
最新刊期
卷 26 , 期 8 , 2021
-
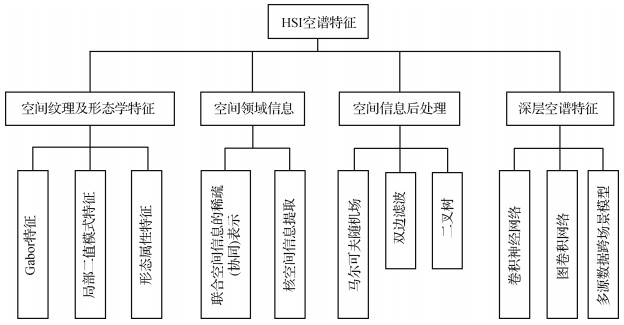 摘要:Hyperspectral imaging spectrometers collect radiation data from the ground in many adjacent and overlapping narrow spectral bands at the same time. The hyperspectral image (HSI) usually has hundreds of bands. Each of these bands contains the reflected light value within the specified range of the electromagnetic spectrum. Thus, the HSI contains a wealth of spectral and radiation information. The development of remote sensing imaging technology has increased the spatial resolution of HSI data obtained by hyperspectral imaging spectrometer. Therefore, HSI can be applied to accurately classify ground objects in various fields, such as geological exploration, precision agriculture, ecological environment, scientific remote sensing, and military target detection. However, many challenges and difficulties are encountered in classification applications because HSI has a large dataset, multiple bands, and strong band correlation. Specifically, the number of dimensionalities of HSI is often more than the number of available training samples. The lack of training samples and high computational cost are the inevitable obstacles in practical classification applications. Dimensionality reduction methods are often used to project HSI data into low-dimensional feature spaces for avoiding "Hughes" phenomenon. Spatial information can help create a more accurate classification map given the high probability of adjacent pixels belonging to the same category. In recent years, an increasing number of studies have applied spatial and spectral information to further improve the accuracy of classification. According to the characteristics and combination of spatial information, spectral information, and classifiers, the methods of spatial-spectral feature extraction for HSI can be defined into three types: spatial texture and morphological feature extraction, spatial neighborhood information acquisition, and spatial information post-processing. For the first type, spatial texture or morphological features (e.g., Gabor, local binary pattern, and morphological attribute features) are extracted in advance to preprocess the spatial information of pixels. In other words, spatial features are extracted through certain structures and rules, and then, the obtained features are sent to the classifier. The second method directly combines the relationship between the pixel and its spatial neighborhood pixels into the classifier. Spatial-spectral information is directly constructed into the classification models (e.g., sparse/collaborative representation of joint spatial information and kernel-based spatial information extraction and classification) through mathematical expressions. As a result, feature extraction and classification can be completed simultaneously. In the third category, spectral features are first classified. Then, the obtained classification results are corrected through spatial information post-processing methods (e.g., random fields, bilateral filtering, and graph segmentation) to further improve the classification accuracy. The traditional spatial-spectral feature extraction method for HSI has small computation, good mathematical theory foundation and explanation, and strong robustness against noise. However, the traditional spatial-spectral feature extraction methods mostly design shallow feature extraction schemes manually, which involves a lot of expert experience and parameter setting and thus affects the ability of feature expression and learning. For HSI data, scattering from other objects can distort the spectral properties of the interest object. In addition, different atmospheric scattering conditions and intra-class variability cause difficulty in extracting spatial-spectral features by traditional methods. Deep neural network has many advantages, such as learning representative and discriminant features, improving information representation through deep structure, and realizing automatic extraction and representation of features. Thus, higher accuracy of HSI classification will be achieved by designing the structure of deep network reasonably. In this study, the application of spatial-spectral feature extraction from deep learning is expounded and analyzed from the perspectives of convolutional neural network (CNN), graph neural network (GNN), and multi-source data cross-scene model. CNN shares weights and uses local connections to extract spatial information effectively. CNN model cannot generally adapt to local regions with various object distributions and geometric appearance because it convolves regular square regions with fixed size and weights. GNN model can represent many potential relationships between data with graphs. As a result, GNN can be applied for spatial-spectral feature extraction and classification for HSI. In some scenes (e.g., complex city scenes), different ground objects composed of the same material or substance need to be distinguished through shape, elevation, texture, and other information. Light detection and ranging data can be used to describe the elevation of the scene and the height of objects and obtain the spatial context and structural information without the effect of time and weather. Therefore, multi-sensor data can be considered to build joint-feature space for more accurate classification in some special scenes. In recent years, spatial-spectral feature extraction techniques for HSI have greatly progressed and achieved satisfactory results. However, the following problems need to be solved. 1) The methods of traditional and deep spatial-spectral feature extraction can be combined to fully utilize their respective advantages. 2) The small-sample-size and over-fitting problems from deep neural network need to be overcome through designing semi-supervised learning, active learning, or self-supervised learning models. 3) Using GNN to train HSI will lead to high computational cost and large memory usage. Thus, the model oriented to reduce the computational complexity should be studied. 4) Combining multi-source data from different sensors should consider reasonably unifying and complementary expressing multi-source data features. 5) Using multi-temporal, hyperspectral, and multi-perspective information to simultaneously mine spatial-spectral-temporal joint-feature information of complex dynamic targets has become a new frontier. 6) Using multi-temporal, hyperspectral and multi-perspective information to simultaneously extract spatial-spectral-temporal features of complex dynamic targets has become a new frontier. 7) With the progress of space remote sensing technologies in China, domestic hyperspectral data will receive more and more attention for research. 8) According to the development trend of big data and machine intelligence, the research on spatial-spectral feature extraction and classification of hyperspectral image based on the combination of applied domain knowledge and hyperspectral data will be a hot topic. From two sides of the traditional and deep spatial-spectral feature extraction in this study, the research status is systematically sorted out and comprehensively summarized. The existing problems are analyzed and evaluated, and the future development trend is evaluated and prospected.关键词:hyperspectral image(HSI);spatial-spectral feature extraction;convolutional neural network(CNN);graph convolutional network(GCN);multi-data fusion;deep neutral network321|920|22更新时间:2024-05-07
摘要:Hyperspectral imaging spectrometers collect radiation data from the ground in many adjacent and overlapping narrow spectral bands at the same time. The hyperspectral image (HSI) usually has hundreds of bands. Each of these bands contains the reflected light value within the specified range of the electromagnetic spectrum. Thus, the HSI contains a wealth of spectral and radiation information. The development of remote sensing imaging technology has increased the spatial resolution of HSI data obtained by hyperspectral imaging spectrometer. Therefore, HSI can be applied to accurately classify ground objects in various fields, such as geological exploration, precision agriculture, ecological environment, scientific remote sensing, and military target detection. However, many challenges and difficulties are encountered in classification applications because HSI has a large dataset, multiple bands, and strong band correlation. Specifically, the number of dimensionalities of HSI is often more than the number of available training samples. The lack of training samples and high computational cost are the inevitable obstacles in practical classification applications. Dimensionality reduction methods are often used to project HSI data into low-dimensional feature spaces for avoiding "Hughes" phenomenon. Spatial information can help create a more accurate classification map given the high probability of adjacent pixels belonging to the same category. In recent years, an increasing number of studies have applied spatial and spectral information to further improve the accuracy of classification. According to the characteristics and combination of spatial information, spectral information, and classifiers, the methods of spatial-spectral feature extraction for HSI can be defined into three types: spatial texture and morphological feature extraction, spatial neighborhood information acquisition, and spatial information post-processing. For the first type, spatial texture or morphological features (e.g., Gabor, local binary pattern, and morphological attribute features) are extracted in advance to preprocess the spatial information of pixels. In other words, spatial features are extracted through certain structures and rules, and then, the obtained features are sent to the classifier. The second method directly combines the relationship between the pixel and its spatial neighborhood pixels into the classifier. Spatial-spectral information is directly constructed into the classification models (e.g., sparse/collaborative representation of joint spatial information and kernel-based spatial information extraction and classification) through mathematical expressions. As a result, feature extraction and classification can be completed simultaneously. In the third category, spectral features are first classified. Then, the obtained classification results are corrected through spatial information post-processing methods (e.g., random fields, bilateral filtering, and graph segmentation) to further improve the classification accuracy. The traditional spatial-spectral feature extraction method for HSI has small computation, good mathematical theory foundation and explanation, and strong robustness against noise. However, the traditional spatial-spectral feature extraction methods mostly design shallow feature extraction schemes manually, which involves a lot of expert experience and parameter setting and thus affects the ability of feature expression and learning. For HSI data, scattering from other objects can distort the spectral properties of the interest object. In addition, different atmospheric scattering conditions and intra-class variability cause difficulty in extracting spatial-spectral features by traditional methods. Deep neural network has many advantages, such as learning representative and discriminant features, improving information representation through deep structure, and realizing automatic extraction and representation of features. Thus, higher accuracy of HSI classification will be achieved by designing the structure of deep network reasonably. In this study, the application of spatial-spectral feature extraction from deep learning is expounded and analyzed from the perspectives of convolutional neural network (CNN), graph neural network (GNN), and multi-source data cross-scene model. CNN shares weights and uses local connections to extract spatial information effectively. CNN model cannot generally adapt to local regions with various object distributions and geometric appearance because it convolves regular square regions with fixed size and weights. GNN model can represent many potential relationships between data with graphs. As a result, GNN can be applied for spatial-spectral feature extraction and classification for HSI. In some scenes (e.g., complex city scenes), different ground objects composed of the same material or substance need to be distinguished through shape, elevation, texture, and other information. Light detection and ranging data can be used to describe the elevation of the scene and the height of objects and obtain the spatial context and structural information without the effect of time and weather. Therefore, multi-sensor data can be considered to build joint-feature space for more accurate classification in some special scenes. In recent years, spatial-spectral feature extraction techniques for HSI have greatly progressed and achieved satisfactory results. However, the following problems need to be solved. 1) The methods of traditional and deep spatial-spectral feature extraction can be combined to fully utilize their respective advantages. 2) The small-sample-size and over-fitting problems from deep neural network need to be overcome through designing semi-supervised learning, active learning, or self-supervised learning models. 3) Using GNN to train HSI will lead to high computational cost and large memory usage. Thus, the model oriented to reduce the computational complexity should be studied. 4) Combining multi-source data from different sensors should consider reasonably unifying and complementary expressing multi-source data features. 5) Using multi-temporal, hyperspectral, and multi-perspective information to simultaneously mine spatial-spectral-temporal joint-feature information of complex dynamic targets has become a new frontier. 6) Using multi-temporal, hyperspectral and multi-perspective information to simultaneously extract spatial-spectral-temporal features of complex dynamic targets has become a new frontier. 7) With the progress of space remote sensing technologies in China, domestic hyperspectral data will receive more and more attention for research. 8) According to the development trend of big data and machine intelligence, the research on spatial-spectral feature extraction and classification of hyperspectral image based on the combination of applied domain knowledge and hyperspectral data will be a hot topic. From two sides of the traditional and deep spatial-spectral feature extraction in this study, the research status is systematically sorted out and comprehensively summarized. The existing problems are analyzed and evaluated, and the future development trend is evaluated and prospected.关键词:hyperspectral image(HSI);spatial-spectral feature extraction;convolutional neural network(CNN);graph convolutional network(GCN);multi-data fusion;deep neutral network321|920|22更新时间:2024-05-07 -
 摘要:Hyperspectral imaging (HSI), also known as imaging spectrometer, originated from remote sensing and has been explored for various applications. This tool has been applied in many fields, such as archaeology and art protection, vegetation and water resources control, food quality and safety control, forensics, crime scene detection, and biomedicine, owing to its advantages in acquiring 2D images in a wide range of electromagnetic spectrum. These applications mainly cover the ultraviolet (UV), visible (VIS), and near-infrared (near-IR or NIR) regions. HSI acquires a 3D dataset called hypercube, with two spatial dimensions and one spectral dimension. Spatially resolved spectral imaging obtained by HSI provides diagnostic information about the tissue physiology, morphology, and composition. Furthermore, HSI can be easily adapted to other conventional techniques, such as microscopy and fundus camera. As an emerging imaging technology, HSI has been explored in a variety of laboratory experiments and clinical trials, which strongly indicates that HSI has a great potential for improving accuracy and reliability in disease detection, diagnosis, monitoring, and image-guided surgeries. In the past two decades, the HSI technology has been rapidly developed in hardware and systems. Most medical HSIs only detect the UV, VIS, and near-IR regions of light. Therefore, the exploration of HSI in the mid-IR spectrum may bring new insights for disease detection, diagnosis, and monitoring. The HSI technology is also combined with other imaging methods, such as preoperative positron emission tomography and intraoperative ultrasound, to overcome the limitation on the penetration of biological tissues and broaden HSI application areas. With the increasing integration of technologies, such as microscopes, colposcopy, laparoscopy, and fundus cameras, HSI is becoming an important part of medical imaging technology, which provides important information for potential clinical applications at the molecular, cell, tissue, and organ level. The clinical application of HSI is clearly in adolescence, and more verification is needed before it can be safely and effectively used in clinical practice. With the development of hardware technology, image analysis methods, and computing capabilities, HSI is used for the diagnosis and monitoring of non-invasive diseases, the identification and quantitative analysis of cancer biomarkers, image-guided minimally invasive surgery, and targeted drug delivery. However, HSI, as an emerging technology, also has certain limitations. At present, the application of hyperspectral detection technology in the medical field is still in the experimental stage. Useful information must be extracted from the large amount of data contained in each medical HSI. Data calibration and correction, data compression, dimensionality reduction, and analysis of data to determine the final results require a certain amount of time, which are also major challenges in the biomedical field. Higher spectral resolution, spatial resolution, and larger spectral database provide substantial spatial and spectral information. Accordingly, the main research topics in the future are the manner by which to quickly collect images of target objects in real time in a short period, effectively integrate spectroscopic instruments and algorithms, accurately diagnose the results, and combine with other imaging methods for fusion data analysis. The HSI is widely used and plays a greater role in the field of biomedicine owing to its continuous development and improvement. This work provides a comprehensive overview of HSI technologies and its medical applications, such as applications in cancer, heart disease, retinopathy, diabetic foot, shock, histopathology, and image-guided surgery. Moreover, this work presents an overview of the literature on the medical HSI technology and its applications. This work reviews the basic principles, structure, and characteristics of HSI system and elaborates the application progress of HSI in disease diagnosis and surgical guidance in recent years and analyzes the limitations of HSI and its future development direction.关键词:medical hyperspectral image;precision medicine;medicine hyperspectral image analysis;disease diagnosis;image-guided surgery332|1568|8更新时间:2024-05-07
摘要:Hyperspectral imaging (HSI), also known as imaging spectrometer, originated from remote sensing and has been explored for various applications. This tool has been applied in many fields, such as archaeology and art protection, vegetation and water resources control, food quality and safety control, forensics, crime scene detection, and biomedicine, owing to its advantages in acquiring 2D images in a wide range of electromagnetic spectrum. These applications mainly cover the ultraviolet (UV), visible (VIS), and near-infrared (near-IR or NIR) regions. HSI acquires a 3D dataset called hypercube, with two spatial dimensions and one spectral dimension. Spatially resolved spectral imaging obtained by HSI provides diagnostic information about the tissue physiology, morphology, and composition. Furthermore, HSI can be easily adapted to other conventional techniques, such as microscopy and fundus camera. As an emerging imaging technology, HSI has been explored in a variety of laboratory experiments and clinical trials, which strongly indicates that HSI has a great potential for improving accuracy and reliability in disease detection, diagnosis, monitoring, and image-guided surgeries. In the past two decades, the HSI technology has been rapidly developed in hardware and systems. Most medical HSIs only detect the UV, VIS, and near-IR regions of light. Therefore, the exploration of HSI in the mid-IR spectrum may bring new insights for disease detection, diagnosis, and monitoring. The HSI technology is also combined with other imaging methods, such as preoperative positron emission tomography and intraoperative ultrasound, to overcome the limitation on the penetration of biological tissues and broaden HSI application areas. With the increasing integration of technologies, such as microscopes, colposcopy, laparoscopy, and fundus cameras, HSI is becoming an important part of medical imaging technology, which provides important information for potential clinical applications at the molecular, cell, tissue, and organ level. The clinical application of HSI is clearly in adolescence, and more verification is needed before it can be safely and effectively used in clinical practice. With the development of hardware technology, image analysis methods, and computing capabilities, HSI is used for the diagnosis and monitoring of non-invasive diseases, the identification and quantitative analysis of cancer biomarkers, image-guided minimally invasive surgery, and targeted drug delivery. However, HSI, as an emerging technology, also has certain limitations. At present, the application of hyperspectral detection technology in the medical field is still in the experimental stage. Useful information must be extracted from the large amount of data contained in each medical HSI. Data calibration and correction, data compression, dimensionality reduction, and analysis of data to determine the final results require a certain amount of time, which are also major challenges in the biomedical field. Higher spectral resolution, spatial resolution, and larger spectral database provide substantial spatial and spectral information. Accordingly, the main research topics in the future are the manner by which to quickly collect images of target objects in real time in a short period, effectively integrate spectroscopic instruments and algorithms, accurately diagnose the results, and combine with other imaging methods for fusion data analysis. The HSI is widely used and plays a greater role in the field of biomedicine owing to its continuous development and improvement. This work provides a comprehensive overview of HSI technologies and its medical applications, such as applications in cancer, heart disease, retinopathy, diabetic foot, shock, histopathology, and image-guided surgery. Moreover, this work presents an overview of the literature on the medical HSI technology and its applications. This work reviews the basic principles, structure, and characteristics of HSI system and elaborates the application progress of HSI in disease diagnosis and surgical guidance in recent years and analyzes the limitations of HSI and its future development direction.关键词:medical hyperspectral image;precision medicine;medicine hyperspectral image analysis;disease diagnosis;image-guided surgery332|1568|8更新时间:2024-05-07
Review

-
 摘要:ObjectiveHyperspectral remote sensing method is a major development in remote sensing field. It uses a lot of narrow band electromagnetic bands to obtain spectral data. It covers visible, near infrared, middle infrared, and far infrared bands, and its spectral resolution can reach the nanometer level. Therefore, hyperspectral remote sensing can find more surface features and has been widely used in covering global environment, land use, resource survey, natural disasters, and even interstellar exploration. Compared with RGB and multispectral images, hyperspectral images not only can improve the information richness but also can provide more reasonable and effective analysis and processing for the related tasks. As a result, they have important application value in many fields. However, the cost of spectral detection systems is relatively high, especially the optical detector that is used to acquire high spectral data. At present, most of the spectrometers can support the spectral imaging from 400 nm to 1 000 nm, while few of them support that from 1 000 nm to 2 500 nm. The reason is that the spectrometer is harder to produce and more expensive with the increase in spectra. The bands of hyperspectral images have internal relations. The performance of low-spectrum spectrometer can be improved by fully utilizing the low spectra to predict high spectra. In other words, the low spectrum spectrometer can be used to obtain the high spectra that are near the spectra which are usually obtained by high-spectrum spectrometer. The cost of getting hyperspectral images will be greatly reduced. Therefore, high spectra prediction has promising applications and prospects in improving spectrometer performance. Nowadays, a single sensor can generally take a limited number of spectra. Thus, the commonly used spectrometers contain multiple sensors. If one of these sensors suffers from a sudden situation and cannot work normally in the process of flight aerial photography, then the data we can obtain will be unusable and we will have to have a flight again, which will cause cost increase and resource waste. Similarly, if a spectrometer mounted on a satellite fails to work normally in case of emergency, then it will suffer much greater loss. However, if we can fully utilize the low spectra to predict high spectra, which means using the low-spectrum spectrometer to obtain the hyperspectral image that is near the spectra from real high-spectrum spectrometer, the loss caused by these situations can be compensated in a great extent.MethodIn recent years, convolutional neural networks (CNNs) have been widely used in various image processing tasks. We propose a hyperspectral image prediction framework based on a CNN as inspired by the great achievements of deep learning in the field of image spatial super resolution. The designed network is based on the residual network, which can fully use multiscale feature maps to obtain better performance and ensure fast convergence. In the CNN, 2D convolution layers use convolution kernels to obtain feature maps, and convolution kernels use relation between space and spectra, which is also helpful to obtain better results. In our network, each of the convolution layers has an activation layer, in which the rectified linear unit function is used. Batch normal layers are used to normalize the feature map, which can improve the feature extracting ability of CNN. Given an input, the proposed network extracts the low-band data features of the hyperspectral image. Then, it uses the extracted features together with the original low-spectra data to predict the high-spectra data for predicting the high spectra with the low spectra. We also design an evaluation system to prove the feasibility and effectiveness of the infrared spectrum prediction. The feasibility is evaluated by three classical image quality evaluation indices (peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and spectral angle (SA)). The feasibility is also evaluated by two classical classification evaluation indices (accuracy and average accuracy) by applying our predicted infrared spectrum to classification tasks.ResultExperiments on Cuprite and Salinas datasets are conducted to validate the effectiveness of the proposed method. On Cuprite dataset, we directly measure the quality of the predicted image through PSNR, SSIM, and SA. On Salinas dataset, we mainly use the predicted image data for classification tasks with support vector machine (SVM) and LeNet. All the experiments are implemented using Torch 1.3 platform with Python 3.7. In our experiments on Cuprite dataset, we use the spectra of the first two sensors to predict the spectra of the third sensor. Five hyperspectral images are present in the original data of Cuprite. The first three spectra of Cuprite are spliced into a large image as the training dataset, and the last two spectra are spliced as the test dataset. In this experiment, 30 training epochs are conducted. The PSNR, SSIM, and SA of the predicted images by the trained network on the test set are 40.145 dB, 0.996, and 0.777 rad, respectively, which indicates that the proposed method can predict high spectra from low spectra, which is near the ground truth. The PSNR, SSIM, and SA on the Salinas dataset are 39.55 dB, 0.997, and 1.78 rad, respectively. The accuracy and average accuracy of SVM and LeNet by using the predicted high-spectra data for classification are both improved by approximately 1% compared with the results which use only low-spectra data.ConclusionAlthough many CNN methods have been proposed to realize spatial super resolution, few of them realize spectral super resolution, which is also important. Therefore, we propose the new application in remote sensing field called spectrum prediction, which uses a CNN to predict high spectra from low spectra. The proposed method can expand the use efficiency of sensor chips and also help deal with spectrometer failure and improve the quality of spectral data.关键词:deep learning;convolutional neural network(CNN);hyperspectral image;spectrum prediction;hyperspectral classification87|161|1更新时间:2024-05-07
摘要:ObjectiveHyperspectral remote sensing method is a major development in remote sensing field. It uses a lot of narrow band electromagnetic bands to obtain spectral data. It covers visible, near infrared, middle infrared, and far infrared bands, and its spectral resolution can reach the nanometer level. Therefore, hyperspectral remote sensing can find more surface features and has been widely used in covering global environment, land use, resource survey, natural disasters, and even interstellar exploration. Compared with RGB and multispectral images, hyperspectral images not only can improve the information richness but also can provide more reasonable and effective analysis and processing for the related tasks. As a result, they have important application value in many fields. However, the cost of spectral detection systems is relatively high, especially the optical detector that is used to acquire high spectral data. At present, most of the spectrometers can support the spectral imaging from 400 nm to 1 000 nm, while few of them support that from 1 000 nm to 2 500 nm. The reason is that the spectrometer is harder to produce and more expensive with the increase in spectra. The bands of hyperspectral images have internal relations. The performance of low-spectrum spectrometer can be improved by fully utilizing the low spectra to predict high spectra. In other words, the low spectrum spectrometer can be used to obtain the high spectra that are near the spectra which are usually obtained by high-spectrum spectrometer. The cost of getting hyperspectral images will be greatly reduced. Therefore, high spectra prediction has promising applications and prospects in improving spectrometer performance. Nowadays, a single sensor can generally take a limited number of spectra. Thus, the commonly used spectrometers contain multiple sensors. If one of these sensors suffers from a sudden situation and cannot work normally in the process of flight aerial photography, then the data we can obtain will be unusable and we will have to have a flight again, which will cause cost increase and resource waste. Similarly, if a spectrometer mounted on a satellite fails to work normally in case of emergency, then it will suffer much greater loss. However, if we can fully utilize the low spectra to predict high spectra, which means using the low-spectrum spectrometer to obtain the hyperspectral image that is near the spectra from real high-spectrum spectrometer, the loss caused by these situations can be compensated in a great extent.MethodIn recent years, convolutional neural networks (CNNs) have been widely used in various image processing tasks. We propose a hyperspectral image prediction framework based on a CNN as inspired by the great achievements of deep learning in the field of image spatial super resolution. The designed network is based on the residual network, which can fully use multiscale feature maps to obtain better performance and ensure fast convergence. In the CNN, 2D convolution layers use convolution kernels to obtain feature maps, and convolution kernels use relation between space and spectra, which is also helpful to obtain better results. In our network, each of the convolution layers has an activation layer, in which the rectified linear unit function is used. Batch normal layers are used to normalize the feature map, which can improve the feature extracting ability of CNN. Given an input, the proposed network extracts the low-band data features of the hyperspectral image. Then, it uses the extracted features together with the original low-spectra data to predict the high-spectra data for predicting the high spectra with the low spectra. We also design an evaluation system to prove the feasibility and effectiveness of the infrared spectrum prediction. The feasibility is evaluated by three classical image quality evaluation indices (peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and spectral angle (SA)). The feasibility is also evaluated by two classical classification evaluation indices (accuracy and average accuracy) by applying our predicted infrared spectrum to classification tasks.ResultExperiments on Cuprite and Salinas datasets are conducted to validate the effectiveness of the proposed method. On Cuprite dataset, we directly measure the quality of the predicted image through PSNR, SSIM, and SA. On Salinas dataset, we mainly use the predicted image data for classification tasks with support vector machine (SVM) and LeNet. All the experiments are implemented using Torch 1.3 platform with Python 3.7. In our experiments on Cuprite dataset, we use the spectra of the first two sensors to predict the spectra of the third sensor. Five hyperspectral images are present in the original data of Cuprite. The first three spectra of Cuprite are spliced into a large image as the training dataset, and the last two spectra are spliced as the test dataset. In this experiment, 30 training epochs are conducted. The PSNR, SSIM, and SA of the predicted images by the trained network on the test set are 40.145 dB, 0.996, and 0.777 rad, respectively, which indicates that the proposed method can predict high spectra from low spectra, which is near the ground truth. The PSNR, SSIM, and SA on the Salinas dataset are 39.55 dB, 0.997, and 1.78 rad, respectively. The accuracy and average accuracy of SVM and LeNet by using the predicted high-spectra data for classification are both improved by approximately 1% compared with the results which use only low-spectra data.ConclusionAlthough many CNN methods have been proposed to realize spatial super resolution, few of them realize spectral super resolution, which is also important. Therefore, we propose the new application in remote sensing field called spectrum prediction, which uses a CNN to predict high spectra from low spectra. The proposed method can expand the use efficiency of sensor chips and also help deal with spectrometer failure and improve the quality of spectral data.关键词:deep learning;convolutional neural network(CNN);hyperspectral image;spectrum prediction;hyperspectral classification87|161|1更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral imaging systems are widely used in various fields owing to their image-spectral characteristic and unique "spectral fingerprint" information. Multispectral imaging systems are generally less costly and more suitable for the large-scale applications compared with hyperspectral imaging systems. Nonetheless, the existing multispectral imaging systems suffer from certain problems, such as high cost, complex structure, difficult operation, and slow response time. Accordingly, a low-cost portable multispectral imaging system based on pulse modulation is proposed in this study, and its imaging parameters are optimized using the objective image quality assessment methods.MethodThis system strives for a high degree of integration in a hardware design. The light source and control central processing unit(CPU) are integrated on a small printed circuit board(PCB). The 18 light emitting diode(LED) pairs of nine different wavelengths are integrated on a circular PCB board to form a circle by using a disc design. The light source can be converged, and the brightness can be improved to a certain extent. The proposed multispectral imaging system is mainly composed of a light source, a control, an image acquisition section, and an image analysis part. The light source part mainly includes nine LED arrays with the center wavelengths of 365 nm, 390 nm, 460 nm, 515 nm, 585 nm, 620 nm, 650 nm, 730 nm, and 840 nm. The control part mainly includes the self-designed LED driver circuit and universal serial bus(USB) power supply, which can light up LED arrays by sending the pulse waves at certain time intervals in time and allows the LED arrays to reach the maximum luminous intensity through the certain impedance matching. The image acquisition part primarily consists of a high-definition infrared industrial camera without the near infrared(IR) cut-off filter, which has an optimal spectral sensing range encompassing the central wavelengths of the selected nine LED arrays. The computer is used to call OpenCV through the Python language to control the camera to take images at a certain frequency. The image analysis part mainly performs the objective image quality assessment algorithms. When the system is executed, the STC89C51 microcontroller emits a pulse wave with a period of T (T is adjustable) to drive nine different wavelengths of LED arrays to light up in time. Subsequently, the computer platform calls the camera modules to capture multispectral images at matching intervals. In the system optimization experiments, we use the sharpness and the blur metrics to objectively evaluate the quality of the obtained multispectral images from three perspectives of camera shooting interval, imaging distance, and light intensity, thus obtaining better system imaging parameters.ResultThe quality of multispectral images acquired from various shooting parameters and shooting conditions under three different scenarios are evaluated. Results show that the image quality of the developed multispectral imaging system is relatively good under the camera shooting interval synchronized with the bead strobe cycle of the LED arrays. The imaging distance is 25 mm, and the light intensity is 45 Lux.ConclusionThe developed multispectral imaging system based on pulse modulation is low-cost, less difficult to operate, has a simple structure, has better imaging quality, has faster imaging speed, and can meet the requirements of large-scale promotion of multispectral imaging systems for various application domains. In addition, the system design methods, design ideas, and experimental protocols covered in the current work may provide references for the subsequent studies.关键词:pulse modulation;multispectral imaging;image quality assessment;experimental design optimization;embedded systems;image processing90|338|3更新时间:2024-05-07
摘要:ObjectiveHyperspectral imaging systems are widely used in various fields owing to their image-spectral characteristic and unique "spectral fingerprint" information. Multispectral imaging systems are generally less costly and more suitable for the large-scale applications compared with hyperspectral imaging systems. Nonetheless, the existing multispectral imaging systems suffer from certain problems, such as high cost, complex structure, difficult operation, and slow response time. Accordingly, a low-cost portable multispectral imaging system based on pulse modulation is proposed in this study, and its imaging parameters are optimized using the objective image quality assessment methods.MethodThis system strives for a high degree of integration in a hardware design. The light source and control central processing unit(CPU) are integrated on a small printed circuit board(PCB). The 18 light emitting diode(LED) pairs of nine different wavelengths are integrated on a circular PCB board to form a circle by using a disc design. The light source can be converged, and the brightness can be improved to a certain extent. The proposed multispectral imaging system is mainly composed of a light source, a control, an image acquisition section, and an image analysis part. The light source part mainly includes nine LED arrays with the center wavelengths of 365 nm, 390 nm, 460 nm, 515 nm, 585 nm, 620 nm, 650 nm, 730 nm, and 840 nm. The control part mainly includes the self-designed LED driver circuit and universal serial bus(USB) power supply, which can light up LED arrays by sending the pulse waves at certain time intervals in time and allows the LED arrays to reach the maximum luminous intensity through the certain impedance matching. The image acquisition part primarily consists of a high-definition infrared industrial camera without the near infrared(IR) cut-off filter, which has an optimal spectral sensing range encompassing the central wavelengths of the selected nine LED arrays. The computer is used to call OpenCV through the Python language to control the camera to take images at a certain frequency. The image analysis part mainly performs the objective image quality assessment algorithms. When the system is executed, the STC89C51 microcontroller emits a pulse wave with a period of T (T is adjustable) to drive nine different wavelengths of LED arrays to light up in time. Subsequently, the computer platform calls the camera modules to capture multispectral images at matching intervals. In the system optimization experiments, we use the sharpness and the blur metrics to objectively evaluate the quality of the obtained multispectral images from three perspectives of camera shooting interval, imaging distance, and light intensity, thus obtaining better system imaging parameters.ResultThe quality of multispectral images acquired from various shooting parameters and shooting conditions under three different scenarios are evaluated. Results show that the image quality of the developed multispectral imaging system is relatively good under the camera shooting interval synchronized with the bead strobe cycle of the LED arrays. The imaging distance is 25 mm, and the light intensity is 45 Lux.ConclusionThe developed multispectral imaging system based on pulse modulation is low-cost, less difficult to operate, has a simple structure, has better imaging quality, has faster imaging speed, and can meet the requirements of large-scale promotion of multispectral imaging systems for various application domains. In addition, the system design methods, design ideas, and experimental protocols covered in the current work may provide references for the subsequent studies.关键词:pulse modulation;multispectral imaging;image quality assessment;experimental design optimization;embedded systems;image processing90|338|3更新时间:2024-05-07
Advances in Hyperspectral Imaging
-
 摘要:ObjectiveRemote sensing scene classification is an important research topic in remote sensing community, and it has provided important data or decision support for land resource planning, coverage mapping, ecological environment monitoring, and other real-world applications. In scene classification, extracting scene-level discriminative features is a key factor to bridge the "semantic gap" between low-level visual attributes and high-level understanding of images. Deep learning models are currently showing excellent performance in remote sensing image analysis, and many convolutional neural network (CNN)-based methods have been widely proposed in feature extraction and classification of remote sensing scene images. Although the aforementioned methods have achieved good results, they are all designed for scene images of high spatial resolution, such as University of California(UC) Merced Land-Use, WHU-RS19, scene image dataset designed by RS_IDEA Group in Wuhan University(SIRI-WHU), RSSCN7, aerial image dataset(AID), a publicly available benchmark for remote sensing image scene classification created by Northwestern Polytechnical University(NWPU-RESISC45), and optical imagery analysis and learning(OPTIMAL-31) datasets. Remote sensing data of high spatial resolution can present spatial details of ground objects. However, they contain less spectral information. As a result, their discriminative ability is relatively limited in scene classification. Hyperspectral images have abundant spectral information, and they have strong discriminative ability for ground objects. However, the existing datasets of hyperspectral images (e.g., Indian Pines, Pavia University, Washington DC Mall, Salinas, and Xiongan New Area) are mostly oriented toward pixel-level classification and are difficult to directly apply on research of scene-level image classification. Tiangong-1 hyperspectral remote sensing scene classification dataset (TG1HRSSC) is produced for scene-level image interpretation. However, the TG1HRSSC dataset is small (204 scene images) and has inconsistent image bands. A hyperspectral remote sensing dataset is constructed for scene classification (HSRS-SC) in this study to overcome the aforementioned disadvantages. The dataset can provide a good benchmark platform for evaluating intelligent algorithms of hyperspectral scene classification.MethodThe HSRS-SC is derived from the aerial data of the Heihe Watershed Allied Telemetry Experimental Research (HiWATER), and raw data can be downloaded from the National Tibetan Plateau/Third Pole Environment Data Center. A large-scale dataset is finally formed after calibration coefficient correction, atmospheric correction, image cropping, and manual visual annotation. To the best of our knowledge, the HSRS-SC is currently the largest hyperspectral scene dataset, and it contains 1 385 hyperspectral scene images which have been resized to 256×256 pixels. The dataset is divided into 5 categories, and the number of samples in each category ranges from 154 to 485. In the HSRS-SC dataset, each hyperspectral scene image has a high spatial resolution (1 m) and a wide wavelength range (from visible light to near-infrared, 380~1 050 nm, 48 bands), which can reflect the detailed spatial and spectral information of ground objects, including cars, roadway, buildings, and vegetation. Specifically, the blue band (450~520 nm) has a certain penetration ability to water bodies; the green band (520~600 nm) is more sensitive to the reflection of vegetation; the red band (630~690 nm) is the main absorption band of chlorophyll; the near-infrared band (760900 nm) reflects the strong reflection of vegetation, and it is also the absorption band of water bodies. The dataset will be publicly available in the near future, and it can be used for non-commercial academic research.ResultThis study uses three classic deep models (i.e., AlexNet, VGGNet-16, and GoogLeNet) to organize experiments under three different schemes for providing benchmark results of HSRS-SC dataset. In the first scheme, false color images are synthesized from the 19th, 13th, and 7th bands of visible light range, and then, they are fed into deep models to extract global scene features. In the second and third schemes, information of the visible light (19th, 13th, and 7th) and near-infrared (46th, 47th, and 48th) bands are comprehensively utilized by fusion approaches of addition and concatenation, respectively. In the experiments, 10 samples per class are randomly selected to finetune pre-trained CNN models, and the rest are used for test set. The experimental results on the HSRS-SC dataset show that the effective utilization of information from different bands of hyperspectral images improves the classification performance, and concatenation fusion achieves better results than addition fusion. Comparing the three CNN models shows that the VGGNet-16 model is more suitable for the HSRS-SC dataset, and the highest overall classification accuracy reaches 93.20%. Furthermore, this study shows confusion matrices of different methods. Effective use of spectral information can reduce the confusion of semantic categories given that vegetation, buildings, roads, water bodies, and rocks have great differences in absorption and reflection at different bands. This study also organizes hyperspectral scene classification experiments to further explore the advantages of hyperspectral scenes. Hyperspectral scenes have a higher accuracy advantage than RGB images under the two training samples.ConclusionThe abovementioned experimental results show that the HSRS-SC dataset can reflect detailed information of ground objects, and it can provide effective data support for semantic understanding of remote sensing scenes. Although experiments in this study adopt three different schemes to utilize the information of the visible light (19th, 13th, and 7th bands) and near-infrared (46th, 47th, and 48th bands) of the hyperspectral scenes, the rich spectral information has not been fully explored. For the future work, suitable models will be designed for feature extraction and classification of hyperspectral remote sensing scenes. We will also further expand the HSRS-SC dataset to ensure its practicality by supplementing more semantic categories and the total number of samples and increasing the diversity of data.关键词:remote sensing;scene classification;hyperspectral image;benchmark dataset;deep learning470|199|6更新时间:2024-05-07
摘要:ObjectiveRemote sensing scene classification is an important research topic in remote sensing community, and it has provided important data or decision support for land resource planning, coverage mapping, ecological environment monitoring, and other real-world applications. In scene classification, extracting scene-level discriminative features is a key factor to bridge the "semantic gap" between low-level visual attributes and high-level understanding of images. Deep learning models are currently showing excellent performance in remote sensing image analysis, and many convolutional neural network (CNN)-based methods have been widely proposed in feature extraction and classification of remote sensing scene images. Although the aforementioned methods have achieved good results, they are all designed for scene images of high spatial resolution, such as University of California(UC) Merced Land-Use, WHU-RS19, scene image dataset designed by RS_IDEA Group in Wuhan University(SIRI-WHU), RSSCN7, aerial image dataset(AID), a publicly available benchmark for remote sensing image scene classification created by Northwestern Polytechnical University(NWPU-RESISC45), and optical imagery analysis and learning(OPTIMAL-31) datasets. Remote sensing data of high spatial resolution can present spatial details of ground objects. However, they contain less spectral information. As a result, their discriminative ability is relatively limited in scene classification. Hyperspectral images have abundant spectral information, and they have strong discriminative ability for ground objects. However, the existing datasets of hyperspectral images (e.g., Indian Pines, Pavia University, Washington DC Mall, Salinas, and Xiongan New Area) are mostly oriented toward pixel-level classification and are difficult to directly apply on research of scene-level image classification. Tiangong-1 hyperspectral remote sensing scene classification dataset (TG1HRSSC) is produced for scene-level image interpretation. However, the TG1HRSSC dataset is small (204 scene images) and has inconsistent image bands. A hyperspectral remote sensing dataset is constructed for scene classification (HSRS-SC) in this study to overcome the aforementioned disadvantages. The dataset can provide a good benchmark platform for evaluating intelligent algorithms of hyperspectral scene classification.MethodThe HSRS-SC is derived from the aerial data of the Heihe Watershed Allied Telemetry Experimental Research (HiWATER), and raw data can be downloaded from the National Tibetan Plateau/Third Pole Environment Data Center. A large-scale dataset is finally formed after calibration coefficient correction, atmospheric correction, image cropping, and manual visual annotation. To the best of our knowledge, the HSRS-SC is currently the largest hyperspectral scene dataset, and it contains 1 385 hyperspectral scene images which have been resized to 256×256 pixels. The dataset is divided into 5 categories, and the number of samples in each category ranges from 154 to 485. In the HSRS-SC dataset, each hyperspectral scene image has a high spatial resolution (1 m) and a wide wavelength range (from visible light to near-infrared, 380~1 050 nm, 48 bands), which can reflect the detailed spatial and spectral information of ground objects, including cars, roadway, buildings, and vegetation. Specifically, the blue band (450~520 nm) has a certain penetration ability to water bodies; the green band (520~600 nm) is more sensitive to the reflection of vegetation; the red band (630~690 nm) is the main absorption band of chlorophyll; the near-infrared band (760900 nm) reflects the strong reflection of vegetation, and it is also the absorption band of water bodies. The dataset will be publicly available in the near future, and it can be used for non-commercial academic research.ResultThis study uses three classic deep models (i.e., AlexNet, VGGNet-16, and GoogLeNet) to organize experiments under three different schemes for providing benchmark results of HSRS-SC dataset. In the first scheme, false color images are synthesized from the 19th, 13th, and 7th bands of visible light range, and then, they are fed into deep models to extract global scene features. In the second and third schemes, information of the visible light (19th, 13th, and 7th) and near-infrared (46th, 47th, and 48th) bands are comprehensively utilized by fusion approaches of addition and concatenation, respectively. In the experiments, 10 samples per class are randomly selected to finetune pre-trained CNN models, and the rest are used for test set. The experimental results on the HSRS-SC dataset show that the effective utilization of information from different bands of hyperspectral images improves the classification performance, and concatenation fusion achieves better results than addition fusion. Comparing the three CNN models shows that the VGGNet-16 model is more suitable for the HSRS-SC dataset, and the highest overall classification accuracy reaches 93.20%. Furthermore, this study shows confusion matrices of different methods. Effective use of spectral information can reduce the confusion of semantic categories given that vegetation, buildings, roads, water bodies, and rocks have great differences in absorption and reflection at different bands. This study also organizes hyperspectral scene classification experiments to further explore the advantages of hyperspectral scenes. Hyperspectral scenes have a higher accuracy advantage than RGB images under the two training samples.ConclusionThe abovementioned experimental results show that the HSRS-SC dataset can reflect detailed information of ground objects, and it can provide effective data support for semantic understanding of remote sensing scenes. Although experiments in this study adopt three different schemes to utilize the information of the visible light (19th, 13th, and 7th bands) and near-infrared (46th, 47th, and 48th bands) of the hyperspectral scenes, the rich spectral information has not been fully explored. For the future work, suitable models will be designed for feature extraction and classification of hyperspectral remote sensing scenes. We will also further expand the HSRS-SC dataset to ensure its practicality by supplementing more semantic categories and the total number of samples and increasing the diversity of data.关键词:remote sensing;scene classification;hyperspectral image;benchmark dataset;deep learning470|199|6更新时间:2024-05-07
Dataset
-
 摘要:ObjectiveHyperspectral imaging systems have become promising auxiliary diagnostic tools for intelligent medicine in recent years, especially in disease diagnosis and image-guided surgery. Hyperspectral image (HSI) has hundreds of contiguous narrow spectral bands from visible to infrared electromagnetic spectrum. These bands provide a wealth of information to distinguish different chemical composition of biological tissue. The reflected, fluorescent, and transmitted light from tissue captured by HSI carry quantitative diagnostic information about tissue pathology. Wealthy spectral bands also contain redundancy, which not only degrades classification performance but also increases computational complexity. Thus, dimensionality reduction (DR) needs to be conducted to reveal the essence of data by discarding redundant information. However, most of the current DR methods are based on spectral vector input (first-order representation) that ignores important correlations in the spatial domain. Although some spectral-spatial joint technologies have been investigated to overcome this disadvantage, they still consider the spectral-spatial feature into first-order data for analysis and ignore the cubic nature of hyperspectral data. Thus, a novel tensor-based Laplacian regularized sparse and low-rank graph (T-LapSLRG) for discriminant analysis is proposed to preserve the original intrinsic structure information of medical hyperspectral data and enhance the discriminant ability of features.MethodSparse and low-rank constraints are suggested in the proposed T-LapSLRG to exploit local and global data structures while tensor analysis is developed to preserve the spatial neighborhood information. Multi-manifold is utilized to enhance the discriminant ability and describe the intrinsic geometric information. Consequently, the proposed method not only can preserve local and global structure information but also can utilize the intrinsic geometric information. Thus, it offers more discriminative power than existing tensor-based DR methods. Vector-based methods treat each pixel as an independent and identically distributed item. By contrast, the samples in T-LapSLRG are represented in the form of a third-order tensor that can preserve the original spatial neighborhood information. In addition, only a small set of the labeled training samples is needed by adopting tensor training samples. With the assumption that the samples belonging to the same class lie on a unique sub-manifold, T-LapSLRG constructs tensor-based within-class graph to characterize the within-class compactness for making the resulting graph more discriminative. In summary, T-LapSLRG jointly utilizes spatial neighborhoods and discriminative and intrinsic structure information that capture the local and global structures and the discriminative information simultaneously and make the resulting graph more robust and discriminative.ResultTo evaluate the effectiveness of the proposed T-LapSLRG, the medical hyperspectral data of membranous nephropathy (MN) is used. The traditional diagnosis methods of MN mainly rely on serological characteristics and renal pathological characteristics, which is tough to reach the intelligent and automated requirements of clinical diagnosis. Two types of MN are used as the experimental verification data, including primary membranous nephropathy (PMN) and hepatitis B virus-related membranous nephropathy (HBV-MN). The microscopic hyperspectral images of PMN and HBV-MN are captured by the line scan hyperspectral imaging system SOC-710 together with the biological microscope CX31RTSF. The SOC-710 system captures 128 spectral bands with 696×520 pixels and a spectral wavelength range from 400 to 1 000 nm. The obtained medical HSI dataset consists of 30 HBV-MN images and 24 PMN images, involving 10 HBV-MN patients and 9 PMN patients. Classification is performed on the obtained low-dimensional features by the classical support vector machine classifier to evaluate the performance of the proposed T-LapSLRG. Four objective quality indices (i.e., individual class accuracy, overall accuracy (OA), average accuracy (AA), and kappa coefficient (Kappa)) are used. The proposed T-LapSLRG outperforms other methods by 1.40% to 34.75% in OA, 1.46% to 36.89% in AA, and 0.031 to 0.73 in Kappa. In addition, the classification accuracy obtained by T-LapSLRG for all patients has reached more than 90%. In clinical diagnosis, the type of disease can be determined when the pixel level accuracy reaches 85% or more.ConclusionIn this study, we proposed a novel tensor-based Laplacian regularized sparse and low-rank graph for discriminant analysis. Experiments on the MN dataset demonstrate that the proposed T-LapSLRG is effective in discriminant analysis with sparse and low-rank constraints and multi-manifold, and significantly improves the classification performance. Experimental results verify the nonnegligible potential of T-LapSLRG for further application in MN identification.关键词:medical hyperspectral image;membranous nephropathy;tensor;dimensionality reduction(DR);graph embedding141|121|1更新时间:2024-05-07
摘要:ObjectiveHyperspectral imaging systems have become promising auxiliary diagnostic tools for intelligent medicine in recent years, especially in disease diagnosis and image-guided surgery. Hyperspectral image (HSI) has hundreds of contiguous narrow spectral bands from visible to infrared electromagnetic spectrum. These bands provide a wealth of information to distinguish different chemical composition of biological tissue. The reflected, fluorescent, and transmitted light from tissue captured by HSI carry quantitative diagnostic information about tissue pathology. Wealthy spectral bands also contain redundancy, which not only degrades classification performance but also increases computational complexity. Thus, dimensionality reduction (DR) needs to be conducted to reveal the essence of data by discarding redundant information. However, most of the current DR methods are based on spectral vector input (first-order representation) that ignores important correlations in the spatial domain. Although some spectral-spatial joint technologies have been investigated to overcome this disadvantage, they still consider the spectral-spatial feature into first-order data for analysis and ignore the cubic nature of hyperspectral data. Thus, a novel tensor-based Laplacian regularized sparse and low-rank graph (T-LapSLRG) for discriminant analysis is proposed to preserve the original intrinsic structure information of medical hyperspectral data and enhance the discriminant ability of features.MethodSparse and low-rank constraints are suggested in the proposed T-LapSLRG to exploit local and global data structures while tensor analysis is developed to preserve the spatial neighborhood information. Multi-manifold is utilized to enhance the discriminant ability and describe the intrinsic geometric information. Consequently, the proposed method not only can preserve local and global structure information but also can utilize the intrinsic geometric information. Thus, it offers more discriminative power than existing tensor-based DR methods. Vector-based methods treat each pixel as an independent and identically distributed item. By contrast, the samples in T-LapSLRG are represented in the form of a third-order tensor that can preserve the original spatial neighborhood information. In addition, only a small set of the labeled training samples is needed by adopting tensor training samples. With the assumption that the samples belonging to the same class lie on a unique sub-manifold, T-LapSLRG constructs tensor-based within-class graph to characterize the within-class compactness for making the resulting graph more discriminative. In summary, T-LapSLRG jointly utilizes spatial neighborhoods and discriminative and intrinsic structure information that capture the local and global structures and the discriminative information simultaneously and make the resulting graph more robust and discriminative.ResultTo evaluate the effectiveness of the proposed T-LapSLRG, the medical hyperspectral data of membranous nephropathy (MN) is used. The traditional diagnosis methods of MN mainly rely on serological characteristics and renal pathological characteristics, which is tough to reach the intelligent and automated requirements of clinical diagnosis. Two types of MN are used as the experimental verification data, including primary membranous nephropathy (PMN) and hepatitis B virus-related membranous nephropathy (HBV-MN). The microscopic hyperspectral images of PMN and HBV-MN are captured by the line scan hyperspectral imaging system SOC-710 together with the biological microscope CX31RTSF. The SOC-710 system captures 128 spectral bands with 696×520 pixels and a spectral wavelength range from 400 to 1 000 nm. The obtained medical HSI dataset consists of 30 HBV-MN images and 24 PMN images, involving 10 HBV-MN patients and 9 PMN patients. Classification is performed on the obtained low-dimensional features by the classical support vector machine classifier to evaluate the performance of the proposed T-LapSLRG. Four objective quality indices (i.e., individual class accuracy, overall accuracy (OA), average accuracy (AA), and kappa coefficient (Kappa)) are used. The proposed T-LapSLRG outperforms other methods by 1.40% to 34.75% in OA, 1.46% to 36.89% in AA, and 0.031 to 0.73 in Kappa. In addition, the classification accuracy obtained by T-LapSLRG for all patients has reached more than 90%. In clinical diagnosis, the type of disease can be determined when the pixel level accuracy reaches 85% or more.ConclusionIn this study, we proposed a novel tensor-based Laplacian regularized sparse and low-rank graph for discriminant analysis. Experiments on the MN dataset demonstrate that the proposed T-LapSLRG is effective in discriminant analysis with sparse and low-rank constraints and multi-manifold, and significantly improves the classification performance. Experimental results verify the nonnegligible potential of T-LapSLRG for further application in MN identification.关键词:medical hyperspectral image;membranous nephropathy;tensor;dimensionality reduction(DR);graph embedding141|121|1更新时间:2024-05-07 -
 摘要:ObjectiveCholangiocarcinoma is a rare but highly malignant tumor. Hyperspectral imaging (HSI), which originated from remote sensing, is an emerging image modality for diagnosis and image-guided surgery. HSI takes the advantage of acquiring 2D images across a wide range of electromagnetic spectrum. HSI can obtain spectral and optical properties of tissue and provide more information than RGB images. Redundant information will persist even though HSI contains tens the amount of data compared with RGB images with the same spatial dimension. Traditional dimensionality reduction methods, such as principal component analysis and kernel method, reduce the data by converting the original spectral space to a low-dimensional one, which is not suitable in end-to-end models. Recently, convolutional neural networks have demonstrated excellent performance on computer vision tasks, including classification, segmentation, and detection. Attention mechanism is used in convolutional neural network(CNN) to improve the representation of feature maps. Typical channel attention modules, such as squeeze-and-excitation net (SENet), squeezes the input features by global average pooling to produce a channel descriptor. However, different channels could have the same mean value. We proposed frequency selecting channel attention (FSCA) mechanism to address this issue. An Inception-FSCA network is also proposed for the segmentation of a hyperspectral image of cholangiocarcinoma tissues.MethodFSCA can exploit the information from different frequency components. This method consists of three steps. First, the input feature map is transformed in the frequency domain by Fourier transform. Second, a representative frequency amplitude is selected to efficiently use the obtained frequencies. These selected frequencies are arranged in a column of vectors. Third, these vectors are sent to two consecutive fully connected layers to obtain a channel weight vector. Then, a sigmoid function is used to scale each channel weight between zero and one. Every element in the channel weight vector is multiplied with the corresponding channel feature. FSCA can adjust the channel information, strengthen the important channels, and suppress the unimportant. This work uses a microscopic hyperspectral imaging system to obtain hyperspectral images of cholangiocarcinoma tissues. These images have a spectral bandwidth from 550 nm to 1 000 nm in 7.5 nm increments, producing a hypercube with 60 spectral bands. Spatial resolution of each image is 1 280×1 024 pixels. The ground truth label is manually annotated by experts. The method is implemented using Python3.6 and TensorFlow1.14.0 on NVDIA TITAN X GPU, Intel i7-9700KF CPU. The learning rate is 0.000 5, the batch size is 256, and the optimization strategy is Adam. Cancerous areas have different sizes, resulting in unbalanced positive and negative samples. Focal loss is chosen as a loss function.ResultWe conducted comparative and ablation experiments on our dataset. We use several evaluation metrics to evaluate the performance of the inception-FSCA. The accuracy, precision, sensitivity, specificity, and Kappa are 0.978 0, 0.965 4, 0.958 6, 0.985 2, and 0.945 6, respectively.ConclusionIn this study, we proposed a Fourier transform frequency selecting channel attention mechanism. The proposed channel attention module can be conveniently inserted in CNN. An Inception-FSCA network is built for the segmentation of hyperspectral images of cholangiocarcinoma tissues. Quantitative results show that our method has excellent performance. Inception-FSCA can be applied in the outer image segmentation and classification tasks.关键词:hyperspectral image of cholangiocarcinoma;convolutional neural network (CNN);image segmentation;channel attention mechanism;Fourier transform107|79|5更新时间:2024-05-07
摘要:ObjectiveCholangiocarcinoma is a rare but highly malignant tumor. Hyperspectral imaging (HSI), which originated from remote sensing, is an emerging image modality for diagnosis and image-guided surgery. HSI takes the advantage of acquiring 2D images across a wide range of electromagnetic spectrum. HSI can obtain spectral and optical properties of tissue and provide more information than RGB images. Redundant information will persist even though HSI contains tens the amount of data compared with RGB images with the same spatial dimension. Traditional dimensionality reduction methods, such as principal component analysis and kernel method, reduce the data by converting the original spectral space to a low-dimensional one, which is not suitable in end-to-end models. Recently, convolutional neural networks have demonstrated excellent performance on computer vision tasks, including classification, segmentation, and detection. Attention mechanism is used in convolutional neural network(CNN) to improve the representation of feature maps. Typical channel attention modules, such as squeeze-and-excitation net (SENet), squeezes the input features by global average pooling to produce a channel descriptor. However, different channels could have the same mean value. We proposed frequency selecting channel attention (FSCA) mechanism to address this issue. An Inception-FSCA network is also proposed for the segmentation of a hyperspectral image of cholangiocarcinoma tissues.MethodFSCA can exploit the information from different frequency components. This method consists of three steps. First, the input feature map is transformed in the frequency domain by Fourier transform. Second, a representative frequency amplitude is selected to efficiently use the obtained frequencies. These selected frequencies are arranged in a column of vectors. Third, these vectors are sent to two consecutive fully connected layers to obtain a channel weight vector. Then, a sigmoid function is used to scale each channel weight between zero and one. Every element in the channel weight vector is multiplied with the corresponding channel feature. FSCA can adjust the channel information, strengthen the important channels, and suppress the unimportant. This work uses a microscopic hyperspectral imaging system to obtain hyperspectral images of cholangiocarcinoma tissues. These images have a spectral bandwidth from 550 nm to 1 000 nm in 7.5 nm increments, producing a hypercube with 60 spectral bands. Spatial resolution of each image is 1 280×1 024 pixels. The ground truth label is manually annotated by experts. The method is implemented using Python3.6 and TensorFlow1.14.0 on NVDIA TITAN X GPU, Intel i7-9700KF CPU. The learning rate is 0.000 5, the batch size is 256, and the optimization strategy is Adam. Cancerous areas have different sizes, resulting in unbalanced positive and negative samples. Focal loss is chosen as a loss function.ResultWe conducted comparative and ablation experiments on our dataset. We use several evaluation metrics to evaluate the performance of the inception-FSCA. The accuracy, precision, sensitivity, specificity, and Kappa are 0.978 0, 0.965 4, 0.958 6, 0.985 2, and 0.945 6, respectively.ConclusionIn this study, we proposed a Fourier transform frequency selecting channel attention mechanism. The proposed channel attention module can be conveniently inserted in CNN. An Inception-FSCA network is built for the segmentation of hyperspectral images of cholangiocarcinoma tissues. Quantitative results show that our method has excellent performance. Inception-FSCA can be applied in the outer image segmentation and classification tasks.关键词:hyperspectral image of cholangiocarcinoma;convolutional neural network (CNN);image segmentation;channel attention mechanism;Fourier transform107|79|5更新时间:2024-05-07
Medical Hyperspectral Imagery
-
 摘要:ObjectiveAnomaly detection is a fundamental problem in hyperspectral remote sensing image processing, and it attracts the interests of several researchers. The anomalies usually refer to the outliers with spectral and spatial signatures that differ from their surroundings. Compared with the background, the anomalies have two main characteristics. First, their spectra are severely different from those of their surroundings, and this phenomenon is called the spectral difference. Meanwhile, the anomalies are usually embedded into the local homogeneous background in a format of several pixels, and this phenomenon is named the spatial difference. Hyperspectral anomaly detection has been widely used in military and civilian applications, such as surveillance, disaster warning, and rescue. In most traditional approaches, anomalies are directly derived from the original hyperspectral image (HSI). However, the HSIs usually deviate from the real scene as limited by the imagery process, such as the complexity of the imagery condition and the limited number of electrons caused by the hundreds of bands. This deviation could reduce the anomaly detection precision. We propose a novel hyperspectral anomaly detection method via the transformation of local gradient profiles to deal with the limitations caused by the low spatial quality. The gradient profile is a 1D profile along the gradient direction of the edge pixel in the image and has been introduced in natural image super resolution. Observations have demonstrated that the shape statistics of the gradient profiles in natural image is quite stable and invariant. In this way, the statistical relationship of the sharpness of the gradient profile between the real scene and the input HSI can be utilized to transform the gradient profiles of the input HSI. Meanwhile, the transformation is applied locally to some probable anomalies to reduce the computational complexity and avoid the disturbance of the background. These transformed gradient profiles are used to provide a constraint on the enhanced HSI.MethodA novel hyperspectral anomaly detection method is proposed in this study. Some probable anomalies are coarsely selected via a threshold to reduce the computational complexity without affecting the detection performance. Specifically, the original HSI is detected via the classical Global-RX(Reed Xiaoli) detector, and the responses in the map are sorted and selected. Meanwhile, the gradient profiles of these coarsely selected anomalies are computed and transformed to obtain the sharper versions. Specifically, the distribution of the gradient profile is fitted by a generalized Gaussian distribution. The transformation from the input gradient profile to the desired one can be computed via a transformation formulation. These transformed gradient profiles are closer to those of the real scene than the original gradient profiles. The original HSI is enhanced with these transformed gradient profiles. Experimental data contain six real HSIs coming from four datasets. The original six HSIs and their enhanced versions are detected via the Global-RX detector. Experimental results demonstrate the necessity of the enhancement. Meanwhile, experimental results on detection accuracy superiority of the proposed method over some other preprocessing techniques, such as the discrete wavelet transformation (DWT-RX), the spectral derivatives (Deriv-RX), and the fractional Fourier entropy (FrFE-RX), further validate the effectiveness of our proposed local gradient profile transformation strategy. We utilize the collaborative representation-based detector (CRD) to detect the enhanced and original HSIs. The enhanced HSIs still achieve higher detection accuracy.ResultWe incorporate six HSIs coming from four datasets, namely, San Diego, AVIRIS(airborne visible/infrared imaging spectrometer)-2, Airport, and Beach, to validate the performance of the proposed method. The quantitative evaluation metrics include the receiver operating curves and the area under the curve (AUC) value. We also exhibit the detection maps of each method for comparison. We validate the necessity of the enhancement. Thus, comparison of detection accuracy is made between the original and enhanced HSIs via the Global-RX detector. AUC values for the six original HSIs are 0.940 2, 0.934 1, 0.840 3, 0.952 5, 0.980 6, and 0.953 8, respectively. The corresponding AUC values for the enhanced HSIs are 0.977 8, 0.984 9, 0.983 5, 0.982 4, 0.998 6, and 0.995 6. Notably, the enhanced HSI always achieves a higher detection accuracy than the original HSI, which proves the necessity of the enhancement. We also compare our proposed method with three other preprocessing techniques, namely, the DWT-RX, Deriv-RX, and the FrFE-RX, which have average AUC values of 0.956 8, 0.957 9, and 0.964 0, respectively. Our proposed method with an average AUC value of 0.987 1 outperforms all the comparison methods. We also utilize the CRD to further validate the effectiveness of our proposed method. The AUC values for the original HSIs detected by the CRD are 0.977 4, 0.985 5, 0.983 6, 0.977 2, 0.991 6, and 0.939 3. The corresponding AUC values for the enhanced HSIs also detected by the CRD are 0.984 0, 0.987 7, 0.990 3, 0.988 8, 0.998 5, and 0.995 0. Notably, enhanced HSIs always outperform the original HSI via the CRD detector. Therefore, the gradient profile transformation is not only effective in promoting the detection accuracy but also outperforms the other preprocessing techniques. Comparing the time required by local and global gradient contour transforms shows that the former can reduce the time complexity by approximately 37.82%.ConclusionIn this study, we propose a novel hyperspectral anomaly detection method that incorporates a local gradient profile transformation to enhance the spatial information of the HSIs before detection. The experiment is conducted on six HSIs from four datasets. Experimental results show that our method outperforms several state-of-the-art anomaly detection approaches. The enhanced HSI and original HSI are detected by the Global-RX and the CRD, respectively. The experimental data demonstrate that the enhanced HSI always achieves a superior detection accuracy.关键词:hyperspectral;remote sensing image;anomaly detection;gradient profiles;information enhancement107|225|0更新时间:2024-05-07
摘要:ObjectiveAnomaly detection is a fundamental problem in hyperspectral remote sensing image processing, and it attracts the interests of several researchers. The anomalies usually refer to the outliers with spectral and spatial signatures that differ from their surroundings. Compared with the background, the anomalies have two main characteristics. First, their spectra are severely different from those of their surroundings, and this phenomenon is called the spectral difference. Meanwhile, the anomalies are usually embedded into the local homogeneous background in a format of several pixels, and this phenomenon is named the spatial difference. Hyperspectral anomaly detection has been widely used in military and civilian applications, such as surveillance, disaster warning, and rescue. In most traditional approaches, anomalies are directly derived from the original hyperspectral image (HSI). However, the HSIs usually deviate from the real scene as limited by the imagery process, such as the complexity of the imagery condition and the limited number of electrons caused by the hundreds of bands. This deviation could reduce the anomaly detection precision. We propose a novel hyperspectral anomaly detection method via the transformation of local gradient profiles to deal with the limitations caused by the low spatial quality. The gradient profile is a 1D profile along the gradient direction of the edge pixel in the image and has been introduced in natural image super resolution. Observations have demonstrated that the shape statistics of the gradient profiles in natural image is quite stable and invariant. In this way, the statistical relationship of the sharpness of the gradient profile between the real scene and the input HSI can be utilized to transform the gradient profiles of the input HSI. Meanwhile, the transformation is applied locally to some probable anomalies to reduce the computational complexity and avoid the disturbance of the background. These transformed gradient profiles are used to provide a constraint on the enhanced HSI.MethodA novel hyperspectral anomaly detection method is proposed in this study. Some probable anomalies are coarsely selected via a threshold to reduce the computational complexity without affecting the detection performance. Specifically, the original HSI is detected via the classical Global-RX(Reed Xiaoli) detector, and the responses in the map are sorted and selected. Meanwhile, the gradient profiles of these coarsely selected anomalies are computed and transformed to obtain the sharper versions. Specifically, the distribution of the gradient profile is fitted by a generalized Gaussian distribution. The transformation from the input gradient profile to the desired one can be computed via a transformation formulation. These transformed gradient profiles are closer to those of the real scene than the original gradient profiles. The original HSI is enhanced with these transformed gradient profiles. Experimental data contain six real HSIs coming from four datasets. The original six HSIs and their enhanced versions are detected via the Global-RX detector. Experimental results demonstrate the necessity of the enhancement. Meanwhile, experimental results on detection accuracy superiority of the proposed method over some other preprocessing techniques, such as the discrete wavelet transformation (DWT-RX), the spectral derivatives (Deriv-RX), and the fractional Fourier entropy (FrFE-RX), further validate the effectiveness of our proposed local gradient profile transformation strategy. We utilize the collaborative representation-based detector (CRD) to detect the enhanced and original HSIs. The enhanced HSIs still achieve higher detection accuracy.ResultWe incorporate six HSIs coming from four datasets, namely, San Diego, AVIRIS(airborne visible/infrared imaging spectrometer)-2, Airport, and Beach, to validate the performance of the proposed method. The quantitative evaluation metrics include the receiver operating curves and the area under the curve (AUC) value. We also exhibit the detection maps of each method for comparison. We validate the necessity of the enhancement. Thus, comparison of detection accuracy is made between the original and enhanced HSIs via the Global-RX detector. AUC values for the six original HSIs are 0.940 2, 0.934 1, 0.840 3, 0.952 5, 0.980 6, and 0.953 8, respectively. The corresponding AUC values for the enhanced HSIs are 0.977 8, 0.984 9, 0.983 5, 0.982 4, 0.998 6, and 0.995 6. Notably, the enhanced HSI always achieves a higher detection accuracy than the original HSI, which proves the necessity of the enhancement. We also compare our proposed method with three other preprocessing techniques, namely, the DWT-RX, Deriv-RX, and the FrFE-RX, which have average AUC values of 0.956 8, 0.957 9, and 0.964 0, respectively. Our proposed method with an average AUC value of 0.987 1 outperforms all the comparison methods. We also utilize the CRD to further validate the effectiveness of our proposed method. The AUC values for the original HSIs detected by the CRD are 0.977 4, 0.985 5, 0.983 6, 0.977 2, 0.991 6, and 0.939 3. The corresponding AUC values for the enhanced HSIs also detected by the CRD are 0.984 0, 0.987 7, 0.990 3, 0.988 8, 0.998 5, and 0.995 0. Notably, enhanced HSIs always outperform the original HSI via the CRD detector. Therefore, the gradient profile transformation is not only effective in promoting the detection accuracy but also outperforms the other preprocessing techniques. Comparing the time required by local and global gradient contour transforms shows that the former can reduce the time complexity by approximately 37.82%.ConclusionIn this study, we propose a novel hyperspectral anomaly detection method that incorporates a local gradient profile transformation to enhance the spatial information of the HSIs before detection. The experiment is conducted on six HSIs from four datasets. Experimental results show that our method outperforms several state-of-the-art anomaly detection approaches. The enhanced HSI and original HSI are detected by the Global-RX and the CRD, respectively. The experimental data demonstrate that the enhanced HSI always achieves a superior detection accuracy.关键词:hyperspectral;remote sensing image;anomaly detection;gradient profiles;information enhancement107|225|0更新时间:2024-05-07 -
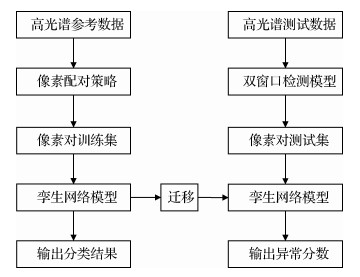 摘要:ObjectiveThe continuous improvement in spectral resolution promotes the development and progress of hyperspectral remote sensing technology. Hyperspectral remote sensing technology has broad application scenarios and great application value and is a major research topic in the field of remote sensing. Anomaly detection of the hyperspectral image is an important branch in the field of hyperspectral remote sensing, and it is widely used in the industry, geological exploration, and other fields. The number of anomalies in the scene is usually small, and the spatial and spectral characteristics are different from the surrounding background. In the hyperspectral field, the spectral characteristics of pixels are usually used to distinguish the background and anomalous targets, that is, the anomalous pixels in the image are searched through the spectral differences. The detection methods based on a statistical model and traditional machine learning will have difficulty building the background model because of the complexity of background pixels. They will also have difficulty selecting the form of kernel function and building the background dictionary due to the lack of prior knowledge. Moreover, traditional anomaly detection algorithms do not effectively mine the deep features of the spectrum, and the rich spectral information in hyperspectral images is not fully utilized. Deep learning has great advantages in processing complex hyperspectral images, and anomaly detection method using deep learning is still a frontier area worthy of exploration and has gradually become the focus of research. Therefore, this study proposes a hyperspectral image anomaly detection method based on siamese neural network with pixel-pair strategy. It uses deep learning technology to extract the deep nonlinear features of hyperspectral images. This method aims to improve the accuracy of anomaly detection and promote the development of hyperspectral image processing and application technology.MethodThe method of anomaly detection in the hyperspectral image based on siamese neural network with pixel-pair feature (PPF-SNN) is divided into three steps. First, the idea of pixel-pair is adopted to amplify training samples because of the scarcity of hyperspectral data samples with real labels and the need for a large number of training data of the deep network model. Specifically, two pixels are randomly selected from the reference data containing multiple types of ground materials for matching. If they come from the same labeled class, then the pair is labeled as 0; if they come from different labeled classes, then the label is 1. Compared with the original datasets, the number of new datasets obtained by pairing increases exponentially to meet the demand of a deep network for the number of datasets. Second, we build a siamese network model with a feature extraction module and feature processing module. The branch network of the feature extraction module adopts the convolutional neural network (CNN) structure with weight sharing, which contains 10 convolutional layers. The feature processing module concatenates the input feature pairs and then extracts the difference features of pixel pairs through a convolutional layer, while the pixel pairs are classified through the fully connected layers. The module uses the extracted pixel pair features to measure the similarity of the input pairs. Then, the new training dataset is used to train the model, and the trained classification model is transferred to the detection process with fixed parameters. Third, the sliding dual-window strategy is used to pair the test set, and the test pixel pair dataset is sent to the network model. Next, the difference score of each pixel compared with the surrounding background pixels is obtained. If the score is close to 1, then the pixel under test tends to be anomalous. If the score is close to 0, then the pixel under test is close to the background. Using this principle, we can identify the anomalous targets in the test scene.ResultTo verify the effectiveness of the proposed algorithm, the experimental part selects two scenes from the San Diego dataset and one scene from the ABU-Airport dataset and uses the traditional algorithms like global RXD (GRXD), local RXD (LRXD), and collaborative representation-based detector (CRD) and the anomaly detection algorithm based on convolutional neural network with pixel-pair feature (PPF-CNN) as the comparative algorithms. The receiver operating curve (ROC) of each algorithm is drawn, and the corresponding area under the ROC curve (AUC) value is calculated as an evaluation index of algorithm performance. In the anomaly detection experimental results of the three scenes, the proposed PPF-SNN has the highest AUC values of 0.993 51, 0.981 21, and 0.984 38, respectively. It can ensure the highest detection rate while keeping the false alarm rate low. The performance of PPF-SNN has obvious advantages over traditional algorithms and PPF-CNN algorithm.ConclusionThe proposed hyperspectral image anomaly detection method based on siamese neural network can extract the deep spectral characteristics of the input pixel pair. According to the difference in its characteristics, the network will learn the distinction between the two. Thus, it can effectively provide the anomaly score of the pixel under test relative to the surrounding background. Compared with PPF-CNN, the proposed method can effectively reduce false alarms. It can also highlight anomalous targets more obviously, improve the detection rate, and exhibit stronger robustness than traditional methods.关键词:hyperspectral image;anomaly detection;deep learning;siamese neural network;pixel-pair strategy;sliding dual-window179|56|3更新时间:2024-05-07
摘要:ObjectiveThe continuous improvement in spectral resolution promotes the development and progress of hyperspectral remote sensing technology. Hyperspectral remote sensing technology has broad application scenarios and great application value and is a major research topic in the field of remote sensing. Anomaly detection of the hyperspectral image is an important branch in the field of hyperspectral remote sensing, and it is widely used in the industry, geological exploration, and other fields. The number of anomalies in the scene is usually small, and the spatial and spectral characteristics are different from the surrounding background. In the hyperspectral field, the spectral characteristics of pixels are usually used to distinguish the background and anomalous targets, that is, the anomalous pixels in the image are searched through the spectral differences. The detection methods based on a statistical model and traditional machine learning will have difficulty building the background model because of the complexity of background pixels. They will also have difficulty selecting the form of kernel function and building the background dictionary due to the lack of prior knowledge. Moreover, traditional anomaly detection algorithms do not effectively mine the deep features of the spectrum, and the rich spectral information in hyperspectral images is not fully utilized. Deep learning has great advantages in processing complex hyperspectral images, and anomaly detection method using deep learning is still a frontier area worthy of exploration and has gradually become the focus of research. Therefore, this study proposes a hyperspectral image anomaly detection method based on siamese neural network with pixel-pair strategy. It uses deep learning technology to extract the deep nonlinear features of hyperspectral images. This method aims to improve the accuracy of anomaly detection and promote the development of hyperspectral image processing and application technology.MethodThe method of anomaly detection in the hyperspectral image based on siamese neural network with pixel-pair feature (PPF-SNN) is divided into three steps. First, the idea of pixel-pair is adopted to amplify training samples because of the scarcity of hyperspectral data samples with real labels and the need for a large number of training data of the deep network model. Specifically, two pixels are randomly selected from the reference data containing multiple types of ground materials for matching. If they come from the same labeled class, then the pair is labeled as 0; if they come from different labeled classes, then the label is 1. Compared with the original datasets, the number of new datasets obtained by pairing increases exponentially to meet the demand of a deep network for the number of datasets. Second, we build a siamese network model with a feature extraction module and feature processing module. The branch network of the feature extraction module adopts the convolutional neural network (CNN) structure with weight sharing, which contains 10 convolutional layers. The feature processing module concatenates the input feature pairs and then extracts the difference features of pixel pairs through a convolutional layer, while the pixel pairs are classified through the fully connected layers. The module uses the extracted pixel pair features to measure the similarity of the input pairs. Then, the new training dataset is used to train the model, and the trained classification model is transferred to the detection process with fixed parameters. Third, the sliding dual-window strategy is used to pair the test set, and the test pixel pair dataset is sent to the network model. Next, the difference score of each pixel compared with the surrounding background pixels is obtained. If the score is close to 1, then the pixel under test tends to be anomalous. If the score is close to 0, then the pixel under test is close to the background. Using this principle, we can identify the anomalous targets in the test scene.ResultTo verify the effectiveness of the proposed algorithm, the experimental part selects two scenes from the San Diego dataset and one scene from the ABU-Airport dataset and uses the traditional algorithms like global RXD (GRXD), local RXD (LRXD), and collaborative representation-based detector (CRD) and the anomaly detection algorithm based on convolutional neural network with pixel-pair feature (PPF-CNN) as the comparative algorithms. The receiver operating curve (ROC) of each algorithm is drawn, and the corresponding area under the ROC curve (AUC) value is calculated as an evaluation index of algorithm performance. In the anomaly detection experimental results of the three scenes, the proposed PPF-SNN has the highest AUC values of 0.993 51, 0.981 21, and 0.984 38, respectively. It can ensure the highest detection rate while keeping the false alarm rate low. The performance of PPF-SNN has obvious advantages over traditional algorithms and PPF-CNN algorithm.ConclusionThe proposed hyperspectral image anomaly detection method based on siamese neural network can extract the deep spectral characteristics of the input pixel pair. According to the difference in its characteristics, the network will learn the distinction between the two. Thus, it can effectively provide the anomaly score of the pixel under test relative to the surrounding background. Compared with PPF-CNN, the proposed method can effectively reduce false alarms. It can also highlight anomalous targets more obviously, improve the detection rate, and exhibit stronger robustness than traditional methods.关键词:hyperspectral image;anomaly detection;deep learning;siamese neural network;pixel-pair strategy;sliding dual-window179|56|3更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral image has rich spectral information. Different materials correspond to different spectral information, which can be applied to disaster warning, agriculture precision, and authenticity identification for some valuable art works. Anomaly detection of hyperspectral images refers to detecting the anomalous pixels in the scene without any prior information, and it is important in military and civil applications. In this way, the anomaly detection of hyperspectral images has gained increasing popularity. The anomalies usually refer to the outliers with spatial and spectral signatures that are severely different from their surroundings. Compared with the background, the anomalies have two main characteristics. First, their spectral information is severely different from that of their surroundings, and this phenomenon is named the spectral difference. Meanwhile, the anomalies are usually embedded into the local homogeneous background in a format of several pixels or even sub-pixels, and this phenomenon is called the spatial difference. Anomalies are often hidden in a large number of background pixels, and they only occupy a small number. Thus, they bring a great challenge to accurate detection. This study proposes a hyperspectral anomaly detection algorithm based on rough localization and collaborative representation of outliers to solve this problem. It is based on the institution that the anomalies often appear in high-frequency detail areas.MethodA novel hyperspectral anomaly detection method based on the rough location and collaborative representation is proposed in this study. This method utilizes the spatial information and inter-spectral information carried by the hyperspectral images simultaneously, which ensures the accuracy of the algorithm. Three modules are included in the whole detection process. First, the original hyperspectral image is degraded in spatial dimension. Second, we can obtain the rough response map of spatial anomaly by measuring the difference between the degraded and original images in spatial dimension and locate the possible abnormal points according to the response value considering that the degradation operation of spatial dimension often loses high-frequency information. Finally, the rough location of outliers is used to guide the collaborative representation between pixels for reconstructing the center pixel. The detection result is further optimized by measuring the difference between the reconstructed center and original pixels. Experimental data contain four real-scenario datasets, namely, the San Diego, Grand Isle, hyperspectral digital image collection equipment(HYDICE), and Honghu datasets. Experimental results demonstrate the effectiveness of the proposed method. Experimental comparison is made with six classical methods, namely, the Global-RX(Reed-Xiaoli) detector (RXD), Local-RX detector (LRX), collaborative representation-based detector (CRD), tensor completion-based detector (TCD), fractional Fourier estimation (FrFE), and low-rank and sparse decomposition model with mixture of Gaussian (LSDM-MoG). The FrFE detector utilizes the fractional Fourier transformation to the spectral information, and it obtains the optimal order and the corresponding spectral feature. The spectral feature is further detected by the Reed-Xiaoli(RX) detector. In this way, the RXD, LRX, and the FrFE all belong to the statistical-based detectors. LSDM-MoG imports the mixture of Gaussian as a regularization term for the low-rank and sparse decomposition model, which is a typical representation-based anomaly detection method. In this way, the CRD, TCD, and the LSDM-MoG all belong to the representation-based detectors.ResultWe incorporate four real-scenario hyperspectral images to validate the performance of the proposed method. The quantitative evaluation metrics include the receiver operating curves and the area under the curve (AUC) value to evaluate the detection accuracy. Meanwhile, we also exhibit the detection maps of each method for visual comparison. The average results of the three datasets indicate that the second optimal mean AUC value (0.992 4) is achieved by the CRD detector. The corresponding mean AUC value achieved by the proposed method is 0.997 3. Compared with the algorithm with the second best performance, the AUC value for the San Diego dataset is increased from 0.978 6 to 0.994 0 by the proposed method. For the HYDICE dataset, the AUC value is increased from 0.996 3 to 0.998 5 by the proposed method compared with the detector with the second best performance. For the Honghu dataset depicting a long river bank in Honghu, Hubei Province of China, the proposed method achieves the AUC value of 0.999 3, which is superior than that of the detector with the second best performance. For the Grand Isle dataset, the AUC value of the proposed detector is slightly lower than that of the LSDM-MoG detector with the optimal performance by a gap of 0.001. However, the visual maps reveal that the false alarm targets generated by the LSDM-MoG are more frequent than those of the proposed method. Experimental results and data analysis demonstrate the effectiveness of the proposed algorithm.ConclusionA rough detection and collaborative representation-based algorithm for anomaly detection of hyperspectral images is proposed in this study. The anomalous and background pixels are coarsely separated by a simple spatial degradation processing. Meanwhile, the coarsely separated background and anomaly response map is utilized to guide the locally collaborative representation between pixels. Purer background characteristics can be expressed with the guidance of the rough detection map, and the suppression of anomalous pixels due to the polluted background in the detection process is avoided. Accordingly, the detection accuracy is improved. Meanwhile, parameters in the collaborative representation process decrease with the reduction in participating elements. Over-fitting phenomenon is unlikely to be produced with the simpler optimization model, which ensures the effectiveness of the algorithm. In this way, the proposed method utilizes not only the spectral characteristics of hyperspectral images but also their spatial characteristics and the prior information of spatial information. Experimental results and comparative analysis demonstrate the effectiveness of the proposed method in anomaly detection.关键词:hyperspectral;remote sensing image;anomaly detection;rough location;collaborative representation126|168|1更新时间:2024-05-07
摘要:ObjectiveHyperspectral image has rich spectral information. Different materials correspond to different spectral information, which can be applied to disaster warning, agriculture precision, and authenticity identification for some valuable art works. Anomaly detection of hyperspectral images refers to detecting the anomalous pixels in the scene without any prior information, and it is important in military and civil applications. In this way, the anomaly detection of hyperspectral images has gained increasing popularity. The anomalies usually refer to the outliers with spatial and spectral signatures that are severely different from their surroundings. Compared with the background, the anomalies have two main characteristics. First, their spectral information is severely different from that of their surroundings, and this phenomenon is named the spectral difference. Meanwhile, the anomalies are usually embedded into the local homogeneous background in a format of several pixels or even sub-pixels, and this phenomenon is called the spatial difference. Anomalies are often hidden in a large number of background pixels, and they only occupy a small number. Thus, they bring a great challenge to accurate detection. This study proposes a hyperspectral anomaly detection algorithm based on rough localization and collaborative representation of outliers to solve this problem. It is based on the institution that the anomalies often appear in high-frequency detail areas.MethodA novel hyperspectral anomaly detection method based on the rough location and collaborative representation is proposed in this study. This method utilizes the spatial information and inter-spectral information carried by the hyperspectral images simultaneously, which ensures the accuracy of the algorithm. Three modules are included in the whole detection process. First, the original hyperspectral image is degraded in spatial dimension. Second, we can obtain the rough response map of spatial anomaly by measuring the difference between the degraded and original images in spatial dimension and locate the possible abnormal points according to the response value considering that the degradation operation of spatial dimension often loses high-frequency information. Finally, the rough location of outliers is used to guide the collaborative representation between pixels for reconstructing the center pixel. The detection result is further optimized by measuring the difference between the reconstructed center and original pixels. Experimental data contain four real-scenario datasets, namely, the San Diego, Grand Isle, hyperspectral digital image collection equipment(HYDICE), and Honghu datasets. Experimental results demonstrate the effectiveness of the proposed method. Experimental comparison is made with six classical methods, namely, the Global-RX(Reed-Xiaoli) detector (RXD), Local-RX detector (LRX), collaborative representation-based detector (CRD), tensor completion-based detector (TCD), fractional Fourier estimation (FrFE), and low-rank and sparse decomposition model with mixture of Gaussian (LSDM-MoG). The FrFE detector utilizes the fractional Fourier transformation to the spectral information, and it obtains the optimal order and the corresponding spectral feature. The spectral feature is further detected by the Reed-Xiaoli(RX) detector. In this way, the RXD, LRX, and the FrFE all belong to the statistical-based detectors. LSDM-MoG imports the mixture of Gaussian as a regularization term for the low-rank and sparse decomposition model, which is a typical representation-based anomaly detection method. In this way, the CRD, TCD, and the LSDM-MoG all belong to the representation-based detectors.ResultWe incorporate four real-scenario hyperspectral images to validate the performance of the proposed method. The quantitative evaluation metrics include the receiver operating curves and the area under the curve (AUC) value to evaluate the detection accuracy. Meanwhile, we also exhibit the detection maps of each method for visual comparison. The average results of the three datasets indicate that the second optimal mean AUC value (0.992 4) is achieved by the CRD detector. The corresponding mean AUC value achieved by the proposed method is 0.997 3. Compared with the algorithm with the second best performance, the AUC value for the San Diego dataset is increased from 0.978 6 to 0.994 0 by the proposed method. For the HYDICE dataset, the AUC value is increased from 0.996 3 to 0.998 5 by the proposed method compared with the detector with the second best performance. For the Honghu dataset depicting a long river bank in Honghu, Hubei Province of China, the proposed method achieves the AUC value of 0.999 3, which is superior than that of the detector with the second best performance. For the Grand Isle dataset, the AUC value of the proposed detector is slightly lower than that of the LSDM-MoG detector with the optimal performance by a gap of 0.001. However, the visual maps reveal that the false alarm targets generated by the LSDM-MoG are more frequent than those of the proposed method. Experimental results and data analysis demonstrate the effectiveness of the proposed algorithm.ConclusionA rough detection and collaborative representation-based algorithm for anomaly detection of hyperspectral images is proposed in this study. The anomalous and background pixels are coarsely separated by a simple spatial degradation processing. Meanwhile, the coarsely separated background and anomaly response map is utilized to guide the locally collaborative representation between pixels. Purer background characteristics can be expressed with the guidance of the rough detection map, and the suppression of anomalous pixels due to the polluted background in the detection process is avoided. Accordingly, the detection accuracy is improved. Meanwhile, parameters in the collaborative representation process decrease with the reduction in participating elements. Over-fitting phenomenon is unlikely to be produced with the simpler optimization model, which ensures the effectiveness of the algorithm. In this way, the proposed method utilizes not only the spectral characteristics of hyperspectral images but also their spatial characteristics and the prior information of spatial information. Experimental results and comparative analysis demonstrate the effectiveness of the proposed method in anomaly detection.关键词:hyperspectral;remote sensing image;anomaly detection;rough location;collaborative representation126|168|1更新时间:2024-05-07 -
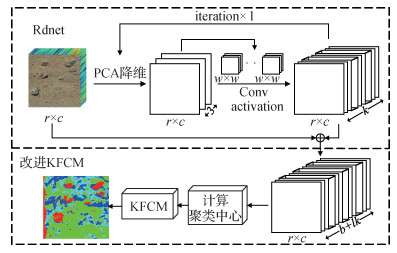 摘要:ObjectiveMarine resource survey is an important component of marine scientific research, which is of great significance to the development and utilization of marine resources and the protection of the marine environment. Polymetallic nodules, otherwise known as manganese nodules, are commonly distributed in the submarine plains of the water depth of 4~6 km. These nodules contain metallic elements, such as manganese, nickel, copper, and cobalt. Polymetallic nodules are regarded as an important oceanic mineral resource. The rich metallic elements of these nodules are relatively rare in terrestrial resources, but they are widely used. Influential countries and research institutions are currently conducting forward-looking investigations on the potential of deep-sea manganese nodules in view of its crucial strategic value. Traditional methods for investigating manganese nodules on the ocean floor are based on mechanical sampling, multi-beam acoustic remote sensing, and optical images. In recent years, the application of hyperspectral imaging technology in deep-sea resource surveys has gradually attracted the attention of researchers. Hyperspectral image refers to the integration of hundreds of continuous spectral bands and high-resolution image data. Each pixel corresponds to a continuous spectral curve, and objects of different materials obtain their unique "optical fingerprints". Using deep-sea hyperspectral images to investigate manganese nodule resources on the ocean floor has more comprehensive information and accurate identification than traditional image methods. This situation is precisely because many prospecting methods based on hyperspectral images have been proposed and applied to the investigation of ocean floor manganese nodules, such as the active hyperspectral imager mounted underwater, due to the superiority of these images in spectral characteristics compared with ordinary images. Platforms or remotely operated submersibles conduct surveys of seabed resources. At present, most processing methods for underwater hyperspectral images use supervised learning methods. However, supervised classification requires the addition of prior data. The following two problems occur in the investigation of marine resources: first, samples are sometimes difficult to obtain, and a perfect spectral database of seabed resources is lacking; second, underwater data are often complicated, and the result of manual calibration largely depends on the experience of the calibration personnel. This condition is vulnerable to interference from certain factors, such as fatigue, chromatic aberration, and environment, and the result will be a larger error. To address this limitation, this work proposes a deep kernel fuzzy C-means (DKFCM) clustering algorithm that combines deep network and fuzzy kernel clustering to realize unsupervised clustering of hyperspectral images of ocean floor manganese nodules.MethodTo extract more effective hyperspectral deep features, the DKFCM algorithm adds a random deep convolutional network Rdnet before improving the fuzzy kernel clustering algorithm to extract the deep spectral information about deep-sea hyperspectral images and use them for hyperspectral image clustering. In the feature extraction network part, the information redundancy is large because the hyperspectral image is composed of a substantial amount of relevant narrow-band spectral information. The huge spectral information can be compressed, the calculation speed is raised, and the calculation cost of the convolution operation is reduced through the dimensionality reduction operation with the principal component analysis(PCA). Then, data after PCA are convolved by randomly selecting some pixels from the data and cutting out a square image around it as the convolution kernel. After the random block convolution operation, the ReLU nonlinear activation function is added to improve the overall feature sparsity. Finally, the first layer of features is obtained. The above-mentioned dimensionality reduction, convolution, and nonlinear activation operations are repeated to extract deeper features. The shallow and deep features are merged as input features for subsequent classification. The clustering algorithm easily becomes unstable and fall into a local optimum because the initial clustering center of the KFCM algorithm is randomly selected. To improve this problem, the improved KFCM algorithm proposed in this work uses the Euclidean distance to measure the similarity and sets the distance between the initial cluster centers as far as possible. The initial cluster centers are finally iterated depending on this rule, and the clustering operation is performed. Finally, the accuracy of manganese nodules was obtained by separating and comparing each kind of substance.ResultThe experiment is divided into three groups for comparison. The clustering algorithms used are K-means clustering, DKmeans (K-means clustering through Rdnet), and the DKFCM clustering proposed in this work. Results show that DKFCM unsupervised clustering can effectively cluster ocean floor resources. In combination with the image data, the accuracy rate of manganese nodules is 76.59%. The overall number of correct nodules increases, the number of false clustering is relatively minimal, and the cluster results are the best. The accuracy of this algorithm is increased by 20.99% compared with K-means clustering. Meanwhile, the accuracy of the algorithm is increased by 13.76% compared with DKmeans clustering. This finding proves that the DKFCM algorithm can achieve high accuracy even without labeled data.ConclusionThe hyperspectral deep fuzzy kernel clustering method proposed in the thesis, which combines deep convolutional network and improved kernel fuzzy clustering method, can extract deep features from deep sea hyperspectral data and use it for clustering. Experimental results show that the DKFCM algorithm realizes unsupervised clustering of deep-sea manganese nodules, which can be utilized for the assessment of marine resources, in the absence of seabed tag data.关键词:hyperspectral image;deep learning;convolutional network;feature extraction;clustering;manganese nodules124|122|1更新时间:2024-05-07
摘要:ObjectiveMarine resource survey is an important component of marine scientific research, which is of great significance to the development and utilization of marine resources and the protection of the marine environment. Polymetallic nodules, otherwise known as manganese nodules, are commonly distributed in the submarine plains of the water depth of 4~6 km. These nodules contain metallic elements, such as manganese, nickel, copper, and cobalt. Polymetallic nodules are regarded as an important oceanic mineral resource. The rich metallic elements of these nodules are relatively rare in terrestrial resources, but they are widely used. Influential countries and research institutions are currently conducting forward-looking investigations on the potential of deep-sea manganese nodules in view of its crucial strategic value. Traditional methods for investigating manganese nodules on the ocean floor are based on mechanical sampling, multi-beam acoustic remote sensing, and optical images. In recent years, the application of hyperspectral imaging technology in deep-sea resource surveys has gradually attracted the attention of researchers. Hyperspectral image refers to the integration of hundreds of continuous spectral bands and high-resolution image data. Each pixel corresponds to a continuous spectral curve, and objects of different materials obtain their unique "optical fingerprints". Using deep-sea hyperspectral images to investigate manganese nodule resources on the ocean floor has more comprehensive information and accurate identification than traditional image methods. This situation is precisely because many prospecting methods based on hyperspectral images have been proposed and applied to the investigation of ocean floor manganese nodules, such as the active hyperspectral imager mounted underwater, due to the superiority of these images in spectral characteristics compared with ordinary images. Platforms or remotely operated submersibles conduct surveys of seabed resources. At present, most processing methods for underwater hyperspectral images use supervised learning methods. However, supervised classification requires the addition of prior data. The following two problems occur in the investigation of marine resources: first, samples are sometimes difficult to obtain, and a perfect spectral database of seabed resources is lacking; second, underwater data are often complicated, and the result of manual calibration largely depends on the experience of the calibration personnel. This condition is vulnerable to interference from certain factors, such as fatigue, chromatic aberration, and environment, and the result will be a larger error. To address this limitation, this work proposes a deep kernel fuzzy C-means (DKFCM) clustering algorithm that combines deep network and fuzzy kernel clustering to realize unsupervised clustering of hyperspectral images of ocean floor manganese nodules.MethodTo extract more effective hyperspectral deep features, the DKFCM algorithm adds a random deep convolutional network Rdnet before improving the fuzzy kernel clustering algorithm to extract the deep spectral information about deep-sea hyperspectral images and use them for hyperspectral image clustering. In the feature extraction network part, the information redundancy is large because the hyperspectral image is composed of a substantial amount of relevant narrow-band spectral information. The huge spectral information can be compressed, the calculation speed is raised, and the calculation cost of the convolution operation is reduced through the dimensionality reduction operation with the principal component analysis(PCA). Then, data after PCA are convolved by randomly selecting some pixels from the data and cutting out a square image around it as the convolution kernel. After the random block convolution operation, the ReLU nonlinear activation function is added to improve the overall feature sparsity. Finally, the first layer of features is obtained. The above-mentioned dimensionality reduction, convolution, and nonlinear activation operations are repeated to extract deeper features. The shallow and deep features are merged as input features for subsequent classification. The clustering algorithm easily becomes unstable and fall into a local optimum because the initial clustering center of the KFCM algorithm is randomly selected. To improve this problem, the improved KFCM algorithm proposed in this work uses the Euclidean distance to measure the similarity and sets the distance between the initial cluster centers as far as possible. The initial cluster centers are finally iterated depending on this rule, and the clustering operation is performed. Finally, the accuracy of manganese nodules was obtained by separating and comparing each kind of substance.ResultThe experiment is divided into three groups for comparison. The clustering algorithms used are K-means clustering, DKmeans (K-means clustering through Rdnet), and the DKFCM clustering proposed in this work. Results show that DKFCM unsupervised clustering can effectively cluster ocean floor resources. In combination with the image data, the accuracy rate of manganese nodules is 76.59%. The overall number of correct nodules increases, the number of false clustering is relatively minimal, and the cluster results are the best. The accuracy of this algorithm is increased by 20.99% compared with K-means clustering. Meanwhile, the accuracy of the algorithm is increased by 13.76% compared with DKmeans clustering. This finding proves that the DKFCM algorithm can achieve high accuracy even without labeled data.ConclusionThe hyperspectral deep fuzzy kernel clustering method proposed in the thesis, which combines deep convolutional network and improved kernel fuzzy clustering method, can extract deep features from deep sea hyperspectral data and use it for clustering. Experimental results show that the DKFCM algorithm realizes unsupervised clustering of deep-sea manganese nodules, which can be utilized for the assessment of marine resources, in the absence of seabed tag data.关键词:hyperspectral image;deep learning;convolutional network;feature extraction;clustering;manganese nodules124|122|1更新时间:2024-05-07
Hyperspectral Target Detection and Recognition
-
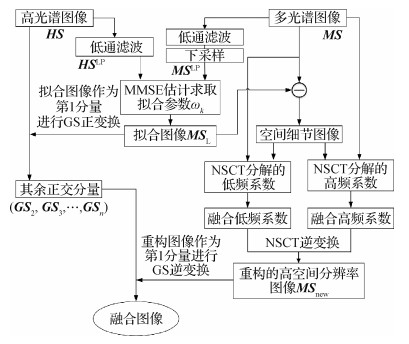 摘要:ObjectiveGaoFen-5 (GF-5) hyperspectral data are important hyperspectral data sources at present. However, its 30 m spatial resolution limits its extensive application. Spatial-spectral fusion can fully utilize data of high spatial resolution like multispectral image (MSI) and data of high spectral resolution like hyperspectral image (HSI). It aims to generate data with high spatial and spectral resolutions at the same time. The ratio of spatial resolution between the two fusion images is usually 4. The Sentinel-2 MSI, which is 10 m resolution, is moderate for fusion with GF-5 HSI. Some scholars have applied a few typical pan-sharpening methods for MSI and HSI fusion based on artificial dataset, such as component substitution and multiresolution analysis methods. Others have adopted some model-based algorithms, such as Bayesian and matrix factorization approaches. However, the result performed on artificial dataset obeys the Wald's protocol instead of the real dataset. The main problem in the methods mentioned above is that some methods enhance the spatial information obviously but distort its spectrum, while others have high spectral fidelity but insufficient enhancement in spatial information. Therefore, we propose a new fusion algorithm called spatial-spectral fusion based on band-adaptive detail injection for GF-5 and Sentinel-2 remote sensing images to obtain the fused image with enhanced spatial resolution and high spectral fidelity. This method is based on the Gram-Schmidt (GS) transform and the nonsubsampled contourlet transform (NSCT).MethodFirst, the band-adaptive grouping strategy is proposed to solve the difficulty in directly fusing two multi-band images. Each band of the HSI is grouped into the most relevant band of the MSI according to the correlation coefficient. This grouping strategy also improves the spectral fidelity of the fused image to some extent. Second, the minimizing mean square error estimator is used to calculate the coefficient for generating the low-resolution MSI (LMSI) in GS transform, which reduces the spectral distortion caused by simulating the LMSI with average weight coefficients in the traditional GS fusion. Then, the GS transformation is applied for the LMSI and the HSI to obtain each GS component. Third, NSCT has advantages in image denoising and enhancement, which can improve the spatial details of the fused image. NSCT is applied on the MSI, the LMSI, and the detail image generated from their difference to obtain high- and low-frequency coefficients. Next, a new high-resolution MSI (HMSI) is produced using weighted strategies. The HMSI has high spatial resolution and some spectral information because the spatial and spectral information in MSI, LMSI, and detail image are integrated into the reconstructed HMSI. Finally, the first component of GS components is replaced with the HMSI, and the image of high spatial and spectral resolutions is generated through the GS inverse transformation.ResultWe perform experiments on the real GF-5 data and Sentinel-2 data with abundant feature types, such as buildings, roads, mountains, plants, water, farmland, and bare land, to verify the reliability and effectiveness of the proposed method. The standard deviation, entropy, universal image quality index, correlation coefficient (CC), erreur relative globale adimensionnelle de Synthèse (ERGAS), and spectral angle mapper (SAM) are used as the quantitative indices to evaluate the quality of the fusion images. Compared with the typical fusion methods, the proposed method has advantages in spatial resolution and spectral fidelity. This method can improve the spatial resolution and has good spectral fidelity for the urban area which is rarely affected by the time phase. The fused image is sharp and has no noise for the vegetation area which is greatly affected by time. Compared with the indices of the traditional GS method, the CC, ERGAS, and SAM of the proposed method are improved by 8%, 26%, and 28%, respectively, which indicates that the spectral fidelity of this method is greatly improved. In addition, spectral curve is an important index to evaluate the quality of HSI. The spectral quality of the fused image is evaluated by comparing the shape and numerical difference of the spectral curve between the fused image and the original HSI in each band. The result shows that the spectral curve of the proposed method is consistent with the original HSI and closer to the original HSI than the GS method.ConclusionWe propose a new spatial-spectral fusion method based on band-adaptive detail injection. No noise is observed in the result, and the spectral curve is consistent with the original spectral curve. Experimental results show that the proposed method has high spatial resolution while mitigating spectral distortion. The high- and low-frequency coefficients of NSCT in the proposed method are reorganized by the weighted fusion rule. In the following research, the NSCT fusion rule can be improved to generate fusion images with better spatial details and higher spectral fidelity.关键词:remote sensing;spatial-spectral fusion;GaoFen-5 (GF-5) satellite;Sentinel-2 satellite;Gram-Schmidt (GS) transform;nonsubsampled contourlet transform (NSCT);hyperspectral image;multi-sensor195|210|4更新时间:2024-05-07
摘要:ObjectiveGaoFen-5 (GF-5) hyperspectral data are important hyperspectral data sources at present. However, its 30 m spatial resolution limits its extensive application. Spatial-spectral fusion can fully utilize data of high spatial resolution like multispectral image (MSI) and data of high spectral resolution like hyperspectral image (HSI). It aims to generate data with high spatial and spectral resolutions at the same time. The ratio of spatial resolution between the two fusion images is usually 4. The Sentinel-2 MSI, which is 10 m resolution, is moderate for fusion with GF-5 HSI. Some scholars have applied a few typical pan-sharpening methods for MSI and HSI fusion based on artificial dataset, such as component substitution and multiresolution analysis methods. Others have adopted some model-based algorithms, such as Bayesian and matrix factorization approaches. However, the result performed on artificial dataset obeys the Wald's protocol instead of the real dataset. The main problem in the methods mentioned above is that some methods enhance the spatial information obviously but distort its spectrum, while others have high spectral fidelity but insufficient enhancement in spatial information. Therefore, we propose a new fusion algorithm called spatial-spectral fusion based on band-adaptive detail injection for GF-5 and Sentinel-2 remote sensing images to obtain the fused image with enhanced spatial resolution and high spectral fidelity. This method is based on the Gram-Schmidt (GS) transform and the nonsubsampled contourlet transform (NSCT).MethodFirst, the band-adaptive grouping strategy is proposed to solve the difficulty in directly fusing two multi-band images. Each band of the HSI is grouped into the most relevant band of the MSI according to the correlation coefficient. This grouping strategy also improves the spectral fidelity of the fused image to some extent. Second, the minimizing mean square error estimator is used to calculate the coefficient for generating the low-resolution MSI (LMSI) in GS transform, which reduces the spectral distortion caused by simulating the LMSI with average weight coefficients in the traditional GS fusion. Then, the GS transformation is applied for the LMSI and the HSI to obtain each GS component. Third, NSCT has advantages in image denoising and enhancement, which can improve the spatial details of the fused image. NSCT is applied on the MSI, the LMSI, and the detail image generated from their difference to obtain high- and low-frequency coefficients. Next, a new high-resolution MSI (HMSI) is produced using weighted strategies. The HMSI has high spatial resolution and some spectral information because the spatial and spectral information in MSI, LMSI, and detail image are integrated into the reconstructed HMSI. Finally, the first component of GS components is replaced with the HMSI, and the image of high spatial and spectral resolutions is generated through the GS inverse transformation.ResultWe perform experiments on the real GF-5 data and Sentinel-2 data with abundant feature types, such as buildings, roads, mountains, plants, water, farmland, and bare land, to verify the reliability and effectiveness of the proposed method. The standard deviation, entropy, universal image quality index, correlation coefficient (CC), erreur relative globale adimensionnelle de Synthèse (ERGAS), and spectral angle mapper (SAM) are used as the quantitative indices to evaluate the quality of the fusion images. Compared with the typical fusion methods, the proposed method has advantages in spatial resolution and spectral fidelity. This method can improve the spatial resolution and has good spectral fidelity for the urban area which is rarely affected by the time phase. The fused image is sharp and has no noise for the vegetation area which is greatly affected by time. Compared with the indices of the traditional GS method, the CC, ERGAS, and SAM of the proposed method are improved by 8%, 26%, and 28%, respectively, which indicates that the spectral fidelity of this method is greatly improved. In addition, spectral curve is an important index to evaluate the quality of HSI. The spectral quality of the fused image is evaluated by comparing the shape and numerical difference of the spectral curve between the fused image and the original HSI in each band. The result shows that the spectral curve of the proposed method is consistent with the original HSI and closer to the original HSI than the GS method.ConclusionWe propose a new spatial-spectral fusion method based on band-adaptive detail injection. No noise is observed in the result, and the spectral curve is consistent with the original spectral curve. Experimental results show that the proposed method has high spatial resolution while mitigating spectral distortion. The high- and low-frequency coefficients of NSCT in the proposed method are reorganized by the weighted fusion rule. In the following research, the NSCT fusion rule can be improved to generate fusion images with better spatial details and higher spectral fidelity.关键词:remote sensing;spatial-spectral fusion;GaoFen-5 (GF-5) satellite;Sentinel-2 satellite;Gram-Schmidt (GS) transform;nonsubsampled contourlet transform (NSCT);hyperspectral image;multi-sensor195|210|4更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral images (HSIs) use imaging spectrometers to collect hundreds of spectral band images from ultraviolet to infrared wavelengths on the same area of the earth's surface. Tens to hundreds of continuous grayscale images are available, and each pixel can extract a spectral curve. Hyperspectral imaging technology closely combines the traditional 2D image remote sensing technology and spectroscopy technology. While acquiring the spatial information of the ground object, it arranges the radiation energy of the measured object according to the wavelength and obtains hundreds of continuous data in a spectral range. It is widely used in various fields, such as environmental monitoring and terrain classification. However, real HSI is often subject to different types of pollution, namely, noise, undersampling, or missing data, because of actual imaging conditions, weather conditions, or data transmission procedures. These types of pollution severely reduce the quality of HSI and limit the accuracy of subsequent processing tasks, such as unmixing and target detection. Restoration from a noisy, undersampling, or incomplete HSI is an ill-posed inverse problem. A common method is to treat each band as a grayscale image or column HSI into 2D matrix and use the method of matrix restoration to process it. Rank minimization is a common strategy to solve such problems. However, the rank function is discrete and non-convex, and the solution of the rank function minimization problem is an nondeterministic polynominal(NP)-hard problem. The convex envelope-nuclear norm of the rank function is usually used to approximate the rank function for solving this problem, and the rank minimization problem is transformed into the nuclear norm minimization problem. Although nuclear norm can achieve good restoration results, it imposes the same shrinkage on all singular values of the matrix due to the limitation of convexity. This imposition results in a finite degree approximation of the rank function. At the same time, HSI is an imaging of the same scene under different spectra, and its data in each band are highly correlated. This correlation is often ignored. The exploration of the low-rank characteristics of HSI by an approach of the column matrix is insufficient.MethodOne of the methods to define the rank of the tensor is tensor singular value decomposition, which can also be solved by the tensor nuclear norm. However, all singular values are treated equally in the definition of the tensor nuclear norm, and the frequency information of the tensor is ignored. In the frequency domain of the tensor, noises are added to the clear hyperspectral image. The image information changes slowly in the low-frequency forward slicing matrix, but it changes markedly in the high-frequency forward slicing matrix. In this study, we propose a frequency-weighted tensor nuclear norm based on the physical properties of tensors in the frequency domain. The original tensor is protected under the condition of removing outliers by appropriately reducing the penalty for the low-frequency forward slicing matrix. The main information is to increase the penalty for the high-frequency forward slicing matrix, which can fully remove the outliers in the tensor. Ultimately, the degree of approximation of the tensor nuclear norm to the tensor rank is improved to enhance the accuracy of restoration. At the same time, we explore the changes in the frequency components of the hyperspectral image when the sparse noise is disturbed through numerical simulation experiments. The sparse noise slightly affects the nuclear norm of the low-frequency band slice matrix, but it influences the high-frequency band slice matrix nuclear norm. The nuclear norm of the low-frequency band slice matrix changes slowly when the noise intensity increases, while that of the high-frequency band slice matrix changes markedly. On this basis, we give the weight adaptive calculation method of each frequency forward slice matrix, increase the adaptive data based on the frequency-weighted tensor nuclear norm, and reduce the human intervention in the parameter adjustment process to ensure robustness of the model.ResultWe compare simulation experiments with related methods on four hyperspectral datasets. On the simulated dataset, the sampling rates are 10%, 20%, and 30%. Compared with the indices of the second best performing model, the peak signal-to-noise ratio (PSNR) index and the structure similarity (SSIM) index on the Washington DC Mall dataset can be increased by 0.98 dB, 1.64 dB, and 1.76 dB, and 0.005 8, 0.019 3, and 0.010 2. Compared with the indices of the second best performing model, the PSNR and SSIM values of the restoration result of the proposed model on the Stuff dataset can be increased by 1.84 dB, 2.65 dB, 2.91 dB, and 0.085 2, 0.042 5, and 0.023 1. The sparse noise intensity values are 0.5 and 0.4. Compared with the indices of the second best performing model, the PSNR and SSIM values of the denoising results of the proposed model on the Pavia dataset can be increased by 8.61 dB and 6.67 dB, and 0.441 and 0.087 41. Compared with the indices of the second best performing model, the PSNR and SSIM values of the denoising results of the proposed model on the Indian dataset can be increased by 10.77 dB and 6.34 dB and 0.403 and 0.033 1.ConclusionThe proposed model considers the original HSI information carried by different frequency slices and the influence of missing or sparse noise on the nuclear norm of each frequency slice. It can better explore the low-rank characteristics of hyperspectral images. Thus, the restored HSI can be maintained. More texture details are restored simultaneously with the main information.关键词:hyperspectral;image restoration;low rank;tensor nuclear norm;frequency domain weighting92|339|3更新时间:2024-05-07
摘要:ObjectiveHyperspectral images (HSIs) use imaging spectrometers to collect hundreds of spectral band images from ultraviolet to infrared wavelengths on the same area of the earth's surface. Tens to hundreds of continuous grayscale images are available, and each pixel can extract a spectral curve. Hyperspectral imaging technology closely combines the traditional 2D image remote sensing technology and spectroscopy technology. While acquiring the spatial information of the ground object, it arranges the radiation energy of the measured object according to the wavelength and obtains hundreds of continuous data in a spectral range. It is widely used in various fields, such as environmental monitoring and terrain classification. However, real HSI is often subject to different types of pollution, namely, noise, undersampling, or missing data, because of actual imaging conditions, weather conditions, or data transmission procedures. These types of pollution severely reduce the quality of HSI and limit the accuracy of subsequent processing tasks, such as unmixing and target detection. Restoration from a noisy, undersampling, or incomplete HSI is an ill-posed inverse problem. A common method is to treat each band as a grayscale image or column HSI into 2D matrix and use the method of matrix restoration to process it. Rank minimization is a common strategy to solve such problems. However, the rank function is discrete and non-convex, and the solution of the rank function minimization problem is an nondeterministic polynominal(NP)-hard problem. The convex envelope-nuclear norm of the rank function is usually used to approximate the rank function for solving this problem, and the rank minimization problem is transformed into the nuclear norm minimization problem. Although nuclear norm can achieve good restoration results, it imposes the same shrinkage on all singular values of the matrix due to the limitation of convexity. This imposition results in a finite degree approximation of the rank function. At the same time, HSI is an imaging of the same scene under different spectra, and its data in each band are highly correlated. This correlation is often ignored. The exploration of the low-rank characteristics of HSI by an approach of the column matrix is insufficient.MethodOne of the methods to define the rank of the tensor is tensor singular value decomposition, which can also be solved by the tensor nuclear norm. However, all singular values are treated equally in the definition of the tensor nuclear norm, and the frequency information of the tensor is ignored. In the frequency domain of the tensor, noises are added to the clear hyperspectral image. The image information changes slowly in the low-frequency forward slicing matrix, but it changes markedly in the high-frequency forward slicing matrix. In this study, we propose a frequency-weighted tensor nuclear norm based on the physical properties of tensors in the frequency domain. The original tensor is protected under the condition of removing outliers by appropriately reducing the penalty for the low-frequency forward slicing matrix. The main information is to increase the penalty for the high-frequency forward slicing matrix, which can fully remove the outliers in the tensor. Ultimately, the degree of approximation of the tensor nuclear norm to the tensor rank is improved to enhance the accuracy of restoration. At the same time, we explore the changes in the frequency components of the hyperspectral image when the sparse noise is disturbed through numerical simulation experiments. The sparse noise slightly affects the nuclear norm of the low-frequency band slice matrix, but it influences the high-frequency band slice matrix nuclear norm. The nuclear norm of the low-frequency band slice matrix changes slowly when the noise intensity increases, while that of the high-frequency band slice matrix changes markedly. On this basis, we give the weight adaptive calculation method of each frequency forward slice matrix, increase the adaptive data based on the frequency-weighted tensor nuclear norm, and reduce the human intervention in the parameter adjustment process to ensure robustness of the model.ResultWe compare simulation experiments with related methods on four hyperspectral datasets. On the simulated dataset, the sampling rates are 10%, 20%, and 30%. Compared with the indices of the second best performing model, the peak signal-to-noise ratio (PSNR) index and the structure similarity (SSIM) index on the Washington DC Mall dataset can be increased by 0.98 dB, 1.64 dB, and 1.76 dB, and 0.005 8, 0.019 3, and 0.010 2. Compared with the indices of the second best performing model, the PSNR and SSIM values of the restoration result of the proposed model on the Stuff dataset can be increased by 1.84 dB, 2.65 dB, 2.91 dB, and 0.085 2, 0.042 5, and 0.023 1. The sparse noise intensity values are 0.5 and 0.4. Compared with the indices of the second best performing model, the PSNR and SSIM values of the denoising results of the proposed model on the Pavia dataset can be increased by 8.61 dB and 6.67 dB, and 0.441 and 0.087 41. Compared with the indices of the second best performing model, the PSNR and SSIM values of the denoising results of the proposed model on the Indian dataset can be increased by 10.77 dB and 6.34 dB and 0.403 and 0.033 1.ConclusionThe proposed model considers the original HSI information carried by different frequency slices and the influence of missing or sparse noise on the nuclear norm of each frequency slice. It can better explore the low-rank characteristics of hyperspectral images. Thus, the restored HSI can be maintained. More texture details are restored simultaneously with the main information.关键词:hyperspectral;image restoration;low rank;tensor nuclear norm;frequency domain weighting92|339|3更新时间:2024-05-07
Hyperspectral Image Fusion and Restoration
-
 摘要:ObjectiveDeep learning-based hyperspectral image (HSI) classification has become an important research point due to its ability to learn adaptive and robust features from training data automatically. However, issues, such as high-dimensionality of spectra, imbalanced and limited labeled samples, and diversity of land cover, persist. Hence, improving the robustness of deep networks under limited samples has become a key research hotpot. Evaluation indices of deep learning methods, such as reproducibility, credibility, efficiency, and accuracy, have also received research attention. Content-guided convolutional neural network (CGCNN) was proposed for HSI classification. Compared with shape-fixed kernels in traditional CNNs, CGCNN can adaptively adjust its kernel shape according to the spatial distribution of land covers; as a result, it can preserve the boundaries and details of land covers in classification maps. In particular, each kernel in content-guided convolution is composed of two kernels, namely, an isotropic kernel used to extract spatial features from HSI and an anisotropic kernel used to control the spatial shape of the isotropic kernel. The isotropic kernel is shared at different sampling regions, similar to regular convolution. However, anisotropic kernels are computed independently according to the local distribution of land covers at different spatial locations. Content-guided convolution cannot be computed in parallel straightforwardly by the deep learning acceleration library (e.g., Tensorflow and PyTorch) due to the unshared anisotropic kernels. To tackle this issue, we propose a parallel computing method for content-guided convolution to allow the CGCNN to be computed efficiently by a graphics processing unit (GPU) and evaluate its performance in hyperspectral image classification.MethodTo make content-guided convolution parallelizable, we break down the content-guided convolution into two steps: weighting the input feature map with the anisotropic kernels, and conducting a standard convolution with the isotropic kernels on the weighted feature map. Although the anisotropic kernels in the content-guided convolution are different at different sampling locations, their sampling grids (receptive fields) are restricted to small windows with a fixed size (e.g., 3×3). If we resample the input feature map into small cubes, in which each cube contains only the needed pixels used to compute the anisotropic kernel weights for its center pixel, then the content-guided convolution can be converted to a pixel-level computation process independent of spatial locations and then be executed on the GPU in parallel. To this end, we propose to construct an index matrix to define the resampling manner and then resample the input feature map to separate the overlapping pixels into non-overlapping pixels by employing the underlying interfaces of the deep learning acceleration library. Finally, a standard convolution is conducted on the weighted feature map to finish the weighting process of the isotropic kernels in the content-guided convolution, which can be easily performed by the deep learning acceleration library. The resampling index matrix is shared in the whole CGCNN and thus only needs to be computed once. The matrix can also be executed efficiently on the GPU because the resampling process is just a data copy operation and does not involve numerical computation.ResultCompared with serial computing, the parallel-accelerated content-guided convolution achieves an average acceleration of nearly 700 times under different conditions. With increasing input scale, the acceleration ratio also increases steadily. As a result, the parallelizable CGCNN can classify the benchmark data sets in seconds. Additionally, in the comparison of classification accuracies, the parallelizable CGCNN shows great ability to preserve details and boundaries compared with other state-of-the-art deep learning-based methods. On the synthetic data set, the classification map acquired by the CGCNN preserves more edges and small objects, while the compared methods lead the classification maps to be smoother. As a result, the overall accuracy of the CGCNN is 7.10% higher than that of the other methods on average. On the two other real data sets (i.e., Indian Pines and Loukia), the CGCNN still achieves the best classification results, with classification accuracies that are 7.21% and 2.70% higher on average than the compared methods, respectively. Furthermore, the sensitivity parameter analysis shows the effect and function of the sensitivity value. Smaller sensitivity value can preserve more details and boundaries, but the outliers and noise are also more; in contrast, larger sensitivity value can suppress more outliers and noise, but the classification map may be smoother and lose more details. The automatic learning mechanism of sensitivity value can achieve a trade-off between the details and smoothness and give a suitable sensitivity for different HSIs according to their spatial contents and training samples. In the evaluation of small-sample learning capacity, the performance advantage of the CGCNN increases compared with the other methods gradually with decreasing number of training samples, indicating the great small-sample learning ability of the CGCNN.ConclusionBy breaking down the content-guided convolution into a series of pixel-level computation processes independent of spatial locations, we propose a parallel computing method for the content-guided convolution to run the CGCNN in parallel on the GPU. Diverse experiments such as comparison of classification accuracies, sensitivity parameter analysis, and evaluation of small-sample learning capacity, demonstrate that the CGCNN can greatly preserve the edges and small objects in classification maps and outperforms the compared methods in quantitative and qualitative performance indices.关键词:content-guided convolution;deep learning;hyperspectral image (HSI) classification;parallel acceleration;edge-preserving classification65|147|3更新时间:2024-05-07
摘要:ObjectiveDeep learning-based hyperspectral image (HSI) classification has become an important research point due to its ability to learn adaptive and robust features from training data automatically. However, issues, such as high-dimensionality of spectra, imbalanced and limited labeled samples, and diversity of land cover, persist. Hence, improving the robustness of deep networks under limited samples has become a key research hotpot. Evaluation indices of deep learning methods, such as reproducibility, credibility, efficiency, and accuracy, have also received research attention. Content-guided convolutional neural network (CGCNN) was proposed for HSI classification. Compared with shape-fixed kernels in traditional CNNs, CGCNN can adaptively adjust its kernel shape according to the spatial distribution of land covers; as a result, it can preserve the boundaries and details of land covers in classification maps. In particular, each kernel in content-guided convolution is composed of two kernels, namely, an isotropic kernel used to extract spatial features from HSI and an anisotropic kernel used to control the spatial shape of the isotropic kernel. The isotropic kernel is shared at different sampling regions, similar to regular convolution. However, anisotropic kernels are computed independently according to the local distribution of land covers at different spatial locations. Content-guided convolution cannot be computed in parallel straightforwardly by the deep learning acceleration library (e.g., Tensorflow and PyTorch) due to the unshared anisotropic kernels. To tackle this issue, we propose a parallel computing method for content-guided convolution to allow the CGCNN to be computed efficiently by a graphics processing unit (GPU) and evaluate its performance in hyperspectral image classification.MethodTo make content-guided convolution parallelizable, we break down the content-guided convolution into two steps: weighting the input feature map with the anisotropic kernels, and conducting a standard convolution with the isotropic kernels on the weighted feature map. Although the anisotropic kernels in the content-guided convolution are different at different sampling locations, their sampling grids (receptive fields) are restricted to small windows with a fixed size (e.g., 3×3). If we resample the input feature map into small cubes, in which each cube contains only the needed pixels used to compute the anisotropic kernel weights for its center pixel, then the content-guided convolution can be converted to a pixel-level computation process independent of spatial locations and then be executed on the GPU in parallel. To this end, we propose to construct an index matrix to define the resampling manner and then resample the input feature map to separate the overlapping pixels into non-overlapping pixels by employing the underlying interfaces of the deep learning acceleration library. Finally, a standard convolution is conducted on the weighted feature map to finish the weighting process of the isotropic kernels in the content-guided convolution, which can be easily performed by the deep learning acceleration library. The resampling index matrix is shared in the whole CGCNN and thus only needs to be computed once. The matrix can also be executed efficiently on the GPU because the resampling process is just a data copy operation and does not involve numerical computation.ResultCompared with serial computing, the parallel-accelerated content-guided convolution achieves an average acceleration of nearly 700 times under different conditions. With increasing input scale, the acceleration ratio also increases steadily. As a result, the parallelizable CGCNN can classify the benchmark data sets in seconds. Additionally, in the comparison of classification accuracies, the parallelizable CGCNN shows great ability to preserve details and boundaries compared with other state-of-the-art deep learning-based methods. On the synthetic data set, the classification map acquired by the CGCNN preserves more edges and small objects, while the compared methods lead the classification maps to be smoother. As a result, the overall accuracy of the CGCNN is 7.10% higher than that of the other methods on average. On the two other real data sets (i.e., Indian Pines and Loukia), the CGCNN still achieves the best classification results, with classification accuracies that are 7.21% and 2.70% higher on average than the compared methods, respectively. Furthermore, the sensitivity parameter analysis shows the effect and function of the sensitivity value. Smaller sensitivity value can preserve more details and boundaries, but the outliers and noise are also more; in contrast, larger sensitivity value can suppress more outliers and noise, but the classification map may be smoother and lose more details. The automatic learning mechanism of sensitivity value can achieve a trade-off between the details and smoothness and give a suitable sensitivity for different HSIs according to their spatial contents and training samples. In the evaluation of small-sample learning capacity, the performance advantage of the CGCNN increases compared with the other methods gradually with decreasing number of training samples, indicating the great small-sample learning ability of the CGCNN.ConclusionBy breaking down the content-guided convolution into a series of pixel-level computation processes independent of spatial locations, we propose a parallel computing method for the content-guided convolution to run the CGCNN in parallel on the GPU. Diverse experiments such as comparison of classification accuracies, sensitivity parameter analysis, and evaluation of small-sample learning capacity, demonstrate that the CGCNN can greatly preserve the edges and small objects in classification maps and outperforms the compared methods in quantitative and qualitative performance indices.关键词:content-guided convolution;deep learning;hyperspectral image (HSI) classification;parallel acceleration;edge-preserving classification65|147|3更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral images have been investigated and hyperspectral image classification has been widely used in many fields in recent years. Long-distance remote sensing hyperspectral images have a lot of mixed pixels due to the low spatial resolution. The ground features originally have unique spectral characteristics, but the mixed pixels reduce the separability of spectral characteristics of different ground, which increases the difficulty of hyperspectral image classification. Observing the spectral curves of long-distance remote sensing hyperspectral images indicates that the spectral curves of the single type show the tendency of larger difference within the class, and the difference between classes becomes smaller because it is mixed with different types of ground features. If the selected samples are insufficient, then misclassification between classes may occur. Moreover, the classification map has "salt and pepper noise", which leads to low classification accuracy. The traditional method uses the spectral-spatial feature joint classification method to increase the constraint of spatial information for improving the classification accuracy. This way can correct some misclassification results, but it does not improve the problem of difficult classification between classes caused by mixed pixels. Thus, a strategy based on grouped rolling guidance filtering is proposed in this study. The linear discriminant analysis (LDA) algorithm is used to generate a discriminative guidance image, and rolling guidance filtering is performed on each band of the hyperspectral image. Spectral curves show the trend of intra-class condensation given that the guidance image contains the information of classification, and the distance between classes increases. At the same time, hyperspectral images have lots of bands, and many adjacent bands may be heavily redundant and fail to provide additional discriminative information. The generalization capability of the classifier is limited when high-dimensional bands are fed back, that is, the curse of dimensionality, under the condition of insufficient labeled pixels. Reducing the number of bands, that is, dimensionality reduction, is an effective strategy to solve these challenges. The embedded band selection is the best comprehensive performance at present because it solves various matrix-based optimization objectives consisting of different loss functions and regularization terms. However, it exhibits sparsity. If multiple features are useful and highly correlated, then least absolute shrinkage and selection operator(LASSO) tends to keep one and drop the rest. This condition affects the stability. We aim to improve its ability to select groups of correlated variables and utilize its group effect to improve classification accuracy. Thus, we use the framework of elastic net logistic regression to enhance band selection, the respective strongly separable bands are selected for each class, and the strongly correlated bands can be retained at the same time.MethodWe focus on enhancing spectral separability and band separability of mixed pixels in this study. The framework of grouped rolling guidance filtering and elastic net logistic regression is used to enhance class separability in spectral characteristics and band selection. First, the hyperspectral images are divided into groups according to the spectral direction, and the training data of each group by performing the LDA algorithm are used to obtain the first projection vector. The most discriminative guidance image is generated for each group of hyperspectral images. Then, rolling guidance filtering is conducted on each band of the hyperspectral image. Spectral curves show the increasing trend of intra-class condensation and distance between classes. We use the framework of elastic net logistic regression to enhance band selection. By constructing L1 and L2 norm regularization constraints on logistic regression objective function, embedded band selection is performed to select bands with strong separability for each category, and bands with strong correlation can be retained as the classification basis. We use the neighborhood optimization method to improve the classification results.ResultWe compare our algorithms with five state-of-the-art classic algorithms on three public datasets, namely, the India Pines, Salinas, and Kennedy Space Center(KSC) datasets. The quantitative evaluation metrics include overall accuracy (OA), kappa coefficient, and average accuracy. We also provide several classification maps of each method for comparison on India Pines dataset. The experiment is repeated 10 times under each experimental condition to improve its reliability and accuracy, and the average value of the 10 experimental results is taken as the final result. Experimental results show that our model outperforms all other methods on India Pines, Salinas, and KSC datasets. Moreover, the OA of the proposed algorithm has achieved 96.61%, 98.66%, and 99.04% on the Indian Pines, Salinas, and KSC datasets, respectively. These values are 1%—4% higher than those of other optimal algorithms. We conduct a series of comparative experiments on Indian Pines to clearly show the effectiveness of different steps of the proposed algorithm. Comparative experiments with a different number of training samples are also performed. The experiment shows that the OA of the proposed method is always the highest under different datasets. By contrast, other comparison algorithms are unstable over different datasets. Therefore, the proposed algorithm can improve the robustness.ConclusionExperiments on three hyperspectral image datasets show that the proposed algorithm enhances class separability in spectral characteristics and band selection compared with other algorithms. The classification accuracy is also significantly improved. The proposed algorithm is suitable for different datasets and has good robustness as well.关键词:remote sensing;hyperspectral image classification;enhanced class separability;grouped rolling guidance filtering;elastic net logistic regress116|193|3更新时间:2024-05-07
摘要:ObjectiveHyperspectral images have been investigated and hyperspectral image classification has been widely used in many fields in recent years. Long-distance remote sensing hyperspectral images have a lot of mixed pixels due to the low spatial resolution. The ground features originally have unique spectral characteristics, but the mixed pixels reduce the separability of spectral characteristics of different ground, which increases the difficulty of hyperspectral image classification. Observing the spectral curves of long-distance remote sensing hyperspectral images indicates that the spectral curves of the single type show the tendency of larger difference within the class, and the difference between classes becomes smaller because it is mixed with different types of ground features. If the selected samples are insufficient, then misclassification between classes may occur. Moreover, the classification map has "salt and pepper noise", which leads to low classification accuracy. The traditional method uses the spectral-spatial feature joint classification method to increase the constraint of spatial information for improving the classification accuracy. This way can correct some misclassification results, but it does not improve the problem of difficult classification between classes caused by mixed pixels. Thus, a strategy based on grouped rolling guidance filtering is proposed in this study. The linear discriminant analysis (LDA) algorithm is used to generate a discriminative guidance image, and rolling guidance filtering is performed on each band of the hyperspectral image. Spectral curves show the trend of intra-class condensation given that the guidance image contains the information of classification, and the distance between classes increases. At the same time, hyperspectral images have lots of bands, and many adjacent bands may be heavily redundant and fail to provide additional discriminative information. The generalization capability of the classifier is limited when high-dimensional bands are fed back, that is, the curse of dimensionality, under the condition of insufficient labeled pixels. Reducing the number of bands, that is, dimensionality reduction, is an effective strategy to solve these challenges. The embedded band selection is the best comprehensive performance at present because it solves various matrix-based optimization objectives consisting of different loss functions and regularization terms. However, it exhibits sparsity. If multiple features are useful and highly correlated, then least absolute shrinkage and selection operator(LASSO) tends to keep one and drop the rest. This condition affects the stability. We aim to improve its ability to select groups of correlated variables and utilize its group effect to improve classification accuracy. Thus, we use the framework of elastic net logistic regression to enhance band selection, the respective strongly separable bands are selected for each class, and the strongly correlated bands can be retained at the same time.MethodWe focus on enhancing spectral separability and band separability of mixed pixels in this study. The framework of grouped rolling guidance filtering and elastic net logistic regression is used to enhance class separability in spectral characteristics and band selection. First, the hyperspectral images are divided into groups according to the spectral direction, and the training data of each group by performing the LDA algorithm are used to obtain the first projection vector. The most discriminative guidance image is generated for each group of hyperspectral images. Then, rolling guidance filtering is conducted on each band of the hyperspectral image. Spectral curves show the increasing trend of intra-class condensation and distance between classes. We use the framework of elastic net logistic regression to enhance band selection. By constructing L1 and L2 norm regularization constraints on logistic regression objective function, embedded band selection is performed to select bands with strong separability for each category, and bands with strong correlation can be retained as the classification basis. We use the neighborhood optimization method to improve the classification results.ResultWe compare our algorithms with five state-of-the-art classic algorithms on three public datasets, namely, the India Pines, Salinas, and Kennedy Space Center(KSC) datasets. The quantitative evaluation metrics include overall accuracy (OA), kappa coefficient, and average accuracy. We also provide several classification maps of each method for comparison on India Pines dataset. The experiment is repeated 10 times under each experimental condition to improve its reliability and accuracy, and the average value of the 10 experimental results is taken as the final result. Experimental results show that our model outperforms all other methods on India Pines, Salinas, and KSC datasets. Moreover, the OA of the proposed algorithm has achieved 96.61%, 98.66%, and 99.04% on the Indian Pines, Salinas, and KSC datasets, respectively. These values are 1%—4% higher than those of other optimal algorithms. We conduct a series of comparative experiments on Indian Pines to clearly show the effectiveness of different steps of the proposed algorithm. Comparative experiments with a different number of training samples are also performed. The experiment shows that the OA of the proposed method is always the highest under different datasets. By contrast, other comparison algorithms are unstable over different datasets. Therefore, the proposed algorithm can improve the robustness.ConclusionExperiments on three hyperspectral image datasets show that the proposed algorithm enhances class separability in spectral characteristics and band selection compared with other algorithms. The classification accuracy is also significantly improved. The proposed algorithm is suitable for different datasets and has good robustness as well.关键词:remote sensing;hyperspectral image classification;enhanced class separability;grouped rolling guidance filtering;elastic net logistic regress116|193|3更新时间:2024-05-07 -
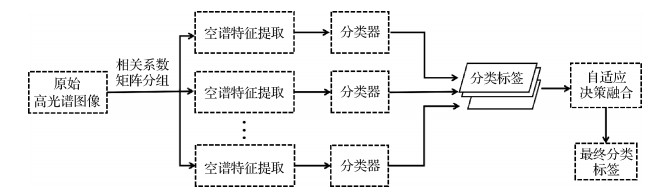 摘要:ObjectiveHyperspectral imagery contains rich spectral and spatial information and transforms remote sensing technology from qualitative to quantitative analysis. It can be widely used in geological prospecting, precision agriculture, ecology environment, and urban remote sensing. However, classification and recognition applications have many difficulties because hyperspectral image has large amount of data, multiple bands, and strong correlation between bands. In particular, the "Hughes" phenomenon caused by the decline in classification accuracy with the increase in data complexity when the number of training samples is limited needs to be addressed. Research on feature extraction and classification algorithm for hyperspectral image has become an important task in hyperspectral data processing to fully utilize the advantages of hyperspectral remote sensing technology and overcome the disadvantages caused by the large number of bands. Multi-classifier system with band-selection dimensionality reduction is effective for hyperspectral image classification, particularly when the size of the training dataset is small. The usual methods of decision fusion strategies at present are hard decision fusion represented by majority vote (MV) and soft decision fusion represented by logarithmic opinion pool (LOGP). These methods use the unified weight coefficient for decision fusion without evaluating the respective classification performance of sub-classifiers and optimizing the allocation of weight coefficients, which will inevitably affect the classification results. Two adaptive decision fusion strategies are studied in this work on the basis of MV and LOGP to solve this problem, and a multi-classifier system is designed for hyperspectral image classification.MethodThe correlation between adjacent bands of hyperspectral image usually appears in groups, the intra-band correlation is strong, and the inter-band correlation is weak. Thus, band selection is used for dimensionality reduction, and band grouping is utilized to feed features to multi-classifiers. Specifically, the hyperspectral data are grouped according to the correlation coefficient matrix. Then, spatial-spectral features are extracted for the bands with strong correlation in each group. Gabor and local binary pattern (LBP) features are proven to be suitable and powerful for hypershectral image(HSI) classification. The former is oriented to global features, and the latter is oriented to local features. These features are investigated for the proposed multi-classifier system. Apart from principal component analysis, two advanced local protection dimensionality reduction methods, namely, locality-preserving nonnegative matrix factorization (LPNMF) and locality fisher discriminant analysis (LFDA), are also used in the proposed system. LPNMF aims to find a low-dimensional subspace and use its single element to represent the categories of ground objects for effectively protecting the diverse local structures of the original hyperspectral image. LFDA is suitable for dimensionality reduction of multi-model data, which can protect the local information between adjacent pixels by linear spectrum. Next, Gaussian mixture model (GMM) classifiers or support vector machine (SVM) classifiers are used to classify each group of features. Finally, the adjustMV decision fusion strategy and adjustLOGP decision fusion strategy are designed, which are based on the weight coefficient optimization allocation for sub-classifiers. They minimize the effect of band groups and abnormal values with low classification accuracy on the final classification results.ResultMultiple features and two classifiers are executed crosswise for classification to verify the effectiveness of the proposed decision fusion strategies and multi-classifier system. Experiments are conducted on two public hyperspectral datasets, namely, the Indian Pines and Pavia University datasets. Experimental results show that the classification accuracies of the adjustMV strategy for Indian Pines and Pavia University datasets are improved by 1.02% and 3.39%, respectively, when Gabor features and GMM classifiers are used for MV decision fusion. When LBP features and SVM classifiers are used for MV decision fusion, the accuracies of the adjustMV strategy for Indian Pines and Pavia University datasets are improved by 1.32% and 0.82%, respectively. GMM classifiers followed by LFDA, LPNMF, or Gabor features, as three basic lines, are conducted into adjustLOGP strategy. For Indian Pines dataset, three adjustLOGP-based algorithms drive higher classification accuracies (18.54%, 5.14%, and 2.87%) than three LOGP-based algorithms. For Pavia University dataset, three adjustLOGP-based algorithms drive higher classification accuracies (2.06%, 5.81%, and 6.99%) than three LOGP based algorithms. Experiments are also conducted on the two datasets with different numbers of training samples and different powers of noise. The proposed adaptive decision fusion strategies still have better classification performance, even in situations of small sample size and environments with noise. It also has better stability by computing the standard deviations from 20 trails. When the number of training samples is 70, the classification accuracies of the two proposed decision fusion strategies on the Indian Pines and Pavia University datasets have 1.97% and 1.03% improvements compared with the unified weight fusion strategies. When the number of training samples is 30, the classification accuracies of the two proposed decision fusion strategies on the Indian Pines and Pavia University datasets have 4.91% and 3.55% improvements. Gaussian noise is added to the two hyperspectral datasets to further study the robustness of the improved strategies. The classification accuracies of 10 decision fusion algorithms are compared in the case that the signal-to-noise ratio(SNR) of noised datasets is 20 dB. Clearly, five adjustMV-based and adjustLOGP-based strategies are superior to the MV-based and LOGP-based strategies in the noise environment.ConclusionTwo adaptive decision fusion strategies and a multi-classifier system are proposed for hyperspectral image classification in this study. The proposed decision fusion strategies consider allocating different weights with higher reliability to sub-classifiers according to their classification performance. The proposed adjustMV can cast a more important vote to obtain a final decision, and the proposed adjustLOGP has a higher probability of a posteriori to increase the probability of a correct decision. The proposed strategies have low complexity, but they can greatly improve the classification accuracy and possess better stability, even under situations of small sample size and environments with noise.关键词:hyperspectral image classification;spatial-spectral feature extraction;decision fusion;majority vote;adaptive weights69|18|1更新时间:2024-05-07
摘要:ObjectiveHyperspectral imagery contains rich spectral and spatial information and transforms remote sensing technology from qualitative to quantitative analysis. It can be widely used in geological prospecting, precision agriculture, ecology environment, and urban remote sensing. However, classification and recognition applications have many difficulties because hyperspectral image has large amount of data, multiple bands, and strong correlation between bands. In particular, the "Hughes" phenomenon caused by the decline in classification accuracy with the increase in data complexity when the number of training samples is limited needs to be addressed. Research on feature extraction and classification algorithm for hyperspectral image has become an important task in hyperspectral data processing to fully utilize the advantages of hyperspectral remote sensing technology and overcome the disadvantages caused by the large number of bands. Multi-classifier system with band-selection dimensionality reduction is effective for hyperspectral image classification, particularly when the size of the training dataset is small. The usual methods of decision fusion strategies at present are hard decision fusion represented by majority vote (MV) and soft decision fusion represented by logarithmic opinion pool (LOGP). These methods use the unified weight coefficient for decision fusion without evaluating the respective classification performance of sub-classifiers and optimizing the allocation of weight coefficients, which will inevitably affect the classification results. Two adaptive decision fusion strategies are studied in this work on the basis of MV and LOGP to solve this problem, and a multi-classifier system is designed for hyperspectral image classification.MethodThe correlation between adjacent bands of hyperspectral image usually appears in groups, the intra-band correlation is strong, and the inter-band correlation is weak. Thus, band selection is used for dimensionality reduction, and band grouping is utilized to feed features to multi-classifiers. Specifically, the hyperspectral data are grouped according to the correlation coefficient matrix. Then, spatial-spectral features are extracted for the bands with strong correlation in each group. Gabor and local binary pattern (LBP) features are proven to be suitable and powerful for hypershectral image(HSI) classification. The former is oriented to global features, and the latter is oriented to local features. These features are investigated for the proposed multi-classifier system. Apart from principal component analysis, two advanced local protection dimensionality reduction methods, namely, locality-preserving nonnegative matrix factorization (LPNMF) and locality fisher discriminant analysis (LFDA), are also used in the proposed system. LPNMF aims to find a low-dimensional subspace and use its single element to represent the categories of ground objects for effectively protecting the diverse local structures of the original hyperspectral image. LFDA is suitable for dimensionality reduction of multi-model data, which can protect the local information between adjacent pixels by linear spectrum. Next, Gaussian mixture model (GMM) classifiers or support vector machine (SVM) classifiers are used to classify each group of features. Finally, the adjustMV decision fusion strategy and adjustLOGP decision fusion strategy are designed, which are based on the weight coefficient optimization allocation for sub-classifiers. They minimize the effect of band groups and abnormal values with low classification accuracy on the final classification results.ResultMultiple features and two classifiers are executed crosswise for classification to verify the effectiveness of the proposed decision fusion strategies and multi-classifier system. Experiments are conducted on two public hyperspectral datasets, namely, the Indian Pines and Pavia University datasets. Experimental results show that the classification accuracies of the adjustMV strategy for Indian Pines and Pavia University datasets are improved by 1.02% and 3.39%, respectively, when Gabor features and GMM classifiers are used for MV decision fusion. When LBP features and SVM classifiers are used for MV decision fusion, the accuracies of the adjustMV strategy for Indian Pines and Pavia University datasets are improved by 1.32% and 0.82%, respectively. GMM classifiers followed by LFDA, LPNMF, or Gabor features, as three basic lines, are conducted into adjustLOGP strategy. For Indian Pines dataset, three adjustLOGP-based algorithms drive higher classification accuracies (18.54%, 5.14%, and 2.87%) than three LOGP-based algorithms. For Pavia University dataset, three adjustLOGP-based algorithms drive higher classification accuracies (2.06%, 5.81%, and 6.99%) than three LOGP based algorithms. Experiments are also conducted on the two datasets with different numbers of training samples and different powers of noise. The proposed adaptive decision fusion strategies still have better classification performance, even in situations of small sample size and environments with noise. It also has better stability by computing the standard deviations from 20 trails. When the number of training samples is 70, the classification accuracies of the two proposed decision fusion strategies on the Indian Pines and Pavia University datasets have 1.97% and 1.03% improvements compared with the unified weight fusion strategies. When the number of training samples is 30, the classification accuracies of the two proposed decision fusion strategies on the Indian Pines and Pavia University datasets have 4.91% and 3.55% improvements. Gaussian noise is added to the two hyperspectral datasets to further study the robustness of the improved strategies. The classification accuracies of 10 decision fusion algorithms are compared in the case that the signal-to-noise ratio(SNR) of noised datasets is 20 dB. Clearly, five adjustMV-based and adjustLOGP-based strategies are superior to the MV-based and LOGP-based strategies in the noise environment.ConclusionTwo adaptive decision fusion strategies and a multi-classifier system are proposed for hyperspectral image classification in this study. The proposed decision fusion strategies consider allocating different weights with higher reliability to sub-classifiers according to their classification performance. The proposed adjustMV can cast a more important vote to obtain a final decision, and the proposed adjustLOGP has a higher probability of a posteriori to increase the probability of a correct decision. The proposed strategies have low complexity, but they can greatly improve the classification accuracy and possess better stability, even under situations of small sample size and environments with noise.关键词:hyperspectral image classification;spatial-spectral feature extraction;decision fusion;majority vote;adaptive weights69|18|1更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral sensors are evolving towards miniaturization and portability with the rapid development of hyperspectral imaging technology. The acquisition of hyperspectral data has become easier and less expensive as a result of this breakthrough. The broad applications of hyperspectral images in various scenes have arisen an increasing demand for high-precision and detailed annotations. The growth of existing hyperspectral classification models mainly focuses on supervised learning, and many of them have reached an almost perfect performance. However, nearly all of these models are trained and evaluated in a single hyperspectral data cube. On this condition, the trained classification model cannot be directly transferred to a new hyperspectral dataset to obtain reliable annotations. The main reason is that different hyperspectral datasets are collected in irrelevant scenes and have covered inconsistent object categories. Accordingly, existing hyperspectral classification models have poor generalization capacity. The further development of the hyperspectral image classification model is also constrained. Consequently, a hyperspectral classification model with a generalization capability and ability to adapt to new and unseen classes across the different datasets must be developed. In this study, we propose a specific unique paradigm, which is to train and evaluate a hyperspectral classification model across different datasets. As previously mentioned, some new and unseen categories might be encountered when evaluating the classification model on another hyperspectral dataset. We introduce zero-shot learning into hyperspectral image classification to address this problem.MethodZero-shot learning can distinguish data from unseen categories, except for identifying data categories that have appeared in the training set. Zero-shot learning is based on the principle of allowing the model learn to understand the semantics of categories at first. Specifically, this mechanism employs auxiliary knowledge (such as attributes) to embed category labels into the semantic space and uses the data in the training set to learn the mapping relationship from images to semantics. On the basis of zero-shot learning, we introduce hyperspectral category label semantics as side information to address the unseen categories in the classification across different datasets. The overall workflow of our model can be divided into three steps. The first step is feature extraction, including hyperspectral image visual feature extraction and label semantics extraction. Hyperspectral image feature extraction aims to obtain high-level hyperspectral features with great capability to distinguish, and we refer to them as visual features. Most existing hyperspectral classification models are designed to extract robust hyperspectral features and have fine classification performance. Hence, we directly fine-tune current models to embed hyperspectral images into visual feature space. In the label semantic extraction, word2vec can map each word to a vector, representing the relationship between words. We employ word2vec model trained on a large external corpus to obtain hyperspectral label vectors. This model embeds a hyperspectral category label into a label semantic space. The second step is feature mapping. According to the choice of embedding space, this mechanism can be divided into visual to semantic feature mapping and semantic to visual feature mapping. Feature mapping is used to map these two features into the same feature space, and the model learns and optimizes the mapping on the basis of the correspondence between the hyperspectral data and annotations in the training set. The learned mapping establishes the correspondence between the hyperspectral visual features and the label semantic features. The third step is to employ this learned mapping to perform label reasoning on the testing set. Specifically, the mapping is applied to the hyperspectral visual features and label semantic features of the testing data, and the corresponding labels for the test set data are inferred by measuring the similarity of the two features.ResultWe selected a pair of datasets collected by the same type of hyperspectral sensor for comparative experiments, namely, the Salinas and Indian Pines datasets. This step is conducted to avoid the issue of differences in the physical representation of the object spectra resulting from hyperspectral data collection by different hyperspectral sensors. The workflow of our method is divided into three steps; thus, we adopt different models in each step for comparative experiments. We compared two visual feature extraction models, different feature mapping models, including visual to semantic feature mapping models, and semantic to visual feature mapping models. The quantitative evaluation metric is top-k accuracy. We listed the results of top-1 accuracy and top-3 accuracy. Experimental results show that the method that employs spatial-spectral united network (SSUN)as the visual feature extraction model and relation network (RN) as the zero-shot learning model reaches the best performance. Comparative experiments in different visual feature extraction models demonstrate that SSUN can obtain more distinguishable features because it considered the features in the spatial and spectral domains. When compared with the results from all models related to feature mapping, the semantic to visual feature mapping models outperform the other approaches. This result indicates that choosing visual feature space as the embedding space is a preferable alternative. We also analyze the reason for the current unsatisfied classification performances in detail.ConclusionIn this study, we propose a specific pattern to train and evaluate the classification model across different datasets to improve the poor migration ability of the existing classification model. We introduce the semantic description of category labels in hyperspectral classification to cope with new and unseen categories in a new hyperspectral dataset and establish the association between seen and new datasets. The experimental results show that the feature extraction model SSUN improves the performance, and the semantic to visual feature mapping model RN outperforms several approaches. In conclusion, the proposed hyperspectral classification model based on zero-shot learning can be trained and evaluated across different datasets. The experimental results indicate that the proposed model has certain development potential in hyperspectral image classification tasks.关键词:hyperspectral image classification;deep learning;feature extraction;zero-shot learning;semantic features of hyperspectral data178|203|1更新时间:2024-05-07
摘要:ObjectiveHyperspectral sensors are evolving towards miniaturization and portability with the rapid development of hyperspectral imaging technology. The acquisition of hyperspectral data has become easier and less expensive as a result of this breakthrough. The broad applications of hyperspectral images in various scenes have arisen an increasing demand for high-precision and detailed annotations. The growth of existing hyperspectral classification models mainly focuses on supervised learning, and many of them have reached an almost perfect performance. However, nearly all of these models are trained and evaluated in a single hyperspectral data cube. On this condition, the trained classification model cannot be directly transferred to a new hyperspectral dataset to obtain reliable annotations. The main reason is that different hyperspectral datasets are collected in irrelevant scenes and have covered inconsistent object categories. Accordingly, existing hyperspectral classification models have poor generalization capacity. The further development of the hyperspectral image classification model is also constrained. Consequently, a hyperspectral classification model with a generalization capability and ability to adapt to new and unseen classes across the different datasets must be developed. In this study, we propose a specific unique paradigm, which is to train and evaluate a hyperspectral classification model across different datasets. As previously mentioned, some new and unseen categories might be encountered when evaluating the classification model on another hyperspectral dataset. We introduce zero-shot learning into hyperspectral image classification to address this problem.MethodZero-shot learning can distinguish data from unseen categories, except for identifying data categories that have appeared in the training set. Zero-shot learning is based on the principle of allowing the model learn to understand the semantics of categories at first. Specifically, this mechanism employs auxiliary knowledge (such as attributes) to embed category labels into the semantic space and uses the data in the training set to learn the mapping relationship from images to semantics. On the basis of zero-shot learning, we introduce hyperspectral category label semantics as side information to address the unseen categories in the classification across different datasets. The overall workflow of our model can be divided into three steps. The first step is feature extraction, including hyperspectral image visual feature extraction and label semantics extraction. Hyperspectral image feature extraction aims to obtain high-level hyperspectral features with great capability to distinguish, and we refer to them as visual features. Most existing hyperspectral classification models are designed to extract robust hyperspectral features and have fine classification performance. Hence, we directly fine-tune current models to embed hyperspectral images into visual feature space. In the label semantic extraction, word2vec can map each word to a vector, representing the relationship between words. We employ word2vec model trained on a large external corpus to obtain hyperspectral label vectors. This model embeds a hyperspectral category label into a label semantic space. The second step is feature mapping. According to the choice of embedding space, this mechanism can be divided into visual to semantic feature mapping and semantic to visual feature mapping. Feature mapping is used to map these two features into the same feature space, and the model learns and optimizes the mapping on the basis of the correspondence between the hyperspectral data and annotations in the training set. The learned mapping establishes the correspondence between the hyperspectral visual features and the label semantic features. The third step is to employ this learned mapping to perform label reasoning on the testing set. Specifically, the mapping is applied to the hyperspectral visual features and label semantic features of the testing data, and the corresponding labels for the test set data are inferred by measuring the similarity of the two features.ResultWe selected a pair of datasets collected by the same type of hyperspectral sensor for comparative experiments, namely, the Salinas and Indian Pines datasets. This step is conducted to avoid the issue of differences in the physical representation of the object spectra resulting from hyperspectral data collection by different hyperspectral sensors. The workflow of our method is divided into three steps; thus, we adopt different models in each step for comparative experiments. We compared two visual feature extraction models, different feature mapping models, including visual to semantic feature mapping models, and semantic to visual feature mapping models. The quantitative evaluation metric is top-k accuracy. We listed the results of top-1 accuracy and top-3 accuracy. Experimental results show that the method that employs spatial-spectral united network (SSUN)as the visual feature extraction model and relation network (RN) as the zero-shot learning model reaches the best performance. Comparative experiments in different visual feature extraction models demonstrate that SSUN can obtain more distinguishable features because it considered the features in the spatial and spectral domains. When compared with the results from all models related to feature mapping, the semantic to visual feature mapping models outperform the other approaches. This result indicates that choosing visual feature space as the embedding space is a preferable alternative. We also analyze the reason for the current unsatisfied classification performances in detail.ConclusionIn this study, we propose a specific pattern to train and evaluate the classification model across different datasets to improve the poor migration ability of the existing classification model. We introduce the semantic description of category labels in hyperspectral classification to cope with new and unseen categories in a new hyperspectral dataset and establish the association between seen and new datasets. The experimental results show that the feature extraction model SSUN improves the performance, and the semantic to visual feature mapping model RN outperforms several approaches. In conclusion, the proposed hyperspectral classification model based on zero-shot learning can be trained and evaluated across different datasets. The experimental results indicate that the proposed model has certain development potential in hyperspectral image classification tasks.关键词:hyperspectral image classification;deep learning;feature extraction;zero-shot learning;semantic features of hyperspectral data178|203|1更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral image (HSI) contains hundreds of spectral bands. The spectral signature of each image pixel acts as a finger print for identification of its material type. Thus, HSI with abundant spectral information is widely used in material recognition and land cover classification. However, the phenomenon of the same objects with dissimilar spectra and the different objects with similar spectra is common in HSI. Specifically, the same ground objects show different spectral curves due to the influence of the surrounding environment, diseases, insect pests, or radioactive substances. Meanwhile, two different features may show the same spectral characteristics in a certain spectral range. As a result, the single spectral information-based classification methods cannot achieve satisfactory ground object discrimination effects. This limitation leads to the salt and pepper noise in the classification maps. Given that HSI is originally 3D cube data, spatial characteristics are complementary to spectral information. The utilization of spatial features, such as shape, texture, and geometrical structures, can improve the land cover discrimination in the pixel-wise classification while reducing the classification noise. However, most spatial methods act on the regular shape or fixed size space area of HSI, which is obviously improper for the complex and diverse land covers. In other words, the region used for spatial feature extraction should adapt to the spatial structure of the image. Moreover, the single-scale feature extraction method in HSI classification cannot effectively express the differences among all land categories and distinguish the boundary of land covers. A multiscale approach appears to be a good solution. We aim to propose an effective classification framework that not only solves the abovementioned problems in HSI but also completes the classification task quickly and efficiently.MethodA novel HSI feature extraction and classification method, which combines multiscale superpixel segmentation and singular spectrum analysis (MSP-SSA), is proposed in this study. This method can fuse the local spatial and spectral trend features of land objects. Three main steps are involved in the proposed method, namely, multiscale spatial segmentation, spectral feature extraction, and the use of a classifier-based decision fusion strategy. Superpixel segmentation can divide an image into local homogeneous regions with different sizes and shapes to improve the consistency of spatial structure information. However, a single segmentation scale cannot adequately express the land surface and distinguish the boundary of objects. In detail, too large scales lead to over-segmentation of the region. This condition hinders the full utilization of all samples in the homogeneous region. Meanwhile, too small scales lead to under-segmentation, which makes the samples come from multiple homogeneous regions. Therefore, the multiscale superpixel segmentation is performed in the first step to extract abundant spatial features of complex and various land objects. The first principal component image after principal component analysis is the basic image of segmentation to reduce the subsequent computation. A set of segmentation scales is defined on the basis of the number of benchmark superpixels. The mean filter is also used to further improve the spectral pixel similarity inside superpixels considering the inevitable existence of interference pixels, such as noise, inside the superpixel. Then, the singular spectrum analysis (SSA), named superpixel SSA, acts on each superpixel to extract spectral trend features. After the mean filter, the mean spectral vector is considered to replace the local spatial features of each superpixel. SSA can decompose the mean spectral vector into several sub-components, where each sub-component has the same size as the original vector. Useful information can be enhanced while noise or less representative signals can be effectively suppressed for improving classification accuracy by selecting sub-component(s) to reconstruct the spectral profile. Superpixel SSA acts on the mean spectral vector of each superpixel, and its processing efficiency is mainly affected by the number of superpixels, which significantly reduces the running time compared with the traditional SSA. Finally, a decision fusion strategy based on a classifier is adopted to obtain the final classification results. The support vector machine classifier is utilized to classify the superpixel feature images in different scales due to the robustness of the variation in data dimension. The majority voting decision fusion method is used to obtain the final classification results because of the different scales of the classification results. This method can reduce the probability of pixels being misclassified in a single scale and further improve the classification accuracy.ResultWe compare our method MSP-SSA with seven state-of-the-art spectral-spatial classification methods that include traditional approaches and deep learning methods on three public datasets, namely, Indian Pines, Pavia University, and 2018 IEEE GRSS Data Fusion Context(IEEE GRSS DFC 2018). The quantitative evaluation metrics include overall accuracy (OA), average accuracy (AA), kappa coefficient, and running time. The classification maps of each method are provided for comparison. The classification results show that MSP-SSA outperforms all other methods on three datasets, and the classification maps show that it can effectively eliminate the noise and preserve the object boundary. Compared with the original data, the features extracted by the proposed MSP-SSA can increase by around 21.9%, 8.6%, and 13.5% in terms of OA, nearly 21.6%, 10.3%, and 15.9% in terms of AA, and approximately 0.25, 0.12, and 0.19 in terms of kappa on Indian Pines (5% samples), Pavia University (1% samples), and IEEE GRSS DFC2018 (0.1% samples), respectively. Compared with the metrics of spectral-spatial residual network (SSRN) on three datasets, the OA of the proposed method increases by 2%, 2.3%, and 3.3%, the AA increases by 1.8%, 3.9%, and 7.2%, and the kappa increases by 2%, 2.3%, and 3.3%. The processing efficiency of our method is also higher than that of SSRN, and the running time is only 18.3%, 45.4%, and 62.1% of the latter. Moreover, the proposed method achieves a classification accuracy of over 87% on the Indian Pines and Pavia University datasets with a small number of training samples.ConclusionWe propose an effective and efficient HSI classification method by integrating and combining several effective technologies. This method can fuse spectral and multiscale spatial features. Diverse experimental results also demonstrate that MSP-SSA outperforms several state-of-the-art approaches and can produce refined results in classification maps.关键词:hyperspectral image classification;superpixel;singular spectrum analysis(SSA);decision fusion;support vector machines(SVM)79|148|5更新时间:2024-05-07
摘要:ObjectiveHyperspectral image (HSI) contains hundreds of spectral bands. The spectral signature of each image pixel acts as a finger print for identification of its material type. Thus, HSI with abundant spectral information is widely used in material recognition and land cover classification. However, the phenomenon of the same objects with dissimilar spectra and the different objects with similar spectra is common in HSI. Specifically, the same ground objects show different spectral curves due to the influence of the surrounding environment, diseases, insect pests, or radioactive substances. Meanwhile, two different features may show the same spectral characteristics in a certain spectral range. As a result, the single spectral information-based classification methods cannot achieve satisfactory ground object discrimination effects. This limitation leads to the salt and pepper noise in the classification maps. Given that HSI is originally 3D cube data, spatial characteristics are complementary to spectral information. The utilization of spatial features, such as shape, texture, and geometrical structures, can improve the land cover discrimination in the pixel-wise classification while reducing the classification noise. However, most spatial methods act on the regular shape or fixed size space area of HSI, which is obviously improper for the complex and diverse land covers. In other words, the region used for spatial feature extraction should adapt to the spatial structure of the image. Moreover, the single-scale feature extraction method in HSI classification cannot effectively express the differences among all land categories and distinguish the boundary of land covers. A multiscale approach appears to be a good solution. We aim to propose an effective classification framework that not only solves the abovementioned problems in HSI but also completes the classification task quickly and efficiently.MethodA novel HSI feature extraction and classification method, which combines multiscale superpixel segmentation and singular spectrum analysis (MSP-SSA), is proposed in this study. This method can fuse the local spatial and spectral trend features of land objects. Three main steps are involved in the proposed method, namely, multiscale spatial segmentation, spectral feature extraction, and the use of a classifier-based decision fusion strategy. Superpixel segmentation can divide an image into local homogeneous regions with different sizes and shapes to improve the consistency of spatial structure information. However, a single segmentation scale cannot adequately express the land surface and distinguish the boundary of objects. In detail, too large scales lead to over-segmentation of the region. This condition hinders the full utilization of all samples in the homogeneous region. Meanwhile, too small scales lead to under-segmentation, which makes the samples come from multiple homogeneous regions. Therefore, the multiscale superpixel segmentation is performed in the first step to extract abundant spatial features of complex and various land objects. The first principal component image after principal component analysis is the basic image of segmentation to reduce the subsequent computation. A set of segmentation scales is defined on the basis of the number of benchmark superpixels. The mean filter is also used to further improve the spectral pixel similarity inside superpixels considering the inevitable existence of interference pixels, such as noise, inside the superpixel. Then, the singular spectrum analysis (SSA), named superpixel SSA, acts on each superpixel to extract spectral trend features. After the mean filter, the mean spectral vector is considered to replace the local spatial features of each superpixel. SSA can decompose the mean spectral vector into several sub-components, where each sub-component has the same size as the original vector. Useful information can be enhanced while noise or less representative signals can be effectively suppressed for improving classification accuracy by selecting sub-component(s) to reconstruct the spectral profile. Superpixel SSA acts on the mean spectral vector of each superpixel, and its processing efficiency is mainly affected by the number of superpixels, which significantly reduces the running time compared with the traditional SSA. Finally, a decision fusion strategy based on a classifier is adopted to obtain the final classification results. The support vector machine classifier is utilized to classify the superpixel feature images in different scales due to the robustness of the variation in data dimension. The majority voting decision fusion method is used to obtain the final classification results because of the different scales of the classification results. This method can reduce the probability of pixels being misclassified in a single scale and further improve the classification accuracy.ResultWe compare our method MSP-SSA with seven state-of-the-art spectral-spatial classification methods that include traditional approaches and deep learning methods on three public datasets, namely, Indian Pines, Pavia University, and 2018 IEEE GRSS Data Fusion Context(IEEE GRSS DFC 2018). The quantitative evaluation metrics include overall accuracy (OA), average accuracy (AA), kappa coefficient, and running time. The classification maps of each method are provided for comparison. The classification results show that MSP-SSA outperforms all other methods on three datasets, and the classification maps show that it can effectively eliminate the noise and preserve the object boundary. Compared with the original data, the features extracted by the proposed MSP-SSA can increase by around 21.9%, 8.6%, and 13.5% in terms of OA, nearly 21.6%, 10.3%, and 15.9% in terms of AA, and approximately 0.25, 0.12, and 0.19 in terms of kappa on Indian Pines (5% samples), Pavia University (1% samples), and IEEE GRSS DFC2018 (0.1% samples), respectively. Compared with the metrics of spectral-spatial residual network (SSRN) on three datasets, the OA of the proposed method increases by 2%, 2.3%, and 3.3%, the AA increases by 1.8%, 3.9%, and 7.2%, and the kappa increases by 2%, 2.3%, and 3.3%. The processing efficiency of our method is also higher than that of SSRN, and the running time is only 18.3%, 45.4%, and 62.1% of the latter. Moreover, the proposed method achieves a classification accuracy of over 87% on the Indian Pines and Pavia University datasets with a small number of training samples.ConclusionWe propose an effective and efficient HSI classification method by integrating and combining several effective technologies. This method can fuse spectral and multiscale spatial features. Diverse experimental results also demonstrate that MSP-SSA outperforms several state-of-the-art approaches and can produce refined results in classification maps.关键词:hyperspectral image classification;superpixel;singular spectrum analysis(SSA);decision fusion;support vector machines(SVM)79|148|5更新时间:2024-05-07 -
 摘要:ObjectiveTerrain classification is an important research task in the field of earth observation using remote sensing technology. The hyperspectral image has rich spectral information; thus, it can be applied to the classification of remote sensing image. With the rapid development of the hyperspectral technology, the hyperspectral remote sensing image processing and analyzing technology has attracted wide attention of academia. The hyperspectral images have dozens or even hundreds of continuous narrow spectral bands compared with the traditional panchromatic band and multi-spectral remote sensing image, which provides detailed spectral and spatial feature information. Accordingly, these images have been widely used in various aspects, such as precision agriculture, city planning, and military defense. Hyperspectral images have high dimensional data, and redundancy and noise exist; thus, transformed data must be utilized for image processing. In the application of hyperspectral image classification, the manner by which to effectively represent the features of hyperspectral image is the most critical step in current studies. In this work, we propose an approach for hyperspectral image classification by using an inverted feature pyramid network and U-Net.MethodThe dimension of the hyperspectral remote sensing image data is high. Principal component analysis (PCA) method plays a significant role in transforming useful information in the images to the most important k characteristic, thus reducing the amount of data and enhancing the data features. After PCA, the data are segmented and collected by means of sliding window. The surrounding area of each pixel is defined as a patch, which is regarded as the input of the proposed network. The category of the pixel is the ground truth label. In the first stage, U-Net is used to extract spatial features of hyperspectral image at the pixel level. The left side of the network is the contraction path, which corresponds to the encoder part of the classic encoder-decoder. The right side of the network is the extension path, which can be regarded as a decoder. The feature maps in the extension path are the result of combining two parts of a feature map along two dimensions, making the acquired features more visible. In the first part, the feature maps from the same layer of contraction path and the feature maps from the upper layer of extension path are simultaneously fed to the attention mechanism. The feature region of this part has a higher weight value. The second part is obtained by deconvolution of the feature graph from the upper layer of the extension path. In a layered way, these feature maps with rich spatial information are fused with feature maps containing rich semantic information obtained by inverted feature pyramid network layers. Therefore, the obtained feature maps have reliable spatial and strong semantic information. Finally, the weight value of the effective features in the image is increased, and the region of irrelevant background is suppressed owing to the attention mechanism. Thus, the classification result of hyperspectral image is acquired.ResultWe conduct experiments to evaluate the effectiveness of the proposed method and attempt to investigate the influence of PCA retained principal component number and the size of input data for the performance of classification. We conduct contrast experiments on four publicly available hyperspectral image datasets to demonstrate the performance of the proposed method: Indian Pines, Pavia University, Salinas, and Urban. Experimental results show that the proposed method for hyperspectral image classification is effective, and the best PCA retained principal component numbers are 3, 20, 10, and 3. Meanwhile, the best input sizes of the proposed model are 64, 32, 32, and 64. We obtain 98.91%, 99.85%, 99.99%, and 87.43% overall classification accuracy rates, 98.07%, 99.39%, 99.09%, and 78.30% average classification accuracy rates, and 0.987, 0.998, 0.999, and 0.831 Kappa values for the four hyperspectral image datasets, respectively, which are higher than those of the other classification algorithms.ConclusionHyperspectral images are capable of accurately presenting the rich terrain information contained in the specific region with the help of hundreds of continuous and subdivided spectral bands; however, useless information exists in each spectral band. The mechanism by which to effectively extract the key terrain information from the data of hyperspectral images and utilize them for classification is the most important and difficult problem. We propose to combine U-Net and the inverted pyramid network for hyperspectral image classification. First, we reduce the dimension of hyperspectral image data with the help of PCA method. We adopt the method of sliding window to build patches after the data dimension is reduced. These patches are fed into the model. U-Net is regarded as the backbone of the proposed network, and it aims to extract the characteristics of a hyperspectral image. Then, the rich characteristics of the spatial information are fused with the features from the inverted pyramid network. Subsequently, the abundant spectral and spatial information is obtained. The utilization of attention mechanism allows the model to effectively focus on spectral and spatial information and reduce the influence of signal-to-noise to classification performance. Experimental results show that the proposed method can be applied to hyperspectral image classification tasks with limited training samples and achieve good classification results. The classification accuracy of a hyperspectral image can also be improved by properly handling the input data. In our future work, we will attempt to investigate the manner by which to make the model's structure less complex while maintaining high hyperspectral image classification performance with less training data samples.关键词:hyperspectral image classification;small samples;inverted feature pyramid network(IFPN);U-Net;feature fusion100|153|3更新时间:2024-05-07
摘要:ObjectiveTerrain classification is an important research task in the field of earth observation using remote sensing technology. The hyperspectral image has rich spectral information; thus, it can be applied to the classification of remote sensing image. With the rapid development of the hyperspectral technology, the hyperspectral remote sensing image processing and analyzing technology has attracted wide attention of academia. The hyperspectral images have dozens or even hundreds of continuous narrow spectral bands compared with the traditional panchromatic band and multi-spectral remote sensing image, which provides detailed spectral and spatial feature information. Accordingly, these images have been widely used in various aspects, such as precision agriculture, city planning, and military defense. Hyperspectral images have high dimensional data, and redundancy and noise exist; thus, transformed data must be utilized for image processing. In the application of hyperspectral image classification, the manner by which to effectively represent the features of hyperspectral image is the most critical step in current studies. In this work, we propose an approach for hyperspectral image classification by using an inverted feature pyramid network and U-Net.MethodThe dimension of the hyperspectral remote sensing image data is high. Principal component analysis (PCA) method plays a significant role in transforming useful information in the images to the most important k characteristic, thus reducing the amount of data and enhancing the data features. After PCA, the data are segmented and collected by means of sliding window. The surrounding area of each pixel is defined as a patch, which is regarded as the input of the proposed network. The category of the pixel is the ground truth label. In the first stage, U-Net is used to extract spatial features of hyperspectral image at the pixel level. The left side of the network is the contraction path, which corresponds to the encoder part of the classic encoder-decoder. The right side of the network is the extension path, which can be regarded as a decoder. The feature maps in the extension path are the result of combining two parts of a feature map along two dimensions, making the acquired features more visible. In the first part, the feature maps from the same layer of contraction path and the feature maps from the upper layer of extension path are simultaneously fed to the attention mechanism. The feature region of this part has a higher weight value. The second part is obtained by deconvolution of the feature graph from the upper layer of the extension path. In a layered way, these feature maps with rich spatial information are fused with feature maps containing rich semantic information obtained by inverted feature pyramid network layers. Therefore, the obtained feature maps have reliable spatial and strong semantic information. Finally, the weight value of the effective features in the image is increased, and the region of irrelevant background is suppressed owing to the attention mechanism. Thus, the classification result of hyperspectral image is acquired.ResultWe conduct experiments to evaluate the effectiveness of the proposed method and attempt to investigate the influence of PCA retained principal component number and the size of input data for the performance of classification. We conduct contrast experiments on four publicly available hyperspectral image datasets to demonstrate the performance of the proposed method: Indian Pines, Pavia University, Salinas, and Urban. Experimental results show that the proposed method for hyperspectral image classification is effective, and the best PCA retained principal component numbers are 3, 20, 10, and 3. Meanwhile, the best input sizes of the proposed model are 64, 32, 32, and 64. We obtain 98.91%, 99.85%, 99.99%, and 87.43% overall classification accuracy rates, 98.07%, 99.39%, 99.09%, and 78.30% average classification accuracy rates, and 0.987, 0.998, 0.999, and 0.831 Kappa values for the four hyperspectral image datasets, respectively, which are higher than those of the other classification algorithms.ConclusionHyperspectral images are capable of accurately presenting the rich terrain information contained in the specific region with the help of hundreds of continuous and subdivided spectral bands; however, useless information exists in each spectral band. The mechanism by which to effectively extract the key terrain information from the data of hyperspectral images and utilize them for classification is the most important and difficult problem. We propose to combine U-Net and the inverted pyramid network for hyperspectral image classification. First, we reduce the dimension of hyperspectral image data with the help of PCA method. We adopt the method of sliding window to build patches after the data dimension is reduced. These patches are fed into the model. U-Net is regarded as the backbone of the proposed network, and it aims to extract the characteristics of a hyperspectral image. Then, the rich characteristics of the spatial information are fused with the features from the inverted pyramid network. Subsequently, the abundant spectral and spatial information is obtained. The utilization of attention mechanism allows the model to effectively focus on spectral and spatial information and reduce the influence of signal-to-noise to classification performance. Experimental results show that the proposed method can be applied to hyperspectral image classification tasks with limited training samples and achieve good classification results. The classification accuracy of a hyperspectral image can also be improved by properly handling the input data. In our future work, we will attempt to investigate the manner by which to make the model's structure less complex while maintaining high hyperspectral image classification performance with less training data samples.关键词:hyperspectral image classification;small samples;inverted feature pyramid network(IFPN);U-Net;feature fusion100|153|3更新时间:2024-05-07 -
 摘要:ObjectiveClassification is a major research task in hyperspectral remote sensing image processing. Extracting appropriate features from hyperspectral remote sensing images is a prerequisite to ensure the accuracy and effectiveness of classification. Traditional feature extraction methods can only extract single, shallow spectral or spatial features and have difficulty extracting deep spatial-spectral features. This limitation results in poor classification accuracy. Compared with traditional classification methods, hyperspectral image classification method based on deep learning model can extract deeper features of hyperspectral image. However, the existing deep learning methods can classify hyperspectral images but have low classification accuracy because of their simple network structure and insufficient feature extraction. Moreover, the parameters of deep network are hundreds of thousands of millions, which need a large number of labeled training samples and longer time to complete the model training. However, manual annotation of hyperspectral images is a time-consuming and laborious project, and only a few labeled samples can usually be used. Therefore, constructing a depth network model for hyperspectral image classification with a small number of training samples is a key research problem. A data expansion method of stacking pixel spatial transformation information is proposed to address the problems of simple network structure and insufficient feature extraction of existing classification methods based on deep learning. A hyperspectral image classification model based on different scales of dual-channel 3D convolutional neural network is also proposed to extract the essential spatial features of hyperspectral image.MethodOn the one hand, the stacking space transform information method is used to expand the training samples for solving the problem of insufficient training samples in the process of hyperspectral image classification. On the other hand, the dual-channel convolutional neural network is used, and its overall structure is composed of preprocessing, data expansion, and dual-channel convolutional neural network (DC-CNN). First, the hyperspectral image is preprocessed to transform the pixels into 3×3 and 5×5 pixel blocks containing certain spatial information as the unit to be processed. Then, the unit to be processed uses the data expansion method of stacking spatial transformation information to expand the data. The expanded dataset is transformed into shape to meet the input dimension of dual-channel convolutional neural network. Then, the pixel blocks of different sizes are input into the branch convolution of different scales of DC-CNN, and they are combined with the spatial spectrum features extracted from the two channels for training to improve the generalization ability of the network. The spatial-spectral features of hyperspectral images can be more comprehensively and fully extracted using different convolution branches to process different sizes of pixel blocks. The information loss caused by dimension reduction can be reduced, and the classification accuracy can be improved. The method of stack space transform information enriches the potential space information of the center pixel and expands the dataset by rotating each pixel and its adjacent pixels, row column transform, and other operations. The expanded pixel blocks are input into dual-channel 3D convolutional neural networks with different scales to learn the deep features of the training set and achieve higher accuracy classification. Three popular hyperspectral image classification methods are selected and compared with this method to verify its effectiveness. The three methods are 2D convolutional neural network (2D-CNN), 3D convolutional neural network (3D-CNN), and siamese neural network (SNN). The network structure of 3D-CNN is the same as that of 3×3 branches of DC-CNN, which can be considered a single-channel network model of DC-CNN.ResultExperimental results show that the Indian Pines and Pavia University datasets achieve 98.34% and 99.63% of the overall classification accuracy, respectively. The running time of different algorithms is also compared. The running time of the proposed algorithm is relatively shorter than that of the comparison algorithm, and this feature ensures the efficiency of the classification model. In addition, this study analyzes the influence of different convolution layers on the classification performance. It verifies that the convolution neural network composed of five convolution layers has the strongest feature extraction ability for hyperspectral images. The proposed method also has good classification performance on two groups of real hyperspectral image datasets. Specifically, the proposed method has certain generalization ability and advantages in running time. In this study, dual-channel convolution neural network is used to complete the deep spatial-spectral feature fusion of hyperspectral image, which fully extracts the hidden information of hyperspectral image and is conducive to the application of deep learning model in hyperspectral image classification. In the follow-up research, we can further explore the effect of multichannel convolution neural network, such as three- and four-channel convolution neural networks in hyperspectral image classification. The application of deep learning method in hyperspectral image can also be promoted.ConclusionThe performance of hyperspectral image classification model with limited training samples is not ideal. Thus, this study proposes a data expansion method of stacking pixel neighborhood spatial information and designs a hyperspectral image classification method based on dual-channel convolutional neural network, which is called DC-CNN. The data expansion method of stacking pixel neighborhood spatial information conducts spatial rotation and transformation on different scale pixel blocks to expand the number of training samples and obtain the hidden spatial information of the center pixel. This method solves the problem of insufficient training samples of depth model and insufficient spatial information extraction of hyperspectral image in feature extraction process. It inputs pixel blocks of different scales through DC-CNN network framework to comprehensively extract more abundant spatial information, completes the deep spatial-spectral information extraction, and inputs the fused spatial spectral features into softmax classifier to achieve more accurate classification.关键词:hyperspectral image;supervised classification;spatial spectrum combination;convolutional neural network(CNN);deep learning;data expansion166|166|4更新时间:2024-05-07
摘要:ObjectiveClassification is a major research task in hyperspectral remote sensing image processing. Extracting appropriate features from hyperspectral remote sensing images is a prerequisite to ensure the accuracy and effectiveness of classification. Traditional feature extraction methods can only extract single, shallow spectral or spatial features and have difficulty extracting deep spatial-spectral features. This limitation results in poor classification accuracy. Compared with traditional classification methods, hyperspectral image classification method based on deep learning model can extract deeper features of hyperspectral image. However, the existing deep learning methods can classify hyperspectral images but have low classification accuracy because of their simple network structure and insufficient feature extraction. Moreover, the parameters of deep network are hundreds of thousands of millions, which need a large number of labeled training samples and longer time to complete the model training. However, manual annotation of hyperspectral images is a time-consuming and laborious project, and only a few labeled samples can usually be used. Therefore, constructing a depth network model for hyperspectral image classification with a small number of training samples is a key research problem. A data expansion method of stacking pixel spatial transformation information is proposed to address the problems of simple network structure and insufficient feature extraction of existing classification methods based on deep learning. A hyperspectral image classification model based on different scales of dual-channel 3D convolutional neural network is also proposed to extract the essential spatial features of hyperspectral image.MethodOn the one hand, the stacking space transform information method is used to expand the training samples for solving the problem of insufficient training samples in the process of hyperspectral image classification. On the other hand, the dual-channel convolutional neural network is used, and its overall structure is composed of preprocessing, data expansion, and dual-channel convolutional neural network (DC-CNN). First, the hyperspectral image is preprocessed to transform the pixels into 3×3 and 5×5 pixel blocks containing certain spatial information as the unit to be processed. Then, the unit to be processed uses the data expansion method of stacking spatial transformation information to expand the data. The expanded dataset is transformed into shape to meet the input dimension of dual-channel convolutional neural network. Then, the pixel blocks of different sizes are input into the branch convolution of different scales of DC-CNN, and they are combined with the spatial spectrum features extracted from the two channels for training to improve the generalization ability of the network. The spatial-spectral features of hyperspectral images can be more comprehensively and fully extracted using different convolution branches to process different sizes of pixel blocks. The information loss caused by dimension reduction can be reduced, and the classification accuracy can be improved. The method of stack space transform information enriches the potential space information of the center pixel and expands the dataset by rotating each pixel and its adjacent pixels, row column transform, and other operations. The expanded pixel blocks are input into dual-channel 3D convolutional neural networks with different scales to learn the deep features of the training set and achieve higher accuracy classification. Three popular hyperspectral image classification methods are selected and compared with this method to verify its effectiveness. The three methods are 2D convolutional neural network (2D-CNN), 3D convolutional neural network (3D-CNN), and siamese neural network (SNN). The network structure of 3D-CNN is the same as that of 3×3 branches of DC-CNN, which can be considered a single-channel network model of DC-CNN.ResultExperimental results show that the Indian Pines and Pavia University datasets achieve 98.34% and 99.63% of the overall classification accuracy, respectively. The running time of different algorithms is also compared. The running time of the proposed algorithm is relatively shorter than that of the comparison algorithm, and this feature ensures the efficiency of the classification model. In addition, this study analyzes the influence of different convolution layers on the classification performance. It verifies that the convolution neural network composed of five convolution layers has the strongest feature extraction ability for hyperspectral images. The proposed method also has good classification performance on two groups of real hyperspectral image datasets. Specifically, the proposed method has certain generalization ability and advantages in running time. In this study, dual-channel convolution neural network is used to complete the deep spatial-spectral feature fusion of hyperspectral image, which fully extracts the hidden information of hyperspectral image and is conducive to the application of deep learning model in hyperspectral image classification. In the follow-up research, we can further explore the effect of multichannel convolution neural network, such as three- and four-channel convolution neural networks in hyperspectral image classification. The application of deep learning method in hyperspectral image can also be promoted.ConclusionThe performance of hyperspectral image classification model with limited training samples is not ideal. Thus, this study proposes a data expansion method of stacking pixel neighborhood spatial information and designs a hyperspectral image classification method based on dual-channel convolutional neural network, which is called DC-CNN. The data expansion method of stacking pixel neighborhood spatial information conducts spatial rotation and transformation on different scale pixel blocks to expand the number of training samples and obtain the hidden spatial information of the center pixel. This method solves the problem of insufficient training samples of depth model and insufficient spatial information extraction of hyperspectral image in feature extraction process. It inputs pixel blocks of different scales through DC-CNN network framework to comprehensively extract more abundant spatial information, completes the deep spatial-spectral information extraction, and inputs the fused spatial spectral features into softmax classifier to achieve more accurate classification.关键词:hyperspectral image;supervised classification;spatial spectrum combination;convolutional neural network(CNN);deep learning;data expansion166|166|4更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral image classification is a basic problem in the field of remote sensing, and it has been one of the research hotspots of numerous scholars. Hyperspectral images contain rich spectral and spatial information, and the classification accuracy of remote sensing images can be improved by using spectral and spatial features. Early traditional models, such as support vector machine and decision trees, could not fully utilize both information. With the development of deep learning technology, an increasing number of scholars use convolutional neural network as a model to extract the features of hyperspectral images. However, two dimensional convolutional neural network(2D-CNN) can only extract the spatial features of hyperspectral images and cannot fully use the band information of remote sensing data. 3D-CNN can efficiently simultaneously extract spectral and spatial features. The recurrent neural network cannot complete the task of hyperspectral image classification because of the difficulty of finding the optimal sequence length and over-fitting. At present, scholars focus on supervised deep learning model, which needs a substantial amount of labeled data to be effectively trained. However, labeled data are difficult and costly in reality. Therefore, the model must have good performance in the unknown world. An unsupervised normal form classification method for spatial-spectral fusion of hyperspectral images is proposed to address the problem that the existing models cannot fully use the spatial and spectral information and require a large amount of data for training. An unsupervised hyperspectral image classification model based on 3D convolution self-encoder is also established.MethodThe 3D convolution auto-encoder(3D-CAE) proposed in this work is composed of an encoder, a decoder, and a classifier. The hyperspectral image is inputted into an encoder after data pre-processing for unsupervised feature extraction to produce a set of feature maps. The network structure of the encoder is a 3D convolutional neural network of three convolution blocks, each of which is made up of two convolution layers and two global max-pooling layers. Batch normalization technique is added to the convolution blocks to prevent over-fitting. The decoder is an inverted encoder, which reconstructs the extracted feature graph into original data, and uses the mean square error function as the loss function to judge the reconstruction error and optimizes the parameters with the Adam algorithm. The classifier consists of three fully connected layers and uses ReLU as the activation function of the fully connected layer to classify the features extracted by the encoder. The backbone network with 3D-CNN as auto-encoder can fully use the spatial and spectral information of hyperspectral images to achieve spatial spectral fusion. The model is also trained end to end, eliminating the need for complex feature engineering and data pre-processing, making it more robust and stable.ResultThe seven methods on Indian Pines, Salinas, Pavia University, and Botswana datasets achieve the best results compared with the traditional single feature and deep learning methods. The overall classification accuracies are 0.948 7, 0.986 6, 0.986 2, and 0.964 9, the average classification accuracies are 0.936 0, 0.992 4, 0.982 9, and 0.965 9, and the Kappa values are 0.941 5, 0.985 1, 0.981 7, and 0.962 0, respectively. Comparative experimental results show that the spatial-spectral fusion and unsupervised learning are effective for hyperspectral remote sensing image classification. The ablation experiment is added because 3D-CAE is composed of a self-encoder and a classifier. Under the condition of the same self-encoder, four classifiers with different structures are used for classification. The experimental results are stable, and the validity of the self-encoder is proved. Five different proportions of datasets are used to prove the generalization of 3D-CAE. The training set proportions are 5%, 8%, 10%, 15%, and 20%. The loss of the auto-encoder and the classifier on the four datasets remained stable and low, and no oscillation was observed, indicating the better generalization of 3D-CAE. Finally, we analyze and discuss the parameters of each deep learning model. 3D-CAE has less parameters and the best classification performance, which proves its high efficiency.ConclusionThe 3D-CAE model proposed in this work fully uses the spectral and spatial features of hyperspectral images. This model also achieves unsupervised feature extraction without substantial pre-processing and high classification accuracy without a large amount of labeled data. Thus, this model is an effective method for hyperspectral image classification.关键词:remote sensing image classification;spatial spectral feature fusion;3D-CNN;auto-encoder;convolutional neural network(CNN);deep learning199|250|2更新时间:2024-05-07
摘要:ObjectiveHyperspectral image classification is a basic problem in the field of remote sensing, and it has been one of the research hotspots of numerous scholars. Hyperspectral images contain rich spectral and spatial information, and the classification accuracy of remote sensing images can be improved by using spectral and spatial features. Early traditional models, such as support vector machine and decision trees, could not fully utilize both information. With the development of deep learning technology, an increasing number of scholars use convolutional neural network as a model to extract the features of hyperspectral images. However, two dimensional convolutional neural network(2D-CNN) can only extract the spatial features of hyperspectral images and cannot fully use the band information of remote sensing data. 3D-CNN can efficiently simultaneously extract spectral and spatial features. The recurrent neural network cannot complete the task of hyperspectral image classification because of the difficulty of finding the optimal sequence length and over-fitting. At present, scholars focus on supervised deep learning model, which needs a substantial amount of labeled data to be effectively trained. However, labeled data are difficult and costly in reality. Therefore, the model must have good performance in the unknown world. An unsupervised normal form classification method for spatial-spectral fusion of hyperspectral images is proposed to address the problem that the existing models cannot fully use the spatial and spectral information and require a large amount of data for training. An unsupervised hyperspectral image classification model based on 3D convolution self-encoder is also established.MethodThe 3D convolution auto-encoder(3D-CAE) proposed in this work is composed of an encoder, a decoder, and a classifier. The hyperspectral image is inputted into an encoder after data pre-processing for unsupervised feature extraction to produce a set of feature maps. The network structure of the encoder is a 3D convolutional neural network of three convolution blocks, each of which is made up of two convolution layers and two global max-pooling layers. Batch normalization technique is added to the convolution blocks to prevent over-fitting. The decoder is an inverted encoder, which reconstructs the extracted feature graph into original data, and uses the mean square error function as the loss function to judge the reconstruction error and optimizes the parameters with the Adam algorithm. The classifier consists of three fully connected layers and uses ReLU as the activation function of the fully connected layer to classify the features extracted by the encoder. The backbone network with 3D-CNN as auto-encoder can fully use the spatial and spectral information of hyperspectral images to achieve spatial spectral fusion. The model is also trained end to end, eliminating the need for complex feature engineering and data pre-processing, making it more robust and stable.ResultThe seven methods on Indian Pines, Salinas, Pavia University, and Botswana datasets achieve the best results compared with the traditional single feature and deep learning methods. The overall classification accuracies are 0.948 7, 0.986 6, 0.986 2, and 0.964 9, the average classification accuracies are 0.936 0, 0.992 4, 0.982 9, and 0.965 9, and the Kappa values are 0.941 5, 0.985 1, 0.981 7, and 0.962 0, respectively. Comparative experimental results show that the spatial-spectral fusion and unsupervised learning are effective for hyperspectral remote sensing image classification. The ablation experiment is added because 3D-CAE is composed of a self-encoder and a classifier. Under the condition of the same self-encoder, four classifiers with different structures are used for classification. The experimental results are stable, and the validity of the self-encoder is proved. Five different proportions of datasets are used to prove the generalization of 3D-CAE. The training set proportions are 5%, 8%, 10%, 15%, and 20%. The loss of the auto-encoder and the classifier on the four datasets remained stable and low, and no oscillation was observed, indicating the better generalization of 3D-CAE. Finally, we analyze and discuss the parameters of each deep learning model. 3D-CAE has less parameters and the best classification performance, which proves its high efficiency.ConclusionThe 3D-CAE model proposed in this work fully uses the spectral and spatial features of hyperspectral images. This model also achieves unsupervised feature extraction without substantial pre-processing and high classification accuracy without a large amount of labeled data. Thus, this model is an effective method for hyperspectral image classification.关键词:remote sensing image classification;spatial spectral feature fusion;3D-CNN;auto-encoder;convolutional neural network(CNN);deep learning199|250|2更新时间:2024-05-07
Hyperspectral Image Classification
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0