
最新刊期
卷 27 , 期 11 , 2022
-
 摘要:Body action oriented recognition issue is an essential domain for video interpretation of computer vision analysis. Its potentials can be focused on accurate video-based features extraction for body actions and the related recognition for multiple applications. The data modes of body action recognition modals can be segmented into RGB, depth, skeleton and fusion, respectively. Our multi-modals based critical analysis reviews the research and development of body action recognition algorithm. Our literature review is systematically focused on current algorithms or models. First, we introduce the key aspects of body action recognition method, which can be divided into video input, feature extraction, classification and output results. Next, we introduce the popular datasets of different data modal in the context of body action recognition, including human motion database(HMDB-51), UCF101 dataset, Something-Something datasets of RGB mode, depth modal and skeleton-mode MSR-Action3D dataset, MSR daily activity dataset, UTD-multimodal human action recognition dataset(MHAD) and RGB mode/depth mode/skeleton modal based NTU RGB + D 60/120 dataset, the characteristics of each dataset are explained in detail. Compared to more action recognition reviews, our contributions can be proposed as following: 1) data modal/method/datasets classifications are more instructive; 2) data modal/fusion for body action recognition is discussed more comprehensively; 3) recent challenges of body action recognition is just developed in deep learning and lacks of early manual features methods. We analyze the pros of manual features and deep learning; and 4) their advantages and disadvantages of different data modal, the challenges of action recognition and the future research direction are discussed. According to the data modal classification, the traditional manual feature and deep learning action recognition methods are reviewed via modals analysis of RGB/depth modal/skeleton, as well as multi-modal fused classification and related fusion methods of RGB modal and depth modal. For RGB modal, the traditional manual feature method is related to spatiotemporal volume, spatiotemporal based interest points and the skeleton trajectory based method. The deep learning method involves 3D convolutional neural network and double flow network. 3D convolution can construct the relationship between spatial and temporal dimensions, and the spatiotemporal features extraction is taken into account. The manual feature depth modal methods involve motion change/appearance features. The depth learning method includes representative point cloud network. Point cloud network is leveraged from image processing network. It can extract action features better via point sets processing. The skeleton modal oriented manual method is mainly based on skeleton features, and the deep learning technique mainly uses graph convolution network. Graph convolution network is suitable for the graph shape characteristics of skeleton data, which is beneficial to the transmission of information between skeletons. Next, we summarize the recognition accuracy of representative algorithms and models on RGB modal HMDB-51 dataset, UCF101 dataset and Something-Something V2 dataset, select the data representing manual feature method and depth learning method, and accomplish a histogram for more specific comparative results. For depth modal, we collect the recognition rates of some algorithms and models on MSR-Action3D dataset and NTU RGB + D 60 depth dataset. For skeleton data, we select NTU RGB + D 60 skeleton dataset and NTU RGB + D 120 skeleton dataset, the recognition accuracy of the model is compared. At the same time, we draw the clue of the parameters that need to be trained in the model in recent years. For the multi-modal fusion method, we adopt NTU RGB + D 60 dataset including RGB modal, depth modal and skeleton modal. The comparative recognition rate of single modal is derived of the same algorithm or model and the improved accuracy after multi-modal fusion. We sorted out that RGB modal, depth modal and skeleton modal have their potentials/drawbacks to match applicable scenarios. The fusion of multiple modals can complement mutual information to a certain extent and improve the recognition effect; manual feature method is suitable for some small datasets, and the algorithm complexity is lower; deep learning is suitable for large datasets and can automatically extract features from a large number of data; more researches have changed from deepening the network to lightweight and high recognition rate network. Finally, the current problems and challenges of body action recognition technology are summarized on the aspects of multiple body action recognition, fast and similar body action recognition, and depth and skeleton data collection. At the same time, the data modal issues are predicted further in terms of effective modal fusion, novel network design, and added attention module.关键词:computer vision;action recognition;deep learning;neural network;multimodal;modal fusion357|235|2更新时间:2024-05-07
摘要:Body action oriented recognition issue is an essential domain for video interpretation of computer vision analysis. Its potentials can be focused on accurate video-based features extraction for body actions and the related recognition for multiple applications. The data modes of body action recognition modals can be segmented into RGB, depth, skeleton and fusion, respectively. Our multi-modals based critical analysis reviews the research and development of body action recognition algorithm. Our literature review is systematically focused on current algorithms or models. First, we introduce the key aspects of body action recognition method, which can be divided into video input, feature extraction, classification and output results. Next, we introduce the popular datasets of different data modal in the context of body action recognition, including human motion database(HMDB-51), UCF101 dataset, Something-Something datasets of RGB mode, depth modal and skeleton-mode MSR-Action3D dataset, MSR daily activity dataset, UTD-multimodal human action recognition dataset(MHAD) and RGB mode/depth mode/skeleton modal based NTU RGB + D 60/120 dataset, the characteristics of each dataset are explained in detail. Compared to more action recognition reviews, our contributions can be proposed as following: 1) data modal/method/datasets classifications are more instructive; 2) data modal/fusion for body action recognition is discussed more comprehensively; 3) recent challenges of body action recognition is just developed in deep learning and lacks of early manual features methods. We analyze the pros of manual features and deep learning; and 4) their advantages and disadvantages of different data modal, the challenges of action recognition and the future research direction are discussed. According to the data modal classification, the traditional manual feature and deep learning action recognition methods are reviewed via modals analysis of RGB/depth modal/skeleton, as well as multi-modal fused classification and related fusion methods of RGB modal and depth modal. For RGB modal, the traditional manual feature method is related to spatiotemporal volume, spatiotemporal based interest points and the skeleton trajectory based method. The deep learning method involves 3D convolutional neural network and double flow network. 3D convolution can construct the relationship between spatial and temporal dimensions, and the spatiotemporal features extraction is taken into account. The manual feature depth modal methods involve motion change/appearance features. The depth learning method includes representative point cloud network. Point cloud network is leveraged from image processing network. It can extract action features better via point sets processing. The skeleton modal oriented manual method is mainly based on skeleton features, and the deep learning technique mainly uses graph convolution network. Graph convolution network is suitable for the graph shape characteristics of skeleton data, which is beneficial to the transmission of information between skeletons. Next, we summarize the recognition accuracy of representative algorithms and models on RGB modal HMDB-51 dataset, UCF101 dataset and Something-Something V2 dataset, select the data representing manual feature method and depth learning method, and accomplish a histogram for more specific comparative results. For depth modal, we collect the recognition rates of some algorithms and models on MSR-Action3D dataset and NTU RGB + D 60 depth dataset. For skeleton data, we select NTU RGB + D 60 skeleton dataset and NTU RGB + D 120 skeleton dataset, the recognition accuracy of the model is compared. At the same time, we draw the clue of the parameters that need to be trained in the model in recent years. For the multi-modal fusion method, we adopt NTU RGB + D 60 dataset including RGB modal, depth modal and skeleton modal. The comparative recognition rate of single modal is derived of the same algorithm or model and the improved accuracy after multi-modal fusion. We sorted out that RGB modal, depth modal and skeleton modal have their potentials/drawbacks to match applicable scenarios. The fusion of multiple modals can complement mutual information to a certain extent and improve the recognition effect; manual feature method is suitable for some small datasets, and the algorithm complexity is lower; deep learning is suitable for large datasets and can automatically extract features from a large number of data; more researches have changed from deepening the network to lightweight and high recognition rate network. Finally, the current problems and challenges of body action recognition technology are summarized on the aspects of multiple body action recognition, fast and similar body action recognition, and depth and skeleton data collection. At the same time, the data modal issues are predicted further in terms of effective modal fusion, novel network design, and added attention module.关键词:computer vision;action recognition;deep learning;neural network;multimodal;modal fusion357|235|2更新时间:2024-05-07 -
 摘要:The lung adenocarcinoma oriented median survival intervals can be significantly extended through specific targeted therapy based on the identified gene-driven following. Current biopsy is regarded as the "gold standard" for gene-driven tumor detection in clinical practice. Such invasive examination has a certain probability of misdiagnosis and missed diagnosis due to the tumor heterogeneity. Moreover, some of the molecular biology detection technologies are time-consuming and costly, such as the next generation of sequencing and fluorescence in situ hybridization. Therefore, radiogenomics has emerged and provided a new non-invasive method for the prediction of tumor molecular typing. As the most commonly-used way to monitor the lung cancer-related curative effect, computed tomography (CT) has its potential of short-term scanning, high resolution and relatively low-cost, which can carry out the tumor evaluation overall. It makes up the deficiency of biopsy to a certain extent. Thanks to the development of molecular targeted drugs in the context of lung adenocarcinoma treatment, most of researchers have been committed to using medical images to predict the molecular typing of lung adenocarcinoma. We carry out the critical review to harness CT images based molecular typing of lung adenocarcinoma. 1) Current situation of lung adenocarcinoma-oriented molecular typing and the key gene mutation types are introduced. 2) Existing CT images-related methods are divided into two categories: the correlation analysis of CT semantic features and the molecular subtype of lung adenocarcinoma, and the prediction model of molecular typing based on machine learning (ML). Among them, the ML-based prediction model is mainly introduced, which includes radiomics model and deep learning neural network model. 3) Some challenging problems are summarized in this field, and the future research direction is predicted. The correlation between semantic features and molecular typing of lung adenocarcinoma is derived of naked eyes visible tumor features. But, the predicted accuracy is still relatively low. Furthermore, the prediction model is demonstrated based on extracted features of radiomics from the segmented tumor images, and the selected radiomics features are input into the machine learning classifier to obtain the final prediction results. This method is still subject to human subjective influence to some extent, such as the stage of tumor segmentation and pre-setting features. To extract higher-level features for higher prediction accuracy, the convolutional neural network based (CNN-based) deep learning technology can beneficial for low-level features learning in tumor images. The deep learning model has less human-derived intervention, but it needs to be trained and verified through a large amount of data, and the expected effect cannot be achieved temporarily via a small sample. A challenging issue is to be tackled for the complex status of genetic mutations in lung adenocarcinoma and a complete and standardized database for generalization ability. With the database development of gradual standardization and expansion, future research direction can be focused on the construction of large-sample deep learning prediction model based on the integration of multiple medical images. To achieve noninvasive and accurate prediction of molecular typing of lung adenocarcinoma, the model optimization should combine clinical information, CT semantic features and radiomics features further.关键词:non small cell lung cancer;adenocarcinoma;molecular typing;radiogenomics;computed tomography (CT)78|71|0更新时间:2024-05-07
摘要:The lung adenocarcinoma oriented median survival intervals can be significantly extended through specific targeted therapy based on the identified gene-driven following. Current biopsy is regarded as the "gold standard" for gene-driven tumor detection in clinical practice. Such invasive examination has a certain probability of misdiagnosis and missed diagnosis due to the tumor heterogeneity. Moreover, some of the molecular biology detection technologies are time-consuming and costly, such as the next generation of sequencing and fluorescence in situ hybridization. Therefore, radiogenomics has emerged and provided a new non-invasive method for the prediction of tumor molecular typing. As the most commonly-used way to monitor the lung cancer-related curative effect, computed tomography (CT) has its potential of short-term scanning, high resolution and relatively low-cost, which can carry out the tumor evaluation overall. It makes up the deficiency of biopsy to a certain extent. Thanks to the development of molecular targeted drugs in the context of lung adenocarcinoma treatment, most of researchers have been committed to using medical images to predict the molecular typing of lung adenocarcinoma. We carry out the critical review to harness CT images based molecular typing of lung adenocarcinoma. 1) Current situation of lung adenocarcinoma-oriented molecular typing and the key gene mutation types are introduced. 2) Existing CT images-related methods are divided into two categories: the correlation analysis of CT semantic features and the molecular subtype of lung adenocarcinoma, and the prediction model of molecular typing based on machine learning (ML). Among them, the ML-based prediction model is mainly introduced, which includes radiomics model and deep learning neural network model. 3) Some challenging problems are summarized in this field, and the future research direction is predicted. The correlation between semantic features and molecular typing of lung adenocarcinoma is derived of naked eyes visible tumor features. But, the predicted accuracy is still relatively low. Furthermore, the prediction model is demonstrated based on extracted features of radiomics from the segmented tumor images, and the selected radiomics features are input into the machine learning classifier to obtain the final prediction results. This method is still subject to human subjective influence to some extent, such as the stage of tumor segmentation and pre-setting features. To extract higher-level features for higher prediction accuracy, the convolutional neural network based (CNN-based) deep learning technology can beneficial for low-level features learning in tumor images. The deep learning model has less human-derived intervention, but it needs to be trained and verified through a large amount of data, and the expected effect cannot be achieved temporarily via a small sample. A challenging issue is to be tackled for the complex status of genetic mutations in lung adenocarcinoma and a complete and standardized database for generalization ability. With the database development of gradual standardization and expansion, future research direction can be focused on the construction of large-sample deep learning prediction model based on the integration of multiple medical images. To achieve noninvasive and accurate prediction of molecular typing of lung adenocarcinoma, the model optimization should combine clinical information, CT semantic features and radiomics features further.关键词:non small cell lung cancer;adenocarcinoma;molecular typing;radiogenomics;computed tomography (CT)78|71|0更新时间:2024-05-07
Review

-
 摘要:ObjectiveDigital image has the ability of intuitive and clear information expression, and always carries a lot of valuable information. Therefore, the security of digital image is very important. With the rapid development and popularization of internet of things (IOT) which contains a large number of low-performance electronic devices, and the demand of security and efficient image encryption method in low computing precision environment is becoming more and more urgent. Recently, the chaos-based encryption system is the kind of most representative image encryption method. This type of encryption method depends on float operations and high computing precision. Therefore, the randomness of these chaotic systems in low computing precision will be severely damaged, and results in a sharp decrease about the security of the corresponding encryption method. Moreover, the high time complexity always causes the chaos-based image encryption methods to failure to meet the actual demand of low performance device. To solve the above problems, this paper proposes a batch encryption method based on prime modulo multiplication linear congruence generator to improve the security and efficiency of image encryption in low computing precision environments.MethodThe main idea of the method is to construct a prime modulo multiplication linear congruence generator, which can work well and generate a uniformly distributed pseudo-random sequence at low computing precision. The main steps are as follows: firstly, the set of images are equally divided into three groups and each group generates one combined image based on XOR operation; secondly, the hash value of the set of images is introduced to update the third combined image; thirdly, we introduce a single-byte based prime modulo multiplication linear congruence generator, the updated combined image and the other two combined images are used as the input of the proposed generator to generate an encryption sequence matrix; then the encryption sequence matrix is used as parameter to scramble images; after that, the encryption sequence matrix is exploited to diffuse the scrambled images, and use XOR operation to generate cipher images; finally, the encryption sequence matrix would be encrypted by the improved 2D-SCL which is the existing state-of-art encryption method, thus the cipher images and encrypted sequence matrix can be safely transmitted.ResultThe proposed encryption method has been evaluated by simulation tests in low (2-8) computing precision surroundings. The simulation results show that the statistical information of cipher image are very good in low precision environment, such as low correlation (close to 0), high information entropy (close to 8) and high pass rate of number of pixel changing rate(NPCR) and unified average changed intensity(UACI) which are greater than 90%. In addition, the simulation results also show that the proposed encryption method works well on many attacks in low precision environment, such as high pixel sensitivity, large key space (more than2128), and high resistance of known-plaintext and chosen-plaintext attack, occlusion attack and noise attack. Moreover, the encryption speed of this method is improved compared with the comparative encryption method which has low time complexity.ConclusionThe proposed method can be effectively operated in low computing precision environment by using the single-byte prime modulo multiplication linear congruence generator instead of chaos system. As simulations results shown that the proposed method not only achieves high security for image encryption in low computing precision environment, but also effectively reduces the time cost of image encryption. In addition, the proposed method also provides a new direction for subsequent research of efficient and security image encryption method.关键词:batch image encryption;low precision;security;encryption speed;prime modulo multiplication linear congruence generator(PMMLCG)101|137|0更新时间:2024-05-07
摘要:ObjectiveDigital image has the ability of intuitive and clear information expression, and always carries a lot of valuable information. Therefore, the security of digital image is very important. With the rapid development and popularization of internet of things (IOT) which contains a large number of low-performance electronic devices, and the demand of security and efficient image encryption method in low computing precision environment is becoming more and more urgent. Recently, the chaos-based encryption system is the kind of most representative image encryption method. This type of encryption method depends on float operations and high computing precision. Therefore, the randomness of these chaotic systems in low computing precision will be severely damaged, and results in a sharp decrease about the security of the corresponding encryption method. Moreover, the high time complexity always causes the chaos-based image encryption methods to failure to meet the actual demand of low performance device. To solve the above problems, this paper proposes a batch encryption method based on prime modulo multiplication linear congruence generator to improve the security and efficiency of image encryption in low computing precision environments.MethodThe main idea of the method is to construct a prime modulo multiplication linear congruence generator, which can work well and generate a uniformly distributed pseudo-random sequence at low computing precision. The main steps are as follows: firstly, the set of images are equally divided into three groups and each group generates one combined image based on XOR operation; secondly, the hash value of the set of images is introduced to update the third combined image; thirdly, we introduce a single-byte based prime modulo multiplication linear congruence generator, the updated combined image and the other two combined images are used as the input of the proposed generator to generate an encryption sequence matrix; then the encryption sequence matrix is used as parameter to scramble images; after that, the encryption sequence matrix is exploited to diffuse the scrambled images, and use XOR operation to generate cipher images; finally, the encryption sequence matrix would be encrypted by the improved 2D-SCL which is the existing state-of-art encryption method, thus the cipher images and encrypted sequence matrix can be safely transmitted.ResultThe proposed encryption method has been evaluated by simulation tests in low (2-8) computing precision surroundings. The simulation results show that the statistical information of cipher image are very good in low precision environment, such as low correlation (close to 0), high information entropy (close to 8) and high pass rate of number of pixel changing rate(NPCR) and unified average changed intensity(UACI) which are greater than 90%. In addition, the simulation results also show that the proposed encryption method works well on many attacks in low precision environment, such as high pixel sensitivity, large key space (more than2128), and high resistance of known-plaintext and chosen-plaintext attack, occlusion attack and noise attack. Moreover, the encryption speed of this method is improved compared with the comparative encryption method which has low time complexity.ConclusionThe proposed method can be effectively operated in low computing precision environment by using the single-byte prime modulo multiplication linear congruence generator instead of chaos system. As simulations results shown that the proposed method not only achieves high security for image encryption in low computing precision environment, but also effectively reduces the time cost of image encryption. In addition, the proposed method also provides a new direction for subsequent research of efficient and security image encryption method.关键词:batch image encryption;low precision;security;encryption speed;prime modulo multiplication linear congruence generator(PMMLCG)101|137|0更新时间:2024-05-07 -
 摘要:ObjectiveUnderwater-relevant object detection aims to localize and recognize the objects of underwater scenarios. Our research is essential for its widespread applications in oceanography, underwater navigation and fish farming. Current deep convolutional neural network based (DCNN-based) object detection is via large-scale trained datasets like pattern analysis, statistical modeling and computational learning visual object classes 2007 (PASCAL VOC 2007) and Microsoft common objects in context (MS COCO) with degradation-ignored. Nevertheless, the issue of degradation-related has to be resolved as mentioned below: 1) the scarce underwater-relevant detection datasets affects its detection accuracy, which inevitably leads to overfitting of deep neural network models. 2) Underwater-relevant images have the features of low contrast, texture distortion and blur under the complicated underwater environment and illumination circumstances, which limits the detection accuracy of the detection algorithms. In practice, image augmentation method is to alleviate the insufficient problem of datasets. However, image augmentation has limited performance improvement of deep neural network models on small datasets. Another feasible detection solution is to restore (enhance) the underwater-relevant image for a clear image (mainly based on deep learning methods), improve its visibility and contrast, and reduce color cast. Actually, some detection results are relied on synthetic datasets training due to the lack of ground truth images. Its enhancement effect of ground truth images largely derived of the quality of synthetic images. Our pre-trained model is effective for underwater scenes because it is difficult to train a high-accuracy detector. Clear images-based deep neural network detection models' training are difficult to generalize underwater scenes directly because of the domain shift issue caused by imaging differences. We develop a plug-and-play feature enhancement module, which can effectively address the domain shift issue between clear images and underwater images via restoring the features of underwater images extracted from the low-level network. The clear image-based detection network training can be directly applied to underwater image object detection.MethodFirst, to synthesize the underwater version based on an improved light scattering model for underwater imaging, we propose an underwater image synthesis method, which first estimates color cast and luminance from real underwater images and integrate them with the estimated scene depth of a clear image. Next, we design a lightweight feature enhancement module named feature de-drifting module Unet (FDM-Unet) originated from the Unet structure. Third, to extract the shallow features of clear images and their corresponding synthetic underwater images, we use common detectors (e.g., you only look once v3 (YOLO v3) and single shot multibox detector (SSD)) pre-trained on clear images. The shallow feature of the underwater image is input into FDM-Unet for feature de-drifting. To supervise the training of FDM-Unet, our calculated mean square error loss is in terms of the interconnections of the enhanced feature and the original shallow feature. Finally, the embedded training results do not include re-training or fine-tuning further after getting the shallow layer of the pre-trained detectors.ResultThe experimental results show that our FDM-Unet can improve the detection accuracy by 8.58% mean average precision (mAP) and 7.71% mAP on the PASCAL VOC 2007 synthetic underwater image test set for pre-trained detectors YOLO v3 and SSD, respectively. In addition, on the real underwater dataset underwater robot professional contest 19 (URPC19), using different proportions of data for fine-tuning, FDM-Unet can improve the detection accuracy by 4.4%~10.6% mAP and 3.9%~10.7% mAP in contrast to the vanilla detectors YOLO v3 and SSD, respectively.ConclusionOur FDM-Unet can be as a plug-and-play module at the cost of increasing the very small number of parameters and calculation. The detection accuracy of the pre-trained model is improved greatly with no need of retraining or fine-tuning the detection model on the synthetic underwater image. Real underwater fine-tuning experiments show that our FDM-Unet can improve the detection performance compared to the baseline. In addition, the fine-tuning performance can improve the pre-trained detection model for real underwater image beyond synthesis image.关键词:convolutional neural network(CNN);object detection;feature enhancement;imaging model;image synthesis261|192|2更新时间:2024-05-07
摘要:ObjectiveUnderwater-relevant object detection aims to localize and recognize the objects of underwater scenarios. Our research is essential for its widespread applications in oceanography, underwater navigation and fish farming. Current deep convolutional neural network based (DCNN-based) object detection is via large-scale trained datasets like pattern analysis, statistical modeling and computational learning visual object classes 2007 (PASCAL VOC 2007) and Microsoft common objects in context (MS COCO) with degradation-ignored. Nevertheless, the issue of degradation-related has to be resolved as mentioned below: 1) the scarce underwater-relevant detection datasets affects its detection accuracy, which inevitably leads to overfitting of deep neural network models. 2) Underwater-relevant images have the features of low contrast, texture distortion and blur under the complicated underwater environment and illumination circumstances, which limits the detection accuracy of the detection algorithms. In practice, image augmentation method is to alleviate the insufficient problem of datasets. However, image augmentation has limited performance improvement of deep neural network models on small datasets. Another feasible detection solution is to restore (enhance) the underwater-relevant image for a clear image (mainly based on deep learning methods), improve its visibility and contrast, and reduce color cast. Actually, some detection results are relied on synthetic datasets training due to the lack of ground truth images. Its enhancement effect of ground truth images largely derived of the quality of synthetic images. Our pre-trained model is effective for underwater scenes because it is difficult to train a high-accuracy detector. Clear images-based deep neural network detection models' training are difficult to generalize underwater scenes directly because of the domain shift issue caused by imaging differences. We develop a plug-and-play feature enhancement module, which can effectively address the domain shift issue between clear images and underwater images via restoring the features of underwater images extracted from the low-level network. The clear image-based detection network training can be directly applied to underwater image object detection.MethodFirst, to synthesize the underwater version based on an improved light scattering model for underwater imaging, we propose an underwater image synthesis method, which first estimates color cast and luminance from real underwater images and integrate them with the estimated scene depth of a clear image. Next, we design a lightweight feature enhancement module named feature de-drifting module Unet (FDM-Unet) originated from the Unet structure. Third, to extract the shallow features of clear images and their corresponding synthetic underwater images, we use common detectors (e.g., you only look once v3 (YOLO v3) and single shot multibox detector (SSD)) pre-trained on clear images. The shallow feature of the underwater image is input into FDM-Unet for feature de-drifting. To supervise the training of FDM-Unet, our calculated mean square error loss is in terms of the interconnections of the enhanced feature and the original shallow feature. Finally, the embedded training results do not include re-training or fine-tuning further after getting the shallow layer of the pre-trained detectors.ResultThe experimental results show that our FDM-Unet can improve the detection accuracy by 8.58% mean average precision (mAP) and 7.71% mAP on the PASCAL VOC 2007 synthetic underwater image test set for pre-trained detectors YOLO v3 and SSD, respectively. In addition, on the real underwater dataset underwater robot professional contest 19 (URPC19), using different proportions of data for fine-tuning, FDM-Unet can improve the detection accuracy by 4.4%~10.6% mAP and 3.9%~10.7% mAP in contrast to the vanilla detectors YOLO v3 and SSD, respectively.ConclusionOur FDM-Unet can be as a plug-and-play module at the cost of increasing the very small number of parameters and calculation. The detection accuracy of the pre-trained model is improved greatly with no need of retraining or fine-tuning the detection model on the synthetic underwater image. Real underwater fine-tuning experiments show that our FDM-Unet can improve the detection performance compared to the baseline. In addition, the fine-tuning performance can improve the pre-trained detection model for real underwater image beyond synthesis image.关键词:convolutional neural network(CNN);object detection;feature enhancement;imaging model;image synthesis261|192|2更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveImage aesthetic assessment is oriented to simulate human perception of beauty and identify image-related aesthetic quality assessment. It is essential for computer vision applications in the context of image forecasting, photos portfolio management, image enhancement and retrieval. Current image aesthetic quality evaluation method has been mainly focused on three major tasks as mentioned below: 1) aesthetic binary classification: divide images quality into high aesthetic and low aesthetic context; 2) aesthetic score regression: calculate the overall aesthetic average score of an image; 3) aesthetics distribution prediction: predict the probability of different aesthetic ratings of an image. Beyond binary classification to aesthetic score regression, more aesthetic information can be provided via the prediction of aesthetic distribution. However, these methods are still restricted of the factors of aesthetic prior knowledge and challenged for the source of aesthetic feeling. Image attributes has rich aesthetic contexts like content, brightness, depth of field and color richness. As a "hub" between image low-level features and aesthetic quality, these attributes can enhance the interpretability of aesthetic evaluation and play an important role in image aesthetic quality assessment. The aesthetic quality of an image is judged with a specific scene in common. Specifically, people make aesthetic judgments according to multiple aesthetic attributes. There is a strong correlation between aesthetic attributes and aesthetic quality, and the aesthetic attributes can provide interpretable details for aesthetic quality assessment. For instance, to assess a portrait image, we focus on the details of the foreground rather than those of the background. In contrast, we tend to treat the details less important than in the assessment of a portrait image for assessing a landscape image. Hence, we facilitate an image aesthetic attribute prediction model based on multi-tasks deep learning technique, which uses scene information to assist image aesthetic attributes prediction. More accurate image aesthetic score prediction is achieved.MethodThe model consists of a two-stream deep residual network. To obtain the scene information of the image, the first stream of the network is trained based on the scene prediction task. To predict the aesthetic attributes and overall aesthetic scores of the image, the second stream is used to extract the aesthetic features of the image, and then combine the two features for training through multi-tasks learning. In order to use the scene information of the image to assist the prediction of aesthetic attributes, we train the first stream of the network to predict the image scene category. After training the scene prediction stream, we train the attribute prediction stream via attributes-labeled aesthetic images. We use concatenation to fuse the features of the dual-stream network, and the full connection layers are trained to obtain the joint distribution of the aesthetic attributes and the overall score. For each image aesthetic attribute, we want to get its individual regression score. Our mean square error (MSE) loss function is used to measure the degree of difference between the predicted value and the ground truth. Our experiment is based on the aesthetic and attributes database (AADB). AADB consists of a total of 10 000 images, and the standard partition is followed on the basis of 8 500 images for training, 500 images for validation and the remaining 1 000 images for testing. We scale the images to 256×256×3 before inputting to the network. The i7-10700 CPU and NVIDIA GTX 1660 super GPU are equipped. The batch size is set to 12, epoch is set to 15, and adam optimization algorithm is used. The learning rate of the backbone network is set to 1E-5, and the learning rate of fully connected network is set to 1E-6. In Combination with the image scene information, the proposed model improves the prediction accuracy in terms of the image aesthetic attributes and aesthetic scores.ResultOur method has improved the prediction accuracy of the majority of aesthetic attributes, and the correlation coefficient of the overall aesthetic score prediction has also improved about 6%, which is feasible to melt scene information into the prediction of aesthetic attributes.ConclusionThe integrated scene information for aesthetic attributes prediction clarify the intimate relation between image scene category and aesthetic attributes, and the experimental results demonstrate that our scene information has its potentials for image aesthetic quality assessment. The future research direction can be focused on deep relationship between scene semantics and image aesthetics. This deep relationship could build a more robust image aesthetic assessment framework, which can consistently improve the performance of image aesthetic quality assessment, as well as enhance the interpretability of aesthetic assessment.关键词:image aesthetic quality assessment;aesthetic attributes;deep convolution network;multi-task learning;scene classification167|441|0更新时间:2024-05-07
摘要:ObjectiveImage aesthetic assessment is oriented to simulate human perception of beauty and identify image-related aesthetic quality assessment. It is essential for computer vision applications in the context of image forecasting, photos portfolio management, image enhancement and retrieval. Current image aesthetic quality evaluation method has been mainly focused on three major tasks as mentioned below: 1) aesthetic binary classification: divide images quality into high aesthetic and low aesthetic context; 2) aesthetic score regression: calculate the overall aesthetic average score of an image; 3) aesthetics distribution prediction: predict the probability of different aesthetic ratings of an image. Beyond binary classification to aesthetic score regression, more aesthetic information can be provided via the prediction of aesthetic distribution. However, these methods are still restricted of the factors of aesthetic prior knowledge and challenged for the source of aesthetic feeling. Image attributes has rich aesthetic contexts like content, brightness, depth of field and color richness. As a "hub" between image low-level features and aesthetic quality, these attributes can enhance the interpretability of aesthetic evaluation and play an important role in image aesthetic quality assessment. The aesthetic quality of an image is judged with a specific scene in common. Specifically, people make aesthetic judgments according to multiple aesthetic attributes. There is a strong correlation between aesthetic attributes and aesthetic quality, and the aesthetic attributes can provide interpretable details for aesthetic quality assessment. For instance, to assess a portrait image, we focus on the details of the foreground rather than those of the background. In contrast, we tend to treat the details less important than in the assessment of a portrait image for assessing a landscape image. Hence, we facilitate an image aesthetic attribute prediction model based on multi-tasks deep learning technique, which uses scene information to assist image aesthetic attributes prediction. More accurate image aesthetic score prediction is achieved.MethodThe model consists of a two-stream deep residual network. To obtain the scene information of the image, the first stream of the network is trained based on the scene prediction task. To predict the aesthetic attributes and overall aesthetic scores of the image, the second stream is used to extract the aesthetic features of the image, and then combine the two features for training through multi-tasks learning. In order to use the scene information of the image to assist the prediction of aesthetic attributes, we train the first stream of the network to predict the image scene category. After training the scene prediction stream, we train the attribute prediction stream via attributes-labeled aesthetic images. We use concatenation to fuse the features of the dual-stream network, and the full connection layers are trained to obtain the joint distribution of the aesthetic attributes and the overall score. For each image aesthetic attribute, we want to get its individual regression score. Our mean square error (MSE) loss function is used to measure the degree of difference between the predicted value and the ground truth. Our experiment is based on the aesthetic and attributes database (AADB). AADB consists of a total of 10 000 images, and the standard partition is followed on the basis of 8 500 images for training, 500 images for validation and the remaining 1 000 images for testing. We scale the images to 256×256×3 before inputting to the network. The i7-10700 CPU and NVIDIA GTX 1660 super GPU are equipped. The batch size is set to 12, epoch is set to 15, and adam optimization algorithm is used. The learning rate of the backbone network is set to 1E-5, and the learning rate of fully connected network is set to 1E-6. In Combination with the image scene information, the proposed model improves the prediction accuracy in terms of the image aesthetic attributes and aesthetic scores.ResultOur method has improved the prediction accuracy of the majority of aesthetic attributes, and the correlation coefficient of the overall aesthetic score prediction has also improved about 6%, which is feasible to melt scene information into the prediction of aesthetic attributes.ConclusionThe integrated scene information for aesthetic attributes prediction clarify the intimate relation between image scene category and aesthetic attributes, and the experimental results demonstrate that our scene information has its potentials for image aesthetic quality assessment. The future research direction can be focused on deep relationship between scene semantics and image aesthetics. This deep relationship could build a more robust image aesthetic assessment framework, which can consistently improve the performance of image aesthetic quality assessment, as well as enhance the interpretability of aesthetic assessment.关键词:image aesthetic quality assessment;aesthetic attributes;deep convolution network;multi-task learning;scene classification167|441|0更新时间:2024-05-07 -
 摘要:ObjectiveVideo-based abnormal behavior detection has been developing based on the intelligent surveillance technology, and it has potentials in public security. However, the issue of video-based spatio-temporal information modeling is challenged for improving the accuracy of anomaly detection. Traditional video-based abnormal behavior detection methods are focused on manual-based features extraction, such as the clear contour, motion information and trajectory of the target. Such methods are constrained of weak representation in massive video data processing. Current deep learning model method can automatically learn and extract advanced features based on massive video stream datasets, which has been widely used in video anomaly detection methods instead of manual-based features. The structural priorities of generative adversarial network (GAN) have been widely used in video anomaly detection tasks. Aiming at the problems of low utilization rate of spatio-temporal features and poor detection effect of traditional GAN, we demonstrate a video anomaly detection algorithm based on the integration of GAN and gating self-attention mechanism.MethodFirst, the gating self-attention mechanism is introduced into the U-net part of the generative network in the GAN, and the self-attention-mechanism-derived distributed weight of the feature maps is assigned layer by layer in the sampling process. The standard U-net network is linked to the features of the targets through the jump connection structure without effective features orientation. Our research is focused on combining the structural optimization of U-net network and gated self-attention mechanism, the feature representation of background regions irrelevant to anomaly detection tasks is suppressed in input video frames, the related feature expression of different targets is highlighted, and the spatio-temporal information is modeled more effectively. Next, to guarantee the consistency between video sequences, we adopt a smoother and faster LiteFlownet network to extract the motion information between video streams. Finally, to generate higher quality frames, the loss-related multi-functions of intensity, gradient and motion are added to enhance the stability of model detection. The adversarial network is trained by PatchGAN. GAN can achieve a good and stable performance after learning adversarial optimization.ResultOur experiments are carried out on the datasets of recognized video abnormal event, such as Chinese University of Hong Kong(CUHK) Avenue, University of California, San Diego(UCSD) Ped1 and UCSD Ped2, and the featured area value under receiver operating curve (ROC), anomaly rule fraction S and peak signal-to-noise ratio (PSNR) are taken as performance evaluation indexes. For the CUHK Avenue dataset, our area under curve(AUC)reaches 87.2%, which is 2.3% higher than those similar methods. For both UCSD Ped1 and UCSD Ped2 datasets, the AUC-values are higher more. At the same time, four ablation experiments are implemented as mentioned below: 1) the model 1 is applied to video anomaly detection tasks using standard U-net as the generative network; 2) the difference of model 2 is clarified that the gating self-attention mechanism is added to the generation network U-net to verify whether the mechanism is effective or not; 3) model 3 adds a gating self-attention mechanism to the generative network U-net, and the LiteFlownet is added to verify the effectiveness of the optical flow network; and 4) our model 4 is illustrated as well. For the generated network U-net and the gating self-attention mechanism, LiteFlownet is added and the gating self-attention mechanism is merged layer by layer at the coding end to perform feature weighting processing and the merged features are identified at the decoding end. Our method can obtain higher AUC values than the other three ablation model methods. We test the trained model and visualize the PSNR value of video sequence frames. The change of PSNR value shows the accuracy of the model for abnormal behavior detection.ConclusionThe experimental results show that our method achieves better recognition results on CUHK Avenue, UCSD Ped1 and UCSD Ped2 datasets, which is more suitable for video anomaly detection tasks, and effectively improves the stability and accuracy of abnormal behavior detection task model. Moreover, the performance of abnormal behavior detection can be significantly improved via using video sequence interframe motion information.关键词:video anomaly detection;generative adversarial network(GAN);U-Net;gating self-attention mechanism;optical flow network178|1337|2更新时间:2024-05-07
摘要:ObjectiveVideo-based abnormal behavior detection has been developing based on the intelligent surveillance technology, and it has potentials in public security. However, the issue of video-based spatio-temporal information modeling is challenged for improving the accuracy of anomaly detection. Traditional video-based abnormal behavior detection methods are focused on manual-based features extraction, such as the clear contour, motion information and trajectory of the target. Such methods are constrained of weak representation in massive video data processing. Current deep learning model method can automatically learn and extract advanced features based on massive video stream datasets, which has been widely used in video anomaly detection methods instead of manual-based features. The structural priorities of generative adversarial network (GAN) have been widely used in video anomaly detection tasks. Aiming at the problems of low utilization rate of spatio-temporal features and poor detection effect of traditional GAN, we demonstrate a video anomaly detection algorithm based on the integration of GAN and gating self-attention mechanism.MethodFirst, the gating self-attention mechanism is introduced into the U-net part of the generative network in the GAN, and the self-attention-mechanism-derived distributed weight of the feature maps is assigned layer by layer in the sampling process. The standard U-net network is linked to the features of the targets through the jump connection structure without effective features orientation. Our research is focused on combining the structural optimization of U-net network and gated self-attention mechanism, the feature representation of background regions irrelevant to anomaly detection tasks is suppressed in input video frames, the related feature expression of different targets is highlighted, and the spatio-temporal information is modeled more effectively. Next, to guarantee the consistency between video sequences, we adopt a smoother and faster LiteFlownet network to extract the motion information between video streams. Finally, to generate higher quality frames, the loss-related multi-functions of intensity, gradient and motion are added to enhance the stability of model detection. The adversarial network is trained by PatchGAN. GAN can achieve a good and stable performance after learning adversarial optimization.ResultOur experiments are carried out on the datasets of recognized video abnormal event, such as Chinese University of Hong Kong(CUHK) Avenue, University of California, San Diego(UCSD) Ped1 and UCSD Ped2, and the featured area value under receiver operating curve (ROC), anomaly rule fraction S and peak signal-to-noise ratio (PSNR) are taken as performance evaluation indexes. For the CUHK Avenue dataset, our area under curve(AUC)reaches 87.2%, which is 2.3% higher than those similar methods. For both UCSD Ped1 and UCSD Ped2 datasets, the AUC-values are higher more. At the same time, four ablation experiments are implemented as mentioned below: 1) the model 1 is applied to video anomaly detection tasks using standard U-net as the generative network; 2) the difference of model 2 is clarified that the gating self-attention mechanism is added to the generation network U-net to verify whether the mechanism is effective or not; 3) model 3 adds a gating self-attention mechanism to the generative network U-net, and the LiteFlownet is added to verify the effectiveness of the optical flow network; and 4) our model 4 is illustrated as well. For the generated network U-net and the gating self-attention mechanism, LiteFlownet is added and the gating self-attention mechanism is merged layer by layer at the coding end to perform feature weighting processing and the merged features are identified at the decoding end. Our method can obtain higher AUC values than the other three ablation model methods. We test the trained model and visualize the PSNR value of video sequence frames. The change of PSNR value shows the accuracy of the model for abnormal behavior detection.ConclusionThe experimental results show that our method achieves better recognition results on CUHK Avenue, UCSD Ped1 and UCSD Ped2 datasets, which is more suitable for video anomaly detection tasks, and effectively improves the stability and accuracy of abnormal behavior detection task model. Moreover, the performance of abnormal behavior detection can be significantly improved via using video sequence interframe motion information.关键词:video anomaly detection;generative adversarial network(GAN);U-Net;gating self-attention mechanism;optical flow network178|1337|2更新时间:2024-05-07 -
 摘要:ObjectiveBolts are widely distributed connecting components in transmission lines for maintaining the safe and stable operation. Bolt-relevant pins loss may threaten to the key components disintegration for transmission lines and even cause large-scale power outages. To eliminate potential safety hazards and ensure the safe and stable operation of the line, it is inevitable to resolve missing-pins bolt issues timely and accurately. Traditional manual-based transmission line inspection has low efficiency, high risk, and is easily restricted by external environmental factors. Unmanned air vehicle (UAV) inspections have emerged to resolve the security problems to a certain extent. The drones-based high-definition inspection pictures are sent back to the ground for manual processing, but this method is still inefficient, and the missed detection rate and false detection rate are relatively high. Current deep learning technique has yielded more target detection algorithms for transmission line inspections. The challenging issues for inspection picture are derived of the size of the bolt structure and its small proportion and its complicated background. Existing target detection algorithms are oriented to obtain feature maps by continuously up-sampling the pictures input to the network. However, the scale of the feature maps tends to be quite smaller in the continuous up-sampling process. The loss of visual detail information in the feature map can get positioning and classification effects better, which is incapable to the recognition and detection of bolt-relevant pins loss, and the detection effect is poor. In order to improve the detection effect of missing pins of bolt in transmission lines, we develop a method based on inter-level cross feature fusion.MethodTo detect multi-scale targets, the single shot multibox detector (SSD) based network is used to output six different scale feature maps. 1) The low-level large-scale feature maps are used to detect small targets, and the high-level small-scale feature maps are used to detect large targets.2) The anchor box mechanism is also introduced into the SSD to guarantee the overall detection in the feature map. Therefore, SSD algorithm is more suitable for detecting bolt-related missing pins in the inspection picture. First, the small target paste data augmentation is carried out on the bolt missing pins fault detection data set. After cutting out the parts corresponding to the missing-pins bolt category and randomly paste into larger-scale inspection pictures, the number of label boxes in the large-scale inspection pictures and the number of images in the data set are both increased to realize data augmentation. Next, the inter-level cross self-adaptive feature fusion module is introduced into SSD network. It can add the feature pyramid structure, improve its structure and increase the level of cross-connection between feature maps. The feature map of the Conv4_3 layer in SSD network is beneficial to the detection of missing-pins bolts. Feature maps of the Conv3_3 layer and the Conv5_3 layer are introduced in terms of the six-layer output feature maps-derived feature pyramid. The fusion of the Conv4_3 layer and the Conv8_2 layer is used to enhance the visual information and semantic information of the feature maps. At the same time, the adaptively spatial feature fusion (ASFF) mechanism is melted into the network to adaptively learn the spatial weights of feature map fusion at various scales, and the obtained weight fusion inspection feature map is used for the final detection. Finally, the K-means clustering method is employed to statistically analyze the size and aspect ratio of the labeled frame for the bolt structure, and the anchor box is adjusted in the original SSD network adequately.ResultThe verification experiments are performed for the effectiveness of the network on the PASCAL VOC(pattern analysis, statistical modeling and computational learning visual object classes) dataset. The improved network has reached a 2.3% growth in detection accuracy compared to the original SSD. In the bolt missing pins detection experiments, the training set and the test set are randomly divided according to the ratio of 7:3. Experimental results show that our detection accuracy is 87.93% for normal bolts, 89.15% for missing-pins bolts. The detection accuracy is increased by 2.71% and 3.99%, respectively.ConclusionOur method has greatly improved the accuracy of bolt-relevant pins loss detection. The detection accuracy of the original SSD network has been significantly improved. Our optimized detection is beneficial to further develop the recognition and detection of other parts in the transmission line.关键词:bolt;missing pins;single shot multibox detector (SSD);inter-level cross feature pyramid;self-adaptive feature fusion;anchor box optimization95|168|1更新时间:2024-05-07
摘要:ObjectiveBolts are widely distributed connecting components in transmission lines for maintaining the safe and stable operation. Bolt-relevant pins loss may threaten to the key components disintegration for transmission lines and even cause large-scale power outages. To eliminate potential safety hazards and ensure the safe and stable operation of the line, it is inevitable to resolve missing-pins bolt issues timely and accurately. Traditional manual-based transmission line inspection has low efficiency, high risk, and is easily restricted by external environmental factors. Unmanned air vehicle (UAV) inspections have emerged to resolve the security problems to a certain extent. The drones-based high-definition inspection pictures are sent back to the ground for manual processing, but this method is still inefficient, and the missed detection rate and false detection rate are relatively high. Current deep learning technique has yielded more target detection algorithms for transmission line inspections. The challenging issues for inspection picture are derived of the size of the bolt structure and its small proportion and its complicated background. Existing target detection algorithms are oriented to obtain feature maps by continuously up-sampling the pictures input to the network. However, the scale of the feature maps tends to be quite smaller in the continuous up-sampling process. The loss of visual detail information in the feature map can get positioning and classification effects better, which is incapable to the recognition and detection of bolt-relevant pins loss, and the detection effect is poor. In order to improve the detection effect of missing pins of bolt in transmission lines, we develop a method based on inter-level cross feature fusion.MethodTo detect multi-scale targets, the single shot multibox detector (SSD) based network is used to output six different scale feature maps. 1) The low-level large-scale feature maps are used to detect small targets, and the high-level small-scale feature maps are used to detect large targets.2) The anchor box mechanism is also introduced into the SSD to guarantee the overall detection in the feature map. Therefore, SSD algorithm is more suitable for detecting bolt-related missing pins in the inspection picture. First, the small target paste data augmentation is carried out on the bolt missing pins fault detection data set. After cutting out the parts corresponding to the missing-pins bolt category and randomly paste into larger-scale inspection pictures, the number of label boxes in the large-scale inspection pictures and the number of images in the data set are both increased to realize data augmentation. Next, the inter-level cross self-adaptive feature fusion module is introduced into SSD network. It can add the feature pyramid structure, improve its structure and increase the level of cross-connection between feature maps. The feature map of the Conv4_3 layer in SSD network is beneficial to the detection of missing-pins bolts. Feature maps of the Conv3_3 layer and the Conv5_3 layer are introduced in terms of the six-layer output feature maps-derived feature pyramid. The fusion of the Conv4_3 layer and the Conv8_2 layer is used to enhance the visual information and semantic information of the feature maps. At the same time, the adaptively spatial feature fusion (ASFF) mechanism is melted into the network to adaptively learn the spatial weights of feature map fusion at various scales, and the obtained weight fusion inspection feature map is used for the final detection. Finally, the K-means clustering method is employed to statistically analyze the size and aspect ratio of the labeled frame for the bolt structure, and the anchor box is adjusted in the original SSD network adequately.ResultThe verification experiments are performed for the effectiveness of the network on the PASCAL VOC(pattern analysis, statistical modeling and computational learning visual object classes) dataset. The improved network has reached a 2.3% growth in detection accuracy compared to the original SSD. In the bolt missing pins detection experiments, the training set and the test set are randomly divided according to the ratio of 7:3. Experimental results show that our detection accuracy is 87.93% for normal bolts, 89.15% for missing-pins bolts. The detection accuracy is increased by 2.71% and 3.99%, respectively.ConclusionOur method has greatly improved the accuracy of bolt-relevant pins loss detection. The detection accuracy of the original SSD network has been significantly improved. Our optimized detection is beneficial to further develop the recognition and detection of other parts in the transmission line.关键词:bolt;missing pins;single shot multibox detector (SSD);inter-level cross feature pyramid;self-adaptive feature fusion;anchor box optimization95|168|1更新时间:2024-05-07 -
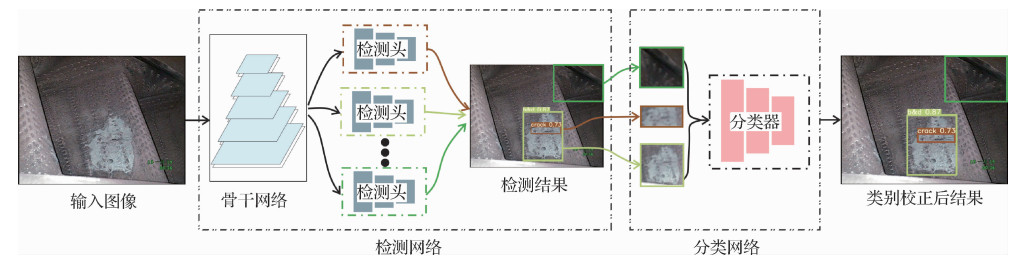 摘要:ObjectiveThe healthy issue of aero-engine is threatened due to high temperature and extreme pressure environment in common. The commonly-used manual inspection method for damage detection is very labor-intensive. Therefore, a high detection accuracy-based computer vision algorithm is cost-effective to detect aero-engine status automatically. The existing bore-scope image damage detection methods are divided into two categories: traditional manual-based and deep learning-based. Traditional detection methods are focused on edge detection or filter detection-like image processing for crack or burn detection. Although traditional methods perform well on simple scenes, they cannot generalize well on the complex images like the erosion and oil contamination-derived regions, and it cannot be extended to the other damages like nick and dent. Most aero-engine damage detection methods are based on deep learning technique to resilient designing features and tuning parameters of traditional methods. Multi-objects detection methods like single shot multibox detector(SSD), you only look once(YOLO) series models are used to detect different damages. However, most of the deep learning-based aero-engine detection methods do not concern about the detection of multiple types of damage in the same region and the low differentiation of damage in the evolution process, which is a limiting factor for the existing state-of-the-art object detectors. To improve the accuracy of detection, we develop an aero-engine damage-oriented detection method via the cascade detector and classifier (Cascade-YOLO). Cascade-YOLO is used to train independent damage detector for each type of damage, which can fully develop the detector of other types of similar damage excluded. Furthermore, a classifier is adopted to modify damage labels after detecting the damages, which is trained with all types of damages.MethodOur YOLO v5-originated cascade-YOLO is developed on object detection benchmarks. There are mainly two differences between Cascade-YOLO and YOLO v5. The first one is that Cascade-YOLO has multiple detection heads for various types of damage detection. The second one is that a multi-class classifier is used to correct damage label in Cascade-YOLO. Specifically, a YOLO v5-based damage detection network is trained by seeing all types' damages as target objects. As the parameters of our backbone network, the parameters of this pre-trained network are used for feature extraction. Thus, the extracted features are suitable for representing all kinds of damages. All parameters of the backbone network are fixed in latter training. Our multiple damage detection heads is employed to extract features based on the backbone network. Each damage detection head is responsible for detecting a single type of damage, which can fully explore the discrimination ability of different types of damages and increase the recall of single type of damage. However, multiple detection heads may fail to classify the damage into correct damage category. To modify the detected label, we adopt a cascade manner via a multi-class classifier after the multi-head detector. We can segment the damage using a modified semantic segmentation method.ResultWe build a bore-scope image dataset with 1 305 images in the context of nine different types of damages, and evaluate six state-of-the-art one-stage object detectors (e.g., single shot multibox detector(SSD), object detector based on multi-level feature pyramid network(M2Det) and YOLO v5) and two-stage object detectors (e.g., region convolutional neural network(Mask R-CNN) and BMask R-CNN) on this dataset. The mean average precision(MAP) of Cascade-YOLO is higher than that of YOLO v5 by 2.49%, and is higher than that of Mask R-CNN by 3.3%. The accuracy and recall of Cascade-YOLO are higher than those of YOLO v5 by 12.59% and 12.46%, respectively.ConclusionOur cascade detector and classifier-based aero-engine damage detection is developed in terms of the tailored bore-scope image. The recall of the damage detection can be increased using a single type damage-oriented independent detection head. The integrated multiple detection heads can detect multiple types of damage. Multiple detection heads share a feature extraction backbone network, which improves the detection efficiency. We adopt a multi-class classifier to correct the labels of the detected damages that having low confidence. Furthermore, we also employ a clear modified semantic segmentation method to segment the damage region. The experiment results show that Cascade-YOLO performances can be qualified for various types of damage detection problem. The Cascade-YOLO is optimized in detection precision, recall and accuracy compared to YOLO v5 and Mask R-CNN. The potential independent detection head method is feasible for the extended damages detection.关键词:damage detection;borescope image;cascade detection;airplane engine;you only look once(YOLO)89|119|2更新时间:2024-05-07
摘要:ObjectiveThe healthy issue of aero-engine is threatened due to high temperature and extreme pressure environment in common. The commonly-used manual inspection method for damage detection is very labor-intensive. Therefore, a high detection accuracy-based computer vision algorithm is cost-effective to detect aero-engine status automatically. The existing bore-scope image damage detection methods are divided into two categories: traditional manual-based and deep learning-based. Traditional detection methods are focused on edge detection or filter detection-like image processing for crack or burn detection. Although traditional methods perform well on simple scenes, they cannot generalize well on the complex images like the erosion and oil contamination-derived regions, and it cannot be extended to the other damages like nick and dent. Most aero-engine damage detection methods are based on deep learning technique to resilient designing features and tuning parameters of traditional methods. Multi-objects detection methods like single shot multibox detector(SSD), you only look once(YOLO) series models are used to detect different damages. However, most of the deep learning-based aero-engine detection methods do not concern about the detection of multiple types of damage in the same region and the low differentiation of damage in the evolution process, which is a limiting factor for the existing state-of-the-art object detectors. To improve the accuracy of detection, we develop an aero-engine damage-oriented detection method via the cascade detector and classifier (Cascade-YOLO). Cascade-YOLO is used to train independent damage detector for each type of damage, which can fully develop the detector of other types of similar damage excluded. Furthermore, a classifier is adopted to modify damage labels after detecting the damages, which is trained with all types of damages.MethodOur YOLO v5-originated cascade-YOLO is developed on object detection benchmarks. There are mainly two differences between Cascade-YOLO and YOLO v5. The first one is that Cascade-YOLO has multiple detection heads for various types of damage detection. The second one is that a multi-class classifier is used to correct damage label in Cascade-YOLO. Specifically, a YOLO v5-based damage detection network is trained by seeing all types' damages as target objects. As the parameters of our backbone network, the parameters of this pre-trained network are used for feature extraction. Thus, the extracted features are suitable for representing all kinds of damages. All parameters of the backbone network are fixed in latter training. Our multiple damage detection heads is employed to extract features based on the backbone network. Each damage detection head is responsible for detecting a single type of damage, which can fully explore the discrimination ability of different types of damages and increase the recall of single type of damage. However, multiple detection heads may fail to classify the damage into correct damage category. To modify the detected label, we adopt a cascade manner via a multi-class classifier after the multi-head detector. We can segment the damage using a modified semantic segmentation method.ResultWe build a bore-scope image dataset with 1 305 images in the context of nine different types of damages, and evaluate six state-of-the-art one-stage object detectors (e.g., single shot multibox detector(SSD), object detector based on multi-level feature pyramid network(M2Det) and YOLO v5) and two-stage object detectors (e.g., region convolutional neural network(Mask R-CNN) and BMask R-CNN) on this dataset. The mean average precision(MAP) of Cascade-YOLO is higher than that of YOLO v5 by 2.49%, and is higher than that of Mask R-CNN by 3.3%. The accuracy and recall of Cascade-YOLO are higher than those of YOLO v5 by 12.59% and 12.46%, respectively.ConclusionOur cascade detector and classifier-based aero-engine damage detection is developed in terms of the tailored bore-scope image. The recall of the damage detection can be increased using a single type damage-oriented independent detection head. The integrated multiple detection heads can detect multiple types of damage. Multiple detection heads share a feature extraction backbone network, which improves the detection efficiency. We adopt a multi-class classifier to correct the labels of the detected damages that having low confidence. Furthermore, we also employ a clear modified semantic segmentation method to segment the damage region. The experiment results show that Cascade-YOLO performances can be qualified for various types of damage detection problem. The Cascade-YOLO is optimized in detection precision, recall and accuracy compared to YOLO v5 and Mask R-CNN. The potential independent detection head method is feasible for the extended damages detection.关键词:damage detection;borescope image;cascade detection;airplane engine;you only look once(YOLO)89|119|2更新时间:2024-05-07 -
 摘要:ObjectiveHuman visual system is beneficial to extracting features of the region of interest in images or videos processing. Computer-vision-derived salient object detection aims to improving the ability of visual interpretation for image preprocessing. The quality of the generated saliency map affects the performance of subsequent vision tasks directly. Current deep-learning-based salient object detection can locate salient objects well in terms of the effective semantic features extraction. The issue of clear-edged objects extraction is essential for improving the following visual tasks. In recent years, the complex scenes-oriented edge accuracy of the objects enhancement has been concerned further. Such models are required to obtain fine edges based on the indirect multiple edge losses for the edges of salient objects supervision. To improve the edge details of the object, some models simply fuse the complementary object features and edge features. These models do not make full use of the edge features, resulting in unidentified edge enhancement. Furthermore, it is necessary to use multi-scale information to extract object features because salient objects have variability of positions and scales in visual scenes. In order to regularize clear edges saliency map, we demonstrate a salient object detection model based on semantic assistance and edge feature.MethodWe use a semantic assistant feature fusion module to optimize the lateral output features of the backbone network. The selective layer features of each fuse the adjacent low-level features with semantic assistance to obtain enough structural information and enhance the feature strength of the salient region, which is helpful to generate a regular saliency map to detect the entire salient objects. We design an edge-branched network to obtain accurate edge features. To enhance the distinguishability of the edge regions for salient objects, the object features are integrated. In addition, a bidirectional multi-scale module extracts the multi-scale information. Thanks to the mechanism of dense connection and feature fusion, the bidirectional multi-scale module gradually fuses the multi-scale features of each adjacent layer, which is beneficial to detect multi-scale objects in the scene. Our experiments are equipped with a single NVIDIA GTX 1080ti graphics-processing unit (GPU) for training and test. We use the DUTS-train datasets to train the model, which contains 10 553 images. The model is trained for convergence with no validation set. The Visual Geometry Group(VGG16) is as the backbone network through the PyTorch deep learning framework. The pre-trained model on ImageNet initializes some parameters of the backbone network, and all newly convolutional layers-added are randomly initialized with "0.01"of variance and "0" of deviation. The hyper-parameters and experimental settings are clarified that the learning rate, weight decay, and momentum are set to 5E-5, 0.000 5, and 0.9, respectively. We use adam optimizer for optimization learning. We carried out back-propagation method based on every ten images. The scale of input image is 256×256 pixels, and random flip is for data enhancement only. The model is trained in 100 iterations totally, and the attenuation is 10 times after 60 iterations.ResultOur model is compared to twelve existing popular saliency models based on four commonly-used datasets, i.e., extended complex scene saliency dataset (ECSSD), Dalian University of Technology and OMRON Corporation (DUT-O), HKU-IS, and DUTS. The analyzed results show that the maximum F-measure values of our model on each of four datasets are 0.940, 0.795, 0.929, and 0.870, the mean absolution error(MAE) values are 0.041, 0.057, 0.034, and 0.043, respectively. Our saliency maps obtained are closer to the ground truth.ConclusionWe develop a model to detect salient objects. The semantic assisted feature and edge feature fusion in the model is beneficial to generate regularized saliency maps in the context of clear object edges. The multi-scale feature extraction improves the performance of salient object detection further.关键词:salient object detection;full convolution neural network;semantic assistance;edge feature fusion;multi-scale extraction71|106|0更新时间:2024-05-07
摘要:ObjectiveHuman visual system is beneficial to extracting features of the region of interest in images or videos processing. Computer-vision-derived salient object detection aims to improving the ability of visual interpretation for image preprocessing. The quality of the generated saliency map affects the performance of subsequent vision tasks directly. Current deep-learning-based salient object detection can locate salient objects well in terms of the effective semantic features extraction. The issue of clear-edged objects extraction is essential for improving the following visual tasks. In recent years, the complex scenes-oriented edge accuracy of the objects enhancement has been concerned further. Such models are required to obtain fine edges based on the indirect multiple edge losses for the edges of salient objects supervision. To improve the edge details of the object, some models simply fuse the complementary object features and edge features. These models do not make full use of the edge features, resulting in unidentified edge enhancement. Furthermore, it is necessary to use multi-scale information to extract object features because salient objects have variability of positions and scales in visual scenes. In order to regularize clear edges saliency map, we demonstrate a salient object detection model based on semantic assistance and edge feature.MethodWe use a semantic assistant feature fusion module to optimize the lateral output features of the backbone network. The selective layer features of each fuse the adjacent low-level features with semantic assistance to obtain enough structural information and enhance the feature strength of the salient region, which is helpful to generate a regular saliency map to detect the entire salient objects. We design an edge-branched network to obtain accurate edge features. To enhance the distinguishability of the edge regions for salient objects, the object features are integrated. In addition, a bidirectional multi-scale module extracts the multi-scale information. Thanks to the mechanism of dense connection and feature fusion, the bidirectional multi-scale module gradually fuses the multi-scale features of each adjacent layer, which is beneficial to detect multi-scale objects in the scene. Our experiments are equipped with a single NVIDIA GTX 1080ti graphics-processing unit (GPU) for training and test. We use the DUTS-train datasets to train the model, which contains 10 553 images. The model is trained for convergence with no validation set. The Visual Geometry Group(VGG16) is as the backbone network through the PyTorch deep learning framework. The pre-trained model on ImageNet initializes some parameters of the backbone network, and all newly convolutional layers-added are randomly initialized with "0.01"of variance and "0" of deviation. The hyper-parameters and experimental settings are clarified that the learning rate, weight decay, and momentum are set to 5E-5, 0.000 5, and 0.9, respectively. We use adam optimizer for optimization learning. We carried out back-propagation method based on every ten images. The scale of input image is 256×256 pixels, and random flip is for data enhancement only. The model is trained in 100 iterations totally, and the attenuation is 10 times after 60 iterations.ResultOur model is compared to twelve existing popular saliency models based on four commonly-used datasets, i.e., extended complex scene saliency dataset (ECSSD), Dalian University of Technology and OMRON Corporation (DUT-O), HKU-IS, and DUTS. The analyzed results show that the maximum F-measure values of our model on each of four datasets are 0.940, 0.795, 0.929, and 0.870, the mean absolution error(MAE) values are 0.041, 0.057, 0.034, and 0.043, respectively. Our saliency maps obtained are closer to the ground truth.ConclusionWe develop a model to detect salient objects. The semantic assisted feature and edge feature fusion in the model is beneficial to generate regularized saliency maps in the context of clear object edges. The multi-scale feature extraction improves the performance of salient object detection further.关键词:salient object detection;full convolution neural network;semantic assistance;edge feature fusion;multi-scale extraction71|106|0更新时间:2024-05-07 -
 摘要:Objectivemultiple-objects-oriented tracking and segmentation aims to track and segment a variety of video-based objects, which is concerned about detection, tracking and segmentation. Such existing methods are derived of tracking and segmenting in the context of multi-objects tracking detection. But, it is challenged to resolve the target occlusion and its contexts for effective features extraction. Our research is focused on a joint multi-object tracking and segmentation method based on the 3D spatiotemporal feature fusion module (STFNet), spatial tri-coordinated attention (STCA) and temporal-reduced self-attention (TRSA), which is adaptively for salient feature representations selection to optimize tracking and segmentation performance.MethodThe STFNet is composed of a 2D encoder and a 3D decoder. First, multiple frames are put into the 2D encoder in consistency and the decoder takes low-resolution features as input. The low-resolution features is implemented for feature fusion through 3 layers of 3D convolutional layers, the spatial features of the key spatial information is then obtained via STCA module, and the key-frame-information-involved temporal features are integrated through the TRSA. They are all merged with the original features. Next, the higher resolution features and the low-level fusion features are put into the 3D convolutional layer (1×1×1) together, and the features of different levels are replicable to aggregate the features with key frame information and salient spatial information. Finally, our STFNet is fitted to the features into the three-dimensional Gaussian distribution of each case. Every Gaussian distribution is assigned different pixels on continuous frames for multi-scenario objects or their background. It can achieve the segmentation of the each target. Specifically, STCA is focused on the attention-enhanced version of the coordinated attention. The coordinated attention is based on the horizontal and vertical attention weights only. The attention mechanism can be linked to the range of local information without the dimensioned channel information. The STCA is added a channel-oriented attention mechanism to retain valid information or discard useless information further. First, the STCA is used to extract horizontal/vertical/channel-oriented features via average pooling. It can encode the information from the three coordinated directions for subsequent extraction of weight coefficients. Next, the STCA performs two-by-two fusion of the three features. Furthermore, it concatenates them and put them into the 1×1 convolution for feature fusion. Next, the STCA is used to put them into the batch of benched layer and a non-linear activation function. The features of the three coordinate directions can be fused. Third, the fusion features are leveraged to obtain the separate attention features for each coordinate direction. The attention features of the same direction are added together, and each direction is obtained through the sigmoid function. Finally, to get the output of the STCA, the weight is multiplied by the original feature. For the TRSA, to solve the frequent occlusion in multi-targets tracking and segmentation, temporal-based multi-features are selected. The designed module make the network pay more attention to the object information of the key frame and weaken the information of the occluded frame. 1) The TRSA put features into three 1×1×1 3D convolutions, and the purpose of the convolutional layer is oriented for reducing dimensions. 2) The TRSA is used to fuse dimensions to obtain three matrices excluded temporal scale, and one-dimension convolution is used to realize dimensionality reduction. It can greatly reduce the amount of matrix operations in the latter stage. 3) The TRSA is used to obtain a low-dimensional matrix through transposing two of the matrices, multiplying the non-transposed matrix and the transposed matrix. The result is put into the SoftMax function to get the attention weight. 4) The attention weight is used to multiply the original feature. The features are restored to the original dimension after increasing dimension, rearranging dimension and entering 3D convolution.ResultOur main testing datasets are based on YouTube video instance segmentation(YouTube-VIS) and multi-object tracking and segmentation(KITTI MOTS). For the YouTube-VIS dataset, we combine YouTube-VIS and common objects in context(COCO) training for the COCO training set and the overlapped part is just 20 object classes. The size of the input image is 640×1 152 pixels. The evaluation indicators like average precision (AP) and average recall (AR) in MaskTrack region convolutional neural network(R-CNN) are used to evaluate the performance of model tracking and segmentation. For the KITTI MOTS dataset, it is trained on the KITTI MOTS training set. The size of input image is 544×1 792 pixels. The evaluation indicators like soft multi-object tracking and segmentation accuracy(sMOTSA), multi-object tracking and segmentation accuracy(MOTSA), multi-object tracking and segmentation precision(MOTSP), and ID switch(IDS) in TrackR-CNN are used to evaluate the performance of model tracking and segmentation. Our data results are augmented by random horizontal flip, video reverse order, and image brightness enhancement. Our experiments are based on using ResNet-101 as the backbone network and initializing the backbone network with the weights of the Mask R-CNN pre-training model trained on the COCO training set. The decoder network weights are used for random initialization weights method. Three loss functions are used for training. The Lovász Hinge loss function is targeted for learning the feature embedding vector, the smoothness loss function is oriented for learning the variance value, and the L2 loss is used for generating the instance center heat map, respectively. For the YouTube-VIS dataset, the AP value is increased by 0.2% compared to the second-performing CompFeat. For the KITTI MOTS dataset, in the car category, compared to the second-performance STEm-Seg, the ID switch index is reduced by 9; in the pedestrian category, compared to the second-performance STEm-Seg, sMOTSA is increased by 0.7%, and MOTSA is increased 0.6%, MOTSP is increased by 0.9%, ID switch index is decreased by 1. At the same time, our ablation experiments are carried out in the KITTI MOTS dataset. The STCA improves the network effect by 0.5% in comparison with the baseline, and the TRSA improves the network effect by 0.3% compared to the baseline. The result shows that our two modules are relatively effective.ConclusionWe demonstrate a multi-objects tracking and segmentation model based on spatiotemporal feature fusion. The model can fully mine the feature information between multiple frames of the video, and it makes the results of target tracking and segmentation more accurate. The Experimental results illustrate that our potential STFNet can optimize target occlusion to a certain extent.关键词:deep learning;multi-object tracking and segmentation(MOTS);3D convolutional neural network;feature fusion;attention mechanism100|181|1更新时间:2024-05-07
摘要:Objectivemultiple-objects-oriented tracking and segmentation aims to track and segment a variety of video-based objects, which is concerned about detection, tracking and segmentation. Such existing methods are derived of tracking and segmenting in the context of multi-objects tracking detection. But, it is challenged to resolve the target occlusion and its contexts for effective features extraction. Our research is focused on a joint multi-object tracking and segmentation method based on the 3D spatiotemporal feature fusion module (STFNet), spatial tri-coordinated attention (STCA) and temporal-reduced self-attention (TRSA), which is adaptively for salient feature representations selection to optimize tracking and segmentation performance.MethodThe STFNet is composed of a 2D encoder and a 3D decoder. First, multiple frames are put into the 2D encoder in consistency and the decoder takes low-resolution features as input. The low-resolution features is implemented for feature fusion through 3 layers of 3D convolutional layers, the spatial features of the key spatial information is then obtained via STCA module, and the key-frame-information-involved temporal features are integrated through the TRSA. They are all merged with the original features. Next, the higher resolution features and the low-level fusion features are put into the 3D convolutional layer (1×1×1) together, and the features of different levels are replicable to aggregate the features with key frame information and salient spatial information. Finally, our STFNet is fitted to the features into the three-dimensional Gaussian distribution of each case. Every Gaussian distribution is assigned different pixels on continuous frames for multi-scenario objects or their background. It can achieve the segmentation of the each target. Specifically, STCA is focused on the attention-enhanced version of the coordinated attention. The coordinated attention is based on the horizontal and vertical attention weights only. The attention mechanism can be linked to the range of local information without the dimensioned channel information. The STCA is added a channel-oriented attention mechanism to retain valid information or discard useless information further. First, the STCA is used to extract horizontal/vertical/channel-oriented features via average pooling. It can encode the information from the three coordinated directions for subsequent extraction of weight coefficients. Next, the STCA performs two-by-two fusion of the three features. Furthermore, it concatenates them and put them into the 1×1 convolution for feature fusion. Next, the STCA is used to put them into the batch of benched layer and a non-linear activation function. The features of the three coordinate directions can be fused. Third, the fusion features are leveraged to obtain the separate attention features for each coordinate direction. The attention features of the same direction are added together, and each direction is obtained through the sigmoid function. Finally, to get the output of the STCA, the weight is multiplied by the original feature. For the TRSA, to solve the frequent occlusion in multi-targets tracking and segmentation, temporal-based multi-features are selected. The designed module make the network pay more attention to the object information of the key frame and weaken the information of the occluded frame. 1) The TRSA put features into three 1×1×1 3D convolutions, and the purpose of the convolutional layer is oriented for reducing dimensions. 2) The TRSA is used to fuse dimensions to obtain three matrices excluded temporal scale, and one-dimension convolution is used to realize dimensionality reduction. It can greatly reduce the amount of matrix operations in the latter stage. 3) The TRSA is used to obtain a low-dimensional matrix through transposing two of the matrices, multiplying the non-transposed matrix and the transposed matrix. The result is put into the SoftMax function to get the attention weight. 4) The attention weight is used to multiply the original feature. The features are restored to the original dimension after increasing dimension, rearranging dimension and entering 3D convolution.ResultOur main testing datasets are based on YouTube video instance segmentation(YouTube-VIS) and multi-object tracking and segmentation(KITTI MOTS). For the YouTube-VIS dataset, we combine YouTube-VIS and common objects in context(COCO) training for the COCO training set and the overlapped part is just 20 object classes. The size of the input image is 640×1 152 pixels. The evaluation indicators like average precision (AP) and average recall (AR) in MaskTrack region convolutional neural network(R-CNN) are used to evaluate the performance of model tracking and segmentation. For the KITTI MOTS dataset, it is trained on the KITTI MOTS training set. The size of input image is 544×1 792 pixels. The evaluation indicators like soft multi-object tracking and segmentation accuracy(sMOTSA), multi-object tracking and segmentation accuracy(MOTSA), multi-object tracking and segmentation precision(MOTSP), and ID switch(IDS) in TrackR-CNN are used to evaluate the performance of model tracking and segmentation. Our data results are augmented by random horizontal flip, video reverse order, and image brightness enhancement. Our experiments are based on using ResNet-101 as the backbone network and initializing the backbone network with the weights of the Mask R-CNN pre-training model trained on the COCO training set. The decoder network weights are used for random initialization weights method. Three loss functions are used for training. The Lovász Hinge loss function is targeted for learning the feature embedding vector, the smoothness loss function is oriented for learning the variance value, and the L2 loss is used for generating the instance center heat map, respectively. For the YouTube-VIS dataset, the AP value is increased by 0.2% compared to the second-performing CompFeat. For the KITTI MOTS dataset, in the car category, compared to the second-performance STEm-Seg, the ID switch index is reduced by 9; in the pedestrian category, compared to the second-performance STEm-Seg, sMOTSA is increased by 0.7%, and MOTSA is increased 0.6%, MOTSP is increased by 0.9%, ID switch index is decreased by 1. At the same time, our ablation experiments are carried out in the KITTI MOTS dataset. The STCA improves the network effect by 0.5% in comparison with the baseline, and the TRSA improves the network effect by 0.3% compared to the baseline. The result shows that our two modules are relatively effective.ConclusionWe demonstrate a multi-objects tracking and segmentation model based on spatiotemporal feature fusion. The model can fully mine the feature information between multiple frames of the video, and it makes the results of target tracking and segmentation more accurate. The Experimental results illustrate that our potential STFNet can optimize target occlusion to a certain extent.关键词:deep learning;multi-object tracking and segmentation(MOTS);3D convolutional neural network;feature fusion;attention mechanism100|181|1更新时间:2024-05-07 -
An image segmentation model in combination with dissimilarity criterion and entropy rate super-pixel
 摘要:ObjectiveHigh-precision image segmentation is a key issue for biomedical image processing. It can aid to understand the anatomical information of biological tissues better. But, the segmentation precision is restricted by the non-uniformity of image intensity and noise-related issues in the process of magnetic resonance imaging (MRI). In addition, more image segmentation effects are constrained by information loss due to multi-modality and spatial neighborhood relations of medical images. Our research is focused on an image segmentation model in combination with dissimilarity criterion and entropy rate super-pixel.MethodOur method is based on a segmentation model in the context of multi-modality feature fusion. This model is composed of three parts as mentioned below: 1) thanks to the entropy rate super-pixel segmentation algorithm (entropy rate super-pixel, ERS), the multi-modality image is pre-segmented to obtain super-pixel blocks, and a new fusion algorithm is illustrated to renumber them, the super-pixel image is then established. The accurate segmentation of common areas in the tissue area is guaranteed in terms of multi-modality fusion-added, and the boundaries of the tissue area can be divided more accurately, and the overall segmentation accuracy is improved. 2) Each super-pixel block is illustrated by a node of the undirected image, and the feature vector is extracted by the gray value of each node. The correlation between nodes is judged by dissimilarity weight, and the feature sequence of adjacent nodes is constructed. The multi-modality and spatial neighborhood information develop the fineness of the boundary, the robustness of local area noise and intensity non-uniformity. Finally, the feature sequence is used as the input of bi-directional long/short-term memory model. To improve the segmentation accuracy, the cross entropy loss is used for training.ResultOur method is compared to some popular algorithms in the context of BrainWeb, MRbrains and BraTS2017 datasets. The BrainWeb dataset is regarded as a simulation dataset based on brain anatomical structure, which contains MR images of T1, T2 and PD. Compared to LSTM-MA(LSTM method with multi-modality and adjacency constraint), our pixel accuracy (PA) is 98.93% (1.28% higher) and the Dice similarity coefficient (DSC) is 97.71% (2.8 higher). The MRbrains dataset contains the ground truth of brain-relevant MR images, which consists of MR image of T1, T1IR and FLAIR modalities. Our demonstration achieves 92.46% in relation to PA metric and 84.74% in terms of DSC metric, which are 0.63% and 1.44% higher than LSTM-MA. The dataset of BraTS2017 is related to the four modalities of MR image like T1, T1CE, T2 and FLAIR. We choose three modalities of them (T1CE, T2 and FLAIR). Final PA and DSC metrics are reached to 98.80% and 99.47%. Furthermore, our convergence speed is in comparison with some popular deep learning techniques like convolutional recurrent decoding network(CRDN), semantic flow network(SFNet) and UNet++. Our competitive convergence results can be obtained when the number of iterations is 40.ConclusionOur analysis can optimize current multi-modality features further. Multi-modality super-pixel blocks are fused by a new fusion algorithm, and a better feature sequence is constructed via the dissimilarity criterion. The final segmentation result is obtained through training and testing of the bidirectional long/short-term memory network. The experimental results show that our method can optimize the applications of image segmentation, and enhance the robustness of image intensity-oriented non-uniformity and noise-related.关键词:image segmentation;multi-modality;super-pixel;bi-directional long short term memory model(BiLSTM);noise robustness107|113|0更新时间:2024-05-07
摘要:ObjectiveHigh-precision image segmentation is a key issue for biomedical image processing. It can aid to understand the anatomical information of biological tissues better. But, the segmentation precision is restricted by the non-uniformity of image intensity and noise-related issues in the process of magnetic resonance imaging (MRI). In addition, more image segmentation effects are constrained by information loss due to multi-modality and spatial neighborhood relations of medical images. Our research is focused on an image segmentation model in combination with dissimilarity criterion and entropy rate super-pixel.MethodOur method is based on a segmentation model in the context of multi-modality feature fusion. This model is composed of three parts as mentioned below: 1) thanks to the entropy rate super-pixel segmentation algorithm (entropy rate super-pixel, ERS), the multi-modality image is pre-segmented to obtain super-pixel blocks, and a new fusion algorithm is illustrated to renumber them, the super-pixel image is then established. The accurate segmentation of common areas in the tissue area is guaranteed in terms of multi-modality fusion-added, and the boundaries of the tissue area can be divided more accurately, and the overall segmentation accuracy is improved. 2) Each super-pixel block is illustrated by a node of the undirected image, and the feature vector is extracted by the gray value of each node. The correlation between nodes is judged by dissimilarity weight, and the feature sequence of adjacent nodes is constructed. The multi-modality and spatial neighborhood information develop the fineness of the boundary, the robustness of local area noise and intensity non-uniformity. Finally, the feature sequence is used as the input of bi-directional long/short-term memory model. To improve the segmentation accuracy, the cross entropy loss is used for training.ResultOur method is compared to some popular algorithms in the context of BrainWeb, MRbrains and BraTS2017 datasets. The BrainWeb dataset is regarded as a simulation dataset based on brain anatomical structure, which contains MR images of T1, T2 and PD. Compared to LSTM-MA(LSTM method with multi-modality and adjacency constraint), our pixel accuracy (PA) is 98.93% (1.28% higher) and the Dice similarity coefficient (DSC) is 97.71% (2.8 higher). The MRbrains dataset contains the ground truth of brain-relevant MR images, which consists of MR image of T1, T1IR and FLAIR modalities. Our demonstration achieves 92.46% in relation to PA metric and 84.74% in terms of DSC metric, which are 0.63% and 1.44% higher than LSTM-MA. The dataset of BraTS2017 is related to the four modalities of MR image like T1, T1CE, T2 and FLAIR. We choose three modalities of them (T1CE, T2 and FLAIR). Final PA and DSC metrics are reached to 98.80% and 99.47%. Furthermore, our convergence speed is in comparison with some popular deep learning techniques like convolutional recurrent decoding network(CRDN), semantic flow network(SFNet) and UNet++. Our competitive convergence results can be obtained when the number of iterations is 40.ConclusionOur analysis can optimize current multi-modality features further. Multi-modality super-pixel blocks are fused by a new fusion algorithm, and a better feature sequence is constructed via the dissimilarity criterion. The final segmentation result is obtained through training and testing of the bidirectional long/short-term memory network. The experimental results show that our method can optimize the applications of image segmentation, and enhance the robustness of image intensity-oriented non-uniformity and noise-related.关键词:image segmentation;multi-modality;super-pixel;bi-directional long short term memory model(BiLSTM);noise robustness107|113|0更新时间:2024-05-07 -
 摘要:ObjectiveVideo-based intelligent action recognition has been developing for computer vision analysis nowadays. It is required to recognize action in a specific scene of video due to such multiple video types. To appreciate sports leisure for users like the meta-video set of various badminton stroke, it can assist coaches to analyze stroke better if badminton strokes can be accurately located and recognized in a badminton video. Sports video analysis like the approach of the badminton stroke recognition can be transferred to tennis and table tennis via similar sports features. For a long time span of video based action recognition method, it is necessary to locate the action time domain. Badminton-oriented video can be as this kind of videos to locate stroke time domains. For the time domain localization of video actions, current research is focused on a clear action switching boundary between adjacent actions in a video, and the foreground or background features of adjacent actions are quite different, such as the action video dataset 50Salads and dataset Breakfast. However, there is no obvious boundary information between foreground and background of adjacent strokes in a badminton video. Therefore, the action recognition based long time span video is not suitable for the localization of badminton strokes. In addition, most existing researches on badminton stroke recognition are based on a static image of a stroke derived from a badminton video, and the stroke recognition of badminton-relevant meta-video is lacking. Our method is focused on an approach for locating and classifying the strokes of ball-control player in an extracted badminton video highlight.MethodFirst, the pose estimation model regional multi-person pose estimation(RMPE) is used to detect human poses in a badminton video highlight. The pose of the targeted player is located via adding prediction scores and position constraints to shield other irrelevant factors of human bones. For the detected pose of targeted player, the node constraints are added to locate arms of the player. The holding arm and the non-holding arm are distinguished according to the difference of the swinging amplitude, and the time domain localization of badminton stroke is carried out by the swinging amplitude variation of the holding arm for extracting the meta-video of badminton stroke. The swing amplitude of the player's arm in a frame is defined as the linear weighted sum of the square of the upper and lower limbs swing vector modulus. Then, the dataset of badminton meta-videos is applied to train convolutional block attention module-temporal segment networks (CBAM-TSN) for predicting badminton strokes in meta-videos, which add convolutional block attention module in temporal segment networks. It is necessary to extract two-stream of meta-videos from dataset beforehand through training CBAM-TSN because temporal segment network (TSN) inherited the structure of two-stream convolutional neural network(CNN). The two-stream is composed of spatial stream (RGB frames) and temporal stream (optical frames). The predicted stroke from the model of CBAM-TSN contains four familiar types: forehand, backhand, overhead and lob. Finally, we classify the overhead scenario into clear or smash by morphology processing, the clear-oriented meta-videos tend to continuous dynamic mask in the background area at the end of the stroke, but the smash-oriented meta-videos have no continuous dynamic mask information in the background area. Our badminton mask in a meta-video is captured based on the result of images morphological processing. The strokes of clear and smash can be distinguished based on position-relevant features of the badminton mask.ResultIn a highlighted badminton video, it shows that the segmentation is correct if a meta video segmented by the method of strokes localization and a meta video extracted manually both contain the same badminton stroke. Our indicator of intersection over union (IoU) is used to evaluate the performance of strokes localization. Furthermore, the performance of badminton strokes classification is evaluated via using machine learning based indicator ROC-AUC, recall and precision. The experiment results show that our IoU of stroke localization in badminton video highlights is reached to 82.6%. The indicator AUC about four kinds of badminton strokes (forehand, backhand, overhead and lob) predicted by the model of CBAM-TSN is all over 0.98, the micro-AUC, macro-AUC, average recall and precision is reached to 0.990 8, 0.990 3, 93.5% and 94.3%, respectively. In addition, the CBAM-TSN is compared to the three popular approaches of action recognition in the context of badminton strokes recognition, gets the highest result on precision, micro-AUC and macro-AUC. The final average recall and precision is reached to 91.2% and 91.6% of each. Therefore, it can effectively locate and classify major player's strokes in a badminton video highlight.ConclusionWe facilitate a novel badminton strokes recognizing method in badminton video highlights, which is in combination with badminton stroke localization and badminton stroke classification. The potential sports video analysis is developed further.关键词:pose estimation;meta video;badminton stroke localization;convolutional block attention module-temporal segment network (CBAM-TSN);morphological processing;badminton stroke recognition352|790|2更新时间:2024-05-07
摘要:ObjectiveVideo-based intelligent action recognition has been developing for computer vision analysis nowadays. It is required to recognize action in a specific scene of video due to such multiple video types. To appreciate sports leisure for users like the meta-video set of various badminton stroke, it can assist coaches to analyze stroke better if badminton strokes can be accurately located and recognized in a badminton video. Sports video analysis like the approach of the badminton stroke recognition can be transferred to tennis and table tennis via similar sports features. For a long time span of video based action recognition method, it is necessary to locate the action time domain. Badminton-oriented video can be as this kind of videos to locate stroke time domains. For the time domain localization of video actions, current research is focused on a clear action switching boundary between adjacent actions in a video, and the foreground or background features of adjacent actions are quite different, such as the action video dataset 50Salads and dataset Breakfast. However, there is no obvious boundary information between foreground and background of adjacent strokes in a badminton video. Therefore, the action recognition based long time span video is not suitable for the localization of badminton strokes. In addition, most existing researches on badminton stroke recognition are based on a static image of a stroke derived from a badminton video, and the stroke recognition of badminton-relevant meta-video is lacking. Our method is focused on an approach for locating and classifying the strokes of ball-control player in an extracted badminton video highlight.MethodFirst, the pose estimation model regional multi-person pose estimation(RMPE) is used to detect human poses in a badminton video highlight. The pose of the targeted player is located via adding prediction scores and position constraints to shield other irrelevant factors of human bones. For the detected pose of targeted player, the node constraints are added to locate arms of the player. The holding arm and the non-holding arm are distinguished according to the difference of the swinging amplitude, and the time domain localization of badminton stroke is carried out by the swinging amplitude variation of the holding arm for extracting the meta-video of badminton stroke. The swing amplitude of the player's arm in a frame is defined as the linear weighted sum of the square of the upper and lower limbs swing vector modulus. Then, the dataset of badminton meta-videos is applied to train convolutional block attention module-temporal segment networks (CBAM-TSN) for predicting badminton strokes in meta-videos, which add convolutional block attention module in temporal segment networks. It is necessary to extract two-stream of meta-videos from dataset beforehand through training CBAM-TSN because temporal segment network (TSN) inherited the structure of two-stream convolutional neural network(CNN). The two-stream is composed of spatial stream (RGB frames) and temporal stream (optical frames). The predicted stroke from the model of CBAM-TSN contains four familiar types: forehand, backhand, overhead and lob. Finally, we classify the overhead scenario into clear or smash by morphology processing, the clear-oriented meta-videos tend to continuous dynamic mask in the background area at the end of the stroke, but the smash-oriented meta-videos have no continuous dynamic mask information in the background area. Our badminton mask in a meta-video is captured based on the result of images morphological processing. The strokes of clear and smash can be distinguished based on position-relevant features of the badminton mask.ResultIn a highlighted badminton video, it shows that the segmentation is correct if a meta video segmented by the method of strokes localization and a meta video extracted manually both contain the same badminton stroke. Our indicator of intersection over union (IoU) is used to evaluate the performance of strokes localization. Furthermore, the performance of badminton strokes classification is evaluated via using machine learning based indicator ROC-AUC, recall and precision. The experiment results show that our IoU of stroke localization in badminton video highlights is reached to 82.6%. The indicator AUC about four kinds of badminton strokes (forehand, backhand, overhead and lob) predicted by the model of CBAM-TSN is all over 0.98, the micro-AUC, macro-AUC, average recall and precision is reached to 0.990 8, 0.990 3, 93.5% and 94.3%, respectively. In addition, the CBAM-TSN is compared to the three popular approaches of action recognition in the context of badminton strokes recognition, gets the highest result on precision, micro-AUC and macro-AUC. The final average recall and precision is reached to 91.2% and 91.6% of each. Therefore, it can effectively locate and classify major player's strokes in a badminton video highlight.ConclusionWe facilitate a novel badminton strokes recognizing method in badminton video highlights, which is in combination with badminton stroke localization and badminton stroke classification. The potential sports video analysis is developed further.关键词:pose estimation;meta video;badminton stroke localization;convolutional block attention module-temporal segment network (CBAM-TSN);morphological processing;badminton stroke recognition352|790|2更新时间:2024-05-07 -
 摘要:ObjectiveDepressive disorder has disabled of individuals behavior ability. According to the Diagnostic and Statistical Manual of Mental Disorders (fifth edition), the typical symptoms of depression is likely to be low mood, loss of interest and lack of energy. The complicated somatic symptoms are manifested inattention, insomnia, slow reaction time, reduced activity and fatigue. Recent assessment of depression severity mainly depends on the interview between the qualified psychiatrist and the patient or interview with their family member or caregiver, combined with their own prior experience. However, depression is a heterogeneous disease derived from different causes and manifestations. Basically, this diagnosis is relatively subjective and unidentified, which is lack of standardization to measure it. Current researches have revealed that the symptoms of depression patients are usually presented through a variety of visual signals, including the patient's facial expressions and body postures, especially the former are significant indicators of depression. Emerging machine learning technique can be used to capture the subtle expression changes, which can be applied to the automatic assessment of depression severity further. The early symptoms of depression can be clarified in time, and even independent diagnostic evaluation can be carried out. In order to achieve clearer evaluation of depression severity, depth features extraction and its application in automatic recognition of depression has been investigated based on facial images.MethodIn order to obtain effective face images-derived global information and make full use of the emotion-rich local areas like eyes and mouth parts in face images, we develop a channel-wise attention mechanism- integrated multi-branches convolutional neural network to extract multiple visual features for automatic depression recognition. First, the original video is sampled every 10 frames to reduce the redundancy of video frames, and the multi-task cascade convolutional neural networks are used to detect and locate the key points of the face. According to the coordinates of the detected key points, the areas of the whole face, eyes and mouth are cropped conversely. Then, 1) to obtain global features, the completed face images are input into a deep convolutional neural network in combination with channel-wise attention mechanism, and 2) to obtain local features, the latter are input into another two deep convolutional neural networks as well. During the training, the images are preprocessed and normalized and the data is enhanced by flipping and clipping. At the feature fusion layer, the features are extracted from three branches networks concatenated. Finally, the fully connected layer outputs the depression score. To demonstrate the feasibility and reliability of our proposal, a series of experiments are performed on the commonly-used The Continuous Audio/Visual Emotion and Depression Recognition Challenge 2013(AVEC 2013) and AVEC2014 datasets.Result1) The AVEC2013 depression database: the mean absolute error (MAE) is 6.74 and the root mean square error (RMSE) is 8.70, which decreased by 4.14 and 4.91 in comparison with the Baseline; 2) the AVEC2014 depression database: the MAE and RMSE are 6.56 and 8.56 of each, which decreased by 2.30 and 2.30 in comparison with the Baseline. Furthermore, our algorithms optimize the MAE and RMSE values further on both databases. Experimental results show that the channel-wise attention mechanism not only speeds up the convergence of network, but also reduces the results of MAE and RMSE. To recognize its depression severity, the integration of eyes and mouth features can significantly decrease the error compared to using global features only. This suggests that the local features in the context of eyes and mouth is an effective supplement to global features in depression recognition, especially the salient information-related eyes conveying. It conforms to clinicians' experience in judging the depression severity.ConclusionWe develop a multi-features-based automatic depression recognition method through using multi-branches deep conventional neural networks, which is implemented in an end-to-end manner. The features extraction and depression recognition are carried out and optimized in terms of a coordinated framework. To model more distinctive features, the channel-wise attention mechanism is added to adaptively assign weights to channels.关键词:depression recognition;channel-wise attention mechanism;deep convolutional neural network;feature fusion;spatial weight120|180|2更新时间:2024-05-07
摘要:ObjectiveDepressive disorder has disabled of individuals behavior ability. According to the Diagnostic and Statistical Manual of Mental Disorders (fifth edition), the typical symptoms of depression is likely to be low mood, loss of interest and lack of energy. The complicated somatic symptoms are manifested inattention, insomnia, slow reaction time, reduced activity and fatigue. Recent assessment of depression severity mainly depends on the interview between the qualified psychiatrist and the patient or interview with their family member or caregiver, combined with their own prior experience. However, depression is a heterogeneous disease derived from different causes and manifestations. Basically, this diagnosis is relatively subjective and unidentified, which is lack of standardization to measure it. Current researches have revealed that the symptoms of depression patients are usually presented through a variety of visual signals, including the patient's facial expressions and body postures, especially the former are significant indicators of depression. Emerging machine learning technique can be used to capture the subtle expression changes, which can be applied to the automatic assessment of depression severity further. The early symptoms of depression can be clarified in time, and even independent diagnostic evaluation can be carried out. In order to achieve clearer evaluation of depression severity, depth features extraction and its application in automatic recognition of depression has been investigated based on facial images.MethodIn order to obtain effective face images-derived global information and make full use of the emotion-rich local areas like eyes and mouth parts in face images, we develop a channel-wise attention mechanism- integrated multi-branches convolutional neural network to extract multiple visual features for automatic depression recognition. First, the original video is sampled every 10 frames to reduce the redundancy of video frames, and the multi-task cascade convolutional neural networks are used to detect and locate the key points of the face. According to the coordinates of the detected key points, the areas of the whole face, eyes and mouth are cropped conversely. Then, 1) to obtain global features, the completed face images are input into a deep convolutional neural network in combination with channel-wise attention mechanism, and 2) to obtain local features, the latter are input into another two deep convolutional neural networks as well. During the training, the images are preprocessed and normalized and the data is enhanced by flipping and clipping. At the feature fusion layer, the features are extracted from three branches networks concatenated. Finally, the fully connected layer outputs the depression score. To demonstrate the feasibility and reliability of our proposal, a series of experiments are performed on the commonly-used The Continuous Audio/Visual Emotion and Depression Recognition Challenge 2013(AVEC 2013) and AVEC2014 datasets.Result1) The AVEC2013 depression database: the mean absolute error (MAE) is 6.74 and the root mean square error (RMSE) is 8.70, which decreased by 4.14 and 4.91 in comparison with the Baseline; 2) the AVEC2014 depression database: the MAE and RMSE are 6.56 and 8.56 of each, which decreased by 2.30 and 2.30 in comparison with the Baseline. Furthermore, our algorithms optimize the MAE and RMSE values further on both databases. Experimental results show that the channel-wise attention mechanism not only speeds up the convergence of network, but also reduces the results of MAE and RMSE. To recognize its depression severity, the integration of eyes and mouth features can significantly decrease the error compared to using global features only. This suggests that the local features in the context of eyes and mouth is an effective supplement to global features in depression recognition, especially the salient information-related eyes conveying. It conforms to clinicians' experience in judging the depression severity.ConclusionWe develop a multi-features-based automatic depression recognition method through using multi-branches deep conventional neural networks, which is implemented in an end-to-end manner. The features extraction and depression recognition are carried out and optimized in terms of a coordinated framework. To model more distinctive features, the channel-wise attention mechanism is added to adaptively assign weights to channels.关键词:depression recognition;channel-wise attention mechanism;deep convolutional neural network;feature fusion;spatial weight120|180|2更新时间:2024-05-07 -
 摘要:ObjectiveThe perception of visual information of human visual system has distorted multi-sensitivities due to multiple categories. Current researches have shown that the human visual system is restricted of the changes or distortions in image perception under some threshold circumstances. This kind of threshold is referred to the just noticeable difference (JND) threshold. JND threshold estimation of images is of great significance for many perceptual image processing applications like the optimized image compression and information hiding. Generally, luminance adaptation and spatial masking effect can be as the key factors to identify the JND threshold. The existing spatial masking models have mainly been evolved on two aspects of contrast masking and texture masking. However, the current texture masking model cannot effectively clarify the influence of JND-threshold-oriented texture roughness. Meanwhile, human visual system has lower sensitivities for perceiving the rough-surfaced changes or differences. First, our research is focused on fractal dimension based (FD-based) description using quantitative-oriented image texture roughness in terms of classic fractal theory. A new FD-based texture masking model is demonstrated as well. Regular higher texture-roughness-based targeted areas have stronger texture masking effect due to the lower texture-roughness-derived weaker texture masking effect. Next, our newly texture is developed an improved spatial masking estimation function based on the integration of a masking model and traditional contrast masking. Finally, the improved spatial mask estimation function is combined with luminance adaptability function for the final JND profile. Considering the visual attention mechanism of the human visual system, we also refine the JND threshold using the classical graph based visual saliency (GBVS) method in visual saliency map.MethodFirst, we get the luminance contrast masking of the original image. Then, we calculate the FD of each block with size 8×8 by the widely-adopted differential box-counting (DBC) method and get a FD map of the original image. Third, the new spatial masking map is obtained via combining the luminance contrast map with the proposed FD map. Forth, we also apply the luminance adaptation map to interpret the influence of luminance on JND. Based on the luminance adaptation map and the new spatial masking map, a direct-multiplication-derived coarse JND map can be obtained by fusing the two maps together. Fifth, considering the visual attention mechanism of human visual system, we refine the coarse JND map using visual saliency. To characterize the influence of visual saliency on JND, we compute the visual saliency map based on the GBVS method and a sigmoid-like control function is formulated. Finally, we can obtain the final JND map by fusing the coarse JND map and the multiplication-based sigmoid-like control function.ResultOur proposed JND profile has the highest visual saliency-induced index(VSI) and the highest mean opinion score(MOS) when injecting the more equivalent noises. Specifically, our model has a 0.001 7 higher average VSI score than the second-best model on Laboratory for Image & Video Engineering(LIVE), and the MOS is 50% higher. On TID2013, the average VSI of our model is 0.001 9 higher than the second-best model, and the MOS is also 40% higher. On categorical subjective image quality(CSIQ), the average VSI of our model is 0.001 3 higher than the second-best model, and the MOS is 9.1% higher as well. In addition, we also conduct the perceptual redundancy removal experiments to demonstrate the application capability of the proposed JND profile. The experimental results shown that our JND model can save 12.5% bytes on JPEG compression.ConclusionOur FD-based JND model can estimate the JND threshold effectively on the texture region. The fractal-based roughness on local areas, we can propose a new texture masking effect to estimate the JND threshold on these areas. To tackle more distorted issues, our model can inject more noise in the areas with high roughness and less noise in the smooth areas.关键词:just noticeable difference (JND);fractal dimension;texture coarseness;spatial masking;texture masking94|124|3更新时间:2024-05-07
摘要:ObjectiveThe perception of visual information of human visual system has distorted multi-sensitivities due to multiple categories. Current researches have shown that the human visual system is restricted of the changes or distortions in image perception under some threshold circumstances. This kind of threshold is referred to the just noticeable difference (JND) threshold. JND threshold estimation of images is of great significance for many perceptual image processing applications like the optimized image compression and information hiding. Generally, luminance adaptation and spatial masking effect can be as the key factors to identify the JND threshold. The existing spatial masking models have mainly been evolved on two aspects of contrast masking and texture masking. However, the current texture masking model cannot effectively clarify the influence of JND-threshold-oriented texture roughness. Meanwhile, human visual system has lower sensitivities for perceiving the rough-surfaced changes or differences. First, our research is focused on fractal dimension based (FD-based) description using quantitative-oriented image texture roughness in terms of classic fractal theory. A new FD-based texture masking model is demonstrated as well. Regular higher texture-roughness-based targeted areas have stronger texture masking effect due to the lower texture-roughness-derived weaker texture masking effect. Next, our newly texture is developed an improved spatial masking estimation function based on the integration of a masking model and traditional contrast masking. Finally, the improved spatial mask estimation function is combined with luminance adaptability function for the final JND profile. Considering the visual attention mechanism of the human visual system, we also refine the JND threshold using the classical graph based visual saliency (GBVS) method in visual saliency map.MethodFirst, we get the luminance contrast masking of the original image. Then, we calculate the FD of each block with size 8×8 by the widely-adopted differential box-counting (DBC) method and get a FD map of the original image. Third, the new spatial masking map is obtained via combining the luminance contrast map with the proposed FD map. Forth, we also apply the luminance adaptation map to interpret the influence of luminance on JND. Based on the luminance adaptation map and the new spatial masking map, a direct-multiplication-derived coarse JND map can be obtained by fusing the two maps together. Fifth, considering the visual attention mechanism of human visual system, we refine the coarse JND map using visual saliency. To characterize the influence of visual saliency on JND, we compute the visual saliency map based on the GBVS method and a sigmoid-like control function is formulated. Finally, we can obtain the final JND map by fusing the coarse JND map and the multiplication-based sigmoid-like control function.ResultOur proposed JND profile has the highest visual saliency-induced index(VSI) and the highest mean opinion score(MOS) when injecting the more equivalent noises. Specifically, our model has a 0.001 7 higher average VSI score than the second-best model on Laboratory for Image & Video Engineering(LIVE), and the MOS is 50% higher. On TID2013, the average VSI of our model is 0.001 9 higher than the second-best model, and the MOS is also 40% higher. On categorical subjective image quality(CSIQ), the average VSI of our model is 0.001 3 higher than the second-best model, and the MOS is 9.1% higher as well. In addition, we also conduct the perceptual redundancy removal experiments to demonstrate the application capability of the proposed JND profile. The experimental results shown that our JND model can save 12.5% bytes on JPEG compression.ConclusionOur FD-based JND model can estimate the JND threshold effectively on the texture region. The fractal-based roughness on local areas, we can propose a new texture masking effect to estimate the JND threshold on these areas. To tackle more distorted issues, our model can inject more noise in the areas with high roughness and less noise in the smooth areas.关键词:just noticeable difference (JND);fractal dimension;texture coarseness;spatial masking;texture masking94|124|3更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveInfrared and visible image fusion is essential to computer vision and image processing. To strengthen the scenes recognition derived of multisource images, more multi-sensors imagery information is required to be fused in relation to infrared and visible images. A fused image is generated for human perception-oriented visual tasks like video surveillance, target recognition and scene understanding. However, the existing fusion methods are usually designed by manually selecting the characteristics to be preserved. The existing fusion methods can be roughly divided into two categories in the context of traditional fusion methods and the deep learning-based fusion methods. For the traditional methods, to comprehensively characterize and decompose the source images, they need to manually design transformation methods. The fusion strategies are manually designed to fuse the decomposed subparts. The manually designed decomposition methods become more and more complex, which leads to the decline of fusion efficiency. For the deep learning-based methods, some methods define the unique characteristics of source images via human observation. The fused images are expected to preserve these characteristics as much as possible. However, it is difficult and unsuitable to identify the vital information through one or a few characteristics. Other methods are focused on preserving higher structural similarity with source images in terms of the fused image. It will reduce the saliency of thermal targets in the fusion result, which is not conductive to the rapid location and capture of thermal targets by the human vision system. Our method is designed to solve these two issues. We develop a new deep learning-based decomposition method for infrared and visible image fusion. Besides, we propose a deep learning-based and quality-guided fusion strategy to fuse the decomposed parts.MethodOur infrared and visible image fusion method is based on the information decomposed and quality-guided fusion strategy. First, we design an image decomposition and representation way, which is based on the convolution neural network (CNN). For each source image, two encoders are used to decompose the source images into the common part and unique part. Based on three loss functions (including a reconstruction loss, a translation loss and a loss to constrain the unique information), four encoders are learned to realize the physical-meaning-related decomposition. For the two decomposed parts, specific fusion strategies are applied for each. For the common parts, a traditional fusion strategy is selected to reduce the computational complexity and improve the fusion efficiency. For the unique parts, a weight encoder is assigned to learn the quality-guided fusion strategy, which can further preserve the complementary information derived from multi-source images. To improve the fusion performance, the metrics is used to evaluate the quality of fused images. The weight encoder generates the corresponding weights according to the unique information. The generator-optimized in the unique information decomposition procedure is used to generate the final fused image according to the fused common part and unique part.ResultOur method is compared to six state-of-the-art visible and infrared image fusion methods on the publicly available dataset named as RoadScene. In addition, the quality-guided fusion strategy is also in compared with four common fusion strategies, including mean, max, addition and
摘要:ObjectiveInfrared and visible image fusion is essential to computer vision and image processing. To strengthen the scenes recognition derived of multisource images, more multi-sensors imagery information is required to be fused in relation to infrared and visible images. A fused image is generated for human perception-oriented visual tasks like video surveillance, target recognition and scene understanding. However, the existing fusion methods are usually designed by manually selecting the characteristics to be preserved. The existing fusion methods can be roughly divided into two categories in the context of traditional fusion methods and the deep learning-based fusion methods. For the traditional methods, to comprehensively characterize and decompose the source images, they need to manually design transformation methods. The fusion strategies are manually designed to fuse the decomposed subparts. The manually designed decomposition methods become more and more complex, which leads to the decline of fusion efficiency. For the deep learning-based methods, some methods define the unique characteristics of source images via human observation. The fused images are expected to preserve these characteristics as much as possible. However, it is difficult and unsuitable to identify the vital information through one or a few characteristics. Other methods are focused on preserving higher structural similarity with source images in terms of the fused image. It will reduce the saliency of thermal targets in the fusion result, which is not conductive to the rapid location and capture of thermal targets by the human vision system. Our method is designed to solve these two issues. We develop a new deep learning-based decomposition method for infrared and visible image fusion. Besides, we propose a deep learning-based and quality-guided fusion strategy to fuse the decomposed parts.MethodOur infrared and visible image fusion method is based on the information decomposed and quality-guided fusion strategy. First, we design an image decomposition and representation way, which is based on the convolution neural network (CNN). For each source image, two encoders are used to decompose the source images into the common part and unique part. Based on three loss functions (including a reconstruction loss, a translation loss and a loss to constrain the unique information), four encoders are learned to realize the physical-meaning-related decomposition. For the two decomposed parts, specific fusion strategies are applied for each. For the common parts, a traditional fusion strategy is selected to reduce the computational complexity and improve the fusion efficiency. For the unique parts, a weight encoder is assigned to learn the quality-guided fusion strategy, which can further preserve the complementary information derived from multi-source images. To improve the fusion performance, the metrics is used to evaluate the quality of fused images. The weight encoder generates the corresponding weights according to the unique information. The generator-optimized in the unique information decomposition procedure is used to generate the final fused image according to the fused common part and unique part.ResultOur method is compared to six state-of-the-art visible and infrared image fusion methods on the publicly available dataset named as RoadScene. In addition, the quality-guided fusion strategy is also in compared with four common fusion strategies, including mean, max, addition and$l_1$ 关键词:image fusion;unique information decomposition;quality guidance;infrared and visible images;deep learning123|2229|1更新时间:2024-05-07 -
 摘要:ObjectiveMulti-view stereo (MVS) network is modeled to resilient a 3D model of a scene in the context of a set of images of a scene derived from photographic parameters-relevant multiple visual angles. This method can reconstruct small and large scales indoor and outdoor scenes both. The emerging virtual-reality-oriented 3D reconstruction technology has been developing nowadays. Traditional MVS methods mainly use manual designed similarity metrics and regularization methods to calculate the dense correspondence of scenes, which can be broadly classified into four categorized algorithms based on point cloud, voxel, variable polygon mesh, and depth map. These methods can achieve good results in ideal Lambert scenes without weakly textured areas, but it often fails to yield satisfactory reconstruction results in cases of texture scarcity, texture repetition, or lighting changes. Recent computer-vision-oriented deep learning techniques have promoted the newly reconstruction structure. The learning-based approach can learn the global semantic information. For example, there are based on the highlights and reflections of the prior for getting the more robust matching effect, so it was successively applied on the basis of the above traditional methods of deep learning. In general, MVS inherits the stereo geometry mechanism of stereo matching and improves the effect of the occlusion problem effectively, and it achieves greater improvement in accuracy and generalization as well. However, the existing methods have normal effects in feature extraction and poor correlation between cost volumes. We facilitate the multi-view stereo network with dual U-Net feature extraction sharing multi-scale cost volumes information.MethodOur improvements are mainly focused on the feature extraction and cost volume regularization pre-processing. First, a dual U-Net module is designed for feature extraction. For all input images with a resolution of 512×640 pixels, after convolution and ReLU, the original image of 3 channels is conveyed to 8 channels and 32 channels, and the feature maps of 1, 1/4 and 1/16 of the original image size are generated by dual pooling-maximized and convolution-sustained, respectively. In the up-sampling stage, the multi-scale features information is sewed and channel dimension is fused for thicker features. The merged convolution and upsampling are continued to obtain a 32-channel feature map with the same resolution as the original image, and it is used as the input and passed through the U-Net network once more to finally obtain three sets of feature maps with different sizes. Such a dual U-Net feature extraction module can keep more detailed features through, downsampling (reduce the spatial dimension of the pooling layer), upsampling (repair the detail and spatial dimension of the object), and side-joining (repair the detail of the target). This can make the following depth estimation results more accurate and complete. Nextly, since the initially constructed cost volumes have no connection between different scales and rely on the upsampling of the feature extraction module only to maintain the connection, resulting in the information of the cost volumes in each layer cannot be transferred, we design a multi-scale cost volume information sharing module in the pre-regularization stage, which separates the cost volumes generated in each layer and fuse them into the next layer. To improve the estimation quality of the depth map, the small-scale cost volume information is fused into the cost volume of the next layer.ResultThe Technical University of Denmark(DTU) dataset used in this experiment is an indoor dataset specially shot and processed for MVS, which can directly obtain the internal and external photographic parameters of each view angle. It consists of 128 multiple objects or scenes based on 79 training scenes, 18 validation scenes and 22 test scenes. The training is equipped on Ubuntu 20.04 with an Intel Core i9-10920X CPU and an NVIDIA 3090 graphics card. There are three main evaluation metrics, which are the average distance from the reconstructed point cloud to the real point cloud, which can be called accuracy (Acc), the average distance from the real point cloud to the reconstructed point cloud, which can be called completeness (Comp) and the average value of accuracy and completeness, which can be called overall (Overall). Some secondary metrics are involved in, which are absolute value of depth error, absolute error and accuracy of 2 mm, absolute error and accuracy of 4 mm, etc. The experimental results show that our three main metrics like Acc, Comp and Overall are improved by about 16.2%, 6.5% and 11.5% compared to the original method.ConclusionOur reconstructed network model is developed via the multi-view stereo network with dual U-Net feature extraction sharing multi-scale cost volumes information method. It has a significant enhancement effect on both feature extraction and cost volume regularization, and the reconstructed accuracy has its feasible potentials.关键词:3D reconstruction;deep learning;multi-view stereo network;double U-Net network;feature extraction;cost volume information sharing123|2332|3更新时间:2024-05-07
摘要:ObjectiveMulti-view stereo (MVS) network is modeled to resilient a 3D model of a scene in the context of a set of images of a scene derived from photographic parameters-relevant multiple visual angles. This method can reconstruct small and large scales indoor and outdoor scenes both. The emerging virtual-reality-oriented 3D reconstruction technology has been developing nowadays. Traditional MVS methods mainly use manual designed similarity metrics and regularization methods to calculate the dense correspondence of scenes, which can be broadly classified into four categorized algorithms based on point cloud, voxel, variable polygon mesh, and depth map. These methods can achieve good results in ideal Lambert scenes without weakly textured areas, but it often fails to yield satisfactory reconstruction results in cases of texture scarcity, texture repetition, or lighting changes. Recent computer-vision-oriented deep learning techniques have promoted the newly reconstruction structure. The learning-based approach can learn the global semantic information. For example, there are based on the highlights and reflections of the prior for getting the more robust matching effect, so it was successively applied on the basis of the above traditional methods of deep learning. In general, MVS inherits the stereo geometry mechanism of stereo matching and improves the effect of the occlusion problem effectively, and it achieves greater improvement in accuracy and generalization as well. However, the existing methods have normal effects in feature extraction and poor correlation between cost volumes. We facilitate the multi-view stereo network with dual U-Net feature extraction sharing multi-scale cost volumes information.MethodOur improvements are mainly focused on the feature extraction and cost volume regularization pre-processing. First, a dual U-Net module is designed for feature extraction. For all input images with a resolution of 512×640 pixels, after convolution and ReLU, the original image of 3 channels is conveyed to 8 channels and 32 channels, and the feature maps of 1, 1/4 and 1/16 of the original image size are generated by dual pooling-maximized and convolution-sustained, respectively. In the up-sampling stage, the multi-scale features information is sewed and channel dimension is fused for thicker features. The merged convolution and upsampling are continued to obtain a 32-channel feature map with the same resolution as the original image, and it is used as the input and passed through the U-Net network once more to finally obtain three sets of feature maps with different sizes. Such a dual U-Net feature extraction module can keep more detailed features through, downsampling (reduce the spatial dimension of the pooling layer), upsampling (repair the detail and spatial dimension of the object), and side-joining (repair the detail of the target). This can make the following depth estimation results more accurate and complete. Nextly, since the initially constructed cost volumes have no connection between different scales and rely on the upsampling of the feature extraction module only to maintain the connection, resulting in the information of the cost volumes in each layer cannot be transferred, we design a multi-scale cost volume information sharing module in the pre-regularization stage, which separates the cost volumes generated in each layer and fuse them into the next layer. To improve the estimation quality of the depth map, the small-scale cost volume information is fused into the cost volume of the next layer.ResultThe Technical University of Denmark(DTU) dataset used in this experiment is an indoor dataset specially shot and processed for MVS, which can directly obtain the internal and external photographic parameters of each view angle. It consists of 128 multiple objects or scenes based on 79 training scenes, 18 validation scenes and 22 test scenes. The training is equipped on Ubuntu 20.04 with an Intel Core i9-10920X CPU and an NVIDIA 3090 graphics card. There are three main evaluation metrics, which are the average distance from the reconstructed point cloud to the real point cloud, which can be called accuracy (Acc), the average distance from the real point cloud to the reconstructed point cloud, which can be called completeness (Comp) and the average value of accuracy and completeness, which can be called overall (Overall). Some secondary metrics are involved in, which are absolute value of depth error, absolute error and accuracy of 2 mm, absolute error and accuracy of 4 mm, etc. The experimental results show that our three main metrics like Acc, Comp and Overall are improved by about 16.2%, 6.5% and 11.5% compared to the original method.ConclusionOur reconstructed network model is developed via the multi-view stereo network with dual U-Net feature extraction sharing multi-scale cost volumes information method. It has a significant enhancement effect on both feature extraction and cost volume regularization, and the reconstructed accuracy has its feasible potentials.关键词:3D reconstruction;deep learning;multi-view stereo network;double U-Net network;feature extraction;cost volume information sharing123|2332|3更新时间:2024-05-07 -
 摘要:ObjectiveWith the development of deep learning, image captioning has achieved great success. Image captioning can not only be applied to infant education, web search, and human-computer interaction but also can aid visual disables to obtain invisible information better. Most image captioning works have been developed for captioning in English. However, the ideal of image captioning should be extended to non-native English speakers further. The main challenge of cross-lingual image captioning is lack of paired image-caption datasets in the context of target language. It is challenged to collect a large-scale image caption dataset for the target language of each. Thanks to existing large-scale English captioning datasets and translation models, using the pivot language (e.g., English) to bridge the image and the target language (e.g., Chinese) is currently the main backbone framework for cross-lingual image captioning. However, such a language-pivoted approach is restricted by dis-fluency and poor semantic relevance to images. We facilitate a cross-lingual image captioning model based on semantic matching and language evaluation.MethodFirst, our model is constructed via a native encoder-decoder framework, which extracts convolulional neural network(CNN)-based image features and generates the description in terms of the recurrent neural network. The pivot language (source language) descriptions are transformed into the target language sentences via a translation API, which is regarded as pseudo captioning labels of the images. Our model is initialized with pseudo-labels. However, the captions generated by the initialized model are in combination with of high-frequency vocabulary, the language style of pseudo-labels, or poor-irrelevant image content. It is worth noting that the pivot language written by humans is a correct description for the image content and contains the consistent semantics of the image. Therefore, considering the semantic guidance of the image content and pivot language, a semantic matching module is proposed based on the source corpus. Moreover, the language style of the generated captions greatly differs from the human-written target languages. To learn the language style of the target languages, a language evaluation module under the guidance of target language is proposed. The above two modules perform the constraints of semantic matching and language style on the optimization of the proposed captioning model. The methodological contributions are listed as following: 1) The semantic matching module is an embedding network in terms of source-domain-related image and language labels. To coordinate the semantic matching between image, pivot language, and generated sentence, these multimodal data is mapped into the embedding space for semantic-relevant calculation. Our model can guarantee the sentence-generated semantic enhancement linked to the visual content in the image. 2) The semantic evaluation module based on corpus in the target domain encourages the style of generated sentences to resemble the target language style. Under the joint rewards of semantic matching and language evaluation, our model is optimized to generate image-related sentences better. The semantic matching reward and language evaluation reward are performed in a reinforcement learning mode.ResultIn order to verify the effectiveness of the proposed model, we carried out two sub-task experiments. 1) The cross-lingual English image captioning task is evaluated on the Microsoft common object in context(MS COCO) image-English dataset, which is trained under image-Chinese captioning from artificial intelligence challenge(AIC-ICC) dataset and MS COCO English corpus. Compared with the state-of-the-art method, our metric values of bilingual evaluation understudy(BLEU)-2, BLEU-3, BLEU-4, and metric for evaluation of translation with explicit ordering(METEOR) have increased by 1.4%, 1.0%, 0.7% and 1.3%, respectively. 2) The cross-lingual Chinese image captioning task is evaluated on the AIC-ICC image-Chinese dataset, which is trained under MS COCO image-English dataset and AIC-ICC Chinese corpus. Compared with the state-of-the-art method, the performances for BLEU-1, BLEU-2, BLEU-3, BLEU-4, METEOR, and consensus-based image description evoluation(CIDEr) have increased by 5.7%, 2.0%, 1.6%, 1.3%, 1.2%, and 3.4% respectively.ConclusionThe semantic matching module yields the model to learn the relevant semantics in image and pivot language description. The language evaluation module learns the data distribution and language style of the target corpus. The semantic and language rewards have their potentials for cross-lingual image captioning, which not only optimize the semantic relevance of the sentence but also improve the fluency of the sentence further.关键词:cross-lingual;image captioning;reinforcement learning;neural network;pivot language434|267|0更新时间:2024-05-07
摘要:ObjectiveWith the development of deep learning, image captioning has achieved great success. Image captioning can not only be applied to infant education, web search, and human-computer interaction but also can aid visual disables to obtain invisible information better. Most image captioning works have been developed for captioning in English. However, the ideal of image captioning should be extended to non-native English speakers further. The main challenge of cross-lingual image captioning is lack of paired image-caption datasets in the context of target language. It is challenged to collect a large-scale image caption dataset for the target language of each. Thanks to existing large-scale English captioning datasets and translation models, using the pivot language (e.g., English) to bridge the image and the target language (e.g., Chinese) is currently the main backbone framework for cross-lingual image captioning. However, such a language-pivoted approach is restricted by dis-fluency and poor semantic relevance to images. We facilitate a cross-lingual image captioning model based on semantic matching and language evaluation.MethodFirst, our model is constructed via a native encoder-decoder framework, which extracts convolulional neural network(CNN)-based image features and generates the description in terms of the recurrent neural network. The pivot language (source language) descriptions are transformed into the target language sentences via a translation API, which is regarded as pseudo captioning labels of the images. Our model is initialized with pseudo-labels. However, the captions generated by the initialized model are in combination with of high-frequency vocabulary, the language style of pseudo-labels, or poor-irrelevant image content. It is worth noting that the pivot language written by humans is a correct description for the image content and contains the consistent semantics of the image. Therefore, considering the semantic guidance of the image content and pivot language, a semantic matching module is proposed based on the source corpus. Moreover, the language style of the generated captions greatly differs from the human-written target languages. To learn the language style of the target languages, a language evaluation module under the guidance of target language is proposed. The above two modules perform the constraints of semantic matching and language style on the optimization of the proposed captioning model. The methodological contributions are listed as following: 1) The semantic matching module is an embedding network in terms of source-domain-related image and language labels. To coordinate the semantic matching between image, pivot language, and generated sentence, these multimodal data is mapped into the embedding space for semantic-relevant calculation. Our model can guarantee the sentence-generated semantic enhancement linked to the visual content in the image. 2) The semantic evaluation module based on corpus in the target domain encourages the style of generated sentences to resemble the target language style. Under the joint rewards of semantic matching and language evaluation, our model is optimized to generate image-related sentences better. The semantic matching reward and language evaluation reward are performed in a reinforcement learning mode.ResultIn order to verify the effectiveness of the proposed model, we carried out two sub-task experiments. 1) The cross-lingual English image captioning task is evaluated on the Microsoft common object in context(MS COCO) image-English dataset, which is trained under image-Chinese captioning from artificial intelligence challenge(AIC-ICC) dataset and MS COCO English corpus. Compared with the state-of-the-art method, our metric values of bilingual evaluation understudy(BLEU)-2, BLEU-3, BLEU-4, and metric for evaluation of translation with explicit ordering(METEOR) have increased by 1.4%, 1.0%, 0.7% and 1.3%, respectively. 2) The cross-lingual Chinese image captioning task is evaluated on the AIC-ICC image-Chinese dataset, which is trained under MS COCO image-English dataset and AIC-ICC Chinese corpus. Compared with the state-of-the-art method, the performances for BLEU-1, BLEU-2, BLEU-3, BLEU-4, METEOR, and consensus-based image description evoluation(CIDEr) have increased by 5.7%, 2.0%, 1.6%, 1.3%, 1.2%, and 3.4% respectively.ConclusionThe semantic matching module yields the model to learn the relevant semantics in image and pivot language description. The language evaluation module learns the data distribution and language style of the target corpus. The semantic and language rewards have their potentials for cross-lingual image captioning, which not only optimize the semantic relevance of the sentence but also improve the fluency of the sentence further.关键词:cross-lingual;image captioning;reinforcement learning;neural network;pivot language434|267|0更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveHigh-incidence diabetic retinopathy (DR) is derived from a diabetic-complication in common. Recent algorithms for DR screening on fundus images are designed to alleviate the issues of uneven distribution of disease and high population density. Traditional DR diagnose is originated from an early-pathological detection, micro-aneurysms (MA) and hemorrhage (H). However, the supervised classification model cannot be effectively trained due to the lack of the lesion labeling, and such medical-oriented pixel-level annotation is time-consuming and labor-intensive. For annotated-lesion-regions-related auxiliary dataset, it is difficult to improve the classification model due to the domain gap. In addition, most of the existing DR diagnostic methods cannot be used to explain the predicted results of medical models. We demonstrate an end-to-end automatic grading algorithm of domain adaptive-learning-based DR, integrated weakly-supervised learning and attention mechanism.MethodFirst, the auxiliary dataset of the labeled lesion area is transferred to train a lesion detection supervision model due for handling the constraints of image-level DR diagnosis label and pixel-level lesion location information. Next, a single-image-labeling DR grading model is considered as a weakly-supervised learning problem to be dealt with. To bridge the domain gap, we facilitate a deep cross-domain generative adversarial network (GAN) model to produce more qualified cross-domain patches. A patches-derived classification model is trained by fine-tuning to filter out irrelevant lesion samples in the target domain, which improves the performance of image-label-based multi-class diagnosis. Finally, attention mechanism is melted into the entire model to strengthen grading interpretability for pathological diagnosis. As a result, the model hypothesis is based on independently and identically distributed local ones in global samples. The local-global relationship between small lesions and completed image is established, and the tracing ability of unclear lesion area is beneficial to classification results of retinal images for the degree of DR (healthy, slighted, moderated and severed).ResultA publicly dataset of Messidor is composed of 1 200 fundus images, which provides image-level diagnostic status of DR severity. Meanwhile, to identify normal/abnormal lesions, IDRiD dataset is targeted as source dataset to develop H + MA (MA and H) binary-class task. The experimental results illustrate our end-to-end framework contributions are shown as following: 1) improve the disease grading ability on the target domain without the lesion labels; 2) achieve domain adaptation across multiple datasets; 3) highlight the unclear regions with attention mechanism. Compared to the challenging benchmark dataset of Messidor, our optimization is based on the accuracy of 71.2% and the AUC(area under curve) value of 80.8%. We evaluate the contributions of different modules, such as sample filtering, domain adaptation, attention-mechanism-based weakly-supervised DR grading. Our ablation results show that the AUC value of these modules is optimized by 11.8%, 20.2% and 15.8%, respectively. It can be sorted out that irrelevant samples filtering can reduce negative impact on the final results, generate GAN-based cross-domain samples, and optimize data heterogeneity. It promotes pathology-related interpretability and enhances the generalization ability of model. Moreover, the ablation experiments analyze the influence of hyper-parameters in detail and the DR-grading-oriented interpretability is visualized.ConclusionOur domain-adaptive-learning based classification method can achieve grading diagnosis of fundus images effectively in the context of the initial lesion detection stage, the transfer learning strategy, as well as the local-global mapping relationship of lesion and entire retinal image. It has potential to distinguish the severity of lesions types and rediscover subtle modifications towards pathological features, and deal with imbalance between lesion and background patches. The image-level monitoring information can effectively and automatically realize grading diagnosis of fundus images without pixel-level lesion annotation data. It can avoid the limitation of manual segmentation and labeling of lesion in medical images as well. Furthermore, its interpretation and support can provide the potential detection of high risk regions. Our model can harness more weakly-supervised classification of medical images further.关键词:diabetic retinopathy(DR);fundus image;attention mechanism;deep learning;weakly-supervised learning;domain adaptation292|1090|1更新时间:2024-05-07
摘要:ObjectiveHigh-incidence diabetic retinopathy (DR) is derived from a diabetic-complication in common. Recent algorithms for DR screening on fundus images are designed to alleviate the issues of uneven distribution of disease and high population density. Traditional DR diagnose is originated from an early-pathological detection, micro-aneurysms (MA) and hemorrhage (H). However, the supervised classification model cannot be effectively trained due to the lack of the lesion labeling, and such medical-oriented pixel-level annotation is time-consuming and labor-intensive. For annotated-lesion-regions-related auxiliary dataset, it is difficult to improve the classification model due to the domain gap. In addition, most of the existing DR diagnostic methods cannot be used to explain the predicted results of medical models. We demonstrate an end-to-end automatic grading algorithm of domain adaptive-learning-based DR, integrated weakly-supervised learning and attention mechanism.MethodFirst, the auxiliary dataset of the labeled lesion area is transferred to train a lesion detection supervision model due for handling the constraints of image-level DR diagnosis label and pixel-level lesion location information. Next, a single-image-labeling DR grading model is considered as a weakly-supervised learning problem to be dealt with. To bridge the domain gap, we facilitate a deep cross-domain generative adversarial network (GAN) model to produce more qualified cross-domain patches. A patches-derived classification model is trained by fine-tuning to filter out irrelevant lesion samples in the target domain, which improves the performance of image-label-based multi-class diagnosis. Finally, attention mechanism is melted into the entire model to strengthen grading interpretability for pathological diagnosis. As a result, the model hypothesis is based on independently and identically distributed local ones in global samples. The local-global relationship between small lesions and completed image is established, and the tracing ability of unclear lesion area is beneficial to classification results of retinal images for the degree of DR (healthy, slighted, moderated and severed).ResultA publicly dataset of Messidor is composed of 1 200 fundus images, which provides image-level diagnostic status of DR severity. Meanwhile, to identify normal/abnormal lesions, IDRiD dataset is targeted as source dataset to develop H + MA (MA and H) binary-class task. The experimental results illustrate our end-to-end framework contributions are shown as following: 1) improve the disease grading ability on the target domain without the lesion labels; 2) achieve domain adaptation across multiple datasets; 3) highlight the unclear regions with attention mechanism. Compared to the challenging benchmark dataset of Messidor, our optimization is based on the accuracy of 71.2% and the AUC(area under curve) value of 80.8%. We evaluate the contributions of different modules, such as sample filtering, domain adaptation, attention-mechanism-based weakly-supervised DR grading. Our ablation results show that the AUC value of these modules is optimized by 11.8%, 20.2% and 15.8%, respectively. It can be sorted out that irrelevant samples filtering can reduce negative impact on the final results, generate GAN-based cross-domain samples, and optimize data heterogeneity. It promotes pathology-related interpretability and enhances the generalization ability of model. Moreover, the ablation experiments analyze the influence of hyper-parameters in detail and the DR-grading-oriented interpretability is visualized.ConclusionOur domain-adaptive-learning based classification method can achieve grading diagnosis of fundus images effectively in the context of the initial lesion detection stage, the transfer learning strategy, as well as the local-global mapping relationship of lesion and entire retinal image. It has potential to distinguish the severity of lesions types and rediscover subtle modifications towards pathological features, and deal with imbalance between lesion and background patches. The image-level monitoring information can effectively and automatically realize grading diagnosis of fundus images without pixel-level lesion annotation data. It can avoid the limitation of manual segmentation and labeling of lesion in medical images as well. Furthermore, its interpretation and support can provide the potential detection of high risk regions. Our model can harness more weakly-supervised classification of medical images further.关键词:diabetic retinopathy(DR);fundus image;attention mechanism;deep learning;weakly-supervised learning;domain adaptation292|1090|1更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveConvolutional neural networks (CNNs) have been widely used in remote sensing scene image classification, but data-driven models are restricted by the data scarcity-related over fitting and low robustness issue. The problems of few labeled samples are still challenged to train model for remote sensing scene image classification task. Therefore, it is required to design an effective algorithm that can adapt to small-scale data. Few-shot learning can be used to improve the generalization ability of model. Current meta-learning-based few-shot remote sensing scene image classification methods can resilient the data-intensive with no higher robustness. A challenging issue of the remote sensing scene samples is derived of small inter-class variation and large intra-class variation, which may lead to low robustness for few-shot learning. Our research is focused on a novel self-supervised learning framework for few-shot remote sensing scene image classification, which can improve the generalization ability of the model via rich intra-class relationships learnt.MethodOur self-supervised learning framework is composed of three modules in relation to data preprocessing, feature extraction and loss function. 1) Data preprocessing module is implemented for resizing and normalization for all inputs, and the supporting set and the query set are constructed for few-shot learning. The supporting set is concerned about small scale labeled images, but the query set has no labels-relevant samples. Few-shot learning method attempts to classify the query samples of using same group-derived supporting set. Furthermore, data preprocessing module can construct a numerous of multiple supporting sets and query sets. 2) Feature extraction module is aimed to extract the features from the inputs, consisting of the supporting features and the query features. The distilled "student-related" knowledge has dual-based feature extraction networks. The "teacher-related" feature extraction module is based on ResNet-50, and the "student-related" dual module has two Conv-64 networks. 3) Loss function module can produce three losses-relevant like few-shot, knowledge distillation and self-supervised contrast. The few-shot loss uses the inherent labels to update the parameters of the "student-related" network, which is produced by metric-based meta-learning. Knowledge-distilled loss is originated from KL (Kullback-Leibler) loss, which calculates the similarity of probability distribution between the "student-related" dual networks and the teachers-related network using the soft labels. The knowledge distillation learning is based on two-stage training process. The "teacher-related" network is used for metric based meta-learning. Then, the "student-related" networks and the "teacher-related" network are trained with the same data, and the output of the "teacher-related" network is used to guide the learning of the "student-related" network by knowledge distillation loss. Additionally, the self-supervised contrastive loss is calculated by measuring the distance between the centers of two classes. We use the self-supervised contrastive loss to perform instance discrimination pretext task through reducing the distances from same classes, and amplifying the different ones. The two self-supervising mechanisms can enable the model to learn richer inter-class relationships, which can improve the generalization ability.ResultOur method is evaluated on North Western Polytechnical University-remote sensing image scene classification (NWPU-RESISC45) dataset, aerial image dataset (AID), and UC merced land use dataset (UCMerced LandUse), respectively. The 5-way 1-shot task and 5-way 5-shot task is carried out on each dataset. Our method is also compared to other five methods, and our benchmark is Relation Net*, which is a metric-based meta-learning method. For the 5-way 1-shot task, it can achieve 72.72%±0.15%, 68.62%±0.76%, and 68.21%±0.65% on the three datasets, respectively, which is 4.43%, 1.93%, and 0.68% higher than Relation Net*. For the 5-way 5-shot task, our result is 3.89%, 2.99%, and 1.25% higher than Relation Net*. The confusion matrix is visualized on the AID and UCMerced LandUse as well. The confusion matrix shows that our self-supervised method can reduce the error outputs from the indistinguishable classes.ConclusionWe develop a self-supervised method to resolve the data scarcity-derived problem of low robustness, which consists of a dual-based "student-related" knowledge distillation mechanism and a self-supervised contrastive learning mechanism. Dual-based "student-related" knowledge distillation uses the soft labels of the "teacher-related" network as the supervision information of the "student-related" network, which can improve the robustness of few-shot learning through richer inter-class relationship and intra-class relationship. The self-supervised contrastive learning method can evaluate the similarity of different class center in a representation space, making the model to learn a class center better. The feasibility of self-supervised distillation and contrastive learning is clarified. It is necessary to integrate self-supervised transfer learning tasks with few-shot remote sensing scene image classification further.关键词:few-shot learning;remote sensing scene classification;self-supervised learning;distillation learning;contrastive learning1808|4120|7更新时间:2024-05-07
摘要:ObjectiveConvolutional neural networks (CNNs) have been widely used in remote sensing scene image classification, but data-driven models are restricted by the data scarcity-related over fitting and low robustness issue. The problems of few labeled samples are still challenged to train model for remote sensing scene image classification task. Therefore, it is required to design an effective algorithm that can adapt to small-scale data. Few-shot learning can be used to improve the generalization ability of model. Current meta-learning-based few-shot remote sensing scene image classification methods can resilient the data-intensive with no higher robustness. A challenging issue of the remote sensing scene samples is derived of small inter-class variation and large intra-class variation, which may lead to low robustness for few-shot learning. Our research is focused on a novel self-supervised learning framework for few-shot remote sensing scene image classification, which can improve the generalization ability of the model via rich intra-class relationships learnt.MethodOur self-supervised learning framework is composed of three modules in relation to data preprocessing, feature extraction and loss function. 1) Data preprocessing module is implemented for resizing and normalization for all inputs, and the supporting set and the query set are constructed for few-shot learning. The supporting set is concerned about small scale labeled images, but the query set has no labels-relevant samples. Few-shot learning method attempts to classify the query samples of using same group-derived supporting set. Furthermore, data preprocessing module can construct a numerous of multiple supporting sets and query sets. 2) Feature extraction module is aimed to extract the features from the inputs, consisting of the supporting features and the query features. The distilled "student-related" knowledge has dual-based feature extraction networks. The "teacher-related" feature extraction module is based on ResNet-50, and the "student-related" dual module has two Conv-64 networks. 3) Loss function module can produce three losses-relevant like few-shot, knowledge distillation and self-supervised contrast. The few-shot loss uses the inherent labels to update the parameters of the "student-related" network, which is produced by metric-based meta-learning. Knowledge-distilled loss is originated from KL (Kullback-Leibler) loss, which calculates the similarity of probability distribution between the "student-related" dual networks and the teachers-related network using the soft labels. The knowledge distillation learning is based on two-stage training process. The "teacher-related" network is used for metric based meta-learning. Then, the "student-related" networks and the "teacher-related" network are trained with the same data, and the output of the "teacher-related" network is used to guide the learning of the "student-related" network by knowledge distillation loss. Additionally, the self-supervised contrastive loss is calculated by measuring the distance between the centers of two classes. We use the self-supervised contrastive loss to perform instance discrimination pretext task through reducing the distances from same classes, and amplifying the different ones. The two self-supervising mechanisms can enable the model to learn richer inter-class relationships, which can improve the generalization ability.ResultOur method is evaluated on North Western Polytechnical University-remote sensing image scene classification (NWPU-RESISC45) dataset, aerial image dataset (AID), and UC merced land use dataset (UCMerced LandUse), respectively. The 5-way 1-shot task and 5-way 5-shot task is carried out on each dataset. Our method is also compared to other five methods, and our benchmark is Relation Net*, which is a metric-based meta-learning method. For the 5-way 1-shot task, it can achieve 72.72%±0.15%, 68.62%±0.76%, and 68.21%±0.65% on the three datasets, respectively, which is 4.43%, 1.93%, and 0.68% higher than Relation Net*. For the 5-way 5-shot task, our result is 3.89%, 2.99%, and 1.25% higher than Relation Net*. The confusion matrix is visualized on the AID and UCMerced LandUse as well. The confusion matrix shows that our self-supervised method can reduce the error outputs from the indistinguishable classes.ConclusionWe develop a self-supervised method to resolve the data scarcity-derived problem of low robustness, which consists of a dual-based "student-related" knowledge distillation mechanism and a self-supervised contrastive learning mechanism. Dual-based "student-related" knowledge distillation uses the soft labels of the "teacher-related" network as the supervision information of the "student-related" network, which can improve the robustness of few-shot learning through richer inter-class relationship and intra-class relationship. The self-supervised contrastive learning method can evaluate the similarity of different class center in a representation space, making the model to learn a class center better. The feasibility of self-supervised distillation and contrastive learning is clarified. It is necessary to integrate self-supervised transfer learning tasks with few-shot remote sensing scene image classification further.关键词:few-shot learning;remote sensing scene classification;self-supervised learning;distillation learning;contrastive learning1808|4120|7更新时间:2024-05-07 -
 摘要:ObjectiveRemote sensing based image processing technology plays an important role in crop planning, vegetation detection and agricultural land detection. The purpose of crop-relevant remote sensing image semantic segmentation is to classify the crop-relevant remote sensing image at pixel level and segment the image into regions with different semantic identification. The semantic segmentation of crop-relevant remote sensing image has been challenging in contrast to natural scene on the two aspects: 1) the number of samples of different categories varies greatly and the distribution is extremely unbalanced. For example, there are much more background-related samples with less samples remaining. The following overfitting and poor robustness problems are appeared for network training. 2) The similarity of appearance features of different crops is presented higher, which makes it difficult to distinguish similar appearance for the network, while the appearance features of the same crop are different, which could cause misclassify the same crop. We develop a semantic segmentation network called class relation network (CRNet) for crop-relevant remote sensing image, which integrates multiple scale class relations. Our experimental data is carried out on Barley Remote Sensing Dataset derived from the Tianchi Big Data Competition. Since the dataset consists of 4 large-size high-resolution remote sensing images, it cannot be as an input to a neural network. First, it is necessary to process the image and cut it into many sub-graphs of 512×512 pixels. Next, there are 11 750 sub-graphs in the dataset after cutting, including 9 413 images in the training set and 2 337 images in the test set. The ratio of the training set is about 4:1 to the test set.MethodOur CRNet is composed of three parts like variant of feature pyramid network encoder, category relation module and decoder. 1) In the encoder, ResNet-34 is used as the backbone network to extract the image features from bottom to top gradually, which can process image details better. Similar to the original feature pyramid structure (from top to bottom), horizontal links are used to fuse high-level semantic features and low-level spatial information. 2) The category relation module consists of three layers of paralleled structure. After the features of the three layers outputted by the encoder pass through the 1×1 convolution layer, the channel dimension is reduced to 5. The 1×1 convolutional layer here can be regarded as a classifier that maps global features into 5 channels, corresponding to the classification category, and each channel can represent features of a targeted category. Then, the feature map of each layer is input into the category feature enhancement(CFE) attention mechanism. The CFE attention module is segmented to channel-based and spatial-relevant. Assigned weights for each category is conducted by learning the correlation between the features of each channel. To clarify the features between different categories, the channel attention mechanism is focused on strengthening the strong-correlated features and suppressing the weak-correlated features. The channel information is encoded in the spatial dimension through global average pooling and global max pooling, and the global context information is modeled to obtain the global features of each channel. The spatial attention module enhances the location information of crops, such as the sites of crops in the farmland. Each location is connected with the horizontal or vertical direction in the feature image via learning the spatial information in the horizontal and vertical directions. The CFE attention module can obtain more distinct features in different categories. The feature differences are identified further between multiple crops. At the same time, more context information is improved for the feature of the same category, which aids to reduce the misclassification of the same crop. 3) In the decoder, the classification relations of different scales are fused and restored to the initial resolution, and the final classification is carried out by fully combining the feature information of each scale. In addition, we use data enhancement to reduce the proportion of background samples and expand the number of samples of other categories. To further alleviate the problem of class imbalance in crop-relevant remote sensing images, a class-balanced loss (CB loss) function is introduced.ResultTo verify the effectiveness of the CRNet, our training model is tested on Barley Remote Sensing dataset, and the mean intersection over union (MIoU) is 68.89%, and the overall accuracy (OA) is 82.59%. Our CRNet is increased by 7.42%, 4.86%, 4.57%, 4.36%, 4.05%, and 3.63% respectively in MIoU in contrast to the Linknet, pyramid scene parsing network (PSPNet), DeepLabv3+, foreground-aware relation network (FarSeg), statistical texture learning network (STLNet) and feature pyramid network(FPN), and our OA is improved by 4.35%, 2.6%, 3.01%, 2.5%, 2.45% and 1.85% of each. The number of parameters and inference speed of CRNet are reached to 21.98 MB and 68 frames/s. Compared to LinkNet and FPN, its number of parameters and inference speed are increased, which are 7.42% and 4.35% higher than LinkNet, 3.63% and 1.85% higher than FPN in MIoU and OA.ConclusionIn the combination of multi-level features and the introduction of category relation module, our CRNet network can distinguish the similar crops more accurately. The same crops are sorted out in the complex ground object background of remote sensing image. The completed target boundary can be extracted more. The experiment shows that our CRNet has its priority for crop-relevant semantic segmentation methods.关键词:crop remote sensing image;semantic segmentation;category relation module;attention mechanism;class-balanced loss(CB loss);Barley Remote Sensing dataset175|186|2更新时间:2024-05-07
摘要:ObjectiveRemote sensing based image processing technology plays an important role in crop planning, vegetation detection and agricultural land detection. The purpose of crop-relevant remote sensing image semantic segmentation is to classify the crop-relevant remote sensing image at pixel level and segment the image into regions with different semantic identification. The semantic segmentation of crop-relevant remote sensing image has been challenging in contrast to natural scene on the two aspects: 1) the number of samples of different categories varies greatly and the distribution is extremely unbalanced. For example, there are much more background-related samples with less samples remaining. The following overfitting and poor robustness problems are appeared for network training. 2) The similarity of appearance features of different crops is presented higher, which makes it difficult to distinguish similar appearance for the network, while the appearance features of the same crop are different, which could cause misclassify the same crop. We develop a semantic segmentation network called class relation network (CRNet) for crop-relevant remote sensing image, which integrates multiple scale class relations. Our experimental data is carried out on Barley Remote Sensing Dataset derived from the Tianchi Big Data Competition. Since the dataset consists of 4 large-size high-resolution remote sensing images, it cannot be as an input to a neural network. First, it is necessary to process the image and cut it into many sub-graphs of 512×512 pixels. Next, there are 11 750 sub-graphs in the dataset after cutting, including 9 413 images in the training set and 2 337 images in the test set. The ratio of the training set is about 4:1 to the test set.MethodOur CRNet is composed of three parts like variant of feature pyramid network encoder, category relation module and decoder. 1) In the encoder, ResNet-34 is used as the backbone network to extract the image features from bottom to top gradually, which can process image details better. Similar to the original feature pyramid structure (from top to bottom), horizontal links are used to fuse high-level semantic features and low-level spatial information. 2) The category relation module consists of three layers of paralleled structure. After the features of the three layers outputted by the encoder pass through the 1×1 convolution layer, the channel dimension is reduced to 5. The 1×1 convolutional layer here can be regarded as a classifier that maps global features into 5 channels, corresponding to the classification category, and each channel can represent features of a targeted category. Then, the feature map of each layer is input into the category feature enhancement(CFE) attention mechanism. The CFE attention module is segmented to channel-based and spatial-relevant. Assigned weights for each category is conducted by learning the correlation between the features of each channel. To clarify the features between different categories, the channel attention mechanism is focused on strengthening the strong-correlated features and suppressing the weak-correlated features. The channel information is encoded in the spatial dimension through global average pooling and global max pooling, and the global context information is modeled to obtain the global features of each channel. The spatial attention module enhances the location information of crops, such as the sites of crops in the farmland. Each location is connected with the horizontal or vertical direction in the feature image via learning the spatial information in the horizontal and vertical directions. The CFE attention module can obtain more distinct features in different categories. The feature differences are identified further between multiple crops. At the same time, more context information is improved for the feature of the same category, which aids to reduce the misclassification of the same crop. 3) In the decoder, the classification relations of different scales are fused and restored to the initial resolution, and the final classification is carried out by fully combining the feature information of each scale. In addition, we use data enhancement to reduce the proportion of background samples and expand the number of samples of other categories. To further alleviate the problem of class imbalance in crop-relevant remote sensing images, a class-balanced loss (CB loss) function is introduced.ResultTo verify the effectiveness of the CRNet, our training model is tested on Barley Remote Sensing dataset, and the mean intersection over union (MIoU) is 68.89%, and the overall accuracy (OA) is 82.59%. Our CRNet is increased by 7.42%, 4.86%, 4.57%, 4.36%, 4.05%, and 3.63% respectively in MIoU in contrast to the Linknet, pyramid scene parsing network (PSPNet), DeepLabv3+, foreground-aware relation network (FarSeg), statistical texture learning network (STLNet) and feature pyramid network(FPN), and our OA is improved by 4.35%, 2.6%, 3.01%, 2.5%, 2.45% and 1.85% of each. The number of parameters and inference speed of CRNet are reached to 21.98 MB and 68 frames/s. Compared to LinkNet and FPN, its number of parameters and inference speed are increased, which are 7.42% and 4.35% higher than LinkNet, 3.63% and 1.85% higher than FPN in MIoU and OA.ConclusionIn the combination of multi-level features and the introduction of category relation module, our CRNet network can distinguish the similar crops more accurately. The same crops are sorted out in the complex ground object background of remote sensing image. The completed target boundary can be extracted more. The experiment shows that our CRNet has its priority for crop-relevant semantic segmentation methods.关键词:crop remote sensing image;semantic segmentation;category relation module;attention mechanism;class-balanced loss(CB loss);Barley Remote Sensing dataset175|186|2更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0