
最新刊期
卷 26 , 期 5 , 2021
-
 摘要:Participating media are frequent in real-world scenes, such as milk, fruit juices, oil, or muddy water in river or ocean scenes. Realistic rendering of participating media is one of the important aspects in the rendering domain. Incoming light interacts with these participating media in a more complex manner than surface rendering: it is refracted at the boundary, absorbed, and scattered as it travels inside the medium. These physical phenomena have different contributions to the overall aspect of the material: refraction focuses light in several parts of the medium, creating high-frequency events, or volume caustics. Scattering blurs incoming light, spreading its contribution. Absorption reduces light intensity as it travels inside the medium. In recent years, several algorithms, such as virtual ray lights (VRL), several extensions to photon mapping culminating with unified points, beams, and paths (UPBP), and manifold exploration Metropolis light transport(MEMLT), have been introduced for rendering participating media. All these methods have greatly improved the simulation of participating media but still encounter problems for simulation of materials with a high albedo, where multiple scattering dominates or high-frequency volumetric caustics effects. Another group of work is called diffusion-based methods. These methods are fast and designed to work with materials with a high albedo. However, these methods produce less accurate results, especially for highly anisotropic media, whereas diffusion-theory-based methods use similarity theory for anisotropic media, which leads to increased inaccuracy. In this paper, several efficient rendering methods are introduced for homogeneous participating media rendering. The first is point-based rendering method for participating media. The point-based method is different from the previous two frameworks (Monte Carlo rendering and density estimation). It first distributes several points in the participating media to generate a point cloud, organizes the point cloud into spatial hierarchy, and then uses it to accelerate the single, second, and multiple scattering computation. For multiple scattering simulation, a precomputed multiple scattering distribution representation in infinite media is presented. With further GPU(graphics processing unit) implementation, this method can achieve interactive efficiency and support the editing of materials and light sources for arbitrary homogeneous participating media, from high-scattered media to high-absorbed media and from isotropic media to highly anisotropic media. The first work is an extension of the point-based method from the surface rendering to volume rendering. Different from the two other frameworks, it is deterministic and noise-free. However, this method is biased. Its target application is material editing or light editing or high-quality rendering with a limited time budget. The second is a precomputed model based on multiple reflections. It precomputes multiple scattering distributions in infinite participating media, proposes a more compact representation than the prior works by analyzing the symmetric of the light distribution, and decreases the number of dimensions from four to three. The precomputed model is then applied to various Monte Carlo rendering methods, such as VRL, UPBP, and MEMET. The original algorithms are in charge of low-order scattering, combined with multiple scattering computed using the precomputed model. Results show substantial improvements in convergence speed and memory costs, and a negligible effect on accuracy. This method is especially interesting for materials with a large albedo and a small mean-free-path, where higher-order scattering effects dominate. It has a limited influence but also a limited cost for more transparent materials with a larger mean-free-path. This method can be used for unidirectional rendering algorithms (e.g., path tracing) and bidirectional algorithms (e.g., VRL), but this method has less impressive speedup in unidirectional algorithms because unidirectional rendering algorithms have difficulties in finding a path for participating media with boundaries. The last introduced method is a path guiding method in participating media rendering, which is under the framework of path tracing. In simple terms, the paths become lost in the medium. Path guiding has been proposed for surface rendering to make the convergence faster by guiding the sampling. In this work, a path guiding solution to translucent materials is introduced. It includes two steps, namely, learning and rendering. In the learning step, the radiance distribution in the volume is learned with path tracing, and this 4D distribution is represent with an SD-tree. In the rendering step, this representation is used for sampling the outgoing direction, combining with the phase function sampling by resampled importance sampling. The key insight of resampled importance sampling is about sampling two multiplied high-frequency functions. The proposed method remarkably improves the performance of light transport simulation in participating media, especially for small lights and media with refractive boundaries. This method can handle any homogeneous participating media, from high scattering to low scattering, from high absorption to low absorption, and from isotropic media to highly anisotropic media. Unlike the previous two works, this method is unbiased. However, it can only handle direction sampling with path guiding and leaves the distance sampling with the original method, which can be further improved. The three methods all target the efficient rendering of homogenous participating media but in different methods.关键词:participating media;rendering;Monte Carlo based methods;path guiding;point-based rendering method;multiple scattering;survey;progress128|155|3更新时间:2024-05-07
摘要:Participating media are frequent in real-world scenes, such as milk, fruit juices, oil, or muddy water in river or ocean scenes. Realistic rendering of participating media is one of the important aspects in the rendering domain. Incoming light interacts with these participating media in a more complex manner than surface rendering: it is refracted at the boundary, absorbed, and scattered as it travels inside the medium. These physical phenomena have different contributions to the overall aspect of the material: refraction focuses light in several parts of the medium, creating high-frequency events, or volume caustics. Scattering blurs incoming light, spreading its contribution. Absorption reduces light intensity as it travels inside the medium. In recent years, several algorithms, such as virtual ray lights (VRL), several extensions to photon mapping culminating with unified points, beams, and paths (UPBP), and manifold exploration Metropolis light transport(MEMLT), have been introduced for rendering participating media. All these methods have greatly improved the simulation of participating media but still encounter problems for simulation of materials with a high albedo, where multiple scattering dominates or high-frequency volumetric caustics effects. Another group of work is called diffusion-based methods. These methods are fast and designed to work with materials with a high albedo. However, these methods produce less accurate results, especially for highly anisotropic media, whereas diffusion-theory-based methods use similarity theory for anisotropic media, which leads to increased inaccuracy. In this paper, several efficient rendering methods are introduced for homogeneous participating media rendering. The first is point-based rendering method for participating media. The point-based method is different from the previous two frameworks (Monte Carlo rendering and density estimation). It first distributes several points in the participating media to generate a point cloud, organizes the point cloud into spatial hierarchy, and then uses it to accelerate the single, second, and multiple scattering computation. For multiple scattering simulation, a precomputed multiple scattering distribution representation in infinite media is presented. With further GPU(graphics processing unit) implementation, this method can achieve interactive efficiency and support the editing of materials and light sources for arbitrary homogeneous participating media, from high-scattered media to high-absorbed media and from isotropic media to highly anisotropic media. The first work is an extension of the point-based method from the surface rendering to volume rendering. Different from the two other frameworks, it is deterministic and noise-free. However, this method is biased. Its target application is material editing or light editing or high-quality rendering with a limited time budget. The second is a precomputed model based on multiple reflections. It precomputes multiple scattering distributions in infinite participating media, proposes a more compact representation than the prior works by analyzing the symmetric of the light distribution, and decreases the number of dimensions from four to three. The precomputed model is then applied to various Monte Carlo rendering methods, such as VRL, UPBP, and MEMET. The original algorithms are in charge of low-order scattering, combined with multiple scattering computed using the precomputed model. Results show substantial improvements in convergence speed and memory costs, and a negligible effect on accuracy. This method is especially interesting for materials with a large albedo and a small mean-free-path, where higher-order scattering effects dominate. It has a limited influence but also a limited cost for more transparent materials with a larger mean-free-path. This method can be used for unidirectional rendering algorithms (e.g., path tracing) and bidirectional algorithms (e.g., VRL), but this method has less impressive speedup in unidirectional algorithms because unidirectional rendering algorithms have difficulties in finding a path for participating media with boundaries. The last introduced method is a path guiding method in participating media rendering, which is under the framework of path tracing. In simple terms, the paths become lost in the medium. Path guiding has been proposed for surface rendering to make the convergence faster by guiding the sampling. In this work, a path guiding solution to translucent materials is introduced. It includes two steps, namely, learning and rendering. In the learning step, the radiance distribution in the volume is learned with path tracing, and this 4D distribution is represent with an SD-tree. In the rendering step, this representation is used for sampling the outgoing direction, combining with the phase function sampling by resampled importance sampling. The key insight of resampled importance sampling is about sampling two multiplied high-frequency functions. The proposed method remarkably improves the performance of light transport simulation in participating media, especially for small lights and media with refractive boundaries. This method can handle any homogeneous participating media, from high scattering to low scattering, from high absorption to low absorption, and from isotropic media to highly anisotropic media. Unlike the previous two works, this method is unbiased. However, it can only handle direction sampling with path guiding and leaves the distance sampling with the original method, which can be further improved. The three methods all target the efficient rendering of homogenous participating media but in different methods.关键词:participating media;rendering;Monte Carlo based methods;path guiding;point-based rendering method;multiple scattering;survey;progress128|155|3更新时间:2024-05-07 -
 摘要:The study of cloth modeling methods has a long history. Cloth simulation has always been a popular and difficult research topic in computer animation. Improving the quality of computer animation and user experience is of great significance. Cloth is a classic flexible material object, which can be seen almost everywhere in people's daily life. The clothing animation of realistic virtual characters can bring a strong sense of visual reality to the virtual characters and can enhance the user experience. It has very broad application prospects in animation production, game entertainment, film and television, and other fields. In addition, this technology can also be applied to the clothing industry, where virtual clothing can be used to design and display clothing more intuitively. In recent years, with the continuous emergence of applications involving virtual reality and human-computer interaction, especially the emergence of network virtual environments with high interactive characteristics, people's demand for high-quality real-time virtual character clothing animation has increased. Efficiently and realistically simulating the movement of cloth (e.g., flags, clothing, tablecloths) on a computer has become a very challenging subject. Cloth animation is an important branch in the field of computer animation, belonging to the category of soft body fabric material deformation animation. In cloth simulation modeling, the accuracy of cloth simulation and the speed of cloth simulation often restrict each other. At present, some traditional cloth simulation methods can only take into account one of the two, and it is difficult to achieve a balance. Therefore, researchers have found a method that can balance the simulation accuracy and simulation speed to a certain degree. It is the focus of research in cloth simulation technology. When performing simulation modeling for flexible fabrics, constructing an appropriate and accurate modeling method has become the key to cloth simulation technology. After years of development of cloth simulation research, there are currently three mainstream cloth modeling methods: geometric modeling-based methods, physics-based modeling methods, and hybrid-based modeling methods. Hybrid-based modeling methods are a combination between geometry-based methods and physics-based methods. They require more calculation time compared with geometric modeling methods and have a lower accuracy compared with physics-based methods. In cloth simulation research, the main problem at present is how to meet the increasing real-time requirements on the basis of ensuring the cloth simulation effect. In response to this problem, researchers have made contributions in different ways, including the continuous development of numerical integration, from explicit Euler integration, implicit Euler integration to fourth-order Runge-Kutta and Verlet integration. The development of numerical integration has reduced the numerical calculation time in cloth simulation to a certain extent. In recent years, algorithms combined with machine learning have emerged in various fields. In computer animation, especially in the field of cloth simulation, researchers have begun to use the idea of machine learning to optimize cloth modeling. The commonly used methods of machine learning are convolutional neural network, recurrent neural network, back propagation(BP) neural network, and random forest. This study reviews the related work of cloth simulation modeling methods and summarizes the research and development of methods in China and abroad. According to the improvement of the cloth integration method, the improvement of the multi-resolution grid, and the use of machine learning methods, the development of the cloth simulation method is briefly described. According to the characteristics of the integral method and the multi-resolution grid method and the characteristics of the application of machine learning methods in cloth simulation, several major types of improved methods are summarized and prospected accordingly. Researchers have some considerations whether to improve the simulation speed or to ensure the speed to improve the simulation accuracy. Because of their different research entry points for the improvement of cloth modeling methods, their research purposes are also different. This article selects several algorithms to make a corresponding comparison and provides some suggestions for learners to learn from.关键词:virtual simulation;cloth simulation;integration method;multi-resolution grid;machine learning;progress232|288|1更新时间:2024-05-07
摘要:The study of cloth modeling methods has a long history. Cloth simulation has always been a popular and difficult research topic in computer animation. Improving the quality of computer animation and user experience is of great significance. Cloth is a classic flexible material object, which can be seen almost everywhere in people's daily life. The clothing animation of realistic virtual characters can bring a strong sense of visual reality to the virtual characters and can enhance the user experience. It has very broad application prospects in animation production, game entertainment, film and television, and other fields. In addition, this technology can also be applied to the clothing industry, where virtual clothing can be used to design and display clothing more intuitively. In recent years, with the continuous emergence of applications involving virtual reality and human-computer interaction, especially the emergence of network virtual environments with high interactive characteristics, people's demand for high-quality real-time virtual character clothing animation has increased. Efficiently and realistically simulating the movement of cloth (e.g., flags, clothing, tablecloths) on a computer has become a very challenging subject. Cloth animation is an important branch in the field of computer animation, belonging to the category of soft body fabric material deformation animation. In cloth simulation modeling, the accuracy of cloth simulation and the speed of cloth simulation often restrict each other. At present, some traditional cloth simulation methods can only take into account one of the two, and it is difficult to achieve a balance. Therefore, researchers have found a method that can balance the simulation accuracy and simulation speed to a certain degree. It is the focus of research in cloth simulation technology. When performing simulation modeling for flexible fabrics, constructing an appropriate and accurate modeling method has become the key to cloth simulation technology. After years of development of cloth simulation research, there are currently three mainstream cloth modeling methods: geometric modeling-based methods, physics-based modeling methods, and hybrid-based modeling methods. Hybrid-based modeling methods are a combination between geometry-based methods and physics-based methods. They require more calculation time compared with geometric modeling methods and have a lower accuracy compared with physics-based methods. In cloth simulation research, the main problem at present is how to meet the increasing real-time requirements on the basis of ensuring the cloth simulation effect. In response to this problem, researchers have made contributions in different ways, including the continuous development of numerical integration, from explicit Euler integration, implicit Euler integration to fourth-order Runge-Kutta and Verlet integration. The development of numerical integration has reduced the numerical calculation time in cloth simulation to a certain extent. In recent years, algorithms combined with machine learning have emerged in various fields. In computer animation, especially in the field of cloth simulation, researchers have begun to use the idea of machine learning to optimize cloth modeling. The commonly used methods of machine learning are convolutional neural network, recurrent neural network, back propagation(BP) neural network, and random forest. This study reviews the related work of cloth simulation modeling methods and summarizes the research and development of methods in China and abroad. According to the improvement of the cloth integration method, the improvement of the multi-resolution grid, and the use of machine learning methods, the development of the cloth simulation method is briefly described. According to the characteristics of the integral method and the multi-resolution grid method and the characteristics of the application of machine learning methods in cloth simulation, several major types of improved methods are summarized and prospected accordingly. Researchers have some considerations whether to improve the simulation speed or to ensure the speed to improve the simulation accuracy. Because of their different research entry points for the improvement of cloth modeling methods, their research purposes are also different. This article selects several algorithms to make a corresponding comparison and provides some suggestions for learners to learn from.关键词:virtual simulation;cloth simulation;integration method;multi-resolution grid;machine learning;progress232|288|1更新时间:2024-05-07
Scholar View

-
 摘要:This is the 26th annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for the editors of journals and potential authors of papers. Specifically, considering the wide distribution of related publications in China, 813 references on image engineering research and technique are selected carefully from 2 785 research papers published in 154 issues of a set of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have higher quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (same as the last 15 years). Analysis and discussions about the statistics of the results of classifications by journal as well as by category are also presented. Analysis on the statistics in 2020 shows that image analysis is receiving the most attention, in which the focuses are mainly on object detection and recognition, image segmentation and edge detection, as well as human biometrics detection and identification. In addition, the studies and applications of image technology in various areas, such as remote sensing, radar, sonar and mapping, as well as biology and medicine are continuously active. In conclusion, this work shows a general and up-to-date picture of the various continuing progresses, either for depth or for width, of image engineering in China in 2020. The statistics for 26 years also provide readers with more comprehensive and credible information on the development trends of various research directions.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics48|97|5更新时间:2024-05-07
摘要:This is the 26th annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for the editors of journals and potential authors of papers. Specifically, considering the wide distribution of related publications in China, 813 references on image engineering research and technique are selected carefully from 2 785 research papers published in 154 issues of a set of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have higher quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (same as the last 15 years). Analysis and discussions about the statistics of the results of classifications by journal as well as by category are also presented. Analysis on the statistics in 2020 shows that image analysis is receiving the most attention, in which the focuses are mainly on object detection and recognition, image segmentation and edge detection, as well as human biometrics detection and identification. In addition, the studies and applications of image technology in various areas, such as remote sensing, radar, sonar and mapping, as well as biology and medicine are continuously active. In conclusion, this work shows a general and up-to-date picture of the various continuing progresses, either for depth or for width, of image engineering in China in 2020. The statistics for 26 years also provide readers with more comprehensive and credible information on the development trends of various research directions.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics48|97|5更新时间:2024-05-07
Review
-
 摘要:ObjectiveGiven a low-resolution image, the task of single image super-resolution (SR) is to reconstruct the corresponding high-resolution image. Due to the ill-posed characteristic of this problem, it is challenging to recover the lost details and well preserve the structures in images. To deal with this problem, different kinds of methods have been proposed in the past two decades, including interpolation-based methods, learning-based methods, and reconstruction-based methods. Recently, convolutional neural network (CNN)-based SR methods have achieved great success and received much attention. Several CNNs have been proposed for the SR task, including residual dense network (RDN), enhanced deep residual network for super-resolution (EDSR), and residual channel attention network. Although superior performance has been achieved, many methods utilize very large-scale networks, which definitely lead to a large number of parameters and heavy computational complexity. For example, RDN costs 22.3 million (M) parameters, and the number of parameters of EDSR even reaches 43 M. As a result, those methods might not be suitable for applications with limited memory and computing resources. To solve the above problem, this study proposes a lightweight CNN model using the two-stage information distillation strategy.MethodThe proposed lightweight CNN model is called two-stage feature-compensated information distillation network (TFIDN). There are three main characteristics in TFIDN. First of all, a highly efficient module, called two-stage feature-compensated information distillation block (TFIDB), is proposed as the basic building block of TFIDN. In each TFIDB, the features can be accurately divided into different parts and then progressively refined by the two stages of information distillation. To this end, 1×1 convolution layers are applied in TFIDB to implicitly learn the packing strategy, which is responsible for selecting the suitable components from the target features for further refinement. Compared with the existing information distillation network (IDN) where only one stage of information distillation is carried out, the proposed two-stage information distillation strategy can extract the features much more precisely. Besides information distillation, TFIDB additionally introduces a feature compensation mechanism, which guarantees the completeness of the features and also enforces the consistence among local memory. More specifically, the operation of feature compensation is performed by concatenating and fusing the cross-layer transferred features and the refined features. Unlike IDN, there is no need to manually adjust the output feature dimensions of different convolution layers in TFIDB; thus, the structure of TFIDB is more flexible. Second, to further increase the ability of feature extraction and discrimination learning, the wide activated super-resolution (WDSR) unit and the channel attention (CA) mechanism are both introduced in TFIDB. To improve the performance of the normal residual learning block, the WDSR unit expands the features before performing activation. To maintain the same number of parameters as that of a normal residual learning block, the input feature dimension of the WDSR unit is set as 32 in this study. Although the CA unit can effectively improve the discrimination learning ability of the network, applying too many CA units could significantly increase the depth of the network. Therefore, only one CA unit is attached at the end of each TFIDB, so as to maintain the efficiency of the network. Because the CA operation is carried out on the precisely refined features, the effectiveness of the network can be ensured. Finally, to build the full TFIDN, a number of TFIDBs are cascaded. To keep a balance between model complexity and performance, the number of TFIDBs is set as 3. To fully take advantage of different levels of information, an information fusion unit (IFU) is designed to fuse the outputs of different TFIDBs. In the existing cascading residual network (CARN), dense connections are utilized among the building blocks, leading to a relatively large number of parameters. Different from CARN, to keep a small number of parameters, IFU only introduces one 1×1 convolution layer, which only results in 3 kilo (K) parameters.ResultThe proposed TFIDN is trained using DIV2K dataset. Five widely used datasets, including Set5, Set14, BSD100, Urban100, and Manga109, are used for testing. The ablation study shows that the proposed building block TFIDB and the IFU both contribute to the superior performance of the network. Compared with six famous lightweight models, including fast super-resolution convolutional neural networks, very deep network for super-resolution, Laplacian pyramid super-resolution network, persistent memory network, IDN, and CARN, the proposed TFIDN is able to achieve the highest peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) values. Specifically, with a scale factor of 2 on five testing datasets, the PSNR improvements of TFIDN over the second best method CARN are 0.29 dB, 0.08 dB, 0.08 dB, 0.27 dB, and 0.42 dB, respectively, whereas the SSIM improvements are 0.001 6, 0.000 9, 0.001 7, 0.003 0, and 0.000 9, respectively. The significant PSNR and SSIM improvements indicate that TFIDN is more effective than CARN. On the other hand, the number of parameters and the number of mult-adds required by TFIDN are 933 K and 53.5 giga (G), respectively, both of which are smaller than those of CARN. This phenomenon suggests that TFIDN is more efficient than CARN. Although the proposed TFIDN consumes more parameters and mult-adds than IDN, TFIDN achieves significantly higher performance in terms of PSNR and SSIM.ConclusionThe proposed two-stage feature-compensated information distillation mechanism is efficient and effective. By cascading a number of TFIDBs and introducing the IFU, the proposed lightweight network TFIDN can achieve a better trade-off in terms of model size, computational complexity, and performance.关键词:super-resolution (SR);convolutional neural network (CNN);information distillation;wide activation;channel attention (CA)119|267|1更新时间:2024-05-07
摘要:ObjectiveGiven a low-resolution image, the task of single image super-resolution (SR) is to reconstruct the corresponding high-resolution image. Due to the ill-posed characteristic of this problem, it is challenging to recover the lost details and well preserve the structures in images. To deal with this problem, different kinds of methods have been proposed in the past two decades, including interpolation-based methods, learning-based methods, and reconstruction-based methods. Recently, convolutional neural network (CNN)-based SR methods have achieved great success and received much attention. Several CNNs have been proposed for the SR task, including residual dense network (RDN), enhanced deep residual network for super-resolution (EDSR), and residual channel attention network. Although superior performance has been achieved, many methods utilize very large-scale networks, which definitely lead to a large number of parameters and heavy computational complexity. For example, RDN costs 22.3 million (M) parameters, and the number of parameters of EDSR even reaches 43 M. As a result, those methods might not be suitable for applications with limited memory and computing resources. To solve the above problem, this study proposes a lightweight CNN model using the two-stage information distillation strategy.MethodThe proposed lightweight CNN model is called two-stage feature-compensated information distillation network (TFIDN). There are three main characteristics in TFIDN. First of all, a highly efficient module, called two-stage feature-compensated information distillation block (TFIDB), is proposed as the basic building block of TFIDN. In each TFIDB, the features can be accurately divided into different parts and then progressively refined by the two stages of information distillation. To this end, 1×1 convolution layers are applied in TFIDB to implicitly learn the packing strategy, which is responsible for selecting the suitable components from the target features for further refinement. Compared with the existing information distillation network (IDN) where only one stage of information distillation is carried out, the proposed two-stage information distillation strategy can extract the features much more precisely. Besides information distillation, TFIDB additionally introduces a feature compensation mechanism, which guarantees the completeness of the features and also enforces the consistence among local memory. More specifically, the operation of feature compensation is performed by concatenating and fusing the cross-layer transferred features and the refined features. Unlike IDN, there is no need to manually adjust the output feature dimensions of different convolution layers in TFIDB; thus, the structure of TFIDB is more flexible. Second, to further increase the ability of feature extraction and discrimination learning, the wide activated super-resolution (WDSR) unit and the channel attention (CA) mechanism are both introduced in TFIDB. To improve the performance of the normal residual learning block, the WDSR unit expands the features before performing activation. To maintain the same number of parameters as that of a normal residual learning block, the input feature dimension of the WDSR unit is set as 32 in this study. Although the CA unit can effectively improve the discrimination learning ability of the network, applying too many CA units could significantly increase the depth of the network. Therefore, only one CA unit is attached at the end of each TFIDB, so as to maintain the efficiency of the network. Because the CA operation is carried out on the precisely refined features, the effectiveness of the network can be ensured. Finally, to build the full TFIDN, a number of TFIDBs are cascaded. To keep a balance between model complexity and performance, the number of TFIDBs is set as 3. To fully take advantage of different levels of information, an information fusion unit (IFU) is designed to fuse the outputs of different TFIDBs. In the existing cascading residual network (CARN), dense connections are utilized among the building blocks, leading to a relatively large number of parameters. Different from CARN, to keep a small number of parameters, IFU only introduces one 1×1 convolution layer, which only results in 3 kilo (K) parameters.ResultThe proposed TFIDN is trained using DIV2K dataset. Five widely used datasets, including Set5, Set14, BSD100, Urban100, and Manga109, are used for testing. The ablation study shows that the proposed building block TFIDB and the IFU both contribute to the superior performance of the network. Compared with six famous lightweight models, including fast super-resolution convolutional neural networks, very deep network for super-resolution, Laplacian pyramid super-resolution network, persistent memory network, IDN, and CARN, the proposed TFIDN is able to achieve the highest peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) values. Specifically, with a scale factor of 2 on five testing datasets, the PSNR improvements of TFIDN over the second best method CARN are 0.29 dB, 0.08 dB, 0.08 dB, 0.27 dB, and 0.42 dB, respectively, whereas the SSIM improvements are 0.001 6, 0.000 9, 0.001 7, 0.003 0, and 0.000 9, respectively. The significant PSNR and SSIM improvements indicate that TFIDN is more effective than CARN. On the other hand, the number of parameters and the number of mult-adds required by TFIDN are 933 K and 53.5 giga (G), respectively, both of which are smaller than those of CARN. This phenomenon suggests that TFIDN is more efficient than CARN. Although the proposed TFIDN consumes more parameters and mult-adds than IDN, TFIDN achieves significantly higher performance in terms of PSNR and SSIM.ConclusionThe proposed two-stage feature-compensated information distillation mechanism is efficient and effective. By cascading a number of TFIDBs and introducing the IFU, the proposed lightweight network TFIDN can achieve a better trade-off in terms of model size, computational complexity, and performance.关键词:super-resolution (SR);convolutional neural network (CNN);information distillation;wide activation;channel attention (CA)119|267|1更新时间:2024-05-07 -
 摘要:ObjectiveSuperpixel segmentation is widely used as a preprocessing step in many computer vision applications. It groups the pixels of an image into homogeneous regions while trying to respect the object boundary. Generally, a good superpixel segmentation method would meet the following three conditions. First, the boundaries of the superpixel should adhere well to the image boundaries. Second, the boundaries of the superpixel should not wing across different objects in the image. Third, superpixels should have similar sizes and regular shapes. In recent years, various superpixel segmentation methods have been proposed; however, most of these state-of-the-art methods only use the pixel information as a clustering feature. Therefore, they can be severely impacted by high-frequency contrast variations and fail to produce equally sized regions having the same texture. To make superpixels robust to contrast variations such as strong gradient texture, we propose a texture-aware superpixel segmentation algorithm that uses patch-level features for clustering purposes.MethodThe main idea of our algorithm is to calculate the color distance by using a specially designed quarter-circular mean filtering operator. Because the mean filtering has the characteristics of noise suppression and texture smoothing and the rotated quarter-circular window ensures that the mean filtering sampled pixels are located inside the superpixels as much as possible, the quarter-circular mean filtering operator has the capacity to identify the texture pattern. The Sobel gradient has the advantages of fast speed and thin edge, but it is easy to be disturbed by strong gradient texture. The interval gradient is characterized by texture suppression and structure preservation, but its edge is too thick. To overcome their shortcomings while retaining their strengths, we devise a hybrid gradient based on the multiplication of the Sobel gradient and interval gradient, which has the advantages of texture suppression, structure preservation, and edge thinning; therefore, its magnitude can represent the possibility that a pixel belongs to the structure. Finally, an integrated structure-avoiding clustering distance is proposed by looking for the maximum hybrid gradient magnitude along the linear path, which can further enhance the boundary adherence of the superpixels.ResultTo verify the universality of our algorithm, we test the Berkeley segmentation dataset (BSDS500), which contains 500 images of indoor, outdoor, human, animal, and other scenes with five manually ground truths. To verify the particularity of our algorithm, we test two mosaic images with strong gradient texture. Unfortunately, these two mosaic images do not have ground truth, and they can only be evaluated subjectively by the human eye. All experiments of our algorithm are run on the Windows platform, which requires the mixed programming of MATLAB and Visual studio. Two main parameters need to be set in our algorithm, namely, the mean filtering window radius and the interval gradient operator radius. As both of them aim to capture the regularity of the texture, we set them the same value. Furthermore, the size of the window radius depends on the texture size; the larger the texture size, the larger the window radius required. Normally, we suggest taking the window radius between 3 and 5. We compare our algorithm with other popular superpixel segmentation methods, and all methods use the code with the optimal parameters provided by the authors to obtain their superpixel segmentation results. The superpixel segmentation performance is tested and judged in terms of the boundary recall, undersegmentation error (UE), achievable segmentation accuracy (ASA), and compactness measure (CM). By testing on the BSDS500 image dataset, our algorithm obtains a 1.5% lower UE value, 0.2% higher ASA value, and 4.3% higher CM value. By testing on many mosaic images with strong gradient textures, our algorithm generates superpixels with not only regular shapes but also better boundary adherence. The experimental results show that our algorithm surpasses the state-of-the-art methods in superpixel segmentation performance on BSDS500 and mosaic images.ConclusionTo make superpixel segmentation robust to high-frequency contrast variations such as strong gradient texture and noise, we propose a texture-aware superpixel segmentation algorithm, which mainly contributes in the following three aspects. First, we design a quarter-circular mean filtering operator, which is sensitive to the texture pattern. Second, we bring forward a hybrid gradient based on the multiplication of the Sobel gradient and interval gradient, which can distinguish between texture and structure pixels. Third, an integrated structure-avoiding clustering distance is devised based on the hybrid gradient magnitude. It aims to prevent the superpixels from crossing the structure boundary and keep the superpixels with regular size. The experimental results show that our algorithm performs equally well or better than state-of-the-art superpixel segmentation methods in terms of the commonly used evaluation metrics. In the face of strong gradient textures, our method can generate superpixels with regular shape and better boundary adherence. Thus, our superpixel segmentation algorithm has great potential in target recognition, target tracking, and significance detection.关键词:image segmentation;superpixel;clustering;strong gradient texture;patch;linear path72|202|4更新时间:2024-05-07
摘要:ObjectiveSuperpixel segmentation is widely used as a preprocessing step in many computer vision applications. It groups the pixels of an image into homogeneous regions while trying to respect the object boundary. Generally, a good superpixel segmentation method would meet the following three conditions. First, the boundaries of the superpixel should adhere well to the image boundaries. Second, the boundaries of the superpixel should not wing across different objects in the image. Third, superpixels should have similar sizes and regular shapes. In recent years, various superpixel segmentation methods have been proposed; however, most of these state-of-the-art methods only use the pixel information as a clustering feature. Therefore, they can be severely impacted by high-frequency contrast variations and fail to produce equally sized regions having the same texture. To make superpixels robust to contrast variations such as strong gradient texture, we propose a texture-aware superpixel segmentation algorithm that uses patch-level features for clustering purposes.MethodThe main idea of our algorithm is to calculate the color distance by using a specially designed quarter-circular mean filtering operator. Because the mean filtering has the characteristics of noise suppression and texture smoothing and the rotated quarter-circular window ensures that the mean filtering sampled pixels are located inside the superpixels as much as possible, the quarter-circular mean filtering operator has the capacity to identify the texture pattern. The Sobel gradient has the advantages of fast speed and thin edge, but it is easy to be disturbed by strong gradient texture. The interval gradient is characterized by texture suppression and structure preservation, but its edge is too thick. To overcome their shortcomings while retaining their strengths, we devise a hybrid gradient based on the multiplication of the Sobel gradient and interval gradient, which has the advantages of texture suppression, structure preservation, and edge thinning; therefore, its magnitude can represent the possibility that a pixel belongs to the structure. Finally, an integrated structure-avoiding clustering distance is proposed by looking for the maximum hybrid gradient magnitude along the linear path, which can further enhance the boundary adherence of the superpixels.ResultTo verify the universality of our algorithm, we test the Berkeley segmentation dataset (BSDS500), which contains 500 images of indoor, outdoor, human, animal, and other scenes with five manually ground truths. To verify the particularity of our algorithm, we test two mosaic images with strong gradient texture. Unfortunately, these two mosaic images do not have ground truth, and they can only be evaluated subjectively by the human eye. All experiments of our algorithm are run on the Windows platform, which requires the mixed programming of MATLAB and Visual studio. Two main parameters need to be set in our algorithm, namely, the mean filtering window radius and the interval gradient operator radius. As both of them aim to capture the regularity of the texture, we set them the same value. Furthermore, the size of the window radius depends on the texture size; the larger the texture size, the larger the window radius required. Normally, we suggest taking the window radius between 3 and 5. We compare our algorithm with other popular superpixel segmentation methods, and all methods use the code with the optimal parameters provided by the authors to obtain their superpixel segmentation results. The superpixel segmentation performance is tested and judged in terms of the boundary recall, undersegmentation error (UE), achievable segmentation accuracy (ASA), and compactness measure (CM). By testing on the BSDS500 image dataset, our algorithm obtains a 1.5% lower UE value, 0.2% higher ASA value, and 4.3% higher CM value. By testing on many mosaic images with strong gradient textures, our algorithm generates superpixels with not only regular shapes but also better boundary adherence. The experimental results show that our algorithm surpasses the state-of-the-art methods in superpixel segmentation performance on BSDS500 and mosaic images.ConclusionTo make superpixel segmentation robust to high-frequency contrast variations such as strong gradient texture and noise, we propose a texture-aware superpixel segmentation algorithm, which mainly contributes in the following three aspects. First, we design a quarter-circular mean filtering operator, which is sensitive to the texture pattern. Second, we bring forward a hybrid gradient based on the multiplication of the Sobel gradient and interval gradient, which can distinguish between texture and structure pixels. Third, an integrated structure-avoiding clustering distance is devised based on the hybrid gradient magnitude. It aims to prevent the superpixels from crossing the structure boundary and keep the superpixels with regular size. The experimental results show that our algorithm performs equally well or better than state-of-the-art superpixel segmentation methods in terms of the commonly used evaluation metrics. In the face of strong gradient textures, our method can generate superpixels with regular shape and better boundary adherence. Thus, our superpixel segmentation algorithm has great potential in target recognition, target tracking, and significance detection.关键词:image segmentation;superpixel;clustering;strong gradient texture;patch;linear path72|202|4更新时间:2024-05-07
Image Processing and Coding
-
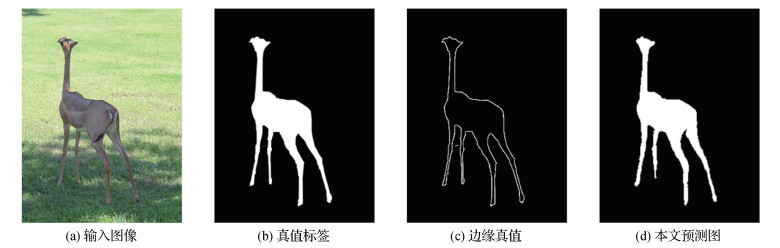 摘要:ObjectiveSalient object detection is a basic task in the field of computer vision, which simulates the human visual attention mechanism and quickly detects attractive objects in the scene that are most likely to represent user query variables and contain the most information. As a preprocessing step of other vision tasks, such as image resizing, visual tracking, person re-identification, and image segmentation, salient object detection plays a very important role. The traditional salient object detection method mainly uses the method of manually extracting features of the image to detect. However, this process is time-consuming and labor-intensive, and the results cannot meet the requirements. With the rise of deep learning, a large number of feature extraction algorithms based on convolutional neural networks have emerged. Compared with traditional feature extraction methods, using deep neural networks to extract features has better quality and more accurate prediction. In order to obtain accurate salient object segmentation results, deep learning-based methods mostly introduce attention mechanisms for feature weighting to suppress noise and redundant information. However, the modeling process of the existing attention mechanism is quite rough, which treats each position in the feature tensor equally and directly solves the attention score. This strategy cannot explicitly learn the global importance of different channels and different spatial regions, which may lead to missed detection or misdetection. To this end, in this study, we propose a deep clustering attention (DCA) mechanism to better model the feature-level pixel-by-pixel relationship.MethodIn this study, the proposed DCA explicitly divides the feature tensors into several categories channel-wise and spatial-wise; that is, it clusters the features into foreground and background sensitive regions. Then, general per-pixel attention weighting is performed within each class, and semantical attention weighting is further performed inter-classes. The idea of DCA is easy to understand, whose parameter quantity is also small and can be deployed in any salient detection network. This method can efficiently separate the foreground and background regions. In addition, through supervised learning on the edges of salient objects, the prediction can get clearer edges, and the results are more accurate.ResultComparison of 19 state-of-the-art methods on six large public datasets demonstrates the effectiveness of DCA in modeling pixel-wise attention, which is very helpful for obtaining finely salient object segmentation mask. On various evaluation indicators, the effects of the model after the deployment of DCA have improved. On the extended cornplex scene saliency(ECSSD) dataset, the performance of DCANet increased by 0.9% over the second place (F-measure value). On the Dalian University of Technology and OMRON Corporation(DUT-OMRON) dataset, the performance of DCANet increased by 0.5% over the second place (F-measure value), and the MAE decreased by 3.2%. On the HKU-IS dataset, the performance of DCANet is 0.3% higher than the second place (F-measure value), and the MAE is reduced by 2.8%. On the pattern analysis, statistical modeling and computational learning(PASCAL)-subset(S) dataset, the performance of DCANet is 0.8% higher than the second place (F-measure value), and the MAE is reduced by 4.2%.ConclusionThe DCA proposed in this study effectively enhances the globally salient scores of foreground sensitive classes through more fine-grained channel partitioning and spatial region partitioning. This paper analyzes the deficiencies of the existing salient object detection algorithm based on attention mechanism and proposes a method for explicitly dividing feature channels and spatial regions. The attention modeling mechanism helps the model training process perceive and adapt tasks quickly. Compared with the existing attention mechanism, the idea of DCA is clear, the effect is significant, and it is simple to deploy. Meanwhile, DCA provides a viable new research direction for the study of more general attention mechanisms.关键词:saliency detection;attention mechanism;deep clustering;spatial-channel decoupling;full convolutional network (FCN)41|33|2更新时间:2024-05-07
摘要:ObjectiveSalient object detection is a basic task in the field of computer vision, which simulates the human visual attention mechanism and quickly detects attractive objects in the scene that are most likely to represent user query variables and contain the most information. As a preprocessing step of other vision tasks, such as image resizing, visual tracking, person re-identification, and image segmentation, salient object detection plays a very important role. The traditional salient object detection method mainly uses the method of manually extracting features of the image to detect. However, this process is time-consuming and labor-intensive, and the results cannot meet the requirements. With the rise of deep learning, a large number of feature extraction algorithms based on convolutional neural networks have emerged. Compared with traditional feature extraction methods, using deep neural networks to extract features has better quality and more accurate prediction. In order to obtain accurate salient object segmentation results, deep learning-based methods mostly introduce attention mechanisms for feature weighting to suppress noise and redundant information. However, the modeling process of the existing attention mechanism is quite rough, which treats each position in the feature tensor equally and directly solves the attention score. This strategy cannot explicitly learn the global importance of different channels and different spatial regions, which may lead to missed detection or misdetection. To this end, in this study, we propose a deep clustering attention (DCA) mechanism to better model the feature-level pixel-by-pixel relationship.MethodIn this study, the proposed DCA explicitly divides the feature tensors into several categories channel-wise and spatial-wise; that is, it clusters the features into foreground and background sensitive regions. Then, general per-pixel attention weighting is performed within each class, and semantical attention weighting is further performed inter-classes. The idea of DCA is easy to understand, whose parameter quantity is also small and can be deployed in any salient detection network. This method can efficiently separate the foreground and background regions. In addition, through supervised learning on the edges of salient objects, the prediction can get clearer edges, and the results are more accurate.ResultComparison of 19 state-of-the-art methods on six large public datasets demonstrates the effectiveness of DCA in modeling pixel-wise attention, which is very helpful for obtaining finely salient object segmentation mask. On various evaluation indicators, the effects of the model after the deployment of DCA have improved. On the extended cornplex scene saliency(ECSSD) dataset, the performance of DCANet increased by 0.9% over the second place (F-measure value). On the Dalian University of Technology and OMRON Corporation(DUT-OMRON) dataset, the performance of DCANet increased by 0.5% over the second place (F-measure value), and the MAE decreased by 3.2%. On the HKU-IS dataset, the performance of DCANet is 0.3% higher than the second place (F-measure value), and the MAE is reduced by 2.8%. On the pattern analysis, statistical modeling and computational learning(PASCAL)-subset(S) dataset, the performance of DCANet is 0.8% higher than the second place (F-measure value), and the MAE is reduced by 4.2%.ConclusionThe DCA proposed in this study effectively enhances the globally salient scores of foreground sensitive classes through more fine-grained channel partitioning and spatial region partitioning. This paper analyzes the deficiencies of the existing salient object detection algorithm based on attention mechanism and proposes a method for explicitly dividing feature channels and spatial regions. The attention modeling mechanism helps the model training process perceive and adapt tasks quickly. Compared with the existing attention mechanism, the idea of DCA is clear, the effect is significant, and it is simple to deploy. Meanwhile, DCA provides a viable new research direction for the study of more general attention mechanisms.关键词:saliency detection;attention mechanism;deep clustering;spatial-channel decoupling;full convolutional network (FCN)41|33|2更新时间:2024-05-07 -
 摘要:ObjectiveWith the rapid development of computer vision technology, the demand for intelligent and humanized transportation systems is gradually increasing. Vehicle logo recognition (VLR) is an important part of intelligent transportation systems, and the requirements for its recognition effect are gradually increasing. Considering the difficulty in achieving the samples of some vehicle logos from real surveillance systems in certain areas and the cost of collecting samples and training, the recognition of vehicle logos under small training samples still has very important application value. Vehicle logos captured from real surveillance systems on the road suffer from the following characteristics: 1) low resolution, 2) easy to blur due to the movement of vehicles, and 3) easily influenced by light from the environment. Thus, the recognition of vehicle logos is still a challenging problem. Given the fact that some vehicle logos have similar structures and part of the vehicle logos has salient features, we consider how to enhance the overall characteristics of vehicle logos from the aspects of symmetrical structural and local saliency, which can benefit VLR, and propose a VLR method based on feature enhancement, called feature enhancement-based vehicle logo recognition (FE-VLR).MethodFE-VLR comprehensively considers the structural similarity features and local salient features of the vehicle logo and then combines them together with the overall features of the vehicle logo to identify the vehicle logo. Based on the analysis of the structural symmetry of the left and right parts of the vehicle logo, this study calculates the similarity value of the image block to express the similarity feature. In addition, a method for calculating salient regions based on the correlation of neighborhood blocks is proposed to locate and extract the salient features of the vehicle logo. First, it extracts similar self-symmetrical features of vehicle logo images and then builds an image pyramid. Under each layer of the pyramid, the overall features and local salient features of the vehicle logos are extracted. Local salient locations are obtained by salient region detection based on the correlation of neighborhood blocks. Finally, a collaborative representation-based classification (CRC) classifier is used to classify the vehicle logos. CRC is a fast and effective classifier suitable for small training samples. The classifier uses the collaborative coding of all samples in the sample dictionary to represent the prediction samples, so as to improve the recognition rate by using the difference of the same attribute between different types of vehicle logos.ResultThe effectiveness of our algorithm is evaluated on the public vehicle logo datasets Vehicle Logo Dataset from Hefei University of Technology (HFUT-VL) and Xiamen University Vehicle Logo Dataset (XMU). The experimental results show that under small training samples, FE-VLR is superior to some other traditional VLR methods and also has higher recognition rates than some convolutional neural network-based methods. On the HFUT-VL dataset, when the number of training samples is 5, the recognition rate of FE-VLR reaches 97.78%, and when the number of training samples is 20, the recognition rate reaches 99.1%. On the more complex XMU dataset, FE-VLR is more efficient and robust. When the number of training samples is equal or less than 15, FE-VLR can improve the recognition rate by at least 7.2% compared with overlapping enhanced patterns of oriented edge magnitudes(OE-POEM). The experimental results show that FE-VLR always has better performance under small samples.ConclusionThe FE-VLR method increases the recognition ability of low-quality and low-resolution vehicle logo images obtained from real surveillance systems on the road, which can better meet the needs of VLR in practical applications. The experimental results on the public HFUT-VL and XMU datasets show that in case of small samples, the recognition rate of FE-VLR is higher than that of other VLR methods and better than some recognition methods based on deep learning models.关键词:vehicle logo recognition(VLR);feature enhancement(FE);self-symmetrical similar features;local salient features;the correlation degree of neighborhood blocks106|184|2更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of computer vision technology, the demand for intelligent and humanized transportation systems is gradually increasing. Vehicle logo recognition (VLR) is an important part of intelligent transportation systems, and the requirements for its recognition effect are gradually increasing. Considering the difficulty in achieving the samples of some vehicle logos from real surveillance systems in certain areas and the cost of collecting samples and training, the recognition of vehicle logos under small training samples still has very important application value. Vehicle logos captured from real surveillance systems on the road suffer from the following characteristics: 1) low resolution, 2) easy to blur due to the movement of vehicles, and 3) easily influenced by light from the environment. Thus, the recognition of vehicle logos is still a challenging problem. Given the fact that some vehicle logos have similar structures and part of the vehicle logos has salient features, we consider how to enhance the overall characteristics of vehicle logos from the aspects of symmetrical structural and local saliency, which can benefit VLR, and propose a VLR method based on feature enhancement, called feature enhancement-based vehicle logo recognition (FE-VLR).MethodFE-VLR comprehensively considers the structural similarity features and local salient features of the vehicle logo and then combines them together with the overall features of the vehicle logo to identify the vehicle logo. Based on the analysis of the structural symmetry of the left and right parts of the vehicle logo, this study calculates the similarity value of the image block to express the similarity feature. In addition, a method for calculating salient regions based on the correlation of neighborhood blocks is proposed to locate and extract the salient features of the vehicle logo. First, it extracts similar self-symmetrical features of vehicle logo images and then builds an image pyramid. Under each layer of the pyramid, the overall features and local salient features of the vehicle logos are extracted. Local salient locations are obtained by salient region detection based on the correlation of neighborhood blocks. Finally, a collaborative representation-based classification (CRC) classifier is used to classify the vehicle logos. CRC is a fast and effective classifier suitable for small training samples. The classifier uses the collaborative coding of all samples in the sample dictionary to represent the prediction samples, so as to improve the recognition rate by using the difference of the same attribute between different types of vehicle logos.ResultThe effectiveness of our algorithm is evaluated on the public vehicle logo datasets Vehicle Logo Dataset from Hefei University of Technology (HFUT-VL) and Xiamen University Vehicle Logo Dataset (XMU). The experimental results show that under small training samples, FE-VLR is superior to some other traditional VLR methods and also has higher recognition rates than some convolutional neural network-based methods. On the HFUT-VL dataset, when the number of training samples is 5, the recognition rate of FE-VLR reaches 97.78%, and when the number of training samples is 20, the recognition rate reaches 99.1%. On the more complex XMU dataset, FE-VLR is more efficient and robust. When the number of training samples is equal or less than 15, FE-VLR can improve the recognition rate by at least 7.2% compared with overlapping enhanced patterns of oriented edge magnitudes(OE-POEM). The experimental results show that FE-VLR always has better performance under small samples.ConclusionThe FE-VLR method increases the recognition ability of low-quality and low-resolution vehicle logo images obtained from real surveillance systems on the road, which can better meet the needs of VLR in practical applications. The experimental results on the public HFUT-VL and XMU datasets show that in case of small samples, the recognition rate of FE-VLR is higher than that of other VLR methods and better than some recognition methods based on deep learning models.关键词:vehicle logo recognition(VLR);feature enhancement(FE);self-symmetrical similar features;local salient features;the correlation degree of neighborhood blocks106|184|2更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveGlaucoma can cause irreversible damage to vision. Glaucoma is often diagnosed on the basis of the cup-to-disc ratio (CDR). A CDR greater than 0.65 is considered to be glaucoma. Therefore, segmenting the optic disc (OD) and optic cup (OC) accurately from fundus images is an important task. The traditional methods used to segment the OD and OC are mainly based on deformable model, graph-cut, edge detection, and super pixel classification. Traditional methods need to manually extract image features, which are easily affected by light and contrast, and the segmentation accuracy is often low. In addition, these methods require careful adjustment of model parameters to achieve performance improvements and are not suitable for large-scale promotion. In recent years, with the development of deep learning, the segmentation methods of OD and OC based on the convolutional neural network (CNN), which can automatically extract image features, have become the main research direction and have achieved better segmentation performance than traditional methods. OC segmentation is more difficult than OD segmentation because the OC boundary is not obvious. The existing methods based on CNN can be divided into two categories. One is joint segmentation; that is, the OD and OC can be segmented simultaneously using the same segmentation network. The other is two-stage segmentation; that is, the OD is segmented first, and then the OC is segmented. Previous studies have shown that the accuracy of joint segmentation is often inferior to that of two-stage segmentation, and joint segmentation can lead to biased optimization result to OD or OC. However, the connection between OD and OC is often ignored in two-stage segmentation. In this study, U-Net is improved, and a two-stage segmentation network called context attention U-Net (CA-Net) is proposed to segment the OD and OC sequentially. The prior knowledge is introduced into the OC segmentation network to further improve the OC segmentation accuracy.MethodFirst, we locate the OD center and crop the region of interest (ROI) from the whole fundus image according to the OD center, which can reduce irrelevant regions. The size of the ROI image is 512×512. Then, the cropped ROI image is transferred by polar transformation from the Cartesian coordinate into the polar coordinate, which can balance disc and cup proportion. Because the OC region always accounts for a low proportion, it easily leads to overfitting and bias in training the deep model. Finally, the transferred images are fed into CA-Net to predict the final OD or OC segmentation maps. The OC is inside the OD, which means that the area that belongs to the OC also belongs to the OD. Specifically, we train two segmentation networks with the same structure to segment the OD and OC, respectively. To segment the OC more accurately, we utilize the connection between the OD and the OC as prior information. The modified pre-trained ResNet34 is used as the feature extraction network to enhance the feature extraction capability. Concretely, the first max pooling layer, the last average pooling layer, and the full connectivity layer are removed from the original ResNet34. Compared with training the deep learning model from scratch, loading pre-trained parameters on ImageNet (ImageNet Large-Scale Visual Recognition Challenge) helps prevent overfitting. Moreover, a context aggregation module (CAM) is proposed to aggregate the context information of images from multiple scales, which exploits the different sizes of atrous convolution to encode the rich semantic information. Because there will be a lot of irrelevant information during the fusion of shallow and deep feature maps, an attention guidance module (AGM) is proposed to recalibrate the feature maps after fusion of shallow and deep feature maps to enhance the useful feature information. In addition, the idea of deep supervision is also used to train the weights of shallow network. Finally, CA-Net outputs the probability map, and the largest connected region is selected as the final segmentation result to remove noise. We do not use any post-processing techniques such as ellipse fitting. DiceLoss is used as loss function to train CA-Net. We use a NVIDIA GeForce GTX 1080 Ti device to train and test the proposed CA-Net.ResultWe conducted experiments on three commonly used public datasets (Drishti-GS1, RIM-ONE-v3, and Refuge) to verify the effectiveness and generalization of CA-Net. We trained the model on the training set and reported the model performance on the test set. The Drishti-GS1 dataset was split into 50 training images and 51 test images. The RIM-ONE-v3 dataset was randomly split into 99 training images and 60 test images. The Refuge dataset was randomly split into 320 training images and 80 test images. Two measures were used to evaluate the results, namely, Dice coefficient (Dice) and intersection-over-union (IOU). For OD segmentation, the Dice and IOU obtained by CA-Net are 0.981 4 and 0.963 5 on the Drishti-GS1 dataset and 0.976 8 and 0.954 6 on the retinal image database for optic nerve evaluation(RIM-ONE)-v3 dataset, respectively. For OC segmentation, the Dice and IOU obtained by CA-Net are 0.926 6 and 0.863 3 on the Drishti-GS1 dataset and 0.864 2 and 0.760 9 on the RIM-ONE-v3 dataset, respectively. Moreover, CA-Net achieved a Dice of 0.975 8 and IOU of 0.952 7 in the case of OD segmentation and a Dice of 0.887 1 and IOU of 0.797 2 in the case of OC segmentation on the Refuge dataset, which further demonstrated the effectiveness and generalization of CA-Net. We also used the Refuge training dataset to train CA-Net and directly evaluated it on the Drishti-GS1 and RIM-ONE-v3 testing datasets. In addition, ablation experiments on the three datasets also showed the effectiveness of each module in the network, such as AGM, CAM, polar transformation, and deep supervision. The experiments also showed that CA-Net could achieve higher segmentation accuracy in the case of Dice and IOU when compared with U-Net, M-Net, and DeepLab v3+. The visual segmentation results also proved that CA-Net could achieve segmentation results more similar to ground truth.ConclusionThis study presents a new two-stage segmentation method based on U-Net for OD and OC segmentation, which is proved to be effective. The experiments showed that CA-Net can obtain better results than other methods on the Drishti-GS1, RIM-ONE-v3, and Refuge datasets. In the future, we will focus on the problem of domain adaptation and solve the problem of OD and OC segmentation when the training samples are insufficient.关键词:Glaucoma;optic disc(OD);optic cup(OC);context aggregation module(CAM);attention guidance module(AGM);deep supervision;prior knowledge129|328|3更新时间:2024-05-07
摘要:ObjectiveGlaucoma can cause irreversible damage to vision. Glaucoma is often diagnosed on the basis of the cup-to-disc ratio (CDR). A CDR greater than 0.65 is considered to be glaucoma. Therefore, segmenting the optic disc (OD) and optic cup (OC) accurately from fundus images is an important task. The traditional methods used to segment the OD and OC are mainly based on deformable model, graph-cut, edge detection, and super pixel classification. Traditional methods need to manually extract image features, which are easily affected by light and contrast, and the segmentation accuracy is often low. In addition, these methods require careful adjustment of model parameters to achieve performance improvements and are not suitable for large-scale promotion. In recent years, with the development of deep learning, the segmentation methods of OD and OC based on the convolutional neural network (CNN), which can automatically extract image features, have become the main research direction and have achieved better segmentation performance than traditional methods. OC segmentation is more difficult than OD segmentation because the OC boundary is not obvious. The existing methods based on CNN can be divided into two categories. One is joint segmentation; that is, the OD and OC can be segmented simultaneously using the same segmentation network. The other is two-stage segmentation; that is, the OD is segmented first, and then the OC is segmented. Previous studies have shown that the accuracy of joint segmentation is often inferior to that of two-stage segmentation, and joint segmentation can lead to biased optimization result to OD or OC. However, the connection between OD and OC is often ignored in two-stage segmentation. In this study, U-Net is improved, and a two-stage segmentation network called context attention U-Net (CA-Net) is proposed to segment the OD and OC sequentially. The prior knowledge is introduced into the OC segmentation network to further improve the OC segmentation accuracy.MethodFirst, we locate the OD center and crop the region of interest (ROI) from the whole fundus image according to the OD center, which can reduce irrelevant regions. The size of the ROI image is 512×512. Then, the cropped ROI image is transferred by polar transformation from the Cartesian coordinate into the polar coordinate, which can balance disc and cup proportion. Because the OC region always accounts for a low proportion, it easily leads to overfitting and bias in training the deep model. Finally, the transferred images are fed into CA-Net to predict the final OD or OC segmentation maps. The OC is inside the OD, which means that the area that belongs to the OC also belongs to the OD. Specifically, we train two segmentation networks with the same structure to segment the OD and OC, respectively. To segment the OC more accurately, we utilize the connection between the OD and the OC as prior information. The modified pre-trained ResNet34 is used as the feature extraction network to enhance the feature extraction capability. Concretely, the first max pooling layer, the last average pooling layer, and the full connectivity layer are removed from the original ResNet34. Compared with training the deep learning model from scratch, loading pre-trained parameters on ImageNet (ImageNet Large-Scale Visual Recognition Challenge) helps prevent overfitting. Moreover, a context aggregation module (CAM) is proposed to aggregate the context information of images from multiple scales, which exploits the different sizes of atrous convolution to encode the rich semantic information. Because there will be a lot of irrelevant information during the fusion of shallow and deep feature maps, an attention guidance module (AGM) is proposed to recalibrate the feature maps after fusion of shallow and deep feature maps to enhance the useful feature information. In addition, the idea of deep supervision is also used to train the weights of shallow network. Finally, CA-Net outputs the probability map, and the largest connected region is selected as the final segmentation result to remove noise. We do not use any post-processing techniques such as ellipse fitting. DiceLoss is used as loss function to train CA-Net. We use a NVIDIA GeForce GTX 1080 Ti device to train and test the proposed CA-Net.ResultWe conducted experiments on three commonly used public datasets (Drishti-GS1, RIM-ONE-v3, and Refuge) to verify the effectiveness and generalization of CA-Net. We trained the model on the training set and reported the model performance on the test set. The Drishti-GS1 dataset was split into 50 training images and 51 test images. The RIM-ONE-v3 dataset was randomly split into 99 training images and 60 test images. The Refuge dataset was randomly split into 320 training images and 80 test images. Two measures were used to evaluate the results, namely, Dice coefficient (Dice) and intersection-over-union (IOU). For OD segmentation, the Dice and IOU obtained by CA-Net are 0.981 4 and 0.963 5 on the Drishti-GS1 dataset and 0.976 8 and 0.954 6 on the retinal image database for optic nerve evaluation(RIM-ONE)-v3 dataset, respectively. For OC segmentation, the Dice and IOU obtained by CA-Net are 0.926 6 and 0.863 3 on the Drishti-GS1 dataset and 0.864 2 and 0.760 9 on the RIM-ONE-v3 dataset, respectively. Moreover, CA-Net achieved a Dice of 0.975 8 and IOU of 0.952 7 in the case of OD segmentation and a Dice of 0.887 1 and IOU of 0.797 2 in the case of OC segmentation on the Refuge dataset, which further demonstrated the effectiveness and generalization of CA-Net. We also used the Refuge training dataset to train CA-Net and directly evaluated it on the Drishti-GS1 and RIM-ONE-v3 testing datasets. In addition, ablation experiments on the three datasets also showed the effectiveness of each module in the network, such as AGM, CAM, polar transformation, and deep supervision. The experiments also showed that CA-Net could achieve higher segmentation accuracy in the case of Dice and IOU when compared with U-Net, M-Net, and DeepLab v3+. The visual segmentation results also proved that CA-Net could achieve segmentation results more similar to ground truth.ConclusionThis study presents a new two-stage segmentation method based on U-Net for OD and OC segmentation, which is proved to be effective. The experiments showed that CA-Net can obtain better results than other methods on the Drishti-GS1, RIM-ONE-v3, and Refuge datasets. In the future, we will focus on the problem of domain adaptation and solve the problem of OD and OC segmentation when the training samples are insufficient.关键词:Glaucoma;optic disc(OD);optic cup(OC);context aggregation module(CAM);attention guidance module(AGM);deep supervision;prior knowledge129|328|3更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveSynthetic aperture radar (SAR) is an active sensor that uses microwave remote sensing technology. Compared with visible and infrared sensors, it is not limited by light, weather, and climate conditions and has all-weather and multi-angle data acquisition capability. With the development of SAR imaging technology, SAR image has been widely used in the military field for intelligence detection, navigation guidance, ocean ship detection, etc. Through the detection of ship target in the SAR image, the ship information of the sea surface, port, and other locations can be obtained quickly, which improves border prevention ability. The traditional methods of SAR ship detection have difficulty in detecting small-scale ships and avoiding the interference of inshore complex background. Moreover, the quality of SAR images needs to be high, and the images need to be preprocessed before detection. In addition, the robustness and generalization of most SAR images are not good enough for specific scenes, and they are susceptible to speckle noise, which has certain limitations. With the development of artificial intelligence, machine learning has been introduced into the SAR image target detection field. Deep learning is an enhanced version of machine learning. Recently, it has been gradually applied for ship detection in SAR images, but some problems need to be addressed. First, the near shore ships are seriously disturbed by the buildings on the shore. The existing detection methods cannot effectively distinguish the ship target from the background, so it is easy to mix the background with the ship target or mistake the target for the background, resulting in missed detection. Second, the existing algorithm cannot accurately locate the closely arranged ship targets, and the positioning effect is poor. It is easy to regard multiple targets as one target, which leads to wrong detection, resulting in low accuracy of detection results or high constant false alarm rate. To solve these problems, this study proposes a detection method based on bidirectional attention feature pyramid network.MethodExperiments are conducted on the SAR ship detection dataset (SSDD) of the public SAR image ship dataset. This dataset comes from the Naval Aviation University, which is a common dataset in this field in China. Affine, fuzzy, and noisy data enhancement operations are performed to improve the generalization ability of the training model. A new bidirectional feature pyramid network is proposed based on the original fully convolutional one-stage (FCOS) object detection network. By connecting the attention mechanism module with each feature graph of the pyramid network, the features of a large amount of semantic information can be extracted. At the same time, we use convolutional block attention module (CBAM) to refine the stitched feature map and combine the idea of path aggregation network for instance segmentation. The bottom-up pyramid module is added to further highlight the prominent features of targets at different scales, so as to improve the ability of the network to accurately locate ship targets in a complex background. Then, a weighted feature fusion method is proposed, which makes the feature information extracted from different feature maps to have different emphases and then combines the salient features with the global non-fuzzy features to improve the ship detection accuracy. Finally, the fused feature map is fed back to the detection network to obtain the final detection result. In addition, a NVIDIA Titan RTX device is used for the experimental platform in this study, and the operating system is Ubuntu 18.04. The batch size of the training is set to the initialization model, the batch size of the training is 8, the total iteration number is 50 000, the initial learning rate is 0.001, the learning rate attenuation coefficient is 0.000 1, the 2 000 attenuation is once, and the kinetic parameters are analyzed at 0.9 mm.ResultWe compared the added modules and found that the added modules have different degrees of improvement compared with the original FCOS method. At the same time, we also compared the experimental results with three other existing models, including SSD, Faster R-CNN (region convolutional neural network), and original FCOS. Experimental results show that the detection accuracy of the proposed algorithm is 9.5% higher than that of the original FCOS method. The detection accuracy of this algorithm reached 90.2% under the same conditions, which was 14.09% higher than that of SSD and 8.5% higher than that of Faster R-CNN. The results show that the model algorithm can obtain accurate results. In addition, in terms of time, the proposed algorithm is 5 ms slower than FCOS. However, the detection speed was 1.6 times higher than that of SSD and 6 times higher than that of Faster R-CNN. In terms of speed, the detection speed of the proposed algorithm is obviously faster than that of other existing methods. From the comparison of experimental results, the proposed algorithm is not only good for the detection of small target ships in deep sea, but also good for the detection of near shore ship targets in the complex background, especially for closely arranged ship targets, with high accuracy of positioning effect.ConclusionBy improving the network features and the feature fusion method, the ship detection algorithm in SAR images is improved on the premise of ensuring the same detection effect of deep-sea ships. Under complex background, the ship positioning effect is compact, and the accuracy of ship detection is effectively enhanced, which is superior to other ship detection methods based on SSDD.关键词:inshore ship;synthetic aperture radar (SAR) image;object detection;complex background;deep learning;small target73|203|6更新时间:2024-05-07
摘要:ObjectiveSynthetic aperture radar (SAR) is an active sensor that uses microwave remote sensing technology. Compared with visible and infrared sensors, it is not limited by light, weather, and climate conditions and has all-weather and multi-angle data acquisition capability. With the development of SAR imaging technology, SAR image has been widely used in the military field for intelligence detection, navigation guidance, ocean ship detection, etc. Through the detection of ship target in the SAR image, the ship information of the sea surface, port, and other locations can be obtained quickly, which improves border prevention ability. The traditional methods of SAR ship detection have difficulty in detecting small-scale ships and avoiding the interference of inshore complex background. Moreover, the quality of SAR images needs to be high, and the images need to be preprocessed before detection. In addition, the robustness and generalization of most SAR images are not good enough for specific scenes, and they are susceptible to speckle noise, which has certain limitations. With the development of artificial intelligence, machine learning has been introduced into the SAR image target detection field. Deep learning is an enhanced version of machine learning. Recently, it has been gradually applied for ship detection in SAR images, but some problems need to be addressed. First, the near shore ships are seriously disturbed by the buildings on the shore. The existing detection methods cannot effectively distinguish the ship target from the background, so it is easy to mix the background with the ship target or mistake the target for the background, resulting in missed detection. Second, the existing algorithm cannot accurately locate the closely arranged ship targets, and the positioning effect is poor. It is easy to regard multiple targets as one target, which leads to wrong detection, resulting in low accuracy of detection results or high constant false alarm rate. To solve these problems, this study proposes a detection method based on bidirectional attention feature pyramid network.MethodExperiments are conducted on the SAR ship detection dataset (SSDD) of the public SAR image ship dataset. This dataset comes from the Naval Aviation University, which is a common dataset in this field in China. Affine, fuzzy, and noisy data enhancement operations are performed to improve the generalization ability of the training model. A new bidirectional feature pyramid network is proposed based on the original fully convolutional one-stage (FCOS) object detection network. By connecting the attention mechanism module with each feature graph of the pyramid network, the features of a large amount of semantic information can be extracted. At the same time, we use convolutional block attention module (CBAM) to refine the stitched feature map and combine the idea of path aggregation network for instance segmentation. The bottom-up pyramid module is added to further highlight the prominent features of targets at different scales, so as to improve the ability of the network to accurately locate ship targets in a complex background. Then, a weighted feature fusion method is proposed, which makes the feature information extracted from different feature maps to have different emphases and then combines the salient features with the global non-fuzzy features to improve the ship detection accuracy. Finally, the fused feature map is fed back to the detection network to obtain the final detection result. In addition, a NVIDIA Titan RTX device is used for the experimental platform in this study, and the operating system is Ubuntu 18.04. The batch size of the training is set to the initialization model, the batch size of the training is 8, the total iteration number is 50 000, the initial learning rate is 0.001, the learning rate attenuation coefficient is 0.000 1, the 2 000 attenuation is once, and the kinetic parameters are analyzed at 0.9 mm.ResultWe compared the added modules and found that the added modules have different degrees of improvement compared with the original FCOS method. At the same time, we also compared the experimental results with three other existing models, including SSD, Faster R-CNN (region convolutional neural network), and original FCOS. Experimental results show that the detection accuracy of the proposed algorithm is 9.5% higher than that of the original FCOS method. The detection accuracy of this algorithm reached 90.2% under the same conditions, which was 14.09% higher than that of SSD and 8.5% higher than that of Faster R-CNN. The results show that the model algorithm can obtain accurate results. In addition, in terms of time, the proposed algorithm is 5 ms slower than FCOS. However, the detection speed was 1.6 times higher than that of SSD and 6 times higher than that of Faster R-CNN. In terms of speed, the detection speed of the proposed algorithm is obviously faster than that of other existing methods. From the comparison of experimental results, the proposed algorithm is not only good for the detection of small target ships in deep sea, but also good for the detection of near shore ship targets in the complex background, especially for closely arranged ship targets, with high accuracy of positioning effect.ConclusionBy improving the network features and the feature fusion method, the ship detection algorithm in SAR images is improved on the premise of ensuring the same detection effect of deep-sea ships. Under complex background, the ship positioning effect is compact, and the accuracy of ship detection is effectively enhanced, which is superior to other ship detection methods based on SSDD.关键词:inshore ship;synthetic aperture radar (SAR) image;object detection;complex background;deep learning;small target73|203|6更新时间:2024-05-07 -
 摘要:ObjectiveRadar echo extrapolation is an important method for short-term precipitation prediction. It can achieve faster and more accurate predictions compared with traditional methods, such as numerical weather forecast and optical flow method. Among them, numerical weather forecasting requires complex and meticulous simulations of physical equations in the atmosphere and then uses observation data as input to predict future weather conditions. The optical flow method is currently the mainstream method used by the meteorological department, but it has two inherent flaws. On the one hand, only two adjacent frames can be used to estimate the optical flow; on the other hand, the radar echo sequence cannot be fully used for prediction. Nevertheless, the radar echo extrapolation method based on deep learning can take full advantage of spatiotemporal sequence data to achieve faster and more accurate prediction. In addition, the echo extrapolation algorithm based on convolutional long short-term memory network (ConvLSTM) has been proved to be effective in real applications, and the effect is superior to other deep learning extrapolation algorithms. However, it ignores the limitations of ordinary convolution operations in the face of locally changing features, and in the extrapolation process, the loss function is simply defined as mean square error (MSE), ignoring the distribution similarity between the extrapolated image and the original image, which is easy to cause information loss. To solve the above problems, an improved echo extrapolation algorithm based on adversarial long short-term memory network (LSTM) is proposed.MethodFirst, in view of the local-invariance limitations of the traditional convolution kernel, we borrowed the idea of the dense optical flow method and constructed a two-dimensional instantaneous velocity field for all pixels to extract the motion information of each part of the object. Based on this idea, ConvLSTM is improved to form flow long short-term memory network (FLSTM), which is an optical flow optimization extrapolation algorithm. The algorithm uses optical flow to track local features, breaking through the limitation of local invariance of general convolution kernels. Then, according to the characteristics of radar sequence data (high-dimensional spatiotemporal data), the convolutional layer is used to extract effective spatial features to reduce spatial redundancy in the encoder, and then deconvolution is used in the decoder to amplify the generated decoded features to the size of the original image to form an output sequence. The convolutional layer and FLSTM are cross-stacked in depth to encode the input spatiotemporal sequence data into a fixed-length vector. The deconvolution and FLSTM are cross-stacked to decode the output sequence from the encoded vector. Finally, in order to obtain extrapolated images with higher accuracy, an adversarial generation network is introduced, and an extrapolation model forms an end-to-end game system deep convolutional generative adversarial flow-based long short-term memory network (DCF-LSTM). In this system, the generation network is the extrapolation model that tends to be stable after pre-training. Then, the pre-trained generation network continue to be alternately trained with the discriminator to further fit the extrapolated image distribution to the real image distribution, thereby improving the accuracy of the extrapolated image.ResultExperiments were carried out under four different reflectance intensities. The DCF-LSTM model is compared with the flow based ConvLSTM (FLSTM) and DC-LSTM, which is an optimized convolutional LSTM by integrating deep convolutional generative adversarial network (DCGAN), and three mainstream meteorological business algorithms. The experimental results show that DCF-LSTM had the best performance under all intensity thresholds. Its probability of detection (POD) and critical success index (CSI) are higher than the other two methods, and it has the lowest false alarm rate (FAR) and mean square error (MSE), especially when the reflectivity is 35 dBZ. The higher the value of POD and CSI, the better the model performance; the lower the FAR value, the more accurate the model. Compared with FLSTM, DCF-LSTM has a 0.012 higher POD, 0.02 lower FAR, 0.015 higher CSI, and 0.115 lower MSE. Compared with DC-LSTM, DCF-LSTM has 0.035 higher POD, 0.03 lower FAR, 0.034 higher CSI, and 0.274 lower MSE. In addition, compared with TrajGRU, ConvLSTM, and Flow methods, DCF-LSTM has a 0.018, 0.047, and 0.099 higher POD; 0.015, 0.036, and 0.083 higher CSI; and 0.012, 0.034, and 0.087 lower FAR, respectively.ConclusionThe experimental results show that the optical flow method can enable the model to learn the dynamic changes of local features in the radar sequence, breaking through the limitation of local invariance of the convolution operation and making the model more resistant to distortion. In addition, the introduction of DCGAN module for further game training prediction model can further increase the accuracy of the results. Compared with the three mainstream meteorological business algorithms, the DCF-LSTM echo extrapolation algorithm proposed in this study has further improved the accuracy of radar extrapolation.关键词:radar echo extrapolation;convolutional long short-term memory network (ConvLSTM);deep convolutional generative adversarial network (DCGAN);optical flow;sequence-to-sequence structure156|318|3更新时间:2024-05-07
摘要:ObjectiveRadar echo extrapolation is an important method for short-term precipitation prediction. It can achieve faster and more accurate predictions compared with traditional methods, such as numerical weather forecast and optical flow method. Among them, numerical weather forecasting requires complex and meticulous simulations of physical equations in the atmosphere and then uses observation data as input to predict future weather conditions. The optical flow method is currently the mainstream method used by the meteorological department, but it has two inherent flaws. On the one hand, only two adjacent frames can be used to estimate the optical flow; on the other hand, the radar echo sequence cannot be fully used for prediction. Nevertheless, the radar echo extrapolation method based on deep learning can take full advantage of spatiotemporal sequence data to achieve faster and more accurate prediction. In addition, the echo extrapolation algorithm based on convolutional long short-term memory network (ConvLSTM) has been proved to be effective in real applications, and the effect is superior to other deep learning extrapolation algorithms. However, it ignores the limitations of ordinary convolution operations in the face of locally changing features, and in the extrapolation process, the loss function is simply defined as mean square error (MSE), ignoring the distribution similarity between the extrapolated image and the original image, which is easy to cause information loss. To solve the above problems, an improved echo extrapolation algorithm based on adversarial long short-term memory network (LSTM) is proposed.MethodFirst, in view of the local-invariance limitations of the traditional convolution kernel, we borrowed the idea of the dense optical flow method and constructed a two-dimensional instantaneous velocity field for all pixels to extract the motion information of each part of the object. Based on this idea, ConvLSTM is improved to form flow long short-term memory network (FLSTM), which is an optical flow optimization extrapolation algorithm. The algorithm uses optical flow to track local features, breaking through the limitation of local invariance of general convolution kernels. Then, according to the characteristics of radar sequence data (high-dimensional spatiotemporal data), the convolutional layer is used to extract effective spatial features to reduce spatial redundancy in the encoder, and then deconvolution is used in the decoder to amplify the generated decoded features to the size of the original image to form an output sequence. The convolutional layer and FLSTM are cross-stacked in depth to encode the input spatiotemporal sequence data into a fixed-length vector. The deconvolution and FLSTM are cross-stacked to decode the output sequence from the encoded vector. Finally, in order to obtain extrapolated images with higher accuracy, an adversarial generation network is introduced, and an extrapolation model forms an end-to-end game system deep convolutional generative adversarial flow-based long short-term memory network (DCF-LSTM). In this system, the generation network is the extrapolation model that tends to be stable after pre-training. Then, the pre-trained generation network continue to be alternately trained with the discriminator to further fit the extrapolated image distribution to the real image distribution, thereby improving the accuracy of the extrapolated image.ResultExperiments were carried out under four different reflectance intensities. The DCF-LSTM model is compared with the flow based ConvLSTM (FLSTM) and DC-LSTM, which is an optimized convolutional LSTM by integrating deep convolutional generative adversarial network (DCGAN), and three mainstream meteorological business algorithms. The experimental results show that DCF-LSTM had the best performance under all intensity thresholds. Its probability of detection (POD) and critical success index (CSI) are higher than the other two methods, and it has the lowest false alarm rate (FAR) and mean square error (MSE), especially when the reflectivity is 35 dBZ. The higher the value of POD and CSI, the better the model performance; the lower the FAR value, the more accurate the model. Compared with FLSTM, DCF-LSTM has a 0.012 higher POD, 0.02 lower FAR, 0.015 higher CSI, and 0.115 lower MSE. Compared with DC-LSTM, DCF-LSTM has 0.035 higher POD, 0.03 lower FAR, 0.034 higher CSI, and 0.274 lower MSE. In addition, compared with TrajGRU, ConvLSTM, and Flow methods, DCF-LSTM has a 0.018, 0.047, and 0.099 higher POD; 0.015, 0.036, and 0.083 higher CSI; and 0.012, 0.034, and 0.087 lower FAR, respectively.ConclusionThe experimental results show that the optical flow method can enable the model to learn the dynamic changes of local features in the radar sequence, breaking through the limitation of local invariance of the convolution operation and making the model more resistant to distortion. In addition, the introduction of DCGAN module for further game training prediction model can further increase the accuracy of the results. Compared with the three mainstream meteorological business algorithms, the DCF-LSTM echo extrapolation algorithm proposed in this study has further improved the accuracy of radar extrapolation.关键词:radar echo extrapolation;convolutional long short-term memory network (ConvLSTM);deep convolutional generative adversarial network (DCGAN);optical flow;sequence-to-sequence structure156|318|3更新时间:2024-05-07 -
 摘要:ObjectiveRemote sensing technology has a wide range of applications in mineral resources, biological resources, environmental monitoring, disaster monitoring, etc. In Earth observation satellites, remote sensing images are subject to many accidental or malicious attacks, resulting in data loss and data integrity destruction. Because remote sensing images may contain confidential information, the safety of remote sensing images has received increasing attention. To solve this problem, an encryption algorithm is used to protect the image and prevent unauthorized access. In the past two decades, chaotic systems have been used as effective solutions for image encryption because of their good ergodicity, pseudo-randomness, initial condition sensitivity, and other properties. From the perspective of image encryption algorithms, various problems such as poor calculation speed and security problems exist. In traditional encryption algorithms based on chaotic technology, the length of the iterative key sequence is proportional to the size of the image, and the remote sensing image has a large capacity. Thus, encryption using chaotic systems, especially high-dimensional chaotic systems, will affect the encryption efficiency. Because deoxyribonucleic acid(DNA) encryption technology has the advantages of high parallelism, low power consumption, and high storage, it is usually combined with chaotic systems for image encryption. However, due to the limited DNA encoding and calculation rules, the encrypted image is still vulnerable. To further improve the encryption efficiency, some algorithms introduce the concept of parallelism into encryption algorithms; however, the current parallel encryption algorithm is mainly based on CPU parallelism and does not consider parallels in the calculation of key sequence. The number of parallels is limited by CPU threads, and it still cannot meet the efficiency requirements. To solve this problem, a graphics processing unit(GPU) parallel remote sensing image encryption algorithm is proposed, which improves the key sequence iteration method and encryption method and proposes a new DNA encoding substitution algorithm, thereby improving the security and efficiency of image encryption algorithms.MethodFirst, the secure Hash algorithm 256 (SHA-256) Hash values of the plain image are used to modify the parameters and initial values of the chaotic system to improve the plain-image sensitivity of the algorithm. Then, two-dimensional Hénon-Sine mapping is used to complete the image scrambling, disturbing the distribution law between pixels; then, the GPU is used to calculate the key sequence in parallel to shorten the encryption time. Multiple chaos is selected, and the initial values of the chaotic system are modified to ensure the randomness of the key sequence. Finally, the key sequence is used to sequentially perform DNA encoding, substitution, addition, exclusive-OR, and decoding operations on the image to complete encryption. During this process, the DNA substitution is completed by the proposed DNA-S-box, which can be replaced nonlinearly. Due to the high degree of parallelism of the algorithm, GPU parallel encryption is used in the DNA encryption process to increase the encryption speed.ResultUsing three remote sensing images of the Landsat-8 satellite to analyze the encryption performance, the experimental results show that the correlation of the adjacent pixels of the remote sensing image encrypted using the algorithm of this study is infinitely close to 0, the information entropy is almost equal to the ideal value of 8, and the plain-image sensitivity is extremely high. The algorithm passed the National Institute of Standards and Technology(NIST) random test and chi-square test, indicating a very high-security performance. Moreover, the speed of the algorithm can reach 80 Mbit/s. The algorithm is used to encrypt the plain image of Lena and compare with other image encryption algorithms. The simulation results show that the key space, correlation of adjacent pixels, number of changing pixel rate(NPCR), unified averaged changed intensity(UACI), and information entropy of the proposed algorithm are closer to the ideal values.ConclusionThis study proposes a remote sensing image encryption algorithm using GPU parallel, which improves the iterative chaotic sequence method and DNA encryption method, so that the encryption algorithm is suitable for GPU parallel computing, thereby increasing the speed of encryption and decryption while ensuring security. The simulation results show that the encryption algorithm has a larger key space, higher sensitivity in plain image, and faster speed compared with other algorithms. The proposed algorithm is suitable for military, medical, remote sensing, and other confidential images, especially large-capacity storage of confidential images and network transmission.关键词:remote sensing images;chaotic systems;DNA sequence;parallel;secure Hash algorithm 256(SHA-256)182|287|6更新时间:2024-05-07
摘要:ObjectiveRemote sensing technology has a wide range of applications in mineral resources, biological resources, environmental monitoring, disaster monitoring, etc. In Earth observation satellites, remote sensing images are subject to many accidental or malicious attacks, resulting in data loss and data integrity destruction. Because remote sensing images may contain confidential information, the safety of remote sensing images has received increasing attention. To solve this problem, an encryption algorithm is used to protect the image and prevent unauthorized access. In the past two decades, chaotic systems have been used as effective solutions for image encryption because of their good ergodicity, pseudo-randomness, initial condition sensitivity, and other properties. From the perspective of image encryption algorithms, various problems such as poor calculation speed and security problems exist. In traditional encryption algorithms based on chaotic technology, the length of the iterative key sequence is proportional to the size of the image, and the remote sensing image has a large capacity. Thus, encryption using chaotic systems, especially high-dimensional chaotic systems, will affect the encryption efficiency. Because deoxyribonucleic acid(DNA) encryption technology has the advantages of high parallelism, low power consumption, and high storage, it is usually combined with chaotic systems for image encryption. However, due to the limited DNA encoding and calculation rules, the encrypted image is still vulnerable. To further improve the encryption efficiency, some algorithms introduce the concept of parallelism into encryption algorithms; however, the current parallel encryption algorithm is mainly based on CPU parallelism and does not consider parallels in the calculation of key sequence. The number of parallels is limited by CPU threads, and it still cannot meet the efficiency requirements. To solve this problem, a graphics processing unit(GPU) parallel remote sensing image encryption algorithm is proposed, which improves the key sequence iteration method and encryption method and proposes a new DNA encoding substitution algorithm, thereby improving the security and efficiency of image encryption algorithms.MethodFirst, the secure Hash algorithm 256 (SHA-256) Hash values of the plain image are used to modify the parameters and initial values of the chaotic system to improve the plain-image sensitivity of the algorithm. Then, two-dimensional Hénon-Sine mapping is used to complete the image scrambling, disturbing the distribution law between pixels; then, the GPU is used to calculate the key sequence in parallel to shorten the encryption time. Multiple chaos is selected, and the initial values of the chaotic system are modified to ensure the randomness of the key sequence. Finally, the key sequence is used to sequentially perform DNA encoding, substitution, addition, exclusive-OR, and decoding operations on the image to complete encryption. During this process, the DNA substitution is completed by the proposed DNA-S-box, which can be replaced nonlinearly. Due to the high degree of parallelism of the algorithm, GPU parallel encryption is used in the DNA encryption process to increase the encryption speed.ResultUsing three remote sensing images of the Landsat-8 satellite to analyze the encryption performance, the experimental results show that the correlation of the adjacent pixels of the remote sensing image encrypted using the algorithm of this study is infinitely close to 0, the information entropy is almost equal to the ideal value of 8, and the plain-image sensitivity is extremely high. The algorithm passed the National Institute of Standards and Technology(NIST) random test and chi-square test, indicating a very high-security performance. Moreover, the speed of the algorithm can reach 80 Mbit/s. The algorithm is used to encrypt the plain image of Lena and compare with other image encryption algorithms. The simulation results show that the key space, correlation of adjacent pixels, number of changing pixel rate(NPCR), unified averaged changed intensity(UACI), and information entropy of the proposed algorithm are closer to the ideal values.ConclusionThis study proposes a remote sensing image encryption algorithm using GPU parallel, which improves the iterative chaotic sequence method and DNA encryption method, so that the encryption algorithm is suitable for GPU parallel computing, thereby increasing the speed of encryption and decryption while ensuring security. The simulation results show that the encryption algorithm has a larger key space, higher sensitivity in plain image, and faster speed compared with other algorithms. The proposed algorithm is suitable for military, medical, remote sensing, and other confidential images, especially large-capacity storage of confidential images and network transmission.关键词:remote sensing images;chaotic systems;DNA sequence;parallel;secure Hash algorithm 256(SHA-256)182|287|6更新时间:2024-05-07
Remote Sensing Image Processing
-
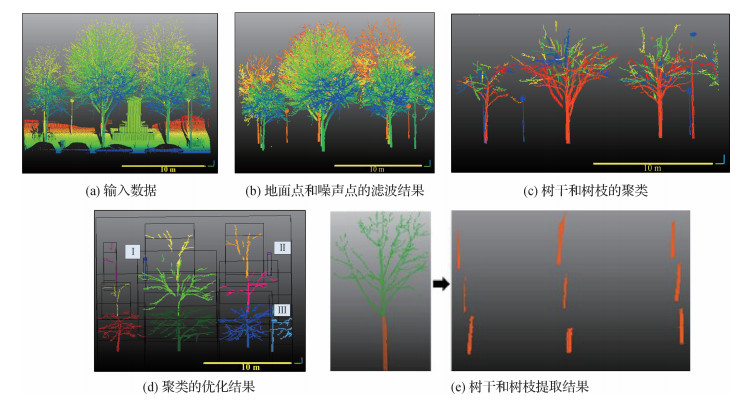 摘要:ObjectiveStreet trees have played a key role in the urban forest resource inventory. Traditional methods of street tree detection and survey are based on 2D satellite images, which have low resolution and lack 3D information. At present, mobile laser scanner systems have been used to successfully collect the 3D side information of urban street trees at a low cost and high efficiency. Hence, this study uses a hierarchical clustering approach to extract street tree stems from mobile laser radar (LiDAR) point clouds. This study proposes a bottom-up hierarchical clustering method to extract urban street trees from mobile laser scanner point clouds. The proposed algorithm calculates the cost of different cluster combination and optimizes the cluster merging.MethodThere are three main steps in the proposed tree stem extraction. The first preprocessing step is to filter noise and ground points to reduce the calculation complexity. The noise point filtering is based on the mean μ and standard deviation σ of K-nearest neighbor points. A point is considered to be an outlier if the average distance to its K-nearest neighbors is above the specified threshold. Points that fall out of the range between μ-σ and μ+σ are regarded as noise points. To remove ground points, we analyze the elevation histogram of points. The second step is to group points from the same tree into one unit based on the clustering approach. Each cluster contains one unique point. The proximity matrix is calculated iteratively. If the cluster set is converged (i.e., the number of clusters is stable), the algorithm will output the clustering results; otherwise, the algorithm goes to the proximity matrix calculation and repeats the above-mentioned steps. The third step is the refinement of results. Given that pole-like objects tend to be regarded as tree stems, we analyze the point distribution. The method is based on the kurtosis of point in the vertical direction. If the kurtosis of a candidate tree cluster falls in μk-1.5σk and μk+ 1.5σk, this cluster will be regarded as a tree; otherwise, this cluster will be regarded as a false tree. μk and σk are the mean and standard deviation kurtosis of a candidate tree cluster, respectively. The proximity matrix required for the hierarchical clustering to measure the difference between clusters is based on the Euclidean distances and the principal direction of local points. The main contribution is to minimize the cluster combination cost by solving the matching problem in graphs.ResultTo evaluate the tree stem clustering, the proposed algorithm is used on two urban scenes. The first scene is from an open benchmark located in Paris, the collection system is mobile laser scanning(MLS), and the date is in January 2013. The second scene is collected by a wearable laser scanning (WLS) system. The WLS device used to perform the study was the ZEB-REVO lightweight mobile laser scanner by GeoSLAM. The proposed algorithm succeeds in extracting 85 out of 96 tree stems from the first dataset and 118 out of 118 tree stems from the second dataset. In the urban scene, if the tree is close to the LiDAR sensor (< 10 m), tree stems and branches will be extracted effectively. However, if trees are far from sensors (> 30 m), the extraction results will contain the main stems and branches only due to the sparse tree points. In the two experimental scenes, the proposed algorithm effectively extracts trees within 50 m, which means that the algorithm works well in an urban street scene. The main contribution is to minimize the cluster combination cost by solving the matching problem in graphs. The proposed bottom-up clustering strategy succeeds in extracting points from the stem regions and achieves the completeness of 94.8%, correctness of 98.5%, and F-score of 0.97 on urban road environments. Given that the proposed results are based on the optimal cluster combination, the robustness of the segmentation of scatter points will be higher than others. The segment of stems is based on the principal direction; therefore, the results will not be affected by the holes or incomplete regions. Moreover, the proposed stem cluster does not rely on a fitting approach. Therefore, the proposed method works for different tree models or structures.ConclusionThe proposed tree stem clustering does not require any prior knowledge of trees (e.g., the number of trees, the location, and geometric shape information). The proposed method is based on the Euclidean distance and principal direction to formulate the proximity matrix and uses the perfect matching in a bipartite graph to optimize the cluster combination. Experiments show that the proposed method succeeds in clustering stems from two complex urban street scenes and is proved to be suitable for various tree structures. The calculation of the optimal cluster combination is effective to reduce the "over-segmentation" and "under-segmentation" in the tree stem detection, improving the clustering accuracy and robustness from 3D point clouds.关键词:3D data processing;computer vision;graph matching;hierarchical clustering;point cloud data;urban street tree98|1607|2更新时间:2024-05-07
摘要:ObjectiveStreet trees have played a key role in the urban forest resource inventory. Traditional methods of street tree detection and survey are based on 2D satellite images, which have low resolution and lack 3D information. At present, mobile laser scanner systems have been used to successfully collect the 3D side information of urban street trees at a low cost and high efficiency. Hence, this study uses a hierarchical clustering approach to extract street tree stems from mobile laser radar (LiDAR) point clouds. This study proposes a bottom-up hierarchical clustering method to extract urban street trees from mobile laser scanner point clouds. The proposed algorithm calculates the cost of different cluster combination and optimizes the cluster merging.MethodThere are three main steps in the proposed tree stem extraction. The first preprocessing step is to filter noise and ground points to reduce the calculation complexity. The noise point filtering is based on the mean μ and standard deviation σ of K-nearest neighbor points. A point is considered to be an outlier if the average distance to its K-nearest neighbors is above the specified threshold. Points that fall out of the range between μ-σ and μ+σ are regarded as noise points. To remove ground points, we analyze the elevation histogram of points. The second step is to group points from the same tree into one unit based on the clustering approach. Each cluster contains one unique point. The proximity matrix is calculated iteratively. If the cluster set is converged (i.e., the number of clusters is stable), the algorithm will output the clustering results; otherwise, the algorithm goes to the proximity matrix calculation and repeats the above-mentioned steps. The third step is the refinement of results. Given that pole-like objects tend to be regarded as tree stems, we analyze the point distribution. The method is based on the kurtosis of point in the vertical direction. If the kurtosis of a candidate tree cluster falls in μk-1.5σk and μk+ 1.5σk, this cluster will be regarded as a tree; otherwise, this cluster will be regarded as a false tree. μk and σk are the mean and standard deviation kurtosis of a candidate tree cluster, respectively. The proximity matrix required for the hierarchical clustering to measure the difference between clusters is based on the Euclidean distances and the principal direction of local points. The main contribution is to minimize the cluster combination cost by solving the matching problem in graphs.ResultTo evaluate the tree stem clustering, the proposed algorithm is used on two urban scenes. The first scene is from an open benchmark located in Paris, the collection system is mobile laser scanning(MLS), and the date is in January 2013. The second scene is collected by a wearable laser scanning (WLS) system. The WLS device used to perform the study was the ZEB-REVO lightweight mobile laser scanner by GeoSLAM. The proposed algorithm succeeds in extracting 85 out of 96 tree stems from the first dataset and 118 out of 118 tree stems from the second dataset. In the urban scene, if the tree is close to the LiDAR sensor (< 10 m), tree stems and branches will be extracted effectively. However, if trees are far from sensors (> 30 m), the extraction results will contain the main stems and branches only due to the sparse tree points. In the two experimental scenes, the proposed algorithm effectively extracts trees within 50 m, which means that the algorithm works well in an urban street scene. The main contribution is to minimize the cluster combination cost by solving the matching problem in graphs. The proposed bottom-up clustering strategy succeeds in extracting points from the stem regions and achieves the completeness of 94.8%, correctness of 98.5%, and F-score of 0.97 on urban road environments. Given that the proposed results are based on the optimal cluster combination, the robustness of the segmentation of scatter points will be higher than others. The segment of stems is based on the principal direction; therefore, the results will not be affected by the holes or incomplete regions. Moreover, the proposed stem cluster does not rely on a fitting approach. Therefore, the proposed method works for different tree models or structures.ConclusionThe proposed tree stem clustering does not require any prior knowledge of trees (e.g., the number of trees, the location, and geometric shape information). The proposed method is based on the Euclidean distance and principal direction to formulate the proximity matrix and uses the perfect matching in a bipartite graph to optimize the cluster combination. Experiments show that the proposed method succeeds in clustering stems from two complex urban street scenes and is proved to be suitable for various tree structures. The calculation of the optimal cluster combination is effective to reduce the "over-segmentation" and "under-segmentation" in the tree stem detection, improving the clustering accuracy and robustness from 3D point clouds.关键词:3D data processing;computer vision;graph matching;hierarchical clustering;point cloud data;urban street tree98|1607|2更新时间:2024-05-07
Remote China LiDAR Conference 2020
-
 摘要:ObjectiveThe semantic segmentation of 3D point cloud is to take the point cloud as input and output the semantic label of each point according to the category. However, the existing semantic segmentation methods based on 3D point cloud are mainly limited to processing on small-scale point cloud blocks. When a large-scale point cloud is cut into small point clouds, the geometric features of the cut boundary can be easily destroyed, which results in obvious boundary phenomena. In addition, traditional semantic segmentation deep networks have difficult in meeting the computational efficiency requirements of large-scale data. Therefore, an efficient deep learning network model that directly takes the original point cloud as input for point cloud semantic segmentation is urgently needed. However, most networks still choose to input small point cloud blocks for training, mainly because there are many difficulties in directly handling point clouds in large scenes. The first is that the spatial size and number of points of the 3D point cloud data collected through sensor scanning are uncertain. This requires that the network does not have a specific number of input points and is not sensitive to the number of points. Second, the geometric structure of large scenes is more complicated than that of small-scale point cloud blocks, which increases the difficulty of segmentation. The third is that the direct processing of point clouds in large scenes will bring a lot of calculations, which poses a huge challenge to existing graphics processing unit(GPU) memory. The main obstacle to be overcome by our framework is to directly deal with large-scale 3D point clouds. For different point cloud spatial structures and points, they can be directly input into the network for training under the condition of ensuring time complexity and space complexity.MethodIn this study, a residual optimization network based on large-scale point cloud semantic segmentation is proposed. First, we choose random sampling as the down-sampling strategy, and its calculation time is independent of the number of points. Each coding layer has a random sampling module. This design makes it possible to gradually increase the dimension of each point feature while gradually reducing the size of the point cloud. The input to the network is the entire large-scale 3D point cloud scene. At the same time, a local feature extraction module is designed to capture the neighbor feature, geometric feature, and semantic feature of each point. The final feature set is obtained by weighted summation of the three types of features. The network introduces an attention mechanism to optimize the feature set, thereby further building a feature aggregation module to aggregate the most discriminative features in the point cloud. Finally, the residual block is added in the feature aggregation module to optimize the training of the network. The network adopts the encoder-decoder structure to realize the construction of the network framework. Different from the traditional encoder-decoder structure, this study adjusts the internal structure of each layer of the encoder for the special application scenario of large scene point cloud, including the down-sampling ratio of point cloud and the dimension of feature output. The output of the network is the score of each point in each category in the dataset. In summary, the network first passes the input point cloud through the multilayer perceptron(MLP) layer to extract the features of center point. Then, five encoding and five decoding layers are used to learn the features of each point. Finally, three fully connected layers are used to predict the semantic label of each point.ResultThe experiment was compared with the latest methods on two datasets, including Stanford large-scale 3D Indoor Spaces Dataset(S3DIS) dataset and Semantic3D dataset. The S3DIS dataset contains 12 semantic elements, which is more fine-grained and challenging than multiple semantic indoor segmentation datasets. Four criteria such as intersection over union (IoU), mean IoU (mIoU), mean accuracy (mAcc), and overall accuracy (OA) were evaluated. We set the k value of the k-nearest neighbor algorithm to 16. The batch number for training is 8, and the batch number for evaluation is 24. The number of training and verification steps for each epoch is 500 and 100, respectively. The maximum epoch during testing is 150. The experiment was conducted using a NVIDIA GTX 1080 Ti GPU. On the S3DIS dataset, our algorithm achieves the best accuracy in OA and mAcc. Compared with the super point graphs (SPG) network that also takes the entire large scene as input, the proposed algorithm improves the OA, mAcc, and mIoU by 1.7%, 8.7%, and 3.8%, respectively. The Semantic3D dataset contains eight semantic classes, covering a wide range of urban outdoor scenes: churches, streets, railroad tracks, squares, villages, football fields, castles, etc. There are about 4 billion manually marked points and various natural and artificial scenes to prevent overfitting of the classifier. We set the batch number for training to 4 and the batch number for evaluation to 16. Other settings are the same as S3DIS. On the Semantic3D dataset, the mIoU value is increased by 3.2%, and the OA is increased by 1.6% compared with the latest algorithm GACNet. Our network also achieved optimal accuracy in multiple categories such as high vegetation, buildings, and remaining hard landscapes. This verifies the outstanding performance of the residual optimization network proposed in large-scale point cloud semantic segmentation in this study, which solves the problem of gradient disappearance and network degradation in the process of feature extraction.ConclusionWe propose a new semantic segmentation framework that introduces the residual network into the semantic segmentation of large-scale point clouds, thereby increasing the network layers and extracting more distinguishing features. Our network shows excellent performance in multiple datasets, making the semantic segmentation results more accurate.关键词:computer vision;three-dimensional point cloud;large scene;semantic segmentation;multi-feature fusion;residual network156|518|7更新时间:2024-05-07
摘要:ObjectiveThe semantic segmentation of 3D point cloud is to take the point cloud as input and output the semantic label of each point according to the category. However, the existing semantic segmentation methods based on 3D point cloud are mainly limited to processing on small-scale point cloud blocks. When a large-scale point cloud is cut into small point clouds, the geometric features of the cut boundary can be easily destroyed, which results in obvious boundary phenomena. In addition, traditional semantic segmentation deep networks have difficult in meeting the computational efficiency requirements of large-scale data. Therefore, an efficient deep learning network model that directly takes the original point cloud as input for point cloud semantic segmentation is urgently needed. However, most networks still choose to input small point cloud blocks for training, mainly because there are many difficulties in directly handling point clouds in large scenes. The first is that the spatial size and number of points of the 3D point cloud data collected through sensor scanning are uncertain. This requires that the network does not have a specific number of input points and is not sensitive to the number of points. Second, the geometric structure of large scenes is more complicated than that of small-scale point cloud blocks, which increases the difficulty of segmentation. The third is that the direct processing of point clouds in large scenes will bring a lot of calculations, which poses a huge challenge to existing graphics processing unit(GPU) memory. The main obstacle to be overcome by our framework is to directly deal with large-scale 3D point clouds. For different point cloud spatial structures and points, they can be directly input into the network for training under the condition of ensuring time complexity and space complexity.MethodIn this study, a residual optimization network based on large-scale point cloud semantic segmentation is proposed. First, we choose random sampling as the down-sampling strategy, and its calculation time is independent of the number of points. Each coding layer has a random sampling module. This design makes it possible to gradually increase the dimension of each point feature while gradually reducing the size of the point cloud. The input to the network is the entire large-scale 3D point cloud scene. At the same time, a local feature extraction module is designed to capture the neighbor feature, geometric feature, and semantic feature of each point. The final feature set is obtained by weighted summation of the three types of features. The network introduces an attention mechanism to optimize the feature set, thereby further building a feature aggregation module to aggregate the most discriminative features in the point cloud. Finally, the residual block is added in the feature aggregation module to optimize the training of the network. The network adopts the encoder-decoder structure to realize the construction of the network framework. Different from the traditional encoder-decoder structure, this study adjusts the internal structure of each layer of the encoder for the special application scenario of large scene point cloud, including the down-sampling ratio of point cloud and the dimension of feature output. The output of the network is the score of each point in each category in the dataset. In summary, the network first passes the input point cloud through the multilayer perceptron(MLP) layer to extract the features of center point. Then, five encoding and five decoding layers are used to learn the features of each point. Finally, three fully connected layers are used to predict the semantic label of each point.ResultThe experiment was compared with the latest methods on two datasets, including Stanford large-scale 3D Indoor Spaces Dataset(S3DIS) dataset and Semantic3D dataset. The S3DIS dataset contains 12 semantic elements, which is more fine-grained and challenging than multiple semantic indoor segmentation datasets. Four criteria such as intersection over union (IoU), mean IoU (mIoU), mean accuracy (mAcc), and overall accuracy (OA) were evaluated. We set the k value of the k-nearest neighbor algorithm to 16. The batch number for training is 8, and the batch number for evaluation is 24. The number of training and verification steps for each epoch is 500 and 100, respectively. The maximum epoch during testing is 150. The experiment was conducted using a NVIDIA GTX 1080 Ti GPU. On the S3DIS dataset, our algorithm achieves the best accuracy in OA and mAcc. Compared with the super point graphs (SPG) network that also takes the entire large scene as input, the proposed algorithm improves the OA, mAcc, and mIoU by 1.7%, 8.7%, and 3.8%, respectively. The Semantic3D dataset contains eight semantic classes, covering a wide range of urban outdoor scenes: churches, streets, railroad tracks, squares, villages, football fields, castles, etc. There are about 4 billion manually marked points and various natural and artificial scenes to prevent overfitting of the classifier. We set the batch number for training to 4 and the batch number for evaluation to 16. Other settings are the same as S3DIS. On the Semantic3D dataset, the mIoU value is increased by 3.2%, and the OA is increased by 1.6% compared with the latest algorithm GACNet. Our network also achieved optimal accuracy in multiple categories such as high vegetation, buildings, and remaining hard landscapes. This verifies the outstanding performance of the residual optimization network proposed in large-scale point cloud semantic segmentation in this study, which solves the problem of gradient disappearance and network degradation in the process of feature extraction.ConclusionWe propose a new semantic segmentation framework that introduces the residual network into the semantic segmentation of large-scale point clouds, thereby increasing the network layers and extracting more distinguishing features. Our network shows excellent performance in multiple datasets, making the semantic segmentation results more accurate.关键词:computer vision;three-dimensional point cloud;large scene;semantic segmentation;multi-feature fusion;residual network156|518|7更新时间:2024-05-07
China LiDAR Conference 2020
-
 摘要:ObjectiveWith the continuous development of digital media, people's demand for animation works continues to increase. Excellent two-dimensional animation works usually require a lot of time and effort. In the animation production process, the key frame line draft images are usually drawn by the original artist, then the intermediate frame line draft images are drawn by multiple ordinary animators, and finally all the line draft images are colored by the coloring staff. In order to improve the production efficiency of two-dimensional animation art, researchers have committed to improving the automation of the production process. At present, data-driven deep learning technology is developing rapidly, which provides a new solution for improving the production efficiency of animation works. Although many data-driven automated methods have been proposed, it is very difficult to obtain training datasets, and there is no public dataset that corresponds to color images and linear images. For this reason, the research work of automatically extracting line draft images from color animation images will provide data support for animation production-related research.MethodEarly image edge extraction methods depend on the setting of parameter values, and fixed parameters cannot be applied to all images. However, the data-driven image edge extraction method is limited by the collection and size of the dataset. Therefore, researchers usually use data enhancement techniques or use images similar to line art, such as boundary images (edge information extracted from color images). This study proposes an automatic extraction model of linear art images based on the cycle-consistent adversarial networks to solve the problem of the difficulty of obtaining real line art images and the distortion of the existing line art image extraction methods. First of all, this study uses a cycle-consistent adversarial network structure to solve the dataset problem without real color images and corresponding line art images. It only uses a few collected real line art images and a large number of color images to learn the model parameters. Then, the mask-guided convolution unit and the mask-guided residual unit are proposed to better autonomously select the intermediate output features of the network. Specifically, the input images of different scales and their corresponding boundary images are input to mask-guided convolution unit to learn the mask parameters of the intermediate feature layer, where the boundary map determines the line area of the line art image and the input image provides prior information. In order to ensure that information is not lost in the process of information encoding, no operations such as pooling that can cause information loss are used in the network design process, but the image resolution is reduced by controlling the size of the convolution kernel and the convolution step length. Finally, this study proposes a boundary constraint loss function. Considering that this study does not have the supervision information corresponding to the input image, the loss function is designed to calculate the difference between the gradient information of the input image and the output image. At the same time, regular constraints are added to ensure that the generated result is consistent with the gradient of the input image. The proposed method mainly restricts the gradient of the input image and the generated image to be consistent.ResultFinally, on the public animation color image dataset Danbooru2018, the line art image extraction results of this method are compared with the results extracted by the Canny edge detection operator, cycle-consistent adversarial networks (CycleGAN), holistically-nested edge detection (HED), and SketchKeras methods. The Canny edge detection operator only extracts the position information of the image gradient. The resulting lines extracted by CycleGAN are blurred and accompanied by missing information, and the lines in some areas cannot be extracted correctly. The line art image extracted by HED has obvious outer contours but seriously lacks internal details. The line art image extracted by SketchKeras is closer to the edge information image and contains the rich gradient change information, which causes the lines to be unclear and noisy. The extracted results of the proposed model are not only clear and have less noise, but also are more in line with the effect drawn by human animators. In order to show the actual performance effect of the proposed method, 30 users between the ages of 20-25 years are invited to score the cartoon line art images extracted by five different methods. A total of 30 sets of test samples are provided. Each user selects the best line art image in each group according to whether the extracted line art image lines are clear, whether there is noise, and whether it is close to the real cartoonist's line art image. The statistical results show that the linear art image extracted by the proposed method is superior to that of other methods in terms of image quality and authenticity. Moreover, the proposed method can not only extract the line art image corresponding to the color animation image, but also extract the line art from the real color image. In the experiment, the model was used to extract line art images from real-world color images, and results similar to animation line art images were obtained. At the same time, the proposed model is better at extracting black border lines, which may be because the borders of the color animation images given in the training set are black lines.ConclusionThis study proposes a model for extracting line art images from color animation images. It trains network parameters through asymmetric data and does not require a large amount of real cartoon line art images. The proposed mask-guided convolution unit and mask-guided residual unit constrain the output features of the intermediate network through the input image and the corresponding boundary image to obtain clearer line results. The proposed boundary consistency loss function introduces a Gaussian regular term to make the boundary of the region with severe gradient change more obvious, and the region with weak gradient change is smoother, reducing the noise in the generated line art image. Finally, the proposed method extracts corresponding line art images from the public animation color dataset Danbooru2018, provides data support for subsequent line art drawing and line art coloring research work, and can also extract results similar to the sketch drawn by an animator from the real color image.关键词:cartoon line art image generation;unpair training data;mask guided convolution unit(MGCU);cycle-consistent adversarial network(CycleGAN);convolutional neural network(CNN)115|142|0更新时间:2024-05-07
摘要:ObjectiveWith the continuous development of digital media, people's demand for animation works continues to increase. Excellent two-dimensional animation works usually require a lot of time and effort. In the animation production process, the key frame line draft images are usually drawn by the original artist, then the intermediate frame line draft images are drawn by multiple ordinary animators, and finally all the line draft images are colored by the coloring staff. In order to improve the production efficiency of two-dimensional animation art, researchers have committed to improving the automation of the production process. At present, data-driven deep learning technology is developing rapidly, which provides a new solution for improving the production efficiency of animation works. Although many data-driven automated methods have been proposed, it is very difficult to obtain training datasets, and there is no public dataset that corresponds to color images and linear images. For this reason, the research work of automatically extracting line draft images from color animation images will provide data support for animation production-related research.MethodEarly image edge extraction methods depend on the setting of parameter values, and fixed parameters cannot be applied to all images. However, the data-driven image edge extraction method is limited by the collection and size of the dataset. Therefore, researchers usually use data enhancement techniques or use images similar to line art, such as boundary images (edge information extracted from color images). This study proposes an automatic extraction model of linear art images based on the cycle-consistent adversarial networks to solve the problem of the difficulty of obtaining real line art images and the distortion of the existing line art image extraction methods. First of all, this study uses a cycle-consistent adversarial network structure to solve the dataset problem without real color images and corresponding line art images. It only uses a few collected real line art images and a large number of color images to learn the model parameters. Then, the mask-guided convolution unit and the mask-guided residual unit are proposed to better autonomously select the intermediate output features of the network. Specifically, the input images of different scales and their corresponding boundary images are input to mask-guided convolution unit to learn the mask parameters of the intermediate feature layer, where the boundary map determines the line area of the line art image and the input image provides prior information. In order to ensure that information is not lost in the process of information encoding, no operations such as pooling that can cause information loss are used in the network design process, but the image resolution is reduced by controlling the size of the convolution kernel and the convolution step length. Finally, this study proposes a boundary constraint loss function. Considering that this study does not have the supervision information corresponding to the input image, the loss function is designed to calculate the difference between the gradient information of the input image and the output image. At the same time, regular constraints are added to ensure that the generated result is consistent with the gradient of the input image. The proposed method mainly restricts the gradient of the input image and the generated image to be consistent.ResultFinally, on the public animation color image dataset Danbooru2018, the line art image extraction results of this method are compared with the results extracted by the Canny edge detection operator, cycle-consistent adversarial networks (CycleGAN), holistically-nested edge detection (HED), and SketchKeras methods. The Canny edge detection operator only extracts the position information of the image gradient. The resulting lines extracted by CycleGAN are blurred and accompanied by missing information, and the lines in some areas cannot be extracted correctly. The line art image extracted by HED has obvious outer contours but seriously lacks internal details. The line art image extracted by SketchKeras is closer to the edge information image and contains the rich gradient change information, which causes the lines to be unclear and noisy. The extracted results of the proposed model are not only clear and have less noise, but also are more in line with the effect drawn by human animators. In order to show the actual performance effect of the proposed method, 30 users between the ages of 20-25 years are invited to score the cartoon line art images extracted by five different methods. A total of 30 sets of test samples are provided. Each user selects the best line art image in each group according to whether the extracted line art image lines are clear, whether there is noise, and whether it is close to the real cartoonist's line art image. The statistical results show that the linear art image extracted by the proposed method is superior to that of other methods in terms of image quality and authenticity. Moreover, the proposed method can not only extract the line art image corresponding to the color animation image, but also extract the line art from the real color image. In the experiment, the model was used to extract line art images from real-world color images, and results similar to animation line art images were obtained. At the same time, the proposed model is better at extracting black border lines, which may be because the borders of the color animation images given in the training set are black lines.ConclusionThis study proposes a model for extracting line art images from color animation images. It trains network parameters through asymmetric data and does not require a large amount of real cartoon line art images. The proposed mask-guided convolution unit and mask-guided residual unit constrain the output features of the intermediate network through the input image and the corresponding boundary image to obtain clearer line results. The proposed boundary consistency loss function introduces a Gaussian regular term to make the boundary of the region with severe gradient change more obvious, and the region with weak gradient change is smoother, reducing the noise in the generated line art image. Finally, the proposed method extracts corresponding line art images from the public animation color dataset Danbooru2018, provides data support for subsequent line art drawing and line art coloring research work, and can also extract results similar to the sketch drawn by an animator from the real color image.关键词:cartoon line art image generation;unpair training data;mask guided convolution unit(MGCU);cycle-consistent adversarial network(CycleGAN);convolutional neural network(CNN)115|142|0更新时间:2024-05-07 -
 摘要:ObjectiveCOVID-19 has caused a severe impact on the medical system and economic growth of countries all over the world. Therefore, the epidemic information of each city has important reference value for governments and enterprises to formulate public health prevention and control measures and decisions in opening the economy. According to relevant research, the infectious disease model and time series model have played an important role in finding potential hosts, confirming human to human transmission, and estimating the basic reproductive number. Related research methods on disease transmission and confirmed case prediction have experienced a series of evolution, including demographic method, dynamic model, social network analysis, flight passenger volume estimation, data mining, and machine learning method. However, the prediction accuracy of these methods still needs to be improved by using spatial information in the study of epidemic transmission. In recent years, the boom of graph deep learning has provided new technologies and methods for the estimation of epidemic spread. From the iteration of trainable parameters in the way of information interaction in early time to the optimization of graph type, propagation mechanism, and output steps, this development process laid the foundation for the generation of graph convolutional neural network(GCN). The development of graph convolution network optimizes the performance of graph neural network in spectral domain and spatial domain by changing convolution kernel and information aggregation mode. The progress of representation learning improves the convenience of graph data processing. The rise of integrated framework realizes more accurate prediction in spatiotemporal data processing represented by traffic flow.MethodCompared with traffic flow prediction, epidemic data prediction has stronger spatial attribute and weaker temporal attribute, which is the reason why GCN is used alone instead of integration approaches. First, according to the data visualization stage of the epidemic information and geographical location and traffic network between the positive correlation, the spatial distribution relationship and traffic connection relationship between affected cities in China are mapped into a graph network and encoded into geographic adjacency matrix, high-speed railway direct matrix, aircraft route direct matrix, and aircraft route or high-speed railway direct matrix. Four cities networks with different connection modes are formed by these four adjacent matrices, and the corresponding GCN model is constructed based on these cities networks, including geographical proximity graph convolutional neural network(GPGCN), airline graph convolutional neural network(ALGCN), high speed railway graph convolutional neural network(HSRGCN), airline and high speed railway graph convolutional neural network(ALHSRGCN). After dividing the training, validation, and test sets at a ratio of 6:2:2, the epidemic data were sliced according to the sliding time window to form a three-dimensional tensor with a size of 30×327×7 as the test set, which was input into the graph deep learning model in batches to participate in convolution operation. The training parameters were updated by information transmission, back propagation, and gradient descent.ResultThe experimental results on the COVID-19 dataset demonstrated that the learning distribution features of spatiotemporal data by the GCN model showed stronger fitting ability than the recurrent neural network model in the training process. It could save more than 75% of the computation cost at the training time level, and the average test set loss on mean absolute error(MAE) and mean square error(MSE) decreased by about 80%. The value of loss would converge to a lower position and achieve a more stable training process so as to obtain more accurate prediction when MSE is chosen as the loss function.ConclusionThe spatiotemporal data learning method in this study has lower operation cost and higher prediction accuracy, which shows better performance especially in the case of spatiotemporal data with stronger spatial characteristics than temporal characteristics. It provides new approaches and ideas for the prediction of epidemic spread range and number of infected people, which is conducive for relevant departments to formulate countermeasures for disease prevention and control decisions in public health events.关键词:deep learning;graph convolutional neural network(GCN);spatiotemporal data processing;Coronavirus Disease 2019(COVID-19);epidemic prediction95|292|0更新时间:2024-05-07
摘要:ObjectiveCOVID-19 has caused a severe impact on the medical system and economic growth of countries all over the world. Therefore, the epidemic information of each city has important reference value for governments and enterprises to formulate public health prevention and control measures and decisions in opening the economy. According to relevant research, the infectious disease model and time series model have played an important role in finding potential hosts, confirming human to human transmission, and estimating the basic reproductive number. Related research methods on disease transmission and confirmed case prediction have experienced a series of evolution, including demographic method, dynamic model, social network analysis, flight passenger volume estimation, data mining, and machine learning method. However, the prediction accuracy of these methods still needs to be improved by using spatial information in the study of epidemic transmission. In recent years, the boom of graph deep learning has provided new technologies and methods for the estimation of epidemic spread. From the iteration of trainable parameters in the way of information interaction in early time to the optimization of graph type, propagation mechanism, and output steps, this development process laid the foundation for the generation of graph convolutional neural network(GCN). The development of graph convolution network optimizes the performance of graph neural network in spectral domain and spatial domain by changing convolution kernel and information aggregation mode. The progress of representation learning improves the convenience of graph data processing. The rise of integrated framework realizes more accurate prediction in spatiotemporal data processing represented by traffic flow.MethodCompared with traffic flow prediction, epidemic data prediction has stronger spatial attribute and weaker temporal attribute, which is the reason why GCN is used alone instead of integration approaches. First, according to the data visualization stage of the epidemic information and geographical location and traffic network between the positive correlation, the spatial distribution relationship and traffic connection relationship between affected cities in China are mapped into a graph network and encoded into geographic adjacency matrix, high-speed railway direct matrix, aircraft route direct matrix, and aircraft route or high-speed railway direct matrix. Four cities networks with different connection modes are formed by these four adjacent matrices, and the corresponding GCN model is constructed based on these cities networks, including geographical proximity graph convolutional neural network(GPGCN), airline graph convolutional neural network(ALGCN), high speed railway graph convolutional neural network(HSRGCN), airline and high speed railway graph convolutional neural network(ALHSRGCN). After dividing the training, validation, and test sets at a ratio of 6:2:2, the epidemic data were sliced according to the sliding time window to form a three-dimensional tensor with a size of 30×327×7 as the test set, which was input into the graph deep learning model in batches to participate in convolution operation. The training parameters were updated by information transmission, back propagation, and gradient descent.ResultThe experimental results on the COVID-19 dataset demonstrated that the learning distribution features of spatiotemporal data by the GCN model showed stronger fitting ability than the recurrent neural network model in the training process. It could save more than 75% of the computation cost at the training time level, and the average test set loss on mean absolute error(MAE) and mean square error(MSE) decreased by about 80%. The value of loss would converge to a lower position and achieve a more stable training process so as to obtain more accurate prediction when MSE is chosen as the loss function.ConclusionThe spatiotemporal data learning method in this study has lower operation cost and higher prediction accuracy, which shows better performance especially in the case of spatiotemporal data with stronger spatial characteristics than temporal characteristics. It provides new approaches and ideas for the prediction of epidemic spread range and number of infected people, which is conducive for relevant departments to formulate countermeasures for disease prevention and control decisions in public health events.关键词:deep learning;graph convolutional neural network(GCN);spatiotemporal data processing;Coronavirus Disease 2019(COVID-19);epidemic prediction95|292|0更新时间:2024-05-07 -
 摘要:ObjectiveWith the rapid development of internet technology, color digital image, the carrier of large amounts of information, not only brings great convenience to people, but also brings some infringements such as tampering and plagiarism. Thus, digital watermarking technology was proposed in the last century. Digital watermarking technology can effectively protect copyrights. However, at present, most of the studies on copyright protection of color digital images use non-blind watermarking methods, while blind watermarking methods mainly focus on binary watermarking techniques and gray-scale watermarking ones, which are difficult to meet the needs of copyright protection of color digital images. In addition, in terms of the robustness of color digital image copyright protection methods, most methods can only resist traditional image attacks, while the resistance to geometric attacks is very weak; that is, most algorithms cannot extract the watermark, or the effect of the extracted watermark is poor after some geometric attacks. At the same time, image geometric processing destroys the color watermarked carrier image, which complicates the blind detection of the color digital watermark image. Thus, a blind color image digital watermarking algorithm with a large watermark capacity, high concealment security, and strong robustness needs to be designed. This study proposes a blind color image watermarking method based on Hamming code and image correction, which can effectively solve the above-mentioned problems.MethodThis algorithm uses the eigenvalue decomposition to obtain all eigenvalues of the pixel block of the host image and quantizes the sum of the absolute values of the eigenvalues to complete the hiding and blind detection of color watermark information. To improve the robustness of the algorithm, the attacks on watermarked images are judged by analyzing the geometric information of the image before extracting the watermark, so as to obtain the attack type of the color watermarked image and correct and restore them accordingly. In detail, when embedding the color watermark, affine transform based on private keys is used to encrypt the color watermark information in order to improve the security of the watermarking algorithm. Each encrypted watermark pixel is converted into an 8-bit binary information bit, and then it is encoded into more robust Hamming codes with the help of Hamming coding theory. Then, eigenvalue decomposition is used to calculate all the eigenvalues of the pixel block in the color carrier image, and the sum of the absolute value of all eigenvalues is quantified to embed the color watermark information. When extracting the color watermark information, the geometric attributes of the color watermarked image are used to judge and correct the watermarked image after various geometric attacks. In the process of judgment, the vertexes of the effective image inside the attacked color watermarked image are first obtained, and then the side and corner information of the effective image is calculated. According to the side and corner information of the effective image, the attack type of the attacked color watermarked image can be obtained. In the process of correction, the parameters of image transformation can be obtained according to the side and corner information of the effective image. Finally, the attacked color watermarked image can be corrected according to the parameters of image transformation and the attack type of the attacked color watermarked image. The extraction process of watermark is the inverse process of watermark embedding process. All the eigenvalues of the pixel block in the color corrected watermarked image are calculated, and the color watermark information is extracted by the proposed quantitative technique. In the recovery process, the extracted watermark information is reconstructed after the processing of the inverse affine transform based on private keys and inverse Hamming coding.ResultTo accurately and effectively compare the performance of the algorithm, the experiments are compared with seven different methods based on the color standard image database. The simulation results show that the proposed algorithm has better performance in visual imperceptibility, robustness, algorithm security, efficiency, and embedding capacity than other methods. In detail, in terms of invisibility, the peak signal-to-noise ratio (PSNR) is 4 dB higher compared with the watermarking method using LU decomposition. In terms of the conventional robustness, the average normalized cross-correlation (NC) is slightly improved compared with the latest Schur decomposition method. In terms of geometric robustness, such as scaling, rotation, and shearing, the NC has certain advantages. At the same time, the extracted watermarks have good visual effect. In the aspect of watermark capacity, the watermark capacity is greatly improved (up to 0.25 bpp) compared with other anti-geometric attack methods. In terms of security, the watermarking algorithm has strong security; the key space of the proposed method reaches 2432. In terms of algorithm efficiency, the running time is greatly improved, which only takes about 3, compared with some watermarking methods that resist geometric attacks.ConclusionTherefore, the experimental data show that the proposed method not only has better watermark invisibility and stronger robustness, but also has larger watermark capacity, higher security, and better real-time performance, which is suitable for the copyright protection of high-security large-capacity color digital images. Future work will focus on the reduction of time complexity of this watermarking algorithm and consider how to apply it in the copyright protection of color digital image in cloud storage.关键词:color image;digital watermarking;Hamming code;image correction;eigenvalue decomposition;affine transform66|175|1更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of internet technology, color digital image, the carrier of large amounts of information, not only brings great convenience to people, but also brings some infringements such as tampering and plagiarism. Thus, digital watermarking technology was proposed in the last century. Digital watermarking technology can effectively protect copyrights. However, at present, most of the studies on copyright protection of color digital images use non-blind watermarking methods, while blind watermarking methods mainly focus on binary watermarking techniques and gray-scale watermarking ones, which are difficult to meet the needs of copyright protection of color digital images. In addition, in terms of the robustness of color digital image copyright protection methods, most methods can only resist traditional image attacks, while the resistance to geometric attacks is very weak; that is, most algorithms cannot extract the watermark, or the effect of the extracted watermark is poor after some geometric attacks. At the same time, image geometric processing destroys the color watermarked carrier image, which complicates the blind detection of the color digital watermark image. Thus, a blind color image digital watermarking algorithm with a large watermark capacity, high concealment security, and strong robustness needs to be designed. This study proposes a blind color image watermarking method based on Hamming code and image correction, which can effectively solve the above-mentioned problems.MethodThis algorithm uses the eigenvalue decomposition to obtain all eigenvalues of the pixel block of the host image and quantizes the sum of the absolute values of the eigenvalues to complete the hiding and blind detection of color watermark information. To improve the robustness of the algorithm, the attacks on watermarked images are judged by analyzing the geometric information of the image before extracting the watermark, so as to obtain the attack type of the color watermarked image and correct and restore them accordingly. In detail, when embedding the color watermark, affine transform based on private keys is used to encrypt the color watermark information in order to improve the security of the watermarking algorithm. Each encrypted watermark pixel is converted into an 8-bit binary information bit, and then it is encoded into more robust Hamming codes with the help of Hamming coding theory. Then, eigenvalue decomposition is used to calculate all the eigenvalues of the pixel block in the color carrier image, and the sum of the absolute value of all eigenvalues is quantified to embed the color watermark information. When extracting the color watermark information, the geometric attributes of the color watermarked image are used to judge and correct the watermarked image after various geometric attacks. In the process of judgment, the vertexes of the effective image inside the attacked color watermarked image are first obtained, and then the side and corner information of the effective image is calculated. According to the side and corner information of the effective image, the attack type of the attacked color watermarked image can be obtained. In the process of correction, the parameters of image transformation can be obtained according to the side and corner information of the effective image. Finally, the attacked color watermarked image can be corrected according to the parameters of image transformation and the attack type of the attacked color watermarked image. The extraction process of watermark is the inverse process of watermark embedding process. All the eigenvalues of the pixel block in the color corrected watermarked image are calculated, and the color watermark information is extracted by the proposed quantitative technique. In the recovery process, the extracted watermark information is reconstructed after the processing of the inverse affine transform based on private keys and inverse Hamming coding.ResultTo accurately and effectively compare the performance of the algorithm, the experiments are compared with seven different methods based on the color standard image database. The simulation results show that the proposed algorithm has better performance in visual imperceptibility, robustness, algorithm security, efficiency, and embedding capacity than other methods. In detail, in terms of invisibility, the peak signal-to-noise ratio (PSNR) is 4 dB higher compared with the watermarking method using LU decomposition. In terms of the conventional robustness, the average normalized cross-correlation (NC) is slightly improved compared with the latest Schur decomposition method. In terms of geometric robustness, such as scaling, rotation, and shearing, the NC has certain advantages. At the same time, the extracted watermarks have good visual effect. In the aspect of watermark capacity, the watermark capacity is greatly improved (up to 0.25 bpp) compared with other anti-geometric attack methods. In terms of security, the watermarking algorithm has strong security; the key space of the proposed method reaches 2432. In terms of algorithm efficiency, the running time is greatly improved, which only takes about 3, compared with some watermarking methods that resist geometric attacks.ConclusionTherefore, the experimental data show that the proposed method not only has better watermark invisibility and stronger robustness, but also has larger watermark capacity, higher security, and better real-time performance, which is suitable for the copyright protection of high-security large-capacity color digital images. Future work will focus on the reduction of time complexity of this watermarking algorithm and consider how to apply it in the copyright protection of color digital image in cloud storage.关键词:color image;digital watermarking;Hamming code;image correction;eigenvalue decomposition;affine transform66|175|1更新时间:2024-05-07 -
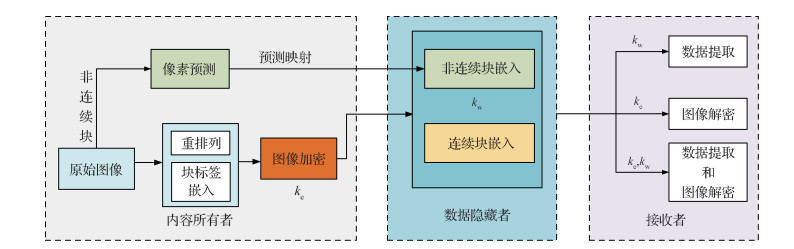 摘要:ObjectiveIn recent years, reversible data hiding (RDH) of encrypted images has attracted considerable attention. The data hider embeds hidden information into a digital image for covert transmission. However, data embedding often causes damage to the original image, which might not be fully recovered after covert transmission. Thus, effectively combining encryption technology and RDH technology for covert transmission of data is necessary. This combinatorial method ensures that images are encrypted and recoverable. Therefore, RDH technology in the ciphertext domain has become a research focus. The algorithms can be roughly divided into two categories: vacating room after encryption(VRAE) and reserving room before encryption(RRBE). The general method of RDH is typically to encrypt a cover image first, then embed hidden information into the encrypted image, and send it to the receiver. The receiver extracts the secret information and decrypts the encrypted image by using the data hiding key and encryption key, respectively. In previous RDH methods, encrypted images have little redundant space, the bit plane utilization of images is low, the embedding capacity is small, and some flipped pixels may lead to image distortion.MethodIn this work, the proposed scheme is mainly divided into the following steps: image preprocessing, block tag embedding, image rearrangement, image encryption, data embedding, data extraction, and image decryption. The content owner divides a grayscale image into eight bit planes, each of which is used for data embedding. The pixel value on each bit plane can be viewed as a binary number, and each bit plane is divided into non-overlapping blocks (such as 4×4), which are divided into discontinuous blocks (with pixel values of 0 and 1) and continuous blocks (with pixel values of 0 or 1). An image is rearranged by blocks, and the original order of block labels is embedded in the rearranged image. At the same time, the content owner makes pixel prediction on all discontinuous blocks of all bit planes and obtains the prediction map. Images after arrangement are encrypted with a stream cipher. The content owner sends the encrypted image along with the prediction map to the data hider. In the data embedding phase, the data hider embeds the data according to a pixel prediction method. For a continuous block, the bottom right pixel is kept unchanged for the recovery of the block, and data are embedded in other positions. As a result, the embedding space of each continuous block is very large. For a discontinuous block, a prediction map is generated, and then a pixel prediction model is used. When the prediction is correct, the corresponding value of the prediction map is 1; otherwise, it is 0. In the discontinuous block, only when the prediction map value is 1, data is embedded at the predicted pixel; otherwise, the predicted pixel remains unchanged without embedding data. Of note, all secret data should be encrypted before embedding. Due to the above data embedding phase, cover images can be restored completely later. The embedding capacity of the discontinuous block is less than that of the continuous block. However, due to the large number of discontinuous blocks in the low bit planes, the embedding capacity of discontinuous blocks is considerable in the whole image. However, in some state-of-the-art schemes, the utilization of low bit planes is not sufficient. The proposed scheme solves the problem by using the pixel prediction model with correction information. The data hider sends marked and encrypted images to the receiver. In the image decryption and data extraction stage, the receiver performs image decryption and data extraction according to different keys.ResultIn the experimental process, various RDH algorithms in the ciphertext domain were used, and a large number of comparison experiments were conducted on the eight grayscale test images to comprehensively compare the two aspects of complete reversibility and embedding efficiency. At the same time, a verification experiment was conducted on the BOSSbase and BOWS-2 dataset. Compared with some state-of-the-art schemes, the embedding rate of the scheme in this study was improved by 42.1% on the BOSSbase dataset and 43.3% on the BOWS-2 dataset. The embedding rate of the proposed scheme reached 3.089 5 and 2.932 0 bit per pixel on the BOSSbase and BOWS-2 dataset, respectively. Compared with other schemes, the proposed scheme embeds data on all bit planes. Unlike other state-of-the-art schemes, the proposed scheme can embed data in the low bit planes because of the pixel prediction method with correction information. Other schemes ignore the contribution of low bit planes to data embedding.ConclusionThe proposed scheme provides a large space for embedding additional information and ensures its security. Moreover, it can achieve higher embedding rate, and the image recovery is quite correct by embedding data in different blocks with different ways and using all bit planes of images, which shows the effectiveness of the proposed scheme. The experimental results show that the embedding performance of the proposed scheme is superior to that of other state-of-the-art schemes for the RDH of encrypted images. In future work, we will focus on improving the embedding efficiency of discontinuous blocks and improving the algorithm so as to increase the embedding capacity of low bit planes.关键词:pixel prediction;all bit planes;image encryption;reversible data hiding(RDH);image recovery119|182|3更新时间:2024-05-07
摘要:ObjectiveIn recent years, reversible data hiding (RDH) of encrypted images has attracted considerable attention. The data hider embeds hidden information into a digital image for covert transmission. However, data embedding often causes damage to the original image, which might not be fully recovered after covert transmission. Thus, effectively combining encryption technology and RDH technology for covert transmission of data is necessary. This combinatorial method ensures that images are encrypted and recoverable. Therefore, RDH technology in the ciphertext domain has become a research focus. The algorithms can be roughly divided into two categories: vacating room after encryption(VRAE) and reserving room before encryption(RRBE). The general method of RDH is typically to encrypt a cover image first, then embed hidden information into the encrypted image, and send it to the receiver. The receiver extracts the secret information and decrypts the encrypted image by using the data hiding key and encryption key, respectively. In previous RDH methods, encrypted images have little redundant space, the bit plane utilization of images is low, the embedding capacity is small, and some flipped pixels may lead to image distortion.MethodIn this work, the proposed scheme is mainly divided into the following steps: image preprocessing, block tag embedding, image rearrangement, image encryption, data embedding, data extraction, and image decryption. The content owner divides a grayscale image into eight bit planes, each of which is used for data embedding. The pixel value on each bit plane can be viewed as a binary number, and each bit plane is divided into non-overlapping blocks (such as 4×4), which are divided into discontinuous blocks (with pixel values of 0 and 1) and continuous blocks (with pixel values of 0 or 1). An image is rearranged by blocks, and the original order of block labels is embedded in the rearranged image. At the same time, the content owner makes pixel prediction on all discontinuous blocks of all bit planes and obtains the prediction map. Images after arrangement are encrypted with a stream cipher. The content owner sends the encrypted image along with the prediction map to the data hider. In the data embedding phase, the data hider embeds the data according to a pixel prediction method. For a continuous block, the bottom right pixel is kept unchanged for the recovery of the block, and data are embedded in other positions. As a result, the embedding space of each continuous block is very large. For a discontinuous block, a prediction map is generated, and then a pixel prediction model is used. When the prediction is correct, the corresponding value of the prediction map is 1; otherwise, it is 0. In the discontinuous block, only when the prediction map value is 1, data is embedded at the predicted pixel; otherwise, the predicted pixel remains unchanged without embedding data. Of note, all secret data should be encrypted before embedding. Due to the above data embedding phase, cover images can be restored completely later. The embedding capacity of the discontinuous block is less than that of the continuous block. However, due to the large number of discontinuous blocks in the low bit planes, the embedding capacity of discontinuous blocks is considerable in the whole image. However, in some state-of-the-art schemes, the utilization of low bit planes is not sufficient. The proposed scheme solves the problem by using the pixel prediction model with correction information. The data hider sends marked and encrypted images to the receiver. In the image decryption and data extraction stage, the receiver performs image decryption and data extraction according to different keys.ResultIn the experimental process, various RDH algorithms in the ciphertext domain were used, and a large number of comparison experiments were conducted on the eight grayscale test images to comprehensively compare the two aspects of complete reversibility and embedding efficiency. At the same time, a verification experiment was conducted on the BOSSbase and BOWS-2 dataset. Compared with some state-of-the-art schemes, the embedding rate of the scheme in this study was improved by 42.1% on the BOSSbase dataset and 43.3% on the BOWS-2 dataset. The embedding rate of the proposed scheme reached 3.089 5 and 2.932 0 bit per pixel on the BOSSbase and BOWS-2 dataset, respectively. Compared with other schemes, the proposed scheme embeds data on all bit planes. Unlike other state-of-the-art schemes, the proposed scheme can embed data in the low bit planes because of the pixel prediction method with correction information. Other schemes ignore the contribution of low bit planes to data embedding.ConclusionThe proposed scheme provides a large space for embedding additional information and ensures its security. Moreover, it can achieve higher embedding rate, and the image recovery is quite correct by embedding data in different blocks with different ways and using all bit planes of images, which shows the effectiveness of the proposed scheme. The experimental results show that the embedding performance of the proposed scheme is superior to that of other state-of-the-art schemes for the RDH of encrypted images. In future work, we will focus on improving the embedding efficiency of discontinuous blocks and improving the algorithm so as to increase the embedding capacity of low bit planes.关键词:pixel prediction;all bit planes;image encryption;reversible data hiding(RDH);image recovery119|182|3更新时间:2024-05-07 -
 摘要:ObjectiveLight detection and ranging (LiDAR) plays an important role in autonomous driving. Even if it is expensive, the number of equipped laser beams is still small, which results in a sparse point cloud density. The sparsity of the LiDAR point cloud makes 3D object detection difficult. The camera is another vital sensor used in autonomous driving because of the mature image recognition methods and its competitive price compared with LiDAR. However, it does not perform as well as LiDAR in 3D object detection task. To perceive the surrounding environment better, this study proposes a LiDAR data enhancement algorithm based on pseudo-LiDAR point cloud correction method to increase the density of LiDAR point cloud, thereby improving the accuracy of 3D object detection. This method has a wide application prospect because it is a general method to densify the point cloud and improve the detection accuracy, which does not depend on specific 3D object detection network structures.MethodThe algorithm can be divided into four steps. In the first step, the depth map is generated on the basis of the stereo RGB images by using depth estimation methods, such as pyramid stereo matching network (PSMNet) and DeepPruner. The approximate 3D coordinates of each pixel corresponding to the LiDAR coordinate system are calculated according to the camera parameters and depth information. The point cloud formed by approximate 3D coordinates is usually called pseudo-LiDAR point cloud. In the second step, the ground points in the original point cloud are removed by ground segmentation method because they will disturb the surface reconstruction process in the following step. In order to improve the performance of ground segmentation, this study designs an iterative random sample consensus (RANSAC) algorithm. A register is used in the iterative RANSAC algorithm to store the points extracted in each iteration, which are planar point cloud but not ground point cloud. The register ensures that the next iteration of RANSAC will not be affected by these non-ground planar points. The iterative RANSAC algorithm performs better than the normal RANSAC algorithm in complex scenarios where the number of points in the non-ground plane is larger than that in a ground plane or there exist multiple ground planes with different angles of inclination. In the third step, the original point cloud is inserted into a k-dimensional tree (KDTree) after ground segmentation. Thereafter, several neighboring points of each point in the pseudo-LiDAR point cloud are obtained by searching in the KDTree. On the basis of these neighboring points, surface reconstruction is performed to catch the local feature around the pseudo-LiDAR point. The Delaunay triangulation surface reconstruction method, which is considered as the optimal surface reconstruction algorithm by many researchers, is used in this step. The result of surface reconstruction is represented as several tiny triangles that cover the whole surface in 3D space. If the distance between the current and last processed approximate 3D point is within the KDTree searching radius, the surface reconstruction result of the last processed point is directly regarded as the surface reconstruction result of the current point to save time by skipping the KDTree searching and surface reconstruction process. Furthermore, because the process of KDTree searching and surface reconstruction is independent for each pseudo-LiDAR point, parallel computation based on OpenMP is used to speed up this step. In the fourth step, the precise 3D coordinates of pseudo-LiDAR point cloud corresponding to the LiDAR coordinate system are derived by the designed computational geometry method. In the computational geometry method, two different depth values are set for each pixel to obtain two points in the 3D coordinate system. The two points determine the line of the light path of this pixel. Then, the precise 3D coordinate of this pixel is considered as the closest point from the origin among all of the intersection points of the light path line and reconstruction triangle surfaces. This computational geometry method realizes the function of pseudo-LiDAR point coordinate correction. To prevent the loss of accuracy, the method avoids using division in the calculation process based on inequality analysis. Finally, the precise 3D points generated in step four are merged with the origin point cloud scanned by LiDAR to obtain the dense point cloud.ResultAfter the densification, the objects in the point cloud have more complete shapes and contours than before, which means that the characteristics of objects are more obvious. In order to further verify the validity of this data enhancement method, the aggregate view object detection (AVOD) and aggregate view object detection with feature pyramid network (AVOD-FPN) methods are implemented to check whether the average precision of 3D object detection on the dense point cloud is higher than that of the original point cloud. The data enhancement algorithm was used on KITTI (Karlsruhe Institute of Technology and Toyota Technological Institute) dataset to obtain a dataset with dense LiDAR point clouds. Then, 3D object detection methods were implemented on the original LiDAR point cloud and dense LiDAR point cloud. After using this data enhancement method, the AP3D-Easy of AVOD increased by 8.25%, and the APBEV-Hard of AVOD-FPN increased by 7.14%.ConclusionA vision-based LiDAR data enhancement algorithm was proposed to increase the density of LiDAR point cloud, thereby improving the accuracy of 3D object detection. The experimental results show that the dense point cloud has good visual quality, and the data enhancement method improves the accuracy of 3D object detection on KITTI dataset.关键词:light detection and ranging(LiDAR);data enhancement;point cloud densification;pseudo-LiDAR point cloud;ground segmentation;3D object detection76|1124|0更新时间:2024-05-07
摘要:ObjectiveLight detection and ranging (LiDAR) plays an important role in autonomous driving. Even if it is expensive, the number of equipped laser beams is still small, which results in a sparse point cloud density. The sparsity of the LiDAR point cloud makes 3D object detection difficult. The camera is another vital sensor used in autonomous driving because of the mature image recognition methods and its competitive price compared with LiDAR. However, it does not perform as well as LiDAR in 3D object detection task. To perceive the surrounding environment better, this study proposes a LiDAR data enhancement algorithm based on pseudo-LiDAR point cloud correction method to increase the density of LiDAR point cloud, thereby improving the accuracy of 3D object detection. This method has a wide application prospect because it is a general method to densify the point cloud and improve the detection accuracy, which does not depend on specific 3D object detection network structures.MethodThe algorithm can be divided into four steps. In the first step, the depth map is generated on the basis of the stereo RGB images by using depth estimation methods, such as pyramid stereo matching network (PSMNet) and DeepPruner. The approximate 3D coordinates of each pixel corresponding to the LiDAR coordinate system are calculated according to the camera parameters and depth information. The point cloud formed by approximate 3D coordinates is usually called pseudo-LiDAR point cloud. In the second step, the ground points in the original point cloud are removed by ground segmentation method because they will disturb the surface reconstruction process in the following step. In order to improve the performance of ground segmentation, this study designs an iterative random sample consensus (RANSAC) algorithm. A register is used in the iterative RANSAC algorithm to store the points extracted in each iteration, which are planar point cloud but not ground point cloud. The register ensures that the next iteration of RANSAC will not be affected by these non-ground planar points. The iterative RANSAC algorithm performs better than the normal RANSAC algorithm in complex scenarios where the number of points in the non-ground plane is larger than that in a ground plane or there exist multiple ground planes with different angles of inclination. In the third step, the original point cloud is inserted into a k-dimensional tree (KDTree) after ground segmentation. Thereafter, several neighboring points of each point in the pseudo-LiDAR point cloud are obtained by searching in the KDTree. On the basis of these neighboring points, surface reconstruction is performed to catch the local feature around the pseudo-LiDAR point. The Delaunay triangulation surface reconstruction method, which is considered as the optimal surface reconstruction algorithm by many researchers, is used in this step. The result of surface reconstruction is represented as several tiny triangles that cover the whole surface in 3D space. If the distance between the current and last processed approximate 3D point is within the KDTree searching radius, the surface reconstruction result of the last processed point is directly regarded as the surface reconstruction result of the current point to save time by skipping the KDTree searching and surface reconstruction process. Furthermore, because the process of KDTree searching and surface reconstruction is independent for each pseudo-LiDAR point, parallel computation based on OpenMP is used to speed up this step. In the fourth step, the precise 3D coordinates of pseudo-LiDAR point cloud corresponding to the LiDAR coordinate system are derived by the designed computational geometry method. In the computational geometry method, two different depth values are set for each pixel to obtain two points in the 3D coordinate system. The two points determine the line of the light path of this pixel. Then, the precise 3D coordinate of this pixel is considered as the closest point from the origin among all of the intersection points of the light path line and reconstruction triangle surfaces. This computational geometry method realizes the function of pseudo-LiDAR point coordinate correction. To prevent the loss of accuracy, the method avoids using division in the calculation process based on inequality analysis. Finally, the precise 3D points generated in step four are merged with the origin point cloud scanned by LiDAR to obtain the dense point cloud.ResultAfter the densification, the objects in the point cloud have more complete shapes and contours than before, which means that the characteristics of objects are more obvious. In order to further verify the validity of this data enhancement method, the aggregate view object detection (AVOD) and aggregate view object detection with feature pyramid network (AVOD-FPN) methods are implemented to check whether the average precision of 3D object detection on the dense point cloud is higher than that of the original point cloud. The data enhancement algorithm was used on KITTI (Karlsruhe Institute of Technology and Toyota Technological Institute) dataset to obtain a dataset with dense LiDAR point clouds. Then, 3D object detection methods were implemented on the original LiDAR point cloud and dense LiDAR point cloud. After using this data enhancement method, the AP3D-Easy of AVOD increased by 8.25%, and the APBEV-Hard of AVOD-FPN increased by 7.14%.ConclusionA vision-based LiDAR data enhancement algorithm was proposed to increase the density of LiDAR point cloud, thereby improving the accuracy of 3D object detection. The experimental results show that the dense point cloud has good visual quality, and the data enhancement method improves the accuracy of 3D object detection on KITTI dataset.关键词:light detection and ranging(LiDAR);data enhancement;point cloud densification;pseudo-LiDAR point cloud;ground segmentation;3D object detection76|1124|0更新时间:2024-05-07
NCIG 2020
-
 摘要:More and more satellites have been launched or will be launched soon. Thus, remote sensing is no longer far away. With the rapid development of aerospace and aviation remote sensing technology, a new era of three-dimensional, multi-level, multi-angle, omni-directional, and all-weather earth observation has arrived. How to activate the value of data and better serve industry applications so as to meet the rapidly growing demand for remote sensing applications has become an urgent issue for remote sensing companies. As a bridge between remote sensing data and industry applications, remote sensing image processing software plays an irreplaceable role in the process of remote sensing industrialization. With the implementation of major strategic projects such as "China's High-Resolution Earth Observation System" (high-score special project) and "National Medium-term to Long-term Civilian Space Infrastructure Development Plan (2015-2025)", domestic high-score remote sensing data is becoming more abundant. Whether these valuable data can play its value and how much value it can play depends on the conversion process from high-scoring remote sensing data to effective information and application services. The value of remote sensing data requires excellent remote sensing image processing software for mining and analysis. At the same time, vigorously developing independent and controllable remote sensing image processing software has increasingly become an urgent requirement to ensure national information security, implement the strategy of aerospace power, enhance technological innovation, and serve social development. Through the research and analysis of the development process of remote sensing satellite data and remote sensing software in China and abroad, the domestic remote sensing software has experienced three stages of development: the budding period, the catch-up period, and the independent innovation period. The remote sensing image processing software pixel information expert (PIE) is taken as an example to illustrate the development progress, typical applications, and future technological development directions of domestic remote sensing software. PIE, a domestically made remote sensing image processing software, was independently developed by PIESAT Information Technology Co., Ltd. (http://www.piesat.cn/). While opening the application of cloud service platform, PIE has evolved from a single general-purpose software plug-in architecture to 3S integration, multi-platform, and multi-load cluster processing; from pure satellite remote sensing image processing to aerospace integrated platform; and from optical load to application mode of optics, radar, and hyperspectral full spectrum. PIE6.0 has developed from a general remote sensing image processing software to PIE-Basic remote sensing image processing software, PIE-Ortho satellite image surveying and mapping processing software, PIE-SAR radar image data processing software, PIE-Hyp hyperspectral image data processing software, PIE-UAV unmanned aerial vehicle image data processing software, PIE-SIAS scale set image analysis software, PIE-AI remote sensing image intelligent processing software, PIE-Map geographic information system software, and many other "families". PIE6.0 has five core capabilities: comprehensive support for multi-source remote sensing loads, intelligent extraction of full-spectrum element information, deep integration of multi-industry and full-business chains, rapid processing of massive remote sensing data, and complete control of independent property rights programs. In order to meet the ever-increasing demand for remote sensing applications, we should build an intelligent, high-performance, and practical remote sensing image processing system; provide a wider, more refined, and more in-depth special service; and gradually develop and improve market mechanisms to establish sustainable development of remote sensing industry capabilities. Domestic remote sensing software continues to develop key technologies, such as remote sensing spatiotemporal big data storage management, intelligent synthesis, incremental cascading update, cleaning analysis and mining, and information security, to improve remote sensing data analysis and processing and knowledge mining and decision support capabilities and to build shared data and codes. The open platform of methods promotes multi-source heterogeneous data sharing and interoperability. In the future, domestic remote sensing software will closely follow industry applications and public needs, advanced technology integration and collaboration, remote sensing on-orbit intelligent real-time processing, and one-stop refined remote sensing cloud services. PIE will continue to increase the contribution rate of science and technology; promote the modernization of remote sensing application capabilities; strengthen the cross-integration of remote sensing applications with big data, cloud computing, artificial intelligence, and other cutting-edge technologies; continue to improve remote sensing data analysis and processing, knowledge discovery, and decision support capabilities; and realize the on-demand acquisition of remote sensing data, the rapid transmission of data, and the focused services of thematic information, so that multi-source remote sensing data can truly become a powerful weapon to promote resource investigation, environmental monitoring, emergency rescue, and so on.关键词:domestic remote sensing software;pixel information expert (PIE);direction of development;cloud service platform;artificial intelligence;big data209|380|4更新时间:2024-05-07
摘要:More and more satellites have been launched or will be launched soon. Thus, remote sensing is no longer far away. With the rapid development of aerospace and aviation remote sensing technology, a new era of three-dimensional, multi-level, multi-angle, omni-directional, and all-weather earth observation has arrived. How to activate the value of data and better serve industry applications so as to meet the rapidly growing demand for remote sensing applications has become an urgent issue for remote sensing companies. As a bridge between remote sensing data and industry applications, remote sensing image processing software plays an irreplaceable role in the process of remote sensing industrialization. With the implementation of major strategic projects such as "China's High-Resolution Earth Observation System" (high-score special project) and "National Medium-term to Long-term Civilian Space Infrastructure Development Plan (2015-2025)", domestic high-score remote sensing data is becoming more abundant. Whether these valuable data can play its value and how much value it can play depends on the conversion process from high-scoring remote sensing data to effective information and application services. The value of remote sensing data requires excellent remote sensing image processing software for mining and analysis. At the same time, vigorously developing independent and controllable remote sensing image processing software has increasingly become an urgent requirement to ensure national information security, implement the strategy of aerospace power, enhance technological innovation, and serve social development. Through the research and analysis of the development process of remote sensing satellite data and remote sensing software in China and abroad, the domestic remote sensing software has experienced three stages of development: the budding period, the catch-up period, and the independent innovation period. The remote sensing image processing software pixel information expert (PIE) is taken as an example to illustrate the development progress, typical applications, and future technological development directions of domestic remote sensing software. PIE, a domestically made remote sensing image processing software, was independently developed by PIESAT Information Technology Co., Ltd. (http://www.piesat.cn/). While opening the application of cloud service platform, PIE has evolved from a single general-purpose software plug-in architecture to 3S integration, multi-platform, and multi-load cluster processing; from pure satellite remote sensing image processing to aerospace integrated platform; and from optical load to application mode of optics, radar, and hyperspectral full spectrum. PIE6.0 has developed from a general remote sensing image processing software to PIE-Basic remote sensing image processing software, PIE-Ortho satellite image surveying and mapping processing software, PIE-SAR radar image data processing software, PIE-Hyp hyperspectral image data processing software, PIE-UAV unmanned aerial vehicle image data processing software, PIE-SIAS scale set image analysis software, PIE-AI remote sensing image intelligent processing software, PIE-Map geographic information system software, and many other "families". PIE6.0 has five core capabilities: comprehensive support for multi-source remote sensing loads, intelligent extraction of full-spectrum element information, deep integration of multi-industry and full-business chains, rapid processing of massive remote sensing data, and complete control of independent property rights programs. In order to meet the ever-increasing demand for remote sensing applications, we should build an intelligent, high-performance, and practical remote sensing image processing system; provide a wider, more refined, and more in-depth special service; and gradually develop and improve market mechanisms to establish sustainable development of remote sensing industry capabilities. Domestic remote sensing software continues to develop key technologies, such as remote sensing spatiotemporal big data storage management, intelligent synthesis, incremental cascading update, cleaning analysis and mining, and information security, to improve remote sensing data analysis and processing and knowledge mining and decision support capabilities and to build shared data and codes. The open platform of methods promotes multi-source heterogeneous data sharing and interoperability. In the future, domestic remote sensing software will closely follow industry applications and public needs, advanced technology integration and collaboration, remote sensing on-orbit intelligent real-time processing, and one-stop refined remote sensing cloud services. PIE will continue to increase the contribution rate of science and technology; promote the modernization of remote sensing application capabilities; strengthen the cross-integration of remote sensing applications with big data, cloud computing, artificial intelligence, and other cutting-edge technologies; continue to improve remote sensing data analysis and processing, knowledge discovery, and decision support capabilities; and realize the on-demand acquisition of remote sensing data, the rapid transmission of data, and the focused services of thematic information, so that multi-source remote sensing data can truly become a powerful weapon to promote resource investigation, environmental monitoring, emergency rescue, and so on.关键词:domestic remote sensing software;pixel information expert (PIE);direction of development;cloud service platform;artificial intelligence;big data209|380|4更新时间:2024-05-07
Frontier
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0