
最新刊期
卷 26 , 期 6 , 2021
-
 摘要:Video processing and compression are the most fundamental research areas in multimedia computing and communication technologies. They play a significant role in bridging video acquisition, video streaming, and video delivery together with the visual information analysis and visual understanding. Video processing and compression are also the foundations of applicational multimedia technologies and support various down-stream video applications. Digital videos are the largest big data in our contemporary modern society. The multimedia industry is the core component of the intellectual information era. The human kind steps into the intellectual information era with the continuous development of artificial intelligence and new generation of information revolution. Many emerging interdisciplinary research topics interact and fuse. Currently, the 5G plus ultra-high definition plus artificial intelligence invokes a novel trend of massive technology revolution in the context of multimedia computing and communication. The video processing and compression techniques also face challenging and intensive reform given this background. The demands for the theoretical and applicational breakthrough research on the compact video data representations, the highly efficient processing pipelines, and the high-performance algorithms are increasing. To address these issues, the academic and industrial society have already made extensive contributions and studies into several cutting-edge research areas and contents, including visual signal representation mechanism of video big data, compact visual information expression, video signal restoration and reconstruction, high-level and low-level vision fusion methods, and their hardware implementations. Based on fundamental theories in discrete signal processing, the active research topics as well as the corresponding state-of-the-art methodologies in the field of video processing and compression are systematically reviewed and analyzed. A comprehensive review of research topics, namely, statistical prior model-based video data representation learning and its processing methods, deep network-based video processing and compression solutions, video coding techniques, and video compression standardization process is provided. More importantly, the challenges of these research areas, the future developing tendency, the state-of-the-art approach as well as the standardization process are also provided from top to bottom. Specifically, the video processing algorithms, including model-based and deep learning based video super-resolution and video restoration solutions are initially reviewed. The video super-resolution contains spatial super-resolution and temporal super-resolution methods. The video restoration focuses on video deblurring and video deraining. The prior model based approaches and neural approaches are reviewed and compared. Subsequently, this paper presents the review of video compression methods from two aspects, namely, conventional coding tool development and learning-based video coding approaches. The former focuses on the modular improvements on predictive coding, transform and quantization, filtering, and entropy coding. With the development of multiple next-generation video coding standards, the scope and depth for the coding tool research in conventional hybrid coding framework are extensively broadened. The latter introduces the deep learning based video coding methods, not only for hybrid coding framework but also for end-to-end coding framework. Deep neural network based coding would definitely become the next jump of high-dimensional multimedia signal coding. For both parts, the detailed technology and standardization are described to shape the overall development of video compression. In addition, the extensive comparative study on these areas between oversea community and domestic community is conducted and analyzed, providing the evidence for the difference and similarity in the current situation. Finally, the future work on theoretical and application studies in video processing and compression is envisioned. In particular, the research between high quality visual effects and high efficiency visual representation would not be separate areas. The fusion of brain-like visual system and encoding mechanism for video processing and compression is a key direction of future research.关键词:multimedia technology;video signal processing;video compression;artificial intelligence;deep learning134|79|4更新时间:2024-05-07
摘要:Video processing and compression are the most fundamental research areas in multimedia computing and communication technologies. They play a significant role in bridging video acquisition, video streaming, and video delivery together with the visual information analysis and visual understanding. Video processing and compression are also the foundations of applicational multimedia technologies and support various down-stream video applications. Digital videos are the largest big data in our contemporary modern society. The multimedia industry is the core component of the intellectual information era. The human kind steps into the intellectual information era with the continuous development of artificial intelligence and new generation of information revolution. Many emerging interdisciplinary research topics interact and fuse. Currently, the 5G plus ultra-high definition plus artificial intelligence invokes a novel trend of massive technology revolution in the context of multimedia computing and communication. The video processing and compression techniques also face challenging and intensive reform given this background. The demands for the theoretical and applicational breakthrough research on the compact video data representations, the highly efficient processing pipelines, and the high-performance algorithms are increasing. To address these issues, the academic and industrial society have already made extensive contributions and studies into several cutting-edge research areas and contents, including visual signal representation mechanism of video big data, compact visual information expression, video signal restoration and reconstruction, high-level and low-level vision fusion methods, and their hardware implementations. Based on fundamental theories in discrete signal processing, the active research topics as well as the corresponding state-of-the-art methodologies in the field of video processing and compression are systematically reviewed and analyzed. A comprehensive review of research topics, namely, statistical prior model-based video data representation learning and its processing methods, deep network-based video processing and compression solutions, video coding techniques, and video compression standardization process is provided. More importantly, the challenges of these research areas, the future developing tendency, the state-of-the-art approach as well as the standardization process are also provided from top to bottom. Specifically, the video processing algorithms, including model-based and deep learning based video super-resolution and video restoration solutions are initially reviewed. The video super-resolution contains spatial super-resolution and temporal super-resolution methods. The video restoration focuses on video deblurring and video deraining. The prior model based approaches and neural approaches are reviewed and compared. Subsequently, this paper presents the review of video compression methods from two aspects, namely, conventional coding tool development and learning-based video coding approaches. The former focuses on the modular improvements on predictive coding, transform and quantization, filtering, and entropy coding. With the development of multiple next-generation video coding standards, the scope and depth for the coding tool research in conventional hybrid coding framework are extensively broadened. The latter introduces the deep learning based video coding methods, not only for hybrid coding framework but also for end-to-end coding framework. Deep neural network based coding would definitely become the next jump of high-dimensional multimedia signal coding. For both parts, the detailed technology and standardization are described to shape the overall development of video compression. In addition, the extensive comparative study on these areas between oversea community and domestic community is conducted and analyzed, providing the evidence for the difference and similarity in the current situation. Finally, the future work on theoretical and application studies in video processing and compression is envisioned. In particular, the research between high quality visual effects and high efficiency visual representation would not be separate areas. The fusion of brain-like visual system and encoding mechanism for video processing and compression is a key direction of future research.关键词:multimedia technology;video signal processing;video compression;artificial intelligence;deep learning134|79|4更新时间:2024-05-07 - 摘要:With the development of mobile Internet and communication technology, multimedia communication technology has become a major demand for the development of the national information industry, which is widely used in video conferencing, various live broadcast applications, telemedicine, remote monitoring, and remote education. However, large-capacity multimedia communication services face pressure on network bandwidth. Media computing is introduced into the communication system, a new multimedia communication research paradigm is established, and a new multimedia coding and transmission method is developed from the perspective of improving the quality of experience (QoE), which fundamentally reduces the pressure on network bandwidth requirements. The quality of experience refers to the subjective evaluation of the relevant performance of the objective information carrier by the information receiver in combination with its own expectations. It is a communication quality evaluation criterion that is different from the quality of service (QoS). This article initially introduces the evaluation criteria of QoE, which are divided into user-based evaluation methods and objective parameter-based methods. The user's subjective score or the measurement of the user's relevant physiological and psychological indicators is used to analyze and infer the user's feelings. The subjective correction of business objective indicators realizes the evaluation of experience quality. Then, multimedia coding methods, including waveform-based coding and content-based coding methods are reviewed. The former effectively encodes any video signal without analyzing the video content, such as a series of video coding standards; the latter identifies objects and related areas in the video sequence and encodes them. Subsequently, this article describes new video transmission methods in the 5G+AI(artificial intelligence) era, such as multiview video coding, 4 K, 8 K video coding, 3D stereo video, point cloud, light field, AR(augmented reality), VR(virtual reality), and other video services. Video services and communication channels are the source and channel parts of the video communication system, respectively, and the relationship between them can usually be compared with the relationship between water sources and water pipes. The continuous development and changes in communication technology, especially the international competition of 5G technology and products, have attracted widespread attention. Channels continuously increase; hence, the transmission rates become fast. Communication becomes ubiquitous. Thus, the rolling development between the source and the channel becomes increasingly influential. Academia and industry mostly solve the high-definition and low-latency challenges faced by video communication systems from two aspects, as follows: video characterization and coding and video transmission. Video coding aims to find effective data compression techniques to reduce the bit rate of video sequences for real-time transmission on a given communication channel. Image compression coding uses the statistical characteristics of the image itself, as well as the user's visual physiology and psychology characteristics, to extract the effective information in the image and remove useless or less useful redundant information. Channel bandwidth varies with different applications and transmission media. Different types of video coding algorithms have been developed; they include effective coding of arbitrary video signals without the need to analyze video content and identify objects and related areas in the video sequence to encode them. The former approach is referred to as a waveform-based encoder, and the latter is a content-based video encoder. With the help of artificial intelligence and machine learning technology, the innovative exploration of information representation from "bit→structure" can effectively overcome the influence of noise and interference in the propagation environment and improve the reliability and efficiency of wireless communication. The amount of data transmitted is greatly reduced by introducing a priori knowledge. The audiovisual service breaks the traditional user-server (content server or content delivery network(CDN) server) video streaming push mode and adds edge computing nodes to satisfy the computing requirements of secondary encoding, virtual scene generation, and scene rendering, generated during the interaction. In the future, the media inevitably aims at "a thousand people with a thousand faces" and develops in the direction of large data volume, large calculation volume, and large communication volume. The business architecture has the characteristics of "cloud-side-end" collaborative computing, which derives richer media applications in the future. The quality of communication system is evaluated from the perspective of QoE. QoE reflects the subjective evaluation of the objective information carrier (voice, image, and video) after the information receiver perceives the objective information carrier's performance. The current QoE evaluation methods are mainly divided into two categories, namely, user-based evaluation methods and evaluation methods based on objective parameters. User-based evaluation methods include all evaluation methods that require user participation. Specific indicators or information about the QoE need to be obtained directly from users. The evaluation methods based on objective parameters realize the evaluation of experience quality through the subjective correction of objective indicators.关键词:computing communication;multimedia communication;evaluation criteria;multimedia coding;multimedia transmission47|49|1更新时间:2024-05-07
-
 摘要:Internet and social networks have become the main platforms for people to access and share various digital media. Among them, media based on images, videos, and audio carry more information and are the most eye-catching. With the rapid development of computer technology, image and video editing software and tools have appeared one after another, such as Photoshop, Adobe Premiere Pro, and VideoStudio. These editing software can be faster and easier to modify the media. The effect of image forgery is realistic, and the effect of video editing and synthesis is natural and smooth. In recent years, the image generation technology has also been greatly developed, and the visual effects of the generated images may be fake. The problem of multimedia forgery attracts people's attention. The purpose of forgery may be entertainment (such as beautifying images), malicious modification of the content of images and videos (such as deliberately modifying photos of political figures or deliberately exaggerating the severity of news events), and malicious copying. Image forgery incidents in recent years also remind people to focus on the security of media content. The authenticity of visual media content decreases and is increasingly being questioned. At present, millions of multimedia data are transmitted via the Internet every day. What type of content is true? What tampering was made behind the wrong content? The digital forensics technology proposed in recent years provides the answer. This technology does not embed a watermark in advance but directly analyzes the content of multimedia data to achieve the purpose of authenticity recognition. The basic principle is that the inherent characteristics of the original multimedia data are consistent and unique and can be used as its own "intrinsic fingerprint". Any tampering or forgery destroys its integrity to a certain extent. In recent years, media tampering has been increasing and has seriously threatened social stability and even national security. Especially with the rapid development of deep learning technology, the perceived gap between fake media and real media decreases. This finding poses a serious challenge to media forensic research and makes multimedia forensics an important issue in the field of information security research direction. Therefore, technologies and tools that can detect erroneous multimedia content are urgently required, and the spread of dangerous erroneous information is avoided. This article aims to summarize the excellent detection and forensics algorithms proposed in the previous multimedia forensics field. In addition to reviewing traditional media forensics methods, we introduce methods based on deep learning. This article summarizes the current mainstream multimedia tampering objects, namely, images, videos, and sounds. Each media form includes traditional tampering methods and artificial intelligence (AI)-based tampering methods. Among them, video tampering is mainly divided into intraframe tampering and interframe tampering. Intraframe tampering takes the video frame as a unit to delete objects on the screen or performing "copy and move" operations, and interframe tampering takes the video sequence as a unit to add or delete frames. Traditional methods for detecting fake videos can be divided into video encoding tracking detection, video content inconsistency detection, video frame repeated tampering, and copy and paste detection. AI-based error video detection technology focuses on detecting artifacts left over from the network generated in the imaging network, which is different from the imaging process of a real camera. The purpose of digital image forensics technology is to verify the integrity and authenticity of digital images. Image forensic methods can be divided into active methods and passive methods. Active image forensics includes embedding watermarks or signatures in digital images. The passive blind forensic (blind forensics) method is not limited by these factors. It distinguishes images by detecting traces of tampering in the image. Common image forgery and tampering include enhancement, modification, area duplication, splicing, and synthesis. The detection of partial replacement image is divided into the following: 1) Area copy and tamper detection, which copies and pastes part of the area in the image to other areas. During the copying process, the copied area may undergo various geometric transformations and postprocessing. 2) Image processing fingerprints detection. The visual difference caused by simple area copying, splicing, and tampering is still evident. The forger performs postprocessing, such as zooming, rotating, and blurring the image, to eliminate these traces. 3) In recompression fingerprint detection, tampered images inevitably undergo recompression; thus, digital image recompression detection can provide a powerful auxiliary basis for digital image forensics. For the traceability detection technology of forged images, most images are captured by the camera. The general physical structure of the camera and the physical differences between different cameras leave traces on the captured images. These traces (camera fingerprints) appear as a series of features on the image, and the acquisition device of this image can be identified by examining the fingerprint of the device embedded in the image. The detection technology for the overall image generated by AI also focuses on detecting the artifacts left by the network generated in the imaging network. In the previous decades, some digital audio forensic studies have focused on detecting various forms of audio tampering. These methods check the metadata of audio files. In addition, the publicly available large-scale data sets and related applications are introduced, and the possible future development directions of the multimedia forensic field is discussed.关键词:multimedia forensics;multimedia traceability;forgery detection;forgery localization;fake face275|188|13更新时间:2024-05-07
摘要:Internet and social networks have become the main platforms for people to access and share various digital media. Among them, media based on images, videos, and audio carry more information and are the most eye-catching. With the rapid development of computer technology, image and video editing software and tools have appeared one after another, such as Photoshop, Adobe Premiere Pro, and VideoStudio. These editing software can be faster and easier to modify the media. The effect of image forgery is realistic, and the effect of video editing and synthesis is natural and smooth. In recent years, the image generation technology has also been greatly developed, and the visual effects of the generated images may be fake. The problem of multimedia forgery attracts people's attention. The purpose of forgery may be entertainment (such as beautifying images), malicious modification of the content of images and videos (such as deliberately modifying photos of political figures or deliberately exaggerating the severity of news events), and malicious copying. Image forgery incidents in recent years also remind people to focus on the security of media content. The authenticity of visual media content decreases and is increasingly being questioned. At present, millions of multimedia data are transmitted via the Internet every day. What type of content is true? What tampering was made behind the wrong content? The digital forensics technology proposed in recent years provides the answer. This technology does not embed a watermark in advance but directly analyzes the content of multimedia data to achieve the purpose of authenticity recognition. The basic principle is that the inherent characteristics of the original multimedia data are consistent and unique and can be used as its own "intrinsic fingerprint". Any tampering or forgery destroys its integrity to a certain extent. In recent years, media tampering has been increasing and has seriously threatened social stability and even national security. Especially with the rapid development of deep learning technology, the perceived gap between fake media and real media decreases. This finding poses a serious challenge to media forensic research and makes multimedia forensics an important issue in the field of information security research direction. Therefore, technologies and tools that can detect erroneous multimedia content are urgently required, and the spread of dangerous erroneous information is avoided. This article aims to summarize the excellent detection and forensics algorithms proposed in the previous multimedia forensics field. In addition to reviewing traditional media forensics methods, we introduce methods based on deep learning. This article summarizes the current mainstream multimedia tampering objects, namely, images, videos, and sounds. Each media form includes traditional tampering methods and artificial intelligence (AI)-based tampering methods. Among them, video tampering is mainly divided into intraframe tampering and interframe tampering. Intraframe tampering takes the video frame as a unit to delete objects on the screen or performing "copy and move" operations, and interframe tampering takes the video sequence as a unit to add or delete frames. Traditional methods for detecting fake videos can be divided into video encoding tracking detection, video content inconsistency detection, video frame repeated tampering, and copy and paste detection. AI-based error video detection technology focuses on detecting artifacts left over from the network generated in the imaging network, which is different from the imaging process of a real camera. The purpose of digital image forensics technology is to verify the integrity and authenticity of digital images. Image forensic methods can be divided into active methods and passive methods. Active image forensics includes embedding watermarks or signatures in digital images. The passive blind forensic (blind forensics) method is not limited by these factors. It distinguishes images by detecting traces of tampering in the image. Common image forgery and tampering include enhancement, modification, area duplication, splicing, and synthesis. The detection of partial replacement image is divided into the following: 1) Area copy and tamper detection, which copies and pastes part of the area in the image to other areas. During the copying process, the copied area may undergo various geometric transformations and postprocessing. 2) Image processing fingerprints detection. The visual difference caused by simple area copying, splicing, and tampering is still evident. The forger performs postprocessing, such as zooming, rotating, and blurring the image, to eliminate these traces. 3) In recompression fingerprint detection, tampered images inevitably undergo recompression; thus, digital image recompression detection can provide a powerful auxiliary basis for digital image forensics. For the traceability detection technology of forged images, most images are captured by the camera. The general physical structure of the camera and the physical differences between different cameras leave traces on the captured images. These traces (camera fingerprints) appear as a series of features on the image, and the acquisition device of this image can be identified by examining the fingerprint of the device embedded in the image. The detection technology for the overall image generated by AI also focuses on detecting the artifacts left by the network generated in the imaging network. In the previous decades, some digital audio forensic studies have focused on detecting various forms of audio tampering. These methods check the metadata of audio files. In addition, the publicly available large-scale data sets and related applications are introduced, and the possible future development directions of the multimedia forensic field is discussed.关键词:multimedia forensics;multimedia traceability;forgery detection;forgery localization;fake face275|188|13更新时间:2024-05-07 -
 摘要:As the construction of smart cities continues to deepen, our country gradually builds multidimensional and omnidirectional sensor systems in roads, railways, and urban rails and other ground transportation fields to build strong data support for smart transportation. Faced with all-weather traffic data collected by sensors, analyzing the data by relying solely on human resources is no longer possible. Therefore, studying the structural analysis technology of traffic video and establishing a safe, flexible, and efficient intelligent transportation system has significant social benefits and application value. Traffic video structural analysis is the core technology in smart transportation. It aims to use artificial intelligence algorithms to parse unstructured traffic video data into structured semantic information that is easy for workers and computers to understand and provide basic technical support for subsequent related tasks. The structural analysis of traffic video is a key technology for smart city construction. It can help the police in quickly locating criminal vehicles and travel routes, greatly improve the police's efficiency in solving crimes, and maintain city safety; it can also automatically identify illegal vehicles and types of violation, constrains people to abide by the traffic order, and realize a smooth urban traffic environment. With the advent of the 5G internet of things era, ultrahigh network bandwidth and transmission speed further improves the quality and efficiency of vehicle video transmission. Efficiently and accurately conducting traffic video structure analysis will be the focus of research in the next few years. Traffic video structural analysis includes vehicle video structural analysis, personnel structural analysis, and behavior analysis. Among them, as a complex, multistep task, vehicle structuring is mainly composed of three subtasks, namely, vehicle detection, vehicle attributes (license plate, type, and color) recognition, and vehicle retrieval and reidentification. Human face structuring and pedestrian structuring are two important research directions in the intelligent analysis of traffic videos. They mainly analyze some apparent attributes of human faces or pedestrians, such as age, gender, mask, backpack, clothing color, and length. Pedestrian behavior analysis refers to the identification and prediction of pedestrian actions. For example, the speed at which pedestrians currently head and in which direction, whether they are answering calls, and whether they have to cross the road. For the task of vehicle structure analysis, first, the object detection technology must be used to quickly and accurately locate the vehicle. Second, on the basis of positioning the vehicle, it fully excavates the visual characteristics of the vehicle, realizes the identification of the inherent attributes of vehicle, and generates structured tags about the vehicle. Finally, on the basis of structured tags, the retrieval technology and reidentification technology are further combined to realize the retrieval and reidentification of a specific vehicle in the massive video data. Personnel structural analysis and behavior analysis can detect and identify pedestrians in traffic videos and conduct structured data extraction and behavior analysis of detected personnel. In the analysis of personnel structure, a person is extracted as a descriptive individual. In terms of face structure, it includes accurate facial positioning, facial feature extraction, and facial feature comparison. In terms of pedestrian structure, it includes gender, age, and age of the person. Various descriptive information includes height, hair accessories, clothing, carrying items, and walking patterns. Pedestrian behavior analysis is carried out on the basis of personnel structure analysis. Behavior analysis refers to the recognition, comprehension, and prediction of pedestrian actions. In the area of big data processing and analysis of traffic video, research on vehicle structuring started earlier and related technologies have also developed rapidly, but it can still be remarkably developed. The premise of vehicle structuring is vehicle detection, which is affected by the shooting scene and the moving speed of the vehicle. Accurately locating the vehicle in the case of low light and the fast vehicle speed is still a problem to be solved. Many types of vehicles are found in the market, and the differences between models of similar brands are small. License plate recognition has become more important. In complex and changeable scenes, the generalization and accuracy of the positioning and recognition algorithm should be further improved. The extensive deployment of traffic monitoring equipment realizes all-weather monitoring of relevant road systems and further increases the difficulty of vehicle retrieval and reidentification tasks. Rapid retrieval or reidentification of target vehicles in complex and changeable scenes is crucial. It requires continuous investment and a much innovative research by scientific researchers. The need for structured pedestrian analysis has gradually emerged with further improvement of urban management. Pedestrian structuring mainly analyzes some apparent attributes of faces or pedestrians, such as age, gender, and clothing style, and provides more detailed data support for subsequent related tasks. Pedestrian structured analysis technology has also ushered in a period of rapid development with the development of deep learning. However, the structured analysis of pedestrians for specific scenarios, such as accurately identifying the age and gender of a person in an unconstrained environment, implementing the deployment of high-precision models in terminal systems with limited resources, and integrating multimodal information to further improve the accuracy of pedestrian attribute recognition, needs further research. Pedestrian behavior analysis is a more advanced task in traffic video big data processing and analysis. It is more challenging due to factors, such as shooting scenes, moving cameras, viewing angles, and lighting changes. Judging from the behavior recognition effect of the mainstream neural network architecture, the current model does not achieve the desired effect on the large-scale behavior data set Kinetic because the existing model still fails to fully learn and model the behavioral timing relationship. In the field of behavior recognition, future research can still focus on recognition models for designing long-time-dependent network architectures, adapting large-scale data sets, and achieving lightweight behavior. With the development of Internet of Things and 5G technologies, the promotion of new technologies has also played an important role in the structural analysis of traffic video. To be equipped with IoT devices has become an inevitable trend for modern cars. Vehicles can be connected to basic transportation facilities (vehicle to infrastructure, V2I) or to surrounding vehicles (vehicle-to-vehicle, V2V). The development of these technologies depends on the common progress of vehicle video structuring and internet of things technology. With the global popularity of 5G technology, rapid transmission of high-quality video data has become a reality. Extracting structured information more efficiently from traffic videos, such as vehicle information, pedestrian information, and behavior prediction, has become more urgent. Researchers should study on improving the performance of related algorithms, should design more efficient hardware systems, and build more efficient traffic video structured analysis systems through software and hardware collaborations. We discuss the related work on traffic video structural analysis in detail from three aspects, as follows: vehicle, personnel, and behavior analysis. Moreover, we summarize these research works and provide some reasonable directions for future work.关键词:traffic video;vehicle structural analysis;personnel structural analysis;behavior structural analysis;vehicle detection;vehicle attribute recognition;vehicle retrieval;human face structural analysis133|344|4更新时间:2024-05-07
摘要:As the construction of smart cities continues to deepen, our country gradually builds multidimensional and omnidirectional sensor systems in roads, railways, and urban rails and other ground transportation fields to build strong data support for smart transportation. Faced with all-weather traffic data collected by sensors, analyzing the data by relying solely on human resources is no longer possible. Therefore, studying the structural analysis technology of traffic video and establishing a safe, flexible, and efficient intelligent transportation system has significant social benefits and application value. Traffic video structural analysis is the core technology in smart transportation. It aims to use artificial intelligence algorithms to parse unstructured traffic video data into structured semantic information that is easy for workers and computers to understand and provide basic technical support for subsequent related tasks. The structural analysis of traffic video is a key technology for smart city construction. It can help the police in quickly locating criminal vehicles and travel routes, greatly improve the police's efficiency in solving crimes, and maintain city safety; it can also automatically identify illegal vehicles and types of violation, constrains people to abide by the traffic order, and realize a smooth urban traffic environment. With the advent of the 5G internet of things era, ultrahigh network bandwidth and transmission speed further improves the quality and efficiency of vehicle video transmission. Efficiently and accurately conducting traffic video structure analysis will be the focus of research in the next few years. Traffic video structural analysis includes vehicle video structural analysis, personnel structural analysis, and behavior analysis. Among them, as a complex, multistep task, vehicle structuring is mainly composed of three subtasks, namely, vehicle detection, vehicle attributes (license plate, type, and color) recognition, and vehicle retrieval and reidentification. Human face structuring and pedestrian structuring are two important research directions in the intelligent analysis of traffic videos. They mainly analyze some apparent attributes of human faces or pedestrians, such as age, gender, mask, backpack, clothing color, and length. Pedestrian behavior analysis refers to the identification and prediction of pedestrian actions. For example, the speed at which pedestrians currently head and in which direction, whether they are answering calls, and whether they have to cross the road. For the task of vehicle structure analysis, first, the object detection technology must be used to quickly and accurately locate the vehicle. Second, on the basis of positioning the vehicle, it fully excavates the visual characteristics of the vehicle, realizes the identification of the inherent attributes of vehicle, and generates structured tags about the vehicle. Finally, on the basis of structured tags, the retrieval technology and reidentification technology are further combined to realize the retrieval and reidentification of a specific vehicle in the massive video data. Personnel structural analysis and behavior analysis can detect and identify pedestrians in traffic videos and conduct structured data extraction and behavior analysis of detected personnel. In the analysis of personnel structure, a person is extracted as a descriptive individual. In terms of face structure, it includes accurate facial positioning, facial feature extraction, and facial feature comparison. In terms of pedestrian structure, it includes gender, age, and age of the person. Various descriptive information includes height, hair accessories, clothing, carrying items, and walking patterns. Pedestrian behavior analysis is carried out on the basis of personnel structure analysis. Behavior analysis refers to the recognition, comprehension, and prediction of pedestrian actions. In the area of big data processing and analysis of traffic video, research on vehicle structuring started earlier and related technologies have also developed rapidly, but it can still be remarkably developed. The premise of vehicle structuring is vehicle detection, which is affected by the shooting scene and the moving speed of the vehicle. Accurately locating the vehicle in the case of low light and the fast vehicle speed is still a problem to be solved. Many types of vehicles are found in the market, and the differences between models of similar brands are small. License plate recognition has become more important. In complex and changeable scenes, the generalization and accuracy of the positioning and recognition algorithm should be further improved. The extensive deployment of traffic monitoring equipment realizes all-weather monitoring of relevant road systems and further increases the difficulty of vehicle retrieval and reidentification tasks. Rapid retrieval or reidentification of target vehicles in complex and changeable scenes is crucial. It requires continuous investment and a much innovative research by scientific researchers. The need for structured pedestrian analysis has gradually emerged with further improvement of urban management. Pedestrian structuring mainly analyzes some apparent attributes of faces or pedestrians, such as age, gender, and clothing style, and provides more detailed data support for subsequent related tasks. Pedestrian structured analysis technology has also ushered in a period of rapid development with the development of deep learning. However, the structured analysis of pedestrians for specific scenarios, such as accurately identifying the age and gender of a person in an unconstrained environment, implementing the deployment of high-precision models in terminal systems with limited resources, and integrating multimodal information to further improve the accuracy of pedestrian attribute recognition, needs further research. Pedestrian behavior analysis is a more advanced task in traffic video big data processing and analysis. It is more challenging due to factors, such as shooting scenes, moving cameras, viewing angles, and lighting changes. Judging from the behavior recognition effect of the mainstream neural network architecture, the current model does not achieve the desired effect on the large-scale behavior data set Kinetic because the existing model still fails to fully learn and model the behavioral timing relationship. In the field of behavior recognition, future research can still focus on recognition models for designing long-time-dependent network architectures, adapting large-scale data sets, and achieving lightweight behavior. With the development of Internet of Things and 5G technologies, the promotion of new technologies has also played an important role in the structural analysis of traffic video. To be equipped with IoT devices has become an inevitable trend for modern cars. Vehicles can be connected to basic transportation facilities (vehicle to infrastructure, V2I) or to surrounding vehicles (vehicle-to-vehicle, V2V). The development of these technologies depends on the common progress of vehicle video structuring and internet of things technology. With the global popularity of 5G technology, rapid transmission of high-quality video data has become a reality. Extracting structured information more efficiently from traffic videos, such as vehicle information, pedestrian information, and behavior prediction, has become more urgent. Researchers should study on improving the performance of related algorithms, should design more efficient hardware systems, and build more efficient traffic video structured analysis systems through software and hardware collaborations. We discuss the related work on traffic video structural analysis in detail from three aspects, as follows: vehicle, personnel, and behavior analysis. Moreover, we summarize these research works and provide some reasonable directions for future work.关键词:traffic video;vehicle structural analysis;personnel structural analysis;behavior structural analysis;vehicle detection;vehicle attribute recognition;vehicle retrieval;human face structural analysis133|344|4更新时间:2024-05-07
lmage Processing & Communication Technology

-
 摘要:Biometrics, such as face, iris, and fingerprint recognition, have become digital identity proof for people to enter the "Internet of Everything". For example, one may be asked to present the biometric identifier for unlocking mobile phones, passing access control at airports, rail stations, and paying at supermarkets or restaurants. Biometric recognition empowers a machine to automatically detect, capture, process, analyze, and recognize digital physiological or behavioral signals with advanced intelligence. Thus, biometrics requires interdisciplinary research of science and technology involving optical engineering, mechanical engineering, electronic engineering, machine learning, pattern recognition, computer vision, digital image processing, signal analysis, cognitive science, neuroscience, human-computer interaction, and information security. Biometrics is a typical and complex pattern recognition problem, which is a frontier research direction of artificial intelligence. In addition, biometric identification is a key development area of Chinese strategies, such as the Development Plan on the New Generation of Artificial Intelligence and the "Internet Plus" Action Plan. The development of biometric identification involves public interest, privacy, ethics, and law issues; thus, it has also attracted widespread attention from the society. This article systematically reviews the development status, emerging directions, existing problems, and feasible ideas of biometrics and comprehensively summarizes the research progress of face, iris, fingerprint, palm print, finger/palm vein, voiceprint, gait recognition, person reidentification, and multimodal biometric fusion. The overview of face recognition includes face detection, facial landmark localization, 2D face feature extraction and recognition, 3D face feature extraction and recognition, facial liveness detection, and face video based biological signal measurement. The overview of iris recognition includes iris image acquisition, iris segmentation and localization, iris liveness detection, iris image quality assessment, iris feature extraction, heterogeneous iris recognition, fusion of iris and other modalities, security problems of iris biometrics, and future trends of iris recognition. The overview of fingerprint recognition includes latent fingerprint recognition, fingerprint liveness detection, distorted fingerprint recognition, 3D fingerprint capturing, and challenges and trends of fingerprint biometrics. The overview of palm print recognition mainly introduces databases, feature models, matching strategies, and open problems of palm print biometrics. The overview of vein biometrics introduces main datasets and algorithms for finger vein, dorsal hand vein, and palm vein, and then points out the remaining unsolved problems and development trend of vein recognition. The overview of gait recognition introduces model-based and model-free methods for gait feature extraction and matching. The overview of person reidentification introduces research progress of new methods under supervised, unsupervised and weakly supervised conditions, gait database virtualization, generative gait models, and new problems, such as clothes changing, black clothes, and partial occlusions. The overview of voiceprint recognition introduces the history of speaker recognition, robustness of voiceprint, spoofing attacks, and antispoofing methods. The overview of multibiometrics introduces image-level, feature-level, score-level, and decision-level information fusion methods and deep learning based fusion approaches. Taking face as the exemplar biometric modality, new research directions that have received great attentions in the field of biometric recognition in recent years, i.e., adversarial attack and defense as well as Deepfake and anti-Deepfake, are also introduced. Finally, we analyze and summarize the three major challenges in the field of biometric recognition——"the blind spot of biometric sensors", "the decision errors of biometric algorithms" and "the red zone of biometric security". Therefore, the sensing, cognition, and security mechanisms of biometrics are necessary to achieve a fundamental breakthrough in the academic research and technologies applications of biometrics in complex scenarios to address the shortcomings of the existing biometric technologies and to move towards the overall goal of developing a new generation of "perceptible", "robust", and "trustworthy" biometric identification technology.关键词:biometrics;face;iris;fingerprint;palmprint;vein;voiceprint;gait;person re-identification;multi-modal477|4127|16更新时间:2024-05-07
摘要:Biometrics, such as face, iris, and fingerprint recognition, have become digital identity proof for people to enter the "Internet of Everything". For example, one may be asked to present the biometric identifier for unlocking mobile phones, passing access control at airports, rail stations, and paying at supermarkets or restaurants. Biometric recognition empowers a machine to automatically detect, capture, process, analyze, and recognize digital physiological or behavioral signals with advanced intelligence. Thus, biometrics requires interdisciplinary research of science and technology involving optical engineering, mechanical engineering, electronic engineering, machine learning, pattern recognition, computer vision, digital image processing, signal analysis, cognitive science, neuroscience, human-computer interaction, and information security. Biometrics is a typical and complex pattern recognition problem, which is a frontier research direction of artificial intelligence. In addition, biometric identification is a key development area of Chinese strategies, such as the Development Plan on the New Generation of Artificial Intelligence and the "Internet Plus" Action Plan. The development of biometric identification involves public interest, privacy, ethics, and law issues; thus, it has also attracted widespread attention from the society. This article systematically reviews the development status, emerging directions, existing problems, and feasible ideas of biometrics and comprehensively summarizes the research progress of face, iris, fingerprint, palm print, finger/palm vein, voiceprint, gait recognition, person reidentification, and multimodal biometric fusion. The overview of face recognition includes face detection, facial landmark localization, 2D face feature extraction and recognition, 3D face feature extraction and recognition, facial liveness detection, and face video based biological signal measurement. The overview of iris recognition includes iris image acquisition, iris segmentation and localization, iris liveness detection, iris image quality assessment, iris feature extraction, heterogeneous iris recognition, fusion of iris and other modalities, security problems of iris biometrics, and future trends of iris recognition. The overview of fingerprint recognition includes latent fingerprint recognition, fingerprint liveness detection, distorted fingerprint recognition, 3D fingerprint capturing, and challenges and trends of fingerprint biometrics. The overview of palm print recognition mainly introduces databases, feature models, matching strategies, and open problems of palm print biometrics. The overview of vein biometrics introduces main datasets and algorithms for finger vein, dorsal hand vein, and palm vein, and then points out the remaining unsolved problems and development trend of vein recognition. The overview of gait recognition introduces model-based and model-free methods for gait feature extraction and matching. The overview of person reidentification introduces research progress of new methods under supervised, unsupervised and weakly supervised conditions, gait database virtualization, generative gait models, and new problems, such as clothes changing, black clothes, and partial occlusions. The overview of voiceprint recognition introduces the history of speaker recognition, robustness of voiceprint, spoofing attacks, and antispoofing methods. The overview of multibiometrics introduces image-level, feature-level, score-level, and decision-level information fusion methods and deep learning based fusion approaches. Taking face as the exemplar biometric modality, new research directions that have received great attentions in the field of biometric recognition in recent years, i.e., adversarial attack and defense as well as Deepfake and anti-Deepfake, are also introduced. Finally, we analyze and summarize the three major challenges in the field of biometric recognition——"the blind spot of biometric sensors", "the decision errors of biometric algorithms" and "the red zone of biometric security". Therefore, the sensing, cognition, and security mechanisms of biometrics are necessary to achieve a fundamental breakthrough in the academic research and technologies applications of biometrics in complex scenarios to address the shortcomings of the existing biometric technologies and to move towards the overall goal of developing a new generation of "perceptible", "robust", and "trustworthy" biometric identification technology.关键词:biometrics;face;iris;fingerprint;palmprint;vein;voiceprint;gait;person re-identification;multi-modal477|4127|16更新时间:2024-05-07 -
 摘要:With the rapid development of internet and mobile internet technologies, many new applications require extensive use of rich text information in natural scenarios, such as sign board recognition and automatic driving. Thus, the analysis and processing of scene text plays an essential role in this field and has increasingly become one of the research hotspots in the field of computer vision. Traditional text detection and recognition methods often rely on manually designed features, with large amount of computation and low efficiency. These methods also lack satisfactory generalization performance for complex scenes. With the development of deep learning in recent years, convolutional neural network has made great progress on scene text detection and recognition. These deep learning-based methods outperform traditional ones by a large margin and have already become the mainstream in the field of text reading in the wild. For scene text detection, the methods can be divided into two categories in accordance with the difference of target objects, as follows: top-down methods and bottom-up methods. Top-down methods mainly inherit the basic idea from general object detection or instance segmentation and directly regress the entire bounding box for the text instance. On the contrary, bottom-up methods, following the idea of traditional ones, initially detect some components of the text instance and then group them together through some rules. Bottom-up methods is more effective in processing text detection of arbitrary shapes and orientations than the top-down methods, and they are not as sensitive to text scaling as top-down methods. However, grouping the detected components into different text instances requires complex design and processing; thus, the inference stage of bottom-up approach becomes inefficient. These methods also encounter some difficulties when detecting long text. In addition, text conglutination occurs when detecting dense text. However, the top-down methods do not have this issue and can have a higher precision for text detection. In recent years, recognizing text in natural scenes (also known as scene text recognition (STR)) has aroused great interest in academia and industry. In particular, the objective of STR is to translate a cropped text instance image into a target string sequence. Although optical character recognition (OCR) in scanned documents has been well developed, STR remains challenging due to many factors (such as very complex backgrounds, various, fonts and imperfect imaging conditions). Early work has relied on hand-crafted features, such as histogram of oriented gradients descriptors, connected components, and stroke width transformation. However, the performance of these approaches is limited by the low capability of features. In recent years, with the increase and development of deep learning, the community has witnessed substantial advancements. In particular, scene text recognition approaches based on deep learning can be roughly divided into two branches, namely, segmentation-based approaches and segmentation-free approaches. Segmentation-based approaches attempt to locate the position of each character from the input text instance image, apply a character classifier to recognize each character, and then group characters into text lines to obtain the final recognition results. Segmentation-free approaches recognize the text instance image as a whole and focus on mapping the entire text instance image into a target string sequence directly. Both branches own their advantages and limitations. Therefore, practitioners should select the best trade-offs according to their needs under different application scenarios. In the previous decades, although the practicality and efficiency of recognition approaches have been significantly improved, future research is still required for generalization ability, evaluation protocols, and scenarios of STR. Finally, end-to-end scene text spotting aims to combine text detection and text recognition into a unified system, which can be optimized in a single pipeline. Bridging the gap between the detection branch and recognition branch is the most essential problem for the design of an end-to-end text spotting system. Similar to general object detection and instance segmentation, end-to-end text spotting methods can be divided into two categories, namely, two-stage methods and one-stage methods. Two-stage methods are mainly based on faster R-CNN(region convolutional neural network) and mask R-CNN, in which region of interest(RoI) pooling/align acts as a bridge between the two branches. However, these operations may lose some information given that the region proposals from region proposal network (RPN) are insufficiently accurate. One-stage methods follow the pipeline of detection then recognition. Various feature-align operations are carefully designed to boost the linking between detection and recognition branches. We sort out and summarize the detection and recognition methods of scene text, and further elaborate and analyze the basic ideas of various methods and their pros and cons. We aim to provide reference for researchers and help in future work.关键词:scene text detection;scene text recognition(STR);end-to-end scene text spotting;deep learning;optical character recognition(OCR);survey193|1307|19更新时间:2024-05-07
摘要:With the rapid development of internet and mobile internet technologies, many new applications require extensive use of rich text information in natural scenarios, such as sign board recognition and automatic driving. Thus, the analysis and processing of scene text plays an essential role in this field and has increasingly become one of the research hotspots in the field of computer vision. Traditional text detection and recognition methods often rely on manually designed features, with large amount of computation and low efficiency. These methods also lack satisfactory generalization performance for complex scenes. With the development of deep learning in recent years, convolutional neural network has made great progress on scene text detection and recognition. These deep learning-based methods outperform traditional ones by a large margin and have already become the mainstream in the field of text reading in the wild. For scene text detection, the methods can be divided into two categories in accordance with the difference of target objects, as follows: top-down methods and bottom-up methods. Top-down methods mainly inherit the basic idea from general object detection or instance segmentation and directly regress the entire bounding box for the text instance. On the contrary, bottom-up methods, following the idea of traditional ones, initially detect some components of the text instance and then group them together through some rules. Bottom-up methods is more effective in processing text detection of arbitrary shapes and orientations than the top-down methods, and they are not as sensitive to text scaling as top-down methods. However, grouping the detected components into different text instances requires complex design and processing; thus, the inference stage of bottom-up approach becomes inefficient. These methods also encounter some difficulties when detecting long text. In addition, text conglutination occurs when detecting dense text. However, the top-down methods do not have this issue and can have a higher precision for text detection. In recent years, recognizing text in natural scenes (also known as scene text recognition (STR)) has aroused great interest in academia and industry. In particular, the objective of STR is to translate a cropped text instance image into a target string sequence. Although optical character recognition (OCR) in scanned documents has been well developed, STR remains challenging due to many factors (such as very complex backgrounds, various, fonts and imperfect imaging conditions). Early work has relied on hand-crafted features, such as histogram of oriented gradients descriptors, connected components, and stroke width transformation. However, the performance of these approaches is limited by the low capability of features. In recent years, with the increase and development of deep learning, the community has witnessed substantial advancements. In particular, scene text recognition approaches based on deep learning can be roughly divided into two branches, namely, segmentation-based approaches and segmentation-free approaches. Segmentation-based approaches attempt to locate the position of each character from the input text instance image, apply a character classifier to recognize each character, and then group characters into text lines to obtain the final recognition results. Segmentation-free approaches recognize the text instance image as a whole and focus on mapping the entire text instance image into a target string sequence directly. Both branches own their advantages and limitations. Therefore, practitioners should select the best trade-offs according to their needs under different application scenarios. In the previous decades, although the practicality and efficiency of recognition approaches have been significantly improved, future research is still required for generalization ability, evaluation protocols, and scenarios of STR. Finally, end-to-end scene text spotting aims to combine text detection and text recognition into a unified system, which can be optimized in a single pipeline. Bridging the gap between the detection branch and recognition branch is the most essential problem for the design of an end-to-end text spotting system. Similar to general object detection and instance segmentation, end-to-end text spotting methods can be divided into two categories, namely, two-stage methods and one-stage methods. Two-stage methods are mainly based on faster R-CNN(region convolutional neural network) and mask R-CNN, in which region of interest(RoI) pooling/align acts as a bridge between the two branches. However, these operations may lose some information given that the region proposals from region proposal network (RPN) are insufficiently accurate. One-stage methods follow the pipeline of detection then recognition. Various feature-align operations are carefully designed to boost the linking between detection and recognition branches. We sort out and summarize the detection and recognition methods of scene text, and further elaborate and analyze the basic ideas of various methods and their pros and cons. We aim to provide reference for researchers and help in future work.关键词:scene text detection;scene text recognition(STR);end-to-end scene text spotting;deep learning;optical character recognition(OCR);survey193|1307|19更新时间:2024-05-07 -
 摘要:Over the last decade, different types of media data such as texts, images, and videos grow rapidly on the internet. Different types of data are used for describing the same events or topics. For example, a web page usually contains not only textual description but also images or videos for illustrating the common content. Such different types of data are referred as multi-modal data, which inspire many applications, e.g., multi-modal retrieval, hot topic detection, and perso-nalize recommendation. Nowadays, mobile devices and emerging social websites (e.g., Facebook, Flickr, YouTube, and Twitter) are diffused across all persons, and a demanding requirement for cross-modal data retrieval is emergent. Accordingly, cross-modal retrieval has attracted considerable attention. One type of data is required as the query to retrieve relevant data of another type. For example, a user can use a text to retrieve relevant pictures or/and videos. The query and its retrieved results can have different modalities; thus, measuring the content similarity between different modalities of data, i.e., reducing heterogeneity gap, remains a challenge. With the rapid development of deep learning techniques, various deep cross-modal retrieval approaches have been proposed to alleviate this problem, and promising performance has been obtained. We aim to review and comb representative methods for deep learning based cross-modal retrieval. We first classify these approaches into three main groups based on the cross-modal information provided, i.e.: 1) co-occurrence information, 2) pairwise information, and 3) semantic information. Co-occurrence information based methods indicate that only co-occurrence information is utilized to learn common representations across multi-modal data, where co-occurrence information indicates that if different modalities of data co-exist in a multi-modal document, then they have the same semantic. Pairwise information based methods indicate that similar pairs and dissimilar pairs are utilized to learn the common representations. A similarity matrix for all modalities is usually provided indicating whether or not two points from the modalities are in the same categories. Semantic information based methods indicate that class label information is provided to learn common representations, where a multi-modal example can have one or more labels with massive manual annotation. Usually, co-occurrence information exists in pairwise information and semantic information based approaches, and pairwise information can be derived when semantic information is provided. However, these relationships do not necessarily hold. In each category, various techniques can be utilized and combined to fully use the provided cross-modal information. We roughly categorize these techniques into seven main classes, as follows: 1) canonical correlation analysis, 2) correspondence preserving, 3) metric learning, 4) likelihood analysis, 5) learning to rank, 6) semantic prediction, and 7) adversarial learning. Canonical correlation analysis methods focus on finding linear combinations of two vectors of random variables with the objective of maximizing the correlation. When combined with deep learning, linear projections are replaced with deep neural networks with extra considerations. Correspondence preserving methods aim at preserving the co-existing relationship of different modalities with the objective of minimizing their distances in the learned embedding space. Usually, the multi-modal correspondence relationship is formed as regularizers or loss functions to enforce a pairwise constraint for learning multi-modal common representations. Metric learning approaches seek to establish a distance function for measuring multi-modal similarities with the objective to pull similar pairs of modalities closer and dissimilar pairs apart. Compared with correspondence preserving and canonical correlation analysis methods, similar pairs and dissimilar pairs are provided as restricted conditions when learning common representations. Likelihood analysis methods, based on Bayesian analysis, are generative approaches with the objective of maximizing the likelihood of the observed multi-modal relationship, e.g., similarity. Conventionally, the maximum likelihood estimation objective is derived to maximize the posterior probability of multi-modal observation. Learning to rank approaches aim to construct a ranking model constrained on the common representations with the objective of maintaining the order of multi-modal similarities. Compared with metric learning methods, explicit ranking loss based objectives are usually developed for ranking similarity optimization. Semantic prediction methods are similar to traditional classification model with the objective of predicting accuracy semantic labels of multi-modal data or their relationships. With such high-level semantics utilized, intramodal structure can effectively reflect learning multi-modal common representations. Adversarial learning approaches refer to methods using generative adversarial networks with the objective of being unable to infer the modality sources for learning common representations. Usually, the generative and discriminative models are carefully designed to form a min-max game for learning statistical inseparable common representations. We introduce several multi-modal datasets in the community, i.e., the Wiki image-text dataset, the INRIA-Websearch dataset, the Flickr30K dataset, the Microsoft common objects in context(MS COCO) dataset, the Real-world Web Image Dataset from National University of Singapore(NUS-WIDE) dataset, the pattern analysis, statistical modelling and computational learning visual object classes(PPSCAL Voc) dataset, and the XMedia dataset. Finally, we discuss open problems and future directions. 1) Some researchers have put forward transferred/extendable/zero-shot cross-modal retrieval, which claims that multi-modal data in the source domain and the target domain can have different semantic annotation categories. 2) Effective cross-modal benchmark data-set containing multiple modal data and with a certain volume for the complex algorithm verification to promote cross-modal retrieval performance with huge data is limited. 3) Labeling all cross-modal data and each sample with accurate annotations is impractical; thus, using these limited and noisy multi-modal data for cross-modal retrieval will be an important research direction. 4) Researchers have designed relatively complex algorithms to improve performance, but the requirements of retrieval efficiency are difficult to satisfy. Therefore, designing efficient and high-performance cross-modal retrieval algorithm is a crucial direction. 5) Embedding different modalities into a common representation space is difficult, and extracting fragment level representation for different modal types and developing more complex fragment-level relationship modeling will be some of the future research directions.关键词:cross-modal retrieval;cross-modal hashing;deep learning;common representation learning;adversarial learning;likelihood analysis;learning to rank508|1266|11更新时间:2024-05-07
摘要:Over the last decade, different types of media data such as texts, images, and videos grow rapidly on the internet. Different types of data are used for describing the same events or topics. For example, a web page usually contains not only textual description but also images or videos for illustrating the common content. Such different types of data are referred as multi-modal data, which inspire many applications, e.g., multi-modal retrieval, hot topic detection, and perso-nalize recommendation. Nowadays, mobile devices and emerging social websites (e.g., Facebook, Flickr, YouTube, and Twitter) are diffused across all persons, and a demanding requirement for cross-modal data retrieval is emergent. Accordingly, cross-modal retrieval has attracted considerable attention. One type of data is required as the query to retrieve relevant data of another type. For example, a user can use a text to retrieve relevant pictures or/and videos. The query and its retrieved results can have different modalities; thus, measuring the content similarity between different modalities of data, i.e., reducing heterogeneity gap, remains a challenge. With the rapid development of deep learning techniques, various deep cross-modal retrieval approaches have been proposed to alleviate this problem, and promising performance has been obtained. We aim to review and comb representative methods for deep learning based cross-modal retrieval. We first classify these approaches into three main groups based on the cross-modal information provided, i.e.: 1) co-occurrence information, 2) pairwise information, and 3) semantic information. Co-occurrence information based methods indicate that only co-occurrence information is utilized to learn common representations across multi-modal data, where co-occurrence information indicates that if different modalities of data co-exist in a multi-modal document, then they have the same semantic. Pairwise information based methods indicate that similar pairs and dissimilar pairs are utilized to learn the common representations. A similarity matrix for all modalities is usually provided indicating whether or not two points from the modalities are in the same categories. Semantic information based methods indicate that class label information is provided to learn common representations, where a multi-modal example can have one or more labels with massive manual annotation. Usually, co-occurrence information exists in pairwise information and semantic information based approaches, and pairwise information can be derived when semantic information is provided. However, these relationships do not necessarily hold. In each category, various techniques can be utilized and combined to fully use the provided cross-modal information. We roughly categorize these techniques into seven main classes, as follows: 1) canonical correlation analysis, 2) correspondence preserving, 3) metric learning, 4) likelihood analysis, 5) learning to rank, 6) semantic prediction, and 7) adversarial learning. Canonical correlation analysis methods focus on finding linear combinations of two vectors of random variables with the objective of maximizing the correlation. When combined with deep learning, linear projections are replaced with deep neural networks with extra considerations. Correspondence preserving methods aim at preserving the co-existing relationship of different modalities with the objective of minimizing their distances in the learned embedding space. Usually, the multi-modal correspondence relationship is formed as regularizers or loss functions to enforce a pairwise constraint for learning multi-modal common representations. Metric learning approaches seek to establish a distance function for measuring multi-modal similarities with the objective to pull similar pairs of modalities closer and dissimilar pairs apart. Compared with correspondence preserving and canonical correlation analysis methods, similar pairs and dissimilar pairs are provided as restricted conditions when learning common representations. Likelihood analysis methods, based on Bayesian analysis, are generative approaches with the objective of maximizing the likelihood of the observed multi-modal relationship, e.g., similarity. Conventionally, the maximum likelihood estimation objective is derived to maximize the posterior probability of multi-modal observation. Learning to rank approaches aim to construct a ranking model constrained on the common representations with the objective of maintaining the order of multi-modal similarities. Compared with metric learning methods, explicit ranking loss based objectives are usually developed for ranking similarity optimization. Semantic prediction methods are similar to traditional classification model with the objective of predicting accuracy semantic labels of multi-modal data or their relationships. With such high-level semantics utilized, intramodal structure can effectively reflect learning multi-modal common representations. Adversarial learning approaches refer to methods using generative adversarial networks with the objective of being unable to infer the modality sources for learning common representations. Usually, the generative and discriminative models are carefully designed to form a min-max game for learning statistical inseparable common representations. We introduce several multi-modal datasets in the community, i.e., the Wiki image-text dataset, the INRIA-Websearch dataset, the Flickr30K dataset, the Microsoft common objects in context(MS COCO) dataset, the Real-world Web Image Dataset from National University of Singapore(NUS-WIDE) dataset, the pattern analysis, statistical modelling and computational learning visual object classes(PPSCAL Voc) dataset, and the XMedia dataset. Finally, we discuss open problems and future directions. 1) Some researchers have put forward transferred/extendable/zero-shot cross-modal retrieval, which claims that multi-modal data in the source domain and the target domain can have different semantic annotation categories. 2) Effective cross-modal benchmark data-set containing multiple modal data and with a certain volume for the complex algorithm verification to promote cross-modal retrieval performance with huge data is limited. 3) Labeling all cross-modal data and each sample with accurate annotations is impractical; thus, using these limited and noisy multi-modal data for cross-modal retrieval will be an important research direction. 4) Researchers have designed relatively complex algorithms to improve performance, but the requirements of retrieval efficiency are difficult to satisfy. Therefore, designing efficient and high-performance cross-modal retrieval algorithm is a crucial direction. 5) Embedding different modalities into a common representation space is difficult, and extracting fragment level representation for different modal types and developing more complex fragment-level relationship modeling will be some of the future research directions.关键词:cross-modal retrieval;cross-modal hashing;deep learning;common representation learning;adversarial learning;likelihood analysis;learning to rank508|1266|11更新时间:2024-05-07
Image Processing & Communication Technology
-
 摘要:3D vision has numerous applications in various areas, such as autonomous vehicles, robotics, digital city, virtual/mixed reality, human-machine interaction, entertainment, and sports. It covers a broad variety of research topics, ranging from 3D data acquisition, 3D modeling, shape analysis, rendering, to interaction. With the rapid development of 3D acquisition sensors (such as low-cost LiDARs, depth cameras, and 3D scanners), 3D data become even more accessible and available. Moreover, the advances in deep learning techniques further boost the development of 3D vision, with a large number of algorithms being proposed recently. We provide a comprehensive review on progress of 3D vision algorithms in recent few years, mostly in the last year. This survey covers seven different topics, including stereo matching, monocular depth estimation, visual localization in large-scale scenes, simultaneous localization and mapping (SLAM), 3D geometric modeling, dynamic human modeling, and point cloud understanding. Although several surveys are now available in the area of 3D vision, this survey is different from few aspects. First, this study covers a wide range of topics in 3D vision and can therefore benefit a broad research community. On the contrary, most existing works mainly focus on a specific topic, such as depth estimation or point cloud learning. Second, this study mainly focuses on the progress in very recent years. Therefore, it can provide the readers with up-to-date information. Third, this paper presents a direct comparison between the progresses in China and abroad. The recent progress in depth image acquisition, including stereo matching and monocular depth estimation, is initially reviewed. The stereo matching algorithms are divided into non-end-to-end stereo matching, end-to-end stereo matching, and unsupervised stereo matching algorithms. The monocular depth estimation algorithms are categorized into depth regression networks and depth completion networks. The depth regression networks are further divided into encoder-decoder networks and composite networks. Then, the recent progress in visual localization, including visual localization in large-scale scenes and SLAM is reviewed. The visual localization algorithms for large-scale scenes are divided into end-to-end and non-end-to-end algorithms, and these non-end-to-end algorithms are further categorized into deep learning-based feature description algorithms, 2D image retrieval-based visual localization algorithms, 2D-3D matching-based visual localization algorithms, and visual localization algorithms based on the fusion of 2D image retrieval and 2D-3D matching. SLAM algorithms are divided into visual SLAM algorithms and multisensor fusion based SLAM algorithms. The recent progress in 3D modeling and understanding, including 3D geometric modeling, dynamic human modeling, and point cloud understanding is further reviewed. 3D geometric modeling algorithms consist of several components, including deep 3D representation learning, deep 3D generative models, structured representation learning and generative models, and deep learning-based 3D modeling. Dynamic human modeling algorithms are divided into multiview RGB modeling algorithms, single-depth camera-based and multiple-depth camera-based algorithms, and single-view RGB modeling methods. Point cloud understanding algorithms are further categorized into semantic segmentation methods and instance segmentation methods for point clouds. The paper is organized as follows. In Section 1, we present the progress in 3D vision outside China. In Section 2, we introduce the progress of 3D vision in China. In Section 3, the 3D vision techniques developed in China and abroad are compared and analyzed. In Section 4, we point out several future research directions in the area.关键词:stereo matching;monocular depth estimation;visual localization;simultaneous localization and mapping(SLAM);3D geometry modeling;dynamic human reconstruction;point cloud understanding507|726|26更新时间:2024-05-07
摘要:3D vision has numerous applications in various areas, such as autonomous vehicles, robotics, digital city, virtual/mixed reality, human-machine interaction, entertainment, and sports. It covers a broad variety of research topics, ranging from 3D data acquisition, 3D modeling, shape analysis, rendering, to interaction. With the rapid development of 3D acquisition sensors (such as low-cost LiDARs, depth cameras, and 3D scanners), 3D data become even more accessible and available. Moreover, the advances in deep learning techniques further boost the development of 3D vision, with a large number of algorithms being proposed recently. We provide a comprehensive review on progress of 3D vision algorithms in recent few years, mostly in the last year. This survey covers seven different topics, including stereo matching, monocular depth estimation, visual localization in large-scale scenes, simultaneous localization and mapping (SLAM), 3D geometric modeling, dynamic human modeling, and point cloud understanding. Although several surveys are now available in the area of 3D vision, this survey is different from few aspects. First, this study covers a wide range of topics in 3D vision and can therefore benefit a broad research community. On the contrary, most existing works mainly focus on a specific topic, such as depth estimation or point cloud learning. Second, this study mainly focuses on the progress in very recent years. Therefore, it can provide the readers with up-to-date information. Third, this paper presents a direct comparison between the progresses in China and abroad. The recent progress in depth image acquisition, including stereo matching and monocular depth estimation, is initially reviewed. The stereo matching algorithms are divided into non-end-to-end stereo matching, end-to-end stereo matching, and unsupervised stereo matching algorithms. The monocular depth estimation algorithms are categorized into depth regression networks and depth completion networks. The depth regression networks are further divided into encoder-decoder networks and composite networks. Then, the recent progress in visual localization, including visual localization in large-scale scenes and SLAM is reviewed. The visual localization algorithms for large-scale scenes are divided into end-to-end and non-end-to-end algorithms, and these non-end-to-end algorithms are further categorized into deep learning-based feature description algorithms, 2D image retrieval-based visual localization algorithms, 2D-3D matching-based visual localization algorithms, and visual localization algorithms based on the fusion of 2D image retrieval and 2D-3D matching. SLAM algorithms are divided into visual SLAM algorithms and multisensor fusion based SLAM algorithms. The recent progress in 3D modeling and understanding, including 3D geometric modeling, dynamic human modeling, and point cloud understanding is further reviewed. 3D geometric modeling algorithms consist of several components, including deep 3D representation learning, deep 3D generative models, structured representation learning and generative models, and deep learning-based 3D modeling. Dynamic human modeling algorithms are divided into multiview RGB modeling algorithms, single-depth camera-based and multiple-depth camera-based algorithms, and single-view RGB modeling methods. Point cloud understanding algorithms are further categorized into semantic segmentation methods and instance segmentation methods for point clouds. The paper is organized as follows. In Section 1, we present the progress in 3D vision outside China. In Section 2, we introduce the progress of 3D vision in China. In Section 3, the 3D vision techniques developed in China and abroad are compared and analyzed. In Section 4, we point out several future research directions in the area.关键词:stereo matching;monocular depth estimation;visual localization;simultaneous localization and mapping(SLAM);3D geometry modeling;dynamic human reconstruction;point cloud understanding507|726|26更新时间:2024-05-07 -
 摘要:3D reconstruction aims to accurately restore the geometry of an actual scene. It is a fundamental and active research field in computer vision and photogrammetry with important theoretical significance and application value. Acquisition of 3D models is highly relevant for various applications, including smart city, virtual tourism, digital heritage preservation, mapping, and navigation. Various technologies that enable 3D modeling have been developed, and each of them has its own benefits and drawbacks for certain applications. The methods can be classified into two categories, namely, active acquisition methods (e.g., LiDAR and radar) and passive ones (i.e., cameras). As a passive acquisition method, cameras are especially power efficient and do not need direct physical contact with the actual world, and 3D model can be effectively rebuilt from a set of 2D multiview images. In addition, with the increasing availability of cameras as commodity sensors in consumer devices, the cost of camera hardware has decreased significantly. Over the last decades, with the popularization of image acquisition systems (including smart phones, consumer-grade digital cameras, and civil drones) and the rapid development of the Internet, normal people can easily obtain a large number of Internet images about an outdoor scene through search engines (such as Google, Bing, or Baidu). Organizing and utilizing these extremely rich and diverse data source to perform efficient, robust, and accurate 3D reconstruction to provide users with actual perception and immersive experience have become a research hotspot and have attracted widespread attention from the academic and industrial circles. For a human, building an accurate and complete 3D representation of the actual world on the fly is natural, but abstracting the underlying problem in a computer program is extremely hard. Nowadays, many of the underlying problems in large-scale outdoor 3D reconstruction are gradually understood, but many problems, which the research community has not deeply understood, still exist. 3D modeling becomes feasible in computer programming by decomposing the entire reconstruction into several simpler subproblems. Thus far, a growing amount and diversity of methods have been proposed to solve the challenging problem. Some researchers focus on solving the overall modeling problem, and more approaches focus on dealing with subreconstruction tasks. In particular, in recent years, modern convolutional neural network (CNN) models have achieved the best quality for object recognition, image segmentation, image translation, and some other challenging computer vision problems. The emergence of deep learning provides new opportunities and increasing interests for the research on large-scale outdoor image 3D reconstruction. However, 3D reconstruction experiences rapid development from traditional period to deep learning era. Interestingly, to the best of our knowledge, no previous work has presented an overview of recent progress in the large-scale outdoor image 3D reconstruction in detail. To conclude the rapid evolution of this field, traditional image-based 3D reconstruction approaches are presented, a comprehensive survey of the recent learning-based developments is provided. Specifically, the basic serial pipeline of large-scale outdoor image 3D reconstruction, including image retrieval, image feature matching, structure from motion, and multiview stereo is described. Then, traditional methods and deep learning-based methods are distinguished, and the development and application of large-scale outdoor image 3D reconstruction technology in each reconstruction subprocess are systematically and comprehensively reviewed. We show that, although deep learning-based methods have achieved overwhelming advantages in other computer vision and natural language processing tasks, geometric-based methods, which are adopted by some common 3D reconstruction systems, still illuminate higher robust and accurate performance in 3D reconstruction. This finding indicates that deep learning methods can be remarkably improved. Subsequently, the datasets and evaluation indicators applicable to large-scale outdoor scenes in each subprocess are summarized in detail. Furthermore, we introduce the datasets used in each subtask and present a comprehensive dataset specifically for 3D reconstruction. Finally, the current mainstream open source and commercial 3D reconstruction systems and the development status of domestic related industries are introduced. Although the image-based 3D reconstruction technology has made great progress in the past 10 years, the current method still has some problems, as follows: 1) For scenes with repeated textures (such as the Temple of Heaven), the structure from motion process fails, resulting in inaccurate registered camera posed and incomplete reconstruction models; for scenes with weak textures (such as lake surface, glass curtain wall), multiview stereo process fails, thereby resulting in holes in the reconstructed model. 2) The current 3D reconstruction system consumes considerable time to reconstruct scenes (especially large-scale scenes); this approach is different from real-time reconstruction. 3) The price of 3D sensors (such as LiDAR and ToF) has dropped significantly; thus, they become closer to consumer applications. Using these sensors to effectively compensate for the lack of image-based 3D reconstruction is still an unsolved problem.关键词:3D reconstruction;image retrieval;image feature matching;structure-from-motion;multi-view-stereo159|613|5更新时间:2024-05-07
摘要:3D reconstruction aims to accurately restore the geometry of an actual scene. It is a fundamental and active research field in computer vision and photogrammetry with important theoretical significance and application value. Acquisition of 3D models is highly relevant for various applications, including smart city, virtual tourism, digital heritage preservation, mapping, and navigation. Various technologies that enable 3D modeling have been developed, and each of them has its own benefits and drawbacks for certain applications. The methods can be classified into two categories, namely, active acquisition methods (e.g., LiDAR and radar) and passive ones (i.e., cameras). As a passive acquisition method, cameras are especially power efficient and do not need direct physical contact with the actual world, and 3D model can be effectively rebuilt from a set of 2D multiview images. In addition, with the increasing availability of cameras as commodity sensors in consumer devices, the cost of camera hardware has decreased significantly. Over the last decades, with the popularization of image acquisition systems (including smart phones, consumer-grade digital cameras, and civil drones) and the rapid development of the Internet, normal people can easily obtain a large number of Internet images about an outdoor scene through search engines (such as Google, Bing, or Baidu). Organizing and utilizing these extremely rich and diverse data source to perform efficient, robust, and accurate 3D reconstruction to provide users with actual perception and immersive experience have become a research hotspot and have attracted widespread attention from the academic and industrial circles. For a human, building an accurate and complete 3D representation of the actual world on the fly is natural, but abstracting the underlying problem in a computer program is extremely hard. Nowadays, many of the underlying problems in large-scale outdoor 3D reconstruction are gradually understood, but many problems, which the research community has not deeply understood, still exist. 3D modeling becomes feasible in computer programming by decomposing the entire reconstruction into several simpler subproblems. Thus far, a growing amount and diversity of methods have been proposed to solve the challenging problem. Some researchers focus on solving the overall modeling problem, and more approaches focus on dealing with subreconstruction tasks. In particular, in recent years, modern convolutional neural network (CNN) models have achieved the best quality for object recognition, image segmentation, image translation, and some other challenging computer vision problems. The emergence of deep learning provides new opportunities and increasing interests for the research on large-scale outdoor image 3D reconstruction. However, 3D reconstruction experiences rapid development from traditional period to deep learning era. Interestingly, to the best of our knowledge, no previous work has presented an overview of recent progress in the large-scale outdoor image 3D reconstruction in detail. To conclude the rapid evolution of this field, traditional image-based 3D reconstruction approaches are presented, a comprehensive survey of the recent learning-based developments is provided. Specifically, the basic serial pipeline of large-scale outdoor image 3D reconstruction, including image retrieval, image feature matching, structure from motion, and multiview stereo is described. Then, traditional methods and deep learning-based methods are distinguished, and the development and application of large-scale outdoor image 3D reconstruction technology in each reconstruction subprocess are systematically and comprehensively reviewed. We show that, although deep learning-based methods have achieved overwhelming advantages in other computer vision and natural language processing tasks, geometric-based methods, which are adopted by some common 3D reconstruction systems, still illuminate higher robust and accurate performance in 3D reconstruction. This finding indicates that deep learning methods can be remarkably improved. Subsequently, the datasets and evaluation indicators applicable to large-scale outdoor scenes in each subprocess are summarized in detail. Furthermore, we introduce the datasets used in each subtask and present a comprehensive dataset specifically for 3D reconstruction. Finally, the current mainstream open source and commercial 3D reconstruction systems and the development status of domestic related industries are introduced. Although the image-based 3D reconstruction technology has made great progress in the past 10 years, the current method still has some problems, as follows: 1) For scenes with repeated textures (such as the Temple of Heaven), the structure from motion process fails, resulting in inaccurate registered camera posed and incomplete reconstruction models; for scenes with weak textures (such as lake surface, glass curtain wall), multiview stereo process fails, thereby resulting in holes in the reconstructed model. 2) The current 3D reconstruction system consumes considerable time to reconstruct scenes (especially large-scale scenes); this approach is different from real-time reconstruction. 3) The price of 3D sensors (such as LiDAR and ToF) has dropped significantly; thus, they become closer to consumer applications. Using these sensors to effectively compensate for the lack of image-based 3D reconstruction is still an unsolved problem.关键词:3D reconstruction;image retrieval;image feature matching;structure-from-motion;multi-view-stereo159|613|5更新时间:2024-05-07 - 摘要:Recently, significant developments of visual sensing have been observed in imaging technology and data processing, thereby providing great opportunities to enhance our ability to perceive and recognize our real world. Therefore, investigations on visual sensing possess important theoretical value and are required for application needs. Surveying the progress to understand the trend in the field of visual sensing and to clarify the future research direction is beneficial. The reviews are generated mainly based on analyzing peer-reviewed academic publications and related reports. A general description on the states of the art and trends about the visual sensing is provided, mainly including laser scanning, high dynamic range (HDR) imaging, polarization imaging, and ocean acoustic tomography. Specifically, for each of these imaging fields, parts discussed include new hardware, processing technology, and application scenarios. Processing of 3D point cloud data has become more effective along with the great progresses in deep learning and the advancement of hardware devices. Meanwhile, applications of 3D point cloud data are increasingly popular for diverse purposes. Over past several years, many domestic institutions and teams focused on developing algorithms for 3D point cloud data processing, such as in feature extraction, semantic labeling and segmentation, and object detection. In particular, several teams have conducted a number of substantive work in the production and sharing of standard data sets, which promote and improve the processing ability and application level of point cloud data. However, at present, the commercial hardware still has some deficiencies. Combining 3D point cloud data with observation from other sensors is a valuable but challenging task. Nevertheless, the laser scanning system is expected to be widely used in transportation, civil engineering, forestry, agriculture, and other civil fields in the future to satisfy different detection and modeling tasks. At the same time, with ongoing advancements in laser scanning equipment, it also plays an important role in understanding natural sciences, such as archaeology and geoscience. High dynamic range imaging is a hot research field in digital image acquisition, processing, display, and applications. Currently, researchers mostly focus on multiple exposure, different modulation methods, and multi detector methods in the HDR imaging. For example, through nonlinear response and multiple exposure imaging, the dynamic range can reach approximately 140 dB, and it can reach approximately 160 dB by using multi detector imaging. Using deep learning directly in HDR image mapping, instead of using traditional methodology, such as optical flow method and the combination of optical flow and neural network, has become a distinguished characteristic. Deep learning neural network has also been gradually applied to single exposure HDR reconstruction and tone mapping. Many domestic research teams have investigated the issues for the combination of deep learning neural network and HDR imaging. As expected, advancements in deep neural network provide a good opportunity for processing HDR imaging, such as in image fusion. With potential advancements in new detector materials, detector design, semiconductor equipment, and technology towards nanotechnology, new detectors with 10 megapixel resolution and dynamic range better than 160 dB will be available and will greatly improve the sensitivity under low illumination. Important fields urgently need breakthrough, including HDR imaging of dynamic scene and acquisition, processing and display of color HDR imaging with large dynamics, and wide color gamut. Compared with the progresses in polarization imaging made by other countries (e.g., the United States of America, Canada, and Japan), the systematicness and practicability in DoFP CMOS chip research domestically still need to be improved. In practice, the domestic institutions have made continuous achievements in many polarization imaging issues, including mosaic removal, polarization defogging, underwater polarization, polarization 3D imaging, imaging polarization spectral remote sensing, airborne polarization imaging, marine environment spectral polarization imaging, and spatial polarization detection. Furthermore, integrated optical detection of land, sea, air, and space is a critical demand, which promotes the rapid development of polarization imaging and sensing. In multisource data fusion, many methods and technologies showed excellent performance in their respective applications correspondingly, including multidimensional data acquisition and intelligent processing of "polarization +", polarization + infrared, polarization + spectrum, polarization + TOF, polarization structured light, fluorescence polarization imaging (FPI), polarization-sensitive optical coherence tomography (PS-OCT), polarization-dependent optical second harmonic imaging, and polarization confocal microscopy imaging. In ocean acoustic tomography, institutions from the United States of America published the largest number of papers, showing distinguished trends from other countries. At the same time, as a country with the largest number of published patents, Japan shows great importance to ocean acoustic tomography and has certain advantages in technological innovation. Compared with institutions from the United States of America and Japan, institutions from China have published relatively a small number of papers and patents in ocean acoustic tomography. With more than 40 years of its development, great progresses were made in theory and technology. However, the application of ocean acoustic tomography still faces the bottleneck of high cost of sea trial, which is also impossibly used as an observation means alone. In conclusion, 1) the 3D modeling based on laser scanning still faces many challenges, although progresses have been made recently. With the development of hardware and progress in data processing, laser scanning system benefits many civil fields in the future to satisfy different detection and modeling tasks; 2) high dynamic range optical imaging technology has been gradually applied to many fields, mainly including infrared imaging, spectral imaging, polarization imaging, ultrasonic imaging, and single photon imaging, which are valuable for multidimensional information acquisition, intelligent processing, and data mining; 3) fully exploiting the potential of polarization imaging has great value. Furthermore, to achieve its better performance, the combination with other advanced imaging sensing technologies is necessary. 4) Marine acoustic tomography needs to be combined with other means to develop a low-cost, long-term observation network, which is based on distributed underwater sensor networks, satellite observations, submarine cables, as well as using artificial and natural noise as sound source of opportunity.关键词:visual sensing;laser scanning;high dynamic range imaging;polarization imaging;ocean acoustic tomography64|69|3更新时间:2024-05-07
-
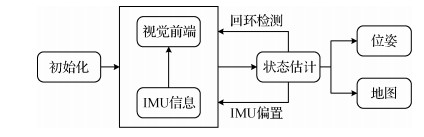 摘要:Visual-inertial navigation and positioning technology is a passive navigation method, which can realize the estimation of ego-motion and the perception of the surrounding environment. In particular, this method can realize six-degree of freedom(DOF) pose estimation of the carrier in GPS-denied environments, such as indoor and underwater environment, and even play a positive role in space exploration. In addition, from a biological point of view, visual-inertial navigation is a bionic navigation method because humans and animals realize their own navigation and positioning through visual and motion perception. The visual-inertial integrated navigation has significant advantages. First, these sensors have the advantages of small size and low cost. Second, different from active navigation, visual-inertial navigation system (VINS) does not rely on external auxiliary devices. The navigation and positioning function can be realized independently without exchanging information with the external environment. Finally, the visual and inertial sensors have very complementary characteristics. For example, the output frequency of visual navigation is low, and no accumulated error is found when it is stationary; it is susceptible to changes in the external environment and cannot adapt to the situation of fast movement. At the same time, the output frequency of inertial navigation is high, and it is robust to the changes in the external environment. It can accurately capture the information of the rapid movement of the carrier, but it has an accumulated error. VINS plays an important role in mobile virtual reality, augmented reality, and autonomous navigation tasks of unmanned system, with an important theoretical research value and practical application requirements. In recent years, the visual-inertial navigation technology has developed rapidly, and many excellent works have emerged and improved the theory of visual-inertial navigation technology. At present, the structure of the algorithm is relatively fixed, and the positioning accuracy of the state-of-the-art VINS in some small-scale structured scenes is as high as centimeter. However, it faces many problems when applied in many complex practical scenes. On the one hand, the real-time performance of the system is difficult to satisfy because visual image processing and back-end optimization bring a large computation burden. Meanwhile, the scale of mapping is a challenge to memory consumption. On the other hand, the performance of this technology in some low-texture, dynamic illumination, large-scale, and dynamic scenes is poor. These complex environments are challenging to the stability of VINS, thereby acting as the major obstacles to the large-scale application of VINS at present. These complex environments directly affect the processing results of the visual front-end and are often difficult to handle by traditional geometric methods. With the strong ability of deep learning technology in image processing, some researchers attempt to use deep learning to replace the traditional image processing technology and even abandon the traditional VINS framework, thereby directly estimating poses with the end-to-end framework. The learning-based method can use the rich semantic information in the image and has more advantages in the complex environment, such as dynamic scene. The purpose of this article is to help those who are interested in VINS to quickly understand the current state of research in this field, as well as the future research directions of interest. The VINS is introduced, and then the research progress of the key technologies in the system, such as initialization, visual front-end processing, state estimation, map construction and maintenance, and information fusion is summarized. In addition, some hot issues, such as visual-inertial navigation algorithm in non-ideal environment and learning-based localization algorithm, are reviewed. The standard datasets used for algorithm evaluation are summarized, and the future development trend of this field is prospected.关键词:visual-inertial navigation system (VINS);simultaneous localization and mapping(SLAM);information fusion;state estimation;deep learning341|699|4更新时间:2024-05-07
摘要:Visual-inertial navigation and positioning technology is a passive navigation method, which can realize the estimation of ego-motion and the perception of the surrounding environment. In particular, this method can realize six-degree of freedom(DOF) pose estimation of the carrier in GPS-denied environments, such as indoor and underwater environment, and even play a positive role in space exploration. In addition, from a biological point of view, visual-inertial navigation is a bionic navigation method because humans and animals realize their own navigation and positioning through visual and motion perception. The visual-inertial integrated navigation has significant advantages. First, these sensors have the advantages of small size and low cost. Second, different from active navigation, visual-inertial navigation system (VINS) does not rely on external auxiliary devices. The navigation and positioning function can be realized independently without exchanging information with the external environment. Finally, the visual and inertial sensors have very complementary characteristics. For example, the output frequency of visual navigation is low, and no accumulated error is found when it is stationary; it is susceptible to changes in the external environment and cannot adapt to the situation of fast movement. At the same time, the output frequency of inertial navigation is high, and it is robust to the changes in the external environment. It can accurately capture the information of the rapid movement of the carrier, but it has an accumulated error. VINS plays an important role in mobile virtual reality, augmented reality, and autonomous navigation tasks of unmanned system, with an important theoretical research value and practical application requirements. In recent years, the visual-inertial navigation technology has developed rapidly, and many excellent works have emerged and improved the theory of visual-inertial navigation technology. At present, the structure of the algorithm is relatively fixed, and the positioning accuracy of the state-of-the-art VINS in some small-scale structured scenes is as high as centimeter. However, it faces many problems when applied in many complex practical scenes. On the one hand, the real-time performance of the system is difficult to satisfy because visual image processing and back-end optimization bring a large computation burden. Meanwhile, the scale of mapping is a challenge to memory consumption. On the other hand, the performance of this technology in some low-texture, dynamic illumination, large-scale, and dynamic scenes is poor. These complex environments are challenging to the stability of VINS, thereby acting as the major obstacles to the large-scale application of VINS at present. These complex environments directly affect the processing results of the visual front-end and are often difficult to handle by traditional geometric methods. With the strong ability of deep learning technology in image processing, some researchers attempt to use deep learning to replace the traditional image processing technology and even abandon the traditional VINS framework, thereby directly estimating poses with the end-to-end framework. The learning-based method can use the rich semantic information in the image and has more advantages in the complex environment, such as dynamic scene. The purpose of this article is to help those who are interested in VINS to quickly understand the current state of research in this field, as well as the future research directions of interest. The VINS is introduced, and then the research progress of the key technologies in the system, such as initialization, visual front-end processing, state estimation, map construction and maintenance, and information fusion is summarized. In addition, some hot issues, such as visual-inertial navigation algorithm in non-ideal environment and learning-based localization algorithm, are reviewed. The standard datasets used for algorithm evaluation are summarized, and the future development trend of this field is prospected.关键词:visual-inertial navigation system (VINS);simultaneous localization and mapping(SLAM);information fusion;state estimation;deep learning341|699|4更新时间:2024-05-07 -
 摘要:3D vision measurement is a new and advanced technology of computer vision and precision measurement. It is the basic support of industry 4.0 and the core and key technology of advanced manufacturing industry characterized by networked and intelligent manufacturing. After decades of development, 3D vision measurement technology has been developed rapidly in basic research and applied research. It has formed the relatively complete direction system of four parts: theoretical method, technical process, system development and product application. 3D vision measurement technology presents a trend of systematic theory, multi-dimensional method, precise precision and rapid speed, which has become an indispensable optimization technology of intelligent manufacturing process control, product quality inspection and guarantee, and complete equipment service test. This paper mainly focuses on typical 3D vision measurement technologies such as single-camera, double-camera and structured-light, and briefly introduces the connotation of the key technologies and summarizes its development status, frontier trends, hot issues and development trends. Single-, stereo-, and multiple cameras-based measuring system belong to passive vision, without external energy being projected on the surface of the object under test. Active vision technique projects some kind of energy onto the object surface, mainly including point-scanning, line-scanning, full-field, and time of flight. Therefore, active vision technique has been widely studied in academic and applied in many fields because of the advantages of high accuracy, non-contact, and automatic data processing. In this paper, the 3D measurement technique of fringe projection profilometry (FPP) and phase measuring deflectometry (PMD) are mainly discussed. FPP-based techniques are widely applied to measure the diffused surface. A set of or one fringe patterns are generated in software and projected by a digital light processing (DLP) projector. From a different viewpoint, an imaging device, normally a charge coupled device(CCD) camera captures the deformed fringe patterns modulated by the object surface under test. Multiple-step phase shifting algorithm or transform-based algorithm (such as Fourier transform, windowed Fourier transform, wavelet transform) can be used to obtain the wrapped phase map from a set of fringe patterns or from one fringe pattern. The wrapped phase needs to be unwrapped by using spatial phase unwrapping or temporal phase unwrapping. Spatial phase unwrapping is suitable to measure objects with smooth surface, while temporal phase unwrapping can measure objects with large step and/or discontinuous surface. In order to obtain 3D shape data, the measuring system needs to be 3D calibrated, which builds up the relationship between unwrapped phase map and 3D data. The absolute phase and the pixel position will be transferred to depth data and horizontal coordinates, respectively. The error will be analyzed in detail to improve the measurement accuracy. PMD-based techniques are mainly applied to measure the specular surface because they have the advantages of high accuracy, large dynamic, automatic data processing, and non-contact operation. The generated fringe patterns are displayed on the liquid crystal device (LCD) screen, instead of being projected on to the measured surface. The reflected fringe patterns by the specular surface are captured by a CCD camera according to the law of reflection. The obtained fringe patterns are processed by the same algorithms in FPP. In order to measure dynamic specular surface, single shot PMD methods have been developed. One fringe image has been modulated by orthogonally modulating two fringe patterns into one image. Or one composite fringe image can be generated by modulating three fringe patterns into the primary color channels of a color image. Therefore, multiple fringe patterns can be obtained from single shot image. The obtained phase information is related to the gradient of the measured specular surface, instead of the depth, so integration procedure is needed to reconstruct the 3D shape. Many integration methods have been studied, such as radial basis function, least square method, and Fourier transform method. Some researchers developed a direct PMD (DPMD) method to measure specular objects with discontinuous surface. This method builds up the direct relationship between the absolute phase and depth data, without integration procedure. One important step in PMD is how to calibrate the geometric parameters of the measuring system, mainly the distance and orientation between the LCD screen, the reference plane (the measured specular surface) and the camera. Error sources have been analyzed to improve the accuracy of the measured data as well. 3D shape data have many applications in the fields of aeronautics and astronautics, car industry, advanced equipment manufacturing measurements, health care industry, and conservation of antiquities. These applications will be described. Finally, the development trend and future prospect of 3D vision measurement are given. Although 3D measurement techniques have been matured, many aspects need to be further improved. The most important are the following two: accuracy and speed. FPP-based and DPM-based techniques can reach micrometer and nanometer level, respectively. Some applications need more high-level accuracy. The third trend is extreme size and environment. The fourth are to measure objects with complex attribute surface. For example, there are objects having high reflective surface and specular/diffuse surface. The fifth trend is on-site measurement, which can be used in machining tools and assembly line. The last one is portable measurement, so that it can be easily integrated into other components.关键词:3D vision measurement;fringe projection profilometry;phase measuring deflectometry;phase calculation;calibration;review466|640|27更新时间:2024-05-07
摘要:3D vision measurement is a new and advanced technology of computer vision and precision measurement. It is the basic support of industry 4.0 and the core and key technology of advanced manufacturing industry characterized by networked and intelligent manufacturing. After decades of development, 3D vision measurement technology has been developed rapidly in basic research and applied research. It has formed the relatively complete direction system of four parts: theoretical method, technical process, system development and product application. 3D vision measurement technology presents a trend of systematic theory, multi-dimensional method, precise precision and rapid speed, which has become an indispensable optimization technology of intelligent manufacturing process control, product quality inspection and guarantee, and complete equipment service test. This paper mainly focuses on typical 3D vision measurement technologies such as single-camera, double-camera and structured-light, and briefly introduces the connotation of the key technologies and summarizes its development status, frontier trends, hot issues and development trends. Single-, stereo-, and multiple cameras-based measuring system belong to passive vision, without external energy being projected on the surface of the object under test. Active vision technique projects some kind of energy onto the object surface, mainly including point-scanning, line-scanning, full-field, and time of flight. Therefore, active vision technique has been widely studied in academic and applied in many fields because of the advantages of high accuracy, non-contact, and automatic data processing. In this paper, the 3D measurement technique of fringe projection profilometry (FPP) and phase measuring deflectometry (PMD) are mainly discussed. FPP-based techniques are widely applied to measure the diffused surface. A set of or one fringe patterns are generated in software and projected by a digital light processing (DLP) projector. From a different viewpoint, an imaging device, normally a charge coupled device(CCD) camera captures the deformed fringe patterns modulated by the object surface under test. Multiple-step phase shifting algorithm or transform-based algorithm (such as Fourier transform, windowed Fourier transform, wavelet transform) can be used to obtain the wrapped phase map from a set of fringe patterns or from one fringe pattern. The wrapped phase needs to be unwrapped by using spatial phase unwrapping or temporal phase unwrapping. Spatial phase unwrapping is suitable to measure objects with smooth surface, while temporal phase unwrapping can measure objects with large step and/or discontinuous surface. In order to obtain 3D shape data, the measuring system needs to be 3D calibrated, which builds up the relationship between unwrapped phase map and 3D data. The absolute phase and the pixel position will be transferred to depth data and horizontal coordinates, respectively. The error will be analyzed in detail to improve the measurement accuracy. PMD-based techniques are mainly applied to measure the specular surface because they have the advantages of high accuracy, large dynamic, automatic data processing, and non-contact operation. The generated fringe patterns are displayed on the liquid crystal device (LCD) screen, instead of being projected on to the measured surface. The reflected fringe patterns by the specular surface are captured by a CCD camera according to the law of reflection. The obtained fringe patterns are processed by the same algorithms in FPP. In order to measure dynamic specular surface, single shot PMD methods have been developed. One fringe image has been modulated by orthogonally modulating two fringe patterns into one image. Or one composite fringe image can be generated by modulating three fringe patterns into the primary color channels of a color image. Therefore, multiple fringe patterns can be obtained from single shot image. The obtained phase information is related to the gradient of the measured specular surface, instead of the depth, so integration procedure is needed to reconstruct the 3D shape. Many integration methods have been studied, such as radial basis function, least square method, and Fourier transform method. Some researchers developed a direct PMD (DPMD) method to measure specular objects with discontinuous surface. This method builds up the direct relationship between the absolute phase and depth data, without integration procedure. One important step in PMD is how to calibrate the geometric parameters of the measuring system, mainly the distance and orientation between the LCD screen, the reference plane (the measured specular surface) and the camera. Error sources have been analyzed to improve the accuracy of the measured data as well. 3D shape data have many applications in the fields of aeronautics and astronautics, car industry, advanced equipment manufacturing measurements, health care industry, and conservation of antiquities. These applications will be described. Finally, the development trend and future prospect of 3D vision measurement are given. Although 3D measurement techniques have been matured, many aspects need to be further improved. The most important are the following two: accuracy and speed. FPP-based and DPM-based techniques can reach micrometer and nanometer level, respectively. Some applications need more high-level accuracy. The third trend is extreme size and environment. The fourth are to measure objects with complex attribute surface. For example, there are objects having high reflective surface and specular/diffuse surface. The fifth trend is on-site measurement, which can be used in machining tools and assembly line. The last one is portable measurement, so that it can be easily integrated into other components.关键词:3D vision measurement;fringe projection profilometry;phase measuring deflectometry;phase calculation;calibration;review466|640|27更新时间:2024-05-07 -
 摘要:Mixed reality systems can provide virtual and real fusion environment, in which the virtual objects add to the real world in real time. Mixed reality systems have been widely used in education, training, heritage preservation, military simulation, equipment manufacturing, surgery, and exhibition. The mixed reality systems use the calibration data to build a virtual camera model, and then draw virtual content in real time based on the head tracking data and the position of the virtual camera. Finally, the virtual content is superimposed in the real environment. The user perceives the virtual object's depth information according to the integration of graphical cues and virtual object rendering features in the virtual and real fusion environment. When the user observes the virtual-real fusion scene presented by the mixed reality system, the following processes are included: 1) different distance information are converted into respective distance signals. The key role in this process is to present the virtual-real fusion scene through rendering technology. The user judges the distance on the basis of the inherent characteristics of the virtual object. 2) The user recognizes other visual stimulus variables in the scene and converts respective distance signal into the final distance signal. The key role in this process is to provide cues of depth information in the virtual and real fusion scene. The user needs to use depth cues to determine the position of the object. 3) They determine the distance relationship between the objects in the scene and convert the final distance signal into the corresponding indicated distance. The key role in this process is the visual law of the human eye when viewing the virtual and real scene. However, problems, such as the lack of visual principles and perception theories that can be used to guide the rendering of virtual and real fusion scenes, the lack of absolute depth information that the graphical clues can provide, and the lack of rendering features of virtual objects, are found. The study on the visual laws and perception theories that can be used to guide the rendering of virtual and real scenes is limited. The visual model and perception laws of the human eye should be studied when viewing virtual-real fusion scenes to form effective application guidance and improve virtual-real fusion scenes to apply visual laws effectively in the design and development of virtual-real fusion scenes and increase the accuracy of depth perception. The rendering effect of the mixed reality application improves the interactive efficiency and user experience of mixed reality applications. The absolute depth information that can be provided by graphical cues in the virtual-real fusion scene is missing. Graphical cues that can provide effective absolute depth information in the scene should be generated, the characteristics of different graphical cues should be extracted, and the effects on depth perception should be quantified to help users perceive the depth of the target object. This approach improves user performance in depth perception and provide a basis for rendering of virtual and real scenes. The rendering dimensions and characteristic indicators of virtual objects in virtual and real fusion scenes are insufficient. Reasonable parameter indicators and effective object rendering methods should be studied, different feature interaction models should be built, and the role of different virtual object rendering characteristics in depth perception should be clarified to determine the characteristics that play a major role in the rendering of virtual objects in virtual and real scenes. Finally, the study can provide a basis for rendering the fusion scene. The visual principle in virtual and real fusion environment rendering is analyzed, and then the rendering of graphical cues and virtual object in virtual and real fusion scenes is summarized, and finally the research trend of depth perception in virtual and real fusion scenes is discussed. When viewing virtual and real scenes, humans perceive objects in the scene through the visual system. The visual function factors related to the perception mechanism and the guiding effect of visual laws on depth perception should be studied to optimize the rendering of virtual and real scenes. With the development and application of perception technology in mixed reality, in recent years, many researchers have carried out studies on ground contact theory, the anisotropy of human eye perception, and the distribution of human eye gaze points in depth perception. The background environment and virtual objects in the virtual and real fusion scene can provide users with depth information cues. Most existing related studies focus on adding various depth cues to the virtual and real fusion scene and explore the relationship between additional depth information and depth perception in the scene through experiments. With the rapid development of computer graphics, in recent years, an increasing number of graphic technologies have been applied to the creation of virtual and real fusion scenes to enhance the depth position prompts of virtual objects, including linear perspective, graphical techniques for prompting position information, and creating X-ray vision Graphics technology. The virtual objects presented in the mixed reality system are an important part of the virtual and real fusion environment. In recent years, to study the role of the inherent characteristics of virtual objects in virtual and real fusion scenes in depth perception, researchers have carried out a large number of quantifications in terms of the size, color, brightness, transparency, texture, and surface lighting of virtual objects through experimental study. These rendering-based virtual object characteristics were extracted from the 17th century painting techniques, but they are different from traditional painting depth cues.关键词:real and virtual fusion environment;scene rendering;depth perception;mixed reality;visual law;depth cues;perceptual matching109|136|4更新时间:2024-05-07
摘要:Mixed reality systems can provide virtual and real fusion environment, in which the virtual objects add to the real world in real time. Mixed reality systems have been widely used in education, training, heritage preservation, military simulation, equipment manufacturing, surgery, and exhibition. The mixed reality systems use the calibration data to build a virtual camera model, and then draw virtual content in real time based on the head tracking data and the position of the virtual camera. Finally, the virtual content is superimposed in the real environment. The user perceives the virtual object's depth information according to the integration of graphical cues and virtual object rendering features in the virtual and real fusion environment. When the user observes the virtual-real fusion scene presented by the mixed reality system, the following processes are included: 1) different distance information are converted into respective distance signals. The key role in this process is to present the virtual-real fusion scene through rendering technology. The user judges the distance on the basis of the inherent characteristics of the virtual object. 2) The user recognizes other visual stimulus variables in the scene and converts respective distance signal into the final distance signal. The key role in this process is to provide cues of depth information in the virtual and real fusion scene. The user needs to use depth cues to determine the position of the object. 3) They determine the distance relationship between the objects in the scene and convert the final distance signal into the corresponding indicated distance. The key role in this process is the visual law of the human eye when viewing the virtual and real scene. However, problems, such as the lack of visual principles and perception theories that can be used to guide the rendering of virtual and real fusion scenes, the lack of absolute depth information that the graphical clues can provide, and the lack of rendering features of virtual objects, are found. The study on the visual laws and perception theories that can be used to guide the rendering of virtual and real scenes is limited. The visual model and perception laws of the human eye should be studied when viewing virtual-real fusion scenes to form effective application guidance and improve virtual-real fusion scenes to apply visual laws effectively in the design and development of virtual-real fusion scenes and increase the accuracy of depth perception. The rendering effect of the mixed reality application improves the interactive efficiency and user experience of mixed reality applications. The absolute depth information that can be provided by graphical cues in the virtual-real fusion scene is missing. Graphical cues that can provide effective absolute depth information in the scene should be generated, the characteristics of different graphical cues should be extracted, and the effects on depth perception should be quantified to help users perceive the depth of the target object. This approach improves user performance in depth perception and provide a basis for rendering of virtual and real scenes. The rendering dimensions and characteristic indicators of virtual objects in virtual and real fusion scenes are insufficient. Reasonable parameter indicators and effective object rendering methods should be studied, different feature interaction models should be built, and the role of different virtual object rendering characteristics in depth perception should be clarified to determine the characteristics that play a major role in the rendering of virtual objects in virtual and real scenes. Finally, the study can provide a basis for rendering the fusion scene. The visual principle in virtual and real fusion environment rendering is analyzed, and then the rendering of graphical cues and virtual object in virtual and real fusion scenes is summarized, and finally the research trend of depth perception in virtual and real fusion scenes is discussed. When viewing virtual and real scenes, humans perceive objects in the scene through the visual system. The visual function factors related to the perception mechanism and the guiding effect of visual laws on depth perception should be studied to optimize the rendering of virtual and real scenes. With the development and application of perception technology in mixed reality, in recent years, many researchers have carried out studies on ground contact theory, the anisotropy of human eye perception, and the distribution of human eye gaze points in depth perception. The background environment and virtual objects in the virtual and real fusion scene can provide users with depth information cues. Most existing related studies focus on adding various depth cues to the virtual and real fusion scene and explore the relationship between additional depth information and depth perception in the scene through experiments. With the rapid development of computer graphics, in recent years, an increasing number of graphic technologies have been applied to the creation of virtual and real fusion scenes to enhance the depth position prompts of virtual objects, including linear perspective, graphical techniques for prompting position information, and creating X-ray vision Graphics technology. The virtual objects presented in the mixed reality system are an important part of the virtual and real fusion environment. In recent years, to study the role of the inherent characteristics of virtual objects in virtual and real fusion scenes in depth perception, researchers have carried out a large number of quantifications in terms of the size, color, brightness, transparency, texture, and surface lighting of virtual objects through experimental study. These rendering-based virtual object characteristics were extracted from the 17th century painting techniques, but they are different from traditional painting depth cues.关键词:real and virtual fusion environment;scene rendering;depth perception;mixed reality;visual law;depth cues;perceptual matching109|136|4更新时间:2024-05-07 -
 摘要:Differential rendering is currently a research focus in virtual reality, computer graphics, and computer vision. Its goal is to reform the rendering pipeline in computer graphics to support gradient backpropagation such that the change in the output image can be related to the change in input geometry or materials. The development of differential rendering technique is highly related to the deep learning, since neural networks are usually represented as computational graphs to support gradient backpropagation using the chain rule. Thus, the gradient backpropagation is the key to convert a computational procedure into a learnable process, which can significantly generalize the deep learning technique to a wide range of applications. Differential rendering follows this trend to integrate gradient backpropagation into rendering pipeline. It can significantly facilitate the gradient computation through auto-differential techniques. In fact, the derivatives of rendering results regarding to the mesh vertex have already computed in variational 3D reconstruction and shape from shading. However, differential rendering integrates the derivative computation into global rendering pipelines and neural networks. Therefore, the rendering process can be directly integrated into optimization or neural network training to approximate rendering pipeline or inverse graphics reasoning; it has wide applications in content creation in augmented/virtual reality, 3D reconstruction, appearance modeling, and inverse design. The advantage of differential rendering over traditional rendering pipeline is that it allows to train neural networks to approximate the forward rendering pipeline. Once trained, the rendering results can be obtained through forward inference of the network, a much faster procedure in many situations. Moreover, the gradient information provided by differential rendering is helpful to improve the efficiency of the global rendering. For instance, the first- and second-order gradients can be used to guide the sampling process in Monte Carlo rendering. Another advantage of differential rendering is that it can directly be used in view interpolation or view synthesis through captured images, which traditional rendering pipeline needs geometry, appearance and lighting information simultaneously to render an image at specified viewpoints. In the application of differential rendering to view synthesis or image-based rendering, the implicit representation of a 3D scene is usually inferred from the captured images directly via deep neural networks supervised by differential rendering loss. Such a process falls into the category of self-supervised learning because ground truth 3D data are not provided during training. It bypasses the expensive multi-view 3D reconstruction and thus significantly simplifies the view synthesis procedure. Numerous representations, such as neural texture, neural volume, and neural implicit function, are proposed to handle freeview point rendering of a 3D scene. However, the training and rendering cost of these methods is still expensive. Thus, reducing their computational cost forms a new research direction. Differential rendering also enables the end-to-end inference of spatially variant bidirectional reflectance distribution function (BRDF) material properties from capture images. The BRDF parameters can be derived from a single image after training the deep neural network on a large amount of data by representing the material properties in a latent space. Moreover, with a differentiable pipeline, the layout of the light sources and projection patterns of dedicated appearance acquisition equipment can be optimized.The recent development of differential rendering, including its application in realistic rendering, 3D reconstruction, and appearance modeling is comprehensively surveyed. We expect this study to further boost the research on differential rendering in academia and industry.关键词:differential rendering;3D reconstruction;appearance modeling;image-based rendering;representation learning;deep learning184|455|3更新时间:2024-05-07
摘要:Differential rendering is currently a research focus in virtual reality, computer graphics, and computer vision. Its goal is to reform the rendering pipeline in computer graphics to support gradient backpropagation such that the change in the output image can be related to the change in input geometry or materials. The development of differential rendering technique is highly related to the deep learning, since neural networks are usually represented as computational graphs to support gradient backpropagation using the chain rule. Thus, the gradient backpropagation is the key to convert a computational procedure into a learnable process, which can significantly generalize the deep learning technique to a wide range of applications. Differential rendering follows this trend to integrate gradient backpropagation into rendering pipeline. It can significantly facilitate the gradient computation through auto-differential techniques. In fact, the derivatives of rendering results regarding to the mesh vertex have already computed in variational 3D reconstruction and shape from shading. However, differential rendering integrates the derivative computation into global rendering pipelines and neural networks. Therefore, the rendering process can be directly integrated into optimization or neural network training to approximate rendering pipeline or inverse graphics reasoning; it has wide applications in content creation in augmented/virtual reality, 3D reconstruction, appearance modeling, and inverse design. The advantage of differential rendering over traditional rendering pipeline is that it allows to train neural networks to approximate the forward rendering pipeline. Once trained, the rendering results can be obtained through forward inference of the network, a much faster procedure in many situations. Moreover, the gradient information provided by differential rendering is helpful to improve the efficiency of the global rendering. For instance, the first- and second-order gradients can be used to guide the sampling process in Monte Carlo rendering. Another advantage of differential rendering is that it can directly be used in view interpolation or view synthesis through captured images, which traditional rendering pipeline needs geometry, appearance and lighting information simultaneously to render an image at specified viewpoints. In the application of differential rendering to view synthesis or image-based rendering, the implicit representation of a 3D scene is usually inferred from the captured images directly via deep neural networks supervised by differential rendering loss. Such a process falls into the category of self-supervised learning because ground truth 3D data are not provided during training. It bypasses the expensive multi-view 3D reconstruction and thus significantly simplifies the view synthesis procedure. Numerous representations, such as neural texture, neural volume, and neural implicit function, are proposed to handle freeview point rendering of a 3D scene. However, the training and rendering cost of these methods is still expensive. Thus, reducing their computational cost forms a new research direction. Differential rendering also enables the end-to-end inference of spatially variant bidirectional reflectance distribution function (BRDF) material properties from capture images. The BRDF parameters can be derived from a single image after training the deep neural network on a large amount of data by representing the material properties in a latent space. Moreover, with a differentiable pipeline, the layout of the light sources and projection patterns of dedicated appearance acquisition equipment can be optimized.The recent development of differential rendering, including its application in realistic rendering, 3D reconstruction, and appearance modeling is comprehensively surveyed. We expect this study to further boost the research on differential rendering in academia and industry.关键词:differential rendering;3D reconstruction;appearance modeling;image-based rendering;representation learning;deep learning184|455|3更新时间:2024-05-07 -
 摘要:With the development of modern imaging 3D reconstruction, haptic interaction and three-dimensional (3D) printing technology, the traditional concept of tumor surgery is undergoing unprecedented revolutionary changes. The tumor treatment is not limited to traditional open surgery, large-area radiotherapy, chemotherapy, and other extensive treatment methods. The popularization of individualized precision surgery planning means that "precision medicine" is gradually applied to clinical surgery, and "precision medicine" mode will also make the treatment of tumor enter a new research area. The physiological anatomy and pathological changes of various organs of the human body are presented as a three-dimensional shape, while medical teaching images, diagnostic medical images, and various endoscopic surgery images are mostly plane images. However, how to interpret them often depends on the professional experience of doctors. This plane display mode limits the effect of medical training, the accuracy of interpretation of diagnostic images and the efficiency of surgical operation. Modern science and technology, stereo display technology provides a carrier with a higher realistic simulation degree for binocular vision function and training and has become a joint research hotspot in the field of computer vision and clinical medicine. Before minimally invasive surgery (MIS), compared with the traditional planar display technology, the immersive stereoscopic display technology can provide more vivid and accurate 3D human physiological and pathological images, making it easier for doctors to judge the layers, shapes, blood vessels and other complex structures and anatomical relations of lesions. At the same time, it can also provide immersive surgical situation simulation for medical training, help doctors quickly master surgical skills, further improve the efficiency of medical diagnosis and reduce the risk of surgery. In the process of minimally invasive surgery, the three-dimensional imaging navigation technology for augmented reality can not only make it easier for doctors to judge the position relationship and distance between the tissues in the surgical area and the surgical instruments, but also provide surgical navigation by superposing the preoperative examination images of the same location. Which is also achieved the accurate minimally invasive surgery. Besides, in the field of remote diagnosis and treatment, which occupies a significant proportion in the sharing of clinical medical resources, stereo display technology can provide the more accurate depth information and more dimensional image information for remote diagnosis, online consultation, and robotic surgery, so that the remote display results of medical data are more authentic and practical. Although at the present stage, the unadaptability of display mode conversion, partial information loss of 3D reconstruction images. Furthermore, the visual fatigue of users is still a problem that needs to be overcome in the field of clinical medicine. The three-dimensional display technology still has a broad space for development in medical science and is a new driving force to promote medical progress in the future. This article comprehensively analyzes the stereo display technology in clinical medicine; the application of minimally invasive surgery is summarized. The research status at home and abroad in remote diagnosis and treatment, from the image diagnosis and surgery training, planning and navigation, the training and education from four aspects, summarizes the stereo display technology research progress in the field of clinical medicine. This article fully analyzes the stereo display technology in the application of clinical medicine, provides an introduction to the field of minimally invasive surgery and remote diagnosis and research status at home and abroad, from the image diagnosis and surgery training, planning and navigation, the training and education from four aspects, summarizes the stereo display technology research progress in the field of clinical medicine. Clinical medicine in the future, with the aid of a 3D image technology, mixed reality technology, interactive technology, and a series of cutting-edge computer technology, can be more intuitive, accurately make the mixed reality device presents visualization of three-dimensional graphics, and provide a series of digital simulation tools, the surgeon can be based on the data communication with others, better-making operation plan. The extended reality technology can be used in the teaching of medical anatomy so that medical students can more intuitively understand the structure of human organs and their spatial position relationship with adjacent organs and tissues. Simultaneously, as an essential achievement to expand the combination of fundamental technology and medical research, virtual surgery is also one of the hot issues in medical research.关键词:stereo display;augment reality;image reconstruction;surgical simulation;surgical navigation;remote surgery109|31|2更新时间:2024-05-07
摘要:With the development of modern imaging 3D reconstruction, haptic interaction and three-dimensional (3D) printing technology, the traditional concept of tumor surgery is undergoing unprecedented revolutionary changes. The tumor treatment is not limited to traditional open surgery, large-area radiotherapy, chemotherapy, and other extensive treatment methods. The popularization of individualized precision surgery planning means that "precision medicine" is gradually applied to clinical surgery, and "precision medicine" mode will also make the treatment of tumor enter a new research area. The physiological anatomy and pathological changes of various organs of the human body are presented as a three-dimensional shape, while medical teaching images, diagnostic medical images, and various endoscopic surgery images are mostly plane images. However, how to interpret them often depends on the professional experience of doctors. This plane display mode limits the effect of medical training, the accuracy of interpretation of diagnostic images and the efficiency of surgical operation. Modern science and technology, stereo display technology provides a carrier with a higher realistic simulation degree for binocular vision function and training and has become a joint research hotspot in the field of computer vision and clinical medicine. Before minimally invasive surgery (MIS), compared with the traditional planar display technology, the immersive stereoscopic display technology can provide more vivid and accurate 3D human physiological and pathological images, making it easier for doctors to judge the layers, shapes, blood vessels and other complex structures and anatomical relations of lesions. At the same time, it can also provide immersive surgical situation simulation for medical training, help doctors quickly master surgical skills, further improve the efficiency of medical diagnosis and reduce the risk of surgery. In the process of minimally invasive surgery, the three-dimensional imaging navigation technology for augmented reality can not only make it easier for doctors to judge the position relationship and distance between the tissues in the surgical area and the surgical instruments, but also provide surgical navigation by superposing the preoperative examination images of the same location. Which is also achieved the accurate minimally invasive surgery. Besides, in the field of remote diagnosis and treatment, which occupies a significant proportion in the sharing of clinical medical resources, stereo display technology can provide the more accurate depth information and more dimensional image information for remote diagnosis, online consultation, and robotic surgery, so that the remote display results of medical data are more authentic and practical. Although at the present stage, the unadaptability of display mode conversion, partial information loss of 3D reconstruction images. Furthermore, the visual fatigue of users is still a problem that needs to be overcome in the field of clinical medicine. The three-dimensional display technology still has a broad space for development in medical science and is a new driving force to promote medical progress in the future. This article comprehensively analyzes the stereo display technology in clinical medicine; the application of minimally invasive surgery is summarized. The research status at home and abroad in remote diagnosis and treatment, from the image diagnosis and surgery training, planning and navigation, the training and education from four aspects, summarizes the stereo display technology research progress in the field of clinical medicine. This article fully analyzes the stereo display technology in the application of clinical medicine, provides an introduction to the field of minimally invasive surgery and remote diagnosis and research status at home and abroad, from the image diagnosis and surgery training, planning and navigation, the training and education from four aspects, summarizes the stereo display technology research progress in the field of clinical medicine. Clinical medicine in the future, with the aid of a 3D image technology, mixed reality technology, interactive technology, and a series of cutting-edge computer technology, can be more intuitive, accurately make the mixed reality device presents visualization of three-dimensional graphics, and provide a series of digital simulation tools, the surgeon can be based on the data communication with others, better-making operation plan. The extended reality technology can be used in the teaching of medical anatomy so that medical students can more intuitively understand the structure of human organs and their spatial position relationship with adjacent organs and tissues. Simultaneously, as an essential achievement to expand the combination of fundamental technology and medical research, virtual surgery is also one of the hot issues in medical research.关键词:stereo display;augment reality;image reconstruction;surgical simulation;surgical navigation;remote surgery109|31|2更新时间:2024-05-07
3D Vision & Graphics Technology
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0