
最新刊期
卷 26 , 期 10 , 2021
-
 摘要:Image classification(IC) is one of important tasks in support of computer vision. Traditional image classification methods have limitations on the aspect of computer vision. Deep learning technology has become more mature than before based on deep convolutional neural network(DCNN) with the development of artificial intelligence(AI) recently. The performance of image classification has been upgraded based on the maturation of the deep convolutional neural network model.This research has mainly focused on a comprehensive overview of image classification in DCNN via the deep convolutional neural network model structure of image classification. Firstly, the modeling methodology has been analyzed and summarized. The DCNN analysis has been formulated into four categories listed below: 1)classic deep convolutional neural networks; 2)deep convolutional neural networks based on the attention mechanism; 3) lightweight networks; 4) the neural architecture search method. DCNN has high optimization capability using convolution to extract effective features of the images and learn feature expression from a large number of samples automatically. DCNN achieves better performance on image classification due to the effective features based on the deeper DCNN research and development. DCNN has been encounting lots of difficulities such as overfitting, vanishing gradient and huge model parameters.Hence, DCNN has become more and more difficult to optimize. The researchers in the context of IC have illustrated different DCNN models for different problems. Researchers have been making the network deeper that before via AlexNet. Subsequently, the classified analyses such as network in network(NIN), Overfeat, ZFNet, Visual Geometry Group(VGGNet), GoogLeNet have been persisted on.The problem of vanishing gradient has been more intensified via the deepening of the network.The optimization of the network becomes more complicated. Researchers have proposed residual network(ResNet) to ease gradient vanishing to improve the performance of image classification greatly. To further improve the performance of ResNet, researchers have issued a series of ResNet variants which can be divided into three categories in terms of different solutions via ResNet variants based on very deep ResNet optimization, ResNet variants based on increasing width and the new dimensions in ResNet variants. The ResNet has been attributed to the use of shortcut connections maximization. Densely connected convolutional network (DenseNet) have been demonstrated and the information flow in DenseNet between each layer has been maximized. To further promote the information flow between layers, the DenseNet variants have been illustrated via DPN(dual path network) and CliqueNet. DCNN based on the attention mechanism has focused on the regions of interest based on the classic DCNN models and channel attention mechanism, spatial attention mechanism and layer attention mechanism can be categorized. DCNN need higher accuracy and a small amount of parameters and fast model calculation speed. The researchers have proposed the lightweight networks such as the ShuffleNet series and MobileNet series. The NAS(neural architecture search) methods using neural networks to automatically design neural networks have been conerned. The NAS methods can be divided into three categories: design search space, model optimization and others. Secondly, The image classification datasets have been commonly presented in common including MNIST(modified NIST(MNIST)) dataset, ImageNet dataset, CIFAR dataset and SVHN(street view house number(SVHN)) dataset. The comparative performance and analysis of experimental results of various models were conducted as well.The accuracy, parameter and FLOPs(floating point operations) analyses to measure the results of classification have been mentioned. The capability of model optimization has been upgraded gradually via the accuracy improvement of image classification, the decreasing amount of parameters of the model and increasing speed of training and inference. Finally, the DCNN model has been constrained some factors. The DCNN model has been mainly used to supervise deep learning for image classification in constraint of the quality and scale of the datasets.The speed and resource consuming of the DCNN model have been upgraded in mobile devices.The measurment and optimization in analyzing the advantages and disadvantages of the DCNN model need to be studied further.The neural architecture search method will be the development direction of future deep convolutional neural network model designs. The DCNN models of image classification have been reviewed and the experimental results of the DCNNs have been demonstrated.关键词:deep learning;image classification(IC);deep convolutional neural networks(DCNN);model structure;model optimization429|291|35更新时间:2024-05-07
摘要:Image classification(IC) is one of important tasks in support of computer vision. Traditional image classification methods have limitations on the aspect of computer vision. Deep learning technology has become more mature than before based on deep convolutional neural network(DCNN) with the development of artificial intelligence(AI) recently. The performance of image classification has been upgraded based on the maturation of the deep convolutional neural network model.This research has mainly focused on a comprehensive overview of image classification in DCNN via the deep convolutional neural network model structure of image classification. Firstly, the modeling methodology has been analyzed and summarized. The DCNN analysis has been formulated into four categories listed below: 1)classic deep convolutional neural networks; 2)deep convolutional neural networks based on the attention mechanism; 3) lightweight networks; 4) the neural architecture search method. DCNN has high optimization capability using convolution to extract effective features of the images and learn feature expression from a large number of samples automatically. DCNN achieves better performance on image classification due to the effective features based on the deeper DCNN research and development. DCNN has been encounting lots of difficulities such as overfitting, vanishing gradient and huge model parameters.Hence, DCNN has become more and more difficult to optimize. The researchers in the context of IC have illustrated different DCNN models for different problems. Researchers have been making the network deeper that before via AlexNet. Subsequently, the classified analyses such as network in network(NIN), Overfeat, ZFNet, Visual Geometry Group(VGGNet), GoogLeNet have been persisted on.The problem of vanishing gradient has been more intensified via the deepening of the network.The optimization of the network becomes more complicated. Researchers have proposed residual network(ResNet) to ease gradient vanishing to improve the performance of image classification greatly. To further improve the performance of ResNet, researchers have issued a series of ResNet variants which can be divided into three categories in terms of different solutions via ResNet variants based on very deep ResNet optimization, ResNet variants based on increasing width and the new dimensions in ResNet variants. The ResNet has been attributed to the use of shortcut connections maximization. Densely connected convolutional network (DenseNet) have been demonstrated and the information flow in DenseNet between each layer has been maximized. To further promote the information flow between layers, the DenseNet variants have been illustrated via DPN(dual path network) and CliqueNet. DCNN based on the attention mechanism has focused on the regions of interest based on the classic DCNN models and channel attention mechanism, spatial attention mechanism and layer attention mechanism can be categorized. DCNN need higher accuracy and a small amount of parameters and fast model calculation speed. The researchers have proposed the lightweight networks such as the ShuffleNet series and MobileNet series. The NAS(neural architecture search) methods using neural networks to automatically design neural networks have been conerned. The NAS methods can be divided into three categories: design search space, model optimization and others. Secondly, The image classification datasets have been commonly presented in common including MNIST(modified NIST(MNIST)) dataset, ImageNet dataset, CIFAR dataset and SVHN(street view house number(SVHN)) dataset. The comparative performance and analysis of experimental results of various models were conducted as well.The accuracy, parameter and FLOPs(floating point operations) analyses to measure the results of classification have been mentioned. The capability of model optimization has been upgraded gradually via the accuracy improvement of image classification, the decreasing amount of parameters of the model and increasing speed of training and inference. Finally, the DCNN model has been constrained some factors. The DCNN model has been mainly used to supervise deep learning for image classification in constraint of the quality and scale of the datasets.The speed and resource consuming of the DCNN model have been upgraded in mobile devices.The measurment and optimization in analyzing the advantages and disadvantages of the DCNN model need to be studied further.The neural architecture search method will be the development direction of future deep convolutional neural network model designs. The DCNN models of image classification have been reviewed and the experimental results of the DCNNs have been demonstrated.关键词:deep learning;image classification(IC);deep convolutional neural networks(DCNN);model structure;model optimization429|291|35更新时间:2024-05-07 -
 摘要:This is an overview of the annual survey series of bibliographies on image engineering in China for the past 25 years. Images are an important medium for human beings to observe the information of the real world around. In its general sense, the word "image" could include all entities that can be visualized by human eyes, such as a still image or picture, a clip of video, as well as graphics, animations, cartoons, charts, drawings, paintings, even also text, etc. Nowadays, with the progress of information science and society, "image" rather than "picture" is used because computers store numerical images of a picture or scene. Image techniques are those techniques that have been invented, designed, implemented, developed, and utilized to treat various types of images for different and specified purposes. They are expanding over wider and wider application areas. They have attracted more and more attention in recent years with the fast advances of mathematic theories and physical principles, as well as the progress of computer and electronic devices, etc. Image engineering (IE) is an integrated discipline/subject comprising the study of all the different branches of image techniques, which has been formally proposed and defined 25 years ago to cover the whole domain. Image engineering, from a perspective more oriented to techniques for treating images, could be referred to as the collection of three related and partially overlapped groups of image techniques, that is, image processing (IP) techniques (in its narrow sense), image analysis (IA) techniques and image understanding (IU) techniques. In a structural sense, IP, IA and IU build up three inter-connected layers of IE. The three layers follow a progression of increasing abstractness and of decreasing compactness from IP to IA to IU. Each of them operates on different elements (IP's operand is pixel, IA's operand is object, and IU's operand is symbol) and works with altered semantic levels (from low level for IP, via middle level for IA, and to high level for IU). The evolving of image engineering is very quickly, its advances are closely related to the development of biomedical engineering, office automation, industrial inspection, intelligent transportation, remote sensing, surveying and mapping, and telecommunications, etc. To follow the development and to record the progress of image engineering, a bibliography series have been started since the propose of image engineering 25 years ago, and this work has been made consecutively till this year. With a set of carefully selected journals and the thoroughly reading on the papers published, several hundreds of papers related to image engineering are chosen each year for further classification and statistical analysis. The motivations and purposes for this work are three folds. 1) to enable the vast number of scientific and technical personnel engaged in image engineering research and image technology applications for grasping the current status of image engineering research and development, 2) to help them for searching relevant literature in a targeted manner, 3) to provide useful information for journal editors and authors. Based on these three points, the statistics and analysis of the previous year's literature related to image engineering are carried out in every year. In particular, three works are mainly conducted. 1) Forming a classification scheme for literatures. The coverage of research and technology in image engineering is quite large. For the analysis to be general for the whole domain and specific for particular direction, a classification scheme in two levels for literatures is formed. The top level is for the research domains in general (main-class), and the bottom level is for the specific research directions (sub-class). With the development of technology, the sub-classes have been adjusted and increased, from the initial 18 sub-classes to the current 23 sub-classes. 2) Analyzing the statistics for main classes of literatures. This analysis could provide a general picture over the different research domains along the years. 3) Analyzing the statistics for sub-classes of literatures. This analysis could deliver a specific figure to the different research directions at the current year. In the past 25 years, a total of 2 964 issues of 15 major Chinese journals on image engineering in China have been selected for this annual survey series. From 65 014 academic research and technical application papers published in these issues, 15 850 papers in the field of image engineering have been chosen, and classified according to the contents, into five broad classes: (A) image processing, (B) image analysis, (C) image understanding, (D) technology application and (E) review. Then they are further divided into 23 professional sub-classes, namely in brief: (A1) image capturing; (A2) image reconstruction from projections; (A3) image filtering, transformation, enhancement, restoration; (A4) image and/or video coding; (A5) image safety and security; (A6) image multiple-resolutions; (B1) image segmentation; (B2) representation, description, and measurement of objects; (B3) analysis of color, shape, texture, structure, motion, spatial relation; (B4) object extraction, tracking, and recognition; (B5) human biometrics (face, organ, etc.) identification; (C1) image registration, matching and fusion; (C2) 3-D modeling and real world/scene recovery; (C3) image perception, interpretation and reasoning; (C4) content-based image and video retrieval; (C5) spatial-temporal technology; (D1) system and hardware; (D2) telecommunication application; (D3) document application; (D4) bio-medical imaging and applications; (D5) remote sensing, radar, surveying and mapping; (D6) other application domains; and (E1) cross category summary and survey. In this paper, these classified data for all 25 years are integrated and analyzed. The foremost intention is to show a progression of image engineering, and to provide a vivid current picture of image engineering. An overview of the literature survey series on image engineering made in the last 25 years is supplied. The idea behind as well as a thorough summary of obtained statistics for this survey are illustrated and discussed. Many useful information regarding the tendency of fast progresses of image engineering can be obtained. According to the statistics collected and analyses performed, it is seen that the field of image engineering has changed enormously in recent years. It is seen that techniques for image engineering being developed, implemented and utilized on a large scale no one would have predicted a few years ago. One interesting point should be mentioned here is that the fast growth and relative increase of image analysis publications over image processing publications are clearly observed. This gives an indication of a general tendency for the image engineering toward to higher layer. After image analysis, image understanding will catch up and come from behind. This trend has already made an appearance, for example, in the International Conference on Image Processing (ICIP 2017), the new research papers related to topic of "Image & Video Interpretation & Understanding" are much more than those related to topic of "Image & Video Analysis" (http://2017.ieeeicip.org/). In addition to the statistical information for publication in these 25 years, some main research directions are analyzed and deliberated, especially those in image processing, image analysis and image understanding, to present more comprehensive and credible information on the development trends of each technique class. Some insights from it are also pointed and discussed. It is evident that through the statistical analysis of the published papers in important journals of image engineering, it cannot only help people understand the general situation of researches and applications, but also provide scientific basis for the development of relevant disciplines and research strategies.关键词:image engineering(IE);image processing(IP);image analysis(IA);image understanding(IU);technique application(TA);literature survey;literature classification;bibliometrics54|88|3更新时间:2024-05-07
摘要:This is an overview of the annual survey series of bibliographies on image engineering in China for the past 25 years. Images are an important medium for human beings to observe the information of the real world around. In its general sense, the word "image" could include all entities that can be visualized by human eyes, such as a still image or picture, a clip of video, as well as graphics, animations, cartoons, charts, drawings, paintings, even also text, etc. Nowadays, with the progress of information science and society, "image" rather than "picture" is used because computers store numerical images of a picture or scene. Image techniques are those techniques that have been invented, designed, implemented, developed, and utilized to treat various types of images for different and specified purposes. They are expanding over wider and wider application areas. They have attracted more and more attention in recent years with the fast advances of mathematic theories and physical principles, as well as the progress of computer and electronic devices, etc. Image engineering (IE) is an integrated discipline/subject comprising the study of all the different branches of image techniques, which has been formally proposed and defined 25 years ago to cover the whole domain. Image engineering, from a perspective more oriented to techniques for treating images, could be referred to as the collection of three related and partially overlapped groups of image techniques, that is, image processing (IP) techniques (in its narrow sense), image analysis (IA) techniques and image understanding (IU) techniques. In a structural sense, IP, IA and IU build up three inter-connected layers of IE. The three layers follow a progression of increasing abstractness and of decreasing compactness from IP to IA to IU. Each of them operates on different elements (IP's operand is pixel, IA's operand is object, and IU's operand is symbol) and works with altered semantic levels (from low level for IP, via middle level for IA, and to high level for IU). The evolving of image engineering is very quickly, its advances are closely related to the development of biomedical engineering, office automation, industrial inspection, intelligent transportation, remote sensing, surveying and mapping, and telecommunications, etc. To follow the development and to record the progress of image engineering, a bibliography series have been started since the propose of image engineering 25 years ago, and this work has been made consecutively till this year. With a set of carefully selected journals and the thoroughly reading on the papers published, several hundreds of papers related to image engineering are chosen each year for further classification and statistical analysis. The motivations and purposes for this work are three folds. 1) to enable the vast number of scientific and technical personnel engaged in image engineering research and image technology applications for grasping the current status of image engineering research and development, 2) to help them for searching relevant literature in a targeted manner, 3) to provide useful information for journal editors and authors. Based on these three points, the statistics and analysis of the previous year's literature related to image engineering are carried out in every year. In particular, three works are mainly conducted. 1) Forming a classification scheme for literatures. The coverage of research and technology in image engineering is quite large. For the analysis to be general for the whole domain and specific for particular direction, a classification scheme in two levels for literatures is formed. The top level is for the research domains in general (main-class), and the bottom level is for the specific research directions (sub-class). With the development of technology, the sub-classes have been adjusted and increased, from the initial 18 sub-classes to the current 23 sub-classes. 2) Analyzing the statistics for main classes of literatures. This analysis could provide a general picture over the different research domains along the years. 3) Analyzing the statistics for sub-classes of literatures. This analysis could deliver a specific figure to the different research directions at the current year. In the past 25 years, a total of 2 964 issues of 15 major Chinese journals on image engineering in China have been selected for this annual survey series. From 65 014 academic research and technical application papers published in these issues, 15 850 papers in the field of image engineering have been chosen, and classified according to the contents, into five broad classes: (A) image processing, (B) image analysis, (C) image understanding, (D) technology application and (E) review. Then they are further divided into 23 professional sub-classes, namely in brief: (A1) image capturing; (A2) image reconstruction from projections; (A3) image filtering, transformation, enhancement, restoration; (A4) image and/or video coding; (A5) image safety and security; (A6) image multiple-resolutions; (B1) image segmentation; (B2) representation, description, and measurement of objects; (B3) analysis of color, shape, texture, structure, motion, spatial relation; (B4) object extraction, tracking, and recognition; (B5) human biometrics (face, organ, etc.) identification; (C1) image registration, matching and fusion; (C2) 3-D modeling and real world/scene recovery; (C3) image perception, interpretation and reasoning; (C4) content-based image and video retrieval; (C5) spatial-temporal technology; (D1) system and hardware; (D2) telecommunication application; (D3) document application; (D4) bio-medical imaging and applications; (D5) remote sensing, radar, surveying and mapping; (D6) other application domains; and (E1) cross category summary and survey. In this paper, these classified data for all 25 years are integrated and analyzed. The foremost intention is to show a progression of image engineering, and to provide a vivid current picture of image engineering. An overview of the literature survey series on image engineering made in the last 25 years is supplied. The idea behind as well as a thorough summary of obtained statistics for this survey are illustrated and discussed. Many useful information regarding the tendency of fast progresses of image engineering can be obtained. According to the statistics collected and analyses performed, it is seen that the field of image engineering has changed enormously in recent years. It is seen that techniques for image engineering being developed, implemented and utilized on a large scale no one would have predicted a few years ago. One interesting point should be mentioned here is that the fast growth and relative increase of image analysis publications over image processing publications are clearly observed. This gives an indication of a general tendency for the image engineering toward to higher layer. After image analysis, image understanding will catch up and come from behind. This trend has already made an appearance, for example, in the International Conference on Image Processing (ICIP 2017), the new research papers related to topic of "Image & Video Interpretation & Understanding" are much more than those related to topic of "Image & Video Analysis" (http://2017.ieeeicip.org/). In addition to the statistical information for publication in these 25 years, some main research directions are analyzed and deliberated, especially those in image processing, image analysis and image understanding, to present more comprehensive and credible information on the development trends of each technique class. Some insights from it are also pointed and discussed. It is evident that through the statistical analysis of the published papers in important journals of image engineering, it cannot only help people understand the general situation of researches and applications, but also provide scientific basis for the development of relevant disciplines and research strategies.关键词:image engineering(IE);image processing(IP);image analysis(IA);image understanding(IU);technique application(TA);literature survey;literature classification;bibliometrics54|88|3更新时间:2024-05-07
Review

-
 摘要:ObjectiveMaritime activities are quite important to human society as they influence economic and social development. Thus, maintaining marine safety is of great significance to promoting social stability. As the main vehicle of marine activities, numerous ships of varying types cruise the sea daily. The fine-grained classification of ships has become one of the basic technologies for marine surveillance. With the development of remote sensing technology, satellite optical remote sensing is becoming one of the main means for marine surveillance due to its wide coverage, low acquisition cost, reliability, and real-time monitoring. As a result, ship classification through optical remote sensing images has attracted the attention of researchers. For the image target recognition task in computer vision, deep learning-based methods outperform traditional methods based on handcrafted features due to the powerful representation ability of convolutional neural networks. Thus, it is natural to combine deep learning technology and ship classification task in optical remote sensing images. However, most deep learning-based algorithms are data-driven, which rely on well-annotated large-scale datasets. To date, problems of small amount of data and few target categories exist in public ship classification datasets with optical remote sensing, which cannot meet the requirements of studies on deep learning-based ship classification tasks, especially the fine-grained ship classification task.MethodOn the basis of the above analysis and requirements, a fine-grained ship collection named FGSC-23 with high-resolution optical remote sensing images is established in this study. There are a total of 4 052 instance chips and 23 categories of targets including 22-category ships and 1-category negative samples in FGSC-23. All the images are obtained from public images of Google Earth and GF-2 satellite, and the ship chips are split from these images. All the ships are labeled by human interpretation. Except for the category labels, the attributes of ship aspect ratio and the angle between the ship's central axis and image's horizontal axis are also annotated. To our knowledge, FGSC-23 contains more fine-grained categories of ships compared with the public datasets. Thus, it can be used for fine-grained ship classification research. Overall, FGSC-23 shares the properties of category diversity, imaging scene diversity, instance label diversity, and category imbalance.ResultExperiments are conducted on the constructed FGSC-23 to test the classification accuracy of classical convolutional neural networks. FGSC-23 is divided into a testing set and training set with a ratio of about 1:4. Models including VGG16(Visual Geometry Group 16-layer net), ResNet50, Inception-v3, DenseNet121, MobileNet, and Xception are trained using the training set and tested on the testing set. The accuracy rate of each category and the overall accuracy rate are recorded, and the visualization of confusion matrixes of the classification results is also given. The overall accuracies of these models are 79.88%, 81.33%, 83.88%, 84.00%, 84.24%, and 87.76%, respectively. Besides these basic classification models, an optimizing model using the ship's attribute feature and enhanced multi-level local features is also tested on FGSC-23. A state-of-the-art classification performance is achieved as 93.58%.ConclusionThe experimental results show that the constructed FGSC-23 can be used to verify the effectiveness of deep learning-based ship classification methods for optical remote sensing images. It is also helpful to promote the development of related researches.关键词:optical remote sensing image;ship;fine-grained recognition;dataset;deep learning546|312|3更新时间:2024-05-07
摘要:ObjectiveMaritime activities are quite important to human society as they influence economic and social development. Thus, maintaining marine safety is of great significance to promoting social stability. As the main vehicle of marine activities, numerous ships of varying types cruise the sea daily. The fine-grained classification of ships has become one of the basic technologies for marine surveillance. With the development of remote sensing technology, satellite optical remote sensing is becoming one of the main means for marine surveillance due to its wide coverage, low acquisition cost, reliability, and real-time monitoring. As a result, ship classification through optical remote sensing images has attracted the attention of researchers. For the image target recognition task in computer vision, deep learning-based methods outperform traditional methods based on handcrafted features due to the powerful representation ability of convolutional neural networks. Thus, it is natural to combine deep learning technology and ship classification task in optical remote sensing images. However, most deep learning-based algorithms are data-driven, which rely on well-annotated large-scale datasets. To date, problems of small amount of data and few target categories exist in public ship classification datasets with optical remote sensing, which cannot meet the requirements of studies on deep learning-based ship classification tasks, especially the fine-grained ship classification task.MethodOn the basis of the above analysis and requirements, a fine-grained ship collection named FGSC-23 with high-resolution optical remote sensing images is established in this study. There are a total of 4 052 instance chips and 23 categories of targets including 22-category ships and 1-category negative samples in FGSC-23. All the images are obtained from public images of Google Earth and GF-2 satellite, and the ship chips are split from these images. All the ships are labeled by human interpretation. Except for the category labels, the attributes of ship aspect ratio and the angle between the ship's central axis and image's horizontal axis are also annotated. To our knowledge, FGSC-23 contains more fine-grained categories of ships compared with the public datasets. Thus, it can be used for fine-grained ship classification research. Overall, FGSC-23 shares the properties of category diversity, imaging scene diversity, instance label diversity, and category imbalance.ResultExperiments are conducted on the constructed FGSC-23 to test the classification accuracy of classical convolutional neural networks. FGSC-23 is divided into a testing set and training set with a ratio of about 1:4. Models including VGG16(Visual Geometry Group 16-layer net), ResNet50, Inception-v3, DenseNet121, MobileNet, and Xception are trained using the training set and tested on the testing set. The accuracy rate of each category and the overall accuracy rate are recorded, and the visualization of confusion matrixes of the classification results is also given. The overall accuracies of these models are 79.88%, 81.33%, 83.88%, 84.00%, 84.24%, and 87.76%, respectively. Besides these basic classification models, an optimizing model using the ship's attribute feature and enhanced multi-level local features is also tested on FGSC-23. A state-of-the-art classification performance is achieved as 93.58%.ConclusionThe experimental results show that the constructed FGSC-23 can be used to verify the effectiveness of deep learning-based ship classification methods for optical remote sensing images. It is also helpful to promote the development of related researches.关键词:optical remote sensing image;ship;fine-grained recognition;dataset;deep learning546|312|3更新时间:2024-05-07
Dataset
-
 摘要:ObjectiveImage-to-image translation involves the automated conversion of input data into a corresponding output image, which differs in characteristics such as color and style. Examples include converting a photograph to a sketch or a visible image to a semantic label map. Translation has various applications in the field of computer vision such facial recognition, person identification, and image dehazing. In 2014, Goodfellow proposed an image generation model based on generative adversarial networks (GANs). This algorithm uses a loss function to classify output images as authentic or fabricated while simultaneously training a generative model to minimize loss. GANs have achieved impressive image generation results using adversarial loss specifically. For example, the image-to-image translation framework Pix2Pix was developed using a GAN architecture. Pix2Pix operates by learning a conditional generative model from input-output image pairs, which is more suitable for translation tasks. In addition, U-Net has often been used as generator networks in place of conventional decoders. While Pix2Pix provides a robust framework for image translation, acquiring sufficient quantities of paired input-output training data can be challenging. In order to solve this problem, cycle-consistent adversarial networks (CycleGANs) were developed by adding an inverse mapping and cycle consistency loss to enforce the relationship between generated and input images. In addition, ResNets have been used as generators to enhance translated image quality. Pix2PixHD offers high-resolution (2 048×1 024 pixels) output using a modified multiscale generator network that includes an instance map in the training step. Although these algorithms have effectively been used for image-to-image translation and a variety of related applications, they typically adopt U-Net or ResNet generators. These single-structure networks struggle to keep high performance across multiple evaluation indicators. As such, this study presents a novel parallel stream-based generator network to increase the robustness across multiple evaluation indicators. Unlike in previous studies, this model consists of two entirely different convolutional neural network (CNN) structures. The output translated visible image of each stream is fused with a linear interpolation-based fusion method to allow for simultaneous optimization of parameters in each model.MethodThe proposed parallel generator network consists of one ResNet processing stream and one DenseNet processing stream, which are fused in parallel. The ResNet stream includes down-sampling and nine Res-Unit feature extraction networks. Each Res-Unit consists of a feedforward neural network exhibiting elementwise addition. Two convolution layers are skipped. Similarly, the DenseNet stream includes down-sampling and nine Den-Unit feature extraction networks. Every Den-Unit is composed of three convolutional layers and two concatenation layers. As a result, the Den-Units output a concatenation of deep feature maps produced in all three convolutional layers. To utilize the advantages of both ResNet and DenseNet streams, two generated images are segmented into low-and high-intensity image parts with an optimal intensity threshold. Then, a linear interpolation method is proposed to fuse the segmented output images of two generator streams in the R, G, B channel respectively. We also design an intensity threshold objective function to obtain optimal parameters in the generator raining process. In addition, to avoid overfitting during training under a small dataset, we modify the discriminator structure by including four convolution-dropout pairs and a convolution layer.ResultWe compared our model with six state-of-the-art saliency models, including CRN(cascaded refinement networks), SIMS(semi-parametric image synthesis), Pix2Pix(pixel to pixel), CycleGAN(cycle generative adversarial networks), MUNIT(multimodal unsupervised image-to-image translation) and GauGAN(group adaptive normalization generative adversarial networks), on a public dataset named "AAU(Aalborg University) RainSnow Traffic Surveillance Dataset". The experimental dataset, which was composed of 22 5-min video sequences acquired from traffic intersections in the Danish cities of Aalborg and Viborg, was used for testing purposes. This dataset was collected at seven different locations with a conventional RGB camera and a thermal camera, each with a resolution of 640×480 pixels, at 20 frames per second. The total experimental dataset consisted of 2 100 RGB-IR image pairs, and each scene was then randomly divided into training and test datasets by 80%-20%. In this study, multi-perspective evaluation results were acquired using the mean square error (MSE), structural similarity index (SSIM), gray intensity histogram correlation, and Bhattacharyya distance. The advantages of a parallel stream-based generator network were assessed by comparing the proposed parallel generator with a ResNet, DenseNet, and residual dense block (RDN)-based hybrid network. We evaluated the average MSE and SSIM values for the test data, produced using four different generators (ParaNet, ResNet, DenseNet, and RDN). The proposed method achieved an average MSE of 34.835 8, which was lower than that of ResNet, DenseNet, and hybrid RDN network. Simultaneously, the average SSIM value produced with the proposed method was 0.747 7, which was also higher than that of DenseNet, ResNet, and RDN. This result shows that the proposed parallel structure-based network produced more effective fusion results than RDB-based hybrid network structure. Moreover, comparative experiments demonstrated that parallel generator structure improves the robustness performance across multi-perspective evaluations for infrared-to-visible image translation. Compared with the six conventional methods, the MSE performance (lower is better) increased by at least 22.30%, and the SSIM (higher is better) decreased by at least 8.55%. The experimental results show that the proposed parallel generator network-based infrared-to-visible image translation deep learning model achieves high performance in terms of MSE or SSIM compared with conventional deep learning models such as CRN, SIMS, Pix2Pix, CycleGAN, MUNIT, and GauGAN.ConclusionA novel parallel stream architecture-based generator network was proposed for infrared-to-visible image translation. Unlike conventional models, the proposed parallel generator structure consists of two different network architectures: a ResNet and a DenseNet. Parallel linear combination-based fusion allowed the model to incorporate benefits from both networks simultaneously. The structure of discriminator networks used in the conditional GAN framework was also improved for training and identifying optimal ParaNet parameters. The experimental results showed that the inclusion of different networks led to increases in common assessment metrics. The MSE, SSIM, and intensity histogram similarity for the proposed parallel generator network were higher than those of existing models. In the future, this algorithm will be applied to image dehazing.关键词:modal translation;ResNet;DenseNet;linear interpolation fusion;parallel generator network81|107|5更新时间:2024-05-07
摘要:ObjectiveImage-to-image translation involves the automated conversion of input data into a corresponding output image, which differs in characteristics such as color and style. Examples include converting a photograph to a sketch or a visible image to a semantic label map. Translation has various applications in the field of computer vision such facial recognition, person identification, and image dehazing. In 2014, Goodfellow proposed an image generation model based on generative adversarial networks (GANs). This algorithm uses a loss function to classify output images as authentic or fabricated while simultaneously training a generative model to minimize loss. GANs have achieved impressive image generation results using adversarial loss specifically. For example, the image-to-image translation framework Pix2Pix was developed using a GAN architecture. Pix2Pix operates by learning a conditional generative model from input-output image pairs, which is more suitable for translation tasks. In addition, U-Net has often been used as generator networks in place of conventional decoders. While Pix2Pix provides a robust framework for image translation, acquiring sufficient quantities of paired input-output training data can be challenging. In order to solve this problem, cycle-consistent adversarial networks (CycleGANs) were developed by adding an inverse mapping and cycle consistency loss to enforce the relationship between generated and input images. In addition, ResNets have been used as generators to enhance translated image quality. Pix2PixHD offers high-resolution (2 048×1 024 pixels) output using a modified multiscale generator network that includes an instance map in the training step. Although these algorithms have effectively been used for image-to-image translation and a variety of related applications, they typically adopt U-Net or ResNet generators. These single-structure networks struggle to keep high performance across multiple evaluation indicators. As such, this study presents a novel parallel stream-based generator network to increase the robustness across multiple evaluation indicators. Unlike in previous studies, this model consists of two entirely different convolutional neural network (CNN) structures. The output translated visible image of each stream is fused with a linear interpolation-based fusion method to allow for simultaneous optimization of parameters in each model.MethodThe proposed parallel generator network consists of one ResNet processing stream and one DenseNet processing stream, which are fused in parallel. The ResNet stream includes down-sampling and nine Res-Unit feature extraction networks. Each Res-Unit consists of a feedforward neural network exhibiting elementwise addition. Two convolution layers are skipped. Similarly, the DenseNet stream includes down-sampling and nine Den-Unit feature extraction networks. Every Den-Unit is composed of three convolutional layers and two concatenation layers. As a result, the Den-Units output a concatenation of deep feature maps produced in all three convolutional layers. To utilize the advantages of both ResNet and DenseNet streams, two generated images are segmented into low-and high-intensity image parts with an optimal intensity threshold. Then, a linear interpolation method is proposed to fuse the segmented output images of two generator streams in the R, G, B channel respectively. We also design an intensity threshold objective function to obtain optimal parameters in the generator raining process. In addition, to avoid overfitting during training under a small dataset, we modify the discriminator structure by including four convolution-dropout pairs and a convolution layer.ResultWe compared our model with six state-of-the-art saliency models, including CRN(cascaded refinement networks), SIMS(semi-parametric image synthesis), Pix2Pix(pixel to pixel), CycleGAN(cycle generative adversarial networks), MUNIT(multimodal unsupervised image-to-image translation) and GauGAN(group adaptive normalization generative adversarial networks), on a public dataset named "AAU(Aalborg University) RainSnow Traffic Surveillance Dataset". The experimental dataset, which was composed of 22 5-min video sequences acquired from traffic intersections in the Danish cities of Aalborg and Viborg, was used for testing purposes. This dataset was collected at seven different locations with a conventional RGB camera and a thermal camera, each with a resolution of 640×480 pixels, at 20 frames per second. The total experimental dataset consisted of 2 100 RGB-IR image pairs, and each scene was then randomly divided into training and test datasets by 80%-20%. In this study, multi-perspective evaluation results were acquired using the mean square error (MSE), structural similarity index (SSIM), gray intensity histogram correlation, and Bhattacharyya distance. The advantages of a parallel stream-based generator network were assessed by comparing the proposed parallel generator with a ResNet, DenseNet, and residual dense block (RDN)-based hybrid network. We evaluated the average MSE and SSIM values for the test data, produced using four different generators (ParaNet, ResNet, DenseNet, and RDN). The proposed method achieved an average MSE of 34.835 8, which was lower than that of ResNet, DenseNet, and hybrid RDN network. Simultaneously, the average SSIM value produced with the proposed method was 0.747 7, which was also higher than that of DenseNet, ResNet, and RDN. This result shows that the proposed parallel structure-based network produced more effective fusion results than RDB-based hybrid network structure. Moreover, comparative experiments demonstrated that parallel generator structure improves the robustness performance across multi-perspective evaluations for infrared-to-visible image translation. Compared with the six conventional methods, the MSE performance (lower is better) increased by at least 22.30%, and the SSIM (higher is better) decreased by at least 8.55%. The experimental results show that the proposed parallel generator network-based infrared-to-visible image translation deep learning model achieves high performance in terms of MSE or SSIM compared with conventional deep learning models such as CRN, SIMS, Pix2Pix, CycleGAN, MUNIT, and GauGAN.ConclusionA novel parallel stream architecture-based generator network was proposed for infrared-to-visible image translation. Unlike conventional models, the proposed parallel generator structure consists of two different network architectures: a ResNet and a DenseNet. Parallel linear combination-based fusion allowed the model to incorporate benefits from both networks simultaneously. The structure of discriminator networks used in the conditional GAN framework was also improved for training and identifying optimal ParaNet parameters. The experimental results showed that the inclusion of different networks led to increases in common assessment metrics. The MSE, SSIM, and intensity histogram similarity for the proposed parallel generator network were higher than those of existing models. In the future, this algorithm will be applied to image dehazing.关键词:modal translation;ResNet;DenseNet;linear interpolation fusion;parallel generator network81|107|5更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveShoeprints are impressions created when footwear is pressed or stamped against a surface during a human's walking, in which the characteristics of the shoe and feet are transferred to the surface. Shoeprints can be divided into two categories: 2D and 3D shoeprints. In this paper, we focus on 2D shoeprints. The shoeprint sequence is defined as the sequential shoeprints in time order, which conveys many important human characteristics, such as foot morphology, walking habits, and identity, and plays a vital role in crime investigations. Existing research has mainly focused on using one single footprint or footprint sequence to recognize a person and has achieved a promising performance. However, unlike shoeprints, footprint sequences seldom appear in most scenarios. Although a single shoeprint is not sufficient to represent a person for the influence of shoe patterns, a shoeprint sequence could be possible because it can additionally provide walking characteristics. Therefore, our goal is to try to identify a person using his/her shoeprint sequence.MethodA shoeprint sequence is a time series that 2D shoeprints from one person repeat at a stable frequency, and we propose a spatial representation named shoeprint energy map set (SEMS) to represent a shoeprint sequence and use it to identify a person in collaboration with the proposed matching score method. An SEMS consists of left/right tread energy maps, left/right step energy maps, and left/right step width energy maps. The tread energy map (TEM) is defined as the average image of all the aligned left or right shoeprint images from a shoeprint sequence, which includes LTEM and RTEM. The LTEM is constructed from left shoeprints only, and the RTEM is computed from right shoeprints only. The TEM carries information about one's personal features such as foot morphology, walking habits, and step angles. The step energy map (SEM) is computed by averaging all aligned step images of multiple walking cycles from a shoeprint sequence. The step image refers to the region cropped from a shoeprint sequence according to the bounding box that only encloses two successive shoeprints. According to which foot is ahead in one walking cycle, step images can be divided into right step images and left step images. Hence, LSEM and RSEM are produced. Compared with TEM, one's SEM carries additional step information such as step length and step width. The step width energy map (SWEM) is constructed by averaging all step width images of multiple walking cycles from a shoeprint sequence, which includes LSWEM and RSWEM. The step width image refers to the image removing the blank region representing the step length from the step image. Different from SEM, the SWEM does not carry one's step length information. The matching score between two shoeprint sequences is defined as the weighted average of the element wise similarity scores of two SEMSs. The element wise similarity score is computed by max pooling of the normalized 2D cross-correlation response map of two corresponding elements such as LTEMs. The weights are learned from the training sets by maximizing the proposed hinge loss function.ResultAccording to the imaging methods, the status of shoes and the kinds of shoe sole patterns, three datasets, namely MUSSRO-SR, MUSSRO-SS, and MUSSRS-SS, are constructed. Volunteers are young college students whose heights range from 155 cm to 185 cm and weights are between 43 kg and 85 kg. MUSSRO-SR consists of 875 shoeprint sequences from 125 volunteers. The shoeprint sequences are captured by the way that each person walks normally on the footprint sequence scanner wearing his/her daily shoes. MUSSRO-SS is composed of 595 shoeprint sequences from 85 persons, and the capturing method is that each volunteer walks normally on the footprint sequence scanner wearing new shoes of same patterns. MUSSRS-SS is constructed by scanning papers, where each of 100 persons walks normally wearing new shoes after stepping in a tray full of black ink. The proposed method is evaluated in identification mode and verification mode. To the best of our knowledge, we have not found shoeprint sequence-based person recognition methods in the literature. Therefore, our method is compared with gait measurement (GM)-based method used in forensic practice. The correct recognition rates (higher is better) in identification mode on three datasets are 100%, 97.65%, and 83%. Compared with GM, the correct recognition rates of the proposed method are increased by 57.6%, 61.18%, and 48.35%. The performances in verification mode are measured by equal error rate (ERR). The lower the EER is, the higher the performance is. The ERR on MUSSRO-SR is 0.36%. Compared with GM, it is decreased by 14.1 percentage points. ERR on MUSSRO-SS is 1.17%, which is decreased by 10.43 percentage points. The ERR on MUSSRS-SS is 6.99%, which is decreased by 10.8 percentage points. Performances on MUSSRO-SR are higher than those on other datasets for the following reasons: 1) Shoeprints left by wearing daily shoes carry unique personal wear characteristics. 2) Shoe patterns are not all the same. Performances on MUSSRS-SS are lower than others for the following reasons: 1) Shoeprints scanned from inked paper carry less personal information than those captured by specified acquisition devices. 2) The amount of ink attached to the sole decreases while a person is walking, which degrades the image quality of shoeprints. In addition, a series of ablation studies is conducted to show the effectiveness of the proposed three kinds of shoeprint energy maps and the matching score computing method.ConclusionIn this study, a shoeprint sequence is used to recognize a person, and constructing an SEMS is proposed to represent a shoeprint sequence, which carries the psychological and behavioral characteristics of humans. Experimental results show the promising, competitive performance of the proposed method. How the sole pattern or substrate material with a large difference affects the performance is not studied, and cross-pattern/substrate material shoeprint sequence recognition is our next work.Moreover, a larger volume dataset is under preparation.关键词:person recognition;shoeprint sequence recognition;shoeprint energy map set(SEMS);tread energy map(TEM);step energy map(SEM);step width energy map(SWEM)76|48|1更新时间:2024-05-07
摘要:ObjectiveShoeprints are impressions created when footwear is pressed or stamped against a surface during a human's walking, in which the characteristics of the shoe and feet are transferred to the surface. Shoeprints can be divided into two categories: 2D and 3D shoeprints. In this paper, we focus on 2D shoeprints. The shoeprint sequence is defined as the sequential shoeprints in time order, which conveys many important human characteristics, such as foot morphology, walking habits, and identity, and plays a vital role in crime investigations. Existing research has mainly focused on using one single footprint or footprint sequence to recognize a person and has achieved a promising performance. However, unlike shoeprints, footprint sequences seldom appear in most scenarios. Although a single shoeprint is not sufficient to represent a person for the influence of shoe patterns, a shoeprint sequence could be possible because it can additionally provide walking characteristics. Therefore, our goal is to try to identify a person using his/her shoeprint sequence.MethodA shoeprint sequence is a time series that 2D shoeprints from one person repeat at a stable frequency, and we propose a spatial representation named shoeprint energy map set (SEMS) to represent a shoeprint sequence and use it to identify a person in collaboration with the proposed matching score method. An SEMS consists of left/right tread energy maps, left/right step energy maps, and left/right step width energy maps. The tread energy map (TEM) is defined as the average image of all the aligned left or right shoeprint images from a shoeprint sequence, which includes LTEM and RTEM. The LTEM is constructed from left shoeprints only, and the RTEM is computed from right shoeprints only. The TEM carries information about one's personal features such as foot morphology, walking habits, and step angles. The step energy map (SEM) is computed by averaging all aligned step images of multiple walking cycles from a shoeprint sequence. The step image refers to the region cropped from a shoeprint sequence according to the bounding box that only encloses two successive shoeprints. According to which foot is ahead in one walking cycle, step images can be divided into right step images and left step images. Hence, LSEM and RSEM are produced. Compared with TEM, one's SEM carries additional step information such as step length and step width. The step width energy map (SWEM) is constructed by averaging all step width images of multiple walking cycles from a shoeprint sequence, which includes LSWEM and RSWEM. The step width image refers to the image removing the blank region representing the step length from the step image. Different from SEM, the SWEM does not carry one's step length information. The matching score between two shoeprint sequences is defined as the weighted average of the element wise similarity scores of two SEMSs. The element wise similarity score is computed by max pooling of the normalized 2D cross-correlation response map of two corresponding elements such as LTEMs. The weights are learned from the training sets by maximizing the proposed hinge loss function.ResultAccording to the imaging methods, the status of shoes and the kinds of shoe sole patterns, three datasets, namely MUSSRO-SR, MUSSRO-SS, and MUSSRS-SS, are constructed. Volunteers are young college students whose heights range from 155 cm to 185 cm and weights are between 43 kg and 85 kg. MUSSRO-SR consists of 875 shoeprint sequences from 125 volunteers. The shoeprint sequences are captured by the way that each person walks normally on the footprint sequence scanner wearing his/her daily shoes. MUSSRO-SS is composed of 595 shoeprint sequences from 85 persons, and the capturing method is that each volunteer walks normally on the footprint sequence scanner wearing new shoes of same patterns. MUSSRS-SS is constructed by scanning papers, where each of 100 persons walks normally wearing new shoes after stepping in a tray full of black ink. The proposed method is evaluated in identification mode and verification mode. To the best of our knowledge, we have not found shoeprint sequence-based person recognition methods in the literature. Therefore, our method is compared with gait measurement (GM)-based method used in forensic practice. The correct recognition rates (higher is better) in identification mode on three datasets are 100%, 97.65%, and 83%. Compared with GM, the correct recognition rates of the proposed method are increased by 57.6%, 61.18%, and 48.35%. The performances in verification mode are measured by equal error rate (ERR). The lower the EER is, the higher the performance is. The ERR on MUSSRO-SR is 0.36%. Compared with GM, it is decreased by 14.1 percentage points. ERR on MUSSRO-SS is 1.17%, which is decreased by 10.43 percentage points. The ERR on MUSSRS-SS is 6.99%, which is decreased by 10.8 percentage points. Performances on MUSSRO-SR are higher than those on other datasets for the following reasons: 1) Shoeprints left by wearing daily shoes carry unique personal wear characteristics. 2) Shoe patterns are not all the same. Performances on MUSSRS-SS are lower than others for the following reasons: 1) Shoeprints scanned from inked paper carry less personal information than those captured by specified acquisition devices. 2) The amount of ink attached to the sole decreases while a person is walking, which degrades the image quality of shoeprints. In addition, a series of ablation studies is conducted to show the effectiveness of the proposed three kinds of shoeprint energy maps and the matching score computing method.ConclusionIn this study, a shoeprint sequence is used to recognize a person, and constructing an SEMS is proposed to represent a shoeprint sequence, which carries the psychological and behavioral characteristics of humans. Experimental results show the promising, competitive performance of the proposed method. How the sole pattern or substrate material with a large difference affects the performance is not studied, and cross-pattern/substrate material shoeprint sequence recognition is our next work.Moreover, a larger volume dataset is under preparation.关键词:person recognition;shoeprint sequence recognition;shoeprint energy map set(SEMS);tread energy map(TEM);step energy map(SEM);step width energy map(SWEM)76|48|1更新时间:2024-05-07 -
 摘要:ObjectiveThe task of video object segmentation (VOS) is to track and segment a single object or multiple objects in a video sequence. VOS is an important issue in the field of computer vision. Its goal is to manually or automatically provide specific object masks on the first frame or reference frame and then segment these specific objects in the entire video sequence. VOS plays an important role in video understanding. According to the types of video object labels, VOS methods can be divided into four categories: unsupervised, interactive, semi-supervised, and weakly supervised. In this study, we deal with the problem of semi-supervised VOS; that is, the ground truth of object mask is only given in the first frame, the segmented object is arbitrary, and no further assumptions are made about the object category. Currently, semi-supervised VOS methods are mostly based on deep learning. These methods can be divided into two types: detection-based methods and matching-based or motion propagation methods. Without using temporal information, detection-based methods learn the appearance model to perform pixel-level detection and object segmentation at each frame of the video. Matching-based or motion propagation methods utilize the temporal correlation of object motion to propagate from the first frame or a given mask frame to the object mask of the subsequent frame. Matching-based methods first calculate the pixel-level matching between the features of the template frame and the current frame in the video and then directly divide each pixel of the current frame from the matching result. There are two types of methods based on motion propagation. One type of method is to introduce optical flow to train the VOS model. Another type of method learns deep object features from the object mask of the previous frame and refines the object mask of the current frame. Most existing methods mainly rely on the reference mask of the first frame (assisted by optical flow or previous mask) to estimate the object segmentation mask. However, due to the limitations of these models in modeling spatial and temporal domain, they easily fail under rapid appearance changes or occlusion. Therefore, a spatial-temporal part-based graph model is proposed to generate robust spatial-temporal object features.MethodIn this study, we propose an encode-decode-based VOS framework for spatial-temporal part-based graph. First, we use the Siamese architecture for the encode model. The input has two branches: the historical image frame branch stream and the current image frame branch stream. To simplify the model, we introduce a Markov hypothesis, that is, given the current frame and
摘要:ObjectiveThe task of video object segmentation (VOS) is to track and segment a single object or multiple objects in a video sequence. VOS is an important issue in the field of computer vision. Its goal is to manually or automatically provide specific object masks on the first frame or reference frame and then segment these specific objects in the entire video sequence. VOS plays an important role in video understanding. According to the types of video object labels, VOS methods can be divided into four categories: unsupervised, interactive, semi-supervised, and weakly supervised. In this study, we deal with the problem of semi-supervised VOS; that is, the ground truth of object mask is only given in the first frame, the segmented object is arbitrary, and no further assumptions are made about the object category. Currently, semi-supervised VOS methods are mostly based on deep learning. These methods can be divided into two types: detection-based methods and matching-based or motion propagation methods. Without using temporal information, detection-based methods learn the appearance model to perform pixel-level detection and object segmentation at each frame of the video. Matching-based or motion propagation methods utilize the temporal correlation of object motion to propagate from the first frame or a given mask frame to the object mask of the subsequent frame. Matching-based methods first calculate the pixel-level matching between the features of the template frame and the current frame in the video and then directly divide each pixel of the current frame from the matching result. There are two types of methods based on motion propagation. One type of method is to introduce optical flow to train the VOS model. Another type of method learns deep object features from the object mask of the previous frame and refines the object mask of the current frame. Most existing methods mainly rely on the reference mask of the first frame (assisted by optical flow or previous mask) to estimate the object segmentation mask. However, due to the limitations of these models in modeling spatial and temporal domain, they easily fail under rapid appearance changes or occlusion. Therefore, a spatial-temporal part-based graph model is proposed to generate robust spatial-temporal object features.MethodIn this study, we propose an encode-decode-based VOS framework for spatial-temporal part-based graph. First, we use the Siamese architecture for the encode model. The input has two branches: the historical image frame branch stream and the current image frame branch stream. To simplify the model, we introduce a Markov hypothesis, that is, given the current frame and$K$ $K$ ${\mathit{\boldsymbol{G}}_{{\rm{ST}}}}$ $K$ $t$ $K$ $t$ ${\mathit{\boldsymbol{G}}_{{\rm{S}}}}$ ${\mathit{\boldsymbol{G}}_{{\rm{ST}}}}$ $K$ 关键词:video object segmentation(VOS);graph convolutional network;spatial-temporal features;attention mechanism;deep neural network77|152|2更新时间:2024-05-07 -
 摘要:ObjectiveSaliency detection is a fundamental technology in computer vision and image processing,which aims to identify the most visually distinctive objects or regions in an image. As a preprocessing step,salient object detection plays a critical role in many computer vision applications,including visual tracking,scene classification,image retrieval,and content-based image compression. While numerous salient object detection methods have been presented,most of them are designed for RGB images only or depth RGB (RGB-D) images. However,these methods remain challenging in some complex scenarios. RGB methods may fail to distinguish salient objects from backgrounds when exposed to similar foreground and background or low-contrast conditions. RGB-D methods also suffer from challenging scenarios characterized by low-light conditions and variations in illumination. Considering that thermal infrared images are invariant to illumination conditions,we propose a multi-path collaborative salient object detection method in this study,which is designed to improve the performance of saliency detection by using the multi-mode feature information of RGB and thermal images.MethodIn this study,we design a novel end-to-end deep neural network for thermal RGB (RGB-T) salient object detection,which consists of an encoder network and a decoder network,including the feature enhance module,the pyramid pooling module,the channel attention module,and the l1-norm fusion strategy. First,the main body of the model contains two backbone networks for extracting the feature representations of RGB and thermal images,respectively. Then,three decoding branches are used to predict the saliency maps in a coordinated and complementary manner for extracted RGB feature,thermal feature,and fusion feature of both,respectively. The two backbone network streams have the same structure,which is based on Visual Geometry Group 19-layer (VGG-19) net. In order to make a better fit with saliency detection task,we only maintain five convolutional blocks of VGG-19 net and discard the last pooling and fully connected layers to preserve more spatial information from the input image. Second,the feature enhance module is used to fully extract and fuse multi-modal complementary cues from RGB and thermal streams. The modified pyramid pooling module is employed to capture global semantic information from deep-level features,which is used to locate salient objects. Finally,in the decoding process,the channel attention mechanism is designed to distinguish the semantic differences between the different channels,thereby improving the decoder's ability to separate salient objects from backgrounds. The entire model is trained in an end-to-end manner. Our training set consists of 900 aligned RGB-T image pairs that are randomly selected from each subset of the VT1000 dataset. To prevent overfitting,we augment the training set by flipping and rotating operations. Our method is implemented with PyTorch toolbox and trained on a PC with GTX 1080Ti GPU and 11 GB of memory. The input images are uniformly resized to 256×256 pixels. The momentum,weight decay,and learning rate are set as 0.9,0.000 5,and 1E-9,respectively. During training,the softmax entropy loss is used to converge the entire network.ResultWe compare our model with four state-of-the-art saliency models,including two RGB-based methods and two RGB-D-based methods,on two public datasets,namely,VT821 and VT1000. The quantitative evaluation metrics contain F-measure,mean absolute error (MAE),and precision-recall(PR) curves,and we also provide several saliency maps of each method for visual comparison. The experimental results demonstrate that our model outperforms other methods,and the saliency maps have more refined shapes under challenging conditions,such as poor illumination and low contrast. Compared with the other four methods in VT821,our method obtains the best results on maximum F-measure and MAE. The maximum F-measure (higher is better) increases by 0.26%,and the MAE (less is better) decreases by 0.17% than the second-ranked method. Compared with the other four methods in VT1000,our model also achieves the best result on maximum F-measure,which reaches 88.05% and increases by 0.46% compared with the second-ranked method. However,the MAE is 3.22%,which increases by 0.09% and is slightly poorer than the first-ranked method.ConclusionWe propose a CNN-based method for RGB-T salient object detection. To the best of our knowledge,existing saliency detection methods are mostly based on RGB or RGB-D images,so it is very meaningful to explore the application of CNN for RGB-T salient object detection. The experimental results on two public RGB-T datasets demonstrate that the method proposed in this study performs better than the state-of-the-art methods,especially for challenging scenes with poor illumination,complex background,or low contrast,which proves that it is effective to improve the performance by fusing multi-modal information from RGB and thermal images. However,public datasets for RGB-T salient detection are lacking,which is very important for the performance of deep learning network. At the same time,detection speed is a key measurement in the preprocessing step of other computer vision tasks. Thus,in the future work,we will collect more high-quality datasets for RGB-T salient detection and design more light-weight models to increase the speed of detection.关键词:RGB-T salient object detection;multi-modal images fusion;multi-path collaborative prediction;channel attention mechanism;pyramid pooling module(PPM)116|1161|5更新时间:2024-05-07
摘要:ObjectiveSaliency detection is a fundamental technology in computer vision and image processing,which aims to identify the most visually distinctive objects or regions in an image. As a preprocessing step,salient object detection plays a critical role in many computer vision applications,including visual tracking,scene classification,image retrieval,and content-based image compression. While numerous salient object detection methods have been presented,most of them are designed for RGB images only or depth RGB (RGB-D) images. However,these methods remain challenging in some complex scenarios. RGB methods may fail to distinguish salient objects from backgrounds when exposed to similar foreground and background or low-contrast conditions. RGB-D methods also suffer from challenging scenarios characterized by low-light conditions and variations in illumination. Considering that thermal infrared images are invariant to illumination conditions,we propose a multi-path collaborative salient object detection method in this study,which is designed to improve the performance of saliency detection by using the multi-mode feature information of RGB and thermal images.MethodIn this study,we design a novel end-to-end deep neural network for thermal RGB (RGB-T) salient object detection,which consists of an encoder network and a decoder network,including the feature enhance module,the pyramid pooling module,the channel attention module,and the l1-norm fusion strategy. First,the main body of the model contains two backbone networks for extracting the feature representations of RGB and thermal images,respectively. Then,three decoding branches are used to predict the saliency maps in a coordinated and complementary manner for extracted RGB feature,thermal feature,and fusion feature of both,respectively. The two backbone network streams have the same structure,which is based on Visual Geometry Group 19-layer (VGG-19) net. In order to make a better fit with saliency detection task,we only maintain five convolutional blocks of VGG-19 net and discard the last pooling and fully connected layers to preserve more spatial information from the input image. Second,the feature enhance module is used to fully extract and fuse multi-modal complementary cues from RGB and thermal streams. The modified pyramid pooling module is employed to capture global semantic information from deep-level features,which is used to locate salient objects. Finally,in the decoding process,the channel attention mechanism is designed to distinguish the semantic differences between the different channels,thereby improving the decoder's ability to separate salient objects from backgrounds. The entire model is trained in an end-to-end manner. Our training set consists of 900 aligned RGB-T image pairs that are randomly selected from each subset of the VT1000 dataset. To prevent overfitting,we augment the training set by flipping and rotating operations. Our method is implemented with PyTorch toolbox and trained on a PC with GTX 1080Ti GPU and 11 GB of memory. The input images are uniformly resized to 256×256 pixels. The momentum,weight decay,and learning rate are set as 0.9,0.000 5,and 1E-9,respectively. During training,the softmax entropy loss is used to converge the entire network.ResultWe compare our model with four state-of-the-art saliency models,including two RGB-based methods and two RGB-D-based methods,on two public datasets,namely,VT821 and VT1000. The quantitative evaluation metrics contain F-measure,mean absolute error (MAE),and precision-recall(PR) curves,and we also provide several saliency maps of each method for visual comparison. The experimental results demonstrate that our model outperforms other methods,and the saliency maps have more refined shapes under challenging conditions,such as poor illumination and low contrast. Compared with the other four methods in VT821,our method obtains the best results on maximum F-measure and MAE. The maximum F-measure (higher is better) increases by 0.26%,and the MAE (less is better) decreases by 0.17% than the second-ranked method. Compared with the other four methods in VT1000,our model also achieves the best result on maximum F-measure,which reaches 88.05% and increases by 0.46% compared with the second-ranked method. However,the MAE is 3.22%,which increases by 0.09% and is slightly poorer than the first-ranked method.ConclusionWe propose a CNN-based method for RGB-T salient object detection. To the best of our knowledge,existing saliency detection methods are mostly based on RGB or RGB-D images,so it is very meaningful to explore the application of CNN for RGB-T salient object detection. The experimental results on two public RGB-T datasets demonstrate that the method proposed in this study performs better than the state-of-the-art methods,especially for challenging scenes with poor illumination,complex background,or low contrast,which proves that it is effective to improve the performance by fusing multi-modal information from RGB and thermal images. However,public datasets for RGB-T salient detection are lacking,which is very important for the performance of deep learning network. At the same time,detection speed is a key measurement in the preprocessing step of other computer vision tasks. Thus,in the future work,we will collect more high-quality datasets for RGB-T salient detection and design more light-weight models to increase the speed of detection.关键词:RGB-T salient object detection;multi-modal images fusion;multi-path collaborative prediction;channel attention mechanism;pyramid pooling module(PPM)116|1161|5更新时间:2024-05-07 -
 摘要:ObjectivePedestrian detection is a research hotspot in the field of image processing and computer vision, and it is widely used in fields such as automatic driving, intelligent monitoring, and intelligent robots. The traditional pedestrian detection method based on background modeling and machine learning can obtain a better pedestrian detection rate under certain conditions, but it cannot meet the requirements of practical applications. As deep convolutional neural networks have made great progress in general object detection, more and more scholars have improved the general object detection framework and introduced it to pedestrian detection. Compared with traditional methods, the accuracy and robustness of pedestrian detection based on deep learning methods have been improved significantly, and many breakthroughs have been made. However, the detection effect for small-scale pedestrians is not ideal. This is mainly due to a series of convolution pool operations of the convolutional neural network, which makes the feature map of small-scale pedestrians smaller, have a lower resolution, and lose serious information, leading to detection failure. To effectively solve the problem of low detection accuracy of traditional pedestrian detection algorithms in the context of low resolution and small pedestrian size, an object detection algorithm called region-based fully convolutional network (R-FCN) is introduced into pedestrian detection. This study proposes an improved small-scale pedestrian detection algorithm for R-FCN.MethodThe method in this study inherits the advantage of R-FCN, which employs the region proposal network to generate candidate regions of interest and position-sensitive score maps to classify and locate targets. At the same time, because the new residual network (ResNet-101) has less calculation, few parameters, and good accuracy, this study uses the ResNet-101 network as the basic network. Compared with the original R-FCN, this study mainly has the following improvements: Considering that the pedestrians in the Caltech dataset have multiple scale transformations, all 3×3 conventional convolutional layers of the Conv5 stage of ResNet-101 are first expanded into deformable convolutional layers. Therefore, the effective step size of the convolution block can be reduced from 32 pixels to 16 pixels, the expansion rate can be changed from 1 to 2, the pad is set to 2, and the step size is 1. Deformable convolution can increase the generalization ability of the model, expand the receptive field of the feature map, and improve the accuracy of R-FCN feature extraction. Then, another position-sensitive score map is added in the training phase. Because the feature distinguishing ability of Conv1-3 stages in ResNet-101 is weaker than that of Conv4 stage, a new layer of position-sensitive score map is added after the Conv4 layer to detect multi-scale pedestrians in parallel with the original position-sensitive score map after the Conv5 layer. Finally, the non-maximum suppression (NMS) method often leads to missed detection of neighbor pedestrians in crowed scenes. Therefore, this study improves the traditional NMS algorithm and proposes the NMS algorithm for bootstrap strategy to solve the problem of pedestrian misdetection.ResultThe experiment is evaluation on the benchmark dataset Caltech. The experimental results show that the improved R-FCN algorithm improves the detection accuracy by 3.29% and 2.78% compared with the representative single shot multiBox detector (SSD) algorithm of the single-stage detector and the faster region convolutional neural netowrk(Faster R-CNN) algorithm of the two-stage detector, respectively. Under the same ResNet-101 basic network, the detection accuracy is 12.10% higher than the original R-FCN algorithm. Online hard example mining (OHEM) is necessary for Caltech, which has achieved a 7.38% improvement because the Caltech dataset contains a large number of confounding instances in complex backgrounds, allowing the full use of OHEM. In the Conv5 stage of the ResNet-101 network, a deformable convolutional layer is used, which is 0.89% higher than the ordinary convolutional layer. Using the multi-path detection structure can increase the detection accuracy by 2.50%. The bootstrap strategy is used to correct the non-maximum suppression, which is 1.67% better than the traditional NMS algorithm.ConclusionThe improved R-FCN model proposed in this study makes the detection accuracy of small-sized pedestrians more accurate and improves the phenomenon of pedestrian false detection in the case of low resolution. Compared with the original R-FCN model, the improved R-FCN model has a better ability to balance the accuracy rate and recall rate of pedestrian detection and has a greater recall rate when ensuring the accuracy rate. However, the accuracy of pedestrian detection in complex scenes is slightly low. Thus, future research will focus on improving the accuracy of pedestrian detection in complex scenes.关键词:pedestrian detection;region-based fully convolutional network(R-FCN);deformable convolution;multipath;non-maximum suppression(NMS);Caltech dataset147|157|3更新时间:2024-05-07
摘要:ObjectivePedestrian detection is a research hotspot in the field of image processing and computer vision, and it is widely used in fields such as automatic driving, intelligent monitoring, and intelligent robots. The traditional pedestrian detection method based on background modeling and machine learning can obtain a better pedestrian detection rate under certain conditions, but it cannot meet the requirements of practical applications. As deep convolutional neural networks have made great progress in general object detection, more and more scholars have improved the general object detection framework and introduced it to pedestrian detection. Compared with traditional methods, the accuracy and robustness of pedestrian detection based on deep learning methods have been improved significantly, and many breakthroughs have been made. However, the detection effect for small-scale pedestrians is not ideal. This is mainly due to a series of convolution pool operations of the convolutional neural network, which makes the feature map of small-scale pedestrians smaller, have a lower resolution, and lose serious information, leading to detection failure. To effectively solve the problem of low detection accuracy of traditional pedestrian detection algorithms in the context of low resolution and small pedestrian size, an object detection algorithm called region-based fully convolutional network (R-FCN) is introduced into pedestrian detection. This study proposes an improved small-scale pedestrian detection algorithm for R-FCN.MethodThe method in this study inherits the advantage of R-FCN, which employs the region proposal network to generate candidate regions of interest and position-sensitive score maps to classify and locate targets. At the same time, because the new residual network (ResNet-101) has less calculation, few parameters, and good accuracy, this study uses the ResNet-101 network as the basic network. Compared with the original R-FCN, this study mainly has the following improvements: Considering that the pedestrians in the Caltech dataset have multiple scale transformations, all 3×3 conventional convolutional layers of the Conv5 stage of ResNet-101 are first expanded into deformable convolutional layers. Therefore, the effective step size of the convolution block can be reduced from 32 pixels to 16 pixels, the expansion rate can be changed from 1 to 2, the pad is set to 2, and the step size is 1. Deformable convolution can increase the generalization ability of the model, expand the receptive field of the feature map, and improve the accuracy of R-FCN feature extraction. Then, another position-sensitive score map is added in the training phase. Because the feature distinguishing ability of Conv1-3 stages in ResNet-101 is weaker than that of Conv4 stage, a new layer of position-sensitive score map is added after the Conv4 layer to detect multi-scale pedestrians in parallel with the original position-sensitive score map after the Conv5 layer. Finally, the non-maximum suppression (NMS) method often leads to missed detection of neighbor pedestrians in crowed scenes. Therefore, this study improves the traditional NMS algorithm and proposes the NMS algorithm for bootstrap strategy to solve the problem of pedestrian misdetection.ResultThe experiment is evaluation on the benchmark dataset Caltech. The experimental results show that the improved R-FCN algorithm improves the detection accuracy by 3.29% and 2.78% compared with the representative single shot multiBox detector (SSD) algorithm of the single-stage detector and the faster region convolutional neural netowrk(Faster R-CNN) algorithm of the two-stage detector, respectively. Under the same ResNet-101 basic network, the detection accuracy is 12.10% higher than the original R-FCN algorithm. Online hard example mining (OHEM) is necessary for Caltech, which has achieved a 7.38% improvement because the Caltech dataset contains a large number of confounding instances in complex backgrounds, allowing the full use of OHEM. In the Conv5 stage of the ResNet-101 network, a deformable convolutional layer is used, which is 0.89% higher than the ordinary convolutional layer. Using the multi-path detection structure can increase the detection accuracy by 2.50%. The bootstrap strategy is used to correct the non-maximum suppression, which is 1.67% better than the traditional NMS algorithm.ConclusionThe improved R-FCN model proposed in this study makes the detection accuracy of small-sized pedestrians more accurate and improves the phenomenon of pedestrian false detection in the case of low resolution. Compared with the original R-FCN model, the improved R-FCN model has a better ability to balance the accuracy rate and recall rate of pedestrian detection and has a greater recall rate when ensuring the accuracy rate. However, the accuracy of pedestrian detection in complex scenes is slightly low. Thus, future research will focus on improving the accuracy of pedestrian detection in complex scenes.关键词:pedestrian detection;region-based fully convolutional network(R-FCN);deformable convolution;multipath;non-maximum suppression(NMS);Caltech dataset147|157|3更新时间:2024-05-07 -
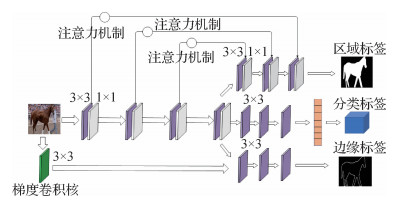 摘要:ObjectiveWith the rapid development of internet technology, digital image processing techniques have become more and more developed in recent years. Nowadays, ordinary users can easily use various software to edit digital images. Although these falsified images can bring us some special visual or entertainment effects, they can also be maliciously tampered. These maliciously tampered images will have a huge impact on litigation evidence collection, criminal investigation, national political and military affairs, etc. Therefore, image forensics research has very important significance. Although the tampered images can be edited in various ways, this study focuses on the detection of image splicing tamper operation. The splicing process of digital images is to copy a small region of a real image and insert it into some region of another real image, so as to tamper the original image content. In the process of inserting the spliced object, some post-processing operations, such as blurring, smoothing, retouching, and blending, may also be used to hide the tampering traces, making the tampered image look more realistic and natural. To solve the problems of state-of-the-art image splicing tamper detection methods, such as low classification accuracy and coarse localizations of the spliced tamper regions, a convolutional neural network for image splicing tamper detection is designed under the guidance of the inconsistency around the tamper edges and the tamper regions to pay more attention on tamper regions and tamper edges.MethodFirst, in the image tampering process, the tamper edges of the spliced objects leave tampering traces, which are important cues for image splicing tamper detection. Therefore, a tamper edge extraction network branch is designed in this study. By learning the inconsistency on both sides of the tamper edges of spliced objects, the tamper edges of spliced tamper regions will be extracted. Considering that it is difficult to make the network converge faster and better due to relatively few tamper edge pixels of the spliced objects, this study expands 6 pixels inward and outward along the tamper edges of the spliced objects, which forms a "doughnut" with a bold tamper edge. It drives the tamper edge extraction network branch to focus on the edge contour of the tampered object by learning the inconsistencies on both sides of the tamper edges. Second, the information contained in each image is different due to factors (e.g., camera equipment, lighting conditions, noising environment) during the image capturing process, which can be helpful in discriminating the tamper regions from their surroundings (i.e., the spliced objects copied from one image to another). Therefore, this study designs a tamper region localization network branch to learn the inconsistency between the spliced region and other regions. We also introduce the attention mechanism into this network branch for the first time to focus on the learning of tamper regions. Finally, a two-category classification network branch for authenticity discrimination is designed, in which 0 denotes untampered images and 1 denotes tampered images. This network branch can quickly and effectively determine whether the input image is a tampered image and help users to jointly determine the final tamper detection result together with the results obtained by the above two network branches. Model training and testing are carried out on the Keras platform with a NVIDIA GeForce GTX 1080Ti GPU card. The stochastic gradient descent method is used to train our model, and the related parameters are batch size of 16, momentum of 0.95, and attenuation rate of 0.000 5. The learning rate is initialized with 0.001 and updated every 6 250 iterations with an update coefficient of 0.99. The total number of iterations is 312 500.ResultOur model is compared with fourstate-of-the-art methods (i.e., multi-task fully convolutional network, fully convolutional network, manipulation tracing network, and MobileNets) on four public datasets, namely, Dresden, a raw images dataset for digital image forensics (RAISE), information forensics and security technical committee (IFS-TC), and common objects in context (COCO) datasets. The classification accuracy of authenticity discrimination of our model increases by 8.3% on the Dresden dataset, 4.6% on the COCO dataset, and 1.0% on the RAISE and IFS-TC datasets. In terms of the localization accuracy of tamper regions, the F1 score and intersection over union(IOU) index are improved by 9.4% and 8.6%, respectively, compared with the existing methods. The network model designed in this study shows excellent generalization ability for images with different resolutions. Our method can not only locate the tamper region and extract the tamper edge well, but also improve the classification accuracy of image authenticity discrimination.ConclusionThe image splicing tamper detection network proposed in this study consists of three network branches, namely, authenticity discrimination classification, tamper region localization, and tamper edge extraction. The three sub-tasks are fused together to promote each other, which greatly improves the performance of each network branch. The proposed method surpasses most existing methods in image splicing tamper detection, and its main performance advantages are as follows: 1) compared with existing methods, the proposed algorithm can more effectively judge whether the images have been tampered; 2) the proposed algorithm is more accurate than existing methods in locating tamper regions. This study expands the ideas and methods for the research work on digital image forensics techniques.关键词:image splicing tamper detection;convolutional neural network(CNN);tamper region localization;tamper edge extraction;authenticity discrimination classification188|162|5更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of internet technology, digital image processing techniques have become more and more developed in recent years. Nowadays, ordinary users can easily use various software to edit digital images. Although these falsified images can bring us some special visual or entertainment effects, they can also be maliciously tampered. These maliciously tampered images will have a huge impact on litigation evidence collection, criminal investigation, national political and military affairs, etc. Therefore, image forensics research has very important significance. Although the tampered images can be edited in various ways, this study focuses on the detection of image splicing tamper operation. The splicing process of digital images is to copy a small region of a real image and insert it into some region of another real image, so as to tamper the original image content. In the process of inserting the spliced object, some post-processing operations, such as blurring, smoothing, retouching, and blending, may also be used to hide the tampering traces, making the tampered image look more realistic and natural. To solve the problems of state-of-the-art image splicing tamper detection methods, such as low classification accuracy and coarse localizations of the spliced tamper regions, a convolutional neural network for image splicing tamper detection is designed under the guidance of the inconsistency around the tamper edges and the tamper regions to pay more attention on tamper regions and tamper edges.MethodFirst, in the image tampering process, the tamper edges of the spliced objects leave tampering traces, which are important cues for image splicing tamper detection. Therefore, a tamper edge extraction network branch is designed in this study. By learning the inconsistency on both sides of the tamper edges of spliced objects, the tamper edges of spliced tamper regions will be extracted. Considering that it is difficult to make the network converge faster and better due to relatively few tamper edge pixels of the spliced objects, this study expands 6 pixels inward and outward along the tamper edges of the spliced objects, which forms a "doughnut" with a bold tamper edge. It drives the tamper edge extraction network branch to focus on the edge contour of the tampered object by learning the inconsistencies on both sides of the tamper edges. Second, the information contained in each image is different due to factors (e.g., camera equipment, lighting conditions, noising environment) during the image capturing process, which can be helpful in discriminating the tamper regions from their surroundings (i.e., the spliced objects copied from one image to another). Therefore, this study designs a tamper region localization network branch to learn the inconsistency between the spliced region and other regions. We also introduce the attention mechanism into this network branch for the first time to focus on the learning of tamper regions. Finally, a two-category classification network branch for authenticity discrimination is designed, in which 0 denotes untampered images and 1 denotes tampered images. This network branch can quickly and effectively determine whether the input image is a tampered image and help users to jointly determine the final tamper detection result together with the results obtained by the above two network branches. Model training and testing are carried out on the Keras platform with a NVIDIA GeForce GTX 1080Ti GPU card. The stochastic gradient descent method is used to train our model, and the related parameters are batch size of 16, momentum of 0.95, and attenuation rate of 0.000 5. The learning rate is initialized with 0.001 and updated every 6 250 iterations with an update coefficient of 0.99. The total number of iterations is 312 500.ResultOur model is compared with fourstate-of-the-art methods (i.e., multi-task fully convolutional network, fully convolutional network, manipulation tracing network, and MobileNets) on four public datasets, namely, Dresden, a raw images dataset for digital image forensics (RAISE), information forensics and security technical committee (IFS-TC), and common objects in context (COCO) datasets. The classification accuracy of authenticity discrimination of our model increases by 8.3% on the Dresden dataset, 4.6% on the COCO dataset, and 1.0% on the RAISE and IFS-TC datasets. In terms of the localization accuracy of tamper regions, the F1 score and intersection over union(IOU) index are improved by 9.4% and 8.6%, respectively, compared with the existing methods. The network model designed in this study shows excellent generalization ability for images with different resolutions. Our method can not only locate the tamper region and extract the tamper edge well, but also improve the classification accuracy of image authenticity discrimination.ConclusionThe image splicing tamper detection network proposed in this study consists of three network branches, namely, authenticity discrimination classification, tamper region localization, and tamper edge extraction. The three sub-tasks are fused together to promote each other, which greatly improves the performance of each network branch. The proposed method surpasses most existing methods in image splicing tamper detection, and its main performance advantages are as follows: 1) compared with existing methods, the proposed algorithm can more effectively judge whether the images have been tampered; 2) the proposed algorithm is more accurate than existing methods in locating tamper regions. This study expands the ideas and methods for the research work on digital image forensics techniques.关键词:image splicing tamper detection;convolutional neural network(CNN);tamper region localization;tamper edge extraction;authenticity discrimination classification188|162|5更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveInfrared (IR) images are based on the thermal radiation of the scene, and they are not susceptible to illumination and weather conditions. IR images are insensitive to the change of the brightness of the scene, and they usually have poor image quality and lack detailed information of the scene. By contrast, visible (VIS) images are sensitive to the optical information of the scene and contain a large amount of texture details. However, in low light and nighttime conditions, VIS images cannot capture the target clearly. IR and VIS images can provide complementary and redundancy information of a scene in the fusion image. Thus, image fusion is an important technique for image processing and computer vision applications such as feature extraction and target recognition. Multi-scale decomposition (MSD) has the advantage of extracting features at different scales, which is one of the most widely used image fusion methods. Many traditional multi-scale transform method signore the different image features of IR and VIS images. Therefore, traditional IR and VIS image fusion methods always lead to problems of missing the edge detail information and suppressing less halo. In this study, an IR and VIS image fusion algorithm based on anisotropic guide filter and phase congruency (PC) is proposed, which preserves edge details and suppresses artifacts effectively.MethodThe proposed scheme can not only preserve the details of source IR and VIS images, but also suppress the halo and artifacts effectively by combining the advantages of edge-preserving filter and PC. First, the input images are decomposed into a base layer and a series of detail layers. The base layer contains large scale variations in intensity, and the detail layers capture enough texture details by anisotropic guided filtering. Second, the saliency maps of the source images are calculated on the PC and Gaussian filter, and then, the binary weight maps are optimized by anisotropic guided filters of different scales, which can reduce noise and suppress halo. Finally, the fusion result is reconstructed by the base and detail layers by reconstruction rules. The main contributions of the proposed algorithm are as follows: 1) An edge-preserving filter based on MSD is employed to extract the image features at different scales. The anisotropic guided filtering weights are optimized based on the local neighborhood variances to achieve strong anisotropic filtering. Thus, this operation cannot only extract the image's texture details and preserve its edge features, but also prevent the halo phenomenon at the edges. 2) A novel weight optimization based on space consistency is proposed, which can reduce the noise and make the surface smooth. The anisotropic guided filtering is used to optimize the weighting maps of each layer, which is obtained by multi-scale edge-preserving decomposition. Compared with the original guide filter, the anisotropic guided filtering addresses the disadvantages of detail halos and the handling of inconsistent structures existing in previous variants of the guided filter. The experimental results show that the proposed scheme cannot only make the detail information more prominent, but also suppress the artifacts effectively. 3) A PC operator is used instead of the Laplace operator to generate the saliency maps from source images because the PC operator is insensitive to variations of contrast and brightness.ResultWe test our method on the TNO image fusion dataset, which contains different military-relevant scenarios that are registered with different multiband camera systems (including Athena, DHV, FEL, and TRICLOBS). Fifteen typical image pairs are chosen to assess the performance of the proposed method and four classical methods. Four representative fusion methods, namely, convolutional neural network (CNN)-based method, dual tree complex wavelet transform (DTCWT)-based method, weighted average fusion algorithm based on guided filtering (GFF), and methods based on anisotropic diffusion and anisotropic diffusion (ADF), are used in this study. CNN is a representative of deep learning (DL)-based methods. DTCWT is a representative of wavelet-based methods. GFF and ADF are representative of edge-preserving filter-based methods. The experimental results demonstrate that the proposed method could effectively extract the target feature information and preserve the background information from source images. The subjective evaluation results show that the proposed method is superior to the other four methods in detail, background, and object representation. The proposed method shows clear advantages not only in subjective evaluation, but also in several objective evaluation metrics. In objective evaluation, four indices are selected, including mutual information (MI), degree of edge information (QAB/F), entropy (EN), and gradient-based mutual information (FMI_gradient).The objective evaluation results show that the proposed algorithm shows obvious advantages on the four metrics. The proposed algorithm has the largest MI and QAB/F values compared with the other four algorithms. This means that the proposed algorithm extracts much more edge and detail information than the other methods. In addition, our method has the best performance on EN and FMI_gradient values.ConclusionWe proposed a new IR and VIS image fusion scheme by combining multi-scale edge-preserving decomposition with anisotropic guided filtering. The multi-scale edge-preserving decomposition can effectively extract the meaningful information from source images, and the anisotropic guided filtering can eliminate artifacts and detail "halos". In addition, to improve the performance of our method, we employ PC operator to obtain saliency maps. The proposed fusion algorithm can effectively suppress halo in fused results and can better retain the edge details and background information of the source image. The experimental results show that the proposed algorithm is more effective in preserving details that exist in VIS images and highlighting target information that exists in IR images compared with the other algorithms. The proposed method can be further improved by combining it with DL-based methods.关键词:image fusion;multi-scale decomposition(MSD);edge-preserving filter;anisotropic guided filtering(AnisGF);phase congruency(PC)87|44|11更新时间:2024-05-07
摘要:ObjectiveInfrared (IR) images are based on the thermal radiation of the scene, and they are not susceptible to illumination and weather conditions. IR images are insensitive to the change of the brightness of the scene, and they usually have poor image quality and lack detailed information of the scene. By contrast, visible (VIS) images are sensitive to the optical information of the scene and contain a large amount of texture details. However, in low light and nighttime conditions, VIS images cannot capture the target clearly. IR and VIS images can provide complementary and redundancy information of a scene in the fusion image. Thus, image fusion is an important technique for image processing and computer vision applications such as feature extraction and target recognition. Multi-scale decomposition (MSD) has the advantage of extracting features at different scales, which is one of the most widely used image fusion methods. Many traditional multi-scale transform method signore the different image features of IR and VIS images. Therefore, traditional IR and VIS image fusion methods always lead to problems of missing the edge detail information and suppressing less halo. In this study, an IR and VIS image fusion algorithm based on anisotropic guide filter and phase congruency (PC) is proposed, which preserves edge details and suppresses artifacts effectively.MethodThe proposed scheme can not only preserve the details of source IR and VIS images, but also suppress the halo and artifacts effectively by combining the advantages of edge-preserving filter and PC. First, the input images are decomposed into a base layer and a series of detail layers. The base layer contains large scale variations in intensity, and the detail layers capture enough texture details by anisotropic guided filtering. Second, the saliency maps of the source images are calculated on the PC and Gaussian filter, and then, the binary weight maps are optimized by anisotropic guided filters of different scales, which can reduce noise and suppress halo. Finally, the fusion result is reconstructed by the base and detail layers by reconstruction rules. The main contributions of the proposed algorithm are as follows: 1) An edge-preserving filter based on MSD is employed to extract the image features at different scales. The anisotropic guided filtering weights are optimized based on the local neighborhood variances to achieve strong anisotropic filtering. Thus, this operation cannot only extract the image's texture details and preserve its edge features, but also prevent the halo phenomenon at the edges. 2) A novel weight optimization based on space consistency is proposed, which can reduce the noise and make the surface smooth. The anisotropic guided filtering is used to optimize the weighting maps of each layer, which is obtained by multi-scale edge-preserving decomposition. Compared with the original guide filter, the anisotropic guided filtering addresses the disadvantages of detail halos and the handling of inconsistent structures existing in previous variants of the guided filter. The experimental results show that the proposed scheme cannot only make the detail information more prominent, but also suppress the artifacts effectively. 3) A PC operator is used instead of the Laplace operator to generate the saliency maps from source images because the PC operator is insensitive to variations of contrast and brightness.ResultWe test our method on the TNO image fusion dataset, which contains different military-relevant scenarios that are registered with different multiband camera systems (including Athena, DHV, FEL, and TRICLOBS). Fifteen typical image pairs are chosen to assess the performance of the proposed method and four classical methods. Four representative fusion methods, namely, convolutional neural network (CNN)-based method, dual tree complex wavelet transform (DTCWT)-based method, weighted average fusion algorithm based on guided filtering (GFF), and methods based on anisotropic diffusion and anisotropic diffusion (ADF), are used in this study. CNN is a representative of deep learning (DL)-based methods. DTCWT is a representative of wavelet-based methods. GFF and ADF are representative of edge-preserving filter-based methods. The experimental results demonstrate that the proposed method could effectively extract the target feature information and preserve the background information from source images. The subjective evaluation results show that the proposed method is superior to the other four methods in detail, background, and object representation. The proposed method shows clear advantages not only in subjective evaluation, but also in several objective evaluation metrics. In objective evaluation, four indices are selected, including mutual information (MI), degree of edge information (QAB/F), entropy (EN), and gradient-based mutual information (FMI_gradient).The objective evaluation results show that the proposed algorithm shows obvious advantages on the four metrics. The proposed algorithm has the largest MI and QAB/F values compared with the other four algorithms. This means that the proposed algorithm extracts much more edge and detail information than the other methods. In addition, our method has the best performance on EN and FMI_gradient values.ConclusionWe proposed a new IR and VIS image fusion scheme by combining multi-scale edge-preserving decomposition with anisotropic guided filtering. The multi-scale edge-preserving decomposition can effectively extract the meaningful information from source images, and the anisotropic guided filtering can eliminate artifacts and detail "halos". In addition, to improve the performance of our method, we employ PC operator to obtain saliency maps. The proposed fusion algorithm can effectively suppress halo in fused results and can better retain the edge details and background information of the source image. The experimental results show that the proposed algorithm is more effective in preserving details that exist in VIS images and highlighting target information that exists in IR images compared with the other algorithms. The proposed method can be further improved by combining it with DL-based methods.关键词:image fusion;multi-scale decomposition(MSD);edge-preserving filter;anisotropic guided filtering(AnisGF);phase congruency(PC)87|44|11更新时间:2024-05-07 -
 摘要:ObjectiveImage fusion is the process of using multiple image information of the same scene according to certain rules to obtain better fusion image. The fusion image contains the outstanding features of the image to be fused, which can improve the utilization of image information and provide more accurate help for later decision-making based on the image. Multi-scale analysis method, sparse representation method, and saliency method are three kinds of image representation methods that can be used in image fusion. Multi-scale analysis method is an active field in image fusion, but only the appropriate transformation method can improve the performance of the fusion image. The sparse representation method has good performance for image representation, but multi-value representation of the image easily leads to the loss of details. The significance method is unique due to its ability to capture the outstanding target in the image. However, visual saliency is a subjective image description index, and the proper construction of saliency map is an urgent problem to be solved. To address the problem of insufficient information and fuzzy edge details in image fusion, an image fusion method of convolution sparsity and detail saliency map analysis is proposed, which combines the advantages of multi-scale analysis, sparse representation method, and saliency method and at the same time avoids their disadvantages as much as possible.MethodFirst, to address the insufficient image information after fusion, a multi-directional method is proposed to construct the adaptive training sample set. Then through dictionary training, a more abundant dictionary filter bank suitable for the image to be fused is obtained. Second, low-and high-frequency subgraphs are obtained by multi-scale analysis. The low-frequency subgraph contains a lot of basic information of source image, and it is represented by convolution sparsity using the trained adaptive dictionary filter bank. In this way, the sparse matrix of global single-value representation is obtained. The activity of each pixel in the image can be represented by the L1 norm of this multidimensional sparse representation coefficient matrix. The more prominent its feature is, the more active the image is, so the weight can be measured by measuring the activity of the image to be fused. Through weight analysis, a weighted fusion rule is constructed to obtain the low-frequency subgraph with more abundant information. At the same time, to solve the problem of fuzzy edge details in the process of fusion, the fusion of high-frequency subgraphs is processed as follows. Because the high-frequency subgraph reflects the singularity of the image, a high-frequency detail saliency graph is constructed to highlight this feature. This detail saliency map is constructed by cross reconstruction of high-and low-frequency subgraphs. According to the distance difference between the high-frequency subgraph and the detail saliency map, similarity analysis is carried out, and a high-frequency fusion rule is established to obtain the high-frequency subgraph with more prominent edge details. Finally, the final fusion image is obtained by inverting the high-frequency and low-frequency subgraphs after fusion.ResultIn the experiment, three sets of gray image sets (including Mfi image set, Irvis image set, Medical image set) and four sets of color image sets (including Cmfi image set, Cirvis image set, Cmedical image set, Crsi image set) are randomly selected to verify the subjective visual and objective values of the proposed method NSST-Self-adaption-CSR-MAP (NSaCM). The results are compared with seven typical fusion methods, including convolutional sparse representation, convolutional sparsity-based morphological component analysis, parameter-adaptive pulse coupled-neural network, convolutional neural network, double-two direction sparse representation, wave-average-max, and non-subsampled contourlet transform and fusion. The experimental results show that the subjective visual effect of NSaCM is obviously better than that of other fusion methods. In the comparison of the average gradient, the objective numerical results of the seven methods mentioned above increased by 39.3%, 32.1%, 34.7%, 28.3%, 35.8%, 28%, and 30.4% on average, respectively. In the comparison of information entropy, the objective numerical results of the seven methods mentioned above increased by 6.2%, 4.5%, 1.9%, 0.4%, 1.5%, 2.4%, and 2.9% on average, respectively. In the comparison of spatial frequencies, the objective numerical results of the seven methods mentioned above increased by 31.8%, 25.8%, 29.7%, 22.2%, 28.6%, 22.9%, and 25.3% on average, respectively. In the comparison of edge strength, the objective numerical results of the seven methods mentioned above increased by 39.5%, 32.1%, 35.1%, 28.8%, 36.6%, 28.7%, and 31.3% on average, respectively.ConclusionNSaCM is suitable for gray and color images. The experimental results show that the fusion image obtained by the proposed method achieves better results in terms of both subjective and objective indicators. As seen from the numerical promotion of information entropy, the fusion image obtained by NSaCM contains more information, inherits more basic information of the source image, and solves the problem of insufficient information to a certain extent. From the numerical enhancement of average gradient, spatial frequency, and edge strength, NSaCM has a better expression of detail contrast. The overall activity of the fused image is higher, and the image content that makes image singularity more obvious is preserved in the fusion process, which solves the problem of edge detail blur in image fusion. However, the real-time performance of this method in terms of time consumption is still lacking, and further research is needed in the future.关键词:multi-scale analysis;adaptive sample set;convolution sparsity;detail saliency map;image fusion82|277|2更新时间:2024-05-07
摘要:ObjectiveImage fusion is the process of using multiple image information of the same scene according to certain rules to obtain better fusion image. The fusion image contains the outstanding features of the image to be fused, which can improve the utilization of image information and provide more accurate help for later decision-making based on the image. Multi-scale analysis method, sparse representation method, and saliency method are three kinds of image representation methods that can be used in image fusion. Multi-scale analysis method is an active field in image fusion, but only the appropriate transformation method can improve the performance of the fusion image. The sparse representation method has good performance for image representation, but multi-value representation of the image easily leads to the loss of details. The significance method is unique due to its ability to capture the outstanding target in the image. However, visual saliency is a subjective image description index, and the proper construction of saliency map is an urgent problem to be solved. To address the problem of insufficient information and fuzzy edge details in image fusion, an image fusion method of convolution sparsity and detail saliency map analysis is proposed, which combines the advantages of multi-scale analysis, sparse representation method, and saliency method and at the same time avoids their disadvantages as much as possible.MethodFirst, to address the insufficient image information after fusion, a multi-directional method is proposed to construct the adaptive training sample set. Then through dictionary training, a more abundant dictionary filter bank suitable for the image to be fused is obtained. Second, low-and high-frequency subgraphs are obtained by multi-scale analysis. The low-frequency subgraph contains a lot of basic information of source image, and it is represented by convolution sparsity using the trained adaptive dictionary filter bank. In this way, the sparse matrix of global single-value representation is obtained. The activity of each pixel in the image can be represented by the L1 norm of this multidimensional sparse representation coefficient matrix. The more prominent its feature is, the more active the image is, so the weight can be measured by measuring the activity of the image to be fused. Through weight analysis, a weighted fusion rule is constructed to obtain the low-frequency subgraph with more abundant information. At the same time, to solve the problem of fuzzy edge details in the process of fusion, the fusion of high-frequency subgraphs is processed as follows. Because the high-frequency subgraph reflects the singularity of the image, a high-frequency detail saliency graph is constructed to highlight this feature. This detail saliency map is constructed by cross reconstruction of high-and low-frequency subgraphs. According to the distance difference between the high-frequency subgraph and the detail saliency map, similarity analysis is carried out, and a high-frequency fusion rule is established to obtain the high-frequency subgraph with more prominent edge details. Finally, the final fusion image is obtained by inverting the high-frequency and low-frequency subgraphs after fusion.ResultIn the experiment, three sets of gray image sets (including Mfi image set, Irvis image set, Medical image set) and four sets of color image sets (including Cmfi image set, Cirvis image set, Cmedical image set, Crsi image set) are randomly selected to verify the subjective visual and objective values of the proposed method NSST-Self-adaption-CSR-MAP (NSaCM). The results are compared with seven typical fusion methods, including convolutional sparse representation, convolutional sparsity-based morphological component analysis, parameter-adaptive pulse coupled-neural network, convolutional neural network, double-two direction sparse representation, wave-average-max, and non-subsampled contourlet transform and fusion. The experimental results show that the subjective visual effect of NSaCM is obviously better than that of other fusion methods. In the comparison of the average gradient, the objective numerical results of the seven methods mentioned above increased by 39.3%, 32.1%, 34.7%, 28.3%, 35.8%, 28%, and 30.4% on average, respectively. In the comparison of information entropy, the objective numerical results of the seven methods mentioned above increased by 6.2%, 4.5%, 1.9%, 0.4%, 1.5%, 2.4%, and 2.9% on average, respectively. In the comparison of spatial frequencies, the objective numerical results of the seven methods mentioned above increased by 31.8%, 25.8%, 29.7%, 22.2%, 28.6%, 22.9%, and 25.3% on average, respectively. In the comparison of edge strength, the objective numerical results of the seven methods mentioned above increased by 39.5%, 32.1%, 35.1%, 28.8%, 36.6%, 28.7%, and 31.3% on average, respectively.ConclusionNSaCM is suitable for gray and color images. The experimental results show that the fusion image obtained by the proposed method achieves better results in terms of both subjective and objective indicators. As seen from the numerical promotion of information entropy, the fusion image obtained by NSaCM contains more information, inherits more basic information of the source image, and solves the problem of insufficient information to a certain extent. From the numerical enhancement of average gradient, spatial frequency, and edge strength, NSaCM has a better expression of detail contrast. The overall activity of the fused image is higher, and the image content that makes image singularity more obvious is preserved in the fusion process, which solves the problem of edge detail blur in image fusion. However, the real-time performance of this method in terms of time consumption is still lacking, and further research is needed in the future.关键词:multi-scale analysis;adaptive sample set;convolution sparsity;detail saliency map;image fusion82|277|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveThe Bézier curve is a widely used tool in the representation of parametric curves. At present,most computer aided design (CAD) systems take the Bézier curve as a basic module. When using the Bézier curve for geometric modeling,it is often necessary to link multiple curves to meet the needs of designing complex curves. In order to satisfy the continuity between the linked Bézier curves,the control points that satisfy the corresponding continuity conditions need to be selected in advance. For linked Bézier curves with low order continuity,the control points of the curves can be adjusted to improve the continuity so as to smooth the linked curves. In theory,the continuity between linked Bézier curves can be improved by arbitrarily adjusting the control points of the curves to make the corresponding continuity conditions hold. However,this kind of adjustment of control points without specific objectives is often unable to meet the needs of practical applications. Given that the continuity can be improved by adjusting the control points of the linked Bézier curves,the control points that need to be adjusted can be optimized according to some specific targets,so that the smooth linked curves meet the corresponding requirements. In practical applications,if the control points of the curves are taken from the real objects,it is often hoped that the distance between the new control points and the original control points is as small as possible. Hence,the minimum distance between the new control points and the original control points can be used as the target to optimize the control points that need to be adjusted. In addition,energy minimization has become a common method for constructing curves and surfaces in CAD and related fields. Thus,the minimum energy can be used as a target to optimize the control points that need to be adjusted. In this study,three methods for smoothing the linked Bézier curves from C0 to C1 and from C1 to C2 by distance and internal energy minimization are given.MethodFirst,the problems to be discussed are described,and the control points to be adjusted are pointed out when smoothing the linked Bézier curves from C0 to C1 and from C1 to C2. Two control points need to be adjusted when smoothing the linked Bézier curves from C0 to C1 or from C1 to C2. However,only one of them needs to be optimized due to the relationship between the two control points that need to be adjusted. Then,the distance minimizations for smoothing the linked Bézier curves from C0 to C1 and from C1 to C2 are presented. Next,the internal energy minimizations for smoothing the linked Bézier curves from C0 to C1 and from C1 to C2 are given. Then,the simultaneous minimization of the distance and the internal energy for smoothing the linked Bézier curves from C0 to C1 and from C1 to C2 are provided. The optimal solutions of the control points that need to be adjusted can be easily obtained by solving the corresponding unconstrained optimization problems. Finally,the comparison of the three minimization methods is given,and the applicable occasions of different methods are pointed out. The distance between the new control points and the original control points by the distance minimization is relatively small,which is suitable for the application when the control points are taken from the real object; the internal energy of the linked curves obtained by the internal energy minimization is relatively small,which is suitable for the application where the energy of the curve is required to be as small as possible; the distance and internal energy minimization simultaneously takes into account the distance between the new control points and the original control points and the internal energy of the linked curves,which is suitable for applications where both targets are required. Some numerical examples are presented to illustrate the effectiveness of the proposed methods.ResultBy using the distance minimization,the total distance between the new control points and the original control points is obviously smaller than that of the other two methods. When the control points of Bézier curves are all taken from the real object,the distance between the new control points and the original control points should not be too large,so the distance minimization method is more suitable. By using the internal energy minimization,the total internal energy of the curves is obviously smaller than that of the other two methods. When the energy of the curve is required to be as small as possible,the internal energy minimization is more suitable. In addition,given that the stretch energy,strain energy,and curvature variation energy correspond to the arc length,curvature,and curvature variation of the curve,the corresponding minimization method can be selected according to the specific requirements. By using the simultaneous minimization of distance and internal energy,the total distance between the new control points and the original control points and the total internal energy of the curves are between the other two methods. When the distance between the new control points and the original control points should not be too large and the energy of the curve should be as small as possible,the method of simultaneous minimization of distance and internal energy is a better choice.ConclusionThe proposed methods provide three effective means for smoothing the linked Bézier curves and are easy to implement. The linked Bézier curves can be effectively smoothed from C0 to C1 and from C1 to C2 by using the proposed methods according to the demand of minimum distance or internal energy. When smoothing other types of link curves,the distance minimization,internal energy minimization,and simultaneous minimization of distance and internal energy proposed in this study maybe useful.关键词:Bezier curve;link;smoothing;control points optimization;distance minimization;internal energy minimization61|23|0更新时间:2024-05-07
摘要:ObjectiveThe Bézier curve is a widely used tool in the representation of parametric curves. At present,most computer aided design (CAD) systems take the Bézier curve as a basic module. When using the Bézier curve for geometric modeling,it is often necessary to link multiple curves to meet the needs of designing complex curves. In order to satisfy the continuity between the linked Bézier curves,the control points that satisfy the corresponding continuity conditions need to be selected in advance. For linked Bézier curves with low order continuity,the control points of the curves can be adjusted to improve the continuity so as to smooth the linked curves. In theory,the continuity between linked Bézier curves can be improved by arbitrarily adjusting the control points of the curves to make the corresponding continuity conditions hold. However,this kind of adjustment of control points without specific objectives is often unable to meet the needs of practical applications. Given that the continuity can be improved by adjusting the control points of the linked Bézier curves,the control points that need to be adjusted can be optimized according to some specific targets,so that the smooth linked curves meet the corresponding requirements. In practical applications,if the control points of the curves are taken from the real objects,it is often hoped that the distance between the new control points and the original control points is as small as possible. Hence,the minimum distance between the new control points and the original control points can be used as the target to optimize the control points that need to be adjusted. In addition,energy minimization has become a common method for constructing curves and surfaces in CAD and related fields. Thus,the minimum energy can be used as a target to optimize the control points that need to be adjusted. In this study,three methods for smoothing the linked Bézier curves from C0 to C1 and from C1 to C2 by distance and internal energy minimization are given.MethodFirst,the problems to be discussed are described,and the control points to be adjusted are pointed out when smoothing the linked Bézier curves from C0 to C1 and from C1 to C2. Two control points need to be adjusted when smoothing the linked Bézier curves from C0 to C1 or from C1 to C2. However,only one of them needs to be optimized due to the relationship between the two control points that need to be adjusted. Then,the distance minimizations for smoothing the linked Bézier curves from C0 to C1 and from C1 to C2 are presented. Next,the internal energy minimizations for smoothing the linked Bézier curves from C0 to C1 and from C1 to C2 are given. Then,the simultaneous minimization of the distance and the internal energy for smoothing the linked Bézier curves from C0 to C1 and from C1 to C2 are provided. The optimal solutions of the control points that need to be adjusted can be easily obtained by solving the corresponding unconstrained optimization problems. Finally,the comparison of the three minimization methods is given,and the applicable occasions of different methods are pointed out. The distance between the new control points and the original control points by the distance minimization is relatively small,which is suitable for the application when the control points are taken from the real object; the internal energy of the linked curves obtained by the internal energy minimization is relatively small,which is suitable for the application where the energy of the curve is required to be as small as possible; the distance and internal energy minimization simultaneously takes into account the distance between the new control points and the original control points and the internal energy of the linked curves,which is suitable for applications where both targets are required. Some numerical examples are presented to illustrate the effectiveness of the proposed methods.ResultBy using the distance minimization,the total distance between the new control points and the original control points is obviously smaller than that of the other two methods. When the control points of Bézier curves are all taken from the real object,the distance between the new control points and the original control points should not be too large,so the distance minimization method is more suitable. By using the internal energy minimization,the total internal energy of the curves is obviously smaller than that of the other two methods. When the energy of the curve is required to be as small as possible,the internal energy minimization is more suitable. In addition,given that the stretch energy,strain energy,and curvature variation energy correspond to the arc length,curvature,and curvature variation of the curve,the corresponding minimization method can be selected according to the specific requirements. By using the simultaneous minimization of distance and internal energy,the total distance between the new control points and the original control points and the total internal energy of the curves are between the other two methods. When the distance between the new control points and the original control points should not be too large and the energy of the curve should be as small as possible,the method of simultaneous minimization of distance and internal energy is a better choice.ConclusionThe proposed methods provide three effective means for smoothing the linked Bézier curves and are easy to implement. The linked Bézier curves can be effectively smoothed from C0 to C1 and from C1 to C2 by using the proposed methods according to the demand of minimum distance or internal energy. When smoothing other types of link curves,the distance minimization,internal energy minimization,and simultaneous minimization of distance and internal energy proposed in this study maybe useful.关键词:Bezier curve;link;smoothing;control points optimization;distance minimization;internal energy minimization61|23|0更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveIn the field of intelligent video surveillance, video target detection serves as a bottom-level task for high-level video analysis technologies such as target tracking and re-recognition, and the false detection and missing detection of low-level target detection are amplified layer by layer. Therefore, improving the accuracy of foreground target detection has important research value.In the foreground detection of video, the result of pixel-level background subtraction is clear and flexible. However, the pixel-level classification method based on sample consistency cannot make full use of the pixel information effectively and obtain full foreground mask when meeting the complex situation of color camouflage and static object, such as error detection of foreground pixels and missing foreground. An algorithm is proposed based on fusing confidences with weight and visual attention to solve this problem effectively.MethodThe advantage of this method is to make full use of the credibility of the sample to construct the background model, combine the secondary detection of color level and texture dimension to overcome the problem of color camouflage effectively, and construct attention mechanism to detect static foreground. The proposed model contains three modules. First, considering the prospect of double-dimension missing detection, the foreground is determined by the sum of fusing with color confidence and texture confidence based on weight. The color confidence and texture confidence of strong correlation samples are summed, and then weighted sum is determined. If it is less than the minimum threshold, then it is judged as foreground; otherwise, it is background. Then, the confidence and weight of the samples are updated adaptively. For the pixels detected as background, the sample template with the minimum confidence in the model is replaced by the current pixel information. If the distance between the current frame pixel and the sample in the model is greater than the given distance threshold, then the sample is valid. The confidence of the effective sample is reduced, and the confidence of the invalid sample is reduced to prevent the valid sample from being updated as much as possible. The static foreground is determined by constructing the visual attention mechanism in the subsequence, and the background model is finally dynamically updated with the strategy of updating the minimum confidence samples. The core of this step is to define a visual attention mechanism to judge whether it is a background based on color saliency and similarity between background and texture. The pixel classification method based on the weighted fusion of confidence and the static foreground detection based on visual attention are used to extract moving foreground and still foreground, respectively, which are combinations of a whole. The foreground mask obtained by the pixel classification method based on the weighted fusion of confidence is used as the candidate region of static foreground detection. When the texture difference is calculated, the sample information of the background model constructed is also needed, and the background model here is the updated background model. The pixels detected as still foreground also cover the pixels that are falsely detected as background by the pixel classification method based on the confidence weighted fusion to guide the updating of model samples. In still foreground detection, when no candidate foreground region exists in the first frame of the subsequence, the static foreground detection of the current subsequence is not carried out, which improves the efficiency of the algorithm.ResultIn this paper, to evaluate the performance of the proposed algorithm, 10 groups of video sequences are randomly selected from the scene background modeling red-green-blue-depth(SBM-RGBD) and change detection workshops 2014(CDW 2014) database for the experiment. Compared with the contrast algorithm, the proposed algorithm performs better in most video sequences and can detect static and camouflaged foreground targets. Overall, from the qualitative point of view, the proposed algorithm is better than the five other algorithms in static foreground and color camouflage detection. The recall and precision indexes of the proposed algorithm are improved by 2.66% and 1.48%, respectively, compared with the second best algorithm.ConclusionQuantitative and qualitative analyses of the experiment show that the proposed algorithm is superior to the other algorithms, achieves the accuracy and recall rate of foreground detection in the complex situation of color camouflage and presence of still objects, and achieves a better detection effect. Experimental results show that the proposed algorithm can effectively detect foreground targets in complex scenes caused by camouflage and static foreground. In addition, foreground target detection can be carried out in actual monitoring scenes.关键词:object detection;foreground detection;confidence;color camouflage;visual attention;static foreground91|136|0更新时间:2024-05-07
摘要:ObjectiveIn the field of intelligent video surveillance, video target detection serves as a bottom-level task for high-level video analysis technologies such as target tracking and re-recognition, and the false detection and missing detection of low-level target detection are amplified layer by layer. Therefore, improving the accuracy of foreground target detection has important research value.In the foreground detection of video, the result of pixel-level background subtraction is clear and flexible. However, the pixel-level classification method based on sample consistency cannot make full use of the pixel information effectively and obtain full foreground mask when meeting the complex situation of color camouflage and static object, such as error detection of foreground pixels and missing foreground. An algorithm is proposed based on fusing confidences with weight and visual attention to solve this problem effectively.MethodThe advantage of this method is to make full use of the credibility of the sample to construct the background model, combine the secondary detection of color level and texture dimension to overcome the problem of color camouflage effectively, and construct attention mechanism to detect static foreground. The proposed model contains three modules. First, considering the prospect of double-dimension missing detection, the foreground is determined by the sum of fusing with color confidence and texture confidence based on weight. The color confidence and texture confidence of strong correlation samples are summed, and then weighted sum is determined. If it is less than the minimum threshold, then it is judged as foreground; otherwise, it is background. Then, the confidence and weight of the samples are updated adaptively. For the pixels detected as background, the sample template with the minimum confidence in the model is replaced by the current pixel information. If the distance between the current frame pixel and the sample in the model is greater than the given distance threshold, then the sample is valid. The confidence of the effective sample is reduced, and the confidence of the invalid sample is reduced to prevent the valid sample from being updated as much as possible. The static foreground is determined by constructing the visual attention mechanism in the subsequence, and the background model is finally dynamically updated with the strategy of updating the minimum confidence samples. The core of this step is to define a visual attention mechanism to judge whether it is a background based on color saliency and similarity between background and texture. The pixel classification method based on the weighted fusion of confidence and the static foreground detection based on visual attention are used to extract moving foreground and still foreground, respectively, which are combinations of a whole. The foreground mask obtained by the pixel classification method based on the weighted fusion of confidence is used as the candidate region of static foreground detection. When the texture difference is calculated, the sample information of the background model constructed is also needed, and the background model here is the updated background model. The pixels detected as still foreground also cover the pixels that are falsely detected as background by the pixel classification method based on the confidence weighted fusion to guide the updating of model samples. In still foreground detection, when no candidate foreground region exists in the first frame of the subsequence, the static foreground detection of the current subsequence is not carried out, which improves the efficiency of the algorithm.ResultIn this paper, to evaluate the performance of the proposed algorithm, 10 groups of video sequences are randomly selected from the scene background modeling red-green-blue-depth(SBM-RGBD) and change detection workshops 2014(CDW 2014) database for the experiment. Compared with the contrast algorithm, the proposed algorithm performs better in most video sequences and can detect static and camouflaged foreground targets. Overall, from the qualitative point of view, the proposed algorithm is better than the five other algorithms in static foreground and color camouflage detection. The recall and precision indexes of the proposed algorithm are improved by 2.66% and 1.48%, respectively, compared with the second best algorithm.ConclusionQuantitative and qualitative analyses of the experiment show that the proposed algorithm is superior to the other algorithms, achieves the accuracy and recall rate of foreground detection in the complex situation of color camouflage and presence of still objects, and achieves a better detection effect. Experimental results show that the proposed algorithm can effectively detect foreground targets in complex scenes caused by camouflage and static foreground. In addition, foreground target detection can be carried out in actual monitoring scenes.关键词:object detection;foreground detection;confidence;color camouflage;visual attention;static foreground91|136|0更新时间:2024-05-07 -
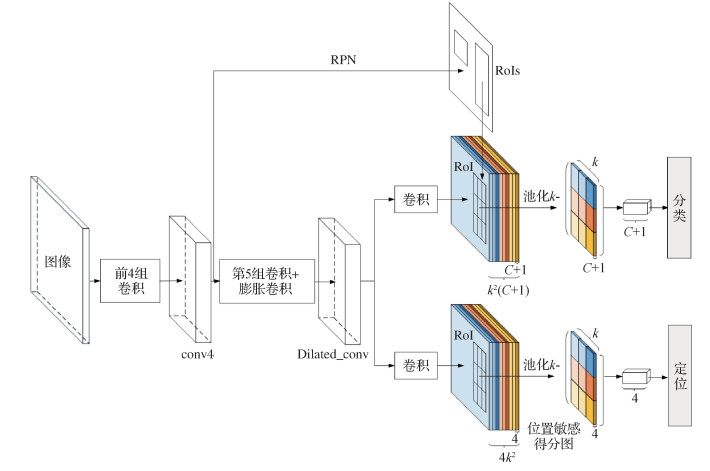 摘要:ObjectiveObject detection is a fundamental task in computer vision applications, and it provides support for subsequent object tracking, instance segmentation, and behavior recognition. The rapid development of deep learning has facilitated the wide use of convolutional neural network in object detection and shifted object detection from the traditional object detection method to the recent object detection method based on deep learning. Still image object detection has considerably progressed in recent years. It aims to determine the category and the position of each object in an image. The task of video object detection is to locate moving object in sequential images and assign the category label to each object. The accuracy of video object detection suffers from degenerated object appearances in videos, such as motion blur, multi-object occlusion, and rare poses. The methods of still image object detection have achieved excellent results. However, directly applying them to video object detection is challenging because still-image detectors may generate false negatives and positives caused by motion blur and object occlusion. Most existing video object detection methods incorporate temporal consistency across frames to improve upon single-frame detections.MethodWe propose a video object detection method guided by dual optical flow networks, which precisely propagate the features from adjacent frames to the feature of the current frame and enhance the feature of the current frame by fusing the features of the adjacent frames. Under the framework of two-stage object detection, the deep convolutional network model is used for the feature extraction to produce the feature in each frame of the video. According to the optical flow field, the features of the adjacent frames are used to compensate the feature of the current frame. According to the time interval between the adjacent frames and the current frame, two different optical flow networks are applied to estimate optical flow fields. Specifically, the optical flow network used for small displacement motion estimation is utilized to estimate the optical flow fields for closer adjacent frames. Moreover, the optical flow network used for large displacement motion estimation is utilized to estimate the optical flow fields for further adjacent frames. The compensated feature maps of multiple frames, as well as the feature map of the current frame, are aggregated according to adaptive weights. The adaptive weights indicate the importance of all compensated feature maps to the current frame. Here, the similarity between the compensated feature map and the feature map extracted from the current frame is measured using the cosine similarity metric. If the compensated feature map gets close to the feature map of the current frame, then the compensated feature map is assigned a larger weight; otherwise, it is assigned a smaller weight. An embedding network that consists of three convolutional layers is also applied on the compensated feature maps and the current feature map to produce the embedding feature maps. Then, we utilize the embedding feature maps to compute the adaptive weights.ResultExperimental results show that the mean average precision (mAP) score of the proposed method on the ImageNet for video object detection (VID) dataset can achieve 76.42%, which is 28.92%, 8.02%, 0.62%, and 0.24% higher than those of the temporal convolutional network, the method combining tubelet proposal network(TPN) with long short memory network, the method of D(& T loss), and flow-guided feature aggregation (FGFA), respectively. We also report the mAP scores over the slow, medium, and fast objects. Our method combining the two optical flow networks improve the mAP scores of slow, medium, and fast objects by 0.2%, 0.48% and 0.23%, respectively, compared with the method of FGFA. Furthermore, that dual optical flow networks can improve the estimation of optical flow field between the adjacent frames and the current frame. Then, the feature of the current frame can be compensated more precisely using adjacent frames.ConclusionConsidering the special temporal correlation of video, the proposed model improves the accuracy of video object detection through the feature aggregation guided by dual optical flow networks under the framework of the two-stage object detection. The usage of dual optical flow networks can accurately compensate the feature of the current frame from the adjacent frames. Accordingly, we can fully utilize the feature of each adjacent frame and reduce false negatives and positives through temporal feature fusion in video object detection.关键词:object detection;convolutional neural network(CNN);motion estimation;motion compensation;optical flow network;feature fusion165|118|1更新时间:2024-05-07
摘要:ObjectiveObject detection is a fundamental task in computer vision applications, and it provides support for subsequent object tracking, instance segmentation, and behavior recognition. The rapid development of deep learning has facilitated the wide use of convolutional neural network in object detection and shifted object detection from the traditional object detection method to the recent object detection method based on deep learning. Still image object detection has considerably progressed in recent years. It aims to determine the category and the position of each object in an image. The task of video object detection is to locate moving object in sequential images and assign the category label to each object. The accuracy of video object detection suffers from degenerated object appearances in videos, such as motion blur, multi-object occlusion, and rare poses. The methods of still image object detection have achieved excellent results. However, directly applying them to video object detection is challenging because still-image detectors may generate false negatives and positives caused by motion blur and object occlusion. Most existing video object detection methods incorporate temporal consistency across frames to improve upon single-frame detections.MethodWe propose a video object detection method guided by dual optical flow networks, which precisely propagate the features from adjacent frames to the feature of the current frame and enhance the feature of the current frame by fusing the features of the adjacent frames. Under the framework of two-stage object detection, the deep convolutional network model is used for the feature extraction to produce the feature in each frame of the video. According to the optical flow field, the features of the adjacent frames are used to compensate the feature of the current frame. According to the time interval between the adjacent frames and the current frame, two different optical flow networks are applied to estimate optical flow fields. Specifically, the optical flow network used for small displacement motion estimation is utilized to estimate the optical flow fields for closer adjacent frames. Moreover, the optical flow network used for large displacement motion estimation is utilized to estimate the optical flow fields for further adjacent frames. The compensated feature maps of multiple frames, as well as the feature map of the current frame, are aggregated according to adaptive weights. The adaptive weights indicate the importance of all compensated feature maps to the current frame. Here, the similarity between the compensated feature map and the feature map extracted from the current frame is measured using the cosine similarity metric. If the compensated feature map gets close to the feature map of the current frame, then the compensated feature map is assigned a larger weight; otherwise, it is assigned a smaller weight. An embedding network that consists of three convolutional layers is also applied on the compensated feature maps and the current feature map to produce the embedding feature maps. Then, we utilize the embedding feature maps to compute the adaptive weights.ResultExperimental results show that the mean average precision (mAP) score of the proposed method on the ImageNet for video object detection (VID) dataset can achieve 76.42%, which is 28.92%, 8.02%, 0.62%, and 0.24% higher than those of the temporal convolutional network, the method combining tubelet proposal network(TPN) with long short memory network, the method of D(& T loss), and flow-guided feature aggregation (FGFA), respectively. We also report the mAP scores over the slow, medium, and fast objects. Our method combining the two optical flow networks improve the mAP scores of slow, medium, and fast objects by 0.2%, 0.48% and 0.23%, respectively, compared with the method of FGFA. Furthermore, that dual optical flow networks can improve the estimation of optical flow field between the adjacent frames and the current frame. Then, the feature of the current frame can be compensated more precisely using adjacent frames.ConclusionConsidering the special temporal correlation of video, the proposed model improves the accuracy of video object detection through the feature aggregation guided by dual optical flow networks under the framework of the two-stage object detection. The usage of dual optical flow networks can accurately compensate the feature of the current frame from the adjacent frames. Accordingly, we can fully utilize the feature of each adjacent frame and reduce false negatives and positives through temporal feature fusion in video object detection.关键词:object detection;convolutional neural network(CNN);motion estimation;motion compensation;optical flow network;feature fusion165|118|1更新时间:2024-05-07 -
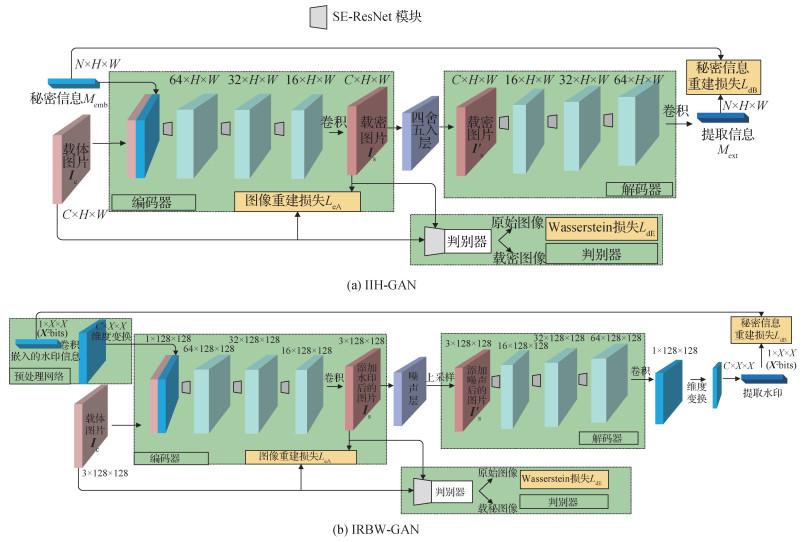 摘要:ObjectiveSteganography is a technique that hides secret information in multimedia without arousing suspicion from the steganalyzer. In a typical case, the steganography system consists of three parts: Alice, Bob, and Eve. The sender Alice hides the secret message in the carrier image(cover), turns it into another image(stego) that does not change its appearance perception, and then sends the stego to the receiver Bob through a public channel. Then, Bob can recover the secret messages from the stego. Eve acts as the steganalyzer to monitor their communications and determine whether secret information is hidden in the stego. In general, image information hiding includes two branches, namely, image steganography and image watermarking. Steganography hides secret information in a carrier and achieves the purpose of secret communication via the transmission of stego images, and the main evaluation metric is security against steganalysis. The principle of watermarking technology is similar to that of steganography, the difference is that its purpose is to use the watermark information embedded in the carrier to protect intellectual property rights, and the metric of watermarking emphasizes robustness against various watermarking attack. Traditional steganography and watermarking algorithms depend on the artificial designed complex feature, which requires the designer's domain knowledge and accumulated experience. Recent work has shown that deep neural networks are highly sensitive to minute perturbations of input images, giving rise to adversarial examples. This property is usually considered a weakness of learned models but can be exploited to enhance the capability of information hiding. Researchers have tried to use generative adversarial networks (GANs) to design steganographic algorithms and robust watermarking algorithms automatically. However, due to the unreasonable design of the neural network structure and other reasons as well as the lacking consideration of several practical problems, state-of-the-art GAN-based information hiding methods have several weaknesses.1) In real-world applications, the pixel value of the decoded image should be a float, but the networks proposed by existing methods set it to an integer. 2) Image steganography based on GANs has insufficient anti-steganalysis ability. 3) Watermarking technology based on deep learning has limited consideration of the types of attacking noises.4) The design of differential noise layer is unreasonable. Thus, the existing GAN-based steganography or watermarking algorithms have deficiencies in information extraction accuracy, embedding capacity, steganography security or watermark robustness, and watermark image quality.MethodThe paper proposes a new end-to-end steganographic model driven by GANs called image information hiding-GAN (IIH-GAN)) and robust blind watermarking model named image robust blind watermark-GAN (IRBW-GAN) for image steganography and robust blind watermarking, respectively. SE-ResNet, a more efficient encoder and decoder structure, is included in the network model, which can optimize the interdependence between network channels and enhance the global feature automatic selection, leading to a more accurate, high-quality information embedding and extraction. The proposed IIH-GAN uses a discriminator to cotrain with the encoder-decoder; thus, it maintains the distribution of the carrier image during adversarial training unchanged and enhances the security in resisting steganalysis. To solve the problem of decoding real images in real-world scenarios, IIH-GAN adds a round layer between the encoder and the decoder. IIH-GAN adds the adversarial examples to the GAN-based steganographic model to remedy the shortcomings of GAN-based steganography in resisting the powerful state-of-the-art deep learning-based steganalysis algorithms. In the watermark model, IRBW-GAN adds a differentiable noise layer between the encoder and the decoder that resists noise attacks, considering various noise attack types and high-intensity noise attacks. For non differentiable JPEG compression noise, a new type of differentiable network layer is proposed for simulation. The datasets used include celebA, BOSSBase, and common object in context(COCO). The existing advanced GAN-based steganography methods, such as Volkhonskiy, Hayes, Hu, and HiDDeN, are used for comparison experiments under the same evaluation metrics of image quality, capacity, decoding accuracy, and steganography security. The watermarking methods for comparison experiments include HiDDeN, ReDMark, and Liu. The watermark image quality and watermark extraction accuracy under various noises are compared. Noise types include Identity, Dropout, Cropout, Gaussian blur, JPEG Compression, Crop, Resize, Mean filtering, and Salt and pepper.ResultExperimental results show that the designed models have remarkable improvements in performance compared with state-of-the-art methods. When the detailed parameters of the trained steganalysis model are known, the adversarial examples are added to the proposed IIH-GAN. This method can reduce the detection accuracy of existing powerful deep learning-based steganalysis, YeNet, from 97.43% to 48.69%, which means the proposed IIH-GAN greatly improves the steganography security. The proposed watermarking model IRBW-GAN can achieve a relative embedding capacity as high as 1 bpp (bits-per-pixel) on a 256×256 pixels image. Compared with other models, the peak signal-to-noise ratio and structural similarity of IRBW-GAN are greatly improved, which means that the image generated by IRBW-GAN has a higher image quality. Compared with the state-of-the-art deep learning-based watermarking methods, when resisting various types and high-intensity noise attacks, IRBW-GAN model considerably improves the watermarked image quality and watermark extraction accuracy while increasing the watermark embedding capacity. The extraction accuracy is increased by approximately 20% compared with other methods under the attack of JEPG compression. The proposed simulated JPEG compression network layer is closer to the real JPEG compression, which can achieve a better robustness against image compression.ConclusionThe proposed IIH-GAN and IRBW-GAN achieve superior performance over state-of-the-art models in the fields of image steganography and watermarking, respectively.关键词:image information hiding;image steganography;generative adversarial networks(GANs);adversarial examples;robust blind watermarking245|211|6更新时间:2024-05-07
摘要:ObjectiveSteganography is a technique that hides secret information in multimedia without arousing suspicion from the steganalyzer. In a typical case, the steganography system consists of three parts: Alice, Bob, and Eve. The sender Alice hides the secret message in the carrier image(cover), turns it into another image(stego) that does not change its appearance perception, and then sends the stego to the receiver Bob through a public channel. Then, Bob can recover the secret messages from the stego. Eve acts as the steganalyzer to monitor their communications and determine whether secret information is hidden in the stego. In general, image information hiding includes two branches, namely, image steganography and image watermarking. Steganography hides secret information in a carrier and achieves the purpose of secret communication via the transmission of stego images, and the main evaluation metric is security against steganalysis. The principle of watermarking technology is similar to that of steganography, the difference is that its purpose is to use the watermark information embedded in the carrier to protect intellectual property rights, and the metric of watermarking emphasizes robustness against various watermarking attack. Traditional steganography and watermarking algorithms depend on the artificial designed complex feature, which requires the designer's domain knowledge and accumulated experience. Recent work has shown that deep neural networks are highly sensitive to minute perturbations of input images, giving rise to adversarial examples. This property is usually considered a weakness of learned models but can be exploited to enhance the capability of information hiding. Researchers have tried to use generative adversarial networks (GANs) to design steganographic algorithms and robust watermarking algorithms automatically. However, due to the unreasonable design of the neural network structure and other reasons as well as the lacking consideration of several practical problems, state-of-the-art GAN-based information hiding methods have several weaknesses.1) In real-world applications, the pixel value of the decoded image should be a float, but the networks proposed by existing methods set it to an integer. 2) Image steganography based on GANs has insufficient anti-steganalysis ability. 3) Watermarking technology based on deep learning has limited consideration of the types of attacking noises.4) The design of differential noise layer is unreasonable. Thus, the existing GAN-based steganography or watermarking algorithms have deficiencies in information extraction accuracy, embedding capacity, steganography security or watermark robustness, and watermark image quality.MethodThe paper proposes a new end-to-end steganographic model driven by GANs called image information hiding-GAN (IIH-GAN)) and robust blind watermarking model named image robust blind watermark-GAN (IRBW-GAN) for image steganography and robust blind watermarking, respectively. SE-ResNet, a more efficient encoder and decoder structure, is included in the network model, which can optimize the interdependence between network channels and enhance the global feature automatic selection, leading to a more accurate, high-quality information embedding and extraction. The proposed IIH-GAN uses a discriminator to cotrain with the encoder-decoder; thus, it maintains the distribution of the carrier image during adversarial training unchanged and enhances the security in resisting steganalysis. To solve the problem of decoding real images in real-world scenarios, IIH-GAN adds a round layer between the encoder and the decoder. IIH-GAN adds the adversarial examples to the GAN-based steganographic model to remedy the shortcomings of GAN-based steganography in resisting the powerful state-of-the-art deep learning-based steganalysis algorithms. In the watermark model, IRBW-GAN adds a differentiable noise layer between the encoder and the decoder that resists noise attacks, considering various noise attack types and high-intensity noise attacks. For non differentiable JPEG compression noise, a new type of differentiable network layer is proposed for simulation. The datasets used include celebA, BOSSBase, and common object in context(COCO). The existing advanced GAN-based steganography methods, such as Volkhonskiy, Hayes, Hu, and HiDDeN, are used for comparison experiments under the same evaluation metrics of image quality, capacity, decoding accuracy, and steganography security. The watermarking methods for comparison experiments include HiDDeN, ReDMark, and Liu. The watermark image quality and watermark extraction accuracy under various noises are compared. Noise types include Identity, Dropout, Cropout, Gaussian blur, JPEG Compression, Crop, Resize, Mean filtering, and Salt and pepper.ResultExperimental results show that the designed models have remarkable improvements in performance compared with state-of-the-art methods. When the detailed parameters of the trained steganalysis model are known, the adversarial examples are added to the proposed IIH-GAN. This method can reduce the detection accuracy of existing powerful deep learning-based steganalysis, YeNet, from 97.43% to 48.69%, which means the proposed IIH-GAN greatly improves the steganography security. The proposed watermarking model IRBW-GAN can achieve a relative embedding capacity as high as 1 bpp (bits-per-pixel) on a 256×256 pixels image. Compared with other models, the peak signal-to-noise ratio and structural similarity of IRBW-GAN are greatly improved, which means that the image generated by IRBW-GAN has a higher image quality. Compared with the state-of-the-art deep learning-based watermarking methods, when resisting various types and high-intensity noise attacks, IRBW-GAN model considerably improves the watermarked image quality and watermark extraction accuracy while increasing the watermark embedding capacity. The extraction accuracy is increased by approximately 20% compared with other methods under the attack of JEPG compression. The proposed simulated JPEG compression network layer is closer to the real JPEG compression, which can achieve a better robustness against image compression.ConclusionThe proposed IIH-GAN and IRBW-GAN achieve superior performance over state-of-the-art models in the fields of image steganography and watermarking, respectively.关键词:image information hiding;image steganography;generative adversarial networks(GANs);adversarial examples;robust blind watermarking245|211|6更新时间:2024-05-07 -
 摘要:ObjectiveForeground segmentation is an essential research in the field of image understanding, which is a pre-processing step for saliency object detection, semantic segmentation, and various pixel-level learning tasks. Given an image, this task aims to provide each pixel a foreground or background annotation. For fully supervision-based methods, satisfactory results can be achieved via multi-instance-based learning. However, when facing the problem under unsupervised conditions, achieving a stable segmentation performance based on fixed rules or a single type of feature is difficult because different images and instances always have variable expressions. Moreover, we find that different types of method have different advantages and disadvantages on different aspects. On the one hand, semantic feature-based learning methods could provide accurate key region extraction of foregrounds but could not generate complete object region and edges in detail. On the other hand, richer detailed expression can be obtained based on an apparent feature-based framework, but it cannot be suitable for variable kinds of cases.MethodBased on the observations, we propose an unsupervised foreground segmentation method based on semantic-apparent feature fusion. First, given a sample, we encode it as semantic and apparent feature map. We use a class activation mapping model pretrained on ImageNet for semantic heat map generation and select saliency and edge maps to express the apparent feature. Each kind of semantic and apparent feature can be used, and the established framework is widely adaptive for each case. Second, to combine the advantages of the two type of features, we split the image as super pixels, and set the expression of four elements as unary and binary semantic and apparent feature, which realizes a comprehensive description of the two types of expressions. Specifically, we build two binary relation matrices to measure the similarity of each pair of super pixels, which are based on apparent and semantic feature. For generating the binary semantic feature, we use the apparent feature-based similarity measure as a weight to provide the element for each super pixel, in which semantic-feature-based similarity measure is utilized for binary apparent feature calculation. Based on the different view for feature encoding, the two types of information could be fused for the first time. Then, we propose a method for adaptive parameter learning to calculate the most suitable feature weights and generate the foreground confidence score map. Based on the four elements, we could establish an equation to express each super pixel's foreground confidence score using the least squares method. For an image, we first select super pixels with higher confident scores of unary semantic and apparent feature on foreground or background. Then, we can learn weights of the four elements and bias' linear combination by least squares estimation. Based on the adaptive parameters, we can achieve a better confidence score inference for each super pixel individually. Third, we use segmentation network to learn foreground common features from different instances. In a weakly supervised semantic segmentation task, the fully supervision-based framework is used for improving pseudo annotations for training data and providing inference results. Inspired by the idea, we use the convolution network to mine foreground common feature from different instances. The trained model could be utilized to optimize the quality of foreground segmentation for both images used for network training and new data directly. A better performance can be achieved by fusing semantic and apparent features as well as cascading the modules of intra image adaptive feature weight learning and inter-image common feature learning.ResultWe test our methods on the pattern analysis, statistical modelling and computational learning visual object classes(PASCAL VOC)2012 training and evaluation set, which include 10 582 and 1 449 samples, respectively. Precision-recall curve as well as F-measure are used as indicators to evaluate the experimental results. Compared with typical semantic and apparent feature-based foreground segmentation methods, the proposed framework achieves superior improvement of baselines. For PASCAL VOC 2012 training set, the F-measure has a 3.5% improvement, while a 3.4% increase is obtained on the validation set. We also focus on the performance on visualized results for analysis the advantages of fusion framework. Based on comparison, we can find that results with accurate, detailed expression can be achieved based on the adaptive feature fusion operation, while incorrect cases can further be modified via multi-instance-based learning framework.ConclusionIn this study, we propose a semantic-apparent feature fusion method for unsupervised foreground segmentation. Given an image as input, we first calculate the semantic and apparent feature of the unary region of each super pixel in image. Then, we integrate two types of features through the cross-use of similarity measure of apparent and semantic feature. Next, we establish a context relationship for each pair of super pixels to calculate the binary feature of each region. Further, we establish an adaptive weight learning strategy. We obtain the weighting parameters for optimal foreground segmentation and achieve the confidence in the image foreground by automatically adjusting the influence of each dimensional feature on the foreground estimation in each specific image instance. Finally, we build a foreground segmentation network model to learn the common features of foreground between different instances and samples. Using the trained network model, the image can be re-inferred to obtain more accurate foreground segmentation results. The experiments on the PASCAL VOC 2012 training set and validation set prove the effectiveness and generalization ability of the algorithm. Moreover, the method proposed can use other foreground segmentation methods as a baseline and is widely used to improve the performance of tasks such as foreground segmentation and weakly supervised semantic segmentation. We also believe that to consider the introduction of various types of semantic and apparent feature fusion as well as adopt alternate iterations to mine the internal spatial context information of image and the common expression features between different instance is a feasible way to improve the performance of foreground segmentation further and an important idea for semantic segmentation tasks.关键词:computer vision;foreground segmentation;unsupervised learning;semantic-apparent feature fusion;natural scene images;PASCAL VOC dataset;adaptive weighting114|123|0更新时间:2024-05-07
摘要:ObjectiveForeground segmentation is an essential research in the field of image understanding, which is a pre-processing step for saliency object detection, semantic segmentation, and various pixel-level learning tasks. Given an image, this task aims to provide each pixel a foreground or background annotation. For fully supervision-based methods, satisfactory results can be achieved via multi-instance-based learning. However, when facing the problem under unsupervised conditions, achieving a stable segmentation performance based on fixed rules or a single type of feature is difficult because different images and instances always have variable expressions. Moreover, we find that different types of method have different advantages and disadvantages on different aspects. On the one hand, semantic feature-based learning methods could provide accurate key region extraction of foregrounds but could not generate complete object region and edges in detail. On the other hand, richer detailed expression can be obtained based on an apparent feature-based framework, but it cannot be suitable for variable kinds of cases.MethodBased on the observations, we propose an unsupervised foreground segmentation method based on semantic-apparent feature fusion. First, given a sample, we encode it as semantic and apparent feature map. We use a class activation mapping model pretrained on ImageNet for semantic heat map generation and select saliency and edge maps to express the apparent feature. Each kind of semantic and apparent feature can be used, and the established framework is widely adaptive for each case. Second, to combine the advantages of the two type of features, we split the image as super pixels, and set the expression of four elements as unary and binary semantic and apparent feature, which realizes a comprehensive description of the two types of expressions. Specifically, we build two binary relation matrices to measure the similarity of each pair of super pixels, which are based on apparent and semantic feature. For generating the binary semantic feature, we use the apparent feature-based similarity measure as a weight to provide the element for each super pixel, in which semantic-feature-based similarity measure is utilized for binary apparent feature calculation. Based on the different view for feature encoding, the two types of information could be fused for the first time. Then, we propose a method for adaptive parameter learning to calculate the most suitable feature weights and generate the foreground confidence score map. Based on the four elements, we could establish an equation to express each super pixel's foreground confidence score using the least squares method. For an image, we first select super pixels with higher confident scores of unary semantic and apparent feature on foreground or background. Then, we can learn weights of the four elements and bias' linear combination by least squares estimation. Based on the adaptive parameters, we can achieve a better confidence score inference for each super pixel individually. Third, we use segmentation network to learn foreground common features from different instances. In a weakly supervised semantic segmentation task, the fully supervision-based framework is used for improving pseudo annotations for training data and providing inference results. Inspired by the idea, we use the convolution network to mine foreground common feature from different instances. The trained model could be utilized to optimize the quality of foreground segmentation for both images used for network training and new data directly. A better performance can be achieved by fusing semantic and apparent features as well as cascading the modules of intra image adaptive feature weight learning and inter-image common feature learning.ResultWe test our methods on the pattern analysis, statistical modelling and computational learning visual object classes(PASCAL VOC)2012 training and evaluation set, which include 10 582 and 1 449 samples, respectively. Precision-recall curve as well as F-measure are used as indicators to evaluate the experimental results. Compared with typical semantic and apparent feature-based foreground segmentation methods, the proposed framework achieves superior improvement of baselines. For PASCAL VOC 2012 training set, the F-measure has a 3.5% improvement, while a 3.4% increase is obtained on the validation set. We also focus on the performance on visualized results for analysis the advantages of fusion framework. Based on comparison, we can find that results with accurate, detailed expression can be achieved based on the adaptive feature fusion operation, while incorrect cases can further be modified via multi-instance-based learning framework.ConclusionIn this study, we propose a semantic-apparent feature fusion method for unsupervised foreground segmentation. Given an image as input, we first calculate the semantic and apparent feature of the unary region of each super pixel in image. Then, we integrate two types of features through the cross-use of similarity measure of apparent and semantic feature. Next, we establish a context relationship for each pair of super pixels to calculate the binary feature of each region. Further, we establish an adaptive weight learning strategy. We obtain the weighting parameters for optimal foreground segmentation and achieve the confidence in the image foreground by automatically adjusting the influence of each dimensional feature on the foreground estimation in each specific image instance. Finally, we build a foreground segmentation network model to learn the common features of foreground between different instances and samples. Using the trained network model, the image can be re-inferred to obtain more accurate foreground segmentation results. The experiments on the PASCAL VOC 2012 training set and validation set prove the effectiveness and generalization ability of the algorithm. Moreover, the method proposed can use other foreground segmentation methods as a baseline and is widely used to improve the performance of tasks such as foreground segmentation and weakly supervised semantic segmentation. We also believe that to consider the introduction of various types of semantic and apparent feature fusion as well as adopt alternate iterations to mine the internal spatial context information of image and the common expression features between different instance is a feasible way to improve the performance of foreground segmentation further and an important idea for semantic segmentation tasks.关键词:computer vision;foreground segmentation;unsupervised learning;semantic-apparent feature fusion;natural scene images;PASCAL VOC dataset;adaptive weighting114|123|0更新时间:2024-05-07 -
 摘要:ObjectiveThe point cloud data of the ground scene collected by LiDAR is large in scale and contains rich spatial structure detail information. Many current point cloud segmentation methods cannot well balance the relationship between the extraction of structure detail information and computation. To solve the problem, the current point cloud learning tasks are mainly divided into direct method and conversion method. The direct method directly extracts features from all point clouds and can obtain more spatial structure information, but the scale of point clouds that can be processed is usually limited. Therefore, the direct method requires other auxiliary processing methods for outdoor scenes with a large data scale. The transformation method adopts projection and voxelization methods to transform the point cloud into a dense representation. The image generated by the point cloud transformation method of projecting the point cloud into 2D graphics is denser and more consistent with people's cognition. Moreover, 2D point clouds are easier to fuse with mature 2D convolutional neural networks (CNN). However, the real spatial structure information will inevitably be lost in the transformation. In addition, for small sample data and small object scenes (such as pedestrians and cyclists), the segmentation performance will decrease. The reasons mainly include the loss of information caused by the imaging characteristics and transformation of LiDAR and the more serious occlusion problems. A scene view point offset method based on the human observation mechanism is proposed in this paper to improve the 3D LiDAR point cloud segmentation performance and solve the problem of loss of spatial detail information in projection.MethodFirst, a spherical projection is exploited to transform the 3D point cloud into a 2D spherical front view (SFV). This method is more consistent with LiDAR imaging, which minimizes the loss of generating new information. Moreover, the generated images are denser, more in line with people's cognition, and easy to be combined with the mature 2D convolutional neural network. In addition, the projection method removes part of the point cloud and reduces the amount of computation. Then, to address the problems of information loss and occlusion, the original viewpoint of SFV is horizontally moved to generate a multiview series. SFV projection solves several problems such as sparseness and occlusion in point clouds, but many spatial details will inevitably be lost in the projection. The 3D object itself can be observed from different angles, and the shape characteristics of different angles can be obtained. Based on this feature, a multi-view observation sequence is formed by moving the projection center to obtain a more reliable sample sequence for point cloud segmentation. In the segmentation network, the information of SFV is downsampled by using the Fire convolutional layer and the maximum pooling layer using a series of network SqueezeSeg. To obtain the full-resolution label features of each point, deconvolution is used to carry out upsampling and obtain the decoding features. The skip layer connection structure is adopted to add the upsampling feature map to the low-level feature map of the same size and better combine the low-level features and high-level semantic features of the network. Although the deviation will improve the segmentation results to some extent, blindly increasing the deviation will add unnecessary computation to the system. Considering the redundancy of the multi-view point sequence, finding the optimal offset point in actual work is important. Finally, the CNN is used to construct the scene viewpoint offset prediction module and predict the optimal scene viewpoint offset.ResultThe dataset adopted in this paper is the converted Karlsruhe Institute of Technology and Toyota Technological Institute(KITTI) dataset. To prove that the proposed method used is suitable for a relatively small dataset, a smaller dataset (contains a training set of 1 182 frames, a validation set of 169 frames) is extracted for ablation experiment verification. In the small sample dataset, after adding the scene viewpoint offset module, the segmentation results of pedestrians and cyclists are improved, and the intersection over union of pedestrians and cyclists at different offset distances are increased by 6.5% and 15.5%, respectively, compared with the original method. After adding the scene viewpoint offset module and the offset prediction module, the crossover ratio of each category is increased by 1.6%3%. On KITTI's raw dataset, compared with other methods, several categories of the intersection over union achieve the best results, and that of the pedestrian increases by 9.1%.ConclusionCombined with the human observation mechanism and LiDAR point cloud imaging characteristics, the method is greatly reduced based on retaining certain 3D space information. High-precision segmentation is efficiently realized to improve point cloud segmentation results easily and adapt to different point cloud segmentation methods. Although the viewpoint shift and the offset prediction method can improve the segmentation results of LiDAR point cloud to a certain extent, an improvement remains possible, especially in the case of a strong correlation between images. Moreover, global and local offset fusion architectures for objects of different types and sizes are designed to utilize the correlation between images, making more accurate, effective predictions for objects in the view.关键词:point cloud segmentation;spherical front view(SFV);scene viewpoint shift;scene viewpoint offset prediction;convolutional neural network(CNN)65|145|5更新时间:2024-05-07
摘要:ObjectiveThe point cloud data of the ground scene collected by LiDAR is large in scale and contains rich spatial structure detail information. Many current point cloud segmentation methods cannot well balance the relationship between the extraction of structure detail information and computation. To solve the problem, the current point cloud learning tasks are mainly divided into direct method and conversion method. The direct method directly extracts features from all point clouds and can obtain more spatial structure information, but the scale of point clouds that can be processed is usually limited. Therefore, the direct method requires other auxiliary processing methods for outdoor scenes with a large data scale. The transformation method adopts projection and voxelization methods to transform the point cloud into a dense representation. The image generated by the point cloud transformation method of projecting the point cloud into 2D graphics is denser and more consistent with people's cognition. Moreover, 2D point clouds are easier to fuse with mature 2D convolutional neural networks (CNN). However, the real spatial structure information will inevitably be lost in the transformation. In addition, for small sample data and small object scenes (such as pedestrians and cyclists), the segmentation performance will decrease. The reasons mainly include the loss of information caused by the imaging characteristics and transformation of LiDAR and the more serious occlusion problems. A scene view point offset method based on the human observation mechanism is proposed in this paper to improve the 3D LiDAR point cloud segmentation performance and solve the problem of loss of spatial detail information in projection.MethodFirst, a spherical projection is exploited to transform the 3D point cloud into a 2D spherical front view (SFV). This method is more consistent with LiDAR imaging, which minimizes the loss of generating new information. Moreover, the generated images are denser, more in line with people's cognition, and easy to be combined with the mature 2D convolutional neural network. In addition, the projection method removes part of the point cloud and reduces the amount of computation. Then, to address the problems of information loss and occlusion, the original viewpoint of SFV is horizontally moved to generate a multiview series. SFV projection solves several problems such as sparseness and occlusion in point clouds, but many spatial details will inevitably be lost in the projection. The 3D object itself can be observed from different angles, and the shape characteristics of different angles can be obtained. Based on this feature, a multi-view observation sequence is formed by moving the projection center to obtain a more reliable sample sequence for point cloud segmentation. In the segmentation network, the information of SFV is downsampled by using the Fire convolutional layer and the maximum pooling layer using a series of network SqueezeSeg. To obtain the full-resolution label features of each point, deconvolution is used to carry out upsampling and obtain the decoding features. The skip layer connection structure is adopted to add the upsampling feature map to the low-level feature map of the same size and better combine the low-level features and high-level semantic features of the network. Although the deviation will improve the segmentation results to some extent, blindly increasing the deviation will add unnecessary computation to the system. Considering the redundancy of the multi-view point sequence, finding the optimal offset point in actual work is important. Finally, the CNN is used to construct the scene viewpoint offset prediction module and predict the optimal scene viewpoint offset.ResultThe dataset adopted in this paper is the converted Karlsruhe Institute of Technology and Toyota Technological Institute(KITTI) dataset. To prove that the proposed method used is suitable for a relatively small dataset, a smaller dataset (contains a training set of 1 182 frames, a validation set of 169 frames) is extracted for ablation experiment verification. In the small sample dataset, after adding the scene viewpoint offset module, the segmentation results of pedestrians and cyclists are improved, and the intersection over union of pedestrians and cyclists at different offset distances are increased by 6.5% and 15.5%, respectively, compared with the original method. After adding the scene viewpoint offset module and the offset prediction module, the crossover ratio of each category is increased by 1.6%3%. On KITTI's raw dataset, compared with other methods, several categories of the intersection over union achieve the best results, and that of the pedestrian increases by 9.1%.ConclusionCombined with the human observation mechanism and LiDAR point cloud imaging characteristics, the method is greatly reduced based on retaining certain 3D space information. High-precision segmentation is efficiently realized to improve point cloud segmentation results easily and adapt to different point cloud segmentation methods. Although the viewpoint shift and the offset prediction method can improve the segmentation results of LiDAR point cloud to a certain extent, an improvement remains possible, especially in the case of a strong correlation between images. Moreover, global and local offset fusion architectures for objects of different types and sizes are designed to utilize the correlation between images, making more accurate, effective predictions for objects in the view.关键词:point cloud segmentation;spherical front view(SFV);scene viewpoint shift;scene viewpoint offset prediction;convolutional neural network(CNN)65|145|5更新时间:2024-05-07 -
 摘要:ObjectiveIntelligent mobile robots are widely used in industry, logistics, home service, and other fields. From complex industrial robots to simple sweeping robots, the ability of simultaneous localization and mapping is essential. Taking the common low-cost sweeping robot as an example, the scheme adopted is to obtain the distance information between the robot and an object in a plane through 2D lidar, and establish occupation grid map by using laser SLAM(simultaneous localization and mapping) to support robot navigation, path planning, and other functions. With the increasing demand of intelligent service, the geometric map with simple information cannot meet the needs of people. Tasks such as "cleaning the chair" and "going to the refrigerator" require the robot to perceive the environment from the geometric level to the content level. In addition to describing the geometric contour of the environment through grid map, the intelligent robot should have the functions of target recognition, semantic segmentation, or scene classification to obtain semantic information. SLAM is a key technology for a mobile robot to explore, perceive, and navigate in an unknown environment, which can be divided into laser SLAM and visual SLAM. Laser SLAM is accurate and convenient for robot navigation and path planning, but it lacks semantic information. The image of visual SLAM can provide rich semantic information with a higher feature discrimination, but the map constructed by visual SLAM cannot be directly used for path planning and navigation. A semantic grid mapping method based on laser camera system is proposed in this paper to realize the construction of semantic map for mobile robot and path planning.MethodTo construct a semantic map that can be used for path planning, this paper uses a monocular camera assisted lidar to extract the object level features and the bounding box segmentation matching algorithm to obtain the semantic laser segmentation data as well as participate in the construction of the map. When the robot constructs the occupation grid map, the grid that stores the semantic information is called the semantic grid. The semantic map updates the occupation probability of the grid corresponding to each object and the semantic information in the grid. Then, through the steps of global optimization, semantic grid clustering, and semantic grid annotation, the semantic grid map with object category and contour is obtained. In addition, semantic tasks are published on the semantic grid map, the semantic weighting algorithm is used to identify the easily moving objects in the environment, and the path planning is improved. This system is mainly divided into three parts: semantic laser data extraction, semantic grid mapping and path planning. The input of the system includes the scanning data of 2D lidar and the pictures of monocular camera, and the output is the semantic grid map that can be used for path planning. Semantic laser segmentation data extraction is based on the laser camera system. The laser radar provides the scanning data in a certain height plane in the space. The module projects the laser segmentation in the camera field of view to the image and matches with the detection frame to obtain the semantic laser segmentation data. When the laser segmentation data are acquired, the semantic grid mapping should be carried out simultaneously. When the laser data are used to construct the grid map, the corresponding objects in the grid are marked with semantics and contour according to the semantic information. Moreover, density-based spatial clustering of applications with noise(DBSCAN) clustering algorithm is used to cluster the grids of the same object category and obtain the grid set representing each independent object. Finally, according to the semantic information of objects in the grid set, the corresponding object positions occupying the grid map are marked with different colors and words, and the semantic grid map is obtained. The semantic grid map contains geometric information and content information of environment, which can provide specific semantic objects for robot path planning and assist robot navigation. Adaptive Monte Carlo localization (AMCL) is used to locate a mobile robot in a 2D environment, and the pose information of a robot is determined. The global path planning uses A* algorithm to plan the global path from the starting point to the target given any target in the map and optimizes it according to the semantic weighting algorithm.ResultThe hardware of the system consists of a mobile robot and a control machine. The robot platform is composed of a kobuki chassis, an Robo Sense(RS) lidar, and a monocular camera. The laptop of the control computer is configured with 2.5 GHz main frequency, Intel Core i5-7300 HQ processor, GTX 1050ti GPU, and 8 G memory. Semantic mapping and path planning system are deployed as software facilities and run in the robot operating system(ROS) environment. The test system is Ubuntu 16.04. First, the performance of semantic laser data extractions is evaluated, and the detection accuracy of different object detection, laser segmentation, and bounding box segmentation matching is measured. Second, the semantic grid mapping experiment realizes the semantic grid mapping of mobile robot in the corridor and office. Results show that the semantic map in this paper integrates the object-level semantics well on the basis of occupying the grid map, enriches the map content, and improves the readability of the map. Finally, in the path planning experiment, the semantic grid map can perceive the environment content, provide semantic information for robot navigation and path planning, and support the intelligent service of robot. Compared with the route in the original map, the path after semantic discrimination is more flexible and more suitable for the situation of mobile objects in map building.ConclusionExperiments in various environments prove that the method proposed can obtain a semantic grid map with a high consistency with the real environment and labeled target information, and the experimental hardware structure is simple, low cost with good performance, and suitable for the navigation and intelligent robotic path plan.关键词:intelligent robot;semantic grid map;laser SLAM(simultaneous localization and mapping);object detection;path planning260|527|0更新时间:2024-05-07
摘要:ObjectiveIntelligent mobile robots are widely used in industry, logistics, home service, and other fields. From complex industrial robots to simple sweeping robots, the ability of simultaneous localization and mapping is essential. Taking the common low-cost sweeping robot as an example, the scheme adopted is to obtain the distance information between the robot and an object in a plane through 2D lidar, and establish occupation grid map by using laser SLAM(simultaneous localization and mapping) to support robot navigation, path planning, and other functions. With the increasing demand of intelligent service, the geometric map with simple information cannot meet the needs of people. Tasks such as "cleaning the chair" and "going to the refrigerator" require the robot to perceive the environment from the geometric level to the content level. In addition to describing the geometric contour of the environment through grid map, the intelligent robot should have the functions of target recognition, semantic segmentation, or scene classification to obtain semantic information. SLAM is a key technology for a mobile robot to explore, perceive, and navigate in an unknown environment, which can be divided into laser SLAM and visual SLAM. Laser SLAM is accurate and convenient for robot navigation and path planning, but it lacks semantic information. The image of visual SLAM can provide rich semantic information with a higher feature discrimination, but the map constructed by visual SLAM cannot be directly used for path planning and navigation. A semantic grid mapping method based on laser camera system is proposed in this paper to realize the construction of semantic map for mobile robot and path planning.MethodTo construct a semantic map that can be used for path planning, this paper uses a monocular camera assisted lidar to extract the object level features and the bounding box segmentation matching algorithm to obtain the semantic laser segmentation data as well as participate in the construction of the map. When the robot constructs the occupation grid map, the grid that stores the semantic information is called the semantic grid. The semantic map updates the occupation probability of the grid corresponding to each object and the semantic information in the grid. Then, through the steps of global optimization, semantic grid clustering, and semantic grid annotation, the semantic grid map with object category and contour is obtained. In addition, semantic tasks are published on the semantic grid map, the semantic weighting algorithm is used to identify the easily moving objects in the environment, and the path planning is improved. This system is mainly divided into three parts: semantic laser data extraction, semantic grid mapping and path planning. The input of the system includes the scanning data of 2D lidar and the pictures of monocular camera, and the output is the semantic grid map that can be used for path planning. Semantic laser segmentation data extraction is based on the laser camera system. The laser radar provides the scanning data in a certain height plane in the space. The module projects the laser segmentation in the camera field of view to the image and matches with the detection frame to obtain the semantic laser segmentation data. When the laser segmentation data are acquired, the semantic grid mapping should be carried out simultaneously. When the laser data are used to construct the grid map, the corresponding objects in the grid are marked with semantics and contour according to the semantic information. Moreover, density-based spatial clustering of applications with noise(DBSCAN) clustering algorithm is used to cluster the grids of the same object category and obtain the grid set representing each independent object. Finally, according to the semantic information of objects in the grid set, the corresponding object positions occupying the grid map are marked with different colors and words, and the semantic grid map is obtained. The semantic grid map contains geometric information and content information of environment, which can provide specific semantic objects for robot path planning and assist robot navigation. Adaptive Monte Carlo localization (AMCL) is used to locate a mobile robot in a 2D environment, and the pose information of a robot is determined. The global path planning uses A* algorithm to plan the global path from the starting point to the target given any target in the map and optimizes it according to the semantic weighting algorithm.ResultThe hardware of the system consists of a mobile robot and a control machine. The robot platform is composed of a kobuki chassis, an Robo Sense(RS) lidar, and a monocular camera. The laptop of the control computer is configured with 2.5 GHz main frequency, Intel Core i5-7300 HQ processor, GTX 1050ti GPU, and 8 G memory. Semantic mapping and path planning system are deployed as software facilities and run in the robot operating system(ROS) environment. The test system is Ubuntu 16.04. First, the performance of semantic laser data extractions is evaluated, and the detection accuracy of different object detection, laser segmentation, and bounding box segmentation matching is measured. Second, the semantic grid mapping experiment realizes the semantic grid mapping of mobile robot in the corridor and office. Results show that the semantic map in this paper integrates the object-level semantics well on the basis of occupying the grid map, enriches the map content, and improves the readability of the map. Finally, in the path planning experiment, the semantic grid map can perceive the environment content, provide semantic information for robot navigation and path planning, and support the intelligent service of robot. Compared with the route in the original map, the path after semantic discrimination is more flexible and more suitable for the situation of mobile objects in map building.ConclusionExperiments in various environments prove that the method proposed can obtain a semantic grid map with a high consistency with the real environment and labeled target information, and the experimental hardware structure is simple, low cost with good performance, and suitable for the navigation and intelligent robotic path plan.关键词:intelligent robot;semantic grid map;laser SLAM(simultaneous localization and mapping);object detection;path planning260|527|0更新时间:2024-05-07 -
 摘要:ObjectiveFeatures have to be more refined to improve the accuracy of image retrieval. As a result, a large amount of irrelevant and redundant features is also produced inevitably, which leads to a high requirement of memory and computation, especially for large-scale image retrieval.Thus, feature selection plays a critical role in image retrieval.Based on the principle of feature number reduction, we propose a novel, effectively connected component feature selection method and explore a tradeoff between image retrieval accuracy and feature selection in this paper.MethodFirst, we construct a pixel-level feature separate graph that contains several connected branches and trivial graphs based on the bag of words(BOW) principle by combining different characteristics such as nearest word cross kernel, feature distance, and feature scale. Then, we calculate the cross kernel among the first D nearest neighbor words of each feature point. If the crossing set is empty and the distance and scale between feature points satisfy the established conditions, we assume that these two feature points belong to the same group. Then, we select features according to the node number of each connected component and the correlation of nearest words of isolated points. In this process, we use inverse document frequency as the weight of the first D nearest neighbor words to measure the contribution. Finally, we transform the problem to minimize the network order of the feature separated graph in guaranteeing the accuracy of image matching and select feature points from isolated point and connected branches. If the maximum cross kernel of the isolated point with other points is greater than the threshold $n$, then we retain it as a valid feature point. If the connected component of the graph is less than the preset threshold $γ$, then we retain these points in the connected branch as valid feature pointsResultWe adopt the public Oxford datasets and Paris datasets, and evaluate the proposed method on the aspects of feature restore requirement, time complex set, and retrieval accuracy using the Kronecker product as the matching kernel. We also compare the proposed method with different feature extraction and selection methods, such as Vlad, spetral regression-locality preserving projection(SR-LPP), and deep learning features. Experimental results demonstrate that the number of features and storage are reduced to more than 50% in guaranteeing the original retrieve accuracy. Compared with other methods, the retrieval time of KD-Tree for the 100 k dictionary is reduced by nearly 58%. The retrieval method is stable, and the selected features have excellent reusability for further clustering and assembling. When using Oxford as a test set, theretrieval accuracies of selected features are similar to the original features in each type of building, and the retrieval accuracy is better for several categories such as Allsouls, Ashmolean, and Keble. Compared with other coding methods and features from fully connected layers, the retrieval accuracy is improved by nearly 7.5% on average.When tested on the Paris dataset, our algorithm improves retrieval accuracy by approximately 2%5% overall.ConclusionExtensive experiments demonstrate the redundancy of largely connected areas and the selectivity of isolated points. We can retain the isolated feature points with the nearest word correlation and finally form a refined feature point set of image by constructing the feature separated graph and discarding the redundant feature points of the large connected area. The retrieval accuracy is comparable with the original feature point set and outperforms the original feature and other encoding methods in several categories. Moreover, the obtained feature points maintain original independence, reduce dimension reduction, and can further achieve clustering. It is convenient to be transplanted and coded in different dictionaries.We attempt to integrate it with principal component analysis(PCA), which can reduce the dimension again only with the time of feature projection, but has an outstanding retrieval effect.关键词:bag of words(BOW);features selection;image retrieval;connected component;aggregated descriptors58|46|0更新时间:2024-05-07
摘要:ObjectiveFeatures have to be more refined to improve the accuracy of image retrieval. As a result, a large amount of irrelevant and redundant features is also produced inevitably, which leads to a high requirement of memory and computation, especially for large-scale image retrieval.Thus, feature selection plays a critical role in image retrieval.Based on the principle of feature number reduction, we propose a novel, effectively connected component feature selection method and explore a tradeoff between image retrieval accuracy and feature selection in this paper.MethodFirst, we construct a pixel-level feature separate graph that contains several connected branches and trivial graphs based on the bag of words(BOW) principle by combining different characteristics such as nearest word cross kernel, feature distance, and feature scale. Then, we calculate the cross kernel among the first D nearest neighbor words of each feature point. If the crossing set is empty and the distance and scale between feature points satisfy the established conditions, we assume that these two feature points belong to the same group. Then, we select features according to the node number of each connected component and the correlation of nearest words of isolated points. In this process, we use inverse document frequency as the weight of the first D nearest neighbor words to measure the contribution. Finally, we transform the problem to minimize the network order of the feature separated graph in guaranteeing the accuracy of image matching and select feature points from isolated point and connected branches. If the maximum cross kernel of the isolated point with other points is greater than the threshold $n$, then we retain it as a valid feature point. If the connected component of the graph is less than the preset threshold $γ$, then we retain these points in the connected branch as valid feature pointsResultWe adopt the public Oxford datasets and Paris datasets, and evaluate the proposed method on the aspects of feature restore requirement, time complex set, and retrieval accuracy using the Kronecker product as the matching kernel. We also compare the proposed method with different feature extraction and selection methods, such as Vlad, spetral regression-locality preserving projection(SR-LPP), and deep learning features. Experimental results demonstrate that the number of features and storage are reduced to more than 50% in guaranteeing the original retrieve accuracy. Compared with other methods, the retrieval time of KD-Tree for the 100 k dictionary is reduced by nearly 58%. The retrieval method is stable, and the selected features have excellent reusability for further clustering and assembling. When using Oxford as a test set, theretrieval accuracies of selected features are similar to the original features in each type of building, and the retrieval accuracy is better for several categories such as Allsouls, Ashmolean, and Keble. Compared with other coding methods and features from fully connected layers, the retrieval accuracy is improved by nearly 7.5% on average.When tested on the Paris dataset, our algorithm improves retrieval accuracy by approximately 2%5% overall.ConclusionExtensive experiments demonstrate the redundancy of largely connected areas and the selectivity of isolated points. We can retain the isolated feature points with the nearest word correlation and finally form a refined feature point set of image by constructing the feature separated graph and discarding the redundant feature points of the large connected area. The retrieval accuracy is comparable with the original feature point set and outperforms the original feature and other encoding methods in several categories. Moreover, the obtained feature points maintain original independence, reduce dimension reduction, and can further achieve clustering. It is convenient to be transplanted and coded in different dictionaries.We attempt to integrate it with principal component analysis(PCA), which can reduce the dimension again only with the time of feature projection, but has an outstanding retrieval effect.关键词:bag of words(BOW);features selection;image retrieval;connected component;aggregated descriptors58|46|0更新时间:2024-05-07
NCIG 2020
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0