
最新刊期
卷 27 , 期 2 , 2022
-
 摘要:Scene depth estimation is one of the key issues in the field of computer vision and an important aspect in the applications such as 3D reconstruction and image synthesis. Monocular depth estimation techniques based on deep learning have developed fast recently. Differentiated network structures have been proposed gradually. The current development of monocular depth estimation techniques based on deep learning and a categorical review of supervised and unsupervised learning-based methods have been illustrated in terms of the characteristics of the network structures. The supervised learning methods have been segmented as following: 1) Multi-scale feature fusion strategies: Different scales images contain different kinds of information via fusing multi-scale features extracted from the images. The demonstrated results of depth estimation can be effectively improved. 2)Conditional random fields (CRFs): CRFs, as one of probabilistic graphical models, have good performance in the field of semantic segmentation. Since depth information has similar data distribution attributes as semantic information, the use of consistent CRFs can be effective for predicting continuous depth values. CRFs can be operated as the loss function in the final part of the network as well as a feature fusion module in the medium layer of the network due to its effectiveness for fuse features. 3)Ordinal relations: One category is the relative depth estimation method which uses ordinal relation straight forward to estimate the relative position of two pixels in the image. The other category defines the depth estimation as an ordinal regression issue, which needs to discretize the continuous depth values into discrete depth labels and perform multi-class classification for the global depth. 4) Multiple image information: It is beneficial to combining various image information in depth estimation to improve the accuracy of depth estimation results whereas the image information of different dimensions (time, space, semantics, etc.) can be implicitly related to the depth of the image scene. Four types of information are often adopted: semantic information, neighborhood information, temporal information and object boundary information. 5)Miscellaneous strategies: Some other supervised learning methods still cannot be easily classified into the above-mentioned methods. 6) Various optimization strategies: Acquiring efficiency optimization, using synthetic data obtained via image style transfer for domain adaptation, and the hardware-oriented optimization for underwater scene depth estimation. The unsupervised learning methods of scene depth estimation are classified as below: 1) Stereo vision: Stereo vision aims to deduce the depth information of each pixel in the image from two or more images. Conventional binocular stereo vision algorithm is based on the stereo disparity, and can reconstruct the three-dimensional geometric information of surrounding scenery from the images captured by two camera sensors in terms of the principle of trigonometry. Researchers transform the depth estimation into an image reconstruction, and unsupervised depth estimation method is realized based on binocular (or multi-ocular) images and predicted disparity maps. 2) Structure from motion (SfM): SfM is a technique that automatically recovers camera parameters and the 3D structure of a scene from multiple images or video sequences. The unsupervised method based on SfM has its similarity to the unsupervised method based on stereo vision. It also transforms the depth estimation into the image reconstruction, but there are many differences in details. First, the SfM-based image reconstruction unsupervised processing method is generally using successive frames, that is, the image of the current frame is used to reconstruct the image of the previous or the next frame. Therefore, this kind of method uses image sequence generally-video as the training data. Second, the unsupervised method based on SfM needs to introduce a module for camera pose estimation in the training process. 3) Adversarial strategies: Generative adversarial networks (GANs) facilitate many imaging tasks with their powerful performance, where a discriminator can judge the results generated by the generator to force the generator to produce the same results as the labels. Adding discriminators to unsupervised learning networks can be effective in improving depth estimation results by optimizing image reconstruction results. 4) Ordinal relationship: Similar to the ordinal regression approach that utilizes ordinal relationships in the supervised learning methods, discrete disparity estimation is also desirable in unsupervised networks. In view of the fact that discrete depth values achieve more robust and sharper depth estimates than conventional regression predictions, discrete operations are equally effective in unsupervised networks. 5) Uncertainty: Since unsupervised learning does not use ground truth depth values, the depth results predicted is in doubt. From this viewpoint, it has been proposed to use the uncertainty of the prediction results of unsupervised methods as a benchmark for judging whether the prediction results are credible, and the results can be optimized in monocular depth estimation tasks. Meanwhile, this review refers to the NYU dataset, Karlsruhe Institute Technology and Toyota Technological Institute at Chicago (KITTI) dataset, Make3D dataset and Cityscapes dataset, which are mainly used in monocular deep estimation tasks, as well as six commonly-used evaluation metrics. Based on these datasets and evaluation metrics, a comparison among the reviewed methods is illustrated. Finally, the review discusses the current status of deep learning-based monocular depth estimation techniques in terms of accuracy, generalizability, application scenarios and uncertainty studies in unsupervised networks.关键词:deep learning;monocular depth estimation;supervised learning;unsupervised learning;multi-scale feature fusion;ordinal relationship;stereo vision775|1132|4更新时间:2024-05-07
摘要:Scene depth estimation is one of the key issues in the field of computer vision and an important aspect in the applications such as 3D reconstruction and image synthesis. Monocular depth estimation techniques based on deep learning have developed fast recently. Differentiated network structures have been proposed gradually. The current development of monocular depth estimation techniques based on deep learning and a categorical review of supervised and unsupervised learning-based methods have been illustrated in terms of the characteristics of the network structures. The supervised learning methods have been segmented as following: 1) Multi-scale feature fusion strategies: Different scales images contain different kinds of information via fusing multi-scale features extracted from the images. The demonstrated results of depth estimation can be effectively improved. 2)Conditional random fields (CRFs): CRFs, as one of probabilistic graphical models, have good performance in the field of semantic segmentation. Since depth information has similar data distribution attributes as semantic information, the use of consistent CRFs can be effective for predicting continuous depth values. CRFs can be operated as the loss function in the final part of the network as well as a feature fusion module in the medium layer of the network due to its effectiveness for fuse features. 3)Ordinal relations: One category is the relative depth estimation method which uses ordinal relation straight forward to estimate the relative position of two pixels in the image. The other category defines the depth estimation as an ordinal regression issue, which needs to discretize the continuous depth values into discrete depth labels and perform multi-class classification for the global depth. 4) Multiple image information: It is beneficial to combining various image information in depth estimation to improve the accuracy of depth estimation results whereas the image information of different dimensions (time, space, semantics, etc.) can be implicitly related to the depth of the image scene. Four types of information are often adopted: semantic information, neighborhood information, temporal information and object boundary information. 5)Miscellaneous strategies: Some other supervised learning methods still cannot be easily classified into the above-mentioned methods. 6) Various optimization strategies: Acquiring efficiency optimization, using synthetic data obtained via image style transfer for domain adaptation, and the hardware-oriented optimization for underwater scene depth estimation. The unsupervised learning methods of scene depth estimation are classified as below: 1) Stereo vision: Stereo vision aims to deduce the depth information of each pixel in the image from two or more images. Conventional binocular stereo vision algorithm is based on the stereo disparity, and can reconstruct the three-dimensional geometric information of surrounding scenery from the images captured by two camera sensors in terms of the principle of trigonometry. Researchers transform the depth estimation into an image reconstruction, and unsupervised depth estimation method is realized based on binocular (or multi-ocular) images and predicted disparity maps. 2) Structure from motion (SfM): SfM is a technique that automatically recovers camera parameters and the 3D structure of a scene from multiple images or video sequences. The unsupervised method based on SfM has its similarity to the unsupervised method based on stereo vision. It also transforms the depth estimation into the image reconstruction, but there are many differences in details. First, the SfM-based image reconstruction unsupervised processing method is generally using successive frames, that is, the image of the current frame is used to reconstruct the image of the previous or the next frame. Therefore, this kind of method uses image sequence generally-video as the training data. Second, the unsupervised method based on SfM needs to introduce a module for camera pose estimation in the training process. 3) Adversarial strategies: Generative adversarial networks (GANs) facilitate many imaging tasks with their powerful performance, where a discriminator can judge the results generated by the generator to force the generator to produce the same results as the labels. Adding discriminators to unsupervised learning networks can be effective in improving depth estimation results by optimizing image reconstruction results. 4) Ordinal relationship: Similar to the ordinal regression approach that utilizes ordinal relationships in the supervised learning methods, discrete disparity estimation is also desirable in unsupervised networks. In view of the fact that discrete depth values achieve more robust and sharper depth estimates than conventional regression predictions, discrete operations are equally effective in unsupervised networks. 5) Uncertainty: Since unsupervised learning does not use ground truth depth values, the depth results predicted is in doubt. From this viewpoint, it has been proposed to use the uncertainty of the prediction results of unsupervised methods as a benchmark for judging whether the prediction results are credible, and the results can be optimized in monocular depth estimation tasks. Meanwhile, this review refers to the NYU dataset, Karlsruhe Institute Technology and Toyota Technological Institute at Chicago (KITTI) dataset, Make3D dataset and Cityscapes dataset, which are mainly used in monocular deep estimation tasks, as well as six commonly-used evaluation metrics. Based on these datasets and evaluation metrics, a comparison among the reviewed methods is illustrated. Finally, the review discusses the current status of deep learning-based monocular depth estimation techniques in terms of accuracy, generalizability, application scenarios and uncertainty studies in unsupervised networks.关键词:deep learning;monocular depth estimation;supervised learning;unsupervised learning;multi-scale feature fusion;ordinal relationship;stereo vision775|1132|4更新时间:2024-05-07 -
 摘要:A sharp increase in point cloud data past decade, which has facilitated to point cloud data processing algorithms. Point cloud registration is the process of converting point cloud data in two or more camera coordinate systems to the world coordinate system to complete the stitching process. In respect of 3D reconstruction, scanning equipment is used to obtain partial information of the scene in common, and the whole scene is reconstructed based on point cloud registration. In respect of high-precision map and positioning, the local point clouds fragments obtained in driving vehicle are registered to the scene map in advance to complete the high-precision positioning of the vehicle. In addition, point cloud registration is also widely used in pose estimation, robotics, medical and other fields. In the real-world point cloud data collection process, there are a lot of noise, abnormal points and low overlap, which brings great challenges to traditional methods. Currently, deep learning has been widely used in the field of point cloud registration and has achieved remarkable results. In order to solve the limitations of traditional methods, some researchers have developed some point cloud registration methods integrated with deep learning technology, which is called deep point cloud registration. First of all, this analysis distinguishes the current deep learning point cloud registration methods according to the presence or absence of correspondence, which is divided into correspondence-free registration and point cloud registration based on correspondence. The main functions of various methods are classified as follows: 1) geometric feature extraction; 2) key point detection; 3) outlier removal; 4)pose estimation; and 5) end-to-end registration. The geometric feature extraction module aims to learn the coding method of the local geometric structure of the point cloud to generate discriminative features based on the network. Key point detection is used to detect points that are essential to the registration task in a large number of input points, and eliminate potential outliers while reducing computational complexity. Point-to-outliers are the final checking step before estimating the motion parameters to ensure the accuracy and efficiency of the solution. In the correspondence-free point cloud registration, a network structure similar to PointNet is used to obtain the global features of the perceived point cloud pose, and the rigid transformation parameters are estimated from the global features. In the performance of evaluation, the feature matching and registration error performance evaluation indicators are illustrated in detail. Feature matching performance metrics mainly include inlier ratio(IR) and feature matching recall(FMR). Registration error performance metrics include root mean square error(RMSE), mean square error(MSE), and mean Absolute error(MAE), relative translation error(RTE), relative rotation error(RRE), chamfer distance(CD) and registration recall(RR). RMSE, MSE and MAE are the most widely used metrics, but they have the disadvantage of Anisotropic. Isotropic RRE and RTE are indicators that actually measure the differences amongst the angle, the translation distance. The above five metrics all have inequal penalties for the registration of axisymmetric point clouds, and CD is the most fair metric. Meanwhile, real data sets registration tends to focus on the success rate of registration. With respect of real data sets, this research provides comparative data for feature matching and outlier removal. In the synthetic data set, this demonstration presents the comparative data of related methods in partial overlap, realtime, and global registration scenarios. At the end, the future research is from the current challenges in this field. 1) The application scenarios faced by point cloud registration are diverse, and it is difficult to develop general algorithms. Therefore, lightweight and efficient dedicated modules are more popular. 2) By dividing the overlap area, partial overlap can be converted into no overlap problem. This method is expected to lift the restrictions on the overlap rate requirements and fundamentally solve the problem of overlapping point cloud registration, so it has greater application value and prospects. 3) Most mainstream methods use multilayer perceptrons(MLPs) to learn saliency from data. 4) Some researchers introduced the random sample consensus(RANSAC) algorithm idea into the neural network, and achieved advanced results, but also led to higher complexity. Therefore, the balance performance and complexity is an issue to be considered in this sub-field. 5) The correspondence-free registration method is based on learning global features related to poses. The global features extracted by existing methods are more sensitive to noise and partial overlap, which is mainly caused by the fusion of some messy information in the global features. Meanwhile, the correspondence-free method has not been widely used in real data, and its robustness is still questioned by some researchers. Robust extraction of the global features for pose perception is also one of the main research issues further.关键词:point cloud registration;deep learning;registration without corresponding;end-to-end registration;correspondence;geometric feature extraction;outliers removal;review250|401|10更新时间:2024-05-07
摘要:A sharp increase in point cloud data past decade, which has facilitated to point cloud data processing algorithms. Point cloud registration is the process of converting point cloud data in two or more camera coordinate systems to the world coordinate system to complete the stitching process. In respect of 3D reconstruction, scanning equipment is used to obtain partial information of the scene in common, and the whole scene is reconstructed based on point cloud registration. In respect of high-precision map and positioning, the local point clouds fragments obtained in driving vehicle are registered to the scene map in advance to complete the high-precision positioning of the vehicle. In addition, point cloud registration is also widely used in pose estimation, robotics, medical and other fields. In the real-world point cloud data collection process, there are a lot of noise, abnormal points and low overlap, which brings great challenges to traditional methods. Currently, deep learning has been widely used in the field of point cloud registration and has achieved remarkable results. In order to solve the limitations of traditional methods, some researchers have developed some point cloud registration methods integrated with deep learning technology, which is called deep point cloud registration. First of all, this analysis distinguishes the current deep learning point cloud registration methods according to the presence or absence of correspondence, which is divided into correspondence-free registration and point cloud registration based on correspondence. The main functions of various methods are classified as follows: 1) geometric feature extraction; 2) key point detection; 3) outlier removal; 4)pose estimation; and 5) end-to-end registration. The geometric feature extraction module aims to learn the coding method of the local geometric structure of the point cloud to generate discriminative features based on the network. Key point detection is used to detect points that are essential to the registration task in a large number of input points, and eliminate potential outliers while reducing computational complexity. Point-to-outliers are the final checking step before estimating the motion parameters to ensure the accuracy and efficiency of the solution. In the correspondence-free point cloud registration, a network structure similar to PointNet is used to obtain the global features of the perceived point cloud pose, and the rigid transformation parameters are estimated from the global features. In the performance of evaluation, the feature matching and registration error performance evaluation indicators are illustrated in detail. Feature matching performance metrics mainly include inlier ratio(IR) and feature matching recall(FMR). Registration error performance metrics include root mean square error(RMSE), mean square error(MSE), and mean Absolute error(MAE), relative translation error(RTE), relative rotation error(RRE), chamfer distance(CD) and registration recall(RR). RMSE, MSE and MAE are the most widely used metrics, but they have the disadvantage of Anisotropic. Isotropic RRE and RTE are indicators that actually measure the differences amongst the angle, the translation distance. The above five metrics all have inequal penalties for the registration of axisymmetric point clouds, and CD is the most fair metric. Meanwhile, real data sets registration tends to focus on the success rate of registration. With respect of real data sets, this research provides comparative data for feature matching and outlier removal. In the synthetic data set, this demonstration presents the comparative data of related methods in partial overlap, realtime, and global registration scenarios. At the end, the future research is from the current challenges in this field. 1) The application scenarios faced by point cloud registration are diverse, and it is difficult to develop general algorithms. Therefore, lightweight and efficient dedicated modules are more popular. 2) By dividing the overlap area, partial overlap can be converted into no overlap problem. This method is expected to lift the restrictions on the overlap rate requirements and fundamentally solve the problem of overlapping point cloud registration, so it has greater application value and prospects. 3) Most mainstream methods use multilayer perceptrons(MLPs) to learn saliency from data. 4) Some researchers introduced the random sample consensus(RANSAC) algorithm idea into the neural network, and achieved advanced results, but also led to higher complexity. Therefore, the balance performance and complexity is an issue to be considered in this sub-field. 5) The correspondence-free registration method is based on learning global features related to poses. The global features extracted by existing methods are more sensitive to noise and partial overlap, which is mainly caused by the fusion of some messy information in the global features. Meanwhile, the correspondence-free method has not been widely used in real data, and its robustness is still questioned by some researchers. Robust extraction of the global features for pose perception is also one of the main research issues further.关键词:point cloud registration;deep learning;registration without corresponding;end-to-end registration;correspondence;geometric feature extraction;outliers removal;review250|401|10更新时间:2024-05-07 -
 摘要:As a 3D representation, point cloud is widely used and brings many challenges to point cloud processing. One of the tasks worth studying is point cloud registration that aims to register multiple point clouds correctly to the same coordinate and form a more complete point cloud. Point cloud registration should deal with the unstructured, uneven, noise, and other interference of the point cloud. It needs a shorter time consumption and achieves a higher accuracy. However, time consumption and precision are often contradictory, but it is optimized to a certain extent is possible. Point cloud registration is widely used in fields such as 3D reconstruction, parameter evaluation, positioning, and posture estimation. Autonomous driving, robotics, augmented reality, and others applications also involve the cloud registration technology. For this reason, various ingenious point cloud registration methods have been developed by researchers. In this paper, several representative point cloud registration methods are sorted out and summarized as a review. Compared with related work, this paper tries to cover various forms of point cloud registration and analyzes the details of several methods. It summarizes the existing methods into nonlearning methods and learning-based methods. Nonlearning methods are divided into classical methods and feature-based methods. Among them, the classic methods include iterative closest point and its variants, normal distributions transform and its variants, and 4-points congruent sets and its variants. Iterative closest point and normal distributions transform and their variants are classical fine registration methods and can achieve a high accuracy, but need a good initial pose. The 4-points congruent sets and its variants are classical coarse registration methods, do not need an initial pose, and can be used as the initial pose for fine registration after this coarse registration. For feature based algorithms, the methods of feature detection, feature description, and feature matching are introduced. They are the main process of a typical point cloud registration method in addition to other steps such as preprocessing of point cloud and calculation and verification of transformation matrix. The features are divided into point-based features, line-based features, surface-based features, and texture-based features. For different features, feature detection, description, and matching are also different, but none of them need an initial position. In addition to registration, these features can also be used for point cloud segmentation, recognition, and other tasks. Similarly, learning-based methods are subdivided into two types: partial learning methods that combine nonlearning components and purely end-to-end learning methods. The partial learning method replaces several components in the nonlearning method with learning-based components and exerts the high speed and high reliability of the learning method, which can bring great improvement to the nonlearning method. This method can also use several learning components designed for other tasks and provide learning components designed for registration tasks for other tasks; thus, it has a high flexibility. Many of these methods are similar to feature-based nonlearning methods and are feature based. However, several methods learn to segment point clouds and then use iterative closest point or normal distributions transform for registration. These partial learning methods have great flexibility, but the data required by partial learning methods are not easy to obtain, and verifying the learning results of partial learning is not easy. The end-to-end learning methods are more convenient to learn, its training data are easier to obtain, and the learning results are easier to verify. The end-to-end method also has a great advantage in speed, which can make full use of the computing power of the graphics processing unit(GPU). Nonlearning methods have lower hardware requirements, are easier to implement, and do not require training. They may not have an advantage in computing speed under the same registration performance, whereas learning-based methods can learn more advanced features in the point cloud, which is very helpful for improving the registration performance but depends on the diversity of the data set and the more advanced deep learning structure. The details of several typical algorithms for each method are introduced, and then the characteristics of these algorithms are compared and summarized. The performance of point cloud registration algorithms is constantly improving, but more point cloud application scenarios also entail higher requirements for point cloud registration, such as the requirements for real-time performance and the effectiveness of noise and lack or repetitive features, and robustness when dealing with unstable point clouds of multiple moving objects. Point cloud registration technology is still a worthy research direction. Point cloud registration technology will inevitably continue to make breakthroughs in speed, precision, and accuracy, and serve more applications.关键词:point cloud;registration;feature;deep learning;review454|177|29更新时间:2024-05-07
摘要:As a 3D representation, point cloud is widely used and brings many challenges to point cloud processing. One of the tasks worth studying is point cloud registration that aims to register multiple point clouds correctly to the same coordinate and form a more complete point cloud. Point cloud registration should deal with the unstructured, uneven, noise, and other interference of the point cloud. It needs a shorter time consumption and achieves a higher accuracy. However, time consumption and precision are often contradictory, but it is optimized to a certain extent is possible. Point cloud registration is widely used in fields such as 3D reconstruction, parameter evaluation, positioning, and posture estimation. Autonomous driving, robotics, augmented reality, and others applications also involve the cloud registration technology. For this reason, various ingenious point cloud registration methods have been developed by researchers. In this paper, several representative point cloud registration methods are sorted out and summarized as a review. Compared with related work, this paper tries to cover various forms of point cloud registration and analyzes the details of several methods. It summarizes the existing methods into nonlearning methods and learning-based methods. Nonlearning methods are divided into classical methods and feature-based methods. Among them, the classic methods include iterative closest point and its variants, normal distributions transform and its variants, and 4-points congruent sets and its variants. Iterative closest point and normal distributions transform and their variants are classical fine registration methods and can achieve a high accuracy, but need a good initial pose. The 4-points congruent sets and its variants are classical coarse registration methods, do not need an initial pose, and can be used as the initial pose for fine registration after this coarse registration. For feature based algorithms, the methods of feature detection, feature description, and feature matching are introduced. They are the main process of a typical point cloud registration method in addition to other steps such as preprocessing of point cloud and calculation and verification of transformation matrix. The features are divided into point-based features, line-based features, surface-based features, and texture-based features. For different features, feature detection, description, and matching are also different, but none of them need an initial position. In addition to registration, these features can also be used for point cloud segmentation, recognition, and other tasks. Similarly, learning-based methods are subdivided into two types: partial learning methods that combine nonlearning components and purely end-to-end learning methods. The partial learning method replaces several components in the nonlearning method with learning-based components and exerts the high speed and high reliability of the learning method, which can bring great improvement to the nonlearning method. This method can also use several learning components designed for other tasks and provide learning components designed for registration tasks for other tasks; thus, it has a high flexibility. Many of these methods are similar to feature-based nonlearning methods and are feature based. However, several methods learn to segment point clouds and then use iterative closest point or normal distributions transform for registration. These partial learning methods have great flexibility, but the data required by partial learning methods are not easy to obtain, and verifying the learning results of partial learning is not easy. The end-to-end learning methods are more convenient to learn, its training data are easier to obtain, and the learning results are easier to verify. The end-to-end method also has a great advantage in speed, which can make full use of the computing power of the graphics processing unit(GPU). Nonlearning methods have lower hardware requirements, are easier to implement, and do not require training. They may not have an advantage in computing speed under the same registration performance, whereas learning-based methods can learn more advanced features in the point cloud, which is very helpful for improving the registration performance but depends on the diversity of the data set and the more advanced deep learning structure. The details of several typical algorithms for each method are introduced, and then the characteristics of these algorithms are compared and summarized. The performance of point cloud registration algorithms is constantly improving, but more point cloud application scenarios also entail higher requirements for point cloud registration, such as the requirements for real-time performance and the effectiveness of noise and lack or repetitive features, and robustness when dealing with unstable point clouds of multiple moving objects. Point cloud registration technology is still a worthy research direction. Point cloud registration technology will inevitably continue to make breakthroughs in speed, precision, and accuracy, and serve more applications.关键词:point cloud;registration;feature;deep learning;review454|177|29更新时间:2024-05-07 -
 摘要:Simultaneous localization and mapping (SLAM) technology is widely used in mobile robot applications, and it focuses on the robot's motion state estimation issue and reconstructing the environment model (map) at the same time. The SLAM science community has promoted the technique to be deployed in various applications in real life nowadays, such as virtual reality, augmented reality, autonomous driving, service robots, etc. In complicated scenarios, SLAM systems empowered with single sensor such as a camera or light detection and ranging(LiDAR) often fail to customize the targeted applications due to the deficiency of accuracy and robustness. Current research analyses have gradually improved SLAM solutions based on multi-sensors, multiple feature primitives, and the integration of multi-dimensional information. This research reviews current methods in the multi-source fusion SLAM realm at three scales: multi-sensor fusion (hybrid system with two or more kinds of sensors such as camera, LiDAR and inertial measurement unit (IMU), and combination methods can be divided into two categories(the loosely-coupled and the tightly-coupled), multi-feature-primitive fusion (point, line, plane, other high-dimensional geometric features, and the featureless direct-based method) and multi-dimensional information fusion (geometric information, semantic information, physical information, and inferred information from deep neural networks). The challenges and future research of multi-source fusion SLAM has been predicted as well. Multi-source fusion systems can implement accurate and robust state estimation and mapping, which can meet the requirements in a wider variety of applications. For instance, the fusion of vision and inertial sensors can illustrate the drift and scale missing issue of visual odometry, while the fusion of LiDAR and inertial measurement unit can improve the system's robustness, especially in unstructured or degraded scenes. The fusion of other sensors, such as sonar, radar and GPS(global positioning system) can extend the applicability further. In addition, the fusion of diverse geometric feature primitives such as feature points, lines, curves, planes, curved surfaces, cubes, and featureless direct-based methods can greatly deduct the degree of valid constraints, which is of great importance for state estimation systems. The reconstructed environmental map with multiple feature primitives is informative in autonomous navigation tasks. Furthermore, data-driven deep-learning-based synthesized analysis in the context of probabilistic model-based methods paves a new path to overcome the challenges of the initial SLAM systems. The learning-based methods (supervised learning, unsupervised learning, and hybrid supervised learning) are gradually applied to various modules of the SLAM system, including relative pose regression, map representation, loop closure detection, and unrolled back-end optimization, etc. Learning-based methods will benefit the performance of SLAM more with more cutting-edge research to fill the gap amongst networks and various original methods. This demonstration is shown as following: 1) The analysis of funder mental mechanisms of multi-sensor fusion and current multi-sensor fusion methods are illustrated; 2) Multi-feature primitive fusion and multi-dimensional information fusion are demonstrated; 3) The current difficulties and challenges of multi-source fusion towards SLAM have been issued; 4) The executive summary has been implemented at the end.关键词:simultaneous localization and mapping(SLAM);multi-source fusion;multi-sensor fusion;multi-feature fusion;multi-dimension information fusion517|689|13更新时间:2024-05-07
摘要:Simultaneous localization and mapping (SLAM) technology is widely used in mobile robot applications, and it focuses on the robot's motion state estimation issue and reconstructing the environment model (map) at the same time. The SLAM science community has promoted the technique to be deployed in various applications in real life nowadays, such as virtual reality, augmented reality, autonomous driving, service robots, etc. In complicated scenarios, SLAM systems empowered with single sensor such as a camera or light detection and ranging(LiDAR) often fail to customize the targeted applications due to the deficiency of accuracy and robustness. Current research analyses have gradually improved SLAM solutions based on multi-sensors, multiple feature primitives, and the integration of multi-dimensional information. This research reviews current methods in the multi-source fusion SLAM realm at three scales: multi-sensor fusion (hybrid system with two or more kinds of sensors such as camera, LiDAR and inertial measurement unit (IMU), and combination methods can be divided into two categories(the loosely-coupled and the tightly-coupled), multi-feature-primitive fusion (point, line, plane, other high-dimensional geometric features, and the featureless direct-based method) and multi-dimensional information fusion (geometric information, semantic information, physical information, and inferred information from deep neural networks). The challenges and future research of multi-source fusion SLAM has been predicted as well. Multi-source fusion systems can implement accurate and robust state estimation and mapping, which can meet the requirements in a wider variety of applications. For instance, the fusion of vision and inertial sensors can illustrate the drift and scale missing issue of visual odometry, while the fusion of LiDAR and inertial measurement unit can improve the system's robustness, especially in unstructured or degraded scenes. The fusion of other sensors, such as sonar, radar and GPS(global positioning system) can extend the applicability further. In addition, the fusion of diverse geometric feature primitives such as feature points, lines, curves, planes, curved surfaces, cubes, and featureless direct-based methods can greatly deduct the degree of valid constraints, which is of great importance for state estimation systems. The reconstructed environmental map with multiple feature primitives is informative in autonomous navigation tasks. Furthermore, data-driven deep-learning-based synthesized analysis in the context of probabilistic model-based methods paves a new path to overcome the challenges of the initial SLAM systems. The learning-based methods (supervised learning, unsupervised learning, and hybrid supervised learning) are gradually applied to various modules of the SLAM system, including relative pose regression, map representation, loop closure detection, and unrolled back-end optimization, etc. Learning-based methods will benefit the performance of SLAM more with more cutting-edge research to fill the gap amongst networks and various original methods. This demonstration is shown as following: 1) The analysis of funder mental mechanisms of multi-sensor fusion and current multi-sensor fusion methods are illustrated; 2) Multi-feature primitive fusion and multi-dimensional information fusion are demonstrated; 3) The current difficulties and challenges of multi-source fusion towards SLAM have been issued; 4) The executive summary has been implemented at the end.关键词:simultaneous localization and mapping(SLAM);multi-source fusion;multi-sensor fusion;multi-feature fusion;multi-dimension information fusion517|689|13更新时间:2024-05-07 -
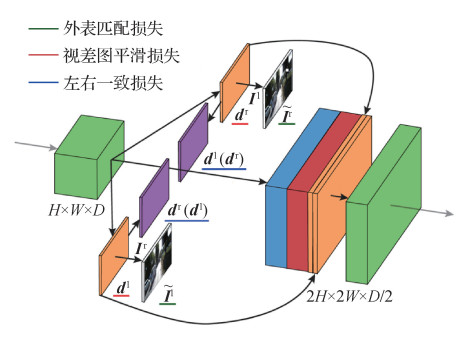 摘要:The development of computer technology promotes the development of computer vision. Nowadays, more researchers focus on the field of 3D vision while monocular depth estimation is one of the basic tasks of 3D vision. Depth estimation from a single image is a critical technology for obtaining scene depth information. This technology has important research value because it has potential applications in intelligent vehicles, robot positioning, and other fields. Compared with traditional depth acquisition methods, monocular depth estimation based on deep learning has the advantages of low cost and simple operation. With the development of deep learning technology, many studies on monocular depth estimation based on deep learning have emerged in recent years, and the performance of monocular depth estimation has made great progress. The monocular depth estimation model needs a large a large amount of data to train the model. The commonly used training data types include RGB and depth (RGB-D) image pairs, stereo image pairs, and image sequences. The depth estimation model training by RGB-D images first extracts the image features through convolutional neural network and then predicts the depth map by using the method of continuous depth value regression. After predicting the depth map, several models use conditional random fields or other methods to optimize the depth map. Unsupervised learning is often used to train the monocular depth estimation model when the training data types are stereo image pairs and image sequences. The monocular estimation model training by stereo image pairs first predicts the disparity map and then estimates depth by using the disparity map. When an image sequence is used to train the model, the model first predicts the depth map of an image in the image sequence, and then the depth estimation model is optimized by images reconstructed by the depth map and other images in the sequence. To improve the accuracy of depth estimation, several researchers use semantic tags, depth range, and other auxiliary information to optimize depth maps. Several data sets can be used for multiple computer vision tasks such as depth estimation and semantic segmentation. Several researchers improve the accuracy of depth estimation by learning depth estimation and semantic segmentation model jointly because depth estimation has a strong correlation with semantic segmentation. When establishing the depth estimation data set, depth camera or light laser detection and ranging (LiDAR) is used to obtain the scene depth. Depth camera and LiDAR are based on the principle that light and other propagation media will reflect when they encounter objects. The depth range obtained by depth cameras and LiDAR is fixed because the propagation medium is dissipated in the transmission, and depth cameras and LiDAR cannot measure depth while the propagation medium energy is very small. Several models first divide the depth range into several depth intervals, take the median value of the depth interval as the depth value of the interval, and then use the method of multiple classifications to predict the depth map. Different training data types not only result in different network model structures but also affect the accuracy of depth estimation. In this review, the current monocular depth estimation methods based on deep learning are surveyed from the perspective of the training data type used by the monocular depth estimation model. Moreover, the single-image training model, the multi-image training model, and the monocular depth estimation model of auxiliary information optimization training are separately discussed. Furthermore, the latest research status of monocular depth estimation is systematically analyzed, and the advantages and disadvantages of various methods are discussed. Finally, the future research trends of monocular depth estimation are summarized.关键词:monocular vision;scene perception;deep learning;3D reconstruction;depth estimation247|154|4更新时间:2024-05-07
摘要:The development of computer technology promotes the development of computer vision. Nowadays, more researchers focus on the field of 3D vision while monocular depth estimation is one of the basic tasks of 3D vision. Depth estimation from a single image is a critical technology for obtaining scene depth information. This technology has important research value because it has potential applications in intelligent vehicles, robot positioning, and other fields. Compared with traditional depth acquisition methods, monocular depth estimation based on deep learning has the advantages of low cost and simple operation. With the development of deep learning technology, many studies on monocular depth estimation based on deep learning have emerged in recent years, and the performance of monocular depth estimation has made great progress. The monocular depth estimation model needs a large a large amount of data to train the model. The commonly used training data types include RGB and depth (RGB-D) image pairs, stereo image pairs, and image sequences. The depth estimation model training by RGB-D images first extracts the image features through convolutional neural network and then predicts the depth map by using the method of continuous depth value regression. After predicting the depth map, several models use conditional random fields or other methods to optimize the depth map. Unsupervised learning is often used to train the monocular depth estimation model when the training data types are stereo image pairs and image sequences. The monocular estimation model training by stereo image pairs first predicts the disparity map and then estimates depth by using the disparity map. When an image sequence is used to train the model, the model first predicts the depth map of an image in the image sequence, and then the depth estimation model is optimized by images reconstructed by the depth map and other images in the sequence. To improve the accuracy of depth estimation, several researchers use semantic tags, depth range, and other auxiliary information to optimize depth maps. Several data sets can be used for multiple computer vision tasks such as depth estimation and semantic segmentation. Several researchers improve the accuracy of depth estimation by learning depth estimation and semantic segmentation model jointly because depth estimation has a strong correlation with semantic segmentation. When establishing the depth estimation data set, depth camera or light laser detection and ranging (LiDAR) is used to obtain the scene depth. Depth camera and LiDAR are based on the principle that light and other propagation media will reflect when they encounter objects. The depth range obtained by depth cameras and LiDAR is fixed because the propagation medium is dissipated in the transmission, and depth cameras and LiDAR cannot measure depth while the propagation medium energy is very small. Several models first divide the depth range into several depth intervals, take the median value of the depth interval as the depth value of the interval, and then use the method of multiple classifications to predict the depth map. Different training data types not only result in different network model structures but also affect the accuracy of depth estimation. In this review, the current monocular depth estimation methods based on deep learning are surveyed from the perspective of the training data type used by the monocular depth estimation model. Moreover, the single-image training model, the multi-image training model, and the monocular depth estimation model of auxiliary information optimization training are separately discussed. Furthermore, the latest research status of monocular depth estimation is systematically analyzed, and the advantages and disadvantages of various methods are discussed. Finally, the future research trends of monocular depth estimation are summarized.关键词:monocular vision;scene perception;deep learning;3D reconstruction;depth estimation247|154|4更新时间:2024-05-07
Review

-
 摘要:ObjectiveIntrinsic decomposition is a key problem in computer vision and graphics applications. It aims at separating lighting effects and material-oriented characteristics of object surfaces of the depicted scene within the image. Intrinsic decomposition from a single input image is highly ill-posed since the amount of unknowns is twice of the known values. Most classical approaches model intrinsic decomposition task with handcrafted priors to generate reasonable decomposition results. But they perform poorly in complicated scenarios as the prior knowledge is too limited to model complicated light-material interactions in real-world scenes. Deep neural network based methods can automatically learn the knowledge from data to avoid using handcrafted priors to model the task. However, due to the dependency on training datasets, the performance of current deep learning based methods is still limited because of various constraints in the current intrinsic datasets. Moreover, the learned networks tend to suffer from poor generalization once there is a large difference between the training and target domain. Another issue of deep neural network based methods is that the limited receptive field probably constrains the ability of the models to exploit the non-local information in the intrinsic component prediction process.MethodA graph convolution based module is designed to fully utilize the non-local cues within the input feature space. The module takes a feature map as input and outputs a feature map with same resolution as the input feature map. For producing the output feature vector for each position, the module uses information that includes the feature of itself, the information extracted from the local neighborhood and the information aggregated from the non-local neighbors that are likely to be very distant. The full intrinsic decomposition framework is constructed by integrating the devised non-local feature learning module into a U-Net network. In addition, to improve the piece-wise smoothness of the produced albedo results, we incorporate a neural network based image refinement module into the full pipeline, which is able to adaptively remove unnecessary artifacts while preserving structural information within the scenes depicted in input images. Simultaneously, there are noticeable limitations in existing intrinsic image datasets including limited sample amount, unrealistic scene and achromatic lighting in shading and sparse annotations, which will cause generalization issues for deep learning models and limit the decomposition performance as well. A new photorealistic rendered dataset for intrinsic image decomposition is proposed, which is rendered by leveraging large-scale 3D indoor scene models, along with high-quality textures and lighting to simulate the real-world environment. The chromatic shading components are first implemented.ResultTo validate the effectiveness of the proposed dataset, several state-of-the-art methods are trained on both the proposed dataset and CGIntrinsics dataset, a previously proposed dataset, and tested on intrinsic image evaluation benchmarks, i.e., intrinsie images in the wild (IIW)/shading annotations in the wild (SAW) test sets. Compared to the variants trained on CGIntrinsics dataset, the variants trained on the proposed dataset demonstrate a 7.29% improvement in averaging weighted human disagreement rate (WHDR) on IIW test set and a 2.74% gain for average precision (AP) on SAW test set. Simultaneously, the proposed graph convolution based network achieves comparable quantitative results on both IIW and SAW test sets and gets significantly better qualitative results. To further investigate the intrinsic decomposition quality for different methods, a number of application tasks including re-lighting and texture/lighting editing are conducted utilizing the generated intrinsic components. The proposed method demonstrates more promising application effects comparing with two state-of-the-art methods, further highlighting its superiority and application potential.ConclusionBased on the non-local priors in classical methods for intrinsic image decomposition, a graph convolutional network for intrinsic decomposition is proposed, in which non-local cues are utilized. To mitigate the issues existed in current intrinsic image datasets, a new high quality photorealistic dataset is rendered, which provides dense labels for albedo and shading. The depicted scenes in the images of the proposed dataset have complicated textures and illuminations that closely approximate general indoor scenes in reality, which helps to mitigate the domain gap issues. The shading labels in this dataset first consider chromatic lighting, which allows the neural networks to better separate material properties and lighting effects, especially for the effects introduced by inter-reflections between diffuse surfaces. The decomposition results of both the proposed method and two current state-of-the-art methods are applied to a range of application scenarios, visually demonstrating the superior decomposition quality and application potentials of the proposed method.关键词:image processing;image understanding;intrinsic image decomposition;graph convolutional neural network(GCN);synthetic dataset313|1076|1更新时间:2024-05-07
摘要:ObjectiveIntrinsic decomposition is a key problem in computer vision and graphics applications. It aims at separating lighting effects and material-oriented characteristics of object surfaces of the depicted scene within the image. Intrinsic decomposition from a single input image is highly ill-posed since the amount of unknowns is twice of the known values. Most classical approaches model intrinsic decomposition task with handcrafted priors to generate reasonable decomposition results. But they perform poorly in complicated scenarios as the prior knowledge is too limited to model complicated light-material interactions in real-world scenes. Deep neural network based methods can automatically learn the knowledge from data to avoid using handcrafted priors to model the task. However, due to the dependency on training datasets, the performance of current deep learning based methods is still limited because of various constraints in the current intrinsic datasets. Moreover, the learned networks tend to suffer from poor generalization once there is a large difference between the training and target domain. Another issue of deep neural network based methods is that the limited receptive field probably constrains the ability of the models to exploit the non-local information in the intrinsic component prediction process.MethodA graph convolution based module is designed to fully utilize the non-local cues within the input feature space. The module takes a feature map as input and outputs a feature map with same resolution as the input feature map. For producing the output feature vector for each position, the module uses information that includes the feature of itself, the information extracted from the local neighborhood and the information aggregated from the non-local neighbors that are likely to be very distant. The full intrinsic decomposition framework is constructed by integrating the devised non-local feature learning module into a U-Net network. In addition, to improve the piece-wise smoothness of the produced albedo results, we incorporate a neural network based image refinement module into the full pipeline, which is able to adaptively remove unnecessary artifacts while preserving structural information within the scenes depicted in input images. Simultaneously, there are noticeable limitations in existing intrinsic image datasets including limited sample amount, unrealistic scene and achromatic lighting in shading and sparse annotations, which will cause generalization issues for deep learning models and limit the decomposition performance as well. A new photorealistic rendered dataset for intrinsic image decomposition is proposed, which is rendered by leveraging large-scale 3D indoor scene models, along with high-quality textures and lighting to simulate the real-world environment. The chromatic shading components are first implemented.ResultTo validate the effectiveness of the proposed dataset, several state-of-the-art methods are trained on both the proposed dataset and CGIntrinsics dataset, a previously proposed dataset, and tested on intrinsic image evaluation benchmarks, i.e., intrinsie images in the wild (IIW)/shading annotations in the wild (SAW) test sets. Compared to the variants trained on CGIntrinsics dataset, the variants trained on the proposed dataset demonstrate a 7.29% improvement in averaging weighted human disagreement rate (WHDR) on IIW test set and a 2.74% gain for average precision (AP) on SAW test set. Simultaneously, the proposed graph convolution based network achieves comparable quantitative results on both IIW and SAW test sets and gets significantly better qualitative results. To further investigate the intrinsic decomposition quality for different methods, a number of application tasks including re-lighting and texture/lighting editing are conducted utilizing the generated intrinsic components. The proposed method demonstrates more promising application effects comparing with two state-of-the-art methods, further highlighting its superiority and application potential.ConclusionBased on the non-local priors in classical methods for intrinsic image decomposition, a graph convolutional network for intrinsic decomposition is proposed, in which non-local cues are utilized. To mitigate the issues existed in current intrinsic image datasets, a new high quality photorealistic dataset is rendered, which provides dense labels for albedo and shading. The depicted scenes in the images of the proposed dataset have complicated textures and illuminations that closely approximate general indoor scenes in reality, which helps to mitigate the domain gap issues. The shading labels in this dataset first consider chromatic lighting, which allows the neural networks to better separate material properties and lighting effects, especially for the effects introduced by inter-reflections between diffuse surfaces. The decomposition results of both the proposed method and two current state-of-the-art methods are applied to a range of application scenarios, visually demonstrating the superior decomposition quality and application potentials of the proposed method.关键词:image processing;image understanding;intrinsic image decomposition;graph convolutional neural network(GCN);synthetic dataset313|1076|1更新时间:2024-05-07
Dataset
-
 摘要:ObjectiveThe conception of digital twin has attracted tremendous attention and developed rapidly in the fields of smart cities, smart transportation, urban planning, and virtual/augmented reality during past years. The basic objective is to visualize, analyze, simulate, and optimize real world scenes by projecting physical objects onto digital 3D models. To apply digital twin technology successfully to downstream applications such as real-time rendering, human-scene interaction, and numerical simulation, the reconstructed 3D models should preferably be geometrically accurate, vectorized, highly simplified, free of self-intersection, and watertight. To satisfy these requirements, a potential solution called structured reconstruction method extracts geometric planes from discrete point clouds or original triangular mesh and splices them into a compact parametric 3D model. Previous methods address this problem by detecting geometric shapes and then assembling them into a polygonal mesh, but these methods usually suffer from two obstacles. First, traditional shape detection methods such as region growing algorithm rely on iteratively propagating geometric constraints around selected seeds. This greedy strategy only considers local properties and cannot guarantee the quality of global configuration. Second, current shape assembly methods typically recover the surface model by slicing the 3D space into polyhedral cells and assigning inside-outside labels to each cell. Most of these slicing-based methods preserve a high computational complexity and can hardly process more than 100 shapes. In this paper, a novel automatic approach that generates concise polygonal meshes from point clouds or raw triangular meshes in an efficient, robust manner relying upon three ingredients is proposed.MethodOur method consists of three steps: shape detection, space partition, and surface extraction. Our algorithm requires as input a point cloud with oriented normal or triangle mesh. The resulting model is guaranteed to be intersection-free and watertight. First, a multi-source region growing algorithm that detects planar shapes from input 3D data through a global way is proposed. This strategy ensures that points or triangular facets located near the boundary of two shapes can be correctly clustered into their corresponding group. Next, the detected planar shapes are used to partition the bounding box of the object into a polyhedral. To avoid the computational burden involved in the shape assembling step, the partition is performed in a hierarchical manner, that is, the 3D space is recursively divided to build a binary space partitioning (BSP) tree. Starting from the initial bounding box, the largest planar shapes are used to divide a polyhedron cell into two. The planar shapes in the polyhedron are also assigned to the new polyhedron cell. If a shape spans the two polyhedrons, it is divided into two to ensure that every shape in the new polyhedron does not exceed its scope. This operation continues until no divisible polyhedron cell remains. It is equivalent to building a BSP tree. Each leaf node of the BSP tree corresponds to a convex polyhedron cell, and all leaf nodes are combined into the initial bounding box. In such a way, a detected shape only partitions the space locally, without causing redundant partitioning. Hierarchical space partition is the key to reducing the search space and improving the overall pipeline efficiency. Finally, the surface is extracted from the hierarchical partition by labeling each polyhedron as inside or outside the reconstructed model. A ray-shooting-based Markov energy function is defined, and a min-cut is operated to find inside-outside labeling that minimizes the energy function. The output surface is defined as the interface facets between the inside and the outside polyhedral.ResultThe robustness and the performance of our method are demonstrated on a variety of man-made objects and even large-scale scenes from three aspects of fidelity, complexity, and running time. A large number of experimental results prove that our algorithm can process objects composed of tens of thousands of planar shapes on a standard computer without a parallelization scheme. Compared with traditional slicing methods, the number of polyhedral cells obtained through this simple, robust mechanism and the running time are reduced by at least two orders of magnitude. Approximately 70% of the calculation time is used for space partition, but the total time can be controlled within 5 s/10 000 points. In addition, the root-mean-square(RMS) error of the simplified model is mostly controlled within 1%, and the simplification ratio of the facets is controlled within 1.5%. The proposed method greatly improves the calculation efficiency and accuracy of the results, and provides a good trade-off between complexity and fidelity.ConclusionOur structural mesh reconstruction pipeline consists of three steps: shape detection, space partition, and surface extraction. Our method is especially suitable for models with rich structural features. The resulting model is guaranteed to be watertight and free of self-intersection while preserving the features of the structure. The limitation of this algorithm is that reconstruction quality mainly depends on the result of shape detection, which only considers the individual model and does not take advantage of the statistical information of the whole dataset. In addition, this algorithm is only for reconstructing watertight models. When the input data have a large area of missing parts (such as the bottom of the building data), the algorithm relies on the bounding box to close the surface. In the future, data-driven methods will be explored to improve shape detection and take advantage of the hierarchical partition for levels of detail (LOD) reconstruction.关键词:geometric modeling;surface reconstruction;shape detection;binary space partitioning(BSP);Markov random field(MRF)191|301|2更新时间:2024-05-07
摘要:ObjectiveThe conception of digital twin has attracted tremendous attention and developed rapidly in the fields of smart cities, smart transportation, urban planning, and virtual/augmented reality during past years. The basic objective is to visualize, analyze, simulate, and optimize real world scenes by projecting physical objects onto digital 3D models. To apply digital twin technology successfully to downstream applications such as real-time rendering, human-scene interaction, and numerical simulation, the reconstructed 3D models should preferably be geometrically accurate, vectorized, highly simplified, free of self-intersection, and watertight. To satisfy these requirements, a potential solution called structured reconstruction method extracts geometric planes from discrete point clouds or original triangular mesh and splices them into a compact parametric 3D model. Previous methods address this problem by detecting geometric shapes and then assembling them into a polygonal mesh, but these methods usually suffer from two obstacles. First, traditional shape detection methods such as region growing algorithm rely on iteratively propagating geometric constraints around selected seeds. This greedy strategy only considers local properties and cannot guarantee the quality of global configuration. Second, current shape assembly methods typically recover the surface model by slicing the 3D space into polyhedral cells and assigning inside-outside labels to each cell. Most of these slicing-based methods preserve a high computational complexity and can hardly process more than 100 shapes. In this paper, a novel automatic approach that generates concise polygonal meshes from point clouds or raw triangular meshes in an efficient, robust manner relying upon three ingredients is proposed.MethodOur method consists of three steps: shape detection, space partition, and surface extraction. Our algorithm requires as input a point cloud with oriented normal or triangle mesh. The resulting model is guaranteed to be intersection-free and watertight. First, a multi-source region growing algorithm that detects planar shapes from input 3D data through a global way is proposed. This strategy ensures that points or triangular facets located near the boundary of two shapes can be correctly clustered into their corresponding group. Next, the detected planar shapes are used to partition the bounding box of the object into a polyhedral. To avoid the computational burden involved in the shape assembling step, the partition is performed in a hierarchical manner, that is, the 3D space is recursively divided to build a binary space partitioning (BSP) tree. Starting from the initial bounding box, the largest planar shapes are used to divide a polyhedron cell into two. The planar shapes in the polyhedron are also assigned to the new polyhedron cell. If a shape spans the two polyhedrons, it is divided into two to ensure that every shape in the new polyhedron does not exceed its scope. This operation continues until no divisible polyhedron cell remains. It is equivalent to building a BSP tree. Each leaf node of the BSP tree corresponds to a convex polyhedron cell, and all leaf nodes are combined into the initial bounding box. In such a way, a detected shape only partitions the space locally, without causing redundant partitioning. Hierarchical space partition is the key to reducing the search space and improving the overall pipeline efficiency. Finally, the surface is extracted from the hierarchical partition by labeling each polyhedron as inside or outside the reconstructed model. A ray-shooting-based Markov energy function is defined, and a min-cut is operated to find inside-outside labeling that minimizes the energy function. The output surface is defined as the interface facets between the inside and the outside polyhedral.ResultThe robustness and the performance of our method are demonstrated on a variety of man-made objects and even large-scale scenes from three aspects of fidelity, complexity, and running time. A large number of experimental results prove that our algorithm can process objects composed of tens of thousands of planar shapes on a standard computer without a parallelization scheme. Compared with traditional slicing methods, the number of polyhedral cells obtained through this simple, robust mechanism and the running time are reduced by at least two orders of magnitude. Approximately 70% of the calculation time is used for space partition, but the total time can be controlled within 5 s/10 000 points. In addition, the root-mean-square(RMS) error of the simplified model is mostly controlled within 1%, and the simplification ratio of the facets is controlled within 1.5%. The proposed method greatly improves the calculation efficiency and accuracy of the results, and provides a good trade-off between complexity and fidelity.ConclusionOur structural mesh reconstruction pipeline consists of three steps: shape detection, space partition, and surface extraction. Our method is especially suitable for models with rich structural features. The resulting model is guaranteed to be watertight and free of self-intersection while preserving the features of the structure. The limitation of this algorithm is that reconstruction quality mainly depends on the result of shape detection, which only considers the individual model and does not take advantage of the statistical information of the whole dataset. In addition, this algorithm is only for reconstructing watertight models. When the input data have a large area of missing parts (such as the bottom of the building data), the algorithm relies on the bounding box to close the surface. In the future, data-driven methods will be explored to improve shape detection and take advantage of the hierarchical partition for levels of detail (LOD) reconstruction.关键词:geometric modeling;surface reconstruction;shape detection;binary space partitioning(BSP);Markov random field(MRF)191|301|2更新时间:2024-05-07 -
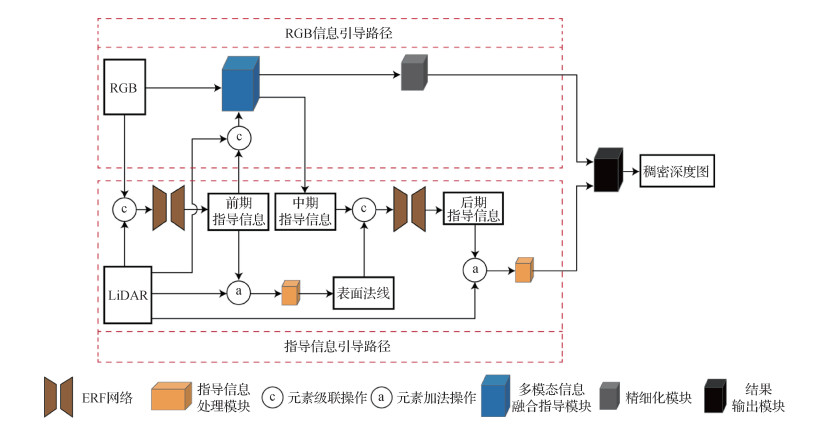 摘要:ObjectiveRecently, depth information plays an important role in the field of autonomous driving and robot navigation, but the sparse depth collected by light detection and ranging (LiDAR) has sparse and noisy deficiencies. To solve such problems, several recently proposed methods that use a single image to guide sparse depth to construct the dense depth map have shown good performance. However, many methods cannot perfectly learn the depth information about edges and details of the object. This paper proposes a multistage guidance network model to cope with this challenge. The deformable convolution and efficient residual factorized(ERF) network are introduced into the network model, and the quality of the dense depth map is improved from the angle of the geometric constraint by surface normal information. The depth and guidance information extracted in the network is dominated, and the information extracted in the RGB picture is used as the guidance information to guide the sparse depth densification and correct the error in depth information.MethodThe multistage guidance network is composed of guidance information guidance path and RGB information guidance path. On the path of guidance information guidance, first, the sparse depth information and RGB images are merged through the ERF network to obtain the initial guidance information, and the sparse depth information and the initial guidance information are input into the guidance information processing module to construct the surface normal. Second, the surface normal and the midterm guidance information obtained by the multimodal information fusion guidance module are input into the ERF network, and the later guidance information containing rich depth information is extracted under the action of the surface normal. The later guidance information is used to guide the sparse depth densification. At the same time, the sparse depth is introduced again to make up for the depth information ignored in the early stage, and then the dense depth map constructed on this path is obtained. On the RGB information guidance path, the initial guidance information can be used to guide the fusion of the sparse depth and the information extracted from the RGB picture, and reduce the influence of sparse depth noise and sparsity. The midterm guidance information and initial dense depth map with rich depth information can be extracted from the multimodal information fusion guidance module. However, the initial dense depth map still contains error information. Through the refined module to correct the dense depth map, the accurate dense depth map can be obtained. The network adds sparse depth and guidance information by adding an operation, which can effectively guide sparse depth densification. Using cascading operation can effectively retain their respective features in different information, which causes the network or module to extract more features. Overall, the initial guidance information is extracted by entering information, which promotes the construction of surface normal and guides the fusion of sparse depth and RGB information. The midterm guidance information is obtained by the multimodal information fusion guidance module, which is the key information to connect two paths. The later guidance information is obtained by fusing the midterm guidance information and the surface normal, which is used to guide the sparse depth densification. From the two paths, on the guidance information guidance path, a dense depth map is constructed by the initial, midterm, and later guidance information to guide the sparse depth; on the RGB information guidance path, the multimodal information fusion guidance module guides the sparse depth through the RGB information.ResultThe proposed network is implemented using PyTorch and Adam optimizer. The parameters of the Adam optimizer are set to β1=0.9 and β2=0.999. The image input to the network is cropped to 256×512 pixels, the graphics card is NVIDIA 3090, the batch size is set to 6, and 30 rounds of training are performed. The initial learning rate is 0.000 125, and the learning rate is reduced by half every 5 rounds. The Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago (KITTI) depth estimation data contains more than 93 000 pairs of ground truth data, aligned LiDAR sparse depth data, and RGB pictures. A total of 85 898 pairs of data can be used to train, and the officially distributed 1 000 pairs of validation set data with ground truth data and 1 000 pairs of test set data without ground truth data can be used to test. The experimental results can be evaluated directly due to the validation set with ground truth data. The test set without ground truth data and the experimental results are required to be submitted to the KITTI official evaluation server to obtain public evaluation results, and the result is an important basis for the performance of a fair assessment model. The validation set and test set do not participate in the training of the network model. The mean square error of the root and the mean square error of inversion root in the evaluation indicators are lower than those of the other methods, and the accuracy of the depth information at the edges and details of the object is more evident.ConclusionA multistage guidance network model for dense depth map construction from LiDAR and RGB information is presented in this paper. The guidance information processing module is used to promote the fusion of guidance information and sparse depth. The multimodal information fusion guidance module can learn a large amount of depth information from sparse depth and RGB pictures. The refined module is used to modify the output results of the multimodal information fusion guidance module. In summary, the dense depth map constructed by the multistage guidance network is composed of the guidance information guidance path and the RGB information guidance path. Two strategies build the dense depth map to form a complementary advantage effectively, using more information to obtain more accurate dense depth maps. Experiments on the KITTI depth estimation data set show that using a multistage guidance network can effectively deal with the depth of the edges and details of the object, and improve the construction quality of dense depth maps.关键词:depth estimation;deep learning;LiDAR;multi-modal data fusion;image processing169|221|3更新时间:2024-05-07
摘要:ObjectiveRecently, depth information plays an important role in the field of autonomous driving and robot navigation, but the sparse depth collected by light detection and ranging (LiDAR) has sparse and noisy deficiencies. To solve such problems, several recently proposed methods that use a single image to guide sparse depth to construct the dense depth map have shown good performance. However, many methods cannot perfectly learn the depth information about edges and details of the object. This paper proposes a multistage guidance network model to cope with this challenge. The deformable convolution and efficient residual factorized(ERF) network are introduced into the network model, and the quality of the dense depth map is improved from the angle of the geometric constraint by surface normal information. The depth and guidance information extracted in the network is dominated, and the information extracted in the RGB picture is used as the guidance information to guide the sparse depth densification and correct the error in depth information.MethodThe multistage guidance network is composed of guidance information guidance path and RGB information guidance path. On the path of guidance information guidance, first, the sparse depth information and RGB images are merged through the ERF network to obtain the initial guidance information, and the sparse depth information and the initial guidance information are input into the guidance information processing module to construct the surface normal. Second, the surface normal and the midterm guidance information obtained by the multimodal information fusion guidance module are input into the ERF network, and the later guidance information containing rich depth information is extracted under the action of the surface normal. The later guidance information is used to guide the sparse depth densification. At the same time, the sparse depth is introduced again to make up for the depth information ignored in the early stage, and then the dense depth map constructed on this path is obtained. On the RGB information guidance path, the initial guidance information can be used to guide the fusion of the sparse depth and the information extracted from the RGB picture, and reduce the influence of sparse depth noise and sparsity. The midterm guidance information and initial dense depth map with rich depth information can be extracted from the multimodal information fusion guidance module. However, the initial dense depth map still contains error information. Through the refined module to correct the dense depth map, the accurate dense depth map can be obtained. The network adds sparse depth and guidance information by adding an operation, which can effectively guide sparse depth densification. Using cascading operation can effectively retain their respective features in different information, which causes the network or module to extract more features. Overall, the initial guidance information is extracted by entering information, which promotes the construction of surface normal and guides the fusion of sparse depth and RGB information. The midterm guidance information is obtained by the multimodal information fusion guidance module, which is the key information to connect two paths. The later guidance information is obtained by fusing the midterm guidance information and the surface normal, which is used to guide the sparse depth densification. From the two paths, on the guidance information guidance path, a dense depth map is constructed by the initial, midterm, and later guidance information to guide the sparse depth; on the RGB information guidance path, the multimodal information fusion guidance module guides the sparse depth through the RGB information.ResultThe proposed network is implemented using PyTorch and Adam optimizer. The parameters of the Adam optimizer are set to β1=0.9 and β2=0.999. The image input to the network is cropped to 256×512 pixels, the graphics card is NVIDIA 3090, the batch size is set to 6, and 30 rounds of training are performed. The initial learning rate is 0.000 125, and the learning rate is reduced by half every 5 rounds. The Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago (KITTI) depth estimation data contains more than 93 000 pairs of ground truth data, aligned LiDAR sparse depth data, and RGB pictures. A total of 85 898 pairs of data can be used to train, and the officially distributed 1 000 pairs of validation set data with ground truth data and 1 000 pairs of test set data without ground truth data can be used to test. The experimental results can be evaluated directly due to the validation set with ground truth data. The test set without ground truth data and the experimental results are required to be submitted to the KITTI official evaluation server to obtain public evaluation results, and the result is an important basis for the performance of a fair assessment model. The validation set and test set do not participate in the training of the network model. The mean square error of the root and the mean square error of inversion root in the evaluation indicators are lower than those of the other methods, and the accuracy of the depth information at the edges and details of the object is more evident.ConclusionA multistage guidance network model for dense depth map construction from LiDAR and RGB information is presented in this paper. The guidance information processing module is used to promote the fusion of guidance information and sparse depth. The multimodal information fusion guidance module can learn a large amount of depth information from sparse depth and RGB pictures. The refined module is used to modify the output results of the multimodal information fusion guidance module. In summary, the dense depth map constructed by the multistage guidance network is composed of the guidance information guidance path and the RGB information guidance path. Two strategies build the dense depth map to form a complementary advantage effectively, using more information to obtain more accurate dense depth maps. Experiments on the KITTI depth estimation data set show that using a multistage guidance network can effectively deal with the depth of the edges and details of the object, and improve the construction quality of dense depth maps.关键词:depth estimation;deep learning;LiDAR;multi-modal data fusion;image processing169|221|3更新时间:2024-05-07 -
 摘要:ObjectiveDepth information is the key sensing information for the autonomous platform. As common depth sensors, the binocular camera can make up for the sparsity of LiDAR and depth camera not suitable for outdoor scenes. Comparing the performance of light detection and ranging (LiDAR) and depth cameras, it is very important to improve the accuracy and speed of the binocular disparity estimation algorithm. Disparity estimation algorithms based on deep learning have its own priority. Disparity estimation and optical flow estimation methods can learn from each other and faciliate new algorithms generation. Inspired by the efficient optical flow estimation algorithm recurrent all-pairs field transforms (RAFT), a unilateral and bilateral multi-scale similarity recursive search method is demonstrated to achieve high-precision binocular disparity estimation. A method of disparity estimation consistency detection for left and right images is proposed to extract reliable estimation regions to resolve inconsistent estimation accuracy and confidence in different regions.MethodThe pyramid pooling module (PPM), skip layer connection and residual structure are conducted in the feature network to extract the representation vector with strong representation capability. The inner product of representation vectors is used to demonstrate the similarity between pixels. The multi-scale similarity is obtained by average pooling. The updated or initial disparity, a certain range of similarity with a large field of view searched in multi-scale similarity according to the disparity (the 0th updating iteration is searched in one direction to the left and other updating iterations are searched in two directions) and context information are integrated together. The integrated information is transmitted to the convolutional recurrent neural network (ConvRNN) of the 0th updating process or the ConvRNN shared by other updating processes to obtain the updated amount of disparity, and the final disparity value is obtained via multiple updating iterations. The disparity of the right image is estimated by reversing the order and conducting left-right flipping of the inputted left and right images, and the confidence of disparity is determined by comparing the absolute value of disparity difference between the matched points of the left and right images and the given threshold. The output of each updating iteration is designated to reduce error gradually with increasing weight and the supervised method is used to train the network. In the training process, the learning rate is reduced by segments, and the root mean square prop(RMSProp) optimization algorithm is used for learning. To improve the inference efficiency, the resolution of the feature network is reduced by 8 times, so the learning up-sampling method is adopted to generate the disparity map with the same resolution of the original image. The disparity of the 8×8 adjacent region of a pixel in the original resolution image is calculated by weighting the disparity of the 3×3 adjacent region of the pixel in the reduced resolution image. The weights are obtained by convoluting the hidden state of the ConvRNN. To reduce the high cost of real-scene disparity data or depth data collection, the Sceneflow dataset generated by the 3D creation suite Blender is used to train and test the network, and the real-scene KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago) data is used to verify the generalization capability of the proposed method.First, on the Flyingthings3D dataset of the Sceneflow dataset, 21 818 pairs of training images of 540×960 pixels are randomly cropped to get images of 256×512 pixels. The cropped images are inputted to the network to train 440 000 iterations. The batch size is set to 4. The trained network is tested on 4 248 pairs of test images. To verify the rationality of adding the unilateral search process, we use ablation experiments on the Sceneflow dataset to compare the performance of networks with and without the unilateral search process. Next, the network trained on Sceneflow data is tested on KITTI training data to verify the generalization ability of the algorithm between simulation data and real-scene data directly. Then, the network trained on the Sceneflow dataset is fine-tuned on the KITTI2012 and KITTI2015 training set (5.5k iterations of training), respectively, and then cross-tested on KITTI2015 and KITTI2012 training sets for qualitative analysis. Finally, the network trained on Sceneflow data is fine-tuned on KITTI2012 and KITTI2015 training sets together (trained 11 000 iterations), and then tested on KITTI2012 and KITTI2015 test sets to verify the performance of the network further. The code is implemented via the TensorFlow framework.ResultBefore reliable region extraction step, the accuracy of this method is comparable to that of state-of-the-art methods on the Sceneflow dataset. The average error is only 0.84 pixels, and the error decreases with the increase of the updating iteration count, while the inference time becomes longer. However, the resiliency between speed and accuracy can be obtained by manipulate the number of updating iterations. After credible region extraction, the error on the Sceneflow dataset is further reduced to the historical best value of 0.21 pixels. On the KITTI benchmark, this method may rank first when only estimated regions are evaluated. The colorized disparity images and point cloud images identified completely that almost all of the occluded regions and a huge amount of areas with large errors are removed based on reliable region extraction.ConclusionThe proposed method has its superiority for binocular disparity estimation. The credible region extraction method can extract high-precision estimation regions efficiently, which improves the disparity reliability of the estimated regions greatly.关键词:binocular disparity estimation;occlusion;convolutional recurrent neural network (CRNN);deep learning;supervised learning101|202|1更新时间:2024-05-07
摘要:ObjectiveDepth information is the key sensing information for the autonomous platform. As common depth sensors, the binocular camera can make up for the sparsity of LiDAR and depth camera not suitable for outdoor scenes. Comparing the performance of light detection and ranging (LiDAR) and depth cameras, it is very important to improve the accuracy and speed of the binocular disparity estimation algorithm. Disparity estimation algorithms based on deep learning have its own priority. Disparity estimation and optical flow estimation methods can learn from each other and faciliate new algorithms generation. Inspired by the efficient optical flow estimation algorithm recurrent all-pairs field transforms (RAFT), a unilateral and bilateral multi-scale similarity recursive search method is demonstrated to achieve high-precision binocular disparity estimation. A method of disparity estimation consistency detection for left and right images is proposed to extract reliable estimation regions to resolve inconsistent estimation accuracy and confidence in different regions.MethodThe pyramid pooling module (PPM), skip layer connection and residual structure are conducted in the feature network to extract the representation vector with strong representation capability. The inner product of representation vectors is used to demonstrate the similarity between pixels. The multi-scale similarity is obtained by average pooling. The updated or initial disparity, a certain range of similarity with a large field of view searched in multi-scale similarity according to the disparity (the 0th updating iteration is searched in one direction to the left and other updating iterations are searched in two directions) and context information are integrated together. The integrated information is transmitted to the convolutional recurrent neural network (ConvRNN) of the 0th updating process or the ConvRNN shared by other updating processes to obtain the updated amount of disparity, and the final disparity value is obtained via multiple updating iterations. The disparity of the right image is estimated by reversing the order and conducting left-right flipping of the inputted left and right images, and the confidence of disparity is determined by comparing the absolute value of disparity difference between the matched points of the left and right images and the given threshold. The output of each updating iteration is designated to reduce error gradually with increasing weight and the supervised method is used to train the network. In the training process, the learning rate is reduced by segments, and the root mean square prop(RMSProp) optimization algorithm is used for learning. To improve the inference efficiency, the resolution of the feature network is reduced by 8 times, so the learning up-sampling method is adopted to generate the disparity map with the same resolution of the original image. The disparity of the 8×8 adjacent region of a pixel in the original resolution image is calculated by weighting the disparity of the 3×3 adjacent region of the pixel in the reduced resolution image. The weights are obtained by convoluting the hidden state of the ConvRNN. To reduce the high cost of real-scene disparity data or depth data collection, the Sceneflow dataset generated by the 3D creation suite Blender is used to train and test the network, and the real-scene KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago) data is used to verify the generalization capability of the proposed method.First, on the Flyingthings3D dataset of the Sceneflow dataset, 21 818 pairs of training images of 540×960 pixels are randomly cropped to get images of 256×512 pixels. The cropped images are inputted to the network to train 440 000 iterations. The batch size is set to 4. The trained network is tested on 4 248 pairs of test images. To verify the rationality of adding the unilateral search process, we use ablation experiments on the Sceneflow dataset to compare the performance of networks with and without the unilateral search process. Next, the network trained on Sceneflow data is tested on KITTI training data to verify the generalization ability of the algorithm between simulation data and real-scene data directly. Then, the network trained on the Sceneflow dataset is fine-tuned on the KITTI2012 and KITTI2015 training set (5.5k iterations of training), respectively, and then cross-tested on KITTI2015 and KITTI2012 training sets for qualitative analysis. Finally, the network trained on Sceneflow data is fine-tuned on KITTI2012 and KITTI2015 training sets together (trained 11 000 iterations), and then tested on KITTI2012 and KITTI2015 test sets to verify the performance of the network further. The code is implemented via the TensorFlow framework.ResultBefore reliable region extraction step, the accuracy of this method is comparable to that of state-of-the-art methods on the Sceneflow dataset. The average error is only 0.84 pixels, and the error decreases with the increase of the updating iteration count, while the inference time becomes longer. However, the resiliency between speed and accuracy can be obtained by manipulate the number of updating iterations. After credible region extraction, the error on the Sceneflow dataset is further reduced to the historical best value of 0.21 pixels. On the KITTI benchmark, this method may rank first when only estimated regions are evaluated. The colorized disparity images and point cloud images identified completely that almost all of the occluded regions and a huge amount of areas with large errors are removed based on reliable region extraction.ConclusionThe proposed method has its superiority for binocular disparity estimation. The credible region extraction method can extract high-precision estimation regions efficiently, which improves the disparity reliability of the estimated regions greatly.关键词:binocular disparity estimation;occlusion;convolutional recurrent neural network (CRNN);deep learning;supervised learning101|202|1更新时间:2024-05-07 -
 摘要:ObjectiveIn micro-optical imaging, the depth-of-field is small, and the image easily becomes defocused. However, accurately evaluating the blur degree of the image according to the point spread function in geometric optics and then calculating the depth of the scene is difficult. Although the traditional method applies edge detection operators to measure the change of the image blur degree, these operators evaluate the blur degree of the image according to the change speed of the edge brightness, no direct mathematical relationship with the system parameters and the depth of the scene exists, and a mathematical model of the relationship between image blurriness, optical system parameters, and scene depth accurately cannot be established. In addition, the evaluation value of blurring degree is closely related to image features such as scene texture and brightness; hence, their robustness is poor. More importantly, in microscopic imaging systems, the effect of light diffraction and refraction is remarkable, and the optical system parameters on the imaging quality are complex and mutually coupled. Most of these evaluation methods are based solely on image characteristics to achieve fuzzy evaluation, without considering the parameters of the optical system, and accurately reflecting the overall characteristics of these systems is difficult. Therefore, studying the quantified and generalized relationship model between the degree of image blur, the depth of the scene, and the systematic parameters based on the transmission characteristics of light in optical imaging is necessary to restore scene depth information and reconstruct the focused images.MethodA general defocused-depth model for optical microscopy systems is proposed in this paper. First, starting from the optical transfer characteristics in the microscopic optical system, the mathematical function relationship between the optical path difference in the optical transfer function and the depth of the scene is established, and the influence of the optical path difference on the optical transfer characteristics is analyzed, that is, the high-frequency response of the optical system is gradually attenuated as the optical path difference increases. According to the composition characteristics of optical imaging, the outline of an image is determined by low-frequency signals, the image details are determined by high-frequency signals, and the loss of image high-frequency signals means image blur. Then, the high-frequency energy parameters are introduced to describe the blur degree of the image. To obtain the high-frequency energy of the image, first, high-pass filtering is performed on the image to obtain a frequency-domain image that only contains the high-frequency information of the image. Then, the sum of the pixel values of the spatial image is calculated by using its inverse Fourier transform to obtain the high-frequency energy parameters of the image, and the mathematical function relationship between the high-frequency energy parameters and the depth of the scene is established through the optical transfer function. Finally, a general fuzzy depth model of the microscope optical system is obtained through normalization and curve fitting.ResultTo verify the defocused depth model of the optical system proposed in this paper, first, depth calculation is performed using the blurred image of the nano square grid. The average error of the depth measured in our experiment is 0.008 μm, and the relative error is 0.8%. Compared with the pixel-by-pixel brightness value comparison method based on the least squares principle, accuracy is improved by approximately 73%. Based on these measurement results, the focused image reconstruction of the blurred grid image is performed. The reconstructed image has a substantial improvement in average gradient and Laplacian value. Compared with the traditional clear reconstruction method based on Gaussian point spread function, the reconstruction accuracy of our method is higher, and the stability is stronger. Finally, the versatility of the blur degree-depth curve to different scenes in this paper is proven through the depth calculation of the striped grid blurred image and the focused image reconstruction.ConclusionThe functional relationship established in this paper can more intuitively reflect the influence of system parameters on optical blur imaging. Using high-frequency energy parameters to characterize the blur characteristics of an image can only measure the degree of image blurring accurately and has a direct functional relationship with the depth of the scene. More importantly, with the fixed parameters of an optical system, the functional relationship established between the normalized system imaging blur degree and the scene depth in this paper is not affected by variation of image texture and brightness. Therefore, it is robust, convenient, and time saving in real applications.关键词:optical microscopy system;blur degree;scene depth;analytic function;optical transmission characteristics;high frequency energy parameter78|2998|0更新时间:2024-05-07
摘要:ObjectiveIn micro-optical imaging, the depth-of-field is small, and the image easily becomes defocused. However, accurately evaluating the blur degree of the image according to the point spread function in geometric optics and then calculating the depth of the scene is difficult. Although the traditional method applies edge detection operators to measure the change of the image blur degree, these operators evaluate the blur degree of the image according to the change speed of the edge brightness, no direct mathematical relationship with the system parameters and the depth of the scene exists, and a mathematical model of the relationship between image blurriness, optical system parameters, and scene depth accurately cannot be established. In addition, the evaluation value of blurring degree is closely related to image features such as scene texture and brightness; hence, their robustness is poor. More importantly, in microscopic imaging systems, the effect of light diffraction and refraction is remarkable, and the optical system parameters on the imaging quality are complex and mutually coupled. Most of these evaluation methods are based solely on image characteristics to achieve fuzzy evaluation, without considering the parameters of the optical system, and accurately reflecting the overall characteristics of these systems is difficult. Therefore, studying the quantified and generalized relationship model between the degree of image blur, the depth of the scene, and the systematic parameters based on the transmission characteristics of light in optical imaging is necessary to restore scene depth information and reconstruct the focused images.MethodA general defocused-depth model for optical microscopy systems is proposed in this paper. First, starting from the optical transfer characteristics in the microscopic optical system, the mathematical function relationship between the optical path difference in the optical transfer function and the depth of the scene is established, and the influence of the optical path difference on the optical transfer characteristics is analyzed, that is, the high-frequency response of the optical system is gradually attenuated as the optical path difference increases. According to the composition characteristics of optical imaging, the outline of an image is determined by low-frequency signals, the image details are determined by high-frequency signals, and the loss of image high-frequency signals means image blur. Then, the high-frequency energy parameters are introduced to describe the blur degree of the image. To obtain the high-frequency energy of the image, first, high-pass filtering is performed on the image to obtain a frequency-domain image that only contains the high-frequency information of the image. Then, the sum of the pixel values of the spatial image is calculated by using its inverse Fourier transform to obtain the high-frequency energy parameters of the image, and the mathematical function relationship between the high-frequency energy parameters and the depth of the scene is established through the optical transfer function. Finally, a general fuzzy depth model of the microscope optical system is obtained through normalization and curve fitting.ResultTo verify the defocused depth model of the optical system proposed in this paper, first, depth calculation is performed using the blurred image of the nano square grid. The average error of the depth measured in our experiment is 0.008 μm, and the relative error is 0.8%. Compared with the pixel-by-pixel brightness value comparison method based on the least squares principle, accuracy is improved by approximately 73%. Based on these measurement results, the focused image reconstruction of the blurred grid image is performed. The reconstructed image has a substantial improvement in average gradient and Laplacian value. Compared with the traditional clear reconstruction method based on Gaussian point spread function, the reconstruction accuracy of our method is higher, and the stability is stronger. Finally, the versatility of the blur degree-depth curve to different scenes in this paper is proven through the depth calculation of the striped grid blurred image and the focused image reconstruction.ConclusionThe functional relationship established in this paper can more intuitively reflect the influence of system parameters on optical blur imaging. Using high-frequency energy parameters to characterize the blur characteristics of an image can only measure the degree of image blurring accurately and has a direct functional relationship with the depth of the scene. More importantly, with the fixed parameters of an optical system, the functional relationship established between the normalized system imaging blur degree and the scene depth in this paper is not affected by variation of image texture and brightness. Therefore, it is robust, convenient, and time saving in real applications.关键词:optical microscopy system;blur degree;scene depth;analytic function;optical transmission characteristics;high frequency energy parameter78|2998|0更新时间:2024-05-07 -
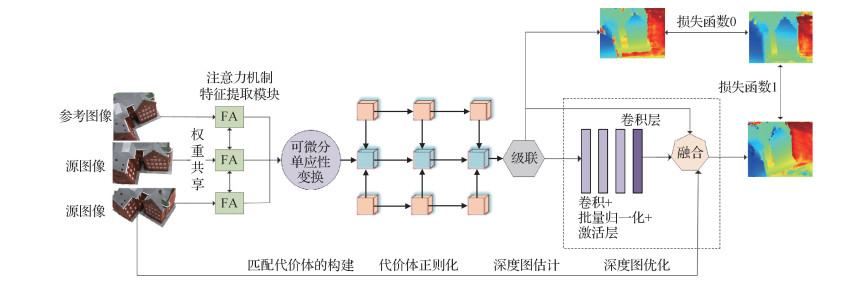 摘要:ObjectiveWith the rapid development of deep learning, multi-view stereo (MVS) research based on learning has also made great progress. The goal of MVS is to reconstruct a highly detailed scene or object under the premise that a series of images and corresponding camera poses and inherent parameters (internal and external parameters of the camera) are known as the 3D geometric model. As a branch of computer vision, it has achieved tremendous development in recent decades and is widely used in many aspects, such as autonomous driving, robot navigation, and remote sensing. Learning-based methods can incorporate global semantic information such as specular reflection and reflection priors to achieve more reliable matching. If the receiving field of convolutional neural network (CNN) is large enough, it can better reconstruct poor texture areas. The existing learning-based MVS reconstruction methods mainly include three categories: voxel-based, point cloud-based, and depth map-based. The voxel-based method divides the 3D space into a regular grid and estimates whether each voxel is attached to the surface. The point cloud-based method runs directly on the point cloud, usually relying on the propagation strategy to make the reconstruction more dense gradually. The depth map method uses the estimated depth map as an intermediate layer to decompose the complex MVS problem into relatively small depth estimation problems per view, only focuses on one reference image and several source images at a time, and then performs regression (fusion) on each depth map to form the final 3D point cloud model. Despite room for improvement in the series of reconstruction methods proposed before, the latest MVS benchmark tests (such as Technical University of Denmark(DTU)) have proven that using depth maps as an intermediate layer can achieve more accurate 3D model reconstruction. Several end-to-end neural networks are proposed to predict the depth of the scene directly from a series of input images (for example, MVSNet and R-MVSNet). Even though the accuracy of these methods has been verified on the DTU datasets, most methods still only use 3D CNN to predict the occupancy of depth maps or voxels, which not only leads to excessive memory consumption but also limits the resolution, and the reconstruction results are not ideal. In response to the above problems, an end-to-end deep learning architecture is proposed in this paper based on the attention mechanism for 3D reconstruction. It is a deep learning framework that takes a reference image and multiple source images as input, and finally obtains the corresponding reference image depth map. The depth map estimation steps are as follows: depth feature extraction, matching cost construction, cost regularization, depth map estimation, and depth map optimization.MethodFirst, the depth features are extracted from the input multiple source images and a reference image. At each layer of feature extraction, an attention layer is added to the feature extraction module to focus on learning important information for deep reasoning to capture remote dependencies in deep reasoning tasks. Second, the differentiable homography deformation is used to construct the feature quantity of the reference cone, and the matching cost volume is constructed. The central idea of the construction cost volume is to calculate the reference under the assumption of each sampling depth and the matching cost between each pixel in the camera and its neighboring camera pixels. Finally, the multilayer U-Net architecture is used to normalize the cost, that is, to down sample the cost volume, extract the context information and adjacent pixel information of different scales, and filter the cost amount. Then, the final refined estimated depth map is generated through regression. In addition, the difference-based cost measurement used in this article not only solves the problem of the input quantity of any view but also can finally aggregate multiple element quantities into one cost quantity. In summary, the following are the two contributions in this work: an attention mechanism applied to the feature extraction module is proposed to focus on learning important information for deep reasoning to capture the remote dependencies of deep reasoning tasks. A multilayer U-Net network is proposed for cost regularization, that is, to down sample the cost volume and extract context information and neighboring pixel information of different scales to filter the cost volume. Then, the final refined estimated depth map is generated through regression.ResultOur method is tested on the DTU datasets and compared with several existing methods. Compared with Colmap, the overall index is increased by 8.5% and the completeness index is increased by 20.7%. Compared with the Gipuma method, the overall index is increased by 13.1%, and the completeness index is increased by 41.6%. Compared with the Tola method, the overall index is increased by 31.9%, and the completeness index is increased by 73.3%. Compared with the Camp method, the overall index is increased by 24.8%, the accuracy index is increased by 39.8%, and the completeness index is increased by 9.7%. Compared with the Furu method, the overall index is increased by 33%, the accuracy index is increased by 17.6%, and the completeness index is increased by 48.4%. Compared with the SurfaceNet method, the overall index is increased by 29.8%, the accuracy index is increased by 1.3%, and the completeness index is increased by 58.3%. Compared with the PruMvsnet method, the overall index is increased by 1.7%, and the accuracy index is increased by 5.8%. Compared with Mvsnet, the overall index is increased by 1.5%, and the completeness is increased by 7%.ConclusionThe test results on the DTU data set show that the network architecture proposed in this paper obtains the current best results in terms of overall indicators, the completeness and accuracy indicators are greatly improved, and the quality of 3D reconstruction is better, which proves the effectiveness of the proposed method.关键词:attention mechanism;multi-layer U-Net;differentiable homography transformation;cost volume regularization;multi-view stereo(MVS)141|171|4更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of deep learning, multi-view stereo (MVS) research based on learning has also made great progress. The goal of MVS is to reconstruct a highly detailed scene or object under the premise that a series of images and corresponding camera poses and inherent parameters (internal and external parameters of the camera) are known as the 3D geometric model. As a branch of computer vision, it has achieved tremendous development in recent decades and is widely used in many aspects, such as autonomous driving, robot navigation, and remote sensing. Learning-based methods can incorporate global semantic information such as specular reflection and reflection priors to achieve more reliable matching. If the receiving field of convolutional neural network (CNN) is large enough, it can better reconstruct poor texture areas. The existing learning-based MVS reconstruction methods mainly include three categories: voxel-based, point cloud-based, and depth map-based. The voxel-based method divides the 3D space into a regular grid and estimates whether each voxel is attached to the surface. The point cloud-based method runs directly on the point cloud, usually relying on the propagation strategy to make the reconstruction more dense gradually. The depth map method uses the estimated depth map as an intermediate layer to decompose the complex MVS problem into relatively small depth estimation problems per view, only focuses on one reference image and several source images at a time, and then performs regression (fusion) on each depth map to form the final 3D point cloud model. Despite room for improvement in the series of reconstruction methods proposed before, the latest MVS benchmark tests (such as Technical University of Denmark(DTU)) have proven that using depth maps as an intermediate layer can achieve more accurate 3D model reconstruction. Several end-to-end neural networks are proposed to predict the depth of the scene directly from a series of input images (for example, MVSNet and R-MVSNet). Even though the accuracy of these methods has been verified on the DTU datasets, most methods still only use 3D CNN to predict the occupancy of depth maps or voxels, which not only leads to excessive memory consumption but also limits the resolution, and the reconstruction results are not ideal. In response to the above problems, an end-to-end deep learning architecture is proposed in this paper based on the attention mechanism for 3D reconstruction. It is a deep learning framework that takes a reference image and multiple source images as input, and finally obtains the corresponding reference image depth map. The depth map estimation steps are as follows: depth feature extraction, matching cost construction, cost regularization, depth map estimation, and depth map optimization.MethodFirst, the depth features are extracted from the input multiple source images and a reference image. At each layer of feature extraction, an attention layer is added to the feature extraction module to focus on learning important information for deep reasoning to capture remote dependencies in deep reasoning tasks. Second, the differentiable homography deformation is used to construct the feature quantity of the reference cone, and the matching cost volume is constructed. The central idea of the construction cost volume is to calculate the reference under the assumption of each sampling depth and the matching cost between each pixel in the camera and its neighboring camera pixels. Finally, the multilayer U-Net architecture is used to normalize the cost, that is, to down sample the cost volume, extract the context information and adjacent pixel information of different scales, and filter the cost amount. Then, the final refined estimated depth map is generated through regression. In addition, the difference-based cost measurement used in this article not only solves the problem of the input quantity of any view but also can finally aggregate multiple element quantities into one cost quantity. In summary, the following are the two contributions in this work: an attention mechanism applied to the feature extraction module is proposed to focus on learning important information for deep reasoning to capture the remote dependencies of deep reasoning tasks. A multilayer U-Net network is proposed for cost regularization, that is, to down sample the cost volume and extract context information and neighboring pixel information of different scales to filter the cost volume. Then, the final refined estimated depth map is generated through regression.ResultOur method is tested on the DTU datasets and compared with several existing methods. Compared with Colmap, the overall index is increased by 8.5% and the completeness index is increased by 20.7%. Compared with the Gipuma method, the overall index is increased by 13.1%, and the completeness index is increased by 41.6%. Compared with the Tola method, the overall index is increased by 31.9%, and the completeness index is increased by 73.3%. Compared with the Camp method, the overall index is increased by 24.8%, the accuracy index is increased by 39.8%, and the completeness index is increased by 9.7%. Compared with the Furu method, the overall index is increased by 33%, the accuracy index is increased by 17.6%, and the completeness index is increased by 48.4%. Compared with the SurfaceNet method, the overall index is increased by 29.8%, the accuracy index is increased by 1.3%, and the completeness index is increased by 58.3%. Compared with the PruMvsnet method, the overall index is increased by 1.7%, and the accuracy index is increased by 5.8%. Compared with Mvsnet, the overall index is increased by 1.5%, and the completeness is increased by 7%.ConclusionThe test results on the DTU data set show that the network architecture proposed in this paper obtains the current best results in terms of overall indicators, the completeness and accuracy indicators are greatly improved, and the quality of 3D reconstruction is better, which proves the effectiveness of the proposed method.关键词:attention mechanism;multi-layer U-Net;differentiable homography transformation;cost volume regularization;multi-view stereo(MVS)141|171|4更新时间:2024-05-07 -
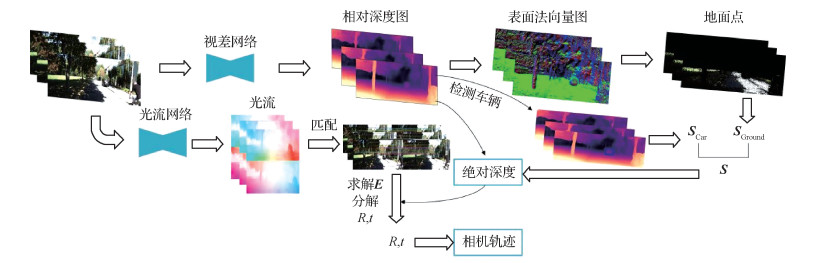 摘要:ObjectiveTrajectory recovery based on the camera uses one or more cameras to collect the image data, but it always causes serious drift in the computed path due to the lack of scale information, as the input of monocular depth estimation is only one monocular sequence, the depth of the objects in the image can have innumerable possibilities, and only the distance relationship between two connected objects can be obtained from the image by distinguishing the border and identifying the brightness of the color. Thus, the monocular camera is rarely used for high-precision applications. To take advantage of the high popularity and low cost of the monocular camera, many researchers have presented learning-based methods to estimate the pose and depth of the camera simultaneously, which is also the target solved by the simultaneous localization and mapping (SLAM) system. Although this method is fast and effective, it is does not work well in several specific areas, such as images with excessively long spans, fewer features, or complex textures. Moreover, the accuracy of the depth is essential for the details of the estimated path. Most researchers use light detection and ranging (LiDAR) to acquire the depth values. It is clearly more accurate than any other sensor, and even almost all of the large datasets use LiDAR to make ground-truth labels. However, it is not popular due to its expensive prices. Others use stereo RGB images to compute the depth, but the algorithm is very complex, slower than other methods, and needs to be calibrated again before use, as the baseline is changed if the images obtained are not collected by your own stereo camera. With the rise of artificial intelligence, the convolutional neural network can be used to train to realize a function needed. Therefore, the monocular camera can be used to implement the task that cannot be finished previously. Geometric space is modeled into the mathematic expression, and the network is promoted to meet the requirement. This work is proven effective, and most of the scholars use a large amount of the labels provided by the dataset to train the network, but it is not really effective because ground-truth labels cannot be obtained in most complex fields, and then these methods will not work again. Therefore, the traditional method is used to resolve the relative poses, and a real-scale recovery method by leveraging the scene geometry in the field of autonomous driving is presented.MethodFirst, the depth network is used to estimate the relative depth map of continuous sequences. Then, the pixels are projected from the pixel plane into 3D geometry space by leveraging the estimated depth values, the optical flow consistency with the forward-backward optical flow estimated from the optical flow network is calculated to catch the effective matching points, the relative poses are solved from the effective points by traditional method, and the scale between the relative depth and pose is consistent. Next, relative depth is used to calculate a surface normal map, which obtains a ground point group due to the geometric relationship, the camera height is calculated by the ground points with the consistent scale, and the initial scale is obtained by adding the information of the camera prior height. The vehicle detection module is introduced to perform compensation on the scale to obtain the final scale and eliminate the deviation of image noise to the computed scale. Finally, an absolute depth map and an integrated motion trajectory are recovered by the computed scale.ResultThe experiment is carried out on the Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago (KITTI) autonomous driving dataset, and the recovered absolute depth and estimated camera motion trajectory are improved in accuracy. The absolute error of the relative depth recovered by the ground truth is 0.114, the absolute error of our method using the computed scale is as low as 0.116, and the camera trajectory is tested in different complex paths. The error between the distance recovered using scale and the ground truth trajectory is only 2.67%, and the restored trajectory is closer to the ground truth trajectory than the oriented FAST and rotated BRIEF-simultaneous localization and mapping(ORB-SLAM2) that uses the traditional method.ConclusionOnly monocular camera data are used input that is applied in the autonomous driving filed in this paper. Self-supervised learning is adopted to calculate the true scale by leveraging the geometric constraints in the scene that do not need any ground-truth labels. Moreover, the depth values in most methods are relative, that is, they are useless in practical application. Without the scale information, no matter how accurate relative depth is, it cannot be used to approximate reality. However, most researchers work like this. They use the trained network to estimate the depth, use the scale computed between the average value of relative depth and ground-truth depth from the labels to unify, and then obtain an extremely lower loss than other methods but with no practical effect. Compared with other traditional methods, in this paper, after adding the real scale, the offset error is lower, the calculation speed is fast, the robustness is high, and ground-truth labels are not needed.关键词:self-supervised learning;autonomous driving;monocular depth estimation;relative pose estimation;scale recovery155|232|0更新时间:2024-05-07
摘要:ObjectiveTrajectory recovery based on the camera uses one or more cameras to collect the image data, but it always causes serious drift in the computed path due to the lack of scale information, as the input of monocular depth estimation is only one monocular sequence, the depth of the objects in the image can have innumerable possibilities, and only the distance relationship between two connected objects can be obtained from the image by distinguishing the border and identifying the brightness of the color. Thus, the monocular camera is rarely used for high-precision applications. To take advantage of the high popularity and low cost of the monocular camera, many researchers have presented learning-based methods to estimate the pose and depth of the camera simultaneously, which is also the target solved by the simultaneous localization and mapping (SLAM) system. Although this method is fast and effective, it is does not work well in several specific areas, such as images with excessively long spans, fewer features, or complex textures. Moreover, the accuracy of the depth is essential for the details of the estimated path. Most researchers use light detection and ranging (LiDAR) to acquire the depth values. It is clearly more accurate than any other sensor, and even almost all of the large datasets use LiDAR to make ground-truth labels. However, it is not popular due to its expensive prices. Others use stereo RGB images to compute the depth, but the algorithm is very complex, slower than other methods, and needs to be calibrated again before use, as the baseline is changed if the images obtained are not collected by your own stereo camera. With the rise of artificial intelligence, the convolutional neural network can be used to train to realize a function needed. Therefore, the monocular camera can be used to implement the task that cannot be finished previously. Geometric space is modeled into the mathematic expression, and the network is promoted to meet the requirement. This work is proven effective, and most of the scholars use a large amount of the labels provided by the dataset to train the network, but it is not really effective because ground-truth labels cannot be obtained in most complex fields, and then these methods will not work again. Therefore, the traditional method is used to resolve the relative poses, and a real-scale recovery method by leveraging the scene geometry in the field of autonomous driving is presented.MethodFirst, the depth network is used to estimate the relative depth map of continuous sequences. Then, the pixels are projected from the pixel plane into 3D geometry space by leveraging the estimated depth values, the optical flow consistency with the forward-backward optical flow estimated from the optical flow network is calculated to catch the effective matching points, the relative poses are solved from the effective points by traditional method, and the scale between the relative depth and pose is consistent. Next, relative depth is used to calculate a surface normal map, which obtains a ground point group due to the geometric relationship, the camera height is calculated by the ground points with the consistent scale, and the initial scale is obtained by adding the information of the camera prior height. The vehicle detection module is introduced to perform compensation on the scale to obtain the final scale and eliminate the deviation of image noise to the computed scale. Finally, an absolute depth map and an integrated motion trajectory are recovered by the computed scale.ResultThe experiment is carried out on the Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago (KITTI) autonomous driving dataset, and the recovered absolute depth and estimated camera motion trajectory are improved in accuracy. The absolute error of the relative depth recovered by the ground truth is 0.114, the absolute error of our method using the computed scale is as low as 0.116, and the camera trajectory is tested in different complex paths. The error between the distance recovered using scale and the ground truth trajectory is only 2.67%, and the restored trajectory is closer to the ground truth trajectory than the oriented FAST and rotated BRIEF-simultaneous localization and mapping(ORB-SLAM2) that uses the traditional method.ConclusionOnly monocular camera data are used input that is applied in the autonomous driving filed in this paper. Self-supervised learning is adopted to calculate the true scale by leveraging the geometric constraints in the scene that do not need any ground-truth labels. Moreover, the depth values in most methods are relative, that is, they are useless in practical application. Without the scale information, no matter how accurate relative depth is, it cannot be used to approximate reality. However, most researchers work like this. They use the trained network to estimate the depth, use the scale computed between the average value of relative depth and ground-truth depth from the labels to unify, and then obtain an extremely lower loss than other methods but with no practical effect. Compared with other traditional methods, in this paper, after adding the real scale, the offset error is lower, the calculation speed is fast, the robustness is high, and ground-truth labels are not needed.关键词:self-supervised learning;autonomous driving;monocular depth estimation;relative pose estimation;scale recovery155|232|0更新时间:2024-05-07
Depth Estimation & 3D Reconstruction
-
 摘要:ObjectiveDeep learning networks are vulnerable to attacks from well-crafted adversarial samples, resulting in neural networks that produce erroneous results. However, the current research on the adversarial attack is often focused on 2D images and convolutional neural network(CNN) networks. Therefore, research on 3D data such as point cloud is minimal. In recent years, deep learning has achieved great success in the application of 3D data. Considering many safety-critical applications in the field of 3D object classification, such as automatic driving, studying how the adversarial samples of point cloud affect the current 3D deep learning network is very important. Recently, researchers have made great progress on many tasks such as object classification and instance segmentation using deep neural networks on the point cloud. PointNet and PointNet++ are the classical representatives. Robustness against attacks has been studied rigorously in 3D deep learning because security has been becoming a vital role in deep learning systems. Many studies have shown that the deep neural network for processing 2D images is extremely weak against adversarial samples. In addition, most of defense methods have been defeated by adversarial attacks. For instance, fast gradient sign method (FGSM) is a very classical attack algorithm, which successfully enables a neural network to recognize a panda as a gibbon, whereas humans are not able to distinguish the difference between the two pictures before and after the attack. Subsequently, the iterative fast gradient sign method (I-FGSM) algorithm is proposed to improve the FGSM algorithm, making the attack more successful and more difficult to defend, and pointing out the difficulty of the challenge posed by adversarial attacks. An important concept is developed in PointNet. Authors of PointNet indicate that PointNet can correctly classify the network only through a subset of the point clouds, which affect the point cloud classification and are called the critical points. Moreover, the authors point out that the strong robustness of PointNet depends on the existence of the critical points. However, the theory of the critical point is still inadequate. The concept of the critical point is very vague because it does not provide the value of importance of each point and subset at all. Therefore, the point cloud saliency map is proposed to solve this problem well because the point cloud saliency map can estimate the importance of every single point. After the importance of each point is computed, the most important k points can be perturbed to generate countermeasure samples and realize the attack on the network.MethodAccording to the basic fact of critical points that have been analyzed above, a point cloud saliency map is first built to enhance the effectiveness of attacks. In saliency map construction, iterative estimation of critical points is used to prevent dependencies between different points. After the saliency score of each point is estimated, the algorithm proposed in this paper perturbs the first k points with the highest saliency score. Specifically, k points with the highest saliency score are selected in the input point cloud and exchanged with the critical points which have the smallest chamfer distance. Chamfer distance is often used to measure the direct difference between two point clouds. The smaller the difference between point clouds is, the smaller the chamfer distance is, that is, point clouds with smaller chamfer distance appear more similar. The proposed method does not only limit the search space but also minimizes the disturbance of the point cloud. Therefore, the adversarial sample of the point cloud is not imperceptible to human eyes.ResultThe experiment is conducted on the Model-Net40 dataset, which has 40 categories of different objects. PointNet and PointNet++, the most popular point cloud classification models, are used as victim networks. Our method is compared with classical white box attack algorithms. Our attack is also validated with several classic defense algorithms. In the case of using PointNet, compared with FGSM, the attack success rate is increased by 38.6%. Similarly, compared with the Jacobian-based saliency map attack (JSMA), the attack success rate is increased by 7.3%. Compared with JSMA, the attack success rate is increased by 41%. Under the restriction of perturbation of 100 points, the network accuracy is reduced to 6.2%. When the random point drop algorithm is attacked, a success rate of 97.9% can still be achieved. When the outlier remove algorithm is attacked, a success rate of 98.6% can be achieved. In the case of using PointNet++, compared with FGSM, the attack success rate is increased by 58.6%, and the attack success rate is increased 85.3%. Under the restriction of perturbation of 100 points, the network accuracy is reduced to 12.8%. When the random point drop algorithm is attacked, a success rate of 94.6% can still be achieved. When the outlier remove algorithm is attacked, our method can still achieve a success rate of 95.6%. Experiments on the influence of the different number of perturbation points on the network are also conducted. When 25, 50, 75, and 100 points are perturbed, the accuracy of the PointNet is decreased to 33.5%, 21.7%, 16.5%, and 13.5%. Similarly, the accuracy of PointNet++ is decreased to 16.3%, 14.7%, 13.2%, and 12.8%.ConclusionThe attack algorithm proposed in this paper consider the efficiency of the attack as well as the imperceptibility of the adversarial samples. The proposed method can attack the mainstream point cloud deep neural network efficiently and achieve better performance. Easily succeeding in the attack is still possible even when attacking several simple defense algorithms.关键词:point cloud adversarial attack;saliency map;Chamfer distance;PointNet;PointNet++87|112|3更新时间:2024-05-07
摘要:ObjectiveDeep learning networks are vulnerable to attacks from well-crafted adversarial samples, resulting in neural networks that produce erroneous results. However, the current research on the adversarial attack is often focused on 2D images and convolutional neural network(CNN) networks. Therefore, research on 3D data such as point cloud is minimal. In recent years, deep learning has achieved great success in the application of 3D data. Considering many safety-critical applications in the field of 3D object classification, such as automatic driving, studying how the adversarial samples of point cloud affect the current 3D deep learning network is very important. Recently, researchers have made great progress on many tasks such as object classification and instance segmentation using deep neural networks on the point cloud. PointNet and PointNet++ are the classical representatives. Robustness against attacks has been studied rigorously in 3D deep learning because security has been becoming a vital role in deep learning systems. Many studies have shown that the deep neural network for processing 2D images is extremely weak against adversarial samples. In addition, most of defense methods have been defeated by adversarial attacks. For instance, fast gradient sign method (FGSM) is a very classical attack algorithm, which successfully enables a neural network to recognize a panda as a gibbon, whereas humans are not able to distinguish the difference between the two pictures before and after the attack. Subsequently, the iterative fast gradient sign method (I-FGSM) algorithm is proposed to improve the FGSM algorithm, making the attack more successful and more difficult to defend, and pointing out the difficulty of the challenge posed by adversarial attacks. An important concept is developed in PointNet. Authors of PointNet indicate that PointNet can correctly classify the network only through a subset of the point clouds, which affect the point cloud classification and are called the critical points. Moreover, the authors point out that the strong robustness of PointNet depends on the existence of the critical points. However, the theory of the critical point is still inadequate. The concept of the critical point is very vague because it does not provide the value of importance of each point and subset at all. Therefore, the point cloud saliency map is proposed to solve this problem well because the point cloud saliency map can estimate the importance of every single point. After the importance of each point is computed, the most important k points can be perturbed to generate countermeasure samples and realize the attack on the network.MethodAccording to the basic fact of critical points that have been analyzed above, a point cloud saliency map is first built to enhance the effectiveness of attacks. In saliency map construction, iterative estimation of critical points is used to prevent dependencies between different points. After the saliency score of each point is estimated, the algorithm proposed in this paper perturbs the first k points with the highest saliency score. Specifically, k points with the highest saliency score are selected in the input point cloud and exchanged with the critical points which have the smallest chamfer distance. Chamfer distance is often used to measure the direct difference between two point clouds. The smaller the difference between point clouds is, the smaller the chamfer distance is, that is, point clouds with smaller chamfer distance appear more similar. The proposed method does not only limit the search space but also minimizes the disturbance of the point cloud. Therefore, the adversarial sample of the point cloud is not imperceptible to human eyes.ResultThe experiment is conducted on the Model-Net40 dataset, which has 40 categories of different objects. PointNet and PointNet++, the most popular point cloud classification models, are used as victim networks. Our method is compared with classical white box attack algorithms. Our attack is also validated with several classic defense algorithms. In the case of using PointNet, compared with FGSM, the attack success rate is increased by 38.6%. Similarly, compared with the Jacobian-based saliency map attack (JSMA), the attack success rate is increased by 7.3%. Compared with JSMA, the attack success rate is increased by 41%. Under the restriction of perturbation of 100 points, the network accuracy is reduced to 6.2%. When the random point drop algorithm is attacked, a success rate of 97.9% can still be achieved. When the outlier remove algorithm is attacked, a success rate of 98.6% can be achieved. In the case of using PointNet++, compared with FGSM, the attack success rate is increased by 58.6%, and the attack success rate is increased 85.3%. Under the restriction of perturbation of 100 points, the network accuracy is reduced to 12.8%. When the random point drop algorithm is attacked, a success rate of 94.6% can still be achieved. When the outlier remove algorithm is attacked, our method can still achieve a success rate of 95.6%. Experiments on the influence of the different number of perturbation points on the network are also conducted. When 25, 50, 75, and 100 points are perturbed, the accuracy of the PointNet is decreased to 33.5%, 21.7%, 16.5%, and 13.5%. Similarly, the accuracy of PointNet++ is decreased to 16.3%, 14.7%, 13.2%, and 12.8%.ConclusionThe attack algorithm proposed in this paper consider the efficiency of the attack as well as the imperceptibility of the adversarial samples. The proposed method can attack the mainstream point cloud deep neural network efficiently and achieve better performance. Easily succeeding in the attack is still possible even when attacking several simple defense algorithms.关键词:point cloud adversarial attack;saliency map;Chamfer distance;PointNet;PointNet++87|112|3更新时间:2024-05-07 -
 摘要:Objective3D shape datasets have been tremendous facilitated nowadays. Data-driven 3D shape analysis has been an active research topic in computer vision and graphics. Apart from regular works, current data-driven works attempted to generalize deep neural networks from images to 3D shapes, including triangular meshes, point clouds and voxel data. Deep neural networks for triangular meshes have been concentrated. 3D meshes have complicated and irregular inter-connection. Most current works tend to keep mesh connectivity unchanged each layer, thus, losing the capability of increased receptive fields when pooling operations are applied. The variational auto-encoder (VAE) has been widely used in various kinds of generation tasks, including generation, interpolation and exploration on triangular meshes. Based on a fully-connected network, the initial MeshVAE requires mega parameters and its generalization capability is often weak. Although the fully connected layers allow changes of mesh connectivity across layers, due to irregular changes, such approaches cannot be directly generalized to convolutional layers. Some works adopt convolutional layers in the VAE structure. However, such convolution operations cannot change the connectivity of the mesh. Sampling operation is also evolved in convolutional neural networks(CNNs) on meshes, but the mesh sampling strategy does not aggregate the whole local neighborhood information when reducing the quantities of vertices. Hence, it is necessary to design a pooling operation for meshes similar to the pooling for images to reduce the amount of network parameters in order to deal with denser models and enhance the generalization ability of the network. Moreover, the defined pooling can support further convolutions and conduct recovery via a corresponding de-pooling operation.MethodA novel mesh pooling operation is illustrated based on edge contraction. The VAE architecture in context of the newly defined pooling operation is built up as well. Mesh simplification is applied to organize a mesh hierarchy with different levels of details, and achieves effective pooling by keeping track of the mapping between coarser and finer meshes. To avoid generating highly irregular triangles in mesh simplification, a modified mesh simplification approach is demonstrated based on the classical edge contraction algorithm. The edge length is an essential indicator for the edge contraction process. So, as one of the criteria, the edge length is incorporated to order pairs of points. The new edge length is added to the original quadric error formulation straightforward. The feature of a new vertex is defined as the average feature of the contracted vertices for average pooling, and alternative pooling operations can be similarly ruled. In the decoding process, the features of the vertices on the simplified mesh are equally assigned to the corresponding contracted vertices on the dense mesh for the inverse operation, de-pooling. The input to the illustrated network is a vertex-based deformation feature representation, which is different from 3D coordinates, encodes deformations defined on vertices in terms of deformation gradients analysis. The demonstrated framework uses a cluster of 3D shapes with the same connectivity to train the network. Such meshes can be easily obtained via consistent re-meshing. The network follows a VAE architecture where pooling operations and graph convolutions are applied. It has qualified generalization capabilities and handles much higher resolution meshes in various applications, such as shape generation and interpolation.ResultThe framework is tested on four datasets, shape completion and animation of people (SCAPE), Swing, Fat and Hand. The capability of the network is tested to generate unseen shapes, and calculate the average root mean squared (RMS) errors. The network with the proposed pooling and without pooling has been initially compared. The RMS error is lower by an average of 6.92% with pooling, which shows the benefits of our pooling and de-pooling operations. The comparisons between the proposed pooling and other pooling or sampling methods are illustrated. The RMS error of the proposed pooling for unseen data is lower on average by 9.34% compared to initial simplification-based pooling, 9.07% compared to uniform remeshing method, 8.06% compared to graph pooling, and 9.64% compared to mesh sampling, which illustrates this modified simplification algorithm is more effective in terms of pooling and the proposed pooling is superior on multiple datasets, demonstrating its generalization capability. The proposed framework is also compared with related mesh-based auto-encoder architectures. Thanks to spectral graph convolutions and the proposed pooling, the method reduces the reconstruction errors of unseen data consistently, showing superior generalizability. For instance, compared with one work which uses the same per-vertex features, the designed network achieves 29% and 32% lower average RMS reconstruction errors on the SCAPE and Face datasets. MeshCNN is compared and the proposed network achieves better results. Moreover, the capability of our framework is demonstrated in shape generation, shape interpolation and shape embedding.ConclusionA newly defined pooling operation, based on a modified mesh simplification algorithm, is integrated into a mesh variational auto-encoder architecture. Our generative model has its good generalization capability. Compared to the original MeshVAE, our method can generate high quality deformable models with richer details.关键词:mesh generation;mesh interpolation;variational auto-encoder(VAE);mesh pooling;edge contraction68|415|0更新时间:2024-05-07
摘要:Objective3D shape datasets have been tremendous facilitated nowadays. Data-driven 3D shape analysis has been an active research topic in computer vision and graphics. Apart from regular works, current data-driven works attempted to generalize deep neural networks from images to 3D shapes, including triangular meshes, point clouds and voxel data. Deep neural networks for triangular meshes have been concentrated. 3D meshes have complicated and irregular inter-connection. Most current works tend to keep mesh connectivity unchanged each layer, thus, losing the capability of increased receptive fields when pooling operations are applied. The variational auto-encoder (VAE) has been widely used in various kinds of generation tasks, including generation, interpolation and exploration on triangular meshes. Based on a fully-connected network, the initial MeshVAE requires mega parameters and its generalization capability is often weak. Although the fully connected layers allow changes of mesh connectivity across layers, due to irregular changes, such approaches cannot be directly generalized to convolutional layers. Some works adopt convolutional layers in the VAE structure. However, such convolution operations cannot change the connectivity of the mesh. Sampling operation is also evolved in convolutional neural networks(CNNs) on meshes, but the mesh sampling strategy does not aggregate the whole local neighborhood information when reducing the quantities of vertices. Hence, it is necessary to design a pooling operation for meshes similar to the pooling for images to reduce the amount of network parameters in order to deal with denser models and enhance the generalization ability of the network. Moreover, the defined pooling can support further convolutions and conduct recovery via a corresponding de-pooling operation.MethodA novel mesh pooling operation is illustrated based on edge contraction. The VAE architecture in context of the newly defined pooling operation is built up as well. Mesh simplification is applied to organize a mesh hierarchy with different levels of details, and achieves effective pooling by keeping track of the mapping between coarser and finer meshes. To avoid generating highly irregular triangles in mesh simplification, a modified mesh simplification approach is demonstrated based on the classical edge contraction algorithm. The edge length is an essential indicator for the edge contraction process. So, as one of the criteria, the edge length is incorporated to order pairs of points. The new edge length is added to the original quadric error formulation straightforward. The feature of a new vertex is defined as the average feature of the contracted vertices for average pooling, and alternative pooling operations can be similarly ruled. In the decoding process, the features of the vertices on the simplified mesh are equally assigned to the corresponding contracted vertices on the dense mesh for the inverse operation, de-pooling. The input to the illustrated network is a vertex-based deformation feature representation, which is different from 3D coordinates, encodes deformations defined on vertices in terms of deformation gradients analysis. The demonstrated framework uses a cluster of 3D shapes with the same connectivity to train the network. Such meshes can be easily obtained via consistent re-meshing. The network follows a VAE architecture where pooling operations and graph convolutions are applied. It has qualified generalization capabilities and handles much higher resolution meshes in various applications, such as shape generation and interpolation.ResultThe framework is tested on four datasets, shape completion and animation of people (SCAPE), Swing, Fat and Hand. The capability of the network is tested to generate unseen shapes, and calculate the average root mean squared (RMS) errors. The network with the proposed pooling and without pooling has been initially compared. The RMS error is lower by an average of 6.92% with pooling, which shows the benefits of our pooling and de-pooling operations. The comparisons between the proposed pooling and other pooling or sampling methods are illustrated. The RMS error of the proposed pooling for unseen data is lower on average by 9.34% compared to initial simplification-based pooling, 9.07% compared to uniform remeshing method, 8.06% compared to graph pooling, and 9.64% compared to mesh sampling, which illustrates this modified simplification algorithm is more effective in terms of pooling and the proposed pooling is superior on multiple datasets, demonstrating its generalization capability. The proposed framework is also compared with related mesh-based auto-encoder architectures. Thanks to spectral graph convolutions and the proposed pooling, the method reduces the reconstruction errors of unseen data consistently, showing superior generalizability. For instance, compared with one work which uses the same per-vertex features, the designed network achieves 29% and 32% lower average RMS reconstruction errors on the SCAPE and Face datasets. MeshCNN is compared and the proposed network achieves better results. Moreover, the capability of our framework is demonstrated in shape generation, shape interpolation and shape embedding.ConclusionA newly defined pooling operation, based on a modified mesh simplification algorithm, is integrated into a mesh variational auto-encoder architecture. Our generative model has its good generalization capability. Compared to the original MeshVAE, our method can generate high quality deformable models with richer details.关键词:mesh generation;mesh interpolation;variational auto-encoder(VAE);mesh pooling;edge contraction68|415|0更新时间:2024-05-07 -
 摘要:ObjectiveComputing low-distortion volumetric mapping while avoiding foldovers is an important issue in computer graphics and geometry processing. Foldover-free volumetric mapping has a wide range of applications in many fields such as mesh deformation, remeshing, mesh optimization, and shape analysis. Objects in the real world contain internal structures. Volumetric mapping not only needs to consider the surface but also needs to deal with internal complex geometric and topological structures. Volumetric mapping must be foldover-free, that is, the determinant of the Jacobian matrix of the volume mapping is greater than 0 everywhere because no negative volume is observed in real objects. The difficulties in generating a foldover-free volumetric mapping are as follows: 1) The input mapping may have foldovers. Removing these foldovers is difficult because the foldover-free constraint is nonlinear and nonconvex. 2) Volumetric mapping needs to satisfy the given position constraints. Position constraints and foldover-free constraints are mutually restricted, and simultaneously meeting these two constraints is difficult. The traditional volumetric mapping generation method mainly includes two cate-gories. Maintenance-based methods start from a foldover-free initialization, try to reduce the mapping distortion by optimizing energy, and use the line search method to prevent the mesh from flipping during the optimization. However, these methods rely on foldover-free initialization, and several of them may require additional input information, which is difficult to obtain. Other methods try to eliminate foldovers in the initial volumetric mapping. These methods do not rely on the foldover-free initialization, and no additional input information is required. However, they cannot guarantee that foldovers can be completely eliminated. Our goal is to generate foldover-free volumetric mappings and make these mappings satisfy the position constraints. However, simultaneously satisfying these two conditions is not trivial.MethodA volumetric mapping generation algorithm guided by Jacobian matrix is proposed to solve this problem. The core of our algorithm is a new deformation method that first relaxes the position constraint and then uses the Jacobian matrix as the deformation guide to deform the mesh to satisfy the position constraint while avoiding foldovers. To achieve this deformation goal, a Jacobian-guided deformation algorithm is proposed. Our findings reveal that although the previous method cannot completely eliminate flips, its Jacobian matrix can be used as a guide for our deformation algorithm. In addition, the position energy is optimized such that the deformed mesh can finally satisfy the position constraints. Finally, the position constraint is fixed, and the distortion of the volumetric mapping is further reduced by optimizing the energy.ResultExperiments are conducted on a large number of complex models. Different target shapes (i.e., a ball, a PolyCube and a general surface) are used as position constraints of the boundary vertices. When the boundary position is constrained to be a ball, the previous method often cannot completely eliminate foldovers because the target shape is very different from the input mesh. However, our method produces good results for these complex models. Our method has no requirements for the initial mapping, and three initialization types are used in our experiment. These initializations include a large number of foldovers, which can be completely eliminated in the end. These experiments prove that our method is robust. Compared with the previous method, our method can theoretically guarantee that the volumetric mapping generated by our method does not have foldovers. Experiment results show that the position energy can be controlled to a very small value, which proves that our method can meet the position constraint requirements.ConclusionThis paper generates foldover-free volumetric mapping and proposes a Jacobian-guided deformation algorithm, which changes the idea of traditional volumetric mapping generation algorithm. Our algorithm can generate foldover-free volumetric mappings and be applied to more research. However, our method also has limitations. Our algorithm needs a reasonable Jacobian matrix as a guide, which affects our deformation results. In addition, although good volumetric mapping results can be generated, no theoretical guarantee ensures that the position constraints can be met.关键词:volumetric mapping;foldover-free;Jacobian guidance;deformation optimization;position constraint;low distortion104|70|0更新时间:2024-05-07
摘要:ObjectiveComputing low-distortion volumetric mapping while avoiding foldovers is an important issue in computer graphics and geometry processing. Foldover-free volumetric mapping has a wide range of applications in many fields such as mesh deformation, remeshing, mesh optimization, and shape analysis. Objects in the real world contain internal structures. Volumetric mapping not only needs to consider the surface but also needs to deal with internal complex geometric and topological structures. Volumetric mapping must be foldover-free, that is, the determinant of the Jacobian matrix of the volume mapping is greater than 0 everywhere because no negative volume is observed in real objects. The difficulties in generating a foldover-free volumetric mapping are as follows: 1) The input mapping may have foldovers. Removing these foldovers is difficult because the foldover-free constraint is nonlinear and nonconvex. 2) Volumetric mapping needs to satisfy the given position constraints. Position constraints and foldover-free constraints are mutually restricted, and simultaneously meeting these two constraints is difficult. The traditional volumetric mapping generation method mainly includes two cate-gories. Maintenance-based methods start from a foldover-free initialization, try to reduce the mapping distortion by optimizing energy, and use the line search method to prevent the mesh from flipping during the optimization. However, these methods rely on foldover-free initialization, and several of them may require additional input information, which is difficult to obtain. Other methods try to eliminate foldovers in the initial volumetric mapping. These methods do not rely on the foldover-free initialization, and no additional input information is required. However, they cannot guarantee that foldovers can be completely eliminated. Our goal is to generate foldover-free volumetric mappings and make these mappings satisfy the position constraints. However, simultaneously satisfying these two conditions is not trivial.MethodA volumetric mapping generation algorithm guided by Jacobian matrix is proposed to solve this problem. The core of our algorithm is a new deformation method that first relaxes the position constraint and then uses the Jacobian matrix as the deformation guide to deform the mesh to satisfy the position constraint while avoiding foldovers. To achieve this deformation goal, a Jacobian-guided deformation algorithm is proposed. Our findings reveal that although the previous method cannot completely eliminate flips, its Jacobian matrix can be used as a guide for our deformation algorithm. In addition, the position energy is optimized such that the deformed mesh can finally satisfy the position constraints. Finally, the position constraint is fixed, and the distortion of the volumetric mapping is further reduced by optimizing the energy.ResultExperiments are conducted on a large number of complex models. Different target shapes (i.e., a ball, a PolyCube and a general surface) are used as position constraints of the boundary vertices. When the boundary position is constrained to be a ball, the previous method often cannot completely eliminate foldovers because the target shape is very different from the input mesh. However, our method produces good results for these complex models. Our method has no requirements for the initial mapping, and three initialization types are used in our experiment. These initializations include a large number of foldovers, which can be completely eliminated in the end. These experiments prove that our method is robust. Compared with the previous method, our method can theoretically guarantee that the volumetric mapping generated by our method does not have foldovers. Experiment results show that the position energy can be controlled to a very small value, which proves that our method can meet the position constraint requirements.ConclusionThis paper generates foldover-free volumetric mapping and proposes a Jacobian-guided deformation algorithm, which changes the idea of traditional volumetric mapping generation algorithm. Our algorithm can generate foldover-free volumetric mappings and be applied to more research. However, our method also has limitations. Our algorithm needs a reasonable Jacobian matrix as a guide, which affects our deformation results. In addition, although good volumetric mapping results can be generated, no theoretical guarantee ensures that the position constraints can be met.关键词:volumetric mapping;foldover-free;Jacobian guidance;deformation optimization;position constraint;low distortion104|70|0更新时间:2024-05-07 -
 摘要:ObjectiveThree dimensional vision analysis is a key research aspect in computer vision research. Point cloud representation preserves the initial geometric information in 3D space under no discretization circumstances. Unfortunately, scanned 3D point clouds are incomplete due to occlusion, constrained sensor resolution and small viewing angle. Hence, a shape completion process is required for downstream 3D computer vision applications. Most deep learning based point cloud completion algorithms demonstrate an encoder-decoder structure and align multilayer perception (MLP) to extract point cloud features at the encoder. However, MLP networks tend to focus on the overall shape of the point cloud, and it is difficult to extract the local structural features of the object effectively. In addition, MLP does not generalize well to new objects, and it is difficult to complete the shape of objects with small training samples. So, it is a challenged issue that an efficient and accurate local structural feature extraction algorithm for point cloud completion.MethodMulti-scale transformer based point cloud completion network (MSTCN) is illustrated. The entire network adopts an encoder decoder structure, which is composed of a multi-scale feature extractor, a pyramid point generator and a transformer based discriminator. The encoder of MSTCN extracts and aggregates the feature information of three types of incomplete point clouds with different resolutions through the transformer module, inputs them into a fully connected network based decoder, and then obtains the missing point clouds as outputs gradually. The feature embedding layer (FEL) and attention layer are melted into the encoder. The former improves the ability of the encoder to extract local structural features of point cloud via sampling and neighborhood grouping, the latter obtains the correlation information amongst points based on an improved self-attention module. As for decoder, pyramid point generator is mainly composed of a full connection layer and reshape operation. On the whole, a network adopts parallel operation on point clouds with three different resolutions, which are generated by the farthest down sampling approach. Similarly, point cloud completion is divided into three stages to achieve coarse-to-fine processing in the pyramid point generator. Based on generative adversarial network (GAN), MSTCN adds a transformer based discriminator at the back end of the decoder, so that the discriminator and the generator can promote each other in joint training and optimize the completion performance of network. The loss function of MSTCN is mainly composed of two parts: generating loss and adversarial loss. Generating loss is the weighted sum of chamfer-distance(CD) between the generated point cloud and its ground-truth of three scales, and adversarial loss is the cross entropy sum of the generated point cloud and its ground-truth through the transformer-based discriminator.ResultThe experiment was compared with the latest methods on the ShapeNet and ModelNet10 datasets. On the ShapeNet dataset, this paper used all of the 16 categories for training, the average CD value of category calculated by MSTCN was reduced by 3.73% as compared to the second best model. Specifically, the CD values of cap, car, chair, earphone, lamp, pistol and table are better than those of point fractal network(PF-Net). On the ModelNet10 dataset, the average CD value of each category calculated by MSTCN was decreased by 12.75% as compared to the second best model. Specifically, the CD values of bathtub, chair, desk, dresser, monitor, night-stand, sofa, table and toilet are better than those of PF-Net. According to the visualization results based on six categories of aircraft, hat, chair, headset, motorcycle and table, MSTCN can accurately complete special structures and generalize to special samples in one category. The ablation studies were also taken on the ShapeNet dataset. As a result, the full MSTCN network performs better than three other networks which were MSTCNs with no feature embedding layer, attention layer and discriminator respectively. It illustrates that the feature embedding layer can make the model more capable to extract local structure information of point clouds, the attention layer can make the model selectively refer to the local structure of the input point cloud when completing. The discriminator can promote the completion effect of network. Meanwhile, three groups of point cloud completion sub models for different missing ratios were trained on ShapeNet dataset to verify the completion robustness of MSTCN model for input point clouds with different missing ratios. The category of chair and visualized the effect of completion are opted. As a result, the MSTCN model always maintains a good point cloud completion effect although the number of input point clouds decreases gradually, in which the completion results of 25% and 50% missing ratios have similar CD values. Even the missing ratio reaches 75%, CD value of the chair category remains at a low level of 2.074/2.456. The entire chair shape can be identified and completed only in accordance with the incomplete chair legs. This demonstration verifies that MSTCN has strong completion robustness while dealing with input point clouds with different missing ratios.ConclusionA multi-scale transformer based point cloud completion network (MSTCN) for point cloud completion has been illustrated. MSTCN can better extract local feature information of the residual point cloud, which makes the result of point cloud completion more accurate. The current point cloud completion algorithm has achieved good results in the completion of a single object. Future research can focus on the completion of large-scale scenes because the incomplete point cloud in scenes has a variety of incomplete types, such as view missing, spherical missing and occlusion missing. It is more challenging and practical to complete large scenes. On the other hand, the point clouds of real scanned scenes have no ground truth point cloud for reference.The unsupervised completion algorithms have its priority than supervised completion algorithms.关键词:three-dimensional point cloud;point cloud completion;autoencoder;attention mechanism;generative adversarial networks(GAN)182|253|9更新时间:2024-05-07
摘要:ObjectiveThree dimensional vision analysis is a key research aspect in computer vision research. Point cloud representation preserves the initial geometric information in 3D space under no discretization circumstances. Unfortunately, scanned 3D point clouds are incomplete due to occlusion, constrained sensor resolution and small viewing angle. Hence, a shape completion process is required for downstream 3D computer vision applications. Most deep learning based point cloud completion algorithms demonstrate an encoder-decoder structure and align multilayer perception (MLP) to extract point cloud features at the encoder. However, MLP networks tend to focus on the overall shape of the point cloud, and it is difficult to extract the local structural features of the object effectively. In addition, MLP does not generalize well to new objects, and it is difficult to complete the shape of objects with small training samples. So, it is a challenged issue that an efficient and accurate local structural feature extraction algorithm for point cloud completion.MethodMulti-scale transformer based point cloud completion network (MSTCN) is illustrated. The entire network adopts an encoder decoder structure, which is composed of a multi-scale feature extractor, a pyramid point generator and a transformer based discriminator. The encoder of MSTCN extracts and aggregates the feature information of three types of incomplete point clouds with different resolutions through the transformer module, inputs them into a fully connected network based decoder, and then obtains the missing point clouds as outputs gradually. The feature embedding layer (FEL) and attention layer are melted into the encoder. The former improves the ability of the encoder to extract local structural features of point cloud via sampling and neighborhood grouping, the latter obtains the correlation information amongst points based on an improved self-attention module. As for decoder, pyramid point generator is mainly composed of a full connection layer and reshape operation. On the whole, a network adopts parallel operation on point clouds with three different resolutions, which are generated by the farthest down sampling approach. Similarly, point cloud completion is divided into three stages to achieve coarse-to-fine processing in the pyramid point generator. Based on generative adversarial network (GAN), MSTCN adds a transformer based discriminator at the back end of the decoder, so that the discriminator and the generator can promote each other in joint training and optimize the completion performance of network. The loss function of MSTCN is mainly composed of two parts: generating loss and adversarial loss. Generating loss is the weighted sum of chamfer-distance(CD) between the generated point cloud and its ground-truth of three scales, and adversarial loss is the cross entropy sum of the generated point cloud and its ground-truth through the transformer-based discriminator.ResultThe experiment was compared with the latest methods on the ShapeNet and ModelNet10 datasets. On the ShapeNet dataset, this paper used all of the 16 categories for training, the average CD value of category calculated by MSTCN was reduced by 3.73% as compared to the second best model. Specifically, the CD values of cap, car, chair, earphone, lamp, pistol and table are better than those of point fractal network(PF-Net). On the ModelNet10 dataset, the average CD value of each category calculated by MSTCN was decreased by 12.75% as compared to the second best model. Specifically, the CD values of bathtub, chair, desk, dresser, monitor, night-stand, sofa, table and toilet are better than those of PF-Net. According to the visualization results based on six categories of aircraft, hat, chair, headset, motorcycle and table, MSTCN can accurately complete special structures and generalize to special samples in one category. The ablation studies were also taken on the ShapeNet dataset. As a result, the full MSTCN network performs better than three other networks which were MSTCNs with no feature embedding layer, attention layer and discriminator respectively. It illustrates that the feature embedding layer can make the model more capable to extract local structure information of point clouds, the attention layer can make the model selectively refer to the local structure of the input point cloud when completing. The discriminator can promote the completion effect of network. Meanwhile, three groups of point cloud completion sub models for different missing ratios were trained on ShapeNet dataset to verify the completion robustness of MSTCN model for input point clouds with different missing ratios. The category of chair and visualized the effect of completion are opted. As a result, the MSTCN model always maintains a good point cloud completion effect although the number of input point clouds decreases gradually, in which the completion results of 25% and 50% missing ratios have similar CD values. Even the missing ratio reaches 75%, CD value of the chair category remains at a low level of 2.074/2.456. The entire chair shape can be identified and completed only in accordance with the incomplete chair legs. This demonstration verifies that MSTCN has strong completion robustness while dealing with input point clouds with different missing ratios.ConclusionA multi-scale transformer based point cloud completion network (MSTCN) for point cloud completion has been illustrated. MSTCN can better extract local feature information of the residual point cloud, which makes the result of point cloud completion more accurate. The current point cloud completion algorithm has achieved good results in the completion of a single object. Future research can focus on the completion of large-scale scenes because the incomplete point cloud in scenes has a variety of incomplete types, such as view missing, spherical missing and occlusion missing. It is more challenging and practical to complete large scenes. On the other hand, the point clouds of real scanned scenes have no ground truth point cloud for reference.The unsupervised completion algorithms have its priority than supervised completion algorithms.关键词:three-dimensional point cloud;point cloud completion;autoencoder;attention mechanism;generative adversarial networks(GAN)182|253|9更新时间:2024-05-07
3D Shape Analysis
-
 摘要:Objective3D shape segmentation is an important task, without which many 3D data processing applications cannot accomplish their work. It has also become a hot research topic in areas, such as digital geometric processing and modeling, and plays a crucial role in finalizing tasks such as 3D printing, 3D shape retrieval, and medical organ segmentation. Recent years have witnessed the continuous development of 3D data acquisition equipment such as laser scanners, RGBD cameras, and stereo cameras, which has resulted in 3D point cloud data enjoying wide usage in 3D shape segmentation tasks. Based on the analysis of the shape the 3D point cloud takes, 3D point cloud segmentation methods involving deep learning solutions are divided into three categories by related research scholars: 1) volumetric-based methods, 2) view-based methods, and 3) point-based methods. Volumetric-based methods first use voxels in 3D space as the definition domain to perform 3D convolution and then expand the convolutional neural network (CNN) to 3D space for feature learning. Finally, point cloud shape segmentation can be realized by aggregating the acquired features. View-based methods use spatial projection to convert the input 3D shape into multiple 2D image views, inputting the stack of images into a 2D CNN to extract the input point cloud shape features, and then, for a refinement of the segmentation results, the input 3D shape features are further processed through the view pool and the CNN. To accommodate situations in which the points of the input cloud are disorderly and irregularly dispersed, point-based methods set up a specific neural network input layer to input the 3D point cloud directly into the network for training to improve the segmentation performance of the 3D point cloud shape. The network cannot achieve efficient co-segmentation of the shape clusters by employing component reconstruction techniques because typical point cloud data lack topology and surface information, and the labeling large data sets is difficult. Considering human beings' notion of object recognition, which is based on parts, as well as other factors, such as the instability of the segmentation caused by the influence of occlusion and the illumination and projection angle in the view-based methods, voxelization of point cloud data is selected in this paper. Moreover, most of the existing deep learning methods used for 3D shape segmentation adopt a supervisory mechanism, and the implementation of automatic 3D shape segmentation methods is difficult without effective usage of the potential connections between shapes. Thus, an unsupervised 3D shape cluster co-segmentation network, based on the implicit decoder (IM-decoder), is used for the realization of the correspondence between semantically related components and the automatic segmentation of 3D shapes in this paper.MethodThe unsupervised 3D shape cluster co-segmentation method, based on the implicit decoder, is divided mainly into three important operations: encoding, feature aggregation, and decoding. The first task of the encoding stage is to carry out an accurate extraction of the features from the input 3D shape. The encoder network designed in this paper is based on traditional CNNs, and the encoder can only process regular 3D data. First, voxelization is carried out on all the points that represent the shape in 3D point cloud form. Then, the Hierarchical Surface Prediction method is used to improve the quality of the reconstructed 3D shape. Finally, the features of the voxelized points are extracted through the CNN encoder, and the shape information is mapped to the feature space. The feature aggregation operation further improves the quality of the extracted features by using the attention module, which aggregates the features of adjacent points in the 3D shape. During the decoding stage, the aggregated features and the 3D coordinates of the points are input to the IM-decoder for an enhancement of the spatial perception of the shape, and the internal and external states of the sampling points relative to the shape components are output after this enhancement. The final co-segmentation is accomplished by a max pooling operation, which is realized through aggregating the implicit fields generated by the decoder.ResultIn this paper, ablation and comparative experiments are conducted on the ShapeNet Part dataset using intersection over union (IoU) and mean intersection over union (mIoU) as evaluation criteria. Experimental results show that the mIoU achieved by our algorithm, when invoked on the ShapeNet Part dataset, reaches 62.1%. Compared with the currently known two types of unsupervised 3D point cloud shape segmentation methods, its mIoU is increased by 22.5% and 18.9%, and the segmentation performance is greatly improved. Compared with the two supervised methods, the mIoU of this algorithm is reduced by 19.3% and 20.2%, but our method could achieve a better segmentation effect on shapes with fewer parts. Moreover, the choice of using the mean square error function as the reconstruction loss function, instead of using the cross-entropy function, results in a higher segmentation accuracy, which is manifested by an improvement of 26.3%, in terms of mIoU. The ablation experiment shows that the attention module designed in this paper could improve the segmentation accuracy of the network by automatically selecting important features from each shape type.ConclusionThe experimental results show that the 3D shape cluster co-segmentation method, which is based on the implicit decoder, achieves a high segmentation accuracy. On the one hand, the method uses CNN-encoder to extract the features of the 3D shape and designs the attention module such that important features are automatically selected, which can further improve the quality of the features. On the other hand, the implicit decoder, constructed by our method, performs collaborative analysis on the joint feature vector, which is composed of the selectively chosen features and the 3D coordinates of the points. Moreover, the implicit field resulting from the fine-tuning of the reconstruction loss function could effectively improve the accuracy of the segmentation.关键词:co-segmentation;shape clusters;implicit decoder;attention module;unsupervised109|284|0更新时间:2024-05-07
摘要:Objective3D shape segmentation is an important task, without which many 3D data processing applications cannot accomplish their work. It has also become a hot research topic in areas, such as digital geometric processing and modeling, and plays a crucial role in finalizing tasks such as 3D printing, 3D shape retrieval, and medical organ segmentation. Recent years have witnessed the continuous development of 3D data acquisition equipment such as laser scanners, RGBD cameras, and stereo cameras, which has resulted in 3D point cloud data enjoying wide usage in 3D shape segmentation tasks. Based on the analysis of the shape the 3D point cloud takes, 3D point cloud segmentation methods involving deep learning solutions are divided into three categories by related research scholars: 1) volumetric-based methods, 2) view-based methods, and 3) point-based methods. Volumetric-based methods first use voxels in 3D space as the definition domain to perform 3D convolution and then expand the convolutional neural network (CNN) to 3D space for feature learning. Finally, point cloud shape segmentation can be realized by aggregating the acquired features. View-based methods use spatial projection to convert the input 3D shape into multiple 2D image views, inputting the stack of images into a 2D CNN to extract the input point cloud shape features, and then, for a refinement of the segmentation results, the input 3D shape features are further processed through the view pool and the CNN. To accommodate situations in which the points of the input cloud are disorderly and irregularly dispersed, point-based methods set up a specific neural network input layer to input the 3D point cloud directly into the network for training to improve the segmentation performance of the 3D point cloud shape. The network cannot achieve efficient co-segmentation of the shape clusters by employing component reconstruction techniques because typical point cloud data lack topology and surface information, and the labeling large data sets is difficult. Considering human beings' notion of object recognition, which is based on parts, as well as other factors, such as the instability of the segmentation caused by the influence of occlusion and the illumination and projection angle in the view-based methods, voxelization of point cloud data is selected in this paper. Moreover, most of the existing deep learning methods used for 3D shape segmentation adopt a supervisory mechanism, and the implementation of automatic 3D shape segmentation methods is difficult without effective usage of the potential connections between shapes. Thus, an unsupervised 3D shape cluster co-segmentation network, based on the implicit decoder (IM-decoder), is used for the realization of the correspondence between semantically related components and the automatic segmentation of 3D shapes in this paper.MethodThe unsupervised 3D shape cluster co-segmentation method, based on the implicit decoder, is divided mainly into three important operations: encoding, feature aggregation, and decoding. The first task of the encoding stage is to carry out an accurate extraction of the features from the input 3D shape. The encoder network designed in this paper is based on traditional CNNs, and the encoder can only process regular 3D data. First, voxelization is carried out on all the points that represent the shape in 3D point cloud form. Then, the Hierarchical Surface Prediction method is used to improve the quality of the reconstructed 3D shape. Finally, the features of the voxelized points are extracted through the CNN encoder, and the shape information is mapped to the feature space. The feature aggregation operation further improves the quality of the extracted features by using the attention module, which aggregates the features of adjacent points in the 3D shape. During the decoding stage, the aggregated features and the 3D coordinates of the points are input to the IM-decoder for an enhancement of the spatial perception of the shape, and the internal and external states of the sampling points relative to the shape components are output after this enhancement. The final co-segmentation is accomplished by a max pooling operation, which is realized through aggregating the implicit fields generated by the decoder.ResultIn this paper, ablation and comparative experiments are conducted on the ShapeNet Part dataset using intersection over union (IoU) and mean intersection over union (mIoU) as evaluation criteria. Experimental results show that the mIoU achieved by our algorithm, when invoked on the ShapeNet Part dataset, reaches 62.1%. Compared with the currently known two types of unsupervised 3D point cloud shape segmentation methods, its mIoU is increased by 22.5% and 18.9%, and the segmentation performance is greatly improved. Compared with the two supervised methods, the mIoU of this algorithm is reduced by 19.3% and 20.2%, but our method could achieve a better segmentation effect on shapes with fewer parts. Moreover, the choice of using the mean square error function as the reconstruction loss function, instead of using the cross-entropy function, results in a higher segmentation accuracy, which is manifested by an improvement of 26.3%, in terms of mIoU. The ablation experiment shows that the attention module designed in this paper could improve the segmentation accuracy of the network by automatically selecting important features from each shape type.ConclusionThe experimental results show that the 3D shape cluster co-segmentation method, which is based on the implicit decoder, achieves a high segmentation accuracy. On the one hand, the method uses CNN-encoder to extract the features of the 3D shape and designs the attention module such that important features are automatically selected, which can further improve the quality of the features. On the other hand, the implicit decoder, constructed by our method, performs collaborative analysis on the joint feature vector, which is composed of the selectively chosen features and the 3D coordinates of the points. Moreover, the implicit field resulting from the fine-tuning of the reconstruction loss function could effectively improve the accuracy of the segmentation.关键词:co-segmentation;shape clusters;implicit decoder;attention module;unsupervised109|284|0更新时间:2024-05-07 -
 摘要:ObjectiveWith the widespread use of depth cameras and 3D scanning equipment, 3D data with point clouds as the main structure have become more readily available to people. As a result, 3D point clouds are widely used in practical applications such as self-driving cars, location recognition, robot localization, and remote sensing. In recent years, the great success of convolutional neural networks (CNNs) has changed the landscape of 2D computer vision. However, CNNs cannot directly process unstructured data such as point clouds due to the disorderly, irregular characteristics of 3D point clouds. Therefore, mine shape features from disordered point clouds have become a viable research direction in point cloud analysis.MethodAn end-to-end multidimensional multilayer neural network (MM-Net), which can directly process point cloud data, is presented in this paper. The multi-dimensional feature correction and fusion (MDCF) module can correct local features in different dimensions rationally. First, the local area division unit, using farthest point sampling and ball query, constructs local areas at different radii from which the 10D geometric relations and local features required are obtained for the module. Inspired by related research, the module uses geometric relations to modify the point-wise features, enhance the interaction between points, and encode useful local features, which are supplemented by point-wise features. Finally, the shape features of different region ranges are fused and mapped to a higher dimensional space. At the same time, the multi-layer feature articulation (MLFA) module focuses on integrating the contextual relationships between local regions to extract global features. In particular, these local regions are seen as distinct nodes, and global features are acquired by using convolution and jump fusion. The MLFA module uses the long-range dependencies between multiple layers to reason about the global shape required for the network. Furthermore, two network architectures (multidimensional multi-layer feature classification network (MM-Net-C) and multidimensional multi-layer feature segmentation network (MM-Net-S)) for point cloud classification and segmentation tasks are designed in this paper. In detail, MM-Net-C goes through three tandem MDCF modules with three layers of interlinked local shape features. The global features are then obtained by connecting and integrating the correlations between each local region through the MLFA module. In MM-Net-S, after processing by the MLFA module, the object data are encoded global feature vector with 1 024 dimensions. Then, the features are summed to obtain shapes that fuse local and global information, so that they are linked to the labels of the objects (e.g., motorbikes, cars). This process is followed by feature propagation, where successive up sampling operations are performed to recover the details in the original object data and to obtain a robust point-wise vector. Finally, the outputs of the different feature propagation layers are integrated and fed into the convolution operation. The features are transformed to obtain an accurate prediction of each point cloud within the object.ResultThe method in this paper is adequately tested on the publicly available ModelNet40 dataset and ShapeNet dataset. The experimental results are compared with various methods. In the ModelNet40 dataset, MM-Net-C is compared with several pnt-based (input point cloud coordinates only), such as dynamic graph convolutional neural network(DGCNN) (92.2%) with 1.9% accuracy improvement and relation-shape convolutional neural network(RS-CNN) (93.6%) with 0.5% accuracy improvement. MM-Net-C is also compared with several pnt-nor (coordinates and normal vectors of the input point cloud) based: point attention transformers(PAT) (91.7%) improves accuracy by 2.4%; PointConv (92.5%) improves accuracy by 1.6%; PointASNL (93.2%) improves accuracy by 0.9%. Even when several studies input more points for training, MM-Net-C still outperforms them. For example, PointNet++ (5 k, 91.9%) improves accuracy by 2.2%, and self-organizing network(SO-Net) (5 k, 93.4%) improves accuracy by 0.7%. In addition, MM-Net-C achieves higher accuracy rates than other studies with less complexity. For example, compared with PointCNN (8.20 M, 91.7%), MM-Net-C has less than one-eighth of the number of parameters while the accuracy rate is increased by 2.4%. Compared with RS-CNN (1.41 M, 93.6%), MM-Net-C has 0.33 M fewer parameters while the accuracy rate is increased by 0.5%. In the ShapeNet dataset, MM-Net-S compared with DGCNN (85.1%), the accuracy is improved by 1.4%; compared with shape-oriented convolutional neural network(SO-CNN) (85.7%), the accuracy is improved by 0.8%; and compared with annularly convolutional neural networks(A-CNN) (86.1%), the accuracy is improved by 0.4%. Ablation experiments are also conducted on the ModelNet40 dataset to confirm the effectiveness of the MM-Net architecture. The ablation experiments results validate the need for the MDCF module and MLFA module design. The results further confirm that MDCF module, which uses rich point-wise features modified and fused with potential local features, can effectively improve the network's mining of shape information within a local region. By contrast, the MLFA module captures contextual information at the global scale and reinforces the long-range dependency links that exist between different layers, effectively enhancing the robustness of the model in dealing with complex shapes. Ablation experiments are conducted on whether the MDCF needs to be designed with different dimensions. The experimental results demonstrate that MM-Net performs better than RS-CNN for the same dimensionality.ConclusionIn this paper, an MM-Net with MDCF module and MLFA module as core components is proposed. After conducting sufficient experiments, thorough comparisons and verifying MM-Net, a higher correct rate is achieved with the advantage of fewer parameters.关键词:three-dimensional point cloud;point cloud classification and segmentation;deep learning;shape features;multi-dimensional feature;multi-layer feature81|84|0更新时间:2024-05-07
摘要:ObjectiveWith the widespread use of depth cameras and 3D scanning equipment, 3D data with point clouds as the main structure have become more readily available to people. As a result, 3D point clouds are widely used in practical applications such as self-driving cars, location recognition, robot localization, and remote sensing. In recent years, the great success of convolutional neural networks (CNNs) has changed the landscape of 2D computer vision. However, CNNs cannot directly process unstructured data such as point clouds due to the disorderly, irregular characteristics of 3D point clouds. Therefore, mine shape features from disordered point clouds have become a viable research direction in point cloud analysis.MethodAn end-to-end multidimensional multilayer neural network (MM-Net), which can directly process point cloud data, is presented in this paper. The multi-dimensional feature correction and fusion (MDCF) module can correct local features in different dimensions rationally. First, the local area division unit, using farthest point sampling and ball query, constructs local areas at different radii from which the 10D geometric relations and local features required are obtained for the module. Inspired by related research, the module uses geometric relations to modify the point-wise features, enhance the interaction between points, and encode useful local features, which are supplemented by point-wise features. Finally, the shape features of different region ranges are fused and mapped to a higher dimensional space. At the same time, the multi-layer feature articulation (MLFA) module focuses on integrating the contextual relationships between local regions to extract global features. In particular, these local regions are seen as distinct nodes, and global features are acquired by using convolution and jump fusion. The MLFA module uses the long-range dependencies between multiple layers to reason about the global shape required for the network. Furthermore, two network architectures (multidimensional multi-layer feature classification network (MM-Net-C) and multidimensional multi-layer feature segmentation network (MM-Net-S)) for point cloud classification and segmentation tasks are designed in this paper. In detail, MM-Net-C goes through three tandem MDCF modules with three layers of interlinked local shape features. The global features are then obtained by connecting and integrating the correlations between each local region through the MLFA module. In MM-Net-S, after processing by the MLFA module, the object data are encoded global feature vector with 1 024 dimensions. Then, the features are summed to obtain shapes that fuse local and global information, so that they are linked to the labels of the objects (e.g., motorbikes, cars). This process is followed by feature propagation, where successive up sampling operations are performed to recover the details in the original object data and to obtain a robust point-wise vector. Finally, the outputs of the different feature propagation layers are integrated and fed into the convolution operation. The features are transformed to obtain an accurate prediction of each point cloud within the object.ResultThe method in this paper is adequately tested on the publicly available ModelNet40 dataset and ShapeNet dataset. The experimental results are compared with various methods. In the ModelNet40 dataset, MM-Net-C is compared with several pnt-based (input point cloud coordinates only), such as dynamic graph convolutional neural network(DGCNN) (92.2%) with 1.9% accuracy improvement and relation-shape convolutional neural network(RS-CNN) (93.6%) with 0.5% accuracy improvement. MM-Net-C is also compared with several pnt-nor (coordinates and normal vectors of the input point cloud) based: point attention transformers(PAT) (91.7%) improves accuracy by 2.4%; PointConv (92.5%) improves accuracy by 1.6%; PointASNL (93.2%) improves accuracy by 0.9%. Even when several studies input more points for training, MM-Net-C still outperforms them. For example, PointNet++ (5 k, 91.9%) improves accuracy by 2.2%, and self-organizing network(SO-Net) (5 k, 93.4%) improves accuracy by 0.7%. In addition, MM-Net-C achieves higher accuracy rates than other studies with less complexity. For example, compared with PointCNN (8.20 M, 91.7%), MM-Net-C has less than one-eighth of the number of parameters while the accuracy rate is increased by 2.4%. Compared with RS-CNN (1.41 M, 93.6%), MM-Net-C has 0.33 M fewer parameters while the accuracy rate is increased by 0.5%. In the ShapeNet dataset, MM-Net-S compared with DGCNN (85.1%), the accuracy is improved by 1.4%; compared with shape-oriented convolutional neural network(SO-CNN) (85.7%), the accuracy is improved by 0.8%; and compared with annularly convolutional neural networks(A-CNN) (86.1%), the accuracy is improved by 0.4%. Ablation experiments are also conducted on the ModelNet40 dataset to confirm the effectiveness of the MM-Net architecture. The ablation experiments results validate the need for the MDCF module and MLFA module design. The results further confirm that MDCF module, which uses rich point-wise features modified and fused with potential local features, can effectively improve the network's mining of shape information within a local region. By contrast, the MLFA module captures contextual information at the global scale and reinforces the long-range dependency links that exist between different layers, effectively enhancing the robustness of the model in dealing with complex shapes. Ablation experiments are conducted on whether the MDCF needs to be designed with different dimensions. The experimental results demonstrate that MM-Net performs better than RS-CNN for the same dimensionality.ConclusionIn this paper, an MM-Net with MDCF module and MLFA module as core components is proposed. After conducting sufficient experiments, thorough comparisons and verifying MM-Net, a higher correct rate is achieved with the advantage of fewer parameters.关键词:three-dimensional point cloud;point cloud classification and segmentation;deep learning;shape features;multi-dimensional feature;multi-layer feature81|84|0更新时间:2024-05-07 -
 摘要:ObjectiveAirborne laser scanning (ALS) offers a mature structure of point cloud data, which can represent complicated geometric information of the real world. Point cloud classification is a critical task in airborne laser detection and ranging applications, such as topographic mapping, power line detection, building reconstruction, etc. However, unavoidable reasons, such as complicated topographic conditions, sensor noise and sparse point cloud density, make ALS point cloud classification very difficult. Original point cloud classification is dependent on manual features, targeted classification conditions and parameter designation. Deep learning-based methods transform 3D point cloud into other representations such as 3D voxels, 2D images and octree structures based on structured networks at the cost of 3D spatial structure information loss. As the requirement for high point cloud density, the lack of adaptability for data and deep features caused in accuracy. Moreover, some networks make multi-modal data fusion or learn multi-level feature representations of points via local structures exploration, but the applications of geometric information of airborne data is constraint to achieve fine-grained classification for geometrically prominent and diverse ALS point cloud. In this paper, we propose a multi-feature fusion and geometric convolutional neural network (MFFGCNN) consisting of ALS data processing, multi-feature fusion and deep geometric features aggregation for point cloud classification.MethodFirst, an ALS point cloud design module, called APD module, is constructed to organize point cloud structure by balancing classes and scale, partitioning point cloud and processing raw coordinates. Next, discriminative typical features are used to supplement the point cloud information at the input feature level. The applications of echo and intensity has been demonstrated as input along with the coordinates into the point-based network, which can preserve the 3D spatial characteristics while making full use of the effective point cloud features. Then, four types of geometric features of points and their K-nearest neighborhoods are calculated by dividing the neighborhood region at three different scales, with local spatial information. A geometric convolution module based on multi-feature fusion, called multi-feature fusion and geometric convolution(FGC) operator, is to encode the global and local spatial geometric structure of points. This design can obtain the hierarchical geometric structure of large area point clouds. At the end, our method aggregates the discriminative deep global and local geometric features in different levels and the input multi-class features into a hierarchical advanced semantic feature, which enables semantic segmentation of airborne LiDAR(light detection and ranging) point clouds by spatial up-sampling.ResultThe comparative analyses are based on the International Society for Photogrammetry and Remote Sensing (ISPRS) 3D labeling benchmark dataset. For the three typical ground features of buildings, ground and trees, the dataset is further divided on initial contained nine categories such as car, facade and shrub. The ALS point cloud is segmented into blocks of 50 m as a batch input into the network. Each feature is extracted from the layer and then processed using batch normalization. The batch number for training and evaluation is 16 and the maximum epoch during training is 200. The test is implemented via a NVIDIA GTX 2060Ti GPU. Mean intersection-over-union (mIoU), mean accuracy (mAcc), and overall accuracy (OA) are evaluated. The results of ablation experiments demonstrate that the FGC module can improve the global accuracy by 8%, which can effectively extract local geometric features. Compared with the 3D spatial coordinate-based method, the overall classification accuracy can improve by 15%. The relative elevation of the neighborhood can reflect elevation directional heterogeneity and ground points can achieve clear classification. Echo features can be validated for advantage in vegetation classification. The introduction of geometric features facilitates the distinction between building points and background points while ensuring the consistency of the building's main body and clear contours. The four classes of geometric features are targeted at the curvature variation, edges, all consistency of the feature and the unique spherical characteristics of the vegetation. It illustrated further that the involvement of multiple classes of features in the semantic segmentation of airborne LiDAR point clouds. The visualization results also demonstrate a stronger model, especially in difficult situations such as buildings surrounded by tall trees and dense buildings with complex roof structures still achieving excellent performance, but there is a potential for improvement in the edges of features, and in the detailed parts of complex scenes.ConclusionThe proposed MFFCGNN network combines the advantages of initial features and deep learning-based models. The demonstrated model can be implemented in 3D city modelling.关键词:point cloud classification;airborne LiDAR;PointNet++;deep learning;multi-feature fusion;geometric convolutional network(GCN)111|212|4更新时间:2024-05-07
摘要:ObjectiveAirborne laser scanning (ALS) offers a mature structure of point cloud data, which can represent complicated geometric information of the real world. Point cloud classification is a critical task in airborne laser detection and ranging applications, such as topographic mapping, power line detection, building reconstruction, etc. However, unavoidable reasons, such as complicated topographic conditions, sensor noise and sparse point cloud density, make ALS point cloud classification very difficult. Original point cloud classification is dependent on manual features, targeted classification conditions and parameter designation. Deep learning-based methods transform 3D point cloud into other representations such as 3D voxels, 2D images and octree structures based on structured networks at the cost of 3D spatial structure information loss. As the requirement for high point cloud density, the lack of adaptability for data and deep features caused in accuracy. Moreover, some networks make multi-modal data fusion or learn multi-level feature representations of points via local structures exploration, but the applications of geometric information of airborne data is constraint to achieve fine-grained classification for geometrically prominent and diverse ALS point cloud. In this paper, we propose a multi-feature fusion and geometric convolutional neural network (MFFGCNN) consisting of ALS data processing, multi-feature fusion and deep geometric features aggregation for point cloud classification.MethodFirst, an ALS point cloud design module, called APD module, is constructed to organize point cloud structure by balancing classes and scale, partitioning point cloud and processing raw coordinates. Next, discriminative typical features are used to supplement the point cloud information at the input feature level. The applications of echo and intensity has been demonstrated as input along with the coordinates into the point-based network, which can preserve the 3D spatial characteristics while making full use of the effective point cloud features. Then, four types of geometric features of points and their K-nearest neighborhoods are calculated by dividing the neighborhood region at three different scales, with local spatial information. A geometric convolution module based on multi-feature fusion, called multi-feature fusion and geometric convolution(FGC) operator, is to encode the global and local spatial geometric structure of points. This design can obtain the hierarchical geometric structure of large area point clouds. At the end, our method aggregates the discriminative deep global and local geometric features in different levels and the input multi-class features into a hierarchical advanced semantic feature, which enables semantic segmentation of airborne LiDAR(light detection and ranging) point clouds by spatial up-sampling.ResultThe comparative analyses are based on the International Society for Photogrammetry and Remote Sensing (ISPRS) 3D labeling benchmark dataset. For the three typical ground features of buildings, ground and trees, the dataset is further divided on initial contained nine categories such as car, facade and shrub. The ALS point cloud is segmented into blocks of 50 m as a batch input into the network. Each feature is extracted from the layer and then processed using batch normalization. The batch number for training and evaluation is 16 and the maximum epoch during training is 200. The test is implemented via a NVIDIA GTX 2060Ti GPU. Mean intersection-over-union (mIoU), mean accuracy (mAcc), and overall accuracy (OA) are evaluated. The results of ablation experiments demonstrate that the FGC module can improve the global accuracy by 8%, which can effectively extract local geometric features. Compared with the 3D spatial coordinate-based method, the overall classification accuracy can improve by 15%. The relative elevation of the neighborhood can reflect elevation directional heterogeneity and ground points can achieve clear classification. Echo features can be validated for advantage in vegetation classification. The introduction of geometric features facilitates the distinction between building points and background points while ensuring the consistency of the building's main body and clear contours. The four classes of geometric features are targeted at the curvature variation, edges, all consistency of the feature and the unique spherical characteristics of the vegetation. It illustrated further that the involvement of multiple classes of features in the semantic segmentation of airborne LiDAR point clouds. The visualization results also demonstrate a stronger model, especially in difficult situations such as buildings surrounded by tall trees and dense buildings with complex roof structures still achieving excellent performance, but there is a potential for improvement in the edges of features, and in the detailed parts of complex scenes.ConclusionThe proposed MFFCGNN network combines the advantages of initial features and deep learning-based models. The demonstrated model can be implemented in 3D city modelling.关键词:point cloud classification;airborne LiDAR;PointNet++;deep learning;multi-feature fusion;geometric convolutional network(GCN)111|212|4更新时间:2024-05-07
3D Point Cloud Segmentation
-
 摘要:ObjectiveImage cropping is a remarkable factor in composing photography's aesthetics, aiming at cropping the region of interest (RoI) with a better aesthetic composition. Image cropping has been widely used in photography, printing, thumbnail generating, and other related fields, especially in image processing/computer vision tasks that need to process a large number of images simultaneously. However, modeling the aesthetic properties of image composition in image cropping is highly challenging due to the subjectivity of image aesthetic assessment (IAA). In the past few years, many researchers tried to maximize the visual important information to crop a target region by feat of salient object detection or eye fixation. The results are often not in line with human preferences due to the lack of consideration of the integrity of image composition. Recently, owing to the powerful representative ability of deep learning (mainly refers to convolutional neural network (CNN)), many data-driven image cropping methods have been proposed and achieved great success. The cropped RoI images have a substantial similarity, making distinguishing the aesthetics between them, which is different from natural IAA, more difficult. Most of existing CNN-based methods only focus on feature corresponding to each cropped RoI and use rough location information, which is not robust enough for complex scenes, spatial deformation, and translation. Few methods consider the fine-grained features and local and global context dependence, which is remarkably beneficial to image composition understanding. Motivated by this, a novel deep attention guided image cropping network with fine-grained feature aggregation, namely, DAIC-Net, is proposed.MethodIn an end-to-end learning manner, the overall model structure of DAIC-Net consists of three modules: semantic feature extraction with channel calibration(ECC), fine-grained feature aggregation (FFA), and global-to-local contextual attention fusion (CAF). Our main idea is to combine the multiscale features and incorporate global and local contexts, which contribute to enhancing informative contextual representation from coarse to fine. First, a backbone is used to extract high-level semantic feature maps of the input in ECC. Three popular architectures, namely, Visual Geometry Group 16-layer network (VGG16), MobileNetV2, and ShuffleNetV2, are tested, and all of the variants achieve competitive performance. The output of the backbone is followed by a squeeze and excitation module, which exploits the attention between channels to calibrate channel features adaptively. Then, an FFA module connects multiscale regional information to generate various fine-grained features. The operation is designed for capturing higher semantic representations and complex composition rules in image composition. Almost no additional running time is observed due to the low-dimensional semantic feature sharing of the FFA module. Moreover, to mimic the human visual attention mechanism, the CAF module is proposed to recalibrate high fine-grained features, generating contextual knowledge for each pixel by selectively scanning from different directions and scales. The input features of the CAF module are re-encoded explicitly by fusing global and local attention features, and it generates top-to-down and left-to-right contextual regional attention for each pixel, obtaining richer context features and facilitating the final decision. Finally, considering the particularity of image cropping scoring regression, a multi-task loss function is defined by incorporating score regression, pairwise comparison, and correlation ranking to train the proposed DAIC-Net. The proposed multi-task loss functions can explicitly rank the aesthetics to model the relations between every two different regions. An NVIDIA GeForce GTX 1060 device is used to train and test the proposed DAIC-Net.ResultThe performance of our method is compared with six state-of-the-art methods on three public datasets, namely, grid anchor based image cropping database (GAICD), image cropping database (ICDB), and flickr cropping database (FCDB). The quantitative evaluation metrics of GAICD contain average Pearson correlation coefficient (
摘要:ObjectiveImage cropping is a remarkable factor in composing photography's aesthetics, aiming at cropping the region of interest (RoI) with a better aesthetic composition. Image cropping has been widely used in photography, printing, thumbnail generating, and other related fields, especially in image processing/computer vision tasks that need to process a large number of images simultaneously. However, modeling the aesthetic properties of image composition in image cropping is highly challenging due to the subjectivity of image aesthetic assessment (IAA). In the past few years, many researchers tried to maximize the visual important information to crop a target region by feat of salient object detection or eye fixation. The results are often not in line with human preferences due to the lack of consideration of the integrity of image composition. Recently, owing to the powerful representative ability of deep learning (mainly refers to convolutional neural network (CNN)), many data-driven image cropping methods have been proposed and achieved great success. The cropped RoI images have a substantial similarity, making distinguishing the aesthetics between them, which is different from natural IAA, more difficult. Most of existing CNN-based methods only focus on feature corresponding to each cropped RoI and use rough location information, which is not robust enough for complex scenes, spatial deformation, and translation. Few methods consider the fine-grained features and local and global context dependence, which is remarkably beneficial to image composition understanding. Motivated by this, a novel deep attention guided image cropping network with fine-grained feature aggregation, namely, DAIC-Net, is proposed.MethodIn an end-to-end learning manner, the overall model structure of DAIC-Net consists of three modules: semantic feature extraction with channel calibration(ECC), fine-grained feature aggregation (FFA), and global-to-local contextual attention fusion (CAF). Our main idea is to combine the multiscale features and incorporate global and local contexts, which contribute to enhancing informative contextual representation from coarse to fine. First, a backbone is used to extract high-level semantic feature maps of the input in ECC. Three popular architectures, namely, Visual Geometry Group 16-layer network (VGG16), MobileNetV2, and ShuffleNetV2, are tested, and all of the variants achieve competitive performance. The output of the backbone is followed by a squeeze and excitation module, which exploits the attention between channels to calibrate channel features adaptively. Then, an FFA module connects multiscale regional information to generate various fine-grained features. The operation is designed for capturing higher semantic representations and complex composition rules in image composition. Almost no additional running time is observed due to the low-dimensional semantic feature sharing of the FFA module. Moreover, to mimic the human visual attention mechanism, the CAF module is proposed to recalibrate high fine-grained features, generating contextual knowledge for each pixel by selectively scanning from different directions and scales. The input features of the CAF module are re-encoded explicitly by fusing global and local attention features, and it generates top-to-down and left-to-right contextual regional attention for each pixel, obtaining richer context features and facilitating the final decision. Finally, considering the particularity of image cropping scoring regression, a multi-task loss function is defined by incorporating score regression, pairwise comparison, and correlation ranking to train the proposed DAIC-Net. The proposed multi-task loss functions can explicitly rank the aesthetics to model the relations between every two different regions. An NVIDIA GeForce GTX 1060 device is used to train and test the proposed DAIC-Net.ResultThe performance of our method is compared with six state-of-the-art methods on three public datasets, namely, grid anchor based image cropping database (GAICD), image cropping database (ICDB), and flickr cropping database (FCDB). The quantitative evaluation metrics of GAICD contain average Pearson correlation coefficient ($\overline {PCC}$ $\overline {SRCC}$ $Acc^K/N$ $wAcc^K/N$ $\overline {SRCC}$ $\overline {PCC}$ 关键词:automatic image cropping;image aesthetics assessment (IAA);region of interest (RoI);spatial pyramid pooling (SPP);attention mechanism;multi-task learning96|468|1更新时间:2024-05-07 -
 摘要:ObjectiveFace texture map generation is a key part of face identification research, in which the face texture can be used to map the pixel information in a two-dimensional (2D) image to the corresponding 3D face model. Currently, there are two initial ways to acquire a face texture. The first one is based on full coverage of head scanning by a laser machine, and the other one is on the face image information. The high accuracy scanning process is assigned for a manipulated circumstance, and captures appearance information well. However, this method is mostly adopted for collecting images for database. The original face texture map based on a 2D image is obtained via splicing the captured image of a targeted head in various of viewing angles simply. Some researchers use raw texture images from five views jointly, which means face texture reconstruction is done under restricted conditions. This method can recover all of the details of the human head according to the pixel information between the complementary face images precisely, but it is difficult to apply in reality, and the different angles images capture illustrate transformations in facial lighting and camera parameters that will cause discontinuous pixel changes in the generated texture. As the pixel information is incomplete for a solo face image, the general method is to perform the texture mapping based on the pixel distribution of the 3D face model in the ultraviolet (UV) space. The overall face-and-head texture can be recovered with pixel averaging and pixel interpolation processes by filling the missing area, but the obtained pixel distribution is quite inconsistent with the original image. A 3D morphable model (3DMM) can restore the facial texture map in a single image, and the 3DMM texture can assign 3D pixel data into the 2D plane with per-pixel alignment based on UV map interpretation. Nevertheless, the texture statistical model is demonstrated to scan under constrained conditions to acquire the low-high frequency and albedo information. This kind of texture model is obtained with some difficulty and it is also challenging for "in-the-wild" image analysis. Meanwhile, such methods cannot recover complicated skin pigment changes and identify layered texture details (such as freckles, pores, moles and surface hair).In general, facial texture reconstruct maps from a solo face image is to be challenged. First, effective pixel information of the profile and the head region will be lost in a solo face image due to the fixed posture, and the UV texture map obtained by conventional ways is incomplete; Next, it is difficult to recover the photorealistic texture from the unrestricted image because the light conditions and camera parameters cannot be confirmed in unconstrained circumstances.MethodA method for generating face panoramic texture maps is proposed based on the generative adversarial networks. The method illustrates the correlative feature between the 2D face image and 3D face mode to obtain the face parameters from the input face image, and an structure is designed that integrates the characteristics of the variational auto-encoder and generative adversarial networks to learn the face-and-head texture features. These face parameter vectors are converted into latent vectors and added as the condition attributes to constrain the generation process of the networks. A panoramic texture map generation model training is conducted on our facial texture dataset. Simultaneously, various attribute discriminators are demonstrated to evaluate and feed the output results back to improve the integrity and authenticity of the result. A face UV texture database is to be built up, some of the samples of which are from the WildUV dataset, which contains nearly 2 000 texture images of individuals with different identities and 5 638 unique facial UV texture maps. In addition, some texture data are obtained via professional 3D scanning testbed. Approximately 400 testers with different identities (250 males, 150 females) offered 2 000 various UV texture maps. Moreover, data augmentation was implemented on perfect texture images. Finally, a total of 10 143 texture samples were used in the demonstration. The samples provide credible data for the generative model.ResultThe results were compared with the state-of-the-art face texture map generation methods. Test images were randomly opted from the CelebA-HQ and labled faces in the wild (LFW) dataset. Based on visual comparison of the generated results, the generated textures are mapped to improve the corresponding 3D models, and it is clear that the results are mapped more completely on the model and reveal more realistic digital examples. Meanwhile, a quantitative evaluation for the completeness of the generated face texture map and the accuracy of the facial region are conducted. The reliability of the restoration of the invisible area in the original image and the capability to retain the facial features were evaluated with peak signal to noise ratio(PSNR) and structural similarity index(SSIM) parameters quantitatively.ConclusionThe results of comparative tests demonstrate that the method for generating a panoramic texture map of solo face can improve incomplete facial texture reconstruction from a solo face image, and facilitate the texture details of the generated texture map. The characteristics of face parameters and generative network models can make the output facial texture maps more complete, especially for the invisible areas of the original image. The pixels are restored clearly and consistently and the texture details are more real.关键词:face image;face texture map;generative adversarial networks(GAN);texture mapping;3D morphable model (3DMM)99|228|3更新时间:2024-05-07
摘要:ObjectiveFace texture map generation is a key part of face identification research, in which the face texture can be used to map the pixel information in a two-dimensional (2D) image to the corresponding 3D face model. Currently, there are two initial ways to acquire a face texture. The first one is based on full coverage of head scanning by a laser machine, and the other one is on the face image information. The high accuracy scanning process is assigned for a manipulated circumstance, and captures appearance information well. However, this method is mostly adopted for collecting images for database. The original face texture map based on a 2D image is obtained via splicing the captured image of a targeted head in various of viewing angles simply. Some researchers use raw texture images from five views jointly, which means face texture reconstruction is done under restricted conditions. This method can recover all of the details of the human head according to the pixel information between the complementary face images precisely, but it is difficult to apply in reality, and the different angles images capture illustrate transformations in facial lighting and camera parameters that will cause discontinuous pixel changes in the generated texture. As the pixel information is incomplete for a solo face image, the general method is to perform the texture mapping based on the pixel distribution of the 3D face model in the ultraviolet (UV) space. The overall face-and-head texture can be recovered with pixel averaging and pixel interpolation processes by filling the missing area, but the obtained pixel distribution is quite inconsistent with the original image. A 3D morphable model (3DMM) can restore the facial texture map in a single image, and the 3DMM texture can assign 3D pixel data into the 2D plane with per-pixel alignment based on UV map interpretation. Nevertheless, the texture statistical model is demonstrated to scan under constrained conditions to acquire the low-high frequency and albedo information. This kind of texture model is obtained with some difficulty and it is also challenging for "in-the-wild" image analysis. Meanwhile, such methods cannot recover complicated skin pigment changes and identify layered texture details (such as freckles, pores, moles and surface hair).In general, facial texture reconstruct maps from a solo face image is to be challenged. First, effective pixel information of the profile and the head region will be lost in a solo face image due to the fixed posture, and the UV texture map obtained by conventional ways is incomplete; Next, it is difficult to recover the photorealistic texture from the unrestricted image because the light conditions and camera parameters cannot be confirmed in unconstrained circumstances.MethodA method for generating face panoramic texture maps is proposed based on the generative adversarial networks. The method illustrates the correlative feature between the 2D face image and 3D face mode to obtain the face parameters from the input face image, and an structure is designed that integrates the characteristics of the variational auto-encoder and generative adversarial networks to learn the face-and-head texture features. These face parameter vectors are converted into latent vectors and added as the condition attributes to constrain the generation process of the networks. A panoramic texture map generation model training is conducted on our facial texture dataset. Simultaneously, various attribute discriminators are demonstrated to evaluate and feed the output results back to improve the integrity and authenticity of the result. A face UV texture database is to be built up, some of the samples of which are from the WildUV dataset, which contains nearly 2 000 texture images of individuals with different identities and 5 638 unique facial UV texture maps. In addition, some texture data are obtained via professional 3D scanning testbed. Approximately 400 testers with different identities (250 males, 150 females) offered 2 000 various UV texture maps. Moreover, data augmentation was implemented on perfect texture images. Finally, a total of 10 143 texture samples were used in the demonstration. The samples provide credible data for the generative model.ResultThe results were compared with the state-of-the-art face texture map generation methods. Test images were randomly opted from the CelebA-HQ and labled faces in the wild (LFW) dataset. Based on visual comparison of the generated results, the generated textures are mapped to improve the corresponding 3D models, and it is clear that the results are mapped more completely on the model and reveal more realistic digital examples. Meanwhile, a quantitative evaluation for the completeness of the generated face texture map and the accuracy of the facial region are conducted. The reliability of the restoration of the invisible area in the original image and the capability to retain the facial features were evaluated with peak signal to noise ratio(PSNR) and structural similarity index(SSIM) parameters quantitatively.ConclusionThe results of comparative tests demonstrate that the method for generating a panoramic texture map of solo face can improve incomplete facial texture reconstruction from a solo face image, and facilitate the texture details of the generated texture map. The characteristics of face parameters and generative network models can make the output facial texture maps more complete, especially for the invisible areas of the original image. The pixels are restored clearly and consistently and the texture details are more real.关键词:face image;face texture map;generative adversarial networks(GAN);texture mapping;3D morphable model (3DMM)99|228|3更新时间:2024-05-07 -
 摘要:ObjectiveIn recent years, with the rapid development of the digital video photography, people pay more attention to the imaging quality of videos with the increasing demand for the immersive experience. Therefore, it is a meaningful challenge to adjust stereoscopic content to the required size to accommodate the different resolutions of 3D display devices. Stereoscopic video retargeting is quite different from image retargeting and 2D video retargeting aims to minimize the shape distortions and optimize disparities with temporal coherence in resizing a stereoscopic video. More constraints of 3D video retargeting should be considered, such as, temporal coherence and depth information. However, the existing 3D video retargeting methods usually consider minimizing the depth distortion but not take the visual experience. Many studies show that the unsuitable disparity causes the visual discomfort and visual fatigue. As a result, someone does not have a great experience in 3D video watching. To solve this problem, our study proposes a method to control the disparity into a comfortable range after 3D video retargeting. Our method considers disparity remapping with temporal coherence and angular parallax. Furthermore, retargeting video may shaky and flickering because of the incoherence between frames. Mesh motion trajectory is utilized to constrain the retargeting video for minimizing the shaking. Considering the above factors, a stereoscopic video retargeting method via mesh warping in optimizing spatiotemporal disparities is proposed in this paper.MethodFirst, the mesh in first frame is constructed, and the stereoscopic saliency based on disparity and edge information is estimated. Then, the mean saliency of each grid for mesh importance is computed. Next, the vertex of the mesh in the original video is traced to obtain the vertex trajectories according to the optic flow method. Temporal coherence between the original and retargeted videos can be established by the motion trajectories. Shape distortion is of great importance in affecting the quality of video retargeting. Generally, a high geometric similarity means to a low shape distortion. Therefore, according to significance information, high similarity between the original and deformed grids in those high-significance regions and low similarity in the low-significance regions are maintained. Thus, the shape-preserving energy term is established by using the similarity transformation to minimize the shape distortion. As vergence-accommodation conflict in 3D display may cause fatigue and discomfort, remapping the disparity map into anthropogenic disparity range to reduce the visual fatigue is substantial. After remapping the disparity map, the disparity change with temporal coherence needs to be controlled. In the end, the total energy term is obtained by adding all the energy terms, the optimal grids are obtained by using the linear least square method, and the original video is mapped to obtain the retargeted video.ResultCompared with the existing seam carving based stereoscopic video retargeting method, the proposed method achieves a better performance in terms of shape preservation, temporal coherence preservation and disparity remapping energy terms. The objective performance evaluated using the existing objective assessment methods are also higher than the comparison methods.ConclusionA spatiotemporal disparity optimization method, which remaps the video disparity to a comfortable range with temporal coherence, is proposed in this paper. A retargeted video that not only satisfies the viewing comfort but also causes less disparity saltation in time domain can be obtained using this method. A stereoscopic video retargeting method based on grid deformation, which according to the saliency information of the video and a grid deformation equation is established to resize the stereoscopic video into our desired resolution, is proposed in this paper. Results show that the proposed method has an excellent performance in shape preserving, time coherence preserving, and disparity optimization. In the next work, combining the cropping method with the grid deformation method to perform stereoscopic video retargeting and reduce the distortion of the salient target further will be considered. The method proposed in this paper can be used in 3D video retargeting with great stereo visual comfort.关键词:stereoscopic video retargeting;mesh warping;spatio-temporal disparity optimization;temporal coherence;visual experience;stereoscopic saliency50|200|0更新时间:2024-05-07
摘要:ObjectiveIn recent years, with the rapid development of the digital video photography, people pay more attention to the imaging quality of videos with the increasing demand for the immersive experience. Therefore, it is a meaningful challenge to adjust stereoscopic content to the required size to accommodate the different resolutions of 3D display devices. Stereoscopic video retargeting is quite different from image retargeting and 2D video retargeting aims to minimize the shape distortions and optimize disparities with temporal coherence in resizing a stereoscopic video. More constraints of 3D video retargeting should be considered, such as, temporal coherence and depth information. However, the existing 3D video retargeting methods usually consider minimizing the depth distortion but not take the visual experience. Many studies show that the unsuitable disparity causes the visual discomfort and visual fatigue. As a result, someone does not have a great experience in 3D video watching. To solve this problem, our study proposes a method to control the disparity into a comfortable range after 3D video retargeting. Our method considers disparity remapping with temporal coherence and angular parallax. Furthermore, retargeting video may shaky and flickering because of the incoherence between frames. Mesh motion trajectory is utilized to constrain the retargeting video for minimizing the shaking. Considering the above factors, a stereoscopic video retargeting method via mesh warping in optimizing spatiotemporal disparities is proposed in this paper.MethodFirst, the mesh in first frame is constructed, and the stereoscopic saliency based on disparity and edge information is estimated. Then, the mean saliency of each grid for mesh importance is computed. Next, the vertex of the mesh in the original video is traced to obtain the vertex trajectories according to the optic flow method. Temporal coherence between the original and retargeted videos can be established by the motion trajectories. Shape distortion is of great importance in affecting the quality of video retargeting. Generally, a high geometric similarity means to a low shape distortion. Therefore, according to significance information, high similarity between the original and deformed grids in those high-significance regions and low similarity in the low-significance regions are maintained. Thus, the shape-preserving energy term is established by using the similarity transformation to minimize the shape distortion. As vergence-accommodation conflict in 3D display may cause fatigue and discomfort, remapping the disparity map into anthropogenic disparity range to reduce the visual fatigue is substantial. After remapping the disparity map, the disparity change with temporal coherence needs to be controlled. In the end, the total energy term is obtained by adding all the energy terms, the optimal grids are obtained by using the linear least square method, and the original video is mapped to obtain the retargeted video.ResultCompared with the existing seam carving based stereoscopic video retargeting method, the proposed method achieves a better performance in terms of shape preservation, temporal coherence preservation and disparity remapping energy terms. The objective performance evaluated using the existing objective assessment methods are also higher than the comparison methods.ConclusionA spatiotemporal disparity optimization method, which remaps the video disparity to a comfortable range with temporal coherence, is proposed in this paper. A retargeted video that not only satisfies the viewing comfort but also causes less disparity saltation in time domain can be obtained using this method. A stereoscopic video retargeting method based on grid deformation, which according to the saliency information of the video and a grid deformation equation is established to resize the stereoscopic video into our desired resolution, is proposed in this paper. Results show that the proposed method has an excellent performance in shape preserving, time coherence preserving, and disparity optimization. In the next work, combining the cropping method with the grid deformation method to perform stereoscopic video retargeting and reduce the distortion of the salient target further will be considered. The method proposed in this paper can be used in 3D video retargeting with great stereo visual comfort.关键词:stereoscopic video retargeting;mesh warping;spatio-temporal disparity optimization;temporal coherence;visual experience;stereoscopic saliency50|200|0更新时间:2024-05-07 -
 摘要:ObjectiveThe feature representation of shape contour plays an important role in shape recognition and retrieval tasks, which is an important issue in the field of pattern recognition and image processing. With the increasing application scenarios of big data, deep learning methods are widely used to deal with masses of images for its effectiveness of learning. To use deep learning methods, for example, the popular convolutional neural network for image classification, an image representation of shape features is necessary. Thus, representing the shape features of object contour as an image, rather than a series of feature values, is desired. Moreover, dealing with various disturbance factors and noise, including viewpoint variation, scaling, partial occlusion, articulation, projective transformation, and noise, is unavoidable because different kinds of cameras and sensors are widely used for image and video capturing. These disturbances and noise decrease the quality of the images and videos, and consequently, the accuracy of the following object recognition and retrieval tasks. To solve the above problems, a visualized all-scale shape representation and recognition method is proposed in this work. In our method, the representation of shape features can be learned by the widely used deep learning models, which is effective for recognition and retrieval tasks in big data application scenarios. The proposed method is also robust to various disturbances and noise.MethodFirst, three kinds of invariant shape features, namely, area feature, arc length feature, and central distance feature, are extracted from the shape contour. The three kinds of shape features are invariant features in different aspects of shape at different dimensions, which are normalized to the size of the shape in the image. The features at all scales in the scale space are extracted to obtain sufficient shape information and fully represent the shape because these three shape features can be extracted at different scales with respect to the shape. After that, all the features in the scale space are compactly represented by a color image. In this image representation, the R, G, and B channels are used to represent the three kinds of invariant shape features. The value of the feature is represented as the value of color. In each channel, the
摘要:ObjectiveThe feature representation of shape contour plays an important role in shape recognition and retrieval tasks, which is an important issue in the field of pattern recognition and image processing. With the increasing application scenarios of big data, deep learning methods are widely used to deal with masses of images for its effectiveness of learning. To use deep learning methods, for example, the popular convolutional neural network for image classification, an image representation of shape features is necessary. Thus, representing the shape features of object contour as an image, rather than a series of feature values, is desired. Moreover, dealing with various disturbance factors and noise, including viewpoint variation, scaling, partial occlusion, articulation, projective transformation, and noise, is unavoidable because different kinds of cameras and sensors are widely used for image and video capturing. These disturbances and noise decrease the quality of the images and videos, and consequently, the accuracy of the following object recognition and retrieval tasks. To solve the above problems, a visualized all-scale shape representation and recognition method is proposed in this work. In our method, the representation of shape features can be learned by the widely used deep learning models, which is effective for recognition and retrieval tasks in big data application scenarios. The proposed method is also robust to various disturbances and noise.MethodFirst, three kinds of invariant shape features, namely, area feature, arc length feature, and central distance feature, are extracted from the shape contour. The three kinds of shape features are invariant features in different aspects of shape at different dimensions, which are normalized to the size of the shape in the image. The features at all scales in the scale space are extracted to obtain sufficient shape information and fully represent the shape because these three shape features can be extracted at different scales with respect to the shape. After that, all the features in the scale space are compactly represented by a color image. In this image representation, the R, G, and B channels are used to represent the three kinds of invariant shape features. The value of the feature is represented as the value of color. In each channel, the$x$ $y$ $x$ $y$ 关键词:shape representation;scale space;invariance;shape recognition;object recognition;object retrieval56|167|2更新时间:2024-05-07 -
 摘要:Objective6D pose estimation is a core problem in 3D object detection and reconstruction. Traditional pose estimation methods usually cannot handle textureless objects. Many post processing procedures have been employed to solve this issue, but they lead to a decline in pose estimation speed. To achieve a fast, single-shot solution, a 6D object pose estimation algorithm based on mask location and heat maps is proposed in this paper. In the prediction of the method, masks are first employed to locate objects, which can reduce the error caused by occlusion. To accelerate mask generation, you only look once v3 (YOLOv3) network is used as the backbone. The algorithm presented in this paper does not require any post processing. Our neural network directly predicts the location of key points at a fast speed.MethodOur algorithm mainly consists of the following steps. First, a segmentation network structure in object detection is used to generate masks. To speed up this process, YOLOv3 is used as the network backbone. Based on the original detection, a branch structure is added by the segmentation network, and deconvolution is used to extract features under different resolutions. Moreover, 1×1, 3×3, and 1×1 kernel size convolution layers are added to each deconvolution. Finally, these features are fused and used for generating object target and mask map by the mean square error as the loss function in the regression loss. Second, an hourglass network is used to predict key points for each object. A form of encoding and decoding is adopted by the hourglass network. In the encoding stage, down sampling and the residual module are used to reduce the scale and extract features, respectively. Up sampling is used to restore the scale during the decoding. Each level of scale passes through the residual module, and the residual module extracts features without changing the data size. To prevent the feature map from losing local information when the scale is enlarged, a multiscale feature constraint is proposed. Two branches are split to retain the original scale information before each down sampling, and a skip layer containing only one convolution kernel of 1 is used. Stitching is performed at the same scale after one up sampling. Four different resolutions used in convolution are spliced into the up sampling, and the initial feature map is combined with the up sampled feature map. The hourglass network is not directly up sampled to the same resolution size as the network input to obtain the heat map by performing regression. Instead, the hourglass network is used as relay supervision, which restricts the final heat map result from the residual network. Finally, the 6D pose of the object is recovered through the perspective-
摘要:Objective6D pose estimation is a core problem in 3D object detection and reconstruction. Traditional pose estimation methods usually cannot handle textureless objects. Many post processing procedures have been employed to solve this issue, but they lead to a decline in pose estimation speed. To achieve a fast, single-shot solution, a 6D object pose estimation algorithm based on mask location and heat maps is proposed in this paper. In the prediction of the method, masks are first employed to locate objects, which can reduce the error caused by occlusion. To accelerate mask generation, you only look once v3 (YOLOv3) network is used as the backbone. The algorithm presented in this paper does not require any post processing. Our neural network directly predicts the location of key points at a fast speed.MethodOur algorithm mainly consists of the following steps. First, a segmentation network structure in object detection is used to generate masks. To speed up this process, YOLOv3 is used as the network backbone. Based on the original detection, a branch structure is added by the segmentation network, and deconvolution is used to extract features under different resolutions. Moreover, 1×1, 3×3, and 1×1 kernel size convolution layers are added to each deconvolution. Finally, these features are fused and used for generating object target and mask map by the mean square error as the loss function in the regression loss. Second, an hourglass network is used to predict key points for each object. A form of encoding and decoding is adopted by the hourglass network. In the encoding stage, down sampling and the residual module are used to reduce the scale and extract features, respectively. Up sampling is used to restore the scale during the decoding. Each level of scale passes through the residual module, and the residual module extracts features without changing the data size. To prevent the feature map from losing local information when the scale is enlarged, a multiscale feature constraint is proposed. Two branches are split to retain the original scale information before each down sampling, and a skip layer containing only one convolution kernel of 1 is used. Stitching is performed at the same scale after one up sampling. Four different resolutions used in convolution are spliced into the up sampling, and the initial feature map is combined with the up sampled feature map. The hourglass network is not directly up sampled to the same resolution size as the network input to obtain the heat map by performing regression. Instead, the hourglass network is used as relay supervision, which restricts the final heat map result from the residual network. Finally, the 6D pose of the object is recovered through the perspective-$n$ 关键词:pose estimation;object segmentation;key point location;hourglass network;feature fusion136|197|3更新时间:2024-05-07
Image & Video Analysis
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0