
最新刊期
卷 26 , 期 2 , 2021
- 摘要:The Conference on Neural Information Processing Systems (NeurIPS), as a top-tier conference in the field of machine learning and also a China Computer Federation(CCF)-A conference, has been receiving lots of attention. NeurIPS 2020 received a record-breaking 9 467 submissions, and finally accepted 1 898 papers, which covered various topics of artificial intelligence(AI), such as deep learning and its applications, reinforcement learning and planning, theory, probabilistic methods, optimization, and the social aspect of machine learning. In this paper, we first reviewed the highlights and statistical information of NeurIPS 2020, for example, using GatherTown (each attendee is represented by a cartoon character) to improve the experience of immersive interactions with each other. Following that, we summarized the invited talks which covered multiple disciplines such as cryptography, feedback control theory, causal inference, and biology. Moreover, we provide a quick review of best papers, orals and some interesting posters, hoping to help readers have a quick glance over NeurIPS 2020.关键词:artificial intelligence(AI);machine learning;deep learning;reinforcement learning;theory;optimization;academic conference;NeurIPS 202068|57|0更新时间:2024-05-07
Frontier

-
 摘要:Deep neural networks(DNNs) have achieved remarkable progress over the past years on a variety of tasks, such as image recognition, speech recognition, and machine translation. One of the most crucial aspects for this progress is novel neural architectures, in which hierarchical feature extractors are learned from data in an end-to-end manner rather than manually designed. Neural network training can be considered an automatic feature engineering process, and its success has been accompanied by an increasing demand for architecture engineering. At present, most neural networks are developed by human experts; however, the process involved is time-consuming and error-prone. Consequently, interest in automated neural architecture search methods has increased recently. Neural architecture search can be regarded as a subfield of automated machine learning, and it significantly overlaps with hyperparameter optimization and meta learning. Neural architecture search can be categorized into three dimensions: search space, search strategy, and performance estimation strategy. The search space defines which architectures can be represented in principle. The choice of search space largely determines the difficulty of optimization and search time. To reduce search time, neural architecture search is typically not applied to the entire network, but instead, the neural network is divided into several blocks and the search space is designed inside the blocks. All the blocks are combined into a whole neural network by using a predefined paradigm. In this manner, the search space can be significantly reduced, saving search time. In accordance with different situations, the architecture of the searched block can be shared or not. If the architecture is not shared, then every block has a unique architecture; otherwise, all the blocks in the neural network exhibit the same architecture. In this manner, search time can be further reduced. The search strategy details how the search space can be explored. Many search strategies can be used to explore the space of neural architectures, including random search, reinforcement learning, evolution algorithm, Bayesian optimization, and gradient-based optimization. A search strategy encompasses the classical exploration-exploitation trade-off. The objective of neural architecture search is typically to find architectures that achieve high predictive performance on unseen data. Performance estimation refers to the process of estimating this performance. The most direct approach is performing complete training and validation of the architecture on target data. This technique is extremely time-consuming, in the order of thousands of graphics processing unit (GPU) days. Thus, we generally do not train each candidate to converge. Instead, methods, such as like weight sharing, early stopping, or searching smaller proxy datasets, are used in the performance estimation strategy, considerably reducing training time for each candidate architecture performance estimation. Weight sharing can be achieved by inheriting weights from pretrained models or searching a one-shot model, whose weights are then shared across different architectures that are merely subgraphs of the one-shot model. The early stopping method estimates performance in accordance with the early stage validation result via learning curve extrapolation. Training on a smaller proxy dataset finds a neural architecture on a small dataset, such as CIFAR-10. Then, the architecture is trained on the target large dataset, such as ImageNet. Compared with neural networks developed by human experts, models found via neural architecture search exhibit better performance on various tasks, such as image classification, image detection, and semantic segmentation. For the ImageNet classification task, for example, MobileNetV3, which was found via neural architecture search, reduced approximately 30% FLOPs compared with the MobileNetV2, which was designed by human experts, with more 3.2% top-1 accuracy. For the Cityscapes segmentation task, Auto-DeepLab-L found via neural architecture search has exhibited better performance than DeepLabv3+, with only half multi-adds. In this survey, we propose several neural architecture methods and applications, demonstrating that neural networks found via neural architecture search outperform manually designed architectures on certain tasks, such as image classification, object detection, and semantic segmentation. However, insights into why specific architectures work efficiently remain minimal. Identifying common motifs, providing an understanding why these motifs are important for high performance, and investigating whether these motifs can be generalized over different problems will be desirable.关键词:artificial intelligence;computer vision;deep neural networks(DNNs);reinforcement learning;evolution algorithm;neural architecture search (NAS)39|73|3更新时间:2024-05-07
摘要:Deep neural networks(DNNs) have achieved remarkable progress over the past years on a variety of tasks, such as image recognition, speech recognition, and machine translation. One of the most crucial aspects for this progress is novel neural architectures, in which hierarchical feature extractors are learned from data in an end-to-end manner rather than manually designed. Neural network training can be considered an automatic feature engineering process, and its success has been accompanied by an increasing demand for architecture engineering. At present, most neural networks are developed by human experts; however, the process involved is time-consuming and error-prone. Consequently, interest in automated neural architecture search methods has increased recently. Neural architecture search can be regarded as a subfield of automated machine learning, and it significantly overlaps with hyperparameter optimization and meta learning. Neural architecture search can be categorized into three dimensions: search space, search strategy, and performance estimation strategy. The search space defines which architectures can be represented in principle. The choice of search space largely determines the difficulty of optimization and search time. To reduce search time, neural architecture search is typically not applied to the entire network, but instead, the neural network is divided into several blocks and the search space is designed inside the blocks. All the blocks are combined into a whole neural network by using a predefined paradigm. In this manner, the search space can be significantly reduced, saving search time. In accordance with different situations, the architecture of the searched block can be shared or not. If the architecture is not shared, then every block has a unique architecture; otherwise, all the blocks in the neural network exhibit the same architecture. In this manner, search time can be further reduced. The search strategy details how the search space can be explored. Many search strategies can be used to explore the space of neural architectures, including random search, reinforcement learning, evolution algorithm, Bayesian optimization, and gradient-based optimization. A search strategy encompasses the classical exploration-exploitation trade-off. The objective of neural architecture search is typically to find architectures that achieve high predictive performance on unseen data. Performance estimation refers to the process of estimating this performance. The most direct approach is performing complete training and validation of the architecture on target data. This technique is extremely time-consuming, in the order of thousands of graphics processing unit (GPU) days. Thus, we generally do not train each candidate to converge. Instead, methods, such as like weight sharing, early stopping, or searching smaller proxy datasets, are used in the performance estimation strategy, considerably reducing training time for each candidate architecture performance estimation. Weight sharing can be achieved by inheriting weights from pretrained models or searching a one-shot model, whose weights are then shared across different architectures that are merely subgraphs of the one-shot model. The early stopping method estimates performance in accordance with the early stage validation result via learning curve extrapolation. Training on a smaller proxy dataset finds a neural architecture on a small dataset, such as CIFAR-10. Then, the architecture is trained on the target large dataset, such as ImageNet. Compared with neural networks developed by human experts, models found via neural architecture search exhibit better performance on various tasks, such as image classification, image detection, and semantic segmentation. For the ImageNet classification task, for example, MobileNetV3, which was found via neural architecture search, reduced approximately 30% FLOPs compared with the MobileNetV2, which was designed by human experts, with more 3.2% top-1 accuracy. For the Cityscapes segmentation task, Auto-DeepLab-L found via neural architecture search has exhibited better performance than DeepLabv3+, with only half multi-adds. In this survey, we propose several neural architecture methods and applications, demonstrating that neural networks found via neural architecture search outperform manually designed architectures on certain tasks, such as image classification, object detection, and semantic segmentation. However, insights into why specific architectures work efficiently remain minimal. Identifying common motifs, providing an understanding why these motifs are important for high performance, and investigating whether these motifs can be generalized over different problems will be desirable.关键词:artificial intelligence;computer vision;deep neural networks(DNNs);reinforcement learning;evolution algorithm;neural architecture search (NAS)39|73|3更新时间:2024-05-07 -
 摘要:Image quality assessment (IQA) has been a fundamental issue in the fields of image processing and computer vision. It has also been extensively applied to other relevant research areas, such as image/video coding, super-resolution and visual enhancement. In general, IQA consists of subjective and objective evaluations. Subjective evaluation always refers to estimating the visual quality of images by subject, with the goal of building test benchmarks. Objective evaluation typically resorts to computational algorithms (i.e., IQA models) to make visual quality predictions, and its ultimate objective is to provide consistent judgment with subjects. The effectiveness of objective IQA models must be verified on test benchmarks built via subjective evaluation. Undoubtedly, subjective evaluation cannot be fully embedded into multimedia processing applications because such process is time-consuming and labor-intensive. By contrast, an objective IQA model can work efficiently as an important module in multimedia processing applications, playing roles in visual image quality monitoring, image filtering, and visual quality enhancement. Given their availability, research on objective IQA models has elicited considerable attention from industries and academia. Objective IQA models can be classified into three categories: full-reference (FR), reduced-reference (RR), and no-reference/blind (NR) models. FR and RR models denote that reference information for estimating the visual quality of images is completely and partially available, respectively. Meanwhile, an NR model indicates that reference information is unavailable for visual quality prediction. Although reference-based IQA models (i.e., FR and RR models) are relatively reliable, their applications are limited to specific scenarios due to their dependence on reference information. By contrast, NR-IQA models are more flexible than reference-based models because they are free from the constraint of reference information. Consequently, NR-IQA models have consistently been a popular research topic over the past decades. In this study, we introduce NR-IQA models published from 2012 to 2020 to provide a comprehensive survey on feature engineering and end-to-end learning techniques in NR-IQA. In accordance with whether subjective quality scores are involved in training procedures, NR-IQA models are classified into two categories: opinion-aware/supervised and opinion-unaware/unsupervised NR-IQA models. To present a clear and integrated description, each category is further divided into two subclasses: traditional machine learning-based models (MLMs) and deep learning-based models (DLMs). For the former subclass, we mostly investigate their individual feature extraction schemes and the principle behind these schemes. In particular, a widely adopted feature extraction approach in MLMs, namely, natural scene statistics (NSS), is introduced in this study. The principle of NSS is as follows: some visual features of quality perfect images follow certain associated distributions; meanwhile, different types of distortions will break this rule in corresponding methods. On the basis of this observation/fact, researchers have proposed many NSS-based NR-IQA methods, in which the estimated parameters of the established distributions are used as quality-aware features. Thereafter, a machine learning algorithm is selected to train the IQA models. Another well-known feature extraction approach described in this study relies on dictionary learning, which is frequently accompanied by sparse coding. The core component of this type of feature extraction approach is to learn a dictionary by searching for a group of over-complete bases. Then, these over-complete bases are used to build a reference system for image representation. A test image can be concretely represented directly or indirectly by the constructed dictionary by using sparse indexes or cluster centroids. Image representations are further used as quality-aware features to capture variations in image quality. For the latter subclass (i.e., DLMs), the design principles described in detail in this paper mostly correspond to different architectures of deep neural networks. In particular, we introduce three different schemes for designing opinion-aware DLMs and commonly used strategies in opinion-unaware DLMs. To guarantee length balance among various contents and clearly exhibit the differences between NR-IQA models designed for natural images and other types of images, we introduce them separately in subsections. In addition, we provide a brief introduction into IQA research on new media, including virtual reality, light field, and underwater sonar images, along with the applications of IQA models. Finally, an in-depth conclusion about NR-IQA models is drawn in the last section. We summarize the current achievements and limitations of MLMs and DLMs. Furthermore, we highlight the potential development trends and directions of NR-IQA models for further improvements from the perspectives of image contents and NR-IQA models.关键词:image quality assessment (IQA);human visual system (HVS);visual perception;natural scene statistics (NSS);machine learning;deep learning257|1276|19更新时间:2024-05-07
摘要:Image quality assessment (IQA) has been a fundamental issue in the fields of image processing and computer vision. It has also been extensively applied to other relevant research areas, such as image/video coding, super-resolution and visual enhancement. In general, IQA consists of subjective and objective evaluations. Subjective evaluation always refers to estimating the visual quality of images by subject, with the goal of building test benchmarks. Objective evaluation typically resorts to computational algorithms (i.e., IQA models) to make visual quality predictions, and its ultimate objective is to provide consistent judgment with subjects. The effectiveness of objective IQA models must be verified on test benchmarks built via subjective evaluation. Undoubtedly, subjective evaluation cannot be fully embedded into multimedia processing applications because such process is time-consuming and labor-intensive. By contrast, an objective IQA model can work efficiently as an important module in multimedia processing applications, playing roles in visual image quality monitoring, image filtering, and visual quality enhancement. Given their availability, research on objective IQA models has elicited considerable attention from industries and academia. Objective IQA models can be classified into three categories: full-reference (FR), reduced-reference (RR), and no-reference/blind (NR) models. FR and RR models denote that reference information for estimating the visual quality of images is completely and partially available, respectively. Meanwhile, an NR model indicates that reference information is unavailable for visual quality prediction. Although reference-based IQA models (i.e., FR and RR models) are relatively reliable, their applications are limited to specific scenarios due to their dependence on reference information. By contrast, NR-IQA models are more flexible than reference-based models because they are free from the constraint of reference information. Consequently, NR-IQA models have consistently been a popular research topic over the past decades. In this study, we introduce NR-IQA models published from 2012 to 2020 to provide a comprehensive survey on feature engineering and end-to-end learning techniques in NR-IQA. In accordance with whether subjective quality scores are involved in training procedures, NR-IQA models are classified into two categories: opinion-aware/supervised and opinion-unaware/unsupervised NR-IQA models. To present a clear and integrated description, each category is further divided into two subclasses: traditional machine learning-based models (MLMs) and deep learning-based models (DLMs). For the former subclass, we mostly investigate their individual feature extraction schemes and the principle behind these schemes. In particular, a widely adopted feature extraction approach in MLMs, namely, natural scene statistics (NSS), is introduced in this study. The principle of NSS is as follows: some visual features of quality perfect images follow certain associated distributions; meanwhile, different types of distortions will break this rule in corresponding methods. On the basis of this observation/fact, researchers have proposed many NSS-based NR-IQA methods, in which the estimated parameters of the established distributions are used as quality-aware features. Thereafter, a machine learning algorithm is selected to train the IQA models. Another well-known feature extraction approach described in this study relies on dictionary learning, which is frequently accompanied by sparse coding. The core component of this type of feature extraction approach is to learn a dictionary by searching for a group of over-complete bases. Then, these over-complete bases are used to build a reference system for image representation. A test image can be concretely represented directly or indirectly by the constructed dictionary by using sparse indexes or cluster centroids. Image representations are further used as quality-aware features to capture variations in image quality. For the latter subclass (i.e., DLMs), the design principles described in detail in this paper mostly correspond to different architectures of deep neural networks. In particular, we introduce three different schemes for designing opinion-aware DLMs and commonly used strategies in opinion-unaware DLMs. To guarantee length balance among various contents and clearly exhibit the differences between NR-IQA models designed for natural images and other types of images, we introduce them separately in subsections. In addition, we provide a brief introduction into IQA research on new media, including virtual reality, light field, and underwater sonar images, along with the applications of IQA models. Finally, an in-depth conclusion about NR-IQA models is drawn in the last section. We summarize the current achievements and limitations of MLMs and DLMs. Furthermore, we highlight the potential development trends and directions of NR-IQA models for further improvements from the perspectives of image contents and NR-IQA models.关键词:image quality assessment (IQA);human visual system (HVS);visual perception;natural scene statistics (NSS);machine learning;deep learning257|1276|19更新时间:2024-05-07 -
 摘要:As a national critical infrastructure, economic artery, and popular transportation, a railway plays an irreplaceable role in supporting the economic and social development of a nation. The rail is the key component of a railway, and correspondingly, rail defect detection is a core activity in railway engineering. Traditional manual inspection is time-consuming and laborious, and its results are easily influenced by various subjective factors. Therefore, automatic defect inspection for maintaining railway safety is highly significant. Considering the advantages of visual inspection in terms of speed, cost, and visualization, this study focuses on machine vision-based techniques. The track structure is first introduced by using the widely used ballastless track as an example. Sample presentation, causal analysis, and impact assessment of typical surface defects are provided. Then, the basic principles and application scenarios of common automatic rail defect detection technologies are briefly reviewed. In particular, ultrasonic techniques can be used to detect rail internal flaws, but it can hardly inspect fatigue damage on rail surface because of factors, such as ultrasonic reflection. Furthermore, detection speed is typically unsatisfactory. Eddy current inspection can obtain information about rail surface defects with the use of a detection coil by measuring the variance of eddy currents generated by an excitation coil. In contrast with ultrasonic technology, eddy current testing is fast and exhibits a distinct advantage in terms of detecting defects, such as shelling and scratch. However, it fails at finding defects that are located at the rail waist and base. Consequently, eddy current detection is frequently used in conjunction with ultrasonic equipment. Notably, eddy current inspection has high requirements for the installation position of the detection coil and the actual operation. Debugging the equipment is a complicated task, and the stability of the detection result is insufficient. Thereafter, current major challenges in the visual inspection of rail defects, namely, inhomogeneity of image qualities, limitation of available features, and difficulty in model updating, are summarized. Then, research actuality in the visual inspection of rail defects is systematically reviewed by categorizing the techniques into foreground, background, blind source separation, and deep learning-based models. One or two representative studies are elaborated in each category, followed by the analysis of technical features and practical limitations. In particular, foreground models typically suppress disturbing noise through operations, such as local image filtering, which can enhance contrast between the defect and the background, and thus, help recognize rail surface defects. This type of models generally exhibits low computational complexity, and thus, can meet the requirements of real-time inspection. However, they easily generate false positives and can hardly segment the defect target. Instead of directly placing emphasis on the defect, background methods model the image background by utilizing the spatial consistency and continuity of the rail image. Similar to foreground models, such methods also exhibit good real-time performance, but effectively decreasing false detection still requires further research. Blind source separation models detect rail defects on the basis of the low rank of the image background and the sparseness of the defect. Compared with the aforementioned two types of models, these approaches do not simply rely on the low-level visual characteristics of the defect target. However, these models tend to require high computational complexity. Deep learning-based models generally exhibit promising performance in the visual inspection of rail defects. However, training a deep learning model frequently requires a large amount of samples, and collecting and labeling numerous defect images can be costly. Moreover, these approaches typically depend on a dataset with specific supervision information, and thus, they may not perform well in other similar scenarios. Finally, future research trends in the visual inspection of rail defects are prospected by targeting the development requirements of smart railways. That is, technologies, such as few-shot or zero-shot learning, multitask learning, and multisource heterogeneous data fusion, should be explored to solve the problems of weak robustness and high false alarm rate existing in current visual inspection systems.关键词:rail defects;visual inspection;foreground;background;blind source separation;deep learning443|787|2更新时间:2024-05-07
摘要:As a national critical infrastructure, economic artery, and popular transportation, a railway plays an irreplaceable role in supporting the economic and social development of a nation. The rail is the key component of a railway, and correspondingly, rail defect detection is a core activity in railway engineering. Traditional manual inspection is time-consuming and laborious, and its results are easily influenced by various subjective factors. Therefore, automatic defect inspection for maintaining railway safety is highly significant. Considering the advantages of visual inspection in terms of speed, cost, and visualization, this study focuses on machine vision-based techniques. The track structure is first introduced by using the widely used ballastless track as an example. Sample presentation, causal analysis, and impact assessment of typical surface defects are provided. Then, the basic principles and application scenarios of common automatic rail defect detection technologies are briefly reviewed. In particular, ultrasonic techniques can be used to detect rail internal flaws, but it can hardly inspect fatigue damage on rail surface because of factors, such as ultrasonic reflection. Furthermore, detection speed is typically unsatisfactory. Eddy current inspection can obtain information about rail surface defects with the use of a detection coil by measuring the variance of eddy currents generated by an excitation coil. In contrast with ultrasonic technology, eddy current testing is fast and exhibits a distinct advantage in terms of detecting defects, such as shelling and scratch. However, it fails at finding defects that are located at the rail waist and base. Consequently, eddy current detection is frequently used in conjunction with ultrasonic equipment. Notably, eddy current inspection has high requirements for the installation position of the detection coil and the actual operation. Debugging the equipment is a complicated task, and the stability of the detection result is insufficient. Thereafter, current major challenges in the visual inspection of rail defects, namely, inhomogeneity of image qualities, limitation of available features, and difficulty in model updating, are summarized. Then, research actuality in the visual inspection of rail defects is systematically reviewed by categorizing the techniques into foreground, background, blind source separation, and deep learning-based models. One or two representative studies are elaborated in each category, followed by the analysis of technical features and practical limitations. In particular, foreground models typically suppress disturbing noise through operations, such as local image filtering, which can enhance contrast between the defect and the background, and thus, help recognize rail surface defects. This type of models generally exhibits low computational complexity, and thus, can meet the requirements of real-time inspection. However, they easily generate false positives and can hardly segment the defect target. Instead of directly placing emphasis on the defect, background methods model the image background by utilizing the spatial consistency and continuity of the rail image. Similar to foreground models, such methods also exhibit good real-time performance, but effectively decreasing false detection still requires further research. Blind source separation models detect rail defects on the basis of the low rank of the image background and the sparseness of the defect. Compared with the aforementioned two types of models, these approaches do not simply rely on the low-level visual characteristics of the defect target. However, these models tend to require high computational complexity. Deep learning-based models generally exhibit promising performance in the visual inspection of rail defects. However, training a deep learning model frequently requires a large amount of samples, and collecting and labeling numerous defect images can be costly. Moreover, these approaches typically depend on a dataset with specific supervision information, and thus, they may not perform well in other similar scenarios. Finally, future research trends in the visual inspection of rail defects are prospected by targeting the development requirements of smart railways. That is, technologies, such as few-shot or zero-shot learning, multitask learning, and multisource heterogeneous data fusion, should be explored to solve the problems of weak robustness and high false alarm rate existing in current visual inspection systems.关键词:rail defects;visual inspection;foreground;background;blind source separation;deep learning443|787|2更新时间:2024-05-07 - 摘要:Traditional convolutional neural networks (CNNs) use convolutional layers and activation functions to achieve nonlinear transformation from input images to output labels. The end-to-end training method is convenient, but it seriously hinders the introduction of prior knowledge regarding remote sensing images, leading to high dependency on the quality and quantity of training samples. The trained parameters of CNNs are used to extract features from input images. However, these features cannot be interpreted. That is, the learning process and the learned features are uninterpretable, further increasing dependency on training samples. Restricted by an end-to-end training method, traditional CNNs can only learn general features from the training set, while the learned general features are difficult to transfer to another training set. At present, CNNs can be used on multiple tasks if the model is trained using a target training set. However, improving training accuracy on a finite training set is an extremely difficult task. Traditional CNNs cannot correlate the features contained in the input data and the requirements of certain applications. In addition, loss functions that can be used in certain applications are limited. Among which, some loss functions can only describe the difference between the predicted results and the corresponding labels. In such case, the network will sacrifice the disadvantaged classes to ensure global optimum, resulting in the loss of detailed information.CNNs construct a complex nonlinear function to transfer input images to output labels. The features learned by CNNs cannot be understood and are also difficult to be merged with other features in an explainable manner. By contrast, artificial features can reflect some aspects of information of an image, and the information contained in artificial features is meaningful, i.e., it can be used in most images. Artificial features can be considered prior knowledge that describes the empirical understanding of images. They cannot fully express the information contained in an image. Consequently, combining the advantages of CNNs and prior knowledge is efficient for learning essential features from images. Riemannian manifold feature space (RMFS) exhibits a powerful feature expression capability, through which the spectral and spatial features of an image can be unified. To benefit from CNNs and RMFS, this study analyzes the contribution of RMFS to the interpretability of CNNs and the corresponding evolution of image features from the perspective of CNN modeling and remote sensing image feature representation. Then, an RMFS-CNN classification framework is proposed to bridge the gap between CNNs and prior knowledge of remote sensing images. First, this study proposes using CNNs instead of traditional mathematical transformations to map the original remote sensing image onto points in RMFS. Mapping via CNNs can overcome the effects of neighboring sizes and modeling methods, improving the feature expression capability of RMFS. Second, the features learned via RMFS-CNN can be customized in RMFS to highlight specific information that can benefit certain applications. Furthermore, the customized features can also be used to design a rule-driven data perceptron on the basis of their interpretability and evolutions. Finally, new RMFS-CNN models based on the rule-driven data perceptron can be proposed. Considering the feature expression capability of RMFS, the proposed RMFS-CNN models will outperform traditional models in terms of learning capability and the stability of learned features. New loss functions, which can control the training process of RMFS-CNN models, can be developed by combining the customized features in RMFS. In general, the proposed RMFS-CNN framework can bridge the gap between remote sensing prior knowledge and CNN models. Its advantages are as follows. 1) Points in RMFS are interpretable due to the excellent feature expression capability of RMFS and the one-to-one correspondence between points in RMFS and pixels in the image domain. Therefore, RMFS can connect remote sensing prior knowledge and the learning capability of CNNs. The use of CNNs to learn specific information from remote sensing prior knowledge is efficient on the one hand, and it can ensure the stability of learned features on the other hand. Consequently, the dependency of CNNs on the quality and quantity of training samples can be reduced. 2) Points in RMFS contain the spectral features of corresponding pixels and spatial connections in the neighborhood system. Pixels representing the same object in the image domain are subject to a linear distribution when mapped onto RMFS. On the basis of these characteristics, RMFS can provide a platform for the interpretable features of remote sensing images. Under the premise of knowing the physical meaning and corresponding distribution of remote sensing images in RMFS, data-driven convolution can be converted into rule-driven data perceptron to improve the learning capability of RMFS-CNN models. The learning process and corresponding learned features can be interpreted using the rule-driven data perceptron. 3) RMFS exhibits another interesting distribution characteristic. Data points that represent the main body of an object construct a linear distribution, whereas data points that represent the edge of the object are randomly distributed in areas far from the linear distribution. This distribution characteristic enables RMFS to express different features of an object separately. Accordingly, features conducive to certain applications can be customized in RMFS and then abstracted by following the rule-driven data perceptron. With their feature customization capability, RMFS-CNN models can be refined in accordance to their input data and applications. 4) The RMFS-CNN framework can express the interpretable features of remote sensing images. These features can then be customized to adapt to the input data and the corresponding applications. The customized features contain useful information for a certain application, which can be used to define a constraint on the loss function to control the training process of RMFS-CNN models. Given that the constraint can force the network to learn features beneficial for the target application, two advantages are implemented: learning favorable features for a certain application can improve the training accuracy of a network on the one hand, and the interpretability of the learned features can be maintained on the other hand. Consequently, the trained network is easier to transfer compared with that of traditional CNNs.关键词:remote sensing image classification;deep learning;convolutional neural network(CNN);Riemannian manifold feature space (RMFS);feature representation;feature customization;model training219|150|3更新时间:2024-05-07
Scholar View
- 摘要:The amount of medical imaging data is increasing rapidly every year. Although large-scale medical imaging data pose considerable challenges to the work of clinicians, they also offer opportunities for improving disease diagnosis and treatment models. Algorithms based on deep learning exhibit advantages over humans in processing big data, analyzing complex and nondeterministic data, and delving into potential information that can be obtained from data. In recent years, an increasing number of scholars have use deep learning to process and analyze medical image data, promoting the rapid development of precision medicine and personalized medicine. The application of deep learning to medical image processing and analysis, which are characterized by multiple diseases, modals, functions, and omics, is relatively extensive. To facilitate the further exploration and effective application of deep learning methods by researchers in the field of medical image processing, this study systematically reviewed relevant research progress, expecting that such review will be beneficial for researchers in this field. First, general thoughts and the current situation of the application of deep learning to medical imaging were clarified from the perspective of deep learning applications to imaging genomics. Second, state-of-the-art ideas and methods and recent improvements in original deep learning methods were comprehensively described. Lastly, existing problems in this field were highlighted and development trends were explored. In accordance with application status, the application of deep learning to medical imaging was divided into three modules: intelligent diagnosis, response evaluation, and prediction prognosis. The modules were subdivided into different diseases for summary, and the advantages and disadvantages of each deep learning method and existing problems and challenges were highlighted. In terms of intelligent diagnosis, the disadvantages of manual doctor diagnosis, such as heavy workload, subjective cognitive susceptibility, low efficiency, and high misdiagnosis rate, are becoming increasingly evident due to the increasing complexity of medical imaging information. The use of deep learning to interpret medical images and then comparing the results with other case records will help doctors locate lesions and assist in diagnosis. Moreover, the burden of doctors and medical misjudgments can be effectively reduced, improving the accuracy of diagnosis and treatment. Further research on the applications of deep learning and computer vision technologies to radiography is a pressing task in the 21st century, particularly for diseases with high incidence, such as brain and fundus disorders. In the follow-up study, we should focus on optimizing the generation of labels, specifying precise pathological regions in medical images, and establishing a strong supervision model instead of a weak one. In addition, deploying a cropping algorithm on a picture archiving and communication system platform will pave the way to algorithm improvement and entry to the clinical environment. In terms of response evaluation, the pathological evaluation of surgical specimens is the only reliable indicator of long-term tumor prognosis. However, these pathological data can only be obtained after completing all preoperative and surgical treatments, and they cannot be used as a guide for adjusting treatment. The development of noninvasive biomarkers with early prediction potential is important. At present, most relevant studies have conducted analysis by using traditional machine learning algorithms or statistical methods. Biological and clinical data extracted using medical imaging artificial intelligence programs designed by precision medicine researchers can determine the level of lymphocyte infiltration into tumors, predict imaging omics indicators of the therapeutic effect of immunotherapy to patients, and guide chemoradiotherapy treatment. The realization and development of this technique are of considerable clinical significance and deserve additional effort from researchers. With regard to prediction prognosis, imaging markers can predict the mutation status of genes, the molecular categories that regulate the activity of treatment-related proteins, and disease status and prognosis by using deep learning. Intelligent processing and analysis of medical images using deep learning is noninvasive, repeatable, and inexpensive. In the succeeding research, the data fusion of different omics should be completed to realize a link model of the reasoning mechanism based on content and semantics. Moreover, a fast retrieval method for structured data should be established by using the correlation relationship among data to develop an intelligent prediction model with high accuracy and strong robustness. Valuable research results and meaningful progress of the intelligent processing and analysis of medical images based on deep learning have been obtained; however, they have not been widely used in the clinical setting. In-depth research on deep learning theories and methods should be conducted further. In particular, the acquisition of a large number of high-quality labeled imaging cases, multicenter research and verification, the visualization of the decision-making process and diagnosis basis, and the establishment of a tripartite evaluation system are critical. Moreover, the development of intelligent medical imaging requires the fusion of big data and medical imaging technologies, clinical experience and multiomics big data, and artificial intelligence and medical imaging capabilities. Medical problems and clinical results should be used as guides to realize micro/macro system precision micro-closed-loop research for solving practical clinical problems, such as accurate tumor segmentation before, during, and after surgery; intelligent disease diagnosis; and noninvasive tracking of treatment effect, treatment response, and disease status.关键词:medical imaging processing;artificial intelligence;deep learning;imaging genomics;precision medicine383|175|7更新时间:2024-05-07
-
 摘要:Smoke-emitting vehicles have gradually become one of the major pollution sources in cities. Algorithms that detect smoke-emitting vehicles from videos have good effects, low cost, and extensive applications. They also do not obstruct traffic. However, they still suffer from high false detection rates and poor interpretability. To fully reflect the research progress of these algorithms, this paper provides a comprehensive summary of articles published from 2016 to 2019. A video black smoke detection framework can be divided into surveillance video preprocessing, suspected smoke area extraction, smoke feature selection, classification, and analysis of algorithm performance. This order can be fine-tuned in accordance with the actual situation. This paper introduces and summarizes video smoke detection frameworks and analyzes the extraction of suspected smoky areas and the selection of smoke features from a hierarchical perspective. The method for extracting suspected smoky areas can be divided into four levels (from low to high): image-level extraction, object-level extraction, pixel-level extraction, and pure smoke reconstruction. The accuracy and stability of an extraction method gradually increases, and high-level methods can generally be applied to the results of low-level methods. Smoke features can be divided into three levels: bottom-, middle-, and high-level features. They are divided in accordance with the number of times of learning-based nonlinear projection, and demarcation points are once and three times. The expression of features becomes stronger and the false detection rate of black smoke decreases as level increases; however, the first two are not strictly linear. Then, the high-level features are generalized from the perspective of interpretability. In addition, this paper summarizes feature extraction methods from the perspective of the presence or absence of deep learning, and then classifies methods into traditional and deep learning. Lastly, the evaluation indexes of algorithms are introduced. At present, video smoke detection algorithms face three challenges: extracting features with increased expressiveness, improving generalization and interpretability, and estimating black smoke concentration. Considering these challenges, this paper provides suggestions on the future development direction of video smoke detection algorithms. First, the level of features should be rationally increased while ensuring expression and computational efficiency to improve feature fusion methods. Second, a deep neural network structure that considers generalization and interpretability should be designed in accordance with the space and motion characteristics of smoke. Further research should be conducted on how to fully alleviate the problems of insufficient number of smoky image training samples and uneven distribution. Third, an adaptive calibration algorithm should be designed to compare the extracted smoky gray level with the Lingerman standard black level.关键词:smoky vehicle detection;feature extraction;smoke classification;interpretability of deep learning;review84|233|0更新时间:2024-05-07
摘要:Smoke-emitting vehicles have gradually become one of the major pollution sources in cities. Algorithms that detect smoke-emitting vehicles from videos have good effects, low cost, and extensive applications. They also do not obstruct traffic. However, they still suffer from high false detection rates and poor interpretability. To fully reflect the research progress of these algorithms, this paper provides a comprehensive summary of articles published from 2016 to 2019. A video black smoke detection framework can be divided into surveillance video preprocessing, suspected smoke area extraction, smoke feature selection, classification, and analysis of algorithm performance. This order can be fine-tuned in accordance with the actual situation. This paper introduces and summarizes video smoke detection frameworks and analyzes the extraction of suspected smoky areas and the selection of smoke features from a hierarchical perspective. The method for extracting suspected smoky areas can be divided into four levels (from low to high): image-level extraction, object-level extraction, pixel-level extraction, and pure smoke reconstruction. The accuracy and stability of an extraction method gradually increases, and high-level methods can generally be applied to the results of low-level methods. Smoke features can be divided into three levels: bottom-, middle-, and high-level features. They are divided in accordance with the number of times of learning-based nonlinear projection, and demarcation points are once and three times. The expression of features becomes stronger and the false detection rate of black smoke decreases as level increases; however, the first two are not strictly linear. Then, the high-level features are generalized from the perspective of interpretability. In addition, this paper summarizes feature extraction methods from the perspective of the presence or absence of deep learning, and then classifies methods into traditional and deep learning. Lastly, the evaluation indexes of algorithms are introduced. At present, video smoke detection algorithms face three challenges: extracting features with increased expressiveness, improving generalization and interpretability, and estimating black smoke concentration. Considering these challenges, this paper provides suggestions on the future development direction of video smoke detection algorithms. First, the level of features should be rationally increased while ensuring expression and computational efficiency to improve feature fusion methods. Second, a deep neural network structure that considers generalization and interpretability should be designed in accordance with the space and motion characteristics of smoke. Further research should be conducted on how to fully alleviate the problems of insufficient number of smoky image training samples and uneven distribution. Third, an adaptive calibration algorithm should be designed to compare the extracted smoky gray level with the Lingerman standard black level.关键词:smoky vehicle detection;feature extraction;smoke classification;interpretability of deep learning;review84|233|0更新时间:2024-05-07 -
 摘要:Rigid object pose estimation, which is one of the most fundamental and challenging problems in computer vision, has elicited considerable attention in recent years. Researchers are searching for methods to obtain multiple degrees of freedom (DOFs) for rigid objects in a 3D scene, such as position translation and azimuth rotation, and to detect object instances from a large number of predefined categories in natural images. Simultaneously, the development of technologies in computer vision have achieved considerable progress in the rigid object pose estimation task, which is an important task in an increasing number of applications, e.g., robotic manipulations, orbit services in space, autonomous driving, and augmented reality. This work extensively reviews most papers related to the development history of rigid object pose estimation, spanning over a quarter century (from the 1990s to 2019). However, a review of the use of a single image in rigid object pose estimation does not exist at present. Most relevant studies focus only on the optimization and improvement of pose estimation in a single-class method and then briefly summarize related work in this field. To provide local and overseas researchers with a more comprehensive understanding of the rigid body target pose process, We reviewed the classification and existing problems based on computer vision systematically. In this study, we summarize each multi-DOF pose estimation method by using a single rigid body target image from major research institutions in the world. We classify various pose estimation methods by comparing their key intermediate representation. Deep learning techniques have emerged as a powerful strategy for learning feature representations directly from data and have led to considerable breakthroughs in the field of generic object pose estimation. This paper provides an extensive review of techniques for 20 years of object pose estimation history at two levels: traditional pose estimation period (e.g., feature-based, template matching-based, and 3D coordinate-based methods) and deep learning-based pose estimation period (e.g., improved traditional methods and direct and indirect estimation methods). Finally, we discuss them in accordance with each relevant technical process, focusing on crucial aspects, such as the general process of pose estimation, methodology evolution and classification, commonly used datasets and evaluation criteria, and overseas and domestic research status and prospects. For each type of pose estimation method, we first find the representation space of the image feature in the articles and use it to determine the specific classification of the method. Then, we conclude the estimation process to determine the image feature extraction method, such as the handcrafted design method and convolutional neural network extraction. In the third step, we determine how to match the feature representation space in the articles, summarize the matching process, and finally, identify the pose optimization method used in the article. To date, all pose estimation methods can be finely classified. At present, the multi-DOF rigid object pose estimation method is mostly effective in a single specific application scenario. No universal method is available for composite scenes. When existing methods meet multiple lighting conditions, highly cluttered scenes, and objects with rotational symmetry, the estimation accuracy and efficiency of the similarity target among classes are significantly reduced. Although a certain type of method and its improved version can achieve considerable accuracy improvement, the results will decline significantly when it is applied to other scenarios or new datasets. When applied to highly occluded complex scenes, the accuracy of this method is frequently halved. Moreover, various types of pose estimation methods rely excessively on specialized datasets, particularly various methods based on deep learning. After training, a neural network exhibits strong learning and reasoning capabilities for similar datasets. When introducing new datasets, the network parameters will require a new training set for learning and fine-tuning. Consequently, the method will rely on a neural network framework to achieve pose estimation of a rigid body. This situation requires a large training dataset for multiple scenarios to learn, making the method more practical; however, accuracy is generally not optimal. By contrast, the accuracy of most advanced single-class estimation can be achieved by researchers' manually designed methods under certain single-scenario conditions, but migration application capability is insufficient. When encountering such problems, researchers typically choose two solutions. The first solution is to apply a deep learning technology, using its powerful feature abstraction and data representation capabilities to improve the overall usability of the estimation method, optimize accuracy, and enhance the effect. The other solution is to improve the handcrafted pose estimation method. A researcher can design an intermediate medium with increased representation capability to improve the applicability of a method while ensuring accuracy. History helps readers build complete knowledge hierarchy and find future directions in this rapidly developing field. By combining existing problems with the boosting effects of current deep learning technologies, we introduce six aspects to be considered, namely, scene-level multi-objective inference, self-supervised learning methods, front-end detection networks, lightweight and efficient network designs, multi-information fusion attitude estimation frameworks, and image data representation space. We prospect all the above aspects from the the perspective of development trends in multi-DOF rigid object pose estimation. The multi-DOF pose estimation method for the single image of a rigid object based on computer vision technology has high research value in many fields. However, further research is necessary for some limitations of current technical methods and application scenarios.关键词:computer vision;single image;rigid object;pose estimation;deep learning127|787|4更新时间:2024-05-07
摘要:Rigid object pose estimation, which is one of the most fundamental and challenging problems in computer vision, has elicited considerable attention in recent years. Researchers are searching for methods to obtain multiple degrees of freedom (DOFs) for rigid objects in a 3D scene, such as position translation and azimuth rotation, and to detect object instances from a large number of predefined categories in natural images. Simultaneously, the development of technologies in computer vision have achieved considerable progress in the rigid object pose estimation task, which is an important task in an increasing number of applications, e.g., robotic manipulations, orbit services in space, autonomous driving, and augmented reality. This work extensively reviews most papers related to the development history of rigid object pose estimation, spanning over a quarter century (from the 1990s to 2019). However, a review of the use of a single image in rigid object pose estimation does not exist at present. Most relevant studies focus only on the optimization and improvement of pose estimation in a single-class method and then briefly summarize related work in this field. To provide local and overseas researchers with a more comprehensive understanding of the rigid body target pose process, We reviewed the classification and existing problems based on computer vision systematically. In this study, we summarize each multi-DOF pose estimation method by using a single rigid body target image from major research institutions in the world. We classify various pose estimation methods by comparing their key intermediate representation. Deep learning techniques have emerged as a powerful strategy for learning feature representations directly from data and have led to considerable breakthroughs in the field of generic object pose estimation. This paper provides an extensive review of techniques for 20 years of object pose estimation history at two levels: traditional pose estimation period (e.g., feature-based, template matching-based, and 3D coordinate-based methods) and deep learning-based pose estimation period (e.g., improved traditional methods and direct and indirect estimation methods). Finally, we discuss them in accordance with each relevant technical process, focusing on crucial aspects, such as the general process of pose estimation, methodology evolution and classification, commonly used datasets and evaluation criteria, and overseas and domestic research status and prospects. For each type of pose estimation method, we first find the representation space of the image feature in the articles and use it to determine the specific classification of the method. Then, we conclude the estimation process to determine the image feature extraction method, such as the handcrafted design method and convolutional neural network extraction. In the third step, we determine how to match the feature representation space in the articles, summarize the matching process, and finally, identify the pose optimization method used in the article. To date, all pose estimation methods can be finely classified. At present, the multi-DOF rigid object pose estimation method is mostly effective in a single specific application scenario. No universal method is available for composite scenes. When existing methods meet multiple lighting conditions, highly cluttered scenes, and objects with rotational symmetry, the estimation accuracy and efficiency of the similarity target among classes are significantly reduced. Although a certain type of method and its improved version can achieve considerable accuracy improvement, the results will decline significantly when it is applied to other scenarios or new datasets. When applied to highly occluded complex scenes, the accuracy of this method is frequently halved. Moreover, various types of pose estimation methods rely excessively on specialized datasets, particularly various methods based on deep learning. After training, a neural network exhibits strong learning and reasoning capabilities for similar datasets. When introducing new datasets, the network parameters will require a new training set for learning and fine-tuning. Consequently, the method will rely on a neural network framework to achieve pose estimation of a rigid body. This situation requires a large training dataset for multiple scenarios to learn, making the method more practical; however, accuracy is generally not optimal. By contrast, the accuracy of most advanced single-class estimation can be achieved by researchers' manually designed methods under certain single-scenario conditions, but migration application capability is insufficient. When encountering such problems, researchers typically choose two solutions. The first solution is to apply a deep learning technology, using its powerful feature abstraction and data representation capabilities to improve the overall usability of the estimation method, optimize accuracy, and enhance the effect. The other solution is to improve the handcrafted pose estimation method. A researcher can design an intermediate medium with increased representation capability to improve the applicability of a method while ensuring accuracy. History helps readers build complete knowledge hierarchy and find future directions in this rapidly developing field. By combining existing problems with the boosting effects of current deep learning technologies, we introduce six aspects to be considered, namely, scene-level multi-objective inference, self-supervised learning methods, front-end detection networks, lightweight and efficient network designs, multi-information fusion attitude estimation frameworks, and image data representation space. We prospect all the above aspects from the the perspective of development trends in multi-DOF rigid object pose estimation. The multi-DOF pose estimation method for the single image of a rigid object based on computer vision technology has high research value in many fields. However, further research is necessary for some limitations of current technical methods and application scenarios.关键词:computer vision;single image;rigid object;pose estimation;deep learning127|787|4更新时间:2024-05-07 -
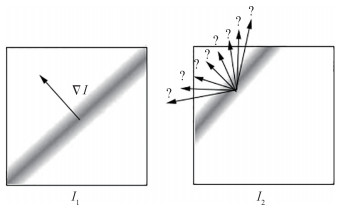 摘要:The motion analysis of fluid image sequences has been an important research topic in the fields of fluid mechanics, medicine, and computer vision. The dense and accurate velocity vector field extracted from image pairs can provide valuable information for these fields. For example, in the field of fluid mechanics, the velocity vector field can be used to calculate the divergence and curl fields of fluid; in the field of meteorology, the analysis of the velocity vector field can be used to provide weather forecast; in the field of medicine, the velocity vector field is applied to match medical images. In recent years, fluid motion estimation technology based on an optical flow method has become a promising direction in this subject due to its unique advantages. Compared with particle image velocimetry based on a correlation method, an optical flow method can obtain a denser velocity field and can estimate the motion of a scalar image and not just a particle image. In addition, an optical flow method can easily introduce various physical constraints in accordance with the motion characteristics of the fluid and obtain more accurate motion estimation results. In accordance with the basic principles of an optical flow method, this paper reviews a fluid motion estimation algorithm based on an optical flow method. Referring to a large number of domestic and foreign studies, existing algorithms are classified in accordance with outstanding problems to be solved: combining the energy minimization function with the knowledge of fluid mechanics, improving robustness to illumination changes, estimating large displacements, and eliminating outliers. Combining the minimization function with the knowledge of fluid mechanics introduces various physical constraints for improving the energy minimization function, providing physically meaningful data items and regularization terms, and improving the accuracy of fluid motion estimation results. Algorithms for improving robustness to illumination changes can be classified into four types: using a high-order constancy assumption to expand data items that depend on the constant brightness assumption, extracting illumination-invariant features in the image for data items, using structure-texture decomposition methods, and establishing a mathematical model for light changes. Various methods are applicable to different light change conditions. For the large displacement estimation problem, the pyramid-based multi-resolution optical flow method is first used; however, this method cannot estimate the large displacement of fine structures. To solve this problem, a hybrid motion estimation method that combines the cross-correlation method with a wavelet-based optical flow method is proposed in recent research. This hybrid method uses the cross-correlation method to calculate the large displacement of a fine structure and then uses an optical flow method to refine and redetermine the flow field, combining the advantages of the two methods. The optical flow estimation method based on wavelet transform provides a good mathematical framework for the multi-resolution estimation algorithm and avoids the linear problem that exists in the "coarse-to-fine" multi-resolution framework when estimating large displacements. Methods for eliminating outliers can be divided into three basic categories: methods that use a robust penalty function, median filtering, and forward-backward optical flow consistency check. In this paper, each kind of method is introduced from the perspective of the problem solving process, and the characteristics and limitations of existing algorithms are analyzed in various outstanding problems. Finally, the major research problems are summarized and discussed, and several possible research directions for the future are proposed. First, an optical flow method introduces various physical constraints into the objective function to conform to fluid motion characteristics. Hence, although accurate estimation results can be obtained, the resulting optical flow equation is too complex to solve, and no good numerical solution is obtained. Second, several methods based on an optical flow method exhibit different advantages under varying light change conditions; they also have corresponding shortcomings. Therefore, further research on how to combine the advantages of various methods to cope with different light changing conditions is particularly important. Third, although the hybrid method that combines the cross-correlation and optical flow methods can utilize the advantages of the two methods to obtain high-resolution motion results for the large displacement problem, this method can only be successfully applied to the motion estimation of particle images at present. Thus, exploring this method for other types of fluid motion images is worthwhile. Finally, an optical flow method requires complex variational optimization and its computational efficiency is low. Although some graphics processing unit(GPU) parallel algorithms proposed in recent years have effectively improved computational efficiency, they still cannot achieve real-time estimation. Therefore, improving the computational efficiency of fluid motion estimation algorithms and realizing real-time estimation are among the directions that are worth studying in the future.关键词:fluid motion estimation;optical flow method;fluid mechanics;illumination change;large displacement estimation;outlier detection101|163|8更新时间:2024-05-07
摘要:The motion analysis of fluid image sequences has been an important research topic in the fields of fluid mechanics, medicine, and computer vision. The dense and accurate velocity vector field extracted from image pairs can provide valuable information for these fields. For example, in the field of fluid mechanics, the velocity vector field can be used to calculate the divergence and curl fields of fluid; in the field of meteorology, the analysis of the velocity vector field can be used to provide weather forecast; in the field of medicine, the velocity vector field is applied to match medical images. In recent years, fluid motion estimation technology based on an optical flow method has become a promising direction in this subject due to its unique advantages. Compared with particle image velocimetry based on a correlation method, an optical flow method can obtain a denser velocity field and can estimate the motion of a scalar image and not just a particle image. In addition, an optical flow method can easily introduce various physical constraints in accordance with the motion characteristics of the fluid and obtain more accurate motion estimation results. In accordance with the basic principles of an optical flow method, this paper reviews a fluid motion estimation algorithm based on an optical flow method. Referring to a large number of domestic and foreign studies, existing algorithms are classified in accordance with outstanding problems to be solved: combining the energy minimization function with the knowledge of fluid mechanics, improving robustness to illumination changes, estimating large displacements, and eliminating outliers. Combining the minimization function with the knowledge of fluid mechanics introduces various physical constraints for improving the energy minimization function, providing physically meaningful data items and regularization terms, and improving the accuracy of fluid motion estimation results. Algorithms for improving robustness to illumination changes can be classified into four types: using a high-order constancy assumption to expand data items that depend on the constant brightness assumption, extracting illumination-invariant features in the image for data items, using structure-texture decomposition methods, and establishing a mathematical model for light changes. Various methods are applicable to different light change conditions. For the large displacement estimation problem, the pyramid-based multi-resolution optical flow method is first used; however, this method cannot estimate the large displacement of fine structures. To solve this problem, a hybrid motion estimation method that combines the cross-correlation method with a wavelet-based optical flow method is proposed in recent research. This hybrid method uses the cross-correlation method to calculate the large displacement of a fine structure and then uses an optical flow method to refine and redetermine the flow field, combining the advantages of the two methods. The optical flow estimation method based on wavelet transform provides a good mathematical framework for the multi-resolution estimation algorithm and avoids the linear problem that exists in the "coarse-to-fine" multi-resolution framework when estimating large displacements. Methods for eliminating outliers can be divided into three basic categories: methods that use a robust penalty function, median filtering, and forward-backward optical flow consistency check. In this paper, each kind of method is introduced from the perspective of the problem solving process, and the characteristics and limitations of existing algorithms are analyzed in various outstanding problems. Finally, the major research problems are summarized and discussed, and several possible research directions for the future are proposed. First, an optical flow method introduces various physical constraints into the objective function to conform to fluid motion characteristics. Hence, although accurate estimation results can be obtained, the resulting optical flow equation is too complex to solve, and no good numerical solution is obtained. Second, several methods based on an optical flow method exhibit different advantages under varying light change conditions; they also have corresponding shortcomings. Therefore, further research on how to combine the advantages of various methods to cope with different light changing conditions is particularly important. Third, although the hybrid method that combines the cross-correlation and optical flow methods can utilize the advantages of the two methods to obtain high-resolution motion results for the large displacement problem, this method can only be successfully applied to the motion estimation of particle images at present. Thus, exploring this method for other types of fluid motion images is worthwhile. Finally, an optical flow method requires complex variational optimization and its computational efficiency is low. Although some graphics processing unit(GPU) parallel algorithms proposed in recent years have effectively improved computational efficiency, they still cannot achieve real-time estimation. Therefore, improving the computational efficiency of fluid motion estimation algorithms and realizing real-time estimation are among the directions that are worth studying in the future.关键词:fluid motion estimation;optical flow method;fluid mechanics;illumination change;large displacement estimation;outlier detection101|163|8更新时间:2024-05-07
Review
-
 摘要:ObjectiveWith the recent rapid development of technologies in cloud computing and mobile internet, screen content coding (SCC) has become a key technology in many popular applications, such as videoconferencing with document or slide sharing, remote desktop, screen sharing, mobile or external display interfacing, and cloud gaming. Typical computer screen content contains a mixture of camera-captured and screen contents. Screen content exhibits highly different characteristics and varied levels of human's visual sensitivity to distortion compared with traditional camera-captured content. Screen content videos are typically not noisy, with sharp edges and multiple repeated patterns. New coding tools for better utilizing the correlation characteristics of screen content are necessary. Accordingly, SCC has become a popular topic in multimedia applications in recent years and has elicited increasing research attention from academia and industry. Several international video coding standards include efficient SCC capability, such as high efficiency video coding (HEVC), versatile video coding (VVC), and second-generation and third-generation audio video coding standard (AVS2 and AVS3, respectively). Repeated identical patterns (i.e., matching patterns) are frequently observed on the same picture of screen content. Two major SCC tools in HEVC SCC were developed in recent years to utilize these repeated identical patterns with a variety of sizes and shapes. These tools are intra block copy (IBC) and palette coding. IBC, also called intra picture block compensation or current picture referencing, is a highly efficient technique for improving coding performance. It is effective for coding repeated identical patterns with a few fixed sizes and shapes. IBC is a direct extension of the traditional inter-prediction technique for the current picture, wherein a current prediction block is predicted from a reference block located in the already reconstrcted regions of the same picture. IBC has been adopted in the HEVC SCC extensions, VVC, and AVS3. In IBC, a displacement vector (DV) is used to signal the relative displacement from the position of the current block to that of the reference block. The coding efficiency of IBC primarily depends on the coding efficiency of DV. The existing DV coding algorithm used in HEVC SCC is the same as the motion vector coding algorithm used in the inter-prediction scheme. However, the existing DV coding algorithm only utilizes the correlations among the DVs of neighboring blocks. Moreover, intra block and inter block matching characteristics exhibit numerous differences. Thus, in accordance with the inherent intra block matching characteristics and different correlations of DV parameters in the IBC algorithm, we propose an improved DV algorithm for further increasing the coding efficiency of IBC. MethodThe DV to be coded has been proven to exhibit numerous correlations not only with neighboring blocks but also with recently coded blocks. To utilize the correlations of DVs with neighboring and recently coded blocks, we first apply an improved DV coding algorithm that adaptively uses DV predictions from either neighboring or recently coded blocks. Second, a direct DV coding scheme that uses a DV region division algorithm and a DV adjusting algorithm is proposed to eliminate redundancies further in the existing DV coding algorithm. Lastly, we evaluate coding performance and complexity on 17 test datasets from the SCC standard test dataset with three encoding configurations. In particular, 13 sequences are selected to represent the most common screen content videos, referred to as the "text and graphics with motion" (TGM) category, and 4 sequences are selected to represent a mixture of natural video and text/graphics, referred to as the "mixed content" category. ResultExperimental results show that the proposed algorithm achieves average Y BD-rate reductions of up to 1.04%, 0.87%, and 0.93% for the TGM category of the SCC common test sequences with lossy all intra (AI), random access, and low-delay B configurations, respectively, compared with the latest HEVC SCC at the same encoding and decoding runtimes. The maximum Y Bjφntegaard Delta(BD)-rate reduction reaches 2.99% in the AI configuration.ConclusionThe experiment results demonstrate that our algorithm outperforms the DV coding algorithm for IBC in HEVC SCC.关键词:high efficiency video coding (HEVC);audio video coding standard (AVS);screen content coding (SCC);displacement vector (DV);prediction coding;direct coding105|183|0更新时间:2024-05-07
摘要:ObjectiveWith the recent rapid development of technologies in cloud computing and mobile internet, screen content coding (SCC) has become a key technology in many popular applications, such as videoconferencing with document or slide sharing, remote desktop, screen sharing, mobile or external display interfacing, and cloud gaming. Typical computer screen content contains a mixture of camera-captured and screen contents. Screen content exhibits highly different characteristics and varied levels of human's visual sensitivity to distortion compared with traditional camera-captured content. Screen content videos are typically not noisy, with sharp edges and multiple repeated patterns. New coding tools for better utilizing the correlation characteristics of screen content are necessary. Accordingly, SCC has become a popular topic in multimedia applications in recent years and has elicited increasing research attention from academia and industry. Several international video coding standards include efficient SCC capability, such as high efficiency video coding (HEVC), versatile video coding (VVC), and second-generation and third-generation audio video coding standard (AVS2 and AVS3, respectively). Repeated identical patterns (i.e., matching patterns) are frequently observed on the same picture of screen content. Two major SCC tools in HEVC SCC were developed in recent years to utilize these repeated identical patterns with a variety of sizes and shapes. These tools are intra block copy (IBC) and palette coding. IBC, also called intra picture block compensation or current picture referencing, is a highly efficient technique for improving coding performance. It is effective for coding repeated identical patterns with a few fixed sizes and shapes. IBC is a direct extension of the traditional inter-prediction technique for the current picture, wherein a current prediction block is predicted from a reference block located in the already reconstrcted regions of the same picture. IBC has been adopted in the HEVC SCC extensions, VVC, and AVS3. In IBC, a displacement vector (DV) is used to signal the relative displacement from the position of the current block to that of the reference block. The coding efficiency of IBC primarily depends on the coding efficiency of DV. The existing DV coding algorithm used in HEVC SCC is the same as the motion vector coding algorithm used in the inter-prediction scheme. However, the existing DV coding algorithm only utilizes the correlations among the DVs of neighboring blocks. Moreover, intra block and inter block matching characteristics exhibit numerous differences. Thus, in accordance with the inherent intra block matching characteristics and different correlations of DV parameters in the IBC algorithm, we propose an improved DV algorithm for further increasing the coding efficiency of IBC. MethodThe DV to be coded has been proven to exhibit numerous correlations not only with neighboring blocks but also with recently coded blocks. To utilize the correlations of DVs with neighboring and recently coded blocks, we first apply an improved DV coding algorithm that adaptively uses DV predictions from either neighboring or recently coded blocks. Second, a direct DV coding scheme that uses a DV region division algorithm and a DV adjusting algorithm is proposed to eliminate redundancies further in the existing DV coding algorithm. Lastly, we evaluate coding performance and complexity on 17 test datasets from the SCC standard test dataset with three encoding configurations. In particular, 13 sequences are selected to represent the most common screen content videos, referred to as the "text and graphics with motion" (TGM) category, and 4 sequences are selected to represent a mixture of natural video and text/graphics, referred to as the "mixed content" category. ResultExperimental results show that the proposed algorithm achieves average Y BD-rate reductions of up to 1.04%, 0.87%, and 0.93% for the TGM category of the SCC common test sequences with lossy all intra (AI), random access, and low-delay B configurations, respectively, compared with the latest HEVC SCC at the same encoding and decoding runtimes. The maximum Y Bjφntegaard Delta(BD)-rate reduction reaches 2.99% in the AI configuration.ConclusionThe experiment results demonstrate that our algorithm outperforms the DV coding algorithm for IBC in HEVC SCC.关键词:high efficiency video coding (HEVC);audio video coding standard (AVS);screen content coding (SCC);displacement vector (DV);prediction coding;direct coding105|183|0更新时间:2024-05-07
Image Processing and Coding
-
 摘要:Objective As one of the important research directions in the field of computer vision, target tracking has a wide range of applications in the fields of video surveillance, human computer interaction, and behavior analysis. A tracking algorithm analyzes target location information in real time in a subsequent sequence of video images by giving the target information (i.e., location and size) in the first frame. At present, target tracking technology has achieved considerable progress, but the robustness of real-time tracking algorithms is still affected by factors, such as target occlusion, illumination change, scale change, fast motion, and background interference. Among these issues, the occlusion problem is the most prominent. A complementary learning correlation filter tracking algorithm updates the template frame by frame. The reliability of the sample is not discriminated during template update, and the sample is not filtered. When background information is complex, particularly when the target is occluded, the template update result will gradually deviate from the target to be tracked. In particular, the color feature is more susceptible to complex environmental factors, aggravating target drift, and thus, template update leads to target drift and occlusion. Method The problem of losing the target persists. The occlusion problem has always limited the accuracy and stability of tracking algorithms. To address this problem, an anti-occlusion multilevel retargeting target tracking algorithm is proposed. This algorithm has three innovations.1) By using the average peak correlation energy, the gradient and color histogram features are dynamically combined to distribute weight reasonably. 2) The target state is determined in real time through peak responses and fluctuations, and the template update strategy is optimized. 3) To address the occlusion problem during the tracking process, a multilevel target relocation strategy is proposed and multilevel filtered feature points are used in the target relocation operation. Feature weight is determined on the basis of the dynamically changing average peak correlation energy, and it is used to combine the gradient and color histogram features for target tracking. After the current frame identifies the target position, target state determination is performed using multi-peak detection and the peak fluctuation condition. If the target state is not ideal, then template update is stopped. Frame-by-frame update is avoided, causing the target to drift, and then target tracking is continued. If target occlusion is determined, then the oriented fast and rotated brief feature of the target is extracted. The nearest neighbor distance ratio of the feature points is matched and filtered, and the nearest neighbor of the negative sample is discarded as secondary screening. Third screening is performed via the generalized Hough transform, the target is relocated, and tracking the target is continued. Result To objectively verify the advantages and disadvantages of the proposed algorithm, 10 groups of image sequences, namely, Basketball, Bird2, CarDark, CarScale, DragonBaby, Girl, Human5, Human8, Singer1, and Walking2, are selected. Nine algorithms, including the proposed algorithm, are selected for the tracking experiments. The eight other algorithms are as follows: kernel correlation filters, discriminative scale space tracking, staple, background-aware correlation filter, spatially regularized correlation filter, scale adaptive multiple features, efficient convolution operators, and spatiotemporal regularized correlation filter. Experimental results for the standard datasets OTB(object tracking benchmark)100 and LaSOT(large-scale single object tracking) show that the accuracy of the algorithm proposed in this study is 0.885 and 0.301, which are 13.5% and 30.3% higher than the original algorithm, respectively. Conclusion In the scenario where in the target is occluded, the target can be repositioned and tracking continues. The optimized template update strategy increases the speed of the algorithm. The determination of the target state effectively estimates the target occlusion problem and can adopt a timely coping strategy to improve the stability of the algorithm in a complex environment.关键词:target tracking;correlation filter;target relocation;occlusion perception;feature extraction47|105|0更新时间:2024-05-07
摘要:Objective As one of the important research directions in the field of computer vision, target tracking has a wide range of applications in the fields of video surveillance, human computer interaction, and behavior analysis. A tracking algorithm analyzes target location information in real time in a subsequent sequence of video images by giving the target information (i.e., location and size) in the first frame. At present, target tracking technology has achieved considerable progress, but the robustness of real-time tracking algorithms is still affected by factors, such as target occlusion, illumination change, scale change, fast motion, and background interference. Among these issues, the occlusion problem is the most prominent. A complementary learning correlation filter tracking algorithm updates the template frame by frame. The reliability of the sample is not discriminated during template update, and the sample is not filtered. When background information is complex, particularly when the target is occluded, the template update result will gradually deviate from the target to be tracked. In particular, the color feature is more susceptible to complex environmental factors, aggravating target drift, and thus, template update leads to target drift and occlusion. Method The problem of losing the target persists. The occlusion problem has always limited the accuracy and stability of tracking algorithms. To address this problem, an anti-occlusion multilevel retargeting target tracking algorithm is proposed. This algorithm has three innovations.1) By using the average peak correlation energy, the gradient and color histogram features are dynamically combined to distribute weight reasonably. 2) The target state is determined in real time through peak responses and fluctuations, and the template update strategy is optimized. 3) To address the occlusion problem during the tracking process, a multilevel target relocation strategy is proposed and multilevel filtered feature points are used in the target relocation operation. Feature weight is determined on the basis of the dynamically changing average peak correlation energy, and it is used to combine the gradient and color histogram features for target tracking. After the current frame identifies the target position, target state determination is performed using multi-peak detection and the peak fluctuation condition. If the target state is not ideal, then template update is stopped. Frame-by-frame update is avoided, causing the target to drift, and then target tracking is continued. If target occlusion is determined, then the oriented fast and rotated brief feature of the target is extracted. The nearest neighbor distance ratio of the feature points is matched and filtered, and the nearest neighbor of the negative sample is discarded as secondary screening. Third screening is performed via the generalized Hough transform, the target is relocated, and tracking the target is continued. Result To objectively verify the advantages and disadvantages of the proposed algorithm, 10 groups of image sequences, namely, Basketball, Bird2, CarDark, CarScale, DragonBaby, Girl, Human5, Human8, Singer1, and Walking2, are selected. Nine algorithms, including the proposed algorithm, are selected for the tracking experiments. The eight other algorithms are as follows: kernel correlation filters, discriminative scale space tracking, staple, background-aware correlation filter, spatially regularized correlation filter, scale adaptive multiple features, efficient convolution operators, and spatiotemporal regularized correlation filter. Experimental results for the standard datasets OTB(object tracking benchmark)100 and LaSOT(large-scale single object tracking) show that the accuracy of the algorithm proposed in this study is 0.885 and 0.301, which are 13.5% and 30.3% higher than the original algorithm, respectively. Conclusion In the scenario where in the target is occluded, the target can be repositioned and tracking continues. The optimized template update strategy increases the speed of the algorithm. The determination of the target state effectively estimates the target occlusion problem and can adopt a timely coping strategy to improve the stability of the algorithm in a complex environment.关键词:target tracking;correlation filter;target relocation;occlusion perception;feature extraction47|105|0更新时间:2024-05-07 -
 摘要:ObjectiveMany minority groups live in China, and the visual styles of their clothing are different. The combination of clothing parsing and the clothing culture of these minority groups plays an important role in realizing the digital protection of the clothing images of these groups and the inheritance of their culture. However, a complete dataset of the clothing images of Chinese minorities remains lacking. The clothing styles of minority groups have complex structures and different visual styles. Semantic labels to distinguish the clothing of different minorities are lacking, and defining the semantic labels of ethnic accessories is a challenging task. Describing information, such as local details, styles, and ethnic characteristics of minority group clothing, is difficult when using existing clothing image parsing methods. Mutual interference between semantic labels leads to unsatisfactory accuracy and precision of clothing image parsing. Therefore, we proposed a clothing parsing method based on visual style and label constraints.MethodOur method primarily parsed minority group clothing through their visual style by fusing local and global features. Then, the label constraint network was used to suppress redundant tags and optimized the preliminary parsing results. First, we defined the general semantic labels of minority group clothing. The distinctive semantic labels were defined in accordance with the combination preference of semantic labels. We set four sets of annotation pairs based on human body parts, with a total of eight label points. Each pair of annotations corresponds to a set of key points on the clothing structure. The upper body garment was marked with the left/right collar, left/right sleeves, and left/right top hem. The lower body garment was marked with the left/right bottom hem. We also marked the visibility of each annotation and used the label annotations to determine whether occlusion occurred in the clothing. Second, combining the training images with the annotation pairs and the self-defined semantic labels, a visual style network was added on the basis of a full convolutional network. A branch was built on the last convolutional layer in the SegNet network. The branch was divided into three parts, with each part respectively dealing with the position and visibility of the annotation pairs and the local and global characteristics of the clothes. The two parts of the local and global features of the clothing were outputted to "fc7_fusion" for fusion. The style features were returned to the SegNet network through a deconvolution layer, and preliminary parsing results were obtained. Finally, a label mapping function was used to convert the preliminary parsing result into a label vector in accordance with the number of labels. Each element indicates whether a corresponding label exists in the preliminary parsing result. Then, the label vector was compared with the true semantic labels in the training set, and the labels were corrected to suppress redundant label probability scores. The label constraint network eliminated redundant and erroneous labels by comparing the labels of the preliminary parsing results with those of the training images. The label constraint network avoided the mutual interference of labels and increased the accuracy of the parsing result. In addition, we constructed a clothing image dataset of 55 minority groups. The primary sources were online shopping sites, such as Taobao, Tmall, and JD. This dataset was expanded by including datasets from other platforms, such as Baidu Pictures, blogs, and forums. A total of 61 710 images were collected. At least 500 images were collected for each minority group.ResultThe proposed method was validated on an image dataset of minority group clothing. Experimental results showed that the detection accuracy of clothing visual style features was higher with annotation pairs. The visual style network efficiently fused local and global features. The label constraint network effectively solved the mutual interference problem of labels. The method proposed in this study improved parsing accuracy on large-scale clothing labels, particularly on skirts with considerable differences in pattern texture and color blocks. The method also improved the small labels of accessories, such as hats and collars. The results of the minority group clothing parsing improved significantly. The pixel accuracy of the parsing results reached 90.54%.ConclusionThe clothing of minority groups is characterized by complicated styles and accessories, lack of semantic labels, and complex labels that interfere with one another. Thus, we proposed a clothing parsing method that fuses visual style with label constraints. We constructed a dataset of minority group clothing images and defined the generic and distinctive semantic labels of minority group clothing. We made pixel-level semantic annotations and set up annotation pairs on the training images. Then, we built a visual style network based on SegNet to obtain preliminary parsing results. Finally, the mutual interference problem of semantic labels was solved through a label constraint network to obtain the final parsing result. Compared with other clothing parsing methods, our method improved the accuracy of minority group clothing image parsing. Inheriting culture and protecting intangible cultural heritage are significant. However, some clothing parsing results of this method are not ideal, particularly the accuracy of small accessories. The semantic labels of minority group clothing are imperfect and insufficiently accurate. Subsequent work will continue to improve the dataset, focusing on the aforementioned issues to further improve the accuracy of minority group clothing parsing.关键词:minority clothing;image parsing;semantic labels;visual style;label constraints72|311|0更新时间:2024-05-07
摘要:ObjectiveMany minority groups live in China, and the visual styles of their clothing are different. The combination of clothing parsing and the clothing culture of these minority groups plays an important role in realizing the digital protection of the clothing images of these groups and the inheritance of their culture. However, a complete dataset of the clothing images of Chinese minorities remains lacking. The clothing styles of minority groups have complex structures and different visual styles. Semantic labels to distinguish the clothing of different minorities are lacking, and defining the semantic labels of ethnic accessories is a challenging task. Describing information, such as local details, styles, and ethnic characteristics of minority group clothing, is difficult when using existing clothing image parsing methods. Mutual interference between semantic labels leads to unsatisfactory accuracy and precision of clothing image parsing. Therefore, we proposed a clothing parsing method based on visual style and label constraints.MethodOur method primarily parsed minority group clothing through their visual style by fusing local and global features. Then, the label constraint network was used to suppress redundant tags and optimized the preliminary parsing results. First, we defined the general semantic labels of minority group clothing. The distinctive semantic labels were defined in accordance with the combination preference of semantic labels. We set four sets of annotation pairs based on human body parts, with a total of eight label points. Each pair of annotations corresponds to a set of key points on the clothing structure. The upper body garment was marked with the left/right collar, left/right sleeves, and left/right top hem. The lower body garment was marked with the left/right bottom hem. We also marked the visibility of each annotation and used the label annotations to determine whether occlusion occurred in the clothing. Second, combining the training images with the annotation pairs and the self-defined semantic labels, a visual style network was added on the basis of a full convolutional network. A branch was built on the last convolutional layer in the SegNet network. The branch was divided into three parts, with each part respectively dealing with the position and visibility of the annotation pairs and the local and global characteristics of the clothes. The two parts of the local and global features of the clothing were outputted to "fc7_fusion" for fusion. The style features were returned to the SegNet network through a deconvolution layer, and preliminary parsing results were obtained. Finally, a label mapping function was used to convert the preliminary parsing result into a label vector in accordance with the number of labels. Each element indicates whether a corresponding label exists in the preliminary parsing result. Then, the label vector was compared with the true semantic labels in the training set, and the labels were corrected to suppress redundant label probability scores. The label constraint network eliminated redundant and erroneous labels by comparing the labels of the preliminary parsing results with those of the training images. The label constraint network avoided the mutual interference of labels and increased the accuracy of the parsing result. In addition, we constructed a clothing image dataset of 55 minority groups. The primary sources were online shopping sites, such as Taobao, Tmall, and JD. This dataset was expanded by including datasets from other platforms, such as Baidu Pictures, blogs, and forums. A total of 61 710 images were collected. At least 500 images were collected for each minority group.ResultThe proposed method was validated on an image dataset of minority group clothing. Experimental results showed that the detection accuracy of clothing visual style features was higher with annotation pairs. The visual style network efficiently fused local and global features. The label constraint network effectively solved the mutual interference problem of labels. The method proposed in this study improved parsing accuracy on large-scale clothing labels, particularly on skirts with considerable differences in pattern texture and color blocks. The method also improved the small labels of accessories, such as hats and collars. The results of the minority group clothing parsing improved significantly. The pixel accuracy of the parsing results reached 90.54%.ConclusionThe clothing of minority groups is characterized by complicated styles and accessories, lack of semantic labels, and complex labels that interfere with one another. Thus, we proposed a clothing parsing method that fuses visual style with label constraints. We constructed a dataset of minority group clothing images and defined the generic and distinctive semantic labels of minority group clothing. We made pixel-level semantic annotations and set up annotation pairs on the training images. Then, we built a visual style network based on SegNet to obtain preliminary parsing results. Finally, the mutual interference problem of semantic labels was solved through a label constraint network to obtain the final parsing result. Compared with other clothing parsing methods, our method improved the accuracy of minority group clothing image parsing. Inheriting culture and protecting intangible cultural heritage are significant. However, some clothing parsing results of this method are not ideal, particularly the accuracy of small accessories. The semantic labels of minority group clothing are imperfect and insufficiently accurate. Subsequent work will continue to improve the dataset, focusing on the aforementioned issues to further improve the accuracy of minority group clothing parsing.关键词:minority clothing;image parsing;semantic labels;visual style;label constraints72|311|0更新时间:2024-05-07 -
 摘要:ObjectiveAfter combining the region proposal network (RPN) with the Siamese network for video target tracking, improved target trackers have been consecutively proposed, all of which have demonstrated relatively high accuracy. Through analysis and comparison, we found that the anchor frame strategy of the RPN module of a Siamese RPN (SiamRPN) generates a large number of anchor frames generated through a sliding window. We then calculate the intersection over union (IOU) between anchor frames to generate candidate regions. Subsequently, we determine the position of target through the classifier and optimize the position of the frame regression. Although this method improves the accuracy of target tracking, it does not consider the semantic features of the target image, resulting in inconsistencies between the anchor frame and the features. It also generates a large number of redundant anchor frames, which exert a certain effect on the accuracy of target tracking, leading to a considerable increase in calculation amount.MethodTo solve this problem, this study proposes a Siamese guided anchor RPN (Siamese GA-RPN). The primary idea is to use semantic features to guide the anchoring and then convolve with the frame to be detected to obtain the response score figure. Lastly, end-to-end training is achieved on the target tracking network. The guided anchoring network is designed with location and shape prediction branches. The two branches use the semantic features extracted by the convolutional neural network (CNN) in the Siamese network to predict the locations wherein the center of the objects of interest exist and the scales and aspect ratios at different locations, reducing the generation of redundant anchors. Then, a feature adaptive module is designed. This module uses the variable convolution layer to modify the original feature map of the tracking target on the basis of the shape information of the anchor frame at each position, reducing the inconsistency between the features and the anchors and improving target tracking accuracy.ResultTracking experiments were performed on three challenging video tracking benchmark datasets: VOT(viedo object tracking)2015, VOT2016, and VOT2017. The algorithm's tracking performance was tested on complex scenes, such as fast target movement, occlusion, and lighting. A quantitative comparison was made on two evaluation indexes: accuracy and robustness. On the VOT2015 dataset, the accuracy of the algorithm was improved by 1.72% and robustness was increased by 5.17% compared with those of the twin RPN network. On the VOT2016 dataset, the accuracy of the algorithm was improved by 3.6% compared with that of the twin RPN network. Meanwhile, robustness was improved by 6.6%. Real-time experiments were performed on the VOT2017 dataset, and the algorithm proposed in this study demonstrates good real-time tracking effect. Simultaneously, this algorithm was compared with the full convolutional Siam (Siam-FC) and Siam-RPN on four video sequences: rainy day, underwater, target occlusion, and poor light. The algorithm developed in this study exhibits good performance in the four scenarios in terms of tracking effect.ConclusionThe anchor frame RPN network proposed in this study improves the effectiveness of anchor frame generation, ensures the consistency of features and anchor frames, achieves the accurate positioning of targets, and solves the problem of anchor frame size target tracking accuracy influences. The experimental results on the three video tracking benchmark data sets show better tracking results, which are better than several top-ranking video tracking algorithms with comprehensive performance, and show good real-time performance. And it can still track the target more accurately in complex video scenes such as change in target scale, occlusion, change in lighting conditions, fast target movement, etc., which shows strong robustness and adaptability.关键词:target tracking;siamese network;region proposal network(RPN);guided anchoring;feature adaptation26|24|4更新时间:2024-05-07
摘要:ObjectiveAfter combining the region proposal network (RPN) with the Siamese network for video target tracking, improved target trackers have been consecutively proposed, all of which have demonstrated relatively high accuracy. Through analysis and comparison, we found that the anchor frame strategy of the RPN module of a Siamese RPN (SiamRPN) generates a large number of anchor frames generated through a sliding window. We then calculate the intersection over union (IOU) between anchor frames to generate candidate regions. Subsequently, we determine the position of target through the classifier and optimize the position of the frame regression. Although this method improves the accuracy of target tracking, it does not consider the semantic features of the target image, resulting in inconsistencies between the anchor frame and the features. It also generates a large number of redundant anchor frames, which exert a certain effect on the accuracy of target tracking, leading to a considerable increase in calculation amount.MethodTo solve this problem, this study proposes a Siamese guided anchor RPN (Siamese GA-RPN). The primary idea is to use semantic features to guide the anchoring and then convolve with the frame to be detected to obtain the response score figure. Lastly, end-to-end training is achieved on the target tracking network. The guided anchoring network is designed with location and shape prediction branches. The two branches use the semantic features extracted by the convolutional neural network (CNN) in the Siamese network to predict the locations wherein the center of the objects of interest exist and the scales and aspect ratios at different locations, reducing the generation of redundant anchors. Then, a feature adaptive module is designed. This module uses the variable convolution layer to modify the original feature map of the tracking target on the basis of the shape information of the anchor frame at each position, reducing the inconsistency between the features and the anchors and improving target tracking accuracy.ResultTracking experiments were performed on three challenging video tracking benchmark datasets: VOT(viedo object tracking)2015, VOT2016, and VOT2017. The algorithm's tracking performance was tested on complex scenes, such as fast target movement, occlusion, and lighting. A quantitative comparison was made on two evaluation indexes: accuracy and robustness. On the VOT2015 dataset, the accuracy of the algorithm was improved by 1.72% and robustness was increased by 5.17% compared with those of the twin RPN network. On the VOT2016 dataset, the accuracy of the algorithm was improved by 3.6% compared with that of the twin RPN network. Meanwhile, robustness was improved by 6.6%. Real-time experiments were performed on the VOT2017 dataset, and the algorithm proposed in this study demonstrates good real-time tracking effect. Simultaneously, this algorithm was compared with the full convolutional Siam (Siam-FC) and Siam-RPN on four video sequences: rainy day, underwater, target occlusion, and poor light. The algorithm developed in this study exhibits good performance in the four scenarios in terms of tracking effect.ConclusionThe anchor frame RPN network proposed in this study improves the effectiveness of anchor frame generation, ensures the consistency of features and anchor frames, achieves the accurate positioning of targets, and solves the problem of anchor frame size target tracking accuracy influences. The experimental results on the three video tracking benchmark data sets show better tracking results, which are better than several top-ranking video tracking algorithms with comprehensive performance, and show good real-time performance. And it can still track the target more accurately in complex video scenes such as change in target scale, occlusion, change in lighting conditions, fast target movement, etc., which shows strong robustness and adaptability.关键词:target tracking;siamese network;region proposal network(RPN);guided anchoring;feature adaptation26|24|4更新时间:2024-05-07 -
 摘要:ObjectivePedestrian detection involves locating all pedestrians in images or videos by using rectangular boxes with confidence scores. Traditional pedestrian detection methods cannot handle situations with different postures and mutual occlusion. In recent years, deep neural networks have performed well in object detection, but they are still unable to solve some challenging issues in pedestrian detection. In this study, we propose a method called DC-CSP(density map and classifier modules with center and scale prediction) to enhance pedestrian detection by combining pedestrian density and score refinement. Under an anchor-free architecture, our method first refines the classification to obtain more accurate confidence scores and then uses different IoU (intersection over union) thresholds to handle varying pedestrian densities with the objective of reducing the omission of occluded pedestrians and the false detection of a single pedestrian.MethodFirst, our DC-CSP network is primarily composed of a center and scale prediction(CSP) subnetwork, a density map module (DMM), and a classifier module (CM). The CSP subnetwork includes a feature extraction module and a detection head module. The feature extraction module uses ResNet-50 as its backbone, in which output feature maps are down-sampled by 4, 8, 16, and 16 with respect to the input image. The shallower features provide more precise localization information, and the deeper features contain more semantic information with larger receptive fields. Thus, we fuse the multi-scale feature maps from all the stages into a single one with a deconvolution layer. Upon the concatenation of feature maps, the detection head module first uses a 3×3 convolutional layer to reduce channel dimension to 256 and then two sibling 1×1 convolutional layers to produce the center heat map and scale map. On the basis of the CSP subnetwork, we design a density estimation module that first utilizes the concatenated feature maps to generate the features of 128 channels via a 1×1 convolutional layer, and then concatenates them with the center heat map and scale map to predict a pedestrian density map with a convolutional kernel of 5×5. The density estimation module integrates diverse features and applies a large kernel to consider surrounding information, generating accurate density maps. Moreover, a CM is designed to use the bounding boxes transformed from the center heat map and the scale map as input. This module utilizes the concatenated feature maps to produce 256-channel features via a 3×3 convolutional layer and then classifies the produced features by using a convolutional layer with a 1×1 kernel. The majority of the confidence scores of the background are below a certain threshold; thus, we can obtain a threshold for easily distinguishing pedestrians from the background. Second, the detection scores in CSP are relatively low and the CM can better discriminate between pedestrians and the background. Therefore, to increase the confidence scores of pedestrians and simultaneously decrease that of the background in the final decision, we design a stage score fusion (SSF) rule to update the detection scores by utilizing the complementarity of the detection head module and CM. In particular, when the classifier judges a sample as a pedestrian, the SSF rule will slightly boost the detection scores. By contrast, when the classifier judges a sample as the background, the SSF rule will slightly decrease. In other cases, a comprehensive judgment will be made by averaging the scores from both modules. Third, an improved adaptive non-maximum suppression (NMS), called the improved adaptive NMS(IAN) post-processing method, based on the estimated pedestrian density map is also proposed to improve the detection results further. In particular, a high IoU threshold will be used for mutually occluded pedestrians to reduce missed detection, and a low IoU threshold will be used for a single pedestrian to reduce false detection. In contrast with adaptive NMS, our IAN method fully considers various scenes. In addition, IAN is based on NMS rather than on soft NMS, and thus, it involves lower computational cost.ResultTo verify the effectiveness of the proposed modules, we conduct a series of ablation experiments in which C-CSP, D-CSP, and DC-CSP respectively represent the addition of the CM, DMM, and both modules to the CSP subnetwork. We conduct quantitative and qualitative analyses on two widely used public datasets, i.e., Citypersons and Caltech, for each setting. The experimental results of C-CSP verify the rationality of the SSF rule and demonstrate that the confidence scores of pedestrians can be increased while that of the background can be decreased. Simultaneously, the experimental results of D-CSP demonstrate the effectiveness of the IAN method, which can considerably reduce missed detection and false detection. For the quantitative analyses of DC-CSP, its log-average miss rate decreases by 0.8%, 1.3%, 1.0%, and 0.8% in the Reasonable, Heavy, Partial, and Bare subsets of Citypersons, respectively, and decreases by 0.3% and 0.7% in the Reasonable and Allsubsets of Caltech, respectively, compared with those of other methods. For the qualitative analyses of DC-CSP, the visualization results show that our method can work well in various scenes, such as pedestrians occluded by other objects, smaller pedestrians, vertical structures, and false reflection. Pedestrians in different scenes can be detected more accurately, and the confidence scores are more convincing. Furthermore, our method can avoid numerous false detections in situations with a complex background.ConclusionIn this study, we propose a deep convolutional neural network with multiple novel modules for pedestrian detection. In particular, the IAN method and the SSF rule are designed to utilize density and classification features, respectively. Our DC-CSP method can considerably alleviate issues in pedestrian detection, such as missed detection, false detection, and inaccurate confidence scores. Its effectiveness and robustness are verified on multiple benchmark datasets.关键词:urban scenes;pedestrian detection;convolutional neural network (CNN);density map;score fusion;adaptive post-processing63|96|2更新时间:2024-05-07
摘要:ObjectivePedestrian detection involves locating all pedestrians in images or videos by using rectangular boxes with confidence scores. Traditional pedestrian detection methods cannot handle situations with different postures and mutual occlusion. In recent years, deep neural networks have performed well in object detection, but they are still unable to solve some challenging issues in pedestrian detection. In this study, we propose a method called DC-CSP(density map and classifier modules with center and scale prediction) to enhance pedestrian detection by combining pedestrian density and score refinement. Under an anchor-free architecture, our method first refines the classification to obtain more accurate confidence scores and then uses different IoU (intersection over union) thresholds to handle varying pedestrian densities with the objective of reducing the omission of occluded pedestrians and the false detection of a single pedestrian.MethodFirst, our DC-CSP network is primarily composed of a center and scale prediction(CSP) subnetwork, a density map module (DMM), and a classifier module (CM). The CSP subnetwork includes a feature extraction module and a detection head module. The feature extraction module uses ResNet-50 as its backbone, in which output feature maps are down-sampled by 4, 8, 16, and 16 with respect to the input image. The shallower features provide more precise localization information, and the deeper features contain more semantic information with larger receptive fields. Thus, we fuse the multi-scale feature maps from all the stages into a single one with a deconvolution layer. Upon the concatenation of feature maps, the detection head module first uses a 3×3 convolutional layer to reduce channel dimension to 256 and then two sibling 1×1 convolutional layers to produce the center heat map and scale map. On the basis of the CSP subnetwork, we design a density estimation module that first utilizes the concatenated feature maps to generate the features of 128 channels via a 1×1 convolutional layer, and then concatenates them with the center heat map and scale map to predict a pedestrian density map with a convolutional kernel of 5×5. The density estimation module integrates diverse features and applies a large kernel to consider surrounding information, generating accurate density maps. Moreover, a CM is designed to use the bounding boxes transformed from the center heat map and the scale map as input. This module utilizes the concatenated feature maps to produce 256-channel features via a 3×3 convolutional layer and then classifies the produced features by using a convolutional layer with a 1×1 kernel. The majority of the confidence scores of the background are below a certain threshold; thus, we can obtain a threshold for easily distinguishing pedestrians from the background. Second, the detection scores in CSP are relatively low and the CM can better discriminate between pedestrians and the background. Therefore, to increase the confidence scores of pedestrians and simultaneously decrease that of the background in the final decision, we design a stage score fusion (SSF) rule to update the detection scores by utilizing the complementarity of the detection head module and CM. In particular, when the classifier judges a sample as a pedestrian, the SSF rule will slightly boost the detection scores. By contrast, when the classifier judges a sample as the background, the SSF rule will slightly decrease. In other cases, a comprehensive judgment will be made by averaging the scores from both modules. Third, an improved adaptive non-maximum suppression (NMS), called the improved adaptive NMS(IAN) post-processing method, based on the estimated pedestrian density map is also proposed to improve the detection results further. In particular, a high IoU threshold will be used for mutually occluded pedestrians to reduce missed detection, and a low IoU threshold will be used for a single pedestrian to reduce false detection. In contrast with adaptive NMS, our IAN method fully considers various scenes. In addition, IAN is based on NMS rather than on soft NMS, and thus, it involves lower computational cost.ResultTo verify the effectiveness of the proposed modules, we conduct a series of ablation experiments in which C-CSP, D-CSP, and DC-CSP respectively represent the addition of the CM, DMM, and both modules to the CSP subnetwork. We conduct quantitative and qualitative analyses on two widely used public datasets, i.e., Citypersons and Caltech, for each setting. The experimental results of C-CSP verify the rationality of the SSF rule and demonstrate that the confidence scores of pedestrians can be increased while that of the background can be decreased. Simultaneously, the experimental results of D-CSP demonstrate the effectiveness of the IAN method, which can considerably reduce missed detection and false detection. For the quantitative analyses of DC-CSP, its log-average miss rate decreases by 0.8%, 1.3%, 1.0%, and 0.8% in the Reasonable, Heavy, Partial, and Bare subsets of Citypersons, respectively, and decreases by 0.3% and 0.7% in the Reasonable and Allsubsets of Caltech, respectively, compared with those of other methods. For the qualitative analyses of DC-CSP, the visualization results show that our method can work well in various scenes, such as pedestrians occluded by other objects, smaller pedestrians, vertical structures, and false reflection. Pedestrians in different scenes can be detected more accurately, and the confidence scores are more convincing. Furthermore, our method can avoid numerous false detections in situations with a complex background.ConclusionIn this study, we propose a deep convolutional neural network with multiple novel modules for pedestrian detection. In particular, the IAN method and the SSF rule are designed to utilize density and classification features, respectively. Our DC-CSP method can considerably alleviate issues in pedestrian detection, such as missed detection, false detection, and inaccurate confidence scores. Its effectiveness and robustness are verified on multiple benchmark datasets.关键词:urban scenes;pedestrian detection;convolutional neural network (CNN);density map;score fusion;adaptive post-processing63|96|2更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:Objective A huge amount of image data have been generated with the development of the Internet of things and artificial intelligence technology and their widespread application to various fields. Understanding image content quickly and accurately and automatically segmenting the target area of an image in accordance with the requirements of the application scene have become the focus of many researchers. In recent years, image semantic segmentation methods based on deep learning have been developed steadily. These methods have been widely used in automatic driving and robot engineering, and have become the primary research task in computer vision. Common convolutional neural networks (CNNs) can efficiently extract the features of an image. They typically operate directly on the entire feature map. However, extremely small targets frequently occur in a local area of an image. The common convolution operation cannot efficiently extract the features of small targets. To solve this problem, the feature image cut module is introduced into the down-sampling process. Method At present, the spatial pyramid pool module and codec structure of a deep CNN (DCNN) have become the mainstream method for image semantic segmentation. The former network can extract the features of an input feature map by using filters or pooling operations with multiple rates and effective fields, and thus, encode the multi-scale context information. Meanwhile, the latter network can capture clearer object boundaries by gradually recovering spatial information. However, many difficulties and challenges persist. The first problem is that the DCNN model has extremely high requirements for the hardware platform and is unsuitable for real-time engineering applications. The second problem is that the resolution of the feature image shrinks after the image is encoded, resulting in the loss of the spatial information of some pixels. The third problem is that the segmentation process cannot effectively consider the image context information (i.e., the relationship among pixels) and cannot fully utilize rich spatial location information. The fourth problem is that DCNNs are not good at capturing feature expression, and thus, achieving a better semantic segmentation effect is difficult. To solve these problems, this study proposes an improved image semantic segmentation algorithm DeepLab IRCNet based on DeepLabv3+ to solve the problem in which DCNNs experience difficulty in extracting the features of small and medium-sized objects. In the encoder part, a DCNN composed of a series of ordinary convolutional layers and multiple inverted residual modules is used to extract features. In the inverted residual module, deep separable convolutions are used instead of ordinary convolutions. When the resolution of the feature image is reduced to 1/16 of the input image, the feature map is divided equally, the feature map after segmentation is enlarged to the size before segmentation, and the feature extraction module is used to share each segmented feature map through parameter sharing. Consequently, the model can focus better on small target objects in the local area after feature segmentation. On the main network, the extracted feature map is continuously inputted into the hollow space pyramid pooling module to capture the multi-scale contextual content information of the image, and the hollow convolution with a void rate of {6, 12, 18} in the atrous spatial pyramid pooling module is used. The sequence also parallels a 1×1 convolutional layer and image pooling, wherein the choice of the void rate is the same as that of DeepLabv3+, improving segmentation performance. Then, a 1×1 convolution is used to obtain the output tensor of the target feature map. In the decoder part, bilinear interpolation is used to up-sample two times, and then the up sampling feature mapis fused with the output feature map of the feature segmentation module in the encoder. Several 3×3 depth separable convolutions are used to redefine the feature, and bilinear interpolation is used for up-sampling. Finally, an image semantic segmentation map that is the same size as the input image is the output. Result In this study, the CamVid(Cambridege-driving labeled video database) dataset is used to verify the proposed method. The mean intersection over union(mIoU) is increased by 1.5 percentage points compared with the DeepLabv3+ model. The verification results show the effectiveness of the proposed method. Conclusion In this study, a feature graph segmentation module is introduced to improve model attention to small objects and address the problem of low semantic segmentation accuracy.关键词:atrous convolution;depth separable convolution;feature image cut;feature extraction network;feature fusion83|181|6更新时间:2024-05-07
摘要:Objective A huge amount of image data have been generated with the development of the Internet of things and artificial intelligence technology and their widespread application to various fields. Understanding image content quickly and accurately and automatically segmenting the target area of an image in accordance with the requirements of the application scene have become the focus of many researchers. In recent years, image semantic segmentation methods based on deep learning have been developed steadily. These methods have been widely used in automatic driving and robot engineering, and have become the primary research task in computer vision. Common convolutional neural networks (CNNs) can efficiently extract the features of an image. They typically operate directly on the entire feature map. However, extremely small targets frequently occur in a local area of an image. The common convolution operation cannot efficiently extract the features of small targets. To solve this problem, the feature image cut module is introduced into the down-sampling process. Method At present, the spatial pyramid pool module and codec structure of a deep CNN (DCNN) have become the mainstream method for image semantic segmentation. The former network can extract the features of an input feature map by using filters or pooling operations with multiple rates and effective fields, and thus, encode the multi-scale context information. Meanwhile, the latter network can capture clearer object boundaries by gradually recovering spatial information. However, many difficulties and challenges persist. The first problem is that the DCNN model has extremely high requirements for the hardware platform and is unsuitable for real-time engineering applications. The second problem is that the resolution of the feature image shrinks after the image is encoded, resulting in the loss of the spatial information of some pixels. The third problem is that the segmentation process cannot effectively consider the image context information (i.e., the relationship among pixels) and cannot fully utilize rich spatial location information. The fourth problem is that DCNNs are not good at capturing feature expression, and thus, achieving a better semantic segmentation effect is difficult. To solve these problems, this study proposes an improved image semantic segmentation algorithm DeepLab IRCNet based on DeepLabv3+ to solve the problem in which DCNNs experience difficulty in extracting the features of small and medium-sized objects. In the encoder part, a DCNN composed of a series of ordinary convolutional layers and multiple inverted residual modules is used to extract features. In the inverted residual module, deep separable convolutions are used instead of ordinary convolutions. When the resolution of the feature image is reduced to 1/16 of the input image, the feature map is divided equally, the feature map after segmentation is enlarged to the size before segmentation, and the feature extraction module is used to share each segmented feature map through parameter sharing. Consequently, the model can focus better on small target objects in the local area after feature segmentation. On the main network, the extracted feature map is continuously inputted into the hollow space pyramid pooling module to capture the multi-scale contextual content information of the image, and the hollow convolution with a void rate of {6, 12, 18} in the atrous spatial pyramid pooling module is used. The sequence also parallels a 1×1 convolutional layer and image pooling, wherein the choice of the void rate is the same as that of DeepLabv3+, improving segmentation performance. Then, a 1×1 convolution is used to obtain the output tensor of the target feature map. In the decoder part, bilinear interpolation is used to up-sample two times, and then the up sampling feature mapis fused with the output feature map of the feature segmentation module in the encoder. Several 3×3 depth separable convolutions are used to redefine the feature, and bilinear interpolation is used for up-sampling. Finally, an image semantic segmentation map that is the same size as the input image is the output. Result In this study, the CamVid(Cambridege-driving labeled video database) dataset is used to verify the proposed method. The mean intersection over union(mIoU) is increased by 1.5 percentage points compared with the DeepLabv3+ model. The verification results show the effectiveness of the proposed method. Conclusion In this study, a feature graph segmentation module is introduced to improve model attention to small objects and address the problem of low semantic segmentation accuracy.关键词:atrous convolution;depth separable convolution;feature image cut;feature extraction network;feature fusion83|181|6更新时间:2024-05-07
lmage Analysis and Recognition
-
 摘要:ObjectiveStereo matching is an important part of the field of binocular stereo vision. It reconstructs 3D objects or scenes through a pair of 2D images by simulating the visual system of human beings. Stereo matching is widely used in various fields, such as unmanned vehicles, 3D noncontact measures, and robot navigation. Most stereo matching algorithms can be divided into two types: global and local stereo matching algorithms. A global algorithm obtains a disparity map by minimizing the energy function; it exhibits the advantage of high matching accuracy. However, a global stereo matching algorithm operates with high computational complexity, and it is difficult to apply to some fields that require programs to act fast. Local matching algorithms use only the neighborhood information of pixels in the window to perform pixel-by-pixel matching, and thus, its matching accuracy is lower than that of global algorithms. Local algorithms have lower computational complexity, expanding the application range of stereo matching. Local stereo matching algorithms generally have four steps: cost computation, cost aggregation, disparity computation, and disparity refinement. In cost computation, the cost value of each pixel in the left and right images is computed by the designed algorithm at all disparity levels. The correlation between the pixel to be matched and the candidate pixel is measured using the cost value; a smaller cost value corresponds to higher relevance. In cost aggregation, a local matching algorithm aggregates the cost value within a matching window by summing, averaging, or using other methods to obtain the cumulative cost value to reduce the impact of outliers. The disparity for each pixel is calculated using local optimization methods and refined using different post-processing methods in the last two steps. However, traditional local stereo matching algorithms cannot fully utilize the edge texture information of images. Thus, such algorithms still exhibit poor performance in matching accuracy in non-occluded regions and regions with disparity discontinuity. A multi-scale stereo matching algorithm based on edge preservation is proposed to meet the real-time requirements for a realistic scene and improve the matching accuracy of an algorithm in non-occluded regions and regions with disparity discontinuity.MethodWe use edge detection to obtain the edge matrix of an image. The values in the obtained edge image are filtered, reassigned, and normalized to obtain an edge weight matrix. In a traditional cost computation algorithm, the method of combining the absolute difference with the gradient fully utilizes the pixel relationship among three channels (R, G, and B) of an image. It exhibits limited improvement in regions with disparity discontinuity and can ensure rapid feature of the algorithm. However, higher matching accuracy cannot be guaranteed at edge regions. We fuse the obtained weight matrix with absolute difference and gradient transformation and then set a truncation threshold for the absolute difference and gradient transform algorithms to reduce the influence of the outlier on cost volume, finally forming a new cost computation function. The new cost computation function can provide a smaller cost volume to the pixels in the texture area belonging to the left and right images, and thus, it achieves better discrimination in edge regions. In cost aggregation, edge weight information is combined with the regularization term of a guided image filter to perform aggregation in a cross-scale framework. By changing the fixed regularization term of the guide filter, a larger smoothing factor is superimposed for pixels closer to the edge in the edge texture region of an image, whereas a smaller smoothing factor is superimposed for points farther away from the edge. Therefore, the points closer to the edge acquire a lower cost value. In the disparity computation, we select the point with the smallest cumulative cost value as the corresponding point to obtain the initial disparity map. This map is processed using disparity refinement methods, such as weighted median filter, hole assignment, and left-to-right consistency check, to obtain the final disparity map.ResultWe test the algorithm on the Middlebury stereo matching benchmark. Experimental results show that the fusion of texture weight information can more effectively distinguish the cost volume of pixels at the edge region and the number of mismatched pixels at the edge regions of the image is considerably reduced. Moreover, after fusing image information at different scales, the matching accuracy of an image in smooth areas is improved. The average error matching rate of the proposed algorithm is reduced by 3.48% compared with the original algorithm for 21 extended image pairs without any disparity refinement steps. The average error matching rate of the proposed algorithm is 5.77% for four standard image pairs on the Middlebury benchmark, which is better than those of the listed comparison algorithms. Moreover, the error matching rate of the proposed algorithm for venus image pairs in non-occluded regions is 0.18%, and the error matching rate in all the regions is 0.39%. The average peak signal-to-noise ratio of the proposed algorithm on 21 extended image pairs is 20.48 dB. The deviation extent of the pixel disparity of the obtained initial disparity map compared with the real disparity map is the smallest among the listed algorithms. The average running time of the proposed algorithm for 21 extended image pairs is 17.74 s. Compared with the original algorithm, the average running time of the proposed algorithm increases by 0.73 s and still maintains good real-time performance.ConclusionIn this study, we propose a stereo matching algorithm based on edge preservation and an improved guided filter. The proposed stereo matching algorithm effectively improves the matching accuracy of an image in texture regions, further reducing the error matching rate in non-occluded regions and regions with disparity discontinuity.关键词:computer vision;local stereo matching;cost computation;edge preservation;guided image filter130|1098|6更新时间:2024-05-07
摘要:ObjectiveStereo matching is an important part of the field of binocular stereo vision. It reconstructs 3D objects or scenes through a pair of 2D images by simulating the visual system of human beings. Stereo matching is widely used in various fields, such as unmanned vehicles, 3D noncontact measures, and robot navigation. Most stereo matching algorithms can be divided into two types: global and local stereo matching algorithms. A global algorithm obtains a disparity map by minimizing the energy function; it exhibits the advantage of high matching accuracy. However, a global stereo matching algorithm operates with high computational complexity, and it is difficult to apply to some fields that require programs to act fast. Local matching algorithms use only the neighborhood information of pixels in the window to perform pixel-by-pixel matching, and thus, its matching accuracy is lower than that of global algorithms. Local algorithms have lower computational complexity, expanding the application range of stereo matching. Local stereo matching algorithms generally have four steps: cost computation, cost aggregation, disparity computation, and disparity refinement. In cost computation, the cost value of each pixel in the left and right images is computed by the designed algorithm at all disparity levels. The correlation between the pixel to be matched and the candidate pixel is measured using the cost value; a smaller cost value corresponds to higher relevance. In cost aggregation, a local matching algorithm aggregates the cost value within a matching window by summing, averaging, or using other methods to obtain the cumulative cost value to reduce the impact of outliers. The disparity for each pixel is calculated using local optimization methods and refined using different post-processing methods in the last two steps. However, traditional local stereo matching algorithms cannot fully utilize the edge texture information of images. Thus, such algorithms still exhibit poor performance in matching accuracy in non-occluded regions and regions with disparity discontinuity. A multi-scale stereo matching algorithm based on edge preservation is proposed to meet the real-time requirements for a realistic scene and improve the matching accuracy of an algorithm in non-occluded regions and regions with disparity discontinuity.MethodWe use edge detection to obtain the edge matrix of an image. The values in the obtained edge image are filtered, reassigned, and normalized to obtain an edge weight matrix. In a traditional cost computation algorithm, the method of combining the absolute difference with the gradient fully utilizes the pixel relationship among three channels (R, G, and B) of an image. It exhibits limited improvement in regions with disparity discontinuity and can ensure rapid feature of the algorithm. However, higher matching accuracy cannot be guaranteed at edge regions. We fuse the obtained weight matrix with absolute difference and gradient transformation and then set a truncation threshold for the absolute difference and gradient transform algorithms to reduce the influence of the outlier on cost volume, finally forming a new cost computation function. The new cost computation function can provide a smaller cost volume to the pixels in the texture area belonging to the left and right images, and thus, it achieves better discrimination in edge regions. In cost aggregation, edge weight information is combined with the regularization term of a guided image filter to perform aggregation in a cross-scale framework. By changing the fixed regularization term of the guide filter, a larger smoothing factor is superimposed for pixels closer to the edge in the edge texture region of an image, whereas a smaller smoothing factor is superimposed for points farther away from the edge. Therefore, the points closer to the edge acquire a lower cost value. In the disparity computation, we select the point with the smallest cumulative cost value as the corresponding point to obtain the initial disparity map. This map is processed using disparity refinement methods, such as weighted median filter, hole assignment, and left-to-right consistency check, to obtain the final disparity map.ResultWe test the algorithm on the Middlebury stereo matching benchmark. Experimental results show that the fusion of texture weight information can more effectively distinguish the cost volume of pixels at the edge region and the number of mismatched pixels at the edge regions of the image is considerably reduced. Moreover, after fusing image information at different scales, the matching accuracy of an image in smooth areas is improved. The average error matching rate of the proposed algorithm is reduced by 3.48% compared with the original algorithm for 21 extended image pairs without any disparity refinement steps. The average error matching rate of the proposed algorithm is 5.77% for four standard image pairs on the Middlebury benchmark, which is better than those of the listed comparison algorithms. Moreover, the error matching rate of the proposed algorithm for venus image pairs in non-occluded regions is 0.18%, and the error matching rate in all the regions is 0.39%. The average peak signal-to-noise ratio of the proposed algorithm on 21 extended image pairs is 20.48 dB. The deviation extent of the pixel disparity of the obtained initial disparity map compared with the real disparity map is the smallest among the listed algorithms. The average running time of the proposed algorithm for 21 extended image pairs is 17.74 s. Compared with the original algorithm, the average running time of the proposed algorithm increases by 0.73 s and still maintains good real-time performance.ConclusionIn this study, we propose a stereo matching algorithm based on edge preservation and an improved guided filter. The proposed stereo matching algorithm effectively improves the matching accuracy of an image in texture regions, further reducing the error matching rate in non-occluded regions and regions with disparity discontinuity.关键词:computer vision;local stereo matching;cost computation;edge preservation;guided image filter130|1098|6更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveImage segmentation tasks suffer from the problem in which multiple overlapping regions are required to be extracted, such as the division of the endocardium and epicardium of the heart's left ventricle. Existing neural network segmentation models typically segment the target based on pixel classification due to the overlapping of pixels in the two regions and then convert the segmentation problem into a classification problem. However, the overlapping area of pixels may not be simultaneously classified well. In general, existing neural networks must train model parameters for each target to obtain accurate segmentation results, reducing segmentation efficiency. To address these issues, we propose a segmentation model, called Seg-CapNet, which is based on a capsule network structure.MethodCurrent segmentation models based on convolutional neural networks control the size of feature maps through operations, such as maximum or average pool, and transmit image feature information from the upper layer to the next layer. Such pooling operations lose the spatial information of components in the process of information transmission. Therefore, the proposed Seg-CapNet model uses a capsule network structure to extract vectors that contain spatial, color, size, and other target information. Compared with current network structures, the output of a capsule network is in vector form, and the information of the target is included in the entity vector through routing iteration. Seg-CapNet utilizes this feature to strip overlapping objects from the image space and convert them into noninterference feature vectors, separating objects with overlapping regions. Then, the spatial position relation of multiple target vectors are reconstructed using fully connected layers. Lastly, the reconstructed image is up-sampled and the segmented image is restored to the same size as the input image. During up-sampling, the feature graph of the up-sampling layer and that of the convolutional layer are skip-connected. This process is conducive to restoring image details and accelerating the training process while the model is backpropagating. To improve segmentation results, we also design a new loss function for constraining segmentation results to ensure that they can maintain a relative position relationship among multiple target areas to follow cardiac morphology. In the loss function based on the Dice coefficient, the ratio constraint of the area beyond the epicardium boundary to the area of the endocardium is added, and thus, the area of the endocardium is divided as far as possible within the outer membrane. To prevent the ratio from becoming too small to influence parameter updating in the backpropagation process, we control its value within an appropriate range through exponential transformation and keep it synchronized with the loss function based on the Dice coefficient. This method is implemented using Python 3.6 and TensorFlow on Nvidia Tesla K80 GPU, Intel E5-2650 CPU, and 10 G main memory. The learning rate is 0.001. Image sizes from different devices are inconsistent because data sources are collected from different imaging devices. However in cardiac magnetic resonance imaging (MRI), the heart is typically located near the center. Therefore, the 128×128 pixel region centered on an image is extracted as the size of the input model image, and image size can be unified, including the image of the whole heart.ResultWe train and verify the Seg-CapNet model on the automated cardiac diagnosis challenge(ACDC)2017, medical image computing and computer-assisted intervention(MICCAI)2013, and MICCAI2009 datasets, and then compare the results with those of the neural network segmentation models, U-Net and SegNet. Experimental results show that the average Dice coefficient of our model increased by 4.7% and the average Hausdorff distance decreased by 22% compared with those of U-Net and SegNet. Moreover, the number of Seg-CapNet parameters was only 54% of that of U-Net and 40% of that of SegNet. Our results illustrate that the proposed model improves segmentation accuracy and reduces training time and complexity. In addition, we validate the performance of the proposed loss function on the ACDC2017 dataset. By comparing the segmentation results of the model before and after random selection and adding the constraint loss function, the new loss function avoids the internal region located outside the epicardium, violating the anatomical structure of the heart. Simultaneously, we calculate the mean Dice value of the segmentation results before and after adding the constraint to the loss function. The experimental results show that Dice value of the segmentation results of the left ventricular endocardium and epicardium with the new loss function increases by an average of 0.6%.ConclusionWe propose a Seg-CapNet model that ensures the simultaneous segmentation of multiple overlapping targets, reduces the number of participants, and accelerates the training process. The results show that our model can maintain good segmentation accuracy while segmenting two overlapping regions of the heart's left ventricle in MRI.关键词:neural network;capsule network;image segmentation;overlapping-area target;cardiac MRI74|235|7更新时间:2024-05-07
摘要:ObjectiveImage segmentation tasks suffer from the problem in which multiple overlapping regions are required to be extracted, such as the division of the endocardium and epicardium of the heart's left ventricle. Existing neural network segmentation models typically segment the target based on pixel classification due to the overlapping of pixels in the two regions and then convert the segmentation problem into a classification problem. However, the overlapping area of pixels may not be simultaneously classified well. In general, existing neural networks must train model parameters for each target to obtain accurate segmentation results, reducing segmentation efficiency. To address these issues, we propose a segmentation model, called Seg-CapNet, which is based on a capsule network structure.MethodCurrent segmentation models based on convolutional neural networks control the size of feature maps through operations, such as maximum or average pool, and transmit image feature information from the upper layer to the next layer. Such pooling operations lose the spatial information of components in the process of information transmission. Therefore, the proposed Seg-CapNet model uses a capsule network structure to extract vectors that contain spatial, color, size, and other target information. Compared with current network structures, the output of a capsule network is in vector form, and the information of the target is included in the entity vector through routing iteration. Seg-CapNet utilizes this feature to strip overlapping objects from the image space and convert them into noninterference feature vectors, separating objects with overlapping regions. Then, the spatial position relation of multiple target vectors are reconstructed using fully connected layers. Lastly, the reconstructed image is up-sampled and the segmented image is restored to the same size as the input image. During up-sampling, the feature graph of the up-sampling layer and that of the convolutional layer are skip-connected. This process is conducive to restoring image details and accelerating the training process while the model is backpropagating. To improve segmentation results, we also design a new loss function for constraining segmentation results to ensure that they can maintain a relative position relationship among multiple target areas to follow cardiac morphology. In the loss function based on the Dice coefficient, the ratio constraint of the area beyond the epicardium boundary to the area of the endocardium is added, and thus, the area of the endocardium is divided as far as possible within the outer membrane. To prevent the ratio from becoming too small to influence parameter updating in the backpropagation process, we control its value within an appropriate range through exponential transformation and keep it synchronized with the loss function based on the Dice coefficient. This method is implemented using Python 3.6 and TensorFlow on Nvidia Tesla K80 GPU, Intel E5-2650 CPU, and 10 G main memory. The learning rate is 0.001. Image sizes from different devices are inconsistent because data sources are collected from different imaging devices. However in cardiac magnetic resonance imaging (MRI), the heart is typically located near the center. Therefore, the 128×128 pixel region centered on an image is extracted as the size of the input model image, and image size can be unified, including the image of the whole heart.ResultWe train and verify the Seg-CapNet model on the automated cardiac diagnosis challenge(ACDC)2017, medical image computing and computer-assisted intervention(MICCAI)2013, and MICCAI2009 datasets, and then compare the results with those of the neural network segmentation models, U-Net and SegNet. Experimental results show that the average Dice coefficient of our model increased by 4.7% and the average Hausdorff distance decreased by 22% compared with those of U-Net and SegNet. Moreover, the number of Seg-CapNet parameters was only 54% of that of U-Net and 40% of that of SegNet. Our results illustrate that the proposed model improves segmentation accuracy and reduces training time and complexity. In addition, we validate the performance of the proposed loss function on the ACDC2017 dataset. By comparing the segmentation results of the model before and after random selection and adding the constraint loss function, the new loss function avoids the internal region located outside the epicardium, violating the anatomical structure of the heart. Simultaneously, we calculate the mean Dice value of the segmentation results before and after adding the constraint to the loss function. The experimental results show that Dice value of the segmentation results of the left ventricular endocardium and epicardium with the new loss function increases by an average of 0.6%.ConclusionWe propose a Seg-CapNet model that ensures the simultaneous segmentation of multiple overlapping targets, reduces the number of participants, and accelerates the training process. The results show that our model can maintain good segmentation accuracy while segmenting two overlapping regions of the heart's left ventricle in MRI.关键词:neural network;capsule network;image segmentation;overlapping-area target;cardiac MRI74|235|7更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveRemote sensing image segmentation is a technique for segmenting the target of interest. In the field of deep learning, convolutional neural networks (CNNs) are typically used to extract image features and then classify each pixel of the image. Remote sensing image segmentation has a wide range of applications, including environmental monitoring, urban construction, and crop classification. It is highly significant in the extraction and analysis of image information. However, high-resolution remote sensing images have a large number of targets with different shapes and sizes, and thus, many difficulties are encountered in achieving image segmentation. A receptive field is an important attribute of CNNs, and the matching degree between the receptive field and target size is related to the completeness and robustness of the extracted target features. If the receptive field matches the target shape well, then the target features contained in the feature map will be complete; otherwise, the feature map will contain many useless features that will interfere with the segmentation task. In existing methods, the square receptive field is used to extract features. However, the shape of targets in remote sensing images are different, and thus, the square receptive field cannot fit the shape of the target well. If the mismatched receptive field is used to extract target features, then useless features will interfere with segmentation. To solve this problem, this study proposes a remote sensing image segmentation model (RSISM) based on an adaptive receptive field mechanism (ARFM), referred to as RSISM-ARFM hereafter.MethodRSISM-ARFM can extract receptive fields with different sizes and ratios while simultaneously channel weighting the features of different receptive fields during feature fusion. In this manner, the receptive field features that match the target shape can be strengthened; otherwise, they are weakened, reducing the interference of useless features while retaining target features. RSISM-ARFM uses an encoder-decoder network as its backbone network. This backbone network consists of an encoder and a decoder. The encoder is used to extract basic convolution features while reducing the size of the feature map to extract deep semantic information. The extracted features in the shallow layer of the encoder contain rich detailed information, such as target location and edge. Meanwhile, the extracted features in the deep layer of the encoder contain semantic information that can help the model identify the target better. To fuse the two parts of information, the decoder concatenates feature maps at different layers to improve the feature extraction capability of the model. On the basis of the backbone network, this study introduces an ARFM. First, the features of different receptive fields are extracted from the encoder. Then, the channel attention module is used to calculate the dependency relationship among the channels of the feature map to generate channel weights. Finally, the feature maps of different receptive fields are weighted. After the aforementioned operations, the model can adaptively adjust the relationship among different receptive fields and select appropriate receptive fields to extract the features of the target.ResultIn this study, we conducted ablation and comparative experiments on the Inria Image Labeling and DeepGlobe Road Extraction datasets. Given the large size of the original images in the datasets, they cannot be used directly in the experiments. Therefore, the training and test sets were cropped to 256×256 pixel images during the experiments. The model was trained first using the training set and then tested using the test set. To verify the effectiveness of RSISM-ARFM, we conducted ablation and comparative experiments using the two aforementioned datasets. Simultaneously, we used different evaluation indexes in the experiments to evaluate the segmentation performance of the model from multiple perspectives. Experimental results show that the proposed method can effectively improve the segmentation accuracy of targets with different shapes. The segmentation result of RSISM-ARFM is the closest to the labeled image, and the details of the targets are the clearest. The intersection over union on the two datasets reaches 76.1% and 61.9%, and the average F1 score reaches 86.5% and 76.5%, respectively. Segmentation performance is better than that of the comparison model.ConclusionThe model proposed in this study adds an ARFM based on an encoder-decoder network. It extracts the features of the receptive fields of different target shapes and sizes and then uses the channel attention module to perform channel weighting adaptively on the features during the feature fusion process. Accordingly, the model extracts complete target features and reduces the introduction of useless features, improving segmentation accuracy.关键词:remote sensing image;convolutional neural network (CNN);image segmentation;adaptive receptive field mechanism (ARFM);channel attention module (CAM)56|54|4更新时间:2024-05-07
摘要:ObjectiveRemote sensing image segmentation is a technique for segmenting the target of interest. In the field of deep learning, convolutional neural networks (CNNs) are typically used to extract image features and then classify each pixel of the image. Remote sensing image segmentation has a wide range of applications, including environmental monitoring, urban construction, and crop classification. It is highly significant in the extraction and analysis of image information. However, high-resolution remote sensing images have a large number of targets with different shapes and sizes, and thus, many difficulties are encountered in achieving image segmentation. A receptive field is an important attribute of CNNs, and the matching degree between the receptive field and target size is related to the completeness and robustness of the extracted target features. If the receptive field matches the target shape well, then the target features contained in the feature map will be complete; otherwise, the feature map will contain many useless features that will interfere with the segmentation task. In existing methods, the square receptive field is used to extract features. However, the shape of targets in remote sensing images are different, and thus, the square receptive field cannot fit the shape of the target well. If the mismatched receptive field is used to extract target features, then useless features will interfere with segmentation. To solve this problem, this study proposes a remote sensing image segmentation model (RSISM) based on an adaptive receptive field mechanism (ARFM), referred to as RSISM-ARFM hereafter.MethodRSISM-ARFM can extract receptive fields with different sizes and ratios while simultaneously channel weighting the features of different receptive fields during feature fusion. In this manner, the receptive field features that match the target shape can be strengthened; otherwise, they are weakened, reducing the interference of useless features while retaining target features. RSISM-ARFM uses an encoder-decoder network as its backbone network. This backbone network consists of an encoder and a decoder. The encoder is used to extract basic convolution features while reducing the size of the feature map to extract deep semantic information. The extracted features in the shallow layer of the encoder contain rich detailed information, such as target location and edge. Meanwhile, the extracted features in the deep layer of the encoder contain semantic information that can help the model identify the target better. To fuse the two parts of information, the decoder concatenates feature maps at different layers to improve the feature extraction capability of the model. On the basis of the backbone network, this study introduces an ARFM. First, the features of different receptive fields are extracted from the encoder. Then, the channel attention module is used to calculate the dependency relationship among the channels of the feature map to generate channel weights. Finally, the feature maps of different receptive fields are weighted. After the aforementioned operations, the model can adaptively adjust the relationship among different receptive fields and select appropriate receptive fields to extract the features of the target.ResultIn this study, we conducted ablation and comparative experiments on the Inria Image Labeling and DeepGlobe Road Extraction datasets. Given the large size of the original images in the datasets, they cannot be used directly in the experiments. Therefore, the training and test sets were cropped to 256×256 pixel images during the experiments. The model was trained first using the training set and then tested using the test set. To verify the effectiveness of RSISM-ARFM, we conducted ablation and comparative experiments using the two aforementioned datasets. Simultaneously, we used different evaluation indexes in the experiments to evaluate the segmentation performance of the model from multiple perspectives. Experimental results show that the proposed method can effectively improve the segmentation accuracy of targets with different shapes. The segmentation result of RSISM-ARFM is the closest to the labeled image, and the details of the targets are the clearest. The intersection over union on the two datasets reaches 76.1% and 61.9%, and the average F1 score reaches 86.5% and 76.5%, respectively. Segmentation performance is better than that of the comparison model.ConclusionThe model proposed in this study adds an ARFM based on an encoder-decoder network. It extracts the features of the receptive fields of different target shapes and sizes and then uses the channel attention module to perform channel weighting adaptively on the features during the feature fusion process. Accordingly, the model extracts complete target features and reduces the introduction of useless features, improving segmentation accuracy.关键词:remote sensing image;convolutional neural network (CNN);image segmentation;adaptive receptive field mechanism (ARFM);channel attention module (CAM)56|54|4更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0