
最新刊期
卷 27 , 期 8 , 2022
-
 摘要:Virtual reality (VR) technology has gradually penetrated into many fields such as medical education, military and entertainment. Given visual quality is the key to the successful application of VR technology, and the image is visual information benched carrier of VR applications, VR image quality evaluation has become an important frontier research direction for quality evaluation. Just like traditional image quality evaluation, VR image quality evaluation can be divided into subjective quality evaluation and objective quality evaluation. Among them, the subjective quality evaluation methods refer to images scoring through human eyes followed by some data processing steps to obtain the subjective scores, while the objective quality evaluation methods focus on the methods of images scoring based on designing the mathematical model using computers to simulate the subjective scoring results as closely as possible. Compared to the subjective quality evaluation, the objective quality evaluation has its priorities s of lower cost, stronger stability and wider application scope. Many researchers in the scientific research institutions and colleges have dedicated to studying the objective quality evaluation of VR images. Our executive summary is focused on the research of objective quality evaluation of VR images. First, the current situation of VR image quality evaluation is summarized. Then, the existing objective quality evaluation models of VR images are mainly introduced and analyzed. According to whether the models need to use the original undistorted image information as modeling reference, current objective quality evaluation models for VR images are divided into two types, including the full-reference (FR) and no-reference (NR) types. The ground truth based FR models need the completed original image information as reference, while the NR models can achieve quality evaluation of a distorted VR image without any reference information. Specifically, the FR models can be divided into two categories for VR images, including the peak-signal-to-noise ratio/structural similarity (PSNR/SSIM) based methods and the machine learning based methods. The latter first extract features from VR images and then train the quality evaluation model via the support vector regression method or the random forest method. The NR models are further divided into three categories: the equirectangular projection (ERP) expression space based methods, the other projection expression spaces based methods and the actual viewing space based methods. These models are classified according to the space in which features are extracted. For the first kind of models, the raw spherical VR image is first transferred to the ERP space for feature expression, while it is converted to other projection spaces or the actual viewing space for the other two kinds of methods. The reason why the ERP expression space based methods are listed as a separate category is that the ERP space is the default and the mostly used projection space. Followed the space transformation, there are also two options for the sequential quality evaluation consisting of the traditional quality evaluation methods and the deep-learning based methods. For the traditional ones, the manual features are first extracted and fused to generate the final quality score or fed into the model trainer to obtain the quality assessment model. For the deep-learning based methods, both the feature extraction and quality prediction steps are conducted based on deep neural networks. The pros and cons of them are further analyzed. In addition, the performance evaluation indexes of the objective quality evaluation models of VR images are introduced, which are consistent to other image quality evaluations. The detailed existing VR image databases are summarized subsequently. Finally, our review focuses on the applications of VR image objective quality evaluation models and predicts the future potentials further.关键词:image quality evaluation;objective evaluation;virtual reality (VR);spherical image;equirectangular projection (ERP)125|410|1更新时间:2024-08-15
摘要:Virtual reality (VR) technology has gradually penetrated into many fields such as medical education, military and entertainment. Given visual quality is the key to the successful application of VR technology, and the image is visual information benched carrier of VR applications, VR image quality evaluation has become an important frontier research direction for quality evaluation. Just like traditional image quality evaluation, VR image quality evaluation can be divided into subjective quality evaluation and objective quality evaluation. Among them, the subjective quality evaluation methods refer to images scoring through human eyes followed by some data processing steps to obtain the subjective scores, while the objective quality evaluation methods focus on the methods of images scoring based on designing the mathematical model using computers to simulate the subjective scoring results as closely as possible. Compared to the subjective quality evaluation, the objective quality evaluation has its priorities s of lower cost, stronger stability and wider application scope. Many researchers in the scientific research institutions and colleges have dedicated to studying the objective quality evaluation of VR images. Our executive summary is focused on the research of objective quality evaluation of VR images. First, the current situation of VR image quality evaluation is summarized. Then, the existing objective quality evaluation models of VR images are mainly introduced and analyzed. According to whether the models need to use the original undistorted image information as modeling reference, current objective quality evaluation models for VR images are divided into two types, including the full-reference (FR) and no-reference (NR) types. The ground truth based FR models need the completed original image information as reference, while the NR models can achieve quality evaluation of a distorted VR image without any reference information. Specifically, the FR models can be divided into two categories for VR images, including the peak-signal-to-noise ratio/structural similarity (PSNR/SSIM) based methods and the machine learning based methods. The latter first extract features from VR images and then train the quality evaluation model via the support vector regression method or the random forest method. The NR models are further divided into three categories: the equirectangular projection (ERP) expression space based methods, the other projection expression spaces based methods and the actual viewing space based methods. These models are classified according to the space in which features are extracted. For the first kind of models, the raw spherical VR image is first transferred to the ERP space for feature expression, while it is converted to other projection spaces or the actual viewing space for the other two kinds of methods. The reason why the ERP expression space based methods are listed as a separate category is that the ERP space is the default and the mostly used projection space. Followed the space transformation, there are also two options for the sequential quality evaluation consisting of the traditional quality evaluation methods and the deep-learning based methods. For the traditional ones, the manual features are first extracted and fused to generate the final quality score or fed into the model trainer to obtain the quality assessment model. For the deep-learning based methods, both the feature extraction and quality prediction steps are conducted based on deep neural networks. The pros and cons of them are further analyzed. In addition, the performance evaluation indexes of the objective quality evaluation models of VR images are introduced, which are consistent to other image quality evaluations. The detailed existing VR image databases are summarized subsequently. Finally, our review focuses on the applications of VR image objective quality evaluation models and predicts the future potentials further.关键词:image quality evaluation;objective evaluation;virtual reality (VR);spherical image;equirectangular projection (ERP)125|410|1更新时间:2024-08-15
Review

-
 摘要:ObjectiveHuman eyes physiological features are challenged to be captured, which can reflect health, fatigue and emotion of human behaviors. Fatigue phenomenon can be judged according to the state of the patients' eyes. The state of the in-class students' eyes can be predicted by instructorsin terms of students' emotion, psychology and cognitive analyses. Targeted consumers can be recognized through their gaze location when shopping. Camera shot cannot be used to capture the changes in pupil size and orientation in the wild. Meanwhile, there is a lack of eye behavior related dataset with fine landmarks detection and segment similar to the real application scenario. Near-infrared and head-mounted cameras could be used to capture eye images. Light is used to distinguish the iris and pupil, which obtain a high-quality image. Head posture, illumination, occlusion and user-camera distance may affect the quality of image. Therefore, the images collection in the laboratory environment are difficult to apply in the real world.MethodAn eye region segmentation and landmark detection dataset can resolve the issue of mismatch results between the indoor and outdoor scenarios. Our research focuses on collection and annotation of a new eye region segment and landmark detection dataset (eye segment and landmark detection dataset, ESLD) in constraint of dataset for fine landmark detection and eye region, which contain multiple types of eye. First, facial images are collected. There are three ways to collect images, including the facial images of user when using the computer, images in the public dataset captured by the ordinary camera and the synthesized eye images, respectively. The number of images is developed to 1 386, 804 and 1 600, respectively. Second, eye region is cut out from the original image. Dlib is used to detect landmarks and eye region is segmented according to the labels of the completed face images involved. For an incomplete face images, eye region should be segment artificially. And then, all eye region images are normalized in 256×128 pixels. The eye region images are restored in a folder according to the type of acquisitions. Finally, annotators are initially to be trained and manually annotated images labels followed. In order to reduce the label error caused by human behavior factors, each annotator selects four images from each type of image for labeling. An experienced annotator will be checked after the landmarks are labeled and completed. The remaining images can be labeled when the annotate standard is reached. Each landmarks location is saved as json file and labelme is used to segment eye region derived the json file. A total of 2 404 images are obtained. Each image contains 16 landmarks around eyes, 12 landmarks around iris and 12 pupil surrounded landmarks. The segment labels are relevant to sclera, iris, and pupil and skip around eyes.ResultOur dataset is classified into training, testing and validation sets by 0.6∶0.2∶0.2. Our demonstration evaluates the proposed dataset using deep learning algorithms and provides baseline for each experiment. First, the model is trained by synthesized eye images. An experiment is conducted to recognize whether the eye is real or not. Our analyzed results show that model cannot recognize real and synthesis accurately, which indicate synthesis eye images can be used as training data. And, deep learning-based algorithms are used to eye region segment. Mask region convolutional neural network(Mask R-CNN) with different backbones are used to train the model. It shows that backbones with deep network structure can obtain high segment accuracy under the same training epoch and the mean average precision (mAP) is 0.965. Finally, Mask R-CNN is modified to landmarks detection task. Euclidean distance is used to test the model and the error is 5.828. Compared to eye region segment task, it is difficult to detect landmarks due to the small region of the eye. Deep structure is efficient to increase the accuracy of landmarks detection with eye region mask.ConclusionESLD is focused on multiple types of eye images in a real environment and bridge the gaps in the fine landmarks detection and segmentation in eye region. To study the relationship between eye state and emotion, a deep learning algorithm can be developed further based on combining ESLD with other datasets.关键词:in the wild;pupil segment;landmark detection;user identification;E-learning;dataset190|205|0更新时间:2024-08-15
摘要:ObjectiveHuman eyes physiological features are challenged to be captured, which can reflect health, fatigue and emotion of human behaviors. Fatigue phenomenon can be judged according to the state of the patients' eyes. The state of the in-class students' eyes can be predicted by instructorsin terms of students' emotion, psychology and cognitive analyses. Targeted consumers can be recognized through their gaze location when shopping. Camera shot cannot be used to capture the changes in pupil size and orientation in the wild. Meanwhile, there is a lack of eye behavior related dataset with fine landmarks detection and segment similar to the real application scenario. Near-infrared and head-mounted cameras could be used to capture eye images. Light is used to distinguish the iris and pupil, which obtain a high-quality image. Head posture, illumination, occlusion and user-camera distance may affect the quality of image. Therefore, the images collection in the laboratory environment are difficult to apply in the real world.MethodAn eye region segmentation and landmark detection dataset can resolve the issue of mismatch results between the indoor and outdoor scenarios. Our research focuses on collection and annotation of a new eye region segment and landmark detection dataset (eye segment and landmark detection dataset, ESLD) in constraint of dataset for fine landmark detection and eye region, which contain multiple types of eye. First, facial images are collected. There are three ways to collect images, including the facial images of user when using the computer, images in the public dataset captured by the ordinary camera and the synthesized eye images, respectively. The number of images is developed to 1 386, 804 and 1 600, respectively. Second, eye region is cut out from the original image. Dlib is used to detect landmarks and eye region is segmented according to the labels of the completed face images involved. For an incomplete face images, eye region should be segment artificially. And then, all eye region images are normalized in 256×128 pixels. The eye region images are restored in a folder according to the type of acquisitions. Finally, annotators are initially to be trained and manually annotated images labels followed. In order to reduce the label error caused by human behavior factors, each annotator selects four images from each type of image for labeling. An experienced annotator will be checked after the landmarks are labeled and completed. The remaining images can be labeled when the annotate standard is reached. Each landmarks location is saved as json file and labelme is used to segment eye region derived the json file. A total of 2 404 images are obtained. Each image contains 16 landmarks around eyes, 12 landmarks around iris and 12 pupil surrounded landmarks. The segment labels are relevant to sclera, iris, and pupil and skip around eyes.ResultOur dataset is classified into training, testing and validation sets by 0.6∶0.2∶0.2. Our demonstration evaluates the proposed dataset using deep learning algorithms and provides baseline for each experiment. First, the model is trained by synthesized eye images. An experiment is conducted to recognize whether the eye is real or not. Our analyzed results show that model cannot recognize real and synthesis accurately, which indicate synthesis eye images can be used as training data. And, deep learning-based algorithms are used to eye region segment. Mask region convolutional neural network(Mask R-CNN) with different backbones are used to train the model. It shows that backbones with deep network structure can obtain high segment accuracy under the same training epoch and the mean average precision (mAP) is 0.965. Finally, Mask R-CNN is modified to landmarks detection task. Euclidean distance is used to test the model and the error is 5.828. Compared to eye region segment task, it is difficult to detect landmarks due to the small region of the eye. Deep structure is efficient to increase the accuracy of landmarks detection with eye region mask.ConclusionESLD is focused on multiple types of eye images in a real environment and bridge the gaps in the fine landmarks detection and segmentation in eye region. To study the relationship between eye state and emotion, a deep learning algorithm can be developed further based on combining ESLD with other datasets.关键词:in the wild;pupil segment;landmark detection;user identification;E-learning;dataset190|205|0更新时间:2024-08-15
Dataset
-
 摘要:ObjectiveThe acquired depth information has led to the research development of three-dimensional reconstruction and stereo vision. However, the acquired depth images issues have challenged of image holes and image noise due to the lack of depth information. The quality of the depth image is as a benched data source for each 3D-vision(3DV) system. Our method is focused on the lack of depth map information repair derived from objective factors in the depth acquisition process. It is required of the high precision, the spatial distribution difference between color and depth features, the interference of noise and blur, and the large scale holes information loss.MethodReal-time ability is relatively crucial in terms of the depth image recovery algorithms serving as pre-processing modules in the 3DV systems. The sequential filling method has been optimized in computational speed by processing each invalid point in one loop. The invalid points based pixels are obtained without depth values. By contrast, depth values captured pixels are referred to as valid points. Therefore, we facilitate a dual-scale sequential filling framework for depth image recovery. We carry out filling priority estimation and depth value prediction of the invalid points in this framework. For the evaluation of the priority of invalid points, we use conditional entropy as the benchmark for evaluating the priority of invalid point filling evaluation and verification. It is incredible to estimate the filling priority and filling depth value through the overall features of a single pixel and its 8-neighborhood. However, the use of multi-scale filtering increases the computational costs severely. We introduce the super-pixel over-segmentation algorithm to segment the input image into more small patches, which ensures the pixels inside the super-pixel homogeneous contexts like color, texture, and depth. We believe that the super-pixels can provide more reliable features in larger scale for priority estimation filling and depth value prediction. In addition, we optioned a simple linear iterative clustering (SLIC) algorithm to handle the super-pixel segmentation task and added a depth difference metric for the image characteristics of RGB-D to make it efficient and reliable. For depth estimation, we use maximum likelihood estimation to estimate the depth of invalid points integrated to the depth value exhaustive method. Finally, the restoration results are integrated on the pixel and super-pixel scales to accurately fill the holes in the depth image.ResultOur method is compared to 7 methods related to dataset Middlebury (MB), which shows great advantages on deep repair effection. The averaged peak signal-to-noise ratio (PSNR) is 47.955 dB and the averaged structural similarity index (SSIM) is 0.998 2. Our PSNR reached 34.697 dB and the SSIM reached 0.978 5 in MB based manual populated data set for deep repair. The method herein verifies that this algorithm has relatively strong efficiency in comparison to time efficiency validation. Our filling priority estimation, depth value prediction and double-scale improvement ability are evaluated in the ablation experimental section separately.ConclusionWe illustrate a dual-scale sequential filling framework for depth image recovery. The experimental results demonstrate that our algorithm proposed has its priority to optimize robustness, precision and efficiency.关键词:depth image recovery;sequential filling;fast approximation of conditional entropy;depth value prediction;super-pixel126|190|0更新时间:2024-08-15
摘要:ObjectiveThe acquired depth information has led to the research development of three-dimensional reconstruction and stereo vision. However, the acquired depth images issues have challenged of image holes and image noise due to the lack of depth information. The quality of the depth image is as a benched data source for each 3D-vision(3DV) system. Our method is focused on the lack of depth map information repair derived from objective factors in the depth acquisition process. It is required of the high precision, the spatial distribution difference between color and depth features, the interference of noise and blur, and the large scale holes information loss.MethodReal-time ability is relatively crucial in terms of the depth image recovery algorithms serving as pre-processing modules in the 3DV systems. The sequential filling method has been optimized in computational speed by processing each invalid point in one loop. The invalid points based pixels are obtained without depth values. By contrast, depth values captured pixels are referred to as valid points. Therefore, we facilitate a dual-scale sequential filling framework for depth image recovery. We carry out filling priority estimation and depth value prediction of the invalid points in this framework. For the evaluation of the priority of invalid points, we use conditional entropy as the benchmark for evaluating the priority of invalid point filling evaluation and verification. It is incredible to estimate the filling priority and filling depth value through the overall features of a single pixel and its 8-neighborhood. However, the use of multi-scale filtering increases the computational costs severely. We introduce the super-pixel over-segmentation algorithm to segment the input image into more small patches, which ensures the pixels inside the super-pixel homogeneous contexts like color, texture, and depth. We believe that the super-pixels can provide more reliable features in larger scale for priority estimation filling and depth value prediction. In addition, we optioned a simple linear iterative clustering (SLIC) algorithm to handle the super-pixel segmentation task and added a depth difference metric for the image characteristics of RGB-D to make it efficient and reliable. For depth estimation, we use maximum likelihood estimation to estimate the depth of invalid points integrated to the depth value exhaustive method. Finally, the restoration results are integrated on the pixel and super-pixel scales to accurately fill the holes in the depth image.ResultOur method is compared to 7 methods related to dataset Middlebury (MB), which shows great advantages on deep repair effection. The averaged peak signal-to-noise ratio (PSNR) is 47.955 dB and the averaged structural similarity index (SSIM) is 0.998 2. Our PSNR reached 34.697 dB and the SSIM reached 0.978 5 in MB based manual populated data set for deep repair. The method herein verifies that this algorithm has relatively strong efficiency in comparison to time efficiency validation. Our filling priority estimation, depth value prediction and double-scale improvement ability are evaluated in the ablation experimental section separately.ConclusionWe illustrate a dual-scale sequential filling framework for depth image recovery. The experimental results demonstrate that our algorithm proposed has its priority to optimize robustness, precision and efficiency.关键词:depth image recovery;sequential filling;fast approximation of conditional entropy;depth value prediction;super-pixel126|190|0更新时间:2024-08-15 -
 摘要:ObjectiveQuick response code (QR code) is a kind of widely used 2D barcode nowadays. A QR code is a square symbol consisting of dark and light modules. There is a great need to accommodate more data in the target area or encode the same input data in a smaller area. The input data is first encoded into a bit stream. Different encoding algorithms may output different bit streams via assigned input data. The length of bit stream determines the version of a QR code, and the version determines the amount of modules per side. A QR code with a smaller version takes a smaller area without the size of modules changing, or has a larger module size without changing the area. The bit stream consists of one or multiple segments, and the encoding mode of each segment is chosen from three modes separately, i.e., numeric mode, alphanumeric mode and byte mode. The numeric mode can only encode digits, and every 3 digits are encoded into 10 bits. The alphanumeric mode can encode digits, upper case letters, and 9 kinds of punctuations, and every 2 characters are encoded into 11 bits. The byte mode can encode any kind of binary data, but each byte is encoded into 8 bits. Compared to using a single mode to encode the overall input data, different modes interchange may result in a shorter bit stream. But different modes switching leads to redundancy on bit stream length.MethodThe key to minimizing the version of QR code is to minimize the length of bit stream. The minimization should balance the redundancy of data encoding and the mode switching efficiency. The QR code specification gives "optimization of bit stream length" in annex. However, the illustration has proposed that the optimization method may not output the minimum bit stream. The demonstration has mentioned algorithms as below. The first algorithm is called "minimization algorithm", which converts the minimization of bit stream length to a dynamic programming problem. The algorithm can output the bit stream with minimum length by resolving the dynamic programming problem. Time cost is bounded in a linear function to the length of input data. The second algorithm is called "URL minimization algorithm", which is optimized for cases that the input data is a uniform resource locator (URL) further. The customized optimization for URL makes use of two properties: 1) the scheme field and the host field of a URL are case-insensitive, and 2) the scheme-specific part of a URL can be escaped. The properties have been guaranteed via request for comments (RFC) 1 738 and RFC 1 035. A lower case letter can only be encoded in byte mode. By converting a lower case letter in a case-insensitive field to an upper case letter, the letter can be encoded in either byte mode or alphanumeric mode. The property provides more options in dynamic programming. In addition, each character in the scheme-specific part of a URL may be converted to an escape sequence. The escape sequence contains 3 alphanumeric mode characters. Hence, it can be encoded in alphanumeric mode or a combination of alphanumeric mode and numeric mode. This kind of conversion also provides more choices in dynamic programming. The URL minimization algorithm takes advantage of such two kinds of conversions to calculate the bit stream of a URL with minimum length.ResultA QR code data set (also called a test set) is constructed to verify the efficiency of the proposed algorithms. The test set is collected from 6 web image search engines, i.e., Baidu, Sogou, 360, Google, Bing, and Yahoo. QR codes with different bit streams or different error correction levels are regarded as different QR codes. The test set contains 2 282 distinct QR codes, where 603 QR codes encode non-URL data and the other 1 679 QR codes encode URL data. Four algorithms are compared on the test set, i.e., 1) the optimization method given in the QR code specification, 2) encoding input data in a single segment, 3) the minimization algorithm, and 4) the URL minimization algorithm. The bit stream lengths of initial QR codes are offered for comparison as well. The demonstrations show that for the non-URL test set, average bit stream length reduces 0.4% (compared to the optimization in the QR code specification), QR codes with reduced bit stream lengths account for 9.1%, and QR codes with reduced versions account for 1.2%; for the URL test set, average bit stream length reduces 13.9%, QR codes with reduced bit stream lengths account for 98.4%, and QR codes with reduced versions account for 31.7%. An ablation study on the two components of URL minimization has been implemented, i.e., 1) utilizing case-insensitive fields and 2) converting characters to escaping sequences. The calculating results have shown that each component has an effect and combining both components achieves the best performance, i.e., the minimum bit stream length and the minimum version. In the context of URL test set, average bit stream length reduces only 0.5% using the minimization algorithm, while the value reduces 9.1% using the URL minimization algorithm; QR codes with reduced bit stream lengths account for 10.4% using the minimization algorithm, but the value is 98.4% for the URL minimization algorithm; QR codes with reduced versions account for 1.3% using the minimization algorithm, while the value is 31.7% for the URL minimization algorithm. The average time cost to encode a message is 2.45 microsecond.ConclusionThe proposed algorithms minimize the length of bit stream. Data capacity of QR codes has been increased without changing QR code format or revising the error correction capability. The URL minimization algorithm is qualified under the huge amounts of QR codes based on URL encoded data. The proposed algorithms are friendly-used, i.e., there are no hyper-parameters to be tuned, and users input data and error correction level only. The illustrated algorithms have been verified in a realistic running speed, and it is proved that the time costs of both algorithms are bounded in a linear function to the length of input data.关键词:2D code;quick response code (QR code);QR code encoding;dynamic programming;uniform resource locators (URL)98|167|0更新时间:2024-08-15
摘要:ObjectiveQuick response code (QR code) is a kind of widely used 2D barcode nowadays. A QR code is a square symbol consisting of dark and light modules. There is a great need to accommodate more data in the target area or encode the same input data in a smaller area. The input data is first encoded into a bit stream. Different encoding algorithms may output different bit streams via assigned input data. The length of bit stream determines the version of a QR code, and the version determines the amount of modules per side. A QR code with a smaller version takes a smaller area without the size of modules changing, or has a larger module size without changing the area. The bit stream consists of one or multiple segments, and the encoding mode of each segment is chosen from three modes separately, i.e., numeric mode, alphanumeric mode and byte mode. The numeric mode can only encode digits, and every 3 digits are encoded into 10 bits. The alphanumeric mode can encode digits, upper case letters, and 9 kinds of punctuations, and every 2 characters are encoded into 11 bits. The byte mode can encode any kind of binary data, but each byte is encoded into 8 bits. Compared to using a single mode to encode the overall input data, different modes interchange may result in a shorter bit stream. But different modes switching leads to redundancy on bit stream length.MethodThe key to minimizing the version of QR code is to minimize the length of bit stream. The minimization should balance the redundancy of data encoding and the mode switching efficiency. The QR code specification gives "optimization of bit stream length" in annex. However, the illustration has proposed that the optimization method may not output the minimum bit stream. The demonstration has mentioned algorithms as below. The first algorithm is called "minimization algorithm", which converts the minimization of bit stream length to a dynamic programming problem. The algorithm can output the bit stream with minimum length by resolving the dynamic programming problem. Time cost is bounded in a linear function to the length of input data. The second algorithm is called "URL minimization algorithm", which is optimized for cases that the input data is a uniform resource locator (URL) further. The customized optimization for URL makes use of two properties: 1) the scheme field and the host field of a URL are case-insensitive, and 2) the scheme-specific part of a URL can be escaped. The properties have been guaranteed via request for comments (RFC) 1 738 and RFC 1 035. A lower case letter can only be encoded in byte mode. By converting a lower case letter in a case-insensitive field to an upper case letter, the letter can be encoded in either byte mode or alphanumeric mode. The property provides more options in dynamic programming. In addition, each character in the scheme-specific part of a URL may be converted to an escape sequence. The escape sequence contains 3 alphanumeric mode characters. Hence, it can be encoded in alphanumeric mode or a combination of alphanumeric mode and numeric mode. This kind of conversion also provides more choices in dynamic programming. The URL minimization algorithm takes advantage of such two kinds of conversions to calculate the bit stream of a URL with minimum length.ResultA QR code data set (also called a test set) is constructed to verify the efficiency of the proposed algorithms. The test set is collected from 6 web image search engines, i.e., Baidu, Sogou, 360, Google, Bing, and Yahoo. QR codes with different bit streams or different error correction levels are regarded as different QR codes. The test set contains 2 282 distinct QR codes, where 603 QR codes encode non-URL data and the other 1 679 QR codes encode URL data. Four algorithms are compared on the test set, i.e., 1) the optimization method given in the QR code specification, 2) encoding input data in a single segment, 3) the minimization algorithm, and 4) the URL minimization algorithm. The bit stream lengths of initial QR codes are offered for comparison as well. The demonstrations show that for the non-URL test set, average bit stream length reduces 0.4% (compared to the optimization in the QR code specification), QR codes with reduced bit stream lengths account for 9.1%, and QR codes with reduced versions account for 1.2%; for the URL test set, average bit stream length reduces 13.9%, QR codes with reduced bit stream lengths account for 98.4%, and QR codes with reduced versions account for 31.7%. An ablation study on the two components of URL minimization has been implemented, i.e., 1) utilizing case-insensitive fields and 2) converting characters to escaping sequences. The calculating results have shown that each component has an effect and combining both components achieves the best performance, i.e., the minimum bit stream length and the minimum version. In the context of URL test set, average bit stream length reduces only 0.5% using the minimization algorithm, while the value reduces 9.1% using the URL minimization algorithm; QR codes with reduced bit stream lengths account for 10.4% using the minimization algorithm, but the value is 98.4% for the URL minimization algorithm; QR codes with reduced versions account for 1.3% using the minimization algorithm, while the value is 31.7% for the URL minimization algorithm. The average time cost to encode a message is 2.45 microsecond.ConclusionThe proposed algorithms minimize the length of bit stream. Data capacity of QR codes has been increased without changing QR code format or revising the error correction capability. The URL minimization algorithm is qualified under the huge amounts of QR codes based on URL encoded data. The proposed algorithms are friendly-used, i.e., there are no hyper-parameters to be tuned, and users input data and error correction level only. The illustrated algorithms have been verified in a realistic running speed, and it is proved that the time costs of both algorithms are bounded in a linear function to the length of input data.关键词:2D code;quick response code (QR code);QR code encoding;dynamic programming;uniform resource locators (URL)98|167|0更新时间:2024-08-15
Image Processing and Coding
-
 摘要:ObjectiveThe action recognition technology is proactive in computer vision contexts, such as intelligent video surveillance, human-computer interaction, virtual reality, and medical image analysis. It plays an important role in the automated and intelligent modern manufacturing process, but the complexity of the actual manufacturing environment has still been challenging. The research direction is attributed to the deep neural networks largely, especially the 3D convolutional networks, which mainly use 3D convolution to capture temporal information. The 3D convolutional networks can extract the spatio-temporal features of videos better with the added temporal dimension compared to 2D convolutional networks. At present, it shows good performance in action recognition through the optical flow melting in 3D convolutional network, but it still cannot solve the problem of human body being occluded, and the computational cost of optical flow is complicated and cannot be applied in real-time scenes. The product qualification rate is required to be satisfied in the context of action recognition application in production scenes. It is necessary to rank out the unqualified products as much as possible while ensuring high accuracy and high true negative rate (TNR) of detection results. It is challenged to optimize the true negative rate among the existing action recognition methods. Our analysis facilitates a packing action recognition method based on dual-view 3D convolutional network.MethodFirst, we extract motion features better through stacked residual frames as inputs, replacing optical flow that is not available in the real-time scene. The original RGB images and the residual frames are input to two parallel 3D ResNeXt101, and a concatenation layer is used to concatenate the features extracted in the last convolution layer of the two 3D ResNext101. Next, we adopts a dual-view structure to resolve the issue of human body being occluded, optimizes 3D ResNeXt101 into a dual-view model, builds up a learnable dual-view pooling layer for multifaceted feature fusion of views, and then uses this dual-view 3D ResNeXt101 model for action recognition. Finally, a noise-reducing self-encoder and two-class support vector machine (SVM) are added in our model to improve the true negative rate (TNR) of the detection results further. The dual-view pooling derived features are input to the noise-reducing self-encoder in the model, and the features are optimized and downscaled by the trained noise-reducing self-encoder, and then the two-class SVM model is used for secondary recognition.ResultWe conducted experiments in a packing scenario and evaluated using two metrics like accuracy rate and true-negative rate. The accuracy of our packing action recognition model is 94.2%, and the true negative rate is 98.9%, which optimizes current action recognition methods. Our accuracy is increased from 91.1% to 95.8% via the dual-view structure. The accuracy of the model is increased from 88.2% to 95.8% based on the residual frames module. If the residual frames module is altered by optical flow module, the accuracy rate is 96.2%, which is equivalent to the model using the residual frames module. The accuracy is only 91.5% that the unique two-class SVM structure added to the model without the denoising autoencoder. Thanks to the optimization and dimensionality reduction of the feature vectors by the denoising autoencoder, the accuracy reaches 94.2% via the combination of the denoising autoencoder and the two-class SVM both, the highest true negative rate of 98.9% obtained. After adding denoising autoencoder and two-class SVM to the model, the true negative rate of the model increased from 95.7% to 98.9%, while the accuracy rate decreased by 1.6%. Our demonstrated result is evaluated in the public dataset UCF (University of Central Florida) 101.Our single-view model obtained an accuracy of 97.1%, which achieved the second highest accuracy among all compared methods, second only to 3D ResNeXt101's 98.0%.ConclusionWe use a dual-view 3D ResNeXt101 model for effective packing action recognition. To obtain richer features from RGB images and differential images, two parallel 3D ResNeXt101 are used to learn spatio-temporal features and a dual-view feature fusion is accomplished using a learnable view pooling layer. In addition, a stacked denoising autoencoder is trained to optimize and downscale the features extracted in terms of the dual-view 3D ResNeXt101 model. To improve the true negative rate, a two-class SVM model is used for secondary detection. Our method can recognize the boxing action of the packing workers accurately and realize the high true negative rate (TNR) of the recognition results.关键词:action recognition;dual-view;3D convolutional neural network;denoising autoencoder;support vectormachine(SVM)115|207|1更新时间:2024-08-15
摘要:ObjectiveThe action recognition technology is proactive in computer vision contexts, such as intelligent video surveillance, human-computer interaction, virtual reality, and medical image analysis. It plays an important role in the automated and intelligent modern manufacturing process, but the complexity of the actual manufacturing environment has still been challenging. The research direction is attributed to the deep neural networks largely, especially the 3D convolutional networks, which mainly use 3D convolution to capture temporal information. The 3D convolutional networks can extract the spatio-temporal features of videos better with the added temporal dimension compared to 2D convolutional networks. At present, it shows good performance in action recognition through the optical flow melting in 3D convolutional network, but it still cannot solve the problem of human body being occluded, and the computational cost of optical flow is complicated and cannot be applied in real-time scenes. The product qualification rate is required to be satisfied in the context of action recognition application in production scenes. It is necessary to rank out the unqualified products as much as possible while ensuring high accuracy and high true negative rate (TNR) of detection results. It is challenged to optimize the true negative rate among the existing action recognition methods. Our analysis facilitates a packing action recognition method based on dual-view 3D convolutional network.MethodFirst, we extract motion features better through stacked residual frames as inputs, replacing optical flow that is not available in the real-time scene. The original RGB images and the residual frames are input to two parallel 3D ResNeXt101, and a concatenation layer is used to concatenate the features extracted in the last convolution layer of the two 3D ResNext101. Next, we adopts a dual-view structure to resolve the issue of human body being occluded, optimizes 3D ResNeXt101 into a dual-view model, builds up a learnable dual-view pooling layer for multifaceted feature fusion of views, and then uses this dual-view 3D ResNeXt101 model for action recognition. Finally, a noise-reducing self-encoder and two-class support vector machine (SVM) are added in our model to improve the true negative rate (TNR) of the detection results further. The dual-view pooling derived features are input to the noise-reducing self-encoder in the model, and the features are optimized and downscaled by the trained noise-reducing self-encoder, and then the two-class SVM model is used for secondary recognition.ResultWe conducted experiments in a packing scenario and evaluated using two metrics like accuracy rate and true-negative rate. The accuracy of our packing action recognition model is 94.2%, and the true negative rate is 98.9%, which optimizes current action recognition methods. Our accuracy is increased from 91.1% to 95.8% via the dual-view structure. The accuracy of the model is increased from 88.2% to 95.8% based on the residual frames module. If the residual frames module is altered by optical flow module, the accuracy rate is 96.2%, which is equivalent to the model using the residual frames module. The accuracy is only 91.5% that the unique two-class SVM structure added to the model without the denoising autoencoder. Thanks to the optimization and dimensionality reduction of the feature vectors by the denoising autoencoder, the accuracy reaches 94.2% via the combination of the denoising autoencoder and the two-class SVM both, the highest true negative rate of 98.9% obtained. After adding denoising autoencoder and two-class SVM to the model, the true negative rate of the model increased from 95.7% to 98.9%, while the accuracy rate decreased by 1.6%. Our demonstrated result is evaluated in the public dataset UCF (University of Central Florida) 101.Our single-view model obtained an accuracy of 97.1%, which achieved the second highest accuracy among all compared methods, second only to 3D ResNeXt101's 98.0%.ConclusionWe use a dual-view 3D ResNeXt101 model for effective packing action recognition. To obtain richer features from RGB images and differential images, two parallel 3D ResNeXt101 are used to learn spatio-temporal features and a dual-view feature fusion is accomplished using a learnable view pooling layer. In addition, a stacked denoising autoencoder is trained to optimize and downscale the features extracted in terms of the dual-view 3D ResNeXt101 model. To improve the true negative rate, a two-class SVM model is used for secondary detection. Our method can recognize the boxing action of the packing workers accurately and realize the high true negative rate (TNR) of the recognition results.关键词:action recognition;dual-view;3D convolutional neural network;denoising autoencoder;support vectormachine(SVM)115|207|1更新时间:2024-08-15 -
 摘要:ObjectiveElectrical power lines construction, plays an important role in the urban development, especially the high-voltage power lines. Engineering vehicles are composed of excavators and wheeled cranes contexts, which are used in construction sites. If the engineering vehicle is working on site surrounding the high-voltage power line, its bucket or boom would probably enter the high-voltage breakdown range when they are lifted, which is very easy to result in accidents such as short circuit breakdowns. So, it is necessary to find out the adequate engineering vehicles working scenario near high-voltage power line. The multiple rotors unmanned aerial vehicle (UAV) is widely used to acquire amounts of aerial images for power lines inspection. The engineering vehicle information should be recognized from these aerial images manually in common. The classical pattern recognition methods and some deep learning models like you only look once version 5 (YOLOv5) has been challenged to some issues of recognizing the engineering vehicle in acquired aerial image, such as inefficiency and inaccuracy. The classical pattern recognition method needs to manually extract the features. Some deep learning models usually have large parameter scale and complex network structure, and are not accurate enough while the training set is small. In order to solve these problems, our research demonstrated an improved capsule network model to recognize engineering vehicles from aerial images. Capsule network improvement is mainly on the two aspects as mentioned below: one is to improve the network structure of the capsule network model, and the other one is to improve the dynamic routing algorithm of the capsule network.MethodFirst, we built up an image dataset, which includes 1 890 aerial images in total. The dataset is then separated into training set and testing set at a ratio of 4 ∶1. Next, we improved the network structure of capsule network through a multi-layer densely connected method to extract more features of the engineering vehicle from the image, named improved model No.1. The multi-layer densely connected capsule network has 3 layers, 5 layers or 7 layers probably. Third, we facilitated the dynamic routing method of the capsule network by replacing the softmax function with the leaky-softmax function to improve the anti-interference performance of the capsule network, named improved model No.2. We named the model with multi-layer densely connected network and the leaky-softmax function as the improved model No.3. Fourth, we embedded several key parameters on those models. The key parameters are related to the number of layers in the capsule network, the routing coefficient and squeeze coefficient in the dynamic routing algorithm.ResultThe aim of first group of experiments is to validate whether the two improved approaches are effective or not. We compared the mean average precision (mAP) of the original capsule network model with improvement model No.1, improvement model No.2 and improvement model No.3. All models use the 3-layer densely connected capsule network. Our experimental results illustrate that the mAP of the improvement model No.1 is 91.70%, and the mAP of the model with improvement No.2 is 90.01%, which are 2.21% and 0.54% each better than the original capsule network. The improvement model No.3 further improves the recognition accuracy, whose mAP reaching 92.10%. The aim of second group of experiments is to classify the issue of the number of network layers influence the mAP of those models. The experimental results demonstrate that the number of network layers influences the mAP greatly. When the number of network layers is small, the mAP increases while the number of network layers increasing. After a peak mAP of recognition shown, the mAP often decreases while the number of network layers increasing. So, their relationship is non-monotonic and nonlinear. In the application case, a 5-layer capsule network has the best recognition mAP. Additionally, the various trends of mAP are not affected by the improvement of dynamic routing algorithm. Furthermore, the efficiency of those improved models all decreased dramatically while the number of capsule network layers increase. And the parameter volume of those improved models is not obviously various, which means that the volume of parameter is irrelevant to the target recognition precision. The aim of third group of experiments is to find out the optimal model with appropriate routing coefficient and squeeze coefficient. This group of experimental results show that the mAP of 5-layer densely connected capsule network reaches up to 94.56% while the routing coefficient is 5 and the squeeze coefficient is l, which is an increase of 5.07% compared to the original capsule network. Meanwhile, the parameter volume of this optimal model is close to original model. Therefore, this optimal model has quite qualified mAP and small parameter volume. The aim of fourth group of experiments is to compare the performance of optimal model with other models. This kind of result shows that our optimal model is better than the classical pattern recognition model and YOLOv5x model in mAP, and the parameter volume of the optimal model is smaller.ConclusionOur research harnessed two approaches to improve the capsule network model for the engineering vehicles recognition derived of UAV aerial images. Our demonstrated experiments illustrate that this improved model has the small parameter volume and quite good recognizing precision, which is very significant for the UAV to recognize the airborne target information.关键词:aerial image of unmanned aerial vehicle(UAV);recognition of engineering vehicle;capsule network;dynamic routing algorithm;densely connected network90|94|1更新时间:2024-08-15
摘要:ObjectiveElectrical power lines construction, plays an important role in the urban development, especially the high-voltage power lines. Engineering vehicles are composed of excavators and wheeled cranes contexts, which are used in construction sites. If the engineering vehicle is working on site surrounding the high-voltage power line, its bucket or boom would probably enter the high-voltage breakdown range when they are lifted, which is very easy to result in accidents such as short circuit breakdowns. So, it is necessary to find out the adequate engineering vehicles working scenario near high-voltage power line. The multiple rotors unmanned aerial vehicle (UAV) is widely used to acquire amounts of aerial images for power lines inspection. The engineering vehicle information should be recognized from these aerial images manually in common. The classical pattern recognition methods and some deep learning models like you only look once version 5 (YOLOv5) has been challenged to some issues of recognizing the engineering vehicle in acquired aerial image, such as inefficiency and inaccuracy. The classical pattern recognition method needs to manually extract the features. Some deep learning models usually have large parameter scale and complex network structure, and are not accurate enough while the training set is small. In order to solve these problems, our research demonstrated an improved capsule network model to recognize engineering vehicles from aerial images. Capsule network improvement is mainly on the two aspects as mentioned below: one is to improve the network structure of the capsule network model, and the other one is to improve the dynamic routing algorithm of the capsule network.MethodFirst, we built up an image dataset, which includes 1 890 aerial images in total. The dataset is then separated into training set and testing set at a ratio of 4 ∶1. Next, we improved the network structure of capsule network through a multi-layer densely connected method to extract more features of the engineering vehicle from the image, named improved model No.1. The multi-layer densely connected capsule network has 3 layers, 5 layers or 7 layers probably. Third, we facilitated the dynamic routing method of the capsule network by replacing the softmax function with the leaky-softmax function to improve the anti-interference performance of the capsule network, named improved model No.2. We named the model with multi-layer densely connected network and the leaky-softmax function as the improved model No.3. Fourth, we embedded several key parameters on those models. The key parameters are related to the number of layers in the capsule network, the routing coefficient and squeeze coefficient in the dynamic routing algorithm.ResultThe aim of first group of experiments is to validate whether the two improved approaches are effective or not. We compared the mean average precision (mAP) of the original capsule network model with improvement model No.1, improvement model No.2 and improvement model No.3. All models use the 3-layer densely connected capsule network. Our experimental results illustrate that the mAP of the improvement model No.1 is 91.70%, and the mAP of the model with improvement No.2 is 90.01%, which are 2.21% and 0.54% each better than the original capsule network. The improvement model No.3 further improves the recognition accuracy, whose mAP reaching 92.10%. The aim of second group of experiments is to classify the issue of the number of network layers influence the mAP of those models. The experimental results demonstrate that the number of network layers influences the mAP greatly. When the number of network layers is small, the mAP increases while the number of network layers increasing. After a peak mAP of recognition shown, the mAP often decreases while the number of network layers increasing. So, their relationship is non-monotonic and nonlinear. In the application case, a 5-layer capsule network has the best recognition mAP. Additionally, the various trends of mAP are not affected by the improvement of dynamic routing algorithm. Furthermore, the efficiency of those improved models all decreased dramatically while the number of capsule network layers increase. And the parameter volume of those improved models is not obviously various, which means that the volume of parameter is irrelevant to the target recognition precision. The aim of third group of experiments is to find out the optimal model with appropriate routing coefficient and squeeze coefficient. This group of experimental results show that the mAP of 5-layer densely connected capsule network reaches up to 94.56% while the routing coefficient is 5 and the squeeze coefficient is l, which is an increase of 5.07% compared to the original capsule network. Meanwhile, the parameter volume of this optimal model is close to original model. Therefore, this optimal model has quite qualified mAP and small parameter volume. The aim of fourth group of experiments is to compare the performance of optimal model with other models. This kind of result shows that our optimal model is better than the classical pattern recognition model and YOLOv5x model in mAP, and the parameter volume of the optimal model is smaller.ConclusionOur research harnessed two approaches to improve the capsule network model for the engineering vehicles recognition derived of UAV aerial images. Our demonstrated experiments illustrate that this improved model has the small parameter volume and quite good recognizing precision, which is very significant for the UAV to recognize the airborne target information.关键词:aerial image of unmanned aerial vehicle(UAV);recognition of engineering vehicle;capsule network;dynamic routing algorithm;densely connected network90|94|1更新时间:2024-08-15 -
 摘要:ObjectiveThe contexts of action analysis and recognition is challenged for a number of applications like video surveillance, personal assistance, human-machine interaction, and sports video analysis. Thanks to the video-based action recognition methods, an skeleton data based approach has been focused on recently due to its complex scenarios. To locate the 2D or 3D spatial coordinates of the joints, the skeleton data is mainly obtained via depth sensors or video-based pose estimation algorithms. Graph convolutional networks (GCNs) have been developed to resolve the issue in terms of the traditional methods cannot capture the completed dependence of joints with no graphical structure of skeleton data. The critical viewpoint is challenged to determine an adaptive graph structure for the skeleton data at the convolutional layers. The spatio-temporal graph convolutional network (ST-GCN) has been facilitated to learn spatial and temporal features simultaneously through the temporal edges plus between the corresponding joints of the spatial graph in consistent frames. However, ST-GCN focuses on the physical connection between joints of the human body in the spatial graph, and ignores internal dependencies in motion. Spatio-temporal modeling and channel-wise dependencies are crucial for capturing motion information in videos for the action recognition task. Despite of the credibility in skeleton-based action recognition of GCNs, the relative improvement of classical attention mechanism applications has been constrained. Our research highlights the importance of spatio-temporal interactions and channel-wise dependencies both in accordance with a novel multi-dimensional feature fusion attention mechanism (M2FA).MethodOur proposed model explicitly leverages comprehensive dependency information by feature fusion module embedded in the framework, which is differentiated from other action recognition models with additional information flow or complicated superposition of multiple existing attention modules. Given medium feature maps, M2FA infers the feature descriptors on the spatial, temporal and channel scales sequentially. The fusion of the feature descriptors filters the input feature maps for adaptive feature refinement. As M2FA is being a lightweight and general module, it can be integrated into any skeleton-based architecture seamlessly with end-to-end trainable attributes following the core recognition methods.ResultTo verify its effectiveness, our algorithm is validated and analyzed on two large-scale skeleton-based action recognition datasets: NTU-RGBD and Kinetics-Skeleton. Our experiments are carried out ablation studies to demonstrate the advantages of multi-dimensional feature fusion on the two datasets. Our analyses demonstrate the merit of M2FA for skeleton-based action recognition. On the Kinetics-Skeleton dataset, the action recognition rate of the proposed algorithm is 1.8% higher than that of the baseline algorithm (2s-AGCN). On cross-view benchmark of NTU-RGBD dataset, the human action recognition accuracy of the proposed method is 96.1%, which is higher than baseline method. In addition, the action recognition rate of the proposed method is 90.1% on cross-subject benchmark of NTU-RGBD dataset. We showed that the skeleton-based action recognition model, known as 2s-AGCN, can be significantly improved in terms of accuracy based on adaptive attention mechanism incorporation. Our multi-dimensional feature fusion attention mechanism, called M2FA, captures spatio-temporal interactions and interconnections between potential channels.ConclusionWe developed a novel multi-dimensional feature fusion attention mechanism (M2FA) that captures spatio-temporal interactions and channel-wise dependencies at the same time. Our experimental results show consistent improvements in classification and its priorities of M2FA.关键词:action recognition;skeleton information;graph convolutional network (GCN);attention mechanism;spatio-temporal interaction;channel-wise dependencies;multi-dimensional feature fusion113|164|4更新时间:2024-08-15
摘要:ObjectiveThe contexts of action analysis and recognition is challenged for a number of applications like video surveillance, personal assistance, human-machine interaction, and sports video analysis. Thanks to the video-based action recognition methods, an skeleton data based approach has been focused on recently due to its complex scenarios. To locate the 2D or 3D spatial coordinates of the joints, the skeleton data is mainly obtained via depth sensors or video-based pose estimation algorithms. Graph convolutional networks (GCNs) have been developed to resolve the issue in terms of the traditional methods cannot capture the completed dependence of joints with no graphical structure of skeleton data. The critical viewpoint is challenged to determine an adaptive graph structure for the skeleton data at the convolutional layers. The spatio-temporal graph convolutional network (ST-GCN) has been facilitated to learn spatial and temporal features simultaneously through the temporal edges plus between the corresponding joints of the spatial graph in consistent frames. However, ST-GCN focuses on the physical connection between joints of the human body in the spatial graph, and ignores internal dependencies in motion. Spatio-temporal modeling and channel-wise dependencies are crucial for capturing motion information in videos for the action recognition task. Despite of the credibility in skeleton-based action recognition of GCNs, the relative improvement of classical attention mechanism applications has been constrained. Our research highlights the importance of spatio-temporal interactions and channel-wise dependencies both in accordance with a novel multi-dimensional feature fusion attention mechanism (M2FA).MethodOur proposed model explicitly leverages comprehensive dependency information by feature fusion module embedded in the framework, which is differentiated from other action recognition models with additional information flow or complicated superposition of multiple existing attention modules. Given medium feature maps, M2FA infers the feature descriptors on the spatial, temporal and channel scales sequentially. The fusion of the feature descriptors filters the input feature maps for adaptive feature refinement. As M2FA is being a lightweight and general module, it can be integrated into any skeleton-based architecture seamlessly with end-to-end trainable attributes following the core recognition methods.ResultTo verify its effectiveness, our algorithm is validated and analyzed on two large-scale skeleton-based action recognition datasets: NTU-RGBD and Kinetics-Skeleton. Our experiments are carried out ablation studies to demonstrate the advantages of multi-dimensional feature fusion on the two datasets. Our analyses demonstrate the merit of M2FA for skeleton-based action recognition. On the Kinetics-Skeleton dataset, the action recognition rate of the proposed algorithm is 1.8% higher than that of the baseline algorithm (2s-AGCN). On cross-view benchmark of NTU-RGBD dataset, the human action recognition accuracy of the proposed method is 96.1%, which is higher than baseline method. In addition, the action recognition rate of the proposed method is 90.1% on cross-subject benchmark of NTU-RGBD dataset. We showed that the skeleton-based action recognition model, known as 2s-AGCN, can be significantly improved in terms of accuracy based on adaptive attention mechanism incorporation. Our multi-dimensional feature fusion attention mechanism, called M2FA, captures spatio-temporal interactions and interconnections between potential channels.ConclusionWe developed a novel multi-dimensional feature fusion attention mechanism (M2FA) that captures spatio-temporal interactions and channel-wise dependencies at the same time. Our experimental results show consistent improvements in classification and its priorities of M2FA.关键词:action recognition;skeleton information;graph convolutional network (GCN);attention mechanism;spatio-temporal interaction;channel-wise dependencies;multi-dimensional feature fusion113|164|4更新时间:2024-08-15 -
 摘要:ObjectiveThe task of action recognition is focused on multi-frame images analysis like the pose of the human body from a given sensor input or recognize the in situ action of the human body through the obtained images. Action recognition has a wide range of applications in ground truth scenarios, such as human interaction, action analysis and monitoring. Specifically, some illegal human behaviors monitoring in public sites related to bus interchange, railway stations and airports. At present, most of skeleton-based methods are required to use spatio-temporal information in order to obtain good results. Graph convolutional network (GCN) can combine space and time information effectively. However, GCN-based methods have high computational complexity. The integrated strategies of attention modules and multi-stream fusion will cause lower efficiency in the completed training process. The issue of algorithm cost as well as ensuring accuracy is essential to be dealt with in action recognition. Shift graph convolutional network (Shift-GCN) is applied shift to GCN effectively. Shift-GCN is composed of novel shift graph operations and lightweight point-wise convolutions, where the shift graph operations provide flexible receptive fields for spatio-temporal graphs. Our proposed Shift-GCN has its priority with more than 10× less computational complexity based on three datasets for skeleton-based action recognition However, the featured network is redundant and the internal structural design of the network has not yet optimized. Therefore, our research analysis optimizes it on the basis of lightweight Shift-GCN and finally gets our own integer sparse graph convolutional network (IntSparse-GCN).MethodIn order to effectively solve the feature redundancy problem of Shift-GCN, we proposes to move each layer of the network on the basis of the feature shift operation that the odd-numbered columns are moved up and the even-numbered columns are moved down and the removed part is replaced with 0. The input and output of is set to an integer multiple of the joint point. First, we adopt a basic network structure similar to the previous network parameters. In the process of designing the number of input and output channels, try to make the 0 in the characteristics of each joint point balanced and finally get the optimization network structure. This network makes the position of almost half of the feature channel 0, which can express features more accurately, making the feature matrix a sparse feature matrix with strong regularity. The network can improve the robustness of the model and the accuracy of recognition more effectively. Next, we analyzed the mask function in Shift-GCN. The results are illustrated that the learned network mask is distributed in a range centered on 0 and the learned weights will focus on few features. Most of features do not require mask intervention. Finally, our experiments found that more than 80% of the mask function is ineffective. Hence, we conducted a lot of experiments and found that the mask value in different intervals is set to 0. The influence is irregular, so we designed an automated traversal method to obtain the most accurate optimized parameters and then get the optimal network model. Not only improves the accuracy of the network, but also reduces the multiplication operation of the feature matrix and the mask vector.ResultOur ablation experiment shows that each algorithm improvement can harness the ability of the overall algorithm. On the X-sub dataset, the Top-1 of 1 stream(s) IntSparse-GCN reached 87.98%, the Top-1 of 1 s IntSparse-GCN+M-Sparse reached 88.01%; the Top-1 of 2 stream(s) IntSparse-GCN reached 89.80%, and the Top-1 of 2 s IntSparse-GCN+M-Sparse's Top-1 reached 89.82%; 4 stream(s) IntSparse-GCN's Top-1 reached 90.72%, 4 s IntSparse-GCN+M-Sparse's Top-1 reached 90.72%., Our evaluation is carried out on the NTU RGB + D dataset, X-view's 1 s IntSparse-GCN+M-Sparse's Top-1 reached 94.89%, and 2 s IntSparse-GCN+M-Sparse's Top-1 reached 96.21%, and the Top-1 of 4 s IntSparse-GCN+M-Sparse reached 96.57% through the ablation experiment, the Top-1 of 1s IntSparse-GCN+M-Sparse reached 92.89%, the Top-1 of 2 s IntSparse-GCN+M-Sparse reached 95.26%, and the Top of 4 s IntSparse-GCN+M-Sparse-1 reached 96.77%, which is 2.17% higher than the original model through the Northwestern-UCLA dataset evaluation. Compared to other representative algorithms, the multiple data sets accuracy and 4 streams have been improved.ConclusionWe first proposed a novel method called IntSparse-GCN. A spatial shift algorithm is introduced based on integer multiples of the channel. Such feature matrix is a sparse feature matrix with strong regularity. The matrix facilitates the possibility to optimize the model pruning. To obtain the most accurate optimization parameters, our research analyzed the mask function in Shift-GCN and designed an automated traversal method. Sparse feature matrix and the mask parameter have potential to pruning and quantification further.关键词:action recognition;lightweight;sparse feature matrix;integer sparse graph convolutional network (IntSparse-GCN);mask function108|175|2更新时间:2024-08-15
摘要:ObjectiveThe task of action recognition is focused on multi-frame images analysis like the pose of the human body from a given sensor input or recognize the in situ action of the human body through the obtained images. Action recognition has a wide range of applications in ground truth scenarios, such as human interaction, action analysis and monitoring. Specifically, some illegal human behaviors monitoring in public sites related to bus interchange, railway stations and airports. At present, most of skeleton-based methods are required to use spatio-temporal information in order to obtain good results. Graph convolutional network (GCN) can combine space and time information effectively. However, GCN-based methods have high computational complexity. The integrated strategies of attention modules and multi-stream fusion will cause lower efficiency in the completed training process. The issue of algorithm cost as well as ensuring accuracy is essential to be dealt with in action recognition. Shift graph convolutional network (Shift-GCN) is applied shift to GCN effectively. Shift-GCN is composed of novel shift graph operations and lightweight point-wise convolutions, where the shift graph operations provide flexible receptive fields for spatio-temporal graphs. Our proposed Shift-GCN has its priority with more than 10× less computational complexity based on three datasets for skeleton-based action recognition However, the featured network is redundant and the internal structural design of the network has not yet optimized. Therefore, our research analysis optimizes it on the basis of lightweight Shift-GCN and finally gets our own integer sparse graph convolutional network (IntSparse-GCN).MethodIn order to effectively solve the feature redundancy problem of Shift-GCN, we proposes to move each layer of the network on the basis of the feature shift operation that the odd-numbered columns are moved up and the even-numbered columns are moved down and the removed part is replaced with 0. The input and output of is set to an integer multiple of the joint point. First, we adopt a basic network structure similar to the previous network parameters. In the process of designing the number of input and output channels, try to make the 0 in the characteristics of each joint point balanced and finally get the optimization network structure. This network makes the position of almost half of the feature channel 0, which can express features more accurately, making the feature matrix a sparse feature matrix with strong regularity. The network can improve the robustness of the model and the accuracy of recognition more effectively. Next, we analyzed the mask function in Shift-GCN. The results are illustrated that the learned network mask is distributed in a range centered on 0 and the learned weights will focus on few features. Most of features do not require mask intervention. Finally, our experiments found that more than 80% of the mask function is ineffective. Hence, we conducted a lot of experiments and found that the mask value in different intervals is set to 0. The influence is irregular, so we designed an automated traversal method to obtain the most accurate optimized parameters and then get the optimal network model. Not only improves the accuracy of the network, but also reduces the multiplication operation of the feature matrix and the mask vector.ResultOur ablation experiment shows that each algorithm improvement can harness the ability of the overall algorithm. On the X-sub dataset, the Top-1 of 1 stream(s) IntSparse-GCN reached 87.98%, the Top-1 of 1 s IntSparse-GCN+M-Sparse reached 88.01%; the Top-1 of 2 stream(s) IntSparse-GCN reached 89.80%, and the Top-1 of 2 s IntSparse-GCN+M-Sparse's Top-1 reached 89.82%; 4 stream(s) IntSparse-GCN's Top-1 reached 90.72%, 4 s IntSparse-GCN+M-Sparse's Top-1 reached 90.72%., Our evaluation is carried out on the NTU RGB + D dataset, X-view's 1 s IntSparse-GCN+M-Sparse's Top-1 reached 94.89%, and 2 s IntSparse-GCN+M-Sparse's Top-1 reached 96.21%, and the Top-1 of 4 s IntSparse-GCN+M-Sparse reached 96.57% through the ablation experiment, the Top-1 of 1s IntSparse-GCN+M-Sparse reached 92.89%, the Top-1 of 2 s IntSparse-GCN+M-Sparse reached 95.26%, and the Top of 4 s IntSparse-GCN+M-Sparse-1 reached 96.77%, which is 2.17% higher than the original model through the Northwestern-UCLA dataset evaluation. Compared to other representative algorithms, the multiple data sets accuracy and 4 streams have been improved.ConclusionWe first proposed a novel method called IntSparse-GCN. A spatial shift algorithm is introduced based on integer multiples of the channel. Such feature matrix is a sparse feature matrix with strong regularity. The matrix facilitates the possibility to optimize the model pruning. To obtain the most accurate optimization parameters, our research analyzed the mask function in Shift-GCN and designed an automated traversal method. Sparse feature matrix and the mask parameter have potential to pruning and quantification further.关键词:action recognition;lightweight;sparse feature matrix;integer sparse graph convolutional network (IntSparse-GCN);mask function108|175|2更新时间:2024-08-15 -
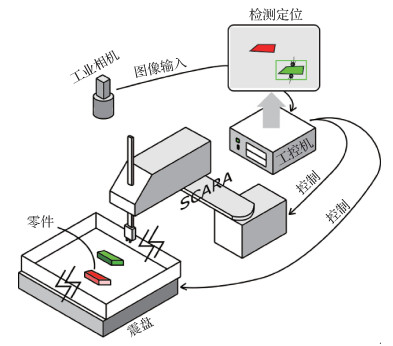 摘要:ObjectiveTexture-less object detection is crucial for industrial components picking systems, where multiple components are assigned to a feeder in random, and the objects is to use a vision-guided robot arm grasps each into a packing box. To improve deployment ability in industrial sites, the algorithm is required to adjust parameters with few samples and run in limited computing resources. The traditional detection methods can be achieved by key-point match quickly. However, industrial components are not textured to extract patch descriptors and build key-point correspondence sufficiently. The appearance of industrial components is dominated by their shape, and leads to template matching methods based on object contours. One classical work is Line2D, which only needs a few samples to build template and running in the CPU platform efficiently. However, it produces false-positive results when two components have a similar silhouette.MethodWe demonstrate a new method called color Line2D (CL2D). CL2D uses object images to extract template information, then running a sliding window template process on the input image to complete object detection. It covers the object shape and color both. We use the gradient direction feature as the shape descriptors, which can be extracted from discrete points on the object contour. Specifically, we compute the oriented gradient of these points on the object image and sliding window, and calculate the cosine value of the angle between each point pair and sum it to sort similarity out. We use the HSV color histogram to represent the appearance of object color as complementary to shape features. We use cosine similarity to compare the histogram between object image and sliding window. The overall framework of CL2D can be categorized into two parts of offline and online. In the offline part, we will build a template database to store the data that may be used in the online matching process in order to speed up the online process. The template database is constructed by the following two steps as mentioned below: first, we annotate relevant information on the object image for extracting template data related to object contour points, foreground area and grasp point. Second, we compute histogram in the context of the foreground area, rotation object image; contour points based gradient orientation to get templates for multi poses of rotation of the object. The online part can be summarized as three steps mentioned below: coarse matching, fine matching, and grasp point localization. First, we use gradient direction templates of different rotation pose, matching on the input image to obtain coarse detection results. The matching process is optimized through gradient direction quantization and pre-computed response maps to achieve a faster matching speed. Second, we use the non-maximum suppression to filter redundant matching results and then compare the color histogram to determine the detection result. Finally, we localize the object grasp point on the input image by a coordinate transformation method. In order to evaluate the performance of texture-less object detection methods, we illustrate YNU-building blocks datasets 2020 (YNU-BBD 2020) to simulate a real industrial scena-rio.ResultOur experimental results demonstrate that the algorithm can process 1 920×1 200 resolution images at an average speed of 2.15 s per frame on a CPU platform. In the case of using only one or two samples per object, CL2D can achieve 67.7% mAP on the YNU-BBD 2020 dataset, which is about 10% relative improvement compared to Lind2D, and 7% to deep learning methods based on the synthetic training data. The qualitative results of comparison with classic texture-less object detection methods show that the CL2D algorithm has its priorities in multi-instance object detection.ConclusionWe propose a texture-less object detection method in terms of the integration of color and shape representation. Our method can be applied in a CPU platform with few samples. It has significant advantages compare to deep learning methods or classical texture-less object detection methods. The proposed method has the potential to be used in industrial components picking systems.关键词:template match;texture-less object detection;color histogram;smart manufacturing;random bin-picking123|294|3更新时间:2024-08-15
摘要:ObjectiveTexture-less object detection is crucial for industrial components picking systems, where multiple components are assigned to a feeder in random, and the objects is to use a vision-guided robot arm grasps each into a packing box. To improve deployment ability in industrial sites, the algorithm is required to adjust parameters with few samples and run in limited computing resources. The traditional detection methods can be achieved by key-point match quickly. However, industrial components are not textured to extract patch descriptors and build key-point correspondence sufficiently. The appearance of industrial components is dominated by their shape, and leads to template matching methods based on object contours. One classical work is Line2D, which only needs a few samples to build template and running in the CPU platform efficiently. However, it produces false-positive results when two components have a similar silhouette.MethodWe demonstrate a new method called color Line2D (CL2D). CL2D uses object images to extract template information, then running a sliding window template process on the input image to complete object detection. It covers the object shape and color both. We use the gradient direction feature as the shape descriptors, which can be extracted from discrete points on the object contour. Specifically, we compute the oriented gradient of these points on the object image and sliding window, and calculate the cosine value of the angle between each point pair and sum it to sort similarity out. We use the HSV color histogram to represent the appearance of object color as complementary to shape features. We use cosine similarity to compare the histogram between object image and sliding window. The overall framework of CL2D can be categorized into two parts of offline and online. In the offline part, we will build a template database to store the data that may be used in the online matching process in order to speed up the online process. The template database is constructed by the following two steps as mentioned below: first, we annotate relevant information on the object image for extracting template data related to object contour points, foreground area and grasp point. Second, we compute histogram in the context of the foreground area, rotation object image; contour points based gradient orientation to get templates for multi poses of rotation of the object. The online part can be summarized as three steps mentioned below: coarse matching, fine matching, and grasp point localization. First, we use gradient direction templates of different rotation pose, matching on the input image to obtain coarse detection results. The matching process is optimized through gradient direction quantization and pre-computed response maps to achieve a faster matching speed. Second, we use the non-maximum suppression to filter redundant matching results and then compare the color histogram to determine the detection result. Finally, we localize the object grasp point on the input image by a coordinate transformation method. In order to evaluate the performance of texture-less object detection methods, we illustrate YNU-building blocks datasets 2020 (YNU-BBD 2020) to simulate a real industrial scena-rio.ResultOur experimental results demonstrate that the algorithm can process 1 920×1 200 resolution images at an average speed of 2.15 s per frame on a CPU platform. In the case of using only one or two samples per object, CL2D can achieve 67.7% mAP on the YNU-BBD 2020 dataset, which is about 10% relative improvement compared to Lind2D, and 7% to deep learning methods based on the synthetic training data. The qualitative results of comparison with classic texture-less object detection methods show that the CL2D algorithm has its priorities in multi-instance object detection.ConclusionWe propose a texture-less object detection method in terms of the integration of color and shape representation. Our method can be applied in a CPU platform with few samples. It has significant advantages compare to deep learning methods or classical texture-less object detection methods. The proposed method has the potential to be used in industrial components picking systems.关键词:template match;texture-less object detection;color histogram;smart manufacturing;random bin-picking123|294|3更新时间:2024-08-15 -
 摘要:ObjectiveObject detection is essential to computer vision and in-depth learning recently. It has been widely used in industrial detection, intelligent transportation, human facial recognition and contexts. There are two main categories of recognized target detection algorithms. One of current target detection algorithms is two-stage algorithm, such as region-based convolution neural network (R-CNN), Fast R-CNN, online hard example mining (OHEM), Faster R-CNN, Mask R-CNN etc. The methods generate target candidate boxes first, and implement the candidate boxes classification and regression following. The other one is single-stage algorithms, such as you only look once (YOLO), single shot multibox detector (SSD) etc. In addition, the demonstrated corner network(CornerNet) & center network(CenterNet)-anchor free models have tried to ignore the anchor frame and conduct detection and matching based on key points, which has achieved quite good results, but there is still a little gap from the detection method based on anchor frame. In the practical application of single-stage target detection, a main challenging issue is target detection like blurred image, small target and occluded object, and the predicted performance and efficiency. Feature fusion can improve the detection ability of difficult targets effectively by fusing different deep and shallow features of the network, which has been used in many improved SSD models in common. However, most of the improved models use feature fusion methods directly, and the specific fusion strategies like the issues of fused graphs option and fused graphs processing. In addition, current attention mechanism can make the feature graph have a certain "focus" effect by giving dimension weight. The issue of combining attention mechanism to single-stage target detection effectively has its potentials.MethodThe shallow Visual Geometry Group (VGG) network in the original SSD algorithm is replaced by the deep residual network as the backbone network. First, an optimized selection method of fusion strategy is designed in accordance with the idea of feature pyramid network (FPN). FPN is applied to the four layers of backbone network output to accomplish the detailed feature information description, the lower layer features are retained by down sampling during enhanced fusion process, while the size of the largest graph remains stable. The speed and performance are taken into account. In the operation sequence, FPN is used first, and then enhanced fusion is used, which is equivalent to one-step reversed FPN, It is better than initial enhancing and following FPN, and final removing the r_c5_conv4 layer which is the same as the r_c5_conv3 layer to reduce the interference. To better describe the target object, the feature mapping combines the detailed features of high pixel feature mapping with the rich semantic representation of low pixel feature mapping. Then, In respect of the ideas of bottleneck attention module (BAM) and squeeze-and-excitation network (SENet), our research designs a parallel dual attention mechanism to integrate the channel and spatial information of the feature map. The dual clustered effect of the feature map on the shape and position of the target is improved through channel attention and spatial attention. The parallel addition processing of channel and spatial attention mechanism strengthens the supervision of key features in terms of the parallel addition of channel attention mechanism and spatial attention mechanism for each feature graph. The key features are strengthened and the redundant interference features are weakened. At the same time, the spatial information in the feature graph is transformed to extract the key spatial position information. Finally, rich semantic information and distinctive features related feature groups are obtained.ResultThis comparative experiment is carried out on pattern analysis, statistical modelling and computational learning visual object classes (PASCAL VOC 2007) and IEEE Transactions on Geoscience and Remote Sensing-High Resolution Remote Sensing Detection (TGRS-HRRSD-Dataset). Our experimental results show that on PASCAL VOC2007 test set with 300×300 input pixels, the accuracy of fusion double attention(FDA)-SSD model reaches 79.8%, which is 2.6%, 1.3%, 1.2% and 1.0% higher than SSD, rainbow single shot detector (RSSD), de-convolution single shot detector (DSSD) and feature fusion single shot detector (FSSD) models, respectively. The detection speed on Titan X is 47 frames per second (FPS), which is equivalent to SSD algorithm, higher than RSSD and DSSD model 12 FPS and 37.5 FPS, respectively. The accuracy of the proposed algorithm is 81.6% on PASCAL VOC2007 test set with 512×512 pixels, and the detection speed on Titan X is 18 FPS, which is better than most algorithms in terms of the obtained accuracy and speed. The accuracy of TGRS-HRRSD-Dataset with 300×300 input pixels is 84.2%. The detection speed of Tesla V100 is 10% higher than SSD model, and the accuracy is improved by 1.5%. Our algorithm has good performance for regular data sets and aerial datasets both, which reflects the stability and portability of the algorithm.ConclusionOur research proposes an optimized feature map selection method and dual attention mechanism. Compared to many existing SSD improved models, this model has its dual advantages in accuracy and speed, and has good performance in the detection of small targets, occluded, blurred images and other challenging targets as well. Although the FDA-SSD model performs well in the SSD, our analysis is mainly based on the optimization of the featured graphs. The future prediction box generation and non-maximum suppression methods have their potentials to be studied further.关键词:single-stage object detection;single shot multibox detector(SSD);feature pyramid network(FPN);feature fusion;attention mechanism121|303|4更新时间:2024-08-15
摘要:ObjectiveObject detection is essential to computer vision and in-depth learning recently. It has been widely used in industrial detection, intelligent transportation, human facial recognition and contexts. There are two main categories of recognized target detection algorithms. One of current target detection algorithms is two-stage algorithm, such as region-based convolution neural network (R-CNN), Fast R-CNN, online hard example mining (OHEM), Faster R-CNN, Mask R-CNN etc. The methods generate target candidate boxes first, and implement the candidate boxes classification and regression following. The other one is single-stage algorithms, such as you only look once (YOLO), single shot multibox detector (SSD) etc. In addition, the demonstrated corner network(CornerNet) & center network(CenterNet)-anchor free models have tried to ignore the anchor frame and conduct detection and matching based on key points, which has achieved quite good results, but there is still a little gap from the detection method based on anchor frame. In the practical application of single-stage target detection, a main challenging issue is target detection like blurred image, small target and occluded object, and the predicted performance and efficiency. Feature fusion can improve the detection ability of difficult targets effectively by fusing different deep and shallow features of the network, which has been used in many improved SSD models in common. However, most of the improved models use feature fusion methods directly, and the specific fusion strategies like the issues of fused graphs option and fused graphs processing. In addition, current attention mechanism can make the feature graph have a certain "focus" effect by giving dimension weight. The issue of combining attention mechanism to single-stage target detection effectively has its potentials.MethodThe shallow Visual Geometry Group (VGG) network in the original SSD algorithm is replaced by the deep residual network as the backbone network. First, an optimized selection method of fusion strategy is designed in accordance with the idea of feature pyramid network (FPN). FPN is applied to the four layers of backbone network output to accomplish the detailed feature information description, the lower layer features are retained by down sampling during enhanced fusion process, while the size of the largest graph remains stable. The speed and performance are taken into account. In the operation sequence, FPN is used first, and then enhanced fusion is used, which is equivalent to one-step reversed FPN, It is better than initial enhancing and following FPN, and final removing the r_c5_conv4 layer which is the same as the r_c5_conv3 layer to reduce the interference. To better describe the target object, the feature mapping combines the detailed features of high pixel feature mapping with the rich semantic representation of low pixel feature mapping. Then, In respect of the ideas of bottleneck attention module (BAM) and squeeze-and-excitation network (SENet), our research designs a parallel dual attention mechanism to integrate the channel and spatial information of the feature map. The dual clustered effect of the feature map on the shape and position of the target is improved through channel attention and spatial attention. The parallel addition processing of channel and spatial attention mechanism strengthens the supervision of key features in terms of the parallel addition of channel attention mechanism and spatial attention mechanism for each feature graph. The key features are strengthened and the redundant interference features are weakened. At the same time, the spatial information in the feature graph is transformed to extract the key spatial position information. Finally, rich semantic information and distinctive features related feature groups are obtained.ResultThis comparative experiment is carried out on pattern analysis, statistical modelling and computational learning visual object classes (PASCAL VOC 2007) and IEEE Transactions on Geoscience and Remote Sensing-High Resolution Remote Sensing Detection (TGRS-HRRSD-Dataset). Our experimental results show that on PASCAL VOC2007 test set with 300×300 input pixels, the accuracy of fusion double attention(FDA)-SSD model reaches 79.8%, which is 2.6%, 1.3%, 1.2% and 1.0% higher than SSD, rainbow single shot detector (RSSD), de-convolution single shot detector (DSSD) and feature fusion single shot detector (FSSD) models, respectively. The detection speed on Titan X is 47 frames per second (FPS), which is equivalent to SSD algorithm, higher than RSSD and DSSD model 12 FPS and 37.5 FPS, respectively. The accuracy of the proposed algorithm is 81.6% on PASCAL VOC2007 test set with 512×512 pixels, and the detection speed on Titan X is 18 FPS, which is better than most algorithms in terms of the obtained accuracy and speed. The accuracy of TGRS-HRRSD-Dataset with 300×300 input pixels is 84.2%. The detection speed of Tesla V100 is 10% higher than SSD model, and the accuracy is improved by 1.5%. Our algorithm has good performance for regular data sets and aerial datasets both, which reflects the stability and portability of the algorithm.ConclusionOur research proposes an optimized feature map selection method and dual attention mechanism. Compared to many existing SSD improved models, this model has its dual advantages in accuracy and speed, and has good performance in the detection of small targets, occluded, blurred images and other challenging targets as well. Although the FDA-SSD model performs well in the SSD, our analysis is mainly based on the optimization of the featured graphs. The future prediction box generation and non-maximum suppression methods have their potentials to be studied further.关键词:single-stage object detection;single shot multibox detector(SSD);feature pyramid network(FPN);feature fusion;attention mechanism121|303|4更新时间:2024-08-15 -
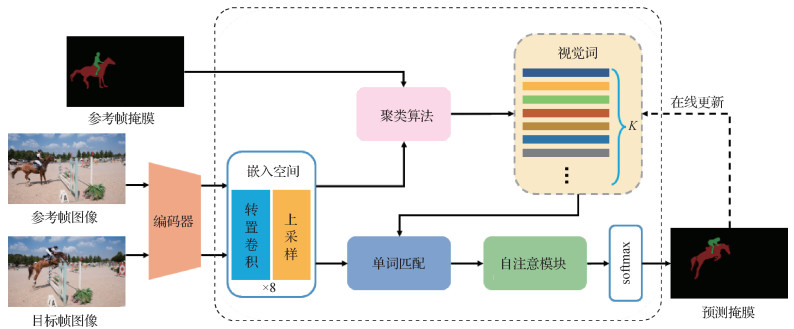 摘要:ObjectiveVideo object segmentation (VOS) involves foreground objects segmentation from the background in a video sequence. Its applications are relevant to video detection, video classification, video summarization, and self-driving. Our research is focused on a semi-supervised setting, which estimates the mask of the target object in the remaining frames of the video based on the target mask given in the initial frame. However, current video object segmentation algorithms are constrained of the issue of irregular shape, interference information and super-fast motion. Hence, our research develops a video object segmentation algorithm based on the integration of visual words and self-attention mechanism.MethodFor the reference frame, the reference frame image is first fed into the encoder to extract features of those resolutions are 1/8 of the original image. Subsequently, the extracted features are fed into the embedding space composed of several 3 × 3 convolution kernels, and the result is up-sampled to the original size. During the training process, the pixels from the same target in the embedding space are close to each other, while the pixels from different targets are far apart. Finally, the visual words representing the target objects are formed by combining the mask information annotated in the reference frames and clustering the pixels in the embedding space using a clustering algorithm. For the target frame, its image is first fed into the encoder and passed through the embedding space, and then a word matching operation is performed to represent the pixels in the embedding space with a certain number of visual words to obtain similarity maps. However, learning visual words is a challenging task because there is no real information about their corresponding object parts. Therefore, a meta-training algorithm is used to alternate between unsupervised learning of visual words and supervised learning of pixel classification given these visual words. The application of visual vocabulary allows for more robust matching because an object may be obscured, deformed, changed perspective, or disappear and reappear from the same video, and its partial appearance may remain the same. Then, the self-attention mechanism is applied to the generated similarity map to capture the global dependency, and the maximum value is taken in the channel direction as the predicted result. To resolve significant appearance changes and global mismatch issues, an efficient online update and global correction mechanism is adopted to improve the accuracy further. For the online update mechanism, the updated timing has an impact on the performance of the model. When the update interval is shorter, the dictionary is updated more frequently, which aids the network to adapt dynamic scenes and fast-moving objects better. However, if the interval is too short, it is possible to cause more noisy visual words, which will affect the performance of the algorithm. Therefore, it is important to use an appropriate update frequency. Here, the visual dictionary is set to be updated every 5 frames. Furthermore, to ensure that the prediction masks used to update visual words in the online update mechanism are reliable, a simple outlier removal process is applied to the prediction masks. Specifically, given a region with the same prediction annotation, the prediction region is accepted only if it intersects the object mask predicted in the previous frame. If there is no intersection, this prediction mask is discarded and the prediction is made directly on it based on the previous result.ResultWe validate the effectiveness and robustness of our method on the challenging DAVIS 2016(densely annotated video segmentation) and DAVIS 2017 datasets. Our method is compared to state-of-the-art methods, with J&F-mean(Jaccard and F-score mean) score of 83.2% on DAVIS 2016, with J&F-mean score of 72.3% on DAVIS 2017. We achieved comparable accuracy to the fine-tuning-based method, and reached a competitive level in terms of the speed/accuracy trade-off of the two video object segmentation datasets.ConclusionThe proposed algorithm can effectively deal with the interference problems caused by occlusion, deformation and viewpoint change, and achieve high quality video object segmentation.关键词:video object segmentation (VOS);Clustering algorithm;visual words;self-attention mechanism;online update mechanism;global correction mechanism77|172|1更新时间:2024-08-15
摘要:ObjectiveVideo object segmentation (VOS) involves foreground objects segmentation from the background in a video sequence. Its applications are relevant to video detection, video classification, video summarization, and self-driving. Our research is focused on a semi-supervised setting, which estimates the mask of the target object in the remaining frames of the video based on the target mask given in the initial frame. However, current video object segmentation algorithms are constrained of the issue of irregular shape, interference information and super-fast motion. Hence, our research develops a video object segmentation algorithm based on the integration of visual words and self-attention mechanism.MethodFor the reference frame, the reference frame image is first fed into the encoder to extract features of those resolutions are 1/8 of the original image. Subsequently, the extracted features are fed into the embedding space composed of several 3 × 3 convolution kernels, and the result is up-sampled to the original size. During the training process, the pixels from the same target in the embedding space are close to each other, while the pixels from different targets are far apart. Finally, the visual words representing the target objects are formed by combining the mask information annotated in the reference frames and clustering the pixels in the embedding space using a clustering algorithm. For the target frame, its image is first fed into the encoder and passed through the embedding space, and then a word matching operation is performed to represent the pixels in the embedding space with a certain number of visual words to obtain similarity maps. However, learning visual words is a challenging task because there is no real information about their corresponding object parts. Therefore, a meta-training algorithm is used to alternate between unsupervised learning of visual words and supervised learning of pixel classification given these visual words. The application of visual vocabulary allows for more robust matching because an object may be obscured, deformed, changed perspective, or disappear and reappear from the same video, and its partial appearance may remain the same. Then, the self-attention mechanism is applied to the generated similarity map to capture the global dependency, and the maximum value is taken in the channel direction as the predicted result. To resolve significant appearance changes and global mismatch issues, an efficient online update and global correction mechanism is adopted to improve the accuracy further. For the online update mechanism, the updated timing has an impact on the performance of the model. When the update interval is shorter, the dictionary is updated more frequently, which aids the network to adapt dynamic scenes and fast-moving objects better. However, if the interval is too short, it is possible to cause more noisy visual words, which will affect the performance of the algorithm. Therefore, it is important to use an appropriate update frequency. Here, the visual dictionary is set to be updated every 5 frames. Furthermore, to ensure that the prediction masks used to update visual words in the online update mechanism are reliable, a simple outlier removal process is applied to the prediction masks. Specifically, given a region with the same prediction annotation, the prediction region is accepted only if it intersects the object mask predicted in the previous frame. If there is no intersection, this prediction mask is discarded and the prediction is made directly on it based on the previous result.ResultWe validate the effectiveness and robustness of our method on the challenging DAVIS 2016(densely annotated video segmentation) and DAVIS 2017 datasets. Our method is compared to state-of-the-art methods, with J&F-mean(Jaccard and F-score mean) score of 83.2% on DAVIS 2016, with J&F-mean score of 72.3% on DAVIS 2017. We achieved comparable accuracy to the fine-tuning-based method, and reached a competitive level in terms of the speed/accuracy trade-off of the two video object segmentation datasets.ConclusionThe proposed algorithm can effectively deal with the interference problems caused by occlusion, deformation and viewpoint change, and achieve high quality video object segmentation.关键词:video object segmentation (VOS);Clustering algorithm;visual words;self-attention mechanism;online update mechanism;global correction mechanism77|172|1更新时间:2024-08-15 -
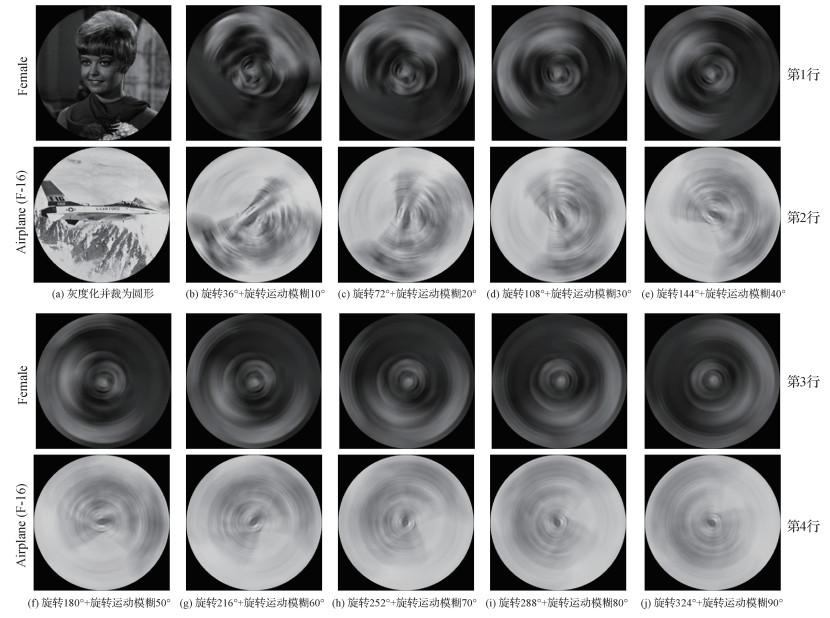 摘要:ObjectiveThe blurred image based target recognition issue is essential to computer vision and pattern recognition. In the process of camera imaging exposure, Image degradation is affected by varied environmental and practical factors like atmospheric interference, camera defocus, relative motion between camera and scene. Therefore, the ideal image features should be invariant to these changes. Image motion blur is caused by and relative motion between camera and scene in the process of exposure time. It can be regarded as the integral of image density function in a certain time interval. According to the motion form of the camera relative to the scene in the three-dimensional space in the exposure time, the motion blur of the image can be divided into linear motion blur, rotational motion blur, radial motion blur and other more complex motion blur formed by the superposition of the above three kinds of blurs. In particular, captured images of high-speed rotating status will produce rotational motion blur. In the aspect of pattern recognition of motion blurred image, most of the works choose the strategy of "deblurring". They carry on the next level image processing after restoring the blurred image as clear as possible. If the preprocessing process of image restoration is eliminated and the image features with motion blur invariance are extracted directly, the efficiency of image recognition will be accelerated. Therefore, recent invariant features constructed motion blurred images has become an important research direction in the field of image recognition. Our research method is focused on sort the invariant features out between original image and blurred image through the mathematical model of blurring and the theory of moment invariants.MethodWhen there is relative motion between the object and the photosensitive element, distorted accumulation of light on the imaging plane will occur in one shutter time, resulting in motion blurred image. The blur path can be regarded as a series of concentric circles centered on the camera and the object in terms of axial rotation between the sensor and the object. The rotational motion of variable speed can be decomposed into standardized multiple rotational motions due to the extremely glimpsed shutter time. We will focus on the rotational motion blur standardization related to known rotation center and constant angular velocity based on degraded model of rotation motion blur and Gaussian-Hermite moment. Our method demonstrated the rotational motion blur Gaussian-Hermite moment built issues and facilitated the existing of low-rank rotational motion blur Gaussian-Hermite moment invariants. Correspondingly, the formation of this kind of image is the superposition mean value of the results of a series of rotation transformations on the original image based on the rotation motion blur degradation model. We illustrated that the rotational motion blur Gaussian-Hermite moments is a linear combination of the Gaussian-Hermite moments of the original image. The construction process of rotational motion blur invariants is the process of eliminating the coefficients of Gaussian-Hermite moments of the original image based on Gaussian-Hermite moments. In this way, Gaussian-Hermite moment based rotational motion blur invariants on is built. We filtrated 5 Gaussian-Hermite moment invariants from exiting rotational geometry moment invariants which had been extended to Gaussian-Hermite moment invariants to construct a highly stable 5-dimensional feature vector and named it as rotational motion blur Gaussian-Hermite moment invariants(RMB_GHMI-5), and we verified that RMB_GHMI-5 had great properties of invariability and distinguishability. Finally, we introduced RMB_GHMI-5 to the field of image retrieval.ResultIn invariance experiment, we validated the invariance ability of the feature vector on the dataset University of Southern California — Signal and Image Processing Institute(USC-SIPI). Two sets of 18 composited blurred images have been made to test RMB_GHMI-5. Our results demonstrate that the feature distance between original image and composited blurred image are extremely weak, which means RMB_GHMI-5 has great invariant attributes. In addition to the image retrieval experiments, we introduce two image datasets in the context of Flavia and Butterfly for original image. Such composited images are blurred of different degree of rotation, rotational motion and Gaussian noise or salt-pepper noise has been used to validate the invariability and distinguishability of RMB_GHMI-5. Compared to 4 distinctive saliency approaches related to leaf images, rotated degrading, rotational motion and Gaussian noise at 80% recall rate, the recognition accuracy of RMB_GHMI-5 is 25.89% higher than salt-pepper noise (39.95%), Poisson noise (22.79%) and multiplicative noise (35.80%). For Butterfly Images degraded by rotation, rotational motion and Gaussian noise at 80% recall rate, the recognition accuracy of RMB_GHMI-5 is 7.18% higher than salt-pepper noise (39.95%), Poisson noise (22.79%) and multiplicative noise (35.80%).ConclusionWe proposed a 5-dimensional feature vector RMB_GHMI-5 which is invariable for rotational motion blur based on Gaussian-Hermite moments. We verified that RMB_GHMI-5 had great potentials of invariability and distinguishability in the field of image retrieval. Our experimental results demonstrate that RMB_GHMI-5 has its priority related to current saliency approaches.关键词:image retrieval;image invariant feature;rotational motion blur;Gaussian-Hermite moment;invariant109|160|1更新时间:2024-08-15
摘要:ObjectiveThe blurred image based target recognition issue is essential to computer vision and pattern recognition. In the process of camera imaging exposure, Image degradation is affected by varied environmental and practical factors like atmospheric interference, camera defocus, relative motion between camera and scene. Therefore, the ideal image features should be invariant to these changes. Image motion blur is caused by and relative motion between camera and scene in the process of exposure time. It can be regarded as the integral of image density function in a certain time interval. According to the motion form of the camera relative to the scene in the three-dimensional space in the exposure time, the motion blur of the image can be divided into linear motion blur, rotational motion blur, radial motion blur and other more complex motion blur formed by the superposition of the above three kinds of blurs. In particular, captured images of high-speed rotating status will produce rotational motion blur. In the aspect of pattern recognition of motion blurred image, most of the works choose the strategy of "deblurring". They carry on the next level image processing after restoring the blurred image as clear as possible. If the preprocessing process of image restoration is eliminated and the image features with motion blur invariance are extracted directly, the efficiency of image recognition will be accelerated. Therefore, recent invariant features constructed motion blurred images has become an important research direction in the field of image recognition. Our research method is focused on sort the invariant features out between original image and blurred image through the mathematical model of blurring and the theory of moment invariants.MethodWhen there is relative motion between the object and the photosensitive element, distorted accumulation of light on the imaging plane will occur in one shutter time, resulting in motion blurred image. The blur path can be regarded as a series of concentric circles centered on the camera and the object in terms of axial rotation between the sensor and the object. The rotational motion of variable speed can be decomposed into standardized multiple rotational motions due to the extremely glimpsed shutter time. We will focus on the rotational motion blur standardization related to known rotation center and constant angular velocity based on degraded model of rotation motion blur and Gaussian-Hermite moment. Our method demonstrated the rotational motion blur Gaussian-Hermite moment built issues and facilitated the existing of low-rank rotational motion blur Gaussian-Hermite moment invariants. Correspondingly, the formation of this kind of image is the superposition mean value of the results of a series of rotation transformations on the original image based on the rotation motion blur degradation model. We illustrated that the rotational motion blur Gaussian-Hermite moments is a linear combination of the Gaussian-Hermite moments of the original image. The construction process of rotational motion blur invariants is the process of eliminating the coefficients of Gaussian-Hermite moments of the original image based on Gaussian-Hermite moments. In this way, Gaussian-Hermite moment based rotational motion blur invariants on is built. We filtrated 5 Gaussian-Hermite moment invariants from exiting rotational geometry moment invariants which had been extended to Gaussian-Hermite moment invariants to construct a highly stable 5-dimensional feature vector and named it as rotational motion blur Gaussian-Hermite moment invariants(RMB_GHMI-5), and we verified that RMB_GHMI-5 had great properties of invariability and distinguishability. Finally, we introduced RMB_GHMI-5 to the field of image retrieval.ResultIn invariance experiment, we validated the invariance ability of the feature vector on the dataset University of Southern California — Signal and Image Processing Institute(USC-SIPI). Two sets of 18 composited blurred images have been made to test RMB_GHMI-5. Our results demonstrate that the feature distance between original image and composited blurred image are extremely weak, which means RMB_GHMI-5 has great invariant attributes. In addition to the image retrieval experiments, we introduce two image datasets in the context of Flavia and Butterfly for original image. Such composited images are blurred of different degree of rotation, rotational motion and Gaussian noise or salt-pepper noise has been used to validate the invariability and distinguishability of RMB_GHMI-5. Compared to 4 distinctive saliency approaches related to leaf images, rotated degrading, rotational motion and Gaussian noise at 80% recall rate, the recognition accuracy of RMB_GHMI-5 is 25.89% higher than salt-pepper noise (39.95%), Poisson noise (22.79%) and multiplicative noise (35.80%). For Butterfly Images degraded by rotation, rotational motion and Gaussian noise at 80% recall rate, the recognition accuracy of RMB_GHMI-5 is 7.18% higher than salt-pepper noise (39.95%), Poisson noise (22.79%) and multiplicative noise (35.80%).ConclusionWe proposed a 5-dimensional feature vector RMB_GHMI-5 which is invariable for rotational motion blur based on Gaussian-Hermite moments. We verified that RMB_GHMI-5 had great potentials of invariability and distinguishability in the field of image retrieval. Our experimental results demonstrate that RMB_GHMI-5 has its priority related to current saliency approaches.关键词:image retrieval;image invariant feature;rotational motion blur;Gaussian-Hermite moment;invariant109|160|1更新时间:2024-08-15
Image Analysis and Recognition
-
 摘要:ObjectiveSemantic segmentation is essential to computer vision application. It assigns each pixel to its corresponding category in an image, which is a pixel leveled multi-classification task. It is of great significance in the fields of automatic driving, virtual reality and medical image processing. The emergence of convolutional neural network (CNN) promotes the rapid development of neural network in various tasks of computer vision. The fully CNN has completely changed the pattern of semantic segmentation contexts. With the advent of depth camera, it is more convenient to obtain the depth images corresponding to color images. The depth image is single-channel, and each value should be ranged from the pixel to the camera plain in the image. Obviously, depth images contain spatial distance information, but color images are relatively insufficient. In the semantic segmentation task, it is difficult for the network to distinguish the adjacent objects with similar appearance in the plain image, but the application of depth image can be released to some extent. RGB-D semantic segmentation is focused on recently. The ways of depth information-embedded visual features can be roughly divided into the following three categories like one-stream, two-streams and multi-tasks. One-stream does not use depth images as additional input to extract features. It only has a backbone network to extract features from color images. In the process of feature extraction, the inherent spatial information of depth images is used to assist visual feature extraction for semantic segmentation improvement. Two-streams use the depth image as an additional input to extract features. There are mainly two backbone networks involved, each of which extracts features from color images and depth images each. In the encoding stage or decoding stage, the extracted visual features are fused with depth features to realize depth information application. Multi-task processes semantic segmentation, depth estimation and surface normal estimation at the same time. Such a method has one common backbone network only. In the process of feature extraction from color images, multi feature interaction can improve the performance of each task. Previous studies have challenged to effective depth information as well, and embedding all depth information into visual features may cause interference to the network. The inherent color and texture information can sometimes clearly distinguish two or more categories in a color image, where the addition of depth information is somewhat gilding the lily. For example, similar depth objects can be distinguished by visual features excluded different visual features, but the addition of depth information will make the network confused and even make wrong judgments. Moreover, the inherent structure of the convolution kernel limits its ability of feature extraction in CNN. To solve this problem, our proposed deformable convolution can learn the offset of the corresponding points according to the input, and extract more effective features in terms of the shape of the object, thus improving the modeling ability of the network. However, it is insufficient to learn the offset only by the input of visual features, because the spatial information of color images is very limited.MethodWe develop a depth guided feature extraction module (DFE), which includes depth guided feature selection module (DFS) and depth embedded deformable convolution module (DDC). First, the proposed depth guided feature selection module concatenates the input of depth features and visual features in order to ignore the interference on the network derived from all depth information, and then selects the features with important influence from the fusion features through the channel attention method. Next, the weight matrix of the depth features is obtained through 1×1 convolution and sigmoid function. After multiplying the depth features and the corresponding weight matrix, the depth information to be embedded in the visual features is obtained. This depth information is then added to the visual features. Since the weight matrix corresponding to the depth features is obtained by learning, the network can adjust the number of depth information adequately, rather than accepting all the depth information. For instance, the proportion of depth information will be increased if the depth information is needed for classification. Otherwise, the proportion of depth information will be decreased. In order to promote the feature extraction capability of deformable convolution completely, the depth embedded deformable convolution module is proposed. Depth information-embedded visual features are taken as input to learn the offset of sampling points. The addition of depth features makes up for the deficiency of geometric information of visual features.ResultIn order to verify the effectiveness of the method, a series of ablation experiments are carried out on the New York University Depth Dataset V2(NYUv2) compared to the current methods. Mean intersection over union (mIoU) and mean pixel accuracy (mPA) are used as the measurement criteria. Our method achieved 51.9% of mIoU and 77.6% of PA on NYUv2, respectively. The visualization results of semantic segmentation are demonstrated to prove the effectiveness of the method.ConclusionWe facilitates the depth guided feature extraction module (DFE), which includes depth guided feature selection module (DFS) and depth embedded deformable convolution module (DDC). DFS can adaptively determine the proportion of depth information in terms of the input of visual features and depth features. DDC enhances the feature extraction capability of deformable convolution through embedding depth information, and can extract more effective features via the shape of objects. In addition, our designed module can be embedded into the current feature extraction network. The depth information can be used to improve the modeling ability of the network effectively.关键词:semantic segmentation;RGB-D;depth guided feature selection (DFS);depth embedded deformable convolution (DDC);depth guided feature extraction (DFE)109|151|1更新时间:2024-08-15
摘要:ObjectiveSemantic segmentation is essential to computer vision application. It assigns each pixel to its corresponding category in an image, which is a pixel leveled multi-classification task. It is of great significance in the fields of automatic driving, virtual reality and medical image processing. The emergence of convolutional neural network (CNN) promotes the rapid development of neural network in various tasks of computer vision. The fully CNN has completely changed the pattern of semantic segmentation contexts. With the advent of depth camera, it is more convenient to obtain the depth images corresponding to color images. The depth image is single-channel, and each value should be ranged from the pixel to the camera plain in the image. Obviously, depth images contain spatial distance information, but color images are relatively insufficient. In the semantic segmentation task, it is difficult for the network to distinguish the adjacent objects with similar appearance in the plain image, but the application of depth image can be released to some extent. RGB-D semantic segmentation is focused on recently. The ways of depth information-embedded visual features can be roughly divided into the following three categories like one-stream, two-streams and multi-tasks. One-stream does not use depth images as additional input to extract features. It only has a backbone network to extract features from color images. In the process of feature extraction, the inherent spatial information of depth images is used to assist visual feature extraction for semantic segmentation improvement. Two-streams use the depth image as an additional input to extract features. There are mainly two backbone networks involved, each of which extracts features from color images and depth images each. In the encoding stage or decoding stage, the extracted visual features are fused with depth features to realize depth information application. Multi-task processes semantic segmentation, depth estimation and surface normal estimation at the same time. Such a method has one common backbone network only. In the process of feature extraction from color images, multi feature interaction can improve the performance of each task. Previous studies have challenged to effective depth information as well, and embedding all depth information into visual features may cause interference to the network. The inherent color and texture information can sometimes clearly distinguish two or more categories in a color image, where the addition of depth information is somewhat gilding the lily. For example, similar depth objects can be distinguished by visual features excluded different visual features, but the addition of depth information will make the network confused and even make wrong judgments. Moreover, the inherent structure of the convolution kernel limits its ability of feature extraction in CNN. To solve this problem, our proposed deformable convolution can learn the offset of the corresponding points according to the input, and extract more effective features in terms of the shape of the object, thus improving the modeling ability of the network. However, it is insufficient to learn the offset only by the input of visual features, because the spatial information of color images is very limited.MethodWe develop a depth guided feature extraction module (DFE), which includes depth guided feature selection module (DFS) and depth embedded deformable convolution module (DDC). First, the proposed depth guided feature selection module concatenates the input of depth features and visual features in order to ignore the interference on the network derived from all depth information, and then selects the features with important influence from the fusion features through the channel attention method. Next, the weight matrix of the depth features is obtained through 1×1 convolution and sigmoid function. After multiplying the depth features and the corresponding weight matrix, the depth information to be embedded in the visual features is obtained. This depth information is then added to the visual features. Since the weight matrix corresponding to the depth features is obtained by learning, the network can adjust the number of depth information adequately, rather than accepting all the depth information. For instance, the proportion of depth information will be increased if the depth information is needed for classification. Otherwise, the proportion of depth information will be decreased. In order to promote the feature extraction capability of deformable convolution completely, the depth embedded deformable convolution module is proposed. Depth information-embedded visual features are taken as input to learn the offset of sampling points. The addition of depth features makes up for the deficiency of geometric information of visual features.ResultIn order to verify the effectiveness of the method, a series of ablation experiments are carried out on the New York University Depth Dataset V2(NYUv2) compared to the current methods. Mean intersection over union (mIoU) and mean pixel accuracy (mPA) are used as the measurement criteria. Our method achieved 51.9% of mIoU and 77.6% of PA on NYUv2, respectively. The visualization results of semantic segmentation are demonstrated to prove the effectiveness of the method.ConclusionWe facilitates the depth guided feature extraction module (DFE), which includes depth guided feature selection module (DFS) and depth embedded deformable convolution module (DDC). DFS can adaptively determine the proportion of depth information in terms of the input of visual features and depth features. DDC enhances the feature extraction capability of deformable convolution through embedding depth information, and can extract more effective features via the shape of objects. In addition, our designed module can be embedded into the current feature extraction network. The depth information can be used to improve the modeling ability of the network effectively.关键词:semantic segmentation;RGB-D;depth guided feature selection (DFS);depth embedded deformable convolution (DDC);depth guided feature extraction (DFE)109|151|1更新时间:2024-08-15 -
 摘要:ObjectiveHuman facial beauty prediction is the research on how to make computers have the ability to judge or predict the beauty of faces similar to humans. However, deep neural networks based facial beauty prediction has challenged the issue of noisy label samples affecting the training of deep neural network models, which thus affects the generalizability of deep neural networks. Noisy labels are mislabeled in the database, which usually affect the training of deep neural network models, thus reduce the generalizability of deep neural networks. To reduce the negative impact of noisy labels on deep neural networks in facial beauty prediction, a self-correcting noisy label method was proposed, which has the features of selection of clean samples for learning and full utilization of all data.MethodOur method is composed of a self-training teacher model mechanism and a re-labeling retraining mechanism. First, two deep convolutional neural networks (CNNs) are initialized with the same structure simultaneously, and the network is used as the teacher model with stronger generalization ability, while the other network is used as the student model. The teacher model can be arbitrarily specified during initialization. Second, small batches of training data are fed to the teacher and student models both at the input side together. The student model receives the sample number and finds the corresponding sample and label for back-propagation training until the generalization ability of the student model exceeds that of the teacher model. Then, the student model shares the optimal parameters to the teacher model, i.e., the original student model becomes the new teacher model, where it is called the self-training teacher model mechanism. After several iterations of training, small batches of data are fed into the teacher model with the strongest generalization ability among all previous training epochs, and its prediction probability of each category is calculated. If the maximum output probability predicted by the teacher model for this data is higher than a certain threshold of the corresponding output probability of the label, it is considered that the sample label should be corrected. The self-training teacher model mechanism is then iteratively executed utilizing the corrected data, where the process above is called the relabeling retraining mechanism. Finally, the teacher model is output as the final model.ResultThe ResNet-18 model pre-trained on the ImageNet database is used as the backbone deep neural network, which is regarded as a baseline method with cross entropy as the loss function. The experiments on the large scale facial beauty database (LSFBD) and SCUT-FBP5500 database are divided into two main parts as mentioned below: 1) the first part is performed under synthetic noise label conditions, i.e., 10%, 20%, and 30% of the training data are selected from each class of facial beauty data on the two databases mentioned above, while their labels are randomly changed. The accuracy of the method in this paper exceeds the baseline method by 5.8%, 4.1% and 3.7% on the LSFBD database at noise rates of 30%, 20% and 10%, respectively. The accuracy exceeds the baseline method by 3.1%, 2.8%, and 2.5% on the SCUT-FBP5500 database, respectively. Therefore, it is demonstrated that our method can reduce the negative impact of noisy labels under synthetic noisy label conditions. 2) The second part is carried out on the original LSFBD database and the original SCUT-FBP5500 database, and our method exceeded the prediction accuracy of the baseline method by 2.7% and 1.2% on the original LSFBD database and the original SCUT-FBP5500 database, respectively. Therefore, our demonstrated illustration can reduce the negative impact of noise labels under the original data conditions.ConclusionOur proposed method of self-correcting noise labels can reduce the negative impact of noise label in human facial beauty prediction in some extent and improve the prediction accuracy based on the LSFBD and SCUT-FBP5500 databases under synthetic noisy label circumstances, the original LSFBD and SCUT-FBP5500 facial beauty databases, respectively.关键词:deep learning;noise labels;facial beauty prediction;characteristics classification;deep neural networks83|139|0更新时间:2024-08-15
摘要:ObjectiveHuman facial beauty prediction is the research on how to make computers have the ability to judge or predict the beauty of faces similar to humans. However, deep neural networks based facial beauty prediction has challenged the issue of noisy label samples affecting the training of deep neural network models, which thus affects the generalizability of deep neural networks. Noisy labels are mislabeled in the database, which usually affect the training of deep neural network models, thus reduce the generalizability of deep neural networks. To reduce the negative impact of noisy labels on deep neural networks in facial beauty prediction, a self-correcting noisy label method was proposed, which has the features of selection of clean samples for learning and full utilization of all data.MethodOur method is composed of a self-training teacher model mechanism and a re-labeling retraining mechanism. First, two deep convolutional neural networks (CNNs) are initialized with the same structure simultaneously, and the network is used as the teacher model with stronger generalization ability, while the other network is used as the student model. The teacher model can be arbitrarily specified during initialization. Second, small batches of training data are fed to the teacher and student models both at the input side together. The student model receives the sample number and finds the corresponding sample and label for back-propagation training until the generalization ability of the student model exceeds that of the teacher model. Then, the student model shares the optimal parameters to the teacher model, i.e., the original student model becomes the new teacher model, where it is called the self-training teacher model mechanism. After several iterations of training, small batches of data are fed into the teacher model with the strongest generalization ability among all previous training epochs, and its prediction probability of each category is calculated. If the maximum output probability predicted by the teacher model for this data is higher than a certain threshold of the corresponding output probability of the label, it is considered that the sample label should be corrected. The self-training teacher model mechanism is then iteratively executed utilizing the corrected data, where the process above is called the relabeling retraining mechanism. Finally, the teacher model is output as the final model.ResultThe ResNet-18 model pre-trained on the ImageNet database is used as the backbone deep neural network, which is regarded as a baseline method with cross entropy as the loss function. The experiments on the large scale facial beauty database (LSFBD) and SCUT-FBP5500 database are divided into two main parts as mentioned below: 1) the first part is performed under synthetic noise label conditions, i.e., 10%, 20%, and 30% of the training data are selected from each class of facial beauty data on the two databases mentioned above, while their labels are randomly changed. The accuracy of the method in this paper exceeds the baseline method by 5.8%, 4.1% and 3.7% on the LSFBD database at noise rates of 30%, 20% and 10%, respectively. The accuracy exceeds the baseline method by 3.1%, 2.8%, and 2.5% on the SCUT-FBP5500 database, respectively. Therefore, it is demonstrated that our method can reduce the negative impact of noisy labels under synthetic noisy label conditions. 2) The second part is carried out on the original LSFBD database and the original SCUT-FBP5500 database, and our method exceeded the prediction accuracy of the baseline method by 2.7% and 1.2% on the original LSFBD database and the original SCUT-FBP5500 database, respectively. Therefore, our demonstrated illustration can reduce the negative impact of noise labels under the original data conditions.ConclusionOur proposed method of self-correcting noise labels can reduce the negative impact of noise label in human facial beauty prediction in some extent and improve the prediction accuracy based on the LSFBD and SCUT-FBP5500 databases under synthetic noisy label circumstances, the original LSFBD and SCUT-FBP5500 facial beauty databases, respectively.关键词:deep learning;noise labels;facial beauty prediction;characteristics classification;deep neural networks83|139|0更新时间:2024-08-15 -
 摘要:ObjectiveTerahertz technology has great application potentials in related to wireless communications, biomedicine, and non-destructive testing. Some terahertz imaging features are suitable for hidden objects detection for human security inspections because terahertz waves can penetrate the substance like ceramics, plastics and cloths and are largely absorbed or reflected by metals, liquids and other substances with no harmless on human body. With the development of terahertz imaging technology and the increasing flow of people in application scenarios, the use of artificial recognition of terahertz images is no longer applicable. In order to solve the problem of hidden objects and dangerous goods detection, current research have focused on using deep learning method to classify and analyze them. Due to the resolution and contrast of the terahertz image are low, the edge information of the target in the image is blurred, the target information is easily confused with the background information, and the target information is unclear in the terahertz image, and the feature information is limited. Therefore, the effectiveness issue of feature information to detect the target in terahertz image is challenged for terahertz image detection.MethodWe facilitates a target detection framework asymmetric feature attention-you only look once(AFA-YOLO) that combines asymmetric feature attention and feature fusion based on the you only look once v4(YOLOv4) algorithm to resolve the barriers of small-scale target detection in terahertz images.cross stage paritial DarkNet53(CSPDarkNet53) is as a feature extraction network for AFA-YOLO and an asymmetric feature attention module in CSPDarkNet53 is designed. First, this module uses asymmetric convolution in the shallow network to enhance the feature extraction capabilities of the network, helping the network model to extract more effective target information from the terahertz image with limited target features; Second, the module melts convolutional block attention module(CBAM) attention force mechanism via using the channel attention mechanism to make the model pay more attention to the important information of the target in the image, suppress unrelated background information to the target, and use the spatial attention mechanism to pay attention to the position information of the target in the terahertz image, allowing the model to optimize target contexts. AFA-YOLO has carried out feature fusion operations as well, the high-level features are enhanced through increasing the information transmission path from the low-level to the high-level in the network. The high-level feature map can obtain fine-grained target appearance information and the positioning and detection of small-scale targets in terahertz images can be optimized.ResultOur research uses the detection accuracy map, missed alarm (MA) rate and detection speed frames per second(FPS) as indicators to carry out related experiments on the terahertz data set. The detection accuracy of AFA-YOLO for the phone is 81.15% compare to the original YOLOv4 algorithm, which is an increase of 4.12%. The detection accuracy of knife is 83.06%, an increased ratio of 3.72%. The model mean average precision(mAP) is 82.36%, which is an increased ratio of 3.92%. The MA is 12.78%, which is a decreased ratio of 2.65%, and the FPS is 32.26, which is lower to 4.06. Additionally, we conduct comparative analysis of different detection algorithms on the terahertz dataset. AFA-YOLO optimized target detection algorithms in terms of recognized detection speed, detection accuracy and missed alarm rate.ConclusionWe facilitate an AFA-YOLO detection framework that combines asymmetric feature attention and feature fusion. Our YOLOv4-based framework melts asymmetric feature attention module into the shallow network and enhances the target information on the high-level feature map. The optimal information ensures real-time detection through improving the detection accuracy of the target in the terahertz image effectively and lowering the missed alarm rate.关键词:terahertz image;small target detection;YOLOv4;asymmetric convolution;attention mechanism;featurefusion85|212|2更新时间:2024-08-15
摘要:ObjectiveTerahertz technology has great application potentials in related to wireless communications, biomedicine, and non-destructive testing. Some terahertz imaging features are suitable for hidden objects detection for human security inspections because terahertz waves can penetrate the substance like ceramics, plastics and cloths and are largely absorbed or reflected by metals, liquids and other substances with no harmless on human body. With the development of terahertz imaging technology and the increasing flow of people in application scenarios, the use of artificial recognition of terahertz images is no longer applicable. In order to solve the problem of hidden objects and dangerous goods detection, current research have focused on using deep learning method to classify and analyze them. Due to the resolution and contrast of the terahertz image are low, the edge information of the target in the image is blurred, the target information is easily confused with the background information, and the target information is unclear in the terahertz image, and the feature information is limited. Therefore, the effectiveness issue of feature information to detect the target in terahertz image is challenged for terahertz image detection.MethodWe facilitates a target detection framework asymmetric feature attention-you only look once(AFA-YOLO) that combines asymmetric feature attention and feature fusion based on the you only look once v4(YOLOv4) algorithm to resolve the barriers of small-scale target detection in terahertz images.cross stage paritial DarkNet53(CSPDarkNet53) is as a feature extraction network for AFA-YOLO and an asymmetric feature attention module in CSPDarkNet53 is designed. First, this module uses asymmetric convolution in the shallow network to enhance the feature extraction capabilities of the network, helping the network model to extract more effective target information from the terahertz image with limited target features; Second, the module melts convolutional block attention module(CBAM) attention force mechanism via using the channel attention mechanism to make the model pay more attention to the important information of the target in the image, suppress unrelated background information to the target, and use the spatial attention mechanism to pay attention to the position information of the target in the terahertz image, allowing the model to optimize target contexts. AFA-YOLO has carried out feature fusion operations as well, the high-level features are enhanced through increasing the information transmission path from the low-level to the high-level in the network. The high-level feature map can obtain fine-grained target appearance information and the positioning and detection of small-scale targets in terahertz images can be optimized.ResultOur research uses the detection accuracy map, missed alarm (MA) rate and detection speed frames per second(FPS) as indicators to carry out related experiments on the terahertz data set. The detection accuracy of AFA-YOLO for the phone is 81.15% compare to the original YOLOv4 algorithm, which is an increase of 4.12%. The detection accuracy of knife is 83.06%, an increased ratio of 3.72%. The model mean average precision(mAP) is 82.36%, which is an increased ratio of 3.92%. The MA is 12.78%, which is a decreased ratio of 2.65%, and the FPS is 32.26, which is lower to 4.06. Additionally, we conduct comparative analysis of different detection algorithms on the terahertz dataset. AFA-YOLO optimized target detection algorithms in terms of recognized detection speed, detection accuracy and missed alarm rate.ConclusionWe facilitate an AFA-YOLO detection framework that combines asymmetric feature attention and feature fusion. Our YOLOv4-based framework melts asymmetric feature attention module into the shallow network and enhances the target information on the high-level feature map. The optimal information ensures real-time detection through improving the detection accuracy of the target in the terahertz image effectively and lowering the missed alarm rate.关键词:terahertz image;small target detection;YOLOv4;asymmetric convolution;attention mechanism;featurefusion85|212|2更新时间:2024-08-15 -
 摘要:ObjectiveTexture filtering is a low-level task in image processing and computer vision, which aims to filter the image through the essential image structure preservation and other texture smoothing details. Current texture filtering algorithms are mainly divided into two categories like local-based and global-based orientation. Traditional methods are challenged to distinguish image structure and strong gradient textures in common. Due to the lack of reliable training set, recent deep learning algorithms often use the results of existing traditional methods as ground truth, so they are unable to refill the gaps of the existing traditional algorithms. For example, texture and structure aware filtering network (TSAFN) performs data synthesis by filling the whole image with the same texture, but textures should be object-dependent. Such a synthesis way will lead to a large gap between synthetic images and real-world images. In order to solve these problems, our novel dataset is generated for texture filtering training, and the image smoothing algorithm is proposed based on directional filtering scales-predicting model.MethodFirst, a texture filtering dataset for deep learning is generated by filling texture images per object structure based on the existing structure images. At the same time, we processed the image structure via smoothing and compression. Hence, the dataset we generated can not only enhance the ability of the algorithm to distinguish strong gradient texture and structure, but also reduce the domain gap between synthetic images and real images. Then, the image smoothing algorithm based on directional filtering scales-predicting model is designed, which includes a scale-aware sub-network and an image smoothing sub-network. The scale-aware sub-network is used to predict directional texture filtering scales map. It not only reflects whether a pixel and its surrounding pixels are in the same texture, but also implies information about whether the pixel is a structural pixel or not. The image smoothing sub-network takes the stack of scales map predicted by the scale-aware sub-network and original image as input, and gets the filtered image through a small amount of convolution layer. It can complete the smoothing and correct the imperfection of the result of scale-aware sub-network quickly. In edge-aware sub-network, we applied the classic U-Net because of its excellent ability to easy use low-level features straightforward, and we change its input and output dimensions. The input of the scale-aware sub-network is the stack of RGB image and gradient map, the output of the scale-aware sub-network is a six-dimensional scales map. The image smoothing sub-network consists of seven convolutional layers, the first six layers are followed by ReLU and batch normalization, while the last layer is followed by sigmoid for preventing the pixel value out of bounds, the input of the image smoothing sub-network is the stack of an image and six-dimensional scales map, the output of the image smoothing sub-network is the filtered image. The number of images related to our training set, test set and verification set are 10 000, 1 500, 1 000, respectively, they were selected from our dataset randomly, and they did not overlap. Our network is implemented in Pytorch toolbox. The input images and ground truth images are clipped to 224×224 pixels for training, the momentum parameter is set to 0.9, the learning rate is set to 1E-2, and the weight decay is 0.000 2. We use an adaptive method, that is, if the loss does not decrease by more than 0.003 for 5 epochs, then the learning rate will be halved. The stochastic gradient descent(SGD) learning procedure is accelerated using a NVIDIA RTX 2080 GPU device.ResultWe compared our algorithm to the five traditional algorithms and two deep learning algorithms on our dataset and other real-world image datasets. The quantitative evaluation metrics used in our dataset contain the peak signal to noise ratio (PSNR), the structural similarity (SSIM), the mean square error (MSE) and the running time. In comparison with the results of different filtering algorithms from our dataset, our PSNR is 2.79 higher (higher is better) than the second-best, our SSIM is 0.013 3 higher (higher is better) than the second-best, our MSE is 6.863 8 lower (less is better) than the second-best, the running time of our method is 0.002 s faster than the second-best. All deep learning algorithms have been re-trained from our dataset, it is sorted out that our algorithm keeps the leading effect in the discrimination of structure and strong gradient texture based on the comparative results of the texture filtering results of real-world images. The results are trained by different datasets are compared in terms of same model, and it is proved that our dataset can make the model have better generalization ability and stronger ability of distinguishing the strong gradient texture and structure.ConclusionOur dataset contains a variety of textures and structures, which can develop the model to distinguish strong gradient texture and object structure better. Our data synthesis method can make the model have better generalization potential ability. Additionally, the designed image smoothing algorithm surpasses the existing methods in performance and speed based on directional filtering scales-predicting model.关键词:deep learning;image smoothing;texture filtering;dataset generation;U-Net87|168|1更新时间:2024-08-15
摘要:ObjectiveTexture filtering is a low-level task in image processing and computer vision, which aims to filter the image through the essential image structure preservation and other texture smoothing details. Current texture filtering algorithms are mainly divided into two categories like local-based and global-based orientation. Traditional methods are challenged to distinguish image structure and strong gradient textures in common. Due to the lack of reliable training set, recent deep learning algorithms often use the results of existing traditional methods as ground truth, so they are unable to refill the gaps of the existing traditional algorithms. For example, texture and structure aware filtering network (TSAFN) performs data synthesis by filling the whole image with the same texture, but textures should be object-dependent. Such a synthesis way will lead to a large gap between synthetic images and real-world images. In order to solve these problems, our novel dataset is generated for texture filtering training, and the image smoothing algorithm is proposed based on directional filtering scales-predicting model.MethodFirst, a texture filtering dataset for deep learning is generated by filling texture images per object structure based on the existing structure images. At the same time, we processed the image structure via smoothing and compression. Hence, the dataset we generated can not only enhance the ability of the algorithm to distinguish strong gradient texture and structure, but also reduce the domain gap between synthetic images and real images. Then, the image smoothing algorithm based on directional filtering scales-predicting model is designed, which includes a scale-aware sub-network and an image smoothing sub-network. The scale-aware sub-network is used to predict directional texture filtering scales map. It not only reflects whether a pixel and its surrounding pixels are in the same texture, but also implies information about whether the pixel is a structural pixel or not. The image smoothing sub-network takes the stack of scales map predicted by the scale-aware sub-network and original image as input, and gets the filtered image through a small amount of convolution layer. It can complete the smoothing and correct the imperfection of the result of scale-aware sub-network quickly. In edge-aware sub-network, we applied the classic U-Net because of its excellent ability to easy use low-level features straightforward, and we change its input and output dimensions. The input of the scale-aware sub-network is the stack of RGB image and gradient map, the output of the scale-aware sub-network is a six-dimensional scales map. The image smoothing sub-network consists of seven convolutional layers, the first six layers are followed by ReLU and batch normalization, while the last layer is followed by sigmoid for preventing the pixel value out of bounds, the input of the image smoothing sub-network is the stack of an image and six-dimensional scales map, the output of the image smoothing sub-network is the filtered image. The number of images related to our training set, test set and verification set are 10 000, 1 500, 1 000, respectively, they were selected from our dataset randomly, and they did not overlap. Our network is implemented in Pytorch toolbox. The input images and ground truth images are clipped to 224×224 pixels for training, the momentum parameter is set to 0.9, the learning rate is set to 1E-2, and the weight decay is 0.000 2. We use an adaptive method, that is, if the loss does not decrease by more than 0.003 for 5 epochs, then the learning rate will be halved. The stochastic gradient descent(SGD) learning procedure is accelerated using a NVIDIA RTX 2080 GPU device.ResultWe compared our algorithm to the five traditional algorithms and two deep learning algorithms on our dataset and other real-world image datasets. The quantitative evaluation metrics used in our dataset contain the peak signal to noise ratio (PSNR), the structural similarity (SSIM), the mean square error (MSE) and the running time. In comparison with the results of different filtering algorithms from our dataset, our PSNR is 2.79 higher (higher is better) than the second-best, our SSIM is 0.013 3 higher (higher is better) than the second-best, our MSE is 6.863 8 lower (less is better) than the second-best, the running time of our method is 0.002 s faster than the second-best. All deep learning algorithms have been re-trained from our dataset, it is sorted out that our algorithm keeps the leading effect in the discrimination of structure and strong gradient texture based on the comparative results of the texture filtering results of real-world images. The results are trained by different datasets are compared in terms of same model, and it is proved that our dataset can make the model have better generalization ability and stronger ability of distinguishing the strong gradient texture and structure.ConclusionOur dataset contains a variety of textures and structures, which can develop the model to distinguish strong gradient texture and object structure better. Our data synthesis method can make the model have better generalization potential ability. Additionally, the designed image smoothing algorithm surpasses the existing methods in performance and speed based on directional filtering scales-predicting model.关键词:deep learning;image smoothing;texture filtering;dataset generation;U-Net87|168|1更新时间:2024-08-15
Image Understanding and Computer Vision
-
 摘要:ObjectiveIn the semantic segmentation of high-resolution remote sensing images, it is difficult to distinguish regions with similar spectral features (such as lawn and trees, roads and buildings) only using visible images for their single-angles. Most of the existing neural network-based methods focus on spectral and contextual feature extraction through a single encoder-decoder network, while geometric features are often not fully mined. The introduction of elevation information can improve the classification results significantly. However, the feature distribution of visible image and elevation data is quite different. Multiple modal flow features cascading simply fails to utilize the complementary information of multimodal data in the early, intermediate and latter stages of the network structure. The simple fusion methods by cascading or adding cannot deal with the noise generated by multimodal fusion clearly, which makes the result poor. In addition, high-resolution remote sensing images usually cover a large area, and the target objects have problems of diverse sizes and uneven distribution. Current researches has involved to model long-range relationships to extract contextual features.MethodWe proposed a multi-source features adaptation fusion network in our researchanalysis. In order to dynamically recalibrate the scene contexted feature maps, we utilize the modal adaptive fusion block to model the correlations explicitly between the two modal feature maps. To release the influence of fusion noise and utilize the complementary information of multi-modal data effectively, modal features are fused by the target categories and context information of pixels in motion. Meanwhile, the global context aggregation module is facilitated to improve the feature demonstration ability of the full convolutional neural network through modeling the remote relationship between pixels. Our model consists of three aspects as mentioned below: 1)the double encoder is responsible for extracting the features of spectrum modality and elevation modality; 2)the modality adaptation fusion block is coordinated to the multi-modal features to enhance the spectral features based on the dynamic elevation information; 3) the global context aggregation module is used to model the global context from the perspective of space and channel.ResultOur efficiency unimodal segmentation architecture (EUSA) is evaluated on the International Society for Photogrammetry and Remote Sensing(ISPRS) Vaihingen and Gaofen Image Dataset(GID) validation set, and the overall accuracy is 90.64% and 82.1%, respectively. Specifically, EUSA optimizes the overall accuracy value and mean intersection over union value by 1.55% and 3.05% respectively in comparison with the value of baseline via introducing a small amount of parameters and computation on ISPRS Vaihingen test set. This proposed modal adaptive block increases the overall accuracy value and mean intersection over union value of 1.32% and 2.33% each on ISPRS Vaihingen test set. Our MSFAFNet has its priorities in terms of the ISPRS Vaihingen test set evaluation, which achieves 90.77% in overall accuracy.ConclusionOur experimental results show that the efficient single-mode segmentation framework EUSA can model the long-range contextual relationships between pixels. To improve the segmentation results of regions in the shadow or with similar textures, we proposed MSFAFNet to extract more effectivefeatures of elevation information.关键词:semantic segmentation;remote sensing images;multi-modal data;modality adaptation fusion;global context aggregation227|192|7更新时间:2024-08-15
摘要:ObjectiveIn the semantic segmentation of high-resolution remote sensing images, it is difficult to distinguish regions with similar spectral features (such as lawn and trees, roads and buildings) only using visible images for their single-angles. Most of the existing neural network-based methods focus on spectral and contextual feature extraction through a single encoder-decoder network, while geometric features are often not fully mined. The introduction of elevation information can improve the classification results significantly. However, the feature distribution of visible image and elevation data is quite different. Multiple modal flow features cascading simply fails to utilize the complementary information of multimodal data in the early, intermediate and latter stages of the network structure. The simple fusion methods by cascading or adding cannot deal with the noise generated by multimodal fusion clearly, which makes the result poor. In addition, high-resolution remote sensing images usually cover a large area, and the target objects have problems of diverse sizes and uneven distribution. Current researches has involved to model long-range relationships to extract contextual features.MethodWe proposed a multi-source features adaptation fusion network in our researchanalysis. In order to dynamically recalibrate the scene contexted feature maps, we utilize the modal adaptive fusion block to model the correlations explicitly between the two modal feature maps. To release the influence of fusion noise and utilize the complementary information of multi-modal data effectively, modal features are fused by the target categories and context information of pixels in motion. Meanwhile, the global context aggregation module is facilitated to improve the feature demonstration ability of the full convolutional neural network through modeling the remote relationship between pixels. Our model consists of three aspects as mentioned below: 1)the double encoder is responsible for extracting the features of spectrum modality and elevation modality; 2)the modality adaptation fusion block is coordinated to the multi-modal features to enhance the spectral features based on the dynamic elevation information; 3) the global context aggregation module is used to model the global context from the perspective of space and channel.ResultOur efficiency unimodal segmentation architecture (EUSA) is evaluated on the International Society for Photogrammetry and Remote Sensing(ISPRS) Vaihingen and Gaofen Image Dataset(GID) validation set, and the overall accuracy is 90.64% and 82.1%, respectively. Specifically, EUSA optimizes the overall accuracy value and mean intersection over union value by 1.55% and 3.05% respectively in comparison with the value of baseline via introducing a small amount of parameters and computation on ISPRS Vaihingen test set. This proposed modal adaptive block increases the overall accuracy value and mean intersection over union value of 1.32% and 2.33% each on ISPRS Vaihingen test set. Our MSFAFNet has its priorities in terms of the ISPRS Vaihingen test set evaluation, which achieves 90.77% in overall accuracy.ConclusionOur experimental results show that the efficient single-mode segmentation framework EUSA can model the long-range contextual relationships between pixels. To improve the segmentation results of regions in the shadow or with similar textures, we proposed MSFAFNet to extract more effectivefeatures of elevation information.关键词:semantic segmentation;remote sensing images;multi-modal data;modality adaptation fusion;global context aggregation227|192|7更新时间:2024-08-15 -
 摘要:ObjectivePixel-wise segmentation for synthetic aperture radar (SAR) images has been challenging due to the constraints of labeled SAR data, as well as the coherent speckle contextual information. Current semantic segmentation is challenged like existing algorithms as mentioned below: First, the ability to capture contextual information is insufficient. Some algorithms ignore contextual information or just focus on local spatial contextual information derived of a few pixels, and lack global spatial contextual information. Second, in order to improve the network performance, researchers are committed to developing the spatial dimension and ignoring the relationship between channels. Third, a neural network based high-level features extracted from the late layers are rich in semantic information and have blurred spatial details. A network based low-level features extraction contains more noise pixel-level information from the early layers. They are isolated from each other, so it is difficult to make full use of them. The most common ways are not efficient based on concatenate them or per-pixel addition.MethodTo solve these problems, a segmentation algorithm is proposed based on fully convolutional neural network (CNN). The whole network is based on the structure of encoder-decoder network. Our research facilitates a contextual encoding module and a feature fusion module for feature extraction and feature fusion. The different rates and channel attention mechanism based contextual encoding module consists of a residual connection, a standard convolution, two dilated convolutions. Among them, the residual connection is designed to neglect network degradation issues. Standard convolution is obtained by local features with 3 × 3 convolution kernel. After convolution, batch normalization and nonlinear activation function ReLU are connected to resist over-fitting. Dilated convolutions with 2 × 2 and 3 × 3 dilated rates extend the perception field and capture multi-scale features and local contextual features further. The channel attention mechanism learns the importance of each feature channel, enhances useful features in terms of this importance, inhibits features, and completes the modeling of the dependency between channels to obtain the context information of channels. First, the feature fusion module based global context features extraction is promoted, the in the high-level features. Specifically, the global average pooling suppresses each feature to a real number, which has a global perception field to some extent. Then, these numbers are embedding into the low-level features. The enhanced low-level features are transmitted to the decoding network, which can improve the effectiveness of up sampling. This module can greatly enhance its semantic representation with no the spatial information of low-level features loss, and improve the effectiveness of their integration. Our research carries out four contextual encoding modules and two feature fusion modules are stacked in the whole network.ResultWe demonstrated seven experimental schemes. In the first scheme, contextual encoder module (CEM) is used as the encoder block only; In the second scheme, we combined the CEM and the feature fusion module (FFM); the rest of them are five related methods like SegNet, U-Net, pyramid scene parsing network (PSPNet), FCN-DK3 and context-aware encoder network(CAEN). Our two real SAR images experiments contain a wealth of information scene experiment are Radarsat-2 Flevoland (RS2-Flevoland) and Radarsat-2 San-Francisco-Bay (RS2-SF-Bay). The option of overall accuracy (OA), average accuracy (AA) and Kappa coefficient is as the evaluation criteria. The OA of the CEM algorithm on the two real SAR images is 91.082% and 90.903% respectively in comparison to the five advanced algorithms mentioned above. The CEM-FFM algorithm increased 2.149% and 2.390% compare to CEM algorithm.ConclusionOur illustration designs a CNN based semantic segmentation algorithm. It is composed of two aspects of contextual encoding module and feature fusion module. The experiments have their priorities of the proposed method with other related algorithms. Our proposed segmentation network has stronger feature extraction ability, and integrates low-level features and high-level features greatly, which improves the feature representation ability of the stable network and more accurate results of image segmentation.关键词:image segmentation;fully convolutional network (FCN);feature fusion;contextual information;synthetic aperture radar (SAR)54|162|0更新时间:2024-08-15
摘要:ObjectivePixel-wise segmentation for synthetic aperture radar (SAR) images has been challenging due to the constraints of labeled SAR data, as well as the coherent speckle contextual information. Current semantic segmentation is challenged like existing algorithms as mentioned below: First, the ability to capture contextual information is insufficient. Some algorithms ignore contextual information or just focus on local spatial contextual information derived of a few pixels, and lack global spatial contextual information. Second, in order to improve the network performance, researchers are committed to developing the spatial dimension and ignoring the relationship between channels. Third, a neural network based high-level features extracted from the late layers are rich in semantic information and have blurred spatial details. A network based low-level features extraction contains more noise pixel-level information from the early layers. They are isolated from each other, so it is difficult to make full use of them. The most common ways are not efficient based on concatenate them or per-pixel addition.MethodTo solve these problems, a segmentation algorithm is proposed based on fully convolutional neural network (CNN). The whole network is based on the structure of encoder-decoder network. Our research facilitates a contextual encoding module and a feature fusion module for feature extraction and feature fusion. The different rates and channel attention mechanism based contextual encoding module consists of a residual connection, a standard convolution, two dilated convolutions. Among them, the residual connection is designed to neglect network degradation issues. Standard convolution is obtained by local features with 3 × 3 convolution kernel. After convolution, batch normalization and nonlinear activation function ReLU are connected to resist over-fitting. Dilated convolutions with 2 × 2 and 3 × 3 dilated rates extend the perception field and capture multi-scale features and local contextual features further. The channel attention mechanism learns the importance of each feature channel, enhances useful features in terms of this importance, inhibits features, and completes the modeling of the dependency between channels to obtain the context information of channels. First, the feature fusion module based global context features extraction is promoted, the in the high-level features. Specifically, the global average pooling suppresses each feature to a real number, which has a global perception field to some extent. Then, these numbers are embedding into the low-level features. The enhanced low-level features are transmitted to the decoding network, which can improve the effectiveness of up sampling. This module can greatly enhance its semantic representation with no the spatial information of low-level features loss, and improve the effectiveness of their integration. Our research carries out four contextual encoding modules and two feature fusion modules are stacked in the whole network.ResultWe demonstrated seven experimental schemes. In the first scheme, contextual encoder module (CEM) is used as the encoder block only; In the second scheme, we combined the CEM and the feature fusion module (FFM); the rest of them are five related methods like SegNet, U-Net, pyramid scene parsing network (PSPNet), FCN-DK3 and context-aware encoder network(CAEN). Our two real SAR images experiments contain a wealth of information scene experiment are Radarsat-2 Flevoland (RS2-Flevoland) and Radarsat-2 San-Francisco-Bay (RS2-SF-Bay). The option of overall accuracy (OA), average accuracy (AA) and Kappa coefficient is as the evaluation criteria. The OA of the CEM algorithm on the two real SAR images is 91.082% and 90.903% respectively in comparison to the five advanced algorithms mentioned above. The CEM-FFM algorithm increased 2.149% and 2.390% compare to CEM algorithm.ConclusionOur illustration designs a CNN based semantic segmentation algorithm. It is composed of two aspects of contextual encoding module and feature fusion module. The experiments have their priorities of the proposed method with other related algorithms. Our proposed segmentation network has stronger feature extraction ability, and integrates low-level features and high-level features greatly, which improves the feature representation ability of the stable network and more accurate results of image segmentation.关键词:image segmentation;fully convolutional network (FCN);feature fusion;contextual information;synthetic aperture radar (SAR)54|162|0更新时间:2024-08-15 -
 摘要:ObjectiveMost object detection techniques identify potential regions through well-designed anchors. The recognition accuracy is related to the setting of anchors intensively. It usually leads to sub-optimal results with no fine tunings when applying to unclear scenarios due to domain gap. The use of anchors constrains the generalization ability of object detection techniques on aerial imagery, and increases the cost of model training and parameter tuning. Moreover, object detection approaches designed for natural scenes represent objects using axis-aligned rectangles (horizontal boxes) that are inadequate when applied to aerial images since objects may have arbitrary orientation when observed from the overhead perspective. A horizontal bounding box involves multiple object instances and redundant background information in common that may confuse the learning algorithm and reduce recognition accuracy in aerial imagery. A better option tends to use oblique rectangles (oriented boxes) in aerial images. Oriented boxes are more compact compared to horizontal boxes, as they have the same direction with objects and closely adhere to objects' boundaries. We propose a novel object detection approach that is anchor-free and is capable to generate oriented bounding boxes in terms of gliding vertices of horizontal ones. Our algorithm is developed based on designated anchor-free detector fully convolutional one-stage object detector (FCOS). FCOS achieves comparable accuracy with anchor-based methods while totally eliminates the need for calibrating anchors and the complex pre and post-processing associated with anchors. It also requires less memory and can leverage more positive samples than its anchor-based counterparts. FCOS was originally designed for object detection in natural scenes observation, we adopt FCOS as our baseline and extend it for oblique object detection in aerial images. Our research contributions are mentioned as below 1) to extend FCOS for oblique object detection; 2) to weak the shape distortion issue of gliding vertex based representation of oriented boxes; and 3) to benchmark the extended FCOS on object detection in aerial images (DOTA).MethodOur method integrates FCOS with gliding vertex approach to realize anchor-free oblique object detection. The following part describes our oriented object detection method on three aspects: network architecture, parameterization of oriented boxes, and experiments we conducted to evaluate the proposed network. Our network consists of a backbone for feature extraction, a feature pyramid network for feature fusion, and multiple detection heads for object recognition. Instead of using an orientation angle to represent the box direction, we adopt the gliding vertex representation for simplicity and robustness. We use ResNets as our backbone as FCOS does. The feature pyramid network fuses multi-level features from the backbone convolutional neural networks (CNN) to detect objects of various scales. Specifically, the C3, C4 and C5 feature maps are taken to produce P3, P4 and P5 by 1×1 convolution and lateral connection. P5 is fed into two subsequent convolutional layers with the stride parameter set to 2 to get P6 and P7. Unlike FCOS, we concatenate feature maps along the channel dimension followed by a 1×1 convolution and batch normalization for feature fusion. For each location on P3, P4, P5, P6 and P7, the network predicts if an object exists at that location as well as the object category. For oriented box regression, we parameterize a box using a 7D real vector: (l, t, r, b, α1, α2, k). The l, t, r, b are the distances from the location to the four sides of the object's horizontal box. These four parameters together demine the size and location of the horizontal bounding box. (α1, α2) denote the gliding offsets on the top and left side of the horizontal bounding box that could be used to derive the coordinates of the first and second vertices of the oriented object. k is the obliquity factor that represents the area ratio between an oriented object and its horizontal bounding box. The obliquity factor describes the tilt degree of an object and guides the network to approximate nearly horizontal objects with the horizontal boxes. With this design, we can generate horizontal and oriented bounding box simultaneously with minimal increase in computing time and complexity. It is worth noting that we only predict gliding distances on two sides of the horizontal bounding box other than four with the assumption that the predicted boxes are parallelograms other than arbitrary quadrilaterals. We use fully convolutional sub-networks for target category classification and location regression that is consistent with FCOS. The detection heads are implemented using four convolutional layers, and take feature maps produced by the feature pyramid network as input. The network outputs are decoded to fetch classification scores as well as box locations.ResultTo illustrate the effectiveness of the proposed object detection approach, we evaluated the extended FCOS on the challenging oriented object detection dataset DOTA with various backbones and inference strategies. Without bells and whistles, our proposed network outperforms the horizontal detection baseline with 33.02% increase in mean average precision (mAP). Compared to you only look once (YOLOv3), it achieves a performance boost of 38.82% in terms of frames per second (FPS). Compared to refined rotation RetinaNet(R3Det), the proposed method improves detection accuracy by 1.53% in terms of mAP. We achieve an mAP of 74.84% on DOTA using ResNet50, that is higher than most one-stage and two-stage detectors.ConclusionThe proposed method has its potentials to optimize single-stage and two-stage detectors in terms of recognition accuracy and time efficiency.关键词:deep learning;remote sensing image;anchor free;feature extraction;multi-scale feature fusion;oblique object detection196|219|0更新时间:2024-08-15
摘要:ObjectiveMost object detection techniques identify potential regions through well-designed anchors. The recognition accuracy is related to the setting of anchors intensively. It usually leads to sub-optimal results with no fine tunings when applying to unclear scenarios due to domain gap. The use of anchors constrains the generalization ability of object detection techniques on aerial imagery, and increases the cost of model training and parameter tuning. Moreover, object detection approaches designed for natural scenes represent objects using axis-aligned rectangles (horizontal boxes) that are inadequate when applied to aerial images since objects may have arbitrary orientation when observed from the overhead perspective. A horizontal bounding box involves multiple object instances and redundant background information in common that may confuse the learning algorithm and reduce recognition accuracy in aerial imagery. A better option tends to use oblique rectangles (oriented boxes) in aerial images. Oriented boxes are more compact compared to horizontal boxes, as they have the same direction with objects and closely adhere to objects' boundaries. We propose a novel object detection approach that is anchor-free and is capable to generate oriented bounding boxes in terms of gliding vertices of horizontal ones. Our algorithm is developed based on designated anchor-free detector fully convolutional one-stage object detector (FCOS). FCOS achieves comparable accuracy with anchor-based methods while totally eliminates the need for calibrating anchors and the complex pre and post-processing associated with anchors. It also requires less memory and can leverage more positive samples than its anchor-based counterparts. FCOS was originally designed for object detection in natural scenes observation, we adopt FCOS as our baseline and extend it for oblique object detection in aerial images. Our research contributions are mentioned as below 1) to extend FCOS for oblique object detection; 2) to weak the shape distortion issue of gliding vertex based representation of oriented boxes; and 3) to benchmark the extended FCOS on object detection in aerial images (DOTA).MethodOur method integrates FCOS with gliding vertex approach to realize anchor-free oblique object detection. The following part describes our oriented object detection method on three aspects: network architecture, parameterization of oriented boxes, and experiments we conducted to evaluate the proposed network. Our network consists of a backbone for feature extraction, a feature pyramid network for feature fusion, and multiple detection heads for object recognition. Instead of using an orientation angle to represent the box direction, we adopt the gliding vertex representation for simplicity and robustness. We use ResNets as our backbone as FCOS does. The feature pyramid network fuses multi-level features from the backbone convolutional neural networks (CNN) to detect objects of various scales. Specifically, the C3, C4 and C5 feature maps are taken to produce P3, P4 and P5 by 1×1 convolution and lateral connection. P5 is fed into two subsequent convolutional layers with the stride parameter set to 2 to get P6 and P7. Unlike FCOS, we concatenate feature maps along the channel dimension followed by a 1×1 convolution and batch normalization for feature fusion. For each location on P3, P4, P5, P6 and P7, the network predicts if an object exists at that location as well as the object category. For oriented box regression, we parameterize a box using a 7D real vector: (l, t, r, b, α1, α2, k). The l, t, r, b are the distances from the location to the four sides of the object's horizontal box. These four parameters together demine the size and location of the horizontal bounding box. (α1, α2) denote the gliding offsets on the top and left side of the horizontal bounding box that could be used to derive the coordinates of the first and second vertices of the oriented object. k is the obliquity factor that represents the area ratio between an oriented object and its horizontal bounding box. The obliquity factor describes the tilt degree of an object and guides the network to approximate nearly horizontal objects with the horizontal boxes. With this design, we can generate horizontal and oriented bounding box simultaneously with minimal increase in computing time and complexity. It is worth noting that we only predict gliding distances on two sides of the horizontal bounding box other than four with the assumption that the predicted boxes are parallelograms other than arbitrary quadrilaterals. We use fully convolutional sub-networks for target category classification and location regression that is consistent with FCOS. The detection heads are implemented using four convolutional layers, and take feature maps produced by the feature pyramid network as input. The network outputs are decoded to fetch classification scores as well as box locations.ResultTo illustrate the effectiveness of the proposed object detection approach, we evaluated the extended FCOS on the challenging oriented object detection dataset DOTA with various backbones and inference strategies. Without bells and whistles, our proposed network outperforms the horizontal detection baseline with 33.02% increase in mean average precision (mAP). Compared to you only look once (YOLOv3), it achieves a performance boost of 38.82% in terms of frames per second (FPS). Compared to refined rotation RetinaNet(R3Det), the proposed method improves detection accuracy by 1.53% in terms of mAP. We achieve an mAP of 74.84% on DOTA using ResNet50, that is higher than most one-stage and two-stage detectors.ConclusionThe proposed method has its potentials to optimize single-stage and two-stage detectors in terms of recognition accuracy and time efficiency.关键词:deep learning;remote sensing image;anchor free;feature extraction;multi-scale feature fusion;oblique object detection196|219|0更新时间:2024-08-15
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0