
最新刊期
卷 27 , 期 12 , 2022
-
 摘要:Dual-pixel (DP) sensor is a kind of Canon-originated hardware technique for autofocusing in 2013. Conventional autofocus methods are divided into two major categories: phase-based and contrast-based methods. However, phase-based autofocusing has higher electronic complexity, and contrast-based autofocusing runs slower in practice. Therefore, current hybrid detection autofocus technique is more concerned, which yields some pixels to imaging and focusing. However, the resolution loss issue cannot be avoided. Hybrid DP-based autofocusing methods enable each pixel to be integrated for both imaging and focusing, which improves the cost-efficiency focusing accuracy. Therefore, it has been widely used in mobile phone cameras and digital single lens reflex (DSLR) cameras. In recent years, DP sensors have been offered by sensor manufacturers and occupied the vast majority of camera sensor market. To guarantee the performance of focusing and imaging, each pixel in a DP-based sensor is equipped with two photodiodes. A DP-based sensor can assign each pixel to two halves and two images can be obtained simultaneously. These two images (DP image pair) could be viewed as a perfectly rectified stereo image pair in relation to a tiny baseline and the same exposure time, or as a two viewing angled light field camera. Unlike stereo image pairs, DP image pairs only have disparity at the out-of-focus regions, while the in-focus regions have no disparity. Defocus disparity, which only exists in the out-of-focus regions, is directly connected with the depth of the scene being captured and is generated by the point spread function. The point spread functions of the left and right views of DP are approximately symmetric, and the point spread functions based focus are relatively symmetric before and after as well. This relationship and the special point spread function can provide extra information for various computer vision tasks. Therefore, the obtained DP image pair can also be used for depth estimation, defocus deblurring and reflection removal beyond automatic focusing applications of the DP sensors. In particular, the relationship between depth and blur size in DP sensor is effective to deal with the depth from defocus task and the defocus deblur task. We critically review the autofocus, imaging principle and current situation of the DP-based sensor. 1) To provide a basic understanding of the dual-pixel sensors, we introduce the dual-pixel imaging model and imaging principle. 2) To specify the breakthrough of them, we carry out comparative analysis related to dual-pixel research in recent years. 3) To develop a reference for researchers further, we trace the current open-source dual-pixel datasets and simulators to facilitate data acquisition. Specifically, we firstly describe dual-pixel from the point of view of enabling automatic focus, where three conventional autofocus methods: 1) phase detection autofocus (PDAF), 2) contrast detection autofocus (CDAF), and 3) hybrid autofocus. The principle and priority of dual-pixel autofocus are critically reviewed in Section I. In Section II, we review the relevant optical concepts and camera imaging model. The imaging principle and geometric features of dual-pixel are introduced on four aspects: 1) dual-pixel geometry, 2) dual-pixel affine ambiguity, 3) dual-pixel point spread function, and 4) the difference between dual-pixel image pair and stereo image pair. It shows that DP image pairs can aid downstream tasks and how to mine effective hidden information from the DP image pairs. DP-based defocus disparity is linked to the contexted depth in terms of the affine ambiguity of dual-pixel, which can be used as a cue of depth estimation, defocus deblur and other related tasks. In Section Ⅲ, we summarize the applications of the DP image pairs in the context of three computer vision tasks: 1) depth estimation, 2) reflection removal, and 3) defocus deblur. As appropriate datasets are fundamental to designing deep learning based architecture of neural networks better in contrast to conventional methods, we briefly introduce the community-derived DP datasets and summarize the algorithm principles of the current DP simulators. Finally, the future challenges and opportunities of the DP sensor have been discussed further in Section V.关键词:dual-pixel(DP);autofocus;deep learning;camera imaging;reflection removal;depth estimation289|2308|0更新时间:2024-05-07
摘要:Dual-pixel (DP) sensor is a kind of Canon-originated hardware technique for autofocusing in 2013. Conventional autofocus methods are divided into two major categories: phase-based and contrast-based methods. However, phase-based autofocusing has higher electronic complexity, and contrast-based autofocusing runs slower in practice. Therefore, current hybrid detection autofocus technique is more concerned, which yields some pixels to imaging and focusing. However, the resolution loss issue cannot be avoided. Hybrid DP-based autofocusing methods enable each pixel to be integrated for both imaging and focusing, which improves the cost-efficiency focusing accuracy. Therefore, it has been widely used in mobile phone cameras and digital single lens reflex (DSLR) cameras. In recent years, DP sensors have been offered by sensor manufacturers and occupied the vast majority of camera sensor market. To guarantee the performance of focusing and imaging, each pixel in a DP-based sensor is equipped with two photodiodes. A DP-based sensor can assign each pixel to two halves and two images can be obtained simultaneously. These two images (DP image pair) could be viewed as a perfectly rectified stereo image pair in relation to a tiny baseline and the same exposure time, or as a two viewing angled light field camera. Unlike stereo image pairs, DP image pairs only have disparity at the out-of-focus regions, while the in-focus regions have no disparity. Defocus disparity, which only exists in the out-of-focus regions, is directly connected with the depth of the scene being captured and is generated by the point spread function. The point spread functions of the left and right views of DP are approximately symmetric, and the point spread functions based focus are relatively symmetric before and after as well. This relationship and the special point spread function can provide extra information for various computer vision tasks. Therefore, the obtained DP image pair can also be used for depth estimation, defocus deblurring and reflection removal beyond automatic focusing applications of the DP sensors. In particular, the relationship between depth and blur size in DP sensor is effective to deal with the depth from defocus task and the defocus deblur task. We critically review the autofocus, imaging principle and current situation of the DP-based sensor. 1) To provide a basic understanding of the dual-pixel sensors, we introduce the dual-pixel imaging model and imaging principle. 2) To specify the breakthrough of them, we carry out comparative analysis related to dual-pixel research in recent years. 3) To develop a reference for researchers further, we trace the current open-source dual-pixel datasets and simulators to facilitate data acquisition. Specifically, we firstly describe dual-pixel from the point of view of enabling automatic focus, where three conventional autofocus methods: 1) phase detection autofocus (PDAF), 2) contrast detection autofocus (CDAF), and 3) hybrid autofocus. The principle and priority of dual-pixel autofocus are critically reviewed in Section I. In Section II, we review the relevant optical concepts and camera imaging model. The imaging principle and geometric features of dual-pixel are introduced on four aspects: 1) dual-pixel geometry, 2) dual-pixel affine ambiguity, 3) dual-pixel point spread function, and 4) the difference between dual-pixel image pair and stereo image pair. It shows that DP image pairs can aid downstream tasks and how to mine effective hidden information from the DP image pairs. DP-based defocus disparity is linked to the contexted depth in terms of the affine ambiguity of dual-pixel, which can be used as a cue of depth estimation, defocus deblur and other related tasks. In Section Ⅲ, we summarize the applications of the DP image pairs in the context of three computer vision tasks: 1) depth estimation, 2) reflection removal, and 3) defocus deblur. As appropriate datasets are fundamental to designing deep learning based architecture of neural networks better in contrast to conventional methods, we briefly introduce the community-derived DP datasets and summarize the algorithm principles of the current DP simulators. Finally, the future challenges and opportunities of the DP sensor have been discussed further in Section V.关键词:dual-pixel(DP);autofocus;deep learning;camera imaging;reflection removal;depth estimation289|2308|0更新时间:2024-05-07 -
 摘要:Deep learning technology is capable of image-style transfer tasks recently. The Chinese characters font transfer is focused on content preservation while the font attribute is converted. Thanks to the emerging deep learning, the workload of font design for Chinese characters can be alleviated effectively and the restrictions of human intervention are avoided as well. However, the quality of generated images is still a challenging issue to be resolved. Our review is aimed at the analysis of the most representative image generation and font transfer methods for Chinese characters. The literature review of contemporary font transfer methods for Chinese characters is systematically summarized and divided into three categories: 1) convolutional neural network based (CNN-based), 2) auto-encoder based (AE-based), and 3) generative adversarial networks based (GAN-based). To avoid information missing in the process of data reconstruction, a convolutional neural network extracted features of images without changing the dimensions of data. Auto-encoder processed the data through a deep neural network to learn the distribution of real samples and generate realistic fake samples. Generative adversarial networks became popular in Chinese characters font transfer after being proposed by Goodfellow. Its structure consists of a generator and a discriminator generally. The core idea of generative adversarial networks came from the Nash equilibrium of game theory, which is reflected in the process of continuous optimization between the generator and discriminator. Its generator learned the distribution of real data, generated fake images, and induced discriminators to make wrong decisions. The discriminator tried to determine whether the input data is real or fake. Through this game between generator and discriminator, the latter could not distinguish the real image from the fake in the end. According to the way of learning font style features of Chinese characters, we divided these methods based on GAN into three categories: 1) self-learning font style features, 2) external font style features, and 3) extractive font style features. We introduced twenty-two font transfer methods for Chinese characters and summarized the performance of these methods in terms of dataset requirements, font category supports, and evaluations for generated images. The key factors of these font transfer methods are introduced, compared, and analyzed, including refining Chinese characters features, relying on a pre-trained model for effective feature extraction, and supporting de-stylization. According to the uniformed table of radicals for Chinese characters, we built a data set consisting of 6 683 simplified and traditional characters in five fonts. To accomplish the transformation from source font (simfs.ttf) to target font (printed font and hand-written font), comparative experiments are carried out on the same data set. The comparative analysis of four archetypal font transfer methods for Chinese characters (Rewrite2, zi2zi, TET-GAN, and Unet-GAN) are implemented. Our quantitative evaluation metrics are composed of root mean square error (RMSE) and Pixel-level accuracy (pix_acc), and several generated results of each method for comparison were shown. The strokes of characters generated by Unet-GAN are the most complete and clear according to the subjective and objective evaluation metrics of generated images, which is competent for the transfer and generation of printing and handwriting font. At the same time, the methods named Rewrite2, zi2zi, and TET-GAN are more suitable for the font transfer task of printing characters, and their ability to generate strokes of Chinese characters needs to be improved. We summarized some challenging issues like blurred strokes of Chinese characters, immature methods of multi-domain transformation, and large-scale training data set applications. The future research direction can be further extended on the aspects of 1) integrating the stylization and de-stylization of Chinese characters, 2) reducing the size of the data set, and 3) extracting features of Chinese characters more effectively. Furthermore, its potential can be associated with information hiding technology for document watermarking and embedding secret messages.关键词:Chinese characters font transfer;image generation;convolutional neural network (CNN);auto-encoder(AE);generate adversarial network (GAN)296|853|2更新时间:2024-05-07
摘要:Deep learning technology is capable of image-style transfer tasks recently. The Chinese characters font transfer is focused on content preservation while the font attribute is converted. Thanks to the emerging deep learning, the workload of font design for Chinese characters can be alleviated effectively and the restrictions of human intervention are avoided as well. However, the quality of generated images is still a challenging issue to be resolved. Our review is aimed at the analysis of the most representative image generation and font transfer methods for Chinese characters. The literature review of contemporary font transfer methods for Chinese characters is systematically summarized and divided into three categories: 1) convolutional neural network based (CNN-based), 2) auto-encoder based (AE-based), and 3) generative adversarial networks based (GAN-based). To avoid information missing in the process of data reconstruction, a convolutional neural network extracted features of images without changing the dimensions of data. Auto-encoder processed the data through a deep neural network to learn the distribution of real samples and generate realistic fake samples. Generative adversarial networks became popular in Chinese characters font transfer after being proposed by Goodfellow. Its structure consists of a generator and a discriminator generally. The core idea of generative adversarial networks came from the Nash equilibrium of game theory, which is reflected in the process of continuous optimization between the generator and discriminator. Its generator learned the distribution of real data, generated fake images, and induced discriminators to make wrong decisions. The discriminator tried to determine whether the input data is real or fake. Through this game between generator and discriminator, the latter could not distinguish the real image from the fake in the end. According to the way of learning font style features of Chinese characters, we divided these methods based on GAN into three categories: 1) self-learning font style features, 2) external font style features, and 3) extractive font style features. We introduced twenty-two font transfer methods for Chinese characters and summarized the performance of these methods in terms of dataset requirements, font category supports, and evaluations for generated images. The key factors of these font transfer methods are introduced, compared, and analyzed, including refining Chinese characters features, relying on a pre-trained model for effective feature extraction, and supporting de-stylization. According to the uniformed table of radicals for Chinese characters, we built a data set consisting of 6 683 simplified and traditional characters in five fonts. To accomplish the transformation from source font (simfs.ttf) to target font (printed font and hand-written font), comparative experiments are carried out on the same data set. The comparative analysis of four archetypal font transfer methods for Chinese characters (Rewrite2, zi2zi, TET-GAN, and Unet-GAN) are implemented. Our quantitative evaluation metrics are composed of root mean square error (RMSE) and Pixel-level accuracy (pix_acc), and several generated results of each method for comparison were shown. The strokes of characters generated by Unet-GAN are the most complete and clear according to the subjective and objective evaluation metrics of generated images, which is competent for the transfer and generation of printing and handwriting font. At the same time, the methods named Rewrite2, zi2zi, and TET-GAN are more suitable for the font transfer task of printing characters, and their ability to generate strokes of Chinese characters needs to be improved. We summarized some challenging issues like blurred strokes of Chinese characters, immature methods of multi-domain transformation, and large-scale training data set applications. The future research direction can be further extended on the aspects of 1) integrating the stylization and de-stylization of Chinese characters, 2) reducing the size of the data set, and 3) extracting features of Chinese characters more effectively. Furthermore, its potential can be associated with information hiding technology for document watermarking and embedding secret messages.关键词:Chinese characters font transfer;image generation;convolutional neural network (CNN);auto-encoder(AE);generate adversarial network (GAN)296|853|2更新时间:2024-05-07 -
 摘要:Atrial fibrillation (AF) is one of the most arrhythmia symptoms nowadays. The incidence rate of AF increases with elder growth and it can reach 10% population over 75 years old. The AF duration can be divided into paroxysmal, persistent and permanent, and it is induced to the morbidity and mortality of cardiovascular diseases severely. It affects more than 30 million people worldwide like reducing the quality of life and linking high risk of cerebral infarction and death. Although the risk can be reduced with appropriate treatment, AF is often latent and difficult to diagnose and intervene quickly. Recent AF-diagnostic methods have composed of cardiac palpation, optical plethysmography, blood pressure monitoring and vibration, electrocardiogram (ECG) and image-based methods. Most of atrial fibrillation has paroxysmal atrial fibrillation. The four diagnostic methods mentioned above may not capture the onset of atrial fibrillation. It is challenged for long-term diagnosis cycles, high costs, low accuracy and vulnerability. Medical imaging promotes contemporary modern medicine, computed tomography (CT) and magnetic resonance imaging (MRI) via transparent image of the cardiac anatomy. The MRI can be as one of the key medical imaging techniques, which of being unaffected by ionizing radiation, having high soft tissue contrast and high spatial resolution. Current images have limited of low signal-to-noise ratio (SNR) and low resolution to a certain extent. AF is regarded as a heart disease of atrial origin. In order to quantify the morphological and pathological changes of the left atrium (LA), it is necessary to segment the LA derived from the medical image. The medical imaging analysis of AF requires accurate LA-related segmentation and quantitative evaluation of the function. The segmentation and functional evaluation of the LA is crucial to improving our understanding and diagnosis of AF. However, segmentation of the LA on medical images is still being challenged. 1) The LA can occupy a small proportion of the image only compared with the background of the image, making it difficult to locate and identify boundary details. 2) The strength of the LA is quite similar to its surrounding chambers, the myocardial wall is thinner, the quality of medical images is not high, the resolution is limited, and the boundaries often appear blurred or missing in the LA surrounding the pulmonary vein (PV). 3) The shapes and sizes of the LA vary significantly thematically as the number and topology of the PV. Our critical review is focused on the integration of current segmentation algorithms and traditional segmentation methods, deep learning based segmentation, and traditional & deep learning-integrated segmentation. Traditional segmentation methods are mainly composed of the active contour model (ACM), atlas segmentation and threshold issue. ACM requires an accurate initial contour. Atlas segmentation requires complete multiple atlas sets and atlas registration, but the manual annotation of atlas sets is a challenging task due to a large number of atlas sets, which makes manual annotation difficult to be completed. In addition, the result of the annotation is vulnerable to be influenced by different taggers and atlas registration is very time-consuming. The threshold method requires the pre-determination of an appropriate threshold, which may be subjective and could ultimately limit the applicability and reproducibility. Although the traditional segmentation methods have achieved certain results, the accuracy of the segmentation is still insufficient. In recent years, deep learning technique has shown its potentials in medical image analysis, and they have qualified in different imaging modes and different clinical applications. It has improved imaging efficiency and quality, image analysis and interpretation and clinical evaluation. With the development of convolutional neural network (CNN), many variant CNN models have emerged, which have made great impacts on the improvement of segmentation algorithms. The full convolutional network (FCN) is a variant of the CNN. Based on the CNN, the FCN uses the 1×1 convolutional layer to update the full connection layer, and changes the height and width of the feature maps of the intermediate layers back to the size of the input image in terms of transposing the convolutional layer, the prediction results and the input image have one-to-one correspondence in the spatial dimension, the FCN can accept input images of any size, and generate segmentation images of the same size. The FCN mainly uses three techniques: 1) convolution, 2) upsampling and 3) skip connection. The FCN uses the skip connection structure to upsample feature maps of the last layer of the network model, and fused with feature maps of the shallow layer, combining the high-level semantic information with the low-level image information. The U-Net is a variant model of the FCN. The U-Net adopts the encoder-decoder architecture to form a U-shaped structure with four downsampling operations followed by four up sampling steps. The U-Net captures global features on the contraction path and achieves precise positioning on the extension path, thus the segmentation problem-solving of complex neuron structures has achieved excellent performance adequately. On this basis, variant models of the 3D U-Net and the Ⅴ-Net are introduced. The training of neural network models requires a large amount of labeled data as there are millions of parameters in the network that need to be optimized. Accurate segmentation of the LA is of great clinical significance for the diagnosis and analysis of AF. However, manual segmentation of the LA is time-consuming and prone to human-related errors. Therefore, the research of automatic segmentation algorithms is essential in assisting diagnosis and clinical decision-making. We summarize the pros and cons of varied segmentation strategies, existing public data sets and clinical applications of atrial fibrillation analysis and its future trends.关键词:atrial fibrillation(AF);medical image;deep learning(DL);left atrium segmentation;left atrium function146|407|1更新时间:2024-05-07
摘要:Atrial fibrillation (AF) is one of the most arrhythmia symptoms nowadays. The incidence rate of AF increases with elder growth and it can reach 10% population over 75 years old. The AF duration can be divided into paroxysmal, persistent and permanent, and it is induced to the morbidity and mortality of cardiovascular diseases severely. It affects more than 30 million people worldwide like reducing the quality of life and linking high risk of cerebral infarction and death. Although the risk can be reduced with appropriate treatment, AF is often latent and difficult to diagnose and intervene quickly. Recent AF-diagnostic methods have composed of cardiac palpation, optical plethysmography, blood pressure monitoring and vibration, electrocardiogram (ECG) and image-based methods. Most of atrial fibrillation has paroxysmal atrial fibrillation. The four diagnostic methods mentioned above may not capture the onset of atrial fibrillation. It is challenged for long-term diagnosis cycles, high costs, low accuracy and vulnerability. Medical imaging promotes contemporary modern medicine, computed tomography (CT) and magnetic resonance imaging (MRI) via transparent image of the cardiac anatomy. The MRI can be as one of the key medical imaging techniques, which of being unaffected by ionizing radiation, having high soft tissue contrast and high spatial resolution. Current images have limited of low signal-to-noise ratio (SNR) and low resolution to a certain extent. AF is regarded as a heart disease of atrial origin. In order to quantify the morphological and pathological changes of the left atrium (LA), it is necessary to segment the LA derived from the medical image. The medical imaging analysis of AF requires accurate LA-related segmentation and quantitative evaluation of the function. The segmentation and functional evaluation of the LA is crucial to improving our understanding and diagnosis of AF. However, segmentation of the LA on medical images is still being challenged. 1) The LA can occupy a small proportion of the image only compared with the background of the image, making it difficult to locate and identify boundary details. 2) The strength of the LA is quite similar to its surrounding chambers, the myocardial wall is thinner, the quality of medical images is not high, the resolution is limited, and the boundaries often appear blurred or missing in the LA surrounding the pulmonary vein (PV). 3) The shapes and sizes of the LA vary significantly thematically as the number and topology of the PV. Our critical review is focused on the integration of current segmentation algorithms and traditional segmentation methods, deep learning based segmentation, and traditional & deep learning-integrated segmentation. Traditional segmentation methods are mainly composed of the active contour model (ACM), atlas segmentation and threshold issue. ACM requires an accurate initial contour. Atlas segmentation requires complete multiple atlas sets and atlas registration, but the manual annotation of atlas sets is a challenging task due to a large number of atlas sets, which makes manual annotation difficult to be completed. In addition, the result of the annotation is vulnerable to be influenced by different taggers and atlas registration is very time-consuming. The threshold method requires the pre-determination of an appropriate threshold, which may be subjective and could ultimately limit the applicability and reproducibility. Although the traditional segmentation methods have achieved certain results, the accuracy of the segmentation is still insufficient. In recent years, deep learning technique has shown its potentials in medical image analysis, and they have qualified in different imaging modes and different clinical applications. It has improved imaging efficiency and quality, image analysis and interpretation and clinical evaluation. With the development of convolutional neural network (CNN), many variant CNN models have emerged, which have made great impacts on the improvement of segmentation algorithms. The full convolutional network (FCN) is a variant of the CNN. Based on the CNN, the FCN uses the 1×1 convolutional layer to update the full connection layer, and changes the height and width of the feature maps of the intermediate layers back to the size of the input image in terms of transposing the convolutional layer, the prediction results and the input image have one-to-one correspondence in the spatial dimension, the FCN can accept input images of any size, and generate segmentation images of the same size. The FCN mainly uses three techniques: 1) convolution, 2) upsampling and 3) skip connection. The FCN uses the skip connection structure to upsample feature maps of the last layer of the network model, and fused with feature maps of the shallow layer, combining the high-level semantic information with the low-level image information. The U-Net is a variant model of the FCN. The U-Net adopts the encoder-decoder architecture to form a U-shaped structure with four downsampling operations followed by four up sampling steps. The U-Net captures global features on the contraction path and achieves precise positioning on the extension path, thus the segmentation problem-solving of complex neuron structures has achieved excellent performance adequately. On this basis, variant models of the 3D U-Net and the Ⅴ-Net are introduced. The training of neural network models requires a large amount of labeled data as there are millions of parameters in the network that need to be optimized. Accurate segmentation of the LA is of great clinical significance for the diagnosis and analysis of AF. However, manual segmentation of the LA is time-consuming and prone to human-related errors. Therefore, the research of automatic segmentation algorithms is essential in assisting diagnosis and clinical decision-making. We summarize the pros and cons of varied segmentation strategies, existing public data sets and clinical applications of atrial fibrillation analysis and its future trends.关键词:atrial fibrillation(AF);medical image;deep learning(DL);left atrium segmentation;left atrium function146|407|1更新时间:2024-05-07
Review

-
 摘要:ObjectiveImages are often distorted by noise during image acquisition, transmission and storage process. The generated noise can degrade image quality and affect image processing, such as edge detection, image segmentation, image recognition and image classification. Image denoising technique plays a key role in image pre-processing for image details preservation. Current Gaussian noise removal denoising techniques is often based on variational model like the total variation (TV) method. It can realize image smoothing through minimizing the corresponding energy function. However, TV-based denoising methods have their staircase effects and detail loss due to local gradient information only. Many researchers integrate the non-local concept into the total variation model after the non-local means was proposed. The existing non-local TV-based methods take advantages of the non-local similarity to denoise the image while keeping the image structure information. Unfortunately, many existing TV-based color image denoising methods fail to fully capture both local and non-local correlations among different image patches, and ignore the fact that the realistic noise varies in different image patches and different color channels. These always lead to over-smoothing and under-smoothing in the denoising result. Our newly TV-based color image denoising method, named adaptive non-local 3D total variation (ANL3DTV), is developed to deal with that.Method1) Decompose the noisy color image into K overlapping color image patches, search for the m most similar neighboring image patches to each center image patch and then group the m image patches together. 2) Vectorize every color image patch in each image patch group and stack them into a 2D noisy matrix. 3) Obtain the corresponding 2D denoised matrices via ANL3DTV. To get the inter-patch and intra-patch correlations, our ANL3DTV takes advantages of a non-local 3D total variation regularization. On the basis of embedding an adaptive weight matrix into the fidelity term of the optimization model, it can automatically control the denoising strength on different color image patches and different color channels in each iteration. The weight matrix is correlated with the estimated noise level of each image patch. 4) Aggregate all the denoised 2D matrices to reconstruct the denoised color image.ResultAccording to different ways to add Gaussian noise, there are two cases in the denoising experiment. In Case 1, the noisy images are corrupted with Gaussian noise with the same noise variance in all color channels. The selected noise levels are σ= 10, 30 and 50. In Case 2, we add Gaussian noise with different noise variances to each color channel. The noise levels are [σR, σG, σB] = [5, 15, 10], [40, 50, 30], [5, 40, 15] and [40, 5, 25]. ANL3DTV is compared to 6 existing TV-based denoising methods. The peak signal-to-noise ratio (PSNR) and structure similarity (SSIM) are adopted to denoising evaluation. The averaged PSNR/SSIM results of ANL3DTV in Case 1 are 32.33 dB/92.99%, 26.92 dB/81.68 and 24.57 dB/73.57%, respectively, and the quantitative results of ANL3DTV in Case 2 are 31.62 dB/92.88%, 24.49 dB/73.02%, 27.47 dB/85.94% and 26.81 dB/81.00%, respectively. Compared with other competing methods, ANL3DTV improves PSNR and SSIM by about 0.16~1.76 dB and 0.12%~6.13%. As can be seen from the denoised images, some competing methods oversmooth the images and lose many structure information. Some mistake noise pattern for the useful edge information and yield obvious ringring artifacts. Our ANL3DTV can remove more noise, preserve more details and suppress more artifacts than the competing methods.ConclusionWe demonstrate an adaptive non-local 3D total variation model for Gaussian noise removal (ANL3DTV). To capture the inter-patch and intra-patch gradient information, ANL3DTV is focused on the non-local 3D total variation regularization. To adaptively adjust the denoising strength on each image patch and each color channel, an adaptive weight matrix into the fidelity term is introduced. To guarantee the feasibility of ANL3DTV mathematically, we develop the iterative solution of ANL3DTV and validate its convergence. The visual results demonstrate our ANL3DTV potentials in noise removal and detail preserving. Furthermore, ANL3DTV achieves more robustness and stablizes noise removal more under different noise levels.关键词:color image denoising;Gaussian noise;non-local similarity;3D total variation;adaptive weight109|464|2更新时间:2024-05-07
摘要:ObjectiveImages are often distorted by noise during image acquisition, transmission and storage process. The generated noise can degrade image quality and affect image processing, such as edge detection, image segmentation, image recognition and image classification. Image denoising technique plays a key role in image pre-processing for image details preservation. Current Gaussian noise removal denoising techniques is often based on variational model like the total variation (TV) method. It can realize image smoothing through minimizing the corresponding energy function. However, TV-based denoising methods have their staircase effects and detail loss due to local gradient information only. Many researchers integrate the non-local concept into the total variation model after the non-local means was proposed. The existing non-local TV-based methods take advantages of the non-local similarity to denoise the image while keeping the image structure information. Unfortunately, many existing TV-based color image denoising methods fail to fully capture both local and non-local correlations among different image patches, and ignore the fact that the realistic noise varies in different image patches and different color channels. These always lead to over-smoothing and under-smoothing in the denoising result. Our newly TV-based color image denoising method, named adaptive non-local 3D total variation (ANL3DTV), is developed to deal with that.Method1) Decompose the noisy color image into K overlapping color image patches, search for the m most similar neighboring image patches to each center image patch and then group the m image patches together. 2) Vectorize every color image patch in each image patch group and stack them into a 2D noisy matrix. 3) Obtain the corresponding 2D denoised matrices via ANL3DTV. To get the inter-patch and intra-patch correlations, our ANL3DTV takes advantages of a non-local 3D total variation regularization. On the basis of embedding an adaptive weight matrix into the fidelity term of the optimization model, it can automatically control the denoising strength on different color image patches and different color channels in each iteration. The weight matrix is correlated with the estimated noise level of each image patch. 4) Aggregate all the denoised 2D matrices to reconstruct the denoised color image.ResultAccording to different ways to add Gaussian noise, there are two cases in the denoising experiment. In Case 1, the noisy images are corrupted with Gaussian noise with the same noise variance in all color channels. The selected noise levels are σ= 10, 30 and 50. In Case 2, we add Gaussian noise with different noise variances to each color channel. The noise levels are [σR, σG, σB] = [5, 15, 10], [40, 50, 30], [5, 40, 15] and [40, 5, 25]. ANL3DTV is compared to 6 existing TV-based denoising methods. The peak signal-to-noise ratio (PSNR) and structure similarity (SSIM) are adopted to denoising evaluation. The averaged PSNR/SSIM results of ANL3DTV in Case 1 are 32.33 dB/92.99%, 26.92 dB/81.68 and 24.57 dB/73.57%, respectively, and the quantitative results of ANL3DTV in Case 2 are 31.62 dB/92.88%, 24.49 dB/73.02%, 27.47 dB/85.94% and 26.81 dB/81.00%, respectively. Compared with other competing methods, ANL3DTV improves PSNR and SSIM by about 0.16~1.76 dB and 0.12%~6.13%. As can be seen from the denoised images, some competing methods oversmooth the images and lose many structure information. Some mistake noise pattern for the useful edge information and yield obvious ringring artifacts. Our ANL3DTV can remove more noise, preserve more details and suppress more artifacts than the competing methods.ConclusionWe demonstrate an adaptive non-local 3D total variation model for Gaussian noise removal (ANL3DTV). To capture the inter-patch and intra-patch gradient information, ANL3DTV is focused on the non-local 3D total variation regularization. To adaptively adjust the denoising strength on each image patch and each color channel, an adaptive weight matrix into the fidelity term is introduced. To guarantee the feasibility of ANL3DTV mathematically, we develop the iterative solution of ANL3DTV and validate its convergence. The visual results demonstrate our ANL3DTV potentials in noise removal and detail preserving. Furthermore, ANL3DTV achieves more robustness and stablizes noise removal more under different noise levels.关键词:color image denoising;Gaussian noise;non-local similarity;3D total variation;adaptive weight109|464|2更新时间:2024-05-07 -
 摘要:ObjectiveSteganography is a novel of technology that involves the embedding of hidden information into digital carriers, such as text, image, voice, or video data. To embed hidden information into the audio carrier with no audio quality loss, audio-based steganography utilizes the redundancy of human auditory and the statistical-based audio carrier among them. The voice-enhanced and packet-loss compensation, and internet low bit rate codec based (iLBC-based) techniques can maintain network-context high voice quality with high packet loss rate, which develops the steganography for the iLBC speech in the field of information hiding in recent years. However, it is challenged to hide information in iLBC due to the high compression issue. Moreover, human auditory system, unlike the human visual system, is highly vulnerable for identifying minor distortions. Most of the existing methods are focused on the processes of linear spectrum frequency coefficient vector quantization, the dynamic codebook searching or the acquired quantization in iLBC. Although these methods have good imperceptibility, they are usually at the expense of steganography capacity, and it is difficult to resist the detection of the deep learning-based steganalysis technology. Therefore, the mutual benefit issue is challenged for the iLBC speech steganography between steganography capacities, imperceptibility, and anti-detection, in which the steganography capacity is as high as possible, the imperceptibility is as good as possible, and the resistance to steganalysis is as strong as possible. We develop a hierarchical-based method of high-capacity steganography in iLBC speech.Method1) The structure of iLBC bitstream is analyzed. 2) The influence of steganography processes in the linear spectrum frequency coefficient vector quantization, the dynamic codebook search, and the gain quantization on the voice quality is clarified based on the perceptual evaluation of speech quality-mean opinion score (PESQ-MOS) and Mel cepstral distortion (MCD). A hierarchical-based steganography position method is demonstrated to choose invulnerable layers and reduce distortions via gain quantization and the dynamic codebook searching in terms of the steganography capacity and the hierarchy priority. For the unfilled layer, an embedded position-selected method based on the Logistic chaotic map is also developed to improve the randomness and security of steganography. 3) The quantization index module is to embed the hidden information for steganography security better.ResultOur hierarchical steganography method realizes the one time extended steganography capacity. Additionally, we adopt the Chinese and English speech data set steganalysis-speech-dataset (SSD) to make comparative experiments, which includes 30 ms and 20 ms frames and 2 s, 5 s, and 10 s speech samples. The experimental results on 5 280 speech samples show that our method can strengthen imperceptibility and alleviate distortions in terms of embedding more hidden information. To validate our anti-detection performance against the deep learning-based steganalyzer, we generate 4 000 original speech samples and 4 000 steganographic speech samples, of which 75% is used as the training set and 25% as the test set. The detection results show that the steganography capacity is less than or equal to 18 bit on 30 ms frame, and 12 bit on 20 ms frame. It can resist the detection of the deep learning-based audio steganalyzer well.ConclusionA hierarchical steganography method with high capacity is developed in the iLBC speech. It has the steganography potential of the iLBC speech for imperceptibility and anti-detection optimization on the premise of the steganography capacity extension.关键词:internet low bit rate codec(iLBC);quantization index modulation;hierarchical steganography;embeddable positions;high capacity66|315|0更新时间:2024-05-07
摘要:ObjectiveSteganography is a novel of technology that involves the embedding of hidden information into digital carriers, such as text, image, voice, or video data. To embed hidden information into the audio carrier with no audio quality loss, audio-based steganography utilizes the redundancy of human auditory and the statistical-based audio carrier among them. The voice-enhanced and packet-loss compensation, and internet low bit rate codec based (iLBC-based) techniques can maintain network-context high voice quality with high packet loss rate, which develops the steganography for the iLBC speech in the field of information hiding in recent years. However, it is challenged to hide information in iLBC due to the high compression issue. Moreover, human auditory system, unlike the human visual system, is highly vulnerable for identifying minor distortions. Most of the existing methods are focused on the processes of linear spectrum frequency coefficient vector quantization, the dynamic codebook searching or the acquired quantization in iLBC. Although these methods have good imperceptibility, they are usually at the expense of steganography capacity, and it is difficult to resist the detection of the deep learning-based steganalysis technology. Therefore, the mutual benefit issue is challenged for the iLBC speech steganography between steganography capacities, imperceptibility, and anti-detection, in which the steganography capacity is as high as possible, the imperceptibility is as good as possible, and the resistance to steganalysis is as strong as possible. We develop a hierarchical-based method of high-capacity steganography in iLBC speech.Method1) The structure of iLBC bitstream is analyzed. 2) The influence of steganography processes in the linear spectrum frequency coefficient vector quantization, the dynamic codebook search, and the gain quantization on the voice quality is clarified based on the perceptual evaluation of speech quality-mean opinion score (PESQ-MOS) and Mel cepstral distortion (MCD). A hierarchical-based steganography position method is demonstrated to choose invulnerable layers and reduce distortions via gain quantization and the dynamic codebook searching in terms of the steganography capacity and the hierarchy priority. For the unfilled layer, an embedded position-selected method based on the Logistic chaotic map is also developed to improve the randomness and security of steganography. 3) The quantization index module is to embed the hidden information for steganography security better.ResultOur hierarchical steganography method realizes the one time extended steganography capacity. Additionally, we adopt the Chinese and English speech data set steganalysis-speech-dataset (SSD) to make comparative experiments, which includes 30 ms and 20 ms frames and 2 s, 5 s, and 10 s speech samples. The experimental results on 5 280 speech samples show that our method can strengthen imperceptibility and alleviate distortions in terms of embedding more hidden information. To validate our anti-detection performance against the deep learning-based steganalyzer, we generate 4 000 original speech samples and 4 000 steganographic speech samples, of which 75% is used as the training set and 25% as the test set. The detection results show that the steganography capacity is less than or equal to 18 bit on 30 ms frame, and 12 bit on 20 ms frame. It can resist the detection of the deep learning-based audio steganalyzer well.ConclusionA hierarchical steganography method with high capacity is developed in the iLBC speech. It has the steganography potential of the iLBC speech for imperceptibility and anti-detection optimization on the premise of the steganography capacity extension.关键词:internet low bit rate codec(iLBC);quantization index modulation;hierarchical steganography;embeddable positions;high capacity66|315|0更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveHuman face recognition has been developing for biometrics applications like online payment and security. Face-related recognition systems are usually deployed in an open environment in reality, which is challenged for the robustness problem. The changing external environment (e.g., improper exposure, poor lighting, extreme weather conditions, background interference), can intervene diversified distortions to the face images like low contrast, blurring and occlusion, which significantly degrades the performance of the face-related recognition system. Therefore, an accurate face image quality assessment method is highly required to improve the performance of the face recognition system from two perspectives as mentioned below: 1) face-related image quality model can be used to filter out low-quality face images since the performance of face recognition systems is often affected by low-quality images, thus avoiding invalid recognition and improving the recognition efficiency. 2) Traditional face recognition features can be enhanced in terms of the integrated facial quality features. In contrast to the traditional image quality assessment approaches, face-related image quality assessment can be achieved with specific face recognition algorithms only. The existing face-related image quality model scan be divided into handcrafted feature-based and deep learning-based.MethodWe develop a new mask-based method for face-related image quality assessment. From the perspective of human recognition, the quality of a face image is mainly determined by the key regions of the face image (eyes, nose, and mouth). Changes in these regions will have different impacts on the recognition performance for face-related images with multi-level quality. A mask added on these regions will also have different impacts for different face images. For example, high-quality images masked tends to have greater impact on the recognition performance compared with low-quality face images. Such a mask can be designed to cover the key regions, and the quality of a face image can be achieved by measuring the influence of the masking operation. Our human face-related image quality model can be segmented into two categories: 1) the masking operation on face images; 2) the quality score regression. Specifically, the mask is added to the key regions at first for an input face image to be evaluated. Next the face image pair is obtained containing the input image and the masked image. Finally, image pair is input into the deep feature extraction module, producing the qualified features. The objective quality score of the input face image is obtained in terms of the feature pair regression. Our method is called mask-based face image quality (MFIQ). For model training, we build a new DDFace(Diversified Distortion Face) database, which contains a total of 350 000 distorted face images of 1 000 people. We use 280 000 face images as the training set and the rest of it as the testing set. We train the model for 40 epochs with the learning rate 0.001 and batch size 32.ResultIn the experiments, five face image datasets are used, including our DDFace-built and four existing face recognition datasets like LFW(Labeled Faces in the Wild), VGGFace2(Visual Geometry Group Face2), CASIA-WebFace(Institute of Automation Chinese Academy of Science-Website Face) and CelebA(CelebFaces Attribute). Our proposed MFIQ model is compared with the popular deep face image quality models, including face quality net-v0 (FaceQnet-v0), face quality net-v1(FaceQnet-v1) and stochastic embedding robustness-face image quality (SER-FIQ). Under the metric area over curve(AOC), our model performance is improved by 14.8%, 0.1%, 2.9%, 3.7% and 4.9% in comparison with LFW, CelebA, DDFace, VGGFace2 and CASIA-WebFace databases, respectively. Furthermore, our MFIQ model is used to predict the face-related image quality in different datasets and the quality distributions of images are calculated. The experimental results show that our distributions predicted is close to the real distributions. Our MFIQ model performance is also compared with the other three models according to face-related images evaluation from singles and multiples. The results show that the proposed MFIQ performs better than SER-FIQ, FaceQnet-v0 and FaceQnet-v1.ConclusionOur research potentials are focused on more robustness and distinguishing ability for the key elements of multiple-level distorted images.关键词:face recognition;image quality assessment;face image utility quality;no reference;mask;pseudo reference105|199|1更新时间:2024-05-07
摘要:ObjectiveHuman face recognition has been developing for biometrics applications like online payment and security. Face-related recognition systems are usually deployed in an open environment in reality, which is challenged for the robustness problem. The changing external environment (e.g., improper exposure, poor lighting, extreme weather conditions, background interference), can intervene diversified distortions to the face images like low contrast, blurring and occlusion, which significantly degrades the performance of the face-related recognition system. Therefore, an accurate face image quality assessment method is highly required to improve the performance of the face recognition system from two perspectives as mentioned below: 1) face-related image quality model can be used to filter out low-quality face images since the performance of face recognition systems is often affected by low-quality images, thus avoiding invalid recognition and improving the recognition efficiency. 2) Traditional face recognition features can be enhanced in terms of the integrated facial quality features. In contrast to the traditional image quality assessment approaches, face-related image quality assessment can be achieved with specific face recognition algorithms only. The existing face-related image quality model scan be divided into handcrafted feature-based and deep learning-based.MethodWe develop a new mask-based method for face-related image quality assessment. From the perspective of human recognition, the quality of a face image is mainly determined by the key regions of the face image (eyes, nose, and mouth). Changes in these regions will have different impacts on the recognition performance for face-related images with multi-level quality. A mask added on these regions will also have different impacts for different face images. For example, high-quality images masked tends to have greater impact on the recognition performance compared with low-quality face images. Such a mask can be designed to cover the key regions, and the quality of a face image can be achieved by measuring the influence of the masking operation. Our human face-related image quality model can be segmented into two categories: 1) the masking operation on face images; 2) the quality score regression. Specifically, the mask is added to the key regions at first for an input face image to be evaluated. Next the face image pair is obtained containing the input image and the masked image. Finally, image pair is input into the deep feature extraction module, producing the qualified features. The objective quality score of the input face image is obtained in terms of the feature pair regression. Our method is called mask-based face image quality (MFIQ). For model training, we build a new DDFace(Diversified Distortion Face) database, which contains a total of 350 000 distorted face images of 1 000 people. We use 280 000 face images as the training set and the rest of it as the testing set. We train the model for 40 epochs with the learning rate 0.001 and batch size 32.ResultIn the experiments, five face image datasets are used, including our DDFace-built and four existing face recognition datasets like LFW(Labeled Faces in the Wild), VGGFace2(Visual Geometry Group Face2), CASIA-WebFace(Institute of Automation Chinese Academy of Science-Website Face) and CelebA(CelebFaces Attribute). Our proposed MFIQ model is compared with the popular deep face image quality models, including face quality net-v0 (FaceQnet-v0), face quality net-v1(FaceQnet-v1) and stochastic embedding robustness-face image quality (SER-FIQ). Under the metric area over curve(AOC), our model performance is improved by 14.8%, 0.1%, 2.9%, 3.7% and 4.9% in comparison with LFW, CelebA, DDFace, VGGFace2 and CASIA-WebFace databases, respectively. Furthermore, our MFIQ model is used to predict the face-related image quality in different datasets and the quality distributions of images are calculated. The experimental results show that our distributions predicted is close to the real distributions. Our MFIQ model performance is also compared with the other three models according to face-related images evaluation from singles and multiples. The results show that the proposed MFIQ performs better than SER-FIQ, FaceQnet-v0 and FaceQnet-v1.ConclusionOur research potentials are focused on more robustness and distinguishing ability for the key elements of multiple-level distorted images.关键词:face recognition;image quality assessment;face image utility quality;no reference;mask;pseudo reference105|199|1更新时间:2024-05-07 -
 摘要:ObjectiveHuman facial expression can be as a human emotion style and information transmission carrier in the process of human-robot interaction. Thanks to the artificial intelligence (AI) development, facial expression recognition (FER) has been developing in the context of emotion understanding, human-robot interaction, safe driving, medical treatment, and communications. However, current facial expression recognition studies have been challenging of some problems like large background interference, complex network model parameters, and poor generalization. We develop a lightweight facial expression recognition method based on improved convolutional neural network (CNN-improved) and channel-weighted in order to improve its recognition and classification and the key feature information mining of facial expressions.MethodHuman facial expression recognition network is focused on facial-related image gathering, image preprocessing, feature extraction, and expression-related classification and recognition, amongst feature extraction is as the key step of the network structure. Our demonstration is illustrated as following: 1) different collections of expression-related datasets are obtained for indoor and outdoor scenarios. 2) Data-enhanced method is used to pre-process the expression-related image through avoiding the distorted background information and resolving the problems of over-fitting and poor robustness related to deep learning algorithms. 3) The lightweight expression network is designed and trained in terms of the enhanced depth-segmented convolutional channel feature. To reduce the network parameters effectively, deep-segmented convolution and global average pooling layer are deployed. The squeeze-and-excitation(SE) module is also embedded to optimize the model. Multi-channels-related compression rates are set to extract facial expression features more efficiently and thus the recognition ability of the network is improved. Our main contributions are clarified as mentioned below: 1) data preprocessing module: it is mainly based on data enhancement operations, such as image size normalization, random rotation and cropping, and random noise-added. The interference information is removed and the generalization of the model is improved. 2) Network model: a convolutional neural network (CNN) is adopted and an enhanced depth-segmented convolution channel feature module (also called basic block) for channel weighting is designed. The space and channel information in the local receptive field are extended by setting different compression rates originated from different convolution layers. 3) Verification: facial expression recognition method is performed on a number of popular public datasets and achieved high recognition accuracy.ResultThe best compression ratio combinations of SE modules are sorted out through experiments and embedded into the constructed lightweight network, and experimental evaluation is carried out on five commonly-used expression datasets. It shows that our recognition accuracy of the three indoor-related expression datasets of FER2013(Facial Expression Recognition 2013), CK+(the extended Cohn-Kanade) and JAFFE(Japanses Female Facial Expression) are 79.73%, 99.32%, and 98.48%, which are improved 5.72%, 0.51% and 0.28%. The two outdoor expression datasets of RAF-DB(Real-world Affective Faces Database) and AffectNet are obtained recognition accuracy of 86.14% and 61.78%, which are improved 2.01% and 0.67%. In contrast to the Xception neural network, a lightweight network is facilitated while the parameters are reduced by 63%. The average recognition speed can reach 128frame/s, which meets the real-time requirements.ConclusionOur lightweight expression recognition method has different weighting capabilities in different channels. The key expression information can be obtained. The generalization of this model is enhanced. To improve the recognition ability of the network effectively, our method can recognize facial expressions accurately based on network simplification and calculation cost optimization.关键词:expression recognition;image processing;convolutional neural network(CNN);depth separable convolution;global average pooling;squeeze-and-excitation(SE) module84|198|1更新时间:2024-05-07
摘要:ObjectiveHuman facial expression can be as a human emotion style and information transmission carrier in the process of human-robot interaction. Thanks to the artificial intelligence (AI) development, facial expression recognition (FER) has been developing in the context of emotion understanding, human-robot interaction, safe driving, medical treatment, and communications. However, current facial expression recognition studies have been challenging of some problems like large background interference, complex network model parameters, and poor generalization. We develop a lightweight facial expression recognition method based on improved convolutional neural network (CNN-improved) and channel-weighted in order to improve its recognition and classification and the key feature information mining of facial expressions.MethodHuman facial expression recognition network is focused on facial-related image gathering, image preprocessing, feature extraction, and expression-related classification and recognition, amongst feature extraction is as the key step of the network structure. Our demonstration is illustrated as following: 1) different collections of expression-related datasets are obtained for indoor and outdoor scenarios. 2) Data-enhanced method is used to pre-process the expression-related image through avoiding the distorted background information and resolving the problems of over-fitting and poor robustness related to deep learning algorithms. 3) The lightweight expression network is designed and trained in terms of the enhanced depth-segmented convolutional channel feature. To reduce the network parameters effectively, deep-segmented convolution and global average pooling layer are deployed. The squeeze-and-excitation(SE) module is also embedded to optimize the model. Multi-channels-related compression rates are set to extract facial expression features more efficiently and thus the recognition ability of the network is improved. Our main contributions are clarified as mentioned below: 1) data preprocessing module: it is mainly based on data enhancement operations, such as image size normalization, random rotation and cropping, and random noise-added. The interference information is removed and the generalization of the model is improved. 2) Network model: a convolutional neural network (CNN) is adopted and an enhanced depth-segmented convolution channel feature module (also called basic block) for channel weighting is designed. The space and channel information in the local receptive field are extended by setting different compression rates originated from different convolution layers. 3) Verification: facial expression recognition method is performed on a number of popular public datasets and achieved high recognition accuracy.ResultThe best compression ratio combinations of SE modules are sorted out through experiments and embedded into the constructed lightweight network, and experimental evaluation is carried out on five commonly-used expression datasets. It shows that our recognition accuracy of the three indoor-related expression datasets of FER2013(Facial Expression Recognition 2013), CK+(the extended Cohn-Kanade) and JAFFE(Japanses Female Facial Expression) are 79.73%, 99.32%, and 98.48%, which are improved 5.72%, 0.51% and 0.28%. The two outdoor expression datasets of RAF-DB(Real-world Affective Faces Database) and AffectNet are obtained recognition accuracy of 86.14% and 61.78%, which are improved 2.01% and 0.67%. In contrast to the Xception neural network, a lightweight network is facilitated while the parameters are reduced by 63%. The average recognition speed can reach 128frame/s, which meets the real-time requirements.ConclusionOur lightweight expression recognition method has different weighting capabilities in different channels. The key expression information can be obtained. The generalization of this model is enhanced. To improve the recognition ability of the network effectively, our method can recognize facial expressions accurately based on network simplification and calculation cost optimization.关键词:expression recognition;image processing;convolutional neural network(CNN);depth separable convolution;global average pooling;squeeze-and-excitation(SE) module84|198|1更新时间:2024-05-07 -
 摘要:ObjectiveHuman eye fixation recognition has been developing in images-related computer vision in recent years. The distinctive salient regions of an image are selected for capturing visual structure better. Recent saliency models are developed through salient object detection, object segmentation and image cropping. Traditional applications are focused on hand-crafted features based on low-level cues (e.g., contrast, texture, color) for saliency prediction. However, these features are easily failed to simulate the complex activation of the human visual system, especially in complex scenarios. Existing eye fixation prediction models often use jump connections to fuse high-level and low-level features, which easily leads to the difficulty of weighing the importance of features between different levels, and the gazing problem are biased toward the center. Commonly, humans are inclined to look at the center of the image when there are no obvious salient regions. We develop layer attention mechanism that different weights are assigned to different layer features for selective layer features extraction, and the channel attention mechanism and spatial attention mechanism are integrated to selectively extract different channel and spatial features in convolutional features. In addition, we facilitate a method of Gaussian learning to solve the problem of the center priors and improve the prediction accuracy.MethodOur eye fixation prediction model is based on multiple attention mechanism network (MAM-Net), which uses three different attention mechanisms to weight the feature information of different layers, different channels, and different image pixels extracted by the ResNet-50 model with dilated convolution. Our network is mainly composed of the feature extraction module, the novel multiple attention mechanism (MAM) module, and the Gaussian learning optimization module. 1) A dilated convolution network is used to capture long-range information via extracting local and global feature maps, which can contain a lot of different receptive fields. 2) A MAM attention module is incorporated features from different contexts of layer, channels, and image pixels of feature maps and output an intermediate saliency map. 3) A Gaussian learning layer is used to select best kernel automatically to blur the intermediate saliency map and generate the final saliency map. Our MAM module aims to optimize the obtained low-level features automatically in the context of rich details and high-level global semantic information features, fully extract channel and spatial information, and prevent over-reliance on high-level features. The Gaussian learning module is used for the final optimization processing since human eyes tend to focus to the image center, which is inconsistent with the prediction results of common methods. The deficiency of setting Gaussian fuzzy parameters is avoided by human prior in our method.ResultExperiments on the public dataset saliency in context(SALICON) show that our results has improved Kullback-Leibler divergence (KLD), shuffled area under region of interest(ROC) curve (sAUC), and information gain (IG) evaluation criteria by 33%, 0.3%, and 6%; 53%, 0.6%, and 192%, respectively.ConclusionWe propose a novel attentive model for predicting human eye fixations on natural images. Our MAM-Net can be used to predict saliency map of an image, which extract high-level and low-level features. The channel and spatial attention mechanism can optimize the feature maps of different layers, and the layer attention mechanism can predict the saliency map of the image composed of high-level and low-level features as well. We illustrate a Gaussian learning blur layer in terms of the integrated saliency maps optimization with different kernel.关键词:eye fixation prediction;multiple attention;layer attention;channel attention;spatial attention;Gaussian learning121|212|0更新时间:2024-05-07
摘要:ObjectiveHuman eye fixation recognition has been developing in images-related computer vision in recent years. The distinctive salient regions of an image are selected for capturing visual structure better. Recent saliency models are developed through salient object detection, object segmentation and image cropping. Traditional applications are focused on hand-crafted features based on low-level cues (e.g., contrast, texture, color) for saliency prediction. However, these features are easily failed to simulate the complex activation of the human visual system, especially in complex scenarios. Existing eye fixation prediction models often use jump connections to fuse high-level and low-level features, which easily leads to the difficulty of weighing the importance of features between different levels, and the gazing problem are biased toward the center. Commonly, humans are inclined to look at the center of the image when there are no obvious salient regions. We develop layer attention mechanism that different weights are assigned to different layer features for selective layer features extraction, and the channel attention mechanism and spatial attention mechanism are integrated to selectively extract different channel and spatial features in convolutional features. In addition, we facilitate a method of Gaussian learning to solve the problem of the center priors and improve the prediction accuracy.MethodOur eye fixation prediction model is based on multiple attention mechanism network (MAM-Net), which uses three different attention mechanisms to weight the feature information of different layers, different channels, and different image pixels extracted by the ResNet-50 model with dilated convolution. Our network is mainly composed of the feature extraction module, the novel multiple attention mechanism (MAM) module, and the Gaussian learning optimization module. 1) A dilated convolution network is used to capture long-range information via extracting local and global feature maps, which can contain a lot of different receptive fields. 2) A MAM attention module is incorporated features from different contexts of layer, channels, and image pixels of feature maps and output an intermediate saliency map. 3) A Gaussian learning layer is used to select best kernel automatically to blur the intermediate saliency map and generate the final saliency map. Our MAM module aims to optimize the obtained low-level features automatically in the context of rich details and high-level global semantic information features, fully extract channel and spatial information, and prevent over-reliance on high-level features. The Gaussian learning module is used for the final optimization processing since human eyes tend to focus to the image center, which is inconsistent with the prediction results of common methods. The deficiency of setting Gaussian fuzzy parameters is avoided by human prior in our method.ResultExperiments on the public dataset saliency in context(SALICON) show that our results has improved Kullback-Leibler divergence (KLD), shuffled area under region of interest(ROC) curve (sAUC), and information gain (IG) evaluation criteria by 33%, 0.3%, and 6%; 53%, 0.6%, and 192%, respectively.ConclusionWe propose a novel attentive model for predicting human eye fixations on natural images. Our MAM-Net can be used to predict saliency map of an image, which extract high-level and low-level features. The channel and spatial attention mechanism can optimize the feature maps of different layers, and the layer attention mechanism can predict the saliency map of the image composed of high-level and low-level features as well. We illustrate a Gaussian learning blur layer in terms of the integrated saliency maps optimization with different kernel.关键词:eye fixation prediction;multiple attention;layer attention;channel attention;spatial attention;Gaussian learning121|212|0更新时间:2024-05-07 -
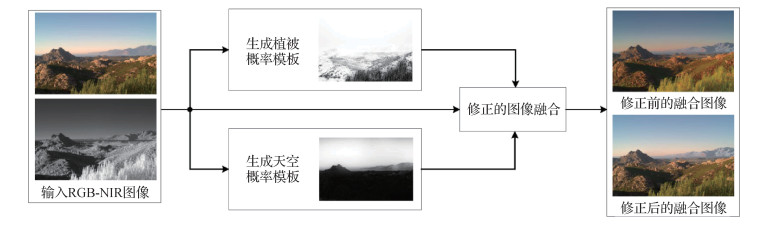 摘要:ObjectiveThe imaging mechanism of near-infrared (NIR) images is different from that of visible images. It can receive the infrared radiation emitted by the object and convert it into grayscale values. Therefore, stronger infrared radiation in the scene yields higher grayscale value in the NIR image and its adaptability to harsh environments (e.g., fog, haze) is better than the visible light imaging. To take advantage of NIR images, RGB-NIR image fusion is a common and effective processing method, which has been widely used in various image vision applications, including recognition, detection and surveillance. Multiple objects will have different imaging results in the same image in terms of their reflection and infrared radiation features, and the same object will have different appearances in visible and NIR images as well. For example, the vegetation part appears as low gray-scale values in the RGB image, but high gray-scale values in the NIR image. In addition, current image fusion algorithms have been challenging in specific regions like vegetation and sky. Therefore, an accurate and robust region detection method is necessary for regional-based processing. However, most algorithms are concerned of single image only and cannot meet the requirements for RGB-NIR image-fused region detection.MethodWe develop a probability-mask generation method from vegetation and sky regions based on RGB-NIR image pairs. The vegetation region: 1) to preserve high contrast and smooth transition, we obtain the ratio of multiple channels of RGB images with the extended normalized difference vegetation index (NDVI). 2) To avoid the extreme case that the red channel is of value minimum or maximum, we use the relationship between NIR and luminance instead of red channel. 3) To get the detection result, we integrate the ratio-guided and the NDVI-extended into the probability mask of vegetation. The sky-region: 1) the local-entropy feature of the RGB image is calculated and a transmission map is for guidance. 2) The guided feature and the extended NDVI is combined, and the results with the height of pixels is enhanced, according to the prior that the sky basically has a great probability of appearing in the upper part of the natural-scene image. 3) The result is a probability mask and considered as the sky detection result. The vegetation and sky detection based algorithms produce corresponding probability masks. We can incorporate them into RGB-NIR image fusion algorithms to improve image quality. The original algorithm uses the Laplacian-Gaussian pyramid and the weight map for multi-scale fusion. We modify the weight map of the NIR image by multiplying it with the vegetation and sky probability masks, and then replace the original NIR weight map with the modified one. The rest of the fusion algorithm remains unchanged.ResultOur algorithm is evaluated on a public dataset containing outdoors images, including country, field, forest, indoor, mountain, old-building, street, urban, and water. To express the health of vegetation in the field of remote sensing, we compare the proposed vegetation detection algorithm with the traditional NDVI. The experimental results of image fusion indicate that our image fusion algorithm can perform better by incorporating the region masks both quantitatively and qualitatively, and produce more realistic and natural images perceptually. Moreover, we analyze the difference between the probability mask and the binary mask when applied to image fusion in the same way. The results show that selected probability mask makes the fused images more colorful and rich in details.ConclusionOur probability mask generation algorithm of vegetation and sky is potential to high accuracy and robustness. Specifically, the detected areas in result images are accurate with clear details and smooth transition, and small objects can be segmented properly. Moreover, our algorithm is beneficial to improving the performance of RGB-NIR image fusion, especially on weight map, making the results have enhanced details and natural colors. It is easy-used without complicated calculations. It is worthy note that our algorithm is more suitable for natural scenes generally.关键词:vegetation detection;sky detection;probability mask;image fusion;visual enhancement53|70|0更新时间:2024-05-07
摘要:ObjectiveThe imaging mechanism of near-infrared (NIR) images is different from that of visible images. It can receive the infrared radiation emitted by the object and convert it into grayscale values. Therefore, stronger infrared radiation in the scene yields higher grayscale value in the NIR image and its adaptability to harsh environments (e.g., fog, haze) is better than the visible light imaging. To take advantage of NIR images, RGB-NIR image fusion is a common and effective processing method, which has been widely used in various image vision applications, including recognition, detection and surveillance. Multiple objects will have different imaging results in the same image in terms of their reflection and infrared radiation features, and the same object will have different appearances in visible and NIR images as well. For example, the vegetation part appears as low gray-scale values in the RGB image, but high gray-scale values in the NIR image. In addition, current image fusion algorithms have been challenging in specific regions like vegetation and sky. Therefore, an accurate and robust region detection method is necessary for regional-based processing. However, most algorithms are concerned of single image only and cannot meet the requirements for RGB-NIR image-fused region detection.MethodWe develop a probability-mask generation method from vegetation and sky regions based on RGB-NIR image pairs. The vegetation region: 1) to preserve high contrast and smooth transition, we obtain the ratio of multiple channels of RGB images with the extended normalized difference vegetation index (NDVI). 2) To avoid the extreme case that the red channel is of value minimum or maximum, we use the relationship between NIR and luminance instead of red channel. 3) To get the detection result, we integrate the ratio-guided and the NDVI-extended into the probability mask of vegetation. The sky-region: 1) the local-entropy feature of the RGB image is calculated and a transmission map is for guidance. 2) The guided feature and the extended NDVI is combined, and the results with the height of pixels is enhanced, according to the prior that the sky basically has a great probability of appearing in the upper part of the natural-scene image. 3) The result is a probability mask and considered as the sky detection result. The vegetation and sky detection based algorithms produce corresponding probability masks. We can incorporate them into RGB-NIR image fusion algorithms to improve image quality. The original algorithm uses the Laplacian-Gaussian pyramid and the weight map for multi-scale fusion. We modify the weight map of the NIR image by multiplying it with the vegetation and sky probability masks, and then replace the original NIR weight map with the modified one. The rest of the fusion algorithm remains unchanged.ResultOur algorithm is evaluated on a public dataset containing outdoors images, including country, field, forest, indoor, mountain, old-building, street, urban, and water. To express the health of vegetation in the field of remote sensing, we compare the proposed vegetation detection algorithm with the traditional NDVI. The experimental results of image fusion indicate that our image fusion algorithm can perform better by incorporating the region masks both quantitatively and qualitatively, and produce more realistic and natural images perceptually. Moreover, we analyze the difference between the probability mask and the binary mask when applied to image fusion in the same way. The results show that selected probability mask makes the fused images more colorful and rich in details.ConclusionOur probability mask generation algorithm of vegetation and sky is potential to high accuracy and robustness. Specifically, the detected areas in result images are accurate with clear details and smooth transition, and small objects can be segmented properly. Moreover, our algorithm is beneficial to improving the performance of RGB-NIR image fusion, especially on weight map, making the results have enhanced details and natural colors. It is easy-used without complicated calculations. It is worthy note that our algorithm is more suitable for natural scenes generally.关键词:vegetation detection;sky detection;probability mask;image fusion;visual enhancement53|70|0更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveReal-scenario image semantic segmentation is likely to be affected by multiple object-context shapes, ranges and illuminations. Current semantic segmentation methods have inaccurate classification results for pedestrians, buildings, road signs and other objects due to their small scales or wide ranges. At the same time, the existing methods are not distinguishable for objects with chromatic aberration, and it is easy to divide the same chromatic aberration-derived object into different objects, or segment different objects with similar colors into the same type of objects. In order to improve the performance of semantic image segmentation, we facilitate a new dual-branch semantic segmentation network in terms of strip pooling and attention mechanism (strip pooling and channel attention net (SPCANet)).Methodthe SPCANet can be used to extract the features of images via spatial and content perceptions. First, we employ the spatial perception Sub-net to augment the receptive field in the horizontal and vertical directions on the down-sampling stage by using dilated convolution and strip pooling with multi-scale. Our specific approach is focused on adding four parallel one-dimensional dilated convolutions with different rates to the horizontal and vertical branches on the basis of strip pooling model (based on the pooling operation which kernel size is n × 1 or 1 × n), which enhance the perception of large-scale objects in the image. Nextly, in order to improve the content perception ability of the model, we use the pre-trained VGG16 (Visual Geometry Group 16-layer network) based on ImageNet dataset as the content-perception sub-net to optimize the embedded features of semantic segmentation via spatial-perception assisted sub-net. The content sub-net can strengthen feature representation in combination with the spatial perception subnet. In addition, the second-order channel attention is used to optimize the feature assignment further between the middle and high-level layers of the network. In the network training period, the target information is focused and assigned a larger weight, and irrelevant information is suppressed and a smaller weight is assigned. By this way, the correlation is activated in the embedding features. To enhance the expression of image channel information, we use covariance and gating mechanism to achieve the second-order channel attention. Our model can be demonstrated sequentially 1) a three-channel color image is as input, 2) the spatial-based and content-oriented sub-nets are transmitted for feature encoding in the embedded space, 3) the two sets of features are fused (using the method of feature fusion for concatenate), and 4) the fused features are sent to a prediction module (head) for classification and the segmentation task.ResultWe use the popular benchmarks (Cityscapes) as the testing data and our results are compared with other deep neural network-based methods (including the existing network published on the Cityscapes official website and the network based on local reproduction from GitHub). We evaluate the performance qualitatively and quantitatively. The qualitative analysis is carried out by means of visual analysis and the experiment is analyzed quantitatively by public popular metrics. 1) From the perspective of the visualization of the segmentation results, the method proposed in this paper has a strong perception of wide-range objects in the image, and the overall segmentation effect is improved obviously; 2) the metrics of segmentation can reflect the result of the experiment as well. Through the experimental data found that the commonly-used metrics such as accuracy (Acc) and the mean intersection over union (mIoU) are significantly improved. The mIoU is increased by 1.2%, and the Acc is increased by 0.7%. The Ablation studies validated the effectiveness of our modules. Among them, the improved strip pooling module has a more obvious improvement effect on the segmentation result. Under the same experimental circumstances based on batch-train dataset with an input size of 512×512×3, the mIoU can be improved by 4%, and then change the input size to 768 under the same experimental conditions, the mIoU is improved by 5%. The use of second-order channel attention makes the model more sensitive to the chromatic aberration part in the image during the training process. From the visualization results based on the Cityscapes batch-train dataset, the classification result such as pedestrians is improved obviously. The stability of other classification needs to be strengthened further. In the selection of content-perception subnet, we use three pre-trained networks on the ImageNet as candidates, including VGG16, ResNet101 and DenseNet101. The pre-trained VGG16 as the content-perception sub-net can achieve the best performance. The supplementary use of content-perception sub-net enhances the information representation ability of feature maps.ConclusionWe develop the image semantic segmentation algorithm in the context of attention mechanism, multi-scale strip pooling and feature fusion. To optimize our image semantic segmentation, it is harnessed by an improved strip pooling technology (the receptive field augmentation with no more parameters), second-order channel attention (channels-between information) and content perception auxiliary network. Our model can clarify the circumstances of inaccurate segmentation caused by multi-scale segmentation of objects. Our joint model with receptive fields and channel information is beneficial to the semantic image segmentation in the real scenario. To reduce the labor cost in data labeling, it can be extended to learn a more generalizing semantic image segmentation neural network through weakly supervised or unsupervised mode further.关键词:image segmentation;attention;strip pooling;atrous convolution;receptive field130|268|2更新时间:2024-05-07
摘要:ObjectiveReal-scenario image semantic segmentation is likely to be affected by multiple object-context shapes, ranges and illuminations. Current semantic segmentation methods have inaccurate classification results for pedestrians, buildings, road signs and other objects due to their small scales or wide ranges. At the same time, the existing methods are not distinguishable for objects with chromatic aberration, and it is easy to divide the same chromatic aberration-derived object into different objects, or segment different objects with similar colors into the same type of objects. In order to improve the performance of semantic image segmentation, we facilitate a new dual-branch semantic segmentation network in terms of strip pooling and attention mechanism (strip pooling and channel attention net (SPCANet)).Methodthe SPCANet can be used to extract the features of images via spatial and content perceptions. First, we employ the spatial perception Sub-net to augment the receptive field in the horizontal and vertical directions on the down-sampling stage by using dilated convolution and strip pooling with multi-scale. Our specific approach is focused on adding four parallel one-dimensional dilated convolutions with different rates to the horizontal and vertical branches on the basis of strip pooling model (based on the pooling operation which kernel size is n × 1 or 1 × n), which enhance the perception of large-scale objects in the image. Nextly, in order to improve the content perception ability of the model, we use the pre-trained VGG16 (Visual Geometry Group 16-layer network) based on ImageNet dataset as the content-perception sub-net to optimize the embedded features of semantic segmentation via spatial-perception assisted sub-net. The content sub-net can strengthen feature representation in combination with the spatial perception subnet. In addition, the second-order channel attention is used to optimize the feature assignment further between the middle and high-level layers of the network. In the network training period, the target information is focused and assigned a larger weight, and irrelevant information is suppressed and a smaller weight is assigned. By this way, the correlation is activated in the embedding features. To enhance the expression of image channel information, we use covariance and gating mechanism to achieve the second-order channel attention. Our model can be demonstrated sequentially 1) a three-channel color image is as input, 2) the spatial-based and content-oriented sub-nets are transmitted for feature encoding in the embedded space, 3) the two sets of features are fused (using the method of feature fusion for concatenate), and 4) the fused features are sent to a prediction module (head) for classification and the segmentation task.ResultWe use the popular benchmarks (Cityscapes) as the testing data and our results are compared with other deep neural network-based methods (including the existing network published on the Cityscapes official website and the network based on local reproduction from GitHub). We evaluate the performance qualitatively and quantitatively. The qualitative analysis is carried out by means of visual analysis and the experiment is analyzed quantitatively by public popular metrics. 1) From the perspective of the visualization of the segmentation results, the method proposed in this paper has a strong perception of wide-range objects in the image, and the overall segmentation effect is improved obviously; 2) the metrics of segmentation can reflect the result of the experiment as well. Through the experimental data found that the commonly-used metrics such as accuracy (Acc) and the mean intersection over union (mIoU) are significantly improved. The mIoU is increased by 1.2%, and the Acc is increased by 0.7%. The Ablation studies validated the effectiveness of our modules. Among them, the improved strip pooling module has a more obvious improvement effect on the segmentation result. Under the same experimental circumstances based on batch-train dataset with an input size of 512×512×3, the mIoU can be improved by 4%, and then change the input size to 768 under the same experimental conditions, the mIoU is improved by 5%. The use of second-order channel attention makes the model more sensitive to the chromatic aberration part in the image during the training process. From the visualization results based on the Cityscapes batch-train dataset, the classification result such as pedestrians is improved obviously. The stability of other classification needs to be strengthened further. In the selection of content-perception subnet, we use three pre-trained networks on the ImageNet as candidates, including VGG16, ResNet101 and DenseNet101. The pre-trained VGG16 as the content-perception sub-net can achieve the best performance. The supplementary use of content-perception sub-net enhances the information representation ability of feature maps.ConclusionWe develop the image semantic segmentation algorithm in the context of attention mechanism, multi-scale strip pooling and feature fusion. To optimize our image semantic segmentation, it is harnessed by an improved strip pooling technology (the receptive field augmentation with no more parameters), second-order channel attention (channels-between information) and content perception auxiliary network. Our model can clarify the circumstances of inaccurate segmentation caused by multi-scale segmentation of objects. Our joint model with receptive fields and channel information is beneficial to the semantic image segmentation in the real scenario. To reduce the labor cost in data labeling, it can be extended to learn a more generalizing semantic image segmentation neural network through weakly supervised or unsupervised mode further.关键词:image segmentation;attention;strip pooling;atrous convolution;receptive field130|268|2更新时间:2024-05-07 -
 摘要:ObjectiveImage semantic segmentation is a pixel-level classification-related issue, which divides each pixel into different categories in the image, which is a sort of extension and expansion of image classification. Its applications have included like scene information understanding, autonomous driving, and clinical diagnosis. However, deep learning models training requires a large amount of labeled data, and obtaining these data is time-consuming and labor-intensive in semantic segmentation. At present, deep semi-supervised learning is focused on to utilize a large amount of unlabeled data and limit the demand for labeled data. However, current methods are challenged for contextual information collection and constraints, and the existing methods for increasing contextual information often increase the network's reasoning speed to varying degrees. So, we develop a semi-supervised semantic segmentation method with manifold regularization on the basis of cross-consistency training.MethodOur research is assumed that the input data and its corresponding prediction results have the same geometric structure on the low-dimensional manifold surface in the high-dimensional original data space. The geometric data structure is used to construct regularization constraints based on this assumption. First, we design the penalty that a manifold regularization term is integrated to make single pixel information and neighborhood context information. This geometric perception is that the data in the original image have the same locally geometric shape in related to the segmented result. Next, the manifold regularization constraint method mentioned above is combined with the current mainstream semi-supervised and weakly-supervised image segmentation algorithms, which illustrates that our manifold regularization algorithm can well adapt to various different segmentation tasks. In the semi-supervised and weakly-supervised manifold regularization algorithms, a cutting-edged cross-consistency training model is selected as our skeleton network, and the semi-supervised training method of cross-consistency is given different forms of perturbation to the encoder output to strengthen the predictive invariance of the model. We use the open source toolbox Pytorch to build the model. The stochastic gradient descent (SGD) method is adopted as the optimization. The operating system of the experimental platform is Centos7, with a graphics processing unit (GPU) of model NVIDIA RTX 2080Ti and a CPU of Intel (R) Core (TM) i7-6850.ResultBy adding manifold regularization constraints, the contextual information is captured in the image, the loss of the intrinsic structure caused by the network is reduced forward calculation process, and the accuracy of the algorithm is improved. In order to verify the effectiveness of the algorithm, experiments are based on two different types of semi-supervised and weakly-supervised semantic segmentation. On the pattern analysis, statistical modeling and computational learning visual object classes 2012 (PASCAL VOC 2012) dataset, the semi-supervised semantic segmentation task is improved by 3.7% compared to the original network. Our weakly supervised semantic segmentation algorithm is improved by 1.1% compared with the original network. Furthermore, we implement visualization of the segmentation results on different models. It can be found that the segmentation results generated by manifold regularization constraints have more refined edges and less error rate.ConclusionOur algorithm is based on the contextual information through manifold regularization constraints, and is optimized in semi-supervised and weak-supervised tasks without changing the original network structure. The experimental results verify that our algorithm is potential to generalization and optimal ability.关键词:deep learning;semantic segmentation;semi-supervised semantic segmentation;weakly-supervised semantic segmentation;cross-consistency training;manifold regularization167|211|2更新时间:2024-05-07
摘要:ObjectiveImage semantic segmentation is a pixel-level classification-related issue, which divides each pixel into different categories in the image, which is a sort of extension and expansion of image classification. Its applications have included like scene information understanding, autonomous driving, and clinical diagnosis. However, deep learning models training requires a large amount of labeled data, and obtaining these data is time-consuming and labor-intensive in semantic segmentation. At present, deep semi-supervised learning is focused on to utilize a large amount of unlabeled data and limit the demand for labeled data. However, current methods are challenged for contextual information collection and constraints, and the existing methods for increasing contextual information often increase the network's reasoning speed to varying degrees. So, we develop a semi-supervised semantic segmentation method with manifold regularization on the basis of cross-consistency training.MethodOur research is assumed that the input data and its corresponding prediction results have the same geometric structure on the low-dimensional manifold surface in the high-dimensional original data space. The geometric data structure is used to construct regularization constraints based on this assumption. First, we design the penalty that a manifold regularization term is integrated to make single pixel information and neighborhood context information. This geometric perception is that the data in the original image have the same locally geometric shape in related to the segmented result. Next, the manifold regularization constraint method mentioned above is combined with the current mainstream semi-supervised and weakly-supervised image segmentation algorithms, which illustrates that our manifold regularization algorithm can well adapt to various different segmentation tasks. In the semi-supervised and weakly-supervised manifold regularization algorithms, a cutting-edged cross-consistency training model is selected as our skeleton network, and the semi-supervised training method of cross-consistency is given different forms of perturbation to the encoder output to strengthen the predictive invariance of the model. We use the open source toolbox Pytorch to build the model. The stochastic gradient descent (SGD) method is adopted as the optimization. The operating system of the experimental platform is Centos7, with a graphics processing unit (GPU) of model NVIDIA RTX 2080Ti and a CPU of Intel (R) Core (TM) i7-6850.ResultBy adding manifold regularization constraints, the contextual information is captured in the image, the loss of the intrinsic structure caused by the network is reduced forward calculation process, and the accuracy of the algorithm is improved. In order to verify the effectiveness of the algorithm, experiments are based on two different types of semi-supervised and weakly-supervised semantic segmentation. On the pattern analysis, statistical modeling and computational learning visual object classes 2012 (PASCAL VOC 2012) dataset, the semi-supervised semantic segmentation task is improved by 3.7% compared to the original network. Our weakly supervised semantic segmentation algorithm is improved by 1.1% compared with the original network. Furthermore, we implement visualization of the segmentation results on different models. It can be found that the segmentation results generated by manifold regularization constraints have more refined edges and less error rate.ConclusionOur algorithm is based on the contextual information through manifold regularization constraints, and is optimized in semi-supervised and weak-supervised tasks without changing the original network structure. The experimental results verify that our algorithm is potential to generalization and optimal ability.关键词:deep learning;semantic segmentation;semi-supervised semantic segmentation;weakly-supervised semantic segmentation;cross-consistency training;manifold regularization167|211|2更新时间:2024-05-07 -
 摘要:ObjectiveImage in-painting is to reconstruct the missing areas of distorted images. This technique is widely used in multiple scenes like image editing, image de-noising, cultural relics preservation. Conventional image in-painting methods are based on patch blocks to fill the missing pixels or to transmit the pixels to the missing region via diffusion mechanism. These methods have achieved regular effects or small defects in in-painting. However, due to the lack of semantic understanding of the image, more generated images often have a non-photorealistic sense of inconsistent semantic structure when filling large-scale consistent holes. Deep learning-based in-painting method can learn the high-level semantic information of the image from a large number of data. Although these methods have made significant progress in image inpainting, they are often unable to reconstruct feasible structures. Current methods are focused on target-completed restoration without sufficient constraints, so the generated images often have the problems of fuzzy boundaries and distorted structures.MethodOur research is aimed to develop a deep image inpainting method guided by semantic segmentation and edge. It divides the image inpainting task into three steps: 1) semantic segmentation reconstruction, 2) edge reconstruction and 3) content restoration. First, the semantic segmentation reconstruction module reconstructs the semantic segmentation structure. Then, the reconstructed semantic segmentation structure is used to guide the reconstruction of the edge structure of the missing area. Finally, the reconstructed semantic segmentation structure and edge structure are used to guide the content restoration of the missing area. Semantic segmentation can represent the global structure information of the image well. 1) The reconstruction of the semantic segmentation structure can improve the accuracy of edge structure-reconstructed. 2) Edge contains rich structural information, reconstructing the edge structure is beneficial to generate more inner details of object. 3) Under the guidance of reconstructed semantic segmentation structure and edge structure, the content restoration can use texture in-painting to clear the boundary of the generated image. The structure is more reasonable, and the texture is more real. Our network structure is based on the generative adversarial network (GAN-based), including generator and discriminator. The generator network uses encoder-decoder structure and the discriminator network uses 70 × 70 PatchGAN structure. Joint loss is adopted in terms of loss function in the three steps, which can approach the in-painting results of each step to real results. The two reconstructed modules of semantic segmentation and edge use adversarial loss and feature matching loss. Our feature matching loss used actually includes L1 loss function. Feature matching loss is similar to perceptual loss, which can clarify the ground truth issue of semantic segmentation structure and edge structure. The content restoration module can add the perception loss and style loss in the context of image in-painting when style loss can reduce the "checkerboard" artifact caused by transpose convolution layer.ResultFirst, we analyze the performance of semantic segmentation reconstruction module quantitatively and qualitatively. The results show that the semantic segmentation reconstruction module can reconstruct the feasibility of semantic segmentation structure. When the mask is small, the pixel accuracy can reach 99.16%, and for the larger mask, the pixel accuracy can also reach 92.64%. Next, we compare the edge reconstruction results quantitatively. It shows that the accuracy and recall of the reconstructed edge structure are optimized further under the guidance of the semantic segmentation structure. Finally, the method proposed is compared with four popular image in-painting methods on CelebAMask HQ (celebfaces attributes mask high quality) dataset and Cityscapes dataset. When the mask ratio is 50%~60%, compared with the second-performing method, the mean absolute error (MAE) on the CelebAMask-HQ dataset is reduced by 4.5%, the peak signal-to-noise ratio (PSNR) is increased by 1.6%, and the structure similarity index measure (SSIM) is increased by 1.7%; the MAE on the Cityscapes dataset is reduced by 4.2%, the PSNR is increased by 1.5%, and the SSIM is increased by 1.9%. Our method is optimized for the three indexes of MAE, PSNR and SSIM, the generated image has more clear boundaries and visibility.ConclusionOur 3-steps image in-painting method introduces the guidance of semantic segmentation structure, which can significantly improve the accuracy of edge reconstruction. In addition, it can reduce structure reconstruction errors effectively through the joint guidance of semantic segmentation structure and edge structure. It has stronger potentials in-painting quality for large-area deletions-oriented in-painting task.关键词:image inpainting;generative adversarial network(GAN);semantic segmentation;edge detection;deeplearning225|476|2更新时间:2024-05-07
摘要:ObjectiveImage in-painting is to reconstruct the missing areas of distorted images. This technique is widely used in multiple scenes like image editing, image de-noising, cultural relics preservation. Conventional image in-painting methods are based on patch blocks to fill the missing pixels or to transmit the pixels to the missing region via diffusion mechanism. These methods have achieved regular effects or small defects in in-painting. However, due to the lack of semantic understanding of the image, more generated images often have a non-photorealistic sense of inconsistent semantic structure when filling large-scale consistent holes. Deep learning-based in-painting method can learn the high-level semantic information of the image from a large number of data. Although these methods have made significant progress in image inpainting, they are often unable to reconstruct feasible structures. Current methods are focused on target-completed restoration without sufficient constraints, so the generated images often have the problems of fuzzy boundaries and distorted structures.MethodOur research is aimed to develop a deep image inpainting method guided by semantic segmentation and edge. It divides the image inpainting task into three steps: 1) semantic segmentation reconstruction, 2) edge reconstruction and 3) content restoration. First, the semantic segmentation reconstruction module reconstructs the semantic segmentation structure. Then, the reconstructed semantic segmentation structure is used to guide the reconstruction of the edge structure of the missing area. Finally, the reconstructed semantic segmentation structure and edge structure are used to guide the content restoration of the missing area. Semantic segmentation can represent the global structure information of the image well. 1) The reconstruction of the semantic segmentation structure can improve the accuracy of edge structure-reconstructed. 2) Edge contains rich structural information, reconstructing the edge structure is beneficial to generate more inner details of object. 3) Under the guidance of reconstructed semantic segmentation structure and edge structure, the content restoration can use texture in-painting to clear the boundary of the generated image. The structure is more reasonable, and the texture is more real. Our network structure is based on the generative adversarial network (GAN-based), including generator and discriminator. The generator network uses encoder-decoder structure and the discriminator network uses 70 × 70 PatchGAN structure. Joint loss is adopted in terms of loss function in the three steps, which can approach the in-painting results of each step to real results. The two reconstructed modules of semantic segmentation and edge use adversarial loss and feature matching loss. Our feature matching loss used actually includes L1 loss function. Feature matching loss is similar to perceptual loss, which can clarify the ground truth issue of semantic segmentation structure and edge structure. The content restoration module can add the perception loss and style loss in the context of image in-painting when style loss can reduce the "checkerboard" artifact caused by transpose convolution layer.ResultFirst, we analyze the performance of semantic segmentation reconstruction module quantitatively and qualitatively. The results show that the semantic segmentation reconstruction module can reconstruct the feasibility of semantic segmentation structure. When the mask is small, the pixel accuracy can reach 99.16%, and for the larger mask, the pixel accuracy can also reach 92.64%. Next, we compare the edge reconstruction results quantitatively. It shows that the accuracy and recall of the reconstructed edge structure are optimized further under the guidance of the semantic segmentation structure. Finally, the method proposed is compared with four popular image in-painting methods on CelebAMask HQ (celebfaces attributes mask high quality) dataset and Cityscapes dataset. When the mask ratio is 50%~60%, compared with the second-performing method, the mean absolute error (MAE) on the CelebAMask-HQ dataset is reduced by 4.5%, the peak signal-to-noise ratio (PSNR) is increased by 1.6%, and the structure similarity index measure (SSIM) is increased by 1.7%; the MAE on the Cityscapes dataset is reduced by 4.2%, the PSNR is increased by 1.5%, and the SSIM is increased by 1.9%. Our method is optimized for the three indexes of MAE, PSNR and SSIM, the generated image has more clear boundaries and visibility.ConclusionOur 3-steps image in-painting method introduces the guidance of semantic segmentation structure, which can significantly improve the accuracy of edge reconstruction. In addition, it can reduce structure reconstruction errors effectively through the joint guidance of semantic segmentation structure and edge structure. It has stronger potentials in-painting quality for large-area deletions-oriented in-painting task.关键词:image inpainting;generative adversarial network(GAN);semantic segmentation;edge detection;deeplearning225|476|2更新时间:2024-05-07 -
 摘要:ObjectiveVideo-based actions understanding has been concerned more under the huge number of internet videos circumstances. As a significant task of video understanding, temporal action detection (TAD) aims at locating the boundary of each action instance and classifying its class label in untrimmed videos. Inspired by the success of object detection, two-stage pipeline dominates the field of TAD: the first stage generates candidate action segments (proposals), which are then labelled with certain classes in the second stage. Overall, performance of TAD largely depends on two aspects: recognizing action patterns and exploring temporal relations. 1) Current methods usually try to recognize the start and end patterns to locate action boundaries, and patterns between boundaries contribute to predicting confidence score of each segment. 2) Much more temporal relations are vital for accurate detection because information in video is closely related temporally, and a broader receptive field helps model to understand context and semantic relations of the whole video. However, existing methods have limitations on these two aspects. In terms of pattern recognition, almost all methods force the model to cater for all kinds of actions (Class-Agnostic), which means that a universal pattern has to be summarized to locate every action's start, end and actionness. This method has challenged for varied patterns dramatically with action classes. As for temporal relations, graph convolution network prevails recently to model temporal relations in video, but this method is computationally costly.MethodWe develop a class-aware network (CAN) with global temporal relations to tackle these two problems and there are two crucial designs in CAN. 1) Different action classes should be treated differently. The model can recognize patterns of various classes unambiguously by this way. Class-aware mechanism (CAM) is embedded into the detection pipeline. It includes several action branches and a universal branch. Each action branch takes charge of one specified class and the universal branch supplies complementary information for more accurate detection. After obtaining a sketchy and general action label of raw video from a video-level classifier, the corresponding action branch of this label in CAM is activated to generate predictions. 2) Gate recurrent unit (GRU)-assisted ternary basenet (TB) is designed to explore temporal relations more effectively. Considering the whole video feature sequence is accessible in offline TAD task, by changing the input order of features, GRU can not only memorize the existed features but also forecast future information gathering. In TB, temporal features are combined simultaneously, so the receptive field of model is not restricted locally but bidirectional extended to the past and future, and thus the video-based global-temporal-relations are built in.ResultOur experiments are carried out on two benchmarks: ActivityNet-1.3 and THUMOS-14. 1) The THUMOS-14 consists of 200 temporally annotated videos in validation set and 213 videos in testing set. A sum of 20 action categories is included. 2) The ActivityNet-1.3 contains 19 994 temporally annotated videos with 200 action classes. Furthermore, the hierarchical structure of all classes is accessible in annotation. The comparative analysis has been conducted as well. 1) On THUMOS-14, the CAN improves the average mean average precision (mAP) to 54.90%. 2) On ActivityNet-1.3, average mAP of CAN is 35.58%, which is higher than its baseline 33.85% and is improved 35.52%. Additionally, ablation experiments demonstrate the effectiveness of our method. Class-aware mechanism and TB contributes to the detection accuracy both. And, TB can build the global-temporal relations effectively with low computational cost compared to graph model, designed by sub-graph localization for temporal action detection (GTAD).ConclusionOur research tends to reveal two key aspects in temporal action detection task: 1) recognize action patterns and 2) exploring temporal relations. The class-aware mechanism (CAM) is designed to detect action segments of different classes rationally and accurately. Moreover, TB provides an effective way to explore temporal relations at frame level. These two ways are integrated into one framework named class-aware network (CAN) with global temporal relations, and has its optimization results on two benchmarks.关键词:video action understanding;video action proposal;video action detection;convolutional neural network(CNN);gate recurrent unit(GRU)82|197|1更新时间:2024-05-07
摘要:ObjectiveVideo-based actions understanding has been concerned more under the huge number of internet videos circumstances. As a significant task of video understanding, temporal action detection (TAD) aims at locating the boundary of each action instance and classifying its class label in untrimmed videos. Inspired by the success of object detection, two-stage pipeline dominates the field of TAD: the first stage generates candidate action segments (proposals), which are then labelled with certain classes in the second stage. Overall, performance of TAD largely depends on two aspects: recognizing action patterns and exploring temporal relations. 1) Current methods usually try to recognize the start and end patterns to locate action boundaries, and patterns between boundaries contribute to predicting confidence score of each segment. 2) Much more temporal relations are vital for accurate detection because information in video is closely related temporally, and a broader receptive field helps model to understand context and semantic relations of the whole video. However, existing methods have limitations on these two aspects. In terms of pattern recognition, almost all methods force the model to cater for all kinds of actions (Class-Agnostic), which means that a universal pattern has to be summarized to locate every action's start, end and actionness. This method has challenged for varied patterns dramatically with action classes. As for temporal relations, graph convolution network prevails recently to model temporal relations in video, but this method is computationally costly.MethodWe develop a class-aware network (CAN) with global temporal relations to tackle these two problems and there are two crucial designs in CAN. 1) Different action classes should be treated differently. The model can recognize patterns of various classes unambiguously by this way. Class-aware mechanism (CAM) is embedded into the detection pipeline. It includes several action branches and a universal branch. Each action branch takes charge of one specified class and the universal branch supplies complementary information for more accurate detection. After obtaining a sketchy and general action label of raw video from a video-level classifier, the corresponding action branch of this label in CAM is activated to generate predictions. 2) Gate recurrent unit (GRU)-assisted ternary basenet (TB) is designed to explore temporal relations more effectively. Considering the whole video feature sequence is accessible in offline TAD task, by changing the input order of features, GRU can not only memorize the existed features but also forecast future information gathering. In TB, temporal features are combined simultaneously, so the receptive field of model is not restricted locally but bidirectional extended to the past and future, and thus the video-based global-temporal-relations are built in.ResultOur experiments are carried out on two benchmarks: ActivityNet-1.3 and THUMOS-14. 1) The THUMOS-14 consists of 200 temporally annotated videos in validation set and 213 videos in testing set. A sum of 20 action categories is included. 2) The ActivityNet-1.3 contains 19 994 temporally annotated videos with 200 action classes. Furthermore, the hierarchical structure of all classes is accessible in annotation. The comparative analysis has been conducted as well. 1) On THUMOS-14, the CAN improves the average mean average precision (mAP) to 54.90%. 2) On ActivityNet-1.3, average mAP of CAN is 35.58%, which is higher than its baseline 33.85% and is improved 35.52%. Additionally, ablation experiments demonstrate the effectiveness of our method. Class-aware mechanism and TB contributes to the detection accuracy both. And, TB can build the global-temporal relations effectively with low computational cost compared to graph model, designed by sub-graph localization for temporal action detection (GTAD).ConclusionOur research tends to reveal two key aspects in temporal action detection task: 1) recognize action patterns and 2) exploring temporal relations. The class-aware mechanism (CAM) is designed to detect action segments of different classes rationally and accurately. Moreover, TB provides an effective way to explore temporal relations at frame level. These two ways are integrated into one framework named class-aware network (CAN) with global temporal relations, and has its optimization results on two benchmarks.关键词:video action understanding;video action proposal;video action detection;convolutional neural network(CNN);gate recurrent unit(GRU)82|197|1更新时间:2024-05-07 -
 摘要:ObjectiveHigh dynamic range (HDR) imaging technology is widely used in modern imaging terminals. Hindered by the performance of the imaging sensor, photographs can capture information only in a limited range. HDR images can be reconstructed effectively through a group of low dynamic range (LDR) images fusion with multiple exposure levels. Due to shooting in real scene accompanied by camera shake and motion of shooting object, different exposures-derived LDR images do not have rigid pixel alignment in space, and the fused HDR results are easy to introduce artifacts, which greatly reduces the image quality. Although the attention based HDR reconstruction methods has a certain effect on improving the image quality, it achieves good results only when the object moves slightly for it does not fully mine the interrelationship in space dimension and channel dimension. When large foreground motion occurs in the scene, there is still a large room for improvement in the effects of these methods. Therefore, it is important to improve the ability of network to eliminate artifacts and restore details in saturated region. We develop multi-scale HDR image reconstruction network guided by spatial-aware channel attention.MethodThe medium-exposure LDR image is used as the reference image, and the remaining images are used as the non-reference images. Therefore, it is necessary to make full use of the effective complementary information of the non-reference images in the process of HDR reconstruction to enhance the dynamic range of the fused image, suppress the invalid information in the non-reference images and prevent the introduction of artifacts and saturation. In order to improve the ability of the network to eliminate artifacts and restore the details of saturated areas, we demonstrate a spatial-aware channel attention mechanism (SACAM) and a multi-scale information reconstruction module (MIM). In the process of mining channel context, SACAM strengthens the spatial relationship of features further via global information extraction and key information of feature channel dimension. Our research is focused on highlighting the importance of useful information in space dimension and channel dimension, and realizing ghost suppression and effective information enhancement in features. The MIM is beneficial to increase the network receptive field, strengthen the significant information of feature space dimension, and make full use of the contextual semantic information of different scale features to reconstruct the final HDR image.ResultOur experiments are carried out on three public HDR datasets, including Kalantari dataset, Sen dataset and Tursun dataset. It can obtain better visual performance and higher objective evaluation results. Specifically, 1) on the Kalantari dataset, our PSNR-L and SSIM-L are 41.101 3 and 0.986 5, respectively. PSNR-μ and SSIM-μ are 43.413 6 and 0.990 2, respectively. HDR-VDP-2 is 64.985 3. In order to verify the generalization performance of each method, we also compare the experimental results on unlabeled Sen dataset and Tursun dataset. 2) On Sen dataset, our method can not only effectively suppress the ghosts, but also resilient clearer image details. 3) On the Tursun dataset, we reconstruct scene structure more real and avoid the artifacts effectively. In addition, ablation study proves the effectiveness of the proposed method.ConclusionA spatial-aware channel attention guided multi-scale HDR reconstruction network (SCAMNet) is facilitated. The spatial aware channel attention mechanism and multi-scale information reconstruction module are integrated into one framework, which effectively solves the artifact caused by target motion and detail recovery in saturated region. To enhance the useful information in the features for the reconstructed image, our spatial-aware channel attention mechanism tends to establish the relationship between features in spatial and channel dimensions. The multi-scale information reconstruction module makes full use of the context semantic relationship of different scale features to further mine the useful information in the input image and reconstruct the HDR image. The potentials of our method are evaluated and verified qualitatively and quantitatively.关键词:multi-exposure image fusion;high dynamic range(HDR);attention;multiscale;ghost suppression128|198|1更新时间:2024-05-07
摘要:ObjectiveHigh dynamic range (HDR) imaging technology is widely used in modern imaging terminals. Hindered by the performance of the imaging sensor, photographs can capture information only in a limited range. HDR images can be reconstructed effectively through a group of low dynamic range (LDR) images fusion with multiple exposure levels. Due to shooting in real scene accompanied by camera shake and motion of shooting object, different exposures-derived LDR images do not have rigid pixel alignment in space, and the fused HDR results are easy to introduce artifacts, which greatly reduces the image quality. Although the attention based HDR reconstruction methods has a certain effect on improving the image quality, it achieves good results only when the object moves slightly for it does not fully mine the interrelationship in space dimension and channel dimension. When large foreground motion occurs in the scene, there is still a large room for improvement in the effects of these methods. Therefore, it is important to improve the ability of network to eliminate artifacts and restore details in saturated region. We develop multi-scale HDR image reconstruction network guided by spatial-aware channel attention.MethodThe medium-exposure LDR image is used as the reference image, and the remaining images are used as the non-reference images. Therefore, it is necessary to make full use of the effective complementary information of the non-reference images in the process of HDR reconstruction to enhance the dynamic range of the fused image, suppress the invalid information in the non-reference images and prevent the introduction of artifacts and saturation. In order to improve the ability of the network to eliminate artifacts and restore the details of saturated areas, we demonstrate a spatial-aware channel attention mechanism (SACAM) and a multi-scale information reconstruction module (MIM). In the process of mining channel context, SACAM strengthens the spatial relationship of features further via global information extraction and key information of feature channel dimension. Our research is focused on highlighting the importance of useful information in space dimension and channel dimension, and realizing ghost suppression and effective information enhancement in features. The MIM is beneficial to increase the network receptive field, strengthen the significant information of feature space dimension, and make full use of the contextual semantic information of different scale features to reconstruct the final HDR image.ResultOur experiments are carried out on three public HDR datasets, including Kalantari dataset, Sen dataset and Tursun dataset. It can obtain better visual performance and higher objective evaluation results. Specifically, 1) on the Kalantari dataset, our PSNR-L and SSIM-L are 41.101 3 and 0.986 5, respectively. PSNR-μ and SSIM-μ are 43.413 6 and 0.990 2, respectively. HDR-VDP-2 is 64.985 3. In order to verify the generalization performance of each method, we also compare the experimental results on unlabeled Sen dataset and Tursun dataset. 2) On Sen dataset, our method can not only effectively suppress the ghosts, but also resilient clearer image details. 3) On the Tursun dataset, we reconstruct scene structure more real and avoid the artifacts effectively. In addition, ablation study proves the effectiveness of the proposed method.ConclusionA spatial-aware channel attention guided multi-scale HDR reconstruction network (SCAMNet) is facilitated. The spatial aware channel attention mechanism and multi-scale information reconstruction module are integrated into one framework, which effectively solves the artifact caused by target motion and detail recovery in saturated region. To enhance the useful information in the features for the reconstructed image, our spatial-aware channel attention mechanism tends to establish the relationship between features in spatial and channel dimensions. The multi-scale information reconstruction module makes full use of the context semantic relationship of different scale features to further mine the useful information in the input image and reconstruct the HDR image. The potentials of our method are evaluated and verified qualitatively and quantitatively.关键词:multi-exposure image fusion;high dynamic range(HDR);attention;multiscale;ghost suppression128|198|1更新时间:2024-05-07 -
 摘要:ObjectiveComputer vision-related object detection has been widely used in public security, clinical, automatic driving and contexts. Current convolutional neural network based (CNN-based) object detectors are divided into one-stage and two-stage according to the process status. The two-stage method is based on a feature extraction network to extract multiple candidate regions at the beginning and the following additional convolution modules are used to perform detection bounding boxes regression and object classification on the candidate regions. The one-stage method is based on a single convolution model to extract features straightforwardly derived from the original image in terms of regression and outputs information, such as the number, position, and size of detection boxes, which has realistic real-time performance. one-stage object detectors like single shot multibox detector(SSD) and you only look once(YOLO) have high real-time performance and high detection accuracy. However, these models require a huge amount computing resources and are challenged to deploy and apply in embedded scenes like automatic driving, automatic production, urban monitoring, human face recognition, and mobile terminals. There are two problems to be resolved in the one-stage object detection network: 1) redundant convolution calculations in the feature extraction and feature fusion parts of the network. Conventional object detection models are usually optimized the width of the model by reducing the number of feature channels in the convolution layer in the feature extraction part and the depth of the model is resilient by reducing the number of convolution layers stacked. However, the redundant calculations cannot be dealt with in the convolution layer and cause intensive detection accuracy loss; 2) one-stage models often use feature pyramid network(FPN) or path aggregation network(PANet) modules for multi-scale feature fusion, which leads to more calculation costs.MethodFirst, we design and construct a variety of efficient lightweight modules. The GhostBottleneck layer is used to optimize the channel dimension and down-sample the feature maps at the same time, which can reduce the computational cost and enhance the feature extraction capability of the backbone. The GhostC3 module is designed for feature extraction and multi-scale feature fusion at different stages, which is cost-effective in feature extraction and keeps the feature extraction capability. An attention module local channel and spatial(LCS) is proposed to enhance the local information of regions and channels, so as to increase the attention of the model to the regions and channels of interest with smaller cost. The efficient spatial pyramid pooling (ESPP) module is designed, in which GhostConv is used to reduce the huge cost of dimension reduction of network deep channel, and the redundant calculation of multiple pooling is optimized. For the extra cost caused by multi-scale feature fusion, a more efficient and lightweight efficient PANet (EPANet) structure is designed, a multi-scale feature weighted fusion is linked to weaken the overhead of channel dimension reduction, and a long skip connection of middle-level features is added to alleviate the problem of feature loss in PANet. A lightweight one-stage object detector framework illustrated based on YOLOv5, which is called Efficient-YOLO. We use the Efficient-YOLO framework to construct two networks with different sizes, E-YOLOm and E-YOLOs. Our methods are implemented in Ubuntu18.04 in terms of PyTorch deep learning framework and the YOLOv5 project. The default parameter settings of the YOLOv5 is used with the version of v5.0 during training. The pre-training weights are not loaded for scratch training on the visual object classes(VOC) dataset. The pre-training weights on the VOC dataset are used for fine-tuning with the same network structure on the GlobalWheat2020 dataset.ResultThe number of parameters in E-YOLOm and E-YOLOs are decreased by 71.5% and 61.6% in comparison with YOLOv5m and YOLOv5s, and the FLOPs of them are decreased by 67.3% and 49.7%. For the average precision(AP), the AP of E-YOLOm on generic object detection dataset VOC is 2.3% lower than YOLOv5m, and E-YOLOs is 3.4% higher than YOLOv5s. To get smaller computation cost and higher detection efficiency, E-YOLOm has 15.5% and 1.7% lower parameters and 1.9% higher FLOPs compared to YOLOv5s, while mAP@0.5 and AP are 3.9% and 11.1% higher than it. Compared with YOLOv5m and YOLOv5s, the AP of E-YOLOm and E-YOLOs are decreased by 1.4% and 0.4% only of each on GlobalWheat2020. This indicates that Efficient-YOLO is also robust for detecting small objects. Similarly, the AP of E-YOLOm is 0.3% higher than those of YOLOv5s. It reflects that Efficient-YOLO is still more efficient in detecting small objects. At the same time, the lightweight improvement of the backbone proposed by Efficient-YOLO is optimized the latest lightweight CNN architectures like ShuffleNetv2 and MobileNetv3. In addition, the GhostBottleneck layer with the stride of 2 is used to upgrade and down-sample the feature in the backbone, and the GhostConv is used to reduce the channel dimension in ESPP. It can reduce the cost of parameters and computation of the model effectively and improve the detection accuracy dramatically. The results indicate that GhostConv can reduce the number of redundant convolution kernels and improve the information content of the output feature map.ConclusionExperiments show that our Efficient-YOLO framework is cost-effective for redundant convolution computation and multi-scale fusion in one-stage object detection networks. It has good robustness. At the same time, our lightweight feature extraction block and attention module can optimize the performance of the detectors further.关键词:convolutional neural network(CNN);object detection;lightweight models;attention module;multi-scale fusion91|240|1更新时间:2024-05-07
摘要:ObjectiveComputer vision-related object detection has been widely used in public security, clinical, automatic driving and contexts. Current convolutional neural network based (CNN-based) object detectors are divided into one-stage and two-stage according to the process status. The two-stage method is based on a feature extraction network to extract multiple candidate regions at the beginning and the following additional convolution modules are used to perform detection bounding boxes regression and object classification on the candidate regions. The one-stage method is based on a single convolution model to extract features straightforwardly derived from the original image in terms of regression and outputs information, such as the number, position, and size of detection boxes, which has realistic real-time performance. one-stage object detectors like single shot multibox detector(SSD) and you only look once(YOLO) have high real-time performance and high detection accuracy. However, these models require a huge amount computing resources and are challenged to deploy and apply in embedded scenes like automatic driving, automatic production, urban monitoring, human face recognition, and mobile terminals. There are two problems to be resolved in the one-stage object detection network: 1) redundant convolution calculations in the feature extraction and feature fusion parts of the network. Conventional object detection models are usually optimized the width of the model by reducing the number of feature channels in the convolution layer in the feature extraction part and the depth of the model is resilient by reducing the number of convolution layers stacked. However, the redundant calculations cannot be dealt with in the convolution layer and cause intensive detection accuracy loss; 2) one-stage models often use feature pyramid network(FPN) or path aggregation network(PANet) modules for multi-scale feature fusion, which leads to more calculation costs.MethodFirst, we design and construct a variety of efficient lightweight modules. The GhostBottleneck layer is used to optimize the channel dimension and down-sample the feature maps at the same time, which can reduce the computational cost and enhance the feature extraction capability of the backbone. The GhostC3 module is designed for feature extraction and multi-scale feature fusion at different stages, which is cost-effective in feature extraction and keeps the feature extraction capability. An attention module local channel and spatial(LCS) is proposed to enhance the local information of regions and channels, so as to increase the attention of the model to the regions and channels of interest with smaller cost. The efficient spatial pyramid pooling (ESPP) module is designed, in which GhostConv is used to reduce the huge cost of dimension reduction of network deep channel, and the redundant calculation of multiple pooling is optimized. For the extra cost caused by multi-scale feature fusion, a more efficient and lightweight efficient PANet (EPANet) structure is designed, a multi-scale feature weighted fusion is linked to weaken the overhead of channel dimension reduction, and a long skip connection of middle-level features is added to alleviate the problem of feature loss in PANet. A lightweight one-stage object detector framework illustrated based on YOLOv5, which is called Efficient-YOLO. We use the Efficient-YOLO framework to construct two networks with different sizes, E-YOLOm and E-YOLOs. Our methods are implemented in Ubuntu18.04 in terms of PyTorch deep learning framework and the YOLOv5 project. The default parameter settings of the YOLOv5 is used with the version of v5.0 during training. The pre-training weights are not loaded for scratch training on the visual object classes(VOC) dataset. The pre-training weights on the VOC dataset are used for fine-tuning with the same network structure on the GlobalWheat2020 dataset.ResultThe number of parameters in E-YOLOm and E-YOLOs are decreased by 71.5% and 61.6% in comparison with YOLOv5m and YOLOv5s, and the FLOPs of them are decreased by 67.3% and 49.7%. For the average precision(AP), the AP of E-YOLOm on generic object detection dataset VOC is 2.3% lower than YOLOv5m, and E-YOLOs is 3.4% higher than YOLOv5s. To get smaller computation cost and higher detection efficiency, E-YOLOm has 15.5% and 1.7% lower parameters and 1.9% higher FLOPs compared to YOLOv5s, while mAP@0.5 and AP are 3.9% and 11.1% higher than it. Compared with YOLOv5m and YOLOv5s, the AP of E-YOLOm and E-YOLOs are decreased by 1.4% and 0.4% only of each on GlobalWheat2020. This indicates that Efficient-YOLO is also robust for detecting small objects. Similarly, the AP of E-YOLOm is 0.3% higher than those of YOLOv5s. It reflects that Efficient-YOLO is still more efficient in detecting small objects. At the same time, the lightweight improvement of the backbone proposed by Efficient-YOLO is optimized the latest lightweight CNN architectures like ShuffleNetv2 and MobileNetv3. In addition, the GhostBottleneck layer with the stride of 2 is used to upgrade and down-sample the feature in the backbone, and the GhostConv is used to reduce the channel dimension in ESPP. It can reduce the cost of parameters and computation of the model effectively and improve the detection accuracy dramatically. The results indicate that GhostConv can reduce the number of redundant convolution kernels and improve the information content of the output feature map.ConclusionExperiments show that our Efficient-YOLO framework is cost-effective for redundant convolution computation and multi-scale fusion in one-stage object detection networks. It has good robustness. At the same time, our lightweight feature extraction block and attention module can optimize the performance of the detectors further.关键词:convolutional neural network(CNN);object detection;lightweight models;attention module;multi-scale fusion91|240|1更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectivePoint cloud-based 3D human pose estimation is one of the key aspects in computer vision. A wide range of its applications have been developing in augmented reality/virtual reality (AR/VR), human-computer interaction (HCI), motion retargeting, and virtual avatar manipulation. Current deep learning-based 3D human pose estimation has been challenging on the following aspects: 1) the 3D human pose estimation task is constrained of the occlusion and self-occlusion ambiguity. Moreover, the noisy point clouds from depth cameras may cause difficulties to learn a proper human pose estimation model. 2) Current depth-image based methods are mainly focused on single image-derived pose estimation, which may ignore the intrinsic priors of human motion smoothness and leads to jittery artifacts results on consistent point cloud sequences. The potential is to leverage point cloud sequences for high-fidelity human pose estimation via human motion smoothness enforcement. However, it is challenging to design an effective way to get human poses by modeling point cloud sequences. 3) It is hard to collect large-scale real image dataset with high-quality 3D human pose annotations for fully-supervised training, while it is easy to collect real dataset with 2D human pose annotations. Moreover, human pose estimation is closely related to motion prediction, which aims to predict the future motion available. The challenging issue is whether 3D human poses estimation and motion prediction can realize mutual benefit.MethodWe develop a method to obtain high fidelity 3D human pose from point cloud sequence. The weakly-supervised deep learning architecture is used to learn 3D human pose from 3D point cloud sequences. We design a dual-level human pose estimation pipeline using point cloud sequences as input. 1) The 2D pose information is estimated from the depth maps, so that the background is removed and the pose-aware point clouds are extracted. To ensure that the normalized sequential point clouds are in the same scale, the point clouds normalization is carried out based on a fixed bounding box for all the point clouds. 2) Pose encoding has been implemented via hierarchical PointNet++ backbone and long short-term memory (LSTM) layers based on the spatial-temporal features of pose-aware point cloud sequences. To improve the optimization effect, a multi-task network is employed to jointly resolve human pose estimation and motion prediction problem. In order to use more training data with 2D human pose annotations and release the ambiguity by the supervision of 2D joints, weakly-supervised learning is adopted in our framework.ResultIn order to validate the performance of the proposed algorithm, several experiments are conducted on two public datasets, including invariant-top view dataset(ITOP) and NTU-RGBD dataset. The performance of our methods is compared to some popular methods including V2VPoseNet, viewpoint invariant method (VI), Inference Embedded method and the weakly supervised adversarial learning methods (WSM). For the ITOP dataset, our mean average precision (mAP) value is 0.99% point higher than that of WSM given the threshold of 10 cm. Compared with VI and Inference Embedded method, each mAP value is 13.18% and 17.96% higher. Each of mean joint errors is 3.33 cm, 5.17 cm, 1.67 cm and 0.67 cm, which is lower than the VI method, Inference Embedded method, V2V-PoseNet and WSM, respectively. The performance gain could be originated from the sequential input data and the constraints from the motion parameters like velocity and the accelerated velocity. 1) The sequential data is encoded through the LSTM units, which could get the smoother prediction and improve the estimation performance. 2) The motion parameters can alleviate the jitters caused by random sampling and yield the direct supervision of the joint coordinates. For the NTU-RGBD dataset, we compare our method with current WSM. The mAP value of our method is 7.03 percentage points higher than that with WSM if the threshold is set to 10 cm. At the same time, ablation experiments are carried out on the ITOP dataset to investigate the effect of multiple components. To understand the effect of the input sequential point clouds, we design experiment with different temporal receptive field of the sequential point clouds. The receptive field is set to 1 for the estimated results of the sequential data excluded. The percentage of correct keypoints (PCK) result drops to the lowest value of 88.57% when the receptive field is set to 1, the PCK values can be increased as the receptive field increases from 1 to 5, and the PCK value becomes more steadily when the receptive field is greater than 13. Our PCK value is 87.55% trained only with fully labeled data and the PCK value of the model trained with fully and weakly labeled data is 90.58%. It shows that our weakly supervised learning methods can improve the performance of our model by 2 point percentage. And, the experiments demonstrate that our weakly supervised learning method can be used for a small amount of fully labeled data as well. Compared with model trained for single task, the mAP of human pose estimation and motion prediction based on multi task network can be improved by more than 2 percentage points.ConclusionTo obtain smoother human pose estimation results, our method can make full use of the prior of human motion continuity. All experiments demonstrate that our contributed components are all effective, and our method can achieve the state-of-the-art performance efficiently on ITOP dataset and NTU-RGBD dataset. The joint training strategy is valid for the mutual tasks of human pose estimation and motion prediction. With the weakly supervised method on sequential data, it can use more easy-to-access training data and our model is robust over different levels of training data annotations. It could be applied to such of scenarios, which require high-quality human poses like motion retargeting and virtual fitting. Our method has its related potentials of using sequential data as input.关键词:human motion;human pose estimation;human motion prediction;point cloud sequence;weakly-supervised learning266|230|1更新时间:2024-05-07
摘要:ObjectivePoint cloud-based 3D human pose estimation is one of the key aspects in computer vision. A wide range of its applications have been developing in augmented reality/virtual reality (AR/VR), human-computer interaction (HCI), motion retargeting, and virtual avatar manipulation. Current deep learning-based 3D human pose estimation has been challenging on the following aspects: 1) the 3D human pose estimation task is constrained of the occlusion and self-occlusion ambiguity. Moreover, the noisy point clouds from depth cameras may cause difficulties to learn a proper human pose estimation model. 2) Current depth-image based methods are mainly focused on single image-derived pose estimation, which may ignore the intrinsic priors of human motion smoothness and leads to jittery artifacts results on consistent point cloud sequences. The potential is to leverage point cloud sequences for high-fidelity human pose estimation via human motion smoothness enforcement. However, it is challenging to design an effective way to get human poses by modeling point cloud sequences. 3) It is hard to collect large-scale real image dataset with high-quality 3D human pose annotations for fully-supervised training, while it is easy to collect real dataset with 2D human pose annotations. Moreover, human pose estimation is closely related to motion prediction, which aims to predict the future motion available. The challenging issue is whether 3D human poses estimation and motion prediction can realize mutual benefit.MethodWe develop a method to obtain high fidelity 3D human pose from point cloud sequence. The weakly-supervised deep learning architecture is used to learn 3D human pose from 3D point cloud sequences. We design a dual-level human pose estimation pipeline using point cloud sequences as input. 1) The 2D pose information is estimated from the depth maps, so that the background is removed and the pose-aware point clouds are extracted. To ensure that the normalized sequential point clouds are in the same scale, the point clouds normalization is carried out based on a fixed bounding box for all the point clouds. 2) Pose encoding has been implemented via hierarchical PointNet++ backbone and long short-term memory (LSTM) layers based on the spatial-temporal features of pose-aware point cloud sequences. To improve the optimization effect, a multi-task network is employed to jointly resolve human pose estimation and motion prediction problem. In order to use more training data with 2D human pose annotations and release the ambiguity by the supervision of 2D joints, weakly-supervised learning is adopted in our framework.ResultIn order to validate the performance of the proposed algorithm, several experiments are conducted on two public datasets, including invariant-top view dataset(ITOP) and NTU-RGBD dataset. The performance of our methods is compared to some popular methods including V2VPoseNet, viewpoint invariant method (VI), Inference Embedded method and the weakly supervised adversarial learning methods (WSM). For the ITOP dataset, our mean average precision (mAP) value is 0.99% point higher than that of WSM given the threshold of 10 cm. Compared with VI and Inference Embedded method, each mAP value is 13.18% and 17.96% higher. Each of mean joint errors is 3.33 cm, 5.17 cm, 1.67 cm and 0.67 cm, which is lower than the VI method, Inference Embedded method, V2V-PoseNet and WSM, respectively. The performance gain could be originated from the sequential input data and the constraints from the motion parameters like velocity and the accelerated velocity. 1) The sequential data is encoded through the LSTM units, which could get the smoother prediction and improve the estimation performance. 2) The motion parameters can alleviate the jitters caused by random sampling and yield the direct supervision of the joint coordinates. For the NTU-RGBD dataset, we compare our method with current WSM. The mAP value of our method is 7.03 percentage points higher than that with WSM if the threshold is set to 10 cm. At the same time, ablation experiments are carried out on the ITOP dataset to investigate the effect of multiple components. To understand the effect of the input sequential point clouds, we design experiment with different temporal receptive field of the sequential point clouds. The receptive field is set to 1 for the estimated results of the sequential data excluded. The percentage of correct keypoints (PCK) result drops to the lowest value of 88.57% when the receptive field is set to 1, the PCK values can be increased as the receptive field increases from 1 to 5, and the PCK value becomes more steadily when the receptive field is greater than 13. Our PCK value is 87.55% trained only with fully labeled data and the PCK value of the model trained with fully and weakly labeled data is 90.58%. It shows that our weakly supervised learning methods can improve the performance of our model by 2 point percentage. And, the experiments demonstrate that our weakly supervised learning method can be used for a small amount of fully labeled data as well. Compared with model trained for single task, the mAP of human pose estimation and motion prediction based on multi task network can be improved by more than 2 percentage points.ConclusionTo obtain smoother human pose estimation results, our method can make full use of the prior of human motion continuity. All experiments demonstrate that our contributed components are all effective, and our method can achieve the state-of-the-art performance efficiently on ITOP dataset and NTU-RGBD dataset. The joint training strategy is valid for the mutual tasks of human pose estimation and motion prediction. With the weakly supervised method on sequential data, it can use more easy-to-access training data and our model is robust over different levels of training data annotations. It could be applied to such of scenarios, which require high-quality human poses like motion retargeting and virtual fitting. Our method has its related potentials of using sequential data as input.关键词:human motion;human pose estimation;human motion prediction;point cloud sequence;weakly-supervised learning266|230|1更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveMulti-modal medical image fusion tends to get more detailed features beyond single modal defection. The deep features of lesions are essential for clinical diagnosis. However, current multi-modal medical image fusion methods are challenged to capture the deep features. The integrity of fusion image is affected when extracting features from a single modal only. In recent years, deep learning technique is developed in image processing, and generative adversarial network (GAN), as an important branch of deep learning, has been widely used in image fusion. GAN not only reduces information loss but also highlights key features through information confrontation between different original images. The deep feature extraction ability of current multi-modal medical image fusion methods is insufficient and some modal features are ignored. We develop a medical image fusion method based on the improved U-Net3+ and cross-modal attention blocks in combination with dual discriminator generation adversative network (UC-DDGAN).MethodThe UC-DDGAN image fusion modal is mainly composed of full scale connected U-Net3+ network structure and two modal features integrated cross-modal attention blocks. The U-Net3+ network can extract deep features, and the cross-modal attention blocks can extract different modal features in terms of the correlation between images. Computed tomography (CT) and magnetic resonance (MR) can be fused through the trained UC-DDGAN, which has a generator and two discriminators. The generator is used to extract the deep features of image and generate fusion image. The generator includes two parts of feature extraction and feature fusion. In the feature extraction part, the encoding and decoding of coordinated U-Net3+ network complete feature extraction. In the coding stage, the input image is down-sampled four times to extract features, and cross-modal attention blocks are added after each down-sampling to obtain two modal composite feature maps. Cross-modal attention block not only calculates self-attention in a single image, but also extends the calculation of attention to two modes. By calculating the relationship between local features and global features of the two modes, the fusion image preserves the overall of image information. In the decoding stage, the decoder receives the feature maps in the context of the same scale encoder and the maximum pooling based smaller scale encoder and the dual up-sampling based large scale encoder. Then, 64 filters with a size of 3×3 are linked to the feature image channels. The synthesized feature maps of each layer are combined and up-sampled. After 1×1 convolution for channel dimension reduction, the feature maps are fused into the image which contains depth features on the full scale of the two modes. In the feature fusion part, to obtain the fusion image with deep details and the key features of the two modes, the two feature maps are synthesized and concatenated via the concat layer, and five convolution modules for channel dimension reduction layer by layer. The discriminator is focused on leveraging original image from fusion image via the distribution of different samples. To identify the credibility of the input images, the characteristics of different modal images are integrated with different distribution. In addition, gradient loss is melted into the loss function calculation, and the weighted sum of gradient loss and pixel loss are as the loss function to optimize the generator.ResultTo validate the quality of fusion image, UC-DDGAN is compared to five popular multi-modal image fusion methods, including Laplasian pyramid(LAP), pulse-coupled neural network(PCNN), convolutional neural network(CNN), fusion generative adversarial network(FusionGAN) and dual discriminator generative adversarial network(DDcGAN). The edges of fusion results obtained by LAP are fuzzy in qualitative, which are challenged to observe the contour of the lesion. The brightness of fusion results obtained by PCNN is too low. The CNN-based fusion results are lack of deep details, and the internal details cannot be observed. The fusion results obtained by using FusionGAN pay too much attention to MR modal images and lose the bone information of CT images. The edges of fusion results obtained by DDcGAN are not smooth enough. 1)The fusion results of cerebral infarction disease obtained by UC-DDGAN can show clear brain gullies, 2)the fusion results of cerebral apoplexy disease can clarify color features, 3)the fusion results of cerebral tumor disease show brain medulla and bone information are fully reserved, and 4)the fusion results of cerebrovascular disease contain deep-based information of brain lobes. To evaluate the performance of UC-DDGAN, quantitative results are based on the selected thirty typical image pairs and five classical methods. The fusion image generated by UC-DDGAN is improved on spatial frequency (SF), structural similarity (SSIM), edge information transfer factor (
摘要:ObjectiveMulti-modal medical image fusion tends to get more detailed features beyond single modal defection. The deep features of lesions are essential for clinical diagnosis. However, current multi-modal medical image fusion methods are challenged to capture the deep features. The integrity of fusion image is affected when extracting features from a single modal only. In recent years, deep learning technique is developed in image processing, and generative adversarial network (GAN), as an important branch of deep learning, has been widely used in image fusion. GAN not only reduces information loss but also highlights key features through information confrontation between different original images. The deep feature extraction ability of current multi-modal medical image fusion methods is insufficient and some modal features are ignored. We develop a medical image fusion method based on the improved U-Net3+ and cross-modal attention blocks in combination with dual discriminator generation adversative network (UC-DDGAN).MethodThe UC-DDGAN image fusion modal is mainly composed of full scale connected U-Net3+ network structure and two modal features integrated cross-modal attention blocks. The U-Net3+ network can extract deep features, and the cross-modal attention blocks can extract different modal features in terms of the correlation between images. Computed tomography (CT) and magnetic resonance (MR) can be fused through the trained UC-DDGAN, which has a generator and two discriminators. The generator is used to extract the deep features of image and generate fusion image. The generator includes two parts of feature extraction and feature fusion. In the feature extraction part, the encoding and decoding of coordinated U-Net3+ network complete feature extraction. In the coding stage, the input image is down-sampled four times to extract features, and cross-modal attention blocks are added after each down-sampling to obtain two modal composite feature maps. Cross-modal attention block not only calculates self-attention in a single image, but also extends the calculation of attention to two modes. By calculating the relationship between local features and global features of the two modes, the fusion image preserves the overall of image information. In the decoding stage, the decoder receives the feature maps in the context of the same scale encoder and the maximum pooling based smaller scale encoder and the dual up-sampling based large scale encoder. Then, 64 filters with a size of 3×3 are linked to the feature image channels. The synthesized feature maps of each layer are combined and up-sampled. After 1×1 convolution for channel dimension reduction, the feature maps are fused into the image which contains depth features on the full scale of the two modes. In the feature fusion part, to obtain the fusion image with deep details and the key features of the two modes, the two feature maps are synthesized and concatenated via the concat layer, and five convolution modules for channel dimension reduction layer by layer. The discriminator is focused on leveraging original image from fusion image via the distribution of different samples. To identify the credibility of the input images, the characteristics of different modal images are integrated with different distribution. In addition, gradient loss is melted into the loss function calculation, and the weighted sum of gradient loss and pixel loss are as the loss function to optimize the generator.ResultTo validate the quality of fusion image, UC-DDGAN is compared to five popular multi-modal image fusion methods, including Laplasian pyramid(LAP), pulse-coupled neural network(PCNN), convolutional neural network(CNN), fusion generative adversarial network(FusionGAN) and dual discriminator generative adversarial network(DDcGAN). The edges of fusion results obtained by LAP are fuzzy in qualitative, which are challenged to observe the contour of the lesion. The brightness of fusion results obtained by PCNN is too low. The CNN-based fusion results are lack of deep details, and the internal details cannot be observed. The fusion results obtained by using FusionGAN pay too much attention to MR modal images and lose the bone information of CT images. The edges of fusion results obtained by DDcGAN are not smooth enough. 1)The fusion results of cerebral infarction disease obtained by UC-DDGAN can show clear brain gullies, 2)the fusion results of cerebral apoplexy disease can clarify color features, 3)the fusion results of cerebral tumor disease show brain medulla and bone information are fully reserved, and 4)the fusion results of cerebrovascular disease contain deep-based information of brain lobes. To evaluate the performance of UC-DDGAN, quantitative results are based on the selected thirty typical image pairs and five classical methods. The fusion image generated by UC-DDGAN is improved on spatial frequency (SF), structural similarity (SSIM), edge information transfer factor ($ {\rm{Q}}^{{\rm{A B / F}}}$ $ {\rm{Q}}^{{\rm{A B / F}}}$ 关键词:U-Net3+;cross-modal attention block;dual discriminator generation adversative network;gradient loss;multimodal medical image fusion87|634|2更新时间:2024-05-07 -
 摘要:ObjectiveAdenomatous polyp is demonstrated as the early manifestation of colorectal cancer. Early intervention is an effective way to prevent colorectal cancer. Current gastroscopy has been regarded as the "gold standard" for detection and prevention of colorectal cancer. However, a certain probability of missed diagnosis is still existed for clinical examination. Deep learning based gastrointestinal endoscopy segmentation method can aid to assess precancerous lesions efficiently, which has a positive effect on diagnosis and clinical intervention. Intestinal polyps are also characterized by small, round and blurred edges, which greatly increase the difficulty of semantic segmentation. Our research is focused on developing an improved algorithm based on the double-layer encoder-decode structure.MethodOur algorithm comprises of upstream and downstream architectures. The attention weight graph generated by the upstream network training is melted into the decoding part of the downstream network. 1) To promote effective network for target area in the image, the generated attention guidance is clarified to the feature map in the decoding process. The background-area-ignored model can be paid more attention to the segmentation contexts, which has a significant effect on small target recognition in semantic segmentation. 2) The edge extraction issue is concerned as well. Due to the similarity of intestinal wall and polyp mucous membrane, the segmentation target edge is blurred. It is essential to strengthen the edge extraction ability of the model and obtain more accurate segmentation results as well. In order to improve the segmentation ability of polyp target boundary, subspace channel attention is integrated into the cross-connection portion of the downstream network for extracting cross-channel information at multi-resolution and refining the edges. Unlike the convolution operation, a self-attention mechanism is involved in. Its ability to model remote dependencies provides an infinite receptive field for the application of visual models. However, traditional attention mechanism brings a huge amount of additional computational overhead. To realize the refine edge effect, the introduction of lightweight subspace channel attention mechanism can feature each space division, reduce the amount of calculation, learn the attention of multiple features, and get the attention of the fusion feature maps. We conduct tests performed on the public datasets Colonoscopy Videos Challenge-ClinicDataBase(CVC-ClinicDB) and Kvasir-Capsule. The CVC-ClinicDB dataset is used to the image data of intestinal polyps collected by conventional colonoscopy and there are 612 pictures in total, while Kvasir-Capsule dataset tends to the image data of polyps collected by Capsule gastroscopy and there are 55 pictures in total. A big gap needs to be bridged in imaging although the same kinds of targets are collected. At the same time, to further prove the robustness of this algorithm, our tests are carried out on the ultrasound nerve segmentation dataset, which has 5 633 ultrasound images of the brachial plexus taken by the imaging surgeon. The resolution of all images are set to 224×224 pixels and it can be randomly scrambled, divided into training set, verification set and test set according to the ratio of 6∶2∶2 and trained on a single GTX 1080Ti GPU. Our saliency network is implemented in Pytorch. In the experiment, binary cross entropy loss function(BCE loss) and Dice loss are proportionally mixed to construct a new Loss function, which has better performance for semantic segmentation of dichotomies. The Adam optimizer is used as well. The initial learning rate is 0.000 3 and the learning rate attenuation is set.ResultThe Dice similariy coefficient(DCS), mean intersection over union(mIoU), precision and recall are used as the quantitative evaluation metrics, and these metrics are all between 0 and 1. The higher of the index is, the segmentation performance of the model is better. The experimental results showed that the DCS of our model on CVC-ClinicDB and Kvasir-Capsule datasets reached 94.22% and 96.02%, respectively. Compared with U-Net, our DCS, mIoU, precision and recall is increased by 1.89%, 2.42%, 1.04%, 1.87% of each in CVC-ClinicDB dataset and 1.06%, 1.9%, 0.4%, 1.58% in Kvasir-Capsule dataset. The robustness of our algorithm on cross-device images is tested further by mixing the two data sets. Among them, DSC is increased by 17% to 20%, Compared with U-Net, the DCS of our model is increased by 16.73% in CVC-KC dataset (trained on CVC-ClinicDB and tested on Kvasir-Capsule) and 1% in KC-CVC dataset (trained on Kvasir-Capsule and tested on CVC-ClinicDB).ConclusionWe propose an attention segmentation model with dual encode-decoder architecture. Our algorithm can improve the effect of medical image segmentation effectively, and has higher accuracy for small target segmentation and edge segmentation on improving colorectal cancer screening strategies.关键词:polyp segmentation;colonoscopy;deep learning;semantic segmentation;attention mechanism;medical image processing137|170|1更新时间:2024-05-07
摘要:ObjectiveAdenomatous polyp is demonstrated as the early manifestation of colorectal cancer. Early intervention is an effective way to prevent colorectal cancer. Current gastroscopy has been regarded as the "gold standard" for detection and prevention of colorectal cancer. However, a certain probability of missed diagnosis is still existed for clinical examination. Deep learning based gastrointestinal endoscopy segmentation method can aid to assess precancerous lesions efficiently, which has a positive effect on diagnosis and clinical intervention. Intestinal polyps are also characterized by small, round and blurred edges, which greatly increase the difficulty of semantic segmentation. Our research is focused on developing an improved algorithm based on the double-layer encoder-decode structure.MethodOur algorithm comprises of upstream and downstream architectures. The attention weight graph generated by the upstream network training is melted into the decoding part of the downstream network. 1) To promote effective network for target area in the image, the generated attention guidance is clarified to the feature map in the decoding process. The background-area-ignored model can be paid more attention to the segmentation contexts, which has a significant effect on small target recognition in semantic segmentation. 2) The edge extraction issue is concerned as well. Due to the similarity of intestinal wall and polyp mucous membrane, the segmentation target edge is blurred. It is essential to strengthen the edge extraction ability of the model and obtain more accurate segmentation results as well. In order to improve the segmentation ability of polyp target boundary, subspace channel attention is integrated into the cross-connection portion of the downstream network for extracting cross-channel information at multi-resolution and refining the edges. Unlike the convolution operation, a self-attention mechanism is involved in. Its ability to model remote dependencies provides an infinite receptive field for the application of visual models. However, traditional attention mechanism brings a huge amount of additional computational overhead. To realize the refine edge effect, the introduction of lightweight subspace channel attention mechanism can feature each space division, reduce the amount of calculation, learn the attention of multiple features, and get the attention of the fusion feature maps. We conduct tests performed on the public datasets Colonoscopy Videos Challenge-ClinicDataBase(CVC-ClinicDB) and Kvasir-Capsule. The CVC-ClinicDB dataset is used to the image data of intestinal polyps collected by conventional colonoscopy and there are 612 pictures in total, while Kvasir-Capsule dataset tends to the image data of polyps collected by Capsule gastroscopy and there are 55 pictures in total. A big gap needs to be bridged in imaging although the same kinds of targets are collected. At the same time, to further prove the robustness of this algorithm, our tests are carried out on the ultrasound nerve segmentation dataset, which has 5 633 ultrasound images of the brachial plexus taken by the imaging surgeon. The resolution of all images are set to 224×224 pixels and it can be randomly scrambled, divided into training set, verification set and test set according to the ratio of 6∶2∶2 and trained on a single GTX 1080Ti GPU. Our saliency network is implemented in Pytorch. In the experiment, binary cross entropy loss function(BCE loss) and Dice loss are proportionally mixed to construct a new Loss function, which has better performance for semantic segmentation of dichotomies. The Adam optimizer is used as well. The initial learning rate is 0.000 3 and the learning rate attenuation is set.ResultThe Dice similariy coefficient(DCS), mean intersection over union(mIoU), precision and recall are used as the quantitative evaluation metrics, and these metrics are all between 0 and 1. The higher of the index is, the segmentation performance of the model is better. The experimental results showed that the DCS of our model on CVC-ClinicDB and Kvasir-Capsule datasets reached 94.22% and 96.02%, respectively. Compared with U-Net, our DCS, mIoU, precision and recall is increased by 1.89%, 2.42%, 1.04%, 1.87% of each in CVC-ClinicDB dataset and 1.06%, 1.9%, 0.4%, 1.58% in Kvasir-Capsule dataset. The robustness of our algorithm on cross-device images is tested further by mixing the two data sets. Among them, DSC is increased by 17% to 20%, Compared with U-Net, the DCS of our model is increased by 16.73% in CVC-KC dataset (trained on CVC-ClinicDB and tested on Kvasir-Capsule) and 1% in KC-CVC dataset (trained on Kvasir-Capsule and tested on CVC-ClinicDB).ConclusionWe propose an attention segmentation model with dual encode-decoder architecture. Our algorithm can improve the effect of medical image segmentation effectively, and has higher accuracy for small target segmentation and edge segmentation on improving colorectal cancer screening strategies.关键词:polyp segmentation;colonoscopy;deep learning;semantic segmentation;attention mechanism;medical image processing137|170|1更新时间:2024-05-07 -
 摘要:ObjectiveIn order to alleviate the COVID-19(corona virus disease 2019) pandemic, the initial implementation is focused on targeting and isolating the infectious patients in time. Traditional PCR(polymerase chain reaction) screening method is challenged for the costly and time-consuming problem. Emerging AI(artificial intelligence)-based deep learning networks have been applied in medical imaging for the COVID-19 diagnosis and pathological lung segmentation nowadays. However, current networks are mostly restricted by the experimental datasets with limited number of chest X-ray (CXR) images, and it merely focuses on a single task of diagnosis or segmentation. Most networks are based on the convolution neural network (CNN). However, the convolution operation of CNN is capable to extract local features derived from intrinsic pixels, and has the long-range dependency constraints for explicitly modeling. We develop a vision transformer network (ViTNet). The multi-head attention (MHA) mechanism is guided for long-range dependency model between pixels.MethodWe built a novel transformer network called ViTNet for diagnosis and segmentation both. The ViTNet is composed of three parts, including dual-path feature embedding, transformer module and segmentation-oriented feature decoder. 1) The embedded dual-path feature is based on two manners for the embedded CXR inputs. One manner is on the basis of 2D convolution with the sliding step equal to convolution kernel size, which divides a CXR to multiple patches and builds an input vector for each patch. The other manner is concerned of a pre-trained feature map (ResNet34-derived) as backbone in terms of deep CXR-based feature extraction. 2) The transformer module is composed of six encoders and one cross-attention module. The 2D-convolution-generated vector sequence is as inputs for transformer encoder. Owing that the encoder inputs are directly extracted from image pixels, they can be considered as the shallow and intuitive feature of CXR. The six encodes are in sequential, transforming the shallow feature to advanced global feature. The cross-attention module is focused on the results obtained by backbone and transformer encoders as inputs, the network can combine the deep abstract feature and encoded shallow feature, and absorb both the global information and the local information in terms of the encoded shallow feature and deep abstract feature, respectively. 3) The feature decoder for segmentation can double the size of feature map and provide the segmentation results. Our network is required to deal with two tasks simultaneously for both of classification and segmentation. A hybrid loss function is employed for their training, which can balance the training efforts between classification and segmentation. The classification loss is the sum of a contrastive loss and a multi-classes cross-entropy loss. The segmentation loss is a binary cross-entropy loss. What is more, a new five-levels CXR dataset is compiled. The dataset samples are based on 2 951 CXRs of COVID-19, 16 964 CXRs of healthy, 6 103 CXRs of bacterial pneumonia, 5 725 CXRs of viral pneumonia, and 6 723 CXRs of opaque lung. In this dataset, COVID-19 CXRs are all labeled with COVID-19 infected lung masks. In our training process, the input images were resized as 448×448 pixels, the learning rate is initially set as 2×10-4 and decreased gradually in a self-adaptive manner, and the total number of iterations is 200, the Adam learning procedure is conducted on four Tesla K80 GPU devices.ResultIn the classification experiments, we compared ViTNet to a general transformer network and five popular CNN deep-learning models (i.e., ResNet18, ResNet50, VGG16(Visual Geometry Group), Inception_v3, and deep layer aggregation network(DLAN) in terms of overall prediction accuracy, recall rate, F1 and kappa evaluator. It can be demonstrated that our model has the best with 95.37% accuracy, followed by Inception_v3 and DLAN with 95.17% and 94.40% accuracy, respectively, and the VGG16 is reached 94.19% accuracy. For the recall rate, F1 and kappa value, our model has better performance than the rest of networks as well. For the segmentation experiments, ViTNet is in comparison with four commonly-used segmentation networks like pyramid scene parsing network (PSPNet), U-Net, U-Net+ and context encoder network (CE-Net). The evaluation indicators used are derived of the accuracy, sensitivity, specificity, Dice coefficient and area under ROC(region of interest) curve (AUC). The experimental results show that our model has its potentials in terms of the accuracy and AUC. The second best sensitivity is performed inferior to U-Net+ only. More specifically, our model achieved the 95.96% accuracy, 78.89% sensitivity, 97.97% specificity, 98.55% AUC and a Dice coefficient of 76.68%. When it comes to the network efficiency, our model speed is 0.56 s per CXR. In addition, we demonstrate the segmentation results of six COVID-19 CXR images obtained by all the segmentation networks. It is reflected that our model has the best segmentation performance in terms of the illustration of Fig. 5. Our model limitation is to classify a COVID-19 group as healthy group incorrectly, which is not feasible. The PCR method for COVID-19 is probably more trustable than the deep-leaning method, but the feedback duration of tested result typically needs for 1 or 2 days.ConclusionA novel ViTNet method is developed, which achieves the auto-diagnosis on CXR and lung region segmentation for COVID-19 infection simultaneously. The ViTNet has its priority in diagnosis performance and demonstrate its potential segmentation ability.关键词:corona virus disease 2019(COVID-19);automatic diagnosis;lung region segmentation;multi-head attention mechanism;hybrid loss173|555|2更新时间:2024-05-07
摘要:ObjectiveIn order to alleviate the COVID-19(corona virus disease 2019) pandemic, the initial implementation is focused on targeting and isolating the infectious patients in time. Traditional PCR(polymerase chain reaction) screening method is challenged for the costly and time-consuming problem. Emerging AI(artificial intelligence)-based deep learning networks have been applied in medical imaging for the COVID-19 diagnosis and pathological lung segmentation nowadays. However, current networks are mostly restricted by the experimental datasets with limited number of chest X-ray (CXR) images, and it merely focuses on a single task of diagnosis or segmentation. Most networks are based on the convolution neural network (CNN). However, the convolution operation of CNN is capable to extract local features derived from intrinsic pixels, and has the long-range dependency constraints for explicitly modeling. We develop a vision transformer network (ViTNet). The multi-head attention (MHA) mechanism is guided for long-range dependency model between pixels.MethodWe built a novel transformer network called ViTNet for diagnosis and segmentation both. The ViTNet is composed of three parts, including dual-path feature embedding, transformer module and segmentation-oriented feature decoder. 1) The embedded dual-path feature is based on two manners for the embedded CXR inputs. One manner is on the basis of 2D convolution with the sliding step equal to convolution kernel size, which divides a CXR to multiple patches and builds an input vector for each patch. The other manner is concerned of a pre-trained feature map (ResNet34-derived) as backbone in terms of deep CXR-based feature extraction. 2) The transformer module is composed of six encoders and one cross-attention module. The 2D-convolution-generated vector sequence is as inputs for transformer encoder. Owing that the encoder inputs are directly extracted from image pixels, they can be considered as the shallow and intuitive feature of CXR. The six encodes are in sequential, transforming the shallow feature to advanced global feature. The cross-attention module is focused on the results obtained by backbone and transformer encoders as inputs, the network can combine the deep abstract feature and encoded shallow feature, and absorb both the global information and the local information in terms of the encoded shallow feature and deep abstract feature, respectively. 3) The feature decoder for segmentation can double the size of feature map and provide the segmentation results. Our network is required to deal with two tasks simultaneously for both of classification and segmentation. A hybrid loss function is employed for their training, which can balance the training efforts between classification and segmentation. The classification loss is the sum of a contrastive loss and a multi-classes cross-entropy loss. The segmentation loss is a binary cross-entropy loss. What is more, a new five-levels CXR dataset is compiled. The dataset samples are based on 2 951 CXRs of COVID-19, 16 964 CXRs of healthy, 6 103 CXRs of bacterial pneumonia, 5 725 CXRs of viral pneumonia, and 6 723 CXRs of opaque lung. In this dataset, COVID-19 CXRs are all labeled with COVID-19 infected lung masks. In our training process, the input images were resized as 448×448 pixels, the learning rate is initially set as 2×10-4 and decreased gradually in a self-adaptive manner, and the total number of iterations is 200, the Adam learning procedure is conducted on four Tesla K80 GPU devices.ResultIn the classification experiments, we compared ViTNet to a general transformer network and five popular CNN deep-learning models (i.e., ResNet18, ResNet50, VGG16(Visual Geometry Group), Inception_v3, and deep layer aggregation network(DLAN) in terms of overall prediction accuracy, recall rate, F1 and kappa evaluator. It can be demonstrated that our model has the best with 95.37% accuracy, followed by Inception_v3 and DLAN with 95.17% and 94.40% accuracy, respectively, and the VGG16 is reached 94.19% accuracy. For the recall rate, F1 and kappa value, our model has better performance than the rest of networks as well. For the segmentation experiments, ViTNet is in comparison with four commonly-used segmentation networks like pyramid scene parsing network (PSPNet), U-Net, U-Net+ and context encoder network (CE-Net). The evaluation indicators used are derived of the accuracy, sensitivity, specificity, Dice coefficient and area under ROC(region of interest) curve (AUC). The experimental results show that our model has its potentials in terms of the accuracy and AUC. The second best sensitivity is performed inferior to U-Net+ only. More specifically, our model achieved the 95.96% accuracy, 78.89% sensitivity, 97.97% specificity, 98.55% AUC and a Dice coefficient of 76.68%. When it comes to the network efficiency, our model speed is 0.56 s per CXR. In addition, we demonstrate the segmentation results of six COVID-19 CXR images obtained by all the segmentation networks. It is reflected that our model has the best segmentation performance in terms of the illustration of Fig. 5. Our model limitation is to classify a COVID-19 group as healthy group incorrectly, which is not feasible. The PCR method for COVID-19 is probably more trustable than the deep-leaning method, but the feedback duration of tested result typically needs for 1 or 2 days.ConclusionA novel ViTNet method is developed, which achieves the auto-diagnosis on CXR and lung region segmentation for COVID-19 infection simultaneously. The ViTNet has its priority in diagnosis performance and demonstrate its potential segmentation ability.关键词:corona virus disease 2019(COVID-19);automatic diagnosis;lung region segmentation;multi-head attention mechanism;hybrid loss173|555|2更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveSynthetic aperture radar (SAR) image based vessels detection is essential for marine-oriented detection and administration. Traditional constant false alarm rate (CFAR) algorithms have contributed on the targets analyses, such as reliance on hand-made features, slow speed, and susceptibility to interference from ship-like objects like roofs and containers. Convolutional neural network (CNN) based detectors have fundamentally improved detection accuracy. However, there are a large number of vessels detection results are restricted of complicated docking directions and multiple sizes in the high-resolution SAR images, so the recognition rate of the model remains low for some, especially small ships in the complex scenarios near the shore. Using the convolution kernel to extract features, the weights in the convolution kernel are multiplied with the values at the corresponding locations of the feature map. Therefore, the matching degree between the convolution kernel shape and the target shape could determine its efficiency and quality of feature extraction to a certain extent. If the shape of the convolution kernel is more similar to the target shape, the extracted feature map will contain the complete information of the target. Otherwise, the feature map will contain many background features that interfere with model classification and localization. Traditional methods are still challenged that the square convolutional kernel does not fit the shape of a ship with a long strip of random docking direction well. So, we tend to develop a backbone network based on deformable cavity convolution for that.MethodWeighted fusion deformable atrous convolution (WFDAC) can somewhat adaptively change the shape and size of the convolution kernels and weight the features extracted by different convolution kernels in terms of the learned weights. In this way, the network can be made to actively learn any feature kernels are more capable of extracting features that match the target shape, thus the information-related is enhanced for the extraction of target region and suppressing background. The WFDAC module consists of two deformable convolutional kernels with different atrous rates and a 1 × 1 convolutional kernel that computes the fusion weights of the two deformable convolutional kernels in parallel. Furthermore, different perceptual fields are resulted in since the two parallel deformable convolutional kernels have different atrous rates. Therefore, deep feature extraction is challenged that smaller atrous rate-derived deformable convolutional kernel may duplicate the features within the perceptual field of larger atrous rate-context deformable convolutional kernel in shallow feature extraction. That is, features within the same receptive field are extracted and fused by at least two cross-layer deformable convolutional kernels. This can enhance the feature extraction efficiency of the network. In addition, to extract the discrepancy between small targets and near shore reefs and coastal zone buildings, we proposed a three-channel mixed attention (TMA) mechanism as well. It uses three parallel branches to obtain the cross-latitude interactions of model parameters by means of rotation and residual connection, as a method to calculate the weight relationship between model parameters. By multiplying the weights with the original parameter values, the differences between small vessels and shaped buildings and islands can be sharpened, and the weight of similarity features between them in model classification can be reduced, thus improving the model fine classification effect.ResultThe ablation and comparative experiments are conducted on SAR image ship datasets: high-resolution SAR images dataset (HRSID) and SAR ship detection dataset (SSDD). The model is first trained using the training set, and then the accuracy of the model is tested using the test set. We use several evaluation metrics to judge the model performance in terms of the internet of union (IoU) and the target pixel size. The experimental results show that our method can improve the detection accuracy of the model for SAR ship targets effectively, especially for small ones. Using our backbone network feature extraction network (FEN) instead of ResNet-50, the results on the HRSID dataset show that the detection accuracy is increased by 3.5%, 2.6%, and 2.9%, respectively on the three detection models: cascade region convolutional neural network (Cascade-RCNN), you only look once v4 (YOLOv4), and border detection (BorderDet). For small ships, an overall accuracy is reached of 89.9%. In order to verify whether the models improve the detection accuracy of small ships in the nearshore-complicated background, we segment the test set of the HRSID dataset into two scenarios: nearshore and offshore. The test analyses show that the accuracy is improved by 3.5% and 1.2% in the nearshore and offshore scenarios, respectively. Additionally, we designed a set of experiments to validate the effect of the atrous rate on the WFDAC module, which the atrous rate of one branch of two parallel deformable convolutions is fixed to 1, and the atrous rate of the other branches are set to 1, 3, and 5 sequentially. The experimental results show that the WFDAC module performs quite well when the atrous rate of one branch is 1 and the atrous rate of the other branch is 3. The overall accuracy on the SSDD dataset reached 95.9%.ConclusionOur backbone network-improved model can change the shape and size of the convolution kernel to focus on acquiring target information and suppressing background information interference. It reduces the false/loss ratio of small ships detection of SAR images effectively in the complex background of near shore.关键词:ship detection;synthetic aperture radar(SAR) image;deformable convolution;visual attention mechanism;atrous convolution149|211|7更新时间:2024-05-07
摘要:ObjectiveSynthetic aperture radar (SAR) image based vessels detection is essential for marine-oriented detection and administration. Traditional constant false alarm rate (CFAR) algorithms have contributed on the targets analyses, such as reliance on hand-made features, slow speed, and susceptibility to interference from ship-like objects like roofs and containers. Convolutional neural network (CNN) based detectors have fundamentally improved detection accuracy. However, there are a large number of vessels detection results are restricted of complicated docking directions and multiple sizes in the high-resolution SAR images, so the recognition rate of the model remains low for some, especially small ships in the complex scenarios near the shore. Using the convolution kernel to extract features, the weights in the convolution kernel are multiplied with the values at the corresponding locations of the feature map. Therefore, the matching degree between the convolution kernel shape and the target shape could determine its efficiency and quality of feature extraction to a certain extent. If the shape of the convolution kernel is more similar to the target shape, the extracted feature map will contain the complete information of the target. Otherwise, the feature map will contain many background features that interfere with model classification and localization. Traditional methods are still challenged that the square convolutional kernel does not fit the shape of a ship with a long strip of random docking direction well. So, we tend to develop a backbone network based on deformable cavity convolution for that.MethodWeighted fusion deformable atrous convolution (WFDAC) can somewhat adaptively change the shape and size of the convolution kernels and weight the features extracted by different convolution kernels in terms of the learned weights. In this way, the network can be made to actively learn any feature kernels are more capable of extracting features that match the target shape, thus the information-related is enhanced for the extraction of target region and suppressing background. The WFDAC module consists of two deformable convolutional kernels with different atrous rates and a 1 × 1 convolutional kernel that computes the fusion weights of the two deformable convolutional kernels in parallel. Furthermore, different perceptual fields are resulted in since the two parallel deformable convolutional kernels have different atrous rates. Therefore, deep feature extraction is challenged that smaller atrous rate-derived deformable convolutional kernel may duplicate the features within the perceptual field of larger atrous rate-context deformable convolutional kernel in shallow feature extraction. That is, features within the same receptive field are extracted and fused by at least two cross-layer deformable convolutional kernels. This can enhance the feature extraction efficiency of the network. In addition, to extract the discrepancy between small targets and near shore reefs and coastal zone buildings, we proposed a three-channel mixed attention (TMA) mechanism as well. It uses three parallel branches to obtain the cross-latitude interactions of model parameters by means of rotation and residual connection, as a method to calculate the weight relationship between model parameters. By multiplying the weights with the original parameter values, the differences between small vessels and shaped buildings and islands can be sharpened, and the weight of similarity features between them in model classification can be reduced, thus improving the model fine classification effect.ResultThe ablation and comparative experiments are conducted on SAR image ship datasets: high-resolution SAR images dataset (HRSID) and SAR ship detection dataset (SSDD). The model is first trained using the training set, and then the accuracy of the model is tested using the test set. We use several evaluation metrics to judge the model performance in terms of the internet of union (IoU) and the target pixel size. The experimental results show that our method can improve the detection accuracy of the model for SAR ship targets effectively, especially for small ones. Using our backbone network feature extraction network (FEN) instead of ResNet-50, the results on the HRSID dataset show that the detection accuracy is increased by 3.5%, 2.6%, and 2.9%, respectively on the three detection models: cascade region convolutional neural network (Cascade-RCNN), you only look once v4 (YOLOv4), and border detection (BorderDet). For small ships, an overall accuracy is reached of 89.9%. In order to verify whether the models improve the detection accuracy of small ships in the nearshore-complicated background, we segment the test set of the HRSID dataset into two scenarios: nearshore and offshore. The test analyses show that the accuracy is improved by 3.5% and 1.2% in the nearshore and offshore scenarios, respectively. Additionally, we designed a set of experiments to validate the effect of the atrous rate on the WFDAC module, which the atrous rate of one branch of two parallel deformable convolutions is fixed to 1, and the atrous rate of the other branches are set to 1, 3, and 5 sequentially. The experimental results show that the WFDAC module performs quite well when the atrous rate of one branch is 1 and the atrous rate of the other branch is 3. The overall accuracy on the SSDD dataset reached 95.9%.ConclusionOur backbone network-improved model can change the shape and size of the convolution kernel to focus on acquiring target information and suppressing background information interference. It reduces the false/loss ratio of small ships detection of SAR images effectively in the complex background of near shore.关键词:ship detection;synthetic aperture radar(SAR) image;deformable convolution;visual attention mechanism;atrous convolution149|211|7更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0