
最新刊期
卷 27 , 期 1 , 2022
-
 摘要:Cyberspace security is intensively related to national security, national strategy and important policy guidance at present. Information content security is an essential part of cyberspace security. The issue of information prevention in context of illegal theft, tampering and destruction during network transmission has become a key aspect on national security and economic development. Image steganography is one of the hot research directions in the field of information security, which can embed secret message in the redundant part of digital images and transmit through open channels to realize safe and reliable covert communication, and has been widely used in national defense and civilian fields. With the rapid development of smart mobile devices and social network systems, digital images transmitted through open networks have become an important new carrier for covert communication, and the image steganography technology adapted to network channels is expected to become an important way of reliable and covert information transmission in open network environment. However, digital images are often subject to compression, scaling, filtering, etc. during the transmitting through social network systems such as Meta, Twitter, WeChat and Weibo, and existing information hiding technologies are often difficult to take both the robustness of embedded information and detection resistance of stego images into account. Hence, research on image robust steganography technology that can resist both multiple image processing attacks and statistical detection, and adapt to network lossy channels has important theoretical value and practical significance. After years of hard work, researchers have proposed new robust steganography technologies resisting multiple image processing attacks and statistical detection. Combining with the application requirements of covert communication in network lossy channels, this article reviews the current robust image steganography technologies. First, the related technologies and development trends of image information hiding technology are introduced from two aspects of image watermarking and steganography. For image watermarking technology, the typical robust watermarking algorithms based on image transformation and features are described separately, to discuss the theoretical and technical support that can provide to realize image robust steganography adapted to lossy channels. For image steganography technology, the typical adaptive steganography algorithms are introduced in both spatial and Joint Photographic Experts Group(JPEG) images, to mine the principle and idea of minimizing costs for message embedding. On this basis, the research framework of image robust steganography technology is divided into cover image selection, robust cover construction, embedding cost measurement, embedding channel selection, source/channel coding, and application security policies. Next, the basic principles of related robust steganography methods are summarized and explained from the above six aspects, such as the complexity-based cover image selection algorithm, robust cover construction algorithms based on coefficients relationship, side-information, and image features, embedding cost calculation algorithms utilizing distortion functions, embedding channel selecting algorithms considering image complex and smooth areas, message coding algorithms combining with error-correcting codes and minimizing cost codes, and application security strategy using data decomposition principle. Subsequently, comparative tests are carried out on the representative related methods in terms of robustness against multiple image processing attacks and detection resistance against statistical steganalysis features, and the recommended robust steganography methods are given based on the requirements of the application scenario. For example, if the target transmission channel only contains JPEG compression attacks, according to whether the compression parameters are known, the robust steganography algorithms based on coefficients relationship that resist multiple parameter JPEG compression attacks can be selected, or the robust steganography algorithms based on quantization step size and channel matching that have strong robustness and high reliability against specific parameter compression attacks can be utilized; if the target transmission channel contains multiple image processing attacks with unknown parameters such as compression and scaling, the robust steganography algorithm combined with Reed Solomon (RS) error correction coding that has strong error correction capability can be selected according to the requirements for communication reliability, or the robust steganography algorithm with strong error detection capability and combined with cyclic redundancy check (CRC) detection/error correction coding can be utilized for reliable covert communication. At last, some problems to be solved in the field of image robust steganography techniques are pointed out, in terms of accurate characterization of the influence of network lossy channels on stego sequence, virtual cover construction with multiple robustness and invisibility and so on. In general, the demand for covert communication in network lossy channels has brought new opportunities and challenges to image steganography, which contains many problems worthy of further research and exploration. Researchers need to make continuous efforts and gradually advance the process of image steganography from the laboratory to real life.关键词:information hiding;lossy channel;robust steganography;image processing attacks;statistical detection208|249|6更新时间:2024-05-07
摘要:Cyberspace security is intensively related to national security, national strategy and important policy guidance at present. Information content security is an essential part of cyberspace security. The issue of information prevention in context of illegal theft, tampering and destruction during network transmission has become a key aspect on national security and economic development. Image steganography is one of the hot research directions in the field of information security, which can embed secret message in the redundant part of digital images and transmit through open channels to realize safe and reliable covert communication, and has been widely used in national defense and civilian fields. With the rapid development of smart mobile devices and social network systems, digital images transmitted through open networks have become an important new carrier for covert communication, and the image steganography technology adapted to network channels is expected to become an important way of reliable and covert information transmission in open network environment. However, digital images are often subject to compression, scaling, filtering, etc. during the transmitting through social network systems such as Meta, Twitter, WeChat and Weibo, and existing information hiding technologies are often difficult to take both the robustness of embedded information and detection resistance of stego images into account. Hence, research on image robust steganography technology that can resist both multiple image processing attacks and statistical detection, and adapt to network lossy channels has important theoretical value and practical significance. After years of hard work, researchers have proposed new robust steganography technologies resisting multiple image processing attacks and statistical detection. Combining with the application requirements of covert communication in network lossy channels, this article reviews the current robust image steganography technologies. First, the related technologies and development trends of image information hiding technology are introduced from two aspects of image watermarking and steganography. For image watermarking technology, the typical robust watermarking algorithms based on image transformation and features are described separately, to discuss the theoretical and technical support that can provide to realize image robust steganography adapted to lossy channels. For image steganography technology, the typical adaptive steganography algorithms are introduced in both spatial and Joint Photographic Experts Group(JPEG) images, to mine the principle and idea of minimizing costs for message embedding. On this basis, the research framework of image robust steganography technology is divided into cover image selection, robust cover construction, embedding cost measurement, embedding channel selection, source/channel coding, and application security policies. Next, the basic principles of related robust steganography methods are summarized and explained from the above six aspects, such as the complexity-based cover image selection algorithm, robust cover construction algorithms based on coefficients relationship, side-information, and image features, embedding cost calculation algorithms utilizing distortion functions, embedding channel selecting algorithms considering image complex and smooth areas, message coding algorithms combining with error-correcting codes and minimizing cost codes, and application security strategy using data decomposition principle. Subsequently, comparative tests are carried out on the representative related methods in terms of robustness against multiple image processing attacks and detection resistance against statistical steganalysis features, and the recommended robust steganography methods are given based on the requirements of the application scenario. For example, if the target transmission channel only contains JPEG compression attacks, according to whether the compression parameters are known, the robust steganography algorithms based on coefficients relationship that resist multiple parameter JPEG compression attacks can be selected, or the robust steganography algorithms based on quantization step size and channel matching that have strong robustness and high reliability against specific parameter compression attacks can be utilized; if the target transmission channel contains multiple image processing attacks with unknown parameters such as compression and scaling, the robust steganography algorithm combined with Reed Solomon (RS) error correction coding that has strong error correction capability can be selected according to the requirements for communication reliability, or the robust steganography algorithm with strong error detection capability and combined with cyclic redundancy check (CRC) detection/error correction coding can be utilized for reliable covert communication. At last, some problems to be solved in the field of image robust steganography techniques are pointed out, in terms of accurate characterization of the influence of network lossy channels on stego sequence, virtual cover construction with multiple robustness and invisibility and so on. In general, the demand for covert communication in network lossy channels has brought new opportunities and challenges to image steganography, which contains many problems worthy of further research and exploration. Researchers need to make continuous efforts and gradually advance the process of image steganography from the laboratory to real life.关键词:information hiding;lossy channel;robust steganography;image processing attacks;statistical detection208|249|6更新时间:2024-05-07 -
 摘要:Digital video is an essential effective medium in the communication world nowadays. It is widely used in news, short video and cable network broadcast video programs. Digital video content is easily copied and spread for infringing users, which makes the digital video face severe privacy difficulties. Video copyright has been concerned consistently. In order to protect and claim video ownership, robust video watermarking is one of the important techniques. As a branch of digital video watermarking, robust video watermarking is a technology to authorize copyright ownership. Embedding secret information into the video object needs to be protected by a specific algorithm. This article shows an overview of video watermarking technology. The application scenarios of different types of video watermarking are introduced, including copyright protection, content protection, content authentication, content filtering, broadcast monitoring and online search overall. The classification methods of video watermarking is illustrated, which can be classified based on watermarking attributes and carrier objects. The main properties of watermarking have been embedding capacity, perceptibility, and robustness. In accordance with the existence of embedding capacity, video watermarking can be divided into zero watermarking and non-zero watermarking. Video watermarking can be divided into visible and invisible watermarking in terms of its perceptibility. Video watermarking can be divided into robust video watermarking, semi-fragile video watermarking, and fragile video watermarking via the robustness. Carrier video formats has mainly evolved 2D video, 3D video and virtual reality(VR) video, among which 2D video is the mainstream video format at present. 2D video watermarking can be further classified based on embedding method and extraction method, in which the embedding method can be divided into content-based video watermarking and bit stream-based video watermarking, and the extraction method can be divided into non-blind extraction, blind detection and semi-blind extraction.Moreover, this paper classifies classical video watermarking methods and video watermarking methods that have emerged in the past five years. A content-based and a bitstream-based perspective have been summarized each. Content-based video watermarking has treated video as a collection of images and watermarking application algorithm on each frame. This simplified method is easy to implement costly. Bitstream-based video watermarking embeds copyright information into video in video encoding and decoding process. Since the embedding process of this type of scheme can run in parallel with the video encoding and decoding process, this scheme is faster and more practical than content-based method. As a consequence, it supports real-time video watermarking applications. In the past five years, researchers have proposed video watermarking schemes based on deep learning and video watermarking methods for new video carriers such as 3D and VR. Among them, the video watermarking scheme based on deep learning replaces hand-designed features to improve the performance of video watermarking scheme. The sequential HiDDeN and StegaStamp data sets have been proposed in the intial stage The current deep learning-based video watermarking methods are all content-based watermarking and have not been developed to bitstream-based watermarking yet. In addition, the types of attacks can be resisted via the video watermarking deep learning method at the early stage. According to the two representations of 3D video, 3D video watermarking is divided into watermarking based on stereo imaging and watermarking based on depth image based rendering(DIBR). The designation of DIBR-based 3D video watermarking not only needs to meet the requirements of 2D video watermarking such as robustness and imperceptibility, but also needs to meet the robustness of the DIBR process. Subsequently, this paper makes a classification and comparative analysis of the video watermarking methods that have emerged in the past five years. The performance of video watermarking scheme is evaluated from the two perspectives of video quality and robustness. The video quality evaluation indices include peak signal to noise ratio(PSNR) and structural similarity index(SSIM) and the robustness evaluation indices include bit error rate(BER), mean opinion score(MOS), and false negative rate(FNR). The relationship between performance of video watermarking and different evaluation index value is not same. The larger the PSNR value is, the higher the visual quality of the video produced. The smaller the BER value is, better robustness of the scheme gained. The larger the normalized cross correlation(NCC)value is, the better the robustness of the scheme formed. The capability of each method has been listed to resist various types of attacks more intuitively in the form of a table. Based on comparative analysis, it is concluded that the robustness against temporal synchronization attacks such as frame deleting, frame averaging, frame inserting, and frame rate conversion in the context of embedded frames issue. If the same watermark is embedded in all video frames, it tends to have poor imperceptibility and poor robustness to video frame cutting, frame averaging, and frame exchanging.If different watermarks are embedded in all key frames according to various video scenes, the robustness to video attacks is improved, especially in the case of video frame cutting, frame averaging, and frame exchanging. The poor imperceptibility of the watermark is still an issue to be resolved. Bitstream-based methods are mainly concerned with re-compression and re-encoding. Most of the proposed bitstream-based methods can resist re-compression and re-encoding, but they are generally not robust against geometric attacks and temporal synchronization attacks. Most of the video watermarking methods based on 3D and VR can well resist compression attacks and noise attacks, but they are generally not robust against geometric attacks such as rotation and cropping. This research has illustrated several aspects that should be considered in the future video watermarking research. For instance, the video watermarking method based on deep learning is in its intial stage and need to be improved. Temporal synchronization attacks and extended attacks have to be concerned consistently. Video watermarking application to more different forms of video signals should be resolved further.关键词:copyright protection;information hiding;digital watermarking;video watermarking;robust video watermarking363|577|4更新时间:2024-05-07
摘要:Digital video is an essential effective medium in the communication world nowadays. It is widely used in news, short video and cable network broadcast video programs. Digital video content is easily copied and spread for infringing users, which makes the digital video face severe privacy difficulties. Video copyright has been concerned consistently. In order to protect and claim video ownership, robust video watermarking is one of the important techniques. As a branch of digital video watermarking, robust video watermarking is a technology to authorize copyright ownership. Embedding secret information into the video object needs to be protected by a specific algorithm. This article shows an overview of video watermarking technology. The application scenarios of different types of video watermarking are introduced, including copyright protection, content protection, content authentication, content filtering, broadcast monitoring and online search overall. The classification methods of video watermarking is illustrated, which can be classified based on watermarking attributes and carrier objects. The main properties of watermarking have been embedding capacity, perceptibility, and robustness. In accordance with the existence of embedding capacity, video watermarking can be divided into zero watermarking and non-zero watermarking. Video watermarking can be divided into visible and invisible watermarking in terms of its perceptibility. Video watermarking can be divided into robust video watermarking, semi-fragile video watermarking, and fragile video watermarking via the robustness. Carrier video formats has mainly evolved 2D video, 3D video and virtual reality(VR) video, among which 2D video is the mainstream video format at present. 2D video watermarking can be further classified based on embedding method and extraction method, in which the embedding method can be divided into content-based video watermarking and bit stream-based video watermarking, and the extraction method can be divided into non-blind extraction, blind detection and semi-blind extraction.Moreover, this paper classifies classical video watermarking methods and video watermarking methods that have emerged in the past five years. A content-based and a bitstream-based perspective have been summarized each. Content-based video watermarking has treated video as a collection of images and watermarking application algorithm on each frame. This simplified method is easy to implement costly. Bitstream-based video watermarking embeds copyright information into video in video encoding and decoding process. Since the embedding process of this type of scheme can run in parallel with the video encoding and decoding process, this scheme is faster and more practical than content-based method. As a consequence, it supports real-time video watermarking applications. In the past five years, researchers have proposed video watermarking schemes based on deep learning and video watermarking methods for new video carriers such as 3D and VR. Among them, the video watermarking scheme based on deep learning replaces hand-designed features to improve the performance of video watermarking scheme. The sequential HiDDeN and StegaStamp data sets have been proposed in the intial stage The current deep learning-based video watermarking methods are all content-based watermarking and have not been developed to bitstream-based watermarking yet. In addition, the types of attacks can be resisted via the video watermarking deep learning method at the early stage. According to the two representations of 3D video, 3D video watermarking is divided into watermarking based on stereo imaging and watermarking based on depth image based rendering(DIBR). The designation of DIBR-based 3D video watermarking not only needs to meet the requirements of 2D video watermarking such as robustness and imperceptibility, but also needs to meet the robustness of the DIBR process. Subsequently, this paper makes a classification and comparative analysis of the video watermarking methods that have emerged in the past five years. The performance of video watermarking scheme is evaluated from the two perspectives of video quality and robustness. The video quality evaluation indices include peak signal to noise ratio(PSNR) and structural similarity index(SSIM) and the robustness evaluation indices include bit error rate(BER), mean opinion score(MOS), and false negative rate(FNR). The relationship between performance of video watermarking and different evaluation index value is not same. The larger the PSNR value is, the higher the visual quality of the video produced. The smaller the BER value is, better robustness of the scheme gained. The larger the normalized cross correlation(NCC)value is, the better the robustness of the scheme formed. The capability of each method has been listed to resist various types of attacks more intuitively in the form of a table. Based on comparative analysis, it is concluded that the robustness against temporal synchronization attacks such as frame deleting, frame averaging, frame inserting, and frame rate conversion in the context of embedded frames issue. If the same watermark is embedded in all video frames, it tends to have poor imperceptibility and poor robustness to video frame cutting, frame averaging, and frame exchanging.If different watermarks are embedded in all key frames according to various video scenes, the robustness to video attacks is improved, especially in the case of video frame cutting, frame averaging, and frame exchanging. The poor imperceptibility of the watermark is still an issue to be resolved. Bitstream-based methods are mainly concerned with re-compression and re-encoding. Most of the proposed bitstream-based methods can resist re-compression and re-encoding, but they are generally not robust against geometric attacks and temporal synchronization attacks. Most of the video watermarking methods based on 3D and VR can well resist compression attacks and noise attacks, but they are generally not robust against geometric attacks such as rotation and cropping. This research has illustrated several aspects that should be considered in the future video watermarking research. For instance, the video watermarking method based on deep learning is in its intial stage and need to be improved. Temporal synchronization attacks and extended attacks have to be concerned consistently. Video watermarking application to more different forms of video signals should be resolved further.关键词:copyright protection;information hiding;digital watermarking;video watermarking;robust video watermarking363|577|4更新时间:2024-05-07 -
 摘要:The word "DeepFake" is an integration of the two words "deep learning" and "fake", mainly relates to artificial neural networks. This research summarizes Deepfake technique based on the visual depth forgery techniques. This review has evolved the aspects as shown below: 1) the history and technical principles of visual deep forgery techniques, including the application of generative countermeasure networks in deep forgery products. The current visual depth forgery methods can be toughly divided into three types: synthetic new face, face modification and face swapping. The method called new face synthesis uses some powerful generation of confrontation networks to generate overall non-existent face images completely. Currently, the popular databases of the new face synthesis technique were generated based on ProGAN and StyleGAN. Each forgery image generated will conduct its own specific generative adversarial network(GAN) fingerprint. The face modification method means to add some facial modifications to the target face. For instance, it can change one's hair color or skin color. It can also modify the gender of the targeted person or add a pair of glasses to the targeted person. This method uses GAN to generate images. The latest StarGAN database can divide the face into multiple areas and modify them simultaneously. The face swap method consists of two parts. The first part is using another person's face to replace the target person in the video. This way is used in the most popular algorithm in visual depth forgery currently, such as DeepFake and FaceSwap. The second part is facial expression exchange, which is also called face reproduction. Face reproduction means replacing one's facial expressions with the facial others, such as changing Obama's expressions and actions to complete a fake "speech". At present, Face2Face and NeuralTextures become popular in visual deep forgery via using face reproduction. Meanwhile, there are some mobile applications can also make fake information in faces. FaceApp which is based on StarGAN is modified various emotional expressions. 2) The current visual deep forgery datasets are summarized and classified. The deep forgery datasets are constantly developing with the improvement of deep forgery techniques and deep forgery detection techniques. This review collects the deep forgery datasets that have received widespread attention recently and puts them together in a demonstrated table to reveal the advantages and disadvantages. 3) The current visual deep forgery detection techniques are segmented. Current deepfake detection methods and models are summarized into four classifications in this overview. The DeepFake detection has relied on specific artifacts, data-driven, inconsistent information and other types of visual depth forgery detection. The overview divided these four types of DeepFake detection methods into more subcategories. The DeepFake subdivided detection method is related to five subcategories based on artifacts, including the fake face blending frame, the artifacts in the middle area of the fake face, the color inconformity of the deep fake products, the artifact inconformity of light source and GAN fingerprints. The review subdivided the data-driven The detection method that attempts to locate the location of a tampered area, and the detection method based on an improved neural network architecture. The classification in DeepFake detection methods based on inconsistent information was devided into three parts based on the aspects as shown such asinconsistent biological signals, inconsistent time series, and detection methods based on inconsistent behavior with real targets. Among the four classfications of DeepFake detection techniques, the one detection method based on artifacts focuses more on the findings of the pixel-level difference between the fake products and real images and vedios. These methods paid more attention to finding discoverable arifacts which made by GANs. On the other hand, the method based on the inconsistency of information focuses on finding information-level differences between fake products and real products. These methods have the advantages of high recognition efficiency and convenient training. While the data-driven method uses various DeepFake datasets and real datas and based on machine learning training to directly use the neural network itself to identify fake products. This overview analyzes the unique advantages and disadvantages of the four classifications and implements visual depth forgery detection. This research has its contributions as shown below: 1) an understanding of the DeepFake generation technology and emergingDeepFak detected method for readers, 2) inform readers of the latest developments, trends and challenges in DeepFake study these years and 3) identify the attacker-defender of the latest trends in the future development of DeepFake and strive to yield priority to the DeepFake detection.关键词:digital forensics;deepfake;machine learning;deep learning;face manipulation391|357|5更新时间:2024-05-07
摘要:The word "DeepFake" is an integration of the two words "deep learning" and "fake", mainly relates to artificial neural networks. This research summarizes Deepfake technique based on the visual depth forgery techniques. This review has evolved the aspects as shown below: 1) the history and technical principles of visual deep forgery techniques, including the application of generative countermeasure networks in deep forgery products. The current visual depth forgery methods can be toughly divided into three types: synthetic new face, face modification and face swapping. The method called new face synthesis uses some powerful generation of confrontation networks to generate overall non-existent face images completely. Currently, the popular databases of the new face synthesis technique were generated based on ProGAN and StyleGAN. Each forgery image generated will conduct its own specific generative adversarial network(GAN) fingerprint. The face modification method means to add some facial modifications to the target face. For instance, it can change one's hair color or skin color. It can also modify the gender of the targeted person or add a pair of glasses to the targeted person. This method uses GAN to generate images. The latest StarGAN database can divide the face into multiple areas and modify them simultaneously. The face swap method consists of two parts. The first part is using another person's face to replace the target person in the video. This way is used in the most popular algorithm in visual depth forgery currently, such as DeepFake and FaceSwap. The second part is facial expression exchange, which is also called face reproduction. Face reproduction means replacing one's facial expressions with the facial others, such as changing Obama's expressions and actions to complete a fake "speech". At present, Face2Face and NeuralTextures become popular in visual deep forgery via using face reproduction. Meanwhile, there are some mobile applications can also make fake information in faces. FaceApp which is based on StarGAN is modified various emotional expressions. 2) The current visual deep forgery datasets are summarized and classified. The deep forgery datasets are constantly developing with the improvement of deep forgery techniques and deep forgery detection techniques. This review collects the deep forgery datasets that have received widespread attention recently and puts them together in a demonstrated table to reveal the advantages and disadvantages. 3) The current visual deep forgery detection techniques are segmented. Current deepfake detection methods and models are summarized into four classifications in this overview. The DeepFake detection has relied on specific artifacts, data-driven, inconsistent information and other types of visual depth forgery detection. The overview divided these four types of DeepFake detection methods into more subcategories. The DeepFake subdivided detection method is related to five subcategories based on artifacts, including the fake face blending frame, the artifacts in the middle area of the fake face, the color inconformity of the deep fake products, the artifact inconformity of light source and GAN fingerprints. The review subdivided the data-driven The detection method that attempts to locate the location of a tampered area, and the detection method based on an improved neural network architecture. The classification in DeepFake detection methods based on inconsistent information was devided into three parts based on the aspects as shown such asinconsistent biological signals, inconsistent time series, and detection methods based on inconsistent behavior with real targets. Among the four classfications of DeepFake detection techniques, the one detection method based on artifacts focuses more on the findings of the pixel-level difference between the fake products and real images and vedios. These methods paid more attention to finding discoverable arifacts which made by GANs. On the other hand, the method based on the inconsistency of information focuses on finding information-level differences between fake products and real products. These methods have the advantages of high recognition efficiency and convenient training. While the data-driven method uses various DeepFake datasets and real datas and based on machine learning training to directly use the neural network itself to identify fake products. This overview analyzes the unique advantages and disadvantages of the four classifications and implements visual depth forgery detection. This research has its contributions as shown below: 1) an understanding of the DeepFake generation technology and emergingDeepFak detected method for readers, 2) inform readers of the latest developments, trends and challenges in DeepFake study these years and 3) identify the attacker-defender of the latest trends in the future development of DeepFake and strive to yield priority to the DeepFake detection.关键词:digital forensics;deepfake;machine learning;deep learning;face manipulation391|357|5更新时间:2024-05-07 -
 摘要:Face recognition technology has been widely used nowadays, such as smart phone unlocking, users' account verification, access control system, financial payment, public security pursuit, and so forth. Face recognition system has been challenging with various face fraud attacks, such as printing photos, screen playing, 3D masks, etc. Bending the printed face to make it have a general three-dimensional structure of the face in practice. Meanwhile, the movement of the key components of the real face can be integrated into the fake face via fake coverage of the printed face with the hollowed-out eyes and mouth. Face spoofing technologies has aimed to present realistic apparent texture, accurate three-dimensional face structure, reasonable face motion, and discriminative target identity features generally. The issue of false face distinguishing, also known as face liveness detection, is of great significance to the security of face recognition systems. This research reviewed current face liveness detection technologies based on hardware, algorithm, data set, technical standards, and practical application. For hardware, some popular tools used for face liveness detection, such as RGB cameras, binocular cameras, (near) infrared cameras, depth cameras, three-dimensional scanners, light field cameras and multispectral imagers. Flash lamps are used for assistance as well. For algorithms, the original methods distinguish a real face and a fake face via analyzing the texture information, motion information, image quality, structure information, and three-dimensional shape in the video or image. The analysis is assisted based on user interaction or changing the environment with flashing. Deep learning technology has been using in face liveness detection as well. It is necessary to opt the appropriate face detection method in accordance with the targeted application scenario. In reality, face liveness detection technologies are mainly used in unsupervised authentication scenarios, such as smartphone unlocking, mobile app login, the self-service terminal of the bank, and attendance machine. The illustrated methods are mainly evolved as following: 1) interactive verification based on a single camera, that is, the target is required to perform cooperative actions, such as shaking the head, blinking, opening mouth, and reading Arabic numerals; 2) the face liveness detection based on "visible light + near-infrared" dual-mode camera, in which near-infrared image is conducive to distinguish skin from other materials; 3) the face liveness detection based on "visible light + depth" dual-mode camera, in which the depth camera used to obtain the three-dimensional information of the object. The two methods latter can extract rich features for face liveness detection based on hardware combinations. Overall, based on multimodal data, the deep learning method has been adopted to obtain the optimal accuracy of liveness verification based on prior knowledge.In early 2018, China Information Security Standardization Technical Committee established the standards of liveness detection technology in the face recognition systems. In 2020, IEEE released the first international standard for face liveness detection (IEEE Std 2790-2020). With the emergence of new fraud methods, the research of face liveness detection will also encounter new challenges. First, face spoofing and face liveness detection will promote and upgrade each other. Therefore, it is particularly important to study the detection of unknown types of face fraud attacks. For unknown types of attacks, a feasible solution is to detect invisible attacks as abnormal samples. Next, the of face fraud upgrading means is related to the update of fraud media. In particular, the progress of high-precision 3D printing, flexible screen, and physiological mask will make face fraud more difficult to detect. Face liveness detection also needs to be developed at the hardware level consistently. It is necessary to explore the application of advanced sensing equipment such as multi-spectrometer, light field camera, and even ultrasound in face liveness detection. Moreover, the deep learning method plays a leading role in obtaining high accuracy. The lack of interpretability is also a major criticism of deep learning. For the application of face liveness detection, the interpretation of the deep learning methods needs to be conducted further. The interpretability mechanism has its priority to the design of the learning model, and to the integration of prior knowledge into the learning model. At last, it is necessary to develop a unified framework for joint face recognition and face liveness detection, which can improve the accuracy of both simultaneously.关键词:face liveness verification;face anti-spoofing;face recognition;deep learning;feature learning266|469|3更新时间:2024-05-07
摘要:Face recognition technology has been widely used nowadays, such as smart phone unlocking, users' account verification, access control system, financial payment, public security pursuit, and so forth. Face recognition system has been challenging with various face fraud attacks, such as printing photos, screen playing, 3D masks, etc. Bending the printed face to make it have a general three-dimensional structure of the face in practice. Meanwhile, the movement of the key components of the real face can be integrated into the fake face via fake coverage of the printed face with the hollowed-out eyes and mouth. Face spoofing technologies has aimed to present realistic apparent texture, accurate three-dimensional face structure, reasonable face motion, and discriminative target identity features generally. The issue of false face distinguishing, also known as face liveness detection, is of great significance to the security of face recognition systems. This research reviewed current face liveness detection technologies based on hardware, algorithm, data set, technical standards, and practical application. For hardware, some popular tools used for face liveness detection, such as RGB cameras, binocular cameras, (near) infrared cameras, depth cameras, three-dimensional scanners, light field cameras and multispectral imagers. Flash lamps are used for assistance as well. For algorithms, the original methods distinguish a real face and a fake face via analyzing the texture information, motion information, image quality, structure information, and three-dimensional shape in the video or image. The analysis is assisted based on user interaction or changing the environment with flashing. Deep learning technology has been using in face liveness detection as well. It is necessary to opt the appropriate face detection method in accordance with the targeted application scenario. In reality, face liveness detection technologies are mainly used in unsupervised authentication scenarios, such as smartphone unlocking, mobile app login, the self-service terminal of the bank, and attendance machine. The illustrated methods are mainly evolved as following: 1) interactive verification based on a single camera, that is, the target is required to perform cooperative actions, such as shaking the head, blinking, opening mouth, and reading Arabic numerals; 2) the face liveness detection based on "visible light + near-infrared" dual-mode camera, in which near-infrared image is conducive to distinguish skin from other materials; 3) the face liveness detection based on "visible light + depth" dual-mode camera, in which the depth camera used to obtain the three-dimensional information of the object. The two methods latter can extract rich features for face liveness detection based on hardware combinations. Overall, based on multimodal data, the deep learning method has been adopted to obtain the optimal accuracy of liveness verification based on prior knowledge.In early 2018, China Information Security Standardization Technical Committee established the standards of liveness detection technology in the face recognition systems. In 2020, IEEE released the first international standard for face liveness detection (IEEE Std 2790-2020). With the emergence of new fraud methods, the research of face liveness detection will also encounter new challenges. First, face spoofing and face liveness detection will promote and upgrade each other. Therefore, it is particularly important to study the detection of unknown types of face fraud attacks. For unknown types of attacks, a feasible solution is to detect invisible attacks as abnormal samples. Next, the of face fraud upgrading means is related to the update of fraud media. In particular, the progress of high-precision 3D printing, flexible screen, and physiological mask will make face fraud more difficult to detect. Face liveness detection also needs to be developed at the hardware level consistently. It is necessary to explore the application of advanced sensing equipment such as multi-spectrometer, light field camera, and even ultrasound in face liveness detection. Moreover, the deep learning method plays a leading role in obtaining high accuracy. The lack of interpretability is also a major criticism of deep learning. For the application of face liveness detection, the interpretation of the deep learning methods needs to be conducted further. The interpretability mechanism has its priority to the design of the learning model, and to the integration of prior knowledge into the learning model. At last, it is necessary to develop a unified framework for joint face recognition and face liveness detection, which can improve the accuracy of both simultaneously.关键词:face liveness verification;face anti-spoofing;face recognition;deep learning;feature learning266|469|3更新时间:2024-05-07 -
 摘要:Generative adversarial network (GAN) has developed multimedia techniques like image generation and image editing. However, the issues of abusing GAN to generate fake identities and fake news can cause severe security risks and pose a great threat to the integrity and authenticity of digital images. Researchers in the field of multimedia forensics have proposed a variety of passive forensics and anti-forensics techniques about GAN-generated images, which has achieved the phased research results. In this article, the latest passive forensics and anti-forensics techniques for GAN-generated images are reviewed systematically. First, the research background and research significance about forensics and anti-forensics techniques of GAN-generated images have been illustrated, which can provide novel theories to protect the integrity and authenticity of digital image against the recent deep-learning based image generation/editing techniques and analyze the reliability of current forensic algorithms. The characteristics of several representative unconditional GANs and conditional GANs are illustrated on the aspect of network structure and training strategy for recent GAN-based image generation/editing techniques, where the visual defects caused by early GAN models have been continuously eliminated. Next, the differences between natural image acquisition and GAN image generation are analyzed, including the related signal processing operations. The abnormal traces of GAN images are explained in terms of color components, texture characteristics and global content. Based on the above theoretical foundation, this article introduces current passive forensics techniques of GAN-generated images in detail, including: GAN-generated image detection algorithm, GAN model identification algorithm and other related forensics issues. According to the types of forensic clues, GAN-generated image detection algorithms can be divided into two categories based on spatial information and frequency domain information respectively. The methodologies of feature extraction and classification about forensics traces are introduced, including hand-crafted feature based and convolutional neural network (CNN) based methods. More specifically, this article emphasizes the development process of CNN based detection algorithms, including preprocessing based on prior knowledge of forensics traces, advanced network structure and other training strategies. According to the experimental results, existing methods achieved promising detection performance in simple forensic scenarios. However, when testing samples suffer from post-processing operations or are generated by unseen GAN models, the detection performance will become dramatically worse. Then, GAN model identification algorithms of GAN-generated images are demonstrated, which can be split into two categories based on spatial information and frequency domain information. The characteristics of other related forensics issues are presented as well, i.e., DeepFake detection, where GAN-based image generation can be regarded as a part of the deep-learning based video forgery pipeline. On the other hand, this article has introduced anti-forensics techniques based on GAN, which includes white-box anti-forensics (attack) methods and black-box anti-forensics (attack) methods according to information required for the attack. Furthermore, existing methods mainly focus on two types of anti-forensics scenarios, including source identification and detection of image editing. Finally, several representative algorithms based on spatial information and frequency domain information are selected for the performance comparison. The open access datasets of GAN-generated images and pristine images are used to construct the training and testing samples. The challenging issues about GAN-based passive forensics are investigated, including robustness against post-processing operations and generalization capability of unknown GAN models. The influence of different preprocessing operations for input images, including resizing and crop, is also investigated. Moreover, the potential confrontation situations in practical applications are also considered, where GAN-generated image detection algorithms are applied to identify anti-forensic pictures based on GAN. Experimental results show that current passive forensics methods are invalid to expose unseen anti-forensic attacks. At present, the passive forensics techniques of GAN-generated images have constructed various technical routes in both the spatial domain and the frequency domain, which are capable to deal with the issues of GAN-generated image detection and GAN model identification in simple scenes. Besides, anti-forensics techniques based on GAN can effectively hide common forensics traces. However, by analyzing the related research works and conducting experiments, we think that the research in this field is still in an initial stage, and there are still many unsolved issues. 1) Insufficient interpretability of forensics and anti-forensics techniques. It is hard to analyze which kind of information (local or global; texture or color) plays a more important role in identifying GAN-generated images while the security of current GAN-based anti-forensics techniques lacks theoretical support; 2) Weak robustness and generalization of forensics techniques. It is valuable to explore other detection frameworks further, such as anomaly detection, which may be more efficient to deal with the continuously updated GAN models and unknown post-processing operations in practical applications; 3) The issue of designing the network structure, loss function and training strategy of anti-forensics techniques to hide newly introduced traces should be explored more carefully due to the lack of anti-forensics capability for multiple feature domains.关键词:digital image forensics;anti-forensics;generative adversarial network(GAN);convolutional neural network(CNN);image generation153|762|5更新时间:2024-05-07
摘要:Generative adversarial network (GAN) has developed multimedia techniques like image generation and image editing. However, the issues of abusing GAN to generate fake identities and fake news can cause severe security risks and pose a great threat to the integrity and authenticity of digital images. Researchers in the field of multimedia forensics have proposed a variety of passive forensics and anti-forensics techniques about GAN-generated images, which has achieved the phased research results. In this article, the latest passive forensics and anti-forensics techniques for GAN-generated images are reviewed systematically. First, the research background and research significance about forensics and anti-forensics techniques of GAN-generated images have been illustrated, which can provide novel theories to protect the integrity and authenticity of digital image against the recent deep-learning based image generation/editing techniques and analyze the reliability of current forensic algorithms. The characteristics of several representative unconditional GANs and conditional GANs are illustrated on the aspect of network structure and training strategy for recent GAN-based image generation/editing techniques, where the visual defects caused by early GAN models have been continuously eliminated. Next, the differences between natural image acquisition and GAN image generation are analyzed, including the related signal processing operations. The abnormal traces of GAN images are explained in terms of color components, texture characteristics and global content. Based on the above theoretical foundation, this article introduces current passive forensics techniques of GAN-generated images in detail, including: GAN-generated image detection algorithm, GAN model identification algorithm and other related forensics issues. According to the types of forensic clues, GAN-generated image detection algorithms can be divided into two categories based on spatial information and frequency domain information respectively. The methodologies of feature extraction and classification about forensics traces are introduced, including hand-crafted feature based and convolutional neural network (CNN) based methods. More specifically, this article emphasizes the development process of CNN based detection algorithms, including preprocessing based on prior knowledge of forensics traces, advanced network structure and other training strategies. According to the experimental results, existing methods achieved promising detection performance in simple forensic scenarios. However, when testing samples suffer from post-processing operations or are generated by unseen GAN models, the detection performance will become dramatically worse. Then, GAN model identification algorithms of GAN-generated images are demonstrated, which can be split into two categories based on spatial information and frequency domain information. The characteristics of other related forensics issues are presented as well, i.e., DeepFake detection, where GAN-based image generation can be regarded as a part of the deep-learning based video forgery pipeline. On the other hand, this article has introduced anti-forensics techniques based on GAN, which includes white-box anti-forensics (attack) methods and black-box anti-forensics (attack) methods according to information required for the attack. Furthermore, existing methods mainly focus on two types of anti-forensics scenarios, including source identification and detection of image editing. Finally, several representative algorithms based on spatial information and frequency domain information are selected for the performance comparison. The open access datasets of GAN-generated images and pristine images are used to construct the training and testing samples. The challenging issues about GAN-based passive forensics are investigated, including robustness against post-processing operations and generalization capability of unknown GAN models. The influence of different preprocessing operations for input images, including resizing and crop, is also investigated. Moreover, the potential confrontation situations in practical applications are also considered, where GAN-generated image detection algorithms are applied to identify anti-forensic pictures based on GAN. Experimental results show that current passive forensics methods are invalid to expose unseen anti-forensic attacks. At present, the passive forensics techniques of GAN-generated images have constructed various technical routes in both the spatial domain and the frequency domain, which are capable to deal with the issues of GAN-generated image detection and GAN model identification in simple scenes. Besides, anti-forensics techniques based on GAN can effectively hide common forensics traces. However, by analyzing the related research works and conducting experiments, we think that the research in this field is still in an initial stage, and there are still many unsolved issues. 1) Insufficient interpretability of forensics and anti-forensics techniques. It is hard to analyze which kind of information (local or global; texture or color) plays a more important role in identifying GAN-generated images while the security of current GAN-based anti-forensics techniques lacks theoretical support; 2) Weak robustness and generalization of forensics techniques. It is valuable to explore other detection frameworks further, such as anomaly detection, which may be more efficient to deal with the continuously updated GAN models and unknown post-processing operations in practical applications; 3) The issue of designing the network structure, loss function and training strategy of anti-forensics techniques to hide newly introduced traces should be explored more carefully due to the lack of anti-forensics capability for multiple feature domains.关键词:digital image forensics;anti-forensics;generative adversarial network(GAN);convolutional neural network(CNN);image generation153|762|5更新时间:2024-05-07 -
 摘要:As a branch of hidden information, reversible data hiding (RDH) has been developed over three decades. The key character of RDH differentiation is the reversibility that can ensure the adequate recovery of both the original image and the hidden message. The applications of targeted occasions have been focused on, such as medical, judicial and military image processing. Currently, RDH community has derived an enormous number of algorithms, each of which entangles a specialty of the other discipline. It may torture the consistent study of primary learners as they cannot control the situation and then feel confused and frustrating. The brief guidance may be required to provide a unique pathway of RDH research. The initial works have put more emphasis on the classical algorithms and aim to awake them simplistic and friendly. The potentials for the future are summarized and new scientific issues are proposed to integrate the RDH with the realistic applications, such as night image processing for surveillance and reconnaissance, image fusion for remote transmission storage, etc. In this review, we aim to provide a straightforward and explicit guideline for the readers with no formal training of this topic. We illustrate the typical RDH algorithms designed for the common images, and explain their motivations of reversible data embedding and extraction. Enlightened by the early-age motivations, we look forward the future directions to strengthen the close cooperation between RDH and the other leading disciplines. The whole paper consists of three parts, i.e., the researches for BMP images which are suited to the uncompressed images, the researches for JPEG images which are suitable for the coding-to-compression domain, and the robust reversible research in which more requirements are considered in the algorithm design to make RDH applicable for the practical case. In the reference list, nearly 100 papers are recommended for the study of this field. Most of the works are published in the top journals and conferences, and the significant influences of originality and innovation have been verified by the high citation rates in the past years. It is found that the RDH society has evolved into the form of great varieties and quantities. RDH is preferred by the expert and primary researchers due to its concise mathematical definition, simple experimental implementation and subtle embedding optimization. Such a simple and clear character allows RDH be easier to form a connection with the various applications without causing obvious conflicts. It is beneficial for the further development to have more discussions about the theoretical generality for diverse medium and introduce new evaluation metrics to guide the RDH design consisted with the practical application requirements. The unique feature of RDH is that it can recover the initial status of image when a change has taken place. It verifies that the image itself has the ability of recovery. In fact, the image is a sort of semantic expression relying on the strong but complicated data correlations. The correlations indicate that the image elements are similar to some extent, and can recover themselves in theory. In the existing works, the designers tend to understand the correlations at first, and then exploit the redundant elements to make space for hiding secret message. In a word, the algorithms revolve around the idea of better understanding the image. Of course, that how to interpret the correlations depends on the human-defined metric. In the current works, we are used to taking the PSNR metric to interpret the image, and then explore the boundary within which the distortion is acceptable and the main semantic information is preserved. However, merely PSNR is not sufficient to interpret the diversity of images. More metrics for different cases are better choices for the development of new and novel algorithms. Generally speaking, the reversibility is acceptable not only for the sensitive fields but also the common ones. The long-term development is feasible if RDH can respond more arising practical demands.关键词:reversible data hiding;overview;reversible embedding in spatial domain;reversible embedding in frequency domain;robust reversible embedding257|351|7更新时间:2024-05-07
摘要:As a branch of hidden information, reversible data hiding (RDH) has been developed over three decades. The key character of RDH differentiation is the reversibility that can ensure the adequate recovery of both the original image and the hidden message. The applications of targeted occasions have been focused on, such as medical, judicial and military image processing. Currently, RDH community has derived an enormous number of algorithms, each of which entangles a specialty of the other discipline. It may torture the consistent study of primary learners as they cannot control the situation and then feel confused and frustrating. The brief guidance may be required to provide a unique pathway of RDH research. The initial works have put more emphasis on the classical algorithms and aim to awake them simplistic and friendly. The potentials for the future are summarized and new scientific issues are proposed to integrate the RDH with the realistic applications, such as night image processing for surveillance and reconnaissance, image fusion for remote transmission storage, etc. In this review, we aim to provide a straightforward and explicit guideline for the readers with no formal training of this topic. We illustrate the typical RDH algorithms designed for the common images, and explain their motivations of reversible data embedding and extraction. Enlightened by the early-age motivations, we look forward the future directions to strengthen the close cooperation between RDH and the other leading disciplines. The whole paper consists of three parts, i.e., the researches for BMP images which are suited to the uncompressed images, the researches for JPEG images which are suitable for the coding-to-compression domain, and the robust reversible research in which more requirements are considered in the algorithm design to make RDH applicable for the practical case. In the reference list, nearly 100 papers are recommended for the study of this field. Most of the works are published in the top journals and conferences, and the significant influences of originality and innovation have been verified by the high citation rates in the past years. It is found that the RDH society has evolved into the form of great varieties and quantities. RDH is preferred by the expert and primary researchers due to its concise mathematical definition, simple experimental implementation and subtle embedding optimization. Such a simple and clear character allows RDH be easier to form a connection with the various applications without causing obvious conflicts. It is beneficial for the further development to have more discussions about the theoretical generality for diverse medium and introduce new evaluation metrics to guide the RDH design consisted with the practical application requirements. The unique feature of RDH is that it can recover the initial status of image when a change has taken place. It verifies that the image itself has the ability of recovery. In fact, the image is a sort of semantic expression relying on the strong but complicated data correlations. The correlations indicate that the image elements are similar to some extent, and can recover themselves in theory. In the existing works, the designers tend to understand the correlations at first, and then exploit the redundant elements to make space for hiding secret message. In a word, the algorithms revolve around the idea of better understanding the image. Of course, that how to interpret the correlations depends on the human-defined metric. In the current works, we are used to taking the PSNR metric to interpret the image, and then explore the boundary within which the distortion is acceptable and the main semantic information is preserved. However, merely PSNR is not sufficient to interpret the diversity of images. More metrics for different cases are better choices for the development of new and novel algorithms. Generally speaking, the reversibility is acceptable not only for the sensitive fields but also the common ones. The long-term development is feasible if RDH can respond more arising practical demands.关键词:reversible data hiding;overview;reversible embedding in spatial domain;reversible embedding in frequency domain;robust reversible embedding257|351|7更新时间:2024-05-07 -
 摘要:Reversible data hiding (RDH) is one branch of data hiding technologies, which can extract the secret data from the marked carrier and recover the original carrier losslessly. In terms of the factor of reversible recovery, RDH has been implemented for media annotation and integrity authentication and integrated to other research aspects, such as reversible steganography, robust reversible watermarking, reversible adversarial samples, and reversible image transformation. In accordance with the content (encrypted or not) of image carrier, RDH can be divided into plaintext domain and encrypted domain each. At the beginning, the targeted research area was fundamentally conducted in plaintext domain. On the basis of ensuring reversible embedding, the improvement of embedding capacity and the decrease of embedding distortion have been mainly addressed. Signal processing in the encrypted domain has obtained extensive attention in privacy protection and data security. RDH in encrypted domain integrates encryption and reversible data hiding technology, aiming at realizing carrier content protection and covert communication simultaneously. The current research in plaintext domain and encrypted domain is summarized and analyzed to assist the readers with the knowhow in time sequence. First, the methods of plaintext domain have been summarized like four methods including difference expansion (DE), histogram shifting (HS), prediction error expansion (PEE), and multiple histogram modification (MHM) and their upgraded versions. PEE is developed on the basis of DE, which has higher embedding capacity, while tends to increase embedding distortion at low embedding capacity. Another classical method HS is proposed to reduce the embedding distortion at low embedding capacity. Subsequently, PEE achieves a qualified balance between embedding capacity and embedding distortion via the shifting operation of HS on the histogram. Various prediction error generation methods and two-dimensional histogram modification can improve the performance of PEE. MHM divides the prediction errors of the image into multiple histograms. The performance is improved further via PEE application in each sub-histogram. The current high-fidelity methods of plaintext domain have basically evolved three steps as following: First, neighboring pixels are applied to calculate the prediction error. Next, cluster regions have generated multiple two-dimensional prediction error histograms via similar complexity. At last, mapping rules have been used in reversible modification to the histograms. Hence, accurate pixel value prediction, qualified histogram generation and adaptive mapping rules can be as the research strategies. The other aspect on the research progress of three types of methods in encrypted domain has been demonstrated, which are based on vacating room after encryption (VRAE), reserving room before encryption (RRBE), and vacating room by encryption (VRBE). The VRAE-based methods require the data hider to vacate embeddable room after encryption. The content owner has utilized the standard encryption algorithm to encrypt the original image straightforward, such as stream encryption, block encryption and homomorphic encryption. For the application of spatial correlation of the original image, the RRBE-based methods allow the content owner to perform some pre-processing before encryption. The content owner utilizes the special encryption algorithm to encrypt the original image via the VRBE-based methods. The local spatial correlation can be preserved in the encrypted image. The initial research in encrypted domain is mainly in accordance with the modifications of the least significant bits. These methods could obtain high-quality decrypted image, while they might not be able to restore the original image losslessly, and their embedding capacity is limited. Since the encrypted image itself is a unique noise signal, the modifications of the most significant bits could greatly increase the embedding capacity with ensuring completed reversibility. The research in plaintext domain tends to reduce the embedding distortion, while the research in encrypted domain tends to increase the embedding capacity, and their development in robustness and security is relatively slow. The evaluation of the current methods is mainly based on the rate-distortion performance in reversibility. As the algorithm complexity increases and the solution space expands, the computational cost also increases inevitably. The efficiency evaluation is a comparison of running time as usual. From the perspective of the development of RDH, it is not recommended to always seek breakthroughs in certain indicators. Scientific evaluation of the performance and efficiency can promote the co-development of various methods. In order to meet different application requirements, future research on RDH should not constrain to the balance between reversibility, embedding capacity, and imperceptibility. Computational cost, robustness, and security issues should be evolved.关键词:content security;data hiding;reversible data hiding;encrypted domain;survey239|114|4更新时间:2024-05-07
摘要:Reversible data hiding (RDH) is one branch of data hiding technologies, which can extract the secret data from the marked carrier and recover the original carrier losslessly. In terms of the factor of reversible recovery, RDH has been implemented for media annotation and integrity authentication and integrated to other research aspects, such as reversible steganography, robust reversible watermarking, reversible adversarial samples, and reversible image transformation. In accordance with the content (encrypted or not) of image carrier, RDH can be divided into plaintext domain and encrypted domain each. At the beginning, the targeted research area was fundamentally conducted in plaintext domain. On the basis of ensuring reversible embedding, the improvement of embedding capacity and the decrease of embedding distortion have been mainly addressed. Signal processing in the encrypted domain has obtained extensive attention in privacy protection and data security. RDH in encrypted domain integrates encryption and reversible data hiding technology, aiming at realizing carrier content protection and covert communication simultaneously. The current research in plaintext domain and encrypted domain is summarized and analyzed to assist the readers with the knowhow in time sequence. First, the methods of plaintext domain have been summarized like four methods including difference expansion (DE), histogram shifting (HS), prediction error expansion (PEE), and multiple histogram modification (MHM) and their upgraded versions. PEE is developed on the basis of DE, which has higher embedding capacity, while tends to increase embedding distortion at low embedding capacity. Another classical method HS is proposed to reduce the embedding distortion at low embedding capacity. Subsequently, PEE achieves a qualified balance between embedding capacity and embedding distortion via the shifting operation of HS on the histogram. Various prediction error generation methods and two-dimensional histogram modification can improve the performance of PEE. MHM divides the prediction errors of the image into multiple histograms. The performance is improved further via PEE application in each sub-histogram. The current high-fidelity methods of plaintext domain have basically evolved three steps as following: First, neighboring pixels are applied to calculate the prediction error. Next, cluster regions have generated multiple two-dimensional prediction error histograms via similar complexity. At last, mapping rules have been used in reversible modification to the histograms. Hence, accurate pixel value prediction, qualified histogram generation and adaptive mapping rules can be as the research strategies. The other aspect on the research progress of three types of methods in encrypted domain has been demonstrated, which are based on vacating room after encryption (VRAE), reserving room before encryption (RRBE), and vacating room by encryption (VRBE). The VRAE-based methods require the data hider to vacate embeddable room after encryption. The content owner has utilized the standard encryption algorithm to encrypt the original image straightforward, such as stream encryption, block encryption and homomorphic encryption. For the application of spatial correlation of the original image, the RRBE-based methods allow the content owner to perform some pre-processing before encryption. The content owner utilizes the special encryption algorithm to encrypt the original image via the VRBE-based methods. The local spatial correlation can be preserved in the encrypted image. The initial research in encrypted domain is mainly in accordance with the modifications of the least significant bits. These methods could obtain high-quality decrypted image, while they might not be able to restore the original image losslessly, and their embedding capacity is limited. Since the encrypted image itself is a unique noise signal, the modifications of the most significant bits could greatly increase the embedding capacity with ensuring completed reversibility. The research in plaintext domain tends to reduce the embedding distortion, while the research in encrypted domain tends to increase the embedding capacity, and their development in robustness and security is relatively slow. The evaluation of the current methods is mainly based on the rate-distortion performance in reversibility. As the algorithm complexity increases and the solution space expands, the computational cost also increases inevitably. The efficiency evaluation is a comparison of running time as usual. From the perspective of the development of RDH, it is not recommended to always seek breakthroughs in certain indicators. Scientific evaluation of the performance and efficiency can promote the co-development of various methods. In order to meet different application requirements, future research on RDH should not constrain to the balance between reversibility, embedding capacity, and imperceptibility. Computational cost, robustness, and security issues should be evolved.关键词:content security;data hiding;reversible data hiding;encrypted domain;survey239|114|4更新时间:2024-05-07 -
 摘要:Three-dimensional (3D) meshes have been mainly used to illustrate virtual surfaces and volumes. 3D meshes have implemented in industrial, medical, and entertainment applications over the past decade, which are of great practical significance for 3D mesh steganography and steganalysis. The application of 3D geometry as host object has been focused over the past few years based on image, audio files and videos processing method in early steganography and steganalysis. Cost effective 3D hardware stimulates the widespread use of 3D meshes in the evolving of the computer aided design(CAD) industry to real-world end-user applications such as virtual reality (VR), web integration, Facebook support, video games, 3D printing and animated movies. Hence, the development of computer graphics has facilitated the production, application and distribution of the emerging generation of 3D geometry digital media. Moreover, the flexible data structure of 3D geometry provides enough space to host security information, making it ideal for use a cover object for steganography. A 3D mesh consists of a set of triangular faces, which is to form an approximation of a real 3D object. A 3D mesh has 3 different synthesized factors: vertices, edges, and faces; a mesh can also be taken as the integration of geometry connectivity, where the geometry provides the 3D positions of all its vertices, and connectivity, which provides the information hidden between different adjacent vertices. A systematic overview of 3D mesh steganography and steganalysis has been issued related to computer graphics and security. The objective projects in the context of the types of steganographic and steganalytic methods have been reviewed in literature. Quantitative evaluation has been conducted from the perspective of security assessment simultaneously. The target of this task is to demonstrate the evaluation procedures in the 3D mesh steganography and steganalysis methods as a whole. It is essential to recognize a growing number of efforts on how to improve the anti-steganalysis efforts in the case of steganographer side and how to improve the steganalysis ability in the case of the steganalyzer side. Some standard evaluation metrics, an overall summary, and an understanding of relevant research results have been evaluated based on the previous analyses. Unlike image steganography which embeds data by modifying pixel values, 3D mesh steganography modifies vertex coordinates or vertex order to embed data. In the latest literature analysis of 3D steganography and steganalysis of Girdhar and Kumar's work, steganography is divided into three categories (geometrical domain, topological domain and representation domain), which reflects the robustness of the algorithms to attacks, and steganalysis is briefly introduced. The entire communities of 3D steganography and steganalysis have to be further promoted. For instance, the geometrical domain can still be divided into two-state domain and the least significant bit(LSB) domain. In addition, the concepts of "steganography" and "watermarking" can be used interchangeably. Watermarking seeks robustness, protects copyright ownership and reduces the counterfeiting of digital multimedia, while steganography seeks un-detectability used for covert communication. They focus has been primarily on analyzing the robustness of the existing methods, while the undetectability of steganography is a more important property because of its practical requirement: covert communication. A more comprehensive survey, a clear taxonomy and several criteria for evaluating robustness and un-detectability has been offered. Conversely, hidden data has been used into reversible data hiding and steganography. For the structure of 3D data, the 3D mesh and RGBD image have been mainly concentrated. 3D meshes as carriers and steganographic techniques have been considered. The steganographic techniques into several domains (two-state domain, LSB domain, permutation domain and transform domain) in a subdivision way have been divided with no small embedding capacities. This demonstration has evolved common digital attacks including affine transform attack, vertex reordering attack, noise addition attack, smoothing attack and simplification attack. In addition, 3D mesh steganalysis has been divided into two aspects (general steganalysis and specific steganalysis). For overall steganalysis, there are YANG208 features, local feature set(LFS)52 features, LFS64 features, LFS76 features, LFS124 features, normal voting tensor(NVT)+ features and 3D wavelet feature set(WFS)228 features respectively. Current methods have revealed strong weaknesses and strengths from which we can learn for future work. In order to evaluate the performance of various steganographic and steganalytic methods clearly, it is important to identify standards for users friendly. Meanwhile, the steganographic performance based on three general requirements (i.e., security, capacity and robustness) has been evaluated. Ensemble learning is an effective way to produce a variety of base classifiers, from which a new classifier with a better performance can be derived, and ensemble classifier is used to evaluate steganalysis performance, a common tool for steganalysis. The datasets proposed are suitable for the princeton segmentation benchmark and the Princeton ModelNet, where the former has 354 objects and the latter has 12 311 mesh objects with 40 categories. Some promising future research directions and challenges in improving the performance of 3D mesh steganography and steganalysis have been highlighted. 3D mesh steganography research has been summarized as following: 1) combining the permutation domain and LSB domain; 2) designing spatial steganographic models; 3) designing steganalysis-resistant permutation steganographic methods; 4) designing 3D mesh batch steganography methods and 5) designing 3D-printing-material-based robust steganography methods. Open issues of 3D mesh steganalysis has been summarized as bellows: 1) rich steganalytic features designation for universal blind steganalysis; 2) designing deep-learning-based steganalysis methods; 3) designing a finer distance metric to improve the steganalysis of permutation steganography and 4) cover source mismatch problem.关键词:3D model;polygonal mesh;information hiding;steganography;steganalysis;survey108|93|3更新时间:2024-05-07
摘要:Three-dimensional (3D) meshes have been mainly used to illustrate virtual surfaces and volumes. 3D meshes have implemented in industrial, medical, and entertainment applications over the past decade, which are of great practical significance for 3D mesh steganography and steganalysis. The application of 3D geometry as host object has been focused over the past few years based on image, audio files and videos processing method in early steganography and steganalysis. Cost effective 3D hardware stimulates the widespread use of 3D meshes in the evolving of the computer aided design(CAD) industry to real-world end-user applications such as virtual reality (VR), web integration, Facebook support, video games, 3D printing and animated movies. Hence, the development of computer graphics has facilitated the production, application and distribution of the emerging generation of 3D geometry digital media. Moreover, the flexible data structure of 3D geometry provides enough space to host security information, making it ideal for use a cover object for steganography. A 3D mesh consists of a set of triangular faces, which is to form an approximation of a real 3D object. A 3D mesh has 3 different synthesized factors: vertices, edges, and faces; a mesh can also be taken as the integration of geometry connectivity, where the geometry provides the 3D positions of all its vertices, and connectivity, which provides the information hidden between different adjacent vertices. A systematic overview of 3D mesh steganography and steganalysis has been issued related to computer graphics and security. The objective projects in the context of the types of steganographic and steganalytic methods have been reviewed in literature. Quantitative evaluation has been conducted from the perspective of security assessment simultaneously. The target of this task is to demonstrate the evaluation procedures in the 3D mesh steganography and steganalysis methods as a whole. It is essential to recognize a growing number of efforts on how to improve the anti-steganalysis efforts in the case of steganographer side and how to improve the steganalysis ability in the case of the steganalyzer side. Some standard evaluation metrics, an overall summary, and an understanding of relevant research results have been evaluated based on the previous analyses. Unlike image steganography which embeds data by modifying pixel values, 3D mesh steganography modifies vertex coordinates or vertex order to embed data. In the latest literature analysis of 3D steganography and steganalysis of Girdhar and Kumar's work, steganography is divided into three categories (geometrical domain, topological domain and representation domain), which reflects the robustness of the algorithms to attacks, and steganalysis is briefly introduced. The entire communities of 3D steganography and steganalysis have to be further promoted. For instance, the geometrical domain can still be divided into two-state domain and the least significant bit(LSB) domain. In addition, the concepts of "steganography" and "watermarking" can be used interchangeably. Watermarking seeks robustness, protects copyright ownership and reduces the counterfeiting of digital multimedia, while steganography seeks un-detectability used for covert communication. They focus has been primarily on analyzing the robustness of the existing methods, while the undetectability of steganography is a more important property because of its practical requirement: covert communication. A more comprehensive survey, a clear taxonomy and several criteria for evaluating robustness and un-detectability has been offered. Conversely, hidden data has been used into reversible data hiding and steganography. For the structure of 3D data, the 3D mesh and RGBD image have been mainly concentrated. 3D meshes as carriers and steganographic techniques have been considered. The steganographic techniques into several domains (two-state domain, LSB domain, permutation domain and transform domain) in a subdivision way have been divided with no small embedding capacities. This demonstration has evolved common digital attacks including affine transform attack, vertex reordering attack, noise addition attack, smoothing attack and simplification attack. In addition, 3D mesh steganalysis has been divided into two aspects (general steganalysis and specific steganalysis). For overall steganalysis, there are YANG208 features, local feature set(LFS)52 features, LFS64 features, LFS76 features, LFS124 features, normal voting tensor(NVT)+ features and 3D wavelet feature set(WFS)228 features respectively. Current methods have revealed strong weaknesses and strengths from which we can learn for future work. In order to evaluate the performance of various steganographic and steganalytic methods clearly, it is important to identify standards for users friendly. Meanwhile, the steganographic performance based on three general requirements (i.e., security, capacity and robustness) has been evaluated. Ensemble learning is an effective way to produce a variety of base classifiers, from which a new classifier with a better performance can be derived, and ensemble classifier is used to evaluate steganalysis performance, a common tool for steganalysis. The datasets proposed are suitable for the princeton segmentation benchmark and the Princeton ModelNet, where the former has 354 objects and the latter has 12 311 mesh objects with 40 categories. Some promising future research directions and challenges in improving the performance of 3D mesh steganography and steganalysis have been highlighted. 3D mesh steganography research has been summarized as following: 1) combining the permutation domain and LSB domain; 2) designing spatial steganographic models; 3) designing steganalysis-resistant permutation steganographic methods; 4) designing 3D mesh batch steganography methods and 5) designing 3D-printing-material-based robust steganography methods. Open issues of 3D mesh steganalysis has been summarized as bellows: 1) rich steganalytic features designation for universal blind steganalysis; 2) designing deep-learning-based steganalysis methods; 3) designing a finer distance metric to improve the steganalysis of permutation steganography and 4) cover source mismatch problem.关键词:3D model;polygonal mesh;information hiding;steganography;steganalysis;survey108|93|3更新时间:2024-05-07 -
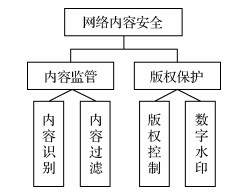 摘要:The emergence of media video has hugely changed and facilitated information spreading, including bad ones. It is urgent to effectively manage and control the production, fabrication, and release of video content nowadays. The inadequate information can be summarized as video content security (VCS). VCS has become an essential part of network content security. The main issues for video content security of media platforms are keyword search, video frame extraction, and manual supervision. Uneven regulatory audit and weak audit capabilities of small and medium-sized platforms are still concerned in common. To interpret the potential risks and practical implications of bad information in the video, the video content supervision system is to construct the video content security evaluation (VCSE). VCSE offers an effective way to guarantee the security of network content. The potential risks in video or video production are identified, analyzed, and evaluated on the systematic aspect in advance. Risk manipulations are implemented to guarantee the proper security management or control functions. VCSE can illustrate content security quantitatively. Video content security evaluation system (VCSES) can provide a scientific basis for clarifying audit priority and decision-making. This research summarizes a system in the context of the content supervision of pornography, violence, terrorism, politics, and bad scenes. The system includes three parts, including standards, content identification, and evaluation methods. The illustrated evaluation process is to improve the feasibility and operability of video content security management. Based on the principle of plan-do-check-act (PDCA), the evaluation process mainly includes the pre-stage, analysis, check, and improvement stage. In the pre-stage, the insecure semantics in the video is identified, and the relevant laws and regulations, technical standards, and technical data of engineering and system are demonstrated. At the analysis stage, the detection method is opted to identify and analyze the potentially lousy information. At the verification stage, secure implementations are facilitated. In comparison with qualitative and quantitative evaluation, the implication of technical and management are offered to eliminate or weaken the chaos factors. In the improvement stage, the proposed scheme is demonstrated for the content that does not conform to the standard in the video. The management system of video risk control measures is implemented. This research summarizes and forms the video content security evaluation index and method from five aspects: content interference, content malice, content sensitivity, content exposure, and content tendency. First, the amount of key frames and problem frames are determined, and the index value is calculated. Next, the weight of the index value is set. At last, the video content security risk value is obtained. The greater the degree of video content security risk is, the higher the risk levels are. The evaluation takes the subjective and objective characteristics of decision-making into account. The video content risk severity level is evaluated from three aspects of high, medium, and low. The ranking of video content security results is more qualified, which improves the efficiency of detecting security risks and provides data support for video content classification. Finally, this research analyzes the challenges and opportunities for video content evaluation. From the perspective of usability, reliability, and efficiency, it summarizes ten aspects to be solved in detail, such as data set, accurate identification, content interference, security prediction, interconnection, content traceability, real-time monitoring, and artificial intelligence. In summary, an overall security evaluation framework, a security evaluation theory, and a technology system have been built up to realize a more accurate evaluation.关键词:network content security;video content;content security evaluation;video analysis;quantitative evaluation90|302|1更新时间:2024-05-07
摘要:The emergence of media video has hugely changed and facilitated information spreading, including bad ones. It is urgent to effectively manage and control the production, fabrication, and release of video content nowadays. The inadequate information can be summarized as video content security (VCS). VCS has become an essential part of network content security. The main issues for video content security of media platforms are keyword search, video frame extraction, and manual supervision. Uneven regulatory audit and weak audit capabilities of small and medium-sized platforms are still concerned in common. To interpret the potential risks and practical implications of bad information in the video, the video content supervision system is to construct the video content security evaluation (VCSE). VCSE offers an effective way to guarantee the security of network content. The potential risks in video or video production are identified, analyzed, and evaluated on the systematic aspect in advance. Risk manipulations are implemented to guarantee the proper security management or control functions. VCSE can illustrate content security quantitatively. Video content security evaluation system (VCSES) can provide a scientific basis for clarifying audit priority and decision-making. This research summarizes a system in the context of the content supervision of pornography, violence, terrorism, politics, and bad scenes. The system includes three parts, including standards, content identification, and evaluation methods. The illustrated evaluation process is to improve the feasibility and operability of video content security management. Based on the principle of plan-do-check-act (PDCA), the evaluation process mainly includes the pre-stage, analysis, check, and improvement stage. In the pre-stage, the insecure semantics in the video is identified, and the relevant laws and regulations, technical standards, and technical data of engineering and system are demonstrated. At the analysis stage, the detection method is opted to identify and analyze the potentially lousy information. At the verification stage, secure implementations are facilitated. In comparison with qualitative and quantitative evaluation, the implication of technical and management are offered to eliminate or weaken the chaos factors. In the improvement stage, the proposed scheme is demonstrated for the content that does not conform to the standard in the video. The management system of video risk control measures is implemented. This research summarizes and forms the video content security evaluation index and method from five aspects: content interference, content malice, content sensitivity, content exposure, and content tendency. First, the amount of key frames and problem frames are determined, and the index value is calculated. Next, the weight of the index value is set. At last, the video content security risk value is obtained. The greater the degree of video content security risk is, the higher the risk levels are. The evaluation takes the subjective and objective characteristics of decision-making into account. The video content risk severity level is evaluated from three aspects of high, medium, and low. The ranking of video content security results is more qualified, which improves the efficiency of detecting security risks and provides data support for video content classification. Finally, this research analyzes the challenges and opportunities for video content evaluation. From the perspective of usability, reliability, and efficiency, it summarizes ten aspects to be solved in detail, such as data set, accurate identification, content interference, security prediction, interconnection, content traceability, real-time monitoring, and artificial intelligence. In summary, an overall security evaluation framework, a security evaluation theory, and a technology system have been built up to realize a more accurate evaluation.关键词:network content security;video content;content security evaluation;video analysis;quantitative evaluation90|302|1更新时间:2024-05-07
Review

-
 摘要:ObjectiveDetecting the image forgery region is a challenging task on the aspect of image forensics. The statistical features and physical characteristics of the image itself methods have been focused on in the traditional detection and localization field. Traditional methods are designed only for a specific forgery, making them difficult to detect images containing diverse forgery approaches. Convolutional neural networks (CNNs) are proposed to various image tasks recently due to extracting adaptive features. Most of these methods have enhanced the noise features of an image. It cannot be qualified that the noise of the forgery region is similar to the original image. In addition, most of CNNs-based forgery region detection methods ignore the imbalanced sample constrained by the small forgery region. It affects the further improvement of detection performance. So, more qualified image features enhancement and problem solving have been focused on due to the small forgery region.MethodA region loss based U-Net for small image forgery region detection is demonstrated. First, the most forgery regions differ from the image background has been investigated. Image anomaly regions could be called where differ from the image background. Splicing the difference tensor between local and dominant image features to the image to enhance the features extracted from these image anomaly regions. This feature augmentation mechanism only needs to be computed once when given an image as input, which significantly reduces training time compared to other state-of-the-art methods. Simutanesouly, a U-Net structure model is illustrated. A modified VGG-16 architecture is used to be the down-sampling part. Several de-convolution layers and convolution layers are utilized to be the up-sampling part. Aiming at retaining the location information of an image, maxpool layers is removed from the down-sampling network. To extract hierarchical features with diverse scales, the stride of last convolution layer in each down-sampling block is set as 2. The upsampling process requires fusing the multi-scale features extracted from the down-sampling process to avoid the loss of image spatial information. To address the final question caused by small forgery regions, a novel region loss has been demonstrated. The illustrated region loss mechanism requires segmenting the learning process of the network into two stages. In the first stage, the targeted binary cross entropy loss(BCELoss) of overall image as a loss function for network training. A relative rough model has been obtained. In the training process of second stage, a multiple candidate region boxes have been generated based on the location information from the model learned in first stage. The option of candidate region box should satisfy two conditions: 1) The candidate region box should contain all forgery regions; 2) The ratio of forgery region and non-forgery region is approximate to 1 ∶1. The oriented candidate region box is called forgery region box. Next, the BCELoss of the image is calculated in the forgery region box and as the second loss for the learning of second stage. Hence, the judging capability about whether pixels are forged in region box is able to be remarkable improved.ResultIt has the priority of the illustrated forgery region detection methods on four standard image forgery datasets, including traditional DWT method and three CNNs-based methods including manipulation tracing network(ManTra-Net), U-Net, and the ringed residual U-Net(RRU-Net). The four standard image forgery datasets are CASI-A image tampering detection evaluation database(CASIA2.0), Columbia uncompressed image splicing detection evaluation dataset(COLUMBIA), a novel database forcopy-move forgery detection(COVERAGE) and NIST nimble 2016 datasets(NIST 2016), respectively. The CASIA2.0 dataset images are small, complex and more challenging. F1 score is used as the benchmark for model evaluation. Moreover, F1 score is improved most on the CASIA2.0 dataset, which is asymptotical 2.17% higher than the second method. To test the robustness of our approach, the F1 score is evaluated as well. U-Net and RRU-Net on images is interfered by JPEG compression and Gaussian blur. The comparison results demonstrate that the method has its optimal robustness. To verify the effectiveness of the proposed feature augmentation mechanism and region loss mechanism in this work, we also perform abundant ablation experiments. Anomaly region feature augmentation modeling has its advantage and models region loss models can achieve its more qualified results.ConclusionA region loss based U-Net architecture is illustrated in order to detect forgery region in images effectively and accurately. It mainly resolves the issue of feature augmentation and small forgery regions. The difference amongst local and dominant features has been sorted out to enhance the features from image anomaly regions. An illustrated region loss enhanced the learning of features in the forgery region caused by imbalanced sample issue. Ablation study has shown that feature augmentation and region loss mechanisms improve the proposed model calculation effectively. In addition, the JPEG compression and Gaussian blur tests also demonstrate the robustness. An effective forgery region detection method is implemented and facilitated.关键词:image forensics;small forgery region detection;feature augmentation;region loss;convolutional neural networks(CNNs);U-Net107|209|3更新时间:2024-05-07
摘要:ObjectiveDetecting the image forgery region is a challenging task on the aspect of image forensics. The statistical features and physical characteristics of the image itself methods have been focused on in the traditional detection and localization field. Traditional methods are designed only for a specific forgery, making them difficult to detect images containing diverse forgery approaches. Convolutional neural networks (CNNs) are proposed to various image tasks recently due to extracting adaptive features. Most of these methods have enhanced the noise features of an image. It cannot be qualified that the noise of the forgery region is similar to the original image. In addition, most of CNNs-based forgery region detection methods ignore the imbalanced sample constrained by the small forgery region. It affects the further improvement of detection performance. So, more qualified image features enhancement and problem solving have been focused on due to the small forgery region.MethodA region loss based U-Net for small image forgery region detection is demonstrated. First, the most forgery regions differ from the image background has been investigated. Image anomaly regions could be called where differ from the image background. Splicing the difference tensor between local and dominant image features to the image to enhance the features extracted from these image anomaly regions. This feature augmentation mechanism only needs to be computed once when given an image as input, which significantly reduces training time compared to other state-of-the-art methods. Simutanesouly, a U-Net structure model is illustrated. A modified VGG-16 architecture is used to be the down-sampling part. Several de-convolution layers and convolution layers are utilized to be the up-sampling part. Aiming at retaining the location information of an image, maxpool layers is removed from the down-sampling network. To extract hierarchical features with diverse scales, the stride of last convolution layer in each down-sampling block is set as 2. The upsampling process requires fusing the multi-scale features extracted from the down-sampling process to avoid the loss of image spatial information. To address the final question caused by small forgery regions, a novel region loss has been demonstrated. The illustrated region loss mechanism requires segmenting the learning process of the network into two stages. In the first stage, the targeted binary cross entropy loss(BCELoss) of overall image as a loss function for network training. A relative rough model has been obtained. In the training process of second stage, a multiple candidate region boxes have been generated based on the location information from the model learned in first stage. The option of candidate region box should satisfy two conditions: 1) The candidate region box should contain all forgery regions; 2) The ratio of forgery region and non-forgery region is approximate to 1 ∶1. The oriented candidate region box is called forgery region box. Next, the BCELoss of the image is calculated in the forgery region box and as the second loss for the learning of second stage. Hence, the judging capability about whether pixels are forged in region box is able to be remarkable improved.ResultIt has the priority of the illustrated forgery region detection methods on four standard image forgery datasets, including traditional DWT method and three CNNs-based methods including manipulation tracing network(ManTra-Net), U-Net, and the ringed residual U-Net(RRU-Net). The four standard image forgery datasets are CASI-A image tampering detection evaluation database(CASIA2.0), Columbia uncompressed image splicing detection evaluation dataset(COLUMBIA), a novel database forcopy-move forgery detection(COVERAGE) and NIST nimble 2016 datasets(NIST 2016), respectively. The CASIA2.0 dataset images are small, complex and more challenging. F1 score is used as the benchmark for model evaluation. Moreover, F1 score is improved most on the CASIA2.0 dataset, which is asymptotical 2.17% higher than the second method. To test the robustness of our approach, the F1 score is evaluated as well. U-Net and RRU-Net on images is interfered by JPEG compression and Gaussian blur. The comparison results demonstrate that the method has its optimal robustness. To verify the effectiveness of the proposed feature augmentation mechanism and region loss mechanism in this work, we also perform abundant ablation experiments. Anomaly region feature augmentation modeling has its advantage and models region loss models can achieve its more qualified results.ConclusionA region loss based U-Net architecture is illustrated in order to detect forgery region in images effectively and accurately. It mainly resolves the issue of feature augmentation and small forgery regions. The difference amongst local and dominant features has been sorted out to enhance the features from image anomaly regions. An illustrated region loss enhanced the learning of features in the forgery region caused by imbalanced sample issue. Ablation study has shown that feature augmentation and region loss mechanisms improve the proposed model calculation effectively. In addition, the JPEG compression and Gaussian blur tests also demonstrate the robustness. An effective forgery region detection method is implemented and facilitated.关键词:image forensics;small forgery region detection;feature augmentation;region loss;convolutional neural networks(CNNs);U-Net107|209|3更新时间:2024-05-07 -
 摘要:ObjectiveImages and videos manipulation is becoming more easy-use and indistinguishable with development of deep learning. Deepfake is a sort of face manipulation technique which poses a great threat to social security and individual rights. Researchers have been working to propose various detection models or frameworks, which can be divided into three categories combined with their inputs factors like frame level, clip level and video level, respectively. Detection models of frame level have focused on single frame and ignore temporal information only, potentially leading to low confidence in videos detection. Although detection models of clip level make use of a sequence of frames simultaneously, the length of sequence is relatively shorter than the real length of a video. Thus, a clip cannot well represent a video. Moreover, video clips are fragmented and may have adverse effect on video level detection. The consecutive frames in a short clip have little difference and cause redundant information, which may cut the detection performance. The video level detection methods use frames of large interval as input and capture more key features to represent qualified video. The existing methods ignore the impact of sample extraction procedure and its expensive computation of decoding video stream. To solve this problem and provide more efficient detection method on face-swap manipulation videos, a detection framework based on the interaction of key frames' features is illustrated.MethodThe proposed detection framework has consisted of two parts: key frames extraction in context of face region images extraction and the detection model. First, an amount of key frames from the video stream have been extracted and checked. Inter-frame decoding is avoided and computation time is deducted via key frames extraction. Next, multitask cascaded convolutional neural networks(MTCNN) is applied to locate the position of face region on the extracted frames. Face images are cropped with 80 margins from them. MTCNN is re-applied to the images extracted before. Compact face images are extracted from them. The face images input are mapped into high dimensional embedding space by Inception-ResNet-V1. This convolution neural network is initialized by pre-trained parameters in face recognition task and updated end-to-end implementation. At last, these features of key frames are melted into an interaction learning module, which contains various self-attention-based encoders. In this module, each key frame feature can learn from every other key frame and update itself. Distinctive abnormal features of manipulated images are extracted via part of linear and non-linear transformations. A global classification vector is concatenated at the first of key frame features, updating along with them, and makes the final decision.ResultThe detection framework has been evaluated on five mainstream datasets listed below: Deepfakes, FaceSwap, FaceShifter, DeepFakeDetection and Celeb-DF, respectively. The three datasets of Deepfakes, FaceSwap, FaceShifter are from FaceForensics++. It achieves accuracies of 97.50%, 97.14%, 96.79%, 97.09% and 98.64%, respectively, with a small quantity of key frames. Original 3D convolution models and LSTM-based models are compared with the illustrated detection model on Celeb-DF in terms of 16 key frames as input. A demonstrated lightweight 3D model(L3D) for deepfake detection has been tested as well. As the samples size is smaller than that of exisited work, R3D, C3D, I3D and L3D have demonstrated poor detection performance while LSTM-based one achieves an accuracy of 98.06%. The demonstrated model is much better than before (99.61%). In the condition that the input is changed to consecutive frames, the proposed model has shown qualified performance 98.64% as well. The time cost of detection is evaluated and illustrated that our framework can detect a video in an average time of 3.17 s, less than major models or with consecutive frames as input. The research strategy of key frame extraction and the framework proposed are shown to be efficient based on the experiments results. A realistic scene has been considered, in which key frames quantity of the video has been checked. A little more frames than training can achieve higher accuracy as the detection model has learned the relation well amongst frames and can be generalized well, but fewer frames can also lead to insufficient information and worse performance. In general, the proposed model can achieve good and stable detection performance, training with 16 key frames.ConclusionAn efficient detection framework for face-swap manipulation videos has been demonstrated. It takes the advantage of key frame extraction that it skips the procedure of inter-frame decoding and get time cutting in the preprocessing step. Based on face region images being cropped from valid key frames' pictures, Inception-ResNet-V1 maps them to a standardized embedding space followed by several layers of self-attention based encoders and linear or non-linear transformations. More meaningful and distinguishing information is captured when every frame feature can learn from each other. The experiments on Celeb-DF dataset demonstrate that the illustrated model outperforms other sequential model and 3D convolution neural networks. The time cost is relatively deducted and the effiency of the proposed framework is improved.关键词:Deepfake detection;face-swap manipulation videos;key frames;hierarchical structure;multi-frame interaction;self-attention mechanism164|271|5更新时间:2024-05-07
摘要:ObjectiveImages and videos manipulation is becoming more easy-use and indistinguishable with development of deep learning. Deepfake is a sort of face manipulation technique which poses a great threat to social security and individual rights. Researchers have been working to propose various detection models or frameworks, which can be divided into three categories combined with their inputs factors like frame level, clip level and video level, respectively. Detection models of frame level have focused on single frame and ignore temporal information only, potentially leading to low confidence in videos detection. Although detection models of clip level make use of a sequence of frames simultaneously, the length of sequence is relatively shorter than the real length of a video. Thus, a clip cannot well represent a video. Moreover, video clips are fragmented and may have adverse effect on video level detection. The consecutive frames in a short clip have little difference and cause redundant information, which may cut the detection performance. The video level detection methods use frames of large interval as input and capture more key features to represent qualified video. The existing methods ignore the impact of sample extraction procedure and its expensive computation of decoding video stream. To solve this problem and provide more efficient detection method on face-swap manipulation videos, a detection framework based on the interaction of key frames' features is illustrated.MethodThe proposed detection framework has consisted of two parts: key frames extraction in context of face region images extraction and the detection model. First, an amount of key frames from the video stream have been extracted and checked. Inter-frame decoding is avoided and computation time is deducted via key frames extraction. Next, multitask cascaded convolutional neural networks(MTCNN) is applied to locate the position of face region on the extracted frames. Face images are cropped with 80 margins from them. MTCNN is re-applied to the images extracted before. Compact face images are extracted from them. The face images input are mapped into high dimensional embedding space by Inception-ResNet-V1. This convolution neural network is initialized by pre-trained parameters in face recognition task and updated end-to-end implementation. At last, these features of key frames are melted into an interaction learning module, which contains various self-attention-based encoders. In this module, each key frame feature can learn from every other key frame and update itself. Distinctive abnormal features of manipulated images are extracted via part of linear and non-linear transformations. A global classification vector is concatenated at the first of key frame features, updating along with them, and makes the final decision.ResultThe detection framework has been evaluated on five mainstream datasets listed below: Deepfakes, FaceSwap, FaceShifter, DeepFakeDetection and Celeb-DF, respectively. The three datasets of Deepfakes, FaceSwap, FaceShifter are from FaceForensics++. It achieves accuracies of 97.50%, 97.14%, 96.79%, 97.09% and 98.64%, respectively, with a small quantity of key frames. Original 3D convolution models and LSTM-based models are compared with the illustrated detection model on Celeb-DF in terms of 16 key frames as input. A demonstrated lightweight 3D model(L3D) for deepfake detection has been tested as well. As the samples size is smaller than that of exisited work, R3D, C3D, I3D and L3D have demonstrated poor detection performance while LSTM-based one achieves an accuracy of 98.06%. The demonstrated model is much better than before (99.61%). In the condition that the input is changed to consecutive frames, the proposed model has shown qualified performance 98.64% as well. The time cost of detection is evaluated and illustrated that our framework can detect a video in an average time of 3.17 s, less than major models or with consecutive frames as input. The research strategy of key frame extraction and the framework proposed are shown to be efficient based on the experiments results. A realistic scene has been considered, in which key frames quantity of the video has been checked. A little more frames than training can achieve higher accuracy as the detection model has learned the relation well amongst frames and can be generalized well, but fewer frames can also lead to insufficient information and worse performance. In general, the proposed model can achieve good and stable detection performance, training with 16 key frames.ConclusionAn efficient detection framework for face-swap manipulation videos has been demonstrated. It takes the advantage of key frame extraction that it skips the procedure of inter-frame decoding and get time cutting in the preprocessing step. Based on face region images being cropped from valid key frames' pictures, Inception-ResNet-V1 maps them to a standardized embedding space followed by several layers of self-attention based encoders and linear or non-linear transformations. More meaningful and distinguishing information is captured when every frame feature can learn from each other. The experiments on Celeb-DF dataset demonstrate that the illustrated model outperforms other sequential model and 3D convolution neural networks. The time cost is relatively deducted and the effiency of the proposed framework is improved.关键词:Deepfake detection;face-swap manipulation videos;key frames;hierarchical structure;multi-frame interaction;self-attention mechanism164|271|5更新时间:2024-05-07 -
 摘要:ObjectiveDigital images have become the main interface for people to acquire and disseminate information. People can easily replace digital image content with fake to achieve a certain purpose via widespread availability of image processing and editing tools. Hence, it is one of the research hotspots in the field of information content security to judge the authenticity of the content of the digital image, and even restore the tampered area. Digital image self-embedding watermarking technology is one of the key technical implications constrained by low authentication accuracy and extremely quality loss without filtering. In order to improve the authentication accuracy and the resistance to filtering and other processing operations, a semi-fragile image self-embedding watermarking algorithm based on block truncation coding is proposed.Method1) Watermarking generation and embedding: the image is divided into 4×4 image blocks, and each 4×4 image block is further divided into 2×2 image blocks. Then, block truncation coding is used to compress and encode each image block as the self-embedding watermarking information of the image block, and hash the self-embedding watermarking as the authentication watermarking information of the image block. At last, the self-embedded watermarking information and the authentication watermarking information form the watermarking information, which is embedded in the mapping block. 2)Tampering detection and recovery: At the beginning, the authentication watermarking information of 4×4 blocks is compared to identify the tampering of the image block, and then set a threshold to determine the tampering of the 2×2 image blocks based on the block truncation coding information and restore it. The algorithm uses block truncation coding to effectively shorten the watermarking information generated for 4×4 image blocks. The watermarking information is just embedded in the lowest two bits of the pixel, the quality of the image is guaranteed following the embedded watermarking and 2×2 image targeted blocks based on interpolation of the quantized information, Eventually, the 2×2 image blocks is restored based on the authentication analysis. The algorithm uses block truncation coding, which effectively shortens the length of the generated watermarking and guarantee the quality of the image while the watermarking is embedded. In addition, the watermarking can be robust to image processing operations such as filtering via the introduction of a tolerable modification threshold in terms of the inspection for tampering of images.ResultThe illustrated algorithm demonstrates that the peak signal-to-noise ratio(PSNR) of watermarked images generated are all higher than 44 dB, and the quality of the restored image can reach 32.7 dB at tampering rate of 50 %. The algorithm takes about 3.15 s to generate and embed watermarking on an image, and it takes about 3.6 s to restore an image. The demonstration analyzes the authentication after smoothing filtering, and verifies that the algorithm has certain robustness to smoothing filtering, and the effect of resisting Gaussian filtering is the most qualified. The robustness of the mean and median filtering is the strongest when the filter core is 3×3, and more than 90 % of the image blocks can be authenticated. The robustness of the mean and median filtering still decreases with the increase of the filter core. The robustness to Gaussian filtering is the strongest when σ is 0.4, and more than 95 % of the image blocks can be authenticated. The robustness of Gaussian filtering decreases with the σ increase. In addition, multi-sets of threshold experiments have been conducted to analyze the impact of the algorithm' s threshold setting in the context of the robustness of smoothing filtering. The results demonstrate that the larger the threshold is, the stronger the robustness generated. The algorithm is still sensitive to severe tampering while the threshold increases.ConclusionTampering and filtering of different scene images is evolved. The illustration of the tolerable modification threshold is sorted out watermarking. It demonstrates that the algorithm can realize the authentication and recovery of the tampering of the local area of the image. Qualified robustness is obtained via regularized processing, such as mean, median and Gaussian filtering. As a result, the comparison with the current methods verifies the advantages of the algorithm in image quality in accordance with watermarking and restoration of image quality.关键词:semi-fragile watermarking;self-embedding;block truncation coding;tampering authentication;tampering recover89|118|1更新时间:2024-05-07
摘要:ObjectiveDigital images have become the main interface for people to acquire and disseminate information. People can easily replace digital image content with fake to achieve a certain purpose via widespread availability of image processing and editing tools. Hence, it is one of the research hotspots in the field of information content security to judge the authenticity of the content of the digital image, and even restore the tampered area. Digital image self-embedding watermarking technology is one of the key technical implications constrained by low authentication accuracy and extremely quality loss without filtering. In order to improve the authentication accuracy and the resistance to filtering and other processing operations, a semi-fragile image self-embedding watermarking algorithm based on block truncation coding is proposed.Method1) Watermarking generation and embedding: the image is divided into 4×4 image blocks, and each 4×4 image block is further divided into 2×2 image blocks. Then, block truncation coding is used to compress and encode each image block as the self-embedding watermarking information of the image block, and hash the self-embedding watermarking as the authentication watermarking information of the image block. At last, the self-embedded watermarking information and the authentication watermarking information form the watermarking information, which is embedded in the mapping block. 2)Tampering detection and recovery: At the beginning, the authentication watermarking information of 4×4 blocks is compared to identify the tampering of the image block, and then set a threshold to determine the tampering of the 2×2 image blocks based on the block truncation coding information and restore it. The algorithm uses block truncation coding to effectively shorten the watermarking information generated for 4×4 image blocks. The watermarking information is just embedded in the lowest two bits of the pixel, the quality of the image is guaranteed following the embedded watermarking and 2×2 image targeted blocks based on interpolation of the quantized information, Eventually, the 2×2 image blocks is restored based on the authentication analysis. The algorithm uses block truncation coding, which effectively shortens the length of the generated watermarking and guarantee the quality of the image while the watermarking is embedded. In addition, the watermarking can be robust to image processing operations such as filtering via the introduction of a tolerable modification threshold in terms of the inspection for tampering of images.ResultThe illustrated algorithm demonstrates that the peak signal-to-noise ratio(PSNR) of watermarked images generated are all higher than 44 dB, and the quality of the restored image can reach 32.7 dB at tampering rate of 50 %. The algorithm takes about 3.15 s to generate and embed watermarking on an image, and it takes about 3.6 s to restore an image. The demonstration analyzes the authentication after smoothing filtering, and verifies that the algorithm has certain robustness to smoothing filtering, and the effect of resisting Gaussian filtering is the most qualified. The robustness of the mean and median filtering is the strongest when the filter core is 3×3, and more than 90 % of the image blocks can be authenticated. The robustness of the mean and median filtering still decreases with the increase of the filter core. The robustness to Gaussian filtering is the strongest when σ is 0.4, and more than 95 % of the image blocks can be authenticated. The robustness of Gaussian filtering decreases with the σ increase. In addition, multi-sets of threshold experiments have been conducted to analyze the impact of the algorithm' s threshold setting in the context of the robustness of smoothing filtering. The results demonstrate that the larger the threshold is, the stronger the robustness generated. The algorithm is still sensitive to severe tampering while the threshold increases.ConclusionTampering and filtering of different scene images is evolved. The illustration of the tolerable modification threshold is sorted out watermarking. It demonstrates that the algorithm can realize the authentication and recovery of the tampering of the local area of the image. Qualified robustness is obtained via regularized processing, such as mean, median and Gaussian filtering. As a result, the comparison with the current methods verifies the advantages of the algorithm in image quality in accordance with watermarking and restoration of image quality.关键词:semi-fragile watermarking;self-embedding;block truncation coding;tampering authentication;tampering recover89|118|1更新时间:2024-05-07
Forgery Detection and Content Recovery
-
 摘要:ObjectiveBig multimedia data is acquired via various multimedia sensors and mobile devices nowadays. It is necessary to implement low-cost sampling compression coding due to the limited computing resources and large data volume of sensors and mobile devices.. Illegal applications from extracting valuable information is to be prevented during sampling and transmission. Compressed sensing has credited for data collection in the internet of things(IoT). As a novel signal acquisition theory, compressed sensing, has been focused on. The compressed sensing framework is a sort of encryption scheme. Compared with conventional encryption schemes, compressed sensing encryption schemes have their advantages, such as low computational cost of encryption process, synchronized realization of encryption and compression, and robustness of ciphertext. The compressed sensing framework for information authority will be concentrated. A way for the recipient has been confirmed the integrity of the information for information tampers. The emerging verification code is to check whether the content of the message has been changed in the process of message delivery, regardless of the accidental or deliberate attack change. The identity verification of the message source is to confirm the source of the message. A sequence value of a certain length is first obtained via the initial compressed message. The sequence value of the same length is generated for the verified message again in accordance with the one mapping method. The initial sequence to get the results have been compared with incomplete data. But, conventional methods are ineffective due to the avalanche effect of compressed sensing. In the compressed sensing framework, the measured value is transmitted instead of the original signal. The receiving end receives the measured value, and the original signal needs to be restored with a restoration algorithm. Compressed sensing can only make the restored signal approximate to the original signal. The message verification sequence generated by the receiving end is completely different from the received verification sequence. In the IoT perception layer, there are some constraints in data acquisition resource and suffer from privacy leakage and illegal tampering. To resolve energy consumption and security in IoT data acquisition, a verifiable image encryption method has been illustrated based on semi-tensor product compression sensing.MethodFirst, The measurement matrix and the verification matrix based on the cascade chaotic system are used to sample the sparse signal in terms of semi-tensor product application. The measured value matrix is further used for Arnold scrambling to obtain the final secret image. Simultaneously, the identity verification code is generated by the identity verification matrix and transmitted on the public channel, and the initial seed of the cascade chaotic system is as the key for transmission on the secure channel.ResultKey space analysis, key sensitivity analysis, image entropy analysis, histogram analysis, correlation analysis, identity verification analysis, compression rate analysis have been tested and analyzed overall. The demonstrated results show that the encrypted image entropy in the scheme illustrated is closer to 8, while the encrypted image correlation coefficient is close to 0.ConclusionThe verifiable encryption algorithm has integrated the advantages of semi-tensor compression perception. The security and integrity of data transmission has been realized effectively in terms of the decrease of energy consumption of data sampling.关键词:semi-tensor product;compressed sensing;message verification mechanism;cascade chaotic system;image encryption55|133|6更新时间:2024-05-07
摘要:ObjectiveBig multimedia data is acquired via various multimedia sensors and mobile devices nowadays. It is necessary to implement low-cost sampling compression coding due to the limited computing resources and large data volume of sensors and mobile devices.. Illegal applications from extracting valuable information is to be prevented during sampling and transmission. Compressed sensing has credited for data collection in the internet of things(IoT). As a novel signal acquisition theory, compressed sensing, has been focused on. The compressed sensing framework is a sort of encryption scheme. Compared with conventional encryption schemes, compressed sensing encryption schemes have their advantages, such as low computational cost of encryption process, synchronized realization of encryption and compression, and robustness of ciphertext. The compressed sensing framework for information authority will be concentrated. A way for the recipient has been confirmed the integrity of the information for information tampers. The emerging verification code is to check whether the content of the message has been changed in the process of message delivery, regardless of the accidental or deliberate attack change. The identity verification of the message source is to confirm the source of the message. A sequence value of a certain length is first obtained via the initial compressed message. The sequence value of the same length is generated for the verified message again in accordance with the one mapping method. The initial sequence to get the results have been compared with incomplete data. But, conventional methods are ineffective due to the avalanche effect of compressed sensing. In the compressed sensing framework, the measured value is transmitted instead of the original signal. The receiving end receives the measured value, and the original signal needs to be restored with a restoration algorithm. Compressed sensing can only make the restored signal approximate to the original signal. The message verification sequence generated by the receiving end is completely different from the received verification sequence. In the IoT perception layer, there are some constraints in data acquisition resource and suffer from privacy leakage and illegal tampering. To resolve energy consumption and security in IoT data acquisition, a verifiable image encryption method has been illustrated based on semi-tensor product compression sensing.MethodFirst, The measurement matrix and the verification matrix based on the cascade chaotic system are used to sample the sparse signal in terms of semi-tensor product application. The measured value matrix is further used for Arnold scrambling to obtain the final secret image. Simultaneously, the identity verification code is generated by the identity verification matrix and transmitted on the public channel, and the initial seed of the cascade chaotic system is as the key for transmission on the secure channel.ResultKey space analysis, key sensitivity analysis, image entropy analysis, histogram analysis, correlation analysis, identity verification analysis, compression rate analysis have been tested and analyzed overall. The demonstrated results show that the encrypted image entropy in the scheme illustrated is closer to 8, while the encrypted image correlation coefficient is close to 0.ConclusionThe verifiable encryption algorithm has integrated the advantages of semi-tensor compression perception. The security and integrity of data transmission has been realized effectively in terms of the decrease of energy consumption of data sampling.关键词:semi-tensor product;compressed sensing;message verification mechanism;cascade chaotic system;image encryption55|133|6更新时间:2024-05-07
Authentication Protection
-
 摘要:ObjectiveSteganography is a way of covert communication to achieve the transmission of a secret message via slight modification of the elements on the cover images without causing suspicion of the steganalysis. Security is capable to embed the secret message with minimal distortion via syndrome-trellis codes (STC), steganographic polar codes (SPC) or optimal analogue embedding. The embedding rate and loss function is demonstrated. The initial symmetric distortions function assigns the same cost for the modification of pixel values ±1. Some adapting methods on top of symmetric distortion have also been generated, demonstrating the effectiveness of asymmetric distortion steganography for improving steganographic security. To improve steganography security, the prompted guidance of the adjustment of the initial cost and previous work has proved that the quantization error information provided via image downsampling used as auxiliary information Steganography does not have the original image before downsampling in many real scenes. For computer vision, super-resolution tasks are rapidly evolving, which can end-to-end generate high-resolution images corresponding to low-resolution images. In order to get the high-resolution images before downsampling based on the downsampled side information, this research has proposed a steganography based on super-resolution networks for estimating side information of spatial domain images. The unique side information provided by the estimated high-resolution images in the downsampling process can effectively improve steganography security excluding high scaling.MethodBased on the initial side information steganography method, the steganographer cover for embedding is obtained via various image processing processes in common, such as the downsampling process involved. A pre-cover downsampling image has been called for obtained cover. This research has briefly proposed some relevant super-resolution networks to assess the quality of the resulting image via peak signal to noise ratio (PSNR) and polarity estimation correctness initially. The network that can make the largest contribution to stenographic security is opted for the first step of estimating the side information, i.e., generating a high-resolution precover image. Current side information estimated steganography methods in the context of JPEG image steganography has derived their side information from the quantization error generated in the JPEG compression process. The cost effective strategy uses the degradation model of the original side information steganography, i.e., the solo polarity of the error is considered without the magnitude of the error. The modification cost of the pixel points is in the same scale. The current loss function in the spatial domain is used to obtain the cost of modification for each pixel. The image form with the same resolution as the cover is acquired via floating-point precision of the pre-cover downsampling. Based on the initial cost, the differentiation amongst the corresponding pixels is used to guide the modification of the pixels to achieve asymmetric distortion adjustment. A steganographic framework for side information has been estimated in spatial domain images based on super-resolution networks.ResultThe initial demonstration compare the degree of improvement in steganographic security for side information estimated based on various super-resolution networks. The residual channel attention network (RCAN) with a scaling of 2 as the side information estimating network model is illustrated at last. The optimal cost adjustment coefficients is experimentally obtained at different embedding rates. Three databases including break our steganographic system (BOSSBase), break our watermarking system 2 (BOWS2) and mixed resized never-compressed (MRNC) and two initial distortion functions in the context of high-pass, low-pass, and low-pass (HILL) and unIversal wavelet relative distortion for the spatial (SUNIWARD) are used to test the security of the demonstrated method against manual feature and network steganalysis. In terms of cross-database steganographic security, such as BOWS2, the security method is significantly improved against spatial rich model (SRM) and steganalysis residual network (SRNet) steganalysis compared with the original method HILL. When the embedding rate is 0.5 bit/pixel, the demonstrated method improves 6.67 % and 6.9 %, respectively. The embedding rate is 0.1 bit/pixel based on the improvement of 1.74 % and 5.8 % each. Meanwhile, this analysis improves 4.04 % and 4.0 %, respectively, over the two traditional steganography methods on cover images set that are not directly derived from the downsampling process. The difference has been shown and the original side information steganography is compared on the training set cover in terms of steganographic security and modification point distribution. Both side information estimated steganography and original side information steganography greatly improve steganographic security, but their modification modes are different. The initial distortion is calculated with the HILL and the embedding rate is 0.1 bit/pixel in particular. The security of the proposed method exceeds that of original side information steganography method by 1.08 % against SRM steganalysis. The embedding rate is 0.5 bit/pixel. The security of the proposed method exceeds that of original side information steganography by 0.6 % against SRNet steganalysis. It is illustrated that the analyzed method has its priority on the steganography of initial side information steganography in some cases.ConclusionThe estimated downsampled side information has been proposed first to adjust the initial cost of modified pixels in order to distinguish the modified loss of pixel points in different directions for asymmetric distortion steganography. To obtain effective auxiliary information, a super-resolution network to estimate the corresponding high-resolution image of the cover has been proposed simultaneously. The cost adjustment integrated strategy is improving the steganographic security effectively. Compared with original side information steganography, the research priority is that it can be widely applied to steganography of multi-sources cover images while original side information steganography cannot be applied, i.e., the original high-resolution image cannot be obtained, and has a wider application scenario than original side information steganography. In addition, the research method can be applied to the field of JPEG domain. Limitation there is still a certain gap based on the illustrated security method in most scenarios where both methods can be applied. The estimated side information steganography method has been developing more suitable network structures and cost modification strategies further.关键词:steganography;side information estimation;super-resolution networks;downsampling;cost adjustment75|85|2更新时间:2024-05-07
摘要:ObjectiveSteganography is a way of covert communication to achieve the transmission of a secret message via slight modification of the elements on the cover images without causing suspicion of the steganalysis. Security is capable to embed the secret message with minimal distortion via syndrome-trellis codes (STC), steganographic polar codes (SPC) or optimal analogue embedding. The embedding rate and loss function is demonstrated. The initial symmetric distortions function assigns the same cost for the modification of pixel values ±1. Some adapting methods on top of symmetric distortion have also been generated, demonstrating the effectiveness of asymmetric distortion steganography for improving steganographic security. To improve steganography security, the prompted guidance of the adjustment of the initial cost and previous work has proved that the quantization error information provided via image downsampling used as auxiliary information Steganography does not have the original image before downsampling in many real scenes. For computer vision, super-resolution tasks are rapidly evolving, which can end-to-end generate high-resolution images corresponding to low-resolution images. In order to get the high-resolution images before downsampling based on the downsampled side information, this research has proposed a steganography based on super-resolution networks for estimating side information of spatial domain images. The unique side information provided by the estimated high-resolution images in the downsampling process can effectively improve steganography security excluding high scaling.MethodBased on the initial side information steganography method, the steganographer cover for embedding is obtained via various image processing processes in common, such as the downsampling process involved. A pre-cover downsampling image has been called for obtained cover. This research has briefly proposed some relevant super-resolution networks to assess the quality of the resulting image via peak signal to noise ratio (PSNR) and polarity estimation correctness initially. The network that can make the largest contribution to stenographic security is opted for the first step of estimating the side information, i.e., generating a high-resolution precover image. Current side information estimated steganography methods in the context of JPEG image steganography has derived their side information from the quantization error generated in the JPEG compression process. The cost effective strategy uses the degradation model of the original side information steganography, i.e., the solo polarity of the error is considered without the magnitude of the error. The modification cost of the pixel points is in the same scale. The current loss function in the spatial domain is used to obtain the cost of modification for each pixel. The image form with the same resolution as the cover is acquired via floating-point precision of the pre-cover downsampling. Based on the initial cost, the differentiation amongst the corresponding pixels is used to guide the modification of the pixels to achieve asymmetric distortion adjustment. A steganographic framework for side information has been estimated in spatial domain images based on super-resolution networks.ResultThe initial demonstration compare the degree of improvement in steganographic security for side information estimated based on various super-resolution networks. The residual channel attention network (RCAN) with a scaling of 2 as the side information estimating network model is illustrated at last. The optimal cost adjustment coefficients is experimentally obtained at different embedding rates. Three databases including break our steganographic system (BOSSBase), break our watermarking system 2 (BOWS2) and mixed resized never-compressed (MRNC) and two initial distortion functions in the context of high-pass, low-pass, and low-pass (HILL) and unIversal wavelet relative distortion for the spatial (SUNIWARD) are used to test the security of the demonstrated method against manual feature and network steganalysis. In terms of cross-database steganographic security, such as BOWS2, the security method is significantly improved against spatial rich model (SRM) and steganalysis residual network (SRNet) steganalysis compared with the original method HILL. When the embedding rate is 0.5 bit/pixel, the demonstrated method improves 6.67 % and 6.9 %, respectively. The embedding rate is 0.1 bit/pixel based on the improvement of 1.74 % and 5.8 % each. Meanwhile, this analysis improves 4.04 % and 4.0 %, respectively, over the two traditional steganography methods on cover images set that are not directly derived from the downsampling process. The difference has been shown and the original side information steganography is compared on the training set cover in terms of steganographic security and modification point distribution. Both side information estimated steganography and original side information steganography greatly improve steganographic security, but their modification modes are different. The initial distortion is calculated with the HILL and the embedding rate is 0.1 bit/pixel in particular. The security of the proposed method exceeds that of original side information steganography method by 1.08 % against SRM steganalysis. The embedding rate is 0.5 bit/pixel. The security of the proposed method exceeds that of original side information steganography by 0.6 % against SRNet steganalysis. It is illustrated that the analyzed method has its priority on the steganography of initial side information steganography in some cases.ConclusionThe estimated downsampled side information has been proposed first to adjust the initial cost of modified pixels in order to distinguish the modified loss of pixel points in different directions for asymmetric distortion steganography. To obtain effective auxiliary information, a super-resolution network to estimate the corresponding high-resolution image of the cover has been proposed simultaneously. The cost adjustment integrated strategy is improving the steganographic security effectively. Compared with original side information steganography, the research priority is that it can be widely applied to steganography of multi-sources cover images while original side information steganography cannot be applied, i.e., the original high-resolution image cannot be obtained, and has a wider application scenario than original side information steganography. In addition, the research method can be applied to the field of JPEG domain. Limitation there is still a certain gap based on the illustrated security method in most scenarios where both methods can be applied. The estimated side information steganography method has been developing more suitable network structures and cost modification strategies further.关键词:steganography;side information estimation;super-resolution networks;downsampling;cost adjustment75|85|2更新时间:2024-05-07 -
 摘要:ObjectiveA huge amount of digital images are transmitted via new media online. In order to reduce the storage cost, initial digital images processing is conducted and, transmitted via the lossy compression channels. Based on original steganography scheme, it is often unable to extract the correct embedded secret messages from the transmitted compressed stego image completely when a stego image is transmitted via the lossy compression channel. The information loss leads to the failure of covert communication. The previous steganography method ignores the robustness performance, and the integrity of secret messages is difficult to be persistent. As an extension of branch of data hiding, some robust watermarking methods cannot ensure that the embedded watermark is extracted entirely. In order to achieve the robustness of the embedded watermark, the size of a watermark is often smaller than the size of secret messages in image steganography. In addition, the robust watermarking schemes ignore the anti-detection performance which decreases the statistical security in common. Hence, a secure and robust JPEG steganography technology is required in practice to ensure the robustness of the transmitted compressed stego images and protect the integrity of secret messages. A challenge to illustrate a robust steganography algorithm with strong anti-compression performance, strong anti-detection performance and high imperceptibility of stego images need to be dealt with. To minimize the loss of image information, a robust steganography algorithm for JPEG image based on the lossless carrier construction and the robust cost design is proposed.MethodFirst, the relevance between security and robustness in steganography is analyzed and demonstrated. The current robust steganography methods utilize syndrome-trellis code (STC) to improve the security of stego image as usual. The amount of modified pixels is decreased via minimizing the distortion. To avoid the influence of error diffusion caused by STC, the presentation of the modified DCT coefficients should be stable excluding other modified coefficients. By constructing the lossless carrier, the balance between security and robustness can be effectively maintained. After differentiating the spatial blocks of a compressed JPEG image processing in the lossy channel, the lossless carrier can be acquired as the robust embedding domain. Next, the distortion minimization in STC is transformed into the minimization of image information loss. By calculating the spatial information loss with a secret bit embedding, a robust cost is designed to measure the anti-compression performance of each DCT coefficient. And the robust cost can efficiently distinguish the robustness of DCT coefficients in lossy compression channels with lower quality factors. At last, STC is utilized to embed secret messages in relation to lossless carrier and robust cost, and an intermediate image is generated. The transmitted compressed stego image maintains high visual quality and strong anti-detection via the lossy compression channel. The secret messages can resist JPEG compression and can be extracted in the right way.ResultThe experiments are conducted via comparing with the conventional JPEG steganography and the common robust steganography on BossBase1.01 image database. Compared with traditional JPEG steganography, the proposed lossless carrier construction as the embedding domain can effectively reduce the average error rate of secret messages extraction by 24.97 %, and improve the average success rate of stego images by 21.35 %. The robust cost can further reduce the average error rate of secret messages extraction by 1.05 %, and improve the average success rate of stego images by 16.12 %, which demonstrates the improved anti-compression performance intensively. Compared with other steganography schemes, the average error rate of secret message extraction is decreased by 95.78 %, 93.17 %, and 87.38 %, respectively. And the average success rate of stego images extraction is 86.69 times, 30.74 times and 4.13 times of other three compared steganography methods. The visual qualities of intermediate images and transmitted compressed stego images keep close to that of the original steganography scheme. In the lossy compression channels with quality factors 50, 60, and 70, the visual qualities of the intermediate images generated by the proposed method are all above 55 dB, and the visual qualities of the transmitted compressed stego images are all above 50 dB. The anti-detection performance is qualified.ConclusionThe illustrated steganography method can resist JPEG compression with a low-quality factor and high compression rate. The lossless carrier construction and robust cost design are analyzed and verified for good robustness performance via minimizing the spatial information loss of stego images.关键词:robust steganography;JPEG images;lossless carrier;robust cost;syndrome-trellis code(STC)73|157|3更新时间:2024-05-07
摘要:ObjectiveA huge amount of digital images are transmitted via new media online. In order to reduce the storage cost, initial digital images processing is conducted and, transmitted via the lossy compression channels. Based on original steganography scheme, it is often unable to extract the correct embedded secret messages from the transmitted compressed stego image completely when a stego image is transmitted via the lossy compression channel. The information loss leads to the failure of covert communication. The previous steganography method ignores the robustness performance, and the integrity of secret messages is difficult to be persistent. As an extension of branch of data hiding, some robust watermarking methods cannot ensure that the embedded watermark is extracted entirely. In order to achieve the robustness of the embedded watermark, the size of a watermark is often smaller than the size of secret messages in image steganography. In addition, the robust watermarking schemes ignore the anti-detection performance which decreases the statistical security in common. Hence, a secure and robust JPEG steganography technology is required in practice to ensure the robustness of the transmitted compressed stego images and protect the integrity of secret messages. A challenge to illustrate a robust steganography algorithm with strong anti-compression performance, strong anti-detection performance and high imperceptibility of stego images need to be dealt with. To minimize the loss of image information, a robust steganography algorithm for JPEG image based on the lossless carrier construction and the robust cost design is proposed.MethodFirst, the relevance between security and robustness in steganography is analyzed and demonstrated. The current robust steganography methods utilize syndrome-trellis code (STC) to improve the security of stego image as usual. The amount of modified pixels is decreased via minimizing the distortion. To avoid the influence of error diffusion caused by STC, the presentation of the modified DCT coefficients should be stable excluding other modified coefficients. By constructing the lossless carrier, the balance between security and robustness can be effectively maintained. After differentiating the spatial blocks of a compressed JPEG image processing in the lossy channel, the lossless carrier can be acquired as the robust embedding domain. Next, the distortion minimization in STC is transformed into the minimization of image information loss. By calculating the spatial information loss with a secret bit embedding, a robust cost is designed to measure the anti-compression performance of each DCT coefficient. And the robust cost can efficiently distinguish the robustness of DCT coefficients in lossy compression channels with lower quality factors. At last, STC is utilized to embed secret messages in relation to lossless carrier and robust cost, and an intermediate image is generated. The transmitted compressed stego image maintains high visual quality and strong anti-detection via the lossy compression channel. The secret messages can resist JPEG compression and can be extracted in the right way.ResultThe experiments are conducted via comparing with the conventional JPEG steganography and the common robust steganography on BossBase1.01 image database. Compared with traditional JPEG steganography, the proposed lossless carrier construction as the embedding domain can effectively reduce the average error rate of secret messages extraction by 24.97 %, and improve the average success rate of stego images by 21.35 %. The robust cost can further reduce the average error rate of secret messages extraction by 1.05 %, and improve the average success rate of stego images by 16.12 %, which demonstrates the improved anti-compression performance intensively. Compared with other steganography schemes, the average error rate of secret message extraction is decreased by 95.78 %, 93.17 %, and 87.38 %, respectively. And the average success rate of stego images extraction is 86.69 times, 30.74 times and 4.13 times of other three compared steganography methods. The visual qualities of intermediate images and transmitted compressed stego images keep close to that of the original steganography scheme. In the lossy compression channels with quality factors 50, 60, and 70, the visual qualities of the intermediate images generated by the proposed method are all above 55 dB, and the visual qualities of the transmitted compressed stego images are all above 50 dB. The anti-detection performance is qualified.ConclusionThe illustrated steganography method can resist JPEG compression with a low-quality factor and high compression rate. The lossless carrier construction and robust cost design are analyzed and verified for good robustness performance via minimizing the spatial information loss of stego images.关键词:robust steganography;JPEG images;lossless carrier;robust cost;syndrome-trellis code(STC)73|157|3更新时间:2024-05-07 -
 摘要:ObjectiveThe transform domain based on information embedding technique has been demonstrated to design robust image watermarking algorithm, which aims to make copyright protection and identify the ownership of the image. For Krawtchouk transform (KT), it converts the real-valued image domain to real-valued transform domain. Its transform domain just represents the stationary information of the image domain. To represent more the image domain information dynamically, the original KT has been extended to discrete fractional Krawtchouk transform (DFrKT) with two more degree of freedom known as fractional orders. DFrKT has been used in many image and signal processing applications. But, more storage memory is required because it converts the real-valued image domain into the complex-valued transform domain during images processing. This research has extended the KT to propose the real discrete fractional Krawtchouk transform (RDFrKT). The RDFrKT inherits the merit of DFrKT and KT. The RDFrKT can hold the property of fractional order determined transform domain and obtain real-valued transform domain representation of image as well. Moreover, an image watermarking algorithm is designed and applied via embedding watermark information in the RDFrKT domain. The effect of RDFrKT for the watermarking algorithm is also compared with the original KT- based image watermarking algorithm.MethodThe RDFrKT has been constructed via taking the real fractional order form of the eigenvalue matrix of KT transform because the eigenvalue decomposition based fractional transform construction method has been proved as an effective way. This construction procedure is as following: First, the transform matrix of KT is performed by eigenvalue decomposition, which generates one eigenvalue matrix and two eigenvector matrixes. Next, the real fractional form of eigenvalue matrix is constructed to generate the RDFrKT transform matrix. Then, the two eigenvector matrixes and the fractional form of eigenvalue matrix are combined so as to generate the RDFrKT transform matrix. A gray image watermarking scheme is designed to embed watermark information in images based on the proposed RDFrKT. The watermarking algorithm employs a block-based watermark embedding strategy. First of all, the original image is divided into 4×4 image blocks, followed by the RDFrKT transform of each block. Second, the singular value decomposition (SVD) is performed on the RDFrKT transform domain of each block, generating one singular value matrix and two singular vector matrixes, known as left singular vector matrix and right singular vector matrix. Third, the watermark is embedded into the first column of the left singular vector matrix of each block. Finally, the watermarked image is acquired via combining the modified left singular vector matrix with the singular value matrix and right singular vector matrix, followed by inversely transforming the modified RDFrKT coefficients to the image domain. The watermark extraction procedure can be regarded as a reversed procedure of the watermark embedding scheme. The received image is divided into 4×4 image blocks. The RDFrKT is performed on each block with fractional orders with the watermark embedding scheme matching. SVD is conducted on the RDFrKT transform domain of each block. The watermark bit can be extracted from the first column of the left singular vector matrix.ResultBased on the public gray image database of Granada University, the proposed RDFrKT-based watermarking algorithm with the same watermark embedding strategy replacing the RDFrKT by discrete cosine transform(DCT) and KT respectively. Moreover, the proposed method is compared with the state-of-art Hu' s method. The quantitative evaluation metrics include peak signal to noise ratio (PSNR) and bit error rate (BER) to evaluate the performance of the proposed RDFrKT-based watermarking method. By embedding watermark information in the test image such that the average PSNR of the watermarked images is 37.58 dB, which customized the watermark invisible requirements. The watermarked image is submitted into various image manipulation and attack situations, including median filter, average filter, Gaussian filter, JPEG compression, image rescaling, salt and peppers noise and Gaussian noise. Watermark is extracted from the attacked watermarked image to verify the robustness of the watermarking method. BER is used to measure the robustness of the watermarking method. A smaller BER value represents qualified robustness performance. By comparing the KT based method and the proposed RDFrKT based method, The illustration shows that the average BER of the proposed RDFrKT based method dropped by 12.39 %, 10.04 %, 18.50 %, 71.49 %, 17.60 %, respectively, corresponding to the attack situations of median filter, average filter, Gaussian filter, JPEG compression, and image scaling.ConclusionThe proposed RDFrKT has evolved the real-valued transform domain property of initial KT and the fractional order manipulated transform domain property of DFrKT. As one application method of RDFrKT, a gray image robust watermarking algorithm has been designated that embeds watermark information in the RDFrKT domain. The demonstration shows that RDFrKT-based watermarking method has better performance to deal with interferences circumstances a, such as median filter, average filter, Gaussian filter, JPEG compression, and image scaling.关键词:real discrete fractional Krawtchouk transform (RDFrKT);Krawtchouk transform (KT);image watermarking;fractional transform;information hiding67|32|1更新时间:2024-05-07
摘要:ObjectiveThe transform domain based on information embedding technique has been demonstrated to design robust image watermarking algorithm, which aims to make copyright protection and identify the ownership of the image. For Krawtchouk transform (KT), it converts the real-valued image domain to real-valued transform domain. Its transform domain just represents the stationary information of the image domain. To represent more the image domain information dynamically, the original KT has been extended to discrete fractional Krawtchouk transform (DFrKT) with two more degree of freedom known as fractional orders. DFrKT has been used in many image and signal processing applications. But, more storage memory is required because it converts the real-valued image domain into the complex-valued transform domain during images processing. This research has extended the KT to propose the real discrete fractional Krawtchouk transform (RDFrKT). The RDFrKT inherits the merit of DFrKT and KT. The RDFrKT can hold the property of fractional order determined transform domain and obtain real-valued transform domain representation of image as well. Moreover, an image watermarking algorithm is designed and applied via embedding watermark information in the RDFrKT domain. The effect of RDFrKT for the watermarking algorithm is also compared with the original KT- based image watermarking algorithm.MethodThe RDFrKT has been constructed via taking the real fractional order form of the eigenvalue matrix of KT transform because the eigenvalue decomposition based fractional transform construction method has been proved as an effective way. This construction procedure is as following: First, the transform matrix of KT is performed by eigenvalue decomposition, which generates one eigenvalue matrix and two eigenvector matrixes. Next, the real fractional form of eigenvalue matrix is constructed to generate the RDFrKT transform matrix. Then, the two eigenvector matrixes and the fractional form of eigenvalue matrix are combined so as to generate the RDFrKT transform matrix. A gray image watermarking scheme is designed to embed watermark information in images based on the proposed RDFrKT. The watermarking algorithm employs a block-based watermark embedding strategy. First of all, the original image is divided into 4×4 image blocks, followed by the RDFrKT transform of each block. Second, the singular value decomposition (SVD) is performed on the RDFrKT transform domain of each block, generating one singular value matrix and two singular vector matrixes, known as left singular vector matrix and right singular vector matrix. Third, the watermark is embedded into the first column of the left singular vector matrix of each block. Finally, the watermarked image is acquired via combining the modified left singular vector matrix with the singular value matrix and right singular vector matrix, followed by inversely transforming the modified RDFrKT coefficients to the image domain. The watermark extraction procedure can be regarded as a reversed procedure of the watermark embedding scheme. The received image is divided into 4×4 image blocks. The RDFrKT is performed on each block with fractional orders with the watermark embedding scheme matching. SVD is conducted on the RDFrKT transform domain of each block. The watermark bit can be extracted from the first column of the left singular vector matrix.ResultBased on the public gray image database of Granada University, the proposed RDFrKT-based watermarking algorithm with the same watermark embedding strategy replacing the RDFrKT by discrete cosine transform(DCT) and KT respectively. Moreover, the proposed method is compared with the state-of-art Hu' s method. The quantitative evaluation metrics include peak signal to noise ratio (PSNR) and bit error rate (BER) to evaluate the performance of the proposed RDFrKT-based watermarking method. By embedding watermark information in the test image such that the average PSNR of the watermarked images is 37.58 dB, which customized the watermark invisible requirements. The watermarked image is submitted into various image manipulation and attack situations, including median filter, average filter, Gaussian filter, JPEG compression, image rescaling, salt and peppers noise and Gaussian noise. Watermark is extracted from the attacked watermarked image to verify the robustness of the watermarking method. BER is used to measure the robustness of the watermarking method. A smaller BER value represents qualified robustness performance. By comparing the KT based method and the proposed RDFrKT based method, The illustration shows that the average BER of the proposed RDFrKT based method dropped by 12.39 %, 10.04 %, 18.50 %, 71.49 %, 17.60 %, respectively, corresponding to the attack situations of median filter, average filter, Gaussian filter, JPEG compression, and image scaling.ConclusionThe proposed RDFrKT has evolved the real-valued transform domain property of initial KT and the fractional order manipulated transform domain property of DFrKT. As one application method of RDFrKT, a gray image robust watermarking algorithm has been designated that embeds watermark information in the RDFrKT domain. The demonstration shows that RDFrKT-based watermarking method has better performance to deal with interferences circumstances a, such as median filter, average filter, Gaussian filter, JPEG compression, and image scaling.关键词:real discrete fractional Krawtchouk transform (RDFrKT);Krawtchouk transform (KT);image watermarking;fractional transform;information hiding67|32|1更新时间:2024-05-07 -
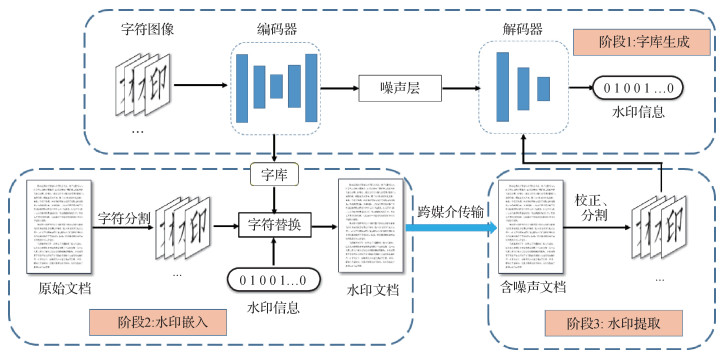 摘要:ObjectiveThe copyright protection has been the hotspot with the amount of digital documents increased dramatically. In order to protect the document copyright and locate the source of the leaked document, watermarking technology innovation for documents has been widely focused on. The protection can be realized via adding invisible digital watermark information (e.g., device number, date, etc.) to the document. To realize the traceability of document leakage, the leaked source can be located by extracting the watermark from the document once the watermarked document is leaked. Meanwhile, the current watermarking technology can also act as a deterrent which effectively reduce the occurrence of the leaking events. The current document watermarking methods can be divided into five categories: document structure based methods, natural language processing based methods, grid pattern based methods, image based methods and font based methods. Among them, the font based methods guarantee the best performance in the view of robustness and transparency. The main idea of such methods is representing the watermark information into the characteristics of the fonts (e.g., the size, shape or brightness) while the modified fonts maintain the high visual consistency with the original one. The robustness, transparency, capacity as well as the integrity can be achieved simultaneously. However, the existing font based methods need to design the modification features manually, and cannot automatically generate the new fonts. For the Chinese character system which contains a large number of characters, such methods will cause a labor cost workload and severely less efficiency. To overcome such drawbacks, this research proposes an automatic font generation based robust document watermarking scheme.MethodThe framework of such scheme is comprised of an end-to-end encoder-decoder structure automatic font generation network, a character selection embedder and a neural network based extractor. With the designed font generation network, the deformed font library is further utilized for embedding the watermark generated automatically. Meanwhile, a differentiable noise layer is complemented between the encoder and the decoder to simulate the distortion process in order to realize the robustness against different distortions, so that the encoder can learn better features to create the new font and the decoder can be trained to be adaptive to such distortions. This research designs a combined noise layer that can effectively simulate the common distortions via the common distortions in digital transmission channels (e.g., screenshots, scaling, Gaussian noise and JPEG compression). The whole font generation network consists of four parts: encoder, noise layer, decoder and adversarial recognizer. The encoder receives the watermark information and the carrier character image to generate the encoded character image. The noise layer adds noise to the encoded image to generate the noisy image. In particular, several of six simulated noise layers (identity mapping layer, scaling layer, translation layer, rotation layer, Gaussian noise layer and Gaussian blur layer) are randomly opted as a combined noise layer at each iteraction. The decoder receives the noisy image and outputs the corresponding watermark label. The adversarial recognizer tries to detect whether the current image is a carrier character image or an encoded one, which aids to improve the visual quality of the generated font. The encoder provides training samples for the extractor to ensure better extraction performance, and the extractor guides the generation direction of encoder to create better character images. The two coordinated modules make the generated font with higher visual quality and stronger robustness. Based on the well trained font generation, the network has generated the watermarked font library via feeding them with an original font library and different watermark signal. Each character in the font library can corresponds to different perturbation, which can be decoded to different watermark signal further. Hence, based on the generated font library, the corresponding character in the codebook is sorted out in the watermark embedding stage according to the current watermark information to replace the current character in the input document. The watermark information can be embedded into the whole original document and generate the watermarked document in this way. In the extraction stage, the whole document is firstly divided into some single character images by character segmentation after receiving the distorted watermarked document transmitted with digital channel. Each character is sent to the pre-trained decoder in the watermarking generation stage. The watermark information embedded in the current character can be accurately extracted. The characters in the document undergo the transformation distortion from digital signal to analog signal (A-D) process and from analog signal to digital signal (D-A) process, and the image quality is greatly reduced in the context of the print-scan scene. Simultaneously, such process that contained various image attacks cannot be accurately simulated by differentiable distortions, so the robustness against print-scanning distortions should be considered as a target. To achieve such robustness, this proposal is a fine-tuning scheme for the extractor which can effectively train the extractor to be adaptive to the print-scanning distortions. Specifically, the font generation model is fixed as a pre-training network and a set of following documents are embedded with watermarks based on the pre-trained embedder. The real print-scanning process is conducted on such documents to generate the distorted image library. Based on the distorted image and its watermark, the decoder is fine-tuned to be adaptive to the distorted features further. The robustness against print-scanning distortion can be achieved.ResultThis scheme embeds 252 bits of watermark into a real document containing 252 Chinese characters in comparison of the visual quality and robustness with other document watermarking methods. The results show that the peak signal to noise ratio(PSNR), structural similarity(SSIM) and subjective quality scores of the proposed scheme are higher with 11.68 dB, 0.08 and 5.8 % respectively, demonstrating the qualified visual quality of the proposed scheme. For the robustness, the watermark extraction rate of the scheme is 100 % under the screenshot and scaling, and the performance under JPEG compression and Gaussian noise is approximately equivalent to that of other methods. For the print-scan scene, the watermark extraction rates of the scheme in the font size of three, four, small four and five are realized 2.4 %, 3.07 %, 1.34 % and 0.02 %, respectively. The qualified performance is achieved under different mismatched printing and scanning qualities as well, which indicates that the scheme has higher robustness in resisting the print-scanning distortions.ConclusionCompared with the existing Chinese character watermarking methods based on the manually designed font library, the proposed scheme can automatically generate the tagged Chinese font library that is similar to the target font visually, which effectively reduces the complexity of the font generation. The experimental results show that the proposed document watermarking scheme has presented better visual quality and embedding capacity. In addition, the proposed scheme maintains the strong robustness against digital editing channel as well as the print-scanning channel. However, the scheme is not suitable yet for print-shooting and screen-shooting process at present. Future research will be concentrated on how to design robust document watermarking schemes for these two scenes.关键词:document watermarking;deep learning;Chinese font generation;anti digital distortion;anti print-scanning distortion104|88|6更新时间:2024-05-07
摘要:ObjectiveThe copyright protection has been the hotspot with the amount of digital documents increased dramatically. In order to protect the document copyright and locate the source of the leaked document, watermarking technology innovation for documents has been widely focused on. The protection can be realized via adding invisible digital watermark information (e.g., device number, date, etc.) to the document. To realize the traceability of document leakage, the leaked source can be located by extracting the watermark from the document once the watermarked document is leaked. Meanwhile, the current watermarking technology can also act as a deterrent which effectively reduce the occurrence of the leaking events. The current document watermarking methods can be divided into five categories: document structure based methods, natural language processing based methods, grid pattern based methods, image based methods and font based methods. Among them, the font based methods guarantee the best performance in the view of robustness and transparency. The main idea of such methods is representing the watermark information into the characteristics of the fonts (e.g., the size, shape or brightness) while the modified fonts maintain the high visual consistency with the original one. The robustness, transparency, capacity as well as the integrity can be achieved simultaneously. However, the existing font based methods need to design the modification features manually, and cannot automatically generate the new fonts. For the Chinese character system which contains a large number of characters, such methods will cause a labor cost workload and severely less efficiency. To overcome such drawbacks, this research proposes an automatic font generation based robust document watermarking scheme.MethodThe framework of such scheme is comprised of an end-to-end encoder-decoder structure automatic font generation network, a character selection embedder and a neural network based extractor. With the designed font generation network, the deformed font library is further utilized for embedding the watermark generated automatically. Meanwhile, a differentiable noise layer is complemented between the encoder and the decoder to simulate the distortion process in order to realize the robustness against different distortions, so that the encoder can learn better features to create the new font and the decoder can be trained to be adaptive to such distortions. This research designs a combined noise layer that can effectively simulate the common distortions via the common distortions in digital transmission channels (e.g., screenshots, scaling, Gaussian noise and JPEG compression). The whole font generation network consists of four parts: encoder, noise layer, decoder and adversarial recognizer. The encoder receives the watermark information and the carrier character image to generate the encoded character image. The noise layer adds noise to the encoded image to generate the noisy image. In particular, several of six simulated noise layers (identity mapping layer, scaling layer, translation layer, rotation layer, Gaussian noise layer and Gaussian blur layer) are randomly opted as a combined noise layer at each iteraction. The decoder receives the noisy image and outputs the corresponding watermark label. The adversarial recognizer tries to detect whether the current image is a carrier character image or an encoded one, which aids to improve the visual quality of the generated font. The encoder provides training samples for the extractor to ensure better extraction performance, and the extractor guides the generation direction of encoder to create better character images. The two coordinated modules make the generated font with higher visual quality and stronger robustness. Based on the well trained font generation, the network has generated the watermarked font library via feeding them with an original font library and different watermark signal. Each character in the font library can corresponds to different perturbation, which can be decoded to different watermark signal further. Hence, based on the generated font library, the corresponding character in the codebook is sorted out in the watermark embedding stage according to the current watermark information to replace the current character in the input document. The watermark information can be embedded into the whole original document and generate the watermarked document in this way. In the extraction stage, the whole document is firstly divided into some single character images by character segmentation after receiving the distorted watermarked document transmitted with digital channel. Each character is sent to the pre-trained decoder in the watermarking generation stage. The watermark information embedded in the current character can be accurately extracted. The characters in the document undergo the transformation distortion from digital signal to analog signal (A-D) process and from analog signal to digital signal (D-A) process, and the image quality is greatly reduced in the context of the print-scan scene. Simultaneously, such process that contained various image attacks cannot be accurately simulated by differentiable distortions, so the robustness against print-scanning distortions should be considered as a target. To achieve such robustness, this proposal is a fine-tuning scheme for the extractor which can effectively train the extractor to be adaptive to the print-scanning distortions. Specifically, the font generation model is fixed as a pre-training network and a set of following documents are embedded with watermarks based on the pre-trained embedder. The real print-scanning process is conducted on such documents to generate the distorted image library. Based on the distorted image and its watermark, the decoder is fine-tuned to be adaptive to the distorted features further. The robustness against print-scanning distortion can be achieved.ResultThis scheme embeds 252 bits of watermark into a real document containing 252 Chinese characters in comparison of the visual quality and robustness with other document watermarking methods. The results show that the peak signal to noise ratio(PSNR), structural similarity(SSIM) and subjective quality scores of the proposed scheme are higher with 11.68 dB, 0.08 and 5.8 % respectively, demonstrating the qualified visual quality of the proposed scheme. For the robustness, the watermark extraction rate of the scheme is 100 % under the screenshot and scaling, and the performance under JPEG compression and Gaussian noise is approximately equivalent to that of other methods. For the print-scan scene, the watermark extraction rates of the scheme in the font size of three, four, small four and five are realized 2.4 %, 3.07 %, 1.34 % and 0.02 %, respectively. The qualified performance is achieved under different mismatched printing and scanning qualities as well, which indicates that the scheme has higher robustness in resisting the print-scanning distortions.ConclusionCompared with the existing Chinese character watermarking methods based on the manually designed font library, the proposed scheme can automatically generate the tagged Chinese font library that is similar to the target font visually, which effectively reduces the complexity of the font generation. The experimental results show that the proposed document watermarking scheme has presented better visual quality and embedding capacity. In addition, the proposed scheme maintains the strong robustness against digital editing channel as well as the print-scanning channel. However, the scheme is not suitable yet for print-shooting and screen-shooting process at present. Future research will be concentrated on how to design robust document watermarking schemes for these two scenes.关键词:document watermarking;deep learning;Chinese font generation;anti digital distortion;anti print-scanning distortion104|88|6更新时间:2024-05-07 -
 摘要:ObjectiveReversible data hiding in encrypted images (RDHEI) aims to embed secret data in the encrypted images to protect users' privacy on cloud storage. It has attracted increasing attention recently since the original plaintext image and the secret data can be restored and extracted lossless. Data differentiation hiding in plaintext images, encrypted images have no correlation between adjacent pixels subject to low image redundancy. The embedding capacity levels of encrypted images have been improving due to its high practical value. The high embedding rate of the plaintext image depends on the image compression algorithm intensively. In terms of the high redundancy between adjacent pixels, more space can be vacated for embedding secret data via the plaintext image compressing. It is difficult to obtain higher compression space in the encrypted domain for the image compression algorithm. Current reversible data hiding algorithms in encrypted images can be divided into three frameworks as belows: vacating room after encryption (VRAE), vacating room by encryption(VRBE) and reserving room before encryption (RRBE). For VRAE, space is vacated via using a compression algorithm in encrypted images directly. This framework is difficult to obtain a high embedding rate in common. For VRBE, more attentions are paid to the impact of the encryption algorithm for the image processing. Customized encryption algorithms make the encrypted images maintain spatial correlation in adjacent pixels locally and make the compression algorithms have high performance in encrypted images as well. However, the current design of the encryption algorithm is relatively reduntant and time-consuming. RRBE is an efficient reversible data hiding framework in encrypted images, reserving room for secret data before the image is encrypted and ensuring high embedding rate and security accuracy both. RRBE is suitable for reversible data hiding in privacy protection. To obtain more compression room and improve the embedding rate of RRBE, this research has proposed a reversible data hiding method in encrypted images based on multi-most significant bit (MSB) planes compression coding.MethodFirst, a new bit-plane joint compression algorithm is designed. The bits in the MSB planes are rearranged to bit-streams that have long consecutive sequences of 0 or 1. The rearrangement scheme is based on block MSB planes and uses four types of scanning(row by row, row by column, column by row, column by column). The four rearranged bit-streams are respectively compressed via the combination of fixed-length coding and Huffman coding. Fixed-length coding takes full advantage of the correlation between bits in MSB planes and compresses the bits that the length of consecutive sequences of 0 or 1 equal to or greater than Ls. It is an extended run-length coding that uses a batch of Lfix bits to represent the length of the consecutive sequence, one bit for the type of this kind of code, and one bit for sequence content. Huffman coding addresses the issue of additional bits originated from the discontinuous short bit-sequence that the length of consecutive sequence of 0 or 1 less than Ls. It uses the Huffman algorithm to construct a codebook of short bit-sequences with the shortest average code length. Next, the shortest compressed bit-stream and the auxiliary information (Ls, Lfix, block size, type of scanning, the length of compressed bit-stream, and codebook) will be the demonstration of the original bit-planes. The content owner can reserve high-capacity room for data hider benefited from this compression algorithm. In order to divide the secret data extraction and image recovery, the vacated room is rearranged into LSB (least significant bit) planes. Then stream cipher with encryption key is utilized to encrypt the rearranged image, the vacated room in LSB planes of the encrypted image can embed secret data in accordance with data hiding key. At last, the receiver can directly extract secret data from LSB planes without compression information in MSB planes and recover the plaintext image without the information of LSB planes directly as well. Legitimate receivers achieve error-free secret data extraction based on data hiding key and lossless recovery of the original plaintext image by encryption key separately.ResultTo evaluate the performance of the proposed algorithm, experiments compare the proposed algorithm with four state-of-the-art RDHEI algorithms on five standard test images and three public datasets (an uncompressed color image database(UCID), Break Our Steganographic System(BOSSBase), and Break Our Watermarking System 2nd(BOWS-2)) and use the embedding rate, PSNR, and SSIM as the quantitative evaluation metrics. First of all, several experiments are replicated on five standard test images to pick the best parameters(Ls, Lfix, and the block size) of the proposed algorithm. Meanwhile, the parameters in the four state-of-the-art RDHEI algorithms are set for their best performance. Experimental results show that the average embedding rates of the proposed algorithm on the three datasets of UCID, BOSSBase, and BOWS-2 reach 2.123 4 bit/pixel, 2.410 7 bit/pixel and 2.380 3 bit/pixel respectively, which are 0.246 6 bit/pixel, 0.088 1 bit/pixel and 0.135 6 bit/pixel higher than the best state-of-the-art algorithm. The PSNR and SSIM are constant values that equal to +∞ and 1 respectively, which show that the proposed algorithm is reversible.ConclusionThis paper proposes a reversible data hiding algorithm in encrypted images based on joint fixed-length coding and Huffman coding with a high compression ratio. By using the correlation between adjacent pixels of a natural image, the multi-MSB planes of the image can be effectively compressed to reserve high-capacity room for embedding secret data. Based on this compression algorithm, a RRBE(reserving room before encryption) method of RDHEI is designed. Experimental results show that the proposed method achieves high embedding rate and separable reversible data hiding in encrypted images with its own priority. Although the embedding rate of the proposed method has been increased compared with the same type of RDHEI methods, the compression ratio is highly correlated with the smoothness of the original plaintext image. Non-smooth images embedding capacity improvement has been further to develop in the future.关键词:reversible data hiding;encrypted domain;fixed-length coding;Huffman coding;separately125|133|2更新时间:2024-05-07
摘要:ObjectiveReversible data hiding in encrypted images (RDHEI) aims to embed secret data in the encrypted images to protect users' privacy on cloud storage. It has attracted increasing attention recently since the original plaintext image and the secret data can be restored and extracted lossless. Data differentiation hiding in plaintext images, encrypted images have no correlation between adjacent pixels subject to low image redundancy. The embedding capacity levels of encrypted images have been improving due to its high practical value. The high embedding rate of the plaintext image depends on the image compression algorithm intensively. In terms of the high redundancy between adjacent pixels, more space can be vacated for embedding secret data via the plaintext image compressing. It is difficult to obtain higher compression space in the encrypted domain for the image compression algorithm. Current reversible data hiding algorithms in encrypted images can be divided into three frameworks as belows: vacating room after encryption (VRAE), vacating room by encryption(VRBE) and reserving room before encryption (RRBE). For VRAE, space is vacated via using a compression algorithm in encrypted images directly. This framework is difficult to obtain a high embedding rate in common. For VRBE, more attentions are paid to the impact of the encryption algorithm for the image processing. Customized encryption algorithms make the encrypted images maintain spatial correlation in adjacent pixels locally and make the compression algorithms have high performance in encrypted images as well. However, the current design of the encryption algorithm is relatively reduntant and time-consuming. RRBE is an efficient reversible data hiding framework in encrypted images, reserving room for secret data before the image is encrypted and ensuring high embedding rate and security accuracy both. RRBE is suitable for reversible data hiding in privacy protection. To obtain more compression room and improve the embedding rate of RRBE, this research has proposed a reversible data hiding method in encrypted images based on multi-most significant bit (MSB) planes compression coding.MethodFirst, a new bit-plane joint compression algorithm is designed. The bits in the MSB planes are rearranged to bit-streams that have long consecutive sequences of 0 or 1. The rearrangement scheme is based on block MSB planes and uses four types of scanning(row by row, row by column, column by row, column by column). The four rearranged bit-streams are respectively compressed via the combination of fixed-length coding and Huffman coding. Fixed-length coding takes full advantage of the correlation between bits in MSB planes and compresses the bits that the length of consecutive sequences of 0 or 1 equal to or greater than Ls. It is an extended run-length coding that uses a batch of Lfix bits to represent the length of the consecutive sequence, one bit for the type of this kind of code, and one bit for sequence content. Huffman coding addresses the issue of additional bits originated from the discontinuous short bit-sequence that the length of consecutive sequence of 0 or 1 less than Ls. It uses the Huffman algorithm to construct a codebook of short bit-sequences with the shortest average code length. Next, the shortest compressed bit-stream and the auxiliary information (Ls, Lfix, block size, type of scanning, the length of compressed bit-stream, and codebook) will be the demonstration of the original bit-planes. The content owner can reserve high-capacity room for data hider benefited from this compression algorithm. In order to divide the secret data extraction and image recovery, the vacated room is rearranged into LSB (least significant bit) planes. Then stream cipher with encryption key is utilized to encrypt the rearranged image, the vacated room in LSB planes of the encrypted image can embed secret data in accordance with data hiding key. At last, the receiver can directly extract secret data from LSB planes without compression information in MSB planes and recover the plaintext image without the information of LSB planes directly as well. Legitimate receivers achieve error-free secret data extraction based on data hiding key and lossless recovery of the original plaintext image by encryption key separately.ResultTo evaluate the performance of the proposed algorithm, experiments compare the proposed algorithm with four state-of-the-art RDHEI algorithms on five standard test images and three public datasets (an uncompressed color image database(UCID), Break Our Steganographic System(BOSSBase), and Break Our Watermarking System 2nd(BOWS-2)) and use the embedding rate, PSNR, and SSIM as the quantitative evaluation metrics. First of all, several experiments are replicated on five standard test images to pick the best parameters(Ls, Lfix, and the block size) of the proposed algorithm. Meanwhile, the parameters in the four state-of-the-art RDHEI algorithms are set for their best performance. Experimental results show that the average embedding rates of the proposed algorithm on the three datasets of UCID, BOSSBase, and BOWS-2 reach 2.123 4 bit/pixel, 2.410 7 bit/pixel and 2.380 3 bit/pixel respectively, which are 0.246 6 bit/pixel, 0.088 1 bit/pixel and 0.135 6 bit/pixel higher than the best state-of-the-art algorithm. The PSNR and SSIM are constant values that equal to +∞ and 1 respectively, which show that the proposed algorithm is reversible.ConclusionThis paper proposes a reversible data hiding algorithm in encrypted images based on joint fixed-length coding and Huffman coding with a high compression ratio. By using the correlation between adjacent pixels of a natural image, the multi-MSB planes of the image can be effectively compressed to reserve high-capacity room for embedding secret data. Based on this compression algorithm, a RRBE(reserving room before encryption) method of RDHEI is designed. Experimental results show that the proposed method achieves high embedding rate and separable reversible data hiding in encrypted images with its own priority. Although the embedding rate of the proposed method has been increased compared with the same type of RDHEI methods, the compression ratio is highly correlated with the smoothness of the original plaintext image. Non-smooth images embedding capacity improvement has been further to develop in the future.关键词:reversible data hiding;encrypted domain;fixed-length coding;Huffman coding;separately125|133|2更新时间:2024-05-07
Steganography Methodology
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0