
最新刊期
卷 25 , 期 7 , 2020
-
 摘要:Many art works have high artistic and commodity values. The production of realistic art works requires considerable time and strict manual skills. With the development of modern science and technology, the use of computer algorithms to synthesize and simulate different art styles is a popular topic in computer vision and image processing. Non-photorealistic rendering (NPR) technique mainly simulates art styles and expresses artistic characteristics. This technique is crucial for the protection and inheritance of art culture. Researchers have simulated and synthesized cartoon, sketch, oil painting, Chinese fine brushwork, calligraphy, and other art works on the basis of traditional image models. The development of deep learning has enabled researchers to use convolutional neural networks to transfer art features from style images to content images. In recent years, NPR research objects have been gradually enriched, research methods have been continuously enhanced, and the application fields of NPR have been expanding widely. However, the simulation and transfer of different styles using computers are challenges and open questions in NPR. This study reviews some NPR progresses in five important aspects, namely, traditional modeling rendering methods, depth learning transfer methods, digital simulation of Chinese unique art works, emotion recognition of art works, and artistic transfer from videos. We summarize the important stylized transfer methods in these aspects and show some simulation results. This paper further summarizes the issues that can be additional study fields in NPR, including research objects, video coherence among different frames, artistic style emotion, and evaluation criteria. Different art styles exist in the world, and the way to simulate these various works remain an open question. Although the transformation of video styles enriches the application field of NPR, it is a problem when the texture is complex, occlusion occurs, or the motion vector is inaccurate. Some artistic details are lost, which may cause discontinuity among video frames. NPR should extract high-level semantic features of art works in addition to simulating low-level artistic style features, such as color and texture. It can effectively improve the accuracy and efficiency of intelligent information retrieval and simulate, protect, and inherit artistic style through high-level semantic feature recognition and transfer. Evaluation standard also remains a problem. Whether the NPR algorithm can simulate real manual traces and users' creative intention has become the standard to evaluate the merits and demerits of the methods. This paper elaborates and concludes the problems that need to be further studied. First, we conclude that improving the generality and rendering efficiency of algorithms can expand research objects and simulate different art styles. Improved NPR algorithms can also raise the coherence among different video frames. Second, the recognition and extraction of emotional and intrinsic mechanism features from different stylistic works are another research fields. We can transfer the emotional and intrinsic features to the simulation results, which can improve the similarity between the results and artistic styles. Finally, the evaluation criteria for simulation results are an important research question. This paper concludes that combination with subjective and objective evaluation models can increase the evaluation accuracy of the results, and the combination can be applied to optimize the parameters of deep learning networks. NPR has important application prospects in computer vision, cultural heritage protection, education, and image processing. However, numerous problems remain to be solved. With the continuous improvement of hardware equipment, the comprehensive application of multidisciplinary knowledge and the expansion of application fields will promote the development of NPR.关键词:non-photorealistic rendering(NPR);image modeling;digital simulation;emotion recognition;evaluation criteria82|84|4更新时间:2024-05-07
摘要:Many art works have high artistic and commodity values. The production of realistic art works requires considerable time and strict manual skills. With the development of modern science and technology, the use of computer algorithms to synthesize and simulate different art styles is a popular topic in computer vision and image processing. Non-photorealistic rendering (NPR) technique mainly simulates art styles and expresses artistic characteristics. This technique is crucial for the protection and inheritance of art culture. Researchers have simulated and synthesized cartoon, sketch, oil painting, Chinese fine brushwork, calligraphy, and other art works on the basis of traditional image models. The development of deep learning has enabled researchers to use convolutional neural networks to transfer art features from style images to content images. In recent years, NPR research objects have been gradually enriched, research methods have been continuously enhanced, and the application fields of NPR have been expanding widely. However, the simulation and transfer of different styles using computers are challenges and open questions in NPR. This study reviews some NPR progresses in five important aspects, namely, traditional modeling rendering methods, depth learning transfer methods, digital simulation of Chinese unique art works, emotion recognition of art works, and artistic transfer from videos. We summarize the important stylized transfer methods in these aspects and show some simulation results. This paper further summarizes the issues that can be additional study fields in NPR, including research objects, video coherence among different frames, artistic style emotion, and evaluation criteria. Different art styles exist in the world, and the way to simulate these various works remain an open question. Although the transformation of video styles enriches the application field of NPR, it is a problem when the texture is complex, occlusion occurs, or the motion vector is inaccurate. Some artistic details are lost, which may cause discontinuity among video frames. NPR should extract high-level semantic features of art works in addition to simulating low-level artistic style features, such as color and texture. It can effectively improve the accuracy and efficiency of intelligent information retrieval and simulate, protect, and inherit artistic style through high-level semantic feature recognition and transfer. Evaluation standard also remains a problem. Whether the NPR algorithm can simulate real manual traces and users' creative intention has become the standard to evaluate the merits and demerits of the methods. This paper elaborates and concludes the problems that need to be further studied. First, we conclude that improving the generality and rendering efficiency of algorithms can expand research objects and simulate different art styles. Improved NPR algorithms can also raise the coherence among different video frames. Second, the recognition and extraction of emotional and intrinsic mechanism features from different stylistic works are another research fields. We can transfer the emotional and intrinsic features to the simulation results, which can improve the similarity between the results and artistic styles. Finally, the evaluation criteria for simulation results are an important research question. This paper concludes that combination with subjective and objective evaluation models can increase the evaluation accuracy of the results, and the combination can be applied to optimize the parameters of deep learning networks. NPR has important application prospects in computer vision, cultural heritage protection, education, and image processing. However, numerous problems remain to be solved. With the continuous improvement of hardware equipment, the comprehensive application of multidisciplinary knowledge and the expansion of application fields will promote the development of NPR.关键词:non-photorealistic rendering(NPR);image modeling;digital simulation;emotion recognition;evaluation criteria82|84|4更新时间:2024-05-07
Scholar View

-
 摘要:The efficient processing of massive amounts of data obtained as a result of the rapid growth of image and video data transmission is becoming increasingly difficult for traditional image retrieval methods. The feature-Hashing technology, which can achieve efficient feature compression and fast feature matching and image retrieval, is introduced to address this issue. The deep learning technology also has unique advantages in feature extraction and compact description. The deep Hashing technology, which combines feature Hashing with deep learning, has become an interesting research topic in the area of large-scale image retrieval in solving the problem of large-scale image retrieval. Image retrieval methods based on deep Hashing have attracted increasing attention. Extensive research on image retrieval technologies using deep Hashing has been conducted in recent years and is reported in this paper. First, the deep Hashing method is divided into unsupervised, semisupervised, and supervised deep Hashing methods according to whether label information is used. Second, unsupervised and semisupervised deep Hashing methods are further divided into two types, namely, unsupervised/semisupervised deep Hashing based on deep network models and GANs (generative adversarial networks). In the unsupervised deep Hashing based on the deep network models, the DeepBit algorithm and the SADH (similarity-adaptive deep Hashing) algorithm are mainly introduced. In the GAN-based unsupervised deep Hashing method, we illustrate the principles of HashGAN, BGAN (binary generative adversarial networks) and PGH (progressive generative Hashing) algorithms. In the semi-supervised deep Hashing method, the SSDH (semi-supervised discriminant Hashing) algorithm based on the depth models and the SSGAH (semi-supervised generative adversarial Hashing) algorithm based on the generated adversarial network are mainly interpreted. Third, the supervised deep Hashing algorithms are divided into deep Hashing methods based on triple labels and data pairs depending on the different types of label information used. Designing loss functions and controlling quantization errors occupies important parts of deep Hashing image retrieval, hence the algorithms are classified in more detail according to different loss functions in several supervised deep Hashing methods. In the deep Hashing methods based on paired supervision information, the algorithm are further classified as deep Hashing methods using square loss function, using cross-entropy loss function, or designing a new loss function. 1) In the Hash method using the square loss function, CNNH (convolutional neural network Hashing) is introduced in detail. 2) In the Hash method using the cross entropy loss function, we mainly describe DPSH (deep supervised Hashing with pairwise labels), DSDH (deep supervised discrete Hashing), HashNet and HashGAN four algorithm models. 3) DSH (deep supervised Hashing) and DVSQ (deep visual-semantic quantization) algorithms design new loss functions in their research. Among the deep Hashing methods based on triple labels, 1) deep Hashing methods using triple loss function are mainly illustrated: NINH (network in network Hashing), DRSCH (deep regularized similarity comparison Hashing), DTQ (deep triplet quantization). And the triple loss function is actually improved from the hinge loss function; 2) the deep Hashing methods using the triple entropy loss function: DTSH (deep supervised Hashing with triplet). Because triple labels require a lot of image preprocessing, there is little research about it. After introducing principles and characteristics of selected classical algorithms, and the advantages and disadvantages of each deep supervised algorithm are analyzed. Fourth, we compare the retrieval performances of each algorithm on two commonly used large-scale datasets, namely, CIFAR-10 and NUS-WIDE. We also investigate the performance of the DPSH algorithm on two specialized datasets, namely, CⅡP(Center for Image and Information Process-ing)-CSID(crime scene investigation image database) and CⅡP-TPID(tread pattern image dataset), and summarize existing deep Hashing-based retrieval technologies. Finally, we discuss the future development of deep Hashing-based retrieval algorithms. Hashing has improved the image retrieval speed on very-large-scale datasets, but the overall retrieval performance remains low. Hashing with deep learning has been extensively used in recent years to extract features of high-level semantic information. The CNNH algorithm is the first of such attempts. The excellent performance of CNNH has opened a new chapter for Hashing-based image retrieval methods. Deep Hashing methods based on paired supervisory information or triplet supervised information have caused improvements in algorithm structure, Hashing function, loss function, and control quantization error. However, the improvement of triple-based deep Hashing methods is limited by their requirement of numerous image-preprocessing works. Deep Hashing methods based on pairwise label information provide some insights into the way to enhance triple-based deep Hashing methods. For example, NINH improves the network structure from CNNH, and the DTSH algorithm is based on the algorithm structure of DPSH. Deep Hashing-based image retrieval methods have their own advantages in retrieval performance. The existing methods have achieved superior retrieval precision, but a space for improvement in controlling quantization error and learning image representation remains. Labeling images one by one will require high labor and time costs because the supervised deep Hashing method highly depends on data labels but the data scale in reality is expanding. Scholars have paid increasing attention to unsupervised deep Hashing technologies and achieved significant performance improvements by combining such technologies with GANs or deep mod-els. Experimental results on two special databases show that the DPSH algorithm performs efficiently on CⅡP-CSID and competitively on CⅡP-TPID. The deep Hashing technology is an effective method for large-scale image retrieval, but major problems remain unsolved. On the basis of the needs of practical applications, the research on unsupervised deep Hashing algorithms requires further attention. Network models and feature learning should also be improved in different ways depending on dataset characteristics and case used. The potential applications of the deep Hashing technology are wide, including biometrics and multimodal retrieval. The experimental results of the DPSH algorithm on two special databases reveal the need to customize network models and feature-learning algorithms in accordance with their cases used. Such a need renders the deep Hashing technology for critical image retrieval research areas and presents a great potential for various specialized industries.关键词:image retrieval;unsupervised;supervised;deep learning;Hashing;deep Hashing223|129|11更新时间:2024-05-07
摘要:The efficient processing of massive amounts of data obtained as a result of the rapid growth of image and video data transmission is becoming increasingly difficult for traditional image retrieval methods. The feature-Hashing technology, which can achieve efficient feature compression and fast feature matching and image retrieval, is introduced to address this issue. The deep learning technology also has unique advantages in feature extraction and compact description. The deep Hashing technology, which combines feature Hashing with deep learning, has become an interesting research topic in the area of large-scale image retrieval in solving the problem of large-scale image retrieval. Image retrieval methods based on deep Hashing have attracted increasing attention. Extensive research on image retrieval technologies using deep Hashing has been conducted in recent years and is reported in this paper. First, the deep Hashing method is divided into unsupervised, semisupervised, and supervised deep Hashing methods according to whether label information is used. Second, unsupervised and semisupervised deep Hashing methods are further divided into two types, namely, unsupervised/semisupervised deep Hashing based on deep network models and GANs (generative adversarial networks). In the unsupervised deep Hashing based on the deep network models, the DeepBit algorithm and the SADH (similarity-adaptive deep Hashing) algorithm are mainly introduced. In the GAN-based unsupervised deep Hashing method, we illustrate the principles of HashGAN, BGAN (binary generative adversarial networks) and PGH (progressive generative Hashing) algorithms. In the semi-supervised deep Hashing method, the SSDH (semi-supervised discriminant Hashing) algorithm based on the depth models and the SSGAH (semi-supervised generative adversarial Hashing) algorithm based on the generated adversarial network are mainly interpreted. Third, the supervised deep Hashing algorithms are divided into deep Hashing methods based on triple labels and data pairs depending on the different types of label information used. Designing loss functions and controlling quantization errors occupies important parts of deep Hashing image retrieval, hence the algorithms are classified in more detail according to different loss functions in several supervised deep Hashing methods. In the deep Hashing methods based on paired supervision information, the algorithm are further classified as deep Hashing methods using square loss function, using cross-entropy loss function, or designing a new loss function. 1) In the Hash method using the square loss function, CNNH (convolutional neural network Hashing) is introduced in detail. 2) In the Hash method using the cross entropy loss function, we mainly describe DPSH (deep supervised Hashing with pairwise labels), DSDH (deep supervised discrete Hashing), HashNet and HashGAN four algorithm models. 3) DSH (deep supervised Hashing) and DVSQ (deep visual-semantic quantization) algorithms design new loss functions in their research. Among the deep Hashing methods based on triple labels, 1) deep Hashing methods using triple loss function are mainly illustrated: NINH (network in network Hashing), DRSCH (deep regularized similarity comparison Hashing), DTQ (deep triplet quantization). And the triple loss function is actually improved from the hinge loss function; 2) the deep Hashing methods using the triple entropy loss function: DTSH (deep supervised Hashing with triplet). Because triple labels require a lot of image preprocessing, there is little research about it. After introducing principles and characteristics of selected classical algorithms, and the advantages and disadvantages of each deep supervised algorithm are analyzed. Fourth, we compare the retrieval performances of each algorithm on two commonly used large-scale datasets, namely, CIFAR-10 and NUS-WIDE. We also investigate the performance of the DPSH algorithm on two specialized datasets, namely, CⅡP(Center for Image and Information Process-ing)-CSID(crime scene investigation image database) and CⅡP-TPID(tread pattern image dataset), and summarize existing deep Hashing-based retrieval technologies. Finally, we discuss the future development of deep Hashing-based retrieval algorithms. Hashing has improved the image retrieval speed on very-large-scale datasets, but the overall retrieval performance remains low. Hashing with deep learning has been extensively used in recent years to extract features of high-level semantic information. The CNNH algorithm is the first of such attempts. The excellent performance of CNNH has opened a new chapter for Hashing-based image retrieval methods. Deep Hashing methods based on paired supervisory information or triplet supervised information have caused improvements in algorithm structure, Hashing function, loss function, and control quantization error. However, the improvement of triple-based deep Hashing methods is limited by their requirement of numerous image-preprocessing works. Deep Hashing methods based on pairwise label information provide some insights into the way to enhance triple-based deep Hashing methods. For example, NINH improves the network structure from CNNH, and the DTSH algorithm is based on the algorithm structure of DPSH. Deep Hashing-based image retrieval methods have their own advantages in retrieval performance. The existing methods have achieved superior retrieval precision, but a space for improvement in controlling quantization error and learning image representation remains. Labeling images one by one will require high labor and time costs because the supervised deep Hashing method highly depends on data labels but the data scale in reality is expanding. Scholars have paid increasing attention to unsupervised deep Hashing technologies and achieved significant performance improvements by combining such technologies with GANs or deep mod-els. Experimental results on two special databases show that the DPSH algorithm performs efficiently on CⅡP-CSID and competitively on CⅡP-TPID. The deep Hashing technology is an effective method for large-scale image retrieval, but major problems remain unsolved. On the basis of the needs of practical applications, the research on unsupervised deep Hashing algorithms requires further attention. Network models and feature learning should also be improved in different ways depending on dataset characteristics and case used. The potential applications of the deep Hashing technology are wide, including biometrics and multimodal retrieval. The experimental results of the DPSH algorithm on two special databases reveal the need to customize network models and feature-learning algorithms in accordance with their cases used. Such a need renders the deep Hashing technology for critical image retrieval research areas and presents a great potential for various specialized industries.关键词:image retrieval;unsupervised;supervised;deep learning;Hashing;deep Hashing223|129|11更新时间:2024-05-07 -
 摘要:Serious games are a new development direction of computer games. They can simulate interactive professional teaching environment and have been widely used in many fields, such as science education, rehabilitation, emergency management, and military training. Serious medical rehabilitation games are mainly used for medical technology training and rehabilitation-assisted treatment. They can train and improve the professional skills of medical staff, reduce the pain and boredom of patients during rehabilitation, and assist patients in rehabilitation treatment. Serious games in military training are mainly used in military modeling and simulation and possess controllability, security, and low cost. Virtual characters are simulated entities with life characteristics for serious games. They have credible behavior and can improve users' experience in serious games. At present, graphics rendering in serious games has gradually matured, but the research on virtual character behavior modeling is only in its first stage. A credible virtual character should have perception, emotion, and behavior. It can respond to the user's operation in time and has a certain reasoning ability. Modeling the behavior of virtual characters requires the knowledge of psychology, cognitive science, and specific domain knowledge. This paper aims to present a control algorithm that reflects the behavior of a virtual character under certain circumstances. This algorithm is an interdisciplinary application, which involves computer graphics, human-computer interaction, and artificial intelligence technologies. This paper summarized the existing studies on virtual character's behavior modeling from four aspects, namely, game plot and behavior, behavior modeling method, behavior learning, and behavior modeling evaluation. In the aspect of game plots and behavior, the design of behavior should contain the plot. The behavior of virtual characters accordingly change with the change in the plot. This condition was illustrated by the virtual character behavior design in the rehabilitation and military training plots. In the aspect of behavior modeling, the behavior modeling methods of virtual characters were summarized. The characteristics of finite state machines and behavior trees were analyzed, the behavioral learning methods were compared, the key elements of reinforcement learning were indicated, and the application of deep reinforcement learning was discussed. Reinforcement learning has four elements, namely, environment, state, action, and reward. Virtual character behavior decision learning could be completed by constantly attempting to obtain environmental rewards. In the aspect of behavior modeling evaluation, three indexes were summarized to evaluate the effectiveness of the model, namely, the real-time behavior of virtual character, the emotion-integrated behavior, and the behavior interactivity. An extremely slow character behavior response will reduce the user's interest in participating in the game, and a timely response will provide the user an efficient and pleasant experience. Users aim to achieve emotional communication with virtual characters in a virtual environment to have a good sense of immersion. A virtual character behavior framework was summarized on the basis of existing studies. It included four modules, namely, sensory input, perception analysis, behavior decision making, and action. Emotional factors are valuable to create virtual characters with credible behavior and realistic movements. They could also increase the appeal of the game. Issues that need additional research were discussed from the perspective of affective computing intervention, game story and scene design, smart phone platform, and multichannel interaction. Virtual characters should be introduced to expand the game plot and assist in teaching to completely realize the function of serious games. Serious games are different from movies. Users do not passively accept, and they learn through constant interaction. A virtual scene without any plot and any virtual character is difficult to attract users. A narrative plot can make it easy to learn. Virtual characters with behavior and emotional expressiveness can enhance users' emotional experience and guide users to learn in a real-life-like situation. The popularity of mobile terminals provides various applications for serious games and attracts many users to use serious games. Multimodel interaction would be popular in the future because single-model interaction will limit user's interaction with the virtual character. A multichannel interaction method could improve the intelligence of virtual characters and could be realized with visual, auditory, tactile, and somatosensory models. The behavior modeling of virtual characters requires comprehensive consideration of game plots, machine learning, and human-computer interaction technologies. Rigid behaviors could not attract users. Building virtual models with autonomous perception, emotion, behavior, learning ability, and multimodel interaction could immensely enhance user's immersion. These models are the development direction of serious games. Serious games provide an intuitive means for education and training. The behavior modeling of virtual characters is a developing core technology of serious games. At present, many problems need to be urgently solved. Affective computing methods, game plots, smartphone operating platforms, and multimodel human-computer interaction should be considered to improve the behavior model of virtual characters. The integration of interdisciplinary knowledge is required to create behavioral credibility, autonomous emotional expression, and convenient interactive virtual characters. These characters could provide a better learning experience for users and are easy to be promoted.关键词:serious game;virtual character;behavior modeling;emotion modeling;behavior learning40|37|2更新时间:2024-05-07
摘要:Serious games are a new development direction of computer games. They can simulate interactive professional teaching environment and have been widely used in many fields, such as science education, rehabilitation, emergency management, and military training. Serious medical rehabilitation games are mainly used for medical technology training and rehabilitation-assisted treatment. They can train and improve the professional skills of medical staff, reduce the pain and boredom of patients during rehabilitation, and assist patients in rehabilitation treatment. Serious games in military training are mainly used in military modeling and simulation and possess controllability, security, and low cost. Virtual characters are simulated entities with life characteristics for serious games. They have credible behavior and can improve users' experience in serious games. At present, graphics rendering in serious games has gradually matured, but the research on virtual character behavior modeling is only in its first stage. A credible virtual character should have perception, emotion, and behavior. It can respond to the user's operation in time and has a certain reasoning ability. Modeling the behavior of virtual characters requires the knowledge of psychology, cognitive science, and specific domain knowledge. This paper aims to present a control algorithm that reflects the behavior of a virtual character under certain circumstances. This algorithm is an interdisciplinary application, which involves computer graphics, human-computer interaction, and artificial intelligence technologies. This paper summarized the existing studies on virtual character's behavior modeling from four aspects, namely, game plot and behavior, behavior modeling method, behavior learning, and behavior modeling evaluation. In the aspect of game plots and behavior, the design of behavior should contain the plot. The behavior of virtual characters accordingly change with the change in the plot. This condition was illustrated by the virtual character behavior design in the rehabilitation and military training plots. In the aspect of behavior modeling, the behavior modeling methods of virtual characters were summarized. The characteristics of finite state machines and behavior trees were analyzed, the behavioral learning methods were compared, the key elements of reinforcement learning were indicated, and the application of deep reinforcement learning was discussed. Reinforcement learning has four elements, namely, environment, state, action, and reward. Virtual character behavior decision learning could be completed by constantly attempting to obtain environmental rewards. In the aspect of behavior modeling evaluation, three indexes were summarized to evaluate the effectiveness of the model, namely, the real-time behavior of virtual character, the emotion-integrated behavior, and the behavior interactivity. An extremely slow character behavior response will reduce the user's interest in participating in the game, and a timely response will provide the user an efficient and pleasant experience. Users aim to achieve emotional communication with virtual characters in a virtual environment to have a good sense of immersion. A virtual character behavior framework was summarized on the basis of existing studies. It included four modules, namely, sensory input, perception analysis, behavior decision making, and action. Emotional factors are valuable to create virtual characters with credible behavior and realistic movements. They could also increase the appeal of the game. Issues that need additional research were discussed from the perspective of affective computing intervention, game story and scene design, smart phone platform, and multichannel interaction. Virtual characters should be introduced to expand the game plot and assist in teaching to completely realize the function of serious games. Serious games are different from movies. Users do not passively accept, and they learn through constant interaction. A virtual scene without any plot and any virtual character is difficult to attract users. A narrative plot can make it easy to learn. Virtual characters with behavior and emotional expressiveness can enhance users' emotional experience and guide users to learn in a real-life-like situation. The popularity of mobile terminals provides various applications for serious games and attracts many users to use serious games. Multimodel interaction would be popular in the future because single-model interaction will limit user's interaction with the virtual character. A multichannel interaction method could improve the intelligence of virtual characters and could be realized with visual, auditory, tactile, and somatosensory models. The behavior modeling of virtual characters requires comprehensive consideration of game plots, machine learning, and human-computer interaction technologies. Rigid behaviors could not attract users. Building virtual models with autonomous perception, emotion, behavior, learning ability, and multimodel interaction could immensely enhance user's immersion. These models are the development direction of serious games. Serious games provide an intuitive means for education and training. The behavior modeling of virtual characters is a developing core technology of serious games. At present, many problems need to be urgently solved. Affective computing methods, game plots, smartphone operating platforms, and multimodel human-computer interaction should be considered to improve the behavior model of virtual characters. The integration of interdisciplinary knowledge is required to create behavioral credibility, autonomous emotional expression, and convenient interactive virtual characters. These characters could provide a better learning experience for users and are easy to be promoted.关键词:serious game;virtual character;behavior modeling;emotion modeling;behavior learning40|37|2更新时间:2024-05-07 -
 摘要:Computer vision plays an important role in detection, recognition, and location analysis in intelligent manufacturing, especially in industry inspection. It has made great contributions to improve the inspection rate, the accuracy of industrial inspection, and the degree of intelligent automation. However, the popularity of computer vision technology is insufficient in intelligent manufacturing because of its several technical application difficulties. Dealing with these problems has become a top priority in the popularization of computer vision in intelligent manufacturing. The three key application bottlenecks are the illumination impacts, sample data that cannot support deep learning, and prior knowledge that cannot support evolutionary algorithms. These bottlenecks make computer vision in intelligent manufacturing inefficient and cannot be applied in several fields. Therefore, these bottlenecks need to be systematically analyzed and resolved. We first summarized the concepts of intelligent manufacturing and computer vision. Then, the development of computer vision in intelligent manufacturing and the demand of intelligent manufacturing for computer vision technology were presented. We elaborated that computer vision could increase the inspection accuracy and rate and provide many details that cannot be found by human beings by comparing it with traditional methods. On the basis of the development status and needs of computer vision in intelligent manufacturing inspection, we proposed three critical bottlenecks in computer vision applications, namely, 1) In the actual industrial situation, uneven illumination is easily obtained because the environment is complex, and the light source is simple. Thus, The problem where the image quality is immensely impacted by illumination should be explored. 2) Obtaining uniform sample data of more than 10 000 levels in the actual industry is difficult. The problem where the sample data cannot support computer vision detection task based on deep learning should be given great importance. 3) Computer judgment cannot achieve the accuracy of professional judgment. Rational addition of human prior knowledge into evolutionary algorithms to reduce the difficulty of deep learning algorithms should be deeply analyzed. Then, we focused on summarizing and analyzing the status, source, and existing solutions of the three problems in sequence. Several widely-accepted or effective methods were analyzed and compared in the sections. We conducted make a feasibility analysis through the qualitative analysis of data and principles to prove that they can be used in intelligent manufacturing. A thorough analysis indicates that: illumination can be solved through some algorithms used in image acquisition; the sample data that cannot support deep learning can be solved using a small sample data processing algorithm and a sample quantity distribution balance method; for prior knowledge that cannot support evolutionary algorithms can be solved through machine learning and reinforcement learning. The methods in the above solutions are numerous and different. Each of them has its own advantages and disadvantages and needs to be researched and improved in specific applications in intelligent manufacturing. This overview summarizes the bottlenecks of computer vision applications in intelligent manufacturing, analyzes the corresponding solutions, and provides specific example methods. The application feasibility of these methods in intelligent manufacturing is also analyzed. The methods described in this paper can be applied to intelligent manufacturing. We propose new ideas for solving bottleneck problems. This paper provides certain reference values for readers and scholars using computer vision in intelligent manufacturing.关键词:intelligent manufacturing;computer vision;illumination uniformity control;sample data augmentation;heuristic knowledge applying119|164|2更新时间:2024-05-07
摘要:Computer vision plays an important role in detection, recognition, and location analysis in intelligent manufacturing, especially in industry inspection. It has made great contributions to improve the inspection rate, the accuracy of industrial inspection, and the degree of intelligent automation. However, the popularity of computer vision technology is insufficient in intelligent manufacturing because of its several technical application difficulties. Dealing with these problems has become a top priority in the popularization of computer vision in intelligent manufacturing. The three key application bottlenecks are the illumination impacts, sample data that cannot support deep learning, and prior knowledge that cannot support evolutionary algorithms. These bottlenecks make computer vision in intelligent manufacturing inefficient and cannot be applied in several fields. Therefore, these bottlenecks need to be systematically analyzed and resolved. We first summarized the concepts of intelligent manufacturing and computer vision. Then, the development of computer vision in intelligent manufacturing and the demand of intelligent manufacturing for computer vision technology were presented. We elaborated that computer vision could increase the inspection accuracy and rate and provide many details that cannot be found by human beings by comparing it with traditional methods. On the basis of the development status and needs of computer vision in intelligent manufacturing inspection, we proposed three critical bottlenecks in computer vision applications, namely, 1) In the actual industrial situation, uneven illumination is easily obtained because the environment is complex, and the light source is simple. Thus, The problem where the image quality is immensely impacted by illumination should be explored. 2) Obtaining uniform sample data of more than 10 000 levels in the actual industry is difficult. The problem where the sample data cannot support computer vision detection task based on deep learning should be given great importance. 3) Computer judgment cannot achieve the accuracy of professional judgment. Rational addition of human prior knowledge into evolutionary algorithms to reduce the difficulty of deep learning algorithms should be deeply analyzed. Then, we focused on summarizing and analyzing the status, source, and existing solutions of the three problems in sequence. Several widely-accepted or effective methods were analyzed and compared in the sections. We conducted make a feasibility analysis through the qualitative analysis of data and principles to prove that they can be used in intelligent manufacturing. A thorough analysis indicates that: illumination can be solved through some algorithms used in image acquisition; the sample data that cannot support deep learning can be solved using a small sample data processing algorithm and a sample quantity distribution balance method; for prior knowledge that cannot support evolutionary algorithms can be solved through machine learning and reinforcement learning. The methods in the above solutions are numerous and different. Each of them has its own advantages and disadvantages and needs to be researched and improved in specific applications in intelligent manufacturing. This overview summarizes the bottlenecks of computer vision applications in intelligent manufacturing, analyzes the corresponding solutions, and provides specific example methods. The application feasibility of these methods in intelligent manufacturing is also analyzed. The methods described in this paper can be applied to intelligent manufacturing. We propose new ideas for solving bottleneck problems. This paper provides certain reference values for readers and scholars using computer vision in intelligent manufacturing.关键词:intelligent manufacturing;computer vision;illumination uniformity control;sample data augmentation;heuristic knowledge applying119|164|2更新时间:2024-05-07
Review
-
 摘要:ObjectiveNonswitching random-valued impulse noise (RVIN) denoisers built with deep convolution neural networks (DCNNs) have many advantages compared with the mainstream switching RVIN removal algorithms in terms of denoising effect and execution efficiency. However, the performance of training-based (data-driven) denoisers in practical applications experiences inaccurate measurement of the distortion level of a given image to be denoised (data dependency problem). A fast noise ratio estimation (NRE) model based on shallow CNN (SCNN) was proposed in this study.MethodThe noise ratio reflecting the distortion level of a given noisy image was estimated using the proposed NRE model. On the basis of the estimated noise ratio, the corresponding DCNN-based denoiser trained at a specific interval of noise ratios can be adaptively exploited to efficiently remove RVIN with high denoised image quality.ResultComparison experiments were conducted to test the validity of the proposed NRE model from three aspects, namely, estimation accuracy, denoising effect, and execution efficiency. We utilized the NRE model to estimate the noise ratios of given noisy images and compared the results with the existing classical RVIN noise reduction algorithms (including PSMF(progressive switching median filter), ROLD-EPR(rank-ordered logarithmic difference edge-preserving regularization), ASWM(adaptive switching median), ROR-NLM(robust outlyingness ratio nonlocal means), MLP-EPR(multilayer perceptron edge-preserving regularization)) to verify its estimation accuracy. Considering that these competing algorithms detect noisy pixels in a pixelwise manner, the number of pixels identified as noise was divided by the total number of pixels in the entire image, and the detection results were transformed as noise ratio to facilitate comparison with the proposed NRE model. Two image sets were used, where the first image set included Lena, House, Peppers, Couple, Hill, Barbara, Boat, Man, Cameraman, and Monarch images, and the second image set was randomly selected from the Business Structure Database. For a fair comparison, all the competing algorithms were implemented on MATLAB 2017b and conducted on the same hardware platform. First, noise ratio detection was performed on the first image set, and Lena, Boat, and House images corrupted with different noise ratios were selected for demonstration. Regarding the estimation accuracy of noise ratio, PSMF, ROLD-EPR, and MLP-EPR algorithms are low. The estimation accuracy of the ASWM algorithm is high at high noise ratios, and the prediction accuracy of the ROR-NLM algorithm is high at medium and low noise ratios. The performance of the proposed NRE model consistently ranks in top two. The root mean square error (RMSE) between the estimation results and the ground-truth noise ratios was used to verify the stability of the proposed NRE model. On the first image set, the NRE model outperforms the second-best algorithm by 0.6%-2.4% in terms of RMSE. In the second image set, the RMSE of the proposed NRE model on 50 images is the smallest, indicating that its stability is the best. Although the estimation accuracies of several switching RVIN removal algorithms are higher than the proposed NRE prediction model in some cases, their execution time is extremely long. We applied different ratios of RVIN noise (10%, 20%, 30%, 40%, 50% and 60%) to Lena image with size of 512×512 pixels to test the denoising effect and used the pretrained NRE model to estimate the noise ratios for the noisy images. A DnCNN-S(DnCNN for specific ratio range) noise reduction model was used to remove the noise in accordance with the estimation results. Experimental results show that the denoising results with the estimated noise ratios are similar to the ground truth values, indicating that the estimation accuracy of the proposed NRE model is satisfactory. As the preprocessing module of denoising algorithms, the execution efficiency of noise detector is used as an evaluation index that determines the execution performance of the entire denoising algorithm. Only the MLP-EPR algorithm and the NRE+DnCNN-S denoising algorithm proposed in this paper can be clearly divided into two stages, namely, noise detection and noise reduction. Therefore, we provided the execution time of the noise detection module for MLP-EPR and NRE+DnCNN-S algorithms in addition to the average execution time. Regarding the execution time of the noise detection module, the MLP-EPR algorithm needs 0.07 s, whereas the proposed NRE model only needs 0.02 s, indicating that the efficiency of the NRE model is relatively high. Experimental results show that the proposed SCNN-based NRE model can quickly and stably measure the distortion level of a given noisy image corrupted by RVIN under different noise ratios. Any nonblind DCNN-based denoiser combined with the proposed NRE model can be seamlessly converted into a blind version.ConclusionExtensive experiments show that the estimation accuracy of the proposed CNN-based NRE model is robust under a wide range of noise ratios. DCNN's inherent data dependence problem can be properly solved when the proposed NRE model is combined with DCNN-based non-switching RVIN deep denoising models.关键词:random-valued impulse noise (RVIN);noise ratio estimation (NRE);shallow convolutional neural network (SCNN);non-pointwise mode;execution efficiency;blind denoising43|55|0更新时间:2024-05-07
摘要:ObjectiveNonswitching random-valued impulse noise (RVIN) denoisers built with deep convolution neural networks (DCNNs) have many advantages compared with the mainstream switching RVIN removal algorithms in terms of denoising effect and execution efficiency. However, the performance of training-based (data-driven) denoisers in practical applications experiences inaccurate measurement of the distortion level of a given image to be denoised (data dependency problem). A fast noise ratio estimation (NRE) model based on shallow CNN (SCNN) was proposed in this study.MethodThe noise ratio reflecting the distortion level of a given noisy image was estimated using the proposed NRE model. On the basis of the estimated noise ratio, the corresponding DCNN-based denoiser trained at a specific interval of noise ratios can be adaptively exploited to efficiently remove RVIN with high denoised image quality.ResultComparison experiments were conducted to test the validity of the proposed NRE model from three aspects, namely, estimation accuracy, denoising effect, and execution efficiency. We utilized the NRE model to estimate the noise ratios of given noisy images and compared the results with the existing classical RVIN noise reduction algorithms (including PSMF(progressive switching median filter), ROLD-EPR(rank-ordered logarithmic difference edge-preserving regularization), ASWM(adaptive switching median), ROR-NLM(robust outlyingness ratio nonlocal means), MLP-EPR(multilayer perceptron edge-preserving regularization)) to verify its estimation accuracy. Considering that these competing algorithms detect noisy pixels in a pixelwise manner, the number of pixels identified as noise was divided by the total number of pixels in the entire image, and the detection results were transformed as noise ratio to facilitate comparison with the proposed NRE model. Two image sets were used, where the first image set included Lena, House, Peppers, Couple, Hill, Barbara, Boat, Man, Cameraman, and Monarch images, and the second image set was randomly selected from the Business Structure Database. For a fair comparison, all the competing algorithms were implemented on MATLAB 2017b and conducted on the same hardware platform. First, noise ratio detection was performed on the first image set, and Lena, Boat, and House images corrupted with different noise ratios were selected for demonstration. Regarding the estimation accuracy of noise ratio, PSMF, ROLD-EPR, and MLP-EPR algorithms are low. The estimation accuracy of the ASWM algorithm is high at high noise ratios, and the prediction accuracy of the ROR-NLM algorithm is high at medium and low noise ratios. The performance of the proposed NRE model consistently ranks in top two. The root mean square error (RMSE) between the estimation results and the ground-truth noise ratios was used to verify the stability of the proposed NRE model. On the first image set, the NRE model outperforms the second-best algorithm by 0.6%-2.4% in terms of RMSE. In the second image set, the RMSE of the proposed NRE model on 50 images is the smallest, indicating that its stability is the best. Although the estimation accuracies of several switching RVIN removal algorithms are higher than the proposed NRE prediction model in some cases, their execution time is extremely long. We applied different ratios of RVIN noise (10%, 20%, 30%, 40%, 50% and 60%) to Lena image with size of 512×512 pixels to test the denoising effect and used the pretrained NRE model to estimate the noise ratios for the noisy images. A DnCNN-S(DnCNN for specific ratio range) noise reduction model was used to remove the noise in accordance with the estimation results. Experimental results show that the denoising results with the estimated noise ratios are similar to the ground truth values, indicating that the estimation accuracy of the proposed NRE model is satisfactory. As the preprocessing module of denoising algorithms, the execution efficiency of noise detector is used as an evaluation index that determines the execution performance of the entire denoising algorithm. Only the MLP-EPR algorithm and the NRE+DnCNN-S denoising algorithm proposed in this paper can be clearly divided into two stages, namely, noise detection and noise reduction. Therefore, we provided the execution time of the noise detection module for MLP-EPR and NRE+DnCNN-S algorithms in addition to the average execution time. Regarding the execution time of the noise detection module, the MLP-EPR algorithm needs 0.07 s, whereas the proposed NRE model only needs 0.02 s, indicating that the efficiency of the NRE model is relatively high. Experimental results show that the proposed SCNN-based NRE model can quickly and stably measure the distortion level of a given noisy image corrupted by RVIN under different noise ratios. Any nonblind DCNN-based denoiser combined with the proposed NRE model can be seamlessly converted into a blind version.ConclusionExtensive experiments show that the estimation accuracy of the proposed CNN-based NRE model is robust under a wide range of noise ratios. DCNN's inherent data dependence problem can be properly solved when the proposed NRE model is combined with DCNN-based non-switching RVIN deep denoising models.关键词:random-valued impulse noise (RVIN);noise ratio estimation (NRE);shallow convolutional neural network (SCNN);non-pointwise mode;execution efficiency;blind denoising43|55|0更新时间:2024-05-07 -
 摘要:ObjectiveCompared with traditional subjective image enhancement methods, image restoration is an objective method to improve the quality of degraded images on the basis of physical models. The result presents no distortion, low noise, and rich image details. The grade of sinter, which is the main raw material for blast furnace ironmaking, is directly related to the condition of the blast furnace and the output of molten iron. The flame image of the tail section of a sinter machine can fully reflect the sintering state of the material layer, which plays an important role in the detection of the quality of a sintered ore. However, the harsh environment of the sintering machine tail has caused numerous interference factors, such as smoke, dust, and uneven brightness. Such factors lead to the degradation of the flame image of the sintered section collected using a camera. An accurate ambient light value is difficult to obtain by using the dark channel principle alone. This limitation results in halo and distortion. Therefore, obtaining a clear and undistorted cross-section flame image of the tailing layer of the sintering machine is the primary problem in accurately identifying the end point of sintering, and it has an important engineering application value for improving the yield of sintered ore and reducing energy consumption. In this study, a new flame image degradation model for the sintered section is established, and an effective flame image restoration algorithm for the sintered section is proposed.MethodThe basis of the image restoration algorithm based on physical model is to establish a degradation model of the image. The atmospheric scattering model proposed by Narasimhan is widely used in the fields of computer vision and image processing. The image degradation model is established based on the atmospheric scattering model; it fully considers the scattering and attenuation characteristics of soot particles in the tail environment of the sintering machine. The model uses a first-order multiscattering method to simplify the multiscattering process of soot and Retinex theory to decompose the image. First, the proposed algorithm calculates the brightness of the original image and adjusts the overall brightness of the image based on the bilateral filtering Retinex method in accordance with the uneven luminance caused by the sintering flame. Second, from the results of image brightness balance, we estimate the ambient light of the sintering machine tail by using the transcendental principle of dark channel and enlarge the image transmissivity distribution with guided filtering. Finally, for the image of the area containing a large region of flame in the smoke environment of the sintering section, we use the tolerance mechanism to improve the transmittance of the flame area and acquire a restored image. This process prevents the color distortion of the restored image and makes the restored image close to the actual situation.ResultIn this experiment, a single image collected is used for restoration and subjective evaluation with four other experimental methods. Results of multiscale Retinex restoration show that the method cannot remove the smoke and dust from the flame image of the sintering section, and the noise is excessively high. Compared with the results of multiscale Retinex, the image noise generated using the method with glow and multiple light colors is smaller, but the details of the flame area are unclear and color distortion appears. The results of dark channel priori method experimental restoration improve some details of the flame area but do not eliminate the influence of soot because the flame area causes uneven brightness of the image. This condition leads to the failure of the dark channel priori to estimate the transmission of the image in the dark scene. The experimental results of the method with boundary constraint and contextual regularization present that the image brightness is balanced in a small range, and the details of the flame area are obvious. However, the overall image brightness is high, and the smoke influence remains. The results of this study show that the brightness of the restored image is balanced, the details of the flame area are clear and distinct from the sintering layer, the color is natural without distortion, and the influences of smoke and dust are eliminated. We use a statistical method for image quality evaluation, pixel value variance, average gradient, contrast, information entropy, and peak signal-to-noise ratio as objective evaluation indexes. The experimental results of dark channel priori method have lower statistics than the original image because the method does not address the problem of uneven brightness of the image caused by the sintering flame area. Compared with the statistics of the original image, the statistics of the image obtained using modified method is improved, but the restored image has the problems of noise and color distortion. The algorithm proposed in this study is superior to other methods. The algorithm results maintain a high image contrast. The image information entropy and the peak signal-to-noise ratio are 17.532 bit and 22.127 dB, respectively, which are significantly higher than those of other algorithms.ConclusionWe study a degradation model for the flame image of the tail section of a sintering machine and propose an effective restoration algorithm. We achieve the brightness balance of the restored image and the effect of smoke removal, which are beneficial to the accurate extraction of sintered flame characteristics and lay a foundation for the subsequent identification of the sintering end point.关键词:image restoration;Retinex;dark channel prior;flame image;sintering machine126|84|0更新时间:2024-05-07
摘要:ObjectiveCompared with traditional subjective image enhancement methods, image restoration is an objective method to improve the quality of degraded images on the basis of physical models. The result presents no distortion, low noise, and rich image details. The grade of sinter, which is the main raw material for blast furnace ironmaking, is directly related to the condition of the blast furnace and the output of molten iron. The flame image of the tail section of a sinter machine can fully reflect the sintering state of the material layer, which plays an important role in the detection of the quality of a sintered ore. However, the harsh environment of the sintering machine tail has caused numerous interference factors, such as smoke, dust, and uneven brightness. Such factors lead to the degradation of the flame image of the sintered section collected using a camera. An accurate ambient light value is difficult to obtain by using the dark channel principle alone. This limitation results in halo and distortion. Therefore, obtaining a clear and undistorted cross-section flame image of the tailing layer of the sintering machine is the primary problem in accurately identifying the end point of sintering, and it has an important engineering application value for improving the yield of sintered ore and reducing energy consumption. In this study, a new flame image degradation model for the sintered section is established, and an effective flame image restoration algorithm for the sintered section is proposed.MethodThe basis of the image restoration algorithm based on physical model is to establish a degradation model of the image. The atmospheric scattering model proposed by Narasimhan is widely used in the fields of computer vision and image processing. The image degradation model is established based on the atmospheric scattering model; it fully considers the scattering and attenuation characteristics of soot particles in the tail environment of the sintering machine. The model uses a first-order multiscattering method to simplify the multiscattering process of soot and Retinex theory to decompose the image. First, the proposed algorithm calculates the brightness of the original image and adjusts the overall brightness of the image based on the bilateral filtering Retinex method in accordance with the uneven luminance caused by the sintering flame. Second, from the results of image brightness balance, we estimate the ambient light of the sintering machine tail by using the transcendental principle of dark channel and enlarge the image transmissivity distribution with guided filtering. Finally, for the image of the area containing a large region of flame in the smoke environment of the sintering section, we use the tolerance mechanism to improve the transmittance of the flame area and acquire a restored image. This process prevents the color distortion of the restored image and makes the restored image close to the actual situation.ResultIn this experiment, a single image collected is used for restoration and subjective evaluation with four other experimental methods. Results of multiscale Retinex restoration show that the method cannot remove the smoke and dust from the flame image of the sintering section, and the noise is excessively high. Compared with the results of multiscale Retinex, the image noise generated using the method with glow and multiple light colors is smaller, but the details of the flame area are unclear and color distortion appears. The results of dark channel priori method experimental restoration improve some details of the flame area but do not eliminate the influence of soot because the flame area causes uneven brightness of the image. This condition leads to the failure of the dark channel priori to estimate the transmission of the image in the dark scene. The experimental results of the method with boundary constraint and contextual regularization present that the image brightness is balanced in a small range, and the details of the flame area are obvious. However, the overall image brightness is high, and the smoke influence remains. The results of this study show that the brightness of the restored image is balanced, the details of the flame area are clear and distinct from the sintering layer, the color is natural without distortion, and the influences of smoke and dust are eliminated. We use a statistical method for image quality evaluation, pixel value variance, average gradient, contrast, information entropy, and peak signal-to-noise ratio as objective evaluation indexes. The experimental results of dark channel priori method have lower statistics than the original image because the method does not address the problem of uneven brightness of the image caused by the sintering flame area. Compared with the statistics of the original image, the statistics of the image obtained using modified method is improved, but the restored image has the problems of noise and color distortion. The algorithm proposed in this study is superior to other methods. The algorithm results maintain a high image contrast. The image information entropy and the peak signal-to-noise ratio are 17.532 bit and 22.127 dB, respectively, which are significantly higher than those of other algorithms.ConclusionWe study a degradation model for the flame image of the tail section of a sintering machine and propose an effective restoration algorithm. We achieve the brightness balance of the restored image and the effect of smoke removal, which are beneficial to the accurate extraction of sintered flame characteristics and lay a foundation for the subsequent identification of the sintering end point.关键词:image restoration;Retinex;dark channel prior;flame image;sintering machine126|84|0更新时间:2024-05-07 -
 摘要:ObjectiveThe rapid development of the Internet communication and multimedia technology has allowed the convenient transmission of substantial video, image, and other multimedia data through networks at any moment. On the one hand, these data may be leaked in the transmission process and illegally used due to the openness and sharing of the internet. On the other hand, several images may contain sensitive information, such as human body images that can potentially reveal the privacy information of one person, including gender, weight, and health status. Remote sensing images may include important information, such as geographical location, sensor parameters, and the spectral characteristics of ground objects. Therefore, the protection of image content and secure communication have become important issues in the field of information security. Since the double random phase encoding (DRPE) was proposed, numerous encryption schemes, such as fractional Fourier transform, gyrator transform, Fresnel transform, and multiparameter discrete fractional Fourier transform, have been introduced in other domains. The majority of such algorithms focus on a single image. Multi-image encryption technology has been widely investigated in recent years to meet the growing demand for data transmission. This paper introduces a multi-image encryption algorithm based on gyrator transform and multiresolution singular value decomposition (MRSVD).MethodFirst, every two images are combined into a complex matrix by precoding and then DRPE in the gyrator domain is performed, where chaotic phase masks are constructed using a modified logistic map. Second, the real and imaginary parts of the transformed results are spliced into a real matrix. MRSVD is implemented to improve the security. With a given mean and variance values, a Gaussian matrix is generated and an orthogonal coefficient matrix is obtained by singular value decomposition. Cipher images are obtained by linear combination of the MRSVD results. Plaintext images can be recovered using an authorized key through the reverse encryption process. The phase masks, rotation angles of gyrator transforms, and parameter of Gaussian matrix are generated by using the modified logistic map, which makes the storage and transmission convenient. The initial states of the modified logistic map are closely related to plaintext images, and this condition results in high-level security.ResultNumerical simulations are performed on 120 grayscale images to demonstrate the feasibility and reliability of the proposal. The peak signal-to-noise ratio (PSNR) values of the decrypted images by using the proposed method with granted keys are larger than 300 dB. This result indicates that the quality of the decrypted images by using the proposed method is better than that obtained using other methods. The histograms of cipher images obey the Gaussian distribution, which is different from the results of plaintext images. The correlation coefficient value of cipher images is much less than 0.20 when keys are slightly changed. The decrypted results with a key that deviates from the correct value of 10-15 are chaotic. The average PSNR value is approximately 8.516 1 dB, and the average structural similarity is close to 0. When the pixel values of plaintext images increase by a small amount, the average number of pixel change rate and the unified average changing intensity are approximately 0.999 0 and 0.333 7, respectively. The key space is up to 5.616 9×1060, which can resist a brute force attack. For the cipher images attacked by Gaussian white noise and cropping, the proposed algorithm can still recover plaintext images and shows better robustness than two other algorithms.ConclusionA multilevel multi-image encryption approach based on gyrator transform and MRSVD is proposed in this study. The chaotic random phase masks and real-valued cipher image is convenient to storage and transmit. The identity orthogonal matrix obtained by singular value decomposition is utilized to share the MRSVD results. Such utilization increases the security of ciphertext. Experimental results demonstrate that the proposed method can restitute plaintext images with high quality and achieves high security and strong robustness. It can be applied for the protection of image content and secure communication.关键词:multi-image encryption;gyrator transform;multi-resolution singular value decomposition(MRSVD);modified logistic map;double random phase encoding42|71|1更新时间:2024-05-07
摘要:ObjectiveThe rapid development of the Internet communication and multimedia technology has allowed the convenient transmission of substantial video, image, and other multimedia data through networks at any moment. On the one hand, these data may be leaked in the transmission process and illegally used due to the openness and sharing of the internet. On the other hand, several images may contain sensitive information, such as human body images that can potentially reveal the privacy information of one person, including gender, weight, and health status. Remote sensing images may include important information, such as geographical location, sensor parameters, and the spectral characteristics of ground objects. Therefore, the protection of image content and secure communication have become important issues in the field of information security. Since the double random phase encoding (DRPE) was proposed, numerous encryption schemes, such as fractional Fourier transform, gyrator transform, Fresnel transform, and multiparameter discrete fractional Fourier transform, have been introduced in other domains. The majority of such algorithms focus on a single image. Multi-image encryption technology has been widely investigated in recent years to meet the growing demand for data transmission. This paper introduces a multi-image encryption algorithm based on gyrator transform and multiresolution singular value decomposition (MRSVD).MethodFirst, every two images are combined into a complex matrix by precoding and then DRPE in the gyrator domain is performed, where chaotic phase masks are constructed using a modified logistic map. Second, the real and imaginary parts of the transformed results are spliced into a real matrix. MRSVD is implemented to improve the security. With a given mean and variance values, a Gaussian matrix is generated and an orthogonal coefficient matrix is obtained by singular value decomposition. Cipher images are obtained by linear combination of the MRSVD results. Plaintext images can be recovered using an authorized key through the reverse encryption process. The phase masks, rotation angles of gyrator transforms, and parameter of Gaussian matrix are generated by using the modified logistic map, which makes the storage and transmission convenient. The initial states of the modified logistic map are closely related to plaintext images, and this condition results in high-level security.ResultNumerical simulations are performed on 120 grayscale images to demonstrate the feasibility and reliability of the proposal. The peak signal-to-noise ratio (PSNR) values of the decrypted images by using the proposed method with granted keys are larger than 300 dB. This result indicates that the quality of the decrypted images by using the proposed method is better than that obtained using other methods. The histograms of cipher images obey the Gaussian distribution, which is different from the results of plaintext images. The correlation coefficient value of cipher images is much less than 0.20 when keys are slightly changed. The decrypted results with a key that deviates from the correct value of 10-15 are chaotic. The average PSNR value is approximately 8.516 1 dB, and the average structural similarity is close to 0. When the pixel values of plaintext images increase by a small amount, the average number of pixel change rate and the unified average changing intensity are approximately 0.999 0 and 0.333 7, respectively. The key space is up to 5.616 9×1060, which can resist a brute force attack. For the cipher images attacked by Gaussian white noise and cropping, the proposed algorithm can still recover plaintext images and shows better robustness than two other algorithms.ConclusionA multilevel multi-image encryption approach based on gyrator transform and MRSVD is proposed in this study. The chaotic random phase masks and real-valued cipher image is convenient to storage and transmit. The identity orthogonal matrix obtained by singular value decomposition is utilized to share the MRSVD results. Such utilization increases the security of ciphertext. Experimental results demonstrate that the proposed method can restitute plaintext images with high quality and achieves high security and strong robustness. It can be applied for the protection of image content and secure communication.关键词:multi-image encryption;gyrator transform;multi-resolution singular value decomposition(MRSVD);modified logistic map;double random phase encoding42|71|1更新时间:2024-05-07 -
 摘要:ObjectiveThe attenuation of light is typically serious even in the purest water after filtration. Experiments show that the attenuation of water is caused by two unrelated physical processes, namely, absorption and scattering. Water has obvious selectivity for light absorption, and the absorption abilities of different spectral regions vary. Such variation leads to the loss of light energy, which makes underwater imaging difficult with such phenomena as low definition and color distortion. The scattering of light by water can be divided into forward and backward scattering. The suspended particles in water cause the attenuation of light in the forward and reverse directions of propagation, which limits the detection range and distance of underwater optical imaging. This limitation results in a decrease in image contrast, blurred details, and degradation. A series of degradation problems has weakened the detection rate and accuracy of defects. Therefore, the denoising and enhancement of images with surface defects of underwater structures are significant. An improved image enhancement algorithm based on turbulence model and multiscale retinex (MSR) is proposed to improve the contrast and sharpness of surface defect images acquired underwater and facilitate the subsequent segmentation, extraction, and recognition of the defect region. The proposed method combines physical model with the nonphysical model method. Thus, this method improves the considerably simple model parameters and poor versatility. The color cast of the enhanced image is considered, and the image noise is suppressed.MethodAn underwater image with uneven illumination is converted from RGB space to Lab space, and histogram equalization (HE) is performed on the luminance space. After the incident light is reflected from the structure surface, it will be affected by the suspended particles from the water before it reaches the imaging device, and the scattering phenomenon will generate noise. The absorption of the spectrum by the water will attenuate the light intensity, and this condition will result in low image contrast. The process is similar to the imaging model of a foggy-degraded image. Thus, the reconstructed method of the degraded image can be used to process the blurred underwater image. The light intensity distribution in the imaged scene after homogenization is similar, which can be approximated as a fixed value. The transmittance of the homogenized image can be estimated in accordance with dark channel prior theory. It describes the medium transmission that is unscattered and reaches the light portion of the imaging system, and it is also the degree of blur at each pixel. It reflects the degree of transparency of the light source components in the scene, which indicates the extent to which the image is affected by the scattering of water. In consideration of the same degraded underwater images and remote sensing images, the two exhibit similarities in optical properties, fluid media, and external forms. The atmospheric turbulence model can accordingly be applied to simulate the degradation process of underwater images. The transmittance obtained above is combined with a general model of atmospheric turbulence to simulate an underwater degradation image by adjusting the transmittance coefficient. The image noise is filtered by Wiener filter, and the filtered image is used as a guide image. An edge-preserved image is obtained using a guide filter to refine. Image enhancement is performed in accordance with retinex theory. The MSR result is color-corrected on the basis of the 3σ criterion to obtain an enhanced underwater image. Multiple images collected under different turbulent environments are selected as the research object. The method proposed in this study is used and compared with classic methods, such as the dark channel, HE, and single-scale retinex (SSR) algorithms. The indicators of signal-to-noise ratio (SNR), peak SNR, information entropy (IE), standard deviation (SD), and average gradient (AG) are evaluated.ResultExperimental results show that the IE and SD of the proposed algorithm are 11.7% and 25.6% higher than those of HE algorithm and SSR, respectively. The AG is 31.2% higher than that of HE algorithm, and the segmentation accuracy is increased by 3.1%. The oversegmentation rate is the lowest among similar algorithms. From the perspective of subjective visual effects, the image after restoration by the dark channel algorithm is rich in color and prominent in detail, but its gray value is mostly distributed in the low-gray area. Such distribution results in a low image recognition rate and an unsatisfactory segmentation effect. The visual effect of HE algorithm is the closest to the original image, but the problem that the gray scale distribution is excessively concentrated remains. The segmentation accuracy is slightly improved compared with that of the dark channel algorithm. The image after SSR shows a color cast phenomenon, and the overall gray value of the image after the dynamically adjusted MSR decreases. The range of gray scale is enlarged, and the color cast effect is improved. The color and detail of the image are the richest, and the visual effect is the most natural among all the tested algorithms.ConclusionOn the basis of the analysis of an underwater image degradation model and the difference among pixels, the image transmittance is estimated, and the gray scale distribution of the enhanced image is expanded by the 3σ criterion. An enhanced underwater image with high contrast, high definition, and balanced color is obtained. The algorithm improves the adaptive problem of the degenerate model with excellent performance in comprehensive indicators, such as IE, SD, and AG. Compared with the dark channel prior method, the proposed method exhibits greatly improved SNR and AG. The edge information of the image is preserved, which provides a good information source for image segmentation and recognition in the next stage.关键词:underwater image enhancement;turbulence model;transmittance;Wiener filtering;multi-scale retinex(MSR);color correction122|145|4更新时间:2024-05-07
摘要:ObjectiveThe attenuation of light is typically serious even in the purest water after filtration. Experiments show that the attenuation of water is caused by two unrelated physical processes, namely, absorption and scattering. Water has obvious selectivity for light absorption, and the absorption abilities of different spectral regions vary. Such variation leads to the loss of light energy, which makes underwater imaging difficult with such phenomena as low definition and color distortion. The scattering of light by water can be divided into forward and backward scattering. The suspended particles in water cause the attenuation of light in the forward and reverse directions of propagation, which limits the detection range and distance of underwater optical imaging. This limitation results in a decrease in image contrast, blurred details, and degradation. A series of degradation problems has weakened the detection rate and accuracy of defects. Therefore, the denoising and enhancement of images with surface defects of underwater structures are significant. An improved image enhancement algorithm based on turbulence model and multiscale retinex (MSR) is proposed to improve the contrast and sharpness of surface defect images acquired underwater and facilitate the subsequent segmentation, extraction, and recognition of the defect region. The proposed method combines physical model with the nonphysical model method. Thus, this method improves the considerably simple model parameters and poor versatility. The color cast of the enhanced image is considered, and the image noise is suppressed.MethodAn underwater image with uneven illumination is converted from RGB space to Lab space, and histogram equalization (HE) is performed on the luminance space. After the incident light is reflected from the structure surface, it will be affected by the suspended particles from the water before it reaches the imaging device, and the scattering phenomenon will generate noise. The absorption of the spectrum by the water will attenuate the light intensity, and this condition will result in low image contrast. The process is similar to the imaging model of a foggy-degraded image. Thus, the reconstructed method of the degraded image can be used to process the blurred underwater image. The light intensity distribution in the imaged scene after homogenization is similar, which can be approximated as a fixed value. The transmittance of the homogenized image can be estimated in accordance with dark channel prior theory. It describes the medium transmission that is unscattered and reaches the light portion of the imaging system, and it is also the degree of blur at each pixel. It reflects the degree of transparency of the light source components in the scene, which indicates the extent to which the image is affected by the scattering of water. In consideration of the same degraded underwater images and remote sensing images, the two exhibit similarities in optical properties, fluid media, and external forms. The atmospheric turbulence model can accordingly be applied to simulate the degradation process of underwater images. The transmittance obtained above is combined with a general model of atmospheric turbulence to simulate an underwater degradation image by adjusting the transmittance coefficient. The image noise is filtered by Wiener filter, and the filtered image is used as a guide image. An edge-preserved image is obtained using a guide filter to refine. Image enhancement is performed in accordance with retinex theory. The MSR result is color-corrected on the basis of the 3σ criterion to obtain an enhanced underwater image. Multiple images collected under different turbulent environments are selected as the research object. The method proposed in this study is used and compared with classic methods, such as the dark channel, HE, and single-scale retinex (SSR) algorithms. The indicators of signal-to-noise ratio (SNR), peak SNR, information entropy (IE), standard deviation (SD), and average gradient (AG) are evaluated.ResultExperimental results show that the IE and SD of the proposed algorithm are 11.7% and 25.6% higher than those of HE algorithm and SSR, respectively. The AG is 31.2% higher than that of HE algorithm, and the segmentation accuracy is increased by 3.1%. The oversegmentation rate is the lowest among similar algorithms. From the perspective of subjective visual effects, the image after restoration by the dark channel algorithm is rich in color and prominent in detail, but its gray value is mostly distributed in the low-gray area. Such distribution results in a low image recognition rate and an unsatisfactory segmentation effect. The visual effect of HE algorithm is the closest to the original image, but the problem that the gray scale distribution is excessively concentrated remains. The segmentation accuracy is slightly improved compared with that of the dark channel algorithm. The image after SSR shows a color cast phenomenon, and the overall gray value of the image after the dynamically adjusted MSR decreases. The range of gray scale is enlarged, and the color cast effect is improved. The color and detail of the image are the richest, and the visual effect is the most natural among all the tested algorithms.ConclusionOn the basis of the analysis of an underwater image degradation model and the difference among pixels, the image transmittance is estimated, and the gray scale distribution of the enhanced image is expanded by the 3σ criterion. An enhanced underwater image with high contrast, high definition, and balanced color is obtained. The algorithm improves the adaptive problem of the degenerate model with excellent performance in comprehensive indicators, such as IE, SD, and AG. Compared with the dark channel prior method, the proposed method exhibits greatly improved SNR and AG. The edge information of the image is preserved, which provides a good information source for image segmentation and recognition in the next stage.关键词:underwater image enhancement;turbulence model;transmittance;Wiener filtering;multi-scale retinex(MSR);color correction122|145|4更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectivePerson reidentification is an important task in video surveillance systems with a goal to establish the correspondence among images or videos of a person taken from different cameras at different times. In accordance with camera types, person re-identification algorithms can be divided into RGB camera-based and depth camera-based ones. RGB camera-based algorithms are generally based on the appearance characteristics of clothes, such as color and texture. Their performances are greatly affected by external conditions, such as illumination variations. On the contrary, depth camera-based algorithms are minimally affected by lighting conditions. Person re-identification algorithms can also be divided into side view-oriented and vertical view-oriented algorithms according to camera-shooting angle. Most body parts can be seen in side-view scenarios, whereas only the plan view of head and shoulders can be seen in vertical-view scenarios. Most existing algorithms are for side-view RGB scenarios, and only a few of them can be directly applied to top-view depth scenarios. For example, they have poor performance in the case of bus-mounted low-resolution depth cameras. Our focus is on person re-identification on depth head and shoulder sequences.MethodThe proposed person re-identification algorithm consists of four modules, namely, head region detection, head depth energy map group (HeDEMaG) construction, HeDEMaG-based multifeature representation and similarity computation, and learning-based score-level fusion and person re-identification. First, the head region detection module is to detect each head region in every frame. The pixel value in a depth image represents the distance between an object and the camera plane. The range that the height of a person distributes is used to roughly segment the candidate head regions. A frame-averaging model is proposed to compute the distance between floor and the camera plane for determining the height of each person with respect to floor. The person's height can be computed by subtracting floor values from the raw frame. The circularity ratio of a head region is used to remove nonhead regions from the candidate regions because the shape of a real head region is similar to a circle. Second, the HeDEMaG construction module is to describe the structural and behavioral characteristics of a walking person's head. Kalman filter and Hungarian matching method are used to track multiple persons' heads in each frame. In the walking process, the head direction may change with time. A principal component analysis(PCA)based method is used to normalize the direction of a person's head regions. Each person's normalized head image sequence is uniformly divided into Rt groups in time order to capture the structural and behavioral characteristics of a person's head in local and overall time periods. The average map of each group is called the head depth energy map, and the set of the head depth energy maps is named as HeDEMaG. Third, the HeDEMaG-based multifeature representation and similarity computation module is to extract features and compute the similarity between the probe and gallery set. The depth, area, projection maps in two directions, Fourier descriptor, and histogram of oriented gradient(HOG) feature of each head depth energy map in HeDEMaG are proposed to represent a person. The similarity on depth is defined as the ratio of the depth difference to the maximum difference between the probe and gallery set. The similarity on area is defined as the ratio of the area difference to the maximum difference between the probe and gallery set. The similarities on projections, Fourier descriptor, and HOG are computed by their correlation coefficients. Fourth, the learning-based similarity score-level fusion and person re-identification module is to identify persons according to the similarity score that is defined as a weighted version of the above-mentioned five similarity values. The fusing weights are learned from the training set by minimizing the cost function that measures the error rate of recognition. In the experiments, we use the label of the top one image in the ranked list as the predicted label of the probe.ResultExperiments are conducted on a public top view person re-identification(TVPR) dataset and two self-built datasets to verify the effectiveness of the proposed algorithm. TVPR consists of videos recorded indoors using a vertical RGB-D camera, and only one person's walking behavior is recorded. We establish two datasets, namely, top-view depth based person identification for laboratory scenarios(TDPI-L) and top-view depth based person identification for bus scenarios(TDPI-B), to verify the performance on multiple persons and real-world scenarios. TDPI-L is composed of videos captured indoors by depth cameras, and more than two persons' walking is recorded in each frame. TDPI-B consists of sequences recorded by bus-mounted low-resolution time of flight(TOF) cameras. Five measures, namely, rank-1, rank-5, macro-F1, cumulative match characteristic(CMC) and average time are used to evaluate the proposed algorithm. The rank-1, rank-5, and macro-F1 of the proposed algorithm are above 61%, 68%, and 67%, respectively, which are at least 11% higher than those of the state-of-the-art algorithms. The ablation studies and the effects of tracking algorithms and parameters on the performance are also discussed.ConclusionThe proposed algorithm is to identify persons in head and shoulder sequences captured by depth cameras from top views. HeDEMaG is proposed to represent the structural and behavioral characteristics of persons. A learning-based fusing weight-computing method is proposed to avoid parameter fine tuning and improve the recognition accuracy. Experimental results show that proposed algorithm outperforms the state-of-the-art algorithms on public available indoor videos and real-world low-resolution bus-mounted videos.关键词:depth camera;top view depth head and shoulder sequence;head depth energy map group (HeDEMaG);similarity fusion weights learning;person re-identification83|113|1更新时间:2024-05-07
摘要:ObjectivePerson reidentification is an important task in video surveillance systems with a goal to establish the correspondence among images or videos of a person taken from different cameras at different times. In accordance with camera types, person re-identification algorithms can be divided into RGB camera-based and depth camera-based ones. RGB camera-based algorithms are generally based on the appearance characteristics of clothes, such as color and texture. Their performances are greatly affected by external conditions, such as illumination variations. On the contrary, depth camera-based algorithms are minimally affected by lighting conditions. Person re-identification algorithms can also be divided into side view-oriented and vertical view-oriented algorithms according to camera-shooting angle. Most body parts can be seen in side-view scenarios, whereas only the plan view of head and shoulders can be seen in vertical-view scenarios. Most existing algorithms are for side-view RGB scenarios, and only a few of them can be directly applied to top-view depth scenarios. For example, they have poor performance in the case of bus-mounted low-resolution depth cameras. Our focus is on person re-identification on depth head and shoulder sequences.MethodThe proposed person re-identification algorithm consists of four modules, namely, head region detection, head depth energy map group (HeDEMaG) construction, HeDEMaG-based multifeature representation and similarity computation, and learning-based score-level fusion and person re-identification. First, the head region detection module is to detect each head region in every frame. The pixel value in a depth image represents the distance between an object and the camera plane. The range that the height of a person distributes is used to roughly segment the candidate head regions. A frame-averaging model is proposed to compute the distance between floor and the camera plane for determining the height of each person with respect to floor. The person's height can be computed by subtracting floor values from the raw frame. The circularity ratio of a head region is used to remove nonhead regions from the candidate regions because the shape of a real head region is similar to a circle. Second, the HeDEMaG construction module is to describe the structural and behavioral characteristics of a walking person's head. Kalman filter and Hungarian matching method are used to track multiple persons' heads in each frame. In the walking process, the head direction may change with time. A principal component analysis(PCA)based method is used to normalize the direction of a person's head regions. Each person's normalized head image sequence is uniformly divided into Rt groups in time order to capture the structural and behavioral characteristics of a person's head in local and overall time periods. The average map of each group is called the head depth energy map, and the set of the head depth energy maps is named as HeDEMaG. Third, the HeDEMaG-based multifeature representation and similarity computation module is to extract features and compute the similarity between the probe and gallery set. The depth, area, projection maps in two directions, Fourier descriptor, and histogram of oriented gradient(HOG) feature of each head depth energy map in HeDEMaG are proposed to represent a person. The similarity on depth is defined as the ratio of the depth difference to the maximum difference between the probe and gallery set. The similarity on area is defined as the ratio of the area difference to the maximum difference between the probe and gallery set. The similarities on projections, Fourier descriptor, and HOG are computed by their correlation coefficients. Fourth, the learning-based similarity score-level fusion and person re-identification module is to identify persons according to the similarity score that is defined as a weighted version of the above-mentioned five similarity values. The fusing weights are learned from the training set by minimizing the cost function that measures the error rate of recognition. In the experiments, we use the label of the top one image in the ranked list as the predicted label of the probe.ResultExperiments are conducted on a public top view person re-identification(TVPR) dataset and two self-built datasets to verify the effectiveness of the proposed algorithm. TVPR consists of videos recorded indoors using a vertical RGB-D camera, and only one person's walking behavior is recorded. We establish two datasets, namely, top-view depth based person identification for laboratory scenarios(TDPI-L) and top-view depth based person identification for bus scenarios(TDPI-B), to verify the performance on multiple persons and real-world scenarios. TDPI-L is composed of videos captured indoors by depth cameras, and more than two persons' walking is recorded in each frame. TDPI-B consists of sequences recorded by bus-mounted low-resolution time of flight(TOF) cameras. Five measures, namely, rank-1, rank-5, macro-F1, cumulative match characteristic(CMC) and average time are used to evaluate the proposed algorithm. The rank-1, rank-5, and macro-F1 of the proposed algorithm are above 61%, 68%, and 67%, respectively, which are at least 11% higher than those of the state-of-the-art algorithms. The ablation studies and the effects of tracking algorithms and parameters on the performance are also discussed.ConclusionThe proposed algorithm is to identify persons in head and shoulder sequences captured by depth cameras from top views. HeDEMaG is proposed to represent the structural and behavioral characteristics of persons. A learning-based fusing weight-computing method is proposed to avoid parameter fine tuning and improve the recognition accuracy. Experimental results show that proposed algorithm outperforms the state-of-the-art algorithms on public available indoor videos and real-world low-resolution bus-mounted videos.关键词:depth camera;top view depth head and shoulder sequence;head depth energy map group (HeDEMaG);similarity fusion weights learning;person re-identification83|113|1更新时间:2024-05-07 -
 摘要:ObjectiveThe convenient and efficient technique of biometric feature identification triggers the wide and profound research on face recognition, which draws extensive concern and has been widely used in various authorization scenarios, including mobile phone unlocking, access control, and face payment. The rise of Internet of Things application terminals including mobile phone cameras make much private facial information of user easily and instantaneously available, which lead to serious threat for the traditional face identification systems. Therefore, more efficient and accurate identifying of face spoofing attacks, including replay and print attacks, reducing threats, and ensuring system security have become an urgent issue to be addressed. Face anti-spoofing mainly ensures that the real entity is displayed in front of the camera, rather than a video or a photo. Many techniques, including convolutional neural network (CNN) methods, have appeared to address this issue and aroused a great concern constantly in recent years. Typically, the hand-crafted features including LBP (local binary pattern), HOG (histogram of oriented gradient) jointly using a kind of classifier such as SVM (support vector machine), is to be the most commonly used technique for face anti-spoofing. However, the diversity of spoofing means still causes great difficulties in manually extracting effective features. Most CNN methods cannot fully exploit the valuable information in the case of temporal dimensionality and thus result in poor detection. To address this issue, this study presents a two-stream spoofing detection network based on a scheme of hybrid pooling.MethodThose methods that only use spatial information to solve the face anti-spoofing problem are not generalized. The face anti-spoofing framework proposed in this paper includes spatial stream, temporal stream and fusion modules. The entire design process of experiment is divided into two aspects, one is to use spatial net to achieve spatial information, and another is to apply the temporal net to acquire temporal information. The algorithm implementation is detailed as following. First, optical flow pictures are extracted from the dataset, on which face detection is performed, the optical flow pictures are utilized as the input of the temporal stream to learn temporal information, and the original face pictures are used as the input of the spatial stream to learn spatial information. Second, a shallow network is adopted for the spatial stream network, in which spatial pyramid pooling is combined with global average pooling at the end of the network to obtain hybrid pooling features. We then perform classification using a fully connected layer. For the temporal stream network, we adopt a deep network using residual blocks given that effective temporal features are difficult to extract. Spatial pyramid pooling and global average pooling are also synthesized at the end of the network for the classification. Results obtained from the spatial and temporal stream networks are used for the final score fusion for improved classification. The choice of different color spaces may affect the final result; thus, we compare the effectiveness of different color spaces by experiment and determine the optimal color space of the presented model.ResultThe proposed method is demonstrated on two public benchmark datasets, namely, CASIA-FASD (CASIA face anti-spoofing database) and replay-attack. We obtain the results of 2.141% EER (equal error rate) in the spatial stream, 9.005% EER in the temporal stream, and 1.701% EER in fusion on CASIA-FASD; and 0.071% EER and 0.109% HTER(half total error rate) in the spatial stream, 17.045% EER and 21.781% HTER in the temporal stream, and 0.091% EER and 0.082% HTER in fusion on replay-attack.ConclusionThe two-stream spoofing detection network combined with the hybrid pooling scheme achieves promising results on different datasets. The proposed method utilizes the effective information in temporal dimensionality. The hybrid of spatial pyramid and global average pooling means can exploit the effective information in multiple scales. We can also relieve the burden of the high dimensionality of datasets. Experimental results obtained from popular datasets demonstrate the merits of the proposed method, especially its robustness to the diversity of spoofing means and the large differences in the quality of image datasets. Our promising results will encourage further work on synthesizing an informative stream and lead to successful solutions for other application domains in the future.关键词:anti-spoofing;convolutional neural network (CNN);two-stream network;optical flow method;spatial pyramid pooling;global average pooling30|19|6更新时间:2024-05-07
摘要:ObjectiveThe convenient and efficient technique of biometric feature identification triggers the wide and profound research on face recognition, which draws extensive concern and has been widely used in various authorization scenarios, including mobile phone unlocking, access control, and face payment. The rise of Internet of Things application terminals including mobile phone cameras make much private facial information of user easily and instantaneously available, which lead to serious threat for the traditional face identification systems. Therefore, more efficient and accurate identifying of face spoofing attacks, including replay and print attacks, reducing threats, and ensuring system security have become an urgent issue to be addressed. Face anti-spoofing mainly ensures that the real entity is displayed in front of the camera, rather than a video or a photo. Many techniques, including convolutional neural network (CNN) methods, have appeared to address this issue and aroused a great concern constantly in recent years. Typically, the hand-crafted features including LBP (local binary pattern), HOG (histogram of oriented gradient) jointly using a kind of classifier such as SVM (support vector machine), is to be the most commonly used technique for face anti-spoofing. However, the diversity of spoofing means still causes great difficulties in manually extracting effective features. Most CNN methods cannot fully exploit the valuable information in the case of temporal dimensionality and thus result in poor detection. To address this issue, this study presents a two-stream spoofing detection network based on a scheme of hybrid pooling.MethodThose methods that only use spatial information to solve the face anti-spoofing problem are not generalized. The face anti-spoofing framework proposed in this paper includes spatial stream, temporal stream and fusion modules. The entire design process of experiment is divided into two aspects, one is to use spatial net to achieve spatial information, and another is to apply the temporal net to acquire temporal information. The algorithm implementation is detailed as following. First, optical flow pictures are extracted from the dataset, on which face detection is performed, the optical flow pictures are utilized as the input of the temporal stream to learn temporal information, and the original face pictures are used as the input of the spatial stream to learn spatial information. Second, a shallow network is adopted for the spatial stream network, in which spatial pyramid pooling is combined with global average pooling at the end of the network to obtain hybrid pooling features. We then perform classification using a fully connected layer. For the temporal stream network, we adopt a deep network using residual blocks given that effective temporal features are difficult to extract. Spatial pyramid pooling and global average pooling are also synthesized at the end of the network for the classification. Results obtained from the spatial and temporal stream networks are used for the final score fusion for improved classification. The choice of different color spaces may affect the final result; thus, we compare the effectiveness of different color spaces by experiment and determine the optimal color space of the presented model.ResultThe proposed method is demonstrated on two public benchmark datasets, namely, CASIA-FASD (CASIA face anti-spoofing database) and replay-attack. We obtain the results of 2.141% EER (equal error rate) in the spatial stream, 9.005% EER in the temporal stream, and 1.701% EER in fusion on CASIA-FASD; and 0.071% EER and 0.109% HTER(half total error rate) in the spatial stream, 17.045% EER and 21.781% HTER in the temporal stream, and 0.091% EER and 0.082% HTER in fusion on replay-attack.ConclusionThe two-stream spoofing detection network combined with the hybrid pooling scheme achieves promising results on different datasets. The proposed method utilizes the effective information in temporal dimensionality. The hybrid of spatial pyramid and global average pooling means can exploit the effective information in multiple scales. We can also relieve the burden of the high dimensionality of datasets. Experimental results obtained from popular datasets demonstrate the merits of the proposed method, especially its robustness to the diversity of spoofing means and the large differences in the quality of image datasets. Our promising results will encourage further work on synthesizing an informative stream and lead to successful solutions for other application domains in the future.关键词:anti-spoofing;convolutional neural network (CNN);two-stream network;optical flow method;spatial pyramid pooling;global average pooling30|19|6更新时间:2024-05-07 -
 摘要:ObjectiveIris refers to the annular area between the black pupil and the white sclera of human eyes. It is a biological characteristic with high stability and discrimination ability. Therefore, the iris recognition technology has already been applied to various practical scenarios. However, many iris recognition systems still fail to assure full reliability when facing different presentation attacks. Thus, iris recognition systems cannot be deployed in conditions with strict security requirements. Iris anti-spoofing is a concerned problem in biometrics demanding robust solutions. Iris anti-spoofing (or iris presentation attack detection) aims to judge whether the input iris image is captured from a living subject. This technology is important to prevent invalid authentication from spoofing attacks and protect the security or benefits of users; it needs to be applied to all authentication systems. Existing state-of-the-art algorithms mainly rely on the deep features of iris textures extracted in original gray-scaled space to distinguish fake irises from genuine ones. However, these features can identify only single fake iris pattern, and genuine and various fake irises are overlapped in the original gray-scaled space. A novel iris anti-spoofing method is thus proposed in this study. The triplet network is equipped with a space transformer that is designed to map the original gray-scaled space into a newly enhanced gray-level space, in which the iris features between a specific genuine iris and various fake irises are highly discriminative.MethodA raw eye image includes sclera, pupil, iris, and periocular areas, but only the information of iris is needed. Consequently, the raw image should be preprocessed before image space mapping. The preprocessing mainly includes iris detection, localization, segmentation, and normalization. After a series of image-preprocessing steps, the original gray-scaled normalized iris images are mapped into a newly enhanced gray-level space using the residual network, in which the iris features are highly discriminative. The pretrained LightCNN (light convolutional neural networks)-4 network is used to extract deep features of iris images in the new space. Triplet and softmax losses are adopted to train the model to accomplish a binary classification task.ResultWe evaluate the proposed method on three available iris image databases. The ND-Contact (notre dame cosmetic contact lenses) and CRIPAC (center for research on intelligent perception and computing)-Printed-Iris databases include only cosmetic contact lenses and printed iris images, respectively. The CASIA (Institute of Automation, Chinese Academy of Sciences)-Iris-Fake database includes various fake iris patterns, such as cosmetic contact lens, printed iris, plastic iris (fake iris textures are printed on plastic eyeball models), and synthetic iris (image generation technology based on GAN(generative adversarial networks)). CRIPAC-Printed-Iris is a newly established fake iris database by us for researching on anti-spoofing attack detection algorithms. We perform evaluations in two different detection settings, namely, "close set" and "open set" detection. The "close set" setup means that the training and testing sets share the same type of presentation attack. The "open set" setup refers to the condition in which the presentation attacks unseen in the training set may appear in the testing set; it is considered in our experiments to provide a comprehensive analysis of the proposed method. Experimental results show that the proposed method can achieve accuracy of 100% and 99.75% on two single fake iris pattern databases in the "close set" detection setup. For the hybrid fake iris pattern database, the proposed method can achieve accuracies of 98.94% and 99.06% in the "open set" detection setup. The ablation study shows that the deep features of iris images in the enhanced gray-level image space are more discriminative than those in the original gray-scaled space.ConclusionThe proposed method first enhances the difference in sharpness between genuine and fake iris textures by a space-mapping approach. Then, it minimizes the intraclass distance, maximizes the interclass distance, and keeps a safe margin by triplet loss between genuine and fake iris samples. Thus, the classification accuracy is improved. The model convergence speed is improved by softmax loss. The triplet loss only aims to local samples; as a result, the network training is unstable, and the convergence speed is slow. Thus, we combine the softmax loss to train the classification network, which can provide a global classification interface (aiming to global samples) to increase the convergence speed of network training. Experimental results demonstrate that the analysis and transformation based on image space can effectively solve the difficulty in separating genuine iris and various types of fake irises in the original gray-scaled space. To the best of our knowledge, this is the first time a deep network can distinguish a genuine iris from various types of fake irises because an obvious difference exists between the genuine iris image and various fake iris images in the enhanced gray-level image space. In the "close set" and "open set" detection settings, the trained network can accurately identify the deep features of a specific genuine iris image and distinguish it from various other fake iris images. Therefore, our proposed method can achieve a state-of-the-art performance in iris anti-spoofing, which indicates its effectiveness. The proposed method further enriches and perfects the generalization of a detection method for iris anti-spoofing attacks.关键词:iris liveness detection;enhanced gray-level space;triplet network;discriminative feature;generalization36|56|6更新时间:2024-05-07
摘要:ObjectiveIris refers to the annular area between the black pupil and the white sclera of human eyes. It is a biological characteristic with high stability and discrimination ability. Therefore, the iris recognition technology has already been applied to various practical scenarios. However, many iris recognition systems still fail to assure full reliability when facing different presentation attacks. Thus, iris recognition systems cannot be deployed in conditions with strict security requirements. Iris anti-spoofing is a concerned problem in biometrics demanding robust solutions. Iris anti-spoofing (or iris presentation attack detection) aims to judge whether the input iris image is captured from a living subject. This technology is important to prevent invalid authentication from spoofing attacks and protect the security or benefits of users; it needs to be applied to all authentication systems. Existing state-of-the-art algorithms mainly rely on the deep features of iris textures extracted in original gray-scaled space to distinguish fake irises from genuine ones. However, these features can identify only single fake iris pattern, and genuine and various fake irises are overlapped in the original gray-scaled space. A novel iris anti-spoofing method is thus proposed in this study. The triplet network is equipped with a space transformer that is designed to map the original gray-scaled space into a newly enhanced gray-level space, in which the iris features between a specific genuine iris and various fake irises are highly discriminative.MethodA raw eye image includes sclera, pupil, iris, and periocular areas, but only the information of iris is needed. Consequently, the raw image should be preprocessed before image space mapping. The preprocessing mainly includes iris detection, localization, segmentation, and normalization. After a series of image-preprocessing steps, the original gray-scaled normalized iris images are mapped into a newly enhanced gray-level space using the residual network, in which the iris features are highly discriminative. The pretrained LightCNN (light convolutional neural networks)-4 network is used to extract deep features of iris images in the new space. Triplet and softmax losses are adopted to train the model to accomplish a binary classification task.ResultWe evaluate the proposed method on three available iris image databases. The ND-Contact (notre dame cosmetic contact lenses) and CRIPAC (center for research on intelligent perception and computing)-Printed-Iris databases include only cosmetic contact lenses and printed iris images, respectively. The CASIA (Institute of Automation, Chinese Academy of Sciences)-Iris-Fake database includes various fake iris patterns, such as cosmetic contact lens, printed iris, plastic iris (fake iris textures are printed on plastic eyeball models), and synthetic iris (image generation technology based on GAN(generative adversarial networks)). CRIPAC-Printed-Iris is a newly established fake iris database by us for researching on anti-spoofing attack detection algorithms. We perform evaluations in two different detection settings, namely, "close set" and "open set" detection. The "close set" setup means that the training and testing sets share the same type of presentation attack. The "open set" setup refers to the condition in which the presentation attacks unseen in the training set may appear in the testing set; it is considered in our experiments to provide a comprehensive analysis of the proposed method. Experimental results show that the proposed method can achieve accuracy of 100% and 99.75% on two single fake iris pattern databases in the "close set" detection setup. For the hybrid fake iris pattern database, the proposed method can achieve accuracies of 98.94% and 99.06% in the "open set" detection setup. The ablation study shows that the deep features of iris images in the enhanced gray-level image space are more discriminative than those in the original gray-scaled space.ConclusionThe proposed method first enhances the difference in sharpness between genuine and fake iris textures by a space-mapping approach. Then, it minimizes the intraclass distance, maximizes the interclass distance, and keeps a safe margin by triplet loss between genuine and fake iris samples. Thus, the classification accuracy is improved. The model convergence speed is improved by softmax loss. The triplet loss only aims to local samples; as a result, the network training is unstable, and the convergence speed is slow. Thus, we combine the softmax loss to train the classification network, which can provide a global classification interface (aiming to global samples) to increase the convergence speed of network training. Experimental results demonstrate that the analysis and transformation based on image space can effectively solve the difficulty in separating genuine iris and various types of fake irises in the original gray-scaled space. To the best of our knowledge, this is the first time a deep network can distinguish a genuine iris from various types of fake irises because an obvious difference exists between the genuine iris image and various fake iris images in the enhanced gray-level image space. In the "close set" and "open set" detection settings, the trained network can accurately identify the deep features of a specific genuine iris image and distinguish it from various other fake iris images. Therefore, our proposed method can achieve a state-of-the-art performance in iris anti-spoofing, which indicates its effectiveness. The proposed method further enriches and perfects the generalization of a detection method for iris anti-spoofing attacks.关键词:iris liveness detection;enhanced gray-level space;triplet network;discriminative feature;generalization36|56|6更新时间:2024-05-07 -
 摘要:ObjectiveIn all the 2D image segmentation, the objects in an image can be generally classified into area objects and linear objects. The two kinds of object extraction or detection are different, comparing to area object extraction, since the linear object is more elongated, discontinuous based algorithms may be more suitable to use, but vague or tiny edges can be easy lost, which will make the under-segmentation problem. The linear target detection has a very wide range of applications, such as lane line detection in transportation, road extraction in aerial images and remote sensing images, rock fracture analysis in rock engineering, and cement cracks and asphalt cracks in building and road construction applications. In all the linear object extraction or identification applications, the crack detection in an image is one of the most difficult linear object detection. In order to avoid having the difficulty for extracting linear objects directly and accurately, and to solve the problem of crack image segmentation, a new image segmentation algorithm for tracking crack central line is proposed.MethodThe new algorithm includes three aspects, namely, 1) After image smoothing using a Gaussian filter, an improved fractional differential function is applied to enhance small and vague cracks. This function has nonzero coefficient compared with traditional Tiansi template, indicating that every neighboring pixel of the testing pixel is used for the central feature point detection; 2) Based on that a crack can be regarded as a river/creep, the crack is of a V shape, and the central line in a crack or river is the deep water line, hence, we try to detect the central lines of cracks. The pixels in the central line are called the feature points in this paper. The feature point extraction of crack central lines is based on Steger algorithm and crack image characteristics, where a 1D curve is extended to a 2D ridge or valley line. Then these structures are modeled using a 1D curve, and the feature point is in the direction when it is a curve feature point: the first derivative is zero, the second derivative takes the extreme value, and the feature points are extracted; 3) Considering the distance between the feature points, short gaps between the neighboring segments or points are connected by a line, and long gaps are filled in a optimal routine based on the basis of the gap length and segment angles. We consider that the extraction of cracks in an image is equivalent that a blind man go to find out rivers/creeks on a silt, he will be first step by step to check if there is a deep water point in his current local area, then mark these points and judge which points belong to the same river/creek, finally makes point connection. We assume that a rough and slender crack in a pavement image is a creek or river filled by water, and the boundary of the crack is the side wall. When the feature points of the crack are obtained, the remaining tasks are to connect adjacent feature points and fill crack central line gaps using the idea of water flow-hydrodynamic theory.ResultWe selected 300 pavement crack and 300 other linear object images in the experiments. Compared with the other four similar traditional algorithms, such as distance transformation, maximum entropy, Otsu, Canny and valley edge detection image segmentation algorithms, the proposed algorithm produces less gaps on the central lines of linear objects or cracks and has less over-segmentation and under-segmentation problems.ConclusionThe proposed algorithm can be used in complex linear object and rough pavement crack images because it can rapidly and accurately extract the central line and overcome the existing image segmentation problems for linear object images.关键词:linear object;crack;fractional differential;Steger;hydrodynamics30|32|1更新时间:2024-05-07
摘要:ObjectiveIn all the 2D image segmentation, the objects in an image can be generally classified into area objects and linear objects. The two kinds of object extraction or detection are different, comparing to area object extraction, since the linear object is more elongated, discontinuous based algorithms may be more suitable to use, but vague or tiny edges can be easy lost, which will make the under-segmentation problem. The linear target detection has a very wide range of applications, such as lane line detection in transportation, road extraction in aerial images and remote sensing images, rock fracture analysis in rock engineering, and cement cracks and asphalt cracks in building and road construction applications. In all the linear object extraction or identification applications, the crack detection in an image is one of the most difficult linear object detection. In order to avoid having the difficulty for extracting linear objects directly and accurately, and to solve the problem of crack image segmentation, a new image segmentation algorithm for tracking crack central line is proposed.MethodThe new algorithm includes three aspects, namely, 1) After image smoothing using a Gaussian filter, an improved fractional differential function is applied to enhance small and vague cracks. This function has nonzero coefficient compared with traditional Tiansi template, indicating that every neighboring pixel of the testing pixel is used for the central feature point detection; 2) Based on that a crack can be regarded as a river/creep, the crack is of a V shape, and the central line in a crack or river is the deep water line, hence, we try to detect the central lines of cracks. The pixels in the central line are called the feature points in this paper. The feature point extraction of crack central lines is based on Steger algorithm and crack image characteristics, where a 1D curve is extended to a 2D ridge or valley line. Then these structures are modeled using a 1D curve, and the feature point is in the direction when it is a curve feature point: the first derivative is zero, the second derivative takes the extreme value, and the feature points are extracted; 3) Considering the distance between the feature points, short gaps between the neighboring segments or points are connected by a line, and long gaps are filled in a optimal routine based on the basis of the gap length and segment angles. We consider that the extraction of cracks in an image is equivalent that a blind man go to find out rivers/creeks on a silt, he will be first step by step to check if there is a deep water point in his current local area, then mark these points and judge which points belong to the same river/creek, finally makes point connection. We assume that a rough and slender crack in a pavement image is a creek or river filled by water, and the boundary of the crack is the side wall. When the feature points of the crack are obtained, the remaining tasks are to connect adjacent feature points and fill crack central line gaps using the idea of water flow-hydrodynamic theory.ResultWe selected 300 pavement crack and 300 other linear object images in the experiments. Compared with the other four similar traditional algorithms, such as distance transformation, maximum entropy, Otsu, Canny and valley edge detection image segmentation algorithms, the proposed algorithm produces less gaps on the central lines of linear objects or cracks and has less over-segmentation and under-segmentation problems.ConclusionThe proposed algorithm can be used in complex linear object and rough pavement crack images because it can rapidly and accurately extract the central line and overcome the existing image segmentation problems for linear object images.关键词:linear object;crack;fractional differential;Steger;hydrodynamics30|32|1更新时间:2024-05-07 -
 摘要:ObjectiveWith the ubiquity of electronic equipment, such as cellphones and cameras, massive video data of people's activities and behaviors in daily life are stored, recorded, and transmitted. Increasing video-based applications, such as video surveillance, have attracted the attention of researchers. However, real-world videos are consistently long and untrimmed. Long untrimmed videos in publicly available datasets for temporal action detection consistently contain several ambiguous frames and a large number of background frames. Accurately locating action proposals and recognizing action labels are difficult. Similar to object proposal generation in object detection task, the task of temporal action detection can be resolved into two phases, where the first phase is to determine the specific durations (starting and ending timestamps) of actions, and the second phase is to identify the category of each action instance. The development of single-action classification in trimmed videos has been extremely successful, whereas the performance of temporal action proposal generation remains unsatisfactory. The phase of candidate action proposal generation experiences time-consuming model training. High-quality proposals contribute to the performance of action detection. The study on temporal proposal generation can effectively and efficiently locate the video content and facilitate video understanding in untrimmed videos. In this work, we focus on the optimization of temporal action proposals for action detection.MethodWe aim to improve the performance of action detection by optimizing temporal action proposals, that is, accurately localizing the boundaries of actions in long untrimmed videos. We propose a temporal proposal optimization (TPO) model for the detection of candidate action proposals. TPO utilizes the advantages of convolutional neural networks (CNNs) and bidirectional long short-term memory (BLSTM) to simultaneously capture the local and global temporal cues. In the proposed TPO model, we introduce connectionist temporal classification (CTC) optimization, which excels at parsing global feature-level classification labels. The global actionness probability calculated by BLSTM and CTC modifies several inexact temporal cues in the local CNN actionness probability. Thus, a probability fusion strategy based on local and global actionness probabilities promotes the accuracy of temporal boundaries of actions in videos and results in the promising performance of temporal action detection. In particular, TPO is composed of three modules, namely, local actionness evaluation module (LAEM), global actionness evaluation module (GAEM), and post processing module (PPM). The extracted features are fed into LAEM and GAEM. Then, LAEM and GAEM generate the global and local actionness probabilities along the temporal dimension, respectively. LAEM is a temporal CNN-based module, and GAEM predicts the global actionness probabilities with the help of BLSTM and CTC losses. LAEM outputs three sequences. Starting and ending probabilities are found in addition to local actionness probabilities. The crossing of starting and ending probability curves builds the candidate temporal proposals. Thus, GAEM captures global actionness probabilities, which is auxiliary to LAEM. Then, the local and global actionness probabilities are fed into PPM to obtain a fused actionness probability curve. Subsequently, we sample the actionness probability curves through linear interpolation to extract proposal-level features. The proposal-level features are fed int a multilayer perceptron) to obtain the confidence score. We use the confidence score to rank the candidate proposals and adopt soft-NMS(non-maximum supression) to remove redundant proposals. Finally, we apply an existing classification model with our generated proposals to evaluate the detection performance of TPO.ResultWe validate the proposed model on two evaluations of action proposal generation and action detection. Experimental results indicate that TPO outperforms other state-of-the-art methods on ActivityNet v1.3 dataset. For the proposal generation, we compare our model with the methods, including SSN(structured segment network), TCN(temporal context network), Prop-SSAD(single shot action detector for proposal), CTAP(complementary temporal action proposal), and BSN(boundary sensitive network). The proposed TPO model performs best and achieves average recall @ average number of proposals of 74.66 and area under a curve of 66.32. For the temporal action detection task, we test the quantitative evaluation metric mean average precision@intersection over union (mAP@IoU). Compared with the existing methods, including SCC(semantic cascade context), CDC(convolutional-de-convolutional), SSN and BSN, TPO achieves the best mAPs of 30.73 and 8.22 under the tIoUs of 0.75 and 0.95, respectively, and obtains the best average mAP of 30.5. Notably, the mAP value decreases with the increase in tIoU value. The tIoU metric reflects the overlap between the generated proposals and the ground truth, where a high tIoU value indicates strict constraints on candidate proposals. Thus, TPO achieves the best mAP performance under high tIoU values (0.75 and 0.95). This result validates the detection performance. TPO generates accurate proposals of action instances with high overlap on the ground truth and improves the detection performance.ConclusionIn this paper, we propose a novel model called TPO for temporal proposal generation that achieves promising performance on ActivityNet v1.3 to resolve the action detection problem. Experimental results demonstrate the effectiveness of TPO. TPO generates temporal proposals with precise boundaries and maintains flexible temporal durations, thereby covering sequential actions in videos with variable-length intervals.关键词:temporal action detection;temporal action proposals;actionness probability;connectionist temporal classification (CTC);convolutional neural network (CNN);bidirectional long short term memory (BLSTM)27|16|3更新时间:2024-05-07
摘要:ObjectiveWith the ubiquity of electronic equipment, such as cellphones and cameras, massive video data of people's activities and behaviors in daily life are stored, recorded, and transmitted. Increasing video-based applications, such as video surveillance, have attracted the attention of researchers. However, real-world videos are consistently long and untrimmed. Long untrimmed videos in publicly available datasets for temporal action detection consistently contain several ambiguous frames and a large number of background frames. Accurately locating action proposals and recognizing action labels are difficult. Similar to object proposal generation in object detection task, the task of temporal action detection can be resolved into two phases, where the first phase is to determine the specific durations (starting and ending timestamps) of actions, and the second phase is to identify the category of each action instance. The development of single-action classification in trimmed videos has been extremely successful, whereas the performance of temporal action proposal generation remains unsatisfactory. The phase of candidate action proposal generation experiences time-consuming model training. High-quality proposals contribute to the performance of action detection. The study on temporal proposal generation can effectively and efficiently locate the video content and facilitate video understanding in untrimmed videos. In this work, we focus on the optimization of temporal action proposals for action detection.MethodWe aim to improve the performance of action detection by optimizing temporal action proposals, that is, accurately localizing the boundaries of actions in long untrimmed videos. We propose a temporal proposal optimization (TPO) model for the detection of candidate action proposals. TPO utilizes the advantages of convolutional neural networks (CNNs) and bidirectional long short-term memory (BLSTM) to simultaneously capture the local and global temporal cues. In the proposed TPO model, we introduce connectionist temporal classification (CTC) optimization, which excels at parsing global feature-level classification labels. The global actionness probability calculated by BLSTM and CTC modifies several inexact temporal cues in the local CNN actionness probability. Thus, a probability fusion strategy based on local and global actionness probabilities promotes the accuracy of temporal boundaries of actions in videos and results in the promising performance of temporal action detection. In particular, TPO is composed of three modules, namely, local actionness evaluation module (LAEM), global actionness evaluation module (GAEM), and post processing module (PPM). The extracted features are fed into LAEM and GAEM. Then, LAEM and GAEM generate the global and local actionness probabilities along the temporal dimension, respectively. LAEM is a temporal CNN-based module, and GAEM predicts the global actionness probabilities with the help of BLSTM and CTC losses. LAEM outputs three sequences. Starting and ending probabilities are found in addition to local actionness probabilities. The crossing of starting and ending probability curves builds the candidate temporal proposals. Thus, GAEM captures global actionness probabilities, which is auxiliary to LAEM. Then, the local and global actionness probabilities are fed into PPM to obtain a fused actionness probability curve. Subsequently, we sample the actionness probability curves through linear interpolation to extract proposal-level features. The proposal-level features are fed int a multilayer perceptron) to obtain the confidence score. We use the confidence score to rank the candidate proposals and adopt soft-NMS(non-maximum supression) to remove redundant proposals. Finally, we apply an existing classification model with our generated proposals to evaluate the detection performance of TPO.ResultWe validate the proposed model on two evaluations of action proposal generation and action detection. Experimental results indicate that TPO outperforms other state-of-the-art methods on ActivityNet v1.3 dataset. For the proposal generation, we compare our model with the methods, including SSN(structured segment network), TCN(temporal context network), Prop-SSAD(single shot action detector for proposal), CTAP(complementary temporal action proposal), and BSN(boundary sensitive network). The proposed TPO model performs best and achieves average recall @ average number of proposals of 74.66 and area under a curve of 66.32. For the temporal action detection task, we test the quantitative evaluation metric mean average precision@intersection over union (mAP@IoU). Compared with the existing methods, including SCC(semantic cascade context), CDC(convolutional-de-convolutional), SSN and BSN, TPO achieves the best mAPs of 30.73 and 8.22 under the tIoUs of 0.75 and 0.95, respectively, and obtains the best average mAP of 30.5. Notably, the mAP value decreases with the increase in tIoU value. The tIoU metric reflects the overlap between the generated proposals and the ground truth, where a high tIoU value indicates strict constraints on candidate proposals. Thus, TPO achieves the best mAP performance under high tIoU values (0.75 and 0.95). This result validates the detection performance. TPO generates accurate proposals of action instances with high overlap on the ground truth and improves the detection performance.ConclusionIn this paper, we propose a novel model called TPO for temporal proposal generation that achieves promising performance on ActivityNet v1.3 to resolve the action detection problem. Experimental results demonstrate the effectiveness of TPO. TPO generates temporal proposals with precise boundaries and maintains flexible temporal durations, thereby covering sequential actions in videos with variable-length intervals.关键词:temporal action detection;temporal action proposals;actionness probability;connectionist temporal classification (CTC);convolutional neural network (CNN);bidirectional long short term memory (BLSTM)27|16|3更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:Objective Human pose tracking in video sequences aims to estimate the pose of a certain person in each frame using image and video cues and consecutively track the human pose throughout the entire video. This field has been increasingly investigated because the development of artificial intelligence and the Internet of Things makes human-computer interaction frequent. Robots or intelligent agents would understand human action and intention by visually tracking human poses. At present, researchers frequently use pictorial structure model to express human poses and use inference methods for tracking. However, the tracking accuracy of current human pose tracking methods needs to be improved, especially for flexible moving arm parts. Although different types of features describe different types of information, the crucial point of human pose tracking depends on utilizing and combining appropriate features. We investigate the construction of effective features to accurately describe the poses of different body parts and propose a method that combines video spatial and temporal features and deep learning features to improve the accuracy of human pose tracking. This paper presents a novel human pose tracking method that effectively uses various video information to optimize human pose tracking in video sequences. Method An evaluation criterion should be used to track a visual target. Human pose is an articulated complex visual target, and evaluating it as a whole leads to ambiguity. In this case, this paper proposes a decomposable human pose expression model that can track each part of human body separately during the video and recombine parts into an entire body pose in each single image. Human pose is expressed as a principal component analysis model of trained contour shape similar to a puppet, and each human part pose contour can be calculated using key points and model parameters. As human pose unpredictably changes, tracking while detecting would improve the human pose tracking accuracy, which is different from traditional visual tracking tasks. During tracking, the video temporal information in the region of each human part target is used to calculate the motion information of each human part pose, and then the motion information is used to propagate the human part contour from each frame to the next. The propagated human parts are treated as human body part candidates in the current frame for subsequent calculation. During propagation, the background motion would disturb and pollute the foreground target motion information, resulting in the deviations of human part candidates obtained through propagation using motion information. To avoid the influence of propagated human part pose deviation, a pictorial structure-based method is adopted to generate additional human body pose candidates and are then decomposed into human body part poses for body part tracking and optimization. The pictorial structure-based method can detect relatively fixed body parts, such as trunk and head, whereas the detection effect of arms is poor because arms move flexibly and their shapes substantially and frequently change. In this circumstance, the problem of arm detection should be solved. A lightweight deep learning network is constructed and trained to generate probability graphs for the key points of human lower arms to solve this problem. Sampling from the generated probability graphs can obtain additional candidates of human lower arm poses. The propagated and generated human part pose candidates need to evaluated. The proposed evaluation method considers image spatial information and deep learning knowledge. Spatial information includes color and contour likelihoods, where the color likelihood function ensures the consistency of part color during tracking, and the contour likelihood function ensures the consistency of human part model contour with image contour feature. The proposed deep learning network can generate probability maps of lower arm feature consistency for each side to reveal the image feature consistency for each calculated lower arm candidates. The spatial and deep learning features work together to evaluate and optimize the part poses for each human part, and the optimized parts are recombined into integrated human pose, where the negative recombined human body poses are eliminated by the shape constraints of the proposed decomposable human model. The recombined optimized human entire pose is the human pose tracking result for the current video frame and is decomposed and propagated to the next frame for subsequent human pose tracking. Result Two publicly available challenging human pose tracking datasets, namely, VideoPose2.0 and YouTubePose datasets, are used to verify the proposed human pose tracking method. For the VideoPose2.0 dataset, the key point accuracy of human pose tracking for shoulders, elbows, and wrists are 90.5%, 82.6%, and 71.2%, respectively, and the average key point accuracy is 81.4%. The results are higher than state-of-the-art methods, such as the method based on conditional random field model (higher by 15.3%), the method based on tree structure reasoning model (higher by 3.9%), and the method based on max-margin Markova model (higher by 8.8%). For the YouTubePose dataset, the key point accuracy of human pose tracking for shoulders, elbows, and wrists are 86.2%, 84.8%, and 81.6%, respectively, and the average key point accuracy is 84.5%. The results are higher than state-of-the-art methods, such as the method based on flowing convent model (higher by 13.7%), the method based on dependent pairwise relation model (higher by 1.1%), and the method based on mixed part sequence reasoning model (higher by 15.9%). The proposed crucial algorithms of additional sampling and feature consistency of lower arm are verified on the VideoPose2.0 dataset, thereby effectively improving the tracking accuracy of lower arm joints by 5.2% and 31.2%, respectively. Conclusion Experimental results show that the proposed human pose tracking method that uses spatial-temporal cues coupled with deep learning probability maps can effectively improve the pose tracking accuracy, especially for the flexible moving lower arms.关键词:human pose tracking;visual target tracking;human-computer interaction;deep learning network;probability map for joints47|56|2更新时间:2024-05-07
摘要:Objective Human pose tracking in video sequences aims to estimate the pose of a certain person in each frame using image and video cues and consecutively track the human pose throughout the entire video. This field has been increasingly investigated because the development of artificial intelligence and the Internet of Things makes human-computer interaction frequent. Robots or intelligent agents would understand human action and intention by visually tracking human poses. At present, researchers frequently use pictorial structure model to express human poses and use inference methods for tracking. However, the tracking accuracy of current human pose tracking methods needs to be improved, especially for flexible moving arm parts. Although different types of features describe different types of information, the crucial point of human pose tracking depends on utilizing and combining appropriate features. We investigate the construction of effective features to accurately describe the poses of different body parts and propose a method that combines video spatial and temporal features and deep learning features to improve the accuracy of human pose tracking. This paper presents a novel human pose tracking method that effectively uses various video information to optimize human pose tracking in video sequences. Method An evaluation criterion should be used to track a visual target. Human pose is an articulated complex visual target, and evaluating it as a whole leads to ambiguity. In this case, this paper proposes a decomposable human pose expression model that can track each part of human body separately during the video and recombine parts into an entire body pose in each single image. Human pose is expressed as a principal component analysis model of trained contour shape similar to a puppet, and each human part pose contour can be calculated using key points and model parameters. As human pose unpredictably changes, tracking while detecting would improve the human pose tracking accuracy, which is different from traditional visual tracking tasks. During tracking, the video temporal information in the region of each human part target is used to calculate the motion information of each human part pose, and then the motion information is used to propagate the human part contour from each frame to the next. The propagated human parts are treated as human body part candidates in the current frame for subsequent calculation. During propagation, the background motion would disturb and pollute the foreground target motion information, resulting in the deviations of human part candidates obtained through propagation using motion information. To avoid the influence of propagated human part pose deviation, a pictorial structure-based method is adopted to generate additional human body pose candidates and are then decomposed into human body part poses for body part tracking and optimization. The pictorial structure-based method can detect relatively fixed body parts, such as trunk and head, whereas the detection effect of arms is poor because arms move flexibly and their shapes substantially and frequently change. In this circumstance, the problem of arm detection should be solved. A lightweight deep learning network is constructed and trained to generate probability graphs for the key points of human lower arms to solve this problem. Sampling from the generated probability graphs can obtain additional candidates of human lower arm poses. The propagated and generated human part pose candidates need to evaluated. The proposed evaluation method considers image spatial information and deep learning knowledge. Spatial information includes color and contour likelihoods, where the color likelihood function ensures the consistency of part color during tracking, and the contour likelihood function ensures the consistency of human part model contour with image contour feature. The proposed deep learning network can generate probability maps of lower arm feature consistency for each side to reveal the image feature consistency for each calculated lower arm candidates. The spatial and deep learning features work together to evaluate and optimize the part poses for each human part, and the optimized parts are recombined into integrated human pose, where the negative recombined human body poses are eliminated by the shape constraints of the proposed decomposable human model. The recombined optimized human entire pose is the human pose tracking result for the current video frame and is decomposed and propagated to the next frame for subsequent human pose tracking. Result Two publicly available challenging human pose tracking datasets, namely, VideoPose2.0 and YouTubePose datasets, are used to verify the proposed human pose tracking method. For the VideoPose2.0 dataset, the key point accuracy of human pose tracking for shoulders, elbows, and wrists are 90.5%, 82.6%, and 71.2%, respectively, and the average key point accuracy is 81.4%. The results are higher than state-of-the-art methods, such as the method based on conditional random field model (higher by 15.3%), the method based on tree structure reasoning model (higher by 3.9%), and the method based on max-margin Markova model (higher by 8.8%). For the YouTubePose dataset, the key point accuracy of human pose tracking for shoulders, elbows, and wrists are 86.2%, 84.8%, and 81.6%, respectively, and the average key point accuracy is 84.5%. The results are higher than state-of-the-art methods, such as the method based on flowing convent model (higher by 13.7%), the method based on dependent pairwise relation model (higher by 1.1%), and the method based on mixed part sequence reasoning model (higher by 15.9%). The proposed crucial algorithms of additional sampling and feature consistency of lower arm are verified on the VideoPose2.0 dataset, thereby effectively improving the tracking accuracy of lower arm joints by 5.2% and 31.2%, respectively. Conclusion Experimental results show that the proposed human pose tracking method that uses spatial-temporal cues coupled with deep learning probability maps can effectively improve the pose tracking accuracy, especially for the flexible moving lower arms.关键词:human pose tracking;visual target tracking;human-computer interaction;deep learning network;probability map for joints47|56|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
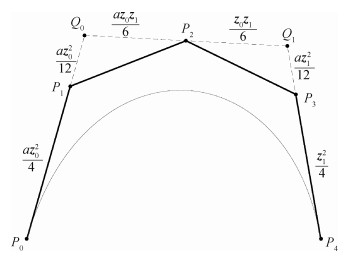 摘要:ObjectiveThe problem of interpolating three distinct planar points using quartic Pythagorean hodograph (PH) curves is studied. PH curves comprise an important class of polynomial curves that form a mathematical foundation of most current computer-aided design (CAD) tools. By incorporating special algebraic structures into their hodograph curves, PH curves exhibit many advanced properties over ordinary polynomial parametric curves. These properties include polynomial arc-length functions and rational offset curves. Thus, PH curves are considered a sophisticated solution for a variety of difficult issues arising in applications (e.g., tool paths) in the fields of computer numerically controlled machining and real-time motion control. For example, the arc-length of a PH curve can be computed without numerical integration, accelerating algorithms for numerically controlled machining. The offsets of a PH curve can also be represented exactly rather than being approximated in CAD systems. Thus, analyzing and manipulating PH curves are of considerable practical value in CAD and other applications. PH curves can be represented as widely used Bézier curves. The most intuitive and efficient method for constructing PH curves is by adjusting the control points of Bézier curves under conditions that guarantee PH properties. Therefore, a variety of methods for identifying PH curves are developed. Another important application of PH curves is the geometric construction of these curves. Considerable work has been conducted on Hermite interpolation with different degrees of PH curves. However, methods for interpolating three or more planar points have been rarely studied.MethodThe necessary and sufficient condition for a planar curve to be a PH curve is a form of a product of complex polynomials, and a Bézier curve and its first derivative are Bernstein polynomials, which are a form of the sum of Bernstein basis functions. We derive a system of complex nonlinear equations by considering the compatibility of the two forms. The geometric meanings of the coefficients are then introduced by presenting several auxiliary points for their Bézier control polygons. To construct a quartic PH curve that interpolates any given three planar points, the first and last points are used as the two endpoints of a Bézier curve. The second point is parameterized by computing the chord lengths by connecting three given points. A complex unknown should be solved considering the integration of the first derivative. The compatibility of complex systems provides a quadratic complex equation with a real coefficient. Thus, in accordance with the fundamental theorem of algebra, two quartic PH curves satisfy any given conditions. A user may interactively construct a series of quartic PH curves by specifying a real coefficient.ResultThe method is implemented using MATLAB. A maximum of two families of quartic PH curves can be constructed for any given three points. Moreover, arc-lengths, bending energy, and absolute rotation numbers can be computed to select the best solution. Curves with low energy and/or an absolute rotation number can be generally regarded as the best solution because curves with a large bending energy and/or absolute rotation numbers are typically self-intersected. Examples show that the shape can be interactively adjusted by changing a real coefficient, determining the parameter value of the cusp. Lastly, the offsets of the constructed quartic PH curves are shown.ConclusionThe proposed method can efficiently construct quartic PH curves for any given three planar points. Only a quadratic complex equation is required to be solved. Thus, the method is robust and efficient. Future studies may consider other applications of the proposed method, e.g., data interpolation using quartic PH splines.关键词:computer aided design (CAD);Bezier curve;control polygon;offset curve;quartic PH curve;interpolation48|62|0更新时间:2024-05-07
摘要:ObjectiveThe problem of interpolating three distinct planar points using quartic Pythagorean hodograph (PH) curves is studied. PH curves comprise an important class of polynomial curves that form a mathematical foundation of most current computer-aided design (CAD) tools. By incorporating special algebraic structures into their hodograph curves, PH curves exhibit many advanced properties over ordinary polynomial parametric curves. These properties include polynomial arc-length functions and rational offset curves. Thus, PH curves are considered a sophisticated solution for a variety of difficult issues arising in applications (e.g., tool paths) in the fields of computer numerically controlled machining and real-time motion control. For example, the arc-length of a PH curve can be computed without numerical integration, accelerating algorithms for numerically controlled machining. The offsets of a PH curve can also be represented exactly rather than being approximated in CAD systems. Thus, analyzing and manipulating PH curves are of considerable practical value in CAD and other applications. PH curves can be represented as widely used Bézier curves. The most intuitive and efficient method for constructing PH curves is by adjusting the control points of Bézier curves under conditions that guarantee PH properties. Therefore, a variety of methods for identifying PH curves are developed. Another important application of PH curves is the geometric construction of these curves. Considerable work has been conducted on Hermite interpolation with different degrees of PH curves. However, methods for interpolating three or more planar points have been rarely studied.MethodThe necessary and sufficient condition for a planar curve to be a PH curve is a form of a product of complex polynomials, and a Bézier curve and its first derivative are Bernstein polynomials, which are a form of the sum of Bernstein basis functions. We derive a system of complex nonlinear equations by considering the compatibility of the two forms. The geometric meanings of the coefficients are then introduced by presenting several auxiliary points for their Bézier control polygons. To construct a quartic PH curve that interpolates any given three planar points, the first and last points are used as the two endpoints of a Bézier curve. The second point is parameterized by computing the chord lengths by connecting three given points. A complex unknown should be solved considering the integration of the first derivative. The compatibility of complex systems provides a quadratic complex equation with a real coefficient. Thus, in accordance with the fundamental theorem of algebra, two quartic PH curves satisfy any given conditions. A user may interactively construct a series of quartic PH curves by specifying a real coefficient.ResultThe method is implemented using MATLAB. A maximum of two families of quartic PH curves can be constructed for any given three points. Moreover, arc-lengths, bending energy, and absolute rotation numbers can be computed to select the best solution. Curves with low energy and/or an absolute rotation number can be generally regarded as the best solution because curves with a large bending energy and/or absolute rotation numbers are typically self-intersected. Examples show that the shape can be interactively adjusted by changing a real coefficient, determining the parameter value of the cusp. Lastly, the offsets of the constructed quartic PH curves are shown.ConclusionThe proposed method can efficiently construct quartic PH curves for any given three planar points. Only a quadratic complex equation is required to be solved. Thus, the method is robust and efficient. Future studies may consider other applications of the proposed method, e.g., data interpolation using quartic PH splines.关键词:computer aided design (CAD);Bezier curve;control polygon;offset curve;quartic PH curve;interpolation48|62|0更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveWith the rapid development of 3D digital imaging technology, increasing applications of computer-aided diagnosis and treatment in oral restoration have gradually become the development trend in this field. A key step in orthodontics is to separate the teeth on the digital 3D dental model. The selection of tooth seed points is crucial in the tooth segmentation method commonly used in computer orthodontics. Most orthodontic software in the industry adopts a segmentation method that requires interactive marking, and the seed point of each tooth is selected on the 3D dental model by human-computer interaction. The efficiency is low. To solve this problem, an automatic selection method for tooth seed points based on feature-steered graph convolutional network (FeaStNet) is proposed.MethodThe seed point position and final segmentation effect of each tooth type are analyzed, and a unified rule is established. A seed point dataset of a dental model is built. A new multiscale graph convolution architecture is constructed using feature-steered graph convolutions to identify the feature information on the 3D dental model. The depth of the network model is deepened to fit the characteristics of the teeth. Training is conducted to adjust parameters, and a multiscale network structure is used to find specific seed points. The prediction model is evaluated using the mean squared difference loss function to improve the accuracy. The feature points identified through the network are regarded as the basic points to find the point closest to the base point on the dental model and set it as the seed point. If the seed point position is accurate, then the teeth are separated from the gums in accordance with the seed point. For the result of inaccurate seed point position, the position of the seed point is corrected by manual operation first and then segmentation is performed. The dental model is simplified to improve the training speed. The simplified model is used to establish an experimental dataset and specify the position of the seed points of different types of teeth.The 3D dental model is divided into the following information for preservation: the 3D coordinate values of all vertices in the dental model, the adjacency relationship of the vertices in the dental model, and the 3D coordinate values of the tooth seed points.The mean squared difference loss function is used to perform an imbalance check. The loss value decreases rapidly at the beginning of training, converges promptly, and tends to be stable after an oscillation period.ResultThe experiment is conducted on a self-built dataset, in which the exact point of the seed point is 88%. In other cases, only the position of a partially inaccurate seed point needs to be adjusted. The base point of the deviation of the teeth is roughly divided into two cases. One is that the seed point of the incisor deviates, and the other is that the molar is not on the tooth surface. After the basic point is acquired, the point closest to the base point on the dental model is determined as a seed point and applied to the orthodontic software to separate the teeth from the gums.The method is simple and fast and has less manual intervention than existing methods. Thus, its work efficiency improved. After the method is applied to the orthodontic software and the hardware platform, the entire segmentation time is accelerated to approximately 7 s. In the path-planning method, the time taken for segmentation is approximately 20 s. The comparison proves that the current method has obvious advantages in speed.ConclusionThe proposed seed-point automatic selection method solves the problem of tooth segmentation requiring interactive marking and automates dental division. It is applicable to all types of dental deformity in patients with tooth model division.The automatic selection of seed points can also be used as a reference for other segmentation methods. In the segmentation of teeth, in addition to the characteristics of seed points, other tooth feature points are important. Future research is suggested to learn additional tooth features, further improve the speed of tooth segmentation, and help doctors improve work efficiency.关键词:orthodontics;tooth segmentation;feature-steered graph convolutions;tooth seed points;3D dental meshes57|55|2更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of 3D digital imaging technology, increasing applications of computer-aided diagnosis and treatment in oral restoration have gradually become the development trend in this field. A key step in orthodontics is to separate the teeth on the digital 3D dental model. The selection of tooth seed points is crucial in the tooth segmentation method commonly used in computer orthodontics. Most orthodontic software in the industry adopts a segmentation method that requires interactive marking, and the seed point of each tooth is selected on the 3D dental model by human-computer interaction. The efficiency is low. To solve this problem, an automatic selection method for tooth seed points based on feature-steered graph convolutional network (FeaStNet) is proposed.MethodThe seed point position and final segmentation effect of each tooth type are analyzed, and a unified rule is established. A seed point dataset of a dental model is built. A new multiscale graph convolution architecture is constructed using feature-steered graph convolutions to identify the feature information on the 3D dental model. The depth of the network model is deepened to fit the characteristics of the teeth. Training is conducted to adjust parameters, and a multiscale network structure is used to find specific seed points. The prediction model is evaluated using the mean squared difference loss function to improve the accuracy. The feature points identified through the network are regarded as the basic points to find the point closest to the base point on the dental model and set it as the seed point. If the seed point position is accurate, then the teeth are separated from the gums in accordance with the seed point. For the result of inaccurate seed point position, the position of the seed point is corrected by manual operation first and then segmentation is performed. The dental model is simplified to improve the training speed. The simplified model is used to establish an experimental dataset and specify the position of the seed points of different types of teeth.The 3D dental model is divided into the following information for preservation: the 3D coordinate values of all vertices in the dental model, the adjacency relationship of the vertices in the dental model, and the 3D coordinate values of the tooth seed points.The mean squared difference loss function is used to perform an imbalance check. The loss value decreases rapidly at the beginning of training, converges promptly, and tends to be stable after an oscillation period.ResultThe experiment is conducted on a self-built dataset, in which the exact point of the seed point is 88%. In other cases, only the position of a partially inaccurate seed point needs to be adjusted. The base point of the deviation of the teeth is roughly divided into two cases. One is that the seed point of the incisor deviates, and the other is that the molar is not on the tooth surface. After the basic point is acquired, the point closest to the base point on the dental model is determined as a seed point and applied to the orthodontic software to separate the teeth from the gums.The method is simple and fast and has less manual intervention than existing methods. Thus, its work efficiency improved. After the method is applied to the orthodontic software and the hardware platform, the entire segmentation time is accelerated to approximately 7 s. In the path-planning method, the time taken for segmentation is approximately 20 s. The comparison proves that the current method has obvious advantages in speed.ConclusionThe proposed seed-point automatic selection method solves the problem of tooth segmentation requiring interactive marking and automates dental division. It is applicable to all types of dental deformity in patients with tooth model division.The automatic selection of seed points can also be used as a reference for other segmentation methods. In the segmentation of teeth, in addition to the characteristics of seed points, other tooth feature points are important. Future research is suggested to learn additional tooth features, further improve the speed of tooth segmentation, and help doctors improve work efficiency.关键词:orthodontics;tooth segmentation;feature-steered graph convolutions;tooth seed points;3D dental meshes57|55|2更新时间:2024-05-07 -
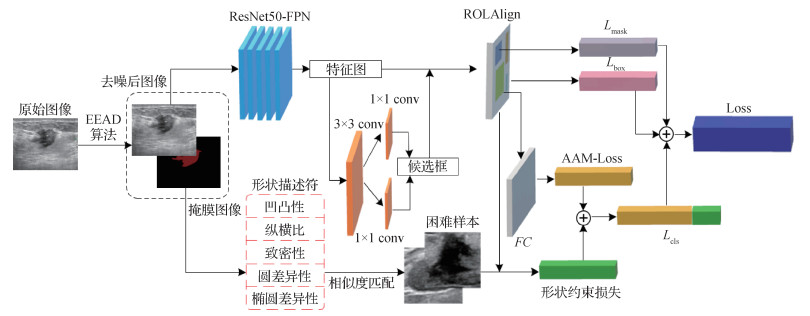 摘要:ObjectiveUltrasound is the primary imagological examination and preoperative assessment for breast nodules. In the qualitative diagnosis of nodules in breast ultrasound images, the breast imaging and reporting data system (BI-RADS) with six levels is commonly used by physicians to evaluate the degree of malignant breast lesions. However, BI-RADS evaluation is time-consuming and mostly based on the morphological features and partial acoustic information of a lesion. Diagnosis relies heavily on the experience of physicians because of the overlapping image expression of benign and malignant breast nodules. The diagnostic accuracy of physicians with different qualifications can differ by up to 30%. Therefore, misdiagnosis or missed diagnosis can easily occur, increasing the needless rate of puncture biopsy. The current computer-assisted breast ultrasound diagnosis requires considerable human interactions. The automation level is low, and accuracy is unfavorable. In recent years, the deep learning method has been applied to the visual tasks such as medical ultrasound image classification and achieved good results. This study proposes an end-to-end model for automatic nodule extraction and classification.MethodAn ultrasound image of the breast is the result of using ultrasonic signals that are reflected by ultrasound when it encounters tissues in the human body. Given the limitation of the imaging mechanism of medical ultrasound, noise interference in breast ultrasound images is typically severe and mostly affected by additive thermal and multiplicative speckle noises. Thermal noise is caused by the heat generated by the capturing device and can be avoided via physical cooling. Speckle noise is a bright and dark particle-like spot formed by the constructive and destructive interference of reflected ultrasonic waves; it is unavoidable because of the principle of ultrasound imaging. For the model of speckle noise in an ultrasound image, this work uses edge enhanced anisotropic diffusion(EEAD) to remove noise as a preprocessing step. Then, an improved loss function is proposed to enhance the discriminant performance of our method with respect to nodules' characteristics of benign and malignant parts. We use a combination of shape descriptors (concavity, aspect ratio, compactness, circle variance, and elliptic variance) to describe difficult samples with similar shapes to other classes, which can be apt to misjudgment. To make such difficult samples more distinguishable, an improved loss function is developed in this study. This function builds the shape constraint loss term of difficult samples to adjust feature mapping.ResultA breast ultrasound dataset with 1 805 images is collected to validate our method. For this dataset, the average diagnosis accuracy(AUC) of physicians with five-year qualifications is 85.3%. However, the classification accuracy, sensitivity, specificity, and area under the curve of our method are 92.58%, 90.44%, 93.72%, and 0.946, respectively, which are superior to those of the comparison algorithms. Moreover, compared with the traditional softmax loss function, the performance can be increased by 5%—12%.ConclusionIn this study, the classification of benign and malignant nodules in two-dimensional ultrasound images of the breast is the main research content, and the advanced achievements in machine learning, computer vision and medicine are taken as the technical support. Aiming at the problems of poor quality of two-dimensional ultrasound images of the breast, small proportion of lesions, overlapping of benign and malignant nodule images, and heavy dependence on doctors' experience in diagnosis, this paper improves the data preprocessing level and algorithm At the level of data preprocessing, the original breast ultrasound data is denoised and expanded to improve the quality of the data set and maximize the utilization of the data set; at the level of algorithm improvement, the model training process is dynamically monitored to dynamically mine difficult samples and regularize the distance between classes to improve the classification effect of benign and malignant. In this study, an end-to-end ultrasound image analysis model of the breast is proposed. This model is pragmatic and useful for clinics. By incorporating medical knowledge into the optimization process and adding the shape constraint loss of difficult samples, the accuracy and robustness of breast benign and malignant diagnoses are considerably improved. Each evaluation result is even higher than that of ultrasound physicians. Thus, our method has a high clinical value.关键词:breast ultrasound image;breast tumor classification;deep learning;loss function;computer aided diagnosis(CAD);difficult sample39|26|3更新时间:2024-05-07
摘要:ObjectiveUltrasound is the primary imagological examination and preoperative assessment for breast nodules. In the qualitative diagnosis of nodules in breast ultrasound images, the breast imaging and reporting data system (BI-RADS) with six levels is commonly used by physicians to evaluate the degree of malignant breast lesions. However, BI-RADS evaluation is time-consuming and mostly based on the morphological features and partial acoustic information of a lesion. Diagnosis relies heavily on the experience of physicians because of the overlapping image expression of benign and malignant breast nodules. The diagnostic accuracy of physicians with different qualifications can differ by up to 30%. Therefore, misdiagnosis or missed diagnosis can easily occur, increasing the needless rate of puncture biopsy. The current computer-assisted breast ultrasound diagnosis requires considerable human interactions. The automation level is low, and accuracy is unfavorable. In recent years, the deep learning method has been applied to the visual tasks such as medical ultrasound image classification and achieved good results. This study proposes an end-to-end model for automatic nodule extraction and classification.MethodAn ultrasound image of the breast is the result of using ultrasonic signals that are reflected by ultrasound when it encounters tissues in the human body. Given the limitation of the imaging mechanism of medical ultrasound, noise interference in breast ultrasound images is typically severe and mostly affected by additive thermal and multiplicative speckle noises. Thermal noise is caused by the heat generated by the capturing device and can be avoided via physical cooling. Speckle noise is a bright and dark particle-like spot formed by the constructive and destructive interference of reflected ultrasonic waves; it is unavoidable because of the principle of ultrasound imaging. For the model of speckle noise in an ultrasound image, this work uses edge enhanced anisotropic diffusion(EEAD) to remove noise as a preprocessing step. Then, an improved loss function is proposed to enhance the discriminant performance of our method with respect to nodules' characteristics of benign and malignant parts. We use a combination of shape descriptors (concavity, aspect ratio, compactness, circle variance, and elliptic variance) to describe difficult samples with similar shapes to other classes, which can be apt to misjudgment. To make such difficult samples more distinguishable, an improved loss function is developed in this study. This function builds the shape constraint loss term of difficult samples to adjust feature mapping.ResultA breast ultrasound dataset with 1 805 images is collected to validate our method. For this dataset, the average diagnosis accuracy(AUC) of physicians with five-year qualifications is 85.3%. However, the classification accuracy, sensitivity, specificity, and area under the curve of our method are 92.58%, 90.44%, 93.72%, and 0.946, respectively, which are superior to those of the comparison algorithms. Moreover, compared with the traditional softmax loss function, the performance can be increased by 5%—12%.ConclusionIn this study, the classification of benign and malignant nodules in two-dimensional ultrasound images of the breast is the main research content, and the advanced achievements in machine learning, computer vision and medicine are taken as the technical support. Aiming at the problems of poor quality of two-dimensional ultrasound images of the breast, small proportion of lesions, overlapping of benign and malignant nodule images, and heavy dependence on doctors' experience in diagnosis, this paper improves the data preprocessing level and algorithm At the level of data preprocessing, the original breast ultrasound data is denoised and expanded to improve the quality of the data set and maximize the utilization of the data set; at the level of algorithm improvement, the model training process is dynamically monitored to dynamically mine difficult samples and regularize the distance between classes to improve the classification effect of benign and malignant. In this study, an end-to-end ultrasound image analysis model of the breast is proposed. This model is pragmatic and useful for clinics. By incorporating medical knowledge into the optimization process and adding the shape constraint loss of difficult samples, the accuracy and robustness of breast benign and malignant diagnoses are considerably improved. Each evaluation result is even higher than that of ultrasound physicians. Thus, our method has a high clinical value.关键词:breast ultrasound image;breast tumor classification;deep learning;loss function;computer aided diagnosis(CAD);difficult sample39|26|3更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveQuick view data generated by high-resolution satellites provide real-time reception and full resolution for quick view imaging. Such imaging offers a timely source of data for practical applications, such as fire detection, moving window display, disaster observation, and military information acquisition. Road extraction from remote sensing images has been a popular research topic in the field of remote sensing image analysis. Traditional object-oriented methods are not highly automated, and road features require prior knowledge for manual selection and design. These conditions lead to problems in real-time road information acquisition. The popular deep learning road extraction method mainly focuses on the improvement of precision and lacks research on the timeliness of road information extraction. Transfer learning can rapidly complete the task in the target area through weight sharing among different fields and make the model algorithm highly personalized. A transfer learning deep network for rapidly extracting roads is constructed to utilize quick view data from high-resolution satellites.MethodFirst, we propose a least-square fitting method of devignetting to solve the most serious radiation problem of TDICCD (time delay and integration charge coupled devices) vignetting phenomenon appearing in raw quick view data. The results of the preprocessing of the quick view data serve as our training dataset. Then, we choose LinkNet as the target network after comparing the performance among different real-time semantic segmentation networks, such as ENet, U-Net, LinkNet, and D-LinkNet. LinkNet is efficient in computation memory, can learn from a relatively small training set, and allows residual unit ease training of deep networks. The rich bypass links each encoder with decoder. Thus, the networks can be designed with few parameters. The encoder starts with a kernel of size 7×7. In the next encoder block, its contracting path to capture context uses 3×3 full convolution. We use batch normalization in each convolutional layer, followed by ReLU nonlinearity. Reflection padding is used to extrapolate the missing context in the training data for predicting the pixels in the border region of the input image. The input of each encoder layer of LinkNet is bypassed to the output of its corresponding decoder. Lost spatial information about the max pooling can then be recovered by the decoder and its upsampling operations. Finally, we modify LinkNet to keep it consistent with ResNet34 network layer features, the so-called fine tuning, for accelerating LinkNet network training process. Fine tuning is a useful efficient method of transfer learning. The use of ResNet34 weight parameter pretrained on ImageNet initializing LinkNet34 can accelerate the network convergence and lead to improved performance with almost no additional cost.ResultIn the process of devignetting quick view data, the least-square linear fitting method proposed in this study can efficiently remove the vignetting strip of the original image, which meets practical applications. In our road extraction experiment, LinkNet34 using the pretrained ResNet34 as encoder has a 6% improvement in Dice accuracy compared with that when using ResNet34 not pretrained on the valid dataset. The time consumption of a single test feature map is reduced by 39 ms, and the test Dice accuracy can reach 88.3%. Pretrained networks substantially reduce training time that also helps prevent overfitting. Consequently, we achieve over 88 % test accuracy and 40 ms test time on the quick view dataset. With an input feature map size of 3×256×256 pixels, the data of Tianjin Binhai with a size of 7 304×6 980 pixels take 54 s. The original LinkNet using ResNet18 as its encoder only has a Dice coefficient of 85.7%. We evaluate ResNet50 and ResNet101 as pretrained encoders. The Dice accuracy of the former is not improved, whereas the latter takes too much test time. We compare the performance of LinkNet34 with those of three other popular deep transfer models for classification, namely, U-Net; two modifications of TernausNet and AlubNet using VGG11 (visual geometry group) and ResNet34 as encoders separately; and a modification of D-LinkNet. The two U-Net modifications are likely to incorrectly recognize roads as background or recognize something nonroad, such as tree, as road. D-LinkNet has higher Dice than LinkNet34 on the validation set, but the testing time takes 59 ms more than that of LinkNet34. LinkNet34 avoids the weaknesses of TernuasNet and AlubNet and makes better predictions than them. The small nonroad gap between two roads can also be avoided. Many methods mix the two roads into one. The method proposed in this study generally achieves good connectivity, accurate edge, and clear outline in the case of complete extraction of the entire road and fine location. It is especially suitable for rural linear roads and the extraction of area roads in towns. However, the extraction effect for complex road networks in urban areas is incomplete.ConclusionIn this study, we build a deep transfer learning neural network, LinkNet34, which uses a pretrained network, ResNet34, as an encoder. ResNet34 allows LinkNet34 to learn without any significant increase in the number of parameters, solves the problem that the bottom layer features randomly initialized with weights of neural networks are inadequately rich, and accelerates network convergence. Our approach demonstrates the improvement in LinkNet34 by the use of the pretrained encoder and the better performance of LinkNet34 than other real-time segmentation architecture. The experimental results show that LinkNet34 can handle road properties, such as narrowness, connectivity, complexity, and long span, to some extent. This architecture proves useful for binary classification with limited data and realizes fast and accurate acquisition of road information. Future research should consider increasing the quick view database. The pretrained network LinkNet34 trains on the expanded quick view database and then transfers. The "semantic gap" between the source and target networks is reduced, and the data distribute similarly. These features are conducive to model initialization.关键词:high-resolution satellite;quick view data;fast road extraction;transfer learning;fine-tuning32|78|1更新时间:2024-05-07
摘要:ObjectiveQuick view data generated by high-resolution satellites provide real-time reception and full resolution for quick view imaging. Such imaging offers a timely source of data for practical applications, such as fire detection, moving window display, disaster observation, and military information acquisition. Road extraction from remote sensing images has been a popular research topic in the field of remote sensing image analysis. Traditional object-oriented methods are not highly automated, and road features require prior knowledge for manual selection and design. These conditions lead to problems in real-time road information acquisition. The popular deep learning road extraction method mainly focuses on the improvement of precision and lacks research on the timeliness of road information extraction. Transfer learning can rapidly complete the task in the target area through weight sharing among different fields and make the model algorithm highly personalized. A transfer learning deep network for rapidly extracting roads is constructed to utilize quick view data from high-resolution satellites.MethodFirst, we propose a least-square fitting method of devignetting to solve the most serious radiation problem of TDICCD (time delay and integration charge coupled devices) vignetting phenomenon appearing in raw quick view data. The results of the preprocessing of the quick view data serve as our training dataset. Then, we choose LinkNet as the target network after comparing the performance among different real-time semantic segmentation networks, such as ENet, U-Net, LinkNet, and D-LinkNet. LinkNet is efficient in computation memory, can learn from a relatively small training set, and allows residual unit ease training of deep networks. The rich bypass links each encoder with decoder. Thus, the networks can be designed with few parameters. The encoder starts with a kernel of size 7×7. In the next encoder block, its contracting path to capture context uses 3×3 full convolution. We use batch normalization in each convolutional layer, followed by ReLU nonlinearity. Reflection padding is used to extrapolate the missing context in the training data for predicting the pixels in the border region of the input image. The input of each encoder layer of LinkNet is bypassed to the output of its corresponding decoder. Lost spatial information about the max pooling can then be recovered by the decoder and its upsampling operations. Finally, we modify LinkNet to keep it consistent with ResNet34 network layer features, the so-called fine tuning, for accelerating LinkNet network training process. Fine tuning is a useful efficient method of transfer learning. The use of ResNet34 weight parameter pretrained on ImageNet initializing LinkNet34 can accelerate the network convergence and lead to improved performance with almost no additional cost.ResultIn the process of devignetting quick view data, the least-square linear fitting method proposed in this study can efficiently remove the vignetting strip of the original image, which meets practical applications. In our road extraction experiment, LinkNet34 using the pretrained ResNet34 as encoder has a 6% improvement in Dice accuracy compared with that when using ResNet34 not pretrained on the valid dataset. The time consumption of a single test feature map is reduced by 39 ms, and the test Dice accuracy can reach 88.3%. Pretrained networks substantially reduce training time that also helps prevent overfitting. Consequently, we achieve over 88 % test accuracy and 40 ms test time on the quick view dataset. With an input feature map size of 3×256×256 pixels, the data of Tianjin Binhai with a size of 7 304×6 980 pixels take 54 s. The original LinkNet using ResNet18 as its encoder only has a Dice coefficient of 85.7%. We evaluate ResNet50 and ResNet101 as pretrained encoders. The Dice accuracy of the former is not improved, whereas the latter takes too much test time. We compare the performance of LinkNet34 with those of three other popular deep transfer models for classification, namely, U-Net; two modifications of TernausNet and AlubNet using VGG11 (visual geometry group) and ResNet34 as encoders separately; and a modification of D-LinkNet. The two U-Net modifications are likely to incorrectly recognize roads as background or recognize something nonroad, such as tree, as road. D-LinkNet has higher Dice than LinkNet34 on the validation set, but the testing time takes 59 ms more than that of LinkNet34. LinkNet34 avoids the weaknesses of TernuasNet and AlubNet and makes better predictions than them. The small nonroad gap between two roads can also be avoided. Many methods mix the two roads into one. The method proposed in this study generally achieves good connectivity, accurate edge, and clear outline in the case of complete extraction of the entire road and fine location. It is especially suitable for rural linear roads and the extraction of area roads in towns. However, the extraction effect for complex road networks in urban areas is incomplete.ConclusionIn this study, we build a deep transfer learning neural network, LinkNet34, which uses a pretrained network, ResNet34, as an encoder. ResNet34 allows LinkNet34 to learn without any significant increase in the number of parameters, solves the problem that the bottom layer features randomly initialized with weights of neural networks are inadequately rich, and accelerates network convergence. Our approach demonstrates the improvement in LinkNet34 by the use of the pretrained encoder and the better performance of LinkNet34 than other real-time segmentation architecture. The experimental results show that LinkNet34 can handle road properties, such as narrowness, connectivity, complexity, and long span, to some extent. This architecture proves useful for binary classification with limited data and realizes fast and accurate acquisition of road information. Future research should consider increasing the quick view database. The pretrained network LinkNet34 trains on the expanded quick view database and then transfers. The "semantic gap" between the source and target networks is reduced, and the data distribute similarly. These features are conducive to model initialization.关键词:high-resolution satellite;quick view data;fast road extraction;transfer learning;fine-tuning32|78|1更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0