with 8 domain adaptation networks, including domain adaptation tasks based on 9 multi-directions on 4 domains: P→T, P→U, P→F, T→P, T→U, T→F, U→P, U→T, and U→F. The evaluation metrics are focused on the accuracy of the target domain data and the t-SNE visualization results, and the ablation experiments is conducted to demonstrate the performance and GPU memory cost of the proposed method. Experimental results show that the MADAN is optimized with an average classification accuracy of 90.141% on the multi-model thyroid ultrasound dataset through 9 transfer tasks. After introducing meta-optimization, the best classification accuracy is achieved in P→U, P→F, T→P, T→F, U→P, and U→F tasks respectively, and the average accuracy of all tasks is improved about 1.67%. The results of the ablation experiments illustrates that the domain adaptation, multi-adversarial structure, and self-attention modules are improved 16.238%, 20.284%, and 18.622%, respectively. The t-SNE visualization images are illustrated that the feature space of the data samples has been preliminarily fused after the multi-level adversarial domain adaptation, and the sample points of the same category are basically aggregated. The multi-adversarial domain adaptation method can achieve fusion results better via the improved meta-optimization strategy. Additionally, the comparative visualization analysis of the heat map verifies the effectiveness of the self-attention module for global geometric feature extraction of the lesion tissue.ConclusionOur research is focused on meta-optimized multi-Adversarial domain adaptation network, including a multi-level generative adversarial structure and a meta-optimization strategy. The experimental results show that the proposed method is performed well in the transfer task of multi-model medical thyroid ultrasound datasets and has better classification results in a completed unsupervised setting.关键词:computer-aided diagnosis(CAD);multi-model thyroid ultrasound image;domain adaptation;meta-optimization;generative adversarial network(GAN)146|272|1更新时间:2024-05-08
摘要:ObjectiveArtificial intelligence based (AI-based) medical clinical diagnosis technique has been developing in recent years. It can alleviate the problems of medical image analysis in China via deep networks modeling and medical image data analysis, such as the shortage of expertises, the imbalance of urban and rural medical resources allocation, and the the imaging accuracy issues. However, clinical-aided are often linked to multi-model data with different characteristics distribution in different hospitals. Therefore, improving the generalization and stability of the cross-model medical diagnosis-consistent model is required for quick response intensively. In order to alleviate the domain shift existing in the ultrasound imaging field, the unsupervised domain adaptation method can be as the one of the most concerning methods at present. It can avoid the manual labeling of ultrasound image data of various models, a single model can be learnt to adapt to the target domain sample set with data deviation through the labeled source domain sample set, which improves the generalizability of convolutional neural network (CNN) to a certain extent. However, current unsupervised domain adaptation research has some challenging constraints, such as poor feature extraction and inconsistent optimization of domain fusion and sample classification. In view of the limitations in related to domain adaptation network, we develop an intergrated domain adaptation network, which focuses on the under-expressed feature of nodular region features in thyroid ultrasound images. This research is aimed to enhance the fusion of source domain features space and target domain features space.MethodIn this study, a new domain adaptation network is constructed called based on domain-adversarial training of neural networks (DANN), called multi-level adversarial domain adaptation network (MADAN). In the training process, we first build a three-layer generator and discriminator structure according to the transition from general to special features, which can obtain more semantic information in the image. To ensure the coordination of the two optimization processes, the sample classification task and the domain fusion task are both implemented via a meta-optimization strategy. Furthermore, to enhance the global geometric features of diseased tissue regions, we embed a self-attention module in the adversarial structure. Our dataset is composed of 6 849 images-selected from ultrasound images in 4 different models, namely P (Philips1), T(Toshiba), F (GE), and U (Philips2). Our domain adaptation network is carried out in the PyTorch toolbox. The input image is resized to 224 × 224 pixels for training, the momentum parameter is set to 0.9, and the learning rate is set to 0.001. The stochastic gradient descent (SGD)-related learning process is accelerated using an NVIDIA GTX TITAN RTX device, which takes approximately 10 hours in 50 000 iterations. It is possible to obtain more effective samples in the context to benign and malignant labels of the source domain, the target domain during the training process, and the labels of the target domain data are not required at all. The training process performs the supervised classification task of the source domain dataset and the domain alignment task. In the testing process, the feature extractor and classifier fitted are used to verify the classification accuracy of the target domain data. In addition, we use t-distributed stochastic neighbor embedding (t-SNE) to visualize the learned data features, which demonstrates the effectiveness of our network further on the feature-fused of different datasets.ResultWe compared our network with 8 domain adaptation networks, including domain adaptation tasks based on 9 multi-directions on 4 domains: P→T, P→U, P→F, T→P, T→U, T→F, U→P, U→T, and U→F. The evaluation metrics are focused on the accuracy of the target domain data and the t-SNE visualization results, and the ablation experiments is conducted to demonstrate the performance and GPU memory cost of the proposed method. Experimental results show that the MADAN is optimized with an average classification accuracy of 90.141% on the multi-model thyroid ultrasound dataset through 9 transfer tasks. After introducing meta-optimization, the best classification accuracy is achieved in P→U, P→F, T→P, T→F, U→P, and U→F tasks respectively, and the average accuracy of all tasks is improved about 1.67%. The results of the ablation experiments illustrates that the domain adaptation, multi-adversarial structure, and self-attention modules are improved 16.238%, 20.284%, and 18.622%, respectively. The t-SNE visualization images are illustrated that the feature space of the data samples has been preliminarily fused after the multi-level adversarial domain adaptation, and the sample points of the same category are basically aggregated. The multi-adversarial domain adaptation method can achieve fusion results better via the improved meta-optimization strategy. Additionally, the comparative visualization analysis of the heat map verifies the effectiveness of the self-attention module for global geometric feature extraction of the lesion tissue.ConclusionOur research is focused on meta-optimized multi-Adversarial domain adaptation network, including a multi-level generative adversarial structure and a meta-optimization strategy. The experimental results show that the proposed method is performed well in the transfer task of multi-model medical thyroid ultrasound datasets and has better classification results in a completed unsupervised setting.关键词:computer-aided diagnosis(CAD);multi-model thyroid ultrasound image;domain adaptation;meta-optimization;generative adversarial network(GAN)146|272|1更新时间:2024-05-08 -
 摘要:ObjectiveImage super-resolution (SR) is a sort of procedure that aims to reconstruct high resolution (HR) images from a given single or a set of low resolution (LR) images. This cost effective medical-related technique can improve the spatial resolution of images in terms of image processing algorithms. However, most of medical image super-resolution methods are focused on a single-modal super-resolution design. Current magnetic resonance imaging based (MRI-based) clinical applications, Multiple modalities are obtained by different parameter settings. In this case, a single modality super-resolution method cannot take advantage of the correlation information amongst multiple modalities, which limits the super-resolution capability. In addition, most existing deep learning based (DL-based) super-resolution models have constrained of a number of trainable parameters, higher computational cost and memory storage in practice. To strengthen multi-modalities correlation information for reconstruction, our research is focused on a lightweight DL model (i.e., residual dense attention network) for multi-modal MR image super-resolution.MethodA residual dense attention network is developed for multi-modal MR image super-resolution. Our network is composed of three parts: 1) shallow feature extraction, 2) feature refinement and 3) image reconstruction. Two of multi-modal MR images are input to the network after stacking. First, a 3 × 3 convolutional layer in the shallow feature extraction part is used to extract the initial feature maps in the low-resolution space. Next, the feature refinement part is mainly composed of several residual dense attention blocks. Each residual dense attention block consists of a residual dense block and an efficient channel attention module. Third, dense connection and local residual learning are adopted to improve the representation capability of the network in the residual dense block. The efficient channel attention module is facilitated the network to adaptively identify the feature maps that are more crucial for reconstruction. The outputs of all residual dense attention modules are stacked together and fed into two convolutional layers. These convolution layers are employed to reduce the channels of the feature maps as well as for feature fusion. After that, a global residual learning strategy is implemented to optimize the information flow further. The initial feature maps are added to the last layer through a skip connection. Finally, the obtained low-resolution feature maps in the image reconstruction part are up-scaled to the high-resolution space by a sub-pixel convolutional layer. Additionally, two symmetric branches are used to reconstruct the super-resolution results of the different modalities. To reconstruct the residual maps of the two modalities, each branch of them consists of two 3 × 3 convolutional layers. To obtain the final super-resolution results, the residual maps are linked to the interpolated low-resolution images. The popular L1 loss is used to optimize the network parameters.ResultIn the experiments, to verify the effectiveness of the proposed method, the MR images of two modalities (i.e., T1-weighted and T2-weighted) from the medical image computing and computer assisted intervention (MICCAI) brain tumor segmentation (BraTS) 2019 are adopted. The original MRI scans are split and segmented into a training set, a validation set and a testing set. To verify the effect of the multi-modal image super-resolution manner and the efficient channel attention module, two sets of ablation experiments are designed. The results show that these two of components can optimize the super-resolution performance more. Furthermore, eight representative image super-resolution methods are used for comparative analysis of performance in the experiments. Experimental results demonstrate that our method can improve these reference methods in terms of both of the objective evaluation and visual quality. Specifically, our method can obtain more competitive results as mentioned below: 1) when the up-scale factor is 2, the peak signal to noise ratio (PSNR) of the T1-weighted and T2-weighted modalities improve by 0.109 8 dB and 0.415 5 dB, respectively; 2) when the up-scale factor is 3, the PSNR of the T2-weighted modality improves by 0.295 9 dB while the T1-weight modality decreases by 0.064 6 dB; 3) when the up-scale factor is 4, the PSNR of the T1-weighted and T2-weighted modalities improve by 0.269 3 dB and 0.042 9 dB, respectively. It is worth noting that our network has a more than 10 times reduction in terms of network parameters compared to the popular reference method.ConclusionThe correlation information of different modalities between MR images is beneficial to image super-resolution. Our multi-modal MR image super-resolution method can achieve high-quality super-resolution results of two modalities simultaneously in an integrated correlation information-based network. It can obtain more competitive performance than the state-of-the-art super-resolution methods with a relative lightweight model.关键词:image super-resolution;multi-modal MR images;convolutional neural networks(CNN);residual learning;dense connection;attention mechanism;multi-modal information fusion242|260|1更新时间:2024-05-08
摘要:ObjectiveImage super-resolution (SR) is a sort of procedure that aims to reconstruct high resolution (HR) images from a given single or a set of low resolution (LR) images. This cost effective medical-related technique can improve the spatial resolution of images in terms of image processing algorithms. However, most of medical image super-resolution methods are focused on a single-modal super-resolution design. Current magnetic resonance imaging based (MRI-based) clinical applications, Multiple modalities are obtained by different parameter settings. In this case, a single modality super-resolution method cannot take advantage of the correlation information amongst multiple modalities, which limits the super-resolution capability. In addition, most existing deep learning based (DL-based) super-resolution models have constrained of a number of trainable parameters, higher computational cost and memory storage in practice. To strengthen multi-modalities correlation information for reconstruction, our research is focused on a lightweight DL model (i.e., residual dense attention network) for multi-modal MR image super-resolution.MethodA residual dense attention network is developed for multi-modal MR image super-resolution. Our network is composed of three parts: 1) shallow feature extraction, 2) feature refinement and 3) image reconstruction. Two of multi-modal MR images are input to the network after stacking. First, a 3 × 3 convolutional layer in the shallow feature extraction part is used to extract the initial feature maps in the low-resolution space. Next, the feature refinement part is mainly composed of several residual dense attention blocks. Each residual dense attention block consists of a residual dense block and an efficient channel attention module. Third, dense connection and local residual learning are adopted to improve the representation capability of the network in the residual dense block. The efficient channel attention module is facilitated the network to adaptively identify the feature maps that are more crucial for reconstruction. The outputs of all residual dense attention modules are stacked together and fed into two convolutional layers. These convolution layers are employed to reduce the channels of the feature maps as well as for feature fusion. After that, a global residual learning strategy is implemented to optimize the information flow further. The initial feature maps are added to the last layer through a skip connection. Finally, the obtained low-resolution feature maps in the image reconstruction part are up-scaled to the high-resolution space by a sub-pixel convolutional layer. Additionally, two symmetric branches are used to reconstruct the super-resolution results of the different modalities. To reconstruct the residual maps of the two modalities, each branch of them consists of two 3 × 3 convolutional layers. To obtain the final super-resolution results, the residual maps are linked to the interpolated low-resolution images. The popular L1 loss is used to optimize the network parameters.ResultIn the experiments, to verify the effectiveness of the proposed method, the MR images of two modalities (i.e., T1-weighted and T2-weighted) from the medical image computing and computer assisted intervention (MICCAI) brain tumor segmentation (BraTS) 2019 are adopted. The original MRI scans are split and segmented into a training set, a validation set and a testing set. To verify the effect of the multi-modal image super-resolution manner and the efficient channel attention module, two sets of ablation experiments are designed. The results show that these two of components can optimize the super-resolution performance more. Furthermore, eight representative image super-resolution methods are used for comparative analysis of performance in the experiments. Experimental results demonstrate that our method can improve these reference methods in terms of both of the objective evaluation and visual quality. Specifically, our method can obtain more competitive results as mentioned below: 1) when the up-scale factor is 2, the peak signal to noise ratio (PSNR) of the T1-weighted and T2-weighted modalities improve by 0.109 8 dB and 0.415 5 dB, respectively; 2) when the up-scale factor is 3, the PSNR of the T2-weighted modality improves by 0.295 9 dB while the T1-weight modality decreases by 0.064 6 dB; 3) when the up-scale factor is 4, the PSNR of the T1-weighted and T2-weighted modalities improve by 0.269 3 dB and 0.042 9 dB, respectively. It is worth noting that our network has a more than 10 times reduction in terms of network parameters compared to the popular reference method.ConclusionThe correlation information of different modalities between MR images is beneficial to image super-resolution. Our multi-modal MR image super-resolution method can achieve high-quality super-resolution results of two modalities simultaneously in an integrated correlation information-based network. It can obtain more competitive performance than the state-of-the-art super-resolution methods with a relative lightweight model.关键词:image super-resolution;multi-modal MR images;convolutional neural networks(CNN);residual learning;dense connection;attention mechanism;multi-modal information fusion242|260|1更新时间:2024-05-08 -
 摘要:ObjectiveHuman liver-detected computerized tomography (CT) images are widely used in the diagnosis of liver diseases. CT images-based liver tumors' symptom is varied in related to its shape, size and location and its low contrast is projected with adjacent tissues. However, the challenging issues are concerned of poor detection ability of small-sized tumors in liver tumor detection and a huge number of parameters of detection network. These challenges are mainly involved in as mentioned below: 1) weak detection ability of small lesions; 2) large amount of model parameters-derived low efficiency and high computational cost; 3) less semantic feature description ability of the model for low-level feature map lesions; 4) poor details-perceptive ability for high-level feature map lesions. In order to solve these problems and improve the detection and recognition ability of the model, we develop a multi-scale EfficientDet-based adaptive fusion network (MAEfficientDet-D0, MAEfficientDet-D1) for liver tumor detection.MethodA multiscale adaptive fusion network method, called MAEfficientDet, is facilitated for liver tumor detection. Our contribitions are based the key asepcts as following: 1) first, efficient inverted bottleneck (EFConv) is designed to replace the mobile inverted bottleneck block of EfficientDet backbone network with efficient inverted bottleneck block, which can effectively reolve the problem of large dimensions and parameters of the squeeze excitation network of mobile-inverted bottleneck block. The structure of the EFConv is to construct multi-channel of input image by expanding convolution to obtain more feature layers. Next, the depth separable convolution is used to extract the features of each layer. Third, a local channel-across interaction strategy with no dimension-reduced is used to realize channel-cross information interaction, and one-dimensional convolution is used to reduce the complexity of the model significantly. Fourth, the number of channels is compressed by dimensional-reduced convolution. Finally, the residual connection is used to alleviate the gradient dispersion and improve the parameter-transfering ability for network model training efficiency. 2) The multiscale blocks (Multiscale-A, Multiscale-B) are focused regional features of liver lesions to expand the effective receptive field of the network and improve the detection ability of small lesions. The internal structure of multi-scale blocks can be divided into multi-branch convolution layers of different cores and maximum pooling operations. Its characteristics are illustrated below: (1) adopting 1 × 1 convolution filtering useless information; (2) using different convolution kernels for different branches to obtain characteristic graphs of different sizes; (3) using the maximum pool operation of different receptive fields to reduce the size of the characteristic map and prevent the network from over fitting; (4) using residuals to improve the efficiency of network parameter transmission. 3) Using multi-channel adaptive weighted feature fusion block (MAWFF) to adaptively fuse the high-level semantic features and the low-level fine-grained features of the liver tumor image. The problems of weak semantics of the low-level lesion feature map and poor details perception of the high-level lesion feature map can be resolved further and the utilization of features and the detection ability of the model are improved. The experimental datasets are composed of liver tumor segmentation challenge dataset (LiTS) and 3D image reconstruction for comparison of algorithm database (3D-IRCADb).ResultThe experiments show that the efficient inversion of bottleneck layer can improve the detection accuracy of fuzzy images effectively while improving a small amount of network complexity. The multi-channel adaptive feature-weighted fusion module fuses the deep features-contextual information effectively and the features-shallowed detail information, which improves the demonstration ability of the model to the lesion features further. The effect of multi-scale adaptive fusion network on liver tumor detection is significantly developed and optimized in terms of the comparative analyses as listed below: 1) LiTS-based: MAEfficientDet-D0 is higher than EfficientDet-D0 by 7.48%, 9.57%, 6.42%, 7.96% and 8.52%, respectively. MAEfficientDet-D1 is increased by 3.47%, 6.64%, 6.33%, 8.12% and 5.02% of each beyond EfficientDet-D1. 2) 3D-IRCADb-based: MAEfficientDet-D0 is increased by 5.51%, 9.82%, 6.16%, 7.39% and 7.63%, respectively beyond EfficientDet-D0. MAEfficientDet-D1 is increased by 5.87%, 6.24%, 5.81%, 9.39% and 6.05%, respectively beyond EfficientDet-D1.ConclusionOur MAEfficientDet-D0 and MAEfficientDet-D1 architectures improve the utilization of features and the detection ability of small lesions. Our detection algorithm has better results on detection accuracy, less parameter amount, calculation cost and running time, as well as its potentials for embedded devices and mobile terminal devices.关键词:MAEfficientDet;efficient inverted bottleneck block;multiscale block;multichannel;feature fusion;adaptive weighting116|182|0更新时间:2024-05-08
摘要:ObjectiveHuman liver-detected computerized tomography (CT) images are widely used in the diagnosis of liver diseases. CT images-based liver tumors' symptom is varied in related to its shape, size and location and its low contrast is projected with adjacent tissues. However, the challenging issues are concerned of poor detection ability of small-sized tumors in liver tumor detection and a huge number of parameters of detection network. These challenges are mainly involved in as mentioned below: 1) weak detection ability of small lesions; 2) large amount of model parameters-derived low efficiency and high computational cost; 3) less semantic feature description ability of the model for low-level feature map lesions; 4) poor details-perceptive ability for high-level feature map lesions. In order to solve these problems and improve the detection and recognition ability of the model, we develop a multi-scale EfficientDet-based adaptive fusion network (MAEfficientDet-D0, MAEfficientDet-D1) for liver tumor detection.MethodA multiscale adaptive fusion network method, called MAEfficientDet, is facilitated for liver tumor detection. Our contribitions are based the key asepcts as following: 1) first, efficient inverted bottleneck (EFConv) is designed to replace the mobile inverted bottleneck block of EfficientDet backbone network with efficient inverted bottleneck block, which can effectively reolve the problem of large dimensions and parameters of the squeeze excitation network of mobile-inverted bottleneck block. The structure of the EFConv is to construct multi-channel of input image by expanding convolution to obtain more feature layers. Next, the depth separable convolution is used to extract the features of each layer. Third, a local channel-across interaction strategy with no dimension-reduced is used to realize channel-cross information interaction, and one-dimensional convolution is used to reduce the complexity of the model significantly. Fourth, the number of channels is compressed by dimensional-reduced convolution. Finally, the residual connection is used to alleviate the gradient dispersion and improve the parameter-transfering ability for network model training efficiency. 2) The multiscale blocks (Multiscale-A, Multiscale-B) are focused regional features of liver lesions to expand the effective receptive field of the network and improve the detection ability of small lesions. The internal structure of multi-scale blocks can be divided into multi-branch convolution layers of different cores and maximum pooling operations. Its characteristics are illustrated below: (1) adopting 1 × 1 convolution filtering useless information; (2) using different convolution kernels for different branches to obtain characteristic graphs of different sizes; (3) using the maximum pool operation of different receptive fields to reduce the size of the characteristic map and prevent the network from over fitting; (4) using residuals to improve the efficiency of network parameter transmission. 3) Using multi-channel adaptive weighted feature fusion block (MAWFF) to adaptively fuse the high-level semantic features and the low-level fine-grained features of the liver tumor image. The problems of weak semantics of the low-level lesion feature map and poor details perception of the high-level lesion feature map can be resolved further and the utilization of features and the detection ability of the model are improved. The experimental datasets are composed of liver tumor segmentation challenge dataset (LiTS) and 3D image reconstruction for comparison of algorithm database (3D-IRCADb).ResultThe experiments show that the efficient inversion of bottleneck layer can improve the detection accuracy of fuzzy images effectively while improving a small amount of network complexity. The multi-channel adaptive feature-weighted fusion module fuses the deep features-contextual information effectively and the features-shallowed detail information, which improves the demonstration ability of the model to the lesion features further. The effect of multi-scale adaptive fusion network on liver tumor detection is significantly developed and optimized in terms of the comparative analyses as listed below: 1) LiTS-based: MAEfficientDet-D0 is higher than EfficientDet-D0 by 7.48%, 9.57%, 6.42%, 7.96% and 8.52%, respectively. MAEfficientDet-D1 is increased by 3.47%, 6.64%, 6.33%, 8.12% and 5.02% of each beyond EfficientDet-D1. 2) 3D-IRCADb-based: MAEfficientDet-D0 is increased by 5.51%, 9.82%, 6.16%, 7.39% and 7.63%, respectively beyond EfficientDet-D0. MAEfficientDet-D1 is increased by 5.87%, 6.24%, 5.81%, 9.39% and 6.05%, respectively beyond EfficientDet-D1.ConclusionOur MAEfficientDet-D0 and MAEfficientDet-D1 architectures improve the utilization of features and the detection ability of small lesions. Our detection algorithm has better results on detection accuracy, less parameter amount, calculation cost and running time, as well as its potentials for embedded devices and mobile terminal devices.关键词:MAEfficientDet;efficient inverted bottleneck block;multiscale block;multichannel;feature fusion;adaptive weighting116|182|0更新时间:2024-05-08
Medical Image Processing
-
 摘要:ObjectiveHyperspectral images(HSI) are widely used in image classification and target detection because of their rich and useful spectral information. Their spatial resolution is required to be optimized further due to the limitation of imaging cameras. Multispectral or panchromatic images with lower spectral resolution have higher spatial resolution compared to hyperspectral images. To improve the spatial resolution of hyperspectral images, they are often fused with multispectral images(MSI) or panchromatic images in the same scene. Dictionary learning is one of the popular algorithms for image fusion, which can be divided into dictionary-spectral learning and dictionary-spatial learning. Using spectral dictionary learning algorithms, high-resolution hyper-spectral images can be expressed as an over-completed spectral dictionary multiplied by sparse coefficients. Spectral dictionary can illustrate the spectral information of high-resolution hyperspectral images, which is originated from k-singular value decomposition(SVD) and the algorithms-related. It is challenged of spatial information loss for spectral dictionary cannot fully express spatial information. Therefore, we develop a new compensated framework to explore more detailed spatial information. To improve the spatial resolution of fusion result, residual spatial information is used to compensate the preliminary result. The residual information is calculated as the error between the image obtained by spectral down sampling through preliminary results and the multispectral image. It is required to inject the residual space information into the preliminary results in an appropriate manner. However, most of the algorithms have limitations for that they only consider the differences between spectral channels but do not consider the differences in spatial. Therefore, the spectral and spatial quality of the fused image will be seriously affected if the extracted errors are injected indiscriminately into a channel.MethodOur method is focused on improving the spatial resolution of hyperspectral image while keeping its spectral information free from distortion. On the basis of fully capturing the spectral information of hyperspectral image through dictionary learning, the residual spatial information is used to compensate for the spatial resolution. First, a fusion method based on local region is designed. To avoid the spectral distortion caused by inappropriate information injection, adjusting the injection degree of residual information adaptively through a coefficient in accordance with the spectral features of the local area. Second, to maintain the consistency of the spatial structure of the fusion results with multispectral image(MSI), the spatial structure of MSI is extracted in the gradient domain, and a variational model is constructed. The coefficients-calculated are incorporated to the spectral dictionary-derived preliminary results to form an optimization term updated alternately. The objective function also contains spectral constraints composed of the target image and HSI, as well as spatial constraint composed of variational components. This function is run iteratively via alternating direction method of multipliers (ADMM). The spatial and spectral constraints-involved fusion model cannot only improve the spatial resolution, but also ensure that the spectral information does not have distortion.ResultOur analysis is compared to six other algorithms on two public datasets. To verify the effectiveness and efficiency of our method, qualitative and quantitative evaluation is carried out in combination with other methods-related through the experimental platform—MATLAB R2018a. For qualitative analysis, our proposed method is capable to get the target image-fused with higher natural and clear visual effect. For quantitative evaluation indicators, compared with the sub-optimal experiment, the Pavia University data set-relevant experimental results are reduced by 4.2%, 4.1% and 2.2% in relation to relative dimensionless global error in synhesis(ERGAS), spectral angle mapper(SAM) and root mean square error(RMSE) indicators. The AVIRIS(airborne visible infrared imaging spectrometer) dataset-related values are reduced by 2.0%, 4.0% and 3.5% of each.ConclusionOur fusion algorithm can effectively improve the spatial resolution preserve spectral information. Furthermore, our algorithm has its optimization and robustness potentially.关键词:remote sensing;hyperspectral and multispectral image fusion;dictionary learning;error compensation;superpixel segmentation150|337|2更新时间:2024-05-08
摘要:ObjectiveHyperspectral images(HSI) are widely used in image classification and target detection because of their rich and useful spectral information. Their spatial resolution is required to be optimized further due to the limitation of imaging cameras. Multispectral or panchromatic images with lower spectral resolution have higher spatial resolution compared to hyperspectral images. To improve the spatial resolution of hyperspectral images, they are often fused with multispectral images(MSI) or panchromatic images in the same scene. Dictionary learning is one of the popular algorithms for image fusion, which can be divided into dictionary-spectral learning and dictionary-spatial learning. Using spectral dictionary learning algorithms, high-resolution hyper-spectral images can be expressed as an over-completed spectral dictionary multiplied by sparse coefficients. Spectral dictionary can illustrate the spectral information of high-resolution hyperspectral images, which is originated from k-singular value decomposition(SVD) and the algorithms-related. It is challenged of spatial information loss for spectral dictionary cannot fully express spatial information. Therefore, we develop a new compensated framework to explore more detailed spatial information. To improve the spatial resolution of fusion result, residual spatial information is used to compensate the preliminary result. The residual information is calculated as the error between the image obtained by spectral down sampling through preliminary results and the multispectral image. It is required to inject the residual space information into the preliminary results in an appropriate manner. However, most of the algorithms have limitations for that they only consider the differences between spectral channels but do not consider the differences in spatial. Therefore, the spectral and spatial quality of the fused image will be seriously affected if the extracted errors are injected indiscriminately into a channel.MethodOur method is focused on improving the spatial resolution of hyperspectral image while keeping its spectral information free from distortion. On the basis of fully capturing the spectral information of hyperspectral image through dictionary learning, the residual spatial information is used to compensate for the spatial resolution. First, a fusion method based on local region is designed. To avoid the spectral distortion caused by inappropriate information injection, adjusting the injection degree of residual information adaptively through a coefficient in accordance with the spectral features of the local area. Second, to maintain the consistency of the spatial structure of the fusion results with multispectral image(MSI), the spatial structure of MSI is extracted in the gradient domain, and a variational model is constructed. The coefficients-calculated are incorporated to the spectral dictionary-derived preliminary results to form an optimization term updated alternately. The objective function also contains spectral constraints composed of the target image and HSI, as well as spatial constraint composed of variational components. This function is run iteratively via alternating direction method of multipliers (ADMM). The spatial and spectral constraints-involved fusion model cannot only improve the spatial resolution, but also ensure that the spectral information does not have distortion.ResultOur analysis is compared to six other algorithms on two public datasets. To verify the effectiveness and efficiency of our method, qualitative and quantitative evaluation is carried out in combination with other methods-related through the experimental platform—MATLAB R2018a. For qualitative analysis, our proposed method is capable to get the target image-fused with higher natural and clear visual effect. For quantitative evaluation indicators, compared with the sub-optimal experiment, the Pavia University data set-relevant experimental results are reduced by 4.2%, 4.1% and 2.2% in relation to relative dimensionless global error in synhesis(ERGAS), spectral angle mapper(SAM) and root mean square error(RMSE) indicators. The AVIRIS(airborne visible infrared imaging spectrometer) dataset-related values are reduced by 2.0%, 4.0% and 3.5% of each.ConclusionOur fusion algorithm can effectively improve the spatial resolution preserve spectral information. Furthermore, our algorithm has its optimization and robustness potentially.关键词:remote sensing;hyperspectral and multispectral image fusion;dictionary learning;error compensation;superpixel segmentation150|337|2更新时间:2024-05-08 -
 摘要:ObjectiveMultispectral image fusion is one of the key tasks in the field of remote sensing (RS). Recent variational model-based and deep learning-based techniques have been developing intensively. However, traditional variational model-based approaches are employed based on linear prior, which is challenged to demonstrate the complicated nonlinear relationship for natural scenarios. Thus, the fusion model is restricted to optimal parameter selection and accurate model design. To resolve these problems, our research is focused on developing a deep network-interpreted for multispectral image and panchromatic image fusion.MethodFirst, we explore a deep prior to describe the relationship between the fusion image and the panchromatic image. Furthermore, a data fidelity term is constructed based on the assumption that the multispectral image is considered to be the down-sampled version of the fusion result. A new fusion model is proposed by integrating the deep prior and the data fidelity term mentioned above. To obtain an accurate fusion result, we first resolve the proposed fusion model by the proximal gradient descent method, which introduces intermediate variables to convert the original optimization problem into several iterative steps. Then, we simplify the iteration function by assuming that the residual for each iteration follows Gaussian distribution. After next, we unroll the above optimization steps into a deep learning network that contains several sub-modules. Therefore, the optimization process of network parameters is driven for a clear physical-based deep fusion network-interpreted via the training data and the proposed physical fusion model both. Moreover, the handcrafted hyper-parameters in the fusion model are also tuned from specific training data, which can resolve the problem of the design of manual parameters in the traditional variational model methods effectively. Specifically, to build an interpretable end-to-end fusion network, we implement the optimization steps in each iteration with different network modules. Furthermore, to deal with the challenging issues of the diversity of sensor spectrum character between different satellites, we use two consecutive 3×3 convolution layers separated with a ReLU nonlinear active layer to represent the optical spectrum transform matrix. For upgrading the intermediate variable-introduced, it is regarded as a denoising problem in related to SwinResUnet. Thanks to the capabilities of extraction of local features and attention of global information, the SwinResUnet incorporates convolutional neural network (CNN) and Swin-Transformer layers into its network architecture. And, a U-Net is adopted as the backbone of SwinResUnet in the deep denoiser, which contains three groups of encoders and decoders with different feature scales. In addition, short connections are established in each group of encoder and decoder for enhancing feature transmission and avoiding gradient explosion. Finally, the
摘要:ObjectiveMultispectral image fusion is one of the key tasks in the field of remote sensing (RS). Recent variational model-based and deep learning-based techniques have been developing intensively. However, traditional variational model-based approaches are employed based on linear prior, which is challenged to demonstrate the complicated nonlinear relationship for natural scenarios. Thus, the fusion model is restricted to optimal parameter selection and accurate model design. To resolve these problems, our research is focused on developing a deep network-interpreted for multispectral image and panchromatic image fusion.MethodFirst, we explore a deep prior to describe the relationship between the fusion image and the panchromatic image. Furthermore, a data fidelity term is constructed based on the assumption that the multispectral image is considered to be the down-sampled version of the fusion result. A new fusion model is proposed by integrating the deep prior and the data fidelity term mentioned above. To obtain an accurate fusion result, we first resolve the proposed fusion model by the proximal gradient descent method, which introduces intermediate variables to convert the original optimization problem into several iterative steps. Then, we simplify the iteration function by assuming that the residual for each iteration follows Gaussian distribution. After next, we unroll the above optimization steps into a deep learning network that contains several sub-modules. Therefore, the optimization process of network parameters is driven for a clear physical-based deep fusion network-interpreted via the training data and the proposed physical fusion model both. Moreover, the handcrafted hyper-parameters in the fusion model are also tuned from specific training data, which can resolve the problem of the design of manual parameters in the traditional variational model methods effectively. Specifically, to build an interpretable end-to-end fusion network, we implement the optimization steps in each iteration with different network modules. Furthermore, to deal with the challenging issues of the diversity of sensor spectrum character between different satellites, we use two consecutive 3×3 convolution layers separated with a ReLU nonlinear active layer to represent the optical spectrum transform matrix. For upgrading the intermediate variable-introduced, it is regarded as a denoising problem in related to SwinResUnet. Thanks to the capabilities of extraction of local features and attention of global information, the SwinResUnet incorporates convolutional neural network (CNN) and Swin-Transformer layers into its network architecture. And, a U-Net is adopted as the backbone of SwinResUnet in the deep denoiser, which contains three groups of encoders and decoders with different feature scales. In addition, short connections are established in each group of encoder and decoder for enhancing feature transmission and avoiding gradient explosion. Finally, the${{\rm{L}}_1}$ ${Q^{2n}}$ ${D_{\rm{s}}}$ ${D_\lambda }$ 关键词:remote sensing(RS);multispectral image(MSI);image fusion;deep learning(DL);interpretable network;proximal gradient descent(PGD)273|223|1更新时间:2024-05-08 -
 摘要:ObjectiveRemote sensing (RS) image fusion issue is focused on developing high-resolution multispectral (HRMS) images through the integration of low-resolution multispectral (LRMS) images and corresponding panchromatic (PAN) high spatial resolution images. Pan-sharpening has been widely developing as a pre-processing tool in the context of multiple vision applications like object detection, environmental surveillance, landscape monitoring, and scenario segmentation. The key issue for pan-sharpening is concerned of different and specific information gathering from multi-source images. The pan-sharpening methods can be divided into multiple methods in related to 1) component substitution (CS), 2) multi-resolution analysis (MRA), 3) model-based, and 4) deep-learning-based. The CS-based easy-use method is challenged for the severe spectral-distorted problem of multi-features-derived between PAN and LRMS images. The multi-resolution analysis (MRA) methods can be used to extract the spatial features from PAN images by multi-scale transformation. These features of high resolution are melted into the up-sampled LRMS images. Although spatial details can be preserved well by these methods, spectral information is likely to be corrupted by the features-melted. For model-based methods, an optimized algorithm is complicated and time-consuming for the model. The deep-learning-based method is qualified but two challenging problems to be resolved: 1) multispectral images up-sampling-derived image quality degradation; 2) multichannel variability-lacked insufficient integration. To alleviate the problems mentioned above, we implement a channel-fused strategy to mine two modalities of information better. Additionally, to resolve the image quality degradation caused by up-sampling multispectral images, a detailed progressive-enhanced module is proposed as well.MethodMost of deep learning-based methods are linked to up-sample the multispectral image straightforward to maintain the same size as the panchromatic image, which degrades the image quality and lose some of the spatial details. To obtain enhanced results gradually, we carry out an implementation for progressive scale detail enhancement via the information of multi-scale panchromatic images. A channel fusion strategy is used to fuse two images in terms of an enhanced multispectral image and the corresponding panchromatic image. The effective and efficient information of the two modalities can be captured for the HRMS-predicted. The process of channel fusion can be summarized in three steps, which are 1) decomposition, 2) fusion, and 3) reconstruction. Specifically, each channel of the enhanced multispectral image is concatenated with the panchromatic image in the decomposition, and a shallow feature is obtained by two 3×3 convolutional layers. The following fusion step is based on a new fusion strategy in terms of 8 structure-preserved modules over the channels. Each structure-preserved module has four branches, the number of them is equal to the number of the channels in the multispectral image, and each branch can be used to extract features from convolutional layers, while residual connections are added to each branch for efficient information transfer. For the reconstruction, to reconstruct high-resolution multispectral images, the obtained features of each channel are first re-integrated through remapping the features.ResultOur model is compared to 8 state-of-the-art saliency models, including the traditional approaches and deep learning methods on two datasets, called GaoFen-2 and QuickBird. The quantitative evaluation metrics are composed of peak signal-to-noise ratio (PSNR), structural similarity (SSIM), correlation coefficient (CC), spectral angle mapper (SAM), erreur relative globale adimensionnelle de synthese (ERGAS), quality-with-no-reference (QNR)
摘要:ObjectiveRemote sensing (RS) image fusion issue is focused on developing high-resolution multispectral (HRMS) images through the integration of low-resolution multispectral (LRMS) images and corresponding panchromatic (PAN) high spatial resolution images. Pan-sharpening has been widely developing as a pre-processing tool in the context of multiple vision applications like object detection, environmental surveillance, landscape monitoring, and scenario segmentation. The key issue for pan-sharpening is concerned of different and specific information gathering from multi-source images. The pan-sharpening methods can be divided into multiple methods in related to 1) component substitution (CS), 2) multi-resolution analysis (MRA), 3) model-based, and 4) deep-learning-based. The CS-based easy-use method is challenged for the severe spectral-distorted problem of multi-features-derived between PAN and LRMS images. The multi-resolution analysis (MRA) methods can be used to extract the spatial features from PAN images by multi-scale transformation. These features of high resolution are melted into the up-sampled LRMS images. Although spatial details can be preserved well by these methods, spectral information is likely to be corrupted by the features-melted. For model-based methods, an optimized algorithm is complicated and time-consuming for the model. The deep-learning-based method is qualified but two challenging problems to be resolved: 1) multispectral images up-sampling-derived image quality degradation; 2) multichannel variability-lacked insufficient integration. To alleviate the problems mentioned above, we implement a channel-fused strategy to mine two modalities of information better. Additionally, to resolve the image quality degradation caused by up-sampling multispectral images, a detailed progressive-enhanced module is proposed as well.MethodMost of deep learning-based methods are linked to up-sample the multispectral image straightforward to maintain the same size as the panchromatic image, which degrades the image quality and lose some of the spatial details. To obtain enhanced results gradually, we carry out an implementation for progressive scale detail enhancement via the information of multi-scale panchromatic images. A channel fusion strategy is used to fuse two images in terms of an enhanced multispectral image and the corresponding panchromatic image. The effective and efficient information of the two modalities can be captured for the HRMS-predicted. The process of channel fusion can be summarized in three steps, which are 1) decomposition, 2) fusion, and 3) reconstruction. Specifically, each channel of the enhanced multispectral image is concatenated with the panchromatic image in the decomposition, and a shallow feature is obtained by two 3×3 convolutional layers. The following fusion step is based on a new fusion strategy in terms of 8 structure-preserved modules over the channels. Each structure-preserved module has four branches, the number of them is equal to the number of the channels in the multispectral image, and each branch can be used to extract features from convolutional layers, while residual connections are added to each branch for efficient information transfer. For the reconstruction, to reconstruct high-resolution multispectral images, the obtained features of each channel are first re-integrated through remapping the features.ResultOur model is compared to 8 state-of-the-art saliency models, including the traditional approaches and deep learning methods on two datasets, called GaoFen-2 and QuickBird. The quantitative evaluation metrics are composed of peak signal-to-noise ratio (PSNR), structural similarity (SSIM), correlation coefficient (CC), spectral angle mapper (SAM), erreur relative globale adimensionnelle de synthese (ERGAS), quality-with-no-reference (QNR)$D_\lambda$ $D_S $ 关键词:pan-sharpening;progressive enhancement;channel fusion;deep learning;multispectral image180|297|1更新时间:2024-05-08
Remote Sensing Image Processing
-
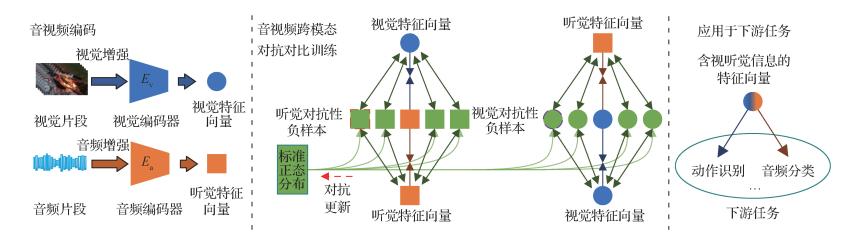 摘要:ObjectiveVideo clip-based vision and audition are two kind of interactive and synchronized symbiotic modalities to develop a self-supervised mode. Current researches demonstrate that human-perception is derived from visual auditory vision to understand dynamic events. Therefore, the feature extracted from audio-visual clips contains richer information. In recent years, data feature-based contrastive learning has promoted visual domain dramatically via the mutual information prediction between pairs of samples. Much more concerns are related to the application of contrastive learning, a self-supervised representation learning paradigm for the audio-visual multi-modal domain. It is essential to deal with the issue of an audio-visual negative sample space construction, where contrastive learning can extract negative samples. To improve the audio-visual feature fusion capability of contrastive learning, our research is focused on building up an efficient audio-visual negative sample space.MethodWe develop a method of audio-visual adversarial contrastive learning for multi-modal self-supervised feature fusion. Visual and auditory negative sample sets are initialized as standard normal distribution, which can construct the audio-visual negative sample space. In order to ensure the scaled audio-visual negative sample space, the number of visual and auditory adversarial negative samples is defined as 65 536. The path of cross-modal adversarial contrastive learning is described as following: 1) we used the paired visual feature and auditory feature extracted from the same video clip as the positive sample, while the auditory adversarial negative samples are used to construct the negative sample space, the visual feature will be close to the corresponding auditory positive sample during the training of cross-modal contrastive learning, while discretes from the auditory adversarial negative samples farther. 2) Auditory adversarial negative samples are updated during cross-modal adversarial learning, which makes them closer to the visual feature. If there is just cross-modal adversarial contrastive learning there, the modal can be actually degenerated into the inner-modal adversarial contrastive learning. The visual and auditory negative samples sets are initialized as standard normal distribution without visual or auditory information, so inner-modal adversarial contrastive learning is also required. We used a pair of visual features in different view as the positive sample further. The negative sample space is still constructed by the visual adversarial negative samples. 3) Visual and auditory feature is composed of inner-modality and cross-modality information both, which can be used to guide downstream tasks like action recognition and audio classification. Specifically, (1)to construct audio-visual negative sample space, visual and audio adversarial negative samples are introduced; (2) to track the indistinguishable audio and visual samples in consistency, the combination of inner-modality and cross-modality adversarial contrastive learning is adopted, which can improve the proposed method effectively to fuse audio-visual self-supervised feature. On the basis of (1) and (2) mentioned above, the audio-visual adversarial contrastive learning framework is simplified further.ResultThe subset of Kinetics-400 dataset is selected for pre-training to obtain audio-visual feature. 1) The audio-visual feature is analyzed qualitatively. The visual feature is applied to guide the supervised network of action recognition. After fine-tuning the supervised network, we visualized the final convolutional layer of the network. Comparing with Cross-cross-audio visual instance discrimination(AVID) method, our visual feature makes the supervised network pay more attention to the various body parts of the person-targeted, which is an effective information source to recognize action.2) The quality of the audio-visual adversarial negative samples are analyzed qualitatively via visualizing the t-distributed stochastic neighbor embedding(t-SNE) figure about the audio-visual feature and the audio-visual adversarial negative samples. The audio-visual adversarial negative sample distribution of our method is looped and similar to an oval shape, while the audio-visual negative sample distribution of Cross-AVID method has small clusters and deletions. It demonstratess that the proposed audio-visual adversarial negative samples can track the audio-visual feature in the iterative process closely, and build a more efficient audio-visual negative sample space. The audio-visual feature is analyzed in quantitative as well. This feature is applied to motion recognition and audio classification. In particular, 1)visual-based Cross-AVID model comparison: our analysis achieves 0.35% and 0.83% of each on the UCF-101 and human metabolome database(HMDB-51) action recognition datasets; 2) audio-based Cross-AVID model comparison: our analysis achieves 2.88% on the ECS-50 environmental sound classification dataset.ConclusionAudio-visual adversarial contrastive learning method can introduce visual and audio adversarial negative samples effectively. To obtain audio-visual feature information, qualitative and quantitative experiments show that the proposed method can well fuse visual and auditory feature. This feature can be implied to improve the accuracy of action recognition and audio classification tasks.关键词:self-supervised feature fusion;adversarial contrastive learning;audio-visual cross-modality;audio-visual adversarial negative sample;pre-training168|197|1更新时间:2024-05-08
摘要:ObjectiveVideo clip-based vision and audition are two kind of interactive and synchronized symbiotic modalities to develop a self-supervised mode. Current researches demonstrate that human-perception is derived from visual auditory vision to understand dynamic events. Therefore, the feature extracted from audio-visual clips contains richer information. In recent years, data feature-based contrastive learning has promoted visual domain dramatically via the mutual information prediction between pairs of samples. Much more concerns are related to the application of contrastive learning, a self-supervised representation learning paradigm for the audio-visual multi-modal domain. It is essential to deal with the issue of an audio-visual negative sample space construction, where contrastive learning can extract negative samples. To improve the audio-visual feature fusion capability of contrastive learning, our research is focused on building up an efficient audio-visual negative sample space.MethodWe develop a method of audio-visual adversarial contrastive learning for multi-modal self-supervised feature fusion. Visual and auditory negative sample sets are initialized as standard normal distribution, which can construct the audio-visual negative sample space. In order to ensure the scaled audio-visual negative sample space, the number of visual and auditory adversarial negative samples is defined as 65 536. The path of cross-modal adversarial contrastive learning is described as following: 1) we used the paired visual feature and auditory feature extracted from the same video clip as the positive sample, while the auditory adversarial negative samples are used to construct the negative sample space, the visual feature will be close to the corresponding auditory positive sample during the training of cross-modal contrastive learning, while discretes from the auditory adversarial negative samples farther. 2) Auditory adversarial negative samples are updated during cross-modal adversarial learning, which makes them closer to the visual feature. If there is just cross-modal adversarial contrastive learning there, the modal can be actually degenerated into the inner-modal adversarial contrastive learning. The visual and auditory negative samples sets are initialized as standard normal distribution without visual or auditory information, so inner-modal adversarial contrastive learning is also required. We used a pair of visual features in different view as the positive sample further. The negative sample space is still constructed by the visual adversarial negative samples. 3) Visual and auditory feature is composed of inner-modality and cross-modality information both, which can be used to guide downstream tasks like action recognition and audio classification. Specifically, (1)to construct audio-visual negative sample space, visual and audio adversarial negative samples are introduced; (2) to track the indistinguishable audio and visual samples in consistency, the combination of inner-modality and cross-modality adversarial contrastive learning is adopted, which can improve the proposed method effectively to fuse audio-visual self-supervised feature. On the basis of (1) and (2) mentioned above, the audio-visual adversarial contrastive learning framework is simplified further.ResultThe subset of Kinetics-400 dataset is selected for pre-training to obtain audio-visual feature. 1) The audio-visual feature is analyzed qualitatively. The visual feature is applied to guide the supervised network of action recognition. After fine-tuning the supervised network, we visualized the final convolutional layer of the network. Comparing with Cross-cross-audio visual instance discrimination(AVID) method, our visual feature makes the supervised network pay more attention to the various body parts of the person-targeted, which is an effective information source to recognize action.2) The quality of the audio-visual adversarial negative samples are analyzed qualitatively via visualizing the t-distributed stochastic neighbor embedding(t-SNE) figure about the audio-visual feature and the audio-visual adversarial negative samples. The audio-visual adversarial negative sample distribution of our method is looped and similar to an oval shape, while the audio-visual negative sample distribution of Cross-AVID method has small clusters and deletions. It demonstratess that the proposed audio-visual adversarial negative samples can track the audio-visual feature in the iterative process closely, and build a more efficient audio-visual negative sample space. The audio-visual feature is analyzed in quantitative as well. This feature is applied to motion recognition and audio classification. In particular, 1)visual-based Cross-AVID model comparison: our analysis achieves 0.35% and 0.83% of each on the UCF-101 and human metabolome database(HMDB-51) action recognition datasets; 2) audio-based Cross-AVID model comparison: our analysis achieves 2.88% on the ECS-50 environmental sound classification dataset.ConclusionAudio-visual adversarial contrastive learning method can introduce visual and audio adversarial negative samples effectively. To obtain audio-visual feature information, qualitative and quantitative experiments show that the proposed method can well fuse visual and auditory feature. This feature can be implied to improve the accuracy of action recognition and audio classification tasks.关键词:self-supervised feature fusion;adversarial contrastive learning;audio-visual cross-modality;audio-visual adversarial negative sample;pre-training168|197|1更新时间:2024-05-08
Multi-modal Information Fusion
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0