
最新刊期
卷 26 , 期 11 , 2021
-
 摘要:With the continuous improvement of China's economic strength and people's living standards, the requirements of the state and the people for electric power are gradually improving. To meet the increasing demand for electricity, the grid system is constantly developing, leading to increased time and capital costs required for the safe operation and maintenance of power grids. The rise of unmanned aerial vehicle (UAV) technology has introduced new detection ideas, which make the intelligent and efficient detection of defects of transmission line components a reality. Compared with manual inspection, UAV has advantages of low cost, high efficiency, strong mobility, and high safety. Thus, it has gradually replaced manual inspection. At the same time, artificial intelligence (AI) technology based on deep learning is also developing rapidly, and the related technology of applying AI to the maintenance of power equipment has developed rapidly in recent years. However, how to accurately and efficiently detect the visual defects of transmission line components is a key problem to be solved. Early component visual defect detection methods based on image processing and feature engineering have high requirements on image quality, and designing features for various transmission line components consumes much time and money. The current UAV aerial photography technology cannot meet the requirements of image quality, and its detection accuracy cannot meet the actual requirements of defect inspection of basic transmission line components. Thus, applying the component visual defect detection method based on image processing and feature engineering to complex real-life scenes is impossible. With deep learning, transmission line component defect detection models based on deep learning can effectively extract transmission line component objects and defects from aerial images with complex backgrounds. Deep learning-based detection models have many other advantages. 1) Deep learning can automatically extract multi-level, multi-angle features from original data instead of artificial design. 2) Deep learning has strong generalization and expression capabilities, that is, it possesses translation invariance. 3) Deep learning is more adaptable to complex real-world environments than traditional techniques. Therefore, the object detection model based on deep learning is an inevitable choice for processing transmission line inspection images. Before applying a deep learning model to the defect detection of key components of transmission lines, a complete defect data set of components should be created for the training of the deep learning model. However, in transmission line component defect detection, no data set is available to the public. This work aims to review the visual defect detection methods of transmission line components. On the basis of extensive research on the visual defect detection of transmission line components, existing detection methods are summarized and analyzed. First, the visual defect detection technology of key parts of transmission lines is described based on traditional algorithms. The development process of deep learning is reviewed, and the advantages and disadvantages of deep learning in defect detection are analyzed. Second, the status of research on the positioning and defect detection of three important components on transmission lines(i.e., insulator, metal, and bolt)is introduced. Third, several key problems, such as sample imbalance, small object detection, and fine-grained detection, in transmission line component defect detection are analyzed. Lastly, the future development trend of transmission line component defect detection technology that meets the requirements of complex-scene grid inspection and fault diagnosis criteria is analyzed. The conclusion is that the development of visual defect detection of transmission line components cannot be separated from the development of deep learning in the field of image processing and image data augmentation. In short, the establishment of a high-precision, high-efficiency, strongly intelligent, multi-level, full-coverage defect detection model of key components of transmission lines on the basis of deep learning remains unrealized.关键词:power equipment operation and maintenance;transmission line components;visual defect detection;deep learning;object detection;knowledge guidance351|408|29更新时间:2024-05-07
摘要:With the continuous improvement of China's economic strength and people's living standards, the requirements of the state and the people for electric power are gradually improving. To meet the increasing demand for electricity, the grid system is constantly developing, leading to increased time and capital costs required for the safe operation and maintenance of power grids. The rise of unmanned aerial vehicle (UAV) technology has introduced new detection ideas, which make the intelligent and efficient detection of defects of transmission line components a reality. Compared with manual inspection, UAV has advantages of low cost, high efficiency, strong mobility, and high safety. Thus, it has gradually replaced manual inspection. At the same time, artificial intelligence (AI) technology based on deep learning is also developing rapidly, and the related technology of applying AI to the maintenance of power equipment has developed rapidly in recent years. However, how to accurately and efficiently detect the visual defects of transmission line components is a key problem to be solved. Early component visual defect detection methods based on image processing and feature engineering have high requirements on image quality, and designing features for various transmission line components consumes much time and money. The current UAV aerial photography technology cannot meet the requirements of image quality, and its detection accuracy cannot meet the actual requirements of defect inspection of basic transmission line components. Thus, applying the component visual defect detection method based on image processing and feature engineering to complex real-life scenes is impossible. With deep learning, transmission line component defect detection models based on deep learning can effectively extract transmission line component objects and defects from aerial images with complex backgrounds. Deep learning-based detection models have many other advantages. 1) Deep learning can automatically extract multi-level, multi-angle features from original data instead of artificial design. 2) Deep learning has strong generalization and expression capabilities, that is, it possesses translation invariance. 3) Deep learning is more adaptable to complex real-world environments than traditional techniques. Therefore, the object detection model based on deep learning is an inevitable choice for processing transmission line inspection images. Before applying a deep learning model to the defect detection of key components of transmission lines, a complete defect data set of components should be created for the training of the deep learning model. However, in transmission line component defect detection, no data set is available to the public. This work aims to review the visual defect detection methods of transmission line components. On the basis of extensive research on the visual defect detection of transmission line components, existing detection methods are summarized and analyzed. First, the visual defect detection technology of key parts of transmission lines is described based on traditional algorithms. The development process of deep learning is reviewed, and the advantages and disadvantages of deep learning in defect detection are analyzed. Second, the status of research on the positioning and defect detection of three important components on transmission lines(i.e., insulator, metal, and bolt)is introduced. Third, several key problems, such as sample imbalance, small object detection, and fine-grained detection, in transmission line component defect detection are analyzed. Lastly, the future development trend of transmission line component defect detection technology that meets the requirements of complex-scene grid inspection and fault diagnosis criteria is analyzed. The conclusion is that the development of visual defect detection of transmission line components cannot be separated from the development of deep learning in the field of image processing and image data augmentation. In short, the establishment of a high-precision, high-efficiency, strongly intelligent, multi-level, full-coverage defect detection model of key components of transmission lines on the basis of deep learning remains unrealized.关键词:power equipment operation and maintenance;transmission line components;visual defect detection;deep learning;object detection;knowledge guidance351|408|29更新时间:2024-05-07 -
 摘要:ObjectiveThe insulator is the key component in transmission lines. Insulators are numerous and widely distributed in transmission lines. They operate in the field for a long time. Affected by high voltage and complex climate, faults, such as defects and cracks, occur easily. Faults have serious consequences and entail economic losses. Therefore, the insulator components in aerial images need to be identified efficiently and accurately to provide a basis for fault diagnosis and other related work. Traditional insulator recognition methods include threshold segmentation based on target features and recognition algorithms based on image enhancement. These methods need features to be designed manually, but manual selection of labeled features is prone to errors or false checks, and the recognition efficiency and accuracy are low. Hence, this approach cannot fully meet actual needs. Compared with traditional methods, such as image segmentation and image enhancement, deep learning extracts insulator features automatically by using a machine, and it is more accurate and faster than manual extraction.Researchers have used the popular algorithm faster region convolutional neural network(Faster RCNN) to identify insulators and generated proposal regions in the last feature layer by convolution to identify insulator targets. This algorithm results in an insufficient number of feature maps to be identified, and the small scale leads to weak semantic information of insulators, which easily causes misdetection and even non-detection. When the single-shot multi-box detector and "you only look once" use a fixed-size convolution kernel to identify insulators with a large scale difference, the semantic information of insulator features with a relatively small scale is reduced, which easily causes small-scale insulation misdetection.MethodAn insulator recognition model based on the improved scale-transferrable network is proposed to address the problems that traditional methods cannot automatically extract insulator features and that the deep learning network is insufficient to extract insulator semantic information. This model meets the requirements of automatic recognition and semantic information enhancement. The length and width of the insulator images are limited to 300×300 pixels. The preprocessed insulator images are outputted to the backbone network Densenet-169. Densenet-169 completes the feature extraction of the insulator images. The improvement work in this study is mainly divided into three parts. First, the feature integration method is used to enhance the semantic information of the feature map generated by Densenet-169. Second, after feature extraction, the semantic information loss of the small-scale insulator becomes serious; therefore, the small-scale feature map in the network is expanded to further enrich the semantic information. Lastly, the parameters of the anchor box are improved to effectively identify the insulator with a large-scale difference. After the improvement work is completed, the accurate position information of the insulator is obtained through bounding box regression, and the insulator is identified.ResultThe experimental data set is composed of composite, glass, and ceramic insulators. The images have a total of 4 350, which include 2 000 composite, 1 350 glass, and 1 000 ceramic insulator images. The scale of each image is preprocessed as 300×300 pixels, and the training and test sets are divided randomly(3 250 and 1 100, respectively). Experimental results show that the model structure is improved, and the recognition accuracy is 96.28%. The improvement in recognition accuracy ranges from 1.98% to 11.99% relative to the traditional Faster RCNN, improved Faster RCNN, and improved region-based fully convolutional neural network(R-FCN).ConclusionThe improved model increases the accuracy of insulator identification significantly and lays a solid foundation for subsequent transmission line detection work. Considering that the total number of anchor boxes is increased due to the improved scaling module, the compression parameters will be considered in future work to reduce the calculation.关键词:scale-transferrable network;insulator recognition;semantic information;feature integration;convolution;pooling;anchor box122|328|3更新时间:2024-05-07
摘要:ObjectiveThe insulator is the key component in transmission lines. Insulators are numerous and widely distributed in transmission lines. They operate in the field for a long time. Affected by high voltage and complex climate, faults, such as defects and cracks, occur easily. Faults have serious consequences and entail economic losses. Therefore, the insulator components in aerial images need to be identified efficiently and accurately to provide a basis for fault diagnosis and other related work. Traditional insulator recognition methods include threshold segmentation based on target features and recognition algorithms based on image enhancement. These methods need features to be designed manually, but manual selection of labeled features is prone to errors or false checks, and the recognition efficiency and accuracy are low. Hence, this approach cannot fully meet actual needs. Compared with traditional methods, such as image segmentation and image enhancement, deep learning extracts insulator features automatically by using a machine, and it is more accurate and faster than manual extraction.Researchers have used the popular algorithm faster region convolutional neural network(Faster RCNN) to identify insulators and generated proposal regions in the last feature layer by convolution to identify insulator targets. This algorithm results in an insufficient number of feature maps to be identified, and the small scale leads to weak semantic information of insulators, which easily causes misdetection and even non-detection. When the single-shot multi-box detector and "you only look once" use a fixed-size convolution kernel to identify insulators with a large scale difference, the semantic information of insulator features with a relatively small scale is reduced, which easily causes small-scale insulation misdetection.MethodAn insulator recognition model based on the improved scale-transferrable network is proposed to address the problems that traditional methods cannot automatically extract insulator features and that the deep learning network is insufficient to extract insulator semantic information. This model meets the requirements of automatic recognition and semantic information enhancement. The length and width of the insulator images are limited to 300×300 pixels. The preprocessed insulator images are outputted to the backbone network Densenet-169. Densenet-169 completes the feature extraction of the insulator images. The improvement work in this study is mainly divided into three parts. First, the feature integration method is used to enhance the semantic information of the feature map generated by Densenet-169. Second, after feature extraction, the semantic information loss of the small-scale insulator becomes serious; therefore, the small-scale feature map in the network is expanded to further enrich the semantic information. Lastly, the parameters of the anchor box are improved to effectively identify the insulator with a large-scale difference. After the improvement work is completed, the accurate position information of the insulator is obtained through bounding box regression, and the insulator is identified.ResultThe experimental data set is composed of composite, glass, and ceramic insulators. The images have a total of 4 350, which include 2 000 composite, 1 350 glass, and 1 000 ceramic insulator images. The scale of each image is preprocessed as 300×300 pixels, and the training and test sets are divided randomly(3 250 and 1 100, respectively). Experimental results show that the model structure is improved, and the recognition accuracy is 96.28%. The improvement in recognition accuracy ranges from 1.98% to 11.99% relative to the traditional Faster RCNN, improved Faster RCNN, and improved region-based fully convolutional neural network(R-FCN).ConclusionThe improved model increases the accuracy of insulator identification significantly and lays a solid foundation for subsequent transmission line detection work. Considering that the total number of anchor boxes is increased due to the improved scaling module, the compression parameters will be considered in future work to reduce the calculation.关键词:scale-transferrable network;insulator recognition;semantic information;feature integration;convolution;pooling;anchor box122|328|3更新时间:2024-05-07 -
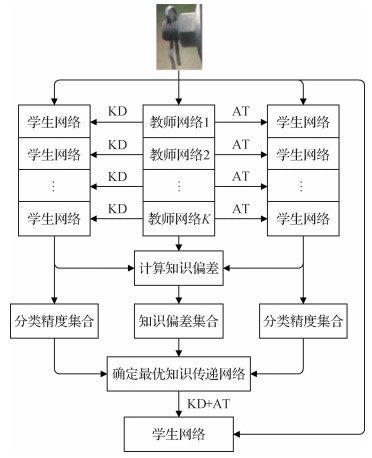 摘要:ObjectiveBolts play a key role in fixing and connecting various metal parts in transmission lines. Defects seriously affect the power transmission of transmission lines. The imaging background of an inspection image is complicated, the imaging distance and angle are variable, and the bolts occupy a small proportion in the inspection image. Thus, bolt defect images of transmission lines have low resolution and scarce visual information, and they usually require a large model with high complexity and excellent performance to classify bolt defects and ensure accuracy. A large model has a complex structure and numerous parameters, and deploying it on a large scale is difficult due to a large amount of computing resources needed in data analysis. A small model has a simple structure and few parameters, but it cannot completely guarantee the accuracy of bolt defect classification. This study proposes an image classification method of transmission line bolt defects based on the optimal knowledge transfer network to compensate for the limitations of bolt defect classification using large and small models.MethodThe width of the large model is changed, that is, the dimension of network feature expression is broadened, to fully mine the target information in the bolt image, thereby increasing the bolt defect knowledge of the transferability of the large model to the small model. To reduce the parameters of the small model considerably and improve its operation and maintenance capabilities, the structure of the small model is simplified to a 10-layer residual network with three residual blocks. The number of convolution kernels of each residual block is 16, 32, and 64. Therefore, the small model still has obvious features that focus on the low gradient of the bolt image in the low layer, the high difference area in the middle layer, and the overall characteristics of the bolt image in the high layer. Then, the large models of different widths use the attention transfer algorithm and the knowledge distillation algorithm to guide the training of the small models, and the accuracy of the small models under different widths after the training is calculated. Afterward, the concept of knowledge deviation is proposed to measure the degree of bolt defect knowledge transfer of large models and select the large model with the best performance in transferring bolt defect knowledge. The performance of the large and small models is mapped on a number line in the form of accuracy. The calculation process of knowledge deviation proceeds as follows. First, the difference in bolt defect classification accuracy between the large model with a known width and the small model being instructed is calculated. Second, the difference in bolt defect classification accuracy between the large model and the small model that is not being instructed is computed. Lastly, the ratio of the two differences before and after the calculation is adopted as the knowledge deviation. The smaller the knowledge deviation is, the greater the degree of bolt defect knowledge transfer is from the large model to the small model. The optimal knowledge transfer model is determined according to the knowledge deviation of different widths and the bolt defect classification accuracy of the small models under different guidance methods. The optimal knowledge transfer model combines the attention algorithm and the knowledge distillation algorithm to guide in small model training and maximize the bolt defect classification performance of the small model.ResultThe self-built bolt defect image classification data set verifies the effectiveness of this method in improving the accuracy of bolt classification of the simplified small model. The data set is constructed by clipping and optimizing the transmission line inspection image. The bolt defect image classification data set contains a total of 6 420 images, including 3 136 normal bolts, 2 820 bolts with missing pins, and 464 bolts with missing nuts, which belong to three categories. Experimental results show that the large model with a width of 5 has the best performance in transferring bolt defect knowledge to the small model, and it increases the bolt defect classification accuracy of the small model by 5.56%. The difference in the accuracy of bolt defect classification between the small model and the optimal knowledge transfer model is only 2.17%. The knowledge deviation is 0.28, and the parameter of the small model is only 0.56% of the parameter of the large model.ConclusionThe proposed bolt defect classification method based on the optimal knowledge transfer network greatly alleviates the problems of large model parameters and low classification accuracy of small models caused by bolt image characteristics. Balance is achieved between the classification accuracy of the bolt defect image and resource consumption. The method meets the requirements of actual field operation and maintenance, such as the work requirements of embedded equipment (e.g., online monitoring in transmission lines) and reduces the resource consumption of transmission line patrol data analysis.关键词:bolt defect classification;optimal knowledge transfer;knowledge deviation;knowledge distillation;attention transfer85|160|1更新时间:2024-05-07
摘要:ObjectiveBolts play a key role in fixing and connecting various metal parts in transmission lines. Defects seriously affect the power transmission of transmission lines. The imaging background of an inspection image is complicated, the imaging distance and angle are variable, and the bolts occupy a small proportion in the inspection image. Thus, bolt defect images of transmission lines have low resolution and scarce visual information, and they usually require a large model with high complexity and excellent performance to classify bolt defects and ensure accuracy. A large model has a complex structure and numerous parameters, and deploying it on a large scale is difficult due to a large amount of computing resources needed in data analysis. A small model has a simple structure and few parameters, but it cannot completely guarantee the accuracy of bolt defect classification. This study proposes an image classification method of transmission line bolt defects based on the optimal knowledge transfer network to compensate for the limitations of bolt defect classification using large and small models.MethodThe width of the large model is changed, that is, the dimension of network feature expression is broadened, to fully mine the target information in the bolt image, thereby increasing the bolt defect knowledge of the transferability of the large model to the small model. To reduce the parameters of the small model considerably and improve its operation and maintenance capabilities, the structure of the small model is simplified to a 10-layer residual network with three residual blocks. The number of convolution kernels of each residual block is 16, 32, and 64. Therefore, the small model still has obvious features that focus on the low gradient of the bolt image in the low layer, the high difference area in the middle layer, and the overall characteristics of the bolt image in the high layer. Then, the large models of different widths use the attention transfer algorithm and the knowledge distillation algorithm to guide the training of the small models, and the accuracy of the small models under different widths after the training is calculated. Afterward, the concept of knowledge deviation is proposed to measure the degree of bolt defect knowledge transfer of large models and select the large model with the best performance in transferring bolt defect knowledge. The performance of the large and small models is mapped on a number line in the form of accuracy. The calculation process of knowledge deviation proceeds as follows. First, the difference in bolt defect classification accuracy between the large model with a known width and the small model being instructed is calculated. Second, the difference in bolt defect classification accuracy between the large model and the small model that is not being instructed is computed. Lastly, the ratio of the two differences before and after the calculation is adopted as the knowledge deviation. The smaller the knowledge deviation is, the greater the degree of bolt defect knowledge transfer is from the large model to the small model. The optimal knowledge transfer model is determined according to the knowledge deviation of different widths and the bolt defect classification accuracy of the small models under different guidance methods. The optimal knowledge transfer model combines the attention algorithm and the knowledge distillation algorithm to guide in small model training and maximize the bolt defect classification performance of the small model.ResultThe self-built bolt defect image classification data set verifies the effectiveness of this method in improving the accuracy of bolt classification of the simplified small model. The data set is constructed by clipping and optimizing the transmission line inspection image. The bolt defect image classification data set contains a total of 6 420 images, including 3 136 normal bolts, 2 820 bolts with missing pins, and 464 bolts with missing nuts, which belong to three categories. Experimental results show that the large model with a width of 5 has the best performance in transferring bolt defect knowledge to the small model, and it increases the bolt defect classification accuracy of the small model by 5.56%. The difference in the accuracy of bolt defect classification between the small model and the optimal knowledge transfer model is only 2.17%. The knowledge deviation is 0.28, and the parameter of the small model is only 0.56% of the parameter of the large model.ConclusionThe proposed bolt defect classification method based on the optimal knowledge transfer network greatly alleviates the problems of large model parameters and low classification accuracy of small models caused by bolt image characteristics. Balance is achieved between the classification accuracy of the bolt defect image and resource consumption. The method meets the requirements of actual field operation and maintenance, such as the work requirements of embedded equipment (e.g., online monitoring in transmission lines) and reduces the resource consumption of transmission line patrol data analysis.关键词:bolt defect classification;optimal knowledge transfer;knowledge deviation;knowledge distillation;attention transfer85|160|1更新时间:2024-05-07 -
 摘要:ObjectiveUnmanned aerial vehicle(UAV)-based transmission line inspection technology has achieved long-term progress and development. The use of computer vision technology to automatically and accurately locate line equipment, such as wires, insulators, and bolts, from aerial inspection images under complex natural backgrounds and accurately detect their defects has become animportant technical issue. The defects inspected by transmission lines mainly include tower, wire, insulator, and metal fitting defects. Given the large size of metal fittings and insulators, their defects are obvious and easy to identify. By contrast, numerous bolts are present in poles, insulators, and metal fittings. Bolts change easily from the normal state to the defect state due to the large number of bolts and complex stress conditions. The use of deep learning has achieved good results in visual detection, identification, and classification of tower, wire, insulator, and metal fitting defects, but only a few studies have been conducted on bolt defects. In addition, bolt defects are not completely visually separable problems; they are visually inseparable, and they can not be solved by object detection algorithms alone. Thus, we believe that the bolt defect detection problem is not only an object detection problem, but also an image classification problem. Multi-label classification of bolts must be implemented efficiently and quickly to provide a basis for defect detection. The convolutional neural network (CNN) is inherently limited by model geometry transformation due to its fixed geometric structure. An offset variable must be added to the position of each sampling point in the convolution kernel to weaken this limitation and improve the feature extraction capability of bolts. By adding these variables, the convolution kernel is given random sampling near the current position and is no longer limited to the previous regular grid points. The convolution operation after expansion is called deformable convolution. Deformable convolution changes the sampling position of the standard convolution kernel by adding an additional offset to the sampling point. The compensation obtained can be learned through training without additional supervision.MethodThe object to be inspected in the transmission line bolt multi-label classification task has similar overall characteristics as those of the object in the general image multi-label classification task. The classification model needs to capture the key local features that can distinguish the attributes of different categories. The idea of using local regions to assist in classification belongs to fine-grained classification. Several studies on fine-grained classification algorithms used detailed local area labels to train the model so that the model can accurately locate the regions containing detailed semantic information. However, this approach requires a huge amount of work in the production of labels. In other studies, unsupervised learning was used to locate key areas. Although this strategy eliminates tedious label-making work, the accuracy of the model in locating key details can not be ensured. The multi-label classification method proposed in this study is mainly divided into three steps.First, navigator-teacher-scrutinizer network(NTS-Net) is used as the basic network, and the feature extraction network is improved into a deformable ResNet-50 network in accordance with the various properties of the bolt target shape. Second, the navigator network in NTS-Net continuously learns and provides k regions with the most information under the guidance of the teacher network to obtain the discriminative region of the bolt target. Lastly, to make the model use discriminant features effectively, the input features of the k regions receiving the most information from the navigator network are extracted, and corresponding feature vectors are generated and connected to the feature vectors of the entire input image. Afterward, the features need to be passed through the channel attention module, which can enhance the feature with a large weight and suppress the feature with a small weight.ResultThis study uses the bolt multi-attribute classification dataset to evaluate the model. The bolt defect images are from samples obtained by UAV line inspection. The data sample has a total of 2 000 pictures, of which 1 500 are used as training samples and 500 are used as test samples. The bolt defect attributes are divided into six categories based the idea of visual separability. Each bolt defect image contains one or more defect attributes, which can be divided into the following six categories: a pin hole is present, shim is present, a nut is present, rust is present, the nut is loose, and the pin is loose; they are labeled 0-5 respectively. In the multi-label classification task in this study, a 1×6 matrix is constructed for each picture as the label of the picture. If the corresponding attribute category exists, the value is set to 1 and vice versa. Experimental results show that the mean average precision of the proposed method in the bolt multi-attribute classification dataset is 84.5%, which is 10%~20% higher than the accuracy of multi-label classification using traditional networks.ConclusionThe feature extraction capability of the network is improved through deformable convolution, and the channel attention mechanism is introduced to realize the efficient utilization of the local features provided by NTS-Net. Experimental results show that the proposed method performs better than the traditional method in the bolt multi-attribute classification dataset. The proposed method provides a new idea for applying multi-attribute information to bolt defect reasoning and realizing bolt defect detection.关键词:bolt defect;deformable convolution;NTS-Net network;multi-label classification;channel attention81|30|5更新时间:2024-05-07
摘要:ObjectiveUnmanned aerial vehicle(UAV)-based transmission line inspection technology has achieved long-term progress and development. The use of computer vision technology to automatically and accurately locate line equipment, such as wires, insulators, and bolts, from aerial inspection images under complex natural backgrounds and accurately detect their defects has become animportant technical issue. The defects inspected by transmission lines mainly include tower, wire, insulator, and metal fitting defects. Given the large size of metal fittings and insulators, their defects are obvious and easy to identify. By contrast, numerous bolts are present in poles, insulators, and metal fittings. Bolts change easily from the normal state to the defect state due to the large number of bolts and complex stress conditions. The use of deep learning has achieved good results in visual detection, identification, and classification of tower, wire, insulator, and metal fitting defects, but only a few studies have been conducted on bolt defects. In addition, bolt defects are not completely visually separable problems; they are visually inseparable, and they can not be solved by object detection algorithms alone. Thus, we believe that the bolt defect detection problem is not only an object detection problem, but also an image classification problem. Multi-label classification of bolts must be implemented efficiently and quickly to provide a basis for defect detection. The convolutional neural network (CNN) is inherently limited by model geometry transformation due to its fixed geometric structure. An offset variable must be added to the position of each sampling point in the convolution kernel to weaken this limitation and improve the feature extraction capability of bolts. By adding these variables, the convolution kernel is given random sampling near the current position and is no longer limited to the previous regular grid points. The convolution operation after expansion is called deformable convolution. Deformable convolution changes the sampling position of the standard convolution kernel by adding an additional offset to the sampling point. The compensation obtained can be learned through training without additional supervision.MethodThe object to be inspected in the transmission line bolt multi-label classification task has similar overall characteristics as those of the object in the general image multi-label classification task. The classification model needs to capture the key local features that can distinguish the attributes of different categories. The idea of using local regions to assist in classification belongs to fine-grained classification. Several studies on fine-grained classification algorithms used detailed local area labels to train the model so that the model can accurately locate the regions containing detailed semantic information. However, this approach requires a huge amount of work in the production of labels. In other studies, unsupervised learning was used to locate key areas. Although this strategy eliminates tedious label-making work, the accuracy of the model in locating key details can not be ensured. The multi-label classification method proposed in this study is mainly divided into three steps.First, navigator-teacher-scrutinizer network(NTS-Net) is used as the basic network, and the feature extraction network is improved into a deformable ResNet-50 network in accordance with the various properties of the bolt target shape. Second, the navigator network in NTS-Net continuously learns and provides k regions with the most information under the guidance of the teacher network to obtain the discriminative region of the bolt target. Lastly, to make the model use discriminant features effectively, the input features of the k regions receiving the most information from the navigator network are extracted, and corresponding feature vectors are generated and connected to the feature vectors of the entire input image. Afterward, the features need to be passed through the channel attention module, which can enhance the feature with a large weight and suppress the feature with a small weight.ResultThis study uses the bolt multi-attribute classification dataset to evaluate the model. The bolt defect images are from samples obtained by UAV line inspection. The data sample has a total of 2 000 pictures, of which 1 500 are used as training samples and 500 are used as test samples. The bolt defect attributes are divided into six categories based the idea of visual separability. Each bolt defect image contains one or more defect attributes, which can be divided into the following six categories: a pin hole is present, shim is present, a nut is present, rust is present, the nut is loose, and the pin is loose; they are labeled 0-5 respectively. In the multi-label classification task in this study, a 1×6 matrix is constructed for each picture as the label of the picture. If the corresponding attribute category exists, the value is set to 1 and vice versa. Experimental results show that the mean average precision of the proposed method in the bolt multi-attribute classification dataset is 84.5%, which is 10%~20% higher than the accuracy of multi-label classification using traditional networks.ConclusionThe feature extraction capability of the network is improved through deformable convolution, and the channel attention mechanism is introduced to realize the efficient utilization of the local features provided by NTS-Net. Experimental results show that the proposed method performs better than the traditional method in the bolt multi-attribute classification dataset. The proposed method provides a new idea for applying multi-attribute information to bolt defect reasoning and realizing bolt defect detection.关键词:bolt defect;deformable convolution;NTS-Net network;multi-label classification;channel attention81|30|5更新时间:2024-05-07 -
 摘要:ObjectiveIn transmission lines, bolts are widely used as a kind of fasteners to connect various parts of transmission lines and make the overall structure stable and safe. However, bolts are easily damaged because of their complex working environment. The damage or loss of a bolt may cause a large area of transmission line failure, which seriously threatens the safety and stability of the power grid. Bolts are the most common components of transmission lines. Thus, bolt defect detection is an important task in transmission line inspection. Good features are difficult extract because of the complex background, small target, small difference between categories, and loss of gradient information. This study proposes a dual-attention scheme to enhance the visual features of different scales and positions.MethodFirst, for different scales, the network extracts the feature map of each layer, uses the multi-scale attention model to obtain the corresponding attention map, calculates the difference of the attention map for adjacent layers, and adds it to the loss function as a regularization term to enhance the fine features of the bolt area. The trained network continuously reduces the difference in the attention maps of different layers. The learned attention maps of different scales are introduced into the network as a kind of context information. This procedure can avoid the loss of important information in the process of feature extraction. No additional regulatory information is required because the attention map is from the network itself. Second, for different positions, bolts appear in specific positions of the accessories, but due to light blocking and other reasons, the characteristics of these positions are not obvious. In this study, we use the feature map to derive a spatial attention map of the image. Each element in the attention map indicates the degree of similarity between two spatial locations. Then, the attention map is used to combine the features of each position with the global feature. This process enhances the features in similar regions and improves the difference degree between dissimilar areas. Hence, the difference between the bolt and the background is increased, and the detection accuracy of the bolt area is improved.ResultThe method is tested on a typical bolt data set for aerial transmission lines. The typical bolt data set contains 1 483 images of three types of bolts. Each image has a size of approximately 3 000×4 000 pixels. A total of 2 692 targets are labeled, and they include 1 443 normal bolt samples, 670 missing bolt samples, and 579 missing nut bolt samples. The ratio of the training set to the test set is 8:2. The baseline model used in this study is the faster region convolutional neural network(Faster R-CNN) model. Experimental results show that compared with the baseline, the proposed model's mean average precision (mAP) is increased by 0.29% when the multi-scale attention module is added. Normal, missing and missing nut bolts increase by 0.62%, 2.54%, and 0.69%, respectively. After the addition of the spatial attention module, the mAP of the model increases by 0.61%; specifically, the AP of normal bolts increases by 0.3%, that of missing bolts increases by 2.05%, and that of missing nut bolts increases by 0.52%. This result is obtained because several shaded nuts of missing bolts are confused with the nuts of normal bolts, leading to misjudgment. After introducing multi-scale attention and spatial attention at the same time, the model's mAP is increased by 2.21%; the AP of the normal, missing, and missing nut bolts is increased by 0.29%, 5.23%, and 1.10%, respectively. These experimental results prove the effectiveness of the bolt defect detection method for aerial transmission lines based on the dual attention mechanism. This study also conducts visualization experiments, including the establishment of feature maps, model training loss function curve, precision-recall(PR) curve, and bolt defect detection result map, to prove that the proposed method can be applied to feature extraction.ConclusionExperimental results prove that the proposed detection method for aerial transmission line bolt defects based on the dual attention mechanism is effective. The process of supervising feature extraction can ensure that abundant useful information is retained when extracting features. For the bolt defect detection task, increasing the difference between the target and the background can improve the detection accuracy of the target area. The visualization experiments verify that the proposed method can retain abundant useful information in the process of feature extraction. The visualized test examples also prove that the proposed method can effectively avoid the problem of misjudgment in bolt defect detection.关键词:dual attention mechanism;multi-scale;spatial position;bolt defect detection;deep learning132|63|16更新时间:2024-05-07
摘要:ObjectiveIn transmission lines, bolts are widely used as a kind of fasteners to connect various parts of transmission lines and make the overall structure stable and safe. However, bolts are easily damaged because of their complex working environment. The damage or loss of a bolt may cause a large area of transmission line failure, which seriously threatens the safety and stability of the power grid. Bolts are the most common components of transmission lines. Thus, bolt defect detection is an important task in transmission line inspection. Good features are difficult extract because of the complex background, small target, small difference between categories, and loss of gradient information. This study proposes a dual-attention scheme to enhance the visual features of different scales and positions.MethodFirst, for different scales, the network extracts the feature map of each layer, uses the multi-scale attention model to obtain the corresponding attention map, calculates the difference of the attention map for adjacent layers, and adds it to the loss function as a regularization term to enhance the fine features of the bolt area. The trained network continuously reduces the difference in the attention maps of different layers. The learned attention maps of different scales are introduced into the network as a kind of context information. This procedure can avoid the loss of important information in the process of feature extraction. No additional regulatory information is required because the attention map is from the network itself. Second, for different positions, bolts appear in specific positions of the accessories, but due to light blocking and other reasons, the characteristics of these positions are not obvious. In this study, we use the feature map to derive a spatial attention map of the image. Each element in the attention map indicates the degree of similarity between two spatial locations. Then, the attention map is used to combine the features of each position with the global feature. This process enhances the features in similar regions and improves the difference degree between dissimilar areas. Hence, the difference between the bolt and the background is increased, and the detection accuracy of the bolt area is improved.ResultThe method is tested on a typical bolt data set for aerial transmission lines. The typical bolt data set contains 1 483 images of three types of bolts. Each image has a size of approximately 3 000×4 000 pixels. A total of 2 692 targets are labeled, and they include 1 443 normal bolt samples, 670 missing bolt samples, and 579 missing nut bolt samples. The ratio of the training set to the test set is 8:2. The baseline model used in this study is the faster region convolutional neural network(Faster R-CNN) model. Experimental results show that compared with the baseline, the proposed model's mean average precision (mAP) is increased by 0.29% when the multi-scale attention module is added. Normal, missing and missing nut bolts increase by 0.62%, 2.54%, and 0.69%, respectively. After the addition of the spatial attention module, the mAP of the model increases by 0.61%; specifically, the AP of normal bolts increases by 0.3%, that of missing bolts increases by 2.05%, and that of missing nut bolts increases by 0.52%. This result is obtained because several shaded nuts of missing bolts are confused with the nuts of normal bolts, leading to misjudgment. After introducing multi-scale attention and spatial attention at the same time, the model's mAP is increased by 2.21%; the AP of the normal, missing, and missing nut bolts is increased by 0.29%, 5.23%, and 1.10%, respectively. These experimental results prove the effectiveness of the bolt defect detection method for aerial transmission lines based on the dual attention mechanism. This study also conducts visualization experiments, including the establishment of feature maps, model training loss function curve, precision-recall(PR) curve, and bolt defect detection result map, to prove that the proposed method can be applied to feature extraction.ConclusionExperimental results prove that the proposed detection method for aerial transmission line bolt defects based on the dual attention mechanism is effective. The process of supervising feature extraction can ensure that abundant useful information is retained when extracting features. For the bolt defect detection task, increasing the difference between the target and the background can improve the detection accuracy of the target area. The visualization experiments verify that the proposed method can retain abundant useful information in the process of feature extraction. The visualized test examples also prove that the proposed method can effectively avoid the problem of misjudgment in bolt defect detection.关键词:dual attention mechanism;multi-scale;spatial position;bolt defect detection;deep learning132|63|16更新时间:2024-05-07 -
 摘要:ObjectivePowerline semantic segmentation of aerial images, as an important content of powerline intelligent inspection research, has received widespread attention. Recently, several deep learning-based methods have been proposed in this field and achieved high accuracy. However, two major problems still need to be solved before deep learning models can be applied in practice. First, the sample size of publicly available datasets is small. Unlike target objects in other semantic segmentation tasks (e.g., cars and buildings), powerlines have few textures and structural features, which make powerlines easy to be misidentified, especially in scenes that are not covered by the training set. Therefore, constructing a training set that contains many different background samples is crucial to improve the generalization capability of the model. The second problem is the conflict between the amount of model computation and the limited terminal computing resources. Previous work has demonstrated that an improved U-Net model can segment powerlines from aerial images with satisfactory accuracy. However, the model is computationally expensive for many resource-constrained inference terminals (e.g., unmanned aerial vehicles(UAVs)).MethodIn this study, the background images in the training set were learned using a generative adversarial network (GAN) to generate a series of pseudo-backgrounds, and curved powerlines were drawn on the generated images by utilizing conic curves. In detail, a multi-scale-based automatic growth model called progressive growing of GANs (PGGAN) was adopted to learn the mapping of a random noise vector to the background images in the training set. Then, its generator was used to generate serials of the background images. These background images and the curved powerlines generated by the conic curves were fused in the alpha channel. We created three training sets. The first one consisted of only 2 000 real background pictures, and the second was a mixture of 10 000 real and generated background images. The third training dataset was composed of 200 generated backgrounds and used to evaluate the similarity between the generated and original images. At the input of the segmentation network, random hue perturbation was applied to the images to enhance the generalization of the model across seasons. Then, the convergence accuracy of U-Net networks with three different loss functions was compared in RGB and grayscale color spaces to determine the best combination. Specifically, we trained U-Net with focal, soft-IoU, and Dice loss functions in RGB and gray spaces and compared the convergence accuracy, convergence speed, and overfitting of the six obtained models. Afterward, sparse regularization was applied to the pre-trained full model, and structured network pruning was performed to reduce the computation load in network inference. A saliency metric that combines first-order Taylor expansion and 2-norm metric was proposed to guide the regularization and pruning process. It provided a higher compression rate compared with the 2-norm that was used in the previous pruning algorithm. Conventional saliency metrics based on first-order expansion can change by orders of magnitude during the regularization process, thus making threshold selection during the iterative process difficult. Compared with these conventional metrics, the proposed metric has a more stable range of values, which enables the use of iteration-based regularization methods. We adopted a 0-norm-based regularization method to widen the saliency gap between important and unimportant neurons. To select the decision threshold, we used an adaptive approach, which was more robust to changes in luminance compared with the fixed-threshold method used in previous work.ResultExperimental results showed that the convergence accuracy of the curved powerline dataset was higher than that of the straight powerline dataset. In RGB space, the hybrid dataset using GAN had higher convergence accuracy than the dataset using only real images, but no significant improvement in gray space was observed due to the possibility of model collapse. We confirmed that hue disturbance can effectively improve the performance of the model across seasons. The experimental results of the different loss functions revealed that the convergence intersection-over-union(IoU) of RGB and gray spaces under their respective optimal loss functions was 0.578 and 0.586, respectively. Dice and soft-IoU had a negligible difference in convergence speed and achieved the best accuracy in gray and RGB spaces, respectively. The convergence of focal loss was the slowest in both spaces, and neither achieved the optimal accuracy. At the pruning stage, by using the conventional 2-norm saliency metric, the proposed gray space lightweight model (IoU of 0.459) reduced the number of floating-point operations per second (FLOPs) and parameters to 3.05% and 0.03% of the full model in RGB space, respectively (IoU of 0.573). When the proposed joint saliency metric was used, the numbers of FLOPs and parameters further decreased to 0.947% and 0.015% of the complete model, respectively, while maintaining an IoU of 0.42. The experiment also showed that the Otsu threshold method worked stably within the appropriate range of illumination changes, and a negligible difference from the optimal threshold was observed.ConclusionImprovements in the dataset and loss function independently enhanced the performance of the baseline model. Sparse regularization and network pruning reduced the network parameters and calculation load, which facilitated the deployment of the model on resource-constrained inferring terminals, such as UAVs. The proposed saliency measure exhibited better compression capabilities than the conventional 2-norm metric, and the adaptive threshold method helped improve the robustness of the model when the luminance changed.关键词:smart inspection;image semantic segmentation;sparse regularization;network pruning;generated adversarial network (GAN)86|76|4更新时间:2024-05-07
摘要:ObjectivePowerline semantic segmentation of aerial images, as an important content of powerline intelligent inspection research, has received widespread attention. Recently, several deep learning-based methods have been proposed in this field and achieved high accuracy. However, two major problems still need to be solved before deep learning models can be applied in practice. First, the sample size of publicly available datasets is small. Unlike target objects in other semantic segmentation tasks (e.g., cars and buildings), powerlines have few textures and structural features, which make powerlines easy to be misidentified, especially in scenes that are not covered by the training set. Therefore, constructing a training set that contains many different background samples is crucial to improve the generalization capability of the model. The second problem is the conflict between the amount of model computation and the limited terminal computing resources. Previous work has demonstrated that an improved U-Net model can segment powerlines from aerial images with satisfactory accuracy. However, the model is computationally expensive for many resource-constrained inference terminals (e.g., unmanned aerial vehicles(UAVs)).MethodIn this study, the background images in the training set were learned using a generative adversarial network (GAN) to generate a series of pseudo-backgrounds, and curved powerlines were drawn on the generated images by utilizing conic curves. In detail, a multi-scale-based automatic growth model called progressive growing of GANs (PGGAN) was adopted to learn the mapping of a random noise vector to the background images in the training set. Then, its generator was used to generate serials of the background images. These background images and the curved powerlines generated by the conic curves were fused in the alpha channel. We created three training sets. The first one consisted of only 2 000 real background pictures, and the second was a mixture of 10 000 real and generated background images. The third training dataset was composed of 200 generated backgrounds and used to evaluate the similarity between the generated and original images. At the input of the segmentation network, random hue perturbation was applied to the images to enhance the generalization of the model across seasons. Then, the convergence accuracy of U-Net networks with three different loss functions was compared in RGB and grayscale color spaces to determine the best combination. Specifically, we trained U-Net with focal, soft-IoU, and Dice loss functions in RGB and gray spaces and compared the convergence accuracy, convergence speed, and overfitting of the six obtained models. Afterward, sparse regularization was applied to the pre-trained full model, and structured network pruning was performed to reduce the computation load in network inference. A saliency metric that combines first-order Taylor expansion and 2-norm metric was proposed to guide the regularization and pruning process. It provided a higher compression rate compared with the 2-norm that was used in the previous pruning algorithm. Conventional saliency metrics based on first-order expansion can change by orders of magnitude during the regularization process, thus making threshold selection during the iterative process difficult. Compared with these conventional metrics, the proposed metric has a more stable range of values, which enables the use of iteration-based regularization methods. We adopted a 0-norm-based regularization method to widen the saliency gap between important and unimportant neurons. To select the decision threshold, we used an adaptive approach, which was more robust to changes in luminance compared with the fixed-threshold method used in previous work.ResultExperimental results showed that the convergence accuracy of the curved powerline dataset was higher than that of the straight powerline dataset. In RGB space, the hybrid dataset using GAN had higher convergence accuracy than the dataset using only real images, but no significant improvement in gray space was observed due to the possibility of model collapse. We confirmed that hue disturbance can effectively improve the performance of the model across seasons. The experimental results of the different loss functions revealed that the convergence intersection-over-union(IoU) of RGB and gray spaces under their respective optimal loss functions was 0.578 and 0.586, respectively. Dice and soft-IoU had a negligible difference in convergence speed and achieved the best accuracy in gray and RGB spaces, respectively. The convergence of focal loss was the slowest in both spaces, and neither achieved the optimal accuracy. At the pruning stage, by using the conventional 2-norm saliency metric, the proposed gray space lightweight model (IoU of 0.459) reduced the number of floating-point operations per second (FLOPs) and parameters to 3.05% and 0.03% of the full model in RGB space, respectively (IoU of 0.573). When the proposed joint saliency metric was used, the numbers of FLOPs and parameters further decreased to 0.947% and 0.015% of the complete model, respectively, while maintaining an IoU of 0.42. The experiment also showed that the Otsu threshold method worked stably within the appropriate range of illumination changes, and a negligible difference from the optimal threshold was observed.ConclusionImprovements in the dataset and loss function independently enhanced the performance of the baseline model. Sparse regularization and network pruning reduced the network parameters and calculation load, which facilitated the deployment of the model on resource-constrained inferring terminals, such as UAVs. The proposed saliency measure exhibited better compression capabilities than the conventional 2-norm metric, and the adaptive threshold method helped improve the robustness of the model when the luminance changed.关键词:smart inspection;image semantic segmentation;sparse regularization;network pruning;generated adversarial network (GAN)86|76|4更新时间:2024-05-07
Frontier Technology of Power Computer Vision

-
 摘要:Although the current intelligent vision system has certain advantages in feature detection, the extraction and matching of large-scale visual information and the cognition of deep-seated visual information remain uncertain and fragile. How to mine and understand the connotation of visual information efficiently, and make cognitive decisions is an engaging research field in computer vision. Especially for the visual cognitive task based on visual perception, the related mathematical logic and image processing methods have not achieved a qualitative breakthrough at present due to limitations by the western philosophy system. It makes the development of computer vision processing intelligent algorithm enter a bottleneck period and completely replacing human to perform more complex operations such as understanding, reasoning, decision making, and learning difficult. The basic framework of hybrid enhanced visual cognition and the application fields and key technologies that can be included in the framework to promote the development of intelligent visual perception and cognitive technology based on the application status of hybrid enhanced intelligence in the field of visual cognition are summarized in this paper. First, on the basis of analyzing the connotation and basic category of intelligent visual perception, human visual perception and psychological cognition are integrated; the definition, category, and deepening of hybrid enhanced visual cognition are discussed; different visual information processing stages are compared and analyzed; and then the basic framework of hybrid enhanced visual cognition on analyzing the development status of relevant cognitive models is constructed. The framework can rely on intelligent algorithms for rapid detection, recognition, understanding, and other processing to maximize the computational potential of "machine"; can effectively enhance the accuracy and reliability of system cognition with timely, appropriate artificial reasoning, prediction, and decision making; and give full play to human cognitive advantages. Second, the representative applications and existing problems of the framework are discussed from four fields, namely, hybrid enhanced visual monitoring, hybrid enhanced visual driving, hybrid enhanced visual decision making, and hybrid enhanced visual sharing, and the hybrid enhanced visual cognitive framework is identified as an expedient measure to enhance computer efficiency and reduce the pressure on people to process information under existing technical conditions. Then, based on high, medium, and low computer vision processing technology systems, the macro and micro relationships of several medium- and high-level visual processing technologies in a hybrid enhanced visual cognition framework are analyzed, focusing on key technologies such as visual analysis, visual enhancement, visual attention, visual understanding, visual reasoning, interactive learning, and cognitive evaluation. This framework will help break through the bottleneck of "weak artificial intelligence" in current visual information cognition and effectively promote the further development of intelligent vision system toward the direction of human-computer deep integration. Next, more indepth research must be carried out on pure basic innovation, efficient human-computer interaction, and flexible connection path.关键词:visual cognition;visual perception;intelligent visual perception;hybrid enhanced visual cognition;man-machine fusion111|231|1更新时间:2024-05-07
摘要:Although the current intelligent vision system has certain advantages in feature detection, the extraction and matching of large-scale visual information and the cognition of deep-seated visual information remain uncertain and fragile. How to mine and understand the connotation of visual information efficiently, and make cognitive decisions is an engaging research field in computer vision. Especially for the visual cognitive task based on visual perception, the related mathematical logic and image processing methods have not achieved a qualitative breakthrough at present due to limitations by the western philosophy system. It makes the development of computer vision processing intelligent algorithm enter a bottleneck period and completely replacing human to perform more complex operations such as understanding, reasoning, decision making, and learning difficult. The basic framework of hybrid enhanced visual cognition and the application fields and key technologies that can be included in the framework to promote the development of intelligent visual perception and cognitive technology based on the application status of hybrid enhanced intelligence in the field of visual cognition are summarized in this paper. First, on the basis of analyzing the connotation and basic category of intelligent visual perception, human visual perception and psychological cognition are integrated; the definition, category, and deepening of hybrid enhanced visual cognition are discussed; different visual information processing stages are compared and analyzed; and then the basic framework of hybrid enhanced visual cognition on analyzing the development status of relevant cognitive models is constructed. The framework can rely on intelligent algorithms for rapid detection, recognition, understanding, and other processing to maximize the computational potential of "machine"; can effectively enhance the accuracy and reliability of system cognition with timely, appropriate artificial reasoning, prediction, and decision making; and give full play to human cognitive advantages. Second, the representative applications and existing problems of the framework are discussed from four fields, namely, hybrid enhanced visual monitoring, hybrid enhanced visual driving, hybrid enhanced visual decision making, and hybrid enhanced visual sharing, and the hybrid enhanced visual cognitive framework is identified as an expedient measure to enhance computer efficiency and reduce the pressure on people to process information under existing technical conditions. Then, based on high, medium, and low computer vision processing technology systems, the macro and micro relationships of several medium- and high-level visual processing technologies in a hybrid enhanced visual cognition framework are analyzed, focusing on key technologies such as visual analysis, visual enhancement, visual attention, visual understanding, visual reasoning, interactive learning, and cognitive evaluation. This framework will help break through the bottleneck of "weak artificial intelligence" in current visual information cognition and effectively promote the further development of intelligent vision system toward the direction of human-computer deep integration. Next, more indepth research must be carried out on pure basic innovation, efficient human-computer interaction, and flexible connection path.关键词:visual cognition;visual perception;intelligent visual perception;hybrid enhanced visual cognition;man-machine fusion111|231|1更新时间:2024-05-07 -
 摘要:Face feature point location is to locate the predefined key facial feature points automatically according to the physiological characteristics of the human face, such as eyes, nose tip, mouth corner, and face contour. It is one of the important problems in face registration, face recognition, 3D face reconstruction, craniofacial analysis, craniofacial registration, and many other related fields. In recent years, various algorithms for facial feature point localization have emerged constantly, but several problems remain in the calibration of feature points, especially in the calibration of 3D facial feature points, such as manual intervention, low or inaccurate number of feature points, and long calibration time. In recent years, convolutional neural networks have been widely used in face feature point detection. This study focuses on the analysis of automatic feature point location methods based on deep learning for 2D and 3D facial data. Training data with real feature point labels in 2D texture image data are abundant. The research of automatic location method of 2D facial feature points based on deep learning is relatively extensive and indepth. The classical methods for 2D data include cascade convolution neural network methods, end-to-end regression methods, auto encoder network methods, different pose estimation methods, and other improved convolutional neural network (CNN) methods. In cascaded regression methods, rough detection is performed first, and then the feature points are finetuned. The end-to-end method propagates the error between the real results and the predicted results until the model converges. Autoencoder methods can select features automatically through encoding and decoding. Head pose estimation has great importance for face feature point detection because image-based methods are always affected by illumination and pose.Head pose estimation and feature points detection is improved by modifying network structure and loss function. The disadvantage of cascade regression method is that it can update the regressor by independent learning, and the descent direction may cancel each other. The flexibility of the end-to-end model is low. CNN is applied to 2D training data with real feature point tags. However, in the case of a 3D, training data with rich real feature point labels are lacking. Therefore, compared with 2D facial feature points, 3D facial feature point location remains a challenge. Several automatic feature point location for 3D data are introduced. The methods for 3D data are mainly based on depth information and 3D morphable model (3DMM). In recent years, with the development of RGB+depth map (RGBD) technology, depth data have attracted more attention. Feature point detection based on depth information has become an important preprocessing step for automatic feature point detection in 3D data. Initialization is crucial for deep data, but information is easily lost. The method based on 3DMM represents 3D face data for locating feature points through deep learning. On the one hand, the shape and expression parameters of 3DMM are highly nonlinear with the image texture information, which makes image mapping difficult to estimate. Compared with 2D face data, 3D face data lack training data with remarkable changes in face shape, race, and expression. Face feature point detection still faces great challenges.In summary, this study explains the meaning of automatic location of facial feature points, summarizes the currently open and commonly used face datasets, introduces various methods of automatic location of feature points for 2D and 3D data, summarizes the research status and application of each domestic and international method, analyzes the problems and development trend of automatic location technology of face feature points in deep learning application on 2D and 3D datasets, and compares the experimental results of the latest methods. In conclusion, the research on automatic location method of 2D face feature points based on deep learning is relatively indepth. Challenges in processing 3D data remain. The current solution for locating feature points is to project 3D face data onto 2D images through cylindrical coordinates, depth maps, 3DMM, and other methods. Information loss is the main problem of these methods. The method of feature point location directly on 3D model needs further exploration and research. The accuracy and speed of feature point location also need to be improved. In the future, 3D facial feature point localization methods based on deep learning will gradually become a trend.关键词:deep learning;2D facial feature point location;3D facial feature point location;convolutional neural network (CNN);registration72|44|0更新时间:2024-05-07
摘要:Face feature point location is to locate the predefined key facial feature points automatically according to the physiological characteristics of the human face, such as eyes, nose tip, mouth corner, and face contour. It is one of the important problems in face registration, face recognition, 3D face reconstruction, craniofacial analysis, craniofacial registration, and many other related fields. In recent years, various algorithms for facial feature point localization have emerged constantly, but several problems remain in the calibration of feature points, especially in the calibration of 3D facial feature points, such as manual intervention, low or inaccurate number of feature points, and long calibration time. In recent years, convolutional neural networks have been widely used in face feature point detection. This study focuses on the analysis of automatic feature point location methods based on deep learning for 2D and 3D facial data. Training data with real feature point labels in 2D texture image data are abundant. The research of automatic location method of 2D facial feature points based on deep learning is relatively extensive and indepth. The classical methods for 2D data include cascade convolution neural network methods, end-to-end regression methods, auto encoder network methods, different pose estimation methods, and other improved convolutional neural network (CNN) methods. In cascaded regression methods, rough detection is performed first, and then the feature points are finetuned. The end-to-end method propagates the error between the real results and the predicted results until the model converges. Autoencoder methods can select features automatically through encoding and decoding. Head pose estimation has great importance for face feature point detection because image-based methods are always affected by illumination and pose.Head pose estimation and feature points detection is improved by modifying network structure and loss function. The disadvantage of cascade regression method is that it can update the regressor by independent learning, and the descent direction may cancel each other. The flexibility of the end-to-end model is low. CNN is applied to 2D training data with real feature point tags. However, in the case of a 3D, training data with rich real feature point labels are lacking. Therefore, compared with 2D facial feature points, 3D facial feature point location remains a challenge. Several automatic feature point location for 3D data are introduced. The methods for 3D data are mainly based on depth information and 3D morphable model (3DMM). In recent years, with the development of RGB+depth map (RGBD) technology, depth data have attracted more attention. Feature point detection based on depth information has become an important preprocessing step for automatic feature point detection in 3D data. Initialization is crucial for deep data, but information is easily lost. The method based on 3DMM represents 3D face data for locating feature points through deep learning. On the one hand, the shape and expression parameters of 3DMM are highly nonlinear with the image texture information, which makes image mapping difficult to estimate. Compared with 2D face data, 3D face data lack training data with remarkable changes in face shape, race, and expression. Face feature point detection still faces great challenges.In summary, this study explains the meaning of automatic location of facial feature points, summarizes the currently open and commonly used face datasets, introduces various methods of automatic location of feature points for 2D and 3D data, summarizes the research status and application of each domestic and international method, analyzes the problems and development trend of automatic location technology of face feature points in deep learning application on 2D and 3D datasets, and compares the experimental results of the latest methods. In conclusion, the research on automatic location method of 2D face feature points based on deep learning is relatively indepth. Challenges in processing 3D data remain. The current solution for locating feature points is to project 3D face data onto 2D images through cylindrical coordinates, depth maps, 3DMM, and other methods. Information loss is the main problem of these methods. The method of feature point location directly on 3D model needs further exploration and research. The accuracy and speed of feature point location also need to be improved. In the future, 3D facial feature point localization methods based on deep learning will gradually become a trend.关键词:deep learning;2D facial feature point location;3D facial feature point location;convolutional neural network (CNN);registration72|44|0更新时间:2024-05-07
Review
-
 摘要:ObjectiveObtaining a high-resolution image directly is very difficult due to the interference of the external environment and hardware conditions. A low-resolution image is usually obtained at first, and then one or more image super-resolution methods are employed to obtain the corresponding high-resolution image. In addition, the number of collected images is large. Therefore, how to reconstruct a high-resolution image from a low-resolution image at a low cost has become a research hotspot in the field of computer vision. This research widely exists in the fields of medicine, remote sensing, and public safety. In recent years, many image super-resolution methods have been proposed, and these techniques can be broadly categorized into interpolation-, projection-, and learning-based methods. Among these methods, the convolutional neural network, a typical approach of the learning-based method, has attracted more attention in recent years but still has several problems. First, the reconstruction effect is often improved by simply deepening the network, which will make the network very complex and increase the difficulty of the training. Second, the high-frequency information in an image is difficult to reconstruct. The attention mechanism has been applied to overcome this problem, but the existing attention mechanisms are usually directly quoted from many high-level vision tasks, without considering the particularity of the super-resolution reconstruction tasks. Third, the existing upsampling methods have several limitations such as feature loss and training oscillations, which are difficult to solve in the field of super-resolution reconstruction. To address these problems, this paper proposes a mixed attention network model based on multiscale feature reuse for super-resolution reconstruction. The model improves the performance of the network by using several novelty strategies including multipath network, long and short hop connections, compensation reconstruction block, and mixed attention mechanism.MethodThe proposed network is mainly composed of five parts: the preprocessing module, the multiscale feature reuse mixed attention module, the upsampling module, the compensation reconstruction module, and the reconstruction module. The first part is the preprocessing module, which uses a convolutional layer to extract shallow features and expand the number of channels in the feature map. The second part is the multiscale feature reuse mixed attention module. This part contains three important subparts including a multichannel network, a mixed attention mechanism, and the jump connections. The multichannel network can increase the receptive fields of different feature maps and improve the reuse of multiscale features. The mixed attention mechanism can better capture the high-frequency information, and the jump connections can reduce the degradation problem of deep network and improve the learning ability. Moreover, the interdependence between shallow features and deep features can be learned by using the depth method and the widening method. The third part is the upsampling module, which uses the subpixel method to upsample the feature map to the target size. The shallow and deep features are upsampled simultaneously and fused to compensate the feature loss caused by the upsampling operation. The fourth part is the compensation reconstruction module, which is composed of a convolutional layer and a mixed attention module. This part is used to perform the secondary feature compensation and stabilize the model training on the feature maps obtained through upsampling. The fifth part is the reconstruction module, which uses a convolutional layer to expand the number of channels of the feature map to the original number to obtain the reconstructed high-resolution image. In the training phase, the DIV2K(DIVerse 2K) dataset is taken as the training set, and each image is processed by several enhancement methods such as random rotation and horizontal flip. Adaptive momentum estimation(ADAM) is used as the optimizer, and L1 is used as the objective function. Each run uses 800 epochs.ResultThe proposed method is compared with several current state-of-the-art methods including super-resolution convolutional neural network(SRCNN), super-resolution using very deep convolutional networks(VDSR), deep Laplacian pyramid super-resolution networks(LapSRN), memory network for image restoration(MemNet), super-resolution network for multiple degradations(SRMDNF), cascading residual network(CARN), multi-path adaptive modulation network(MAMNet), and the simplified version of residual channel attention network (RCAN-mini). Peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are applied to evaluate the performance of these algorithms on widely used benchmark testsets such as Set5, Set14, BSD100(Berkeley segmentation dataset), and Urban100. When the scale factor is 3, the PSNR/SSIM values obtained by this model on each testsets are 34.40 dB/0.927 3, 30.35 dB/0.842 7, 29.11 dB/0.805 2, and 28.23 dB/0.854 0 in order. In terms of PSNR index, compared with RCAN-mini, it is increased by 0.15 dB, 0.08 dB, 0.07 dB, and 0.24 dB on four testsets. Compared with other methods, the reconstruction results are also improved.ConclusionA multiscale feature reuse mixed attention network, which applies a new network structure and an attention mechanism to improve the performance of super-resolution, is proposed. This model is compared with other methods by quantization experiment and visual experiment. Experiment results show that the proposed method can achieve the best reconstruction effect on the edge and texture information and can obtain higher values on the evaluation indicators of PSNR and SSIM than other methods.关键词:super-resolution reconstruction;multi-scale feature reuse;mixed attention;feature compensation;edge60|35|3更新时间:2024-05-07
摘要:ObjectiveObtaining a high-resolution image directly is very difficult due to the interference of the external environment and hardware conditions. A low-resolution image is usually obtained at first, and then one or more image super-resolution methods are employed to obtain the corresponding high-resolution image. In addition, the number of collected images is large. Therefore, how to reconstruct a high-resolution image from a low-resolution image at a low cost has become a research hotspot in the field of computer vision. This research widely exists in the fields of medicine, remote sensing, and public safety. In recent years, many image super-resolution methods have been proposed, and these techniques can be broadly categorized into interpolation-, projection-, and learning-based methods. Among these methods, the convolutional neural network, a typical approach of the learning-based method, has attracted more attention in recent years but still has several problems. First, the reconstruction effect is often improved by simply deepening the network, which will make the network very complex and increase the difficulty of the training. Second, the high-frequency information in an image is difficult to reconstruct. The attention mechanism has been applied to overcome this problem, but the existing attention mechanisms are usually directly quoted from many high-level vision tasks, without considering the particularity of the super-resolution reconstruction tasks. Third, the existing upsampling methods have several limitations such as feature loss and training oscillations, which are difficult to solve in the field of super-resolution reconstruction. To address these problems, this paper proposes a mixed attention network model based on multiscale feature reuse for super-resolution reconstruction. The model improves the performance of the network by using several novelty strategies including multipath network, long and short hop connections, compensation reconstruction block, and mixed attention mechanism.MethodThe proposed network is mainly composed of five parts: the preprocessing module, the multiscale feature reuse mixed attention module, the upsampling module, the compensation reconstruction module, and the reconstruction module. The first part is the preprocessing module, which uses a convolutional layer to extract shallow features and expand the number of channels in the feature map. The second part is the multiscale feature reuse mixed attention module. This part contains three important subparts including a multichannel network, a mixed attention mechanism, and the jump connections. The multichannel network can increase the receptive fields of different feature maps and improve the reuse of multiscale features. The mixed attention mechanism can better capture the high-frequency information, and the jump connections can reduce the degradation problem of deep network and improve the learning ability. Moreover, the interdependence between shallow features and deep features can be learned by using the depth method and the widening method. The third part is the upsampling module, which uses the subpixel method to upsample the feature map to the target size. The shallow and deep features are upsampled simultaneously and fused to compensate the feature loss caused by the upsampling operation. The fourth part is the compensation reconstruction module, which is composed of a convolutional layer and a mixed attention module. This part is used to perform the secondary feature compensation and stabilize the model training on the feature maps obtained through upsampling. The fifth part is the reconstruction module, which uses a convolutional layer to expand the number of channels of the feature map to the original number to obtain the reconstructed high-resolution image. In the training phase, the DIV2K(DIVerse 2K) dataset is taken as the training set, and each image is processed by several enhancement methods such as random rotation and horizontal flip. Adaptive momentum estimation(ADAM) is used as the optimizer, and L1 is used as the objective function. Each run uses 800 epochs.ResultThe proposed method is compared with several current state-of-the-art methods including super-resolution convolutional neural network(SRCNN), super-resolution using very deep convolutional networks(VDSR), deep Laplacian pyramid super-resolution networks(LapSRN), memory network for image restoration(MemNet), super-resolution network for multiple degradations(SRMDNF), cascading residual network(CARN), multi-path adaptive modulation network(MAMNet), and the simplified version of residual channel attention network (RCAN-mini). Peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are applied to evaluate the performance of these algorithms on widely used benchmark testsets such as Set5, Set14, BSD100(Berkeley segmentation dataset), and Urban100. When the scale factor is 3, the PSNR/SSIM values obtained by this model on each testsets are 34.40 dB/0.927 3, 30.35 dB/0.842 7, 29.11 dB/0.805 2, and 28.23 dB/0.854 0 in order. In terms of PSNR index, compared with RCAN-mini, it is increased by 0.15 dB, 0.08 dB, 0.07 dB, and 0.24 dB on four testsets. Compared with other methods, the reconstruction results are also improved.ConclusionA multiscale feature reuse mixed attention network, which applies a new network structure and an attention mechanism to improve the performance of super-resolution, is proposed. This model is compared with other methods by quantization experiment and visual experiment. Experiment results show that the proposed method can achieve the best reconstruction effect on the edge and texture information and can obtain higher values on the evaluation indicators of PSNR and SSIM than other methods.关键词:super-resolution reconstruction;multi-scale feature reuse;mixed attention;feature compensation;edge60|35|3更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveHashing techniques have attracted much attention and are widely applied in the nearest neighbor search for image retrieval on large-scale datasets due to the low storage cost and fast retrieval speed. With the great development of deep learning, deep neural networks have been widely incorporated in image hashing retrieval, and existing deep learning-based hashing methods demonstrate the effectiveness of the end-to-end deep learning architecture for hashing learning. However, these methods have several problems. First, these existing deep hashing methods ignore the guiding role of deep image feature information in training deep hashing functions. Second, most deep hashing methods are to solve a relaxed problem first to simplify the optimization involved in a binary code learning procedure and then quantize the solved continuous solution to achieve the approximate binary solution. This optimization strategy leads to a large binary quantization error, result ing in the generation of suboptimal hash codes. Thus, to solve these two problems, a self-supervised deep discrete hashing method (SSDDH) is proposed in this study.MethodThe proposed SSDDH consists of two steps. First, using matrix decomposition, the binary hash code is obtained by solving the self-supervised loss function composed of the deep feature matrix extracted by the convolutional neural network and the image label matrix. The obtained binary hash code is used as the supervision information to guide the training of deep hash function. Second, a pair-wise loss function is constructed to maintain the similarity between the hash codes generated by deep hash function while maintaining the similarity between these hash codes and binary hash codes. The discrete optimization algorithm is used to solve the optimal solution of the objective function, thus effectively reducing the binary quantization error.ResultSeveral experiments are conducted on three public datasets to validate the performance of the proposed algorithm. The first experiment compares the mean average precision (mAP) values of different existing hash methods on different hash code lengths, including unsupervised methods, supervised shallow methods, and supervised deep methods. The performance experimental results show that the mAP of our method SSDDH achieves the best performance in all cases with different values of the code length. On the CIFAR-10 and NUS-WIDE(web image dataset from National University of Singapore) datasets, the mAP of SSDDH is 3% higher than the next highest method named DPSH(deep pairwise-supervised hashing). On the Flickr dataset, SSDDH is also 1% higher than the highest method DPSH. The second experiment involves the CIFAR-10 dataset. The precision recall (PR) curves of DPSH and SSDDH are plotted. Query result comparison shows the PR curves of DPSH and SSDDH with 48-bit hash codes on CIFAR-10, and our SSDDH remarkably outperforms its competitor. SSDDH and DPSH are also compared in terms of the accuracy of the top 20 returned images when the hash code length is 48 bits. The result of the experiment is visualized for easy observation. We also found that the retrieval performance of SSDDH is considerably higher than that of DPSH. Experiment 3 is designed for parameter sensitivity analysis of SSDDH. Here, a parameter is used, while the others are fixed. Our method is insensitive to the parameters. This finding relatively demonstrates the robustness and effectiveness of the proposed method. Experiment 4 is conducted on CIFAR-10 when the hash code length is 48 bits to explore the difference between DPSH and SSDDH in time complexity. At the later stage of model training, SSDDH performance is better than DPSH at the same time consumption.ConclusionConsidering that the existing deep hash methods ignore the guiding role of deep image feature information in the training of deep hash function and have the problem of large binary quantization error, this study proposes a self-supervised deep discrete hashing method named SSDDH. The deep feature matrix extracted by the convolutional neural network and the image label matrix are used to obtain the binary hash codes and make the binary hash codes the supervised information to guide the training of deep hash function. The similarity between the hash codes generated by deep hash function and the similarity between these hash codes and binary hash codes are maintained by constructing a pair-wise loss function. The binary quantization error is effectively reduced using the discrete cyclic coordinate descent. Comparison with several existing methods on three commonly used public datasets proves that this method is more efficient than the existing hash retrieval method. Future work lies in two aspects: First, focus will be on learning better fine-grained representation with more effectively. Second, semi-supervised regularization will be applied to our framework to make full use of the unlabeled data. Both will be employed to boost the image retrieval accuracy further. Third, our current approach will be extended to cross-modal retrieval, such as given a text query, to obtain all semantic relevant images from the database.关键词:deep learning;image retrieval;hash learning;self-supervised;discrete optimization99|58|2更新时间:2024-05-07
摘要:ObjectiveHashing techniques have attracted much attention and are widely applied in the nearest neighbor search for image retrieval on large-scale datasets due to the low storage cost and fast retrieval speed. With the great development of deep learning, deep neural networks have been widely incorporated in image hashing retrieval, and existing deep learning-based hashing methods demonstrate the effectiveness of the end-to-end deep learning architecture for hashing learning. However, these methods have several problems. First, these existing deep hashing methods ignore the guiding role of deep image feature information in training deep hashing functions. Second, most deep hashing methods are to solve a relaxed problem first to simplify the optimization involved in a binary code learning procedure and then quantize the solved continuous solution to achieve the approximate binary solution. This optimization strategy leads to a large binary quantization error, result ing in the generation of suboptimal hash codes. Thus, to solve these two problems, a self-supervised deep discrete hashing method (SSDDH) is proposed in this study.MethodThe proposed SSDDH consists of two steps. First, using matrix decomposition, the binary hash code is obtained by solving the self-supervised loss function composed of the deep feature matrix extracted by the convolutional neural network and the image label matrix. The obtained binary hash code is used as the supervision information to guide the training of deep hash function. Second, a pair-wise loss function is constructed to maintain the similarity between the hash codes generated by deep hash function while maintaining the similarity between these hash codes and binary hash codes. The discrete optimization algorithm is used to solve the optimal solution of the objective function, thus effectively reducing the binary quantization error.ResultSeveral experiments are conducted on three public datasets to validate the performance of the proposed algorithm. The first experiment compares the mean average precision (mAP) values of different existing hash methods on different hash code lengths, including unsupervised methods, supervised shallow methods, and supervised deep methods. The performance experimental results show that the mAP of our method SSDDH achieves the best performance in all cases with different values of the code length. On the CIFAR-10 and NUS-WIDE(web image dataset from National University of Singapore) datasets, the mAP of SSDDH is 3% higher than the next highest method named DPSH(deep pairwise-supervised hashing). On the Flickr dataset, SSDDH is also 1% higher than the highest method DPSH. The second experiment involves the CIFAR-10 dataset. The precision recall (PR) curves of DPSH and SSDDH are plotted. Query result comparison shows the PR curves of DPSH and SSDDH with 48-bit hash codes on CIFAR-10, and our SSDDH remarkably outperforms its competitor. SSDDH and DPSH are also compared in terms of the accuracy of the top 20 returned images when the hash code length is 48 bits. The result of the experiment is visualized for easy observation. We also found that the retrieval performance of SSDDH is considerably higher than that of DPSH. Experiment 3 is designed for parameter sensitivity analysis of SSDDH. Here, a parameter is used, while the others are fixed. Our method is insensitive to the parameters. This finding relatively demonstrates the robustness and effectiveness of the proposed method. Experiment 4 is conducted on CIFAR-10 when the hash code length is 48 bits to explore the difference between DPSH and SSDDH in time complexity. At the later stage of model training, SSDDH performance is better than DPSH at the same time consumption.ConclusionConsidering that the existing deep hash methods ignore the guiding role of deep image feature information in the training of deep hash function and have the problem of large binary quantization error, this study proposes a self-supervised deep discrete hashing method named SSDDH. The deep feature matrix extracted by the convolutional neural network and the image label matrix are used to obtain the binary hash codes and make the binary hash codes the supervised information to guide the training of deep hash function. The similarity between the hash codes generated by deep hash function and the similarity between these hash codes and binary hash codes are maintained by constructing a pair-wise loss function. The binary quantization error is effectively reduced using the discrete cyclic coordinate descent. Comparison with several existing methods on three commonly used public datasets proves that this method is more efficient than the existing hash retrieval method. Future work lies in two aspects: First, focus will be on learning better fine-grained representation with more effectively. Second, semi-supervised regularization will be applied to our framework to make full use of the unlabeled data. Both will be employed to boost the image retrieval accuracy further. Third, our current approach will be extended to cross-modal retrieval, such as given a text query, to obtain all semantic relevant images from the database.关键词:deep learning;image retrieval;hash learning;self-supervised;discrete optimization99|58|2更新时间:2024-05-07 -
 摘要:ObjectiveRoad extraction is one of the primary tasks in the field of remote sensing. It has been applied in many areas, such as urban planning, route optimization, and navigation. Especially in the event of disasters such as mudslides, floods, and earthquakes, road information will suddenly change. Embedding road extraction models on the mobile terminal has an essential application value for rapid rescue. In recent years, deep learning has provided new ideas for realizing road pixel-level extraction, such as the classic image segmentation network UNet and the improved road extraction networks based on UNet, such as Residual UNet, LinkNet, and D-LinkNet. They can achieve road extraction better than traditional methods based on primary image feature extraction. However, these methods that rely on deep convolutional networks still have two problems: 1) cloud occlusion seriously affects the retrieval of information about ground objects in remote sensing images. At present, these convolutional network models are all trained on clear remote sensing images and do not consider the effect of cloud occlusion on road extraction. Their road extraction performance on cloudy remote sensing images is substantially reduced. 2) Network lightweight design has been an engaging area of research for several years. None of the above models based on deep learning considers the lightweight design of deep convolutional networks, which adds considerable difficulty to the deployment of these models. To address these road extraction problems, a lightweight UNet (L-UNet) is proposed, and road extraction is implemented in an end-to-end manner in the cloud occlusion scene.Method1) To address the problem of cloud occlusion, the Perlin noise is used to simulate a cloud layer image, and then the artificial cloud layer image and an RGB remote sensing image merge through the alpha coefficient to simulate the cloud occlusion scene. This simulation method is used to extend the cloudless road extraction dataset. Specifically, 20 000 artificial cloud layer images have been generated before the network training. During training, cloud layer images are randomly sampled with replacement. The selected cloud layer image is merged with the clear remote sensing image in the training dataset, thereby simulating the continually changing cloud occlusion scenes. 2) In terms of network lightweight, UNet, a fully convolutional neural network, is improved to obtain L-UNet. The main improvement is the use of mobile inverted bottleneck convolutional blocks (MBConv) in the encoder. The MBConv first uses depthwise separable convolution, which considerably reduces the number of network params. However, the performance of road extraction only using depthwise separable convolution is not ideal; thus, expand convolution is added. Expand convolution with several 1×1 convolution kernels can increase the number of feature channels for each layer in the encoder part. Therefore, each layer of the network can learn more abundant features. The MBConv also uses a squeeze-and-excitation block. The block consists of two parts: global pooling for squeeze and 1×1 convolution with swish function for excitation. The squeeze-and-excitation block rationalizes the relative weights between the output feature maps of each layer. It highlights the feature information related to roads and clouds, which is beneficial to the segmentation tasks. Moreover, the swish is selected as the activation function rather than the rectified linear unit (ReLU). The L-UNet model reduces the param of the original UNet model and achieves better results. 3) The training loss function is the sum of the binary cross-entropy loss and the dice coefficient loss. The optimizer for network training is Adam, which has an initial learning rate of 2E-4. The encoder parameters of L-UNet are initialized to "ImageNet" pretrained model parameters. Then, the training is finetuned. The PyTorch deep learning framework is selected to implement L-UNet model construction and experiment. L-UNet performs 233 epochs of training on two NVIDIA GTX 1080 TI GPUs and finally converges.ResultNetwork training and comparison experiments are carried out on the DeepGlobe road extraction extended dataset. 1) In the trial of comparing the network structure, the baseline network is UNet# that only contains depthwise separable convolution. When the expand convolution and squeeze-and-excitation block are added separately, the corresponding intersection over union (IoU) values increase by 1.12% and 8.45%, respectively. Adding the expand convolution and squeeze-and-excitation block simultaneously increases the IoU index by 16.24%. 2) L-UNet is compared with other networks on the extended test dataset. The IoU index of L-UNet rises by 4.65% compared with UNet. The IoU index increases by 1.97% compared with D-LinkNet, which is the second most powerful. The L-UNet param is only 22.28 M, which is 1/7 of UNet and 1/5 of D-LinkNet. The Mask-IoU and Mask-P indices, which are used to measure the network's road prediction performance in the cloud occlusion area, are also higher than those of other networks. 3) For road extraction tests on several real cloudy remote sensing images from Sentinel-2 satellite, the performance of L-UNet remains the best. The average IoU of the detection results is higher than D-LinkNet's 19.47% and UNet's 31.87%.ConclusionThis paper studies the problem of road extraction from remote sensing images in cloud occlusion scenes. Simulated cloud layers are added on existing datasets, and extended datasets are used to improve the robustness of existing deep learning-based methods against cloud occlusion interference. The proposed L-UNet network architecture dramatically reduces the param and has excellent performance for road extraction given cloud cover. It can even predict road labels under thick clouds through known visible road edges and trends; thus, its road detection results have a better consistency. Other tasks for extracting remotely sensed ground objects with cloud cover can also use our method in future work.关键词:road extraction;lightweight UNet (L-UNet);remote sensing image;cloud occlusion simulation;deep learning137|358|2更新时间:2024-05-07
摘要:ObjectiveRoad extraction is one of the primary tasks in the field of remote sensing. It has been applied in many areas, such as urban planning, route optimization, and navigation. Especially in the event of disasters such as mudslides, floods, and earthquakes, road information will suddenly change. Embedding road extraction models on the mobile terminal has an essential application value for rapid rescue. In recent years, deep learning has provided new ideas for realizing road pixel-level extraction, such as the classic image segmentation network UNet and the improved road extraction networks based on UNet, such as Residual UNet, LinkNet, and D-LinkNet. They can achieve road extraction better than traditional methods based on primary image feature extraction. However, these methods that rely on deep convolutional networks still have two problems: 1) cloud occlusion seriously affects the retrieval of information about ground objects in remote sensing images. At present, these convolutional network models are all trained on clear remote sensing images and do not consider the effect of cloud occlusion on road extraction. Their road extraction performance on cloudy remote sensing images is substantially reduced. 2) Network lightweight design has been an engaging area of research for several years. None of the above models based on deep learning considers the lightweight design of deep convolutional networks, which adds considerable difficulty to the deployment of these models. To address these road extraction problems, a lightweight UNet (L-UNet) is proposed, and road extraction is implemented in an end-to-end manner in the cloud occlusion scene.Method1) To address the problem of cloud occlusion, the Perlin noise is used to simulate a cloud layer image, and then the artificial cloud layer image and an RGB remote sensing image merge through the alpha coefficient to simulate the cloud occlusion scene. This simulation method is used to extend the cloudless road extraction dataset. Specifically, 20 000 artificial cloud layer images have been generated before the network training. During training, cloud layer images are randomly sampled with replacement. The selected cloud layer image is merged with the clear remote sensing image in the training dataset, thereby simulating the continually changing cloud occlusion scenes. 2) In terms of network lightweight, UNet, a fully convolutional neural network, is improved to obtain L-UNet. The main improvement is the use of mobile inverted bottleneck convolutional blocks (MBConv) in the encoder. The MBConv first uses depthwise separable convolution, which considerably reduces the number of network params. However, the performance of road extraction only using depthwise separable convolution is not ideal; thus, expand convolution is added. Expand convolution with several 1×1 convolution kernels can increase the number of feature channels for each layer in the encoder part. Therefore, each layer of the network can learn more abundant features. The MBConv also uses a squeeze-and-excitation block. The block consists of two parts: global pooling for squeeze and 1×1 convolution with swish function for excitation. The squeeze-and-excitation block rationalizes the relative weights between the output feature maps of each layer. It highlights the feature information related to roads and clouds, which is beneficial to the segmentation tasks. Moreover, the swish is selected as the activation function rather than the rectified linear unit (ReLU). The L-UNet model reduces the param of the original UNet model and achieves better results. 3) The training loss function is the sum of the binary cross-entropy loss and the dice coefficient loss. The optimizer for network training is Adam, which has an initial learning rate of 2E-4. The encoder parameters of L-UNet are initialized to "ImageNet" pretrained model parameters. Then, the training is finetuned. The PyTorch deep learning framework is selected to implement L-UNet model construction and experiment. L-UNet performs 233 epochs of training on two NVIDIA GTX 1080 TI GPUs and finally converges.ResultNetwork training and comparison experiments are carried out on the DeepGlobe road extraction extended dataset. 1) In the trial of comparing the network structure, the baseline network is UNet# that only contains depthwise separable convolution. When the expand convolution and squeeze-and-excitation block are added separately, the corresponding intersection over union (IoU) values increase by 1.12% and 8.45%, respectively. Adding the expand convolution and squeeze-and-excitation block simultaneously increases the IoU index by 16.24%. 2) L-UNet is compared with other networks on the extended test dataset. The IoU index of L-UNet rises by 4.65% compared with UNet. The IoU index increases by 1.97% compared with D-LinkNet, which is the second most powerful. The L-UNet param is only 22.28 M, which is 1/7 of UNet and 1/5 of D-LinkNet. The Mask-IoU and Mask-P indices, which are used to measure the network's road prediction performance in the cloud occlusion area, are also higher than those of other networks. 3) For road extraction tests on several real cloudy remote sensing images from Sentinel-2 satellite, the performance of L-UNet remains the best. The average IoU of the detection results is higher than D-LinkNet's 19.47% and UNet's 31.87%.ConclusionThis paper studies the problem of road extraction from remote sensing images in cloud occlusion scenes. Simulated cloud layers are added on existing datasets, and extended datasets are used to improve the robustness of existing deep learning-based methods against cloud occlusion interference. The proposed L-UNet network architecture dramatically reduces the param and has excellent performance for road extraction given cloud cover. It can even predict road labels under thick clouds through known visible road edges and trends; thus, its road detection results have a better consistency. Other tasks for extracting remotely sensed ground objects with cloud cover can also use our method in future work.关键词:road extraction;lightweight UNet (L-UNet);remote sensing image;cloud occlusion simulation;deep learning137|358|2更新时间:2024-05-07 -
 摘要:ObjectiveWhile dealing with high-resolution remote sensing image scene recognition,classical supervised machine learning algorithms are considered effective on two conditions,namely,1) test samples should be in the same feature space with training samples,and 2) adequate labeled samples should be provided to train the model fully. Deep learning algorithms,which achieve remarkable results in image classification and object detection for the past few years,generally require a large number of labeled samples to learn the accurate parameters.The main image classification methods select raining and test samples randomly from the same dataset,and adopt cross validation to testify the effectiveness of the model. However,obtaining scene labels is time consuming and expensive for remote sensing images. To deal with the insufficiency of labeled samples in remote sensing image scene recognition and the problem that labeled samples cannot be shared between different datasets due to different sensors and complex light conditions,deep learning architecture and adversarial learning are investigated. A feature transfer method based on adversarial variational autoencoder is proposed.MethodFeature transfer architecture can be divided into three parts. The first part is the pretrain model.Given the limited samples with scene labels,the unsupervised learning model,variational autoencoder(VAE),is adopted. The VAE is unsupervised trained on the source dataset,and the encoder part in the VAE is finetuned together with classifier network using labeled samples in the source dataset. The second part is adversarial learning module. In most of the research,adversarial learning is adopted to generate new samples,while the idea is used to transfer the features from source domain to target domain in this paper.Parameters of the finetuned encoder network for the source dataset are then used to initialize the target encoder. Using the idea of adversarial training in generative adversarial networks (GAN),a discrimination network is introduced into the training of the target encoder. The goal of the target encoder is to extract features in the target domain to have as much affinity to those of the source domain as possible,such that the discrimination network cannot distinguish the features are from either the source domain or target domain. The goal of the discrimination network is to optimize the parameters for better distinction. It is called adversarial learning because of the contradiction between the purpose of encoder and discrimination network. The features extracted by the target encoder increasingly resemble those by the source encoder by training and updating the parameters of the target encoder and the discrimination network alternately. In this manner,by the time the discrimination network can no longer differentiate between source features and target features,we can assume that the target encoder can extract similar features to the source samples,and remote sensing feature transfer between the source domain and target domain is accomplished. The third part is target finetuning and test module. A small number of labeled samples in target domain is employed to finetune the target encoder and source classifier,and the other samples are used for evaluation.ResultTwo remote sensing scene recognition datasets,UCMerced-21 and NWPU-RESISC45,are adopted to prove the effectiveness of the proposed feature transfer method. SUN397,a natural scene recognition dataset is employed as an attempt for the cross-view feature transfer. Eight common scene types between the three datasets,namely,baseball field,beach,farmland,forest,harbor,industrial area,overpass,and river/lake,are selected for the feature transfer task.Correlation alignment (CORAL) and balanced distribution adaptation (BDA) are used as comparisons. In the experiments of adversarial learning between two remote sensing scene recognition datasets,the proposed method boosts the recognition accuracy by about 10% compared with the network trained only by the samples in the source domain.Resultsimprove more substantially when few samples in the target domain are involved. Compared with CORAL and BDA,the proposed method improves scene recognition accuracy by more than 3% when using a few samples in the target domain and between 10%~40% without samples in the target domain. When using the information of a natural scene image,the improvement is not as much as that of a remote sensing image,but the scene recognition accuracy using the proposed feature transfer method is still increased by approximately 6% after unsupervised feature transfer and 36% after a small number of samples in the target domain are involved in finetuning.ConclusionIn this paper,an adversarial transfer learning network is proposed. The experimental results show that the proposed adversarial learning method can make the most of sample information of other dataset when the labeled samples are insufficient in the target domain. The proposed method can achieve the feature transfer between different datasets and scene recognition effectively,and remarkably improve the scene recognition accuracy.关键词:haze scene;image recognition;multiple features;multiple adversarial;domain shift108|153|2更新时间:2024-05-07
摘要:ObjectiveWhile dealing with high-resolution remote sensing image scene recognition,classical supervised machine learning algorithms are considered effective on two conditions,namely,1) test samples should be in the same feature space with training samples,and 2) adequate labeled samples should be provided to train the model fully. Deep learning algorithms,which achieve remarkable results in image classification and object detection for the past few years,generally require a large number of labeled samples to learn the accurate parameters.The main image classification methods select raining and test samples randomly from the same dataset,and adopt cross validation to testify the effectiveness of the model. However,obtaining scene labels is time consuming and expensive for remote sensing images. To deal with the insufficiency of labeled samples in remote sensing image scene recognition and the problem that labeled samples cannot be shared between different datasets due to different sensors and complex light conditions,deep learning architecture and adversarial learning are investigated. A feature transfer method based on adversarial variational autoencoder is proposed.MethodFeature transfer architecture can be divided into three parts. The first part is the pretrain model.Given the limited samples with scene labels,the unsupervised learning model,variational autoencoder(VAE),is adopted. The VAE is unsupervised trained on the source dataset,and the encoder part in the VAE is finetuned together with classifier network using labeled samples in the source dataset. The second part is adversarial learning module. In most of the research,adversarial learning is adopted to generate new samples,while the idea is used to transfer the features from source domain to target domain in this paper.Parameters of the finetuned encoder network for the source dataset are then used to initialize the target encoder. Using the idea of adversarial training in generative adversarial networks (GAN),a discrimination network is introduced into the training of the target encoder. The goal of the target encoder is to extract features in the target domain to have as much affinity to those of the source domain as possible,such that the discrimination network cannot distinguish the features are from either the source domain or target domain. The goal of the discrimination network is to optimize the parameters for better distinction. It is called adversarial learning because of the contradiction between the purpose of encoder and discrimination network. The features extracted by the target encoder increasingly resemble those by the source encoder by training and updating the parameters of the target encoder and the discrimination network alternately. In this manner,by the time the discrimination network can no longer differentiate between source features and target features,we can assume that the target encoder can extract similar features to the source samples,and remote sensing feature transfer between the source domain and target domain is accomplished. The third part is target finetuning and test module. A small number of labeled samples in target domain is employed to finetune the target encoder and source classifier,and the other samples are used for evaluation.ResultTwo remote sensing scene recognition datasets,UCMerced-21 and NWPU-RESISC45,are adopted to prove the effectiveness of the proposed feature transfer method. SUN397,a natural scene recognition dataset is employed as an attempt for the cross-view feature transfer. Eight common scene types between the three datasets,namely,baseball field,beach,farmland,forest,harbor,industrial area,overpass,and river/lake,are selected for the feature transfer task.Correlation alignment (CORAL) and balanced distribution adaptation (BDA) are used as comparisons. In the experiments of adversarial learning between two remote sensing scene recognition datasets,the proposed method boosts the recognition accuracy by about 10% compared with the network trained only by the samples in the source domain.Resultsimprove more substantially when few samples in the target domain are involved. Compared with CORAL and BDA,the proposed method improves scene recognition accuracy by more than 3% when using a few samples in the target domain and between 10%~40% without samples in the target domain. When using the information of a natural scene image,the improvement is not as much as that of a remote sensing image,but the scene recognition accuracy using the proposed feature transfer method is still increased by approximately 6% after unsupervised feature transfer and 36% after a small number of samples in the target domain are involved in finetuning.ConclusionIn this paper,an adversarial transfer learning network is proposed. The experimental results show that the proposed adversarial learning method can make the most of sample information of other dataset when the labeled samples are insufficient in the target domain. The proposed method can achieve the feature transfer between different datasets and scene recognition effectively,and remarkably improve the scene recognition accuracy.关键词:haze scene;image recognition;multiple features;multiple adversarial;domain shift108|153|2更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveWith the rapid development of 3D acquisition technologies, point cloud has wide applications in many areas, such as medicine, autonomous driving, and robotics. As a dominant technique in artificial intelligence(AI), deep learning has been successfully used to solve various 2D vision problems and has shown great potential in solving 3D vision problems. Using regular grid convolutional neural networks (CNN) for non-Euclidian space of point cloud data and capturing the hidden shapes from irregular points remains challenging. In recent years, deep learning-based methods have been more effective in point cloud classification and segmentation than traditional methods. Deep learning-based methods can be divided into three groups: pointwise methods, convolutional-based methods, and graph convolutional-based methods. These methods include two important processes: feature extraction and feature aggregation. Most of the methods focus on the design of feature extraction and pay less attention to feature aggregation. At present, most point cloud classification and segmentation methods based on deep learning use max pooling for feature aggregation. However, using the maximum value features of neighborhood features in local neighborhood features has the problem of information loss caused by ignoring other neighborhood information.MethodThis paper proposes a dynamic graph convolution with spatial attention for point cloud classification and segmentation method based on deep learning-dynamic graph convolution spatial attention (DGCSA) neural networks. The key of the network is to learn from the relationship between the neighbor points and the center point, which avoid the information loss caused by feature aggregation using max pool layers in feature aggregation. This network is composed of a dynamic graph convolution module and a spatial attention (SA) module. The dynamic graph convolution module mainly performs K-nearest neighbor (KNN) search algorithm and multiple-layer perception. For each point cloud, it first uses the KNN algorithm to search its neighbor points. Then, it extracts the features of the neighbor points and center points by convolutional layers. The K-nearest neighbors of each point vary in different network layers, leading to a dynamic graph structure updated with layers. After feature extraction, it applies a point-based SA module to learn the local features that are more representative than the maximum feature automatically. The key of the SA module is to use the attention mechanism to calculate the weight of K-neighbor points of the center point. It consists of four units: 1) attention activation unit, 2) attention scores unit, 3) weighted features unit, and 4) multilayer perceptron unit. First, the attention activation of each potential feature is learned through the fully connected layer. Second, the attention score of the corresponding feature is calculated by applying the SoftMax function on the attention activation value. The learned attention score can be regarded as a mask for automatically selecting useful potential features. Third, the attention score is multiplied by the corresponding elements of the local neighborhood features to generate a set of weighted features. Finally, the sum of the weighted features is determined to obtain the locally representative local features, followed by another fully connected convolutional layer to control the output dimension of the SA module. The SA module has strong learning ability, thereby improving the classification and segmentation accuracy of the model. DGCSA implements a high-performance classification and segmentation of point clouds by stacking several dynamic graph convolution modules and SA modules. Moreover, feature fusion is used to fuse the output features of different spatial attention layers that can effectively obtain the global and local characteristics of point cloud data, achieving better classification and segmentation results.ResultTo evaluate the performance of the proposed DGCSA model, experiments are carried out in classification, instance segmentation, and semantic scene segmentation on the datasets of ModelNet40, ShapeNetPart, and Stanford large-scale 3D Indoor spaces dataset, respectively. Experiment results show that the overall accuracy (OA) of our method reaches 93.4%, which is 0.8% higher than the baseline network dynamic graph CNN (DGCNN). The mean intersection-to-union (mIoU) of instance segmentation reaches 85.3%, which is 0.2% higher than DGCNN; for indoor scene segmentation, the mIoU of the six-fold cross-validation reaches 59.1%, which is 3.0% higher than DGCNN. Overall, the classification accuracy of our method on the ModelNet40 dataset surpasses that of most existing point cloud classification methods, such as PointNet, PointNet++, and PointCNN. The accuracy of DGCSA in instance segmentation and indoor scene segmentation reaches the segmentation accuracy of the current excellent point cloud segmentation network. Furthermore, the validity of the SA module is verified by an ablation study, where the max pooling operations in PointNet and linked dynamic graph CNN (LDGCNN) are replaced by the SA module. The classification results on the ModelNet40 dataset show that the SA module contributes to a more than 0.5% increase of classification accuracy for PointNet and LDGCNN.ConclusionDGCSA can effectively aggregate local features of point cloud data and achieve better classification and segmentation results. Through the design of SA module, this network solves the problem of partial information loss in the aggregation local neighborhood information. The SA module fully considers all neighborhood contributions, selectively strengthens the features containing useful information, and suppresses useless features. Combining the spatial attention module with the dynamic graph convolution module, our network can improve the accuracy of classification, instance segmentation, and indoor scene segmentation. In addition, the spatial attention module can integrate with other point cloud classification model and substantially improve the model performance. Our future work will improve the accuracy of DGCSA in segmentation task in the condition of an unbalanced dataset.关键词:point cloud;dynamic graph convolution;spatial attention(SA);classification;segmentation150|129|6更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of 3D acquisition technologies, point cloud has wide applications in many areas, such as medicine, autonomous driving, and robotics. As a dominant technique in artificial intelligence(AI), deep learning has been successfully used to solve various 2D vision problems and has shown great potential in solving 3D vision problems. Using regular grid convolutional neural networks (CNN) for non-Euclidian space of point cloud data and capturing the hidden shapes from irregular points remains challenging. In recent years, deep learning-based methods have been more effective in point cloud classification and segmentation than traditional methods. Deep learning-based methods can be divided into three groups: pointwise methods, convolutional-based methods, and graph convolutional-based methods. These methods include two important processes: feature extraction and feature aggregation. Most of the methods focus on the design of feature extraction and pay less attention to feature aggregation. At present, most point cloud classification and segmentation methods based on deep learning use max pooling for feature aggregation. However, using the maximum value features of neighborhood features in local neighborhood features has the problem of information loss caused by ignoring other neighborhood information.MethodThis paper proposes a dynamic graph convolution with spatial attention for point cloud classification and segmentation method based on deep learning-dynamic graph convolution spatial attention (DGCSA) neural networks. The key of the network is to learn from the relationship between the neighbor points and the center point, which avoid the information loss caused by feature aggregation using max pool layers in feature aggregation. This network is composed of a dynamic graph convolution module and a spatial attention (SA) module. The dynamic graph convolution module mainly performs K-nearest neighbor (KNN) search algorithm and multiple-layer perception. For each point cloud, it first uses the KNN algorithm to search its neighbor points. Then, it extracts the features of the neighbor points and center points by convolutional layers. The K-nearest neighbors of each point vary in different network layers, leading to a dynamic graph structure updated with layers. After feature extraction, it applies a point-based SA module to learn the local features that are more representative than the maximum feature automatically. The key of the SA module is to use the attention mechanism to calculate the weight of K-neighbor points of the center point. It consists of four units: 1) attention activation unit, 2) attention scores unit, 3) weighted features unit, and 4) multilayer perceptron unit. First, the attention activation of each potential feature is learned through the fully connected layer. Second, the attention score of the corresponding feature is calculated by applying the SoftMax function on the attention activation value. The learned attention score can be regarded as a mask for automatically selecting useful potential features. Third, the attention score is multiplied by the corresponding elements of the local neighborhood features to generate a set of weighted features. Finally, the sum of the weighted features is determined to obtain the locally representative local features, followed by another fully connected convolutional layer to control the output dimension of the SA module. The SA module has strong learning ability, thereby improving the classification and segmentation accuracy of the model. DGCSA implements a high-performance classification and segmentation of point clouds by stacking several dynamic graph convolution modules and SA modules. Moreover, feature fusion is used to fuse the output features of different spatial attention layers that can effectively obtain the global and local characteristics of point cloud data, achieving better classification and segmentation results.ResultTo evaluate the performance of the proposed DGCSA model, experiments are carried out in classification, instance segmentation, and semantic scene segmentation on the datasets of ModelNet40, ShapeNetPart, and Stanford large-scale 3D Indoor spaces dataset, respectively. Experiment results show that the overall accuracy (OA) of our method reaches 93.4%, which is 0.8% higher than the baseline network dynamic graph CNN (DGCNN). The mean intersection-to-union (mIoU) of instance segmentation reaches 85.3%, which is 0.2% higher than DGCNN; for indoor scene segmentation, the mIoU of the six-fold cross-validation reaches 59.1%, which is 3.0% higher than DGCNN. Overall, the classification accuracy of our method on the ModelNet40 dataset surpasses that of most existing point cloud classification methods, such as PointNet, PointNet++, and PointCNN. The accuracy of DGCSA in instance segmentation and indoor scene segmentation reaches the segmentation accuracy of the current excellent point cloud segmentation network. Furthermore, the validity of the SA module is verified by an ablation study, where the max pooling operations in PointNet and linked dynamic graph CNN (LDGCNN) are replaced by the SA module. The classification results on the ModelNet40 dataset show that the SA module contributes to a more than 0.5% increase of classification accuracy for PointNet and LDGCNN.ConclusionDGCSA can effectively aggregate local features of point cloud data and achieve better classification and segmentation results. Through the design of SA module, this network solves the problem of partial information loss in the aggregation local neighborhood information. The SA module fully considers all neighborhood contributions, selectively strengthens the features containing useful information, and suppresses useless features. Combining the spatial attention module with the dynamic graph convolution module, our network can improve the accuracy of classification, instance segmentation, and indoor scene segmentation. In addition, the spatial attention module can integrate with other point cloud classification model and substantially improve the model performance. Our future work will improve the accuracy of DGCSA in segmentation task in the condition of an unbalanced dataset.关键词:point cloud;dynamic graph convolution;spatial attention(SA);classification;segmentation150|129|6更新时间:2024-05-07 -
 摘要:ObjectivePoint cloud classification is one of the hotspots of computer vision research. Among of various kinds of processing stages, accurately describing the local neighborhood structure of the point cloud and extracting the point cloud feature sets with strong expressive ability has become the key to point cloud classification. Traditionally, two methods can be used for modeling the neighborhood structure of point clouds: single-scale description and multiscale description. The former has a limited expressive ability, whereas the latter has a strong description ability but comes with a high computational complexity. To solve the above problems, this paper proposes a sparse voxel pyramid structure to express the local neighborhood structure of the point cloud and provides the corresponding point cloud classification and optimization method.MethodFirst, after a comparative analysis of related point cloud classification methods, the paper describes in detail the structure of the proposed sparse voxel pyramid, analyzes the advantages of the sparse voxel pyramid in expressing the neighborhood structure of the point cloud, and provides the method to express the local neighborhood of the point could with this structure. When calculating point features, the influence of candidate points on the local feature calculation results gradually decreases as the distance decreases. Thus, a fixed number of neighbors is used to construct each layer of the sparse voxel pyramid. For each voxel, a sparse voxel pyramid of N layers is constructed, and the voxel radius of the 0th layer is set to R. The value of N can be set according to the computing power of hardware resources. The R value is the smallest voxel value in the entire voxel pyramid, and its size can be set according to the point cloud density and range of the scene. The voxel radius of each subsequent layer of the pyramid is in turn twice that of the previous layer. The voxel radius of the Nth layer is 2NR, and each layer contains the same number of K voxels. Each point in the original point cloud is built into a spatial K-nearest neighbor index in voxel point clouds of different scales to form a sparse voxel pyramid by downsampling the original point cloud according to the above-mentioned proportions. This method can determine the multiscale neighborhood of the center point only based on a fixed-size K value. Near the center point, the point cloud density maintains the original density. As the distance from the center point increases, the density of neighboring points becomes sparser. Based on the sparse voxel pyramid structure, the local neighborhood constructed by points at different scales is used to extract feature-value-based features, neighborhood geometric features, projection features, and fast point feature histogram features of corresponding points. Then, the single point features are aggregated, the random forest method is used for supervised classification, and then the multilabel graph cut method is used to optimize the above classification results. After calculating the fast point feature histogram feature of each point, the histogram intersection core is used to calculate the edge potential between neighboring points.ResultThis paper selects three public datasets for experiments, namely, the ground-based Semantic3D dataset, the airborne LiDAR scanning data obtained by the airborne laser scanning system ALTM 2050 in different regions, and point cloud dataset at the main entrance of the Munich Technical University campus in Arcisstrasse by mobile LiDAR system, to verify the effectiveness of this method. The evaluation indicators used in the experiment are accuracy, recall, and F1 value. Sparse voxel pyramids of different scales are used for feature extraction and feature vector aggregation owing to the difference in point cloud density and coverage. Using the method proposed in this paper, the overall classification accuracy of the experimental results on the ground Semantic3D dataset can reach 89%, the classification accuracy of the airborne LiDAR scan dataset can reach 96%, and the classification accuracy of the mobile LiDAR scan dataset can reach 89%. Experimental results show that compared with other comparison methods, the multiscale features based on sparse voxel pyramids proposed can express the local structure of point clouds more effectively and robustly. When the receiving field of the voxel pyramid increases, the density of neighboring points decreases as the distance from the center point increases, which effectively reduces the amount of calculation. In addition, the histogram feature of fast point feature is used to calculate the difference between adjacent points through the histogram intersection kernel, which is used as the weight of the edge in the structural graph model to improve the optimization effect. This method is more accurate than the traditional method that uses Euclidean distance as the weight. The multilabel graph cut method can further optimize the results of single-point classification and provide better optimization results on issues such as the incorrect classification of vegetation into buildings and vice versa. In areas with large natural terrain undulations, the classification accuracy of terrain and low vegetation is greatly affected by the undulations of natural terrain in different regions, and misclassification easily occurs. By contrast, the classification accuracy on higher features such as tall vegetation, buildings, and pedestrians is less affected by the terrain, and the accuracy is higher.ConclusionOverall, compared with other similar and more advanced methods, the multiscale features extracted by the proposed method maintain the local structure information while considering a larger range of point cloud structure information, thereby improving the point cloud classification accuracy.关键词:point cloud classfication;sparse voxel pyramid;multi-scale feature;multi-label graph cut;histogram intersection kernel58|32|4更新时间:2024-05-07
摘要:ObjectivePoint cloud classification is one of the hotspots of computer vision research. Among of various kinds of processing stages, accurately describing the local neighborhood structure of the point cloud and extracting the point cloud feature sets with strong expressive ability has become the key to point cloud classification. Traditionally, two methods can be used for modeling the neighborhood structure of point clouds: single-scale description and multiscale description. The former has a limited expressive ability, whereas the latter has a strong description ability but comes with a high computational complexity. To solve the above problems, this paper proposes a sparse voxel pyramid structure to express the local neighborhood structure of the point cloud and provides the corresponding point cloud classification and optimization method.MethodFirst, after a comparative analysis of related point cloud classification methods, the paper describes in detail the structure of the proposed sparse voxel pyramid, analyzes the advantages of the sparse voxel pyramid in expressing the neighborhood structure of the point cloud, and provides the method to express the local neighborhood of the point could with this structure. When calculating point features, the influence of candidate points on the local feature calculation results gradually decreases as the distance decreases. Thus, a fixed number of neighbors is used to construct each layer of the sparse voxel pyramid. For each voxel, a sparse voxel pyramid of N layers is constructed, and the voxel radius of the 0th layer is set to R. The value of N can be set according to the computing power of hardware resources. The R value is the smallest voxel value in the entire voxel pyramid, and its size can be set according to the point cloud density and range of the scene. The voxel radius of each subsequent layer of the pyramid is in turn twice that of the previous layer. The voxel radius of the Nth layer is 2NR, and each layer contains the same number of K voxels. Each point in the original point cloud is built into a spatial K-nearest neighbor index in voxel point clouds of different scales to form a sparse voxel pyramid by downsampling the original point cloud according to the above-mentioned proportions. This method can determine the multiscale neighborhood of the center point only based on a fixed-size K value. Near the center point, the point cloud density maintains the original density. As the distance from the center point increases, the density of neighboring points becomes sparser. Based on the sparse voxel pyramid structure, the local neighborhood constructed by points at different scales is used to extract feature-value-based features, neighborhood geometric features, projection features, and fast point feature histogram features of corresponding points. Then, the single point features are aggregated, the random forest method is used for supervised classification, and then the multilabel graph cut method is used to optimize the above classification results. After calculating the fast point feature histogram feature of each point, the histogram intersection core is used to calculate the edge potential between neighboring points.ResultThis paper selects three public datasets for experiments, namely, the ground-based Semantic3D dataset, the airborne LiDAR scanning data obtained by the airborne laser scanning system ALTM 2050 in different regions, and point cloud dataset at the main entrance of the Munich Technical University campus in Arcisstrasse by mobile LiDAR system, to verify the effectiveness of this method. The evaluation indicators used in the experiment are accuracy, recall, and F1 value. Sparse voxel pyramids of different scales are used for feature extraction and feature vector aggregation owing to the difference in point cloud density and coverage. Using the method proposed in this paper, the overall classification accuracy of the experimental results on the ground Semantic3D dataset can reach 89%, the classification accuracy of the airborne LiDAR scan dataset can reach 96%, and the classification accuracy of the mobile LiDAR scan dataset can reach 89%. Experimental results show that compared with other comparison methods, the multiscale features based on sparse voxel pyramids proposed can express the local structure of point clouds more effectively and robustly. When the receiving field of the voxel pyramid increases, the density of neighboring points decreases as the distance from the center point increases, which effectively reduces the amount of calculation. In addition, the histogram feature of fast point feature is used to calculate the difference between adjacent points through the histogram intersection kernel, which is used as the weight of the edge in the structural graph model to improve the optimization effect. This method is more accurate than the traditional method that uses Euclidean distance as the weight. The multilabel graph cut method can further optimize the results of single-point classification and provide better optimization results on issues such as the incorrect classification of vegetation into buildings and vice versa. In areas with large natural terrain undulations, the classification accuracy of terrain and low vegetation is greatly affected by the undulations of natural terrain in different regions, and misclassification easily occurs. By contrast, the classification accuracy on higher features such as tall vegetation, buildings, and pedestrians is less affected by the terrain, and the accuracy is higher.ConclusionOverall, compared with other similar and more advanced methods, the multiscale features extracted by the proposed method maintain the local structure information while considering a larger range of point cloud structure information, thereby improving the point cloud classification accuracy.关键词:point cloud classfication;sparse voxel pyramid;multi-scale feature;multi-label graph cut;histogram intersection kernel58|32|4更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveIn recent years, with the continuous improvement of computer hardware performance and the continuous in depth research of virtual plant modeling and landscape design in the fields of film and television and games, plant shape modeling has become possible and necessary. As one of the important organs of plants, leaves have complex physiological and morphological characteristics, which are difficult to represent in virtual scenes. Therefore, 3D reconstruction of plant leaves is a very challenging subject. Current 3D reconstruction methods have two main types. 1) External equipment such as laser or radar are used to measure the distance of the target by transmitting signals and then receiving the signals reflected by the target object to obtain the 3D shape of the surface. 2) Using the principle of binocular vision, two or more images are obtained from different perspectives in the same scene, then the 3D shape of the object is obtained according to the parallax between the images. The former requires the introduction of external equipment, which is costly and difficult to operate, whereas the latter needs to detect and match the feature points between the acquired image sequences due to the reconstruction based on multiple images. The acquisition of a single image is simple, and the problem of feature matching of multiple images is eliminated. However, due to the less information contained in a single image and to recover the 3D shape of plant leaves from the limited information, this paper is based on the method of the shape from shading (SFS) and preprocesses the image to add a priori to the 3D shape estimation. The brightness statistic information obtained from the image and the prior information of plant morphological characteristics are used to recover the final 3D shape of the leaf.MethodWhen restoring the 3D shape of a single plant leaf image, the restoration of the surface shape is divided into two aspects: surface detail and surface macroscopic geometric shape. First, based on SFS, a distance field offset algorithm is designed according to the image skeleton to enhance the surface details of 3D shapes. The edge detection method is used to detect the leaf veins as the skeleton of the image, and the distance from the image skeleton is used as the constraint of the SFS minimization method to enhance the surface detail display. Then, to address the deficiencies of SFS in recovering the macroscopic geometric shape, various factors that affect the macroscopic geometric shape are considered, and the characteristics of leaf surface unevenness and curvature are finally realized. Selecting control points according to the statistical distribution of image brightness is proposed to control the change of the surface macroscopic geometric shape, and the distance field constraint of the blade central axis is used to restore the macroscopic geometric shape. According to the brightness statistics, the image is divided into bright-dark areas, the centroid of the unconnected areas of the bright and dark regions is used as the control point, and the cubic Bezier surface is used to generate the concave and convex characteristics of the blade surface. The overall bending of the blade can be estimated based on the distance from each point of the blade to the central axis because most blades have a certain degree of bending about the central axis and the curvature at the central axis changes the most. The two weights for the restoration of the surface macroscopic geometric shape are set based on the similarity between the restored reflection map and the input image, and the surface details are finally added to the macroscopic geometric shape to obtain the final 3D shape of the target object.ResultPlant leaf images are selected for experiments, and their 3D restoration results are compared with those of other methods (including Tsai linear approach, Zheng minimization approach, SIRFS(shape, illumination, and reflectance from shading), and variational approach). Experimental results show that the method proposed enhances the display of surface details and has evident changes in macroscopic geometric shape. To verify the applicability of the method in the restoration of object surface details, namely, recovering the surface details of coins and dinosaurs, the experimental results prove that the proposed method of enhancing surface details is also applicable to other objects. In addition, using the ratio of error to information entropy is proposed to describe the effect of 3D reconstruction of the target. Error describes the accuracy of restoration, and information entropy describes the richness of information. The larger the entropy is, the greater the difference between the depth of restoration, which means larger surface macroscopic geometry changes. When the error is smaller and the information entropy is larger, the ratio of error to information entropy is smaller and the recovery effect is better.ConclusionTo address the 3D reconstruction problem of a single plant leaf image, decomposing the problem into two aspects is proposed: surface details and macroscopic geometric shape. Based on SFS, the surface details are enhanced according to the skeleton feature, the surface macroscopic geometric shape is jointly restored using the statistical distribution of image brightness and the axial distance field constraints of the leaves, the final 3D shape is obtained by combining the surface details and the macroscopic geometric shape, and the feasibility of the proposed method is verified by multiple sets of experiments.关键词:3D restoration;shape from shading(SFS);single image;image skeleton;image brightness statistics;distance field constraint99|220|1更新时间:2024-05-07
摘要:ObjectiveIn recent years, with the continuous improvement of computer hardware performance and the continuous in depth research of virtual plant modeling and landscape design in the fields of film and television and games, plant shape modeling has become possible and necessary. As one of the important organs of plants, leaves have complex physiological and morphological characteristics, which are difficult to represent in virtual scenes. Therefore, 3D reconstruction of plant leaves is a very challenging subject. Current 3D reconstruction methods have two main types. 1) External equipment such as laser or radar are used to measure the distance of the target by transmitting signals and then receiving the signals reflected by the target object to obtain the 3D shape of the surface. 2) Using the principle of binocular vision, two or more images are obtained from different perspectives in the same scene, then the 3D shape of the object is obtained according to the parallax between the images. The former requires the introduction of external equipment, which is costly and difficult to operate, whereas the latter needs to detect and match the feature points between the acquired image sequences due to the reconstruction based on multiple images. The acquisition of a single image is simple, and the problem of feature matching of multiple images is eliminated. However, due to the less information contained in a single image and to recover the 3D shape of plant leaves from the limited information, this paper is based on the method of the shape from shading (SFS) and preprocesses the image to add a priori to the 3D shape estimation. The brightness statistic information obtained from the image and the prior information of plant morphological characteristics are used to recover the final 3D shape of the leaf.MethodWhen restoring the 3D shape of a single plant leaf image, the restoration of the surface shape is divided into two aspects: surface detail and surface macroscopic geometric shape. First, based on SFS, a distance field offset algorithm is designed according to the image skeleton to enhance the surface details of 3D shapes. The edge detection method is used to detect the leaf veins as the skeleton of the image, and the distance from the image skeleton is used as the constraint of the SFS minimization method to enhance the surface detail display. Then, to address the deficiencies of SFS in recovering the macroscopic geometric shape, various factors that affect the macroscopic geometric shape are considered, and the characteristics of leaf surface unevenness and curvature are finally realized. Selecting control points according to the statistical distribution of image brightness is proposed to control the change of the surface macroscopic geometric shape, and the distance field constraint of the blade central axis is used to restore the macroscopic geometric shape. According to the brightness statistics, the image is divided into bright-dark areas, the centroid of the unconnected areas of the bright and dark regions is used as the control point, and the cubic Bezier surface is used to generate the concave and convex characteristics of the blade surface. The overall bending of the blade can be estimated based on the distance from each point of the blade to the central axis because most blades have a certain degree of bending about the central axis and the curvature at the central axis changes the most. The two weights for the restoration of the surface macroscopic geometric shape are set based on the similarity between the restored reflection map and the input image, and the surface details are finally added to the macroscopic geometric shape to obtain the final 3D shape of the target object.ResultPlant leaf images are selected for experiments, and their 3D restoration results are compared with those of other methods (including Tsai linear approach, Zheng minimization approach, SIRFS(shape, illumination, and reflectance from shading), and variational approach). Experimental results show that the method proposed enhances the display of surface details and has evident changes in macroscopic geometric shape. To verify the applicability of the method in the restoration of object surface details, namely, recovering the surface details of coins and dinosaurs, the experimental results prove that the proposed method of enhancing surface details is also applicable to other objects. In addition, using the ratio of error to information entropy is proposed to describe the effect of 3D reconstruction of the target. Error describes the accuracy of restoration, and information entropy describes the richness of information. The larger the entropy is, the greater the difference between the depth of restoration, which means larger surface macroscopic geometry changes. When the error is smaller and the information entropy is larger, the ratio of error to information entropy is smaller and the recovery effect is better.ConclusionTo address the 3D reconstruction problem of a single plant leaf image, decomposing the problem into two aspects is proposed: surface details and macroscopic geometric shape. Based on SFS, the surface details are enhanced according to the skeleton feature, the surface macroscopic geometric shape is jointly restored using the statistical distribution of image brightness and the axial distance field constraints of the leaves, the final 3D shape is obtained by combining the surface details and the macroscopic geometric shape, and the feasibility of the proposed method is verified by multiple sets of experiments.关键词:3D restoration;shape from shading(SFS);single image;image skeleton;image brightness statistics;distance field constraint99|220|1更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveMost of the computed tomography (CT) image analysis networks based on deep learning are designed for a single lesion type, such that they are incapable of detecting multiple types of lesions. The general CT image analysis network focusing on accurate, timely diagnosis and treatment of patients is urgently needed. The public medical image set is quite difficult to build because doctors or researchers must process the existing CT images more efficiently and diagnose diseases more accurately. To improve the performance of CT image analysis networks, several scholars have constructed 3D convolutional neural networks (3D CNN) to extract substantial spatial features which have better performances than those of 2D CNN. However, the high computational complexity in 3D CNN restricts the depth of the designed networks, resulting in performance bottlenecks. Recently, the CT image dataset with multiple lesion types, DeepLesion, has contributed to the universal network construction for lesion detection and segmentation task on CT images. Different lesion scales and types cause a large burden on lesion detection and segmentation. To address the problems and improve the performance of CT image analysis networks, we propose a model based on deep convolutional networks to accomplish the tasks of multi-organ lesion detection and segmentation on CT images, which will help doctors diagnose the disease quickly and accurately.MethodThe proposed model mainly consists of two parts. 1) Backbone networks. To extract multi-dimension, multi-scale features, we integrate bidirectional feature pyramid networks and densely connected convolutional networks into the backbone network. The model's inputs are the combination of CT key slice and the neighboring slices, where the former provides ground truth information, and the latter provide the 3D context. Combining the backbone network with feature fusion method enables the 2D network to extract spatial information from adjacent slices. Thus, the network can use features of the adjacent slices and key slice, and network performance can be improved by utilizing the 3D context from the CT slices. Moreover, we try to simplify and fine tune the network structure such that our model has a better performance as well as low computational complexity than the original architecture. 2) Detection and segmentation branches. To produce high-quality, typical proposals, we place the features fused with 3D context into the region of proposal network. The cascaded R-CNN (region convolutional neural network) with gradually increasing threshold resamples the generated proposals, and the high-quality proposals are fed into the detection and segmentation branches. We set the anchor ratios to 1:2, 1:1, and 2:1, and the sizes in region of proposal networks to 16, 24, 32, 48, and 96 for the different scales of lesions. We take different cascaded stages with different value of intersection over union such as 0.5, 0.6, and 0.7 to find the suitable cascaded stages. The original region of interest (ROI) pool method is substituted with ROI align for better performances.ResultWe validate the network's performance on the dataset DeepLesion containing 32 120 CT images with different types of lesions. We split the dataset into three subsets, namely, training set, testing set, and validating set, with proportions of 70%, 15%, and 15%, respectively. We employ the stochastic gradient descent method to train the proposed model with an initial learning rate of 0.001. The rate will drop to 1/10 of the original value in the fourth and sixth epoch (eight epochs in total for training). Four groups of comparative experiments are conducted to explore the effects of different networks on detection and segmentation performance. Multiple network structures such as feature pyramid networks (FPN), bidirectional feature pyramid networks (BiFPN), feature fusion, and different number of cascade stages and segmentation branch are considered in our experiments. Experimental results show that BiFPN can function well in the detection task compared with FPN. Moreover, detection performance is greatly improved by using the feature fusion method. As the number of cascaded stages increases, detection accuracy drops slightly, while the performance of segmentation improves greatly. In addition, the networks without a segmentation branch can detect lesions more accurately than those with a segmentation branch. Hence, we recognize a negative relationship between detection and segmentation tasks. We can select different structures for distinct requirements on detection or segmentation accuracy to achieve satisfying results. If doctors or researchers want to diagnose lesions more accurately, the baseline network without a segmentation branch can meet the requirements. For more accurate segmentation results, baseline network with three cascaded stages network can achieve the goal. We present the results from the three-stage cascaded networks. The results show that the average detection accuracy of our model on the DeepLesion test set is 83.15%, while the average distance error between the segmentation prediction result and the real weak label of response evaluation criteria in solid tumors (RECIST)'s endpoint is 1.27 mm, and the average radius error is 1.69 mm. Our network's performance in segmentation is superior to the multitask universal lesion analysis network for joint lesion detection, tagging, and segmentation and auto RECIST. The inference time per image in our network is 91.7 ms.ConclusionThe proposed model achieves good detection and segmentation performance on CT images, and takes less time to predict. It is suitable for accomplishing lesion detection and segmentation in CT images with similar lesion types in the DeepLesion dataset. Our model trained on DeepLesion can help doctors diagnose lesions on multiple organs using a computer.关键词:deep learning;computed tomography(CT)images;lesion detection;lesion segmentation;DeepLeison67|31|0更新时间:2024-05-07
摘要:ObjectiveMost of the computed tomography (CT) image analysis networks based on deep learning are designed for a single lesion type, such that they are incapable of detecting multiple types of lesions. The general CT image analysis network focusing on accurate, timely diagnosis and treatment of patients is urgently needed. The public medical image set is quite difficult to build because doctors or researchers must process the existing CT images more efficiently and diagnose diseases more accurately. To improve the performance of CT image analysis networks, several scholars have constructed 3D convolutional neural networks (3D CNN) to extract substantial spatial features which have better performances than those of 2D CNN. However, the high computational complexity in 3D CNN restricts the depth of the designed networks, resulting in performance bottlenecks. Recently, the CT image dataset with multiple lesion types, DeepLesion, has contributed to the universal network construction for lesion detection and segmentation task on CT images. Different lesion scales and types cause a large burden on lesion detection and segmentation. To address the problems and improve the performance of CT image analysis networks, we propose a model based on deep convolutional networks to accomplish the tasks of multi-organ lesion detection and segmentation on CT images, which will help doctors diagnose the disease quickly and accurately.MethodThe proposed model mainly consists of two parts. 1) Backbone networks. To extract multi-dimension, multi-scale features, we integrate bidirectional feature pyramid networks and densely connected convolutional networks into the backbone network. The model's inputs are the combination of CT key slice and the neighboring slices, where the former provides ground truth information, and the latter provide the 3D context. Combining the backbone network with feature fusion method enables the 2D network to extract spatial information from adjacent slices. Thus, the network can use features of the adjacent slices and key slice, and network performance can be improved by utilizing the 3D context from the CT slices. Moreover, we try to simplify and fine tune the network structure such that our model has a better performance as well as low computational complexity than the original architecture. 2) Detection and segmentation branches. To produce high-quality, typical proposals, we place the features fused with 3D context into the region of proposal network. The cascaded R-CNN (region convolutional neural network) with gradually increasing threshold resamples the generated proposals, and the high-quality proposals are fed into the detection and segmentation branches. We set the anchor ratios to 1:2, 1:1, and 2:1, and the sizes in region of proposal networks to 16, 24, 32, 48, and 96 for the different scales of lesions. We take different cascaded stages with different value of intersection over union such as 0.5, 0.6, and 0.7 to find the suitable cascaded stages. The original region of interest (ROI) pool method is substituted with ROI align for better performances.ResultWe validate the network's performance on the dataset DeepLesion containing 32 120 CT images with different types of lesions. We split the dataset into three subsets, namely, training set, testing set, and validating set, with proportions of 70%, 15%, and 15%, respectively. We employ the stochastic gradient descent method to train the proposed model with an initial learning rate of 0.001. The rate will drop to 1/10 of the original value in the fourth and sixth epoch (eight epochs in total for training). Four groups of comparative experiments are conducted to explore the effects of different networks on detection and segmentation performance. Multiple network structures such as feature pyramid networks (FPN), bidirectional feature pyramid networks (BiFPN), feature fusion, and different number of cascade stages and segmentation branch are considered in our experiments. Experimental results show that BiFPN can function well in the detection task compared with FPN. Moreover, detection performance is greatly improved by using the feature fusion method. As the number of cascaded stages increases, detection accuracy drops slightly, while the performance of segmentation improves greatly. In addition, the networks without a segmentation branch can detect lesions more accurately than those with a segmentation branch. Hence, we recognize a negative relationship between detection and segmentation tasks. We can select different structures for distinct requirements on detection or segmentation accuracy to achieve satisfying results. If doctors or researchers want to diagnose lesions more accurately, the baseline network without a segmentation branch can meet the requirements. For more accurate segmentation results, baseline network with three cascaded stages network can achieve the goal. We present the results from the three-stage cascaded networks. The results show that the average detection accuracy of our model on the DeepLesion test set is 83.15%, while the average distance error between the segmentation prediction result and the real weak label of response evaluation criteria in solid tumors (RECIST)'s endpoint is 1.27 mm, and the average radius error is 1.69 mm. Our network's performance in segmentation is superior to the multitask universal lesion analysis network for joint lesion detection, tagging, and segmentation and auto RECIST. The inference time per image in our network is 91.7 ms.ConclusionThe proposed model achieves good detection and segmentation performance on CT images, and takes less time to predict. It is suitable for accomplishing lesion detection and segmentation in CT images with similar lesion types in the DeepLesion dataset. Our model trained on DeepLesion can help doctors diagnose lesions on multiple organs using a computer.关键词:deep learning;computed tomography(CT)images;lesion detection;lesion segmentation;DeepLeison67|31|0更新时间:2024-05-07 -
 摘要:ObjectiveWhile dealing with high-resolution remote sensing image scene recognition, classical supervised machine learning algorithms are considered effective on two conditions, namely, 1) test samples should be in the same feature space with training samples, and 2) adequate labeled samples should be provided to train the model fully. Deep learning algorithms, which achieve remarkable results in image classification and object detection for the past few years, generally require a large number of labeled samples to learn the accurate parameters. The main image classification methods select training and test samples randomly from the same dataset, and adopt cross validation to testify the effectiveness of the model. However, obtaining scene labels is time consuming and expensive for remote sensing images. To deal with the insufficiency of labeled samples in remote sensing image scene recognition and the problem that labeled samples cannot be shared between different datasets due to different sensors and complex light conditions, deep learning architecture and adversarial learning are investigated. A feature transfer method based on adversarial variational autoencoder (VAE) is proposed.MethodFeature transfer architecture can be divided into three parts. The first part is the pretrain module. Given the limited samples with scene labels, the unsupervised learning model, VAE, is adopted. The VAE is unsupervised trained on the source dataset, and the encoder part in the VAE is finetuned together with classifier network using labeled samples in the source dataset. The second part is adversarial learning module. In most of the research, adversarial learning is adopted to generate new samples, while the idea is used to transfer the features from source domain to target domain in this paper. Parameters of the finetuned encoder network for the source dataset are then used to initialize the target encoder. Using the idea of adversarial training in generative adversarial networks (GAN), a discrimination network is introduced into the training of the target encoder. The goal of the target encoder is to extract features in the target domain to have as much affinity to those of the source domain as possible, such that the discrimination network cannot distinguish the features are from either the source domain or target domain. The goal of the discrimination network is to optimize the parameters for better distinction. It is called adversarial learning because of the contradiction between the purpose of encoder and discrimination network. The features extracted by the target encoder increasingly resemble those by the source encoder by training and updating the parameters of the target encoder and the discrimination network alternately. In this manner, by the time the discrimination network can no longer differentiate between source features and target features, we can assume that the target encoder can extract similar features to the source samples, and remote sensing feature transfer between the source domain and target domain is accomplished. The third part is target finetuning and test module. A small number of labeled samples in target domain is employed to finetune the target encoder and source classifier, and the other samples are used for evaluation.ResultTwo remote sensing scene recognition datasets, UCMerced-21 and NWPU-RESISC45, are adopted to prove the effectiveness of the proposed feature transfer method. SUN397, a natural scene recognition dataset is employed as an attempt for the cross-view feature transfer. Eight common scene types between the three datasets, namely, baseball field, beach, farmland, forest, harbor, industrial area, overpass, and river/lake, are selected for the feature transfer task. Correlation alignment (CORAL) and balanced distribution adaptation (BDA) are used as comparisons. In the experiments of adversarial learning between two remote sensing scene recognition datasets, the proposed method boosts the recognition accuracy by about 10% compared with the network trained only by the samples in the source domain. Results improve more substantially when few samples in the target domain are involved. Compared with CORAL and BDA, the proposed method improves scene recognition accuracy by more than 3% when using a few samples in the target domain and between 10%~40% without samples in the target domain. When using the information of a natural scene image, the improvement is not as much as that of a remote sensing image, but the scene recognition accuracy using the proposed feature transfer method is still increased by approximately 6% after unsupervised feature transfer and 36% after a small number of samples in the target domain are involved in finetuning.ConclusionIn this paper, an adversarial VAE-based transfer learning network is proposed. The experimental results show that the proposed adversarial learning method can make the most of sample information of other dataset when the labeled samples are insufficient in the target domain. The proposed method can achieve the feature transfer between different datasets and scene recognition effectively, and remarkably improve the scene recognition accuracy.关键词:scene recognition;remote sensing image;adversarial learning;transfer learning;variational autoencoder(VAE)95|137|0更新时间:2024-05-07
摘要:ObjectiveWhile dealing with high-resolution remote sensing image scene recognition, classical supervised machine learning algorithms are considered effective on two conditions, namely, 1) test samples should be in the same feature space with training samples, and 2) adequate labeled samples should be provided to train the model fully. Deep learning algorithms, which achieve remarkable results in image classification and object detection for the past few years, generally require a large number of labeled samples to learn the accurate parameters. The main image classification methods select training and test samples randomly from the same dataset, and adopt cross validation to testify the effectiveness of the model. However, obtaining scene labels is time consuming and expensive for remote sensing images. To deal with the insufficiency of labeled samples in remote sensing image scene recognition and the problem that labeled samples cannot be shared between different datasets due to different sensors and complex light conditions, deep learning architecture and adversarial learning are investigated. A feature transfer method based on adversarial variational autoencoder (VAE) is proposed.MethodFeature transfer architecture can be divided into three parts. The first part is the pretrain module. Given the limited samples with scene labels, the unsupervised learning model, VAE, is adopted. The VAE is unsupervised trained on the source dataset, and the encoder part in the VAE is finetuned together with classifier network using labeled samples in the source dataset. The second part is adversarial learning module. In most of the research, adversarial learning is adopted to generate new samples, while the idea is used to transfer the features from source domain to target domain in this paper. Parameters of the finetuned encoder network for the source dataset are then used to initialize the target encoder. Using the idea of adversarial training in generative adversarial networks (GAN), a discrimination network is introduced into the training of the target encoder. The goal of the target encoder is to extract features in the target domain to have as much affinity to those of the source domain as possible, such that the discrimination network cannot distinguish the features are from either the source domain or target domain. The goal of the discrimination network is to optimize the parameters for better distinction. It is called adversarial learning because of the contradiction between the purpose of encoder and discrimination network. The features extracted by the target encoder increasingly resemble those by the source encoder by training and updating the parameters of the target encoder and the discrimination network alternately. In this manner, by the time the discrimination network can no longer differentiate between source features and target features, we can assume that the target encoder can extract similar features to the source samples, and remote sensing feature transfer between the source domain and target domain is accomplished. The third part is target finetuning and test module. A small number of labeled samples in target domain is employed to finetune the target encoder and source classifier, and the other samples are used for evaluation.ResultTwo remote sensing scene recognition datasets, UCMerced-21 and NWPU-RESISC45, are adopted to prove the effectiveness of the proposed feature transfer method. SUN397, a natural scene recognition dataset is employed as an attempt for the cross-view feature transfer. Eight common scene types between the three datasets, namely, baseball field, beach, farmland, forest, harbor, industrial area, overpass, and river/lake, are selected for the feature transfer task. Correlation alignment (CORAL) and balanced distribution adaptation (BDA) are used as comparisons. In the experiments of adversarial learning between two remote sensing scene recognition datasets, the proposed method boosts the recognition accuracy by about 10% compared with the network trained only by the samples in the source domain. Results improve more substantially when few samples in the target domain are involved. Compared with CORAL and BDA, the proposed method improves scene recognition accuracy by more than 3% when using a few samples in the target domain and between 10%~40% without samples in the target domain. When using the information of a natural scene image, the improvement is not as much as that of a remote sensing image, but the scene recognition accuracy using the proposed feature transfer method is still increased by approximately 6% after unsupervised feature transfer and 36% after a small number of samples in the target domain are involved in finetuning.ConclusionIn this paper, an adversarial VAE-based transfer learning network is proposed. The experimental results show that the proposed adversarial learning method can make the most of sample information of other dataset when the labeled samples are insufficient in the target domain. The proposed method can achieve the feature transfer between different datasets and scene recognition effectively, and remarkably improve the scene recognition accuracy.关键词:scene recognition;remote sensing image;adversarial learning;transfer learning;variational autoencoder(VAE)95|137|0更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveSatellite video is a new type of remote sensing system, which is capable of dynamic video and conventional image capturing. Compared with conventional very-high-resolution (VHR) remote sensing systems, a video satellite observes the Earth with a real-time temporal resolution, which has led to studies in the field of traffic density estimation, object detection, and 3D reconstruction. Satellite video has a strong potential in monitoring traffic, animal migration, and ships entering and leaving ports due to its high temporal resolution. Despite much research in the field of conventional video, relatively minimal work has been performed in object tracking for satellite video. Existing object tracking methods primarily emphasize relatively large objects, such as trains and planes. Several researchers have explored replacing or fusing the motion feature for a more accurate prediction of object position. However, few studies have focused on solving the problem caused by the insufficient amount of information of smaller objects, such as vehicles. Tracking vehicles in satellite video has three main challenges. The main challenge is the small size of the target. While the size of a single frame can be as large as 12 000×4 000 pixels, moving targets, such as cars, can be very small and only occupy 10~30 pixels. The second challenge is the lack of clear texture because the vehicle targets contain limited and/or confusing information. The third challenge is that unlike aircraft and ships, vehicles are more likely to appear in situations where the background is complex, which makes tracking the vehicle more challenging. For instance, a vehicle may make quick turns, appear partially to the vehicle, or be marked by instant changes in illumination. Selecting or constructing a single image feature that can handle all the situations mentioned above is difficult. Using multiple complementary image features is proposed by merging them into a unified framework based on a lightweight kernelized correlation filter to tackle these challenges.MethodFirst, two complementary features with certain invariance and discriminative ability, histogram of gradients (HOG) and raw pixels, are used as descriptors of the target image patch. HOG is tied to edge information of vehicles, such as orientations, offering some discriminative ability. A HOG-based tracker can distinguish targets even when partial occlusion occurs or when illumination or road color changes. However, it would be unable to correctly classify the target from similar shapes in its surroundings, suffering from the problems caused by insufficient information. However, the raw pixel feature describes all contents in the image patch without processing, and more information can be kept without post-processing considering the smaller size of vehicles. It is invariant to the plane motion of a rigid object under low-texture information and to tracking vehicles in terms of orientation changes. However, it fails to track vehicles that are partially occluded or in changes of road color and illumination. A response map merging strategy is proposed to fuse the complementary image features by maintaining two trackers, one using the HOG feature to discriminate the target and the other using the raw pixel feature to improve invariance. In this manner, a peak response may arise at a new position, representing invariance and discriminative ability. Finally, restricted by the insufficient information of the target and the discriminative ability of the observation model, responses usually show a multipeak pattern when a disturbance exists. A response distribution criterion-based model updater is exploited to measure the distribution of merged responses. Using a correlation filter facilitates multiple vehicle tracking due to its calculation speed and online training mechanism.ResultOur model is compared with six state-of-the-art correlation filter-based models. Experiments are performed on eight satellite videos captured in different locations worldwide under challenging situations, such as illumination variance, quick turn, partial occlusion, and road color change. Precision plot and success plot are adopted for evaluation. Ablation experiments are performed to demonstrate the efficiency of the method proposed, and quantitative assessments show that our method leads to an effective balance between two trackers. Moreover, visualization results of three videos show how our method achieves a balance between the two trackers. Our method outperforms all the six state-of-the-art methods and achieves a balance between the base trackers.ConclusionIn this paper, a new tracker fused with complementary image features for vehicle tracking in satellite videos is proposed. To overcome the difficulties posed by the small size of the target and the lack of texture and complex background in satellite video tracking, combining the use of HOG and raw pixel features is proposed by merging the response maps of the two trackers to increase their discriminative and invariance abilities. Experiments on eight satellite videos under challenging circumstances demonstrate that our method outperforms other state-of-the-art algorithms in precision plots and success plots.关键词:object tracking;satellite video;kernelized correlation filter;feature fusion;vehicle tracking102|146|1更新时间:2024-05-07
摘要:ObjectiveSatellite video is a new type of remote sensing system, which is capable of dynamic video and conventional image capturing. Compared with conventional very-high-resolution (VHR) remote sensing systems, a video satellite observes the Earth with a real-time temporal resolution, which has led to studies in the field of traffic density estimation, object detection, and 3D reconstruction. Satellite video has a strong potential in monitoring traffic, animal migration, and ships entering and leaving ports due to its high temporal resolution. Despite much research in the field of conventional video, relatively minimal work has been performed in object tracking for satellite video. Existing object tracking methods primarily emphasize relatively large objects, such as trains and planes. Several researchers have explored replacing or fusing the motion feature for a more accurate prediction of object position. However, few studies have focused on solving the problem caused by the insufficient amount of information of smaller objects, such as vehicles. Tracking vehicles in satellite video has three main challenges. The main challenge is the small size of the target. While the size of a single frame can be as large as 12 000×4 000 pixels, moving targets, such as cars, can be very small and only occupy 10~30 pixels. The second challenge is the lack of clear texture because the vehicle targets contain limited and/or confusing information. The third challenge is that unlike aircraft and ships, vehicles are more likely to appear in situations where the background is complex, which makes tracking the vehicle more challenging. For instance, a vehicle may make quick turns, appear partially to the vehicle, or be marked by instant changes in illumination. Selecting or constructing a single image feature that can handle all the situations mentioned above is difficult. Using multiple complementary image features is proposed by merging them into a unified framework based on a lightweight kernelized correlation filter to tackle these challenges.MethodFirst, two complementary features with certain invariance and discriminative ability, histogram of gradients (HOG) and raw pixels, are used as descriptors of the target image patch. HOG is tied to edge information of vehicles, such as orientations, offering some discriminative ability. A HOG-based tracker can distinguish targets even when partial occlusion occurs or when illumination or road color changes. However, it would be unable to correctly classify the target from similar shapes in its surroundings, suffering from the problems caused by insufficient information. However, the raw pixel feature describes all contents in the image patch without processing, and more information can be kept without post-processing considering the smaller size of vehicles. It is invariant to the plane motion of a rigid object under low-texture information and to tracking vehicles in terms of orientation changes. However, it fails to track vehicles that are partially occluded or in changes of road color and illumination. A response map merging strategy is proposed to fuse the complementary image features by maintaining two trackers, one using the HOG feature to discriminate the target and the other using the raw pixel feature to improve invariance. In this manner, a peak response may arise at a new position, representing invariance and discriminative ability. Finally, restricted by the insufficient information of the target and the discriminative ability of the observation model, responses usually show a multipeak pattern when a disturbance exists. A response distribution criterion-based model updater is exploited to measure the distribution of merged responses. Using a correlation filter facilitates multiple vehicle tracking due to its calculation speed and online training mechanism.ResultOur model is compared with six state-of-the-art correlation filter-based models. Experiments are performed on eight satellite videos captured in different locations worldwide under challenging situations, such as illumination variance, quick turn, partial occlusion, and road color change. Precision plot and success plot are adopted for evaluation. Ablation experiments are performed to demonstrate the efficiency of the method proposed, and quantitative assessments show that our method leads to an effective balance between two trackers. Moreover, visualization results of three videos show how our method achieves a balance between the two trackers. Our method outperforms all the six state-of-the-art methods and achieves a balance between the base trackers.ConclusionIn this paper, a new tracker fused with complementary image features for vehicle tracking in satellite videos is proposed. To overcome the difficulties posed by the small size of the target and the lack of texture and complex background in satellite video tracking, combining the use of HOG and raw pixel features is proposed by merging the response maps of the two trackers to increase their discriminative and invariance abilities. Experiments on eight satellite videos under challenging circumstances demonstrate that our method outperforms other state-of-the-art algorithms in precision plots and success plots.关键词:object tracking;satellite video;kernelized correlation filter;feature fusion;vehicle tracking102|146|1更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0