
最新刊期
卷 27 , 期 5 , 2022
-
 摘要:Underwater optical images have played a key role in related to marine resource development, marine environment protection and marine engineering. Due to the harsh and complex underwater environment, the raw underwater optical images are challenged to the quality degradation, which are mainly introduced via an underwater scenario of light selective absorption and scattering. The degraded underwater images have low contrast, blurred details and color distortion, which severely restrict its performance and applications of underwater intelligent processing systems. In particular, the current deep learning based underwater image recovering has been facilitated currently. Our review first analyzes the mechanism of underwater image degradation, as well as describes the existing underwater imaging models and summarizes the challenges of underwater image reconstruction. Then, we trace the evolving of underwater optical image reconstruction methods. In accordance with the deep learning technology and the physical imaging models contextual, the existing algorithms are segmented into four categories for underwater images recovering methods, which are traditional image enhancement, traditional image restoration, deep-learning-based image enhancement and deep-learning-based image restoration. These four types of existing timescale methods are then discussed and analyzed, including their theories, features, pros and cons, respectively. Specifically, the traditional image enhancement methods tend to deliver unnatural results with color deviations and under-enhancement or over-enhancement of local area to improve the visibility of the underwater images effectively. Conversely, the traditional image restoration methods are based on the mechanism of underwater image degradation and a challenging issue is constrained of the limitations of imaging models and priori knowledge in diverse underwater scenarios. The deep learning based restoration methods is facilitated to nonlinear fitting capabilities of neural networks with an error stacking barrier and insufficient restoration results. The deep-learning-based enhancement methods are comparatively robust and suitable to recover diverse underwater images with flexible neural networks. However, they are relatively difficult to converge, and their generalization capability is insufficient. We introduce the current public underwater image datasets, which can be divided into two categories, and summarize their features and applications, respectively. Moreover, we also demonstrate more evaluation metrics for the quality of underwater images. To evaluate their performance quantitatively and qualitatively, we conduct experiments on eight typical underwater image reconstruction methods further. Three benchmarks are optioned for color cast removal, contrast improvement and comprehensive test. Our demonstrated results indicate that none of these methods are robust enough to recover diverse types of underwater images. The reconstruction of better underwater optical images is a big challenge issue of improving the robustness and generalization of reconstruction, developing more lightweight networks or processing algorithms of real-time applications, utilizing underwater image reconstruction to harness vision tasks ability, as well as establishing an underwater images quality assessment system.关键词:underwater degraded image;deep learning;image enhancement;image restoration;underwater benchmark;underwater image quality assessment345|511|3更新时间:2024-05-07
摘要:Underwater optical images have played a key role in related to marine resource development, marine environment protection and marine engineering. Due to the harsh and complex underwater environment, the raw underwater optical images are challenged to the quality degradation, which are mainly introduced via an underwater scenario of light selective absorption and scattering. The degraded underwater images have low contrast, blurred details and color distortion, which severely restrict its performance and applications of underwater intelligent processing systems. In particular, the current deep learning based underwater image recovering has been facilitated currently. Our review first analyzes the mechanism of underwater image degradation, as well as describes the existing underwater imaging models and summarizes the challenges of underwater image reconstruction. Then, we trace the evolving of underwater optical image reconstruction methods. In accordance with the deep learning technology and the physical imaging models contextual, the existing algorithms are segmented into four categories for underwater images recovering methods, which are traditional image enhancement, traditional image restoration, deep-learning-based image enhancement and deep-learning-based image restoration. These four types of existing timescale methods are then discussed and analyzed, including their theories, features, pros and cons, respectively. Specifically, the traditional image enhancement methods tend to deliver unnatural results with color deviations and under-enhancement or over-enhancement of local area to improve the visibility of the underwater images effectively. Conversely, the traditional image restoration methods are based on the mechanism of underwater image degradation and a challenging issue is constrained of the limitations of imaging models and priori knowledge in diverse underwater scenarios. The deep learning based restoration methods is facilitated to nonlinear fitting capabilities of neural networks with an error stacking barrier and insufficient restoration results. The deep-learning-based enhancement methods are comparatively robust and suitable to recover diverse underwater images with flexible neural networks. However, they are relatively difficult to converge, and their generalization capability is insufficient. We introduce the current public underwater image datasets, which can be divided into two categories, and summarize their features and applications, respectively. Moreover, we also demonstrate more evaluation metrics for the quality of underwater images. To evaluate their performance quantitatively and qualitatively, we conduct experiments on eight typical underwater image reconstruction methods further. Three benchmarks are optioned for color cast removal, contrast improvement and comprehensive test. Our demonstrated results indicate that none of these methods are robust enough to recover diverse types of underwater images. The reconstruction of better underwater optical images is a big challenge issue of improving the robustness and generalization of reconstruction, developing more lightweight networks or processing algorithms of real-time applications, utilizing underwater image reconstruction to harness vision tasks ability, as well as establishing an underwater images quality assessment system.关键词:underwater degraded image;deep learning;image enhancement;image restoration;underwater benchmark;underwater image quality assessment345|511|3更新时间:2024-05-07 -
 摘要:The visual quality of captured images in rainy weather conditions is constrained to the outdoor vision degradation. It is essential to design relevant rain removal algorithms. Due to the lack of temporal information, single image rain removal is challenging compared to video-based rain removal. The target of single image rain removal analysis is to restore the rain-removed background image from the corresponding rain-affected image. Current deep learning based vision tasks construct diverse data-driven frameworks like single image rain removal task via multiple network modules. Current research tasks are focusing on the quality of datasets, the design of single image deraining algorithms, the subsequent high-level vision tasks, and the design of performance evaluation metrics. Specifically, the quality of rain datasets largely affects the performance of deep learning based single image deraining methods, since the generalization ability of deep single image rain removal is highly related to the domain gap between synthesized training dataset and real testing dataset. Besides, rain removal plays an important preprocessing role in outdoor visual tasks because its result would affect the performance of the subsequent visual task. Additionally, the design of image quality assessment (IQA) metrics is quite important for the fair quantitative analysis of human perception of image quality in general image restoration tasks. We conducted critical literature review for deep learning based single image rain removal from the four aspects as mentioned below: 1) dataset generation in rain weather conditions; 2) representative deep neural network based single image rain removal algorithms; 3) the research of the downstream high-level task in rainy days and 4) performance metrics for evaluating single image rain removal algorithms. Specifically, in terms of the generation manners, the current rain image datasets are roughly divided into four categories as following: 1) synthesizing rain streaks based on photo-realistic rendering technique and then adding them on clear images based on simple physical model; 2) constructing rain images based on complex physical model via manual parameters setting; 3) generating rain images based on generative adversarial network (GAN); 4) collecting paired rain-free/rain-affected images by shooting different scenarios and adjusting camera parameters. We reviewed the download links of the existing representative rain image datasets. For deep learning based single image rain removal methods, we review the supervised and semi-/unsupervised rain removal methods for single task and joint tasks in terms of task scenarios, learning mechanisms and network design. Here, single task is relevant to rain drop removal, rain streak, rain fog, heavy rain; and the integrated analyses of removal of rain drop and rain streak, or multiple noises removal. Furthermore, we overview the construction manners of representative network architectures, including simplified convolutional neural networks based (CNNs-based) multi-branches architecture, GAN-based mechanism, recurrent and multi-stage framework, multi-scale architecture, the integration of encoder-decoder modules, attention mechanism or transformer based module as well as model-driven and data-driven learning manners. Since the implicit or explicit embedding of domain knowledge can promote network construction, we provide a detailed survey in the context of the relationship between rain removal methods and domain knowledge.We illustrated that the domain knowledge and the learning of benched networks has the potential to improve the generalization performance of single image rain removal algorithm further. Based on the real high-level outdoor vision tasks in rain weather, it would be meaningful to use the joint processing strategies of low-level and high-level tasks and the customized construction of rainy datasets. Meanwhile, we reviewed and clarified some related literatures of high-level computer vision tasks and comprehensively analyzed the performance evaluation metrics in the context of full-reference metrics and non-reference metrics. We analyzed the potential challenges of single image rain removal further in the context of feasible benchmark datasets construction, future fair evaluation metrics designing, and the optimized integration of rain removal and high-level vision tasks.关键词:single image rain removal;deep neural network;rain image dataset;rain image synthesis;model-driven and data-driven methodology;follow-up high-level vision task;performance evaluation metrics255|814|2更新时间:2024-05-07
摘要:The visual quality of captured images in rainy weather conditions is constrained to the outdoor vision degradation. It is essential to design relevant rain removal algorithms. Due to the lack of temporal information, single image rain removal is challenging compared to video-based rain removal. The target of single image rain removal analysis is to restore the rain-removed background image from the corresponding rain-affected image. Current deep learning based vision tasks construct diverse data-driven frameworks like single image rain removal task via multiple network modules. Current research tasks are focusing on the quality of datasets, the design of single image deraining algorithms, the subsequent high-level vision tasks, and the design of performance evaluation metrics. Specifically, the quality of rain datasets largely affects the performance of deep learning based single image deraining methods, since the generalization ability of deep single image rain removal is highly related to the domain gap between synthesized training dataset and real testing dataset. Besides, rain removal plays an important preprocessing role in outdoor visual tasks because its result would affect the performance of the subsequent visual task. Additionally, the design of image quality assessment (IQA) metrics is quite important for the fair quantitative analysis of human perception of image quality in general image restoration tasks. We conducted critical literature review for deep learning based single image rain removal from the four aspects as mentioned below: 1) dataset generation in rain weather conditions; 2) representative deep neural network based single image rain removal algorithms; 3) the research of the downstream high-level task in rainy days and 4) performance metrics for evaluating single image rain removal algorithms. Specifically, in terms of the generation manners, the current rain image datasets are roughly divided into four categories as following: 1) synthesizing rain streaks based on photo-realistic rendering technique and then adding them on clear images based on simple physical model; 2) constructing rain images based on complex physical model via manual parameters setting; 3) generating rain images based on generative adversarial network (GAN); 4) collecting paired rain-free/rain-affected images by shooting different scenarios and adjusting camera parameters. We reviewed the download links of the existing representative rain image datasets. For deep learning based single image rain removal methods, we review the supervised and semi-/unsupervised rain removal methods for single task and joint tasks in terms of task scenarios, learning mechanisms and network design. Here, single task is relevant to rain drop removal, rain streak, rain fog, heavy rain; and the integrated analyses of removal of rain drop and rain streak, or multiple noises removal. Furthermore, we overview the construction manners of representative network architectures, including simplified convolutional neural networks based (CNNs-based) multi-branches architecture, GAN-based mechanism, recurrent and multi-stage framework, multi-scale architecture, the integration of encoder-decoder modules, attention mechanism or transformer based module as well as model-driven and data-driven learning manners. Since the implicit or explicit embedding of domain knowledge can promote network construction, we provide a detailed survey in the context of the relationship between rain removal methods and domain knowledge.We illustrated that the domain knowledge and the learning of benched networks has the potential to improve the generalization performance of single image rain removal algorithm further. Based on the real high-level outdoor vision tasks in rain weather, it would be meaningful to use the joint processing strategies of low-level and high-level tasks and the customized construction of rainy datasets. Meanwhile, we reviewed and clarified some related literatures of high-level computer vision tasks and comprehensively analyzed the performance evaluation metrics in the context of full-reference metrics and non-reference metrics. We analyzed the potential challenges of single image rain removal further in the context of feasible benchmark datasets construction, future fair evaluation metrics designing, and the optimized integration of rain removal and high-level vision tasks.关键词:single image rain removal;deep neural network;rain image dataset;rain image synthesis;model-driven and data-driven methodology;follow-up high-level vision task;performance evaluation metrics255|814|2更新时间:2024-05-07 -
 摘要:Low-light image enhancement aims to improve the visual perception quality of captured data in the context of low-light scenarios. The purpose of low-light image enhancement is to improve the visual quality via image brightness enhancement. Low-light image enhancement is a key factor to low-light face detection and nighttime semantic segmentation.Our systematic and detailed review is focused on the recent development of low-light image enhancement., We first carry out a comprehensive and systematic analysis for low-light image enhancement on the three aspects as mentioned below: 1) the development of low-light image datasets, 2) the development of low-light image enhancement technology, and 3) the experimental evaluation synthesis. Finally, our demonstrated results are summarized and forecasted in related to low-light image enhancement further.First of all, as far as the existing low-light image enhancement data set is concerned, it reveals a trend in the scale of sizes (small to large), multi-scenarios(solo to diverse), and data involvement degree(simple to complex). Most of the data sets are attributed to unpaired data, and the target pairwise data sets cannot be effectively synthesized due to the difficulty of illumination in low-light image enhancement modeling. The existing pairs of low illumination image data set labels are mainly subjected to manual parameter settings like the exposure time adjustment or expertise modification).The existing reference images in pairs of data sets have challenged to represent the scene information captured in low-light observation accurately. In addition, the construction process of some data sets is relevant to detection or segmentation labels. It is necessary to establish a connection and explore the impact of low-level visual tasks with high-level visual tasks and faciliate high-level visual tasks like detection and semantic segmentation in a low-light scenario.Second, existing low-light image enhancement techniques can be roughly divided into three categories: 1) distribution-based mapping, 2)model-based optimization, and 3) deep learning, respectively. Data-driven deep learning technology has significantly promoted the development of low-light image enhancement. Thanks to the development of the existing low-light image enhancement technology, the traditional model design method has been transformed into data-driven deep learning technology. Among them, It can resolve low-light image enhancement issue based on mapping the value distribution of low-light input to amplify smaller values (displayed as dark), while exposure unevenness is still the a challenged issue to deal with. The model optimization based methods make assumptions about the ground truth via a priori regular condition designation, and do not depend on the amount of training data, but achieve relatively stable performance through the image analysis itself. The deep learning based image enhancement method is to learn via a large amount of training data and realize image enhancement based on designing a deep network-related/independent of the physical model. The trend moves towards semi-supervised/unsupervised/self-supervised learning mechanisms from fully supervised learning mechanisms and focuses more on image enhancement quality when pairwise ground truth data is not available. However, the loss function design in the training process and the training relies on the design of the loss function and the adjustment of network parameters. The existing enhanced network structure is gradually changing from complex to lightweight. Simultaneously, the improvement of visual quality is related to the running speed of the network. There is a lack of effective indicators that can accurately reflect the enhanced image quality due to the specialty of the low-light image enhancement. Currently, a series of downstream high-level vision tasks have been adopting to evaluate the quality of enhanced images and transferring to user-friendly low-light visual image enhancement to high-level vision task performance priority.Meanwhile, a series of experimental evaluations demonstrate that existing optimized model based methods have better generalization ability than those deep learning based methods, while existing unsupervised learning techniques are more robust and efficient than fully supervised learning methods. It can be obtained from the high-level vision tasks in low-light scenes that low-light enhancement has a certain effect on more tasks although good visual effects has not obtained higher high-level vision task accuracy. This indirect confirmation of the disparity of the visual quality expression is orientated from existing works and high-level visual tasks. It is worth noting that the results obtained of trained networks on paired data lack generality and make it difficult to characterize natural image distributions. The unsupervised method can generate enhanced results to satisfy the natural image distribution via ta natural image distribution related loss function, The following four potential research perspectives are proposed, including 1)the inherent laws issue of low-light images in different scenes and reduce the dependence on paired data to endow the algorithm with scene-independent generalization ability; 2) an efficient network framework construction for low-light image enhancement tasks; 3) an effective learning strategy to make the framework learn completely; and 4) a connection between low-light image enhancement and high-level vision tasks (e.g., detection).关键词:low-light image enhancement;Retinex theory;illumination estimation;deep learning;low-light face detection688|997|16更新时间:2024-05-07
摘要:Low-light image enhancement aims to improve the visual perception quality of captured data in the context of low-light scenarios. The purpose of low-light image enhancement is to improve the visual quality via image brightness enhancement. Low-light image enhancement is a key factor to low-light face detection and nighttime semantic segmentation.Our systematic and detailed review is focused on the recent development of low-light image enhancement., We first carry out a comprehensive and systematic analysis for low-light image enhancement on the three aspects as mentioned below: 1) the development of low-light image datasets, 2) the development of low-light image enhancement technology, and 3) the experimental evaluation synthesis. Finally, our demonstrated results are summarized and forecasted in related to low-light image enhancement further.First of all, as far as the existing low-light image enhancement data set is concerned, it reveals a trend in the scale of sizes (small to large), multi-scenarios(solo to diverse), and data involvement degree(simple to complex). Most of the data sets are attributed to unpaired data, and the target pairwise data sets cannot be effectively synthesized due to the difficulty of illumination in low-light image enhancement modeling. The existing pairs of low illumination image data set labels are mainly subjected to manual parameter settings like the exposure time adjustment or expertise modification).The existing reference images in pairs of data sets have challenged to represent the scene information captured in low-light observation accurately. In addition, the construction process of some data sets is relevant to detection or segmentation labels. It is necessary to establish a connection and explore the impact of low-level visual tasks with high-level visual tasks and faciliate high-level visual tasks like detection and semantic segmentation in a low-light scenario.Second, existing low-light image enhancement techniques can be roughly divided into three categories: 1) distribution-based mapping, 2)model-based optimization, and 3) deep learning, respectively. Data-driven deep learning technology has significantly promoted the development of low-light image enhancement. Thanks to the development of the existing low-light image enhancement technology, the traditional model design method has been transformed into data-driven deep learning technology. Among them, It can resolve low-light image enhancement issue based on mapping the value distribution of low-light input to amplify smaller values (displayed as dark), while exposure unevenness is still the a challenged issue to deal with. The model optimization based methods make assumptions about the ground truth via a priori regular condition designation, and do not depend on the amount of training data, but achieve relatively stable performance through the image analysis itself. The deep learning based image enhancement method is to learn via a large amount of training data and realize image enhancement based on designing a deep network-related/independent of the physical model. The trend moves towards semi-supervised/unsupervised/self-supervised learning mechanisms from fully supervised learning mechanisms and focuses more on image enhancement quality when pairwise ground truth data is not available. However, the loss function design in the training process and the training relies on the design of the loss function and the adjustment of network parameters. The existing enhanced network structure is gradually changing from complex to lightweight. Simultaneously, the improvement of visual quality is related to the running speed of the network. There is a lack of effective indicators that can accurately reflect the enhanced image quality due to the specialty of the low-light image enhancement. Currently, a series of downstream high-level vision tasks have been adopting to evaluate the quality of enhanced images and transferring to user-friendly low-light visual image enhancement to high-level vision task performance priority.Meanwhile, a series of experimental evaluations demonstrate that existing optimized model based methods have better generalization ability than those deep learning based methods, while existing unsupervised learning techniques are more robust and efficient than fully supervised learning methods. It can be obtained from the high-level vision tasks in low-light scenes that low-light enhancement has a certain effect on more tasks although good visual effects has not obtained higher high-level vision task accuracy. This indirect confirmation of the disparity of the visual quality expression is orientated from existing works and high-level visual tasks. It is worth noting that the results obtained of trained networks on paired data lack generality and make it difficult to characterize natural image distributions. The unsupervised method can generate enhanced results to satisfy the natural image distribution via ta natural image distribution related loss function, The following four potential research perspectives are proposed, including 1)the inherent laws issue of low-light images in different scenes and reduce the dependence on paired data to endow the algorithm with scene-independent generalization ability; 2) an efficient network framework construction for low-light image enhancement tasks; 3) an effective learning strategy to make the framework learn completely; and 4) a connection between low-light image enhancement and high-level vision tasks (e.g., detection).关键词:low-light image enhancement;Retinex theory;illumination estimation;deep learning;low-light face detection688|997|16更新时间:2024-05-07 -
 摘要:Images and videos quality has a great impact on the information acquisition of human behavior visual system. Image/video quality assessment (I/VQA) can be regarded as a key factor for multimedia and network video services nowadays. The quality assessment methods are mainly segmented into qualitative and quantitative models. Qualitative methods conduct quality assessment based on the human's eyes, which cost lots of manpower and time consuming resources. Quantitative quality assessment simulates human observation and it can automatically forecast input quality for those of I/VQA researchers. Our review is critical reviewed quality assessment(QA) methods like full reference (FR), reduced reference (RR) and no reference (NR) methods, which are categorized based on the "clean" data capability (the reference image with no distortion). The full reference methods assess the quality of the distorted images with comparison of the "clean" data. The pros of these methods are better performance, low complexity and good robustness. The cons are that the reference images are challenged to obtain in the in-situ scenarios. Compared with the full reference methods, the reduced reference methods reduce the number of the reference images based on featured reference data to predict the quality. All reference data are not required for the no reference methods. Traditional IQA methods are mainly based on structural similarity, human visual system (HVS) and natural scene statistical theory (NSS). The structure similarity based methods assesses the measurement quality derived of the structural information changes; the HVS based methods are based on some human eyes features; Natural scene statistics based methods fit the transformed coefficients distribution of images or videos and compare the gap of reference coefficients and test coefficients. The emerging deep learning methods based on convolutional neural network (CNN) extract image features through convolutional operations and implement logistic regression to update the models. The learning capability of the IQA-oriented CNN has its priority. VQA models are mainly divided into two categories. One category is that the temporal video quality can be obtained based on the IQA methods for single frame, and then integrate the quality of all frames. The integration methods are mainly divided into general average and weighted average methods in which the weights can be obtained in terms of manual setting or learning. The other one is forthe three dimensions (3D) video as mentioned below: First, extracting the coefficient distribution by 3D transformation or using 3D CNN to extract features, and then fitting the coefficient distribution or mapping the features to obtain the final quality. Compared to traditional methods, learning-based methods have higher complexity, but better performance. Most of the current VQA methods also use CNN as the backbone structure, which assists in the overall model construction. Our critical review analyzes the growth of I/VQA and lists some representative algorithms. Then, we review some I/VQA based literatures from two aspects, including traditional methods and deep learning-based methods, respectively. The capability of representative algorithms is analyzed derived of Spearman rank order correlation coefficient(SROCC) and Pearson linear correlation coefficient(PLCC) evaluation indexes in terms of laboratory for image & video engineering(LIVE), categorical subjective image quality database(CSIQ), TID2013 and other datasets. Finally, the challenging issues of quality assessment are summarized and predicted.关键词:image/video quality assessment(I/VQA);structural information;human vision system(HVS);natural scene statistics(NSS);deep learning290|323|4更新时间:2024-05-07
摘要:Images and videos quality has a great impact on the information acquisition of human behavior visual system. Image/video quality assessment (I/VQA) can be regarded as a key factor for multimedia and network video services nowadays. The quality assessment methods are mainly segmented into qualitative and quantitative models. Qualitative methods conduct quality assessment based on the human's eyes, which cost lots of manpower and time consuming resources. Quantitative quality assessment simulates human observation and it can automatically forecast input quality for those of I/VQA researchers. Our review is critical reviewed quality assessment(QA) methods like full reference (FR), reduced reference (RR) and no reference (NR) methods, which are categorized based on the "clean" data capability (the reference image with no distortion). The full reference methods assess the quality of the distorted images with comparison of the "clean" data. The pros of these methods are better performance, low complexity and good robustness. The cons are that the reference images are challenged to obtain in the in-situ scenarios. Compared with the full reference methods, the reduced reference methods reduce the number of the reference images based on featured reference data to predict the quality. All reference data are not required for the no reference methods. Traditional IQA methods are mainly based on structural similarity, human visual system (HVS) and natural scene statistical theory (NSS). The structure similarity based methods assesses the measurement quality derived of the structural information changes; the HVS based methods are based on some human eyes features; Natural scene statistics based methods fit the transformed coefficients distribution of images or videos and compare the gap of reference coefficients and test coefficients. The emerging deep learning methods based on convolutional neural network (CNN) extract image features through convolutional operations and implement logistic regression to update the models. The learning capability of the IQA-oriented CNN has its priority. VQA models are mainly divided into two categories. One category is that the temporal video quality can be obtained based on the IQA methods for single frame, and then integrate the quality of all frames. The integration methods are mainly divided into general average and weighted average methods in which the weights can be obtained in terms of manual setting or learning. The other one is forthe three dimensions (3D) video as mentioned below: First, extracting the coefficient distribution by 3D transformation or using 3D CNN to extract features, and then fitting the coefficient distribution or mapping the features to obtain the final quality. Compared to traditional methods, learning-based methods have higher complexity, but better performance. Most of the current VQA methods also use CNN as the backbone structure, which assists in the overall model construction. Our critical review analyzes the growth of I/VQA and lists some representative algorithms. Then, we review some I/VQA based literatures from two aspects, including traditional methods and deep learning-based methods, respectively. The capability of representative algorithms is analyzed derived of Spearman rank order correlation coefficient(SROCC) and Pearson linear correlation coefficient(PLCC) evaluation indexes in terms of laboratory for image & video engineering(LIVE), categorical subjective image quality database(CSIQ), TID2013 and other datasets. Finally, the challenging issues of quality assessment are summarized and predicted.关键词:image/video quality assessment(I/VQA);structural information;human vision system(HVS);natural scene statistics(NSS);deep learning290|323|4更新时间:2024-05-07 -
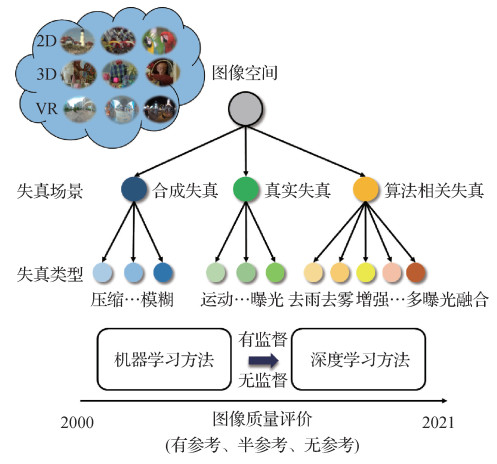 摘要:Image quality assessment (IQA) has been widely applied to multimedia processing, such as low-quality image screening, parameter tuning, and algorithm optimization. IQA models can be classified into three categories like full-reference (FR), reduced-reference (RR) and no-reference/blind (NR/B) models in terms of the accessibility to reference information. The FR and RR IQA models are based on full and partial reference information each while NR/B models can assess image visual quality without reference information. The early IQA models mainly relies on feature engineering, and their performance is limited by the representation ability of hand-crafted features. Benefiting from the excellent representation ability of deep neural networks, the deep learning based IQA models have shown superior performance and surpassed the feature engineering based IQA models, especially in representing large number of images. Due to the strong representation ability, the deep learning based IQA models have attracted most of our attention in the past decade. Additionally, IQA models have been introduced to image restoration, super-resolution and other tasks to improve algorithm performance and facilitate better benchmarks. For instance, some differentiable FR-IQA models like structural similarity(SSIM) and multi-scale SSIM(MSSIM) can be used straightforward via optimization, facilitating the relevant models training. In the development of IQA research, image distortion plays an important role. Both image quality database construction and IQA models are developed by considering distortion. Previous IQA studies are constrained of dozens of pristine images, and then generate their distorted images via disrupting the pristine images artificially. Benefiting from the uniformity of this type of images, the global quality score of each image in the early image quality databases can be regarded as the quality label of the image patches (e.g., 32×32 pixels) extracted from the corresponding image. Consequently, huge amount of data like local patches and the associated global quality scores can be carried out to learn the mapping function from local patch to visual quality. However, the patch-based strategy may be problematic, since such a small patch is unable to capture image context information. Besides, this data augmentation operation could not be simply adapted to quality assessment of authentic distorted images and other types of images such as 3D synthesized images, since authentic distortions are much more complex than simulated distortions and the distortions in 3D synthesized images exhibit non-uniform distribution. Customized solutions regarding to image distortion are required to be implemented in IQA models, e.g., we can use local variation measurement and global change modeling to capture the distortion in 3D synthesized images. Our research mainly introduces the distortion-related IQA models from 2011 to 2021, aiming to facilitate a review on the evolution of image quality databases and IQA models both. In the light of image distortion categories, IQA models are classified into three categories: the models for simulated distortions, the models for authentic distortions, and the models for the distortions related to algorithms. Specifically, simulated distortions are also called artificial distortions, which show uniform distribution, including Gaussian noise and motion blur, etc. Authentic distortions are mainly introduced in the context of image photography scenario, shooting equipment, inadequate operation in shooting process. In comparison of simulated distortions, authentic distortions are more complicated, leading to the challenge of data collection. Authentic distortions can be also classified into several major types, like out-of-focus, blur and over-exposure. A large number of authentical distorted images collection need to be followed some distortion rules, and it is a labor-intensive task. The distortions related to algorithms refer to the image degradations occurred in the resultant images due to the intrinsic defects or the limited performance of image processing or computer vision algorithms, and a distinctive characteristic of this type of distortions is that their distributions are inhomogeneous, which differs from other two types of distortions. Overall, current public image quality databases are initial to be promoted, including the details of image data sources and database construction. The designation of IQA models is then involved in. Finally, we summarize the IQA models introduced in this paper, and point out the potential development directions in the future.关键词:image quality assessment(IQA);image processing;visual perception;computer vision;machine learning;deep learning535|1176|7更新时间:2024-05-07
摘要:Image quality assessment (IQA) has been widely applied to multimedia processing, such as low-quality image screening, parameter tuning, and algorithm optimization. IQA models can be classified into three categories like full-reference (FR), reduced-reference (RR) and no-reference/blind (NR/B) models in terms of the accessibility to reference information. The FR and RR IQA models are based on full and partial reference information each while NR/B models can assess image visual quality without reference information. The early IQA models mainly relies on feature engineering, and their performance is limited by the representation ability of hand-crafted features. Benefiting from the excellent representation ability of deep neural networks, the deep learning based IQA models have shown superior performance and surpassed the feature engineering based IQA models, especially in representing large number of images. Due to the strong representation ability, the deep learning based IQA models have attracted most of our attention in the past decade. Additionally, IQA models have been introduced to image restoration, super-resolution and other tasks to improve algorithm performance and facilitate better benchmarks. For instance, some differentiable FR-IQA models like structural similarity(SSIM) and multi-scale SSIM(MSSIM) can be used straightforward via optimization, facilitating the relevant models training. In the development of IQA research, image distortion plays an important role. Both image quality database construction and IQA models are developed by considering distortion. Previous IQA studies are constrained of dozens of pristine images, and then generate their distorted images via disrupting the pristine images artificially. Benefiting from the uniformity of this type of images, the global quality score of each image in the early image quality databases can be regarded as the quality label of the image patches (e.g., 32×32 pixels) extracted from the corresponding image. Consequently, huge amount of data like local patches and the associated global quality scores can be carried out to learn the mapping function from local patch to visual quality. However, the patch-based strategy may be problematic, since such a small patch is unable to capture image context information. Besides, this data augmentation operation could not be simply adapted to quality assessment of authentic distorted images and other types of images such as 3D synthesized images, since authentic distortions are much more complex than simulated distortions and the distortions in 3D synthesized images exhibit non-uniform distribution. Customized solutions regarding to image distortion are required to be implemented in IQA models, e.g., we can use local variation measurement and global change modeling to capture the distortion in 3D synthesized images. Our research mainly introduces the distortion-related IQA models from 2011 to 2021, aiming to facilitate a review on the evolution of image quality databases and IQA models both. In the light of image distortion categories, IQA models are classified into three categories: the models for simulated distortions, the models for authentic distortions, and the models for the distortions related to algorithms. Specifically, simulated distortions are also called artificial distortions, which show uniform distribution, including Gaussian noise and motion blur, etc. Authentic distortions are mainly introduced in the context of image photography scenario, shooting equipment, inadequate operation in shooting process. In comparison of simulated distortions, authentic distortions are more complicated, leading to the challenge of data collection. Authentic distortions can be also classified into several major types, like out-of-focus, blur and over-exposure. A large number of authentical distorted images collection need to be followed some distortion rules, and it is a labor-intensive task. The distortions related to algorithms refer to the image degradations occurred in the resultant images due to the intrinsic defects or the limited performance of image processing or computer vision algorithms, and a distinctive characteristic of this type of distortions is that their distributions are inhomogeneous, which differs from other two types of distortions. Overall, current public image quality databases are initial to be promoted, including the details of image data sources and database construction. The designation of IQA models is then involved in. Finally, we summarize the IQA models introduced in this paper, and point out the potential development directions in the future.关键词:image quality assessment(IQA);image processing;visual perception;computer vision;machine learning;deep learning535|1176|7更新时间:2024-05-07
Review

-
 摘要:ObjectiveUnderwater images processing are essential to marine issues in the context of defense, environmental protection and engineering. However, there are always severe quality degradation issues like color cast, blur, and low contrast are greatly restricted the quality of underwater imaging and operation systems due to the inner-water light attenuation/scattering and the microbe derived absorption/reflection of light. Underwater image enhancement (UIE) algorithms have been demonstrated to improve the quality of underwater images nowadays. The two aspects of challenges are critical to be illustrated as below: one of huge gap between the synthesized and in-situ underwater images processing are constrained of complicated degradations of diverse underwater environments. The other is challenged that the existing objective image quality metrics are matched to evaluate the in-situ quality of various UIE algorithms. To resolve the above two issues, our demonstration has illustrated as following: first, we build up a real-world underwater image quality evaluation dataset to compare the performance of different UIE algorithms based on a collection of in-situ underwater images. Next, we evaluate the performance of existing image quality evaluation metrics on our generated dataset.MethodFirst, we collect 100 real-world underwater images, including 60 color cast-dominant and 40 blur-dominant ones, and apply 10 representative UIE algorithms to enhance the 100 raw underwater images. A total number of 1 000 enhanced results (10 results for each raw underwater image) are generated. Next, we conduct complex human subjective studies to evaluate the performance of different UIE algorithms based on the pairwise comparison (PC) strategy. Thirdly, we analyze the results obtained from our subjective studies to demonstrate the reliability of our human subjective studies and get insights on the pros and cons of each UIE algorithm. The Bradley-Terry (B-T) model on the PC results obtained B-T scores as the ground truth quality scores of the enhanced underwater images. Finally, we test the capabilities of existing image quality metrics via the correlations between the B-T scores and the predicted 10 existing representative no-reference image quality metrics for evaluating UIE results.ResultWe illustrates the Kendall coefficient of inner subjects' protocols, a convergence analysis and conducts a significance test to verify the dataset. The Kendall coefficient of inner subjects' protocols on the full-set is around 0.41, which demonstrates a qualified inter-subject consistency level. Such coefficient is slightly different on the two subsets, i.e., 0.39 and 0.44 on the color cast subset and blur subset, respectively. In respect of the convergence analysis, the mean and the variance of each underwater image enhancement algorithms tend to be clarified in the context of the increasing of the number of votes and the number of images.The similar subjective scores are obtained for each underwater enhancement algorithms. The significance for test results demonstrates that GL-Net is the best and underwater image enhancement convolutional neural network(UWCNN) is the worst for the adopted 10 UIE algorithms. In addition, there is slight difference on the performance rankings of different UIE algorithms on the two subsets. Finally, an existing no-reference image quality metrics can be unqualified for UIE algorithms evaluation.ConclusionOur first contribution is based on an in-situ underwater image quality evaluation dataset through conducting human subjective studies to compare the performance of various UIE algorithms with a collection of in-situ underwater images. The other one is that the performance of existing image quality evaluation methods is evaluated based on our dataset and the limitation of the existing image quality metrics is identified for UIE quality evaluation. Overall, this research targets underwater image quality evaluation metrics. All the images and collected data involved are available at: https://github.com/yia-yuese/RealUWIQ-dataset.关键词:image quality evaluation;underwater image enhancement;subject image quality assessment;dataset;pairwise comparison(PC)469|459|1更新时间:2024-05-07
摘要:ObjectiveUnderwater images processing are essential to marine issues in the context of defense, environmental protection and engineering. However, there are always severe quality degradation issues like color cast, blur, and low contrast are greatly restricted the quality of underwater imaging and operation systems due to the inner-water light attenuation/scattering and the microbe derived absorption/reflection of light. Underwater image enhancement (UIE) algorithms have been demonstrated to improve the quality of underwater images nowadays. The two aspects of challenges are critical to be illustrated as below: one of huge gap between the synthesized and in-situ underwater images processing are constrained of complicated degradations of diverse underwater environments. The other is challenged that the existing objective image quality metrics are matched to evaluate the in-situ quality of various UIE algorithms. To resolve the above two issues, our demonstration has illustrated as following: first, we build up a real-world underwater image quality evaluation dataset to compare the performance of different UIE algorithms based on a collection of in-situ underwater images. Next, we evaluate the performance of existing image quality evaluation metrics on our generated dataset.MethodFirst, we collect 100 real-world underwater images, including 60 color cast-dominant and 40 blur-dominant ones, and apply 10 representative UIE algorithms to enhance the 100 raw underwater images. A total number of 1 000 enhanced results (10 results for each raw underwater image) are generated. Next, we conduct complex human subjective studies to evaluate the performance of different UIE algorithms based on the pairwise comparison (PC) strategy. Thirdly, we analyze the results obtained from our subjective studies to demonstrate the reliability of our human subjective studies and get insights on the pros and cons of each UIE algorithm. The Bradley-Terry (B-T) model on the PC results obtained B-T scores as the ground truth quality scores of the enhanced underwater images. Finally, we test the capabilities of existing image quality metrics via the correlations between the B-T scores and the predicted 10 existing representative no-reference image quality metrics for evaluating UIE results.ResultWe illustrates the Kendall coefficient of inner subjects' protocols, a convergence analysis and conducts a significance test to verify the dataset. The Kendall coefficient of inner subjects' protocols on the full-set is around 0.41, which demonstrates a qualified inter-subject consistency level. Such coefficient is slightly different on the two subsets, i.e., 0.39 and 0.44 on the color cast subset and blur subset, respectively. In respect of the convergence analysis, the mean and the variance of each underwater image enhancement algorithms tend to be clarified in the context of the increasing of the number of votes and the number of images.The similar subjective scores are obtained for each underwater enhancement algorithms. The significance for test results demonstrates that GL-Net is the best and underwater image enhancement convolutional neural network(UWCNN) is the worst for the adopted 10 UIE algorithms. In addition, there is slight difference on the performance rankings of different UIE algorithms on the two subsets. Finally, an existing no-reference image quality metrics can be unqualified for UIE algorithms evaluation.ConclusionOur first contribution is based on an in-situ underwater image quality evaluation dataset through conducting human subjective studies to compare the performance of various UIE algorithms with a collection of in-situ underwater images. The other one is that the performance of existing image quality evaluation methods is evaluated based on our dataset and the limitation of the existing image quality metrics is identified for UIE quality evaluation. Overall, this research targets underwater image quality evaluation metrics. All the images and collected data involved are available at: https://github.com/yia-yuese/RealUWIQ-dataset.关键词:image quality evaluation;underwater image enhancement;subject image quality assessment;dataset;pairwise comparison(PC)469|459|1更新时间:2024-05-07
Dataset
-
 摘要:ObjectiveThe acquired images relating fog, mist and damp weather conditions are subjected to the atmospheric scattering, affecting the observation and target analysis of intelligent detection systems. The scattering of reflected lights deduct the contrast of images in the context of the increased scene depth, and the uneven sky illumination constrains images visibility. This two constraints yield to deduction and fuzzes on the weak texture in foggy images. The degradation of foggy images affects the pixels based statistical distributions like saturation and weber contrast and changes the statistical distribution between pixels, such as target contour intensity. Thus, visual perception quality related to natural scene statistical (NSS) features of fog image and the target detection accuracy related target category semantic (TCS) features are significantly different with ground truth, Traditional image restoration methods can build the defogging mapping to improve image contrast based on the conventional scattering model. But, it is challenged to remove the severe scattering of image features. Deep learning based image enhancement methods have better scattering image removal results close to the distribution of training data. It is a challenged issue of insufficient generalization ability like dense artifacts for ground truth foggy images derived of complex degradation the degradation in synthetic foggy images excluded. Current methods have focused on semi-supervision technique based generalization ability improvement but the large domain distance constrains between real and synthetic foggy images existing. To optimize the image features, current deep learning based methods are challenged to achieve the niches between visual quality and machine perception quality via image classification or target detection. To interpret pros and cons of prior-based and deep leaning based methods, a semi-supervision prior hyrid network for feature enhancement is illustrated to demonstrate the feature enhancement for detection and object analysis.MethodOur research is designated to a semi-supervision prior hybrid network for NSS and TCS feature enhancement. First, a prior based fog inversion module is used to remove the atmospheric scattering effect and restore the uneven illumination in foggy images. The method is based on an extended atmospheric scattering model and a regional gradient constrained prior for transmission estimation and illumination decomposition. Then, a feature enhancement module is designed based on the condition generative adversarial network (CGAN) as a subsequent module, which regards the defogged image as the input image. The generator uses six Res-blocks with the instance norm layer and a long skip connection to achieve the image domain translation of defogged images. There are three discriminators in the network. The style and feature discriminator with five convolution layers and leakReLU layers are used to identify the image style between "defogged" and "clear", promoting the generator using the adversarial technique with CGAN loss in pixel-level and feature-level. Excluded the CGAN loss for further removing the scattering degradation in defogged images, the generator is also trained based on a content loss, which constrains the details distortion in the image translation process. Moreover, our research analyzes the domain differences between the defogged image and the clear image in the target feature level, and utilizes a target cumulative vector loss based a target sematic discriminator to guide the refinement of target outline in the defogged image. Thus, the feature enhancement module is implemented to contrast and brightness related NSS features and improve the performance of TCS features about target clearance. The reversed features are constrained to match the CGAN loss and content loss in terms of the information differences between image features and image pixel performance. Our network resolves the interconnections between the traditional method and the convolutional neural network (CNN) module and obtains the enhanced result via the scattering removal and feature enhancement. It is beneficial to solve the dependence of feature learning on synthetic paired training data and the instability of semi-supervision learning in realizing image translation. Abstract features representations is also improved through definite direction and fine granularity related feature learning method. The traditional image enhancement module is optimized to make the best defogged result via parameters adjusting. The feature enhancement module is trained with adaptive moment estimation(ADAM) optimizer for 250 epochs with the momentum takes the values of 0.5 and 0.999. The learning rate is set to 2E-4. And unpaired 270×170 patches randomly cropped from 2 000 defogged real-world images and 2 000 clearance images are taken as the inputs of the generator and discriminator. The train and test processes are carried out by PyTorch in a X86 computer with a core i7 3.0 GHz processor, 64 GB RAM and a NVIDIA 2080ti graphic.ResultOur experimental results are compared with 5 state-of-the-art enhancement methods, including the 2 traditional approaches and 3 deep learning methods on 2 public fog ground truth image datasets called RTTS(real-world task-driven testing set) and foggy driving dense dataset. RTTS dataset contains 4 322 foggy or dim images and foggy driving dense dataset has 21 dense fog online images collection. The quantitative evaluation metrics contain the image quality index and the detection quality index. The quality indexes are composed of the enhanced gradient ratio R and the blind image quality analyzer integrated local natural image quality evaluator(IL-NIQE). The detection indexes are based on mean average precision(MAP) and recall. We also demonstrated more enhanced results of each method for qualitative comparison in the experimental section. In RTTS and foggy driving dense dataset, compared with the method ranking second in each index, the mean R value is improved 50.83%, the mean IL-NIQE value is improved 6.33%, the MAP value is improved 6.40% and the mean Recall value is improved 7.79%. The enhanced results from the proposed method are much similar to clear color, brightness and contrast images qualitatively. The obtained experimental results illustrates that our network can improves the visual quality and machine perception for the foggy image captured in bad weather conditions with more than 50 (frame/s)/Mp as well.ConclusionOur semi-supervision prior hybrid network integrates traditional restoration methods and deep learning based enhancement models for multi-level feature enhancement, achieving the enhancement of NSS features and TCS features. Our illustrations demonstrates our method has its priority for real foggy images in terms of image quality and object detectable ability for intelligent detection system.关键词:foggy image dehazing;feature enhancement;prior hyrid network;semi-supervison learning;image domain translation174|462|2更新时间:2024-05-07
摘要:ObjectiveThe acquired images relating fog, mist and damp weather conditions are subjected to the atmospheric scattering, affecting the observation and target analysis of intelligent detection systems. The scattering of reflected lights deduct the contrast of images in the context of the increased scene depth, and the uneven sky illumination constrains images visibility. This two constraints yield to deduction and fuzzes on the weak texture in foggy images. The degradation of foggy images affects the pixels based statistical distributions like saturation and weber contrast and changes the statistical distribution between pixels, such as target contour intensity. Thus, visual perception quality related to natural scene statistical (NSS) features of fog image and the target detection accuracy related target category semantic (TCS) features are significantly different with ground truth, Traditional image restoration methods can build the defogging mapping to improve image contrast based on the conventional scattering model. But, it is challenged to remove the severe scattering of image features. Deep learning based image enhancement methods have better scattering image removal results close to the distribution of training data. It is a challenged issue of insufficient generalization ability like dense artifacts for ground truth foggy images derived of complex degradation the degradation in synthetic foggy images excluded. Current methods have focused on semi-supervision technique based generalization ability improvement but the large domain distance constrains between real and synthetic foggy images existing. To optimize the image features, current deep learning based methods are challenged to achieve the niches between visual quality and machine perception quality via image classification or target detection. To interpret pros and cons of prior-based and deep leaning based methods, a semi-supervision prior hyrid network for feature enhancement is illustrated to demonstrate the feature enhancement for detection and object analysis.MethodOur research is designated to a semi-supervision prior hybrid network for NSS and TCS feature enhancement. First, a prior based fog inversion module is used to remove the atmospheric scattering effect and restore the uneven illumination in foggy images. The method is based on an extended atmospheric scattering model and a regional gradient constrained prior for transmission estimation and illumination decomposition. Then, a feature enhancement module is designed based on the condition generative adversarial network (CGAN) as a subsequent module, which regards the defogged image as the input image. The generator uses six Res-blocks with the instance norm layer and a long skip connection to achieve the image domain translation of defogged images. There are three discriminators in the network. The style and feature discriminator with five convolution layers and leakReLU layers are used to identify the image style between "defogged" and "clear", promoting the generator using the adversarial technique with CGAN loss in pixel-level and feature-level. Excluded the CGAN loss for further removing the scattering degradation in defogged images, the generator is also trained based on a content loss, which constrains the details distortion in the image translation process. Moreover, our research analyzes the domain differences between the defogged image and the clear image in the target feature level, and utilizes a target cumulative vector loss based a target sematic discriminator to guide the refinement of target outline in the defogged image. Thus, the feature enhancement module is implemented to contrast and brightness related NSS features and improve the performance of TCS features about target clearance. The reversed features are constrained to match the CGAN loss and content loss in terms of the information differences between image features and image pixel performance. Our network resolves the interconnections between the traditional method and the convolutional neural network (CNN) module and obtains the enhanced result via the scattering removal and feature enhancement. It is beneficial to solve the dependence of feature learning on synthetic paired training data and the instability of semi-supervision learning in realizing image translation. Abstract features representations is also improved through definite direction and fine granularity related feature learning method. The traditional image enhancement module is optimized to make the best defogged result via parameters adjusting. The feature enhancement module is trained with adaptive moment estimation(ADAM) optimizer for 250 epochs with the momentum takes the values of 0.5 and 0.999. The learning rate is set to 2E-4. And unpaired 270×170 patches randomly cropped from 2 000 defogged real-world images and 2 000 clearance images are taken as the inputs of the generator and discriminator. The train and test processes are carried out by PyTorch in a X86 computer with a core i7 3.0 GHz processor, 64 GB RAM and a NVIDIA 2080ti graphic.ResultOur experimental results are compared with 5 state-of-the-art enhancement methods, including the 2 traditional approaches and 3 deep learning methods on 2 public fog ground truth image datasets called RTTS(real-world task-driven testing set) and foggy driving dense dataset. RTTS dataset contains 4 322 foggy or dim images and foggy driving dense dataset has 21 dense fog online images collection. The quantitative evaluation metrics contain the image quality index and the detection quality index. The quality indexes are composed of the enhanced gradient ratio R and the blind image quality analyzer integrated local natural image quality evaluator(IL-NIQE). The detection indexes are based on mean average precision(MAP) and recall. We also demonstrated more enhanced results of each method for qualitative comparison in the experimental section. In RTTS and foggy driving dense dataset, compared with the method ranking second in each index, the mean R value is improved 50.83%, the mean IL-NIQE value is improved 6.33%, the MAP value is improved 6.40% and the mean Recall value is improved 7.79%. The enhanced results from the proposed method are much similar to clear color, brightness and contrast images qualitatively. The obtained experimental results illustrates that our network can improves the visual quality and machine perception for the foggy image captured in bad weather conditions with more than 50 (frame/s)/Mp as well.ConclusionOur semi-supervision prior hybrid network integrates traditional restoration methods and deep learning based enhancement models for multi-level feature enhancement, achieving the enhancement of NSS features and TCS features. Our illustrations demonstrates our method has its priority for real foggy images in terms of image quality and object detectable ability for intelligent detection system.关键词:foggy image dehazing;feature enhancement;prior hyrid network;semi-supervison learning;image domain translation174|462|2更新时间:2024-05-07 -
 摘要:ObjectiveThe quality of captured images tends to yellowish color distortion, reduced contrast, and detailed information loss in the sand dust atmosphere due to the suspended particles derived incident light absorption and scattering. The issues of outdoor computer vision systems like video surveillance, video navigation and intelligent transportation are severely constrained. Traditional sand dust image enhancement methods are originated from visual perception based sand dust image enhancement and physical model based sand dust image restoration. The visual perception based method is not restricted of the physical imaging model. The visual quality is based on color correction and contrast enhancement. The recovered image still has insufficient color distortion, image brightness and image contrast. Physical models based sand dust image restoration is related to additional assumptions and less prior robustness, complex parameters calculation. Nowadays, existing deep learning-based sand dust image enhancement methods are migrated from the deep learning based haze images methods. Although these methods has achieved good results for haze image processing, the color of the output image still has different degrees of distortion, and the sharpness of the image is also relatively poor in terms of transferred and enhanced sand dust images. An enhanced convolutional neural network (CNN) method of restored color sand dust images can be used to resolve and improve the issues mentioned above.MethodOur proposed network structure consists of a sand dust color correction subnet and a dust removal enhancement subnet. We illustrated a novel sand dust color correction network structure to improve gray world algorithm. First, the proposed sand dust color correction subnet (SDCC) is used to correct the color cast of the sand dust image. The sand dust image is de-composed into 3 channels of R, G, and B. For each channel, a convolutional layer with a convolution kernel size of 3 is used to conducted, and each feature map is processed to obtain color correction image via gray world algorithm. To enhance the sand dust images quality, a benched color-corrected image is transmitted into the dust removal enhancement subnet in the context of adaptive instance normalized-residual blocks (AIN-ResBlock). The dust removal enhancement subnet takes the sand image and the color correction image as input, and uses the adaptive instance normalization module to adaptively restore the color distortion issues in the feature mapping in the dust removal enhancement subnet, and realizes the image sand removal through the residual block. Our AIN-ResBlock is capable to resolve the blurred details and missing image content for the natural color factors of the restored image. Additionally, in view of the difficulty in obtaining pairs of sand dust images and their corresponding clear images as training samples for deep learning, a sand dust image synthesis method is illustrated based on a physical imaging model. Absorb and scatter light to attenuate, and the attenuation degree of light of different colors is different. We optioned 15 color marks close to the color of the sand dust image, and simulate the sand dust image under 15 different conditions, and a large-scale dataset of clear image and sand dust images is finally constructed. Our loss function used is composed of
摘要:ObjectiveThe quality of captured images tends to yellowish color distortion, reduced contrast, and detailed information loss in the sand dust atmosphere due to the suspended particles derived incident light absorption and scattering. The issues of outdoor computer vision systems like video surveillance, video navigation and intelligent transportation are severely constrained. Traditional sand dust image enhancement methods are originated from visual perception based sand dust image enhancement and physical model based sand dust image restoration. The visual perception based method is not restricted of the physical imaging model. The visual quality is based on color correction and contrast enhancement. The recovered image still has insufficient color distortion, image brightness and image contrast. Physical models based sand dust image restoration is related to additional assumptions and less prior robustness, complex parameters calculation. Nowadays, existing deep learning-based sand dust image enhancement methods are migrated from the deep learning based haze images methods. Although these methods has achieved good results for haze image processing, the color of the output image still has different degrees of distortion, and the sharpness of the image is also relatively poor in terms of transferred and enhanced sand dust images. An enhanced convolutional neural network (CNN) method of restored color sand dust images can be used to resolve and improve the issues mentioned above.MethodOur proposed network structure consists of a sand dust color correction subnet and a dust removal enhancement subnet. We illustrated a novel sand dust color correction network structure to improve gray world algorithm. First, the proposed sand dust color correction subnet (SDCC) is used to correct the color cast of the sand dust image. The sand dust image is de-composed into 3 channels of R, G, and B. For each channel, a convolutional layer with a convolution kernel size of 3 is used to conducted, and each feature map is processed to obtain color correction image via gray world algorithm. To enhance the sand dust images quality, a benched color-corrected image is transmitted into the dust removal enhancement subnet in the context of adaptive instance normalized-residual blocks (AIN-ResBlock). The dust removal enhancement subnet takes the sand image and the color correction image as input, and uses the adaptive instance normalization module to adaptively restore the color distortion issues in the feature mapping in the dust removal enhancement subnet, and realizes the image sand removal through the residual block. Our AIN-ResBlock is capable to resolve the blurred details and missing image content for the natural color factors of the restored image. Additionally, in view of the difficulty in obtaining pairs of sand dust images and their corresponding clear images as training samples for deep learning, a sand dust image synthesis method is illustrated based on a physical imaging model. Absorb and scatter light to attenuate, and the attenuation degree of light of different colors is different. We optioned 15 color marks close to the color of the sand dust image, and simulate the sand dust image under 15 different conditions, and a large-scale dataset of clear image and sand dust images is finally constructed. Our loss function used is composed of$ L_1$ $ L_1$ $ e$ $ \bar{γ}$ $ σ$ 关键词:sand dust image;sand dust image enhancement;color correction;adaptive instance normalization residual block;synthetic sand dust image dataset245|446|1更新时间:2024-05-07 -
 摘要:ObjectiveVision-based computer systems can be used to process and analyze acquired images and videos in fuzzy weather like rainy, snowy, sleet or foggy. These image quality degradation issues derived from severe weather conditions will significantly distort the image visual quality and reduce the performance of the computer vision system. Hence, it is important to develop computer image deraining automatic processing algorithms. Our research focuses on the issue of single image based removing rain streaks. The traditional image rain removal model is mainly based on the prior information to remove the rain from the image. It regards the rain image as a combination of the rain layer and the background layer, and defines the separation of the rain layer and the background layer by the image deraining task. Due to the existing differences in related to direction, density, and size of rain streaks in rain images, a single image derived de-raining issue is a challenging computer vision task currently. Deep learning has benefited to de-raining images but existing models has challenges like excessive rain removal or insufficient rain removal on complicated images scenario. The high-frequency edge information of some complex images is erased during the rain removal process, or rain components remaining in the rain removal image. We propose this paper proposes the three-dimension attention and Transformer de-raining network (TDATDN) single image rain removal network, which improves the image rain removal network based on the encoder-decoder architecture and integrates 3D attention, Transformer and encoder-decoder take advantages of the structure to enhance the image to the rain effect. Our training dataset consists of 12 000 pairs of training images (including three types of rain images with different rain densities), and 1 200 test set images are used to test the rain removal effect. The input image size is scaled to 256×256 for training and testing. Adam optimizer is used for training and learning. The initial learning rate is set to 1×10-4, and its network epoch number is 100. The learning rate is multiplied by 0.5 when reach 15 times.MethodOur method melts the three-dimension attention mechanism into the residual dense block structure to resolve the challenge of high-dimensional feature fusion via the residual dense block channel. Then, our proposed three-dimension attention residual dense block as the backbone network to build an encoder-decoder-based architecture image de-raining network, and uses Transformer mechanism to calculate the global contextual relevance of the deep semantic information of the network. The Transformer obtained self-attention feature encoding by is up-sampling operation based on the decoder structure image restoration path. To obtain a rain removal result with richer high-frequency details the up-sampling operation obtains the feature map of the image is spliced in the channel direction with the corresponding encoder-based feature map. For the image high-frequency information loss and the structure information is erased in the rain removal process, our problem solving combines the multi-scale structure similarity loss with the commonly used image de-raining loss function to improve the training of the de-raining network.ResultOur TDATDN network is demonstrated on the Rain12000 rain streaks dataset. Among them, the peak signal to noise ratio (PSNR) reached 33.01 dB, and the structural similarity (SSIM) reached 0.927 8. A comparative experiment was carried out to verify the fusion algorithm results. The result of the comparative experiment illustrated that our algorithm has its priority to improve the effect of a single image oriented rain removing.ConclusionOur image de-raining network takes the advantages of 3D attention mechanism, Transformer and encoder-decoder architecture into account.关键词:single image deraining;convolutional neural network(CNN);Transformer;3D attention;U-Net175|280|4更新时间:2024-05-07
摘要:ObjectiveVision-based computer systems can be used to process and analyze acquired images and videos in fuzzy weather like rainy, snowy, sleet or foggy. These image quality degradation issues derived from severe weather conditions will significantly distort the image visual quality and reduce the performance of the computer vision system. Hence, it is important to develop computer image deraining automatic processing algorithms. Our research focuses on the issue of single image based removing rain streaks. The traditional image rain removal model is mainly based on the prior information to remove the rain from the image. It regards the rain image as a combination of the rain layer and the background layer, and defines the separation of the rain layer and the background layer by the image deraining task. Due to the existing differences in related to direction, density, and size of rain streaks in rain images, a single image derived de-raining issue is a challenging computer vision task currently. Deep learning has benefited to de-raining images but existing models has challenges like excessive rain removal or insufficient rain removal on complicated images scenario. The high-frequency edge information of some complex images is erased during the rain removal process, or rain components remaining in the rain removal image. We propose this paper proposes the three-dimension attention and Transformer de-raining network (TDATDN) single image rain removal network, which improves the image rain removal network based on the encoder-decoder architecture and integrates 3D attention, Transformer and encoder-decoder take advantages of the structure to enhance the image to the rain effect. Our training dataset consists of 12 000 pairs of training images (including three types of rain images with different rain densities), and 1 200 test set images are used to test the rain removal effect. The input image size is scaled to 256×256 for training and testing. Adam optimizer is used for training and learning. The initial learning rate is set to 1×10-4, and its network epoch number is 100. The learning rate is multiplied by 0.5 when reach 15 times.MethodOur method melts the three-dimension attention mechanism into the residual dense block structure to resolve the challenge of high-dimensional feature fusion via the residual dense block channel. Then, our proposed three-dimension attention residual dense block as the backbone network to build an encoder-decoder-based architecture image de-raining network, and uses Transformer mechanism to calculate the global contextual relevance of the deep semantic information of the network. The Transformer obtained self-attention feature encoding by is up-sampling operation based on the decoder structure image restoration path. To obtain a rain removal result with richer high-frequency details the up-sampling operation obtains the feature map of the image is spliced in the channel direction with the corresponding encoder-based feature map. For the image high-frequency information loss and the structure information is erased in the rain removal process, our problem solving combines the multi-scale structure similarity loss with the commonly used image de-raining loss function to improve the training of the de-raining network.ResultOur TDATDN network is demonstrated on the Rain12000 rain streaks dataset. Among them, the peak signal to noise ratio (PSNR) reached 33.01 dB, and the structural similarity (SSIM) reached 0.927 8. A comparative experiment was carried out to verify the fusion algorithm results. The result of the comparative experiment illustrated that our algorithm has its priority to improve the effect of a single image oriented rain removing.ConclusionOur image de-raining network takes the advantages of 3D attention mechanism, Transformer and encoder-decoder architecture into account.关键词:single image deraining;convolutional neural network(CNN);Transformer;3D attention;U-Net175|280|4更新时间:2024-05-07 -
 摘要:ObjectiveImages captured in rainy days are blurred due to the influence of raindrops or rain lines, which directly affects the accuracy of outdoor vision tasks, such as image segmentation, object recognition, and object tracking. Image deraining technology aims to recover the lost details in the target scene by detecting and removing the rain streak information in the rain image. According to the imaging principle of the image, the rain streak information in the image can be regarded as a kind of additive noise. Many traditional methods can use some prior information such as the direction, morphological structure and color of rain lines to remove rain noise and obtain a background layer without rain. However, due to the incomplete detection of rain streak information, many methods cannot completely remove rain streaks, resulting in residual rain streaks in the rain removal results.MethodBased on the existing problems, we propose a rain removal method based on adaptive morphological filtering and multi-scale convolutional sparse coding. First, according to the diversity of the width and length of the rain streak structure, a set of multi-scale structuring element operators is constructed by using the dilation operation in the morphology to filter out the rain streak information in the image. The size of the filter operator determines the degree of filtering. If the size of the filter operator is too large, more information will be filtered out, resulting in the loss of image texture. On the contrary, if the size of the filter operator is too small, the rain streak information cannot be completely filter out, resulting in the residual rain streak information in the image. Therefore, in order to control the degree of morphological filtering and avoid filtering out too much texture information of the image itself, an adaptive morphological filtering method is proposed. The method controls the size of the filter operator by comparing the wavelet filtering results with the morphological filtering results, so as to obtain low-frequency components with less rain streak information and rich texture information. Next, this method aims to preserve the texture information of the image itself in the low-frequency component as much as possible. Therefore, according considering the inevitable loss of image details in image filtering, the steerable total variation (STV) regularization method is used to detect the texture information of the image itself filtered out in the filtering, and supplement it to the low-frequency components. to obtain good deraining results, detecting accurate rain layer information is the key to deraining methods. Based on the above steps, a high frequency component (i.e., rain layer) containing rain streak information the rain layer can be obtained by subtracting the detected low frequency component from the rain image. Then, to further refine the rain layer, we propose a high-frequency separation method based on multi-scale convolution sparse coding (MS-CSC) to reduce the non-rain streak information in the high-frequency components and obtain a more accurate rain layer. In this process, in order to better detect the rain pattern information, by analyzing the falling direction of rain, two gradient constraints for the horizontal direction x and the vertical direction y are constructed to constrain the solution of the rain layer. The rain grain gradient information mainly exists in the x direction, and the gradient information in the y direction is sparse. Therefore, because the gradient information of the rain streaks in the x direction is relatively rich, this paper constructs the gradient sparse term in the x direction by using the difference between the high frequency component and the reconstructed rain layer to ensure the rain streak reconstruction in the main direction y. Since the rain streak gradient information in the y direction is sparse, the gradient sparse term of the rain layer in the y direction is directly constructed to constrain the rain pattern information in the x direction. By combining the CSC method and the constructed two gradient constraints, a directional gradient-regularized MS-CSC model is constructed to solve for an accurate rain layer. In this model, a dictionary needs to be constructed to implement the encoding of the rain layer. According to the diversity of rain streak structures in image scenes, this paper constructs a multi-scale dictionary to encode rain streak information of different sizes by using dictionaries of different sizes. Finally, the image de-rained result (i.e., the background layer) is obtained by subtracting the rain layer from the rain image.ResultTo verify the effectiveness of the proposed method, we compared it with some state-of-the-art deraining methods, including some traditional and deep learning-based methods. Our demonstrated results illustrate that the proposed average peak signal-to-noise ratio(PSNR) and structural similarity(SSIM) index is improved by 0.95 and 0.005 2 based on the simulated dataset. Moreover, our simulation method has its priority of qualitative visual effects and quantitative evaluation indexes.ConclusionThe integrated MS-CSC and adaptive morphological filtering method can remove rain streaks effectively. The recovery image has its clearer edge texture and details after rain removal. Additionally, our deraining algorithm method has strong generalization capability.关键词:image deraining;adaptive morphological filter;total variation model;directional gradient regularization;multi-scale convolution sparse coding(MS-CSC)115|125|0更新时间:2024-05-07
摘要:ObjectiveImages captured in rainy days are blurred due to the influence of raindrops or rain lines, which directly affects the accuracy of outdoor vision tasks, such as image segmentation, object recognition, and object tracking. Image deraining technology aims to recover the lost details in the target scene by detecting and removing the rain streak information in the rain image. According to the imaging principle of the image, the rain streak information in the image can be regarded as a kind of additive noise. Many traditional methods can use some prior information such as the direction, morphological structure and color of rain lines to remove rain noise and obtain a background layer without rain. However, due to the incomplete detection of rain streak information, many methods cannot completely remove rain streaks, resulting in residual rain streaks in the rain removal results.MethodBased on the existing problems, we propose a rain removal method based on adaptive morphological filtering and multi-scale convolutional sparse coding. First, according to the diversity of the width and length of the rain streak structure, a set of multi-scale structuring element operators is constructed by using the dilation operation in the morphology to filter out the rain streak information in the image. The size of the filter operator determines the degree of filtering. If the size of the filter operator is too large, more information will be filtered out, resulting in the loss of image texture. On the contrary, if the size of the filter operator is too small, the rain streak information cannot be completely filter out, resulting in the residual rain streak information in the image. Therefore, in order to control the degree of morphological filtering and avoid filtering out too much texture information of the image itself, an adaptive morphological filtering method is proposed. The method controls the size of the filter operator by comparing the wavelet filtering results with the morphological filtering results, so as to obtain low-frequency components with less rain streak information and rich texture information. Next, this method aims to preserve the texture information of the image itself in the low-frequency component as much as possible. Therefore, according considering the inevitable loss of image details in image filtering, the steerable total variation (STV) regularization method is used to detect the texture information of the image itself filtered out in the filtering, and supplement it to the low-frequency components. to obtain good deraining results, detecting accurate rain layer information is the key to deraining methods. Based on the above steps, a high frequency component (i.e., rain layer) containing rain streak information the rain layer can be obtained by subtracting the detected low frequency component from the rain image. Then, to further refine the rain layer, we propose a high-frequency separation method based on multi-scale convolution sparse coding (MS-CSC) to reduce the non-rain streak information in the high-frequency components and obtain a more accurate rain layer. In this process, in order to better detect the rain pattern information, by analyzing the falling direction of rain, two gradient constraints for the horizontal direction x and the vertical direction y are constructed to constrain the solution of the rain layer. The rain grain gradient information mainly exists in the x direction, and the gradient information in the y direction is sparse. Therefore, because the gradient information of the rain streaks in the x direction is relatively rich, this paper constructs the gradient sparse term in the x direction by using the difference between the high frequency component and the reconstructed rain layer to ensure the rain streak reconstruction in the main direction y. Since the rain streak gradient information in the y direction is sparse, the gradient sparse term of the rain layer in the y direction is directly constructed to constrain the rain pattern information in the x direction. By combining the CSC method and the constructed two gradient constraints, a directional gradient-regularized MS-CSC model is constructed to solve for an accurate rain layer. In this model, a dictionary needs to be constructed to implement the encoding of the rain layer. According to the diversity of rain streak structures in image scenes, this paper constructs a multi-scale dictionary to encode rain streak information of different sizes by using dictionaries of different sizes. Finally, the image de-rained result (i.e., the background layer) is obtained by subtracting the rain layer from the rain image.ResultTo verify the effectiveness of the proposed method, we compared it with some state-of-the-art deraining methods, including some traditional and deep learning-based methods. Our demonstrated results illustrate that the proposed average peak signal-to-noise ratio(PSNR) and structural similarity(SSIM) index is improved by 0.95 and 0.005 2 based on the simulated dataset. Moreover, our simulation method has its priority of qualitative visual effects and quantitative evaluation indexes.ConclusionThe integrated MS-CSC and adaptive morphological filtering method can remove rain streaks effectively. The recovery image has its clearer edge texture and details after rain removal. Additionally, our deraining algorithm method has strong generalization capability.关键词:image deraining;adaptive morphological filter;total variation model;directional gradient regularization;multi-scale convolution sparse coding(MS-CSC)115|125|0更新时间:2024-05-07 -
 摘要:ObjectiveRain streak tends to image degradation, which hinders image restoration, image segmentation and objects orientation. The existing methods are originated from such de-rained methods in related to kernel, low rank approximation and dictionary learning, respectively. The convolutional neural network (CNN) based de-rained image method is commonly facilitated via a single network. It is challenging to remove all rain streaks through a single network due to its multi-shapes, directions and densities.We present a single image rain removal method based on multi scale progressive residual network (MSPRNet).MethodA multiscale progressive rain removal network model is proposed based on the residual network. A multi-scale progressive residual network is facilitated, which consists of 3 sub-networks like preliminary rain removal sub network, residual rain streak removal sub network and image restoration sub network. Each sub-network is designed with different receptive fields to process different scale rain streak images and realize gradual rain removal and image restoration. Specifically, the large-scale rain streak of rain image is first removed through the preliminary rain removal sub network with large receptive field to obtain the rain streak image, and then the rain image is obtained. Next, the rain streaks image and the preliminary rain removal image obtained from the previous sub network are as the input, the residual rain streak is further removed through the residual rain streak removal sub network. Finally, the intermediate rain removal image and the residual rain streaks image are input into the image restoration sub network to recover the information of the partial background image removed in the preliminary rain removal sub network. The image structure information loss in the de-rained imaging process is gradually restored through this progressive network. The sparse residual images are derived of rain streaks and some image structures for each sub-network. The residual image is optioned as the intermediate output of the network, and the de-rained image is obtained through subtracting the trained residual rain streaks image in terms of the input of rain image. Each sub network is mainly composed of attention module and improved residual block module. Therefore, the information on the residual branch of the residual block is not fully utilized in the entire network learning process. Considering that each residual branch of residual network contains important information, A newly residual network structure is harnessed in terms of each residual branch of residual network. Simultaneously, attention mechanism is introduced into each sub network to guide the rain removal of the improved residual network module. Meanwhile, the structure of attention module is simplified and guided to reduce the parameters.ResultOur experiment is compared with the latest 8 methods on 5 commonly synthetic rain image datasets (Rain100L, Rain100H, Rain12, Rain1200 and Rain1400) and a real rain image dataset. As the training dataset, we selected 200 synthetic rain images from Rain100L, 1 800 synthetic rain images from Rain100H, 1 200 synthetic rain images from Rain1200 and 5 600 synthetic rain images from Rain1400. The demonstrated results are evaluated by peak signal to noise ratio (PSNR), structural similarity (SSIM) and feature similarity (FSIM). The PSNR, SSIM and FSIM obtained MSPRNet are 36.50 dB, 0.985 and 0.988 on the Rain100L dataset, 27.75 dB, 0.895 and 0.931 on the Rain100H dataset, 36.31 dB, 0.971 and 0.979 on the Rain12 dataset, 31.80 dB, 0.932 and 0.963 on the Rain1200 dataset, 32.68 dB, 0.959 and 0.968 on the Rain1200 dataset. The SSIM improvements of MSPRNet over the second best method are 0.018, 0.028, 0.012, 0.007 and 0.07, respectively. In addition, further analysis shows that the performance of MSPRNet on SSIM is better than that of PSNR. SSIM measures image similarity from brightness, contrast and structure, and it is more corresponded to human visual sense than PSNR. In addition, the ablation experiment is conducted based on Rain100L dataset. The experimental results demonstrate that the lack of each sub network will lead to the degradation of rain removal performance. Our multi scale progressive network algorithm can deal with the rain removal effect of a single network.ConclusionOur algorithm can obtain good objective evaluation index value and the qualified visual effect. In the process of rain removal, MSPRNet gradually separates the rain streaks from the rainy images to solve rain streaks overlapping issue effectively. Furthermore, the edge information loss is restored in the process of rain removal through the image restoration sub network. MSPRNet can effectively remove the rain streak and maintain the details of the image.关键词:single image de-rained;deep learning;convolutional neural network(CNN);residual network;attention mechanism126|173|4更新时间:2024-05-07
摘要:ObjectiveRain streak tends to image degradation, which hinders image restoration, image segmentation and objects orientation. The existing methods are originated from such de-rained methods in related to kernel, low rank approximation and dictionary learning, respectively. The convolutional neural network (CNN) based de-rained image method is commonly facilitated via a single network. It is challenging to remove all rain streaks through a single network due to its multi-shapes, directions and densities.We present a single image rain removal method based on multi scale progressive residual network (MSPRNet).MethodA multiscale progressive rain removal network model is proposed based on the residual network. A multi-scale progressive residual network is facilitated, which consists of 3 sub-networks like preliminary rain removal sub network, residual rain streak removal sub network and image restoration sub network. Each sub-network is designed with different receptive fields to process different scale rain streak images and realize gradual rain removal and image restoration. Specifically, the large-scale rain streak of rain image is first removed through the preliminary rain removal sub network with large receptive field to obtain the rain streak image, and then the rain image is obtained. Next, the rain streaks image and the preliminary rain removal image obtained from the previous sub network are as the input, the residual rain streak is further removed through the residual rain streak removal sub network. Finally, the intermediate rain removal image and the residual rain streaks image are input into the image restoration sub network to recover the information of the partial background image removed in the preliminary rain removal sub network. The image structure information loss in the de-rained imaging process is gradually restored through this progressive network. The sparse residual images are derived of rain streaks and some image structures for each sub-network. The residual image is optioned as the intermediate output of the network, and the de-rained image is obtained through subtracting the trained residual rain streaks image in terms of the input of rain image. Each sub network is mainly composed of attention module and improved residual block module. Therefore, the information on the residual branch of the residual block is not fully utilized in the entire network learning process. Considering that each residual branch of residual network contains important information, A newly residual network structure is harnessed in terms of each residual branch of residual network. Simultaneously, attention mechanism is introduced into each sub network to guide the rain removal of the improved residual network module. Meanwhile, the structure of attention module is simplified and guided to reduce the parameters.ResultOur experiment is compared with the latest 8 methods on 5 commonly synthetic rain image datasets (Rain100L, Rain100H, Rain12, Rain1200 and Rain1400) and a real rain image dataset. As the training dataset, we selected 200 synthetic rain images from Rain100L, 1 800 synthetic rain images from Rain100H, 1 200 synthetic rain images from Rain1200 and 5 600 synthetic rain images from Rain1400. The demonstrated results are evaluated by peak signal to noise ratio (PSNR), structural similarity (SSIM) and feature similarity (FSIM). The PSNR, SSIM and FSIM obtained MSPRNet are 36.50 dB, 0.985 and 0.988 on the Rain100L dataset, 27.75 dB, 0.895 and 0.931 on the Rain100H dataset, 36.31 dB, 0.971 and 0.979 on the Rain12 dataset, 31.80 dB, 0.932 and 0.963 on the Rain1200 dataset, 32.68 dB, 0.959 and 0.968 on the Rain1200 dataset. The SSIM improvements of MSPRNet over the second best method are 0.018, 0.028, 0.012, 0.007 and 0.07, respectively. In addition, further analysis shows that the performance of MSPRNet on SSIM is better than that of PSNR. SSIM measures image similarity from brightness, contrast and structure, and it is more corresponded to human visual sense than PSNR. In addition, the ablation experiment is conducted based on Rain100L dataset. The experimental results demonstrate that the lack of each sub network will lead to the degradation of rain removal performance. Our multi scale progressive network algorithm can deal with the rain removal effect of a single network.ConclusionOur algorithm can obtain good objective evaluation index value and the qualified visual effect. In the process of rain removal, MSPRNet gradually separates the rain streaks from the rainy images to solve rain streaks overlapping issue effectively. Furthermore, the edge information loss is restored in the process of rain removal through the image restoration sub network. MSPRNet can effectively remove the rain streak and maintain the details of the image.关键词:single image de-rained;deep learning;convolutional neural network(CNN);residual network;attention mechanism126|173|4更新时间:2024-05-07
Image defogging/deraining
-
 摘要:ObjectiveThe backlit image is a kind of redundant reflection derived of the light straightforward to the camera, resulting in dramatic reduced visibility of region of interest (ROI) in the captured image. Different from ordinary low-light images, the backlit image has a wider grayscale range due to the extremely dark and bright parts. Traditional enhancement algorithms restore brightness and details of backlit parts in terms of overexposure and color distortion. Fusion technology or threshold segmentation is difficult to implement sufficient enhancement or adequate segmentation accuracy due to uneven images gray distribution. A transparency-guided backlit image enhancement method is demonstrated based on an improved fusion strategy.MethodThe backlit image enhancing challenge is to segment and restore the backlit region, which is regarded as the foreground and the rest as the background. First, the deep image matting model like encoder-decoder network and refinement network is illustrated. The backlit image and its related trimap are input into the encoder-decoder network to get the preliminary transparency value matrix. The output is melted into the refinement network to calculate the transparency value of each pixel, which constitutes the same scale alpha matte as the original image. The range of transparency value is between 0 and 1, 0 and 1 indicates pixels in the normal exposure region and the backlit region, respectively. The value between 0 and 1 is targeted to the overlapped regions. The alpha matte can be used to substitute the traditional weight map for subsequent fusion processing in terms of processed non-zero pixels. Next, the backlit image is converted into HSV(hue, saturation, value) space to extract the luminance component and the adaptive logarithmic transformation is conducted to enhance brightness in terms of the base value obtained from the number of low-gray image pixels. Contrast-limited adaptive histogram equalization is also adopted to enhance the contrast of the luminance component while logarithmic transformation can only be stretched or compressed gray values. Subsequently, Laplacian pyramid fusion is illustrated on the two improved luminance components. The obtained result was integrated into the original hue component and saturation component and it is converted to RGB space to obtain the global enhanced image. Finally, the alpha matte is used to linearly fuse the source image and the global enhanced image to maintain the brightness of non-backlit area.ResultOur demonstration is compared to existing methods, including histogram equalization (HE), multi-scale Retinex (MSR), zero-reference deep curve estimation(Zero-DCE), attention guided low-light image enhancement(AGLLNet) and learning-based restoration (LBR). Information entropy (IE), blind image quality indicator (BIQI) and natural image quality evaluation (NIQE) are utilized to evaluate the restored image quality. IE is used to measure the richness of image information. The larger the value is, the richer the information and the higher the image quality are. BIQI performs distortion recognition is based on the calculated degradation rate of the image, and a small value represents a high quality image. NIQE compares the image with the designed natural image model, and the lower the value is, the higher the image sharpness is. Both subjective visual effects and objective image quality evaluation indicators are analyzed further. Our qualitatiave analysis can demonstrate better backlit image, no artifacts and natural visual effect, while HE causes color distortion and serious halo phenomenon in non-backlit region. MSR processes the three color channels each to cause the color information loss, Zero-DCE lacks color saturation and the enhancement effect of AGLLNet is not clarified. LBR is limited to segmentation accuracy, leading to color distortion and edge artifacts. Our quantitative algorithm illustrates its priorities in IE, BIQI and NIQE, improving by 0.137 and 3.153 compared with AGLLNet in IE and BIQI, respectively, and 3.5% in NIQE compared with Zero-DCE.ConclusionWe introduced the deep image matting with precise segmentation capability to detect and identify the backlit region. An enhanced image brightness component is obtained via the improved Laplacian pyramid based fusion strategy. Our demonstration improves the brightness and contrast of the backlit image and restores the details and color information. The over-exposure and insufficient enhancement can be resolved further. Artifacts and distortion issues are not involved in our algorithm, and the improvement of objective quality evaluation index validates the backlight image enhancement.关键词:image processing;backlight image enhancement;deep image matting;gray stretching;pyramid fusion198|269|4更新时间:2024-05-07
摘要:ObjectiveThe backlit image is a kind of redundant reflection derived of the light straightforward to the camera, resulting in dramatic reduced visibility of region of interest (ROI) in the captured image. Different from ordinary low-light images, the backlit image has a wider grayscale range due to the extremely dark and bright parts. Traditional enhancement algorithms restore brightness and details of backlit parts in terms of overexposure and color distortion. Fusion technology or threshold segmentation is difficult to implement sufficient enhancement or adequate segmentation accuracy due to uneven images gray distribution. A transparency-guided backlit image enhancement method is demonstrated based on an improved fusion strategy.MethodThe backlit image enhancing challenge is to segment and restore the backlit region, which is regarded as the foreground and the rest as the background. First, the deep image matting model like encoder-decoder network and refinement network is illustrated. The backlit image and its related trimap are input into the encoder-decoder network to get the preliminary transparency value matrix. The output is melted into the refinement network to calculate the transparency value of each pixel, which constitutes the same scale alpha matte as the original image. The range of transparency value is between 0 and 1, 0 and 1 indicates pixels in the normal exposure region and the backlit region, respectively. The value between 0 and 1 is targeted to the overlapped regions. The alpha matte can be used to substitute the traditional weight map for subsequent fusion processing in terms of processed non-zero pixels. Next, the backlit image is converted into HSV(hue, saturation, value) space to extract the luminance component and the adaptive logarithmic transformation is conducted to enhance brightness in terms of the base value obtained from the number of low-gray image pixels. Contrast-limited adaptive histogram equalization is also adopted to enhance the contrast of the luminance component while logarithmic transformation can only be stretched or compressed gray values. Subsequently, Laplacian pyramid fusion is illustrated on the two improved luminance components. The obtained result was integrated into the original hue component and saturation component and it is converted to RGB space to obtain the global enhanced image. Finally, the alpha matte is used to linearly fuse the source image and the global enhanced image to maintain the brightness of non-backlit area.ResultOur demonstration is compared to existing methods, including histogram equalization (HE), multi-scale Retinex (MSR), zero-reference deep curve estimation(Zero-DCE), attention guided low-light image enhancement(AGLLNet) and learning-based restoration (LBR). Information entropy (IE), blind image quality indicator (BIQI) and natural image quality evaluation (NIQE) are utilized to evaluate the restored image quality. IE is used to measure the richness of image information. The larger the value is, the richer the information and the higher the image quality are. BIQI performs distortion recognition is based on the calculated degradation rate of the image, and a small value represents a high quality image. NIQE compares the image with the designed natural image model, and the lower the value is, the higher the image sharpness is. Both subjective visual effects and objective image quality evaluation indicators are analyzed further. Our qualitatiave analysis can demonstrate better backlit image, no artifacts and natural visual effect, while HE causes color distortion and serious halo phenomenon in non-backlit region. MSR processes the three color channels each to cause the color information loss, Zero-DCE lacks color saturation and the enhancement effect of AGLLNet is not clarified. LBR is limited to segmentation accuracy, leading to color distortion and edge artifacts. Our quantitative algorithm illustrates its priorities in IE, BIQI and NIQE, improving by 0.137 and 3.153 compared with AGLLNet in IE and BIQI, respectively, and 3.5% in NIQE compared with Zero-DCE.ConclusionWe introduced the deep image matting with precise segmentation capability to detect and identify the backlit region. An enhanced image brightness component is obtained via the improved Laplacian pyramid based fusion strategy. Our demonstration improves the brightness and contrast of the backlit image and restores the details and color information. The over-exposure and insufficient enhancement can be resolved further. Artifacts and distortion issues are not involved in our algorithm, and the improvement of objective quality evaluation index validates the backlight image enhancement.关键词:image processing;backlight image enhancement;deep image matting;gray stretching;pyramid fusion198|269|4更新时间:2024-05-07 -
 摘要:ObjectiveLow-light images capturing is common used in the night or dark scenario. In a low-light imaging scenario, the number of photons penetrating the lens is tiny, resulting in poor image quality, poor visibility, low contrast, more noise, and color distortion. Low-light images constrain many subsequent image processing tasks on the aspects of image classification, target recognition, intelligent monitoring and object recognition. The current low-light level image enhancement technology has mainly two challenging issues as following: 1) space-independent image brightness; 2) non-uniform noise. The spatial feature distribution of real low-light images is complex, and the number of penetrating photons varies greatly at different spatial positions, resulting in strong light-related variability in the image space. Existing deep learning methods can effectively improve the illumination characteristics in artificially generated datasets, but the overall image visibility and the enhancement effect of underexposed areas need to be improved for the space-restricted low illumination. For instance, de-noising will ignore some image details before image enhancement. It is difficult to reconstruct high-noise pixel information, and de-noising will easily lead to blurred images after enhancement. Our attention mechanism and contextual information based low-light image enhancement method can fully enhance the image to suppress potential noise and maintain color consistency.MethodOur demonstration constructs an end-to-end low-light enhancement network, using U-Net as the basic framework, which mainly includes channel attention modules, encoders, decoders, cross-scale context modules and feature fusion modules. The backbone network is mainly guided by mixed attention block. The input is the low-light image to be enhanced, and the output is an enhanced high-quality noise-free color image of the same size. After the low-light enhancement network extracts the shallow features of the input original low-light image, it first uses the channel attention module to learn the weight of each channel, and assigns more weight to the useful color information channel to extract more effective image color features. Then, the channel weight and the original low-light image are used as the input of the encoder, and the semantic features of the image are extracted by the mixed attention block. Mixed attention block extracts input features from spatial information and channel information respectively. It is beneficial to restore the brightness and color information of the image and noise suppression via the location of noise in the image and the color features of different channels. In the decoder part, the de-convolution module restores the semantic features extracted by mixed attention block to high-resolution images. In addition, a cross-scale context module is designed to fuse cross-scale skip connections based on the skip connections performed on the corresponding scale features of conventional encoders and decoders.ResultIn respect of qualitative evaluation, our method is slightly higher than the reference image in fitting the overall contrast of the image, but it is better than all other contrast methods in terms of color details and noise suppression. In terms of quantitative evaluation indicators of image quality, including peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and perceptual image patch similarity (LPIPS). The methods proposed in this paper have also achieved excellent results, which are 0.74 dB, 0.153 and 0.172 higher than the optimal values of other methods. The results show that our proposed method can enhance the brightness of the image and maintain the consistency of the image color, better remove the influence of noise in the dark area of the image, and naturally retain the texture details of the image.ConclusionOur method has its priority in brightness enhancement, noise suppression, image texture structure and color consistency.关键词:image processing;low-light image enhancement;deep learning;attention mechanism;contextual information92|336|5更新时间:2024-05-07
摘要:ObjectiveLow-light images capturing is common used in the night or dark scenario. In a low-light imaging scenario, the number of photons penetrating the lens is tiny, resulting in poor image quality, poor visibility, low contrast, more noise, and color distortion. Low-light images constrain many subsequent image processing tasks on the aspects of image classification, target recognition, intelligent monitoring and object recognition. The current low-light level image enhancement technology has mainly two challenging issues as following: 1) space-independent image brightness; 2) non-uniform noise. The spatial feature distribution of real low-light images is complex, and the number of penetrating photons varies greatly at different spatial positions, resulting in strong light-related variability in the image space. Existing deep learning methods can effectively improve the illumination characteristics in artificially generated datasets, but the overall image visibility and the enhancement effect of underexposed areas need to be improved for the space-restricted low illumination. For instance, de-noising will ignore some image details before image enhancement. It is difficult to reconstruct high-noise pixel information, and de-noising will easily lead to blurred images after enhancement. Our attention mechanism and contextual information based low-light image enhancement method can fully enhance the image to suppress potential noise and maintain color consistency.MethodOur demonstration constructs an end-to-end low-light enhancement network, using U-Net as the basic framework, which mainly includes channel attention modules, encoders, decoders, cross-scale context modules and feature fusion modules. The backbone network is mainly guided by mixed attention block. The input is the low-light image to be enhanced, and the output is an enhanced high-quality noise-free color image of the same size. After the low-light enhancement network extracts the shallow features of the input original low-light image, it first uses the channel attention module to learn the weight of each channel, and assigns more weight to the useful color information channel to extract more effective image color features. Then, the channel weight and the original low-light image are used as the input of the encoder, and the semantic features of the image are extracted by the mixed attention block. Mixed attention block extracts input features from spatial information and channel information respectively. It is beneficial to restore the brightness and color information of the image and noise suppression via the location of noise in the image and the color features of different channels. In the decoder part, the de-convolution module restores the semantic features extracted by mixed attention block to high-resolution images. In addition, a cross-scale context module is designed to fuse cross-scale skip connections based on the skip connections performed on the corresponding scale features of conventional encoders and decoders.ResultIn respect of qualitative evaluation, our method is slightly higher than the reference image in fitting the overall contrast of the image, but it is better than all other contrast methods in terms of color details and noise suppression. In terms of quantitative evaluation indicators of image quality, including peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and perceptual image patch similarity (LPIPS). The methods proposed in this paper have also achieved excellent results, which are 0.74 dB, 0.153 and 0.172 higher than the optimal values of other methods. The results show that our proposed method can enhance the brightness of the image and maintain the consistency of the image color, better remove the influence of noise in the dark area of the image, and naturally retain the texture details of the image.ConclusionOur method has its priority in brightness enhancement, noise suppression, image texture structure and color consistency.关键词:image processing;low-light image enhancement;deep learning;attention mechanism;contextual information92|336|5更新时间:2024-05-07 -
 摘要:ObjectiveSuspended particles will absorb and scatter light in seawater. It tends to be low contrast and intensive color distortion due to the attenuated multi-wavelengths for underwater robots based images capturing. Deep learning based underwater image enhancement is facilitated to resolve this issue of unclear acquired images recently. Compared to the traditional methods, convolutional neural network(CNN) based underwater image processing has its priority in quality improvement qualitatively and quantitatively. A basic-based method generates its relevant high-quality images via a low-quality underwater image processing. The single network is challenging to obtain multi-dimensional features. For instance, the color is intensively biased in some CNN-based methods and the enhanced images are sometimes over-smoothed, which will have great impact on the following computer vision tasks like objective detection and segmentation. Some networks utilize the depth maps to enhance the underwater images, but it is a challenge to obtain accurate depth maps.MethodA multi-residual learning network is demonstrated to enhance underwater images. Our framework is composed of 3 modules in the context of pre-processing, feature extraction, and feature fusion. In the pre-processing module, the sigmoid correction is handled to pre-process the contrast of the degraded image, producing a strong contrast modified image. Next, a two-branch network is designated for feature extraction. The degraded image is fed into branch 1, i.e., the residual channel attention branch network where channel attention modules are incorporated to emphasize the efficient features. Meanwhile, the modified image and the degraded image are concatenated and transferred to branch 2, i.e., the residual enhancement branch network where structures and edges of the images are preserved and enhanced based on stacked residual blocks and dense connection. Finally, the feature fusion module conducts generated features collection for further fusion. The generated features penetrate into several residual blocks for enhancement based on feature extraction modules. An adaptive mask is then applied to the enhanced features and the outputs of branch 1. Similarly, the outputs of branch 1 and branch 2 are also processed by the adaptive mask. At the end, all results from the masks are added for final image reconstruction. To train our network, we introduce a loss function that includes content perception, mean square error, gradient, and structural similarity (SSIM) for end-to-end training.ResultWe use 800 images as the training dataset based on the regular underwater image benchmark dataset (UIEB) and 90 UIEB-based referenced images as the test dataset. Our proposed scheme is tailored to underwater image enhancement methods, including the model-free methods, the physical model-based methods, as well as the deep learning-based methods. Two reference indexes including peak signal-to-noise ratio (PSNR) and SSIM, and a non-reference index underwater image quality measure (UIQM) are employed to evaluate the enhancement results. The demonstrated results illustrate that our method achieves averaged PSNR of 20.739 4 dB, averaged SSIM of 0.876 8, and averaged UIQM of 3.183 3. Specifically, our method plays well in UIQM, which is an essential underwater image quality measurement index and reflects the color, sharpness, and contrast of underwater images straightforward. Moreover, our method achieves the smallest standard deviation of all compared methods, indicating the robustness of our proposed method.ConclusionWe visualize the enhanced underwater images for qualitative evaluation. Our analyzed results improve the color and contrast and preserve rich textures for the enhanced images with no over-exposing and over-smoothing effect. Our method is beneficial to blueish images quality improvement in deep water scenarios.关键词:convolutional neural network(CNN);dense concatenation network;underwater image enhancement;feature extraction;channel attention80|190|0更新时间:2024-05-07
摘要:ObjectiveSuspended particles will absorb and scatter light in seawater. It tends to be low contrast and intensive color distortion due to the attenuated multi-wavelengths for underwater robots based images capturing. Deep learning based underwater image enhancement is facilitated to resolve this issue of unclear acquired images recently. Compared to the traditional methods, convolutional neural network(CNN) based underwater image processing has its priority in quality improvement qualitatively and quantitatively. A basic-based method generates its relevant high-quality images via a low-quality underwater image processing. The single network is challenging to obtain multi-dimensional features. For instance, the color is intensively biased in some CNN-based methods and the enhanced images are sometimes over-smoothed, which will have great impact on the following computer vision tasks like objective detection and segmentation. Some networks utilize the depth maps to enhance the underwater images, but it is a challenge to obtain accurate depth maps.MethodA multi-residual learning network is demonstrated to enhance underwater images. Our framework is composed of 3 modules in the context of pre-processing, feature extraction, and feature fusion. In the pre-processing module, the sigmoid correction is handled to pre-process the contrast of the degraded image, producing a strong contrast modified image. Next, a two-branch network is designated for feature extraction. The degraded image is fed into branch 1, i.e., the residual channel attention branch network where channel attention modules are incorporated to emphasize the efficient features. Meanwhile, the modified image and the degraded image are concatenated and transferred to branch 2, i.e., the residual enhancement branch network where structures and edges of the images are preserved and enhanced based on stacked residual blocks and dense connection. Finally, the feature fusion module conducts generated features collection for further fusion. The generated features penetrate into several residual blocks for enhancement based on feature extraction modules. An adaptive mask is then applied to the enhanced features and the outputs of branch 1. Similarly, the outputs of branch 1 and branch 2 are also processed by the adaptive mask. At the end, all results from the masks are added for final image reconstruction. To train our network, we introduce a loss function that includes content perception, mean square error, gradient, and structural similarity (SSIM) for end-to-end training.ResultWe use 800 images as the training dataset based on the regular underwater image benchmark dataset (UIEB) and 90 UIEB-based referenced images as the test dataset. Our proposed scheme is tailored to underwater image enhancement methods, including the model-free methods, the physical model-based methods, as well as the deep learning-based methods. Two reference indexes including peak signal-to-noise ratio (PSNR) and SSIM, and a non-reference index underwater image quality measure (UIQM) are employed to evaluate the enhancement results. The demonstrated results illustrate that our method achieves averaged PSNR of 20.739 4 dB, averaged SSIM of 0.876 8, and averaged UIQM of 3.183 3. Specifically, our method plays well in UIQM, which is an essential underwater image quality measurement index and reflects the color, sharpness, and contrast of underwater images straightforward. Moreover, our method achieves the smallest standard deviation of all compared methods, indicating the robustness of our proposed method.ConclusionWe visualize the enhanced underwater images for qualitative evaluation. Our analyzed results improve the color and contrast and preserve rich textures for the enhanced images with no over-exposing and over-smoothing effect. Our method is beneficial to blueish images quality improvement in deep water scenarios.关键词:convolutional neural network(CNN);dense concatenation network;underwater image enhancement;feature extraction;channel attention80|190|0更新时间:2024-05-07 -
 摘要:ObjectiveDigital photos have been evolved in human life. However, backlight images are captured due to its unidentified factors in the context of its scenarios. Without careful control of lighting, important objects can disappear in the backlight areas, causing backlight images to become a fatal problem of image quality degradation. The theoretical cause of backlight image is that the object being photographed is located right between the light source and the shooting lens, the overall dynamic range of the light in the same picture is extremely large. Due to the limitation of the photosensitive element, the general camera cannot incorporate all the levels of detail into the latitude range, resulting in poor shooting results, which further causes problems such as barren visual quality of the entire image, color degradation of meaningful areas and loss of detail information in the image. Current image enhancement methods are focused on the aspect of global enhancement, and there is an issue of excessive enhancement or insufficient enhancement for backlight images. Moreover, deep learning based image enhancement method is mainly related to the low-illumination image enhancement task, which cannot take the backlight images enhancement of underexposed and overexposed regions into account simultaneously. We illustrate an attention-based backlight image enhancement network (ABIEN), which can resolve non-pairing image sets via learning the pixel-wise mapping relationship between the backlight image and the enhanced image, and facilitate network training to enhance underexposed and overexposed regions.MethodFirst, our demonstrated network is designated to learn the mapping parameters between the backlight image and the restored image to obtain paired datasets in an iterative way, and the enhanced image is obtained based on learned mapping parameters to transform the backlight image. Pixel-level parameters avoid the disadvantages of the previous methods without distinction enhancement and achieve targeted enhancement. Next, in order to enhance the underexposed region and suppress the overexposed region, the attention mechanism is carried out to focus on the two aspects of trained network. Experiments show that the attention mechanism in the network can distinguish the underexposed region and overexposed region in the backlight image more accurately, and promote the optimal mapping parameters generated by the network. Finally, in order to solve the problems of artifact and halo in most image restoration works, we harness a strategy of retaining the original resolution to extract the features of each depth of the backboned network. The feature information extraction based on this strategy solves the problem of poor feature information caused by single scale resolution. Besides, the artifact and halo issues can be further deducted.ResultIn comparison of multi-scale retinex with color restoration (MSRCR), fusion-based method(Fusion-based), learning-based restoration(Learning-based), naturalness preserved enhancement algorithm (NPEA) and exposure correction network (ExCNet) methods, our demonstration is focused on enhanced image exposure more, which are more real color retention and fewer artifacts. Lightness order error (LOE), visibility level descriptor (VLD) and contrast-distorted image quality assessment (CDIQA) are utilized to evaluate the image quality restored by different methods. LOE index is used to evaluate the changes of image brightness order statistics caused by halo, artifact, contour and ringing, which affect the visual perception quality of the image. The smaller LOE value is, the better the restoration method is. VLD is computing the ratio between the gradient of the visible edges between the image before and after the restoration method, and the higher value of VLD means the better visual quality of the image. CDIQA can be regarded as an indicator to evaluate the content richness of an image. A high CDIQA value indicates better image quality. By comparing the proposed method with others, it is proved that our LOE value, VLD and CDIQA indicators have their priority both. The processing running speed of our method is relatively faster which can meet the real-time application in real scenario.ConclusionOur backlight image enhancement method can melt the attention mechanism and the original resolution retention strategy into the feature learning at all layers of the network and mine the detailed information overall. Subjective and objective evaluations were conducted to corroborate the superiority of the proposed approach over the others. The experimental results show that the proposed enhancement method can satisfactorily rectify the underexposure and overexposure problems that coexist in backlight images, demonstrating its superiority in restoring image details over the other competitors. Additionally, the artifacts in the image are effectively suppressed, both backlight and non-backlight regions without introducing annoying side effects. A high processing efficiency makes the proposed method have a good application prospect.关键词:backlight image;image enhancement;convolutional neural network(CNN);attention mechanism;zero-referencesample235|581|4更新时间:2024-05-07
摘要:ObjectiveDigital photos have been evolved in human life. However, backlight images are captured due to its unidentified factors in the context of its scenarios. Without careful control of lighting, important objects can disappear in the backlight areas, causing backlight images to become a fatal problem of image quality degradation. The theoretical cause of backlight image is that the object being photographed is located right between the light source and the shooting lens, the overall dynamic range of the light in the same picture is extremely large. Due to the limitation of the photosensitive element, the general camera cannot incorporate all the levels of detail into the latitude range, resulting in poor shooting results, which further causes problems such as barren visual quality of the entire image, color degradation of meaningful areas and loss of detail information in the image. Current image enhancement methods are focused on the aspect of global enhancement, and there is an issue of excessive enhancement or insufficient enhancement for backlight images. Moreover, deep learning based image enhancement method is mainly related to the low-illumination image enhancement task, which cannot take the backlight images enhancement of underexposed and overexposed regions into account simultaneously. We illustrate an attention-based backlight image enhancement network (ABIEN), which can resolve non-pairing image sets via learning the pixel-wise mapping relationship between the backlight image and the enhanced image, and facilitate network training to enhance underexposed and overexposed regions.MethodFirst, our demonstrated network is designated to learn the mapping parameters between the backlight image and the restored image to obtain paired datasets in an iterative way, and the enhanced image is obtained based on learned mapping parameters to transform the backlight image. Pixel-level parameters avoid the disadvantages of the previous methods without distinction enhancement and achieve targeted enhancement. Next, in order to enhance the underexposed region and suppress the overexposed region, the attention mechanism is carried out to focus on the two aspects of trained network. Experiments show that the attention mechanism in the network can distinguish the underexposed region and overexposed region in the backlight image more accurately, and promote the optimal mapping parameters generated by the network. Finally, in order to solve the problems of artifact and halo in most image restoration works, we harness a strategy of retaining the original resolution to extract the features of each depth of the backboned network. The feature information extraction based on this strategy solves the problem of poor feature information caused by single scale resolution. Besides, the artifact and halo issues can be further deducted.ResultIn comparison of multi-scale retinex with color restoration (MSRCR), fusion-based method(Fusion-based), learning-based restoration(Learning-based), naturalness preserved enhancement algorithm (NPEA) and exposure correction network (ExCNet) methods, our demonstration is focused on enhanced image exposure more, which are more real color retention and fewer artifacts. Lightness order error (LOE), visibility level descriptor (VLD) and contrast-distorted image quality assessment (CDIQA) are utilized to evaluate the image quality restored by different methods. LOE index is used to evaluate the changes of image brightness order statistics caused by halo, artifact, contour and ringing, which affect the visual perception quality of the image. The smaller LOE value is, the better the restoration method is. VLD is computing the ratio between the gradient of the visible edges between the image before and after the restoration method, and the higher value of VLD means the better visual quality of the image. CDIQA can be regarded as an indicator to evaluate the content richness of an image. A high CDIQA value indicates better image quality. By comparing the proposed method with others, it is proved that our LOE value, VLD and CDIQA indicators have their priority both. The processing running speed of our method is relatively faster which can meet the real-time application in real scenario.ConclusionOur backlight image enhancement method can melt the attention mechanism and the original resolution retention strategy into the feature learning at all layers of the network and mine the detailed information overall. Subjective and objective evaluations were conducted to corroborate the superiority of the proposed approach over the others. The experimental results show that the proposed enhancement method can satisfactorily rectify the underexposure and overexposure problems that coexist in backlight images, demonstrating its superiority in restoring image details over the other competitors. Additionally, the artifacts in the image are effectively suppressed, both backlight and non-backlight regions without introducing annoying side effects. A high processing efficiency makes the proposed method have a good application prospect.关键词:backlight image;image enhancement;convolutional neural network(CNN);attention mechanism;zero-referencesample235|581|4更新时间:2024-05-07
Low illumination image enhancement
-
 摘要:ObjectiveSingle image super-resolution (SISR) aims to restore a high-resolution (HR) image through adding high-frequency details to its corresponding low-resolution (LR). Such application scenarios like medical imaging and remote sensing harness super-resolve LR images to multiple scales to customize the accuracy requirement. Moreover, these scales should not be restricted to integers but arbitrary positive numbers. However, a scalable super-resolution(SR) model training will leak a high computational and storage cost. Hence, it is of great significance to construct a single SR model that can process arbitrary scale factors. Deep learning technology has greatly improved the performance of SISR, but most of them are designed for specific integer scale factors. Early pre-sampling methods like the super-resolution convolutional neural network (SRCNN) can achieve continuous-scale upsampling but low computational efficiency. The post-upsampling methods use the deconvolutional or sub-pixel layer of the final step of network to obtain upsampling. However, the structure of the sub-pixel layer and deconvolutional layer is related to the scale factor, resulting in the SR network just be trained for a single scale factor each time. multi-scale deep super-resolution (MDSR) uses multiple upsampling branches to process different scale factors, but it can only super-resolve trained integer scales. Meta super-resolution (Meta-SR) is the first scale-arbitrary SR network that builds a meta-upsampling module. The meta-upsampling module uses a fully connected network to dynamically predict the weights of feature mapping in the span of the LR space and HR space. However, the Meta-SR upsampling module has high computational complexity and the number of parameters in the feature extraction part is extremely huge.MethodWe illustrated a cross-scale coupling network (CSCN) for continuous-scale image SR. First, we devise a fully convolutional cross-scale coupled upsampling (CSC-Up) module to reach potential decimal scale efficient and end-to-end results. Our strategy is a continuous-scale upsampling module construction through coupling features of multiple scales. The CSC-up module first maps LR features to multiple HR spaces based on a variety of multiscales derived of multiple upsampling branches. Then, the features of multiple HR spaces are adaptively fused to obtain the SR image of the targeted scale. The CSC-Up module can be easily plugged into existing SR networks. We only need to replace the original upsampling module with our CSC-Up module to obtain a continuous-scale SR network. Second, multi-scale features extraction is beneficial to SR tasks. We facilitate a novel cross-scale convolutional (CS-Conv) layer, which can adaptively extract and couple features from multiple scales and exploit cross-scale contextual information. In addition, we utilize a feedback mechanism in the cross-scale feature learning part, using high-level features to refine low-level ones. Such a recurrent structure can increase the capacity of the network without the number of parameters generated. We train our model on the 800 images of diverse 2K resalution(DIV2K) dataset. In the training step, we randomly crop LR patches of size 32×32 as inputs. The input LR patches are generated based on the bicubic downsampling model and rotated or flipped for data augmentation in random. Our model is trained for 400 epochs with a mini-batch size of 16, and each epoch contains 1 000 iterations. The initial learning rate is 1×10-3 and halves at the 1.5×105, 2.5×105 and 3.5×105 iterations. Our demonstration is implemented based on the PyTorch framework and one Telsa V100 GPU training.ResultOur method is in comparison with two state-of-the-art (SotA) continuous-scale SR methods, Meta-EDSR(enhanced deep super-resolution) and Meta-RDN. Meanwhile, we define a new benchmark via bicubic resampling the output of a residual dense network (RDN) to the target size, named Bi-RDN. To verify the generality of our CSC-Up module, we replace the original upsampling layer of the RDN with a CSC-Up module and construct a continuous-scale RDN (CS-RDN). We also use the self-ensemble method to further improve the performance of CSCN, named CSCN+. The quantitative evaluation metrics in related to peak signal-to-noise ratio (PSNR) and structure similarity index metric (SSIM). Our CSCN obtains comparable results with Meta-RDN, and CSCN+ obtains the good results on all scale factors. CS-RDN also obtains satisfactory results, demonstrating that the proposed CSC-Up module can be well adapted to the existing SR methods and obtain satisfactory non-integer SR results. We also compare our CSCN with six SotA methods on integer scale factors, including super-resolution convolutional neural network(SRCNN), coarse-to-fine SRCNN (CFSRCNN), RDN, SR feedback network (SRFBN), iterative SR network (ISRN), and meta-RDN, respectively. Comparing the results of RDN and CS-RDN, we sort out that our CSC-Up module can achieve comparable or better results to that of a single-scale upsampling module. Meanwhile, our proposed CSCN and CS-RDN can be trained once and release a single model. Our proposed CSCN uses a simpler and more efficient continuous-scale upsampling module and obtains corresponding results with Meta-SR. CSCN+ achieves the best performance on all datasets and scales. Moreover, the number of parameters in our model is 6 M, which is only 27% of Meta-RDN (22 M). Benefiting from the feedback structure, our method can well balance the number of network parameters and model performance. Thus, our proposed CSCN and CSCN+ are prior to comparing SotAs.ConclusionWe propose a novel CSC-Up model that can be easily plugged into the existing SR networks to activate the continuous-scale SR. We also introduce a CS-Conv layer to learn scale-robust features and adopt feedback connections to design a lightweight CSCN. Compared with the previous single-scale SR networks, the proposed CSCN tends to time efficiency and suitable model storage space.关键词:deep learning;single image super-resolution(SISR);continuous-scale;cross-scale coupling;cross-scale convolution66|142|2更新时间:2024-05-07
摘要:ObjectiveSingle image super-resolution (SISR) aims to restore a high-resolution (HR) image through adding high-frequency details to its corresponding low-resolution (LR). Such application scenarios like medical imaging and remote sensing harness super-resolve LR images to multiple scales to customize the accuracy requirement. Moreover, these scales should not be restricted to integers but arbitrary positive numbers. However, a scalable super-resolution(SR) model training will leak a high computational and storage cost. Hence, it is of great significance to construct a single SR model that can process arbitrary scale factors. Deep learning technology has greatly improved the performance of SISR, but most of them are designed for specific integer scale factors. Early pre-sampling methods like the super-resolution convolutional neural network (SRCNN) can achieve continuous-scale upsampling but low computational efficiency. The post-upsampling methods use the deconvolutional or sub-pixel layer of the final step of network to obtain upsampling. However, the structure of the sub-pixel layer and deconvolutional layer is related to the scale factor, resulting in the SR network just be trained for a single scale factor each time. multi-scale deep super-resolution (MDSR) uses multiple upsampling branches to process different scale factors, but it can only super-resolve trained integer scales. Meta super-resolution (Meta-SR) is the first scale-arbitrary SR network that builds a meta-upsampling module. The meta-upsampling module uses a fully connected network to dynamically predict the weights of feature mapping in the span of the LR space and HR space. However, the Meta-SR upsampling module has high computational complexity and the number of parameters in the feature extraction part is extremely huge.MethodWe illustrated a cross-scale coupling network (CSCN) for continuous-scale image SR. First, we devise a fully convolutional cross-scale coupled upsampling (CSC-Up) module to reach potential decimal scale efficient and end-to-end results. Our strategy is a continuous-scale upsampling module construction through coupling features of multiple scales. The CSC-up module first maps LR features to multiple HR spaces based on a variety of multiscales derived of multiple upsampling branches. Then, the features of multiple HR spaces are adaptively fused to obtain the SR image of the targeted scale. The CSC-Up module can be easily plugged into existing SR networks. We only need to replace the original upsampling module with our CSC-Up module to obtain a continuous-scale SR network. Second, multi-scale features extraction is beneficial to SR tasks. We facilitate a novel cross-scale convolutional (CS-Conv) layer, which can adaptively extract and couple features from multiple scales and exploit cross-scale contextual information. In addition, we utilize a feedback mechanism in the cross-scale feature learning part, using high-level features to refine low-level ones. Such a recurrent structure can increase the capacity of the network without the number of parameters generated. We train our model on the 800 images of diverse 2K resalution(DIV2K) dataset. In the training step, we randomly crop LR patches of size 32×32 as inputs. The input LR patches are generated based on the bicubic downsampling model and rotated or flipped for data augmentation in random. Our model is trained for 400 epochs with a mini-batch size of 16, and each epoch contains 1 000 iterations. The initial learning rate is 1×10-3 and halves at the 1.5×105, 2.5×105 and 3.5×105 iterations. Our demonstration is implemented based on the PyTorch framework and one Telsa V100 GPU training.ResultOur method is in comparison with two state-of-the-art (SotA) continuous-scale SR methods, Meta-EDSR(enhanced deep super-resolution) and Meta-RDN. Meanwhile, we define a new benchmark via bicubic resampling the output of a residual dense network (RDN) to the target size, named Bi-RDN. To verify the generality of our CSC-Up module, we replace the original upsampling layer of the RDN with a CSC-Up module and construct a continuous-scale RDN (CS-RDN). We also use the self-ensemble method to further improve the performance of CSCN, named CSCN+. The quantitative evaluation metrics in related to peak signal-to-noise ratio (PSNR) and structure similarity index metric (SSIM). Our CSCN obtains comparable results with Meta-RDN, and CSCN+ obtains the good results on all scale factors. CS-RDN also obtains satisfactory results, demonstrating that the proposed CSC-Up module can be well adapted to the existing SR methods and obtain satisfactory non-integer SR results. We also compare our CSCN with six SotA methods on integer scale factors, including super-resolution convolutional neural network(SRCNN), coarse-to-fine SRCNN (CFSRCNN), RDN, SR feedback network (SRFBN), iterative SR network (ISRN), and meta-RDN, respectively. Comparing the results of RDN and CS-RDN, we sort out that our CSC-Up module can achieve comparable or better results to that of a single-scale upsampling module. Meanwhile, our proposed CSCN and CS-RDN can be trained once and release a single model. Our proposed CSCN uses a simpler and more efficient continuous-scale upsampling module and obtains corresponding results with Meta-SR. CSCN+ achieves the best performance on all datasets and scales. Moreover, the number of parameters in our model is 6 M, which is only 27% of Meta-RDN (22 M). Benefiting from the feedback structure, our method can well balance the number of network parameters and model performance. Thus, our proposed CSCN and CSCN+ are prior to comparing SotAs.ConclusionWe propose a novel CSC-Up model that can be easily plugged into the existing SR networks to activate the continuous-scale SR. We also introduce a CS-Conv layer to learn scale-robust features and adopt feedback connections to design a lightweight CSCN. Compared with the previous single-scale SR networks, the proposed CSCN tends to time efficiency and suitable model storage space.关键词:deep learning;single image super-resolution(SISR);continuous-scale;cross-scale coupling;cross-scale convolution66|142|2更新时间:2024-05-07 -
 摘要:ObjectiveSingle image super-resolution is an essential task for vision applications to enhance the spatial resolution based image quality in the context of computer vision. Deep learning based methods are beneficial to single image super-resolution nowadays. Low-resolution images are regarded as clear images without blur effects. However, low-resolution images in real scenes are constrained of blur artifacts factors like camera shake and object motion. The degradation derived blur artifacts could be amplified in the super-resolution reconstruction process. Hence, our research focus on the single image super-resolution task to resolve motion blurred issue.MethodOur Transformer fusion network (TFN) can be handle super-resolution reconstruction of low-resolution blurred images for super-resolution reconstruction of blurred images. Our TFN method implements a dual-branch strategy to remove some blurring regions based on super-resolution reconstruction of blurry images. First, we facilitate a deblurring module (DM) to extract deblurring features like clear edge structures. Specifically, we use the encoder-decoder architecture to design our DM module. For the encoder part of DM module, we use three convolutional layers to decrease the spatial resolution of feature maps and increase the channels of feature maps. For the decoder part of DM module, we use two de-convolutional layers to increase the spatial resolution of feature maps and decrease the channels of feature maps. In terms of the supervision of L1 deblurring loss function, the DM module is used to generate the clear feature maps in related to the down-sampling and up-sampling process of the DM module. But, our DM module tends to some detailed information loss of input images due to detailed information removal with the blur artifacts. Then, we designate additional texture feature extraction module (TFEM) to extract detailed texture features. The TFEM module is composed of six residual blocks, which can resolve some gradient explosion issues and speed up convergence. Apparently, the TFEM does not have down-sampling and up-sampling process like DM module, so TFEM can extract more detailed texture features than DM although this features has some blur artifacts. In order to take advantage of both clear deblurring features extracted by DM module and the detailed features extracted by TFEM module, we make use of a Transformer fusion module (TFM) to fuse them. We can use the clear deblurring features and detailed features in TFM module. We customize the multi-head attention layer to design the TFM module. Because the input of the transformer encoder part is one dimensional vector, we use flatten and unflatten operations in the TFM module. In addition, we can use the TFM module to fuse deblurring features extracted by the DM module and detailed texture features extracted by the TFEM module more effectively in the global sematic level based on long-range and global dependencies multi-head attention capturing ability. Finally, we use reconstruction module (RM) to carry out super-resolution reconstruction based on the fusion features obtained to generate a better super-resolved image.ResultThe extensive experiments demonstrate that our method generates sharper super-resolved images based on low-resolution blurred input images. We compare the proposed TFN to several algorithms, including the tailored single image super-resolution methods, the joint image deblurring and image super-resolution approaches, the combinations of image super-resolution algorithms and non-uniform deblurring algorithms. Specially, the single image super-resolution methods are based on the residual channel attention network(RCAN) and holistic attention network(HAN) algorithms, the image deblurring methods are melted scale-recurrent network(SRN) and deblur generative adversarial network(DBGAN) in, and the joint image deblurring and image super-resolution approaches are integrated the gated fusion network(GFN). To further evaluate the proposed TFN, we conduct experiments on two test data sets, including GOPRO test dataset and Kohler dataset. For GOPRO test dataset, the peak signal-to-noise ratio(PSNR) value of our TFN based super-resolved results by is 0.12 dB, 0.18 dB, and 0.07 dB higher than the very recent work of GFN for the 2×, 4× and 8× scales, respectively. For Kohler dataset, the PSNR value of our TFN based super-resolved results is 0.17 dB, 0.28 dB, and 0.16 dB in the 2×, 4× and 8× scales, respectively. In addition, the PSNR value of model with DM model result is 1.04 dB higher than model with TFEM in ablation study. the PSNR value of model with DM and TFME module is 1.84 dB and 0.80 dB higher than model with TFEM, and model with DM respectively. The PSNR value of TFN model with TFEM, DM, and TFM, which is 2.28 dB, 1.24 dB, and 0.44 dB higher than model with TFEM, model with DM, and model with TFEM/DM, respectively. To sum up, the GOPRO dataset based ablation experiments illustrates that the TFM promote global semantic hierarchical feature fusion in the context of deblurring features and detailed texture features, which greatly improves the effect of the network on the super-resolution reconstruction of low-resolution blurred images. The GOPRO test dataset and Kohler dataset based experimental results illustrates our network has a certain improvement of visual results qualitatively quantitatively.ConclusionWe harnesses a Transformer fusion network for blurred image super-resolution. This network can super-resolve blurred image and remove blur artifacts, to fuse DB-module-extracted deblurring features by and TFEM-module-extracted texture features via a transformer fusion module. In the transformer fusion module, we uses the multi-head self-attention layer to calculate the response of local information of the feature map to global information, which can effectively fuse deblurring features and detailed texture features at the global semantic level and improves the effect of super-resolution reconstruction of blurred images. Extensive ablation experiments and comparative experiment demonstrate that our TFN demonstrations have its priority on the visual result quantity and quantitative ability.关键词:super-resolution;single image super-resolution;blurred images;fusion network;Transformer163|245|5更新时间:2024-05-07
摘要:ObjectiveSingle image super-resolution is an essential task for vision applications to enhance the spatial resolution based image quality in the context of computer vision. Deep learning based methods are beneficial to single image super-resolution nowadays. Low-resolution images are regarded as clear images without blur effects. However, low-resolution images in real scenes are constrained of blur artifacts factors like camera shake and object motion. The degradation derived blur artifacts could be amplified in the super-resolution reconstruction process. Hence, our research focus on the single image super-resolution task to resolve motion blurred issue.MethodOur Transformer fusion network (TFN) can be handle super-resolution reconstruction of low-resolution blurred images for super-resolution reconstruction of blurred images. Our TFN method implements a dual-branch strategy to remove some blurring regions based on super-resolution reconstruction of blurry images. First, we facilitate a deblurring module (DM) to extract deblurring features like clear edge structures. Specifically, we use the encoder-decoder architecture to design our DM module. For the encoder part of DM module, we use three convolutional layers to decrease the spatial resolution of feature maps and increase the channels of feature maps. For the decoder part of DM module, we use two de-convolutional layers to increase the spatial resolution of feature maps and decrease the channels of feature maps. In terms of the supervision of L1 deblurring loss function, the DM module is used to generate the clear feature maps in related to the down-sampling and up-sampling process of the DM module. But, our DM module tends to some detailed information loss of input images due to detailed information removal with the blur artifacts. Then, we designate additional texture feature extraction module (TFEM) to extract detailed texture features. The TFEM module is composed of six residual blocks, which can resolve some gradient explosion issues and speed up convergence. Apparently, the TFEM does not have down-sampling and up-sampling process like DM module, so TFEM can extract more detailed texture features than DM although this features has some blur artifacts. In order to take advantage of both clear deblurring features extracted by DM module and the detailed features extracted by TFEM module, we make use of a Transformer fusion module (TFM) to fuse them. We can use the clear deblurring features and detailed features in TFM module. We customize the multi-head attention layer to design the TFM module. Because the input of the transformer encoder part is one dimensional vector, we use flatten and unflatten operations in the TFM module. In addition, we can use the TFM module to fuse deblurring features extracted by the DM module and detailed texture features extracted by the TFEM module more effectively in the global sematic level based on long-range and global dependencies multi-head attention capturing ability. Finally, we use reconstruction module (RM) to carry out super-resolution reconstruction based on the fusion features obtained to generate a better super-resolved image.ResultThe extensive experiments demonstrate that our method generates sharper super-resolved images based on low-resolution blurred input images. We compare the proposed TFN to several algorithms, including the tailored single image super-resolution methods, the joint image deblurring and image super-resolution approaches, the combinations of image super-resolution algorithms and non-uniform deblurring algorithms. Specially, the single image super-resolution methods are based on the residual channel attention network(RCAN) and holistic attention network(HAN) algorithms, the image deblurring methods are melted scale-recurrent network(SRN) and deblur generative adversarial network(DBGAN) in, and the joint image deblurring and image super-resolution approaches are integrated the gated fusion network(GFN). To further evaluate the proposed TFN, we conduct experiments on two test data sets, including GOPRO test dataset and Kohler dataset. For GOPRO test dataset, the peak signal-to-noise ratio(PSNR) value of our TFN based super-resolved results by is 0.12 dB, 0.18 dB, and 0.07 dB higher than the very recent work of GFN for the 2×, 4× and 8× scales, respectively. For Kohler dataset, the PSNR value of our TFN based super-resolved results is 0.17 dB, 0.28 dB, and 0.16 dB in the 2×, 4× and 8× scales, respectively. In addition, the PSNR value of model with DM model result is 1.04 dB higher than model with TFEM in ablation study. the PSNR value of model with DM and TFME module is 1.84 dB and 0.80 dB higher than model with TFEM, and model with DM respectively. The PSNR value of TFN model with TFEM, DM, and TFM, which is 2.28 dB, 1.24 dB, and 0.44 dB higher than model with TFEM, model with DM, and model with TFEM/DM, respectively. To sum up, the GOPRO dataset based ablation experiments illustrates that the TFM promote global semantic hierarchical feature fusion in the context of deblurring features and detailed texture features, which greatly improves the effect of the network on the super-resolution reconstruction of low-resolution blurred images. The GOPRO test dataset and Kohler dataset based experimental results illustrates our network has a certain improvement of visual results qualitatively quantitatively.ConclusionWe harnesses a Transformer fusion network for blurred image super-resolution. This network can super-resolve blurred image and remove blur artifacts, to fuse DB-module-extracted deblurring features by and TFEM-module-extracted texture features via a transformer fusion module. In the transformer fusion module, we uses the multi-head self-attention layer to calculate the response of local information of the feature map to global information, which can effectively fuse deblurring features and detailed texture features at the global semantic level and improves the effect of super-resolution reconstruction of blurred images. Extensive ablation experiments and comparative experiment demonstrate that our TFN demonstrations have its priority on the visual result quantity and quantitative ability.关键词:super-resolution;single image super-resolution;blurred images;fusion network;Transformer163|245|5更新时间:2024-05-07
Image super resolution
-
 摘要:ObjectiveImage quality is constrained of over-exposure or under-exposure due to the higher dynamic range is much than image capture/display devices in real scene. There is two problem-solving as mentioned below: The first one is to obtain high dynamic range (HDR) images using high dynamic imaging devices. Then, the tone mapping algorithm is used to compress the HDR images to deduct dynamic range (LDR) images for displaying on LDR display devices; The second method, which is named as exposure fusion, fuses multi-exposure levels images to obtain the LDR image straight forward. Compared to the first one, the second exposure fusion method is not costly subjected to HDR capture devices and has its lower computational complexity. However, exposure fusion techniques may introduce some artifacts (e.g., halos, edges blurring and details losing) in final generated images.MethodOur two crucial tasks facilitate these issues and improve the performance of the exposure fusion. First, an improved guided image filtering, which is referred to as weighted aggregating guided image filtering (WAGIF), demonstrated and extracted fine details based on multiple exposed images. The employed average aggregation is indiscriminate for all patches in guided image filtering (GIF), in some of which the filtering output of a pixel located on the edges is close to the mean which is far beyond the expected value, and yields blurring edges. A novel weighted aggregation strategy for GIF is issued to improve the edge-preserving performance. Different from the average aggregation related to the original GIF, multi-windows predictions of the interest pixel are aggregated via weighting instead of averaged value. Moreover, the weights-oriented are assigned in terms of mean square errors (MSE). Then, the WAGIF and the original GIF are compared and the experimental results demonstrate that our WAGIF achieves sharper edges and cut halo artifacts intensively. Next, an overall WAGIF-based detail-enhanced exposure fusion algorithm is illustrated. Our exposed multi-images fusion approach first extracts detailed layers via WAGIF simultaneously. These detailed layers are then synthesized to obtain a fine detail layer. Finally, the overall detailed layer is integrated to a medium fused image. Similar to the image decomposition technique in single image detail enhancement and tone mapping, each image input image sequence, which contains several of exposed images, is decomposed to a benched layer and a WAGIF-based detailed layer. Then, all detail layers of input images are synthesized to a single detail map via a specified transition function which guarantees that a pixel has a larger weight in a qualified exposed image than an under/over-exposed images. Furthermore, a detailed extraction conducted reflects weak edges or invisible under/over-exposed regions. Hence, the WAGIF-based details extraction tends to some information loss in under/over-exposed regions while each input image is decomposed each. A targeted task is employed to generate a single aggregation weight map in terms of the relationships between all input images, and then the generated weight map is applied for all images decomposition.ResultOur overall detailed-enhanced exposure fusion algorithm is validated on 17 sections of classical multi-exposure image sequences and the experimental results are compared with more fusion approaches, like weighted guided image filtering (WGIF) and gradient dynamic guided image filtering (GDGIF). The optioned quantitative evaluation metrics contain information entropy (IE), mutual information entropy (MIE), and averaged gradient (AG). "Madison" and "Memorial" sequences are adopted in our algorithm. The "Madison" sequences based algorithm has an average increase of 0.19% in MIE, 0.58% in MIE, and 13.29% in AG, respectively. Our "Memorial" sequences based algorithm has an average improvement of 0.13% in IE, 1.06% in MIE, and 16.34% in AG. Furthermore, our algorithm has better edge-preserving performance and its fused images priority qualitatively.ConclusionOur demonstrated illustrations can obtain qualified preserve edges and details. Quantified evaluation metrics like IE, MIE and AG are further conducted for multi-algorithms comparison each prioritized evaluation.关键词:multi-exposure image fusion;detail extraction;guided image filtering(GIF);weighted aggregation;halo artifacts113|525|2更新时间:2024-05-07
摘要:ObjectiveImage quality is constrained of over-exposure or under-exposure due to the higher dynamic range is much than image capture/display devices in real scene. There is two problem-solving as mentioned below: The first one is to obtain high dynamic range (HDR) images using high dynamic imaging devices. Then, the tone mapping algorithm is used to compress the HDR images to deduct dynamic range (LDR) images for displaying on LDR display devices; The second method, which is named as exposure fusion, fuses multi-exposure levels images to obtain the LDR image straight forward. Compared to the first one, the second exposure fusion method is not costly subjected to HDR capture devices and has its lower computational complexity. However, exposure fusion techniques may introduce some artifacts (e.g., halos, edges blurring and details losing) in final generated images.MethodOur two crucial tasks facilitate these issues and improve the performance of the exposure fusion. First, an improved guided image filtering, which is referred to as weighted aggregating guided image filtering (WAGIF), demonstrated and extracted fine details based on multiple exposed images. The employed average aggregation is indiscriminate for all patches in guided image filtering (GIF), in some of which the filtering output of a pixel located on the edges is close to the mean which is far beyond the expected value, and yields blurring edges. A novel weighted aggregation strategy for GIF is issued to improve the edge-preserving performance. Different from the average aggregation related to the original GIF, multi-windows predictions of the interest pixel are aggregated via weighting instead of averaged value. Moreover, the weights-oriented are assigned in terms of mean square errors (MSE). Then, the WAGIF and the original GIF are compared and the experimental results demonstrate that our WAGIF achieves sharper edges and cut halo artifacts intensively. Next, an overall WAGIF-based detail-enhanced exposure fusion algorithm is illustrated. Our exposed multi-images fusion approach first extracts detailed layers via WAGIF simultaneously. These detailed layers are then synthesized to obtain a fine detail layer. Finally, the overall detailed layer is integrated to a medium fused image. Similar to the image decomposition technique in single image detail enhancement and tone mapping, each image input image sequence, which contains several of exposed images, is decomposed to a benched layer and a WAGIF-based detailed layer. Then, all detail layers of input images are synthesized to a single detail map via a specified transition function which guarantees that a pixel has a larger weight in a qualified exposed image than an under/over-exposed images. Furthermore, a detailed extraction conducted reflects weak edges or invisible under/over-exposed regions. Hence, the WAGIF-based details extraction tends to some information loss in under/over-exposed regions while each input image is decomposed each. A targeted task is employed to generate a single aggregation weight map in terms of the relationships between all input images, and then the generated weight map is applied for all images decomposition.ResultOur overall detailed-enhanced exposure fusion algorithm is validated on 17 sections of classical multi-exposure image sequences and the experimental results are compared with more fusion approaches, like weighted guided image filtering (WGIF) and gradient dynamic guided image filtering (GDGIF). The optioned quantitative evaluation metrics contain information entropy (IE), mutual information entropy (MIE), and averaged gradient (AG). "Madison" and "Memorial" sequences are adopted in our algorithm. The "Madison" sequences based algorithm has an average increase of 0.19% in MIE, 0.58% in MIE, and 13.29% in AG, respectively. Our "Memorial" sequences based algorithm has an average improvement of 0.13% in IE, 1.06% in MIE, and 16.34% in AG. Furthermore, our algorithm has better edge-preserving performance and its fused images priority qualitatively.ConclusionOur demonstrated illustrations can obtain qualified preserve edges and details. Quantified evaluation metrics like IE, MIE and AG are further conducted for multi-algorithms comparison each prioritized evaluation.关键词:multi-exposure image fusion;detail extraction;guided image filtering(GIF);weighted aggregation;halo artifacts113|525|2更新时间:2024-05-07 -
 摘要:ObjectiveThe integrity of information transmission can be achieved if the image is intact currently. However, the required image files are often damaged or obscured, such as the damage of old photos, and the obscuration of the required content in the surveillance image. The purpose of damaged images restoration is to fill the damaged part in terms of the recognized region in the damaged image. The regular method of image restoration inserts the damaged area in accordance with the surrounding information based on texture synthesis technology linearly. Although this type of method can repair the texture, it lacks the manipulation of the global structure and image semantics of the damaged image. Deep-learning-based damaged image restoration methods have been illustrated via the classical context-encoders model. Although this method can perform better restoration on the color and content of the damaged image, the effect on the detail texture restoration is not ideal, and the restoration result appears blurred. When the damaged area is large, the repair effect is not qualified due to the lack of available information. Simultaneously, there are fewer analyses on high-resolution damaged image restoration now. Most of the existing damaged image restoration experiments use 128×128×3 and smaller images, and there are fewer experiments to repair 512×512×3 and larger images. In order to solve the two problems of large-area damaged image repair and high-resolution image repair, this analysis demonstrates a restoration method based on convolutional auto-encoder generative adversarial network (CAE-GAN).MethodThe generator is trained to learn the mapping relationship from Gaussian noise to the low-dimensional feature matrix, and then the generated feature matrix is upgraded to a high-resolution image, and the generated image similar to the intact part of the image to be repaired is sorted out. The corresponding part restoration on the damaged image to complete the repair of the high-resolution damaged image. First, high-resolution images are encoded and then decoded via the convolutional auto-encoder training part. Then, the parameters fix of the convolutional auto-encoder is adopted to assist in training the adversarial generation network part. The generator can generate different codes based on random Gaussian noise and then be decoded into high-resolution images based on the trained decoder. At the end, an overall connected network training for search can generate appropriate noise. After the noise is up-sampled by the generator and decoder, it will output a generated image similar to the image to be repaired, and cover the corresponding part on the damaged image, and then realize the repair of high-resolution damaged images.ResultBy segmenting the mapping relationships that are difficult to learn, the learning barriers of a single mapping relationship is declined, and the model training effect is improved. The repair experiments are conducted on the CelebA dataset, the street view house number(SVHN) dataset, the Oxford 102 flowers dataset, and the Stanford cars dataset. This demonstration illustrates that the method predicts the information of a large area of missing areas in a good way. Compared with the context-encoders(CE) method, the method improves the restoration effect on images with large damaged areas significantly. The content of the repaired damaged area is closer to the related intact parts, and the texture connection is smoother. The peak signal to noise ratio (PSNR) value can be increased to 31.6%, and the structural similarity (SSIM) value can be increased to 18.0%. The PSNR value can be increased by 24.4%, and the SSIM value can be increased by 50.0%.ConclusionTherefore, the method is suitable for the image restoration based on large-area damaged images and high-resolution images.关键词:damaged image repair;high resolution;generative adversarial networks(GAN);large area damage;deep learning118|170|2更新时间:2024-05-07
摘要:ObjectiveThe integrity of information transmission can be achieved if the image is intact currently. However, the required image files are often damaged or obscured, such as the damage of old photos, and the obscuration of the required content in the surveillance image. The purpose of damaged images restoration is to fill the damaged part in terms of the recognized region in the damaged image. The regular method of image restoration inserts the damaged area in accordance with the surrounding information based on texture synthesis technology linearly. Although this type of method can repair the texture, it lacks the manipulation of the global structure and image semantics of the damaged image. Deep-learning-based damaged image restoration methods have been illustrated via the classical context-encoders model. Although this method can perform better restoration on the color and content of the damaged image, the effect on the detail texture restoration is not ideal, and the restoration result appears blurred. When the damaged area is large, the repair effect is not qualified due to the lack of available information. Simultaneously, there are fewer analyses on high-resolution damaged image restoration now. Most of the existing damaged image restoration experiments use 128×128×3 and smaller images, and there are fewer experiments to repair 512×512×3 and larger images. In order to solve the two problems of large-area damaged image repair and high-resolution image repair, this analysis demonstrates a restoration method based on convolutional auto-encoder generative adversarial network (CAE-GAN).MethodThe generator is trained to learn the mapping relationship from Gaussian noise to the low-dimensional feature matrix, and then the generated feature matrix is upgraded to a high-resolution image, and the generated image similar to the intact part of the image to be repaired is sorted out. The corresponding part restoration on the damaged image to complete the repair of the high-resolution damaged image. First, high-resolution images are encoded and then decoded via the convolutional auto-encoder training part. Then, the parameters fix of the convolutional auto-encoder is adopted to assist in training the adversarial generation network part. The generator can generate different codes based on random Gaussian noise and then be decoded into high-resolution images based on the trained decoder. At the end, an overall connected network training for search can generate appropriate noise. After the noise is up-sampled by the generator and decoder, it will output a generated image similar to the image to be repaired, and cover the corresponding part on the damaged image, and then realize the repair of high-resolution damaged images.ResultBy segmenting the mapping relationships that are difficult to learn, the learning barriers of a single mapping relationship is declined, and the model training effect is improved. The repair experiments are conducted on the CelebA dataset, the street view house number(SVHN) dataset, the Oxford 102 flowers dataset, and the Stanford cars dataset. This demonstration illustrates that the method predicts the information of a large area of missing areas in a good way. Compared with the context-encoders(CE) method, the method improves the restoration effect on images with large damaged areas significantly. The content of the repaired damaged area is closer to the related intact parts, and the texture connection is smoother. The peak signal to noise ratio (PSNR) value can be increased to 31.6%, and the structural similarity (SSIM) value can be increased to 18.0%. The PSNR value can be increased by 24.4%, and the SSIM value can be increased by 50.0%.ConclusionTherefore, the method is suitable for the image restoration based on large-area damaged images and high-resolution images.关键词:damaged image repair;high resolution;generative adversarial networks(GAN);large area damage;deep learning118|170|2更新时间:2024-05-07 -
 摘要:ObjectiveDistorted old photos restoration is a challenging issue in practice. Photos are severely eroded in harsh environments, resulting in unclear photo content or even permanent damage, such as scratches, noise, blur and color fading. First, distorted old photos are digitized and implemented (such as Adobe Photoshop) to harness pixel-level manual fine restoration via image processing software. However, manual restoration is time consuming and a batch of manual restoration is more challenged. Traditional methods restore distorted photos (such as digital filtering, edge detection, image patching, etc.) based on multiple restoration algorithms. However, incoherent or unclear restoration results are produced. A large number of deep learning methods have been facilitated nowadays. However, most of the deep learning methods originated from single degradation or several integrated degradations affect generalization ability because the synthesized artificial data cannot represent the real degradation process and data distribution. Based on the framework of generative adversarial network, our problem solving restores distorted old photos through introducing reference priors and generative priors, which improve the restoration quality and generalization performance of distorted old photos.MethodThe reference image option is a key factor to implement our method. A high-quality reference image is linked to the following features: 1) Structure similarity: the reference image and the distorted old photos should be similar to image structure. 2) Feature similarity: the distorted old photos restoration focuses more on the restoration of portraits. The resolution of the previous camera was generally not high and portraits are the core of the photo. The portrait content of the reference image should be as similar as possible to the portrait content in the targeted photos, including gender, age, posture, etc. Theoretically, the closer the two images are, the better the similarity coupling between features, more effective prior information can be obtained. Our method picks potential reference images up based on 2 portrait datasets of CelebFaces Atributes Dataset(CelebA) and Flickr faces high quality(FFHQ), using structural similarity as an indicator. The image structural similarity is greater than 0.9 as an appropriated reference image; the reference image is further aligned with the distorted old photo through feature point detection. Our demonstration first extracts the shallow features of the reference image and the distorted old photos. The method uses a 3×3 convolution to extract the reference image features and uses 3 kernel sizes (7×7, 5×5, 3×3) convolutions to extract the shallow features of targeted photos. The shallow features of the reference image and the targeted photos are then encoded each to obtain deep semantics features in multiple-scales and latent semantic codes. Our 2 latent semantic codes are fused in latent space to obtain deep semantic codes through a series of overall interlinked layers. Deep semantic codes use the generative prior via compressed pre-trained generative model to generate generative prior features and guide spatial multi-feature (SMF) transformation condition attention block to fuse reference semantic features, generative prior features and distorted old photo features. Specifically, the distorted photo features are segmented into two sections, one section remains identity connection to ensure the fidelity of the restoration, and its copy is fused with generative prior features simultaneously. The other one is projected to affine transformation via the compressed reference semantic features. Finally, the 2 sections are interconnected and then the deep semantic codes are used for attention fusion. The fused features are related to the decoded features through the skip connection and residual connection, a following 3×3 convolution is used to reconstruct the restored photos. We build up a distorted old photo dataset excluded synthetic data.ResultOur quantitative illustrations compares the results of the method with 6 state-of-the-art methods on 4 evaluation metrics, including signal-to-noise ratio (PSNR), the structural similarity index (SSIM), the learned perceptual image patch similarity (LPIPS) and Fréchet inception distance (FID), which comprehensively consider the average pixel error, structural similarity, data distribution, and so on. Our demonstration is significantly better than other comparison methods in all evaluation metrics. The analyzed results of all numerical metrics are illustrated as mentioned below: the PSNR is 23.69 dB, the SSIM is 0.828 3, the LPIPS is 0.309 and the FID is 71.53, which are improved by 0.75 dB, 0.019 7, 13.69%, and 19.86%, respectively. Our qualitative method compares all the results of restoration methods. The best structured defects restoration quality is significantly better than other methods and the restoration results are more consistent and natural, such as missing, scratches, etc., our unstructured defects method also facilitates comparable and better restoration results. Fewer parameters (43.44 M) and faster inference time are obtained (mean 248 ms for 256×256 resolution distorted old photos).ConclusionOur reference priors and generative priors' method restore distorted old photos. The semantic information of reference priors and generative model compressed portrait priors are facilitated to qualitative and quantitative restoration both.关键词:deep learning;generative adversarial network(GAN);distorted old photos restoration;reference prior;generative prior;spatial feature transformation;encoder-decoder network;multi-scale perception144|216|1更新时间:2024-05-07
摘要:ObjectiveDistorted old photos restoration is a challenging issue in practice. Photos are severely eroded in harsh environments, resulting in unclear photo content or even permanent damage, such as scratches, noise, blur and color fading. First, distorted old photos are digitized and implemented (such as Adobe Photoshop) to harness pixel-level manual fine restoration via image processing software. However, manual restoration is time consuming and a batch of manual restoration is more challenged. Traditional methods restore distorted photos (such as digital filtering, edge detection, image patching, etc.) based on multiple restoration algorithms. However, incoherent or unclear restoration results are produced. A large number of deep learning methods have been facilitated nowadays. However, most of the deep learning methods originated from single degradation or several integrated degradations affect generalization ability because the synthesized artificial data cannot represent the real degradation process and data distribution. Based on the framework of generative adversarial network, our problem solving restores distorted old photos through introducing reference priors and generative priors, which improve the restoration quality and generalization performance of distorted old photos.MethodThe reference image option is a key factor to implement our method. A high-quality reference image is linked to the following features: 1) Structure similarity: the reference image and the distorted old photos should be similar to image structure. 2) Feature similarity: the distorted old photos restoration focuses more on the restoration of portraits. The resolution of the previous camera was generally not high and portraits are the core of the photo. The portrait content of the reference image should be as similar as possible to the portrait content in the targeted photos, including gender, age, posture, etc. Theoretically, the closer the two images are, the better the similarity coupling between features, more effective prior information can be obtained. Our method picks potential reference images up based on 2 portrait datasets of CelebFaces Atributes Dataset(CelebA) and Flickr faces high quality(FFHQ), using structural similarity as an indicator. The image structural similarity is greater than 0.9 as an appropriated reference image; the reference image is further aligned with the distorted old photo through feature point detection. Our demonstration first extracts the shallow features of the reference image and the distorted old photos. The method uses a 3×3 convolution to extract the reference image features and uses 3 kernel sizes (7×7, 5×5, 3×3) convolutions to extract the shallow features of targeted photos. The shallow features of the reference image and the targeted photos are then encoded each to obtain deep semantics features in multiple-scales and latent semantic codes. Our 2 latent semantic codes are fused in latent space to obtain deep semantic codes through a series of overall interlinked layers. Deep semantic codes use the generative prior via compressed pre-trained generative model to generate generative prior features and guide spatial multi-feature (SMF) transformation condition attention block to fuse reference semantic features, generative prior features and distorted old photo features. Specifically, the distorted photo features are segmented into two sections, one section remains identity connection to ensure the fidelity of the restoration, and its copy is fused with generative prior features simultaneously. The other one is projected to affine transformation via the compressed reference semantic features. Finally, the 2 sections are interconnected and then the deep semantic codes are used for attention fusion. The fused features are related to the decoded features through the skip connection and residual connection, a following 3×3 convolution is used to reconstruct the restored photos. We build up a distorted old photo dataset excluded synthetic data.ResultOur quantitative illustrations compares the results of the method with 6 state-of-the-art methods on 4 evaluation metrics, including signal-to-noise ratio (PSNR), the structural similarity index (SSIM), the learned perceptual image patch similarity (LPIPS) and Fréchet inception distance (FID), which comprehensively consider the average pixel error, structural similarity, data distribution, and so on. Our demonstration is significantly better than other comparison methods in all evaluation metrics. The analyzed results of all numerical metrics are illustrated as mentioned below: the PSNR is 23.69 dB, the SSIM is 0.828 3, the LPIPS is 0.309 and the FID is 71.53, which are improved by 0.75 dB, 0.019 7, 13.69%, and 19.86%, respectively. Our qualitative method compares all the results of restoration methods. The best structured defects restoration quality is significantly better than other methods and the restoration results are more consistent and natural, such as missing, scratches, etc., our unstructured defects method also facilitates comparable and better restoration results. Fewer parameters (43.44 M) and faster inference time are obtained (mean 248 ms for 256×256 resolution distorted old photos).ConclusionOur reference priors and generative priors' method restore distorted old photos. The semantic information of reference priors and generative model compressed portrait priors are facilitated to qualitative and quantitative restoration both.关键词:deep learning;generative adversarial network(GAN);distorted old photos restoration;reference prior;generative prior;spatial feature transformation;encoder-decoder network;multi-scale perception144|216|1更新时间:2024-05-07 -
 摘要:ObjectiveHuman iris image recognition has achieved qualified accuracy based on most recognized databases. But, the real captured iris images are presented low-quality occlusion derived from the light spot, upper and lower eyelid, leading to the quality lossin iris recognition and segmentation. Recent development of deep learning has promoted the great progress image completion method. However, since most convolutional neural networks (CNNs) are difficult to capture global cues, iris image completion remains a challenging task in the context of the large corrupted regions and complex texture and structural patterns. Most CNNs are targeted on local features extraction with unqualified captured global cues in practice. Current transformer architecture has been introduced to visual tasks. The visual transformer harnesses complex spatial transforms and long-distance feature dependencies for global representations in terms of self-attention mechanism and multi-layer perceptron (MLP) structure. Visual transformers have their challenges to identify ignored local feature details in related to the discriminability decreases between background and foreground. The CNN-based convolution operations targets on local features extraction with unqualified captured global representations. The visual transformer based cascaded self-attention modules can capture long-distance feature dependencies with local feature loss details. We illustrate a region attention mechanism based dual iris completion network, which uses the bilateral guided aggregation layer to fuse convolutional local features with transformer-based global representations within interoperable scenario. To improve recognition capability, the impact of the occluded region on iris image pre-processing and recognition can be significantly reduced based on the missing iris information completion.MethodA region attention mechanism based dual iris completion network contains a Transformer encoder and a CNN encoder. Specifically, we use the Transformer encoder and the CNN encoder to extract the global and local features of the iris image, respectively. To better utilize the extracted global and local iris images, a fusion network is adopted to preserve the global and local features of the images based on the integration of the global modeling capability of Transformer and the local modeling capability of CNN both, which improve the quality of the repaired iris images, as well as maintain the global and local consistency of the images. Furthermore, we propose a region attention module to efficiently achieve the completion of the occluded regions. Beyond the pixel-level image reconstruction constraints, an effective identity preserving constraint is also designed to ensure the identity consistency between the input and the completed image. Pytorch framework is used to implement our method and evaluate it on the CASIA(Institute of Automation, Chinese Academy of Sciences) iris dataset. We use peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) as the evaluation metrics for the generation quality, PSNR is the reversed result of comparing each pixel of an image, which can reflect the ground truth of the generated image and is an objective standard for evaluating the image. SSIM estimates the holistic similarity between two images, while iris recognition as the evaluation metric for the identity preserving quality.ResultOur extended demonstration results on the CASIA iris dataset demonstrate that our method is capable to generate visually qualified iris completion results with identity preserving qualitatively and quantitatively. Furthermore, we have performed experiments on images with same type of occlusion. Images for training and testing are set to the resolution of 160×160 pixels for fair comparisons. The qualitative results have shown that the repaired results of our demonstration perform well in terms of region retention and global consistency compared to the other three methods. The quantitative comparisons are conducted in two metrics. For the repaired results of different occlusion types, our PSNR and SSIM are optimal to represent better the occluded iris images restoration and the consistency of the repaired results. To verify the effectiveness of the method in improving the accuracy of iris segmentation, we use white occlusion to simulate light spot occlusion. The segmentation results of repaired images are more accurate compared to those of the occluded images. Specifically, our method achieves 63% on true accept rate(TAR)(0.1%false accept rate(FAR)), which significantly more qualified that the baseline by 43.8% in terms of 64×64 pixels. The ablation studies are implemented to demonstrate the effectiveness of the components of our network structure.ConclusionWe facilitates a region attention mechanism based dual iris completion network, which utilizes transformer and CNN to extract both the global topology and local details of iris images. A fusion network is employed to fuse the global and local features. A region attention module and identity preserving loss are also issued to guide the completion task. The extended quantitative and qualitative results demonstrate the effectiveness of our iris completion method in terms of CASIA iris dataset.关键词:iris inpainting;iris recognition;iris segmentation;Transformer;convolutional neural network(CNN);attention117|218|2更新时间:2024-05-07
摘要:ObjectiveHuman iris image recognition has achieved qualified accuracy based on most recognized databases. But, the real captured iris images are presented low-quality occlusion derived from the light spot, upper and lower eyelid, leading to the quality lossin iris recognition and segmentation. Recent development of deep learning has promoted the great progress image completion method. However, since most convolutional neural networks (CNNs) are difficult to capture global cues, iris image completion remains a challenging task in the context of the large corrupted regions and complex texture and structural patterns. Most CNNs are targeted on local features extraction with unqualified captured global cues in practice. Current transformer architecture has been introduced to visual tasks. The visual transformer harnesses complex spatial transforms and long-distance feature dependencies for global representations in terms of self-attention mechanism and multi-layer perceptron (MLP) structure. Visual transformers have their challenges to identify ignored local feature details in related to the discriminability decreases between background and foreground. The CNN-based convolution operations targets on local features extraction with unqualified captured global representations. The visual transformer based cascaded self-attention modules can capture long-distance feature dependencies with local feature loss details. We illustrate a region attention mechanism based dual iris completion network, which uses the bilateral guided aggregation layer to fuse convolutional local features with transformer-based global representations within interoperable scenario. To improve recognition capability, the impact of the occluded region on iris image pre-processing and recognition can be significantly reduced based on the missing iris information completion.MethodA region attention mechanism based dual iris completion network contains a Transformer encoder and a CNN encoder. Specifically, we use the Transformer encoder and the CNN encoder to extract the global and local features of the iris image, respectively. To better utilize the extracted global and local iris images, a fusion network is adopted to preserve the global and local features of the images based on the integration of the global modeling capability of Transformer and the local modeling capability of CNN both, which improve the quality of the repaired iris images, as well as maintain the global and local consistency of the images. Furthermore, we propose a region attention module to efficiently achieve the completion of the occluded regions. Beyond the pixel-level image reconstruction constraints, an effective identity preserving constraint is also designed to ensure the identity consistency between the input and the completed image. Pytorch framework is used to implement our method and evaluate it on the CASIA(Institute of Automation, Chinese Academy of Sciences) iris dataset. We use peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) as the evaluation metrics for the generation quality, PSNR is the reversed result of comparing each pixel of an image, which can reflect the ground truth of the generated image and is an objective standard for evaluating the image. SSIM estimates the holistic similarity between two images, while iris recognition as the evaluation metric for the identity preserving quality.ResultOur extended demonstration results on the CASIA iris dataset demonstrate that our method is capable to generate visually qualified iris completion results with identity preserving qualitatively and quantitatively. Furthermore, we have performed experiments on images with same type of occlusion. Images for training and testing are set to the resolution of 160×160 pixels for fair comparisons. The qualitative results have shown that the repaired results of our demonstration perform well in terms of region retention and global consistency compared to the other three methods. The quantitative comparisons are conducted in two metrics. For the repaired results of different occlusion types, our PSNR and SSIM are optimal to represent better the occluded iris images restoration and the consistency of the repaired results. To verify the effectiveness of the method in improving the accuracy of iris segmentation, we use white occlusion to simulate light spot occlusion. The segmentation results of repaired images are more accurate compared to those of the occluded images. Specifically, our method achieves 63% on true accept rate(TAR)(0.1%false accept rate(FAR)), which significantly more qualified that the baseline by 43.8% in terms of 64×64 pixels. The ablation studies are implemented to demonstrate the effectiveness of the components of our network structure.ConclusionWe facilitates a region attention mechanism based dual iris completion network, which utilizes transformer and CNN to extract both the global topology and local details of iris images. A fusion network is employed to fuse the global and local features. A region attention module and identity preserving loss are also issued to guide the completion task. The extended quantitative and qualitative results demonstrate the effectiveness of our iris completion method in terms of CASIA iris dataset.关键词:iris inpainting;iris recognition;iris segmentation;Transformer;convolutional neural network(CNN);attention117|218|2更新时间:2024-05-07 -
 摘要:ObjectiveImage de-blurring task aims at a qualified image derived from the low-quality blurred one. Traditional fuzzy kernels based de-blurring techniques are challenging to sort out ideal fuzzy kernel for each pixel. Current restoration methods are based on manpowered prior knowledge of the images. Simultaneously, generalization capability is constrained to be extended. To harness image de-blurring processing, convolutional neural network (CNN)model has its priority in computer vision in the context of deep learning techniques. Nevertheless, poor CNN structure adaptive issues like over-fitting are extremely constrained of parameters and topology. A challenged image de-blurring tasks is to capture detailed texture. Tiny feature constrained images restoration have their deficiencies like inadequate detail information and indistinct image edge. To facilitate image in-painting and super-resolution restoration, generative adversarial networks (GAN) has its priority to preserve texture details.an adversarial network based end-to-end framework for image de-blurring is demonstrated based on GAN-based image-to-image translation, which can speed up multifaceted image restoration process.MethodFirst, a variety of modified residual blocks are cascaded to build a multi-scale architecture, which facilitates extracting features from coarse to fine so that more texture details in a blurred image could be well restored. Next, extensive convolution module extended the receptive fields in parallel with no computational burden. Thirdly, channel attention mechanism is also applied to strengthen weights of useful features and suppress the invalid ones simultaneously via inter-channel modeling interdependencies. Finally, network-based perceptual loss is integrated with conventional mean squared error (MSE) to serve as the total loss function in order to maintain the fidelity of the image content. Consequently, our restored images quality can be guaranteed on the aspect of qualified semantic and fine texture details both. The application of minimum MSE loss between pixels also makes the generated de-blurred image have smoother edge information.ResultGoPro database is adopted for our model training and testing, including 3 214 pairs of samples among which 2 013 pairs are used as training set and the remaining 1 111 pairs serve as testing data. To enhance the generalization capability of the network, data augmentation techniques like flipping and random angle rotation are conducted. Each training sample is randomly cropped into 256×256 pixels resolution images, and pixel values of clear and blurred images are all normalized to the range of [-1, 1]. In order to comprehensively evaluate the our method, several indicators like peak signal to noise ratio (PSNR), structural similarity (SSIM) and restoration time are used for evaluation. Our experimental results have demonstrated that overall performance of proposed method is satisfactory, which can effectively eliminate the blurred region in images. Compared with some other existing works, our method increases PSNR by 3.8% in less running time, which indicates the feasibility and superiority of our proposal. Restored images obtained by proposed method have clarified edges, and our method is efficient to restore the blurry images with different sizes of blur kernels to a certain extent. It is also found that while applying the restored images to the YOLO-v4(you only look once) object detection task, the results have been significantly improved regarding the identification accuracy and the confidence coefficient both, which reflects that designed strategies in proposed method.ConclusionOur image de-blurring method aims at blurred images and extracts features sufficiently from coarse to fine. Specifically, multi-scale improved residual blocks are cascaded for learned subtle texture details. Parallel enlarged convolution and channel attention mechanism are also intervened in our model to improve their adopted residual blocks capability. Moreover, trained loss function is modified via perceptual loss introducing to traditional mean square errors. Consequently, quality of restored images can be guaranteed to some extent like sharper edges and more abundant detail information. Our analyzed results have demonstrated their qualified and efficient priorities.关键词:attention mechanism;image restoration;deep learning;generative adversarial network(GAN);multi-scale141|283|3更新时间:2024-05-07
摘要:ObjectiveImage de-blurring task aims at a qualified image derived from the low-quality blurred one. Traditional fuzzy kernels based de-blurring techniques are challenging to sort out ideal fuzzy kernel for each pixel. Current restoration methods are based on manpowered prior knowledge of the images. Simultaneously, generalization capability is constrained to be extended. To harness image de-blurring processing, convolutional neural network (CNN)model has its priority in computer vision in the context of deep learning techniques. Nevertheless, poor CNN structure adaptive issues like over-fitting are extremely constrained of parameters and topology. A challenged image de-blurring tasks is to capture detailed texture. Tiny feature constrained images restoration have their deficiencies like inadequate detail information and indistinct image edge. To facilitate image in-painting and super-resolution restoration, generative adversarial networks (GAN) has its priority to preserve texture details.an adversarial network based end-to-end framework for image de-blurring is demonstrated based on GAN-based image-to-image translation, which can speed up multifaceted image restoration process.MethodFirst, a variety of modified residual blocks are cascaded to build a multi-scale architecture, which facilitates extracting features from coarse to fine so that more texture details in a blurred image could be well restored. Next, extensive convolution module extended the receptive fields in parallel with no computational burden. Thirdly, channel attention mechanism is also applied to strengthen weights of useful features and suppress the invalid ones simultaneously via inter-channel modeling interdependencies. Finally, network-based perceptual loss is integrated with conventional mean squared error (MSE) to serve as the total loss function in order to maintain the fidelity of the image content. Consequently, our restored images quality can be guaranteed on the aspect of qualified semantic and fine texture details both. The application of minimum MSE loss between pixels also makes the generated de-blurred image have smoother edge information.ResultGoPro database is adopted for our model training and testing, including 3 214 pairs of samples among which 2 013 pairs are used as training set and the remaining 1 111 pairs serve as testing data. To enhance the generalization capability of the network, data augmentation techniques like flipping and random angle rotation are conducted. Each training sample is randomly cropped into 256×256 pixels resolution images, and pixel values of clear and blurred images are all normalized to the range of [-1, 1]. In order to comprehensively evaluate the our method, several indicators like peak signal to noise ratio (PSNR), structural similarity (SSIM) and restoration time are used for evaluation. Our experimental results have demonstrated that overall performance of proposed method is satisfactory, which can effectively eliminate the blurred region in images. Compared with some other existing works, our method increases PSNR by 3.8% in less running time, which indicates the feasibility and superiority of our proposal. Restored images obtained by proposed method have clarified edges, and our method is efficient to restore the blurry images with different sizes of blur kernels to a certain extent. It is also found that while applying the restored images to the YOLO-v4(you only look once) object detection task, the results have been significantly improved regarding the identification accuracy and the confidence coefficient both, which reflects that designed strategies in proposed method.ConclusionOur image de-blurring method aims at blurred images and extracts features sufficiently from coarse to fine. Specifically, multi-scale improved residual blocks are cascaded for learned subtle texture details. Parallel enlarged convolution and channel attention mechanism are also intervened in our model to improve their adopted residual blocks capability. Moreover, trained loss function is modified via perceptual loss introducing to traditional mean square errors. Consequently, quality of restored images can be guaranteed to some extent like sharper edges and more abundant detail information. Our analyzed results have demonstrated their qualified and efficient priorities.关键词:attention mechanism;image restoration;deep learning;generative adversarial network(GAN);multi-scale141|283|3更新时间:2024-05-07
Image inpainting
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0