
最新刊期
卷 26 , 期 1 , 2021
-
 摘要:With the continuous improvement of vehicle intelligence, the interaction of vehicles with the surrounding environment through perception is increasing. The environment that needs to be dealt with, including many factors such as roads, surrounding traffic and weather conditions, is becoming increasing complex. Limited by the development cycle and cost, especially safety factors and the consideration of complex and diverse working conditions, traditional open road or closed field tests are difficult to meet the requirements of intelligent driving testing. Therefore, simulation test based on digital virtual technology has become a new important means for intelligent driving testing and verification. The simulation test mainly adopts a combination of accurate physical modeling, efficient numerical simulation, and high-fidelity image rendering to realistically construct human-vehicle environment models, including vehicles, roads, weather and lighting, and traffic, and various types of vehicles. The construction of virtual scenarios is a key technology simulation and is particularly important for improving the pressure and acceleration of intelligent driving testing. The virtual scenarios can meet the needs of a large number of diverse test samples to reflect the complex and changeable application environment of intelligent driving. They can also provide a large number of labeled datasets for machine learning that can contain rich data with boundary feature scenario content and lay a solid data foundation for deep learning perception and reinforcement learning planning algorithms. Therefore, the simulation scenario construction technology for intelligent driving test has been investigated worldwide in the current automotive intelligence. As an emerging technology, it still faces many challenges, and its methods need to be studied in depth. This paper systematically expounds the progress and current situation of domestic and foreign studies in simulation scenario construction technology, including automatic scenario construction methods and traffic simulation modeling methods, and focuses on some issues worthy of in-depth study. In the research of scenario construction methods, the key elements and characteristics of the limited scenarios can reflect the infinite richness and complex driving environment. A deep understanding of the network structure and mutual coupling of the scenario is essential for the research of virtual scenario construction. Establishing a description method of the scenario limit and boundary characteristics to form the scenario automated generation method can maximize the potential of accelerated testing of intelligent driving. Researchers have promoted the rapid development of scenario generation technology from different perspectives. However, they often use parameter traversal search ideas to determine the system state space. The development and testing is time consuming and labor intensive due to the unlimited expansion of scenario search. The construction of a scenario with dangerous characteristics requires in-depth exploration of the safety boundary of the ego vehicle driving. Thus, the constructed corner scenario can provide effective information corresponding to real driving for realizing the enhanced generation of the corner characteristics of the scenario. This condition responds to the accelerated testing of intelligent driving systems above level four. In terms of traffic modeling methods, a deep understanding of the driving behavior and interaction characteristics of vehicles is the basis and primary task. Determining the influence law of vehicle driving motion in data information and establishing the traffic model with random dangerous characteristics are the key to realize intelligent driving testing. The current data-driven traffic simulation modeling research mainly describes the microscopic behavior of traffic, but the accurate and true description of driving behavior characteristics is insufficient. The model input is the mutual movement relationship between the vehicle and the surrounding vehicles, and the model output is the speed or trajectory of the vehicle's movement. However, the diversity of results mainly depends on the amount of input data. If the amount of input data is small, the simulation results are monotonous, relying excessively on input data, and lack versatility. Simulating the motion and interaction behavior of different types of agents in a heterogeneous environment is difficult, especially at traffic intersections. At present, replacing the role of physical mechanism models in generality is difficult. This paper introduces the application of PanoSim simulation platform developed by our team and the related research in 2020 China Intelligent Driving Challenge and World Intelligent Driving Challenge. The intelligent driving challenge is based on a variety of scenarios and traffic environments built by the PanoSim simulation environment. This condition allows participating teams to access the simulation scenario database for obtaining vehicle-mounted sensor information in the simulation environment, such as camera video streams, millimeter wave radar data, lidar point cloud data, and true value information. The simulation scenarios of the intelligent driving challenge are mainly divided into two categories: decision-control and perception-decision-control groups. With the continuous development of computer software and hardware, real-time graphics and image processing, virtual reality, especially parallel processing and image rendering and other simulation technologies, and the environment simulation, and sensor modeling technology, the simulation technology for vehicle testing will become the key factor of vehicle intelligent driving technology, product development, and core competency of technology and products.关键词:vehicle intelligent driving;virtual simulation;simulation test;scenario construction;traffic modeling;intelligent driving challenge128|216|9更新时间:2024-05-08
摘要:With the continuous improvement of vehicle intelligence, the interaction of vehicles with the surrounding environment through perception is increasing. The environment that needs to be dealt with, including many factors such as roads, surrounding traffic and weather conditions, is becoming increasing complex. Limited by the development cycle and cost, especially safety factors and the consideration of complex and diverse working conditions, traditional open road or closed field tests are difficult to meet the requirements of intelligent driving testing. Therefore, simulation test based on digital virtual technology has become a new important means for intelligent driving testing and verification. The simulation test mainly adopts a combination of accurate physical modeling, efficient numerical simulation, and high-fidelity image rendering to realistically construct human-vehicle environment models, including vehicles, roads, weather and lighting, and traffic, and various types of vehicles. The construction of virtual scenarios is a key technology simulation and is particularly important for improving the pressure and acceleration of intelligent driving testing. The virtual scenarios can meet the needs of a large number of diverse test samples to reflect the complex and changeable application environment of intelligent driving. They can also provide a large number of labeled datasets for machine learning that can contain rich data with boundary feature scenario content and lay a solid data foundation for deep learning perception and reinforcement learning planning algorithms. Therefore, the simulation scenario construction technology for intelligent driving test has been investigated worldwide in the current automotive intelligence. As an emerging technology, it still faces many challenges, and its methods need to be studied in depth. This paper systematically expounds the progress and current situation of domestic and foreign studies in simulation scenario construction technology, including automatic scenario construction methods and traffic simulation modeling methods, and focuses on some issues worthy of in-depth study. In the research of scenario construction methods, the key elements and characteristics of the limited scenarios can reflect the infinite richness and complex driving environment. A deep understanding of the network structure and mutual coupling of the scenario is essential for the research of virtual scenario construction. Establishing a description method of the scenario limit and boundary characteristics to form the scenario automated generation method can maximize the potential of accelerated testing of intelligent driving. Researchers have promoted the rapid development of scenario generation technology from different perspectives. However, they often use parameter traversal search ideas to determine the system state space. The development and testing is time consuming and labor intensive due to the unlimited expansion of scenario search. The construction of a scenario with dangerous characteristics requires in-depth exploration of the safety boundary of the ego vehicle driving. Thus, the constructed corner scenario can provide effective information corresponding to real driving for realizing the enhanced generation of the corner characteristics of the scenario. This condition responds to the accelerated testing of intelligent driving systems above level four. In terms of traffic modeling methods, a deep understanding of the driving behavior and interaction characteristics of vehicles is the basis and primary task. Determining the influence law of vehicle driving motion in data information and establishing the traffic model with random dangerous characteristics are the key to realize intelligent driving testing. The current data-driven traffic simulation modeling research mainly describes the microscopic behavior of traffic, but the accurate and true description of driving behavior characteristics is insufficient. The model input is the mutual movement relationship between the vehicle and the surrounding vehicles, and the model output is the speed or trajectory of the vehicle's movement. However, the diversity of results mainly depends on the amount of input data. If the amount of input data is small, the simulation results are monotonous, relying excessively on input data, and lack versatility. Simulating the motion and interaction behavior of different types of agents in a heterogeneous environment is difficult, especially at traffic intersections. At present, replacing the role of physical mechanism models in generality is difficult. This paper introduces the application of PanoSim simulation platform developed by our team and the related research in 2020 China Intelligent Driving Challenge and World Intelligent Driving Challenge. The intelligent driving challenge is based on a variety of scenarios and traffic environments built by the PanoSim simulation environment. This condition allows participating teams to access the simulation scenario database for obtaining vehicle-mounted sensor information in the simulation environment, such as camera video streams, millimeter wave radar data, lidar point cloud data, and true value information. The simulation scenarios of the intelligent driving challenge are mainly divided into two categories: decision-control and perception-decision-control groups. With the continuous development of computer software and hardware, real-time graphics and image processing, virtual reality, especially parallel processing and image rendering and other simulation technologies, and the environment simulation, and sensor modeling technology, the simulation technology for vehicle testing will become the key factor of vehicle intelligent driving technology, product development, and core competency of technology and products.关键词:vehicle intelligent driving;virtual simulation;simulation test;scenario construction;traffic modeling;intelligent driving challenge128|216|9更新时间:2024-05-08 -
 摘要:An autonomous driving system(ADS) is a cyber-physical system that integrates a number of complicated software modules, such as high-precision sensors, artificial intelligence, and navigation systems. The autonomous driving software in this system performs sensing, positioning, forecasting, planning, and controlling tasks. With the development of artificial intelligence technologies and the continuous upgrading of onboard hardware devices, advanced autonomous driving software has been applied in a variety of safety-critical scenarios. Thus, the testing technology that assures its stability and reliability has naturally become the focus of academia and industry. To summarize the advance of the testing technology of autonomous driving software, this paper first characterizes the architecture and design of autonomous driving software. It presents the reference architecture of autonomous driving software and details the primary functionality of each component. It also introduces the interaction between these components and summarizes the features and challenges of autonomous driving software testing. Then, this paper extensively reviews the literature, providing a comprehensive discussion on the testing technology of autonomous driving software, which includes three related topics: simulation-based testing, real-scenario testing, and component-oriented testing. Simulation testing provides a method to examine the behaviors of real vehicle software in virtual environments. It constructs the internal and external factors and conditions that influence the software system to simulate various situations faced by autonomous vehicles with different degrees. This paper examines two critical components of simulation testing: the simulation methods and simulation targets. With regard to the simulation methods, software simulation, semi-physical simulation, and X-in-the-loop simulation are investigated. Currently, all these simulation methods are widely employed in autonomous driving software testing. They are capable of reflecting the behaviors of autonomous driving software under various virtual environments and thus enable engineers to test autonomous driving software at a much lower cost. For the simulation targets, this paper details the simulation of static environments, dynamic scenarios, sensors, and vehicle dynamics. Various simulation techniques are designed for these targets and are further employed to test different functionalities of autonomous driving software. For each simulation target, this paper discusses its usage and state-of-the-art simulation techniques. However, because simulation testing can reflect the behavior of autonomous driving software only in a virtual environment, it cannot completely represent the testing results under real scenarios. Compared with simulation testing, the cost of real scenario testing is relatively high, and the testing scale is often small. Thus, it cannot cover the input field and operating environment completely. However, real scenario testing is critical in quality assurance because it is the only way to identify the performance of autonomous driving software under real physical settings. This paper introduces the real-scenario testing cases conducted by the manufacturers of autonomous driving cars, which provide solid data that reflect the real road traffic scenario for the simulation testing of autonomous driving software. Component-oriented testing focuses on assuring the quality of individual components of autonomous driving software. In modern autonomous driving software, deep neural networks (DNNs) play a critical role. They are employed to assist in various driving tasks, such as perception, decision, and planning. However, testing the DNN-embedded software component is significantly different from conventional software components because their business logic is learned from massive data but is not defined with interpretable rules. To ensure the quality of these components, software engineers often adopt data-driven testing techniques. This paper introduces data-driven testing techniques for three primary components, i.e., perception, decision and planning, and controlling. For the perception component, the primary challenge is to generate test data to input into various sensors, such as LiDAR, radar, and camera. The existing solutions are often built based on a mutation algorithm to augment the seed dataset, with the goal of increasing neuron coverages. For the decision and planning component, some researchers leverage reinforcement learning algorithms to combine traditional path planning algorithms, expert systems, and machine learning techniques to enhance the testing engines. For the controlling component, the testing often involves the hardware, including speed controller, steering controller, braking controller, and stability controller. Researchers have evaluated the performance and reliability of controller-oriented algorithms and explored automated test generation methods. Finally, this paper summarizes and analyzes the current challenges of automatic driving software testing and prospects for the future research direction and emphasis of automatic driving software testing technology.关键词:autonomous driving software;survey;simulation testing;data-driven testing;software testing165|712|7更新时间:2024-05-08
摘要:An autonomous driving system(ADS) is a cyber-physical system that integrates a number of complicated software modules, such as high-precision sensors, artificial intelligence, and navigation systems. The autonomous driving software in this system performs sensing, positioning, forecasting, planning, and controlling tasks. With the development of artificial intelligence technologies and the continuous upgrading of onboard hardware devices, advanced autonomous driving software has been applied in a variety of safety-critical scenarios. Thus, the testing technology that assures its stability and reliability has naturally become the focus of academia and industry. To summarize the advance of the testing technology of autonomous driving software, this paper first characterizes the architecture and design of autonomous driving software. It presents the reference architecture of autonomous driving software and details the primary functionality of each component. It also introduces the interaction between these components and summarizes the features and challenges of autonomous driving software testing. Then, this paper extensively reviews the literature, providing a comprehensive discussion on the testing technology of autonomous driving software, which includes three related topics: simulation-based testing, real-scenario testing, and component-oriented testing. Simulation testing provides a method to examine the behaviors of real vehicle software in virtual environments. It constructs the internal and external factors and conditions that influence the software system to simulate various situations faced by autonomous vehicles with different degrees. This paper examines two critical components of simulation testing: the simulation methods and simulation targets. With regard to the simulation methods, software simulation, semi-physical simulation, and X-in-the-loop simulation are investigated. Currently, all these simulation methods are widely employed in autonomous driving software testing. They are capable of reflecting the behaviors of autonomous driving software under various virtual environments and thus enable engineers to test autonomous driving software at a much lower cost. For the simulation targets, this paper details the simulation of static environments, dynamic scenarios, sensors, and vehicle dynamics. Various simulation techniques are designed for these targets and are further employed to test different functionalities of autonomous driving software. For each simulation target, this paper discusses its usage and state-of-the-art simulation techniques. However, because simulation testing can reflect the behavior of autonomous driving software only in a virtual environment, it cannot completely represent the testing results under real scenarios. Compared with simulation testing, the cost of real scenario testing is relatively high, and the testing scale is often small. Thus, it cannot cover the input field and operating environment completely. However, real scenario testing is critical in quality assurance because it is the only way to identify the performance of autonomous driving software under real physical settings. This paper introduces the real-scenario testing cases conducted by the manufacturers of autonomous driving cars, which provide solid data that reflect the real road traffic scenario for the simulation testing of autonomous driving software. Component-oriented testing focuses on assuring the quality of individual components of autonomous driving software. In modern autonomous driving software, deep neural networks (DNNs) play a critical role. They are employed to assist in various driving tasks, such as perception, decision, and planning. However, testing the DNN-embedded software component is significantly different from conventional software components because their business logic is learned from massive data but is not defined with interpretable rules. To ensure the quality of these components, software engineers often adopt data-driven testing techniques. This paper introduces data-driven testing techniques for three primary components, i.e., perception, decision and planning, and controlling. For the perception component, the primary challenge is to generate test data to input into various sensors, such as LiDAR, radar, and camera. The existing solutions are often built based on a mutation algorithm to augment the seed dataset, with the goal of increasing neuron coverages. For the decision and planning component, some researchers leverage reinforcement learning algorithms to combine traditional path planning algorithms, expert systems, and machine learning techniques to enhance the testing engines. For the controlling component, the testing often involves the hardware, including speed controller, steering controller, braking controller, and stability controller. Researchers have evaluated the performance and reliability of controller-oriented algorithms and explored automated test generation methods. Finally, this paper summarizes and analyzes the current challenges of automatic driving software testing and prospects for the future research direction and emphasis of automatic driving software testing technology.关键词:autonomous driving software;survey;simulation testing;data-driven testing;software testing165|712|7更新时间:2024-05-08 -
 摘要:Research on fully automatic driving has been largely spurred by some important international challenges and competitions, such as the well-known Defense Advanced Research Projects Agency Grand Challenge held in 2005. Self-driving cars and autonomous vehicles have migrated from laboratory development and testing conditions to driving on public roads. Self-driving cars are autonomous decision-making systems that process streams of observations coming from different on-board sources, such as cameras, radars, lidars, ultrasonic sensors, global positioning system units, and/or inertial sensors. The development of autonomous vehicles offers a decrease in road accidents and traffic congestions. Most driving scenarios can be simply solved with classical perception, path planning, and motion control methods. However, the remaining unsolved scenarios are corner cases where traditional methods fail. In the past decade, advances in the field of artificial intelligence (AI) and machine learning (ML) have greatly promoted the development of autonomous driving. Autonomous driving is a challenging application domain for ML. ML methods can be divided into supervised learning, unsupervised learning, and reinforcement learning (RL). RL is a family of algorithms that allow agents to learn how to act in different situations. In other words, a map or a policy is established from situations (states) to actions to maximize a numerical reward signal. Most autonomous vehicles have a modular hierarchical structure and can be divided into four components or four layers, namely, perception, decision making, control, and actuator. RL is suitable for decision making and control in complex traffic scenarios to improve the safety and comfort of autonomous driving. Traditional controllers utilize an a priori model composed of fixed parameters. When robots or other autonomous systems are used in complex environments, such as driving, traditional controllers cannot foresee every possible situation that the system has to cope with. An RL controller is a learning controller and uses training information to learn their models over time. With every gathered batch of training data, the approximation of the true system model becomes accurate. Deep neural networks have been applied as function approximators for RL agents, thereby allowing agents to generalize knowledge to new unseen situations, along with new algorithms for problems with continuous state and action spaces. This paper mainly introduces the current status and progress of the application of RL methods in autonomous driving control. This paper consists of five sections. The first section introduces the background of autonomous driving and some basic knowledge about ML and RL. The second section briefly describes the architecture of autonomous driving framework. The control layer is an important part of an autonomous vehicle and has always been a key area of autonomous driving technology research. The control system of autonomous driving mainly includes lateral control and longitudinal control, namely, steering control and velocity control. Lateral control deals with the path tracking problem, and longitudinal control deals with the problem of tracking the reference speed and keeping a safe distance from the preceding vehicle. The third section introduces the basic principles of RL methods and focuses on the current research status of RL in autonomous driving control. RL algorithms are based on Markov decision process and aim to learn mapping from situations to actions to maximize a scalar reward or reinforcement signal. RL is a new and extremely old topic in AI. It gradually became an active and identifiable area of ML in 1980 s. Q-learning is a widely used RL algorithm. However, it is based on tabular setting and can only deal with those problems with low dimension and discrete state/action spaces. A primary goal of AI is to solve complex tasks from unprocessed, high-dimensional, sensory input. Significant progress has been made by combining deep learning for sensory processing with RL, resulting in the "deep Q network" (DQN) algorithm that is capable of human-level performance on many Atari video games using unprocessed pixels for input. However, DQN can only handle discrete and low-dimensional action spaces. Deep deterministic policy gradient was proposed to handle those problems with continuous state/action spaces. It can learn policies directly from raw pixel inputs. The fourth section generalizes some typical applications of RL algorithm in autonomous driving, including some studies of our team. Unlike supervised learning, RL is more suitable for decision making and control of autonomous driving. Most of the RL algorithms used in autonomous driving mostly combine deep learning and use raw pixels as input to achieve end-to-end control. The last section discusses the challenges encountered in the application of RL algorithms in autonomous driving control. The first challenge is how to deploy the RL model trained on a simulator to run in a real environment and ensure safety. The second challenge is the RL problem in an environment with multiple participants. Multiagent RL is a direction of RL development, but training multiagents is more complicated than training a single agent. The third challenge is how to train an agent with a reasonable reward function. In most RL settings, we typically assume that a reward function is given, but this is not always the case. Imitation learning and reverse RL provide an effective solution for obtaining the real reward function that makes the performance of the agent close to a human. This article helps to understand the advantages and limitations of RL methods in autonomous driving control, the potential of deep RL, and can serve as reference for the design of automatic driving control systems.关键词:autonomous driving;decision control;Markov decision process(MDP);reinforcement learning(RL);data-driven;autonomous learning414|128|5更新时间:2024-05-08
摘要:Research on fully automatic driving has been largely spurred by some important international challenges and competitions, such as the well-known Defense Advanced Research Projects Agency Grand Challenge held in 2005. Self-driving cars and autonomous vehicles have migrated from laboratory development and testing conditions to driving on public roads. Self-driving cars are autonomous decision-making systems that process streams of observations coming from different on-board sources, such as cameras, radars, lidars, ultrasonic sensors, global positioning system units, and/or inertial sensors. The development of autonomous vehicles offers a decrease in road accidents and traffic congestions. Most driving scenarios can be simply solved with classical perception, path planning, and motion control methods. However, the remaining unsolved scenarios are corner cases where traditional methods fail. In the past decade, advances in the field of artificial intelligence (AI) and machine learning (ML) have greatly promoted the development of autonomous driving. Autonomous driving is a challenging application domain for ML. ML methods can be divided into supervised learning, unsupervised learning, and reinforcement learning (RL). RL is a family of algorithms that allow agents to learn how to act in different situations. In other words, a map or a policy is established from situations (states) to actions to maximize a numerical reward signal. Most autonomous vehicles have a modular hierarchical structure and can be divided into four components or four layers, namely, perception, decision making, control, and actuator. RL is suitable for decision making and control in complex traffic scenarios to improve the safety and comfort of autonomous driving. Traditional controllers utilize an a priori model composed of fixed parameters. When robots or other autonomous systems are used in complex environments, such as driving, traditional controllers cannot foresee every possible situation that the system has to cope with. An RL controller is a learning controller and uses training information to learn their models over time. With every gathered batch of training data, the approximation of the true system model becomes accurate. Deep neural networks have been applied as function approximators for RL agents, thereby allowing agents to generalize knowledge to new unseen situations, along with new algorithms for problems with continuous state and action spaces. This paper mainly introduces the current status and progress of the application of RL methods in autonomous driving control. This paper consists of five sections. The first section introduces the background of autonomous driving and some basic knowledge about ML and RL. The second section briefly describes the architecture of autonomous driving framework. The control layer is an important part of an autonomous vehicle and has always been a key area of autonomous driving technology research. The control system of autonomous driving mainly includes lateral control and longitudinal control, namely, steering control and velocity control. Lateral control deals with the path tracking problem, and longitudinal control deals with the problem of tracking the reference speed and keeping a safe distance from the preceding vehicle. The third section introduces the basic principles of RL methods and focuses on the current research status of RL in autonomous driving control. RL algorithms are based on Markov decision process and aim to learn mapping from situations to actions to maximize a scalar reward or reinforcement signal. RL is a new and extremely old topic in AI. It gradually became an active and identifiable area of ML in 1980 s. Q-learning is a widely used RL algorithm. However, it is based on tabular setting and can only deal with those problems with low dimension and discrete state/action spaces. A primary goal of AI is to solve complex tasks from unprocessed, high-dimensional, sensory input. Significant progress has been made by combining deep learning for sensory processing with RL, resulting in the "deep Q network" (DQN) algorithm that is capable of human-level performance on many Atari video games using unprocessed pixels for input. However, DQN can only handle discrete and low-dimensional action spaces. Deep deterministic policy gradient was proposed to handle those problems with continuous state/action spaces. It can learn policies directly from raw pixel inputs. The fourth section generalizes some typical applications of RL algorithm in autonomous driving, including some studies of our team. Unlike supervised learning, RL is more suitable for decision making and control of autonomous driving. Most of the RL algorithms used in autonomous driving mostly combine deep learning and use raw pixels as input to achieve end-to-end control. The last section discusses the challenges encountered in the application of RL algorithms in autonomous driving control. The first challenge is how to deploy the RL model trained on a simulator to run in a real environment and ensure safety. The second challenge is the RL problem in an environment with multiple participants. Multiagent RL is a direction of RL development, but training multiagents is more complicated than training a single agent. The third challenge is how to train an agent with a reasonable reward function. In most RL settings, we typically assume that a reward function is given, but this is not always the case. Imitation learning and reverse RL provide an effective solution for obtaining the real reward function that makes the performance of the agent close to a human. This article helps to understand the advantages and limitations of RL methods in autonomous driving control, the potential of deep RL, and can serve as reference for the design of automatic driving control systems.关键词:autonomous driving;decision control;Markov decision process(MDP);reinforcement learning(RL);data-driven;autonomous learning414|128|5更新时间:2024-05-08 -
 摘要:As a key infrastructure to realize autonomous driving, an autonomous driving map can provide a large amount of accurate and semantically rich data to help users understand the surrounding environment in a more detailed scale; assist perception, positioning, driving planning, and decision control; and meet various high-level application requirements in the era of intelligence and then effectively promote the development and commercial application of China's autonomous driving related fields. An autonomous driving map data standard guides the production and application of autonomous driving maps, thus serving as the benchmark for the standardization of autonomous driving map data. At present, there is an urgent need for autonomous driving map standardization is urgently needed in the fields related to autonomous driving in China, and map data standardization has become a hot issue of common concern in the industry. To solve the problem of autonomous driving map data standardization and promote the efficient development of autonomous driving maps, this paper conducts a comparative study on data standards of autonomous driving maps. First, this paper briefly introduces the mainstream autonomous driving map data standards at home and abroad. Popular international autonomous driving map data standards mainly include NDS(navigation data standard), OpenDrive, and Kiwi. The development of autonomous driving map data standards in China started relatively late compared with that in foreign countries. Most of the relevant standards are in the state of formulation or project approval and have not been commercialized on a large scale. At present, domestic mainstream autonomous driving map data standards mainly include intelligent transportation system-intelligent map data model and exchange format specification, road high-precision electronic navigation map data specification, and Apollo OpenDrive. Second, this paper analyzes and compares four of them, namely, NDS, OpenDrive, intelligent transportation system-intelligent map data model and exchange format specification, and road high-precision electronic navigation map data specification. The comparative research is mainly carried out from four dimensions of data structure, data model, map rendering and collaborative application, and the proposed principles for data standard compilation are given in each dimension: 1) In terms of data structures, the data structure of autonomous driving map can be divided into logical structure and physical structure, which are closely related and often serve as the basic content of each data standard to determine the definition of data standard in map data file storage format and data logic organization model, thus directly affecting the compilation of data standard. By comparing and analyzing the data structures defined by the four autonomous driving map data standards, this paper clearly suggests that the database technology should be used to store map data in the form of tables, and the hierarchical data organization method should be adopted to support flexible and efficient data storage, interaction, and update. 2) In terms of data models, the data model is used to specify the elements (objects), attributes, and relationships contained in the autonomous driving map data, and explains how to carry out data classification, coding, geometry, and topology representation, thus often serving as the core content of each data standard. By comparing and analyzing the data models defined by the four autonomous driving map data standards, this paper clearly suggests that, on the basis of further expanding the data content of autonomous driving map to include more relevant elements and attributes, a method similar to map layerization should be adopted to modularize the data organization (including geometric topology network data), to improve the flexibility and applicability of autonomous driving maps. 3) In terms of map rendering, autonomous driving map will be oriented to the human-computer shared environment in the future, which needs to meet the needs of both human map recognition and machine understanding. Therefore, the map data standard should include map rendering and support hierarchical map display to improve the efficiency of map display and path calculation. 4) In terms of collaborative applications, after years of development, a standard navigation map has become rich in road traffic information, such as point-of-interest information, which focuses on describing the real world in a macro sense. By contrast, an autonomous driving map focuses on describing the environmental conditions of roads and surrounding areas, as well as the topological connection relationship between lanes. Although an autonomous driving map has more accurate road and lane geometry data, it lacks the rich data content of standard navigation maps and especially lacks point-of-interest information, which makes the navigation function difficult to realize. To address this problem, the cooperative application relationship between autonomous driving map and standard navigation map needs to be established, which can ensure complementary information between an autonomous driving map and a standard navigation map, and then effectively deal with different requirements. On the basis of the results of comparative analysis, this paper summarizes the principles that should be followed when compiling the data standard of autonomous driving maps. By analyzing and comparing the data standards of autonomous driving map, this paper summarizes the proposed principles in compiling data standards, which are of reference significance to the formulation of relevant specifications and standards in China.关键词:autonomous driving;autonomous driving map;data standard;autonomous driving map data standard;compiling principle181|297|22更新时间:2024-05-08
摘要:As a key infrastructure to realize autonomous driving, an autonomous driving map can provide a large amount of accurate and semantically rich data to help users understand the surrounding environment in a more detailed scale; assist perception, positioning, driving planning, and decision control; and meet various high-level application requirements in the era of intelligence and then effectively promote the development and commercial application of China's autonomous driving related fields. An autonomous driving map data standard guides the production and application of autonomous driving maps, thus serving as the benchmark for the standardization of autonomous driving map data. At present, there is an urgent need for autonomous driving map standardization is urgently needed in the fields related to autonomous driving in China, and map data standardization has become a hot issue of common concern in the industry. To solve the problem of autonomous driving map data standardization and promote the efficient development of autonomous driving maps, this paper conducts a comparative study on data standards of autonomous driving maps. First, this paper briefly introduces the mainstream autonomous driving map data standards at home and abroad. Popular international autonomous driving map data standards mainly include NDS(navigation data standard), OpenDrive, and Kiwi. The development of autonomous driving map data standards in China started relatively late compared with that in foreign countries. Most of the relevant standards are in the state of formulation or project approval and have not been commercialized on a large scale. At present, domestic mainstream autonomous driving map data standards mainly include intelligent transportation system-intelligent map data model and exchange format specification, road high-precision electronic navigation map data specification, and Apollo OpenDrive. Second, this paper analyzes and compares four of them, namely, NDS, OpenDrive, intelligent transportation system-intelligent map data model and exchange format specification, and road high-precision electronic navigation map data specification. The comparative research is mainly carried out from four dimensions of data structure, data model, map rendering and collaborative application, and the proposed principles for data standard compilation are given in each dimension: 1) In terms of data structures, the data structure of autonomous driving map can be divided into logical structure and physical structure, which are closely related and often serve as the basic content of each data standard to determine the definition of data standard in map data file storage format and data logic organization model, thus directly affecting the compilation of data standard. By comparing and analyzing the data structures defined by the four autonomous driving map data standards, this paper clearly suggests that the database technology should be used to store map data in the form of tables, and the hierarchical data organization method should be adopted to support flexible and efficient data storage, interaction, and update. 2) In terms of data models, the data model is used to specify the elements (objects), attributes, and relationships contained in the autonomous driving map data, and explains how to carry out data classification, coding, geometry, and topology representation, thus often serving as the core content of each data standard. By comparing and analyzing the data models defined by the four autonomous driving map data standards, this paper clearly suggests that, on the basis of further expanding the data content of autonomous driving map to include more relevant elements and attributes, a method similar to map layerization should be adopted to modularize the data organization (including geometric topology network data), to improve the flexibility and applicability of autonomous driving maps. 3) In terms of map rendering, autonomous driving map will be oriented to the human-computer shared environment in the future, which needs to meet the needs of both human map recognition and machine understanding. Therefore, the map data standard should include map rendering and support hierarchical map display to improve the efficiency of map display and path calculation. 4) In terms of collaborative applications, after years of development, a standard navigation map has become rich in road traffic information, such as point-of-interest information, which focuses on describing the real world in a macro sense. By contrast, an autonomous driving map focuses on describing the environmental conditions of roads and surrounding areas, as well as the topological connection relationship between lanes. Although an autonomous driving map has more accurate road and lane geometry data, it lacks the rich data content of standard navigation maps and especially lacks point-of-interest information, which makes the navigation function difficult to realize. To address this problem, the cooperative application relationship between autonomous driving map and standard navigation map needs to be established, which can ensure complementary information between an autonomous driving map and a standard navigation map, and then effectively deal with different requirements. On the basis of the results of comparative analysis, this paper summarizes the principles that should be followed when compiling the data standard of autonomous driving maps. By analyzing and comparing the data standards of autonomous driving map, this paper summarizes the proposed principles in compiling data standards, which are of reference significance to the formulation of relevant specifications and standards in China.关键词:autonomous driving;autonomous driving map;data standard;autonomous driving map data standard;compiling principle181|297|22更新时间:2024-05-08 -
 摘要:A visual perception module can use cameras to obtain various image features for detecting peripheral information, such as vehicles, pedestrians, and traffic signs in the visual field of self-driving vehicle. This module is an effective and low cost perception method for autonomous driving. Motion planning provides self-driving vehicles with a series of motion parameters and driving actions from the initial state to the target state of the vehicle. It makes the vehicle subject to collision avoidance and dynamic constraints from the external environment and spatial-temporal constraint from the internal system during the whole traveling process. Traditional autonomous driving approaches refer to constructing intermediate processes from the sensor inputs to the actuator outputs into a plurality of independent submodules, such as perception, planning, decision making, and control. However, traditional modular approaches require the design and selection of features, camera calibration, and manual adjustment of parameters. Therefore, autonomous driving systems based on traditional modular approaches do not have complete autonomy. With the rapid development of big data, computer performance, and deep learning algorithms, increasing researchers apply deep learning to autonomous driving. An end-to-end model based on deep learning obtains the vehicle motion parameters directly from the perceived data and can fully embody the autonomy of autonomous driving. Thus, this model has been widely investigated in recent years. The representative and cutting-edge papers published locally and overseas are summarized in this paper to fully review the research progress of end-to-end motion planning for autonomous driving with visual perception. Applications of the end-to-end model in computer vision tasks and games are introduced. The complexity of tasks solved by end-to-end approaches is higher than that of autonomous driving in some other fields. End-to-end approaches can be successfully applied in the commercial field of autonomous driving. The important roles of visual perception and motion planning in end-to-end autonomous driving are analyzed by comparing the advantages and disadvantages of different input and output modes. On the basis of the learning methods of autonomous vehicles, the implementation methods of end-to-end motion planning for autonomous driving with visual perception are divided into imitation learning and reinforcement learning. Imitation learning methods can be divided into two major mainstream algorithms, namely, behavior cloning and dataset aggregation. Two recently proposed imitation learning methods, including observation imitation and conditional imitation learning, are analyzed. In reinforcement learning, value-based and policy-based methods are mainly introduced. Advanced reinforcement learning methods, such as inverse reinforcement learning and hierarchical reinforcement learning, are presented. The research of the end-to-end model for autonomous driving faces transitions from virtual scenarios to real scenarios at this stage. Transfer learning methods are combined from three aspects, including image conversion, domain adaptation, and domain randomization. On this basis, the basic idea and network structure of each method are described. Autonomous driving models are usually evaluated in a simulation environment by means of public datasets and simulation platforms. The datasets and simulation platforms related to autonomous driving are listed and analyzed from the perspectives of publication time, configuration, and applicable condition. The existing problems, challenges, thinking, and outlook are summarized. End-to-end motion planning for autonomous driving with visual perception has strong universality and simple structure. However, explaining and ensuring absolute safety are difficult. The method of generating accountable intermediate representation is expected to solve the inexplicable problem. Therefore, end-to-end motion planning methods for autonomous driving with visual perception have a broad application prospect and research value. However, many studies are needed to improve the limitations of the proposed model in the future.关键词:visual perception;motion planning;end-to-end;autonomous driving;imitation learning;reinforcement learning198|617|6更新时间:2024-05-08
摘要:A visual perception module can use cameras to obtain various image features for detecting peripheral information, such as vehicles, pedestrians, and traffic signs in the visual field of self-driving vehicle. This module is an effective and low cost perception method for autonomous driving. Motion planning provides self-driving vehicles with a series of motion parameters and driving actions from the initial state to the target state of the vehicle. It makes the vehicle subject to collision avoidance and dynamic constraints from the external environment and spatial-temporal constraint from the internal system during the whole traveling process. Traditional autonomous driving approaches refer to constructing intermediate processes from the sensor inputs to the actuator outputs into a plurality of independent submodules, such as perception, planning, decision making, and control. However, traditional modular approaches require the design and selection of features, camera calibration, and manual adjustment of parameters. Therefore, autonomous driving systems based on traditional modular approaches do not have complete autonomy. With the rapid development of big data, computer performance, and deep learning algorithms, increasing researchers apply deep learning to autonomous driving. An end-to-end model based on deep learning obtains the vehicle motion parameters directly from the perceived data and can fully embody the autonomy of autonomous driving. Thus, this model has been widely investigated in recent years. The representative and cutting-edge papers published locally and overseas are summarized in this paper to fully review the research progress of end-to-end motion planning for autonomous driving with visual perception. Applications of the end-to-end model in computer vision tasks and games are introduced. The complexity of tasks solved by end-to-end approaches is higher than that of autonomous driving in some other fields. End-to-end approaches can be successfully applied in the commercial field of autonomous driving. The important roles of visual perception and motion planning in end-to-end autonomous driving are analyzed by comparing the advantages and disadvantages of different input and output modes. On the basis of the learning methods of autonomous vehicles, the implementation methods of end-to-end motion planning for autonomous driving with visual perception are divided into imitation learning and reinforcement learning. Imitation learning methods can be divided into two major mainstream algorithms, namely, behavior cloning and dataset aggregation. Two recently proposed imitation learning methods, including observation imitation and conditional imitation learning, are analyzed. In reinforcement learning, value-based and policy-based methods are mainly introduced. Advanced reinforcement learning methods, such as inverse reinforcement learning and hierarchical reinforcement learning, are presented. The research of the end-to-end model for autonomous driving faces transitions from virtual scenarios to real scenarios at this stage. Transfer learning methods are combined from three aspects, including image conversion, domain adaptation, and domain randomization. On this basis, the basic idea and network structure of each method are described. Autonomous driving models are usually evaluated in a simulation environment by means of public datasets and simulation platforms. The datasets and simulation platforms related to autonomous driving are listed and analyzed from the perspectives of publication time, configuration, and applicable condition. The existing problems, challenges, thinking, and outlook are summarized. End-to-end motion planning for autonomous driving with visual perception has strong universality and simple structure. However, explaining and ensuring absolute safety are difficult. The method of generating accountable intermediate representation is expected to solve the inexplicable problem. Therefore, end-to-end motion planning methods for autonomous driving with visual perception have a broad application prospect and research value. However, many studies are needed to improve the limitations of the proposed model in the future.关键词:visual perception;motion planning;end-to-end;autonomous driving;imitation learning;reinforcement learning198|617|6更新时间:2024-05-08
Review

-
 摘要:ObjectiveAs a promising solution to traffic congestion and accidents, intelligent vehicles are receiving increasing attention. Efficient visual perception technology can meet the safety, comfortable, and convenience requirements of intelligent vehicles. Therefore, visual perception is a key technology in intelligent vehicle systems. Intelligent driving focuses on improving visual performance under complex tasks. However, the complex imaging conditions bring significant challenges to visual perception research. As we know, vision models rely on diverse datasets to ensure performance. Unfortunately, obtaining annotations by hand is cumbersome, labor intensive, and error prone. Moreover, the cost of data collection and annotation is high. As a result of the limitation of model design and data diversity, general visual tasks still face problems such as weather and illumination changes, and occlusions. A critical question arises naturally: How could we ensure that an intelligent vehicle is able to drive safely in complex and challenging traffic? In this paper, the artificial systems, computational experiments, and parallel execution (ACP) method is introduced into the field of visual perception. We propose parallel visual perception for intelligent driving. The purpose of this paper is to solve the problem of reasonable training and evaluation of the vision model of intelligent driving, which is helpful for the further application of intelligent vehicles.MethodParallel visual perception consists of three parts: artificial driving scene, computational experiments, and parallel execution. Specifically, artificial driving scene is a scene defined by software, which is completed by modern 3D model software, computer graphics, and virtual reality. Artificial driving scene modeling adopts the combination of artificial subsystems, which is helpful for intelligent driving to perceive and understand the experiment of complex conditions. In the artificial scene, we use computer graphics to automatically generate accurate ground-truth labels, including semantic/instance segmentation, object bounding box, object tracking, optical flow, and depth. According to the imaging conditions, we design 19 challenging tasks divided into normal, environmental, and difficult tasks. The reliability of the vision model requires repeatable computational experiments to obtain the optimal solution. Two models of computational experiments are used, namely, learning and training, and experiment and evaluation. In the training stage, the artificial driving scene provides a large variety of virtual images, which, combined with the real images, can improve the performance of the vision model. Therefore, the experiment can be conducted in an artificial driving scene at a low cost and with high efficiency. In the evaluation stage, complex imaging conditions (weather, illumination, and occlusion) in an artificial driving scene can be used to comprehensively evaluate the performance of the vision model. The vision algorithm can be specially tested, which is helpful to improve the visual perception performance of intelligent driving. The parallel execution in artificial and real driving scenes can ensure dynamic and long-term vision model training and evaluation. Through the virtual and real interaction method, the experimental results of the vision model in the artificial driving scene can become a possible result of the real system.ResultThis paper presents a systematic method to design driving scene tasks and generate virtual datasets for vehicle intelligence testing research. Currently, the virtual dataset consists of 39 010 frames (virtual training data with 27 970 frames, normal tasks with 5 520 frames, environmental tasks with 2 760 frames, and difficult tasks with 2 760 frames) taken from our constructed artificial scenes. In addition, we conduct a series of comparative experiments for visual object detection. In the training stage, the experimental results show that the training data with large scale and diversity can greatly improve the performance of object detection. In addition, the data augmentation method can significantly improve the accuracy of the vision models. For instance, the highest accuracy of the mixed training sets is 60.9%, and that of KPC(KITTI(Karlsruhe Institute of Technology and Toyta Technological Institute), PASCAL VOC(pattern analysis, statistical modelling and computational learning visual object classes), MS COCO(Microsoft common objects in context)) and pure virtual data decreased by 17.9% and 5.3%, respectively. In the evaluation stage, compared with the baseline model, the average accuracy of normal tasks (-30° and up-down) decreased by 11.3%, environmental tasks (fog) by 21.0%, and difficult tasks (all challenges) by 33.7%. Experimental results suggest that 1) object detectors are slightly disturbed under different camera angles and are more challenged when the height and angle of the camera are changed simultaneously. The vision model of intelligent vehicle is prone to overfitting, which is why object detection can be performed under limited conditions only; 2) the vision model cannot obtain the features of different environments from the training data. Therefore, bad weather (e.g., fog and rain) causes a stronger degradation of performance than normal tasks; and 3) the performance of object detection will be greatly influenced in difficult tasks, which is mainly caused by the poor generalization performance of the vision model.ConclusionIn this study, we use computer graphics, virtual reality technology, and machine learning theory to build artificial driving scenes and generate a realistic and challenging virtual driving dataset. On this basis, we conduct visual perception experiments under complex imaging conditions. The vision models of intelligent vehicle are effectively trained and evaluated in artificial and real driving scenes. In the future, we plan to add more visual challenges to the artificial driving scene.关键词:intelligent driving;parallel intelligence;virtual image;synthetic image;object detection96|231|4更新时间:2024-05-08
摘要:ObjectiveAs a promising solution to traffic congestion and accidents, intelligent vehicles are receiving increasing attention. Efficient visual perception technology can meet the safety, comfortable, and convenience requirements of intelligent vehicles. Therefore, visual perception is a key technology in intelligent vehicle systems. Intelligent driving focuses on improving visual performance under complex tasks. However, the complex imaging conditions bring significant challenges to visual perception research. As we know, vision models rely on diverse datasets to ensure performance. Unfortunately, obtaining annotations by hand is cumbersome, labor intensive, and error prone. Moreover, the cost of data collection and annotation is high. As a result of the limitation of model design and data diversity, general visual tasks still face problems such as weather and illumination changes, and occlusions. A critical question arises naturally: How could we ensure that an intelligent vehicle is able to drive safely in complex and challenging traffic? In this paper, the artificial systems, computational experiments, and parallel execution (ACP) method is introduced into the field of visual perception. We propose parallel visual perception for intelligent driving. The purpose of this paper is to solve the problem of reasonable training and evaluation of the vision model of intelligent driving, which is helpful for the further application of intelligent vehicles.MethodParallel visual perception consists of three parts: artificial driving scene, computational experiments, and parallel execution. Specifically, artificial driving scene is a scene defined by software, which is completed by modern 3D model software, computer graphics, and virtual reality. Artificial driving scene modeling adopts the combination of artificial subsystems, which is helpful for intelligent driving to perceive and understand the experiment of complex conditions. In the artificial scene, we use computer graphics to automatically generate accurate ground-truth labels, including semantic/instance segmentation, object bounding box, object tracking, optical flow, and depth. According to the imaging conditions, we design 19 challenging tasks divided into normal, environmental, and difficult tasks. The reliability of the vision model requires repeatable computational experiments to obtain the optimal solution. Two models of computational experiments are used, namely, learning and training, and experiment and evaluation. In the training stage, the artificial driving scene provides a large variety of virtual images, which, combined with the real images, can improve the performance of the vision model. Therefore, the experiment can be conducted in an artificial driving scene at a low cost and with high efficiency. In the evaluation stage, complex imaging conditions (weather, illumination, and occlusion) in an artificial driving scene can be used to comprehensively evaluate the performance of the vision model. The vision algorithm can be specially tested, which is helpful to improve the visual perception performance of intelligent driving. The parallel execution in artificial and real driving scenes can ensure dynamic and long-term vision model training and evaluation. Through the virtual and real interaction method, the experimental results of the vision model in the artificial driving scene can become a possible result of the real system.ResultThis paper presents a systematic method to design driving scene tasks and generate virtual datasets for vehicle intelligence testing research. Currently, the virtual dataset consists of 39 010 frames (virtual training data with 27 970 frames, normal tasks with 5 520 frames, environmental tasks with 2 760 frames, and difficult tasks with 2 760 frames) taken from our constructed artificial scenes. In addition, we conduct a series of comparative experiments for visual object detection. In the training stage, the experimental results show that the training data with large scale and diversity can greatly improve the performance of object detection. In addition, the data augmentation method can significantly improve the accuracy of the vision models. For instance, the highest accuracy of the mixed training sets is 60.9%, and that of KPC(KITTI(Karlsruhe Institute of Technology and Toyta Technological Institute), PASCAL VOC(pattern analysis, statistical modelling and computational learning visual object classes), MS COCO(Microsoft common objects in context)) and pure virtual data decreased by 17.9% and 5.3%, respectively. In the evaluation stage, compared with the baseline model, the average accuracy of normal tasks (-30° and up-down) decreased by 11.3%, environmental tasks (fog) by 21.0%, and difficult tasks (all challenges) by 33.7%. Experimental results suggest that 1) object detectors are slightly disturbed under different camera angles and are more challenged when the height and angle of the camera are changed simultaneously. The vision model of intelligent vehicle is prone to overfitting, which is why object detection can be performed under limited conditions only; 2) the vision model cannot obtain the features of different environments from the training data. Therefore, bad weather (e.g., fog and rain) causes a stronger degradation of performance than normal tasks; and 3) the performance of object detection will be greatly influenced in difficult tasks, which is mainly caused by the poor generalization performance of the vision model.ConclusionIn this study, we use computer graphics, virtual reality technology, and machine learning theory to build artificial driving scenes and generate a realistic and challenging virtual driving dataset. On this basis, we conduct visual perception experiments under complex imaging conditions. The vision models of intelligent vehicle are effectively trained and evaluated in artificial and real driving scenes. In the future, we plan to add more visual challenges to the artificial driving scene.关键词:intelligent driving;parallel intelligence;virtual image;synthetic image;object detection96|231|4更新时间:2024-05-08 -
 摘要:ObjectiveComputer vision makes the camera and computer the "eyes" of the computer, which can have the abilities of segmentation, classification, recognition, tracking and decision-making. In recent years, computer vision technology has been widely used in intelligent transportation, unmanned driving, robot navigation, intelligent video monitoring, and many other fields. At present, the camera has become the most commonly used sensing equipment in automatic driving and smart cities, generating massive image and video data. We can realize real-time analysis and processing of these data only by relying on computer vision technology. We can detect all kinds of objects in real time and obtain their position and motion states accurately from the image video. However, the actual scene has a very high complexity. Many complex factors interweave together, which poses a great challenge to the visual computing system. At present, computer vision technology is mainly based on the deep learning method through large-scale data-driven mechanisms. Sufficient data are needed due to the heavy dependence of its training algorithm mechanism on datasets. However, collecting and labeling large-scale image data from actual scenes are time-consuming and labor-intensive tasks, and usually, only small-scale and limited diversity of image data can be obtained. For example, Microsoft common objects in context(MS COCO), a popular dataset used for instance segmentation tasks, has a size of about 300 000 and mainly 91 categories. Expressing the complexity of reality and simulate the real situation is difficult. The model trained on the limited dataset will lack practical significance, because the dataset is not large enough to represent the real data distribution and cannot guarantee the effectiveness of practical application.MethodThe theory of social computing and parallel systems is proposed based on artificial systems, computational experiments, and parallel execution (ACP). The ACP methodology plays an essential role in modeling and control of complex systems. A virtual artificial society is constructed to connect the virtual and the real world through parallel management. On the basis of the existing facts, artificial system is used to model the behavior of complex systems by using advanced computing experiments and then analyze its behavior and interact with reality to obtain a better operating system than reality. To address the bottleneck of deep learning in the field of computer vision, this paper proposes parallel vision, a visual analysis framework based on parallel learning. Parallel vision is an intelligent visual perception framework that is an extension of the ACP methodology into the computer vision field. In the framework of parallel vision, large-scale realistic artificial images can be obtained easily to give support to the vision algorithm with enough well-labeled image data. In this way, the computer can be turned into a "laboratory" of computational intelligence. First, the artificial image system simulates the imaging conditions that may appear in the actual image, uses the internal parameters of the system to automatically obtain the annotation information, and obtains the required artificial images. Then, we use the predictive learning method to design the visual perception model, and then we use the computational experiment method to conduct experiments. Various experiments are conducted on a rich supply of image data generated in the artificial image system. Studying the influence of difficult scenes such as complex environmental conditions on the visual perception model is convenient; thus, some uncontrollable factors in practice can be transformed into controllable factors, and the interpretability of the visual model is increased. Finally, we use prescriptive learning method to optimize model parameters. The difficulty of the visual perception model in the actual scene can be used to guide the model training in the artificial scene. We learn and optimize the visual perception model online through virtual-real interaction. This paper also conducted an application case study to preliminarily demonstrate the effectiveness of the proposed framework. This case can work over synthetic images with accurate annotations and real images without any labels. The virtual-real interaction guides the model to learn useful information from synthetic data while keeping consistent with real data. We first analyze the data distribution discrepancy from a probabilistic perspective and divide it into image-level and instance-level discrepancies. Then, we design two components to align these discrepancies, i.e., global-level alignment and local-level alignment. Furthermore, a consistency alignment component is proposed to encourage the consistency between the global-level and the local-level alignment components.ResultWe evaluate the proposed approach on the real Cityscapes dataset by adapting from virtual SYNTHIA(synthetic collection of imagery and annotations), Virtual KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute), and VIPER(visual perception benchmark) datasets. Experimental results demonstrate that it achieves significantly better performance than state-of-the-art methods.ConclusionParallel vision is an important research direction in the field of visual computing. Through combination with deep learning, more and more intelligent vision systems will be developed and applied.关键词:computer vision;parallel learning;parallel vision;visual perception model;instance segmentation;object detection182|213|2更新时间:2024-05-08
摘要:ObjectiveComputer vision makes the camera and computer the "eyes" of the computer, which can have the abilities of segmentation, classification, recognition, tracking and decision-making. In recent years, computer vision technology has been widely used in intelligent transportation, unmanned driving, robot navigation, intelligent video monitoring, and many other fields. At present, the camera has become the most commonly used sensing equipment in automatic driving and smart cities, generating massive image and video data. We can realize real-time analysis and processing of these data only by relying on computer vision technology. We can detect all kinds of objects in real time and obtain their position and motion states accurately from the image video. However, the actual scene has a very high complexity. Many complex factors interweave together, which poses a great challenge to the visual computing system. At present, computer vision technology is mainly based on the deep learning method through large-scale data-driven mechanisms. Sufficient data are needed due to the heavy dependence of its training algorithm mechanism on datasets. However, collecting and labeling large-scale image data from actual scenes are time-consuming and labor-intensive tasks, and usually, only small-scale and limited diversity of image data can be obtained. For example, Microsoft common objects in context(MS COCO), a popular dataset used for instance segmentation tasks, has a size of about 300 000 and mainly 91 categories. Expressing the complexity of reality and simulate the real situation is difficult. The model trained on the limited dataset will lack practical significance, because the dataset is not large enough to represent the real data distribution and cannot guarantee the effectiveness of practical application.MethodThe theory of social computing and parallel systems is proposed based on artificial systems, computational experiments, and parallel execution (ACP). The ACP methodology plays an essential role in modeling and control of complex systems. A virtual artificial society is constructed to connect the virtual and the real world through parallel management. On the basis of the existing facts, artificial system is used to model the behavior of complex systems by using advanced computing experiments and then analyze its behavior and interact with reality to obtain a better operating system than reality. To address the bottleneck of deep learning in the field of computer vision, this paper proposes parallel vision, a visual analysis framework based on parallel learning. Parallel vision is an intelligent visual perception framework that is an extension of the ACP methodology into the computer vision field. In the framework of parallel vision, large-scale realistic artificial images can be obtained easily to give support to the vision algorithm with enough well-labeled image data. In this way, the computer can be turned into a "laboratory" of computational intelligence. First, the artificial image system simulates the imaging conditions that may appear in the actual image, uses the internal parameters of the system to automatically obtain the annotation information, and obtains the required artificial images. Then, we use the predictive learning method to design the visual perception model, and then we use the computational experiment method to conduct experiments. Various experiments are conducted on a rich supply of image data generated in the artificial image system. Studying the influence of difficult scenes such as complex environmental conditions on the visual perception model is convenient; thus, some uncontrollable factors in practice can be transformed into controllable factors, and the interpretability of the visual model is increased. Finally, we use prescriptive learning method to optimize model parameters. The difficulty of the visual perception model in the actual scene can be used to guide the model training in the artificial scene. We learn and optimize the visual perception model online through virtual-real interaction. This paper also conducted an application case study to preliminarily demonstrate the effectiveness of the proposed framework. This case can work over synthetic images with accurate annotations and real images without any labels. The virtual-real interaction guides the model to learn useful information from synthetic data while keeping consistent with real data. We first analyze the data distribution discrepancy from a probabilistic perspective and divide it into image-level and instance-level discrepancies. Then, we design two components to align these discrepancies, i.e., global-level alignment and local-level alignment. Furthermore, a consistency alignment component is proposed to encourage the consistency between the global-level and the local-level alignment components.ResultWe evaluate the proposed approach on the real Cityscapes dataset by adapting from virtual SYNTHIA(synthetic collection of imagery and annotations), Virtual KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute), and VIPER(visual perception benchmark) datasets. Experimental results demonstrate that it achieves significantly better performance than state-of-the-art methods.ConclusionParallel vision is an important research direction in the field of visual computing. Through combination with deep learning, more and more intelligent vision systems will be developed and applied.关键词:computer vision;parallel learning;parallel vision;visual perception model;instance segmentation;object detection182|213|2更新时间:2024-05-08
Parallel Driving
-
 摘要:ObjectivePedestrian detection is a crucial safety factor in autonomous driving scenarios. Consistent pedestrian detection results play a particular role in path planning and pedestrian collision avoidance. In recent years, pedestrian detection algorithms have become a research hotspot in the field of autonomous driving. For the pedestrian detection task, several problems need to be solved. 1) Pedestrian occlusion in traffic scenes. Pedestrian occlusion is a challenging driving safety problem in autonomous driving scenarios. Pedestrians who are obscured by other objects (such as buildings, vehicles, and other pedestrians) are difficult to detect. 2) Small pedestrian detection accuracy needs to be improved. In an autonomous driving environment, the accuracy of pedestrian detection plays a crucial role in vehicle control systems based on vision algorithms. When the vehicle speed is fast, the pedestrians at a long distance need to be detected accurately. With the need for low algorithm power consumption and good operating efficiency, designing an algorithm suitable for pedestrian detection to maintain excellent detection performance under the premise of achieving real-time performance is a difficult problem.MethodThis paper proposed a real-time pedestrian detection algorithm called scale-aware and efficient object detection (Scale-aware EfficientDet) based on EfficientDet, which achieves state-of-the-art performance in object detection. Our approach aimed to solve the problems of high time consumption, pedestrian occlusion, and low accuracy of small pedestrian detection results in autonomous driving scenarios. Most of the computing power and running time of the existing object detection algorithms are consumed in the visual feature extraction stage, so the use of a lightweight feature extraction network is a crucial factor in improving the efficiency of the algorithm. Our method uses EfficientDet in feature extraction to ensure the algorithm's computational efficiency and power consumption balance. Our approach aimed to observe occluded pedestrians precisely. The loss function was introduced to improve the model's detection accuracy of occlusion phenomena. The function can enhance the feature difference between pedestrians and other objects, and reduce the feature difference between occlude pedestrians and normal pedestrians. In terms of improving the accuracy of small target pedestrian detection, we use the scale-aware mechanism to enhance the algorithm's detection accuracy for small target pedestrians.ResultThe Caltech pedestrian dataset was used for model comparison. You only look once (YOLO), YOLOv3 scale-aware fast region-based convolutional neural network (fast R-CNN), and other algorithms are selected for comparison. In terms of operating efficiency, our algorithm achieves 35 frame/s with continuous input of a single frame image and a working efficiency of 70 frame/s with multi-image input. In the test of model accuracy, our algorithm is more accurate than YOLOv3, SA-FastRCNN(scale-aware fast region-based convolutional neural network), EfficientDet, and other algorithms. In the preliminaries and finals of the China Intelligent Vehicle Championship(CIVC) 2020, the safety and obstacle avoidance links all received full marks.ConclusionTo address the problems of detection speed in pedestrian detection in autonomous driving, this paper designs the scale-aware EfficientDet real-time pedestrian detector, which is based on the efficient and high-precision EfficientDet. Our method solved the insufficient detection accuracy for occluded pedestrians and the high missed detection rate of small-scale pedestrians. In accordance with the occlusion characteristics of pedestrians, the loss function with repulsive force is used to solve the problem of pedestrian occlusion. Considering the significant differences in visual appearance and extracted feature maps between small-scale and large-scale pedestrians, scale-aware networks are used separately to minimize the missed detection rate of small-scale pedestrians. The improvements in these two aspects further improve the robustness of the designed detector. In future work, our methods can be adjusted to improve detection performance, find optimization methods, and improve neural networks. The detection performance and detection accuracy can be further improved to promote its better application in the field of autonomous driving.关键词:automated driving;pedestrian detection;object detection;EfficientDet;convolutional neural network(CNN)53|43|6更新时间:2024-05-08
摘要:ObjectivePedestrian detection is a crucial safety factor in autonomous driving scenarios. Consistent pedestrian detection results play a particular role in path planning and pedestrian collision avoidance. In recent years, pedestrian detection algorithms have become a research hotspot in the field of autonomous driving. For the pedestrian detection task, several problems need to be solved. 1) Pedestrian occlusion in traffic scenes. Pedestrian occlusion is a challenging driving safety problem in autonomous driving scenarios. Pedestrians who are obscured by other objects (such as buildings, vehicles, and other pedestrians) are difficult to detect. 2) Small pedestrian detection accuracy needs to be improved. In an autonomous driving environment, the accuracy of pedestrian detection plays a crucial role in vehicle control systems based on vision algorithms. When the vehicle speed is fast, the pedestrians at a long distance need to be detected accurately. With the need for low algorithm power consumption and good operating efficiency, designing an algorithm suitable for pedestrian detection to maintain excellent detection performance under the premise of achieving real-time performance is a difficult problem.MethodThis paper proposed a real-time pedestrian detection algorithm called scale-aware and efficient object detection (Scale-aware EfficientDet) based on EfficientDet, which achieves state-of-the-art performance in object detection. Our approach aimed to solve the problems of high time consumption, pedestrian occlusion, and low accuracy of small pedestrian detection results in autonomous driving scenarios. Most of the computing power and running time of the existing object detection algorithms are consumed in the visual feature extraction stage, so the use of a lightweight feature extraction network is a crucial factor in improving the efficiency of the algorithm. Our method uses EfficientDet in feature extraction to ensure the algorithm's computational efficiency and power consumption balance. Our approach aimed to observe occluded pedestrians precisely. The loss function was introduced to improve the model's detection accuracy of occlusion phenomena. The function can enhance the feature difference between pedestrians and other objects, and reduce the feature difference between occlude pedestrians and normal pedestrians. In terms of improving the accuracy of small target pedestrian detection, we use the scale-aware mechanism to enhance the algorithm's detection accuracy for small target pedestrians.ResultThe Caltech pedestrian dataset was used for model comparison. You only look once (YOLO), YOLOv3 scale-aware fast region-based convolutional neural network (fast R-CNN), and other algorithms are selected for comparison. In terms of operating efficiency, our algorithm achieves 35 frame/s with continuous input of a single frame image and a working efficiency of 70 frame/s with multi-image input. In the test of model accuracy, our algorithm is more accurate than YOLOv3, SA-FastRCNN(scale-aware fast region-based convolutional neural network), EfficientDet, and other algorithms. In the preliminaries and finals of the China Intelligent Vehicle Championship(CIVC) 2020, the safety and obstacle avoidance links all received full marks.ConclusionTo address the problems of detection speed in pedestrian detection in autonomous driving, this paper designs the scale-aware EfficientDet real-time pedestrian detector, which is based on the efficient and high-precision EfficientDet. Our method solved the insufficient detection accuracy for occluded pedestrians and the high missed detection rate of small-scale pedestrians. In accordance with the occlusion characteristics of pedestrians, the loss function with repulsive force is used to solve the problem of pedestrian occlusion. Considering the significant differences in visual appearance and extracted feature maps between small-scale and large-scale pedestrians, scale-aware networks are used separately to minimize the missed detection rate of small-scale pedestrians. The improvements in these two aspects further improve the robustness of the designed detector. In future work, our methods can be adjusted to improve detection performance, find optimization methods, and improve neural networks. The detection performance and detection accuracy can be further improved to promote its better application in the field of autonomous driving.关键词:automated driving;pedestrian detection;object detection;EfficientDet;convolutional neural network(CNN)53|43|6更新时间:2024-05-08 -
 摘要:ObjectiveVisual object tracking (VOT) is widely used in scenes, such as car navigation, automatic video surveillance, and human-computer interaction. It is a basic research task in video applications and needs to infer the correspondence between the target and the frame. Given the position of any object of interest in the first frame of the video, its position is estimated in all subsequent frames with the highest possible accuracy. Similar to VOT, semi-supervised video object segmentation (VOS) requires segmentation of target objects on subsequent video sequences given the initial frame mask. It is also a basic research task of computer vision. However, the target object may experience large changes in pose, proportion, and appearance in the entire video sequence. It may encounter abnormal conditions, such as occlusion, rapid movement, and truncation. Therefore, performing robust VOT and VOS in a semi-supervised manner in video sequences is challenging. The continuous nature of the video sequence itself brings additional contextual information to VOS. The interframe consistency of video enables the network to effectively transfer information from frame to frame. In VOS, the information from previous frames can be regarded as temporal context and can provide useful hints for subsequent predictions. Therefore, the effective use of additional information brought by video is extremely important for video tasks. For the research of VOT and VOS, various multitask processing frameworks have been proposed by scholars. However, the accuracy and robustness of such frameworks are poor. This paper proposes a multitask end-to-end framework for real-time VOT and VOS to address these problems. This framework combines multi-scale context information and video interframe information.MethodIn this work, depthwise convolution is changed from depthwise convolution to atrous depthwise convolution, thereby forming the atrous depthwise separable convolution. In accordance with different atrous ratios, the convolution can have different receptive fields while maintaining its lightweight. This study designs an atrous spatial pyramid pooling module with many atrous ratios composed of atrous depthwise separable convolution and applies it to the VOS branch. The network can capture multi-scale context. This work uses 1, 3, 6, 9, 12, 24, 36, and 48 atrous ratios to convolve the feature map with different receptive fields and utilizes adaptive pooling for the feature map. These feature maps are concatenated, and a convolution kernel of 1×1 is used to transform the feature map channel. The feature map outputted by the model has rich multi-scale context information through these operations. This module uses the atrous depthwise separable convolution with different atrous rates for enabling the network to predict multi-scale targets. Continuity is a unique property of video sequences and causes additional contextual information to video tasks. The interframe consistency of video enables the network to effectively transfer information from frame to frame. In the VOS, the information from previous frames can be regarded as temporal context information and can provide useful hints for subsequent predictions. Therefore, the effective use of additional information brought by video is extremely important for video tasks. Inspired by the reference-guided mask propagation algorithm, a mask propagation module is added to the VOS branch for providing location and segmentation information to the network. The proposed mask propagation module is composed of 3×3 convolutions with atrous ratios of 2, 3, and 6. In our architecture, a multi-scale atrous spatial pyramid pooling module composed of atrous depthwise separable convolutions and an interframe mask propagation module with interframe information are used. These modules provide the network with strong ability to segment multi-scale target objects and has better robustness.ResultAll experiments in this work are performed using NVIDIA TITAN X graphics cards. The network in this article is trained in two stages. The training sets used in different stages are different due to their different nature. In the first stage of training, this work uses Youtube-VOS, common objects in context(COCO), DETection(ImageNet-DET), and ImageNet-VID (VIDeo) datasets. For the datasets without mask ground truth, the mask branch is not trained. For a video sequence with only a single frame, the picture and mask of the previous frame are set in the interframe mask propagation module to be the same as the current frame. Inspired by SiamMask, this article uses stochastic gradient descent optimizer algorithm and a warm-up training strategy. The learning rate increases from 1×10-3 to 5×10-3 in the first 5 epochs. A logarithmic decay strategy was then used to reduce the learning rate to 2.5×10-4 through 15 epochs of learning. In the second stage, this article only uses the Youtube-VOS and COCO datasets for training. The two datasets have mask truth values to improve the segmentation effect of video objects. The second stage uses a logarithmic decay strategy to reduce the learning rate from 2.5×10-4 to 1.0×10-4 through 20 epochs. The expected average overlaps of the proposed method on the VOT-2016 and VOT-2018 datasets reach 0.462 and 0.408, respectively, which is approximately 0.03 higher than SiamMask. The proposed method achieves advanced results and shows better robustness. Competitive results are also achieved on the DAVIS-2016 and DAVIS-2017 datasets of VOS. On DAVIS-2017 dataset of multitarget object segmentation, the proposed method has better performance than SiamMask. The evaluation indexes JM and FM reach 56.0 and 59.0, respectively, and the decay values of the region and the contour are JD and FD. Their values are 17.9 and 19.8, respectively, which are lower than those in SiamMask. The running speed is 45 frames per second, reaching a real-time running speed.ConclusionIn this study, we proposed a multitask end-to-end framework of real-time VOT and VOS. The proposed method integrates multi-scale context information and video interframe information, fully captures multi-scale context information, and utilizes the information between video frames. These features make the network robust to segmentation of multi-scale target objects.关键词:visual object tracking(VOT);video object segmentation(VOS);fully convolutional network(FCN);atrous spatial pyramid pooling;inter-frame mask propagation44|46|4更新时间:2024-05-08
摘要:ObjectiveVisual object tracking (VOT) is widely used in scenes, such as car navigation, automatic video surveillance, and human-computer interaction. It is a basic research task in video applications and needs to infer the correspondence between the target and the frame. Given the position of any object of interest in the first frame of the video, its position is estimated in all subsequent frames with the highest possible accuracy. Similar to VOT, semi-supervised video object segmentation (VOS) requires segmentation of target objects on subsequent video sequences given the initial frame mask. It is also a basic research task of computer vision. However, the target object may experience large changes in pose, proportion, and appearance in the entire video sequence. It may encounter abnormal conditions, such as occlusion, rapid movement, and truncation. Therefore, performing robust VOT and VOS in a semi-supervised manner in video sequences is challenging. The continuous nature of the video sequence itself brings additional contextual information to VOS. The interframe consistency of video enables the network to effectively transfer information from frame to frame. In VOS, the information from previous frames can be regarded as temporal context and can provide useful hints for subsequent predictions. Therefore, the effective use of additional information brought by video is extremely important for video tasks. For the research of VOT and VOS, various multitask processing frameworks have been proposed by scholars. However, the accuracy and robustness of such frameworks are poor. This paper proposes a multitask end-to-end framework for real-time VOT and VOS to address these problems. This framework combines multi-scale context information and video interframe information.MethodIn this work, depthwise convolution is changed from depthwise convolution to atrous depthwise convolution, thereby forming the atrous depthwise separable convolution. In accordance with different atrous ratios, the convolution can have different receptive fields while maintaining its lightweight. This study designs an atrous spatial pyramid pooling module with many atrous ratios composed of atrous depthwise separable convolution and applies it to the VOS branch. The network can capture multi-scale context. This work uses 1, 3, 6, 9, 12, 24, 36, and 48 atrous ratios to convolve the feature map with different receptive fields and utilizes adaptive pooling for the feature map. These feature maps are concatenated, and a convolution kernel of 1×1 is used to transform the feature map channel. The feature map outputted by the model has rich multi-scale context information through these operations. This module uses the atrous depthwise separable convolution with different atrous rates for enabling the network to predict multi-scale targets. Continuity is a unique property of video sequences and causes additional contextual information to video tasks. The interframe consistency of video enables the network to effectively transfer information from frame to frame. In the VOS, the information from previous frames can be regarded as temporal context information and can provide useful hints for subsequent predictions. Therefore, the effective use of additional information brought by video is extremely important for video tasks. Inspired by the reference-guided mask propagation algorithm, a mask propagation module is added to the VOS branch for providing location and segmentation information to the network. The proposed mask propagation module is composed of 3×3 convolutions with atrous ratios of 2, 3, and 6. In our architecture, a multi-scale atrous spatial pyramid pooling module composed of atrous depthwise separable convolutions and an interframe mask propagation module with interframe information are used. These modules provide the network with strong ability to segment multi-scale target objects and has better robustness.ResultAll experiments in this work are performed using NVIDIA TITAN X graphics cards. The network in this article is trained in two stages. The training sets used in different stages are different due to their different nature. In the first stage of training, this work uses Youtube-VOS, common objects in context(COCO), DETection(ImageNet-DET), and ImageNet-VID (VIDeo) datasets. For the datasets without mask ground truth, the mask branch is not trained. For a video sequence with only a single frame, the picture and mask of the previous frame are set in the interframe mask propagation module to be the same as the current frame. Inspired by SiamMask, this article uses stochastic gradient descent optimizer algorithm and a warm-up training strategy. The learning rate increases from 1×10-3 to 5×10-3 in the first 5 epochs. A logarithmic decay strategy was then used to reduce the learning rate to 2.5×10-4 through 15 epochs of learning. In the second stage, this article only uses the Youtube-VOS and COCO datasets for training. The two datasets have mask truth values to improve the segmentation effect of video objects. The second stage uses a logarithmic decay strategy to reduce the learning rate from 2.5×10-4 to 1.0×10-4 through 20 epochs. The expected average overlaps of the proposed method on the VOT-2016 and VOT-2018 datasets reach 0.462 and 0.408, respectively, which is approximately 0.03 higher than SiamMask. The proposed method achieves advanced results and shows better robustness. Competitive results are also achieved on the DAVIS-2016 and DAVIS-2017 datasets of VOS. On DAVIS-2017 dataset of multitarget object segmentation, the proposed method has better performance than SiamMask. The evaluation indexes JM and FM reach 56.0 and 59.0, respectively, and the decay values of the region and the contour are JD and FD. Their values are 17.9 and 19.8, respectively, which are lower than those in SiamMask. The running speed is 45 frames per second, reaching a real-time running speed.ConclusionIn this study, we proposed a multitask end-to-end framework of real-time VOT and VOS. The proposed method integrates multi-scale context information and video interframe information, fully captures multi-scale context information, and utilizes the information between video frames. These features make the network robust to segmentation of multi-scale target objects.关键词:visual object tracking(VOT);video object segmentation(VOS);fully convolutional network(FCN);atrous spatial pyramid pooling;inter-frame mask propagation44|46|4更新时间:2024-05-08 -
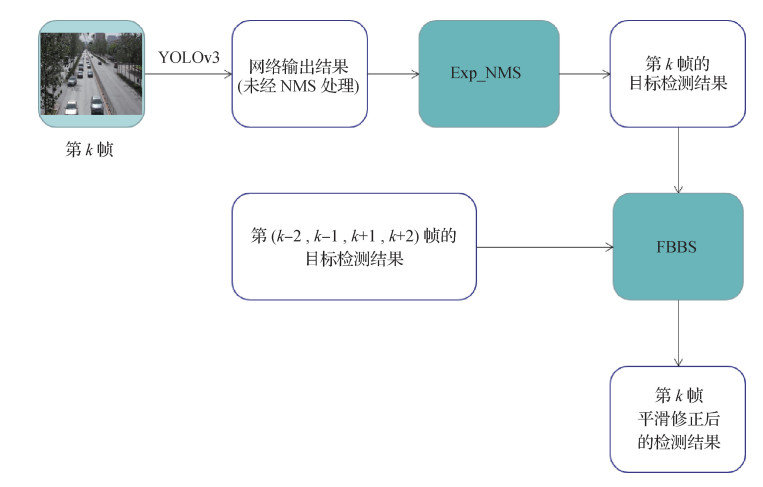 摘要:ObjectiveWith the development of convolutional neural networks (CNNs), the speed and accuracy of CNN-based object detection algorithms have remarkably improved. However, the bounding boxes of the same target change intensively in adjacent frames when the algorithms are applied to the videos frame by frame, thereby reflecting the poor stability of the bounding box. This problem has received minimal attention because the object detection for single image does not have this problem. In the object detection from video (VID), stability refers to whether the bounding box of the same target changes smoothly and uniformly in successive video frames. Accuracy refers to the degree of overlap between the bounding box and the actual position. Mean average precision (mAP) is the commonly used evaluation index. It only considers the accuracy and ignores the stability. However, the stability of bounding box is extremely important for engineering applications. In self-driving systems, system stability is directly related to driving safety. At present, the self-driving study enters the L5 stage, and the vehicle driving control needs to sense and predict the movement of surrounding vehicles and pedestrians to make decisions rather than simply reacting in accordance with specific external conditions. Object detection is the basic algorithm of self-driving system to sense the surrounding environment. Poor stability negatively impact all the algorithms that analyze the object detection result, ultimately reducing the stability of the entire self-driving system and creating potential safety hazards. Thus, designing strategies to solve this problem are necessary. We propose expanded non-maximum suppression (Exp_NMS) and frame bounding box smoothing (FBBS) strategies in this paper.MethodWe design the Exp_NMS and FBBS strategies on the basis of YOLO(you only look once)v3 object detection algorithm. The overall process of the algorithm is to send the video frame by frame to the YOLOv3 network for object detection. We then use Exp_NMS to eliminate redundant bounding boxes and utilize FBBS to smooth the results. In the Exp_NMS strategy, the results are obtained by fusing multiple bounding box information because the original NMS strategy may directly discard some bounding boxes and cause poor stability. In the FBBS strategy, we use the adjacent frame information association thinking, which is widely used in VID algorithms. Different from conventional strategies, FBBS uses least squares regression to achieve information transmission between adjacent frames rather than additional information, such as optical flow. FBBS has a certain optimization effect on multidetection and missed detection errors and has a better effect on the stability problem.ResultThe scenarios in engineering applications are variable and complicated. Thus, the scenarios in training dataset should be as many as possible in the experiment. This paper uses MIO-TCD(miovision traffic camera dataset) as the object detection training dataset collected from thousands of real traffic scenarios and utilize UA-DETRAC(University at Albany datection and tracking benchmark dataset) as the test dataset. The MIO-TCD dataset cannot evaluate the multiobject tracking results. This paper uses YOLOv3 and Kalman filter multiobject tracking algorithms for verification experiments. The stability of the bounding box has a significant effect on the tracking algorithm, and most tracking algorithms are based on Kalman filter. This paper designs a parameter called average track-tortuosity (AT) to measure the stability of the bounding box and the smoothness of the tracking trajectory. Experimental results prove that our method can significantly improve the stability of the bounding box without affecting its accuracy, and the accuracy of the tracking algorithm is improved. Multiple object tracking accuracy is increased by 6.0%, and track id switch is reduced by 16.8% when Exp_NMS and FBBS are used. The number of tracking false positive errors is reduced by 45.83%, the AT is decreased by 36.57%, and mAP is only reduced by 0.07%.ConclusionIn this paper, we design two strategies from the perspective of NMS and adjacent frame information association by analyzing the causes and manifestations of the bounding box stability problem. The experimental results show that the two strategies can significantly enhance the stability of bounding box without affecting its accuracy.关键词:convolutional neural network(CNN);object detection from video(VID);stability of bounding box;non-maximum suppression (NMS);adjacent-frames information association114|390|3更新时间:2024-05-08
摘要:ObjectiveWith the development of convolutional neural networks (CNNs), the speed and accuracy of CNN-based object detection algorithms have remarkably improved. However, the bounding boxes of the same target change intensively in adjacent frames when the algorithms are applied to the videos frame by frame, thereby reflecting the poor stability of the bounding box. This problem has received minimal attention because the object detection for single image does not have this problem. In the object detection from video (VID), stability refers to whether the bounding box of the same target changes smoothly and uniformly in successive video frames. Accuracy refers to the degree of overlap between the bounding box and the actual position. Mean average precision (mAP) is the commonly used evaluation index. It only considers the accuracy and ignores the stability. However, the stability of bounding box is extremely important for engineering applications. In self-driving systems, system stability is directly related to driving safety. At present, the self-driving study enters the L5 stage, and the vehicle driving control needs to sense and predict the movement of surrounding vehicles and pedestrians to make decisions rather than simply reacting in accordance with specific external conditions. Object detection is the basic algorithm of self-driving system to sense the surrounding environment. Poor stability negatively impact all the algorithms that analyze the object detection result, ultimately reducing the stability of the entire self-driving system and creating potential safety hazards. Thus, designing strategies to solve this problem are necessary. We propose expanded non-maximum suppression (Exp_NMS) and frame bounding box smoothing (FBBS) strategies in this paper.MethodWe design the Exp_NMS and FBBS strategies on the basis of YOLO(you only look once)v3 object detection algorithm. The overall process of the algorithm is to send the video frame by frame to the YOLOv3 network for object detection. We then use Exp_NMS to eliminate redundant bounding boxes and utilize FBBS to smooth the results. In the Exp_NMS strategy, the results are obtained by fusing multiple bounding box information because the original NMS strategy may directly discard some bounding boxes and cause poor stability. In the FBBS strategy, we use the adjacent frame information association thinking, which is widely used in VID algorithms. Different from conventional strategies, FBBS uses least squares regression to achieve information transmission between adjacent frames rather than additional information, such as optical flow. FBBS has a certain optimization effect on multidetection and missed detection errors and has a better effect on the stability problem.ResultThe scenarios in engineering applications are variable and complicated. Thus, the scenarios in training dataset should be as many as possible in the experiment. This paper uses MIO-TCD(miovision traffic camera dataset) as the object detection training dataset collected from thousands of real traffic scenarios and utilize UA-DETRAC(University at Albany datection and tracking benchmark dataset) as the test dataset. The MIO-TCD dataset cannot evaluate the multiobject tracking results. This paper uses YOLOv3 and Kalman filter multiobject tracking algorithms for verification experiments. The stability of the bounding box has a significant effect on the tracking algorithm, and most tracking algorithms are based on Kalman filter. This paper designs a parameter called average track-tortuosity (AT) to measure the stability of the bounding box and the smoothness of the tracking trajectory. Experimental results prove that our method can significantly improve the stability of the bounding box without affecting its accuracy, and the accuracy of the tracking algorithm is improved. Multiple object tracking accuracy is increased by 6.0%, and track id switch is reduced by 16.8% when Exp_NMS and FBBS are used. The number of tracking false positive errors is reduced by 45.83%, the AT is decreased by 36.57%, and mAP is only reduced by 0.07%.ConclusionIn this paper, we design two strategies from the perspective of NMS and adjacent frame information association by analyzing the causes and manifestations of the bounding box stability problem. The experimental results show that the two strategies can significantly enhance the stability of bounding box without affecting its accuracy.关键词:convolutional neural network(CNN);object detection from video(VID);stability of bounding box;non-maximum suppression (NMS);adjacent-frames information association114|390|3更新时间:2024-05-08 -
 摘要:ObjectiveIntelligent connected vehicles are an important direction in intelligent transportation in China. In the development of intelligent networked vehicle systems, the detection of lane markings in complex environments is a key link. The safety of drug delivery, meal transport, and medical waste recovery can be guaranteed if the unmanned driving and intelligent network connected vehicle technology can be applied to epidemic prevention and control, especially in the epidemic of COVID-2019. The frequency of contact between medical staff and patients and the risk of cross infection of virus can be reduced. However, the current lane detection algorithms are mostly based on visual feature information, such as color, gray level, and edge. The accuracy of model detection is greatly affected by the environment. This condition makes the accuracy of existing lane detection algorithms difficult to meet the performance requirements of intelligent networked vehicles. The length, width, and direction of lanes have strong regularity, and they have the characteristics of serialization and structure association. These characteristics are not affected by visibility, weather, and obstacles. Vision-based lane detection method has high accuracy in scenes with high definition and without obstacles. For this reason, a lane detection model based on vision and spatial distribution is proposed to eliminate the influence of environment on lane detection. Our research can provide accurate lane information for the development of intelligent driving system.MethodWhen a traffic image set is transformed into a bird's eye view, its original scale changes, and the lane interval is short. The you only look once v3 (YOLO v3) algorithm has significant advantages in speed and accuracy of detecting small objects. Thus, it is used as lane detector in this study. However, the distribution density of lane in the longitudinal direction is greater than that in the horizontal direction. The network structure of YOLO v3 is improved by increasing the vertical detection density to reduce the influence of the change in aspect ratio on target detection. The image is divided into S×2S grids during lane detection, and the obtained YOLO v3 (S×2S) is suitable for lane detection. However, the YOLO v3 (S×2S) lane detection algorithm ignores the spatial information of lane. In the case of poor light and vehicle occlusion, the accuracy of lane detection is poor. Bidirectional gated recurrent unit-lane, (BGRU-L), a lane detection model based on lane distribution law, is proposed by considering that the spatial distribution of lane is unaffected by the environment. This model is used to improve the generalization ability of the lane detection model in complex scenes. This study combines visual information and spatial distribution relationship to avoid the large error of single lane detector and effectively reduce the uncertainty of the system. A confidence-based Dempster-Shafer (D-S) algorithm is used to fuse the detection results of YOLO v3 (S×2S) and BGRU-L detection results for guaranteeing the output of the optimal lane position.ResultKarlsruhe Institute of Technology and Toyoko Technological Institute(KITTI) is a commonly used traffic dataset and includes scenes, such as sunny, cloudy, highway, and urban roads. The scenes are increased under complicated working conditions, such as rain, tunnel, and night, to ensure coverage. In this study, the scene in a game, Euro Truck Simulator 2 (ETS2), is used as a supplement dataset. ETS2 is divided into two categories: conventional scene ETS2_conv (sunny, cloudy) and comprehensive scene ETS2_comp (sunny, cloudy, night, rain, and tunnel), to accurately evaluate the effectiveness of the algorithm. On the KITTI dataset, the accuracy of YOLO v3 (S×2S) detection is improved with the increase in detection grid density of YOLO v3, with mean average precision (mAP) of 88.39%. BGRU-L uses the spatial distribution relationship of the lane sequence to detect the location of lane, and the mAP is 76.14%. The reliability-based D-S algorithm is used to fuse the lane detection results of YOLO v3 (S×2S) and BGRU-L, and the final mAP of lane detection is raised to 90.28%. On the ETS2 dataset, the mAP values in the ETS2_conv (Euro Truck Simulator 2 convention, ETS2_conv) and ETS2_complex (Euro Truck Simulator 2 complex, ETS2_complex) scenarios are 92.49% and 91.73%, respectively, by using the lane detection model that combines visual information and spatial distribution relationships.ConclusionThis study explores the detection schemes based on machine vision and the spatial distribution relationship of lane to address the difficulty in accurately detecting lanes in complex scenes. On the basis of the characteristics of inconsistent distribution density of lane in bird's eye view, the obtained model, YOLO v3 (S×2S), is suitable for the detection of small-size and large aspect ratio targets by improving the grid density of YOLO v3 model. Experimental results show that the YOLO v3 (S×2S) is significantly higher than YOLO v3 in terms of lane detection accuracy. The lane detection model based on visual information has certain limitations and cannot achieve high-precision detection requirements in complex scenes. However, the length, width, and direction of lane have strong regularity and has the characteristics of serialization and structural correlation. BGRU-L, a lane prediction model based on the spatial distribution of lane, is unaffected by the environment and has strong generalization ability in rain, night, tunnel, and other scenarios. This study uses the D-S algorithm based on confidence to fuse the detection results of YOLO v3 (S×2S) and BGRU-L to avoid the large errors that may exist in the single lane detection model and effectively reduce the uncertainty of the system. The results of lane detection in complex scenes can meet the requirements of intelligent vehicles.关键词:machine vision;lane line detection;grid density;spatial distribution;D-S fusion118|65|4更新时间:2024-05-08
摘要:ObjectiveIntelligent connected vehicles are an important direction in intelligent transportation in China. In the development of intelligent networked vehicle systems, the detection of lane markings in complex environments is a key link. The safety of drug delivery, meal transport, and medical waste recovery can be guaranteed if the unmanned driving and intelligent network connected vehicle technology can be applied to epidemic prevention and control, especially in the epidemic of COVID-2019. The frequency of contact between medical staff and patients and the risk of cross infection of virus can be reduced. However, the current lane detection algorithms are mostly based on visual feature information, such as color, gray level, and edge. The accuracy of model detection is greatly affected by the environment. This condition makes the accuracy of existing lane detection algorithms difficult to meet the performance requirements of intelligent networked vehicles. The length, width, and direction of lanes have strong regularity, and they have the characteristics of serialization and structure association. These characteristics are not affected by visibility, weather, and obstacles. Vision-based lane detection method has high accuracy in scenes with high definition and without obstacles. For this reason, a lane detection model based on vision and spatial distribution is proposed to eliminate the influence of environment on lane detection. Our research can provide accurate lane information for the development of intelligent driving system.MethodWhen a traffic image set is transformed into a bird's eye view, its original scale changes, and the lane interval is short. The you only look once v3 (YOLO v3) algorithm has significant advantages in speed and accuracy of detecting small objects. Thus, it is used as lane detector in this study. However, the distribution density of lane in the longitudinal direction is greater than that in the horizontal direction. The network structure of YOLO v3 is improved by increasing the vertical detection density to reduce the influence of the change in aspect ratio on target detection. The image is divided into S×2S grids during lane detection, and the obtained YOLO v3 (S×2S) is suitable for lane detection. However, the YOLO v3 (S×2S) lane detection algorithm ignores the spatial information of lane. In the case of poor light and vehicle occlusion, the accuracy of lane detection is poor. Bidirectional gated recurrent unit-lane, (BGRU-L), a lane detection model based on lane distribution law, is proposed by considering that the spatial distribution of lane is unaffected by the environment. This model is used to improve the generalization ability of the lane detection model in complex scenes. This study combines visual information and spatial distribution relationship to avoid the large error of single lane detector and effectively reduce the uncertainty of the system. A confidence-based Dempster-Shafer (D-S) algorithm is used to fuse the detection results of YOLO v3 (S×2S) and BGRU-L detection results for guaranteeing the output of the optimal lane position.ResultKarlsruhe Institute of Technology and Toyoko Technological Institute(KITTI) is a commonly used traffic dataset and includes scenes, such as sunny, cloudy, highway, and urban roads. The scenes are increased under complicated working conditions, such as rain, tunnel, and night, to ensure coverage. In this study, the scene in a game, Euro Truck Simulator 2 (ETS2), is used as a supplement dataset. ETS2 is divided into two categories: conventional scene ETS2_conv (sunny, cloudy) and comprehensive scene ETS2_comp (sunny, cloudy, night, rain, and tunnel), to accurately evaluate the effectiveness of the algorithm. On the KITTI dataset, the accuracy of YOLO v3 (S×2S) detection is improved with the increase in detection grid density of YOLO v3, with mean average precision (mAP) of 88.39%. BGRU-L uses the spatial distribution relationship of the lane sequence to detect the location of lane, and the mAP is 76.14%. The reliability-based D-S algorithm is used to fuse the lane detection results of YOLO v3 (S×2S) and BGRU-L, and the final mAP of lane detection is raised to 90.28%. On the ETS2 dataset, the mAP values in the ETS2_conv (Euro Truck Simulator 2 convention, ETS2_conv) and ETS2_complex (Euro Truck Simulator 2 complex, ETS2_complex) scenarios are 92.49% and 91.73%, respectively, by using the lane detection model that combines visual information and spatial distribution relationships.ConclusionThis study explores the detection schemes based on machine vision and the spatial distribution relationship of lane to address the difficulty in accurately detecting lanes in complex scenes. On the basis of the characteristics of inconsistent distribution density of lane in bird's eye view, the obtained model, YOLO v3 (S×2S), is suitable for the detection of small-size and large aspect ratio targets by improving the grid density of YOLO v3 model. Experimental results show that the YOLO v3 (S×2S) is significantly higher than YOLO v3 in terms of lane detection accuracy. The lane detection model based on visual information has certain limitations and cannot achieve high-precision detection requirements in complex scenes. However, the length, width, and direction of lane have strong regularity and has the characteristics of serialization and structural correlation. BGRU-L, a lane prediction model based on the spatial distribution of lane, is unaffected by the environment and has strong generalization ability in rain, night, tunnel, and other scenarios. This study uses the D-S algorithm based on confidence to fuse the detection results of YOLO v3 (S×2S) and BGRU-L to avoid the large errors that may exist in the single lane detection model and effectively reduce the uncertainty of the system. The results of lane detection in complex scenes can meet the requirements of intelligent vehicles.关键词:machine vision;lane line detection;grid density;spatial distribution;D-S fusion118|65|4更新时间:2024-05-08 -
 摘要:ObjectivePath tracking is the key part of an automatic driving vehicle running along a road according to the perception system and decision system results. The control module involved in path tracking is the lowest-level software algorithm module of autopilot, which includes two parts: lateral control and longitudinal control. Steering control is mainly responsible for vehicle steering output control, and longitudinal control is mainly responsible for throttle and brake control. The steering control algorithm tracks and controls the path of the two upper frameworks on the basis of perception and decision, and it optimizes the tracking error to ensure the stability and comfort of the self-driving vehicle. Current tracking algorithms mainly include model-free lateral control algorithm and model-based lateral control algorithm. The representative of model free lateral control algorithm is proportion integration differentiation (PID) control. The PID algorithm is difficult to use in controlling automatic driving vehicles without considering the physical characteristics of the vehicle and in high-speed and complex environments. The model-based lateral control algorithm includes the lateral control algorithm based on vehicle kinematics model and the lateral dynamics algorithm based on vehicle dynamic model. The former is represented by the Stanley method based on front-wheel feedback and rear-wheel control based on rear-wheel feedback. The latter is represented by the lateral control algorithm of linear quadratic regulator based on the dynamic model. Algorithms based on the vehicle model need to accurately model the kinematic or dynamic characteristics of the vehicle and usually need to simplify the model to predict the state of vehicle tracking deviation by simplifying the modeling of the model. This approach thus achieves accurate control of the vehicle. In addition, these two lateral control algorithms do not consider the coupling characteristics with longitudinal control, which limits the tracking performance of the control algorithm. To address the problems of high-complexity vehicle model and current path tracking algorithm, this paper proposes a model free-steering control algorithm based on speed-adaptive preview.MethodIn the face of highly complex or unknown dynamic performance of the vehicle dynamics model, accurately calculating the state equation of vehicle path tracking deviation through dynamic characteristics is impossible. However, due to the complex dynamic characteristics, the control quantity obtained through kinematic characteristics will cause many errors, especially in the case of high-speed driving, large curvature, and nondifferentiable path. The cumulative error of these two methods may lead to a self-driving car going out of control. Therefore, the model-free control method can achieve stable and accurate path tracking performance in the full speed range under complex dynamic conditions. Considering the stable tracking in scenes with non-conductance and large curvature, this paper uses the speed-adaptive preview method to enhance the stability of autopilot under complex road conditions. According to the intelligent driving vehicle model studied in this paper, the control input includes the lateral distance difference between the vehicle and the tracking path, the angle between the vehicle and the tracking path, and the coupling parameters of the longitudinal speed of the vehicle. The output of the control algorithm includes the steering wheel angle, the throttle opening, and the brake master cylinder pressure. The former mainly controls the direction of the vehicle, while the latter controls the forward speed. In this paper, the output control equation of vehicle steering control is established first according to the deviation distance and angle between the vehicle and the tracking path. This method realizes stable tracking at low speed under the condition of highly complex dynamics and differentiable tracking path. At the same time, the tracking preview distance is set adaptively according to the vehicle longitudinal speed, and the speed coupling parameters are added to the equation to realize the stable tracking of the vehicle in the full speed range and all types of paths.ResultTo verify the proposed path tracking algorithm based on speed-adaptive preview, we participated in the 2020 China Intelligent Vehicle Championship and World Intelligent Driving Challenge online simulation competitions. In this experiment and competition, PanoSim automatic driving simulation system and Simulink simulation software are used for the simulation experiment. The test road is a 10 km test freeway provided by Panosim, and it includes five sections with large curvature and five sections with small curvature. In this paper, we select a typical section of the small curvature section and large curvature section to test the algorithm. Under the dynamic model with a high-degree-of-freedom dynamic model, the proposed algorithm can achieve the performance of lateral deviation |Δ
摘要:ObjectivePath tracking is the key part of an automatic driving vehicle running along a road according to the perception system and decision system results. The control module involved in path tracking is the lowest-level software algorithm module of autopilot, which includes two parts: lateral control and longitudinal control. Steering control is mainly responsible for vehicle steering output control, and longitudinal control is mainly responsible for throttle and brake control. The steering control algorithm tracks and controls the path of the two upper frameworks on the basis of perception and decision, and it optimizes the tracking error to ensure the stability and comfort of the self-driving vehicle. Current tracking algorithms mainly include model-free lateral control algorithm and model-based lateral control algorithm. The representative of model free lateral control algorithm is proportion integration differentiation (PID) control. The PID algorithm is difficult to use in controlling automatic driving vehicles without considering the physical characteristics of the vehicle and in high-speed and complex environments. The model-based lateral control algorithm includes the lateral control algorithm based on vehicle kinematics model and the lateral dynamics algorithm based on vehicle dynamic model. The former is represented by the Stanley method based on front-wheel feedback and rear-wheel control based on rear-wheel feedback. The latter is represented by the lateral control algorithm of linear quadratic regulator based on the dynamic model. Algorithms based on the vehicle model need to accurately model the kinematic or dynamic characteristics of the vehicle and usually need to simplify the model to predict the state of vehicle tracking deviation by simplifying the modeling of the model. This approach thus achieves accurate control of the vehicle. In addition, these two lateral control algorithms do not consider the coupling characteristics with longitudinal control, which limits the tracking performance of the control algorithm. To address the problems of high-complexity vehicle model and current path tracking algorithm, this paper proposes a model free-steering control algorithm based on speed-adaptive preview.MethodIn the face of highly complex or unknown dynamic performance of the vehicle dynamics model, accurately calculating the state equation of vehicle path tracking deviation through dynamic characteristics is impossible. However, due to the complex dynamic characteristics, the control quantity obtained through kinematic characteristics will cause many errors, especially in the case of high-speed driving, large curvature, and nondifferentiable path. The cumulative error of these two methods may lead to a self-driving car going out of control. Therefore, the model-free control method can achieve stable and accurate path tracking performance in the full speed range under complex dynamic conditions. Considering the stable tracking in scenes with non-conductance and large curvature, this paper uses the speed-adaptive preview method to enhance the stability of autopilot under complex road conditions. According to the intelligent driving vehicle model studied in this paper, the control input includes the lateral distance difference between the vehicle and the tracking path, the angle between the vehicle and the tracking path, and the coupling parameters of the longitudinal speed of the vehicle. The output of the control algorithm includes the steering wheel angle, the throttle opening, and the brake master cylinder pressure. The former mainly controls the direction of the vehicle, while the latter controls the forward speed. In this paper, the output control equation of vehicle steering control is established first according to the deviation distance and angle between the vehicle and the tracking path. This method realizes stable tracking at low speed under the condition of highly complex dynamics and differentiable tracking path. At the same time, the tracking preview distance is set adaptively according to the vehicle longitudinal speed, and the speed coupling parameters are added to the equation to realize the stable tracking of the vehicle in the full speed range and all types of paths.ResultTo verify the proposed path tracking algorithm based on speed-adaptive preview, we participated in the 2020 China Intelligent Vehicle Championship and World Intelligent Driving Challenge online simulation competitions. In this experiment and competition, PanoSim automatic driving simulation system and Simulink simulation software are used for the simulation experiment. The test road is a 10 km test freeway provided by Panosim, and it includes five sections with large curvature and five sections with small curvature. In this paper, we select a typical section of the small curvature section and large curvature section to test the algorithm. Under the dynamic model with a high-degree-of-freedom dynamic model, the proposed algorithm can achieve the performance of lateral deviation |Δd | < 0.1 m on the ultra-high speed (>220 km/h) straight-line, and small-curvature tracking path, and |Δd | < 0.3 m on the high-speed (>150 km/h) high-curvature curve tracking path.ConclusionIn this paper, the path tracking algorithm based on speed preview is proposed, and the model free lateral control algorithm is studied to realize the control coverage from a simple to a complex vehicle model; the optimization of vehicle lateral control by a speed coupler is studied to realize the full speed range control coverage of the vehicle; and the controller based on speed-adaptive preview is studied to realize the transition from the differentiable path to the nondifferentiable path. To some extent, the problem of control hysteresis and overshoot is solved.关键词:automatic driving;steering control;path tracking;preview;velocity coupling;PanoSim153|236|2更新时间:2024-05-08 -
 摘要:ObjectiveFatigue driving is one of the main causes of traffic accidents. Drivers in fatigue state will have reduced alertness, weakened ability to deal with abnormal events, and inability to react traffic control and dangerous events, which will lead to accidents. The current technology for detecting fatigue driving behavior can be divided into three methods based on physiological parameters, vehicle behavior, and facial feature analysis. Detection methods based on physiological parameters require various sensors. These sensors use physiological signals to detect the driver's drowsiness, but they need contact with the driver's body, rely on expensive equipment, and are invasive. Detection methods based on vehicle behavior use vehicle behavior parameters, such as lane departure detection, steering wheel angle, and yaw angle information, to detect driving fatigue behavior, but they also depend on external factors such as road conditions. Detection methods based on facial feature analysis need to extract feature points from the driver's facial features and compare the driver's performance in fatigue or normal conditions by detecting fatigue behavior characteristics such as eye state, blinking, and yawning. Compared with the two earlier methods, this method has the advantages of noninvasiveness and easy implementation. In several current methods, spatiotemporal features cannot be well integrated, and interference of background and noise on recognition is not removed. This paper proposes a driving fatigue detection method based on pseudo 3D (P3D) convolutional neural network(CNN) and attention mechanism to solve these problems.MethodThe dataset is cropped into small videos of around 5 s each. The training video data interval is 90 video frames, and the picture resolution is set to 80×80×3. First, the feature map of each frame is fully extracted through the P3D module to generate a fixed-size feature set. Second, the P3D structure uses a 1×3×3 convolution kernel and a 3×1×1 convolution kernel to simulate 3×3×3 convolution in the spatial and time domains, decoupling 3×3×3 convolutions in time and space. Based on the feature that P3D decouples 3×3×3 convolutions in time and space, a module named P3D-Attention is proposed. The 3D convolutional neural network and attention mechanism are integrated to improve the correlation of important channel features, increase the global correlation of feature graphs, and remove the interference of background and noise on recognition by translating 3D temporal and spatial features into 2D features and embedding them in the dual-channel and spatial attention modules. The dual-channel attention module is used to apply attention on video frames and channels of each frame, which removes the interference of background and noise on recognition. For driving scenarios, this paper selects convolution kernels of different sizes to adapt to convolution features of different depths and uses the adaptive spatial attention module to make the model training converge faster and better. Afterward, 2D global average pooling layer is used instead of 3D global average pooling layer to obtain more expressive features, improving network convergence speed. Finally, the softmax classification layer is used for classification.ResultA comparative test is performed on the public dataset——a yawning detection dataset(YawDD). The detection accuracy of the method in this paper reaches 98.75%, and the recall rate of the yawning category reaches 100%.On the University of Texas at Arlington real-life drowsiness dataset(UTA-RLDD), the F1-score detection accuracy of the method in this paper reaches 99.64% on the test set, and the recall rate reaches 100% in the drowsy category. In terms of running time and model size, experimental results show that compared with the long short-term memory(LSTM) fusion method using ImageNet-trained Inception_v3 model, the algorithm in this paper has evident advantages in terms of running time and predicts that a 5 s video will take 660 ms on average, which is 11% of it. In terms of the size of the unpruned model, the method of Inception-v3 plus LSTM has 396.15 MB, and the model size in this paper is 42.5 MB, which is 1/9 of it.ConclusionA driving fatigue detection method based on P3D convolutional neural network and attention mechanism is proposed. Attention mechanisms are used to remove background and noise from recognition interference, improve the accuracy of driving fatigue detection, distinguish yawning behavior from mouth opening and mouth closing behaviors such as talking, and analyze yawning behavior, blinking, and head characteristic movements. The further work of this paper will 1)verify whether features can be extracted through a smaller network structure, design a more efficient network structure, and further reduce the size of the model. 2)Future work will also focus on using 3D convolution to distinguish more complicated driving behaviors because distracted driving behavior not only needs to focus on predicting the driver's fatigue status.关键词:3D convolutional neural network(CNN);pseudo-3D(P3D) convolutional;global average pooling;attention mechanisms;fatigue driving83|266|4更新时间:2024-05-08
摘要:ObjectiveFatigue driving is one of the main causes of traffic accidents. Drivers in fatigue state will have reduced alertness, weakened ability to deal with abnormal events, and inability to react traffic control and dangerous events, which will lead to accidents. The current technology for detecting fatigue driving behavior can be divided into three methods based on physiological parameters, vehicle behavior, and facial feature analysis. Detection methods based on physiological parameters require various sensors. These sensors use physiological signals to detect the driver's drowsiness, but they need contact with the driver's body, rely on expensive equipment, and are invasive. Detection methods based on vehicle behavior use vehicle behavior parameters, such as lane departure detection, steering wheel angle, and yaw angle information, to detect driving fatigue behavior, but they also depend on external factors such as road conditions. Detection methods based on facial feature analysis need to extract feature points from the driver's facial features and compare the driver's performance in fatigue or normal conditions by detecting fatigue behavior characteristics such as eye state, blinking, and yawning. Compared with the two earlier methods, this method has the advantages of noninvasiveness and easy implementation. In several current methods, spatiotemporal features cannot be well integrated, and interference of background and noise on recognition is not removed. This paper proposes a driving fatigue detection method based on pseudo 3D (P3D) convolutional neural network(CNN) and attention mechanism to solve these problems.MethodThe dataset is cropped into small videos of around 5 s each. The training video data interval is 90 video frames, and the picture resolution is set to 80×80×3. First, the feature map of each frame is fully extracted through the P3D module to generate a fixed-size feature set. Second, the P3D structure uses a 1×3×3 convolution kernel and a 3×1×1 convolution kernel to simulate 3×3×3 convolution in the spatial and time domains, decoupling 3×3×3 convolutions in time and space. Based on the feature that P3D decouples 3×3×3 convolutions in time and space, a module named P3D-Attention is proposed. The 3D convolutional neural network and attention mechanism are integrated to improve the correlation of important channel features, increase the global correlation of feature graphs, and remove the interference of background and noise on recognition by translating 3D temporal and spatial features into 2D features and embedding them in the dual-channel and spatial attention modules. The dual-channel attention module is used to apply attention on video frames and channels of each frame, which removes the interference of background and noise on recognition. For driving scenarios, this paper selects convolution kernels of different sizes to adapt to convolution features of different depths and uses the adaptive spatial attention module to make the model training converge faster and better. Afterward, 2D global average pooling layer is used instead of 3D global average pooling layer to obtain more expressive features, improving network convergence speed. Finally, the softmax classification layer is used for classification.ResultA comparative test is performed on the public dataset——a yawning detection dataset(YawDD). The detection accuracy of the method in this paper reaches 98.75%, and the recall rate of the yawning category reaches 100%.On the University of Texas at Arlington real-life drowsiness dataset(UTA-RLDD), the F1-score detection accuracy of the method in this paper reaches 99.64% on the test set, and the recall rate reaches 100% in the drowsy category. In terms of running time and model size, experimental results show that compared with the long short-term memory(LSTM) fusion method using ImageNet-trained Inception_v3 model, the algorithm in this paper has evident advantages in terms of running time and predicts that a 5 s video will take 660 ms on average, which is 11% of it. In terms of the size of the unpruned model, the method of Inception-v3 plus LSTM has 396.15 MB, and the model size in this paper is 42.5 MB, which is 1/9 of it.ConclusionA driving fatigue detection method based on P3D convolutional neural network and attention mechanism is proposed. Attention mechanisms are used to remove background and noise from recognition interference, improve the accuracy of driving fatigue detection, distinguish yawning behavior from mouth opening and mouth closing behaviors such as talking, and analyze yawning behavior, blinking, and head characteristic movements. The further work of this paper will 1)verify whether features can be extracted through a smaller network structure, design a more efficient network structure, and further reduce the size of the model. 2)Future work will also focus on using 3D convolution to distinguish more complicated driving behaviors because distracted driving behavior not only needs to focus on predicting the driver's fatigue status.关键词:3D convolutional neural network(CNN);pseudo-3D(P3D) convolutional;global average pooling;attention mechanisms;fatigue driving83|266|4更新时间:2024-05-08 -
 摘要:ObjectiveDriver fatigue is known to be directly related to road safety and is a leading cause of traffic fatalities and injuries of seated drivers. Previous studies used many fatigue driving detection methods to detect and analyze the fatigue status of seated drivers. These methods aim to improve detection accuracy and usually include driving behavioral features (e.g., steering wheel motion, lane keeping) and physiological features (e.g., eye and face movement, heart rate variability, electroencephalogram, electroocoulogram, electrocardiogram). Physiological features, such as eye movement, are widely used to predict driver fatigue because they are nonintrusive and independent on the driving context. However, fatigue driving detection under occluded face conditions is challenging and needs a robust algorithm of eye feature extraction. The literature showed that most eye tracking methods require high-resolution images. This condition leads to low processing speed and difficultly on real-time eye tracking. In this study, a fatigue driving detection method based on self-quotient image (SQI) and gradient image co-occurrence matrix was presented. This improved method is based on gray level and gradient co-occurrence matrix. The proposed method provides a new approach for predicting fatigue status on driver fatigue applications in a short time.MethodIn this study, a six-degree of freedom vibration table and driving simulator were used to model the driving context. The eye fatigued state of seated driver in real time was recorded by using an RGB camera mounted in the front of the driver. A single shot multibox detector face detection algorithm was used to extract the driver's facial region from the recorded video with ResNet10 as the front network. An ensemble of regression trees facial landmark location algorithm was used to calibrate the driver's eye area for each frame of the recorded video. A gray-level image and an SQI of each frame was combined to obtain the co-occurrence matrix of the driver's eye image. The statistic of numerical characteristics of the SQI and gradient image co-occurrence matrix of driver's eye images was analyzed. The driver's eye states were determined in accordance with the statistical features of the matrix and had a large variation. Percentage of eyelid closure(PERCLOS) over the pupil over time and maximum closing duration(MCD) were utilized to predict the state transition of seated driver from nonfatigue to fatigue.ResultWe compared our method with other fatigue driving detection methods based on eye aspect ratio and based on convolutional neural network (CNN) model. The quantitative evaluation metrics contained face detection accuracy, detection accuracy of open and closed states of the eye, and blink detection accuracy. The experiment results show that our model has better performance than other methods in video datasets. These datasets were captured in the driving context modeled by six-degree of freedom vibration table and driving simulator. The following cases were studied to predict the fatigue status of seated driver. One case was detected under occluded face conditions (e.g., wearing a mask and wearing glass), and the other case had no mask or glass. The accuracy of eye state analysis of method 1 is 97.68%, but the accuracy depends on the positioning accuracy of facial landmarks. However, the overall detection speed of the algorithm is slow and sensitive to whether the driver wore a mask. This condition makes the detection of the eye state module invalid. Classifying the driver eye state with the CNN takes a long time, and the eye state accuracy of method 2 is more than 96%. However, the success rate of blink detection is approximately zero for hard video samples. As a comparison, the proposed algorithm has better performance in face detection, eye opening and closing, and blink accuracies. The accuracy of opening and closing the eyes reaches 98.73% for a video sample of drivers' face under occlusion, such as wearing a mask. The recognition precision is 99.52% for a video sample of drivers without mask or glass, and the video sample processing frame rate is up to 32 frame/s.ConclusionIn this study, we proposed a fatigue driving detection method based on SQI and gradient image co-occurrence matrix. The experiment results demonstrate that our method has better performance than other several fatigue driving detection methods and can detect effectively the driver's eyes state when they open and close in real time. The proposed method has high accuracy and processing speed.关键词:fatigue driving;face detection;facial landmarks detection;self-quotient image (SQI);co-occurrence matrix;percentage of eyelid closure (PERCLOS)85|173|2更新时间:2024-05-08
摘要:ObjectiveDriver fatigue is known to be directly related to road safety and is a leading cause of traffic fatalities and injuries of seated drivers. Previous studies used many fatigue driving detection methods to detect and analyze the fatigue status of seated drivers. These methods aim to improve detection accuracy and usually include driving behavioral features (e.g., steering wheel motion, lane keeping) and physiological features (e.g., eye and face movement, heart rate variability, electroencephalogram, electroocoulogram, electrocardiogram). Physiological features, such as eye movement, are widely used to predict driver fatigue because they are nonintrusive and independent on the driving context. However, fatigue driving detection under occluded face conditions is challenging and needs a robust algorithm of eye feature extraction. The literature showed that most eye tracking methods require high-resolution images. This condition leads to low processing speed and difficultly on real-time eye tracking. In this study, a fatigue driving detection method based on self-quotient image (SQI) and gradient image co-occurrence matrix was presented. This improved method is based on gray level and gradient co-occurrence matrix. The proposed method provides a new approach for predicting fatigue status on driver fatigue applications in a short time.MethodIn this study, a six-degree of freedom vibration table and driving simulator were used to model the driving context. The eye fatigued state of seated driver in real time was recorded by using an RGB camera mounted in the front of the driver. A single shot multibox detector face detection algorithm was used to extract the driver's facial region from the recorded video with ResNet10 as the front network. An ensemble of regression trees facial landmark location algorithm was used to calibrate the driver's eye area for each frame of the recorded video. A gray-level image and an SQI of each frame was combined to obtain the co-occurrence matrix of the driver's eye image. The statistic of numerical characteristics of the SQI and gradient image co-occurrence matrix of driver's eye images was analyzed. The driver's eye states were determined in accordance with the statistical features of the matrix and had a large variation. Percentage of eyelid closure(PERCLOS) over the pupil over time and maximum closing duration(MCD) were utilized to predict the state transition of seated driver from nonfatigue to fatigue.ResultWe compared our method with other fatigue driving detection methods based on eye aspect ratio and based on convolutional neural network (CNN) model. The quantitative evaluation metrics contained face detection accuracy, detection accuracy of open and closed states of the eye, and blink detection accuracy. The experiment results show that our model has better performance than other methods in video datasets. These datasets were captured in the driving context modeled by six-degree of freedom vibration table and driving simulator. The following cases were studied to predict the fatigue status of seated driver. One case was detected under occluded face conditions (e.g., wearing a mask and wearing glass), and the other case had no mask or glass. The accuracy of eye state analysis of method 1 is 97.68%, but the accuracy depends on the positioning accuracy of facial landmarks. However, the overall detection speed of the algorithm is slow and sensitive to whether the driver wore a mask. This condition makes the detection of the eye state module invalid. Classifying the driver eye state with the CNN takes a long time, and the eye state accuracy of method 2 is more than 96%. However, the success rate of blink detection is approximately zero for hard video samples. As a comparison, the proposed algorithm has better performance in face detection, eye opening and closing, and blink accuracies. The accuracy of opening and closing the eyes reaches 98.73% for a video sample of drivers' face under occlusion, such as wearing a mask. The recognition precision is 99.52% for a video sample of drivers without mask or glass, and the video sample processing frame rate is up to 32 frame/s.ConclusionIn this study, we proposed a fatigue driving detection method based on SQI and gradient image co-occurrence matrix. The experiment results demonstrate that our method has better performance than other several fatigue driving detection methods and can detect effectively the driver's eyes state when they open and close in real time. The proposed method has high accuracy and processing speed.关键词:fatigue driving;face detection;facial landmarks detection;self-quotient image (SQI);co-occurrence matrix;percentage of eyelid closure (PERCLOS)85|173|2更新时间:2024-05-08
Object Detection and Tracking
-
 摘要:ObjectiveScene depth information plays a vital role in many current research topics, such as 3D reconstruction, obstacle detection, and visual navigation. Obtaining dense and accurate depth image information often requires expensive equipment, resulting in high costs. The method of using color images for depth estimation does not require expensive equipment and has a wider range of applications. Stereo matching is a traditional method used for estimating the depth with RGB images. A large estimation error is found for weak texture regions because stereo matching relies heavily on feature matching. With the wide application of convolutional neural networks in image processing, the depth estimation of monocular images has been widely investigated. However, the monocular image is essentially a pathological problem because it lacks depth clues related to motion and stereo. Many methods are currently used to estimate the depth of monocular image. Without the use of real depth data, the method of using binocular images for unsupervised learning uses image reconstruction as a supervised signal to train a depth estimation model. This task currently has achieved a large breakthrough although depth estimation depends on the geometric features. How to effectively use the information in the shallow features of the image and how to add geometric constraints to the prediction output while ensuring high convergence performance have been widely investigated to improve the accuracy of depth estimation. In the commonly used multi-scale estimation, the sampling method of bilinear interpolation has local differentiability, easily making the network fall into a local minimum and affecting the training effect. A method based on local plane parameter prediction is proposed to address these problems. This method is applied to multi-scale prediction by using a completely differentiable method with geometric constraints, thereby effectively limiting the convergence of multi-scale depth map prediction in the same direction.MethodThis study presents an unsupervised monocular depth estimation network based on local plane parameter prediction. The main structure is a coding-decoding network and is mainly composed of three parts: a ResNet50-based coding network, a decoding network that introduces a serial double attention mechanism in the skip layer connection, and multi-scale prediction using local plane parameter estimation module. During the training, the network estimates the depth of an image in stereo images, reconstructs another view, and uses the real image of the other view as a supervision for training. Our training set includes 22 600 images in the KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago) dataset. The model is built on PyTorch framework, and the input image is 640×192 pixels for training. NVIDIA GTX 2080 equipment is used for training, and the training involves 20 epochs. In the multi-scale prediction module, we convert the depth estimation problem into a local plane parameter estimation problem. The local plane parameter prediction module is used to replace upsampling and depth map generation in multi-scale estimation. The depth map prediction of each scale is restored to the standard scale in accordance with the local plane parameters. The standard scale depth map is obtained in accordance with a pinhole camera model to avoid the local differentiability caused by bilinear interpolation, thereby effectively avoiding falling into the local minimum value. A serial attention mechanism is introduced in the network layer hopping connection to obtain clear edge contour information.ResultWe compared our model with multiple unsupervised and supervised methods on the KITTI test dataset. Quantitative evaluation indicators include absolute relative error (Abs Rel), squared relative error (Sq Rel), linear root mean square error (RMSE), logarithmic root mean square error (RMSElog), and threshold accuracy index
摘要:ObjectiveScene depth information plays a vital role in many current research topics, such as 3D reconstruction, obstacle detection, and visual navigation. Obtaining dense and accurate depth image information often requires expensive equipment, resulting in high costs. The method of using color images for depth estimation does not require expensive equipment and has a wider range of applications. Stereo matching is a traditional method used for estimating the depth with RGB images. A large estimation error is found for weak texture regions because stereo matching relies heavily on feature matching. With the wide application of convolutional neural networks in image processing, the depth estimation of monocular images has been widely investigated. However, the monocular image is essentially a pathological problem because it lacks depth clues related to motion and stereo. Many methods are currently used to estimate the depth of monocular image. Without the use of real depth data, the method of using binocular images for unsupervised learning uses image reconstruction as a supervised signal to train a depth estimation model. This task currently has achieved a large breakthrough although depth estimation depends on the geometric features. How to effectively use the information in the shallow features of the image and how to add geometric constraints to the prediction output while ensuring high convergence performance have been widely investigated to improve the accuracy of depth estimation. In the commonly used multi-scale estimation, the sampling method of bilinear interpolation has local differentiability, easily making the network fall into a local minimum and affecting the training effect. A method based on local plane parameter prediction is proposed to address these problems. This method is applied to multi-scale prediction by using a completely differentiable method with geometric constraints, thereby effectively limiting the convergence of multi-scale depth map prediction in the same direction.MethodThis study presents an unsupervised monocular depth estimation network based on local plane parameter prediction. The main structure is a coding-decoding network and is mainly composed of three parts: a ResNet50-based coding network, a decoding network that introduces a serial double attention mechanism in the skip layer connection, and multi-scale prediction using local plane parameter estimation module. During the training, the network estimates the depth of an image in stereo images, reconstructs another view, and uses the real image of the other view as a supervision for training. Our training set includes 22 600 images in the KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago) dataset. The model is built on PyTorch framework, and the input image is 640×192 pixels for training. NVIDIA GTX 2080 equipment is used for training, and the training involves 20 epochs. In the multi-scale prediction module, we convert the depth estimation problem into a local plane parameter estimation problem. The local plane parameter prediction module is used to replace upsampling and depth map generation in multi-scale estimation. The depth map prediction of each scale is restored to the standard scale in accordance with the local plane parameters. The standard scale depth map is obtained in accordance with a pinhole camera model to avoid the local differentiability caused by bilinear interpolation, thereby effectively avoiding falling into the local minimum value. A serial attention mechanism is introduced in the network layer hopping connection to obtain clear edge contour information.ResultWe compared our model with multiple unsupervised and supervised methods on the KITTI test dataset. Quantitative evaluation indicators include absolute relative error (Abs Rel), squared relative error (Sq Rel), linear root mean square error (RMSE), logarithmic root mean square error (RMSElog), and threshold accuracy index$\delta $ 关键词:unsupervised learning;monocular depth estimation;attention mechanism;local plane parameters prediction;local differentiability94|154|3更新时间:2024-05-08 -
 摘要:ObjectivePath tracking is not a new topic, being part of the various components of an autonomous vehicle that aim to steer the vehicle to track a defined path. The traditional steering controller, which uses location information and path information to steer autonomous vehicles, cannot achieve human-like driving behaviors according to real-life driving scenes or environments. When human-like steering behavior is considered a feature in the steering model, the steering problem of autonomous vehicles becomes challenging. The traditional steering controller tracks the defined path by predicting the steering angle of the front wheel according to the current location of the vehicles and the path information, but it is only a purely mechanical driving behavior rather than a human-like driving behavior. Thus, researchers employ a neural network as a steering model, training the neural network by using the images captured from the front-facing camera mounted on the vehicle along with the associated steering angles either from the perspective of human beings or simulators; this network is also known as end-to-end neural network. Nevertheless, most of the existing neural networks consider only the visual camera frames as input, ignoring other available information such as location, motion, and model of vehicle. The training dataset of the end-to-end neural network is supposed to cover all kinds of driving weather or scenes, such as rainy day, snow day, overexposure, and underexposure, so that the network can learn as much as possible the relationship between the image frames and driving behaviors, and enhance the universality of the neural network. The end-to-end neural network also relies on large-scale training datasets to enhance the robustness of the network. Overdependence on cameras results in the steering performance being greatly affected by the environment. Therefore, the combination of the traditional steering controller and end-to-end neural network can complement each other's advantages. With the use of only small-scale datasets that cover fewer driving scenes for training, the control behaviors of the new network can be human-like, robust, and able to cover multiple driving scenes. In this paper, we proposed a fusion neural network framework called deep pure pursuit (deep PP) to incorporate a convolutional neural network (CNN) with a traditional steering controller to build a robust steering model.MethodIn this study, a human-like steering model that fuses visual geometry group network (VGG)-type CNN and a traditional steering controller is built. The VGG-type CNN consists of 8 layers, including three convolutional layers, three pooling layers, and two fully connected layers. It uses 3×3 non-stride convolutions with 32, 64, and 128 kernels are used. Following each convolutional layer, a 2×2 max-pooling layer with stride 2 is configured to decrease the used parameters. The fully connected layers are designed to function as a controller for steering. While CNN extracts visual features from video frames, PP is employed to utilize the location information and motion model information. Fifty target points of the defined path ahead of the vehicle are selected to calculate the predict front-wheel steering angle by PP. The minimum and maximum look-ahead distance of PP are separately set to 1.5 m and 20 m, respectively, ahead of the vehicle. After visual features from the CNN model and 50 steering angles from PP are extracted, a combinational feature vector is proposed to integrate visual features with 50 steering angles. The features are concatenated with the fully connected layers to build the mapping relationship. In our augmentation, the images are flipped and rotated to improve the self-recovery capacities from a poor location or orientation. In each image, the bottom 30 pixels and the top 40 pixels are cropped to remove the front of the car and most of the sky above the horizon, and then the processed images are resized to a lower resolution to accelerate the training and testing. Our model is implemented in Google's TensorFlow. The experiments are conducted on a Titan X GPU. The max number of epochs is set to 10. Each epoch contains 10 000 frames to train the model. The batch size is set to 32. Adam optimizer with learning rate 1E-4 is deployed to train our model. The activation function of our model is ReLU. Root mean square error(RMSE) was used to evaluate the performance of different models.ResultTo train and validate our proposed solution, we collect datasets by using CARLA(Center for Advanced Research on Language Acquisition) simulator and a real-life autonomous vehicle. In the simulation dataset, we trained the models under the ClearNoon weather parameter and evaluated on 14 instances of poor driving weather. In the real-life dataset, 13 080 frames are collected for training, and 2 770 frames are collected for testing. We compared our model with a CNN model of the Udacity challenge and a traditional steering controller, PP, in verifying the effectiveness of deep PP. Experiment results show that our steering model can track the steering commands from the autopilot in CARLA more closely than CNN and PP can under 14 instances of poor driving conditions and improve the RMSE by 50.28% and 35.39%, separately. In real-life experiments, the proposed model is tested on a real-life dataset to prove its applicability. The discussion of different look-ahead distance demonstrates that PP controller is sensitive to the look-head distance. The maximal deviation from the human driver's steering commands reaches 0.245 2 rad. The discussion of location noise on the PP controller and deep PP proves that deep PP can better maintain robustness to location drift.ConclusionIn this study, we proposed a fusion neural network framework that incorporates visual features from the camera with additional location information and motion model information. Experiment results show that our model can track the steering commands of autopilot or human driver more closely than the CNN model of the Udacity challenge and PP and maintained high robustness under 14 poor driving conditions.关键词:autonomous driving;end-to-end;steering model;path tracking;deep learning;pure pursuit172|830|1更新时间:2024-05-08
摘要:ObjectivePath tracking is not a new topic, being part of the various components of an autonomous vehicle that aim to steer the vehicle to track a defined path. The traditional steering controller, which uses location information and path information to steer autonomous vehicles, cannot achieve human-like driving behaviors according to real-life driving scenes or environments. When human-like steering behavior is considered a feature in the steering model, the steering problem of autonomous vehicles becomes challenging. The traditional steering controller tracks the defined path by predicting the steering angle of the front wheel according to the current location of the vehicles and the path information, but it is only a purely mechanical driving behavior rather than a human-like driving behavior. Thus, researchers employ a neural network as a steering model, training the neural network by using the images captured from the front-facing camera mounted on the vehicle along with the associated steering angles either from the perspective of human beings or simulators; this network is also known as end-to-end neural network. Nevertheless, most of the existing neural networks consider only the visual camera frames as input, ignoring other available information such as location, motion, and model of vehicle. The training dataset of the end-to-end neural network is supposed to cover all kinds of driving weather or scenes, such as rainy day, snow day, overexposure, and underexposure, so that the network can learn as much as possible the relationship between the image frames and driving behaviors, and enhance the universality of the neural network. The end-to-end neural network also relies on large-scale training datasets to enhance the robustness of the network. Overdependence on cameras results in the steering performance being greatly affected by the environment. Therefore, the combination of the traditional steering controller and end-to-end neural network can complement each other's advantages. With the use of only small-scale datasets that cover fewer driving scenes for training, the control behaviors of the new network can be human-like, robust, and able to cover multiple driving scenes. In this paper, we proposed a fusion neural network framework called deep pure pursuit (deep PP) to incorporate a convolutional neural network (CNN) with a traditional steering controller to build a robust steering model.MethodIn this study, a human-like steering model that fuses visual geometry group network (VGG)-type CNN and a traditional steering controller is built. The VGG-type CNN consists of 8 layers, including three convolutional layers, three pooling layers, and two fully connected layers. It uses 3×3 non-stride convolutions with 32, 64, and 128 kernels are used. Following each convolutional layer, a 2×2 max-pooling layer with stride 2 is configured to decrease the used parameters. The fully connected layers are designed to function as a controller for steering. While CNN extracts visual features from video frames, PP is employed to utilize the location information and motion model information. Fifty target points of the defined path ahead of the vehicle are selected to calculate the predict front-wheel steering angle by PP. The minimum and maximum look-ahead distance of PP are separately set to 1.5 m and 20 m, respectively, ahead of the vehicle. After visual features from the CNN model and 50 steering angles from PP are extracted, a combinational feature vector is proposed to integrate visual features with 50 steering angles. The features are concatenated with the fully connected layers to build the mapping relationship. In our augmentation, the images are flipped and rotated to improve the self-recovery capacities from a poor location or orientation. In each image, the bottom 30 pixels and the top 40 pixels are cropped to remove the front of the car and most of the sky above the horizon, and then the processed images are resized to a lower resolution to accelerate the training and testing. Our model is implemented in Google's TensorFlow. The experiments are conducted on a Titan X GPU. The max number of epochs is set to 10. Each epoch contains 10 000 frames to train the model. The batch size is set to 32. Adam optimizer with learning rate 1E-4 is deployed to train our model. The activation function of our model is ReLU. Root mean square error(RMSE) was used to evaluate the performance of different models.ResultTo train and validate our proposed solution, we collect datasets by using CARLA(Center for Advanced Research on Language Acquisition) simulator and a real-life autonomous vehicle. In the simulation dataset, we trained the models under the ClearNoon weather parameter and evaluated on 14 instances of poor driving weather. In the real-life dataset, 13 080 frames are collected for training, and 2 770 frames are collected for testing. We compared our model with a CNN model of the Udacity challenge and a traditional steering controller, PP, in verifying the effectiveness of deep PP. Experiment results show that our steering model can track the steering commands from the autopilot in CARLA more closely than CNN and PP can under 14 instances of poor driving conditions and improve the RMSE by 50.28% and 35.39%, separately. In real-life experiments, the proposed model is tested on a real-life dataset to prove its applicability. The discussion of different look-ahead distance demonstrates that PP controller is sensitive to the look-head distance. The maximal deviation from the human driver's steering commands reaches 0.245 2 rad. The discussion of location noise on the PP controller and deep PP proves that deep PP can better maintain robustness to location drift.ConclusionIn this study, we proposed a fusion neural network framework that incorporates visual features from the camera with additional location information and motion model information. Experiment results show that our model can track the steering commands of autopilot or human driver more closely than the CNN model of the Udacity challenge and PP and maintained high robustness under 14 poor driving conditions.关键词:autonomous driving;end-to-end;steering model;path tracking;deep learning;pure pursuit172|830|1更新时间:2024-05-08 -
 摘要:ObjectiveDepth images play an important role in robotics, 3D reconstruction, and autonomous driving. However, depth sensors, such as Microsoft Kinect and Intel RealSense, produce depth images with missing data. In some fields, such as those using high-dimension maps for autonomous driving (including RGB images and depth images), objects not belonging to these maps (people, cars, etc.) should be removed. The corresponding areas are blank (i.e., missing data) after removing objects from the depth image. Therefore, depth images with missing data should be repaired to accomplish some 3D tasks. Depth image inpainting approaches can be divided into two groups: image-guided depth image inpainting and single-depth image inpainting approaches. Image-guided depth image inpainting approaches repair depth images through information on the ground truth of its color images or its previous frames or its next frames. Without this information, these approaches are useless. Single-depth image inpainting approaches cannot repair images without any information from other color images. Currently, only a few studies have tackled this issue by using and improving depth low-rank components in depth images. Current single-depth image inpainting methods only repair depth images with sparse missing data rather than small or large holes. Generative adversarial network (GAN)-based approaches have been widely researched for RGB image inpainting and have achieved state-of-the-art (SOTA) results. However, to the best of our knowledge, no GAN-based approach is reported for depth image inpainting. The reasons are as follows. On the one hand, the depth image records the distance between different objects and lacks texture information. Some researchers have expressed concerns about whether convolutional neural networks (CNNs) can extract depth image features well due to this characteristic. On the other hand, no public depth image datasets are available for CNN-based approaches to train. For the first reason, CNNs have been verified that they can extract features of depth images. For the second reason, the Baidu company released the Apollo scape dataset in 2018 that contains 43 592 depth ground truth images. These images are sufficient to explore the GAN-based approach for depth image inpainting. Therefore, we explore a single-depth image inpainting approach.MethodIn this paper, we provided a GAN called edge-guided GAN for depth image inpainting. We first obtained the edge image of the deficient depth image by using the Canny algorithm and then combined the deficient depth image and its edge image into two-channel data. These data are used as inputs to the edge-guided GAN, and the output is the repaired depth image. The edge image presents the edge information of a deficient depth image that guides inpainting. The edge-guided GAN contains a generator and a discriminator. The generator is an encoder-decoder architecture and is designed for depth image inpainting. This generator first uses two asymmetric convolutional network(ACNet) layers and six residual block layers to extract depth image features and then utilizes two convolution transpose layers to generate a repaired depth image. ACNet can be trained to achieve a better performance than standard square-kernel convolutional layers but only uses less GPU memory. The discriminator uses repaired depth images or the ground truth of depth images as inputs and predicts whether the inputs are true or fake depth images. The architecture of the discriminator is similar to that of PatchGAN and contains five stand convolution layers. The loss functions of generator and a discriminator are designed. The input of the discriminator includes the ground truth of the depth image and the depth image generated by the generator. The discriminator loss can be separated into two categories. When the inputs are ground truth, the discriminator loss is the binary cross entropy (BCE) loss of its results with one. When the inputs are the generated depth image, the discriminator loss is the BCE loss of its results with zero. Therefore, the total loss of the discriminator is the average of the sum of the above two losses. The loss function of generator is the average of L1 loss between the pixels of deficient depth image and the pixels of depth image after inpainting. The optimization goal of edge-guided GAN is to minimize the generator loss and maximize the discriminator loss.ResultWe trained four commonly used methods and edge-guided GAN without edge information for comparison to verify the performance of our edge-guided GAN. When the size of input is 256×256 pixels and the size of mask is 32×32 pixels, the peak signal to noise ratio of edge-guided GAN is 35.250 8. Compared with the second performance method, the peak signal-to-noise ratio (higher is better) increases by 15.76%. When the size of mask is 64×64, the peak signal-to-noise ratio of edge-guided GAN is 29.157 3. Compared with the second method, the peak signal-to-noise ratio increases by 18.64%. The peak signal-to-noise ratios of all methods with 32×32 masks are higher than the corresponding methods with 64×64 masks. We conducted an experiment to verify the performance of edge-guided GAN on object removal. In this experiment, the objects that need to be removed were set as mask, and the edge-guided GAN achieved SOTA results.ConclusionThe proposed edge-guided GAN is a single-depth image inpainting approach with high accuracy. This method takes the edge information of deficient depth image as the constraint condition, and its architecture and loss functions can effectively extract the features of deficient depth image.关键词:generative adversarial network(GAN);depth image inpainting approaches;Edge-guided GAN;edge information;the Apollo scape dataset50|65|3更新时间:2024-05-08
摘要:ObjectiveDepth images play an important role in robotics, 3D reconstruction, and autonomous driving. However, depth sensors, such as Microsoft Kinect and Intel RealSense, produce depth images with missing data. In some fields, such as those using high-dimension maps for autonomous driving (including RGB images and depth images), objects not belonging to these maps (people, cars, etc.) should be removed. The corresponding areas are blank (i.e., missing data) after removing objects from the depth image. Therefore, depth images with missing data should be repaired to accomplish some 3D tasks. Depth image inpainting approaches can be divided into two groups: image-guided depth image inpainting and single-depth image inpainting approaches. Image-guided depth image inpainting approaches repair depth images through information on the ground truth of its color images or its previous frames or its next frames. Without this information, these approaches are useless. Single-depth image inpainting approaches cannot repair images without any information from other color images. Currently, only a few studies have tackled this issue by using and improving depth low-rank components in depth images. Current single-depth image inpainting methods only repair depth images with sparse missing data rather than small or large holes. Generative adversarial network (GAN)-based approaches have been widely researched for RGB image inpainting and have achieved state-of-the-art (SOTA) results. However, to the best of our knowledge, no GAN-based approach is reported for depth image inpainting. The reasons are as follows. On the one hand, the depth image records the distance between different objects and lacks texture information. Some researchers have expressed concerns about whether convolutional neural networks (CNNs) can extract depth image features well due to this characteristic. On the other hand, no public depth image datasets are available for CNN-based approaches to train. For the first reason, CNNs have been verified that they can extract features of depth images. For the second reason, the Baidu company released the Apollo scape dataset in 2018 that contains 43 592 depth ground truth images. These images are sufficient to explore the GAN-based approach for depth image inpainting. Therefore, we explore a single-depth image inpainting approach.MethodIn this paper, we provided a GAN called edge-guided GAN for depth image inpainting. We first obtained the edge image of the deficient depth image by using the Canny algorithm and then combined the deficient depth image and its edge image into two-channel data. These data are used as inputs to the edge-guided GAN, and the output is the repaired depth image. The edge image presents the edge information of a deficient depth image that guides inpainting. The edge-guided GAN contains a generator and a discriminator. The generator is an encoder-decoder architecture and is designed for depth image inpainting. This generator first uses two asymmetric convolutional network(ACNet) layers and six residual block layers to extract depth image features and then utilizes two convolution transpose layers to generate a repaired depth image. ACNet can be trained to achieve a better performance than standard square-kernel convolutional layers but only uses less GPU memory. The discriminator uses repaired depth images or the ground truth of depth images as inputs and predicts whether the inputs are true or fake depth images. The architecture of the discriminator is similar to that of PatchGAN and contains five stand convolution layers. The loss functions of generator and a discriminator are designed. The input of the discriminator includes the ground truth of the depth image and the depth image generated by the generator. The discriminator loss can be separated into two categories. When the inputs are ground truth, the discriminator loss is the binary cross entropy (BCE) loss of its results with one. When the inputs are the generated depth image, the discriminator loss is the BCE loss of its results with zero. Therefore, the total loss of the discriminator is the average of the sum of the above two losses. The loss function of generator is the average of L1 loss between the pixels of deficient depth image and the pixels of depth image after inpainting. The optimization goal of edge-guided GAN is to minimize the generator loss and maximize the discriminator loss.ResultWe trained four commonly used methods and edge-guided GAN without edge information for comparison to verify the performance of our edge-guided GAN. When the size of input is 256×256 pixels and the size of mask is 32×32 pixels, the peak signal to noise ratio of edge-guided GAN is 35.250 8. Compared with the second performance method, the peak signal-to-noise ratio (higher is better) increases by 15.76%. When the size of mask is 64×64, the peak signal-to-noise ratio of edge-guided GAN is 29.157 3. Compared with the second method, the peak signal-to-noise ratio increases by 18.64%. The peak signal-to-noise ratios of all methods with 32×32 masks are higher than the corresponding methods with 64×64 masks. We conducted an experiment to verify the performance of edge-guided GAN on object removal. In this experiment, the objects that need to be removed were set as mask, and the edge-guided GAN achieved SOTA results.ConclusionThe proposed edge-guided GAN is a single-depth image inpainting approach with high accuracy. This method takes the edge information of deficient depth image as the constraint condition, and its architecture and loss functions can effectively extract the features of deficient depth image.关键词:generative adversarial network(GAN);depth image inpainting approaches;Edge-guided GAN;edge information;the Apollo scape dataset50|65|3更新时间:2024-05-08 -
 摘要:ObjectiveIn recent years, deep learning neural network has continued to develop, and excellent results have been achieved in the fields of computer vision, natural language processing, and speech recognition. In autonomous driving technology, the environment perception is an important application. The environment perception mainly processes the collected image information about the surrounding environment. Thus, deep learning is an important section in this link. However, the number of layers of existing neural network models continues to increase with the continuous increase in the complexity of processing problems. Thus, the number of overall parameters of the network and the required computing power are increasing. These models run well on platforms with sufficient computing power, such as server platforms with sufficient computing power. However, many deep neural network models are difficult to be deployed on embedded platforms with limited computing and storage resources, such as autonomous driving platforms. Compressing the existing deep neural network models is necessary to solve the contradiction between the huge amount of calculation required for the application of deep neural networks and the limited computing power of embedded platforms. This process can reduce the number of model parameters and computing power. This paper proposes a greedy network pruning method based on the existing model compression method. The propose method incorporates the probability distribution of weights to reduce redundant connections in the network model and improve the computational efficiency and parameters of the model.MethodThe current pruning method mainly uses the property of weight parameter as a criterion for parameter importance evaluation. The 1 norm of the convolution kernel weight parameter is used as the basis for determining the importance. However, this method ignores the variation of weight during training. In the pruning process, many methods use the trained model to perform one-time pruning. Thus, the accuracy of the model after pruning is difficult to maintain. the proposed is inspired by the study of uncertain graphs to solve the above problem. The probability distribution of weights is introduced, and the importance of the connection is jointly judged in accordance with the probability distribution of the weight parameter value and the size of the current weight in the training. The importance of the network connection and the effect of cutting the connection on the loss function are jointly used. The degree of influence collectively represents the contribution rate of this network connection to the result, thereby serving as the basis for pruning the network connection. In the stage of greedy pruning of the model, the proposed method uses incremental pruning to control the scale and speed of pruning. Iterative pruning and restoration are performed for a small proportion of connections until the state of the current sparse connections no longer changes. The pruning scale is gradually expanded until the expected model compression effect is achieved. Therefore, the incremental pruning and recovery strategy can avoid the weight gradient explosion problem caused by excessive pruning, improve the pruning efficiency and model stability, and realize dynamic pruning compared with the one-time pruning process based on the weight parameters. The proposed pruning method guarantees the maximum compression of the model's volume while maintaining its accuracy.ResultThe experiment uses networks of different depths for experiments, including CifarSmall, AlexNet, and visual geometry group(VGG)16, and nets with residual connections, including ResNet34 and ResNet50 networks, to verify the applicability of the proposed method to different depth networks. The experimental dataset uses the commonly used classification datasets, including CIFAR-10 and ImageNet ILSVRC(ImageNet Large Scale Visual Recognition Challenge)-2012, making it convenient for comparison with other methods. The main comparison content of the experiment includes the proposed method and the dynamic network pruning strategy on CIFAR-10. The pruning effect of the proposed method and the current state-of-the-art (SOTA) pruning algorithm HRank is compared on the Imagenet dataset in ResNet50. Experimental results prove that the accuracy of the proposed method is higher than that of the dynamic network pruning strategy at various pruning rates on the Cifar10 dataset. On the ImageNet data set, the proposed method effectively compresses the number of parameters of AlexNet and VGG16 by 5.9 and 11.4 times, respectively, with a small loss of accuracy. The number of training iterations required is more than that of the dynamic network pruning strategy. Effective compression can be performed for the residual type networks ResNet34 and ResNet50. For the ResNet50 network, a larger compression rate is achieved with a small increase in accuracy loss compared with the current SOTA method HRank.ConclusionThe greedy pruning strategy fused with probability distribution solves the uncertainty problem of deep neural network pruning, improves the stability of the network after model compression, and realizes the compression of the number of network model parameters while ensuring the accuracy of the model. Experimental results prove that the proposed method has a good compression effect for many types. The probability distribution of the weight parameters introduced in this research can be used as an important basis for the subsequent parameter importance criterion in the pruning research. The incremental pruning and the connection recovery in the pruning process used in this article are important for accuracy maintenance, However, optimizing and accelerating the reasoning of the sparse model obtained after pruning needs further research.关键词:deep learning;neural network;model compression;probability distribution;network pruning129|122|2更新时间:2024-05-08
摘要:ObjectiveIn recent years, deep learning neural network has continued to develop, and excellent results have been achieved in the fields of computer vision, natural language processing, and speech recognition. In autonomous driving technology, the environment perception is an important application. The environment perception mainly processes the collected image information about the surrounding environment. Thus, deep learning is an important section in this link. However, the number of layers of existing neural network models continues to increase with the continuous increase in the complexity of processing problems. Thus, the number of overall parameters of the network and the required computing power are increasing. These models run well on platforms with sufficient computing power, such as server platforms with sufficient computing power. However, many deep neural network models are difficult to be deployed on embedded platforms with limited computing and storage resources, such as autonomous driving platforms. Compressing the existing deep neural network models is necessary to solve the contradiction between the huge amount of calculation required for the application of deep neural networks and the limited computing power of embedded platforms. This process can reduce the number of model parameters and computing power. This paper proposes a greedy network pruning method based on the existing model compression method. The propose method incorporates the probability distribution of weights to reduce redundant connections in the network model and improve the computational efficiency and parameters of the model.MethodThe current pruning method mainly uses the property of weight parameter as a criterion for parameter importance evaluation. The 1 norm of the convolution kernel weight parameter is used as the basis for determining the importance. However, this method ignores the variation of weight during training. In the pruning process, many methods use the trained model to perform one-time pruning. Thus, the accuracy of the model after pruning is difficult to maintain. the proposed is inspired by the study of uncertain graphs to solve the above problem. The probability distribution of weights is introduced, and the importance of the connection is jointly judged in accordance with the probability distribution of the weight parameter value and the size of the current weight in the training. The importance of the network connection and the effect of cutting the connection on the loss function are jointly used. The degree of influence collectively represents the contribution rate of this network connection to the result, thereby serving as the basis for pruning the network connection. In the stage of greedy pruning of the model, the proposed method uses incremental pruning to control the scale and speed of pruning. Iterative pruning and restoration are performed for a small proportion of connections until the state of the current sparse connections no longer changes. The pruning scale is gradually expanded until the expected model compression effect is achieved. Therefore, the incremental pruning and recovery strategy can avoid the weight gradient explosion problem caused by excessive pruning, improve the pruning efficiency and model stability, and realize dynamic pruning compared with the one-time pruning process based on the weight parameters. The proposed pruning method guarantees the maximum compression of the model's volume while maintaining its accuracy.ResultThe experiment uses networks of different depths for experiments, including CifarSmall, AlexNet, and visual geometry group(VGG)16, and nets with residual connections, including ResNet34 and ResNet50 networks, to verify the applicability of the proposed method to different depth networks. The experimental dataset uses the commonly used classification datasets, including CIFAR-10 and ImageNet ILSVRC(ImageNet Large Scale Visual Recognition Challenge)-2012, making it convenient for comparison with other methods. The main comparison content of the experiment includes the proposed method and the dynamic network pruning strategy on CIFAR-10. The pruning effect of the proposed method and the current state-of-the-art (SOTA) pruning algorithm HRank is compared on the Imagenet dataset in ResNet50. Experimental results prove that the accuracy of the proposed method is higher than that of the dynamic network pruning strategy at various pruning rates on the Cifar10 dataset. On the ImageNet data set, the proposed method effectively compresses the number of parameters of AlexNet and VGG16 by 5.9 and 11.4 times, respectively, with a small loss of accuracy. The number of training iterations required is more than that of the dynamic network pruning strategy. Effective compression can be performed for the residual type networks ResNet34 and ResNet50. For the ResNet50 network, a larger compression rate is achieved with a small increase in accuracy loss compared with the current SOTA method HRank.ConclusionThe greedy pruning strategy fused with probability distribution solves the uncertainty problem of deep neural network pruning, improves the stability of the network after model compression, and realizes the compression of the number of network model parameters while ensuring the accuracy of the model. Experimental results prove that the proposed method has a good compression effect for many types. The probability distribution of the weight parameters introduced in this research can be used as an important basis for the subsequent parameter importance criterion in the pruning research. The incremental pruning and the connection recovery in the pruning process used in this article are important for accuracy maintenance, However, optimizing and accelerating the reasoning of the sparse model obtained after pruning needs further research.关键词:deep learning;neural network;model compression;probability distribution;network pruning129|122|2更新时间:2024-05-08
Scene Perception and Simulation of Autonomous Driving
-
 摘要:ObjectiveCamera calibration is one of the key factors of the perception in advanced driver-assistance systems (ADAS) and many other applications. Traditional camera calibration methods and even some state-of-the-art calibration algorithms, which are currently widely used in factories, strongly rely on specific scenes and specific markers. Existing methods to calibrate the extrinsic parameters of the camera are inconvenient and inaccurate, and current algorithms have some obvious disadvantages, which might cause serious accidents, damage the vehicle, or threaten the safety of passengers. Theoretically, once calibrated, the extrinsic parameters of the camera, including the position and the posture of camera installation, will be fixed and stable. However, the extrinsic parameters of a camera change throughout the lifetime of a vehicle. Real-time dynamic calibration is useful in cases when vehicles are transported or when cameras are removed for maintenance or replacement. Other extrinsic parameter calibration methods solves the estimation by simultaneous localization and mapping or visual inertia odometry (VIO) technologies. These methods try to extract point features and match points with the same characters, and the spatial transformation of different frames is calculated accordingly from the matched point pairs. However, according to the absence of texture information such as when one is in an indoor environment, the accuracy of extrinsic parameters is not always satisfactory. The common situation is that the algorithm cannot obtain any feature from the existing frames or the features that are obtained are not enough to calculate the position. To solve this problem and achieve the requirement of ADAS, this paper proposes a self-calibrating method that is based on aligning the detected lanes by the camera with a high-definition (HD) map.MethodFeature extraction is the first step of calibration. The most common feature extraction method is to acquire features from frames, calculate the gradient or other specific information of every single pixel, and select the pixels with the most significant values as the detected features. In this paper, we introduce a state-of-the-art algorithm that uses deep learning to detect lane points in the images grabbed from the camera. Some parts of the extrinsic parameters, including longitudinal translation, are unobservable when the vehicle is moving; thus, a data filtering and post-processing method is proposed. Images are classified into three classes: invalid frame, data frame, and key frame. The data filtering rule will efficiently divide the obtained frames into these three types according to the information the frame carries. Then, in the next step, the reprojection error (or loss) is defined in the imaging plane. The process consists of four steps: 1) The lane detected in the HD map is projected to the image plane, and the nearest neighborhood is associated with every detected lane point. This step is similar to feature matching, but it focuses only on the distance of the nearest potential match points. 2) The distance of points and the normal vectorial angle is calculated, and different weights are assigned based on different image types. 3) The geometric constraints of lanes in the image plane and frame of the camera are solved. The initial guess of the extrinsic parameter is determined; the guess is often imprecise and valid only in the cases when the lane is a straight line and the camera translation is known. 4) A gradient descent-based iterative optimal method is used to minimize the reprojection error, and the optimal extrinsic parameter could be determined at the same time. We use such methods to calibrate the camera extrinsic for the vehicles because of several reasons and advantages. The extrinsic parameters are calibrated by using gradient descent because extrinsic parameters are hypothesized to change slowly enough during the lifetime of a vehicle. Therefore, optimizing the extrinsic parameters by using gradient descent could maintain the accuracy of the current extrinsic parameters. Even when outliers occur, the system could remain stable for a period of time rather than have rapidly changing extrinsic parameters, which is considered dangerous when the vehicle is in motion. Deep learning is used to calibrate the extrinsic parameters because the lanes look different according to different road conditions. With any current method, losing some features of the lane points is common. However, the deep learning method does not have such problems; with enough training data, lanes in any extreme case could be used, even in totally different environments or in most cases of extreme weather.ResultExperiments on an open road show that the designed loss function is meaningful and convex. With 250 iterations, the proposed method can converge to the true extrinsic parameter, and its rotation accuracy is 0.2° and the translation accuracy is 0.03 m. Compared with the VIO-based and another lane detection-based method, our approach is more accurate with the HD map information. Another experiment shows that the proposed method can quickly converge to the new true value when extrinsic parameters change dynamically.ConclusionWith the use of lane detection, the proposed method does not depend on specific scenarios or marks. Through the matching of the detected lane and the HD map with numerical optimization, the calibration can be performed in real time, and it improves the accuracy of extrinsic parameters more significantly than other methods. The accuracy of the proposed method meets the requirements of ADAS, showing great value in the field of industry.关键词:extrinsic parameter calibration;map alignment;lane;gradient descent;online calibration172|332|1更新时间:2024-05-08
摘要:ObjectiveCamera calibration is one of the key factors of the perception in advanced driver-assistance systems (ADAS) and many other applications. Traditional camera calibration methods and even some state-of-the-art calibration algorithms, which are currently widely used in factories, strongly rely on specific scenes and specific markers. Existing methods to calibrate the extrinsic parameters of the camera are inconvenient and inaccurate, and current algorithms have some obvious disadvantages, which might cause serious accidents, damage the vehicle, or threaten the safety of passengers. Theoretically, once calibrated, the extrinsic parameters of the camera, including the position and the posture of camera installation, will be fixed and stable. However, the extrinsic parameters of a camera change throughout the lifetime of a vehicle. Real-time dynamic calibration is useful in cases when vehicles are transported or when cameras are removed for maintenance or replacement. Other extrinsic parameter calibration methods solves the estimation by simultaneous localization and mapping or visual inertia odometry (VIO) technologies. These methods try to extract point features and match points with the same characters, and the spatial transformation of different frames is calculated accordingly from the matched point pairs. However, according to the absence of texture information such as when one is in an indoor environment, the accuracy of extrinsic parameters is not always satisfactory. The common situation is that the algorithm cannot obtain any feature from the existing frames or the features that are obtained are not enough to calculate the position. To solve this problem and achieve the requirement of ADAS, this paper proposes a self-calibrating method that is based on aligning the detected lanes by the camera with a high-definition (HD) map.MethodFeature extraction is the first step of calibration. The most common feature extraction method is to acquire features from frames, calculate the gradient or other specific information of every single pixel, and select the pixels with the most significant values as the detected features. In this paper, we introduce a state-of-the-art algorithm that uses deep learning to detect lane points in the images grabbed from the camera. Some parts of the extrinsic parameters, including longitudinal translation, are unobservable when the vehicle is moving; thus, a data filtering and post-processing method is proposed. Images are classified into three classes: invalid frame, data frame, and key frame. The data filtering rule will efficiently divide the obtained frames into these three types according to the information the frame carries. Then, in the next step, the reprojection error (or loss) is defined in the imaging plane. The process consists of four steps: 1) The lane detected in the HD map is projected to the image plane, and the nearest neighborhood is associated with every detected lane point. This step is similar to feature matching, but it focuses only on the distance of the nearest potential match points. 2) The distance of points and the normal vectorial angle is calculated, and different weights are assigned based on different image types. 3) The geometric constraints of lanes in the image plane and frame of the camera are solved. The initial guess of the extrinsic parameter is determined; the guess is often imprecise and valid only in the cases when the lane is a straight line and the camera translation is known. 4) A gradient descent-based iterative optimal method is used to minimize the reprojection error, and the optimal extrinsic parameter could be determined at the same time. We use such methods to calibrate the camera extrinsic for the vehicles because of several reasons and advantages. The extrinsic parameters are calibrated by using gradient descent because extrinsic parameters are hypothesized to change slowly enough during the lifetime of a vehicle. Therefore, optimizing the extrinsic parameters by using gradient descent could maintain the accuracy of the current extrinsic parameters. Even when outliers occur, the system could remain stable for a period of time rather than have rapidly changing extrinsic parameters, which is considered dangerous when the vehicle is in motion. Deep learning is used to calibrate the extrinsic parameters because the lanes look different according to different road conditions. With any current method, losing some features of the lane points is common. However, the deep learning method does not have such problems; with enough training data, lanes in any extreme case could be used, even in totally different environments or in most cases of extreme weather.ResultExperiments on an open road show that the designed loss function is meaningful and convex. With 250 iterations, the proposed method can converge to the true extrinsic parameter, and its rotation accuracy is 0.2° and the translation accuracy is 0.03 m. Compared with the VIO-based and another lane detection-based method, our approach is more accurate with the HD map information. Another experiment shows that the proposed method can quickly converge to the new true value when extrinsic parameters change dynamically.ConclusionWith the use of lane detection, the proposed method does not depend on specific scenarios or marks. Through the matching of the detected lane and the HD map with numerical optimization, the calibration can be performed in real time, and it improves the accuracy of extrinsic parameters more significantly than other methods. The accuracy of the proposed method meets the requirements of ADAS, showing great value in the field of industry.关键词:extrinsic parameter calibration;map alignment;lane;gradient descent;online calibration172|332|1更新时间:2024-05-08 -
 摘要:ObjectiveLiDAR simultaneous localization and mapping (SLAM) is an important component of the field of intelligent robotics. The robot should be able to perceive the information of the surrounding environment and accurately locate its own position, which is also the premise for the robot to autonomously navigate. Building the entire map requires the single vehicle to drive all over the whole area, which makes the mapping periods longer. In addition, more data require more computing power for onboard units. To solve the above problems, a cooperative LiDAR SLAM for multi-vehicles based on edge computing method is proposed. This method can make the load balance by offloading tasks to the edge server. Aside from ensuring accurate localization of the single vehicle, it can also increase the reusability of the mapping results for multi-vehicles. This study models the computation offloading decision-making problem among multi-vehicles as a task offloading game. It designs the offloading algorithm based on the potential game to compute the task scheduling sequence. The concept of relative confidence is introduced to reduce the odometer error in the process of mapping as much as possible, which also makes our merged maps of multi-vehicles more accurate.MethodFirst, this study constructs a threshold-based offloading function that includes latency constraint and signal quality constraint. Then, this study proves that the minimum latency problem of multi-vehicles is a potential game. The potential game always reaches the Nash equilibrium and has limited improved properties. Therefore, the relevant strategy based on the potential game is designed for offloading tasks. With the characteristics of the Nash equilibrium, our algorithm ensures that vehicles in equilibrium can obtain mutually satisfactory solutions. This study introduces the concept of
摘要:ObjectiveLiDAR simultaneous localization and mapping (SLAM) is an important component of the field of intelligent robotics. The robot should be able to perceive the information of the surrounding environment and accurately locate its own position, which is also the premise for the robot to autonomously navigate. Building the entire map requires the single vehicle to drive all over the whole area, which makes the mapping periods longer. In addition, more data require more computing power for onboard units. To solve the above problems, a cooperative LiDAR SLAM for multi-vehicles based on edge computing method is proposed. This method can make the load balance by offloading tasks to the edge server. Aside from ensuring accurate localization of the single vehicle, it can also increase the reusability of the mapping results for multi-vehicles. This study models the computation offloading decision-making problem among multi-vehicles as a task offloading game. It designs the offloading algorithm based on the potential game to compute the task scheduling sequence. The concept of relative confidence is introduced to reduce the odometer error in the process of mapping as much as possible, which also makes our merged maps of multi-vehicles more accurate.MethodFirst, this study constructs a threshold-based offloading function that includes latency constraint and signal quality constraint. Then, this study proves that the minimum latency problem of multi-vehicles is a potential game. The potential game always reaches the Nash equilibrium and has limited improved properties. Therefore, the relevant strategy based on the potential game is designed for offloading tasks. With the characteristics of the Nash equilibrium, our algorithm ensures that vehicles in equilibrium can obtain mutually satisfactory solutions. This study introduces the concept of$\alpha $ $\alpha $ $\alpha $ $\alpha $ 关键词:edge computing;simultaneous localization and mapping(SLAM);task offloading;multi-vehicle collaboration;autonomous driving200|176|3更新时间:2024-05-08
High-Definition Map Construction and SLAM
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0