
最新刊期
卷 26 , 期 3 , 2021
-
 摘要:Medical big data mainly include electronic health record data, such as medical imaging data and genetic information data, among which medical imaging data takes up the most of medical data currently. One of the problems that researchers in computer science are greatly concerned about is how to apply medical big data in clinical practice.Artificial intelligence (AI) provides a good way to address this problem. AI algorithms, particularly deep learning, have demonstrated remarkable progress in image-recognition tasks. Historically, in radiology practice, trained physicians visually assess medical images for the detection, characterization, and monitoring of diseases. AI methods excel at automatically recognizing complex patterns in imaging data and providing quantitative, rather than qualitative, assessments of radiographic characteristics. Methods ranging from convolutional neural networks to variational autoencoders have found myriad applications in the medical image analysis field, propelling it forward at a rapid pace. In this review, by combining recent work and the latest research progress of big data analysis of medical images until 2020, we have summarized the theory, main process, and evaluation results of multiple deep learning algorithms in some fields of medical image analysis, including magnetic resonance imaging (MRI), pathology imaging, ultrasound imaging, electrical signals, digital radiography, molybdenum target, and diabetic eye imaging, using deep learning. MRI is one of the main research areas of medical image analysis. The existing research literature includes Alzheimer's disease MRI, Parkinson's disease MRI, brain tumor MRI, prostate cancer MRI, and cardiac MRI. MRI is also divided into two-dimensional and three-dimensional image analysis, especially for three-dimensional data, where insufficient data volume leads to problems such as overfitting, large calculations, and slow training.Medical ultrasound (also known as diagnostic sonography or ultrasonography) is a diagnostic imaging technique or therapeutic application of ultrasound. It is used to create an image of internal body structures such as tendons, muscles, joints, blood vessels, and internal organs. It aims to find the source of a disease or to exclude pathology. The practice of examining pregnant women using ultrasound is called obstetric ultrasonography and was an early development and application of clinical ultrasonography.Ultrasonography uses sound waves with higher frequencies than those audible to humans (>20 000 Hz). Ultrasonic images, also known as sonograms, are made by sending ultrasound pulses into the tissue using a probe. The ultrasound pulses echo off tissues with different reflection properties and are recorded and displayed as an image.Many different types of images can be formed. The most common is a B-mode image (brightness), which displays the acoustic impedance of a two-dimensional cross-section of a tissue. Other types can display blood flow, tissue motion over time, the location of blood, the presence of specific molecules, the stiffness of a tissue, or the anatomy of a three-dimensional region. Pathology is the gold standard for diagnosing some diseases, especially digital image of pathology.We specifically discuss AI combined with digital pathology images for diagnosis.Electroencephalography (EEG) is an electrophysiological monitoring method to record the electrical activity of the brain. It is typically noninvasive, with the electrodes placed along the scalp.However, invasive electrodes are sometimes used, for example in electrocorticography, sometimes called intracranial EEG. EEG is most often used to diagnose epilepsy, which causes abnormalities in EEG readings. It is also used to diagnose sleep disorders, depth of anesthesia, coma, encephalopathies, and brain death. EEG used to be a first-line method of diagnosis for tumors, stroke, and other focal brain disorders, but its use has decreased with the advent of high-resolution anatomical imaging techniques such as MRI and computed tomography (CT). Despite limited spatial resolution, EEG continues to be a valuable tool for research and diagnosis. It is one of the few mobile techniques available and offers millisecond-range temporal resolution, which is not possible with CT, positron emission tomography (PET), or MRI.Electrocardiography(ECG or EKG) is the process of producing an electrocardiogram. It is a graph of voltage versus time of the electrical activity of the heart using electrodes placed on the skin. These electrodes detect small electrical changes that are a consequence of cardiac muscle depolarization followed by repolarization during each cardiac cycle (heartbeat). Changes in the normal ECG pattern occur in numerous cardiac abnormalities, including cardiac rhythm disturbances (e.g., atrial fibrillation and ventricular tachycardia), inadequate coronary artery blood flow (e.g., myocardial ischemia and myocardial infarction), and electrolyte disturbances (e.g., hypokalemia and hyperkalemia).We analyzed the advantages and disadvantages of existing algorithms and the important and difficult points in the field of medical imaging, and introduced the application of intelligent imaging and deep learning in the field of big data analysis and early disease diagnosis. The current algorithms in the field of medical imaging have made considerable progress, but there is still a lot of room for development. We also focus on the optimization and improvement of different algorithms in different sub-fields under a variety of segmentation and classification indicators (e.g., Dice, IoU, accuracy and recall rate), and we look forward to the future development hotspots in this field. Deep learning has developed rapidly in the field of medical imaging and has broad prospects for development. It plays an important role in the early diagnosis of diseases. It can effectively improve the work efficiency of doctors and reduce their burden. Moreover, it has important theoretical research and practical application value.关键词:deep learning;target segmentation;magnetic resonance imaging(MRI);pathology;ultrasound;review199|301|11更新时间:2024-05-07
摘要:Medical big data mainly include electronic health record data, such as medical imaging data and genetic information data, among which medical imaging data takes up the most of medical data currently. One of the problems that researchers in computer science are greatly concerned about is how to apply medical big data in clinical practice.Artificial intelligence (AI) provides a good way to address this problem. AI algorithms, particularly deep learning, have demonstrated remarkable progress in image-recognition tasks. Historically, in radiology practice, trained physicians visually assess medical images for the detection, characterization, and monitoring of diseases. AI methods excel at automatically recognizing complex patterns in imaging data and providing quantitative, rather than qualitative, assessments of radiographic characteristics. Methods ranging from convolutional neural networks to variational autoencoders have found myriad applications in the medical image analysis field, propelling it forward at a rapid pace. In this review, by combining recent work and the latest research progress of big data analysis of medical images until 2020, we have summarized the theory, main process, and evaluation results of multiple deep learning algorithms in some fields of medical image analysis, including magnetic resonance imaging (MRI), pathology imaging, ultrasound imaging, electrical signals, digital radiography, molybdenum target, and diabetic eye imaging, using deep learning. MRI is one of the main research areas of medical image analysis. The existing research literature includes Alzheimer's disease MRI, Parkinson's disease MRI, brain tumor MRI, prostate cancer MRI, and cardiac MRI. MRI is also divided into two-dimensional and three-dimensional image analysis, especially for three-dimensional data, where insufficient data volume leads to problems such as overfitting, large calculations, and slow training.Medical ultrasound (also known as diagnostic sonography or ultrasonography) is a diagnostic imaging technique or therapeutic application of ultrasound. It is used to create an image of internal body structures such as tendons, muscles, joints, blood vessels, and internal organs. It aims to find the source of a disease or to exclude pathology. The practice of examining pregnant women using ultrasound is called obstetric ultrasonography and was an early development and application of clinical ultrasonography.Ultrasonography uses sound waves with higher frequencies than those audible to humans (>20 000 Hz). Ultrasonic images, also known as sonograms, are made by sending ultrasound pulses into the tissue using a probe. The ultrasound pulses echo off tissues with different reflection properties and are recorded and displayed as an image.Many different types of images can be formed. The most common is a B-mode image (brightness), which displays the acoustic impedance of a two-dimensional cross-section of a tissue. Other types can display blood flow, tissue motion over time, the location of blood, the presence of specific molecules, the stiffness of a tissue, or the anatomy of a three-dimensional region. Pathology is the gold standard for diagnosing some diseases, especially digital image of pathology.We specifically discuss AI combined with digital pathology images for diagnosis.Electroencephalography (EEG) is an electrophysiological monitoring method to record the electrical activity of the brain. It is typically noninvasive, with the electrodes placed along the scalp.However, invasive electrodes are sometimes used, for example in electrocorticography, sometimes called intracranial EEG. EEG is most often used to diagnose epilepsy, which causes abnormalities in EEG readings. It is also used to diagnose sleep disorders, depth of anesthesia, coma, encephalopathies, and brain death. EEG used to be a first-line method of diagnosis for tumors, stroke, and other focal brain disorders, but its use has decreased with the advent of high-resolution anatomical imaging techniques such as MRI and computed tomography (CT). Despite limited spatial resolution, EEG continues to be a valuable tool for research and diagnosis. It is one of the few mobile techniques available and offers millisecond-range temporal resolution, which is not possible with CT, positron emission tomography (PET), or MRI.Electrocardiography(ECG or EKG) is the process of producing an electrocardiogram. It is a graph of voltage versus time of the electrical activity of the heart using electrodes placed on the skin. These electrodes detect small electrical changes that are a consequence of cardiac muscle depolarization followed by repolarization during each cardiac cycle (heartbeat). Changes in the normal ECG pattern occur in numerous cardiac abnormalities, including cardiac rhythm disturbances (e.g., atrial fibrillation and ventricular tachycardia), inadequate coronary artery blood flow (e.g., myocardial ischemia and myocardial infarction), and electrolyte disturbances (e.g., hypokalemia and hyperkalemia).We analyzed the advantages and disadvantages of existing algorithms and the important and difficult points in the field of medical imaging, and introduced the application of intelligent imaging and deep learning in the field of big data analysis and early disease diagnosis. The current algorithms in the field of medical imaging have made considerable progress, but there is still a lot of room for development. We also focus on the optimization and improvement of different algorithms in different sub-fields under a variety of segmentation and classification indicators (e.g., Dice, IoU, accuracy and recall rate), and we look forward to the future development hotspots in this field. Deep learning has developed rapidly in the field of medical imaging and has broad prospects for development. It plays an important role in the early diagnosis of diseases. It can effectively improve the work efficiency of doctors and reduce their burden. Moreover, it has important theoretical research and practical application value.关键词:deep learning;target segmentation;magnetic resonance imaging(MRI);pathology;ultrasound;review199|301|11更新时间:2024-05-07
Scholar View

-
 摘要:Deep learning has a tremendous influence on numerous research fields due to its outstanding performance in representing high-level feature for high-dimensional data. Especially in computer vision field, deep learning has shown its powerful abilities for various tasks such as image classification, object detection, and image segmentation. Normally, when constructing networks and using the deep learning-based method, a suitable neural network architecture is designed for our data and task, a reasonable task-oriented objective function is set, and a large amount of labeled training data is used to calculate the target loss, optimize the model parameters by the gradient descent method, and finally train an "end-to-end" deep neural network model to perform our task. Data, as the driving forces for deep learning, is areessential for training the model. With sufficient data, the overfitting problem during training can be alleviated, and the parametric search space can be expanded such that the model can be further optimized toward the global optimal solution. However, in several areas or tasks, attaining sufficient labeled samples for training a model is difficult and expensive. As a result, the overfitting problem during training occurs often and prevents deep learning models from achieving a higher performance. Thus, many methods have been proposed to address this issue, and data augmentation becomes one of the most important solutions to addressthis problem by increasing the amount and variety for the limited data set. Innumerable works have proven the effectiveness of data augmentation for improving the performance of deep learning models, which can be traced back to the seminal work of convolutional neural networks-LeNet. In this review, we examine the most representative image data augmentation methods for deep learning. This review can facilitate the researchers to adopt the appropriate methods for their task and promote the research progression of data augmentation. Current diverse data augmentation methods that can relieve the overfitting problem in deep learning models are compared and analyzed. Based on the difference of internal mechanism, a taxonomy for data augmentation methods is proposed with four classes: single data warping, multiple data mixing, learning the data distribution, and learning the augmentation strategy. First, for the image data, single data warping generates new data by image transformation over spatial space or spectral space. These methods can be divided into five categories: geometric transformations, color space transformations, sharpness transformations, noise injection, and local erasing.These methods have been widely used in image data augmentation for a long time due to their simplicity. Second, multiple data mixing can be divided according to the mixture in image space and the mixture in feature space. The mixing modes include linear mixing and nonlinear mixing for more than one image. Although mixing images seems to be a counter-intuitive method for data augmentation, experiments in many works have proven its effectiveness in improving the performance of the deep learning model. Third, the methods of learning data distribution try to capture the potential probability distribution of training data and generate new samples by sampling in that data distribution. This goal can be achieved by adversarial networks. Therefore this kind of data augmentation method is mainly based on generative adversarial network and the application of image-to-image translation. Fourth, the methods of learning augmentation strategy try to train a model to select the optimal data augmentation strategy adaptively according to the characteristics of the data or task. This goal can be achieved by metalearning, replacing data augmentation with a trainable neural network. The strategy searching problem can also be solved by reinforcement learning. When performing data augmentation in practical applications, researchers can select and combine the most suitable methods from the above methods according to the characteristics of data and tasks to form a set of effective data augmentation schemes, which in turn provides a stronger motivation for the application of deep learning methods with more effective training data. Although a better data augmentation strategy can be obtained more intelligently through learning data distribution or searching data augmentation strategies, how to customize an optimal data augmentation scheme automatically for a given task remains to be studied. In the future, conducting theoretical analysis and experimental verification of the suitability of various data augmentation methods for different data and tasks is of great research significance and application value, and will enable researchers to customize an optimal data augmentation scheme for their task. A large gap remains in applying the idea of metalearning in performing data augmentation, constructing a "data augmentation network" to learn an optimal way of data warping or data mixing. Moreover, improving the ability of generative adversarial networks(GAN)to fit the data distribution more perfectly is substantial because the oversampling in real data space should be the ideal manner of obtaining unobserved new data infinitely. The real world has numerous cross-domain and cross-modality data. The style transfer ability of encoder-decoder networks and GAN can formulate mapping functions between the different data distributions and achieve the complementation of data in different domains. Thus, exploring the application of "image-to-image translation" in different fields has bright prospects.关键词:deep learning;overfitting;data augmentation;image transformation;generative adversarial networks(GAN);meta-learning;reinforcement learning578|592|18更新时间:2024-05-07
摘要:Deep learning has a tremendous influence on numerous research fields due to its outstanding performance in representing high-level feature for high-dimensional data. Especially in computer vision field, deep learning has shown its powerful abilities for various tasks such as image classification, object detection, and image segmentation. Normally, when constructing networks and using the deep learning-based method, a suitable neural network architecture is designed for our data and task, a reasonable task-oriented objective function is set, and a large amount of labeled training data is used to calculate the target loss, optimize the model parameters by the gradient descent method, and finally train an "end-to-end" deep neural network model to perform our task. Data, as the driving forces for deep learning, is areessential for training the model. With sufficient data, the overfitting problem during training can be alleviated, and the parametric search space can be expanded such that the model can be further optimized toward the global optimal solution. However, in several areas or tasks, attaining sufficient labeled samples for training a model is difficult and expensive. As a result, the overfitting problem during training occurs often and prevents deep learning models from achieving a higher performance. Thus, many methods have been proposed to address this issue, and data augmentation becomes one of the most important solutions to addressthis problem by increasing the amount and variety for the limited data set. Innumerable works have proven the effectiveness of data augmentation for improving the performance of deep learning models, which can be traced back to the seminal work of convolutional neural networks-LeNet. In this review, we examine the most representative image data augmentation methods for deep learning. This review can facilitate the researchers to adopt the appropriate methods for their task and promote the research progression of data augmentation. Current diverse data augmentation methods that can relieve the overfitting problem in deep learning models are compared and analyzed. Based on the difference of internal mechanism, a taxonomy for data augmentation methods is proposed with four classes: single data warping, multiple data mixing, learning the data distribution, and learning the augmentation strategy. First, for the image data, single data warping generates new data by image transformation over spatial space or spectral space. These methods can be divided into five categories: geometric transformations, color space transformations, sharpness transformations, noise injection, and local erasing.These methods have been widely used in image data augmentation for a long time due to their simplicity. Second, multiple data mixing can be divided according to the mixture in image space and the mixture in feature space. The mixing modes include linear mixing and nonlinear mixing for more than one image. Although mixing images seems to be a counter-intuitive method for data augmentation, experiments in many works have proven its effectiveness in improving the performance of the deep learning model. Third, the methods of learning data distribution try to capture the potential probability distribution of training data and generate new samples by sampling in that data distribution. This goal can be achieved by adversarial networks. Therefore this kind of data augmentation method is mainly based on generative adversarial network and the application of image-to-image translation. Fourth, the methods of learning augmentation strategy try to train a model to select the optimal data augmentation strategy adaptively according to the characteristics of the data or task. This goal can be achieved by metalearning, replacing data augmentation with a trainable neural network. The strategy searching problem can also be solved by reinforcement learning. When performing data augmentation in practical applications, researchers can select and combine the most suitable methods from the above methods according to the characteristics of data and tasks to form a set of effective data augmentation schemes, which in turn provides a stronger motivation for the application of deep learning methods with more effective training data. Although a better data augmentation strategy can be obtained more intelligently through learning data distribution or searching data augmentation strategies, how to customize an optimal data augmentation scheme automatically for a given task remains to be studied. In the future, conducting theoretical analysis and experimental verification of the suitability of various data augmentation methods for different data and tasks is of great research significance and application value, and will enable researchers to customize an optimal data augmentation scheme for their task. A large gap remains in applying the idea of metalearning in performing data augmentation, constructing a "data augmentation network" to learn an optimal way of data warping or data mixing. Moreover, improving the ability of generative adversarial networks(GAN)to fit the data distribution more perfectly is substantial because the oversampling in real data space should be the ideal manner of obtaining unobserved new data infinitely. The real world has numerous cross-domain and cross-modality data. The style transfer ability of encoder-decoder networks and GAN can formulate mapping functions between the different data distributions and achieve the complementation of data in different domains. Thus, exploring the application of "image-to-image translation" in different fields has bright prospects.关键词:deep learning;overfitting;data augmentation;image transformation;generative adversarial networks(GAN);meta-learning;reinforcement learning578|592|18更新时间:2024-05-07
Review
-
 摘要:ObjectiveIn the robot's path planning and obstacle avoidance process, measuring the relative distance between the target and the sensor is very important. Distance measurement methods based on optical sensors have the advantages of portability, intuitiveness, and low cost. Therefore, they are widely used in real applications. Visual distance measurement methods commonly include monocular visual measurement and binocular visual measurement. There are two main methods for binocular image measurement: estimating the distance between the target and the camera by comparing two blurred images with different optical parameters or measuring the distance by comparing the parallax maps of these two images. However, both methods require sufficient baseline distance between the left and right cameras. Therefore, they are not suitable for smaller installation sites (unmanned boats). Furthermore, they are computationally expensive and difficult to be used in real-time applications. Monocular vision measurement was first proposed by Pentland. The basic principle is calculating the distance between the edge in the target image and the camera through the brightness changes on both sides of the target edge. Compared with binocular vision measurement, monocular vision measurement requires only one camera, and its calculation principle is simple. However, the following problems still exist in practical applications. 1) These methods are based on the exact position evaluation of the target step edge in a single image. However, this condition is difficult to be satisfied in practical applications. Therefore, a preprocessing module for detecting edges should be added, which increases the complexity and reduces the adaptability of these methods. 2) When using the Gaussian filter to approximate the fuzzy point spread function, the problems of losing the edge of slow change and the low accuracy of edge positioning in Gaussian filtering are ignored. The positioning accuracy directly affects the accuracy of monocular measurement. 3) The blurring degree of an image is related directly to the accuracy of measurement. In spite of this, the distance measurement is performed by the method to re-blur the target image multiple times. Moreover, the quantitative relationship between the number of re-blur process and the accuracy of the distance measurement is unknown. Therefore, the distance measurement accuracy is difficult to control and improve from the perspective of active blurring.MethodThis study proposes an adaptive method of measuring distance on the basis of a single blurred image and the B-spline wavelet function. First, the Laplacian operator is introduced to quantitatively evaluate the blurring degree of the original image and locate the target edge automatically. According to the principle of blurring, the blurring degree of the original image increases as the number of re-blur increases. When the blurring degree reaches a certain amount, it will change more slowly until it cannot judge the change in the blurring degree caused by two adjacent re-blurs. On the other hand, as the re-blur number increases, the distance measurement accuracy first increases and then decreases rapidly when the re-blur number reaches a certain value. Therefore, the relationship among the calculated blurring degree, re-blur number, and distance measurement error is established. Then, the B-spline wavelet function is used to replace the traditional Gaussian filter to re-blur the target image actively, and the optimal re-blur number is adaptively calculated for different scene images on the basis of the relationship among the blurring degree of image, number of blurs, and measurement error. Finally, according to the change ratio of the blurring degree on both sides of the step edge in the original blurred image, the distance between the edge and the camera is calculated.ResultA comparison experiment with respect to different practical images is conducted. The experimental results show that the method in this study has higher accuracy than the method of measuring distance on the basis of re-blur with the Gaussian function. Comparatively, the average relative error decreases by 5%. Furthermore, when the distance measurement is performed on the same image with different re-blur numbers, the measurement accuracy is higher with the optimal re-blur number obtained with the relationship among the blurring degree of image, number of blurs, and measurement error.ConclusionOur proposed distance measurement method combines the advantages of traditional distance measurement method with the Gaussian function and the cubic B-spline function. Owing to the advantages of B-spline in progressive optimization and the optimal re-blur number achievement method, our method has higher measurement accuracy, adaptivity, and robustness.关键词:monocular vision;measure distance;B-spline wavelet;Laplace operator;evaluation of the blurring degree56|158|2更新时间:2024-05-07
摘要:ObjectiveIn the robot's path planning and obstacle avoidance process, measuring the relative distance between the target and the sensor is very important. Distance measurement methods based on optical sensors have the advantages of portability, intuitiveness, and low cost. Therefore, they are widely used in real applications. Visual distance measurement methods commonly include monocular visual measurement and binocular visual measurement. There are two main methods for binocular image measurement: estimating the distance between the target and the camera by comparing two blurred images with different optical parameters or measuring the distance by comparing the parallax maps of these two images. However, both methods require sufficient baseline distance between the left and right cameras. Therefore, they are not suitable for smaller installation sites (unmanned boats). Furthermore, they are computationally expensive and difficult to be used in real-time applications. Monocular vision measurement was first proposed by Pentland. The basic principle is calculating the distance between the edge in the target image and the camera through the brightness changes on both sides of the target edge. Compared with binocular vision measurement, monocular vision measurement requires only one camera, and its calculation principle is simple. However, the following problems still exist in practical applications. 1) These methods are based on the exact position evaluation of the target step edge in a single image. However, this condition is difficult to be satisfied in practical applications. Therefore, a preprocessing module for detecting edges should be added, which increases the complexity and reduces the adaptability of these methods. 2) When using the Gaussian filter to approximate the fuzzy point spread function, the problems of losing the edge of slow change and the low accuracy of edge positioning in Gaussian filtering are ignored. The positioning accuracy directly affects the accuracy of monocular measurement. 3) The blurring degree of an image is related directly to the accuracy of measurement. In spite of this, the distance measurement is performed by the method to re-blur the target image multiple times. Moreover, the quantitative relationship between the number of re-blur process and the accuracy of the distance measurement is unknown. Therefore, the distance measurement accuracy is difficult to control and improve from the perspective of active blurring.MethodThis study proposes an adaptive method of measuring distance on the basis of a single blurred image and the B-spline wavelet function. First, the Laplacian operator is introduced to quantitatively evaluate the blurring degree of the original image and locate the target edge automatically. According to the principle of blurring, the blurring degree of the original image increases as the number of re-blur increases. When the blurring degree reaches a certain amount, it will change more slowly until it cannot judge the change in the blurring degree caused by two adjacent re-blurs. On the other hand, as the re-blur number increases, the distance measurement accuracy first increases and then decreases rapidly when the re-blur number reaches a certain value. Therefore, the relationship among the calculated blurring degree, re-blur number, and distance measurement error is established. Then, the B-spline wavelet function is used to replace the traditional Gaussian filter to re-blur the target image actively, and the optimal re-blur number is adaptively calculated for different scene images on the basis of the relationship among the blurring degree of image, number of blurs, and measurement error. Finally, according to the change ratio of the blurring degree on both sides of the step edge in the original blurred image, the distance between the edge and the camera is calculated.ResultA comparison experiment with respect to different practical images is conducted. The experimental results show that the method in this study has higher accuracy than the method of measuring distance on the basis of re-blur with the Gaussian function. Comparatively, the average relative error decreases by 5%. Furthermore, when the distance measurement is performed on the same image with different re-blur numbers, the measurement accuracy is higher with the optimal re-blur number obtained with the relationship among the blurring degree of image, number of blurs, and measurement error.ConclusionOur proposed distance measurement method combines the advantages of traditional distance measurement method with the Gaussian function and the cubic B-spline function. Owing to the advantages of B-spline in progressive optimization and the optimal re-blur number achievement method, our method has higher measurement accuracy, adaptivity, and robustness.关键词:monocular vision;measure distance;B-spline wavelet;Laplace operator;evaluation of the blurring degree56|158|2更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveAn appearance model plays a key role in the performance of visual object tracking. In recent years, tracking algorithms based on network modulation learn an appearance model by building an effective subnetwork, and thus, they can more robustly match the target in the search frames. The algorithms exhibite xcellent performance in many object tracking benchmarks. However, these tracking methods disregard the importance of high-order feature information, causing a drift when large-scale target appearance occurs. This study utilizes a global contextual attention-enhanced second-order network to model target appearance.This network is helpful in enhancing nonlinear modeling capability in visual tracking.MethodThe tracker includes two components: target estimation and classification components. It can be regarded as a two-stage tracker. Combined with the method based on Siamese networks, the speed of this method is relatively slow. The target estimation component is trained off-line to predict the overlapping of the target and the estimated bounding boxes. This tracker presents an effective network architecture for visual tracking.This architecture includes two novel module designs. The first design is called pixel-wisely global contextual attention (pGCA), which leverages bidirectional long short-term memory(Bi-LSTM) to sweep row-wisely and column-wisely across feature maps and fully capture the global context information of each pixel. The other design is second-order pooling modulation (SPM), which uses the feature covariance matrix of the template frame to learn a second-order modulation vector. Then, the modulation vector channel-wisely multiplies the intermediate feature maps of the query image to transfer the target-specific information from the template frame to the query frame. In addition, this study selects the widely adopted ResNet-50 as our backbone network.This network is pretrained on ImageNet classification task. Given the input template image X0 with bounding box b0 and query image X, this studyselects the feature maps of the third and fourth layers for subsequent processing. The feature maps are fed into the pGCA module and the precise region of interest pooling (PrPool) module, which are used to obtain the features of the annotation area.The maps are then concatenated to yield the multi-scale features enhanced by global context information. Moreover, to handle them is aligned feature caused by the large-scale deformation between the query and the template images, the tracker injects two deformable convolution blocks into the bottom branch for feature alignment. Then, the fused feature is passed through two branches of SPM, generating two modulation vectors that channel-wisely multiply the corresponding feature layers on the bottom branch of the search frame. The fused feature is more helpful to the performance of the tracker via network modulation instead of a correlation in Siamese networks. Thereafter, the modulated features are fed into two PrPool layers and then concatenated. The output features are finally fed into the intersection over union predictor module that is composed of three fully connected layers. Given the annotated ground truth, the tracker minimizes the estimation error to train all the network parameters in an end-to-end manner. The classification component is a two-layer full convolutional neural network. In contrast with the estimation component, it trains online to predict a target confidence score. Thus, this component can provide a rough 2D location of the object. During online learning, the objective function is optimized using the conjugate gradient method instead of stochastic gradient descent for real-time tracking. For the robustness of the tracker, this study uses an averaging strategy to update object appearance in this component.This strategy has been widely been used in discriminative correlation filters. For this strategy, this study assumes that the appearance of the object changes smoothly and consistently in succession. Simultaneously, it the strategy can fully utilize the information of the previous frame. The overall tracking process involves using the classification to obtain a rough location of the target, which is a response map with dimensions of 14×14×1. This tracker can distinguish the specific foreground and background in accordance with the response map. Gaussian sampling is used to obtain some predicted target bounding boxes. Before selecting which predicted bounding box is the tracking result, the tracker trains the estimation component off-line. The predicted bounding boxes are fed to the estimation component. The highest score in the estimation component determines which box is the tracking result.ResultThe tracker validates the effectiveness and robustness of the proposed method on the OTB100(object tracking benchmark) and the challenging VOT2018(visual object tracking) datasets. The proposed method achieves the best performance in terms of success plots and precision plots with an area under the curve (AUC) score of 67.9% and a precision score 87.9%, outperforming the state-of-the-art ATOM(accurate tracking by overlap maximization) by 1.5% in terms of AUC score.Simultaneously, the expected average overlap (EAO) score of our method ranks first, with 0.441 1, significantly outperforming the second best-performing method ATOM by 4%, with an EAO score of 0.401 1.ConclusionThis study proposes a visual tracker that uses network modulation.This tracker includes pGCA and SPM modules. The pGCA module leverages Bi-LSTM to capture the global context information of each pixel.The SPM module uses the feature covariance matrix of the template frame to learn a second-order modulation vector to model target appearance. It reduces the information loss of the first frame and enhances the correlation between features. The tracker utilizes an averaging strategy to update object appearance in the classification component for robustness. Therefore, the proposed tracker significantly outperforms state-of-the-art methods in terms of accuracy and efficiency.关键词:visual object tracking(VOT);convolutional neural network(CNN);network modulation;global context;attention mechanism68|110|1更新时间:2024-05-07
摘要:ObjectiveAn appearance model plays a key role in the performance of visual object tracking. In recent years, tracking algorithms based on network modulation learn an appearance model by building an effective subnetwork, and thus, they can more robustly match the target in the search frames. The algorithms exhibite xcellent performance in many object tracking benchmarks. However, these tracking methods disregard the importance of high-order feature information, causing a drift when large-scale target appearance occurs. This study utilizes a global contextual attention-enhanced second-order network to model target appearance.This network is helpful in enhancing nonlinear modeling capability in visual tracking.MethodThe tracker includes two components: target estimation and classification components. It can be regarded as a two-stage tracker. Combined with the method based on Siamese networks, the speed of this method is relatively slow. The target estimation component is trained off-line to predict the overlapping of the target and the estimated bounding boxes. This tracker presents an effective network architecture for visual tracking.This architecture includes two novel module designs. The first design is called pixel-wisely global contextual attention (pGCA), which leverages bidirectional long short-term memory(Bi-LSTM) to sweep row-wisely and column-wisely across feature maps and fully capture the global context information of each pixel. The other design is second-order pooling modulation (SPM), which uses the feature covariance matrix of the template frame to learn a second-order modulation vector. Then, the modulation vector channel-wisely multiplies the intermediate feature maps of the query image to transfer the target-specific information from the template frame to the query frame. In addition, this study selects the widely adopted ResNet-50 as our backbone network.This network is pretrained on ImageNet classification task. Given the input template image X0 with bounding box b0 and query image X, this studyselects the feature maps of the third and fourth layers for subsequent processing. The feature maps are fed into the pGCA module and the precise region of interest pooling (PrPool) module, which are used to obtain the features of the annotation area.The maps are then concatenated to yield the multi-scale features enhanced by global context information. Moreover, to handle them is aligned feature caused by the large-scale deformation between the query and the template images, the tracker injects two deformable convolution blocks into the bottom branch for feature alignment. Then, the fused feature is passed through two branches of SPM, generating two modulation vectors that channel-wisely multiply the corresponding feature layers on the bottom branch of the search frame. The fused feature is more helpful to the performance of the tracker via network modulation instead of a correlation in Siamese networks. Thereafter, the modulated features are fed into two PrPool layers and then concatenated. The output features are finally fed into the intersection over union predictor module that is composed of three fully connected layers. Given the annotated ground truth, the tracker minimizes the estimation error to train all the network parameters in an end-to-end manner. The classification component is a two-layer full convolutional neural network. In contrast with the estimation component, it trains online to predict a target confidence score. Thus, this component can provide a rough 2D location of the object. During online learning, the objective function is optimized using the conjugate gradient method instead of stochastic gradient descent for real-time tracking. For the robustness of the tracker, this study uses an averaging strategy to update object appearance in this component.This strategy has been widely been used in discriminative correlation filters. For this strategy, this study assumes that the appearance of the object changes smoothly and consistently in succession. Simultaneously, it the strategy can fully utilize the information of the previous frame. The overall tracking process involves using the classification to obtain a rough location of the target, which is a response map with dimensions of 14×14×1. This tracker can distinguish the specific foreground and background in accordance with the response map. Gaussian sampling is used to obtain some predicted target bounding boxes. Before selecting which predicted bounding box is the tracking result, the tracker trains the estimation component off-line. The predicted bounding boxes are fed to the estimation component. The highest score in the estimation component determines which box is the tracking result.ResultThe tracker validates the effectiveness and robustness of the proposed method on the OTB100(object tracking benchmark) and the challenging VOT2018(visual object tracking) datasets. The proposed method achieves the best performance in terms of success plots and precision plots with an area under the curve (AUC) score of 67.9% and a precision score 87.9%, outperforming the state-of-the-art ATOM(accurate tracking by overlap maximization) by 1.5% in terms of AUC score.Simultaneously, the expected average overlap (EAO) score of our method ranks first, with 0.441 1, significantly outperforming the second best-performing method ATOM by 4%, with an EAO score of 0.401 1.ConclusionThis study proposes a visual tracker that uses network modulation.This tracker includes pGCA and SPM modules. The pGCA module leverages Bi-LSTM to capture the global context information of each pixel.The SPM module uses the feature covariance matrix of the template frame to learn a second-order modulation vector to model target appearance. It reduces the information loss of the first frame and enhances the correlation between features. The tracker utilizes an averaging strategy to update object appearance in the classification component for robustness. Therefore, the proposed tracker significantly outperforms state-of-the-art methods in terms of accuracy and efficiency.关键词:visual object tracking(VOT);convolutional neural network(CNN);network modulation;global context;attention mechanism68|110|1更新时间:2024-05-07 -
 摘要:ObjectiveAlthough the backgrocund-aware correlation filters (BACF) algorithm increases the number of samples and guarantees the sample quality, the algorithm performs equal weight training on the background information, resulting in the problem of target drift when the target is similar to the background information in complex scenes. The value weight training method ignores the priority of sample collection in the target movement direction and the importance of weight distribution. If the sample sampling method can be effectively designed in the target movement direction and the sample weights can be allocated reasonably, the tracking effect will be improved, and the target drift will be solved effectively. Therefore, this paper adds Kalman filtering to the BACF algorithm framework.MethodFor the single-target tracking problem, the algorithm in this paper only takes the motion vector from the predicted value and does not locate the target according to constant speed or acceleration. The target position is still determined by the response peak value. The maximum response value is obtained by linear interpolation. The target location is determined. When the speed is zero, the response peak of the target positioning in the previous frame image is still used to determine the target position in the current frame image. Kalman filtering is used to predict the target's motion state and direction, and the background information in the target's motion direction and non-motion direction is subjected to filter training to ensure that the training weight assigned to the background information in the target's motion direction is higher than the non-motion direction weights. The objective function problem is optimized and solved, auxiliary factor g is constructed, the augmented Lagrangian multiplier methodis usedto place the constraints in the optimization function, and the alternating solution method (alternating direction method of multipliers(ADMM) is used to optimize the filter and auxiliary factors, andreduce computational complexity.ResultThis paper selects standard data sets OTB50(abject tracking benchmark) and OTB100 to facilitate experimental comparison with the current mainstream algorithms. OTB50 is a commonly used tracking dataset, which contains 50 groups of video sequences and has 11 different attributes, such as lighting changes and occlusions. OTB100 containsan additional 50 test sequences based on OTB50. Each sequence may have different video attributes, making tracking challenges difficult. The algorithm in this paper uses one-pass evaluation (OPE) to analyze the performance of the algorithm, and tracking accuracy and success rate as the evaluation criteria. In video sequence Board_1, the algorithm in this paper, ECO(efficient convolution operators), SRDCF(spatially regularized correlation filters), and DeepSTRCF(deep spatial-temporal regularized) can achieve accurate tracking, but the speed of the algorithm in this paper is substantially better than that of the three two algorithms of ECO, SRDCF, and DeepSTRCF. In video sequence Panda_1, the tracking effect of the algorithm in this paper is stable under a low resolution. In video sequence Box_1, only the algorithm in this paper can accurately track the target from the initial frame to the last frame because the Kalman filter is used to predict the direction of the target and distinguish the target from the background information effectively. The tracker is prevented from tracking other similar background information. Experimental results show that the average accuracy rate and average success rate of the algorithm on datasets OTB50 and OTB100 are 0.804 and 0.748, respectively, which are 7% and 16% higher than the BACF algorithm, respectively. In tracking the experimental sequence, the tracking success rate and tracking accuracy of the algorithm in this paper are high and meet the real-time requirements, and the tracking performance is good.ConclusionThis paper uses Kalman filtering to predict the direction and state of the target, assigns different weights to the background information in different directions, performs filter training, and obtains the maximum response value based on linear interpolation to determine the target position. The ADMM method is used to transform the problem of solving the target model into two subproblems with the optimal solution. The online adaptive method is used to solve the problem of target deformation in model update. Numerous comparative experiments are performed on OTB50 and OTB100 datasets. On OTB50, the algorithm success rate and accuracy rate of this paper are 0.720 and 0.777, respectively. On OTB100, the algorithm success rate and accuracy rate of this paper are 0.773 and 0.828, respectively.Both are better than the current mainstream algorithms, which shows that the algorithm in this paper has better accuracy and robustness. In background sensing, the sample sampling method and weight allocation directly affect target tracking performance. The next step is to conduct an in-depth research on the construction of a speed-adaptive sample collection model.关键词:computer vision;target tracking;correlation filter;background-aware;Kalman filters;alternating direction method of multipliers (ADMM)121|222|5更新时间:2024-05-07
摘要:ObjectiveAlthough the backgrocund-aware correlation filters (BACF) algorithm increases the number of samples and guarantees the sample quality, the algorithm performs equal weight training on the background information, resulting in the problem of target drift when the target is similar to the background information in complex scenes. The value weight training method ignores the priority of sample collection in the target movement direction and the importance of weight distribution. If the sample sampling method can be effectively designed in the target movement direction and the sample weights can be allocated reasonably, the tracking effect will be improved, and the target drift will be solved effectively. Therefore, this paper adds Kalman filtering to the BACF algorithm framework.MethodFor the single-target tracking problem, the algorithm in this paper only takes the motion vector from the predicted value and does not locate the target according to constant speed or acceleration. The target position is still determined by the response peak value. The maximum response value is obtained by linear interpolation. The target location is determined. When the speed is zero, the response peak of the target positioning in the previous frame image is still used to determine the target position in the current frame image. Kalman filtering is used to predict the target's motion state and direction, and the background information in the target's motion direction and non-motion direction is subjected to filter training to ensure that the training weight assigned to the background information in the target's motion direction is higher than the non-motion direction weights. The objective function problem is optimized and solved, auxiliary factor g is constructed, the augmented Lagrangian multiplier methodis usedto place the constraints in the optimization function, and the alternating solution method (alternating direction method of multipliers(ADMM) is used to optimize the filter and auxiliary factors, andreduce computational complexity.ResultThis paper selects standard data sets OTB50(abject tracking benchmark) and OTB100 to facilitate experimental comparison with the current mainstream algorithms. OTB50 is a commonly used tracking dataset, which contains 50 groups of video sequences and has 11 different attributes, such as lighting changes and occlusions. OTB100 containsan additional 50 test sequences based on OTB50. Each sequence may have different video attributes, making tracking challenges difficult. The algorithm in this paper uses one-pass evaluation (OPE) to analyze the performance of the algorithm, and tracking accuracy and success rate as the evaluation criteria. In video sequence Board_1, the algorithm in this paper, ECO(efficient convolution operators), SRDCF(spatially regularized correlation filters), and DeepSTRCF(deep spatial-temporal regularized) can achieve accurate tracking, but the speed of the algorithm in this paper is substantially better than that of the three two algorithms of ECO, SRDCF, and DeepSTRCF. In video sequence Panda_1, the tracking effect of the algorithm in this paper is stable under a low resolution. In video sequence Box_1, only the algorithm in this paper can accurately track the target from the initial frame to the last frame because the Kalman filter is used to predict the direction of the target and distinguish the target from the background information effectively. The tracker is prevented from tracking other similar background information. Experimental results show that the average accuracy rate and average success rate of the algorithm on datasets OTB50 and OTB100 are 0.804 and 0.748, respectively, which are 7% and 16% higher than the BACF algorithm, respectively. In tracking the experimental sequence, the tracking success rate and tracking accuracy of the algorithm in this paper are high and meet the real-time requirements, and the tracking performance is good.ConclusionThis paper uses Kalman filtering to predict the direction and state of the target, assigns different weights to the background information in different directions, performs filter training, and obtains the maximum response value based on linear interpolation to determine the target position. The ADMM method is used to transform the problem of solving the target model into two subproblems with the optimal solution. The online adaptive method is used to solve the problem of target deformation in model update. Numerous comparative experiments are performed on OTB50 and OTB100 datasets. On OTB50, the algorithm success rate and accuracy rate of this paper are 0.720 and 0.777, respectively. On OTB100, the algorithm success rate and accuracy rate of this paper are 0.773 and 0.828, respectively.Both are better than the current mainstream algorithms, which shows that the algorithm in this paper has better accuracy and robustness. In background sensing, the sample sampling method and weight allocation directly affect target tracking performance. The next step is to conduct an in-depth research on the construction of a speed-adaptive sample collection model.关键词:computer vision;target tracking;correlation filter;background-aware;Kalman filters;alternating direction method of multipliers (ADMM)121|222|5更新时间:2024-05-07 -
 摘要:ObjectiveObject detection is a fundamental task in computer vision applications, which provides support for subsequent object tracking, semantic segmentation, and behavior recognition. Recent years have witnessed substantial progress in still image object detection based on deep convolutional neural network (DCNN). The task of still image object detection is to determine the category and position of each object in an image. Video object detection aims to locate a moving object in sequential images and assign a specific category label to each object. The accuracy of video object detection suffers from degenerated object appearances in videos, such as motion blur, multiobject occlusion, and rare poses. The methods of still image object detection achieve excellent results, but directly applying them to video object detection is challenging. According to the temporal and spatial information in videos, most existing video object detection methods improve the accuracy of moving object detection by considering spatiotemporal consistency based on still image object detection.MethodIn this paper, we propose a video object detection method using fusion of single shot multibox detector (SSD) and spatiotemporal features. Under the framework of SSD, temporal and spatial information of the video are applied to video object detection through the optical flow network and the feature pyramid network. On the one hand, the network combining residual network (ResNet) 101 with four extra convolutional layers is used for feature extraction to produce the feature map in each frame of the video. An optical flow network estimates the optical flow fields between the current frame and multiple adjacent frames to enhance the feature of the current frame. The feature maps from adjacent frames are compensated to the current frame according to the optical flow fields. The multiple compensated feature maps as well the feature map of the current frame are aggregated according to adaptive weights. The adaptive weights indicate the importance of all compensated feature maps to the current frame. Here, the cosine similarity metric is utilized to measure the similarity between the compensated feature map and the feature map extracted from the current frame. If the compensated feature map is close to the feature map of the current frame, then the compensated feature map is assigned a larger weight; otherwise, it is assigned a smaller weight. Moreover, an embedding network that consists of three convolutional layers is applied on the compensated feature maps and the current feature map to produce the embedding feature maps, and the embedding feature maps are used to compute the adaptive weights. On the other hand, the feature pyramid network is used to extract multiscale feature maps that are used to detect the object of different sizes. The low-and high-level feature maps are used to detect smaller and larger objects, respectively. For the problem of small object detection in the original SSD network, the low-level feature map is combined with the high-level feature map to enhance the semantic information of the low-level feature map via upsampling operation and a 1×1 convolutional layer. The upsampling operation is used to extend the high-level feature map to the same resolution as the low-level feature map, and the 1×1 convolution layer is used to reduce the channel dimensions of the low-level feature map to be consistent with those of the high-level feature map. Then, multiscale feature maps are input into the detection network to predict bounding boxes, and nonmaximum suppression is carried out to filter the redundant bounding boxes and obtain the final bounding boxes.ResultExperimental results show that the mean average precision (mAP) score of the proposed method on the ImageNet VID(ImageNet for video object detection) dataset can reach 72.0%, which is 24.5%, 3.6%, and 2.5% higher than those of the temporal convolutional network, the method combining tubelet proposal network with long short memory network, and the method combining SSD and siamese network, respectively. In addition, an ablation experiment is conducted with five network structures, namely, 16-layer visual geometry group(VGG16) network, ResNet101 network, the network combining ResNet101 with feature pyramid network, and the network combining ResNet101 with spatiotemporal fusion. The network structure combining ResNet101 with spatiotemporal fusion improves the mAP score by 11.8%, 7.0%, and 1.2% compared with the first four network structures. For further analysis, the mAP scores of the slow, medium, and fast objects are reported in addition to the standard mAP score. Our method combined with optical flow improves the mAP score of slow, medium, and fast objects by 0.6%, 1.9%, and 2.3%, respectively, compared with the network structure combining ResNet101 with feature pyramid network. Experimental results show that the proposed method can improve the accuracy of video object detection, especially the performance of fast object detection.ConclusionTemporal and spatial correlation of the video by spatiotemporal fusion are used to improve the accuracy of video object detection in the proposed method. Using the optical flow network in video object detection can compensate the feature map of the current frame according to the feature maps of multiple adjacent frames. False negatives and false positives can be reduced through temporal feature fusion in video object detection. In addition, multiscale feature maps produced by the feature pyramid network can detect the object of different sizes, and the multiscale feature map fusion can enhance the semantic information of the low-level feature map, which improves the detection ability of the low-level feature map for small objects.关键词:object detection;single shot multibox detector (SSD);feature fusion;optical flow;feature pyramid network98|212|7更新时间:2024-05-07
摘要:ObjectiveObject detection is a fundamental task in computer vision applications, which provides support for subsequent object tracking, semantic segmentation, and behavior recognition. Recent years have witnessed substantial progress in still image object detection based on deep convolutional neural network (DCNN). The task of still image object detection is to determine the category and position of each object in an image. Video object detection aims to locate a moving object in sequential images and assign a specific category label to each object. The accuracy of video object detection suffers from degenerated object appearances in videos, such as motion blur, multiobject occlusion, and rare poses. The methods of still image object detection achieve excellent results, but directly applying them to video object detection is challenging. According to the temporal and spatial information in videos, most existing video object detection methods improve the accuracy of moving object detection by considering spatiotemporal consistency based on still image object detection.MethodIn this paper, we propose a video object detection method using fusion of single shot multibox detector (SSD) and spatiotemporal features. Under the framework of SSD, temporal and spatial information of the video are applied to video object detection through the optical flow network and the feature pyramid network. On the one hand, the network combining residual network (ResNet) 101 with four extra convolutional layers is used for feature extraction to produce the feature map in each frame of the video. An optical flow network estimates the optical flow fields between the current frame and multiple adjacent frames to enhance the feature of the current frame. The feature maps from adjacent frames are compensated to the current frame according to the optical flow fields. The multiple compensated feature maps as well the feature map of the current frame are aggregated according to adaptive weights. The adaptive weights indicate the importance of all compensated feature maps to the current frame. Here, the cosine similarity metric is utilized to measure the similarity between the compensated feature map and the feature map extracted from the current frame. If the compensated feature map is close to the feature map of the current frame, then the compensated feature map is assigned a larger weight; otherwise, it is assigned a smaller weight. Moreover, an embedding network that consists of three convolutional layers is applied on the compensated feature maps and the current feature map to produce the embedding feature maps, and the embedding feature maps are used to compute the adaptive weights. On the other hand, the feature pyramid network is used to extract multiscale feature maps that are used to detect the object of different sizes. The low-and high-level feature maps are used to detect smaller and larger objects, respectively. For the problem of small object detection in the original SSD network, the low-level feature map is combined with the high-level feature map to enhance the semantic information of the low-level feature map via upsampling operation and a 1×1 convolutional layer. The upsampling operation is used to extend the high-level feature map to the same resolution as the low-level feature map, and the 1×1 convolution layer is used to reduce the channel dimensions of the low-level feature map to be consistent with those of the high-level feature map. Then, multiscale feature maps are input into the detection network to predict bounding boxes, and nonmaximum suppression is carried out to filter the redundant bounding boxes and obtain the final bounding boxes.ResultExperimental results show that the mean average precision (mAP) score of the proposed method on the ImageNet VID(ImageNet for video object detection) dataset can reach 72.0%, which is 24.5%, 3.6%, and 2.5% higher than those of the temporal convolutional network, the method combining tubelet proposal network with long short memory network, and the method combining SSD and siamese network, respectively. In addition, an ablation experiment is conducted with five network structures, namely, 16-layer visual geometry group(VGG16) network, ResNet101 network, the network combining ResNet101 with feature pyramid network, and the network combining ResNet101 with spatiotemporal fusion. The network structure combining ResNet101 with spatiotemporal fusion improves the mAP score by 11.8%, 7.0%, and 1.2% compared with the first four network structures. For further analysis, the mAP scores of the slow, medium, and fast objects are reported in addition to the standard mAP score. Our method combined with optical flow improves the mAP score of slow, medium, and fast objects by 0.6%, 1.9%, and 2.3%, respectively, compared with the network structure combining ResNet101 with feature pyramid network. Experimental results show that the proposed method can improve the accuracy of video object detection, especially the performance of fast object detection.ConclusionTemporal and spatial correlation of the video by spatiotemporal fusion are used to improve the accuracy of video object detection in the proposed method. Using the optical flow network in video object detection can compensate the feature map of the current frame according to the feature maps of multiple adjacent frames. False negatives and false positives can be reduced through temporal feature fusion in video object detection. In addition, multiscale feature maps produced by the feature pyramid network can detect the object of different sizes, and the multiscale feature map fusion can enhance the semantic information of the low-level feature map, which improves the detection ability of the low-level feature map for small objects.关键词:object detection;single shot multibox detector (SSD);feature fusion;optical flow;feature pyramid network98|212|7更新时间:2024-05-07 -
 摘要:ObjectiveAs an important part of intelligent transportation systems, automatic license plate detection and recognition (ALPR) has always been a research hotspot in the field of computer vision. With the development of deep learning technology and new requirements for license plate recognition in the field of unmanned driving and safe cities as well as the upgrading challenges brought by complex license plate images taken by mobile phones and various mobile terminal devices, license plate recognition technology is now facing new challenges, mainly reflected in license plate background color; size and type varying in different countries; susceptibility of license plate images to complex environmental factors, such as poor lighting conditions, rain, snow, and complex background information interference; and diversity of acquisition equipment (such as mobile phone and law enforcement recorder) in real ALPR application, which leads to various irregular distortions of license plate images. The shape of a license plate is usually rectangular, with a fixed aspect ratio and definite color; hence, edge information and color features are frequently used to detect license plates in traditional ALPR techniques. These methods are highly efficient in controlled scenarios such as the entrance of a parking lot, but they are very sensitive to illumination variation, multiple viewpoints, stains, occlusion, image blur, and other influencing factors of the license plate image in natural scenarios, and the detection result is far from reaching application level. Methods based on deep learning technology have made remarkable achievements in license plate detection and character recognition tasks, and their recognition accuracy is higher than that of traditional ALPR techniques. However, they simply treat the license plate as a regular rectangular area and fail to consider the problem that the license plate will be distorted into an irregular quadrilateral in natural scenarios. These methods all use the anchor-based object detector to detect the license plate, but the size of the anchor is usually fixed, resulting in low detection accuracy for the object with a large distortion. License plates captured in natural scenarios are often distorted, especially in surveillance and cellphone videos; thus, the recognition accuracy of methods based on deep learning technology can still be improved. This paper designs a distorted license plate detection model in natural scenarios, named distorted license plate detection network (DLPD-Net), to solve the problem of irregular, distorted license plate in natural scenarios and make full use of the license plate shape characteristics.MethodFor the first time, DLPD-Net applies the anchor-free object detection method to license plate detection. Instead of using the anchor to obtain the proposal license plate regions, it predicts the license plate center based on the heat map and offset map of the license plate. First, DLPD-Net uses ResNet-50 to extract the feature map of the input image, and then obtains the feature map of nine channels by using a detection block (including heat map, offset map, and affine transformation parameter map). Local peaks in the heat map are taken as the center of the license plate, and a square with fixed size is assumed at this location. Affine transformation parameters obtained by regression are used to construct the affine matrix, and the imaginary square is transformed into a quadrilateral corresponding to the shape of the license plate. Finally, the license plate region is obtained by using the offset value to translate the quadrilateral, then a distorted license plate is extracted and corrected to a plane rectangle similar to the front view. A complete loss function is designed, which consists of three parts, namely, heat map loss, offset loss, and affine loss, to train DLPD-Net effectively. Focal loss function is used to train the heat map and address the imbalance of positive and negative samples in license plate center prediction. L1 loss is used to train the offset map and obtain the local offset of each object center because the existence of the output stride will lead to the discretization error of real object coordinates. Affine loss is obtained by calculating the difference between the transformation value of the unit square's corners and the normalized value of the license plate's corners, and then summing.ResultOn the one hand, the performance of DLPD-Net is evaluated on the CD-HARD dataset, and results show that DLPD-Net could find the corners of distorted license plates well. On the other hand, based on DLPD-Net, this paper designs a distorted license plate recognition system in natural scenarios, which is composed of three modules: vehicle detection module, license plate detection, and correction module and license plate character recognition module. Experimental results show that compared with other commercial systems and license plate detection methods proposed in paper, DLPD-Net outperforms in distorted license plate detection and can improve the recognition accuracy of the license plate recognition system. In the CD-HARD dataset, the system's recognition accuracy is 79.4%, 4.4%12.1% higher than that of other methods, and the average processing time is 237 ms. In the AOLP dataset, the system's recognition accuracy reaches 96.6%, and that is 94.9% without augmented samples, which is 1.6%25.2% higher than that of other methods, and the average processing time is 185 ms.ConclusionA distorted license plate detection model in natural scenarios, named DLPD-Net, is proposed. The model can extract the distorted license plate from the image and correct it into a plane rectangle similar to the front view, which is very useful for license plate character recognition. Based on DLPD-Net, an ALPR system is proposed. Experimental results show that DLPD-Net can achieve license plate detection under various distortion conditions in challenging datasets. It is robust and has a very good detection effect in complex natural scenarios such as occlusion, dirt, and image blur. The distorted license plate recognition system based on DLPD-Net is more practicable in unconstrained natural scenarios.关键词:automatic license plate detection and recognition(ALPR);deep learning;license plate detection;license plate correction;character recognition82|125|1更新时间:2024-05-07
摘要:ObjectiveAs an important part of intelligent transportation systems, automatic license plate detection and recognition (ALPR) has always been a research hotspot in the field of computer vision. With the development of deep learning technology and new requirements for license plate recognition in the field of unmanned driving and safe cities as well as the upgrading challenges brought by complex license plate images taken by mobile phones and various mobile terminal devices, license plate recognition technology is now facing new challenges, mainly reflected in license plate background color; size and type varying in different countries; susceptibility of license plate images to complex environmental factors, such as poor lighting conditions, rain, snow, and complex background information interference; and diversity of acquisition equipment (such as mobile phone and law enforcement recorder) in real ALPR application, which leads to various irregular distortions of license plate images. The shape of a license plate is usually rectangular, with a fixed aspect ratio and definite color; hence, edge information and color features are frequently used to detect license plates in traditional ALPR techniques. These methods are highly efficient in controlled scenarios such as the entrance of a parking lot, but they are very sensitive to illumination variation, multiple viewpoints, stains, occlusion, image blur, and other influencing factors of the license plate image in natural scenarios, and the detection result is far from reaching application level. Methods based on deep learning technology have made remarkable achievements in license plate detection and character recognition tasks, and their recognition accuracy is higher than that of traditional ALPR techniques. However, they simply treat the license plate as a regular rectangular area and fail to consider the problem that the license plate will be distorted into an irregular quadrilateral in natural scenarios. These methods all use the anchor-based object detector to detect the license plate, but the size of the anchor is usually fixed, resulting in low detection accuracy for the object with a large distortion. License plates captured in natural scenarios are often distorted, especially in surveillance and cellphone videos; thus, the recognition accuracy of methods based on deep learning technology can still be improved. This paper designs a distorted license plate detection model in natural scenarios, named distorted license plate detection network (DLPD-Net), to solve the problem of irregular, distorted license plate in natural scenarios and make full use of the license plate shape characteristics.MethodFor the first time, DLPD-Net applies the anchor-free object detection method to license plate detection. Instead of using the anchor to obtain the proposal license plate regions, it predicts the license plate center based on the heat map and offset map of the license plate. First, DLPD-Net uses ResNet-50 to extract the feature map of the input image, and then obtains the feature map of nine channels by using a detection block (including heat map, offset map, and affine transformation parameter map). Local peaks in the heat map are taken as the center of the license plate, and a square with fixed size is assumed at this location. Affine transformation parameters obtained by regression are used to construct the affine matrix, and the imaginary square is transformed into a quadrilateral corresponding to the shape of the license plate. Finally, the license plate region is obtained by using the offset value to translate the quadrilateral, then a distorted license plate is extracted and corrected to a plane rectangle similar to the front view. A complete loss function is designed, which consists of three parts, namely, heat map loss, offset loss, and affine loss, to train DLPD-Net effectively. Focal loss function is used to train the heat map and address the imbalance of positive and negative samples in license plate center prediction. L1 loss is used to train the offset map and obtain the local offset of each object center because the existence of the output stride will lead to the discretization error of real object coordinates. Affine loss is obtained by calculating the difference between the transformation value of the unit square's corners and the normalized value of the license plate's corners, and then summing.ResultOn the one hand, the performance of DLPD-Net is evaluated on the CD-HARD dataset, and results show that DLPD-Net could find the corners of distorted license plates well. On the other hand, based on DLPD-Net, this paper designs a distorted license plate recognition system in natural scenarios, which is composed of three modules: vehicle detection module, license plate detection, and correction module and license plate character recognition module. Experimental results show that compared with other commercial systems and license plate detection methods proposed in paper, DLPD-Net outperforms in distorted license plate detection and can improve the recognition accuracy of the license plate recognition system. In the CD-HARD dataset, the system's recognition accuracy is 79.4%, 4.4%12.1% higher than that of other methods, and the average processing time is 237 ms. In the AOLP dataset, the system's recognition accuracy reaches 96.6%, and that is 94.9% without augmented samples, which is 1.6%25.2% higher than that of other methods, and the average processing time is 185 ms.ConclusionA distorted license plate detection model in natural scenarios, named DLPD-Net, is proposed. The model can extract the distorted license plate from the image and correct it into a plane rectangle similar to the front view, which is very useful for license plate character recognition. Based on DLPD-Net, an ALPR system is proposed. Experimental results show that DLPD-Net can achieve license plate detection under various distortion conditions in challenging datasets. It is robust and has a very good detection effect in complex natural scenarios such as occlusion, dirt, and image blur. The distorted license plate recognition system based on DLPD-Net is more practicable in unconstrained natural scenarios.关键词:automatic license plate detection and recognition(ALPR);deep learning;license plate detection;license plate correction;character recognition82|125|1更新时间:2024-05-07 -
 摘要:ObjectiveHaze is a very common phenomenon in nature scenes, which mainly leads to poor image quality. Image dehazing has important research significance in practical applications, such as machine vision and intelligent transportation primarily because fog reduces image contrast, resulting in instability of feature extraction methods and recognition systems. Traditional defogging algorithms based on prior knowledge, such as maximizing saturation and dark channels, have unstable effects on certain specific scenes, such as color distortion and halo. Traditional learning-based defogging methods are prone to overfitting due to lack of insufficient labeled training data and feature redundancy.MethodWe propose a two-phase strategy for feature extraction to improve effectiveness and representation capabilities of existing features for fog and haze by analyzing the advantages and drawbacks of existing image defogging methods. In the first phase, inspired by the successes of dark channel defogging method, similarity of Gabor filters, and human vision responses, the paper extracts color saturation, minimum color channel, maximum color channel, and Gabor responses of gray-scale images as initial fog features. Gabor filters are set to have eight orientations and five scales for a total of 40 responses of Gabor filters. Hence, the initial fog features in the first phase are 43 dimensional for each pixel. This paper extracts the minimum, maximum, mean, variance, skewness, kurtosis, and Gaussian average of each local region on every feature map of the first phase to improve the robustness of these initial features. These features are seven dimensional for each pixel of a feature map extracted in the first phase. Thus, The paper extracts 43×7=301 features in the second phase for each pixel. These features are formed as a 301-dimensional feature vector for each pixel, which has very powerful representation capabilities. Finally, we adopt support vector machine with 301-dimensional feature vectors to train a regression model between a 301-dimensional feature vector and a transmission rate.ResultThe paper performs experiments on several public data sets to compare our method and several image defogging methods, including deep-learning-based algorithms. Experimental results show that the algorithm in this paper achieves a very good defogging effect. For the evaluation index of average gradient, the value of this algorithm is 4.475, which is higher than all the comparison algorithms. For the peak signal-to-noise ratio, the value of the algorithm in this paper is second, with a value of 18.150 dB, second only to the multiscale convolutional neural network defogging algorithm. For structural similarity, the algorithm in this paper is 0.867, which is high. For brightness and contrast after defogging, the proposed algorithm is also in the forefront. Our method's defogging results are similar to those obtained by existing deep-learning-based defogging methods. In several cases, our results are even better than those of deep learning methods. The experimental results validate that our two-phase features can represent fog and haze. We also implement an effective image defogging method from a small labeled training dataset.ConclusionThis paper can greatly enhance the robustness and representation capabilities of initial fog features, and we can use only a small training data set to train a suitable model that has very good generalization performance by using a two-phase feature extraction strategy.关键词:image defogging;image enhancement;feature extraction;support vector machine(SVM);machine learning108|276|4更新时间:2024-05-07
摘要:ObjectiveHaze is a very common phenomenon in nature scenes, which mainly leads to poor image quality. Image dehazing has important research significance in practical applications, such as machine vision and intelligent transportation primarily because fog reduces image contrast, resulting in instability of feature extraction methods and recognition systems. Traditional defogging algorithms based on prior knowledge, such as maximizing saturation and dark channels, have unstable effects on certain specific scenes, such as color distortion and halo. Traditional learning-based defogging methods are prone to overfitting due to lack of insufficient labeled training data and feature redundancy.MethodWe propose a two-phase strategy for feature extraction to improve effectiveness and representation capabilities of existing features for fog and haze by analyzing the advantages and drawbacks of existing image defogging methods. In the first phase, inspired by the successes of dark channel defogging method, similarity of Gabor filters, and human vision responses, the paper extracts color saturation, minimum color channel, maximum color channel, and Gabor responses of gray-scale images as initial fog features. Gabor filters are set to have eight orientations and five scales for a total of 40 responses of Gabor filters. Hence, the initial fog features in the first phase are 43 dimensional for each pixel. This paper extracts the minimum, maximum, mean, variance, skewness, kurtosis, and Gaussian average of each local region on every feature map of the first phase to improve the robustness of these initial features. These features are seven dimensional for each pixel of a feature map extracted in the first phase. Thus, The paper extracts 43×7=301 features in the second phase for each pixel. These features are formed as a 301-dimensional feature vector for each pixel, which has very powerful representation capabilities. Finally, we adopt support vector machine with 301-dimensional feature vectors to train a regression model between a 301-dimensional feature vector and a transmission rate.ResultThe paper performs experiments on several public data sets to compare our method and several image defogging methods, including deep-learning-based algorithms. Experimental results show that the algorithm in this paper achieves a very good defogging effect. For the evaluation index of average gradient, the value of this algorithm is 4.475, which is higher than all the comparison algorithms. For the peak signal-to-noise ratio, the value of the algorithm in this paper is second, with a value of 18.150 dB, second only to the multiscale convolutional neural network defogging algorithm. For structural similarity, the algorithm in this paper is 0.867, which is high. For brightness and contrast after defogging, the proposed algorithm is also in the forefront. Our method's defogging results are similar to those obtained by existing deep-learning-based defogging methods. In several cases, our results are even better than those of deep learning methods. The experimental results validate that our two-phase features can represent fog and haze. We also implement an effective image defogging method from a small labeled training dataset.ConclusionThis paper can greatly enhance the robustness and representation capabilities of initial fog features, and we can use only a small training data set to train a suitable model that has very good generalization performance by using a two-phase feature extraction strategy.关键词:image defogging;image enhancement;feature extraction;support vector machine(SVM);machine learning108|276|4更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveDefocus blur detection (DBD) is devoted to distinguishing the sharp and the blurred pixels, which has wide applications and is an important problem in computer vision. The DBD result can be applied to many computer vision tasks, such as deblurring, blur magnification, and object saliency detection. According to the adopted image features, the DBD methods can be generally divided into two categories: hand-crafted feature-based traditional DBD methods and deep-feature-based DBD methods. The former utilize low-level blur features, such as gradient, frequency, singular value, local binary pattern, and simple classifiers to distinguish sharp image regions and blurred image regions. These low-level blur features are extracted from image patches, which results in loss of high-level semantic information. Although the traditional DBD methods do not need many training exemplars, they perform unsatisfactorily when images have complex scenes, especially in homogeneous regions and dark regions. More recent DBD methods propose to learn the representation of blur and sharp by using a large volume of images to extract task-adaptive features. Blur prediction can be generated by an end-to-end convolutional neural network (CNN), which is more efficient than traditional DBD methods. CNN can extract multiscale convolutional features, which is very useful for different vision problems, due to the hierarchical nonlinear ensemble of convolutional, rectified linear unit, and pooling layers. Generally, bottom layers extract low-level texture features that can improve the details of the detection results, whereas top layers extract high-level semantic features that are useful for conquering noise and background cluster. Most of the present methods integrate multiscale low-level texture features and high-level semantic features in their networks to generate robust defocus blur results. Although the existing DBD methods achieve better blur detection results than the hand-crafted feature-based methods, they still suffer from scale ambiguity and incomplete detection boundaries when processing images with complex scenes. In this paper, we propose a novel DBD framework that extracts multiscale convolutional features from images with different scales. Then, we use four branches of multiscale result refinement subnetworks to generate blur results at different feature scales. Lastly, we use a multiscale result fusion layer to generate the final blur results.MethodThe proposed network architecture consists of three parts: multiscale feature extraction subnetwork (FEN), multiscale result refinement subnetwork (RRN), and multiscale result fusion layer (RFL). We use visual geometry group(VGG16) as our basic feature extractor. We remove fully connected layers and the last pooling layer to increase image feature resolution. FEN consists of three basic feature extractors and a feature integration branch that integrates convolutional features of the same layers extracted from different scaled images. RRN is built by five convolutional long-short term memories (Conv-LSTM) layers to generate multiscale blur estimation from multiscale convolutional features. RFL consists of two convolutional layers with filter sizes of 3×3×32 and 1×1×1. We first resize the input image with different ratios and extract multiscale convolutional features from each resized image by FEN.FEN also integrates the features of the corresponding layers to explore the merits of features extracted from different images. Then, we feed the highest convolutional features of each branch of FEN into RRN to produce coarse blur maps. The blur maps producing the features are robust to noise and background clusters due to highest layers' extracted semantic features. However, these blur maps are in low resolutions that provide better guidance for fine-scale blur estimation. Thus, we gradually incorporate lower layers' higher resolution features into Conv-LSTMs to generate more precise blur maps. Multiscale convolutional features are integrated by the Conv-LSTMs from top to bottom in each branch of RRN. RFL is responsible for fusing the blur maps generated by the four branches. We concatenate the last prediction maps of each branch of RRN with the first integrated features of the first layer from the FEN as input for RFL to generate the final blur map because features of shallow layer contains a large amount of detail structure information that can improve the DBD result. We use the combination of F-measure, precision, recall, mean absolute error (MAE), and cross-entropy as our loss function for network pretraining and training. We add supervised signal at each prediction layers, which can directly pass the gradient to the corresponding layers and make the network optimization easier. We randomly select 2 000 images from the Berkeley segmentation dataset, uncompressed color image database, and Pascal2008 to synthesize blur images to pretrain the proposed network. The real training set consists of 1 204 images, which are selected from Dalian University of Technology(DUT) and The Chinese University of Hong Kong (CUHK) datasets. We augment the real training images by rotation, flipping, and cropping, enlarging the training data by 15 times. This operation greatly improves network performance. Our network is implemented by Keras. We resize the input images and ground truths to 320×320 pixels. We use adaptive moment estimation optimizer. We set the learning rate to 1×10-5 and divide by 10 in every five epochs until 1×10-8. We initialize FEN by VGG16 weights trained on ImageNet. We initialize the remaining layers by "Xavier Uniform". We conduct pretraining and training using Nvidia RTX 2080Ti. The whole training takes approximately one day.ResultWe train and test our network on two public blur detection datasets, DUT and CUHK, and compare our method with 10 state-of-the-art DBD methods. On the DUT dataset, our method achieves 38.8% relative MAE reduction and 5.4% relative F0.3 improvement over DeFusionNet(DBD network via recurrently fusing and refining multi-scale deep features). On this dataset, our method is the only one whose F0.3 is higher than 0.87 and whose MAE is lower than 0.1. On the CUHK dataset, our method achieves 36.7% relative MAE reduction and 9.7% relative F0.3 improvement over the local binary pattern. The proposed DBD method performs well in several challenging cases including homogeneous region and background cluster. Our blur detection is more precise at the detection boundaries. We conduct different ablation analysis to verify the effectiveness of our model.ConclusionWe propose the coarse-to-fine multiscale DBD method, which extracts multiscale convolutional features from images with different resize ratios, and generate multiscale blur estimation with Conv-LSTMs. Conv-LSTMs integrate the semantic information of deep layer with detail information of the shallow layer to refine the blur maps. We produce the final blur map by integrating the blur maps generated from different-sized images and the low-level fused features. Our method generates more precise DBD results in different image scenes compared with other DBD methods in various scenes.关键词:defocus blur detection(DBD);multi-scale features;Conv-LSTM (convolutional long-short term memory);coarse-to-fine;multi-layer supervision77|50|1更新时间:2024-05-07
摘要:ObjectiveDefocus blur detection (DBD) is devoted to distinguishing the sharp and the blurred pixels, which has wide applications and is an important problem in computer vision. The DBD result can be applied to many computer vision tasks, such as deblurring, blur magnification, and object saliency detection. According to the adopted image features, the DBD methods can be generally divided into two categories: hand-crafted feature-based traditional DBD methods and deep-feature-based DBD methods. The former utilize low-level blur features, such as gradient, frequency, singular value, local binary pattern, and simple classifiers to distinguish sharp image regions and blurred image regions. These low-level blur features are extracted from image patches, which results in loss of high-level semantic information. Although the traditional DBD methods do not need many training exemplars, they perform unsatisfactorily when images have complex scenes, especially in homogeneous regions and dark regions. More recent DBD methods propose to learn the representation of blur and sharp by using a large volume of images to extract task-adaptive features. Blur prediction can be generated by an end-to-end convolutional neural network (CNN), which is more efficient than traditional DBD methods. CNN can extract multiscale convolutional features, which is very useful for different vision problems, due to the hierarchical nonlinear ensemble of convolutional, rectified linear unit, and pooling layers. Generally, bottom layers extract low-level texture features that can improve the details of the detection results, whereas top layers extract high-level semantic features that are useful for conquering noise and background cluster. Most of the present methods integrate multiscale low-level texture features and high-level semantic features in their networks to generate robust defocus blur results. Although the existing DBD methods achieve better blur detection results than the hand-crafted feature-based methods, they still suffer from scale ambiguity and incomplete detection boundaries when processing images with complex scenes. In this paper, we propose a novel DBD framework that extracts multiscale convolutional features from images with different scales. Then, we use four branches of multiscale result refinement subnetworks to generate blur results at different feature scales. Lastly, we use a multiscale result fusion layer to generate the final blur results.MethodThe proposed network architecture consists of three parts: multiscale feature extraction subnetwork (FEN), multiscale result refinement subnetwork (RRN), and multiscale result fusion layer (RFL). We use visual geometry group(VGG16) as our basic feature extractor. We remove fully connected layers and the last pooling layer to increase image feature resolution. FEN consists of three basic feature extractors and a feature integration branch that integrates convolutional features of the same layers extracted from different scaled images. RRN is built by five convolutional long-short term memories (Conv-LSTM) layers to generate multiscale blur estimation from multiscale convolutional features. RFL consists of two convolutional layers with filter sizes of 3×3×32 and 1×1×1. We first resize the input image with different ratios and extract multiscale convolutional features from each resized image by FEN.FEN also integrates the features of the corresponding layers to explore the merits of features extracted from different images. Then, we feed the highest convolutional features of each branch of FEN into RRN to produce coarse blur maps. The blur maps producing the features are robust to noise and background clusters due to highest layers' extracted semantic features. However, these blur maps are in low resolutions that provide better guidance for fine-scale blur estimation. Thus, we gradually incorporate lower layers' higher resolution features into Conv-LSTMs to generate more precise blur maps. Multiscale convolutional features are integrated by the Conv-LSTMs from top to bottom in each branch of RRN. RFL is responsible for fusing the blur maps generated by the four branches. We concatenate the last prediction maps of each branch of RRN with the first integrated features of the first layer from the FEN as input for RFL to generate the final blur map because features of shallow layer contains a large amount of detail structure information that can improve the DBD result. We use the combination of F-measure, precision, recall, mean absolute error (MAE), and cross-entropy as our loss function for network pretraining and training. We add supervised signal at each prediction layers, which can directly pass the gradient to the corresponding layers and make the network optimization easier. We randomly select 2 000 images from the Berkeley segmentation dataset, uncompressed color image database, and Pascal2008 to synthesize blur images to pretrain the proposed network. The real training set consists of 1 204 images, which are selected from Dalian University of Technology(DUT) and The Chinese University of Hong Kong (CUHK) datasets. We augment the real training images by rotation, flipping, and cropping, enlarging the training data by 15 times. This operation greatly improves network performance. Our network is implemented by Keras. We resize the input images and ground truths to 320×320 pixels. We use adaptive moment estimation optimizer. We set the learning rate to 1×10-5 and divide by 10 in every five epochs until 1×10-8. We initialize FEN by VGG16 weights trained on ImageNet. We initialize the remaining layers by "Xavier Uniform". We conduct pretraining and training using Nvidia RTX 2080Ti. The whole training takes approximately one day.ResultWe train and test our network on two public blur detection datasets, DUT and CUHK, and compare our method with 10 state-of-the-art DBD methods. On the DUT dataset, our method achieves 38.8% relative MAE reduction and 5.4% relative F0.3 improvement over DeFusionNet(DBD network via recurrently fusing and refining multi-scale deep features). On this dataset, our method is the only one whose F0.3 is higher than 0.87 and whose MAE is lower than 0.1. On the CUHK dataset, our method achieves 36.7% relative MAE reduction and 9.7% relative F0.3 improvement over the local binary pattern. The proposed DBD method performs well in several challenging cases including homogeneous region and background cluster. Our blur detection is more precise at the detection boundaries. We conduct different ablation analysis to verify the effectiveness of our model.ConclusionWe propose the coarse-to-fine multiscale DBD method, which extracts multiscale convolutional features from images with different resize ratios, and generate multiscale blur estimation with Conv-LSTMs. Conv-LSTMs integrate the semantic information of deep layer with detail information of the shallow layer to refine the blur maps. We produce the final blur map by integrating the blur maps generated from different-sized images and the low-level fused features. Our method generates more precise DBD results in different image scenes compared with other DBD methods in various scenes.关键词:defocus blur detection(DBD);multi-scale features;Conv-LSTM (convolutional long-short term memory);coarse-to-fine;multi-layer supervision77|50|1更新时间:2024-05-07 -
 摘要:ObjectiveA generative adversarial network (GAN) is a currently popular unsupervised generation model that generates images via game learning of the generative and discriminative models. The generative model uses Gaussian noise to generate probability distribution, and the discriminative model distinguishes between the generated and real probability distributions. In the ideal state, the discriminative model cannot distinguish between the two data distributions. However, achieving Nash equilibrium between the generative and discriminative models is difficult. Simultaneously, some problems, such as unstable training, gradient disappearance, and poor image quality, occur. Therefore, many studies have been conducted to address these problems, and these studies can be divided into two directions. One direction involves selecting the appropriate loss function, and the other direction involves changing the structure of GAN, e.g., from a fully connected neural network to a convolutional neural network (CNN). A typical work involves deep convolutional GANs (DCGANs), which adopts CNN and batch normalization (BN). Although DCGAN shave achieved good performance, some problems persist in the training process. Increasing the number of network layers leads to more errors, particularly gradient disappearance when the number of neural network layers is extremely high. In addition, BN leads to poor stability in the training process, particularly with small batch samples. In general, as the number of layers increases, the number of parameters increases and backpropagation becomes difficult as the number of layers increases, resulting in some problems, such as unstable training and gradient disappearance. In addition, the generative model directly generates images step by step, and a lower level network cannot determine the features learned by a higher level network, and thus, the diversity of the generated images is not sufficiently rich. To address the a fore mentioned problems, a residual GAN (Re-GAN) is proposed based on a residual network (ResNet) and group normalization (GN).MethodResNet has been recently proposed to solve the problem of network degradation caused by too many layers of a deep neural network and has been applied to image classification due to its good performance. In contrast with BN, GN divides channels into groups and calculates the normalized mean and variance within each group. Calculation is stable and independent of batch size. Therefore, we apply ResNet and GN to GAN to propose Re-GAN. First, a residual module ResNet is introduced into the generative model of GAN by adding the input and the mapping to the output of the layer to prevent gradient disappearance and enhance training stability. Moreover, the residual module ResNet optimizes feature transmission between neural network layers and enhances the diversity and quality of the generated image. Second, Re-GAN adopts the standardized GN to adapt to different batch learning. GN can reduce the difficulty of standardization caused by the lack of training samples and stabilize the training process of the network. Moreover, when the number of samples is sufficient, GN can make the calculated results match well with the sample distribution and exhibit good compatibility.ResultTo verify the effectiveness of the proposed algorithm Re-GAN, we compare it with DCGAN and Wasserstein-GAN (WGAN) with different batches of samples on three datasets namely, Cifar10, CcelebA, and LSUN bedroom. Two evaluation criteria, i.e., inception score (IS) and Fréchet inception distance (FID), are adopted in our experiments. As a common evaluation criterion for GAN, IS uses the inception network trained on ImageNet to calculate the information of the generated images. IS focuses on the evaluation of the quality but not the diversity of the generated images. When IS is larger, the quality of the generated images is better. FID is more robust to noise and more suitable for describing the diversity of the generated images. It is computed via a set of generated images and a set of ground images. When FID is smaller, the diversity of the generated images is better. We can obtain the following experimental results. 1) When the batch number is 64, the IS of the proposed algorithm Re-GAN is 5% higher than that of DCGAN and 30% higher than that of WGAN. When the batch is 4, the IS of Re-GAN is 0.2% higher than that of DCGAN and 13% higher than that of WGAN. These results show that the images generated by Re-GAN exhibit good diversity regardless of batch size. 2) When the batch number is 64, the FID of Re-GAN is 18% lower than that of DCGAN and 11% lower than that of WGAN. When the batch number is 4, the FID of Re-GAN is 4% lower than that of DCGAN and 10% lower than that of WGAN. These results indicate that the proposed algorithm Re-GAN can generate images with higher quality. 3) Training instability and gradient disappearance are alleviated during the training process.ConclusionThe performance of the proposed Re-GAN is tested using two evaluation criteria, i.e., IS and FID, on three datasets. Extensive experiments are conducted, and the experimental results indicate the following findings. In the aspect of image generation, Re-GAN generates high-quality images with rich diversity. In the aspect of network training, Re-GAN guarantees that training exhibits better compatibility regardless of whether the batch is large or small, and then it makes the training process more stable and alleviates gradient disappearance. In addition, compared with DCGAN and WGAN, the proposed Re-GAN exhibits better performance, which can be attributed to the ResNet and GN adopted in Re-GAN.关键词:image generation;deep learning;convolutional neural network (CNN);generative adversarial network (GAN);residual network (ResNet);group normalization (GN)252|308|5更新时间:2024-05-07
摘要:ObjectiveA generative adversarial network (GAN) is a currently popular unsupervised generation model that generates images via game learning of the generative and discriminative models. The generative model uses Gaussian noise to generate probability distribution, and the discriminative model distinguishes between the generated and real probability distributions. In the ideal state, the discriminative model cannot distinguish between the two data distributions. However, achieving Nash equilibrium between the generative and discriminative models is difficult. Simultaneously, some problems, such as unstable training, gradient disappearance, and poor image quality, occur. Therefore, many studies have been conducted to address these problems, and these studies can be divided into two directions. One direction involves selecting the appropriate loss function, and the other direction involves changing the structure of GAN, e.g., from a fully connected neural network to a convolutional neural network (CNN). A typical work involves deep convolutional GANs (DCGANs), which adopts CNN and batch normalization (BN). Although DCGAN shave achieved good performance, some problems persist in the training process. Increasing the number of network layers leads to more errors, particularly gradient disappearance when the number of neural network layers is extremely high. In addition, BN leads to poor stability in the training process, particularly with small batch samples. In general, as the number of layers increases, the number of parameters increases and backpropagation becomes difficult as the number of layers increases, resulting in some problems, such as unstable training and gradient disappearance. In addition, the generative model directly generates images step by step, and a lower level network cannot determine the features learned by a higher level network, and thus, the diversity of the generated images is not sufficiently rich. To address the a fore mentioned problems, a residual GAN (Re-GAN) is proposed based on a residual network (ResNet) and group normalization (GN).MethodResNet has been recently proposed to solve the problem of network degradation caused by too many layers of a deep neural network and has been applied to image classification due to its good performance. In contrast with BN, GN divides channels into groups and calculates the normalized mean and variance within each group. Calculation is stable and independent of batch size. Therefore, we apply ResNet and GN to GAN to propose Re-GAN. First, a residual module ResNet is introduced into the generative model of GAN by adding the input and the mapping to the output of the layer to prevent gradient disappearance and enhance training stability. Moreover, the residual module ResNet optimizes feature transmission between neural network layers and enhances the diversity and quality of the generated image. Second, Re-GAN adopts the standardized GN to adapt to different batch learning. GN can reduce the difficulty of standardization caused by the lack of training samples and stabilize the training process of the network. Moreover, when the number of samples is sufficient, GN can make the calculated results match well with the sample distribution and exhibit good compatibility.ResultTo verify the effectiveness of the proposed algorithm Re-GAN, we compare it with DCGAN and Wasserstein-GAN (WGAN) with different batches of samples on three datasets namely, Cifar10, CcelebA, and LSUN bedroom. Two evaluation criteria, i.e., inception score (IS) and Fréchet inception distance (FID), are adopted in our experiments. As a common evaluation criterion for GAN, IS uses the inception network trained on ImageNet to calculate the information of the generated images. IS focuses on the evaluation of the quality but not the diversity of the generated images. When IS is larger, the quality of the generated images is better. FID is more robust to noise and more suitable for describing the diversity of the generated images. It is computed via a set of generated images and a set of ground images. When FID is smaller, the diversity of the generated images is better. We can obtain the following experimental results. 1) When the batch number is 64, the IS of the proposed algorithm Re-GAN is 5% higher than that of DCGAN and 30% higher than that of WGAN. When the batch is 4, the IS of Re-GAN is 0.2% higher than that of DCGAN and 13% higher than that of WGAN. These results show that the images generated by Re-GAN exhibit good diversity regardless of batch size. 2) When the batch number is 64, the FID of Re-GAN is 18% lower than that of DCGAN and 11% lower than that of WGAN. When the batch number is 4, the FID of Re-GAN is 4% lower than that of DCGAN and 10% lower than that of WGAN. These results indicate that the proposed algorithm Re-GAN can generate images with higher quality. 3) Training instability and gradient disappearance are alleviated during the training process.ConclusionThe performance of the proposed Re-GAN is tested using two evaluation criteria, i.e., IS and FID, on three datasets. Extensive experiments are conducted, and the experimental results indicate the following findings. In the aspect of image generation, Re-GAN generates high-quality images with rich diversity. In the aspect of network training, Re-GAN guarantees that training exhibits better compatibility regardless of whether the batch is large or small, and then it makes the training process more stable and alleviates gradient disappearance. In addition, compared with DCGAN and WGAN, the proposed Re-GAN exhibits better performance, which can be attributed to the ResNet and GN adopted in Re-GAN.关键词:image generation;deep learning;convolutional neural network (CNN);generative adversarial network (GAN);residual network (ResNet);group normalization (GN)252|308|5更新时间:2024-05-07 -
 摘要:ObjectiveThe limitations of external environment, hardware conditions, and network resources will cause the images we obtain in daily life to be low-resolution images, which will affect the accuracy of images used in other applications. Therefore, super-resolution reconstruction technology has become a very important research topic. This technique can be used to recover super-resolution images. High-resolution images can be reconstructed from the information relationship between high-resolution and low-resolution images. Obtaining the correspondence between high-resolution and low-resolution images is the key to image super-resolution reconstruction technology. It is a basic method for neural networks to solve the problem of image super-resolution by using the single-channel network to learn the feature information relationship between high resolution and low resolution. However, the feature information of the image is easily lost in the shallow layer, and the low utilization of the feature information leads to an unsatisfactory reconstruction effect when the image magnification is large, and the restoration ability of the image detail information is poor. Simply deepening the depth of the network will increase the training time and difficulty of the network, which will waste a large amount of hardware resources and time. A multi-channel recursive residual network model is proposed to solve these problems. This model can improve network training efficiency by iterating the residual network blocks and enhance the detailed information reconstruction capability through multi-channel and cross-learning mechanisms.MethodA multi-channel recursive cross-residual network model is designed. The use of a large number of convolutional layers in the model explains why training takes a large amount of time. Fewer convolutional layers will reduce network reconstruction performance. Therefore, the method of recursive residual network blocks is used to deepen the network depth and speed up the network training. First, a multi-channel recursive cross-residual network model is designed. The model uses recursive multiplexing of residual network blocks to form a 32-layer recursive network, thereby reducing network parameters and increasing network depth. This model can speed up network training and obtain richer information. Then, the amount of feature information which has a great influence on reconstruction performance, obtained by deepening the network, is limited. Characteristic information is easily lost in the network. Therefore, multi-channel networks are used to obtain richer feature information, increase the access to information, and reduce the rate of information loss. This method can improve the ability of the network to reconstruct image detail information. Finally, the degree of information fusion in the network is increased to facilitate image super-resolution reconstruction. A multi-channel network cross-learning mechanism is introduced to speed up the fusion of feature information of different channels, promote parameter transfer, and effectively improve the training efficiency and information fusion degree.ResultExperimental results measure the performance of the algorithm by using peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and network training time. Bicubic, A+, super-resolution convolutional neural network(SRCNN), super-resolution using very deep convolutional network(VDSR), deep Laplacian pyramid networks for fast and accurate super-resolution(LapSRN), and enhanced deep residual network for single image super-resolution-baseline(EDSR_baseline) are used for comparison in open datasets. Training is performed on the DIV2K(DIVerse 2K) dataset, where the network uses 800 as the training dataset and 100 as the validation dataset. Tests are then performed on the Set5, Set14, BSD100, and Urban100 datasets with 219 test data. Three reconstruction models are designed, which are enlarged at×2, ×3, and×4 resolutions, to facilitate the comparison of common algorithms. In the experiments, experimental data and reconstructed images are analyzed in detail. Compared with traditional serial networks, recursive networks can improve network efficiency and reduce network computing time. Especially in the Urban100 data set with more details, the experiments show that compared with Bicubic, SRCNN, VDSR, LapSRN, and traditional series networks, average PSNR increases by 3.87 dB, 1.93 dB, 1.00 dB, 1.12 dB, and 0.48 dB, respectively. The visual effect is also clearer than that of the previous algorithm. Compared with the traditional tandem network, network training efficiency is improved by 30%.ConclusionThe proposed network overcomes the shortcomings of single-channel deep networks and accelerates network convergence and information fusion by adding recursive residual networks and cross-learning mechanisms. In addition, recursive residual networks can accelerate network convergence and solve problems such as gradients during network training. Experimental results show that compared with the existing reconstruction methods, this method can obtain higher PSNR and SSIM, and can improve substantially in images with more detailed information. Thus, this method has the advantages of short training time, low information redundancy, and better reconstruction effect. In the future, we will consider continuing to optimize the recursive network scale and network cross-learning mechanism.关键词:super-resolution reconstruction;multi-channel;recursion;cross;residual network model114|476|25更新时间:2024-05-07
摘要:ObjectiveThe limitations of external environment, hardware conditions, and network resources will cause the images we obtain in daily life to be low-resolution images, which will affect the accuracy of images used in other applications. Therefore, super-resolution reconstruction technology has become a very important research topic. This technique can be used to recover super-resolution images. High-resolution images can be reconstructed from the information relationship between high-resolution and low-resolution images. Obtaining the correspondence between high-resolution and low-resolution images is the key to image super-resolution reconstruction technology. It is a basic method for neural networks to solve the problem of image super-resolution by using the single-channel network to learn the feature information relationship between high resolution and low resolution. However, the feature information of the image is easily lost in the shallow layer, and the low utilization of the feature information leads to an unsatisfactory reconstruction effect when the image magnification is large, and the restoration ability of the image detail information is poor. Simply deepening the depth of the network will increase the training time and difficulty of the network, which will waste a large amount of hardware resources and time. A multi-channel recursive residual network model is proposed to solve these problems. This model can improve network training efficiency by iterating the residual network blocks and enhance the detailed information reconstruction capability through multi-channel and cross-learning mechanisms.MethodA multi-channel recursive cross-residual network model is designed. The use of a large number of convolutional layers in the model explains why training takes a large amount of time. Fewer convolutional layers will reduce network reconstruction performance. Therefore, the method of recursive residual network blocks is used to deepen the network depth and speed up the network training. First, a multi-channel recursive cross-residual network model is designed. The model uses recursive multiplexing of residual network blocks to form a 32-layer recursive network, thereby reducing network parameters and increasing network depth. This model can speed up network training and obtain richer information. Then, the amount of feature information which has a great influence on reconstruction performance, obtained by deepening the network, is limited. Characteristic information is easily lost in the network. Therefore, multi-channel networks are used to obtain richer feature information, increase the access to information, and reduce the rate of information loss. This method can improve the ability of the network to reconstruct image detail information. Finally, the degree of information fusion in the network is increased to facilitate image super-resolution reconstruction. A multi-channel network cross-learning mechanism is introduced to speed up the fusion of feature information of different channels, promote parameter transfer, and effectively improve the training efficiency and information fusion degree.ResultExperimental results measure the performance of the algorithm by using peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and network training time. Bicubic, A+, super-resolution convolutional neural network(SRCNN), super-resolution using very deep convolutional network(VDSR), deep Laplacian pyramid networks for fast and accurate super-resolution(LapSRN), and enhanced deep residual network for single image super-resolution-baseline(EDSR_baseline) are used for comparison in open datasets. Training is performed on the DIV2K(DIVerse 2K) dataset, where the network uses 800 as the training dataset and 100 as the validation dataset. Tests are then performed on the Set5, Set14, BSD100, and Urban100 datasets with 219 test data. Three reconstruction models are designed, which are enlarged at×2, ×3, and×4 resolutions, to facilitate the comparison of common algorithms. In the experiments, experimental data and reconstructed images are analyzed in detail. Compared with traditional serial networks, recursive networks can improve network efficiency and reduce network computing time. Especially in the Urban100 data set with more details, the experiments show that compared with Bicubic, SRCNN, VDSR, LapSRN, and traditional series networks, average PSNR increases by 3.87 dB, 1.93 dB, 1.00 dB, 1.12 dB, and 0.48 dB, respectively. The visual effect is also clearer than that of the previous algorithm. Compared with the traditional tandem network, network training efficiency is improved by 30%.ConclusionThe proposed network overcomes the shortcomings of single-channel deep networks and accelerates network convergence and information fusion by adding recursive residual networks and cross-learning mechanisms. In addition, recursive residual networks can accelerate network convergence and solve problems such as gradients during network training. Experimental results show that compared with the existing reconstruction methods, this method can obtain higher PSNR and SSIM, and can improve substantially in images with more detailed information. Thus, this method has the advantages of short training time, low information redundancy, and better reconstruction effect. In the future, we will consider continuing to optimize the recursive network scale and network cross-learning mechanism.关键词:super-resolution reconstruction;multi-channel;recursion;cross;residual network model114|476|25更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveRainfall is one of the important factors that affects global climate change and system environment. Conducting the spatiotemporal correlation analysis of rainfall data for exploring regional climate characteristics and monitoring climate abnormal conditions has great significance. However, the spatial and temporal correlation analysis of rainfall data is a complicated, time-consuming process due to the drastic spatiotemporal variation and spatial heterogeneity of rainfall, and the diversity of rainfall data. It is closely related to the geographical locations of meteorological stations and the time series of rainfall. Therefore, a visual analysis method for the spatiotemporal correlation analysis of rainfall data in the paper is proposed by considering the spatial locations of meteorological stations and the rainfall variations over a long period of time. Based on spatiotemporal visualization analysis of rainfall data, the spatiotemporal correlation characteristics and climate characteristics of rainfall are further quantified.MethodA map view is first used to reflect the basic information of rainfall and meteorological stations, enabling users to select meteorological stations interactively. The spatial correlation of rainfall data is explored by using the local Moran index, allowing the interactive selection of one or more sites and the temporal analysis of the mean value of the local Moran index. The temporal changes and outliers of rainfall data are presented by using periodic matrix graph and the circular box-and-whisker graph, respectively. The spatial interpolation map is obtained by an ordinary Kriging interpolation method, and the accuracy of the interpolation result is further evaluated. Finally, a set of continent user interactions is integrated into the visualization system to help users easily conduct spatiotemporal exploration of rainfall data and deeply obtain insights into the features of interest hidden in the complex rainfall data structures.ResultTaking the monthly rainfall data set of Anhui meteorological observation stations from 1971 to 2014 as an example, the experimental results show the following. 1) The visual interactive system of our study can intuitively and efficiently explore the spatiotemporal variation characteristics and anomalies of regional rainfall time series. The spatial distribution differences of regional precipitation can be clearly shown in the map view. The periodic matrix view can directly reflect the basic periodic rule that the rainfall is mainly concentrated in the spring and summer seasons and the minimum in winter, and reflect the interannual differences of rainfall in different months of the station and several evident rainfall anomalies. Furthermore, the long-term series variability of precipitation in different months and the drought and flood conditions in different seasons from 1971 to 2010 in Anhui Province can be rapidly analyzed and observed by the box-and-whisker graph and ring graph. 2) The spatial distribution pattern, spatial dependence, and heterogeneity of rainfall information of different stations can be effectively explored by using the thermal diagram and time series diagram of Moran's I values. Results show that the monthly rainfall in Anhui Province has a strong local aggregation pattern and zonal regularity, and a different spatial structure at different times, which reflects the complex, changeable influence of climate and terrain on rainfall. 3) The spatial variation of regional rainfall climate characteristics at different time scales can be clearly analyzed by using the precipitation spatial interpolation map using ordinary Kriging method. Unexpectedly, the average precipitation in July of Anhui Province from 1971 to 2010 is mostly concentrated in the north, west, and southwest.ConclusionA visual analysis system is developed to help users explore and analyze the spatiotemporal correlation, extreme conditions, and regional climate features of rainfall data interactively. It is more intuitive, efficient, and easier to operate than the traditional analysis software. The system can effectively discover several unexpected phenomena and conclusions of experts, and further verify the existing conclusions. Furthermore, the system has good extensibility, which can be applied to the visual analysis of not only spatiotemporal correlation characteristics of precipitation data but also other geographical spatiotemporal observation data, such as temperature data, sunshine hour data, and air quality data. Our visual analysis system can help experts in related fields explore and analyze rainfall spatiotemporal data. A large amount of experimental results and expert feedback further verify the effectiveness and practicality of the proposed method. Only precipitation data are analyzed, a large amount of other types of meteorological monitoring data remain, and substantial spatial and temporal characteristics between the data are noted. The function of visual analysis in this paper must be further expanded to achieve the visual analysis of multiple meteorological monitoring data. In addition, a certain correlation is observed between different meteorological monitoring data. Although this system can effectively explore the spatiotemporal correlation characteristics of rainfall data, the correlation characteristics and modeling between rainfall data and other meteorological monitoring data have not been involved. In the future work, we will focus on the development of visual analysis methods for relationship modeling of multiple meteorological monitoring data.关键词:rainfall;spatio-temporal correlation features;periodic variation characteristic;Moran's I;ordinary Kriging interpolation125|140|0更新时间:2024-05-07
摘要:ObjectiveRainfall is one of the important factors that affects global climate change and system environment. Conducting the spatiotemporal correlation analysis of rainfall data for exploring regional climate characteristics and monitoring climate abnormal conditions has great significance. However, the spatial and temporal correlation analysis of rainfall data is a complicated, time-consuming process due to the drastic spatiotemporal variation and spatial heterogeneity of rainfall, and the diversity of rainfall data. It is closely related to the geographical locations of meteorological stations and the time series of rainfall. Therefore, a visual analysis method for the spatiotemporal correlation analysis of rainfall data in the paper is proposed by considering the spatial locations of meteorological stations and the rainfall variations over a long period of time. Based on spatiotemporal visualization analysis of rainfall data, the spatiotemporal correlation characteristics and climate characteristics of rainfall are further quantified.MethodA map view is first used to reflect the basic information of rainfall and meteorological stations, enabling users to select meteorological stations interactively. The spatial correlation of rainfall data is explored by using the local Moran index, allowing the interactive selection of one or more sites and the temporal analysis of the mean value of the local Moran index. The temporal changes and outliers of rainfall data are presented by using periodic matrix graph and the circular box-and-whisker graph, respectively. The spatial interpolation map is obtained by an ordinary Kriging interpolation method, and the accuracy of the interpolation result is further evaluated. Finally, a set of continent user interactions is integrated into the visualization system to help users easily conduct spatiotemporal exploration of rainfall data and deeply obtain insights into the features of interest hidden in the complex rainfall data structures.ResultTaking the monthly rainfall data set of Anhui meteorological observation stations from 1971 to 2014 as an example, the experimental results show the following. 1) The visual interactive system of our study can intuitively and efficiently explore the spatiotemporal variation characteristics and anomalies of regional rainfall time series. The spatial distribution differences of regional precipitation can be clearly shown in the map view. The periodic matrix view can directly reflect the basic periodic rule that the rainfall is mainly concentrated in the spring and summer seasons and the minimum in winter, and reflect the interannual differences of rainfall in different months of the station and several evident rainfall anomalies. Furthermore, the long-term series variability of precipitation in different months and the drought and flood conditions in different seasons from 1971 to 2010 in Anhui Province can be rapidly analyzed and observed by the box-and-whisker graph and ring graph. 2) The spatial distribution pattern, spatial dependence, and heterogeneity of rainfall information of different stations can be effectively explored by using the thermal diagram and time series diagram of Moran's I values. Results show that the monthly rainfall in Anhui Province has a strong local aggregation pattern and zonal regularity, and a different spatial structure at different times, which reflects the complex, changeable influence of climate and terrain on rainfall. 3) The spatial variation of regional rainfall climate characteristics at different time scales can be clearly analyzed by using the precipitation spatial interpolation map using ordinary Kriging method. Unexpectedly, the average precipitation in July of Anhui Province from 1971 to 2010 is mostly concentrated in the north, west, and southwest.ConclusionA visual analysis system is developed to help users explore and analyze the spatiotemporal correlation, extreme conditions, and regional climate features of rainfall data interactively. It is more intuitive, efficient, and easier to operate than the traditional analysis software. The system can effectively discover several unexpected phenomena and conclusions of experts, and further verify the existing conclusions. Furthermore, the system has good extensibility, which can be applied to the visual analysis of not only spatiotemporal correlation characteristics of precipitation data but also other geographical spatiotemporal observation data, such as temperature data, sunshine hour data, and air quality data. Our visual analysis system can help experts in related fields explore and analyze rainfall spatiotemporal data. A large amount of experimental results and expert feedback further verify the effectiveness and practicality of the proposed method. Only precipitation data are analyzed, a large amount of other types of meteorological monitoring data remain, and substantial spatial and temporal characteristics between the data are noted. The function of visual analysis in this paper must be further expanded to achieve the visual analysis of multiple meteorological monitoring data. In addition, a certain correlation is observed between different meteorological monitoring data. Although this system can effectively explore the spatiotemporal correlation characteristics of rainfall data, the correlation characteristics and modeling between rainfall data and other meteorological monitoring data have not been involved. In the future work, we will focus on the development of visual analysis methods for relationship modeling of multiple meteorological monitoring data.关键词:rainfall;spatio-temporal correlation features;periodic variation characteristic;Moran's I;ordinary Kriging interpolation125|140|0更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectivePrecise segmentation of breast cancer tumors is of great concern. For women, breast cancer is a common tumor disease with a high incidence, and obtaining accurate diagnosis in the early stage of breast cancer has always been the key to preventing breast cancer. Doctors can improve the accuracy of the diagnosis of breast tumors by obtaining accurate information on the edge and shape of the tumor. Common breast imaging techniques include ultrasound imaging, magnetic resonance imaging (MRI), and X-ray imaging. However, X-ray imaging often causes radiation damage to breast tissue in women, whereas MRI imaging is not only expensive but also needs a longer scanning time. Compared with the two methods above, the ultrasound imaging detection method has the advantages of no radiation damage to tissue, ease of use, imaging the front of any breast, fast imaging speed, and cheap price. However, ultrasound images rely more on professional ultrasound doctors because of problems such as speckle noise and low resolution than other commonly used techniques. Thus, experienced, well-trained doctors are needed in the diagnostic process. In recent years, improving the accuracy of diagnosis by combining medical imaging technology with computer science and technology to segment tumors accurately and help related medical personnel in diagnosis and identification has become a trend. In the past 10 years, various methods, such as thresholding method, clustering-based algorithm, graph-based algorithm, and active contour algorithm, have been used to segment breast tumors on ultrasound images. However, these methods have limited ability to represent features. In the past few years, deep convolutional neural networks have become more widely used in visual recognition tasks. They can automatically find suitable features for target data and tasks. The convolutional network has existed for a long time. However, the hardware environment at that time limited its development because the size of the training set and the size of the network structure parameters require a large amount of computation. Fully convolutional network (FCN) is an effective convolutional neural network for semantic segmentation. It can be trained in an end-to-end and pixel-to-pixel manner. Its input image size is arbitrary, and the output image is a picture with its corresponding size, containing the target information. U-Net is an improvement of the FCN model. It not only solves the above problems but also can make full use of sample image to train a biological medical image well.MethodIn this paper, a deep learning segmentation model is proposed based on the U-Net framework, combining the "Res paths" to reduce the difference between the encoder and decoder feature maps, and establish a new connection composed of dense units. The "Res paths" consist of a series of residual units, which are composed of a 3×3 convolution kernel and a 1×1 convolution kernel. The number of residual units is 4, 3, 2, and 1 in order, set along four "residual paths (Res paths)" in the framework. The new connection is a dense block from the input of feature maps to the decoding part, and the input of each layer concatenated by the output of each previous layer alleviates the loss of feature information and the disappearance of gradient. The dataset from Chongming branch of Xinhua Hospital in Shanghai is applied in this paper. The dataset is obtained by Samsung RS80A color Doppler ultrasound diagnostic instrument (equipped with a high-frequency probe l3-12a). These images obtained from the instrument clearly show the morphology, internal structure, and surrounding tissues of the lesion. All patients from this dataset are female, aged from 24 to 86, in non-pregnancy and lactation, and have no history of radiotherapy, chemotherapy, or endocrine therapy before the examination. Ten-fold cross validation is used, and 538 breast ultrasound tumor images selected from the dataset are randomly divided into 10 cases. In one case, 54 breast ultrasound images are tested, and the 484 remaining pictures are used for training. In the experiment, 484 images are doubled to 968 images by image augmentation with image data generator. During training, 48 pictures of breast cancer tumors are randomly selected for validation. Keras is used to build the model framework. Training the model is started on NVIDIA Titan 1080 GPU utilizing the weights "he_normal" to initialize the parameters of the model. Our proposed model is trained by employing the Adam optimizer, using cross entropy as the loss function, and setting batch size, β1, β2, and learning rate to 4, 0.9, 0.999, and 0.000 1, respectively.ResultThe three models are cross-checked 10 times (U-Net, U-Net with Res, and the proposed model) using the same test sample sets, validation samples sets, and training sample sets each time. The first model is the classic U-Net model. The second model adds "residual paths" to the basic network structure of U-Net. The third method, proposed by us, is an improvement on the second method. Based on the second method, a new connection is introduced. The epochs of the three previous models are 80, 100, and 120 in order. Compared with the classic U-Net model, the true positive, Jaccard similarity (JS), and Dice coefficients of the proposed model are 0.870 7, 0.803 7, and 0.882 4, respectively, improving by 1.08%, 2.14%, and 2.01%, respectively. The indices of false positive and Hausdorff distance are 0.104 and 22.311 4, respectively, decreasing by 1.68% and 1.410 2, respectively. In the test set of every 54 pictures, the total average number of tumor pictures of JS > 0.75 is 42.1 up to a maximum of 46. Experimental results show that the proposed improved algorithm improves the results.ConclusionThe proposed segmentation model based on U-Net network and combining the residual path with the new junction improves the precision of segmentation of breast ultrasound tumor images.关键词:tumor segmentation;breast ultrasound;convolutional network;residual paths (Res paths);dense block48|163|0更新时间:2024-05-07
摘要:ObjectivePrecise segmentation of breast cancer tumors is of great concern. For women, breast cancer is a common tumor disease with a high incidence, and obtaining accurate diagnosis in the early stage of breast cancer has always been the key to preventing breast cancer. Doctors can improve the accuracy of the diagnosis of breast tumors by obtaining accurate information on the edge and shape of the tumor. Common breast imaging techniques include ultrasound imaging, magnetic resonance imaging (MRI), and X-ray imaging. However, X-ray imaging often causes radiation damage to breast tissue in women, whereas MRI imaging is not only expensive but also needs a longer scanning time. Compared with the two methods above, the ultrasound imaging detection method has the advantages of no radiation damage to tissue, ease of use, imaging the front of any breast, fast imaging speed, and cheap price. However, ultrasound images rely more on professional ultrasound doctors because of problems such as speckle noise and low resolution than other commonly used techniques. Thus, experienced, well-trained doctors are needed in the diagnostic process. In recent years, improving the accuracy of diagnosis by combining medical imaging technology with computer science and technology to segment tumors accurately and help related medical personnel in diagnosis and identification has become a trend. In the past 10 years, various methods, such as thresholding method, clustering-based algorithm, graph-based algorithm, and active contour algorithm, have been used to segment breast tumors on ultrasound images. However, these methods have limited ability to represent features. In the past few years, deep convolutional neural networks have become more widely used in visual recognition tasks. They can automatically find suitable features for target data and tasks. The convolutional network has existed for a long time. However, the hardware environment at that time limited its development because the size of the training set and the size of the network structure parameters require a large amount of computation. Fully convolutional network (FCN) is an effective convolutional neural network for semantic segmentation. It can be trained in an end-to-end and pixel-to-pixel manner. Its input image size is arbitrary, and the output image is a picture with its corresponding size, containing the target information. U-Net is an improvement of the FCN model. It not only solves the above problems but also can make full use of sample image to train a biological medical image well.MethodIn this paper, a deep learning segmentation model is proposed based on the U-Net framework, combining the "Res paths" to reduce the difference between the encoder and decoder feature maps, and establish a new connection composed of dense units. The "Res paths" consist of a series of residual units, which are composed of a 3×3 convolution kernel and a 1×1 convolution kernel. The number of residual units is 4, 3, 2, and 1 in order, set along four "residual paths (Res paths)" in the framework. The new connection is a dense block from the input of feature maps to the decoding part, and the input of each layer concatenated by the output of each previous layer alleviates the loss of feature information and the disappearance of gradient. The dataset from Chongming branch of Xinhua Hospital in Shanghai is applied in this paper. The dataset is obtained by Samsung RS80A color Doppler ultrasound diagnostic instrument (equipped with a high-frequency probe l3-12a). These images obtained from the instrument clearly show the morphology, internal structure, and surrounding tissues of the lesion. All patients from this dataset are female, aged from 24 to 86, in non-pregnancy and lactation, and have no history of radiotherapy, chemotherapy, or endocrine therapy before the examination. Ten-fold cross validation is used, and 538 breast ultrasound tumor images selected from the dataset are randomly divided into 10 cases. In one case, 54 breast ultrasound images are tested, and the 484 remaining pictures are used for training. In the experiment, 484 images are doubled to 968 images by image augmentation with image data generator. During training, 48 pictures of breast cancer tumors are randomly selected for validation. Keras is used to build the model framework. Training the model is started on NVIDIA Titan 1080 GPU utilizing the weights "he_normal" to initialize the parameters of the model. Our proposed model is trained by employing the Adam optimizer, using cross entropy as the loss function, and setting batch size, β1, β2, and learning rate to 4, 0.9, 0.999, and 0.000 1, respectively.ResultThe three models are cross-checked 10 times (U-Net, U-Net with Res, and the proposed model) using the same test sample sets, validation samples sets, and training sample sets each time. The first model is the classic U-Net model. The second model adds "residual paths" to the basic network structure of U-Net. The third method, proposed by us, is an improvement on the second method. Based on the second method, a new connection is introduced. The epochs of the three previous models are 80, 100, and 120 in order. Compared with the classic U-Net model, the true positive, Jaccard similarity (JS), and Dice coefficients of the proposed model are 0.870 7, 0.803 7, and 0.882 4, respectively, improving by 1.08%, 2.14%, and 2.01%, respectively. The indices of false positive and Hausdorff distance are 0.104 and 22.311 4, respectively, decreasing by 1.68% and 1.410 2, respectively. In the test set of every 54 pictures, the total average number of tumor pictures of JS > 0.75 is 42.1 up to a maximum of 46. Experimental results show that the proposed improved algorithm improves the results.ConclusionThe proposed segmentation model based on U-Net network and combining the residual path with the new junction improves the precision of segmentation of breast ultrasound tumor images.关键词:tumor segmentation;breast ultrasound;convolutional network;residual paths (Res paths);dense block48|163|0更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveSaliency in the detection of aerial remote sensing image can have many military and life applications. On the one hand, the spatial resolution of remote sensing image is becoming higher with the improvement of technology. On the other hand, it can be applied in urban traffic planning, military target tracking, ground object classification, and other aspects. Most of the advanced target detection algorithms (such as Fast region with convolutional neural network (R-CNN), Mask R-CNN, and single shot multibox detector (SSD)) are tested on the general data set. However, the classifier based on the training of the general data set does not have a good detection effect on the aerial remote sensing image primarily due to the particularity of the aerial remote sensing image. An aerial remote sensing image is taken from a height of several hundred meters or even up to 10 000 m due to scale diversity. Thus, the sizes of similar objects in the remote sensing image differ. Taking the ship in the port as an example, the super large ship is nearly 400 meters long, and the small ship is tens of meters long. Aerial remote sensing images are shot from a high-altitude perspective, and the objects presented are all top views, which are quite different from the data set (horizontal perspective) generally used due to the particularity of perspective, which will lead to the poor effect of the trained target detection algorithm in practical application of remote sensing images. In the small target problem, most of the targets in the aerial remote sensing image are small (tens of pixels or even several pixels), the amount of information of these targets in the image is very small, and the mainstream target detection algorithm is not ideal for the detection effect of small targets in these remote sensing images mainly because the detection method based on convolutional neural network uses the pooling layer, resulting in a lower original amount of information. For example, the target image of 24×24 pixels is transformed into 1×1 pixel after four pooling layers, and the dimension is very low to be classified. The background complexity is high because the aerial remote sensing image is taken from a high altitude, its field of vision is relatively large (usually covers several square kilometers), and the image contains tens of thousands of backgrounds, resulting in the integration of the background and the small target, which has a strong interference on detection. Generally, the recognition rate of a small target in the remote sensing image is low, the scale is diverse, the direction is disordered, and the background is complex. On the one hand, edge information is lost when a small target is pooled. On the other hand, the semantic information of the feature map is not strong enough to detect the corresponding target. In this paper, a parallel high-resolution network structure combined with long short-term memory (LSTM) is proposed to replace the basic detection network visual geometry group 16-layer net (VGG16) of SSD and improve the detection accuracy of the algorithm for aerial targets.MethodThis paper introduces high-resolution network (HRNet) network and LSTM network in the SSD model. The largest feature of the HR-Net parallel network is that the input image can always maintain a high-resolution output. This parallel network structure and traditional top-down extraction feature are then up sampled and restored. The feature size is different. The parallel structure effectively reduces the number of down sampling and the loss of feature information of the target edge to be detected. The LSTM network is a variant of the circulatory neural network. The R-CNN cannot be deeply trained due to the disappearance of the gradient. The LSTM network combines short-term memory with long-term memory through subtle door control, which solves the gradient disappearance to a certain extent. To address the problem of gradient explosion, first, the method of parallel high-resolution feature map in HRNet is used to build the residual module. The first stage is the high-resolution subnetwork, which gradually increases the high-resolution subnetwork to the low-resolution subnetwork, and the multistage subnetwork is connected in parallel. Second, repeated feature fusion is carried out to obtain rich feature information. Finally, the feature map of each subnet is sampled and fused, the channel information is integrated with bidirectional LSTM, and context information is effectively used to form a multiscale detection.ResultBy applying the improved network to SSD algorithm, this paper compares it with the SSD method on common objects in context (COCO) 2017 dataset, Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago (KITTI), and University of Chinese Academy of Sciences-Aerial Object Detection (UCAS-AOD) of aviation target dataset. In the COCO2017 dataset, the model mean average precision is 41.6%, which is 10.4% higher than that of SSD513 + ResNet101. In the KITTI and UCAS-AOD datasets, the mean average precision (mAP) of this model is 69.4% and 69.3%, respectively. On COCO2017 dataset, KITTI dataset and UCAS-AOD dataset, the average detection accuracy of this algorithm increased by 10.4%, 7.3% and 8.8% compared with SSD513.ConclusionResults show that this method can reduce the miss detection rate of a small target and improve the average detection accuracy of the entire target.关键词:aerial remote sensing image;machine vision;small target detection;parallel high resolution network;long short-term memory (LSTM);COCO dataset;UCAS-AOD dataset232|204|12更新时间:2024-05-07
摘要:ObjectiveSaliency in the detection of aerial remote sensing image can have many military and life applications. On the one hand, the spatial resolution of remote sensing image is becoming higher with the improvement of technology. On the other hand, it can be applied in urban traffic planning, military target tracking, ground object classification, and other aspects. Most of the advanced target detection algorithms (such as Fast region with convolutional neural network (R-CNN), Mask R-CNN, and single shot multibox detector (SSD)) are tested on the general data set. However, the classifier based on the training of the general data set does not have a good detection effect on the aerial remote sensing image primarily due to the particularity of the aerial remote sensing image. An aerial remote sensing image is taken from a height of several hundred meters or even up to 10 000 m due to scale diversity. Thus, the sizes of similar objects in the remote sensing image differ. Taking the ship in the port as an example, the super large ship is nearly 400 meters long, and the small ship is tens of meters long. Aerial remote sensing images are shot from a high-altitude perspective, and the objects presented are all top views, which are quite different from the data set (horizontal perspective) generally used due to the particularity of perspective, which will lead to the poor effect of the trained target detection algorithm in practical application of remote sensing images. In the small target problem, most of the targets in the aerial remote sensing image are small (tens of pixels or even several pixels), the amount of information of these targets in the image is very small, and the mainstream target detection algorithm is not ideal for the detection effect of small targets in these remote sensing images mainly because the detection method based on convolutional neural network uses the pooling layer, resulting in a lower original amount of information. For example, the target image of 24×24 pixels is transformed into 1×1 pixel after four pooling layers, and the dimension is very low to be classified. The background complexity is high because the aerial remote sensing image is taken from a high altitude, its field of vision is relatively large (usually covers several square kilometers), and the image contains tens of thousands of backgrounds, resulting in the integration of the background and the small target, which has a strong interference on detection. Generally, the recognition rate of a small target in the remote sensing image is low, the scale is diverse, the direction is disordered, and the background is complex. On the one hand, edge information is lost when a small target is pooled. On the other hand, the semantic information of the feature map is not strong enough to detect the corresponding target. In this paper, a parallel high-resolution network structure combined with long short-term memory (LSTM) is proposed to replace the basic detection network visual geometry group 16-layer net (VGG16) of SSD and improve the detection accuracy of the algorithm for aerial targets.MethodThis paper introduces high-resolution network (HRNet) network and LSTM network in the SSD model. The largest feature of the HR-Net parallel network is that the input image can always maintain a high-resolution output. This parallel network structure and traditional top-down extraction feature are then up sampled and restored. The feature size is different. The parallel structure effectively reduces the number of down sampling and the loss of feature information of the target edge to be detected. The LSTM network is a variant of the circulatory neural network. The R-CNN cannot be deeply trained due to the disappearance of the gradient. The LSTM network combines short-term memory with long-term memory through subtle door control, which solves the gradient disappearance to a certain extent. To address the problem of gradient explosion, first, the method of parallel high-resolution feature map in HRNet is used to build the residual module. The first stage is the high-resolution subnetwork, which gradually increases the high-resolution subnetwork to the low-resolution subnetwork, and the multistage subnetwork is connected in parallel. Second, repeated feature fusion is carried out to obtain rich feature information. Finally, the feature map of each subnet is sampled and fused, the channel information is integrated with bidirectional LSTM, and context information is effectively used to form a multiscale detection.ResultBy applying the improved network to SSD algorithm, this paper compares it with the SSD method on common objects in context (COCO) 2017 dataset, Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago (KITTI), and University of Chinese Academy of Sciences-Aerial Object Detection (UCAS-AOD) of aviation target dataset. In the COCO2017 dataset, the model mean average precision is 41.6%, which is 10.4% higher than that of SSD513 + ResNet101. In the KITTI and UCAS-AOD datasets, the mean average precision (mAP) of this model is 69.4% and 69.3%, respectively. On COCO2017 dataset, KITTI dataset and UCAS-AOD dataset, the average detection accuracy of this algorithm increased by 10.4%, 7.3% and 8.8% compared with SSD513.ConclusionResults show that this method can reduce the miss detection rate of a small target and improve the average detection accuracy of the entire target.关键词:aerial remote sensing image;machine vision;small target detection;parallel high resolution network;long short-term memory (LSTM);COCO dataset;UCAS-AOD dataset232|204|12更新时间:2024-05-07 -
 摘要:ObjectiveShip detection based on remotely sensed images aims to locate ships, which is of great significance in national water surveillance and territorial security. The rectangular bounding boxes for target location in the typical deep learning method are usually in the horizontal-vertical direction, whereas the distribution of ships on remotely sensed images is arbitrarily oriented or in varying directions. For narrow and long ships with arbitrary directions, the vertical-horizontal bounding box is fairly rough. When the ship deviates from the vertical or horizontal direction, the bounding box is inaccurate, and the bounding box has many nonship pixels. If multiple ships are close to one another on the image, several ships may not be located because they are overlapped by the bounding boxes of the neighboring ships. Therefore, using a finer bounding box in detection is beneficial for detecting ship targets, and more precise ship positioning information is helpful for subsequent ship target recognition. For this reason, the classical deep-learning-based target detection is extended, and a finer minimum circumscribed rectangular bounding box is utilized to locate the ship target. Existing extended detection algorithms can be divided into two categories: one-stage detection and two-stage detection. One-stage detection directly outputs the target's location estimation, whereas two-stage detection classifies the proposed regions to eliminate the false targets. The disadvantage of two-stage detection is its slower speed. One-stage detection is faster, but its false alarm rate is higher for narrow and long ships. A fast detection algorithm based on dense sub-region segmentation is proposed according to the shape characteristics of ship targets to reduce the false alarm rate of one-stage detection and further improve the detection speed.MethodThe basic idea of our algorithm is to segment a ship into several sub-regions on which detection and combination are carried out, according to the long and narrow shape characteristic of ships. First, the whole ship is intensively segmented along its long axis direction into several local sub-regions contained in square annotation boxes to maximize the proportion of the pixel area belonging to the ship, namely, the effective area ratio in every annotation box.The influence of background noise on a sub-region annotation box could be suppressed, and the reliable generalization ability of the sub-regions detection network is obtained. The multi-resolution structure is applied to the core detection network that contains three output branches from coarse resolution to fine resolution. The density of sub-region segmentation is estimated according to the minimum spatial compression ratio of the output branches to ensure that the sub-regions of the same ship are connected in each output branch. Second, the core sub-region detection network is trained, and several overlapping sub-regions in the coarse branches are reorganized during training. In the output layer with a finer resolution, the spatially adjacent sub-regions may be mapped to the same point in the output grid because the sub-regions are densely distributed. This process is called sub-region overlapping. Each point in the output grid can only correspond to one sub-region target at most; thus, these sub-regions should be reorganized into a new pseudo sub-region. The center point of the pseudo sub-region is the average value of the center points of the original sub-regions, and the size of the pseudo sub-region is consistent with that of the original sub-regions. With different resolutions in the output layer, the center points of the pseudo sub-region are slightly different, but the overall difference is not large. Lastly, the detected sub-regions are merged based on the subgraph segmentation method. The whole remotely sensed image is modeled as a graph, where each detected sub-region is recognized as a single node. The connectivity between every two sub-regions is constructed according to their spatial distance and size difference. The sub-graph segmentation is clustered into sub-regions belonging to the same ship. Based on the spatial distribution of the clustered sub-regions, the key parameters of the corresponding ship such as length, width, and rotation angle are estimated. Compared with conventional deep learning target detection methods, the core detection network structure of the proposed algorithm remains unchanged, and the post processing of sub-region merging replaces common non maximum suppression post processing.ResultOur algorithm is compared with five state-of-the-art detection algorithms, namely, improved YOLOv3(you only look once), RRCNN(rotated region convolutional neural network), RRPN(rotation region proposal netwrok), R-DFPN-3(rotation dense feature pyramid network), and R-DFPN-4 on the HRSC2016(high resolution ship collections) dataset. The improved YOLOv3 belongs to one-stage detection, and the four other algorithms belong to two-stage detection. The quantitative evaluation metrics include mean average precision(mAP) and mean consuming time(mCT). Experiment results show that our algorithm outperforms all other algorithms on the HRSC2016 dataset. Compared with the result of R-DFPN-4 with the highest detection accuracy in comparison algorithms, mAP (i.e., higher is better) increases by 1.9%, and mCT(i.e., less is better) decreases by 57.9%. Compared with the result of improved YOLOv3 with the fastest detection speed in comparison algorithms, mAP increases by 3.6%, and mCT decreases by 31.4%. The running speed of our algorithm and the conventional YOLOv3 algorithm are further analyzed and compared. The core detection network applied to our algorithm is the same as that of the conventional YOLOv3 algorithm; thus, the running speed differs only in the post processing phase. The sub-region merging of our algorithm takes about 11 ms, and the nom-maximum-suppression(NMS) of conventional YOLOv3 takes approximately 5 ms on the HRSC2016 dataset. Compared with the conventional YOLOv3 algorithm, our algorithm can obtain finer positioning information for the rotating ships, and running time increases by only 9%.ConclusionA dense sub-region segmentation-based, arbitrarily oriented ship detection algorithm by using the long-and-narrow shape characteristics of the ship target is proposed. The experiment results show that our algorithm outperforms several state-of-the-art arbitrary-oriented ship detection algorithms, especially in detection speed.关键词:arbitrary direction ship detection;dense sub-region segmentation;sub-graph segmentation;sub-region merging;fast detection58|73|1更新时间:2024-05-07
摘要:ObjectiveShip detection based on remotely sensed images aims to locate ships, which is of great significance in national water surveillance and territorial security. The rectangular bounding boxes for target location in the typical deep learning method are usually in the horizontal-vertical direction, whereas the distribution of ships on remotely sensed images is arbitrarily oriented or in varying directions. For narrow and long ships with arbitrary directions, the vertical-horizontal bounding box is fairly rough. When the ship deviates from the vertical or horizontal direction, the bounding box is inaccurate, and the bounding box has many nonship pixels. If multiple ships are close to one another on the image, several ships may not be located because they are overlapped by the bounding boxes of the neighboring ships. Therefore, using a finer bounding box in detection is beneficial for detecting ship targets, and more precise ship positioning information is helpful for subsequent ship target recognition. For this reason, the classical deep-learning-based target detection is extended, and a finer minimum circumscribed rectangular bounding box is utilized to locate the ship target. Existing extended detection algorithms can be divided into two categories: one-stage detection and two-stage detection. One-stage detection directly outputs the target's location estimation, whereas two-stage detection classifies the proposed regions to eliminate the false targets. The disadvantage of two-stage detection is its slower speed. One-stage detection is faster, but its false alarm rate is higher for narrow and long ships. A fast detection algorithm based on dense sub-region segmentation is proposed according to the shape characteristics of ship targets to reduce the false alarm rate of one-stage detection and further improve the detection speed.MethodThe basic idea of our algorithm is to segment a ship into several sub-regions on which detection and combination are carried out, according to the long and narrow shape characteristic of ships. First, the whole ship is intensively segmented along its long axis direction into several local sub-regions contained in square annotation boxes to maximize the proportion of the pixel area belonging to the ship, namely, the effective area ratio in every annotation box.The influence of background noise on a sub-region annotation box could be suppressed, and the reliable generalization ability of the sub-regions detection network is obtained. The multi-resolution structure is applied to the core detection network that contains three output branches from coarse resolution to fine resolution. The density of sub-region segmentation is estimated according to the minimum spatial compression ratio of the output branches to ensure that the sub-regions of the same ship are connected in each output branch. Second, the core sub-region detection network is trained, and several overlapping sub-regions in the coarse branches are reorganized during training. In the output layer with a finer resolution, the spatially adjacent sub-regions may be mapped to the same point in the output grid because the sub-regions are densely distributed. This process is called sub-region overlapping. Each point in the output grid can only correspond to one sub-region target at most; thus, these sub-regions should be reorganized into a new pseudo sub-region. The center point of the pseudo sub-region is the average value of the center points of the original sub-regions, and the size of the pseudo sub-region is consistent with that of the original sub-regions. With different resolutions in the output layer, the center points of the pseudo sub-region are slightly different, but the overall difference is not large. Lastly, the detected sub-regions are merged based on the subgraph segmentation method. The whole remotely sensed image is modeled as a graph, where each detected sub-region is recognized as a single node. The connectivity between every two sub-regions is constructed according to their spatial distance and size difference. The sub-graph segmentation is clustered into sub-regions belonging to the same ship. Based on the spatial distribution of the clustered sub-regions, the key parameters of the corresponding ship such as length, width, and rotation angle are estimated. Compared with conventional deep learning target detection methods, the core detection network structure of the proposed algorithm remains unchanged, and the post processing of sub-region merging replaces common non maximum suppression post processing.ResultOur algorithm is compared with five state-of-the-art detection algorithms, namely, improved YOLOv3(you only look once), RRCNN(rotated region convolutional neural network), RRPN(rotation region proposal netwrok), R-DFPN-3(rotation dense feature pyramid network), and R-DFPN-4 on the HRSC2016(high resolution ship collections) dataset. The improved YOLOv3 belongs to one-stage detection, and the four other algorithms belong to two-stage detection. The quantitative evaluation metrics include mean average precision(mAP) and mean consuming time(mCT). Experiment results show that our algorithm outperforms all other algorithms on the HRSC2016 dataset. Compared with the result of R-DFPN-4 with the highest detection accuracy in comparison algorithms, mAP (i.e., higher is better) increases by 1.9%, and mCT(i.e., less is better) decreases by 57.9%. Compared with the result of improved YOLOv3 with the fastest detection speed in comparison algorithms, mAP increases by 3.6%, and mCT decreases by 31.4%. The running speed of our algorithm and the conventional YOLOv3 algorithm are further analyzed and compared. The core detection network applied to our algorithm is the same as that of the conventional YOLOv3 algorithm; thus, the running speed differs only in the post processing phase. The sub-region merging of our algorithm takes about 11 ms, and the nom-maximum-suppression(NMS) of conventional YOLOv3 takes approximately 5 ms on the HRSC2016 dataset. Compared with the conventional YOLOv3 algorithm, our algorithm can obtain finer positioning information for the rotating ships, and running time increases by only 9%.ConclusionA dense sub-region segmentation-based, arbitrarily oriented ship detection algorithm by using the long-and-narrow shape characteristics of the ship target is proposed. The experiment results show that our algorithm outperforms several state-of-the-art arbitrary-oriented ship detection algorithms, especially in detection speed.关键词:arbitrary direction ship detection;dense sub-region segmentation;sub-graph segmentation;sub-region merging;fast detection58|73|1更新时间:2024-05-07 -
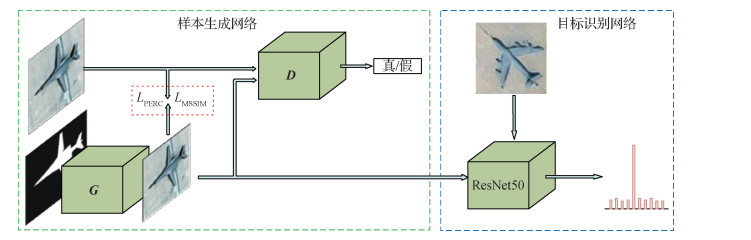 摘要:ObjectiveAircraft type recognition is a fundamental problem in remote sensing image interpretation, which aims to identify the type of aircraft in an image. Aircraft type recognition algorithms have been widely studied and improved ceaselessly. The traditional recognition algorithms are efficient, but their accuracy is limited by the small capacity and poor robustness. The deep-learning-based methods have been widely implemented because of good robustness and generalization, especially in the object recognition task. In remote sensing scenes, the objects are sparsely distributed; hence, the available samples are few. In addition, labeling is time consuming, resulting in a modest number of labeled samples. Generally, the deep-learning-based models rely on a large amount of labeled data due to thousands of weights needed to learn. Consequently, these models suffer from scarce data that are insufficient to meet the demand of large-scale datasets, especially in the remote sensing scene. Generative adversarial network (GAN) can produce realistic synthetic data and enlarge the scale of the real dataset. However, these algorithms usually take random noises as input; therefore, they are unable to control the position, angle, size, and category of objects in synthetic images. Conditional GAN (CGAN) have been proposed by previous researchers to generate synthetic images with designated content in a controlled scheme. CGANs take the pixel-wise labeled images as the input data and output the generated images that meet constraints from its corresponding input images. However, these generative adversarial models have been widely studied for natural sceneries, which are not suitable for remote sensing imageries due to the complex scenes and low resolutions. Hence, the GANs perform poorly when adopted to generate remote sensing images. An aircraft recognition framework of remote sensing images based on sample generation is proposed, which consists of an improved CGAN and a recognition model, to alleviate the lack of real samples and deal with the problems mentioned above.MethodIn this framework, the masks of real aircraft images are labeled pixel by pixel. The masks of images serve as the conditions of the CGAN that are trained by the pairs of real aircraft images and corresponding masks. In this manner, the location, scale, and type of aircraft in the synthetic images can be controlled. Perceptual loss is introduced to promote the ability of the CGANs to model the scenes of remote sensing. The L2 distance between the features of real images and synthetic images extracted by the VGG-16 (visual geometry group 16-layer net) network measures the perceptual loss between the real images and synthetic images. Masked structural similarity (SSIM) loss is proposed, which forces the CGAN to focus on the masked region and improve the quality of the aircraft region in the synthetic images. SSIM is a measurement of image quantity according to the structure and texture. Masked SSIM loss is the sum of the product between masks and SSIM pixel by pixel. Afterward, the loss function of the CGAN consists of perceptual loss, masked SSIM loss, and origin CGAN loss. The recognition model in this framework is ResNet-50, which outputs the type and recognition score of an aircraft. In this paper, the recognition model trained on synthetic images is compared with the model trained on real images. The remote sensing images from QuickBird are cropped to build the real dataset, in which 800 images for each type are used for training and 1 000 images are used for testing. After data augmentation, the training dataset consists of 40 000 images, and the synthetic dataset consists of synthetic images generated by the generation module with flipped, rotated, and scaled masks. The generators are selected from different training stages to generate 2 000 synthetic images per type and determine the best end time in the training procedure. The chosen generator is used to produce different numbers of images for 10 aircraft types and find an acceptable number of synthetic images. These synthetic images serve as the training set for the recognition model, whose performances are compared. All our experiments are carried out on a single NVIDIA K80 GPU device with the framework of Pytorch, and the Adam optimizer is implemented to train the CGAN and ResNet-50 for 100 epochs.ResultThe quantities of the synthetic images from the generator with and without our proposed loss functions on the training dataset are compared. The quantitative evaluation metrics contain peak signal to noise ratio (PSNR) and SSIM. Results show that PSNR and SSIM increase by 0.88 and 0.346 using our method, respectively. In addition, recognition accuracy increases with the training epoch of the generator and the number of synthetic images. Finally, the accuracy of the recognition model trained on the synthetic dataset is 0.33% less than that of the real dataset.ConclusionAn aircraft recognition framework of remote sensing images based on sample generation is proposed. The experiment results show that our method effectively improves the ability of CGAN to model the remote sensing scenes and alleviates the absence of data.关键词:deep learning;convolutional neural network;generative adversarial network (GAN);optical remote sensing images;object recognition113|148|2更新时间:2024-05-07
摘要:ObjectiveAircraft type recognition is a fundamental problem in remote sensing image interpretation, which aims to identify the type of aircraft in an image. Aircraft type recognition algorithms have been widely studied and improved ceaselessly. The traditional recognition algorithms are efficient, but their accuracy is limited by the small capacity and poor robustness. The deep-learning-based methods have been widely implemented because of good robustness and generalization, especially in the object recognition task. In remote sensing scenes, the objects are sparsely distributed; hence, the available samples are few. In addition, labeling is time consuming, resulting in a modest number of labeled samples. Generally, the deep-learning-based models rely on a large amount of labeled data due to thousands of weights needed to learn. Consequently, these models suffer from scarce data that are insufficient to meet the demand of large-scale datasets, especially in the remote sensing scene. Generative adversarial network (GAN) can produce realistic synthetic data and enlarge the scale of the real dataset. However, these algorithms usually take random noises as input; therefore, they are unable to control the position, angle, size, and category of objects in synthetic images. Conditional GAN (CGAN) have been proposed by previous researchers to generate synthetic images with designated content in a controlled scheme. CGANs take the pixel-wise labeled images as the input data and output the generated images that meet constraints from its corresponding input images. However, these generative adversarial models have been widely studied for natural sceneries, which are not suitable for remote sensing imageries due to the complex scenes and low resolutions. Hence, the GANs perform poorly when adopted to generate remote sensing images. An aircraft recognition framework of remote sensing images based on sample generation is proposed, which consists of an improved CGAN and a recognition model, to alleviate the lack of real samples and deal with the problems mentioned above.MethodIn this framework, the masks of real aircraft images are labeled pixel by pixel. The masks of images serve as the conditions of the CGAN that are trained by the pairs of real aircraft images and corresponding masks. In this manner, the location, scale, and type of aircraft in the synthetic images can be controlled. Perceptual loss is introduced to promote the ability of the CGANs to model the scenes of remote sensing. The L2 distance between the features of real images and synthetic images extracted by the VGG-16 (visual geometry group 16-layer net) network measures the perceptual loss between the real images and synthetic images. Masked structural similarity (SSIM) loss is proposed, which forces the CGAN to focus on the masked region and improve the quality of the aircraft region in the synthetic images. SSIM is a measurement of image quantity according to the structure and texture. Masked SSIM loss is the sum of the product between masks and SSIM pixel by pixel. Afterward, the loss function of the CGAN consists of perceptual loss, masked SSIM loss, and origin CGAN loss. The recognition model in this framework is ResNet-50, which outputs the type and recognition score of an aircraft. In this paper, the recognition model trained on synthetic images is compared with the model trained on real images. The remote sensing images from QuickBird are cropped to build the real dataset, in which 800 images for each type are used for training and 1 000 images are used for testing. After data augmentation, the training dataset consists of 40 000 images, and the synthetic dataset consists of synthetic images generated by the generation module with flipped, rotated, and scaled masks. The generators are selected from different training stages to generate 2 000 synthetic images per type and determine the best end time in the training procedure. The chosen generator is used to produce different numbers of images for 10 aircraft types and find an acceptable number of synthetic images. These synthetic images serve as the training set for the recognition model, whose performances are compared. All our experiments are carried out on a single NVIDIA K80 GPU device with the framework of Pytorch, and the Adam optimizer is implemented to train the CGAN and ResNet-50 for 100 epochs.ResultThe quantities of the synthetic images from the generator with and without our proposed loss functions on the training dataset are compared. The quantitative evaluation metrics contain peak signal to noise ratio (PSNR) and SSIM. Results show that PSNR and SSIM increase by 0.88 and 0.346 using our method, respectively. In addition, recognition accuracy increases with the training epoch of the generator and the number of synthetic images. Finally, the accuracy of the recognition model trained on the synthetic dataset is 0.33% less than that of the real dataset.ConclusionAn aircraft recognition framework of remote sensing images based on sample generation is proposed. The experiment results show that our method effectively improves the ability of CGAN to model the remote sensing scenes and alleviates the absence of data.关键词:deep learning;convolutional neural network;generative adversarial network (GAN);optical remote sensing images;object recognition113|148|2更新时间:2024-05-07 -
 摘要:ObjectiveSemantic analysis of remote sensing (RS) images has always been an important research topic in computer vision community. It has been widely used in related fields such as military surveillance, mapping navigation, and urban planning. Researchers can easily obtain various informative features for the following decision making by exploring and analyzing the semantic information of RS images. However, the richer, finer visual information in high-resolution RS images also puts forward higher requirements for image segmentation techniques. Traditional segmentation methods usually employ low-level visual features such as grayscale, color, spatial texture, and geometric shape to divide an image into several disjoint regions. Generally, such features are called hand-crafted ones, which are empirically defined and may be less semantically meaningful. Compared with traditional segmentation methods, semantic segmentation approaches based on deep convolutional neural networks (CNNs) are capable of learning hierarchical visual features for representing images in different semantic levels. Typical CNN-based semantic segmentation approaches mainly focus on mitigating semantic ambiguity via providing rich information. However, RS images have higher background complexity than images of nature scene. For example, they usually contain many types of geometric objects and cover massive redundant background areas. Simply employing a certain type of feature or even CNN-based ones may not be sufficient in such case. Taking single-category object extraction task in RS images for example, on the one hand, negative objects may have similar visual presentations with the expected target. These redundant, noisy semantic information may confuse the network and finally decrease the segmentation performance. On the other hand, the CNN-based feature is good at encoding the context information rather than the fine details of an image, making the CNN-based models have difficulty obtaining the precise prediction of object boundaries. Therefore, aiming at these problems in high-resolution RS image segmentation, this paper proposes an edge loss enhanced network for semantic segmentation that comprehensively utilizes the boundary information and hierarchical deep features.MethodThe backbone of the proposed model is a fully convolutional network that is abbreviated from a visual geometry group 16-layer net (VGG-16) structure by removing all fully connected layers and its fifth pooling layer. A side output structure is introduced for each convolutional layer of our backbone network to extract all possible rich, informative features from the input image. The side output structure starts with a (1×1, 1) convolutional layer (a specific convolutional layer is denoted as (n×n, c) where n and c are the size and number of kernels, respectively), followed by an element-wise summation layer for accumulating features in each scale. Then, a (1×1, 1) convolutional layer is used to concentrate hybrid features. The side output structure makes full use of the features of each convolutional layer of our backbone and helps the network capture the fine details of the image. The side-output features are further gradually aggregated from the deep layers to shallow layers by a deep-supervised short connection structure to enhance the connections between features crossing scales. To this end, each side output feature is first encoded by a residual convolution unit then introduced to another one of a nearby shallow stage with necessary upsampling. The short connection structure enables a multilevel, multiscale fusion during feature encoding and is proven effective in the experiment. Finally, for each fused side output feature, a (3×3, 128) convolutional layer is first used to unify its number of feature channels then send it to two paralleled branches, namely, an edge loss enhancement branch and an ordinary segmentation branch. In each edge loss enhancement branch, a Laplace operator coupled with a residual convolution unit is adopted to obtain the target boundary. The detected boundary is supervised by the ground truth that is generated by directly computing the gradient of existing semantic annotation of training samples. It does not require additional manual work for edge labeling. Experimental results show that the edge loss enhancement branch helps refine the target boundary as well as maintain the integrity of the target region.ResultFirst, two datasets with human annotations that include the RS images of the planted greenhouses in the north of China and the photovoltaic panels collected by Google Earth are organized to evaluate the effectiveness of the proposed method. Then, visual and numerical comparisons are conducted between the proposed method and several popular semantic segmentation methods. In addition, an ablation study is included to illustrate the contribution of essential components in the proposed architecture. The experimental results show that our method outperforms other competing approaches on both datasets in the comparisons of precision-recall curves and mean absolute error (MAE). The precision achieved by our method is constantly above 0.8 when recall rate in the range of 0 to 0.9. The MAE achieved by our method is 0.079 1/0.036 2 which is the best of all evaluation results. In addition, the ablation study clearly illustrates the effectiveness of each individual functional block. First, the baseline of the proposed architecture obtains a poor result with MAE of 0.204 4 on the northern greenhouse dataset. Then, the residual convolutional units help reduce MAE by 31%, and the value further drops to 0.084 8 when the short connection structure is added to fuse the multiscale features of the network. Finally, the edge loss enhancement structure helps successfully lower MAE to 0.079 1, which is decreased by 61% compared with the baseline model. The results indicate that all components are necessary to obtain a good feature segmentation result.ConclusionIn summary, compared with the competing methods, the proposed method is capable of extracting the target region more accurately from the complex background of RS images with a clearer target boundary.关键词:high resolution remote sensing imagery;convolutional neural network (CNN);semantic segmentation;multi-feature fusion;edge loss reinforced network;mean absolute error(MAE)84|286|2更新时间:2024-05-07
摘要:ObjectiveSemantic analysis of remote sensing (RS) images has always been an important research topic in computer vision community. It has been widely used in related fields such as military surveillance, mapping navigation, and urban planning. Researchers can easily obtain various informative features for the following decision making by exploring and analyzing the semantic information of RS images. However, the richer, finer visual information in high-resolution RS images also puts forward higher requirements for image segmentation techniques. Traditional segmentation methods usually employ low-level visual features such as grayscale, color, spatial texture, and geometric shape to divide an image into several disjoint regions. Generally, such features are called hand-crafted ones, which are empirically defined and may be less semantically meaningful. Compared with traditional segmentation methods, semantic segmentation approaches based on deep convolutional neural networks (CNNs) are capable of learning hierarchical visual features for representing images in different semantic levels. Typical CNN-based semantic segmentation approaches mainly focus on mitigating semantic ambiguity via providing rich information. However, RS images have higher background complexity than images of nature scene. For example, they usually contain many types of geometric objects and cover massive redundant background areas. Simply employing a certain type of feature or even CNN-based ones may not be sufficient in such case. Taking single-category object extraction task in RS images for example, on the one hand, negative objects may have similar visual presentations with the expected target. These redundant, noisy semantic information may confuse the network and finally decrease the segmentation performance. On the other hand, the CNN-based feature is good at encoding the context information rather than the fine details of an image, making the CNN-based models have difficulty obtaining the precise prediction of object boundaries. Therefore, aiming at these problems in high-resolution RS image segmentation, this paper proposes an edge loss enhanced network for semantic segmentation that comprehensively utilizes the boundary information and hierarchical deep features.MethodThe backbone of the proposed model is a fully convolutional network that is abbreviated from a visual geometry group 16-layer net (VGG-16) structure by removing all fully connected layers and its fifth pooling layer. A side output structure is introduced for each convolutional layer of our backbone network to extract all possible rich, informative features from the input image. The side output structure starts with a (1×1, 1) convolutional layer (a specific convolutional layer is denoted as (n×n, c) where n and c are the size and number of kernels, respectively), followed by an element-wise summation layer for accumulating features in each scale. Then, a (1×1, 1) convolutional layer is used to concentrate hybrid features. The side output structure makes full use of the features of each convolutional layer of our backbone and helps the network capture the fine details of the image. The side-output features are further gradually aggregated from the deep layers to shallow layers by a deep-supervised short connection structure to enhance the connections between features crossing scales. To this end, each side output feature is first encoded by a residual convolution unit then introduced to another one of a nearby shallow stage with necessary upsampling. The short connection structure enables a multilevel, multiscale fusion during feature encoding and is proven effective in the experiment. Finally, for each fused side output feature, a (3×3, 128) convolutional layer is first used to unify its number of feature channels then send it to two paralleled branches, namely, an edge loss enhancement branch and an ordinary segmentation branch. In each edge loss enhancement branch, a Laplace operator coupled with a residual convolution unit is adopted to obtain the target boundary. The detected boundary is supervised by the ground truth that is generated by directly computing the gradient of existing semantic annotation of training samples. It does not require additional manual work for edge labeling. Experimental results show that the edge loss enhancement branch helps refine the target boundary as well as maintain the integrity of the target region.ResultFirst, two datasets with human annotations that include the RS images of the planted greenhouses in the north of China and the photovoltaic panels collected by Google Earth are organized to evaluate the effectiveness of the proposed method. Then, visual and numerical comparisons are conducted between the proposed method and several popular semantic segmentation methods. In addition, an ablation study is included to illustrate the contribution of essential components in the proposed architecture. The experimental results show that our method outperforms other competing approaches on both datasets in the comparisons of precision-recall curves and mean absolute error (MAE). The precision achieved by our method is constantly above 0.8 when recall rate in the range of 0 to 0.9. The MAE achieved by our method is 0.079 1/0.036 2 which is the best of all evaluation results. In addition, the ablation study clearly illustrates the effectiveness of each individual functional block. First, the baseline of the proposed architecture obtains a poor result with MAE of 0.204 4 on the northern greenhouse dataset. Then, the residual convolutional units help reduce MAE by 31%, and the value further drops to 0.084 8 when the short connection structure is added to fuse the multiscale features of the network. Finally, the edge loss enhancement structure helps successfully lower MAE to 0.079 1, which is decreased by 61% compared with the baseline model. The results indicate that all components are necessary to obtain a good feature segmentation result.ConclusionIn summary, compared with the competing methods, the proposed method is capable of extracting the target region more accurately from the complex background of RS images with a clearer target boundary.关键词:high resolution remote sensing imagery;convolutional neural network (CNN);semantic segmentation;multi-feature fusion;edge loss reinforced network;mean absolute error(MAE)84|286|2更新时间:2024-05-07 -
 摘要:ObjectiveRemote sensing building object segmentation is one of the important applications in image processing, which plays a vital role in smart city planning and urban change detection. However, building objects in remote sensing images have many complex characteristics, such as variable sizes, dense distributions, diverse topological shapes, complex backgrounds, and presence of occlusions and shadows. Traditional building segmentation algorithms are mainly based on manually designed features such as shapes, edges, and shadow features. These features are shallow features of the building target and cannot well express high-level semantic information, resulting in low recognition accuracy. By contrast, deep convolutional networks show excellent performance in pixel-level classification of natural images. Various fully convolutional network based image segmentation models have been continuously proposed. Most of these models use deconvolution or bilinear interpolation after feature extraction. Feature upsampling and pixel-by-pixel classification are used to segment the input image. The deep features of the building are extracted using highly nonlinear mapping and a large amount of data training, which overcomes the shortcomings of traditional algorithms. However, upsampling cannot completely compensate the information loss caused by repeated convolution and pooling operations in the deep convolutional network model. Therefore, the prediction results are relatively rough, such as small target misclassification, inaccurate boundaries, and other issues. In the field of remote sensing, public data sets are few. Training excellent deep convolutional networks is difficult, and the robustness of the network needs to be further improved. Aiming at the above problems, this paper proposes a conditional generative adversarial network (Ra-CGAN) with multilevel channel attention mechanism to segment remote sensing building objects.MethodA generative model with a multilevel channel attention mechanism is first built. The model is based on a coding and decoding structure that solves small target misses by fusing deep semantics and shallow details with attention. Second, a discriminative network is built and used to distinguish whether the input comes from the real label map or the segmentation map generated by the model. The segmentation result (accuracy and smoothness) is improved by correcting the difference between the two maps. The downsampling method without pooling is used in the discriminator to enhance the propagation of the gradient. Finally, the generated model and the discriminant model are alternately confronted for training through the constraint of the conditional variable of the labelled image. Learning the higher-order data distribution characteristics results in more continuity for the target space. The loss function uses a hybrid loss function, which comes from the cross-entropy loss function brought by the generated map and the real label map in the generation mode. The discriminator predicts the generated image as the loss value brought by the real label image. Experiments are performed on the WHU Building Dataset and Satellite Dataset II datasets. The first dataset has a dense building with many types and accurate labels, and can provide comprehensive, representative evaluation capabilities for the model. Another dataset with a higher segmentation difficulty is used to verify the robustness and scalability of the model. The lighting information and background information of the building are more complex than those of the first dataset. The experiment uses the PyTorch deep learning framework. The size of original image and the label image are unified to 512×512 pixels for training, the learning rate of Adam is set to 0.000 2, the momentum parameter is 0.5, the batch-size is 12, and the epoch is 200 times. Acceleration is performed using NVIDIA GTX TITAN Xp. Evaluation indicators include intersection over union (IOU), precision, recall, and F1-score.ResultExperiments are performed on the WHU Building Dataset and Satellite Dataset II datasets, and the methods are compared with the latest literature. Experimental results show that in the WHU dataset, the segmentation performance of the Ra-CGAN model is substantially improved compared with models without attention mechanism and adversarial training. Space continuity and integrity of the complex building and small building, and smoothness of building edges are considerably improved. Compared with U-Net, IOU value is increased by 3.75%, and F1-score is increased by 2.52%. Compared with the second-performance model, IOU value is increased by 1.1%, and F1-score is increased by 1.1%. In the Satellite Dataset II, Ra-CGAN obtains more ideal results in terms of target integrity and smoothness than other models, especially in the case of insufficient data samples. Compared with U-Net, IOU value is increased by 7.26%, and F1-score is increased by 6.68%. Compared with the second-placed model, IOU value is increased by 1.7% and F1-score is increased by 1.6%.ConclusionA CGAN remote sensing building object segmentation model with multilevel channel attention mechanism, which combines the advantages of multilevel channel attention mechanism generation model and conditional generative adversarial networks, is proposed. Experimental results show that our model is superior to several state-of-the-art segmentation methods. Much more accurate remote sensing building object segmentation results are obtained on different datasets, proving that the model exhibits better robustness and scalability.关键词:deep convolutional neural network;remote sensing image segmentation;conditional generative adversarial network (CGAN);attention mechanism;multi-scale feature fusion97|172|6更新时间:2024-05-07
摘要:ObjectiveRemote sensing building object segmentation is one of the important applications in image processing, which plays a vital role in smart city planning and urban change detection. However, building objects in remote sensing images have many complex characteristics, such as variable sizes, dense distributions, diverse topological shapes, complex backgrounds, and presence of occlusions and shadows. Traditional building segmentation algorithms are mainly based on manually designed features such as shapes, edges, and shadow features. These features are shallow features of the building target and cannot well express high-level semantic information, resulting in low recognition accuracy. By contrast, deep convolutional networks show excellent performance in pixel-level classification of natural images. Various fully convolutional network based image segmentation models have been continuously proposed. Most of these models use deconvolution or bilinear interpolation after feature extraction. Feature upsampling and pixel-by-pixel classification are used to segment the input image. The deep features of the building are extracted using highly nonlinear mapping and a large amount of data training, which overcomes the shortcomings of traditional algorithms. However, upsampling cannot completely compensate the information loss caused by repeated convolution and pooling operations in the deep convolutional network model. Therefore, the prediction results are relatively rough, such as small target misclassification, inaccurate boundaries, and other issues. In the field of remote sensing, public data sets are few. Training excellent deep convolutional networks is difficult, and the robustness of the network needs to be further improved. Aiming at the above problems, this paper proposes a conditional generative adversarial network (Ra-CGAN) with multilevel channel attention mechanism to segment remote sensing building objects.MethodA generative model with a multilevel channel attention mechanism is first built. The model is based on a coding and decoding structure that solves small target misses by fusing deep semantics and shallow details with attention. Second, a discriminative network is built and used to distinguish whether the input comes from the real label map or the segmentation map generated by the model. The segmentation result (accuracy and smoothness) is improved by correcting the difference between the two maps. The downsampling method without pooling is used in the discriminator to enhance the propagation of the gradient. Finally, the generated model and the discriminant model are alternately confronted for training through the constraint of the conditional variable of the labelled image. Learning the higher-order data distribution characteristics results in more continuity for the target space. The loss function uses a hybrid loss function, which comes from the cross-entropy loss function brought by the generated map and the real label map in the generation mode. The discriminator predicts the generated image as the loss value brought by the real label image. Experiments are performed on the WHU Building Dataset and Satellite Dataset II datasets. The first dataset has a dense building with many types and accurate labels, and can provide comprehensive, representative evaluation capabilities for the model. Another dataset with a higher segmentation difficulty is used to verify the robustness and scalability of the model. The lighting information and background information of the building are more complex than those of the first dataset. The experiment uses the PyTorch deep learning framework. The size of original image and the label image are unified to 512×512 pixels for training, the learning rate of Adam is set to 0.000 2, the momentum parameter is 0.5, the batch-size is 12, and the epoch is 200 times. Acceleration is performed using NVIDIA GTX TITAN Xp. Evaluation indicators include intersection over union (IOU), precision, recall, and F1-score.ResultExperiments are performed on the WHU Building Dataset and Satellite Dataset II datasets, and the methods are compared with the latest literature. Experimental results show that in the WHU dataset, the segmentation performance of the Ra-CGAN model is substantially improved compared with models without attention mechanism and adversarial training. Space continuity and integrity of the complex building and small building, and smoothness of building edges are considerably improved. Compared with U-Net, IOU value is increased by 3.75%, and F1-score is increased by 2.52%. Compared with the second-performance model, IOU value is increased by 1.1%, and F1-score is increased by 1.1%. In the Satellite Dataset II, Ra-CGAN obtains more ideal results in terms of target integrity and smoothness than other models, especially in the case of insufficient data samples. Compared with U-Net, IOU value is increased by 7.26%, and F1-score is increased by 6.68%. Compared with the second-placed model, IOU value is increased by 1.7% and F1-score is increased by 1.6%.ConclusionA CGAN remote sensing building object segmentation model with multilevel channel attention mechanism, which combines the advantages of multilevel channel attention mechanism generation model and conditional generative adversarial networks, is proposed. Experimental results show that our model is superior to several state-of-the-art segmentation methods. Much more accurate remote sensing building object segmentation results are obtained on different datasets, proving that the model exhibits better robustness and scalability.关键词:deep convolutional neural network;remote sensing image segmentation;conditional generative adversarial network (CGAN);attention mechanism;multi-scale feature fusion97|172|6更新时间:2024-05-07 -
 摘要:ObjectiveHigh-precision monitoring of the spatial distribution of urban green space has important social, economic, and ecological benefits for optimizing the spatial structure of such space, maintaining urban ecological balance, and developing green city construction. As the first civilian optical satellite with high spatial resolution, Gaofen2 (GF-2) exhibits the remarkable characteristics of sub-meter high spatial resolution and wide coverage. GF2 provides important data support to multiple fields, such as urban environmental monitoring and urban green space information extraction. However, traditional classification methods still encounter many problems. For example, training a method to be an effective classifier for massive data is difficult, and the accuracy of classification results is generally low. The use of massive high-resolution remote sensing images to achieve large-scale rapid and accurate urban green space distribution extraction is an urgent task for urban planning managers. With the rapid development of deep learning technology, full convolutional networks (FCN) provide novel creative possibilities for semantic segmentation and realize pixel-level classification of images in the field of deep learning for the first time. Inspired by the U-Net network structure, we applied an improved U-Net to urban green space classification for the first time and proposed an automatic classification technique for urban green space by using high-resolution remote sensing images.MethodFirst, we improved the U-Net model to obtain the U-Net+ model. The main structure of U-Net+ is composed of an encoder and a decoder that can achieve end-to-end training. The encoding channel realizes the multi-scale feature recognition of an image through four-time maximum pooling, and the decoding channel restores the position and detailed information of an image through upsampling. The network uses skip connection to realize the fusion of feature information with the same scale at different levels, overcoming accuracy loss caused by upsampling. In addition, we improved the model by adding batch normalization (BN) after each layer of network convolution operation, effectively regulating the input of the network layer and improving model training speed and network generalization capability. To solve the overfitting problem, which is easily produced by the limited sample training set, we added the dropout layer with a 50% probability of dropping neurons after the convolution operation of the fourth and fifth layers of the network. Second, deep learning requires a large amount of label data related to the classification objectives for training. However, existing open-source datasets cannot meet the requirements of the urban green space classification task. Manually establishing an urban green space tag dataset is necessary. We selected three typical urban green space sample areas in Beijing (urban parks, residential areas, and golf courses) as study areas. By combining GF-2 images and Google Earth remote sensing images in summer and winter, we drew all types of urban green space in the study areas through visual interpretation by using ArcGIS. The visual interpretation results are corrected with actual field investigation. Third, random cropping and data augmentation techniques are adopted to expand the dataset, ensuring the randomness of the samples and enhancing the stability of the model while fully utilizing image information. We adopt the Adam optimizer with an initial learning rate of 0.000 1.Result1) The overall classification accuracy of the U-Net+ model is improved by 1.06% compared with that of the original U-Net. After 40 training epochs, the accuracy of the U-Net+ model reaches a high level, and the loss function realizes rapid convergence. The U-Net+ model effectively prevents overfitting and improves generalization capability. 2) To verify the effectiveness of our method, the classification accuracy of the U-Net+ results is compared with those of three traditional classification methods, namely, maximum likelihood estimation (MLE), neural networks (NNs), and support vector machine (SVM), and three semantic segmentation models, i.e., U-Net, SegNet, and DeepLabv3+. Among the seven classification methods, the U-Net+ model achieves the highest overall classification accuracy for urban green space. The seven classification methods are arranged in order of classification accuracy from large to small: U-Net+ (92.73%) > U-Net (91.67%) > SegNet (88.98%) > DeepLabv3+ (87.41%) > SVM (81.32%) > NNs (79.92%) > MLE (77.21%). 3) In the three types of urban green space, evergreen trees have the highest classification accuracy (F1=93.65%), followed by grassland (F1=92.55%) and deciduous trees (F1=86.55%). 4) Deep learning exhibits strong fault-tolerant capability for training samples. By training and learning a large number of label data, it can effectively reduce the impact of errors and improve recognition capability, making it more suitable for urban green space information extraction than traditional remote sensing classification methods.ConclusionDeep learning urban green space classification methods can fully mine the spectral, textural, and potential feature information of data. Meanwhile, the U-Net+ model proposed in this study can also effectively reduce the salt-and-pepper noise the classification process and realize high-precision pixel-level classification of urban green space. The improved U-Net+ can effectively improve the accuracy of automatic classification of urban green space in high-resolution remote sensing images and provide a new intelligent interpretation method for urban green space classification in the future.关键词:urban green space;convolutional neural network (CNN);U-Net;high-resolution remote sensing;semantic segmentation285|211|18更新时间:2024-05-07
摘要:ObjectiveHigh-precision monitoring of the spatial distribution of urban green space has important social, economic, and ecological benefits for optimizing the spatial structure of such space, maintaining urban ecological balance, and developing green city construction. As the first civilian optical satellite with high spatial resolution, Gaofen2 (GF-2) exhibits the remarkable characteristics of sub-meter high spatial resolution and wide coverage. GF2 provides important data support to multiple fields, such as urban environmental monitoring and urban green space information extraction. However, traditional classification methods still encounter many problems. For example, training a method to be an effective classifier for massive data is difficult, and the accuracy of classification results is generally low. The use of massive high-resolution remote sensing images to achieve large-scale rapid and accurate urban green space distribution extraction is an urgent task for urban planning managers. With the rapid development of deep learning technology, full convolutional networks (FCN) provide novel creative possibilities for semantic segmentation and realize pixel-level classification of images in the field of deep learning for the first time. Inspired by the U-Net network structure, we applied an improved U-Net to urban green space classification for the first time and proposed an automatic classification technique for urban green space by using high-resolution remote sensing images.MethodFirst, we improved the U-Net model to obtain the U-Net+ model. The main structure of U-Net+ is composed of an encoder and a decoder that can achieve end-to-end training. The encoding channel realizes the multi-scale feature recognition of an image through four-time maximum pooling, and the decoding channel restores the position and detailed information of an image through upsampling. The network uses skip connection to realize the fusion of feature information with the same scale at different levels, overcoming accuracy loss caused by upsampling. In addition, we improved the model by adding batch normalization (BN) after each layer of network convolution operation, effectively regulating the input of the network layer and improving model training speed and network generalization capability. To solve the overfitting problem, which is easily produced by the limited sample training set, we added the dropout layer with a 50% probability of dropping neurons after the convolution operation of the fourth and fifth layers of the network. Second, deep learning requires a large amount of label data related to the classification objectives for training. However, existing open-source datasets cannot meet the requirements of the urban green space classification task. Manually establishing an urban green space tag dataset is necessary. We selected three typical urban green space sample areas in Beijing (urban parks, residential areas, and golf courses) as study areas. By combining GF-2 images and Google Earth remote sensing images in summer and winter, we drew all types of urban green space in the study areas through visual interpretation by using ArcGIS. The visual interpretation results are corrected with actual field investigation. Third, random cropping and data augmentation techniques are adopted to expand the dataset, ensuring the randomness of the samples and enhancing the stability of the model while fully utilizing image information. We adopt the Adam optimizer with an initial learning rate of 0.000 1.Result1) The overall classification accuracy of the U-Net+ model is improved by 1.06% compared with that of the original U-Net. After 40 training epochs, the accuracy of the U-Net+ model reaches a high level, and the loss function realizes rapid convergence. The U-Net+ model effectively prevents overfitting and improves generalization capability. 2) To verify the effectiveness of our method, the classification accuracy of the U-Net+ results is compared with those of three traditional classification methods, namely, maximum likelihood estimation (MLE), neural networks (NNs), and support vector machine (SVM), and three semantic segmentation models, i.e., U-Net, SegNet, and DeepLabv3+. Among the seven classification methods, the U-Net+ model achieves the highest overall classification accuracy for urban green space. The seven classification methods are arranged in order of classification accuracy from large to small: U-Net+ (92.73%) > U-Net (91.67%) > SegNet (88.98%) > DeepLabv3+ (87.41%) > SVM (81.32%) > NNs (79.92%) > MLE (77.21%). 3) In the three types of urban green space, evergreen trees have the highest classification accuracy (F1=93.65%), followed by grassland (F1=92.55%) and deciduous trees (F1=86.55%). 4) Deep learning exhibits strong fault-tolerant capability for training samples. By training and learning a large number of label data, it can effectively reduce the impact of errors and improve recognition capability, making it more suitable for urban green space information extraction than traditional remote sensing classification methods.ConclusionDeep learning urban green space classification methods can fully mine the spectral, textural, and potential feature information of data. Meanwhile, the U-Net+ model proposed in this study can also effectively reduce the salt-and-pepper noise the classification process and realize high-precision pixel-level classification of urban green space. The improved U-Net+ can effectively improve the accuracy of automatic classification of urban green space in high-resolution remote sensing images and provide a new intelligent interpretation method for urban green space classification in the future.关键词:urban green space;convolutional neural network (CNN);U-Net;high-resolution remote sensing;semantic segmentation285|211|18更新时间:2024-05-07 -
 摘要:ObjectiveSpatiotemporal fusion of satellite images is an important problem in the research of remote sensing fusion. With the intensification of global environmental changes, satellite remote sensing data plays an indispensable role in monitoring crop growth and landform changes. In the field of dynamic monitoring, high temporal resolution becomes an important attribute of required remote sensing data because continuous observation is basic requirement for dynamic monitoring. Moreover, the fragmentation of the global terrestrial landscape makes these applications require remote sensing data with higher spatial resolutions. However, remote sensing data with high spatial and high temporal resolutions are difficult to be captured by current satellite platforms due to constraints of technology and cost. For example, Landsat images mainly have a high spatial resolution but a low temporal resolution. By contrast, MODIS(moderate-resolution imaging spectroradiometer) images have a high temporal resolution but a low spatial resolution. Spatiotemporal fusion provides an effective method to fuse the two types of remote sensing data featured by complementary spatial and temporal properties (Landsat and MODIS images are typical representatives) to generate fused data with high spatial and high temporal resolutions, which can also bring great convenience to our research on the actual terrain and landform changes.MethodA spatiotemporal fusion method based on the conditional generative adversarial network (CGAN), which can effectively handle massive remote sensing data in practical applications, is proposed to solve this problem. As for CGAN, GAN(generative advensarial network) is extended to CGAN that introduces the internal ground truth image as the condition variable to guide discriminator network learning, making the training of the network more directional and easier. In this study, the asymmetric Laplacian pyramid network is used as the generator of the CGAN, and the VGG(visual geometry group) net is taken as the discriminator of the CGAN. The asymmetric Laplacian pyramid network mainly consists of two branches: a high-frequency branch (mainly extracts the image details or residual images) and a low-frequency extraction branch (extracts shallow features). The two branches progressively reconstruct the images in a coarse-to-fine manner. The discriminator of the CGAN is the VGG19 (visual geometry group 19-layer net) network, where the ReLU activation function is replaced by the Leaky ReLU function, and the number of channels of the convolutional kernels is increased by a factor of 2 from 64 to 1 024. Then, a fully connected layer and a sigmoid activation function are used to obtain the probability of the sample class. In this study, a CGAN model is designed for the nonlinear mapping and a CGAN superresolution model for downsampled Landsat to reconstruct original Landsat images. Compared with existing shallow learning methods, especially for the sparse-representation-based ones, the proposed CGAN based model has the following merits: 1) explicitly correlating MODIS and downsampled Landsat images by learning a nonlinear mapping relationship, 2) automatically learning and extracting effective image features and image details, and 3) unifying feature extraction, nonlinear mapping, and image reconstruction into one optimization framework. In the training stage, a nonlinear mapping is first trained between the MODIS and downsampled Landsat data using the CGAN model. Then, multiscale superresolution CGAN is trained between the downsampled Landsat and original Landsat data. The prediction procedure contains two layers, and each layer consists of a CGAN-based prediction and a fusion model. The fusion model takes the high pass model which will be explained in the next paper. One of the two layers achieves nonlinear mapping from the MODIS to downsampled Landsat data, and the other layer is the superresolution reconstructed network of the set that is used to perform image superresolution of two and five times of upsampling scales, respectively.ResultFour indicators are commonly used to evaluate the performance of spatiotemporal fusion of remote sensing images. The first one is root mean square error, which measures the radiometric between the fusion result and ground truth. The spectral angle mapper is leveraged as the second index to measure the spectral distortion of the result. The structural similarity is taken as the third metric, measuring the similarity of the overall spatial structures between the fusion result and ground truth. Finally, the erreur relative global adimensionnelle de synthese is selected as the last index to evaluate the overall fusion result. Extensive evaluations are executed on two groups of commonly used Landsat-MODIS benchmark datasets. For the fusion results, a quantitative evaluation of the visual effects of all predicted dates and one key date shows that the method can achieve more accurate fusion results compared with sparse representation-based methods and deep convolutional networks.ConclusionA CGAN model that introduces an external condition to reconstruct images better is proposed. A non-linear mapping CGAN is trained to deal with the highly nonlinear correspondence relations between between downsampled Landset and MODIS data. Moreover, a multiscale superresolution CGAN is trained to bridge the huge spatial resolution gap (10 times) between original and downsampled Landsat data. Experimental verification is performed on existing methods, such as sparse representation-based methods and deep convolutional neural network methods. Experiment results show that our model outperforms several state-of-the-art spatiotemporal fusion approaches.关键词:spatiotemporal fusion;deep learning;conditional generative adversarial network(CGAN);Laplacian pyramid network;remote sensing image processing62|44|3更新时间:2024-05-07
摘要:ObjectiveSpatiotemporal fusion of satellite images is an important problem in the research of remote sensing fusion. With the intensification of global environmental changes, satellite remote sensing data plays an indispensable role in monitoring crop growth and landform changes. In the field of dynamic monitoring, high temporal resolution becomes an important attribute of required remote sensing data because continuous observation is basic requirement for dynamic monitoring. Moreover, the fragmentation of the global terrestrial landscape makes these applications require remote sensing data with higher spatial resolutions. However, remote sensing data with high spatial and high temporal resolutions are difficult to be captured by current satellite platforms due to constraints of technology and cost. For example, Landsat images mainly have a high spatial resolution but a low temporal resolution. By contrast, MODIS(moderate-resolution imaging spectroradiometer) images have a high temporal resolution but a low spatial resolution. Spatiotemporal fusion provides an effective method to fuse the two types of remote sensing data featured by complementary spatial and temporal properties (Landsat and MODIS images are typical representatives) to generate fused data with high spatial and high temporal resolutions, which can also bring great convenience to our research on the actual terrain and landform changes.MethodA spatiotemporal fusion method based on the conditional generative adversarial network (CGAN), which can effectively handle massive remote sensing data in practical applications, is proposed to solve this problem. As for CGAN, GAN(generative advensarial network) is extended to CGAN that introduces the internal ground truth image as the condition variable to guide discriminator network learning, making the training of the network more directional and easier. In this study, the asymmetric Laplacian pyramid network is used as the generator of the CGAN, and the VGG(visual geometry group) net is taken as the discriminator of the CGAN. The asymmetric Laplacian pyramid network mainly consists of two branches: a high-frequency branch (mainly extracts the image details or residual images) and a low-frequency extraction branch (extracts shallow features). The two branches progressively reconstruct the images in a coarse-to-fine manner. The discriminator of the CGAN is the VGG19 (visual geometry group 19-layer net) network, where the ReLU activation function is replaced by the Leaky ReLU function, and the number of channels of the convolutional kernels is increased by a factor of 2 from 64 to 1 024. Then, a fully connected layer and a sigmoid activation function are used to obtain the probability of the sample class. In this study, a CGAN model is designed for the nonlinear mapping and a CGAN superresolution model for downsampled Landsat to reconstruct original Landsat images. Compared with existing shallow learning methods, especially for the sparse-representation-based ones, the proposed CGAN based model has the following merits: 1) explicitly correlating MODIS and downsampled Landsat images by learning a nonlinear mapping relationship, 2) automatically learning and extracting effective image features and image details, and 3) unifying feature extraction, nonlinear mapping, and image reconstruction into one optimization framework. In the training stage, a nonlinear mapping is first trained between the MODIS and downsampled Landsat data using the CGAN model. Then, multiscale superresolution CGAN is trained between the downsampled Landsat and original Landsat data. The prediction procedure contains two layers, and each layer consists of a CGAN-based prediction and a fusion model. The fusion model takes the high pass model which will be explained in the next paper. One of the two layers achieves nonlinear mapping from the MODIS to downsampled Landsat data, and the other layer is the superresolution reconstructed network of the set that is used to perform image superresolution of two and five times of upsampling scales, respectively.ResultFour indicators are commonly used to evaluate the performance of spatiotemporal fusion of remote sensing images. The first one is root mean square error, which measures the radiometric between the fusion result and ground truth. The spectral angle mapper is leveraged as the second index to measure the spectral distortion of the result. The structural similarity is taken as the third metric, measuring the similarity of the overall spatial structures between the fusion result and ground truth. Finally, the erreur relative global adimensionnelle de synthese is selected as the last index to evaluate the overall fusion result. Extensive evaluations are executed on two groups of commonly used Landsat-MODIS benchmark datasets. For the fusion results, a quantitative evaluation of the visual effects of all predicted dates and one key date shows that the method can achieve more accurate fusion results compared with sparse representation-based methods and deep convolutional networks.ConclusionA CGAN model that introduces an external condition to reconstruct images better is proposed. A non-linear mapping CGAN is trained to deal with the highly nonlinear correspondence relations between between downsampled Landset and MODIS data. Moreover, a multiscale superresolution CGAN is trained to bridge the huge spatial resolution gap (10 times) between original and downsampled Landsat data. Experimental verification is performed on existing methods, such as sparse representation-based methods and deep convolutional neural network methods. Experiment results show that our model outperforms several state-of-the-art spatiotemporal fusion approaches.关键词:spatiotemporal fusion;deep learning;conditional generative adversarial network(CGAN);Laplacian pyramid network;remote sensing image processing62|44|3更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0