
最新刊期
卷 25 , 期 8 , 2020
-
 摘要:Diffusion magnetic resonance imaging is currently the only non-invasive white matter fiber imaging method that provides a new tool for understanding the fiber structure of thee living brain and shows great significance in the fields of clinical medicine,disease analysis,and neuroscience. The diffusion of water molecules in the brain due to the influence of nerve fibers exhibits anisotropy. Diffusion magnetic resonance imaging indirectly characterizes the local structural information of a fiber by measuring the water molecule diffusion attenuation signal of each voxel. Fiber tracking is an important step in diffusion magnetic resonance imaging where the spatial orientation information of voxels is integrated to depict anatomically significant fiber space structures. Many studies on the white fiber tracking algorithm have been published over the past two decades since its introduction in 1998. However,a large number of studies and clinical applications have shown that this tracking algorithm reconstructs a large number of false fibers. To provide researchers with a systematic understanding of the field and to provide clinicians with a basis for selecting fiber tracking algorithms,this paper quantitatively evaluates and qualitatively compares nine of the most commonly used algorithms. The typical algorithms are introduced in detail from the perspectives of deterministic,probabilistic,and global optimization. The deterministic algorithm focuses on the streamlines tracking and fiber assignment by continuous tracking (FACT) algorithms. The probabilistic tracking algorithm focuses on the Bayesian probability tracking framework,the Bayesian-framework-based particle filtering tractography (PFT),and unscented Kalman filter (UKF). Meanwhile,the global tracking algorithm focuses on the graph-based fiber tracking and Gibbs tracking algorithms and introduces the anatomically constrained tractography (ACT) algorithm-which is commonly used in fiber tracking-and the fiber tracking algorithm combined with machine learning. The simulated Fibercup and International Society for Magnetic Resonance in Medicine(ISMRM) 2015 challenge data are then used to test and compare the results of the nine algorithms (TensorDet,SD_Stream,FACT,iFOD2,ACT_iFOD2,PFT,UKF,Gibbs,and MLBT(machine learning based tractograph)) and to calculate the Tractometer quantitative indicators of their results. The advantages and disadvantages of these algorithms are then determined,and clinical data are used for experimental verification. The intrinsic connection and differences among these algorithms are then analyzed by combining the experimental results with algorithm theory. The deterministic tracking algorithm selects the only largest possible direction for fiber tracking at each step. This algorithm is simple and easy to implement and can quickly obtain the fiber tracking result. However,the local direction of the fiber caused by the noise of the image voxel is inaccurate and further leads to deterministic tracking. Meanwhile,the probabilistic tracking algorithm selects the tracking direction of the fiber from its probability distribution in the local direction and produces a highly comprehensive fiber tracking result that can describe the complex fiber structure region. However,sampling from the probability distribution of the local direction of the fiber produces a large number of pseudofibers and subsequently produces confusing imaging results. The probabilistic fiber tracking based on the Bayesian framework calculates the posterior probability of the fiber distribution and samples the fiber tracking direction from the posterior probability,thereby effectively reducing the number of pseudofibers. The global fiber tracking algorithm is optimized from a global perspective to obtain the fiber trajectory that is most suitable for the global diffusion magnetic resonance imaging(dMRI) signal in order to avoid the cumulative error of the deterministic and probabilistic tracking algorithms. However,while the main structure of the fiber tracking results is obvious,their detailed structure is imperceptible. The calculation results also cannot guarantee convergence and require a large amount of calculations,which is not conducive to practical clinical application. The ACT algorithm is mainly applied as a screening mechanism for the fiber results and needs to be combined with other fiber tracking algorithms to reduce its error fiber ratio. The results have varying degrees of impact on subsequent fiber tracking algorithms based on the accuracy of the ACT step results. The machine learning algorithm guides the tracking of fiber trajectories through a random forest classifier generated via specimen training. However,the current machine learning algorithm only post-processes the fiber tracking results and needs to be trained with the tracking results of other algorithms. In this case,the fiber tracking results are greatly influenced by the training specimen. Fiber tracking has high research and application value for analyzing human brain nerve fiber connections. Different algorithms for fiber tracking have their own advantages and disadvantages. At present,a tracking algorithm that can address the disadvantages and combine the advantages of other algorithms is yet to be devised. The results of the proposed fiber tracking algorithm also show a certain gap from the actual situation,and drawing a highly accurate fiber trajectory remains a challenge.关键词:diffusion magnetic resonance imaging(dMRI);anisotropy;white matter tractography(WMT);Bayesian;global optimization;International Society for Magnetic Resonance in Medicine(ISMRM) 2015 challenge data20|38|3更新时间:2024-05-07
摘要:Diffusion magnetic resonance imaging is currently the only non-invasive white matter fiber imaging method that provides a new tool for understanding the fiber structure of thee living brain and shows great significance in the fields of clinical medicine,disease analysis,and neuroscience. The diffusion of water molecules in the brain due to the influence of nerve fibers exhibits anisotropy. Diffusion magnetic resonance imaging indirectly characterizes the local structural information of a fiber by measuring the water molecule diffusion attenuation signal of each voxel. Fiber tracking is an important step in diffusion magnetic resonance imaging where the spatial orientation information of voxels is integrated to depict anatomically significant fiber space structures. Many studies on the white fiber tracking algorithm have been published over the past two decades since its introduction in 1998. However,a large number of studies and clinical applications have shown that this tracking algorithm reconstructs a large number of false fibers. To provide researchers with a systematic understanding of the field and to provide clinicians with a basis for selecting fiber tracking algorithms,this paper quantitatively evaluates and qualitatively compares nine of the most commonly used algorithms. The typical algorithms are introduced in detail from the perspectives of deterministic,probabilistic,and global optimization. The deterministic algorithm focuses on the streamlines tracking and fiber assignment by continuous tracking (FACT) algorithms. The probabilistic tracking algorithm focuses on the Bayesian probability tracking framework,the Bayesian-framework-based particle filtering tractography (PFT),and unscented Kalman filter (UKF). Meanwhile,the global tracking algorithm focuses on the graph-based fiber tracking and Gibbs tracking algorithms and introduces the anatomically constrained tractography (ACT) algorithm-which is commonly used in fiber tracking-and the fiber tracking algorithm combined with machine learning. The simulated Fibercup and International Society for Magnetic Resonance in Medicine(ISMRM) 2015 challenge data are then used to test and compare the results of the nine algorithms (TensorDet,SD_Stream,FACT,iFOD2,ACT_iFOD2,PFT,UKF,Gibbs,and MLBT(machine learning based tractograph)) and to calculate the Tractometer quantitative indicators of their results. The advantages and disadvantages of these algorithms are then determined,and clinical data are used for experimental verification. The intrinsic connection and differences among these algorithms are then analyzed by combining the experimental results with algorithm theory. The deterministic tracking algorithm selects the only largest possible direction for fiber tracking at each step. This algorithm is simple and easy to implement and can quickly obtain the fiber tracking result. However,the local direction of the fiber caused by the noise of the image voxel is inaccurate and further leads to deterministic tracking. Meanwhile,the probabilistic tracking algorithm selects the tracking direction of the fiber from its probability distribution in the local direction and produces a highly comprehensive fiber tracking result that can describe the complex fiber structure region. However,sampling from the probability distribution of the local direction of the fiber produces a large number of pseudofibers and subsequently produces confusing imaging results. The probabilistic fiber tracking based on the Bayesian framework calculates the posterior probability of the fiber distribution and samples the fiber tracking direction from the posterior probability,thereby effectively reducing the number of pseudofibers. The global fiber tracking algorithm is optimized from a global perspective to obtain the fiber trajectory that is most suitable for the global diffusion magnetic resonance imaging(dMRI) signal in order to avoid the cumulative error of the deterministic and probabilistic tracking algorithms. However,while the main structure of the fiber tracking results is obvious,their detailed structure is imperceptible. The calculation results also cannot guarantee convergence and require a large amount of calculations,which is not conducive to practical clinical application. The ACT algorithm is mainly applied as a screening mechanism for the fiber results and needs to be combined with other fiber tracking algorithms to reduce its error fiber ratio. The results have varying degrees of impact on subsequent fiber tracking algorithms based on the accuracy of the ACT step results. The machine learning algorithm guides the tracking of fiber trajectories through a random forest classifier generated via specimen training. However,the current machine learning algorithm only post-processes the fiber tracking results and needs to be trained with the tracking results of other algorithms. In this case,the fiber tracking results are greatly influenced by the training specimen. Fiber tracking has high research and application value for analyzing human brain nerve fiber connections. Different algorithms for fiber tracking have their own advantages and disadvantages. At present,a tracking algorithm that can address the disadvantages and combine the advantages of other algorithms is yet to be devised. The results of the proposed fiber tracking algorithm also show a certain gap from the actual situation,and drawing a highly accurate fiber trajectory remains a challenge.关键词:diffusion magnetic resonance imaging(dMRI);anisotropy;white matter tractography(WMT);Bayesian;global optimization;International Society for Magnetic Resonance in Medicine(ISMRM) 2015 challenge data20|38|3更新时间:2024-05-07 -
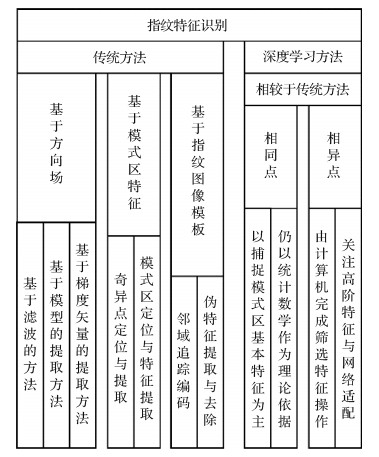 摘要:Biometrics,which is an important means of identity authentication,has been integrated into all aspects of daily life. The convenience and efficiency of single-modal biometrics and the reliability of multimodal biometrics have enabled the feature extraction technology to play a key role in directly affecting recognition results. As feature extraction techniques mature,researchers are turning their attention to the relevance of biometrics. In this research,the feature extraction methods in single-modal and multimodal biometrics are the object. We first review the feature extraction methods of face and fingerprint through the literature. The fingerprint feature extraction methods can roughly be divided into two categories. The first category calculates the fingerprint direction,which completes the estimation and judgment of the fingerprint local or the hole direction field. This method can be subdivided into three categories,which utilize gradient vector,filter,or mathematical model to build the fingerprint direction field. The second category targets the fingerprint pattern area,and the widely utilized methods are presented in this paper. Face feature extraction is based on the face representation process. Face representation can be divided into 2D-and 3D-based face representation methods according to different data represented by face. Pixels,including different color or points,are converted into feature vectors for different facial features that are invisible to the naked eye. In the traditional identification method,this recognition process relies on the accumulation of biometrics and recognition experience known to humans. A computer can learn and generalize when machine learning and deep learning are introduced. It can gradually overcome the cognitive deficit of humanity in face recognition and other fields. We analyze feature classification based on empirical knowledge and computer logic sampling extraction based on deep learning and operate these methods on single mode and multimode. The modeling of the correlation among biometrics that may progress in the future is explored on the basis of a comparison of multimodal biometrics. The knowledge gained in the field of computer science comes entirely from the natural evolution of our own or the Earth. Current results of single-modal and multimodal biometric technologies have saturated with the current requirements for identity verification applications. The high-efficiency and high-precision biofeature extraction method and the feature extraction requirements under the biorecognition framework are matched effectively. However,the study of the correlation among different biometrics remains blank. Such study is significant not only for image processing but also for many subdisciplines in the biological field. In this paper,we explain the feasibility of modeling the correlation among biometrics from the perspective of image processing. The assumption that biometrics can be converted into one another in the form of computer images is based on the following points:1) the origin of biometrics comes from DNA strands,which makes the characteristics of each individual possess mutualism and universality; 2) features obtained from images do not have the irreversibility of complex transformation processes,such as DNA to protein construction; 3) the aggregation,analysis,and coding of features can be realized on computers,and the vision of a computer gives it a stability that is far superior to that of human vision in the classification process. Biometric feature extraction methods based on single-modality and multimodality have been applied extensively. The current results of single-modal and multimodal biometric extraction techniques are reviewed,and the correlation between biometrics and their application prospects is determined.关键词:biometric feature extraction;fingerprint;face;multimodal;relevance53|161|2更新时间:2024-05-07
摘要:Biometrics,which is an important means of identity authentication,has been integrated into all aspects of daily life. The convenience and efficiency of single-modal biometrics and the reliability of multimodal biometrics have enabled the feature extraction technology to play a key role in directly affecting recognition results. As feature extraction techniques mature,researchers are turning their attention to the relevance of biometrics. In this research,the feature extraction methods in single-modal and multimodal biometrics are the object. We first review the feature extraction methods of face and fingerprint through the literature. The fingerprint feature extraction methods can roughly be divided into two categories. The first category calculates the fingerprint direction,which completes the estimation and judgment of the fingerprint local or the hole direction field. This method can be subdivided into three categories,which utilize gradient vector,filter,or mathematical model to build the fingerprint direction field. The second category targets the fingerprint pattern area,and the widely utilized methods are presented in this paper. Face feature extraction is based on the face representation process. Face representation can be divided into 2D-and 3D-based face representation methods according to different data represented by face. Pixels,including different color or points,are converted into feature vectors for different facial features that are invisible to the naked eye. In the traditional identification method,this recognition process relies on the accumulation of biometrics and recognition experience known to humans. A computer can learn and generalize when machine learning and deep learning are introduced. It can gradually overcome the cognitive deficit of humanity in face recognition and other fields. We analyze feature classification based on empirical knowledge and computer logic sampling extraction based on deep learning and operate these methods on single mode and multimode. The modeling of the correlation among biometrics that may progress in the future is explored on the basis of a comparison of multimodal biometrics. The knowledge gained in the field of computer science comes entirely from the natural evolution of our own or the Earth. Current results of single-modal and multimodal biometric technologies have saturated with the current requirements for identity verification applications. The high-efficiency and high-precision biofeature extraction method and the feature extraction requirements under the biorecognition framework are matched effectively. However,the study of the correlation among different biometrics remains blank. Such study is significant not only for image processing but also for many subdisciplines in the biological field. In this paper,we explain the feasibility of modeling the correlation among biometrics from the perspective of image processing. The assumption that biometrics can be converted into one another in the form of computer images is based on the following points:1) the origin of biometrics comes from DNA strands,which makes the characteristics of each individual possess mutualism and universality; 2) features obtained from images do not have the irreversibility of complex transformation processes,such as DNA to protein construction; 3) the aggregation,analysis,and coding of features can be realized on computers,and the vision of a computer gives it a stability that is far superior to that of human vision in the classification process. Biometric feature extraction methods based on single-modality and multimodality have been applied extensively. The current results of single-modal and multimodal biometric extraction techniques are reviewed,and the correlation between biometrics and their application prospects is determined.关键词:biometric feature extraction;fingerprint;face;multimodal;relevance53|161|2更新时间:2024-05-07
Review

-
 摘要:ObjectiveGait has become a popular research topic that is currently investigated by using visual and machine learning methods. However,most of these studies are concentrated in the field of human identification and use 2D RGB images. In contrast to these studies,this paper investigates abnormal gait recognition by using 3D data. A method based on 3D point cloud data and the semantic body model is then proposed for view-invariant abnormal gait recognition. Compared with traditional 2D abnormal gait recognition approaches,the proposed 3D-based method can easily deal with many obstacles in abnormal gait modelling and recognition processes,including view-invariant problems and interference from external items.MethodThe point cloud data of human gait are obtained by using an infrared structured light sensor,which is a 3D depth camera that uses a structure projector and reflecting light receiver to gain the depth information of an object and calculate its point cloud data. Although the point cloud data of the human body are also in 3D,they are generally unstructured,thereby influencing the 3D representation of the human body and posture. To deal with this problem,a 3D parametric human body learned from the 3D body dataset by using a statistic method is introduced in this paper. The parameterized human body model refers to the description and construction of the corresponding visual human body mesh through abstract high-order semantic features,such as height,weight,age,gender,and skeletal joints. The parameters are determined by using statistical learning methods. The human body is embedded into the model,and the 3D parametric model can be deformed both in shapes and poses. Unlike traditional methods that directly model the 3D body from point cloud data via the point cloud reduction algorithm and triangle mesh grid method,the related 3D parameterized body model is deformed to fit the point cloud data in both shape and posture. The standard 3D human model proposed in this paper is constructed based on the body shape PCA (principal component analysis) analysis and skin method. An observation function that measures the similarity of the deformed 3D model with the raw point cloud data of the human body is also introduced. An accurate deformation of the 3D body is ensured by iteratively minimizing the observation function. After the 3D model estimation process,the features of the raw point cloud data of the human body are converted into a high-level structured representation of the human body. This process not only abstracts the unstructured data to a high-order semantic description but also effectively reduces the dimensionality of the original data. After 3D modelling and structured feature representation,a convolution gated recurrent unit (ConvGRU) recurrent neural network is applied to extract the temporal-spatial features of the projected depth gait images. ConvGRU has the advantages of both convolutional and recurrent neural networks,the latter of which is based on the gate structure. The tow gates (i.e.,reset and update gates) help the model memorize useful information and forget useless data. In the final classification process,the samples are divided into positive,negative,and anchor samples. The anchor sample is the sample itself,the positive samples are same-category samples that belong to different objects,and the negative samples are those that belong to opposite categories. Training the classifier by using the triples elements strategy can improve its ability to discriminate small feature differences of different categories. At the same time,a virtual 3D sample synthesizing method based on body,pose,and view deformation is proposed to deal with the data shortage problem of abnormal gait. Compared with normal gait datasets,abnormal gait data,especially 3D abnormal datasets,are rare and difficult to obtain. Moreover,given the limited amount of ground truth data,most of the abnormal data are imitated by the experimental participates. As a result,the virtual synthesizing method can help extend the training data and improve the generalization ability of the abnormal gait classification model.ResultExperiments were performed by using the CSU(Central South University) abnormal 3D gait database and the depth-included human action video (DHA) dataset,and different abnormal gait or action recognition methods were compared with the proposed approach. In the CSU abnormal gait database,the rank-1 mean detection and recognition rate of abnormal gait is 96.6% at the 0°,45°,and 90° views. In the 90°-0° cross view recognition experiment,the proposed method outperforms the other approaches that use DMHI(difference motion history image) or DMM-CNN(depth motion map-convolutional neural network) as feature representation by at least 25%. Meanwhile,in the DHA dataset,the proposed method result has a rank-1 mean detection and recognition rate of near 98%,which is 2% to 3% higher than that of novel approaches,including DMM based methods.ConclusionBased on the feature extraction method of the 3D parameterized human body model,abnormal gait image data can be abstracted to high-order descriptions and effectively complete the feature extraction and dimensionality reduction of the original data. ConvGRU can extract the spatial and temporal features of the abnormal gait data well. The virtual sample synthesis and triple classification methods can be combined to classify and recognize abnormal gait data from different views. The proposed method not only improves the recognition accuracy of abnormal gait under various view angles but also provides a new approach for the detection and recognition of abnormal gait.关键词:machine vision;human recognition;3D abnormal gait modeling;virtual sample generation;convolutional recurrent neural network28|18|0更新时间:2024-05-07
摘要:ObjectiveGait has become a popular research topic that is currently investigated by using visual and machine learning methods. However,most of these studies are concentrated in the field of human identification and use 2D RGB images. In contrast to these studies,this paper investigates abnormal gait recognition by using 3D data. A method based on 3D point cloud data and the semantic body model is then proposed for view-invariant abnormal gait recognition. Compared with traditional 2D abnormal gait recognition approaches,the proposed 3D-based method can easily deal with many obstacles in abnormal gait modelling and recognition processes,including view-invariant problems and interference from external items.MethodThe point cloud data of human gait are obtained by using an infrared structured light sensor,which is a 3D depth camera that uses a structure projector and reflecting light receiver to gain the depth information of an object and calculate its point cloud data. Although the point cloud data of the human body are also in 3D,they are generally unstructured,thereby influencing the 3D representation of the human body and posture. To deal with this problem,a 3D parametric human body learned from the 3D body dataset by using a statistic method is introduced in this paper. The parameterized human body model refers to the description and construction of the corresponding visual human body mesh through abstract high-order semantic features,such as height,weight,age,gender,and skeletal joints. The parameters are determined by using statistical learning methods. The human body is embedded into the model,and the 3D parametric model can be deformed both in shapes and poses. Unlike traditional methods that directly model the 3D body from point cloud data via the point cloud reduction algorithm and triangle mesh grid method,the related 3D parameterized body model is deformed to fit the point cloud data in both shape and posture. The standard 3D human model proposed in this paper is constructed based on the body shape PCA (principal component analysis) analysis and skin method. An observation function that measures the similarity of the deformed 3D model with the raw point cloud data of the human body is also introduced. An accurate deformation of the 3D body is ensured by iteratively minimizing the observation function. After the 3D model estimation process,the features of the raw point cloud data of the human body are converted into a high-level structured representation of the human body. This process not only abstracts the unstructured data to a high-order semantic description but also effectively reduces the dimensionality of the original data. After 3D modelling and structured feature representation,a convolution gated recurrent unit (ConvGRU) recurrent neural network is applied to extract the temporal-spatial features of the projected depth gait images. ConvGRU has the advantages of both convolutional and recurrent neural networks,the latter of which is based on the gate structure. The tow gates (i.e.,reset and update gates) help the model memorize useful information and forget useless data. In the final classification process,the samples are divided into positive,negative,and anchor samples. The anchor sample is the sample itself,the positive samples are same-category samples that belong to different objects,and the negative samples are those that belong to opposite categories. Training the classifier by using the triples elements strategy can improve its ability to discriminate small feature differences of different categories. At the same time,a virtual 3D sample synthesizing method based on body,pose,and view deformation is proposed to deal with the data shortage problem of abnormal gait. Compared with normal gait datasets,abnormal gait data,especially 3D abnormal datasets,are rare and difficult to obtain. Moreover,given the limited amount of ground truth data,most of the abnormal data are imitated by the experimental participates. As a result,the virtual synthesizing method can help extend the training data and improve the generalization ability of the abnormal gait classification model.ResultExperiments were performed by using the CSU(Central South University) abnormal 3D gait database and the depth-included human action video (DHA) dataset,and different abnormal gait or action recognition methods were compared with the proposed approach. In the CSU abnormal gait database,the rank-1 mean detection and recognition rate of abnormal gait is 96.6% at the 0°,45°,and 90° views. In the 90°-0° cross view recognition experiment,the proposed method outperforms the other approaches that use DMHI(difference motion history image) or DMM-CNN(depth motion map-convolutional neural network) as feature representation by at least 25%. Meanwhile,in the DHA dataset,the proposed method result has a rank-1 mean detection and recognition rate of near 98%,which is 2% to 3% higher than that of novel approaches,including DMM based methods.ConclusionBased on the feature extraction method of the 3D parameterized human body model,abnormal gait image data can be abstracted to high-order descriptions and effectively complete the feature extraction and dimensionality reduction of the original data. ConvGRU can extract the spatial and temporal features of the abnormal gait data well. The virtual sample synthesis and triple classification methods can be combined to classify and recognize abnormal gait data from different views. The proposed method not only improves the recognition accuracy of abnormal gait under various view angles but also provides a new approach for the detection and recognition of abnormal gait.关键词:machine vision;human recognition;3D abnormal gait modeling;virtual sample generation;convolutional recurrent neural network28|18|0更新时间:2024-05-07 -
 摘要:ObjectiveA pointwise convolution network (PCN) has great potential for the classification and segmentation of point cloud data. The pointwise convolution operator in each layer directly functions on the point cloud data to generate the local feature vectors point-by-point. The PCN can solve the problems caused by dimension increase and information loss because of the avoidance of point data structuration. However,the structure of PCN is responsible for the consistent maintenance of the point cloud during the implementation of pointwise convolution. Consequently,the PCN has no constituent that can describe the global features of point cloud. The PCN essentially needs a characteristic expansion considering the global features in terms of classification and segmentation accuracies for the point cloud data.MethodA so-called central point radiation model is proposed in this paper to pointwisely describe the global geometric properties. With the introduction of the radiation model into feature concatenation,the result ant extended PCN (EPCN) realizes a complete representation of local and global features for point cloud classification and segmentation. First,the point cloud in the central point radiation model is regarded as a set of projection point on the object surface by a radiation line from the central point. The amplitude of radiation vector determines the owner surface and tightness of each point around the central point,and the direction specifies the pointwise encircling direction and contributing radiation line. The central point is prescribed by the calculation of coordinate information in the point cloud,and the pointwise radiation vector is generated. Thus,the central point radiation model is constructed to describe global features. Second,the local feature description of the point cloud data at each depth is obtained through a multilayer pointwise convolution. The coordinates of the point cloud data provide an index for retrieving point attributes and determining the neighborhood points involved in the convolution of a concerned point. The pointwise convolution traverses all points in the point cloud and completely yields the pointwise local features. Finally,an EPCN is derived through the concatenation of the global features from the central point radiation model and the local features from the pointwise convolution. The complete feature description vector is adopted as the input of the fully connected layer of PCN for the category label prediction,and the input of the pointwise convolution layer is used for the label prediction point-by-point.ResultThe classification and segmentation performance of the proposed EPCN model are validated on the point cloud data sets of ModelNet40 and S3DIS(Stanford large-scale 3D indoor dataset),respectively. The EPCN classification on ModelNet40 leads to 1.8% and 3.5% increases in mean and m-class accuracies compared with the PCN. The EPCN segmentation on S3DIS provides 0.7% and 2.2% increases in s-mean and ms-class accuracies compared with the PCN.ConclusionExperimental results verify the effectiveness of the proposed central point radiation model for the global feature extraction of the point cloud data. The EPCN model provides an improved performance in terms of classification and segmentation.关键词:point cloud;pointwise convolution;central point radiation model;classification;segmentation;feature extension67|31|3更新时间:2024-05-07
摘要:ObjectiveA pointwise convolution network (PCN) has great potential for the classification and segmentation of point cloud data. The pointwise convolution operator in each layer directly functions on the point cloud data to generate the local feature vectors point-by-point. The PCN can solve the problems caused by dimension increase and information loss because of the avoidance of point data structuration. However,the structure of PCN is responsible for the consistent maintenance of the point cloud during the implementation of pointwise convolution. Consequently,the PCN has no constituent that can describe the global features of point cloud. The PCN essentially needs a characteristic expansion considering the global features in terms of classification and segmentation accuracies for the point cloud data.MethodA so-called central point radiation model is proposed in this paper to pointwisely describe the global geometric properties. With the introduction of the radiation model into feature concatenation,the result ant extended PCN (EPCN) realizes a complete representation of local and global features for point cloud classification and segmentation. First,the point cloud in the central point radiation model is regarded as a set of projection point on the object surface by a radiation line from the central point. The amplitude of radiation vector determines the owner surface and tightness of each point around the central point,and the direction specifies the pointwise encircling direction and contributing radiation line. The central point is prescribed by the calculation of coordinate information in the point cloud,and the pointwise radiation vector is generated. Thus,the central point radiation model is constructed to describe global features. Second,the local feature description of the point cloud data at each depth is obtained through a multilayer pointwise convolution. The coordinates of the point cloud data provide an index for retrieving point attributes and determining the neighborhood points involved in the convolution of a concerned point. The pointwise convolution traverses all points in the point cloud and completely yields the pointwise local features. Finally,an EPCN is derived through the concatenation of the global features from the central point radiation model and the local features from the pointwise convolution. The complete feature description vector is adopted as the input of the fully connected layer of PCN for the category label prediction,and the input of the pointwise convolution layer is used for the label prediction point-by-point.ResultThe classification and segmentation performance of the proposed EPCN model are validated on the point cloud data sets of ModelNet40 and S3DIS(Stanford large-scale 3D indoor dataset),respectively. The EPCN classification on ModelNet40 leads to 1.8% and 3.5% increases in mean and m-class accuracies compared with the PCN. The EPCN segmentation on S3DIS provides 0.7% and 2.2% increases in s-mean and ms-class accuracies compared with the PCN.ConclusionExperimental results verify the effectiveness of the proposed central point radiation model for the global feature extraction of the point cloud data. The EPCN model provides an improved performance in terms of classification and segmentation.关键词:point cloud;pointwise convolution;central point radiation model;classification;segmentation;feature extension67|31|3更新时间:2024-05-07 -
 摘要:ObjectiveVideo object segmentation is an important topic in the field of computer vision. However,the existing segmentation methods are unable to address some issues,such as irregular objects,noise optical flows,and fast movements. To this end,this paper proposes an effective and efficient algorithm that solves these issues based on feature consistency.MethodThe proposed segmentation algorithm framework is based on the graph theory method of Markov random field (MRF). First,the Gaussian mixture model (GMM) is applied to model the color features of pre-specified marked areas,and the segmented data items are obtained. Second,a spatiotemporal smoothing term is established by combining various characteristics,such as color and optical flow direction. The algorithm then adds energy constraints based on feature consistency to enhance the appearance consistency of the segmentation results. The added energy belongs to a higher-order energy constraint,thereby significantly increasing the computational complexity of energy optimization. The energy optimization problem is solved by adding auxiliary nodes to improve the speed of the algorithm. The higher-order constraint term comes from the idea of text classification,which is used in this paper to model the higher-order term of the segmentation equation. Each super-pixel point corresponds to a text,and the scale-invariant feature transform (SIFT) feature point in the super-pixel point is used as a word in the text. The higher-order term is modeled afterward via extraction and clustering. Given the running speed of the algorithm,auxiliary nodes are added to optimize the high-order term. The high-order term is approximated to the data and smoothing items,and then the graph cutting algorithm is used to complete the segmentation.ResultThe test data were taken from the DAVIS_2016(densely annotated video segmentation) dataset,which contains 50 sets of data,of which 30 and 20 are sets of training and verification data,respectively. This dataset has a resolution of 854×480 pixels. Given that many methods are based on MRF expansion,α=0.3 and β=0.2 are empirically set in the proposed algorithm to maintain a capability balance among the data,smoothing,and feature consistency items. Similar to extant methods,the number of submodels used to establish the Gaussian mixture model for the front/background is set to 5,σh=σh=0.1. This paper focuses on the verification and evaluation of the proposed feature consistency constraint terms and sets β=0 and β=0.2 to divide the videos under the constraint condition. The experimental results show that the IoU score with higher-order constraints is 10.2% higher than that without higher-order constraints. To demonstrate its effectiveness,the proposed method is compared with some other classical video segmentation algorithms based on graph theory. The experimental results highlight the competitive segmentation effect of the proposed algorithm. Meanwhile,the average IoU score reported in this paper is slightly lower than that of the video segmenfation via object flow(OFL) algorithm because the latter continuously iteratively optimizes the optical flow calculation results to achieve a relatively high segmentation accuracy. The proposed algorithm takes nearly 10 seconds on average to segment each frame,which is shorter than the running time of other algorithms. For instance,although the OFL algorithm reports a slightly higher accuracy,its average processing time for each frame is approximately 1 minute,which is 6 times longer than that of the proposed algorithm. In sum,the proposed algorithm can achieve the same segmentation effect with a much lower computational complexity than the OFL algorithm. However,the accuracy of its segmentation results is 1.6% lower than that of the results obtained by the OFL algorithm. Nevertheless,in terms of running speed,the proposed algorithm is ahead of other methods and is approximately 6 times faster than the OFL algorithm.ConclusionExperimental results show that when the current/background color is not clear enough,the foreground object and the background are often confused,thereby resulting in incorrect segmentation. However,when the global feature consistency constraint is added,the proposed algorithm can optimize the segmentation result of each frame by the feature statistics of the entire video. By using global information to optimize local information,the proposed segmentation method shows strong robustness to random noise,irregular motions,blurry backgrounds,and other problems in the video. According to the experimental results,the proposed algorithm spends most of its time in calculating the optical flow and can be replaced by a more efficient motion estimation algorithm in the future. However,compared with other segmentation algorithms,the proposed method shows great advantages in its performance. Based on the MRF framework,the proposed segmentation algorithm integrates the constraints of feature consistency and improves both segmentation accuracy and operation speed without increasing computational complexity. However,this method has several shortcomings. First,given that the proposed algorithm segments a video based on super pixels,the segmentation results depend on the segmentation accuracy of these super pixels. Second,the proposed high-order feature energy constraint has no obvious effect on feature-free regions because the SIFT feature points detected in similar regions will be greatly reduced,thereby creating super-pixel blocks that are unable to detect a sufficient number of feature points,which subsequently influences the global statistics of front/background features and prevents the proposed method from optimizing the segmentation results of feature-free regions. Similar to traditional methods,the optical flow creates a bottleneck in the performance of the proposed method. Therefore,additional efforts should be devoted in finding a highly efficient replacement strategy. As mentioned before,the method based on graph theory (including the proposed method) still lags behind the current end-to-end video segmentation methods based on convolutional neural network (CNN) in terms of segmentation accuracy. Future works should then attempt to combine these two approaches to benefit from their respective advantages.关键词:video object segmentation;feature consistency;Markov random field (MRF);auxiliary node;energy optimization30|30|3更新时间:2024-05-07
摘要:ObjectiveVideo object segmentation is an important topic in the field of computer vision. However,the existing segmentation methods are unable to address some issues,such as irregular objects,noise optical flows,and fast movements. To this end,this paper proposes an effective and efficient algorithm that solves these issues based on feature consistency.MethodThe proposed segmentation algorithm framework is based on the graph theory method of Markov random field (MRF). First,the Gaussian mixture model (GMM) is applied to model the color features of pre-specified marked areas,and the segmented data items are obtained. Second,a spatiotemporal smoothing term is established by combining various characteristics,such as color and optical flow direction. The algorithm then adds energy constraints based on feature consistency to enhance the appearance consistency of the segmentation results. The added energy belongs to a higher-order energy constraint,thereby significantly increasing the computational complexity of energy optimization. The energy optimization problem is solved by adding auxiliary nodes to improve the speed of the algorithm. The higher-order constraint term comes from the idea of text classification,which is used in this paper to model the higher-order term of the segmentation equation. Each super-pixel point corresponds to a text,and the scale-invariant feature transform (SIFT) feature point in the super-pixel point is used as a word in the text. The higher-order term is modeled afterward via extraction and clustering. Given the running speed of the algorithm,auxiliary nodes are added to optimize the high-order term. The high-order term is approximated to the data and smoothing items,and then the graph cutting algorithm is used to complete the segmentation.ResultThe test data were taken from the DAVIS_2016(densely annotated video segmentation) dataset,which contains 50 sets of data,of which 30 and 20 are sets of training and verification data,respectively. This dataset has a resolution of 854×480 pixels. Given that many methods are based on MRF expansion,α=0.3 and β=0.2 are empirically set in the proposed algorithm to maintain a capability balance among the data,smoothing,and feature consistency items. Similar to extant methods,the number of submodels used to establish the Gaussian mixture model for the front/background is set to 5,σh=σh=0.1. This paper focuses on the verification and evaluation of the proposed feature consistency constraint terms and sets β=0 and β=0.2 to divide the videos under the constraint condition. The experimental results show that the IoU score with higher-order constraints is 10.2% higher than that without higher-order constraints. To demonstrate its effectiveness,the proposed method is compared with some other classical video segmentation algorithms based on graph theory. The experimental results highlight the competitive segmentation effect of the proposed algorithm. Meanwhile,the average IoU score reported in this paper is slightly lower than that of the video segmenfation via object flow(OFL) algorithm because the latter continuously iteratively optimizes the optical flow calculation results to achieve a relatively high segmentation accuracy. The proposed algorithm takes nearly 10 seconds on average to segment each frame,which is shorter than the running time of other algorithms. For instance,although the OFL algorithm reports a slightly higher accuracy,its average processing time for each frame is approximately 1 minute,which is 6 times longer than that of the proposed algorithm. In sum,the proposed algorithm can achieve the same segmentation effect with a much lower computational complexity than the OFL algorithm. However,the accuracy of its segmentation results is 1.6% lower than that of the results obtained by the OFL algorithm. Nevertheless,in terms of running speed,the proposed algorithm is ahead of other methods and is approximately 6 times faster than the OFL algorithm.ConclusionExperimental results show that when the current/background color is not clear enough,the foreground object and the background are often confused,thereby resulting in incorrect segmentation. However,when the global feature consistency constraint is added,the proposed algorithm can optimize the segmentation result of each frame by the feature statistics of the entire video. By using global information to optimize local information,the proposed segmentation method shows strong robustness to random noise,irregular motions,blurry backgrounds,and other problems in the video. According to the experimental results,the proposed algorithm spends most of its time in calculating the optical flow and can be replaced by a more efficient motion estimation algorithm in the future. However,compared with other segmentation algorithms,the proposed method shows great advantages in its performance. Based on the MRF framework,the proposed segmentation algorithm integrates the constraints of feature consistency and improves both segmentation accuracy and operation speed without increasing computational complexity. However,this method has several shortcomings. First,given that the proposed algorithm segments a video based on super pixels,the segmentation results depend on the segmentation accuracy of these super pixels. Second,the proposed high-order feature energy constraint has no obvious effect on feature-free regions because the SIFT feature points detected in similar regions will be greatly reduced,thereby creating super-pixel blocks that are unable to detect a sufficient number of feature points,which subsequently influences the global statistics of front/background features and prevents the proposed method from optimizing the segmentation results of feature-free regions. Similar to traditional methods,the optical flow creates a bottleneck in the performance of the proposed method. Therefore,additional efforts should be devoted in finding a highly efficient replacement strategy. As mentioned before,the method based on graph theory (including the proposed method) still lags behind the current end-to-end video segmentation methods based on convolutional neural network (CNN) in terms of segmentation accuracy. Future works should then attempt to combine these two approaches to benefit from their respective advantages.关键词:video object segmentation;feature consistency;Markov random field (MRF);auxiliary node;energy optimization30|30|3更新时间:2024-05-07 -
 摘要:ObjectiveLandmark recognition,which is a new application in computer vision,has been increasing investigated in the past several years and has been widely used to implement landmark image recognition function in image retrieval. However,this application has many problems unsolved,such as the global features are sensitive to view change,and the local features are sensitive to light change. Most existing methods based on convolutional neural network (CNN) are used to extract image features for replacing traditional feature extraction methods,such as scale-invariant feature transform(SIFT) or speeded up robust feature (SURF). At present,the best model is deep local feature(DeLF),but its retrieval needs the combination of product quantization(PQ) and K-dimensional(KD) trees. The process is complex and consumes approximately 6 GB of display memory,which is unsuitable for rapid deployment and use,and the most time-consuming process is random sample consensus.MethodA multiple feature fusion method is needed when focusing on the problems of a single feature,and multiple features can be horizontally connected to create a single vector for improving the performance of CNN global features. For large-scale landmark data,manual labeling of images is time consuming and laborious,and artificial cognitive bias exists in labeling. To minimize human work in labeling images,weakly supervised loss,such as the additive angular margin loss function(ArcFace loss function),which is improved from standard cross-entry loss and changes the Euclidean distances to angular domain,is used to train the model in image-level annotations. The ArcFace loss function performs well in facial recognition and image classification and is easy to use in other deep learning applications. This paper provides the values of the parameters in ArcFace loss function and the proof process. Thus,a weakly supervised recognition model based on ArcFace loss and multiple feature fusion is proposed for landmark recognition. The proposed model uses ResNet50 as its trunk and has two steps in model training,including the trunk's finetuning and attention layer's training. Finetuning uses the Google landmark image dataset,and the trunk is finetuned on the weights pretrained on the ImageNet dataset. The average pooling layer is replaced by a generalized mean(GeM) pooling layer because it is proven useful in image retrieval. The attention mechanism is built using two convolutional layers that use 1×1 kernel to train the features focusing on the local features needed. Image preprocessing is required before training. The preprocessing consists of three stages,including center crop/resize and random crop. People usually prefer to place buildings and themselves in the center of images. Thus,a center crop method is suitable to ignore the problems occurring in padding or resizing. The proposed model uses classification training to complete the image retrieval task. The final input image size is set to 4482. This value is a compromise value because the input image size in image retrieval is usually 800×8001 500×1 500 pixels and the classification size is 224×224~300×300 pixels. The image is center cropped first,and then its size is resized to 500×500 pixels because it is a useful method to enhance the data through random cropping. For inference,the image is center cropped and directly resized to 448×448 pixels because it only needs to be processed twice. The inference of this model is divided into three parts,namely,extracting global features,obtaining local features,and feature fusion. For the inputted query image,the global feature is first extracted from the embedding layer of CNN fine-tuned by ArcFace loss function; Second,the attention mechanism is used to obtain local features in the middle layer of the network,and the useful local features must be larger than the threshold; finally,two features are fused,and the results that are the most similar with the current query image in the database are obtained through image retrieval.ResultWe compared the proposed model with several state-of-the-art models,including the traditional approaches and deep learning methods on two public reviewed datasets,namely,Oxford and Paris building datasets. The two datasets are reconstructed in 2018 and are classified into three levels,namely,easy,medium,and hard. Three groups of comparisons are used in the experiment,and they are all compared on the reviewed Oxford and Paris datasets. The first group is to compare the proposed model's performance with other models,such as HesAff-rSIFT-VLAD and VggNet-NetVLAD. The second group is designed to compare the performance of single global feature with the performance of fused features. The last group compares the results obtained from the whiting of the extracted features at different layers of the proposed model. Results show that the feature fusion method can make the shallow network achieve the effect of deep pretrained network,and the mean average precision(mAP) increases by approximately 1% compared with the global features on the two previously mentioned datasets. The proposed model achieves satisfactory results in urban street view images.ConclusionIn this study,we proposed a composite model that contains a CNN,an attention model,and a fusion algorithm to fuse two types of features. Experimental results show that the proposed model performs well,the fusion algorithm improves its performance,and the performance in urban street datasets ensures the practical application value of the proposed model.关键词:landmark recognition;additive angular margin loss function(ArcFace loss function);attention mechanism;multiple features fusion;convolutional neural network(CNN)31|17|2更新时间:2024-05-07
摘要:ObjectiveLandmark recognition,which is a new application in computer vision,has been increasing investigated in the past several years and has been widely used to implement landmark image recognition function in image retrieval. However,this application has many problems unsolved,such as the global features are sensitive to view change,and the local features are sensitive to light change. Most existing methods based on convolutional neural network (CNN) are used to extract image features for replacing traditional feature extraction methods,such as scale-invariant feature transform(SIFT) or speeded up robust feature (SURF). At present,the best model is deep local feature(DeLF),but its retrieval needs the combination of product quantization(PQ) and K-dimensional(KD) trees. The process is complex and consumes approximately 6 GB of display memory,which is unsuitable for rapid deployment and use,and the most time-consuming process is random sample consensus.MethodA multiple feature fusion method is needed when focusing on the problems of a single feature,and multiple features can be horizontally connected to create a single vector for improving the performance of CNN global features. For large-scale landmark data,manual labeling of images is time consuming and laborious,and artificial cognitive bias exists in labeling. To minimize human work in labeling images,weakly supervised loss,such as the additive angular margin loss function(ArcFace loss function),which is improved from standard cross-entry loss and changes the Euclidean distances to angular domain,is used to train the model in image-level annotations. The ArcFace loss function performs well in facial recognition and image classification and is easy to use in other deep learning applications. This paper provides the values of the parameters in ArcFace loss function and the proof process. Thus,a weakly supervised recognition model based on ArcFace loss and multiple feature fusion is proposed for landmark recognition. The proposed model uses ResNet50 as its trunk and has two steps in model training,including the trunk's finetuning and attention layer's training. Finetuning uses the Google landmark image dataset,and the trunk is finetuned on the weights pretrained on the ImageNet dataset. The average pooling layer is replaced by a generalized mean(GeM) pooling layer because it is proven useful in image retrieval. The attention mechanism is built using two convolutional layers that use 1×1 kernel to train the features focusing on the local features needed. Image preprocessing is required before training. The preprocessing consists of three stages,including center crop/resize and random crop. People usually prefer to place buildings and themselves in the center of images. Thus,a center crop method is suitable to ignore the problems occurring in padding or resizing. The proposed model uses classification training to complete the image retrieval task. The final input image size is set to 4482. This value is a compromise value because the input image size in image retrieval is usually 800×8001 500×1 500 pixels and the classification size is 224×224~300×300 pixels. The image is center cropped first,and then its size is resized to 500×500 pixels because it is a useful method to enhance the data through random cropping. For inference,the image is center cropped and directly resized to 448×448 pixels because it only needs to be processed twice. The inference of this model is divided into three parts,namely,extracting global features,obtaining local features,and feature fusion. For the inputted query image,the global feature is first extracted from the embedding layer of CNN fine-tuned by ArcFace loss function; Second,the attention mechanism is used to obtain local features in the middle layer of the network,and the useful local features must be larger than the threshold; finally,two features are fused,and the results that are the most similar with the current query image in the database are obtained through image retrieval.ResultWe compared the proposed model with several state-of-the-art models,including the traditional approaches and deep learning methods on two public reviewed datasets,namely,Oxford and Paris building datasets. The two datasets are reconstructed in 2018 and are classified into three levels,namely,easy,medium,and hard. Three groups of comparisons are used in the experiment,and they are all compared on the reviewed Oxford and Paris datasets. The first group is to compare the proposed model's performance with other models,such as HesAff-rSIFT-VLAD and VggNet-NetVLAD. The second group is designed to compare the performance of single global feature with the performance of fused features. The last group compares the results obtained from the whiting of the extracted features at different layers of the proposed model. Results show that the feature fusion method can make the shallow network achieve the effect of deep pretrained network,and the mean average precision(mAP) increases by approximately 1% compared with the global features on the two previously mentioned datasets. The proposed model achieves satisfactory results in urban street view images.ConclusionIn this study,we proposed a composite model that contains a CNN,an attention model,and a fusion algorithm to fuse two types of features. Experimental results show that the proposed model performs well,the fusion algorithm improves its performance,and the performance in urban street datasets ensures the practical application value of the proposed model.关键词:landmark recognition;additive angular margin loss function(ArcFace loss function);attention mechanism;multiple features fusion;convolutional neural network(CNN)31|17|2更新时间:2024-05-07 -
 摘要:ObjectiveFine-grained image retrieval is a major issue in current fine-grained image analysis and computer vision. Traditional methods typically retrieve similar replicated images, which are primarily based on large-scale coarse-grained retrieval but with low precision. Fine-grained image retrieval belongs to fine-grained image identification and retrieval subclasses. The traditional image retrieval task extracts only the coarse-grained features of images and cannot be effectively used for fine-grained retrieval. It also lacks key semantic attributes, and this deficiency brings difficulty in distinguishing the nuances among parts. The difficulty in fine-grained image retrieval is that the traditional coarse-grained feature extraction cannot represent images effectively. Fine-grained images of the same subclasses also cause a significant difference due to such factors as shape, posture, and color; consequently, search results cannot be effectively applied to actual needs. Compared with conventional image analysis problems, fine-grained image retrieval is more challenging due to the inter-level subcategories of its smaller class differences and the class differences within the larger ones. A fine-grained image retrieval method by part detection and semantic network for various shoe images is therefore proposed to solve the above-mentioned problems.MethodFirst, part-based detection is conducted to detect undetected shoe images through an annotated training dataset of shoe images. Second, the semantic network is trained based on the semantic attributes of the detected shoe and training images, and feature vectors are extracted. Third, principal component analysis is used for dimensionality reduction. Finally, the results are implemented and output by metric learning to calculate the similarity among images, and fine-grained image retrieval is implemented. On the UT-Zap50K dataset, fine-grained shoe attributes are defined for the shoe images in combination with the component area of shoes. The toe area defines a shape attribute that contains five attribute values. Two attributes of shape and height are defined for the heel area, which contains 13 attribute values. A height attribute is defined for the upper area, which contains four attribute values. A closed-mode attribute is defined for the upper area, which contains nine attribute values. Footwear global properties are defined to include colors and styles, which contain 20 attribute values.ResultThe experiment is compared with four methods with good retrieval performance on the UT-Zap50K dataset. The retrieval accuracy is improved by nearly 6%. Compared with the semantic hierarchy of attribute convolutional neural network(SHOE-CNN) retrieval method of the same task, the proposed method has higher retrieval accuracy. The proposed semantic network is compared with traditional GIST(generalized search trees) features, the linear support vector machine(LSVM) method, and the deep learning method to illustrate the effectiveness of the proposed retrieval method. The performance is evaluated in terms of the accuracy of top-K retrieval. Results show that the method based on deep learning is much better than the traditional GIST features and LSVM method. The retrieval accuracy of this method is better than that of the metric network and SHOE-CNN by combining a metric learning algorithm.ConclusionA fine-grained shoe image retrieval method is proposed to address the low accuracy of shoe image retrieval caused by the lack of fine visual description of traditional image features. The method can accurately detect different parts of a shoe image and define the detailed semantic attributes of the shoe image. The visual attribute features of the shoe image are obtained by training the semantic network. The problem of unsatisfied accuracy of shoe image retrieval caused by using only coarse-grained features to represent images is solved. The experimental results show that the proposed method can retrieve the same image as the image to be detected on the UT-Zap50K dataset. The accuracy can reach 80% and 86% while ensuring the running efficiency. However, this method exhibits shortcomings. On the one hand, the accuracy of partial image detection is low because of the many styles and complexity of shoes. On the other hand, the prediction of some semantic attributes is inaccurate, and the fine-grained semantic attributes of shoe images are imperfect. The follow-up work will focus on these issues to improve the search accuracy, and the application issues will be extended to different scenarios.关键词:fine-grained image retrieval;shoe image;part detection;semantic network;feature vector;metric learning56|79|3更新时间:2024-05-07
摘要:ObjectiveFine-grained image retrieval is a major issue in current fine-grained image analysis and computer vision. Traditional methods typically retrieve similar replicated images, which are primarily based on large-scale coarse-grained retrieval but with low precision. Fine-grained image retrieval belongs to fine-grained image identification and retrieval subclasses. The traditional image retrieval task extracts only the coarse-grained features of images and cannot be effectively used for fine-grained retrieval. It also lacks key semantic attributes, and this deficiency brings difficulty in distinguishing the nuances among parts. The difficulty in fine-grained image retrieval is that the traditional coarse-grained feature extraction cannot represent images effectively. Fine-grained images of the same subclasses also cause a significant difference due to such factors as shape, posture, and color; consequently, search results cannot be effectively applied to actual needs. Compared with conventional image analysis problems, fine-grained image retrieval is more challenging due to the inter-level subcategories of its smaller class differences and the class differences within the larger ones. A fine-grained image retrieval method by part detection and semantic network for various shoe images is therefore proposed to solve the above-mentioned problems.MethodFirst, part-based detection is conducted to detect undetected shoe images through an annotated training dataset of shoe images. Second, the semantic network is trained based on the semantic attributes of the detected shoe and training images, and feature vectors are extracted. Third, principal component analysis is used for dimensionality reduction. Finally, the results are implemented and output by metric learning to calculate the similarity among images, and fine-grained image retrieval is implemented. On the UT-Zap50K dataset, fine-grained shoe attributes are defined for the shoe images in combination with the component area of shoes. The toe area defines a shape attribute that contains five attribute values. Two attributes of shape and height are defined for the heel area, which contains 13 attribute values. A height attribute is defined for the upper area, which contains four attribute values. A closed-mode attribute is defined for the upper area, which contains nine attribute values. Footwear global properties are defined to include colors and styles, which contain 20 attribute values.ResultThe experiment is compared with four methods with good retrieval performance on the UT-Zap50K dataset. The retrieval accuracy is improved by nearly 6%. Compared with the semantic hierarchy of attribute convolutional neural network(SHOE-CNN) retrieval method of the same task, the proposed method has higher retrieval accuracy. The proposed semantic network is compared with traditional GIST(generalized search trees) features, the linear support vector machine(LSVM) method, and the deep learning method to illustrate the effectiveness of the proposed retrieval method. The performance is evaluated in terms of the accuracy of top-K retrieval. Results show that the method based on deep learning is much better than the traditional GIST features and LSVM method. The retrieval accuracy of this method is better than that of the metric network and SHOE-CNN by combining a metric learning algorithm.ConclusionA fine-grained shoe image retrieval method is proposed to address the low accuracy of shoe image retrieval caused by the lack of fine visual description of traditional image features. The method can accurately detect different parts of a shoe image and define the detailed semantic attributes of the shoe image. The visual attribute features of the shoe image are obtained by training the semantic network. The problem of unsatisfied accuracy of shoe image retrieval caused by using only coarse-grained features to represent images is solved. The experimental results show that the proposed method can retrieve the same image as the image to be detected on the UT-Zap50K dataset. The accuracy can reach 80% and 86% while ensuring the running efficiency. However, this method exhibits shortcomings. On the one hand, the accuracy of partial image detection is low because of the many styles and complexity of shoes. On the other hand, the prediction of some semantic attributes is inaccurate, and the fine-grained semantic attributes of shoe images are imperfect. The follow-up work will focus on these issues to improve the search accuracy, and the application issues will be extended to different scenarios.关键词:fine-grained image retrieval;shoe image;part detection;semantic network;feature vector;metric learning56|79|3更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveWith the development of deep learning, the problem of image generation has achieved great progress. Text-to-image generation is an important research field based on deep learning image generation. A large number of related papers conducted by researchers have proposed to implement text-to-image. However, a significant limitation exists, that is, the model will behave poorly in terms of relationships when generating images involving multiple objects. The existing solution is to replace the description text with a scene graph structure that closely represents the scene relationship in the image and then use the scene graphs to generate an image. Scene graphs are the preferred structured representation between natural language and images, which is conducive to the transfer of information between objects in the graphs. Although the scene graphs to image generation model solve the problem of image generation, including multiple objects and relationships, the existing scene graphs to image generation model ultimately produce images with lower quality, and the object details are unremarkable compared with real samples. A model with improved performance should be developed to generate high-quality images and to solve large errors.MethodWe propose a model called image generation from scene graphs with a graph attention network (GA-SG2IM), which is an improved model implementing image generation from scene graphs, to generate high-quality images containing multiple objects and relationships. The proposed model mainly realizes image generation in three parts:First, a feature extraction network is used to realize the feature extraction of the scene graphs. The attention network of the graphs introduces the attention mechanism in the convolution network of original graphs, enabling the output object vector to have strong expression ability. The object vector is then passed to the improved object layout network for obtaining a respectful and factual scene layout. Finally, the scene layout is passed to the cascaded refinement network for obtaining the final output image. A network of discriminators consisting of an object discriminator and an image discriminator is connected to the end to ensure that the generated image is sufficiently realistic. At the same time, we use feature matching as our image loss function to ensure that the final generated and real images are similar in semantics and to obtain high-quality images.ResultWe use the COCO-Stuff image dataset to train and validate the proposed model. The dataset includes more than 40 000 images of different scenes, where each of them provides annotation information of the borders and segmentation masks of the objects in the image, and the annotation information can be used to synthesize and input the scene graph of the proposed model. We train the proposed model to generate 64×64 images and compare them with other image generation models to prove its feasibility. At the same time, the quantitative results of the Inception Score and the bounding box intersection over union(IoU) of the generated image are compared to determine the improvement effects of the proposed model and SG2IM(image generation from scene graph) and StackGAN models. The final experimental results show that the proposed model achieves an Inception Score of 7.8, which increases by 0.5 compared with the SG2IM model.ConclusionQualitative experimental results show that the proposed model can realize the generation of complex scene images containing multiple objects and relationships and improves the quality of the generated images to a certain extent, making the final generated images clear and the object details evident. A machine can autonomously model its input data and takes a step toward "wisdom" when it can generate high-quality images containing multiple objects and relationships. Our next goal is to enable the proposed model for generating real-time high-resolution images, such as photographic images, which requires many theoretical supports and practical operations.关键词:image generation from scene graphs;graph attention network;scene layout;feature matching;cascaded refinement network43|27|3更新时间:2024-05-07
摘要:ObjectiveWith the development of deep learning, the problem of image generation has achieved great progress. Text-to-image generation is an important research field based on deep learning image generation. A large number of related papers conducted by researchers have proposed to implement text-to-image. However, a significant limitation exists, that is, the model will behave poorly in terms of relationships when generating images involving multiple objects. The existing solution is to replace the description text with a scene graph structure that closely represents the scene relationship in the image and then use the scene graphs to generate an image. Scene graphs are the preferred structured representation between natural language and images, which is conducive to the transfer of information between objects in the graphs. Although the scene graphs to image generation model solve the problem of image generation, including multiple objects and relationships, the existing scene graphs to image generation model ultimately produce images with lower quality, and the object details are unremarkable compared with real samples. A model with improved performance should be developed to generate high-quality images and to solve large errors.MethodWe propose a model called image generation from scene graphs with a graph attention network (GA-SG2IM), which is an improved model implementing image generation from scene graphs, to generate high-quality images containing multiple objects and relationships. The proposed model mainly realizes image generation in three parts:First, a feature extraction network is used to realize the feature extraction of the scene graphs. The attention network of the graphs introduces the attention mechanism in the convolution network of original graphs, enabling the output object vector to have strong expression ability. The object vector is then passed to the improved object layout network for obtaining a respectful and factual scene layout. Finally, the scene layout is passed to the cascaded refinement network for obtaining the final output image. A network of discriminators consisting of an object discriminator and an image discriminator is connected to the end to ensure that the generated image is sufficiently realistic. At the same time, we use feature matching as our image loss function to ensure that the final generated and real images are similar in semantics and to obtain high-quality images.ResultWe use the COCO-Stuff image dataset to train and validate the proposed model. The dataset includes more than 40 000 images of different scenes, where each of them provides annotation information of the borders and segmentation masks of the objects in the image, and the annotation information can be used to synthesize and input the scene graph of the proposed model. We train the proposed model to generate 64×64 images and compare them with other image generation models to prove its feasibility. At the same time, the quantitative results of the Inception Score and the bounding box intersection over union(IoU) of the generated image are compared to determine the improvement effects of the proposed model and SG2IM(image generation from scene graph) and StackGAN models. The final experimental results show that the proposed model achieves an Inception Score of 7.8, which increases by 0.5 compared with the SG2IM model.ConclusionQualitative experimental results show that the proposed model can realize the generation of complex scene images containing multiple objects and relationships and improves the quality of the generated images to a certain extent, making the final generated images clear and the object details evident. A machine can autonomously model its input data and takes a step toward "wisdom" when it can generate high-quality images containing multiple objects and relationships. Our next goal is to enable the proposed model for generating real-time high-resolution images, such as photographic images, which requires many theoretical supports and practical operations.关键词:image generation from scene graphs;graph attention network;scene layout;feature matching;cascaded refinement network43|27|3更新时间:2024-05-07 -
 摘要:ObjectiveThe results of image captioning can be influenced by the richness of image features, but existing methods only use one encoder for feature extraction and are thereby unable to learn the semantics of images, which may lead to inaccurate captions for images with complicated content. Meanwhile, to generate accurate and reasonable captions, the ability of language modules to process sentences of complex contexts plays an important role. However, the current mainstream methods that use RNN(recurrent neural network) or LSTM(long short-term memory) tend to ignore the basic hierarchical structure of sentences and therefore do not work well in expressing long sequences of words. To address these issues, an image captioning model based on cross-layer multi-model feature fusion and causal convolutional decoding(CMFF/CD) is proposed in this paper.MethodIn the visual feature extraction stage, given the feature information loss during the propagation of image features in the convolutional layer, a cross-layer feature fusion structure from the low to high levels is added to realize an information complementarity between the semantic and detail features. Afterward, multiple encoders are trained to conduct feature extraction on the input image. When the information contained in an image is highly complex, these encoders play a supplementary role in fully describing and representing image semantics. Each image in the training dataset corresponds to artificially labeled sentences that are used to train the language decoder. When the sentences are longer and more complex, the learning ability of the language model is reduced, thereby presenting a challenge in learning the relationship among objects. Causal convolution can model long sequences of words to express complex contexts and is therefore used in the proposed language module to obtain the word features. An attention mechanism is then proposed to match the image features with the word features. Each word feature corresponds to an object feature in the image. The model not only accurately describes the image content but also learns the correlation between the text information and different regions of an image. The prediction probability of words is determined by the prediction module by using the Softmax function.ResultThe model was validated on different Microsoft common objects in context (MS COCO) and Flickr30k datasets by using various evaluation methods. The experimental results demonstrate that the proposed model has a comparable and competing performance, especially in describing complex scene images. Compared with other mainstream methods, the proposed model not only specifies the scene information of an image (e.g., restaurants) but also identifies specific objects in the scene and accurately describe their categories. Compared with attention fully convolutional network (ATT-FCN), spatial and channel-wise attention(Sca)-convolutional neural network(CNN), and part-of-speech(POS), the proposed model generates richer image information in description sentences and has a better processing effect on long-sequence words. This model can describe "toothbrush, sink/tunnel/audience", "bed trailer, bus/mother/cruise ship", and other objects in an image, whereas other models based on the CNN + LSTM architecture are unable to do such. Although the ConvCap model, which also uses the CNN + CNN architecture, can describe multiple objects in an image and assign them some attribute descriptions, the CMFF/CD model provides more accurate and detailed descriptions, such as "bread, peppers/curtain, blow dryer". In addition, while these two models are able to describe "computer", the "desktop computer" description of the proposed model is more accurate than the "black computer" description derived by the ConvCap model. Meanwhile, the sentence structure derived by the proposed model is very similar to human expression. Given the quality of sentences produced, the bilingual evaluation understudy(BLEU)-1 indicator, which reflects the accuracy of word generation, of the proposed model reaches 72.1%. This model also obtains a 6.0% higher B-4 compared with the Hard-ATT("Hard" attention) method, thereby highlighting its excellent ability in matching local image features with word vectors. The proposed model can also fully utilize local information to express the content in detail. This model also outperforms the emb-gLSTM method in terms of B-1 and CIDEr(consensus-based image description evaluation) by 5.1% and 13.3%, respectively, and the ConvCap method, which also uses the CNN + CNN strategy, in terms of B-1 by 0.3%.ConclusionThe proposed captioning model can effectively extract and preserve the semantic information in complex background images and process long sequences of words. In expressing the hierarchical relationship among complex background information, the proposed model effectively uses convolutional neural networks (i.e., causal convolution) to process text information. The experimental results show that the proposed model achieves highly accurate image content descriptions and highly abundant information expression.关键词:image caption;cross-layer feature fusion;convolution decoding;causal convolution;attention mechanism47|28|3更新时间:2024-05-07
摘要:ObjectiveThe results of image captioning can be influenced by the richness of image features, but existing methods only use one encoder for feature extraction and are thereby unable to learn the semantics of images, which may lead to inaccurate captions for images with complicated content. Meanwhile, to generate accurate and reasonable captions, the ability of language modules to process sentences of complex contexts plays an important role. However, the current mainstream methods that use RNN(recurrent neural network) or LSTM(long short-term memory) tend to ignore the basic hierarchical structure of sentences and therefore do not work well in expressing long sequences of words. To address these issues, an image captioning model based on cross-layer multi-model feature fusion and causal convolutional decoding(CMFF/CD) is proposed in this paper.MethodIn the visual feature extraction stage, given the feature information loss during the propagation of image features in the convolutional layer, a cross-layer feature fusion structure from the low to high levels is added to realize an information complementarity between the semantic and detail features. Afterward, multiple encoders are trained to conduct feature extraction on the input image. When the information contained in an image is highly complex, these encoders play a supplementary role in fully describing and representing image semantics. Each image in the training dataset corresponds to artificially labeled sentences that are used to train the language decoder. When the sentences are longer and more complex, the learning ability of the language model is reduced, thereby presenting a challenge in learning the relationship among objects. Causal convolution can model long sequences of words to express complex contexts and is therefore used in the proposed language module to obtain the word features. An attention mechanism is then proposed to match the image features with the word features. Each word feature corresponds to an object feature in the image. The model not only accurately describes the image content but also learns the correlation between the text information and different regions of an image. The prediction probability of words is determined by the prediction module by using the Softmax function.ResultThe model was validated on different Microsoft common objects in context (MS COCO) and Flickr30k datasets by using various evaluation methods. The experimental results demonstrate that the proposed model has a comparable and competing performance, especially in describing complex scene images. Compared with other mainstream methods, the proposed model not only specifies the scene information of an image (e.g., restaurants) but also identifies specific objects in the scene and accurately describe their categories. Compared with attention fully convolutional network (ATT-FCN), spatial and channel-wise attention(Sca)-convolutional neural network(CNN), and part-of-speech(POS), the proposed model generates richer image information in description sentences and has a better processing effect on long-sequence words. This model can describe "toothbrush, sink/tunnel/audience", "bed trailer, bus/mother/cruise ship", and other objects in an image, whereas other models based on the CNN + LSTM architecture are unable to do such. Although the ConvCap model, which also uses the CNN + CNN architecture, can describe multiple objects in an image and assign them some attribute descriptions, the CMFF/CD model provides more accurate and detailed descriptions, such as "bread, peppers/curtain, blow dryer". In addition, while these two models are able to describe "computer", the "desktop computer" description of the proposed model is more accurate than the "black computer" description derived by the ConvCap model. Meanwhile, the sentence structure derived by the proposed model is very similar to human expression. Given the quality of sentences produced, the bilingual evaluation understudy(BLEU)-1 indicator, which reflects the accuracy of word generation, of the proposed model reaches 72.1%. This model also obtains a 6.0% higher B-4 compared with the Hard-ATT("Hard" attention) method, thereby highlighting its excellent ability in matching local image features with word vectors. The proposed model can also fully utilize local information to express the content in detail. This model also outperforms the emb-gLSTM method in terms of B-1 and CIDEr(consensus-based image description evaluation) by 5.1% and 13.3%, respectively, and the ConvCap method, which also uses the CNN + CNN strategy, in terms of B-1 by 0.3%.ConclusionThe proposed captioning model can effectively extract and preserve the semantic information in complex background images and process long sequences of words. In expressing the hierarchical relationship among complex background information, the proposed model effectively uses convolutional neural networks (i.e., causal convolution) to process text information. The experimental results show that the proposed model achieves highly accurate image content descriptions and highly abundant information expression.关键词:image caption;cross-layer feature fusion;convolution decoding;causal convolution;attention mechanism47|28|3更新时间:2024-05-07 -
 摘要:ObjectiveWith the continuous improvement of artificial intelligence technology, Adaboost algorithm based on Haar-like features has gained an important position in the endless stream of machine learning algorithms. Adaboost is widely used in the fields of medicine, transportation, and security. However, the Adaboost face detection algorithm based on Haar-like features, which is applied to video streams, has a long training time and low detection efficiency. This paper then proposes a novel Adaboost face detection algorithm based on the interval threshold.MethodThe integral value is used to quickly calculate the feature value of a face image, whereas the extracted feature values are used to analyze the Haar-like features of the final face recognition result. Comparing the feature values of face smaples and non-human face samples, and realized that the human and non-human faces are then determined by calculating the frequencies of different feature value intervals, and the final image is drawn. After a statistical analysis of the Haar-like eigenvalues of images, these two types of faces have been well distinguished within a certain eigenvalue interval, and a weak classifier based on double threshold is proposed accordingly. The interval threshold is used to select the weak classifier to simplify the calculation steps, shorten the training time, improve the face recognition and classification ability, and reduce the false alarm rate. Enhancing the weak classifier also improves the classification accuracy of the strong classifier by amplifying the Adaboost algorithm, whereas using a cascade structure increases the final face detection accuracy. This approach greatly accelerates the threshold search, and using the interval threshold instead of a single threshold guarantees an accurate threshold search. An interval threshold weak classifier corresponds to two single threshold weak classifiers, and using a strong classifier can effectively increased detection effect by 2.66%, Besides, training time reduced to 624.45 s.ResultThe performance of improved algorithm was compared with that of the traditional Adaboost algorithm and is verified by using the MIT(massachusetts Institute of Technology) standard face database. In the experiment, 1 500 and 3 000 face and non-face samples were randomly selected for testing. The experimental simulation results of the traditional and proposed Adaboost algorithms were then compared in terms of training time, detection time, detection rate, and false alarm rate. The training time of the improved algrithm was 1.44 times faster than traditional ones. And the detection rate was improved to 94.93%. Both algorithms showed a low detection rate, low false alarm rate, and poor recognition ability with a small number of weak classifiers. However, increasing the number of weak classifiers improved both detection and false alarm rates. In the case of the same detection rate, the improved Adaboost algorithm demonstrated less requirements for weak classifiers, shorter detection time, and 6.03% lower false alarm rate compared with its traditional counterpart. To verify its high practicability, the improved Adaboost algorithm was applied to real face detection, and the experimental results show that this algorithm outperforms the traditional algorithm in terms of detection efficiency, error rate, and detection accuracy. To verify whether the improved Adaboost algorithm is highly advanced, 400, 1 400, and 2 592 face images were selected from the ORL(Olivetti Research Laboratory), FERET(face recognition technology), and CMU Multi-PIE databases, respectively. The performance of the improved Adaboost algorithm was separately tested on these three groups of faces with the popular SVM(support vector machine), DL(deep learning), CNN(convolutional neural networks), and skin color models. The improved algorithm shows a higher detection efficiency compared with the traditional algorithm and has a 95.3% correct detection rate.ConclusionThis paper proposes a dual-threshold Adaboost fast training algorithm that demonstrates efficient face detection, fast training speed, and excellent test results. Experimental results show that under the same cascade structure and number of weak classifiers, the improved Adaboost algorithm is generally superior to the single threshold. The improved algorithm also has shorter face training time requirements, improved face detection accuracy, and better performance and practicability compared with its traditional counterpart. The ROC(receiver operating characteristic) curves show that the improved algorithm achieves better results with fewer weak classifiers. In actual picture detection applications, the improved Adaboost algorithm is superior to the traditional algorithm in terms of training and detection and can meet actual needs. Therefore, it can better meet the actual demand for simultaneous detection of multiple faces in densely populated areas, such as stadiums.关键词:face detection;Adaboost algorithm;statistical analysis;Haar-like features;interval threshold22|42|2更新时间:2024-05-07
摘要:ObjectiveWith the continuous improvement of artificial intelligence technology, Adaboost algorithm based on Haar-like features has gained an important position in the endless stream of machine learning algorithms. Adaboost is widely used in the fields of medicine, transportation, and security. However, the Adaboost face detection algorithm based on Haar-like features, which is applied to video streams, has a long training time and low detection efficiency. This paper then proposes a novel Adaboost face detection algorithm based on the interval threshold.MethodThe integral value is used to quickly calculate the feature value of a face image, whereas the extracted feature values are used to analyze the Haar-like features of the final face recognition result. Comparing the feature values of face smaples and non-human face samples, and realized that the human and non-human faces are then determined by calculating the frequencies of different feature value intervals, and the final image is drawn. After a statistical analysis of the Haar-like eigenvalues of images, these two types of faces have been well distinguished within a certain eigenvalue interval, and a weak classifier based on double threshold is proposed accordingly. The interval threshold is used to select the weak classifier to simplify the calculation steps, shorten the training time, improve the face recognition and classification ability, and reduce the false alarm rate. Enhancing the weak classifier also improves the classification accuracy of the strong classifier by amplifying the Adaboost algorithm, whereas using a cascade structure increases the final face detection accuracy. This approach greatly accelerates the threshold search, and using the interval threshold instead of a single threshold guarantees an accurate threshold search. An interval threshold weak classifier corresponds to two single threshold weak classifiers, and using a strong classifier can effectively increased detection effect by 2.66%, Besides, training time reduced to 624.45 s.ResultThe performance of improved algorithm was compared with that of the traditional Adaboost algorithm and is verified by using the MIT(massachusetts Institute of Technology) standard face database. In the experiment, 1 500 and 3 000 face and non-face samples were randomly selected for testing. The experimental simulation results of the traditional and proposed Adaboost algorithms were then compared in terms of training time, detection time, detection rate, and false alarm rate. The training time of the improved algrithm was 1.44 times faster than traditional ones. And the detection rate was improved to 94.93%. Both algorithms showed a low detection rate, low false alarm rate, and poor recognition ability with a small number of weak classifiers. However, increasing the number of weak classifiers improved both detection and false alarm rates. In the case of the same detection rate, the improved Adaboost algorithm demonstrated less requirements for weak classifiers, shorter detection time, and 6.03% lower false alarm rate compared with its traditional counterpart. To verify its high practicability, the improved Adaboost algorithm was applied to real face detection, and the experimental results show that this algorithm outperforms the traditional algorithm in terms of detection efficiency, error rate, and detection accuracy. To verify whether the improved Adaboost algorithm is highly advanced, 400, 1 400, and 2 592 face images were selected from the ORL(Olivetti Research Laboratory), FERET(face recognition technology), and CMU Multi-PIE databases, respectively. The performance of the improved Adaboost algorithm was separately tested on these three groups of faces with the popular SVM(support vector machine), DL(deep learning), CNN(convolutional neural networks), and skin color models. The improved algorithm shows a higher detection efficiency compared with the traditional algorithm and has a 95.3% correct detection rate.ConclusionThis paper proposes a dual-threshold Adaboost fast training algorithm that demonstrates efficient face detection, fast training speed, and excellent test results. Experimental results show that under the same cascade structure and number of weak classifiers, the improved Adaboost algorithm is generally superior to the single threshold. The improved algorithm also has shorter face training time requirements, improved face detection accuracy, and better performance and practicability compared with its traditional counterpart. The ROC(receiver operating characteristic) curves show that the improved algorithm achieves better results with fewer weak classifiers. In actual picture detection applications, the improved Adaboost algorithm is superior to the traditional algorithm in terms of training and detection and can meet actual needs. Therefore, it can better meet the actual demand for simultaneous detection of multiple faces in densely populated areas, such as stadiums.关键词:face detection;Adaboost algorithm;statistical analysis;Haar-like features;interval threshold22|42|2更新时间:2024-05-07 -
 摘要:ObjectiveSemantic segmentation is a fundamental problem in the field of computer vision where the category of each pixel in the image needs to be labeled. Traditional semantic segmentation uses a manual design to extract image features or edge information and uses the extracted features to obtain the final segmentation map through machine learning algorithms. With the rise of deep convolutional networks, some scholars have applied convolutional neural networks to semantic segmentation to improve its accuracy. However, the existing semantic segmentation algorithms face some problems. First, a contradiction is observed between the perceptual field of view and the resolution. When obtaining a large perceptual field of view, the resolution is often reduced, thereby generating poor segmentation results. Second, each channel of the feature map represents a feature. Objects at different positions should pay attention to different features, but the existing algorithms often ignore such difference. Third, the existing algorithms often use simple cascading or addition when fusing feature maps of different perception fields. For objects of different sizes, the various characteristics of the visual field are not given the same amount of importance.MethodTo address the aforementioned problems, this paper designs a semantic segmentation algorithm based on the dilated convolution and attention mechanism. First, two paths are used to collect the features. One of these paths uses dilated convolution to collect spatial information. This path initially utilizes a convolution kernel with a step size of 2 for fast downsampling and then experimentally selects a feature map with a downsampling factor of 4. Afterward, an expansion convolution with expansion ratios of 1, 2, and 4 is selected, and the obtained results are cascaded as the final feature map output while maintaining the resolution to obtain high-resolution feature maps. Meanwhile, the second path uses ResNet to collect features and obtain an expanded field of view. The ResNet network uses a residual structure that can well integrate shallow features with deep ones while simultaneously avoiding the difficulty of convergence during training. Feature maps are extracted with 16 and 32 times downsampling size from the ResNet network to expand the perception field. The attention mechanism module is then applied to assign weights to each part of feature maps to reflect their specificity. The attention mechanism is divided into the spatial attention, channel attention, and pyramid attention mechanisms. The spatial attention mechanism obtains the weight of each position on the feature map by extracting the information of different channels. Global maximization and average pooling are initially utilized in the spatial dimension. In this way, the characteristic information of different channels at each position is synthesized and used as the initial attention weight. Afterward, the initial spatial attention weights are processed by convolutional layers and batch normalization operations to further learn the feature information and are outputted as the final spatial attention weights. The channel attention mechanism obtains the weight of different channels by extracting the information of each channel. Maximum and average global pooling are initially applied in the channel dimension. Through these two pooling operations, the feature information on each channel is extracted, and the number of parameters is reduced. The output is treated as the initial attention weight, and a 3×3 convolution layer is used to further learn the attention weight, enhance the salient features, and suppress the irrelevant features. The pyramid attention mechanism uses a convolution of different perception fields and obtains the weights for each position in different channels. The initial feature map is operated by using convolution kernels with sizes 1×1, 3×3, and 5×5 to fully extract features at different levels of the feature map, and the output is treated as the initial attention weight. The feature maps are then multiplied to obtain the final state. Weights are assigned to the channel of each position on the feature map to effectively make the salient features get more attention and to suppress the irrelevant features. The three weights obtained are then merged to obtain the final attention weight. A feature fusion module is designed to fuse the features of different perception fields of the two paths in order to ascribe varying degrees of importance to the features of different perception fields. In the feature fusion module, the feature maps obtained from the two paths are upsampled to the same size by using a quadratic linear difference. Given that the features of different perception fields have varying degrees of importance, the obtained feature maps are initially cascaded, global pooling is applied to obtain the feature weights of each channel, and weights are adaptively assigned to each feature map. These maps are then upsampled to the original image size to obtain the final segmentation result.ResultThe results were validated on the Camvid and Cityscapes datasets with mean intersection over union(MIoU) and precision as metrics. The proposed model achieved 69.47% MIoU and 92.32% precision on Camvid, which were 1.3% and 3.09% higher than those of the model with the second-highest performance. Meanwhile, on Cityscapes, the proposed model achieved 78.48% MIoU and 93.83% precision, which were 1.16% and 3.60% higher than those of the model with the second-highest performance. The proposed algorithm also outperforms the other algorithms in terms of visual effects.ConclusionThis paper designs a new semantic segmentation algorithm that uses dilated convolution and ResNet to collect image features and obtains different features of the image in large and small perception fields. Using dilated convolution improves the resolution while ensuring the perceived field of view. An attention mechanism module is also designed to assign weights to each feature map and to facilitate model learning. A feature fusion module is then designed to fuse the features of different perception fields and reflect their specificity. Experiments show that the proposed algorithm outperforms the other algorithms in terms of accuracy and shows a certain application value.关键词:semantic segmentation;convolutional neural network;perception field;dilated convolution;attention mechanism;feature fusion30|29|7更新时间:2024-05-07
摘要:ObjectiveSemantic segmentation is a fundamental problem in the field of computer vision where the category of each pixel in the image needs to be labeled. Traditional semantic segmentation uses a manual design to extract image features or edge information and uses the extracted features to obtain the final segmentation map through machine learning algorithms. With the rise of deep convolutional networks, some scholars have applied convolutional neural networks to semantic segmentation to improve its accuracy. However, the existing semantic segmentation algorithms face some problems. First, a contradiction is observed between the perceptual field of view and the resolution. When obtaining a large perceptual field of view, the resolution is often reduced, thereby generating poor segmentation results. Second, each channel of the feature map represents a feature. Objects at different positions should pay attention to different features, but the existing algorithms often ignore such difference. Third, the existing algorithms often use simple cascading or addition when fusing feature maps of different perception fields. For objects of different sizes, the various characteristics of the visual field are not given the same amount of importance.MethodTo address the aforementioned problems, this paper designs a semantic segmentation algorithm based on the dilated convolution and attention mechanism. First, two paths are used to collect the features. One of these paths uses dilated convolution to collect spatial information. This path initially utilizes a convolution kernel with a step size of 2 for fast downsampling and then experimentally selects a feature map with a downsampling factor of 4. Afterward, an expansion convolution with expansion ratios of 1, 2, and 4 is selected, and the obtained results are cascaded as the final feature map output while maintaining the resolution to obtain high-resolution feature maps. Meanwhile, the second path uses ResNet to collect features and obtain an expanded field of view. The ResNet network uses a residual structure that can well integrate shallow features with deep ones while simultaneously avoiding the difficulty of convergence during training. Feature maps are extracted with 16 and 32 times downsampling size from the ResNet network to expand the perception field. The attention mechanism module is then applied to assign weights to each part of feature maps to reflect their specificity. The attention mechanism is divided into the spatial attention, channel attention, and pyramid attention mechanisms. The spatial attention mechanism obtains the weight of each position on the feature map by extracting the information of different channels. Global maximization and average pooling are initially utilized in the spatial dimension. In this way, the characteristic information of different channels at each position is synthesized and used as the initial attention weight. Afterward, the initial spatial attention weights are processed by convolutional layers and batch normalization operations to further learn the feature information and are outputted as the final spatial attention weights. The channel attention mechanism obtains the weight of different channels by extracting the information of each channel. Maximum and average global pooling are initially applied in the channel dimension. Through these two pooling operations, the feature information on each channel is extracted, and the number of parameters is reduced. The output is treated as the initial attention weight, and a 3×3 convolution layer is used to further learn the attention weight, enhance the salient features, and suppress the irrelevant features. The pyramid attention mechanism uses a convolution of different perception fields and obtains the weights for each position in different channels. The initial feature map is operated by using convolution kernels with sizes 1×1, 3×3, and 5×5 to fully extract features at different levels of the feature map, and the output is treated as the initial attention weight. The feature maps are then multiplied to obtain the final state. Weights are assigned to the channel of each position on the feature map to effectively make the salient features get more attention and to suppress the irrelevant features. The three weights obtained are then merged to obtain the final attention weight. A feature fusion module is designed to fuse the features of different perception fields of the two paths in order to ascribe varying degrees of importance to the features of different perception fields. In the feature fusion module, the feature maps obtained from the two paths are upsampled to the same size by using a quadratic linear difference. Given that the features of different perception fields have varying degrees of importance, the obtained feature maps are initially cascaded, global pooling is applied to obtain the feature weights of each channel, and weights are adaptively assigned to each feature map. These maps are then upsampled to the original image size to obtain the final segmentation result.ResultThe results were validated on the Camvid and Cityscapes datasets with mean intersection over union(MIoU) and precision as metrics. The proposed model achieved 69.47% MIoU and 92.32% precision on Camvid, which were 1.3% and 3.09% higher than those of the model with the second-highest performance. Meanwhile, on Cityscapes, the proposed model achieved 78.48% MIoU and 93.83% precision, which were 1.16% and 3.60% higher than those of the model with the second-highest performance. The proposed algorithm also outperforms the other algorithms in terms of visual effects.ConclusionThis paper designs a new semantic segmentation algorithm that uses dilated convolution and ResNet to collect image features and obtains different features of the image in large and small perception fields. Using dilated convolution improves the resolution while ensuring the perceived field of view. An attention mechanism module is also designed to assign weights to each feature map and to facilitate model learning. A feature fusion module is then designed to fuse the features of different perception fields and reflect their specificity. Experiments show that the proposed algorithm outperforms the other algorithms in terms of accuracy and shows a certain application value.关键词:semantic segmentation;convolutional neural network;perception field;dilated convolution;attention mechanism;feature fusion30|29|7更新时间:2024-05-07 -
 摘要:ObjectiveThe existing multi-focus image fusion approaches based on deep learning methods consider a convolutional neural network (CNN) as a classifier. These methods use CNNs to classify pixels into focused or defocused pixels, and corresponding fusion rules are designed in accordance with the classified pixels. The expected full-focused image mainly depends on handcraft labeled data and fusion rule and is constructed on the learned feature maps. The training process is learned based on label pixel. However, manually labeling a focused or defocused pixel is an arduous problem and may lead to inaccurate focus prediction. Existing multi-focus datasets are constructed by adding Gaussian blur to some parts of full-focused images, which makes the training data unrealistic. To solve these issues and enable CNN to adaptively adjust fusion rules, a novel multi-focus image fusion algorithm based on self-learning fusion rules is proposed.MethodAutoencoders are unsupervised learning networks, and their hidden layer can be considered a feature representation of the input samples. Multi-focus images are usually collected from the same scene with public scene information and private focus information, and the paired images should be encoded in their common and private feature spaces, respectively. This study uses joint convolutional autoencoders (JCAEs) to learn structured features. JCAEs consist of public and private branches. The public branches share weights to obtain the common encoding features of multiple input images, and the private branches can acquire private encoding features. A fusion layer with concentrating operation is designed to obtain a self-learned fusion rule and constrain the entire fusion network to work in an end-to-end style. The initial focus map is regarded as a prior input to enable the network to learn precise details. Current multi-focus image fusion algorithms based on deep learning train networks by applying data augmentation to datasets and utilize various skills to adjust the networks. The design of fusion rules is significant. Fusion rules generally comprise direct cascading fusion and pixel-level aspects. The cascading fusion stacks multiple inputs and then blends with the next convolutional layer to help networks gain rich image features. Pixel-level fusion rules are formed with maximum, sum, and mean rules, which can be selected depending on the characteristics of datasets. The mean rule is introduced based on cascading fusion to make the network feasible for achieving the autonomous adjustment of the fusion rules in the training process. The fusion rules of JCAEs are quantitatively and qualitatively discussed to identify the way they work in the process. Image entropy is used to represent the amount of information contained in the aggregated features of grayscale distribution in images. The fusion rules are reasonably demonstrated by calculating the retaining information of the feature map in the network fusion layer. In this study, a pair of multi-focus images is fed into the network, and the feature map of the convolution operation pertaining to the fusion layer is trained to produce fused images. The fusion rules can be visually interpreted by comparing the image information quantity and the learned weight value subjectively. Instead of using the basic loss function to train CNN, the model adds a local strategy to the loss function, including structural similarity index measure and mean squared error. Such a strategy can effectively drive the fusion unit to learn pixel-wise features and ensure accurate image restoration. More accurate and abstract features can be obtained when source images are passed through deep networks rather than shallow networks. However, problems, such as gradient vanishing and high network convergence time, occur in the back-propagation stage of deep networks. The residual network skips a few training layers by using skip connection or shortcut and can easily learn residual images rather than the original input image. Therefore, we use the short connection strategy to improve the feature learning ability of JCAEs.ResultThe model is trained on the Keras framework based on TensorFlow. We test our model on Lytro dataset and conduct subjective and objective evaluations with existing multi-focus fusion algorithms to verify the performance of the proposed fusion method. The dataset has been widely used in multi-focus image fusion research. We magnify the key areas, such as the region between focused and defocused pixels in the fusion image, to illustrate the differences of fusion images in detail. From the perspective of subjective evaluation, the model can effectively fuse the focus area and shun the artifacts in the fused image. Detailed information is fused, and thus, the visual effect is naturally clear. From the perspective of objective evaluation, a comparison of the image of the model fusion with the fusion image of other mainstream multi-focus image fusion algorithms demonstrates that the average precision of the entropy, Qw, correlation coefficient, and visual information fidelity are the best, which are 7.457 4, 0.917 7, 0.978 8, and 0.890 8, respectively.ConclusionMost deep learning-based multi-focus image fusion methods fulfill a pattern, that is, employing CNN to classify pixels into focused and defocused ones, manually designing fusion rules in accordance with the classified pixels, and conducting a fusion operation on the original spatial domain or learned feature map to acquire a fused full-focused image. This pipeline ignores considerable useful information of the middle layer and heavily relies on labeled data. To solve the above-mentioned problems, this study proposes a multi-focus image fusion algorithm with self-learning style. A fusion layer is designed based on JCAEs. We discuss its network structure, the loss function design, and a method on how to embed pixel-wise prior knowledge. In this way, the network can output vivid fused images. We also provide a reasonable geometric interpretation of the learnable fusion operation on quantitative and qualitative levels. The experiments demonstrate that the model is reasonable and effective; it can not only achieve self-learning of fusion rules but also performs efficiently with subjective visual perception and objective evaluation metrics. This work offers a new idea for the fusion of multi-focus images, which will be beneficial to further understand the mechanism of deep learning-based multi-focus image fusion and motivate us to develop an interpretable image fusion method with popular neural networks.关键词:multi-focus image fusion;auto-encoders;self-learning;end-to-end;structural similarity24|30|2更新时间:2024-05-07
摘要:ObjectiveThe existing multi-focus image fusion approaches based on deep learning methods consider a convolutional neural network (CNN) as a classifier. These methods use CNNs to classify pixels into focused or defocused pixels, and corresponding fusion rules are designed in accordance with the classified pixels. The expected full-focused image mainly depends on handcraft labeled data and fusion rule and is constructed on the learned feature maps. The training process is learned based on label pixel. However, manually labeling a focused or defocused pixel is an arduous problem and may lead to inaccurate focus prediction. Existing multi-focus datasets are constructed by adding Gaussian blur to some parts of full-focused images, which makes the training data unrealistic. To solve these issues and enable CNN to adaptively adjust fusion rules, a novel multi-focus image fusion algorithm based on self-learning fusion rules is proposed.MethodAutoencoders are unsupervised learning networks, and their hidden layer can be considered a feature representation of the input samples. Multi-focus images are usually collected from the same scene with public scene information and private focus information, and the paired images should be encoded in their common and private feature spaces, respectively. This study uses joint convolutional autoencoders (JCAEs) to learn structured features. JCAEs consist of public and private branches. The public branches share weights to obtain the common encoding features of multiple input images, and the private branches can acquire private encoding features. A fusion layer with concentrating operation is designed to obtain a self-learned fusion rule and constrain the entire fusion network to work in an end-to-end style. The initial focus map is regarded as a prior input to enable the network to learn precise details. Current multi-focus image fusion algorithms based on deep learning train networks by applying data augmentation to datasets and utilize various skills to adjust the networks. The design of fusion rules is significant. Fusion rules generally comprise direct cascading fusion and pixel-level aspects. The cascading fusion stacks multiple inputs and then blends with the next convolutional layer to help networks gain rich image features. Pixel-level fusion rules are formed with maximum, sum, and mean rules, which can be selected depending on the characteristics of datasets. The mean rule is introduced based on cascading fusion to make the network feasible for achieving the autonomous adjustment of the fusion rules in the training process. The fusion rules of JCAEs are quantitatively and qualitatively discussed to identify the way they work in the process. Image entropy is used to represent the amount of information contained in the aggregated features of grayscale distribution in images. The fusion rules are reasonably demonstrated by calculating the retaining information of the feature map in the network fusion layer. In this study, a pair of multi-focus images is fed into the network, and the feature map of the convolution operation pertaining to the fusion layer is trained to produce fused images. The fusion rules can be visually interpreted by comparing the image information quantity and the learned weight value subjectively. Instead of using the basic loss function to train CNN, the model adds a local strategy to the loss function, including structural similarity index measure and mean squared error. Such a strategy can effectively drive the fusion unit to learn pixel-wise features and ensure accurate image restoration. More accurate and abstract features can be obtained when source images are passed through deep networks rather than shallow networks. However, problems, such as gradient vanishing and high network convergence time, occur in the back-propagation stage of deep networks. The residual network skips a few training layers by using skip connection or shortcut and can easily learn residual images rather than the original input image. Therefore, we use the short connection strategy to improve the feature learning ability of JCAEs.ResultThe model is trained on the Keras framework based on TensorFlow. We test our model on Lytro dataset and conduct subjective and objective evaluations with existing multi-focus fusion algorithms to verify the performance of the proposed fusion method. The dataset has been widely used in multi-focus image fusion research. We magnify the key areas, such as the region between focused and defocused pixels in the fusion image, to illustrate the differences of fusion images in detail. From the perspective of subjective evaluation, the model can effectively fuse the focus area and shun the artifacts in the fused image. Detailed information is fused, and thus, the visual effect is naturally clear. From the perspective of objective evaluation, a comparison of the image of the model fusion with the fusion image of other mainstream multi-focus image fusion algorithms demonstrates that the average precision of the entropy, Qw, correlation coefficient, and visual information fidelity are the best, which are 7.457 4, 0.917 7, 0.978 8, and 0.890 8, respectively.ConclusionMost deep learning-based multi-focus image fusion methods fulfill a pattern, that is, employing CNN to classify pixels into focused and defocused ones, manually designing fusion rules in accordance with the classified pixels, and conducting a fusion operation on the original spatial domain or learned feature map to acquire a fused full-focused image. This pipeline ignores considerable useful information of the middle layer and heavily relies on labeled data. To solve the above-mentioned problems, this study proposes a multi-focus image fusion algorithm with self-learning style. A fusion layer is designed based on JCAEs. We discuss its network structure, the loss function design, and a method on how to embed pixel-wise prior knowledge. In this way, the network can output vivid fused images. We also provide a reasonable geometric interpretation of the learnable fusion operation on quantitative and qualitative levels. The experiments demonstrate that the model is reasonable and effective; it can not only achieve self-learning of fusion rules but also performs efficiently with subjective visual perception and objective evaluation metrics. This work offers a new idea for the fusion of multi-focus images, which will be beneficial to further understand the mechanism of deep learning-based multi-focus image fusion and motivate us to develop an interpretable image fusion method with popular neural networks.关键词:multi-focus image fusion;auto-encoders;self-learning;end-to-end;structural similarity24|30|2更新时间:2024-05-07 -
 摘要:ObjectiveThe unceasing progress in China's economy and urbanization has caused the increase in internal expressway mileage and automobiles, and this situation leads to concern on traffic jam among Chinese people. In view of the increasing requirements for safe driving by operators, autonomous driving techniques have attracted widespread attention from domestic and foreign scholars. However, automotive active safety techniques remain in the stage of R & D and testing in China. Many problems, such as few practical products, low-precision safety distance model (SDM), difficulty in obtaining key parameters, and disregarding drivers' characteristics, exist. Corresponding research is accordingly necessary. The vehicle-road visual collaboration technology, which is the core technology for the field of automotive active safety, is applied reasonably to anti-collision early warning systems. Compared with ultrasound, laser, and radar, the technology has the following advantages:the collected vehicle-road parameter information is more abundant, no perceived blind zone exists, the state of dangerous vehicles is dynamically predicted, it is not restricted by view block, and it is more affordable and suitable for the human eye's information capture habits. The rapid and accurate detection of preceding vehicles and the establishment of a stable and reliable SDM are two difficulties. To overcome these problems, a freeway anti-collision-warning algorithm based on vehicle-road visual collaboration was proposed.MethodThe environment was sensed through the driving recorder. The road lane line, the vehicle speed, and the position of the vehicle in front were combined to realize the anti-collision warning. The algorithm mainly includes three parts, namely, the construction of an SDM, the lane detection based on you only look once v3(YOLOv3), and the anti-collision-warning algorithm based on the visual collaboration of the road. A real-time calculation method for the safety zone was proposed to construct an SDM between the current and preceding vehicles. The lateral distance of the safety zone was obtained by detecting and fitting the mathematical model of the lane line. A speed detection algorithm was proposed to calculate the current vehicle's driving speed based on video images. The longitudinal distance of the safety zone was obtained through the current vehicle's driving speed and the driver's behavioral and perceptual response characteristics. The early warning area of the safety zone was constituted through the horizontal and vertical distances between lane lines. SDM was built using the safe area real-time calculation algorithm to form an early warning safety zone in front of the current vehicle. The deep neural network YOLOv3 was used to detect preceding vehicles in real time for obtaining the location information of the vehicle. After the input image was detected with YOLOv3, the category where the object belongs to and the coordinate information of the object were predicted. The lower-right (or lower-left) coordinates of the bounding box of the vehicle was used to improve the accuracy of the early warning. The real-time calculation technology of the safety zone and the results of lane-line tracking were combined through the vehicle-road visual collaborative algorithm to build a safety early warning area on the road that changes with the vehicle speed in real time. The coordinate information of the vehicle in a video was obtained using YOLOv3. Different tips depending on where the vehicle was in the video were given through the anti-collision-warning algorithm based on vehicle-road visual collaboration.ResultThe proposed method was tested and evaluated on the video captured by a driving recorder, which was acquired from a passenger transportation company in Huai'an. The sequence of the test video was Test_1 to Test_20, and these video sequences contained different highway driving environments that can effectively verify the pros and cons of the algorithm. Vehicle detection experiments were performed on a desktop computer with an NVIDIA GeForce GTX 1070TI GPU. The collision-warning experiment was performed on a Mazda CX-4 with millimeter-wave radar and a laser rangefinder. The test section was Changshen Expressway. The experiments showed that the vehicle detection accuracy of the retrained YOLOv3 algorithm is up to 98.04%. Compared with the forward obstruction warning system of Mazda CX-4, the proposed algorithm can achieve side and forward warning, and an alarm is issued 0.8 s in advance. Although the proposed method demonstrates a good result in terms of detection speed, accuracy, and collision early warning, the construction of SDM can still be further improved compared with other algorithms because the research on the lane-line detection is limited on a good weather. Further research will be conducted in the case of poor visibility, such as rain, fog, and night.ConclusionCompared with the traditional anti-collision-warning method based on vehicle ultrasound, radar, or laser ranging, the proposed method can effectively improve the accuracy of early warning and better guarantee the driving safety on expressways. The algorithm has four advantages. First, progressive probabilistic Hough transform combined with morphological filtering, which had good robustness to interference noise and high detection accuracy, was proposed to detect lane lines. Second, real-time computing technology of safety zone, which considered the behavioral and intuitive response characteristics of drivers and was in line with the real driving situation, was proposed to construct SDM. Third, theYOLOv3 target detection algorithm was used to realize single-category detection, which further improved the video frames to reach 43 frame per second with guaranteed accuracy. Finally, the vehicle position information and road SDM were considered, and an anti-collision warning algorithm based on vehicle-road vision coordination was proposed. This advantage effectively improved the accuracy of vehicle warning and ensured the driving safety of drivers.关键词:forward anti-collision warning;safety distance model(SDM);lane detection;vehicle real-time detection;you only look once v3(YOLOv3)23|35|3更新时间:2024-05-07
摘要:ObjectiveThe unceasing progress in China's economy and urbanization has caused the increase in internal expressway mileage and automobiles, and this situation leads to concern on traffic jam among Chinese people. In view of the increasing requirements for safe driving by operators, autonomous driving techniques have attracted widespread attention from domestic and foreign scholars. However, automotive active safety techniques remain in the stage of R & D and testing in China. Many problems, such as few practical products, low-precision safety distance model (SDM), difficulty in obtaining key parameters, and disregarding drivers' characteristics, exist. Corresponding research is accordingly necessary. The vehicle-road visual collaboration technology, which is the core technology for the field of automotive active safety, is applied reasonably to anti-collision early warning systems. Compared with ultrasound, laser, and radar, the technology has the following advantages:the collected vehicle-road parameter information is more abundant, no perceived blind zone exists, the state of dangerous vehicles is dynamically predicted, it is not restricted by view block, and it is more affordable and suitable for the human eye's information capture habits. The rapid and accurate detection of preceding vehicles and the establishment of a stable and reliable SDM are two difficulties. To overcome these problems, a freeway anti-collision-warning algorithm based on vehicle-road visual collaboration was proposed.MethodThe environment was sensed through the driving recorder. The road lane line, the vehicle speed, and the position of the vehicle in front were combined to realize the anti-collision warning. The algorithm mainly includes three parts, namely, the construction of an SDM, the lane detection based on you only look once v3(YOLOv3), and the anti-collision-warning algorithm based on the visual collaboration of the road. A real-time calculation method for the safety zone was proposed to construct an SDM between the current and preceding vehicles. The lateral distance of the safety zone was obtained by detecting and fitting the mathematical model of the lane line. A speed detection algorithm was proposed to calculate the current vehicle's driving speed based on video images. The longitudinal distance of the safety zone was obtained through the current vehicle's driving speed and the driver's behavioral and perceptual response characteristics. The early warning area of the safety zone was constituted through the horizontal and vertical distances between lane lines. SDM was built using the safe area real-time calculation algorithm to form an early warning safety zone in front of the current vehicle. The deep neural network YOLOv3 was used to detect preceding vehicles in real time for obtaining the location information of the vehicle. After the input image was detected with YOLOv3, the category where the object belongs to and the coordinate information of the object were predicted. The lower-right (or lower-left) coordinates of the bounding box of the vehicle was used to improve the accuracy of the early warning. The real-time calculation technology of the safety zone and the results of lane-line tracking were combined through the vehicle-road visual collaborative algorithm to build a safety early warning area on the road that changes with the vehicle speed in real time. The coordinate information of the vehicle in a video was obtained using YOLOv3. Different tips depending on where the vehicle was in the video were given through the anti-collision-warning algorithm based on vehicle-road visual collaboration.ResultThe proposed method was tested and evaluated on the video captured by a driving recorder, which was acquired from a passenger transportation company in Huai'an. The sequence of the test video was Test_1 to Test_20, and these video sequences contained different highway driving environments that can effectively verify the pros and cons of the algorithm. Vehicle detection experiments were performed on a desktop computer with an NVIDIA GeForce GTX 1070TI GPU. The collision-warning experiment was performed on a Mazda CX-4 with millimeter-wave radar and a laser rangefinder. The test section was Changshen Expressway. The experiments showed that the vehicle detection accuracy of the retrained YOLOv3 algorithm is up to 98.04%. Compared with the forward obstruction warning system of Mazda CX-4, the proposed algorithm can achieve side and forward warning, and an alarm is issued 0.8 s in advance. Although the proposed method demonstrates a good result in terms of detection speed, accuracy, and collision early warning, the construction of SDM can still be further improved compared with other algorithms because the research on the lane-line detection is limited on a good weather. Further research will be conducted in the case of poor visibility, such as rain, fog, and night.ConclusionCompared with the traditional anti-collision-warning method based on vehicle ultrasound, radar, or laser ranging, the proposed method can effectively improve the accuracy of early warning and better guarantee the driving safety on expressways. The algorithm has four advantages. First, progressive probabilistic Hough transform combined with morphological filtering, which had good robustness to interference noise and high detection accuracy, was proposed to detect lane lines. Second, real-time computing technology of safety zone, which considered the behavioral and intuitive response characteristics of drivers and was in line with the real driving situation, was proposed to construct SDM. Third, theYOLOv3 target detection algorithm was used to realize single-category detection, which further improved the video frames to reach 43 frame per second with guaranteed accuracy. Finally, the vehicle position information and road SDM were considered, and an anti-collision warning algorithm based on vehicle-road vision coordination was proposed. This advantage effectively improved the accuracy of vehicle warning and ensured the driving safety of drivers.关键词:forward anti-collision warning;safety distance model(SDM);lane detection;vehicle real-time detection;you only look once v3(YOLOv3)23|35|3更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveA fusion mutation strategy that considers global and local processing is proposed in this paper to solve the low acceptance probability, asymmetry of sampling quantity and illumination distribution in the uneven brightness area, and poor fluidity in the uneven brightness region of the multiplexed Metropolis light transport algorithm.MethodThe local pixel plane luminance uniformity is dynamically measured as a whole through variance, and the sampling step size is adaptively adjusted, that is, the number of samples per pixel location is recorded. The current sampled pixel is measured through variance, and the brightness uniformity in the eight neighborhoods and the sampling step size of the current Markov chain are adjusted by the calculation result of variance when the samples reaches the threshold of the current sampled pixel and the current sample is the first sample of the Markov chain or the first sample after the large mutation. Then, the eight-neighbor sampling weight is calculated by considering the number of samples and illumination when the number of samples of the current sampled pixel reaches the threshold and the current sample is a small mutation.ResultThe experiment is divided into two parts. The first part verifies the effectiveness of adjusting the sampling step size on the image distribution and selects the lengthened and shortened step size parameters in accordance with the relationship between the obtained local eight-neighbor luminance variance and the step size in the uniform or uneven brightness region. The optimal combination of parameters enables to adaptively adjust the sampling step size in accordance with the scene. Results show that the adaptively adjusting of sampling step size can effectively guide the samples to enhance the sampling in the uneven brightness region for improving the rendering of the details and the flow of samples in the uneven brightness region that cannot be perceived by the human eye to better traverse the pixel plane. The second part combines the sampling quantity and illumination distribution strategy with the adaptively adjusting of sampling step size strategy to form a fusion mutation strategy and is compared with the multiplexed Metropolis light transport algorithm, sampling quantity and illumination distribution strategy, and adaptively adjusting of sampling step size strategy under different lighting and material scenarios. Results show that the fusion mutation strategy algorithm uses the advantages of sampling quantity and illumination distribution and adaptively adjusting of sampling step size strategy. As shown in rendered resulting graphs, the fusion mutation algorithm renders the highlighting effect and makes the rendering result of the uneven brightness region exquisite. The fusion mutation algorithm is realistic in terms of detail performance. As shown in the obtained sampling density distribution maps, the fusion mutation algorithm enhances the sampling in the uneven brightness region, improves the mobility of samples in the uniform region, and verifies the effectiveness of adaptively adjusting of sampling step size strategy. For the evaluation of rendered data indicators, the fusion mutation strategy combined with the adaptively adjusting step strategy and the method of taking the sampling quantity and illumination distribution is compared with the original algorithm. The fusion mutation algorithm improves the indicators in a balanced manner on the basis of the rendering time between the adaptively adjusting of sampling step size and sampling quantity and illumination distribution strategies.ConclusionA fusion mutation strategy that combines the dynamically adjusting of sampling step size strategy, which is a global sampling strategy, and the enhanced highlight area with sampling and lighting effect strategy, which is a local sampling strategy, is proposed in this paper. On the one hand, the proposed method can help the Markov chain to shorten the sampling step size in areas, where the brightness is different and the acceptance probability is low, and modify the sampling weight in the intensively changing brightness region to improve the local sampling quantity and illumination distribution asymmetry. On the other hand, the Markov chain is easily trapped in the local where the brightness is uniform because of the constraint of the multiplexed Metropolis light transport(MMLT) algorithm. The proposed method lengthens the sampling step size to accelerate the flow of samples within the region to improve the ergodicity of the algorithm.关键词:fusion mutation strategy;multiplexed Metropolis;sampling step size;acceptance probability;variance;bright-ness uniformity16|21|0更新时间:2024-05-07
摘要:ObjectiveA fusion mutation strategy that considers global and local processing is proposed in this paper to solve the low acceptance probability, asymmetry of sampling quantity and illumination distribution in the uneven brightness area, and poor fluidity in the uneven brightness region of the multiplexed Metropolis light transport algorithm.MethodThe local pixel plane luminance uniformity is dynamically measured as a whole through variance, and the sampling step size is adaptively adjusted, that is, the number of samples per pixel location is recorded. The current sampled pixel is measured through variance, and the brightness uniformity in the eight neighborhoods and the sampling step size of the current Markov chain are adjusted by the calculation result of variance when the samples reaches the threshold of the current sampled pixel and the current sample is the first sample of the Markov chain or the first sample after the large mutation. Then, the eight-neighbor sampling weight is calculated by considering the number of samples and illumination when the number of samples of the current sampled pixel reaches the threshold and the current sample is a small mutation.ResultThe experiment is divided into two parts. The first part verifies the effectiveness of adjusting the sampling step size on the image distribution and selects the lengthened and shortened step size parameters in accordance with the relationship between the obtained local eight-neighbor luminance variance and the step size in the uniform or uneven brightness region. The optimal combination of parameters enables to adaptively adjust the sampling step size in accordance with the scene. Results show that the adaptively adjusting of sampling step size can effectively guide the samples to enhance the sampling in the uneven brightness region for improving the rendering of the details and the flow of samples in the uneven brightness region that cannot be perceived by the human eye to better traverse the pixel plane. The second part combines the sampling quantity and illumination distribution strategy with the adaptively adjusting of sampling step size strategy to form a fusion mutation strategy and is compared with the multiplexed Metropolis light transport algorithm, sampling quantity and illumination distribution strategy, and adaptively adjusting of sampling step size strategy under different lighting and material scenarios. Results show that the fusion mutation strategy algorithm uses the advantages of sampling quantity and illumination distribution and adaptively adjusting of sampling step size strategy. As shown in rendered resulting graphs, the fusion mutation algorithm renders the highlighting effect and makes the rendering result of the uneven brightness region exquisite. The fusion mutation algorithm is realistic in terms of detail performance. As shown in the obtained sampling density distribution maps, the fusion mutation algorithm enhances the sampling in the uneven brightness region, improves the mobility of samples in the uniform region, and verifies the effectiveness of adaptively adjusting of sampling step size strategy. For the evaluation of rendered data indicators, the fusion mutation strategy combined with the adaptively adjusting step strategy and the method of taking the sampling quantity and illumination distribution is compared with the original algorithm. The fusion mutation algorithm improves the indicators in a balanced manner on the basis of the rendering time between the adaptively adjusting of sampling step size and sampling quantity and illumination distribution strategies.ConclusionA fusion mutation strategy that combines the dynamically adjusting of sampling step size strategy, which is a global sampling strategy, and the enhanced highlight area with sampling and lighting effect strategy, which is a local sampling strategy, is proposed in this paper. On the one hand, the proposed method can help the Markov chain to shorten the sampling step size in areas, where the brightness is different and the acceptance probability is low, and modify the sampling weight in the intensively changing brightness region to improve the local sampling quantity and illumination distribution asymmetry. On the other hand, the Markov chain is easily trapped in the local where the brightness is uniform because of the constraint of the multiplexed Metropolis light transport(MMLT) algorithm. The proposed method lengthens the sampling step size to accelerate the flow of samples within the region to improve the ergodicity of the algorithm.关键词:fusion mutation strategy;multiplexed Metropolis;sampling step size;acceptance probability;variance;bright-ness uniformity16|21|0更新时间:2024-05-07 -
 摘要:ObjectiveThe deformation body simulation technology has been continuously developed in recent years and has been widely investigated in virtual simulation. It has been widely used in animation, design, and games. In the computer virtual environment, rapid and accurate self-collision detection can immensely enhance the realistic sense of deformation body simulation. A cloth is a representative deformable body composed of a large number of geometric elements, which is characterized by thin and soft, and easy to deform, squeeze, and wrinkle. Therefore, fabric self-collision should be detected and penetration should be prevented to ensure the reality of fabric simulation. Data analysis shows that self-collision detection takes 60% 80% of the time in the simulated scene of a deformed body. Self-collision detection of cloth frequently consumes considerable time resources. For the deformation model without thickness, such as cloth, whether the fabric itself has a collision is difficult to determine through traditional collision detection in real time. Therefore, self-collision detection is a cutting-edge problem in cloth simulation. The self-collision detection effect of a deformed body, such as cloth, largely determines the authenticity of virtual simulation. Real-time is a difficult point in self-collision detection. Self-collision detection consumes considerable time because the cloth model consists of many primitives. Most existing self-collision detection algorithms focus on improving the test speed. The traditional self-collision detection algorithm uses bounding box test, which is extremely large and complex. It cannot meet the accuracy and real-time requirements at the same time. In other words, the pursuit of accuracy will prolong the time consumed by calculation, and the pursuit of real-time will reduce the detection accuracy. The above conditions will make the simulation effect insufficiently real. A previous work combined the normal cone test with traditional collision detection method, reduced the computation of intersection detection, and improved the detection speed to improve the speed of self-collision detection without affecting the detection accuracy. The calculation of the intersection test of the primitives is reduced by constructing a hybrid hierarchy composed of various bounding boxes to improve the fit of the bounding box. However, the improved algorithm cannot meet the real-time and accuracy requirements. This paper proposes a method combining the aixe align bounding box (AABB)-circular hybrid hierarchy of deep neural networks to solve the above problems.MethodThis paper proposes an AABB-circular hybrid hierarchical bounding box that integrates deep neural networks. The working principle is described as follows. First, an AABB-circular hybrid hierarchical bounding box tree is built for the clothing model. The AABB hierarchical boundary box tree is constructed for the model, and the three vertices of the triangle are used to calculate the circular boundary frame of the leaf nodes. Second, a bounding volume test tree (BVTT) is generated in accordance with the AABB-circular hierarchical bounding box. Third, the corresponding normal cone is calculated for the nodes in the constructed BVTT tree. Fourth, a bounding box test is performed first, followed by a normal cone test, and multiple pairs of potential collision primitives are outputted. Finally, multiple pairs of collision triangles are outputted by performing a primitive intersection test on the potential collision primitive.ResultExperimental results shows that the proposed method achieves a balance between accuracy and time consumption on the premise of finding the optimal number of hidden layers in the deep neural network and the optimal number of nodes in each layer. The AABB-oriented bounding box(OBB) algorithm takes 19% to 33% less time than the classic self-collision detection algorithm. We compared the proposed method with the AABB-OBB method and three classical methods in terms of time consumption of updating, detecting, and primitive testing to verify the advantages of the proposed method in computation time. Experimental results show that the proposed method consumes a small amount of update time, optimizes the speed of primitive crossover testing, and reduces the overall time consumption. We compared the proposed method with the AABB-OBB method and three classic methods in the primitive intersection test to verify its superiority in terms of fit. The proposed method has the least number of pattern intersection tests and the best fit.ConclusionAn AABB-circular hybrid hierarchical self-collision detection method based on deep neural network is proposed. The AABB and the round form a hybrid layer bounding box to perform self-collision detection on the cloth. The intersection of the circular bounding box is detected using a deep neural network. Compared with the classic AABB-OBB bounding box and the classic three bounding boxes, the accuracy and timeliness of the AABB-circular hybrid hierarchical bounding box with fusion deep neural network are verified from multiple indicators.关键词:self-collision detection;hybrid bounding volume hierarchy;circular bounding volume;deep neural network(DNN);graph element intersection test20|20|6更新时间:2024-05-07
摘要:ObjectiveThe deformation body simulation technology has been continuously developed in recent years and has been widely investigated in virtual simulation. It has been widely used in animation, design, and games. In the computer virtual environment, rapid and accurate self-collision detection can immensely enhance the realistic sense of deformation body simulation. A cloth is a representative deformable body composed of a large number of geometric elements, which is characterized by thin and soft, and easy to deform, squeeze, and wrinkle. Therefore, fabric self-collision should be detected and penetration should be prevented to ensure the reality of fabric simulation. Data analysis shows that self-collision detection takes 60% 80% of the time in the simulated scene of a deformed body. Self-collision detection of cloth frequently consumes considerable time resources. For the deformation model without thickness, such as cloth, whether the fabric itself has a collision is difficult to determine through traditional collision detection in real time. Therefore, self-collision detection is a cutting-edge problem in cloth simulation. The self-collision detection effect of a deformed body, such as cloth, largely determines the authenticity of virtual simulation. Real-time is a difficult point in self-collision detection. Self-collision detection consumes considerable time because the cloth model consists of many primitives. Most existing self-collision detection algorithms focus on improving the test speed. The traditional self-collision detection algorithm uses bounding box test, which is extremely large and complex. It cannot meet the accuracy and real-time requirements at the same time. In other words, the pursuit of accuracy will prolong the time consumed by calculation, and the pursuit of real-time will reduce the detection accuracy. The above conditions will make the simulation effect insufficiently real. A previous work combined the normal cone test with traditional collision detection method, reduced the computation of intersection detection, and improved the detection speed to improve the speed of self-collision detection without affecting the detection accuracy. The calculation of the intersection test of the primitives is reduced by constructing a hybrid hierarchy composed of various bounding boxes to improve the fit of the bounding box. However, the improved algorithm cannot meet the real-time and accuracy requirements. This paper proposes a method combining the aixe align bounding box (AABB)-circular hybrid hierarchy of deep neural networks to solve the above problems.MethodThis paper proposes an AABB-circular hybrid hierarchical bounding box that integrates deep neural networks. The working principle is described as follows. First, an AABB-circular hybrid hierarchical bounding box tree is built for the clothing model. The AABB hierarchical boundary box tree is constructed for the model, and the three vertices of the triangle are used to calculate the circular boundary frame of the leaf nodes. Second, a bounding volume test tree (BVTT) is generated in accordance with the AABB-circular hierarchical bounding box. Third, the corresponding normal cone is calculated for the nodes in the constructed BVTT tree. Fourth, a bounding box test is performed first, followed by a normal cone test, and multiple pairs of potential collision primitives are outputted. Finally, multiple pairs of collision triangles are outputted by performing a primitive intersection test on the potential collision primitive.ResultExperimental results shows that the proposed method achieves a balance between accuracy and time consumption on the premise of finding the optimal number of hidden layers in the deep neural network and the optimal number of nodes in each layer. The AABB-oriented bounding box(OBB) algorithm takes 19% to 33% less time than the classic self-collision detection algorithm. We compared the proposed method with the AABB-OBB method and three classical methods in terms of time consumption of updating, detecting, and primitive testing to verify the advantages of the proposed method in computation time. Experimental results show that the proposed method consumes a small amount of update time, optimizes the speed of primitive crossover testing, and reduces the overall time consumption. We compared the proposed method with the AABB-OBB method and three classic methods in the primitive intersection test to verify its superiority in terms of fit. The proposed method has the least number of pattern intersection tests and the best fit.ConclusionAn AABB-circular hybrid hierarchical self-collision detection method based on deep neural network is proposed. The AABB and the round form a hybrid layer bounding box to perform self-collision detection on the cloth. The intersection of the circular bounding box is detected using a deep neural network. Compared with the classic AABB-OBB bounding box and the classic three bounding boxes, the accuracy and timeliness of the AABB-circular hybrid hierarchical bounding box with fusion deep neural network are verified from multiple indicators.关键词:self-collision detection;hybrid bounding volume hierarchy;circular bounding volume;deep neural network(DNN);graph element intersection test20|20|6更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectivePatients with chronic ulcerative colitis (UC) have a significantly increased risk of developing colon cancer, and an early detection via colonoscopy is necessary. Assisted diagnosis of UC is among the computer-assisted diagnostic topics in medical gastrointestinal endoscopy research that aims to find reliable features for identifying lesions in intestinal images. The typical endoscopic findings from UC images include loss of vascular patterns, granularity, bleeding mucous membranes, and ulcers. UC often repeats recurrence and remission cycles during its course and may be accompanied by parenteral complications. The risk of colon cancer increases when UC extensively affects the large intestine for long periods. However, endoscopes take a large amount of intestinal images, and noise interference, such as shadows, is often observed in these images. Therefore, accurate image features must be identified, and computer-aided diagnosis must be provided to physicians. The extant convolutional neural networks have demonstrated extraordinary capabilities in image classification but requires the support of large datasets and a very long training process. In sparsely coded image recognition, sparse coding pyramid matching (SCSPM) applies selective sparse coding to extract the significant characteristics of scale-invariant feature transform (SIFT) descriptors for local image blocks. Sparse coding also maximizes pooling on multiple spatial scales to combine translation and scale invariance instead of averaging the pools in the histogram. Locally constrained linear coding (LLC) refers to the rapid implementation of local coordinate coding, where local constraints are used to project each descriptor onto a local coordinate system. However, sparse coding cannot obtain an accurate image representation. The theory of compressed sensing is based on the sparseness of the signal and uses an underdetermined random observation matrix for sampling such signal. Each measurement value is not the signal itself but a linear combination function of multiple signals, that is, each measurement contains a small amount of information for all signals. The sparse reconstruction algorithm is used to achieve an accurate reconstruction of signals or an approximate reconstruction with certain errors. To solve the problems in UC and normal intestinal image classification, an image feature based on a combination of compressed sensing and spatial pyramid pooling is proposed in this paper.MethodThis paper proposes compressed perceptual spatial pyramid pooling (CSSPP) image features. First, block recursive least squares (BRLS) and K-singular value decomposition(K-SVD) dictionary learning are used to train some positive and negative datasets to obtain two initial dictionaries for comparing the two algorithms. Second, an alternating optimization algorithm based on the UC image prior perception matrix and sparse dictionary is developed. When finding the optimal perception matrix, the Gram matrix of the equivalent dictionary is considered, the sparse representation error is designed as prior knowledge, and the performance of the system is tested at different sampling rates. In dictionary optimization, the influence of the perception matrix on dictionary errors is considered, and the impact of different sparsity on classification accuracy is tested. Using the obtained sensing matrix and sparse dictionary to obtain sparse representations of all datasets in a compressed sensing framework can address the problem where the original image classification method based on sparse coding cannot accurately represent images. The maximum and average spatial pyramid pooling methods are then used to divide the image into 21 regions on multiple scales to extract CSSPP features. By introducing compressed sensing, the information of sparse representation is richer and more accurate than that of sparse coding. A linear kernel support vector machine (SVM) is used for image classification.ResultThe proposed algorithm was trained on 100 UC and 100 normal images taken from the Kvasir dataset. During the training phase, the mean square error of the dictionary obtained by BRLS training was slightly lower than that of K-SVD. The highest image restoration accuracy was obtained at a sampling rate of 31.25%. The performance of the two pooling features was examined under different sparsity. The maximum pooling in training accuracy was significantly higher than the average. The quantitative evaluation indicators include sensitivity, specificity, accuracy, receiver operating characferistic(ROC) curve, area under curve(AUC) value, and time efficiency. Tests were then performed on all 2 000 datasets, and the classification results show that the features can improve the auxiliary diagnosis of UC images. Compared with bag of features (BOF), SCSPM, and LLC, using the SVM classification results increases the AUC values by 0.092, 0.035, and 0.015, the sensitivity by 9.19%, 2.84%, and -0.24%, the specificity by 15.52%, 5.15%, and 4.77%, and the accuracy by 12.35%, 3.99%, and 2.27%, respectively. Compared with BOF and SCSPM, the running time was reduced by 2 164.5 and 1 455.6 seconds, respectively.ConclusionThe auxiliary diagnosis model of UC proposed in this paper combines the advantages of compressed sensing and spatial pyramid pooling to obtain highly accurate detection results for identifying infected images. Compressed sensing was utilized instead of sparse coding to obtain the ideal classification results. Similar to neural networks, sufficient information is needed to train the system to obtain highly accurate results. Medical-image-assisted diagnosis requires highly comprehensive and rich image information as criterion. Using highly comprehensive image features to replace human subjective features presents a promising development trend. Therefore, the next goal is to provide doctors with auxiliary diagnosis of UC in real time. Accordingly, how to increase the complexity of the algorithm and the real-time nature of the system needs to be studied in the future.关键词:ulcerative colitis (UC);computer aided diagnosis;compressed sensing(CS);alternate optimization;spatial pyramid pooling(SPP)25|38|1更新时间:2024-05-07
摘要:ObjectivePatients with chronic ulcerative colitis (UC) have a significantly increased risk of developing colon cancer, and an early detection via colonoscopy is necessary. Assisted diagnosis of UC is among the computer-assisted diagnostic topics in medical gastrointestinal endoscopy research that aims to find reliable features for identifying lesions in intestinal images. The typical endoscopic findings from UC images include loss of vascular patterns, granularity, bleeding mucous membranes, and ulcers. UC often repeats recurrence and remission cycles during its course and may be accompanied by parenteral complications. The risk of colon cancer increases when UC extensively affects the large intestine for long periods. However, endoscopes take a large amount of intestinal images, and noise interference, such as shadows, is often observed in these images. Therefore, accurate image features must be identified, and computer-aided diagnosis must be provided to physicians. The extant convolutional neural networks have demonstrated extraordinary capabilities in image classification but requires the support of large datasets and a very long training process. In sparsely coded image recognition, sparse coding pyramid matching (SCSPM) applies selective sparse coding to extract the significant characteristics of scale-invariant feature transform (SIFT) descriptors for local image blocks. Sparse coding also maximizes pooling on multiple spatial scales to combine translation and scale invariance instead of averaging the pools in the histogram. Locally constrained linear coding (LLC) refers to the rapid implementation of local coordinate coding, where local constraints are used to project each descriptor onto a local coordinate system. However, sparse coding cannot obtain an accurate image representation. The theory of compressed sensing is based on the sparseness of the signal and uses an underdetermined random observation matrix for sampling such signal. Each measurement value is not the signal itself but a linear combination function of multiple signals, that is, each measurement contains a small amount of information for all signals. The sparse reconstruction algorithm is used to achieve an accurate reconstruction of signals or an approximate reconstruction with certain errors. To solve the problems in UC and normal intestinal image classification, an image feature based on a combination of compressed sensing and spatial pyramid pooling is proposed in this paper.MethodThis paper proposes compressed perceptual spatial pyramid pooling (CSSPP) image features. First, block recursive least squares (BRLS) and K-singular value decomposition(K-SVD) dictionary learning are used to train some positive and negative datasets to obtain two initial dictionaries for comparing the two algorithms. Second, an alternating optimization algorithm based on the UC image prior perception matrix and sparse dictionary is developed. When finding the optimal perception matrix, the Gram matrix of the equivalent dictionary is considered, the sparse representation error is designed as prior knowledge, and the performance of the system is tested at different sampling rates. In dictionary optimization, the influence of the perception matrix on dictionary errors is considered, and the impact of different sparsity on classification accuracy is tested. Using the obtained sensing matrix and sparse dictionary to obtain sparse representations of all datasets in a compressed sensing framework can address the problem where the original image classification method based on sparse coding cannot accurately represent images. The maximum and average spatial pyramid pooling methods are then used to divide the image into 21 regions on multiple scales to extract CSSPP features. By introducing compressed sensing, the information of sparse representation is richer and more accurate than that of sparse coding. A linear kernel support vector machine (SVM) is used for image classification.ResultThe proposed algorithm was trained on 100 UC and 100 normal images taken from the Kvasir dataset. During the training phase, the mean square error of the dictionary obtained by BRLS training was slightly lower than that of K-SVD. The highest image restoration accuracy was obtained at a sampling rate of 31.25%. The performance of the two pooling features was examined under different sparsity. The maximum pooling in training accuracy was significantly higher than the average. The quantitative evaluation indicators include sensitivity, specificity, accuracy, receiver operating characferistic(ROC) curve, area under curve(AUC) value, and time efficiency. Tests were then performed on all 2 000 datasets, and the classification results show that the features can improve the auxiliary diagnosis of UC images. Compared with bag of features (BOF), SCSPM, and LLC, using the SVM classification results increases the AUC values by 0.092, 0.035, and 0.015, the sensitivity by 9.19%, 2.84%, and -0.24%, the specificity by 15.52%, 5.15%, and 4.77%, and the accuracy by 12.35%, 3.99%, and 2.27%, respectively. Compared with BOF and SCSPM, the running time was reduced by 2 164.5 and 1 455.6 seconds, respectively.ConclusionThe auxiliary diagnosis model of UC proposed in this paper combines the advantages of compressed sensing and spatial pyramid pooling to obtain highly accurate detection results for identifying infected images. Compressed sensing was utilized instead of sparse coding to obtain the ideal classification results. Similar to neural networks, sufficient information is needed to train the system to obtain highly accurate results. Medical-image-assisted diagnosis requires highly comprehensive and rich image information as criterion. Using highly comprehensive image features to replace human subjective features presents a promising development trend. Therefore, the next goal is to provide doctors with auxiliary diagnosis of UC in real time. Accordingly, how to increase the complexity of the algorithm and the real-time nature of the system needs to be studied in the future.关键词:ulcerative colitis (UC);computer aided diagnosis;compressed sensing(CS);alternate optimization;spatial pyramid pooling(SPP)25|38|1更新时间:2024-05-07 -
 摘要:ObjectiveLiver, which is the largest organ in the abdomen, plays a vital role in the metabolism of the human body. Early detection, accurate diagnosis, and further treatment of liver disease are important and helpful to increase the chances for survival. Computed tomography (CT) is an effective tool to detect focal liver lesions due to its robust and accurate imaging techniques. Multiphase CT scans are generally divided into four phases, namely, noncontrast, arterial, portal, and delay. Radiological practice mainly relies on clinicians to analyze the liver. Physicians need to look back or forward in different phases. This task is time and energy consuming. Liver lesion detection also depends on experienced professional physicians. The identification and diagnosis of different liver lesions are challenging tasks for inexperienced doctors due to the similarity among CT images. Therefore, an effective computer-aided diagnosis (CAD) method for doctors should be designed and developed. Most existing research methods based on CAD are mainly deep learning. Convolutional neural network in deep learning is a data-driven approach, which means it requires much training data to make a model learn the good features for a specific classification. However, a large-scale and well-annotated dataset is extremely difficult to construct due to the lack of data and the cost of labeling data. In accordance with research and analysis, the current methods for liver lesion classification can be divided into two categories, namely, methods based on data and features. The former focuses on expanding data to increase data diversity. The latter mainly studies the way to modify a network to improve the classification ability. These methods have two major drawbacks. First, appearance invariance cannot be controlled when new samples of a specific class are generated. Second, the feature extraction of lesion region cannot be enhanced adaptively.MethodTo solve the above-mentioned problems and improve classification performance, this study proposes a novel method for liver tumor classification by combining feature reuse and attention mechanism. Our contributions are threefold. First, we design a feature reuse module to preprocess medical images. We limit the image intensity values of all CT scans to the range of[-100, 400] Hounsfield unit to eliminate the influences of unrelated tissues or organs on the classification of liver lesions in CT images. A new spatial dimension is added to the 2D pixel matrix, and we concatenate three times for the pixel matrix along the new dimension to generate an efficient feature map with a pseudo-RGB channel. We conduct data augmentation of natural images (such as cut, flip, and fill) to expand medical images and increase their diversity. The feature reuse module not only can enhance the overall representation of original image features but also can effectively avoid the overfitting problem caused by a small sample. Second, we introduce the feature extraction module from two aspects, namely, local and global feature extraction. The local feature extraction block is a pixel-to-pixel modeling, which can enhance the extraction of lesion features by generating a weight factor for each pixel. This block mainly includes two branches, namely, trunk and weight. We feed any given feature map into two group convolution layers in the trunk branch to extract deep and high-dimensional features. It is also fed into the weight branch of encoder-decoder to generate a coefficient factor for each pixel. Lesion features are acquired adaptively by weighting the two branches. The global feature extraction block focuses on the relationship among channels. It can generate a weighting factor by pooling spatially to selectively recalibrate the importance of each feature channel. The ways of local and global feature extraction blocks are processed in parallel to fully mine semantic information with data. Third, we use the training strategy of transfer learning to train the proposed classification model. During training, we transfer the same network layer parameters of SENet(squeeze-and-excitation networks) as those of the proposed network model.ResultWe perform comprehensive experiments on 514 CT slices from 120 patients to evaluate the proposed method thoroughly. The average classification accuracy of the proposed method is 87.78%, which shows an improvement of 9.73% over the baseline model (SENet34). The classification recall rates of metastasis, hemangioma, hepatocellular carcinoma, and healthy liver tissues are 79.47%, 79.67%, 85.73%, and 98.31%, respectively, by using the algorithm in this paper. Compared with the current mainstream classification models, DensNet, SENet, SE_Resnext, CBAM, and SKNet, the proposed model is excellent in many evaluation indicators. The average accuracy, recall rate, precision, F1-score, and area under ROC curve(AUC) are 87.78%, 84.43%, 84.59%, 84.44%, and 97.50%, respectively, by utilizing the proposed architecture. The ablation experiment proves the effectiveness of the proposed design.ConclusionThe feature reuse module can preprocess medical images to alleviate the overfitting problems caused by lack of data. The feature extraction module based on attention mechanism can mine data features effectively. Our proposed method significantly improves the results of the classification of liver tumors in CT images. Thus, it provides a reliable basis for clinical diagnosis and makes computer-assisted diagnosis possible.关键词:deep learning;liver lesion classification;attention mechanism;feature reuse;feature extraction42|81|0更新时间:2024-05-07
摘要:ObjectiveLiver, which is the largest organ in the abdomen, plays a vital role in the metabolism of the human body. Early detection, accurate diagnosis, and further treatment of liver disease are important and helpful to increase the chances for survival. Computed tomography (CT) is an effective tool to detect focal liver lesions due to its robust and accurate imaging techniques. Multiphase CT scans are generally divided into four phases, namely, noncontrast, arterial, portal, and delay. Radiological practice mainly relies on clinicians to analyze the liver. Physicians need to look back or forward in different phases. This task is time and energy consuming. Liver lesion detection also depends on experienced professional physicians. The identification and diagnosis of different liver lesions are challenging tasks for inexperienced doctors due to the similarity among CT images. Therefore, an effective computer-aided diagnosis (CAD) method for doctors should be designed and developed. Most existing research methods based on CAD are mainly deep learning. Convolutional neural network in deep learning is a data-driven approach, which means it requires much training data to make a model learn the good features for a specific classification. However, a large-scale and well-annotated dataset is extremely difficult to construct due to the lack of data and the cost of labeling data. In accordance with research and analysis, the current methods for liver lesion classification can be divided into two categories, namely, methods based on data and features. The former focuses on expanding data to increase data diversity. The latter mainly studies the way to modify a network to improve the classification ability. These methods have two major drawbacks. First, appearance invariance cannot be controlled when new samples of a specific class are generated. Second, the feature extraction of lesion region cannot be enhanced adaptively.MethodTo solve the above-mentioned problems and improve classification performance, this study proposes a novel method for liver tumor classification by combining feature reuse and attention mechanism. Our contributions are threefold. First, we design a feature reuse module to preprocess medical images. We limit the image intensity values of all CT scans to the range of[-100, 400] Hounsfield unit to eliminate the influences of unrelated tissues or organs on the classification of liver lesions in CT images. A new spatial dimension is added to the 2D pixel matrix, and we concatenate three times for the pixel matrix along the new dimension to generate an efficient feature map with a pseudo-RGB channel. We conduct data augmentation of natural images (such as cut, flip, and fill) to expand medical images and increase their diversity. The feature reuse module not only can enhance the overall representation of original image features but also can effectively avoid the overfitting problem caused by a small sample. Second, we introduce the feature extraction module from two aspects, namely, local and global feature extraction. The local feature extraction block is a pixel-to-pixel modeling, which can enhance the extraction of lesion features by generating a weight factor for each pixel. This block mainly includes two branches, namely, trunk and weight. We feed any given feature map into two group convolution layers in the trunk branch to extract deep and high-dimensional features. It is also fed into the weight branch of encoder-decoder to generate a coefficient factor for each pixel. Lesion features are acquired adaptively by weighting the two branches. The global feature extraction block focuses on the relationship among channels. It can generate a weighting factor by pooling spatially to selectively recalibrate the importance of each feature channel. The ways of local and global feature extraction blocks are processed in parallel to fully mine semantic information with data. Third, we use the training strategy of transfer learning to train the proposed classification model. During training, we transfer the same network layer parameters of SENet(squeeze-and-excitation networks) as those of the proposed network model.ResultWe perform comprehensive experiments on 514 CT slices from 120 patients to evaluate the proposed method thoroughly. The average classification accuracy of the proposed method is 87.78%, which shows an improvement of 9.73% over the baseline model (SENet34). The classification recall rates of metastasis, hemangioma, hepatocellular carcinoma, and healthy liver tissues are 79.47%, 79.67%, 85.73%, and 98.31%, respectively, by using the algorithm in this paper. Compared with the current mainstream classification models, DensNet, SENet, SE_Resnext, CBAM, and SKNet, the proposed model is excellent in many evaluation indicators. The average accuracy, recall rate, precision, F1-score, and area under ROC curve(AUC) are 87.78%, 84.43%, 84.59%, 84.44%, and 97.50%, respectively, by utilizing the proposed architecture. The ablation experiment proves the effectiveness of the proposed design.ConclusionThe feature reuse module can preprocess medical images to alleviate the overfitting problems caused by lack of data. The feature extraction module based on attention mechanism can mine data features effectively. Our proposed method significantly improves the results of the classification of liver tumors in CT images. Thus, it provides a reliable basis for clinical diagnosis and makes computer-assisted diagnosis possible.关键词:deep learning;liver lesion classification;attention mechanism;feature reuse;feature extraction42|81|0更新时间:2024-05-07 -
 摘要:ObjectiveDiabetic retinopathy (DR) is a diabetic complication with high incidence and blindness rate. The diagnosis of DR through color fundus images requires experienced clinicians to identify the presence and significance of many small features. This requirement, along with a complex grading system, makes the diagnosis a difficult and time-consuming task. The small difference among various grades of retinal images and the limited experience of clinicians usually lead to misdiagnosis and missed diagnosis. The large population of diabetic patients and their massive screening requirements have generated interest in a computer-aided and fully automatic diagnosis of DR. The present diagnostic classification of artificial DR is poor, time consuming, and laborious. On this basis, an automatic classification method for DR with a high-efficiency network (EfficientNet) incorporating an attention mechanism (A-EfficientNet) is proposed in this study. The goal of accurate classification is achieved by using the strategy of transfer learning to guide the classification model to learn the features among lesions.MethodThe characteristics of DR dataset present that noise in images and labels is unavoidable in raw dataset. This condition indicates a high demand for the robustness of our classification system. Preprocessing of retinal images mainly includes retinal image culling, noise reduction, enhancement, and normalization of retinal images. The images after such preprocessing will improve the performance of the classification network, and the computing power of the computer will also be accelerated. We use EfficientNet as the basic network for feature extraction. The migration-learning strategy is adopted to learn and train A-EfficientNet with DR datasets. We design an attention mechanism in EfficientNet to address the problem of small differences among lesions in the dataset and prevent the network from misclassifying fine-grained features in retinal image categories. The mechanism not only can extract features from fundus images but also can focus on the lesion area. The EfficientNet classification model integrated with the attention mechanism(A-EfficientNet) can match images with image label categories to achieve the classification task of retinal images. With fully connected layers and softmax, the model is used to learn for classifying DR status as DRfree, mild DR, moderate DR, severe DR, and proliferative DR.ResultExperimental results show that, in the case of insufficient samples of retinal images, the use of transfer learning and data enhancement strategies can help the classification model extract deep features for classification. A-EfficientNet can learn the features in the training samples and pay attention to the differences among various categories of features to achieve accurate classification. The reference to the attention mechanism greatly improves the performance of the classification network. In summary, a high-efficiency network (EfficientNet) incorporating an attention mechanism is proposed in this study. The network plays a positive role in extracting lesion features at various stages of images. The classification accuracy of the model for lesions reaches 97.2%. To improve the classification efficiency, the results of the two-category model indicates sensitivity of 95.6% on the high-specificity operating point and specificity of 98.7% on the high-sensitivity operating point. The result shows that the model achieves a kappa score of 0.840, which is higher than that of the existing non ensemble model. Therefore, the classification model based on the attention mechanism and EfficientNet can accurately distinguish the lesion types of retinopathy. Transfer-learning strategies and data augmentation provide accurate information and assistance for the accurate classification of fundus images. A-EfficientNet reflects the good classification performance of the model and the robustness of the network-learning ability.ConclusionIn this study, we use A-EfficientNet to realize automatic classification of retinal images. We also propose a new classification framework for DR, which mainly benefits from four parts, namely, the image-preprocessing stage, the transfer-learning strategy, the introduction of data enhancement, and A-EfficientNet for feature extraction. The dataset used in the experiment has problems, such as noise, artifacts, and unsuccessful focusing. After such problematic data are removed, the dataset is denoised and normalized to facilitate the classification network for calculating and learning the data. When the training samples are insufficient, the introduction of data enhancement meets the data requirements of the deep learning classification model, satisfies the model's learning of the data, and improves the generalization ability of the model. The introduction of an attention mechanism based on EfficientNet can improve the classification performance of the algorithm. Therefore, the automatic classification algorithm for DR incorporating the attention mechanism of EfficientNet can effectively improve the efficiency of DR screening, avoid the limitations of artificial feature extraction and image classification, and solve the problem of over fitting caused by insufficient sample data. The experimental results show that this method can be used to diagnose DR. It can operate efficiently without marking the information of suspicious lesions and thus avoids the time-consuming work of labeling lesions by experts and reduces false positives. The classification model can also be referenced in the classification tasks of other images.关键词:mutil-classification of diabetic retinopathy;high-efficiency network (EfficientNet);attention mechanism;deep learning;transfer learning;deep features61|62|1更新时间:2024-05-07
摘要:ObjectiveDiabetic retinopathy (DR) is a diabetic complication with high incidence and blindness rate. The diagnosis of DR through color fundus images requires experienced clinicians to identify the presence and significance of many small features. This requirement, along with a complex grading system, makes the diagnosis a difficult and time-consuming task. The small difference among various grades of retinal images and the limited experience of clinicians usually lead to misdiagnosis and missed diagnosis. The large population of diabetic patients and their massive screening requirements have generated interest in a computer-aided and fully automatic diagnosis of DR. The present diagnostic classification of artificial DR is poor, time consuming, and laborious. On this basis, an automatic classification method for DR with a high-efficiency network (EfficientNet) incorporating an attention mechanism (A-EfficientNet) is proposed in this study. The goal of accurate classification is achieved by using the strategy of transfer learning to guide the classification model to learn the features among lesions.MethodThe characteristics of DR dataset present that noise in images and labels is unavoidable in raw dataset. This condition indicates a high demand for the robustness of our classification system. Preprocessing of retinal images mainly includes retinal image culling, noise reduction, enhancement, and normalization of retinal images. The images after such preprocessing will improve the performance of the classification network, and the computing power of the computer will also be accelerated. We use EfficientNet as the basic network for feature extraction. The migration-learning strategy is adopted to learn and train A-EfficientNet with DR datasets. We design an attention mechanism in EfficientNet to address the problem of small differences among lesions in the dataset and prevent the network from misclassifying fine-grained features in retinal image categories. The mechanism not only can extract features from fundus images but also can focus on the lesion area. The EfficientNet classification model integrated with the attention mechanism(A-EfficientNet) can match images with image label categories to achieve the classification task of retinal images. With fully connected layers and softmax, the model is used to learn for classifying DR status as DRfree, mild DR, moderate DR, severe DR, and proliferative DR.ResultExperimental results show that, in the case of insufficient samples of retinal images, the use of transfer learning and data enhancement strategies can help the classification model extract deep features for classification. A-EfficientNet can learn the features in the training samples and pay attention to the differences among various categories of features to achieve accurate classification. The reference to the attention mechanism greatly improves the performance of the classification network. In summary, a high-efficiency network (EfficientNet) incorporating an attention mechanism is proposed in this study. The network plays a positive role in extracting lesion features at various stages of images. The classification accuracy of the model for lesions reaches 97.2%. To improve the classification efficiency, the results of the two-category model indicates sensitivity of 95.6% on the high-specificity operating point and specificity of 98.7% on the high-sensitivity operating point. The result shows that the model achieves a kappa score of 0.840, which is higher than that of the existing non ensemble model. Therefore, the classification model based on the attention mechanism and EfficientNet can accurately distinguish the lesion types of retinopathy. Transfer-learning strategies and data augmentation provide accurate information and assistance for the accurate classification of fundus images. A-EfficientNet reflects the good classification performance of the model and the robustness of the network-learning ability.ConclusionIn this study, we use A-EfficientNet to realize automatic classification of retinal images. We also propose a new classification framework for DR, which mainly benefits from four parts, namely, the image-preprocessing stage, the transfer-learning strategy, the introduction of data enhancement, and A-EfficientNet for feature extraction. The dataset used in the experiment has problems, such as noise, artifacts, and unsuccessful focusing. After such problematic data are removed, the dataset is denoised and normalized to facilitate the classification network for calculating and learning the data. When the training samples are insufficient, the introduction of data enhancement meets the data requirements of the deep learning classification model, satisfies the model's learning of the data, and improves the generalization ability of the model. The introduction of an attention mechanism based on EfficientNet can improve the classification performance of the algorithm. Therefore, the automatic classification algorithm for DR incorporating the attention mechanism of EfficientNet can effectively improve the efficiency of DR screening, avoid the limitations of artificial feature extraction and image classification, and solve the problem of over fitting caused by insufficient sample data. The experimental results show that this method can be used to diagnose DR. It can operate efficiently without marking the information of suspicious lesions and thus avoids the time-consuming work of labeling lesions by experts and reduces false positives. The classification model can also be referenced in the classification tasks of other images.关键词:mutil-classification of diabetic retinopathy;high-efficiency network (EfficientNet);attention mechanism;deep learning;transfer learning;deep features61|62|1更新时间:2024-05-07
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0