
最新刊期
卷 27 , 期 6 , 2022
-
 摘要:Visual object detection aims to locate and recognize objects in images, which is one of the classical tasks in the field of computer vision and also the premise and foundation of many computer vision tasks. Visual object detection plays a very important role in the applications of automatic driving, video surveillance, which has attracted extensive attention of the researches in past few decades. In recent years, with the development of the technique of deep learning, visual object detection has also made great progress. This paper focuses on a deep survey on deep learning based visual object detection, including monocular object detection and stereo object detection. First, we summarize the pipeline of deep object detection during the training and inference. The training process is composed of data pre-processing, detection network design, and label assignment and loss function in common. Data pre-processing (e.g., multi-scale training and flip) aims to enhance the diversity of the given training data, which can improve detection performance of object detector. Detection network usually consists of three key parts like the backbone (e.g., Visual Geometry Group(VGG) and ResNet), feature fusion module (e.g., feature pyramid network(FPN)), and prediction network (e.g., region of interest head network(RoI head)). Label assignment aims to assign the true value for each prediction, and loss function can supervise the network training. During inference, we adopt the trained detector to generate the detection bounding-boxes and employ the post-processing step (e.g., non-maximum suppression(NMS)) to combine the bounding-boxes. Second, we illustrate a deep review on monocular object detection, including anchor-based, anchor-free, and end-to-end methods, respectively. Anchor-based methods design some default anchors and perform classification and regression based on these default anchors, which can be further split into two-stage and one-stage methods. Two-stage methods first generate some candidate proposals based on the default anchors, and second classify/regress these proposals. Compared to two-stage methods, one-stage methods directly perform classification and regression on default anchors directly, which usually have a faster inference speed. The representative two-stage methods are regional-based convolutional neural network (R-CNN) series, and the representative one-stage methods are you only look once (YOLO) and single shot detector (SSD). Compared to anchor-based methods, more robust anchor-free methods perform classification and regression without any hand-crafted default anchors. We split anchor-free methods into keypoint-based methods, and center-based methods. Keypoint-based methods predict multiple keypoints of objects for localization, while center-based methods predict the left, right, top, and bottom distances to the object boundary. The representative keypoint-based method is CornerNet, and the representative center-based methods are fully convolutional one-stage detector (FCOS) and CenterNet. The anchor-based methods and anchor-free methods mentioned above require the post-processing to remove the redundant detection results for each object in common. To solve this problem, the recently introduced end-to-end methods directly predict one bounding box for each object straightforward, which can avoid the post-processing. The representative end-to-end method is detection transformer (DETR) that performs prediction via a transformer module. In addition, we review some classical modules employed in monocular object detection, including feature pyramid structure, prediction network design, label assignment and loss function. The feature pyramid structure employs different layers to detect multi-scaled objects, which can deal with scale variance issue. Prediction network design contains the re-designs of classification and regression, which aims to better deal with these two sub-tasks. Label assignment and loss function aim to better guide detector training. Third, we introduce stereo object detection. According to the coordinate space of features, existing detectors are divided into two categories: frustum-based and inverse-projection-based approaches. Frustum-based approaches directly predict 3D objects on features in the image frustum space. Stereo R-CNN and StereoCenterNet construct stereo features in the image frustum space via concatenating a pair of unary features concatenation. Plane-sweeping is another method of constructing frustum features as cost volumes, which is used in instance-depth-aware 3D detection (IDA-3D) and YOLOStereo3D. In contrast to the frustum-based approaches, inverse-projection-based approaches explicitly project the pixels or frustum features into 3D Cartesian space. There are mainly three manners of the inverse projection: projecting all pixels to the full 3D space as a pseudo point cloud, projecting the cost volume features to 3D feature volume features, or projecting the pixels in each region proposal to an instance-level point cloud. Pseudo-LiDAR is a pioneer method that transforms stereo images to their point cloud representation, which embraces the advances in both disparity estimation and LiDAR-based 3D detection. Deep stereo geometry network (DSGN) projects the frustum-based cost volume features to 3D volume features and further squeezes them into bird's eye view (BEV) for detection. Disp R-CNN leverages Mask R-CNN, a representative 2D instance segmentation model, and generates a set of instance-level point clouds for each stereo image pair. Based on the summary of monocular and stereo object detection, we further compare the progress of domestic and foreign researches, and present some representative universities or companies on visual object detection. Finally, we present some development tendency in visual object detection, including efficient end-to-end object detection, self-supervised object detection, long-tailed object detection, few-shot and zero-shot object detection, large-scale stereo object detection dataset, weakly-supervised stereo object detection.关键词:visual object detection;deep learning;monocular;stereo;anchor723|683|43更新时间:2024-08-15
摘要:Visual object detection aims to locate and recognize objects in images, which is one of the classical tasks in the field of computer vision and also the premise and foundation of many computer vision tasks. Visual object detection plays a very important role in the applications of automatic driving, video surveillance, which has attracted extensive attention of the researches in past few decades. In recent years, with the development of the technique of deep learning, visual object detection has also made great progress. This paper focuses on a deep survey on deep learning based visual object detection, including monocular object detection and stereo object detection. First, we summarize the pipeline of deep object detection during the training and inference. The training process is composed of data pre-processing, detection network design, and label assignment and loss function in common. Data pre-processing (e.g., multi-scale training and flip) aims to enhance the diversity of the given training data, which can improve detection performance of object detector. Detection network usually consists of three key parts like the backbone (e.g., Visual Geometry Group(VGG) and ResNet), feature fusion module (e.g., feature pyramid network(FPN)), and prediction network (e.g., region of interest head network(RoI head)). Label assignment aims to assign the true value for each prediction, and loss function can supervise the network training. During inference, we adopt the trained detector to generate the detection bounding-boxes and employ the post-processing step (e.g., non-maximum suppression(NMS)) to combine the bounding-boxes. Second, we illustrate a deep review on monocular object detection, including anchor-based, anchor-free, and end-to-end methods, respectively. Anchor-based methods design some default anchors and perform classification and regression based on these default anchors, which can be further split into two-stage and one-stage methods. Two-stage methods first generate some candidate proposals based on the default anchors, and second classify/regress these proposals. Compared to two-stage methods, one-stage methods directly perform classification and regression on default anchors directly, which usually have a faster inference speed. The representative two-stage methods are regional-based convolutional neural network (R-CNN) series, and the representative one-stage methods are you only look once (YOLO) and single shot detector (SSD). Compared to anchor-based methods, more robust anchor-free methods perform classification and regression without any hand-crafted default anchors. We split anchor-free methods into keypoint-based methods, and center-based methods. Keypoint-based methods predict multiple keypoints of objects for localization, while center-based methods predict the left, right, top, and bottom distances to the object boundary. The representative keypoint-based method is CornerNet, and the representative center-based methods are fully convolutional one-stage detector (FCOS) and CenterNet. The anchor-based methods and anchor-free methods mentioned above require the post-processing to remove the redundant detection results for each object in common. To solve this problem, the recently introduced end-to-end methods directly predict one bounding box for each object straightforward, which can avoid the post-processing. The representative end-to-end method is detection transformer (DETR) that performs prediction via a transformer module. In addition, we review some classical modules employed in monocular object detection, including feature pyramid structure, prediction network design, label assignment and loss function. The feature pyramid structure employs different layers to detect multi-scaled objects, which can deal with scale variance issue. Prediction network design contains the re-designs of classification and regression, which aims to better deal with these two sub-tasks. Label assignment and loss function aim to better guide detector training. Third, we introduce stereo object detection. According to the coordinate space of features, existing detectors are divided into two categories: frustum-based and inverse-projection-based approaches. Frustum-based approaches directly predict 3D objects on features in the image frustum space. Stereo R-CNN and StereoCenterNet construct stereo features in the image frustum space via concatenating a pair of unary features concatenation. Plane-sweeping is another method of constructing frustum features as cost volumes, which is used in instance-depth-aware 3D detection (IDA-3D) and YOLOStereo3D. In contrast to the frustum-based approaches, inverse-projection-based approaches explicitly project the pixels or frustum features into 3D Cartesian space. There are mainly three manners of the inverse projection: projecting all pixels to the full 3D space as a pseudo point cloud, projecting the cost volume features to 3D feature volume features, or projecting the pixels in each region proposal to an instance-level point cloud. Pseudo-LiDAR is a pioneer method that transforms stereo images to their point cloud representation, which embraces the advances in both disparity estimation and LiDAR-based 3D detection. Deep stereo geometry network (DSGN) projects the frustum-based cost volume features to 3D volume features and further squeezes them into bird's eye view (BEV) for detection. Disp R-CNN leverages Mask R-CNN, a representative 2D instance segmentation model, and generates a set of instance-level point clouds for each stereo image pair. Based on the summary of monocular and stereo object detection, we further compare the progress of domestic and foreign researches, and present some representative universities or companies on visual object detection. Finally, we present some development tendency in visual object detection, including efficient end-to-end object detection, self-supervised object detection, long-tailed object detection, few-shot and zero-shot object detection, large-scale stereo object detection dataset, weakly-supervised stereo object detection.关键词:visual object detection;deep learning;monocular;stereo;anchor723|683|43更新时间:2024-08-15 -
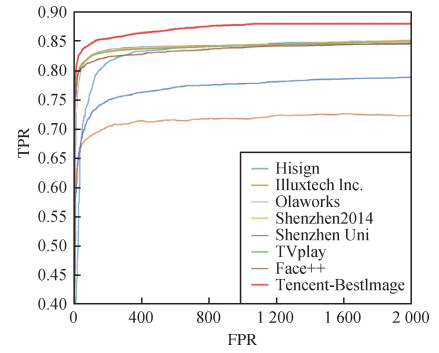 摘要:Public security and social governance is essential to national development nowadays. It is challenged to prevent large-scale riots in communities and various city crimes for spatial and timescaled social governance in corona virus disease 2019(Covid-19) likehighly accurate human identity verification, highly efficient human behavior analysis and crowd flow track and trace. The core of the challenge is to use computer vision technologies to extract visual information in complex scenarios and to fully express, identify and understand the relationship between human behavior and scenes to improve the degree of social administration and governance. Complex scenarios oriented visual technologies recognition can improve the efficiency of social intelligence and accelerate the process of intelligent social governance. The main challenge of human recognition is composed of three aspects as mentioned below: 1) the diversity attack derived from mask occlusion attack, affecting the security of human identity recognition; 2) the large span of time and space information has affected the accuracy of multiple ages oriented face recognition (especially tens of millions of scales retrieval); 3) the complex and changeable scenarios are required for the high robustness of the system and adapt to diverse environments. Therefore, it is necessary to facilitate technologies of remote human identity verification related to the high degree of security, face recognition accuracy, human behavior analysis and scene semantic recognition. The motion analysis of individual behavior and group interaction trend are the key components of complex scenarios based human visual contexts. In detail, individual behavior analysis mainly includes video-based pedestrian re-recognition and video-based action recognition. The group interaction recognition is mainly based on video question-and-answer and dialogue. Video-based network can record the multi-source cameras derived individuals/groups image information. Multi-camera based human behavior research of group segmentation, group tracking, group behavior analysis and abnormal behavior detection. However, it is extremely complex that the individual behavior/group interaction is recorded by multiple cameras in real scenarios, and it is still a great challenge to improve the performance of multi-camera and multi-objective behavior recognition through integrated modeling of real scene structure, individual behavior and group interaction. The video-based network recognition of individual and group behavior mainly depends on visual information in related to scene, individual and group captured. Nonetheless, complex scenarios based individual behavior analysis and group interaction recognition require human knowledge and prior knowledge without visual information in common.Specifically, a crowdsourced data application has improved visual computing performance and visual question-and-answer and dialogue and visual language navigation. The inherited knowledge in crowdsourced data can develop a data-driven machine learning model for comprehensive knowledge and prior applications in individual behavior analysis and group interaction recognition, and establish a new method of data-driven and knowledge-guided visual computing. In addition, the facial expression behavior can be recognized as the human facial micro-motions like speech the voice of language. Speech emotion recognition can capture and understand human emotions and beneficial to support the learning mode of human-machine collaboration better. It is important for research to get deeper into the technology of human visual recognition. Current researches have been focused on human facial expression recognition, speech emotion recognition, expression synthesis, and speech emotion synthesis. We carried out about the contexts of complex scenarios based real-time human identification, individual behavior and group interaction understanding analysis, visual speech emotion recognition and synthesis, comprehensive utilization of knowledge and a priori mode of machine learning. The research and application scenarios for the visual ability is facilitated for complex scenarios. We summarize the current situations, and predict the frontier technologies and development trends. The human visual recognition technology will harness the visual ability to recognize relationship between humans, behavior and scenes. It is potential to improve the capability of standard data construction, model computing resources, and model robustness and interpretability further.关键词:complex scenes;visual understanding;human recognition;deep learning;behavior analysis130|484|0更新时间:2024-08-15
摘要:Public security and social governance is essential to national development nowadays. It is challenged to prevent large-scale riots in communities and various city crimes for spatial and timescaled social governance in corona virus disease 2019(Covid-19) likehighly accurate human identity verification, highly efficient human behavior analysis and crowd flow track and trace. The core of the challenge is to use computer vision technologies to extract visual information in complex scenarios and to fully express, identify and understand the relationship between human behavior and scenes to improve the degree of social administration and governance. Complex scenarios oriented visual technologies recognition can improve the efficiency of social intelligence and accelerate the process of intelligent social governance. The main challenge of human recognition is composed of three aspects as mentioned below: 1) the diversity attack derived from mask occlusion attack, affecting the security of human identity recognition; 2) the large span of time and space information has affected the accuracy of multiple ages oriented face recognition (especially tens of millions of scales retrieval); 3) the complex and changeable scenarios are required for the high robustness of the system and adapt to diverse environments. Therefore, it is necessary to facilitate technologies of remote human identity verification related to the high degree of security, face recognition accuracy, human behavior analysis and scene semantic recognition. The motion analysis of individual behavior and group interaction trend are the key components of complex scenarios based human visual contexts. In detail, individual behavior analysis mainly includes video-based pedestrian re-recognition and video-based action recognition. The group interaction recognition is mainly based on video question-and-answer and dialogue. Video-based network can record the multi-source cameras derived individuals/groups image information. Multi-camera based human behavior research of group segmentation, group tracking, group behavior analysis and abnormal behavior detection. However, it is extremely complex that the individual behavior/group interaction is recorded by multiple cameras in real scenarios, and it is still a great challenge to improve the performance of multi-camera and multi-objective behavior recognition through integrated modeling of real scene structure, individual behavior and group interaction. The video-based network recognition of individual and group behavior mainly depends on visual information in related to scene, individual and group captured. Nonetheless, complex scenarios based individual behavior analysis and group interaction recognition require human knowledge and prior knowledge without visual information in common.Specifically, a crowdsourced data application has improved visual computing performance and visual question-and-answer and dialogue and visual language navigation. The inherited knowledge in crowdsourced data can develop a data-driven machine learning model for comprehensive knowledge and prior applications in individual behavior analysis and group interaction recognition, and establish a new method of data-driven and knowledge-guided visual computing. In addition, the facial expression behavior can be recognized as the human facial micro-motions like speech the voice of language. Speech emotion recognition can capture and understand human emotions and beneficial to support the learning mode of human-machine collaboration better. It is important for research to get deeper into the technology of human visual recognition. Current researches have been focused on human facial expression recognition, speech emotion recognition, expression synthesis, and speech emotion synthesis. We carried out about the contexts of complex scenarios based real-time human identification, individual behavior and group interaction understanding analysis, visual speech emotion recognition and synthesis, comprehensive utilization of knowledge and a priori mode of machine learning. The research and application scenarios for the visual ability is facilitated for complex scenarios. We summarize the current situations, and predict the frontier technologies and development trends. The human visual recognition technology will harness the visual ability to recognize relationship between humans, behavior and scenes. It is potential to improve the capability of standard data construction, model computing resources, and model robustness and interpretability further.关键词:complex scenes;visual understanding;human recognition;deep learning;behavior analysis130|484|0更新时间:2024-08-15 -
 摘要:Current intelligent transportation system (ITS) issue is challenged to improve conventional transportation engineering solutions nowadays. ITS has integrated advanced information and communication technologies (ICTs) into the holistic transportation system for a safe, efficient, comfortable and environment friendly transport ecological construction. A variety of ITS applications and services have emerged in the intelligent traffic management system, autonomous driving system, and cooperative vehicle-infrastructure system (CVIS). To realise the intelligentisation of the traffic management, the intelligent traffic management system is mainly supported by optimised smart traffic facilities. Autonomous driving is mainly based on vehicle intelligence, relying on the cooperation of visual perception, radar perception, positioning system, on-board computing and artificial intelligence. The CVIS depends on the collaborative work of intelligent vehicles, roadside equipment and cloud platforms in support of the internet of vehicles (IOV) to fully implement dynamic real-time information interaction between vehicles and related traffic issues to achieve the vehicle-road collaborative management and traffic safety. Image processing is one of the core technologies that can support the deployment of a large number of ITS applications. It is based on computer algorithms application to extract useful visual sensor data derived information, including image enhancement and restoration, feature extraction and classification, as well as the semantic and instance segmentation. Image enhancement and restoration refers to improve the visual performance of the image and render more suitable image for human or machine analysis to deal with the image quality reduction issues of the challenging traffic system scenarios. Image feature extraction and classification technology is the core of object detection for accurate images or videos derived traffic objects locating and identifying, which is the basis for solving more complex higher-level tasks such as segmentation, scene understanding, object tracking, image description, event detection and activity recognition. To achieve higher-precision environmental perception in ITS, the semantic and instance segmentation realises pixel-level image classification based on scene semantic information in terms of the provision of different labels for instances of the same category. These image processing technologies can illustrate crucial references and information to enhance the capabilities of the perception, recognition, object detection, tracking, and path planning modules for more ITS applications. The multifaceted scenarios integration provides important technical support for intelligent traffic management, autonomous driving and the CVIS. In addition, the wide deployment of sensing devices places tremendous demands on data transmission and processing. As the widely recognised data processing technology, the centralised cloud computing is challenged to meet the real-time requirements of most massive data applications in ITS, which leads to uncertainty and barriers in the transmission process. Differentiated from the centralised cloud computing, the multi-access edge computing (MEC) technology deploys sensing, computation, and storage resources close to the network edge and provide a low-latency response-based platform for ITS, high bandwidth, and real-time applications and services access to network information. Our research reviews the current development status and typical applications of ITS. We focus on current image processing and MEC technologies for ITS. Future research direction of ITS and its related image processing and MEC technologies are predicted.关键词:intelligent transportation system(ITS);image processing;edge computing;autonomous driving;cooperative vehicle-infrastructure system(CVIS);deep learning386|128|8更新时间:2024-08-15
摘要:Current intelligent transportation system (ITS) issue is challenged to improve conventional transportation engineering solutions nowadays. ITS has integrated advanced information and communication technologies (ICTs) into the holistic transportation system for a safe, efficient, comfortable and environment friendly transport ecological construction. A variety of ITS applications and services have emerged in the intelligent traffic management system, autonomous driving system, and cooperative vehicle-infrastructure system (CVIS). To realise the intelligentisation of the traffic management, the intelligent traffic management system is mainly supported by optimised smart traffic facilities. Autonomous driving is mainly based on vehicle intelligence, relying on the cooperation of visual perception, radar perception, positioning system, on-board computing and artificial intelligence. The CVIS depends on the collaborative work of intelligent vehicles, roadside equipment and cloud platforms in support of the internet of vehicles (IOV) to fully implement dynamic real-time information interaction between vehicles and related traffic issues to achieve the vehicle-road collaborative management and traffic safety. Image processing is one of the core technologies that can support the deployment of a large number of ITS applications. It is based on computer algorithms application to extract useful visual sensor data derived information, including image enhancement and restoration, feature extraction and classification, as well as the semantic and instance segmentation. Image enhancement and restoration refers to improve the visual performance of the image and render more suitable image for human or machine analysis to deal with the image quality reduction issues of the challenging traffic system scenarios. Image feature extraction and classification technology is the core of object detection for accurate images or videos derived traffic objects locating and identifying, which is the basis for solving more complex higher-level tasks such as segmentation, scene understanding, object tracking, image description, event detection and activity recognition. To achieve higher-precision environmental perception in ITS, the semantic and instance segmentation realises pixel-level image classification based on scene semantic information in terms of the provision of different labels for instances of the same category. These image processing technologies can illustrate crucial references and information to enhance the capabilities of the perception, recognition, object detection, tracking, and path planning modules for more ITS applications. The multifaceted scenarios integration provides important technical support for intelligent traffic management, autonomous driving and the CVIS. In addition, the wide deployment of sensing devices places tremendous demands on data transmission and processing. As the widely recognised data processing technology, the centralised cloud computing is challenged to meet the real-time requirements of most massive data applications in ITS, which leads to uncertainty and barriers in the transmission process. Differentiated from the centralised cloud computing, the multi-access edge computing (MEC) technology deploys sensing, computation, and storage resources close to the network edge and provide a low-latency response-based platform for ITS, high bandwidth, and real-time applications and services access to network information. Our research reviews the current development status and typical applications of ITS. We focus on current image processing and MEC technologies for ITS. Future research direction of ITS and its related image processing and MEC technologies are predicted.关键词:intelligent transportation system(ITS);image processing;edge computing;autonomous driving;cooperative vehicle-infrastructure system(CVIS);deep learning386|128|8更新时间:2024-08-15 -
 摘要:Visual understanding, e.g., object detection, semantic/instance segmentation, and action recognition, plays a crucial role in many real-world applications including human-machine interaction, autonomous driving, etc. Recently, deep networks have made great progress in these tasks under the full supervision regime. Based on convolutional neural network (CNN), a series of representative deep models have been developed for these visual understanding tasks, e.g., you only look once (YOLO) and Fast/Faster R-CNN(region CNN) for object detection, fully convolutional networks(FCN) and DeepLab for semantic segmentation, Mask R-CNN and you only look at coefficients (YOLACT) for instance segmentation. Recently, driven by novel network backbone, e.g., Transformer, the performance of these tasks have been further boosted under full supervision regime. However, supervised learning relies on massive accurate annotations, which are usually laborious and costly. By taking semantic segmentation as an example, it is very laborious and costly for collecting dense annotations, i.e., pixel-wise segmentation masks, while weak supervision annotations, e.g., bounding box annotations, point annotations, are much easier to collect. Moreover, for video action recognition, the scenes in videos are very complicated, and it is very likely to be impossible to annotate all the actions with accurate time intervals. Alternatively, weakly supervised learning is effective in reducing the cost of data annotations, and thus is very important to the development and applications of visual understanding. Taking object detection, semantic/instance segmentation, and action recognition as examples, this article aims to provide a survey on recent progress in weakly supervised visual understanding, while pointing out several challenges and opportunities. To begin with, we first introduce two representative weakly supervised learning methods, including multiple instance learning (MIL) and expectation-maximization (EM) algorithms. Despite of different network architectures in recent weakly supervised learning methods, most existing methods can be categorized into the family of MIL or EM. As for object localization and detection, we respectively review the methods based on MIL and class attention map (CAM), where self-training and switching between supervision settings are specifically introduced. By formulating weakly supervised object detection (WSOD) as the problem of MIL-based proposal classification, WSOD methods tend to focus on discriminative parts of object, e.g., head for human or animals may be simply detected to represent the entire object, yielding significant performance drops in comparison to fully supervised object detection. To address this issue, self-training and switching between supervision settings have been respectively developed, and transfer learning has also been introduced to exploit auxiliary information from other tasks, e.g., semantic segmentation. As for weakly supervised object localization, CAM is a popular solution to predict the object position where objects from one class with the highest activation value can be found. Similarly, CAM based localization methods are also facing the issue of discriminative parts, and several solutions, e.g., suppressing the most discriminative parts and attention-based self-produced guidance, have been proposed. Based on pattern analysis, statistical modeling and computational learning visual object classes(PASCAL VOC) and Microsoft common objects in context(MS COCO) datasets, several representative weakly supervised object localization and detection methods have been evaluated, showing performance gaps between fully supervised methods. As for semantic segmentation, we consider several representative weak supervision settings including bounding box annotations, image-level class annotations, point or scribble annotations. In comparison to segmentation mask annotations, these weak annotations cannot provide accurate pixel-wise supervision. Image-level class annotations are the most convenient and easiest way, and the key issue of image-level weakly supervised semantic segmentation methods is to exploit the correlation between class labels and segmentation masks. Based on CAM, coarse segmentation results can be obtained, while facing inaccurate segmentation masks and focusing on discriminative parts. To refine segmentation masks, several strategies are introduced including iterative erasing, learning similarity between pixels, and joint learning of saliency detection and weakly supervised semantic segmentation. Point or scribble annotations and bounding box annotations can provide more accurate localization information than image-level class annotations. Among them, bounding box annotations is likely to be a good solution to balance the annotation cost and performance of weakly supervised semantic segmentation under EM framework. Moreover, weakly supervised instance segmentation is more challenging than weakly supervised semantic segmentation, since a pixel is not only assigned to an object class but also is accurately assigned to one specific object. In this article, we consider bounding box annotations and image-level annotations for weakly supervised instance segmentation. Based on image-level class annotations, peak response map in CAM is highly correlated with object instances, and can be adopted in weakly supervised instance segmentation. Based on bounding box annotations, weakly supervised instance segmentation can be formulated as MIL, where instance masks are usually more accurate than those based on image-level class annotations. Besides, in these weakly supervised segmentation methods, post-processing techniques, e.g., dense conditional random field, are usually adopted to further refine the segmentation masks. On PASCAL VOC and MS COCO datasets, representative weakly supervised semantic and instance segmentation methods with different levels of annotations are evaluated. As for video action recognition, it is much more difficult to collect accurate annotations of all the actions due to complicated scenes in videos, and thus weakly supervised action recognition is attracting research attention in recent years. In this article, we introduce the models and algorithms for different weak supervision settings including film scripts, action sequences, video-level class labels and single-frame labels. Finally, the challenges and opportunities are analyzed and discussed. For these visual understanding tasks, the performance of weakly supervised methods still has improvement room in comparison to fully supervised methods. When applying in the wild, it is also a valuable and challenging topic to exploit large amount of unlabeled and noisy data. In future, weakly supervised visual understanding methods also will benefit from multi-task learning and large-scale pre-trained models. For an example, vision and language pre-trained models, e.g., contrastive language-image pre-training (CLIP), is potential to provide knowledge to significantly improve the performance of weakly supervised visual understanding tasks.关键词:weakly supervised learning;object localization;object detection;semantic segmentation;instance segmentation;action recognition182|372|10更新时间:2024-08-15
摘要:Visual understanding, e.g., object detection, semantic/instance segmentation, and action recognition, plays a crucial role in many real-world applications including human-machine interaction, autonomous driving, etc. Recently, deep networks have made great progress in these tasks under the full supervision regime. Based on convolutional neural network (CNN), a series of representative deep models have been developed for these visual understanding tasks, e.g., you only look once (YOLO) and Fast/Faster R-CNN(region CNN) for object detection, fully convolutional networks(FCN) and DeepLab for semantic segmentation, Mask R-CNN and you only look at coefficients (YOLACT) for instance segmentation. Recently, driven by novel network backbone, e.g., Transformer, the performance of these tasks have been further boosted under full supervision regime. However, supervised learning relies on massive accurate annotations, which are usually laborious and costly. By taking semantic segmentation as an example, it is very laborious and costly for collecting dense annotations, i.e., pixel-wise segmentation masks, while weak supervision annotations, e.g., bounding box annotations, point annotations, are much easier to collect. Moreover, for video action recognition, the scenes in videos are very complicated, and it is very likely to be impossible to annotate all the actions with accurate time intervals. Alternatively, weakly supervised learning is effective in reducing the cost of data annotations, and thus is very important to the development and applications of visual understanding. Taking object detection, semantic/instance segmentation, and action recognition as examples, this article aims to provide a survey on recent progress in weakly supervised visual understanding, while pointing out several challenges and opportunities. To begin with, we first introduce two representative weakly supervised learning methods, including multiple instance learning (MIL) and expectation-maximization (EM) algorithms. Despite of different network architectures in recent weakly supervised learning methods, most existing methods can be categorized into the family of MIL or EM. As for object localization and detection, we respectively review the methods based on MIL and class attention map (CAM), where self-training and switching between supervision settings are specifically introduced. By formulating weakly supervised object detection (WSOD) as the problem of MIL-based proposal classification, WSOD methods tend to focus on discriminative parts of object, e.g., head for human or animals may be simply detected to represent the entire object, yielding significant performance drops in comparison to fully supervised object detection. To address this issue, self-training and switching between supervision settings have been respectively developed, and transfer learning has also been introduced to exploit auxiliary information from other tasks, e.g., semantic segmentation. As for weakly supervised object localization, CAM is a popular solution to predict the object position where objects from one class with the highest activation value can be found. Similarly, CAM based localization methods are also facing the issue of discriminative parts, and several solutions, e.g., suppressing the most discriminative parts and attention-based self-produced guidance, have been proposed. Based on pattern analysis, statistical modeling and computational learning visual object classes(PASCAL VOC) and Microsoft common objects in context(MS COCO) datasets, several representative weakly supervised object localization and detection methods have been evaluated, showing performance gaps between fully supervised methods. As for semantic segmentation, we consider several representative weak supervision settings including bounding box annotations, image-level class annotations, point or scribble annotations. In comparison to segmentation mask annotations, these weak annotations cannot provide accurate pixel-wise supervision. Image-level class annotations are the most convenient and easiest way, and the key issue of image-level weakly supervised semantic segmentation methods is to exploit the correlation between class labels and segmentation masks. Based on CAM, coarse segmentation results can be obtained, while facing inaccurate segmentation masks and focusing on discriminative parts. To refine segmentation masks, several strategies are introduced including iterative erasing, learning similarity between pixels, and joint learning of saliency detection and weakly supervised semantic segmentation. Point or scribble annotations and bounding box annotations can provide more accurate localization information than image-level class annotations. Among them, bounding box annotations is likely to be a good solution to balance the annotation cost and performance of weakly supervised semantic segmentation under EM framework. Moreover, weakly supervised instance segmentation is more challenging than weakly supervised semantic segmentation, since a pixel is not only assigned to an object class but also is accurately assigned to one specific object. In this article, we consider bounding box annotations and image-level annotations for weakly supervised instance segmentation. Based on image-level class annotations, peak response map in CAM is highly correlated with object instances, and can be adopted in weakly supervised instance segmentation. Based on bounding box annotations, weakly supervised instance segmentation can be formulated as MIL, where instance masks are usually more accurate than those based on image-level class annotations. Besides, in these weakly supervised segmentation methods, post-processing techniques, e.g., dense conditional random field, are usually adopted to further refine the segmentation masks. On PASCAL VOC and MS COCO datasets, representative weakly supervised semantic and instance segmentation methods with different levels of annotations are evaluated. As for video action recognition, it is much more difficult to collect accurate annotations of all the actions due to complicated scenes in videos, and thus weakly supervised action recognition is attracting research attention in recent years. In this article, we introduce the models and algorithms for different weak supervision settings including film scripts, action sequences, video-level class labels and single-frame labels. Finally, the challenges and opportunities are analyzed and discussed. For these visual understanding tasks, the performance of weakly supervised methods still has improvement room in comparison to fully supervised methods. When applying in the wild, it is also a valuable and challenging topic to exploit large amount of unlabeled and noisy data. In future, weakly supervised visual understanding methods also will benefit from multi-task learning and large-scale pre-trained models. For an example, vision and language pre-trained models, e.g., contrastive language-image pre-training (CLIP), is potential to provide knowledge to significantly improve the performance of weakly supervised visual understanding tasks.关键词:weakly supervised learning;object localization;object detection;semantic segmentation;instance segmentation;action recognition182|372|10更新时间:2024-08-15 - 摘要:With the development and application of artificial intelligence, intelligent analysis and interpretation of big remotely sensed data using artificial intelligence technology has become a future development trend. By synthesizing domestic and foreign literature and related reports, it sorts out the fields of remote sensing data precision processing, remote sensing data spatio-temporal processing and analysis, remote sensing object classification and identification, remote sensing data association mining, remote sensing open source datasets and sharing platforms. Firstly, for the task of precise processing of remote sensing data, the purpose is to image process and calibrate the spectral reflection or radar scattering data obtained by the sensor, and restore them to image products accurately related to some information dimensions of ground objects. This paper reviews the research progress of refined processing from two aspects: the improvement of imaging quality of remote sensing data such as optics and SAR(synthetic aperture radar) and the reconstruction of low-quality images. The research progress of quantitative improvement is analyzed from two aspects: local feature matching and regional feature matching of remote sensing images. The exploration of existing technologies verifies the feasibility of high-precision remote sensing data processing through artificial intelligence technology. Secondly, for the task of spatio-temporal processing and analysis of remote sensing data, through the comprehensive analysis of multi temporal images, compared with single temporal remote sensing images, it can further show the dynamic changes of the earth's surface and reveal the evolution law of ground objects. For remote sensing applications of multi temporal images, such as monitoring of forest degradation, crop growth, urban expansion and wetland loss, the lack of data caused by clouds and their shadows will prolong the time interval of image acquisition, cause the problem of irregular time interval, and increase the difficulty of subsequent time series processing and analysis. This paper reviews its research progress from two aspects: remote sensing image time series restoration and multi-source remote sensing temporal and spatial fusion. Thirdly, for the task of remote sensing object classification and recognition, most of the existing processing and analysis methods do not make full use of the powerful autonomous learning ability of computers, rely on limited information acquisition and calculation methods, and are difficult to meet the performance requirements such as accuracy and false alarm rate. This paper reviews the research progress of typical feature element extraction and multi element parallel extraction. The existing technology explores how to combine artificial intelligence methods on the basis of traditional artificial mathematical analysis methods to quantitatively describe and analyze target models and mechanisms in remote sensing data to improve target interpretation accuracy. Finally, for the task of remote sensing data association mining, the research progress is reviewed from two aspects: data organization association and professional knowledge graph construction. It shows that there are still some problems in the field of remote sensing data, such as scattered application, difficult to form a knowledge graph and realize knowledge accumulation, updating and optimization. Based on massive multi-source heterogeneous remote sensing data, realizing the rapid association, organization and analysis of multi-dimensional information in time and space is an important direction in the future. In addition, facing the development needs of big intelligence analysis technology, this paper also reviews the research progress of remote sensing open source data set and sharing platform. On this basis, the research situation of intelligent analysis and interpretation of remote sensing data is combed and summarized, and the future development trend and prospect of this field are given.关键词:remote sensing big data;data processing;spatio-temporal processing and analysis;target element classification and identification;data association mining;open source datasets;sharing platform385|174|10更新时间:2024-08-15
-
 摘要:Video is the conceptual base of visual information processing technology. The frame rate of traditional video is tens of Hertz, which is incapable to represent the Ultra-high speed change process of light. It also constrains to the speed of machine vision. The concept of video is originated from film imaging, which can't unleash the full potential of electronic and digital technology. The spike vision model generates a spike when the photon energy captured by a photosensitive device reaches the predefined threshold. The longer the spike timing is, the weaker the received light signals are. The occurred light intensity can be inferred to achieve consistent imaging. Current research of spiking vision is focused on developing disruptive ultra-high speed imaging chips and cameras that are 1 000 times faster than videos. It is substituting traditional paradigm derived from machine vision speed linear growth of computing power. Based on the biological evidence and physical principle of spiking vision, our review analyzes the software simulator of spiking vision, the computational process of the photon propagation simulation, spiking vision based visual image reconstruction, and the detailed mechanism of photoelectric sensor structure and the chip design. Our review reveals the ultra-high speed target motion detection, and spiking neural networks based tracking and recognition. The evolution of spiking vision is forecasted. Future spiking vision based chip and system has multifaceted potentials to further harness the industrial tasks (e.g., the monitoring of high-speed train, power grid, turbine and intelligent manufacturing), civil applications (e.g., high-speed camera, intelligent transportation, auxiliary driving, judicial forensics and sports arbitration), and national defense construction (e.g., high-speed confrontation campaigns).关键词:spiking vision;spiking neural networks;visual information processing;brain-inspired vision;artificial intelligence210|1166|6更新时间:2024-08-15
摘要:Video is the conceptual base of visual information processing technology. The frame rate of traditional video is tens of Hertz, which is incapable to represent the Ultra-high speed change process of light. It also constrains to the speed of machine vision. The concept of video is originated from film imaging, which can't unleash the full potential of electronic and digital technology. The spike vision model generates a spike when the photon energy captured by a photosensitive device reaches the predefined threshold. The longer the spike timing is, the weaker the received light signals are. The occurred light intensity can be inferred to achieve consistent imaging. Current research of spiking vision is focused on developing disruptive ultra-high speed imaging chips and cameras that are 1 000 times faster than videos. It is substituting traditional paradigm derived from machine vision speed linear growth of computing power. Based on the biological evidence and physical principle of spiking vision, our review analyzes the software simulator of spiking vision, the computational process of the photon propagation simulation, spiking vision based visual image reconstruction, and the detailed mechanism of photoelectric sensor structure and the chip design. Our review reveals the ultra-high speed target motion detection, and spiking neural networks based tracking and recognition. The evolution of spiking vision is forecasted. Future spiking vision based chip and system has multifaceted potentials to further harness the industrial tasks (e.g., the monitoring of high-speed train, power grid, turbine and intelligent manufacturing), civil applications (e.g., high-speed camera, intelligent transportation, auxiliary driving, judicial forensics and sports arbitration), and national defense construction (e.g., high-speed confrontation campaigns).关键词:spiking vision;spiking neural networks;visual information processing;brain-inspired vision;artificial intelligence210|1166|6更新时间:2024-08-15 -
 摘要:Computational imaging breaks the limitation of traditional digital imaging to acquire the information deeper (e.g., high dynamic range imaging and low light imaging) and broader (e.g., spectrum, light field, and 3D imaging). Driven by industry, especially mobile phone manufacturer medical and automotive, computational imaging has become ubiquitous in our daily lives and plays a critical role in accelerating the revolution of industry. It is a new imaging technique that combines illumination, optics, image sensors, and post-processing algorithms. This review takes the latest methods, algorithms, and applications as the mainline and reports the state-of-the-art progress by jointly analyzing the articles and reports at home and aboard. This review covers the topics of end-to-end optics and algorithms design, high dynamic range imaging, light-field imaging, spectrum imaging, lensless imaging, low light imaging, 3D imaging, and computational photography. It focuses on the development status, frontier dynamics, hot issues, and trends in each computational imaging topic. The camera systems have long-term been designed in separated steps: experience-driven lens design followed by costume designed post-processing. Such a general-propose approach achieved success in the past but left the question open for specific tasks and the best compromise among optics, post-processing, and costs. Recent advances aim to build the gap in an end-to-end fashion. To realize the joint optics and algorithms designing, different differentiable optics models have been realized step by step, including the differentiable diffractive optics model, the differentiable refractive optics, and the differentiable complex lens model based on differentiable ray-tracing. Beyond the goal of capturing a sharp and clear image on the sensor, it offers enormous design flexibility that can not only find a compromise between optics and post-processing, but also open up the design space for optical encoding. The end-to-end camera design offers competitive alternatives to modern optics and camera system design. High dynamic range (HDR) imaging has become a commodity imaging technique as evidenced by its applications across many domains, including mobile consumer photography, robotics, drones, surveillance, content capture for display, driver assistance systems, and autonomous driving. This review analyzes the advantages, disadvantages, and industrial applications through analyzing a series of HDR imaging techniques, including optical modulation, multi-exposure, multi-sensor fusion, and post-processing algorithms. Conventional cameras do not record most of the information about the light distribution entering from the world. Light-field imaging records the full 4D light field measuring the amount of light traveling along each ray that intersects the sensor. This review reports how the light field is applied to super-resolution, depth estimation, 3D measurement, and so on and analyzes the state-of-the-art method and industrial application. It also reports the research progress and industrial application in particle image velocimetry and 3D flame imaging. Spectral imaging technique has been used widely and successfully in resource assessment, environmental monitoring, disaster warning, and other remote sensing domains. Spectral image data can be described as a three-dimensional cube. This imaging technique involves capturing the spectrum for each pixel in an image; As a result, the digital images produce detailed characterizations of the scene or object. This review explains multiple methods to acquire spectrum volume data, including the current multi-channel filter, solving the wavelength response curve inversely based on deep learning, diffraction grating, multiplexing, metasurface, and other optimizations to achieve hyper-spectrum acquisition. Lensless imaging eliminates the need for geometric isomorphism between a scene and an image while constructing compact and lightweight imaging systems. It has been applied to bright-field imaging, cytometry, holography, phase recovery, fluorescence, and the quantitative sensing of specific sample properties derived from such images. However, the low reconstructed signal-to-noise ratio makes it an unsolved challenging inverse problem. This review reports the recent progress in designing and optimizing planar optical elements and high-quality image reconstruction algorithms combined with specific applications. Imaging under a low light illumination will be affected by Poisson noise, which becomes increasingly strong as the power of the light source decreases. In the meantime, a series of visual degradation like decreased visibility, intensive noise, and biased color will occur. This review analyzes the challenges of low light imaging and conclude the corresponding solutions, including the noise removal methods of single/multi-frame, flash, and new sensors to deal with the conditions when the sensor exposure to low light. Shape acquisition of three-dimensional objects plays a vital role for various real-world applications, including automotive, machine vision, reverse engineering, industrial inspections, and medical imaging. This review reports the latest active solutions which have been widely applied, including structured light, direct time-of-flight, and indirect time-of-flight. It also notes the difficulties like ambient light (e.g., sunlight), indirect inference (e.g., the mutual reflection of the concave surface, scattering of foggy) of depth acquisition based on those active methods. The use of computation methods in photography refers to digital image capture and processing techniques that use digital calculation instead of optical processes. It can not only improve the camera ability but also add more new features that were not possible at all with traditional film-based photography. Computational photography is an essential branch of computation imaging developed from traditional photography — however, computational photography emphasizes taking a photograph digitally. Limited by the physical size and image quality, computational photography focuses on reasonably arranging the computational resources and showing the high-quality image that pleasures the customer's feeling. As 90 percent of the information transmitted to our human brain is visual, the imaging system plays a vital role for most future intelligence systems. Computational imaging drastically releases human information acquisition ability in no matter depth or scope. For new techniques like metaverse, computational imaging offers a general input tool to collect multi-dimensional visual information for rebuilding the virtual world. This review covers key technological developments, applications, insights, and challenges over the recent years and examines current trends to predict future capabilities.关键词:end-to-end camera design;high dynamic range imaging;light-field imaging;spectral imaging;lensless imaging;low light imaging;active 3D imaging;computational photography471|2241|7更新时间:2024-08-15
摘要:Computational imaging breaks the limitation of traditional digital imaging to acquire the information deeper (e.g., high dynamic range imaging and low light imaging) and broader (e.g., spectrum, light field, and 3D imaging). Driven by industry, especially mobile phone manufacturer medical and automotive, computational imaging has become ubiquitous in our daily lives and plays a critical role in accelerating the revolution of industry. It is a new imaging technique that combines illumination, optics, image sensors, and post-processing algorithms. This review takes the latest methods, algorithms, and applications as the mainline and reports the state-of-the-art progress by jointly analyzing the articles and reports at home and aboard. This review covers the topics of end-to-end optics and algorithms design, high dynamic range imaging, light-field imaging, spectrum imaging, lensless imaging, low light imaging, 3D imaging, and computational photography. It focuses on the development status, frontier dynamics, hot issues, and trends in each computational imaging topic. The camera systems have long-term been designed in separated steps: experience-driven lens design followed by costume designed post-processing. Such a general-propose approach achieved success in the past but left the question open for specific tasks and the best compromise among optics, post-processing, and costs. Recent advances aim to build the gap in an end-to-end fashion. To realize the joint optics and algorithms designing, different differentiable optics models have been realized step by step, including the differentiable diffractive optics model, the differentiable refractive optics, and the differentiable complex lens model based on differentiable ray-tracing. Beyond the goal of capturing a sharp and clear image on the sensor, it offers enormous design flexibility that can not only find a compromise between optics and post-processing, but also open up the design space for optical encoding. The end-to-end camera design offers competitive alternatives to modern optics and camera system design. High dynamic range (HDR) imaging has become a commodity imaging technique as evidenced by its applications across many domains, including mobile consumer photography, robotics, drones, surveillance, content capture for display, driver assistance systems, and autonomous driving. This review analyzes the advantages, disadvantages, and industrial applications through analyzing a series of HDR imaging techniques, including optical modulation, multi-exposure, multi-sensor fusion, and post-processing algorithms. Conventional cameras do not record most of the information about the light distribution entering from the world. Light-field imaging records the full 4D light field measuring the amount of light traveling along each ray that intersects the sensor. This review reports how the light field is applied to super-resolution, depth estimation, 3D measurement, and so on and analyzes the state-of-the-art method and industrial application. It also reports the research progress and industrial application in particle image velocimetry and 3D flame imaging. Spectral imaging technique has been used widely and successfully in resource assessment, environmental monitoring, disaster warning, and other remote sensing domains. Spectral image data can be described as a three-dimensional cube. This imaging technique involves capturing the spectrum for each pixel in an image; As a result, the digital images produce detailed characterizations of the scene or object. This review explains multiple methods to acquire spectrum volume data, including the current multi-channel filter, solving the wavelength response curve inversely based on deep learning, diffraction grating, multiplexing, metasurface, and other optimizations to achieve hyper-spectrum acquisition. Lensless imaging eliminates the need for geometric isomorphism between a scene and an image while constructing compact and lightweight imaging systems. It has been applied to bright-field imaging, cytometry, holography, phase recovery, fluorescence, and the quantitative sensing of specific sample properties derived from such images. However, the low reconstructed signal-to-noise ratio makes it an unsolved challenging inverse problem. This review reports the recent progress in designing and optimizing planar optical elements and high-quality image reconstruction algorithms combined with specific applications. Imaging under a low light illumination will be affected by Poisson noise, which becomes increasingly strong as the power of the light source decreases. In the meantime, a series of visual degradation like decreased visibility, intensive noise, and biased color will occur. This review analyzes the challenges of low light imaging and conclude the corresponding solutions, including the noise removal methods of single/multi-frame, flash, and new sensors to deal with the conditions when the sensor exposure to low light. Shape acquisition of three-dimensional objects plays a vital role for various real-world applications, including automotive, machine vision, reverse engineering, industrial inspections, and medical imaging. This review reports the latest active solutions which have been widely applied, including structured light, direct time-of-flight, and indirect time-of-flight. It also notes the difficulties like ambient light (e.g., sunlight), indirect inference (e.g., the mutual reflection of the concave surface, scattering of foggy) of depth acquisition based on those active methods. The use of computation methods in photography refers to digital image capture and processing techniques that use digital calculation instead of optical processes. It can not only improve the camera ability but also add more new features that were not possible at all with traditional film-based photography. Computational photography is an essential branch of computation imaging developed from traditional photography — however, computational photography emphasizes taking a photograph digitally. Limited by the physical size and image quality, computational photography focuses on reasonably arranging the computational resources and showing the high-quality image that pleasures the customer's feeling. As 90 percent of the information transmitted to our human brain is visual, the imaging system plays a vital role for most future intelligence systems. Computational imaging drastically releases human information acquisition ability in no matter depth or scope. For new techniques like metaverse, computational imaging offers a general input tool to collect multi-dimensional visual information for rebuilding the virtual world. This review covers key technological developments, applications, insights, and challenges over the recent years and examines current trends to predict future capabilities.关键词:end-to-end camera design;high dynamic range imaging;light-field imaging;spectral imaging;lensless imaging;low light imaging;active 3D imaging;computational photography471|2241|7更新时间:2024-08-15 -
 摘要:Mobile internet real-time rendering technology facilitates key technical capabilities on the aspects of three dimensions (3D) visualization, computer vision, virtual reality, augmented reality, extended reality, and meta-universe. 3D visualization applications based on online real-time rendering technology have been widely scattered on multiple mobile Internet platforms. 3D based Internet applications have been transformed into new online visualization applications with 3D virtual scenes as the main interactive object and intensive immersion to deal with service locations and time constrained issues of the mobile Internet. Our review is focused on four platforms, including mobile terminals, web terminals, cloud terminals and multi-terminals collaboration. First, we investigate the "graphics processing unit" on mobile devices, which is the critical factor of mobile online real-time graphics rendering, and analyze its recent computing ability, designing, and optimization issues. We examined the possibility of hosting desktop-level rendering algorithms on mobile rendering devices, taking the ray-tracing approach as an example. We analyzed the rendering algorithms issues can be accelerated on the power and bandwidth constrained mobile orientation. We reviewed mobile rendering tools like mobile graphics application programming interface(API) and game engines, and conduct comparative category analysis for their performance. Second, we discussed the current Web3D online rendering mechanisms represented by the combination of WebGL2.0 and HTML5 in terms of web-oriented online real-time graphics rendering; we compared the technical features and rendering performance of well-known Web3D engines, and review the support of mainstream game engines for Web3D applications; we examined the challenged technologies of Web3D lightweighting solutions in related to the online real-time rendering of large-scale Web3D scenes like Web3D scene lightweighting and peer-to-peer networking(P2P) progressive transmission. In respect of online real-time graphics cloud rendering, we analyzed the remote rendering architecture of cloud rendering system; We revealed the core service layer of cloud rendering system in terms of cloud services——"platform as a service (PaaS)", and sorted its three major functions out like application hosting, resource scheduling, and streaming; we analyzed two types of cloud-rendering optimization strategies derived from video stream compression and rendering latency mitigation; we described the core application of online cloud rendering system——the "cloud game", and compared the system framework, technical features, and user experience of some of the latest "cloud game" applications. To enable multi-end collaborative online graphics rendering, we analyzed the rendering-task sharing and collaboration of the end-cloud system; we examined the collaboration pattern and technical features of the end-edge-cloud rendering system based on the introduction of edge computing; we make use of rendering resources toanalyze the load balancing optimization issues originated from computing power deployment and resource scheduling of the multi-end rendering system. Finally, we listed the current industry based online real-time cloud rendering systems, including NVIDIA-derived CloudXR, unity-based render streaming, Microsoft Azure remote rendering, and Kujiale cloud-based home decoration and design platform. We compared these systems through their framework, technical features and rendering effects.关键词:online real-time rendering;cloud rendering;Web3D;end-cloud collaboration;remote rendering219|905|1更新时间:2024-08-15
摘要:Mobile internet real-time rendering technology facilitates key technical capabilities on the aspects of three dimensions (3D) visualization, computer vision, virtual reality, augmented reality, extended reality, and meta-universe. 3D visualization applications based on online real-time rendering technology have been widely scattered on multiple mobile Internet platforms. 3D based Internet applications have been transformed into new online visualization applications with 3D virtual scenes as the main interactive object and intensive immersion to deal with service locations and time constrained issues of the mobile Internet. Our review is focused on four platforms, including mobile terminals, web terminals, cloud terminals and multi-terminals collaboration. First, we investigate the "graphics processing unit" on mobile devices, which is the critical factor of mobile online real-time graphics rendering, and analyze its recent computing ability, designing, and optimization issues. We examined the possibility of hosting desktop-level rendering algorithms on mobile rendering devices, taking the ray-tracing approach as an example. We analyzed the rendering algorithms issues can be accelerated on the power and bandwidth constrained mobile orientation. We reviewed mobile rendering tools like mobile graphics application programming interface(API) and game engines, and conduct comparative category analysis for their performance. Second, we discussed the current Web3D online rendering mechanisms represented by the combination of WebGL2.0 and HTML5 in terms of web-oriented online real-time graphics rendering; we compared the technical features and rendering performance of well-known Web3D engines, and review the support of mainstream game engines for Web3D applications; we examined the challenged technologies of Web3D lightweighting solutions in related to the online real-time rendering of large-scale Web3D scenes like Web3D scene lightweighting and peer-to-peer networking(P2P) progressive transmission. In respect of online real-time graphics cloud rendering, we analyzed the remote rendering architecture of cloud rendering system; We revealed the core service layer of cloud rendering system in terms of cloud services——"platform as a service (PaaS)", and sorted its three major functions out like application hosting, resource scheduling, and streaming; we analyzed two types of cloud-rendering optimization strategies derived from video stream compression and rendering latency mitigation; we described the core application of online cloud rendering system——the "cloud game", and compared the system framework, technical features, and user experience of some of the latest "cloud game" applications. To enable multi-end collaborative online graphics rendering, we analyzed the rendering-task sharing and collaboration of the end-cloud system; we examined the collaboration pattern and technical features of the end-edge-cloud rendering system based on the introduction of edge computing; we make use of rendering resources toanalyze the load balancing optimization issues originated from computing power deployment and resource scheduling of the multi-end rendering system. Finally, we listed the current industry based online real-time cloud rendering systems, including NVIDIA-derived CloudXR, unity-based render streaming, Microsoft Azure remote rendering, and Kujiale cloud-based home decoration and design platform. We compared these systems through their framework, technical features and rendering effects.关键词:online real-time rendering;cloud rendering;Web3D;end-cloud collaboration;remote rendering219|905|1更新时间:2024-08-15
Visual Understanding & Computational Imaging

-
 摘要:Optimal data access and massive data derived information extraction has become an essential technology nowadays. Table-related paradigm is a kind of efficient structure for the clustered data designation, display and analysis. It has been widely used on Internet and vertical fields due to its simplicity and intuitiveness. Computer based tables, pictures or portable document format(PDF) files as the carrier will cause structural information loss. It is challenged to trace the original tables back. Inefficient manual based input has more errors. Therefore, two decadal researches have focused on the computer automatic recognition of tables issues originated from documents or PDF files and multiple tasks loop. To obtain the table structure and content and extract specific information, table recognition aims to detect the table via the image or PDF and other electronic files automatically. It is composed of three tasks recognition types like table area detection, table structure recognition and table content recognition. There are two types of existed table recognition methods in common. One is based on optical character recognition (OCR) technology to recognize the characters in the table directly, and then analyze and identify the position of the characters. The other one is to obtain the key intersections and the positions of each frameline of the table through digital image processing to analyze the relationship between cells in the table. However, most of these methods are only applicable to a single field and have poor generalization ability. At the same time, it is constrained of some experience-based threshold design. Thanks to the development of deep learning technology, semantic segmentation algorithm, object detection algorithm, text sequence generation algorithm, pre training model and related technologies facilitates technical problem solving for table recognition. Most deep learning algorithms have carried out adaptive transformation according to the characteristics of tables, which can improve the effect of table recognition. It uses object detection algorithm for table detection task. Object detection and text sequence generation algorithms are mainly used for table structure recognition. Most pre training models have played a good effect on the aspect of table content recognition. But many table structure recognition algorithms still cannot handle these well for wireless tables and less line tables. On the aspects of table images of natural scenes, the relevant algorithms have challenged to achieve the annotation in practice due to the influence of brightness and inclination. A large number of datasets provide sufficient data support for the training of table recognition model and improve the effect of the model currently. However, there are some challenging issues between these datasets multiple annotation formats and different evaluation indicators. Some datasets provide the hyper text markup language(HTML) code of the structure only in the field of table structure recognition and some datasets provide the location of cells in the table and the corresponding row and column attributes. Some datasets are based on the position of cells or the content of cells in accordance with evaluation indicators. Some datasets are based on the adjacent relationship between cells or the editing distance between HTML codes for the recognition of table structure. Our research critically reviews the research situation of three sub tasks like table detection, structure recognition and content recognition and try to predict future research direction further.关键词:table area detection;table structure recognition;table content recognition;deep learning;table cell recognition;table information extraction457|647|8更新时间:2024-08-15
摘要:Optimal data access and massive data derived information extraction has become an essential technology nowadays. Table-related paradigm is a kind of efficient structure for the clustered data designation, display and analysis. It has been widely used on Internet and vertical fields due to its simplicity and intuitiveness. Computer based tables, pictures or portable document format(PDF) files as the carrier will cause structural information loss. It is challenged to trace the original tables back. Inefficient manual based input has more errors. Therefore, two decadal researches have focused on the computer automatic recognition of tables issues originated from documents or PDF files and multiple tasks loop. To obtain the table structure and content and extract specific information, table recognition aims to detect the table via the image or PDF and other electronic files automatically. It is composed of three tasks recognition types like table area detection, table structure recognition and table content recognition. There are two types of existed table recognition methods in common. One is based on optical character recognition (OCR) technology to recognize the characters in the table directly, and then analyze and identify the position of the characters. The other one is to obtain the key intersections and the positions of each frameline of the table through digital image processing to analyze the relationship between cells in the table. However, most of these methods are only applicable to a single field and have poor generalization ability. At the same time, it is constrained of some experience-based threshold design. Thanks to the development of deep learning technology, semantic segmentation algorithm, object detection algorithm, text sequence generation algorithm, pre training model and related technologies facilitates technical problem solving for table recognition. Most deep learning algorithms have carried out adaptive transformation according to the characteristics of tables, which can improve the effect of table recognition. It uses object detection algorithm for table detection task. Object detection and text sequence generation algorithms are mainly used for table structure recognition. Most pre training models have played a good effect on the aspect of table content recognition. But many table structure recognition algorithms still cannot handle these well for wireless tables and less line tables. On the aspects of table images of natural scenes, the relevant algorithms have challenged to achieve the annotation in practice due to the influence of brightness and inclination. A large number of datasets provide sufficient data support for the training of table recognition model and improve the effect of the model currently. However, there are some challenging issues between these datasets multiple annotation formats and different evaluation indicators. Some datasets provide the hyper text markup language(HTML) code of the structure only in the field of table structure recognition and some datasets provide the location of cells in the table and the corresponding row and column attributes. Some datasets are based on the position of cells or the content of cells in accordance with evaluation indicators. Some datasets are based on the adjacent relationship between cells or the editing distance between HTML codes for the recognition of table structure. Our research critically reviews the research situation of three sub tasks like table detection, structure recognition and content recognition and try to predict future research direction further.关键词:table area detection;table structure recognition;table content recognition;deep learning;table cell recognition;table information extraction457|647|8更新时间:2024-08-15 -
 摘要:Big data analysis can skip the data content and mine intelligence from the data context, therefore encryption cannot meet the requirement for secure communication. Steganography is a technique to embed secret messages in various covers (such as digital images, audio, video or text) to achieve covert communication, which is an effective method to cope with big data intelligence acquisition and a necessary complement to cryptography. The advances of artificial intelligence, especially deep learning, in computer vision, speech and natural language processing in recent years have brought new opportunities and challenges to steganography, prompting a series of new ideas and methods in image, audio and video, and text steganography. This paper will introduce the concept, classification, main role and research significance of steganography, and outline the development history, research status and application scenarios of steganography. It is noted that although there are differences in steganography on various covers, their core pursuits have commonalities, which can be refined into general steganographic coding problems. Therefore, this paper will first introduce the basic ideas and key technologies of steganography, and then introduce the progress of steganography for the most important and popular covers, including image, video, audio and text. According to the development of steganographic coding, it can be divided into coding problems under five cost models: constant cost, two-level cost, multi-level cost, non-binary cost, non-additive cost. The coding efficiency and security have been greatly improved. With the effective steganographic coding methods, the focus of research turns to how to define the distortion introduce by embedding message. As for image steganography, this paper reviews model-based steganography, natural steganography, side-information steganography, adversarial steganography. The confrontation between steganography and steganalysis is getting fierce. The distribution of cover image is better preserved. Video is composed of multiple images, so image steganography can be directly used in the spatial domain of video. However, the video will always be compressed to save storage space and the steganography on the compression domain of video is more practical. Many motion-vector based video steganographic schemes have been proposed, which also benefit from the development of steganographic coding. Deep learning based video steganography is a more straight way for embedding messages, which can be also robust to loss video processing, such as recompression, cropping, Gaussian filtering. There are also quite a number of video steganographic tools on the internet, e.g., OpenPuff. Audio can be seen as a part of video, and audio steganography can be divided into time domain and compression domain as well. The audio steganography has its own character, like echo hiding. Since the audio synthesis is very powerful and popular used, some generative audio steganography methods have also been proposed and show superior performance. Previous mentioned mediums will be easily lossy processed, while text seems to be more robust. Text steganography can be divided into format-based steganography and content-based steganography. Content-based steganography is more popular, where generative linguistic steganography shows strong vitality. The international and domestic development status of steganography from five aspects are separately summarized. The advantages and disadvantages of international and domestic development are compared. With these comparisons and corresponding analysis, we also give the development trend from five aspects: steganographic coding, image steganography, video steganography, audio steganography, and text steganography. Better error correction codes are promisingly transferred to better steganographic codes. Robust image steganography is an urgent need, because lossy operations are adopted on online social networks. Fast video steganography is also a potential direction since livestreaming and short-video are current hot spots. Latent codes edition is a direction of improving the performance of generative steganography. In a nutshell, this paper reviews steganography on multimedia and gives future directions of different aspects.关键词:steganographic codes;text steganography;image steganography;audio steganography;video steganography288|177|6更新时间:2024-08-15
摘要:Big data analysis can skip the data content and mine intelligence from the data context, therefore encryption cannot meet the requirement for secure communication. Steganography is a technique to embed secret messages in various covers (such as digital images, audio, video or text) to achieve covert communication, which is an effective method to cope with big data intelligence acquisition and a necessary complement to cryptography. The advances of artificial intelligence, especially deep learning, in computer vision, speech and natural language processing in recent years have brought new opportunities and challenges to steganography, prompting a series of new ideas and methods in image, audio and video, and text steganography. This paper will introduce the concept, classification, main role and research significance of steganography, and outline the development history, research status and application scenarios of steganography. It is noted that although there are differences in steganography on various covers, their core pursuits have commonalities, which can be refined into general steganographic coding problems. Therefore, this paper will first introduce the basic ideas and key technologies of steganography, and then introduce the progress of steganography for the most important and popular covers, including image, video, audio and text. According to the development of steganographic coding, it can be divided into coding problems under five cost models: constant cost, two-level cost, multi-level cost, non-binary cost, non-additive cost. The coding efficiency and security have been greatly improved. With the effective steganographic coding methods, the focus of research turns to how to define the distortion introduce by embedding message. As for image steganography, this paper reviews model-based steganography, natural steganography, side-information steganography, adversarial steganography. The confrontation between steganography and steganalysis is getting fierce. The distribution of cover image is better preserved. Video is composed of multiple images, so image steganography can be directly used in the spatial domain of video. However, the video will always be compressed to save storage space and the steganography on the compression domain of video is more practical. Many motion-vector based video steganographic schemes have been proposed, which also benefit from the development of steganographic coding. Deep learning based video steganography is a more straight way for embedding messages, which can be also robust to loss video processing, such as recompression, cropping, Gaussian filtering. There are also quite a number of video steganographic tools on the internet, e.g., OpenPuff. Audio can be seen as a part of video, and audio steganography can be divided into time domain and compression domain as well. The audio steganography has its own character, like echo hiding. Since the audio synthesis is very powerful and popular used, some generative audio steganography methods have also been proposed and show superior performance. Previous mentioned mediums will be easily lossy processed, while text seems to be more robust. Text steganography can be divided into format-based steganography and content-based steganography. Content-based steganography is more popular, where generative linguistic steganography shows strong vitality. The international and domestic development status of steganography from five aspects are separately summarized. The advantages and disadvantages of international and domestic development are compared. With these comparisons and corresponding analysis, we also give the development trend from five aspects: steganographic coding, image steganography, video steganography, audio steganography, and text steganography. Better error correction codes are promisingly transferred to better steganographic codes. Robust image steganography is an urgent need, because lossy operations are adopted on online social networks. Fast video steganography is also a potential direction since livestreaming and short-video are current hot spots. Latent codes edition is a direction of improving the performance of generative steganography. In a nutshell, this paper reviews steganography on multimedia and gives future directions of different aspects.关键词:steganographic codes;text steganography;image steganography;audio steganography;video steganography288|177|6更新时间:2024-08-15 -
 摘要:Advanced medical imaging technology facilitates human brain recognition and its disease diagnosis research like positron emission tomography (PET) and magnetic resonance imaging (MRI). The changes of structure, function, metabolism, and signaling pathways yield richer multimodal image data for disease diagnosis research. Traditional clinical imaging techniques are mostly based on qualitative interpretation. The signal intensity of acquired images are differentiated for normal tissues, resulting in uncertainty in image contrast due to the microscopic scaled structure and function changes in tissue disease pathology. It is an effective way to obtain accurate and reliable detection of lesion features while the tissue contrast changes intensively higher than the noise level. In comparison to qualitative medical imaging, the current measurement focuses on physiology and physics related parameters to generate its quantitative parameter map. Quantitative parameters have their own physical units in common and their quantitative values reflect the physiological and physical information of the object mathematically. Quantitative measurement of tissue is essential to physiopathological modeling. The relationship between image nuances and pathology, realize in-depth clinical data mining for accurate diagnosis based on the integration of effective model analysis. The quantitative integration of cross-modalities and multiple imaging mechanisms medical imaging has been developed in brain tumors and neuropsychiatric diseases. While quantitative imaging technology is challenging in clinical settings, no matter due to its long acquisition time or its different image presentation. The common quantitative PET and MRI measurements are based on data fitting from multiple measurement. The multiple measurements are time consuming and costly. The modeling and simulation of micro-physiological systems still need to be continuously developed and improved, including the development from static models to dynamic models. Our research review and discuss the key technical issues and development of existing quantitative imaging technologies for human brain microstructure and physiological function indicators detection through PET and MRI methods. The clinical applications and future directions are introduced as well. Specifically, we focus on the establishment of quantitative models, the measurement of quantitative parameters and imaging methods, the influencing factors in the measurement, and the clinical application of related technologies. First, the review of quantitative MRI is based on the current situation and deficiencies of single-parameter quantification and the development trendency of simultaneous multi-parameter quantification. Then, it introduces two methods of myelin imaging based on the quantification of microscopic parameters, including multicomponent T2 quantification and ultrashort echo based myelin imaging. An introduction to the comparability and reproducibility of magnetic resonance quantitative imaging is followed on, especially magnetic resonance diffusion imaging. Second, the review of quantitative PET is based on the most extensive metabolic kinetic model-the compartment model. To extend quantitative error sources like model option, image quality, and input functions, the relationship between physiological parameters and tracer uptake is clarified and three aspects of measurement error are analyzed in detail. The latest development is reviewed based on hardware equipment, image reconstruction methods and quantitative analysis methods. The future MRI quantification, PET quantification and PET/MRI quantification are briefly predicted further.关键词:multi-modal imaging;quantitative magnetic resonance imaging (MRI);quantitative positron emission tomography (PET);simultaneous multi-parameter quantification;myelin water faction quantification;multi-center fusion;compartment model251|101|3更新时间:2024-08-15
摘要:Advanced medical imaging technology facilitates human brain recognition and its disease diagnosis research like positron emission tomography (PET) and magnetic resonance imaging (MRI). The changes of structure, function, metabolism, and signaling pathways yield richer multimodal image data for disease diagnosis research. Traditional clinical imaging techniques are mostly based on qualitative interpretation. The signal intensity of acquired images are differentiated for normal tissues, resulting in uncertainty in image contrast due to the microscopic scaled structure and function changes in tissue disease pathology. It is an effective way to obtain accurate and reliable detection of lesion features while the tissue contrast changes intensively higher than the noise level. In comparison to qualitative medical imaging, the current measurement focuses on physiology and physics related parameters to generate its quantitative parameter map. Quantitative parameters have their own physical units in common and their quantitative values reflect the physiological and physical information of the object mathematically. Quantitative measurement of tissue is essential to physiopathological modeling. The relationship between image nuances and pathology, realize in-depth clinical data mining for accurate diagnosis based on the integration of effective model analysis. The quantitative integration of cross-modalities and multiple imaging mechanisms medical imaging has been developed in brain tumors and neuropsychiatric diseases. While quantitative imaging technology is challenging in clinical settings, no matter due to its long acquisition time or its different image presentation. The common quantitative PET and MRI measurements are based on data fitting from multiple measurement. The multiple measurements are time consuming and costly. The modeling and simulation of micro-physiological systems still need to be continuously developed and improved, including the development from static models to dynamic models. Our research review and discuss the key technical issues and development of existing quantitative imaging technologies for human brain microstructure and physiological function indicators detection through PET and MRI methods. The clinical applications and future directions are introduced as well. Specifically, we focus on the establishment of quantitative models, the measurement of quantitative parameters and imaging methods, the influencing factors in the measurement, and the clinical application of related technologies. First, the review of quantitative MRI is based on the current situation and deficiencies of single-parameter quantification and the development trendency of simultaneous multi-parameter quantification. Then, it introduces two methods of myelin imaging based on the quantification of microscopic parameters, including multicomponent T2 quantification and ultrashort echo based myelin imaging. An introduction to the comparability and reproducibility of magnetic resonance quantitative imaging is followed on, especially magnetic resonance diffusion imaging. Second, the review of quantitative PET is based on the most extensive metabolic kinetic model-the compartment model. To extend quantitative error sources like model option, image quality, and input functions, the relationship between physiological parameters and tracer uptake is clarified and three aspects of measurement error are analyzed in detail. The latest development is reviewed based on hardware equipment, image reconstruction methods and quantitative analysis methods. The future MRI quantification, PET quantification and PET/MRI quantification are briefly predicted further.关键词:multi-modal imaging;quantitative magnetic resonance imaging (MRI);quantitative positron emission tomography (PET);simultaneous multi-parameter quantification;myelin water faction quantification;multi-center fusion;compartment model251|101|3更新时间:2024-08-15 -
 摘要:Benefiting from the development of the Internet of things, human-computer interaction devices have been widely used in people's daily life. Human-computer interaction is no longer limited to the input and output modes of a single sensory channel (vision, touch, hearing, smell and taste). Multi-modal human-computer interaction aims to exchange information between human and computer by using multi-modal information such as speech, image, text, eye movement and touch. Multi-modal human-computer interaction includes multi-modal information input from human to computer and multi-modal information presentation from computer to human and it is a comprehensive discipline closely related to cognitive psychology, ergonomics, multimedia technology and virtual reality technology. At present, multi-modal human-computer interaction and various kinds of academic and technology in the field of image and graphics are more and more closely combined. In the era of big data and artificial intelligence, multi-modal human-computer interaction technology, as the technical carrier of human-machine-thing, is closely related to the development of image and graphics, artificial intelligence, emotional computing, physiological and psychological assessment, Internet big data, office education, medical rehabilitation and other fields. The research on multi-modal human-computer interaction first appeared in the 1990 s, and a number of works proposed an interactive method combining speech and gesture. In recent years, the emergence of immersive visualization provides a new multi-modal interactive interface for human-computer interaction: an immersive environment that integrates visual, auditory, tactile and other sensory channels. Visualization is an important scientific technology for data analysis and exploration. It converts abstract data into graphical representations and facilitates analytical reasoning through interactive interfaces. In today's data explosion, visualization transforms complex big data into easy-to-understand content, improving people's ability to understand and explore data. The traditional interactive interface can only support a flat visual design, including data mapping channels and data interaction methods, and cannot meet the analysis needs in the context of the big data area. In the area of big data, data visualization will have problems such as limited presentation space, abstract data expression, and data occlusion. The emergence of immersive visualization provides a broad presentation space for high-dimensional big data visualization, integrating multi-sensing channels and multi-modalities. Interaction allows users to interact with data naturally and in parallel using multiple channels. The interaction technology based on sound field perception can be divided into three types according to the working principle: measure and identify the acoustic characteristics of a specific space, passage or the change of the acoustic characteristics caused by the action; use the sound wave measurement of the microphone array to achieve sound source localization, the sound source can emit specific carrier audio to improve the positioning accuracy and robustness; the machine learning algorithm recognizes the sound from a specific scene, environment or human body. The technical solution includes a single method based on sound field perception and a sensor fusion solution. In the physical interaction system, the user interacts with the virtual environment by using the physical objects existing in the real environment. In recent years, the integration of physical interaction interface technology into virtual reality and augmented reality has become a mainstream direction in this field, and the concept of "physical mixed reality" has gradually formed, which is also the conceptual basis of passive haptics. The haptics of physical interaction can be divided into three ways: static passive haptics; passive haptics with feedback and active force haptics. Since active haptic devices are relatively expensive, there are few current researches, and the main research directions are still static passive haptics and encounter-type haptics. Regarding the mixed reality interaction mode of passive haptics, the current research levels of various countries and institutions in the world are not very different, but there is a slight emphasis. Wearable interaction is mainly divided into research on gesture interaction and touch interaction mainly in the form of wristbands, skin electronic technology and interaction design. Gesture input is considered to be one of the core contents of "natural human-machine interface", and it is also suitable for exploring the input methods of wearable devices. The key to realizing gesture input lies in sensing technology. At present, in the field of human-computer interaction, the sensing technology for gesture recognition based on infrared light, motion sensor, electromagnetic, capacitive, ultrasonic, camera and biological signals has been deeply studied. As the natural interface between people and the outside world, the skin has been initially used to explore its role in information interaction, and its applications in several aspects have demonstrated its advantages. The human-computer dialogue interaction process involves multiple modules such as speech recognition, emotion recognition, dialogue system, and speech synthesis. First, the user's speech is converted into corresponding text and emotion labels through speech recognition and emotion recognition modules. The dialogue system is then used to understand what the user is saying and generate dialogue responses. Finally, the speech synthesis module converts the dialogue responses into speech to interact with the user. How to effectively integrate information of different modalities in the human-computer interaction system and improve the quality of human-computer interaction is also worthy of attention. Multi-modal fusion methods can be divided into three types: feature layer fusion methods, decision layer fusion methods, and hybrid fusion methods. The feature layer fusion method maps the features extracted from multiple modalities into a feature vector through a certain transformation and then sends it to the classification model to obtain the final decision. The decision-level fusion method combines the decisions obtained from different modal information to obtain the final decision. The hybrid fusion method adopts both the feature layer fusion method and the decision layer fusion method. This paper systematically reviews the development status and emerging directions of multi-modal human-computer interaction, and thoroughly combs the research progress of big data visualization interaction, interaction based on sound field perception, near-eye display entity interaction, wearable interaction, and human-computer dialogue interaction. This article believes that expanding new interaction methods, designing efficient interaction combinations of various modalities, building miniaturized interactive devices, cross-device distributed interaction, and improving the robustness of interactive algorithms in open environments are the future works of multi-modal human-computer interaction.关键词:multi-modal human-computer interaction;big data visualization interaction;sound field perception interaction;entity interaction;wearable interaction;human-computer dialogue interaction762|572|17更新时间:2024-08-15
摘要:Benefiting from the development of the Internet of things, human-computer interaction devices have been widely used in people's daily life. Human-computer interaction is no longer limited to the input and output modes of a single sensory channel (vision, touch, hearing, smell and taste). Multi-modal human-computer interaction aims to exchange information between human and computer by using multi-modal information such as speech, image, text, eye movement and touch. Multi-modal human-computer interaction includes multi-modal information input from human to computer and multi-modal information presentation from computer to human and it is a comprehensive discipline closely related to cognitive psychology, ergonomics, multimedia technology and virtual reality technology. At present, multi-modal human-computer interaction and various kinds of academic and technology in the field of image and graphics are more and more closely combined. In the era of big data and artificial intelligence, multi-modal human-computer interaction technology, as the technical carrier of human-machine-thing, is closely related to the development of image and graphics, artificial intelligence, emotional computing, physiological and psychological assessment, Internet big data, office education, medical rehabilitation and other fields. The research on multi-modal human-computer interaction first appeared in the 1990 s, and a number of works proposed an interactive method combining speech and gesture. In recent years, the emergence of immersive visualization provides a new multi-modal interactive interface for human-computer interaction: an immersive environment that integrates visual, auditory, tactile and other sensory channels. Visualization is an important scientific technology for data analysis and exploration. It converts abstract data into graphical representations and facilitates analytical reasoning through interactive interfaces. In today's data explosion, visualization transforms complex big data into easy-to-understand content, improving people's ability to understand and explore data. The traditional interactive interface can only support a flat visual design, including data mapping channels and data interaction methods, and cannot meet the analysis needs in the context of the big data area. In the area of big data, data visualization will have problems such as limited presentation space, abstract data expression, and data occlusion. The emergence of immersive visualization provides a broad presentation space for high-dimensional big data visualization, integrating multi-sensing channels and multi-modalities. Interaction allows users to interact with data naturally and in parallel using multiple channels. The interaction technology based on sound field perception can be divided into three types according to the working principle: measure and identify the acoustic characteristics of a specific space, passage or the change of the acoustic characteristics caused by the action; use the sound wave measurement of the microphone array to achieve sound source localization, the sound source can emit specific carrier audio to improve the positioning accuracy and robustness; the machine learning algorithm recognizes the sound from a specific scene, environment or human body. The technical solution includes a single method based on sound field perception and a sensor fusion solution. In the physical interaction system, the user interacts with the virtual environment by using the physical objects existing in the real environment. In recent years, the integration of physical interaction interface technology into virtual reality and augmented reality has become a mainstream direction in this field, and the concept of "physical mixed reality" has gradually formed, which is also the conceptual basis of passive haptics. The haptics of physical interaction can be divided into three ways: static passive haptics; passive haptics with feedback and active force haptics. Since active haptic devices are relatively expensive, there are few current researches, and the main research directions are still static passive haptics and encounter-type haptics. Regarding the mixed reality interaction mode of passive haptics, the current research levels of various countries and institutions in the world are not very different, but there is a slight emphasis. Wearable interaction is mainly divided into research on gesture interaction and touch interaction mainly in the form of wristbands, skin electronic technology and interaction design. Gesture input is considered to be one of the core contents of "natural human-machine interface", and it is also suitable for exploring the input methods of wearable devices. The key to realizing gesture input lies in sensing technology. At present, in the field of human-computer interaction, the sensing technology for gesture recognition based on infrared light, motion sensor, electromagnetic, capacitive, ultrasonic, camera and biological signals has been deeply studied. As the natural interface between people and the outside world, the skin has been initially used to explore its role in information interaction, and its applications in several aspects have demonstrated its advantages. The human-computer dialogue interaction process involves multiple modules such as speech recognition, emotion recognition, dialogue system, and speech synthesis. First, the user's speech is converted into corresponding text and emotion labels through speech recognition and emotion recognition modules. The dialogue system is then used to understand what the user is saying and generate dialogue responses. Finally, the speech synthesis module converts the dialogue responses into speech to interact with the user. How to effectively integrate information of different modalities in the human-computer interaction system and improve the quality of human-computer interaction is also worthy of attention. Multi-modal fusion methods can be divided into three types: feature layer fusion methods, decision layer fusion methods, and hybrid fusion methods. The feature layer fusion method maps the features extracted from multiple modalities into a feature vector through a certain transformation and then sends it to the classification model to obtain the final decision. The decision-level fusion method combines the decisions obtained from different modal information to obtain the final decision. The hybrid fusion method adopts both the feature layer fusion method and the decision layer fusion method. This paper systematically reviews the development status and emerging directions of multi-modal human-computer interaction, and thoroughly combs the research progress of big data visualization interaction, interaction based on sound field perception, near-eye display entity interaction, wearable interaction, and human-computer dialogue interaction. This article believes that expanding new interaction methods, designing efficient interaction combinations of various modalities, building miniaturized interactive devices, cross-device distributed interaction, and improving the robustness of interactive algorithms in open environments are the future works of multi-modal human-computer interaction.关键词:multi-modal human-computer interaction;big data visualization interaction;sound field perception interaction;entity interaction;wearable interaction;human-computer dialogue interaction762|572|17更新时间:2024-08-15 -
 摘要:The Chinese nation culture, which is of abundant resources, various categories and art styles, origins from the Chinese nation and is deeply rooted in ordinary people, has kept a long record of the historical memory and continued the cultural vein. Indeed, the Chinese nation culture is the foundation and the soul of the Chinese nation. The cultural heritage, which has the trait of widespread dissemination, long history, various styles, unique form of expression and being nonrenewable, is the precious information for exploring the development of the ancient human civilization. Nowadays, with the rapid development of information technology and the widespread impact of globalization, the formation of cultural inheritance has changed fundamentally, especially in the way of interpersonal inheritance style of the non-material cultural heritage. Therefore, there is an urgent need to construct bridges between the resource and the media, the content and the technology in order to sustain the digital inheritance of the Chinese cultural heritage. This paper is organised based on the advanced intelligent computing, digital media and virtual reality/augmented reality technology, and combines the dissemination process and artistic characteristics of the cultural heritage. From the perspective of the development status, frontier trends, hot issues and development trends, the key activation technologies are analyzed and summarized in terms of the collection of cultural heritage, the combination of virtual and real intelligent display and interaction, and the construction of intelligent platforms. Firstly, in the aspect of the collection of cultural heritage, in the view of the bottleneck problems that exist in the digitization of complex cultural relics, the key technologies of digital collection and reconstruction are introduced; the feature extraction algorithms of cultural heritage elements, themes, styles, etc., as well as the key technologies in the process of digital simulation to analyze the compositional features, distribution features, color features, and modeling features of cultural heritage are summarized; the key technologies of cultural heritage understanding and construction that are based on semantic feature analysis, understanding and recognition are introduced; the advantages and disadvantages of traditional image processing and deep learning methods in the process of digital simulation of national culture are analysed and discussed, and the characteristics and efficiency of the current algorithms are compared. Besides, the existing problems and difficulties are expounded, and an insight into the future of digital simulation of national culture is provided. Next, in the aspect of the combination of virtual and real intelligent display and interaction, for the characteristics of physical display and virtual display of cultural heritage, the key technologies of digital restoration of cultural heritage are reviewed. The important role of cutting-edge information technology including multi-modal image processing, few-shot learning and stylized image generation methods is introduced. Meanwhile, the cutting-edge research based on multi-source heterogeneous big data analysis, knowledge graph and deep learning in the digital restoration of cultural heritage are also reviewed. To satisfied the interactive 3D display needs of cultural heritage, the content-based natural human-computer interaction technology is introduced, which is combined with text, audio, video, semantics and story retrieval of cultural history. Virtual interactive presentation of new technologies is introduced in terms of real-time realistic technology, virtual-real fusion rendering, and augmented reality technology. Last but not least, in the aspect of intelligent platform construction, there still remains many problems at present, such as the decentralized system management of the cultural heritage intelligent platform, which leads to poor business collaboration, and due to the lack of unified data, it is still difficult to share data mutually. Also, the problems of the difficulty in system maintenance, the high management costs, and the inconvenience for users still need to be solved. In the view of the above mentioned problems, the key technology research of the cultural heritage big data model and the private cloud architecture and the related intelligent platform construction projects are introduced. The above key activation technologies of cultural heritage are actively integrated into the major national development strategies, and these technologies are conducive to excavating and improving the protection and inheritance technology of national cultural heritage, promoting their rational use, and expanding their dissemination influence, which is of great significance to carry forward Chinese civilization, promote cultural prosperity, build demonstration areas for ethnic minorities and enhance cultural confidence.关键词:cultural heritage;digitizing;virtual restoration;virtual interaction;intelligent platform221|1592|4更新时间:2024-08-15
摘要:The Chinese nation culture, which is of abundant resources, various categories and art styles, origins from the Chinese nation and is deeply rooted in ordinary people, has kept a long record of the historical memory and continued the cultural vein. Indeed, the Chinese nation culture is the foundation and the soul of the Chinese nation. The cultural heritage, which has the trait of widespread dissemination, long history, various styles, unique form of expression and being nonrenewable, is the precious information for exploring the development of the ancient human civilization. Nowadays, with the rapid development of information technology and the widespread impact of globalization, the formation of cultural inheritance has changed fundamentally, especially in the way of interpersonal inheritance style of the non-material cultural heritage. Therefore, there is an urgent need to construct bridges between the resource and the media, the content and the technology in order to sustain the digital inheritance of the Chinese cultural heritage. This paper is organised based on the advanced intelligent computing, digital media and virtual reality/augmented reality technology, and combines the dissemination process and artistic characteristics of the cultural heritage. From the perspective of the development status, frontier trends, hot issues and development trends, the key activation technologies are analyzed and summarized in terms of the collection of cultural heritage, the combination of virtual and real intelligent display and interaction, and the construction of intelligent platforms. Firstly, in the aspect of the collection of cultural heritage, in the view of the bottleneck problems that exist in the digitization of complex cultural relics, the key technologies of digital collection and reconstruction are introduced; the feature extraction algorithms of cultural heritage elements, themes, styles, etc., as well as the key technologies in the process of digital simulation to analyze the compositional features, distribution features, color features, and modeling features of cultural heritage are summarized; the key technologies of cultural heritage understanding and construction that are based on semantic feature analysis, understanding and recognition are introduced; the advantages and disadvantages of traditional image processing and deep learning methods in the process of digital simulation of national culture are analysed and discussed, and the characteristics and efficiency of the current algorithms are compared. Besides, the existing problems and difficulties are expounded, and an insight into the future of digital simulation of national culture is provided. Next, in the aspect of the combination of virtual and real intelligent display and interaction, for the characteristics of physical display and virtual display of cultural heritage, the key technologies of digital restoration of cultural heritage are reviewed. The important role of cutting-edge information technology including multi-modal image processing, few-shot learning and stylized image generation methods is introduced. Meanwhile, the cutting-edge research based on multi-source heterogeneous big data analysis, knowledge graph and deep learning in the digital restoration of cultural heritage are also reviewed. To satisfied the interactive 3D display needs of cultural heritage, the content-based natural human-computer interaction technology is introduced, which is combined with text, audio, video, semantics and story retrieval of cultural history. Virtual interactive presentation of new technologies is introduced in terms of real-time realistic technology, virtual-real fusion rendering, and augmented reality technology. Last but not least, in the aspect of intelligent platform construction, there still remains many problems at present, such as the decentralized system management of the cultural heritage intelligent platform, which leads to poor business collaboration, and due to the lack of unified data, it is still difficult to share data mutually. Also, the problems of the difficulty in system maintenance, the high management costs, and the inconvenience for users still need to be solved. In the view of the above mentioned problems, the key technology research of the cultural heritage big data model and the private cloud architecture and the related intelligent platform construction projects are introduced. The above key activation technologies of cultural heritage are actively integrated into the major national development strategies, and these technologies are conducive to excavating and improving the protection and inheritance technology of national cultural heritage, promoting their rational use, and expanding their dissemination influence, which is of great significance to carry forward Chinese civilization, promote cultural prosperity, build demonstration areas for ethnic minorities and enhance cultural confidence.关键词:cultural heritage;digitizing;virtual restoration;virtual interaction;intelligent platform221|1592|4更新时间:2024-08-15 - 摘要:Humans are emotional creatures. Emotion plays a key role in various intelligent actions, including perception, decision-making, logical reasoning, and social interaction. Emotion is an important and dispensable component in the realization of human-computer interaction and machine intelligence. Recently, with the explosive growth of multimedia data and the rapid development of artificial intelligence, affective computing and understanding has attracted much research attention. It aims to establish a harmonious human-computer environment by giving the computing machines the ability to recognize, understand, express, and adapt to human emotions, and to make computers have higher and more comprehensive intelligence. Based on the input signals, such as speech, text, image, action and gait, and physiological signals, affective computing and understanding can be divided into multiple research topics. In this paper, we will comprehensively review the development of four important topics in affective computing and understanding, including multi-modal emotion recognition, autism emotion recognition, affective image content analysis, and facial expression recognition. For each topic, we first introduce the research background, problem definition, and research significance. Specifically, we introduce how such topics were proposed, what the corresponding tasks do, and why it is important in different applications. Second, we introduce the international and domestic research on emotion data annotation, feature extraction, learning algorithms, performance comparison and analysis of some representative methods, and famous research teams. Emotion data annotation is conducted to evaluate the performances of affective computing and understanding algorithms. We briefly summarize how categorical and dimensional emotion representation models in psychology are used to construct datasets and the comparisons between these datasets. Feature extraction aims to extract discriminative features to represent emotions. We summarize both hand-crafted features in the early years and deep features in the deep learning era. Learning algorithms aim to learn a mapping between extracted features and emotions. We also summarize and compare both traditional and deep models. For a better understanding of how existing methods work, we report the emotion recognition results of some representative and influential methods on multiple datasets and give some detailed analysis. To better track the latest research for beginners, we briefly introduce some famous research teams with their research focus and main contributions. After that, we systematically compare the international and domestic research, and analyze the advantages and disadvantages of domestic research, which would motivate and boost the future research for domestic researchers and engineers. Finally, we discuss some challenges and promising research directions in the future for each topic, such as 1) image content and context understanding, viewer contextual and prior knowledge modeling, group emotion clustering, viewer and image interaction, and efficient learning for affective image content analysis; 2) data collection and annotation, real-time facial expression analysis, hybrid expression recognition, personalized emotion expression, and user privacy. Since emotion is an abstract, subjective, and complex high-level semantic concept, there are still some limitations of existing methods, and many challenges still remain unsolved. Such promising future research directions would help to reach the emotional intelligence for a better human-computer interaction.关键词:affective computing;emotion recognition;autism;image recognition;expression recognition593|1629|6更新时间:2024-08-15
-
 摘要:The human brain is the most complex network system in the world. Different types of brain atlas provide brain tissue or connection information from different aspects. With the development of image acquisition and biological detection technology, researchers reveal that combing multi-modal brain data is able to provide more information through exploiting the rich multimodal information that exits, for example it can inform us about how brain structure shapes brain function, in which way they are impacted by psychopathology and which functional or structural aspects of physiology could drive human behavior and cognition. Through summarizing the representative multi-modal brain fusion technologies in recent years, we first divide them into two categories in this review, brain-imaging fusion and brain-data fusion. 1)Brain-imaging fusion refers to the fusion of data with fine spatial information such as brain images (magnetic resonance imaging, etc.) and histological images (cell body staining, axon staining, etc.), through which could help construct a multi-modal multi-scale brain map covering both structure and function information. For example, the Julich-Brain Atlas, a three-dimensional atlas containing cytoarchitectonic maps of cortical areas and subcortical nuclei, is built through the fusion of magnetic resonance imaging and histological slices, allowing comparison of functional activations, networks, genetic expression patterns, anatomical structures, and other data obtained across different studies in a common stereotaxic reference space. The multiscale brain atlas brings together data from these different levels of nervous system organization to form a better understanding of between-scale relationships of brain structure, function, and behavior in health and disease. 2)Brain-data fusion refers to applying brain atlas with spatial information to fuse biological big data without spatial information (genome, electrophysiology, cognition and behavior, etc.), through which could help make up the shortcomings from single modality and capitalize on joint information among modalities to dig out new information. For example, combing brain atlas with electroencephalogram data can simultaneously extract signals with high spatial and temporal resolution. For each fusion type discussed above, we elaborate the representative research progress at home and abroad in recent years, as well as their comparison in the current review. Then, in order to promote the development of this filed, we introduce several multi-modal datasets in the community, i.e., UK Biobank, Human Connectome Project(HCP), Chinese Imaging Genetics(CHIMGEN), Adolescent Brain Cognitive Development(ABCD), Philadelphia Neurodevelopmental Cohort(PNC), IMAGEN, Pediatric Imaging, Neurocognition, and Genetics(PING), Autism Brain Imaging Data Exchang(ABIDE), Alzheimer's Disease Neuroimaging Initiative(ADNI), ADHD-200, PRIMatE Data Exchange (PRIME-DE), National Chimpanzee Brain Resource(NCBR), the Allen Atlas and EBRAINS Reference Atlas. Finally, we discuss the important problems to be solved and the future direction in this field. The common challenge of this filed is how to integrate the information from different scales and modalities to build a multi-modal and cross-scale brain atlas, and how to analyze the neural mechanism of major brain diseases based on the new brain atlas, and forming a new paradigm for brain disorder diagnosis and treatment paradigm at last. To achieve this major goal, 1)the acquisition of high-quality big data is the important foundation, which rely on the development of acquisition equipments. 2)The high resolution of data (i.e., cell and neuron level)raises large storaging and quick processing demands. 3)Developing new fusion methods based on artificial intelligence is also one of the urgent issues in multi-modal fusion research.关键词:brain atlas;cross-modal;spatial information;brain imaging;multi-omics;public dataset223|847|1更新时间:2024-08-15
摘要:The human brain is the most complex network system in the world. Different types of brain atlas provide brain tissue or connection information from different aspects. With the development of image acquisition and biological detection technology, researchers reveal that combing multi-modal brain data is able to provide more information through exploiting the rich multimodal information that exits, for example it can inform us about how brain structure shapes brain function, in which way they are impacted by psychopathology and which functional or structural aspects of physiology could drive human behavior and cognition. Through summarizing the representative multi-modal brain fusion technologies in recent years, we first divide them into two categories in this review, brain-imaging fusion and brain-data fusion. 1)Brain-imaging fusion refers to the fusion of data with fine spatial information such as brain images (magnetic resonance imaging, etc.) and histological images (cell body staining, axon staining, etc.), through which could help construct a multi-modal multi-scale brain map covering both structure and function information. For example, the Julich-Brain Atlas, a three-dimensional atlas containing cytoarchitectonic maps of cortical areas and subcortical nuclei, is built through the fusion of magnetic resonance imaging and histological slices, allowing comparison of functional activations, networks, genetic expression patterns, anatomical structures, and other data obtained across different studies in a common stereotaxic reference space. The multiscale brain atlas brings together data from these different levels of nervous system organization to form a better understanding of between-scale relationships of brain structure, function, and behavior in health and disease. 2)Brain-data fusion refers to applying brain atlas with spatial information to fuse biological big data without spatial information (genome, electrophysiology, cognition and behavior, etc.), through which could help make up the shortcomings from single modality and capitalize on joint information among modalities to dig out new information. For example, combing brain atlas with electroencephalogram data can simultaneously extract signals with high spatial and temporal resolution. For each fusion type discussed above, we elaborate the representative research progress at home and abroad in recent years, as well as their comparison in the current review. Then, in order to promote the development of this filed, we introduce several multi-modal datasets in the community, i.e., UK Biobank, Human Connectome Project(HCP), Chinese Imaging Genetics(CHIMGEN), Adolescent Brain Cognitive Development(ABCD), Philadelphia Neurodevelopmental Cohort(PNC), IMAGEN, Pediatric Imaging, Neurocognition, and Genetics(PING), Autism Brain Imaging Data Exchang(ABIDE), Alzheimer's Disease Neuroimaging Initiative(ADNI), ADHD-200, PRIMatE Data Exchange (PRIME-DE), National Chimpanzee Brain Resource(NCBR), the Allen Atlas and EBRAINS Reference Atlas. Finally, we discuss the important problems to be solved and the future direction in this field. The common challenge of this filed is how to integrate the information from different scales and modalities to build a multi-modal and cross-scale brain atlas, and how to analyze the neural mechanism of major brain diseases based on the new brain atlas, and forming a new paradigm for brain disorder diagnosis and treatment paradigm at last. To achieve this major goal, 1)the acquisition of high-quality big data is the important foundation, which rely on the development of acquisition equipments. 2)The high resolution of data (i.e., cell and neuron level)raises large storaging and quick processing demands. 3)Developing new fusion methods based on artificial intelligence is also one of the urgent issues in multi-modal fusion research.关键词:brain atlas;cross-modal;spatial information;brain imaging;multi-omics;public dataset223|847|1更新时间:2024-08-15
Data Mining and Information Interaction
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0