
最新刊期
卷 27 , 期 10 , 2022
-
 摘要:The growth of multimedia technology has leveraged more available multifaceted media data. Human-perceptive multiple media data fusion has promoted the research and development (R&D) of artificial intelligence (AI) for computer vision. It has a wide range of applications like remote sensing image interpretation, biomedicine, and depth estimation. Multimodality can be as a form of representation of things (RoT). It refers to the description of things from multiple perspectives. Early AI-oriented technology is focused on a single modality of data. Current human-perceptive researches have clarified that each modality has a relatively independent description of things (IDoT), and the use of complementary representations of multimodal data tend to three-dimensional further. Recent processing and applications of multimodal data has been intensively developed like sentiment analysis, machine translation, natural language processing, and biomedicine. Our critical review is focused on the development of multimodality. Computer-vision-oriented multimodal learning is mainly used to analyze the related multimodal data on the aspects of images and videos, modalities-ranged learning and complemented information, and image detection and recognition, semantic segmentation, and video action prediction, etc. Multimodal data has its priority for objects description. First, it is challenged to collect large-scale, high-quality multimodal datasets due to the equipment-limited like multiple imaging devices and sensors. Next, Image and video data processing and labeling are time-consuming and labor-intensive. Based on the limited-data-derived multimodal learning methods, the multimodal data limited methods in the context of computer vision can be segmented into five aspects, including few-shot learning, lack of strong supervised information, active learning, data denoising and data augmentation. The multi-features of samples and the models evolution are critically reviewed as mentioned below: 1) in the case of insufficient multi-modal data, the few-shot learning method has the cognitive ability to make correct judgments via learning a small number of samples only, and it can effectively learn the target features in the case of lack of data. 2) Due to the high cost of the data labeling process, it is challenged to obtain all the ground truth labels of all modalities for strongly supervised learning of the model. The incomplete supervised methods are composed of weakly supervised, unsupervised, semi-supervised, and self-supervised learning methods in common. These methods can optimize modal labeling information and cost-effective manual labeling. 3) The active learning method is based on the integration of prior knowledge and learning regulatory via designing a model using autonomous learning ability, and it is committed to the maximum optimization of few samples. Labeling costs can be effectively reduced in consistency based on the optimized options of samples. 4) Multimodal data denoising refers to reducing data noise, restoring the original data, and then extracting the information of interest. 5) In order to make full use of limited multi-modal data, few-samples-conditioned data enhancement method extends realistic data by performing a series of transformation operations on the original data set. In addition, the data sets are used for the multimodal learning method limited data. Its potential applications are introduced like human pose estimation and person re-identification, and the performance of the existing algorithms is compared and analyzed. The pros and cons, as well as the future development direction, are projected as following: 1) a lightweight multimodal data processing method: we argue that limited-data-conditioned multimodal learning still has the challenge of mobile-devices-oriented models applications. When the existing methods fuse the information of multiple modalities, it is generally necessary to use two or above networks for feature extraction, and then fuse the features. Therefore, the large number of parameters and the complex structure of the model limit its application to mobile devices. Future lightweight model has its potentials. 2) A commonly-used multimodal intelligent processing model: most of existing multimodal data processing methods are derived from the developed multi-algorithms for multitasks, which need to be trained on specific tasks. This tailored training method greatly increases the cost of developing models, making it difficult to meet the needs of more application scenarios. Therefore, for the data of different modalities, it is necessary to promote a consensus perception model to learn the general representation of multimodal data and the parameters and features of the general model can be shared for multiple scenarios. 3) A multi-sources knowledge and data driven model: it is possible to introduce featured data and knowledge of multi-modal data beyond, establish an integrated knowledge-data-driven model, and enhance the model's performance and interpretability.关键词:multimodal data;limited data;deep learning;fusion algorithms;computer vision156|328|5更新时间:2024-05-07
摘要:The growth of multimedia technology has leveraged more available multifaceted media data. Human-perceptive multiple media data fusion has promoted the research and development (R&D) of artificial intelligence (AI) for computer vision. It has a wide range of applications like remote sensing image interpretation, biomedicine, and depth estimation. Multimodality can be as a form of representation of things (RoT). It refers to the description of things from multiple perspectives. Early AI-oriented technology is focused on a single modality of data. Current human-perceptive researches have clarified that each modality has a relatively independent description of things (IDoT), and the use of complementary representations of multimodal data tend to three-dimensional further. Recent processing and applications of multimodal data has been intensively developed like sentiment analysis, machine translation, natural language processing, and biomedicine. Our critical review is focused on the development of multimodality. Computer-vision-oriented multimodal learning is mainly used to analyze the related multimodal data on the aspects of images and videos, modalities-ranged learning and complemented information, and image detection and recognition, semantic segmentation, and video action prediction, etc. Multimodal data has its priority for objects description. First, it is challenged to collect large-scale, high-quality multimodal datasets due to the equipment-limited like multiple imaging devices and sensors. Next, Image and video data processing and labeling are time-consuming and labor-intensive. Based on the limited-data-derived multimodal learning methods, the multimodal data limited methods in the context of computer vision can be segmented into five aspects, including few-shot learning, lack of strong supervised information, active learning, data denoising and data augmentation. The multi-features of samples and the models evolution are critically reviewed as mentioned below: 1) in the case of insufficient multi-modal data, the few-shot learning method has the cognitive ability to make correct judgments via learning a small number of samples only, and it can effectively learn the target features in the case of lack of data. 2) Due to the high cost of the data labeling process, it is challenged to obtain all the ground truth labels of all modalities for strongly supervised learning of the model. The incomplete supervised methods are composed of weakly supervised, unsupervised, semi-supervised, and self-supervised learning methods in common. These methods can optimize modal labeling information and cost-effective manual labeling. 3) The active learning method is based on the integration of prior knowledge and learning regulatory via designing a model using autonomous learning ability, and it is committed to the maximum optimization of few samples. Labeling costs can be effectively reduced in consistency based on the optimized options of samples. 4) Multimodal data denoising refers to reducing data noise, restoring the original data, and then extracting the information of interest. 5) In order to make full use of limited multi-modal data, few-samples-conditioned data enhancement method extends realistic data by performing a series of transformation operations on the original data set. In addition, the data sets are used for the multimodal learning method limited data. Its potential applications are introduced like human pose estimation and person re-identification, and the performance of the existing algorithms is compared and analyzed. The pros and cons, as well as the future development direction, are projected as following: 1) a lightweight multimodal data processing method: we argue that limited-data-conditioned multimodal learning still has the challenge of mobile-devices-oriented models applications. When the existing methods fuse the information of multiple modalities, it is generally necessary to use two or above networks for feature extraction, and then fuse the features. Therefore, the large number of parameters and the complex structure of the model limit its application to mobile devices. Future lightweight model has its potentials. 2) A commonly-used multimodal intelligent processing model: most of existing multimodal data processing methods are derived from the developed multi-algorithms for multitasks, which need to be trained on specific tasks. This tailored training method greatly increases the cost of developing models, making it difficult to meet the needs of more application scenarios. Therefore, for the data of different modalities, it is necessary to promote a consensus perception model to learn the general representation of multimodal data and the parameters and features of the general model can be shared for multiple scenarios. 3) A multi-sources knowledge and data driven model: it is possible to introduce featured data and knowledge of multi-modal data beyond, establish an integrated knowledge-data-driven model, and enhance the model's performance and interpretability.关键词:multimodal data;limited data;deep learning;fusion algorithms;computer vision156|328|5更新时间:2024-05-07 -
 摘要:Image big data and easy-use models such as deep networks(DNs) have expedited artificial intelligence (AI) currently. But, the issue for limited images which are often captured from complex, hostile and other scenarios has been challenging still yet: objects are too small to be recognized; the boundaries are fuzzy-overlapped; or even all the object information indicated in the images is uncertain due to camouflages and occlusions. The limited image data are featured with small-sample, small-object, incompleteness, uncertainty. Obviously, the tackle of limited image data is different from image big data: 1) image big data fits Gaussian distributions (mean u and σ) in terms of statistical central limit theorem, especially when data scales are much larger than data dimensions. This feature is beneficial to make statistical inference by the 3σ rule, which indicates that 99.73% of samples are within the range of [u-3σ, u+3σ]. Possibly due to the concentration saliency fundamental, the statistical AI models such as DNs become very popular and seemly successful. However, for small dataset, the statistical consistency is usually poor, and the robust features cannot be identified based on concentration saliency. Thus, the statistical inference AI models are not feasible for small training data. 2) Image objects are often mutually occluded in costly and rare scenarios, and the delicate camouflages and masks, poor and complex luminous environment, as well as hostile disturbances, often make the image information itself or the information dimensions incomplete and unconfident. These issues make the computation load very heavy because the missed information or dimension has a large number of possibilities. 3) A large number of big data techniques have been proposed and seem very competitive in image processing field. For example, the DNs have achieved the best rank in many image big datasets publicly available. These features have extremely highlighted the contribution of DNs. However, many face recognition systems do not meet the requirement of accuracy and precision even when the face data is big enough. The statistical inference models such DNs cannot do precise inference, and some errors do exist due to the statistical inference itself. For limited image data, the consequence has been declined further especially when the number of samples is less than the dimensions. The partition boundaries in the sample space cannot be uniquely fixed by training samples. That is to say, to determine the inference model needs to solve irreversible inverse problems, meaning that the definite model cannot be uniquely fixed, and only a reduced model can be fixed. For any query sample, the simplified model cannot give an explicit solution, and only a subspace can just be given which is constituted of possible solutions. How to choose an appropriate solution from the subspace is still challenging, and seemingly there are no effective and general ways. Many techniques seem a little effective on studying limited image dataset, such as level-set methods, fussy logic methods, all these methods are based on the probability metrics measuring the divergence between the existent limited image data and the apriori knowledge or the specific background. That is to say, the cost functions indicating membership degrees, levels etc. are very critical for these methods.关键词:limited image data;central limit theorem;irreversible inverse problem;fussy logic;research paradigm95|127|0更新时间:2024-05-07
摘要:Image big data and easy-use models such as deep networks(DNs) have expedited artificial intelligence (AI) currently. But, the issue for limited images which are often captured from complex, hostile and other scenarios has been challenging still yet: objects are too small to be recognized; the boundaries are fuzzy-overlapped; or even all the object information indicated in the images is uncertain due to camouflages and occlusions. The limited image data are featured with small-sample, small-object, incompleteness, uncertainty. Obviously, the tackle of limited image data is different from image big data: 1) image big data fits Gaussian distributions (mean u and σ) in terms of statistical central limit theorem, especially when data scales are much larger than data dimensions. This feature is beneficial to make statistical inference by the 3σ rule, which indicates that 99.73% of samples are within the range of [u-3σ, u+3σ]. Possibly due to the concentration saliency fundamental, the statistical AI models such as DNs become very popular and seemly successful. However, for small dataset, the statistical consistency is usually poor, and the robust features cannot be identified based on concentration saliency. Thus, the statistical inference AI models are not feasible for small training data. 2) Image objects are often mutually occluded in costly and rare scenarios, and the delicate camouflages and masks, poor and complex luminous environment, as well as hostile disturbances, often make the image information itself or the information dimensions incomplete and unconfident. These issues make the computation load very heavy because the missed information or dimension has a large number of possibilities. 3) A large number of big data techniques have been proposed and seem very competitive in image processing field. For example, the DNs have achieved the best rank in many image big datasets publicly available. These features have extremely highlighted the contribution of DNs. However, many face recognition systems do not meet the requirement of accuracy and precision even when the face data is big enough. The statistical inference models such DNs cannot do precise inference, and some errors do exist due to the statistical inference itself. For limited image data, the consequence has been declined further especially when the number of samples is less than the dimensions. The partition boundaries in the sample space cannot be uniquely fixed by training samples. That is to say, to determine the inference model needs to solve irreversible inverse problems, meaning that the definite model cannot be uniquely fixed, and only a reduced model can be fixed. For any query sample, the simplified model cannot give an explicit solution, and only a subspace can just be given which is constituted of possible solutions. How to choose an appropriate solution from the subspace is still challenging, and seemingly there are no effective and general ways. Many techniques seem a little effective on studying limited image dataset, such as level-set methods, fussy logic methods, all these methods are based on the probability metrics measuring the divergence between the existent limited image data and the apriori knowledge or the specific background. That is to say, the cost functions indicating membership degrees, levels etc. are very critical for these methods.关键词:limited image data;central limit theorem;irreversible inverse problem;fussy logic;research paradigm95|127|0更新时间:2024-05-07 -
 摘要:ObjectiveUrban video surveillance systems have been developing dramatically nowadays. The surveillance videos analysis is essential for security but a huge amount of labor-intensive data processing is highly time-consuming and costly. Intelligent video analysis can be as an effective way to deal with that. To analyze the concrete pedestrians'event, person re-identification is a basic issue of matching pedestrians across non-overlapping cameras views for obtaining the trajectories of persons in a camera network. The cross-camera scene variations are the key challenges for person re-identification, such as illumination, resolution, occlusions and background clutters. Thanks to the development of deep learning, single-modality visible image matching has achieved remarkable performance on benchmark datasets. However, visible image matching is not applicable in low-light scenarios like night-time outdoor scenes or dark indoor scenes. To resilient the related low-light issues, most of surveillance cameras can automatically switch to acquire near infrared images, which are visually different from visible images. When person re-identification is required for the penetration between normal-light and low-light, current person re-identification performance for cross-modality matching between visible images and infrared images cannot be satisfied. Thus, it is necessary to analyze the visible-infrared cross-modality person re-identification further.For visible-infrared cross-modality person re-identification, there are two key challenges as mentioned below: first, the spectrums and visual appearances of visible images and infrared images are significantly different. Visible images contain three channels of red (R), green (G) and blue (B) responses, while infrared images contain only one channel of near infrared responses. This leads to big modality gap. Next, lack of labeled data is still challenged based on manpower-based identification of the same pedestrian across visible image and infrared image. Current multi-modality benchmark dataset contains 500 personal identities only, which is not sufficient for training deep models. Existing visible-infrared cross-modality person re-identification methods mainly focus on bridging the modality gap. The small labeled data problem is still largely ignored by these methods.MethodTo provide prior knowledge for learning cross-modality matching model, we study self-supervised information mining on single-modality data based on auxiliary labeled visible images. First, we propose a data augmentation method called random single-channel mask. For three-channel visible images as input, random masks are applied to preserve the information of only one channel, to realize the robustness of features against spectrum change. The random single-channel mask can force the first layer of convolutional neural network to learn kernels that are specific to R, G or B channels for extracting shared appearance shape features. Furthermore, for pre-training and fine-tuning, we propose mutual learning between single-channel model and three-channel model. To mine and transfer cross-spectrum robust self-supervision information, mutual learning leverages the interrelations between single-channel data and three-channel data. We sort out that the three-channel model focuses on extracting color-sensitive features, and the single-channel model focuses on extracting color-invariant features. Transferring complementary knowledge by mutual learning improves the matching performance of the cross-modality matching model.ResultExtensive comparative experiments were conducted on SYSU-MM01, RGBNT201 and RegDB datasets. Compared with the state-of-the-art methods, our method improve mean average precision (mAP) on RGBNT201 by 5% at most.ConclusionWe propose a single-modality cross-spectrum self-supervised information mining method, which utilizes auxiliary single-modality visible images to mine cross-spectrum robust self-supervision information. The prior knowledge of the self-supervision information can guide single-modality pretraining and multi-modality finetuning for achieving better matching ability of the cross-modality person re-identification model.关键词:person re-identification;cross-modality retrieval;infrared image;self-supervised learning;mutual learning123|199|5更新时间:2024-05-07
摘要:ObjectiveUrban video surveillance systems have been developing dramatically nowadays. The surveillance videos analysis is essential for security but a huge amount of labor-intensive data processing is highly time-consuming and costly. Intelligent video analysis can be as an effective way to deal with that. To analyze the concrete pedestrians'event, person re-identification is a basic issue of matching pedestrians across non-overlapping cameras views for obtaining the trajectories of persons in a camera network. The cross-camera scene variations are the key challenges for person re-identification, such as illumination, resolution, occlusions and background clutters. Thanks to the development of deep learning, single-modality visible image matching has achieved remarkable performance on benchmark datasets. However, visible image matching is not applicable in low-light scenarios like night-time outdoor scenes or dark indoor scenes. To resilient the related low-light issues, most of surveillance cameras can automatically switch to acquire near infrared images, which are visually different from visible images. When person re-identification is required for the penetration between normal-light and low-light, current person re-identification performance for cross-modality matching between visible images and infrared images cannot be satisfied. Thus, it is necessary to analyze the visible-infrared cross-modality person re-identification further.For visible-infrared cross-modality person re-identification, there are two key challenges as mentioned below: first, the spectrums and visual appearances of visible images and infrared images are significantly different. Visible images contain three channels of red (R), green (G) and blue (B) responses, while infrared images contain only one channel of near infrared responses. This leads to big modality gap. Next, lack of labeled data is still challenged based on manpower-based identification of the same pedestrian across visible image and infrared image. Current multi-modality benchmark dataset contains 500 personal identities only, which is not sufficient for training deep models. Existing visible-infrared cross-modality person re-identification methods mainly focus on bridging the modality gap. The small labeled data problem is still largely ignored by these methods.MethodTo provide prior knowledge for learning cross-modality matching model, we study self-supervised information mining on single-modality data based on auxiliary labeled visible images. First, we propose a data augmentation method called random single-channel mask. For three-channel visible images as input, random masks are applied to preserve the information of only one channel, to realize the robustness of features against spectrum change. The random single-channel mask can force the first layer of convolutional neural network to learn kernels that are specific to R, G or B channels for extracting shared appearance shape features. Furthermore, for pre-training and fine-tuning, we propose mutual learning between single-channel model and three-channel model. To mine and transfer cross-spectrum robust self-supervision information, mutual learning leverages the interrelations between single-channel data and three-channel data. We sort out that the three-channel model focuses on extracting color-sensitive features, and the single-channel model focuses on extracting color-invariant features. Transferring complementary knowledge by mutual learning improves the matching performance of the cross-modality matching model.ResultExtensive comparative experiments were conducted on SYSU-MM01, RGBNT201 and RegDB datasets. Compared with the state-of-the-art methods, our method improve mean average precision (mAP) on RGBNT201 by 5% at most.ConclusionWe propose a single-modality cross-spectrum self-supervised information mining method, which utilizes auxiliary single-modality visible images to mine cross-spectrum robust self-supervision information. The prior knowledge of the self-supervision information can guide single-modality pretraining and multi-modality finetuning for achieving better matching ability of the cross-modality person re-identification model.关键词:person re-identification;cross-modality retrieval;infrared image;self-supervised learning;mutual learning123|199|5更新时间:2024-05-07 -
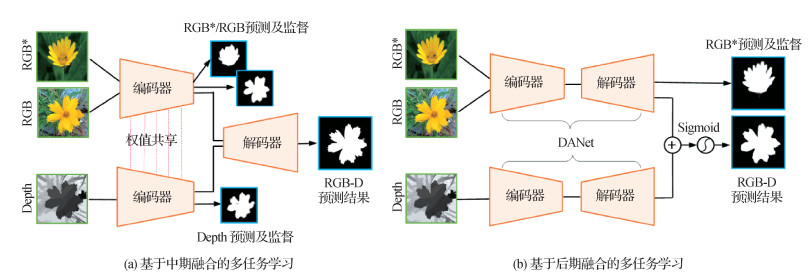 摘要:ObjectiveSalient object detection is mainly used in computer vision pre-processing like video/image segmentation, visual tracking and video/image compression. Current RGB-depth(RGB-D) salient object detection(SOD) can be categorized into fully supervision and self-supervision. Fully supervised RGB-D SOD can effectively fuse the complementary information of two different modes for RGB images input and the corresponding depth maps by means of the three types of fusion (early/middle/late). To capture contextual information, self-supervised salient object detection uses a small number of unlabeled samples for pre-training. However, existing RGB-D salient object detection methods are mostly trained on a small RGB-D training set in a fully supervised manner, so their generalization ability is greatly restricted. Thanks to the emerging few-shot learning methods, our RGB-D salient object detection uses model hypothesis space optimization and training sample augmentation to explore and solve RGB-D salient object detection with few-shot learning.MethodFor model hypothesis space optimization, it can transfer the learned knowledge from extra RGB salient object detection task to RGB-D salient object detection task based on multi-task learning of RGB and RGB-D salient object detection tasks, and the hypothesis space of the model is constrained by sharing model parameters. Model-oriented, takeing into account middle and late fusions can add additional supervision to the network, therefore, the JL-DCF model is selected for middle fusion and the DANet† model is optioned for late fusion. To improve the effectiveness and generalization of RGB-D salient object detection tasks, RGB-D and RGB are simultaneously input into the network for online training and optimization in terms of JL-DCF, and the coarse prediction of RGB is supervised to optimize the network. In view of the commonality between the semantic segmentation and the saliency detection, the dual attention network for scene segmentation(DANet) model is transferred to the RGB-D salient object detection network, named DANet†. Similar to JL-DCF joint training, additional RGB supervision is added to the RGB branch of the two-stream DANet†. Furthermore, the training sample augmentation generates the related depth map based on the additional RGB data in terms of the depth estimation algorithm, and uses the RGB and the synthesized depth map for the training of the RGB-D salient object detection task. We adopt ResNet-101 as our network backbone. The scale of input image is 320×320×3 in JL-DCF network, and the scale of DANet† network input image is fixed to 480×480×3. The depth map is transformed into three-channel map by gray scale mapping. Our training set is composed of data from NJU2K, NLPR and DUTS, and the test set is NJU2K, NLPR, STERE, RGBD135, LFSD, SIP, DUT-RGBD, ReDWeb-S, DUTS (it is worth noting that, DUT-RGBD and ReDWeb-S are tested in the completed dataset based on 1 200 samples and 3 179 samples, respectively). The evaluation metrics are demonstrated as following: S measure (
摘要:ObjectiveSalient object detection is mainly used in computer vision pre-processing like video/image segmentation, visual tracking and video/image compression. Current RGB-depth(RGB-D) salient object detection(SOD) can be categorized into fully supervision and self-supervision. Fully supervised RGB-D SOD can effectively fuse the complementary information of two different modes for RGB images input and the corresponding depth maps by means of the three types of fusion (early/middle/late). To capture contextual information, self-supervised salient object detection uses a small number of unlabeled samples for pre-training. However, existing RGB-D salient object detection methods are mostly trained on a small RGB-D training set in a fully supervised manner, so their generalization ability is greatly restricted. Thanks to the emerging few-shot learning methods, our RGB-D salient object detection uses model hypothesis space optimization and training sample augmentation to explore and solve RGB-D salient object detection with few-shot learning.MethodFor model hypothesis space optimization, it can transfer the learned knowledge from extra RGB salient object detection task to RGB-D salient object detection task based on multi-task learning of RGB and RGB-D salient object detection tasks, and the hypothesis space of the model is constrained by sharing model parameters. Model-oriented, takeing into account middle and late fusions can add additional supervision to the network, therefore, the JL-DCF model is selected for middle fusion and the DANet† model is optioned for late fusion. To improve the effectiveness and generalization of RGB-D salient object detection tasks, RGB-D and RGB are simultaneously input into the network for online training and optimization in terms of JL-DCF, and the coarse prediction of RGB is supervised to optimize the network. In view of the commonality between the semantic segmentation and the saliency detection, the dual attention network for scene segmentation(DANet) model is transferred to the RGB-D salient object detection network, named DANet†. Similar to JL-DCF joint training, additional RGB supervision is added to the RGB branch of the two-stream DANet†. Furthermore, the training sample augmentation generates the related depth map based on the additional RGB data in terms of the depth estimation algorithm, and uses the RGB and the synthesized depth map for the training of the RGB-D salient object detection task. We adopt ResNet-101 as our network backbone. The scale of input image is 320×320×3 in JL-DCF network, and the scale of DANet† network input image is fixed to 480×480×3. The depth map is transformed into three-channel map by gray scale mapping. Our training set is composed of data from NJU2K, NLPR and DUTS, and the test set is NJU2K, NLPR, STERE, RGBD135, LFSD, SIP, DUT-RGBD, ReDWeb-S, DUTS (it is worth noting that, DUT-RGBD and ReDWeb-S are tested in the completed dataset based on 1 200 samples and 3 179 samples, respectively). The evaluation metrics are demonstrated as following: S measure (${S_\alpha }$ $F_\beta ^{\max }$ $E_\varphi ^{\max }$ $M$ $\alpha $ 关键词:multi-modal detection;RGB-D saliency detection;few-shot learning;multi-task learning;depth estimation236|283|1更新时间:2024-05-07
Limited Image Data

-
 摘要:Object detection is essential for various of applications like semantic segmentation and human facial recognition, and it has been widely employed in public security related scenarios, including automatic driving, industrial control, and aerospace applications. Traditional object detection technology requires manual-based feature extraction and machine learning methods for classification, which is costly and inaccuracy for detection. Recent deep learning based object detection technology has gradually replaced the traditional object detection technology due to its high detection efficiency and accuracy. However, it has been proved that convolutional neural network (CNN) can be easily fooled by some imperceptible perturbations. These images with the added imperceptible perturbations are called adversarial examples. Adversarial examples were first discovered in the field of image classification, and were gradually developed into other fields. To clarify the vulnerabilities of adversarial attack and deep object detection system it is of great significance to improve the robustness and security of the deep learning based object detection model by using a holistic approach. We aims to enhancing the robustness of object detection models and putting forward defense strategies better in terms of analyzing and summarizing the adversarial attack and defense methods for object detection recently. First, our review is focused on the discussion of the development of object detection, and then introduces the origin, growth, motives of emergence and related terminologies of adversarial examples. The commonly evaluation metrics used and data sets in the generation of adversarial examples in object detection are also introduced. Then, 15 adversarial example generation algorithms for object detection, according to the generation of perturbation level classification, are classified as global perturbation attack and local perturbation attack. A secondary classification under the global perturbation attack is made in terms of the types of of attacks detector like attack on two-stage network, attack on one-stage network, and attack on both kinds of networks. Furthermore, these attack methods are classified and summarized from the following perspectives as mentioned below: 1) the attack methods can be divided into black box attack and white box attack based on the issue of whether the attacker knows the information of the model's internal structure and parameters or not. 2) The attack methods can be divided into target attack and non-target attack derived from the identification results of the generated adversarial examples. 3) The attack methods can be divided into three categories: L0, L2 and L∞ via the perturbation norm used by the attack algorithm. 4) The attack methods can be divided into single loss function attack and combined loss function attack based on the loss function design of attack algorithm. These methods are summarized and analyzed on six aspects of the object detector type and the loss function design, and the following rules of the current adversarial example generation technology for object detection are obtained: 1) diversities of attack forms: a variety of adversarial loss functions are combined with the design of adversarial attack methods, such as background loss and context loss. In addition, the diversity of attack forms is also reflected in the context of diversity of attack methods. Global perturbations and local perturbations are represented by patch attacks both. 2) Diversities of attack objects: with the development of object detection technology, the types of detectors become more diverse, which makes the adversarial examples generation technology against detectors become more changeable, including one-stage attack, two-stage attack, as well as the attack against anchor-free detector. It is credible that future adversarial examples attacks against new techniques of object detection have its potentials. 3) Most of the existing adversarial attack methods are white box attack methods for specific detector, while few are black box attack methods. The reason is that object detection model is more complex and the training cycle is longer compared to image classification, so attacking object detection requires more model information to generate reliable adversarial examples. The issue of designing more and more effective black box attacks can be as a future research direction as well. Additionally, we select four classical methods of those are dense adversary generation (DAG), robust adversarial perturbation (RAP), unified and efficient adversary (UEA), and targeted adversarial objectness gradient attacks (TOG), and carry out comparative analysis through experiments. Then, the commonly attack and defense strategies are introduced from the perspectives of preprocessing and improving the robustness of the model, and these methods are summarized. The current methods of defense against examples are few, and the effect is not sufficient due to the specialty of object detection. Furthermore, the transferability of these models is compared to you only look once (YOLO)-Darknet and single shot multibox detector (SSD300) models, and the experimental results show that the UEA method has the best transferability among these methods. Finally, we summarize the challenges in the generation and defense of adversarial examples for object detection from the following three perspectives: 1) to enhance the transferability of adversarial examples for object detection. Transfer ability is one of the most important metrics to measure adversarial examples, especially in object detection technology. It is potential to enhance the transferability of adversarial examples to attack most object detection systems. 2) To facilitate adversarial defense for object detection. Current adversarial examples attack paths are lack of effective defenses. To enhance the robustness of object detection, it is developed for defense research against adversarial examples further. 3) Decrease the disturbance size and increase the generation speed of adversarial examples. Future development of it is possible to develop adversarial examples for object detection in related to shorter generation time and smaller generation disturbance in the future.关键词:object detection;adversarial examples;deep learning;adversarial defense;global perturbation;local perturbation561|542|8更新时间:2024-05-07
摘要:Object detection is essential for various of applications like semantic segmentation and human facial recognition, and it has been widely employed in public security related scenarios, including automatic driving, industrial control, and aerospace applications. Traditional object detection technology requires manual-based feature extraction and machine learning methods for classification, which is costly and inaccuracy for detection. Recent deep learning based object detection technology has gradually replaced the traditional object detection technology due to its high detection efficiency and accuracy. However, it has been proved that convolutional neural network (CNN) can be easily fooled by some imperceptible perturbations. These images with the added imperceptible perturbations are called adversarial examples. Adversarial examples were first discovered in the field of image classification, and were gradually developed into other fields. To clarify the vulnerabilities of adversarial attack and deep object detection system it is of great significance to improve the robustness and security of the deep learning based object detection model by using a holistic approach. We aims to enhancing the robustness of object detection models and putting forward defense strategies better in terms of analyzing and summarizing the adversarial attack and defense methods for object detection recently. First, our review is focused on the discussion of the development of object detection, and then introduces the origin, growth, motives of emergence and related terminologies of adversarial examples. The commonly evaluation metrics used and data sets in the generation of adversarial examples in object detection are also introduced. Then, 15 adversarial example generation algorithms for object detection, according to the generation of perturbation level classification, are classified as global perturbation attack and local perturbation attack. A secondary classification under the global perturbation attack is made in terms of the types of of attacks detector like attack on two-stage network, attack on one-stage network, and attack on both kinds of networks. Furthermore, these attack methods are classified and summarized from the following perspectives as mentioned below: 1) the attack methods can be divided into black box attack and white box attack based on the issue of whether the attacker knows the information of the model's internal structure and parameters or not. 2) The attack methods can be divided into target attack and non-target attack derived from the identification results of the generated adversarial examples. 3) The attack methods can be divided into three categories: L0, L2 and L∞ via the perturbation norm used by the attack algorithm. 4) The attack methods can be divided into single loss function attack and combined loss function attack based on the loss function design of attack algorithm. These methods are summarized and analyzed on six aspects of the object detector type and the loss function design, and the following rules of the current adversarial example generation technology for object detection are obtained: 1) diversities of attack forms: a variety of adversarial loss functions are combined with the design of adversarial attack methods, such as background loss and context loss. In addition, the diversity of attack forms is also reflected in the context of diversity of attack methods. Global perturbations and local perturbations are represented by patch attacks both. 2) Diversities of attack objects: with the development of object detection technology, the types of detectors become more diverse, which makes the adversarial examples generation technology against detectors become more changeable, including one-stage attack, two-stage attack, as well as the attack against anchor-free detector. It is credible that future adversarial examples attacks against new techniques of object detection have its potentials. 3) Most of the existing adversarial attack methods are white box attack methods for specific detector, while few are black box attack methods. The reason is that object detection model is more complex and the training cycle is longer compared to image classification, so attacking object detection requires more model information to generate reliable adversarial examples. The issue of designing more and more effective black box attacks can be as a future research direction as well. Additionally, we select four classical methods of those are dense adversary generation (DAG), robust adversarial perturbation (RAP), unified and efficient adversary (UEA), and targeted adversarial objectness gradient attacks (TOG), and carry out comparative analysis through experiments. Then, the commonly attack and defense strategies are introduced from the perspectives of preprocessing and improving the robustness of the model, and these methods are summarized. The current methods of defense against examples are few, and the effect is not sufficient due to the specialty of object detection. Furthermore, the transferability of these models is compared to you only look once (YOLO)-Darknet and single shot multibox detector (SSD300) models, and the experimental results show that the UEA method has the best transferability among these methods. Finally, we summarize the challenges in the generation and defense of adversarial examples for object detection from the following three perspectives: 1) to enhance the transferability of adversarial examples for object detection. Transfer ability is one of the most important metrics to measure adversarial examples, especially in object detection technology. It is potential to enhance the transferability of adversarial examples to attack most object detection systems. 2) To facilitate adversarial defense for object detection. Current adversarial examples attack paths are lack of effective defenses. To enhance the robustness of object detection, it is developed for defense research against adversarial examples further. 3) Decrease the disturbance size and increase the generation speed of adversarial examples. Future development of it is possible to develop adversarial examples for object detection in related to shorter generation time and smaller generation disturbance in the future.关键词:object detection;adversarial examples;deep learning;adversarial defense;global perturbation;local perturbation561|542|8更新时间:2024-05-07 -
 摘要:To obtain smooth edge information that can accurately describe the local features and conform to the functional sub structure, the superpixel/voxel segmentation algorithm divides the points with the similar structure information into the same sub region. It is widely used in the field of magnetic resonance imaging (MRI) segmentation. We carry out the comparative performance analysis of different algorithms in brain tumor medical image segmentation. Our algorithms are used to set the number of superpixel seed points directly in the contexts of graph-based, normalized cut, entropy rate, topology preserving regularization, lazy random walk, Turbopixels, density-based spatial clustering of applications with noise(DBSCAN), linear spectral clustering(LSC), and simple linear iterative clustering algorithm (SLIC), respectively. Due to the watershed and the superpixel lattice algorithms cannot achieve accurate manipulations of the number of superpixels, it is required to achieve the superpixel segmentation of the brain tumor images in BraTS 2018 dataset. The graph-based algorithm can segment the core tumor region accurately and identify the brain tumor region with vascular filling effectively. However, it is insufficient for the segmentation accuracy of the completed and enhanced tumor regions of slightly. The performance of the normalized cut algorithm can obtain the brain tumor boundary derived of strong dependence information and retain the characteristic information of the tumor boundary. However, the algorithm divides the lesion region, the gray matter, and the white matter into the same superpixel. The whole tumor region can be divided into the multiple regions, which cannot represent the functional substructure of human brains effectively. The superpixel lattice algorithm can obtain the core tumor location better, but the segmented superpixel boundary does not have the strong attachment. The boundary information of the enhanced tumor can be obtained based on the entropy rate algorithm accurately, which has the obvious density difference between the tumor region and the surrounding tumor. Yet, the generated shape of superpixel boundary is irregular, which cannot express the clear neighborhood information. The topology preserving regularization algorithm can describe the focus accurately, but it cannot clarify the large mass span issue. The lazy random walk algorithm can generate more regular core tumor superpixel boundary, but it can not obtain enhanced tumor boundary information and cannot retain the characteristics of tumor boundary information. The watershed algorithm can obtain the weak boundary information of peripheral edema and intratumoral hemorrhage caused by brain tumor with obvious space occupying effect or lateral ventricular extrusion. However, the obtained superpixel does not conform to the structure of brain functional, which tends to different superpixel from the division of the same functional blocks. The Turbopixels algorithm overcomes the problem that the number of superpixels is different in the initial setting, which leads to the difference of the accuracy of the segmentation results and enhances the robustness of the algorithm. However, the algorithm has little contrast to the whole gray level and the accuracy of segmentation is greatly reduced with the presence of adhesion between the brain tumor location and the surrounding tissues. The DBSCAN algorithm can obtain the core tumor information and identify the necrotic region and the liquefied region in accordance with the image density, which can provide tumor information for complications. However, the algorithm is more sensitive to the noise points and is not robust to the boundary information. The LSC algorithm can release boundary blur and fuzziness of medical imaging equipment. But, the superpixel boundary divides the brain regions with the same features and functional substructures into the multiple blocks, which cannot reflect the shape, size, appearance, other forms of brain tumors, and the pull with the surrounding meninges or blood vessels. The SLIC algorithm has a strong compact and complete retention of feature continuity, which can extract brain tumor features. However, there is a lot of redundancy in the algorithm calculation process, which is challenged to large-scale object segmentation operation, the SLICO algorithm is improved through the SLIC algorithm, which has the high efficient segmentation with low computational complexity. In conclusion, such algorithms can preserve tumor boundary information and have local focal information better in related to graph-based, the normalized cut, the lazy random walk, the DBSCAN, and the LSC. The four algorithms keep the shape structure of the superpixel more complete and compact in regular like topology preserving regularization, Turbopixels, SLIC, and SLICO. Furthermore, the feature description of the lesion boundary is smooth and soft to make up the boundary deficiency. We summarize the current results and applications of various superpixel/voxel algorithms. The performance of the algorithm is analyzed by four indexes like boundary recall, under-segmentation error, compactness measure, and achievable segmentation accuracy. The superpixel/voxel algorithm can improve the efficiency of medical image processing with large object efficiency, which is beneficial to the expression of local information of the brain structure. Some future challenging issues are predicted as mentioned below: 1) to divide the brain function and regions without brain structure into the same sub region; 2) to resolve over-fitting or insufficient segmentation caused by abnormal points and noise points near the boundary; 3) to integrate multi-modal lesion information via machine learning.关键词:image processing;magnetic resonance imaging(MRI);superpixel/voxel;brain tumor segmentation;evaluation indicators142|345|0更新时间:2024-05-07
摘要:To obtain smooth edge information that can accurately describe the local features and conform to the functional sub structure, the superpixel/voxel segmentation algorithm divides the points with the similar structure information into the same sub region. It is widely used in the field of magnetic resonance imaging (MRI) segmentation. We carry out the comparative performance analysis of different algorithms in brain tumor medical image segmentation. Our algorithms are used to set the number of superpixel seed points directly in the contexts of graph-based, normalized cut, entropy rate, topology preserving regularization, lazy random walk, Turbopixels, density-based spatial clustering of applications with noise(DBSCAN), linear spectral clustering(LSC), and simple linear iterative clustering algorithm (SLIC), respectively. Due to the watershed and the superpixel lattice algorithms cannot achieve accurate manipulations of the number of superpixels, it is required to achieve the superpixel segmentation of the brain tumor images in BraTS 2018 dataset. The graph-based algorithm can segment the core tumor region accurately and identify the brain tumor region with vascular filling effectively. However, it is insufficient for the segmentation accuracy of the completed and enhanced tumor regions of slightly. The performance of the normalized cut algorithm can obtain the brain tumor boundary derived of strong dependence information and retain the characteristic information of the tumor boundary. However, the algorithm divides the lesion region, the gray matter, and the white matter into the same superpixel. The whole tumor region can be divided into the multiple regions, which cannot represent the functional substructure of human brains effectively. The superpixel lattice algorithm can obtain the core tumor location better, but the segmented superpixel boundary does not have the strong attachment. The boundary information of the enhanced tumor can be obtained based on the entropy rate algorithm accurately, which has the obvious density difference between the tumor region and the surrounding tumor. Yet, the generated shape of superpixel boundary is irregular, which cannot express the clear neighborhood information. The topology preserving regularization algorithm can describe the focus accurately, but it cannot clarify the large mass span issue. The lazy random walk algorithm can generate more regular core tumor superpixel boundary, but it can not obtain enhanced tumor boundary information and cannot retain the characteristics of tumor boundary information. The watershed algorithm can obtain the weak boundary information of peripheral edema and intratumoral hemorrhage caused by brain tumor with obvious space occupying effect or lateral ventricular extrusion. However, the obtained superpixel does not conform to the structure of brain functional, which tends to different superpixel from the division of the same functional blocks. The Turbopixels algorithm overcomes the problem that the number of superpixels is different in the initial setting, which leads to the difference of the accuracy of the segmentation results and enhances the robustness of the algorithm. However, the algorithm has little contrast to the whole gray level and the accuracy of segmentation is greatly reduced with the presence of adhesion between the brain tumor location and the surrounding tissues. The DBSCAN algorithm can obtain the core tumor information and identify the necrotic region and the liquefied region in accordance with the image density, which can provide tumor information for complications. However, the algorithm is more sensitive to the noise points and is not robust to the boundary information. The LSC algorithm can release boundary blur and fuzziness of medical imaging equipment. But, the superpixel boundary divides the brain regions with the same features and functional substructures into the multiple blocks, which cannot reflect the shape, size, appearance, other forms of brain tumors, and the pull with the surrounding meninges or blood vessels. The SLIC algorithm has a strong compact and complete retention of feature continuity, which can extract brain tumor features. However, there is a lot of redundancy in the algorithm calculation process, which is challenged to large-scale object segmentation operation, the SLICO algorithm is improved through the SLIC algorithm, which has the high efficient segmentation with low computational complexity. In conclusion, such algorithms can preserve tumor boundary information and have local focal information better in related to graph-based, the normalized cut, the lazy random walk, the DBSCAN, and the LSC. The four algorithms keep the shape structure of the superpixel more complete and compact in regular like topology preserving regularization, Turbopixels, SLIC, and SLICO. Furthermore, the feature description of the lesion boundary is smooth and soft to make up the boundary deficiency. We summarize the current results and applications of various superpixel/voxel algorithms. The performance of the algorithm is analyzed by four indexes like boundary recall, under-segmentation error, compactness measure, and achievable segmentation accuracy. The superpixel/voxel algorithm can improve the efficiency of medical image processing with large object efficiency, which is beneficial to the expression of local information of the brain structure. Some future challenging issues are predicted as mentioned below: 1) to divide the brain function and regions without brain structure into the same sub region; 2) to resolve over-fitting or insufficient segmentation caused by abnormal points and noise points near the boundary; 3) to integrate multi-modal lesion information via machine learning.关键词:image processing;magnetic resonance imaging(MRI);superpixel/voxel;brain tumor segmentation;evaluation indicators142|345|0更新时间:2024-05-07 -
 摘要:Deep learning based data format is mainly related to voice, image and video. A regular data structure is usually represented in Euclidean space. The graph structure representation of non-Euclidean data can be used more widely in practice. A typical data structure graphs can describe the features of objects and the relationship between objects simultaneously. Therefore, the application research of graphs in deep learning has been focused on as a future research direction. However, learning data are generated from non-Euclidean spaces in common, and these data features and their relational structure can be defined by graphs. The graph neural network is facilitated to extend the neural network via process data processing in the graph domain. Each node is clarified by updating the expression of the node related to the neighbor node and the edge structure, which designates a research framework for subsequent research. With the help of the graph neural network framework, the graph convolutional neural network defines the updating functions on the convolutional aspect, information dissemination and aggregation between nodes is completed in terms of the convolution theorem to the graph signal. The graph convolutional neural network becomes an effective way of graph data related modeling. Most existing models have only two or three layers of shallow model architecture due to the challenge of over-smoothing phenomenon of deep layer graph structure. The over-smoothing phenomenon is that the graph convolutional neural network fuses node features smoothly via replicable Laplacian applications from different neighborhoods. The smoothing operation makes the vertex features of the same cluster be similar, which simplifies the classification task. But, the expression of each node tends to converge to a certain value in the graph when the number of layers is deepened, and the vertices become indistinguishable in different clusters. Existing researches have shown that graph convolution is similar to a local filter, which is a linear combination of feature vectors of neighboring neighbors. A shallow graph convolutional neural network cannot transmit the full label information to the entire graph with only a few labels, which cannot explore the global graph structure in the graph convolutional neural network. At the same time, deep graph convolutional neural networks require a larger receiving domain. One of the key advantages provided by deep architecture in computer vision is that they can compose complex functions from simple structures. Inspired by the convolutional neural network, the deep structure of the graph convolutional neural network can obtain more node representation information theoretically, so many researchers conduct in-depth research on its hierarchical information. According to the aggregation and transmission features of the graph convolutional neural network algorithm, the core of transferring hierarchical structure algorithms to graph data analysis lies in the construction of layer-level convolution operators and the fusion of information between layer levels. We review the graph network level information mining algorithms. First, we discuss the current situation and existing issues of graph convolutional neural networks, and then introduce the development of graph convolutional neural network hierarchy algorithms, and propose a new category method in term of the different layer information processing of graph convolution. Existing algorithms are divided into regularization methods and architecture adjustment methods. Regular methods focus on the construction of layer-level convolution operators. To deepen the graph neural network and slow down the occurrence of over-smoothing graph structure relationships are used to constrain the information transmission in the convolution process. Next, architecture adjustment methods are based on information fusion between levels to enrich the representation of nodes, including various residual connections like knowledge jumps or affine skip connections. At the same time, we demonstrate that the hierarchical feature nodes are obtained in the graph structure through the hierarchical features experiment. The hierarchical feature nodes can only be classified by the graph convolutional neural network at the corresponding depth. The graph network hierarchical information mining algorithm uses different data mining methods to classify different characteristic nodes via a unified model and an end-to-end paradigm. If there is a model that can classify hierarchical feature nodes at each level successfully, the task of graph network node classification will make good result. Finally, the main application fields of the graph convolutional neural network hierarchical information mining model are summarized, and the future research direction are predicted from four aspects of computing efficiency, large-scale data, dynamic graphs and application scenarios. Graph network hierarchical information mining is a deeper exploration of graph neural networks. The hierarchical information interaction, transfer and dynamic evolution can obtain the richer node information from the shallow to deep information of the graph neural network. We clarify the adopted issue of deep structured graph neural networks further. The effectiveness of information mining issue between levels has to be developed further although some of hierarchical graph convolutional network algorithms can slow down the occurrence of over-smoothing.关键词:hierarchical structure;graph convolutional networks(GCN);attention mechanism;artificial intelligence;deep learning143|974|1更新时间:2024-05-07
摘要:Deep learning based data format is mainly related to voice, image and video. A regular data structure is usually represented in Euclidean space. The graph structure representation of non-Euclidean data can be used more widely in practice. A typical data structure graphs can describe the features of objects and the relationship between objects simultaneously. Therefore, the application research of graphs in deep learning has been focused on as a future research direction. However, learning data are generated from non-Euclidean spaces in common, and these data features and their relational structure can be defined by graphs. The graph neural network is facilitated to extend the neural network via process data processing in the graph domain. Each node is clarified by updating the expression of the node related to the neighbor node and the edge structure, which designates a research framework for subsequent research. With the help of the graph neural network framework, the graph convolutional neural network defines the updating functions on the convolutional aspect, information dissemination and aggregation between nodes is completed in terms of the convolution theorem to the graph signal. The graph convolutional neural network becomes an effective way of graph data related modeling. Most existing models have only two or three layers of shallow model architecture due to the challenge of over-smoothing phenomenon of deep layer graph structure. The over-smoothing phenomenon is that the graph convolutional neural network fuses node features smoothly via replicable Laplacian applications from different neighborhoods. The smoothing operation makes the vertex features of the same cluster be similar, which simplifies the classification task. But, the expression of each node tends to converge to a certain value in the graph when the number of layers is deepened, and the vertices become indistinguishable in different clusters. Existing researches have shown that graph convolution is similar to a local filter, which is a linear combination of feature vectors of neighboring neighbors. A shallow graph convolutional neural network cannot transmit the full label information to the entire graph with only a few labels, which cannot explore the global graph structure in the graph convolutional neural network. At the same time, deep graph convolutional neural networks require a larger receiving domain. One of the key advantages provided by deep architecture in computer vision is that they can compose complex functions from simple structures. Inspired by the convolutional neural network, the deep structure of the graph convolutional neural network can obtain more node representation information theoretically, so many researchers conduct in-depth research on its hierarchical information. According to the aggregation and transmission features of the graph convolutional neural network algorithm, the core of transferring hierarchical structure algorithms to graph data analysis lies in the construction of layer-level convolution operators and the fusion of information between layer levels. We review the graph network level information mining algorithms. First, we discuss the current situation and existing issues of graph convolutional neural networks, and then introduce the development of graph convolutional neural network hierarchy algorithms, and propose a new category method in term of the different layer information processing of graph convolution. Existing algorithms are divided into regularization methods and architecture adjustment methods. Regular methods focus on the construction of layer-level convolution operators. To deepen the graph neural network and slow down the occurrence of over-smoothing graph structure relationships are used to constrain the information transmission in the convolution process. Next, architecture adjustment methods are based on information fusion between levels to enrich the representation of nodes, including various residual connections like knowledge jumps or affine skip connections. At the same time, we demonstrate that the hierarchical feature nodes are obtained in the graph structure through the hierarchical features experiment. The hierarchical feature nodes can only be classified by the graph convolutional neural network at the corresponding depth. The graph network hierarchical information mining algorithm uses different data mining methods to classify different characteristic nodes via a unified model and an end-to-end paradigm. If there is a model that can classify hierarchical feature nodes at each level successfully, the task of graph network node classification will make good result. Finally, the main application fields of the graph convolutional neural network hierarchical information mining model are summarized, and the future research direction are predicted from four aspects of computing efficiency, large-scale data, dynamic graphs and application scenarios. Graph network hierarchical information mining is a deeper exploration of graph neural networks. The hierarchical information interaction, transfer and dynamic evolution can obtain the richer node information from the shallow to deep information of the graph neural network. We clarify the adopted issue of deep structured graph neural networks further. The effectiveness of information mining issue between levels has to be developed further although some of hierarchical graph convolutional network algorithms can slow down the occurrence of over-smoothing.关键词:hierarchical structure;graph convolutional networks(GCN);attention mechanism;artificial intelligence;deep learning143|974|1更新时间:2024-05-07 -
 摘要:The multimedia imaging technology can meet people's visual demands to a certain extent. People can easily obtain high-quality images through mobile devices, so people begin to pay more attention to their aesthetic experience of images, which makes the image aesthetics assessment (IAA) method become a hotspot issue and frontier technology in the current image processing and computer vision fields. Intelligent IAA can be developed to imitate people's aesthetic perception of images and predict the results of aesthetic evaluation automatically. Aesthetic-preference images can be screened out. Consequently, IAA is critical to be applied in photography, beauty, photo album management, interface design, and marketing. Generally, IAA can be classified into two categories, including generic image aesthetics assessment (GIAA) and personalized image aesthetics assessment (PIAA). Early researches believe that people have a consensus on the aesthetic experience of images, and leverage the general photography rules to describe most people's visual aesthetics on images, which are usually affected by many factors, such as light intensity, color richness, and composition. Most of the current GIAA model can predict most people's aesthetic evaluation results of images. GIAA models can be divided into three aesthetic-related tasks like classification, score regression and distribution prediction. The aesthetic classification task is focused on dividing the image into two classes of "high" and "low" according to the aesthetic experience of most people. The research goal of the aesthetic score regression task can predict the aesthetic score of an image. This task leverages the average aesthetic ratings of most people as the image aesthetic score for regression modeling. However, the two tasks shown above need to convert different people's aesthetic ratings of images into a unified result ("high" or "low" and score). Label uncertainty is derived from people's aesthetic experience of images, which makes it difficult for the consensus result. Therefore, the predictable aesthetic distribution is more concerned to reflect people's subjectivity. The goal of the aesthetic distribution prediction task can predict the aesthetic distribution results of multiple people's ratings of an image. This task predicts the aesthetic distribution straightforward and converts the aesthetic distribution result into aesthetic scores and aesthetic classes. Consequently, recent GIAA models researches are mainly focused on the task of aesthetic distribution prediction. Although the aesthetic distribution prediction task of the GIAA model can reflect people's subjectivity of image aesthetics to a certain extent, the task can realize people's visual aesthetic preferences from the image level only. Besides, it is more realistic to develop the PIAA model for specification beneficial from the growth of customized services. Therefore, the PIAA model has received great attention recently, which can predict the accurate aesthetic results for customized users. We introduce the existing PIAA models published from 2014 to 2020 due to the lack of reviews on PIAA models. Generally, the PIAA model faces two challenges for specific users as mentioned below: First, PIAA is a typical small sample learning task. This is because the PIAA model is a real-time system for specific users, which cannot force users to annotate a large number of images aesthetically. In addition, a small number of image samples can just be obtained for model training. Second, the user's subjective characteristics become important factors to affect their aesthetic perception of images since the user's aesthetic experience of images is highly subjective. Meanwhile, users' aesthetic experience is influenced by many subjective factors like emotion and personality traits. Therefore, the existing framework of the PIAA model is mainly divided into two stages based on machine learning or deep learning. In the first stage, the GIAA dataset rated by a large number of users is used to obtain the prior knowledge of the PIAA model through supervision training for the smalls sized sample learning issue of the PIAA task. In the second stage, a user's PIAA dataset is used for fine-tuning on the prior knowledge model for the high subjectivity of users' image aesthetic experience, and the subjective knowledge of users is integrated to obtain the PIAA model that conforms to the user's aesthetic perception. The existing PIAA models can be divided into three categories like collaborative filtering based PIAA models, user interaction based PIAA models, and aesthetic difference based PIAA models. To demonstrate the differences between these three PIAA models, we first introduce each of the three PIAA models separately. Then, we summarize the design clues, pros and cons of existing PIAA models. Meanwhile, we introduce the commonly used datasets and evaluation criteria of PIAA models, as well as the application prospect of PIAA models in precision marketing, personalized recommendation systems, personalized visual enhancement, and personalized art design. Finally, the future direction of the PIAA model is predicted in subjective characteristic analysis and knowledge-driven modeling.关键词:personalized image aesthetics;evaluation metrics;aesthetic experience;subjective characteristics;know-ledge-driven212|928|0更新时间:2024-05-07
摘要:The multimedia imaging technology can meet people's visual demands to a certain extent. People can easily obtain high-quality images through mobile devices, so people begin to pay more attention to their aesthetic experience of images, which makes the image aesthetics assessment (IAA) method become a hotspot issue and frontier technology in the current image processing and computer vision fields. Intelligent IAA can be developed to imitate people's aesthetic perception of images and predict the results of aesthetic evaluation automatically. Aesthetic-preference images can be screened out. Consequently, IAA is critical to be applied in photography, beauty, photo album management, interface design, and marketing. Generally, IAA can be classified into two categories, including generic image aesthetics assessment (GIAA) and personalized image aesthetics assessment (PIAA). Early researches believe that people have a consensus on the aesthetic experience of images, and leverage the general photography rules to describe most people's visual aesthetics on images, which are usually affected by many factors, such as light intensity, color richness, and composition. Most of the current GIAA model can predict most people's aesthetic evaluation results of images. GIAA models can be divided into three aesthetic-related tasks like classification, score regression and distribution prediction. The aesthetic classification task is focused on dividing the image into two classes of "high" and "low" according to the aesthetic experience of most people. The research goal of the aesthetic score regression task can predict the aesthetic score of an image. This task leverages the average aesthetic ratings of most people as the image aesthetic score for regression modeling. However, the two tasks shown above need to convert different people's aesthetic ratings of images into a unified result ("high" or "low" and score). Label uncertainty is derived from people's aesthetic experience of images, which makes it difficult for the consensus result. Therefore, the predictable aesthetic distribution is more concerned to reflect people's subjectivity. The goal of the aesthetic distribution prediction task can predict the aesthetic distribution results of multiple people's ratings of an image. This task predicts the aesthetic distribution straightforward and converts the aesthetic distribution result into aesthetic scores and aesthetic classes. Consequently, recent GIAA models researches are mainly focused on the task of aesthetic distribution prediction. Although the aesthetic distribution prediction task of the GIAA model can reflect people's subjectivity of image aesthetics to a certain extent, the task can realize people's visual aesthetic preferences from the image level only. Besides, it is more realistic to develop the PIAA model for specification beneficial from the growth of customized services. Therefore, the PIAA model has received great attention recently, which can predict the accurate aesthetic results for customized users. We introduce the existing PIAA models published from 2014 to 2020 due to the lack of reviews on PIAA models. Generally, the PIAA model faces two challenges for specific users as mentioned below: First, PIAA is a typical small sample learning task. This is because the PIAA model is a real-time system for specific users, which cannot force users to annotate a large number of images aesthetically. In addition, a small number of image samples can just be obtained for model training. Second, the user's subjective characteristics become important factors to affect their aesthetic perception of images since the user's aesthetic experience of images is highly subjective. Meanwhile, users' aesthetic experience is influenced by many subjective factors like emotion and personality traits. Therefore, the existing framework of the PIAA model is mainly divided into two stages based on machine learning or deep learning. In the first stage, the GIAA dataset rated by a large number of users is used to obtain the prior knowledge of the PIAA model through supervision training for the smalls sized sample learning issue of the PIAA task. In the second stage, a user's PIAA dataset is used for fine-tuning on the prior knowledge model for the high subjectivity of users' image aesthetic experience, and the subjective knowledge of users is integrated to obtain the PIAA model that conforms to the user's aesthetic perception. The existing PIAA models can be divided into three categories like collaborative filtering based PIAA models, user interaction based PIAA models, and aesthetic difference based PIAA models. To demonstrate the differences between these three PIAA models, we first introduce each of the three PIAA models separately. Then, we summarize the design clues, pros and cons of existing PIAA models. Meanwhile, we introduce the commonly used datasets and evaluation criteria of PIAA models, as well as the application prospect of PIAA models in precision marketing, personalized recommendation systems, personalized visual enhancement, and personalized art design. Finally, the future direction of the PIAA model is predicted in subjective characteristic analysis and knowledge-driven modeling.关键词:personalized image aesthetics;evaluation metrics;aesthetic experience;subjective characteristics;know-ledge-driven212|928|0更新时间:2024-05-07 -
 摘要:Glaucoma is a kind of human-related eyes disease derived from optic nerve and vision barrier. In most cases, the drainage system of human eyes is blocked and the liquid cannot be passed through, so the produced pressure will change the optic nerve in the eyes and lead to the collapse of the visual acuity. Although it is incurable, the progression of optic nerve injury can be preserved through intraocular pressure decreasing medication and surgery. Therefore, it is essential to prevent vision loss and even blindness for patients in early stage detection and timely treatment. In addition, the main manifestations of glaucoma are the enlargement of optic disc depression and the change of optic cup morphology, so the ratio of the optic disc to optic cup is one of the most important indexes in evaluating glaucoma screening. Nowadays, the segmentation of optic disc and optic cup has become an important part of the medical image field and has been widely concerned for a long time. However, the features of the fundus color make the potential to produce similar brightness areas, leading to the quite division difficulty of the optic disc and the optic cup. In the actual segmentation process, the accuracy and robustness of the optic disc and the optic cup segmentation can be guaranteed by dealing with the effects of the feature accurately and timely. Therefore, we summarized the existing methods of the optic disc and optic cup segmentation of retinal images. Our methods are divided into five categories like horizontal set, modal, energy functional, partition, and the hybrid contexts based on machine learning. At the same time, the machanism of each scheme are summarized and analyzed like the its basicconcepts, the theoretical basis, the key technologies, the framework flow, the advantages and the disadvantages. We carry out a detailed analysis and description like typical data sets, which are suitable for glaucoma diagnosis. Specifically, it is related to the name of the data set, the source, and the features of retinal images involved. To evaluate the segmentation results and the diagnosis of glaucoma, we faciliated the calculation methods of some important quantitative index parameters, such as cup-to-disc ratio(COR), glaucoma risk index(GRI) and neural retinal edge ratio. Moreover, quantification index of a various of segmentation results of the optic disc and optic cup in multiple data sets (i.e., relative area difference, overlap area ratio, and non-overlapping area ratio, Dice measurement, accuracy) and the quantitative indicators for diagnosis of glaucoma (i.e., CDR error, average error, root mean square error) are summarized. Thanks to the continuous development of deep learning technology glaucoma diagnostic technology has become possible to obtain more precise segmentation through continuous training. Many image processing and machine learning techniques are widely used in the existing optic disc and optic cup segmentation methods. We demonstrate the diagnosis of glaucoma research algorithms to review the features and links between various algorithms. It is beneficial to promote the application of optic disc and optic cup segmentation in the clinical screening of glaucoma diseases further. Additionally, it can improve the work efficiency of clinicians, which provides an important theoretical research significance for the clinical diagnosis of glaucoma.关键词:retinal image;optic disc segmentation;optic cup segmentation;Glaucoma;diagnosis217|1177|0更新时间:2024-05-07
摘要:Glaucoma is a kind of human-related eyes disease derived from optic nerve and vision barrier. In most cases, the drainage system of human eyes is blocked and the liquid cannot be passed through, so the produced pressure will change the optic nerve in the eyes and lead to the collapse of the visual acuity. Although it is incurable, the progression of optic nerve injury can be preserved through intraocular pressure decreasing medication and surgery. Therefore, it is essential to prevent vision loss and even blindness for patients in early stage detection and timely treatment. In addition, the main manifestations of glaucoma are the enlargement of optic disc depression and the change of optic cup morphology, so the ratio of the optic disc to optic cup is one of the most important indexes in evaluating glaucoma screening. Nowadays, the segmentation of optic disc and optic cup has become an important part of the medical image field and has been widely concerned for a long time. However, the features of the fundus color make the potential to produce similar brightness areas, leading to the quite division difficulty of the optic disc and the optic cup. In the actual segmentation process, the accuracy and robustness of the optic disc and the optic cup segmentation can be guaranteed by dealing with the effects of the feature accurately and timely. Therefore, we summarized the existing methods of the optic disc and optic cup segmentation of retinal images. Our methods are divided into five categories like horizontal set, modal, energy functional, partition, and the hybrid contexts based on machine learning. At the same time, the machanism of each scheme are summarized and analyzed like the its basicconcepts, the theoretical basis, the key technologies, the framework flow, the advantages and the disadvantages. We carry out a detailed analysis and description like typical data sets, which are suitable for glaucoma diagnosis. Specifically, it is related to the name of the data set, the source, and the features of retinal images involved. To evaluate the segmentation results and the diagnosis of glaucoma, we faciliated the calculation methods of some important quantitative index parameters, such as cup-to-disc ratio(COR), glaucoma risk index(GRI) and neural retinal edge ratio. Moreover, quantification index of a various of segmentation results of the optic disc and optic cup in multiple data sets (i.e., relative area difference, overlap area ratio, and non-overlapping area ratio, Dice measurement, accuracy) and the quantitative indicators for diagnosis of glaucoma (i.e., CDR error, average error, root mean square error) are summarized. Thanks to the continuous development of deep learning technology glaucoma diagnostic technology has become possible to obtain more precise segmentation through continuous training. Many image processing and machine learning techniques are widely used in the existing optic disc and optic cup segmentation methods. We demonstrate the diagnosis of glaucoma research algorithms to review the features and links between various algorithms. It is beneficial to promote the application of optic disc and optic cup segmentation in the clinical screening of glaucoma diseases further. Additionally, it can improve the work efficiency of clinicians, which provides an important theoretical research significance for the clinical diagnosis of glaucoma.关键词:retinal image;optic disc segmentation;optic cup segmentation;Glaucoma;diagnosis217|1177|0更新时间:2024-05-07
Review
-
 摘要:ObjectiveThe issue of images interpretation can be used in human cancer diagnosis contexts. It can help law enforcement officers to forensics via license plate images as well. Single super-resolution image process restores the high-resolution image based on a low-resolution image. It is the key to mapping reconstruction to clarify the relationship between the low-resolution image and the high-resolution image. Emerging neural networks have developed super-resolution image contexts. To improve the clarity of reconstructed images, theses novel networks are used to learn information feature between low-resolution images and high-resolution images. It is challenged that the mapping is many-to-one between the output high-resolution image and the input low-resolution image, which tends to determine the high-resolution image via more network depth only. The specific mapping relationship is difficult to be identified between low-resolution images. We facilitate a reconstructed super-resolution image method based on multi-supervised smoothing loss function, this method can clarify the possible mapping space between the low-resolution image and the high-resolution image in terms of the added constraints to the objective function, and improves the quality of the reconstructed image.MethodOur method is composed of two channels like low-resolution (LR) image up-sampling and high-resolution (HR) image down-sampling. Each channel is divided into two stages, and each stage includes 4 modules in the context of a shallow feature extraction, an iterative sampling error feedback mechanism based sampling, a global feature fusion, and an image reconstruction, respectively. Our analysis compares the results of the first stage of the LR image upsampling channel to the results of the first stage of the HR image downsampling channel. To map the function space accurately, the HR original image and the second stage result of the HR image downsampling channel are as the constraints to form multi-supervision, and the smoothed multi-supervised loss function ensures that the gradient is transmitted in the global scope, the channel attention module is added to the method in order to reduce the computational complexity of the network and get more effective features. The channel attention module can extract useful features and suppress invalid features to speed up network convergence. In order to improve the network ability to reconstruct image detail information, we introduce a global feature fusion module, which improves the degree of information fusion in the network, and utilizes shallow information and detailed texture effectively.ResultWe use the DIV2K (diverse 2k resolution high quality images)dataset as the training dataset. The DIV2K dataset is organized by 800 training images, 100 verification images and 100 test images. To verify the algorithm performance, we carry out quantitative and qualitative analyses both. The quantitative tests are performed on benchmark test sets, such as Set5, Set14, Berkeley segmentation dataset (BSD100), urban scenes dataset (Urban100), and 109 manga volumes dataset (Manga109). The results are compared to Bicubic, super-resolution convolutional neural network (SRCNN), fast super-resolution convolutional neural network (FSRCNN), Laplacian pyramid super-resolution network (LapSRN), very deep super-resolution convolutional networks (VDSR), deep back-projection networks for super-resolution (DBPN), and dual regression networks (DRN), our peak signal-to-noise ratio of the algorithm is 32.29 dB, 28.85 dB, 27.61 dB, 26.16 dB and 30.87 dB, respectively when the magnification factor is 4; the reconstructed image of this algorithm has richer texture in terms of the qualitative analysis and the reconstructed image is closer to the real image with a clear outline.ConclusionOur multi-supervision smoothing loss function is used as the objective function, and the objective function mapping space is clear. In addition, the network calculation complexity is reduced through adding the channel attention module and the global feature fusion module. The network convergence speed is accelerated, and the shallow features are fully utilized. Our experimental results show that the multi-supervised smoothing loss function based image reconstruction results have improved the quality of the reconstructed image and the processing of high-frequency detail in comparison with some typical super-resolution algorithms.关键词:super-resolution reconstruction;iterative sampling;multi-supervision;mapping space;smoothing loss function121|150|0更新时间:2024-05-07
摘要:ObjectiveThe issue of images interpretation can be used in human cancer diagnosis contexts. It can help law enforcement officers to forensics via license plate images as well. Single super-resolution image process restores the high-resolution image based on a low-resolution image. It is the key to mapping reconstruction to clarify the relationship between the low-resolution image and the high-resolution image. Emerging neural networks have developed super-resolution image contexts. To improve the clarity of reconstructed images, theses novel networks are used to learn information feature between low-resolution images and high-resolution images. It is challenged that the mapping is many-to-one between the output high-resolution image and the input low-resolution image, which tends to determine the high-resolution image via more network depth only. The specific mapping relationship is difficult to be identified between low-resolution images. We facilitate a reconstructed super-resolution image method based on multi-supervised smoothing loss function, this method can clarify the possible mapping space between the low-resolution image and the high-resolution image in terms of the added constraints to the objective function, and improves the quality of the reconstructed image.MethodOur method is composed of two channels like low-resolution (LR) image up-sampling and high-resolution (HR) image down-sampling. Each channel is divided into two stages, and each stage includes 4 modules in the context of a shallow feature extraction, an iterative sampling error feedback mechanism based sampling, a global feature fusion, and an image reconstruction, respectively. Our analysis compares the results of the first stage of the LR image upsampling channel to the results of the first stage of the HR image downsampling channel. To map the function space accurately, the HR original image and the second stage result of the HR image downsampling channel are as the constraints to form multi-supervision, and the smoothed multi-supervised loss function ensures that the gradient is transmitted in the global scope, the channel attention module is added to the method in order to reduce the computational complexity of the network and get more effective features. The channel attention module can extract useful features and suppress invalid features to speed up network convergence. In order to improve the network ability to reconstruct image detail information, we introduce a global feature fusion module, which improves the degree of information fusion in the network, and utilizes shallow information and detailed texture effectively.ResultWe use the DIV2K (diverse 2k resolution high quality images)dataset as the training dataset. The DIV2K dataset is organized by 800 training images, 100 verification images and 100 test images. To verify the algorithm performance, we carry out quantitative and qualitative analyses both. The quantitative tests are performed on benchmark test sets, such as Set5, Set14, Berkeley segmentation dataset (BSD100), urban scenes dataset (Urban100), and 109 manga volumes dataset (Manga109). The results are compared to Bicubic, super-resolution convolutional neural network (SRCNN), fast super-resolution convolutional neural network (FSRCNN), Laplacian pyramid super-resolution network (LapSRN), very deep super-resolution convolutional networks (VDSR), deep back-projection networks for super-resolution (DBPN), and dual regression networks (DRN), our peak signal-to-noise ratio of the algorithm is 32.29 dB, 28.85 dB, 27.61 dB, 26.16 dB and 30.87 dB, respectively when the magnification factor is 4; the reconstructed image of this algorithm has richer texture in terms of the qualitative analysis and the reconstructed image is closer to the real image with a clear outline.ConclusionOur multi-supervision smoothing loss function is used as the objective function, and the objective function mapping space is clear. In addition, the network calculation complexity is reduced through adding the channel attention module and the global feature fusion module. The network convergence speed is accelerated, and the shallow features are fully utilized. Our experimental results show that the multi-supervised smoothing loss function based image reconstruction results have improved the quality of the reconstructed image and the processing of high-frequency detail in comparison with some typical super-resolution algorithms.关键词:super-resolution reconstruction;iterative sampling;multi-supervision;mapping space;smoothing loss function121|150|0更新时间:2024-05-07 -
 摘要:ObjectiveCurrent deep learning technology is beneficial to video super-resolution(SR) reconstruction. The existing methods are constrained of the accuracy of motion estimation and compensation based on optical flow estimation, and the reconstruction effect of large-scale moving targets is poor. The deformable convolutional alignment network captures the target's motion information via learning adaptive receptive fields, and provides a new solution for video super-resolution reconstruction. To reconstruct realistic high-resolution(HR) video frames, our lightweight-attention-constrained deformable alignment network aims to use a less model parameters network to make full use of the redundant information between the reference frame and adjacent frames.MethodOur attention constraint alignment network (ACAN) consists of three key components like feature extraction module, attention constraint alignment sub-network and dynamic fusion. First, the 5 layers are designed in terms of shared weights feature extraction module in the context of three ground residuals without batch normalization (BN) layer and two residuals atrous spatial pyramid pooling (res_ASPP). To extract multi-scale information and multi-level information without increasing the amount of parameters, the two residuals atrous spatial pyramid pooling and three ground residuals are connected alternately without batch normalization layer. After that, the polar axis constraint and the attention mechanism are integrated to design a lightweight attention constraint alignment sub-network (ACAS). The network regulates the input features of deformable convolution via capturing the global correspondence between adjacent frames and reference frames in the time domain under polar axis constraints, and generates a reasonable offset to achieve implicit alignment. Specifically, the ACAS is introduced through combining the deformable convolution with attention and polar axis constraint. The three attention constraint blocks (ACB) involved ACAS to constrain the features on the horizontal axis of neighboring frames. To find out the most similar features, it can code the feature correlation between any two positions along the horizontal line. At the same time, an effective mask is designed to solve the unavoidable occlusion phenomenon in the video. In the feature extraction module, we send extracted features to the alignment module to generate alignment features with exact matching relationships. In the ablation experiment, we verified that the network can well capture the matching relationship between the reference frame and the adjacent frame using a layer of ACB. However, the network can capture the matching relationship between adjacent frames and the reference frame and handle the status of large motion in the video based on the cascaded three-layer ACB. Therefore, we select a cascaded three-layer ACB network during network design. We illustrate a dynamic fusion branch, which is composed of 16 dynamic fusion blocks. Each block is made of two spatial feature transformation (SFT) layers and two 1×1 convolutions. This branch fuses the time alignment features of the reference frame in the forward neural network and the spatial features of the original low-resolution(LR) frame at different stages. Finally, the high-resolution frame is reconstructed and to be trained. Vimeo-90K is a widely used training dataset and is evaluated in conjunction with the Vid4 test dataset in common. In the training process, this network is trained on Vimeo-90K dataset and tested on Vid4 and REDS4 datasets. The loss function chooses the Charbonnier penalty function solely. The channel size of each layer is set to 64 for the final comparison, where we designates that the alignment module is composed of a layer of attention constraint alignment module, while that the assigned alignment module is cascading from three layers of attention constraint alignment module.Additionally, the network makes use of seven consecutive frames as input. Our RGB patches of a size of 64 × 64 are used as input to the video SR, with the mini-batch size set to 16. We use the Adam optimizer to update the network parameters. The initial learning rate is set to 4e-4. All experiments are conducted on PyTorch 1.0 and four Nvidia Tesla T4 GPUs.ResultOur experiment is evaluated on two benchmark datasets quantitatively, including Vid4 and realistic and diverse scenes dataset(REDS4), and the proposed combined method obtained better results in the image quality indicators peak signal to noise ratio (PSNR) and structural similarity (SSIM). Our results are compared the model to 10 recognized super resolution models, including single image super resolution(SISR) and video super resolution(VSR) methods on two common datasets(Vid4, REDS4).The quantitative evaluations are involved of PSNR and SSIM, and the reconstructed images of each method are provided for comparison. Our reconstruction results show that the proposed model can recover precise details, and the effectiveness of the proposed alignment module with polar axis constraints is verified by comparing the results of no alignment operation and the results of one or three layers of attention constraint alignment. Without the use of alignment, the PSNR score is 22.11 dB, with one layer of ACB PSNR score increased by 1.81 dB, and with three layers of ACB, the PSNR score is increased by 1.21 dB. This result proves the effectiveness of attention constraint to aligning blocks, and the network of cascaded three-layer ACB can capture long-distance spatial information. The dynamic fusion (DF) module is also verified, and the comparative experiment shows that the DF module can improve the reconstruction performance. Our results demonstrate that the PSNR score on the Vid4 data set has increased by more than 0.33 dB compared to EDVR_M, which is an increase of about 1.2%.Compared with EDVR_M, the PSNR score has increased by 0.49 dB on the REDS4 dataset, which is an increase of about 1.6%. Moreover, under the condition of the same PSNR scores, the proposed model parameters are nearly 50% less than that of recurrent back-projection network(RBPN). Our PSNR value is much higher than dynamic upsampling filter(DUF) in terms of the same number of parameters. The PSNR is increased by 0.21 dB although the number of parameters is slightly higher than that of EDVR_M in our model.Conclusionthe number of model parameters is reduced dramatically in the attentional alignment network through the polar axis constraint. To achieve high quality reconstruction results, the distance information can be captured for feature alignment.It can integrate the spatio-temporal features of video frames.关键词:video super resolution(VSR);lightweight network;deformable convolution;attentional constraint;dynamic fusion mechanism;residual atrous spatial pyramid pooling101|202|0更新时间:2024-05-07
摘要:ObjectiveCurrent deep learning technology is beneficial to video super-resolution(SR) reconstruction. The existing methods are constrained of the accuracy of motion estimation and compensation based on optical flow estimation, and the reconstruction effect of large-scale moving targets is poor. The deformable convolutional alignment network captures the target's motion information via learning adaptive receptive fields, and provides a new solution for video super-resolution reconstruction. To reconstruct realistic high-resolution(HR) video frames, our lightweight-attention-constrained deformable alignment network aims to use a less model parameters network to make full use of the redundant information between the reference frame and adjacent frames.MethodOur attention constraint alignment network (ACAN) consists of three key components like feature extraction module, attention constraint alignment sub-network and dynamic fusion. First, the 5 layers are designed in terms of shared weights feature extraction module in the context of three ground residuals without batch normalization (BN) layer and two residuals atrous spatial pyramid pooling (res_ASPP). To extract multi-scale information and multi-level information without increasing the amount of parameters, the two residuals atrous spatial pyramid pooling and three ground residuals are connected alternately without batch normalization layer. After that, the polar axis constraint and the attention mechanism are integrated to design a lightweight attention constraint alignment sub-network (ACAS). The network regulates the input features of deformable convolution via capturing the global correspondence between adjacent frames and reference frames in the time domain under polar axis constraints, and generates a reasonable offset to achieve implicit alignment. Specifically, the ACAS is introduced through combining the deformable convolution with attention and polar axis constraint. The three attention constraint blocks (ACB) involved ACAS to constrain the features on the horizontal axis of neighboring frames. To find out the most similar features, it can code the feature correlation between any two positions along the horizontal line. At the same time, an effective mask is designed to solve the unavoidable occlusion phenomenon in the video. In the feature extraction module, we send extracted features to the alignment module to generate alignment features with exact matching relationships. In the ablation experiment, we verified that the network can well capture the matching relationship between the reference frame and the adjacent frame using a layer of ACB. However, the network can capture the matching relationship between adjacent frames and the reference frame and handle the status of large motion in the video based on the cascaded three-layer ACB. Therefore, we select a cascaded three-layer ACB network during network design. We illustrate a dynamic fusion branch, which is composed of 16 dynamic fusion blocks. Each block is made of two spatial feature transformation (SFT) layers and two 1×1 convolutions. This branch fuses the time alignment features of the reference frame in the forward neural network and the spatial features of the original low-resolution(LR) frame at different stages. Finally, the high-resolution frame is reconstructed and to be trained. Vimeo-90K is a widely used training dataset and is evaluated in conjunction with the Vid4 test dataset in common. In the training process, this network is trained on Vimeo-90K dataset and tested on Vid4 and REDS4 datasets. The loss function chooses the Charbonnier penalty function solely. The channel size of each layer is set to 64 for the final comparison, where we designates that the alignment module is composed of a layer of attention constraint alignment module, while that the assigned alignment module is cascading from three layers of attention constraint alignment module.Additionally, the network makes use of seven consecutive frames as input. Our RGB patches of a size of 64 × 64 are used as input to the video SR, with the mini-batch size set to 16. We use the Adam optimizer to update the network parameters. The initial learning rate is set to 4e-4. All experiments are conducted on PyTorch 1.0 and four Nvidia Tesla T4 GPUs.ResultOur experiment is evaluated on two benchmark datasets quantitatively, including Vid4 and realistic and diverse scenes dataset(REDS4), and the proposed combined method obtained better results in the image quality indicators peak signal to noise ratio (PSNR) and structural similarity (SSIM). Our results are compared the model to 10 recognized super resolution models, including single image super resolution(SISR) and video super resolution(VSR) methods on two common datasets(Vid4, REDS4).The quantitative evaluations are involved of PSNR and SSIM, and the reconstructed images of each method are provided for comparison. Our reconstruction results show that the proposed model can recover precise details, and the effectiveness of the proposed alignment module with polar axis constraints is verified by comparing the results of no alignment operation and the results of one or three layers of attention constraint alignment. Without the use of alignment, the PSNR score is 22.11 dB, with one layer of ACB PSNR score increased by 1.81 dB, and with three layers of ACB, the PSNR score is increased by 1.21 dB. This result proves the effectiveness of attention constraint to aligning blocks, and the network of cascaded three-layer ACB can capture long-distance spatial information. The dynamic fusion (DF) module is also verified, and the comparative experiment shows that the DF module can improve the reconstruction performance. Our results demonstrate that the PSNR score on the Vid4 data set has increased by more than 0.33 dB compared to EDVR_M, which is an increase of about 1.2%.Compared with EDVR_M, the PSNR score has increased by 0.49 dB on the REDS4 dataset, which is an increase of about 1.6%. Moreover, under the condition of the same PSNR scores, the proposed model parameters are nearly 50% less than that of recurrent back-projection network(RBPN). Our PSNR value is much higher than dynamic upsampling filter(DUF) in terms of the same number of parameters. The PSNR is increased by 0.21 dB although the number of parameters is slightly higher than that of EDVR_M in our model.Conclusionthe number of model parameters is reduced dramatically in the attentional alignment network through the polar axis constraint. To achieve high quality reconstruction results, the distance information can be captured for feature alignment.It can integrate the spatio-temporal features of video frames.关键词:video super resolution(VSR);lightweight network;deformable convolution;attentional constraint;dynamic fusion mechanism;residual atrous spatial pyramid pooling101|202|0更新时间:2024-05-07 -
 摘要:ObjectiveImage inpainting for computer vision has been widely used in the context of image and video editing, medical, public security. Constrained of large missing regions in the image, most existing methods usually fail to generate sustainable semantic content to ensure the visual consistency between the repaired image and real image due to the very limited amount of information provided by non-missing regions. The inpainting results of the generator are often be distorted such as color difference, blurring and other artifacts. In addition, the model design has become complex in pursuit of high quality inpainting results, especially the two-stage network structure. The first stage predicts the image contents of missing regions coarsely. The following prediction is fed into the second stage to refine the previous inpainting results. This improves the inpainting effect of the model to some extent, but the two-stage network structure often lead to more inefficient training time and the dependency issue, which means the image inpainting effect is strongly dependent on the result of the first stage.MethodWe propose a dual decoders based enhancing semantic consistency of image inpainting. First, we use consistency loss to reduce the difference of the image between encoder and corresponding decoder. Meanwhile, perceptual loss and style loss are combined to improve the similarity between the repaired image and the real image. These loss functions are defined in the high-level deep features, which can motivate the network to capture the contextual semantic information of the images better, thus producing semantically content in consistency and ensuring the visual consistency between the repaired image and real image. Second, we illustrated a single encoder network structure and a simple and reconstructed paths based dual decoder to eliminate training cost and the dependence of the inpainting effect of the two-stage network structure on the first stage. Simple paths predict the content of missing regions in the image roughly, reconstructed paths generate higher quality inpainting effect, and the inpainting results are regularized by sharing weights. The dual decoder structure allows two inpainting paths to be performed independently at the same time, eliminating the dependency problem in the two-stage network structure and training cost. Finally, we apply the U-Net structure and introduce a skip connection between the encoder and decoder to improve the feature extraction ability, which resolves information loss through down-sampling. Additionally, the dilated convolution is utilized in the encoder to enlarge the receptive field of the model, and the multi-scale attention module is added in the decoder to enhance extracting features extraction ability from distant regions.ResultWe carried out experiments on three datasets, such as CelebA, Stanford Cars and UCF Google Street View. In general, there are usually regular and irregular missing regions in images. To fairly evaluate, we have performed experiments on images with centering and irregular holes. All masks and images are set to the resolution of 256×256 pixels for training and testing. The missing region of the central regular mask is set to 128×128 pixels, and the irregular mask is randomly generated. The qualitative experimental result have shown that our method generates more effectiveness compared to the other six methods, and the repaired image is more consistent visually with the real image. Furthermore, the quantitative comparisons are conducted in five metrics like mean square error (MSE, L2), peak signal-to-noise ratio (PSNR), structural similarity (SSIM), Fréchet inception distance (FID) and inception score (IS) between the proposed method and other methods. Our experimental results indicate that our repaired images have its potentials of visual improvement and numerical performance. For example, the FID is 12.893 in the CelebA dataset in the case of regular missing regions, the FID (lower is better)is decreased by 39.2% compared to the second method. In addition, the PSNR (higher is better) is increased by 12.64%, 6.77% and 4.41% in the UCF Google Street View dataset, respectively. Meanwhile, we carry out ablation studies to verify the effectiveness of the proposed dual decoder. The effectiveness of loss function, multi-scale attention, and U-Net is also verified. Our model can enhance the visual consistency effectively between the repaired and real images, which is capable to produce more effective content for the missing regions of the images.ConclusionA novel image inpainting model is facilitated based on the multiple optimizations in network structure, training time, and image inpainting results. Our proposed method reduces the training time of the model effectively via utilizing a dual decoder and resolve the dependency issue in the two-stage network model simultaneously. The repaired images of our method has better visual consistency in related to consistency loss, perceptual loss, multi-scale attention module. Some limitations of the inpainting effect is challenged to be customized further for complex image structure.关键词:image inpainting;semantic consistency;dual decoder;skip connection;multi-scale attention module111|251|3更新时间:2024-05-07
摘要:ObjectiveImage inpainting for computer vision has been widely used in the context of image and video editing, medical, public security. Constrained of large missing regions in the image, most existing methods usually fail to generate sustainable semantic content to ensure the visual consistency between the repaired image and real image due to the very limited amount of information provided by non-missing regions. The inpainting results of the generator are often be distorted such as color difference, blurring and other artifacts. In addition, the model design has become complex in pursuit of high quality inpainting results, especially the two-stage network structure. The first stage predicts the image contents of missing regions coarsely. The following prediction is fed into the second stage to refine the previous inpainting results. This improves the inpainting effect of the model to some extent, but the two-stage network structure often lead to more inefficient training time and the dependency issue, which means the image inpainting effect is strongly dependent on the result of the first stage.MethodWe propose a dual decoders based enhancing semantic consistency of image inpainting. First, we use consistency loss to reduce the difference of the image between encoder and corresponding decoder. Meanwhile, perceptual loss and style loss are combined to improve the similarity between the repaired image and the real image. These loss functions are defined in the high-level deep features, which can motivate the network to capture the contextual semantic information of the images better, thus producing semantically content in consistency and ensuring the visual consistency between the repaired image and real image. Second, we illustrated a single encoder network structure and a simple and reconstructed paths based dual decoder to eliminate training cost and the dependence of the inpainting effect of the two-stage network structure on the first stage. Simple paths predict the content of missing regions in the image roughly, reconstructed paths generate higher quality inpainting effect, and the inpainting results are regularized by sharing weights. The dual decoder structure allows two inpainting paths to be performed independently at the same time, eliminating the dependency problem in the two-stage network structure and training cost. Finally, we apply the U-Net structure and introduce a skip connection between the encoder and decoder to improve the feature extraction ability, which resolves information loss through down-sampling. Additionally, the dilated convolution is utilized in the encoder to enlarge the receptive field of the model, and the multi-scale attention module is added in the decoder to enhance extracting features extraction ability from distant regions.ResultWe carried out experiments on three datasets, such as CelebA, Stanford Cars and UCF Google Street View. In general, there are usually regular and irregular missing regions in images. To fairly evaluate, we have performed experiments on images with centering and irregular holes. All masks and images are set to the resolution of 256×256 pixels for training and testing. The missing region of the central regular mask is set to 128×128 pixels, and the irregular mask is randomly generated. The qualitative experimental result have shown that our method generates more effectiveness compared to the other six methods, and the repaired image is more consistent visually with the real image. Furthermore, the quantitative comparisons are conducted in five metrics like mean square error (MSE, L2), peak signal-to-noise ratio (PSNR), structural similarity (SSIM), Fréchet inception distance (FID) and inception score (IS) between the proposed method and other methods. Our experimental results indicate that our repaired images have its potentials of visual improvement and numerical performance. For example, the FID is 12.893 in the CelebA dataset in the case of regular missing regions, the FID (lower is better)is decreased by 39.2% compared to the second method. In addition, the PSNR (higher is better) is increased by 12.64%, 6.77% and 4.41% in the UCF Google Street View dataset, respectively. Meanwhile, we carry out ablation studies to verify the effectiveness of the proposed dual decoder. The effectiveness of loss function, multi-scale attention, and U-Net is also verified. Our model can enhance the visual consistency effectively between the repaired and real images, which is capable to produce more effective content for the missing regions of the images.ConclusionA novel image inpainting model is facilitated based on the multiple optimizations in network structure, training time, and image inpainting results. Our proposed method reduces the training time of the model effectively via utilizing a dual decoder and resolve the dependency issue in the two-stage network model simultaneously. The repaired images of our method has better visual consistency in related to consistency loss, perceptual loss, multi-scale attention module. Some limitations of the inpainting effect is challenged to be customized further for complex image structure.关键词:image inpainting;semantic consistency;dual decoder;skip connection;multi-scale attention module111|251|3更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveVisual target tracking can be applied to the computer vision analysis, such as video surveillance, unmanned autopilot systems, and human-computer interaction. Thermal infrared cameras have the advantages of long-range of action, strong penetrating ability, hidden objects. As a branch of visual tracking, RGBT(RGB-thermal) tracking aims to estimate the status of the target in a video sequence by aggregating complementary data from two different modalities given the groundtruth bounding box of the first frame of the video sequence. Previous RGBT tracking algorithms are constrained of traditional handcraft features or insufficient to explore and utilize complementary information from different modalities. In order to explore the complementary information between the two modalities, we propose a dynamic interaction and fusion method for RGBT tracking.MethodGenerally, RGB images capture visual appearance information (e.g., colors and textures) of target, and thermal images acquire temperature information which is robust to the conditions of lighting and background clutter. To obtain more powerful representations, we can introduce the useful information of another modality. However, the fusion of different modalities is opted from addition or concatenation in common due to some noisy information of the obtained modality features. First, a modality interaction module is demonstrated to suppress clutter noise based on the multiplication operation. Second, a fusion module is designed to gather cross-modality features of all layers. It captures different abstractions of target representations for more accurate localization. Third, a complementary gate mechanism guided learning structure calculates the complementary features of different modalities. As the input of the gate, we use the modality-specific features and the cross-modality features obtained from the fusion module. The output of the gate is a numerical value. To obtain the complementary features, we carry out a dot product operation on this value and the cross-modality features. Finally, a dynamic weighting loss is presented to optimize the parameters of the network adaptively in terms of the constraints of the consistency and uncertainty of the prediction results of two modality-specific branches. Our method is evaluated on two standard RGBT tracking datasets, like GTOT(grayscale thermal object tracking) and RGBT234. The two evaluation indicators(precision rate and success rate) is illustrated to measure the performance of tracking. Our model is built through the open source toolbox Pytorch, and the stochastic gradient descent method is optimized. Our implementation runs on the platform of PyTorch with 4.2 GHz Intel Core I7-7700K and NVIDIA GeForce GTX 1080Ti GPU.ResultWe conduct many comparative experiments on the RGBT234 and GTOT datasets. Based on the GTOT dataset analysis, our method (86.1%, 70.9%) exceeds baseline tracker (80.6%, 65.6%) by 5.5% in precision rate(PR) and 5.3% in success rate(SR). our method (79.2%, 55.8%) is 7.0% higher in PR and 6.3% higher in SR than the baseline tracker in terms of the RGBT234 dataset analysis. Compared to the second-performing tracking method, on the RGBT234 dataset, our method is 2.6% higher than DAPNet (76.6%) in PR, and 2.1% higher than DAPNet(53.7%) in SR. At the same time, we conduct component analysis experiments on two datasets. Our experimental results illustrate that each module can improve the performance of tracking.ConclusionOur RGBT target tracking algorithm obtains rich semantic and spatial information through modal interaction and fusion modules, and uses the gate mechanism to explore the complementarity between different modalities. Dynamic weighting loss is illustrated to adaptively optimize the parameters in the model in accordance with the constraints of the prediction results of two modality-specific branches.关键词:modality interaction;modality fusion;complementary features learning;modality-specific information;RGBT object tracking269|180|4更新时间:2024-05-07
摘要:ObjectiveVisual target tracking can be applied to the computer vision analysis, such as video surveillance, unmanned autopilot systems, and human-computer interaction. Thermal infrared cameras have the advantages of long-range of action, strong penetrating ability, hidden objects. As a branch of visual tracking, RGBT(RGB-thermal) tracking aims to estimate the status of the target in a video sequence by aggregating complementary data from two different modalities given the groundtruth bounding box of the first frame of the video sequence. Previous RGBT tracking algorithms are constrained of traditional handcraft features or insufficient to explore and utilize complementary information from different modalities. In order to explore the complementary information between the two modalities, we propose a dynamic interaction and fusion method for RGBT tracking.MethodGenerally, RGB images capture visual appearance information (e.g., colors and textures) of target, and thermal images acquire temperature information which is robust to the conditions of lighting and background clutter. To obtain more powerful representations, we can introduce the useful information of another modality. However, the fusion of different modalities is opted from addition or concatenation in common due to some noisy information of the obtained modality features. First, a modality interaction module is demonstrated to suppress clutter noise based on the multiplication operation. Second, a fusion module is designed to gather cross-modality features of all layers. It captures different abstractions of target representations for more accurate localization. Third, a complementary gate mechanism guided learning structure calculates the complementary features of different modalities. As the input of the gate, we use the modality-specific features and the cross-modality features obtained from the fusion module. The output of the gate is a numerical value. To obtain the complementary features, we carry out a dot product operation on this value and the cross-modality features. Finally, a dynamic weighting loss is presented to optimize the parameters of the network adaptively in terms of the constraints of the consistency and uncertainty of the prediction results of two modality-specific branches. Our method is evaluated on two standard RGBT tracking datasets, like GTOT(grayscale thermal object tracking) and RGBT234. The two evaluation indicators(precision rate and success rate) is illustrated to measure the performance of tracking. Our model is built through the open source toolbox Pytorch, and the stochastic gradient descent method is optimized. Our implementation runs on the platform of PyTorch with 4.2 GHz Intel Core I7-7700K and NVIDIA GeForce GTX 1080Ti GPU.ResultWe conduct many comparative experiments on the RGBT234 and GTOT datasets. Based on the GTOT dataset analysis, our method (86.1%, 70.9%) exceeds baseline tracker (80.6%, 65.6%) by 5.5% in precision rate(PR) and 5.3% in success rate(SR). our method (79.2%, 55.8%) is 7.0% higher in PR and 6.3% higher in SR than the baseline tracker in terms of the RGBT234 dataset analysis. Compared to the second-performing tracking method, on the RGBT234 dataset, our method is 2.6% higher than DAPNet (76.6%) in PR, and 2.1% higher than DAPNet(53.7%) in SR. At the same time, we conduct component analysis experiments on two datasets. Our experimental results illustrate that each module can improve the performance of tracking.ConclusionOur RGBT target tracking algorithm obtains rich semantic and spatial information through modal interaction and fusion modules, and uses the gate mechanism to explore the complementarity between different modalities. Dynamic weighting loss is illustrated to adaptively optimize the parameters in the model in accordance with the constraints of the prediction results of two modality-specific branches.关键词:modality interaction;modality fusion;complementary features learning;modality-specific information;RGBT object tracking269|180|4更新时间:2024-05-07 -
 摘要:ObjectiveHuman facial expression is as one of the key information carriers that cannot be ignored in interpersonal communication. The development of facial expression recognition promotes the resilience of human-computer interaction. At present, to the issue of the performance of facial expression recognition has been improved in human-computer interaction systems like medical intelligence, interactive robots and deep focus monitoring. Facial expression recognition can be divided into two categories like static based image sand video sequence based dynamic images. In the current "short video" era, video has adopted more facial expression information than static images. Compared with static images, video sequences are composed of multi frames of static images, and facial expression intensity of each frame image is featured. Therefore, video sequence based facial expression recognition should be focused on the spatial information of each frame and temporal information in the video sequences, and the importance of each frame image for the whole video expression recognition. The early hand-crafted features are insufficient for generalization ability of the trained model, such as Gabor representations, local binary patterns (LBP). Current deep learning technology has developed a series of deep neural networks to extract facial expression features. The representative deep neural network mainly includes convolutional neural network (CNN), long short-term memory (LSTM). The importance of each frame in video sequence is necessary to be concerned for video expression recognition. In order to make full use of the spatio-temporal scaled information in video sequences and driving factors of multi-frame images on video expression recognition, an end-to-end CNN + LSTM + Transformer video sequence expression recognition method is proposed.MethodFirst, a video sequence is divided into short video clips with a fixed number of frames, and the deep residual network is used to learn high-level facial expression features from each frame of the video clip. Next, the high-level temporal dimension features and attention features are learned further from the spatial feature sequence of the video clip via designing a suitable LSTM and Transformer model, and cascaded into the full connection layer to output the expression classification score of the video clip. Finally, the expression classification scores of all video clips are pooled to achieve the final expression classification task. Our method demonstrates the spatial and the temporal features both. We use transformer to extract the attention feature of fragment frame to improve the expression recognition rate of the model in terms of the difference of facial expression intensity in each frame of video sequence. In addition, the cross-entropy loss function is used to train the emotion recognition model in an end-to-end way, which aids the model to learn more effective facial expression features. Through CNN + LSTM + Transformer model training, the size of batch is set to 4, the learning rate is set to 5×10-5, and the maximum number of cycles is set to 80, respectively.ResultThe importance of frame attention features learned from the Transformer model is greater than that of temporal scaled features, the optimized accuracy of each is 60.72% and 75.44% on BAUM-1 s (Bahcesehir University multimodal) and RML (Ryerson Multimedia Lab) datasets via combining CNN + LSTM + Transformer model. It shows that there is a certain degree of complementarity among the three features learned by CNN, LSTM and Transformer. The combination of the three features can improve the performance of video expression recognition effectively. Furthermore, our averaged accuracy has its potentials on BAUM-1 s and RML datasets.ConclusionOur research develops an end-to-end video sequence-based expression method based on CNN + LSTM + Transformer. It integrates CNN, LSTM and Transformer models to learn the video features of high-level, spatial features, temporal features and video frame attention. The BAUM-1 s and RML-related experimental results illustrate that the proposed method can improve the performance of video sequence-based expression recognition model effectively.关键词:video sequence;facial expression recognition;spatial-temporal dimension;deep residual network;long short-term memory network (LSTM);end-to-end;Transformer57|154|3更新时间:2024-05-07
摘要:ObjectiveHuman facial expression is as one of the key information carriers that cannot be ignored in interpersonal communication. The development of facial expression recognition promotes the resilience of human-computer interaction. At present, to the issue of the performance of facial expression recognition has been improved in human-computer interaction systems like medical intelligence, interactive robots and deep focus monitoring. Facial expression recognition can be divided into two categories like static based image sand video sequence based dynamic images. In the current "short video" era, video has adopted more facial expression information than static images. Compared with static images, video sequences are composed of multi frames of static images, and facial expression intensity of each frame image is featured. Therefore, video sequence based facial expression recognition should be focused on the spatial information of each frame and temporal information in the video sequences, and the importance of each frame image for the whole video expression recognition. The early hand-crafted features are insufficient for generalization ability of the trained model, such as Gabor representations, local binary patterns (LBP). Current deep learning technology has developed a series of deep neural networks to extract facial expression features. The representative deep neural network mainly includes convolutional neural network (CNN), long short-term memory (LSTM). The importance of each frame in video sequence is necessary to be concerned for video expression recognition. In order to make full use of the spatio-temporal scaled information in video sequences and driving factors of multi-frame images on video expression recognition, an end-to-end CNN + LSTM + Transformer video sequence expression recognition method is proposed.MethodFirst, a video sequence is divided into short video clips with a fixed number of frames, and the deep residual network is used to learn high-level facial expression features from each frame of the video clip. Next, the high-level temporal dimension features and attention features are learned further from the spatial feature sequence of the video clip via designing a suitable LSTM and Transformer model, and cascaded into the full connection layer to output the expression classification score of the video clip. Finally, the expression classification scores of all video clips are pooled to achieve the final expression classification task. Our method demonstrates the spatial and the temporal features both. We use transformer to extract the attention feature of fragment frame to improve the expression recognition rate of the model in terms of the difference of facial expression intensity in each frame of video sequence. In addition, the cross-entropy loss function is used to train the emotion recognition model in an end-to-end way, which aids the model to learn more effective facial expression features. Through CNN + LSTM + Transformer model training, the size of batch is set to 4, the learning rate is set to 5×10-5, and the maximum number of cycles is set to 80, respectively.ResultThe importance of frame attention features learned from the Transformer model is greater than that of temporal scaled features, the optimized accuracy of each is 60.72% and 75.44% on BAUM-1 s (Bahcesehir University multimodal) and RML (Ryerson Multimedia Lab) datasets via combining CNN + LSTM + Transformer model. It shows that there is a certain degree of complementarity among the three features learned by CNN, LSTM and Transformer. The combination of the three features can improve the performance of video expression recognition effectively. Furthermore, our averaged accuracy has its potentials on BAUM-1 s and RML datasets.ConclusionOur research develops an end-to-end video sequence-based expression method based on CNN + LSTM + Transformer. It integrates CNN, LSTM and Transformer models to learn the video features of high-level, spatial features, temporal features and video frame attention. The BAUM-1 s and RML-related experimental results illustrate that the proposed method can improve the performance of video sequence-based expression recognition model effectively.关键词:video sequence;facial expression recognition;spatial-temporal dimension;deep residual network;long short-term memory network (LSTM);end-to-end;Transformer57|154|3更新时间:2024-05-07 -
 摘要:ObjectiveGlobal clean energy development has promoted the annual installed capacity of photovoltaic (PV), and the following failure rate of PV panel has been increasing as well. Traditional PV panel fault detection relies on manual inspection, which has low efficiency and high false detection rate. Currently, the intelligent PV panel fault detection method is more practical based on machine vision. To solve PV panel fault detection, many studies used convolutional neural networks (CNNs), and these models are based on supervised learning. However, supervised learning method is not adequate due to the lack of negative samples. Our research is focused on training a semi supervised network that detects anomalies using a dataset that is highly biased towards a particular class, i.e., only use positive samples for training. The generative adversarial network (GAN) can produce good output through the mutual game learning of two modules (at least) in the framework, including the generative model and the discriminant model. Conditional GAN introduces condition variable via generator and discriminator. This additional condition variable can be used to guide the generated data by generator. The gradient descent is challenged more while the number of layers of neural network increasing. Most activation or weight execution methods are challenged in the context of gradient disappearance, gradient explosion and non-convergence. To improve the generalization performance of the deep convolution network, gradient centralization (
摘要:ObjectiveGlobal clean energy development has promoted the annual installed capacity of photovoltaic (PV), and the following failure rate of PV panel has been increasing as well. Traditional PV panel fault detection relies on manual inspection, which has low efficiency and high false detection rate. Currently, the intelligent PV panel fault detection method is more practical based on machine vision. To solve PV panel fault detection, many studies used convolutional neural networks (CNNs), and these models are based on supervised learning. However, supervised learning method is not adequate due to the lack of negative samples. Our research is focused on training a semi supervised network that detects anomalies using a dataset that is highly biased towards a particular class, i.e., only use positive samples for training. The generative adversarial network (GAN) can produce good output through the mutual game learning of two modules (at least) in the framework, including the generative model and the discriminant model. Conditional GAN introduces condition variable via generator and discriminator. This additional condition variable can be used to guide the generated data by generator. The gradient descent is challenged more while the number of layers of neural network increasing. Most activation or weight execution methods are challenged in the context of gradient disappearance, gradient explosion and non-convergence. To improve the generalization performance of the deep convolution network, gradient centralization ($ {\rm{GC}}$ $ L$ $ {\rm{GC}}$ $ {\rm{GC}}$ 关键词:abnormal detection;generative adversarial network (GAN);photovoltaic power generation;deep convolutional;gradient centralization(GC)117|57|0更新时间:2024-05-07 -
 摘要:ObjectiveX-ray image detection is essential for prohibited items in the context of security inspection of those are different types, large-scale changes and most unidentified prohibited items. Traditional image processing models are concerned of to the status of missed and false inspections, resulting in a low model recall rate, and non-ideal analysis in real-time detection. Differentiated from regular optical images, X-ray images tends to the overlapping phenomena derived of a large number of stacked objects. It is challenged to extract effective multiple overlapping objects information for the deep learning models. The multiple overlapping objects are checked as a new object, resulting in poor classification effect and low detection accuracy. Our feature enhancement fusion network(FEFNet)is facilitated to the issue of X-ray detection of prohibited items based on multi-scale features and global context.MethodFirst, the feature enhancement fusion model improves you only look once v3(YOLOv3)' s feature extractor darknet53 through adding a spatial coordinated attention mechanism. The improved feature extractor is called coordinate darknet, which embeds in situ information into the channel attention and aggregates features in two spatial directions. Coordinate darknet can extract more salient and discriminatory information to improve the feature extractor's ability. Specifically, the coordinated attention module is melted into the last four residual stages of the original darknet53, including two pooling modules. To obtain feature vectors in different directions, the width and height of the feature map are pooled adaptively. To obtain attention vectors in different directions, the feature vectors are processed in different directions through the batch normalization layer and activation layer. What' s more, the obtained attention vector is applied to the input feature map to yield the model to the detailed information. Next, our bilinear second-order fusion module extracts global context features. The module encodes the highest-dimensional semantic feature information output by a melted one-dimensional vector into the feature extraction backbone network. To obtain a spatial pixel correlation matrix, the bilinear pooling is used to a two-dimensional feature undergoes second-order fusion. To output the final global context features information, the correlation matrix is multiplied by the input features up-sampled and spliced with the feature pyramid. Among them, the bilinear pool operation first obtains the fusion matrix by bilinear fusion (multiplication) of two one-dimensional vectors at the same position, and sums and pools all positions following, and obtains final L2 normalization and softmax operation after the fusion feature. Finally, the feature pyramid layer is improved in response to the problem of different scales of prohibited items. Our cross-scale fusion feature pyramid module improves the ability of multi-scale prohibited items. The multi-scale feature pyramid outputs a total of 4 feature maps of different scales as predictions, and the sizes from small to large are 13×13 pixels, 26×26 pixels, 52×52 pixels, and 104×104 pixels. Small-scale feature maps can predict large-scale targets, and large-scale feature maps are used to improve the predicting ability of small targets. In addition, the concatenate operation is replaced with adding, which can keep more activation mapping from the coordinate darknet. Meanwhile, the global context feature is connected to other local features straightforward derived of second-order fusion, and this information optimizes the obscure and occlusion phenomenon.ResultOur experiment is trained and verified on the security inspection X-ray(SIXRay-Lite) dataset, which include 7 408 samples of training data and 1 500 test data samples. Our EFENet is compared to other object detection models as well, such as single shot detection(SSD), Faster R-CNN, RetinaNet, YOLOv5, and asymmetrical convolution multi-view neural network(ACMNet). This experimental results show that our method achieves 85.64% mean average precision(mAP) on the SIXray-Lite dataset, which is 11.24% higher than the original YOLOv3. Among them, the average detection accuracy of gun is 95.15%, the average detection accuracy of knife is 81.43%, the average detection accuracy of wrench is 81.65%, the average detection accuracy of plier is 85.95%, and the average detection accuracy of scissor is 84.00%. Our comparative analyses demonstrate the priority of our proposed model as mentioned below: 1)in comparison with the SSD model, the mAP of the FEFNet model is increased by 13.97%; 2) compared to the RetinaNet model, the mAP of the FEFNet model is increased by 7.40%; 3) compared to the Faster R-CNN model, the mAP of the FEFNet model is increased by 5.48%; 4) compared to the YOLOv5 model, the mAP of the FEFNet model is only increased 3.61%, and 5)compared to the ACMNet model, the mAP of the FEFNet model is increased by 1.34%.ConclusionOur FEFNet can be optimized to extract significant difference features, reduce background noise interference, and improve the detection ability of multi-scale and small prohibited items. The combination of global context feature information and multi-scale local feature can alleviate the visual occlusion and obscure phenomenon between prohibited items effectively, and improve the overall detection accuracy of the model while ensuring the real-time performance.关键词:prohibited items detection;X-ray image;features enhancement fusion;attention mechanism;multi-scale fusion;global context features98|311|5更新时间:2024-05-07
摘要:ObjectiveX-ray image detection is essential for prohibited items in the context of security inspection of those are different types, large-scale changes and most unidentified prohibited items. Traditional image processing models are concerned of to the status of missed and false inspections, resulting in a low model recall rate, and non-ideal analysis in real-time detection. Differentiated from regular optical images, X-ray images tends to the overlapping phenomena derived of a large number of stacked objects. It is challenged to extract effective multiple overlapping objects information for the deep learning models. The multiple overlapping objects are checked as a new object, resulting in poor classification effect and low detection accuracy. Our feature enhancement fusion network(FEFNet)is facilitated to the issue of X-ray detection of prohibited items based on multi-scale features and global context.MethodFirst, the feature enhancement fusion model improves you only look once v3(YOLOv3)' s feature extractor darknet53 through adding a spatial coordinated attention mechanism. The improved feature extractor is called coordinate darknet, which embeds in situ information into the channel attention and aggregates features in two spatial directions. Coordinate darknet can extract more salient and discriminatory information to improve the feature extractor's ability. Specifically, the coordinated attention module is melted into the last four residual stages of the original darknet53, including two pooling modules. To obtain feature vectors in different directions, the width and height of the feature map are pooled adaptively. To obtain attention vectors in different directions, the feature vectors are processed in different directions through the batch normalization layer and activation layer. What' s more, the obtained attention vector is applied to the input feature map to yield the model to the detailed information. Next, our bilinear second-order fusion module extracts global context features. The module encodes the highest-dimensional semantic feature information output by a melted one-dimensional vector into the feature extraction backbone network. To obtain a spatial pixel correlation matrix, the bilinear pooling is used to a two-dimensional feature undergoes second-order fusion. To output the final global context features information, the correlation matrix is multiplied by the input features up-sampled and spliced with the feature pyramid. Among them, the bilinear pool operation first obtains the fusion matrix by bilinear fusion (multiplication) of two one-dimensional vectors at the same position, and sums and pools all positions following, and obtains final L2 normalization and softmax operation after the fusion feature. Finally, the feature pyramid layer is improved in response to the problem of different scales of prohibited items. Our cross-scale fusion feature pyramid module improves the ability of multi-scale prohibited items. The multi-scale feature pyramid outputs a total of 4 feature maps of different scales as predictions, and the sizes from small to large are 13×13 pixels, 26×26 pixels, 52×52 pixels, and 104×104 pixels. Small-scale feature maps can predict large-scale targets, and large-scale feature maps are used to improve the predicting ability of small targets. In addition, the concatenate operation is replaced with adding, which can keep more activation mapping from the coordinate darknet. Meanwhile, the global context feature is connected to other local features straightforward derived of second-order fusion, and this information optimizes the obscure and occlusion phenomenon.ResultOur experiment is trained and verified on the security inspection X-ray(SIXRay-Lite) dataset, which include 7 408 samples of training data and 1 500 test data samples. Our EFENet is compared to other object detection models as well, such as single shot detection(SSD), Faster R-CNN, RetinaNet, YOLOv5, and asymmetrical convolution multi-view neural network(ACMNet). This experimental results show that our method achieves 85.64% mean average precision(mAP) on the SIXray-Lite dataset, which is 11.24% higher than the original YOLOv3. Among them, the average detection accuracy of gun is 95.15%, the average detection accuracy of knife is 81.43%, the average detection accuracy of wrench is 81.65%, the average detection accuracy of plier is 85.95%, and the average detection accuracy of scissor is 84.00%. Our comparative analyses demonstrate the priority of our proposed model as mentioned below: 1)in comparison with the SSD model, the mAP of the FEFNet model is increased by 13.97%; 2) compared to the RetinaNet model, the mAP of the FEFNet model is increased by 7.40%; 3) compared to the Faster R-CNN model, the mAP of the FEFNet model is increased by 5.48%; 4) compared to the YOLOv5 model, the mAP of the FEFNet model is only increased 3.61%, and 5)compared to the ACMNet model, the mAP of the FEFNet model is increased by 1.34%.ConclusionOur FEFNet can be optimized to extract significant difference features, reduce background noise interference, and improve the detection ability of multi-scale and small prohibited items. The combination of global context feature information and multi-scale local feature can alleviate the visual occlusion and obscure phenomenon between prohibited items effectively, and improve the overall detection accuracy of the model while ensuring the real-time performance.关键词:prohibited items detection;X-ray image;features enhancement fusion;attention mechanism;multi-scale fusion;global context features98|311|5更新时间:2024-05-07 -
 摘要:ObjectiveVehicles motion are prone to traffic accidents on the expressway due to their high speed, which mainly include rear-end collisions, punctures, scratches, side collisions, etc. Among them, high-speed rear-end collisions, overtaking and lane changing accounted for t the most losses of them. Therefore, it is essential to analyze the driving safety and reduce the occurrence of accidents. Thanks to the development of deep learning, vision-based vehicle driving safety early warning analysis technology is currently an important research direction for vehicle aided driving.We propose an early warning algorithm for vehicle-road visual collaborative driving safety in expressway scenes.MethodThe vehicles motion safety early warning algorithm in synchronized vehicles-road visual expressway scenarios is facilitated. First, we illustrated a vehicle motion recorder to monitor and combine vehicle target recognition and positioning, a safe distance model, and analyzes driving safety based on a multi-lane early warning algorithm. It is composed of three parts like vehicle target recognition and positioning technology, safety distance model and multi-lanes warning algorithm. The image processing technology is as the input to detect the distance between the vehicle ahead and the vehicle body. A safe distance model early warning fusion algorithm is, performed to safety analysis on the motion of the vehicle. Our deep convolutional neural network of single feature you look only once v4(SF_YOLOv4)detects and tracks the vehicle ahead accurately. Then, the range of the vehicles is calculated in terms of the perspective transformation principle combined with the vehicle position information. Finally, a safe distance model and fusion algorithm are proposed to analyze the vehicle safety. In the target detection part, our method is improved on the basis of YOLOv4. The backbone network is replaced by CSPDarknet53 with a smaller layer of cross stage paritial Darknet17(CSPDarknet17) network, which reduces the number of model parameters and calculations, improves the speed of target detection, and the accuracy of target detection for a single scene less affected. Our four-feature pyramid network(F-FPN) is illustrated to construct a feature pyramid, and the 104×104 scale feature map is added to the feature network. It can improve the detection effect of small targets effectively. In the distance calculation part, the monocular vision calculation principle is used to perform perspective transformation on the selected area. The corresponding equations are fitted in the horizontal and vertical directions to calculate the distance via the referenced lane and lane line data. In the part of the safety distance, the braking loss of the vehicle motion is ignored according to the energy change of the vehicle during braking. During the braking process, the kinetic energy is converted into work to overcome friction, work to overcome wind resistance, and work to overcome inertia. The safety distance model calculates the safety zone in the multiple lanes ahead. In the part of the safety warning model, a multi-lanes forward safety warning scheme is proposed. The corresponding warning is given in according with the corresponding position of the vehicle in the adjacent lane ahead, which can effectively avoid collision accidents caused by rear-end collisions and abnormal lane changes.ResultWe use mean average precision(mAP), frames per second(FPS), recall, model parameters, model calculations to evaluate the target detection network. At the same time, different algorithms are used to carry out comparative experiments on self-built data sets. The safety distance is verified by selecting different vehicle data. a real video data set of vehicles motion on express way is established by simulating the actual high-speed vehicle motion environment. According to the experimental analysis, the main potentials of the algorithm are as follows: 1) a single-stage feature neural network (SF_YOLOv4) is proposed to detect vehicle targets in a single scene quickly. The detection speed is greatly improved through achieving precise positioning of the vehicle in front, improving the detection effect of small targets, and ensuring the accuracy in the case of unclear change. Our experiments show that the SF_YOLOv4 can detect the vehicle ahead in real time with 93.55% accuracy, and the detection speed is 25 frames per second; 2) Our safe distance model is melted the momentum and energy conservation of the vehicle in motion, and the mechanical features of the vehicle are in consistency under actual driving conditions. Our verified safety distance model calculates the braking distance error of different types of vehicles is less than 0.1 m; 3) A multi-lanes safety warning algorithm is illustrated to construct a safety warning area for adjacent vehicles in front of the vehicle.ConclusionOur SF_YOLOv4 target detection model can achieve a perfect match between detection speed and accuracy. The proposed early warning model of safety fusion realize the changes of vehicle positions on adjacent lanes of expressways, and can predict the impact of rear-end collisions, overtaking and lane changes. Once the vehicle is outside the multi-lane safety warning zone ahead, the safety distance will be displayed in real time, and the target vehicle will be marked, and the driver will be reminded to drive safely; when the vehicle enters the warning zone, in addition to the real-time display of the safety distance, the mark will also be calculated. The distance between the vehicle and the workshop is displayed to the driver in real time, and the driver is reminded to avoid a collision once a vehicle in the corresponding lane, and a reminder is issued through voice and other means. Compared to the traditional method, the early warning effect is more objective, the warning range is wider, and the safety of highway driving can be improvedeffectively.关键词:safety analysis;anti-collision warning;vehicle target detection;safe distance model;you look only once v4(YOLOv4);vehicle distance calculation96|217|1更新时间:2024-05-07
摘要:ObjectiveVehicles motion are prone to traffic accidents on the expressway due to their high speed, which mainly include rear-end collisions, punctures, scratches, side collisions, etc. Among them, high-speed rear-end collisions, overtaking and lane changing accounted for t the most losses of them. Therefore, it is essential to analyze the driving safety and reduce the occurrence of accidents. Thanks to the development of deep learning, vision-based vehicle driving safety early warning analysis technology is currently an important research direction for vehicle aided driving.We propose an early warning algorithm for vehicle-road visual collaborative driving safety in expressway scenes.MethodThe vehicles motion safety early warning algorithm in synchronized vehicles-road visual expressway scenarios is facilitated. First, we illustrated a vehicle motion recorder to monitor and combine vehicle target recognition and positioning, a safe distance model, and analyzes driving safety based on a multi-lane early warning algorithm. It is composed of three parts like vehicle target recognition and positioning technology, safety distance model and multi-lanes warning algorithm. The image processing technology is as the input to detect the distance between the vehicle ahead and the vehicle body. A safe distance model early warning fusion algorithm is, performed to safety analysis on the motion of the vehicle. Our deep convolutional neural network of single feature you look only once v4(SF_YOLOv4)detects and tracks the vehicle ahead accurately. Then, the range of the vehicles is calculated in terms of the perspective transformation principle combined with the vehicle position information. Finally, a safe distance model and fusion algorithm are proposed to analyze the vehicle safety. In the target detection part, our method is improved on the basis of YOLOv4. The backbone network is replaced by CSPDarknet53 with a smaller layer of cross stage paritial Darknet17(CSPDarknet17) network, which reduces the number of model parameters and calculations, improves the speed of target detection, and the accuracy of target detection for a single scene less affected. Our four-feature pyramid network(F-FPN) is illustrated to construct a feature pyramid, and the 104×104 scale feature map is added to the feature network. It can improve the detection effect of small targets effectively. In the distance calculation part, the monocular vision calculation principle is used to perform perspective transformation on the selected area. The corresponding equations are fitted in the horizontal and vertical directions to calculate the distance via the referenced lane and lane line data. In the part of the safety distance, the braking loss of the vehicle motion is ignored according to the energy change of the vehicle during braking. During the braking process, the kinetic energy is converted into work to overcome friction, work to overcome wind resistance, and work to overcome inertia. The safety distance model calculates the safety zone in the multiple lanes ahead. In the part of the safety warning model, a multi-lanes forward safety warning scheme is proposed. The corresponding warning is given in according with the corresponding position of the vehicle in the adjacent lane ahead, which can effectively avoid collision accidents caused by rear-end collisions and abnormal lane changes.ResultWe use mean average precision(mAP), frames per second(FPS), recall, model parameters, model calculations to evaluate the target detection network. At the same time, different algorithms are used to carry out comparative experiments on self-built data sets. The safety distance is verified by selecting different vehicle data. a real video data set of vehicles motion on express way is established by simulating the actual high-speed vehicle motion environment. According to the experimental analysis, the main potentials of the algorithm are as follows: 1) a single-stage feature neural network (SF_YOLOv4) is proposed to detect vehicle targets in a single scene quickly. The detection speed is greatly improved through achieving precise positioning of the vehicle in front, improving the detection effect of small targets, and ensuring the accuracy in the case of unclear change. Our experiments show that the SF_YOLOv4 can detect the vehicle ahead in real time with 93.55% accuracy, and the detection speed is 25 frames per second; 2) Our safe distance model is melted the momentum and energy conservation of the vehicle in motion, and the mechanical features of the vehicle are in consistency under actual driving conditions. Our verified safety distance model calculates the braking distance error of different types of vehicles is less than 0.1 m; 3) A multi-lanes safety warning algorithm is illustrated to construct a safety warning area for adjacent vehicles in front of the vehicle.ConclusionOur SF_YOLOv4 target detection model can achieve a perfect match between detection speed and accuracy. The proposed early warning model of safety fusion realize the changes of vehicle positions on adjacent lanes of expressways, and can predict the impact of rear-end collisions, overtaking and lane changes. Once the vehicle is outside the multi-lane safety warning zone ahead, the safety distance will be displayed in real time, and the target vehicle will be marked, and the driver will be reminded to drive safely; when the vehicle enters the warning zone, in addition to the real-time display of the safety distance, the mark will also be calculated. The distance between the vehicle and the workshop is displayed to the driver in real time, and the driver is reminded to avoid a collision once a vehicle in the corresponding lane, and a reminder is issued through voice and other means. Compared to the traditional method, the early warning effect is more objective, the warning range is wider, and the safety of highway driving can be improvedeffectively.关键词:safety analysis;anti-collision warning;vehicle target detection;safe distance model;you look only once v4(YOLOv4);vehicle distance calculation96|217|1更新时间:2024-05-07 -
 摘要:ObjectiveThe human body size measurement is developed in garment making based on contact and non-contact methods. The manual contact measurement mainly uses soft ruler and other tools to measure by hand. This method is time costly and inaccuracy, which is not appropriate for large-scaled human body size collection. The intelligent non-contact human body measurement obtains human body size through some equipment and instruments, which has the features of high efficiency, easy use and quick response. Traditional non-contact human body measurement is constrained of external factors, such as single color background and fixed lighting scenario. In addition, the traditional methods extract less number of human key points, or the position of human key points have some deviation for the human body with particular size. To further address these issues, we construct a convolution neural network model and facilitate the method for segmenting human body and detecting the key points. Meanwhile, we focus on the measurement method of shoulder width based on Bezier curve, as well as the measurement method of body circumference based on double ellipse fitting.MethodThree images of the front, side and back of the human body are captured through the camera. The acquired image is segmented using the Deeplavb3+ algorithm and the human body contour is obtained. Lightweight OpenPose algorithm is employed to detect the 13 human body key points, including shoulder joint, elbow joint, wrist joint, hip joint, knee joint, ankle joint, etc. First, the end point of shoulder is identified by integrated information of human shoulder joints because the angle between the tangent lines at the end of shoulder is less than the angle of its surrounding point. The two endpoints of shoulder curve can be regarded as the starting point and the ending point of the quadratic Bezier curve based on the similarity of shoulder curve and Bezier curve. Next, the intersection of the tangent lines of the two ends of shoulder width curve is used as the control point of the quadratic Bezier curve. The shoulder width is obtained by the calculated length of shoulder Bezier curve. The range of waist is determined by the key points of hip joint and elbow joint in the human contour curve. The average waist width and thickness within the range are taken as the width and thickness of the human waist. The waist curve of human body is as two ellipses with equal long axes and unequal short axes. The double ellipse fitting model is established for human circumference curve. The parameters of the double ellipse fitting model are trained by linear regression method. Finally, the waist length of human body is obtained with the circumference of the double ellipse fitting curves. Similarly, the measurement position of chest and hip circumference is roughly determined in accordance with the results of human segmentation and key detected points. The measurement curve of the whole chest and hip circumference is fitted to obtain the curve length.Resultwe compare the human key point detection performance of three algorithms, including Lightweight OpenPose, contour-based detection, and human proportion based detection. Our experimental results show that Lightweight OpenPose can extract human key points more accurately.Additionally, we also compare the network results and computation of OpenPose to Lightweight OpenPose. The results show that Lightweight OpenPose can simplify the computation and guarantee the detection accuracy. We select 100 shoulder categories for data evaluation of the measurement of shoulder width, including flat, wide or narrow, and sliding one. We compare the shoulder width measurement performance of three algorithms, including vanishing point and proportion based algorithm, regression analysis and the proposed algorithm. These experimental results demonstrate that our average absolute error of shoulder width measured is less than 2 cm. For the measurement of human circumference, 132 samples are selected for data evaluation. For the measurement of waist circumference, we evaluate four methods related to regression analysis method, support vector machine (SVM)-based waist circumference estimation algorithm, direct ellipse fitting method and the proposed algorithm. For the measurement of chest and hip circumference, we carry out the evaluations of three methods like regression analysis method, direct ellipse fitting method and the proposed algorithm. The comparative results show that the average abstract error of the proposed algorithm is within 3 cm, which is suitable for the national measurement standard.ConclusionOur algorithm evaluate the accuracy of human body size measurement, which reduces the dependence of the non-contact measurement on the external environment and equipment, improves the robustness of the system, and promotes the non-contact measurement in practice. The future research potentials can be improved through the robustness of human body segmentation method, the elimination of hair or other racial bodies on shoulder width and chest circumference measurement, and the detection accuracy of shoulder endpoint and chest positioning. It is challenged that more integrated human body data like chest, waist or hip contour need to be estimated for potential features of individual-based human body size further.关键词:OpenPose;Deeplabv3+;Bezier curve;curve fitting;body size measurement64|48|2更新时间:2024-05-07
摘要:ObjectiveThe human body size measurement is developed in garment making based on contact and non-contact methods. The manual contact measurement mainly uses soft ruler and other tools to measure by hand. This method is time costly and inaccuracy, which is not appropriate for large-scaled human body size collection. The intelligent non-contact human body measurement obtains human body size through some equipment and instruments, which has the features of high efficiency, easy use and quick response. Traditional non-contact human body measurement is constrained of external factors, such as single color background and fixed lighting scenario. In addition, the traditional methods extract less number of human key points, or the position of human key points have some deviation for the human body with particular size. To further address these issues, we construct a convolution neural network model and facilitate the method for segmenting human body and detecting the key points. Meanwhile, we focus on the measurement method of shoulder width based on Bezier curve, as well as the measurement method of body circumference based on double ellipse fitting.MethodThree images of the front, side and back of the human body are captured through the camera. The acquired image is segmented using the Deeplavb3+ algorithm and the human body contour is obtained. Lightweight OpenPose algorithm is employed to detect the 13 human body key points, including shoulder joint, elbow joint, wrist joint, hip joint, knee joint, ankle joint, etc. First, the end point of shoulder is identified by integrated information of human shoulder joints because the angle between the tangent lines at the end of shoulder is less than the angle of its surrounding point. The two endpoints of shoulder curve can be regarded as the starting point and the ending point of the quadratic Bezier curve based on the similarity of shoulder curve and Bezier curve. Next, the intersection of the tangent lines of the two ends of shoulder width curve is used as the control point of the quadratic Bezier curve. The shoulder width is obtained by the calculated length of shoulder Bezier curve. The range of waist is determined by the key points of hip joint and elbow joint in the human contour curve. The average waist width and thickness within the range are taken as the width and thickness of the human waist. The waist curve of human body is as two ellipses with equal long axes and unequal short axes. The double ellipse fitting model is established for human circumference curve. The parameters of the double ellipse fitting model are trained by linear regression method. Finally, the waist length of human body is obtained with the circumference of the double ellipse fitting curves. Similarly, the measurement position of chest and hip circumference is roughly determined in accordance with the results of human segmentation and key detected points. The measurement curve of the whole chest and hip circumference is fitted to obtain the curve length.Resultwe compare the human key point detection performance of three algorithms, including Lightweight OpenPose, contour-based detection, and human proportion based detection. Our experimental results show that Lightweight OpenPose can extract human key points more accurately.Additionally, we also compare the network results and computation of OpenPose to Lightweight OpenPose. The results show that Lightweight OpenPose can simplify the computation and guarantee the detection accuracy. We select 100 shoulder categories for data evaluation of the measurement of shoulder width, including flat, wide or narrow, and sliding one. We compare the shoulder width measurement performance of three algorithms, including vanishing point and proportion based algorithm, regression analysis and the proposed algorithm. These experimental results demonstrate that our average absolute error of shoulder width measured is less than 2 cm. For the measurement of human circumference, 132 samples are selected for data evaluation. For the measurement of waist circumference, we evaluate four methods related to regression analysis method, support vector machine (SVM)-based waist circumference estimation algorithm, direct ellipse fitting method and the proposed algorithm. For the measurement of chest and hip circumference, we carry out the evaluations of three methods like regression analysis method, direct ellipse fitting method and the proposed algorithm. The comparative results show that the average abstract error of the proposed algorithm is within 3 cm, which is suitable for the national measurement standard.ConclusionOur algorithm evaluate the accuracy of human body size measurement, which reduces the dependence of the non-contact measurement on the external environment and equipment, improves the robustness of the system, and promotes the non-contact measurement in practice. The future research potentials can be improved through the robustness of human body segmentation method, the elimination of hair or other racial bodies on shoulder width and chest circumference measurement, and the detection accuracy of shoulder endpoint and chest positioning. It is challenged that more integrated human body data like chest, waist or hip contour need to be estimated for potential features of individual-based human body size further.关键词:OpenPose;Deeplabv3+;Bezier curve;curve fitting;body size measurement64|48|2更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveLung cancer threatens human health severely. It is one of the malignant tumors with the fastest increase in morbidity and mortality and the greatest threat to the life of the population. In the past 50 years, many countries have addressed that the incidence and mortality of lung cancer have increased significantly. The incidence and mortality of lung cancer rank the first among all the malignant tumors. Recent ultrasound elastography technology has been gradually applied to diagnose the benign and malignant bronchial lymph nodes to aid the degree analysis of lung cancer. Ultrasonic elastography provides more information than conventional two-dimensional ultrasound via the evaluation of lesion toughness. Color Doppler energy imaging superimposes the color coding system on the conventional ultrasound image. In general, the hardness of the diseased lymph node is relatively large, and the degree of deformation is small after being squeezed, which is represented as blue color in the elastic image. The normal lymph node is relatively soft, which is represented as red or green colors in the elastic image. Bronchial ultrasound elastography is generated through the squeezing deformation issues of the lymph nodes in related to the record of heartbeat, breathing movement and the pulsation of blood vessels around the lungs. In bronchial ultrasound elastic images, the precise positioning of the lymph node area is of great significance to the diagnosis accuracy of the disease. However, this kind of task is time-consuming and laborious due to its manual segmentation in clinical. We carried out the deep learning based automatic segmentation method of mediastinal lymph nodes in bronchial ultrasound elastic images via U-Net-type architectures.MethodA dataset consisting of 205 bronchial ultrasound elastic images and corresponding segmentation labels is collected. The lymph nodes of each image are manually segmented and labeled. Based on this dataset, six classic deep network models based on U-Net are tested. The U-Net has an encoder-decoder structure. The encoder aims to capture more advanced semantic features and reduce the spatial dimension of the feature map gradually, while the decoder is used to restore spatial details and dimensions. We design a new U-Net-based bronchial ultrasound elastic image segmentation method based on the integration of context extractor and attention mechanism. To avoid gradient explosion and disappearance, the encoder is the ResNet-34 pretrained on ImageNet with no average pooling layer and the fully connected layer. The context extractor is used to extract high-level semantic information further from the output of the encoder while preserving as much spatial information as possible. The attention mechanism aims to select features that are more important to the current task. The prediction result of the segmentation network is the probability value of the pixel classification, so a binarization operation is performed by setting the threshold to 0.5. That is, the pixels are assigned to 0 if the probability value is less than 0.5 and otherwise is 1. In this way, the segmented binary image is obtained.ResultTo verify the performance of different networks, a five-fold cross validation evaluation is conducted on the dataset. That is, we divide the dataset into five equal parts in random, and four of them is as the training set each time and the remaining one is as the testing set. The preprocessing operations are related to data cropping, data augmentation and normalized operation on the training set. The input images and the ground-truth segmentation maps are resized to 320×320 pixels. Data augmentation approaches include random vertical flip and random angle rotation. The Adam optimizer is selected and the learning rate is set to 0.000 1. The batch size is set to 8. The number of epoch is 150. The GPU used in the experiment is GeForce RTX 2080Ti. The segmentation task is implemented using python3.7 under the Ubuntu16.04.1 operating system and the core framework is pytorch1.7.1. The results of Dice coefficient, sensitivity and specificity of U-Net network lymph node segmentation are 0.820 7, 85.08% and 96.82%, respectively. On this basis, the segmentation performances of other modified versions of U-Net are all improved to a certain extent. Among them, our Dice coefficient, sensitivity and specificity are 0.845 1, 87.92% and 97.04% of each, which are 0.024 4, 2.84% and 0.22% higher than the baseline U-Net, respectively. Compared to the other methods, the Dice coefficient and the sensitivity achieve the first place, while the specificity ranks the second.ConclusionOur analyses demonstrate that deep learning models represented by U-Net have great potential in the segmentation of mediastinal lymph nodes in bronchial ultrasound elastic images. Fused by the context extractor and attention mechanism, the integrated U-Net network can improve the segmentation accuracy to a certain extent. In addition, the illustrated dataset can promote the research of lymph node segmentation in bronchial ultrasound elastic images. Our method can be used for the segmentation of lymph nodes in bronchial ultrasound elastography images. It has potentials for the segmentation of more medical imaging organs and tumors as well. However, due to the relatively small scale of the dataset, there is still large room for further improvement on the segmentation performance, although the data augmentation approaches have been performed. To improve the segmentation accuracy further, it is required to increase the scale of the dataset in consistency.关键词:ultrasound elastography;lymph node segmentation;deep learning;U-Net;context extractor;attention mechanism103|462|5更新时间:2024-05-07
摘要:ObjectiveLung cancer threatens human health severely. It is one of the malignant tumors with the fastest increase in morbidity and mortality and the greatest threat to the life of the population. In the past 50 years, many countries have addressed that the incidence and mortality of lung cancer have increased significantly. The incidence and mortality of lung cancer rank the first among all the malignant tumors. Recent ultrasound elastography technology has been gradually applied to diagnose the benign and malignant bronchial lymph nodes to aid the degree analysis of lung cancer. Ultrasonic elastography provides more information than conventional two-dimensional ultrasound via the evaluation of lesion toughness. Color Doppler energy imaging superimposes the color coding system on the conventional ultrasound image. In general, the hardness of the diseased lymph node is relatively large, and the degree of deformation is small after being squeezed, which is represented as blue color in the elastic image. The normal lymph node is relatively soft, which is represented as red or green colors in the elastic image. Bronchial ultrasound elastography is generated through the squeezing deformation issues of the lymph nodes in related to the record of heartbeat, breathing movement and the pulsation of blood vessels around the lungs. In bronchial ultrasound elastic images, the precise positioning of the lymph node area is of great significance to the diagnosis accuracy of the disease. However, this kind of task is time-consuming and laborious due to its manual segmentation in clinical. We carried out the deep learning based automatic segmentation method of mediastinal lymph nodes in bronchial ultrasound elastic images via U-Net-type architectures.MethodA dataset consisting of 205 bronchial ultrasound elastic images and corresponding segmentation labels is collected. The lymph nodes of each image are manually segmented and labeled. Based on this dataset, six classic deep network models based on U-Net are tested. The U-Net has an encoder-decoder structure. The encoder aims to capture more advanced semantic features and reduce the spatial dimension of the feature map gradually, while the decoder is used to restore spatial details and dimensions. We design a new U-Net-based bronchial ultrasound elastic image segmentation method based on the integration of context extractor and attention mechanism. To avoid gradient explosion and disappearance, the encoder is the ResNet-34 pretrained on ImageNet with no average pooling layer and the fully connected layer. The context extractor is used to extract high-level semantic information further from the output of the encoder while preserving as much spatial information as possible. The attention mechanism aims to select features that are more important to the current task. The prediction result of the segmentation network is the probability value of the pixel classification, so a binarization operation is performed by setting the threshold to 0.5. That is, the pixels are assigned to 0 if the probability value is less than 0.5 and otherwise is 1. In this way, the segmented binary image is obtained.ResultTo verify the performance of different networks, a five-fold cross validation evaluation is conducted on the dataset. That is, we divide the dataset into five equal parts in random, and four of them is as the training set each time and the remaining one is as the testing set. The preprocessing operations are related to data cropping, data augmentation and normalized operation on the training set. The input images and the ground-truth segmentation maps are resized to 320×320 pixels. Data augmentation approaches include random vertical flip and random angle rotation. The Adam optimizer is selected and the learning rate is set to 0.000 1. The batch size is set to 8. The number of epoch is 150. The GPU used in the experiment is GeForce RTX 2080Ti. The segmentation task is implemented using python3.7 under the Ubuntu16.04.1 operating system and the core framework is pytorch1.7.1. The results of Dice coefficient, sensitivity and specificity of U-Net network lymph node segmentation are 0.820 7, 85.08% and 96.82%, respectively. On this basis, the segmentation performances of other modified versions of U-Net are all improved to a certain extent. Among them, our Dice coefficient, sensitivity and specificity are 0.845 1, 87.92% and 97.04% of each, which are 0.024 4, 2.84% and 0.22% higher than the baseline U-Net, respectively. Compared to the other methods, the Dice coefficient and the sensitivity achieve the first place, while the specificity ranks the second.ConclusionOur analyses demonstrate that deep learning models represented by U-Net have great potential in the segmentation of mediastinal lymph nodes in bronchial ultrasound elastic images. Fused by the context extractor and attention mechanism, the integrated U-Net network can improve the segmentation accuracy to a certain extent. In addition, the illustrated dataset can promote the research of lymph node segmentation in bronchial ultrasound elastic images. Our method can be used for the segmentation of lymph nodes in bronchial ultrasound elastography images. It has potentials for the segmentation of more medical imaging organs and tumors as well. However, due to the relatively small scale of the dataset, there is still large room for further improvement on the segmentation performance, although the data augmentation approaches have been performed. To improve the segmentation accuracy further, it is required to increase the scale of the dataset in consistency.关键词:ultrasound elastography;lymph node segmentation;deep learning;U-Net;context extractor;attention mechanism103|462|5更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveMesoscale eddy analysis is developed in the field of world's oceans and marginal seas. The multi-scale response mechanism and feedback interaction of mesoscale eddy and ocean phenomena has been promoted through mesoscale eddy generation, growth and extinction, the large scale spatial mesoscale eddy is essential to the issues of transport and distribution of global marine contexts of energy, heat and fresh water in terms of the feature of irregular three-dimensional structure and multifaceted dynamics. Therefore, the automatic detection of ocean mesoscale eddy can be used to understand the evolution of ocean mesoscale eddy and the role of ocean mesoscale eddy in material transport and energy transfer. The traditional ocean mesoscale eddy detection methods are mostly adopted based on the physical parameter, flow field geometric feature or both of them. The mesoscale eddies are detected by setting appropriate threshold artificially. The emerging deep learning technology is beneficial to ocean mesoscale eddy detection methods based on deep network model. A classifier is used to classify mesoscale eddy based on manual design and features extraction. The traditional algorithm has good mesoscale eddy detection effect via horizontal bounding box. However, the marine scenario of mesoscale eddy is complicated and ocean mesoscale eddy has the feature of irregular shape, complicated structure and length-width ratio uncertainty and dense distribution. The traditional threshold-dependent detection algorithm has constrained of its rigid and poor generalization ability. The horizontal boundary box methods have redundant horizontal detection region, nested detection box and overlapped issue. Therefore, we propose an automatic detection method of ocean mesoscale eddy based on multi-scale rotating anchor mechanism.MethodWe visualize and normalize the satellite remote sensing sea level height anomaly data. The visual dataset is annotated based on ocean mesoscale eddy understanding and global daily ocean eddy satellite altimeter data. To expand small number of accurate expert annotation data sets, we use two-dimensional image processing strategy to construct the training set, such as adding noise and clipping operation. The basic features are derived of the factors of scale and signal noise ratio. We construct an automatic mesoscale eddy detection model based on multi-scale rotating anchor mechanism and one-stage object detection network RetinaNet. In the network structure, ResNet backbone network extract mesoscale eddy feature through introducing residual mapping and jump connection into the network. The feature information of the obtained residual block is added into the following residual block. It avoids the problem of gradient disappearance and deeper feature information loss effectively. At the same time, we use the feature pyramid network structure to integrate the low-level and high-level features of mesoscale eddy. It provides spatial and high-level semantic feature information of complex structure, different scales and more rapid sustainable changes. To cover the multi-oriented mesoscale eddy object with arbitrary shapes, it is generated that multi-scale rotation detection anchors are composed of scale, multi-aspect ratio and multi-rotation angles for each grid point of the output feature map. We integrate the classification and regression subnetworks, in which the classification subnetwork predict the probability of the presence of the object spatially, and the regression subnetwork predict location information via the regression transformation of predictive bounding box and the generated anchor. Finally, non-maximum suppression is used to obtain the final detection result.ResultThanks to multi-scale rotating anchor mechanism, this experiment shows that our ocean mesoscale eddy automatic detection method can improve the issues of low detection precision, detect box nesting and overlapping via large aspect ratio of ocean mesoscale eddy, the deductible area of horizontal detection. It can detect the existence of multi-core eddy effectively. Furthermore, comparative analysis is conducted in same data set between feature pyramid networks (FPNs), faster region-convolutional neural networks (Faster R-CNNs) and ours. It shows that the optimal detection accuracy can reach 90.22%, which is 8% higher than the horizontal bounding box detection method, and there is not much difference in speed. Then, we evaluate the accuracy, recall and F1 value amongst the Indian Ocean, Pacific Ocean and Atlantic Ocean. At the same time, the center and scale information of mesoscale eddy can be obtained based on the output position information of the boundary box. Finally, we carried out an empirical analysis of the rotation detection of oceanic mesoscale eddies in the Indian Ocean, Pacific Ocean, Atlantic Ocean and equatorial waters, which illustrates that the model has its potential generalization ability.ConclusionOur research is focused on detection redundancy, overlapping and nested detection boxes in the horizontal bounding box detection method. We facilitate a deep network model based on a one-stage target detection network RetinaNet and promote the generation mechanism of multi-scaled rotating anchors via multifaceted ratio and multi-rotation, and the integrated classification and regression subnetworks. Non-maximum suppression is used to obtain the final detection results. The features of mesoscale eddy are demonstrated based on irregular shape, complex and variable structure, uncertain ratio and dense distribution, The redundancy, overlap and nesting barriers of the horizontal detection box region are released effectively and the existence of multi-core eddy can be detected. Our method improves detection accuracy and guarantee the detection speed compared to the popular object detection methods in recent three years. We evaluated the experimental effectiveness of data augmentation on the original dataset, the noise-added dataset, and the noise-trimmed dataset. We carry out the accuracy, recall and F1 value analysis based on multiple oceans like the Indian Ocean, Pacific Ocean and Atlantic Ocean, which demonstrates the generalization ability of the model.关键词:object rotation detection;ocean mesoscale eddy;sea level anomaly;deep learning;multi-scale rotating anchor78|339|2更新时间:2024-05-07
摘要:ObjectiveMesoscale eddy analysis is developed in the field of world's oceans and marginal seas. The multi-scale response mechanism and feedback interaction of mesoscale eddy and ocean phenomena has been promoted through mesoscale eddy generation, growth and extinction, the large scale spatial mesoscale eddy is essential to the issues of transport and distribution of global marine contexts of energy, heat and fresh water in terms of the feature of irregular three-dimensional structure and multifaceted dynamics. Therefore, the automatic detection of ocean mesoscale eddy can be used to understand the evolution of ocean mesoscale eddy and the role of ocean mesoscale eddy in material transport and energy transfer. The traditional ocean mesoscale eddy detection methods are mostly adopted based on the physical parameter, flow field geometric feature or both of them. The mesoscale eddies are detected by setting appropriate threshold artificially. The emerging deep learning technology is beneficial to ocean mesoscale eddy detection methods based on deep network model. A classifier is used to classify mesoscale eddy based on manual design and features extraction. The traditional algorithm has good mesoscale eddy detection effect via horizontal bounding box. However, the marine scenario of mesoscale eddy is complicated and ocean mesoscale eddy has the feature of irregular shape, complicated structure and length-width ratio uncertainty and dense distribution. The traditional threshold-dependent detection algorithm has constrained of its rigid and poor generalization ability. The horizontal boundary box methods have redundant horizontal detection region, nested detection box and overlapped issue. Therefore, we propose an automatic detection method of ocean mesoscale eddy based on multi-scale rotating anchor mechanism.MethodWe visualize and normalize the satellite remote sensing sea level height anomaly data. The visual dataset is annotated based on ocean mesoscale eddy understanding and global daily ocean eddy satellite altimeter data. To expand small number of accurate expert annotation data sets, we use two-dimensional image processing strategy to construct the training set, such as adding noise and clipping operation. The basic features are derived of the factors of scale and signal noise ratio. We construct an automatic mesoscale eddy detection model based on multi-scale rotating anchor mechanism and one-stage object detection network RetinaNet. In the network structure, ResNet backbone network extract mesoscale eddy feature through introducing residual mapping and jump connection into the network. The feature information of the obtained residual block is added into the following residual block. It avoids the problem of gradient disappearance and deeper feature information loss effectively. At the same time, we use the feature pyramid network structure to integrate the low-level and high-level features of mesoscale eddy. It provides spatial and high-level semantic feature information of complex structure, different scales and more rapid sustainable changes. To cover the multi-oriented mesoscale eddy object with arbitrary shapes, it is generated that multi-scale rotation detection anchors are composed of scale, multi-aspect ratio and multi-rotation angles for each grid point of the output feature map. We integrate the classification and regression subnetworks, in which the classification subnetwork predict the probability of the presence of the object spatially, and the regression subnetwork predict location information via the regression transformation of predictive bounding box and the generated anchor. Finally, non-maximum suppression is used to obtain the final detection result.ResultThanks to multi-scale rotating anchor mechanism, this experiment shows that our ocean mesoscale eddy automatic detection method can improve the issues of low detection precision, detect box nesting and overlapping via large aspect ratio of ocean mesoscale eddy, the deductible area of horizontal detection. It can detect the existence of multi-core eddy effectively. Furthermore, comparative analysis is conducted in same data set between feature pyramid networks (FPNs), faster region-convolutional neural networks (Faster R-CNNs) and ours. It shows that the optimal detection accuracy can reach 90.22%, which is 8% higher than the horizontal bounding box detection method, and there is not much difference in speed. Then, we evaluate the accuracy, recall and F1 value amongst the Indian Ocean, Pacific Ocean and Atlantic Ocean. At the same time, the center and scale information of mesoscale eddy can be obtained based on the output position information of the boundary box. Finally, we carried out an empirical analysis of the rotation detection of oceanic mesoscale eddies in the Indian Ocean, Pacific Ocean, Atlantic Ocean and equatorial waters, which illustrates that the model has its potential generalization ability.ConclusionOur research is focused on detection redundancy, overlapping and nested detection boxes in the horizontal bounding box detection method. We facilitate a deep network model based on a one-stage target detection network RetinaNet and promote the generation mechanism of multi-scaled rotating anchors via multifaceted ratio and multi-rotation, and the integrated classification and regression subnetworks. Non-maximum suppression is used to obtain the final detection results. The features of mesoscale eddy are demonstrated based on irregular shape, complex and variable structure, uncertain ratio and dense distribution, The redundancy, overlap and nesting barriers of the horizontal detection box region are released effectively and the existence of multi-core eddy can be detected. Our method improves detection accuracy and guarantee the detection speed compared to the popular object detection methods in recent three years. We evaluated the experimental effectiveness of data augmentation on the original dataset, the noise-added dataset, and the noise-trimmed dataset. We carry out the accuracy, recall and F1 value analysis based on multiple oceans like the Indian Ocean, Pacific Ocean and Atlantic Ocean, which demonstrates the generalization ability of the model.关键词:object rotation detection;ocean mesoscale eddy;sea level anomaly;deep learning;multi-scale rotating anchor78|339|2更新时间:2024-05-07 -
 摘要:ObjectiveDue to sample imbalance in the existing road extraction methods in remote sensing images, we facilitate the deep convolutional neural aggregation network model, integrated attention mechanism and dilation convolutional (A & D-UNet) to optimize the issues of low automation, less extraction accuracy, and unstable model training.MethodTo reduce the complexity of deep network model training, the A & D-UNet model uses residual learning unit (RLU) in the encoder part based on the classical U-Net network structure. To highlight road feature information, the convolutional block attention module (CBAM) is applied to assign weights optimally from channel and spatial dimensions both to accept a larger range of receptive filed, the following road features information is obtained by dilated convolutional unit (DCU). The A & D-UNet model takes full advantage of residual learning, dilated convolution, and attention mechanisms to simplify the training of the model, obtain more global information, and improve the utilization of shallow features, respectively. First, RLU, as a component of the backbone feature extraction network, takes advantage of identity mapping to avoid the problem of difficult training and degradation of the model caused by deep and continuous convolutional neural networks. Second, DCU makes full use of the road feature map after the fourth down-sampling of the model and integrates the contextual information of the road features through the consistent dilation convolution with different dilation rates. Finally, CBAM multiplies the attention to road features by the form of weighted assignment along the sequential channel dimension and spatial dimension, which improves the attention to shallow features, reduces the interference of background noise information. The binary cross-entropy (BCE) loss function is used to train the model in image segmentation tasks in common. However, it often makes the model fall into local minima when facing the challenge of the unbalanced number of road samples in remote sensing images. To improve the road segmentation performance of the model, BCE and Dice loss functions are combined to train the A & D-UNet model. To validate the effectiveness of the model, our experiments are conducted on the publicly available Massachusetts road dataset (MRDS) and deep globe road dataset. Due to the large number of blank areas in the MRDS and the constraints of computer computing resources, these remotely sensed images are cropped to a size of 256 × 256 pixels, and contained blank areas are removed. Through the above processing steps, 2 230 training images and 161 test images are generated. In order to compare the performance of this model in the roadway extraction task, we carry out synchronized road extraction experiments to visually analyze the results of road extraction via three network models, classical U-Net, LinkNet, and D-LinkNet. In addition, such five evaluation metrics like overall precision (OA), precision (P), recall (R), F1-score (F1), and intersection over union (IoU) are used for a comprehensive assessment to analyze the extraction effectiveness of the four models quantitatively.ResultThe following experimental results are obtained through the comparative result of road extraction maps and quantitative analysis of metrics evaluation: 1) the model proposed in this work has better recognition performance in three cases of obvious road-line characteristics (ORLC), incomplete road label data (IRLD), and the road blocked by trees (RBBT). A & D-UNet model extracts road results that are similar to the ground truth of road label images with clear linear relationship of roads. It can learn the relevant features of roads through large training data sets of remote sensing images, avoiding the wrong extraction of roads in the case of IRLD. It can extract road information better by DCU and CBAM in the RBBT case, which improves the accuracy of model classification prediction. 2) The A & D-UNet network model is optimized compared algorithms in the evaluation metrics of OA, F1, and IoU, reaching 95.27%, 77.96% and 79.89% in the Massachusetts road testsets, respectively. To alleviate the degradation problem of the model caused by more convolutional layers to a certain extent, the A & D-UNet model uses RLU as the encoder in comparison with the classical U-Net network, and its OA, F1, and IoU are improved by 0.99%, 6.40%, and 4.08%, respectively. Meanwhile, the A & D-UNet model improves OA, F1, and IoU on the test set by 1.21%, 5.12%, and 3.93% over LinkNet through DCU and CBAM, respectively. 3) The F1 score and IoU of A & D-UNet model are trained and improved by 0.26% and 0.18% each via the compound loss function. This indicates that the loss function combined by BCE and Dice can handle the problem of imbalance between positive and negative samples, thus improving the accuracy of the model prediction classification. Through the above comparative analysis between different models and different loss functions, it is obvious that our A & D-UNet road extraction model has better extraction capability. 4) Judged from testing with the deep globe road dataset, we can obtain the OA, F1 score, and IoU of the A & D-UNet model(each of them is 94.01%, 77.06%, and 78.44%), which shows that the A & D-UNet model has a better extraction effect on main roads with obvious road-line characteristics, narrow road unmarked in label data/overshadowed roads.ConclusionOur A & D-UNet aggregation network model is demonstrated based on RLU with DCU and CBAM. It uses a combination of BCE and Dice loss functions and MRDS for training and shows better extraction results. The road extraction model is integrated to residual learning, attention mechanism and dilated convolution. This novel aggregation network model is featured with high automation, high extraction accuracy, and good extraction effect. Compared to current classical algorithms, it alleviates problems such as difficulties in model training caused by deep convolutional networks through RLU, uses DCU to integrate detailed information of road features, and enhances the degree of utilization of shallow information using CBAM. Additionally, the integrated BCE and Dice loss function optimize the issue of unbalanced sample of road regions and background regions.关键词:road information;residual learning unit (RLU);convolutional block attention module (CBAM);dilated convolution unit (DCU);loss function139|742|6更新时间:2024-05-07
摘要:ObjectiveDue to sample imbalance in the existing road extraction methods in remote sensing images, we facilitate the deep convolutional neural aggregation network model, integrated attention mechanism and dilation convolutional (A & D-UNet) to optimize the issues of low automation, less extraction accuracy, and unstable model training.MethodTo reduce the complexity of deep network model training, the A & D-UNet model uses residual learning unit (RLU) in the encoder part based on the classical U-Net network structure. To highlight road feature information, the convolutional block attention module (CBAM) is applied to assign weights optimally from channel and spatial dimensions both to accept a larger range of receptive filed, the following road features information is obtained by dilated convolutional unit (DCU). The A & D-UNet model takes full advantage of residual learning, dilated convolution, and attention mechanisms to simplify the training of the model, obtain more global information, and improve the utilization of shallow features, respectively. First, RLU, as a component of the backbone feature extraction network, takes advantage of identity mapping to avoid the problem of difficult training and degradation of the model caused by deep and continuous convolutional neural networks. Second, DCU makes full use of the road feature map after the fourth down-sampling of the model and integrates the contextual information of the road features through the consistent dilation convolution with different dilation rates. Finally, CBAM multiplies the attention to road features by the form of weighted assignment along the sequential channel dimension and spatial dimension, which improves the attention to shallow features, reduces the interference of background noise information. The binary cross-entropy (BCE) loss function is used to train the model in image segmentation tasks in common. However, it often makes the model fall into local minima when facing the challenge of the unbalanced number of road samples in remote sensing images. To improve the road segmentation performance of the model, BCE and Dice loss functions are combined to train the A & D-UNet model. To validate the effectiveness of the model, our experiments are conducted on the publicly available Massachusetts road dataset (MRDS) and deep globe road dataset. Due to the large number of blank areas in the MRDS and the constraints of computer computing resources, these remotely sensed images are cropped to a size of 256 × 256 pixels, and contained blank areas are removed. Through the above processing steps, 2 230 training images and 161 test images are generated. In order to compare the performance of this model in the roadway extraction task, we carry out synchronized road extraction experiments to visually analyze the results of road extraction via three network models, classical U-Net, LinkNet, and D-LinkNet. In addition, such five evaluation metrics like overall precision (OA), precision (P), recall (R), F1-score (F1), and intersection over union (IoU) are used for a comprehensive assessment to analyze the extraction effectiveness of the four models quantitatively.ResultThe following experimental results are obtained through the comparative result of road extraction maps and quantitative analysis of metrics evaluation: 1) the model proposed in this work has better recognition performance in three cases of obvious road-line characteristics (ORLC), incomplete road label data (IRLD), and the road blocked by trees (RBBT). A & D-UNet model extracts road results that are similar to the ground truth of road label images with clear linear relationship of roads. It can learn the relevant features of roads through large training data sets of remote sensing images, avoiding the wrong extraction of roads in the case of IRLD. It can extract road information better by DCU and CBAM in the RBBT case, which improves the accuracy of model classification prediction. 2) The A & D-UNet network model is optimized compared algorithms in the evaluation metrics of OA, F1, and IoU, reaching 95.27%, 77.96% and 79.89% in the Massachusetts road testsets, respectively. To alleviate the degradation problem of the model caused by more convolutional layers to a certain extent, the A & D-UNet model uses RLU as the encoder in comparison with the classical U-Net network, and its OA, F1, and IoU are improved by 0.99%, 6.40%, and 4.08%, respectively. Meanwhile, the A & D-UNet model improves OA, F1, and IoU on the test set by 1.21%, 5.12%, and 3.93% over LinkNet through DCU and CBAM, respectively. 3) The F1 score and IoU of A & D-UNet model are trained and improved by 0.26% and 0.18% each via the compound loss function. This indicates that the loss function combined by BCE and Dice can handle the problem of imbalance between positive and negative samples, thus improving the accuracy of the model prediction classification. Through the above comparative analysis between different models and different loss functions, it is obvious that our A & D-UNet road extraction model has better extraction capability. 4) Judged from testing with the deep globe road dataset, we can obtain the OA, F1 score, and IoU of the A & D-UNet model(each of them is 94.01%, 77.06%, and 78.44%), which shows that the A & D-UNet model has a better extraction effect on main roads with obvious road-line characteristics, narrow road unmarked in label data/overshadowed roads.ConclusionOur A & D-UNet aggregation network model is demonstrated based on RLU with DCU and CBAM. It uses a combination of BCE and Dice loss functions and MRDS for training and shows better extraction results. The road extraction model is integrated to residual learning, attention mechanism and dilated convolution. This novel aggregation network model is featured with high automation, high extraction accuracy, and good extraction effect. Compared to current classical algorithms, it alleviates problems such as difficulties in model training caused by deep convolutional networks through RLU, uses DCU to integrate detailed information of road features, and enhances the degree of utilization of shallow information using CBAM. Additionally, the integrated BCE and Dice loss function optimize the issue of unbalanced sample of road regions and background regions.关键词:road information;residual learning unit (RLU);convolutional block attention module (CBAM);dilated convolution unit (DCU);loss function139|742|6更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral imagery (HSI) consists of hundreds of narrow spectral bands and provides richer spectral information than infrared and multispectral images. Its features can distinguish targets from the background, and has been widely applied in many remote-sensing tasks, such as intelligent agriculture and mineral exploration. In many circumstance, however, targets are hard to be detected because of the existed prior spectral information is related to the background or targets. Anomaly detection can detect potential targets that differ from the surrounding background in an unsupervised manner. Anomalies focus on small scaled manual objects embedded in the surrounding background, and they differ from the background in terms of spectral information. As a typical unsupervised non-linear feature extractor, autoencoder (AE) contexts are applied in hyperspectral anomaly detection tasks. AE-based anomaly detection framework is getting more and more attention and many algorithms are developed to improve the detection performance. However, those AE-based anomaly detectors are hard to distinguish anomalies from the background due to lots of noise or outliers in training set. To minimize the objective function, the AE tends to learn the features of these noise and outliers. We facilitate spatial-coordinated autoencoder (ScAE) tackle these two issues mentioned above.MethodThanks to infrared patch-image model in suppressing the background and highlighting weak targets, a patch-image model is designed for hyperspectral images to be introduced in ScAE. Specifically, the patches are extended to form a matrix based on the first three components of HSI, the low-rank and sparse matrix decomposition (LRaSMD) is developed. The sparse part contains the target information and the background is suppressed. Thus, the training samples are opted based on the response of the decomposed sparse part, pixels with lower values and vice versa. The picked training samples are more clearly than utilizing the entire dataset or random selection strategy, and these samples are employed to update the weights of AE networks. The traditional gradients descend method and the backward propagation strategy is used to fine-tune AE. After some iterations, the vanilla AE is upgraded to be an effective hyperspectral anomaly detector. The reconstruction residual is utilized as the criterion to determine whether a pixel under the test (PUT) is anomalous or not. In order to take full advantage of the spatial information, a spatial-responses non-negative weight of patch-image model is introduced to increase the discrimination between the background and anomalies further, and the final detection result is obtained via fusing the spectral result and the weight matrix with Hadamard product.ResultWe evaluate our ScAE detector on three challenging hyperspectral image datasets with different size, namely Sandiego-1, Sandiego-2 and Botanical Garden. First, we design a set of experiment to figure out the issue of influential parameters for the final detection result. There are three parameters which are closely related with the detection performance. After extensive experiments, we found that ScAE is cohesive to the trade-off parameter and patch-related parameter, but is less to the number of hidden layers. Then, we conduct an ablation study to clarify the feasibility of the ScAE framework. The detection performance illustrates that patch-image model is optimal in suppressing the background while highlighting weak anomalies compared to attribute filter (AF). Our selection strategy gains higher area under the curve (AUC) values than randomly selection strategy. It is worth noting that a weight matrix related spatial and spectral information fusion can improve the detection result, as AUC values demonstrated. Finally, we compare our ScAE detector to three classical anomaly detectors and two popular hyperspectral anomaly detector, namely global Reed-Xiaoli (GRX), LRaSMD-based Mahalanobis distance method (LSMAD), traditional AE, fractional Fourier entropy (FrFE) and feature extraction and background purification anomaly detector (FEBPAD), respectively. Such parameters are set to get optimal detection performance for the six detectors all. The corresponding AUC values of ScAE are 0.990 4, 0.988 8 and 0.997 0 for Sandiego-1, Sandiego-2 and Botanical Garden, respectively. The detection result illustrates that ScAE obtains the highest AUC values amongst the six hypersepctral anomaly detectors. Moreover, ScAE generates the lowest false alarm rate (FAR) when all of the anomalous pixels are detected in three datasets all.ConclusionA novel AE-based hyperspectral anomaly detection algorithm is developed that spectral-detected spatial information can enhance the segmentation ability between anomalies and the background. The comparative experiments demonstrate our ScAE detector has its feasibility and potentials for hyperspectral anomaly detection.关键词:hyperspectral imagery(HSI);anomaly detection;patch-image model;autoencoder (AE);spatial-spectral feature fusion206|183|0更新时间:2024-05-07
摘要:ObjectiveHyperspectral imagery (HSI) consists of hundreds of narrow spectral bands and provides richer spectral information than infrared and multispectral images. Its features can distinguish targets from the background, and has been widely applied in many remote-sensing tasks, such as intelligent agriculture and mineral exploration. In many circumstance, however, targets are hard to be detected because of the existed prior spectral information is related to the background or targets. Anomaly detection can detect potential targets that differ from the surrounding background in an unsupervised manner. Anomalies focus on small scaled manual objects embedded in the surrounding background, and they differ from the background in terms of spectral information. As a typical unsupervised non-linear feature extractor, autoencoder (AE) contexts are applied in hyperspectral anomaly detection tasks. AE-based anomaly detection framework is getting more and more attention and many algorithms are developed to improve the detection performance. However, those AE-based anomaly detectors are hard to distinguish anomalies from the background due to lots of noise or outliers in training set. To minimize the objective function, the AE tends to learn the features of these noise and outliers. We facilitate spatial-coordinated autoencoder (ScAE) tackle these two issues mentioned above.MethodThanks to infrared patch-image model in suppressing the background and highlighting weak targets, a patch-image model is designed for hyperspectral images to be introduced in ScAE. Specifically, the patches are extended to form a matrix based on the first three components of HSI, the low-rank and sparse matrix decomposition (LRaSMD) is developed. The sparse part contains the target information and the background is suppressed. Thus, the training samples are opted based on the response of the decomposed sparse part, pixels with lower values and vice versa. The picked training samples are more clearly than utilizing the entire dataset or random selection strategy, and these samples are employed to update the weights of AE networks. The traditional gradients descend method and the backward propagation strategy is used to fine-tune AE. After some iterations, the vanilla AE is upgraded to be an effective hyperspectral anomaly detector. The reconstruction residual is utilized as the criterion to determine whether a pixel under the test (PUT) is anomalous or not. In order to take full advantage of the spatial information, a spatial-responses non-negative weight of patch-image model is introduced to increase the discrimination between the background and anomalies further, and the final detection result is obtained via fusing the spectral result and the weight matrix with Hadamard product.ResultWe evaluate our ScAE detector on three challenging hyperspectral image datasets with different size, namely Sandiego-1, Sandiego-2 and Botanical Garden. First, we design a set of experiment to figure out the issue of influential parameters for the final detection result. There are three parameters which are closely related with the detection performance. After extensive experiments, we found that ScAE is cohesive to the trade-off parameter and patch-related parameter, but is less to the number of hidden layers. Then, we conduct an ablation study to clarify the feasibility of the ScAE framework. The detection performance illustrates that patch-image model is optimal in suppressing the background while highlighting weak anomalies compared to attribute filter (AF). Our selection strategy gains higher area under the curve (AUC) values than randomly selection strategy. It is worth noting that a weight matrix related spatial and spectral information fusion can improve the detection result, as AUC values demonstrated. Finally, we compare our ScAE detector to three classical anomaly detectors and two popular hyperspectral anomaly detector, namely global Reed-Xiaoli (GRX), LRaSMD-based Mahalanobis distance method (LSMAD), traditional AE, fractional Fourier entropy (FrFE) and feature extraction and background purification anomaly detector (FEBPAD), respectively. Such parameters are set to get optimal detection performance for the six detectors all. The corresponding AUC values of ScAE are 0.990 4, 0.988 8 and 0.997 0 for Sandiego-1, Sandiego-2 and Botanical Garden, respectively. The detection result illustrates that ScAE obtains the highest AUC values amongst the six hypersepctral anomaly detectors. Moreover, ScAE generates the lowest false alarm rate (FAR) when all of the anomalous pixels are detected in three datasets all.ConclusionA novel AE-based hyperspectral anomaly detection algorithm is developed that spectral-detected spatial information can enhance the segmentation ability between anomalies and the background. The comparative experiments demonstrate our ScAE detector has its feasibility and potentials for hyperspectral anomaly detection.关键词:hyperspectral imagery(HSI);anomaly detection;patch-image model;autoencoder (AE);spatial-spectral feature fusion206|183|0更新时间:2024-05-07 -
 摘要:ObjectiveSynthetic aperture radar(SAR) imaging is interfered with the echo due to electromagnetic waves penetrate the rough object surface by emitting electromagnetic pulses and receiving reflected echo imaging, resulting in coherent spot noise. However, its multi-temporal and all-weather features are used in maritime applications like rescue, monitoring and vessel transportation supervision. Constant false alarm rate algorithm is use for SAR image target detection in common. It has the simple algorithm structure, but the complex and uneven distribution of ocean clutter types can cause missing detection. In the case of multiple targets, it is easy to appear that the reference unit contains target information, so the amplitude of target signal may be greater than the clutter amplitude, resulting in the estimated threshold is far greater than the real threshold. The constant false alarm rate algorithm cannot obtain the ideal detection effect. In recent years, with the rapid development of deep learning, object detection algorithms based on deep learning have achieved good results in optical image object detection. SAR images are different from optical images in that the targets in SAR images are mostly small-scale ships with bright spots and lack obvious details. Similar targets such as islands, buildings and so on will form similar ship shapes after electromagnetic wave reflection. Therefore, the application of optical detection models directly to SAR images cannot achieve ideal results. Feature pyramid network adopts top-down layer by layer fusion, so the high-level feature map lacks spatial location information, and the fusion of each level largely loses the semantic information contained in high-level features, while the semantic information of low-level features is insufficient. In order to improve the model detection accuracy and make the model more robust, a SAR image detection model with adaptive weight pyramid and branch strong correlation is proposed in this paper.MethodThe high-level features extracted by ResNet101 contain rich semantic information, and the underlying features contain rich spatial information. To have a better detection effect of target detection model, the feature map is required to contain semantic information and spatial location information both. Therefore, the featured information needs to be adopted based on a more effective fusion mechanism for fusion. It is necessary to use effective weights to guide the fusion mechanism for to the integration of more effective information. Our adaptive weight pyramid module is demonstrated, which first samples the feature map to make it have the same scale, then stitches concatenation the feature map after each layer of sampling into channel dimensions, adjusts the number of channels by 1×1 convolution, and generates the weight in the end through the Softmax function. To get a feature map of the layer, multiply each layer feature by the corresponding weight, and the other layers are analogy. Its fusion removes some redundant information under the weighting of machine learning. Multiple features are extracted through 1×1 and 3×3 symmetric convolution kernels and 1×3 and 3×1 asymmetric convolution kernels, following the feature fusion of classification branch and regression branch by the branch correlation module. The feature diagram contains the classification branch information in the regression branch based on the fused classification and regression features. In the detection phase, the candidate boxes are removed related to accurate positioning and low classification confidence, which reduces the detection accuracy of the model greatly. In order to solve this problem, the intersection over union(IoU) detection head is constructed in the regression branch, and IoU it is used for classification branch, thus avoiding the problem of the candidate box with high IoU low classification confidence being suppressed. In order to balance the IoU branch and the classification branch, the constrained balance factor is designed sand can guide the regression branch optimization candidate box better.ResultOur model is evaluated on the public remote sensing dataset SSDD(SAR ship detection), which had 1 160 pictures, including 2 456 vessel targets. The dataset is divided dataset into training sets and test sets by a ratio of 7 : 3, and enhanced the learning ability of the model by rotating, flipping, brightness and increasing Gaussian noise. All the experimental environments are based on ubuntu16.04 LTS operating system, equipped with CPU for lntel (R) Core (TM) i7-7700@3.6 GHz ×8, graphics card for NVIDIA GTX1080Ti memory for 11 GB, running under the Tensorflow framework, through CUDA8.0 and cuDNN5.0 accelerated training. Our model learning rate is set to 0.000 5, the learning rate is attenuated by 1/10 per 40 k iterations, and the network is convergent at 80 k iterations completely. The non-maximum suppression threshold is 0.5 and the predicted probability threshold is 0.6. The recall rate, accuracy rate, average accuracy, F1 value and detection speed are represented as the evaluation indexes of the model. The model realizes the best detection effect in terms of equilibrium factor takes 0.4. The final recall rate is increased from 89.17% to 93.63%, the accuracy rate is increased from 87.94% to 95.08%, the average accuracy is increased from 86.91% to 90.53%, F1 value is increased from 88.55% to 94.53%, and the detection speed reached 20.14 frame/s.ConclusionOur experimental results demonstrate that the feature map targets fused by adaptive weight pyramids are more prominent, and the strong correlated branches module enhances the correlation between the classification branch and the regression branch, and improves the candidate box regression ability. Our model has it potential to meet the real-time detection requirement of SAR imaging.关键词:object detection;synthetic aperture radar(SAR);adaptive weight;related branches;balance factor95|358|2更新时间:2024-05-07
摘要:ObjectiveSynthetic aperture radar(SAR) imaging is interfered with the echo due to electromagnetic waves penetrate the rough object surface by emitting electromagnetic pulses and receiving reflected echo imaging, resulting in coherent spot noise. However, its multi-temporal and all-weather features are used in maritime applications like rescue, monitoring and vessel transportation supervision. Constant false alarm rate algorithm is use for SAR image target detection in common. It has the simple algorithm structure, but the complex and uneven distribution of ocean clutter types can cause missing detection. In the case of multiple targets, it is easy to appear that the reference unit contains target information, so the amplitude of target signal may be greater than the clutter amplitude, resulting in the estimated threshold is far greater than the real threshold. The constant false alarm rate algorithm cannot obtain the ideal detection effect. In recent years, with the rapid development of deep learning, object detection algorithms based on deep learning have achieved good results in optical image object detection. SAR images are different from optical images in that the targets in SAR images are mostly small-scale ships with bright spots and lack obvious details. Similar targets such as islands, buildings and so on will form similar ship shapes after electromagnetic wave reflection. Therefore, the application of optical detection models directly to SAR images cannot achieve ideal results. Feature pyramid network adopts top-down layer by layer fusion, so the high-level feature map lacks spatial location information, and the fusion of each level largely loses the semantic information contained in high-level features, while the semantic information of low-level features is insufficient. In order to improve the model detection accuracy and make the model more robust, a SAR image detection model with adaptive weight pyramid and branch strong correlation is proposed in this paper.MethodThe high-level features extracted by ResNet101 contain rich semantic information, and the underlying features contain rich spatial information. To have a better detection effect of target detection model, the feature map is required to contain semantic information and spatial location information both. Therefore, the featured information needs to be adopted based on a more effective fusion mechanism for fusion. It is necessary to use effective weights to guide the fusion mechanism for to the integration of more effective information. Our adaptive weight pyramid module is demonstrated, which first samples the feature map to make it have the same scale, then stitches concatenation the feature map after each layer of sampling into channel dimensions, adjusts the number of channels by 1×1 convolution, and generates the weight in the end through the Softmax function. To get a feature map of the layer, multiply each layer feature by the corresponding weight, and the other layers are analogy. Its fusion removes some redundant information under the weighting of machine learning. Multiple features are extracted through 1×1 and 3×3 symmetric convolution kernels and 1×3 and 3×1 asymmetric convolution kernels, following the feature fusion of classification branch and regression branch by the branch correlation module. The feature diagram contains the classification branch information in the regression branch based on the fused classification and regression features. In the detection phase, the candidate boxes are removed related to accurate positioning and low classification confidence, which reduces the detection accuracy of the model greatly. In order to solve this problem, the intersection over union(IoU) detection head is constructed in the regression branch, and IoU it is used for classification branch, thus avoiding the problem of the candidate box with high IoU low classification confidence being suppressed. In order to balance the IoU branch and the classification branch, the constrained balance factor is designed sand can guide the regression branch optimization candidate box better.ResultOur model is evaluated on the public remote sensing dataset SSDD(SAR ship detection), which had 1 160 pictures, including 2 456 vessel targets. The dataset is divided dataset into training sets and test sets by a ratio of 7 : 3, and enhanced the learning ability of the model by rotating, flipping, brightness and increasing Gaussian noise. All the experimental environments are based on ubuntu16.04 LTS operating system, equipped with CPU for lntel (R) Core (TM) i7-7700@3.6 GHz ×8, graphics card for NVIDIA GTX1080Ti memory for 11 GB, running under the Tensorflow framework, through CUDA8.0 and cuDNN5.0 accelerated training. Our model learning rate is set to 0.000 5, the learning rate is attenuated by 1/10 per 40 k iterations, and the network is convergent at 80 k iterations completely. The non-maximum suppression threshold is 0.5 and the predicted probability threshold is 0.6. The recall rate, accuracy rate, average accuracy, F1 value and detection speed are represented as the evaluation indexes of the model. The model realizes the best detection effect in terms of equilibrium factor takes 0.4. The final recall rate is increased from 89.17% to 93.63%, the accuracy rate is increased from 87.94% to 95.08%, the average accuracy is increased from 86.91% to 90.53%, F1 value is increased from 88.55% to 94.53%, and the detection speed reached 20.14 frame/s.ConclusionOur experimental results demonstrate that the feature map targets fused by adaptive weight pyramids are more prominent, and the strong correlated branches module enhances the correlation between the classification branch and the regression branch, and improves the candidate box regression ability. Our model has it potential to meet the real-time detection requirement of SAR imaging.关键词:object detection;synthetic aperture radar(SAR);adaptive weight;related branches;balance factor95|358|2更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0