
最新刊期
卷 26 , 期 7 , 2021
-
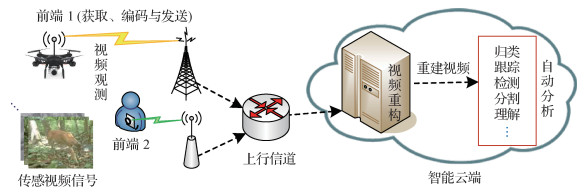 摘要:Uplink streaming media has an emerging strategic value in the civil-military integration field. For uplink streaming media applications, any compressive sensing video stream has technological advantages in terms of low-complexity terminal, good error resilience, and widely available signals. This technology is becoming one of the main issues in visual communication research. The compressive sensing video stream is a new type of visual communication whose functional modules mainly consist of front-end video observation and cloud-end video reconstruction. The core technology of compressive sensing video stream has not developed to a degree that can be standardized. When the uplink streaming media provides a large number of video sensing signals not for human viewing but for universal machine vision, any compressive-sensing video stream utilizes a new signal-processing mechanism that can avoid the shortage of existing uplink streaming technologies to first obtain additional information and then discard it. Based on the application characteristics of uplink streaming media, this study analyzes the basic theories and key technologies of compressive-sensing video stream, i.e., performance metrics, parallel block computational imaging, low-complexity video encoding, video reconstruction, and semantic quality evaluation. The latest research progress is also investigated and compared in this survey. The video sensing signal is usually divided into group-of-frames (GOF), and each GOF is further divided into a key frame and several non-key frames. As block compressive sensing (BCS) requires less sensing or storage resources at the front end, it not only realizes the lightweight observation matrix but also transmits block-by-block or in parallel. In a compressive sensing video stream, the GOF-BCS block array denotes the set of all BCS blocks in a GOF. The existing compressive sensing video stream adopts such a technical framework as single-frame observation, open-loop encoding, and fidelity-guided reconstruction. The study results show that for uplink streaming media, the existing compressive-sensing video stream faces bottleneck problems such as uncontrollable observation efficiency, lack of bitstream adaptation, and low reconstruction quality. Therefore, the technology development trend of compressive-sensing video streams have to be examined. The research directions of future compressive sensing video streams aim to focus on the following aspects. 1) Efficiency-optimized GOF-BCS block-array layout. The existing compressive-sensing video stream only uses a simple combination of GOF frame number, BCS block size, and sampling rate, which is a special layout of the GOF-BCS block-array. This special layout lacks a rationality proof. Therefore, we need to compare and analyze various block-array layouts and spatial-temporal partitions, and then design a universally optimized GOF-BCS block-array to quickly generate the observation vectors with more spatiotemporal semantics. At the same time, this approach is conducive to the hierarchical sparse modeling of video reconstruction. 2) Observation control and bitstream adaptation of video sensing signal. During video encoding, a trade-off occurs between the sampling rate and quantization depth. In subsequent study, an important task is to know how to construct the distribution model of observation vectors and adaptively adjust the sampling rate and quantization depth. Based on an efficiency-optimized GOF-BCS block-array, the novel compressive sensing video stream may improve the observation efficiency at the front end, and adapt both low-complexity encoding and wireless transmission. Through the dynamic interaction between source and channel at the front end, the feedback coordination is formed between video observation and wireless transmission, and the front-end complexity may be quantitatively controlled. 3) During video reconstruction, an important methodology is to obtain the sparse solution of the underdetermined system by prior modeling. When the hierarchical sparse model cannot stably represent the observation vectors, the data-driven reconstruction mechanism can make up for the deficiency of prior modeling. Future research will construct the generation and recovery mechanism of partial reversible signals, and explore the hybrid reconstruction mechanism of hierarchical sparse model and deep neural network (DNN). 4) Semantic quality assessment model for any reconstructed block-array. At present, the quality evaluation of reconstructed videos is limited to pixel-level fidelity. For universal machine vision, the video reconstruction relies more on semantic quality evaluation. On the basis of sparse residual prediction reconstruction, the cloud end gradually adds the data-driven reconstruction by DNN. By integrating the semantic quality assessment model, the video reconstruction mechanism with memory learning may be provided at cloud end. 5) A new technical framework will combine the high-efficiency observation and semantic-guided hybrid reconstruction. One of the important research directions is to construct the effective division and cooperation between the front and cloud ends. Besides the complexity-controllable front end, the new technical framework should demonstrate the higher semantic quality in video reconstruction and enhance the interpretability of compressive-sensing deep learning. For the video-sensing signal with dynamic scene changes, the new technical framework can balance the observation distortion, bitrate, and power consumption at any resource-constrained front end. The research directions are expected to break through the limitations of the existing compressive-sensing video stream. Such key technologies have to be developed as high-efficiency observation and semantic-guided hybrid reconstruction, which can further highlight the unique advantage and quantitative evolution of compressive-sensing video stream technology for uplink streaming media applications.关键词:video stream;observation efficiency;bitstream adaptation;semantic quality;video reconstruction;review81|282|1更新时间:2024-05-07
摘要:Uplink streaming media has an emerging strategic value in the civil-military integration field. For uplink streaming media applications, any compressive sensing video stream has technological advantages in terms of low-complexity terminal, good error resilience, and widely available signals. This technology is becoming one of the main issues in visual communication research. The compressive sensing video stream is a new type of visual communication whose functional modules mainly consist of front-end video observation and cloud-end video reconstruction. The core technology of compressive sensing video stream has not developed to a degree that can be standardized. When the uplink streaming media provides a large number of video sensing signals not for human viewing but for universal machine vision, any compressive-sensing video stream utilizes a new signal-processing mechanism that can avoid the shortage of existing uplink streaming technologies to first obtain additional information and then discard it. Based on the application characteristics of uplink streaming media, this study analyzes the basic theories and key technologies of compressive-sensing video stream, i.e., performance metrics, parallel block computational imaging, low-complexity video encoding, video reconstruction, and semantic quality evaluation. The latest research progress is also investigated and compared in this survey. The video sensing signal is usually divided into group-of-frames (GOF), and each GOF is further divided into a key frame and several non-key frames. As block compressive sensing (BCS) requires less sensing or storage resources at the front end, it not only realizes the lightweight observation matrix but also transmits block-by-block or in parallel. In a compressive sensing video stream, the GOF-BCS block array denotes the set of all BCS blocks in a GOF. The existing compressive sensing video stream adopts such a technical framework as single-frame observation, open-loop encoding, and fidelity-guided reconstruction. The study results show that for uplink streaming media, the existing compressive-sensing video stream faces bottleneck problems such as uncontrollable observation efficiency, lack of bitstream adaptation, and low reconstruction quality. Therefore, the technology development trend of compressive-sensing video streams have to be examined. The research directions of future compressive sensing video streams aim to focus on the following aspects. 1) Efficiency-optimized GOF-BCS block-array layout. The existing compressive-sensing video stream only uses a simple combination of GOF frame number, BCS block size, and sampling rate, which is a special layout of the GOF-BCS block-array. This special layout lacks a rationality proof. Therefore, we need to compare and analyze various block-array layouts and spatial-temporal partitions, and then design a universally optimized GOF-BCS block-array to quickly generate the observation vectors with more spatiotemporal semantics. At the same time, this approach is conducive to the hierarchical sparse modeling of video reconstruction. 2) Observation control and bitstream adaptation of video sensing signal. During video encoding, a trade-off occurs between the sampling rate and quantization depth. In subsequent study, an important task is to know how to construct the distribution model of observation vectors and adaptively adjust the sampling rate and quantization depth. Based on an efficiency-optimized GOF-BCS block-array, the novel compressive sensing video stream may improve the observation efficiency at the front end, and adapt both low-complexity encoding and wireless transmission. Through the dynamic interaction between source and channel at the front end, the feedback coordination is formed between video observation and wireless transmission, and the front-end complexity may be quantitatively controlled. 3) During video reconstruction, an important methodology is to obtain the sparse solution of the underdetermined system by prior modeling. When the hierarchical sparse model cannot stably represent the observation vectors, the data-driven reconstruction mechanism can make up for the deficiency of prior modeling. Future research will construct the generation and recovery mechanism of partial reversible signals, and explore the hybrid reconstruction mechanism of hierarchical sparse model and deep neural network (DNN). 4) Semantic quality assessment model for any reconstructed block-array. At present, the quality evaluation of reconstructed videos is limited to pixel-level fidelity. For universal machine vision, the video reconstruction relies more on semantic quality evaluation. On the basis of sparse residual prediction reconstruction, the cloud end gradually adds the data-driven reconstruction by DNN. By integrating the semantic quality assessment model, the video reconstruction mechanism with memory learning may be provided at cloud end. 5) A new technical framework will combine the high-efficiency observation and semantic-guided hybrid reconstruction. One of the important research directions is to construct the effective division and cooperation between the front and cloud ends. Besides the complexity-controllable front end, the new technical framework should demonstrate the higher semantic quality in video reconstruction and enhance the interpretability of compressive-sensing deep learning. For the video-sensing signal with dynamic scene changes, the new technical framework can balance the observation distortion, bitrate, and power consumption at any resource-constrained front end. The research directions are expected to break through the limitations of the existing compressive-sensing video stream. Such key technologies have to be developed as high-efficiency observation and semantic-guided hybrid reconstruction, which can further highlight the unique advantage and quantitative evolution of compressive-sensing video stream technology for uplink streaming media applications.关键词:video stream;observation efficiency;bitstream adaptation;semantic quality;video reconstruction;review81|282|1更新时间:2024-05-07
Review

-
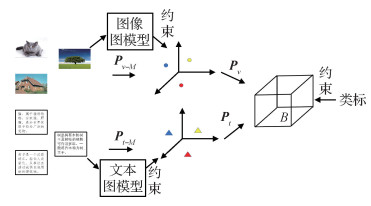 摘要:ObjectiveWith the rapid development of multimedia technology, the scale of multimedia data has been growing rapidly. For example, people are used to describing the things they want to show with multimedia data such as texts, images, and videos. Obtaining the relevant results of one modality using another modality is a good objective. In this sense, how to effectively perform semantic correlation analysis and measure the similarity between the data has gradually become a hot research topic. As the representation of different modal data is heterogeneous, it poses a great challenge to the cross-modal retrieval task. Hashing-based methods have received great attention in cross-modal retrieval because of its fast retrieval speed and low storage consumption. To solve the problem of heterogeneity between different modalities of the data, most of the current supervised hashing algorithms directly map different modal data into the Hamming space. However, these methods have the following limitations: 1) The data from each modality have different feature representations, and the dimensions of their feature spaces vary greatly. Therefore, it is difficult for these methods to obtain a consistent hash code by directly mapping the data from different modalities into the same Hamming space. 2) Although label information has been considered for these hashing methods, the structural information of the original data is ignored, which could result in a less-representative hash code to encode the original structural information in each modality. To solve these issues, a novel hashing algorithm called structure-preserving hashing with coupled projections (SPHCP) is proposed in this paper for cross-modal retrieval.MethodConsidering the heterogeneity between the cross-modal data, this algorithm first projects the data from different modalities into their respective subspaces to reduce the modal difference. A local graph model is also designed in the subspace learning to maintain the structural consistency between the samples. Then, to build a semantic relationship between different modalities, the algorithm maps the subspace features to the Hamming space to obtain a consistent hash code. At the same time, the label constraint is exploited to improve the discriminant power of the obtained hash codes. Finally, the algorithm measures the similarity of different modal data in terms of the Hamming distance.ResultWe compared our model with several state-of-the-art methods on three public datasets, namely, Wikipedia, MIRFlickr, and Pascal Sentence. The mean average precision (mAP) is used as the quantitative evaluation metric. We first test our method on two benchmark datasets, Wikipedia and MIRFlickr. To evaluate the impact of hash-code length on the performance of the algorithm, this experiment set the hash code length to 16, 32, 64, and 128 bits. The experimental results show that for both the text-retrieving image task and image-retrieving text task, our proposed method outperforms the existing methods in each length setting. To further measure the performance of our proposed method on the dataset with deep features, we test the algorithm on the Pascal Sentence dataset. The experimental results show that our SPHCP algorithm can also achieve higher mAP on such dataset with deep features. In general, cross-modal retrieval methods based on deep networks can handle nonlinear features well, so their retrieval accuracy is supposed to be higher than that of traditional methods, but they need much more computational power. As a "shallow" method, the proposed SPHCP algorithm is competitive with deep methods in terms of mAP. Therefore, as an interesting direction, our framework can be used in conjunction with the deep learning method in the future, i.e., using deep learning to extract the features of images and text offline, and using the SPHCP algorithm for fast retrieval. Furthermore, we analyze the parameter sensitivity of the proposed algorithm. As this algorithm has 7 parameters, a controlled variable method is used for evaluation. The experimental results show that the proposed algorithm is not sensitive to parameters, which means that the training process does not require much optimization time, making it suitable for practical application.ConclusionIn this study, a novel method called SPHCP is proposed to solve the problems mentioned. First, aiming at the "modal gap" between cross-modal data, the scheme of coupled projections is applied to gradually reduce the modal difference of multimedia data. In this way, a more consistent hash code can be obtained. Second, considering the structural information and semantic discrimination of the original data, the algorithm introduces the graph model in subspace learning, which can maintain the intra-class and inter-class relationship of the samples. Finally, a label constraint is introduced to improve the discriminability of the hash code. The experiments on the benchmark datasets verify the effectiveness of the proposed algorithm. Specifically, compared with the second-best method, SPHCP achieves an improvement by 6% and 3% on Wikipedia for two retrieval tasks. On MIRFlickr, SPHCP achieves an improvement by 2% and 5%. On Pascal Sentence, the improvement is approximately 10% and 7%. However, the proposed method requires a large amount of computing power when dealing with large-scale data, because SPHCP introduces a graph model to maintain the structural information between the data. The calculation of the structural information between each sample leads to a larger computing complexity.In future research, we will introduce nonlinear feature mapping into our SPHCP framework to improve its scalability when dealing with nonlinear feature data. Furthermore, we can extend the SPHCP from a cross-modal retrieval algorithm to a multi-modal version.关键词:cross-modal retrieval;Hashing;structure-preserving;graph model;coupled projections;subspace learning95|165|0更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of multimedia technology, the scale of multimedia data has been growing rapidly. For example, people are used to describing the things they want to show with multimedia data such as texts, images, and videos. Obtaining the relevant results of one modality using another modality is a good objective. In this sense, how to effectively perform semantic correlation analysis and measure the similarity between the data has gradually become a hot research topic. As the representation of different modal data is heterogeneous, it poses a great challenge to the cross-modal retrieval task. Hashing-based methods have received great attention in cross-modal retrieval because of its fast retrieval speed and low storage consumption. To solve the problem of heterogeneity between different modalities of the data, most of the current supervised hashing algorithms directly map different modal data into the Hamming space. However, these methods have the following limitations: 1) The data from each modality have different feature representations, and the dimensions of their feature spaces vary greatly. Therefore, it is difficult for these methods to obtain a consistent hash code by directly mapping the data from different modalities into the same Hamming space. 2) Although label information has been considered for these hashing methods, the structural information of the original data is ignored, which could result in a less-representative hash code to encode the original structural information in each modality. To solve these issues, a novel hashing algorithm called structure-preserving hashing with coupled projections (SPHCP) is proposed in this paper for cross-modal retrieval.MethodConsidering the heterogeneity between the cross-modal data, this algorithm first projects the data from different modalities into their respective subspaces to reduce the modal difference. A local graph model is also designed in the subspace learning to maintain the structural consistency between the samples. Then, to build a semantic relationship between different modalities, the algorithm maps the subspace features to the Hamming space to obtain a consistent hash code. At the same time, the label constraint is exploited to improve the discriminant power of the obtained hash codes. Finally, the algorithm measures the similarity of different modal data in terms of the Hamming distance.ResultWe compared our model with several state-of-the-art methods on three public datasets, namely, Wikipedia, MIRFlickr, and Pascal Sentence. The mean average precision (mAP) is used as the quantitative evaluation metric. We first test our method on two benchmark datasets, Wikipedia and MIRFlickr. To evaluate the impact of hash-code length on the performance of the algorithm, this experiment set the hash code length to 16, 32, 64, and 128 bits. The experimental results show that for both the text-retrieving image task and image-retrieving text task, our proposed method outperforms the existing methods in each length setting. To further measure the performance of our proposed method on the dataset with deep features, we test the algorithm on the Pascal Sentence dataset. The experimental results show that our SPHCP algorithm can also achieve higher mAP on such dataset with deep features. In general, cross-modal retrieval methods based on deep networks can handle nonlinear features well, so their retrieval accuracy is supposed to be higher than that of traditional methods, but they need much more computational power. As a "shallow" method, the proposed SPHCP algorithm is competitive with deep methods in terms of mAP. Therefore, as an interesting direction, our framework can be used in conjunction with the deep learning method in the future, i.e., using deep learning to extract the features of images and text offline, and using the SPHCP algorithm for fast retrieval. Furthermore, we analyze the parameter sensitivity of the proposed algorithm. As this algorithm has 7 parameters, a controlled variable method is used for evaluation. The experimental results show that the proposed algorithm is not sensitive to parameters, which means that the training process does not require much optimization time, making it suitable for practical application.ConclusionIn this study, a novel method called SPHCP is proposed to solve the problems mentioned. First, aiming at the "modal gap" between cross-modal data, the scheme of coupled projections is applied to gradually reduce the modal difference of multimedia data. In this way, a more consistent hash code can be obtained. Second, considering the structural information and semantic discrimination of the original data, the algorithm introduces the graph model in subspace learning, which can maintain the intra-class and inter-class relationship of the samples. Finally, a label constraint is introduced to improve the discriminability of the hash code. The experiments on the benchmark datasets verify the effectiveness of the proposed algorithm. Specifically, compared with the second-best method, SPHCP achieves an improvement by 6% and 3% on Wikipedia for two retrieval tasks. On MIRFlickr, SPHCP achieves an improvement by 2% and 5%. On Pascal Sentence, the improvement is approximately 10% and 7%. However, the proposed method requires a large amount of computing power when dealing with large-scale data, because SPHCP introduces a graph model to maintain the structural information between the data. The calculation of the structural information between each sample leads to a larger computing complexity.In future research, we will introduce nonlinear feature mapping into our SPHCP framework to improve its scalability when dealing with nonlinear feature data. Furthermore, we can extend the SPHCP from a cross-modal retrieval algorithm to a multi-modal version.关键词:cross-modal retrieval;Hashing;structure-preserving;graph model;coupled projections;subspace learning95|165|0更新时间:2024-05-07 -
 摘要:ObjectiveVisual retrieval methods need to accurately and efficiently retrieve the most relevant visual content from large-scale images or video datasets. However, due to a large amount of image data and high feature dimensionality in the dataset, existing methods face difficulty in ensuring fast retrieval speed and good retrieval results. Hashing is a widely studied solution for approximate nearest neighbor search, which aims to convert high-dimensional data items into a low-dimensional representation or a hash code consisting of a set of bit sequences. Locality-sensitive hashing (LSH) is a data-independent, unsupervised hashing algorithm that provides asymptotic theoretical properties, thereby ensuring performance. LSH is considered as one of the most common methods for fast nearest-neighbor search in high-dimensional space. Nevertheless, if the number of hash functions k is set too small, it leads to too many data items falling into each hash bucket, thus increasing the query response time. By contrast, if k is set too large, the number of data items in each hash bucket is reduced. Moreover, to achieve the desired search accuracy, LSH usually needs to use long hash codes, thereby reducing the recall rate. Although the use of multiple hash tables can alleviate this problem, it significantly increases memory cost and query time. Besides, due to the semantic gap between the visual semantic space and metric space, LSH may not obtain good search performance.MethodFor visual retrieval of high-dimensional data, we first propose a hash algorithm called weighted semantic locality-sensitive hashing (WSLSH), which is based on feature space partitioning, to address the aforementioned drawbacks of LSH. While building the indices, WSLSH considers the distance relationship between reference and query features, divides the reference feature space into two subspaces by a two-layer visual dictionary, and employs weighted-semantic locality sensitive hashing in each subspace to index, thereby forming a hierarchical index structure. The proposed algorithm can rapidly converge the target to a small range in the process of large-scale retrieval and make accurate queries, which greatly improves the retrieval speed. Then, dynamic variable-length hashing codes are applied in a hashing table to retrieve multiple hashing buckets, which can reduce the number of hashing tables and improve the retrieval speed based on guaranteeing the retrieval performance. Through these two improvements, the retrieval speed can be greatly improved. In addition, to solve the random instability of LSH, statistical information reflecting the semantics of reference feature space is introduced into the LSH function, and a simple projection semantic-hashing function is designed to ensure the stability of the retrieval performance.ResultExperiment results on Holidays, Oxford5k, and DataSetB datasets show that the retrieval accuracy and retrieval speed are effectively improved in comparison with the representative unsupervised hash methods. WSLSH achieves the shortest average retrieval time (0.034 25 s) on DataSetB. When the encoding length is 64 bit, the mean average precision (mAP) of the WSLSH algorithm is improved by 1.2%32.6%, 1.7%19.1%, and 2.6%28.6%. WSLSH is not highly sensitive to the size change of the reference feature subset involved, so the retrieval time does not change significantly, which reflects the retrieval advantage of WSLSH for large-scale datasets. With the increase of encoding length, the performance of the WSLSH algorithm is improved gradually. When the encoding length is 64 bit, the WSLSH algorithm obtains the highest precision and recall on the three datasets, which is superior to other compared methods.ConclusionThe LSH algorithm is improved by performing feature space division twice, weighting the number of hash indexes of reference features, dynamically using variable-length hash codes, and introducing a simple-projection semantic-hash function. Thus, the proposed WSLSH algorithm has faster retrieval speed. In the case of long encoding length, WSLSH achieves better performance than the compared works and shows high application value for large-scale image datasets.关键词:feature space partitioning;locality-sensitive hashing(LSH);dynamic variable-length hashing code;visual retrieval;nearest neighbor search77|163|1更新时间:2024-05-07
摘要:ObjectiveVisual retrieval methods need to accurately and efficiently retrieve the most relevant visual content from large-scale images or video datasets. However, due to a large amount of image data and high feature dimensionality in the dataset, existing methods face difficulty in ensuring fast retrieval speed and good retrieval results. Hashing is a widely studied solution for approximate nearest neighbor search, which aims to convert high-dimensional data items into a low-dimensional representation or a hash code consisting of a set of bit sequences. Locality-sensitive hashing (LSH) is a data-independent, unsupervised hashing algorithm that provides asymptotic theoretical properties, thereby ensuring performance. LSH is considered as one of the most common methods for fast nearest-neighbor search in high-dimensional space. Nevertheless, if the number of hash functions k is set too small, it leads to too many data items falling into each hash bucket, thus increasing the query response time. By contrast, if k is set too large, the number of data items in each hash bucket is reduced. Moreover, to achieve the desired search accuracy, LSH usually needs to use long hash codes, thereby reducing the recall rate. Although the use of multiple hash tables can alleviate this problem, it significantly increases memory cost and query time. Besides, due to the semantic gap between the visual semantic space and metric space, LSH may not obtain good search performance.MethodFor visual retrieval of high-dimensional data, we first propose a hash algorithm called weighted semantic locality-sensitive hashing (WSLSH), which is based on feature space partitioning, to address the aforementioned drawbacks of LSH. While building the indices, WSLSH considers the distance relationship between reference and query features, divides the reference feature space into two subspaces by a two-layer visual dictionary, and employs weighted-semantic locality sensitive hashing in each subspace to index, thereby forming a hierarchical index structure. The proposed algorithm can rapidly converge the target to a small range in the process of large-scale retrieval and make accurate queries, which greatly improves the retrieval speed. Then, dynamic variable-length hashing codes are applied in a hashing table to retrieve multiple hashing buckets, which can reduce the number of hashing tables and improve the retrieval speed based on guaranteeing the retrieval performance. Through these two improvements, the retrieval speed can be greatly improved. In addition, to solve the random instability of LSH, statistical information reflecting the semantics of reference feature space is introduced into the LSH function, and a simple projection semantic-hashing function is designed to ensure the stability of the retrieval performance.ResultExperiment results on Holidays, Oxford5k, and DataSetB datasets show that the retrieval accuracy and retrieval speed are effectively improved in comparison with the representative unsupervised hash methods. WSLSH achieves the shortest average retrieval time (0.034 25 s) on DataSetB. When the encoding length is 64 bit, the mean average precision (mAP) of the WSLSH algorithm is improved by 1.2%32.6%, 1.7%19.1%, and 2.6%28.6%. WSLSH is not highly sensitive to the size change of the reference feature subset involved, so the retrieval time does not change significantly, which reflects the retrieval advantage of WSLSH for large-scale datasets. With the increase of encoding length, the performance of the WSLSH algorithm is improved gradually. When the encoding length is 64 bit, the WSLSH algorithm obtains the highest precision and recall on the three datasets, which is superior to other compared methods.ConclusionThe LSH algorithm is improved by performing feature space division twice, weighting the number of hash indexes of reference features, dynamically using variable-length hash codes, and introducing a simple-projection semantic-hash function. Thus, the proposed WSLSH algorithm has faster retrieval speed. In the case of long encoding length, WSLSH achieves better performance than the compared works and shows high application value for large-scale image datasets.关键词:feature space partitioning;locality-sensitive hashing(LSH);dynamic variable-length hashing code;visual retrieval;nearest neighbor search77|163|1更新时间:2024-05-07
Image Processing and Coding
-
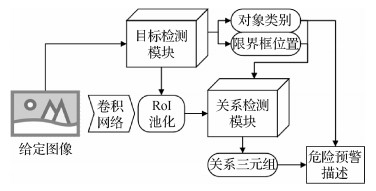 摘要:ObjectiveThe past decade has seen a steady increase in deep learning areas, where extensive research has been published to improve the learning capabilities of deep neural networks. Thus, a growing number of regulators in the electric power industry utilize such deep learning techniques with powerful recognition and detection capabilities to build their surveillance systems, which greatly reduce the risk of major accidents in daily work. However, most of the current early-warning systems are based on object detection technologies, which can only provide annotations of dangerous targets within the image, ignoring the significant information about unary relationships of electrical equipment and binary relationships between paired objects. This condition limits the capabilities of emergency recognition and forewarning. With the presence of powerful object detectors such as Faster region convolutional neural network (R-CNN) and huge visual datasets such as visual genome, visual relationship detection has attracted much attention in recent years. By utilizing the basic building blocks for single-object detection and understanding, visual relationship detection aims to not only accurately localize a pair of objects but also precisely determine the predicate between them. As a mid-level learning task, visual relationship detection can capture the detailed semantics of visual scenes by explicitly modeling objects along with their relationships with other objects. This approach bridges the gap between low-level visual tasks and high-level vision-language tasks, as well as helps machines to solve more challenging visual tasks such as image captioning, visual question answering, and image generation. However, the difficulty is in developing robust algorithms to recognize relationships between paired objects with challenging factors, such as highly diverse visual features in the same predicate category, incomplete annotation and long-tailed distribution in the dataset, and optimum predicate matching problem. Although numerous methods have been proposed to build efficient relationship detectors, few of them concentrate on applying detection technologies to actual use.MethodDifferent from existing methods, our method introduces the visual relationship detection technology into current early-warning systems. Specifically, our method not only identifies dangerous objects but also recognizes the potential unary or binary relationships that may cause an accident. To sum up, we propose a two-stage emergency recognition and forewarning system for the electric power industry. The system consists of a pre-trained object-detection module and a relationship detection module. The pipeline of our system mainly includes three stages. First, we train an object-detection module based on Faster R-CNN in advance. When given an image, the pre-trained object detector localizes all the object bounding boxes and annotates their categories. Then, the relationship-detection module integrates multiple cues (visual appearance, spatial location, and semantic embedding) to compute the predicate confidence of all the object pairs, and output the top instances as the relationship predictions. Finally, based on the targets and relationship information provided by the detectors, our system performs emergency prediction and generates a warning description that may help regulators in the electric power industry to make suitable decisions.ResultWe conduct several experiments to prove the efficiency and superiority of our method. First, we collect and build a dataset consisting of large amounts of images from multiple scenarios in the electric power industry. Using instructions from experts, we define and label the relationship categories that may pose risks to the images in the dataset. Then, according to the number of objects forming a relationship, we divide the dataset into two parts. Thus, our experiments involve two relevant tasks to evaluate the proposed method: unary relationship detection and binary relationship detection. For the unary relationship detection, we use precision and recall as thee valuation metrics. For the binary relationship detection, the evaluation metrics are Recall@5 and Recall@10. As our proposed relationship-detection module contains multiple cues to learn the holistic representation of a relationship instance, we conduct ablation experiments to explore their influence on the final performance. Experiment results show that the detector that uses visual, spatial, and semantic features as input achieve the best performance of 86.80% in Recall@5 and 93.93% in Recall@10.ConclusionExtensive experiments show that our proposed method is efficient and effective in detecting defective electrical equipment and dangerous relationships between paired objects. Moreover, we formulate a pre-defined rule to generate the early-warning description according to the results of the object and relationship detectors. All of the proposed methods can help regulators take proper and timely actions to avoid harmful accidents in the electric power industry.关键词:emergency early-warning;object detection;visual relationship detection;multimodal feature fusion;multi-label margin loss66|206|2更新时间:2024-05-07
摘要:ObjectiveThe past decade has seen a steady increase in deep learning areas, where extensive research has been published to improve the learning capabilities of deep neural networks. Thus, a growing number of regulators in the electric power industry utilize such deep learning techniques with powerful recognition and detection capabilities to build their surveillance systems, which greatly reduce the risk of major accidents in daily work. However, most of the current early-warning systems are based on object detection technologies, which can only provide annotations of dangerous targets within the image, ignoring the significant information about unary relationships of electrical equipment and binary relationships between paired objects. This condition limits the capabilities of emergency recognition and forewarning. With the presence of powerful object detectors such as Faster region convolutional neural network (R-CNN) and huge visual datasets such as visual genome, visual relationship detection has attracted much attention in recent years. By utilizing the basic building blocks for single-object detection and understanding, visual relationship detection aims to not only accurately localize a pair of objects but also precisely determine the predicate between them. As a mid-level learning task, visual relationship detection can capture the detailed semantics of visual scenes by explicitly modeling objects along with their relationships with other objects. This approach bridges the gap between low-level visual tasks and high-level vision-language tasks, as well as helps machines to solve more challenging visual tasks such as image captioning, visual question answering, and image generation. However, the difficulty is in developing robust algorithms to recognize relationships between paired objects with challenging factors, such as highly diverse visual features in the same predicate category, incomplete annotation and long-tailed distribution in the dataset, and optimum predicate matching problem. Although numerous methods have been proposed to build efficient relationship detectors, few of them concentrate on applying detection technologies to actual use.MethodDifferent from existing methods, our method introduces the visual relationship detection technology into current early-warning systems. Specifically, our method not only identifies dangerous objects but also recognizes the potential unary or binary relationships that may cause an accident. To sum up, we propose a two-stage emergency recognition and forewarning system for the electric power industry. The system consists of a pre-trained object-detection module and a relationship detection module. The pipeline of our system mainly includes three stages. First, we train an object-detection module based on Faster R-CNN in advance. When given an image, the pre-trained object detector localizes all the object bounding boxes and annotates their categories. Then, the relationship-detection module integrates multiple cues (visual appearance, spatial location, and semantic embedding) to compute the predicate confidence of all the object pairs, and output the top instances as the relationship predictions. Finally, based on the targets and relationship information provided by the detectors, our system performs emergency prediction and generates a warning description that may help regulators in the electric power industry to make suitable decisions.ResultWe conduct several experiments to prove the efficiency and superiority of our method. First, we collect and build a dataset consisting of large amounts of images from multiple scenarios in the electric power industry. Using instructions from experts, we define and label the relationship categories that may pose risks to the images in the dataset. Then, according to the number of objects forming a relationship, we divide the dataset into two parts. Thus, our experiments involve two relevant tasks to evaluate the proposed method: unary relationship detection and binary relationship detection. For the unary relationship detection, we use precision and recall as thee valuation metrics. For the binary relationship detection, the evaluation metrics are Recall@5 and Recall@10. As our proposed relationship-detection module contains multiple cues to learn the holistic representation of a relationship instance, we conduct ablation experiments to explore their influence on the final performance. Experiment results show that the detector that uses visual, spatial, and semantic features as input achieve the best performance of 86.80% in Recall@5 and 93.93% in Recall@10.ConclusionExtensive experiments show that our proposed method is efficient and effective in detecting defective electrical equipment and dangerous relationships between paired objects. Moreover, we formulate a pre-defined rule to generate the early-warning description according to the results of the object and relationship detectors. All of the proposed methods can help regulators take proper and timely actions to avoid harmful accidents in the electric power industry.关键词:emergency early-warning;object detection;visual relationship detection;multimodal feature fusion;multi-label margin loss66|206|2更新时间:2024-05-07 -
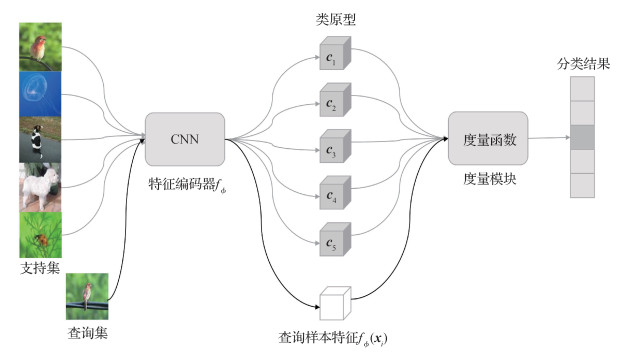 摘要:ObjectiveDeep learning has made remarkable achievements in many fields such as image recognition, object detection, and speech recognition. However, most of the extraordinary achievements of these models depend on extraordinary data size. Existing deep-learning models often need large-scale training data. Building large-scale training data sets not only necessitates a large amount of manpower and material resources but are also not feasible in scenarios such as obtaining a large number of rare image class data samples. Inspired by the fact that human children can learn how to distinguish an object through a small number of samples, few-shot image classification aims to identify target categories with only a few labeled samples. Image recognition based on few-shot learning solves the problem in which a deep learning model needs large-scale training data. At present, the mainstream methods of few-shot image recognition are based on meta learning, which mainly includes three methods: meta learning based on metric, meta learning based on optimization, and meta learning based on model. The method of meta learning is divided into two stages: training and testing. However, most of the metric-based meta-learning methods do not use few shots of the target class in the training stage, which leads to a lack of good generalization ability of these models. These metric-based meta-learning models often show high accuracy in the training stage, but the recognition effect for few-shot image categories in the test stage is poor. The deep feature representation learned by the models cannot be effectively generalized to the target class. To improve the generalization ability of the few-shot learning image recognition method, this study proposes a few-shot learning method based on class semantic similarity supervision.MethodThe method proposed in this paper mainly includes two parts: the first step is to obtain the class similarity matrix between the image dataset classes, and the second step is to use the class similarity matrix as additional supervision information to train the few-shot image recognition model. The details are as follows: a common crawl database containing one billion level webpage data is used to train an unsupervised word-vector learning algorithm GloVe model (global vectors for word representation), which generates 300 dimensional vectors for every word. For classes whose names contain more than one word, we match all the words in the training GloVe model and find their word-embedding vectors. By averaging these word-embedding vectors, we obtain the word embedding vector of the class name. Then, the cosine distance between the word-embedding vectors of classes is used to represent the semantic similarity between classes. In addition to the negative logarithm loss caused by the category labels of the original prototypical networks, this study introduces the semantic similarity measure between categories as the extra supervision information in the training stage of the model to establish the implicit relationship between the source class and few-shot target class. This condition enables the model to have better generalization ability. Furthermore, the loss of class semantic similarity can constrain the features of samples within and between classes learned by the model so that the sample features within each class are more similar, and the distribution of sample features between different classes is more consistent with the semantic similarity between categories. By introducing the loss of class semantic similarity to supervise the training process of the model, our proposed model can implicitly learn the relationship between different classes and obtain a feature representation with more constraint and generalization abilities of class sample features.ResultThis study compared the proposed model with several state-of-the-art few-shot image classification models, including prototypical, matching, and relation networks and other classic methods. In this study, a large number of experiments are conducted on miniImageNet and tieredImageNet. The results show that the proposed method is effective and competitive with the current advanced methods. To ensure fair comparison with the advanced methods, the classical paradigm of meta learning is used to train and test the model, and many experiments are conducted on the widely used 5-way 1-shot and 5-way 5-shot settings. The experimental results show that on the 5-way 1-shot and 5-way 5-shot settings of the miniImageNet dataset, the classification accuracy of the proposed method is improved by 1.9% and 0.32%, respectively, compared with the classical few-shot image recognition meta-learning method prototypical networks. In the tieredImageNet dataset on the 5-way 1-shot setting, the classification accuracy rate is improved by 0.33% compared with that in the prototypical networks. On the 5-way 5-shot setting of the tieredImageNet dataset, the proposed model achieves a competitive result compared with the prototypical networks. At the same time, several ablation experiments are conducted to verify the effectiveness of the key modules of the proposed method, and the influence of prior information of class semantic similarity on the experimental results is analyzed from multiple perspectives.ConclusionThis study proposed a few-shot image recognition model based on class semantic similarity supervision, which improves the generalization ability and class-feature constraint ability of the few-shot image recognition model. Experimental results show that the proposed method improves the accuracy of few-shot image recognition.关键词:few shot learning;image recognition;feature representation;class semantic similarity supervision;generalization ability103|111|5更新时间:2024-05-07
摘要:ObjectiveDeep learning has made remarkable achievements in many fields such as image recognition, object detection, and speech recognition. However, most of the extraordinary achievements of these models depend on extraordinary data size. Existing deep-learning models often need large-scale training data. Building large-scale training data sets not only necessitates a large amount of manpower and material resources but are also not feasible in scenarios such as obtaining a large number of rare image class data samples. Inspired by the fact that human children can learn how to distinguish an object through a small number of samples, few-shot image classification aims to identify target categories with only a few labeled samples. Image recognition based on few-shot learning solves the problem in which a deep learning model needs large-scale training data. At present, the mainstream methods of few-shot image recognition are based on meta learning, which mainly includes three methods: meta learning based on metric, meta learning based on optimization, and meta learning based on model. The method of meta learning is divided into two stages: training and testing. However, most of the metric-based meta-learning methods do not use few shots of the target class in the training stage, which leads to a lack of good generalization ability of these models. These metric-based meta-learning models often show high accuracy in the training stage, but the recognition effect for few-shot image categories in the test stage is poor. The deep feature representation learned by the models cannot be effectively generalized to the target class. To improve the generalization ability of the few-shot learning image recognition method, this study proposes a few-shot learning method based on class semantic similarity supervision.MethodThe method proposed in this paper mainly includes two parts: the first step is to obtain the class similarity matrix between the image dataset classes, and the second step is to use the class similarity matrix as additional supervision information to train the few-shot image recognition model. The details are as follows: a common crawl database containing one billion level webpage data is used to train an unsupervised word-vector learning algorithm GloVe model (global vectors for word representation), which generates 300 dimensional vectors for every word. For classes whose names contain more than one word, we match all the words in the training GloVe model and find their word-embedding vectors. By averaging these word-embedding vectors, we obtain the word embedding vector of the class name. Then, the cosine distance between the word-embedding vectors of classes is used to represent the semantic similarity between classes. In addition to the negative logarithm loss caused by the category labels of the original prototypical networks, this study introduces the semantic similarity measure between categories as the extra supervision information in the training stage of the model to establish the implicit relationship between the source class and few-shot target class. This condition enables the model to have better generalization ability. Furthermore, the loss of class semantic similarity can constrain the features of samples within and between classes learned by the model so that the sample features within each class are more similar, and the distribution of sample features between different classes is more consistent with the semantic similarity between categories. By introducing the loss of class semantic similarity to supervise the training process of the model, our proposed model can implicitly learn the relationship between different classes and obtain a feature representation with more constraint and generalization abilities of class sample features.ResultThis study compared the proposed model with several state-of-the-art few-shot image classification models, including prototypical, matching, and relation networks and other classic methods. In this study, a large number of experiments are conducted on miniImageNet and tieredImageNet. The results show that the proposed method is effective and competitive with the current advanced methods. To ensure fair comparison with the advanced methods, the classical paradigm of meta learning is used to train and test the model, and many experiments are conducted on the widely used 5-way 1-shot and 5-way 5-shot settings. The experimental results show that on the 5-way 1-shot and 5-way 5-shot settings of the miniImageNet dataset, the classification accuracy of the proposed method is improved by 1.9% and 0.32%, respectively, compared with the classical few-shot image recognition meta-learning method prototypical networks. In the tieredImageNet dataset on the 5-way 1-shot setting, the classification accuracy rate is improved by 0.33% compared with that in the prototypical networks. On the 5-way 5-shot setting of the tieredImageNet dataset, the proposed model achieves a competitive result compared with the prototypical networks. At the same time, several ablation experiments are conducted to verify the effectiveness of the key modules of the proposed method, and the influence of prior information of class semantic similarity on the experimental results is analyzed from multiple perspectives.ConclusionThis study proposed a few-shot image recognition model based on class semantic similarity supervision, which improves the generalization ability and class-feature constraint ability of the few-shot image recognition model. Experimental results show that the proposed method improves the accuracy of few-shot image recognition.关键词:few shot learning;image recognition;feature representation;class semantic similarity supervision;generalization ability103|111|5更新时间:2024-05-07 -
 摘要:ObjectiveObject distance estimation is a fundamental problem in 3D vision. However, most successful object distance estimators need extra 3D information from active depth cameras or laser scanner, which increases the cost. Stereo vision is a convenient and cheap solution for this problem. Modern object distance estimation solutions are mainly based on deep neural network, which provides better accuracy than traditional methods. Deep learning-based solutions are of two main types. The first solution is combining a 2D object detector and a stereo image disparity estimator. The disparity estimator outputs depth information of the image, and the object detector detects object boxes or masks from the image. Then, the detected object boxes or masks are applied to the depth image to extract the pixel depth in the detected box, are then sorted, and the closest is selected to represent the distance of the object. However, such systems are not accurate enough to solve this problem according to the experiments. The second solution is to use a monocular 3D object detector. Such detectors can output 3D bounding boxes of objects, which indicate their distance. 3D object detectors are more accurate, but need annotations of 3D bounding box coordinates for training, which require special devices to collect data and entail high labelling costs. Therefore, we need a solution that has good accuracy while keeping the simplicity of model training.MethodWe propose a region convolutional neural network(R-CNN)-based network to perform object detection and distance estimation from stereo images simultaneously. This network can be trained only using object distance labels, which is easy to apply to many fields such as surveillance scenes and robot motion. We utilize stereo region proposal network to extract proposals of the corresponding target bounding box from the left view and right view images in one step. Then, a stereo bounding-box regression module is used to regress corresponding bounding-box coordinates simultaneously. The disparity could be calculated from the corresponding bounding box coordinate at x axis, but the obtained distance from disparity may be inaccurate due to the reciprocal relation between depth and disparity. Therefore, we propose a disparity estimation branch to estimate object disparity accurately. This branch estimates object-wise disparity from local object features from corresponding areas in the left view and right view images. This process can be treated as regression, so we can use a similar network structure as the stereo bounding-box regression module. However, the disparity estimated by this branch is still inaccurate. Inspired by other disparity image estimation methods, we propose to use a similar structure as disparity image estimation networks in this module. We use groupwise correlation and 3D convolutional stacked-hourglass network structure to construct this disparity estimation branch.ResultWe validated and trained our method on Karlsruhe Institute of Technology and Toyota Technological Institute(KITTI) dataset to show that our network is accurate for this task. We compare our method with other types of methods, including disparity image estimation-based methods and 3D object detection-based methods. We also provide qualitative experiment results by visualizing distance-estimation errors on the left view image. Our method outperforms disparity image estimation-based methods by a large scale, and is comparable with or superior to 3D object detection-based methods, which require 3D box annotation. In addition, we also compare experiments between different disparity estimation solutions proposed in this paper, showing that our proposed disparity estimation branch helps our network to obtain much more robust object distance, and the network structure based on 3D convolutional stacked-hourglass further improves the object-distance estimation accuracy. To prove that our method can be applied to surveillance stereo-object distance estimation, we collect and labeled a new dataset containing surveillance pedestrian scenes. The dataset contains 3 265 images shot by a stereo camera, and we label all the pedestrians in the left-view images with their bounding box as well as the pixel position of their head and foot, which helps to recover the pedestrian distance from the disparity image. We perform similar experiments on this dataset, which proved that our method can be applied to surveillance scenes effectively and accurately. As this dataset does not contain 3D bounding box annotation, 3D object detection-based methods cannot be applied in this scenario.ConclusionIn this study, we propose an R-CNN-based network to perform object detection and distance estimation simultaneously from stereo images. The experiment results show that our model is accurate enough and easy to train and apply to other fields.关键词:stereo vision;object distance estimation;disparity estimation;deep neural network;3D convolution;surveillance scene115|177|3更新时间:2024-05-07
摘要:ObjectiveObject distance estimation is a fundamental problem in 3D vision. However, most successful object distance estimators need extra 3D information from active depth cameras or laser scanner, which increases the cost. Stereo vision is a convenient and cheap solution for this problem. Modern object distance estimation solutions are mainly based on deep neural network, which provides better accuracy than traditional methods. Deep learning-based solutions are of two main types. The first solution is combining a 2D object detector and a stereo image disparity estimator. The disparity estimator outputs depth information of the image, and the object detector detects object boxes or masks from the image. Then, the detected object boxes or masks are applied to the depth image to extract the pixel depth in the detected box, are then sorted, and the closest is selected to represent the distance of the object. However, such systems are not accurate enough to solve this problem according to the experiments. The second solution is to use a monocular 3D object detector. Such detectors can output 3D bounding boxes of objects, which indicate their distance. 3D object detectors are more accurate, but need annotations of 3D bounding box coordinates for training, which require special devices to collect data and entail high labelling costs. Therefore, we need a solution that has good accuracy while keeping the simplicity of model training.MethodWe propose a region convolutional neural network(R-CNN)-based network to perform object detection and distance estimation from stereo images simultaneously. This network can be trained only using object distance labels, which is easy to apply to many fields such as surveillance scenes and robot motion. We utilize stereo region proposal network to extract proposals of the corresponding target bounding box from the left view and right view images in one step. Then, a stereo bounding-box regression module is used to regress corresponding bounding-box coordinates simultaneously. The disparity could be calculated from the corresponding bounding box coordinate at x axis, but the obtained distance from disparity may be inaccurate due to the reciprocal relation between depth and disparity. Therefore, we propose a disparity estimation branch to estimate object disparity accurately. This branch estimates object-wise disparity from local object features from corresponding areas in the left view and right view images. This process can be treated as regression, so we can use a similar network structure as the stereo bounding-box regression module. However, the disparity estimated by this branch is still inaccurate. Inspired by other disparity image estimation methods, we propose to use a similar structure as disparity image estimation networks in this module. We use groupwise correlation and 3D convolutional stacked-hourglass network structure to construct this disparity estimation branch.ResultWe validated and trained our method on Karlsruhe Institute of Technology and Toyota Technological Institute(KITTI) dataset to show that our network is accurate for this task. We compare our method with other types of methods, including disparity image estimation-based methods and 3D object detection-based methods. We also provide qualitative experiment results by visualizing distance-estimation errors on the left view image. Our method outperforms disparity image estimation-based methods by a large scale, and is comparable with or superior to 3D object detection-based methods, which require 3D box annotation. In addition, we also compare experiments between different disparity estimation solutions proposed in this paper, showing that our proposed disparity estimation branch helps our network to obtain much more robust object distance, and the network structure based on 3D convolutional stacked-hourglass further improves the object-distance estimation accuracy. To prove that our method can be applied to surveillance stereo-object distance estimation, we collect and labeled a new dataset containing surveillance pedestrian scenes. The dataset contains 3 265 images shot by a stereo camera, and we label all the pedestrians in the left-view images with their bounding box as well as the pixel position of their head and foot, which helps to recover the pedestrian distance from the disparity image. We perform similar experiments on this dataset, which proved that our method can be applied to surveillance scenes effectively and accurately. As this dataset does not contain 3D bounding box annotation, 3D object detection-based methods cannot be applied in this scenario.ConclusionIn this study, we propose an R-CNN-based network to perform object detection and distance estimation simultaneously from stereo images. The experiment results show that our model is accurate enough and easy to train and apply to other fields.关键词:stereo vision;object distance estimation;disparity estimation;deep neural network;3D convolution;surveillance scene115|177|3更新时间:2024-05-07 -
 摘要:ObjectiveText can be seen everywhere, such as on street signs, billboards, newspapers, and other items. The text on these items expresses the information they intend to convey. The ability of text detection determines the level of text recognition and understanding of the scene. With the rapid development of modern technologies such as computer vision and internet of things, many emerging application scenarios need to extract text information from images. In recent years, some new methods for detecting scene text have been proposed. However, many of these methods are slow in detection because of the complexity of the large post-processing methods of the model, which limits their actual deployment. On the other hand, the previous high-efficiency text detectors mainly used quadrilateral bounding boxes for prediction, and accurately predicting arbitrary-shaped scenes is difficult.MethodIn this paper, an efficient arbitrary shape text detector called non-local pixel aggregation network (non-local PAN) is proposed. Non-local PAN follows a segmentation-based method to detect scene text instances. To increase the detection speed, the backbone network must be a lightweight network. However, the presentation capabilities of lightweight backbone networks are usually weak. Therefore, a non-local module is added to the backbone network to enhance its ability to extract features. Resnet-18 is used as the backbone network of non-local PAN, and non-local modules are embedded before the last residual block of the third layer. In addition, a feature-vector fusion module is designed to fuse feature vectors of different levels to enhance the feature expression of scene texts of different scales. The feature-vector fusion module is formed by concatenating multiple feature-vector fusion blocks. Causal convolution is the core component of the feature-vector fusion block. After training, the method can predict the fused feature vector based on the previously input feature vector. This study also uses a lightweight segmentation head that can effectively process features with a small computational cost. The segmentation head contains two key modules, namely, feature pyramid enhancement module (FPEM) and feature fusion module (FFM). FPEM is cascadable and has a low computational cost. It can be attached behind the backbone network to deepen the characteristics of different scales and make the network more expressive. Then, FFM merges the features generated by FPEM at different depths into the final features for segmentation. Non-local PAN uses the predicted text area to describe the complete shape of the text instance and predicts the core of the text to distinguish various text instances. The network also predicts the similarity vector of each text pixel to guide each pixel to the correct core.ResultThis method is compared with other methods on three scene-text datasets, and it has outstanding performance in speed and accuracy. On the International Conference on Document Analysis and Recognition(ICDAR) 2015 dataset, the F value of this method is 0.9% higher than that of the best method, and the detection speed reaches 23.1 frame/s. On the Curve Text in the Wild(CTW) 1500 dataset, the F value of this method is 1.2% higher than that of the best method, and the detection speed reaches 71.8 frame/s. On the total-text dataset, the F value of this method is 1.3% higher than that of the best method, and the detection speed reaches 34.3 frame/s, which is far beyond the result of other methods. In addition, we design parameter setting experiments to explore the best location for non-local module embedding. Experiments have proved that the effect of embedding the non-local module is better than non-embedding, indicating that non-local modules play an active role in the detection process. According to the detection accuracy, the effect of embedding non-local blocks into the second, third, and fourth layers of ResNet-18 is significant, while the effect of embedding the fifth layer is not obvious. Among the methods, embedding non-local blocks in the third layer has the best effect. We designed ablation experiments on the ICDAR 2015 dataset for the non-local and feature-vector fusion modules. The experimental results prove that the superiority of the non-local module does not come from deepening the network but from its own structural characteristics. The feature vector fusion module also plays an active role in the scene text-detection process, which combines feature maps of different scales to enhance the feature expression of scene texts with variable scales.ConclusionIn this paper, an efficient text detection method for arbitrary shape scene is proposed, which considers accuracy and realtime. The experimental results show that the performance of our model is better than that of previous methods, and our model is superior in accuracy and speed.关键词:object detection;scene text detection;neural network;non-local module;pixel aggregation;real-time detection;arbitrary shape62|47|4更新时间:2024-05-07
摘要:ObjectiveText can be seen everywhere, such as on street signs, billboards, newspapers, and other items. The text on these items expresses the information they intend to convey. The ability of text detection determines the level of text recognition and understanding of the scene. With the rapid development of modern technologies such as computer vision and internet of things, many emerging application scenarios need to extract text information from images. In recent years, some new methods for detecting scene text have been proposed. However, many of these methods are slow in detection because of the complexity of the large post-processing methods of the model, which limits their actual deployment. On the other hand, the previous high-efficiency text detectors mainly used quadrilateral bounding boxes for prediction, and accurately predicting arbitrary-shaped scenes is difficult.MethodIn this paper, an efficient arbitrary shape text detector called non-local pixel aggregation network (non-local PAN) is proposed. Non-local PAN follows a segmentation-based method to detect scene text instances. To increase the detection speed, the backbone network must be a lightweight network. However, the presentation capabilities of lightweight backbone networks are usually weak. Therefore, a non-local module is added to the backbone network to enhance its ability to extract features. Resnet-18 is used as the backbone network of non-local PAN, and non-local modules are embedded before the last residual block of the third layer. In addition, a feature-vector fusion module is designed to fuse feature vectors of different levels to enhance the feature expression of scene texts of different scales. The feature-vector fusion module is formed by concatenating multiple feature-vector fusion blocks. Causal convolution is the core component of the feature-vector fusion block. After training, the method can predict the fused feature vector based on the previously input feature vector. This study also uses a lightweight segmentation head that can effectively process features with a small computational cost. The segmentation head contains two key modules, namely, feature pyramid enhancement module (FPEM) and feature fusion module (FFM). FPEM is cascadable and has a low computational cost. It can be attached behind the backbone network to deepen the characteristics of different scales and make the network more expressive. Then, FFM merges the features generated by FPEM at different depths into the final features for segmentation. Non-local PAN uses the predicted text area to describe the complete shape of the text instance and predicts the core of the text to distinguish various text instances. The network also predicts the similarity vector of each text pixel to guide each pixel to the correct core.ResultThis method is compared with other methods on three scene-text datasets, and it has outstanding performance in speed and accuracy. On the International Conference on Document Analysis and Recognition(ICDAR) 2015 dataset, the F value of this method is 0.9% higher than that of the best method, and the detection speed reaches 23.1 frame/s. On the Curve Text in the Wild(CTW) 1500 dataset, the F value of this method is 1.2% higher than that of the best method, and the detection speed reaches 71.8 frame/s. On the total-text dataset, the F value of this method is 1.3% higher than that of the best method, and the detection speed reaches 34.3 frame/s, which is far beyond the result of other methods. In addition, we design parameter setting experiments to explore the best location for non-local module embedding. Experiments have proved that the effect of embedding the non-local module is better than non-embedding, indicating that non-local modules play an active role in the detection process. According to the detection accuracy, the effect of embedding non-local blocks into the second, third, and fourth layers of ResNet-18 is significant, while the effect of embedding the fifth layer is not obvious. Among the methods, embedding non-local blocks in the third layer has the best effect. We designed ablation experiments on the ICDAR 2015 dataset for the non-local and feature-vector fusion modules. The experimental results prove that the superiority of the non-local module does not come from deepening the network but from its own structural characteristics. The feature vector fusion module also plays an active role in the scene text-detection process, which combines feature maps of different scales to enhance the feature expression of scene texts with variable scales.ConclusionIn this paper, an efficient text detection method for arbitrary shape scene is proposed, which considers accuracy and realtime. The experimental results show that the performance of our model is better than that of previous methods, and our model is superior in accuracy and speed.关键词:object detection;scene text detection;neural network;non-local module;pixel aggregation;real-time detection;arbitrary shape62|47|4更新时间:2024-05-07 -
 摘要:ObjectivePanoramic images introduce distortion in the process of acquisition, compression, and transmission. To provide viewers with a real experience, the resolution of a panoramic image is higher than that of the traditional image. The higher the resolution is, the more bandwidth is needed for transmission, and the more space is needed for storage. Therefore, image compression technology is conducive to improving transmission efficiency. At the same time, the compression distortion is introduced. With the increasing demand of viewers for panoramic image/video visual experience, the research on virtual reality visual system becomes increasingly important, and the quality evaluation of panoramic image/video is an indispensable part. The traditional subjective observation process of image is realized through the screen, and the design of objective quality assessment algorithm is based on 2D planes. When assessing the quality of panoramic images, viewers need to freely switch the perspective to observe the whole spherical scene with the help of head-mounted equipment. However, the transmission, storage, and processing are all in the projection format of the panoramic image, which causes the problem of inconsistency between the observation and processing spaces. As a result, the traditional assessment algorithm cannot accurately reflect the viewers' real feelings when observing the sphere, and cannot directly reflect the distortion degree of the spherical scene. To solve the problem of inconsistency between the observation and processing spaces, this study proposes a phase-consistency guided panoramic image quality assessment (PC-PIQA) algorithm.MethodThe structure and texture information are rich in high-resolution panoramic images, and they are the important features of the human visual system to understand the scene content. The proposed PC-PIQA model can solve the inconsistency between the observation space and processing plane by utilizing the features. Its panoramic statistical similarity is only related to the description parameters rather than the video content. First, the equirectangular projection format is mapped to the cube map projection (CMP) format, and the panoramic weight under the CMP format is used to solve the problem of inconsistent observation space and processing space.Then, the high-order phase-consistent mutual information of a single plane in the CMP format is calculated to describe the similarity of structural information between the reference image and distorted image at different orders.Next, the texture similarity is calculated by using the similarity of the first-order phase congruence local entropy. Finally, the visual quality of a single plane can be obtained by fusing the two parts of quality. According to the human eye's attention to the panoramic content, the different perceptual weights are assigned to six planes to obtain the overall quality score.ResultExperiments are conducted on the panoramic evaluation data set called omnidirectional image quality assessment (OIQA). The original images are added by four different types of distortion, including JPEG compression, JPEG2000 compression, Gaussian blur, and Gaussian noise. The proposed algorithm is compared with six kinds of mainstream algorithm performance, including peak signal-to-noise ratio (PSNR), structural similarity (SSIM), craster parabolic projection PSNR (CPP-PSNR), weighted-to-spherically-uniform PSNR (WS-PSNR), spherical PSNR (S-PSNR) and weighted-to-spherically-uniform SSIM (WS-SSIM). The assessment criteria contains four indicators, including Pearson linear correlation coefficient (PLCC), Spearman rank-order correlation coefficient (SRCC), Kendall rank-order correlation coefficient (KRCC), and root of mean square error (RMSE). In addition, we also list the performance obtained separately for structural similarity based on the panoramic weighted-mutual information (PW-MI) and texture similarity based on the panoramic weighted-local entropy (PW-LE), which can prove that each factor plays a significant role in improving the performance. The experimental results show that the PLCC and SRCC indexes of this proposed algorithm are approximately 0.4 higher than that of the other existing models, and the RMSE index is approximately 0.9 lower. All the indexes are the best compared with the other existing six panoramic image-quality assessment algorithms. Meanwhile, the individual performance of PV-MI and PV-LE is also better than that of the reference panoramic algorithms. The algorithm not only solves the problem of inconsistency between the observation and processing spaces, but also has robustness to different distortion types and achieves the best fitting effect. The human visual system has different sensitivities to different scales of images, and experiment results show that the sampling scales with parameters of 2 and 4 perform better. Therefore, the mutual information of each order of phase consistency on the two scales and the local entropy of the first order of phase consistency are finally fused. The high-order phase consistency has a negative effect on the calculation of similarity. The proposed model performs best when using the local entropy with the first-order phase consistency.ConclusionThe proposed algorithm solves the problem of inconsistency between the observation and processing space, and combines the multi-scale mutual information similarity and local entropy similarity based on human eye perception to obtain an objective score that is more consistent with the human eye perception. The assessment result is more accurate and consistent with the human visual system.The panoramic quality evaluation model proposed in this paper is classified as a traditional algorithm. With the development of deep learning, the framework implemented by neural networks can also obtain high accuracy. Further experiments are needed to determine if our model can be further integrated into neural network-based panoramic quality assessment.关键词:panoramic image/video;quality assessment;human visual system;phase consistency;structural similarity(SSIM);texture similarity51|47|1更新时间:2024-05-07
摘要:ObjectivePanoramic images introduce distortion in the process of acquisition, compression, and transmission. To provide viewers with a real experience, the resolution of a panoramic image is higher than that of the traditional image. The higher the resolution is, the more bandwidth is needed for transmission, and the more space is needed for storage. Therefore, image compression technology is conducive to improving transmission efficiency. At the same time, the compression distortion is introduced. With the increasing demand of viewers for panoramic image/video visual experience, the research on virtual reality visual system becomes increasingly important, and the quality evaluation of panoramic image/video is an indispensable part. The traditional subjective observation process of image is realized through the screen, and the design of objective quality assessment algorithm is based on 2D planes. When assessing the quality of panoramic images, viewers need to freely switch the perspective to observe the whole spherical scene with the help of head-mounted equipment. However, the transmission, storage, and processing are all in the projection format of the panoramic image, which causes the problem of inconsistency between the observation and processing spaces. As a result, the traditional assessment algorithm cannot accurately reflect the viewers' real feelings when observing the sphere, and cannot directly reflect the distortion degree of the spherical scene. To solve the problem of inconsistency between the observation and processing spaces, this study proposes a phase-consistency guided panoramic image quality assessment (PC-PIQA) algorithm.MethodThe structure and texture information are rich in high-resolution panoramic images, and they are the important features of the human visual system to understand the scene content. The proposed PC-PIQA model can solve the inconsistency between the observation space and processing plane by utilizing the features. Its panoramic statistical similarity is only related to the description parameters rather than the video content. First, the equirectangular projection format is mapped to the cube map projection (CMP) format, and the panoramic weight under the CMP format is used to solve the problem of inconsistent observation space and processing space.Then, the high-order phase-consistent mutual information of a single plane in the CMP format is calculated to describe the similarity of structural information between the reference image and distorted image at different orders.Next, the texture similarity is calculated by using the similarity of the first-order phase congruence local entropy. Finally, the visual quality of a single plane can be obtained by fusing the two parts of quality. According to the human eye's attention to the panoramic content, the different perceptual weights are assigned to six planes to obtain the overall quality score.ResultExperiments are conducted on the panoramic evaluation data set called omnidirectional image quality assessment (OIQA). The original images are added by four different types of distortion, including JPEG compression, JPEG2000 compression, Gaussian blur, and Gaussian noise. The proposed algorithm is compared with six kinds of mainstream algorithm performance, including peak signal-to-noise ratio (PSNR), structural similarity (SSIM), craster parabolic projection PSNR (CPP-PSNR), weighted-to-spherically-uniform PSNR (WS-PSNR), spherical PSNR (S-PSNR) and weighted-to-spherically-uniform SSIM (WS-SSIM). The assessment criteria contains four indicators, including Pearson linear correlation coefficient (PLCC), Spearman rank-order correlation coefficient (SRCC), Kendall rank-order correlation coefficient (KRCC), and root of mean square error (RMSE). In addition, we also list the performance obtained separately for structural similarity based on the panoramic weighted-mutual information (PW-MI) and texture similarity based on the panoramic weighted-local entropy (PW-LE), which can prove that each factor plays a significant role in improving the performance. The experimental results show that the PLCC and SRCC indexes of this proposed algorithm are approximately 0.4 higher than that of the other existing models, and the RMSE index is approximately 0.9 lower. All the indexes are the best compared with the other existing six panoramic image-quality assessment algorithms. Meanwhile, the individual performance of PV-MI and PV-LE is also better than that of the reference panoramic algorithms. The algorithm not only solves the problem of inconsistency between the observation and processing spaces, but also has robustness to different distortion types and achieves the best fitting effect. The human visual system has different sensitivities to different scales of images, and experiment results show that the sampling scales with parameters of 2 and 4 perform better. Therefore, the mutual information of each order of phase consistency on the two scales and the local entropy of the first order of phase consistency are finally fused. The high-order phase consistency has a negative effect on the calculation of similarity. The proposed model performs best when using the local entropy with the first-order phase consistency.ConclusionThe proposed algorithm solves the problem of inconsistency between the observation and processing space, and combines the multi-scale mutual information similarity and local entropy similarity based on human eye perception to obtain an objective score that is more consistent with the human eye perception. The assessment result is more accurate and consistent with the human visual system.The panoramic quality evaluation model proposed in this paper is classified as a traditional algorithm. With the development of deep learning, the framework implemented by neural networks can also obtain high accuracy. Further experiments are needed to determine if our model can be further integrated into neural network-based panoramic quality assessment.关键词:panoramic image/video;quality assessment;human visual system;phase consistency;structural similarity(SSIM);texture similarity51|47|1更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveTemporal action localization is one of the most important tasks in video understanding and has great application prospects in practice. With the rise of various online video applications, the number of short videos on the Internet has increased sharply, many of which contain different human behaviors. A model that can automatically locate and classify human action segments in videos is needed to detect and distinguish human behavior in short videos quickly and efficiently. However, public security departments also need real-time human behavior detection systems to help monitor and provide early warning of public safety incidents. In the task of temporal action localization, the human action segments in a video must be classified and regressed simultaneously. Accurately locating the boundaries of human behavior segments is more difficult than classifying known segments. A video always contains action segments of different temporal lengths, and detecting action segments with a short duration is especially difficult because short-duration action segment is easily ignored by the detection model or regarded as part of a closer, longer-duration segment. Existing methods have various attempts to improve the detection accuracy of human behavior fragments with different durations. In this paper, a 3D feature pyramid hierarchy is proposed to enhance the network's ability to detect action segments of different temporal durations.MethodA new two-stage network with a proposal network followed by a classifier named 3D feature pyramid convolutional network(3D-FPCN) is proposed. In 3D-FPCN, feature extraction is performed through the 3D feature pyramid feature extraction network built. The 3D feature pyramid feature extraction network has a bottom-up pathway and a top-down pathway. The bottom-up pathway simultaneously encodes the temporal and spatial characteristics of consecutive input frames through a series of 3D convolutional neural networks to obtain highly abstract feature maps. The top-down pathway uses a series of deconvolutional networks and lateral connection layers to fuse high-abstraction and high-resolution features, and obtain low-level feature maps. Through the feature pyramid feature extraction network, multilevel feature maps with different abstraction levels and different resolutions can be obtained. Highly abstract feature maps are used for the classification and regression of long-duration human action segments, and high-resolution feature maps are used for the regression and classification of short-duration human action segments, which can effectively improve the detection effect of the network on human behavior fragments of different durations. The whole network takes RGB frames as input and generates feature maps of different resolutions and abstract degrees via a feature pyramid structure. These feature maps of different levels mainly play a role in the latter two stages of the network. First, the anchor mechanism is used in the proposal stage. Thus, anchor segments of different temporal lengths have corresponding receptive fields of different sizes, and this is equivalent to a receptive field calibration. Second, in the region of interest pooling stage, different proposal segments are mapped to corresponding level feature maps for prediction, which makes feature prediction more targeted and balances the requirements for the abstraction and resolution of feature maps for action segments' classification and regression.ResultOur model is evaluated on the THUMOS'14 dataset. Compared with other classic methods that do not use optical flow features, our network surpasses most of them. Specifically, when the intersection over union threshold is set to 0.5, the mean average precision (mAP) of 3D-FPCN is up to 37.4%. Compared with the classic two-stage network region convolutional 3D network(R-C3D), the mAP of our method is increased by 8.5 percentage points. The comparison results of the detection precision on different class human action segments when the intersection ratio threshold is 0.5 are shown. The detection result of 3D-FPCN for short-duration human actions segments is greatly improved compared with other methods. For example, 3D-FPCN's detection accuracy of basketball dunk and cliff diving is 10% higher than that of the same two-stage network method R-C3D, and the detection accuracy of pole vault is higher than the multi-stage segment convolutional neural network(SCNN) is about 40%. This finding proves the improvement of our model for detecting short-duration human action segments. An ablation test is also conducted in the feature pyramid feature extraction network to explore the effect of this structure on the model. When the feature pyramid structure is removed from the network, the detection accuracy of the network is approximately 2% lower than before when the intersection over union threshold is 0.5. When only the multilevel feature map generated by the feature pyramid structure is used in the first stage of the network, which is the proposal generation stage, the detection accuracy is only 0.2% higher than the model with the feature pyramid structure removed. This finding proves that the feature pyramid hierarchy can effectively enhance the detection of action with different durations, and it mainly works in the second stage of the network, which is region of interest pooling stage.ConclusionA two-stage temporal action localization network 3D-FPCN is proposed based on 3D feature pyramid feature extraction network. The network takes continuous RGB frames as input, which can quickly and effectively detect human action segments in short videos. Through a number of experiments, the superiority of the model is proven, and the mechanism of the 3D feature pyramid structure in the model is discussed and explored. The 3D feature pyramid structure effectively improves the model's ability to detect short-duration human action segments, but the overall mAP of the model remains low. In the next work, the model will be improved, and different feature inputs will be introduced to study the method of temporal action localization further. We hope that our work can inspire other researchers and promote the development of the field.关键词:temporal action localization;feature pyramid network;deep learning;computer vision;video understanding100|136|2更新时间:2024-05-07
摘要:ObjectiveTemporal action localization is one of the most important tasks in video understanding and has great application prospects in practice. With the rise of various online video applications, the number of short videos on the Internet has increased sharply, many of which contain different human behaviors. A model that can automatically locate and classify human action segments in videos is needed to detect and distinguish human behavior in short videos quickly and efficiently. However, public security departments also need real-time human behavior detection systems to help monitor and provide early warning of public safety incidents. In the task of temporal action localization, the human action segments in a video must be classified and regressed simultaneously. Accurately locating the boundaries of human behavior segments is more difficult than classifying known segments. A video always contains action segments of different temporal lengths, and detecting action segments with a short duration is especially difficult because short-duration action segment is easily ignored by the detection model or regarded as part of a closer, longer-duration segment. Existing methods have various attempts to improve the detection accuracy of human behavior fragments with different durations. In this paper, a 3D feature pyramid hierarchy is proposed to enhance the network's ability to detect action segments of different temporal durations.MethodA new two-stage network with a proposal network followed by a classifier named 3D feature pyramid convolutional network(3D-FPCN) is proposed. In 3D-FPCN, feature extraction is performed through the 3D feature pyramid feature extraction network built. The 3D feature pyramid feature extraction network has a bottom-up pathway and a top-down pathway. The bottom-up pathway simultaneously encodes the temporal and spatial characteristics of consecutive input frames through a series of 3D convolutional neural networks to obtain highly abstract feature maps. The top-down pathway uses a series of deconvolutional networks and lateral connection layers to fuse high-abstraction and high-resolution features, and obtain low-level feature maps. Through the feature pyramid feature extraction network, multilevel feature maps with different abstraction levels and different resolutions can be obtained. Highly abstract feature maps are used for the classification and regression of long-duration human action segments, and high-resolution feature maps are used for the regression and classification of short-duration human action segments, which can effectively improve the detection effect of the network on human behavior fragments of different durations. The whole network takes RGB frames as input and generates feature maps of different resolutions and abstract degrees via a feature pyramid structure. These feature maps of different levels mainly play a role in the latter two stages of the network. First, the anchor mechanism is used in the proposal stage. Thus, anchor segments of different temporal lengths have corresponding receptive fields of different sizes, and this is equivalent to a receptive field calibration. Second, in the region of interest pooling stage, different proposal segments are mapped to corresponding level feature maps for prediction, which makes feature prediction more targeted and balances the requirements for the abstraction and resolution of feature maps for action segments' classification and regression.ResultOur model is evaluated on the THUMOS'14 dataset. Compared with other classic methods that do not use optical flow features, our network surpasses most of them. Specifically, when the intersection over union threshold is set to 0.5, the mean average precision (mAP) of 3D-FPCN is up to 37.4%. Compared with the classic two-stage network region convolutional 3D network(R-C3D), the mAP of our method is increased by 8.5 percentage points. The comparison results of the detection precision on different class human action segments when the intersection ratio threshold is 0.5 are shown. The detection result of 3D-FPCN for short-duration human actions segments is greatly improved compared with other methods. For example, 3D-FPCN's detection accuracy of basketball dunk and cliff diving is 10% higher than that of the same two-stage network method R-C3D, and the detection accuracy of pole vault is higher than the multi-stage segment convolutional neural network(SCNN) is about 40%. This finding proves the improvement of our model for detecting short-duration human action segments. An ablation test is also conducted in the feature pyramid feature extraction network to explore the effect of this structure on the model. When the feature pyramid structure is removed from the network, the detection accuracy of the network is approximately 2% lower than before when the intersection over union threshold is 0.5. When only the multilevel feature map generated by the feature pyramid structure is used in the first stage of the network, which is the proposal generation stage, the detection accuracy is only 0.2% higher than the model with the feature pyramid structure removed. This finding proves that the feature pyramid hierarchy can effectively enhance the detection of action with different durations, and it mainly works in the second stage of the network, which is region of interest pooling stage.ConclusionA two-stage temporal action localization network 3D-FPCN is proposed based on 3D feature pyramid feature extraction network. The network takes continuous RGB frames as input, which can quickly and effectively detect human action segments in short videos. Through a number of experiments, the superiority of the model is proven, and the mechanism of the 3D feature pyramid structure in the model is discussed and explored. The 3D feature pyramid structure effectively improves the model's ability to detect short-duration human action segments, but the overall mAP of the model remains low. In the next work, the model will be improved, and different feature inputs will be introduced to study the method of temporal action localization further. We hope that our work can inspire other researchers and promote the development of the field.关键词:temporal action localization;feature pyramid network;deep learning;computer vision;video understanding100|136|2更新时间:2024-05-07 -
 摘要:ObjectiveThe proliferation of social media has revolutionized the way people acquire information. A growing number of people choose to share information, and express and exchange opinions through social media. Unfortunately, because a large number of users do not carefully verify the released content when posting information and sharing their opinions, various rumors have been fostered on social media platforms. The extensive spread of these rumors is expected to bring new threats to the political, economic, and cultural fields and affect people's lives. To strengthen the detection of rumors and prevent their spread, many approaches to rumor detection have been proposed. An early rumor detection platform (e.g., snopes.com) mainly reported through users, and then invited experts or institutions in related fields to confirm. Although these methods can achieve the purpose of rumor detection, the timeliness of detection has obvious limitations. Thus, how to detect rumors automatically has become a key research direction in recent years. To date, many automatic detection approaches have been proposed to improve the efficiency of rumor detection, including feature construction-based and neural network-based methods. The feature construction-based methods rely on hand-craft features to train rumor classifiers and neural network-based methods using neural networks to automatically extract deep features. Compared with traditional methods, models based on deep neural networks can automatically learn the underlying deep representation of rumors and extract more effective semantic features. However, these methods may suffer from the following limitations. 1) At post level, many existing methods only consider the text content. In fact, posts often contain various types of information (e.g., text and images), and the visual information are often used as an auxiliary information to judge the credibility of posts in reality. Therefore, the key to detecting rumors is obtaining the multi-modal information of the posts and systematically integrating the textual and visual information. 2) At the event level, existing approaches typically only use the temporal sequence model to capture temporal features of events. Local and global information has not been well investigated yet. In practice, local and global features are important because the former helps distinguish between posts of subtle differences, and the latter helps capture features that repeatedly present in the event. Therefore, based on encoding the temporal information of the event, local and global information should be exploited to obtain a fine-grained feature of the event for event encoding collaboratively.MethodTo overcome these limitations, this paper presents a novel multi-modal multi-level event network (MMEN) for rumor detection, which can effectively use multi-modal post information and combine multi-level encoding strategies to construct a representation of each news event. MMEN employs an encoding network that jointly exploits multiple encoding strategies such as mean pooling, recurrent neural networks, and convolutional networks to model the global, temporal, and local information of each event. Then, these various types of information are combined into a unified deep model. Specifically, our model consists of the following three components: 1) The multi-modal post embedding layer employs bidirectional encode representations form transformers(BERT) to generate the text content embedding vector and use Visual Geometry Group-19(VGG-19) to obtain the visual content. 2) The multi-level event encoding network utilizes three-level encodings to capture global, temporal, and local information. The first level is a global encoder through the mean pooling, which represents the elements that are repeatedly present in the posts. The second is a temporal encoder that exploits a bidirectional recurrent neural network to use past and future information of a given post sequence. The third level is a local encoder by utilizing more subtle local representation of events. Then, the encoding results are combined to describe the events in a coarse-to-fine fashion. 3) The rumor detector layer aims to classify each event as either fake or authentic. The detector exploits a fully connected layer with corresponding activation function to generate predicted probability to determine whether the event is a rumor or not.ResultIn this study, the public datasets Pheme and Twitter are used to evaluate the effectiveness of the MMEN. The quantitative evaluation metrics included accuracy, precision, recall, and F1 score. We also perform five-fold cross-validation throughout all experiments. The experiments demonstrate that our proposed MMEN has improved accuracy by more than 4% over current best practices. MMEN has an accuracy of 82.2% on the Pheme dataset and 87.0% on the Twitter dataset. We compare our model MMEN with five state-of-the-art baseline models. Compared with all the baselines, the MMEN achieves the best performance and outperforms other rumor detection methods in most cases. To examine the usefulness of each component in the MMEN and demonstrate its effectiveness, we compare variants of MMEN. The experiment results show that the multi-modal features learned by the multimodal post embedding layer can improve the accuracy of rumor detection by nearly 0.2% on the two datasets. The experimental results also show that the temporal encoder has a stronger effect on detection accuracy.ConclusionIn this study, we design a novel MMEN for rumor detection. Experiments and comparisons demonstrate that our model is more robust and effective than state-of-the-art baselines based on two public datasets for rumor detection. We attribute the superiority of MMEN to its two properties. The MMEN takes advantage of the multiple modalities of posts, and the proposed multi-level encoder jointly exploits multiple encoding strategies to generate powerful and complementary features progressively.关键词:multi-modal;rumor detection;social media;multi-level encoding strategy;event network122|201|1更新时间:2024-05-07
摘要:ObjectiveThe proliferation of social media has revolutionized the way people acquire information. A growing number of people choose to share information, and express and exchange opinions through social media. Unfortunately, because a large number of users do not carefully verify the released content when posting information and sharing their opinions, various rumors have been fostered on social media platforms. The extensive spread of these rumors is expected to bring new threats to the political, economic, and cultural fields and affect people's lives. To strengthen the detection of rumors and prevent their spread, many approaches to rumor detection have been proposed. An early rumor detection platform (e.g., snopes.com) mainly reported through users, and then invited experts or institutions in related fields to confirm. Although these methods can achieve the purpose of rumor detection, the timeliness of detection has obvious limitations. Thus, how to detect rumors automatically has become a key research direction in recent years. To date, many automatic detection approaches have been proposed to improve the efficiency of rumor detection, including feature construction-based and neural network-based methods. The feature construction-based methods rely on hand-craft features to train rumor classifiers and neural network-based methods using neural networks to automatically extract deep features. Compared with traditional methods, models based on deep neural networks can automatically learn the underlying deep representation of rumors and extract more effective semantic features. However, these methods may suffer from the following limitations. 1) At post level, many existing methods only consider the text content. In fact, posts often contain various types of information (e.g., text and images), and the visual information are often used as an auxiliary information to judge the credibility of posts in reality. Therefore, the key to detecting rumors is obtaining the multi-modal information of the posts and systematically integrating the textual and visual information. 2) At the event level, existing approaches typically only use the temporal sequence model to capture temporal features of events. Local and global information has not been well investigated yet. In practice, local and global features are important because the former helps distinguish between posts of subtle differences, and the latter helps capture features that repeatedly present in the event. Therefore, based on encoding the temporal information of the event, local and global information should be exploited to obtain a fine-grained feature of the event for event encoding collaboratively.MethodTo overcome these limitations, this paper presents a novel multi-modal multi-level event network (MMEN) for rumor detection, which can effectively use multi-modal post information and combine multi-level encoding strategies to construct a representation of each news event. MMEN employs an encoding network that jointly exploits multiple encoding strategies such as mean pooling, recurrent neural networks, and convolutional networks to model the global, temporal, and local information of each event. Then, these various types of information are combined into a unified deep model. Specifically, our model consists of the following three components: 1) The multi-modal post embedding layer employs bidirectional encode representations form transformers(BERT) to generate the text content embedding vector and use Visual Geometry Group-19(VGG-19) to obtain the visual content. 2) The multi-level event encoding network utilizes three-level encodings to capture global, temporal, and local information. The first level is a global encoder through the mean pooling, which represents the elements that are repeatedly present in the posts. The second is a temporal encoder that exploits a bidirectional recurrent neural network to use past and future information of a given post sequence. The third level is a local encoder by utilizing more subtle local representation of events. Then, the encoding results are combined to describe the events in a coarse-to-fine fashion. 3) The rumor detector layer aims to classify each event as either fake or authentic. The detector exploits a fully connected layer with corresponding activation function to generate predicted probability to determine whether the event is a rumor or not.ResultIn this study, the public datasets Pheme and Twitter are used to evaluate the effectiveness of the MMEN. The quantitative evaluation metrics included accuracy, precision, recall, and F1 score. We also perform five-fold cross-validation throughout all experiments. The experiments demonstrate that our proposed MMEN has improved accuracy by more than 4% over current best practices. MMEN has an accuracy of 82.2% on the Pheme dataset and 87.0% on the Twitter dataset. We compare our model MMEN with five state-of-the-art baseline models. Compared with all the baselines, the MMEN achieves the best performance and outperforms other rumor detection methods in most cases. To examine the usefulness of each component in the MMEN and demonstrate its effectiveness, we compare variants of MMEN. The experiment results show that the multi-modal features learned by the multimodal post embedding layer can improve the accuracy of rumor detection by nearly 0.2% on the two datasets. The experimental results also show that the temporal encoder has a stronger effect on detection accuracy.ConclusionIn this study, we design a novel MMEN for rumor detection. Experiments and comparisons demonstrate that our model is more robust and effective than state-of-the-art baselines based on two public datasets for rumor detection. We attribute the superiority of MMEN to its two properties. The MMEN takes advantage of the multiple modalities of posts, and the proposed multi-level encoder jointly exploits multiple encoding strategies to generate powerful and complementary features progressively.关键词:multi-modal;rumor detection;social media;multi-level encoding strategy;event network122|201|1更新时间:2024-05-07 -
 摘要:ObjectiveHuman action recognition is one of the research hotspots in computer vision because of its wide application in human-computer interaction, virtual reality, and video surveillance. With the development of related technology in recent years, the human action recognition algorithm based on deep learning has achieved good recognition performance when the sample size is sufficient. However, studying human action recognition is difficult when the sample size is small or missing. The emergence of zero-shot recognition technology has solved these problems and attracted considerable attention because it can directly classify the "unseen" categories that are not in the training set. In the past decade, numerous methods have been conducted to perform zero-shot human action recognition by using video features and achieved promising improvement. However, most of the current methods are based on single modality data and few studies have been conducted on multimodal fusion. To study the influence of multiple modality fusion on zero-shot human action recognition, this study proposes a zero-shot human action recognition framework based on multimodal fusion(ZSAR-MF).MethodUnlike most of the previous methods based on the fusion of external information and video features or only research on single-modality video features, tour study focuses on the influence of sensor features that are most related to the activity state to improve the recognition performance. The zero-shot human-action recognition framework based on multimodal fusion is mainly composed of a sensor feature-extraction module, classification module, and video feature extraction module. Specifically, the sensor feature-extraction module uses convolutional neural network (CNN) to extract the acceleration and heart rate features of human actions and predict the most relevant feature words for each action. The classification module uses the word vectors of all concepts (sensor features, actions names, and object names) to generate action category classifiers. The "seen" category classifiers are obtained by learning the training data of these categories, and the "unseen" category classifiers are generalized from the "seen" category classifiers by using graph convolutional network (GCN).The video feature-extraction module extracts the video features of each action and maps the attributes of human actions, object scores, and sensor features into the attribute-feature space. Finally, the classifiers generated by the classification module are used to evaluate the feature of each video to calculate the action class scores.ResultThe experiment is conducted on the Stanford-ECM dataset with sensor and video data. The dataset includes 23 types of human action video and heart rate and acceleration data synchronized with the collected video. Our experiment can be divided into three steps. First, we remove the 7 actions that do not meet the experimental conditions and select the remaining 16 actions as the experimental dataset. Then, we select three methods to perform experiments on zero-shot human action recognition. A comparison of the experimental results show that the results of zero-shot action recognition via two-stream GCNs and knowledge graphs (TS-GCN) method are approximately 8% higher than that of zero-shot image classification based on generated countermeasure network (ZSIC-GAN) method, which proves the auxiliary role of knowledge graphs in action description by using external semantic information and the advantage of GCN. Compared with the ZSIC-GAN and TS-GCN methods, our proposed method have recognition results that are 12% and 4% higher than that of the ZSIC-GAN and TS-GCN method, respectively, which proves that for zero-shot human-action recognition, the fusion method of the sensor and video features is better than the method that only uses video features. Furthermore, we verify the influence of the number of layers of GCN on the recognition accuracy and analyze the reasons for this result. The experimental results show that adding more layers to the three-layer model cannot significantly improve the recognition accuracy of the model. One of the potential reasons for this situation is that the amount of training data is too small, and an overfitting problem occurs in the deeper network.ConclusionSensor and video data can comprehensively describe human activity patterns from different views, which provide convenience for zero-shot human-action recognition based on multimodal fusion. Unlike most of the multimodal fusion methods based on the text description of the action or the audio data and image features, our study uses the sensor and video features that are most related to the active state to realize the multimodal fusion, and pays close attention to the original features of the action. In general, our zero-shot human-action recognition framework based on multimodal fusion includes three parts: sensor feature-extraction module, classification module, and video feature-extraction module. This framework integrates video features and features extracted from sensor data. The two features are modeled by using the knowledge graphs, and the entire network is optimized by using classification loss function. The experimental results on the Stanford-ECM dataset demonstrate the effectiveness of our proposed zero-shot human-action recognition framework based on multimodal fusion. By fully fusing sensor and video features, we significantly improve the accuracy of zero-shot human-action recognition.关键词:zero-shot;multimodal fusion;action recognition;sensor data;video features193|195|3更新时间:2024-05-07
摘要:ObjectiveHuman action recognition is one of the research hotspots in computer vision because of its wide application in human-computer interaction, virtual reality, and video surveillance. With the development of related technology in recent years, the human action recognition algorithm based on deep learning has achieved good recognition performance when the sample size is sufficient. However, studying human action recognition is difficult when the sample size is small or missing. The emergence of zero-shot recognition technology has solved these problems and attracted considerable attention because it can directly classify the "unseen" categories that are not in the training set. In the past decade, numerous methods have been conducted to perform zero-shot human action recognition by using video features and achieved promising improvement. However, most of the current methods are based on single modality data and few studies have been conducted on multimodal fusion. To study the influence of multiple modality fusion on zero-shot human action recognition, this study proposes a zero-shot human action recognition framework based on multimodal fusion(ZSAR-MF).MethodUnlike most of the previous methods based on the fusion of external information and video features or only research on single-modality video features, tour study focuses on the influence of sensor features that are most related to the activity state to improve the recognition performance. The zero-shot human-action recognition framework based on multimodal fusion is mainly composed of a sensor feature-extraction module, classification module, and video feature extraction module. Specifically, the sensor feature-extraction module uses convolutional neural network (CNN) to extract the acceleration and heart rate features of human actions and predict the most relevant feature words for each action. The classification module uses the word vectors of all concepts (sensor features, actions names, and object names) to generate action category classifiers. The "seen" category classifiers are obtained by learning the training data of these categories, and the "unseen" category classifiers are generalized from the "seen" category classifiers by using graph convolutional network (GCN).The video feature-extraction module extracts the video features of each action and maps the attributes of human actions, object scores, and sensor features into the attribute-feature space. Finally, the classifiers generated by the classification module are used to evaluate the feature of each video to calculate the action class scores.ResultThe experiment is conducted on the Stanford-ECM dataset with sensor and video data. The dataset includes 23 types of human action video and heart rate and acceleration data synchronized with the collected video. Our experiment can be divided into three steps. First, we remove the 7 actions that do not meet the experimental conditions and select the remaining 16 actions as the experimental dataset. Then, we select three methods to perform experiments on zero-shot human action recognition. A comparison of the experimental results show that the results of zero-shot action recognition via two-stream GCNs and knowledge graphs (TS-GCN) method are approximately 8% higher than that of zero-shot image classification based on generated countermeasure network (ZSIC-GAN) method, which proves the auxiliary role of knowledge graphs in action description by using external semantic information and the advantage of GCN. Compared with the ZSIC-GAN and TS-GCN methods, our proposed method have recognition results that are 12% and 4% higher than that of the ZSIC-GAN and TS-GCN method, respectively, which proves that for zero-shot human-action recognition, the fusion method of the sensor and video features is better than the method that only uses video features. Furthermore, we verify the influence of the number of layers of GCN on the recognition accuracy and analyze the reasons for this result. The experimental results show that adding more layers to the three-layer model cannot significantly improve the recognition accuracy of the model. One of the potential reasons for this situation is that the amount of training data is too small, and an overfitting problem occurs in the deeper network.ConclusionSensor and video data can comprehensively describe human activity patterns from different views, which provide convenience for zero-shot human-action recognition based on multimodal fusion. Unlike most of the multimodal fusion methods based on the text description of the action or the audio data and image features, our study uses the sensor and video features that are most related to the active state to realize the multimodal fusion, and pays close attention to the original features of the action. In general, our zero-shot human-action recognition framework based on multimodal fusion includes three parts: sensor feature-extraction module, classification module, and video feature-extraction module. This framework integrates video features and features extracted from sensor data. The two features are modeled by using the knowledge graphs, and the entire network is optimized by using classification loss function. The experimental results on the Stanford-ECM dataset demonstrate the effectiveness of our proposed zero-shot human-action recognition framework based on multimodal fusion. By fully fusing sensor and video features, we significantly improve the accuracy of zero-shot human-action recognition.关键词:zero-shot;multimodal fusion;action recognition;sensor data;video features193|195|3更新时间:2024-05-07 -
 摘要:ObjectiveTarget object tracking is important in computer vision. Player-tracking algorithms in broadcast soccer videos provide basic data support for the analysis of soccer matches. Several challenges occur in soccer player tracking, including a rapid move of the target player, occlusion, and disturbance of similar players when they attack, defend, and scramble for the ball. However, no perfect tracking algorithm specifically for soccer video is available. The following challenges remain in the player tracking of broadcast soccer videos: 1) A small patch of target players in the video frame is not conducive to feature extraction. 2) Similar players often interfere with the target player. 3) Occlusion of the target player by other players often occurs, requiring the algorithm to distinguish intra-class targets. 4) Relocating the target after tracking drift is difficult. Thus, a prevalent topic in current research is how to handle the challenges in the soccer scene and improve the accuracy of player tracking.MethodBased on a depth analysis of the characteristics of a soccer player, we propose and design a player-aware tracking algorithm by fusing a distractor-aware color model and the target-aware deep model. In the color model, the color histogram of the target player, background, and distractors are extracted. The color model based on the Bayesian classifier aims to identify the foreground target from the background by color information in the search region. Three primary color components in the RGB color space are divided into 16 color regions by uniform quantization. The color histogram of the corresponding region can be obtained by calculating the number of pixels in each color interval. Distractors are non-target candidate regions whose similarity scores are larger than a certain threshold in the response map. As with the foreground-background color model, the color histogram of the target and distractor is counted, and the likelihood probability that the pixel belongs to the target in the target-distractor item is obtained. In the deep model, Siamese networks are adopted to calculate the similarity between the search and target regions. The target-aware deep model embeds deep features into the Siamese network, calculates the similarity between the output of the template branch and detects branches to obtain a response map of the search region. The well-known Visual Geometry Group(VGG) feature extraction network is adopted as a backbone network. In feature space, each channel of feature represents a different feature-representation capability, and specific combinations of features can recognize specific categories. The response of one category only focuses on specific deep-feature channels but not all feature channels. For the current tracking player, we design a small regression network to select feature channels related to the tracking player from VGG deep features. The structure of the small regression network is composed of one convolution layer with one convolution kernel. The size of the convolution kernel is the same as that of the target feature. The regression network aims to fit the features of the target sample to Gaussian distribution. In addition, to solve the problem of tracking drift, a global-local tracking strategy is designed to track the entire target and upper part of the target. Both global and local trackers have the same network architecture, including a distractor-aware color model branch and target-aware deep model branch. When a great difference in tracking results exists between the global and local trackers, the effectiveness of each tracker is analyzed and location revision is performed. In online tracking, both global and local trackers are used to track the whole and upper part of the target. When one tracker drifts, another is used to revise the target position. According to the intersection over union of the target of the global and local trackers, the tracking results can be classified into stable and unstable states. A stable state is when the intersection over union of the target boxes of the local and global trackers is greater than a certain threshold, while an unstable state indicates less than that threshold. In the unstable state, the following factors are considered simultaneously to analyze the tracker: main color similarity of the target in the current and initial frames, maximum response value of the response map, and moving distance from the center of the previous frame to the current frame. The lower the main color similarity, the more likely the tracker will be lost to the non-target player. The smaller the maximum response value of the response map, the lower is the reliability of the tracker. The moving distance of the tracker box is greater than a certain threshold, which indicates that the tracker is likely to have a sudden tracking drift in the current frame.ResultWe select 10 state-of-the-art tracking algorithms and compare them with the proposed algorithm on the public soccer dataset. The ablation experiment on the global-local tracking strategy is expanded. Experimental results show that the average valid overlap rate of the proposed tracking algorithm is 0.560 3, and when the target player is occluded by players in the same team and different teams, the average valid overlap rate of the proposed algorithm is 3.7% and 6.6% higher than that of the second-ranked algorithm, respectively.The evaluation results demonstrate that the player-aware tracking algorithm is more effective than other algorithms in addressing the disturbance by other similar players. However, the tracking speed is slow due to the increase of computational complexity by introducing the color model, deep model, and global-local tracking strategy.ConclusionWe summarize the entire process of the proposed tracking algorithm and analyze the experimental results. Three strategies, namely, distractor-aware color model, target-aware deep model, and global-local tracking strategy, are demonstrated to play a crucial role in player tracking. In terms of the color model, the color histogram of the target player, background, and distractor are extracted, and the likelihood probability that each pixel in the search region belongs to the target is calculated by using the Bayesian formula. In terms of the deep model, a small regression network is adopted to select feature channels related to the target object from the deep feature, and the Siamese network is used to calculate the similarity between the search region and target object. To alleviate tracking drift, we use the global-local strategy to track the whole target and upper body of the target so that the failure location can be revised. This study provides a basic reference for further research on player tracking in broadcast soccer videos.关键词:computer vision;image processing;object tracking;player tracking;distractor aware;target aware;global-local tracking strategy176|271|0更新时间:2024-05-07
摘要:ObjectiveTarget object tracking is important in computer vision. Player-tracking algorithms in broadcast soccer videos provide basic data support for the analysis of soccer matches. Several challenges occur in soccer player tracking, including a rapid move of the target player, occlusion, and disturbance of similar players when they attack, defend, and scramble for the ball. However, no perfect tracking algorithm specifically for soccer video is available. The following challenges remain in the player tracking of broadcast soccer videos: 1) A small patch of target players in the video frame is not conducive to feature extraction. 2) Similar players often interfere with the target player. 3) Occlusion of the target player by other players often occurs, requiring the algorithm to distinguish intra-class targets. 4) Relocating the target after tracking drift is difficult. Thus, a prevalent topic in current research is how to handle the challenges in the soccer scene and improve the accuracy of player tracking.MethodBased on a depth analysis of the characteristics of a soccer player, we propose and design a player-aware tracking algorithm by fusing a distractor-aware color model and the target-aware deep model. In the color model, the color histogram of the target player, background, and distractors are extracted. The color model based on the Bayesian classifier aims to identify the foreground target from the background by color information in the search region. Three primary color components in the RGB color space are divided into 16 color regions by uniform quantization. The color histogram of the corresponding region can be obtained by calculating the number of pixels in each color interval. Distractors are non-target candidate regions whose similarity scores are larger than a certain threshold in the response map. As with the foreground-background color model, the color histogram of the target and distractor is counted, and the likelihood probability that the pixel belongs to the target in the target-distractor item is obtained. In the deep model, Siamese networks are adopted to calculate the similarity between the search and target regions. The target-aware deep model embeds deep features into the Siamese network, calculates the similarity between the output of the template branch and detects branches to obtain a response map of the search region. The well-known Visual Geometry Group(VGG) feature extraction network is adopted as a backbone network. In feature space, each channel of feature represents a different feature-representation capability, and specific combinations of features can recognize specific categories. The response of one category only focuses on specific deep-feature channels but not all feature channels. For the current tracking player, we design a small regression network to select feature channels related to the tracking player from VGG deep features. The structure of the small regression network is composed of one convolution layer with one convolution kernel. The size of the convolution kernel is the same as that of the target feature. The regression network aims to fit the features of the target sample to Gaussian distribution. In addition, to solve the problem of tracking drift, a global-local tracking strategy is designed to track the entire target and upper part of the target. Both global and local trackers have the same network architecture, including a distractor-aware color model branch and target-aware deep model branch. When a great difference in tracking results exists between the global and local trackers, the effectiveness of each tracker is analyzed and location revision is performed. In online tracking, both global and local trackers are used to track the whole and upper part of the target. When one tracker drifts, another is used to revise the target position. According to the intersection over union of the target of the global and local trackers, the tracking results can be classified into stable and unstable states. A stable state is when the intersection over union of the target boxes of the local and global trackers is greater than a certain threshold, while an unstable state indicates less than that threshold. In the unstable state, the following factors are considered simultaneously to analyze the tracker: main color similarity of the target in the current and initial frames, maximum response value of the response map, and moving distance from the center of the previous frame to the current frame. The lower the main color similarity, the more likely the tracker will be lost to the non-target player. The smaller the maximum response value of the response map, the lower is the reliability of the tracker. The moving distance of the tracker box is greater than a certain threshold, which indicates that the tracker is likely to have a sudden tracking drift in the current frame.ResultWe select 10 state-of-the-art tracking algorithms and compare them with the proposed algorithm on the public soccer dataset. The ablation experiment on the global-local tracking strategy is expanded. Experimental results show that the average valid overlap rate of the proposed tracking algorithm is 0.560 3, and when the target player is occluded by players in the same team and different teams, the average valid overlap rate of the proposed algorithm is 3.7% and 6.6% higher than that of the second-ranked algorithm, respectively.The evaluation results demonstrate that the player-aware tracking algorithm is more effective than other algorithms in addressing the disturbance by other similar players. However, the tracking speed is slow due to the increase of computational complexity by introducing the color model, deep model, and global-local tracking strategy.ConclusionWe summarize the entire process of the proposed tracking algorithm and analyze the experimental results. Three strategies, namely, distractor-aware color model, target-aware deep model, and global-local tracking strategy, are demonstrated to play a crucial role in player tracking. In terms of the color model, the color histogram of the target player, background, and distractor are extracted, and the likelihood probability that each pixel in the search region belongs to the target is calculated by using the Bayesian formula. In terms of the deep model, a small regression network is adopted to select feature channels related to the target object from the deep feature, and the Siamese network is used to calculate the similarity between the search region and target object. To alleviate tracking drift, we use the global-local strategy to track the whole target and upper body of the target so that the failure location can be revised. This study provides a basic reference for further research on player tracking in broadcast soccer videos.关键词:computer vision;image processing;object tracking;player tracking;distractor aware;target aware;global-local tracking strategy176|271|0更新时间:2024-05-07 -
 摘要:ObjectiveThe recognition of multi-person interaction behavior has wide applications in real life. At present, human activity analysis research mainly focuses on classifying video clips of behaviors of individual persons, but the problem of understanding complex human activities with relationships between multiple people has not been resolved. When performing multi-person behavior recognition, the body information is more abundant and the description of the two-person action features are more complex. The problems such as complex recognition methods and low recognition accuracy occur easily. When the recognition object changes from a single person to multiple people, we not only need to pay attention to the action information of each person but also need to notice the interaction information between different subjects. At present, the interaction information of multiple people cannot be extracted well. To solve this problem effectively, we propose a multi-person interaction behavior-recognition algorithm based on skeleton graph convolution.MethodThe advantage of this method is that it can fully utilize the spatial and temporal dependence information between human joints. We design the interaction information between skeletons to discover the potential relationships between different individuals and different key points. By capturing the additional interaction information, we can improve the accuracy of action recognition. Considering the characteristics of multi-person interaction behavior, this study proposes a spatio-temporal graph convolution model based on skeleton. In terms of space, we have various designs for single-person and multi-person connections. We design the single-person connection within each frame. Apart from the physical connections between the points of the body, some potential correlations are also added between joints that represent non-physical connections such as the left and right hands of a single person. We design the interaction connection between two people within each frame. We use Euclidean distance to measure the correlation between interaction nodes and determine which points between the two persons have a certain connection. Through this method, the connection of the key points between the two persons in the frame not only can add new and necessary interaction connections, which can be used as a bridge to describe the interaction information of the two persons' actions, but can also prevent noise connections and cause the underlying graph to have a certain sparseness. In the time dimension, we segment the action sequence. Every three frames of action are used as a processing unit. We design the joints between three adjacent frames, and use more adjacent joints to expand the receptive field to help us learn the change information in the time domain. Through the modeling design in the time and space dimensions, we have obtained a complex action skeleton diagram. We use the generalized graph convolution model to extract and summarize the two people action features, and approximate high-order fast Chebyshev polynomials of spectral graph convolution to obtain high-level feature maps. At the same time, to enhance the extraction of time domain information, we propose the application of sliced recurrent neural network(RNN) to video action recognition to enhance the characterization of two people actions. By dividing the input sequence into multiple equiling subsequences and using a separate RNN network for feature extraction on each subsequence, we can calculate each subsequence at the same time, thereby overcoming the limitations of sliced RNN that cannot be parallelized. Through the information transfer between layers, the local information on the subsequence can be integrated in the high-level network, which can integrate and summarize the information from local to global, and the network can capture the entire action-sequence dependent information. For the loss of information at the slice, we have solved this problem by taking the three frame actions as a processing unit.ResultThis study validates the proposed algorithm on two datasets (UT-Interaction and SBU) and compares them with other advanced interaction-recognition methods. The UT-Interaction dataset contains six classes of actions and the SBU interaction dataset has eight classes of actions. We use 10-fold and 5-fold cross-validation for evaluation. In the UT-Interaction dataset, compared with H-LSTCM(Chierarchical long-short-term concurrent memory) and other methods, the performance improves by 0.7% based on the second-best algorithm. In the SBU dataset, compared with GCNConv, RotClips+MTCNN, SGCConv, and other methods, the algorithm has been improved by 5.2%, 1.03%, and 1.2% respectively. At the same time, fusion experiments are conducted in the SBU dataset to verify the effectiveness of various connections and sliced RNN. This method can effectively extract additional information on interactions, and has a good effect on the recognition of interaction actions.ConclusionIn this paper, the interactive recognition method of fusion spatio-temporal graph convolution has high accuracy for the recognition of interactive actions, and it is generally applicable to the recognition of behaviors that generate interaction between objects.关键词:action recognition;interaction information;spatial-temporal modeling;graph convolution;sliced recurrent neural network(RNN)140|152|4更新时间:2024-05-07
摘要:ObjectiveThe recognition of multi-person interaction behavior has wide applications in real life. At present, human activity analysis research mainly focuses on classifying video clips of behaviors of individual persons, but the problem of understanding complex human activities with relationships between multiple people has not been resolved. When performing multi-person behavior recognition, the body information is more abundant and the description of the two-person action features are more complex. The problems such as complex recognition methods and low recognition accuracy occur easily. When the recognition object changes from a single person to multiple people, we not only need to pay attention to the action information of each person but also need to notice the interaction information between different subjects. At present, the interaction information of multiple people cannot be extracted well. To solve this problem effectively, we propose a multi-person interaction behavior-recognition algorithm based on skeleton graph convolution.MethodThe advantage of this method is that it can fully utilize the spatial and temporal dependence information between human joints. We design the interaction information between skeletons to discover the potential relationships between different individuals and different key points. By capturing the additional interaction information, we can improve the accuracy of action recognition. Considering the characteristics of multi-person interaction behavior, this study proposes a spatio-temporal graph convolution model based on skeleton. In terms of space, we have various designs for single-person and multi-person connections. We design the single-person connection within each frame. Apart from the physical connections between the points of the body, some potential correlations are also added between joints that represent non-physical connections such as the left and right hands of a single person. We design the interaction connection between two people within each frame. We use Euclidean distance to measure the correlation between interaction nodes and determine which points between the two persons have a certain connection. Through this method, the connection of the key points between the two persons in the frame not only can add new and necessary interaction connections, which can be used as a bridge to describe the interaction information of the two persons' actions, but can also prevent noise connections and cause the underlying graph to have a certain sparseness. In the time dimension, we segment the action sequence. Every three frames of action are used as a processing unit. We design the joints between three adjacent frames, and use more adjacent joints to expand the receptive field to help us learn the change information in the time domain. Through the modeling design in the time and space dimensions, we have obtained a complex action skeleton diagram. We use the generalized graph convolution model to extract and summarize the two people action features, and approximate high-order fast Chebyshev polynomials of spectral graph convolution to obtain high-level feature maps. At the same time, to enhance the extraction of time domain information, we propose the application of sliced recurrent neural network(RNN) to video action recognition to enhance the characterization of two people actions. By dividing the input sequence into multiple equiling subsequences and using a separate RNN network for feature extraction on each subsequence, we can calculate each subsequence at the same time, thereby overcoming the limitations of sliced RNN that cannot be parallelized. Through the information transfer between layers, the local information on the subsequence can be integrated in the high-level network, which can integrate and summarize the information from local to global, and the network can capture the entire action-sequence dependent information. For the loss of information at the slice, we have solved this problem by taking the three frame actions as a processing unit.ResultThis study validates the proposed algorithm on two datasets (UT-Interaction and SBU) and compares them with other advanced interaction-recognition methods. The UT-Interaction dataset contains six classes of actions and the SBU interaction dataset has eight classes of actions. We use 10-fold and 5-fold cross-validation for evaluation. In the UT-Interaction dataset, compared with H-LSTCM(Chierarchical long-short-term concurrent memory) and other methods, the performance improves by 0.7% based on the second-best algorithm. In the SBU dataset, compared with GCNConv, RotClips+MTCNN, SGCConv, and other methods, the algorithm has been improved by 5.2%, 1.03%, and 1.2% respectively. At the same time, fusion experiments are conducted in the SBU dataset to verify the effectiveness of various connections and sliced RNN. This method can effectively extract additional information on interactions, and has a good effect on the recognition of interaction actions.ConclusionIn this paper, the interactive recognition method of fusion spatio-temporal graph convolution has high accuracy for the recognition of interactive actions, and it is generally applicable to the recognition of behaviors that generate interaction between objects.关键词:action recognition;interaction information;spatial-temporal modeling;graph convolution;sliced recurrent neural network(RNN)140|152|4更新时间:2024-05-07 -
 摘要:ObjectiveWith the rapid development of mobile internet and artificial intelligence, a growing number of video applications are gradually occupying people's daily life. Large volumes of video data are generated every day. In addition to the large number and high memory occupation of video data, the video content itself is complex, and often contains many characters, actions, and scenes. Thus, the video task is more challenging and urgent than the common image understanding task. How to process and analyze these video data is a challenging problem for many researchers. Due to the shooting angle and fast motion, the objects in the video often appear fuzzy and diverse, and a wide gap exists between the quality of the common image data set and that of the video dataset. Video instance segmentation is an extension of instance segmentation in the video field, which includes the detecting, segmenting, and tracking object instances. The method not only needs to assign the pixels of each frame to the corresponding semantic categories and object instances but also associate the instance objects across the entire video sequence. The problems of video defocus, motion blur, and partial occlusion in video images cause difficulty in video instance segmentation and result in poor performance. The existing video-instance segmentation algorithms mainly use the image-instance segmentation algorithms to further predict the target mask in every frame. Then, tracking algorithms are used to associate the detection results to generate the mask sequence along the video to solve the problem of instance segmentation in video. However, these algorithms rely on the initial image detection performance, and ignore the use of temporal context information, resulting in the lack of effective transmission and exchange of information between different frames, which makes the classification and segmentation performance not ideal in difficult video scenes.MethodTo solve this problem, this study designs a multi-task learning video instance segmentation model based on temporal feature fusion. We combine the feature pyramid network and scaled dot-product attention operation in the temporal domain. Feature pyramid network is a feature extractor designed according to the concept of feature pyramid, which aims to improve the accuracy and speed. It replaces the feature extractor in fast region convolutional neural network(R-CNN) and generates a higher-quality feature graph pyramid. In general, the feature pyramid network has two feature fusion ways of a bottom-up line and a top-down line. The bottom-up way is the forward process of the network, but top-down is intended to sample the top-level features, and then conduct element-wise addition with the corresponding features of the previous layer. The scaled dot-product attention is the basic component of the multi-head attention module in the transformer, which is a popular encoder-to-decoder attention network in machine translation. With the temporal feature fusion module, the object features detected by other frames are weighted and aggregated to the current image features to strengthen the feature response of candidate object and suppress the background information. Then, the spatial semantic information of the image is enriched by fusing multi-scale features of the current frame. Thus, the model can capture the fine correlation information between other frames and the current frame, and selectively aggregate the important features of other frames to enhance the representation of the current features. At the same time, point prediction network added to the segmentation module improves the segmentation precision compared with the general segmentation network of fully convolutional neural network. Then, the objects are detected, segmented, and tracked simultaneously in the video by our end-to-end multi-task learning video instance segmentation framework.ResultExperiments on YouTube-VIS dataset show that our method improves the mean average precision of video instance segmentation by near 2% compared with current methods. We also conduct a series of ablation experiments. On the one hand, we add different segmentation network modules in the model, and compare the effect of the fully convolutional network and point predict segmentation network on the two-stage video instance segmentation model. On the other hand, because the temporal feature-fusion module needs to select the RPN(region proposal network) candidate objects of the auxiliary frame for information fusion in the training stage, experimental comparison is needed for different number settings of RPN objects. We find the best result 32.7% AP with 10 RPN objects using. This result shows that the proposed temporal feature-fusion module improves the effect of video segmentation.ConclusionIn this study, a two-stage video-instance segmentation model with temporal feature fusion module is proposed. In the first stage, the backbone network ResNet extracts features from an input image, and the temporal feature-fusion module further extracts features of multiple scales through feature pyramid networks, and aggregates the object feature information detected by other frames to enhance the feature response of the current frame. Then, the region proposal network extracts multiple candidate objects from the image. In the second stage, the features of proposal objects are input into three parallel network heads to obtain the corresponding results. The detection network head obtains the object classification and position in the current image, the segmentation network head obtains the instance segmentation mask of the current image, and the associated network head achieves the continuous association of the object by matching the most similar instance object in the instance storage space. In summary, our video instance segmentation model combines the feature pyramid network and scaled dot-product attention operation to the video temporal-feature fusion, which improves the accuracy of the video segmentation result.关键词:computer vision;instance segmentation;video instance segmentation;scaled dot-product attention;multi-scale fusion196|174|1更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of mobile internet and artificial intelligence, a growing number of video applications are gradually occupying people's daily life. Large volumes of video data are generated every day. In addition to the large number and high memory occupation of video data, the video content itself is complex, and often contains many characters, actions, and scenes. Thus, the video task is more challenging and urgent than the common image understanding task. How to process and analyze these video data is a challenging problem for many researchers. Due to the shooting angle and fast motion, the objects in the video often appear fuzzy and diverse, and a wide gap exists between the quality of the common image data set and that of the video dataset. Video instance segmentation is an extension of instance segmentation in the video field, which includes the detecting, segmenting, and tracking object instances. The method not only needs to assign the pixels of each frame to the corresponding semantic categories and object instances but also associate the instance objects across the entire video sequence. The problems of video defocus, motion blur, and partial occlusion in video images cause difficulty in video instance segmentation and result in poor performance. The existing video-instance segmentation algorithms mainly use the image-instance segmentation algorithms to further predict the target mask in every frame. Then, tracking algorithms are used to associate the detection results to generate the mask sequence along the video to solve the problem of instance segmentation in video. However, these algorithms rely on the initial image detection performance, and ignore the use of temporal context information, resulting in the lack of effective transmission and exchange of information between different frames, which makes the classification and segmentation performance not ideal in difficult video scenes.MethodTo solve this problem, this study designs a multi-task learning video instance segmentation model based on temporal feature fusion. We combine the feature pyramid network and scaled dot-product attention operation in the temporal domain. Feature pyramid network is a feature extractor designed according to the concept of feature pyramid, which aims to improve the accuracy and speed. It replaces the feature extractor in fast region convolutional neural network(R-CNN) and generates a higher-quality feature graph pyramid. In general, the feature pyramid network has two feature fusion ways of a bottom-up line and a top-down line. The bottom-up way is the forward process of the network, but top-down is intended to sample the top-level features, and then conduct element-wise addition with the corresponding features of the previous layer. The scaled dot-product attention is the basic component of the multi-head attention module in the transformer, which is a popular encoder-to-decoder attention network in machine translation. With the temporal feature fusion module, the object features detected by other frames are weighted and aggregated to the current image features to strengthen the feature response of candidate object and suppress the background information. Then, the spatial semantic information of the image is enriched by fusing multi-scale features of the current frame. Thus, the model can capture the fine correlation information between other frames and the current frame, and selectively aggregate the important features of other frames to enhance the representation of the current features. At the same time, point prediction network added to the segmentation module improves the segmentation precision compared with the general segmentation network of fully convolutional neural network. Then, the objects are detected, segmented, and tracked simultaneously in the video by our end-to-end multi-task learning video instance segmentation framework.ResultExperiments on YouTube-VIS dataset show that our method improves the mean average precision of video instance segmentation by near 2% compared with current methods. We also conduct a series of ablation experiments. On the one hand, we add different segmentation network modules in the model, and compare the effect of the fully convolutional network and point predict segmentation network on the two-stage video instance segmentation model. On the other hand, because the temporal feature-fusion module needs to select the RPN(region proposal network) candidate objects of the auxiliary frame for information fusion in the training stage, experimental comparison is needed for different number settings of RPN objects. We find the best result 32.7% AP with 10 RPN objects using. This result shows that the proposed temporal feature-fusion module improves the effect of video segmentation.ConclusionIn this study, a two-stage video-instance segmentation model with temporal feature fusion module is proposed. In the first stage, the backbone network ResNet extracts features from an input image, and the temporal feature-fusion module further extracts features of multiple scales through feature pyramid networks, and aggregates the object feature information detected by other frames to enhance the feature response of the current frame. Then, the region proposal network extracts multiple candidate objects from the image. In the second stage, the features of proposal objects are input into three parallel network heads to obtain the corresponding results. The detection network head obtains the object classification and position in the current image, the segmentation network head obtains the instance segmentation mask of the current image, and the associated network head achieves the continuous association of the object by matching the most similar instance object in the instance storage space. In summary, our video instance segmentation model combines the feature pyramid network and scaled dot-product attention operation to the video temporal-feature fusion, which improves the accuracy of the video segmentation result.关键词:computer vision;instance segmentation;video instance segmentation;scaled dot-product attention;multi-scale fusion196|174|1更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveLiver tumors are the most aggressive malignancies in the human body. The definition of lesion type and lesion period based on computed tomography(CT) images determines the diagnosis and strategy of the treatment, which requires professional knowledge and rich experience of experts to classify them. Fatigue is easily experienced when the workload is heavy, and even experienced senior experts have difficulty avoiding misdiagnosis. Deep learning can avoid the drawbacks of traditional machine learning that takes a certain amount of time to manually extract the features of the image and perform dimensionality reduction, and is capable of extracting high-dimensional features of an image. Using deep learning to assist doctors in diagnosis is important. In the existing medical image classification task, the challenge of the low accuracy of tumor classification, the weak capability of the feature extraction, and the rough dataset still remain. To address these tasks, this study presents a method with a multi-scale and deep feature extraction classification network.MethodFirst, we extract the region of interest (ROI) according to the contours of the liver tumors that were labeled by experienced radiologists, along with the ROI of healthy livers. The ROI is extracted to capture the features of the lesion area and surrounding tissue, which is relative to the size of the lesion. Due to the different sizes of the lesion area, the size of the extracted ROI is also different. Then, the pixel value is converted and data augmentation is performed. The dataset is Hounsfield windows, the range of CT values is (-1 024, 3 071), and the range of digital imaging and communications in medicine(DICOM) image is (0, 4 096). The pixel values of DICOM images have to be converted to CT values. First, we read rescale_intercept and rescale_slope from the DICOM header file, and then we use the formula to convert. Thereafter, we limit the CT values of liver datasets to [-100, 400] Hounsfield HU to avoid the influence of the background noise of the unrelated organs or tissues. We perform several data augmentation methods such as flipping, rotation, and transforming to expand the diversity of the datasets. Then, these images are sent into the MD_SENet for classification. The MD_SENet network is a SE_ResNet-like convolution neural network that can achieve end-to-end classification. The SE_ResNet learns the important features automatically from each channel to strengthen the useful features and suppress useless ones. MD_SENet network is much deeper than SE_ResNet. Our contributions are the following: 1) Hierarchical residual-like connections are used to improve multi-scale expression and increase the receptive field of each network layer. In the study, the image features after 1×1 convolution layers are divided into four groups. Each group of features passes through the 3×3 residual-like convolution groups, which improves the multi-scale feature extraction of networks and enhances the acquisition of focus areas features. 2) Channel attention and spatial attention are used to further focus on effective information on medical images. We let the feature images first go through the channel attention module, then we multiply its input and output to go through the spatial attention module. Then, we multiply the output of the spatial attention module and its input, which can pay more attention to the features of the lesion area and reduce the influence of background noise. 3) Atrous convolutions connected in parallel which refer to the spatial pyramid pooling, then we use 1×1 convolution layers to strengthen the feature. Finally, we concatenate the output and use softmax in classification. In this way, we can expand the receptive field and increase the image resolution, which can improve the feature expression ability and prevent the loss of information effectively. 4) The ordinary convolution is replaced by octave convolution to reduce the number of parameters and improve the classification performance. In this study, we compared the results of DenseNet, ResNet, MnasNet, MobileNet, ShuffleNet, SK_ResNet, and SE_ResNet with those of our MD_SENet, all of which were trained on the liver dataset. During the experiment, due to the limitation of graphics processing unit(GPU) memory, we set a batch size of 16 with Adam optimization and learning rate of 0.002 for 150 epochs. We used the dataset in Pytorch framework, Ubuntu 16.04. All experiments used the NVIDIA GeForce GTX 1060 Ti GPU to verify the effectiveness of our proposed method.ResultOur training set consists of 4 096 images and the test set consists of 1 021 images for the liver dataset. The classification accuracy of our proposed method is 87.74% and is 9.92% higher than the baseline (SE_ResNet101). Our module achieves the best result compared with the state-of-the-art network and achieved 86.04% recall, 87% precision, 86.42% F1-score under various evaluation indicators. Ablation experiments are conducted to verify the effectiveness of the method.ConclusionIn this study, we proposed a method to classify the liver tumors accurately. We combined the method into professional medical software so that we can provide a foundation that physicians can use in early diagnosis and treatment.关键词:deep learning;liver lesion classification;multi-scale features;feature extraction;dilated convolution66|159|1更新时间:2024-05-07
摘要:ObjectiveLiver tumors are the most aggressive malignancies in the human body. The definition of lesion type and lesion period based on computed tomography(CT) images determines the diagnosis and strategy of the treatment, which requires professional knowledge and rich experience of experts to classify them. Fatigue is easily experienced when the workload is heavy, and even experienced senior experts have difficulty avoiding misdiagnosis. Deep learning can avoid the drawbacks of traditional machine learning that takes a certain amount of time to manually extract the features of the image and perform dimensionality reduction, and is capable of extracting high-dimensional features of an image. Using deep learning to assist doctors in diagnosis is important. In the existing medical image classification task, the challenge of the low accuracy of tumor classification, the weak capability of the feature extraction, and the rough dataset still remain. To address these tasks, this study presents a method with a multi-scale and deep feature extraction classification network.MethodFirst, we extract the region of interest (ROI) according to the contours of the liver tumors that were labeled by experienced radiologists, along with the ROI of healthy livers. The ROI is extracted to capture the features of the lesion area and surrounding tissue, which is relative to the size of the lesion. Due to the different sizes of the lesion area, the size of the extracted ROI is also different. Then, the pixel value is converted and data augmentation is performed. The dataset is Hounsfield windows, the range of CT values is (-1 024, 3 071), and the range of digital imaging and communications in medicine(DICOM) image is (0, 4 096). The pixel values of DICOM images have to be converted to CT values. First, we read rescale_intercept and rescale_slope from the DICOM header file, and then we use the formula to convert. Thereafter, we limit the CT values of liver datasets to [-100, 400] Hounsfield HU to avoid the influence of the background noise of the unrelated organs or tissues. We perform several data augmentation methods such as flipping, rotation, and transforming to expand the diversity of the datasets. Then, these images are sent into the MD_SENet for classification. The MD_SENet network is a SE_ResNet-like convolution neural network that can achieve end-to-end classification. The SE_ResNet learns the important features automatically from each channel to strengthen the useful features and suppress useless ones. MD_SENet network is much deeper than SE_ResNet. Our contributions are the following: 1) Hierarchical residual-like connections are used to improve multi-scale expression and increase the receptive field of each network layer. In the study, the image features after 1×1 convolution layers are divided into four groups. Each group of features passes through the 3×3 residual-like convolution groups, which improves the multi-scale feature extraction of networks and enhances the acquisition of focus areas features. 2) Channel attention and spatial attention are used to further focus on effective information on medical images. We let the feature images first go through the channel attention module, then we multiply its input and output to go through the spatial attention module. Then, we multiply the output of the spatial attention module and its input, which can pay more attention to the features of the lesion area and reduce the influence of background noise. 3) Atrous convolutions connected in parallel which refer to the spatial pyramid pooling, then we use 1×1 convolution layers to strengthen the feature. Finally, we concatenate the output and use softmax in classification. In this way, we can expand the receptive field and increase the image resolution, which can improve the feature expression ability and prevent the loss of information effectively. 4) The ordinary convolution is replaced by octave convolution to reduce the number of parameters and improve the classification performance. In this study, we compared the results of DenseNet, ResNet, MnasNet, MobileNet, ShuffleNet, SK_ResNet, and SE_ResNet with those of our MD_SENet, all of which were trained on the liver dataset. During the experiment, due to the limitation of graphics processing unit(GPU) memory, we set a batch size of 16 with Adam optimization and learning rate of 0.002 for 150 epochs. We used the dataset in Pytorch framework, Ubuntu 16.04. All experiments used the NVIDIA GeForce GTX 1060 Ti GPU to verify the effectiveness of our proposed method.ResultOur training set consists of 4 096 images and the test set consists of 1 021 images for the liver dataset. The classification accuracy of our proposed method is 87.74% and is 9.92% higher than the baseline (SE_ResNet101). Our module achieves the best result compared with the state-of-the-art network and achieved 86.04% recall, 87% precision, 86.42% F1-score under various evaluation indicators. Ablation experiments are conducted to verify the effectiveness of the method.ConclusionIn this study, we proposed a method to classify the liver tumors accurately. We combined the method into professional medical software so that we can provide a foundation that physicians can use in early diagnosis and treatment.关键词:deep learning;liver lesion classification;multi-scale features;feature extraction;dilated convolution66|159|1更新时间:2024-05-07 -
 摘要:ObjectivePulmonary nodules are early forms of lung cancer, one of the most threatening malignancies for human health and life. As an important means of lung cancer screening, low-dose computerized tomographic scanning has been widely used in health examinations. However, a large amount of computed tomography(CT) data brings a heavy workload to doctors and radiologists, and high-intensity work can result in misdiagnosis. With the rapid development of artificial intelligence technology, computer-aided lung-nodule detection based on deep learning has attracted much attention. As the size of pulmonary nodules varies greatly, representing features on multiple scales is critical for nodule detection tasks. To solve the problem of difficulty in detection caused by the large difference in size of nodules, this paper proposes a 3D multi-scale pulmonary nodule detection method in chest CT sequence images based on deep convolutional neural network.MethodThe method mainly consists of two stages: 1) nodule candidate detection stage that maximizes system sensitivity, and 2) false positive reduction stage that minimizes the number of false positive nodules. Specifically, a series of preprocessing operations is performed on the original CT images first, and the regions of interest (ROIs) of lung nodules are obtained by cropping. In the training phase of the nodule candidate detection network, after the preprocessing steps, data augmentation is performed by randomly rotating, flipping, and scaling. Then, nodule cubes and non-nodule cubes with a size of 128×128×128 are randomly cropped out and input to the network. The nodule candidate detection network uses the combination of the squeeze-and-excitation units and the Res2Net modules as the backbone structure, so that the convolutions of the same layer have a variety of receptive fields. Thus, the network can extract the multi-scale feature information of pulmonary nodules. In addition, the nodule candidate detection network also uses the region proposal network structure that introduces context enhancement module and spatial attention module to identify region candidates. In the test phase of the nodule candidate detection network, the preprocessed CT image is divided into several small patches of size 208×208×208, which are used as the inputs of the network, and adjacent small patches overlap 32 pixels. For each CT image, the nodule candidates obtained from all small patches are summarized, and the nodules with higher overlap are merged through non-maximum suppression with an intersection over union(IOU) threshold of 0.1 to obtain the detection results. In the training phase of the false positive reduction network, because the average number of false positive nodules per scan is 22 obtained through experiments in the nodule candidate detection network, the positive samples are augmented by 22 times to balance the number of positive and negative samples. The augmentation methods are consistent with the methods in the training phase of the nodule candidate detection network. The false positive reduction network mainly consisting of Res2Net modules and squeeze-and-excitation units further classifies nodule candidates to reduce the number of false positives. The testing phase of the false positive reduction network takes the nodule candidate coordinates obtained by the nodule candidate detection network as the centers, and crops cubes of size 48×48×48 as the inputs of the false-positive reduction network. The outputs of the false-positive reduction network are the confidences of nodule candidate cubes. Among them, the squeeze-and-excitation unit can capture the channel dependence comprehensively, which makes the channel weight that contains abundant nodule information significant, and makes the channel weight without nodule information small. Res2Net module increases the receptive field of each output feature map without increasing the computational load, which causes the network to have stronger multi-scale representation ability. The region proposal network can take images of any scale as input and output a series of region candidates with scores, which are robust. Context enhancement module can fuse high-level semantic information and low-level position information. Its structure is simple, the implementation is easy, and the calculation cost is low, but it has good performance. The spatial attention module enables the network to pay more attention to the ROIs, which can reduce the difficulty of accurately distinguishing because of the visual similarity between pulmonary nodules and the structures such as blood vessels and shadows around the pulmonary nodules. The effectiveness of this method is validated on the publicly available dataset LUNA16(lung nodule analysis 16) and extensive ablation validation experiments are conducted to demonstrate the contribution of each key component to our proposed framework. The LUNA16 dataset is a subset of LIDC-IDRI(lung image database consortium and image database resource initiative), the largest public dataset of lung nodules. The LUNA16 dataset excludes CT images with slice thickness greater than 2.5 mm from the LIDC-IDRI dataset. A total of 888 CT images remain, with slice thickness of 0.62.5 mm, spatial resolution of 0.460.98 mm, and average diameter of 8.3 mm. The criteria for judging a nodule in the LUNA16 dataset is that at least three of the four radiologists believe that the diameter of the nodule is greater than 3 mm. Therefore, a total of 1 186 positive nodules are annotated in the dataset. The evaluation metric, FROC(free-response receiver operating characteristic curves), is the average recall rate at the average number of false positive nodules at 0.125, 0.25, 0.5, 1, 2, 4, and 8 per scan, which is the official evaluation metric for the LUNA16 dataset.ResultThe experimental results show that in the nodule candidate detection stage, the sensitivity can reach 0.983 when the average number of false positives per scan is 22. Compared with the benchmark ResNet + FPN(feature pyramid network) method, the average sensitivity and the maximum sensitivity are increased by 2.6%and 0.8%, respectively. For the entire 3D multi-scale pulmonary nodule detection network, when the average number of false positives per scan is 1, the sensitivity is 0.924.ConclusionCompared with the state-of-the-art methods, our method not only improves the sensitivity of pulmonary nodule detection but also effectively controls the number of false positives and achieves better performance. As this method can only output the position information of nodules, in actual lung cancer screening, the growth position, edge shape, and internal structure of the nodules are all significant for clinical diagnosis. Analysis of the characteristics of the nodules can make this method more practical.关键词:pulmonary nodule detection;convolutional neural network(CNN);multi-scale;region proposal network;context enhancement;spatial attention;false positive reduction85|170|3更新时间:2024-05-07
摘要:ObjectivePulmonary nodules are early forms of lung cancer, one of the most threatening malignancies for human health and life. As an important means of lung cancer screening, low-dose computerized tomographic scanning has been widely used in health examinations. However, a large amount of computed tomography(CT) data brings a heavy workload to doctors and radiologists, and high-intensity work can result in misdiagnosis. With the rapid development of artificial intelligence technology, computer-aided lung-nodule detection based on deep learning has attracted much attention. As the size of pulmonary nodules varies greatly, representing features on multiple scales is critical for nodule detection tasks. To solve the problem of difficulty in detection caused by the large difference in size of nodules, this paper proposes a 3D multi-scale pulmonary nodule detection method in chest CT sequence images based on deep convolutional neural network.MethodThe method mainly consists of two stages: 1) nodule candidate detection stage that maximizes system sensitivity, and 2) false positive reduction stage that minimizes the number of false positive nodules. Specifically, a series of preprocessing operations is performed on the original CT images first, and the regions of interest (ROIs) of lung nodules are obtained by cropping. In the training phase of the nodule candidate detection network, after the preprocessing steps, data augmentation is performed by randomly rotating, flipping, and scaling. Then, nodule cubes and non-nodule cubes with a size of 128×128×128 are randomly cropped out and input to the network. The nodule candidate detection network uses the combination of the squeeze-and-excitation units and the Res2Net modules as the backbone structure, so that the convolutions of the same layer have a variety of receptive fields. Thus, the network can extract the multi-scale feature information of pulmonary nodules. In addition, the nodule candidate detection network also uses the region proposal network structure that introduces context enhancement module and spatial attention module to identify region candidates. In the test phase of the nodule candidate detection network, the preprocessed CT image is divided into several small patches of size 208×208×208, which are used as the inputs of the network, and adjacent small patches overlap 32 pixels. For each CT image, the nodule candidates obtained from all small patches are summarized, and the nodules with higher overlap are merged through non-maximum suppression with an intersection over union(IOU) threshold of 0.1 to obtain the detection results. In the training phase of the false positive reduction network, because the average number of false positive nodules per scan is 22 obtained through experiments in the nodule candidate detection network, the positive samples are augmented by 22 times to balance the number of positive and negative samples. The augmentation methods are consistent with the methods in the training phase of the nodule candidate detection network. The false positive reduction network mainly consisting of Res2Net modules and squeeze-and-excitation units further classifies nodule candidates to reduce the number of false positives. The testing phase of the false positive reduction network takes the nodule candidate coordinates obtained by the nodule candidate detection network as the centers, and crops cubes of size 48×48×48 as the inputs of the false-positive reduction network. The outputs of the false-positive reduction network are the confidences of nodule candidate cubes. Among them, the squeeze-and-excitation unit can capture the channel dependence comprehensively, which makes the channel weight that contains abundant nodule information significant, and makes the channel weight without nodule information small. Res2Net module increases the receptive field of each output feature map without increasing the computational load, which causes the network to have stronger multi-scale representation ability. The region proposal network can take images of any scale as input and output a series of region candidates with scores, which are robust. Context enhancement module can fuse high-level semantic information and low-level position information. Its structure is simple, the implementation is easy, and the calculation cost is low, but it has good performance. The spatial attention module enables the network to pay more attention to the ROIs, which can reduce the difficulty of accurately distinguishing because of the visual similarity between pulmonary nodules and the structures such as blood vessels and shadows around the pulmonary nodules. The effectiveness of this method is validated on the publicly available dataset LUNA16(lung nodule analysis 16) and extensive ablation validation experiments are conducted to demonstrate the contribution of each key component to our proposed framework. The LUNA16 dataset is a subset of LIDC-IDRI(lung image database consortium and image database resource initiative), the largest public dataset of lung nodules. The LUNA16 dataset excludes CT images with slice thickness greater than 2.5 mm from the LIDC-IDRI dataset. A total of 888 CT images remain, with slice thickness of 0.62.5 mm, spatial resolution of 0.460.98 mm, and average diameter of 8.3 mm. The criteria for judging a nodule in the LUNA16 dataset is that at least three of the four radiologists believe that the diameter of the nodule is greater than 3 mm. Therefore, a total of 1 186 positive nodules are annotated in the dataset. The evaluation metric, FROC(free-response receiver operating characteristic curves), is the average recall rate at the average number of false positive nodules at 0.125, 0.25, 0.5, 1, 2, 4, and 8 per scan, which is the official evaluation metric for the LUNA16 dataset.ResultThe experimental results show that in the nodule candidate detection stage, the sensitivity can reach 0.983 when the average number of false positives per scan is 22. Compared with the benchmark ResNet + FPN(feature pyramid network) method, the average sensitivity and the maximum sensitivity are increased by 2.6%and 0.8%, respectively. For the entire 3D multi-scale pulmonary nodule detection network, when the average number of false positives per scan is 1, the sensitivity is 0.924.ConclusionCompared with the state-of-the-art methods, our method not only improves the sensitivity of pulmonary nodule detection but also effectively controls the number of false positives and achieves better performance. As this method can only output the position information of nodules, in actual lung cancer screening, the growth position, edge shape, and internal structure of the nodules are all significant for clinical diagnosis. Analysis of the characteristics of the nodules can make this method more practical.关键词:pulmonary nodule detection;convolutional neural network(CNN);multi-scale;region proposal network;context enhancement;spatial attention;false positive reduction85|170|3更新时间:2024-05-07 -
 摘要:ObjectiveDiabetic retinopathy (DR) is a common blinding retinal disease that cannot be cured in the later stage, and requires patients to be diagnosed and treated at an early stage; otherwise, it causes permanent vision loss. The prevalence of diabetic retinopathy is extremely high in China, and is in the stage of rapid growth. At present, China has become the country that has the largest number of patients with diabetic retinopathy. Diagnosis of DR is usually performed by analyzing fundus medical images. Detection of microscopic lesions such as microaneurysms in retinal images is necessary in grading diabetic retinopathy with neural networks. This condition requires the attention mechanism to simulate the focus of the human eyes and focus on the local area with information. However, most of the present methods only consider the attention in the spatial domain and ignore the information in the channel attention, which cause difficulty in distinguishing the small lesions. To solve this problem, a fine-grained grading method based on multi-channel attention selection (FGMAS) mechanism is proposed for the grading of diabetic retinopathy in this paper.MethodThis method combines fine-grained classification with a multi-channel attention selection mechanism. First, the structure of fine-grained classification is adopted to improve the recognition accuracy of small differences between categories by obtaining local regional features. Then, the characteristics of different feature layers in the channel domain with different information content are used to select high-information channels. The model establishes the relationship between information content and classification confidence, and obtains the lesion area that is conducive to classification results. Finally, the local and global features are combined to improve the accuracy of classification. In addition, considering the relationship between the channel characteristic information of each layer and the classification confidence, this study also introduces Rank_loss to optimize the channel information of each layer. The loss function enables the regions with higher classification confidence to have higher information content and obtain better classification results.ResultTwo open retinal datasets (Kaggle and Messidor) are used to evaluate the effectiveness of the proposed fine-grained grading method and multi-channel attention selection mechanism. The experimental results show that FGMAS performs a five-level classification on the Kaggle dataset with better results than the existing method, with an average accuracy of 0.577, which is 3.4%10.4% higher than the accuracy of other methods. The first category shows small lesion points, which are difficult to distinguish in other methods. However, the accuracy rate of 0.301 can be obtained through FGMAS proposed in this paper, which is better than other methods with the improvement of 11%18.9%, such as 0.190 of VGGNet with Extra Kernel/LGI (VNXK/LGI). Meanwhile, FGMAS is used in the Messidor dataset to perform a dichotomous task, including recommended reference/non-reference and normal/abnormal classification. In the reference/non-reference classification task, the experimental results are 0.912 of accuracy and 0.962 of AUC(area under the curve), which is superior to the existing methods by 0.1%1.9% and 0.5%9.9%, respectively. In the normal/abnormal classification task, the experimental results are 0.909 of accuracy and 0.950 of AUC, which are improved by 2.9%8.8% and 0.4%8.9% respectively, compared with existing methods. In addition, parameter experiments are set up in this study, and the function of each parameter and optimal parameter selection result are analyzed in detail.ConclusionThis study proposes a fine-grained grading model that combines the fine-grained classification and multi-channel attention models. In addition, Rank_loss combines the ranking result and information of every layer. It is used to obtain the local feature area, which is beneficial to the classification result. According to the experimental results, the model can obtain good results in five-classification and two-classification tasks.关键词:diabetic retinopathy(DR);lesion grading;fine-grained grading;deep learning;multi-channel attention selection;local feature extraction89|71|3更新时间:2024-05-07
摘要:ObjectiveDiabetic retinopathy (DR) is a common blinding retinal disease that cannot be cured in the later stage, and requires patients to be diagnosed and treated at an early stage; otherwise, it causes permanent vision loss. The prevalence of diabetic retinopathy is extremely high in China, and is in the stage of rapid growth. At present, China has become the country that has the largest number of patients with diabetic retinopathy. Diagnosis of DR is usually performed by analyzing fundus medical images. Detection of microscopic lesions such as microaneurysms in retinal images is necessary in grading diabetic retinopathy with neural networks. This condition requires the attention mechanism to simulate the focus of the human eyes and focus on the local area with information. However, most of the present methods only consider the attention in the spatial domain and ignore the information in the channel attention, which cause difficulty in distinguishing the small lesions. To solve this problem, a fine-grained grading method based on multi-channel attention selection (FGMAS) mechanism is proposed for the grading of diabetic retinopathy in this paper.MethodThis method combines fine-grained classification with a multi-channel attention selection mechanism. First, the structure of fine-grained classification is adopted to improve the recognition accuracy of small differences between categories by obtaining local regional features. Then, the characteristics of different feature layers in the channel domain with different information content are used to select high-information channels. The model establishes the relationship between information content and classification confidence, and obtains the lesion area that is conducive to classification results. Finally, the local and global features are combined to improve the accuracy of classification. In addition, considering the relationship between the channel characteristic information of each layer and the classification confidence, this study also introduces Rank_loss to optimize the channel information of each layer. The loss function enables the regions with higher classification confidence to have higher information content and obtain better classification results.ResultTwo open retinal datasets (Kaggle and Messidor) are used to evaluate the effectiveness of the proposed fine-grained grading method and multi-channel attention selection mechanism. The experimental results show that FGMAS performs a five-level classification on the Kaggle dataset with better results than the existing method, with an average accuracy of 0.577, which is 3.4%10.4% higher than the accuracy of other methods. The first category shows small lesion points, which are difficult to distinguish in other methods. However, the accuracy rate of 0.301 can be obtained through FGMAS proposed in this paper, which is better than other methods with the improvement of 11%18.9%, such as 0.190 of VGGNet with Extra Kernel/LGI (VNXK/LGI). Meanwhile, FGMAS is used in the Messidor dataset to perform a dichotomous task, including recommended reference/non-reference and normal/abnormal classification. In the reference/non-reference classification task, the experimental results are 0.912 of accuracy and 0.962 of AUC(area under the curve), which is superior to the existing methods by 0.1%1.9% and 0.5%9.9%, respectively. In the normal/abnormal classification task, the experimental results are 0.909 of accuracy and 0.950 of AUC, which are improved by 2.9%8.8% and 0.4%8.9% respectively, compared with existing methods. In addition, parameter experiments are set up in this study, and the function of each parameter and optimal parameter selection result are analyzed in detail.ConclusionThis study proposes a fine-grained grading model that combines the fine-grained classification and multi-channel attention models. In addition, Rank_loss combines the ranking result and information of every layer. It is used to obtain the local feature area, which is beneficial to the classification result. According to the experimental results, the model can obtain good results in five-classification and two-classification tasks.关键词:diabetic retinopathy(DR);lesion grading;fine-grained grading;deep learning;multi-channel attention selection;local feature extraction89|71|3更新时间:2024-05-07
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0