
最新刊期
卷 27 , 期 7 , 2022
-
 摘要:Fine-grained image recognition aims to study the visual recognition of different sub-categories at the fine-grained level under a certain traditional semantic category. In many scenarios such as smart cities, public safety, ecological protection, and agriculture, fine-grained image recognition has important scientific significance and application values. In recent years, fine-grained image recognition has made great progress with the help of deep learning, but its reliance on large-scale, high-quality of fine-grained image data has become a bottleneck restricting the promotion and popularization of fine-grained image recognition. Our research focuses on the traditional fine-grained image recognition, fine-grained recognition under the webly-supervised setting, and the features and methods of fine-grained recognition datasets, and the challenge and approaches for the webly-supervised fine-grained recognition. Our research develops the traditional fine-grained image recognition datasets, the traditional webly-supervised image recognition datasets and the webly-supervised fine-grained image recognition datasets, respectively. Specifically, the webly-supervised datasets have the similar attributes of large intra class differences and small inter class differences in the traditional fine-grained datasets. Meanwhile, the webly-supervised datasets have the challenges on noises, data bias and long-tailed distribution. Regarding the traditional fine-grained recognition, there are 3 core paradigms to resolve vision issue. The first is fine-grained image recognition based on localization-classification sub-networks. The second one is fine-grained image recognition via end-to-end feature encoding. The final is fine-grained image recognition derived of external information. Due to the data in the webly-supervision datasets is obtained from the internet, there exists a lot of noise data. Noise data can affect the training of the deep models. Regarding noise data, it can be segmented into 2 categories like irrelevant data and ambiguous data. Irrelevant data refers to the data error that has unknown categories like maps, tables and article screenshots. Ambiguous data refers to the image objects related to tag categories and others. There are 2 kind of problem solving of noise data, i.e., clustering and cross validation. Our research introduces the key clustering methods, analyzes their advantages and disadvantages, and discusses the results and possibilities of these methods in webly-supervised fine-grained images. For cross validation, our demonstration proposed a brief introduction to traditional cross validation and illustrated a customized cross validation method used in the ACCV(Asian Conference on Computer Vision) WebFG(the webly-supervised fine-grained image recognition) 2020 competition. In the internet, data is generated/uploaded via users with their own perceptions. In this process, the data bias factors affected by various factors in the context of culture, politics and environment. Due to the similarity between fine-grained categories, the problem of data bias is particularly dominated in fine-grained datasets. The main data bias deducted method are knowledge distillation, label smoothing and data enhancement. The data bias in the webly-supervision datasets will affect the training of the model, and the dark knowledge generated in the knowledge distillation can release the data bias. There are 3 learning schemes of knowledge distillation in related to offline distillation, online distillation and self-distillation. Label smoothing can reduce label cost of the model and conduct the data error alarming, it can also release the data error on the model training. Due to the data bias, the quantity and quality of data cannot be guaranteed. An effective way to alleviate the data bias is via the number of samples increase in the dataset. However, the accuracy of manual introduction of data cannot be guaranteed due to the small difference between fine-grained categories. Data enhancement becomes an effective method to handle data bias of fine-grained dataset. For fine-grained categories, only a small number of categories are commonly seen in daily life, and there are many fine-grained categories that cannot be seen in daily life. The internet can truly reflect the state of natural life, so the long-tailed distribution on the internet is also a challenge to deal with the real scenario from internet. In general, the main solutions of long-tailed distribution recognition are resampling, reweighting and novel network structures. More specifically, resampling refers to the reverse weighting of different categories of images in accordance with the number of samples, which leads to 2 methods, including under sampling of the head category and over sampling of the tail category. Reweighting is mainly reflected in the loss function. The specific operation is to add a larger penalty weight to the loss function of the tail category. A novel of network structure can decouple the network and train it each and decompose the learning based process into representation and classifier. These experiments illustrate the demonstrated results have their priorities in resampling and reweighting. In particular, our research reviews and discusses the relevant situation and champion solutions of WebFG the world's first webly-supervised fine-grained image recognition competition, held with Nanjing University of Science and Technology as well.关键词:webly-supervised;fine-grained image recognition;noise data;long-tailed distribution;small inter-class variance;review358|277|3更新时间:2024-05-07
摘要:Fine-grained image recognition aims to study the visual recognition of different sub-categories at the fine-grained level under a certain traditional semantic category. In many scenarios such as smart cities, public safety, ecological protection, and agriculture, fine-grained image recognition has important scientific significance and application values. In recent years, fine-grained image recognition has made great progress with the help of deep learning, but its reliance on large-scale, high-quality of fine-grained image data has become a bottleneck restricting the promotion and popularization of fine-grained image recognition. Our research focuses on the traditional fine-grained image recognition, fine-grained recognition under the webly-supervised setting, and the features and methods of fine-grained recognition datasets, and the challenge and approaches for the webly-supervised fine-grained recognition. Our research develops the traditional fine-grained image recognition datasets, the traditional webly-supervised image recognition datasets and the webly-supervised fine-grained image recognition datasets, respectively. Specifically, the webly-supervised datasets have the similar attributes of large intra class differences and small inter class differences in the traditional fine-grained datasets. Meanwhile, the webly-supervised datasets have the challenges on noises, data bias and long-tailed distribution. Regarding the traditional fine-grained recognition, there are 3 core paradigms to resolve vision issue. The first is fine-grained image recognition based on localization-classification sub-networks. The second one is fine-grained image recognition via end-to-end feature encoding. The final is fine-grained image recognition derived of external information. Due to the data in the webly-supervision datasets is obtained from the internet, there exists a lot of noise data. Noise data can affect the training of the deep models. Regarding noise data, it can be segmented into 2 categories like irrelevant data and ambiguous data. Irrelevant data refers to the data error that has unknown categories like maps, tables and article screenshots. Ambiguous data refers to the image objects related to tag categories and others. There are 2 kind of problem solving of noise data, i.e., clustering and cross validation. Our research introduces the key clustering methods, analyzes their advantages and disadvantages, and discusses the results and possibilities of these methods in webly-supervised fine-grained images. For cross validation, our demonstration proposed a brief introduction to traditional cross validation and illustrated a customized cross validation method used in the ACCV(Asian Conference on Computer Vision) WebFG(the webly-supervised fine-grained image recognition) 2020 competition. In the internet, data is generated/uploaded via users with their own perceptions. In this process, the data bias factors affected by various factors in the context of culture, politics and environment. Due to the similarity between fine-grained categories, the problem of data bias is particularly dominated in fine-grained datasets. The main data bias deducted method are knowledge distillation, label smoothing and data enhancement. The data bias in the webly-supervision datasets will affect the training of the model, and the dark knowledge generated in the knowledge distillation can release the data bias. There are 3 learning schemes of knowledge distillation in related to offline distillation, online distillation and self-distillation. Label smoothing can reduce label cost of the model and conduct the data error alarming, it can also release the data error on the model training. Due to the data bias, the quantity and quality of data cannot be guaranteed. An effective way to alleviate the data bias is via the number of samples increase in the dataset. However, the accuracy of manual introduction of data cannot be guaranteed due to the small difference between fine-grained categories. Data enhancement becomes an effective method to handle data bias of fine-grained dataset. For fine-grained categories, only a small number of categories are commonly seen in daily life, and there are many fine-grained categories that cannot be seen in daily life. The internet can truly reflect the state of natural life, so the long-tailed distribution on the internet is also a challenge to deal with the real scenario from internet. In general, the main solutions of long-tailed distribution recognition are resampling, reweighting and novel network structures. More specifically, resampling refers to the reverse weighting of different categories of images in accordance with the number of samples, which leads to 2 methods, including under sampling of the head category and over sampling of the tail category. Reweighting is mainly reflected in the loss function. The specific operation is to add a larger penalty weight to the loss function of the tail category. A novel of network structure can decouple the network and train it each and decompose the learning based process into representation and classifier. These experiments illustrate the demonstrated results have their priorities in resampling and reweighting. In particular, our research reviews and discusses the relevant situation and champion solutions of WebFG the world's first webly-supervised fine-grained image recognition competition, held with Nanjing University of Science and Technology as well.关键词:webly-supervised;fine-grained image recognition;noise data;long-tailed distribution;small inter-class variance;review358|277|3更新时间:2024-05-07
Scholar View

-
 摘要:Maritime surveillance videos based object detection methods aims to meet the quick response requirements through an effective ship detection and recognition system against the backdrop of smart ocean technology. Our research has focused on this aspects as mentioned below: 1) to summarize current approaches and datasets and discuss the challenging issues of them; 2) to analyze the features and the challenges of maritime surveillance ship detection; 3) to clarify the credibility of their accuracy and efficiency and demonstrate our research potential further. In the first phase, we summarize existing ship detection algorithms based on maritime surveillance videos, introduce the common ship detection datasets and ship detection methods available, and some evaluation metrics followed for ship detection tasks. Customized attention is yielded to the interconnected results between traditional computer vision algorithms for ship identification, which mainly consist of modules such as horizon detection, background subtraction and foreground extraction, and some deep learning methods based on fast region convolutional neural network (Fast R-CNN), single shot multibox detector (SSD) and you only look once (YOLO). It can be sorted out that although mean average precision (mAP) metric remains recognized index to measure the performance of models, its effectiveness issue is still discussed in terms of ship detection tasks and present novel metrics, including bottom edge proximity (BEP), n-multiple object detection precision (N-MODP) and n-multiple object detection accuracy (N-MODA). Current datasets are capable to detect vessels motion via deep learning models. But, the accuracy and robustness of training are required to be improved greatly due to extreme weather condition and light variation or inconsistent labels. In the second phase, we evaluate the features and challenges for ship detection. The difference lies between ship detection and regular object detection. For example, a coastline platform or a ship sensor have very large visible ranges and leading to a big scale variability. In addition, it is challenged to design a set of models adapt to various image domain scenarios derived from extreme marine weather conditions. Photographic system has to withstand exposure to extremes of temperature, high vibration levels, humidity and chemicals as well. The harsh environment combined with noise pollution and limited network bandwidth can cause the loss of image quality and make uncertainty with information loss for the models. In the third phase, we improve the accuracy and efficiency of ship detection algorithms and evaluate some common methods for ship detection technology on the three aspects as following: 1) multi-scale feature fusion: we carry out convolutional neural network (CNN) models manipulation based on different input scales and backbones. Some of the object detection models are degraded when facing large variations result from large field of view among ship objects during voyage. It is suggested that input scale determines the upper bound of accuracy of CNN models, and CNN models or backbones which are specially designed for multi-scale detection tasks narrow the gap of accuracy between different input scales. 2) Data augmentation: Waves and wind induce pitch and roll rotations on the sea, which is demanding for ship detection. Moreover, weather change and day-night brightness variation mean the image data shall be in multiple domains, which requires the detection models to be robust to images from different domains, or even from domains that have not been included in training samples. In light of the above-mentioned variables and marine based camera motion results, we evaluate the performance improvement when data augmentation is applied to image translation and rotation. We also adjust photo brightness and use Gaussian blur to simulate the blur caused by water condensed on cameras. Almost 5% increase is observed in mAP, verifying the robustness of data augmentation in ship detection. Other effective approaches include domain transfer based on generative adversarial network (GAN) or domain-independent models derived of multi-domain object detection tasks. 3) Light-weighted models and energy optimization: Computing complexity is constrained of semantic constraints like the horizon; Common object detection optimization is used to lower computation load, including light-weighted backbones like MobileNet and ShuffleNet. We calculate the parameter quantity and computing operation quantity of object detection models as well as each accuracy of them. We recommended that further studies should be considered on the following aspects: 1) to develop new datasets or existing datasets improvement based on sufficient coverage of possible conditions, high-quality annotations, precise classification and easier extension, respectively; 2) to decrease arithmetic operations and energy consumption in object detection models; 3) to strengthen multi-scale target detection modeling; 4) to enhance data fusion between object detection in multi-sensors images and the semantic ability of single image or multiple images interpretation.关键词:ship object detection;maritime surveillance dataset;small object detection;data augmentation;performance optimization for convolutional neural network140|529|2更新时间:2024-05-07
摘要:Maritime surveillance videos based object detection methods aims to meet the quick response requirements through an effective ship detection and recognition system against the backdrop of smart ocean technology. Our research has focused on this aspects as mentioned below: 1) to summarize current approaches and datasets and discuss the challenging issues of them; 2) to analyze the features and the challenges of maritime surveillance ship detection; 3) to clarify the credibility of their accuracy and efficiency and demonstrate our research potential further. In the first phase, we summarize existing ship detection algorithms based on maritime surveillance videos, introduce the common ship detection datasets and ship detection methods available, and some evaluation metrics followed for ship detection tasks. Customized attention is yielded to the interconnected results between traditional computer vision algorithms for ship identification, which mainly consist of modules such as horizon detection, background subtraction and foreground extraction, and some deep learning methods based on fast region convolutional neural network (Fast R-CNN), single shot multibox detector (SSD) and you only look once (YOLO). It can be sorted out that although mean average precision (mAP) metric remains recognized index to measure the performance of models, its effectiveness issue is still discussed in terms of ship detection tasks and present novel metrics, including bottom edge proximity (BEP), n-multiple object detection precision (N-MODP) and n-multiple object detection accuracy (N-MODA). Current datasets are capable to detect vessels motion via deep learning models. But, the accuracy and robustness of training are required to be improved greatly due to extreme weather condition and light variation or inconsistent labels. In the second phase, we evaluate the features and challenges for ship detection. The difference lies between ship detection and regular object detection. For example, a coastline platform or a ship sensor have very large visible ranges and leading to a big scale variability. In addition, it is challenged to design a set of models adapt to various image domain scenarios derived from extreme marine weather conditions. Photographic system has to withstand exposure to extremes of temperature, high vibration levels, humidity and chemicals as well. The harsh environment combined with noise pollution and limited network bandwidth can cause the loss of image quality and make uncertainty with information loss for the models. In the third phase, we improve the accuracy and efficiency of ship detection algorithms and evaluate some common methods for ship detection technology on the three aspects as following: 1) multi-scale feature fusion: we carry out convolutional neural network (CNN) models manipulation based on different input scales and backbones. Some of the object detection models are degraded when facing large variations result from large field of view among ship objects during voyage. It is suggested that input scale determines the upper bound of accuracy of CNN models, and CNN models or backbones which are specially designed for multi-scale detection tasks narrow the gap of accuracy between different input scales. 2) Data augmentation: Waves and wind induce pitch and roll rotations on the sea, which is demanding for ship detection. Moreover, weather change and day-night brightness variation mean the image data shall be in multiple domains, which requires the detection models to be robust to images from different domains, or even from domains that have not been included in training samples. In light of the above-mentioned variables and marine based camera motion results, we evaluate the performance improvement when data augmentation is applied to image translation and rotation. We also adjust photo brightness and use Gaussian blur to simulate the blur caused by water condensed on cameras. Almost 5% increase is observed in mAP, verifying the robustness of data augmentation in ship detection. Other effective approaches include domain transfer based on generative adversarial network (GAN) or domain-independent models derived of multi-domain object detection tasks. 3) Light-weighted models and energy optimization: Computing complexity is constrained of semantic constraints like the horizon; Common object detection optimization is used to lower computation load, including light-weighted backbones like MobileNet and ShuffleNet. We calculate the parameter quantity and computing operation quantity of object detection models as well as each accuracy of them. We recommended that further studies should be considered on the following aspects: 1) to develop new datasets or existing datasets improvement based on sufficient coverage of possible conditions, high-quality annotations, precise classification and easier extension, respectively; 2) to decrease arithmetic operations and energy consumption in object detection models; 3) to strengthen multi-scale target detection modeling; 4) to enhance data fusion between object detection in multi-sensors images and the semantic ability of single image or multiple images interpretation.关键词:ship object detection;maritime surveillance dataset;small object detection;data augmentation;performance optimization for convolutional neural network140|529|2更新时间:2024-05-07 -
 摘要:Computer vision technology has been intensively developed nowadays and it is essential to facilitate image classification and human face identification. Machine learning based methods have been used as basic technologies to carry out computer vision tasks. The core of this technology is to distinguish the location and category of the target via manual image feature designation for targeted tasks. However, the manual design process is costly. Current emerging deep learning-based technology can automatically learn effective features from labeled or unlabeled data in a supervised or unsupervised manner and facilitate image recognition and target detection tasks. Deep learning based pedestrian detection technology is one of the aspects its development. Our pedestrian detection is to identify pedestrian targets in a scenario of input single frame image or image sequence and determine the localization of the pedestrians in the targeted image. Due to the complicated scenarios and the uniqueness of pedestrian targets, deep learning based pedestrian detection technology has challenged two key issues shown below: 1) one aspect is the occlusion issue. The other one is that, the human body structure information of pedestrians is severely affected in the case of severe occlusion. As a result, the visual features of the occluded pedestrians are differentiated from those of the un-occluded ones leading to false negatives during inference. Due to the diversity of occlusion patterns, it is challenged to analyze which part is occluded accurately, and locates on-site capability for pedestrian detection algorithms; 2) the other challenge is scale-based variance. The pedestrians' detection status is constrained of crowded or sparse scenario l. For a tiny target, due to the lack of sufficient semantic information, the detector is likely to misjudge it as background noise. Simultaneously, it is challenged for a set of clear anchors that can match it perfectly for a large-scale target during the training procedure. Moreover, large-scale pedestrian instances often have clear internal texture and skeleton features, while small-scale ones often only have blurred edge information. Therefore, a unified framework designation is required to for large and small targets both. Our research carries out an overview of related works on several of deep learning-based pedestrian detection algorithms. Our analysis is targeted on current improvement of the mainstream pedestrian detection framework from three aspects, including anchor-based algorithm, anchor-free algorithm and technology modification (e.g., loss function and non-maximum suppression). In the scope of anchor-based methods, this research is mainly focused on pedestrian detectors based on Faster region-based convolutional neural network (R-CNN) or single shot multi-box detector (SSD) baseline, in which region proposals are firstly to generate and refined to get the final detection subsequently. In the context of these algorithms, current designation is for customized pedestrian modules whether it is based on single-stage or two-stage anchor-based detectors. We summarize them into the categories as following: 1) partial-based methods: local part features contain more pedestrian occlusion and deformation information, and thus some methods like occlusion-aware R-CNN (OR-CNN) have investigated to extract part-level features to improve occluded pedestrian detection performance. In addition to using extra part detectors or delineating partial regions manually, several pedestrian detection methods like mask-guided attention network(MGAN) use the attention mechanism to enhance the features of visible pedestrian regions while suppressing the features of occluded ones. 2) Hybrid methods: such methods like Bi-box or PedHunter built two-branch networks for both part and full-body prediction, and introduce a fusion mechanism to ensure more robustness on the aspects of local and global features of pedestrians both. 3) Cascaded methods: to improve localization quality, cascade structure has been also applied for pedestrian detection. Cascade R-CNN, auto regressive network(AP-Ped) and asymptotic localization fitting network(ALFNet) stacked multiple head predictors for multi-stage regressions of the proposals, and thus the pedestrian detection boxes can be gradually refined to obtain optimized localization results. 4) Multi-scale methods: these methods are integrated to robust feature representation by fusing high-level and low-level features like feature pyramid network (FPN) to tackle with scale variance in pedestrian detection. In the scope of anchor-free methods, our demonstration illustrates the two detectors like point-based, center scale predictor (CSP) and line-based, topology localization (TLL). Our two methods do not use the pre-defined anchor boxes and thus split into the anchor-free paradigm. These anchor-free methods can avoid the redundant background information brought by the pre-defined boxes, so it has relatively better performance for small-scale and occluded pedestrian detection. In addition, our research also summarizes improvements in general technologies that can be used in both anchor-based and anchor-free detectors. The modification of loss function represented by repulsion loss (RepLoss) is designed to bring the proposal and its matched ground-truth box closer while keeping it away from other ground-truth boxes. Another key technique is non-maximum suppression (NMS), which is usually used to reduce duplicated detection results. Representative methods among them are adaptive NMS and R2 NMS, and they usually aim to find a more suitable post-processing threshold for the pedestrian detector to deal with the occlusion issue. The regular datasets like Caltech, Citypersons and its corresponding challenging subsets (e.g., reasonable and heavy) are introduced in details. On the basis of the evaluation metric of log-average miss rate, our overview promotes a comparison of the performance on different subsets targeting at various challenging tasks, and provides an experimental analysis.关键词:pedestrian detection;deep learning;convolutional neural network (CNN);occlusion target detection;small-scale target detection422|301|9更新时间:2024-05-07
摘要:Computer vision technology has been intensively developed nowadays and it is essential to facilitate image classification and human face identification. Machine learning based methods have been used as basic technologies to carry out computer vision tasks. The core of this technology is to distinguish the location and category of the target via manual image feature designation for targeted tasks. However, the manual design process is costly. Current emerging deep learning-based technology can automatically learn effective features from labeled or unlabeled data in a supervised or unsupervised manner and facilitate image recognition and target detection tasks. Deep learning based pedestrian detection technology is one of the aspects its development. Our pedestrian detection is to identify pedestrian targets in a scenario of input single frame image or image sequence and determine the localization of the pedestrians in the targeted image. Due to the complicated scenarios and the uniqueness of pedestrian targets, deep learning based pedestrian detection technology has challenged two key issues shown below: 1) one aspect is the occlusion issue. The other one is that, the human body structure information of pedestrians is severely affected in the case of severe occlusion. As a result, the visual features of the occluded pedestrians are differentiated from those of the un-occluded ones leading to false negatives during inference. Due to the diversity of occlusion patterns, it is challenged to analyze which part is occluded accurately, and locates on-site capability for pedestrian detection algorithms; 2) the other challenge is scale-based variance. The pedestrians' detection status is constrained of crowded or sparse scenario l. For a tiny target, due to the lack of sufficient semantic information, the detector is likely to misjudge it as background noise. Simultaneously, it is challenged for a set of clear anchors that can match it perfectly for a large-scale target during the training procedure. Moreover, large-scale pedestrian instances often have clear internal texture and skeleton features, while small-scale ones often only have blurred edge information. Therefore, a unified framework designation is required to for large and small targets both. Our research carries out an overview of related works on several of deep learning-based pedestrian detection algorithms. Our analysis is targeted on current improvement of the mainstream pedestrian detection framework from three aspects, including anchor-based algorithm, anchor-free algorithm and technology modification (e.g., loss function and non-maximum suppression). In the scope of anchor-based methods, this research is mainly focused on pedestrian detectors based on Faster region-based convolutional neural network (R-CNN) or single shot multi-box detector (SSD) baseline, in which region proposals are firstly to generate and refined to get the final detection subsequently. In the context of these algorithms, current designation is for customized pedestrian modules whether it is based on single-stage or two-stage anchor-based detectors. We summarize them into the categories as following: 1) partial-based methods: local part features contain more pedestrian occlusion and deformation information, and thus some methods like occlusion-aware R-CNN (OR-CNN) have investigated to extract part-level features to improve occluded pedestrian detection performance. In addition to using extra part detectors or delineating partial regions manually, several pedestrian detection methods like mask-guided attention network(MGAN) use the attention mechanism to enhance the features of visible pedestrian regions while suppressing the features of occluded ones. 2) Hybrid methods: such methods like Bi-box or PedHunter built two-branch networks for both part and full-body prediction, and introduce a fusion mechanism to ensure more robustness on the aspects of local and global features of pedestrians both. 3) Cascaded methods: to improve localization quality, cascade structure has been also applied for pedestrian detection. Cascade R-CNN, auto regressive network(AP-Ped) and asymptotic localization fitting network(ALFNet) stacked multiple head predictors for multi-stage regressions of the proposals, and thus the pedestrian detection boxes can be gradually refined to obtain optimized localization results. 4) Multi-scale methods: these methods are integrated to robust feature representation by fusing high-level and low-level features like feature pyramid network (FPN) to tackle with scale variance in pedestrian detection. In the scope of anchor-free methods, our demonstration illustrates the two detectors like point-based, center scale predictor (CSP) and line-based, topology localization (TLL). Our two methods do not use the pre-defined anchor boxes and thus split into the anchor-free paradigm. These anchor-free methods can avoid the redundant background information brought by the pre-defined boxes, so it has relatively better performance for small-scale and occluded pedestrian detection. In addition, our research also summarizes improvements in general technologies that can be used in both anchor-based and anchor-free detectors. The modification of loss function represented by repulsion loss (RepLoss) is designed to bring the proposal and its matched ground-truth box closer while keeping it away from other ground-truth boxes. Another key technique is non-maximum suppression (NMS), which is usually used to reduce duplicated detection results. Representative methods among them are adaptive NMS and R2 NMS, and they usually aim to find a more suitable post-processing threshold for the pedestrian detector to deal with the occlusion issue. The regular datasets like Caltech, Citypersons and its corresponding challenging subsets (e.g., reasonable and heavy) are introduced in details. On the basis of the evaluation metric of log-average miss rate, our overview promotes a comparison of the performance on different subsets targeting at various challenging tasks, and provides an experimental analysis.关键词:pedestrian detection;deep learning;convolutional neural network (CNN);occlusion target detection;small-scale target detection422|301|9更新时间:2024-05-07 -
 摘要:Salient object detection (SOD) visual technology is a simulation of human vision and cognitive system nowadays. Current deep learning method is a computational simulation for human brain. Traditional SOD methods are required to design complicated hand-craft features to extract multi-level features, and then use machine learning or other methods for fusion and refinement. Each step of SOD can be internalized into the deep learning based neural network model related to a variety of algorithms. To provide reference for our intelligent SOD methods, recent SOD are sorted out from the perspective of principles, basic ideas and algorithms in detail. First, we briefly review the classic framework of traditional SOD methods to extract SOD technology like multi-level features fusion. Current challenges are related to time-consuming preprocessing, complex feature designing and lack of robust. Traditional methods are based on contrasting features, which tend to identify the boundary of the object and the corresponding internal noise. However, the SOD task is more concerned with the scope of the object and constrained of the internal homogeneous area to be suppressed. In addition, the spatial domain features extractions are disturbed of the effects of light and complex background, it is difficult to be integrated with other features effectively. These unstable issues are resulted in. Next, we analyzes a sort of fully supervised implementation architectures for significant deep learning based object detection in the context of the early fusion model, series of recurrent convolution neural network (CNN) architecture, series of full convolution network architecture as well as the feature extraction and fusion enhanced attention mechanism. The internal mechanism and connection of these methods are discussed. "The early fusion model" refers to the fusion strategy of traditional features and deep learning features in terms of artificial rules (such as vector stitching) in 2015. This strategic artificial feature fusion rules are lack of theories and mechanisms. CNN method is only used for high-level features extraction. Each super pixel needs to be traversed and input into the neural network, which is time-consuming. Recurrent CNN constant updates the recognition results to identify the target through introducing the forgetting mechanism. Thanks to this, multi-level features can naturally aggregate with each other using less parameters, which can achieve a better result than the single feed forward network. Full convolution network (FCN) is qualified for end-to-end multi-classification tasks at pixel level in complex background greatly enhanced the detection capability. To aggregate multi-level features, current researches are conducted based on FCN and illustrated a large number of customized models based on multiple strategies, including improving the fusion method in the network, compensating for the network's extraction accuracy of boundary information. Recent the attention mechanism module have become a useful supplement for neural network model. Not only does attention mechanism improve the precision of salient object detection, but also makes the thought of "salient" deliberated that it can only be applied in the classification task at pixel level. So the "salient concepts" can be used in object detection and lightweight model. Thirdly, The weak supervision and multi-task issues have their potentials because the training of full supervision salient object detection method requires expensive pixel-level annotation. Since the task-oriented CNN classification can focus and locate objects with image based tag semantics in the context of detailed salient maps optimization. Meanwhile, the sample updating method needs to be designed because the weakly supervised samples are insufficient to the refinement after generating initial salient map. At last, we introduce the application and development of generative adversarial network (GAN) and graph neural network (GNN) in SOD. Thanks to neural network theory, GNN and GAN have also been applied to SOD task. Based on of summarizing the existing methods, future SOD are predicted like feature fusion mode improvement, collaborative significant object detection, weak supervision and multi-task strategy, and multi-categories image significance detection. In these scenarios, the data has a more complex or fuzzy distribution (e.g., no longer subject to Euclidean spatial distribution). The solution should be more capable to describe the features further.关键词:salient object detection (SOD);deep learning;recurrent convolutional neural network(RCNN);fully convolutional network (FCN);attention mechanism;weakly supervised and multi-tasks strategy113|257|6更新时间:2024-05-07
摘要:Salient object detection (SOD) visual technology is a simulation of human vision and cognitive system nowadays. Current deep learning method is a computational simulation for human brain. Traditional SOD methods are required to design complicated hand-craft features to extract multi-level features, and then use machine learning or other methods for fusion and refinement. Each step of SOD can be internalized into the deep learning based neural network model related to a variety of algorithms. To provide reference for our intelligent SOD methods, recent SOD are sorted out from the perspective of principles, basic ideas and algorithms in detail. First, we briefly review the classic framework of traditional SOD methods to extract SOD technology like multi-level features fusion. Current challenges are related to time-consuming preprocessing, complex feature designing and lack of robust. Traditional methods are based on contrasting features, which tend to identify the boundary of the object and the corresponding internal noise. However, the SOD task is more concerned with the scope of the object and constrained of the internal homogeneous area to be suppressed. In addition, the spatial domain features extractions are disturbed of the effects of light and complex background, it is difficult to be integrated with other features effectively. These unstable issues are resulted in. Next, we analyzes a sort of fully supervised implementation architectures for significant deep learning based object detection in the context of the early fusion model, series of recurrent convolution neural network (CNN) architecture, series of full convolution network architecture as well as the feature extraction and fusion enhanced attention mechanism. The internal mechanism and connection of these methods are discussed. "The early fusion model" refers to the fusion strategy of traditional features and deep learning features in terms of artificial rules (such as vector stitching) in 2015. This strategic artificial feature fusion rules are lack of theories and mechanisms. CNN method is only used for high-level features extraction. Each super pixel needs to be traversed and input into the neural network, which is time-consuming. Recurrent CNN constant updates the recognition results to identify the target through introducing the forgetting mechanism. Thanks to this, multi-level features can naturally aggregate with each other using less parameters, which can achieve a better result than the single feed forward network. Full convolution network (FCN) is qualified for end-to-end multi-classification tasks at pixel level in complex background greatly enhanced the detection capability. To aggregate multi-level features, current researches are conducted based on FCN and illustrated a large number of customized models based on multiple strategies, including improving the fusion method in the network, compensating for the network's extraction accuracy of boundary information. Recent the attention mechanism module have become a useful supplement for neural network model. Not only does attention mechanism improve the precision of salient object detection, but also makes the thought of "salient" deliberated that it can only be applied in the classification task at pixel level. So the "salient concepts" can be used in object detection and lightweight model. Thirdly, The weak supervision and multi-task issues have their potentials because the training of full supervision salient object detection method requires expensive pixel-level annotation. Since the task-oriented CNN classification can focus and locate objects with image based tag semantics in the context of detailed salient maps optimization. Meanwhile, the sample updating method needs to be designed because the weakly supervised samples are insufficient to the refinement after generating initial salient map. At last, we introduce the application and development of generative adversarial network (GAN) and graph neural network (GNN) in SOD. Thanks to neural network theory, GNN and GAN have also been applied to SOD task. Based on of summarizing the existing methods, future SOD are predicted like feature fusion mode improvement, collaborative significant object detection, weak supervision and multi-task strategy, and multi-categories image significance detection. In these scenarios, the data has a more complex or fuzzy distribution (e.g., no longer subject to Euclidean spatial distribution). The solution should be more capable to describe the features further.关键词:salient object detection (SOD);deep learning;recurrent convolutional neural network(RCNN);fully convolutional network (FCN);attention mechanism;weakly supervised and multi-tasks strategy113|257|6更新时间:2024-05-07
Review
-
 摘要:ObjectiveImage has become an important carrier of information acquisition and dissemination recently. The real scenario images are constrained by low-quality features. It is challenged to resolve contrast degradation, color deviation, and information loss issues for low visibility images related to rain, fog, underwater, and low illumination. Current enhancement processing is beneficial to enhance the high-level application performance of the low-quality images. However, some enhancement methods can enhance the high-level application effects of low-quality image, but some enhancement methods have a weak effect or even negative effect. Therefore, it is vital to systematically develop the enhancement processing effect in high-level applications of low-quality images. Our research is focused on low-quality images (underwater images, haze images) and takes the effect of image high-level application based on salient object detection.MethodFirst, these low-quality images are processed via various current image enhancement approaches. Salient object detection is then performed on the enhanced images. Then, the influence of image enhancement on salient object detection performance is compared and analyzed. We implement a classification in the context of image enhancement and salient object detection methods. We conduct an analysis about those models further. Furthermore, we explore some regularized image enhancement methods and salient object detection approaches. Finally, the applications of image enhancement for salient object detection are verified via scientific objective and/or subjective evaluation.ResultThe experimental results demonstrate that the image enhancement methods for salient object detection are not clarified in low-quality images.ConclusionHence, we summarize the same enhancement method to illustrate the different effects for different salient object detection. First, the current existing enhancement methods are mainly designed to meet human visual effects, while images like those are not necessarily consistent with the needs of high-level applications. It is a challenge that the effect of image enhancement on salient object detection. It needs an option for effective enhancement method based on salient object detection. Our research challenge issues should focus on the following aspects as mentioned below: first, it should be refined in the light of the different low-quality image degradation factors. Different low-quality images show different degradation results for different degradation, such as color shift of underwater imaging, and object blur of hazed image. We should pick and exploit corresponding low-quality image enhancement and salient object detection methods towards various degradation issues, as well as probe the influence of these enhancement methods on salient object detection for low-quality images further. Second, the interaction between enhancement methods and salient detection methods should be developed. Generally, Salient object detection for low-quality images by enhancement mainly includes two parts: image enhancement and salient object detection. However, different enhancement methods have different effects on salient object detection for low-quality images. Therefore, it is necessary to study the internal mechanism of different image enhancement methods and different image salient object detection methods, and explore the deeper correlation between the design of the image enhancement model and the construction of the salient object detection model further. Third, we should focus on exploiting an end-to-end framework for it. It is challenging to obtain good salient object detection results on the aspect of the degradation of low-quality images. To develop an end-to-end framework, future work can be based on the fusion of low-quality image enhancement and salient object detection models.关键词:underwater image;haze image;image enhancement;salient object detection;image processing138|1106|4更新时间:2024-05-07
摘要:ObjectiveImage has become an important carrier of information acquisition and dissemination recently. The real scenario images are constrained by low-quality features. It is challenged to resolve contrast degradation, color deviation, and information loss issues for low visibility images related to rain, fog, underwater, and low illumination. Current enhancement processing is beneficial to enhance the high-level application performance of the low-quality images. However, some enhancement methods can enhance the high-level application effects of low-quality image, but some enhancement methods have a weak effect or even negative effect. Therefore, it is vital to systematically develop the enhancement processing effect in high-level applications of low-quality images. Our research is focused on low-quality images (underwater images, haze images) and takes the effect of image high-level application based on salient object detection.MethodFirst, these low-quality images are processed via various current image enhancement approaches. Salient object detection is then performed on the enhanced images. Then, the influence of image enhancement on salient object detection performance is compared and analyzed. We implement a classification in the context of image enhancement and salient object detection methods. We conduct an analysis about those models further. Furthermore, we explore some regularized image enhancement methods and salient object detection approaches. Finally, the applications of image enhancement for salient object detection are verified via scientific objective and/or subjective evaluation.ResultThe experimental results demonstrate that the image enhancement methods for salient object detection are not clarified in low-quality images.ConclusionHence, we summarize the same enhancement method to illustrate the different effects for different salient object detection. First, the current existing enhancement methods are mainly designed to meet human visual effects, while images like those are not necessarily consistent with the needs of high-level applications. It is a challenge that the effect of image enhancement on salient object detection. It needs an option for effective enhancement method based on salient object detection. Our research challenge issues should focus on the following aspects as mentioned below: first, it should be refined in the light of the different low-quality image degradation factors. Different low-quality images show different degradation results for different degradation, such as color shift of underwater imaging, and object blur of hazed image. We should pick and exploit corresponding low-quality image enhancement and salient object detection methods towards various degradation issues, as well as probe the influence of these enhancement methods on salient object detection for low-quality images further. Second, the interaction between enhancement methods and salient detection methods should be developed. Generally, Salient object detection for low-quality images by enhancement mainly includes two parts: image enhancement and salient object detection. However, different enhancement methods have different effects on salient object detection for low-quality images. Therefore, it is necessary to study the internal mechanism of different image enhancement methods and different image salient object detection methods, and explore the deeper correlation between the design of the image enhancement model and the construction of the salient object detection model further. Third, we should focus on exploiting an end-to-end framework for it. It is challenging to obtain good salient object detection results on the aspect of the degradation of low-quality images. To develop an end-to-end framework, future work can be based on the fusion of low-quality image enhancement and salient object detection models.关键词:underwater image;haze image;image enhancement;salient object detection;image processing138|1106|4更新时间:2024-05-07 -
 摘要:ObjectiveEffective automatic grouping of data into clusters, especially clustering high-dimensional datasets, is one of the key issues in machine learning and data analysis. It is related to many aspects of signal processing applications, including computer vision, pattern recognition, speech and audio recognition, wireless communication and text classification. Current clustering algorithms are constrained of high computational complexity and poor performance in processing high-dimensional data due to the dimension disaster. Deep neural networks based clustering methods have its potential for real data clustering derived of their high representational ability. Autoencoder (AE) or variational autoencoder (VAE) clustering networks improve clustering effectiveness. But, their clustering performance is easy to be distorted intensively because of poor features extraction in distinguishing clear and unclear data or posterior collapse to clarify determining its posterior parameters of the latent variable of VAE, and they are insufficient to segment multiple classes, especially share very similar mean and variance in the context of clustering a multiclass dataset or two different classes. We demonstrate a clustering network based on VAE with the prior of Gaussian mixture (GM) distribution in terms of the deficiency of AE and VAE.MethodThe VAE, a maximum likelihood generative model, maximizes evidence lower bound (ELBO) via minimizing model reconstruction errors. Its difference of potential cost is through Kullback-Leibler (KL) divergence between the posterior distribution and the hypothesized prior, and then establishes maximum marginal log-likelihood (LL) of the data observed. Due to the approximate posterior distribution used VAE as a benched Gaussian distribution, it is challenged to match the ground truth posterior and have its priority of the KL term in ELBO, and the latent variable space may be arbitrarily complicated or even multimodal. To further improve the description of latent variables, a VAE is facilitated based on a latent variable prior of GM distribution. Its GM distribution prior linked data representation is approximated using the posterior distribution of the latent variable composed of a GM model, and the reconstruction error and the KL divergence based cost function between posterior and prior distribution is adopted to train the GM model based VAE. Due to the KL divergence between two GM distribution functions without a closed form solution, we use the approximate variational lower bound solution of the cost function with the aid of the fact that the KL divergence between the two single Gaussians has a closed-form solution, and implement the VAE using GM distribution priors optimization to resolve the KL divergence. A VAE based clustering network is constructed through a clustering layer combination behind the VAE. To improve the clustering performance, the STUDENT's t-distribution is used as a kernel to compute the soft assignment of the latent features of the VAE between the embedded point and the cluster centroid. Furthermore, a KL divergence cost is constructed between the soft assignment and its auxiliary target distribution. The commonly used VAE utilizes fully-connected neural networks to compute the latent variable, which generates more over fitted data parameters. Thus, the clustering network is carried out by convolutional neural networks (CNNs), which consist of three convolutional layers and two fully-connected layers, without fully-connected neural networks, and no pooling layers used in the network because it will result in loss of useful information of the data. The network is trained by optimizing the KL divergence cost using stochastic gradient descent (SGD) method with the initial network parameters from the VAE. Our clustering network was obtained by the two-step training mentioned above like acquired VAE, as the initial value to train the following clustering layer.ResultTo test the effectiveness of the proposed algorithm, our network is evaluated on the multiclass benchmark datasets MNIST(Modified National Institute of Standards and Technology Database) which contains images of 10 categories of handwritten digits, and Fashion-MNIST which consists of grayscale images associated to a 10 segmented label. Our algorithm achieves 95.86% accuracy (ACC) and 91% normalized mutual information (NMI) on MNIST, ACC 61.34% and 62.5% NMI on Fashion-NMIST. Our network demonstration has the similar performance to ClusterGAN with fewer parameters and less memory space. The experimental results illustrate that our network achieves feasible clustering performance.ConclusionWe construct a VAE based clustering network with the prior of GM distribution. A novel framed VAE is established to improve the representation ability of the latent variable based on a latent variable prior of GM distribution. The KL divergence between posterior and prior GM distribution is optimized to achieve latent variable features of VAE and reconstruct its input well. To improve the clustering performance, the clustering network is trained by optimizing the KL divergence between the soft distribution of the latent features of the VAE and the auxiliary target distribution of the soft assignment. We focus on the issue of where the number of Gaussian components in prior and posterior is different and the ability of the representation of the model on complex texture features further.关键词:clustering;Gaussian mixture distribution;variational autoencoder(VAE);soft assignment;Kullback-Leibler(KL) divergence142|89|0更新时间:2024-05-07
摘要:ObjectiveEffective automatic grouping of data into clusters, especially clustering high-dimensional datasets, is one of the key issues in machine learning and data analysis. It is related to many aspects of signal processing applications, including computer vision, pattern recognition, speech and audio recognition, wireless communication and text classification. Current clustering algorithms are constrained of high computational complexity and poor performance in processing high-dimensional data due to the dimension disaster. Deep neural networks based clustering methods have its potential for real data clustering derived of their high representational ability. Autoencoder (AE) or variational autoencoder (VAE) clustering networks improve clustering effectiveness. But, their clustering performance is easy to be distorted intensively because of poor features extraction in distinguishing clear and unclear data or posterior collapse to clarify determining its posterior parameters of the latent variable of VAE, and they are insufficient to segment multiple classes, especially share very similar mean and variance in the context of clustering a multiclass dataset or two different classes. We demonstrate a clustering network based on VAE with the prior of Gaussian mixture (GM) distribution in terms of the deficiency of AE and VAE.MethodThe VAE, a maximum likelihood generative model, maximizes evidence lower bound (ELBO) via minimizing model reconstruction errors. Its difference of potential cost is through Kullback-Leibler (KL) divergence between the posterior distribution and the hypothesized prior, and then establishes maximum marginal log-likelihood (LL) of the data observed. Due to the approximate posterior distribution used VAE as a benched Gaussian distribution, it is challenged to match the ground truth posterior and have its priority of the KL term in ELBO, and the latent variable space may be arbitrarily complicated or even multimodal. To further improve the description of latent variables, a VAE is facilitated based on a latent variable prior of GM distribution. Its GM distribution prior linked data representation is approximated using the posterior distribution of the latent variable composed of a GM model, and the reconstruction error and the KL divergence based cost function between posterior and prior distribution is adopted to train the GM model based VAE. Due to the KL divergence between two GM distribution functions without a closed form solution, we use the approximate variational lower bound solution of the cost function with the aid of the fact that the KL divergence between the two single Gaussians has a closed-form solution, and implement the VAE using GM distribution priors optimization to resolve the KL divergence. A VAE based clustering network is constructed through a clustering layer combination behind the VAE. To improve the clustering performance, the STUDENT's t-distribution is used as a kernel to compute the soft assignment of the latent features of the VAE between the embedded point and the cluster centroid. Furthermore, a KL divergence cost is constructed between the soft assignment and its auxiliary target distribution. The commonly used VAE utilizes fully-connected neural networks to compute the latent variable, which generates more over fitted data parameters. Thus, the clustering network is carried out by convolutional neural networks (CNNs), which consist of three convolutional layers and two fully-connected layers, without fully-connected neural networks, and no pooling layers used in the network because it will result in loss of useful information of the data. The network is trained by optimizing the KL divergence cost using stochastic gradient descent (SGD) method with the initial network parameters from the VAE. Our clustering network was obtained by the two-step training mentioned above like acquired VAE, as the initial value to train the following clustering layer.ResultTo test the effectiveness of the proposed algorithm, our network is evaluated on the multiclass benchmark datasets MNIST(Modified National Institute of Standards and Technology Database) which contains images of 10 categories of handwritten digits, and Fashion-MNIST which consists of grayscale images associated to a 10 segmented label. Our algorithm achieves 95.86% accuracy (ACC) and 91% normalized mutual information (NMI) on MNIST, ACC 61.34% and 62.5% NMI on Fashion-NMIST. Our network demonstration has the similar performance to ClusterGAN with fewer parameters and less memory space. The experimental results illustrate that our network achieves feasible clustering performance.ConclusionWe construct a VAE based clustering network with the prior of GM distribution. A novel framed VAE is established to improve the representation ability of the latent variable based on a latent variable prior of GM distribution. The KL divergence between posterior and prior GM distribution is optimized to achieve latent variable features of VAE and reconstruct its input well. To improve the clustering performance, the clustering network is trained by optimizing the KL divergence between the soft distribution of the latent features of the VAE and the auxiliary target distribution of the soft assignment. We focus on the issue of where the number of Gaussian components in prior and posterior is different and the ability of the representation of the model on complex texture features further.关键词:clustering;Gaussian mixture distribution;variational autoencoder(VAE);soft assignment;Kullback-Leibler(KL) divergence142|89|0更新时间:2024-05-07 -
 摘要:ObjectiveDeep learning network training models is based on labeled data. It is challenged to obtain pixel-level label annotations for labor-intensive semantic segmentation. However, the convolution operator of the segmentation network has single local receptive field as the generator, but the size of each convolution kernel is very limited, and each convolution operation just cover a tiny pixel-related neighborhood. The height and width of long-range feature map is dramatically declined due to the constraints of multi-layer convolution and pooling operations. The lower the layer is, the larger the area is covered, which is via the mapped convolution kernel retrace to the original image, which makes it difficult to capture the long-range feature relationship. It is a challenge to coordinate multiple convolutional layers to capture these dependent parameter values in detail via optimization algorithm. Therefore, the long-range dependency between different regions of the image can just be modeled through multiple convolutional layers or the enlargement of the convolution kernel, but this local convolution structural approach also loses the computational efficiency. In addition, another generative adversarial network (GAN) challenge is the manipulation ability of the discriminator. The discriminator training is equivalent to training a good evaluator to estimate the density ratio between the generated distribution and the target distribution. The discriminator based density ratio estimation is inaccurate and unstable in related to high-dimensional space in common. The better the discriminator is trained, the more severed gradient returned to the generator is ignored, and the training process will be cut once the gradient completely disappeared. The traditional method proposes that the parameter matrix of the discriminator is required to meet the Lipschitz constraint, but this method is not detailed enough. The method limit the parameter matrix factors, but it is not greater than a certain value. Although the Lipschitz constraint can also be guaranteed, the structure of the entire parameter matrix is disturbed due to the changed proportional relationship between the parameters.MethodThe semi-supervised adversarial learning application can effectively reduce the number of manually generated labels to semantic image segmentation in the training process. Our segmentation network is used as the generator of the GAN, and the segmentation network outputs the semantic label probability map of a targeted image. Hence, the output of the segmentation network is possible close to the ground truth label in space. The fully convolutional neural network (CNN) is used as the discriminator. When doing semi-supervised training, the discriminator can distinguish the ground truth label map from the class probability map predicted by the segmentation network. The discriminator network generates a confidence map that it can be used as a supervision signal to guide the cross-entropy loss. Based on the confidence map, it is easy to see the regions in the prediction distribution that are close to the ground truth label distribution, and then use the masked cross-entropy loss to make the segmentation network trust and train these credible predictions. This method is similar to the probabilistic graphical model. The network does not increase the computational load because redundant post-processing modules are not appeared in the test phase and discriminator is not needed in the inference process. We extend two layers of self-attention modules to the segmentation network of GAN, and model the semantic dependency in the spatial dimension. The segmentation network as a generator can precisely coordinate the fine details of each pixel position on the feature map with the fine details in the distance part of the image through this attention module. The self-attention module is optional to aggregate the features at each location via a weighted sum on the features of multifaceted locations. Therefore, the relationship between widely discrete spatial regions in the input image can be effectively processed based on pixel-level ground truth data. A good balance is achieved between long-range dependency modeling capabilities and computational efficiency. We carry out spectral normalization to the discriminator of the adversarial network during the training process. This method introduces Lipschitz continuity constraints from the perspective of the spectral norm of the parameter matrix of each layer of neural network. The neural network beyond the disturbance of the input image and make the training process more stable and easier to converge. This is a more refined way to make the discriminator meet Lipschitz connectivity, which limits the violent degree of function changes and makes the model more stable. This weighted normalization method can not only stabilize the training of the discriminator network, but also obtain satisfactory performance without intensive adjustment of the unique hyper-parameters, and is easy to implement and requires less calculation. When spectral normalization is applied to adversarial generation networks on semantic segmentation tasks, the generated cases are also more diverse than traditional weight normalization. In the absence of complementary regularization techniques, spectral normalization can even improve the quality of the generated image better than other weight normalization and gradient loss.ResultOur experiment is compared to the latest 9 methods derived from the Cityscapes dataset and the pattern analysis, statistical modeling and computational learning visual object classes(PASCAL VOC 2012) dataset. In the Cityscapes dataset, the performance is improved by 2.3% to 3.2% compared to the baseline model. In the PASCAL VOC 2012 dataset, the performance is improved by 1.4% to 2.5% over the baseline model. Simultaneously an ablation experiment is conducted on the PASCAL VOC 2012 dataset.ConclusionThe semantic segmentation method of semi-supervised adversarial learning proposed uses the introduced self-attention mechanism to capture the dependence between pixels on the feature map. The application of spectral normalization to stabilize the adversarial generation network has its qualified robustness and effectiveness.关键词:semi-supervised learning;convolutional neural network (CNN);semantic image segmentation;generative adversarial network (GAN);self-attention mechanism;spectral normalization133|196|1更新时间:2024-05-07
摘要:ObjectiveDeep learning network training models is based on labeled data. It is challenged to obtain pixel-level label annotations for labor-intensive semantic segmentation. However, the convolution operator of the segmentation network has single local receptive field as the generator, but the size of each convolution kernel is very limited, and each convolution operation just cover a tiny pixel-related neighborhood. The height and width of long-range feature map is dramatically declined due to the constraints of multi-layer convolution and pooling operations. The lower the layer is, the larger the area is covered, which is via the mapped convolution kernel retrace to the original image, which makes it difficult to capture the long-range feature relationship. It is a challenge to coordinate multiple convolutional layers to capture these dependent parameter values in detail via optimization algorithm. Therefore, the long-range dependency between different regions of the image can just be modeled through multiple convolutional layers or the enlargement of the convolution kernel, but this local convolution structural approach also loses the computational efficiency. In addition, another generative adversarial network (GAN) challenge is the manipulation ability of the discriminator. The discriminator training is equivalent to training a good evaluator to estimate the density ratio between the generated distribution and the target distribution. The discriminator based density ratio estimation is inaccurate and unstable in related to high-dimensional space in common. The better the discriminator is trained, the more severed gradient returned to the generator is ignored, and the training process will be cut once the gradient completely disappeared. The traditional method proposes that the parameter matrix of the discriminator is required to meet the Lipschitz constraint, but this method is not detailed enough. The method limit the parameter matrix factors, but it is not greater than a certain value. Although the Lipschitz constraint can also be guaranteed, the structure of the entire parameter matrix is disturbed due to the changed proportional relationship between the parameters.MethodThe semi-supervised adversarial learning application can effectively reduce the number of manually generated labels to semantic image segmentation in the training process. Our segmentation network is used as the generator of the GAN, and the segmentation network outputs the semantic label probability map of a targeted image. Hence, the output of the segmentation network is possible close to the ground truth label in space. The fully convolutional neural network (CNN) is used as the discriminator. When doing semi-supervised training, the discriminator can distinguish the ground truth label map from the class probability map predicted by the segmentation network. The discriminator network generates a confidence map that it can be used as a supervision signal to guide the cross-entropy loss. Based on the confidence map, it is easy to see the regions in the prediction distribution that are close to the ground truth label distribution, and then use the masked cross-entropy loss to make the segmentation network trust and train these credible predictions. This method is similar to the probabilistic graphical model. The network does not increase the computational load because redundant post-processing modules are not appeared in the test phase and discriminator is not needed in the inference process. We extend two layers of self-attention modules to the segmentation network of GAN, and model the semantic dependency in the spatial dimension. The segmentation network as a generator can precisely coordinate the fine details of each pixel position on the feature map with the fine details in the distance part of the image through this attention module. The self-attention module is optional to aggregate the features at each location via a weighted sum on the features of multifaceted locations. Therefore, the relationship between widely discrete spatial regions in the input image can be effectively processed based on pixel-level ground truth data. A good balance is achieved between long-range dependency modeling capabilities and computational efficiency. We carry out spectral normalization to the discriminator of the adversarial network during the training process. This method introduces Lipschitz continuity constraints from the perspective of the spectral norm of the parameter matrix of each layer of neural network. The neural network beyond the disturbance of the input image and make the training process more stable and easier to converge. This is a more refined way to make the discriminator meet Lipschitz connectivity, which limits the violent degree of function changes and makes the model more stable. This weighted normalization method can not only stabilize the training of the discriminator network, but also obtain satisfactory performance without intensive adjustment of the unique hyper-parameters, and is easy to implement and requires less calculation. When spectral normalization is applied to adversarial generation networks on semantic segmentation tasks, the generated cases are also more diverse than traditional weight normalization. In the absence of complementary regularization techniques, spectral normalization can even improve the quality of the generated image better than other weight normalization and gradient loss.ResultOur experiment is compared to the latest 9 methods derived from the Cityscapes dataset and the pattern analysis, statistical modeling and computational learning visual object classes(PASCAL VOC 2012) dataset. In the Cityscapes dataset, the performance is improved by 2.3% to 3.2% compared to the baseline model. In the PASCAL VOC 2012 dataset, the performance is improved by 1.4% to 2.5% over the baseline model. Simultaneously an ablation experiment is conducted on the PASCAL VOC 2012 dataset.ConclusionThe semantic segmentation method of semi-supervised adversarial learning proposed uses the introduced self-attention mechanism to capture the dependence between pixels on the feature map. The application of spectral normalization to stabilize the adversarial generation network has its qualified robustness and effectiveness.关键词:semi-supervised learning;convolutional neural network (CNN);semantic image segmentation;generative adversarial network (GAN);self-attention mechanism;spectral normalization133|196|1更新时间:2024-05-07 -
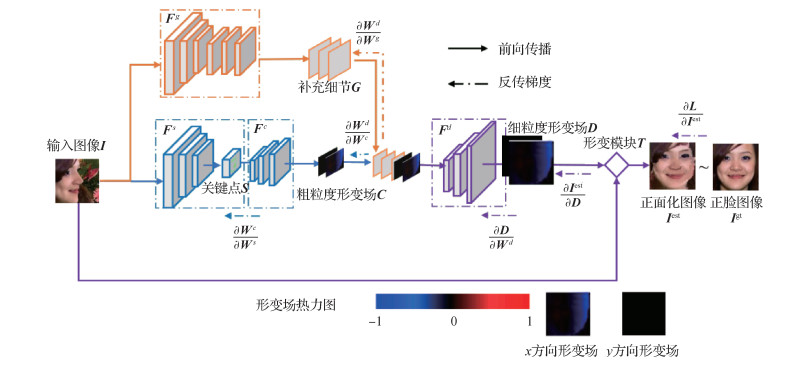 摘要:ObjectiveFace recognition is currently challenging in the context of large variations in pose, expression, aging, lighting and occlusion. Pose variations tend to large non-planar face transformation among these factors. To address the pose variations, previous methods mainly attempt to extract pose invariant feature or frontalize non-frontal faces. Among them, the frontalization methods can release discriminative feature learning via pose variations elimination. There are mainly two kinds of face frontalization methods : 2D and 3D frontalization methods. 2D methods can generate more natural frontal faces but it may lose facial structural information, which is the key factor of identity discrimination. 3D methods can well preserve facial structural information, but are not so flexible. In summary, both 3D methods and 2D methods have information loss in the frontalized faces especially for large pose variations like invisible pixels in 3D morphable model or pixel aberrance in 2D generative methods.MethodWe propose a novel coarse-to-fine morphing field network (CFMF-Net), combining both 2D and 3D face transformation methods to frontalize a non-frontal face image via the coarse-to-fine optimized morphing field for shifting each pixel. Thanks to the flexibility of 2D learning based methods and structure preservation of 3D morphable model-based methods, our proposed morphing learning method makes the learning process easier and reduces the probability of over-fitting. First, a coarse morphing field is learned to capture the major structure variation of single face image. Then, a residual module based facial information extraction is designed to promote the coarse morphing field of those output concatenated with the coarse morphing field to generate the final fine morphing field for face image input. The overall framework is for the pixel correspondences regression but not pixel values. The work ensures that all pixels in the frontalized face image are taken from the input non-frontal image, thus reducing information distortion to a large extent. Therefore, the identity information related to the input non-frontal face images are well preserved with favorable visual results, thus further facilitating the subsequent face recognition task. To achieve more accurate morphing field output, our design of the coarse-to-fine morphing field learning assures the robustness of learned morphing field and the residual complementing branch.ResultTo verify the effectiveness of our proposed work, extensive experiments on multi pose, illumination, expressions (MultiPIE), labeled faces in the wild (LFW), celebrities in frontal-profile in the wild (CFP) and intelligence advanced research projects activity Janus benchmark-A (IJB-A) datasets are carried out and the results are compared with other face transformation methods. Among these testing sets, MultiPIE, CFP and IJB-A datasets are all with full pose variation. In addition, IJB-A contains full pose variations as well as other complicated variations like low resolution and occlusion. The experiments follow the same training and testing protocol with previous works, i.e., training with both original and frontalized face images. For fair comparison, the commonly used LightCNN-29 is developed as the recognition model. Our method outperforms related works on the large pose testing protocol of MultiPIE and CFP and comparable performance on LFW and IJB-A. Additionally, our visualization results also show that our method can well preserve the identity information. Furthermore, the ablation study presents the feasibility of the coarse-to-fine framework in our CFMF-Net. In a word, the recognition accuracies and visualization results demonstrate that the proposed CFMF-Net can generate frontalized faces with identity information preserved and achieve higher large pose face recognition accuracy as well.ConclusionA coarse-to-fine morphing field learning framework frontalizes face images by shifting pixels to ensure the flexible learnability and identity information preservation. To improve its accuracy, the flexible learnability yields the network to optimize face frontalization objective without predefined 3D transformation rules. Moreover, the learned morphing field for each pixel makes the output frontal face shifted from the input image only, reducing the information loss. Simultaneously, the design of coarse-to-fine and residual architecture ensures more robust and accurate results further.关键词:large pose face recognition;face frontalization;morphing field learning;coarse-to-fine learning;fully convolutional network124|88|2更新时间:2024-05-07
摘要:ObjectiveFace recognition is currently challenging in the context of large variations in pose, expression, aging, lighting and occlusion. Pose variations tend to large non-planar face transformation among these factors. To address the pose variations, previous methods mainly attempt to extract pose invariant feature or frontalize non-frontal faces. Among them, the frontalization methods can release discriminative feature learning via pose variations elimination. There are mainly two kinds of face frontalization methods : 2D and 3D frontalization methods. 2D methods can generate more natural frontal faces but it may lose facial structural information, which is the key factor of identity discrimination. 3D methods can well preserve facial structural information, but are not so flexible. In summary, both 3D methods and 2D methods have information loss in the frontalized faces especially for large pose variations like invisible pixels in 3D morphable model or pixel aberrance in 2D generative methods.MethodWe propose a novel coarse-to-fine morphing field network (CFMF-Net), combining both 2D and 3D face transformation methods to frontalize a non-frontal face image via the coarse-to-fine optimized morphing field for shifting each pixel. Thanks to the flexibility of 2D learning based methods and structure preservation of 3D morphable model-based methods, our proposed morphing learning method makes the learning process easier and reduces the probability of over-fitting. First, a coarse morphing field is learned to capture the major structure variation of single face image. Then, a residual module based facial information extraction is designed to promote the coarse morphing field of those output concatenated with the coarse morphing field to generate the final fine morphing field for face image input. The overall framework is for the pixel correspondences regression but not pixel values. The work ensures that all pixels in the frontalized face image are taken from the input non-frontal image, thus reducing information distortion to a large extent. Therefore, the identity information related to the input non-frontal face images are well preserved with favorable visual results, thus further facilitating the subsequent face recognition task. To achieve more accurate morphing field output, our design of the coarse-to-fine morphing field learning assures the robustness of learned morphing field and the residual complementing branch.ResultTo verify the effectiveness of our proposed work, extensive experiments on multi pose, illumination, expressions (MultiPIE), labeled faces in the wild (LFW), celebrities in frontal-profile in the wild (CFP) and intelligence advanced research projects activity Janus benchmark-A (IJB-A) datasets are carried out and the results are compared with other face transformation methods. Among these testing sets, MultiPIE, CFP and IJB-A datasets are all with full pose variation. In addition, IJB-A contains full pose variations as well as other complicated variations like low resolution and occlusion. The experiments follow the same training and testing protocol with previous works, i.e., training with both original and frontalized face images. For fair comparison, the commonly used LightCNN-29 is developed as the recognition model. Our method outperforms related works on the large pose testing protocol of MultiPIE and CFP and comparable performance on LFW and IJB-A. Additionally, our visualization results also show that our method can well preserve the identity information. Furthermore, the ablation study presents the feasibility of the coarse-to-fine framework in our CFMF-Net. In a word, the recognition accuracies and visualization results demonstrate that the proposed CFMF-Net can generate frontalized faces with identity information preserved and achieve higher large pose face recognition accuracy as well.ConclusionA coarse-to-fine morphing field learning framework frontalizes face images by shifting pixels to ensure the flexible learnability and identity information preservation. To improve its accuracy, the flexible learnability yields the network to optimize face frontalization objective without predefined 3D transformation rules. Moreover, the learned morphing field for each pixel makes the output frontal face shifted from the input image only, reducing the information loss. Simultaneously, the design of coarse-to-fine and residual architecture ensures more robust and accurate results further.关键词:large pose face recognition;face frontalization;morphing field learning;coarse-to-fine learning;fully convolutional network124|88|2更新时间:2024-05-07 -
 摘要:ObjectiveHuman facial expression recognition (FER) is one of the key issues of computer vision analysis like human-computer interaction, medical care and intelligent driving. FER research has mainly two challenges in related to expression feature extraction and classification recognition. Current methods are mainly design facial expression features artificially, while deep learning based methods can independently learn to obtain semantic facial expression features. The deep learning based FER technology can integrate the two training processes of feature extraction and facial expression recognition. It has strong generalization ability and good recognition accuracy currently. Most of the existing FER algorithms are based on expression video sequences or a single peak expression scenario. However, the generation of expression corresponds to a continuous dynamic change process of facial muscles, and the motion-based expression peak frame identifies completed expression information in common. Our method demonstrates a spatio-temporal and features based deep neural network to analyze and understand video sequences derived expression information to improve expression recognition ability.MethodOur network learn the static "spatial feature" of the expression and its dynamic "temporal feature" based on the video sequence, respectively. First, we illustrate a deep metric fusion network based on triplet loss learning. Our network is composed of two sub-modules like deep convolutional neural network (DCNN) module and N-metric module. The DCNN module is derived from a general convolutional neural network (CNN) to extract common detailed CNN facial features. In this module, the Visual Geometry Group 16-layer net (VGG16)-face network model structure is adopted where the output of its final 4 096-dimensional fully connected layer is used as the benched CNN feature. The N-metric module contains fully multiple connected layer branches. Each branch uses a triplet loss function to implement the supervised learning to represent different expression semantic multi-features. These dual-features representations are fused through two fully connected layers further. A more robust and spatial feature expression is illustrated. The each two fully connected layers have 256 hidden units and the output of each branch is merged together in a concatenating manner in the DCNN module. In the N-metric module, all of fully connected layer branches are shared to the same CNN feature. For example, the output of the final fully connected layer is used as the input of each branch in the DCNN module. In addition, a fixed dimension fully connected layer is used via each branch and it is associated with a certain threshold sampling for learning the corresponding feature embedding. Each branch is supervised and learned by the corresponding triple loss function. Next, facial expressions are essential to facial expression changes in motion because the changes are integrated to the overall facial expression changing. Existing methods are challenged to extract the dynamic expression features in the context of consecutive frames derived time domain through manual design or deep learning methods. But, manual-designed features are constrained of facial image sequence based temporal features extraction. The image sequence related deep neural network is insufficient to employ the prior knowledge of the key features of the face as well due to the non-learning temporal featured expressions. Our landmark-trajectory convolutional neural network analyzes the trajectory in the video sequence and learns the dynamic "temporal features" of the expression sequence consequently, which extracts the accurate motion characteristics of facial expressions in the time domain. Our network consists of four convolutional layers and two fully connected layers. The input of the landmark trajectory CNN (LTCNN) sub-network is a similar feature map constructed based on the trajectory of facial expression in the video. Third, a fine-tuning based fusion strategy is conducted to combine the learned features of two network modules obtained further, which achieves the temporal and spatial features based fusion result optimally. We train the deep metric fusion (DMF) and LTCNN sub-networks each, combine the two sub-networks through feature fusion, and fine-tuning them in an end-to-end manner sequentially. The implemented hyper-parameters are used for fine-tuning training in DMF sub-network optimization.ResultOur demonstrated FEC algorithm is tested and verified on three public facial expression databases in terms of the extended Cohn-Kanade dataset (CK+), the MMI facial expression database (MMI), and the Oulu-CASIA NIR&VIS facial expression database (Oulu-CASIA). Our method achieves the recognition accuracy of 98.46%, 82.96%, and 87.12% on the databases of CK+, MMI, and Oulu-CASIA, respectively.ConclusionFor our deep learning based network integrated temporal and the spatial features both to realize video sequences based FER. In the network, our two sub-modules are used to learn the "spatial features" of the facial expression at the peak frame and the "temporal features" of facial expression motion. Finally, a fusion strategy is carried out to achieve better fusion effect of temporal and spatial features based on overall fine-tuning. Our FER method has its potentials to develop further.关键词:facial expression recognition(FER);deep learning;deep metric learning;triplet loss;feature fusion138|93|2更新时间:2024-05-07
摘要:ObjectiveHuman facial expression recognition (FER) is one of the key issues of computer vision analysis like human-computer interaction, medical care and intelligent driving. FER research has mainly two challenges in related to expression feature extraction and classification recognition. Current methods are mainly design facial expression features artificially, while deep learning based methods can independently learn to obtain semantic facial expression features. The deep learning based FER technology can integrate the two training processes of feature extraction and facial expression recognition. It has strong generalization ability and good recognition accuracy currently. Most of the existing FER algorithms are based on expression video sequences or a single peak expression scenario. However, the generation of expression corresponds to a continuous dynamic change process of facial muscles, and the motion-based expression peak frame identifies completed expression information in common. Our method demonstrates a spatio-temporal and features based deep neural network to analyze and understand video sequences derived expression information to improve expression recognition ability.MethodOur network learn the static "spatial feature" of the expression and its dynamic "temporal feature" based on the video sequence, respectively. First, we illustrate a deep metric fusion network based on triplet loss learning. Our network is composed of two sub-modules like deep convolutional neural network (DCNN) module and N-metric module. The DCNN module is derived from a general convolutional neural network (CNN) to extract common detailed CNN facial features. In this module, the Visual Geometry Group 16-layer net (VGG16)-face network model structure is adopted where the output of its final 4 096-dimensional fully connected layer is used as the benched CNN feature. The N-metric module contains fully multiple connected layer branches. Each branch uses a triplet loss function to implement the supervised learning to represent different expression semantic multi-features. These dual-features representations are fused through two fully connected layers further. A more robust and spatial feature expression is illustrated. The each two fully connected layers have 256 hidden units and the output of each branch is merged together in a concatenating manner in the DCNN module. In the N-metric module, all of fully connected layer branches are shared to the same CNN feature. For example, the output of the final fully connected layer is used as the input of each branch in the DCNN module. In addition, a fixed dimension fully connected layer is used via each branch and it is associated with a certain threshold sampling for learning the corresponding feature embedding. Each branch is supervised and learned by the corresponding triple loss function. Next, facial expressions are essential to facial expression changes in motion because the changes are integrated to the overall facial expression changing. Existing methods are challenged to extract the dynamic expression features in the context of consecutive frames derived time domain through manual design or deep learning methods. But, manual-designed features are constrained of facial image sequence based temporal features extraction. The image sequence related deep neural network is insufficient to employ the prior knowledge of the key features of the face as well due to the non-learning temporal featured expressions. Our landmark-trajectory convolutional neural network analyzes the trajectory in the video sequence and learns the dynamic "temporal features" of the expression sequence consequently, which extracts the accurate motion characteristics of facial expressions in the time domain. Our network consists of four convolutional layers and two fully connected layers. The input of the landmark trajectory CNN (LTCNN) sub-network is a similar feature map constructed based on the trajectory of facial expression in the video. Third, a fine-tuning based fusion strategy is conducted to combine the learned features of two network modules obtained further, which achieves the temporal and spatial features based fusion result optimally. We train the deep metric fusion (DMF) and LTCNN sub-networks each, combine the two sub-networks through feature fusion, and fine-tuning them in an end-to-end manner sequentially. The implemented hyper-parameters are used for fine-tuning training in DMF sub-network optimization.ResultOur demonstrated FEC algorithm is tested and verified on three public facial expression databases in terms of the extended Cohn-Kanade dataset (CK+), the MMI facial expression database (MMI), and the Oulu-CASIA NIR&VIS facial expression database (Oulu-CASIA). Our method achieves the recognition accuracy of 98.46%, 82.96%, and 87.12% on the databases of CK+, MMI, and Oulu-CASIA, respectively.ConclusionFor our deep learning based network integrated temporal and the spatial features both to realize video sequences based FER. In the network, our two sub-modules are used to learn the "spatial features" of the facial expression at the peak frame and the "temporal features" of facial expression motion. Finally, a fusion strategy is carried out to achieve better fusion effect of temporal and spatial features based on overall fine-tuning. Our FER method has its potentials to develop further.关键词:facial expression recognition(FER);deep learning;deep metric learning;triplet loss;feature fusion138|93|2更新时间:2024-05-07 -
 摘要:ObjectiveFootprints are the highest rate of material evidence left and extracted from crime scene in general. Footprint retrieval and comparison plays an important role in criminal investigation. Footprint features are identified via the foot shape and bone structure of the person involved and have its features of specificity and stability. Meanwhile, footprints can reveal their essential behavior in the context of the physiological and behavioral characteristics. It is related to the biological features like height, body shape, gender, age and walking habits. Medical research results illustrates that footprint pressure information of each person is unique. It is challenged to improve the rate of discovery, extraction and utilization of footprints in criminal investigation. The retrieval of footprint image is of great significance, which will provide theoretical basis and technical support for footprint comparison and identification. Footprint images have different modes due to the diverse scenarios and tools of extraction. The global information of cross-modal barefoot images is unique, which can realize retrieval-oriented. The retrieval orientation retrieves the corresponding image of cross-modes. The traditional cross-modal retrieval methods are mainly in the context of subspace method and objective model method. These retrieval methods are difficult to obtain distinguishable features. The deep learning based retrieval methods construct multi-modal public space via convolutional neural network (CNN). The high-level semantic features of image can be captured in terms of iterative optimization of network parameters, to lower the multi-modal heterogeneity.MethodA cross-modal barefoot footprint retrieval algorithm based on non-local attention two-branch network is demonstrated to resolve the issue of intra-class wide distance and inter-class narrow distance in fine-grained images. The collected barefoot footprint images involve optical mode and pressure mode. The median filter is applied to remove noises for all images, and the data augmentation method is used to expand the footprint images of each mode. In the feature extraction module, the pre-trained ResNet50 is used as basic network to extract the inherent features of each mode. In the feature embedding module, parameter sharing is realized by splicing feature vectors, and a multi-modal sharing space is constructed. All the residual blocks in the Layer2 and Layer3 of the ResNet50 use a non-local attention mechanism to capture long-range dependence, obtain a large receptive field, and highlight common features quickly. Simultaneously, cross-entropy loss and triplet loss are used to better learn multi-modal sharing space in order to reduce intra-class differences and increase inter-class differences of features. Our research tool is equipped with two NVIDIA 2070TI graphics CARDS, and the network is built in PyTorch. The size of the barefoot footprint images is 224×224 pixels. The stochastic gradient descent (SGD) optimizer is used for training. The number of iterations is 81, and the initial learning rate is 0.01. The trained network is validated by using the validation set, and the mean average precision (mAP) and rank values are obtained. In addition, the optimal model is saved in accordance with the highest rank1 value. The backup model is based on the test set, and the data of the final experimental results are recorded and saved.ResultA cross-modal retrieval dataset is collected and constructed through a 138 person sample. Our comparative experiments are carried out to verify the effect of non-local attention mechanism in related to the retrieval efficiency, multiple loss functions and different pooling methods based on feature embedding modules. Our illustrated algorithm is compared to fine-grained cross-modal retrieval derived fine-grained cross-model (FGC) method and the RGB-infrared cross-modal person re-identification based hetero-center (HC) method. The number of people in the training set, verification set and test set is 82, 28 and 28, respectively, including 16 400 images, 5 600 images and 5 600 images each. The ratio of query images and retrieval images in the verification set and test set is 1:2. The evaluation indexes of the experiment are mAP mean (mAP_Avg) and rank1 mean (rank1_Avg) of two retrieval modes. Our analysis demonstrates that the algorithm illustrated has a higher precision, and the mAP_Avg and rank1_Avg are 83.95% and 96.5%, respectively. Compared with FGC and HC, the evaluation indexes of the proposed algorithm is 40.01% and 36.50% (higher than FGC), and 26.07% and 19.32% (higher than HC).ConclusionA cross-modal barefoot footprint retrieval algorithm is facilitated based on a non-local attention dual-branch network through the integration of non-local attention mechanism and double constraint loss. Our algorithm considers the uniqueness and correlation of in-modal and inter-modal features, and improves the performance of cross-modal barefoot footprint retrieval further, which can provide theoretical basis and technical support for footprint comparison and identification.关键词:image retrieval;cross-modal footprint retrieval;non-local attention mechanism;two-branch network;barefoot footprint image95|173|2更新时间:2024-05-07
摘要:ObjectiveFootprints are the highest rate of material evidence left and extracted from crime scene in general. Footprint retrieval and comparison plays an important role in criminal investigation. Footprint features are identified via the foot shape and bone structure of the person involved and have its features of specificity and stability. Meanwhile, footprints can reveal their essential behavior in the context of the physiological and behavioral characteristics. It is related to the biological features like height, body shape, gender, age and walking habits. Medical research results illustrates that footprint pressure information of each person is unique. It is challenged to improve the rate of discovery, extraction and utilization of footprints in criminal investigation. The retrieval of footprint image is of great significance, which will provide theoretical basis and technical support for footprint comparison and identification. Footprint images have different modes due to the diverse scenarios and tools of extraction. The global information of cross-modal barefoot images is unique, which can realize retrieval-oriented. The retrieval orientation retrieves the corresponding image of cross-modes. The traditional cross-modal retrieval methods are mainly in the context of subspace method and objective model method. These retrieval methods are difficult to obtain distinguishable features. The deep learning based retrieval methods construct multi-modal public space via convolutional neural network (CNN). The high-level semantic features of image can be captured in terms of iterative optimization of network parameters, to lower the multi-modal heterogeneity.MethodA cross-modal barefoot footprint retrieval algorithm based on non-local attention two-branch network is demonstrated to resolve the issue of intra-class wide distance and inter-class narrow distance in fine-grained images. The collected barefoot footprint images involve optical mode and pressure mode. The median filter is applied to remove noises for all images, and the data augmentation method is used to expand the footprint images of each mode. In the feature extraction module, the pre-trained ResNet50 is used as basic network to extract the inherent features of each mode. In the feature embedding module, parameter sharing is realized by splicing feature vectors, and a multi-modal sharing space is constructed. All the residual blocks in the Layer2 and Layer3 of the ResNet50 use a non-local attention mechanism to capture long-range dependence, obtain a large receptive field, and highlight common features quickly. Simultaneously, cross-entropy loss and triplet loss are used to better learn multi-modal sharing space in order to reduce intra-class differences and increase inter-class differences of features. Our research tool is equipped with two NVIDIA 2070TI graphics CARDS, and the network is built in PyTorch. The size of the barefoot footprint images is 224×224 pixels. The stochastic gradient descent (SGD) optimizer is used for training. The number of iterations is 81, and the initial learning rate is 0.01. The trained network is validated by using the validation set, and the mean average precision (mAP) and rank values are obtained. In addition, the optimal model is saved in accordance with the highest rank1 value. The backup model is based on the test set, and the data of the final experimental results are recorded and saved.ResultA cross-modal retrieval dataset is collected and constructed through a 138 person sample. Our comparative experiments are carried out to verify the effect of non-local attention mechanism in related to the retrieval efficiency, multiple loss functions and different pooling methods based on feature embedding modules. Our illustrated algorithm is compared to fine-grained cross-modal retrieval derived fine-grained cross-model (FGC) method and the RGB-infrared cross-modal person re-identification based hetero-center (HC) method. The number of people in the training set, verification set and test set is 82, 28 and 28, respectively, including 16 400 images, 5 600 images and 5 600 images each. The ratio of query images and retrieval images in the verification set and test set is 1:2. The evaluation indexes of the experiment are mAP mean (mAP_Avg) and rank1 mean (rank1_Avg) of two retrieval modes. Our analysis demonstrates that the algorithm illustrated has a higher precision, and the mAP_Avg and rank1_Avg are 83.95% and 96.5%, respectively. Compared with FGC and HC, the evaluation indexes of the proposed algorithm is 40.01% and 36.50% (higher than FGC), and 26.07% and 19.32% (higher than HC).ConclusionA cross-modal barefoot footprint retrieval algorithm is facilitated based on a non-local attention dual-branch network through the integration of non-local attention mechanism and double constraint loss. Our algorithm considers the uniqueness and correlation of in-modal and inter-modal features, and improves the performance of cross-modal barefoot footprint retrieval further, which can provide theoretical basis and technical support for footprint comparison and identification.关键词:image retrieval;cross-modal footprint retrieval;non-local attention mechanism;two-branch network;barefoot footprint image95|173|2更新时间:2024-05-07 -
 摘要:ObjectiveThe scene graph can construct a graph structure for image interpretation. The image objects and inter-relations are represented via nodes and edges. However, the existing methods have focused on the visual features and lack of semantic information. While the semantic information can provide robust feature and improve the capability of inference. In addition, it is challenged of long-tailed distribution issue in the dataset. The 30 regular relationships account for 69% of the sample size, while the triplet of 20 irregular relationships just has 31% of the sample size. Most of methods cannot maintain qualified results on the rare triplets and tend to infer the regular one. To improve the reasoning ability of irregular triples, we demonstrated a scene graph generation algorithm to generate robust features.MethodThe components of this network are semantic encoding, feature encoding, target inference, and relationship reasoning. The semantic coding module first represents the word in region description into low dimension via word embedding. Thanks to the Word2Vec model is trained on a large corpus database, it can better represent the semantics of words based on complete word embedding. We use the Word2Vec network to traverse the region description of the dataset and extract the intermediate word embedding vectors of 150 types of targets and 50 types of relationships as the semantic information. Additionally, in this module, we explicitly calculate global statistical knowledge, which can represent the global characters of the dataset. We use graph convolution networks to integrate them with semantic information. This method can get global semantic information, which strengthens the reasoning capability of rare triplets. The feature encoding module extracts the visual image features based on faster region convolutional neural network (Faster R-CNN). We remove its classification network and use its feature extraction network, region proposal network, and region of interest pooling layer to get visual features of image processing. In the target reasoning and the relationship reasoning modules, visual features and global semantic information are fused to obtain global semantic features via different feature fusion methods. These features applications can enhance the performance of rare triplets through clarifying the differences of target and relationship. In respect of the target reasoning module, we use graphs to represent the images and use gated graph neural networks to aggregate the context information. After three times step iteration, the target feature has been completely improved, we train a classifier to determine the target classes using these final global semantic features. Objects' classes can benefit to the reasoning capability of relationships. In respect of the relationship in reasoning module, we use both object class and the global semantic feature of relationship to conduct reasoning work. We use gated recurrent units to refine features and reasoning the relationship. Each relationship feature will aggregate information derived from the corresponding object pair. Meanwhile, a parser is used to construct the scene graph to describe structured images.ResultWe carried out experiments on the public visual genome dataset and compared it with 10 methods proposed. We actually conduct predicate classification, scene graph classification, and scene graph generation tasks, respectively. Ablation experiments were also performed. The average recall reached 44.2% and 55.3% under each setting, respectively. Compared with the neural motifs method, the R@50 of the scene graph classification task has a 1.3% improvement. With respect of the visualization part, we visualize the results of the scene graph generation task. The target location and their class in the original image are marked. The target and relationship classes are represented based on node and edge. Compared with the second score obtained in the quantitative analysis part, our network enhances the reasoning capability of rare relationships significantly in terms of the reasoning capability of target and common relationships improvement.ConclusionOur demonstrated algorithms facilitate the reasoning capability of rare triplets. It has good performance on regular-based triplets reasoning as well as scene graph generation.关键词:scene graph;global semantic information;target inference;relationship reasoning;image interpretation104|250|0更新时间:2024-05-07
摘要:ObjectiveThe scene graph can construct a graph structure for image interpretation. The image objects and inter-relations are represented via nodes and edges. However, the existing methods have focused on the visual features and lack of semantic information. While the semantic information can provide robust feature and improve the capability of inference. In addition, it is challenged of long-tailed distribution issue in the dataset. The 30 regular relationships account for 69% of the sample size, while the triplet of 20 irregular relationships just has 31% of the sample size. Most of methods cannot maintain qualified results on the rare triplets and tend to infer the regular one. To improve the reasoning ability of irregular triples, we demonstrated a scene graph generation algorithm to generate robust features.MethodThe components of this network are semantic encoding, feature encoding, target inference, and relationship reasoning. The semantic coding module first represents the word in region description into low dimension via word embedding. Thanks to the Word2Vec model is trained on a large corpus database, it can better represent the semantics of words based on complete word embedding. We use the Word2Vec network to traverse the region description of the dataset and extract the intermediate word embedding vectors of 150 types of targets and 50 types of relationships as the semantic information. Additionally, in this module, we explicitly calculate global statistical knowledge, which can represent the global characters of the dataset. We use graph convolution networks to integrate them with semantic information. This method can get global semantic information, which strengthens the reasoning capability of rare triplets. The feature encoding module extracts the visual image features based on faster region convolutional neural network (Faster R-CNN). We remove its classification network and use its feature extraction network, region proposal network, and region of interest pooling layer to get visual features of image processing. In the target reasoning and the relationship reasoning modules, visual features and global semantic information are fused to obtain global semantic features via different feature fusion methods. These features applications can enhance the performance of rare triplets through clarifying the differences of target and relationship. In respect of the target reasoning module, we use graphs to represent the images and use gated graph neural networks to aggregate the context information. After three times step iteration, the target feature has been completely improved, we train a classifier to determine the target classes using these final global semantic features. Objects' classes can benefit to the reasoning capability of relationships. In respect of the relationship in reasoning module, we use both object class and the global semantic feature of relationship to conduct reasoning work. We use gated recurrent units to refine features and reasoning the relationship. Each relationship feature will aggregate information derived from the corresponding object pair. Meanwhile, a parser is used to construct the scene graph to describe structured images.ResultWe carried out experiments on the public visual genome dataset and compared it with 10 methods proposed. We actually conduct predicate classification, scene graph classification, and scene graph generation tasks, respectively. Ablation experiments were also performed. The average recall reached 44.2% and 55.3% under each setting, respectively. Compared with the neural motifs method, the R@50 of the scene graph classification task has a 1.3% improvement. With respect of the visualization part, we visualize the results of the scene graph generation task. The target location and their class in the original image are marked. The target and relationship classes are represented based on node and edge. Compared with the second score obtained in the quantitative analysis part, our network enhances the reasoning capability of rare relationships significantly in terms of the reasoning capability of target and common relationships improvement.ConclusionOur demonstrated algorithms facilitate the reasoning capability of rare triplets. It has good performance on regular-based triplets reasoning as well as scene graph generation.关键词:scene graph;global semantic information;target inference;relationship reasoning;image interpretation104|250|0更新时间:2024-05-07 -
 摘要:ObjectiveFew-shot learning (FSL) aims to learn emerged visual categories derived from constraint samples. A scenario of few-shot learning is the model learning via the classification strategy in the meta-train phase. It is required to recognize previously unseen classes with few labeled data in the meta-test phase. Current few-shot image classification methods focus on a robust global representation based learning., It is challenged to facilitate in-situ fine-grained image classification in spite of a common few-shot image classification existing. Such a global representation cannot capture the local and subtle features well, which is critical for fine-grained image recognition. The fine-grained image datasets samples are constrained due to the high cost of labeling, which is a tailored scenario of few-shot learning. Therefore, fine-grained images recognition is lack of annotated data. To fulfill image classification, fine-grained image recognition is based on the most discriminative region location and the discriminate features utilization. However, many fine-grained image recognition methods cannot be straightforward to the fine-grained few-shot task due to limited annotation data (e.g., bounding box). Thus, it is necessary to promote the few-shot learning and the fine-grained few-shot learning tasks both.MethodWeakly-supervised object localization (WSOL) analysis is beneficial to the fine-grained few-shot classification task. Most fine-grained few-shot datasets are merely involved the label-based annotation due to the high cost of the pixel-level annotation. In addition, WSOL can provide the most discriminative regions directly, which is critical to general image classification and fine-grained image classification both. However, many existing WSOL methods cannot achieve complete localization of objects. For instance, class activation map (CAM) can update the last few layers of the classification network to obtain the merely class activation map via global maximum pooling and fully connected layers. To tackle these issues, we yield a self-attention based complementary module (SACM) to fulfill the WSOL. Our SACM contains the channel-based attention module (CBAM) and classifier module. Based on the spatial attention mechanism of the feature maps, CBAM can directly generate the saliency mask for the feature maps. A complementary non-saliency mask can be obtained through the threshold at the same time. To obtain the saliency and complementary non-saliency feature maps each, the saliency mask and the complementary non-saliency mask spatial-wise multiplies with the feature map. The classifier can obtain a more complete class activation map by assigning the saliency and non-saliency feature maps into the same category. Subsequently, we utilize the class activation map to filter and obtain the useful local feature descriptors for classification, which is as the descriptor representation. Additionally, images, the metric method cannot be directly applied to the fine-grained few-shot image classification in terms of common images based few-shot classification. We harness the semantic alignment distance to measure the distance between the two fine-grained images through the optioned feature descriptors and the naive Bayes nearest neighbor (NBNN) algorithm. First, we clarify the most neighboring descriptor among the supporting set through cosine distance for each query feature descriptor, which is denoted as the most neighboring cosine distance. Then, we accumulate the most neighboring cosine distance of each optioned feature descriptor to obtain the semantic alignment distance. The above two phases are merged into the semantic alignment module (SAM). Each feature descriptor in the query image can be accurately aligned by the support feature descriptor through the nearest neighbor cosine distance. This guarantees that the content between the query image and the supporting image can be semantically aligned. Meanwhile, each feature descriptor has a larger search space than the previous high-dimensional feature vector representation, which is equivalent to classification in a relative "high-data" regime, thereby improving the tolerance of the metric to noise.ResultWe carried out a large number of experiments to verify the performance. On the miniImageNet dataset, the proposed method gains 0.56% and 5.02% improvement than the second place under the 1-shot and 5-shot settings, respectively. On the fine-grained datasets Stanford Dogs and Stanford Cars, our method improves by 4.18%, 7.49%, and 16.13, 5.17% under 1-shot setting and 5-shot setting, respectively. In CUB 200-2011, our method also improves 1.82% under 5-shot. Our approach can be applied to both general few-shot learning and fine-grained few-shot learning. The ablation experiment demonstrates that to feature descriptors filtering improves the performance of fine-grained few-shot recognition via SACM-based activation map classification. Meanwhile, our proposed semantic alignment distance improves the classification performance of few-shot classification under the same conditions compared to the Euclidean distance. Extra visualization illustrates the proposed SACM can localize the key interval objects based on merely label-based annotations.ConclusionOur WSOL-based fine-grained few-shot learning method has its priorities for common and fine-grained few-shot learning both.关键词:weakly-supervised object localization(WSOL);few-shot learning(FSL);fine-grained image classification;fine-grained few-shot learning;feature descriptors176|1900|1更新时间:2024-05-07
摘要:ObjectiveFew-shot learning (FSL) aims to learn emerged visual categories derived from constraint samples. A scenario of few-shot learning is the model learning via the classification strategy in the meta-train phase. It is required to recognize previously unseen classes with few labeled data in the meta-test phase. Current few-shot image classification methods focus on a robust global representation based learning., It is challenged to facilitate in-situ fine-grained image classification in spite of a common few-shot image classification existing. Such a global representation cannot capture the local and subtle features well, which is critical for fine-grained image recognition. The fine-grained image datasets samples are constrained due to the high cost of labeling, which is a tailored scenario of few-shot learning. Therefore, fine-grained images recognition is lack of annotated data. To fulfill image classification, fine-grained image recognition is based on the most discriminative region location and the discriminate features utilization. However, many fine-grained image recognition methods cannot be straightforward to the fine-grained few-shot task due to limited annotation data (e.g., bounding box). Thus, it is necessary to promote the few-shot learning and the fine-grained few-shot learning tasks both.MethodWeakly-supervised object localization (WSOL) analysis is beneficial to the fine-grained few-shot classification task. Most fine-grained few-shot datasets are merely involved the label-based annotation due to the high cost of the pixel-level annotation. In addition, WSOL can provide the most discriminative regions directly, which is critical to general image classification and fine-grained image classification both. However, many existing WSOL methods cannot achieve complete localization of objects. For instance, class activation map (CAM) can update the last few layers of the classification network to obtain the merely class activation map via global maximum pooling and fully connected layers. To tackle these issues, we yield a self-attention based complementary module (SACM) to fulfill the WSOL. Our SACM contains the channel-based attention module (CBAM) and classifier module. Based on the spatial attention mechanism of the feature maps, CBAM can directly generate the saliency mask for the feature maps. A complementary non-saliency mask can be obtained through the threshold at the same time. To obtain the saliency and complementary non-saliency feature maps each, the saliency mask and the complementary non-saliency mask spatial-wise multiplies with the feature map. The classifier can obtain a more complete class activation map by assigning the saliency and non-saliency feature maps into the same category. Subsequently, we utilize the class activation map to filter and obtain the useful local feature descriptors for classification, which is as the descriptor representation. Additionally, images, the metric method cannot be directly applied to the fine-grained few-shot image classification in terms of common images based few-shot classification. We harness the semantic alignment distance to measure the distance between the two fine-grained images through the optioned feature descriptors and the naive Bayes nearest neighbor (NBNN) algorithm. First, we clarify the most neighboring descriptor among the supporting set through cosine distance for each query feature descriptor, which is denoted as the most neighboring cosine distance. Then, we accumulate the most neighboring cosine distance of each optioned feature descriptor to obtain the semantic alignment distance. The above two phases are merged into the semantic alignment module (SAM). Each feature descriptor in the query image can be accurately aligned by the support feature descriptor through the nearest neighbor cosine distance. This guarantees that the content between the query image and the supporting image can be semantically aligned. Meanwhile, each feature descriptor has a larger search space than the previous high-dimensional feature vector representation, which is equivalent to classification in a relative "high-data" regime, thereby improving the tolerance of the metric to noise.ResultWe carried out a large number of experiments to verify the performance. On the miniImageNet dataset, the proposed method gains 0.56% and 5.02% improvement than the second place under the 1-shot and 5-shot settings, respectively. On the fine-grained datasets Stanford Dogs and Stanford Cars, our method improves by 4.18%, 7.49%, and 16.13, 5.17% under 1-shot setting and 5-shot setting, respectively. In CUB 200-2011, our method also improves 1.82% under 5-shot. Our approach can be applied to both general few-shot learning and fine-grained few-shot learning. The ablation experiment demonstrates that to feature descriptors filtering improves the performance of fine-grained few-shot recognition via SACM-based activation map classification. Meanwhile, our proposed semantic alignment distance improves the classification performance of few-shot classification under the same conditions compared to the Euclidean distance. Extra visualization illustrates the proposed SACM can localize the key interval objects based on merely label-based annotations.ConclusionOur WSOL-based fine-grained few-shot learning method has its priorities for common and fine-grained few-shot learning both.关键词:weakly-supervised object localization(WSOL);few-shot learning(FSL);fine-grained image classification;fine-grained few-shot learning;feature descriptors176|1900|1更新时间:2024-05-07 -
 摘要:ObjectiveThe highway mileage China has outreached 150 000 kilometers till 2020 guided by Highway Network Planning 2013-2030. Road conditions evaluation has become one critical issue for China highway network further. Road crack detection is one of the key techniques to identify and locate crack objects for traffic safety. However, deep learning based cracked objects detection is challenged to cracked pixels and non-cracked pixels issues of single image. Current attention mechanism is recognized as a deep learning module. It strengthens the consistency of weight-related of crack objects during the training process, and improves the deep learning based crack detection performance. The low accuracy of the typical deep neural network needs to be improved in terms of the crack image detection of more complex background and more interference. Thanks to the road crack dataset of Crack500, our deep learning based road crack detection network is facilitated in the context of dual attention mechanism.MethodTo deal with the issues mentioned above, a dual attention mechanism integrated road crack detection network is designed. The ResNet-101 network that used dilated convolution is as the basic feature extraction network of the model. The ResNet network has the following features as below: 1) the number of parameters can be manipulated; 2) our network levels are clarified, and the number of multilayer's feature maps have their output features ability; 3) the network uses fewer pooling layers and redundant downsampling layers to improve transmission efficiency; 4) the network does not use dropout layer but batch normalization(BN) and global average pooling layer to regularize training process for speeding up; 5) when the number of network layers is high, the number of 3×3 convolution layers is reduced, and 1×1 convolution layers are used to control the number of input and output feature maps. The ResNet-101 network contains a total of 4 residual groups, including 3, 4, 23, and 3 residual blocks, respectively. Therefore, a lightweight attention mechanism is relevant to the end of the residual module for a residual attention module. The lightweight attention mechanism is composed of spatial attention mechanism and channel attention mechanism. The 4 residual groups of ResNet-101 used 3, 4, 23, and 3 residual attention modules, respectively. It is used to enhance consistent weight relationship of the crack objects to realize replicated features extraction of the higher layer of the crack. Giving a medium feature map, the weights relationship is sequentially inferred along the two dimensions of space and channel. Then, multiplying the original feature map to meet the adequate features. It can be seamlessly integrated into any convolutional neural network (CNN) architecture. It also can be trained end-to-end with the CNN together. Our demonstration introduced a non-local attention mechanism at the end of the ResNet-101 network. We obtained the related weight of the highest layer crack feature and achieved the crack detection result. Similarly, the attention mechanism of non-local computing module is related to spatial attention mechanism and channel attention mechanism. Spatial features are updated by the weighted features aggregation in all spots of the image. The weight is determined in terms of the similarity of the features in the two spaces. The channel attention mechanism also applies a similar self-attention mechanism to learn the relationship between any two channel mappings. It updates each channel through the weighted aggregation of all channels as well. Our coding work is implemented based on the pytorch deep learning framework. We carried out stochastic gradient descent(SGD) optimization with an initial learning rate of 0.000 1. The mean intersection over union (mIoU), pixel accuracy (PA), and iteration time are as the evaluation indicators of deep learning models.ResultThe effectiveness of this network is verified through 4 categories of comparative experiments. The first category is used to evaluate the detection performance of various combination ways of channel attention mechanism and spatial attention mechanism in the residual attention module. The best interactive way is to integrate channel attention mechanism and spatial attention mechanism in parallel. Compared to the other two interactive ways, the mIoU increases 2.11% and 11.29%each; each PA increases by 2.08% and 0.23%. The second result is used to evaluate the effectiveness of the residual attention module., the residual attention module added mIoU and PA increase by 2.34% and 3.01% in comparison with non-residual attention module. The third illustration is used to contrast the effect of common convolution and dilated convolution, the mIoU and PA of using dilated convolution increased by 6.65% and 4.18%. The final one is used to evaluate the detection performance of our network and some deep neural networks. Compared to fully convolutional network (FCN), pyramid scene parsing network (PSPNet), image cascade network (ICNet), point-wise spatial attention network (PSANet), dense atrous spatial pyramid pooling (DenseASPP) FCN, PSPNet, ICNet, our mIoU obtained increases by 7.67%, 1.54%, 6.51%, 7.76%, 7.70%, respectively. Our PA results increases by 2.94%, 0.42%, 3.34%, 2.13%, -1.59%, respectively.ConclusionOur network is combined the ResNet-101 network with dilated convolution and dual attention mechanism. While maintaining the resolution of the feature map and improving the receptive field, this network has its priority to adapt to crack objects with complex background and more interference. Our analyzed results show that our mIoU and PA results have promoted current deep neural networks ability.关键词:deep learning;residual network;dual attention mechanism;road crack detection;Crack500 dataset222|281|5更新时间:2024-05-07
摘要:ObjectiveThe highway mileage China has outreached 150 000 kilometers till 2020 guided by Highway Network Planning 2013-2030. Road conditions evaluation has become one critical issue for China highway network further. Road crack detection is one of the key techniques to identify and locate crack objects for traffic safety. However, deep learning based cracked objects detection is challenged to cracked pixels and non-cracked pixels issues of single image. Current attention mechanism is recognized as a deep learning module. It strengthens the consistency of weight-related of crack objects during the training process, and improves the deep learning based crack detection performance. The low accuracy of the typical deep neural network needs to be improved in terms of the crack image detection of more complex background and more interference. Thanks to the road crack dataset of Crack500, our deep learning based road crack detection network is facilitated in the context of dual attention mechanism.MethodTo deal with the issues mentioned above, a dual attention mechanism integrated road crack detection network is designed. The ResNet-101 network that used dilated convolution is as the basic feature extraction network of the model. The ResNet network has the following features as below: 1) the number of parameters can be manipulated; 2) our network levels are clarified, and the number of multilayer's feature maps have their output features ability; 3) the network uses fewer pooling layers and redundant downsampling layers to improve transmission efficiency; 4) the network does not use dropout layer but batch normalization(BN) and global average pooling layer to regularize training process for speeding up; 5) when the number of network layers is high, the number of 3×3 convolution layers is reduced, and 1×1 convolution layers are used to control the number of input and output feature maps. The ResNet-101 network contains a total of 4 residual groups, including 3, 4, 23, and 3 residual blocks, respectively. Therefore, a lightweight attention mechanism is relevant to the end of the residual module for a residual attention module. The lightweight attention mechanism is composed of spatial attention mechanism and channel attention mechanism. The 4 residual groups of ResNet-101 used 3, 4, 23, and 3 residual attention modules, respectively. It is used to enhance consistent weight relationship of the crack objects to realize replicated features extraction of the higher layer of the crack. Giving a medium feature map, the weights relationship is sequentially inferred along the two dimensions of space and channel. Then, multiplying the original feature map to meet the adequate features. It can be seamlessly integrated into any convolutional neural network (CNN) architecture. It also can be trained end-to-end with the CNN together. Our demonstration introduced a non-local attention mechanism at the end of the ResNet-101 network. We obtained the related weight of the highest layer crack feature and achieved the crack detection result. Similarly, the attention mechanism of non-local computing module is related to spatial attention mechanism and channel attention mechanism. Spatial features are updated by the weighted features aggregation in all spots of the image. The weight is determined in terms of the similarity of the features in the two spaces. The channel attention mechanism also applies a similar self-attention mechanism to learn the relationship between any two channel mappings. It updates each channel through the weighted aggregation of all channels as well. Our coding work is implemented based on the pytorch deep learning framework. We carried out stochastic gradient descent(SGD) optimization with an initial learning rate of 0.000 1. The mean intersection over union (mIoU), pixel accuracy (PA), and iteration time are as the evaluation indicators of deep learning models.ResultThe effectiveness of this network is verified through 4 categories of comparative experiments. The first category is used to evaluate the detection performance of various combination ways of channel attention mechanism and spatial attention mechanism in the residual attention module. The best interactive way is to integrate channel attention mechanism and spatial attention mechanism in parallel. Compared to the other two interactive ways, the mIoU increases 2.11% and 11.29%each; each PA increases by 2.08% and 0.23%. The second result is used to evaluate the effectiveness of the residual attention module., the residual attention module added mIoU and PA increase by 2.34% and 3.01% in comparison with non-residual attention module. The third illustration is used to contrast the effect of common convolution and dilated convolution, the mIoU and PA of using dilated convolution increased by 6.65% and 4.18%. The final one is used to evaluate the detection performance of our network and some deep neural networks. Compared to fully convolutional network (FCN), pyramid scene parsing network (PSPNet), image cascade network (ICNet), point-wise spatial attention network (PSANet), dense atrous spatial pyramid pooling (DenseASPP) FCN, PSPNet, ICNet, our mIoU obtained increases by 7.67%, 1.54%, 6.51%, 7.76%, 7.70%, respectively. Our PA results increases by 2.94%, 0.42%, 3.34%, 2.13%, -1.59%, respectively.ConclusionOur network is combined the ResNet-101 network with dilated convolution and dual attention mechanism. While maintaining the resolution of the feature map and improving the receptive field, this network has its priority to adapt to crack objects with complex background and more interference. Our analyzed results show that our mIoU and PA results have promoted current deep neural networks ability.关键词:deep learning;residual network;dual attention mechanism;road crack detection;Crack500 dataset222|281|5更新时间:2024-05-07 -
 摘要:ObjectiveComputer graphics based cloth simulation method is developed on the aspects of film and television industry, game animation and mechanical simulation. The collision detection algorithm is a key step of cloth simulation for the operation of the simulation system. The collision detection algorithm resists the virtual penetration of objects. Reliability and real-time features have been the two key issues for collision detection. The algorithms reliability is related to the clarification of accurate objects features, which plays an important role in the field of mechanical simulation and virtual surgery. Real-time ability is required to have fast computing power, and the high requirements of gaming industry. The current challenge of collision detection algorithms is the incompatibility of the two features. Recent multi-precision cloth model is based on high accuracy and low accuracy both. However, the response efficiency and reliability of this model is challenged to precision improvement. The efficiency cannot be guaranteed high-precision cloth models in common. A low-precision cloth model is subjected to the reliability of the simulation effect. The cloth issues are required to complete the collision processing in a short time. Collision detection is costly and time consuming. The penetration issues will be occurred in low response of collision. Efficient collision detection algorithms aid to improve the efficiency of the simulation system. Our open neural networks library (OpenNN) based collision detection algorithm is facilitated to improve the low speed and inaccuracy of cloth soft body collision detection in a virtual environment.MethodFirst, the bounding box technology is commonly improved in collision detection. Our network uses the existing bounding box technology to illustrate a root node double-layer bounding box algorithm, which uses the clarified axis aligned bounding box(AABB) and sphere bounding box to remove basic primitives quickly that have not collided. Second, a collision detection algorithm is proposed based on an OpenNN neural network. The cloth soft body detection needs to process a large amount of basic primitive information in the collision detection process, and the neural network can process a large amount of data. Our research proposes a new collision detection method, which provides an effective way for the detection process. The collision object and its particles collide scenario are obtained through the simulation of the physical cloth system and the orientations of the cloth particles. The integrated data set is segmented into training subset, selection subset and test subset. They account for 60%, 20%, and 20% of the original data set, respectively. The position of the cloth particles and the position of the collision object are input into the neural network model, and the neural network model is used to predict which particles in the cloth will collide. The calculation of in situ new particles eliminates the collision in respond to the colliding particles.ResultThe same complex cloth detection model is through cloth simulation experiments and compare to the detection time consumption of single bounding box algorithm, hybrid bounding box algorithm, root node double-layer bounding box algorithm, deep neural network (DNN) fused self-collision detection algorithm, and OpenNN based collision detection algorithm. The root node dual-layer bounding box algorithm is optimized due to shortened time is from 5.51% to 11.32%. The total time based on the OpenNN algorithm is reduced by 11.70% compared to the root node dual-layer bounding box algorithm. In comparison with the DNN fused self-collision detection algorithm, it is reduced by 6.62%. The accuracy of the cloth model increases by 84%, the time used by the traditional physical collision detection method has increased by 96%, and the DNN fused self-collision detection algorithm has increased by 90.11%. Our improved OpenNN neural network based collision detection algorithm increases the detection time by 68.37%. Meanwhile, the algorithm can predict collision particles accurately and effectively. Through the collision experiment with sharp objects in extreme scenarios, there is no penetration appeared, which verifies the reliability of our algorithm.ConclusionOur root node dual-layer bounding box algorithm is time efficiency for the collision of simple models in the simulation scene. An OpenNN neural network based collision detection algorithm has its priorities for complicated models.关键词:collision detection;cloth simulation;neural network;axis aligned bounding box(AABB);double-layer bounding box71|215|1更新时间:2024-05-07
摘要:ObjectiveComputer graphics based cloth simulation method is developed on the aspects of film and television industry, game animation and mechanical simulation. The collision detection algorithm is a key step of cloth simulation for the operation of the simulation system. The collision detection algorithm resists the virtual penetration of objects. Reliability and real-time features have been the two key issues for collision detection. The algorithms reliability is related to the clarification of accurate objects features, which plays an important role in the field of mechanical simulation and virtual surgery. Real-time ability is required to have fast computing power, and the high requirements of gaming industry. The current challenge of collision detection algorithms is the incompatibility of the two features. Recent multi-precision cloth model is based on high accuracy and low accuracy both. However, the response efficiency and reliability of this model is challenged to precision improvement. The efficiency cannot be guaranteed high-precision cloth models in common. A low-precision cloth model is subjected to the reliability of the simulation effect. The cloth issues are required to complete the collision processing in a short time. Collision detection is costly and time consuming. The penetration issues will be occurred in low response of collision. Efficient collision detection algorithms aid to improve the efficiency of the simulation system. Our open neural networks library (OpenNN) based collision detection algorithm is facilitated to improve the low speed and inaccuracy of cloth soft body collision detection in a virtual environment.MethodFirst, the bounding box technology is commonly improved in collision detection. Our network uses the existing bounding box technology to illustrate a root node double-layer bounding box algorithm, which uses the clarified axis aligned bounding box(AABB) and sphere bounding box to remove basic primitives quickly that have not collided. Second, a collision detection algorithm is proposed based on an OpenNN neural network. The cloth soft body detection needs to process a large amount of basic primitive information in the collision detection process, and the neural network can process a large amount of data. Our research proposes a new collision detection method, which provides an effective way for the detection process. The collision object and its particles collide scenario are obtained through the simulation of the physical cloth system and the orientations of the cloth particles. The integrated data set is segmented into training subset, selection subset and test subset. They account for 60%, 20%, and 20% of the original data set, respectively. The position of the cloth particles and the position of the collision object are input into the neural network model, and the neural network model is used to predict which particles in the cloth will collide. The calculation of in situ new particles eliminates the collision in respond to the colliding particles.ResultThe same complex cloth detection model is through cloth simulation experiments and compare to the detection time consumption of single bounding box algorithm, hybrid bounding box algorithm, root node double-layer bounding box algorithm, deep neural network (DNN) fused self-collision detection algorithm, and OpenNN based collision detection algorithm. The root node dual-layer bounding box algorithm is optimized due to shortened time is from 5.51% to 11.32%. The total time based on the OpenNN algorithm is reduced by 11.70% compared to the root node dual-layer bounding box algorithm. In comparison with the DNN fused self-collision detection algorithm, it is reduced by 6.62%. The accuracy of the cloth model increases by 84%, the time used by the traditional physical collision detection method has increased by 96%, and the DNN fused self-collision detection algorithm has increased by 90.11%. Our improved OpenNN neural network based collision detection algorithm increases the detection time by 68.37%. Meanwhile, the algorithm can predict collision particles accurately and effectively. Through the collision experiment with sharp objects in extreme scenarios, there is no penetration appeared, which verifies the reliability of our algorithm.ConclusionOur root node dual-layer bounding box algorithm is time efficiency for the collision of simple models in the simulation scene. An OpenNN neural network based collision detection algorithm has its priorities for complicated models.关键词:collision detection;cloth simulation;neural network;axis aligned bounding box(AABB);double-layer bounding box71|215|1更新时间:2024-05-07 -
 摘要:ObjectiveGait is a kind of human walking pattern, which is one of the key biometric features for person identification. As a non-contact and long-distance recognition way to capture human identity information, gait recognition has been developed in video surveillance and public security. Gait recognition algorithms can be segmented into two mainstreams like appearance-based methods and the model-based methods. The appearance-based methods extract gait from a sequence of silhouette images in common. However, the appearance-based methods are basically affected by appearance changes like non-rigid clothing deformation and background clutters. Different from the appearance-based methods, the model-based methods commonly leverage body structure or motion prior to model gait pattern and more robust to appearance variations. Actually, it is challenged to identify a universal model for gait description, and the previous pre-defined models can be constrained in certain scenarios. Recent model-based methods are focused on deep learning-based pose estimation to model key-points of human body. But the estimated pose model constrains the redundant noises in subject to pose estimators and occlusion. In summary, the appearance-based methods are based visual features description while the model-based methods tend to describe a semantic level-based motion and structure. We aim to design a novel approach for gait recognition beyond the existed two methods mentioned above and improve gait recognition ability via the added appearance features and pose features.Methodwe design a dual-branch network for gait recognition. The input data are fed into a dual-branch network to extract appearance features and pose features each. Then, the two kinds of features are merged into the final gait features in the context of feature fusion module. In detail, we adopt an optimal network GaitSet as the appearance branch to extract appearance features from silhouette images and design a two-stream convolutional neural network (CNN) to extract pose features from pose key-points based on the position information and motion information. Meanwhile, a squeeze-and-excitation feature fusion module (SEFM) is designed to merge two kinds of features via the weights of two kinds of features learning. In the squeeze step, appearance feature maps and pose feature maps are integrated via pooling, concatenation, and projection. In the excitation step, we obtain the weighted feature maps of appearance and pose via projection and Hadamard product. The two kinds of feature maps are down-sampled and concatenated into the final gait feature in accordance with adaptive weighting. To verify the appearance features and pose features, we design two variants of SEFM in related to SEFM-A and SEFM-P further. The SEFM module merges appearance features and pose features in mutual; the SEFM-A module merges pose features into appearance features and appearance features remain unchanged; the SEFM-P module merges appearance features into pose features and no pose features changed. Our algorithm is based on Pytorch and the evaluation is carried out on database CASIA(Institute of Automation, Chinese Academy of Sciences) Gait Dataset B (CASIA-B). We adopt the AlphaPose algorithm to extract pose key-points from origin RGB videos, and use silhouette images obtained. In each iteration of the training process, we randomly select 16 subjects and select 8 random samples of each subject further. Every sample of them contains a sub-sequence of 30 frames. Consequently, each batch has 3 840 image-skeleton pairs. We adopt the Adam optimizer to optimize the network for 60 000 iterations. The initial learning rate is set to 0.000 2 for the pose branch, and 0.000 1 for the appearance branch and the SEFM, and then the learning rate is cut10 times at the 45 000-th iteration.ResultWe first verify the effectiveness of the dual-branch network and feature fusion modules. Our demonstration illustrates that our dual-branch network can enhance performance and there is a clear complementary effect between appearance features and pose features. The Rank-1 accuracies of five feature fusion modules like SEFM, SEFM-A, SEFM-P, Concatenation, and multi-modal transfer module (MMTM) are 83.5%, 81.9%, 93.4%, 92.6% and 79.5%, respectively. These results demonstrate that appearance features are more discriminative because there are noises existed in pose features. Our SEFM-P is capable to merge two features in the feature fusion procedure via noises suppression. Then, we compare our methods to advanced gait recognition methods like CNNs, event-based gait recognition(EV-Gait), GaitSet, and PoseGait. We conduct the experiments with two protocols and evaluate the rank-1 accuracy of three walking scenarios in the context of normal walking, bag-carrying, and coat-wearing. Our method archives the best performance in all experimental protocols. Our three scenarios-based rank-1 accuracies are reached 93.4%, 84.8%, and 70.9% in protocol 1. The results of protocol 2 are obtained by 95.7%, 87.8%, 77.0%, respectively. Comparing to the second-best method of GaitSet, the rank-1 accuracies in the context of coat-wearing walking scenario are improved by 8.4% and 6.6%.ConclusionWe harness a novel gait recognition network based on the fusions of appearance features and pose features. Our analyzed results demonstrated that our method can develop two kinds of features and the appearance variations is more robust, especially for clothing changes scenario.关键词:biometric recognition;gait recognition;feature fusion;two-branch network;squeeze-and-excitation module;human body pose estimation;gait silhouette images179|179|5更新时间:2024-05-07
摘要:ObjectiveGait is a kind of human walking pattern, which is one of the key biometric features for person identification. As a non-contact and long-distance recognition way to capture human identity information, gait recognition has been developed in video surveillance and public security. Gait recognition algorithms can be segmented into two mainstreams like appearance-based methods and the model-based methods. The appearance-based methods extract gait from a sequence of silhouette images in common. However, the appearance-based methods are basically affected by appearance changes like non-rigid clothing deformation and background clutters. Different from the appearance-based methods, the model-based methods commonly leverage body structure or motion prior to model gait pattern and more robust to appearance variations. Actually, it is challenged to identify a universal model for gait description, and the previous pre-defined models can be constrained in certain scenarios. Recent model-based methods are focused on deep learning-based pose estimation to model key-points of human body. But the estimated pose model constrains the redundant noises in subject to pose estimators and occlusion. In summary, the appearance-based methods are based visual features description while the model-based methods tend to describe a semantic level-based motion and structure. We aim to design a novel approach for gait recognition beyond the existed two methods mentioned above and improve gait recognition ability via the added appearance features and pose features.Methodwe design a dual-branch network for gait recognition. The input data are fed into a dual-branch network to extract appearance features and pose features each. Then, the two kinds of features are merged into the final gait features in the context of feature fusion module. In detail, we adopt an optimal network GaitSet as the appearance branch to extract appearance features from silhouette images and design a two-stream convolutional neural network (CNN) to extract pose features from pose key-points based on the position information and motion information. Meanwhile, a squeeze-and-excitation feature fusion module (SEFM) is designed to merge two kinds of features via the weights of two kinds of features learning. In the squeeze step, appearance feature maps and pose feature maps are integrated via pooling, concatenation, and projection. In the excitation step, we obtain the weighted feature maps of appearance and pose via projection and Hadamard product. The two kinds of feature maps are down-sampled and concatenated into the final gait feature in accordance with adaptive weighting. To verify the appearance features and pose features, we design two variants of SEFM in related to SEFM-A and SEFM-P further. The SEFM module merges appearance features and pose features in mutual; the SEFM-A module merges pose features into appearance features and appearance features remain unchanged; the SEFM-P module merges appearance features into pose features and no pose features changed. Our algorithm is based on Pytorch and the evaluation is carried out on database CASIA(Institute of Automation, Chinese Academy of Sciences) Gait Dataset B (CASIA-B). We adopt the AlphaPose algorithm to extract pose key-points from origin RGB videos, and use silhouette images obtained. In each iteration of the training process, we randomly select 16 subjects and select 8 random samples of each subject further. Every sample of them contains a sub-sequence of 30 frames. Consequently, each batch has 3 840 image-skeleton pairs. We adopt the Adam optimizer to optimize the network for 60 000 iterations. The initial learning rate is set to 0.000 2 for the pose branch, and 0.000 1 for the appearance branch and the SEFM, and then the learning rate is cut10 times at the 45 000-th iteration.ResultWe first verify the effectiveness of the dual-branch network and feature fusion modules. Our demonstration illustrates that our dual-branch network can enhance performance and there is a clear complementary effect between appearance features and pose features. The Rank-1 accuracies of five feature fusion modules like SEFM, SEFM-A, SEFM-P, Concatenation, and multi-modal transfer module (MMTM) are 83.5%, 81.9%, 93.4%, 92.6% and 79.5%, respectively. These results demonstrate that appearance features are more discriminative because there are noises existed in pose features. Our SEFM-P is capable to merge two features in the feature fusion procedure via noises suppression. Then, we compare our methods to advanced gait recognition methods like CNNs, event-based gait recognition(EV-Gait), GaitSet, and PoseGait. We conduct the experiments with two protocols and evaluate the rank-1 accuracy of three walking scenarios in the context of normal walking, bag-carrying, and coat-wearing. Our method archives the best performance in all experimental protocols. Our three scenarios-based rank-1 accuracies are reached 93.4%, 84.8%, and 70.9% in protocol 1. The results of protocol 2 are obtained by 95.7%, 87.8%, 77.0%, respectively. Comparing to the second-best method of GaitSet, the rank-1 accuracies in the context of coat-wearing walking scenario are improved by 8.4% and 6.6%.ConclusionWe harness a novel gait recognition network based on the fusions of appearance features and pose features. Our analyzed results demonstrated that our method can develop two kinds of features and the appearance variations is more robust, especially for clothing changes scenario.关键词:biometric recognition;gait recognition;feature fusion;two-branch network;squeeze-and-excitation module;human body pose estimation;gait silhouette images179|179|5更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveCurrent visual question answering (VQA) methods are mostly based on attention mechanism and multimodal fusion. Deep learning have intensively promoted computer vision and natural language processing (NLP) both. Interdisciplinary area between language and vision like VQA has been focused on. VQA is composed of an AI-completed task and it yields a proxy to evaluate our progress towards artificial intelligence (AI)-based quick response reasoning. A VQA based model needs to fully understand the visual scene of the image, especially the interaction between multiple objects. This task inherently requires visual reasoning beyond the relationships between the image objects.MethodOur question-guided spatial relationship graph reasoning (QG-SRGR) model is demonstrated in order to solve the issue of spatial relationship reasoning in VQA, which uses the inherent spatial relationship properties between image objects. First, saliency-based attention mechanism is used in our model, the salient visual objects and visual features are extracted by using faster region-based convolutional neural network (Faster R-CNN). Next, the visual objects and their spatial relationships are structured as a spatial relation graph. The visual objects in the image are defined as vertices of spatial relation graph, and the edges of the graph are dynamically constructed by the inherently spatial relation between the visual objects. Then, question-guided focused attention is used to conduct question-based spatial relation reasoning. Focused attention is divided into node attention and edge attention. Node attention is used to find the most relevant visual objects to the question, and edge attention is used to discover the spatial relation that most relevant to the question. Furthermore, the gated graph reasoning network (GGRN) is constructed based on the node attention weights and the edge attention weights, and the features of the neighbor nodes are aggregated by GGRN. Therefore, the deep interaction information between nodes can be obtained, the visual feature representation with spatial perception can be learned, and the question-based spatial relationship reasoning can also be achieved. Finally, the image features with spatial relation-aware and question features are fused to predict the right answer.ResultOur QG-SRGR model is trained, validated and tested on the VQA v2.0 dataset. The results illustrate that the overall accuracy is 66.43% on the Test-dev set, where the accuracy of answering "Yes" or "No" questions is 83.58%, the accuracy of answering counting questions is 45.61%, and the accuracy of answering other questions types is 56.62%. The Test-std set based accuracies calculated are 66.65%, 83.86%, 45.36% and 56.93%, respectively. QG-SRGR model improves the average accuracy achieved by the ReasonNet model by 2.73%, 4.41%, 5.37% and 0.65% respectively on the overall, Yes/No, counting and other questions beyond the Test-std set. In addition, the ablation experiments are carried out on validation set. The results of ablation experiments verify the effectiveness of our method.ConclusionOur proposed QG-SRGR model can better match the text information of the question with the image target regions and the spatial relationships of objects, especially for the spatial relationship reasoning oriented questions. Our illustrated QG-SRGR model demonstrates its priority on reasoning ability.关键词:visual question answering (VQA);graph convolution neural network (GCN);attention mechanism;spatial relation reasoning;multimodal learning123|209|2更新时间:2024-05-07
摘要:ObjectiveCurrent visual question answering (VQA) methods are mostly based on attention mechanism and multimodal fusion. Deep learning have intensively promoted computer vision and natural language processing (NLP) both. Interdisciplinary area between language and vision like VQA has been focused on. VQA is composed of an AI-completed task and it yields a proxy to evaluate our progress towards artificial intelligence (AI)-based quick response reasoning. A VQA based model needs to fully understand the visual scene of the image, especially the interaction between multiple objects. This task inherently requires visual reasoning beyond the relationships between the image objects.MethodOur question-guided spatial relationship graph reasoning (QG-SRGR) model is demonstrated in order to solve the issue of spatial relationship reasoning in VQA, which uses the inherent spatial relationship properties between image objects. First, saliency-based attention mechanism is used in our model, the salient visual objects and visual features are extracted by using faster region-based convolutional neural network (Faster R-CNN). Next, the visual objects and their spatial relationships are structured as a spatial relation graph. The visual objects in the image are defined as vertices of spatial relation graph, and the edges of the graph are dynamically constructed by the inherently spatial relation between the visual objects. Then, question-guided focused attention is used to conduct question-based spatial relation reasoning. Focused attention is divided into node attention and edge attention. Node attention is used to find the most relevant visual objects to the question, and edge attention is used to discover the spatial relation that most relevant to the question. Furthermore, the gated graph reasoning network (GGRN) is constructed based on the node attention weights and the edge attention weights, and the features of the neighbor nodes are aggregated by GGRN. Therefore, the deep interaction information between nodes can be obtained, the visual feature representation with spatial perception can be learned, and the question-based spatial relationship reasoning can also be achieved. Finally, the image features with spatial relation-aware and question features are fused to predict the right answer.ResultOur QG-SRGR model is trained, validated and tested on the VQA v2.0 dataset. The results illustrate that the overall accuracy is 66.43% on the Test-dev set, where the accuracy of answering "Yes" or "No" questions is 83.58%, the accuracy of answering counting questions is 45.61%, and the accuracy of answering other questions types is 56.62%. The Test-std set based accuracies calculated are 66.65%, 83.86%, 45.36% and 56.93%, respectively. QG-SRGR model improves the average accuracy achieved by the ReasonNet model by 2.73%, 4.41%, 5.37% and 0.65% respectively on the overall, Yes/No, counting and other questions beyond the Test-std set. In addition, the ablation experiments are carried out on validation set. The results of ablation experiments verify the effectiveness of our method.ConclusionOur proposed QG-SRGR model can better match the text information of the question with the image target regions and the spatial relationships of objects, especially for the spatial relationship reasoning oriented questions. Our illustrated QG-SRGR model demonstrates its priority on reasoning ability.关键词:visual question answering (VQA);graph convolution neural network (GCN);attention mechanism;spatial relation reasoning;multimodal learning123|209|2更新时间:2024-05-07 -
 摘要:ObjectiveThe adversarial example is a sort of deep neural model data that may lead to output error in relevant to added-perturbation for original image. Perturbation is one of the key factors in the process of adversarial example generation, which yields the model to generate output error with no distortion of original image or human vision perception. Based on the analysis mentioned above, the weak perception of vision and the attack success rate can be as the two essential factors to evaluate the adversarial example. The objective evaluation criteria of current algorithms for visual imperceptibility are relatively consistent: the three channels RGB images may generate better visual imperceptibility as the lower pixel value decreased. The objective evaluation criteria can just resist the range of the perturbation. But, the affected area and perturbation distribution is required to be involved in. Our method aims to illustrate an algorithm to enhance the weak perceptibility of the adversarial examples via the targeted area constraint and the perturbation distribution. Our algorithm design is carried out on the aspects as mentioned below: 1) the perturbation should be distributed in the same semantic region of the image as far as possible like the target area or background; 2) the distribution of the perturbation is necessary to be consistent with the image structure as much as possible; 3) the generation of invalid perturbation is required to reduce as much as possible.MethodWe demonstrate an algorithm to weaken the visual perceptibility of the adversarial paradigms via constrained area and distribution of the black-box conditioned perturbation, which is segmented into two steps: first, the critical regions of image are extracted by convolution network with attention mechanism. The critical region refers to the area that has great influence on the output of the model. The possibility of output error could be increased if the perturbation is melted. If the critical region meets the ideal value, adding perturbation to the region would result the output error of classification model. In order to train the convolution network used to extract the critical region, Gaussian noise is taken as the perturbation in first step, and the perturbation value is fixed on. The first perturbation step is added to the extracted critical area to generate the adversarial example. Then, the adversarial examples are transmitted to the discriminator and the classification model to be attacked each and obtain the loss calculation. In the second step, the weights of the extraction network are identified. The images are fed into the generator with self-attention mechanism and the extraction network to generate perturbation and the critical regions. The perturbation is multiplied by the critical region and melted with the image to generate adversarial examples. The losses are calculated while the generator is optimized after the adversarial examples are fed into the discriminator and the classification model that would be attacked. Moreover, the performance of the second steps perturbation should be better than or equal to the Gaussian noise used in first step, which sets a lower constraint for the success rate of the second step. In the first step of training, we would calculate the perception loss between the original image and the critical regions based on convolution network extraction. Global perception loss was first used in the image style transfer task to maintain the image structure information for the task overall, which can keep the consistency between the perturbation and the image structures to lower the visual perceptibility of the adversarial example.ResultWe compared our algorithm to 9 existed algorithms, including white-box algorithm and black-box algorithm based on three public datasets. The quantitative evaluation metrics contained the structure similarity (SSIM, higher is better), the mean square error (MSE, less is better) and the attack success rate (ASR, higher is better). MSE is used to measure the intensity of perturbation, and SSIM evaluates the influence of perturbation on the image on the aspects of structured information. We also facilitate several adversarial examples generated by difference algorithms to compare the qualitative perceptibility. Our experiment illustrates that the attack success rate of the proposed method is similar to that of the existing methods on three consensus networks. The difference is less than 3% on the low-resolution dataset like CIFAR-10, and on the medium and high-resolution datasets like Tiny-ImageNet and ImageNet is less than 0.5%. Compared to fast gradient sign method(FGSM), basic iterative method(BIM), DeepFool, perceptual color distance C & W(PerC-C & W), auto projected gradient descent(APGD), AutoAttack and AdvGAN, our CIFAR-10 based MSE is lower by 45.1%, 34.91%, 29.3%, 75.6%, 69.0%, 53.9% and 42.1%, respectively, and SSIM is higher by 11.7%, 8%, 0.8%, 18.6%, 7.73%, 4.56%, 8.4%, respectively. Compared to FGSM, BIM, PerC-C & W, APGD, AutoAttack and AdvGAN, the Tiny-ImageNet based MSE is lower by 69.7%, 63.8%, 71.6%, 82.21%, 79.09% and 72.7%, respectively, and SSIM is higher by 10.1%, 8.5%, 38.1%, 5.08%, 1.12% and 12.8%, respectively.ConclusionOur analysis is focused on the existing issues in the evaluation of the perceptibility of the current methods, and proposes a method to enhance the visual imperceptibility of the adversarial examples. The three datasets based results indicate that the attack success rate of our algorithm has its priorities of better visual imperceptibility in terms of qualitative and quantitative evaluation.关键词:adversarial examples;visual perceptibility;adversarial perturbation;generative adversarial network (GAN);black-box attack139|190|3更新时间:2024-05-07
摘要:ObjectiveThe adversarial example is a sort of deep neural model data that may lead to output error in relevant to added-perturbation for original image. Perturbation is one of the key factors in the process of adversarial example generation, which yields the model to generate output error with no distortion of original image or human vision perception. Based on the analysis mentioned above, the weak perception of vision and the attack success rate can be as the two essential factors to evaluate the adversarial example. The objective evaluation criteria of current algorithms for visual imperceptibility are relatively consistent: the three channels RGB images may generate better visual imperceptibility as the lower pixel value decreased. The objective evaluation criteria can just resist the range of the perturbation. But, the affected area and perturbation distribution is required to be involved in. Our method aims to illustrate an algorithm to enhance the weak perceptibility of the adversarial examples via the targeted area constraint and the perturbation distribution. Our algorithm design is carried out on the aspects as mentioned below: 1) the perturbation should be distributed in the same semantic region of the image as far as possible like the target area or background; 2) the distribution of the perturbation is necessary to be consistent with the image structure as much as possible; 3) the generation of invalid perturbation is required to reduce as much as possible.MethodWe demonstrate an algorithm to weaken the visual perceptibility of the adversarial paradigms via constrained area and distribution of the black-box conditioned perturbation, which is segmented into two steps: first, the critical regions of image are extracted by convolution network with attention mechanism. The critical region refers to the area that has great influence on the output of the model. The possibility of output error could be increased if the perturbation is melted. If the critical region meets the ideal value, adding perturbation to the region would result the output error of classification model. In order to train the convolution network used to extract the critical region, Gaussian noise is taken as the perturbation in first step, and the perturbation value is fixed on. The first perturbation step is added to the extracted critical area to generate the adversarial example. Then, the adversarial examples are transmitted to the discriminator and the classification model to be attacked each and obtain the loss calculation. In the second step, the weights of the extraction network are identified. The images are fed into the generator with self-attention mechanism and the extraction network to generate perturbation and the critical regions. The perturbation is multiplied by the critical region and melted with the image to generate adversarial examples. The losses are calculated while the generator is optimized after the adversarial examples are fed into the discriminator and the classification model that would be attacked. Moreover, the performance of the second steps perturbation should be better than or equal to the Gaussian noise used in first step, which sets a lower constraint for the success rate of the second step. In the first step of training, we would calculate the perception loss between the original image and the critical regions based on convolution network extraction. Global perception loss was first used in the image style transfer task to maintain the image structure information for the task overall, which can keep the consistency between the perturbation and the image structures to lower the visual perceptibility of the adversarial example.ResultWe compared our algorithm to 9 existed algorithms, including white-box algorithm and black-box algorithm based on three public datasets. The quantitative evaluation metrics contained the structure similarity (SSIM, higher is better), the mean square error (MSE, less is better) and the attack success rate (ASR, higher is better). MSE is used to measure the intensity of perturbation, and SSIM evaluates the influence of perturbation on the image on the aspects of structured information. We also facilitate several adversarial examples generated by difference algorithms to compare the qualitative perceptibility. Our experiment illustrates that the attack success rate of the proposed method is similar to that of the existing methods on three consensus networks. The difference is less than 3% on the low-resolution dataset like CIFAR-10, and on the medium and high-resolution datasets like Tiny-ImageNet and ImageNet is less than 0.5%. Compared to fast gradient sign method(FGSM), basic iterative method(BIM), DeepFool, perceptual color distance C & W(PerC-C & W), auto projected gradient descent(APGD), AutoAttack and AdvGAN, our CIFAR-10 based MSE is lower by 45.1%, 34.91%, 29.3%, 75.6%, 69.0%, 53.9% and 42.1%, respectively, and SSIM is higher by 11.7%, 8%, 0.8%, 18.6%, 7.73%, 4.56%, 8.4%, respectively. Compared to FGSM, BIM, PerC-C & W, APGD, AutoAttack and AdvGAN, the Tiny-ImageNet based MSE is lower by 69.7%, 63.8%, 71.6%, 82.21%, 79.09% and 72.7%, respectively, and SSIM is higher by 10.1%, 8.5%, 38.1%, 5.08%, 1.12% and 12.8%, respectively.ConclusionOur analysis is focused on the existing issues in the evaluation of the perceptibility of the current methods, and proposes a method to enhance the visual imperceptibility of the adversarial examples. The three datasets based results indicate that the attack success rate of our algorithm has its priorities of better visual imperceptibility in terms of qualitative and quantitative evaluation.关键词:adversarial examples;visual perceptibility;adversarial perturbation;generative adversarial network (GAN);black-box attack139|190|3更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveQuantitative evaluation of artworks is essential to experimental aesthetics, computational aesthetics, computer art and artificial intelligence (AI) art. Previous studies have proposed a variety of aesthetic qualities, such as objective indicators such as self-similarity and complexity, as well as subjective indicators such as aesthetic preference, emotion and style. Computational aesthetics focuses on the measurement and calculation of objective physical characteristics of artworks, while experimental aesthetics tends to measure subjective aesthetic feelings. However, for the art of calligraphy, previous studies have ignored a special aesthetic quality-traceability, that is, the viewer can reconstruct the movement process of brush movement by observing the static strokes on a piece of calligraphy artwork. In classical calligraphy theory, traceability is regarded as the characteristic of calligraphy art different from other categories. However, there is still a lack of empirical research on traceability. In view of this, this paper is just aimed at the empirical study of traceability. One potential application field of traceability evaluation is digital calligraphy, especially the aesthetic evaluation of dynamic calligraphy. At present, some studies have tried to reproduce the formation process of calligraphy handwriting with dynamic effect, but there is no appropriate quantitative evaluation means, especially it is impossible to confirm whether the dynamic work improves the traceability relative to the original piece. The proposed traceability evaluation method is facilitated to resolve the issue, which is a group of theoretic metrics with a perceptual experiment. In addition, the influence of the animated ink effect on the traceability of calligraphy work is studied.MethodTheoretic metrics of traceability and a corresponding perceptual measurement experiment are proposed. The basic concept is that traceability can be decomposed into two psychological factors-sequential perception and velocity perception. Sequential perception refers to the ability to determine the sequential order of brushstrokes. Velocity perception refers to the ability to sense the writing direction and speed along strokes. Theoretic metrics are constructed to quantify the sequential perception and velocity perception. Correspondingly, a perceptual experiment is designed to do the actual measurement of the above two types of perception. The objectives of the experiment are 1) to testify the validity of the proposed metrics of traceability, and 2) to study the influence of animated ink effects on traceability. The experimental stimuli is generated by 3 steps as following: 1) by performing the graphic transformation of mirroring and rotation, generates 8 distorted versions of the chosen calligraphic character "Qiu"; 2) by augmenting the 8 version with 7 animated ink effects, generates a total of 56 samples; 3) for each sample, add marking points at the ends and turns of the handwriting lines. Then, 1 641 participants were recruited for the experiments in the form of online test. Each participant is shown a randomly chosen piece of the 64 stimuli, and then do 2 subjective rating tasks on mark points: judging their sequential order, rating the writing direction and speed. By applying the proposed metrics to experimental data, the traceability of the original calligraphic character "Qiu" and its 7 animated versions is compared quantitatively.ResultOur experimental results demonstrate that the evaluation method is feasible, and found that the appropriate use of animated ink effects, that is, the ink animation flowing along the handwriting traces, enhances the traceability of calligraphy artworks. The Statistics also show some detailed findings, as listed below: 1) although the reversed flowing ink effect improves sequential perception, the perceived sequential order is opposite to the real writing direction; 2) artworks without flowing ink effect show low traceability under the interference of graphic transform; 3) the perceived sequential order may be the same as, or reverse to the original writing order, under graphic transforms; 4) although the sequentiality is high under each graphic transform, it is low when it is calculated based on the data of all graphic transforms; 5) if reversed flowing ink effect is mixed in, the effect of enhancing the sequential perception will be weakened, but the weakening degree shows nonlinear relationship with the proportion of forward and reversed flowing ink; 6) animated ink can improve the perception of writing direction, but it has little effect on the perception of writing speed.ConclusionOur proposed metrics and experiment can quantify the traceability of visual artworks. With appropriate animated ink effects, the traceability of calligraphy artworks is improved. The limitation of the experiment is that it can only approximate the proposed theoretical metrics roughly, and the experimental sample is limited to a single calligraphy character. In addition, the proposed method cannot measure writing movements such as "Ti, An, Dun, Cuo", which are typical ways of writing motions in classical calligraphy theory.关键词:traceability;calligraphy;empirical aesthetics;aesthetic psychology;psychological perception;animation effects104|376|0更新时间:2024-05-07
摘要:ObjectiveQuantitative evaluation of artworks is essential to experimental aesthetics, computational aesthetics, computer art and artificial intelligence (AI) art. Previous studies have proposed a variety of aesthetic qualities, such as objective indicators such as self-similarity and complexity, as well as subjective indicators such as aesthetic preference, emotion and style. Computational aesthetics focuses on the measurement and calculation of objective physical characteristics of artworks, while experimental aesthetics tends to measure subjective aesthetic feelings. However, for the art of calligraphy, previous studies have ignored a special aesthetic quality-traceability, that is, the viewer can reconstruct the movement process of brush movement by observing the static strokes on a piece of calligraphy artwork. In classical calligraphy theory, traceability is regarded as the characteristic of calligraphy art different from other categories. However, there is still a lack of empirical research on traceability. In view of this, this paper is just aimed at the empirical study of traceability. One potential application field of traceability evaluation is digital calligraphy, especially the aesthetic evaluation of dynamic calligraphy. At present, some studies have tried to reproduce the formation process of calligraphy handwriting with dynamic effect, but there is no appropriate quantitative evaluation means, especially it is impossible to confirm whether the dynamic work improves the traceability relative to the original piece. The proposed traceability evaluation method is facilitated to resolve the issue, which is a group of theoretic metrics with a perceptual experiment. In addition, the influence of the animated ink effect on the traceability of calligraphy work is studied.MethodTheoretic metrics of traceability and a corresponding perceptual measurement experiment are proposed. The basic concept is that traceability can be decomposed into two psychological factors-sequential perception and velocity perception. Sequential perception refers to the ability to determine the sequential order of brushstrokes. Velocity perception refers to the ability to sense the writing direction and speed along strokes. Theoretic metrics are constructed to quantify the sequential perception and velocity perception. Correspondingly, a perceptual experiment is designed to do the actual measurement of the above two types of perception. The objectives of the experiment are 1) to testify the validity of the proposed metrics of traceability, and 2) to study the influence of animated ink effects on traceability. The experimental stimuli is generated by 3 steps as following: 1) by performing the graphic transformation of mirroring and rotation, generates 8 distorted versions of the chosen calligraphic character "Qiu"; 2) by augmenting the 8 version with 7 animated ink effects, generates a total of 56 samples; 3) for each sample, add marking points at the ends and turns of the handwriting lines. Then, 1 641 participants were recruited for the experiments in the form of online test. Each participant is shown a randomly chosen piece of the 64 stimuli, and then do 2 subjective rating tasks on mark points: judging their sequential order, rating the writing direction and speed. By applying the proposed metrics to experimental data, the traceability of the original calligraphic character "Qiu" and its 7 animated versions is compared quantitatively.ResultOur experimental results demonstrate that the evaluation method is feasible, and found that the appropriate use of animated ink effects, that is, the ink animation flowing along the handwriting traces, enhances the traceability of calligraphy artworks. The Statistics also show some detailed findings, as listed below: 1) although the reversed flowing ink effect improves sequential perception, the perceived sequential order is opposite to the real writing direction; 2) artworks without flowing ink effect show low traceability under the interference of graphic transform; 3) the perceived sequential order may be the same as, or reverse to the original writing order, under graphic transforms; 4) although the sequentiality is high under each graphic transform, it is low when it is calculated based on the data of all graphic transforms; 5) if reversed flowing ink effect is mixed in, the effect of enhancing the sequential perception will be weakened, but the weakening degree shows nonlinear relationship with the proportion of forward and reversed flowing ink; 6) animated ink can improve the perception of writing direction, but it has little effect on the perception of writing speed.ConclusionOur proposed metrics and experiment can quantify the traceability of visual artworks. With appropriate animated ink effects, the traceability of calligraphy artworks is improved. The limitation of the experiment is that it can only approximate the proposed theoretical metrics roughly, and the experimental sample is limited to a single calligraphy character. In addition, the proposed method cannot measure writing movements such as "Ti, An, Dun, Cuo", which are typical ways of writing motions in classical calligraphy theory.关键词:traceability;calligraphy;empirical aesthetics;aesthetic psychology;psychological perception;animation effects104|376|0更新时间:2024-05-07
Computer Graphics
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0