
最新刊期
卷 26 , 期 12 , 2021
-
 摘要:Deep visual generation has aimed to create synthetic photo-realistic visual contents (such as images and videos) that could fool or please human perceptions according to some specific requirements. In fact, many human activities belong to the field of visual generation, e.g., advertisement making, house designing and film making. However, these tasks normally can only be done by experts with professional skills gained through long-term training and the help of professional software such as Adobe Photoshop. Besides, it may also take a very long time to produce photo-realistic contents since the process can be very tedious and cumbersome. Thus, how to make these processes automated is a very important yet non-trivial problem. Nowadays, deep visual generation has become a significant research direction in computer vision and machine learning, and has been applied in many tasks, such as automatic content generation, beautification, rendering and data augmentation. Thanks to the current deep generative methods can be categorized into two groups: variational auto-encoder (VAE) based methods and generative adversarial networks (GANs) based methods. Based on encoder-decoder architecture, VAE methods first map input data into a latent distribution, and then minimize the distance between the latent distribution and some prior distribution, e.g., Gaussian distribution. A well-trained VAE model could be used in the tasks of dimensionality reduction and image generation. However, an inevitable gap between the latent distribution and prior distribution would make the generated images/videos blurred. Unlike the VAE model, GAN has learned a mapping between input and output distributions to synthesize sharper images/videos. A GAN model has contained two major modules. A generator has aimed to generate the fake data and a discriminator has distinguished whether a sample is fake or not. To produce plausible fake data, the generator has been matched the distribution of real data and synthesized fake data that would fulfill the requirements of reality and diversity. The optimization problem of learning the generator and discriminator has been formulated into a two-player minimax game. During the training, the two modules have been optimized alternately using stochastic gradient methods. At the end of the training, the generator and discriminator have been supposed to reach a Nash Equilibria of the minimax game. Due to the development of GAN model, more deep visual generation applications and tasks have occurred based on GAN model. The six typical tasks for deep visual generation have been presented as follows: 1) Image generation from noises: it is the earliest task of deep visual generation in which GAN model seeks to generate an image (e.g., face image) from random noises. 2) Image generation from images: it tries to transform a given image into a new one (e.g., from black-and-white image to color image). This task can be applied to applications like style transfer and image reconstruction. 3) Image generation from texts: it is a very natural task just like that humans describe the content of a painting and then the painters draw the corresponding images based on the texts. 4) Video generation from images: it aims to turn a static image into a dynamic video, which can be used in time-lapse photography, making animated videos from pictures, etc. 5) Video generation from videos: it is mainly used for video style transfer, video super-resolution and so on. 6) Video generation from texts: it is more difficult than image generation from texts since it needs the generated videos focusing on both semantical alignments with text and consistency among video frames. The challenges in deep visual generation have been analyzed and discussed. First, rather than 2D data, we should try to generate high-quality 3D data, which contains more information and details. Second, we could pay more attention to video generation instead of only image generation. Third, we could conduct some researches on controllable deep visual generation methods, which are more practical in real-world applications. Finally, we could try to expand the style transfer methods from two domains to multiple domains. In this review, we have summarized very recent works on deep adversarial visual generation through a systematic investigation. The review has mainly included an introduction of deep visual generation background, typical generation models, an overview of mainstream deep visual generation tasks and related algorithms. The deep adversarial visual generation research has been conducted further.关键词:deep learning;visual generation;generative adversarial networks (GANs);image generation;video generation;3D-depth image generation;style transfer;controllable generation209|179|1更新时间:2024-05-07
摘要:Deep visual generation has aimed to create synthetic photo-realistic visual contents (such as images and videos) that could fool or please human perceptions according to some specific requirements. In fact, many human activities belong to the field of visual generation, e.g., advertisement making, house designing and film making. However, these tasks normally can only be done by experts with professional skills gained through long-term training and the help of professional software such as Adobe Photoshop. Besides, it may also take a very long time to produce photo-realistic contents since the process can be very tedious and cumbersome. Thus, how to make these processes automated is a very important yet non-trivial problem. Nowadays, deep visual generation has become a significant research direction in computer vision and machine learning, and has been applied in many tasks, such as automatic content generation, beautification, rendering and data augmentation. Thanks to the current deep generative methods can be categorized into two groups: variational auto-encoder (VAE) based methods and generative adversarial networks (GANs) based methods. Based on encoder-decoder architecture, VAE methods first map input data into a latent distribution, and then minimize the distance between the latent distribution and some prior distribution, e.g., Gaussian distribution. A well-trained VAE model could be used in the tasks of dimensionality reduction and image generation. However, an inevitable gap between the latent distribution and prior distribution would make the generated images/videos blurred. Unlike the VAE model, GAN has learned a mapping between input and output distributions to synthesize sharper images/videos. A GAN model has contained two major modules. A generator has aimed to generate the fake data and a discriminator has distinguished whether a sample is fake or not. To produce plausible fake data, the generator has been matched the distribution of real data and synthesized fake data that would fulfill the requirements of reality and diversity. The optimization problem of learning the generator and discriminator has been formulated into a two-player minimax game. During the training, the two modules have been optimized alternately using stochastic gradient methods. At the end of the training, the generator and discriminator have been supposed to reach a Nash Equilibria of the minimax game. Due to the development of GAN model, more deep visual generation applications and tasks have occurred based on GAN model. The six typical tasks for deep visual generation have been presented as follows: 1) Image generation from noises: it is the earliest task of deep visual generation in which GAN model seeks to generate an image (e.g., face image) from random noises. 2) Image generation from images: it tries to transform a given image into a new one (e.g., from black-and-white image to color image). This task can be applied to applications like style transfer and image reconstruction. 3) Image generation from texts: it is a very natural task just like that humans describe the content of a painting and then the painters draw the corresponding images based on the texts. 4) Video generation from images: it aims to turn a static image into a dynamic video, which can be used in time-lapse photography, making animated videos from pictures, etc. 5) Video generation from videos: it is mainly used for video style transfer, video super-resolution and so on. 6) Video generation from texts: it is more difficult than image generation from texts since it needs the generated videos focusing on both semantical alignments with text and consistency among video frames. The challenges in deep visual generation have been analyzed and discussed. First, rather than 2D data, we should try to generate high-quality 3D data, which contains more information and details. Second, we could pay more attention to video generation instead of only image generation. Third, we could conduct some researches on controllable deep visual generation methods, which are more practical in real-world applications. Finally, we could try to expand the style transfer methods from two domains to multiple domains. In this review, we have summarized very recent works on deep adversarial visual generation through a systematic investigation. The review has mainly included an introduction of deep visual generation background, typical generation models, an overview of mainstream deep visual generation tasks and related algorithms. The deep adversarial visual generation research has been conducted further.关键词:deep learning;visual generation;generative adversarial networks (GANs);image generation;video generation;3D-depth image generation;style transfer;controllable generation209|179|1更新时间:2024-05-07 -
 摘要:Human computer interaction technology has been promoting to realize intelligent human-computer interaction. The user's emotional experience in the human-computer interaction system has been facilitated based on the realization of emotional interaction. Emotional interaction has been intended to use widely via Gartner's analysis next decade. The agent can be real or virtual to detect the user's emotion and adjust the user's emotion. It can greatly enhance the user's experience in human-computer interaction on the aspects of psychological rehabilitation, E-education, digital entertainment, smart home, virtual tourism, E-commerce and etc. The research of agent's affective computing has involved in computer graphics, virtual reality, human-computer-based interaction, machine learning, psychology, social science. Based on Scopus database, 2 080 journal papers have been optioned via using virtual human (agent, multimodal) plus emotional interaction as the key words each. The perspective of agent's perceptions and influence of users' emotions have been analyzed and summarized. The importance of multi-channel in emotion perception and the typical machine learning algorithms in emotion recognition have been summarized from the perspective of agent's perception of users' emotions. The external and internal factors affecting users' emotions have been analyzed from the perspective of agent's influence on users' emotions. The emotional architecture, emotional generation and expression algorithms have been implemented. Customized evaluation methods have been applied to improve the accuracy of the affective computing algorithm. The importance of emotional agent in human-computer interaction has been analyzed. Four key steps of agent affective computing have been summarized based on current studies: 1) An agent expressed its emotion to the user. 2) The user gave their feedback to the agent (they may or may not express their satisfaction or dissatisfaction via some channels like facial expressions). 3) The real-time agent perceived the user's emotional state and intention and adjustable emotional performance to respond to user's feedback. 4) A standard (e.g., the completion of emotion regulation task, the end of plot) has been reached, the agent stopped interacting with the user, otherwise, returns to step 1). The current studies have shown that user's expressed emotions via facial expressions, voices, postures, physiological signals and texts on the aspect of user emotion recognition. The multi-channel method has been more reliable than the single channel method. Machine learning can be used to extract emotional features. Typical machine learning algorithms and their applicable scenarios have been sorted out based on CNN (convolutional neural network) nowadays. Some solutions have been facilitated to resolve insufficient data and over fitting issues. Spatial distance, the number of agents, the appearance of the agent, brightness and shadow have been set as external factors. Agent's autonomous emotion expression has been targeted as the internal factor. An agent should have an emotional architecture and use facial expression, eye gaze, posture, head movement gesture and other channels to express its emotion. The accuracy of the emotional classification model and users' feelings has been assessed based on an affective computing model. The statistical sampling analysis has been listed in the table. The existing emotional agents such as low intelligence, lack of common-sense database, lack of interactivity have been as the constrained factors. The research of agent affective computing in the field of human-computer interaction has been developed further. An affective computing for human-computer-based interaction and an agent could be a channel of emotional interaction. Knowledge-based database and appropriated machine learning algorithms have been adopted to build an agent with the ability of emotion perception and emotion regulation. Qualified physiological detection equipment and sustainable enrichment of emotional information assessment methods have developed the affective computing further.关键词:human-computer interaction;agent;affective computing;emotion;perception;performance312|444|2更新时间:2024-05-07
摘要:Human computer interaction technology has been promoting to realize intelligent human-computer interaction. The user's emotional experience in the human-computer interaction system has been facilitated based on the realization of emotional interaction. Emotional interaction has been intended to use widely via Gartner's analysis next decade. The agent can be real or virtual to detect the user's emotion and adjust the user's emotion. It can greatly enhance the user's experience in human-computer interaction on the aspects of psychological rehabilitation, E-education, digital entertainment, smart home, virtual tourism, E-commerce and etc. The research of agent's affective computing has involved in computer graphics, virtual reality, human-computer-based interaction, machine learning, psychology, social science. Based on Scopus database, 2 080 journal papers have been optioned via using virtual human (agent, multimodal) plus emotional interaction as the key words each. The perspective of agent's perceptions and influence of users' emotions have been analyzed and summarized. The importance of multi-channel in emotion perception and the typical machine learning algorithms in emotion recognition have been summarized from the perspective of agent's perception of users' emotions. The external and internal factors affecting users' emotions have been analyzed from the perspective of agent's influence on users' emotions. The emotional architecture, emotional generation and expression algorithms have been implemented. Customized evaluation methods have been applied to improve the accuracy of the affective computing algorithm. The importance of emotional agent in human-computer interaction has been analyzed. Four key steps of agent affective computing have been summarized based on current studies: 1) An agent expressed its emotion to the user. 2) The user gave their feedback to the agent (they may or may not express their satisfaction or dissatisfaction via some channels like facial expressions). 3) The real-time agent perceived the user's emotional state and intention and adjustable emotional performance to respond to user's feedback. 4) A standard (e.g., the completion of emotion regulation task, the end of plot) has been reached, the agent stopped interacting with the user, otherwise, returns to step 1). The current studies have shown that user's expressed emotions via facial expressions, voices, postures, physiological signals and texts on the aspect of user emotion recognition. The multi-channel method has been more reliable than the single channel method. Machine learning can be used to extract emotional features. Typical machine learning algorithms and their applicable scenarios have been sorted out based on CNN (convolutional neural network) nowadays. Some solutions have been facilitated to resolve insufficient data and over fitting issues. Spatial distance, the number of agents, the appearance of the agent, brightness and shadow have been set as external factors. Agent's autonomous emotion expression has been targeted as the internal factor. An agent should have an emotional architecture and use facial expression, eye gaze, posture, head movement gesture and other channels to express its emotion. The accuracy of the emotional classification model and users' feelings has been assessed based on an affective computing model. The statistical sampling analysis has been listed in the table. The existing emotional agents such as low intelligence, lack of common-sense database, lack of interactivity have been as the constrained factors. The research of agent affective computing in the field of human-computer interaction has been developed further. An affective computing for human-computer-based interaction and an agent could be a channel of emotional interaction. Knowledge-based database and appropriated machine learning algorithms have been adopted to build an agent with the ability of emotion perception and emotion regulation. Qualified physiological detection equipment and sustainable enrichment of emotional information assessment methods have developed the affective computing further.关键词:human-computer interaction;agent;affective computing;emotion;perception;performance312|444|2更新时间:2024-05-07 -
 摘要:The four core technologies of automatic driving have evolved environment perception, precise positioning, path planning. and line control execution. Perfect planning must establish a deep understanding of the surrounding environment for environmental perception, especially the dynamic environment. Visual environment perception has played a key role in the development of autonomous vehicles. It has been widely used in intelligent rearview mirror, reversing radar, 360° panorama, driving recorder, collision warning, traffic light recognition, lane departure, line-parallel assistance, automatic parking and etc. The traditional way to obtain environmental information is the narrow-angle pinhole camera, which has limited field of vision and blind area. Multiple cameras are often needed to be covered around the car body, which not only increases the cost, but also increases the information processing time. Fisheye lens perception can be an effective way to use for environmental information. The large field of view (FOV) can provide the entire hemisphere view of 180°. Theoretically, The capability to cover 360° to avoid visual blindness, reduce the occlusion of visual objects, provide more information for visual perception and greatly reduce the processing time with only two cameras. Based on deep learning, processing surrounded image has been mainly processed in two ways. First, the surrounded fisheye image is transformed into ordinary normal image based on the image correction and distortion. The corrected image has been processed via classical image processing algorithm. The disadvantage is that image distortion can damage image quality, especially the image edges, lead to important visual information missing, the closer the image edge, the more loss of information. Second, the distorted fisheye image has been modeled and processed directly. The complexity of the fisheye image geometric process (model) cannot make the algorithm to migrate to the surrounded fisheye image very well, which is determined by the imaging characteristics of ordinary image and fisheye image, there is no surround fisheye image modeling model with better effect. Finally, there is no representative public dataset to carry out unified evaluation of the vision algorithm, and there is also a lack of a large number of data for model training. The related research directions of the fisheye image including the correction processing of the fisheye image have been summarized. Subdivided into the fisheye image correction method based on calibration has been conducted and the fisheye image correction method based on the projection transformation model has been demonstrated; the target detection in the fisheye image has been mainly introduced to pedestrian detection as well. The city road environment semantic segmentation, pseudo fisheye image dataset generation method has mainly been introduced based on the semantic segmentation of fisheye images. The other fisheye image modeling methods have been used to list the approximate proportion of these research directions and analyze the application background and real-time characteristics of the environment of automatic driving vehicle. In addition, the general datasets of the fisheye image has included the size of these datasets, publishing time, annotation category and etc. The experimental results of object detection methods and semantic segmentation methods in the fisheye image have been compared and analyzed. The evaluation dataset of fisheye image, the construction of algorithm model of fisheye image and the efficiency of the model issues have been discussed. The fisheye image processing has been benefited from the development of weak supervised and unsupervised learning.关键词:automatic drive;surround fisheye images;image correction;object detection;semantic segmentation;fisheye image dataset;research overview135|426|0更新时间:2024-05-07
摘要:The four core technologies of automatic driving have evolved environment perception, precise positioning, path planning. and line control execution. Perfect planning must establish a deep understanding of the surrounding environment for environmental perception, especially the dynamic environment. Visual environment perception has played a key role in the development of autonomous vehicles. It has been widely used in intelligent rearview mirror, reversing radar, 360° panorama, driving recorder, collision warning, traffic light recognition, lane departure, line-parallel assistance, automatic parking and etc. The traditional way to obtain environmental information is the narrow-angle pinhole camera, which has limited field of vision and blind area. Multiple cameras are often needed to be covered around the car body, which not only increases the cost, but also increases the information processing time. Fisheye lens perception can be an effective way to use for environmental information. The large field of view (FOV) can provide the entire hemisphere view of 180°. Theoretically, The capability to cover 360° to avoid visual blindness, reduce the occlusion of visual objects, provide more information for visual perception and greatly reduce the processing time with only two cameras. Based on deep learning, processing surrounded image has been mainly processed in two ways. First, the surrounded fisheye image is transformed into ordinary normal image based on the image correction and distortion. The corrected image has been processed via classical image processing algorithm. The disadvantage is that image distortion can damage image quality, especially the image edges, lead to important visual information missing, the closer the image edge, the more loss of information. Second, the distorted fisheye image has been modeled and processed directly. The complexity of the fisheye image geometric process (model) cannot make the algorithm to migrate to the surrounded fisheye image very well, which is determined by the imaging characteristics of ordinary image and fisheye image, there is no surround fisheye image modeling model with better effect. Finally, there is no representative public dataset to carry out unified evaluation of the vision algorithm, and there is also a lack of a large number of data for model training. The related research directions of the fisheye image including the correction processing of the fisheye image have been summarized. Subdivided into the fisheye image correction method based on calibration has been conducted and the fisheye image correction method based on the projection transformation model has been demonstrated; the target detection in the fisheye image has been mainly introduced to pedestrian detection as well. The city road environment semantic segmentation, pseudo fisheye image dataset generation method has mainly been introduced based on the semantic segmentation of fisheye images. The other fisheye image modeling methods have been used to list the approximate proportion of these research directions and analyze the application background and real-time characteristics of the environment of automatic driving vehicle. In addition, the general datasets of the fisheye image has included the size of these datasets, publishing time, annotation category and etc. The experimental results of object detection methods and semantic segmentation methods in the fisheye image have been compared and analyzed. The evaluation dataset of fisheye image, the construction of algorithm model of fisheye image and the efficiency of the model issues have been discussed. The fisheye image processing has been benefited from the development of weak supervised and unsupervised learning.关键词:automatic drive;surround fisheye images;image correction;object detection;semantic segmentation;fisheye image dataset;research overview135|426|0更新时间:2024-05-07
Review

-
 摘要:Objective Good quality images with rich information and good visual effect have been concerned in digital imaging. Due to the limitation of "dynamic range", existing imaging equipment cannot record all the details of one scene via one exposure imaging, which seriously affects the visual effect and key information retention of source images. A mismatch in the dynamic range has been caused to real scene amongst existing imaging, display equipment and human eye's response. The dynamic range can be regarded as the brightness ratio between the brightest and darkest points in natural scene ima-ges. The dynamic range of human visual system is 105: 1. The dynamic range of images captured/displayed by digital imaging/display equipment is only 102: 1, which is significantly lower than the corresponding one of human visual system. Multi-exposure image fusion has provided a simple and effective way to solve the mismatch of dynamic range between existing imaging/display equipment and human eye. Multi-exposure image fusion has been used to perform the weighted fusion of multiple images via various cameras at different exposure levels. The information of source images has been maximally retained in the fused images, which ensures the fused images have the high-dynamic-range visual effect that matches the resolution of human eyes. Method Multi-exposure image fusion methods have usually categorized into spatial domain methods and transform domain methods. Spatial domain fusion methods either first divide source image sequences into image blocks according to certain rules and then perform the fusion of image blocks, or directly do the pixel-based fusion. The fused images often have different problems, such as unnatural connection of transition areas and uneven brightness distribution, which causes the low structural similarity between the fused images and source images. Transform domain fusion methods first decompose source images into the transform domain, and then perform the fusion according to certain fusion rules. Image decomposition has mainly divided into multi-scale decomposition and two-scale decomposition. Multi-scale decomposition requires up-sampling and down-sampling operations, which cause a certain degree of image information loss. Two-scale decomposition does not contain up-sampling and down-sampling operations, which avoids the problem of information loss caused by multi-scale decomposition, and avoids the shortcomings of spatial domain method to a certain extent. Two-scale decomposition can be directly decomposed into base and detail layers using filters, but the selection of filters seriously affects the quality of the fused images. A new exposure fusion algorithm based on two-scale decomposition and color prior has been proposed to obtain visual effect images like high-quality HDR (high dynamic range) images. The details of overexposed area and dark area can be involved in and the fused image has good color saturation. The main contributions have shown as follows: 1) To use the difference between image brightness and image saturation to determine the degree of exposure; To combine the difference and the image contrast as a quality measure. This method can distinguish the overexposed area and the unexposed area quickly and efficiently. The texture details of the overexposed area and the unexposed area have been considered. The color saturation and contrast of the fused image have been improved. 2) A fusion method based on two-scale decomposition has been presented. Fast guided filter to decompose the image can reduce the halo artifacts of the fused image to a certain extent, which makes the image have better visual effect. The detailed research workflows have shown as follows: First, the image has been decomposed by fast guided filtering. The obtained detail layer has been enhanced, which retains more detailed information, and reduces the halo artifacts of the fused image. Next, based on the color prior, the difference between brightness and saturation has been used to determine the degree of image exposure. The difference and the image contrast have been combined to calculate the fusion weight of multi-exposure images, ensuring the brightness and contrast of the fused images at the same time. At last, the guided filtering has been used to optimize the weight map, suppress noise, increase the pixels correlation and improve the visual effect of the fused images. Result 24 sets of multi-exposure image sequences have been included. From the overall contrast and color saturation of the fused images and the details of both overexposed and underexposed areas have been improved on the perspective of subjective evaluation. In terms of the analysis of objective evaluation criteria, two different quality evaluation algorithms have used to evaluate the fused results of multi-exposure image sequences. The evaluation results have shown that the averages of corresponding indicators reach 0.982 and 0.970 each. The two different structural similarity indexes have been improved, with an average improvement of 1.2% and 1.1% respectively. Conclusion According to subjective and objective evaluations, the good fusion performance of significant processing effects on image contrast, color saturation and detail information retention has been outreached. The algorithm has three main advantages with respect to low complexity, simple implementation and relatively fast running speed, to customize mobile devices. It can be applied to imaging equipment with low dynamic range to obtain ideal images.关键词:multi-exposure fusion (MEF);high dynamic range imaging;guided filtering;fast guided filtering;color prior63|134|1更新时间:2024-05-07
摘要:Objective Good quality images with rich information and good visual effect have been concerned in digital imaging. Due to the limitation of "dynamic range", existing imaging equipment cannot record all the details of one scene via one exposure imaging, which seriously affects the visual effect and key information retention of source images. A mismatch in the dynamic range has been caused to real scene amongst existing imaging, display equipment and human eye's response. The dynamic range can be regarded as the brightness ratio between the brightest and darkest points in natural scene ima-ges. The dynamic range of human visual system is 105: 1. The dynamic range of images captured/displayed by digital imaging/display equipment is only 102: 1, which is significantly lower than the corresponding one of human visual system. Multi-exposure image fusion has provided a simple and effective way to solve the mismatch of dynamic range between existing imaging/display equipment and human eye. Multi-exposure image fusion has been used to perform the weighted fusion of multiple images via various cameras at different exposure levels. The information of source images has been maximally retained in the fused images, which ensures the fused images have the high-dynamic-range visual effect that matches the resolution of human eyes. Method Multi-exposure image fusion methods have usually categorized into spatial domain methods and transform domain methods. Spatial domain fusion methods either first divide source image sequences into image blocks according to certain rules and then perform the fusion of image blocks, or directly do the pixel-based fusion. The fused images often have different problems, such as unnatural connection of transition areas and uneven brightness distribution, which causes the low structural similarity between the fused images and source images. Transform domain fusion methods first decompose source images into the transform domain, and then perform the fusion according to certain fusion rules. Image decomposition has mainly divided into multi-scale decomposition and two-scale decomposition. Multi-scale decomposition requires up-sampling and down-sampling operations, which cause a certain degree of image information loss. Two-scale decomposition does not contain up-sampling and down-sampling operations, which avoids the problem of information loss caused by multi-scale decomposition, and avoids the shortcomings of spatial domain method to a certain extent. Two-scale decomposition can be directly decomposed into base and detail layers using filters, but the selection of filters seriously affects the quality of the fused images. A new exposure fusion algorithm based on two-scale decomposition and color prior has been proposed to obtain visual effect images like high-quality HDR (high dynamic range) images. The details of overexposed area and dark area can be involved in and the fused image has good color saturation. The main contributions have shown as follows: 1) To use the difference between image brightness and image saturation to determine the degree of exposure; To combine the difference and the image contrast as a quality measure. This method can distinguish the overexposed area and the unexposed area quickly and efficiently. The texture details of the overexposed area and the unexposed area have been considered. The color saturation and contrast of the fused image have been improved. 2) A fusion method based on two-scale decomposition has been presented. Fast guided filter to decompose the image can reduce the halo artifacts of the fused image to a certain extent, which makes the image have better visual effect. The detailed research workflows have shown as follows: First, the image has been decomposed by fast guided filtering. The obtained detail layer has been enhanced, which retains more detailed information, and reduces the halo artifacts of the fused image. Next, based on the color prior, the difference between brightness and saturation has been used to determine the degree of image exposure. The difference and the image contrast have been combined to calculate the fusion weight of multi-exposure images, ensuring the brightness and contrast of the fused images at the same time. At last, the guided filtering has been used to optimize the weight map, suppress noise, increase the pixels correlation and improve the visual effect of the fused images. Result 24 sets of multi-exposure image sequences have been included. From the overall contrast and color saturation of the fused images and the details of both overexposed and underexposed areas have been improved on the perspective of subjective evaluation. In terms of the analysis of objective evaluation criteria, two different quality evaluation algorithms have used to evaluate the fused results of multi-exposure image sequences. The evaluation results have shown that the averages of corresponding indicators reach 0.982 and 0.970 each. The two different structural similarity indexes have been improved, with an average improvement of 1.2% and 1.1% respectively. Conclusion According to subjective and objective evaluations, the good fusion performance of significant processing effects on image contrast, color saturation and detail information retention has been outreached. The algorithm has three main advantages with respect to low complexity, simple implementation and relatively fast running speed, to customize mobile devices. It can be applied to imaging equipment with low dynamic range to obtain ideal images.关键词:multi-exposure fusion (MEF);high dynamic range imaging;guided filtering;fast guided filtering;color prior63|134|1更新时间:2024-05-07 -
 摘要:Objective Image fusion technology is of great significance for image recognition and comprehension. Infrared and visible image fusion has been widely applied in computer vision, target detection, video surveillance, military and many other areas. The weakened target, unclear background details, blurred edges and low fusion efficiency have been existing due to high algorithm complexity in fusion. The dual-scale methods can reduce the complexity of the algorithm and obtain satisfying results in the first level of decomposition itself compared to most multi-scale methods that require more than two decomposition levels, with utilizing the large difference of information on the two scales. However, insufficient extraction of salient features and neglect of the influence of noise which may lead to unexpected fusion effect. Dual-scale decomposition has been combined to the saliency analysis and spatial consistency for acquiring high-quality fusion of infrared and visible images. Method The visual saliency has been used to integrate the important and valuable information of the source images into the fused image. The spatial consistency has been fully considered to prevent the influence of noise on the fusion results. First, the mean filter has been used to filter the source image, to separate the high-frequency and low-frequency information in the image: the base image containing low-frequency information has been obtained first. The detail image containing high-frequency information has been acquired second via subtracting from the source image. Next, a simple weighted average fusion rule, that is, the arithmetic average rule, has been used to fuse the base image via the different sensitivity of the human visual system to the information of base image and detail image. The common features of the source images can be preserved and the redundant information of the fused base image can be reduced; For the detail image, the fusion weight based on visual saliency has been selected to guide the weighting. The saliency information of the image can be extracted using the difference between the mean and the median filter output. The saliency map of the source images can be obtained via Gaussian filter on the output difference. Therefore, the initial weight map has been constructed via the visual saliency. Furthermore, combined with the principle of spatial consistency, the initial weight map has been optimized based on guided filtering for the purpose of reducing noise and keeping the boundary aligned. The detail image can be fused under the guidance of the final weight map obtained. Therefore, the target, background details and edge information can be enhanced and the noise can be released. At last, the dual-scale reconstruction has been performed to obtain the final fused image of the fused base image and detail image. Result Based on the different characteristics of traditional and deep learning methods, two groups of different gray images from TNO and other public datasets have been opted for comparison experiments. The subjective and objective evaluations have been conducted with other methods to verify the effectiveness and superiority performance of the proposed method on the experimental platform MATLAB R2018a.The key prominent areas have been marked with white boxes in the results to fit the subjective analysis for illustrating the differences of the fused images in detail. The subjective analyzing method can comprehensively and accurately extract the information to obtain clear visual effect based on the source images and the fused image. First, the first group of experimental images and the effectiveness of the proposed method in improving the fusion effect can be verified on the aspect of objective evaluation. Next, the qualified average precision of average gradient, edge intensity, spatial frequency, feature mutual information and cross-entropy have been presented quantitatively, which are 3.990 7, 41.793 7, 10.536 6, 0.446 0 and 1.489 7, respectively. At last, the proposed method has shown obvious advantages in the second group of experimental images compared with a deep learning method. The highest entropy has been obtained both. An average increase of 91.28%, 91.45%, 85.10%, 0.18% and 45.45% in the above five metrics have been acquired respectively. Conclusion Due to the complexity of salient feature extraction and the uncertainty of noise in the fusion process, the extensive experiments have demonstrated that some existing fusion methods are inevitably limited, and the fusion effect cannot meet high-quality requirements of image processing. By contrast, the proposed method combining the dual-scale decomposition and the fusion weight based on visual saliency has achieved good results. The enhancement effect of the target, background details and edge information are particularly significant including anti-noise performance. High-quality fusion of multiple groups of images can be achieved quickly and effectively for providing the possibility of real-time fusion of infrared and visible images. The actual effect of this method has been more qualified in comparison with a fusion method based on deep learning framework. The further research method has been more universal and can be used to fuse multi-source and other multi-source and multi-mode images.关键词:infrared image;visible image;saliency analysis;spatial consistency;dual-scale decomposition;image fusion71|158|9更新时间:2024-05-07
摘要:Objective Image fusion technology is of great significance for image recognition and comprehension. Infrared and visible image fusion has been widely applied in computer vision, target detection, video surveillance, military and many other areas. The weakened target, unclear background details, blurred edges and low fusion efficiency have been existing due to high algorithm complexity in fusion. The dual-scale methods can reduce the complexity of the algorithm and obtain satisfying results in the first level of decomposition itself compared to most multi-scale methods that require more than two decomposition levels, with utilizing the large difference of information on the two scales. However, insufficient extraction of salient features and neglect of the influence of noise which may lead to unexpected fusion effect. Dual-scale decomposition has been combined to the saliency analysis and spatial consistency for acquiring high-quality fusion of infrared and visible images. Method The visual saliency has been used to integrate the important and valuable information of the source images into the fused image. The spatial consistency has been fully considered to prevent the influence of noise on the fusion results. First, the mean filter has been used to filter the source image, to separate the high-frequency and low-frequency information in the image: the base image containing low-frequency information has been obtained first. The detail image containing high-frequency information has been acquired second via subtracting from the source image. Next, a simple weighted average fusion rule, that is, the arithmetic average rule, has been used to fuse the base image via the different sensitivity of the human visual system to the information of base image and detail image. The common features of the source images can be preserved and the redundant information of the fused base image can be reduced; For the detail image, the fusion weight based on visual saliency has been selected to guide the weighting. The saliency information of the image can be extracted using the difference between the mean and the median filter output. The saliency map of the source images can be obtained via Gaussian filter on the output difference. Therefore, the initial weight map has been constructed via the visual saliency. Furthermore, combined with the principle of spatial consistency, the initial weight map has been optimized based on guided filtering for the purpose of reducing noise and keeping the boundary aligned. The detail image can be fused under the guidance of the final weight map obtained. Therefore, the target, background details and edge information can be enhanced and the noise can be released. At last, the dual-scale reconstruction has been performed to obtain the final fused image of the fused base image and detail image. Result Based on the different characteristics of traditional and deep learning methods, two groups of different gray images from TNO and other public datasets have been opted for comparison experiments. The subjective and objective evaluations have been conducted with other methods to verify the effectiveness and superiority performance of the proposed method on the experimental platform MATLAB R2018a.The key prominent areas have been marked with white boxes in the results to fit the subjective analysis for illustrating the differences of the fused images in detail. The subjective analyzing method can comprehensively and accurately extract the information to obtain clear visual effect based on the source images and the fused image. First, the first group of experimental images and the effectiveness of the proposed method in improving the fusion effect can be verified on the aspect of objective evaluation. Next, the qualified average precision of average gradient, edge intensity, spatial frequency, feature mutual information and cross-entropy have been presented quantitatively, which are 3.990 7, 41.793 7, 10.536 6, 0.446 0 and 1.489 7, respectively. At last, the proposed method has shown obvious advantages in the second group of experimental images compared with a deep learning method. The highest entropy has been obtained both. An average increase of 91.28%, 91.45%, 85.10%, 0.18% and 45.45% in the above five metrics have been acquired respectively. Conclusion Due to the complexity of salient feature extraction and the uncertainty of noise in the fusion process, the extensive experiments have demonstrated that some existing fusion methods are inevitably limited, and the fusion effect cannot meet high-quality requirements of image processing. By contrast, the proposed method combining the dual-scale decomposition and the fusion weight based on visual saliency has achieved good results. The enhancement effect of the target, background details and edge information are particularly significant including anti-noise performance. High-quality fusion of multiple groups of images can be achieved quickly and effectively for providing the possibility of real-time fusion of infrared and visible images. The actual effect of this method has been more qualified in comparison with a fusion method based on deep learning framework. The further research method has been more universal and can be used to fuse multi-source and other multi-source and multi-mode images.关键词:infrared image;visible image;saliency analysis;spatial consistency;dual-scale decomposition;image fusion71|158|9更新时间:2024-05-07 -
 摘要:ObjectiveDeep convolutional neural network has shown strong reconstruction ability in image super-resolution (SR) task. Efficient super-resolution has a great practical application scenario due to the popularity of intelligent edge devices such as mobile phones. A very lightweight and efficient super-resolution network has been proposed. The proposed method has reduced the number of parameters and floating point operations(FLOPs) greatly and achieved excellent reconstruction performance based on recursive feature selection module and parameter sharing mechanism. MethodThe proposed lightweight attention feature selection recursive network (AFSNet)has mainly evolved three key components: low-level feature extraction, high-level feature extraction and upsample reconstruction. In the low-level feature extraction part, the input low-resolution image has passed through a 3×3 convolutional layer to extract the low-level features. In the high-level feature extraction part, a recursive feature selection module(FSM) to capture the high-level features has been designed. At the end of the network, a shared upsample block to super-resolve low-level and high-level features has been utilized to obtain the final high-resolution image. Specifically, the FSM has contained a feature enhancement block and an efficient channel attention block. The feature enhancement block has four convolutional layers. Different from other cascaded convolutional layers, this block has retained part of features in each convolutional layer and fused them at the end of this module. Features extracted from different convolutional layers have different levels of hierarchical information, so the proposed network can choose to preserve part of them step-by-step and aggregate them at the end of this module. An efficient channel attention (ECA) block has been presented following the feature enhancement block. Different from the channel attention (CA) in the residual channel attention networks(RCAN), the ECA has avoided the dimensionality reduction operation, which involves two 1×1 convolutional layers to realize no-linear mapping and cross-channel interaction. A local cross-channel interaction strategy has been implemented excluded dimensionality reduction via one-dimensional (1D) convolution. Furthermore, ECA block has adaptively opted kernel size of 1D convolution for determining coverage of local cross-channel interaction. The proposed ECA block has not increased the parameter numbers to improve the reconstruction performance.This network has employed recursive mechanism to share parameters across the efficient feature enhancement block as well to reduce the number of parameters extremely. In the end of the high-level feature extraction part, this network has concatenated and fused the output of all the FSM. The research network can capture valuable contextual information via this multi-stage feature fusion (MSFF) mechanism. In the upsample reconstruction part, this network has utilized a shared upsample block to reconstruct the low-level and high-level features into a high-resolution image, which includes a convolutional layer and a sub-pixel layer. The high-resolution image has fused low and high frequency information together without increasing the parameter numbers. ResultThe DF2K dataset as training dataset has been adopted, which includes 800 images from the DIV2K dataset and 2 650 images from the Flickr2k dataset. Data augmentation has been performed based on random horizontal flipping and 90 degree rotation further. The corresponding low-resolution image has been obtained by bicubic downsampling from the high-resolution image (the downscale scale is×2, ×3, ×4). The evaluation has used five benchmark datasets: Set5, Set14, B100, Urban100 and Manga109 respectively. Peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) have been used as the evaluation metrics to measure reconstruction performance.The AFSNet crops borders and the metrics in the luminance channel of transformed YCbCr space have been calculated following the evaluation protocol in residual dense network(RDN). In training process, 16 low-resoution patches of size 48×48 and their corresponding high-resolution patches have been randomly cropped. In the high-level feature extraction stage, six recursive feature selection modules have been used. The number of channels in each convolution layer C=64 for our FSM has been set. In each channel split operation, the features of 16 channels have been preserved. The remaining 48 channels have been continued to perform the next convolution. The network parameters with Adam optimizer have been optimized. The network has been trained using L1 loss function. The initial learning rate has been set to 2E-4 and decreased half for every 200 epochs. The network has been implemented under the PyTorch framework with an NVIDIA 2080 Ti GPU for acceleration. The proposed AFSNet with several state-of-the-art lightweight convolutional neural networks(CNNs)-based SISR methods has been compared. The AFSNet has achieved the best performance in terms of both PSNR and SSIM among all compared methods in almost all benchmark datasets excluded×2 results on the Set5. The AFSNet has much less parameter numbers and much smaller FLOPs in particular. For×4 SR in the Set14 test dataset, the PSNR results have increased 0.4 dB, 0.6 dB and 0.43 dB respectively compared with SRFBN-S, IDN and CARN-M. The parameter numbers of AFSNet have been decreased by 47%, 53% and 38%. Meanwhile, the 24.5 G FLOPs of AFSNet have been superior to 30 G FLOPs as usual. In addition, the AFSNet has conducted ablation study on the effectiveness of the ECA module and MSFF mechanism. The AFSNet has selected×4 Set5 as test dataset.The PSNR results have been decrease by 0.09 dB and 0.11 dB, which shows the effectiveness of the proposed ECA module and MSFF mechanism when the AFSsNet dropped out ECA module and MSFF mechanism respectively. ConclusionThe research has presented a lightweight attention feature selection recursive network for super-resolution, which improved reconstruction performance without large parameters and FLOPs. The network has employed a 3×3 convolutional layer in the low-level feature extraction part to extract low-resolution(LR) low-level features, then six recursive feature selection modules have been used to learn non-linear mapping and exploit high-level features. The FSM has preserved hierarchical features step-by-step and aggregated them according to the importance of candidate features based on the proposed efficient channel attention module evalution. Meanwhile, multi-stage feature fusion by concatenating outputs of all the FSM has been conducted to effectively capture contextual information of different stages. The extracted low-level and high-level features have been upsampled by a parameter-shared upsample block.关键词:image super-resolution;lightweight networks;recursive mechanism;parameter share;feature enhancement;efficient channel attention63|26|1更新时间:2024-05-07
摘要:ObjectiveDeep convolutional neural network has shown strong reconstruction ability in image super-resolution (SR) task. Efficient super-resolution has a great practical application scenario due to the popularity of intelligent edge devices such as mobile phones. A very lightweight and efficient super-resolution network has been proposed. The proposed method has reduced the number of parameters and floating point operations(FLOPs) greatly and achieved excellent reconstruction performance based on recursive feature selection module and parameter sharing mechanism. MethodThe proposed lightweight attention feature selection recursive network (AFSNet)has mainly evolved three key components: low-level feature extraction, high-level feature extraction and upsample reconstruction. In the low-level feature extraction part, the input low-resolution image has passed through a 3×3 convolutional layer to extract the low-level features. In the high-level feature extraction part, a recursive feature selection module(FSM) to capture the high-level features has been designed. At the end of the network, a shared upsample block to super-resolve low-level and high-level features has been utilized to obtain the final high-resolution image. Specifically, the FSM has contained a feature enhancement block and an efficient channel attention block. The feature enhancement block has four convolutional layers. Different from other cascaded convolutional layers, this block has retained part of features in each convolutional layer and fused them at the end of this module. Features extracted from different convolutional layers have different levels of hierarchical information, so the proposed network can choose to preserve part of them step-by-step and aggregate them at the end of this module. An efficient channel attention (ECA) block has been presented following the feature enhancement block. Different from the channel attention (CA) in the residual channel attention networks(RCAN), the ECA has avoided the dimensionality reduction operation, which involves two 1×1 convolutional layers to realize no-linear mapping and cross-channel interaction. A local cross-channel interaction strategy has been implemented excluded dimensionality reduction via one-dimensional (1D) convolution. Furthermore, ECA block has adaptively opted kernel size of 1D convolution for determining coverage of local cross-channel interaction. The proposed ECA block has not increased the parameter numbers to improve the reconstruction performance.This network has employed recursive mechanism to share parameters across the efficient feature enhancement block as well to reduce the number of parameters extremely. In the end of the high-level feature extraction part, this network has concatenated and fused the output of all the FSM. The research network can capture valuable contextual information via this multi-stage feature fusion (MSFF) mechanism. In the upsample reconstruction part, this network has utilized a shared upsample block to reconstruct the low-level and high-level features into a high-resolution image, which includes a convolutional layer and a sub-pixel layer. The high-resolution image has fused low and high frequency information together without increasing the parameter numbers. ResultThe DF2K dataset as training dataset has been adopted, which includes 800 images from the DIV2K dataset and 2 650 images from the Flickr2k dataset. Data augmentation has been performed based on random horizontal flipping and 90 degree rotation further. The corresponding low-resolution image has been obtained by bicubic downsampling from the high-resolution image (the downscale scale is×2, ×3, ×4). The evaluation has used five benchmark datasets: Set5, Set14, B100, Urban100 and Manga109 respectively. Peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) have been used as the evaluation metrics to measure reconstruction performance.The AFSNet crops borders and the metrics in the luminance channel of transformed YCbCr space have been calculated following the evaluation protocol in residual dense network(RDN). In training process, 16 low-resoution patches of size 48×48 and their corresponding high-resolution patches have been randomly cropped. In the high-level feature extraction stage, six recursive feature selection modules have been used. The number of channels in each convolution layer C=64 for our FSM has been set. In each channel split operation, the features of 16 channels have been preserved. The remaining 48 channels have been continued to perform the next convolution. The network parameters with Adam optimizer have been optimized. The network has been trained using L1 loss function. The initial learning rate has been set to 2E-4 and decreased half for every 200 epochs. The network has been implemented under the PyTorch framework with an NVIDIA 2080 Ti GPU for acceleration. The proposed AFSNet with several state-of-the-art lightweight convolutional neural networks(CNNs)-based SISR methods has been compared. The AFSNet has achieved the best performance in terms of both PSNR and SSIM among all compared methods in almost all benchmark datasets excluded×2 results on the Set5. The AFSNet has much less parameter numbers and much smaller FLOPs in particular. For×4 SR in the Set14 test dataset, the PSNR results have increased 0.4 dB, 0.6 dB and 0.43 dB respectively compared with SRFBN-S, IDN and CARN-M. The parameter numbers of AFSNet have been decreased by 47%, 53% and 38%. Meanwhile, the 24.5 G FLOPs of AFSNet have been superior to 30 G FLOPs as usual. In addition, the AFSNet has conducted ablation study on the effectiveness of the ECA module and MSFF mechanism. The AFSNet has selected×4 Set5 as test dataset.The PSNR results have been decrease by 0.09 dB and 0.11 dB, which shows the effectiveness of the proposed ECA module and MSFF mechanism when the AFSsNet dropped out ECA module and MSFF mechanism respectively. ConclusionThe research has presented a lightweight attention feature selection recursive network for super-resolution, which improved reconstruction performance without large parameters and FLOPs. The network has employed a 3×3 convolutional layer in the low-level feature extraction part to extract low-resolution(LR) low-level features, then six recursive feature selection modules have been used to learn non-linear mapping and exploit high-level features. The FSM has preserved hierarchical features step-by-step and aggregated them according to the importance of candidate features based on the proposed efficient channel attention module evalution. Meanwhile, multi-stage feature fusion by concatenating outputs of all the FSM has been conducted to effectively capture contextual information of different stages. The extracted low-level and high-level features have been upsampled by a parameter-shared upsample block.关键词:image super-resolution;lightweight networks;recursive mechanism;parameter share;feature enhancement;efficient channel attention63|26|1更新时间:2024-05-07 -
 摘要:ObjectiveAs an important branch of image processing, image super-resolution has attracted extensive attention of many scholars. The attention mechanism has originally been applied to machine translation in deep learning. As an extension of the attention mechanism, the channel attention mechanism has been widely used in image super-resolution. A single image super-resolution using region-level channel attention has been proposed. A region-level channel attention mechanism has been presented in the network, which can assign different attention to different channels in different regions. Meanwhile, the high-frequency aware loss has been demonstrated with aiming at the characteristics that L1 and L2 losses commonly used at present tend to produce very smooth results. This loss function has strengthened the weight of losses at high-frequency positions to the generation of high-frequency details. MethodThe network structure has consisted of three parts: low-level feature extraction, high-level feature extraction and image reconstruction. In the low-level feature extraction part, the algorithm used 1 layer of 3×3 convolution. The high-level feature extraction part has contained a non-local module and several residual dense block attention modules. The non-local module has extracted the non-local similarity information via the non-local operation. Sub-pixel convolutional layer has been used before calculating non-local similar information. The calculation has been conducted at low resolution. Dense connection has been used in the residual dense block attention modules to facilitate the network adaptive accumulation of features of different layers. Meanwhile, residual learning has been used to further optimize the gradient propagation problem. Region-level channel attention mechanism has been introduced to pay attention to information in different regions adaptively. The initial non-local similarity information has been added to the last layer by skip connection. In the image reconstruction part, sub-pixel convolution has been used to up-sampling operation on features and a 3×3 convolutional layer has been used to obtain the final reconstruction result. In terms of loss function, the high-frequency aware loss has been operated for enhancing the network's ability of reconstructing high frequency details. Before training, the locations of high-frequency details in the image have been extracted. During training, more weight has been added to the losses at these locations to better learn the reconstruction process of high-frequency details. The whole training process has been divided into two stages. In the first stage, L1 loss has used to train the network. In the second stage, the high-frequency aware loss and L1 loss has used to fine-tune the model of the first stage together. ResultRegion-level channel attention and the high-frequency aware loss have been verified via ablation study. The model using the region-level channel attention is significantly better on peak signal to noise ratio (PSNR). The high-frequency aware loss and L1 loss together to fine-tune the model is better on PSNR than the model only use L1 loss to fine-tune. The good effect of the region-level channel attention and the high-frequency aware loss have been verified both at the same time. Set5, Set14, Berkeley segmentation dataset (BSD100) and Urban100 have been selected for testing in comparison with other algorithms. The comparison algorithms have included Bicubic, image super-resolution using deep convolutional networks (SRCNN), accurate image super-resolution using very deep convolutional networks (VDSR), image super-resolution using very deep residual channel attention networks (RCAN), feedback network for image super-resolution (SRFBN) and single image super-resolution via a holistic attention network (HAN) respectively. On the subjective effect of the present, the results with a factor of 4, three of the results have been selected for display. The results generated by the algorithm have presented more rich in texture without any blurring or distortion. In the presentation of objective indicators, PSNR and structural similarity (SSIM) have been used as indicators to make a comprehensive comparison under three different factors of 2, 3 and 4, respectively. PSNR of the model with amplification factor of 4 under four standard test sets is 32.51 dB, 28.82 dB, 27.72 dB and 26.66 dB, respectively. Conclusion A super-resolution algorithm using region-level channel attention mechanism has been commonly used channel attention in region-level. Based on the high-frequency aware loss, the network can reconstruct high frequency details by increasing the attention degree of the network to the high frequency detail location. The experimental results have shown that the proposed algorithm has its priority in objective indicators and subjective effects via using region-level channel attention mechanism and high-frequency aware loss.关键词:deep learning;convolutional neural network(CNN);super-resolution;attention mechanism;non-local neural network159|255|4更新时间:2024-05-07
摘要:ObjectiveAs an important branch of image processing, image super-resolution has attracted extensive attention of many scholars. The attention mechanism has originally been applied to machine translation in deep learning. As an extension of the attention mechanism, the channel attention mechanism has been widely used in image super-resolution. A single image super-resolution using region-level channel attention has been proposed. A region-level channel attention mechanism has been presented in the network, which can assign different attention to different channels in different regions. Meanwhile, the high-frequency aware loss has been demonstrated with aiming at the characteristics that L1 and L2 losses commonly used at present tend to produce very smooth results. This loss function has strengthened the weight of losses at high-frequency positions to the generation of high-frequency details. MethodThe network structure has consisted of three parts: low-level feature extraction, high-level feature extraction and image reconstruction. In the low-level feature extraction part, the algorithm used 1 layer of 3×3 convolution. The high-level feature extraction part has contained a non-local module and several residual dense block attention modules. The non-local module has extracted the non-local similarity information via the non-local operation. Sub-pixel convolutional layer has been used before calculating non-local similar information. The calculation has been conducted at low resolution. Dense connection has been used in the residual dense block attention modules to facilitate the network adaptive accumulation of features of different layers. Meanwhile, residual learning has been used to further optimize the gradient propagation problem. Region-level channel attention mechanism has been introduced to pay attention to information in different regions adaptively. The initial non-local similarity information has been added to the last layer by skip connection. In the image reconstruction part, sub-pixel convolution has been used to up-sampling operation on features and a 3×3 convolutional layer has been used to obtain the final reconstruction result. In terms of loss function, the high-frequency aware loss has been operated for enhancing the network's ability of reconstructing high frequency details. Before training, the locations of high-frequency details in the image have been extracted. During training, more weight has been added to the losses at these locations to better learn the reconstruction process of high-frequency details. The whole training process has been divided into two stages. In the first stage, L1 loss has used to train the network. In the second stage, the high-frequency aware loss and L1 loss has used to fine-tune the model of the first stage together. ResultRegion-level channel attention and the high-frequency aware loss have been verified via ablation study. The model using the region-level channel attention is significantly better on peak signal to noise ratio (PSNR). The high-frequency aware loss and L1 loss together to fine-tune the model is better on PSNR than the model only use L1 loss to fine-tune. The good effect of the region-level channel attention and the high-frequency aware loss have been verified both at the same time. Set5, Set14, Berkeley segmentation dataset (BSD100) and Urban100 have been selected for testing in comparison with other algorithms. The comparison algorithms have included Bicubic, image super-resolution using deep convolutional networks (SRCNN), accurate image super-resolution using very deep convolutional networks (VDSR), image super-resolution using very deep residual channel attention networks (RCAN), feedback network for image super-resolution (SRFBN) and single image super-resolution via a holistic attention network (HAN) respectively. On the subjective effect of the present, the results with a factor of 4, three of the results have been selected for display. The results generated by the algorithm have presented more rich in texture without any blurring or distortion. In the presentation of objective indicators, PSNR and structural similarity (SSIM) have been used as indicators to make a comprehensive comparison under three different factors of 2, 3 and 4, respectively. PSNR of the model with amplification factor of 4 under four standard test sets is 32.51 dB, 28.82 dB, 27.72 dB and 26.66 dB, respectively. Conclusion A super-resolution algorithm using region-level channel attention mechanism has been commonly used channel attention in region-level. Based on the high-frequency aware loss, the network can reconstruct high frequency details by increasing the attention degree of the network to the high frequency detail location. The experimental results have shown that the proposed algorithm has its priority in objective indicators and subjective effects via using region-level channel attention mechanism and high-frequency aware loss.关键词:deep learning;convolutional neural network(CNN);super-resolution;attention mechanism;non-local neural network159|255|4更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectivePoint cloud semantic segmentation has been an essential visual task for scene understanding from two-dimensional vision to three-dimensional vision. Deep learning processing point cloud has been divided into three methods as following: point-based method, projection-based method and voxel-based method. Projection-based methods have obtained a two-dimensional image from the point cloud based on spherical projection. The semantic segmentation on the point cloud has been conducted via a two-dimensional convolution neural network method. The original point cloud has been restored via some post-processing. However, those methods have usually only been used for LiDAR point clouds. Voxel-based methods have often consumed a lot of memory due to voxel representation. The above two methods have both represented the unstructured point cloud into a structured form and processed it via a two-dimensional convolutional neural network or a three-dimensional convolutional neural network. However, this method will lose geometric details. Point-based methods have often consumed more memory subjected to additional neighborhood information storage. Some existing methods have usually divided the entire point cloud into blocks for processing. However, this method will destroy the geometric structure of the scene to cause incomplete information capture from the scene. In addition, some point-based methods in large-scale scenes have the problem of insufficient receptive fields caused by shallow network structures due to excessive memory consumption. A computation-based and memory-efficient network structure has been presented that can be used for end-to-end large-scale scene semantic segmentation.MethodThe spatial depthwise residual (SDR) block has been designed via combining the spatial depthwise convolution and residual structure to learn geometric features from the point cloud effectively. The receptive field has been regarded as one of the key factors in semantic segmentation. In order to increase the receptive field, a dilated feature aggregation (DFA) module, which has a larger receptive field than the SDR block, but with less calculation. The core idea of this module has reduced computational consumption and memory consumption via down sampling. Combining SDR block and DFA module, SDRNet, a deeper encoder-decoder network structure has been constructed, which can be applied to large-scale scenes semantic segmentation. The data distribution of the input data has affected the training process of the network. Data distribution is not conducive to network learning based on the analysis of input data of the convolution kernel. Hierarchical normalization (HN) can reduce the learning difficulty of the convolution kernel. A special SDR block has been used for a kind of rotation invariance of sparse LiDAR point clouds. Before convolution, the point and its neighborhood have been first rotated to a fixed angle. The influence of the rotation of the radar data around the Z-axis can be eliminated. The prediction result has not be changed via the rotated point cloud around the Z-axis. This special SDR block can significantly improve the performance of the network when processing LiDAR point clouds.ResultThe stanford large-scale 3D indoor space(S3DIS) dataset and the Karlsruhe Institute of Technology and Toyota Technological Institute(SemanticKITTI) dataset have been used. Different parameters for different tasks to adapt to the application scenarios of the task have been setup. A larger model for higher accuracy has been constructed because the S3DIS task has been focused on accuracy. The SemanticKITTI scene has required more speed. A lighter hyperparameter has been chosen. The designed model has been compared with several state-of-the-art models on the S3DIS datasets by using 6-flod cross validation. Mean intersection over union (mIoU), mean accuracy (mAcc) and overall accuracy (OA) have been evaluated on the S3DIS dataset. The method has achieved 88.9% OA, 82.4% mAcc and 71.7% mIoU each. These methods have presented well on different metrics. The online single scan evaluation has been conducted on the SemanticKITTI dataset. 59.1% mIoU has been obtained. The method has achieved better results in mIoU and several accuracy of several classes in comparison with point-based methods and projection-based methods. In an unmanned driving scenario like SemanticKITTI, the inference speed of the mode is a crucial factor. In addition, the inference speed of SDRNet with the different number of points has been tested. When the number of points is 50 K, the network processing point cloud speed can reach 11 frames per second (fps) by using a machine with NVIDIA RTX and i7-8700K. Moreover, this paper has constructed experiment of ablation study to explain the performance of each part of the model further.ConclusionThe experiments on the S3DIS dataset SemanticKITTI dataset have shown that the research method can directly perform semantic segmentation in large-scale point cloud scenes. It can extract information from the scene effectively and achieve high accuracy. The experiment of ablation study on S3DIS area-5 has demonstrated that both DFA and HN can improve performance. The experiment of ablation study on SemanticKITTI validation set has presented that eliminating the influence of rotation by using the special SDR block can effectively improve the performance of the network. The higher accuracy and a relatively fast speed have been achieved via analyzing the relationship between the number of points and the frame rate.关键词:deep learning;semantic segmentation;normalization;point cloud;residual neural network;receptive field63|178|3更新时间:2024-05-07
摘要:ObjectivePoint cloud semantic segmentation has been an essential visual task for scene understanding from two-dimensional vision to three-dimensional vision. Deep learning processing point cloud has been divided into three methods as following: point-based method, projection-based method and voxel-based method. Projection-based methods have obtained a two-dimensional image from the point cloud based on spherical projection. The semantic segmentation on the point cloud has been conducted via a two-dimensional convolution neural network method. The original point cloud has been restored via some post-processing. However, those methods have usually only been used for LiDAR point clouds. Voxel-based methods have often consumed a lot of memory due to voxel representation. The above two methods have both represented the unstructured point cloud into a structured form and processed it via a two-dimensional convolutional neural network or a three-dimensional convolutional neural network. However, this method will lose geometric details. Point-based methods have often consumed more memory subjected to additional neighborhood information storage. Some existing methods have usually divided the entire point cloud into blocks for processing. However, this method will destroy the geometric structure of the scene to cause incomplete information capture from the scene. In addition, some point-based methods in large-scale scenes have the problem of insufficient receptive fields caused by shallow network structures due to excessive memory consumption. A computation-based and memory-efficient network structure has been presented that can be used for end-to-end large-scale scene semantic segmentation.MethodThe spatial depthwise residual (SDR) block has been designed via combining the spatial depthwise convolution and residual structure to learn geometric features from the point cloud effectively. The receptive field has been regarded as one of the key factors in semantic segmentation. In order to increase the receptive field, a dilated feature aggregation (DFA) module, which has a larger receptive field than the SDR block, but with less calculation. The core idea of this module has reduced computational consumption and memory consumption via down sampling. Combining SDR block and DFA module, SDRNet, a deeper encoder-decoder network structure has been constructed, which can be applied to large-scale scenes semantic segmentation. The data distribution of the input data has affected the training process of the network. Data distribution is not conducive to network learning based on the analysis of input data of the convolution kernel. Hierarchical normalization (HN) can reduce the learning difficulty of the convolution kernel. A special SDR block has been used for a kind of rotation invariance of sparse LiDAR point clouds. Before convolution, the point and its neighborhood have been first rotated to a fixed angle. The influence of the rotation of the radar data around the Z-axis can be eliminated. The prediction result has not be changed via the rotated point cloud around the Z-axis. This special SDR block can significantly improve the performance of the network when processing LiDAR point clouds.ResultThe stanford large-scale 3D indoor space(S3DIS) dataset and the Karlsruhe Institute of Technology and Toyota Technological Institute(SemanticKITTI) dataset have been used. Different parameters for different tasks to adapt to the application scenarios of the task have been setup. A larger model for higher accuracy has been constructed because the S3DIS task has been focused on accuracy. The SemanticKITTI scene has required more speed. A lighter hyperparameter has been chosen. The designed model has been compared with several state-of-the-art models on the S3DIS datasets by using 6-flod cross validation. Mean intersection over union (mIoU), mean accuracy (mAcc) and overall accuracy (OA) have been evaluated on the S3DIS dataset. The method has achieved 88.9% OA, 82.4% mAcc and 71.7% mIoU each. These methods have presented well on different metrics. The online single scan evaluation has been conducted on the SemanticKITTI dataset. 59.1% mIoU has been obtained. The method has achieved better results in mIoU and several accuracy of several classes in comparison with point-based methods and projection-based methods. In an unmanned driving scenario like SemanticKITTI, the inference speed of the mode is a crucial factor. In addition, the inference speed of SDRNet with the different number of points has been tested. When the number of points is 50 K, the network processing point cloud speed can reach 11 frames per second (fps) by using a machine with NVIDIA RTX and i7-8700K. Moreover, this paper has constructed experiment of ablation study to explain the performance of each part of the model further.ConclusionThe experiments on the S3DIS dataset SemanticKITTI dataset have shown that the research method can directly perform semantic segmentation in large-scale point cloud scenes. It can extract information from the scene effectively and achieve high accuracy. The experiment of ablation study on S3DIS area-5 has demonstrated that both DFA and HN can improve performance. The experiment of ablation study on SemanticKITTI validation set has presented that eliminating the influence of rotation by using the special SDR block can effectively improve the performance of the network. The higher accuracy and a relatively fast speed have been achieved via analyzing the relationship between the number of points and the frame rate.关键词:deep learning;semantic segmentation;normalization;point cloud;residual neural network;receptive field63|178|3更新时间:2024-05-07 -
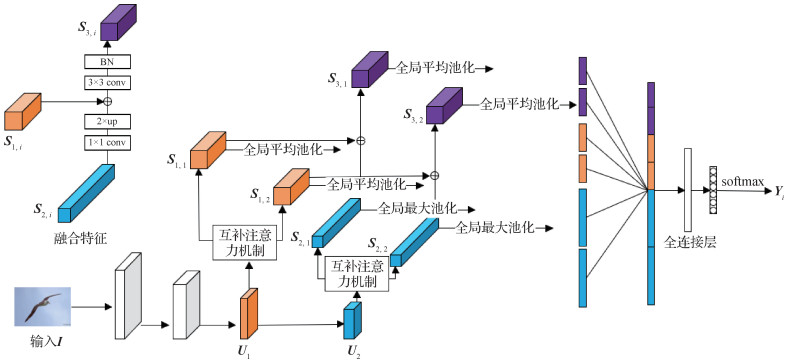 摘要:ObjectiveFine-grained image classification has aimed at classifying objects based on very similar categories, such as subcategories of birds, dogs and cars in comparison with coarse-grained image classification. Due to the characteristic of small inter-class variation and large intra-class variation, fine-grained image classification has been more challenging than general image classification. The key is to extract the subtle discriminative features of the object. The attention mechanism can actively learn the salient features of the target, which has been widely used in various image feature extraction tasks. The traditional attention mechanism has one obstacle that the effective characteristics of the objects. e.g., SE (squeeze-and-excitation) attention mechanism, OSME (one-squeeze multi-excitation) attention mechanism and BAM (bottleneck attention module) cannot be adequately extracted. The traditional attention mechanism has focused on the most salient features of the target and suppressed the feature representation of other regions. The suppressed regions have usually contained the effective features of the target. The feature representation can be obtained more adequate via extracting the features form the suppressed regions of object to propose a new attention mechanism, called complementary attention mechanism (complemented SE, CSE), which can extract more effective features of the target.MethodA new complemented attention mechanism CSE based on the SE attention mechanism has been proposed. The complementary attention mechanism has been divided into three steps. 1) the SE attention mechanism has been used to extract the most significant discriminative features of the target and the suppressed features. 2) The SE attention mechanism to extract secondary salient features has been used for the suppressed features again. 3) Two kinds of features fusing have obtained a more efficient feature representation. Moreover, a cross-layer network structure has extracted the significance features of different layers and fused them to get the final characteristic representation for all information of the object mining. In the experimental stage, the model in PyTorch has been developed and ResNet50 (pretrained on ImageNet) as convolutional neural network(CNN) backbone has been used. The input images have been resized to 448×448 pixels for training and testing. The model has been trained using the SGD (stochastic gradient descent) with momentum of 0.9, weight decay of 0.000 5 and the learning rate of 0.001. The model has been trained for 150 epochs and the learning rate decayed by 0.1 every 30 epochs.ResultIn order to verify the effectiveness, the experiments have been conducted on four fine-grained datasets: CUB-Birds, Stanford Dogs, Stanford Cars and FGVC-Aircraft. The classification accuracy has been achieved with the following percentages: 87.9%, 89.1%, 93.9% and 92.4%, respectively. The results have shown that the method has achieved the same effect as the state-of-the-art methods. In the ablation study, the capability of three attention mechanisms (SE, OSME and CSE) has been compared to extract features in the same conditions. The results have shown that CSE attention mechanism improved by 1.1% and 0.6%, respectively, in the CUB-Birds dataset, and improved by 1.7% and 1%, respectively, in the Stanford Dogs dataset compared with SE attention mechanism and OSME attention mechanism. The feature visualization has been conducted to see the regional features of attention mechanism more intuitive. All results have shown that CSE attention mechanism has more powerful ability of feature extraction than SE attention mechanism and OSME attention mechanism. The validity of each structure in the network on the CUB-Birds dataset has been verified.ConclusionTo solve the problem of insufficient feature extraction in traditional attention mechanisms, a complemented attention method for fine-grained image classification have been proposed, which focused on improving the ability of the attention mechanism to extract features and obtaining efficient representation of target features. The CSE attention mechanism has been more concerned to discriminative regional characteristics than the SE attention mechanism and the OSME attention mechanism in ablation study.关键词:fine-grained;attention mechanism;image classification;feature extraction;feature representation173|225|2更新时间:2024-05-07
摘要:ObjectiveFine-grained image classification has aimed at classifying objects based on very similar categories, such as subcategories of birds, dogs and cars in comparison with coarse-grained image classification. Due to the characteristic of small inter-class variation and large intra-class variation, fine-grained image classification has been more challenging than general image classification. The key is to extract the subtle discriminative features of the object. The attention mechanism can actively learn the salient features of the target, which has been widely used in various image feature extraction tasks. The traditional attention mechanism has one obstacle that the effective characteristics of the objects. e.g., SE (squeeze-and-excitation) attention mechanism, OSME (one-squeeze multi-excitation) attention mechanism and BAM (bottleneck attention module) cannot be adequately extracted. The traditional attention mechanism has focused on the most salient features of the target and suppressed the feature representation of other regions. The suppressed regions have usually contained the effective features of the target. The feature representation can be obtained more adequate via extracting the features form the suppressed regions of object to propose a new attention mechanism, called complementary attention mechanism (complemented SE, CSE), which can extract more effective features of the target.MethodA new complemented attention mechanism CSE based on the SE attention mechanism has been proposed. The complementary attention mechanism has been divided into three steps. 1) the SE attention mechanism has been used to extract the most significant discriminative features of the target and the suppressed features. 2) The SE attention mechanism to extract secondary salient features has been used for the suppressed features again. 3) Two kinds of features fusing have obtained a more efficient feature representation. Moreover, a cross-layer network structure has extracted the significance features of different layers and fused them to get the final characteristic representation for all information of the object mining. In the experimental stage, the model in PyTorch has been developed and ResNet50 (pretrained on ImageNet) as convolutional neural network(CNN) backbone has been used. The input images have been resized to 448×448 pixels for training and testing. The model has been trained using the SGD (stochastic gradient descent) with momentum of 0.9, weight decay of 0.000 5 and the learning rate of 0.001. The model has been trained for 150 epochs and the learning rate decayed by 0.1 every 30 epochs.ResultIn order to verify the effectiveness, the experiments have been conducted on four fine-grained datasets: CUB-Birds, Stanford Dogs, Stanford Cars and FGVC-Aircraft. The classification accuracy has been achieved with the following percentages: 87.9%, 89.1%, 93.9% and 92.4%, respectively. The results have shown that the method has achieved the same effect as the state-of-the-art methods. In the ablation study, the capability of three attention mechanisms (SE, OSME and CSE) has been compared to extract features in the same conditions. The results have shown that CSE attention mechanism improved by 1.1% and 0.6%, respectively, in the CUB-Birds dataset, and improved by 1.7% and 1%, respectively, in the Stanford Dogs dataset compared with SE attention mechanism and OSME attention mechanism. The feature visualization has been conducted to see the regional features of attention mechanism more intuitive. All results have shown that CSE attention mechanism has more powerful ability of feature extraction than SE attention mechanism and OSME attention mechanism. The validity of each structure in the network on the CUB-Birds dataset has been verified.ConclusionTo solve the problem of insufficient feature extraction in traditional attention mechanisms, a complemented attention method for fine-grained image classification have been proposed, which focused on improving the ability of the attention mechanism to extract features and obtaining efficient representation of target features. The CSE attention mechanism has been more concerned to discriminative regional characteristics than the SE attention mechanism and the OSME attention mechanism in ablation study.关键词:fine-grained;attention mechanism;image classification;feature extraction;feature representation173|225|2更新时间:2024-05-07 -
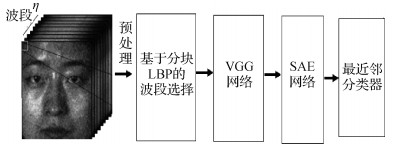 摘要:ObjectiveThe applications of hyperspectral face imaging have been getting more and more concerned due to the low cost of hyperspectral camera. Hyperspectral imaging has been providing sufficient distinctive information along the spectral dimension for unconstrainted face recognition system. The hyperspectral face images have been taking challenges such as low signal to noise ratio, high computational complexity and cross-band misalignment. High data dimensionality can result in high computational costs. Not all spectral bands are equally informative and discriminative. The useless spectral band usage may even produce noises and weaken the performance. Spatial feature extraction and optimal bands selection have been two vital issues for robust hyperspectral face recognition. The feature representation based on deep learning has obtained excellent performance in image classification tasks. The deep neural networks to extract spatial features for hyperspectral face data have been focused on. A novel hyperspectral face recognition method based on automatic bands selection and visual geometry group network (VGG net) with the success of VGG net in traditional face recognition.MethodFirst, an improved AdaBoost algorithm has been built up to select the optimal bands for different facial regions. One face has been divided into 3×5 partition mode based on the robust 68 landmarks from the cascade regression method to get the adaptive spectral features for different facial organs. Next, support vector machine (SVM) has been opted as a weak classifier for AdaBoost ensemble learning for bands selection. SVM is more suitable for small sample and high dimension sets, and lower sensitivity to imbalanced datasets, which are the characteristics of hyperspectral face data. Thus, the AdaBoost SVM algorithm has been used to select optimal bands (ranging from 450 nm to 1 090 nm) for hyperspectral face recognition. The AdaBoost SVM is based on partition local binary pattern (LBP) features. Second, a convolutional neural network (CNN) structure has been built for deep feature extraction in each hyperspectral face image based on VGG12 deep network. Therefore, VGG12 network can fulfill the deep feature extraction in spatial domain. Third, a three-layer stacked auto-encoder (SAE) has been trained to mine the discriminative and compact features amongst different bands. Finally, the nearest neighbor classifier has been applied to get the final results. The automatic bands selection is based on partition LBP features instead of original images. The optimal bands selection can choose the most suitable bands for different regions in faces. The second novelty has combined the supervised deep network (VGG12) with unsupervised learning network (SAE) to fully mine within and between spectral features in hyperspectral faces.ResultTo verify the effectiveness of the proposed hyperspectral face recognition method, the comparative experiments have been conducted on public UWA hyperspectral face database (UWA-HSFD) and Hong Kong Polytechnic University hyperspectral face database (PolyU-HSFD) databases where the spectral bands vary from 400 to 1 090 nm with the spectral interval of 10 nm. The two datasets have been preprocessed and normalized to 220×180 hyperspectral face images. The ratio of the test set of the training set is 1:1. The first half samples have been used as the training set and the rest have been used as the test set. The VGG12 network has been trained based on the multi-spectral bands cycle. The objective function of the network is Adam. The super parameters of VGG12 are set as follows: α=0.001, β1=0.9, β2=0.999, epoch=10. The learning rate of SAE network is 0.000 1 and epoch is 10. The all experiments have been implemented on the computer platform whose configuration is of 2.6 GHz CPU, 8 GB GPU. In contrast experiment 1, the bands selection algorithm based on partition LBP features has been superior to the traditional method based on the whole faces. The main reason is that partition LBP features can improve the influence of non-alignment factors of hyperspectral facial data and select optimal bands combination for the different face regions. In contrast experiments 2, the method with SAE model can get a higher recognition rate than that without SAE model by introducing little computational complexity (about 15% consuming time). In contrast experiment 3, compared with the existing deep learning network, the proposed VGG12 network, retaining only 68 spectral bands, achieves the highest recognition rates (96.8% and 97.2%) on both databases.ConclusionThe experiment results have shown that the combination of bands selection and VGG12 is feasible and effective for the performance improvement of hyperspectral face recognition.关键词:hyperspectral face recognition;local binary pattern (LBP);VGG net;bands selection;AdaBoost SVM82|204|0更新时间:2024-05-07
摘要:ObjectiveThe applications of hyperspectral face imaging have been getting more and more concerned due to the low cost of hyperspectral camera. Hyperspectral imaging has been providing sufficient distinctive information along the spectral dimension for unconstrainted face recognition system. The hyperspectral face images have been taking challenges such as low signal to noise ratio, high computational complexity and cross-band misalignment. High data dimensionality can result in high computational costs. Not all spectral bands are equally informative and discriminative. The useless spectral band usage may even produce noises and weaken the performance. Spatial feature extraction and optimal bands selection have been two vital issues for robust hyperspectral face recognition. The feature representation based on deep learning has obtained excellent performance in image classification tasks. The deep neural networks to extract spatial features for hyperspectral face data have been focused on. A novel hyperspectral face recognition method based on automatic bands selection and visual geometry group network (VGG net) with the success of VGG net in traditional face recognition.MethodFirst, an improved AdaBoost algorithm has been built up to select the optimal bands for different facial regions. One face has been divided into 3×5 partition mode based on the robust 68 landmarks from the cascade regression method to get the adaptive spectral features for different facial organs. Next, support vector machine (SVM) has been opted as a weak classifier for AdaBoost ensemble learning for bands selection. SVM is more suitable for small sample and high dimension sets, and lower sensitivity to imbalanced datasets, which are the characteristics of hyperspectral face data. Thus, the AdaBoost SVM algorithm has been used to select optimal bands (ranging from 450 nm to 1 090 nm) for hyperspectral face recognition. The AdaBoost SVM is based on partition local binary pattern (LBP) features. Second, a convolutional neural network (CNN) structure has been built for deep feature extraction in each hyperspectral face image based on VGG12 deep network. Therefore, VGG12 network can fulfill the deep feature extraction in spatial domain. Third, a three-layer stacked auto-encoder (SAE) has been trained to mine the discriminative and compact features amongst different bands. Finally, the nearest neighbor classifier has been applied to get the final results. The automatic bands selection is based on partition LBP features instead of original images. The optimal bands selection can choose the most suitable bands for different regions in faces. The second novelty has combined the supervised deep network (VGG12) with unsupervised learning network (SAE) to fully mine within and between spectral features in hyperspectral faces.ResultTo verify the effectiveness of the proposed hyperspectral face recognition method, the comparative experiments have been conducted on public UWA hyperspectral face database (UWA-HSFD) and Hong Kong Polytechnic University hyperspectral face database (PolyU-HSFD) databases where the spectral bands vary from 400 to 1 090 nm with the spectral interval of 10 nm. The two datasets have been preprocessed and normalized to 220×180 hyperspectral face images. The ratio of the test set of the training set is 1:1. The first half samples have been used as the training set and the rest have been used as the test set. The VGG12 network has been trained based on the multi-spectral bands cycle. The objective function of the network is Adam. The super parameters of VGG12 are set as follows: α=0.001, β1=0.9, β2=0.999, epoch=10. The learning rate of SAE network is 0.000 1 and epoch is 10. The all experiments have been implemented on the computer platform whose configuration is of 2.6 GHz CPU, 8 GB GPU. In contrast experiment 1, the bands selection algorithm based on partition LBP features has been superior to the traditional method based on the whole faces. The main reason is that partition LBP features can improve the influence of non-alignment factors of hyperspectral facial data and select optimal bands combination for the different face regions. In contrast experiments 2, the method with SAE model can get a higher recognition rate than that without SAE model by introducing little computational complexity (about 15% consuming time). In contrast experiment 3, compared with the existing deep learning network, the proposed VGG12 network, retaining only 68 spectral bands, achieves the highest recognition rates (96.8% and 97.2%) on both databases.ConclusionThe experiment results have shown that the combination of bands selection and VGG12 is feasible and effective for the performance improvement of hyperspectral face recognition.关键词:hyperspectral face recognition;local binary pattern (LBP);VGG net;bands selection;AdaBoost SVM82|204|0更新时间:2024-05-07 -
 摘要:ObjectiveSkeleton-based action recognition has been concerned in recent years, as the dynamics of human skeletons has significant information for the task of action recognition. The action of human skeletons can be seen as time series of human poses, or the combination of human joint trajectories. The trajectory of important joints indicating the action class has conveyed the most significant information among all the human joints. The trajectories of these joints have been subjected to some distortions when performing the same action under different attempts. In this case, two similar trajectories of corresponding joints should share a basic shape. However, these two trajectories have appeared in diverse kinds of distortions due to individual factors. These distortions have been caused by spatial and temporal factors. Spatial factors have included the change of viewpoints, different skeleton sizes and action amplitudes, while temporal factors indicate time scaling along the time series, denoting the order and speed of performing specific action. All the spatial factors can be modeled by the affine transformation in 3D space, whereas the uniform time scaling has been commonly discussed case, which can be seen as affine transformation in 1D space. These two kinds of distortions as the spatio-temporal dual affine transformation have been combined. A novel invariant feature under these distortions has been proposed and utilized for facilitating skeleton-based action recognition. A kind of feature invariant based on the spatio-temporal affine transformation has aided the identification of similar trajectories to be beneficial for action recognition.MethodA general method for constructing spatio-temporal dual affine differential invariant (STDADI) has been proposed. The rational polynomial of derivatives of joint trajectories to obtain the invariants has been utilized in detail via eliminating the transformation parameters effectively. Robust, coordinate-system-independent feature has calculated directly from the 3D coordinates. Bounding the degree of polynomial and the order of derivatives, we generate 8 independent STDADIs and combine them as an invariant vector at each moment for each human joint. Moreover, an intuitive and effective method called channel augmentation has been proposed to extend input data with STDADI along the channel dimension for training and evaluation. Specifically, the coordinate vector and the STDADI vector at each joint for each frame have been concatenated. Channel augmentation has introduced invariant information into input data without changing the inner structure of neural networks. The spatio-temporal graph convolutional networks (ST-GCN) as the basic network have been used. The skeleton data modeling as a graph structure has envolved spatial and temporal connections between human joints simultaneously. Particularly, it has exploited local pattern and correlation from human skeletons. In other words, the importance of joints along the action sequence has been expressed as the weights of human joints in the spatio-temporal graph. This is in line with our STDADI, because both of them focus on describing joint dynamics, and our features further provide an invariant expression which is not affected by the distortions.ResultThe synthetic data has been examined to verify the effectiveness of STDADI as well as the large-scale action recognition dataset. First, 3D spiral line and selected joint trajectory based on NTU-RGB+D applied with random transformation parameters has shown that STDADI is invariant under the spatio-temporal affine transformations. Next, the effectiveness of the proposed feature and method has been validated on the large-scale action recognition dataset NTU(Nanyang Technological University)RGB+D (NTU 60) and its extended version NTU-RGB+D 120 (NTU 120), which is currently the largest dataset with 3D joint annotations captured in a constrained indoor environment, and perform some detailed study to examine the contributions of STDADI. A data augmentation technique as well as the original ST-GCN have been as the baseline methods. The data augmentation technique has involved rotation, scaling and shear transformations of 3D skeletons. The same training strategy and hyper-parameters as the original ST-GCN have been used. ST-GCN + channel augmentation has performed well. Compared with the ST-GCN using raw data, in NTU 60, the cross-subject and cross-view recognition accuracy has been increased by 1.9% and 3.0%, respectively; in NTU 120, the cross-subject and cross-setup recognition accuracy has increased by 5.6% and 4.5% respectively. As it is mainly consisted of 3D geometric transformations, the accuracy in cross-view recognition has been much improved but contributes little to the cross-subject setting for data augmentation. The spatio-temporal dual affine transformation assumption has been validated on both evaluation criteria.ConclusionA general method for constructing spatio-temporal dual affine differential invariant (STDADI) has been proposed. The effectiveness of this invariant feature using a channel augmentation technique has been proved on the large-scale action recognition dataset NTU-RGB+D and NTU-RGB+D 120. The combination of hand-crafted features and data-driven methods has improved the accuracy and generalization well.关键词:motion analysis;skeleton-based action recognition;spatio-temporal dual affine transformation;differential invariant features;channel augmentation;generalization ability93|220|1更新时间:2024-05-07
摘要:ObjectiveSkeleton-based action recognition has been concerned in recent years, as the dynamics of human skeletons has significant information for the task of action recognition. The action of human skeletons can be seen as time series of human poses, or the combination of human joint trajectories. The trajectory of important joints indicating the action class has conveyed the most significant information among all the human joints. The trajectories of these joints have been subjected to some distortions when performing the same action under different attempts. In this case, two similar trajectories of corresponding joints should share a basic shape. However, these two trajectories have appeared in diverse kinds of distortions due to individual factors. These distortions have been caused by spatial and temporal factors. Spatial factors have included the change of viewpoints, different skeleton sizes and action amplitudes, while temporal factors indicate time scaling along the time series, denoting the order and speed of performing specific action. All the spatial factors can be modeled by the affine transformation in 3D space, whereas the uniform time scaling has been commonly discussed case, which can be seen as affine transformation in 1D space. These two kinds of distortions as the spatio-temporal dual affine transformation have been combined. A novel invariant feature under these distortions has been proposed and utilized for facilitating skeleton-based action recognition. A kind of feature invariant based on the spatio-temporal affine transformation has aided the identification of similar trajectories to be beneficial for action recognition.MethodA general method for constructing spatio-temporal dual affine differential invariant (STDADI) has been proposed. The rational polynomial of derivatives of joint trajectories to obtain the invariants has been utilized in detail via eliminating the transformation parameters effectively. Robust, coordinate-system-independent feature has calculated directly from the 3D coordinates. Bounding the degree of polynomial and the order of derivatives, we generate 8 independent STDADIs and combine them as an invariant vector at each moment for each human joint. Moreover, an intuitive and effective method called channel augmentation has been proposed to extend input data with STDADI along the channel dimension for training and evaluation. Specifically, the coordinate vector and the STDADI vector at each joint for each frame have been concatenated. Channel augmentation has introduced invariant information into input data without changing the inner structure of neural networks. The spatio-temporal graph convolutional networks (ST-GCN) as the basic network have been used. The skeleton data modeling as a graph structure has envolved spatial and temporal connections between human joints simultaneously. Particularly, it has exploited local pattern and correlation from human skeletons. In other words, the importance of joints along the action sequence has been expressed as the weights of human joints in the spatio-temporal graph. This is in line with our STDADI, because both of them focus on describing joint dynamics, and our features further provide an invariant expression which is not affected by the distortions.ResultThe synthetic data has been examined to verify the effectiveness of STDADI as well as the large-scale action recognition dataset. First, 3D spiral line and selected joint trajectory based on NTU-RGB+D applied with random transformation parameters has shown that STDADI is invariant under the spatio-temporal affine transformations. Next, the effectiveness of the proposed feature and method has been validated on the large-scale action recognition dataset NTU(Nanyang Technological University)RGB+D (NTU 60) and its extended version NTU-RGB+D 120 (NTU 120), which is currently the largest dataset with 3D joint annotations captured in a constrained indoor environment, and perform some detailed study to examine the contributions of STDADI. A data augmentation technique as well as the original ST-GCN have been as the baseline methods. The data augmentation technique has involved rotation, scaling and shear transformations of 3D skeletons. The same training strategy and hyper-parameters as the original ST-GCN have been used. ST-GCN + channel augmentation has performed well. Compared with the ST-GCN using raw data, in NTU 60, the cross-subject and cross-view recognition accuracy has been increased by 1.9% and 3.0%, respectively; in NTU 120, the cross-subject and cross-setup recognition accuracy has increased by 5.6% and 4.5% respectively. As it is mainly consisted of 3D geometric transformations, the accuracy in cross-view recognition has been much improved but contributes little to the cross-subject setting for data augmentation. The spatio-temporal dual affine transformation assumption has been validated on both evaluation criteria.ConclusionA general method for constructing spatio-temporal dual affine differential invariant (STDADI) has been proposed. The effectiveness of this invariant feature using a channel augmentation technique has been proved on the large-scale action recognition dataset NTU-RGB+D and NTU-RGB+D 120. The combination of hand-crafted features and data-driven methods has improved the accuracy and generalization well.关键词:motion analysis;skeleton-based action recognition;spatio-temporal dual affine transformation;differential invariant features;channel augmentation;generalization ability93|220|1更新时间:2024-05-07 -
 摘要:ObjectiveVarious existing saliency detection methods have been widely used in saliency images processing. Current saliency detection algorithm can only get the significant target with clear center and blurred edges, losing some important boundary information. The existing saliency detection algorithm based on low-rank matrix recovery has required the use of kernel norms to constrain the low-rank matrix. An unsupervised low-rank matrix restoration iterative re-weighted least squares method has been proposed based on multi-scale segmentation prior information for image saliency detection.MethodFirst, the input image has been divided into three levels of granularity: fine-grained, medium-granular and coarse-grained. Fine-grained segmentation can divide an image into multiple superpixels. Medium-grain size segmentation can also segment the image but produce fewer regions. Coarse-grain size segmentation can maximize the separation of significant objects from the background but the image may be under-segmented. The segmentation prior information has been obtained from the fusion of fine-grained and coarse-grained priors. Next, the fused segmentation prior information has been obtained. A coarse significant map has been generated based on iterative re-weighted least squares method. At last, the fused significant map has been post-smoothed via using a medium-grained segmentation prior. The final visual saliency map has been acquired.ResultThe experiment has used the three datasets of Microsoft Research Asia 10K (MSRA10K), salient object detection dataset (SOD) and extended complex scene saliency dataset (ECSSD) for testing with comparison of the existing eleven algorithms. The demonstrated algorithm can generate significant target accuracy and clear boundaries of the significant graph. The MSRA10K dataset has contained images of various salient objects of different sizes but only one salient object in each image. The highest area under receiver operating characteristic (ROC) curve value and F-measure value on the MSRA10K dataset have been achieved among them. The mean absolute error (MAE) value has been second only to the structured matrix decomposition (SMD) algorithm and robust back ground detection (RBD) algorithm. The area under ROC curve (AUC) value and F-measure value have been improved by 3.9% and 12.3% respectively compared with the suboptimal algorithm robust principal component analysis (RPCA). A simplified priori functionality and no supervision, and even has implemented the hierarchical fusion of hierarchical co-salient object detection via color names (HCNs) algorithm and the exploiting color name (HCN) algorithm. It is hard to choose the appropriate ratio to suppress the background without the size of the object like the frequency-based frequency-tuned (FT) algorithm. The RPCA algorithm has not considered the spatial structure of the image. The outline of the salient target that can be detected in the MSRA10K dataset with a salient target single. The SOD dataset has contained images of multiple salient objects (independent or adjacent). In the SOD dataset, the algorithm of this paper is superior to other algorithms except SMD algorithm in terms of AUC value, F-measure value and MAE value. The AUC value is second only to the SMD algorithm, smoothness constraint (SC) algorithm and graph-based visual saliency (GBVS) algorithm. The F-measure value is lower than the best algorithm SMD 2.6%. The algorithm in this paper is superior to other algorithms except SMD algorithm in terms of AUC value, F-measure value and MAE value. The algorithm is effective in the case of multiple salient targets. However, the performance of saliency filters (SF), segmentation driven low-rank matrix recovery (SLR), robust back ground detection (RBD) is greatly reduced. Just as the SLR algorithm introduces a segmentation prior first, making it more sensitive to the number of significant targets in the image. As for SF due to its dependence on contrast, its AUC value and F-measure value decrease sharply as the significant target increases. The SF algorithm has divided the salient targets that are not significantly contrasted with the background into the background due to multiple salient targets in the two contrast metrics. The RBD algorithm has relied on the boundary connectivity of the background to segment the image caused poorly performance when detecting multiple salient target images. The ECSSD dataset has contained background complex images as well as significant targets of varying sizes. On the ECSSD dataset, the highest F-measure value of 75.5% has been achieved. The AUC value has been slightly lower than the optimal algorithm SC 1%, while the MAE value is slightly lower than the optimal algorithm HCNs 2%. The highest F-measure values and where the AUC and MAE values have been slightly lower than those of the SC algorithm and the HCNs algorithm. The SC algorithm with deformation smoothness constraint is only slightly inferior to the ECSSD dataset. The SMD algorithm has performed well on the MSRA10K dataset and the SOD dataset and moderated on the ECSSD dataset. The tree structure method of capturing image information is not applicable to images with complex backgrounds. Method such as GBVS, foreground-background segmentation (FBS), SF, and RBD have relied on methods like visual saliency, foreground enhancement, background enhancement and the use of a tree structure. Cues like suppression, contrast bias and center bias have not maintained good performance.ConclusionA multi-scale saliency detection algorithm has been demonstrated. First, a coarse saliency map by iterative reweighted least squares method based on the prior of multiscale segmentation has been generated. Second, the coarse saliency map by iterative reweighted least squares has been fused. Finally, the qualified saliency map by smooth fusion of the significant maps with medium granularity has been obtained. The algorithm with the latest methods on three public datasets of MSRA10K, SOD, and ECSSD has been verified. Significant targets have been achieved based on accurate, clear boundary saliency segmentation results. The algorithm has presented more robust.关键词:salient object detection;multiscale segmentation prior;low-rank recovery;iterative re-weighted least squares method;foreground complex;background complex68|164|0更新时间:2024-05-07
摘要:ObjectiveVarious existing saliency detection methods have been widely used in saliency images processing. Current saliency detection algorithm can only get the significant target with clear center and blurred edges, losing some important boundary information. The existing saliency detection algorithm based on low-rank matrix recovery has required the use of kernel norms to constrain the low-rank matrix. An unsupervised low-rank matrix restoration iterative re-weighted least squares method has been proposed based on multi-scale segmentation prior information for image saliency detection.MethodFirst, the input image has been divided into three levels of granularity: fine-grained, medium-granular and coarse-grained. Fine-grained segmentation can divide an image into multiple superpixels. Medium-grain size segmentation can also segment the image but produce fewer regions. Coarse-grain size segmentation can maximize the separation of significant objects from the background but the image may be under-segmented. The segmentation prior information has been obtained from the fusion of fine-grained and coarse-grained priors. Next, the fused segmentation prior information has been obtained. A coarse significant map has been generated based on iterative re-weighted least squares method. At last, the fused significant map has been post-smoothed via using a medium-grained segmentation prior. The final visual saliency map has been acquired.ResultThe experiment has used the three datasets of Microsoft Research Asia 10K (MSRA10K), salient object detection dataset (SOD) and extended complex scene saliency dataset (ECSSD) for testing with comparison of the existing eleven algorithms. The demonstrated algorithm can generate significant target accuracy and clear boundaries of the significant graph. The MSRA10K dataset has contained images of various salient objects of different sizes but only one salient object in each image. The highest area under receiver operating characteristic (ROC) curve value and F-measure value on the MSRA10K dataset have been achieved among them. The mean absolute error (MAE) value has been second only to the structured matrix decomposition (SMD) algorithm and robust back ground detection (RBD) algorithm. The area under ROC curve (AUC) value and F-measure value have been improved by 3.9% and 12.3% respectively compared with the suboptimal algorithm robust principal component analysis (RPCA). A simplified priori functionality and no supervision, and even has implemented the hierarchical fusion of hierarchical co-salient object detection via color names (HCNs) algorithm and the exploiting color name (HCN) algorithm. It is hard to choose the appropriate ratio to suppress the background without the size of the object like the frequency-based frequency-tuned (FT) algorithm. The RPCA algorithm has not considered the spatial structure of the image. The outline of the salient target that can be detected in the MSRA10K dataset with a salient target single. The SOD dataset has contained images of multiple salient objects (independent or adjacent). In the SOD dataset, the algorithm of this paper is superior to other algorithms except SMD algorithm in terms of AUC value, F-measure value and MAE value. The AUC value is second only to the SMD algorithm, smoothness constraint (SC) algorithm and graph-based visual saliency (GBVS) algorithm. The F-measure value is lower than the best algorithm SMD 2.6%. The algorithm in this paper is superior to other algorithms except SMD algorithm in terms of AUC value, F-measure value and MAE value. The algorithm is effective in the case of multiple salient targets. However, the performance of saliency filters (SF), segmentation driven low-rank matrix recovery (SLR), robust back ground detection (RBD) is greatly reduced. Just as the SLR algorithm introduces a segmentation prior first, making it more sensitive to the number of significant targets in the image. As for SF due to its dependence on contrast, its AUC value and F-measure value decrease sharply as the significant target increases. The SF algorithm has divided the salient targets that are not significantly contrasted with the background into the background due to multiple salient targets in the two contrast metrics. The RBD algorithm has relied on the boundary connectivity of the background to segment the image caused poorly performance when detecting multiple salient target images. The ECSSD dataset has contained background complex images as well as significant targets of varying sizes. On the ECSSD dataset, the highest F-measure value of 75.5% has been achieved. The AUC value has been slightly lower than the optimal algorithm SC 1%, while the MAE value is slightly lower than the optimal algorithm HCNs 2%. The highest F-measure values and where the AUC and MAE values have been slightly lower than those of the SC algorithm and the HCNs algorithm. The SC algorithm with deformation smoothness constraint is only slightly inferior to the ECSSD dataset. The SMD algorithm has performed well on the MSRA10K dataset and the SOD dataset and moderated on the ECSSD dataset. The tree structure method of capturing image information is not applicable to images with complex backgrounds. Method such as GBVS, foreground-background segmentation (FBS), SF, and RBD have relied on methods like visual saliency, foreground enhancement, background enhancement and the use of a tree structure. Cues like suppression, contrast bias and center bias have not maintained good performance.ConclusionA multi-scale saliency detection algorithm has been demonstrated. First, a coarse saliency map by iterative reweighted least squares method based on the prior of multiscale segmentation has been generated. Second, the coarse saliency map by iterative reweighted least squares has been fused. Finally, the qualified saliency map by smooth fusion of the significant maps with medium granularity has been obtained. The algorithm with the latest methods on three public datasets of MSRA10K, SOD, and ECSSD has been verified. Significant targets have been achieved based on accurate, clear boundary saliency segmentation results. The algorithm has presented more robust.关键词:salient object detection;multiscale segmentation prior;low-rank recovery;iterative re-weighted least squares method;foreground complex;background complex68|164|0更新时间:2024-05-07 -
 摘要:ObjectiveNational production safety data in 2019 has showed that 95% of production safety accidents were caused by unsafe behaviors of workers, including improperly wearing protection supplies. Therefore, safety helmet wearing detection has played a vital role in safety production. An end-to-end detection algorithm with high accuracy and strong generalization ability is of great significance to ensure operators' personal safety and reduce safety accidents. Safety helmet wearing detection has belonged to the category of target detection. Early target detection algorithms have been mostly conducted via manual feature construction. With the development of deep learning, target detection has been divided into "two-stage detection" and "one-stage detection" and these series of detectors greatly improved the detection speed and detection accuracy. However, the current deep learning algorithms have failed to ensure accurate detection of small targets, and are not generally applicable in various scenarios, resulting in poor generalization ability and week anti-interference ability. To solve these problems, a safety helmet wearing detection method that combines environmental characteristics and improved you only look once version 4 (YOLOv4) has been proposed to achieve efficient detection of safety helmets wearing.MethodBased on YOLOv4, cross stage partial darknet53 (CSPDarknet53) has been as backbone network, path aggregation network (PANET) and spatial pyramid pooling (SPP) as neck. The feature maps have been achieved with three different sizes of YOLOv4. With the input size 608×608 pixels, the resulting resolutions of YOLO head have been 76×76 pixels, 38×38 pixels, and 19×19 pixels respectively. Due to the great difference between the high-level and low-level feature map information, the given input original image has extracted feature to achieve the same resolution as the YOLO head. For the input original image, a 3×3 convolution operation has been conducted via a batch normalization (BN) layer for normalization operation and ReLU with unilateral suppression and sparse activation as the activation function. The above process has been iterated until the resolution of the feature map is consistent with the size of the corresponding YOLO head. Then, under the condition that the receptive field is consistent, the output feature maps with three different sizes of YOLOv4 have been added to the feature maps obtained by feature extraction from the original image, thereby fusing high-level features with low-level features to capture more detailed information. After that, 3×3 convolution operation has been used for the fused feature maps to reduce the aliasing effect after feature map fusion to get three sizes of output. The feature map obtained by feature extraction of the original image has represented a shallow network with high resolution and more detailed features to predict the location information while YOLO head represents a deep network with low resolution and more semantic features, which helps to decide the category information. The model can achieve higher accuracy in detecting large and small targets via combining the two feature maps. Moreover, data enhancement techniques have been used, such as random cropping, CutMix, simulating environment corrupted with noise and using adversarial samples for adversarial training, to add small disturbances to the training data. The training data has been enhanced to improve the generalization ability of the model and the robustness of the model has been improved.ResultThe improved YOLOv4 has been tested on the open source safety helmet wearing dataset (SHWD). The mean average precision (mAP) has reached 91.55% and the recall reached 98.62%. Compared with the existing CornerNet-Lite, Faster region convolutional neural network (RCNN), YOLOv3, YOLOv4 and other algorithms, the proposed method can achieve improved performance in mAP and recall. When compared with traditional YOLOv4, this improved YOLOv4 can increase mAP and recall by 5.2% and 5.79% respectively. The data enhancement methods adopted in this paper has improved the mAP of CornerNet-Lite, Faster RCNN, YOLOv3, YOLOv4 and Improved YOLOv4 from 2% to 5%. The improved YOLOv4 has increased mAP by 4.27% from 91.55% to 95.82%. In addition, the proposed method has more stable performance after data enhancement when testing under different environmental conditions. For instance, the detection performance of night images has been highly improved with mAP increasing from 67.73% to 84.10%. The comparison of experimental results via adding adversarial samples in the training set has shown that the recall of the proposed model has increased by 0.29% and the mAP has increased by 0.56%.ConclusionThe method which fuses environmental features and improved YOLOv4 has been proposed for safety helmet wearing detection. The proposed method has used convolutional neural networks to extract convolutional features, and improve the efficiency of feature extraction and target detection greatly. Moreover, the effective combined information of high and low layers by fusing different feature maps can improve the detection accuracy of small targets. The multiple data enhancement methods have been used to improve the robustness of the model in complex scenarios. The end-to-end training of the detection algorithm has been realized and achieved the accuracy, generalization ability and robustness of the model improvement for the effective detection of safety helmet wearing.关键词:safety helmet wearing detection;feature map fusion;data enhancement;adversarial examples;YOLOv4105|95|9更新时间:2024-05-07
摘要:ObjectiveNational production safety data in 2019 has showed that 95% of production safety accidents were caused by unsafe behaviors of workers, including improperly wearing protection supplies. Therefore, safety helmet wearing detection has played a vital role in safety production. An end-to-end detection algorithm with high accuracy and strong generalization ability is of great significance to ensure operators' personal safety and reduce safety accidents. Safety helmet wearing detection has belonged to the category of target detection. Early target detection algorithms have been mostly conducted via manual feature construction. With the development of deep learning, target detection has been divided into "two-stage detection" and "one-stage detection" and these series of detectors greatly improved the detection speed and detection accuracy. However, the current deep learning algorithms have failed to ensure accurate detection of small targets, and are not generally applicable in various scenarios, resulting in poor generalization ability and week anti-interference ability. To solve these problems, a safety helmet wearing detection method that combines environmental characteristics and improved you only look once version 4 (YOLOv4) has been proposed to achieve efficient detection of safety helmets wearing.MethodBased on YOLOv4, cross stage partial darknet53 (CSPDarknet53) has been as backbone network, path aggregation network (PANET) and spatial pyramid pooling (SPP) as neck. The feature maps have been achieved with three different sizes of YOLOv4. With the input size 608×608 pixels, the resulting resolutions of YOLO head have been 76×76 pixels, 38×38 pixels, and 19×19 pixels respectively. Due to the great difference between the high-level and low-level feature map information, the given input original image has extracted feature to achieve the same resolution as the YOLO head. For the input original image, a 3×3 convolution operation has been conducted via a batch normalization (BN) layer for normalization operation and ReLU with unilateral suppression and sparse activation as the activation function. The above process has been iterated until the resolution of the feature map is consistent with the size of the corresponding YOLO head. Then, under the condition that the receptive field is consistent, the output feature maps with three different sizes of YOLOv4 have been added to the feature maps obtained by feature extraction from the original image, thereby fusing high-level features with low-level features to capture more detailed information. After that, 3×3 convolution operation has been used for the fused feature maps to reduce the aliasing effect after feature map fusion to get three sizes of output. The feature map obtained by feature extraction of the original image has represented a shallow network with high resolution and more detailed features to predict the location information while YOLO head represents a deep network with low resolution and more semantic features, which helps to decide the category information. The model can achieve higher accuracy in detecting large and small targets via combining the two feature maps. Moreover, data enhancement techniques have been used, such as random cropping, CutMix, simulating environment corrupted with noise and using adversarial samples for adversarial training, to add small disturbances to the training data. The training data has been enhanced to improve the generalization ability of the model and the robustness of the model has been improved.ResultThe improved YOLOv4 has been tested on the open source safety helmet wearing dataset (SHWD). The mean average precision (mAP) has reached 91.55% and the recall reached 98.62%. Compared with the existing CornerNet-Lite, Faster region convolutional neural network (RCNN), YOLOv3, YOLOv4 and other algorithms, the proposed method can achieve improved performance in mAP and recall. When compared with traditional YOLOv4, this improved YOLOv4 can increase mAP and recall by 5.2% and 5.79% respectively. The data enhancement methods adopted in this paper has improved the mAP of CornerNet-Lite, Faster RCNN, YOLOv3, YOLOv4 and Improved YOLOv4 from 2% to 5%. The improved YOLOv4 has increased mAP by 4.27% from 91.55% to 95.82%. In addition, the proposed method has more stable performance after data enhancement when testing under different environmental conditions. For instance, the detection performance of night images has been highly improved with mAP increasing from 67.73% to 84.10%. The comparison of experimental results via adding adversarial samples in the training set has shown that the recall of the proposed model has increased by 0.29% and the mAP has increased by 0.56%.ConclusionThe method which fuses environmental features and improved YOLOv4 has been proposed for safety helmet wearing detection. The proposed method has used convolutional neural networks to extract convolutional features, and improve the efficiency of feature extraction and target detection greatly. Moreover, the effective combined information of high and low layers by fusing different feature maps can improve the detection accuracy of small targets. The multiple data enhancement methods have been used to improve the robustness of the model in complex scenarios. The end-to-end training of the detection algorithm has been realized and achieved the accuracy, generalization ability and robustness of the model improvement for the effective detection of safety helmet wearing.关键词:safety helmet wearing detection;feature map fusion;data enhancement;adversarial examples;YOLOv4105|95|9更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveThe goal of 3D human body reconstruction has been building a credible and reliable human body model. The credibility of the reconstructed results cannot be guaranteed entirely subject to the mismatch issue between predicted posture angle value and the real human joint movement based on the skinned multi-person linear model (SMPL). A prior of the joint rotation angle value range make the reconstruction result to fit human joint mechanical structure. The rationality and effectiveness of the value range setting combined with a simple reconstruction method have been demonstrated more better than the 3D SMPL-based reconstruction. The reconstruction accuracy of the model has been significantly improved.MethodThe two-stage 3D human body reconstruction method has tailored the reconstruction to improve the credibility and provide more details of the 3D human body model effectively in terms of the range setting verification. In the first stage, the description has been preprocessed to reduce noise, to extract key information as well as to remove the background of the image. In the second stage, the reconstruction has been completed via using the posture and shape parameters of the human body in the image learned with the residual network based on the SMPL model. The UP-3D dataset has been used. The details of reconstruction algorithm have been presented as follows: first, the human silhouette image has been extracted based on the render light image in via the UP-3D dataset with the priority of the acquired segmentation of the human body in the dataset. An RGB image of human body with uniform size can be obtained via removing the background of the original image based on the silhouette image. Next, the resized RGB image and the Render light image has been concatenated and used as the input of the pose regression. Silhouette has been input into the body shape regression simultaneously. The residual network has been used to learn human body posture parameters and body shape parameters based on the parametric statistical body shape model. At last, the range of the predicted body parameters based on the residual network computing has been supervised. The useful predicted body parameters and the posture parameters in supervision have been input into the SMPL model to generate a three-dimensional human body model via the same posture and shape as the original RGB image. The loss function has been consisted of three parts: predicted parameters loss, projection loss and vertex loss. The experiments have shown that adding vertex loss can effectively control the regression direction and suppress the "unequal cost" regression in the regression process by comparing the impact of adding vertex loss to the global loss on the prediction results. The learned posture parameter values supervision has been issued in the research. The way to set the value range based on ergonomics and mechanical structure for supervision exceed the single loss function prediction result. By combining intermediate supervision and prediction value result supervision, the posture parameters have been constrained to the regression range to make the learning value conform to the linkage of human motion joints. The reconstruction model has been more realistic. The method of setting the value range has been issued as follows: first, the movement of each joint has been divided based on the connection structure of the human body shutdown. Then, the degree of movement has been calculated. The joint rotation range has been presented based on the SMPL model in real situation. Finally, the range analysis combined with the simple reconstruction method has been presented to verify the credibility versus previous experiments.ResultThe experiments have been conducted via the UP-3D. It was compared with the models that generated directly from the learning results without using axis-angle prior to limit predictions. The reconstruction accuracy has improved significantly when the axis-angle used as the loss parameter. The average error has reduced by 15.1%. The average error has reached to 7.0% lower than the two-stage reconstruction method that generated the reconstruction model directly from the prediction via using all the loss functions. The reconstruction results have been compared with the UP-3D dataset for credibility to shown a significant joint linkage effect.ConclusionThe range setting of the joint rotation angle has played an essential role in the process of the regression of the SMPL model pose parameters for 3D human reconstruction. The reconstructed model has been fit the human joint motion linkage more.关键词:SMPL(skinned multi-person linear model) model;3D human reconstruction;joints angle;reconstruction authenticity;joint linkage85|1205|1更新时间:2024-05-07
摘要:ObjectiveThe goal of 3D human body reconstruction has been building a credible and reliable human body model. The credibility of the reconstructed results cannot be guaranteed entirely subject to the mismatch issue between predicted posture angle value and the real human joint movement based on the skinned multi-person linear model (SMPL). A prior of the joint rotation angle value range make the reconstruction result to fit human joint mechanical structure. The rationality and effectiveness of the value range setting combined with a simple reconstruction method have been demonstrated more better than the 3D SMPL-based reconstruction. The reconstruction accuracy of the model has been significantly improved.MethodThe two-stage 3D human body reconstruction method has tailored the reconstruction to improve the credibility and provide more details of the 3D human body model effectively in terms of the range setting verification. In the first stage, the description has been preprocessed to reduce noise, to extract key information as well as to remove the background of the image. In the second stage, the reconstruction has been completed via using the posture and shape parameters of the human body in the image learned with the residual network based on the SMPL model. The UP-3D dataset has been used. The details of reconstruction algorithm have been presented as follows: first, the human silhouette image has been extracted based on the render light image in via the UP-3D dataset with the priority of the acquired segmentation of the human body in the dataset. An RGB image of human body with uniform size can be obtained via removing the background of the original image based on the silhouette image. Next, the resized RGB image and the Render light image has been concatenated and used as the input of the pose regression. Silhouette has been input into the body shape regression simultaneously. The residual network has been used to learn human body posture parameters and body shape parameters based on the parametric statistical body shape model. At last, the range of the predicted body parameters based on the residual network computing has been supervised. The useful predicted body parameters and the posture parameters in supervision have been input into the SMPL model to generate a three-dimensional human body model via the same posture and shape as the original RGB image. The loss function has been consisted of three parts: predicted parameters loss, projection loss and vertex loss. The experiments have shown that adding vertex loss can effectively control the regression direction and suppress the "unequal cost" regression in the regression process by comparing the impact of adding vertex loss to the global loss on the prediction results. The learned posture parameter values supervision has been issued in the research. The way to set the value range based on ergonomics and mechanical structure for supervision exceed the single loss function prediction result. By combining intermediate supervision and prediction value result supervision, the posture parameters have been constrained to the regression range to make the learning value conform to the linkage of human motion joints. The reconstruction model has been more realistic. The method of setting the value range has been issued as follows: first, the movement of each joint has been divided based on the connection structure of the human body shutdown. Then, the degree of movement has been calculated. The joint rotation range has been presented based on the SMPL model in real situation. Finally, the range analysis combined with the simple reconstruction method has been presented to verify the credibility versus previous experiments.ResultThe experiments have been conducted via the UP-3D. It was compared with the models that generated directly from the learning results without using axis-angle prior to limit predictions. The reconstruction accuracy has improved significantly when the axis-angle used as the loss parameter. The average error has reduced by 15.1%. The average error has reached to 7.0% lower than the two-stage reconstruction method that generated the reconstruction model directly from the prediction via using all the loss functions. The reconstruction results have been compared with the UP-3D dataset for credibility to shown a significant joint linkage effect.ConclusionThe range setting of the joint rotation angle has played an essential role in the process of the regression of the SMPL model pose parameters for 3D human reconstruction. The reconstructed model has been fit the human joint motion linkage more.关键词:SMPL(skinned multi-person linear model) model;3D human reconstruction;joints angle;reconstruction authenticity;joint linkage85|1205|1更新时间:2024-05-07 -
 摘要:ObjectiveManhattan world has been an abbreviation for structured scenes that satisfy the Manhattan world assumption, such as artificial indoor and outdoor scenes. It has a strong structural regularity and is in accordance with the Cartesian coordinate system. Manhattan world can be derived that the three dominant directions correspond to the three orthogonal vanishing points. The vanishing point, as a structural feature in the Manhattan world, can explicitly reflect the attitude relationship between the camera coordinate and the world coordinate. In order to use this characteristic of vanishing points to assist visual self-localization, 3D reconstruction and scene recognition, it is of optical importance to accurately estimate vanishing points. A novel and more accurate vanishing points estimation algorithm based on monocular images and nonlinear optimization has been issued.MethodFirst, the current state of the art vanishing point estimation has been analyzed based on random sample consistency (RANSAC). Next, through the analysis and improvement of the single parameterization of straight lines, candidate hypotheses generated using the orthogonality constraints and the RANSAC process, the vanishing point estimates can be obtained more quickly and accurately as the initial value for subsequent operations. At last, the error measurement calculated during line classification has been reused to construct the least squares optimization problem, and non-linear optimization is used to solve it. In order to ensure the accuracy of the iteration and the optimality of the results, a robust kernel function has been used as well.Resultthe proposed algorithm has been compared with the state of the art RANSAC based method via simulation experiments and experiments based on public database. In the simulation experiment, the angular deviation has been reduced about 24.6% in the form of axial angle compared with RCM (R3_CM1) and RCMI (R3_CM1_Iter) method. When there is a prior information constraint, the angular deviation is only 0.06 degree, decreased by an order of magnitude, which means the accuracy is greatly improved. In the public York urban city database (YUD), the performance of the proposed algorithm has been improved compared with the RCM method and RCMI method. The angular deviation has been reduced by 27.2% and 23.8%. The statistical results have shown that the angular deviation of 80% of the vanishing point estimation results is less than 1.5 degree. In addition, a statistical analysis of the running time has been performed in the simulation experiment. The average optimization time for each image frame is 0.008 s, which can ensure the overall real-time performance.ConclusionThe vanishing point estimation algorithm proposed has been more qualified than the RANSAC-based method. The estimation results have shown its superiority in terms of both accuracy and robustness, with no effect on the real-time performance.关键词:Manhattan world;vanishing point(VP);random sample consistency (RANSAC);nonlinear optimization;error measurement63|130|2更新时间:2024-05-07
摘要:ObjectiveManhattan world has been an abbreviation for structured scenes that satisfy the Manhattan world assumption, such as artificial indoor and outdoor scenes. It has a strong structural regularity and is in accordance with the Cartesian coordinate system. Manhattan world can be derived that the three dominant directions correspond to the three orthogonal vanishing points. The vanishing point, as a structural feature in the Manhattan world, can explicitly reflect the attitude relationship between the camera coordinate and the world coordinate. In order to use this characteristic of vanishing points to assist visual self-localization, 3D reconstruction and scene recognition, it is of optical importance to accurately estimate vanishing points. A novel and more accurate vanishing points estimation algorithm based on monocular images and nonlinear optimization has been issued.MethodFirst, the current state of the art vanishing point estimation has been analyzed based on random sample consistency (RANSAC). Next, through the analysis and improvement of the single parameterization of straight lines, candidate hypotheses generated using the orthogonality constraints and the RANSAC process, the vanishing point estimates can be obtained more quickly and accurately as the initial value for subsequent operations. At last, the error measurement calculated during line classification has been reused to construct the least squares optimization problem, and non-linear optimization is used to solve it. In order to ensure the accuracy of the iteration and the optimality of the results, a robust kernel function has been used as well.Resultthe proposed algorithm has been compared with the state of the art RANSAC based method via simulation experiments and experiments based on public database. In the simulation experiment, the angular deviation has been reduced about 24.6% in the form of axial angle compared with RCM (R3_CM1) and RCMI (R3_CM1_Iter) method. When there is a prior information constraint, the angular deviation is only 0.06 degree, decreased by an order of magnitude, which means the accuracy is greatly improved. In the public York urban city database (YUD), the performance of the proposed algorithm has been improved compared with the RCM method and RCMI method. The angular deviation has been reduced by 27.2% and 23.8%. The statistical results have shown that the angular deviation of 80% of the vanishing point estimation results is less than 1.5 degree. In addition, a statistical analysis of the running time has been performed in the simulation experiment. The average optimization time for each image frame is 0.008 s, which can ensure the overall real-time performance.ConclusionThe vanishing point estimation algorithm proposed has been more qualified than the RANSAC-based method. The estimation results have shown its superiority in terms of both accuracy and robustness, with no effect on the real-time performance.关键词:Manhattan world;vanishing point(VP);random sample consistency (RANSAC);nonlinear optimization;error measurement63|130|2更新时间:2024-05-07 -
 摘要:ObjectiveDeep learning has been widely used in the field of computer vision. The application of target recognition on driverless vehicles field via using the extraction based on convolutional neural networks (CNNs). However, the environment of traffic road is complex and changeable, it is difficult to achieve obstacle detection under the actual traffic conditions. The variable characteristic of yielded traffic pedestrian makes pedestrian detection more prominent in road obstacle detection. 1) Currently, most pedestrian recognition models are trained and tested based on a simple background, and few researches have been done on the recognition effect of pedestrian targets in complex road traffic realities. Image parallax has been customized in target ranging based on the development of binocular stereo vision. Image pairs have been captured via binocular stereo vision cameras. Parallax value for left and right images have been calculated based stereo matching algorithms. The depth maps have been obtained based on disparity maps further. Ultimately, the detection of road obstacles is implemented. 2) The difficulties to extract, match and track image sequence feature points and reconstruct projection scenes have been resolving. A new algorithm has been proposed to extract obstacle coordinate information on U-V histograms via counting disparity values in the U-V direction. The two-dimensional plane information in the original image has been converted into line segment information in the U-V direction via calculating the U-V parallax image. Least squares method, Hough transform and other line extraction methods have been used to extract road and obstacle-related line segments further. 3) This type of method is simple to calculate and is conducive to real-time performance, but has a large impact on noise in complex environments. The methodology which combines deep learning and modifies U-V parallax algorithm has proposed to realize the detection of road pedestrians (including recognition and location of pedestrian) that improve the driving safety of vehicles on the road.MethodThe binocular road intelligent perception system has been used to collect road pedestrian foreground images. The training dataset has been established based on the data collected under four types of roadways. RetinaNet model has been utilized on pedestrian recognition. A deep residual network (ResNet) has been as a feature extraction network. The feature pyramid network (FPN) has been used to form multi-scale features to strengthen the feature network containing multi-scale target information. The two feature networks have been applied respectively. Two fully convolutional network (FCN) subnetworks with the same structure with different parameters have been used to implement tasks including the target box category classification and bounding box position regression. Pedestrian data library has been established to feed RetinaNet network for training and testing in training phase. The trials-based batch size has been set to 24 and learning rate has been to be 0.000 1. The accomplishment completion of training process has reached 100 epochs. Random 400 samples have been chosen from training samples as validation data to test the model performance in each time of training. Counting iteration loss value in each epoch and selected the model corresponding to the minimum value as pedestrian recognition model. The horizontal gradient filtering has been conducted on the left image, and then calculates the Birchfield and Tomasi (BT) cost value of the left and right images have been calculated subsequently. The cost value of the left and right images has been fused, and the current cost value has been substituted replaced based on the sum of the cost value of the area around the pixel via traversing pixel by pixel. The cost value has been optimize using semi-global matching (SGM) cost aggregation algorithm. The disparity corresponding to the lowest matching error has been opted to calculate the image disparity based on winner takes all (WTA). The false parallax value has been eliminated via confidence detection, and the parallax holes have been supplemented via sub-pixel interpolation. The left and right consistency has been used to eliminate the parallax error caused by the left and right occlusion. The disparity map has presented noisy due to the interference of the complicated environment of the traffic road. First, the median filtering has been used to perform preliminary denoising processing on the disparity map to obtain a better disparity map. The parallax statistical range has narrowed to inside bounding box to remove irrelevant parallax interference as much as possible. Next, through traversing all the parallax values within the target pedestrian rectangular bounding box to find. The maximum parallax value has replaced all other parallax values in the bounding box. The number of disparities in the U-V direction has been re-counted based on the improved disparity map. At last, the coordinate positions of pedestrians have been obtained. The improved U-V parallax algorithm has filled the parallax holes inside of the bounding box and replaced the noise parallax with the maximum parallax value to improve the accuracy of pedestrian positioning.ResultCompared with the artificial statistical results, the recall rate is 96.27% based on the experimental statistics of the pedestrian recognition results of the self-training RetinaNet model of the 2 500 m continuous test section. In comparison of the you only look once v3 (YOLOv3) and Tiny-YOLOv3 methods under four traffic conditions, the average F-value can reach 96.42%, 0.9% higher than YOLOv3, and 3.03% higher than Tiny-YOLOv3. A calibration block to shoot 20 pairs of binocular images at different distances of 3 m, 4 m, and 5 m in the laboratory to verify the distance measurement algorithm. The calculated standard deviation has been less than 0.01.ConclusionIn this study, RetinaNet model combined with U-V parallax algorithm have been proposed to identify and positioning the pedestrians. Effectively pedestrian detection in the traffic environment has been proposed, and it is significance for the safety of driverless vehicles.关键词:pedestrian detection;deep learning;RetinaNet;semi-global block matching (SGBM) algorithm;U-V parallax algorithm123|126|6更新时间:2024-05-07
摘要:ObjectiveDeep learning has been widely used in the field of computer vision. The application of target recognition on driverless vehicles field via using the extraction based on convolutional neural networks (CNNs). However, the environment of traffic road is complex and changeable, it is difficult to achieve obstacle detection under the actual traffic conditions. The variable characteristic of yielded traffic pedestrian makes pedestrian detection more prominent in road obstacle detection. 1) Currently, most pedestrian recognition models are trained and tested based on a simple background, and few researches have been done on the recognition effect of pedestrian targets in complex road traffic realities. Image parallax has been customized in target ranging based on the development of binocular stereo vision. Image pairs have been captured via binocular stereo vision cameras. Parallax value for left and right images have been calculated based stereo matching algorithms. The depth maps have been obtained based on disparity maps further. Ultimately, the detection of road obstacles is implemented. 2) The difficulties to extract, match and track image sequence feature points and reconstruct projection scenes have been resolving. A new algorithm has been proposed to extract obstacle coordinate information on U-V histograms via counting disparity values in the U-V direction. The two-dimensional plane information in the original image has been converted into line segment information in the U-V direction via calculating the U-V parallax image. Least squares method, Hough transform and other line extraction methods have been used to extract road and obstacle-related line segments further. 3) This type of method is simple to calculate and is conducive to real-time performance, but has a large impact on noise in complex environments. The methodology which combines deep learning and modifies U-V parallax algorithm has proposed to realize the detection of road pedestrians (including recognition and location of pedestrian) that improve the driving safety of vehicles on the road.MethodThe binocular road intelligent perception system has been used to collect road pedestrian foreground images. The training dataset has been established based on the data collected under four types of roadways. RetinaNet model has been utilized on pedestrian recognition. A deep residual network (ResNet) has been as a feature extraction network. The feature pyramid network (FPN) has been used to form multi-scale features to strengthen the feature network containing multi-scale target information. The two feature networks have been applied respectively. Two fully convolutional network (FCN) subnetworks with the same structure with different parameters have been used to implement tasks including the target box category classification and bounding box position regression. Pedestrian data library has been established to feed RetinaNet network for training and testing in training phase. The trials-based batch size has been set to 24 and learning rate has been to be 0.000 1. The accomplishment completion of training process has reached 100 epochs. Random 400 samples have been chosen from training samples as validation data to test the model performance in each time of training. Counting iteration loss value in each epoch and selected the model corresponding to the minimum value as pedestrian recognition model. The horizontal gradient filtering has been conducted on the left image, and then calculates the Birchfield and Tomasi (BT) cost value of the left and right images have been calculated subsequently. The cost value of the left and right images has been fused, and the current cost value has been substituted replaced based on the sum of the cost value of the area around the pixel via traversing pixel by pixel. The cost value has been optimize using semi-global matching (SGM) cost aggregation algorithm. The disparity corresponding to the lowest matching error has been opted to calculate the image disparity based on winner takes all (WTA). The false parallax value has been eliminated via confidence detection, and the parallax holes have been supplemented via sub-pixel interpolation. The left and right consistency has been used to eliminate the parallax error caused by the left and right occlusion. The disparity map has presented noisy due to the interference of the complicated environment of the traffic road. First, the median filtering has been used to perform preliminary denoising processing on the disparity map to obtain a better disparity map. The parallax statistical range has narrowed to inside bounding box to remove irrelevant parallax interference as much as possible. Next, through traversing all the parallax values within the target pedestrian rectangular bounding box to find. The maximum parallax value has replaced all other parallax values in the bounding box. The number of disparities in the U-V direction has been re-counted based on the improved disparity map. At last, the coordinate positions of pedestrians have been obtained. The improved U-V parallax algorithm has filled the parallax holes inside of the bounding box and replaced the noise parallax with the maximum parallax value to improve the accuracy of pedestrian positioning.ResultCompared with the artificial statistical results, the recall rate is 96.27% based on the experimental statistics of the pedestrian recognition results of the self-training RetinaNet model of the 2 500 m continuous test section. In comparison of the you only look once v3 (YOLOv3) and Tiny-YOLOv3 methods under four traffic conditions, the average F-value can reach 96.42%, 0.9% higher than YOLOv3, and 3.03% higher than Tiny-YOLOv3. A calibration block to shoot 20 pairs of binocular images at different distances of 3 m, 4 m, and 5 m in the laboratory to verify the distance measurement algorithm. The calculated standard deviation has been less than 0.01.ConclusionIn this study, RetinaNet model combined with U-V parallax algorithm have been proposed to identify and positioning the pedestrians. Effectively pedestrian detection in the traffic environment has been proposed, and it is significance for the safety of driverless vehicles.关键词:pedestrian detection;deep learning;RetinaNet;semi-global block matching (SGBM) algorithm;U-V parallax algorithm123|126|6更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveObject localization and parameter extraction have been one of the vital applications for remote sensing image interpretation and the basis of information extraction nowadays. The acquired accuracy is the key factor to improve the accuracy of information inversion. As a typical man-made object with circle shape in remote sensing image, the high-precision localization and parameter extraction of floating roof oil tank have been the representative application issues. The elevation of the top cover of the floating roof oil tank has been fluctuated up and down with the change of oil storage volume. The remote sensing image of the oil tank has presented different circle shadows and multiple circle areas in terms of the elevation change. The localization and parameter extraction analysis of the oil tank has referred to the measurement of the center position of the tank roof, the center position of the circular-arc-shaped shadow cast has projected by the sunshine on the floating roof and the radius of the oil tank image, which is of great significance for the inversion of the oil tank structure and the oil storage information. However, the distribution and overlapping characteristics of circles in oil tank images have related to many factors, such as illumination, cloud cover, satellite observation and imaging conditions, background environment, side wall occlusion and so on. Therefore, for localization and parameter extraction of floating roof oil tank, it is necessary to develop a localization and parameter extraction method to adapt with circle shaped objects. The traditional parameterized feature extraction method has included Hough transform and template matching. The emerging deep learning method has been developed recently. Traditional parameterized feature extraction method can make effective use of the circumference feature with the non-learnable and the poor applicability of parameters. The lower automation has relied on priori knowledge to adjust parameters manually. The method based on deep learning has its advantages to use the training of the existing labeled images to solve the parameters of the network, which improves the degree of automation. For objects with circular structure, convolutional neural networks (CNNs) can predict the radius and get accurate location of the circle center. The disadvantages have been described as follows: First, the main feature of an object with circular structure such as oil tank is on the circumference, but not in the circle. The neural networks need to traverse all the pixels, which leads to redundant computation and a low processing efficiency. Next, CNN has increased the receptive field and aggregated the spatial features via cascading networks subject to the receptive field. At last, abundant training samples requirement has not existed in traditional parameterized feature extraction method. This research has proposed a method of low calculation and high precision by combining the traditional feature extraction method with deep learning to resolve the problem of localization and parameter extraction of oil tank in remote sensing images, which no longer needs to sacrifice resolution or increase the network.MethodA CNN has been constructed via fast radial symmetry transform (FRST). The training process and parameter has been sorted out. The image is processed by FRST and the original image and the processed image are superimposed as two channels of the image into a new dual channel image, which is input into the designed CNN for processing. The result has been compared with the result of the single channel original image into the same CNN for processing. The experiment is based on a self-made dataset of SkySat satellite data, compared under two CNN architectures, and ran once under two fixed random seeds. This method has illustrated the priori knowledge of circular feature into the deep learning process effectively. Low-computational complexity has been presented. High-precision localization based on relatively few layers of network has been realized.ResultThe experimental results have shown that the accuracy of the proposed method is effectively improved at the same network level and the average prediction error is reduced by 17.42%. Moreover, the prediction error has been decreased by 19.19% on average in the shallower network. In the deeper network, the prediction error has been deducted by 15.66% on average.ConclusionThis research has demonstrated the transform domain features combined with deep learning to improve the accuracy of the localization and parameter extraction of oil tank in remote sensing images effectively.关键词:remote sensing image;oil tank;localization;parameter extraction;deep learning;fast radial symmetry transform(FRST)94|219|2更新时间:2024-05-07
摘要:ObjectiveObject localization and parameter extraction have been one of the vital applications for remote sensing image interpretation and the basis of information extraction nowadays. The acquired accuracy is the key factor to improve the accuracy of information inversion. As a typical man-made object with circle shape in remote sensing image, the high-precision localization and parameter extraction of floating roof oil tank have been the representative application issues. The elevation of the top cover of the floating roof oil tank has been fluctuated up and down with the change of oil storage volume. The remote sensing image of the oil tank has presented different circle shadows and multiple circle areas in terms of the elevation change. The localization and parameter extraction analysis of the oil tank has referred to the measurement of the center position of the tank roof, the center position of the circular-arc-shaped shadow cast has projected by the sunshine on the floating roof and the radius of the oil tank image, which is of great significance for the inversion of the oil tank structure and the oil storage information. However, the distribution and overlapping characteristics of circles in oil tank images have related to many factors, such as illumination, cloud cover, satellite observation and imaging conditions, background environment, side wall occlusion and so on. Therefore, for localization and parameter extraction of floating roof oil tank, it is necessary to develop a localization and parameter extraction method to adapt with circle shaped objects. The traditional parameterized feature extraction method has included Hough transform and template matching. The emerging deep learning method has been developed recently. Traditional parameterized feature extraction method can make effective use of the circumference feature with the non-learnable and the poor applicability of parameters. The lower automation has relied on priori knowledge to adjust parameters manually. The method based on deep learning has its advantages to use the training of the existing labeled images to solve the parameters of the network, which improves the degree of automation. For objects with circular structure, convolutional neural networks (CNNs) can predict the radius and get accurate location of the circle center. The disadvantages have been described as follows: First, the main feature of an object with circular structure such as oil tank is on the circumference, but not in the circle. The neural networks need to traverse all the pixels, which leads to redundant computation and a low processing efficiency. Next, CNN has increased the receptive field and aggregated the spatial features via cascading networks subject to the receptive field. At last, abundant training samples requirement has not existed in traditional parameterized feature extraction method. This research has proposed a method of low calculation and high precision by combining the traditional feature extraction method with deep learning to resolve the problem of localization and parameter extraction of oil tank in remote sensing images, which no longer needs to sacrifice resolution or increase the network.MethodA CNN has been constructed via fast radial symmetry transform (FRST). The training process and parameter has been sorted out. The image is processed by FRST and the original image and the processed image are superimposed as two channels of the image into a new dual channel image, which is input into the designed CNN for processing. The result has been compared with the result of the single channel original image into the same CNN for processing. The experiment is based on a self-made dataset of SkySat satellite data, compared under two CNN architectures, and ran once under two fixed random seeds. This method has illustrated the priori knowledge of circular feature into the deep learning process effectively. Low-computational complexity has been presented. High-precision localization based on relatively few layers of network has been realized.ResultThe experimental results have shown that the accuracy of the proposed method is effectively improved at the same network level and the average prediction error is reduced by 17.42%. Moreover, the prediction error has been decreased by 19.19% on average in the shallower network. In the deeper network, the prediction error has been deducted by 15.66% on average.ConclusionThis research has demonstrated the transform domain features combined with deep learning to improve the accuracy of the localization and parameter extraction of oil tank in remote sensing images effectively.关键词:remote sensing image;oil tank;localization;parameter extraction;deep learning;fast radial symmetry transform(FRST)94|219|2更新时间:2024-05-07 -
 摘要:ObjectiveRemote sensing image registration is a process of matching and superimposing multiple sets of images. It plays an important role in many fields such as climate change, urban change and crustal movement. Currently, most remote sensing registration methods can be generally divided into two categories: traditional based methods and deep learning based methods. The traditional remote sensing registration algorithms can be labor-cost and weaken adaptive learning to cause time-consuming registration. Even though the remote sensing image registration algorithms based on deep learning reduce the labor cost and improve the ability of model adaptive learning, the accuracy and the running time still need to be improved. A parametric synthesized spatial transformation network has been proposed that can be probably used for bidirectional consistent registration of remote sensing images.MethodsAn end-to-end method is proposed for registration, which mainly includes feature extraction, feature matching and parameter regression. First, the feature extraction network has been designated based on the spatial transformation network model: the local network in the context of spatial transformation network has been more deepening via jumping connection. Four sets of full convolution modules are added, each of which is composed of four full convolution layers. Meanwhile, every two sets of four full convolution layers in each module are connected based on the same jumping connection structure. In order to ensure the integrity of data transmission, the beginning and the ending of each module are connected by jumping structure as well. Then two parameters have been synthesized which are regressed by local network. Following the process of grid generator and sampler, the input images are transformed to generate two saliency images with the same region based on affine transformation. Thus, fine-tuning residual structure has been used for feature extraction to obtain the targeted feature map. Next, a feature matching structure is designed to conduct bidirectional consistent matching. A matching branch is added to obtain the correlation from the source image to the target image and the correlation originated from the target image to the source image via Pearson correlation coefficient. The parameter regression network with two regression parameters have been leaked out based on the regression of matching relationship in two directions to maintain the consistency of registration. At last, the grid loss function has been iterated in consistency. The optimized bidirectional consistency parameters have been calculated via weighted and synthesized regression. The final registration is completed after sampling.ResultThe experimental results have been compared with two classical methods, which are scale-invariant feature transform (SIFT) and speeded up robust features(SURF).Simultaneously the latest methods proposed in recent three years have been compared as well, such as convolutional neural network architecture for geometric matching (CNNGeo), CNN-Registration (multi-temporal remote sensing image registration) and robust matching network (RMNet). Registration results have illustrated that our research is qualified in qualitative visual effects and has good results in quantitative evaluation indexes. Based on the Aerial Image Dataset, "the percentage of correct key points" compared with the above five methods have been implemented, and the accuracy is increased by 36.2%, 75.9%, 53.6%, 29.9% and 1.7%, respectively. Registration time is reduced by 9.24 s, 7.16 s, 48.29 s, 1.06 s and 4.06 s. Since the gap between CNNGeo method, RMNet method and the method proposed, it cannot be clearly identified via the percentage of correct keypoints(PCK) evaluation index, the grid loss and the average grid loss for further comparison. Compared with the above two methods, the grid loss in this research has been increased by 3.48% and 2.66%, the average grid loss has been increased by 2.67% and 0.2% respectively. The gradient of the research method and RMNet method has decreased fastest in the grid loss line chart and average grid loss line chart. It has demonstrated that the accuracy of proposed method is higher via the histogram comparison between the method proposed and the RMNet method. The improved feature extraction network has been used to replace the feature extraction network in the CNNGeo method, and the PCK index is increased by 4.6% compared with the original benchmark network (CNNGeo). The improved matching relationship is replaced via the matching relationship in the CNNGeo method.The PCK index is improved by 3.9% compared with the original benchmark network. Bidirectional parameter of weighted synthesis has been further improved. The PCK index is increased by 14.1% compared with the original benchmark network. The experimental results have shown that the method proposed has its advantages in accuracy and efficient operation.ConclusionThe registration method is applicable for three types of remote sensing image registration applications, such as temporal variation (multi-temporal), visual diversity (multi-viewpoints) and different sensors (multi-modal). The proposed algorithm has illustrated more qualified registration accuracy and registration efficiency.关键词:image processing;remote sensing image registration;spatial transformation network(STN);parameter synthesis;bidirectional consistency60|227|3更新时间:2024-05-07
摘要:ObjectiveRemote sensing image registration is a process of matching and superimposing multiple sets of images. It plays an important role in many fields such as climate change, urban change and crustal movement. Currently, most remote sensing registration methods can be generally divided into two categories: traditional based methods and deep learning based methods. The traditional remote sensing registration algorithms can be labor-cost and weaken adaptive learning to cause time-consuming registration. Even though the remote sensing image registration algorithms based on deep learning reduce the labor cost and improve the ability of model adaptive learning, the accuracy and the running time still need to be improved. A parametric synthesized spatial transformation network has been proposed that can be probably used for bidirectional consistent registration of remote sensing images.MethodsAn end-to-end method is proposed for registration, which mainly includes feature extraction, feature matching and parameter regression. First, the feature extraction network has been designated based on the spatial transformation network model: the local network in the context of spatial transformation network has been more deepening via jumping connection. Four sets of full convolution modules are added, each of which is composed of four full convolution layers. Meanwhile, every two sets of four full convolution layers in each module are connected based on the same jumping connection structure. In order to ensure the integrity of data transmission, the beginning and the ending of each module are connected by jumping structure as well. Then two parameters have been synthesized which are regressed by local network. Following the process of grid generator and sampler, the input images are transformed to generate two saliency images with the same region based on affine transformation. Thus, fine-tuning residual structure has been used for feature extraction to obtain the targeted feature map. Next, a feature matching structure is designed to conduct bidirectional consistent matching. A matching branch is added to obtain the correlation from the source image to the target image and the correlation originated from the target image to the source image via Pearson correlation coefficient. The parameter regression network with two regression parameters have been leaked out based on the regression of matching relationship in two directions to maintain the consistency of registration. At last, the grid loss function has been iterated in consistency. The optimized bidirectional consistency parameters have been calculated via weighted and synthesized regression. The final registration is completed after sampling.ResultThe experimental results have been compared with two classical methods, which are scale-invariant feature transform (SIFT) and speeded up robust features(SURF).Simultaneously the latest methods proposed in recent three years have been compared as well, such as convolutional neural network architecture for geometric matching (CNNGeo), CNN-Registration (multi-temporal remote sensing image registration) and robust matching network (RMNet). Registration results have illustrated that our research is qualified in qualitative visual effects and has good results in quantitative evaluation indexes. Based on the Aerial Image Dataset, "the percentage of correct key points" compared with the above five methods have been implemented, and the accuracy is increased by 36.2%, 75.9%, 53.6%, 29.9% and 1.7%, respectively. Registration time is reduced by 9.24 s, 7.16 s, 48.29 s, 1.06 s and 4.06 s. Since the gap between CNNGeo method, RMNet method and the method proposed, it cannot be clearly identified via the percentage of correct keypoints(PCK) evaluation index, the grid loss and the average grid loss for further comparison. Compared with the above two methods, the grid loss in this research has been increased by 3.48% and 2.66%, the average grid loss has been increased by 2.67% and 0.2% respectively. The gradient of the research method and RMNet method has decreased fastest in the grid loss line chart and average grid loss line chart. It has demonstrated that the accuracy of proposed method is higher via the histogram comparison between the method proposed and the RMNet method. The improved feature extraction network has been used to replace the feature extraction network in the CNNGeo method, and the PCK index is increased by 4.6% compared with the original benchmark network (CNNGeo). The improved matching relationship is replaced via the matching relationship in the CNNGeo method.The PCK index is improved by 3.9% compared with the original benchmark network. Bidirectional parameter of weighted synthesis has been further improved. The PCK index is increased by 14.1% compared with the original benchmark network. The experimental results have shown that the method proposed has its advantages in accuracy and efficient operation.ConclusionThe registration method is applicable for three types of remote sensing image registration applications, such as temporal variation (multi-temporal), visual diversity (multi-viewpoints) and different sensors (multi-modal). The proposed algorithm has illustrated more qualified registration accuracy and registration efficiency.关键词:image processing;remote sensing image registration;spatial transformation network(STN);parameter synthesis;bidirectional consistency60|227|3更新时间:2024-05-07 -
 摘要:ObjectiveThe efficient detection of ocean front is of great significance to study the efficient detection of ocean front for marine ecosystem, fishery resources assessment, fishery forecast and typhoon track prediction. Gradient threshold method and edge detection algorithm have been widely used in ocean front detection. Traditional gradient method mainly depends on the gradient threshold, the sea area with gradient value greater than the set threshold has been regarded as the existence of ocean front. However, the selection criteria of threshold cannot tailor the requirements of accurate detection of complex and diverse ocean fronts due to artificial setting dependence, so it is more suitable for the object detection with fixed edge (such as land). During to the weak edge information of ocean front, it is difficult to achieve the good effect through the traditional edge extraction algorithm. A new automatic detection method to detect the small data volume and weak marginal characteristics of ocean fronts has been considering. Based on the advantages of the Mask R-CNN (region convolutional neural network) for instance segmentation, an improved Mask R-CNN network has been applied to the detection of ocean fronts. The ocean front detection method based on the modified Mask R-CNN has evolved the establishment of ocean front detection standards and data preprocessing, such as data expansion, data enhancement and labeling operations. High-precision detection of ocean fronts has been realized based on multiple iterations of training and parameter correction.MethodFirst, the remote sensing images have been performed expansion operations for the small amount of data and the weak edge characteristics, such as rotating, flipping and cropping. Total 2 100 images have been obtained including 800 original images, 500 rotation and flip processing images and 800 random cropping processing images. Meanwhile, sea surface temperatures (SST) remote sensing images have been enhanced based on deep closest point (DCP) and contrast limited adaptive histogram equalization (CLAHE) algorithms. Next, based on migration learning, using the general image classification network model trained on the common objects in context (COCO) dataset as the pre-training model, and using training datasets to train the pre-trained model. In order to meet the needs of ocean front detection, the residual network (ResNet) and feature pyramid network (FPN) model in Mask R-CNN have been optimized respectively. Limited training data leads to over fitting of the deep residual network and poor detection results. Considering the scarcity of ocean front data and the difficulty of constructing training set, the shallow ResNet-18 network has been used to detect ocean front. Multi-scale fusion feature maps have been predicted to enhance the detection effect of ocean front respectively through the full use of the high-resolution and high-level semantic information of low-level features.ResultIn order to verify the effectiveness of the method, three training datasets of grayscale image, RGB image and gradient image have been designed. Using LabelMe software to label the dataset, and then achieving high-precision detection of ocean fronts by multiple iterations of training and parameter correction. In addition, the weighted harmonic mean Micro-F1 and intersection over union (IoU) have both been used to evaluate the detection accuracy and target location accuracy of the model. In the experiment and analysis section, several groups of comparative experiments have been designed from experimental model. In order to evaluate the robustness and effectiveness of the method, images collection of global ocean fronts has been conducted to make three different datasets and perform multiple different iterations on the datasets. The results have shown that the training has effectively converged, and the detection accuracy of the model has also increased, reaching more than 0.85 after 25 000 iterations. In order to further verify the proposed ocean front detection results based on Mask R-CNN, the three training sets have been trained separately. The experimental results have shown that gradient images have been both higher than RGB images and grayscale images to detect ocean fronts, the positioning accuracy and detection accuracy. In order to highlight the advantages of this model for ocean front detection, this research has compared it with you only look once (YOLOv3) and Mask R-CNN models under three different datasets. The three training datasets have been trained for 30 000 times under different models. The results have demonstrated that the positioning accuracy IoU and accuracy F1 of the ocean front detection method proposed are improved. The detection accuracy of this method is 84.33%, and Micro-F1 is 86.57%. Compared with the YOLOv3 and Mask R-CNN algorithms, the Micro-F1 value has increased by 4.27% and 3.01% respectively. Rapid identification of ocean fronts is the key to practical fishery applications. The running time of the RGB image set under different network models and different iteration times has been presented. Under different iterations, the proposed model takes much less time than YOLOv3. At last, in order to evaluate the effectiveness of the method in the detection of strong and weak fronts, the strong and weak fronts in the three datasets have been screened and trained separately. The results have shown that the accuracy of the method in the detection of strong ocean fronts can be achieved all above 80% higher.ConclusionA reasonable ocean front detection standard has been setup combined with the weak edge characteristics of ocean front. By designing some comparative experiments to verify the high-precision detection effect of the method proposed in this paper on ocean fronts.关键词:deep learning;Mask R-CNN;weak edge;image enhancement;ocean front detection88|39|2更新时间:2024-05-07
摘要:ObjectiveThe efficient detection of ocean front is of great significance to study the efficient detection of ocean front for marine ecosystem, fishery resources assessment, fishery forecast and typhoon track prediction. Gradient threshold method and edge detection algorithm have been widely used in ocean front detection. Traditional gradient method mainly depends on the gradient threshold, the sea area with gradient value greater than the set threshold has been regarded as the existence of ocean front. However, the selection criteria of threshold cannot tailor the requirements of accurate detection of complex and diverse ocean fronts due to artificial setting dependence, so it is more suitable for the object detection with fixed edge (such as land). During to the weak edge information of ocean front, it is difficult to achieve the good effect through the traditional edge extraction algorithm. A new automatic detection method to detect the small data volume and weak marginal characteristics of ocean fronts has been considering. Based on the advantages of the Mask R-CNN (region convolutional neural network) for instance segmentation, an improved Mask R-CNN network has been applied to the detection of ocean fronts. The ocean front detection method based on the modified Mask R-CNN has evolved the establishment of ocean front detection standards and data preprocessing, such as data expansion, data enhancement and labeling operations. High-precision detection of ocean fronts has been realized based on multiple iterations of training and parameter correction.MethodFirst, the remote sensing images have been performed expansion operations for the small amount of data and the weak edge characteristics, such as rotating, flipping and cropping. Total 2 100 images have been obtained including 800 original images, 500 rotation and flip processing images and 800 random cropping processing images. Meanwhile, sea surface temperatures (SST) remote sensing images have been enhanced based on deep closest point (DCP) and contrast limited adaptive histogram equalization (CLAHE) algorithms. Next, based on migration learning, using the general image classification network model trained on the common objects in context (COCO) dataset as the pre-training model, and using training datasets to train the pre-trained model. In order to meet the needs of ocean front detection, the residual network (ResNet) and feature pyramid network (FPN) model in Mask R-CNN have been optimized respectively. Limited training data leads to over fitting of the deep residual network and poor detection results. Considering the scarcity of ocean front data and the difficulty of constructing training set, the shallow ResNet-18 network has been used to detect ocean front. Multi-scale fusion feature maps have been predicted to enhance the detection effect of ocean front respectively through the full use of the high-resolution and high-level semantic information of low-level features.ResultIn order to verify the effectiveness of the method, three training datasets of grayscale image, RGB image and gradient image have been designed. Using LabelMe software to label the dataset, and then achieving high-precision detection of ocean fronts by multiple iterations of training and parameter correction. In addition, the weighted harmonic mean Micro-F1 and intersection over union (IoU) have both been used to evaluate the detection accuracy and target location accuracy of the model. In the experiment and analysis section, several groups of comparative experiments have been designed from experimental model. In order to evaluate the robustness and effectiveness of the method, images collection of global ocean fronts has been conducted to make three different datasets and perform multiple different iterations on the datasets. The results have shown that the training has effectively converged, and the detection accuracy of the model has also increased, reaching more than 0.85 after 25 000 iterations. In order to further verify the proposed ocean front detection results based on Mask R-CNN, the three training sets have been trained separately. The experimental results have shown that gradient images have been both higher than RGB images and grayscale images to detect ocean fronts, the positioning accuracy and detection accuracy. In order to highlight the advantages of this model for ocean front detection, this research has compared it with you only look once (YOLOv3) and Mask R-CNN models under three different datasets. The three training datasets have been trained for 30 000 times under different models. The results have demonstrated that the positioning accuracy IoU and accuracy F1 of the ocean front detection method proposed are improved. The detection accuracy of this method is 84.33%, and Micro-F1 is 86.57%. Compared with the YOLOv3 and Mask R-CNN algorithms, the Micro-F1 value has increased by 4.27% and 3.01% respectively. Rapid identification of ocean fronts is the key to practical fishery applications. The running time of the RGB image set under different network models and different iteration times has been presented. Under different iterations, the proposed model takes much less time than YOLOv3. At last, in order to evaluate the effectiveness of the method in the detection of strong and weak fronts, the strong and weak fronts in the three datasets have been screened and trained separately. The results have shown that the accuracy of the method in the detection of strong ocean fronts can be achieved all above 80% higher.ConclusionA reasonable ocean front detection standard has been setup combined with the weak edge characteristics of ocean front. By designing some comparative experiments to verify the high-precision detection effect of the method proposed in this paper on ocean fronts.关键词:deep learning;Mask R-CNN;weak edge;image enhancement;ocean front detection88|39|2更新时间:2024-05-07 -
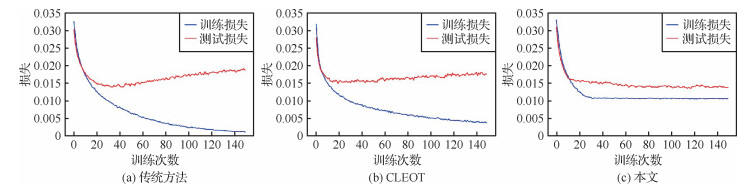 摘要:ObjectiveWith the development of deep learning technology,deep neural networks have been widely used in various tasks of remote sensing,such as image retrieval,scene classification and change detection. Although these deep learning methods constantly refresh the accuracy of remote sensing applications on specific datasets,they require massive data with millions of reliable annotations,which are impractical or expensive for real-world applications. In contrast,when the accuracy of labels is too low,the performance of these deep learning methods will decline sharply. In order to reduce the labeling cost and improve the labeling speed,researchers have proposed a variety of greedy annotation methods to improve labeling efficiency via clustering and crowd sourcing information. The performance of deep learning methods will decline dramatically once the label noise is introduced into the dataset. It is necessary to construct a noise robust deep learning method for remote sensing image processing to improve generalization performance. A noise robust and lightweight deep learning method for remote sensing scene classification and retrieval have been proposed to resolve performance degradation,which can effectively improve the classification and hash retrieval performance on remote sensing dataset under label noise. Furthermore,the proposed method can complete classification and hash retrieval tasks at the same time.MethodFirst,a lightweight deep neural network named mobile GPU-aware network C (MoGA-C) as the backbone has been used to keep the lightweight of deep learning model,which has been proposed by Xiaomi AI Lab. MoGA-C has been obtained based on mobile GPU-aware (MoGA) neural network structure search algorithm. Various skills of lightweight network design have been integrated to ensure the lightweight of the network in the process of MoGA-C network design. Next,a double-branch structure behind deep neural network has been performed to the tasks of classification and retrieval simultaneously,which can not only avoid the degradation of classification performance caused by the insertion of hash layer,but also effectively increase the classification accuracy under label noise by integrating the results of double-branch. At last,the whole network has been fine-tuned during training process in order to improve the learning ability of deep neural network,which effectively improved the classification performance under low ratio label noise. A loss benchmark in the process of network fine-tuning has been set to reduce over-fitting to label noise in the middle and later stage of training,which limited the lower boundary of training loss and reduced the over-fitting under high ratio noise effectively.ResultThe proposed method has been evaluated via comparing it with other eight state of the art methods on two public remote sensing classification datasets. The research method has performed well under different noise ratios,which is 7.8% higher than sub-optimal method on aerial image datasets (AID) dataset and 8.1% higher on benchmark created by Northwestern Polytechnical University for remote sensing image scene classification covering 45 scene classes (NWPU-RESISC45) dataset in average. The inference speed has reached 2.8 times faster than the classification loss with entropic optimal transport (CLEOT) method. The floating point operations (FLOPs) and parameters are less than 5% of that in CLEOT method. The method has 5.9% average improvement under three different hash bits compared with the metric-learning based deep hashing network (MiLaN) method on AID dataset in the task of remote sensing image retrieval.ConclusionA lightweight and noise robust method for remote sensing scene classification and retrieval has been demonstrated to resolve the problem of performance degradation of remote sensing image processing methods under label noise. The proposed method can perform the tasks of classification and hash retrieval at the same time and improve the classification and retrieval performance under label noise effectively. First of all,a lightweight network has been opted as the backbone to ensure the lightweight of the model. Secondly,a parallel double-branch structure has been designed in order to complete the classification and hash retrieval tasks at the same time,the classification performance of the model has been improved further via combining the double-branch prediction results. Finally,the training loss has subjected to a positive value to reduce the over-fitting of label noise effectively via setting a loss benchmark. To compare with other methods,the classification and hash retrieval experiments have been conducted on two public datasets. The experimental results have presented that the proposed method not only has high efficiency,but also has good robustness to different ratios of label noise.关键词:label noise;robust learning;image classification;image retrieval;hash learning;lightweight network580|267|0更新时间:2024-05-07
摘要:ObjectiveWith the development of deep learning technology,deep neural networks have been widely used in various tasks of remote sensing,such as image retrieval,scene classification and change detection. Although these deep learning methods constantly refresh the accuracy of remote sensing applications on specific datasets,they require massive data with millions of reliable annotations,which are impractical or expensive for real-world applications. In contrast,when the accuracy of labels is too low,the performance of these deep learning methods will decline sharply. In order to reduce the labeling cost and improve the labeling speed,researchers have proposed a variety of greedy annotation methods to improve labeling efficiency via clustering and crowd sourcing information. The performance of deep learning methods will decline dramatically once the label noise is introduced into the dataset. It is necessary to construct a noise robust deep learning method for remote sensing image processing to improve generalization performance. A noise robust and lightweight deep learning method for remote sensing scene classification and retrieval have been proposed to resolve performance degradation,which can effectively improve the classification and hash retrieval performance on remote sensing dataset under label noise. Furthermore,the proposed method can complete classification and hash retrieval tasks at the same time.MethodFirst,a lightweight deep neural network named mobile GPU-aware network C (MoGA-C) as the backbone has been used to keep the lightweight of deep learning model,which has been proposed by Xiaomi AI Lab. MoGA-C has been obtained based on mobile GPU-aware (MoGA) neural network structure search algorithm. Various skills of lightweight network design have been integrated to ensure the lightweight of the network in the process of MoGA-C network design. Next,a double-branch structure behind deep neural network has been performed to the tasks of classification and retrieval simultaneously,which can not only avoid the degradation of classification performance caused by the insertion of hash layer,but also effectively increase the classification accuracy under label noise by integrating the results of double-branch. At last,the whole network has been fine-tuned during training process in order to improve the learning ability of deep neural network,which effectively improved the classification performance under low ratio label noise. A loss benchmark in the process of network fine-tuning has been set to reduce over-fitting to label noise in the middle and later stage of training,which limited the lower boundary of training loss and reduced the over-fitting under high ratio noise effectively.ResultThe proposed method has been evaluated via comparing it with other eight state of the art methods on two public remote sensing classification datasets. The research method has performed well under different noise ratios,which is 7.8% higher than sub-optimal method on aerial image datasets (AID) dataset and 8.1% higher on benchmark created by Northwestern Polytechnical University for remote sensing image scene classification covering 45 scene classes (NWPU-RESISC45) dataset in average. The inference speed has reached 2.8 times faster than the classification loss with entropic optimal transport (CLEOT) method. The floating point operations (FLOPs) and parameters are less than 5% of that in CLEOT method. The method has 5.9% average improvement under three different hash bits compared with the metric-learning based deep hashing network (MiLaN) method on AID dataset in the task of remote sensing image retrieval.ConclusionA lightweight and noise robust method for remote sensing scene classification and retrieval has been demonstrated to resolve the problem of performance degradation of remote sensing image processing methods under label noise. The proposed method can perform the tasks of classification and hash retrieval at the same time and improve the classification and retrieval performance under label noise effectively. First of all,a lightweight network has been opted as the backbone to ensure the lightweight of the model. Secondly,a parallel double-branch structure has been designed in order to complete the classification and hash retrieval tasks at the same time,the classification performance of the model has been improved further via combining the double-branch prediction results. Finally,the training loss has subjected to a positive value to reduce the over-fitting of label noise effectively via setting a loss benchmark. To compare with other methods,the classification and hash retrieval experiments have been conducted on two public datasets. The experimental results have presented that the proposed method not only has high efficiency,but also has good robustness to different ratios of label noise.关键词:label noise;robust learning;image classification;image retrieval;hash learning;lightweight network580|267|0更新时间:2024-05-07 -
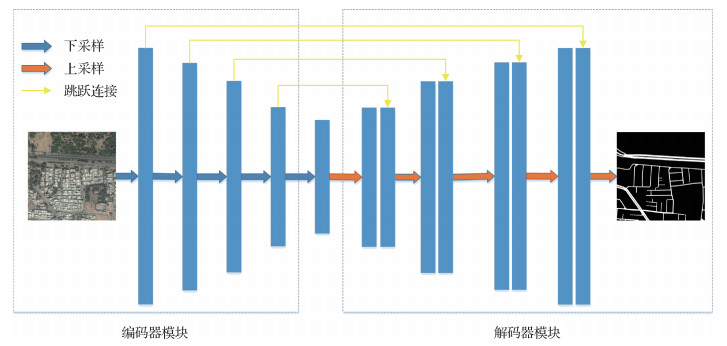 摘要:ObjectiveRoad extraction from remote sensing images has played an important role in city planning, traffic management, vehicle navigation, map updating and other fields nowadays, the characteristics of the road area in the remote sensing image have been affected by many factors such as lighting, noise and occlusion in the image acquisition process. A huge number of similar non-road objects, such as building areas and water areas have interfered with the road area recognition process simultaneously. The above two factors have increased the difficulty of road extraction from remote sensing images. Supervised learning-based road extraction algorithms such as support vector machines and traditional artificial neural networks have to artificially design features so as to train classification models. The recognition rate of these traditional methods has been significantly decreased when facing with the interference of the similar non-road targets and the rich information of the background in the images. Recently, a variety of deep learning techniques of convolutional neural networks have been widely used in the field of remote sensing image processing based on its efficient feature learning ability. Deep learning network has made a great progress in road extraction. It can not only obtain the overall network structure of the road, but also the clear boundaries of the road. A U-Net road segmentation network has been proposed improve the road extraction quality based on the context information and attention mechanism.MethodA novel deep neural network for road extraction from remote sensing images has been proposed based on the symmetrical structure of U-Net network and attention mechanism. In the network structure, the introduction of the pre-trained Resnet-34 network can effectively extract image features at different granularities. Resnet-34 residual network has been used as the backbone network of the novel U-Net network. Residual learning can greatly reduce the training time of the deep network, avoid the phenomenon of gradient disappearance, and improve the training accuracy. Meanwhile, the context information has contained the interaction information between different objects, the interaction information between the object and the scene, which can be used as features to combine the various parts between the roads and distinguish the road and the background. The context information extraction module can integrate the context information to ensure that the geometric topology of the road is extracted in the image. To adjust the feature weights, the attention mechanism module can be transmitted by the skip connection, strengthened by the feature information of the road area, suppressed by the feature information of the non-road area improved by the segmentation effect of the road edge thereby effectively improving the accuracy of road segmentation. The improved model has resolved the incomplete and disconnected road structure to a certain extent by adding the context information extraction module. Furthermore, the decoder combined attention mechanism has been used to adjust the feature weights of skip connections to improve the segmentation effect of the road edge area. Combining attention mechanism and context information extraction module can effectively use global and local remote sensing image information to improve the road extraction performance.ResultThe model on the Deep Globe 2018 road extraction challenge dataset has been tested to evaluate the performance of the proposed model quantitatively. The Deep Global satellite road extraction dataset has contained 6 226 pairs of RGB satellite remote sensing images and labeled with dimension of 1 024×1 024 pixels. The dataset has been divided into 5 500 training set and 726 test set in the experiments. In order to evaluate the performance of the road segmentation model, two semantic segmentation performance indices have been commonly used in remote sensing image road segmentation: recall rate (recall) and intersection over union (IOU). The comprehensive experiments have shown that the recall rate and intersection over union of the proposed algorithm for the Deep Globe 2018 road extraction challenge dataset reached 0.847 2 and 0.691 5, respectively. The proposed model can segment a continuous road network. At the same time, the missing location information has been effectively restored to make the edges of the road clearer. The proposed algorithm can improve the use of remote sensing image information by adding context information module and attention mechanism. Compared with U-Net, context encoder network(CE-Net) and other models, it has higher accuracy and robustness.ConclusionA road extraction model for remote sensing images combined context information and attention mechanism has been proposed. The novel model has benefited from its pre-trained Resnet-34 backbone network and utilization of context information. Utilization of context information has solved incomplete and disconnected road structure to a certain extent. The decoder of the attention mechanism has improved the segmentation effect of the road edge area. The experimental results have demonstrated that the network achieved good results of road extraction from remote sensing images. The proposed method has improved the road segmentation accuracy and displayed the potential in remote sensing image processing.关键词:U-Net;deep learning;remote sensing image;road extraction;residual network;attention mechanism204|1839|5更新时间:2024-05-07
摘要:ObjectiveRoad extraction from remote sensing images has played an important role in city planning, traffic management, vehicle navigation, map updating and other fields nowadays, the characteristics of the road area in the remote sensing image have been affected by many factors such as lighting, noise and occlusion in the image acquisition process. A huge number of similar non-road objects, such as building areas and water areas have interfered with the road area recognition process simultaneously. The above two factors have increased the difficulty of road extraction from remote sensing images. Supervised learning-based road extraction algorithms such as support vector machines and traditional artificial neural networks have to artificially design features so as to train classification models. The recognition rate of these traditional methods has been significantly decreased when facing with the interference of the similar non-road targets and the rich information of the background in the images. Recently, a variety of deep learning techniques of convolutional neural networks have been widely used in the field of remote sensing image processing based on its efficient feature learning ability. Deep learning network has made a great progress in road extraction. It can not only obtain the overall network structure of the road, but also the clear boundaries of the road. A U-Net road segmentation network has been proposed improve the road extraction quality based on the context information and attention mechanism.MethodA novel deep neural network for road extraction from remote sensing images has been proposed based on the symmetrical structure of U-Net network and attention mechanism. In the network structure, the introduction of the pre-trained Resnet-34 network can effectively extract image features at different granularities. Resnet-34 residual network has been used as the backbone network of the novel U-Net network. Residual learning can greatly reduce the training time of the deep network, avoid the phenomenon of gradient disappearance, and improve the training accuracy. Meanwhile, the context information has contained the interaction information between different objects, the interaction information between the object and the scene, which can be used as features to combine the various parts between the roads and distinguish the road and the background. The context information extraction module can integrate the context information to ensure that the geometric topology of the road is extracted in the image. To adjust the feature weights, the attention mechanism module can be transmitted by the skip connection, strengthened by the feature information of the road area, suppressed by the feature information of the non-road area improved by the segmentation effect of the road edge thereby effectively improving the accuracy of road segmentation. The improved model has resolved the incomplete and disconnected road structure to a certain extent by adding the context information extraction module. Furthermore, the decoder combined attention mechanism has been used to adjust the feature weights of skip connections to improve the segmentation effect of the road edge area. Combining attention mechanism and context information extraction module can effectively use global and local remote sensing image information to improve the road extraction performance.ResultThe model on the Deep Globe 2018 road extraction challenge dataset has been tested to evaluate the performance of the proposed model quantitatively. The Deep Global satellite road extraction dataset has contained 6 226 pairs of RGB satellite remote sensing images and labeled with dimension of 1 024×1 024 pixels. The dataset has been divided into 5 500 training set and 726 test set in the experiments. In order to evaluate the performance of the road segmentation model, two semantic segmentation performance indices have been commonly used in remote sensing image road segmentation: recall rate (recall) and intersection over union (IOU). The comprehensive experiments have shown that the recall rate and intersection over union of the proposed algorithm for the Deep Globe 2018 road extraction challenge dataset reached 0.847 2 and 0.691 5, respectively. The proposed model can segment a continuous road network. At the same time, the missing location information has been effectively restored to make the edges of the road clearer. The proposed algorithm can improve the use of remote sensing image information by adding context information module and attention mechanism. Compared with U-Net, context encoder network(CE-Net) and other models, it has higher accuracy and robustness.ConclusionA road extraction model for remote sensing images combined context information and attention mechanism has been proposed. The novel model has benefited from its pre-trained Resnet-34 backbone network and utilization of context information. Utilization of context information has solved incomplete and disconnected road structure to a certain extent. The decoder of the attention mechanism has improved the segmentation effect of the road edge area. The experimental results have demonstrated that the network achieved good results of road extraction from remote sensing images. The proposed method has improved the road segmentation accuracy and displayed the potential in remote sensing image processing.关键词:U-Net;deep learning;remote sensing image;road extraction;residual network;attention mechanism204|1839|5更新时间:2024-05-07 -
 摘要:ObjectiveWater body detection has shown important applications in flood disaster assessment,water resource value estimation and ecological environment protection based on remote sensing imagery. Deep semantic segmentation network has achieved great success in the pixel-level remote sensing image classification. Water body detection performance can be reasonably expected based on the deep semantic segmentation network. However,the excellent performance of deep semantic segmentation network is highly dependent on the large-scale and high-quality pixel-level labels. This research paper has intended to leverage the existing open water cover products to create water labels corresponding to remote sensing images in order to reduce the workload of labeling and meantime maintain the fair detection accuracy. The existing open water cover products have a low spatial resolution and contain a certain degree of errors. The noisy low-resolution water labels have inevitably affected the training of deep semantic segmentation network for water body detection. A weakly supervised deep learning method to train deep semantic segmentation network have been taken into consideration to resolve the difficulties. The optimization method to train deep semantic segmentation network using the noisy low-resolution labels for the high accuracy of water detection has been presented based on minimizing the manual annotation cost.MethodIn the training stage,the original dataset has been divided into several non-overlapped sub-datasets. The deep semantic segmentation network has been trained on each sub-dataset. The trained deep semantic segmentation networks with different sub-datasets have updated the labels simultaneously. As the non-overlapped sub-datasets generally have different data distributions,the detection performance of different networks with different sub-datasets is also complementary. The prediction of the same region by different networks is different,so the multi-perspective deep semantic segmentation network can realize the collaborative update of labels. The updated labels have been used to repeat the above process to re-train new deep semantic segmentation networks. Following each step of iteration,the output of the network has been used as the new labels. The noisy labels have been removed with the iteration process. The range of truth value of the water has also be expanded continuously along with the iteration process. Several good deep semantic segmentation networks can be obtained after a few iterations. In the test stage,the multi-source remote sensing images have been predicted by several deep semantic segmentation networks representing different perspectives and producing the final water detection voting results.ResultThe multi-source remote sensing image training dataset,validation dataset and testing dataset have been built up for verification. The multi-source remote sensing imagery has composed of Sentinel-1 SAR (synthetic aperture radar) images and Sentinel-2 optical images. The training dataset has contained 150 000 multi-source remote sensing samples with the size of 256×256 pixels. The labels of the training dataset have been intercepted with the public MODIS (moderate-resolution imaging spectroradiometer) water coverage products in geographic scale. The spatial resolution of the training dataset is low and contains massive noise. The validation dataset has contained 100 samples with the size of 256×256 pixels and the testing dataset have contained 400 samples with the size of 256×256 pixels,and the labels from the validation and testing datasets have accurately annotated with the aid of domain experts. The training,validation and testing datasets have not been overlapped each and the dataset can geographically cover in global scale. Experimental results have shown that the proposed method is convergent,and the accuracy tends to be stable based on four iterations. The fusion of optical and SAR images can improve the accuracy of water body detection. The IoU (intersection over union) has increased by 5.5% compared with the traditional water index segmentation method. The IoU has increases by 7.2% compared with the deep semantic segmentation network directly using the noisy low-resolution water labels.ConclusionThe experimental results have shown that the current method can converge fast,and the fusion of optical and SAR images can improve the detection results. On the premise of the usage of the noisy low-resolution water labels,the water body detection accuracy of the trained multi-perspective model is obviously better than the traditional water index segmentation method and the deep semantic segmentation network based on the direct learning of the noisy low-resolution water labels. The accuracy of the traditional deep semantic segmentation method is slightly lower than that of the traditional water index method,which indicates that the effectiveness of deep learning highly depends on the quality of the training data labels. The noisy low-resolution water labels have reduced the effect of deep learning. The effect of the proposed method on small rivers and lakes has been analyzed. The accuracy on small rivers and lakes has decreased slightly. The result has still higher than the traditional water index method and the deep learning method with the direct training of the noisy low-resolution water labels.关键词:water body detection;multi-source remote sensing image;noisy low-resolution labels;weakly supervised deep semantic segmentation network110|176|7更新时间:2024-05-07
摘要:ObjectiveWater body detection has shown important applications in flood disaster assessment,water resource value estimation and ecological environment protection based on remote sensing imagery. Deep semantic segmentation network has achieved great success in the pixel-level remote sensing image classification. Water body detection performance can be reasonably expected based on the deep semantic segmentation network. However,the excellent performance of deep semantic segmentation network is highly dependent on the large-scale and high-quality pixel-level labels. This research paper has intended to leverage the existing open water cover products to create water labels corresponding to remote sensing images in order to reduce the workload of labeling and meantime maintain the fair detection accuracy. The existing open water cover products have a low spatial resolution and contain a certain degree of errors. The noisy low-resolution water labels have inevitably affected the training of deep semantic segmentation network for water body detection. A weakly supervised deep learning method to train deep semantic segmentation network have been taken into consideration to resolve the difficulties. The optimization method to train deep semantic segmentation network using the noisy low-resolution labels for the high accuracy of water detection has been presented based on minimizing the manual annotation cost.MethodIn the training stage,the original dataset has been divided into several non-overlapped sub-datasets. The deep semantic segmentation network has been trained on each sub-dataset. The trained deep semantic segmentation networks with different sub-datasets have updated the labels simultaneously. As the non-overlapped sub-datasets generally have different data distributions,the detection performance of different networks with different sub-datasets is also complementary. The prediction of the same region by different networks is different,so the multi-perspective deep semantic segmentation network can realize the collaborative update of labels. The updated labels have been used to repeat the above process to re-train new deep semantic segmentation networks. Following each step of iteration,the output of the network has been used as the new labels. The noisy labels have been removed with the iteration process. The range of truth value of the water has also be expanded continuously along with the iteration process. Several good deep semantic segmentation networks can be obtained after a few iterations. In the test stage,the multi-source remote sensing images have been predicted by several deep semantic segmentation networks representing different perspectives and producing the final water detection voting results.ResultThe multi-source remote sensing image training dataset,validation dataset and testing dataset have been built up for verification. The multi-source remote sensing imagery has composed of Sentinel-1 SAR (synthetic aperture radar) images and Sentinel-2 optical images. The training dataset has contained 150 000 multi-source remote sensing samples with the size of 256×256 pixels. The labels of the training dataset have been intercepted with the public MODIS (moderate-resolution imaging spectroradiometer) water coverage products in geographic scale. The spatial resolution of the training dataset is low and contains massive noise. The validation dataset has contained 100 samples with the size of 256×256 pixels and the testing dataset have contained 400 samples with the size of 256×256 pixels,and the labels from the validation and testing datasets have accurately annotated with the aid of domain experts. The training,validation and testing datasets have not been overlapped each and the dataset can geographically cover in global scale. Experimental results have shown that the proposed method is convergent,and the accuracy tends to be stable based on four iterations. The fusion of optical and SAR images can improve the accuracy of water body detection. The IoU (intersection over union) has increased by 5.5% compared with the traditional water index segmentation method. The IoU has increases by 7.2% compared with the deep semantic segmentation network directly using the noisy low-resolution water labels.ConclusionThe experimental results have shown that the current method can converge fast,and the fusion of optical and SAR images can improve the detection results. On the premise of the usage of the noisy low-resolution water labels,the water body detection accuracy of the trained multi-perspective model is obviously better than the traditional water index segmentation method and the deep semantic segmentation network based on the direct learning of the noisy low-resolution water labels. The accuracy of the traditional deep semantic segmentation method is slightly lower than that of the traditional water index method,which indicates that the effectiveness of deep learning highly depends on the quality of the training data labels. The noisy low-resolution water labels have reduced the effect of deep learning. The effect of the proposed method on small rivers and lakes has been analyzed. The accuracy on small rivers and lakes has decreased slightly. The result has still higher than the traditional water index method and the deep learning method with the direct training of the noisy low-resolution water labels.关键词:water body detection;multi-source remote sensing image;noisy low-resolution labels;weakly supervised deep semantic segmentation network110|176|7更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0