
最新刊期
卷 25 , 期 6 , 2020
-
 摘要:Semantic segmentation is a fundamental task in computer vision applications, such as scene analysis and behavior recognition. The recent years have witnessed significant progress in semantic image segmentation based on deep convolutional neural network(DCNN). Semantic segmentation is a type of pixel-level image understanding with the objective of assigning a semantic label for each pixel of a given image. Object detection only locates the bounding box of the object, while the task of semantic segmentation is to segment an image into several meaningful objects and then assign a specific semantic label to each object. The difficulty of image semantic segmentation mostly originates from three aspects: object, category, and background. From the perspective of objects, when an object is in different lighting, angle of view, and distance, or when it is still or moving, the image taken will significantly differ. Occlusion may also occur between adjacent objects. In terms of categories, objects from the same category have dissimilarities and objects from different categories have similarities. From the background perspective, a simple background helps output accurate semantic segmentation results, but the background of real scenes is complex. In this study, we provide a systematic review of recent advances in DCNN methods for semantic segmentation. In this paper, we first discuss the difficulties and challenges in semantic segmentation and provide datasets and quantitative metrics for evaluating the performance of these methods. Then, we detail how recent CNN-based semantic segmentation methods work and analyze their strengths and limitations. According to whether to use pixel-level labeled images to train the network, these methods are grouped into two categories: supervised and weakly supervised learning-based semantic segmentation. Supervised semantic segmentation requires pixel-level annotations. By contrast, weakly supervised semantic segmentation aims to segment images by class labels, bounding boxes, and scribbles. In this study, we divide supervised semantic segmentation models into four groups: encoder-decoder methods, feature map-based methods, probability map-based methods, and various strategies. In an encoder-decoder network, an encoder module gradually reduces feature maps and captures high semantic information, while a decoder module gradually recovers spatial information. At present, most state-of-the-art deep CNN for semantic segmentation originate from a common forerunner, i.e., the fully convolutional network (FCN), which is an encoder-decoder network. FCN transforms existing and well-known classification models, such as AlexNet, visual geometry group 16-layer net (VGG16), GoogLeNet, and ResNet, into fully convolutional models by replacing fully connected layers with convolutional ones to output spatial maps instead of classification scores. Such maps are upsampled using deconvolutions to produce dense per-pixel labeled outputs. A feature map-based method aims to take complete advantage of the context information of a feature map, including its spatial context (position) and scale context (size), facilitating the segmentation and parsing of an image. These methods obtain the spatial and scale contexts by increasing the receptive field and fusing multiscale information, effectively improving the performance of the network. Some models, such as the pyramid scene parsing network or Deeplab v3, perform spatial pyramid pooling at several different scales (including image-level pooling) or apply several parallel atrous convolutions with different rates. These models have presented promising results by involving the spatial and scale contexts. A probability map-based method combines the semantic context (probability) and the spatial context (location) with postprocess probability score maps and semantic label predictions primarily through the use of a probabilistic graph model. A probabilistic graph is a probabilistic model that uses a graph to present conditional dependence between random variables. It is the combination of probability and graph theories. Probabilistic graph models have several types, such as conditional random fields (CRFs), Markov random fields, and Bayesian networks. Object boundary is refined and network performance is improved by establishing semantic relationships between pixels. This family of approaches typically includes CRF-recurrent neural networks, deep parsing networks, and EncNet. Some methods combine two or more of the aforementioned strategies to significantly improve the segmentation performance of a network, such as a global convolutional network, DeepLab v1, DeepLab v2, DeepLab v3+, and a discriminative feature network. In accordance with the type of weak supervision used by a training network, weakly supervised semantic segmentation methods are divided into four groups: class label-based, bounding box-based, scribble-based, and various forms of annotations. Class-label annotations only indicate the presence of an object. Thus, the substantial problem in class label-based methods is accurately assigning image-level labels to their corresponding pixels. In general, this problem can be solved by using the multiple instance learning-based strategy to train models for semantic segmentation or adopting an alternative training procedure based on the expectation-maximization algorithm to dynamically predict semantic foreground and background pixels. A recent work attempted to increase the quality of an object localization map by integrating a seed region growing technique into the segmentation network, significantly increasing pixel accuracy. Bounding box-based methods use bounding boxes and class labels as supervision information. By using region proposal methods and the traditional image segmentation theory to generate candidate segmentation masks, a convolutional network is trained under the supervision of these approximate segmentation masks. BoxSup proposes a recursive training procedure wherein a convolutional network is trained under the supervision of segment object proposals. In turn, the updated network improves the segmentation mask used for training. Scribble-supervised training methods apply a graphical model to propagate information from scribbles to unmarked pixels on the basis of spatial constraints, appearance, and semantic content, accounting for two tasks. The first task is to propagate the class labels from scribbles to other pixels and fully annotate an image. The second task is to learn a convolutional network for semantic segmentation. We compare some semantic segmentation methods of supervised learning and weakly supervised learning on the PASCAL VOC (pattern analysis, statistical modelling and computational learning visual object classes) 2012 dataset. We also give the optimal methods of supervised learning methools and wedakly supervised learning methods, and the corresponding MIoU(mean intersection-over-union). Lastly, we present related research areas, including video semantic segmentation, 3D dataset semantic segmentation, real-time semantic segmentation, and instance segmentation. Image semantic segmentation is a popular topic in the fields of computer vision and artificial intelligence. Many applications require accurate and efficient segmentation models, e.g., autonomous driving, indoor navigation, and smart medicine. Thus, further work should be conducted on semantic segmentation to improve the accuracy of object boundaries and the performance of semantic segmentation.关键词:semantic segmentation;convolutional neural network (CNN);supervised learning;weakly supervised learning68|109|22更新时间:2024-05-07
摘要:Semantic segmentation is a fundamental task in computer vision applications, such as scene analysis and behavior recognition. The recent years have witnessed significant progress in semantic image segmentation based on deep convolutional neural network(DCNN). Semantic segmentation is a type of pixel-level image understanding with the objective of assigning a semantic label for each pixel of a given image. Object detection only locates the bounding box of the object, while the task of semantic segmentation is to segment an image into several meaningful objects and then assign a specific semantic label to each object. The difficulty of image semantic segmentation mostly originates from three aspects: object, category, and background. From the perspective of objects, when an object is in different lighting, angle of view, and distance, or when it is still or moving, the image taken will significantly differ. Occlusion may also occur between adjacent objects. In terms of categories, objects from the same category have dissimilarities and objects from different categories have similarities. From the background perspective, a simple background helps output accurate semantic segmentation results, but the background of real scenes is complex. In this study, we provide a systematic review of recent advances in DCNN methods for semantic segmentation. In this paper, we first discuss the difficulties and challenges in semantic segmentation and provide datasets and quantitative metrics for evaluating the performance of these methods. Then, we detail how recent CNN-based semantic segmentation methods work and analyze their strengths and limitations. According to whether to use pixel-level labeled images to train the network, these methods are grouped into two categories: supervised and weakly supervised learning-based semantic segmentation. Supervised semantic segmentation requires pixel-level annotations. By contrast, weakly supervised semantic segmentation aims to segment images by class labels, bounding boxes, and scribbles. In this study, we divide supervised semantic segmentation models into four groups: encoder-decoder methods, feature map-based methods, probability map-based methods, and various strategies. In an encoder-decoder network, an encoder module gradually reduces feature maps and captures high semantic information, while a decoder module gradually recovers spatial information. At present, most state-of-the-art deep CNN for semantic segmentation originate from a common forerunner, i.e., the fully convolutional network (FCN), which is an encoder-decoder network. FCN transforms existing and well-known classification models, such as AlexNet, visual geometry group 16-layer net (VGG16), GoogLeNet, and ResNet, into fully convolutional models by replacing fully connected layers with convolutional ones to output spatial maps instead of classification scores. Such maps are upsampled using deconvolutions to produce dense per-pixel labeled outputs. A feature map-based method aims to take complete advantage of the context information of a feature map, including its spatial context (position) and scale context (size), facilitating the segmentation and parsing of an image. These methods obtain the spatial and scale contexts by increasing the receptive field and fusing multiscale information, effectively improving the performance of the network. Some models, such as the pyramid scene parsing network or Deeplab v3, perform spatial pyramid pooling at several different scales (including image-level pooling) or apply several parallel atrous convolutions with different rates. These models have presented promising results by involving the spatial and scale contexts. A probability map-based method combines the semantic context (probability) and the spatial context (location) with postprocess probability score maps and semantic label predictions primarily through the use of a probabilistic graph model. A probabilistic graph is a probabilistic model that uses a graph to present conditional dependence between random variables. It is the combination of probability and graph theories. Probabilistic graph models have several types, such as conditional random fields (CRFs), Markov random fields, and Bayesian networks. Object boundary is refined and network performance is improved by establishing semantic relationships between pixels. This family of approaches typically includes CRF-recurrent neural networks, deep parsing networks, and EncNet. Some methods combine two or more of the aforementioned strategies to significantly improve the segmentation performance of a network, such as a global convolutional network, DeepLab v1, DeepLab v2, DeepLab v3+, and a discriminative feature network. In accordance with the type of weak supervision used by a training network, weakly supervised semantic segmentation methods are divided into four groups: class label-based, bounding box-based, scribble-based, and various forms of annotations. Class-label annotations only indicate the presence of an object. Thus, the substantial problem in class label-based methods is accurately assigning image-level labels to their corresponding pixels. In general, this problem can be solved by using the multiple instance learning-based strategy to train models for semantic segmentation or adopting an alternative training procedure based on the expectation-maximization algorithm to dynamically predict semantic foreground and background pixels. A recent work attempted to increase the quality of an object localization map by integrating a seed region growing technique into the segmentation network, significantly increasing pixel accuracy. Bounding box-based methods use bounding boxes and class labels as supervision information. By using region proposal methods and the traditional image segmentation theory to generate candidate segmentation masks, a convolutional network is trained under the supervision of these approximate segmentation masks. BoxSup proposes a recursive training procedure wherein a convolutional network is trained under the supervision of segment object proposals. In turn, the updated network improves the segmentation mask used for training. Scribble-supervised training methods apply a graphical model to propagate information from scribbles to unmarked pixels on the basis of spatial constraints, appearance, and semantic content, accounting for two tasks. The first task is to propagate the class labels from scribbles to other pixels and fully annotate an image. The second task is to learn a convolutional network for semantic segmentation. We compare some semantic segmentation methods of supervised learning and weakly supervised learning on the PASCAL VOC (pattern analysis, statistical modelling and computational learning visual object classes) 2012 dataset. We also give the optimal methods of supervised learning methools and wedakly supervised learning methods, and the corresponding MIoU(mean intersection-over-union). Lastly, we present related research areas, including video semantic segmentation, 3D dataset semantic segmentation, real-time semantic segmentation, and instance segmentation. Image semantic segmentation is a popular topic in the fields of computer vision and artificial intelligence. Many applications require accurate and efficient segmentation models, e.g., autonomous driving, indoor navigation, and smart medicine. Thus, further work should be conducted on semantic segmentation to improve the accuracy of object boundaries and the performance of semantic segmentation.关键词:semantic segmentation;convolutional neural network (CNN);supervised learning;weakly supervised learning68|109|22更新时间:2024-05-07
Review

-
 摘要:ObjectiveUnder the background of the continuously increasing quantity of digital documents transmitted over the Internet, efficient and practical data hiding techniques should be designed to protect intellectual property rights. Digital watermarking techniques have been historically used to ensure security in terms of ownership protection and tamper-proofing for various data formats, including images, audio, video, natural language processing software, and relational databases. This study focuses on audio watermarking. In general, digital audio watermarking refers to the technology of embedding useful data (watermark data) within a host audio without substantially degrading the perceptual quality of the host audio. For different purposes, audio watermarking can be divided into two classifications: robust and fragile audio watermarking. The former is used to protect ownership of digital audio. By contrast, the latter is used to authenticate digital audio, i.e., to ensure the integrity of digital audio. A digital watermarking scheme generally has three major properties: imperceptibility, robustness, and payload. Imperceptibility indicates that the watermarked audio is perceptually indistinguishable from the original one. This property is required to maintain the commercial value of audio data or the secrecy of embedded data. Robustness refers to the ability of a watermark to survive various attacks, such as JPEG/MP3 compression, additive noise, filtering, and amplification. Payload refers to the total amount of information that can be hidden within digital audio. Imperceptibility, robustness, and payload are three major requirements of any digital audio watermarking system to guarantee desired functionalities. However, a trade-off exists among them from the information-theoretic perspective. Simultaneously improving robustness, imperceptibility, and payload has been a challenge for digital audio watermarking algorithms. A digital audio watermarking scheme must be robust against various possible attacks. Attacks that attempt to destroy or invalidate watermarks can be classified into two types: noise-like common signal processing operations and desynchronization attacks. Desynchronization attacks are more difficult to address than other types of attacks. Designing a robust digital audio watermarking algorithm against desynchronization attacks is a challenging task.MethodIn this study, we propose a new second-generation digital audio watermarking in the undecimated discrete wavelet transform (UDWT) domain based on robust local audio features. First, robust audio feature points are detected by utilizing a smooth gradient. These feature points are always invariant to common signal processing operations and desynchronization attacks. Then, local digital audio segments, centering at the detected audio feature points, are extracted for watermarking use. Lastly, a watermark is embedded into local digital audio segments in the UDWT domain by modulating low-frequency coefficients. We use robust significant UDWT coefficients that can effectively capture important audio texture features to accurately locate watermark embedding/extraction position, even when under desynchronization attacks.ResultTo evaluate the performance of our scheme, watermark imperceptibility and robustness tests are conducted for the proposed watermarking algorithm. The watermark detection results of the proposed algorithm are compared with those of several state-of-the-art audio watermarking schemes against various attacks under equal conditions. All the audio signals in the test are music with 16 bit/sample, 44.1 kHz sample rates, and 15 s duration. All our experiments are executed on a personal computer with Intel Core i7-4790 CPU 3.60 GHz, 16 GB memory, and Microsoft Windows 7 Ultimate operating system. Moreover, MATLAB R2016a is used to perform the simulation experiments. To quantitatively evaluate the imperceptibility performance of the proposed watermarking algorithm, we also calculate signal-to-noise ratio (SNR), which is an objective criterion and always used to evaluate audio quality. The SNR of the proposed scheme is improved by 5.7 dB on average, demonstrating its effectiveness in terms of the invisibility of the watermark. Watermark robustness is measured as the correctly extracted percentage of extracted segments. The average detection rate remains at 0.925 and 0.913, which are higher than those of most traditional algorithms. Therefore, the experimental results show that the proposed approach exhibits good transparency and strong robustness against common audio processing activities, such as MP3 compression, resampling, and requantization. The scheme also demonstrates good robustness against desynchronization attacks, such as random cropping, pitch-scale modification, and jittering.ConclusionAn audio watermarking algorithm based on robust feature points of the wavelet domain is proposed on the basis of audio content features and the stability of the low-frequency coefficient of UDWT. First, the original audio is dealt with using UDWT, and then by calculating the first-order gradient responses of the low-frequency coefficient, ranking these responses in descending order, and selecting the highest response as criterion to set the threshold. From these processes, stable and evenly distributed feature points are obtained. Then, the robust feature point is set for identification, and audio watermarking is embedded. Finally, the low-frequency coefficient is inserted into watermarking via quantization index modulation. The proposed scheme effectively solves the disadvantages of poor stability and uneven distribution of audio feature points, improving the resistance of digital audio watermarks to pitch-scale modification, random cropping, and jittering attacks.关键词:digital audio watermarking;desynchronization attacks;feature points;smooth gradient;undecimated discrete wavelet transform (UDWT)34|24|1更新时间:2024-05-07
摘要:ObjectiveUnder the background of the continuously increasing quantity of digital documents transmitted over the Internet, efficient and practical data hiding techniques should be designed to protect intellectual property rights. Digital watermarking techniques have been historically used to ensure security in terms of ownership protection and tamper-proofing for various data formats, including images, audio, video, natural language processing software, and relational databases. This study focuses on audio watermarking. In general, digital audio watermarking refers to the technology of embedding useful data (watermark data) within a host audio without substantially degrading the perceptual quality of the host audio. For different purposes, audio watermarking can be divided into two classifications: robust and fragile audio watermarking. The former is used to protect ownership of digital audio. By contrast, the latter is used to authenticate digital audio, i.e., to ensure the integrity of digital audio. A digital watermarking scheme generally has three major properties: imperceptibility, robustness, and payload. Imperceptibility indicates that the watermarked audio is perceptually indistinguishable from the original one. This property is required to maintain the commercial value of audio data or the secrecy of embedded data. Robustness refers to the ability of a watermark to survive various attacks, such as JPEG/MP3 compression, additive noise, filtering, and amplification. Payload refers to the total amount of information that can be hidden within digital audio. Imperceptibility, robustness, and payload are three major requirements of any digital audio watermarking system to guarantee desired functionalities. However, a trade-off exists among them from the information-theoretic perspective. Simultaneously improving robustness, imperceptibility, and payload has been a challenge for digital audio watermarking algorithms. A digital audio watermarking scheme must be robust against various possible attacks. Attacks that attempt to destroy or invalidate watermarks can be classified into two types: noise-like common signal processing operations and desynchronization attacks. Desynchronization attacks are more difficult to address than other types of attacks. Designing a robust digital audio watermarking algorithm against desynchronization attacks is a challenging task.MethodIn this study, we propose a new second-generation digital audio watermarking in the undecimated discrete wavelet transform (UDWT) domain based on robust local audio features. First, robust audio feature points are detected by utilizing a smooth gradient. These feature points are always invariant to common signal processing operations and desynchronization attacks. Then, local digital audio segments, centering at the detected audio feature points, are extracted for watermarking use. Lastly, a watermark is embedded into local digital audio segments in the UDWT domain by modulating low-frequency coefficients. We use robust significant UDWT coefficients that can effectively capture important audio texture features to accurately locate watermark embedding/extraction position, even when under desynchronization attacks.ResultTo evaluate the performance of our scheme, watermark imperceptibility and robustness tests are conducted for the proposed watermarking algorithm. The watermark detection results of the proposed algorithm are compared with those of several state-of-the-art audio watermarking schemes against various attacks under equal conditions. All the audio signals in the test are music with 16 bit/sample, 44.1 kHz sample rates, and 15 s duration. All our experiments are executed on a personal computer with Intel Core i7-4790 CPU 3.60 GHz, 16 GB memory, and Microsoft Windows 7 Ultimate operating system. Moreover, MATLAB R2016a is used to perform the simulation experiments. To quantitatively evaluate the imperceptibility performance of the proposed watermarking algorithm, we also calculate signal-to-noise ratio (SNR), which is an objective criterion and always used to evaluate audio quality. The SNR of the proposed scheme is improved by 5.7 dB on average, demonstrating its effectiveness in terms of the invisibility of the watermark. Watermark robustness is measured as the correctly extracted percentage of extracted segments. The average detection rate remains at 0.925 and 0.913, which are higher than those of most traditional algorithms. Therefore, the experimental results show that the proposed approach exhibits good transparency and strong robustness against common audio processing activities, such as MP3 compression, resampling, and requantization. The scheme also demonstrates good robustness against desynchronization attacks, such as random cropping, pitch-scale modification, and jittering.ConclusionAn audio watermarking algorithm based on robust feature points of the wavelet domain is proposed on the basis of audio content features and the stability of the low-frequency coefficient of UDWT. First, the original audio is dealt with using UDWT, and then by calculating the first-order gradient responses of the low-frequency coefficient, ranking these responses in descending order, and selecting the highest response as criterion to set the threshold. From these processes, stable and evenly distributed feature points are obtained. Then, the robust feature point is set for identification, and audio watermarking is embedded. Finally, the low-frequency coefficient is inserted into watermarking via quantization index modulation. The proposed scheme effectively solves the disadvantages of poor stability and uneven distribution of audio feature points, improving the resistance of digital audio watermarks to pitch-scale modification, random cropping, and jittering attacks.关键词:digital audio watermarking;desynchronization attacks;feature points;smooth gradient;undecimated discrete wavelet transform (UDWT)34|24|1更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveMany saliency detection algorithms use background priors to improve algorithm performance. In the past, however, most traditional models simply used the edge region around an image as the background region, resulting in false detection in cases wherein a salient object touches the edge of the image. To accurately apply background priors, we propose a saliency detection method that integrates the background block reselection process.MethodFirst, the original image is segmented using a superpixel segmentation algorithm, namely, simple linear iterative clustering (SLIC), to generate a superpixel image. Then, a background prior, a central prior, and a color distribution feature are used to select a partial superpixel block from the superpixel image to form a seed vector, which constructs a diffusion matrix. Second, the seed vector is diffused by the diffusion matrix to obtain a preliminary saliency map. Then, the preliminary saliency map is used as an input and then diffused by the diffusion matrix to obtain a second saliency map to obtain high-level features. Third, we develop a background block reselection process in accordance with the idea of Fisher's criterion. The two-layer saliency map is first fed into the background block reselection algorithm to extract background blocks. Then, we use the selected background blocks to form the background vector, which can be utilized to construct a new diffusion matrix. Lastly, the seed vector is diffused by the new diffusion matrix to obtain a background saliency map. Fourth, the background and two-layer saliency maps are nonlinearly fused to obtain the final saliency map.ResultThe experiments are performed on five general datasets: Microsoft Research Asia 10K (MSRA10K), extended complex scene saliency dataset (ECSSD), Dalian University of Technology and OMRON Corporation (DUT-OMRON), salient object dataset (SOD), and segmentation evaluation database 2 (SED2). Our method is compared with six recent algorithms, namely, generic promotion of diffusion-based salient object detection (GP), inner and inter label propagation: salient object detection in the wild (LPS), saliency detection via cellular automata (BSCA), salient object detection via structured matrix decomposition (SMD), salient region detection using a diffusion process on a two-layer sparse graph (TSG), and salient object detection via a multifeature diffusion-based method LMH (salient object detection via multi-feature diffusion-based method), by using three evaluation indicators: PR(precision-recall) curve, F index, and mean absolute error (MAE). On the MSRA10K dataset, MAE achieved the minimum value in all the comparison algorithms. Compared with the preimproved algorithm LMH, the F value increased by 0.84% and MAE decreased by 1.9%. On the ECSSD dataset, MAE was the second and the F value reached the maximum value in all the methods. Compared with the algorithm LMH, the F value increased by 1.33%. On the SED2 dataset, MAE and F values were both second in all the methods. Compared with the algorithm LMH, the F value increased by 0.7% and MAE decreased by 0.93%. Simultaneously, we separately extract the generated background saliency map and the final saliency map from our method and compare them with the corresponding high-level saliency map and final saliency map generated using the algorithm LMH. The experiment shows that our method also performs better at the subjective level. The salient objects in the saliency map are more complete and exhibit higher confidence, which is consistent with the phenomenon that recall rate in the objective comparison is better than that of the algorithm LMH. In addition, we experimentally verify the process of dynamically selecting thresholds in the proposed background block reselection process. The F-indexes obtained on three datasets (MSRA10K, SOD, and SED2) are better than those in the corresponding static processes. On ECSSD, the performance on the dataset is basically the same as that in the static process. However, the performance on the DUT-OMRON dataset is not as good as that in the static process. Consequently, we conduct theoretical analysis and verify the experiment by increasing the selection interval of the background block.ConclusionThe proposed saliency detection method can better apply the background prior, such that the final detection effect is better at the subjective and objective indicator levels. Simultaneously, the proposed method performs better when dealing with the type of image in which the salient region touches the edge of the image. In addition, the comparative experiment on the dynamic selection process of thresholds shows that the process of dynamically selecting thresholds is effective and reliable.关键词:saliency detection;background priori;re-selection of background block;Fisher criterion;diffusion method19|25|1更新时间:2024-05-07
摘要:ObjectiveMany saliency detection algorithms use background priors to improve algorithm performance. In the past, however, most traditional models simply used the edge region around an image as the background region, resulting in false detection in cases wherein a salient object touches the edge of the image. To accurately apply background priors, we propose a saliency detection method that integrates the background block reselection process.MethodFirst, the original image is segmented using a superpixel segmentation algorithm, namely, simple linear iterative clustering (SLIC), to generate a superpixel image. Then, a background prior, a central prior, and a color distribution feature are used to select a partial superpixel block from the superpixel image to form a seed vector, which constructs a diffusion matrix. Second, the seed vector is diffused by the diffusion matrix to obtain a preliminary saliency map. Then, the preliminary saliency map is used as an input and then diffused by the diffusion matrix to obtain a second saliency map to obtain high-level features. Third, we develop a background block reselection process in accordance with the idea of Fisher's criterion. The two-layer saliency map is first fed into the background block reselection algorithm to extract background blocks. Then, we use the selected background blocks to form the background vector, which can be utilized to construct a new diffusion matrix. Lastly, the seed vector is diffused by the new diffusion matrix to obtain a background saliency map. Fourth, the background and two-layer saliency maps are nonlinearly fused to obtain the final saliency map.ResultThe experiments are performed on five general datasets: Microsoft Research Asia 10K (MSRA10K), extended complex scene saliency dataset (ECSSD), Dalian University of Technology and OMRON Corporation (DUT-OMRON), salient object dataset (SOD), and segmentation evaluation database 2 (SED2). Our method is compared with six recent algorithms, namely, generic promotion of diffusion-based salient object detection (GP), inner and inter label propagation: salient object detection in the wild (LPS), saliency detection via cellular automata (BSCA), salient object detection via structured matrix decomposition (SMD), salient region detection using a diffusion process on a two-layer sparse graph (TSG), and salient object detection via a multifeature diffusion-based method LMH (salient object detection via multi-feature diffusion-based method), by using three evaluation indicators: PR(precision-recall) curve, F index, and mean absolute error (MAE). On the MSRA10K dataset, MAE achieved the minimum value in all the comparison algorithms. Compared with the preimproved algorithm LMH, the F value increased by 0.84% and MAE decreased by 1.9%. On the ECSSD dataset, MAE was the second and the F value reached the maximum value in all the methods. Compared with the algorithm LMH, the F value increased by 1.33%. On the SED2 dataset, MAE and F values were both second in all the methods. Compared with the algorithm LMH, the F value increased by 0.7% and MAE decreased by 0.93%. Simultaneously, we separately extract the generated background saliency map and the final saliency map from our method and compare them with the corresponding high-level saliency map and final saliency map generated using the algorithm LMH. The experiment shows that our method also performs better at the subjective level. The salient objects in the saliency map are more complete and exhibit higher confidence, which is consistent with the phenomenon that recall rate in the objective comparison is better than that of the algorithm LMH. In addition, we experimentally verify the process of dynamically selecting thresholds in the proposed background block reselection process. The F-indexes obtained on three datasets (MSRA10K, SOD, and SED2) are better than those in the corresponding static processes. On ECSSD, the performance on the dataset is basically the same as that in the static process. However, the performance on the DUT-OMRON dataset is not as good as that in the static process. Consequently, we conduct theoretical analysis and verify the experiment by increasing the selection interval of the background block.ConclusionThe proposed saliency detection method can better apply the background prior, such that the final detection effect is better at the subjective and objective indicator levels. Simultaneously, the proposed method performs better when dealing with the type of image in which the salient region touches the edge of the image. In addition, the comparative experiment on the dynamic selection process of thresholds shows that the process of dynamically selecting thresholds is effective and reliable.关键词:saliency detection;background priori;re-selection of background block;Fisher criterion;diffusion method19|25|1更新时间:2024-05-07 -
 摘要:ObjectiveSalient object detection aims to localize and segment the most conspicuous and eye-attracting objects or regions in an image. Its results are usually expressed by saliency maps, in which the intensity of each pixel presents the strength of the probability that the pixel belongs to a salient region. Visual saliency detection has been used as a pre-processing step to facilitate a wide range of vision applications, including image and video compression, image retargeting, visual tracking, and robot navigation. Traditional saliency detection models focus on handcrafted features and prior information for detection, such as background prior, center prior, and contrast prior. However, these models are less applicable to a wide range of problems in practice. For example, salient objects are difficult to recognize when the background and salient objects share similar visual attributes. Moreover, failure may occur when multiple salient objects overlap partly or entirely with one another. With the rise of deep convolutional neural networks (CNNs), visual saliency detection has achieved rapid progress in the recent years. It has been successful in overcoming the disadvantages of handcrafted-feature-based approaches and greatly enhancing the performance of saliency detection. These CNNs-based models have shown their superiority on feature extraction. They also efficiently capture high-level information on the objects and their cluttered surroundings, thus achieving better performance compared with the traditional methods, especially the emergence of fully convolutional networks (FCN). Most mainstream saliency detection algorithms are now based on FCN. The FCN model unifies the two stages of feature extraction and saliency calculation and optimizes it through supervised learning. As a result, the features extracted by FCN network have stronger advantages in expression and robustness than do handcrafted features. However, existing saliency approaches share common drawbacks, such as difficulties in uniformly highlighting the entire salient objects with explicit boundaries and heterogeneous regions in complex images. This drawback is largely due to the lack of sufficient and rich features for detecting salient objects.MethodIn this study, we propose a simple but efficient CNN for pixel-wise saliency prediction to capture various features simultaneously. It also utilizes ulti-scale information from different convolutional layers of a CNN. To design a FCN-like network that is capable of carrying out the task of pixel-level saliency inference, we develop a multi-scale deep CNN for discovering more information in saliency computation. The multi-scale feature extraction network generates feature maps with different resolution from different side outputs of convolutional layer groups of a base network. The shallow convolutional layers contain rich detailed structure information at the expense of global representation. By contrast, the deep convolutional layers contain rich semantic information but lack spatial context. It is also capable of incorporating high-level semantic cues and low-level detailed information in a data-driven framework. Finally, to efficiently preserve object boundaries and uniform interior region, we adopt a fully connected conditional random field (CRF) model to refine the estimated saliency map.ResultExtensive experiments are conducted on the six most widely used and challenging benchmark datasets, namely, DUT-OMRON(Dalian University of Technology and OMRON Corporation), ECSSD(extended complex scene saliency dataset), SED2(segmentation evalution database 2), HKU, PASCAL-S, and SOD (salient objects dataset). The F-measure scores of our proposed scheme on these six benchmark datasets are 0.696, 0.876, 0.797, 0.868, 0.772, and 0.785, respectively. The max F-measure scores are 0.747, 0.899, 0.859, 0.889, 0.814, and 0.833, respectively. The weighted F-measure scores are 0.656, 0.854, 0.772, 0.844, 0.732, and 0.762, respectively. The mean absolute error (MAE) scores are 0.074, 0.061, 0.093, 0.049, 0.099, and 0.124, respectively. We compare our proposed method with 14 state-of-the-art methods as well. Results demonstrate the efficiency and robustness of the proposed approach against the 14 state-of-the-art methods in terms of popular evaluation metrics.ConclusionWe propose an efficient FCN-like salient object detection model that can generate rich and efficient features. The algorithm used in this study is robust to image saliency detection in various scenarios. Simultaneously, the boundary and inner area of the salient object are uniform, and the detection result is accurate.关键词:salient object detection(SOD);saliency;convolutional neural network(CNN);multi-scale features;data-driven24|27|4更新时间:2024-05-07
摘要:ObjectiveSalient object detection aims to localize and segment the most conspicuous and eye-attracting objects or regions in an image. Its results are usually expressed by saliency maps, in which the intensity of each pixel presents the strength of the probability that the pixel belongs to a salient region. Visual saliency detection has been used as a pre-processing step to facilitate a wide range of vision applications, including image and video compression, image retargeting, visual tracking, and robot navigation. Traditional saliency detection models focus on handcrafted features and prior information for detection, such as background prior, center prior, and contrast prior. However, these models are less applicable to a wide range of problems in practice. For example, salient objects are difficult to recognize when the background and salient objects share similar visual attributes. Moreover, failure may occur when multiple salient objects overlap partly or entirely with one another. With the rise of deep convolutional neural networks (CNNs), visual saliency detection has achieved rapid progress in the recent years. It has been successful in overcoming the disadvantages of handcrafted-feature-based approaches and greatly enhancing the performance of saliency detection. These CNNs-based models have shown their superiority on feature extraction. They also efficiently capture high-level information on the objects and their cluttered surroundings, thus achieving better performance compared with the traditional methods, especially the emergence of fully convolutional networks (FCN). Most mainstream saliency detection algorithms are now based on FCN. The FCN model unifies the two stages of feature extraction and saliency calculation and optimizes it through supervised learning. As a result, the features extracted by FCN network have stronger advantages in expression and robustness than do handcrafted features. However, existing saliency approaches share common drawbacks, such as difficulties in uniformly highlighting the entire salient objects with explicit boundaries and heterogeneous regions in complex images. This drawback is largely due to the lack of sufficient and rich features for detecting salient objects.MethodIn this study, we propose a simple but efficient CNN for pixel-wise saliency prediction to capture various features simultaneously. It also utilizes ulti-scale information from different convolutional layers of a CNN. To design a FCN-like network that is capable of carrying out the task of pixel-level saliency inference, we develop a multi-scale deep CNN for discovering more information in saliency computation. The multi-scale feature extraction network generates feature maps with different resolution from different side outputs of convolutional layer groups of a base network. The shallow convolutional layers contain rich detailed structure information at the expense of global representation. By contrast, the deep convolutional layers contain rich semantic information but lack spatial context. It is also capable of incorporating high-level semantic cues and low-level detailed information in a data-driven framework. Finally, to efficiently preserve object boundaries and uniform interior region, we adopt a fully connected conditional random field (CRF) model to refine the estimated saliency map.ResultExtensive experiments are conducted on the six most widely used and challenging benchmark datasets, namely, DUT-OMRON(Dalian University of Technology and OMRON Corporation), ECSSD(extended complex scene saliency dataset), SED2(segmentation evalution database 2), HKU, PASCAL-S, and SOD (salient objects dataset). The F-measure scores of our proposed scheme on these six benchmark datasets are 0.696, 0.876, 0.797, 0.868, 0.772, and 0.785, respectively. The max F-measure scores are 0.747, 0.899, 0.859, 0.889, 0.814, and 0.833, respectively. The weighted F-measure scores are 0.656, 0.854, 0.772, 0.844, 0.732, and 0.762, respectively. The mean absolute error (MAE) scores are 0.074, 0.061, 0.093, 0.049, 0.099, and 0.124, respectively. We compare our proposed method with 14 state-of-the-art methods as well. Results demonstrate the efficiency and robustness of the proposed approach against the 14 state-of-the-art methods in terms of popular evaluation metrics.ConclusionWe propose an efficient FCN-like salient object detection model that can generate rich and efficient features. The algorithm used in this study is robust to image saliency detection in various scenarios. Simultaneously, the boundary and inner area of the salient object are uniform, and the detection result is accurate.关键词:salient object detection(SOD);saliency;convolutional neural network(CNN);multi-scale features;data-driven24|27|4更新时间:2024-05-07 -
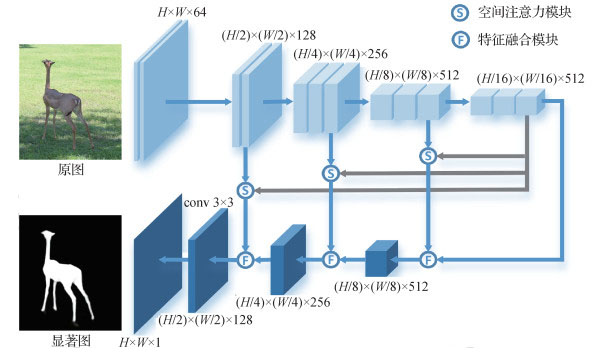 摘要:ObjectiveIn contrast with semantic segmentation and edge detection, saliency detection focuses on finding the most attractive target in an image. Saliency maps can be widely used as a preprocessing step in various computer vision tasks, such as image retrieval, image segmentation, object recognition, object detection, and visual tracking. In computer graphics, a map scan is used in non-photorealistic rendering, automatic image cropping, video summarization, and image retargeting. Early saliency detection methods mostly measure the salient score through basic characteristics, such as color, texture, and contrast. Although considerable progress has been achieved, handcrafted features typically lack global information and tend to highlight the edges of salient targets rather than the overall area to describe complex scenes and structures. Given the development of deep learning, the introduction of convolutional neural networks frees saliency detection from the restraint of traditional handcrafted features and achieves the best results at present. Fully convolutional networks (FCNs) stack convolution and pooling layers to obtain global semantic information. Spatial structure information may be lost and the edge information of saliency targets may be destroyed when we increase the receptive field to obtain global semantic features. Thus, the FCN cannot satisfy the requirement of a complex saliency detection task. To obtain accurate saliency maps, some studies have attempted to introduce handcrafted features to retain the edge of a saliency target and obtain the final saliency maps by combining the extracted edge's handcrafted features with the higher-level features of the FCN. However, the extraction of handcrafted features takes considerable time. Details may be gradually lost in the process of transforming features from low level to high level. Some studies have achieved good results; they combine high- and low-level features and use low-level features to enrich the details of high-level features. Many models based on multilevel feature fusion have been proposed in recent years, including multi flow, side fusion, bottom-up, and top-down structures. These models focus on network structures and disregard the importance of transmission and the difference between high- and low-level features. This condition may cause the loss of the global semantic information of high-level features and increase the interference of low-level features. Multilevel features play an important role in saliency detection. The method of multilevel feature extraction and fusion is one of the important research directions in saliency detection. To solve the problems of feature fusion and sensitivity to background interference, this study proposes a new saliency detection method based on feature pyramid networks and spatial attention. This method achieves the fusion and transmission of multilevel features with simple network architecture.MethodWe propose a multilevel feature fusion network architecture based on a feature pyramid network and spatial attention to integrate different levels of features. The proposed architecture adopts the feature pyramid network, which is the classic bottom-up and top-down structure, as the backbone network and focuses on the optimization of multilevel feature fusion and the transmission process. The network proposed in this work consists of two parts. The first part is the bottom-up convolution part, which is used to extract features. The second part is the top-down upsampling part. Each upsampling of high-level features will be fused with the low-level features of the corresponding scale and transmitted forward. The feature pyramid network removes the high-resolution feature before the first pooling to reduce computation. Multilevel features are extracted using visual geometry group (VGG)-16, which is one of the most excellent feature extraction networks. To improve the quality of feature fusion, a multilevel feature fusion module that optimizes the fusion and transmission processes of high-level features and various low-level features through the pooling and convolution of different scales is designed. To reduce the background interference of low-level features, a spatial attention module that supplies global semantic information for low-level features through attention maps obtained from high-level features via the pooling and convolution of different scales is designed. These attention maps can assist low-level features to highlight the foreground and suppress the background.ResultThe experimental results show that the saliency maps obtained using the proposed method are highly similar to the ground truth maps in four standard datasets, namely, DUTS, DUT-OMRON(Dalian University of Technology and OMRON Corporation), HKU-IS, and extended complex scene saliency dataset(ECSSD), the max F-measure MaxF increased by 1.04%, and mean absolute error (MAE) decreased by 4.35% compared with the second in the DUTS-test dataset. The method proposed in this study performs the best in simple or complex scenes. The network exhibits good feature fusion and edge learning abilities, which can effectively suppress the background of salient areas and fuse the details of low-level features. The saliency maps from our method have more complete salient areas and clearer edges. The results in terms of four common evaluation indexes are better than those obtained by nine state-of-the-art methods.ConclusionIn this study, the fusion of multilevel features is realized well by using a simple network structure. The multilevel feature fusion module can retain the location information of saliency targets and improve the quality of feature fusion and transmission. The spatial attention module reduces the background details and makes the saliency areas more complete. This module realizes feature selection and avoids the interference of background noise. Many experiments have proven the performance of the model and the effectiveness of each module proposed in this work.关键词:saliency detection;deep learning;feature pyramid;feature fusion;spatial attention34|24|4更新时间:2024-05-07
摘要:ObjectiveIn contrast with semantic segmentation and edge detection, saliency detection focuses on finding the most attractive target in an image. Saliency maps can be widely used as a preprocessing step in various computer vision tasks, such as image retrieval, image segmentation, object recognition, object detection, and visual tracking. In computer graphics, a map scan is used in non-photorealistic rendering, automatic image cropping, video summarization, and image retargeting. Early saliency detection methods mostly measure the salient score through basic characteristics, such as color, texture, and contrast. Although considerable progress has been achieved, handcrafted features typically lack global information and tend to highlight the edges of salient targets rather than the overall area to describe complex scenes and structures. Given the development of deep learning, the introduction of convolutional neural networks frees saliency detection from the restraint of traditional handcrafted features and achieves the best results at present. Fully convolutional networks (FCNs) stack convolution and pooling layers to obtain global semantic information. Spatial structure information may be lost and the edge information of saliency targets may be destroyed when we increase the receptive field to obtain global semantic features. Thus, the FCN cannot satisfy the requirement of a complex saliency detection task. To obtain accurate saliency maps, some studies have attempted to introduce handcrafted features to retain the edge of a saliency target and obtain the final saliency maps by combining the extracted edge's handcrafted features with the higher-level features of the FCN. However, the extraction of handcrafted features takes considerable time. Details may be gradually lost in the process of transforming features from low level to high level. Some studies have achieved good results; they combine high- and low-level features and use low-level features to enrich the details of high-level features. Many models based on multilevel feature fusion have been proposed in recent years, including multi flow, side fusion, bottom-up, and top-down structures. These models focus on network structures and disregard the importance of transmission and the difference between high- and low-level features. This condition may cause the loss of the global semantic information of high-level features and increase the interference of low-level features. Multilevel features play an important role in saliency detection. The method of multilevel feature extraction and fusion is one of the important research directions in saliency detection. To solve the problems of feature fusion and sensitivity to background interference, this study proposes a new saliency detection method based on feature pyramid networks and spatial attention. This method achieves the fusion and transmission of multilevel features with simple network architecture.MethodWe propose a multilevel feature fusion network architecture based on a feature pyramid network and spatial attention to integrate different levels of features. The proposed architecture adopts the feature pyramid network, which is the classic bottom-up and top-down structure, as the backbone network and focuses on the optimization of multilevel feature fusion and the transmission process. The network proposed in this work consists of two parts. The first part is the bottom-up convolution part, which is used to extract features. The second part is the top-down upsampling part. Each upsampling of high-level features will be fused with the low-level features of the corresponding scale and transmitted forward. The feature pyramid network removes the high-resolution feature before the first pooling to reduce computation. Multilevel features are extracted using visual geometry group (VGG)-16, which is one of the most excellent feature extraction networks. To improve the quality of feature fusion, a multilevel feature fusion module that optimizes the fusion and transmission processes of high-level features and various low-level features through the pooling and convolution of different scales is designed. To reduce the background interference of low-level features, a spatial attention module that supplies global semantic information for low-level features through attention maps obtained from high-level features via the pooling and convolution of different scales is designed. These attention maps can assist low-level features to highlight the foreground and suppress the background.ResultThe experimental results show that the saliency maps obtained using the proposed method are highly similar to the ground truth maps in four standard datasets, namely, DUTS, DUT-OMRON(Dalian University of Technology and OMRON Corporation), HKU-IS, and extended complex scene saliency dataset(ECSSD), the max F-measure MaxF increased by 1.04%, and mean absolute error (MAE) decreased by 4.35% compared with the second in the DUTS-test dataset. The method proposed in this study performs the best in simple or complex scenes. The network exhibits good feature fusion and edge learning abilities, which can effectively suppress the background of salient areas and fuse the details of low-level features. The saliency maps from our method have more complete salient areas and clearer edges. The results in terms of four common evaluation indexes are better than those obtained by nine state-of-the-art methods.ConclusionIn this study, the fusion of multilevel features is realized well by using a simple network structure. The multilevel feature fusion module can retain the location information of saliency targets and improve the quality of feature fusion and transmission. The spatial attention module reduces the background details and makes the saliency areas more complete. This module realizes feature selection and avoids the interference of background noise. Many experiments have proven the performance of the model and the effectiveness of each module proposed in this work.关键词:saliency detection;deep learning;feature pyramid;feature fusion;spatial attention34|24|4更新时间:2024-05-07 -
 摘要:ObjectiveVisual object tracking is an important research subject in computer vision. It has extensive applications that include surveillance, human-computer interaction, and medical imaging. The goal of tracking is to estimate the states of a moving target in a video sequence. Considerable effort has been devoted to this field, but many challenges remain due to appearance variations caused by heavy occlusion, illumination variation, and fast motion. Low-rank approximation can acquire the underlying structure of a target because some candidate particles have extremely similar appearance. This approximation can prune irrelevant particles and is robust to global appearance changes, such as pose change and illumination variation. Sparse representation formulates candidate particles by using a linear combination of a few dictionary templates. This representation is robust against local appearance changes, e.g., partial occlusions. Therefore, combining low-rank approximation with sparsity representation can improve the efficiency and effectiveness of object tracking. However, object tracking via low-rank sparse learning easily results in tracking drift when facing objects with fast motion and severe occlusions. Therefore, reverse low-rank sparse learning with a variation regularization-based tracking algorithm is proposed.MethodFirst, a low-rank constraint is used to restrain the temporal correlation of the objective appearance, and thus, remove the uncorrelated particles and adapt the object appearance change. The rank minimization problem is known to be computationally intractable. Hence, we resort to minimizing its convex envelope via a nuclear norm. Second, the traditional sparse representation method requires solving numerous L1 optimization problems. Computational cost increases linearly with the number of candidate particles. We build an inverse sparse representation formulation for object appearance using candidate particles to represent the target template inversely, reducing the number of L1 optimization problems for online tracking from candidate particles to one. Third, variation regularization is introduced to model the sparse coefficient difference. The variation method can model the variable selection problem in bounded variation space, which can restrict object appearance with only a slight difference between consecutive frames but allow the existing difference between individual frames to jump discontinuously, and thus, adapt to fast object motion. Lastly, an online updating scheme based on alternating iteration is proposed for tracking computation. Each iteration updates one variable at a time. Meanwhile, the other variables are fixed to their latest values. To accommodate target appearance change, we also use a local updating scheme to update the local parts individually. This scheme captures changes in target appearance even when heavy occlusion occurs. In such case, the unoccluded local parts are still updated in the target template and the occluded ones are discarded. Consequently, we can obtain a representation coefficient for the observation model and realize online tracking.ResultTo evaluate our proposed tracker, qualitative and quantitative analyses are performed using MATLAB on benchmark tracking sequences (occlusion 1, David, boy, deer) obtained from OTB (object tracking benchmark) datasets. The selected videos include many challenging factors in visual tracking, such as occlusion, fast motion, illumination, and scale variation. The experimental results show that when faced with these challenging situations in the benchmark tracking dataset, the proposed algorithm can perform tracking effectively in complicated scenes. Comparative studies with five state-of-the-art visual trackers, namely, DDL (discriminative dictionary learning), SCM (sparse collaborative model), LLR (locally low-rank representation), IST (inverse sparse tracker), and CNT (convolutional networks training) are conducted. To achieve fair comparison, we use publicly available source codes or results provided by the authors. Among these trackers, DDL, SCM, LLR, and IST are the most relevant. Compared with the CNT tracker, we mostly consider that deep networks have attracted considerable attention in complicated visual tracking tasks. For qualitative comparison, the representative tracking results are discussed on the basis of the major challenging factors in each video. For quantitative comparison, the central pixel error (CPE), which records the Euclidean distance between the central location of the tracked target and the manually labeled ground truth, is used. When the metric value is smaller, the tracking results are more accurate. From the evolution process of CPE versus frame number, our tracker achieves the best results in these challenging sequences. In particular, our tracker outperforms the SCM, IST, and CNT trackers in terms of occlusion, illumination, and scale variation sequences. It outperforms the LLR, IST, and DDL trackers in terms of fast motion sequences. These results demonstrate the effectiveness and robustness of our tracker to occlusion, illumination, scale variation, and fast motion.ConclusionQualitative and quantitative evaluations demonstrate that the proposed algorithm achieves higher precision compared with many state-of-the-art algorithms. In particular, it exhibits better adaptability for objects with fast motion. In the future, we will extend our tracker by applying deep learning to enhance its discriminatory ability.关键词:object tracking;variation method;sparse representation;low-rank constraint;particle filter50|46|1更新时间:2024-05-07
摘要:ObjectiveVisual object tracking is an important research subject in computer vision. It has extensive applications that include surveillance, human-computer interaction, and medical imaging. The goal of tracking is to estimate the states of a moving target in a video sequence. Considerable effort has been devoted to this field, but many challenges remain due to appearance variations caused by heavy occlusion, illumination variation, and fast motion. Low-rank approximation can acquire the underlying structure of a target because some candidate particles have extremely similar appearance. This approximation can prune irrelevant particles and is robust to global appearance changes, such as pose change and illumination variation. Sparse representation formulates candidate particles by using a linear combination of a few dictionary templates. This representation is robust against local appearance changes, e.g., partial occlusions. Therefore, combining low-rank approximation with sparsity representation can improve the efficiency and effectiveness of object tracking. However, object tracking via low-rank sparse learning easily results in tracking drift when facing objects with fast motion and severe occlusions. Therefore, reverse low-rank sparse learning with a variation regularization-based tracking algorithm is proposed.MethodFirst, a low-rank constraint is used to restrain the temporal correlation of the objective appearance, and thus, remove the uncorrelated particles and adapt the object appearance change. The rank minimization problem is known to be computationally intractable. Hence, we resort to minimizing its convex envelope via a nuclear norm. Second, the traditional sparse representation method requires solving numerous L1 optimization problems. Computational cost increases linearly with the number of candidate particles. We build an inverse sparse representation formulation for object appearance using candidate particles to represent the target template inversely, reducing the number of L1 optimization problems for online tracking from candidate particles to one. Third, variation regularization is introduced to model the sparse coefficient difference. The variation method can model the variable selection problem in bounded variation space, which can restrict object appearance with only a slight difference between consecutive frames but allow the existing difference between individual frames to jump discontinuously, and thus, adapt to fast object motion. Lastly, an online updating scheme based on alternating iteration is proposed for tracking computation. Each iteration updates one variable at a time. Meanwhile, the other variables are fixed to their latest values. To accommodate target appearance change, we also use a local updating scheme to update the local parts individually. This scheme captures changes in target appearance even when heavy occlusion occurs. In such case, the unoccluded local parts are still updated in the target template and the occluded ones are discarded. Consequently, we can obtain a representation coefficient for the observation model and realize online tracking.ResultTo evaluate our proposed tracker, qualitative and quantitative analyses are performed using MATLAB on benchmark tracking sequences (occlusion 1, David, boy, deer) obtained from OTB (object tracking benchmark) datasets. The selected videos include many challenging factors in visual tracking, such as occlusion, fast motion, illumination, and scale variation. The experimental results show that when faced with these challenging situations in the benchmark tracking dataset, the proposed algorithm can perform tracking effectively in complicated scenes. Comparative studies with five state-of-the-art visual trackers, namely, DDL (discriminative dictionary learning), SCM (sparse collaborative model), LLR (locally low-rank representation), IST (inverse sparse tracker), and CNT (convolutional networks training) are conducted. To achieve fair comparison, we use publicly available source codes or results provided by the authors. Among these trackers, DDL, SCM, LLR, and IST are the most relevant. Compared with the CNT tracker, we mostly consider that deep networks have attracted considerable attention in complicated visual tracking tasks. For qualitative comparison, the representative tracking results are discussed on the basis of the major challenging factors in each video. For quantitative comparison, the central pixel error (CPE), which records the Euclidean distance between the central location of the tracked target and the manually labeled ground truth, is used. When the metric value is smaller, the tracking results are more accurate. From the evolution process of CPE versus frame number, our tracker achieves the best results in these challenging sequences. In particular, our tracker outperforms the SCM, IST, and CNT trackers in terms of occlusion, illumination, and scale variation sequences. It outperforms the LLR, IST, and DDL trackers in terms of fast motion sequences. These results demonstrate the effectiveness and robustness of our tracker to occlusion, illumination, scale variation, and fast motion.ConclusionQualitative and quantitative evaluations demonstrate that the proposed algorithm achieves higher precision compared with many state-of-the-art algorithms. In particular, it exhibits better adaptability for objects with fast motion. In the future, we will extend our tracker by applying deep learning to enhance its discriminatory ability.关键词:object tracking;variation method;sparse representation;low-rank constraint;particle filter50|46|1更新时间:2024-05-07 -
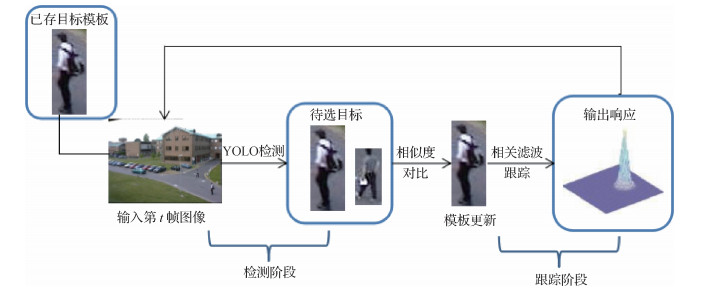 摘要:ObjectiveVideo-based object detection and tracking have always been a research topic of high concern in the academic field of computer vision. Video object tracking has important research significance and broad application prospects in intelligent monitoring,human-computer interaction,robot vision navigation,and other aspects. Although the theoretical research of video object tracking technology has made considerable progress and several achievements have entered the practical stage,research on this technology still faces tremendous challenges,such as scale change,illumination change,motion blur,object deformation,and object occlusion,which result in many difficulties in visual tracking,particularly object scale mutation within a short time. It will lead to the loss of tracking elements,and the accumulation of tracking errors will lead to tracking drift. If the object scale is consistent,then considerable scale information will be lost. Thus,scale mutation is a challenging task in object tracking. To solve this problem,this study proposes an adaptive scale mutation tracking algorithm (kernelized correlation filter_you only look once,KCF_YOLO).MethodThe algorithm uses a correlation filter tracker to realize fast tracking in the training phase of tracking and uses you only look once (YOLO) V3 neural network in the detection phase. An adaptive template updating strategy is also designed. This strategy uses the method of comparing the color features of the detected object with the object template and the similarity of the image fingerprint features after fusion to determine whether occlusion occurs and whether the object template should be updated in the current frame. In the first frame of the video,the object is selected,assuming that the category of the object to be tracked is human. The object area is stored as the object template T. The object is selected,and it enters the training stage. The KCF algorithm is used for tracking. KCF extracts the multichannel history of gradients features of the object template. In the tracking process,1.5 times of the object template is selected as the object search range of the next frame,considerably reducing the search range. Tracking speed is remarkably improved. When the frame number is a multiple of 20,it enters the detection stage and uses YOLO V3 for object detection. YOLO V3 identifies all the people (P1,P2, P3,…,Pn) in the current frame image. All the people to be identified are compared with the object template stored before 20 frames,and their color and image fingerprint features are extracted and compared with similarity (the similarity selection image fingerprint algorithm and color features are combined). If the similarity is greater than the average similarity of the first 20 frames,then the object template will be updated to the person with the greatest similarity. Simultaneously,the scale of the tracking box will be updated in accordance with the YOLO detection to achieve scale adaptation; otherwise,the object is judged as occluded and the template will not be updated. In the tracking phase,the updated or not updated object template is used as the latest status of the object in the tracking process for subsequent tracking. The preceding steps are repeated every 20 frames until the video and tracking end. The color and phase features are complementary. The image fingerprint feature selects the perceptual Hash(PHash) algorithm. After the discrete cosine transformation,the internal information of the image is mostly concentrated in the low-frequency area,reducing the calculation scope to the low-frequency area and losing color information. The color feature counts the distribution of colors in the entire image. The combination ensures the accuracy of similarity. A total of 11 video sequences representative of scale mutation in the object tracking benchmark(OTB)-2015 dataset are tested to prove the effectiveness of the proposed method. The results show that the average tracking accuracy of this algorithm is 0.955,and the average tracking speed is 36 frames/s. The self-made data of object reproduction are completely occluded for 130 frames. The result shows that tracking accuracy is 0.9,proving the validity of the algorithm that combines kernel correlation filtering and the YOLO V3 network. Compared with the classical scale adaptive tracking algorithm,accuracy is improved by 31.74% on average.ConclusionIn this study,we adopt the ideas of correlation filtering and neural network to detect and track targets,improving the adaptability of the algorithm to scale mutation in the object tracking process. The experimental results show that the detection strategy can correct the tracking drift caused by the subsequent scale mutation and ensure the effectiveness of the adaptive template updating strategy. To address the problems of the traditional nuclear correlation filter being unable to deal with a sudden change in object scale within a short time and the slow tracking speed of a neural network,this work establishes a bridge between a correlation filter and a neural network. The tracker that combines a correlation filter and a neural network opens a new way.关键词:object tracking;correlation filtering;neural network detection;scale mutation;scale adaptation33|33|2更新时间:2024-05-07
摘要:ObjectiveVideo-based object detection and tracking have always been a research topic of high concern in the academic field of computer vision. Video object tracking has important research significance and broad application prospects in intelligent monitoring,human-computer interaction,robot vision navigation,and other aspects. Although the theoretical research of video object tracking technology has made considerable progress and several achievements have entered the practical stage,research on this technology still faces tremendous challenges,such as scale change,illumination change,motion blur,object deformation,and object occlusion,which result in many difficulties in visual tracking,particularly object scale mutation within a short time. It will lead to the loss of tracking elements,and the accumulation of tracking errors will lead to tracking drift. If the object scale is consistent,then considerable scale information will be lost. Thus,scale mutation is a challenging task in object tracking. To solve this problem,this study proposes an adaptive scale mutation tracking algorithm (kernelized correlation filter_you only look once,KCF_YOLO).MethodThe algorithm uses a correlation filter tracker to realize fast tracking in the training phase of tracking and uses you only look once (YOLO) V3 neural network in the detection phase. An adaptive template updating strategy is also designed. This strategy uses the method of comparing the color features of the detected object with the object template and the similarity of the image fingerprint features after fusion to determine whether occlusion occurs and whether the object template should be updated in the current frame. In the first frame of the video,the object is selected,assuming that the category of the object to be tracked is human. The object area is stored as the object template T. The object is selected,and it enters the training stage. The KCF algorithm is used for tracking. KCF extracts the multichannel history of gradients features of the object template. In the tracking process,1.5 times of the object template is selected as the object search range of the next frame,considerably reducing the search range. Tracking speed is remarkably improved. When the frame number is a multiple of 20,it enters the detection stage and uses YOLO V3 for object detection. YOLO V3 identifies all the people (P1,P2, P3,…,Pn) in the current frame image. All the people to be identified are compared with the object template stored before 20 frames,and their color and image fingerprint features are extracted and compared with similarity (the similarity selection image fingerprint algorithm and color features are combined). If the similarity is greater than the average similarity of the first 20 frames,then the object template will be updated to the person with the greatest similarity. Simultaneously,the scale of the tracking box will be updated in accordance with the YOLO detection to achieve scale adaptation; otherwise,the object is judged as occluded and the template will not be updated. In the tracking phase,the updated or not updated object template is used as the latest status of the object in the tracking process for subsequent tracking. The preceding steps are repeated every 20 frames until the video and tracking end. The color and phase features are complementary. The image fingerprint feature selects the perceptual Hash(PHash) algorithm. After the discrete cosine transformation,the internal information of the image is mostly concentrated in the low-frequency area,reducing the calculation scope to the low-frequency area and losing color information. The color feature counts the distribution of colors in the entire image. The combination ensures the accuracy of similarity. A total of 11 video sequences representative of scale mutation in the object tracking benchmark(OTB)-2015 dataset are tested to prove the effectiveness of the proposed method. The results show that the average tracking accuracy of this algorithm is 0.955,and the average tracking speed is 36 frames/s. The self-made data of object reproduction are completely occluded for 130 frames. The result shows that tracking accuracy is 0.9,proving the validity of the algorithm that combines kernel correlation filtering and the YOLO V3 network. Compared with the classical scale adaptive tracking algorithm,accuracy is improved by 31.74% on average.ConclusionIn this study,we adopt the ideas of correlation filtering and neural network to detect and track targets,improving the adaptability of the algorithm to scale mutation in the object tracking process. The experimental results show that the detection strategy can correct the tracking drift caused by the subsequent scale mutation and ensure the effectiveness of the adaptive template updating strategy. To address the problems of the traditional nuclear correlation filter being unable to deal with a sudden change in object scale within a short time and the slow tracking speed of a neural network,this work establishes a bridge between a correlation filter and a neural network. The tracker that combines a correlation filter and a neural network opens a new way.关键词:object tracking;correlation filtering;neural network detection;scale mutation;scale adaptation33|33|2更新时间:2024-05-07 -
 摘要:ObjectiveTarget tracking is one of the basic problems in the field of computer vision. It is widely used in security monitoring,military operations,and automatic driving,among others. Tracking algorithms based on correlation filtering have been developed rapidly in recent years because of their fast and efficient features. However,designing a robust tracking algorithm remains a challenging problem due to background clutter,illumination variation,fast motion,rotation,and other complex factors. Building an effective appearance model is a key factor in tracking the success of an algorithm. The expressions of the current appearance model have two major types. In the first type,the appearance model is based on manual design. The common artificial design appearance model is the histogram of oriented gradients (HOG) feature because this feature can efficiently describe the contour and shape information of a target by calculating the direction gradient of the local area of the detected image. In the second type,the appearance model is based on deep learning. Low-level convolutional features contain rich texture information but are unable to adapt to background changes. High-level convolutional features contain rich semantic information that distinguishes backgrounds from targets even in complex contexts. Different informations of an image are described due to varying features; thus,this study proposes a correlation filter tracking method to achieve the effect of adaptive multifeature fusion.MethodIn this work,the DSST(discriminative scale space tracking) correlation filter is adopted as the benchmark algorithm,and conv1 and conv5 of the convolutional neural network (CNN) ImageNet-VGG (visual geometry group)-2 048 are used. First,the HOG feature of the target is extracted. Then,the high-and low-level convolutional features of the target are extracted using the CNN. The characteristic response graph is obtained. The maximum peak and shape of the response graph reflect the accurate information of the tracking results. Second,to evaluate the validity of the feature,using the area ratio of the peak as the new index is proposed to distinguish the confidence level of the correlation response graph. The validity of each feature is evaluated using an adaptive threshold segmentation method. If the peak of the response graph is sharp and the periphery is smooth,then the tracking result is reliable. The weight ratio of the feature fusion is obtained,such that the feature is improved and the fusion coefficient is increased. Lastly,the response graph of each feature is fused in accordance with the fusion coefficient,the final response output is calculated,and the target response position is determined from the maximum response value in the response graph. Scale-dependent filter estimation scales are reintroduced to achieve adaptive target tracking.ResultTo effectively evaluate the performance of the proposed method,the algorithm is tested on the public dataset OTB (object tracking benchmark)-2013. The 50 videos mostly contain 11 different challenges encountered in the target tracking process (including background complex,deformation,object disappearance,and scale variation). This study compares the algorithm with seven mainstream algorithms. The accuracy and success rate are used as the evaluation and tracking performance indicators. These algorithms are divided into two major categories: traditional tracking algorithms with representative and top ranks: ASLA (adaptive structural local sparse appearance),SCM (sparsity-based collaborative model),TLD (tracking-learning-detection). Correlation filtering algorithms: CFNet (correlation filter networks),KCF (kernel correlation filter),DSST,SAMF (scale adaptive with multiple features). The experimental results show that the proposed algorithm achieves the highest success rate and accuracy compared with the other algorithms. The accuracy of the proposed method on the OTB-2013 dataset is 77.8%. Those of the other algorithms are as follows: CFNet (76.1%),DSST (74.6%),KCF (73.5%),SAMF (72.5%),and the traditional algorithm SCM (67.8%). The success rate of the algorithm proposed in this work is 71.5%. Those of the other algorithms are CFNet (71.4%),DSST (67.5%),SAMF (66.2%),and KCF (61.1%). The algorithm presented in this study increases tracking accuracy by 4% and improves success rate by 6%. From the aforementioned experimental data analysis,the method can effectively improve tracking performance. The proposed method ranks first in terms of accuracy compared with CFNet,DSST,SAMF,and KCF in seven attributes: background clutter,deformation,out-of-view,illumination variation,in-plane rotation,out-of-plane rotation,and fast motion. Compared with the other algorithms,the algorithm proposed in this study achieves the highest success rate in the scenes of nine attributes.ConclusionDifferent information of an image are described due to varying features; thus,this study proposes a correlation filter tracking method to achieve the effect of adaptive multifeature fusion. A CNN is used to extract high- and low-layer convolutional and HOG features. The adaptive threshold segmentation method is proposed to evaluate the validity of each feature. The two-layer convolutional and HOG features are adaptively fused. The response graph is fused in accordance with the fusion coefficient using feature validity analysis. Compared with most feature fusion methods that connect features serially or in parallel,this algorithm increases the fusion weight of a single feature with strong discriminability,and the appearance model of the target can be accurately represented. Therefore,the proposed algorithm exhibits strong robustness and tracking accuracy in scenarios with low resolution and scale variation. The presented target tracking method will be further studied in the future under occlusion,motion blur,and fast motion conditions.关键词:target tracking;convolution feature;correlation filter;feature fusion;adaptive threshold segmentation45|68|6更新时间:2024-05-07
摘要:ObjectiveTarget tracking is one of the basic problems in the field of computer vision. It is widely used in security monitoring,military operations,and automatic driving,among others. Tracking algorithms based on correlation filtering have been developed rapidly in recent years because of their fast and efficient features. However,designing a robust tracking algorithm remains a challenging problem due to background clutter,illumination variation,fast motion,rotation,and other complex factors. Building an effective appearance model is a key factor in tracking the success of an algorithm. The expressions of the current appearance model have two major types. In the first type,the appearance model is based on manual design. The common artificial design appearance model is the histogram of oriented gradients (HOG) feature because this feature can efficiently describe the contour and shape information of a target by calculating the direction gradient of the local area of the detected image. In the second type,the appearance model is based on deep learning. Low-level convolutional features contain rich texture information but are unable to adapt to background changes. High-level convolutional features contain rich semantic information that distinguishes backgrounds from targets even in complex contexts. Different informations of an image are described due to varying features; thus,this study proposes a correlation filter tracking method to achieve the effect of adaptive multifeature fusion.MethodIn this work,the DSST(discriminative scale space tracking) correlation filter is adopted as the benchmark algorithm,and conv1 and conv5 of the convolutional neural network (CNN) ImageNet-VGG (visual geometry group)-2 048 are used. First,the HOG feature of the target is extracted. Then,the high-and low-level convolutional features of the target are extracted using the CNN. The characteristic response graph is obtained. The maximum peak and shape of the response graph reflect the accurate information of the tracking results. Second,to evaluate the validity of the feature,using the area ratio of the peak as the new index is proposed to distinguish the confidence level of the correlation response graph. The validity of each feature is evaluated using an adaptive threshold segmentation method. If the peak of the response graph is sharp and the periphery is smooth,then the tracking result is reliable. The weight ratio of the feature fusion is obtained,such that the feature is improved and the fusion coefficient is increased. Lastly,the response graph of each feature is fused in accordance with the fusion coefficient,the final response output is calculated,and the target response position is determined from the maximum response value in the response graph. Scale-dependent filter estimation scales are reintroduced to achieve adaptive target tracking.ResultTo effectively evaluate the performance of the proposed method,the algorithm is tested on the public dataset OTB (object tracking benchmark)-2013. The 50 videos mostly contain 11 different challenges encountered in the target tracking process (including background complex,deformation,object disappearance,and scale variation). This study compares the algorithm with seven mainstream algorithms. The accuracy and success rate are used as the evaluation and tracking performance indicators. These algorithms are divided into two major categories: traditional tracking algorithms with representative and top ranks: ASLA (adaptive structural local sparse appearance),SCM (sparsity-based collaborative model),TLD (tracking-learning-detection). Correlation filtering algorithms: CFNet (correlation filter networks),KCF (kernel correlation filter),DSST,SAMF (scale adaptive with multiple features). The experimental results show that the proposed algorithm achieves the highest success rate and accuracy compared with the other algorithms. The accuracy of the proposed method on the OTB-2013 dataset is 77.8%. Those of the other algorithms are as follows: CFNet (76.1%),DSST (74.6%),KCF (73.5%),SAMF (72.5%),and the traditional algorithm SCM (67.8%). The success rate of the algorithm proposed in this work is 71.5%. Those of the other algorithms are CFNet (71.4%),DSST (67.5%),SAMF (66.2%),and KCF (61.1%). The algorithm presented in this study increases tracking accuracy by 4% and improves success rate by 6%. From the aforementioned experimental data analysis,the method can effectively improve tracking performance. The proposed method ranks first in terms of accuracy compared with CFNet,DSST,SAMF,and KCF in seven attributes: background clutter,deformation,out-of-view,illumination variation,in-plane rotation,out-of-plane rotation,and fast motion. Compared with the other algorithms,the algorithm proposed in this study achieves the highest success rate in the scenes of nine attributes.ConclusionDifferent information of an image are described due to varying features; thus,this study proposes a correlation filter tracking method to achieve the effect of adaptive multifeature fusion. A CNN is used to extract high- and low-layer convolutional and HOG features. The adaptive threshold segmentation method is proposed to evaluate the validity of each feature. The two-layer convolutional and HOG features are adaptively fused. The response graph is fused in accordance with the fusion coefficient using feature validity analysis. Compared with most feature fusion methods that connect features serially or in parallel,this algorithm increases the fusion weight of a single feature with strong discriminability,and the appearance model of the target can be accurately represented. Therefore,the proposed algorithm exhibits strong robustness and tracking accuracy in scenarios with low resolution and scale variation. The presented target tracking method will be further studied in the future under occlusion,motion blur,and fast motion conditions.关键词:target tracking;convolution feature;correlation filter;feature fusion;adaptive threshold segmentation45|68|6更新时间:2024-05-07 -
 摘要:ObjectiveIn complex electronic warfare,radar emitter identification is an essential component of electronic intelligence and support systems; its related technology remains a critical factor in measuring the level of electronic countermeasure equipment technology. Radar emitter identification refers to extracting signal characteristics and then inputting the features into the classifier for identification. With the improvement of electronic technology,various jamming techniques have been applied to radar,making the identification of individual signal differences difficult. In addition,There are many types of radar signals,various modulation methods,and wide frequency coverage. Small individual feature differences between radar signals. There are a lot of noise,clutter and multipath interference in signals. Researchers mainly conduct the following two aspects,one is to extract the effective individual characteristics of the signal; the other is to optimize the classifier. Extracting signal discriminability characteristics using traditional radiation source identification techniques,such as template matching,classifier design,and decision matching,is challenging. Radar source identification technology is developing in the field of artificial intelligence. In cognitive ability,radiation source identification technology has a lot of room for development in the intelligent field. In the face of complex and diverse radar radiation source signals,existing radar radiation source identification algorithms are no longer able to cope with dense radar radiation source identification tasks. Given the robust data analysis capabilities of deep learning,convolutional neural network (CNN) are among the earliest and most widely used deep learning models. CNN has been used in radar source identification. In general,a CNN consists of the convolutional,pooling,activation,and fully connected layers. The convolutional layer and the layer stack structure extract powerful features and different features of data,respectively. The activation layer is used to enhance the feature expression ability of a network. The pooling layer can reduce dimensions and sparse feature layers. Feature combination and classification are performed at the full connection layer. In accordance with the characteristics of the radar radiation source signal,we propose a new radar source identification method based on CNN.MethodFirstly,the data pre-processing unit is used to reduce the interference of noise on the signal. Secondly,the obtained signals are first extracted from their different domain features,and then the training set test set is divided. The third step is to design a convolutional neural network to extract and classify the extracted signals. At last,evaluate the performance of the method using test samples. The proposed method realizes the accurate identification of radar radiation source,which can fully mine the deep individual information of the radiation source signal. To extract the individual implicit features of the radiation source signal,our CNN has five layers; the first three are convolutional and the remaining two are fully connected layers. The kernel of the third convolutional layer and the pooling layer is set to 1D. Rectified linear unit (ReLU) nonlinearity is applied to the output of every convolutional and fully connected layer. ReLU improves network non-linearity. We use dropout,which can prevent overfitting,in the first two fully connected layers. The role of dropout is to randomly inactivate some neurons. The first convolutional layer filters with 36 kernels of size 3 with a stride of 1. The second convolution layer is consistent with the parameters of the first convolutional layer. The third convolutional layer has 64 kernels of size 5 with a stride of 1. The specific steps of the algorithm are as follows. First,the original radar data are preprocessed,i.e.,signal noise reduction and normalization. Second,we extract different characteristics of the signal. Lastly,the CNN is trained using different features.ResultThe training set ratios are 20%,40%,60%,and 80% of the total number of samples. This study compares the recognition accuracy of CNN when the input is a different feature and compares the recognition accuracy of the support vector machine (SVM),extreme learning machine (ELM),and depth Q network (DQN) models in deep reinforcement learning. Experiments show that the input of the network is different domain characteristics when the training set ratio is 80%; a high recognition rate can be obtained. Recognition accuracy rate reaches 100% and 99% for the spectral and fuzzy function slice features,respectively. When the input is the frequency domain feature with 80% of the training set,we compare the performance of SVM. Our method outperforms SVM. In particular,it improves accuracy by 0.9%. When the input is the fuzzy function slice feature,the accuracy rate of our method is improved by 16.13% and 1.87% compared with the SVM and ELM classifiers,respectively. Compared with the current popular recognition algorithm DQN,the improvement is 0.15%. In the experiment,when the input is a fuzzy function slice feature and the frequency offset values are 3 and 5,the four classifiers all obtain good recognition results. In particular,the method proposed in this paper has the highest recognition accuracy. It shows that choosing the optimal "near-zero" slice is helpful for the identification of radar radiation source.ConclusionThe CNN designed in this study exhibits a strong feature expression ability. The experiment results show that our proposed method extracts the implicit features of signal discrimination and obtains a stable recognition rate. This method simplifies the network structure and requires less experience and hyperparameters in the same situation. It can improve the recognition accuracy of radar emitters.关键词:deep learning;radar emitter identification;convolutional neural network (CNN);recognition accuracy;frequency domain feature;fuzzy function slice34|31|1更新时间:2024-05-07
摘要:ObjectiveIn complex electronic warfare,radar emitter identification is an essential component of electronic intelligence and support systems; its related technology remains a critical factor in measuring the level of electronic countermeasure equipment technology. Radar emitter identification refers to extracting signal characteristics and then inputting the features into the classifier for identification. With the improvement of electronic technology,various jamming techniques have been applied to radar,making the identification of individual signal differences difficult. In addition,There are many types of radar signals,various modulation methods,and wide frequency coverage. Small individual feature differences between radar signals. There are a lot of noise,clutter and multipath interference in signals. Researchers mainly conduct the following two aspects,one is to extract the effective individual characteristics of the signal; the other is to optimize the classifier. Extracting signal discriminability characteristics using traditional radiation source identification techniques,such as template matching,classifier design,and decision matching,is challenging. Radar source identification technology is developing in the field of artificial intelligence. In cognitive ability,radiation source identification technology has a lot of room for development in the intelligent field. In the face of complex and diverse radar radiation source signals,existing radar radiation source identification algorithms are no longer able to cope with dense radar radiation source identification tasks. Given the robust data analysis capabilities of deep learning,convolutional neural network (CNN) are among the earliest and most widely used deep learning models. CNN has been used in radar source identification. In general,a CNN consists of the convolutional,pooling,activation,and fully connected layers. The convolutional layer and the layer stack structure extract powerful features and different features of data,respectively. The activation layer is used to enhance the feature expression ability of a network. The pooling layer can reduce dimensions and sparse feature layers. Feature combination and classification are performed at the full connection layer. In accordance with the characteristics of the radar radiation source signal,we propose a new radar source identification method based on CNN.MethodFirstly,the data pre-processing unit is used to reduce the interference of noise on the signal. Secondly,the obtained signals are first extracted from their different domain features,and then the training set test set is divided. The third step is to design a convolutional neural network to extract and classify the extracted signals. At last,evaluate the performance of the method using test samples. The proposed method realizes the accurate identification of radar radiation source,which can fully mine the deep individual information of the radiation source signal. To extract the individual implicit features of the radiation source signal,our CNN has five layers; the first three are convolutional and the remaining two are fully connected layers. The kernel of the third convolutional layer and the pooling layer is set to 1D. Rectified linear unit (ReLU) nonlinearity is applied to the output of every convolutional and fully connected layer. ReLU improves network non-linearity. We use dropout,which can prevent overfitting,in the first two fully connected layers. The role of dropout is to randomly inactivate some neurons. The first convolutional layer filters with 36 kernels of size 3 with a stride of 1. The second convolution layer is consistent with the parameters of the first convolutional layer. The third convolutional layer has 64 kernels of size 5 with a stride of 1. The specific steps of the algorithm are as follows. First,the original radar data are preprocessed,i.e.,signal noise reduction and normalization. Second,we extract different characteristics of the signal. Lastly,the CNN is trained using different features.ResultThe training set ratios are 20%,40%,60%,and 80% of the total number of samples. This study compares the recognition accuracy of CNN when the input is a different feature and compares the recognition accuracy of the support vector machine (SVM),extreme learning machine (ELM),and depth Q network (DQN) models in deep reinforcement learning. Experiments show that the input of the network is different domain characteristics when the training set ratio is 80%; a high recognition rate can be obtained. Recognition accuracy rate reaches 100% and 99% for the spectral and fuzzy function slice features,respectively. When the input is the frequency domain feature with 80% of the training set,we compare the performance of SVM. Our method outperforms SVM. In particular,it improves accuracy by 0.9%. When the input is the fuzzy function slice feature,the accuracy rate of our method is improved by 16.13% and 1.87% compared with the SVM and ELM classifiers,respectively. Compared with the current popular recognition algorithm DQN,the improvement is 0.15%. In the experiment,when the input is a fuzzy function slice feature and the frequency offset values are 3 and 5,the four classifiers all obtain good recognition results. In particular,the method proposed in this paper has the highest recognition accuracy. It shows that choosing the optimal "near-zero" slice is helpful for the identification of radar radiation source.ConclusionThe CNN designed in this study exhibits a strong feature expression ability. The experiment results show that our proposed method extracts the implicit features of signal discrimination and obtains a stable recognition rate. This method simplifies the network structure and requires less experience and hyperparameters in the same situation. It can improve the recognition accuracy of radar emitters.关键词:deep learning;radar emitter identification;convolutional neural network (CNN);recognition accuracy;frequency domain feature;fuzzy function slice34|31|1更新时间:2024-05-07 -
 摘要:ObjectiveImage stitching is a technology for solving the field-of-view (FOV) limitation of images by stitching multiple overlapping images to generate a wide-FOV image. Parallax image stitching remains a challenging problem. Although numerous methods and abundant commercial tools are beneficial in helping users organize and appreciate photo collections,many of these tools fail to provide convincing results when parallax images are given. Parallax image stitching methods with local homography transforms for partitioning cells are the most popular. However,many of these methods have a high rate of wrongly matching feature points and low accuracy in aligning feature points in different viewpoint images. We propose a novel stitching method using the hierarchical agglomerative clustering of feature points with their plane similarity information to improve the precision rate of matching feature points.MethodFirst,we develop a feature point shift algorithm using the clustering results of the feature points with planar information. The scale-invariant transform feature points of all the images with different viewpoints are extracted. The k-nearest neighbors for each feature point are found using the k-d (lk-dimension) tree algorithm.
摘要:ObjectiveImage stitching is a technology for solving the field-of-view (FOV) limitation of images by stitching multiple overlapping images to generate a wide-FOV image. Parallax image stitching remains a challenging problem. Although numerous methods and abundant commercial tools are beneficial in helping users organize and appreciate photo collections,many of these tools fail to provide convincing results when parallax images are given. Parallax image stitching methods with local homography transforms for partitioning cells are the most popular. However,many of these methods have a high rate of wrongly matching feature points and low accuracy in aligning feature points in different viewpoint images. We propose a novel stitching method using the hierarchical agglomerative clustering of feature points with their plane similarity information to improve the precision rate of matching feature points.MethodFirst,we develop a feature point shift algorithm using the clustering results of the feature points with planar information. The scale-invariant transform feature points of all the images with different viewpoints are extracted. The k-nearest neighbors for each feature point are found using the k-d (lk-dimension) tree algorithm.$ K$ 关键词:image stitching;image registration;hierarchical clustering;parallax image;local homography transformation;feature point match30|26|0更新时间:2024-05-07 -
 摘要:ObjectiveImage semantic segmentation is an important research topic in the field of computer vision. It refers to dividing an input image into multiple regions with semantic meaning,i.e.,assigning a semantic category to each pixel in the image. Many studies on image semantic segmentation based on deep learning have been conducted recently in China and overseas. Current mainstream methods are based on supervised deep learning. However,deep learning requires a large number of training samples,and the image semantic segmentation problem requires category labeling for each pixel in the training sample. On the one hand,pixel-level labeling is difficult. On the other hand,a large number of sample labels means high manual labeling costs. Therefore,image semantic segmentation based on weak supervision has become a research focus in recent years. Weakly supervised learning uses a weak label that is faster and easier to obtain,such as points,bounding boxes,and scribbles,for training. The major difficulty in weakly supervised learning is that weakly labeled data do not contain the location and contour information required for training.MethodTo solve the problem of missing edge information in a weak label for semantic segmentation,our primary objective is to fully utilize multilayer features extracted by a convolutional neural network (CNN). Our contributions include the following: first,a dynamic mask generation method for extracting the edges of image foreground targets is proposed. The method uses a bounding box as the initial foreground edge contour and iteratively adjusts it with the multilayer features of a CNN with a Gaussian mixture model. The input data of the dynamic mask generation method include bounding box label data and CNN feature maps. During each iteration,eigenvectors from a specific feature map are normalized and used to initialize the Gaussian mixture model,whose training samples are selected in accordance with the edges generated in the last iteration. The probability of all the sample points with respect to the Gaussian mixture model is calculated,and a fine-tuned contour is generated on the basis of these probabilities. In our dynamic mask generation process,the final mask generation iteration uses the original image feature to improve edge accuracy. Simultaneously,high-level features are used for mask initialization to reduce semantic level errors in edge information. Second,a weak supervised semantic segmentation method based on dynamic mask generation is proposed. The generated dynamic mask is used as supervision information in the semantic segmentation training process to feedback the CNN. In each training step,the mask is dynamically generated in accordance with the forward propagation result of each input image,and the mask is used instead of the traditional pixel-level annotation to complete the calculation of the loss function. The semantic segmentation model is trained in an end-to-end manner. A dynamic mask is only generated during the training process,and the test process only requires the forward propagation of the CNN.ResultThe segmentation accuracy of our method on the Pascal visual object classes(VOC)2012 dataset is 78.06%. Compared with existing weakly supervised semantic segmentation methods,such as box supervised(BoxSup) method,weakly and semi-supervised learning(WSSL) method,simple does it(SDI) method,and cut and paste(CaP) method,accuracy increases by 14.71%,4.04%,3.10%,and 0.92%,respectively. On the Berkeley deep drive(BDD 100K) dataset,the segmentation accuracy of our method is 61.56%. Compared with Boxsup,WSSL,SDI,and CaP,the accuracy increases by 10.39%,3.12%,1.35%,and 2.04%,respectively. The method has improved segmentation accuracy in the categories of pedestrians,cars,and traffic lights. Improvements are achieved in the categories of trucks and buses. The foreground targets of the two categories are typically large,and simple features tend to result in unsatisfactory segmentation. After the fusion of the underlying,middle,and high-level features in this study,the segmentation accuracy of such large targets is relatively significantly improved.ConclusionHigh-level features are used to estimate the approximate shape and position of the foreground object and generate rough edges,which will be corrected layer by layer with multilayer features. High-level semantic features can decrease edge information error in the semantic level,and low-level image features improve the accuracy of the edge. The training speed of our method is relatively slow because of the dynamic mask generation in each training step. However,test speed does not slow down because only the forward propagation calculation of the CNN is required.关键词:semantic segmentation;weakly supervised learning;Gaussian mixture model(GMM);fully convolutional network(FCN);feature fusion36|18|3更新时间:2024-05-07
摘要:ObjectiveImage semantic segmentation is an important research topic in the field of computer vision. It refers to dividing an input image into multiple regions with semantic meaning,i.e.,assigning a semantic category to each pixel in the image. Many studies on image semantic segmentation based on deep learning have been conducted recently in China and overseas. Current mainstream methods are based on supervised deep learning. However,deep learning requires a large number of training samples,and the image semantic segmentation problem requires category labeling for each pixel in the training sample. On the one hand,pixel-level labeling is difficult. On the other hand,a large number of sample labels means high manual labeling costs. Therefore,image semantic segmentation based on weak supervision has become a research focus in recent years. Weakly supervised learning uses a weak label that is faster and easier to obtain,such as points,bounding boxes,and scribbles,for training. The major difficulty in weakly supervised learning is that weakly labeled data do not contain the location and contour information required for training.MethodTo solve the problem of missing edge information in a weak label for semantic segmentation,our primary objective is to fully utilize multilayer features extracted by a convolutional neural network (CNN). Our contributions include the following: first,a dynamic mask generation method for extracting the edges of image foreground targets is proposed. The method uses a bounding box as the initial foreground edge contour and iteratively adjusts it with the multilayer features of a CNN with a Gaussian mixture model. The input data of the dynamic mask generation method include bounding box label data and CNN feature maps. During each iteration,eigenvectors from a specific feature map are normalized and used to initialize the Gaussian mixture model,whose training samples are selected in accordance with the edges generated in the last iteration. The probability of all the sample points with respect to the Gaussian mixture model is calculated,and a fine-tuned contour is generated on the basis of these probabilities. In our dynamic mask generation process,the final mask generation iteration uses the original image feature to improve edge accuracy. Simultaneously,high-level features are used for mask initialization to reduce semantic level errors in edge information. Second,a weak supervised semantic segmentation method based on dynamic mask generation is proposed. The generated dynamic mask is used as supervision information in the semantic segmentation training process to feedback the CNN. In each training step,the mask is dynamically generated in accordance with the forward propagation result of each input image,and the mask is used instead of the traditional pixel-level annotation to complete the calculation of the loss function. The semantic segmentation model is trained in an end-to-end manner. A dynamic mask is only generated during the training process,and the test process only requires the forward propagation of the CNN.ResultThe segmentation accuracy of our method on the Pascal visual object classes(VOC)2012 dataset is 78.06%. Compared with existing weakly supervised semantic segmentation methods,such as box supervised(BoxSup) method,weakly and semi-supervised learning(WSSL) method,simple does it(SDI) method,and cut and paste(CaP) method,accuracy increases by 14.71%,4.04%,3.10%,and 0.92%,respectively. On the Berkeley deep drive(BDD 100K) dataset,the segmentation accuracy of our method is 61.56%. Compared with Boxsup,WSSL,SDI,and CaP,the accuracy increases by 10.39%,3.12%,1.35%,and 2.04%,respectively. The method has improved segmentation accuracy in the categories of pedestrians,cars,and traffic lights. Improvements are achieved in the categories of trucks and buses. The foreground targets of the two categories are typically large,and simple features tend to result in unsatisfactory segmentation. After the fusion of the underlying,middle,and high-level features in this study,the segmentation accuracy of such large targets is relatively significantly improved.ConclusionHigh-level features are used to estimate the approximate shape and position of the foreground object and generate rough edges,which will be corrected layer by layer with multilayer features. High-level semantic features can decrease edge information error in the semantic level,and low-level image features improve the accuracy of the edge. The training speed of our method is relatively slow because of the dynamic mask generation in each training step. However,test speed does not slow down because only the forward propagation calculation of the CNN is required.关键词:semantic segmentation;weakly supervised learning;Gaussian mixture model(GMM);fully convolutional network(FCN);feature fusion36|18|3更新时间:2024-05-07 -
 摘要:ObjectiveThe depth feature representation of the 3D model is the key and premise of 3D target recognition and 3D model semantic segmentation. It has broad application prospects in the fields of robot, automatic driving, virtual reality, and remote sensing mapping. Semantic segmentation has achieved great progress with the help of deep learning, but most of the methods are used to process 2D images. Given the large amount of data, uneven density, and irregular shape of unstructured 3D point clouds, their classification and segmentation still have enormous challenges. Traditional convolutional neural networks (CNNs) require regularized data as input. The point cloud needs to be converted into multi-view or a voxel mesh to process. The existing deep learning network used for directly processing point cloud data solves the disorder problem of point cloud through the pooling layer of CNN. Thus, the network model can directly classify and segment the point cloud data. As for the classification and segmentation model dealing with point cloud data, its accuracy is closely related to the ability of the network to describe global and local features. Existing feature extraction networks often combine global features with local features at different scales, ignoring the structural information and position relationship among points. Thus, the global feature vectors with more significant features cannot be generated in the pooling layer, resulting in low classification and segmentation accuracy.MethodTo improve the performance of the network model, the graph CNN (GCN) and the improved pooling layer function are introduced in the classification and segmentation model. The method can enhance the ability of local feature representation and obtain more abundant global features. The processing ability of the network model to point cloud data can be improved. In the GCN, a graph structure is constructed by connecting the vertex with the nearest K points through the K-nearest neighbor algorithm. The convolution operation is then carried out on the edge and relative position relationship of the adjacent point pairs in the graph structure. Consequently, the more detailed local features implicit in the point cloud data are extracted. The graph structure in the GCN model is not fixed. It is dynamically updated and the graph convolution module can be stacked numerous times in the network to further perceive the local characteristics of point cloud data. In the network pooling layer, a hybrid pooling structure is adopted composed of two parallel pooling channels to obtain the global feature vectors. The maximum pooling channel is used to obtain the maximal feature vector, while another maximum-average pooling channel is used to obtain a synthetic feature concerning the maximal and mean feature vectors. The acquired characteristic vectors are concatenated to obtain the final global feature vector of the network. Consequently, the network provides good robustness for the jittered data.ResultThe datasets ModelNet40, ShapeNet, and Stanford 3D indoor semantics (S3DIS) are mostly used for testing the performance of classification, partial segmentation, and semantic scene segmentation. Several experiments are carried out on the above three datasets to validate the performance of the model. In the classification experiment of ModelNet40, the proposed model achieves a better classification effect compared with the other competitive models. The overall accuracy and average classification accuracy are improved by 4% and 3.7%, respectively, compared with PointNet. In the partial segmentation ShapeNet dataset, the mean intersection-over-union (mIoU) is used as the index for evaluating model segmentation performance. In the comparison test, the proposed model in this study also obtains a satisfactory segmentation result. Specifically, our model's mIoU is 1.4% higher than that of PointNet. In S3DIS indoor scene dataset, our model's mIoU is 9.8% higher than PointNet. Furthermore, different pooling functions are tested and investigated to verify the effectiveness of the proposed hybrid pooling function in this study. Results show that the proposed hybrid pooling function in this study improves the average classification accuracy, exhibiting a 0.9% increase compared with the pooling function by PointNet.ConclusionExperimental results show that the local features of point cloud data can be effectively extracted by introducing GCN into the network model. The hybrid pooling function also yields great improvement in generating global characteristics with additional information. In general, the proposed network model can effectively obtain the global and local features of point cloud data and achieve better classification and segmentation effects.关键词:point cloud;deep learning;graph convolution neural network (GCN);hybrid pooling function;classification and segmentation;joint feature22|22|4更新时间:2024-05-07
摘要:ObjectiveThe depth feature representation of the 3D model is the key and premise of 3D target recognition and 3D model semantic segmentation. It has broad application prospects in the fields of robot, automatic driving, virtual reality, and remote sensing mapping. Semantic segmentation has achieved great progress with the help of deep learning, but most of the methods are used to process 2D images. Given the large amount of data, uneven density, and irregular shape of unstructured 3D point clouds, their classification and segmentation still have enormous challenges. Traditional convolutional neural networks (CNNs) require regularized data as input. The point cloud needs to be converted into multi-view or a voxel mesh to process. The existing deep learning network used for directly processing point cloud data solves the disorder problem of point cloud through the pooling layer of CNN. Thus, the network model can directly classify and segment the point cloud data. As for the classification and segmentation model dealing with point cloud data, its accuracy is closely related to the ability of the network to describe global and local features. Existing feature extraction networks often combine global features with local features at different scales, ignoring the structural information and position relationship among points. Thus, the global feature vectors with more significant features cannot be generated in the pooling layer, resulting in low classification and segmentation accuracy.MethodTo improve the performance of the network model, the graph CNN (GCN) and the improved pooling layer function are introduced in the classification and segmentation model. The method can enhance the ability of local feature representation and obtain more abundant global features. The processing ability of the network model to point cloud data can be improved. In the GCN, a graph structure is constructed by connecting the vertex with the nearest K points through the K-nearest neighbor algorithm. The convolution operation is then carried out on the edge and relative position relationship of the adjacent point pairs in the graph structure. Consequently, the more detailed local features implicit in the point cloud data are extracted. The graph structure in the GCN model is not fixed. It is dynamically updated and the graph convolution module can be stacked numerous times in the network to further perceive the local characteristics of point cloud data. In the network pooling layer, a hybrid pooling structure is adopted composed of two parallel pooling channels to obtain the global feature vectors. The maximum pooling channel is used to obtain the maximal feature vector, while another maximum-average pooling channel is used to obtain a synthetic feature concerning the maximal and mean feature vectors. The acquired characteristic vectors are concatenated to obtain the final global feature vector of the network. Consequently, the network provides good robustness for the jittered data.ResultThe datasets ModelNet40, ShapeNet, and Stanford 3D indoor semantics (S3DIS) are mostly used for testing the performance of classification, partial segmentation, and semantic scene segmentation. Several experiments are carried out on the above three datasets to validate the performance of the model. In the classification experiment of ModelNet40, the proposed model achieves a better classification effect compared with the other competitive models. The overall accuracy and average classification accuracy are improved by 4% and 3.7%, respectively, compared with PointNet. In the partial segmentation ShapeNet dataset, the mean intersection-over-union (mIoU) is used as the index for evaluating model segmentation performance. In the comparison test, the proposed model in this study also obtains a satisfactory segmentation result. Specifically, our model's mIoU is 1.4% higher than that of PointNet. In S3DIS indoor scene dataset, our model's mIoU is 9.8% higher than PointNet. Furthermore, different pooling functions are tested and investigated to verify the effectiveness of the proposed hybrid pooling function in this study. Results show that the proposed hybrid pooling function in this study improves the average classification accuracy, exhibiting a 0.9% increase compared with the pooling function by PointNet.ConclusionExperimental results show that the local features of point cloud data can be effectively extracted by introducing GCN into the network model. The hybrid pooling function also yields great improvement in generating global characteristics with additional information. In general, the proposed network model can effectively obtain the global and local features of point cloud data and achieve better classification and segmentation effects.关键词:point cloud;deep learning;graph convolution neural network (GCN);hybrid pooling function;classification and segmentation;joint feature22|22|4更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveVisual object tracking, which has a profound theoretical basis and application value, is one of the basic problems in computer vision research. Visual object tracking technology has wide applications but faces increasingly complex environments. Factors, such as scale changes, occlusion, and illumination variation, bring uncertain interferences to visual tracking. Research on robust, accurate, and fast visual object tracking algorithms should be conducted further. In recent years, two categories of discriminant model methods based on a discriminative correlation filter and the Siamese neural network have achieved high accuracy and robustness in the tracking problem. However, tracking methods based on the Siamese network are limited by the huge computation amount of a convolutional neural network (CNN) and can only be performed on high-performance GPUs(graphics processing units). The computing requirement seriously affects the application of this type of methods in the practical engineering environment. Tracking methods based on a discriminative correlation filter have simple frameworks, and thus, can use manually setting features to learn and update an object's representation and achieve real-time tracking on a single CPU(central processing unit). This types of real-time tracking algorithm has been applied well to mobile platforms, such as unmanned aerial vehicles. Under the traditional correlation filtering framework, updating the correlation filter frame by frame will lead to an excessively large computational load and affect real-time performance. The sparse model updating strategy proposed in recent years simply sets a fixed updating interval, reducing the convergence speed of the tracking model and easily losing track when the object changes rapidly. The tracking ability of the two types of correlation filtering tracking algorithms cannot meet the increasing application requirements in complex environments. For the correlation filter updating strategy, this study proposes a dynamic updating algorithm based on appearance representation analysis to optimize computation and improve tracking accuracy.MethodFirst, optical flow features are used to estimate the appearance state of an object. We calculate the dense optical flow of the predicted target region's image. When the object is simply shifting, the optical flow's amplitude of each pixel is small, and the direction lacks a uniform rule because the image of the target area changes minimally. However, when the object is deforming or being occluded, the deformed part will generate a considerably larger optical flow, which differs from common objects. In this study, optical flow histogram information is extracted by dividing an image into m×n grids. The average optical flow amplitudes and angles of each pixel are counted in each grid to form the histogram feature vector. A support vector machine is then used to classify feature vectors to estimate the object's current appearance state. After appearance state analysis, the optical flow amplitude in the object region of the current frame is counted, and a statistical histogram of optical flow amplitude with an interval of 0.5 is constructed. The updating interval of the filter model is set in accordance with the magnitude of the main optical flow amplitude and the target category to realize the adaptive updating of the correlation filter. Moreover, the foreground-background separation operation based on discrete cosine transform in the first frame is used to obtain accurate labeling information, reduce similar background interference, and further optimize the learning of object representation.ResultThis algorithm is tested on the OTB100(object tracking benchmark with 100 sequences) dataset and compared with ECO-HC(efficient convolution operators using hand-crafted features), SRDCF(spatially regularized discriminative correlation filter), Staple(sum of template and pixel-wise learners), KCF(kernelized correlation filter), DSST(discriminative scale space tracker) and CSK(circulant structure of tracking-by-detection with kernels), which are fast tracking algorithms. On five typical challenging video image sequences, the algorithm proposed in this study achieved higher tracking overlap through the update interval adaptively setting model. It solved the overfitting problem of traditional frame-by-frame updating algorithms, such as Staple, and the problem in ECO-HC which is easy to lose fast-changing objects owing to the sparse updating strategy. The comprehensive quantitative analysis results on the entire OTB100 dataset showed that the tracking accuracy and success rate of the algorithm proposed in this work are 86.4% and 64.9%, respectively. The tracking accuracy and robustness of our algorithm are the best compared with other fast-tracking algorithms that can run on a CPU. Moreover, under highly challenging and complex environments, including in-plane rotation, occlusion, out of view, and illumination variation, our algorithm's precision was 3.0%, 4.4%, 5.2%, and 6.0% higher than that of the algorithm at second place, and the success rate was 1.9%, 3.1%, 4.9%, and 4.0% higher. In the running speed test on CPU i7-6850k, the frames per second of the algorithm developed in this work is 32.15, and the computational load is less than that of the frame-by-frame updating algorithm, thereby meeting the real-time requirements for tracking problems.ConclusionThis study proposed a dynamic updating correlation filter tracking algorithm based on appearance representation analysis. A series of comparison results shows that the improved algorithm in this work can consider the robust tracking of slow-changing objects and the accurate tracking of fast-changing objects to achieve excellent real-time performance suitable for project deployment and application.关键词:object tracking;correlation filtering;optical flow;appearance state analysis;adaptive model update25|19|1更新时间:2024-05-07
摘要:ObjectiveVisual object tracking, which has a profound theoretical basis and application value, is one of the basic problems in computer vision research. Visual object tracking technology has wide applications but faces increasingly complex environments. Factors, such as scale changes, occlusion, and illumination variation, bring uncertain interferences to visual tracking. Research on robust, accurate, and fast visual object tracking algorithms should be conducted further. In recent years, two categories of discriminant model methods based on a discriminative correlation filter and the Siamese neural network have achieved high accuracy and robustness in the tracking problem. However, tracking methods based on the Siamese network are limited by the huge computation amount of a convolutional neural network (CNN) and can only be performed on high-performance GPUs(graphics processing units). The computing requirement seriously affects the application of this type of methods in the practical engineering environment. Tracking methods based on a discriminative correlation filter have simple frameworks, and thus, can use manually setting features to learn and update an object's representation and achieve real-time tracking on a single CPU(central processing unit). This types of real-time tracking algorithm has been applied well to mobile platforms, such as unmanned aerial vehicles. Under the traditional correlation filtering framework, updating the correlation filter frame by frame will lead to an excessively large computational load and affect real-time performance. The sparse model updating strategy proposed in recent years simply sets a fixed updating interval, reducing the convergence speed of the tracking model and easily losing track when the object changes rapidly. The tracking ability of the two types of correlation filtering tracking algorithms cannot meet the increasing application requirements in complex environments. For the correlation filter updating strategy, this study proposes a dynamic updating algorithm based on appearance representation analysis to optimize computation and improve tracking accuracy.MethodFirst, optical flow features are used to estimate the appearance state of an object. We calculate the dense optical flow of the predicted target region's image. When the object is simply shifting, the optical flow's amplitude of each pixel is small, and the direction lacks a uniform rule because the image of the target area changes minimally. However, when the object is deforming or being occluded, the deformed part will generate a considerably larger optical flow, which differs from common objects. In this study, optical flow histogram information is extracted by dividing an image into m×n grids. The average optical flow amplitudes and angles of each pixel are counted in each grid to form the histogram feature vector. A support vector machine is then used to classify feature vectors to estimate the object's current appearance state. After appearance state analysis, the optical flow amplitude in the object region of the current frame is counted, and a statistical histogram of optical flow amplitude with an interval of 0.5 is constructed. The updating interval of the filter model is set in accordance with the magnitude of the main optical flow amplitude and the target category to realize the adaptive updating of the correlation filter. Moreover, the foreground-background separation operation based on discrete cosine transform in the first frame is used to obtain accurate labeling information, reduce similar background interference, and further optimize the learning of object representation.ResultThis algorithm is tested on the OTB100(object tracking benchmark with 100 sequences) dataset and compared with ECO-HC(efficient convolution operators using hand-crafted features), SRDCF(spatially regularized discriminative correlation filter), Staple(sum of template and pixel-wise learners), KCF(kernelized correlation filter), DSST(discriminative scale space tracker) and CSK(circulant structure of tracking-by-detection with kernels), which are fast tracking algorithms. On five typical challenging video image sequences, the algorithm proposed in this study achieved higher tracking overlap through the update interval adaptively setting model. It solved the overfitting problem of traditional frame-by-frame updating algorithms, such as Staple, and the problem in ECO-HC which is easy to lose fast-changing objects owing to the sparse updating strategy. The comprehensive quantitative analysis results on the entire OTB100 dataset showed that the tracking accuracy and success rate of the algorithm proposed in this work are 86.4% and 64.9%, respectively. The tracking accuracy and robustness of our algorithm are the best compared with other fast-tracking algorithms that can run on a CPU. Moreover, under highly challenging and complex environments, including in-plane rotation, occlusion, out of view, and illumination variation, our algorithm's precision was 3.0%, 4.4%, 5.2%, and 6.0% higher than that of the algorithm at second place, and the success rate was 1.9%, 3.1%, 4.9%, and 4.0% higher. In the running speed test on CPU i7-6850k, the frames per second of the algorithm developed in this work is 32.15, and the computational load is less than that of the frame-by-frame updating algorithm, thereby meeting the real-time requirements for tracking problems.ConclusionThis study proposed a dynamic updating correlation filter tracking algorithm based on appearance representation analysis. A series of comparison results shows that the improved algorithm in this work can consider the robust tracking of slow-changing objects and the accurate tracking of fast-changing objects to achieve excellent real-time performance suitable for project deployment and application.关键词:object tracking;correlation filtering;optical flow;appearance state analysis;adaptive model update25|19|1更新时间:2024-05-07 -
 摘要:ObjectiveWith the continuous development of convolutional neural network (CNN) used in deep learning in recent years, 3D object detection networks based on deep learning have also made outstanding development. 3D object detection aims to identify the class, location, orientation, and size of a target object in 3D space. It is widely used in the visual field, such as autonomous driving, intelligent monitoring, and medical analysis. The feature extracted by a deep learning network is important in detection accuracy. The detection task is similar to human vision; that is, it also needs to distinguish the difference between the background and the objects. In human vision, attention is given to target objects, while the background is disregarded. Therefore, paying more attention to the target area and less attention to the background area is better when performing object detection in an image. However, a CNN does not distinguish which areas and channels in an image should be given more and less attention. Thus, the features extracted by a CNN not only lack the dependence relationship between different regions but also the dependence relationship between different channels. The current 3D object detection method based on a deep learning network uses a combination of pooling layers behind the multilayer convolution layer. These network structures generally use maximum or averaging pooling in feature maps. They aim to adjust the receptive field size of the extracted features. However, transforming the receptive field of the features of the pooling layers must be performed by removing some information, causing a considerable loss of feature information. Information loss may result in detected errors. Therefore, a CNN should expand the receptive field without losing information, obtaining good detection results. To address the shortcomings of the aforementioned 3D target detection methods, this study proposes a two-stage 3D object detection network that combines mixed domain attention and dilated convolution.MethodIn this study, a 3D object detection network based on a deep learning network is built. Integrating the spatial domain attention mechanism into the input layer of the network transforms the spatial position of the input information, preserving regional features that require more attention. Incorporating the channel domain attention mechanism into the network computes the channel weights of the extracted features, obtaining the key channel features. The features are mixed by combining the aforementioned spatial and channel domain attention mechanisms. Second, the output layer of the feature extractor integrates the network layer that is combined with the dilated convolution and the channel domain attention mechanism, and thus, our network can expand the receptive field of the extracted features without losing spatial resolution. In accordance with the different obtained receptive fields, the features can determine their channel weights and then fuse these feature weights through different schemes to obtain the channel weights of their global receptive fields and identify key channel features. In addition, the feature pyramid network structure is introduced to construct the feature extractor of our network, through which our network can extract high-resolution feature maps, considerably improving the detection performance of our network. Lastly, our network architecture is based on a two-stage region proposal network, which can regress to accurate 3D bounding boxes.ResultA series of experiments has been conducted on the KITTI(A project of Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago) dataset using the method proposed in this study. Cases wherein the object is slightly to severely occluded are denoted as "easy", "moderate", and "hard" in the tables. In the car class in the test set, the values of AP3D that represents average accuracy of 3D object detection box obtained are 83.45%, 74.29%, and 67.92%; and the values of APBEV that represents average accuracy of 2D detection box from bird's eye view obtained are 89.61%, 87.05%, and 79.69%. In the pedestrian class, the values of AP3D obtained are 52.23%, 44.91%, and 41.64%; and the values of APBEV obtained are 59.73%, 53.97%, and 49.62%. In the cyclist class, the values of AP3D obtained are 65.02%, 54.38%, and 47.97%; and the values of APBEVobtained are 69.13%, 59.69%, and 52.11%. We also perform ablation experiments on the test set. The experiment results show that in the car class and relative to the proposed method, the average value of AP3D obtained after removing the pyramid structure is reduced by approximately 6.09%, the average value of AP3D obtained after removing the mixed domain attention structure is reduced by approximately 0.99%, and the average value of AP3D obtained after removing the dilated convolution structure is reduced by approximately 0.71%.ConclusionFor the research on 3D object detection task, we propose a two-stage 3D object detection network that combines dilated convolution and mixed domain attention. The experiment results show that the proposed method outperforms several existing state-of-the-art 3D object detection methods and obtains accurate detection results, and it can be effectively applied to outdoor automatic driving.关键词:3D object detection;attention mechanism;dilated convolution;receptive field;feature pyramid network;convolutional neural network(CNN)23|17|3更新时间:2024-05-07
摘要:ObjectiveWith the continuous development of convolutional neural network (CNN) used in deep learning in recent years, 3D object detection networks based on deep learning have also made outstanding development. 3D object detection aims to identify the class, location, orientation, and size of a target object in 3D space. It is widely used in the visual field, such as autonomous driving, intelligent monitoring, and medical analysis. The feature extracted by a deep learning network is important in detection accuracy. The detection task is similar to human vision; that is, it also needs to distinguish the difference between the background and the objects. In human vision, attention is given to target objects, while the background is disregarded. Therefore, paying more attention to the target area and less attention to the background area is better when performing object detection in an image. However, a CNN does not distinguish which areas and channels in an image should be given more and less attention. Thus, the features extracted by a CNN not only lack the dependence relationship between different regions but also the dependence relationship between different channels. The current 3D object detection method based on a deep learning network uses a combination of pooling layers behind the multilayer convolution layer. These network structures generally use maximum or averaging pooling in feature maps. They aim to adjust the receptive field size of the extracted features. However, transforming the receptive field of the features of the pooling layers must be performed by removing some information, causing a considerable loss of feature information. Information loss may result in detected errors. Therefore, a CNN should expand the receptive field without losing information, obtaining good detection results. To address the shortcomings of the aforementioned 3D target detection methods, this study proposes a two-stage 3D object detection network that combines mixed domain attention and dilated convolution.MethodIn this study, a 3D object detection network based on a deep learning network is built. Integrating the spatial domain attention mechanism into the input layer of the network transforms the spatial position of the input information, preserving regional features that require more attention. Incorporating the channel domain attention mechanism into the network computes the channel weights of the extracted features, obtaining the key channel features. The features are mixed by combining the aforementioned spatial and channel domain attention mechanisms. Second, the output layer of the feature extractor integrates the network layer that is combined with the dilated convolution and the channel domain attention mechanism, and thus, our network can expand the receptive field of the extracted features without losing spatial resolution. In accordance with the different obtained receptive fields, the features can determine their channel weights and then fuse these feature weights through different schemes to obtain the channel weights of their global receptive fields and identify key channel features. In addition, the feature pyramid network structure is introduced to construct the feature extractor of our network, through which our network can extract high-resolution feature maps, considerably improving the detection performance of our network. Lastly, our network architecture is based on a two-stage region proposal network, which can regress to accurate 3D bounding boxes.ResultA series of experiments has been conducted on the KITTI(A project of Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago) dataset using the method proposed in this study. Cases wherein the object is slightly to severely occluded are denoted as "easy", "moderate", and "hard" in the tables. In the car class in the test set, the values of AP3D that represents average accuracy of 3D object detection box obtained are 83.45%, 74.29%, and 67.92%; and the values of APBEV that represents average accuracy of 2D detection box from bird's eye view obtained are 89.61%, 87.05%, and 79.69%. In the pedestrian class, the values of AP3D obtained are 52.23%, 44.91%, and 41.64%; and the values of APBEV obtained are 59.73%, 53.97%, and 49.62%. In the cyclist class, the values of AP3D obtained are 65.02%, 54.38%, and 47.97%; and the values of APBEVobtained are 69.13%, 59.69%, and 52.11%. We also perform ablation experiments on the test set. The experiment results show that in the car class and relative to the proposed method, the average value of AP3D obtained after removing the pyramid structure is reduced by approximately 6.09%, the average value of AP3D obtained after removing the mixed domain attention structure is reduced by approximately 0.99%, and the average value of AP3D obtained after removing the dilated convolution structure is reduced by approximately 0.71%.ConclusionFor the research on 3D object detection task, we propose a two-stage 3D object detection network that combines dilated convolution and mixed domain attention. The experiment results show that the proposed method outperforms several existing state-of-the-art 3D object detection methods and obtains accurate detection results, and it can be effectively applied to outdoor automatic driving.关键词:3D object detection;attention mechanism;dilated convolution;receptive field;feature pyramid network;convolutional neural network(CNN)23|17|3更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectivePhysics-based smoke simulation is an important topic in computer graphics. Realistically simulating turbulent smoke flows is generally computationally expensive due to intrinsic small-scale structures that require sophisticated nondissipative solvers with a relatively high resolution. To effectively preserve small-scale structures, neural networks have been recently proposed and applied. However, the common problem in previous models for upsampling fluid flow fields with added small-scale structures is that the upsampled fluid field may not be sufficiently close to the corresponding high-resolution simulations. This problem may produce visual artifacts as important features, e.g., vortex rings that require high-resolution samples to capture can be overlooked. The difficulty behind such upsampling, which considerably differs from image upsampling, is that the flow structures between high- and low-resolution simulations can substantially differ. This structure inconsistency becomes increasingly evident when high and low resolutions differ significantly from local nonlinear vortex structures to the global shape of turbulent flow distributions. To enable upsampling with close similarity to its high-resolution simulation counterpart, local and global information should be acquired and encoded. In this study, we propose a novel dictionary-based neural network for synthesizing the high-frequency components of a turbulent smoke flow from a very low-resolution simulation. By learning a local generative scheme from a large set of patches that exist in high-resolution simulations, our network can faithfully synthesize a high-resolution smoke flow that closely resembles the corresponding high-resolution simulations, with well-preserved important features and considerably improved computing efficiency.MethodFirst, high- and low-resolution turbulent smoke data are simulated using a high-precision numerical method. We propose a feature vector that encodes the local velocity information of each 3D patch, global position, and time. This vector can help accurately predict local high-frequency components. Then, we construct a novel neural network based on the dictionary learning framework; this network simultaneously learns the dictionary and the associated coefficients. High-resolution smoke data have more details than low-resolution smoke data; thus, the former has a more complex spatial structure. Accordingly, we add gradient loss to maintain the spatial structure, with a regularization term to prevent overfitting. The advantage of our model is that it jointly optimizes all the layer parameters from end to end. After the training process, our neural network can learn a complex mapping function to efficiently synthesize high-resolution turbulent smoke patch data. During online synthesis given a low-resolution simulation, the trained neural network is used to predict overlapping local patches in parallel, with convolution in overlapping regions to ensure smooth transition.ResultOn the basis of the experimental results, we propose a novel dictionary-based neural network as a small-scale structure predictor to address such upsampling problem. The proposed neural network can produce spatially and temporally consistent high-resolution flow fields from very low-resolution simulations that closely approximate the direct high-resolution simulation results, with considerably improved computational efficiency. Our method faithfully preserves small-scale structures by comparing low- and high-resolution simulations. With our learning-based fast smoke simulation method, efficiency is improved by one order of magnitude compared with direct simulations at a resolution of 200×400×200 with highly similar results.ConclusionIn this study, we address the crucial problem of synthesizing a high-resolution flow field from a very low-resolution simulation to achieve efficient smoke animation. The synthesized high-resolution flows can closely approximate their simulation counterparts. To produce a high-resolution flow field, we design a novel neural network that is motivated by dictionary learning and a new feature descriptor that encodes local and global information. The neural network can be used for efficient synthesis to quickly predict flow details in high resolutions. Parallel implementations of such mechanisms are realized on a GPU, with comparisons with numerical simulations to highlight the advantages of our method.关键词:smoke simulation;neural network;particle system;computer animation;dictionary learning20|18|0更新时间:2024-05-07
摘要:ObjectivePhysics-based smoke simulation is an important topic in computer graphics. Realistically simulating turbulent smoke flows is generally computationally expensive due to intrinsic small-scale structures that require sophisticated nondissipative solvers with a relatively high resolution. To effectively preserve small-scale structures, neural networks have been recently proposed and applied. However, the common problem in previous models for upsampling fluid flow fields with added small-scale structures is that the upsampled fluid field may not be sufficiently close to the corresponding high-resolution simulations. This problem may produce visual artifacts as important features, e.g., vortex rings that require high-resolution samples to capture can be overlooked. The difficulty behind such upsampling, which considerably differs from image upsampling, is that the flow structures between high- and low-resolution simulations can substantially differ. This structure inconsistency becomes increasingly evident when high and low resolutions differ significantly from local nonlinear vortex structures to the global shape of turbulent flow distributions. To enable upsampling with close similarity to its high-resolution simulation counterpart, local and global information should be acquired and encoded. In this study, we propose a novel dictionary-based neural network for synthesizing the high-frequency components of a turbulent smoke flow from a very low-resolution simulation. By learning a local generative scheme from a large set of patches that exist in high-resolution simulations, our network can faithfully synthesize a high-resolution smoke flow that closely resembles the corresponding high-resolution simulations, with well-preserved important features and considerably improved computing efficiency.MethodFirst, high- and low-resolution turbulent smoke data are simulated using a high-precision numerical method. We propose a feature vector that encodes the local velocity information of each 3D patch, global position, and time. This vector can help accurately predict local high-frequency components. Then, we construct a novel neural network based on the dictionary learning framework; this network simultaneously learns the dictionary and the associated coefficients. High-resolution smoke data have more details than low-resolution smoke data; thus, the former has a more complex spatial structure. Accordingly, we add gradient loss to maintain the spatial structure, with a regularization term to prevent overfitting. The advantage of our model is that it jointly optimizes all the layer parameters from end to end. After the training process, our neural network can learn a complex mapping function to efficiently synthesize high-resolution turbulent smoke patch data. During online synthesis given a low-resolution simulation, the trained neural network is used to predict overlapping local patches in parallel, with convolution in overlapping regions to ensure smooth transition.ResultOn the basis of the experimental results, we propose a novel dictionary-based neural network as a small-scale structure predictor to address such upsampling problem. The proposed neural network can produce spatially and temporally consistent high-resolution flow fields from very low-resolution simulations that closely approximate the direct high-resolution simulation results, with considerably improved computational efficiency. Our method faithfully preserves small-scale structures by comparing low- and high-resolution simulations. With our learning-based fast smoke simulation method, efficiency is improved by one order of magnitude compared with direct simulations at a resolution of 200×400×200 with highly similar results.ConclusionIn this study, we address the crucial problem of synthesizing a high-resolution flow field from a very low-resolution simulation to achieve efficient smoke animation. The synthesized high-resolution flows can closely approximate their simulation counterparts. To produce a high-resolution flow field, we design a novel neural network that is motivated by dictionary learning and a new feature descriptor that encodes local and global information. The neural network can be used for efficient synthesis to quickly predict flow details in high resolutions. Parallel implementations of such mechanisms are realized on a GPU, with comparisons with numerical simulations to highlight the advantages of our method.关键词:smoke simulation;neural network;particle system;computer animation;dictionary learning20|18|0更新时间:2024-05-07 -
 摘要:ObjectiveBas-relief is a semi-stereoscopic sculpture between 2D and 3D space that is typically attached to a plane. It is frequently used to decorate buildings, coins, badges, ceramics, and utensils. It occupies less space and enhances stereo sense mostly through lines. Research on bas-relief is focused on two modeling techniques: 3D models and 2D images. It is performed in three aspects: enhancing the continuity of the height field, preserving the original structure and details, and avoiding the attenuation of the stereoscopic effect. The bas-relief modeling technique based on a 3D model starts from the aspects of spatial, gradient, or normal domains, and compresses the depth values of the 3D model in a given visual direction to generate the bas-relief model. The bas-relief modeling technique based on a 2D image extracts the gray information from the image and converts it into depth information, completing the reconstruction from the image to the bas-relief model. However, minimal attention has been given to the repair and optimization of existing bas-reliefs. Many low-quality bas-relief models exist in practice. Bas-relief models frequently appear as grayscale images during storage or transmission, such as lossy compressed JPG (joint photographic experts group) images, to reduce file size or protect the work. The quality of bas-reliefs directly transformed from such lossy compressed images is rough. The model surfaces present evident block distribution and boundary noise, which seriously reduce the overall visual effect. Moreover, the greater the degree of image compression is, the more obvious the model noise will be. The lossy compression of grayscale image reduces the quality and overall visual effect of corresponding bas-relief model. Considering the large number of bas-relief grayscale images on the network, how to recover high-quality bas-relief models is a problem that is worthy of further study. This study proposes a novel algorithm for bas-relief optimization based on local adaptive sparse representation and nonlocal group low-rank approximation.MethodThe algorithm has two stages. In the first stage, the initial grayscale image is divided into patches of the same size, and the edge patches are extracted for denoising. Then, patches are processed via sparse representation and low-rank approximation. On the one hand, the edge-denoised patches are trained using the K-SVD (k-singular value decomposition) dictionary learning algorithm to obtain an overcomplete dictionary that is used to sparsely decompose noisy patches to obtain the corresponding sparse coding. On the other hand, the K-means clustering algorithm is used to classify the external dictionary library constructed in advance into k classes. A similar matrix for low-rank approximation is formed by similar patches selected from the k cluster centers. Further feature enhancement processing is performed on the low-rank approximation results. Combined with the results of edge denoising, sparse code reconstruction, and feature enhancement, new patches are generated using a least squares solution to reconstruct a new height field. The second stage is similar to the structure of the first stage, and the primary difference is the block matching operation. In the first stage, although the noisy patches are smoothed and denoised by external clean data, the consistency between patches and similar patches in the external dictionary library is constrained, resulting in insufficient smoothness between the patches of the height field. Therefore, block matching is realized by the nonlocal similarity of the reconstructed height field in the second stage to ensure consistency between patches, thereby improving the smoothing effect on bas-reliefs.ResultBy comparing the bas-relief reconstruction results of the proposed method with those of block-matching and 3D filtering (BM3D), weighted nuclear norm minimization (WNNM), sparsifying transform learning and low-rank (STROLLR), and trilateral weighted sparse coding (TWSC) at different image compression rates (70%, 50%, and 30%), we determine that BM3D and STROLLR exhibit better feature retention, but their smoothing effect is the worst. WNNM presents model breakage. The smoothing effect of TWSC is better than those of BM3D and STROLLR, but features are also smoothed simultaneously, resulting in inconspicuous details. The proposed method is further compared with shape from shading (SFS), which is an image-based 3D model reconstruction method for transforming 2D images into 3D models. Under different illumination conditions, SFS calculates depth information through the shadow and brightness of an image and then combines it with the reflected illumination model to realize the reconstruction of the 3D model. The overall structure shape of the 3D model generated using SFS is reasonable, but the following shortcomings exist. First, the reconstruction results of SFS are insufficiently fine to restore lines and features. Second, the model produced via SFS is influenced by light source, position, and direction. Third, numerous bump grooves are found in the reconstruction model of SFS. With the influences of light and shadow, local areas are either bright or dark. The model looks complicated because of the lines generated by bump grooves. By contrast, the proposed method is clearer, more intuitive, and exhibits better performance in terms of the smoothing, feature enhancement, and edge denoising of bas-reliefs. The experiment compares the operating efficiencies of different methods. The time taken by the four smoothing methods is in ascending order as follows: BM3D, WNNM, TWSC, and STROLLR. The proposed method takes longer than the four aforementioned methods. For a grayscale image of 1 024×1 024 pixels, the average computing time of the proposed method is 1 000 s, which is approximately 1.5 times of STROLLR. The time spent by SFS is only 40%60% that of the proposed method. Although the computing time of the proposed method is longer, its optimization ability for 3D models is greater, and the visual effect is more significant.ConclusionSparse representation contains the differences between patches, effectively retaining the details of bas-relief. Low-rank approximation contains the correlation between patches and exhibits a good smoothing effect. The proposed method achieves the complementarity of sparse representation and low-rank approximation, and comprehensively considers the local sparsity of patches and nonlocal similarity between patches. The experiment shows that the proposed method effectively improves the overall visual effect of bas-relief models and provides a new method for bas-relief optimization.关键词:bas-relief;smoothing and denoising;sparse representation;block matching;low-rank approximation36|40|1更新时间:2024-05-07
摘要:ObjectiveBas-relief is a semi-stereoscopic sculpture between 2D and 3D space that is typically attached to a plane. It is frequently used to decorate buildings, coins, badges, ceramics, and utensils. It occupies less space and enhances stereo sense mostly through lines. Research on bas-relief is focused on two modeling techniques: 3D models and 2D images. It is performed in three aspects: enhancing the continuity of the height field, preserving the original structure and details, and avoiding the attenuation of the stereoscopic effect. The bas-relief modeling technique based on a 3D model starts from the aspects of spatial, gradient, or normal domains, and compresses the depth values of the 3D model in a given visual direction to generate the bas-relief model. The bas-relief modeling technique based on a 2D image extracts the gray information from the image and converts it into depth information, completing the reconstruction from the image to the bas-relief model. However, minimal attention has been given to the repair and optimization of existing bas-reliefs. Many low-quality bas-relief models exist in practice. Bas-relief models frequently appear as grayscale images during storage or transmission, such as lossy compressed JPG (joint photographic experts group) images, to reduce file size or protect the work. The quality of bas-reliefs directly transformed from such lossy compressed images is rough. The model surfaces present evident block distribution and boundary noise, which seriously reduce the overall visual effect. Moreover, the greater the degree of image compression is, the more obvious the model noise will be. The lossy compression of grayscale image reduces the quality and overall visual effect of corresponding bas-relief model. Considering the large number of bas-relief grayscale images on the network, how to recover high-quality bas-relief models is a problem that is worthy of further study. This study proposes a novel algorithm for bas-relief optimization based on local adaptive sparse representation and nonlocal group low-rank approximation.MethodThe algorithm has two stages. In the first stage, the initial grayscale image is divided into patches of the same size, and the edge patches are extracted for denoising. Then, patches are processed via sparse representation and low-rank approximation. On the one hand, the edge-denoised patches are trained using the K-SVD (k-singular value decomposition) dictionary learning algorithm to obtain an overcomplete dictionary that is used to sparsely decompose noisy patches to obtain the corresponding sparse coding. On the other hand, the K-means clustering algorithm is used to classify the external dictionary library constructed in advance into k classes. A similar matrix for low-rank approximation is formed by similar patches selected from the k cluster centers. Further feature enhancement processing is performed on the low-rank approximation results. Combined with the results of edge denoising, sparse code reconstruction, and feature enhancement, new patches are generated using a least squares solution to reconstruct a new height field. The second stage is similar to the structure of the first stage, and the primary difference is the block matching operation. In the first stage, although the noisy patches are smoothed and denoised by external clean data, the consistency between patches and similar patches in the external dictionary library is constrained, resulting in insufficient smoothness between the patches of the height field. Therefore, block matching is realized by the nonlocal similarity of the reconstructed height field in the second stage to ensure consistency between patches, thereby improving the smoothing effect on bas-reliefs.ResultBy comparing the bas-relief reconstruction results of the proposed method with those of block-matching and 3D filtering (BM3D), weighted nuclear norm minimization (WNNM), sparsifying transform learning and low-rank (STROLLR), and trilateral weighted sparse coding (TWSC) at different image compression rates (70%, 50%, and 30%), we determine that BM3D and STROLLR exhibit better feature retention, but their smoothing effect is the worst. WNNM presents model breakage. The smoothing effect of TWSC is better than those of BM3D and STROLLR, but features are also smoothed simultaneously, resulting in inconspicuous details. The proposed method is further compared with shape from shading (SFS), which is an image-based 3D model reconstruction method for transforming 2D images into 3D models. Under different illumination conditions, SFS calculates depth information through the shadow and brightness of an image and then combines it with the reflected illumination model to realize the reconstruction of the 3D model. The overall structure shape of the 3D model generated using SFS is reasonable, but the following shortcomings exist. First, the reconstruction results of SFS are insufficiently fine to restore lines and features. Second, the model produced via SFS is influenced by light source, position, and direction. Third, numerous bump grooves are found in the reconstruction model of SFS. With the influences of light and shadow, local areas are either bright or dark. The model looks complicated because of the lines generated by bump grooves. By contrast, the proposed method is clearer, more intuitive, and exhibits better performance in terms of the smoothing, feature enhancement, and edge denoising of bas-reliefs. The experiment compares the operating efficiencies of different methods. The time taken by the four smoothing methods is in ascending order as follows: BM3D, WNNM, TWSC, and STROLLR. The proposed method takes longer than the four aforementioned methods. For a grayscale image of 1 024×1 024 pixels, the average computing time of the proposed method is 1 000 s, which is approximately 1.5 times of STROLLR. The time spent by SFS is only 40%60% that of the proposed method. Although the computing time of the proposed method is longer, its optimization ability for 3D models is greater, and the visual effect is more significant.ConclusionSparse representation contains the differences between patches, effectively retaining the details of bas-relief. Low-rank approximation contains the correlation between patches and exhibits a good smoothing effect. The proposed method achieves the complementarity of sparse representation and low-rank approximation, and comprehensively considers the local sparsity of patches and nonlocal similarity between patches. The experiment shows that the proposed method effectively improves the overall visual effect of bas-relief models and provides a new method for bas-relief optimization.关键词:bas-relief;smoothing and denoising;sparse representation;block matching;low-rank approximation36|40|1更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveGlaucoma is one of the most common eye diseases it can lead to severe vision loss and even permanent blindness. Glaucoma is the primary cause of irreversible blindness worldwide. Diagnosing the disease in its early stage is significant for decreasing the mental and financial pressures of patients. The diagnosis of glaucoma using retinal fundus images is achieved by calculating cup to disc ratio (CDR). The optic disc (OD) is a central yellowish region in retinal fundus images. The optic cup (OC) is the bright central part of the OD that presents variable sizes. Any changes in the shapes of OD and OC may indicate glaucoma. A high CDR value shows that the eye is suffering from glaucoma to a large extent. Therefore,the detection of OC and OD in fundus images is an important step in the clinical diagnosis of glaucoma. The accurate segmentation of OC and OD is facing serious challenges,including severe intensity inhomogeneity,complex fundus image structure,grayscale overlap between different structures,and interference with blood vessels and lesions. Therefore,to accurately segment the OC and OD regions in fundus images,we present a novel OC and OD segmentation method based on a two-layer level set describer in this study. This approach can simultaneously extract the boundaries of OD and OC.MethodOur proposed method consists of four steps. First,OC and OD contours are represented by two different layers of a one-level set function by constructing a two-layer level set model. Fundus images are typically inhomogeneous in gray levels. OC and OD regions exhibit different brightness characteristics compared with the background region in retinal fundus images. Therefore,the local intensity information of an image is used as data term to derive the evolution of the active contours and overcome intensity inhomogeneity in fundus images. Second,the distance constraint is established on the basis of the position relationship between OC and OD. The contours of OC and OD in fundus images are approximately two ellipse shapes. OC is located inside OD,and the distance between OC and OD varies smoothly. The distance constraint term is introduced to restrain the distance between the two-level layers of the one-level set function. The major contribution of the distance constraint term is that the relationship between OC and OD contours in a one-level set function is simpler to establish compared with using multiphase level set methods. Third,considering the complex structure of fundus images,the interference of blood vessels and lesions leads to sharp changes in contours,considerably affecting the accuracy of segmentation results. Therefore,we use the prior information that OC and OD always approach an ellipse shape to guide the segmentation process. In accordance with the geometric characteristics of OC and OD,the shape prior information of OC and OD is introduced to constrain the evolution of the active contour and realize the accurate segmentation of OC and OD. Lastly,we build an integral energy function by integrating the aforementioned three terms. Meanwhile,the traditional length penalty term is also included in the final integral energy function. The final energy function consists of four parts: local intensity information,distance constraint,prior information,and traditional length penalty terms. The segmentation of OC and OD is achieved by minimizing the final integral energy function using the gradient descent method. When the convergence condition of the level set function is satisfied,we obtain the final optimized level set function. We acquire OC and OD contours that correspond to the 0- and k-layers of the optimized level set function.ResultThe proposed method is validated using the CDRISHTI-GS1 dataset provided by the Aravind Eye Hospital of India with a true outline annotation of OC and OD. The dataset consists of 101 color retinal fundus images; each of which has a field of view of 30° and a resolution of 2 896×1 944 pixels. This dataset is primarily used to verify the robustness and effectiveness of OC and OD segmentation methods. The method proposed in this study achieves 81.04% of the average OD overlap rate,67.52% of the average OC overlap rate,0.719 of the OC F1-score,and 0.845 of the OD F1-score on the CDRISHTI-GS1 dataset. The method outperforms the OC and OD segmentation method based on the combination of shifted filter responses filter model,the shape prior constraint-based multiphase Chan-Vese model,and the cluster fusion-based level set method. We also show the visual results of the experimental process. The bias field and bias-corrected image are displayed to illustrate how the proposed method overcomes intensity inhomogeneity in fundus images. The histograms of the original image and the bias-corrected images are provided to present an intuitive result of the corrected image intensity.ConclusionThis method successfully performs the segmentation of OC and OD regions by representing OC and OD contours with different level layers of a one-level set function. The intensity inhomogeneity of fundus images is effectively processed using the local information data term. The distance constraint term achieves a smooth change in distance between OC and OD contours. The ellipse shape prior constraint overcomes the blood vessels and lesions in fundus images,and the final segmented OC and OD contours are approximately two ellipse shapes. The experimental results show that the proposed method can simultaneously and accurately segment OC and OD regions. Moreover,it exhibits superior performance over other methods.关键词:retinal fundus images;two-layer level set method;optic cup segmentation;optic disc segmentation;shape prior constraint51|57|3更新时间:2024-05-07
摘要:ObjectiveGlaucoma is one of the most common eye diseases it can lead to severe vision loss and even permanent blindness. Glaucoma is the primary cause of irreversible blindness worldwide. Diagnosing the disease in its early stage is significant for decreasing the mental and financial pressures of patients. The diagnosis of glaucoma using retinal fundus images is achieved by calculating cup to disc ratio (CDR). The optic disc (OD) is a central yellowish region in retinal fundus images. The optic cup (OC) is the bright central part of the OD that presents variable sizes. Any changes in the shapes of OD and OC may indicate glaucoma. A high CDR value shows that the eye is suffering from glaucoma to a large extent. Therefore,the detection of OC and OD in fundus images is an important step in the clinical diagnosis of glaucoma. The accurate segmentation of OC and OD is facing serious challenges,including severe intensity inhomogeneity,complex fundus image structure,grayscale overlap between different structures,and interference with blood vessels and lesions. Therefore,to accurately segment the OC and OD regions in fundus images,we present a novel OC and OD segmentation method based on a two-layer level set describer in this study. This approach can simultaneously extract the boundaries of OD and OC.MethodOur proposed method consists of four steps. First,OC and OD contours are represented by two different layers of a one-level set function by constructing a two-layer level set model. Fundus images are typically inhomogeneous in gray levels. OC and OD regions exhibit different brightness characteristics compared with the background region in retinal fundus images. Therefore,the local intensity information of an image is used as data term to derive the evolution of the active contours and overcome intensity inhomogeneity in fundus images. Second,the distance constraint is established on the basis of the position relationship between OC and OD. The contours of OC and OD in fundus images are approximately two ellipse shapes. OC is located inside OD,and the distance between OC and OD varies smoothly. The distance constraint term is introduced to restrain the distance between the two-level layers of the one-level set function. The major contribution of the distance constraint term is that the relationship between OC and OD contours in a one-level set function is simpler to establish compared with using multiphase level set methods. Third,considering the complex structure of fundus images,the interference of blood vessels and lesions leads to sharp changes in contours,considerably affecting the accuracy of segmentation results. Therefore,we use the prior information that OC and OD always approach an ellipse shape to guide the segmentation process. In accordance with the geometric characteristics of OC and OD,the shape prior information of OC and OD is introduced to constrain the evolution of the active contour and realize the accurate segmentation of OC and OD. Lastly,we build an integral energy function by integrating the aforementioned three terms. Meanwhile,the traditional length penalty term is also included in the final integral energy function. The final energy function consists of four parts: local intensity information,distance constraint,prior information,and traditional length penalty terms. The segmentation of OC and OD is achieved by minimizing the final integral energy function using the gradient descent method. When the convergence condition of the level set function is satisfied,we obtain the final optimized level set function. We acquire OC and OD contours that correspond to the 0- and k-layers of the optimized level set function.ResultThe proposed method is validated using the CDRISHTI-GS1 dataset provided by the Aravind Eye Hospital of India with a true outline annotation of OC and OD. The dataset consists of 101 color retinal fundus images; each of which has a field of view of 30° and a resolution of 2 896×1 944 pixels. This dataset is primarily used to verify the robustness and effectiveness of OC and OD segmentation methods. The method proposed in this study achieves 81.04% of the average OD overlap rate,67.52% of the average OC overlap rate,0.719 of the OC F1-score,and 0.845 of the OD F1-score on the CDRISHTI-GS1 dataset. The method outperforms the OC and OD segmentation method based on the combination of shifted filter responses filter model,the shape prior constraint-based multiphase Chan-Vese model,and the cluster fusion-based level set method. We also show the visual results of the experimental process. The bias field and bias-corrected image are displayed to illustrate how the proposed method overcomes intensity inhomogeneity in fundus images. The histograms of the original image and the bias-corrected images are provided to present an intuitive result of the corrected image intensity.ConclusionThis method successfully performs the segmentation of OC and OD regions by representing OC and OD contours with different level layers of a one-level set function. The intensity inhomogeneity of fundus images is effectively processed using the local information data term. The distance constraint term achieves a smooth change in distance between OC and OD contours. The ellipse shape prior constraint overcomes the blood vessels and lesions in fundus images,and the final segmented OC and OD contours are approximately two ellipse shapes. The experimental results show that the proposed method can simultaneously and accurately segment OC and OD regions. Moreover,it exhibits superior performance over other methods.关键词:retinal fundus images;two-layer level set method;optic cup segmentation;optic disc segmentation;shape prior constraint51|57|3更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveThe resolution of a remote sensing image increases with the rapid development of remote sensing technology. A high-resolution image has high spatial and temporal resolutions, providing conditions for real-time monitoring and change detection. Change detection in remote sensing is used to detect changes in the same regions at different periods. The purpose of this study is to find a change in the same region between specific periods. However, with the improvement in the spatial resolution of remote sensing images, the difference in the spatial texture information of the same object increases. The features of remote sensing images are becoming increasingly complex and diverse. Traditional change detection methods experience difficulty in obtaining good results from high-resolution remote sensing images. Unsupervised deep learning algorithms suffer from difficulty in extracting valid features and making them equal in areas wherein different objects have the same spectra and similar objects have different spectra. To improve the change detection accuracy of high-resolution remote sensing images, particularly for effective judgment in areas with considerable texture differences in different periods at the same location, this study proposes a deep learning and superpixel segmentation method for high-resolution remote sensing image change detection.MethodThe algorithm of the deep learning and superpixel-based method for high-resolution remote sensing image change detection exhibits the following characteristics. First, finite labeled data are divided into patches as training samples. Simultaneously, a multiscale patch feature fusion network-based convolutional neural network (MPFF-CNN) is designed. The final model parameters and patch size are determined by testing the different sizes of patches. A preliminary change detection result of the test image can be obtained using this network. Second, the superpixel segmentation algorithm is used to segment the test image into many nonoverlapping homogenous regions and transfer the segmentation result to the preliminary test result to obtain the change detection result with a segmentation mark. An optimal segmentation scale is difficult to obtain in high-resolution remote sensing images. Thus, a multiscale segmentation algorithm is used in this work. Third, the quantities of changed and unchanged pixels of each superpixel in the change detection result with the segmentation marker are statistically evaluated using the hand-crank voting algorithm. All the pixel values of the superpixel are replaced with the pixel values. The categories are more under this superpixel. All the change detection results are stacked to a hypercolumn. Lastly, the quantities of changed and unchanged pixels of each spectrum in the hypercolumn is counted using the hand-crank voting algorithm. If the number of changed pixels is more than that of the unchanged pixels in each spectrum, then the spatial position of the spectrum has a pixel value of 1; otherwise, the pixel value is 0.ResultTo estimate the accuracy of the proposed change detection algorithm, experiments are conducted on the Guangdong change detection dataset and the Hong Kong change detection dataset. Four widely used methods are selected for comparison, including the fuzzy C-means-based, support vector machine-based, deep belief network-based, and long short-term memory-based methods. The experimental results of change detection in both datasets indicate that MPFF-CNN exhibits an outstanding performance, which is better than the results of the CNN-based model at a single patch size. The change detection results obtained by the multiple superpixel scale are better than those of the single superpixel scale in both datasets. The percentages of correct classification and kappa obtained by deep learning combined with superpixel (MPFF-CNN-SP) are 97% and 80% for the Guangdong change detection dataset, respectively. MPFF-CNN-SP is 1% and 6% higher than MPFF-CNN. MPFF-CNN-SP is better than all the compared algorithms. Similarly, the percentages of correct classification and kappa obtained by MPFF-CNN-SP for the Hong Kong change detection dataset are 99% and 81%, respectively. MPFF-CNN-SP is 1% and 8% higher than MPFF-CNN. MPFF-CNN-SP is superior to all the compared algorithms.ConclusionThe multiscale patch feature fusion method is better than the CNN-based method of training a single patch size. The multiscale patch feature fusion network-based CNN in this work can adequately gain the spatial information and other effective features of patches. Moreover, it does not cause severe overfitting. The multiscale superpixel segmentation results after double hand-raising voting algorithms are significantly stronger than the segmentation results of a single-scale superpixel segmentation. The deep learning and superpixel method transforms the detection unit from patch to superpixel, effectively judging different texture information of the same object and significantly improving change detection accuracy.关键词:high-resolution remote sensing image;change detection;deep learning;super pixel;multiscale of patch feature fusion56|35|9更新时间:2024-05-07
摘要:ObjectiveThe resolution of a remote sensing image increases with the rapid development of remote sensing technology. A high-resolution image has high spatial and temporal resolutions, providing conditions for real-time monitoring and change detection. Change detection in remote sensing is used to detect changes in the same regions at different periods. The purpose of this study is to find a change in the same region between specific periods. However, with the improvement in the spatial resolution of remote sensing images, the difference in the spatial texture information of the same object increases. The features of remote sensing images are becoming increasingly complex and diverse. Traditional change detection methods experience difficulty in obtaining good results from high-resolution remote sensing images. Unsupervised deep learning algorithms suffer from difficulty in extracting valid features and making them equal in areas wherein different objects have the same spectra and similar objects have different spectra. To improve the change detection accuracy of high-resolution remote sensing images, particularly for effective judgment in areas with considerable texture differences in different periods at the same location, this study proposes a deep learning and superpixel segmentation method for high-resolution remote sensing image change detection.MethodThe algorithm of the deep learning and superpixel-based method for high-resolution remote sensing image change detection exhibits the following characteristics. First, finite labeled data are divided into patches as training samples. Simultaneously, a multiscale patch feature fusion network-based convolutional neural network (MPFF-CNN) is designed. The final model parameters and patch size are determined by testing the different sizes of patches. A preliminary change detection result of the test image can be obtained using this network. Second, the superpixel segmentation algorithm is used to segment the test image into many nonoverlapping homogenous regions and transfer the segmentation result to the preliminary test result to obtain the change detection result with a segmentation mark. An optimal segmentation scale is difficult to obtain in high-resolution remote sensing images. Thus, a multiscale segmentation algorithm is used in this work. Third, the quantities of changed and unchanged pixels of each superpixel in the change detection result with the segmentation marker are statistically evaluated using the hand-crank voting algorithm. All the pixel values of the superpixel are replaced with the pixel values. The categories are more under this superpixel. All the change detection results are stacked to a hypercolumn. Lastly, the quantities of changed and unchanged pixels of each spectrum in the hypercolumn is counted using the hand-crank voting algorithm. If the number of changed pixels is more than that of the unchanged pixels in each spectrum, then the spatial position of the spectrum has a pixel value of 1; otherwise, the pixel value is 0.ResultTo estimate the accuracy of the proposed change detection algorithm, experiments are conducted on the Guangdong change detection dataset and the Hong Kong change detection dataset. Four widely used methods are selected for comparison, including the fuzzy C-means-based, support vector machine-based, deep belief network-based, and long short-term memory-based methods. The experimental results of change detection in both datasets indicate that MPFF-CNN exhibits an outstanding performance, which is better than the results of the CNN-based model at a single patch size. The change detection results obtained by the multiple superpixel scale are better than those of the single superpixel scale in both datasets. The percentages of correct classification and kappa obtained by deep learning combined with superpixel (MPFF-CNN-SP) are 97% and 80% for the Guangdong change detection dataset, respectively. MPFF-CNN-SP is 1% and 6% higher than MPFF-CNN. MPFF-CNN-SP is better than all the compared algorithms. Similarly, the percentages of correct classification and kappa obtained by MPFF-CNN-SP for the Hong Kong change detection dataset are 99% and 81%, respectively. MPFF-CNN-SP is 1% and 8% higher than MPFF-CNN. MPFF-CNN-SP is superior to all the compared algorithms.ConclusionThe multiscale patch feature fusion method is better than the CNN-based method of training a single patch size. The multiscale patch feature fusion network-based CNN in this work can adequately gain the spatial information and other effective features of patches. Moreover, it does not cause severe overfitting. The multiscale superpixel segmentation results after double hand-raising voting algorithms are significantly stronger than the segmentation results of a single-scale superpixel segmentation. The deep learning and superpixel method transforms the detection unit from patch to superpixel, effectively judging different texture information of the same object and significantly improving change detection accuracy.关键词:high-resolution remote sensing image;change detection;deep learning;super pixel;multiscale of patch feature fusion56|35|9更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0