
最新刊期
卷 27 , 期 9 , 2022
-
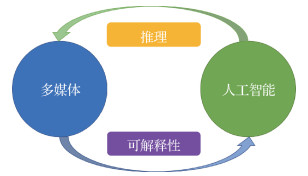 摘要:Multimedia can be regarded as an integration of various medium such as videos, static images, audios, and texts. Thanks to the rapid development of emerging multimedia applications and services, a huge amount of multimedia data has been generated to advance multimedia research. Furthermore, multimedia research has made great progress in image/video processing and analysis, including search, recommendation, streaming, and content delivery. Since artificial intelligence (AI) became an official academic discipline in the 1 950 s, it has experienced a "new" wave of boost based on deep learning techniques. Its development has been witnessed in the past decades, including expert systems, intelligent search and optimization, symbolic and logical reasoning, probabilistic methods, statistical learning methods, artificial neural networks, etc. As such, a natural question arises: "What will happen when multimedia meets AI?" To answer this question, we introduce the concept of multimedia intelligence by investigating the mutual influences between multimedia and AI. Multimedia drives AI towards a more explainable paradigm, because semantic information is able to enhance the explainability of AI models. At the same time, AI is beneficial for multimedia technology to pocess the advanced ability of reasoning. AI promotes the human-like perception and reasoning processes, which can lead to more inferable multimedia processing and analizing techniques. These mutual influences form a loop in which multimedia and AI interactively enhance each other. To sum up, we discuss the recent advances in literature and share our insights on future research directions deserving further study. We hope this paper can bring new inspirations for future development of multimedia intelligence.关键词:multimedia technology;artificial intelligence(AI);multimedia intelligence;multimedia reasoning;explainable artificial intelligence225|291|1更新时间:2024-08-15
摘要:Multimedia can be regarded as an integration of various medium such as videos, static images, audios, and texts. Thanks to the rapid development of emerging multimedia applications and services, a huge amount of multimedia data has been generated to advance multimedia research. Furthermore, multimedia research has made great progress in image/video processing and analysis, including search, recommendation, streaming, and content delivery. Since artificial intelligence (AI) became an official academic discipline in the 1 950 s, it has experienced a "new" wave of boost based on deep learning techniques. Its development has been witnessed in the past decades, including expert systems, intelligent search and optimization, symbolic and logical reasoning, probabilistic methods, statistical learning methods, artificial neural networks, etc. As such, a natural question arises: "What will happen when multimedia meets AI?" To answer this question, we introduce the concept of multimedia intelligence by investigating the mutual influences between multimedia and AI. Multimedia drives AI towards a more explainable paradigm, because semantic information is able to enhance the explainability of AI models. At the same time, AI is beneficial for multimedia technology to pocess the advanced ability of reasoning. AI promotes the human-like perception and reasoning processes, which can lead to more inferable multimedia processing and analizing techniques. These mutual influences form a loop in which multimedia and AI interactively enhance each other. To sum up, we discuss the recent advances in literature and share our insights on future research directions deserving further study. We hope this paper can bring new inspirations for future development of multimedia intelligence.关键词:multimedia technology;artificial intelligence(AI);multimedia intelligence;multimedia reasoning;explainable artificial intelligence225|291|1更新时间:2024-08-15 -
 摘要:We review the recent development of cross-media intelligence, analyze its new trends and challenges, and discuss future prospects of cross-media intelligence. Cross-media intelligence is focused on the integration of multi-source and multi-modal data. It attempts to use the relationship between different media data for high-level semantic understanding and logical reasoning. Existing cross-media algorithms mainly follow the paradigm of "single media representation" to "multimedia integration", in which the two processes of feature learning and logical reasoning are relatively disconnected. It is unlikely to synthesize multi-source and multi-level semantic information to obtain unified features, which hinders the mutual benefits of the reasoning and learning process. This paradigm is lack of the process of explicit knowledge accumulation and multi-level structure understanding. At the same time, it restricts the interpretability and robustness of the model. We interpret new representation method, i.e., visual knowledge. Visual knowledge driven cross-media intelligence has the features of multi-level modeling and knowledge reasoning. Its built-in mechanisms can implement operations and reconstruction visually, which learns knowledge alignment and association. To establish a unified way of knowledge representation learning, the theory of visual knowledge has been illustrated as mentioned below: 1) we introduce three key factors of visual contexts, i.e., concept, visual relationship, and visual reasoning. Visual knowledge has capable of knowledge representations abstraction and multiple knowledge complementing. Visual relations represent the relationship between visual concepts and provide an effective basis for more complex cross-media visual reasoning. We demonstrate visual-based spatio-temporal and causal relationships, but the visual relationship is not limited to these categories. We recommend that the pairwise visual relationships should be extended to multi-objects cascade relationships and the integrated spatio-temporal and causal representations effectively. Visual knowledge is derived of visual concepts and visual relationships, enabling more interpretive and generalized high-level cross-media visual reasoning. Visual knowledge develops a structured knowledge representation, a multi-level basis for visual reasoning, and realizes an effective demonstration for neural network decisions. Broadly, the referred visual reasoning includes a variety of visual operations, such as prediction, reconstruction, association and decomposition. 2) We discuss the applications of visual knowledge, and introduce detailed analysis on their future challenges. We select three applications of those are structured representation of visual knowledge, operation and reasoning of visual knowledge, and cross-media reconstruction and generation. Visual knowledge is predicted to resolve the ambiguity problems in relational descriptions and suppress data bias effectively. It is worth noting that these three specific applications are involved some cross-media intelligence examples of visual knowledge only. Although hand-crafted features are less capable of abstracting multimedia data than deep learning features, these descriptors tend to be more interpretable. The effective integration of hand-crafted features and deep learning features for cross-media representation modeling is a typical application of visual knowledge representation in the context of cross-media intelligence. The structured representation of visual knowledge contributes to the improvement of model interpretability. 3) We analyze the advantages of visual knowledge. It aids to achieve a unified framework driven by both data and knowledge, learn explainable structured representations, and promote cross-media knowledge association and intelligent reasoning. Thanks to the development of visual knowledge based cross-media intelligence, more emerging cross-media intelligence applications will be developed. The decision-making assistance process is more credible through the structural and multi-granularity representation of visual knowledge and the integrated optimization of multi-source and cross-domain data. The reasoning process can be reviewed and clarified, and the model generalization ability can be improved systematically. These factors provide a new powerful pivot for the evolution of cross-media intelligence. Visual knowledge can improve the generative models greatly and enhance the application of simulation technology. Future visual knowledge can be used as a prior to improve the rendering of scenes, realize interactive visual editing tools and controllable semantic understanding of scene objects. A data-driven and visual knowledge derived graphics system will be focused on the integration of the strengths of data and rules, semantic features extraction of visual data, model complexity optimization, simulation improvement, and realistic and sustainable content in new perspectives and new scenarios.关键词:cross-media intelligence;visual knowledge;visual concepts;visual relationships;visual reasoning124|349|1更新时间:2024-08-15
摘要:We review the recent development of cross-media intelligence, analyze its new trends and challenges, and discuss future prospects of cross-media intelligence. Cross-media intelligence is focused on the integration of multi-source and multi-modal data. It attempts to use the relationship between different media data for high-level semantic understanding and logical reasoning. Existing cross-media algorithms mainly follow the paradigm of "single media representation" to "multimedia integration", in which the two processes of feature learning and logical reasoning are relatively disconnected. It is unlikely to synthesize multi-source and multi-level semantic information to obtain unified features, which hinders the mutual benefits of the reasoning and learning process. This paradigm is lack of the process of explicit knowledge accumulation and multi-level structure understanding. At the same time, it restricts the interpretability and robustness of the model. We interpret new representation method, i.e., visual knowledge. Visual knowledge driven cross-media intelligence has the features of multi-level modeling and knowledge reasoning. Its built-in mechanisms can implement operations and reconstruction visually, which learns knowledge alignment and association. To establish a unified way of knowledge representation learning, the theory of visual knowledge has been illustrated as mentioned below: 1) we introduce three key factors of visual contexts, i.e., concept, visual relationship, and visual reasoning. Visual knowledge has capable of knowledge representations abstraction and multiple knowledge complementing. Visual relations represent the relationship between visual concepts and provide an effective basis for more complex cross-media visual reasoning. We demonstrate visual-based spatio-temporal and causal relationships, but the visual relationship is not limited to these categories. We recommend that the pairwise visual relationships should be extended to multi-objects cascade relationships and the integrated spatio-temporal and causal representations effectively. Visual knowledge is derived of visual concepts and visual relationships, enabling more interpretive and generalized high-level cross-media visual reasoning. Visual knowledge develops a structured knowledge representation, a multi-level basis for visual reasoning, and realizes an effective demonstration for neural network decisions. Broadly, the referred visual reasoning includes a variety of visual operations, such as prediction, reconstruction, association and decomposition. 2) We discuss the applications of visual knowledge, and introduce detailed analysis on their future challenges. We select three applications of those are structured representation of visual knowledge, operation and reasoning of visual knowledge, and cross-media reconstruction and generation. Visual knowledge is predicted to resolve the ambiguity problems in relational descriptions and suppress data bias effectively. It is worth noting that these three specific applications are involved some cross-media intelligence examples of visual knowledge only. Although hand-crafted features are less capable of abstracting multimedia data than deep learning features, these descriptors tend to be more interpretable. The effective integration of hand-crafted features and deep learning features for cross-media representation modeling is a typical application of visual knowledge representation in the context of cross-media intelligence. The structured representation of visual knowledge contributes to the improvement of model interpretability. 3) We analyze the advantages of visual knowledge. It aids to achieve a unified framework driven by both data and knowledge, learn explainable structured representations, and promote cross-media knowledge association and intelligent reasoning. Thanks to the development of visual knowledge based cross-media intelligence, more emerging cross-media intelligence applications will be developed. The decision-making assistance process is more credible through the structural and multi-granularity representation of visual knowledge and the integrated optimization of multi-source and cross-domain data. The reasoning process can be reviewed and clarified, and the model generalization ability can be improved systematically. These factors provide a new powerful pivot for the evolution of cross-media intelligence. Visual knowledge can improve the generative models greatly and enhance the application of simulation technology. Future visual knowledge can be used as a prior to improve the rendering of scenes, realize interactive visual editing tools and controllable semantic understanding of scene objects. A data-driven and visual knowledge derived graphics system will be focused on the integration of the strengths of data and rules, semantic features extraction of visual data, model complexity optimization, simulation improvement, and realistic and sustainable content in new perspectives and new scenarios.关键词:cross-media intelligence;visual knowledge;visual concepts;visual relationships;visual reasoning124|349|1更新时间:2024-08-15 -
 摘要:The marine-oriented research is essential to high-quality of human-based development. But, the current recognition of the ocean system is less than 5%. To understand the ocean, big marine data is acquired from observation, monitoring, investigation and statistics. Thanks to the development of the multi-scaled ocean observation system, the extensive of multi-modal marine oriented data has developed via remote sensing image, spatio-temporal analysis, simulation data, literature review and video & audio monitoring. To resilient the sustainable development of human society, current deep analysis and multimodal ocean data mining method has promoted the marine understanding on the aspects of ocean dynamic processes, energy and material cycles, the evolution of blue life, scientific discovery, healthy environment, and the quick response of extreme weather and climate change. Compared to traditional big data, the multi-modal big ocean data has its unique features, such as the super-giant system (covering 71% of the earth's surface, daily increment (10 TB), super multi-perspectives ("land-sea-air-ice-earth based" coupling, "hydrometeorological-acoustical-optical and electromagnetic-based" polymorphism), super spatial scale ("centimeter to hundreds kilometer based"), and temporal scale ("micro-second to inter-decadal based"). These features-derived challenges of existing multi-modal intelligent computing technology have to deal with such problems as cross-scale and multi-modal fusion analyses, multi-disciplinary and multi-domain coordinated reasoning, large computing power based multi-architecture compatible applications. We systematically introduce the cross-cutting researches of intelligent perception, cognition, and prediction for marine phenomena/processes based on multimodal data technology. First, we clarify the research objects, scientific problems, and typical application scenarios of marine multimodal intelligent computing through the evolution analysis of the lifecycle of marine science big data. Next, we target the differences between ocean data distribution and calculation patterns. We illustrate the uniqueness and scientific challenges of multimodal big marine data on the basis of modeling description, cross-modal correlation, inference prediction, and high-performance computing. 1) To bridge the "task gap" between big data and specific tasks for modeling description, we focus on effective feature extraction for related tasks of causality, differentiation, significance and robustness. The ocean-oriented differences and challenges are mainly discussed from six aspects including dynamic changes of physical structure, complex environmental noise, large intra-class differences, lack of reliable labels, unbalanced samples, and less public datasets. 2) To construct multi-circle layer, multi-scale and multi-perspective heterogeneous data, the cross-modal correlation modeling is obtained for reasonable integration of multi-model, effective reasoning of cross-model, and the multi-modalities of "heterogeneous gap bridging" through task matching, semantic consistency, and spatio-temporal correlation. The ocean field issue is mainly affected by four aspects of uneven data, large scale span, strong constraints of temporal and spatial, and high correlation of dimensions. 3) To fill the "unknown gap" of spatio-temporal information loss in the evolution of ocean, the reasoning and prediction requires the prior knowledge, experience, and reasoning ability in the field of modeling. The main differences of ocean fields are reflected in the three issues of dynamic evolution, spatio-temporal heterogeneity, and non-independent samples. 4) To reduce the "computing gap" between complex computing and real-time online analysis of marine super-giant systems, it is necessary to deal with the huge amount of data challenges in high-performance computing problems like increased resolution and the ocean processes refinement of online response analysis. In addition, we sort out and introduce existing work of typical application scenarios, such as marine multimedia content analysis, visual analysis, big data prediction, and high-performance computing. 1) Multimedia content analysis: we compare the technical features of existing marine research methods on the five aspects of target recognition, target re-identification, target retrieval, phenomenon/process recognition, and open datasets. 2) Visual analysis of marine big data: we summarize the matching issues of dynamic changes of physical structure, high correlation dimensions, and large-scale spans from the perspective of visualization, visualization analysis, and visualization system. 3) Ocean multimodal big data reasoning prediction: we review the existing research work from the perspectives of data-driven prediction and prediction of marine environmental variables, construction of marine knowledge graph, and knowledge reasoning. 4) High-performance computing issues of ocean multi-modal big data: we introduce and compare the relevant work on the three perspectives of memory-computing collaboration, multi-model acceleration, and giant system evaluation. Finally, we predict the ocean multimodal intelligent computing issues to be resolved and the future direction of it.关键词:marine big data;multimodal;marine multimedia content analysis;marine knowledge graph;marine big data prediction;marine oriented high performance computing;re-identification of marine object409|832|1更新时间:2024-08-15
摘要:The marine-oriented research is essential to high-quality of human-based development. But, the current recognition of the ocean system is less than 5%. To understand the ocean, big marine data is acquired from observation, monitoring, investigation and statistics. Thanks to the development of the multi-scaled ocean observation system, the extensive of multi-modal marine oriented data has developed via remote sensing image, spatio-temporal analysis, simulation data, literature review and video & audio monitoring. To resilient the sustainable development of human society, current deep analysis and multimodal ocean data mining method has promoted the marine understanding on the aspects of ocean dynamic processes, energy and material cycles, the evolution of blue life, scientific discovery, healthy environment, and the quick response of extreme weather and climate change. Compared to traditional big data, the multi-modal big ocean data has its unique features, such as the super-giant system (covering 71% of the earth's surface, daily increment (10 TB), super multi-perspectives ("land-sea-air-ice-earth based" coupling, "hydrometeorological-acoustical-optical and electromagnetic-based" polymorphism), super spatial scale ("centimeter to hundreds kilometer based"), and temporal scale ("micro-second to inter-decadal based"). These features-derived challenges of existing multi-modal intelligent computing technology have to deal with such problems as cross-scale and multi-modal fusion analyses, multi-disciplinary and multi-domain coordinated reasoning, large computing power based multi-architecture compatible applications. We systematically introduce the cross-cutting researches of intelligent perception, cognition, and prediction for marine phenomena/processes based on multimodal data technology. First, we clarify the research objects, scientific problems, and typical application scenarios of marine multimodal intelligent computing through the evolution analysis of the lifecycle of marine science big data. Next, we target the differences between ocean data distribution and calculation patterns. We illustrate the uniqueness and scientific challenges of multimodal big marine data on the basis of modeling description, cross-modal correlation, inference prediction, and high-performance computing. 1) To bridge the "task gap" between big data and specific tasks for modeling description, we focus on effective feature extraction for related tasks of causality, differentiation, significance and robustness. The ocean-oriented differences and challenges are mainly discussed from six aspects including dynamic changes of physical structure, complex environmental noise, large intra-class differences, lack of reliable labels, unbalanced samples, and less public datasets. 2) To construct multi-circle layer, multi-scale and multi-perspective heterogeneous data, the cross-modal correlation modeling is obtained for reasonable integration of multi-model, effective reasoning of cross-model, and the multi-modalities of "heterogeneous gap bridging" through task matching, semantic consistency, and spatio-temporal correlation. The ocean field issue is mainly affected by four aspects of uneven data, large scale span, strong constraints of temporal and spatial, and high correlation of dimensions. 3) To fill the "unknown gap" of spatio-temporal information loss in the evolution of ocean, the reasoning and prediction requires the prior knowledge, experience, and reasoning ability in the field of modeling. The main differences of ocean fields are reflected in the three issues of dynamic evolution, spatio-temporal heterogeneity, and non-independent samples. 4) To reduce the "computing gap" between complex computing and real-time online analysis of marine super-giant systems, it is necessary to deal with the huge amount of data challenges in high-performance computing problems like increased resolution and the ocean processes refinement of online response analysis. In addition, we sort out and introduce existing work of typical application scenarios, such as marine multimedia content analysis, visual analysis, big data prediction, and high-performance computing. 1) Multimedia content analysis: we compare the technical features of existing marine research methods on the five aspects of target recognition, target re-identification, target retrieval, phenomenon/process recognition, and open datasets. 2) Visual analysis of marine big data: we summarize the matching issues of dynamic changes of physical structure, high correlation dimensions, and large-scale spans from the perspective of visualization, visualization analysis, and visualization system. 3) Ocean multimodal big data reasoning prediction: we review the existing research work from the perspectives of data-driven prediction and prediction of marine environmental variables, construction of marine knowledge graph, and knowledge reasoning. 4) High-performance computing issues of ocean multi-modal big data: we introduce and compare the relevant work on the three perspectives of memory-computing collaboration, multi-model acceleration, and giant system evaluation. Finally, we predict the ocean multimodal intelligent computing issues to be resolved and the future direction of it.关键词:marine big data;multimodal;marine multimedia content analysis;marine knowledge graph;marine big data prediction;marine oriented high performance computing;re-identification of marine object409|832|1更新时间:2024-08-15
Scholar View

-
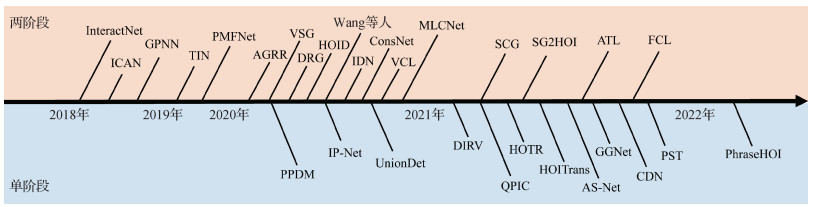 摘要:Human-object interaction (HOI) detection is essential for intelligent human behaviors analysis. Our review is focused on a fine-grain scaled image or video based human behaviors analysis through the localization of interactive human-object pairs and their recognition of interaction types. HOI detection has developed high-level visual applications like dangerous behaviors detection and human-robot interaction. Recent deep learning based methods have facilitated current HOI detection. Our critical review is carried out in terms of recent deep learning based HOI detection methods. We introduce an accelerated progress of image-level HOI detection because the growth of datasets is a key factor for the review of deep learning. First, the datasets and benchmarks of image-level HOI detection is introduced based on an annotation granularity. Therefore, the conventional image-level HOI detection datasets are assigned to three levels of instance, partial and pixel. We introduce the image collection, annotation, and statics information of every level for each dataset. Next, we analyze the conventional HOI detection methods via deep-learning-structured assignment. We summarize traditional HOI detection methods into two main folds further based on a serial architecture of two-stage fold and an end-to-end framework of one-stage fold. Two-stage methods are composed of two split serial stages, where an instance detector is initial to be used for human-object detection, and a following designed interaction classifier is applied for the interaction types reasoning between the targeted human-object detection. To clarify an accurate interaction classifier, our two-stage fold methods are mostly concerned of the two stages. However, one-stage methods are melted into an end-to-end framework, where HOI triplets can be directly detected in an end-to-end manner. Additionally, one-stage methods can also be regarded as a top-down paradigm. An anchor is designed to denote interaction and first be detected in association with human and object. Specifically, we retrace the representative methods and analyze the growth paths of such two folds. Moreover, we demonstrate the pros and cons analysis of the two folds and their potentials. At the beginning, we introduce the two-stage methods sequentially. The two-stage fold into the multi-stream pipeline and graph-based pipeline is divided based on the design of the second stage. Then, the introduced one-stage methods are split into point-based, bounding box-based, and query-based contexts in terms of multiple settings of the interaction anchor. At the end, we review the progress of zero-shot HOI detection. Meanwhile, the growth analysis of video-level HOI detection is reviewed based on datasets and methods. Finally, the future directions of HOI detection are predicted as mentioned below: 1) large-scale pre-trained model-guided HOI detection: the complex HOI types are hard to be annotated for all due to multiple human-object interaction derived of various behaviors. Therefore, zero-shot HOI discovery is a challenging issue in the future. 2) Self-supervised pre-training for HOI detection: it is originated from the mechanism view, where a large-scale image-text pre-trained model hypothesis can much properly benefit for HOI understanding, and 3) efficient video HOI detection: it is hard to detect video-based HOIs efficiently for conventional multi-phases detection mechanisms. Our critical analysis reviewed deep learning based human-object interaction detection tasks systematically.关键词:human-object interaction detection(HOI);action understanding;deep learning;object detection;interaction detection161|565|2更新时间:2024-08-15
摘要:Human-object interaction (HOI) detection is essential for intelligent human behaviors analysis. Our review is focused on a fine-grain scaled image or video based human behaviors analysis through the localization of interactive human-object pairs and their recognition of interaction types. HOI detection has developed high-level visual applications like dangerous behaviors detection and human-robot interaction. Recent deep learning based methods have facilitated current HOI detection. Our critical review is carried out in terms of recent deep learning based HOI detection methods. We introduce an accelerated progress of image-level HOI detection because the growth of datasets is a key factor for the review of deep learning. First, the datasets and benchmarks of image-level HOI detection is introduced based on an annotation granularity. Therefore, the conventional image-level HOI detection datasets are assigned to three levels of instance, partial and pixel. We introduce the image collection, annotation, and statics information of every level for each dataset. Next, we analyze the conventional HOI detection methods via deep-learning-structured assignment. We summarize traditional HOI detection methods into two main folds further based on a serial architecture of two-stage fold and an end-to-end framework of one-stage fold. Two-stage methods are composed of two split serial stages, where an instance detector is initial to be used for human-object detection, and a following designed interaction classifier is applied for the interaction types reasoning between the targeted human-object detection. To clarify an accurate interaction classifier, our two-stage fold methods are mostly concerned of the two stages. However, one-stage methods are melted into an end-to-end framework, where HOI triplets can be directly detected in an end-to-end manner. Additionally, one-stage methods can also be regarded as a top-down paradigm. An anchor is designed to denote interaction and first be detected in association with human and object. Specifically, we retrace the representative methods and analyze the growth paths of such two folds. Moreover, we demonstrate the pros and cons analysis of the two folds and their potentials. At the beginning, we introduce the two-stage methods sequentially. The two-stage fold into the multi-stream pipeline and graph-based pipeline is divided based on the design of the second stage. Then, the introduced one-stage methods are split into point-based, bounding box-based, and query-based contexts in terms of multiple settings of the interaction anchor. At the end, we review the progress of zero-shot HOI detection. Meanwhile, the growth analysis of video-level HOI detection is reviewed based on datasets and methods. Finally, the future directions of HOI detection are predicted as mentioned below: 1) large-scale pre-trained model-guided HOI detection: the complex HOI types are hard to be annotated for all due to multiple human-object interaction derived of various behaviors. Therefore, zero-shot HOI discovery is a challenging issue in the future. 2) Self-supervised pre-training for HOI detection: it is originated from the mechanism view, where a large-scale image-text pre-trained model hypothesis can much properly benefit for HOI understanding, and 3) efficient video HOI detection: it is hard to detect video-based HOIs efficiently for conventional multi-phases detection mechanisms. Our critical analysis reviewed deep learning based human-object interaction detection tasks systematically.关键词:human-object interaction detection(HOI);action understanding;deep learning;object detection;interaction detection161|565|2更新时间:2024-08-15 -
 摘要:Current image and video data have been increasing dramatically in terms of huge artificial intelligence (AI)-generated contents. The derived face reenactment has been developing based on generated facial images or videos. Given source face information and driving motion information, face reenactment aims to generate a reenacted face or corresponding reenacted face video of driving motion information in related to the animation of expression, mouth shape, eye gazing and pose while preserving the identity information of the source face. Face reenactment methods can generate a variety of multiple feature-based and motion-based face videos, which are widely used with less constraints and becomes a research focus in the field of face generation. However, almost no reviews are specially written for the aspect of face reenactment. In view of this, we carry out the critical review of the development of face reenactment beyond DeepFake detection contexts. Our review is focused on the nine perspectives as following: 1) the universal process of face reenactment model; 2) facial information representation; 3) key challenges and barriers; 4) the classification of related methods; 5) introduction of various face reenactment methods; 6) evaluation metrics; 7) commonly used datasets; 8) practical applications; and 9) conclusion and future prospect. The identity information and background information is extracted from source faces while motion features are extracted from driving information, which are combined to generate the reenacted faces. Generally, latent codes, 3D morphable face models (3DMM) coefficients, facial landmarks and facial action units are all served as motion features. Besides, there exist several challenges and problems which are always focused in related research. The identity mismatch problem means the inability of face reenactment model to preserve the identity of source faces. The issue of temporal or background inconsistency indicates that the generated face videos are related to the cross-framing jitter or obvious artifacts between the facial contour and the background. The constraints of identity are originated from the model design and training procedure, which can merely reenact the specific person seen in the training data. As for the category of face reenactment methods, image-driven methods and cross-modality-driven methods are involved according to the modality of driving information. Based on the difference of driving information representation, image-driven methods can be divided into four categories. The driving information representation includes facial landmarks, 3DMM, motion field prediction and feature decoupling. The subclasses of identity restriction (yes/no issue) can be melted into the landmark-based and 3DMM-based methods further in terms of whether the model could generate unseen subjects or not. Our demonstration of each category, corresponding model flowchart and following improvement work will be illustrated in detail. As for the cross-modality driven methods, the text and audio related methods are introduced, which are ill-posed questions due to audio or text facial motion information may have multiple corresponding solutions. For instance, different facial poses or motions of same identity can produce basically the same audio. Cross-modality face reenactment is challenged to attract attention, which will also be introduced comprehensively. Text driven methods are developed based on three stages in terms of driving content progressively, which are extra required audio, restricted text-driven and arbitrary text-driven. The audio driven methods can be further divided into two categories depending on whether additional driving information is demanded or not. The additional driving information refers to eye blinking label or head pose videos, which offer auxiliary information in generation procedure. Moreover, comparative experiments are conducted to evaluate the performance between various methods. Image quality and facial motion accuracy are taken into consideration during evaluation. The peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), cumulative probability of blur detection (CPBD), frechet inception distance (FID) or other traditional image generation evaluation metrics are adopted together. To judge the facial motion accuracy, landmark difference, action unit detection analysis, and pose difference are utilized. In most facial-related cases, the landmarks, the presence of action unit or Euler angle are predicted all via corresponding pre-trained models. As for audio driven methods, the lip synchronization extent is also estimated in the aid of the pretrained evaluation model. Apart from the objective evaluations, subjective metrics like user study are applied as well. Furthermore, the commonly-used datasets in face reenactment are illustrated, each of which contains face images or videos of various expressions, view angles, illumination conditions or corresponding talking audios. The videos are usually collected from the interviews, news broadcast or actor recording. To reflect different level of difficulties, the image and video datasets are tested related to indoor and outdoor scenario. Commonly, the indoor scenario refers to white or grey walls while the outdoor scenario denotes actual moving scenes or the news live room. As for conclusion part, the practical applications and potential threats are critically illustrated. Face reenactment can contribute to entertainment industry like movie video dubbing, video production, game character avatar or old photo colorization. It can be utilized in conference compressing, online customer service, virtual uploader or 3D digital person as well. However, it is warning that misused face reenactment behaviors of lawbreakers can be used for calumniate, false information spreading or harmful media content creation in DeepFake, which will definitely damage the social stability and causing panic on social media. Therefore, it is important to consider more ethical issues of face reenactment. Furthermore, the development status of each category and corresponding future directions are displayed. Overall, model optimization and generation-scenario robustness are served as the two main concerns. Optimization issue is focused on data dependence alleviation, feature disentanglement, real time testing or evaluation metric improvement. Robustness improvement of face reenactment denotes generate high-quality reenacted faces under situations like face occlusion, outdoor scenario, large pose faces or complicated illumination. In a word, our critical review covers the universal pipeline of face reenactment model, main challenges, the classification and detailed explanation about each category of methods, the evaluation metrics and commonly used datasets, the current research analysis and prospects. The potential introduction and guidance of face reenactment research is facilitated.关键词:artificial intelligence (AI);computer vision;deep learning;generative adversarial network(GAN);deepfake;face reenactment176|530|1更新时间:2024-08-15
摘要:Current image and video data have been increasing dramatically in terms of huge artificial intelligence (AI)-generated contents. The derived face reenactment has been developing based on generated facial images or videos. Given source face information and driving motion information, face reenactment aims to generate a reenacted face or corresponding reenacted face video of driving motion information in related to the animation of expression, mouth shape, eye gazing and pose while preserving the identity information of the source face. Face reenactment methods can generate a variety of multiple feature-based and motion-based face videos, which are widely used with less constraints and becomes a research focus in the field of face generation. However, almost no reviews are specially written for the aspect of face reenactment. In view of this, we carry out the critical review of the development of face reenactment beyond DeepFake detection contexts. Our review is focused on the nine perspectives as following: 1) the universal process of face reenactment model; 2) facial information representation; 3) key challenges and barriers; 4) the classification of related methods; 5) introduction of various face reenactment methods; 6) evaluation metrics; 7) commonly used datasets; 8) practical applications; and 9) conclusion and future prospect. The identity information and background information is extracted from source faces while motion features are extracted from driving information, which are combined to generate the reenacted faces. Generally, latent codes, 3D morphable face models (3DMM) coefficients, facial landmarks and facial action units are all served as motion features. Besides, there exist several challenges and problems which are always focused in related research. The identity mismatch problem means the inability of face reenactment model to preserve the identity of source faces. The issue of temporal or background inconsistency indicates that the generated face videos are related to the cross-framing jitter or obvious artifacts between the facial contour and the background. The constraints of identity are originated from the model design and training procedure, which can merely reenact the specific person seen in the training data. As for the category of face reenactment methods, image-driven methods and cross-modality-driven methods are involved according to the modality of driving information. Based on the difference of driving information representation, image-driven methods can be divided into four categories. The driving information representation includes facial landmarks, 3DMM, motion field prediction and feature decoupling. The subclasses of identity restriction (yes/no issue) can be melted into the landmark-based and 3DMM-based methods further in terms of whether the model could generate unseen subjects or not. Our demonstration of each category, corresponding model flowchart and following improvement work will be illustrated in detail. As for the cross-modality driven methods, the text and audio related methods are introduced, which are ill-posed questions due to audio or text facial motion information may have multiple corresponding solutions. For instance, different facial poses or motions of same identity can produce basically the same audio. Cross-modality face reenactment is challenged to attract attention, which will also be introduced comprehensively. Text driven methods are developed based on three stages in terms of driving content progressively, which are extra required audio, restricted text-driven and arbitrary text-driven. The audio driven methods can be further divided into two categories depending on whether additional driving information is demanded or not. The additional driving information refers to eye blinking label or head pose videos, which offer auxiliary information in generation procedure. Moreover, comparative experiments are conducted to evaluate the performance between various methods. Image quality and facial motion accuracy are taken into consideration during evaluation. The peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), cumulative probability of blur detection (CPBD), frechet inception distance (FID) or other traditional image generation evaluation metrics are adopted together. To judge the facial motion accuracy, landmark difference, action unit detection analysis, and pose difference are utilized. In most facial-related cases, the landmarks, the presence of action unit or Euler angle are predicted all via corresponding pre-trained models. As for audio driven methods, the lip synchronization extent is also estimated in the aid of the pretrained evaluation model. Apart from the objective evaluations, subjective metrics like user study are applied as well. Furthermore, the commonly-used datasets in face reenactment are illustrated, each of which contains face images or videos of various expressions, view angles, illumination conditions or corresponding talking audios. The videos are usually collected from the interviews, news broadcast or actor recording. To reflect different level of difficulties, the image and video datasets are tested related to indoor and outdoor scenario. Commonly, the indoor scenario refers to white or grey walls while the outdoor scenario denotes actual moving scenes or the news live room. As for conclusion part, the practical applications and potential threats are critically illustrated. Face reenactment can contribute to entertainment industry like movie video dubbing, video production, game character avatar or old photo colorization. It can be utilized in conference compressing, online customer service, virtual uploader or 3D digital person as well. However, it is warning that misused face reenactment behaviors of lawbreakers can be used for calumniate, false information spreading or harmful media content creation in DeepFake, which will definitely damage the social stability and causing panic on social media. Therefore, it is important to consider more ethical issues of face reenactment. Furthermore, the development status of each category and corresponding future directions are displayed. Overall, model optimization and generation-scenario robustness are served as the two main concerns. Optimization issue is focused on data dependence alleviation, feature disentanglement, real time testing or evaluation metric improvement. Robustness improvement of face reenactment denotes generate high-quality reenacted faces under situations like face occlusion, outdoor scenario, large pose faces or complicated illumination. In a word, our critical review covers the universal pipeline of face reenactment model, main challenges, the classification and detailed explanation about each category of methods, the evaluation metrics and commonly used datasets, the current research analysis and prospects. The potential introduction and guidance of face reenactment research is facilitated.关键词:artificial intelligence (AI);computer vision;deep learning;generative adversarial network(GAN);deepfake;face reenactment176|530|1更新时间:2024-08-15 -
 摘要:Multimodal machine learning has been challenging for labor-intensive and labeled cost and data migration constraints, which requires amount of retraining process, resulting in low efficiency and imbalanced resources allocation for multiple training tasks. To learn the internal knowledge representation and meet the requirement of the related downstream visual language multimodal tasks, pre-training model is carried out for large-scale data training task through self-supervision, the multiple modes information extraction and integration of the data set context, etc. The exploration of pre-trained models is focused on cheaper labeled data due to the expensive human labels. First, the model is pre-trained based on cheap labeled data, and the model is fine-tuned using less expensive human annotations. Large-scale data and long time span training are often required to pre-train the model because of the less information and noise derived from cheap labeled data. The large-scale unlabeled-data-based pre-trained model not only transfer the more general knowledge to the target task through the learned unlabeled data, but also get a better parameter initial point through the pre-training learning. The future multimodal contexts have their potentials like learning demonstration, sentiment analysis and task-oriented large-scale human-computer interactions. Multimodal pre-training models can be as a pathway derived of weak artificial intelligence from local to global. It is possible to transfer multi-tasks learning results to non-supervision multi-domains data automatically and quickly. The plain text pre-training model can cover less online data only, and richer data have not been fully utilized and learned. Multimodal-contexts are benefited from information gathering, context perception, knowledge learning, and demonstration. To generate commonly-used artificial intelligence model, the pre-training model has been developing from single-modal to multi-modal. The intensive growth of pre-training models has extended to the field of visual and textual interaction since 2019. Thanks to the large-scale image-text pairs and video data online and the growth of pre-training technique like self-supervised learning, the visual-language multimodal pre-training model has been promoted and bridged the gap between different visual-language tasks, which optimizes multi-task training and improves the performance of specific tasks. Current multimodal researches are challenged to an intelligent system organizing, multimodal information perceiving and the semantic gap bridging. We review existing pre-training datasets and pre-training methods, and propose a systematic overview of the latest and traditional methods. The universals and differences between the methods are critical analyzed, and the experimental conditions of each model are summarized on specific downstream tasks. Finally, the challenges and future research direction of visual language pre-training are predicted.关键词:multimodal machine learning;visual language multimodality;pre-training;self-supervised learning;image-text pre-training;video-text pre-training281|1789|8更新时间:2024-08-15
摘要:Multimodal machine learning has been challenging for labor-intensive and labeled cost and data migration constraints, which requires amount of retraining process, resulting in low efficiency and imbalanced resources allocation for multiple training tasks. To learn the internal knowledge representation and meet the requirement of the related downstream visual language multimodal tasks, pre-training model is carried out for large-scale data training task through self-supervision, the multiple modes information extraction and integration of the data set context, etc. The exploration of pre-trained models is focused on cheaper labeled data due to the expensive human labels. First, the model is pre-trained based on cheap labeled data, and the model is fine-tuned using less expensive human annotations. Large-scale data and long time span training are often required to pre-train the model because of the less information and noise derived from cheap labeled data. The large-scale unlabeled-data-based pre-trained model not only transfer the more general knowledge to the target task through the learned unlabeled data, but also get a better parameter initial point through the pre-training learning. The future multimodal contexts have their potentials like learning demonstration, sentiment analysis and task-oriented large-scale human-computer interactions. Multimodal pre-training models can be as a pathway derived of weak artificial intelligence from local to global. It is possible to transfer multi-tasks learning results to non-supervision multi-domains data automatically and quickly. The plain text pre-training model can cover less online data only, and richer data have not been fully utilized and learned. Multimodal-contexts are benefited from information gathering, context perception, knowledge learning, and demonstration. To generate commonly-used artificial intelligence model, the pre-training model has been developing from single-modal to multi-modal. The intensive growth of pre-training models has extended to the field of visual and textual interaction since 2019. Thanks to the large-scale image-text pairs and video data online and the growth of pre-training technique like self-supervised learning, the visual-language multimodal pre-training model has been promoted and bridged the gap between different visual-language tasks, which optimizes multi-task training and improves the performance of specific tasks. Current multimodal researches are challenged to an intelligent system organizing, multimodal information perceiving and the semantic gap bridging. We review existing pre-training datasets and pre-training methods, and propose a systematic overview of the latest and traditional methods. The universals and differences between the methods are critical analyzed, and the experimental conditions of each model are summarized on specific downstream tasks. Finally, the challenges and future research direction of visual language pre-training are predicted.关键词:multimodal machine learning;visual language multimodality;pre-training;self-supervised learning;image-text pre-training;video-text pre-training281|1789|8更新时间:2024-08-15 -
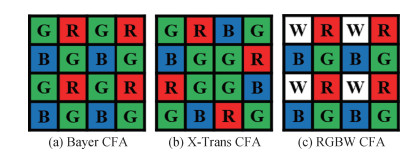 摘要:The Bayer array image demosaicing technology is one of the essential parts in the digital image signal processing process mechanism, which reconstructs the sparsely sampled Bayer array image into a completed RGB image. In terms of a single-sensor image acquisition of Bayer color filter array, single color channel value is just recorded by the position of each pixel. The other two color channels information needs to be reconstructed by the Bayer color filter array demosaicking technology. The reconstruction effect of qualified RGB information determines the accuracy of computer vision analysis like image segmentation and face recognition. Deep learning based Bayer array image demosaicing technology has promoted more high-performance algorithms nowadays. To recognize the principle and development of image demosaicing algorithms, we review some classic algorithms and analyze the key concepts. First, an overview is illustrated for the Bayer sampling array and image demosaicing technology. Next, we divide the existing methods into two categories in accordance with traditional methods and deep learning methods. The pros and cons of different methods are analyzed and the information transmission issue of the learning-based demosaicing network is focused on. We introduce traditional demosaicing methods in brief based on the basic principle, growth path and applications of the residual interpolation algorithms. Specifically, we divide the learning-based methods into single demosaic algorithms and joint multi-task demosaic algorithms derived of the independence of the demosaicing task. Single demosaicing algorithms can be divided into three categories of those are two-stage demosaicing network, three-stage demosaicing network, and end-to-end demosaicing network. Joint multi-task demosaic algorithms are mostly based on end-to-end multiple networks structure like full convolution, residual, densely connected, U-Net, feature pyramid, and generative adversarial network (GAN). At the same time, we compare seven representative methods to the two benched datasets of Kodak and McMaster, including three traditional methods and four deep learning methods. In addition, we introduce common public datasets and performance evaluation metrics peak signal-to-noise ratio (PSNR) and structural similarity in the field of demosaicing. Finally, we analyze the technical problems faced by the current image demosaicing technology and the future development direction from the perspectives of its network depth, computing efficiency, and feasibility. Our experimental results show that the deep learning based method surpasses the traditional methods in terms of objective quality evaluation indicators and subjective vision. We clarified that the highest PSNR value of the learning-based methods on the Kodak dataset surpassed the traditional methods by 12.73 dB, and the highest PSNR value of the learning-based methods on the McMaster dataset surpassed the traditional methods by 5.10 dB. The traditional method obtains the estimated value of the color image via the degradation model of the Bayer array image and some prior information. However, some distortion issues appear in the clear edges and multi-textured areas of the reconstructed image, such as color artifacts and checkerboard effects. Current deep learning methods have become the main development prospects in the field of demosaicing. Although the reconstructed image of learning-based methods is more similar to the original image than the traditional method on the visual effect and accuracy, it also has the problem of high computational cost and poor practical applicability. It is challenged to guarantee the accuracy of network algorithms and reduce the computational cost of the network both. Therefore, a high-performance and effective image demosaicing method has to be developed further in terms of datasets option, network structure optimization, and improvement of computing efficiency.关键词:demosaicking;Bayer array image;image processing;deep learning;convolutional neural network (CNN);review396|504|2更新时间:2024-08-15
摘要:The Bayer array image demosaicing technology is one of the essential parts in the digital image signal processing process mechanism, which reconstructs the sparsely sampled Bayer array image into a completed RGB image. In terms of a single-sensor image acquisition of Bayer color filter array, single color channel value is just recorded by the position of each pixel. The other two color channels information needs to be reconstructed by the Bayer color filter array demosaicking technology. The reconstruction effect of qualified RGB information determines the accuracy of computer vision analysis like image segmentation and face recognition. Deep learning based Bayer array image demosaicing technology has promoted more high-performance algorithms nowadays. To recognize the principle and development of image demosaicing algorithms, we review some classic algorithms and analyze the key concepts. First, an overview is illustrated for the Bayer sampling array and image demosaicing technology. Next, we divide the existing methods into two categories in accordance with traditional methods and deep learning methods. The pros and cons of different methods are analyzed and the information transmission issue of the learning-based demosaicing network is focused on. We introduce traditional demosaicing methods in brief based on the basic principle, growth path and applications of the residual interpolation algorithms. Specifically, we divide the learning-based methods into single demosaic algorithms and joint multi-task demosaic algorithms derived of the independence of the demosaicing task. Single demosaicing algorithms can be divided into three categories of those are two-stage demosaicing network, three-stage demosaicing network, and end-to-end demosaicing network. Joint multi-task demosaic algorithms are mostly based on end-to-end multiple networks structure like full convolution, residual, densely connected, U-Net, feature pyramid, and generative adversarial network (GAN). At the same time, we compare seven representative methods to the two benched datasets of Kodak and McMaster, including three traditional methods and four deep learning methods. In addition, we introduce common public datasets and performance evaluation metrics peak signal-to-noise ratio (PSNR) and structural similarity in the field of demosaicing. Finally, we analyze the technical problems faced by the current image demosaicing technology and the future development direction from the perspectives of its network depth, computing efficiency, and feasibility. Our experimental results show that the deep learning based method surpasses the traditional methods in terms of objective quality evaluation indicators and subjective vision. We clarified that the highest PSNR value of the learning-based methods on the Kodak dataset surpassed the traditional methods by 12.73 dB, and the highest PSNR value of the learning-based methods on the McMaster dataset surpassed the traditional methods by 5.10 dB. The traditional method obtains the estimated value of the color image via the degradation model of the Bayer array image and some prior information. However, some distortion issues appear in the clear edges and multi-textured areas of the reconstructed image, such as color artifacts and checkerboard effects. Current deep learning methods have become the main development prospects in the field of demosaicing. Although the reconstructed image of learning-based methods is more similar to the original image than the traditional method on the visual effect and accuracy, it also has the problem of high computational cost and poor practical applicability. It is challenged to guarantee the accuracy of network algorithms and reduce the computational cost of the network both. Therefore, a high-performance and effective image demosaicing method has to be developed further in terms of datasets option, network structure optimization, and improvement of computing efficiency.关键词:demosaicking;Bayer array image;image processing;deep learning;convolutional neural network (CNN);review396|504|2更新时间:2024-08-15
Review
-
 摘要:ObjectiveHuman facial images interpretation is based on personal identity information like communication, access control and payment. However, advanced deep forgery technology causes faked facial information intensively. It is challenged to distinguish faked information from real ones. Most of the existing deep learning methods have weak generalization ability to unseen forgeries. Our method is focused on detecting the consistency of source features. The source features of deepfakes are inconsistent while source features are consistent in real images.MethodFirst, a destructive module of facial structure is designed to reshuffle image patches. It allows our model to local details and abnormal regions. It restricts overfitting to face structure semantics, which are irrelevant to our deepfake detection task. Next, we extract the shallow, medium and deep features from the backbone network. We develop a multi-level feature fusion module to guide the fusion of features at different levels. Specifically, shallower leveled features can provide more detailed forged clues to the deeper level, while deeper features can suppress some irrelevant details in the features at the shallower level and extend the regional details of the abnormal region. The network can pay attention to the real or fake semantics better at all levels. In the backbone network, the shallow, medium and deep features are obtained via a channel attention module, and then merge them into a guided dual feature fusion module. It is accomplished based on the guided dual fusion of shallow features to deep features and the guided fusion of deep features to shallow features. The feature maps output are added together by the two fusion modules. In this way, we can mine forgery-related information better in each layer. Third, we extract a global feature vector from the fused features. To obtain a consistency map, we calculate the similarity between the global feature vector and each local feature vector (i.e., the feature vector at each local position). The inconsistent areas are highlighted in this map. We multiply the output of the multi-level feature fusion module by the consistency map. The obtained result is combined with the output of the backbone network to the classifier for the final binary classification. We use forged area labels to learn better and label the forged area of each face image in sequential: 1) to align the forged face image for its corresponding real face image and calculate the difference between their corresponding pixel values; 2) to generate a difference image of those spatial size are kept equivalent between real and fake face images; 3) to convert the difference image to a grayscale image through converting each pixel value to [0, 1] linearly, the difference image is binarized with a threshold of 0.1, resulting in the final forged area label. Our main contributions are shown as below: 1) to capture the inconsistent source features in forged images, a global consistency module is developed; 2) to make the network pay more attention to forged information and suppress irrelevant background details at the same time, a multi-level feature guided fusion module is facilitated; 3) to prevent our model from overfitting to face structure semantics, a destructive module of facial structure is designed to distinguish fake faces from real ones. Our method achieves good performance for the intra-dataset test and the cross-dataset test both. The test results show that we achieve highly competitive detection accuracy and generalization performance. During the experiment, we take 30 frames with equal spacing for each video in the training set, 100 frames for each video in the test set. For each image, we choose the largest detected sample and convert its size to 320×320 pixels. For experimental settings, we use Adam optimization with a learning rate of 0.000 2. The batch size is 16.ResultOur method is compared to 8 latest methods on two datasets (including five forgery methods). In the FaceForensics++ (FF++) dataset, we obtain the best performance. On the FF++ (low-quality) dataset, the area under the curve(AUC) value is increased by 1.6% in comparison with the second best result. For the generalization experiment of four forgery methods in FF++, we achieve better result beyond the baseline. For the cross-dataset generalization experiment (trained on FF++ dataset and tested on Celeb-DF dataset), we achieve the best AUC on both datasets. In addition, the ablation experiments are carried out on FF++ dataset to verify the effectiveness of each module as well.ConclusionThis method can detect deepfakes accurately and has good generalization performance. It has potential to deal with the threat of deep forgery.关键词:face forgery detection;deep fakes;multi-level feature learning;global consistency;attention mechanism125|253|5更新时间:2024-08-15
摘要:ObjectiveHuman facial images interpretation is based on personal identity information like communication, access control and payment. However, advanced deep forgery technology causes faked facial information intensively. It is challenged to distinguish faked information from real ones. Most of the existing deep learning methods have weak generalization ability to unseen forgeries. Our method is focused on detecting the consistency of source features. The source features of deepfakes are inconsistent while source features are consistent in real images.MethodFirst, a destructive module of facial structure is designed to reshuffle image patches. It allows our model to local details and abnormal regions. It restricts overfitting to face structure semantics, which are irrelevant to our deepfake detection task. Next, we extract the shallow, medium and deep features from the backbone network. We develop a multi-level feature fusion module to guide the fusion of features at different levels. Specifically, shallower leveled features can provide more detailed forged clues to the deeper level, while deeper features can suppress some irrelevant details in the features at the shallower level and extend the regional details of the abnormal region. The network can pay attention to the real or fake semantics better at all levels. In the backbone network, the shallow, medium and deep features are obtained via a channel attention module, and then merge them into a guided dual feature fusion module. It is accomplished based on the guided dual fusion of shallow features to deep features and the guided fusion of deep features to shallow features. The feature maps output are added together by the two fusion modules. In this way, we can mine forgery-related information better in each layer. Third, we extract a global feature vector from the fused features. To obtain a consistency map, we calculate the similarity between the global feature vector and each local feature vector (i.e., the feature vector at each local position). The inconsistent areas are highlighted in this map. We multiply the output of the multi-level feature fusion module by the consistency map. The obtained result is combined with the output of the backbone network to the classifier for the final binary classification. We use forged area labels to learn better and label the forged area of each face image in sequential: 1) to align the forged face image for its corresponding real face image and calculate the difference between their corresponding pixel values; 2) to generate a difference image of those spatial size are kept equivalent between real and fake face images; 3) to convert the difference image to a grayscale image through converting each pixel value to [0, 1] linearly, the difference image is binarized with a threshold of 0.1, resulting in the final forged area label. Our main contributions are shown as below: 1) to capture the inconsistent source features in forged images, a global consistency module is developed; 2) to make the network pay more attention to forged information and suppress irrelevant background details at the same time, a multi-level feature guided fusion module is facilitated; 3) to prevent our model from overfitting to face structure semantics, a destructive module of facial structure is designed to distinguish fake faces from real ones. Our method achieves good performance for the intra-dataset test and the cross-dataset test both. The test results show that we achieve highly competitive detection accuracy and generalization performance. During the experiment, we take 30 frames with equal spacing for each video in the training set, 100 frames for each video in the test set. For each image, we choose the largest detected sample and convert its size to 320×320 pixels. For experimental settings, we use Adam optimization with a learning rate of 0.000 2. The batch size is 16.ResultOur method is compared to 8 latest methods on two datasets (including five forgery methods). In the FaceForensics++ (FF++) dataset, we obtain the best performance. On the FF++ (low-quality) dataset, the area under the curve(AUC) value is increased by 1.6% in comparison with the second best result. For the generalization experiment of four forgery methods in FF++, we achieve better result beyond the baseline. For the cross-dataset generalization experiment (trained on FF++ dataset and tested on Celeb-DF dataset), we achieve the best AUC on both datasets. In addition, the ablation experiments are carried out on FF++ dataset to verify the effectiveness of each module as well.ConclusionThis method can detect deepfakes accurately and has good generalization performance. It has potential to deal with the threat of deep forgery.关键词:face forgery detection;deep fakes;multi-level feature learning;global consistency;attention mechanism125|253|5更新时间:2024-08-15 -
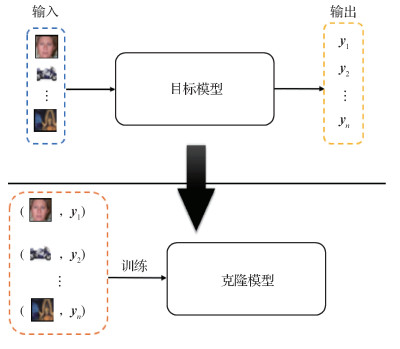 摘要:ObjectiveCurrent model stealing attack issue is a sub-field in artificial intelligence (AI) security. It tends to steal privacy information of the target model including its structures, parameters and functionality. Our research is focused on the model functionality stealing attacks. We target a deep learning based multi-classifier model and train a clone model to replicate the functionality of the black-box target classifier. Currently, most of stealing-functionality-attacks are oriented on querying data. These methods replicate the black-box target classifier by analyzing the querying data and the response from the target model. The kind of attacks based on generative models is popular and these methods have obtained promising results in functionality stealing. However, there are two main challenges to be faced as mentioned below: first, target image classifiers are trained on real images in common. Since these methods do not use ground truth data to supervise the training phase of generative models, the generated images are distorted to noise images rather than real images. In other words, the image data used by these methods is with few sematic information, leading to that the prediction of target model is with few effective guidance for the training of the clone model. Such images restrict the effect of training the clone model. Second, to train the generative model, it is necessary to initiate multiple queries to the target classifier. A severe burden is bear on query budgets. Since the target model is a black-box model, we need to use its approximated gradient to obtain generator via zero-gradient estimation. Hence, the generator cannot obtain accurate gradient information for updating itself.MethodWe try to utilize the generative adversarial nets (GAN) and the contrastive learning to steal target classifier functionality. The key aspect of our research is on the basis of the GAN-based prior information extraction of ground truth images on public datasets, aiming to make the prediction from the target classifier model be with effective guidance for the training of the clone model. To make the generated images more realistic, the public datasets are introduced to supervise the training of the generator. To enhance the effectiveness of generative models, we adopt deep convolutional GAN(DCGAN) as the backbone, where the generator and discriminator are composed of convolutional layers both with non-linear activation functions. To update the generator, we illustrate the target model derived gradient information via zero-order gradient evaluation for the training of clone model. Simultaneously, we leverage the public dataset to guide the training of the GAN, aiming to make the generator obtain the information of ground truth images. In other words, the public dataset plays a role as a regularization term. Its application constrains the solution space for the generator. In this way, the generator can produce approximated ground truth images to make the prediction of the target model produce more physical information for manipulating the clone model training. To reduce the query budgets, we pre-train the GAN on public datasets to make it obtain prior information of real images before training the clone model. Our method can make the generator learn better for the training need of clone model in comparison with previous approaches of the random-initialized generator training. To expand the objective function of training clone model, we introduce contrastive learning to the model stealing attacks area. Traditional model functionality stealing attack methods train the clone model only by maximizing the similarity of predictions from two models to one image. Here, we use the contrastive learning manner to consider the diversity of predictions from two models to different images. The positive pair consists of the predictions from two models to one image and the negative pair is made up with the predictions from two models to two different images. To measure the diversity of two predictions, we attempt to use cosine similarity to represent the similarity of two predictions. Then, we use the InfoNCE loss function to achieve the similarity maximization of positive pairs and diversity maximization of negative pairs at the same time.ResultTo demonstrate the performances of our methods, we carry out model functionality stealing attacks on two different black-box target classifiers. The two classifiers of Canadian Insititute for Advanced Research-10(CIFAR-10) and street view house numbers(SVHN) are presented. Each of model structure is based on ResNet-34 and the structures of clone models are based on resnet-18 both. The used public datasets are not be overlapped with the training datasets of target classifiers. We test them on CIFAR-10 and SVHN test datasets following our trained clone models. The accuracy results of these clone models are 92.3% and 91.8%of each. Normalized clone accuracy is achieved 0.97 × and 0.98 × of each. Specially, our result can achieve 5% improvements for the CIFAR-10 target model in terms of normalized clone accuracy over the data-free model extraction(DFME). Our method achieves promising results for reducing querying budgets as well. To make the accuracy of clone model reach 85% on the CIFAR-10 test datasets, DFME is required to spend 8.6 M budgets. But, our method spends 5.8 M budgets only, which is 2.8 M smaller than DFME. Our method is required to spend 9.4 M budgets for reaching the 90% accuracy, which is not half enough to the DFME of 20 M budgets. These results demonstrate that our method improve the performances of functionality stealing attack methods based on generative models. It is beneficial for reducing the query budgets as well.ConclusionWe propose a novel model functionality stealing attack method, which trains the clone model guided by prior information of ground truth images and the contrastive learning manner. The experimental results show that our optimized model has its potentials and the querying budgets can be reduced effectively.关键词:model functionality stealing;generative model;contrastive learning;adversarial attack;artificial intelligencesecurity174|180|0更新时间:2024-08-15
摘要:ObjectiveCurrent model stealing attack issue is a sub-field in artificial intelligence (AI) security. It tends to steal privacy information of the target model including its structures, parameters and functionality. Our research is focused on the model functionality stealing attacks. We target a deep learning based multi-classifier model and train a clone model to replicate the functionality of the black-box target classifier. Currently, most of stealing-functionality-attacks are oriented on querying data. These methods replicate the black-box target classifier by analyzing the querying data and the response from the target model. The kind of attacks based on generative models is popular and these methods have obtained promising results in functionality stealing. However, there are two main challenges to be faced as mentioned below: first, target image classifiers are trained on real images in common. Since these methods do not use ground truth data to supervise the training phase of generative models, the generated images are distorted to noise images rather than real images. In other words, the image data used by these methods is with few sematic information, leading to that the prediction of target model is with few effective guidance for the training of the clone model. Such images restrict the effect of training the clone model. Second, to train the generative model, it is necessary to initiate multiple queries to the target classifier. A severe burden is bear on query budgets. Since the target model is a black-box model, we need to use its approximated gradient to obtain generator via zero-gradient estimation. Hence, the generator cannot obtain accurate gradient information for updating itself.MethodWe try to utilize the generative adversarial nets (GAN) and the contrastive learning to steal target classifier functionality. The key aspect of our research is on the basis of the GAN-based prior information extraction of ground truth images on public datasets, aiming to make the prediction from the target classifier model be with effective guidance for the training of the clone model. To make the generated images more realistic, the public datasets are introduced to supervise the training of the generator. To enhance the effectiveness of generative models, we adopt deep convolutional GAN(DCGAN) as the backbone, where the generator and discriminator are composed of convolutional layers both with non-linear activation functions. To update the generator, we illustrate the target model derived gradient information via zero-order gradient evaluation for the training of clone model. Simultaneously, we leverage the public dataset to guide the training of the GAN, aiming to make the generator obtain the information of ground truth images. In other words, the public dataset plays a role as a regularization term. Its application constrains the solution space for the generator. In this way, the generator can produce approximated ground truth images to make the prediction of the target model produce more physical information for manipulating the clone model training. To reduce the query budgets, we pre-train the GAN on public datasets to make it obtain prior information of real images before training the clone model. Our method can make the generator learn better for the training need of clone model in comparison with previous approaches of the random-initialized generator training. To expand the objective function of training clone model, we introduce contrastive learning to the model stealing attacks area. Traditional model functionality stealing attack methods train the clone model only by maximizing the similarity of predictions from two models to one image. Here, we use the contrastive learning manner to consider the diversity of predictions from two models to different images. The positive pair consists of the predictions from two models to one image and the negative pair is made up with the predictions from two models to two different images. To measure the diversity of two predictions, we attempt to use cosine similarity to represent the similarity of two predictions. Then, we use the InfoNCE loss function to achieve the similarity maximization of positive pairs and diversity maximization of negative pairs at the same time.ResultTo demonstrate the performances of our methods, we carry out model functionality stealing attacks on two different black-box target classifiers. The two classifiers of Canadian Insititute for Advanced Research-10(CIFAR-10) and street view house numbers(SVHN) are presented. Each of model structure is based on ResNet-34 and the structures of clone models are based on resnet-18 both. The used public datasets are not be overlapped with the training datasets of target classifiers. We test them on CIFAR-10 and SVHN test datasets following our trained clone models. The accuracy results of these clone models are 92.3% and 91.8%of each. Normalized clone accuracy is achieved 0.97 × and 0.98 × of each. Specially, our result can achieve 5% improvements for the CIFAR-10 target model in terms of normalized clone accuracy over the data-free model extraction(DFME). Our method achieves promising results for reducing querying budgets as well. To make the accuracy of clone model reach 85% on the CIFAR-10 test datasets, DFME is required to spend 8.6 M budgets. But, our method spends 5.8 M budgets only, which is 2.8 M smaller than DFME. Our method is required to spend 9.4 M budgets for reaching the 90% accuracy, which is not half enough to the DFME of 20 M budgets. These results demonstrate that our method improve the performances of functionality stealing attack methods based on generative models. It is beneficial for reducing the query budgets as well.ConclusionWe propose a novel model functionality stealing attack method, which trains the clone model guided by prior information of ground truth images and the contrastive learning manner. The experimental results show that our optimized model has its potentials and the querying budgets can be reduced effectively.关键词:model functionality stealing;generative model;contrastive learning;adversarial attack;artificial intelligencesecurity174|180|0更新时间:2024-08-15
Multimedia Intelligent Security
-
 摘要:ObjectiveCurrent visual tracking has been developed dramatically based on deep neural networks. The task of single object visual tracking aims at tracking random objects in a sequential video streaming through yielding the bounding box of the object bounding box in the initial frame. It can be an essential task for multiple computer vision applications like surveillance systems, robotics and human-computer interaction. The simplified, small scale, easy-used and feed-forward trackers are preferred due to resources-constrained application scenarios. Most of methods are focused on top performance. Instead, we break this paradox from another perspective through the key temporal cues modeling inside our model and the ignorance of model update process and large-scaled models. The intrinsic qualities are required to be developed in the research community (i.e., video streaming). A video analysis task is beneficial to formulate the basis of the tracking task itself. First, the object has a spatial displacement constraint, which means the object locations in adjacent frames will not be widely ranged unless dramatic camera motions happened. Almost visual trackers are followed this path and a new framed search objects is overlapped starting from the location in the last frame. Next, the potential temporal appearance consistency problem, which indicates the target information from preceding frames changes smoothly. This could be regarded as the temporal context, which can provide clear cues for the following predictions. However, the second feature has not been fully explored in the literature. Existing methods is leveraged temporal appearance consistency in two ways as mentioned below: 1) use the target information only in the first frame by modeling visual tracking as a matching problem between the given initial patch and the follow-up frames. Siamese-network-based methods are the most popular and effective methods in this category. They applied a one-shot learning scheme for visual tracking, where the object patch in the first frame is treated as an exemplar, and the patches in the search regions within the consecutive frames are regarded as the candidate instances. The task is transferred to find the most similar instance from each frame. This paradigm ignores other historical frames completely, deals with each frame independently and causes tremendous information loss. 2) Use the given initial patch and the historical target patches both targets at every frame or selected frames to predict the object location in a new frame, including traditional and deep-neural-network-based ones. Traditional trackers based methods like the correlation filter (CF) can learn their models or classifiers from the first frame and update models in the subsequent frames with a small learning rate. Our diverse deep-neural-network-based methods first learn their models offline with vast training data and fine-tune the models online at the initial frame and other frames. However, the solution remains open to balancing the accuracy and latency, especially in deep-neural-network-based methods. Also, network finetuning is forbidden in some practical applications when it is deployed in inference chips, which hinders the wide deployment of these methods.MethodWe facilitate a novel and straightforward tracker to re-formulate the visual tracking problem from the perspective of video analysis. A new temporal-aware network (TAN) is designed to encode target information from multiple frames, which aims at taking advantage of the temporal appearance consistency and the spatial displacement constraint in the forward path without an online model update. To exchange and fuse information from historical frames input, we introduce temporal aggregation modules in TAN and empower our tracker TAN with the ability to learn spatio-temporal features. To balance the computational burden resulting from the multi-frame inputs and tracking accuracy, we employ a shallow network ResNet-18 as our feature extraction backbone and achieve a high speed of over 70 frame/s. Our tracker runs completely feed-forward and can adapt to the target's appearance changes with our offline-trained, temporal-encoded TAN because previous temporal appearance consistency is maintained by the first frame or historical frames, which require expensive online finetuning to be adaptable. To construct a completed simple tracking pipeline further, we design a novel anchor-free and proposal-free target estimation method, which can detect the four corners, including top-left, top-right, bottom-left, and bottom-right, with a corner detection head in TAN. As target locations can be determined by a pair of top-left and bottom-right corners or top-right and bottom-left, we make use of a center score map to indicate the confidence of these two bounding boxes rather than complicated embedding constraints, which can easily locate the target. Thanks to a corner-based target estimation mechanism, our tracker is capable of handling challenging scenarios for significant changes involved.ResultWithout bells and whistles, our method has its potentials on several public datasets, such as online object tracking: a benchmark 50(OTB50), OTB100, TrackingNet, a high-quality benchmark for large-scale single object tracking(LaSOT), and a benchmark and simulator for UAV tracking(UAV)123. Our real-time speed optimization and simplified pipeline make TAN more suitable for real applications, especially resource-limited platforms where the large models and online model updates are not supported.ConclusionThe proposed tracker will provide a new perspective for single-object tracking by mining the video nature, especially the temporal appearance consistency of this task.关键词:computer vision;object tracking;spatial-temporal feature coding;arbitrary target tracking;corner tracking;temporal appearance consistency;high-speed tracking84|231|2更新时间:2024-08-15
摘要:ObjectiveCurrent visual tracking has been developed dramatically based on deep neural networks. The task of single object visual tracking aims at tracking random objects in a sequential video streaming through yielding the bounding box of the object bounding box in the initial frame. It can be an essential task for multiple computer vision applications like surveillance systems, robotics and human-computer interaction. The simplified, small scale, easy-used and feed-forward trackers are preferred due to resources-constrained application scenarios. Most of methods are focused on top performance. Instead, we break this paradox from another perspective through the key temporal cues modeling inside our model and the ignorance of model update process and large-scaled models. The intrinsic qualities are required to be developed in the research community (i.e., video streaming). A video analysis task is beneficial to formulate the basis of the tracking task itself. First, the object has a spatial displacement constraint, which means the object locations in adjacent frames will not be widely ranged unless dramatic camera motions happened. Almost visual trackers are followed this path and a new framed search objects is overlapped starting from the location in the last frame. Next, the potential temporal appearance consistency problem, which indicates the target information from preceding frames changes smoothly. This could be regarded as the temporal context, which can provide clear cues for the following predictions. However, the second feature has not been fully explored in the literature. Existing methods is leveraged temporal appearance consistency in two ways as mentioned below: 1) use the target information only in the first frame by modeling visual tracking as a matching problem between the given initial patch and the follow-up frames. Siamese-network-based methods are the most popular and effective methods in this category. They applied a one-shot learning scheme for visual tracking, where the object patch in the first frame is treated as an exemplar, and the patches in the search regions within the consecutive frames are regarded as the candidate instances. The task is transferred to find the most similar instance from each frame. This paradigm ignores other historical frames completely, deals with each frame independently and causes tremendous information loss. 2) Use the given initial patch and the historical target patches both targets at every frame or selected frames to predict the object location in a new frame, including traditional and deep-neural-network-based ones. Traditional trackers based methods like the correlation filter (CF) can learn their models or classifiers from the first frame and update models in the subsequent frames with a small learning rate. Our diverse deep-neural-network-based methods first learn their models offline with vast training data and fine-tune the models online at the initial frame and other frames. However, the solution remains open to balancing the accuracy and latency, especially in deep-neural-network-based methods. Also, network finetuning is forbidden in some practical applications when it is deployed in inference chips, which hinders the wide deployment of these methods.MethodWe facilitate a novel and straightforward tracker to re-formulate the visual tracking problem from the perspective of video analysis. A new temporal-aware network (TAN) is designed to encode target information from multiple frames, which aims at taking advantage of the temporal appearance consistency and the spatial displacement constraint in the forward path without an online model update. To exchange and fuse information from historical frames input, we introduce temporal aggregation modules in TAN and empower our tracker TAN with the ability to learn spatio-temporal features. To balance the computational burden resulting from the multi-frame inputs and tracking accuracy, we employ a shallow network ResNet-18 as our feature extraction backbone and achieve a high speed of over 70 frame/s. Our tracker runs completely feed-forward and can adapt to the target's appearance changes with our offline-trained, temporal-encoded TAN because previous temporal appearance consistency is maintained by the first frame or historical frames, which require expensive online finetuning to be adaptable. To construct a completed simple tracking pipeline further, we design a novel anchor-free and proposal-free target estimation method, which can detect the four corners, including top-left, top-right, bottom-left, and bottom-right, with a corner detection head in TAN. As target locations can be determined by a pair of top-left and bottom-right corners or top-right and bottom-left, we make use of a center score map to indicate the confidence of these two bounding boxes rather than complicated embedding constraints, which can easily locate the target. Thanks to a corner-based target estimation mechanism, our tracker is capable of handling challenging scenarios for significant changes involved.ResultWithout bells and whistles, our method has its potentials on several public datasets, such as online object tracking: a benchmark 50(OTB50), OTB100, TrackingNet, a high-quality benchmark for large-scale single object tracking(LaSOT), and a benchmark and simulator for UAV tracking(UAV)123. Our real-time speed optimization and simplified pipeline make TAN more suitable for real applications, especially resource-limited platforms where the large models and online model updates are not supported.ConclusionThe proposed tracker will provide a new perspective for single-object tracking by mining the video nature, especially the temporal appearance consistency of this task.关键词:computer vision;object tracking;spatial-temporal feature coding;arbitrary target tracking;corner tracking;temporal appearance consistency;high-speed tracking84|231|2更新时间:2024-08-15 -
 摘要:ObjectiveVideo-based multiple object tracking is one of the essential tasks in computer vision like automatic driving and intelligent video surveillance system. Most of the multiple object tracking methods tend to obtain object detection results first. The integrated strategies are used to link detection bounding boxes and form object trajectories. Current object detection contexts have been developing recently. But, the challenging inconsistency issues are required to be resolved in multiple object tracking, which affected the multi-objects tracking accuracy. The multi-objects tracking inconsistency can be classified into three types as mentioned below: 1) the inconsistency between the centers of the object bounding boxes and those object identity features. Many multiple object tracking methods are extracted the object re-identification(ReID) features at the object bounding boxes centers and these features are used to in associate with objects. However, those oriented ReID features are incapable to reflect the appearance of objects accurately due to the occlusion. The offsets are appeared between the best ReID feature extraction positions and bounding box centers. Current feature extraction strategy will lead to the spatial consistency problem. 2) The inconsistency of the object center response between consecutive frames. Some objects can be detected and tracked in the contexted frames due to the occlusion in videos. It causes consecutive frames loss and the inconsistency between the object-center-responsed heatmaps of two consecutive frames. 3) The inconsistency of the similarity assessment in the training process and testing process. Most of association step is considered as a classification problem and the cross entropy loss is used to train the model while the inter-object relations are ignored in the testing process. The feature cosine similarities of each pair of objects are used to associate them. To improve the accuracy of tracking, we facilitate a multiple object tracking method based on consistency optimization.MethodThese inconsistencies issues are validated based on spatial, temporal and featured scales. In view of the inconsistency between the centers of the object detection bounding boxes and the identity features, we predict the offsets from the centers of the detection bounding boxes to the feature centers for each object. To predict the best ReID feature extraction positions, we use the object centers and the offsets as well. We extract the ReID features of objects at those predicted positions and use these features to reflect objects. In view of the inconsistency of the response between frames, the spatial correlation module is used to calculate the offset information between adjacent frames. Based on the offset information, the object center response of the previous frame is transformed by deformable convolution to obtain the inter-frame consistency response information, which is enhanced to the current frame. To resolve the inconsistency of similarity measures in training and test process, we develop a feature orthogonal loss function, which considers the similarity relationship between the two objects during training. To detect and track objects, we integrate these three improved consistency results with FairMOT method.ResultThe performance of our method is compared to existing methods on three datasets. The comparative results are illustrated as following: 1) our multiple object tracking accuracy(MOTA) value is 71.2% on the MOT17 dataset, which is increased by 1.6% in comparison with the FairMOT method without consistency improvement; 2) the MOTA value is 60.2% on the MOT20 dataset, which is increased by 3.2%; 3) the MOTA value is 36.1% on the Hieve dataset, which is increased by 1.1%. At the same time, we conduct ablation studies on MOT17 dataset to verify the effectiveness of different components in our method, which shows that the proposed method improves the consistency in multiple objects tracking significantly. In ablation studies, we find that the identity switch numbers are decreased via the added ReID feature extraction position offsets and the feature orthogonal loss function. The model-based extraction position offsets can get the object appearance features at the right positions and the feature orthogonal loss function can learn the object appearance features in the right way. We also visualize the predicted ReID feature extraction positions and object bounding boxes centers, and the visualization results show that our predicted positions are closer to the object appearance features rather than the physical centers, which is feasible to the extraction position offsets.ConclusionOur multiple objects tracking method can achieve the spatio-temporal consistency of object features better in training and testing, which makes the model track objects more accurately.关键词:multiple object tracking (MOT);consistency;feature extraction position offset;feature orthogonal loss;inter-frame enhancement206|253|1更新时间:2024-08-15
摘要:ObjectiveVideo-based multiple object tracking is one of the essential tasks in computer vision like automatic driving and intelligent video surveillance system. Most of the multiple object tracking methods tend to obtain object detection results first. The integrated strategies are used to link detection bounding boxes and form object trajectories. Current object detection contexts have been developing recently. But, the challenging inconsistency issues are required to be resolved in multiple object tracking, which affected the multi-objects tracking accuracy. The multi-objects tracking inconsistency can be classified into three types as mentioned below: 1) the inconsistency between the centers of the object bounding boxes and those object identity features. Many multiple object tracking methods are extracted the object re-identification(ReID) features at the object bounding boxes centers and these features are used to in associate with objects. However, those oriented ReID features are incapable to reflect the appearance of objects accurately due to the occlusion. The offsets are appeared between the best ReID feature extraction positions and bounding box centers. Current feature extraction strategy will lead to the spatial consistency problem. 2) The inconsistency of the object center response between consecutive frames. Some objects can be detected and tracked in the contexted frames due to the occlusion in videos. It causes consecutive frames loss and the inconsistency between the object-center-responsed heatmaps of two consecutive frames. 3) The inconsistency of the similarity assessment in the training process and testing process. Most of association step is considered as a classification problem and the cross entropy loss is used to train the model while the inter-object relations are ignored in the testing process. The feature cosine similarities of each pair of objects are used to associate them. To improve the accuracy of tracking, we facilitate a multiple object tracking method based on consistency optimization.MethodThese inconsistencies issues are validated based on spatial, temporal and featured scales. In view of the inconsistency between the centers of the object detection bounding boxes and the identity features, we predict the offsets from the centers of the detection bounding boxes to the feature centers for each object. To predict the best ReID feature extraction positions, we use the object centers and the offsets as well. We extract the ReID features of objects at those predicted positions and use these features to reflect objects. In view of the inconsistency of the response between frames, the spatial correlation module is used to calculate the offset information between adjacent frames. Based on the offset information, the object center response of the previous frame is transformed by deformable convolution to obtain the inter-frame consistency response information, which is enhanced to the current frame. To resolve the inconsistency of similarity measures in training and test process, we develop a feature orthogonal loss function, which considers the similarity relationship between the two objects during training. To detect and track objects, we integrate these three improved consistency results with FairMOT method.ResultThe performance of our method is compared to existing methods on three datasets. The comparative results are illustrated as following: 1) our multiple object tracking accuracy(MOTA) value is 71.2% on the MOT17 dataset, which is increased by 1.6% in comparison with the FairMOT method without consistency improvement; 2) the MOTA value is 60.2% on the MOT20 dataset, which is increased by 3.2%; 3) the MOTA value is 36.1% on the Hieve dataset, which is increased by 1.1%. At the same time, we conduct ablation studies on MOT17 dataset to verify the effectiveness of different components in our method, which shows that the proposed method improves the consistency in multiple objects tracking significantly. In ablation studies, we find that the identity switch numbers are decreased via the added ReID feature extraction position offsets and the feature orthogonal loss function. The model-based extraction position offsets can get the object appearance features at the right positions and the feature orthogonal loss function can learn the object appearance features in the right way. We also visualize the predicted ReID feature extraction positions and object bounding boxes centers, and the visualization results show that our predicted positions are closer to the object appearance features rather than the physical centers, which is feasible to the extraction position offsets.ConclusionOur multiple objects tracking method can achieve the spatio-temporal consistency of object features better in training and testing, which makes the model track objects more accurately.关键词:multiple object tracking (MOT);consistency;feature extraction position offset;feature orthogonal loss;inter-frame enhancement206|253|1更新时间:2024-08-15
Object Intelligent Detection
-
 摘要:ObjectiveDeep neural networks technology promotes the research and development of computer vision and natural language processing intensively. Multiple applications like human face recognition, optical character recognition (OCR), and machine translation have been widely used. Recent development enable the machine learning to deal with more complex multimodal learning tasks that involve vision and language modalities, e.g., visual captioning, image-text retrieval, referring expression comprehension, and visual question answering (VQA). Given an arbitrary image and a natural language question, the VQA task is focused on an image-content-oriented and question-guided understanding of the fine-grained semantics and the following complex reasoning answer. The VQA task tends to be as the generalization of the rest of multimodal learning tasks. Thus, an effective VQA algorithms is a key step toward artificial general intelligence (AGI). Recent VQA have realized human-level performance on the commonly used benchmarks of VQA. However, most existing VQA methods are focused on visual objects of images only, while neglecting the recognition of textual content in the image. In many real-world scenarios, the image text can transmit essential information for scene understanding and reasoning, such as the number of a traffic sign or the brand awareness of a product. The ignorance of textual information is constraint of the applicability of the VQA methods in practice, especially for visually-impaired users. Due to the importance of the developing textual information for image interpretation, most researches intend to incorporate textual content into VQA for a scene text VQA task organizing. Specifically, the questions involve the textual contents in the scene text VQA task. The learned VQA model is required to establish unified associations among the question, visual object and the scene text. The reasoning is followed to generate a correct answer. To address the scene text VQA task, a model of multimodal multi-copy mesh(M4C) is faciliated based on the transformer architecture. Multimodal heterogeneous features are as input, a multimodal transformer is used to capture the interactions between input features, and the answers are predicted in an iterative manner. Despite of the strengths of M4C, it still has the two weaknesses as following: 1) the relative spatial relationship cannot be illustrated well between paired objects although each visual object and OCR object encode its absolute spatial location. It is challenged to achieve accurate spatial reasoning for M4C model; 2) the predicted words of answering are selected from either a dynamic OCR vocabulary or a fixed answer vocabulary. The semantic relationships are not explicitly considered in M4C between the multi-sources words. At the iterative answer prediction stage, it is challenged to understand the potential semantic associations between multiple sources derived words.MethodTo resolve the weaknesses of M4C mentioned above, we improve the reference of M4C model by introducing two added knowledge like the spatial relationship and semantic relationship, and a knowledge-representation-enhanced M4C (KR-M4C) approach is demonstrated to integrate the two types of knowledge representations simultaneously. Additionally, the spatial relationship knowledge encodes the relative spatial positions between each paired object (including the visual objects and OCR objects) in terms of their bounding box coordinates. The semantic relationship knowledge encodes the semantic similarity between the text words and the predicted answer words in accordance with the similarity calculated from their GloVe word embeddings. The two types of knowledge representation are encoded as unified knowledge representations. To match the knowledge representations adequately, the multi-head attention (MHA) module of M4C is modified to be a KRMHA module. By stacking the KRMHA modules in depth, the KR-M4C model performs spatial and semantic reasoning to improve the model performance over the reference M4C model.ResultThe KR-M4C approach is verified that our extended experiments are conducted on two benchmark datasets of text VQA(TextVQA) and scene text VQA(ST-VQA) based on same experimental settings. The demonstrated results are shown as below: 1) excluded of extra training data, KR-M4C obtains an accuracy improvement of 2.4% over existing optimization on the test set of TextVQA; 2) KR-M4C achieves an average normalized levenshtein similarity (ANLS) score of 0.555 on the test set of ST-VQA, which is 5% higher than theresult of SA-M4C. To verify the synergistic effect of two types of introduced knowledge further, comprehensive ablation studies are carried out on TextVQA, and the demonstrated results can support our hypothesis of those two types of knowledge are proactively and mutually to model performance. Finally, some visualized cases are provided to verify the effects of the two introduced knowledge representations. The spatial relationship knowledge improve the ability to localize key objects in the image, whilst the improved semantic relationship knowledge is perceived of the contextual words via the iterative answer decoding.ConclusionA novel KR-M4C method is introduced for the scene text VQA task. KR-M4C has its priority for the knowledge enhancement beyond the TextVQA and ST-VQA datasets.关键词:scene text visual question answering;knowledge representation;attention mechanism;Transformer;multimodal fusion257|242|0更新时间:2024-08-15
摘要:ObjectiveDeep neural networks technology promotes the research and development of computer vision and natural language processing intensively. Multiple applications like human face recognition, optical character recognition (OCR), and machine translation have been widely used. Recent development enable the machine learning to deal with more complex multimodal learning tasks that involve vision and language modalities, e.g., visual captioning, image-text retrieval, referring expression comprehension, and visual question answering (VQA). Given an arbitrary image and a natural language question, the VQA task is focused on an image-content-oriented and question-guided understanding of the fine-grained semantics and the following complex reasoning answer. The VQA task tends to be as the generalization of the rest of multimodal learning tasks. Thus, an effective VQA algorithms is a key step toward artificial general intelligence (AGI). Recent VQA have realized human-level performance on the commonly used benchmarks of VQA. However, most existing VQA methods are focused on visual objects of images only, while neglecting the recognition of textual content in the image. In many real-world scenarios, the image text can transmit essential information for scene understanding and reasoning, such as the number of a traffic sign or the brand awareness of a product. The ignorance of textual information is constraint of the applicability of the VQA methods in practice, especially for visually-impaired users. Due to the importance of the developing textual information for image interpretation, most researches intend to incorporate textual content into VQA for a scene text VQA task organizing. Specifically, the questions involve the textual contents in the scene text VQA task. The learned VQA model is required to establish unified associations among the question, visual object and the scene text. The reasoning is followed to generate a correct answer. To address the scene text VQA task, a model of multimodal multi-copy mesh(M4C) is faciliated based on the transformer architecture. Multimodal heterogeneous features are as input, a multimodal transformer is used to capture the interactions between input features, and the answers are predicted in an iterative manner. Despite of the strengths of M4C, it still has the two weaknesses as following: 1) the relative spatial relationship cannot be illustrated well between paired objects although each visual object and OCR object encode its absolute spatial location. It is challenged to achieve accurate spatial reasoning for M4C model; 2) the predicted words of answering are selected from either a dynamic OCR vocabulary or a fixed answer vocabulary. The semantic relationships are not explicitly considered in M4C between the multi-sources words. At the iterative answer prediction stage, it is challenged to understand the potential semantic associations between multiple sources derived words.MethodTo resolve the weaknesses of M4C mentioned above, we improve the reference of M4C model by introducing two added knowledge like the spatial relationship and semantic relationship, and a knowledge-representation-enhanced M4C (KR-M4C) approach is demonstrated to integrate the two types of knowledge representations simultaneously. Additionally, the spatial relationship knowledge encodes the relative spatial positions between each paired object (including the visual objects and OCR objects) in terms of their bounding box coordinates. The semantic relationship knowledge encodes the semantic similarity between the text words and the predicted answer words in accordance with the similarity calculated from their GloVe word embeddings. The two types of knowledge representation are encoded as unified knowledge representations. To match the knowledge representations adequately, the multi-head attention (MHA) module of M4C is modified to be a KRMHA module. By stacking the KRMHA modules in depth, the KR-M4C model performs spatial and semantic reasoning to improve the model performance over the reference M4C model.ResultThe KR-M4C approach is verified that our extended experiments are conducted on two benchmark datasets of text VQA(TextVQA) and scene text VQA(ST-VQA) based on same experimental settings. The demonstrated results are shown as below: 1) excluded of extra training data, KR-M4C obtains an accuracy improvement of 2.4% over existing optimization on the test set of TextVQA; 2) KR-M4C achieves an average normalized levenshtein similarity (ANLS) score of 0.555 on the test set of ST-VQA, which is 5% higher than theresult of SA-M4C. To verify the synergistic effect of two types of introduced knowledge further, comprehensive ablation studies are carried out on TextVQA, and the demonstrated results can support our hypothesis of those two types of knowledge are proactively and mutually to model performance. Finally, some visualized cases are provided to verify the effects of the two introduced knowledge representations. The spatial relationship knowledge improve the ability to localize key objects in the image, whilst the improved semantic relationship knowledge is perceived of the contextual words via the iterative answer decoding.ConclusionA novel KR-M4C method is introduced for the scene text VQA task. KR-M4C has its priority for the knowledge enhancement beyond the TextVQA and ST-VQA datasets.关键词:scene text visual question answering;knowledge representation;attention mechanism;Transformer;multimodal fusion257|242|0更新时间:2024-08-15 -
 摘要:ObjectiveImage captioning aims at automatically generating lingual descriptions of images. It has a wide variety of applications scenarios like image indexing, medical imaging reports generation and human-machine interaction. To generate fluent sentences of the gathered information all, an algorithm of image captioning is called to recognize the scenes, entities and their relationships of the image. A deep encoder-decoder framework has been developed to resolve the issue past decades. The convolutional neural networks based (CNNs-based) encoder extracts feature vectors of the image and the recurrent neural networks based (RNNs-based) decoder generates image descriptions. Recent image captioning is driven by the development of attention mechanism. It improves the performance of image captioners via attending to informative image regions. Most attention models are based on the previously generated words as inputs when the next attending phases are predicted. Due to the lack of relevant textual guidance, most existing works are challenged of "attention defocus", i.e., they fail to concentrate on correct image regions when generating the target words. As a result, contemporary models are prone to "hallucinating" objects, or missing informative visual clues, and make attention model be less interpretable. So, we facilitate an integrated hierarchical architecture and dynamic fusion strategy.MethodThe estimated word provides useful knowledge for predicting more grounded regions, although it is hard to localize the correct regions from the previously generated words at once. To refine the attention mechanism and improve the predicted words, we design a hierarchical architecture based on a series of captioning decoders. Our architecture is a hierarchical variant extended from the conventional encoder-decoder framework. Specifically, the first step is focused on the standard image captioning models, which generates a coarse description as a draft. To ground correct image regions with proper generated words, the latter one takes the outputs from the early decoder. Since the former decoder provides more predictable information to the target word, the attention accuracy is improved in latter decoders. To ground the final predicted words properly in this hierarchical architecture, attended regions from the early decoder can be well validated by the later decoders in a coarse-to-fine manner. Furthermore, we carry out a dynamic fusion strategy to aggregate the coarse-to-fine predictions from different decoders. Noteworthy, our manipulated gating mechanism is focused on the contributions from different decoders to the final word prediction. Differentiated from the previous gating mechanism managing the weight from each pathway, the contributions are jointed with a softmax schema from each decoder, which incorporates contextual information from all decoders to estimate the overall weight distribution. The dynamic fusion strategy provides rich fine-grained image descriptions and alleviates the problem of "vanishing gradients", which makes the learning of the hierarchical architecture easier.ResultOur method is evaluated on Microsoft common objects in context (MS COCO) and Flickr30K, which are the common benchmark for image captioning. The MS COCO dataset is composed of 120 k images, and the Flickr30K includes 31 k examples. Each image of both datasets is provided with five descriptions. The model is trained and tested using the Karpathy splits. The quantitative evaluation metrics are related to bilingual evaluation understudy (BLEU), metric for evaluation of translation with explicit ordering (MEREOR), and consensus-based image description evaluation (CIDEr). We compare the performance of our model with 12 current methods. On MS COCO, our analysis is optimized by 0.5 and 1.0 of each beyond BLEU-1 and CIDEr. Our result achieves a CIDEr of 69.94 on Flickr30K. Compared to the baseline method (Transformer), our performance is optimized 4.6 of CIDEr on MS COCO and 3.8 on Flickr30K, which verifies that our method improves the accuracy of the predicted sentences effectively. In addition, our qualitative results demonstrate that the proposed method provides rich fine-grained image descriptions in comparison with other methods. Our method describes the number of appeared objects precisely when they belong to the same category. Our method could also describe small objects accurately. To further verify the effectiveness of the proposed hierarchical architecture, we visualize the attention mechanism and it shows that our method attends to discriminative parts of the target objects. In contrast, the baseline method may focus on irrelevant backgrounds, which leads to false predictions straightforward.ConclusionOur research is focused on a hierarchical architecture with dynamic fusion strategy for image captioning. The hierarchical architecture consists of a sequence of captioning decoders that refine the attention mechanism. To generate final sentence with rich fine-grained information, the dynamic fusion strategy aggregates different decoders. The ablation study demonstrates the effectiveness of each module in our proposed network. Our optimized results are demonstrated through the comparative experiments on MS COCO and Flickr30K datasets.关键词:image captioning;attention mechanism;Transformer;hierarchical decoders;dynamic fusion;gating mechanism178|273|1更新时间:2024-08-15
摘要:ObjectiveImage captioning aims at automatically generating lingual descriptions of images. It has a wide variety of applications scenarios like image indexing, medical imaging reports generation and human-machine interaction. To generate fluent sentences of the gathered information all, an algorithm of image captioning is called to recognize the scenes, entities and their relationships of the image. A deep encoder-decoder framework has been developed to resolve the issue past decades. The convolutional neural networks based (CNNs-based) encoder extracts feature vectors of the image and the recurrent neural networks based (RNNs-based) decoder generates image descriptions. Recent image captioning is driven by the development of attention mechanism. It improves the performance of image captioners via attending to informative image regions. Most attention models are based on the previously generated words as inputs when the next attending phases are predicted. Due to the lack of relevant textual guidance, most existing works are challenged of "attention defocus", i.e., they fail to concentrate on correct image regions when generating the target words. As a result, contemporary models are prone to "hallucinating" objects, or missing informative visual clues, and make attention model be less interpretable. So, we facilitate an integrated hierarchical architecture and dynamic fusion strategy.MethodThe estimated word provides useful knowledge for predicting more grounded regions, although it is hard to localize the correct regions from the previously generated words at once. To refine the attention mechanism and improve the predicted words, we design a hierarchical architecture based on a series of captioning decoders. Our architecture is a hierarchical variant extended from the conventional encoder-decoder framework. Specifically, the first step is focused on the standard image captioning models, which generates a coarse description as a draft. To ground correct image regions with proper generated words, the latter one takes the outputs from the early decoder. Since the former decoder provides more predictable information to the target word, the attention accuracy is improved in latter decoders. To ground the final predicted words properly in this hierarchical architecture, attended regions from the early decoder can be well validated by the later decoders in a coarse-to-fine manner. Furthermore, we carry out a dynamic fusion strategy to aggregate the coarse-to-fine predictions from different decoders. Noteworthy, our manipulated gating mechanism is focused on the contributions from different decoders to the final word prediction. Differentiated from the previous gating mechanism managing the weight from each pathway, the contributions are jointed with a softmax schema from each decoder, which incorporates contextual information from all decoders to estimate the overall weight distribution. The dynamic fusion strategy provides rich fine-grained image descriptions and alleviates the problem of "vanishing gradients", which makes the learning of the hierarchical architecture easier.ResultOur method is evaluated on Microsoft common objects in context (MS COCO) and Flickr30K, which are the common benchmark for image captioning. The MS COCO dataset is composed of 120 k images, and the Flickr30K includes 31 k examples. Each image of both datasets is provided with five descriptions. The model is trained and tested using the Karpathy splits. The quantitative evaluation metrics are related to bilingual evaluation understudy (BLEU), metric for evaluation of translation with explicit ordering (MEREOR), and consensus-based image description evaluation (CIDEr). We compare the performance of our model with 12 current methods. On MS COCO, our analysis is optimized by 0.5 and 1.0 of each beyond BLEU-1 and CIDEr. Our result achieves a CIDEr of 69.94 on Flickr30K. Compared to the baseline method (Transformer), our performance is optimized 4.6 of CIDEr on MS COCO and 3.8 on Flickr30K, which verifies that our method improves the accuracy of the predicted sentences effectively. In addition, our qualitative results demonstrate that the proposed method provides rich fine-grained image descriptions in comparison with other methods. Our method describes the number of appeared objects precisely when they belong to the same category. Our method could also describe small objects accurately. To further verify the effectiveness of the proposed hierarchical architecture, we visualize the attention mechanism and it shows that our method attends to discriminative parts of the target objects. In contrast, the baseline method may focus on irrelevant backgrounds, which leads to false predictions straightforward.ConclusionOur research is focused on a hierarchical architecture with dynamic fusion strategy for image captioning. The hierarchical architecture consists of a sequence of captioning decoders that refine the attention mechanism. To generate final sentence with rich fine-grained information, the dynamic fusion strategy aggregates different decoders. The ablation study demonstrates the effectiveness of each module in our proposed network. Our optimized results are demonstrated through the comparative experiments on MS COCO and Flickr30K datasets.关键词:image captioning;attention mechanism;Transformer;hierarchical decoders;dynamic fusion;gating mechanism178|273|1更新时间:2024-08-15 -
 摘要:ObjectiveThe issue of uncontrolled-scenes-oriented human face recognition is challenged of series of uncontrollable factors like image perspective changes and face pose variations. Facial images reconstruction enables the interface between uncontrolled scenarios and matured recognition techniques. It aims to synthesize a standardized facial image derived from an arbitrary light and pose face image. The reconstructed facial image can be as a commonly used human face recognition method with no additional introduced inference. Beyond a pre-processing model of facial imaging contexts (e.g., recognition, semantic parsing, and animation generation, etc.), it has potentials in virtual and augmented reality like facial clipping, decoration and reconstruction. It is challenging to pursue 3D-rotation-derived predictable objects and the same of preserved identity for multi-view generations. Many classical tackling approaches have been proposed, which can be categorized into model-driven-based approaches, data-driven-based approaches, and a combination of both. Recent generative adversarial networks (GANs) have shown good results in multi-view generation. However, some high requirements of these methods have to be resolved in the training dataset, such as accurate input and output of image alignment and rich facial prior. We facilitate a novel facial reconstruction method beyond its image alignment and prior information.MethodOur two-level representation integration inference network is composed of three aspects on a high-level facial semantic information encoder, a low-level facial visual information encoder, and an integrated multi-information decoder. The encoding process is concerned of the learning issue of richer identity representation information in terms of an arbitrary-posed facial image. The convolution weights of the pre-trained face recognition model is melted into our semantic encoder. The face recognition model is trained on a large-scale dataset, which enables the encoder to adapt complex face variations through facial prior knowledge. Benefiting from the face recognition model's ability for identity information, our semantic analysis could obtain accurate semantic representation information. We illustrate a visual encoder to complement the texture features in the network in terms of reconstructed facial texture information. Additionally, the receptive field of convolution neural networks has a significant impact on the nonlinear mapping capability. To obtain accurate prediction results and optimize the extraction of texture information further, a larger receptive field could meet the requirement for mapping process of multi-sources networks. The downsampling and dilated convolutions are integrated for feature extraction, i.e., each downsampling module in the network consists of a downsampling convolution and a dilated convolution. The dilated convolution can effectively increase the corresponding mapping range of each reconstructed pixel in the context of network layers and improve the receptive field of each layer of the network. The image reconstruction task is very sensitive to the low-level visual information of the image. If the coding-derived visual representation is combined with the semantic representation directly, the image reconstruction process of the model will be restricted of the visual representation and ignore the guiding function of the semantic representation. Therefore, the key to our multiple information integration process is first focused on the mapping relationship of the probability distribution of facial images in the feature space, and the following representation information of facial reconstruction is realized. To obtain the final analysis of facial reconstruction, the representation information is decoded at the end of the network.ResultOur method is compared to 8 state-of-the-art facial methods on Multi-PIE(multi-pose, illumination and expression) dataset. The quantitative evaluation metric is Rank-1 recognition rates and the qualitative analysis is based on the visual effect of reconstructed images. The experiment results show that our model could get more optimized results. In addition, our method can save 79% of the number of parameters and 42% of the number of computational operations compared to the current state-of-the-art flow-based feature warping model(FFWM) method. To fully validate the effectiveness of the proposed method, we analyze the effects of dual coding paths, multiple information integration and the different loss functions on the model performance. To match the real uncontrolled scenarios, we evaluate the proposed method on the CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences—WebFace) dataset. At the same time, we carry out quantitative and qualitative method compared to existing methods.ConclusionWe develop a two-level representational integrated inference network, which integrate the low-level visual facial features and the high-level semantic features. It optimizes reconstructed results and higher recognition accuracy with lower computational complexity and shows its priority of generalization performance in uncontrolled scenes as well.关键词:face frontalization;arbitrary pose;dual encoding path;visual representation;semantic representation;fusion algorithm105|161|0更新时间:2024-08-15
摘要:ObjectiveThe issue of uncontrolled-scenes-oriented human face recognition is challenged of series of uncontrollable factors like image perspective changes and face pose variations. Facial images reconstruction enables the interface between uncontrolled scenarios and matured recognition techniques. It aims to synthesize a standardized facial image derived from an arbitrary light and pose face image. The reconstructed facial image can be as a commonly used human face recognition method with no additional introduced inference. Beyond a pre-processing model of facial imaging contexts (e.g., recognition, semantic parsing, and animation generation, etc.), it has potentials in virtual and augmented reality like facial clipping, decoration and reconstruction. It is challenging to pursue 3D-rotation-derived predictable objects and the same of preserved identity for multi-view generations. Many classical tackling approaches have been proposed, which can be categorized into model-driven-based approaches, data-driven-based approaches, and a combination of both. Recent generative adversarial networks (GANs) have shown good results in multi-view generation. However, some high requirements of these methods have to be resolved in the training dataset, such as accurate input and output of image alignment and rich facial prior. We facilitate a novel facial reconstruction method beyond its image alignment and prior information.MethodOur two-level representation integration inference network is composed of three aspects on a high-level facial semantic information encoder, a low-level facial visual information encoder, and an integrated multi-information decoder. The encoding process is concerned of the learning issue of richer identity representation information in terms of an arbitrary-posed facial image. The convolution weights of the pre-trained face recognition model is melted into our semantic encoder. The face recognition model is trained on a large-scale dataset, which enables the encoder to adapt complex face variations through facial prior knowledge. Benefiting from the face recognition model's ability for identity information, our semantic analysis could obtain accurate semantic representation information. We illustrate a visual encoder to complement the texture features in the network in terms of reconstructed facial texture information. Additionally, the receptive field of convolution neural networks has a significant impact on the nonlinear mapping capability. To obtain accurate prediction results and optimize the extraction of texture information further, a larger receptive field could meet the requirement for mapping process of multi-sources networks. The downsampling and dilated convolutions are integrated for feature extraction, i.e., each downsampling module in the network consists of a downsampling convolution and a dilated convolution. The dilated convolution can effectively increase the corresponding mapping range of each reconstructed pixel in the context of network layers and improve the receptive field of each layer of the network. The image reconstruction task is very sensitive to the low-level visual information of the image. If the coding-derived visual representation is combined with the semantic representation directly, the image reconstruction process of the model will be restricted of the visual representation and ignore the guiding function of the semantic representation. Therefore, the key to our multiple information integration process is first focused on the mapping relationship of the probability distribution of facial images in the feature space, and the following representation information of facial reconstruction is realized. To obtain the final analysis of facial reconstruction, the representation information is decoded at the end of the network.ResultOur method is compared to 8 state-of-the-art facial methods on Multi-PIE(multi-pose, illumination and expression) dataset. The quantitative evaluation metric is Rank-1 recognition rates and the qualitative analysis is based on the visual effect of reconstructed images. The experiment results show that our model could get more optimized results. In addition, our method can save 79% of the number of parameters and 42% of the number of computational operations compared to the current state-of-the-art flow-based feature warping model(FFWM) method. To fully validate the effectiveness of the proposed method, we analyze the effects of dual coding paths, multiple information integration and the different loss functions on the model performance. To match the real uncontrolled scenarios, we evaluate the proposed method on the CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences—WebFace) dataset. At the same time, we carry out quantitative and qualitative method compared to existing methods.ConclusionWe develop a two-level representational integrated inference network, which integrate the low-level visual facial features and the high-level semantic features. It optimizes reconstructed results and higher recognition accuracy with lower computational complexity and shows its priority of generalization performance in uncontrolled scenes as well.关键词:face frontalization;arbitrary pose;dual encoding path;visual representation;semantic representation;fusion algorithm105|161|0更新时间:2024-08-15
Multimedia Analysis and Understanding
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0