
最新刊期
卷 25 , 期 5 , 2020
- 摘要:With the rapid development of earth observation technology, remote sensing opens up the possibility of multiplatform, multisensor, and multiangle observation, and the acquisition ability of multimodal datasets in a joint manner has been considerably improved. Extensive attention has been given to multisource data fusion because such technology can be used to improve the performance of processing approaches with respect to available applications. In this study, we focus on reviewing state-of-the-art multisource remote image fusion. Three typical problems, namely, pansharpening, hypersharpening, and the fusion of hyperspectral ands multispectral images, have been comprehensively investigated. A mathematical modeling view of many important contributions specifically dedicated to the three topics is provided.First, the major challenge and complex imaging relationship between available multisource spatial-spectral remote sensing images are discussed. As an inverse problem of recovering the latent high-resolution image from two branches of incomplete observed multichannel data, the challenge lies in the ill-posed condition caused by insufficient supplementary information, optical blur, and noise. Therefore, the existing data fusion method still has considerable room for resolution enhancing with complementary information preserving capacity. Second, a comprehensive survey is conducted for the representative mathematical modeling paradigms, including the component substitution scheme, multiresolution analysis framework, Bayesian model, variational model, and data- and model-driven optimization methods, and their existing problems. From the point of view of Bayesian fusion modeling, this study analyzes the key role and modeling mechanism of complementary features, preserving data fidelity and image prior terms in the optimization model. Then, this work summarizes the new trends in image priori modeling, including fractional-order regularization, nonlocal regularization, structured sparse representation, matrix low rank, tensor representation, and compound regularization with analytical and deep priors. Lastly, the major challenges and possible research direction in each area are outlined and discussed. The hybrid analytical model and data-driven framework will be important research directions. Breaking through the technical bottleneck of existing model optimization-based fusion methods with the imaging degradation model, data compact representation, and efficient computation, and developing fusion methods with improved spectral-preserving performance and reduced computational complexity are necessary. To cope with the big data problem, high-performance computing on big data platforms, such as Hadoop and SPARK, will obtain promising applications for multisource data-accelerated-based fusion.关键词:image fusion;Pansharpening;inverse problem;regularization;model optimization;data driven;deep learning39|31|11更新时间:2024-05-08
Scholar View

-
 摘要:This is the 25th annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for the editors of journals and potential authors of papers. Considering the wide distribution of related publications in China, 761 references on image engineering research and technique are selected carefully from 2 854 research papers published in 148 issues of a set of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have higher quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (same as the last 14 years). Analysis and discussions about the statistics of the results of classifications by journal and by category are also presented. In addition, as a roundup of the quarter of a century for this review series, the 15 856 articles in the field of image engineering selected from 65 040 academic research and technical applications published in a total of 2 964 issues over the past 25 years are divided into five periods of five-years, comprehensive statistics and analysis were made on the selection of image engineering literature and the number of image engineering literatures in each category and in each class. Analysis on the statistics in 2019 shows that image analysis is receiving the most attention, in which the focuses are on object detection and recognition, image segmentation and edge detection, and object feature extraction and analysis. The studies and applications of image technology in various areas, such as remote sensing, radar, and mapping, are continuously active. According to the comparison of 25 years of statistical data, it can be seen that the number of literatures in some classes of the four categories of image processing, image analysis, image understanding, and technology applications has kept ahead, but there are also some classes that the numbers are gradually decreasing, reflecting changes in different research directions over the years. This work shows a general and op-to-date picture of the various progresses, either for depth or for width, of image engineering in China in 2019. The statistics for 25 years also provide readers with more comprehensive and credible information on the development trends of various research directions.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics67|54|5更新时间:2024-05-08
摘要:This is the 25th annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for the editors of journals and potential authors of papers. Considering the wide distribution of related publications in China, 761 references on image engineering research and technique are selected carefully from 2 854 research papers published in 148 issues of a set of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have higher quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (same as the last 14 years). Analysis and discussions about the statistics of the results of classifications by journal and by category are also presented. In addition, as a roundup of the quarter of a century for this review series, the 15 856 articles in the field of image engineering selected from 65 040 academic research and technical applications published in a total of 2 964 issues over the past 25 years are divided into five periods of five-years, comprehensive statistics and analysis were made on the selection of image engineering literature and the number of image engineering literatures in each category and in each class. Analysis on the statistics in 2019 shows that image analysis is receiving the most attention, in which the focuses are on object detection and recognition, image segmentation and edge detection, and object feature extraction and analysis. The studies and applications of image technology in various areas, such as remote sensing, radar, and mapping, are continuously active. According to the comparison of 25 years of statistical data, it can be seen that the number of literatures in some classes of the four categories of image processing, image analysis, image understanding, and technology applications has kept ahead, but there are also some classes that the numbers are gradually decreasing, reflecting changes in different research directions over the years. This work shows a general and op-to-date picture of the various progresses, either for depth or for width, of image engineering in China in 2019. The statistics for 25 years also provide readers with more comprehensive and credible information on the development trends of various research directions.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics67|54|5更新时间:2024-05-08
Review
-
 摘要:ObjectiveMultimedia forensics and copyright protection have become hot issues in the society. The widespread use of portable cameras, mobile phones, and surveillance cameras has led to an explosive growth in the amount of digital video data. Although people enjoy the convenience given by the popularity of digital multimedia, they also experience considerable security problems. Double compression for digital video file is a necessary procedure for malicious video content modification. The detection for double compression is also an important auxiliary measure for video content forensics. Content-tampered video inevitably undergo two or more re-compression operations. If the video test is judged to have undergone multiple re-compressions, it is more likely to undergo content tampering operation. At present, high efficiency video coding (HEVC) video double compression detection with different coding parameters achieves high accuracy. However, in the compression process with the same coding parameters, the trace of HEVC video double compression is very small and the detection is considerably more difficult. For most attackers, their concern is focused on the modification of video content. With the video stream containing the video parameter set and the image parameter set, the video editing software generally uses the same parameters for re-compression as default setting. This study proposes a detection algorithm for video double compression with the same coding parameters. The proposed algorithm is based on the video quality degradation mechanism.MethodAfter multiple compression times with the same coding parameters, the video quality tends to be unchanged. The single compressed and double compressed videos can be distinguished by the degree of video quality degradation. Video coding is based on rate-distortion optimization to balance the bitrate and distortion to choose the optimal parameters for the encoder. When the video is compressed with the same coding parameters, the trace of video re-compression operations is extremely little because of the slight changes in division mode of the coding unit to the prediction unit (PU) and the little influence on the distribution of PU size type. Thus, the double compression with the same parameters is more difficult to detect. Given that the transform quantization coding process of each coding unit is independent, the quantization error and its distribution characteristics are independent, too. The discontinuous boundaries of adjacent blocks will affect the mode selection of intra-prediction. In the process of motion compensation prediction, the predicted values of adjacent blocks come from different positions of different images, which results in the numerical discontinuity of the predicted residual at the block boundary. It will affect the selection of motion vectors predicted between frames and reference pictures. This study proposes a detection algorithm based on two kinds of video features: the I frame PU mode (intra-coded picture prediction unit mode, IPUM) and the P frame PU mode (predicted picture prediction unit mode, PPUM). These video features are extracted from the luminance component (Y) in I frame and P frame, respectively. First, the IPUM and PPUM features are extracted from the tested HEVC videos. Then, the video is compressed three times with the same coding parameters. In this study, the above features are repetitively extracted for each compressing time. A larger number of PU should be selected as the statistical feature because the numbers of PU of different sizes in I frame and P frame are quite different. Finally, the average different PU modes of the nth compression and the (n+1)th compression of each I frame and P frame at the same position are counted to form a 6-dimensional feature set, which is sent to a support vector machine (SVM) for classification.ResultThe experiment is composed of three resolution video sets: common intermediate format (CIF) (352×288 pixels), 720p (1 280×720 pixels), and 1 080p (1 920×1 080 pixels). To increase the number of video samples, each test sequence is clipped into smaller video clips. Each video clip contains 100 frames. If the video exceeds 1 000 frames, only the first 1 000 frames are considered to generate the samples in our experiments. Accordingly, a total of 132 CIF-video sequence segments, 87 720p-video sequence segments, and 98 1080p-video sequence segments are obtained. For each set, 4/5 positive samples and their corresponding negative samples are randomly selected as the training set, while the rest are used as the test set. The binary classification is applied by using the SVM classifier with radial basis function kernel. The optimized parameters, gamma and cost, are determined by using grid search with fivefold cross validation. The final detection accuracy values are collected by averaging the accuracy results from 30 repetitions of the experimental test, where the training and testing data are randomly selected for each time. Considering the computational complexity of the experiment, the repetition of re-compression for each experimental test is especially important. With the increase in the times of re-compression, the computational complexity of video encoding and decoding will increase linearly. However, the classification accuracy is not significantly improved. Thus, the repetition of re-compression is finally adjusted to three. The average detection accuracies for the different video test datasets, CIF, 720p, and 1 080p, are 95.45%, 94.8%, and 95.53%, respectively. In addition, video compression is usually affected by coding parameters. Group of pictures (GOP) is the basic coding unit of video compression. The interval of GOP has a significant impact on video quality owing to the error propagation in the inter-coding process. In the CIF dataset, the detection accuracy of this method with different GOP reaches more than 90%. With the increase of GOP, the detection accuracy will decline slightly. The final experimental test is regarding frame deletion, which is a common operation of video tampering. In the CIF dataset, the detection accuracy of video re-compression with 10 consecutive deleted frames can maintain above 88%, which means the proposed method is robust to frame deletion.ConclusionIn this study, the law of video quality degradation is revealed by the changed number of different PU modes in the same position of I frame and P frame. In sum, our proposed method clearly performs well in different test situations. The detection accuracy of the proposed method can reach high rates of different GOP settings, video resolutions, and frame deletion rate.关键词:video forensics;double video compression;high efficiency video coding (HEVC);the same coding parameters;quality degradation;prediction unit (PU)79|117|1更新时间:2024-05-08
摘要:ObjectiveMultimedia forensics and copyright protection have become hot issues in the society. The widespread use of portable cameras, mobile phones, and surveillance cameras has led to an explosive growth in the amount of digital video data. Although people enjoy the convenience given by the popularity of digital multimedia, they also experience considerable security problems. Double compression for digital video file is a necessary procedure for malicious video content modification. The detection for double compression is also an important auxiliary measure for video content forensics. Content-tampered video inevitably undergo two or more re-compression operations. If the video test is judged to have undergone multiple re-compressions, it is more likely to undergo content tampering operation. At present, high efficiency video coding (HEVC) video double compression detection with different coding parameters achieves high accuracy. However, in the compression process with the same coding parameters, the trace of HEVC video double compression is very small and the detection is considerably more difficult. For most attackers, their concern is focused on the modification of video content. With the video stream containing the video parameter set and the image parameter set, the video editing software generally uses the same parameters for re-compression as default setting. This study proposes a detection algorithm for video double compression with the same coding parameters. The proposed algorithm is based on the video quality degradation mechanism.MethodAfter multiple compression times with the same coding parameters, the video quality tends to be unchanged. The single compressed and double compressed videos can be distinguished by the degree of video quality degradation. Video coding is based on rate-distortion optimization to balance the bitrate and distortion to choose the optimal parameters for the encoder. When the video is compressed with the same coding parameters, the trace of video re-compression operations is extremely little because of the slight changes in division mode of the coding unit to the prediction unit (PU) and the little influence on the distribution of PU size type. Thus, the double compression with the same parameters is more difficult to detect. Given that the transform quantization coding process of each coding unit is independent, the quantization error and its distribution characteristics are independent, too. The discontinuous boundaries of adjacent blocks will affect the mode selection of intra-prediction. In the process of motion compensation prediction, the predicted values of adjacent blocks come from different positions of different images, which results in the numerical discontinuity of the predicted residual at the block boundary. It will affect the selection of motion vectors predicted between frames and reference pictures. This study proposes a detection algorithm based on two kinds of video features: the I frame PU mode (intra-coded picture prediction unit mode, IPUM) and the P frame PU mode (predicted picture prediction unit mode, PPUM). These video features are extracted from the luminance component (Y) in I frame and P frame, respectively. First, the IPUM and PPUM features are extracted from the tested HEVC videos. Then, the video is compressed three times with the same coding parameters. In this study, the above features are repetitively extracted for each compressing time. A larger number of PU should be selected as the statistical feature because the numbers of PU of different sizes in I frame and P frame are quite different. Finally, the average different PU modes of the nth compression and the (n+1)th compression of each I frame and P frame at the same position are counted to form a 6-dimensional feature set, which is sent to a support vector machine (SVM) for classification.ResultThe experiment is composed of three resolution video sets: common intermediate format (CIF) (352×288 pixels), 720p (1 280×720 pixels), and 1 080p (1 920×1 080 pixels). To increase the number of video samples, each test sequence is clipped into smaller video clips. Each video clip contains 100 frames. If the video exceeds 1 000 frames, only the first 1 000 frames are considered to generate the samples in our experiments. Accordingly, a total of 132 CIF-video sequence segments, 87 720p-video sequence segments, and 98 1080p-video sequence segments are obtained. For each set, 4/5 positive samples and their corresponding negative samples are randomly selected as the training set, while the rest are used as the test set. The binary classification is applied by using the SVM classifier with radial basis function kernel. The optimized parameters, gamma and cost, are determined by using grid search with fivefold cross validation. The final detection accuracy values are collected by averaging the accuracy results from 30 repetitions of the experimental test, where the training and testing data are randomly selected for each time. Considering the computational complexity of the experiment, the repetition of re-compression for each experimental test is especially important. With the increase in the times of re-compression, the computational complexity of video encoding and decoding will increase linearly. However, the classification accuracy is not significantly improved. Thus, the repetition of re-compression is finally adjusted to three. The average detection accuracies for the different video test datasets, CIF, 720p, and 1 080p, are 95.45%, 94.8%, and 95.53%, respectively. In addition, video compression is usually affected by coding parameters. Group of pictures (GOP) is the basic coding unit of video compression. The interval of GOP has a significant impact on video quality owing to the error propagation in the inter-coding process. In the CIF dataset, the detection accuracy of this method with different GOP reaches more than 90%. With the increase of GOP, the detection accuracy will decline slightly. The final experimental test is regarding frame deletion, which is a common operation of video tampering. In the CIF dataset, the detection accuracy of video re-compression with 10 consecutive deleted frames can maintain above 88%, which means the proposed method is robust to frame deletion.ConclusionIn this study, the law of video quality degradation is revealed by the changed number of different PU modes in the same position of I frame and P frame. In sum, our proposed method clearly performs well in different test situations. The detection accuracy of the proposed method can reach high rates of different GOP settings, video resolutions, and frame deletion rate.关键词:video forensics;double video compression;high efficiency video coding (HEVC);the same coding parameters;quality degradation;prediction unit (PU)79|117|1更新时间:2024-05-08 -
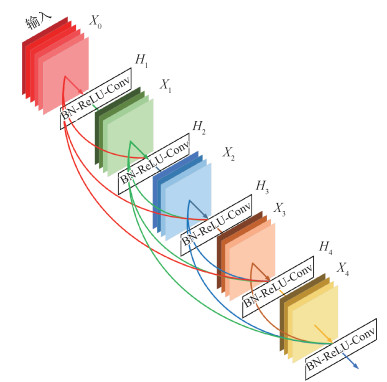 摘要:ObjectiveNon-uniform blind deblurring is a challenging problem in image processing and computer vision communities. Motion blur can be caused by a variety of reasons, such as the motion of multiple objects, camera shake, and scene depth variation. Traditional methods applied various constraints to model the characteristics of blur and utilized different natural image prior to the regularization of the solution space. Most of these methods involve heuristic parameter-tuning and expensive computation. Blur kernels are more complicated than these assumptions. Thus, these methods are not useful for real world images. Impressive results have been obtained in image processing with the development of neural networks. Scholars use neural networks for image generation. In this study, motion deblurring is regarded as a special problem of image generation. We also propose a fast deblurring method based on neural network without using multi-scale, unlike other scholars.MethodFirst, this study adopts the densely connected convolutional network (DenseNets) which recently performed well in image classification direction. Improvements are made for the model to make it suitable for image generation. Our network is a full convolutional network designed to accept various sizes of input images. The input images are trained through two convolutional layers to obtain a total of 256 feature maps with the dimension of 64×64 pixels. Then, these feature maps are introduced into the DenseNets containing bottleneck layers and transitions. The output of bottleneck layers in each dense block is 1 024 feature maps, while the output of the last convolution layer of each dense block is 256 feature maps. Finally, the output of the DenseNets is restored to the size of the original image by three convolutional layers. A residual connection is added between the input and output to preserve the color information of the original image as much as possible. We also speed up the time of training. To ensure the efficiency of deblurring, this network uses only nine dense layers and does not use the multi-scale model adopted by other scholars. However, this method can still guarantee the quality of the restored image. In this study, every layer in DenseNets is connected. With this method, the intermediate information in the network can be fully utilized. In our experiment, the denser the connection among the layers, the better the results obtained. Generative adversarial networks (GANs) help image generation domain achieve a qualitative fly-by. The images generated this way are closer to the real-world image in terms of overall details. Therefore, we also use this idea to improve the performance of deblurring. In terms of the loss function, we use perceptual loss to measure the difference between restored and sharp images. We choose the VGG(visual geometry group)-19 conv3.3 feature maps to define the loss function because a shallower network can better represent the texture information of an image. In the image deblurring field, we focus on restoring the texture and edges of the object rather than wasting too much computation to determine its exact position. Thus, we choose the latter one in meansquare error (MSE) loss and perceptual loss.ResultCompared with typical traditional deblurring methods and the recent neural network-based method, the performance of the algorithm is estimated by testing the restoring time, peak signal to noise ratio (PSNR), and structural similarity (SSIM) between the restored and sharp images. Experimental results show that the restored image via our method is clearer than those of others. Moreover, the average PSNR on the test set increased by 0.91, which is obviously superior to that of the traditional deblurring algorithm. According to the qualitative comparison, our method can handle the details of blurry image better than other approaches can. Our proposed method can also restore the small objects, such as text in the image. Results of other relative datasets are also better than other methods. Abandoning the multi-scale approach leads to multiple advantages, such as effectively reduced parameters, shorter training time, and reduced restoring time up to 0.32 s.ConclusionOur algorithm has a simple network structure and good restoring effect. The speed of image generation is also significantly faster than that of other methods. At the same time, the proposed method is robust and suitable for dealing with various image degradation problems caused by motion blur.关键词:motion blur;blind deblurring;generative adversarial network(GAN);densely connected convolution network(DenseNets);perceptual loss;fully convolution network(FCN)70|94|9更新时间:2024-05-08
摘要:ObjectiveNon-uniform blind deblurring is a challenging problem in image processing and computer vision communities. Motion blur can be caused by a variety of reasons, such as the motion of multiple objects, camera shake, and scene depth variation. Traditional methods applied various constraints to model the characteristics of blur and utilized different natural image prior to the regularization of the solution space. Most of these methods involve heuristic parameter-tuning and expensive computation. Blur kernels are more complicated than these assumptions. Thus, these methods are not useful for real world images. Impressive results have been obtained in image processing with the development of neural networks. Scholars use neural networks for image generation. In this study, motion deblurring is regarded as a special problem of image generation. We also propose a fast deblurring method based on neural network without using multi-scale, unlike other scholars.MethodFirst, this study adopts the densely connected convolutional network (DenseNets) which recently performed well in image classification direction. Improvements are made for the model to make it suitable for image generation. Our network is a full convolutional network designed to accept various sizes of input images. The input images are trained through two convolutional layers to obtain a total of 256 feature maps with the dimension of 64×64 pixels. Then, these feature maps are introduced into the DenseNets containing bottleneck layers and transitions. The output of bottleneck layers in each dense block is 1 024 feature maps, while the output of the last convolution layer of each dense block is 256 feature maps. Finally, the output of the DenseNets is restored to the size of the original image by three convolutional layers. A residual connection is added between the input and output to preserve the color information of the original image as much as possible. We also speed up the time of training. To ensure the efficiency of deblurring, this network uses only nine dense layers and does not use the multi-scale model adopted by other scholars. However, this method can still guarantee the quality of the restored image. In this study, every layer in DenseNets is connected. With this method, the intermediate information in the network can be fully utilized. In our experiment, the denser the connection among the layers, the better the results obtained. Generative adversarial networks (GANs) help image generation domain achieve a qualitative fly-by. The images generated this way are closer to the real-world image in terms of overall details. Therefore, we also use this idea to improve the performance of deblurring. In terms of the loss function, we use perceptual loss to measure the difference between restored and sharp images. We choose the VGG(visual geometry group)-19 conv3.3 feature maps to define the loss function because a shallower network can better represent the texture information of an image. In the image deblurring field, we focus on restoring the texture and edges of the object rather than wasting too much computation to determine its exact position. Thus, we choose the latter one in meansquare error (MSE) loss and perceptual loss.ResultCompared with typical traditional deblurring methods and the recent neural network-based method, the performance of the algorithm is estimated by testing the restoring time, peak signal to noise ratio (PSNR), and structural similarity (SSIM) between the restored and sharp images. Experimental results show that the restored image via our method is clearer than those of others. Moreover, the average PSNR on the test set increased by 0.91, which is obviously superior to that of the traditional deblurring algorithm. According to the qualitative comparison, our method can handle the details of blurry image better than other approaches can. Our proposed method can also restore the small objects, such as text in the image. Results of other relative datasets are also better than other methods. Abandoning the multi-scale approach leads to multiple advantages, such as effectively reduced parameters, shorter training time, and reduced restoring time up to 0.32 s.ConclusionOur algorithm has a simple network structure and good restoring effect. The speed of image generation is also significantly faster than that of other methods. At the same time, the proposed method is robust and suitable for dealing with various image degradation problems caused by motion blur.关键词:motion blur;blind deblurring;generative adversarial network(GAN);densely connected convolution network(DenseNets);perceptual loss;fully convolution network(FCN)70|94|9更新时间:2024-05-08 -
 摘要:ObjectiveTo extract image features that can fully express image semantic information, reduce projection errors in Hash retrieval, and generate more compact binary Hash codes, a method based on dense network and improved supervised Hashing with kernels is proposed.MethodThe pre-processed image data set is used to train the dense network. To reduce the over-fitting phenomenon, L2 regularization term is added into the cross entropy as a new loss function. When the dense network model is training, batch normalization (BN) algorithm and root mean square prop (RMSProp) optimization algorithm are used to improve the accuracy and robustness of the model. High-level semantic features of images with trained and optimized dense network model are removed to enhance the ability of image features to express image information and build an image feature library of the image dataset. The kernel principal component analysis projection is then performed on the extracted image features. The nonlinear information implicit in the image features is fully exploited to reduce the projection error. The supervised kernel Hash method is also used to supervise the image features, enhance the resolution of the linear inseparable image feature data, and map the features to the Hamming space. According to the correspondence between the inner product of Hash code and Hamming distance and the semantic similarity monitoring matrix composed of image label information, the Hamming distance is optimized to generate a more compact binary Hash code. Next, the image feature Hash code library of the image dataset is constructed. Finally, the same operation is performed on the input query image to obtain the Hash code of the query image. The Hamming distance between the Hash code of the query image and the Hash code of the image feature in the image dataset is compared to measure the similarity. The retrieved similar images are returned in ascending order.ResultTo verify the effectiveness, expansion, and efficiency of the proposed method, our method is used respectively in Paris6K and lung nodule analysis 16(LUNA16) datasets. It is also compared with other six commonly used Hashing methods. The average retrieval accuracy is compared in 12, 24, 32, 48, 64, and 128 bits of code length. Experimental results show that the average retrieval accuracy increases with the increase of Hash code length. When the Hash code length increases to a certain value, the average retrieval accuracy decreases. The average retrieval accuracy of the proposed method is always higher than that of the other six Hash methods. Except for the semantic Hashing method, the average retrieval accuracy value reaches the maximum when the Hash code length is 48 bits. Other Hash methods, including the proposed method, have the maximum average retrieval accuracy value when the Hash code length is 64 bits, and the retrieval accuracy is better. When the Hash code length is 64 bits, the average retrieval accuracy value of the proposed method is as high as 89.2% and 92.9% in the Paris6K and LUNA16 datasets, respectively. The time complexity of the proposed method and the convolutional neural network (CNN) Hashing method is compared in the Paris6K and LUNA16 data sets when the Hash code length is 12, 24, 32, 48, 64, and 128 bits. Results show that the time complexity of the proposed method is reduced under different Hash code lengths and is efficient to a certain degree.ConclusionA method based on dense network and improved supervised Hashing with kernels is proposed. This method improves the expression ability of image features and projection accuracy and is superior to other similar methods in average retrieval accuracy, recall rate, and precision rate. It improves the retrieval performance to some extent. It has a lower time complexity of algorithm than the method of CNN Hashing method. In addition, the proposed method has better extensibility, which can be used not only in the field of color image retrieval but also in the field of medical gray scale image retrieval.关键词:dense convolutional network(DenseNet);supervised Hashing with Kernels;Image features;projection error;kernel principal component analysis(KPCA)24|19|0更新时间:2024-05-08
摘要:ObjectiveTo extract image features that can fully express image semantic information, reduce projection errors in Hash retrieval, and generate more compact binary Hash codes, a method based on dense network and improved supervised Hashing with kernels is proposed.MethodThe pre-processed image data set is used to train the dense network. To reduce the over-fitting phenomenon, L2 regularization term is added into the cross entropy as a new loss function. When the dense network model is training, batch normalization (BN) algorithm and root mean square prop (RMSProp) optimization algorithm are used to improve the accuracy and robustness of the model. High-level semantic features of images with trained and optimized dense network model are removed to enhance the ability of image features to express image information and build an image feature library of the image dataset. The kernel principal component analysis projection is then performed on the extracted image features. The nonlinear information implicit in the image features is fully exploited to reduce the projection error. The supervised kernel Hash method is also used to supervise the image features, enhance the resolution of the linear inseparable image feature data, and map the features to the Hamming space. According to the correspondence between the inner product of Hash code and Hamming distance and the semantic similarity monitoring matrix composed of image label information, the Hamming distance is optimized to generate a more compact binary Hash code. Next, the image feature Hash code library of the image dataset is constructed. Finally, the same operation is performed on the input query image to obtain the Hash code of the query image. The Hamming distance between the Hash code of the query image and the Hash code of the image feature in the image dataset is compared to measure the similarity. The retrieved similar images are returned in ascending order.ResultTo verify the effectiveness, expansion, and efficiency of the proposed method, our method is used respectively in Paris6K and lung nodule analysis 16(LUNA16) datasets. It is also compared with other six commonly used Hashing methods. The average retrieval accuracy is compared in 12, 24, 32, 48, 64, and 128 bits of code length. Experimental results show that the average retrieval accuracy increases with the increase of Hash code length. When the Hash code length increases to a certain value, the average retrieval accuracy decreases. The average retrieval accuracy of the proposed method is always higher than that of the other six Hash methods. Except for the semantic Hashing method, the average retrieval accuracy value reaches the maximum when the Hash code length is 48 bits. Other Hash methods, including the proposed method, have the maximum average retrieval accuracy value when the Hash code length is 64 bits, and the retrieval accuracy is better. When the Hash code length is 64 bits, the average retrieval accuracy value of the proposed method is as high as 89.2% and 92.9% in the Paris6K and LUNA16 datasets, respectively. The time complexity of the proposed method and the convolutional neural network (CNN) Hashing method is compared in the Paris6K and LUNA16 data sets when the Hash code length is 12, 24, 32, 48, 64, and 128 bits. Results show that the time complexity of the proposed method is reduced under different Hash code lengths and is efficient to a certain degree.ConclusionA method based on dense network and improved supervised Hashing with kernels is proposed. This method improves the expression ability of image features and projection accuracy and is superior to other similar methods in average retrieval accuracy, recall rate, and precision rate. It improves the retrieval performance to some extent. It has a lower time complexity of algorithm than the method of CNN Hashing method. In addition, the proposed method has better extensibility, which can be used not only in the field of color image retrieval but also in the field of medical gray scale image retrieval.关键词:dense convolutional network(DenseNet);supervised Hashing with Kernels;Image features;projection error;kernel principal component analysis(KPCA)24|19|0更新时间:2024-05-08
Image Processing and Coding
-
 摘要:ObjectiveSemantic segmentation is a core computer vision task where one aims to densely assign labels to each pixel in the input image, such as person, car, road, pole, traffic light, or tree. Convolutional neural network-based approaches achieve state-of-the-art performance on various semantic segmentation tasks with applications for autonomous driving, image editing, and video monitoring. Despite such progress, these models often rely on massive amounts of pixel-level labels. However, for a real urban scene task, large amounts of labeled data are unavailable because of the high labor of annotating segmentation ground truth. When the labeled dataset is difficult to obtain, adversarial-training-based methods are preferred. These methods seek to adapt by confusing the domain discriminator with domain alignment standalone from task-specific learning under a separate loss. Another challenge is that a large difference exists between source data and target data in real scenarios. For instance, the distribution of appearance for objects and scenes may vary in different places, and even weather and lighting conditions can change significantly at the same place. In particular, such differences are often called as "domain gaps" and could cause significantly decreased performance. Unsupervised domain adaptation seeks to overcome such problems without target domain labels. Domain adaption aims to bridge the source and target domains by learning domain-invariant feature representations without using target labels. Such efforts have been made by using a deep learning network like AdaptSegNet, which has gained good results in the semantic segmentation of urban scenes. However, the network is trained directly using the synthetic dataset GTA5 and the real urban scene dataset Cityscapes, which exhibit a domain gap in gray, structure, and edge information. The fixed learning rate is employed in the model during the adversarial learning of different feature layers. In sum, segmentation accuracy needs to be improved.MethodTo handle these problems, a new domain adaptation method is proposed for urban scene semantic segmentation. To reduce the domain gap between source and target datasets, knowledge transfer or domain adaption is proposed to close the gap between source and target domains. This work is based on adversarial learning. First, the semantic-aware grad-generative adversarial network(GAN) (SG-GAN) is introduced to pre-process the synthetic dataset of GTA5. As a result, a new dataset SG-GTA5 is generated, which brings the newly dataset SG-GTA5 considerably closer to the urban scene dataset Cityscapes in gray, structure, and edge information. It is also suitable to substitute the original dataset GTA5 in AdaptSegNet. Second, the newly dataset SG-GTA5 is used as input of our network. To further enhance the adapted model and handle the fixed learning rate of AdaptSegNet, a multi-level adversarial network is constructed to effectively perform output space domain adaptation at different feature levels. Third, an adaptive learning rate is introduced in different feature levels of the network. Fourth, the loss value of different levels is adjusted by the proposed adaptive learning rate. Thus, the network's parameters can be updated dynamically. Fifth, a new convolution layer is added into the discriminator of GAN. As a result, the discriminant ability of the network is enhanced. For the discriminator, we use an architecture that uses fully convolutional layers to replace all fully connected layers to retain the spatial information. This architecture is composed of six convolution layers with 4×4 kernel and a stride of 2 for the first four kernels, a stride of 1 for the fifth kernel and channel numbers of 64, 128, 256, 512, 1 024, and 1, respectively. Except for the last layer, each convolution layer is followed by a leaky ReLU parameterized by 0.2. An up-sampling layer is added to the last convolution layer for re-scaling the output to the input size. No batch-normalization layers are used because we jointly train the discriminator with the segmentation network using a small batch size. For the segmentation network, it is essential to build upon a good baseline model to achieve high-quality segmentation results. We adopt the DeepLab-v2 framework with ResNet-101 model pre-trained on ImageNet as our segmentation baseline network. Similar to the recent work on semantic segmentation, we remove the last classification layer and modify the stride of the last two convolution layers from 2 to 1, making the resolution of the output feature maps effectively 1/8 times the input image size. To enlarge the receptive field, we apply dilated convolution layers in conv4 and conv5 layers with a stride of 2 and 4, respectively. After the last layer, we use the atrous spatial pyramid pooling (ASPP)as the final classifier. Finally, the batch normalization(BN) layers are removed because the discriminator network is trained with small batch generator network. Furthermore, we implement our network using the PyTorch toolbox on a single GTX1080Ti GPU with 11 GB memory.ResultThe new model is verified using the Cityscapes dataset. Experimental results demonstrate that the presented model is capable of segmenting more complex targets in the urban traffic scene precisely. The model also performs well against existing state-of-the-art segmentation model in terms of accuracy and visual quality. The segmentation accuracy of sidewalk, wall, pole, car and sky are improved by 9.6%, 5.9%, 4.9%, 5.5%, and 4.8%, respectively.ConclusionThe effectiveness of the proposed model is validated by using the real urban scene Cityscapes. The segmentation precision is improved through the presented dataset preprocessing scheme on the synthetic dataset of GTA5 by using the SG-GAN model, which makes the newly dataset SG-GTA5 much closer to the urban scene dataset Cityscapes on gray, structure, and edge information. The presented data preprocessing method also reduces the adversarial loss value effectively and avoids gradient explosion during the back propagation process. The network's learning capability is also further strengthened and the model's segmentation precision is improved through the presented adaptive learning rate, which is used for different adversarial layers to adjust the loss value of each layer. The learning rate can also update network parameters dynamically and optimize the performance of the generator and discriminator network. Finally, the discrimination capability of the proposed model is further improved by adding a new convolution layer in the discriminator, which enables the model to learn high layer semantic information. The domain shift is also alleviated to some extent.关键词:urban scene;semantic segmentation;generative adversarial network(GAN);domain adaptation;adapt learning rate36|34|4更新时间:2024-05-08
摘要:ObjectiveSemantic segmentation is a core computer vision task where one aims to densely assign labels to each pixel in the input image, such as person, car, road, pole, traffic light, or tree. Convolutional neural network-based approaches achieve state-of-the-art performance on various semantic segmentation tasks with applications for autonomous driving, image editing, and video monitoring. Despite such progress, these models often rely on massive amounts of pixel-level labels. However, for a real urban scene task, large amounts of labeled data are unavailable because of the high labor of annotating segmentation ground truth. When the labeled dataset is difficult to obtain, adversarial-training-based methods are preferred. These methods seek to adapt by confusing the domain discriminator with domain alignment standalone from task-specific learning under a separate loss. Another challenge is that a large difference exists between source data and target data in real scenarios. For instance, the distribution of appearance for objects and scenes may vary in different places, and even weather and lighting conditions can change significantly at the same place. In particular, such differences are often called as "domain gaps" and could cause significantly decreased performance. Unsupervised domain adaptation seeks to overcome such problems without target domain labels. Domain adaption aims to bridge the source and target domains by learning domain-invariant feature representations without using target labels. Such efforts have been made by using a deep learning network like AdaptSegNet, which has gained good results in the semantic segmentation of urban scenes. However, the network is trained directly using the synthetic dataset GTA5 and the real urban scene dataset Cityscapes, which exhibit a domain gap in gray, structure, and edge information. The fixed learning rate is employed in the model during the adversarial learning of different feature layers. In sum, segmentation accuracy needs to be improved.MethodTo handle these problems, a new domain adaptation method is proposed for urban scene semantic segmentation. To reduce the domain gap between source and target datasets, knowledge transfer or domain adaption is proposed to close the gap between source and target domains. This work is based on adversarial learning. First, the semantic-aware grad-generative adversarial network(GAN) (SG-GAN) is introduced to pre-process the synthetic dataset of GTA5. As a result, a new dataset SG-GTA5 is generated, which brings the newly dataset SG-GTA5 considerably closer to the urban scene dataset Cityscapes in gray, structure, and edge information. It is also suitable to substitute the original dataset GTA5 in AdaptSegNet. Second, the newly dataset SG-GTA5 is used as input of our network. To further enhance the adapted model and handle the fixed learning rate of AdaptSegNet, a multi-level adversarial network is constructed to effectively perform output space domain adaptation at different feature levels. Third, an adaptive learning rate is introduced in different feature levels of the network. Fourth, the loss value of different levels is adjusted by the proposed adaptive learning rate. Thus, the network's parameters can be updated dynamically. Fifth, a new convolution layer is added into the discriminator of GAN. As a result, the discriminant ability of the network is enhanced. For the discriminator, we use an architecture that uses fully convolutional layers to replace all fully connected layers to retain the spatial information. This architecture is composed of six convolution layers with 4×4 kernel and a stride of 2 for the first four kernels, a stride of 1 for the fifth kernel and channel numbers of 64, 128, 256, 512, 1 024, and 1, respectively. Except for the last layer, each convolution layer is followed by a leaky ReLU parameterized by 0.2. An up-sampling layer is added to the last convolution layer for re-scaling the output to the input size. No batch-normalization layers are used because we jointly train the discriminator with the segmentation network using a small batch size. For the segmentation network, it is essential to build upon a good baseline model to achieve high-quality segmentation results. We adopt the DeepLab-v2 framework with ResNet-101 model pre-trained on ImageNet as our segmentation baseline network. Similar to the recent work on semantic segmentation, we remove the last classification layer and modify the stride of the last two convolution layers from 2 to 1, making the resolution of the output feature maps effectively 1/8 times the input image size. To enlarge the receptive field, we apply dilated convolution layers in conv4 and conv5 layers with a stride of 2 and 4, respectively. After the last layer, we use the atrous spatial pyramid pooling (ASPP)as the final classifier. Finally, the batch normalization(BN) layers are removed because the discriminator network is trained with small batch generator network. Furthermore, we implement our network using the PyTorch toolbox on a single GTX1080Ti GPU with 11 GB memory.ResultThe new model is verified using the Cityscapes dataset. Experimental results demonstrate that the presented model is capable of segmenting more complex targets in the urban traffic scene precisely. The model also performs well against existing state-of-the-art segmentation model in terms of accuracy and visual quality. The segmentation accuracy of sidewalk, wall, pole, car and sky are improved by 9.6%, 5.9%, 4.9%, 5.5%, and 4.8%, respectively.ConclusionThe effectiveness of the proposed model is validated by using the real urban scene Cityscapes. The segmentation precision is improved through the presented dataset preprocessing scheme on the synthetic dataset of GTA5 by using the SG-GAN model, which makes the newly dataset SG-GTA5 much closer to the urban scene dataset Cityscapes on gray, structure, and edge information. The presented data preprocessing method also reduces the adversarial loss value effectively and avoids gradient explosion during the back propagation process. The network's learning capability is also further strengthened and the model's segmentation precision is improved through the presented adaptive learning rate, which is used for different adversarial layers to adjust the loss value of each layer. The learning rate can also update network parameters dynamically and optimize the performance of the generator and discriminator network. Finally, the discrimination capability of the proposed model is further improved by adding a new convolution layer in the discriminator, which enables the model to learn high layer semantic information. The domain shift is also alleviated to some extent.关键词:urban scene;semantic segmentation;generative adversarial network(GAN);domain adaptation;adapt learning rate36|34|4更新时间:2024-05-08 -
 摘要:ObjectiveMultiphase image segmentation, an extension of two-phase image segmentation, is designed to partition images automatically into different regions according to different image features. It is a basic problem in image processing, image analysis, and computer vision. Variational image segmentation Vese-Chan model is a basic model of multiphase image segmentation that can construct characteristic functions for different phases or regions using fewer label functions, thus producing small-scale solutions. Graph cut (GC) algorithm can transform the optimization problem of energy function into the min-cut/max-flow problem, which greatly improves computational efficiency. In the spatially discrete setting, the computational results of the min-cut method are influenced by the discrete grid, resulting in measurement errors. In recent years, the continuous max-flow (CMF) method was proposed. As a continuous expression of the classical GC algorithm, CMF can keep the high efficiency of the GC algorithm and overcome measurement errors caused by the discretization of the classical GC algorithm. On the basis of the framework of variational theory, the CMF method for multiphase image segmentation Potts model and two-phase image segmentation Chan-Vese model was proposed and studied. However, a CMF method for the Vese-Chan model has not been studied. Therefore, we propose a CMF method for multiphase image segmentation Vese-Chan model based on convex relaxation and study its computational effectiveness and efficiency.MethodIn this study, binary label functions are used to construct different characteristic functions for different phases according to the relationship between a natural number and a binary representation of partitioned regions. The characteristic functions are divided into two parts according to the value of binary expression, i.e., 0 or 1. The characteristic functions are different. The date term of the segmentation model is also divided into two parts. Therefore, multiphase image segmentation can be transformed into two-phase image segmentation. This model can be expressed as a symmetric form of label functions, which are beneficial to interpret and realize. We introduce three dual variables, namely, source flow, sink flow, and spatial flow field. Next, we rewrite the optimization problem of energy function for the Vese-Chan model, including the above three dual variables. Flow conservation conditions are obtained by solving minimum problems of energy function. The Vese-Chan model can be transformed into a continuous max-flow problem corresponding to the min-cut problem. To improve computational efficiency in the experiments, we likewise design the alternating direction method of multipliers (ADMM) by introducing Lagrange multipliers and penalty parameters for the proposed model. The main idea of alternating optimization is to solve the optimization problem of one variable by fixing other variables. Therefore, the optimization problem of energy function can be transformed into three simple sub-problems of optimization, which can be achieved and solved more easily. For example, to solve one sub-problem on the source flow variable, the sink flow variable and spatial flow field variable should be fixed. Three dual variables must be calculated and Lagrange multipliers should be updated at each step. All of these variable need projection to satisfy the range of values. When the energy error formula is satisfied, the computational iteration stops. To represent the boundary of images after segmenting, it is necessary to threshold convex relaxed label functions into binary label functions. Finally, we can obtain segmentation results according to the binary label functions.ResultNumerical experiments are performed on gray and colored images. According to the area numbers of images, numerical experiments are divided into three parts: experiments using two binary label functions, three binary label functions, and four binary label functions. Segmentation results are represented by curves of different colors. In particular, to accurately represent the segmentation effects for complicated images, we obtain the approximate segmentation results. For the segmentation effectiveness, experimental results prove that the ADMM method and our proposed method have the same segmentation effectiveness for simple synthetic images. However, compared with ADMM, our proposed method is more accurate for complex images, such as medical and remote sensing images. Moreover, our method can achieve better separation for segmented objects and background. For the computational efficiency, we use two binary label functions to compare the efficiency of four gray images, including synthetic images, a natural image, and a medical image. The acceleration ratios of computational time for our proposed method are 6.35%, 10.75%, 12.39%, and 7.83%, respectively. For the experiment of three binary label functions, three gray images are compared, including synthetic images and a remote sensing image are compared. The computational times of our proposed method improve by 12.32%, 15.45%, and 14.04% for each image. For the experiment of four binary label functions, we compare two color images, including a natural image and a synthetic image. The computational times of our proposed method improve by 16.69% and 20.07%. In the experiments, our proposed method reduces the number of iterations and improves the convergence speed. By comparing the acceleration ratio of computational time with the increase of region phases or the complexity of the image, the advantages of the computational efficiency for our method are more evident.ConclusionContinuous max-flow method is used to solve the multiphase image segmentation Vese-Chan model. Numerical experiments are performed to demonstrate the superiority of our method in terms of computational effectiveness and efficiency for medical images, remote sensing images, and color images. Our method can be applied to multiphase segmentation for three-dimensional reconstruction of medical images in the future.关键词:multiphase image segmentation;Vese-Chan model;convex relaxation;continuous max-flow method(CMF);alternating direction method of multipliers(ADMM)17|15|0更新时间:2024-05-08
摘要:ObjectiveMultiphase image segmentation, an extension of two-phase image segmentation, is designed to partition images automatically into different regions according to different image features. It is a basic problem in image processing, image analysis, and computer vision. Variational image segmentation Vese-Chan model is a basic model of multiphase image segmentation that can construct characteristic functions for different phases or regions using fewer label functions, thus producing small-scale solutions. Graph cut (GC) algorithm can transform the optimization problem of energy function into the min-cut/max-flow problem, which greatly improves computational efficiency. In the spatially discrete setting, the computational results of the min-cut method are influenced by the discrete grid, resulting in measurement errors. In recent years, the continuous max-flow (CMF) method was proposed. As a continuous expression of the classical GC algorithm, CMF can keep the high efficiency of the GC algorithm and overcome measurement errors caused by the discretization of the classical GC algorithm. On the basis of the framework of variational theory, the CMF method for multiphase image segmentation Potts model and two-phase image segmentation Chan-Vese model was proposed and studied. However, a CMF method for the Vese-Chan model has not been studied. Therefore, we propose a CMF method for multiphase image segmentation Vese-Chan model based on convex relaxation and study its computational effectiveness and efficiency.MethodIn this study, binary label functions are used to construct different characteristic functions for different phases according to the relationship between a natural number and a binary representation of partitioned regions. The characteristic functions are divided into two parts according to the value of binary expression, i.e., 0 or 1. The characteristic functions are different. The date term of the segmentation model is also divided into two parts. Therefore, multiphase image segmentation can be transformed into two-phase image segmentation. This model can be expressed as a symmetric form of label functions, which are beneficial to interpret and realize. We introduce three dual variables, namely, source flow, sink flow, and spatial flow field. Next, we rewrite the optimization problem of energy function for the Vese-Chan model, including the above three dual variables. Flow conservation conditions are obtained by solving minimum problems of energy function. The Vese-Chan model can be transformed into a continuous max-flow problem corresponding to the min-cut problem. To improve computational efficiency in the experiments, we likewise design the alternating direction method of multipliers (ADMM) by introducing Lagrange multipliers and penalty parameters for the proposed model. The main idea of alternating optimization is to solve the optimization problem of one variable by fixing other variables. Therefore, the optimization problem of energy function can be transformed into three simple sub-problems of optimization, which can be achieved and solved more easily. For example, to solve one sub-problem on the source flow variable, the sink flow variable and spatial flow field variable should be fixed. Three dual variables must be calculated and Lagrange multipliers should be updated at each step. All of these variable need projection to satisfy the range of values. When the energy error formula is satisfied, the computational iteration stops. To represent the boundary of images after segmenting, it is necessary to threshold convex relaxed label functions into binary label functions. Finally, we can obtain segmentation results according to the binary label functions.ResultNumerical experiments are performed on gray and colored images. According to the area numbers of images, numerical experiments are divided into three parts: experiments using two binary label functions, three binary label functions, and four binary label functions. Segmentation results are represented by curves of different colors. In particular, to accurately represent the segmentation effects for complicated images, we obtain the approximate segmentation results. For the segmentation effectiveness, experimental results prove that the ADMM method and our proposed method have the same segmentation effectiveness for simple synthetic images. However, compared with ADMM, our proposed method is more accurate for complex images, such as medical and remote sensing images. Moreover, our method can achieve better separation for segmented objects and background. For the computational efficiency, we use two binary label functions to compare the efficiency of four gray images, including synthetic images, a natural image, and a medical image. The acceleration ratios of computational time for our proposed method are 6.35%, 10.75%, 12.39%, and 7.83%, respectively. For the experiment of three binary label functions, three gray images are compared, including synthetic images and a remote sensing image are compared. The computational times of our proposed method improve by 12.32%, 15.45%, and 14.04% for each image. For the experiment of four binary label functions, we compare two color images, including a natural image and a synthetic image. The computational times of our proposed method improve by 16.69% and 20.07%. In the experiments, our proposed method reduces the number of iterations and improves the convergence speed. By comparing the acceleration ratio of computational time with the increase of region phases or the complexity of the image, the advantages of the computational efficiency for our method are more evident.ConclusionContinuous max-flow method is used to solve the multiphase image segmentation Vese-Chan model. Numerical experiments are performed to demonstrate the superiority of our method in terms of computational effectiveness and efficiency for medical images, remote sensing images, and color images. Our method can be applied to multiphase segmentation for three-dimensional reconstruction of medical images in the future.关键词:multiphase image segmentation;Vese-Chan model;convex relaxation;continuous max-flow method(CMF);alternating direction method of multipliers(ADMM)17|15|0更新时间:2024-05-08 -
 摘要:ObjectivePerson re-identification (ReID) refers to the retrieval of target pedestrians from multiple non-overlapping cameras. This technology can be widely used in various fields. In the security field, police can quickly track and retrieve the location of suspects and easily find missing individuals by using person ReID. In the field of album management, users manage electronic albums according to person ReID. In the field of e-commerce, managers of unmanned supermarkets use person ReID to track user behavior. However, this technology poses a variety of challenges, such as low resolution, light change, background clutter, variable pedestrian action, and occlusion of pedestrian body parts. Numerous methods have been proposed to solve these problems. The traditional methods mainly include two ways, namely, feature design and distance metric. The main idea of feature design is to design a feature representation with strong discriminability and robustness. Thus, an expressive feature can be extracted from a pedestrian image. The distance metric method is used to reduce the distance among similar pedestrian images while increasing the distance among different pedestrian images. In recent years, deep learning has been widely used in the field of computer vision. Given the popularity of deep learning, person ReID based on deep learning has achieved higher recognition rate than traditional methods. The deep learning method mainly uses convolutional neural networks (CNNs) to classify pedestrian images, extract the representation of pedestrian images from the network, and determine whether pedestrian pairs form matches by calculating the similarity between pedestrian pairs. In this work, the proposed method is based on a CNN. We observe that the problems of misjudgment due to the occlusion of pedestrian body parts and misalignment between pedestrian image pairs are frequent. Thus, we attempt to focus on pedestrian parts with distinctive features and ignore other parts with interference information to determine whether pedestrian pairs captured by different cameras form matches. We then propose a method for person ReID using attention and attributes to overcome pedestrian occlusion and misalignment problem in ReID.MethodOur method introduces the attribute information of pedestrians. Attribute information is divided into local and global attributes. The local attributes are composed of the head, upper body, hand, and lower body part attributes. The global attributes include gender and age. The proposed method falls into two stages: training and test stages. In the training stage, the improved ResNet50 network is used as the basic framework to extract features. The training stage is composed of two branches: a global branch and a local branch. In the global branch, features are used as the global feature to classify identity and global attributes. Meanwhile, in the local branch, multiple processes are involved. First, features are extended into multiple channels. Second, we obtain the point with the highest response value per channel. Third, we cluster these points, and the cluster points are divided into four pedestrian parts. Fourth, we obtain the weight of the distinctive feature on each pedestrian part through calculation. Fifth, the weights of these four parts are multiplied by the initial features to obtain the total features of each part. Finally, the total features of these four parts are classified according to the identity and corresponding attributes. In the test stage, the part and global features are extracted through the trained network and concatenated as joint features. The similarity between pedestrian pairs is calculated to determine whether the pedestrian pairs form matches. In this method, the network locates pedestrian parts by using attribute information. At the same time, the attention mechanisms of the network are used to obtain discriminative features of pedestrian parts.ResultThe proposed method uses attribute information in the Market-1501_attribute and DukeMTMC-attribute datasets and then evaluates the Market-1501 and DukeMTMC-reid datasets. In the field of person ReID, two evaluation protocols are used to evaluate the performance of the model: cumulative matching characteristics (CMC) curve and mean average precision (mAP). The following steps are performed to draw the CMC curve. First, we calculate the Euclidean distance between the probe image and the gallery images. Second, we sort the ranking order of all gallery images from the image with the shortest distance to the longest distance for each probe image. Finally, the true match percentage of the top m sorted images is calculated and called as rank-m. Specifically, rank-1 is an important indicator of person ReID. The following steps are performed to complete the mAP. First, we compute the average precision, which is the area under the precise-recall curve of each probe image. Next, the mean of average precision of all probe images is calculated. In the Market-1501 and DukeMTMC-reid datasets, the rank-1 accuracies are 90.67% and 80.2%, respectively, whereas the mAP accuracies are 76.65% and 62.14%, respectively. Recently, the re-ranking method has been widely used in the field of person ReID. In the re-ranking method, the rank-1 accuracies are 92.4% and 84.15%, whereas the mAP accuracies are 87.5% and 78.41%. Compared with other state-of-the-art methods, our accuracies are greatly improved.ConclusionIn this study, we propose a method for ReID based on attention and attributes. This proposed method can direct attention toward pedestrian parts by learning the attributes of pedestrians. Then, the attention mechanism can be used to learn the distinctive features of pedestrians. Even if pedestrians are occluded and misaligned, the proposed method can still achieve high accuracy.关键词:person re-identification;global feature;local feature;pedestrians part;attention mechanism;attribute information32|37|9更新时间:2024-05-08
摘要:ObjectivePerson re-identification (ReID) refers to the retrieval of target pedestrians from multiple non-overlapping cameras. This technology can be widely used in various fields. In the security field, police can quickly track and retrieve the location of suspects and easily find missing individuals by using person ReID. In the field of album management, users manage electronic albums according to person ReID. In the field of e-commerce, managers of unmanned supermarkets use person ReID to track user behavior. However, this technology poses a variety of challenges, such as low resolution, light change, background clutter, variable pedestrian action, and occlusion of pedestrian body parts. Numerous methods have been proposed to solve these problems. The traditional methods mainly include two ways, namely, feature design and distance metric. The main idea of feature design is to design a feature representation with strong discriminability and robustness. Thus, an expressive feature can be extracted from a pedestrian image. The distance metric method is used to reduce the distance among similar pedestrian images while increasing the distance among different pedestrian images. In recent years, deep learning has been widely used in the field of computer vision. Given the popularity of deep learning, person ReID based on deep learning has achieved higher recognition rate than traditional methods. The deep learning method mainly uses convolutional neural networks (CNNs) to classify pedestrian images, extract the representation of pedestrian images from the network, and determine whether pedestrian pairs form matches by calculating the similarity between pedestrian pairs. In this work, the proposed method is based on a CNN. We observe that the problems of misjudgment due to the occlusion of pedestrian body parts and misalignment between pedestrian image pairs are frequent. Thus, we attempt to focus on pedestrian parts with distinctive features and ignore other parts with interference information to determine whether pedestrian pairs captured by different cameras form matches. We then propose a method for person ReID using attention and attributes to overcome pedestrian occlusion and misalignment problem in ReID.MethodOur method introduces the attribute information of pedestrians. Attribute information is divided into local and global attributes. The local attributes are composed of the head, upper body, hand, and lower body part attributes. The global attributes include gender and age. The proposed method falls into two stages: training and test stages. In the training stage, the improved ResNet50 network is used as the basic framework to extract features. The training stage is composed of two branches: a global branch and a local branch. In the global branch, features are used as the global feature to classify identity and global attributes. Meanwhile, in the local branch, multiple processes are involved. First, features are extended into multiple channels. Second, we obtain the point with the highest response value per channel. Third, we cluster these points, and the cluster points are divided into four pedestrian parts. Fourth, we obtain the weight of the distinctive feature on each pedestrian part through calculation. Fifth, the weights of these four parts are multiplied by the initial features to obtain the total features of each part. Finally, the total features of these four parts are classified according to the identity and corresponding attributes. In the test stage, the part and global features are extracted through the trained network and concatenated as joint features. The similarity between pedestrian pairs is calculated to determine whether the pedestrian pairs form matches. In this method, the network locates pedestrian parts by using attribute information. At the same time, the attention mechanisms of the network are used to obtain discriminative features of pedestrian parts.ResultThe proposed method uses attribute information in the Market-1501_attribute and DukeMTMC-attribute datasets and then evaluates the Market-1501 and DukeMTMC-reid datasets. In the field of person ReID, two evaluation protocols are used to evaluate the performance of the model: cumulative matching characteristics (CMC) curve and mean average precision (mAP). The following steps are performed to draw the CMC curve. First, we calculate the Euclidean distance between the probe image and the gallery images. Second, we sort the ranking order of all gallery images from the image with the shortest distance to the longest distance for each probe image. Finally, the true match percentage of the top m sorted images is calculated and called as rank-m. Specifically, rank-1 is an important indicator of person ReID. The following steps are performed to complete the mAP. First, we compute the average precision, which is the area under the precise-recall curve of each probe image. Next, the mean of average precision of all probe images is calculated. In the Market-1501 and DukeMTMC-reid datasets, the rank-1 accuracies are 90.67% and 80.2%, respectively, whereas the mAP accuracies are 76.65% and 62.14%, respectively. Recently, the re-ranking method has been widely used in the field of person ReID. In the re-ranking method, the rank-1 accuracies are 92.4% and 84.15%, whereas the mAP accuracies are 87.5% and 78.41%. Compared with other state-of-the-art methods, our accuracies are greatly improved.ConclusionIn this study, we propose a method for ReID based on attention and attributes. This proposed method can direct attention toward pedestrian parts by learning the attributes of pedestrians. Then, the attention mechanism can be used to learn the distinctive features of pedestrians. Even if pedestrians are occluded and misaligned, the proposed method can still achieve high accuracy.关键词:person re-identification;global feature;local feature;pedestrians part;attention mechanism;attribute information32|37|9更新时间:2024-05-08 -
 摘要:ObjectivePerson re-identification (ReID) is a computer vision task of re-identifying a queried person across non-overlapping surveillance camera views developed at different locations by matching images of the person. Given the fundamental problem of intelligent surveillance analysis, person ReID has attracted increasing interest in recent years among computer vision and pattern recognition research communities. Although great progress has been made in person ReID, it still has challenges, such as occlusion, illumination, pose variance, and background clutter. The key to solving these difficulties is to efficiently design a convolutional neural network (CNN) architecture that can extract discriminative feature representations. Specifically, the architecture should be capable of compacting the "intraclass" variation (obtained from the same individual) and separating the "interclass" variation (obtained from different individuals). The algorithm process of person ReID mainly includes two stages, namely, feature extraction and distance measurement. Most contemporary studies have focused on feature extraction because a good feature can effectively distinguish different persons. Thus, the designed CNN network needs to have good representation for the global and local features of different individuals. To fully mine the information contained in the image, we fuse the features of the same image at different resolutions to obtain a stronger feature representation and develop a multi-resolution feature attention fusion method for person ReID.MethodAt present, mainstream person ReID methods are based on classical networks such as ResNet and VGG(visual geometry group)-Net. The main characteristic of these networks is that the resolution of the feature maps becomes increasingly smaller as the network continuously deepens. Moreover, their high-level features contain sufficient semantic information but lack spatial information. However, for tasks involving person ReID, the spatial information of an individual is necessary. The high-resolution network (HRNet) is a multi-branch network that can maintain high-resolution representations throughout the whole process. HRNet is constructed by interleaving convolutions, which are helpful for obtaining different granularity features. It also helps in the information exchange among different branches. HRNet can output four different resolution feature representations. In this study, we first evaluate the performance of different resolution feature representations. Results show that the performance of these feature representations is not consistent on different datasets. Therefore, we propose an attention module to fuse the different resolution feature representations. The attention module can generate four weights, which add up to 1. The different resolution feature representations can be updated according to different weights. The final feature representation is the accumulation of the four different updated features.ResultExperiments are conducted on three ReID datasets: Market1501, CUHK03, and DukeMTMC-ReID. Results indicate that our method pushes the performance to an exceptional level compared with most existing methods. Rank-1 accuracy is achieved with the following percentages: 95.6%, 72.8%, and 90.5%. Moreover, mAP(mean average precision) scores of 89.2%, 70.4%, and 81.5% are obtained on Market1501, CUHK03, and DukeMTMC-ReID datasets, respectively. Our method achieves state-of-the-art results on the DukeMTMC-ReID dataset and yields competitive performance with the state-of-the-art methods on Market1501 and CUHK03 datasets. The mAP score of our method is also the highest on the Market1501 dataset. In the ablation study, we evaluate the influence of three situations on the performance of our model, namely, the attention module at different locations, the images with different resolutions, and the weights of different normalization methods. Results show that the behind attention mechanism is better than the front attention mechanism. In addition, the image resolution has little influence on the performance, and the Sigmoid normalization method outperforms the softmax normalization method.ConclusionIn this study, we proposed a multi-resolution attention fused method for person ReID. HRNet is an original network used to extract coarse-grain and fine-grain features, which are helpful for person ReID. Through ablation study, we found that the performance of different resolution feature representations is not consistent on different datasets. Thus, we proposed an attention module to fuse the different resolution features. The attention module outputs four weights to represent the importance of the different resolution features. The fused feature was obtained by accumulating the updated features. The experiments were conducted on Market1501, CUHK03, and DukeMTMC-ReID datasets. Results showed that our method outperforms several state-of-the-art person ReID approaches and that the attention fused method improves the performance.关键词:high-resolution network (HRNet);interleaving convolution;attention mechanism;multi-resolution feature representation;feature fusion;person re-identification65|66|7更新时间:2024-05-08
摘要:ObjectivePerson re-identification (ReID) is a computer vision task of re-identifying a queried person across non-overlapping surveillance camera views developed at different locations by matching images of the person. Given the fundamental problem of intelligent surveillance analysis, person ReID has attracted increasing interest in recent years among computer vision and pattern recognition research communities. Although great progress has been made in person ReID, it still has challenges, such as occlusion, illumination, pose variance, and background clutter. The key to solving these difficulties is to efficiently design a convolutional neural network (CNN) architecture that can extract discriminative feature representations. Specifically, the architecture should be capable of compacting the "intraclass" variation (obtained from the same individual) and separating the "interclass" variation (obtained from different individuals). The algorithm process of person ReID mainly includes two stages, namely, feature extraction and distance measurement. Most contemporary studies have focused on feature extraction because a good feature can effectively distinguish different persons. Thus, the designed CNN network needs to have good representation for the global and local features of different individuals. To fully mine the information contained in the image, we fuse the features of the same image at different resolutions to obtain a stronger feature representation and develop a multi-resolution feature attention fusion method for person ReID.MethodAt present, mainstream person ReID methods are based on classical networks such as ResNet and VGG(visual geometry group)-Net. The main characteristic of these networks is that the resolution of the feature maps becomes increasingly smaller as the network continuously deepens. Moreover, their high-level features contain sufficient semantic information but lack spatial information. However, for tasks involving person ReID, the spatial information of an individual is necessary. The high-resolution network (HRNet) is a multi-branch network that can maintain high-resolution representations throughout the whole process. HRNet is constructed by interleaving convolutions, which are helpful for obtaining different granularity features. It also helps in the information exchange among different branches. HRNet can output four different resolution feature representations. In this study, we first evaluate the performance of different resolution feature representations. Results show that the performance of these feature representations is not consistent on different datasets. Therefore, we propose an attention module to fuse the different resolution feature representations. The attention module can generate four weights, which add up to 1. The different resolution feature representations can be updated according to different weights. The final feature representation is the accumulation of the four different updated features.ResultExperiments are conducted on three ReID datasets: Market1501, CUHK03, and DukeMTMC-ReID. Results indicate that our method pushes the performance to an exceptional level compared with most existing methods. Rank-1 accuracy is achieved with the following percentages: 95.6%, 72.8%, and 90.5%. Moreover, mAP(mean average precision) scores of 89.2%, 70.4%, and 81.5% are obtained on Market1501, CUHK03, and DukeMTMC-ReID datasets, respectively. Our method achieves state-of-the-art results on the DukeMTMC-ReID dataset and yields competitive performance with the state-of-the-art methods on Market1501 and CUHK03 datasets. The mAP score of our method is also the highest on the Market1501 dataset. In the ablation study, we evaluate the influence of three situations on the performance of our model, namely, the attention module at different locations, the images with different resolutions, and the weights of different normalization methods. Results show that the behind attention mechanism is better than the front attention mechanism. In addition, the image resolution has little influence on the performance, and the Sigmoid normalization method outperforms the softmax normalization method.ConclusionIn this study, we proposed a multi-resolution attention fused method for person ReID. HRNet is an original network used to extract coarse-grain and fine-grain features, which are helpful for person ReID. Through ablation study, we found that the performance of different resolution feature representations is not consistent on different datasets. Thus, we proposed an attention module to fuse the different resolution features. The attention module outputs four weights to represent the importance of the different resolution features. The fused feature was obtained by accumulating the updated features. The experiments were conducted on Market1501, CUHK03, and DukeMTMC-ReID datasets. Results showed that our method outperforms several state-of-the-art person ReID approaches and that the attention fused method improves the performance.关键词:high-resolution network (HRNet);interleaving convolution;attention mechanism;multi-resolution feature representation;feature fusion;person re-identification65|66|7更新时间:2024-05-08 -
 摘要:ObjectiveTens of accidents involving helicopters occur every year owing to collisions with trees, wires, poles, and man-made buildings at low altitude. Just in 2014—2016, there were 96 crashes caused by hitting power lines around the world. Thus, warnings and avoiding wires are important for the low-altitude flight safety of helicopters and unmanned aerial vehicles. According to relevant studies, utilization of optical images is an effective way to identify wires. Traditional methods use manual filters to extract features of power lines and then use Hough transform to detect the lines. Machine learning methods, such as VGG (visual geometry group) 16 and random forest (RF), can only obtain a classification result for a picture, which makes confirming accuracy difficult. The full connection layer of the traditional convolutional neural network (CNN) is effective at classification tasks. However, it cannot carry out pixel segmentation tasks because of the loss of location information. By contrast, the fully convolutional network has no full connection layer, which misses location information. One kind of fully convolutional network, U-Net, is proposed to solve problems such as cell segmentation and retina segmentation. U-Net works well under the conditions of a small amount of samples and a small slice. A three-channel image is input into the network. Through the encoder and decoder, it finally becomes a one-channel feature map via 1×1 kernel size convolution. To obtain the final value between 0 and 1, Sigmoid activation function is used before every convolution layer. In this study, a CNN recognition method based on U-net is proposed to detect power lines.MethodFirst, we obtain a power line data set containing 8 000 images with 4 000 pairs of visible and infrared images. The image size is 128×128 pixels, with each image having a pixel ground truth label. The network receptive field calculation formula is used to determine the depth of our network. Next, adjustments are made on this basis network to choose the best model. The basis network is named the U-Net-0 model. The U-Net-1 model removes the lower pooling layer in the U-Net-0 model and changes the step size of the convolution layer before the lower pooling layer to 2. It also removes the upper pooling layer and changes the convolution layer after the upper pooling layer to the inverse convolution layer with a step size of 2. Compared with U-Net-0, the U-Net-2 model eliminates the upper and lower pooling layers and the convolution layer in the middle, thereby reducing the network depth. In the U-Net-3 model, decoding is expected to be a dimensionality reduction process. Therefore, the number of convolution kernels of the decoding part is limited, and the number of parameters of feature graph output of each layer is not larger than that of the previous layer. Pictures with complex backgrounds are likewise used to generate a large number of paired synthetic data, including power line images with pixel labels. The generated synthetic data are then used for network training. For each image, the power line contains a small number of pixels. Thus, focal loss is used to balance the impact of a large number of negative samples. The four models use the same optimizer named "Adam", which can automatically adjust the learning rate on the basis of SGD (stochastic gradient descent). The training procedure of each model is accelerated using an NVIDIA GTX 1080 TI device, which takes approximately 18 hours in 6 000 iterations with a batch size of 64. Loss, F1 score, and intersection-over-union (IoU) are the three evaluative criteria for trained models. The best model usually has low loss and high F1 score and IoU. Each model is used on visible and infrared images. The two results are combined to make a judgment. The power line, regardless of which of the same pair includes it, is finally considered detected in the mixed result.ResultAfter these four models are tested on the data set, the number of correctly identified pixels and IoU on each image is counted. According to the statistical results, the IoU of most image recognition results exceeds 0.2, and the threshold of 30 pixels as the result classification is relatively good. If more than 30 pixels are identified on an image, this image might include a power line. By this standard, the proposed method achieves a recognition rate over 99%, while the false alarms are less than 2%. Moreover, VGG16, which is trained on 3 800 pairs of images and tested on 200 pairs of images, only obtains a recognition rate of 95% and a false alarm rate of 37%. RF is affected by feature extraction methods. Thus, the recognition rate and false alarm rate fluctuate greatly. For example, RF with local binary patterns has a recognition rate of 63.5% and a false alarm rate of 36.3% on infrared images. In addition, RF with discrete cosine transform obtains a recognition rate of 92.95% and a false alarm rate of 13.95% on infrared images. Although U-Net-3 has more learnable parameters than U-Net-2, its performance is substantially worse.ConclusionOur models have higher recognition rates and lower false alarm rates than do other traditional methods on the same dataset. Results show that our models are more effective than other methods and can even clearly extract power lines from background. Our models are trained on synthetic data and tested on real data, which means better generalization performance. The comparison of the four models also shows that the number of parameters cannot completely determine the performance of the network and that the reasonable structure is important. However, our current models have a small receptive field and cannot be used for power line recognition in high-resolution images. In the future, the models will be further studied to increase their receptive field for adapting to larger images without greatly increasing the number of parameters.关键词:fully convolutional network(FCN);power line recognition;low-altitude flight safety;synthetic data;multisource images57|154|5更新时间:2024-05-08
摘要:ObjectiveTens of accidents involving helicopters occur every year owing to collisions with trees, wires, poles, and man-made buildings at low altitude. Just in 2014—2016, there were 96 crashes caused by hitting power lines around the world. Thus, warnings and avoiding wires are important for the low-altitude flight safety of helicopters and unmanned aerial vehicles. According to relevant studies, utilization of optical images is an effective way to identify wires. Traditional methods use manual filters to extract features of power lines and then use Hough transform to detect the lines. Machine learning methods, such as VGG (visual geometry group) 16 and random forest (RF), can only obtain a classification result for a picture, which makes confirming accuracy difficult. The full connection layer of the traditional convolutional neural network (CNN) is effective at classification tasks. However, it cannot carry out pixel segmentation tasks because of the loss of location information. By contrast, the fully convolutional network has no full connection layer, which misses location information. One kind of fully convolutional network, U-Net, is proposed to solve problems such as cell segmentation and retina segmentation. U-Net works well under the conditions of a small amount of samples and a small slice. A three-channel image is input into the network. Through the encoder and decoder, it finally becomes a one-channel feature map via 1×1 kernel size convolution. To obtain the final value between 0 and 1, Sigmoid activation function is used before every convolution layer. In this study, a CNN recognition method based on U-net is proposed to detect power lines.MethodFirst, we obtain a power line data set containing 8 000 images with 4 000 pairs of visible and infrared images. The image size is 128×128 pixels, with each image having a pixel ground truth label. The network receptive field calculation formula is used to determine the depth of our network. Next, adjustments are made on this basis network to choose the best model. The basis network is named the U-Net-0 model. The U-Net-1 model removes the lower pooling layer in the U-Net-0 model and changes the step size of the convolution layer before the lower pooling layer to 2. It also removes the upper pooling layer and changes the convolution layer after the upper pooling layer to the inverse convolution layer with a step size of 2. Compared with U-Net-0, the U-Net-2 model eliminates the upper and lower pooling layers and the convolution layer in the middle, thereby reducing the network depth. In the U-Net-3 model, decoding is expected to be a dimensionality reduction process. Therefore, the number of convolution kernels of the decoding part is limited, and the number of parameters of feature graph output of each layer is not larger than that of the previous layer. Pictures with complex backgrounds are likewise used to generate a large number of paired synthetic data, including power line images with pixel labels. The generated synthetic data are then used for network training. For each image, the power line contains a small number of pixels. Thus, focal loss is used to balance the impact of a large number of negative samples. The four models use the same optimizer named "Adam", which can automatically adjust the learning rate on the basis of SGD (stochastic gradient descent). The training procedure of each model is accelerated using an NVIDIA GTX 1080 TI device, which takes approximately 18 hours in 6 000 iterations with a batch size of 64. Loss, F1 score, and intersection-over-union (IoU) are the three evaluative criteria for trained models. The best model usually has low loss and high F1 score and IoU. Each model is used on visible and infrared images. The two results are combined to make a judgment. The power line, regardless of which of the same pair includes it, is finally considered detected in the mixed result.ResultAfter these four models are tested on the data set, the number of correctly identified pixels and IoU on each image is counted. According to the statistical results, the IoU of most image recognition results exceeds 0.2, and the threshold of 30 pixels as the result classification is relatively good. If more than 30 pixels are identified on an image, this image might include a power line. By this standard, the proposed method achieves a recognition rate over 99%, while the false alarms are less than 2%. Moreover, VGG16, which is trained on 3 800 pairs of images and tested on 200 pairs of images, only obtains a recognition rate of 95% and a false alarm rate of 37%. RF is affected by feature extraction methods. Thus, the recognition rate and false alarm rate fluctuate greatly. For example, RF with local binary patterns has a recognition rate of 63.5% and a false alarm rate of 36.3% on infrared images. In addition, RF with discrete cosine transform obtains a recognition rate of 92.95% and a false alarm rate of 13.95% on infrared images. Although U-Net-3 has more learnable parameters than U-Net-2, its performance is substantially worse.ConclusionOur models have higher recognition rates and lower false alarm rates than do other traditional methods on the same dataset. Results show that our models are more effective than other methods and can even clearly extract power lines from background. Our models are trained on synthetic data and tested on real data, which means better generalization performance. The comparison of the four models also shows that the number of parameters cannot completely determine the performance of the network and that the reasonable structure is important. However, our current models have a small receptive field and cannot be used for power line recognition in high-resolution images. In the future, the models will be further studied to increase their receptive field for adapting to larger images without greatly increasing the number of parameters.关键词:fully convolutional network(FCN);power line recognition;low-altitude flight safety;synthetic data;multisource images57|154|5更新时间:2024-05-08 -
 摘要:ObjectiveThe development of online digital media technology has promoted the sharing and spreading of natural art images. However, given the increasing number of art images, effective classification and retrieval are urgent problems that need to be solved. In the face of massive art image data, problems may occur in traditional manual feature extraction methods, such as tagging errors and subjective tagging. Moreover, the professional requirements of classifiers are relatively high. Convolutional neural networks (CNNs) are widely used in image classification because of its automatic feature extraction characteristics. Most of these network models are used for feature extraction in key areas of photographed images. However, natural art images are different from photographed images. Specifically, the distribution of overall style features and local detail features is evidently uniform. Selective kernel networks (SKNet) can adaptively adjust their receptive field size according to the input image to select multi-scale spatial information. However, the softmax gating mechanism in the module only strengthens the dependence between the channels of the feature map after the convolution operation of the receptive field with large response to stimulus. It also ignores the role of local detail features. Squeeze-and-excitation networks (SENet) can enhance the features in different channels but cannot extract the overall features and local detail features of the input. To fully extract and enhance the overall style features and local detail features of art images and realize the automatic classification and retrieval of art images, we combine the characteristics of SKNet and SENet to build a block called double kernel squeeze-and-excitation (DKSE) module. DKSE blocks and depthwise separable convolutions are mainly used to construct a CNN to classify art images.MethodSKNet can capture the overall features and local detail features with different scales. According to the multi-scale structural characteristics of SKNet, we build the DKSE module with two branches. Each branch has a different convolutional kernel to extract the overall features and the local detail features and fuse the feature maps obtained by convolution operation. Then, according to the idea of compression and excitation in SENet, the fusion feature map spatial information is compressed into the channel descriptor by global average pooling (GAP). After the GAP operation, 1×1 convolutional kernel is used to compress and activate the feature map. The weight of normalization between (0, 1) is obtained through sigmoid gating mechanism. The weight is rescaled to the feature map of the different branches. The final output of the block is obtained by fusing the rescaled feature maps. Thus, more representative art image characteristics are extracted. In this study, we choose engraving, Chinese painting, oil painting, opaque watercolor painting and watercolor painting for classification. To enhance the data of artistic images, the images with high resolution of art images are artificially extracted and cut randomly into 299×299 pixels. The modules with rich style information are then selected. After the data augmentation, a total of 25 634 images under the five kinds of art images are obtained. The CNN is constructed by multiple DKSE modules and depthwise separable convolutions to classify the five kinds of art images. In all the experiments, 80% of the art images under each kind are randomly selected as the training sets, while the remaining 20% of the datasets are used as verification sets. Our CNN is implemented in a Keras frame. The input images are resized to 299×299 pixels for training. The Adam optimizer is used in the experiments. The initial value of learning rate is 0.001, a mini-batch size of 32 is observed, and the total of training epochs is 120. In the training process, the training sets rotate randomly from 0° to 20°, and the horizontal or vertical direction is randomly shifted between 0% and 10% and flipped randomly to enhance the generalization ability of the proposed CNN. The learning rate is decreased by a factor of 10 if the accuracy of training sets does not improve after three training cycles.ResultOur network model is used to classify the data with or without data enhancement processing. The accuracy of art image classification after data augmentation is 9.21% higher than that of unenhanced processing. Compared with other network models and traditional art image classification methods, the classification accuracy of our method is 86.55%, more than 26.35% higher than that of traditional art image classification methods. Compared with Inception-V4 networks, the number of parameters is approximately 33% of the number of Inception-V4 parameters, and the time spent is approximately 25%. In this study, we place the proposed DKSE module in three different positions of the network and then verify the influence of DKSE on the classification results. When the module is placed at the third depthwise separable convolution of the network model, the reduction ratio is set to 4 and the convolution kernel sizes on the branches are 1×1 and 5×5. Moreover, the classification accuracy is 87.58%, which is 1.58% higher than that of the other eight state-of-the-art network models. The classification accuracy of the reduction ratio of 4 is superior to the reduction ratio set to 16. We use gradient-weighted class activation mapping (Grad-CAM) algorithm with our network model, ours + SK model and ours + SE model, to visualize the overall features and local detail features of each kind of art images. Experimental results show that compared with the other two network models, our network model can fully extract the overall features and local detail features of art images.ConclusionExperimental results show that the proposed DKSE module can effectively improve the classification performance of the network model and fully extract the overall features and local detail features of the art images. The network model in this study has better classification accuracy than do the other CNN models.关键词:art image classification;depthwise separable convolution;convolutional neural network (CNN);overall feature;local detail feature40|19|3更新时间:2024-05-08
摘要:ObjectiveThe development of online digital media technology has promoted the sharing and spreading of natural art images. However, given the increasing number of art images, effective classification and retrieval are urgent problems that need to be solved. In the face of massive art image data, problems may occur in traditional manual feature extraction methods, such as tagging errors and subjective tagging. Moreover, the professional requirements of classifiers are relatively high. Convolutional neural networks (CNNs) are widely used in image classification because of its automatic feature extraction characteristics. Most of these network models are used for feature extraction in key areas of photographed images. However, natural art images are different from photographed images. Specifically, the distribution of overall style features and local detail features is evidently uniform. Selective kernel networks (SKNet) can adaptively adjust their receptive field size according to the input image to select multi-scale spatial information. However, the softmax gating mechanism in the module only strengthens the dependence between the channels of the feature map after the convolution operation of the receptive field with large response to stimulus. It also ignores the role of local detail features. Squeeze-and-excitation networks (SENet) can enhance the features in different channels but cannot extract the overall features and local detail features of the input. To fully extract and enhance the overall style features and local detail features of art images and realize the automatic classification and retrieval of art images, we combine the characteristics of SKNet and SENet to build a block called double kernel squeeze-and-excitation (DKSE) module. DKSE blocks and depthwise separable convolutions are mainly used to construct a CNN to classify art images.MethodSKNet can capture the overall features and local detail features with different scales. According to the multi-scale structural characteristics of SKNet, we build the DKSE module with two branches. Each branch has a different convolutional kernel to extract the overall features and the local detail features and fuse the feature maps obtained by convolution operation. Then, according to the idea of compression and excitation in SENet, the fusion feature map spatial information is compressed into the channel descriptor by global average pooling (GAP). After the GAP operation, 1×1 convolutional kernel is used to compress and activate the feature map. The weight of normalization between (0, 1) is obtained through sigmoid gating mechanism. The weight is rescaled to the feature map of the different branches. The final output of the block is obtained by fusing the rescaled feature maps. Thus, more representative art image characteristics are extracted. In this study, we choose engraving, Chinese painting, oil painting, opaque watercolor painting and watercolor painting for classification. To enhance the data of artistic images, the images with high resolution of art images are artificially extracted and cut randomly into 299×299 pixels. The modules with rich style information are then selected. After the data augmentation, a total of 25 634 images under the five kinds of art images are obtained. The CNN is constructed by multiple DKSE modules and depthwise separable convolutions to classify the five kinds of art images. In all the experiments, 80% of the art images under each kind are randomly selected as the training sets, while the remaining 20% of the datasets are used as verification sets. Our CNN is implemented in a Keras frame. The input images are resized to 299×299 pixels for training. The Adam optimizer is used in the experiments. The initial value of learning rate is 0.001, a mini-batch size of 32 is observed, and the total of training epochs is 120. In the training process, the training sets rotate randomly from 0° to 20°, and the horizontal or vertical direction is randomly shifted between 0% and 10% and flipped randomly to enhance the generalization ability of the proposed CNN. The learning rate is decreased by a factor of 10 if the accuracy of training sets does not improve after three training cycles.ResultOur network model is used to classify the data with or without data enhancement processing. The accuracy of art image classification after data augmentation is 9.21% higher than that of unenhanced processing. Compared with other network models and traditional art image classification methods, the classification accuracy of our method is 86.55%, more than 26.35% higher than that of traditional art image classification methods. Compared with Inception-V4 networks, the number of parameters is approximately 33% of the number of Inception-V4 parameters, and the time spent is approximately 25%. In this study, we place the proposed DKSE module in three different positions of the network and then verify the influence of DKSE on the classification results. When the module is placed at the third depthwise separable convolution of the network model, the reduction ratio is set to 4 and the convolution kernel sizes on the branches are 1×1 and 5×5. Moreover, the classification accuracy is 87.58%, which is 1.58% higher than that of the other eight state-of-the-art network models. The classification accuracy of the reduction ratio of 4 is superior to the reduction ratio set to 16. We use gradient-weighted class activation mapping (Grad-CAM) algorithm with our network model, ours + SK model and ours + SE model, to visualize the overall features and local detail features of each kind of art images. Experimental results show that compared with the other two network models, our network model can fully extract the overall features and local detail features of art images.ConclusionExperimental results show that the proposed DKSE module can effectively improve the classification performance of the network model and fully extract the overall features and local detail features of the art images. The network model in this study has better classification accuracy than do the other CNN models.关键词:art image classification;depthwise separable convolution;convolutional neural network (CNN);overall feature;local detail feature40|19|3更新时间:2024-05-08
Image Analysis and Recognition
-
 摘要:ObjectiveWith the great breakthrough of deep convolutional neural networks (CNNs), tremendous state-of-the-art networks have been created to significantly improve image classification and utilize modern CNN-based object detectors. Image classification and detection research has matured and entered the industrial stage. However, detecting objects in complex samples and high frame rate videos remains a challenging task in the field of computer vision, especially considering that samples and videos are filled with huge numbers of small and dense instances in each frame. The issues of state-of-the-art networks do not make a tradeoff between accuracy and efficiency for detecting small dense targets as the priority consideration. Thus, in this study, we propose a deep hybrid network, namely, snap pyramid network (SPNet).MethodOur model is incorporated with dense optical flow technique in the enhanced one-stage architecture. First, the complete inner visualization of feature-extract net and pyramid net is built to mine out the critical factors of small dense objects. Through this method, the contextual information is found to be a significant key and should thus be fully utilized in the feature extraction. Moreover, sharing the context in multiple convolutional templates of the network is essential for the high semantic information from the deep templates, which help the shallow templates precisely predict the target location. Accordingly, our proposed hybrid net called SPNet is presented. It is composed of two parts, namely, MainNet and TrackNet. For the MainNet, the inception and feature weight control (FWC) modules are designed to modify the conventional network architecture. The whole MainNet consists of the BackBone network (the core of MainNet, which can efficiently extract feature information) and the feature pyramid network (FPN) network to predict classification and candidate box position. Inception greatly reduces the parameter quantity. FWC can raise the weight of essential features that help detect prospective targets while suppressing the features of non-target and other disturbances. To further accelerate the training speed, swish activation and group normalization are also employed to enhance SPNet. The training speed and validation accuracy of MainNet is better than YOLO (you only look once) and SSD (single shot multibox detector). As a result, the performance and robustness for small dense object detection can be substantially improved in key frames of the video. For the TrackNet, dense optical flow field technique is applied in the adjacent frame to obtain the FlowMap. Next, to substantially improve the detection efficiency, FlowMap is mapped with the FeatureMap through a pyramid structure instead of the traditional fully convolutional net. This method markedly shortens the time because optical flow calculation on GPU(graphics processing unit) is much faster than the feature extraction of convolutional network. Then, in the adjacent frame, only FPN, a light-type network, needs to be calculated.ResultThe model is trained and validated thoroughly by MS COCO(Microsoft common objects in context). Trained results demonstrate that the proposed SPNet can make a tradeoff between accuracy and efficiency for detecting small dense objects in a video stream, obtaining 52.8% accuracy on MS COCO, 75.96% on PASCAL VOC, and speeding up to 70 frame/s.ConclusionExperimental results show that SPNet can effectively detect small and tough targets with complexity. Multiplexing optical flow technology also greatly improves the detection efficiency and obtains good detection results. The investigation shows that improving the network performance is crucial to the research on the internal structure of the network and the exploration of its internal process. The performance is remarkably improved by the complete visualization of the network structure and the overall optimization of the network architecture.关键词:computer vision;deep learning;complex target detection;one-stage network;optical flow84|181|0更新时间:2024-05-08
摘要:ObjectiveWith the great breakthrough of deep convolutional neural networks (CNNs), tremendous state-of-the-art networks have been created to significantly improve image classification and utilize modern CNN-based object detectors. Image classification and detection research has matured and entered the industrial stage. However, detecting objects in complex samples and high frame rate videos remains a challenging task in the field of computer vision, especially considering that samples and videos are filled with huge numbers of small and dense instances in each frame. The issues of state-of-the-art networks do not make a tradeoff between accuracy and efficiency for detecting small dense targets as the priority consideration. Thus, in this study, we propose a deep hybrid network, namely, snap pyramid network (SPNet).MethodOur model is incorporated with dense optical flow technique in the enhanced one-stage architecture. First, the complete inner visualization of feature-extract net and pyramid net is built to mine out the critical factors of small dense objects. Through this method, the contextual information is found to be a significant key and should thus be fully utilized in the feature extraction. Moreover, sharing the context in multiple convolutional templates of the network is essential for the high semantic information from the deep templates, which help the shallow templates precisely predict the target location. Accordingly, our proposed hybrid net called SPNet is presented. It is composed of two parts, namely, MainNet and TrackNet. For the MainNet, the inception and feature weight control (FWC) modules are designed to modify the conventional network architecture. The whole MainNet consists of the BackBone network (the core of MainNet, which can efficiently extract feature information) and the feature pyramid network (FPN) network to predict classification and candidate box position. Inception greatly reduces the parameter quantity. FWC can raise the weight of essential features that help detect prospective targets while suppressing the features of non-target and other disturbances. To further accelerate the training speed, swish activation and group normalization are also employed to enhance SPNet. The training speed and validation accuracy of MainNet is better than YOLO (you only look once) and SSD (single shot multibox detector). As a result, the performance and robustness for small dense object detection can be substantially improved in key frames of the video. For the TrackNet, dense optical flow field technique is applied in the adjacent frame to obtain the FlowMap. Next, to substantially improve the detection efficiency, FlowMap is mapped with the FeatureMap through a pyramid structure instead of the traditional fully convolutional net. This method markedly shortens the time because optical flow calculation on GPU(graphics processing unit) is much faster than the feature extraction of convolutional network. Then, in the adjacent frame, only FPN, a light-type network, needs to be calculated.ResultThe model is trained and validated thoroughly by MS COCO(Microsoft common objects in context). Trained results demonstrate that the proposed SPNet can make a tradeoff between accuracy and efficiency for detecting small dense objects in a video stream, obtaining 52.8% accuracy on MS COCO, 75.96% on PASCAL VOC, and speeding up to 70 frame/s.ConclusionExperimental results show that SPNet can effectively detect small and tough targets with complexity. Multiplexing optical flow technology also greatly improves the detection efficiency and obtains good detection results. The investigation shows that improving the network performance is crucial to the research on the internal structure of the network and the exploration of its internal process. The performance is remarkably improved by the complete visualization of the network structure and the overall optimization of the network architecture.关键词:computer vision;deep learning;complex target detection;one-stage network;optical flow84|181|0更新时间:2024-05-08 -
 摘要:ObjectiveVisual question-answering (VQA) belongs to the intersection of computer vision and natural language processing and is one of the key research directions in the field of artificial intelligence. VQA is an important task for conducting research in the field of artificial intelligence because of its multimodal nature, clear evaluation protocol, and potential real-world applications. The prevailing approach to VQA is based on three components. First, question-answering is posed as a classification over a set of candidate answers. Questions in the current VQA datasets are mostly visual in nature, where the correct answers are composed of a small set of key words or phrases. Second, most VQA models are based on a deep neural network that implements a joint embedding of image and question features. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are used to map the two inputs into a vector representation of fixed size. Third, due to the success of deep learning in solving supervised learning problems, the whole neural network is trained end-to-end from questions, images, and their ground truth answers. However, using global image features as visual input will introduce noise at the stage of predicting the answer. Inspired by human visual attention and the development of related research, visual attention mechanism has been widely used in VQA to alleviate the problem. Most conventional visual attention mechanisms used in VQA models are of the top-down variety. These attention mechanisms are typically trained to attend selectively to the output of one or more layers of a CNN and predict the weight of each region in the image. This method ignores image content. Thus, image information cannot be further represented. In humans, attention will be focused more on the objects or other salient image regions. To generate more human-like question answers, objects and other salient image regions are a much more natural basis for attention. In addition, owing to the lack of long-term memory modules, information is lost during the reasoning of answers. Therefore, wrong answers can be inferred, which will affect the VQA effect. To solve the above problems, we propose a VQA model based on bottom-up attention and memory network, which improves the accuracy of VQA by enhancing the representation and memory of image content.MethodWe use image features from bottom-up attention to provide region-specific features rather than the traditional CNN grid-like feature maps. We implement bottom-up attention using faster R-CNN (region-based CNN) in conjunction with the ResNet-101 CNN, which represents a natural expression of a bottom-up attention mechanism. To pre-train the bottom-up attention model, we first initialize faster R-CNN with ResNet-101 pre-trained for classification on ImageNet. Then, it is trained on visual genome data. To aid the learning of good feature representations, we introduce an additional training output to predict attribute classes in addition to object classes. To improve computational efficiency, questions are trimmed to a maximum of 14 words. The extra words are then simply discarded, and the questions shorter than 14 words are end-padded with vectors of zeros. We use bi-directional gated recurrent unit (GRU) to extract the question features and its final state as our question embedding. The purpose of the memory network is to retrieve the information needed to answer the question from the input image facts and memorize them for a long time. To improve understanding of the question and image, especially when the question requires transmission reasoning, the memory network may need to transfer the input several times and update the memory after each transmission. Memory network is composed of two parts: attention mechanism module and episode memory update module. Each iteration will calculate the weight of the input vector through the attention mechanism to generate a new memory and then update the memory through the memory update module. The image features and question representations will be input into the memory network to obtain the final episodic memory. Finally, the representations of the question and the final episodic memory are passed through nonlinear full connection layers and combined with a simple concatenation, and then the result is fed into the output classifier to deduce the correct answer. Unlike the softmax classifier, which is commonly used in most VQA models, we treat VQA as a multi-label classification task and use sigmoid activation function to predict a score for each of the
摘要:ObjectiveVisual question-answering (VQA) belongs to the intersection of computer vision and natural language processing and is one of the key research directions in the field of artificial intelligence. VQA is an important task for conducting research in the field of artificial intelligence because of its multimodal nature, clear evaluation protocol, and potential real-world applications. The prevailing approach to VQA is based on three components. First, question-answering is posed as a classification over a set of candidate answers. Questions in the current VQA datasets are mostly visual in nature, where the correct answers are composed of a small set of key words or phrases. Second, most VQA models are based on a deep neural network that implements a joint embedding of image and question features. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are used to map the two inputs into a vector representation of fixed size. Third, due to the success of deep learning in solving supervised learning problems, the whole neural network is trained end-to-end from questions, images, and their ground truth answers. However, using global image features as visual input will introduce noise at the stage of predicting the answer. Inspired by human visual attention and the development of related research, visual attention mechanism has been widely used in VQA to alleviate the problem. Most conventional visual attention mechanisms used in VQA models are of the top-down variety. These attention mechanisms are typically trained to attend selectively to the output of one or more layers of a CNN and predict the weight of each region in the image. This method ignores image content. Thus, image information cannot be further represented. In humans, attention will be focused more on the objects or other salient image regions. To generate more human-like question answers, objects and other salient image regions are a much more natural basis for attention. In addition, owing to the lack of long-term memory modules, information is lost during the reasoning of answers. Therefore, wrong answers can be inferred, which will affect the VQA effect. To solve the above problems, we propose a VQA model based on bottom-up attention and memory network, which improves the accuracy of VQA by enhancing the representation and memory of image content.MethodWe use image features from bottom-up attention to provide region-specific features rather than the traditional CNN grid-like feature maps. We implement bottom-up attention using faster R-CNN (region-based CNN) in conjunction with the ResNet-101 CNN, which represents a natural expression of a bottom-up attention mechanism. To pre-train the bottom-up attention model, we first initialize faster R-CNN with ResNet-101 pre-trained for classification on ImageNet. Then, it is trained on visual genome data. To aid the learning of good feature representations, we introduce an additional training output to predict attribute classes in addition to object classes. To improve computational efficiency, questions are trimmed to a maximum of 14 words. The extra words are then simply discarded, and the questions shorter than 14 words are end-padded with vectors of zeros. We use bi-directional gated recurrent unit (GRU) to extract the question features and its final state as our question embedding. The purpose of the memory network is to retrieve the information needed to answer the question from the input image facts and memorize them for a long time. To improve understanding of the question and image, especially when the question requires transmission reasoning, the memory network may need to transfer the input several times and update the memory after each transmission. Memory network is composed of two parts: attention mechanism module and episode memory update module. Each iteration will calculate the weight of the input vector through the attention mechanism to generate a new memory and then update the memory through the memory update module. The image features and question representations will be input into the memory network to obtain the final episodic memory. Finally, the representations of the question and the final episodic memory are passed through nonlinear full connection layers and combined with a simple concatenation, and then the result is fed into the output classifier to deduce the correct answer. Unlike the softmax classifier, which is commonly used in most VQA models, we treat VQA as a multi-label classification task and use sigmoid activation function to predict a score for each of the$N$ 关键词:visual question answering (VQA);bottom-up;attention mechanism;memory network;multimodal fusion;multi-classification23|31|7更新时间:2024-05-08 -
 摘要:ObjectiveImage stitching technology aims to resample a group of interrelated (overlapping) images into a single image with a large angle of view and high resolution. This technology effectively overcomes the density limitation of a sensor array on the focal plane of common image acquisition equipment. Currently, numerous applications, such as realize virtual reality, security monitoring, and remote sensing detection, use the image stitching technology to obtain visual information of macro scenes and achievements have been made in the development of image stitching technology. However, due to the complexity of scene content, illumination conditions, and the changeability of camera pose, the acquisition of natural-looking visual effects of stitching image still depends mainly on post-processing interactively. Especially for applications with low measurement requirements and emphasis on visual experience, the parameter-free image stitching technology ignoring prior knowledge (scene 3D structure, camera parameters) is more valuable. To this end, this study presents a novel approach of stitching parametric-free images by comprehensively considering the process of image registration and fusion.MethodThe ghost phenomenon originates from an inaccurate image transformation model. Potential parameter estimation error has the greatest impact on the visual experience of stitching images. At present, the effective way to solve the problem is to find an optimal seam-line in overlapping regions of images to be stitched and take only one image pixel on each side of the seam-line for image fusion operation. Usually, the parameters of image transformation model are estimated using a set of control points located in overlapping regions of images. Thus, the accuracy of transformation at control points is better than that at non-control points. Accordingly, this study proposes to automatically generate an optimal seam-line from matched feature points for image stitching purpose. This technology mainly involves two aspects. The first one is the twice registration framework based on modified TPS (thin plate spline) transformation. It is established to meet the needs of error-free control point registration and automatic generation of reliable seam-line. In this step, the global homograph mapping and local mapping adjustment based on radial basis function are ingeniously incorporated into the uniform spatial transformation framework. Thus, it maintains perspective geometry and reduces local distortion in stitching image as much as possible. The second one is the reliable seam-line generated based on the fact that the registration accuracy of control point pixels is better than that of non-control point pixels in the process of image transformation. In this step, the initial seam-line is primarily searched out from triangulated control points in the reference image. Then, it is refined by adding more control points through dynamic programming matching process and remapping non-control point pixels with the transformation parameters estimated in advance. With the small registration error of pixels on seam-line, troublesome ghost phenomenon in stitching images can be effectively suppressed with computationally simpler image fusion operation.ResultThe experiments on two sets of standard images from the Internet are performed and compared with state-of-the-art methods in extant literature. The transformation accuracy of training set and test set of matching control points is found to be the highest in this study, whereas the local distortion of mosaic images is the smallest. Moreover, the stitching test is also performed on multiple videos with two different scenes. Its visual mosaic effect is quite natural.ConclusionThe proposed method has a natural transition between images' overlapping and non-overlapping areas and achieves better visual effect in stitching images. Furthermore, it requires no prior knowledge on images, and its parameters can be solved linearly. Thus, it exhibits huge potential for application.关键词:image stitching;image transformation;image fusion;seam-line generation;panoramic image;thin plate spline(TPS)47|44|3更新时间:2024-05-08
摘要:ObjectiveImage stitching technology aims to resample a group of interrelated (overlapping) images into a single image with a large angle of view and high resolution. This technology effectively overcomes the density limitation of a sensor array on the focal plane of common image acquisition equipment. Currently, numerous applications, such as realize virtual reality, security monitoring, and remote sensing detection, use the image stitching technology to obtain visual information of macro scenes and achievements have been made in the development of image stitching technology. However, due to the complexity of scene content, illumination conditions, and the changeability of camera pose, the acquisition of natural-looking visual effects of stitching image still depends mainly on post-processing interactively. Especially for applications with low measurement requirements and emphasis on visual experience, the parameter-free image stitching technology ignoring prior knowledge (scene 3D structure, camera parameters) is more valuable. To this end, this study presents a novel approach of stitching parametric-free images by comprehensively considering the process of image registration and fusion.MethodThe ghost phenomenon originates from an inaccurate image transformation model. Potential parameter estimation error has the greatest impact on the visual experience of stitching images. At present, the effective way to solve the problem is to find an optimal seam-line in overlapping regions of images to be stitched and take only one image pixel on each side of the seam-line for image fusion operation. Usually, the parameters of image transformation model are estimated using a set of control points located in overlapping regions of images. Thus, the accuracy of transformation at control points is better than that at non-control points. Accordingly, this study proposes to automatically generate an optimal seam-line from matched feature points for image stitching purpose. This technology mainly involves two aspects. The first one is the twice registration framework based on modified TPS (thin plate spline) transformation. It is established to meet the needs of error-free control point registration and automatic generation of reliable seam-line. In this step, the global homograph mapping and local mapping adjustment based on radial basis function are ingeniously incorporated into the uniform spatial transformation framework. Thus, it maintains perspective geometry and reduces local distortion in stitching image as much as possible. The second one is the reliable seam-line generated based on the fact that the registration accuracy of control point pixels is better than that of non-control point pixels in the process of image transformation. In this step, the initial seam-line is primarily searched out from triangulated control points in the reference image. Then, it is refined by adding more control points through dynamic programming matching process and remapping non-control point pixels with the transformation parameters estimated in advance. With the small registration error of pixels on seam-line, troublesome ghost phenomenon in stitching images can be effectively suppressed with computationally simpler image fusion operation.ResultThe experiments on two sets of standard images from the Internet are performed and compared with state-of-the-art methods in extant literature. The transformation accuracy of training set and test set of matching control points is found to be the highest in this study, whereas the local distortion of mosaic images is the smallest. Moreover, the stitching test is also performed on multiple videos with two different scenes. Its visual mosaic effect is quite natural.ConclusionThe proposed method has a natural transition between images' overlapping and non-overlapping areas and achieves better visual effect in stitching images. Furthermore, it requires no prior knowledge on images, and its parameters can be solved linearly. Thus, it exhibits huge potential for application.关键词:image stitching;image transformation;image fusion;seam-line generation;panoramic image;thin plate spline(TPS)47|44|3更新时间:2024-05-08
Image Understanding and Computer Vision
-
 摘要:ObjectiveShape editing has been extensively researched for its applications in the fields of computer graphics and computer animation. Shape editing methods based on control units are widely used because they are intuitive, effective, and easy to implement during operation on animation characters. Generally, for an input 3D animation shape, the editing method first establishes the relationship between the shape and control units. It then calculates the weights of the points on the shape affected by each control unit and completes shape editing by applying transformations on the control units and updating the points on the shape by a linear combination of the control units with the pre-computed weights. Usually, the editing result depends seriously on weight calculation. Although numerous methods of weight computation have been introduced, most of them cannot effectively or efficiently handle control skeletons. In addition, the linear combination of rotation is no longer a rotation. Thus, the transformation of 3D skeletons is very complicated, and the transformation of local frame at bone joint points is difficult to determine. In this study, our proposed algorithm is aimed at editing 2D images, from 2D domain to 3D domain. In our editing method, the control units are classified into real units (or user-defined units) and virtual units. The virtual control units are generated by our virtual unit insertion algorithm. A novel insertion algorithm of virtual control unit is developed for the control skeletons in 3D space. An improved transformation method of skeleton joint point frame is also proposed to maintain the volume of the shape around the joint points of the skeletons, resulting in naturally smoother editing results.MethodTo achieve a smooth editing result, we utilize the Bezier function with 5° as the basic function for weight computation because of its
摘要:ObjectiveShape editing has been extensively researched for its applications in the fields of computer graphics and computer animation. Shape editing methods based on control units are widely used because they are intuitive, effective, and easy to implement during operation on animation characters. Generally, for an input 3D animation shape, the editing method first establishes the relationship between the shape and control units. It then calculates the weights of the points on the shape affected by each control unit and completes shape editing by applying transformations on the control units and updating the points on the shape by a linear combination of the control units with the pre-computed weights. Usually, the editing result depends seriously on weight calculation. Although numerous methods of weight computation have been introduced, most of them cannot effectively or efficiently handle control skeletons. In addition, the linear combination of rotation is no longer a rotation. Thus, the transformation of 3D skeletons is very complicated, and the transformation of local frame at bone joint points is difficult to determine. In this study, our proposed algorithm is aimed at editing 2D images, from 2D domain to 3D domain. In our editing method, the control units are classified into real units (or user-defined units) and virtual units. The virtual control units are generated by our virtual unit insertion algorithm. A novel insertion algorithm of virtual control unit is developed for the control skeletons in 3D space. An improved transformation method of skeleton joint point frame is also proposed to maintain the volume of the shape around the joint points of the skeletons, resulting in naturally smoother editing results.MethodTo achieve a smooth editing result, we utilize the Bezier function with 5° as the basic function for weight computation because of its${C^2}$ ${C^2}$ ${C^2}$ 关键词:linear blending;smooth manipulation;region decomposition;parallel computing;mesh deformation32|24|0更新时间:2024-05-08
Computer Graphics
-
 摘要:ObjectiveMusculoskeletal ultrasound (MSKUS) is an imaging diagnosis method commonly applied in the diagnosis and treatment of musculoskeletal diseases. The feature detection of MSKUS image plays an important role in image registration, image analysis of MSKUS images, and extended field-of-view ultrasound imaging, requiring extraction of the effective feature points. However, the contrast of the ultrasound image is low, and speckle noise and image artifacts are presented in the MSKUS images. These limitations negatively affect the extraction of the feature points of MSKUS image. Consequently, the accuracy of image registration and the quality of image stitching are affected. This condition may lead to misalignment and fracture of anatomical structure on the MSKUS panoramic image. An algorithm suitable for detecting feature points of MSKUS images has not been clearly determined. The objectives of this study are to evaluate the performance of the four local feature detection algorithms on stitching MSKUS sequence images, including scale invariant feature transform (SIFT), speeded-up robust features (SURF), oriented FAST and rotated binary robust independent elementary features(ORB), and features from accelerated segment test (FAST) combined with SIFT descriptor, and to provide a basis and reference solution of feature detection for MSKUS image registration and extended field-of-view ultrasound imaging in future research.MethodUltrasound image sequences of the quadriceps muscles in five normal human subjects are collected. From the image sequence of each subject, 10 images are resampled every five frames for image feature detection and image stitching. The classical image stitching method proposed by Brown is adopted in this study, which includes the following three main steps. First, the feature points of the MSKUS image are extracted by SIFT, SURF, ORB, and FAST-SIFT. Then, based on the obtained feature points and their corresponding feature point descriptors, the nearest neighbor distance ratio method is applied to achieve rough feature matching, and the random sample consensus (RANSAC) algorithm is used to realize fine feature matching. The projection transformation matrix is taken as the basic model to estimate the optimal deformation matrix between the two images. Finally, the deformation matrix between the two images is used to obtain the internal parameters of the camera and the external parameters of the camera. These camera parameters can be used to transform the 10 images into the coordinate system of the reference image. After coordinate transformation, all the 10 images are stitched together. Then, the MSKUS panorama is post-processed using the maximum flow minimum cut algorithm to find the unwell-stitched overlapped area. The multiband fusion is used to reduce the artificial and rough seam zones. The MSKUS panorama is eventually obtained. To evaluate the performance of the four algorithms SIFT, SURF, ORB algorithms, and FAST-SIFT, detection of feature points, feature matching, image registration, and image stitching are assessed.ResultThe experimental results show that compared with SIFT, SURF, and ORB algorithms, FAST-SIFT is able to extract more uniform distribution feature points and detect most of the end points of the muscle fibers. Furthermore, the detection time of feature points by using FAST-SIFT is much shorter of approximately 4 ms.The average number of matching points in FAST-SIFT is the largest, which is 2~5 times as many as other feature detection algorithms. FAST-SIFT algorithm has the highest correct rate of feature matching. The mean value of mutual information and normalized cross-correlation coefficient of FAST-SIFT are 1.016 and 0.748, respectively, which are higher than that of the other three feature detection algorithms. Result indicates high accuracy of image registration. Moreover, the stitched panorama of MSKUS by using the FAST-SIFT algorithm shows good image stitching, that is, no obvious misalignment and fracture of anatomical structure are found.ConclusionCompared with SIFT, SURF, and ORB, FAST-SIFT algorithm is more suitable to extract the feature points of MSKUS image. It has advantages in the distribution of feature points, the detection time of feature points, the average number of matching points, the correct rate of feature matching, image registration accuracy, and image stitching result.关键词:musculoskeletal ultrasound image;feature detection;feature matching;image registration;image stitching38|41|1更新时间:2024-05-08
摘要:ObjectiveMusculoskeletal ultrasound (MSKUS) is an imaging diagnosis method commonly applied in the diagnosis and treatment of musculoskeletal diseases. The feature detection of MSKUS image plays an important role in image registration, image analysis of MSKUS images, and extended field-of-view ultrasound imaging, requiring extraction of the effective feature points. However, the contrast of the ultrasound image is low, and speckle noise and image artifacts are presented in the MSKUS images. These limitations negatively affect the extraction of the feature points of MSKUS image. Consequently, the accuracy of image registration and the quality of image stitching are affected. This condition may lead to misalignment and fracture of anatomical structure on the MSKUS panoramic image. An algorithm suitable for detecting feature points of MSKUS images has not been clearly determined. The objectives of this study are to evaluate the performance of the four local feature detection algorithms on stitching MSKUS sequence images, including scale invariant feature transform (SIFT), speeded-up robust features (SURF), oriented FAST and rotated binary robust independent elementary features(ORB), and features from accelerated segment test (FAST) combined with SIFT descriptor, and to provide a basis and reference solution of feature detection for MSKUS image registration and extended field-of-view ultrasound imaging in future research.MethodUltrasound image sequences of the quadriceps muscles in five normal human subjects are collected. From the image sequence of each subject, 10 images are resampled every five frames for image feature detection and image stitching. The classical image stitching method proposed by Brown is adopted in this study, which includes the following three main steps. First, the feature points of the MSKUS image are extracted by SIFT, SURF, ORB, and FAST-SIFT. Then, based on the obtained feature points and their corresponding feature point descriptors, the nearest neighbor distance ratio method is applied to achieve rough feature matching, and the random sample consensus (RANSAC) algorithm is used to realize fine feature matching. The projection transformation matrix is taken as the basic model to estimate the optimal deformation matrix between the two images. Finally, the deformation matrix between the two images is used to obtain the internal parameters of the camera and the external parameters of the camera. These camera parameters can be used to transform the 10 images into the coordinate system of the reference image. After coordinate transformation, all the 10 images are stitched together. Then, the MSKUS panorama is post-processed using the maximum flow minimum cut algorithm to find the unwell-stitched overlapped area. The multiband fusion is used to reduce the artificial and rough seam zones. The MSKUS panorama is eventually obtained. To evaluate the performance of the four algorithms SIFT, SURF, ORB algorithms, and FAST-SIFT, detection of feature points, feature matching, image registration, and image stitching are assessed.ResultThe experimental results show that compared with SIFT, SURF, and ORB algorithms, FAST-SIFT is able to extract more uniform distribution feature points and detect most of the end points of the muscle fibers. Furthermore, the detection time of feature points by using FAST-SIFT is much shorter of approximately 4 ms.The average number of matching points in FAST-SIFT is the largest, which is 2~5 times as many as other feature detection algorithms. FAST-SIFT algorithm has the highest correct rate of feature matching. The mean value of mutual information and normalized cross-correlation coefficient of FAST-SIFT are 1.016 and 0.748, respectively, which are higher than that of the other three feature detection algorithms. Result indicates high accuracy of image registration. Moreover, the stitched panorama of MSKUS by using the FAST-SIFT algorithm shows good image stitching, that is, no obvious misalignment and fracture of anatomical structure are found.ConclusionCompared with SIFT, SURF, and ORB, FAST-SIFT algorithm is more suitable to extract the feature points of MSKUS image. It has advantages in the distribution of feature points, the detection time of feature points, the average number of matching points, the correct rate of feature matching, image registration accuracy, and image stitching result.关键词:musculoskeletal ultrasound image;feature detection;feature matching;image registration;image stitching38|41|1更新时间:2024-05-08
Medical Image Processing
-
 摘要:ObjectiveHigh-resolution remote sensing image segmentation refers to the task of assigning a semantic label to each pixel in an image. Recently, with the rapid development of remote sensing technology, we have been able to easily obtain very-high resolution remote sensing images with a ground sampling distance of 5 cm to 10 cm. However, the very heterogeneous appearance of objects, such as buildings, streets, trees, and cars, in very-high-resolution data makes this task challenging, leading to high intraclass variance while the inter-class variance is low. A research hotspot is on detailed 2D semantic segmentation that assigns labels to multiple object categories. Traditional image processing methods depend on the extraction technique of the vectorization model, for example, based on region segmentation, line analysis, and shadow analysis. Another mainstream study relies on supervised classifiers with manually designed features. These models were not generalized when dealing with high-resolution remote sensing images. Recently, deep learning-based technology has helped explore the high-level semantic information in imaged and provide an end-to-end approach for semantic segmentation.MethodBased on DeepLab V3+, we proposed an adaptive constructed neural network, which contains two connected modules, namely, the segmentation module and the tree module. When segmenting remote-sensing images, which contain multiscale objects, understanding the context is important. To handle the problem of segmenting objects at multiple scales, DeepLab V3+ employs atrous convolution in cascade or in parallel captures multiscale context by adopting multiple atrous rates. We adopted a similar idea in designing the segmentation module. This module uses an encoder-decoder architecture. The encoder is composed of four structures: EntryFlow, MiddleFlow, ExitFlow, and atrous spatial pyramid pooling(ASPP). In addition, the decoder is composed of two layers of SeparableConv blocks. The middle flow has two Xception blocks, which are linear stacks of depth-separable convolutional layers with residual connections. The segmentation module could capture well the multiscale features in the context. However, these features pay less attention to the easily confused classes. The other core contribution of the proposed method is the tree module. This module is constructed adaptively during the training. In each round, the method computes the confusion matrix on the evaluation data and calculates the confusion degrees between every two classes. A graph could be constructed according to the confusion matrix, and we can obtain a certain tree structure through the minimum cut algorithm. According to the tree structure, we build the tree module, in which each node is a ResNeXt unit. These nodes are connected by the concatenated connections. The tree module helped distinguish the pixels between easily confused classes by adding several neural layers to process their features. To implement the proposed method, the segmentation model is based on the MXNet framework and uses two Nvidia GeForce GTX1080 Ti graphic cards for accelerated training. The input size of the image block is 640×640 pixels due to memory limitation. We set the momentum (momentum) to 0.9, the initial learning rate to 0.01, adjust the learning rate to 0.001 when the training reaches half, and adjust the learning rate to 0.000 1 when the training reaches 3/4. We perform data augmentation before training due to the small amount of data in the ISPRS(International Society for Photogrammetry and Remote Sensing) remote sensing dataset. For each piece of raw data, we rotate the image center by 10° each time and cut out the largest square tile. In this way, each training image can obtain 36 sets of pictures after rotation. In addition, because the original training image is very large in size, to directly place the entire image into the network for training is not possible. Thus, it needs to be cropped into image blocks of 640×640 pixels. We apply an overlap-tile strategy to ensure no obvious cracks in the segmentation result map after splicing.ResultThe model in this study performed the best in terms of overall accuracy (OA), which reached 90.4% and 90.7% on the Vaihingen and Potsdam datasets, respectively. This result indicates that the model can achieve high segmentation accuracy. In addition, in the performance of easily confused categories, for example, low shrub vegetation (low_veg) and trees, F1 values have greatly improved. In experiments of the Vaihingen dataset, the F1 values of the low shrub vegetation and tree species reached 83.6% and 89.6%, respectively. In experiments of the Potsdam dataset, the F1 values of the low shrub vegetation and tree species reached 86.8% and 87.1%. As for the average F1 value, the scores of the model on the Vaihingen and Potsdam datasets are 89.3% and 92.0%, respectively. This number is much higher than the other latest methods, indicating that the model in this study is the best for both the segmentation of remote sensing images and the average performance of each category. Additionally, compared with the model without the tree module, the proposed method has higher segmentation accuracy for each category. The OA by using tree module increased by 1.1%, and the average F1 value increased by 0.6% in the Vaihingen dataset. The OA and the average F1 value increased by 1.3% and 0.9% in the Potsdam dataset. The result shows that the tree module does not only target a certain category but also improves the overall segmentation accuracy.ConclusionThe proposed network can effectively improve the overall semantic segmentation accuracy of high-resolution remote sensing images. The experimental results show that the proposed segmentation module with the tree module is greatly improved due to the reduction of the error on easily confused pixels. The proposed method in this study is universal and suitable for a wide range of application scenarios.关键词:convolutional neural networks(CNN);remote sensing images;semantic segmentation;tree like structure;Deeplab v3+79|62|5更新时间:2024-05-08
摘要:ObjectiveHigh-resolution remote sensing image segmentation refers to the task of assigning a semantic label to each pixel in an image. Recently, with the rapid development of remote sensing technology, we have been able to easily obtain very-high resolution remote sensing images with a ground sampling distance of 5 cm to 10 cm. However, the very heterogeneous appearance of objects, such as buildings, streets, trees, and cars, in very-high-resolution data makes this task challenging, leading to high intraclass variance while the inter-class variance is low. A research hotspot is on detailed 2D semantic segmentation that assigns labels to multiple object categories. Traditional image processing methods depend on the extraction technique of the vectorization model, for example, based on region segmentation, line analysis, and shadow analysis. Another mainstream study relies on supervised classifiers with manually designed features. These models were not generalized when dealing with high-resolution remote sensing images. Recently, deep learning-based technology has helped explore the high-level semantic information in imaged and provide an end-to-end approach for semantic segmentation.MethodBased on DeepLab V3+, we proposed an adaptive constructed neural network, which contains two connected modules, namely, the segmentation module and the tree module. When segmenting remote-sensing images, which contain multiscale objects, understanding the context is important. To handle the problem of segmenting objects at multiple scales, DeepLab V3+ employs atrous convolution in cascade or in parallel captures multiscale context by adopting multiple atrous rates. We adopted a similar idea in designing the segmentation module. This module uses an encoder-decoder architecture. The encoder is composed of four structures: EntryFlow, MiddleFlow, ExitFlow, and atrous spatial pyramid pooling(ASPP). In addition, the decoder is composed of two layers of SeparableConv blocks. The middle flow has two Xception blocks, which are linear stacks of depth-separable convolutional layers with residual connections. The segmentation module could capture well the multiscale features in the context. However, these features pay less attention to the easily confused classes. The other core contribution of the proposed method is the tree module. This module is constructed adaptively during the training. In each round, the method computes the confusion matrix on the evaluation data and calculates the confusion degrees between every two classes. A graph could be constructed according to the confusion matrix, and we can obtain a certain tree structure through the minimum cut algorithm. According to the tree structure, we build the tree module, in which each node is a ResNeXt unit. These nodes are connected by the concatenated connections. The tree module helped distinguish the pixels between easily confused classes by adding several neural layers to process their features. To implement the proposed method, the segmentation model is based on the MXNet framework and uses two Nvidia GeForce GTX1080 Ti graphic cards for accelerated training. The input size of the image block is 640×640 pixels due to memory limitation. We set the momentum (momentum) to 0.9, the initial learning rate to 0.01, adjust the learning rate to 0.001 when the training reaches half, and adjust the learning rate to 0.000 1 when the training reaches 3/4. We perform data augmentation before training due to the small amount of data in the ISPRS(International Society for Photogrammetry and Remote Sensing) remote sensing dataset. For each piece of raw data, we rotate the image center by 10° each time and cut out the largest square tile. In this way, each training image can obtain 36 sets of pictures after rotation. In addition, because the original training image is very large in size, to directly place the entire image into the network for training is not possible. Thus, it needs to be cropped into image blocks of 640×640 pixels. We apply an overlap-tile strategy to ensure no obvious cracks in the segmentation result map after splicing.ResultThe model in this study performed the best in terms of overall accuracy (OA), which reached 90.4% and 90.7% on the Vaihingen and Potsdam datasets, respectively. This result indicates that the model can achieve high segmentation accuracy. In addition, in the performance of easily confused categories, for example, low shrub vegetation (low_veg) and trees, F1 values have greatly improved. In experiments of the Vaihingen dataset, the F1 values of the low shrub vegetation and tree species reached 83.6% and 89.6%, respectively. In experiments of the Potsdam dataset, the F1 values of the low shrub vegetation and tree species reached 86.8% and 87.1%. As for the average F1 value, the scores of the model on the Vaihingen and Potsdam datasets are 89.3% and 92.0%, respectively. This number is much higher than the other latest methods, indicating that the model in this study is the best for both the segmentation of remote sensing images and the average performance of each category. Additionally, compared with the model without the tree module, the proposed method has higher segmentation accuracy for each category. The OA by using tree module increased by 1.1%, and the average F1 value increased by 0.6% in the Vaihingen dataset. The OA and the average F1 value increased by 1.3% and 0.9% in the Potsdam dataset. The result shows that the tree module does not only target a certain category but also improves the overall segmentation accuracy.ConclusionThe proposed network can effectively improve the overall semantic segmentation accuracy of high-resolution remote sensing images. The experimental results show that the proposed segmentation module with the tree module is greatly improved due to the reduction of the error on easily confused pixels. The proposed method in this study is universal and suitable for a wide range of application scenarios.关键词:convolutional neural networks(CNN);remote sensing images;semantic segmentation;tree like structure;Deeplab v3+79|62|5更新时间:2024-05-08 -
 摘要:ObjectiveHyperspectral remote sensing has become a promising research field and is applied to various aspects. Hyperspectral image classification has become a key part of hyperspectral image processing. However, high-dimensional data structures bring new challenges for hyperspectral image classification. In particular, problems may occur in the feature extraction and classification process of a hyperspectral image dataset, e.g., the Hughes phenomenon, because of the unbalance between the high-dimensionality of the data and the limited number of training samples. To improve the accuracy of hyperspectral image classification, we propose a hyperspectral image classification algorithm based on ensemble extreme learning machine (ELM) with cumulative variation quotient, referred to as EELM with cumulative variation quotient (CVQ-EELM).MethodIn this study, the coefficient of variation is usually used as the index to show the data dispersion. Compared with the standard deviation, its main advantage is that it is not affected by the measurement scale. In particular, the coefficient of variation takes into account the influence of the average value of the data. The coefficient of variation is improved and applied to the dimensionality reduction of the HIS dataset. First, the cumulative variation functions of the intraclass and the interclass and the cumulative variation quotient are proposed. In actual operation, some pixels may contain multiple ground objects, while the gray values of the intraclass are quite different. Therefore, the cumulative variation function of the interclass and the cumulative variation function of the intraclass should be comprehensively considered to define the cumulative variation quotient function of bands. On the premise of the same band, the quotient of the norm of the interclass' cumulative variation function and the sum of the norm of the intraclass' cumulative variation function is called the cumulative variation quotient of the band. If the cumulative variation quotient of the band is far from 1, it means that the classification effect is better by using this band. If the cumulative variation quotient of band is close to 1, it means that the classification effect is poor by using this band. The inefficient bands are eliminated on the basis of the cumulative variation quotient function. Second, to provide the input information of hyperspectral bands for ELM and considering the strong correlation relationship between neighboring bands, average grouping is performed for the remaining effective bands after eliminating the inefficient bands. A certain number of bands are then selected by the weighted-random-selecting-based approach to reduce the dimension of the hyperspectral image dataset. Specifically, the hyperspectral bands are grouped on average and then the weights of each group are calculated based on the cumulative variation quotient. The bands of each group are selected randomly according to their weights. Finally, the spatial spectral features extracted after dimensionality reduction are sampled repeatedly to train several weak ELM classifiers. The results of several weak classifiers are majority voted to build a strong classifier.ResultThree well-known HIS datasets (Indian Pines, Pavia University scene, and Salinas) are used to verify the effectiveness of the proposed method. SVM (support vector machine), ELM, GELM (ELM with Gabor), KELM (ELM with kernel), GELM-CK (GELM with composite kernel), KELM-CK (KELM with composite kernel), and SS-EELM (spatial-spectral and ensemble ELM) serve as the benchmark algorithms to measure the performance of the proposed CVQ-EELM. SVM, ELM, GELM, and KELM methods use only spectral features. Although SVM and KELM introduce the kernel function and increase the computational cost, SVM and KELM have better classification performance than ELM and GELM. GELM-CK, KELM-CK, SS-EELM, and CVQ-EELM methods incorporate the spatial information into the spectral information. The four spatial-spectral-feature-based methods show better classification performance than the four spectral-feature-based methods. Further analysis shows that the classification capacities of KELM-CK, SS-EELM, and CVQ-EELM are better than that of GELM-CK. However, KELM-CK, SS-EELM, and CVQ-EELM are amenable to more time cost than GELM-CK. For example, in three typical HIS datasets, KELM-CK method consumes classification times up to 15.8 s, 143 s, and 54.6 s, respectively. Although SS-EELM avoids referencing kernel functions, SS-EELM based on the ensemble extreme learning machines also has a large operation time, equal to 32.4 s, 85.5 s, and 171 s. The proposed CVQ-EELM only needs 15.2 s, 60.4 s, and 169.4 s to do so. The time-consuming characteristic of the SS-EELM and CVQ-EELM algorithms is related to the number of weak classifiers. Specifically, the greater the number of weak classifiers, the more time-consuming the algorithm will take. Compared with KELM-CK, the time-consuming growth rates of SS-EELM and CVQ-EELM are smaller with an increasing number of samples. When the spatial-spectral features of the same category are quite different, the proposed CVQ-EELM outperforms KELM-CK and SS-EELM. For example, in two typical HIS datasets (Indian Pines and Pavia University scene), overall accuracy (OA) of the proposed CVQ-EELM is 98.0% and 98.9%, respectively; OA of KELM-CK is 97.8% and 98.8%, respectively; and OA of SS-EELM is 97.2% and 98.6%, respectively. The computational cost of CVQ-EELM is also still lower than that of SS-EELM in two typical HIS datasets. According to the above experimental comparison, the computational cost of CVQ-EELM is similar to that of KELM-CK in the Indian Pines dataset. However, the classification accuracy of CVQ-EELM is higher than that of KELM-CK. Especially in the Pavia University dataset, the computational cost of CVQ-EELM is still low, approximately 2.5 times faster than KELM-CK. Moreover, the classification accuracy of CVQ-EELM is higher than KELM-CK. Therefore, the proposed CVQ-EELM has the best classification performance among all the classification algorithms.ConclusionThe conclusion shows that the proposed algorithm optimizes the band selection strategy of average grouping through the cumulative variation quotient function. For hyperspectral data sets with a wide distribution of various objects and a large difference in spatial-spectral features of similar objects, the characteristics of spectral differences can be extracted effectively. The proposed CVQ-EELM has the advantages of few adjustable parameters and fast training speed. It also outperforms various state-of-the-art hyperspectral image classification counterparts in terms of classification accuracy.关键词:hyperspectral image;extreme learning machine (ELM);cumulative variation ratio;voting;classification15|15|2更新时间:2024-05-08
摘要:ObjectiveHyperspectral remote sensing has become a promising research field and is applied to various aspects. Hyperspectral image classification has become a key part of hyperspectral image processing. However, high-dimensional data structures bring new challenges for hyperspectral image classification. In particular, problems may occur in the feature extraction and classification process of a hyperspectral image dataset, e.g., the Hughes phenomenon, because of the unbalance between the high-dimensionality of the data and the limited number of training samples. To improve the accuracy of hyperspectral image classification, we propose a hyperspectral image classification algorithm based on ensemble extreme learning machine (ELM) with cumulative variation quotient, referred to as EELM with cumulative variation quotient (CVQ-EELM).MethodIn this study, the coefficient of variation is usually used as the index to show the data dispersion. Compared with the standard deviation, its main advantage is that it is not affected by the measurement scale. In particular, the coefficient of variation takes into account the influence of the average value of the data. The coefficient of variation is improved and applied to the dimensionality reduction of the HIS dataset. First, the cumulative variation functions of the intraclass and the interclass and the cumulative variation quotient are proposed. In actual operation, some pixels may contain multiple ground objects, while the gray values of the intraclass are quite different. Therefore, the cumulative variation function of the interclass and the cumulative variation function of the intraclass should be comprehensively considered to define the cumulative variation quotient function of bands. On the premise of the same band, the quotient of the norm of the interclass' cumulative variation function and the sum of the norm of the intraclass' cumulative variation function is called the cumulative variation quotient of the band. If the cumulative variation quotient of the band is far from 1, it means that the classification effect is better by using this band. If the cumulative variation quotient of band is close to 1, it means that the classification effect is poor by using this band. The inefficient bands are eliminated on the basis of the cumulative variation quotient function. Second, to provide the input information of hyperspectral bands for ELM and considering the strong correlation relationship between neighboring bands, average grouping is performed for the remaining effective bands after eliminating the inefficient bands. A certain number of bands are then selected by the weighted-random-selecting-based approach to reduce the dimension of the hyperspectral image dataset. Specifically, the hyperspectral bands are grouped on average and then the weights of each group are calculated based on the cumulative variation quotient. The bands of each group are selected randomly according to their weights. Finally, the spatial spectral features extracted after dimensionality reduction are sampled repeatedly to train several weak ELM classifiers. The results of several weak classifiers are majority voted to build a strong classifier.ResultThree well-known HIS datasets (Indian Pines, Pavia University scene, and Salinas) are used to verify the effectiveness of the proposed method. SVM (support vector machine), ELM, GELM (ELM with Gabor), KELM (ELM with kernel), GELM-CK (GELM with composite kernel), KELM-CK (KELM with composite kernel), and SS-EELM (spatial-spectral and ensemble ELM) serve as the benchmark algorithms to measure the performance of the proposed CVQ-EELM. SVM, ELM, GELM, and KELM methods use only spectral features. Although SVM and KELM introduce the kernel function and increase the computational cost, SVM and KELM have better classification performance than ELM and GELM. GELM-CK, KELM-CK, SS-EELM, and CVQ-EELM methods incorporate the spatial information into the spectral information. The four spatial-spectral-feature-based methods show better classification performance than the four spectral-feature-based methods. Further analysis shows that the classification capacities of KELM-CK, SS-EELM, and CVQ-EELM are better than that of GELM-CK. However, KELM-CK, SS-EELM, and CVQ-EELM are amenable to more time cost than GELM-CK. For example, in three typical HIS datasets, KELM-CK method consumes classification times up to 15.8 s, 143 s, and 54.6 s, respectively. Although SS-EELM avoids referencing kernel functions, SS-EELM based on the ensemble extreme learning machines also has a large operation time, equal to 32.4 s, 85.5 s, and 171 s. The proposed CVQ-EELM only needs 15.2 s, 60.4 s, and 169.4 s to do so. The time-consuming characteristic of the SS-EELM and CVQ-EELM algorithms is related to the number of weak classifiers. Specifically, the greater the number of weak classifiers, the more time-consuming the algorithm will take. Compared with KELM-CK, the time-consuming growth rates of SS-EELM and CVQ-EELM are smaller with an increasing number of samples. When the spatial-spectral features of the same category are quite different, the proposed CVQ-EELM outperforms KELM-CK and SS-EELM. For example, in two typical HIS datasets (Indian Pines and Pavia University scene), overall accuracy (OA) of the proposed CVQ-EELM is 98.0% and 98.9%, respectively; OA of KELM-CK is 97.8% and 98.8%, respectively; and OA of SS-EELM is 97.2% and 98.6%, respectively. The computational cost of CVQ-EELM is also still lower than that of SS-EELM in two typical HIS datasets. According to the above experimental comparison, the computational cost of CVQ-EELM is similar to that of KELM-CK in the Indian Pines dataset. However, the classification accuracy of CVQ-EELM is higher than that of KELM-CK. Especially in the Pavia University dataset, the computational cost of CVQ-EELM is still low, approximately 2.5 times faster than KELM-CK. Moreover, the classification accuracy of CVQ-EELM is higher than KELM-CK. Therefore, the proposed CVQ-EELM has the best classification performance among all the classification algorithms.ConclusionThe conclusion shows that the proposed algorithm optimizes the band selection strategy of average grouping through the cumulative variation quotient function. For hyperspectral data sets with a wide distribution of various objects and a large difference in spatial-spectral features of similar objects, the characteristics of spectral differences can be extracted effectively. The proposed CVQ-EELM has the advantages of few adjustable parameters and fast training speed. It also outperforms various state-of-the-art hyperspectral image classification counterparts in terms of classification accuracy.关键词:hyperspectral image;extreme learning machine (ELM);cumulative variation ratio;voting;classification15|15|2更新时间:2024-05-08
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0