
最新刊期
卷 25 , 期 4 , 2020
-
 摘要:The task of object detection is to accurately and efficiently identify and locate a large number of predefined objects from images. It aims to locate interested objects from images, accurately determine the categories of each object, and provide the boundaries of each object. Since the proposal of Hinton on the use of deep neural network for automatic learning of high-level features in multimedia data, object detection based on deep learning has become an important research hotspot in computer vision. With the wide application of deep learning, the accuracy and efficiency of object detection are greatly improved. However, object detection based on deep learning still have four key technology challenges, namely, improving and optimizing the mainstream object detection algorithms, balancing the detection speed and accuracy, improving the small object detection accuracy, achieving multiclass object detection, and lightweighting the detection model. In view of the above challenges, this study analyzes and summarizes the existing research methods from different aspects. On the basis of extensive literature research, this work analyzed the methods of improving and optimizing the mainstream object detection algorithm from three aspects:the improvement of two-stage object detection algorithm, the improvement of single-stage object detection algorithm, and the combination of two-stage object detection algorithm and single-stage object detection algorithm. In the improvement of the two-stage object detection algorithm, some classical two-stage object detection algorithms, such as R-CNN (region based convolutional neural network), SPPNet(spatial pyramid pooling net), Fast R-CNN, and Faster R-CNN, and some state-of-the-art two-stage object detection algorithms, including Mask R-CNN, Soft-NMS(non maximum suppression), and Softer-NMS, are mainly described. In the improvement of single-stage object detection algorithm, some classical single-stage object detection algorithms, such as YOLO(you only look once)v1, SSD(single shot multiBox detector), and YOLOv2, and the state-of-the-art single-stage object detection algorithms, including YOLOv3, are mainly described. In the combination of two-stage and one-stage object detection algorithms, RON(reverse connection with objectness prior networks) and RefineDet algorithms are mainly described. This study analyzes and summarizes the methods to improve the accuracy of small object detection from five perspectives:using new backbone network, increasing visual field, feature fusion, cascade convolution neural network, and modifying the training method of the model. The new backbone network mainly introduces DetNet, DenseNet, and DarkNet. The backbone network DarkNet is introduced in detail in the improvement of single segment object detection algorithm. It mainly includes two backbone network architectures:DarkNet-19 application in YOLOv2 and DarkNet-53 application in YOLOv3. The related algorithms of increasing receptive field mainly include RFB(receptive field block) Net and TridentNet. The methods of feature fusion mainly involve feature pyramid networks, DES(detection with enriched semantics), and NAS-FPN(neural architecture search-feature pyramid networks). The related algorithms of cascade convolutional neural network mainly include Cascade R-CNN and HRNet. The related algorithms of model training mode optimization mainly consist of YOLOv2, SNIP(scale normalization for image pyramids), and Perceptual GAN(generative adversarial networks). In this study, the method of multiclass object detection is analyzed from the point of view of training method and network structure. The related algorithms of training method optimization mainly include large scale detection through Adaptation, YOLO9000, and Soft Sampling. The related algorithms of network structure improvement mainly include R-FCN-3000. This study analyzes the methods used in lightweight detection model from the perspective of network structure, such as ShuffleNetv1, ShuffleNetv2, MobileNetv1, MobileNetv2, and Mobile Netv3. MobileNetv1 uses depthwise separable convolution to reduce the parameters and computational complexity of the model, and employs pointwise convolution to solve the problem of information flow between the feature maps. MobileNetv2 uses linear bottlenecks to remove the nonlinear activation layer behind the small dimension output layer, thus ensuring the expressive ability of the model. MobileNetv2 also utilizes inverted residual block to improve the model. MobileNetv3 employs complementary search technology combination and network structure improvement to improve the detection accuracy and speed of the model. In this study, the common datasets, such as Caltech, Tiny Images, Cifar, Sun, Places, and Open Images, and the commonly used datasets, including PASCAL VOC 2007, PASCAL VOC 2012, MS COCO(common objects in context), and ImageNet, are introduced in detail. The information of each dataset is summarized, and a set of datasets is established. A table of general datasets is presented, and the dataset name, total images, number of categories, image size, started year, and characteristics of each dataset are introduced in detail. At the same time, the main performance indexes of object detection algorithms, such as accuracy, precision, recall, average precision, and mean average precision, are introduced in detail. Finally, according to the object detection, this work introduces the main performance indicators in detail. Four key technical challenges in the process of measurement, research, and development are compared and analyzed. In addition, a table is set up to describe the performance of some representative algorithms in object detection from the aspects of algorithm name, backbone network, input image size, test dataset, detection accuracy, detection speed, and single-stage or two-stage partition. The traditional object detection algorithm, the improvement and optimization algorithm of the mainstream object detection algorithm, the related information of the small object detection accuracy algorithm, and the multicategory object detection algorithm are improved, to predict and prospect the problems to be solved in object detection and the future research direction. The related research of object detection is still a hot spot in computer vision and pattern recognition. Several high-precision and efficient algorithms are proposed constantly, and increasing research directions will be developed in the future. The key technologies of object detection based on in-depth learning need to be solved in the next step. The future research directions mainly include how to make the model suitable for the detection needs of specific scenarios, how to achieve accurate object detection problems under the condition of lack of prior knowledge, how to obtain high-performance backbone network and information, how to add rich image semantic information, how to improve the interpretability of deep learning model, and how to automate the realization of the optimal network architecture.关键词:object detection;deep learning;small object;multi-class;lightweighting404|245|85更新时间:2024-05-07
摘要:The task of object detection is to accurately and efficiently identify and locate a large number of predefined objects from images. It aims to locate interested objects from images, accurately determine the categories of each object, and provide the boundaries of each object. Since the proposal of Hinton on the use of deep neural network for automatic learning of high-level features in multimedia data, object detection based on deep learning has become an important research hotspot in computer vision. With the wide application of deep learning, the accuracy and efficiency of object detection are greatly improved. However, object detection based on deep learning still have four key technology challenges, namely, improving and optimizing the mainstream object detection algorithms, balancing the detection speed and accuracy, improving the small object detection accuracy, achieving multiclass object detection, and lightweighting the detection model. In view of the above challenges, this study analyzes and summarizes the existing research methods from different aspects. On the basis of extensive literature research, this work analyzed the methods of improving and optimizing the mainstream object detection algorithm from three aspects:the improvement of two-stage object detection algorithm, the improvement of single-stage object detection algorithm, and the combination of two-stage object detection algorithm and single-stage object detection algorithm. In the improvement of the two-stage object detection algorithm, some classical two-stage object detection algorithms, such as R-CNN (region based convolutional neural network), SPPNet(spatial pyramid pooling net), Fast R-CNN, and Faster R-CNN, and some state-of-the-art two-stage object detection algorithms, including Mask R-CNN, Soft-NMS(non maximum suppression), and Softer-NMS, are mainly described. In the improvement of single-stage object detection algorithm, some classical single-stage object detection algorithms, such as YOLO(you only look once)v1, SSD(single shot multiBox detector), and YOLOv2, and the state-of-the-art single-stage object detection algorithms, including YOLOv3, are mainly described. In the combination of two-stage and one-stage object detection algorithms, RON(reverse connection with objectness prior networks) and RefineDet algorithms are mainly described. This study analyzes and summarizes the methods to improve the accuracy of small object detection from five perspectives:using new backbone network, increasing visual field, feature fusion, cascade convolution neural network, and modifying the training method of the model. The new backbone network mainly introduces DetNet, DenseNet, and DarkNet. The backbone network DarkNet is introduced in detail in the improvement of single segment object detection algorithm. It mainly includes two backbone network architectures:DarkNet-19 application in YOLOv2 and DarkNet-53 application in YOLOv3. The related algorithms of increasing receptive field mainly include RFB(receptive field block) Net and TridentNet. The methods of feature fusion mainly involve feature pyramid networks, DES(detection with enriched semantics), and NAS-FPN(neural architecture search-feature pyramid networks). The related algorithms of cascade convolutional neural network mainly include Cascade R-CNN and HRNet. The related algorithms of model training mode optimization mainly consist of YOLOv2, SNIP(scale normalization for image pyramids), and Perceptual GAN(generative adversarial networks). In this study, the method of multiclass object detection is analyzed from the point of view of training method and network structure. The related algorithms of training method optimization mainly include large scale detection through Adaptation, YOLO9000, and Soft Sampling. The related algorithms of network structure improvement mainly include R-FCN-3000. This study analyzes the methods used in lightweight detection model from the perspective of network structure, such as ShuffleNetv1, ShuffleNetv2, MobileNetv1, MobileNetv2, and Mobile Netv3. MobileNetv1 uses depthwise separable convolution to reduce the parameters and computational complexity of the model, and employs pointwise convolution to solve the problem of information flow between the feature maps. MobileNetv2 uses linear bottlenecks to remove the nonlinear activation layer behind the small dimension output layer, thus ensuring the expressive ability of the model. MobileNetv2 also utilizes inverted residual block to improve the model. MobileNetv3 employs complementary search technology combination and network structure improvement to improve the detection accuracy and speed of the model. In this study, the common datasets, such as Caltech, Tiny Images, Cifar, Sun, Places, and Open Images, and the commonly used datasets, including PASCAL VOC 2007, PASCAL VOC 2012, MS COCO(common objects in context), and ImageNet, are introduced in detail. The information of each dataset is summarized, and a set of datasets is established. A table of general datasets is presented, and the dataset name, total images, number of categories, image size, started year, and characteristics of each dataset are introduced in detail. At the same time, the main performance indexes of object detection algorithms, such as accuracy, precision, recall, average precision, and mean average precision, are introduced in detail. Finally, according to the object detection, this work introduces the main performance indicators in detail. Four key technical challenges in the process of measurement, research, and development are compared and analyzed. In addition, a table is set up to describe the performance of some representative algorithms in object detection from the aspects of algorithm name, backbone network, input image size, test dataset, detection accuracy, detection speed, and single-stage or two-stage partition. The traditional object detection algorithm, the improvement and optimization algorithm of the mainstream object detection algorithm, the related information of the small object detection accuracy algorithm, and the multicategory object detection algorithm are improved, to predict and prospect the problems to be solved in object detection and the future research direction. The related research of object detection is still a hot spot in computer vision and pattern recognition. Several high-precision and efficient algorithms are proposed constantly, and increasing research directions will be developed in the future. The key technologies of object detection based on in-depth learning need to be solved in the next step. The future research directions mainly include how to make the model suitable for the detection needs of specific scenarios, how to achieve accurate object detection problems under the condition of lack of prior knowledge, how to obtain high-performance backbone network and information, how to add rich image semantic information, how to improve the interpretability of deep learning model, and how to automate the realization of the optimal network architecture.关键词:object detection;deep learning;small object;multi-class;lightweighting404|245|85更新时间:2024-05-07
Review

-
 摘要:ObjectiveFacial images are widely used in many applications such as social media, medical systems, and smart transportation systems. Such data, however, are inherently sensitive and private. Individuals' private information may be leaked if their facial images are released directly in the application systems. In social network platforms, attackers can use the facial images of individuals to attack their sensitive information. Many classical privacy-preserving methods, such as k-anonymous and data encryption, have been proposed to handle the privacy problem in facial images. However, the classical methods always rely on strong background assumptions, which cannot be supported in real-world applications. Differential privacy is the state-of-the-art method used to address the privacy concerns in data publication, which provides rigorous guarantees for the privacy of each user by adding randomized noise in Google Chrome, Apple iOS, and macOS. Therefore, to protect the private information in facial images, this paper proposes three efficient algorithms, namely, low rank-based private facial image release algorithm (LRA), singular value decomposition (SVD)-based private facial image release algorithm (SRA), and enhanced SVD-based private facial image release algorithm (ESRA), which are based on matrix decomposition combined with differential privacy.MethodThe three algorithms employed the real-valued matrix to model facial images in which each cell corresponds to each pixel point of facial images. Based on the real-valued matrix, the neighborhood of some facial images can be defined easily, which are crucial bases to use Laplace mechanism to generate Laplace noise. Then, LRA, SRA, and ESRA rely on low-rank decomposition and SVD to compress facial images. This step aims to reduce the Laplace noise and boost the accuracy of the publication of facial images. The three algorithms use the Laplace mechanism to inject noise into each value of the compressed facial image to ensure differential privacy. Finally, the three algorithms use matrix algebraic operations to reconstruct the noisy facial image. However, in the SRA and ESRA algorithms, two sources of errors are encountered:1) Laplace error (LE) due to Laplace noise injected and 2) reconstruction error (RE) caused by lossy compression. The two errors are controlled by r parameter, which is the compression factor in the SRA and ESRA algorithms. Setting the compact parameter r constrains the LE and RE. The SRA algorithm sets the parameter in a heuristic manner in which one may fix the value in terms of experiences. However, the choice of r in the SRA algorithm is a problem because a large r leads to excessive LE, while a small r makes the RE extremely large. Furthermore, r cannot be directly set based on the real-valued matrix; otherwise, the choice of r itself violates differential privacy. Based on the preceding observation, the ESRA algorithm is proposed to handle the problem caused by the selection of the parameter r. The main idea of the ESRA algorithm involves two steps:employing exponential mechanism to sample r elements in the decomposition matrix and injecting the Laplace noise into the elements. According to the sequential composition of differential privacy, the two steps in the ESRA algorithm meet ε-differential privacy.ResultOn the basis of the SVM classification and information entropy technique, two group experiments were conducted over six real facial image datasets (Yale, ORL, CMU, Yale B, Faces95, and Faces94) to evaluate the quality of the facial images generated from the LRA, SRA, ESRA, LAP(Laplace-based facial image protection), LRM(low-rank mechanism), and MM(matrix mechanism) algorithms using a variety of metrics, including precision, recall, F1 score, and entropy. Our experiments show that the proposed LRA, SRA, and ESRA algorithms outperform LAP, LRM, and MM in terms of the abovementioned six metrics. For example, based on the Faces95 dataset, ε=0.1 and matrix=200×180 were set to compare the precision of ESRA, LRM, LRA, and LAP. Result show that the precision of ESRA is 40 and 20 times that of LAP, LRA, and LRM. Based on the six datasets, ESRA achieves better accuracy than LRA and SRA. For example, on the Faces94 dataset, the matrix=200×180 was set and the privacy budget ε (i.e., 0.1, 0.5, 0.9, and 1.3) was varied to study the utility of each algorithm. Results show that the utility measures of all algorithms increase when ε increases. When ε varies from 0.1 to 1.3, ESRA still achieves better precision, recall, F1-score, and entropy than the other algorithms.ConclusionThe oretical analysis and extensive experiments were conducted to compare our algorithms with the LAP, LRM, and MM algorithms. Results show that the proposed algorithms could achieve better utility and outperform the existing solutions. In addition, the proposed algorithms provided new ideas and technical support for further research on facial image release with differential privacy in several application systems.关键词:facial image;privacy protection;differential privacy;matrix decomposition;low-rank decomposition;singular value decomposition(SVD)77|109|3更新时间:2024-05-07
摘要:ObjectiveFacial images are widely used in many applications such as social media, medical systems, and smart transportation systems. Such data, however, are inherently sensitive and private. Individuals' private information may be leaked if their facial images are released directly in the application systems. In social network platforms, attackers can use the facial images of individuals to attack their sensitive information. Many classical privacy-preserving methods, such as k-anonymous and data encryption, have been proposed to handle the privacy problem in facial images. However, the classical methods always rely on strong background assumptions, which cannot be supported in real-world applications. Differential privacy is the state-of-the-art method used to address the privacy concerns in data publication, which provides rigorous guarantees for the privacy of each user by adding randomized noise in Google Chrome, Apple iOS, and macOS. Therefore, to protect the private information in facial images, this paper proposes three efficient algorithms, namely, low rank-based private facial image release algorithm (LRA), singular value decomposition (SVD)-based private facial image release algorithm (SRA), and enhanced SVD-based private facial image release algorithm (ESRA), which are based on matrix decomposition combined with differential privacy.MethodThe three algorithms employed the real-valued matrix to model facial images in which each cell corresponds to each pixel point of facial images. Based on the real-valued matrix, the neighborhood of some facial images can be defined easily, which are crucial bases to use Laplace mechanism to generate Laplace noise. Then, LRA, SRA, and ESRA rely on low-rank decomposition and SVD to compress facial images. This step aims to reduce the Laplace noise and boost the accuracy of the publication of facial images. The three algorithms use the Laplace mechanism to inject noise into each value of the compressed facial image to ensure differential privacy. Finally, the three algorithms use matrix algebraic operations to reconstruct the noisy facial image. However, in the SRA and ESRA algorithms, two sources of errors are encountered:1) Laplace error (LE) due to Laplace noise injected and 2) reconstruction error (RE) caused by lossy compression. The two errors are controlled by r parameter, which is the compression factor in the SRA and ESRA algorithms. Setting the compact parameter r constrains the LE and RE. The SRA algorithm sets the parameter in a heuristic manner in which one may fix the value in terms of experiences. However, the choice of r in the SRA algorithm is a problem because a large r leads to excessive LE, while a small r makes the RE extremely large. Furthermore, r cannot be directly set based on the real-valued matrix; otherwise, the choice of r itself violates differential privacy. Based on the preceding observation, the ESRA algorithm is proposed to handle the problem caused by the selection of the parameter r. The main idea of the ESRA algorithm involves two steps:employing exponential mechanism to sample r elements in the decomposition matrix and injecting the Laplace noise into the elements. According to the sequential composition of differential privacy, the two steps in the ESRA algorithm meet ε-differential privacy.ResultOn the basis of the SVM classification and information entropy technique, two group experiments were conducted over six real facial image datasets (Yale, ORL, CMU, Yale B, Faces95, and Faces94) to evaluate the quality of the facial images generated from the LRA, SRA, ESRA, LAP(Laplace-based facial image protection), LRM(low-rank mechanism), and MM(matrix mechanism) algorithms using a variety of metrics, including precision, recall, F1 score, and entropy. Our experiments show that the proposed LRA, SRA, and ESRA algorithms outperform LAP, LRM, and MM in terms of the abovementioned six metrics. For example, based on the Faces95 dataset, ε=0.1 and matrix=200×180 were set to compare the precision of ESRA, LRM, LRA, and LAP. Result show that the precision of ESRA is 40 and 20 times that of LAP, LRA, and LRM. Based on the six datasets, ESRA achieves better accuracy than LRA and SRA. For example, on the Faces94 dataset, the matrix=200×180 was set and the privacy budget ε (i.e., 0.1, 0.5, 0.9, and 1.3) was varied to study the utility of each algorithm. Results show that the utility measures of all algorithms increase when ε increases. When ε varies from 0.1 to 1.3, ESRA still achieves better precision, recall, F1-score, and entropy than the other algorithms.ConclusionThe oretical analysis and extensive experiments were conducted to compare our algorithms with the LAP, LRM, and MM algorithms. Results show that the proposed algorithms could achieve better utility and outperform the existing solutions. In addition, the proposed algorithms provided new ideas and technical support for further research on facial image release with differential privacy in several application systems.关键词:facial image;privacy protection;differential privacy;matrix decomposition;low-rank decomposition;singular value decomposition(SVD)77|109|3更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveChange detection aims at detecting the difference of the images captured from same scene in different time observations. This condition is an important research problem in computer vision. However, the traditional change detection methods, which use the handcrafted features and heuristic models, suffer from lighting variations and camera pose differences, resulting in bad change detection results. Recent deep learning-based convolutional neural networks (CNN) achieve huge success on several computer vision problems, such as image classification, semantic segmentation, and saliency detection. The main reason of the success of the deep learning-based methods is the abstract ability of CNN. To conquer the bad effects of lighting variations and camera pose differences, we can employ deep learning-based CNN in change detection problems. Unlike semantic segmentation, change detection inputs image pairs of two time observations. Thus, a key research problem is how to design an effective architecture of CNN, which can fully explore the intrinsic changes of the image pairs. To generate robust change detection results, we propose in this study a multiscale deep feature fusion-based change detection (MDFCD).MethodThe proposed MDFCD network has two streams of feature extracting sub-networks, which share weight parameters. Each sub-network is responsible for learning to extract semantic features from the corresponding RGB image. We use VGG(visual geometry group)16 as the basic backbone of the proposed MDFCD. The last fully connected layers of VGG16 are removed to save the spatial resolution of the features of the last convolutional layer. We adopt the features of convolutional blocks Conv3, Conv4, and Conv5 of VGG16 as our multiscale deep features because they can capture high-level, middle-level, and low-level features. Then, the Enc (encoding) module is proposed to fuse the deep features from the two time observations of the same convolutional block. We use "concat" operation to concatenate the features. The resulted features are input into Enc to generate change detection adaptive features at the corresponding feature level. The encoded features from the lower layer are upsampled twice in height and width. Then, we concatenate the deep features of the previous layers' convolutional blocks. Subsequently, Enc is used again to learn adaptive features. By progressively incorporating the features from Conv5 to Conv3, we obtain deep fusion of CNN features at multiple scales. To generate robust change detection, we add a convolutional layer with 2×3×3 convolutional filters to generate change prediction at each scale encoding module. Then, the change predictions of all scales are concatenated together to produce final change detection results. Note that we use bicubic upsampling operation to upsample the change detection map at each scale to the size of the input image.ResultWe compared three benchmark datasets, namely, VL_CMU_CD(visual localization of Carnegie Mellon University for change detection), PCD(panoramic change detection), CDnet(change detection net), by the state-of-the-art change detection methods, that is, FGCD(fine-grained change detection), SC_SOBS(SC-self-organizing background subtraction), SuBSENSE(self-balanced sensitirity segmenter), and FCN(fully convolutional network). We employed F1-measure, recall, precision, specific, FPR(false positive rate), FNR(false negative rate), PWC(percentage of wrong classification) to evaluate the difference of the compared change detection methods. The experiments show that MDFCD are better than the other compared methods. Among the compared methods, deep learning-based change detection method FCD performs the best. On VL_CMU_CD, the F1-measure and Precision of MDFCD achieve 12.2% and 24.4% relative improvements over the second-placed change detection method FCN, respectively. On PCD, the F1-measure and precision of MDFCD obtain 2.1% and 17.7% relative improvements over FCN, respectively. On CDnet, compared with FCN, our F1-measure and precision achieve 8.5% and 5.8% relative improvements, respectively. From the experiments, we can find that MDFCD can detect the fine grained changes, such as telegraph poles. The proposed MDFCD are better in distinguishing the real changes with false changes caused by lighting variations and camera pose difference compared with FCN.ConclusionWe studied how to effectively explore the deep convolutional neural networks for change detection problem. MDFCD network is proposed to alleviate the bad effects introduced by lighting variations and camera pose differences. The proposed method adopts a siamese network with VGG16 as the backbone. Each path is responsible for extracting deep features from reference and query images. We also proposed encoding module that fuses multiscale deep convolutional features and learn change detection adaptive features. The deep features are integrated together from high layers' semantic features with low layers' texture features. With this fusion strategy, the proposed method can generate more robust change detection results than other compared methods. The high layers' semantic features can effectively avoid the negative changes caused by lighting and season change. Meanwhile, the low layers' texture features help the proposed method obtain accurate changes at the object boundaries. Compared with deep learning method, FCN, where in the input is concatenate reference and query images, our method of extracting features with respect to each image can extract representatively features for change detection. However, as a general problem of deep learning-based methods, one should use large volume of training images to train CNNs. Another problem is that the present change detection methods pay considerable attention on region changes but not on object-level changes. In our future work, we plan to use weak supervised and unsupervised method to study the change detection to avoid using pixel-level labeled training images. We also plan to study incorporating object detection in change detection to generate object-level changes.关键词:change detection;feature fusion;multiscale;siamese network;deep learning51|30|6更新时间:2024-05-07
摘要:ObjectiveChange detection aims at detecting the difference of the images captured from same scene in different time observations. This condition is an important research problem in computer vision. However, the traditional change detection methods, which use the handcrafted features and heuristic models, suffer from lighting variations and camera pose differences, resulting in bad change detection results. Recent deep learning-based convolutional neural networks (CNN) achieve huge success on several computer vision problems, such as image classification, semantic segmentation, and saliency detection. The main reason of the success of the deep learning-based methods is the abstract ability of CNN. To conquer the bad effects of lighting variations and camera pose differences, we can employ deep learning-based CNN in change detection problems. Unlike semantic segmentation, change detection inputs image pairs of two time observations. Thus, a key research problem is how to design an effective architecture of CNN, which can fully explore the intrinsic changes of the image pairs. To generate robust change detection results, we propose in this study a multiscale deep feature fusion-based change detection (MDFCD).MethodThe proposed MDFCD network has two streams of feature extracting sub-networks, which share weight parameters. Each sub-network is responsible for learning to extract semantic features from the corresponding RGB image. We use VGG(visual geometry group)16 as the basic backbone of the proposed MDFCD. The last fully connected layers of VGG16 are removed to save the spatial resolution of the features of the last convolutional layer. We adopt the features of convolutional blocks Conv3, Conv4, and Conv5 of VGG16 as our multiscale deep features because they can capture high-level, middle-level, and low-level features. Then, the Enc (encoding) module is proposed to fuse the deep features from the two time observations of the same convolutional block. We use "concat" operation to concatenate the features. The resulted features are input into Enc to generate change detection adaptive features at the corresponding feature level. The encoded features from the lower layer are upsampled twice in height and width. Then, we concatenate the deep features of the previous layers' convolutional blocks. Subsequently, Enc is used again to learn adaptive features. By progressively incorporating the features from Conv5 to Conv3, we obtain deep fusion of CNN features at multiple scales. To generate robust change detection, we add a convolutional layer with 2×3×3 convolutional filters to generate change prediction at each scale encoding module. Then, the change predictions of all scales are concatenated together to produce final change detection results. Note that we use bicubic upsampling operation to upsample the change detection map at each scale to the size of the input image.ResultWe compared three benchmark datasets, namely, VL_CMU_CD(visual localization of Carnegie Mellon University for change detection), PCD(panoramic change detection), CDnet(change detection net), by the state-of-the-art change detection methods, that is, FGCD(fine-grained change detection), SC_SOBS(SC-self-organizing background subtraction), SuBSENSE(self-balanced sensitirity segmenter), and FCN(fully convolutional network). We employed F1-measure, recall, precision, specific, FPR(false positive rate), FNR(false negative rate), PWC(percentage of wrong classification) to evaluate the difference of the compared change detection methods. The experiments show that MDFCD are better than the other compared methods. Among the compared methods, deep learning-based change detection method FCD performs the best. On VL_CMU_CD, the F1-measure and Precision of MDFCD achieve 12.2% and 24.4% relative improvements over the second-placed change detection method FCN, respectively. On PCD, the F1-measure and precision of MDFCD obtain 2.1% and 17.7% relative improvements over FCN, respectively. On CDnet, compared with FCN, our F1-measure and precision achieve 8.5% and 5.8% relative improvements, respectively. From the experiments, we can find that MDFCD can detect the fine grained changes, such as telegraph poles. The proposed MDFCD are better in distinguishing the real changes with false changes caused by lighting variations and camera pose difference compared with FCN.ConclusionWe studied how to effectively explore the deep convolutional neural networks for change detection problem. MDFCD network is proposed to alleviate the bad effects introduced by lighting variations and camera pose differences. The proposed method adopts a siamese network with VGG16 as the backbone. Each path is responsible for extracting deep features from reference and query images. We also proposed encoding module that fuses multiscale deep convolutional features and learn change detection adaptive features. The deep features are integrated together from high layers' semantic features with low layers' texture features. With this fusion strategy, the proposed method can generate more robust change detection results than other compared methods. The high layers' semantic features can effectively avoid the negative changes caused by lighting and season change. Meanwhile, the low layers' texture features help the proposed method obtain accurate changes at the object boundaries. Compared with deep learning method, FCN, where in the input is concatenate reference and query images, our method of extracting features with respect to each image can extract representatively features for change detection. However, as a general problem of deep learning-based methods, one should use large volume of training images to train CNNs. Another problem is that the present change detection methods pay considerable attention on region changes but not on object-level changes. In our future work, we plan to use weak supervised and unsupervised method to study the change detection to avoid using pixel-level labeled training images. We also plan to study incorporating object detection in change detection to generate object-level changes.关键词:change detection;feature fusion;multiscale;siamese network;deep learning51|30|6更新时间:2024-05-07 -
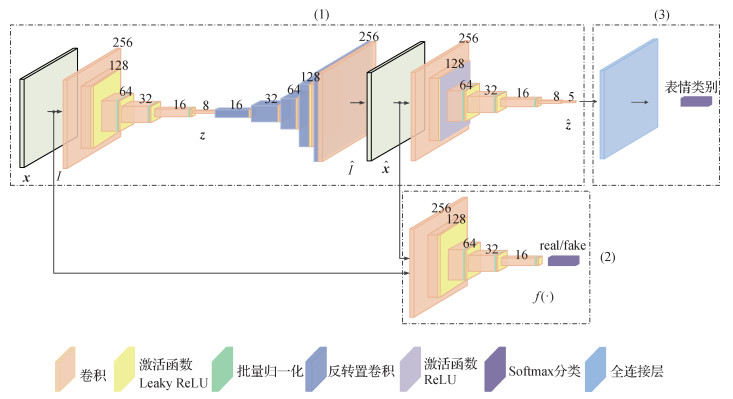 摘要:ObjectiveChina has a large population of 1.3 billion in 2005, accounting for 19% of the world's population. This number is equivalent to the population of Europe or Africa added to the populations of Australia, North America, and Central America. It is one of the few populous countries in the world, and its huge population size has brought many problems. With the rapid development of the economy, the number of people working outside of their homes is increasing, the population is moving frequently, and the safety of the floating population is even difficult to control. The huge mobile population provides the city's infrastructure and public services tremendous pressure. Thus, to conduct a comprehensive check on the area of adult traffic, which is time-consuming and labor-intensive, is difficult for security and related staff. Particularly, complex environmental safety problems, such as subways, railway stations, and airports, are becoming increasingly serious. Unstable events occur frequently, security situation is receiving much attention, and urban management and service systems are seriously lagging behind. These conditions need to be improved, especially after the September 11 incident in the United States. The situation has aroused widespread concern in the international community. Meanwhile, expression is the most intuitive way for humans to express emotions. In addition to language communication, expressions are extremely effective means of communication. People usually express their inner feelings through specific expressions. Expression can be used to judge other person's thoughts. For expressions used to express information, psychologist Mehrabian summed up a formula:emotional expression=7% of words + 38% of sound + 55% of facial expressions. Expression is one of the most important features of human emotion recognition. Expression is the emotional state expressed by facial muscle changes. Through the facial expression of the person's face, to evaluate abnormal psychological state, speculate on extreme emotions, and observe the facial expressions of pedestrians in the subway, railway station, and airport to further judge the psychology of the person is possible. We provide technical support to determine who is suspicious and prevent certain criminal activities in a timely manner. Strengthening urban surveillance and identifying the facial expressions of criminals are especially important. Expression plays an important role in human emotion cognition. However, factors affecting facial expression recognition in safety screening are extremely large, and the large intra-class gap seriously inflluences the accuracy of facial expression recognition. The problem of large gaps in facial expression recognition in a real environment is solved by identifying suspected molecules to be monitored should be identified, and the security personnel should prepare in advance to accurately identify them. Facial expressions are also particularly important for preventing security problems. The era of large data has arrived. Meanwhile, with the advancement of computer hardware, deep learning continues to develop. The traditional facial expression recognition method cannot meet the needs of the development of the times, and a new algorithm based on deep learning facial expression recognition is coming soon. Learning methods are widely used in facial expression recognition. Although facial recognition intelligent recognition technology has a long history of research, a large number of research methods have been proposed. However, due to the large facial expression gap, the expression is complex, and the influencing factors are many. The current intelligent recognition effect of facial expression results is not ideal. Considering the deep learning because of its powerful expressive ability, this study introduces the model structure of traditional neural network and carries out corresponding experiments and analysis in the context of real-life facial expression recognition and proposes real-world facial expression recognition research based on deep learning. In the next period, real-world facial expression recognition will make considerable progress. This work further studies the realistic facial expression recognition based on deep learning.MethodThis study constructs a new IC-GAN(intra-class gap GAN(generative adversarial network)) recognition network model, providing good adaptability to the facial expression recognition task with large gap within the class. The network consists of a convolutional layer, a fully connected layer, an active layer, a BathNorm layer, and a Softmax layer, in which a convolutional assembly encoder and a decoder are used to perform deep feature extraction on facial expression images, and download and parse from the network. The video self-made mixed facial expression data set is based on the real environment, the image is expanded, and the facial expression data are normalized. The complexity of the facial expression features with large differences within the class also increased the network training and network recognition. The momentum-based Adam is used to update the network weight, adjust the network parameters, and optimize the network structure based on this factor. In this study, the facial expression category data are trained based on the Pytorch platform in deep learning and tested on the verification set of the self-made mixed facial expression data set.ResultWhen the input image is 256×256 pixels, the IC-GAN network model can reduce the false positive rate of the expression in large difference in the class, image blur, and facial expression incompleteness, and improve the system robustness. Compared with deep belief network(DBN) deep trust network and GoogLeNet network, the recognition result of IC-GAN network is 11% higher than that of DBN network and 8.3% higher than that of GoogLeNet network.ConclusionThe IC-GAN accuracy in facial expression recognition with large gaps in the class is verified by experiments. This condition reduces the misunderstanding rate of facial expressions in large intra-class differences, improves the system robustness, and lays down the solid foundation for facial expression generation.关键词:deep learning;generative adversarial network(GAN);intra-class gap GAN(IC-GAN);facial expression recognition50|80|1更新时间:2024-05-07
摘要:ObjectiveChina has a large population of 1.3 billion in 2005, accounting for 19% of the world's population. This number is equivalent to the population of Europe or Africa added to the populations of Australia, North America, and Central America. It is one of the few populous countries in the world, and its huge population size has brought many problems. With the rapid development of the economy, the number of people working outside of their homes is increasing, the population is moving frequently, and the safety of the floating population is even difficult to control. The huge mobile population provides the city's infrastructure and public services tremendous pressure. Thus, to conduct a comprehensive check on the area of adult traffic, which is time-consuming and labor-intensive, is difficult for security and related staff. Particularly, complex environmental safety problems, such as subways, railway stations, and airports, are becoming increasingly serious. Unstable events occur frequently, security situation is receiving much attention, and urban management and service systems are seriously lagging behind. These conditions need to be improved, especially after the September 11 incident in the United States. The situation has aroused widespread concern in the international community. Meanwhile, expression is the most intuitive way for humans to express emotions. In addition to language communication, expressions are extremely effective means of communication. People usually express their inner feelings through specific expressions. Expression can be used to judge other person's thoughts. For expressions used to express information, psychologist Mehrabian summed up a formula:emotional expression=7% of words + 38% of sound + 55% of facial expressions. Expression is one of the most important features of human emotion recognition. Expression is the emotional state expressed by facial muscle changes. Through the facial expression of the person's face, to evaluate abnormal psychological state, speculate on extreme emotions, and observe the facial expressions of pedestrians in the subway, railway station, and airport to further judge the psychology of the person is possible. We provide technical support to determine who is suspicious and prevent certain criminal activities in a timely manner. Strengthening urban surveillance and identifying the facial expressions of criminals are especially important. Expression plays an important role in human emotion cognition. However, factors affecting facial expression recognition in safety screening are extremely large, and the large intra-class gap seriously inflluences the accuracy of facial expression recognition. The problem of large gaps in facial expression recognition in a real environment is solved by identifying suspected molecules to be monitored should be identified, and the security personnel should prepare in advance to accurately identify them. Facial expressions are also particularly important for preventing security problems. The era of large data has arrived. Meanwhile, with the advancement of computer hardware, deep learning continues to develop. The traditional facial expression recognition method cannot meet the needs of the development of the times, and a new algorithm based on deep learning facial expression recognition is coming soon. Learning methods are widely used in facial expression recognition. Although facial recognition intelligent recognition technology has a long history of research, a large number of research methods have been proposed. However, due to the large facial expression gap, the expression is complex, and the influencing factors are many. The current intelligent recognition effect of facial expression results is not ideal. Considering the deep learning because of its powerful expressive ability, this study introduces the model structure of traditional neural network and carries out corresponding experiments and analysis in the context of real-life facial expression recognition and proposes real-world facial expression recognition research based on deep learning. In the next period, real-world facial expression recognition will make considerable progress. This work further studies the realistic facial expression recognition based on deep learning.MethodThis study constructs a new IC-GAN(intra-class gap GAN(generative adversarial network)) recognition network model, providing good adaptability to the facial expression recognition task with large gap within the class. The network consists of a convolutional layer, a fully connected layer, an active layer, a BathNorm layer, and a Softmax layer, in which a convolutional assembly encoder and a decoder are used to perform deep feature extraction on facial expression images, and download and parse from the network. The video self-made mixed facial expression data set is based on the real environment, the image is expanded, and the facial expression data are normalized. The complexity of the facial expression features with large differences within the class also increased the network training and network recognition. The momentum-based Adam is used to update the network weight, adjust the network parameters, and optimize the network structure based on this factor. In this study, the facial expression category data are trained based on the Pytorch platform in deep learning and tested on the verification set of the self-made mixed facial expression data set.ResultWhen the input image is 256×256 pixels, the IC-GAN network model can reduce the false positive rate of the expression in large difference in the class, image blur, and facial expression incompleteness, and improve the system robustness. Compared with deep belief network(DBN) deep trust network and GoogLeNet network, the recognition result of IC-GAN network is 11% higher than that of DBN network and 8.3% higher than that of GoogLeNet network.ConclusionThe IC-GAN accuracy in facial expression recognition with large gaps in the class is verified by experiments. This condition reduces the misunderstanding rate of facial expressions in large intra-class differences, improves the system robustness, and lays down the solid foundation for facial expression generation.关键词:deep learning;generative adversarial network(GAN);intra-class gap GAN(IC-GAN);facial expression recognition50|80|1更新时间:2024-05-07 -
 摘要:ObjectiveUyghur belongs to adhesive language, and the formation and meaning of words in Uyghur language depend on affix connection, which add affixes to the stems to achieve different semantic meaning. For example, in Uyghur "مەكتەپنى" refers to school, and it could be added by a first person singular in Uyghur "ىر" as a suffix to form a new word "بەرسىڭىز", which means my school. During adding suffixes, certain morphological changes will occur at the tail of the stems. In addition, phonetic change also happens at that process, such as weakling (some morphological changes occur at the tail of a stem), epenthesis (a few characters were added at the tail of the stem), and deletion(a few characters were deleted at the tail of the stem). Multiple phonetic changes also appear simultaneously, causing further morphological change. All the semorphological changes form the word different from the stem. Therefore, using the current word spotting technique, only a specific Uyghur vocabulary can be retrieved, and a certain stem cannot search its corresponding suffixed words. In addition, traditional word spotting approaches only aim at the number of the matching sets and noton the spatial relationship of the matching sets. Therefore, some drawbacks for word spotting technique occur. This study proposes Uyghur-printed suffix word retrieval based on mapping relationship that take advantage of the spatial relationship of the matching sets to retrieve the corresponding suffix words of the stems.MethodThe process of the proposed approach is described as follows.First, the segmentation algorithm segments printed the Uyghur document images to word image corps. Then, the local features of the Uyghur word image are extracted. To compare the efficiency of the different local features, scale-invariant feature transform(SIFT) and speeded up robust features(SURF) have been adopted. The experiment result shows that SIFT feature has better performance than SURF because SIFT can obtain more feature points than SURF, and the distribution of SIFT feature points is more diverse than SURF, which is very helpful for further retrieval steps. However, SURF is more efficient than SIFT considering the time efficiency. Then, Brute-Force matching and fast library for approximate nearest neighbor(FLANN) bilateral feature matching have been adopted as matching algorithm. The experiment result shows that FLANN bilateral feature matching has better performance than Brute-Force matching because FLANN bilateral feature matching can filter more mismatch pairs than Brute-Force matching. In addition, the correctness of the feature matching set is very important to the following suffix word retrieval, and the accuracy of FLANN bilateral feature matching is very outstanding. Finally, the feature matching sets are subjected to homography transformation and perspective transformation to the Uyghur word image for the final retrieval steps. After homography transformation and perspective transformation, a quadrilateral is built. If this quadrilateral belongs to rectangle and the right part of the acquired rectangle simply match with the outline of the query word image, then the retrieved word belongs to corresponding suffixed words of the query stem.Meanwhile, if this quadrilateral does not belong to rectangle and does not match with the outline of the query word image, then the retrieved word does not belong to the corresponding suffixed words of the query stem but to the mismatch. This result indicates that the proposed method not only can retrieve corresponding suffixed words of the query word but also can filter the mismatch word. In other words, the feature matching sets are transformed into a spatial relationship and are further determined whether the retrieved word belongs to suffix word or mismatched word according to the spatial relationship. The spatial relationship of the feature matching set is searched for the suffix word, thereby implementing the printed Uyghur Text image suffix word retrieval.ResultThe experimental data selected 17 648 segmented word images in 190 Uyghur print text images and 30 word images, which have 167 corresponding suffix words considered as the search terms. In the experiment, we used different local feature algorithms to suffix retrieval. The comparison results show that the SIFT algorithm's suffix retrieval effect is better than SURF algorithm, and its accuracy and recall rate reach 94.23% and 88.02%, respectively. In addition, we carried out comparative experiments in different situations, such as weakling, epenthesis, deletion, and replacement. Moreover, multiple phonetic changes appear simultaneously and change in the tail of the word stem. In those five different situations, the retrieval result of changes in the tail of the word stem was the best, and its accuracy and recall rate reach 98.9% and 96.07%, respectively. The main reason for this result is that the changes in the tail of the word stem do not make very obvious formation changes of the stem word, which can be very helpful for the suffix word retrieval. However, in different cases, multiple phonetic changes appear simultaneously that the accuracy and recall rate of the retrieval reach 66.6% and 22.2%. The reason for such low performance is that multiple phonetic changes simultaneously change the formation of the stem part in the suffix word.In addition, several characters in the stem part have been replaced by other characters, which are very difficult to retrieve its corresponding suffix word by the original stem word. However, this kind of situation only takes few percentages of the whole morphological changes.ConclusionTherefore, the proposed algorithm meets the different retrieval needs of users. The method of suffix word retrieval based on mapping relationship is also the first implementation of Uyghur suffix word retrieval method. The Uyghur suffix image is efficiently retrieved by the spatial relationship between the matching sets.关键词:Uyghur language;suffix word retrieval;local feature;homograph;perspective transform20|24|0更新时间:2024-05-07
摘要:ObjectiveUyghur belongs to adhesive language, and the formation and meaning of words in Uyghur language depend on affix connection, which add affixes to the stems to achieve different semantic meaning. For example, in Uyghur "مەكتەپنى" refers to school, and it could be added by a first person singular in Uyghur "ىر" as a suffix to form a new word "بەرسىڭىز", which means my school. During adding suffixes, certain morphological changes will occur at the tail of the stems. In addition, phonetic change also happens at that process, such as weakling (some morphological changes occur at the tail of a stem), epenthesis (a few characters were added at the tail of the stem), and deletion(a few characters were deleted at the tail of the stem). Multiple phonetic changes also appear simultaneously, causing further morphological change. All the semorphological changes form the word different from the stem. Therefore, using the current word spotting technique, only a specific Uyghur vocabulary can be retrieved, and a certain stem cannot search its corresponding suffixed words. In addition, traditional word spotting approaches only aim at the number of the matching sets and noton the spatial relationship of the matching sets. Therefore, some drawbacks for word spotting technique occur. This study proposes Uyghur-printed suffix word retrieval based on mapping relationship that take advantage of the spatial relationship of the matching sets to retrieve the corresponding suffix words of the stems.MethodThe process of the proposed approach is described as follows.First, the segmentation algorithm segments printed the Uyghur document images to word image corps. Then, the local features of the Uyghur word image are extracted. To compare the efficiency of the different local features, scale-invariant feature transform(SIFT) and speeded up robust features(SURF) have been adopted. The experiment result shows that SIFT feature has better performance than SURF because SIFT can obtain more feature points than SURF, and the distribution of SIFT feature points is more diverse than SURF, which is very helpful for further retrieval steps. However, SURF is more efficient than SIFT considering the time efficiency. Then, Brute-Force matching and fast library for approximate nearest neighbor(FLANN) bilateral feature matching have been adopted as matching algorithm. The experiment result shows that FLANN bilateral feature matching has better performance than Brute-Force matching because FLANN bilateral feature matching can filter more mismatch pairs than Brute-Force matching. In addition, the correctness of the feature matching set is very important to the following suffix word retrieval, and the accuracy of FLANN bilateral feature matching is very outstanding. Finally, the feature matching sets are subjected to homography transformation and perspective transformation to the Uyghur word image for the final retrieval steps. After homography transformation and perspective transformation, a quadrilateral is built. If this quadrilateral belongs to rectangle and the right part of the acquired rectangle simply match with the outline of the query word image, then the retrieved word belongs to corresponding suffixed words of the query stem.Meanwhile, if this quadrilateral does not belong to rectangle and does not match with the outline of the query word image, then the retrieved word does not belong to the corresponding suffixed words of the query stem but to the mismatch. This result indicates that the proposed method not only can retrieve corresponding suffixed words of the query word but also can filter the mismatch word. In other words, the feature matching sets are transformed into a spatial relationship and are further determined whether the retrieved word belongs to suffix word or mismatched word according to the spatial relationship. The spatial relationship of the feature matching set is searched for the suffix word, thereby implementing the printed Uyghur Text image suffix word retrieval.ResultThe experimental data selected 17 648 segmented word images in 190 Uyghur print text images and 30 word images, which have 167 corresponding suffix words considered as the search terms. In the experiment, we used different local feature algorithms to suffix retrieval. The comparison results show that the SIFT algorithm's suffix retrieval effect is better than SURF algorithm, and its accuracy and recall rate reach 94.23% and 88.02%, respectively. In addition, we carried out comparative experiments in different situations, such as weakling, epenthesis, deletion, and replacement. Moreover, multiple phonetic changes appear simultaneously and change in the tail of the word stem. In those five different situations, the retrieval result of changes in the tail of the word stem was the best, and its accuracy and recall rate reach 98.9% and 96.07%, respectively. The main reason for this result is that the changes in the tail of the word stem do not make very obvious formation changes of the stem word, which can be very helpful for the suffix word retrieval. However, in different cases, multiple phonetic changes appear simultaneously that the accuracy and recall rate of the retrieval reach 66.6% and 22.2%. The reason for such low performance is that multiple phonetic changes simultaneously change the formation of the stem part in the suffix word.In addition, several characters in the stem part have been replaced by other characters, which are very difficult to retrieve its corresponding suffix word by the original stem word. However, this kind of situation only takes few percentages of the whole morphological changes.ConclusionTherefore, the proposed algorithm meets the different retrieval needs of users. The method of suffix word retrieval based on mapping relationship is also the first implementation of Uyghur suffix word retrieval method. The Uyghur suffix image is efficiently retrieved by the spatial relationship between the matching sets.关键词:Uyghur language;suffix word retrieval;local feature;homograph;perspective transform20|24|0更新时间:2024-05-07 -
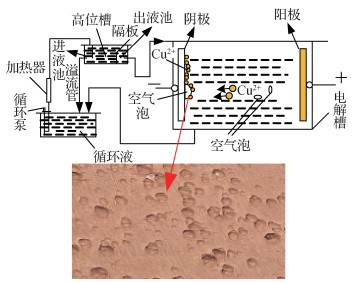 摘要:ObjectiveFrom the global copper demand area, China still occupies the world's largest consumer of copper, accounting for nearly 40% of global total demand. Chinese economic data and news have been the focus of the copper market. In recent years, China's copper processing industry has shown a steady growth, and industry output gradually expanded. Copper processing materials are widely used in almost all national economy industries. Electrolytic copper plays an important role in copper smelting industry. During copper electrolysis, a large amount of air mixed in electrolyte is the main reason for the pores on the surface of copper cathode. The electrolyte dissolved gas is oversaturated to produce gas phase core, which gradually grows to form bubbles, and attaches to the surface of the cathode copper plate to form insulation point. This condition hinders the precipitation of copper ions, resulting in the appearance of bumps on the surface quality of copper plate. The surface quality of the copper plate is usually identified by the operator's eyes to determine the classification to solve the problem of low accuracy and efficiency of manually discriminating the surface quality of electrolytic cathode copper plate. This study proposes an intelligent recognition method of copper plate surface-raised image based on chaotic bird swarm algorithm.MethodTo enhance the global searching ability of the algorithm, the chaos theory is improved to make it enter into a completely chaotic state. The improved chaos theory was introduced based on the local optimal judgment of birds' own fitness value. In the iteration of bird flock, low-quality individuals were selected alternately to carry out chaos and dynamic step position update to increase the population diversity to avoid local optimization of the algorithm. Based on the analysis of surface defects of the copper plate, the base point growth method is proposed to design and detect structural elements. In addition, the texture of copper plate image is eliminated by combining with the morphological operation to improve the algorithm accuracy in calculating the raised area. The birds used Kapur-Sahoo-Wong(KSW) entropy as the fitness function to segment the copper plate images at the best threshold. Background pixels are mixed with raised category pixels in the initial segmentation result due to uneven illumination. Therefore, this study classifies the pixel of the corrected copper plate image through eight neighborhood search and takes it as the final segmentation result. According to the statistics of the number of raised pixels in the segmented image, the actual raised area proportion is obtained to determine whether the copper plate is qualified or defective. In this work, three copper plates with the smallest raised area are selected from 30 copper plates with fixed defective products through rough recognition by the human eyes. The exact bulge ratio is calculated using the algorithm in this study. To strengthen the fault tolerance rate of the algorithm, appropriate adjustment was made on the basis of the minimum value as the final threshold of copper plate classification. In addition, two arbitrary copper plates were selected to verify the method.ResultThe algorithm in this study is compared with genetic algorithm(GA), chicken swarm optimization(CSO), glowworm swarm optimization(GSO), and bird swarm algorithm(BSA) in three indexes of time, fitness value, and structural similarity index measurement(SSIM) value, respectively. Experimental results show that the fitness value of the algorithm in this study was increased by 0.0030.701, and the SSIM value was increased by 0.0750.169.The finding reveals the fault tolerance and superiority of this algorithm in the calculation of the proportion of copper plate surface bulge.ConclusionThe proposed method can effectively detect the proportion of copper surface bulge area and classify qualified and defective products, thus providing a reference to determine the surface quality of electrolytic copper in metallurgical industry.关键词:copper plate defects;threshold segmentation;bird swarm algorithm(BSA);chaos theory;base growth method;Kapur-Sahoo-Wong(KSW) entropy method56|70|1更新时间:2024-05-07
摘要:ObjectiveFrom the global copper demand area, China still occupies the world's largest consumer of copper, accounting for nearly 40% of global total demand. Chinese economic data and news have been the focus of the copper market. In recent years, China's copper processing industry has shown a steady growth, and industry output gradually expanded. Copper processing materials are widely used in almost all national economy industries. Electrolytic copper plays an important role in copper smelting industry. During copper electrolysis, a large amount of air mixed in electrolyte is the main reason for the pores on the surface of copper cathode. The electrolyte dissolved gas is oversaturated to produce gas phase core, which gradually grows to form bubbles, and attaches to the surface of the cathode copper plate to form insulation point. This condition hinders the precipitation of copper ions, resulting in the appearance of bumps on the surface quality of copper plate. The surface quality of the copper plate is usually identified by the operator's eyes to determine the classification to solve the problem of low accuracy and efficiency of manually discriminating the surface quality of electrolytic cathode copper plate. This study proposes an intelligent recognition method of copper plate surface-raised image based on chaotic bird swarm algorithm.MethodTo enhance the global searching ability of the algorithm, the chaos theory is improved to make it enter into a completely chaotic state. The improved chaos theory was introduced based on the local optimal judgment of birds' own fitness value. In the iteration of bird flock, low-quality individuals were selected alternately to carry out chaos and dynamic step position update to increase the population diversity to avoid local optimization of the algorithm. Based on the analysis of surface defects of the copper plate, the base point growth method is proposed to design and detect structural elements. In addition, the texture of copper plate image is eliminated by combining with the morphological operation to improve the algorithm accuracy in calculating the raised area. The birds used Kapur-Sahoo-Wong(KSW) entropy as the fitness function to segment the copper plate images at the best threshold. Background pixels are mixed with raised category pixels in the initial segmentation result due to uneven illumination. Therefore, this study classifies the pixel of the corrected copper plate image through eight neighborhood search and takes it as the final segmentation result. According to the statistics of the number of raised pixels in the segmented image, the actual raised area proportion is obtained to determine whether the copper plate is qualified or defective. In this work, three copper plates with the smallest raised area are selected from 30 copper plates with fixed defective products through rough recognition by the human eyes. The exact bulge ratio is calculated using the algorithm in this study. To strengthen the fault tolerance rate of the algorithm, appropriate adjustment was made on the basis of the minimum value as the final threshold of copper plate classification. In addition, two arbitrary copper plates were selected to verify the method.ResultThe algorithm in this study is compared with genetic algorithm(GA), chicken swarm optimization(CSO), glowworm swarm optimization(GSO), and bird swarm algorithm(BSA) in three indexes of time, fitness value, and structural similarity index measurement(SSIM) value, respectively. Experimental results show that the fitness value of the algorithm in this study was increased by 0.0030.701, and the SSIM value was increased by 0.0750.169.The finding reveals the fault tolerance and superiority of this algorithm in the calculation of the proportion of copper plate surface bulge.ConclusionThe proposed method can effectively detect the proportion of copper surface bulge area and classify qualified and defective products, thus providing a reference to determine the surface quality of electrolytic copper in metallurgical industry.关键词:copper plate defects;threshold segmentation;bird swarm algorithm(BSA);chaos theory;base growth method;Kapur-Sahoo-Wong(KSW) entropy method56|70|1更新时间:2024-05-07 -
 摘要:ObjectiveMulti-object tracking is an important research topic in computer vision. Although several previous studies have dealt with varieties of particular problems in multi-object tracking, many challenges are still observed, such as object detection errors, missed detection, frequent and long-term occlusion of objects in complex scenes, and identity switches of tracking objects with similar appearance. All of which are easy to lead to trajectory drift or tracking interruption. With the improvement of object detection, the object tracking method based on detection shows good performance. The key of tracking-by-detection algorithm is the data association between detection points, which mainly consists of two types, namely, frame-by-frame association and multi-frame association. Frame-by-frame data association refers to the association between detection points in the two consecutive frames, which is carried out according to the properties of detection points, such as appearance, location, and size. Tracking drift or failure is likely to occur when object is blocked, misdetected or similar appearance exist due to that the frame-by-frame data association only contains the information of the previous two frames. Multi-frame data association establishes a relational model by using object detection information of multiple frames rather than only previous two frames. This condition can effectively reduce the object error association and deal with occlusion. However, if the occlusion time is longer than the time segment needed for multi-frame data association, the detection points before and after still cannot be successfully associated, and the tracking will also be interrupted. Moreover, this method needs all detection information before tracking, which cannot meet the real-time requirement. Aiming at the problems of ID switches and trajectory fragmentation caused by long-term occlusion, an online multi-object tracking algorithm based on adaptive online discriminative appearance learning and hierarchical association is proposed for multi-object tracking in complex scenes. This process combines the low-level appearance, position-size characteristics used in local association, and high-level motion model established in global association and can meet the real-time tracking requirement.MethodIn this study, multi-object tracking is divided into two stages according to track confidence:local association and global association. The establishment of the object robust appearance model is the key to local association and global association. An online incremental linear discriminant analysis(ILDA) method was introduced to discriminate the appearances of objects and adaptively update the object appearance models based on the difference value between the new sample and the mean of object samples to address the problem of identity switches. The reliable tracklet with high confidence in the local association stage is associated with the current frame detections by low-level properties of detection points:appearance and position-size similarity, which allows reliable trajectories to grow constantly. The unreliable tracklet with low confidence in the global association stage resulted from long-term occlusion is further associated. In this stage, the candidate object consists of two kinds. One is the detection points that are not associated in local association, and the other one is continuous trajectory with high confidence meeting the time condition. The end time of trajectory is before the current time. When we associate detection points that reappear after long-term occlusion, only appearance similarity is utilized within a validation range without the position-size property due to the unreliable motion dynamics of unreliable objects. At the same time, introducing a valid association range is related to the trajectory confidence. Once the track confidence is reduced, the valid association range is increased because the distance between a drifting track and the corresponding object can grow large if the track drift persists. This condition allows us to reassign drifting tracks to detections of reappearing objects, which is even distant from the corresponding tracks. When two track fragments are associated, a motion model is introduced to determine whether the two trajectories belong to the same object. In this condition, the average velocity vector angle of the two track fragments is larger than a threshold, indicating that it may include unreliable tracks. Thus, we only consider appearance similarity between the pair. Otherwise, we combine the appearance, position size, and motion similarity to make an association between the pair. If two track fragments are associated successfully, the linear interpolation is used to fill the lost interval of this object. Thus, the two trajectory fragments can be connected effectively.ResultWe compared our method with 10 state-of-the-art multi-object tracking algorithms, including five offline tracking approaches and five online tracking methods on three public datasets, namely, PETS09-S2L1, TUD-Stadmitte, and Town-Center. The quantitative evaluation metrics contained multi-object tracking accuracy (MOTA), multi-object tracking precision (MOTP), the number of identity switches (IDS), the ratio of mostly tracked trajectories (MT), the ratio of mostly lost trajectories (ML), and the number of track fragmentation (Frag). The experiment results illustrate that our tracking method outperforms in MOTA and MOTP compared with selected online multi-object tracking methods, which include two tracking approaches based on hierarchical association. In addition, the proposed approach performs almost the same or even better when compared with offline tracking methods. In the PETS09-S2L1 data set, the proposed approaches are superior to other comparators in MOTP, IDS, and Frag. MOTP increased by 6.1%, IDS reduced by 5, and Frag reduced by 21. In TUD-Stadmitte dataset, IDS reduced by 4. Compared with online tracking approaches, the MOTP and MOTA increased by 36.3% and 11.1%, respectively. In Town-Center dataset, MOTA and MT increased by 5.2% and 16.9%, respectively. IDS and Frag reduced by 60 and 84, respectively, and ML decreased by 1.5%.ConclusionIn this study, we take the idea of hierarchical data association, proposing a multi-object tracking based on adaptive online discriminative appearance learning and hierarchical association. The experiment results indicate that our method has a good solution to the problems of ID switches and trajectory fragmentation caused by long-term occlusion in complex scenes.关键词:multi-object tracking;local association;global association;track confidence;incremental linear discriminant analysis(ILDA)45|218|6更新时间:2024-05-07
摘要:ObjectiveMulti-object tracking is an important research topic in computer vision. Although several previous studies have dealt with varieties of particular problems in multi-object tracking, many challenges are still observed, such as object detection errors, missed detection, frequent and long-term occlusion of objects in complex scenes, and identity switches of tracking objects with similar appearance. All of which are easy to lead to trajectory drift or tracking interruption. With the improvement of object detection, the object tracking method based on detection shows good performance. The key of tracking-by-detection algorithm is the data association between detection points, which mainly consists of two types, namely, frame-by-frame association and multi-frame association. Frame-by-frame data association refers to the association between detection points in the two consecutive frames, which is carried out according to the properties of detection points, such as appearance, location, and size. Tracking drift or failure is likely to occur when object is blocked, misdetected or similar appearance exist due to that the frame-by-frame data association only contains the information of the previous two frames. Multi-frame data association establishes a relational model by using object detection information of multiple frames rather than only previous two frames. This condition can effectively reduce the object error association and deal with occlusion. However, if the occlusion time is longer than the time segment needed for multi-frame data association, the detection points before and after still cannot be successfully associated, and the tracking will also be interrupted. Moreover, this method needs all detection information before tracking, which cannot meet the real-time requirement. Aiming at the problems of ID switches and trajectory fragmentation caused by long-term occlusion, an online multi-object tracking algorithm based on adaptive online discriminative appearance learning and hierarchical association is proposed for multi-object tracking in complex scenes. This process combines the low-level appearance, position-size characteristics used in local association, and high-level motion model established in global association and can meet the real-time tracking requirement.MethodIn this study, multi-object tracking is divided into two stages according to track confidence:local association and global association. The establishment of the object robust appearance model is the key to local association and global association. An online incremental linear discriminant analysis(ILDA) method was introduced to discriminate the appearances of objects and adaptively update the object appearance models based on the difference value between the new sample and the mean of object samples to address the problem of identity switches. The reliable tracklet with high confidence in the local association stage is associated with the current frame detections by low-level properties of detection points:appearance and position-size similarity, which allows reliable trajectories to grow constantly. The unreliable tracklet with low confidence in the global association stage resulted from long-term occlusion is further associated. In this stage, the candidate object consists of two kinds. One is the detection points that are not associated in local association, and the other one is continuous trajectory with high confidence meeting the time condition. The end time of trajectory is before the current time. When we associate detection points that reappear after long-term occlusion, only appearance similarity is utilized within a validation range without the position-size property due to the unreliable motion dynamics of unreliable objects. At the same time, introducing a valid association range is related to the trajectory confidence. Once the track confidence is reduced, the valid association range is increased because the distance between a drifting track and the corresponding object can grow large if the track drift persists. This condition allows us to reassign drifting tracks to detections of reappearing objects, which is even distant from the corresponding tracks. When two track fragments are associated, a motion model is introduced to determine whether the two trajectories belong to the same object. In this condition, the average velocity vector angle of the two track fragments is larger than a threshold, indicating that it may include unreliable tracks. Thus, we only consider appearance similarity between the pair. Otherwise, we combine the appearance, position size, and motion similarity to make an association between the pair. If two track fragments are associated successfully, the linear interpolation is used to fill the lost interval of this object. Thus, the two trajectory fragments can be connected effectively.ResultWe compared our method with 10 state-of-the-art multi-object tracking algorithms, including five offline tracking approaches and five online tracking methods on three public datasets, namely, PETS09-S2L1, TUD-Stadmitte, and Town-Center. The quantitative evaluation metrics contained multi-object tracking accuracy (MOTA), multi-object tracking precision (MOTP), the number of identity switches (IDS), the ratio of mostly tracked trajectories (MT), the ratio of mostly lost trajectories (ML), and the number of track fragmentation (Frag). The experiment results illustrate that our tracking method outperforms in MOTA and MOTP compared with selected online multi-object tracking methods, which include two tracking approaches based on hierarchical association. In addition, the proposed approach performs almost the same or even better when compared with offline tracking methods. In the PETS09-S2L1 data set, the proposed approaches are superior to other comparators in MOTP, IDS, and Frag. MOTP increased by 6.1%, IDS reduced by 5, and Frag reduced by 21. In TUD-Stadmitte dataset, IDS reduced by 4. Compared with online tracking approaches, the MOTP and MOTA increased by 36.3% and 11.1%, respectively. In Town-Center dataset, MOTA and MT increased by 5.2% and 16.9%, respectively. IDS and Frag reduced by 60 and 84, respectively, and ML decreased by 1.5%.ConclusionIn this study, we take the idea of hierarchical data association, proposing a multi-object tracking based on adaptive online discriminative appearance learning and hierarchical association. The experiment results indicate that our method has a good solution to the problems of ID switches and trajectory fragmentation caused by long-term occlusion in complex scenes.关键词:multi-object tracking;local association;global association;track confidence;incremental linear discriminant analysis(ILDA)45|218|6更新时间:2024-05-07
Image Analysis and Recognition
-
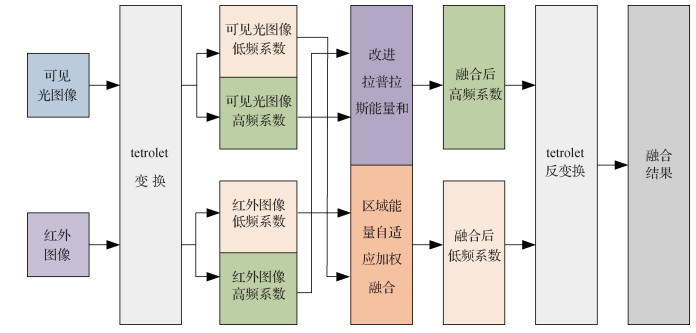 摘要:ObjectiveImage fusion is an important form of information fusion, which is widely used in image understanding and computer vision. It combines multiple images that are described in the same scene in different forms to obtain accurate and comprehensive information processing. The fused image can provide effective information for subsequent image processing to some extent. Among them, infrared and visible image fusion is a hot issue in image fusion. By combining the background information in the visible light image with the target features in the infrared image, the information of the two images can be fully fused, which can describe comprehensively and accurately, improve the target features and background recognition in the scene, and enhance people's perception and understanding of the image. General infrared and visible image fusion algorithms can achieve the purpose of cognitive scenes but cannot reflect the detailed features of the scene in a detailed way to further improve the scene identification to provide effective information for subsequent image processing. Aiming at such problems, this study proposes a tetrolet-based multiscale geometric transformation fusion algorithm to improve the shortcomings of existing algorithms. The tetrolet transform divides the source image into several image blocks and transforms each image block to obtain low-frequency coefficients and high-frequency coefficients. The low frequency and high frequency coefficients of all image blocks are arranged and integrated into an image matrix to obtain the low frequency and high frequency coefficients of the source image.MethodFirst, the infrared and visible light images are mapped to the tetrolet transform domain, and the two images are correspondingly subjected to tetrolet transformation. According to the four-lattice patchwork filling theory, the best filling method is selected based on the criterion of the maximum first-order norm among the 117 filling methods. In this way, the respective low-frequency coefficients and high-frequency coefficients of the infrared and visible images are calculated. Then, the low-frequency coefficients of the two are combined with the theory of regional energy and the traditional weighting method. By taking advantage of the variability of regional energy and the correlation of regional pixels, the weighting coefficients are adaptively selected for fusion to obtain the fused low-frequency coefficients according to the constant change of the central pixel. For the high-frequency coefficients of the two images, the traditional Laplace energy only according to the up, down, left, and right four Laplace operators of the direction is calculated. Considering that the pixel points in the diagonal direction also contribute to the calculation of the sum-modified-Laplacian, this study uses the improved eight-direction Laplace operator calculation method to calculate the Laplace energy and introduce the regional smoothness as the threshold value. If the sum-modified-Laplacian is above the threshold value, the weighted coefficient is calculated according to smoothness and threshold value to carry out weighted fusion. Otherwise, the fusion rule is set according to the maximum and minimum values of sum-modified-Laplacian of the two high-frequency components to obtain the high-frequency coefficient after fusion. Finally, the low-frequency and high-frequency coefficients obtained after the fusion are reconstructed to obtain the fused image.ResultThe fusion results of three sets of infrared and visible images are compared with the contourlet transformation (CL), discrete wavelet transformation (DWT), and nonsubsampled contourlet transformation (NSCT) methods. From the perspective of visual effect, the fusion image of the algorithm in this study is superior to the other three methods in image background, scene object, and detail embodiment. In terms of objective indicators, the running time required by the algorithm in this study is 0.37 s shorter than that of the NSCT method compared with the other three methods. In addition, the average gradient (AvG) and spatial frequency (SF) values of the fused images are greatly improved, with the maximum increases of 5.42 and 2.75, respectively. In addition, the peak signal to noise ratio (PSNR), information entropy (IE), and structural similarity index (SSIM) values are slightly increased, with the improvement ranges of 0.25, 0.12, and 0.19, respectively. The experimental results show that the proposed algorithm in this study improves the fusion image of effect and quality to a certain extent.ConclusionThis work proposes an infrared and visible image fusion method based on regional energy and improved multidirectional Laplace energy. The infrared image and visible light image are mapped into the transform domain by tetrolet transformation, which is decomposed into low frequency coefficient and high frequency. The fusion of the low-frequency coefficients is carried out based on the regional energy theory and the adaptive weighted fusion criterion. According to the improved Laplace energy and the regional smoothness, the high-frequency coefficients of the infrared and visible images are selected to achieve the fusion of the high-frequency coefficients. The fusion results of low frequency and high frequency coefficients are obtained by inverse transformation. Compared with the fusion results of the other three transform domain algorithms, the fused images not only enhance the background information but also remarkably improve the embodiment of the details in the scene. This condition has certain advantages in objective evaluation indexes, such as average gradient and peak signal-to-noise ratio. The observer's ability to understand the scene has been improving.关键词:image fusion;tetrolet transform;region energy adaptive;Laplacian operator;sum-modified-Laplacian37|22|10更新时间:2024-05-07
摘要:ObjectiveImage fusion is an important form of information fusion, which is widely used in image understanding and computer vision. It combines multiple images that are described in the same scene in different forms to obtain accurate and comprehensive information processing. The fused image can provide effective information for subsequent image processing to some extent. Among them, infrared and visible image fusion is a hot issue in image fusion. By combining the background information in the visible light image with the target features in the infrared image, the information of the two images can be fully fused, which can describe comprehensively and accurately, improve the target features and background recognition in the scene, and enhance people's perception and understanding of the image. General infrared and visible image fusion algorithms can achieve the purpose of cognitive scenes but cannot reflect the detailed features of the scene in a detailed way to further improve the scene identification to provide effective information for subsequent image processing. Aiming at such problems, this study proposes a tetrolet-based multiscale geometric transformation fusion algorithm to improve the shortcomings of existing algorithms. The tetrolet transform divides the source image into several image blocks and transforms each image block to obtain low-frequency coefficients and high-frequency coefficients. The low frequency and high frequency coefficients of all image blocks are arranged and integrated into an image matrix to obtain the low frequency and high frequency coefficients of the source image.MethodFirst, the infrared and visible light images are mapped to the tetrolet transform domain, and the two images are correspondingly subjected to tetrolet transformation. According to the four-lattice patchwork filling theory, the best filling method is selected based on the criterion of the maximum first-order norm among the 117 filling methods. In this way, the respective low-frequency coefficients and high-frequency coefficients of the infrared and visible images are calculated. Then, the low-frequency coefficients of the two are combined with the theory of regional energy and the traditional weighting method. By taking advantage of the variability of regional energy and the correlation of regional pixels, the weighting coefficients are adaptively selected for fusion to obtain the fused low-frequency coefficients according to the constant change of the central pixel. For the high-frequency coefficients of the two images, the traditional Laplace energy only according to the up, down, left, and right four Laplace operators of the direction is calculated. Considering that the pixel points in the diagonal direction also contribute to the calculation of the sum-modified-Laplacian, this study uses the improved eight-direction Laplace operator calculation method to calculate the Laplace energy and introduce the regional smoothness as the threshold value. If the sum-modified-Laplacian is above the threshold value, the weighted coefficient is calculated according to smoothness and threshold value to carry out weighted fusion. Otherwise, the fusion rule is set according to the maximum and minimum values of sum-modified-Laplacian of the two high-frequency components to obtain the high-frequency coefficient after fusion. Finally, the low-frequency and high-frequency coefficients obtained after the fusion are reconstructed to obtain the fused image.ResultThe fusion results of three sets of infrared and visible images are compared with the contourlet transformation (CL), discrete wavelet transformation (DWT), and nonsubsampled contourlet transformation (NSCT) methods. From the perspective of visual effect, the fusion image of the algorithm in this study is superior to the other three methods in image background, scene object, and detail embodiment. In terms of objective indicators, the running time required by the algorithm in this study is 0.37 s shorter than that of the NSCT method compared with the other three methods. In addition, the average gradient (AvG) and spatial frequency (SF) values of the fused images are greatly improved, with the maximum increases of 5.42 and 2.75, respectively. In addition, the peak signal to noise ratio (PSNR), information entropy (IE), and structural similarity index (SSIM) values are slightly increased, with the improvement ranges of 0.25, 0.12, and 0.19, respectively. The experimental results show that the proposed algorithm in this study improves the fusion image of effect and quality to a certain extent.ConclusionThis work proposes an infrared and visible image fusion method based on regional energy and improved multidirectional Laplace energy. The infrared image and visible light image are mapped into the transform domain by tetrolet transformation, which is decomposed into low frequency coefficient and high frequency. The fusion of the low-frequency coefficients is carried out based on the regional energy theory and the adaptive weighted fusion criterion. According to the improved Laplace energy and the regional smoothness, the high-frequency coefficients of the infrared and visible images are selected to achieve the fusion of the high-frequency coefficients. The fusion results of low frequency and high frequency coefficients are obtained by inverse transformation. Compared with the fusion results of the other three transform domain algorithms, the fused images not only enhance the background information but also remarkably improve the embodiment of the details in the scene. This condition has certain advantages in objective evaluation indexes, such as average gradient and peak signal-to-noise ratio. The observer's ability to understand the scene has been improving.关键词:image fusion;tetrolet transform;region energy adaptive;Laplacian operator;sum-modified-Laplacian37|22|10更新时间:2024-05-07 -
 摘要:ObjectiveSketch-to-photo translation has a wide range of applications in the public safety and digital entertainment area. For example, it can help the police find fugitives and missing children or generate an avatar of social account. The existing algorithm of sketch-to-photo translation can only translate sketches into photos under the same age group. However, it does not solve the problem of cross-age sketch-to-photo translation. Cross-age sketch-to-photo translation characters also have a wide range of applications. For example, when the sketch image of the police at hand is out of date after a long time, the task can generate an aging photo based on outdated sketches to help the police find the suspect. Given that paired cross-age sketches and photo images are difficult to obtain, no data sets are available. To solve this problem, this study combines dual generative adversarial networks (DualGANs) and identity-preserved conditional generative adversarial networks (IPCGANs) to propose double dual generative adversarial networks (D-DualGANs).MethodDualGANs have the advantage of two-way conversion without the need to pair samples. However, it can only achieve a two-way conversion of an attribute and cannot achieve the conversion of two attributes at the same time. IPCGANs can complete the aging or rejuvenation of the face while retaining the personalized features of the person's face, but it cannot complete the two-way change between different age groups. This article considers the span of age as a domain conversion problem and considers the cross-age sketch-to-photo translation task as a problem of style and age conversion. We combined the characteristics of the above network to build D-DualGANs by setting up four generators and four discriminators to combat training. The method not only learns the mapping of the sketch domain to the photo domain and the mapping of the photo domain to the sketch domain but also learns the mapping of the source age group to the target age group and the mapping of the target age group to the original age group. In D-DualGANs, the original sketch image or the original photo image is successively completed by the four generators to achieve the four-domain conversion to obtain cross-age photo images or cross-age sketch images and reconstructed same-age sketch images or reconstructed same-age photo images. The generator is optimized by measuring the distance between the generated cross-age image and the reconstructed image of the same age by full reconstruction loss. We also used the identity retention module to introduce reconstructed identity loss to maintain the personalized features of the face. Eventually, the input sketch images and photo images from the different age groups are converted into photos and sketches of the other age group. This method does not require paired samples, currently overcoming the problem of lack of paired samples of cross-age sketches and photos.ResultThe experiments combine the images of the CUFS(CUHK(Chinese University of Hong Kong)-face sketeh database) and CUSFS(CUHK face sketch face recognition technology database) sketch photo datasets and produces corresponding age labels for each image based on the results of the age estimation software. According to the age label, the sketch and photo images in the datasets are divided into three groups of 11~30, 31~50, and 50+, and each age group is evenly distributed. Six D-DualGAN models were trained to realize the two-two conversion between sketches and photographic images of the three age groups, namely, the 11~30 sketch and the 31~50 photo, the 11~30 sketch and the 50+ photo, the 31~50 sketch and the 11~30 photo, the 31~50 sketch and the 50+ photo, the 50+ sketch and the 31~50 photo, the 50+ sketch and the 11~30 photo. As there is little research on cross-age sketch-to-photo translation. To illustrate the effectiveness of the method, the generated image obtained by this method is compared with the generated image obtained by DualGANs and then by IPCGANs. Our images are of good quality with less distortion and noise. Using an age estimate CNN to judge the age accuracy of the generated image, the mean absolute error (MAE) of our method is lower than the direct addition of DualGANs and IPCGANs. To evaluate the similarity between the generated image and the original image, we invite volunteers unrelated to this study to determine whether the generated image is the same as the original image. The results show that the resulting aging image is similar, and the resulting younger image is poor. Among them, the 31~50 photos generated by 11~30 sketches are the same as the original image.ConclusionD-DualGANs proposed in this study provides knowledge on mapping and inverse mapping between the sketch domain and the photo domain and the mapping and inverse mapping between the different age groups. It also converts both the age and style properties of the input image. Photo images of different ages can be generated from a given sketch image. Through the introduced reconstructed identity loss and complete identity loss, the generated image effectively retains the identity features of the original image. Thus, the problem of image cross-style and cross-age translation is solved effectively. D-DualGANs can be used as a general framework to solve other computer vision tasks that need to complete two attribute conversions at the same time. However, some shortcomings are still observed in this method. For example, conversion between the different age groups requires training different models, such as to achieve 11~30 sketches to 31~50 photos and 11~30 sketches to 50+ photos. To train two D-DualGAN models separately is necessary. This work is cumbersome in practical applications and can be used as an improvement direction in the future so that training a network model can achieve conversion between all age groups.关键词:generative adversarial networks(GAN);image translation;face aging;heterogeneous image synthesis;face sketch synthesis71|172|2更新时间:2024-05-07
摘要:ObjectiveSketch-to-photo translation has a wide range of applications in the public safety and digital entertainment area. For example, it can help the police find fugitives and missing children or generate an avatar of social account. The existing algorithm of sketch-to-photo translation can only translate sketches into photos under the same age group. However, it does not solve the problem of cross-age sketch-to-photo translation. Cross-age sketch-to-photo translation characters also have a wide range of applications. For example, when the sketch image of the police at hand is out of date after a long time, the task can generate an aging photo based on outdated sketches to help the police find the suspect. Given that paired cross-age sketches and photo images are difficult to obtain, no data sets are available. To solve this problem, this study combines dual generative adversarial networks (DualGANs) and identity-preserved conditional generative adversarial networks (IPCGANs) to propose double dual generative adversarial networks (D-DualGANs).MethodDualGANs have the advantage of two-way conversion without the need to pair samples. However, it can only achieve a two-way conversion of an attribute and cannot achieve the conversion of two attributes at the same time. IPCGANs can complete the aging or rejuvenation of the face while retaining the personalized features of the person's face, but it cannot complete the two-way change between different age groups. This article considers the span of age as a domain conversion problem and considers the cross-age sketch-to-photo translation task as a problem of style and age conversion. We combined the characteristics of the above network to build D-DualGANs by setting up four generators and four discriminators to combat training. The method not only learns the mapping of the sketch domain to the photo domain and the mapping of the photo domain to the sketch domain but also learns the mapping of the source age group to the target age group and the mapping of the target age group to the original age group. In D-DualGANs, the original sketch image or the original photo image is successively completed by the four generators to achieve the four-domain conversion to obtain cross-age photo images or cross-age sketch images and reconstructed same-age sketch images or reconstructed same-age photo images. The generator is optimized by measuring the distance between the generated cross-age image and the reconstructed image of the same age by full reconstruction loss. We also used the identity retention module to introduce reconstructed identity loss to maintain the personalized features of the face. Eventually, the input sketch images and photo images from the different age groups are converted into photos and sketches of the other age group. This method does not require paired samples, currently overcoming the problem of lack of paired samples of cross-age sketches and photos.ResultThe experiments combine the images of the CUFS(CUHK(Chinese University of Hong Kong)-face sketeh database) and CUSFS(CUHK face sketch face recognition technology database) sketch photo datasets and produces corresponding age labels for each image based on the results of the age estimation software. According to the age label, the sketch and photo images in the datasets are divided into three groups of 11~30, 31~50, and 50+, and each age group is evenly distributed. Six D-DualGAN models were trained to realize the two-two conversion between sketches and photographic images of the three age groups, namely, the 11~30 sketch and the 31~50 photo, the 11~30 sketch and the 50+ photo, the 31~50 sketch and the 11~30 photo, the 31~50 sketch and the 50+ photo, the 50+ sketch and the 31~50 photo, the 50+ sketch and the 11~30 photo. As there is little research on cross-age sketch-to-photo translation. To illustrate the effectiveness of the method, the generated image obtained by this method is compared with the generated image obtained by DualGANs and then by IPCGANs. Our images are of good quality with less distortion and noise. Using an age estimate CNN to judge the age accuracy of the generated image, the mean absolute error (MAE) of our method is lower than the direct addition of DualGANs and IPCGANs. To evaluate the similarity between the generated image and the original image, we invite volunteers unrelated to this study to determine whether the generated image is the same as the original image. The results show that the resulting aging image is similar, and the resulting younger image is poor. Among them, the 31~50 photos generated by 11~30 sketches are the same as the original image.ConclusionD-DualGANs proposed in this study provides knowledge on mapping and inverse mapping between the sketch domain and the photo domain and the mapping and inverse mapping between the different age groups. It also converts both the age and style properties of the input image. Photo images of different ages can be generated from a given sketch image. Through the introduced reconstructed identity loss and complete identity loss, the generated image effectively retains the identity features of the original image. Thus, the problem of image cross-style and cross-age translation is solved effectively. D-DualGANs can be used as a general framework to solve other computer vision tasks that need to complete two attribute conversions at the same time. However, some shortcomings are still observed in this method. For example, conversion between the different age groups requires training different models, such as to achieve 11~30 sketches to 31~50 photos and 11~30 sketches to 50+ photos. To train two D-DualGAN models separately is necessary. This work is cumbersome in practical applications and can be used as an improvement direction in the future so that training a network model can achieve conversion between all age groups.关键词:generative adversarial networks(GAN);image translation;face aging;heterogeneous image synthesis;face sketch synthesis71|172|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveMultimodal medical image registration is a key step in medical image analysis and processing as it complements the information from different modality images and provides doctors with a variety of information about diseased tissues or organs. This method enables doctors to make accurate diagnosis and treatment plans. Image registration based on image synthesis is the main method for achieving high-precision registration. A high-quality composite image indicates good registration effect. However, current image-based registration algorithm has poor robustness in synthetic models and provides an insufficient representation of synthetic image feature information, resulting in low registration accuracy. In recent years, owing to the success of deep learning in many fields, medical image registration based on deep learning has become a focus of research. The synthetic model is trained according to the modal type of the image to be registered, and the synthetic model bidirectional synthetic image is used to guide the subsequent registration. Anatomical information is employed to guide the registration and improve the accuracy of multimodal image registration. Therefore, a multimodal brain image registration method based on residual dense relative average conditional generative adversarial network (RD-RaCGAN) is proposed in this study.MethodFirst, the RD-RaCGAN image synthesis model is constructed by combining the advantages of the relative average discriminator in the relativistic average generative adversarial network, which can enhance the model stability, and the advantages of the conditional generative adversarial network, which can improve the quality of the generated data, and also the ability of residual dense blocks to fully extract the characteristics of the deep network. Residual dense blocks are utilized as core components for building a generator. The purpose of this generator is to capture the law of sample distribution and generate a target image with specific significance, that is, to input a floating magnetic resonance (MR) or reference computed tomography (CT) image and generate the corresponding synthetic CT or synthetic MR image. The convolution neural network is used as a relative average discriminator, which correctly distinguishes an image generated by the generator from the real image. The generator and relative average discriminator perform confrontational training. First, the generator is fixed to train the relative average discriminator.Then, the relative average discriminator is fixed to train the generator, and the loop training is subsequently continued. During training, the least square function optimization generator and relative average discriminator, which are more stable and less saturated than the cross entropy function are selected. The ability of the generator and the relative average discriminator is enhanced, and the image generated by the generator can be falsified. At this point, the synthetic model training is completed. Subsequently, the CT image and MR image to be registered are bidirectionally synthesized into the corresponding reference MR image and floating CT image through the RD-RaCGAN synthesis model that has been trained. Four images obtained by bidirectional synthesis are registered by a region-adaptive registration algorithm. Specifically, the key points of the bone information are selected from the reference CT image and the floating CT image.The key points of the soft tissue information are selected from the floating MR image and the reference MR image, and the estimation of the deformation field is guided by the extracted key points. In other words, one deformation field is estimated from the floating CT image to the reference CT image, and a deformation field is estimated from the floating MR image to the reference MR image. At the same time, the idea of hierarchical symmetry is adopted to further guide the registration. The key points in the image are gradually increased when the reference and floating images are close to each other.Moreover, anatomical information is used to optimize the two deformation fields continuously until the difference between the two deformation fields reaches a minimum. The two deformation fields are fused to form the deformation field between the reference CT image and floating MR image. Finally, the deformation field is applied to the floating image to complete registration. Given that the synthesis of a target image from two images to be registered through the synthesis model requires time, the algorithm efficiency in this study is slightly lower than that of D.Demons(diffeomorphic demons) and ANTs-SyN(advanced normalization toolbox-symmetric normalization).ResultGiven that the quality of the synthesized image directly affects registration accuracy, three sets of contrast experiments are designed to verify the effect of the algorithm in this study. Different algorithms are by MR synthesis CT, and different algorithms are compared by CT synthesis MR, and comparison of the effect of different registration algorithms. The experimental results show that the target image synthesized by the synthesis model in this study is superior to those obtained by the other methods in terms of visual effect and objective evaluation index. The target image synthesized by RD-RaCGAN is similar to the real image and has less noise than the target images generated by the other synthetic methods. As can be seen from the bones of the synthesized brain image and the area near the air interface, the synthetic model in this work visually shows realistic texture details. Compared with the Powell-optimized MI(mutual information) method, ANTs-SyN, D.Demons, Cue-Aware Net(cue-aware deep regression network), and I-SI(intensity and spatial information) image registration methods, the normalized mutual information increased by 43.71%, 12.87%, 10.59%, 0.47%, and 5.59%, respectively. In addition, the mean square root error decreased by 39.80%, 38.67%, 15.68%, 4.38%, and 2.61%, respectively. The results obtained by the registration algorithm in this study are close to the reference image. The registration effect diagram that the difference between the registration image and the reference image obtained by the algorithm in this study is smaller than that obtained by the other three methods. Small difference between the two images means good registration effect.ConclusionThis study proposes a multimodal brain image registration method based on RD-RaCGAN, which solves the problem of the poor robustness of the model synthesis algorithm based on image synthesis, leading to the inaccuracy of the synthetic image and the poor registration effect.关键词:medical image registration;image synthesis;RaGAN (relativistic average generative adversarial network);residual dense blocks;least squares;CGAN (conditional generative adversarial network)79|87|3更新时间:2024-05-07
摘要:ObjectiveMultimodal medical image registration is a key step in medical image analysis and processing as it complements the information from different modality images and provides doctors with a variety of information about diseased tissues or organs. This method enables doctors to make accurate diagnosis and treatment plans. Image registration based on image synthesis is the main method for achieving high-precision registration. A high-quality composite image indicates good registration effect. However, current image-based registration algorithm has poor robustness in synthetic models and provides an insufficient representation of synthetic image feature information, resulting in low registration accuracy. In recent years, owing to the success of deep learning in many fields, medical image registration based on deep learning has become a focus of research. The synthetic model is trained according to the modal type of the image to be registered, and the synthetic model bidirectional synthetic image is used to guide the subsequent registration. Anatomical information is employed to guide the registration and improve the accuracy of multimodal image registration. Therefore, a multimodal brain image registration method based on residual dense relative average conditional generative adversarial network (RD-RaCGAN) is proposed in this study.MethodFirst, the RD-RaCGAN image synthesis model is constructed by combining the advantages of the relative average discriminator in the relativistic average generative adversarial network, which can enhance the model stability, and the advantages of the conditional generative adversarial network, which can improve the quality of the generated data, and also the ability of residual dense blocks to fully extract the characteristics of the deep network. Residual dense blocks are utilized as core components for building a generator. The purpose of this generator is to capture the law of sample distribution and generate a target image with specific significance, that is, to input a floating magnetic resonance (MR) or reference computed tomography (CT) image and generate the corresponding synthetic CT or synthetic MR image. The convolution neural network is used as a relative average discriminator, which correctly distinguishes an image generated by the generator from the real image. The generator and relative average discriminator perform confrontational training. First, the generator is fixed to train the relative average discriminator.Then, the relative average discriminator is fixed to train the generator, and the loop training is subsequently continued. During training, the least square function optimization generator and relative average discriminator, which are more stable and less saturated than the cross entropy function are selected. The ability of the generator and the relative average discriminator is enhanced, and the image generated by the generator can be falsified. At this point, the synthetic model training is completed. Subsequently, the CT image and MR image to be registered are bidirectionally synthesized into the corresponding reference MR image and floating CT image through the RD-RaCGAN synthesis model that has been trained. Four images obtained by bidirectional synthesis are registered by a region-adaptive registration algorithm. Specifically, the key points of the bone information are selected from the reference CT image and the floating CT image.The key points of the soft tissue information are selected from the floating MR image and the reference MR image, and the estimation of the deformation field is guided by the extracted key points. In other words, one deformation field is estimated from the floating CT image to the reference CT image, and a deformation field is estimated from the floating MR image to the reference MR image. At the same time, the idea of hierarchical symmetry is adopted to further guide the registration. The key points in the image are gradually increased when the reference and floating images are close to each other.Moreover, anatomical information is used to optimize the two deformation fields continuously until the difference between the two deformation fields reaches a minimum. The two deformation fields are fused to form the deformation field between the reference CT image and floating MR image. Finally, the deformation field is applied to the floating image to complete registration. Given that the synthesis of a target image from two images to be registered through the synthesis model requires time, the algorithm efficiency in this study is slightly lower than that of D.Demons(diffeomorphic demons) and ANTs-SyN(advanced normalization toolbox-symmetric normalization).ResultGiven that the quality of the synthesized image directly affects registration accuracy, three sets of contrast experiments are designed to verify the effect of the algorithm in this study. Different algorithms are by MR synthesis CT, and different algorithms are compared by CT synthesis MR, and comparison of the effect of different registration algorithms. The experimental results show that the target image synthesized by the synthesis model in this study is superior to those obtained by the other methods in terms of visual effect and objective evaluation index. The target image synthesized by RD-RaCGAN is similar to the real image and has less noise than the target images generated by the other synthetic methods. As can be seen from the bones of the synthesized brain image and the area near the air interface, the synthetic model in this work visually shows realistic texture details. Compared with the Powell-optimized MI(mutual information) method, ANTs-SyN, D.Demons, Cue-Aware Net(cue-aware deep regression network), and I-SI(intensity and spatial information) image registration methods, the normalized mutual information increased by 43.71%, 12.87%, 10.59%, 0.47%, and 5.59%, respectively. In addition, the mean square root error decreased by 39.80%, 38.67%, 15.68%, 4.38%, and 2.61%, respectively. The results obtained by the registration algorithm in this study are close to the reference image. The registration effect diagram that the difference between the registration image and the reference image obtained by the algorithm in this study is smaller than that obtained by the other three methods. Small difference between the two images means good registration effect.ConclusionThis study proposes a multimodal brain image registration method based on RD-RaCGAN, which solves the problem of the poor robustness of the model synthesis algorithm based on image synthesis, leading to the inaccuracy of the synthetic image and the poor registration effect.关键词:medical image registration;image synthesis;RaGAN (relativistic average generative adversarial network);residual dense blocks;least squares;CGAN (conditional generative adversarial network)79|87|3更新时间:2024-05-07 -
 摘要:ObjectiveComputer-aided diagnosis of lung cancer is the automatic recognition of lung lesions in computed tomography (CT) images through a computer image processing technology. Given that lung lesions are located in the lung areas, the contours of lung areas should be automatically marked on lung images first. Thus, lung segmentation is the first step in the computer-aided diagnosis of lung cancer. Current segmentation methods for pulmonary parenchyma, including normal and pathological, can be divided into three categories according to visual appearance, location relationship of shape, and whether or not the method is a hybrid. Methods based on visual appearance mostly consider the lower gray values of lung areas instead of surrounding tissues. Therefore, a pathological lung (especially including interstitial lung disease) is segmented by a classifier on the basis of gray and texture features. These methods mainly introduce the anatomical relationship of the lungs with the heart, liver, spleen, and rib. Hybrid methods establishes shape models and evolves lung contours according to surface features. They can achieve good segmentation results without noise samples in training sets but does not consider the problem of noise samples in the training sets during the construction of training shape models. The active shape model (ASM) based on principal component analysis (PCA) is an outstanding method, which can only deal with Gaussian noise. ASM is a statistical deformation model and uses PCA to obtain the average shape and the allowable range of shape of a training sample set and then establishes a shape model. ASM establishes a local feature appearance model according to the training sample set. Finally, ASM evolves the contour of the test image on the basis of the local feature appearance and shape models. Robust PCA (RPCA) in low rank theory is robust to any kind of noise. In addition, the shapes of a training sample set have a low rank attribute because the anatomical shapes of the human lungs are roughly the same. Therefore, this study combined RPCA with ASM to solve the problem that the correct shape model cannot be obtained because of noise samples in training sets.MethodFirst, a traditional method was used to segment the pulmonary region of training samples and generate lung boundary contours. The segmentation steps include extra-pulmonary region exclusion by iteration threshold and region growing segmentation methods, trachea elimination, internal cavity filling, liver elimination, and left and right lung separation. Second, we extracted 96 marker points on the left or right lung boundary contour. We assigned these marker points as
摘要:ObjectiveComputer-aided diagnosis of lung cancer is the automatic recognition of lung lesions in computed tomography (CT) images through a computer image processing technology. Given that lung lesions are located in the lung areas, the contours of lung areas should be automatically marked on lung images first. Thus, lung segmentation is the first step in the computer-aided diagnosis of lung cancer. Current segmentation methods for pulmonary parenchyma, including normal and pathological, can be divided into three categories according to visual appearance, location relationship of shape, and whether or not the method is a hybrid. Methods based on visual appearance mostly consider the lower gray values of lung areas instead of surrounding tissues. Therefore, a pathological lung (especially including interstitial lung disease) is segmented by a classifier on the basis of gray and texture features. These methods mainly introduce the anatomical relationship of the lungs with the heart, liver, spleen, and rib. Hybrid methods establishes shape models and evolves lung contours according to surface features. They can achieve good segmentation results without noise samples in training sets but does not consider the problem of noise samples in the training sets during the construction of training shape models. The active shape model (ASM) based on principal component analysis (PCA) is an outstanding method, which can only deal with Gaussian noise. ASM is a statistical deformation model and uses PCA to obtain the average shape and the allowable range of shape of a training sample set and then establishes a shape model. ASM establishes a local feature appearance model according to the training sample set. Finally, ASM evolves the contour of the test image on the basis of the local feature appearance and shape models. Robust PCA (RPCA) in low rank theory is robust to any kind of noise. In addition, the shapes of a training sample set have a low rank attribute because the anatomical shapes of the human lungs are roughly the same. Therefore, this study combined RPCA with ASM to solve the problem that the correct shape model cannot be obtained because of noise samples in training sets.MethodFirst, a traditional method was used to segment the pulmonary region of training samples and generate lung boundary contours. The segmentation steps include extra-pulmonary region exclusion by iteration threshold and region growing segmentation methods, trachea elimination, internal cavity filling, liver elimination, and left and right lung separation. Second, we extracted 96 marker points on the left or right lung boundary contour. We assigned these marker points as$x $ $y $ 关键词:low rank(LR);active shape model (ASM);robust principal component analysis (RPCA);lung segmentation;noise samples11|4|0更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveIsland is naturally formed around the ocean and exposed the sea level at high tide. As a special resource, islands play an important role in ocean development and utilization. Most of the island shorelines were extracted based on the compared and analyzed historical charts, topographic maps, and field survey results, which had several shortcomings, such as difficult observation, high cost, and long period. As a noncontact detection method, remote sensing has become the most important data source for island research. In recent years, deep learning has been widely used in various fields because of its ability to extract image features and to fit complex problems. In this study, a novel segmentation method for island shoreline was proposed, which was designed by the optimum index factor (OIF), convolutional neural network model (CNN), and a fully connected conditional random field (CRF).MethodThe proposed method included three aspects:1) According to the multiband characteristics of the remote sensing, the optimal band combination was selected based on the OIF. OIF is defined as the ratio of standard deviation of the combined bands to the correlation coefficients of each band. In this study, taking Landsat-8 remote sensing image as data source, the spectral characteristic information of each band of the image was analyzed based on OIF, and then 1, 5, and 6 bands were selected as the optimal band combination, which is considered as the input data for the island shoreline segmentation.2) According to the large coverage characteristics of the remote sensing, a deep convolution neural network model, Deeplab, was selected to obtain essential features of the input image. In general, segmentation methods extracted the characteristics of training samples relying on the artificial experiences, and a single-layer feature, without a hierarchical structure, was obtained by learning. These methods could supply shallow structures and simple features. This condition is the inadequacy of island shoreline segmentation. Thus, given that Deep CNN architecture has the ability to effectively encode spectral and spatial information, it had quickly become the prominent tool in remote sensing applications. Here, the representative deep CNN architecture and Deeplab neural network were selected. Deeplab neural network consists of three parts:(1) ResNet-101 residual network, which is used as the backbone network to the high-dimensional characteristics of remote sensing images. Residual learning can reduce the burden of deep network training, reduce the phenomenon of gradient disappearance caused by several layers, and improve the training accuracy. (2) Dilated convolution in Deeplab neural network, which can aggregate multiscale contextual information without losing resolution or analyzing rescaled images, increase the performance of dense prediction architectures by aggregating multiscale contextual information. (3) Deeplab neural network, which includes aurous spatial pyramid pooling (ASPP) module. It uses dilated convolution with different sampling rates and can effectively capture multiscale information of island images. 3) The island shoreline was optimized by the fully connected conditional random field. As an excellent representative of a probabilistic graphical model, the fully connected conditional random field can incorporate the spatial contextual information in the aspects of labels and observed data. The uniqueness of this model is that it can be flexible to modeling posterior distribution directly. We pre-classify the entire remote sending image into certain island shoreline types via the Deeplab model by using the results of class membership probabilities as the unary potential in the CRF model. The pairwise potential of CRF is defined by a linear combination of Gaussian kernels, which form a fully connected neighbor structure instead of the common four-neighbor or eight-neighbor structure. We use the mean field approximation method to obtain super pixels and correct the classification results by calculating their average posterior probabilities.ResultTaking four different islands as example, the island shorelines were segmented by the proposed method, full convolutional neural network (FCN) model, Deeplab model, and the visual interpretation method. Taking the relative error of area and perimeter of the island and the mean intersection over union (MIoU) as the accuracy parameters, the shoreline segmentation results of the four islands were compared. In addition, the relative error of area and perimeter of the proposed method (perimeter) are reduced by 4.6% and 17.7%, respectively. MIoU of the proposed method is increased by 5.2%.ConclusionThe comparison results showed that the proposed method overcomes the shortcomings of the traditional segmentation methods for island shoreline segmentation, and it takes full use of the band information of the remote sensing images.关键词:island shoreline;image segmentation;deep learning;optimum index factor;Deeplab neural network;fully connected conditional random fields83|5|4更新时间:2024-05-07
摘要:ObjectiveIsland is naturally formed around the ocean and exposed the sea level at high tide. As a special resource, islands play an important role in ocean development and utilization. Most of the island shorelines were extracted based on the compared and analyzed historical charts, topographic maps, and field survey results, which had several shortcomings, such as difficult observation, high cost, and long period. As a noncontact detection method, remote sensing has become the most important data source for island research. In recent years, deep learning has been widely used in various fields because of its ability to extract image features and to fit complex problems. In this study, a novel segmentation method for island shoreline was proposed, which was designed by the optimum index factor (OIF), convolutional neural network model (CNN), and a fully connected conditional random field (CRF).MethodThe proposed method included three aspects:1) According to the multiband characteristics of the remote sensing, the optimal band combination was selected based on the OIF. OIF is defined as the ratio of standard deviation of the combined bands to the correlation coefficients of each band. In this study, taking Landsat-8 remote sensing image as data source, the spectral characteristic information of each band of the image was analyzed based on OIF, and then 1, 5, and 6 bands were selected as the optimal band combination, which is considered as the input data for the island shoreline segmentation.2) According to the large coverage characteristics of the remote sensing, a deep convolution neural network model, Deeplab, was selected to obtain essential features of the input image. In general, segmentation methods extracted the characteristics of training samples relying on the artificial experiences, and a single-layer feature, without a hierarchical structure, was obtained by learning. These methods could supply shallow structures and simple features. This condition is the inadequacy of island shoreline segmentation. Thus, given that Deep CNN architecture has the ability to effectively encode spectral and spatial information, it had quickly become the prominent tool in remote sensing applications. Here, the representative deep CNN architecture and Deeplab neural network were selected. Deeplab neural network consists of three parts:(1) ResNet-101 residual network, which is used as the backbone network to the high-dimensional characteristics of remote sensing images. Residual learning can reduce the burden of deep network training, reduce the phenomenon of gradient disappearance caused by several layers, and improve the training accuracy. (2) Dilated convolution in Deeplab neural network, which can aggregate multiscale contextual information without losing resolution or analyzing rescaled images, increase the performance of dense prediction architectures by aggregating multiscale contextual information. (3) Deeplab neural network, which includes aurous spatial pyramid pooling (ASPP) module. It uses dilated convolution with different sampling rates and can effectively capture multiscale information of island images. 3) The island shoreline was optimized by the fully connected conditional random field. As an excellent representative of a probabilistic graphical model, the fully connected conditional random field can incorporate the spatial contextual information in the aspects of labels and observed data. The uniqueness of this model is that it can be flexible to modeling posterior distribution directly. We pre-classify the entire remote sending image into certain island shoreline types via the Deeplab model by using the results of class membership probabilities as the unary potential in the CRF model. The pairwise potential of CRF is defined by a linear combination of Gaussian kernels, which form a fully connected neighbor structure instead of the common four-neighbor or eight-neighbor structure. We use the mean field approximation method to obtain super pixels and correct the classification results by calculating their average posterior probabilities.ResultTaking four different islands as example, the island shorelines were segmented by the proposed method, full convolutional neural network (FCN) model, Deeplab model, and the visual interpretation method. Taking the relative error of area and perimeter of the island and the mean intersection over union (MIoU) as the accuracy parameters, the shoreline segmentation results of the four islands were compared. In addition, the relative error of area and perimeter of the proposed method (perimeter) are reduced by 4.6% and 17.7%, respectively. MIoU of the proposed method is increased by 5.2%.ConclusionThe comparison results showed that the proposed method overcomes the shortcomings of the traditional segmentation methods for island shoreline segmentation, and it takes full use of the band information of the remote sensing images.关键词:island shoreline;image segmentation;deep learning;optimum index factor;Deeplab neural network;fully connected conditional random fields83|5|4更新时间:2024-05-07 -
 摘要:ObjectiveObtaining soil moisture data with high temporal and spatial resolution is important for agricultural management and scientific research. The goal of this study is to use the Fengyun meteorological satellite as the data source, and utilize the advantage of convolutional neural network (CNN) that can independently learn the deep correlation between input variables to obtain high-quality soil moisture data. Fengyun 3 meteorological satellite is China's second-generation meteorological satellite. The goal of Fengyun 3 is to acquire all-weather, multi-spectral and 3D observations of global atmospheric and geophysical elements, providing satellite observation data to medium-term numerical weather prediction; monitoring ecological environment and large-scale natural disasters; providing satellite meteorological information for global environmental change, global climate change research, and others. The medium-resolution spectral imager Ⅱ (MERSI-Ⅱ) is one of the main loads of Fengyun 3D (FY-3D) and is equipped with 25 channels, including 16 visible-near-infrared channels, 3 short-wave infrared channels, and 6 medium-long infrared channels. Among the 25 channels, 6 channels with 250 m ground resolution and 19 channels with 1 000 m ground resolution are obtained. The research used FY-3D to obtain high-precision soil moisture data and constructed a soil moisture monitoring technology system that can greatly reduce the dependence on foreign data, operating cost of large-scale monitoring systems, and improve system stability, safety, and monitoring timeliness. Improving the ability of meteorological services and level of domestic satellite applications is important. To obtain high spatial and temporal resolution soil moisture data using Fengyun satellite imagery, this study proposes a method of extracting soil moisture data using convolutional neural network(CNN).MethodCNN is a new machine learning technology that was newly developed in recent years and has attracted research attention because of its powerful autonomous learning ability. This technology has achieved great success in image classification, image segmentation, and other fields. This study constructed a soil moisture convolutional neural network (SMCNN) to achieve the goal of obtaining large-scale high-precision soil moisture monitoring using FY-3D remote sensing image. The SMCNN model includes seven parts, namely, input, temperature subnetwork, normalized difference vegetation index (NDVI) extraction module, enhanced vegetation index (EVI) extraction module, surface albedo extraction module, soil moisture subnetwork, and output. The temperature and soil moisture subnetworks contain a feature extractor and an encoder. The feature extractor is used to generate a feature vector for each pixel, where the feature extractor of the temperature subnetwork has 11 convolutional layers, and the feature extractor of the humidity subnetwork consists of 9 convolutional layers, and the convolutional layer uses a 1×1 type convolution kernel. The encoder is used to fit the extracted features to the target variable. Both subnetworks use the average variance as a loss function. In the model training stage, the preprocessed FY-3D image and corresponding observation point data are used as inputs, and in the model test phase, only the preprocessed FY-3D image is used as the input. The temperature subnetwork is used to obtain the ground temperature from the FY-3D image, the NDVI extraction module is used to extract the NDVI from the FY-3D image, the EVI extraction module is used to extract the EVI from the FY-3D image, and the surface albedo extraction module is used to obtain surface albedo. The extraction results of the aforementioned four parts are used as input to the soil moisture subnetwork. The soil moisture subnetwork uses the extracted ground temperature, NDVI, EVI, and ground albedo to retrieve soil moisture. The output of the model is the pixel-by-pixel soil moisture value. The model is trained using a stochastic gradient descent algorithm, and finally the trained model is used to extract regional soil moisture data.ResultNingxia was selected as the experimental area. The FY-3D used in this study is all from the satellite ground receiving station of Ningxia Meteorological Bureau, including 161 images in 2018 and 92 images in 2019, with a total of 253. After the images were stitched together, a total of 92 images covering the entire territory of Ningxia were formed. The ground observation data used in this study came from the automatic weather station deployed by the Ningxia Meteorological Bureau. The time range was from January 1, 2016 to June 30, 2019. A total of 36 ground temperature stations and 37 soil moisture stations were observed. To verify the validity and rationality of this proposed method, we selected the linear regression and back propagation(BP) neural network models as the contrast models to conduct the data experiment. The mean square error was selected as the evaluation index. The comparison experimental results show that the RMSE of the SMCNN model is 0.006 7, which is higher than the comparison model. The experimental results show that the SMCNN model has advantages in extracting soil moisture from wind cloud images.ConclusionThe SMCNN model proposed in this paper fully utilizes deep learning technology to learn independently and improves the accuracy of obtaining soil moisture. The main contributions of this study are as follows:1) Based on the analysis of the characteristics of FY-3D data, a step-by-step inversion strategy is established for the inversion of soil moisture requirements, and each step inversion uses a more relevant variable. The proposed strategy is an important reference for inverting other variables. 2) CNNs are used to construct network structures for inversion of surface temperature and soil moisture, and organized into a complete soil moisture inversion network structure. This structure enables direct access to soil moisture data from FY-3D data. 3) The feature value extracted by the 1×1 type convolution kernel used can be regarded as a spectral index and has a physical meaning. The main disadvantage of this study is that in the late stage of crop growth, the effect of vegetation index becomes invalid due to the saturation problem, which influences the inversion effect. This study aims to find other suitable supplementary parameters to introduce into the model to solve the effect of vegetation index saturation.关键词:deep learning;convolutional neural network;Fengyun 3D remote sensing;data fitting;soil moisture;Ningxia Hui Autonomous Region11|4|3更新时间:2024-05-07
摘要:ObjectiveObtaining soil moisture data with high temporal and spatial resolution is important for agricultural management and scientific research. The goal of this study is to use the Fengyun meteorological satellite as the data source, and utilize the advantage of convolutional neural network (CNN) that can independently learn the deep correlation between input variables to obtain high-quality soil moisture data. Fengyun 3 meteorological satellite is China's second-generation meteorological satellite. The goal of Fengyun 3 is to acquire all-weather, multi-spectral and 3D observations of global atmospheric and geophysical elements, providing satellite observation data to medium-term numerical weather prediction; monitoring ecological environment and large-scale natural disasters; providing satellite meteorological information for global environmental change, global climate change research, and others. The medium-resolution spectral imager Ⅱ (MERSI-Ⅱ) is one of the main loads of Fengyun 3D (FY-3D) and is equipped with 25 channels, including 16 visible-near-infrared channels, 3 short-wave infrared channels, and 6 medium-long infrared channels. Among the 25 channels, 6 channels with 250 m ground resolution and 19 channels with 1 000 m ground resolution are obtained. The research used FY-3D to obtain high-precision soil moisture data and constructed a soil moisture monitoring technology system that can greatly reduce the dependence on foreign data, operating cost of large-scale monitoring systems, and improve system stability, safety, and monitoring timeliness. Improving the ability of meteorological services and level of domestic satellite applications is important. To obtain high spatial and temporal resolution soil moisture data using Fengyun satellite imagery, this study proposes a method of extracting soil moisture data using convolutional neural network(CNN).MethodCNN is a new machine learning technology that was newly developed in recent years and has attracted research attention because of its powerful autonomous learning ability. This technology has achieved great success in image classification, image segmentation, and other fields. This study constructed a soil moisture convolutional neural network (SMCNN) to achieve the goal of obtaining large-scale high-precision soil moisture monitoring using FY-3D remote sensing image. The SMCNN model includes seven parts, namely, input, temperature subnetwork, normalized difference vegetation index (NDVI) extraction module, enhanced vegetation index (EVI) extraction module, surface albedo extraction module, soil moisture subnetwork, and output. The temperature and soil moisture subnetworks contain a feature extractor and an encoder. The feature extractor is used to generate a feature vector for each pixel, where the feature extractor of the temperature subnetwork has 11 convolutional layers, and the feature extractor of the humidity subnetwork consists of 9 convolutional layers, and the convolutional layer uses a 1×1 type convolution kernel. The encoder is used to fit the extracted features to the target variable. Both subnetworks use the average variance as a loss function. In the model training stage, the preprocessed FY-3D image and corresponding observation point data are used as inputs, and in the model test phase, only the preprocessed FY-3D image is used as the input. The temperature subnetwork is used to obtain the ground temperature from the FY-3D image, the NDVI extraction module is used to extract the NDVI from the FY-3D image, the EVI extraction module is used to extract the EVI from the FY-3D image, and the surface albedo extraction module is used to obtain surface albedo. The extraction results of the aforementioned four parts are used as input to the soil moisture subnetwork. The soil moisture subnetwork uses the extracted ground temperature, NDVI, EVI, and ground albedo to retrieve soil moisture. The output of the model is the pixel-by-pixel soil moisture value. The model is trained using a stochastic gradient descent algorithm, and finally the trained model is used to extract regional soil moisture data.ResultNingxia was selected as the experimental area. The FY-3D used in this study is all from the satellite ground receiving station of Ningxia Meteorological Bureau, including 161 images in 2018 and 92 images in 2019, with a total of 253. After the images were stitched together, a total of 92 images covering the entire territory of Ningxia were formed. The ground observation data used in this study came from the automatic weather station deployed by the Ningxia Meteorological Bureau. The time range was from January 1, 2016 to June 30, 2019. A total of 36 ground temperature stations and 37 soil moisture stations were observed. To verify the validity and rationality of this proposed method, we selected the linear regression and back propagation(BP) neural network models as the contrast models to conduct the data experiment. The mean square error was selected as the evaluation index. The comparison experimental results show that the RMSE of the SMCNN model is 0.006 7, which is higher than the comparison model. The experimental results show that the SMCNN model has advantages in extracting soil moisture from wind cloud images.ConclusionThe SMCNN model proposed in this paper fully utilizes deep learning technology to learn independently and improves the accuracy of obtaining soil moisture. The main contributions of this study are as follows:1) Based on the analysis of the characteristics of FY-3D data, a step-by-step inversion strategy is established for the inversion of soil moisture requirements, and each step inversion uses a more relevant variable. The proposed strategy is an important reference for inverting other variables. 2) CNNs are used to construct network structures for inversion of surface temperature and soil moisture, and organized into a complete soil moisture inversion network structure. This structure enables direct access to soil moisture data from FY-3D data. 3) The feature value extracted by the 1×1 type convolution kernel used can be regarded as a spectral index and has a physical meaning. The main disadvantage of this study is that in the late stage of crop growth, the effect of vegetation index becomes invalid due to the saturation problem, which influences the inversion effect. This study aims to find other suitable supplementary parameters to introduce into the model to solve the effect of vegetation index saturation.关键词:deep learning;convolutional neural network;Fengyun 3D remote sensing;data fitting;soil moisture;Ningxia Hui Autonomous Region11|4|3更新时间:2024-05-07 -
 摘要:ObjectiveThe classification of different earth objects is an important task in remote sensing image processing. However, the classification results are highly sensitive to weather conditions, especially haze and cloud. The cloud is different from the haze, but distinguishing between a thin cloud and haze is difficult due to the large coverage width of the remote sensing satellite. These weather conditions degrade the features of earth objects and decrease the interpretation accuracy of the features as well as the classification accuracy of different earth objects. The conventional methods of haze and thin cloud removal are designed to obtain the haze-free image by adjusting the contrast and saturation. Representative methods mainly include image dehazing algorithms based on the atmospheric scattering model and image contrast enhancement algorithms based on frequency domain analysis. The former is one of the most common methods which combined with the atmospheric physical model, can effectively remove haze and thin clouds. However, this model is complex and many of its parameters need to be set artificially if no appropriate constraint conditions exist, and new noise interference appears during the process of haze and cloud removal. Therefore, the dark channel prior (DCP) algorithm simplifies this model through prior knowledge, which makes haze and cloud removal easier and more efficient. Another method uses frequency domain analysis to enhance the image contrast, this method restores images by maximizing their contrast locally. However, this method does not combine with atmospheric scattering model and cannot be applied to complex scenes. In addition to these methods of haze and cloud removal with a single image, the multitemporal remote sensing image is used to remove the cloud by comparing these images of the same area in different periods. However, this type of method requires complicated image sampling and processing procedures. Therefore, the research on haze and cloud removal with a single remote sensing image is important. The GF-2 satellite is the first civil optical remote-sensing satellite independently developed by China with a spatial resolution better than 1 m. Haze and cloud regions are observed in the optical remote sensing images of southwestern China collected by GF-2. In this study, the southwestern region was selected as the study area. A haze thickness map (HTM) algorithm combined with Gaussian curvature filtering was proposed to remove the haze and cloud for GF-2 optical images.MethodWeather factors cause visible light scattering when the scattered natural light is added to the target objects, and leads to the degradation of a remote sensing image. The traditional HTM algorithm achieves haze removal by calculating the HTM to represent uneven haze. The HTM is derived from the technology of dark-object subtraction. In this paper, the HTM is calculated by searching dark pixels using a local non-overlapping window for the entire image in red band, and smoothed by Gaussian curvature filtering and interpolated up to the size of the original band. The curvature filter can reduce noise interference during image processing and effectively preserve the edge information. Compared with guided filtering and bilateral filtering, this method can improve accuracy and preserve the local details of the image better. The improved 2D maximum entropy is used to automatically determine the segmentation threshold by extracting and correcting the highly bright patches in HTM to improve the accuracy of the obtained HTM. In a local area at the edge points, the HTM values have small variation and the haze is usually in the low-frequency part of the image, thereby correcting the pixel values at the edges by replacing the minimum with the mean. Finally, a haze-free image is restored by precise HTM.ResultFive types of images were selected and degraded by uneven haze and cloud from different regions for comparison. The evaluation results demonstrated that the improved method is superior to the conventional methods. In this paper, the improved DCP, traditional HTM algorithm, and improved algorithm are compared. Four evaluation indicators including the average grayscale, average gradient, signal-to-noise ratio (SNR), and contrast are used to compare the image de-hazing quality of the different methods. The average grayscale value can reflect whether the dehazing is effective. As the cloud is removed, the average grayscale of the image decreases. The average gradient reflects the details of the image and the change in texture information. The SNR can reflect the noise level such as haze and cloud. The contrast can reflect the clarity of the image. The results of the improved algorithm show that the average grayscale is reduced by 34.96%, the average gradient is increased by 18.48%, the SNR is increased by 34.77%, and the contrast is increased by 39.41%. The qualitative and quantitative experimental results demonstrate that our method can deal with uneven haze and cloud, and the dehazing result is superior to the conventional methods.ConclusionIn this study, the haze and thin cloud are processed based on the traditional haze detection method. The results show that the improved method is suitable for uneven haze and cloud problems, can recover a haze-free image, effectively improve the image detail information and visuals according to the human vision, as well as improve the utilization rate of remote sensing satellite images and avoid overfitting. Therefore, the improved HTM algorithm can achieve the sufficient de-hazing result and reduce the color distortion phenomenon.关键词:remote sensing image;Gaussian curvature filtering;uneven haze and cloud removal;2D maximum entropy;GF-212|4|1更新时间:2024-05-07
摘要:ObjectiveThe classification of different earth objects is an important task in remote sensing image processing. However, the classification results are highly sensitive to weather conditions, especially haze and cloud. The cloud is different from the haze, but distinguishing between a thin cloud and haze is difficult due to the large coverage width of the remote sensing satellite. These weather conditions degrade the features of earth objects and decrease the interpretation accuracy of the features as well as the classification accuracy of different earth objects. The conventional methods of haze and thin cloud removal are designed to obtain the haze-free image by adjusting the contrast and saturation. Representative methods mainly include image dehazing algorithms based on the atmospheric scattering model and image contrast enhancement algorithms based on frequency domain analysis. The former is one of the most common methods which combined with the atmospheric physical model, can effectively remove haze and thin clouds. However, this model is complex and many of its parameters need to be set artificially if no appropriate constraint conditions exist, and new noise interference appears during the process of haze and cloud removal. Therefore, the dark channel prior (DCP) algorithm simplifies this model through prior knowledge, which makes haze and cloud removal easier and more efficient. Another method uses frequency domain analysis to enhance the image contrast, this method restores images by maximizing their contrast locally. However, this method does not combine with atmospheric scattering model and cannot be applied to complex scenes. In addition to these methods of haze and cloud removal with a single image, the multitemporal remote sensing image is used to remove the cloud by comparing these images of the same area in different periods. However, this type of method requires complicated image sampling and processing procedures. Therefore, the research on haze and cloud removal with a single remote sensing image is important. The GF-2 satellite is the first civil optical remote-sensing satellite independently developed by China with a spatial resolution better than 1 m. Haze and cloud regions are observed in the optical remote sensing images of southwestern China collected by GF-2. In this study, the southwestern region was selected as the study area. A haze thickness map (HTM) algorithm combined with Gaussian curvature filtering was proposed to remove the haze and cloud for GF-2 optical images.MethodWeather factors cause visible light scattering when the scattered natural light is added to the target objects, and leads to the degradation of a remote sensing image. The traditional HTM algorithm achieves haze removal by calculating the HTM to represent uneven haze. The HTM is derived from the technology of dark-object subtraction. In this paper, the HTM is calculated by searching dark pixels using a local non-overlapping window for the entire image in red band, and smoothed by Gaussian curvature filtering and interpolated up to the size of the original band. The curvature filter can reduce noise interference during image processing and effectively preserve the edge information. Compared with guided filtering and bilateral filtering, this method can improve accuracy and preserve the local details of the image better. The improved 2D maximum entropy is used to automatically determine the segmentation threshold by extracting and correcting the highly bright patches in HTM to improve the accuracy of the obtained HTM. In a local area at the edge points, the HTM values have small variation and the haze is usually in the low-frequency part of the image, thereby correcting the pixel values at the edges by replacing the minimum with the mean. Finally, a haze-free image is restored by precise HTM.ResultFive types of images were selected and degraded by uneven haze and cloud from different regions for comparison. The evaluation results demonstrated that the improved method is superior to the conventional methods. In this paper, the improved DCP, traditional HTM algorithm, and improved algorithm are compared. Four evaluation indicators including the average grayscale, average gradient, signal-to-noise ratio (SNR), and contrast are used to compare the image de-hazing quality of the different methods. The average grayscale value can reflect whether the dehazing is effective. As the cloud is removed, the average grayscale of the image decreases. The average gradient reflects the details of the image and the change in texture information. The SNR can reflect the noise level such as haze and cloud. The contrast can reflect the clarity of the image. The results of the improved algorithm show that the average grayscale is reduced by 34.96%, the average gradient is increased by 18.48%, the SNR is increased by 34.77%, and the contrast is increased by 39.41%. The qualitative and quantitative experimental results demonstrate that our method can deal with uneven haze and cloud, and the dehazing result is superior to the conventional methods.ConclusionIn this study, the haze and thin cloud are processed based on the traditional haze detection method. The results show that the improved method is suitable for uneven haze and cloud problems, can recover a haze-free image, effectively improve the image detail information and visuals according to the human vision, as well as improve the utilization rate of remote sensing satellite images and avoid overfitting. Therefore, the improved HTM algorithm can achieve the sufficient de-hazing result and reduce the color distortion phenomenon.关键词:remote sensing image;Gaussian curvature filtering;uneven haze and cloud removal;2D maximum entropy;GF-212|4|1更新时间:2024-05-07
Remote Sensing Image Processing
-
 摘要:ObjectiveDuring hyperspectral remote sensing imaging, each captured pixel in the image always has mixed spectrum of several pure constituent spectra due to the low spatial resolution of hyperspectral cameras and the diversity of spectral signatures in nature scenes. The mixed pixels limit the application of hyperspectral images (HSI), such as target detection, classification, and change detection, to a great extent. In many real-world applications, subpixel level accuracy is often required to improve the performance. Thus, the unmixing is very essential in the HSI analysis. In most scenarios, the spectral signatures in HSI, also termed endmembers, are unknown in advance. Therefore, the unmixing has to be performed in an unsupervised way, usually involving two steps, namely, endmember extraction and abundance coefficient estimation. In this study, we assume that the generation of mixed pixels in HSI is based on a linear mixing model. Moreover, the observed HSI, endmembers in the image, and the corresponding abundances are all non-negative, according to their physical meaning. In recent years, non-negative matrix factorization (NMF) based approaches has received extensive attention and become a research hotspot because of making full use of the HSI sparsity. However, existing non-negative matrix factorization-based approaches are not robust enough for noisy HSI data. The main reason is that a least square loss function, which is sensitive to noise and prone to large deviations, is always used for endmember extraction in these approaches. To overcome the drawbacks of NMF-based approaches, we can improve the robustness of the unmixing approaches by choosing a new loss function, which is robust. In this study, we utilize more robust L1 loss function for NMF when performing the endmember extraction and proposed a novel unsupervised hyperspectral unmixing method based on robust NMF.MethodTo perform the unsupervised hyperspectral unmixing, with the endmembers unknown, both endmember extraction and the corresponding abundance fraction estimation are needed to be solved. The hyperspectral unmixing problem can be modeled as a NMF due to the similarity of underlying mathematical models. In real scenes, hyperspectral image data often contains noise and missing values, and objective functions used for endmember extraction in existing NMF-based approaches are sensitive to noise and prone to large deviations. Therefore, we use the L1 norm on the reconstruction error term instead of the common L2 norm to construct a new objective function. However, the new objective function is nonconvex. We can obtain the global optimal solution of one variable when the other is fixed. In addition, considering the nonsmooth L1 norm term, to solve the optimization problem in the proposed unmixing approach is challenging. Thus, we propose an efficient multiplicative updating algorithm with the theory of the iterative reweighted least squares. In this way, each iteration can guarantee positive result. Finally, we can obtain the extracted endmembers and estimated abundances when iterative convergences.ResultTo verify the effectiveness and competitiveness of the proposed unsupervised unmixing, synthetic and real-world dataset are used in the experiments. The performance of the proposed approach is comprehensively evaluated with visual observations and quantitative measures. For quantitative comparison, three categories of evaluation indexes are used in this study. The indexes to measure the quality of the endmember extraction are the spectral angle distance (SAD) and the spectral information divergence (SID). Similarly, the performance discriminators to evaluate the accuracy of the abundance estimation are the abundance angle distance (AAD) and the abundance information divergence (AID). Moreover, the metrics to evaluate the performance of the reconstruction of spectral mixtures are the root mean square error (RMSE) and the signal to reconstruction error (SRE).With the synthetic dataset, we compare the proposed method with five representative methods. Among them, vertex component analysis (VCA) is a classic geometrical-based method and also the initialization of the proposed method. Minimum volume constrained nonnegative matrix factorization (MVCNMF), robust collaborative NMF (RCoNMF), and total variation regularized reweighted sparse NMF (TVWSNMF) are NMF-based approaches, and an untied denoising autoencoder with sparsity for spectral unmixing (uDAS) is deep learning-based approach. The experimental results showed that, when signal-to-noise ratio (SNR) is 20 dB, the SAD (less is better) of the proposed algorithm decreased by 41.3%, 43%, 65.6%, 10.5%, and 58.0% compared with the VCA, MVCNMF, RCoNMF, TVWSNMF, and uDAS; the SID (less is better) decreased by 68.9%, 83.6%, 95.5%, 62.2%, and 97.0%; the AAD (less is better) decreased by 28.5%, 12.5%, 45.8%, 8.4%, and 42.5%; the AID (less is better) decreased by 38.1%, 28.7%, 51.1%, 17.2%, and 49.7%; the RMSE (less is better) decreased by 48.3%, 31.2%, 68.9%, 33.5%, and 67.8%; and SRE (dB) (higher is better) increased by 23.7%, 14.5%, 60.0%, 9.3%, and 47.3%, respectively. With the real world data set, the ability of the proposed approach to extract endmembers can be evaluated using the corresponding USGS(United States Geological Survey) library signatures. Moreover, given that the ground truth abundance maps are unknown exactly, the abundance estimation results can only be evaluated qualitatively. The experimental results demonstrated that the extracted endmembers achieved a good match with the ground truth signatures. In addition, the proposed approach achieved piecewise smooth abundance maps with high spatial consistency.ConclusionIn this study, we proposed a novel NMF-based unmixing approach to perform the unsupervised hyperspectral unmixing in noisy environments. Different from the current NMF-based unmixing approaches, robust L1 norm is used as the reconstruction error term in the objective function to improve the accuracy of the endmember extraction and abundance estimation. Compared with the state-of-the-art approaches, experimental results of synthetic data set and real world data set illustrate that the proposed approach performs well under different noise conditions, especially in low SNR.关键词:nonnegative matrix factorization (NMF);unsupervised mixed pixel unmixing;endmember extraction;abundance estimation;hyperspectral image (HSI)13|4|2更新时间:2024-05-07
摘要:ObjectiveDuring hyperspectral remote sensing imaging, each captured pixel in the image always has mixed spectrum of several pure constituent spectra due to the low spatial resolution of hyperspectral cameras and the diversity of spectral signatures in nature scenes. The mixed pixels limit the application of hyperspectral images (HSI), such as target detection, classification, and change detection, to a great extent. In many real-world applications, subpixel level accuracy is often required to improve the performance. Thus, the unmixing is very essential in the HSI analysis. In most scenarios, the spectral signatures in HSI, also termed endmembers, are unknown in advance. Therefore, the unmixing has to be performed in an unsupervised way, usually involving two steps, namely, endmember extraction and abundance coefficient estimation. In this study, we assume that the generation of mixed pixels in HSI is based on a linear mixing model. Moreover, the observed HSI, endmembers in the image, and the corresponding abundances are all non-negative, according to their physical meaning. In recent years, non-negative matrix factorization (NMF) based approaches has received extensive attention and become a research hotspot because of making full use of the HSI sparsity. However, existing non-negative matrix factorization-based approaches are not robust enough for noisy HSI data. The main reason is that a least square loss function, which is sensitive to noise and prone to large deviations, is always used for endmember extraction in these approaches. To overcome the drawbacks of NMF-based approaches, we can improve the robustness of the unmixing approaches by choosing a new loss function, which is robust. In this study, we utilize more robust L1 loss function for NMF when performing the endmember extraction and proposed a novel unsupervised hyperspectral unmixing method based on robust NMF.MethodTo perform the unsupervised hyperspectral unmixing, with the endmembers unknown, both endmember extraction and the corresponding abundance fraction estimation are needed to be solved. The hyperspectral unmixing problem can be modeled as a NMF due to the similarity of underlying mathematical models. In real scenes, hyperspectral image data often contains noise and missing values, and objective functions used for endmember extraction in existing NMF-based approaches are sensitive to noise and prone to large deviations. Therefore, we use the L1 norm on the reconstruction error term instead of the common L2 norm to construct a new objective function. However, the new objective function is nonconvex. We can obtain the global optimal solution of one variable when the other is fixed. In addition, considering the nonsmooth L1 norm term, to solve the optimization problem in the proposed unmixing approach is challenging. Thus, we propose an efficient multiplicative updating algorithm with the theory of the iterative reweighted least squares. In this way, each iteration can guarantee positive result. Finally, we can obtain the extracted endmembers and estimated abundances when iterative convergences.ResultTo verify the effectiveness and competitiveness of the proposed unsupervised unmixing, synthetic and real-world dataset are used in the experiments. The performance of the proposed approach is comprehensively evaluated with visual observations and quantitative measures. For quantitative comparison, three categories of evaluation indexes are used in this study. The indexes to measure the quality of the endmember extraction are the spectral angle distance (SAD) and the spectral information divergence (SID). Similarly, the performance discriminators to evaluate the accuracy of the abundance estimation are the abundance angle distance (AAD) and the abundance information divergence (AID). Moreover, the metrics to evaluate the performance of the reconstruction of spectral mixtures are the root mean square error (RMSE) and the signal to reconstruction error (SRE).With the synthetic dataset, we compare the proposed method with five representative methods. Among them, vertex component analysis (VCA) is a classic geometrical-based method and also the initialization of the proposed method. Minimum volume constrained nonnegative matrix factorization (MVCNMF), robust collaborative NMF (RCoNMF), and total variation regularized reweighted sparse NMF (TVWSNMF) are NMF-based approaches, and an untied denoising autoencoder with sparsity for spectral unmixing (uDAS) is deep learning-based approach. The experimental results showed that, when signal-to-noise ratio (SNR) is 20 dB, the SAD (less is better) of the proposed algorithm decreased by 41.3%, 43%, 65.6%, 10.5%, and 58.0% compared with the VCA, MVCNMF, RCoNMF, TVWSNMF, and uDAS; the SID (less is better) decreased by 68.9%, 83.6%, 95.5%, 62.2%, and 97.0%; the AAD (less is better) decreased by 28.5%, 12.5%, 45.8%, 8.4%, and 42.5%; the AID (less is better) decreased by 38.1%, 28.7%, 51.1%, 17.2%, and 49.7%; the RMSE (less is better) decreased by 48.3%, 31.2%, 68.9%, 33.5%, and 67.8%; and SRE (dB) (higher is better) increased by 23.7%, 14.5%, 60.0%, 9.3%, and 47.3%, respectively. With the real world data set, the ability of the proposed approach to extract endmembers can be evaluated using the corresponding USGS(United States Geological Survey) library signatures. Moreover, given that the ground truth abundance maps are unknown exactly, the abundance estimation results can only be evaluated qualitatively. The experimental results demonstrated that the extracted endmembers achieved a good match with the ground truth signatures. In addition, the proposed approach achieved piecewise smooth abundance maps with high spatial consistency.ConclusionIn this study, we proposed a novel NMF-based unmixing approach to perform the unsupervised hyperspectral unmixing in noisy environments. Different from the current NMF-based unmixing approaches, robust L1 norm is used as the reconstruction error term in the objective function to improve the accuracy of the endmember extraction and abundance estimation. Compared with the state-of-the-art approaches, experimental results of synthetic data set and real world data set illustrate that the proposed approach performs well under different noise conditions, especially in low SNR.关键词:nonnegative matrix factorization (NMF);unsupervised mixed pixel unmixing;endmember extraction;abundance estimation;hyperspectral image (HSI)13|4|2更新时间:2024-05-07
Column of ChinaMM 2019
-
 摘要:ObjectiveAutomatic facial expression recognition (FER) aims at designing a model to identify human emotions automatically from facial images. Several methods have been proposed in the past 20 years, and all the previous works can be generally divided into two categories:image-based methods and video-based methods. In this study, we propose a new image-based FER method, guided with facial landmarks. Facial expression is actually an ultimate representation of facial muscle movement, which consists of various facial action units (AUs) distributing among the facial organs. Meanwhile, the purpose of facial landmark detection is to localize the position and shape of face and facial organs. Thus, a good relationship is observed between the facial expression and facial landmark detection. Based on this observation, some works try to combine the facial expression recognition and facial landmark localization with different strategies, and most of them extract the geometric features or only pay attention to texture information around landmarks to recognize the facial expression. Although these methods achieved great results, they still have some issues. They assist the task of FER by using given facial landmarks as prior information, but internal connection between them is ignored. To solve this problem, a deep multitask framework is proposed in this study.MethodA multitask network is designed to recognize facial expressions and locate facial landmarks simultaneously because both tasks pay attention to features around facial organs, including the eyebrows, eyes, nose, and mouth (points around the external counter are abandoned). However, to obtain the ground truth of facial landmarks in practices is not easy, especially in some FER benchmarks. We utilize a stacked hourglass network to detect facial landmark points first because stacked hourglass network achieves excellent performance in the task of face alignment, which was also demonstrated in the 2nd Facial Landmark Localization Competition conjunction with CVPR(IEEE Conference on Computer Vision and Pattern Recognition) 2017. The designed network has two branches, corresponding to two tasks accordingly. Considering the relationships between the two tasks, they share two convolution layers in the first. The structure of facial landmark localization is simple, including three convolution layers and a fully connected layer because it simply assists the facial expression recognition in selecting feature. For the branch of facial expression recognition, its structure is complicated, in which the inception module is introduced and convolution kernels with different size are applied to capture the multiscale features. Two tasks are optimized together with a unified loss to learn the network parameters, in which the popular distance loss and the entropy loss are designed to facial landmark localization and facial expression recognition. Although features around the facial landmarks obtain good response under the supervision of two tasks, other areas still exist some noises. For example, part collar is retained in the cropped face image, which has a bad effect on facial expression recognition. To deal with this issue, location attention maps are created with the landmarks obtained in the branch of facial landmark localization. The proposed location attention map is a weight matrix sharing the same size with the corresponding feature maps, and it indicates the importance of each position. Inspired by the stacked hourglass network, a series of heat maps is generated first by taking the coordinate of each point as the mean value and selecting an appropriate variance with Gaussian distribution. Then, the max-pooling operation is conducted to merge these maps to generate the location attention map. The generated location attention maps rely on the performance of facial landmark localization since they utilize the position of key points detetected in the first branch. Thus, valid features may be filtered out when the detected landmarks are with a large deviation. This problem can be alleviated by adjusting the variance of Gaussian distribution in the small offset, but it does not work while the predicted landmarks deviate from the ground truth greatly. Intermediate supervision is introduced to facial landmark localization to solve such a problem by adding the facial expression recognition task with a small weight. The final loss consists of three parts:intermediate supervision loss, facial landmark localization loss in the first branch, and facial expression recognition loss in the second branch.ResultTo validate the effectiveness of proposed method, ablation studies are conducted on three popular databases:CK+ (Cohn-Kanade dataset), Oulu (Oulu-CASIA NIR & VIS facial expression database), and MMI (MMI facial expression database). We also investigate the performance of the multitask network and single-task network to evaluate the importance of introducing the landmark localization to facial expression recognition. The experimental results demonstrate that the proposed multitask network outperforms the traditional convolution networks, and the recognition accuracy on three databases improves by 0.93%, 1.71%, and 2.92%, respectively. Experimental results also prove that generated location attention map is effective, and recognition accuracy improves by 0.14%, 2.43%, and 1.82%, respectively, on three databases. Finally, the performance on three databases reaches peak while adding intermediate supervision. Recognition accuracy on Oulu and MMI databases increases by 0.14% and 0.54%, respectively. Intermediate supervision has minimal effect on CK+ database because samples on this database are simple and predicted landmarks do not have significant deviation.ConclusionA multitask network is designed to recognize the facial expression and localize the facial landmark simultaneously, and the experimental results demonstrated that the relationship information between the task of facial expression recognition and landmark localization is useful for facial expression recognition. The proposed location attention map improved the recognition accuracy and revealed that features distributed among facial organs are powerful for facial expression recognition. Meanwhile, introduced intermediate supervision helps improve the performance of facial landmark localization so that generated location attention map can filter out noise accurately.关键词:facial expression recognition(FER);facial landmark detection;multi-task;attention model;intermediate supervision13|4|4更新时间:2024-05-07
摘要:ObjectiveAutomatic facial expression recognition (FER) aims at designing a model to identify human emotions automatically from facial images. Several methods have been proposed in the past 20 years, and all the previous works can be generally divided into two categories:image-based methods and video-based methods. In this study, we propose a new image-based FER method, guided with facial landmarks. Facial expression is actually an ultimate representation of facial muscle movement, which consists of various facial action units (AUs) distributing among the facial organs. Meanwhile, the purpose of facial landmark detection is to localize the position and shape of face and facial organs. Thus, a good relationship is observed between the facial expression and facial landmark detection. Based on this observation, some works try to combine the facial expression recognition and facial landmark localization with different strategies, and most of them extract the geometric features or only pay attention to texture information around landmarks to recognize the facial expression. Although these methods achieved great results, they still have some issues. They assist the task of FER by using given facial landmarks as prior information, but internal connection between them is ignored. To solve this problem, a deep multitask framework is proposed in this study.MethodA multitask network is designed to recognize facial expressions and locate facial landmarks simultaneously because both tasks pay attention to features around facial organs, including the eyebrows, eyes, nose, and mouth (points around the external counter are abandoned). However, to obtain the ground truth of facial landmarks in practices is not easy, especially in some FER benchmarks. We utilize a stacked hourglass network to detect facial landmark points first because stacked hourglass network achieves excellent performance in the task of face alignment, which was also demonstrated in the 2nd Facial Landmark Localization Competition conjunction with CVPR(IEEE Conference on Computer Vision and Pattern Recognition) 2017. The designed network has two branches, corresponding to two tasks accordingly. Considering the relationships between the two tasks, they share two convolution layers in the first. The structure of facial landmark localization is simple, including three convolution layers and a fully connected layer because it simply assists the facial expression recognition in selecting feature. For the branch of facial expression recognition, its structure is complicated, in which the inception module is introduced and convolution kernels with different size are applied to capture the multiscale features. Two tasks are optimized together with a unified loss to learn the network parameters, in which the popular distance loss and the entropy loss are designed to facial landmark localization and facial expression recognition. Although features around the facial landmarks obtain good response under the supervision of two tasks, other areas still exist some noises. For example, part collar is retained in the cropped face image, which has a bad effect on facial expression recognition. To deal with this issue, location attention maps are created with the landmarks obtained in the branch of facial landmark localization. The proposed location attention map is a weight matrix sharing the same size with the corresponding feature maps, and it indicates the importance of each position. Inspired by the stacked hourglass network, a series of heat maps is generated first by taking the coordinate of each point as the mean value and selecting an appropriate variance with Gaussian distribution. Then, the max-pooling operation is conducted to merge these maps to generate the location attention map. The generated location attention maps rely on the performance of facial landmark localization since they utilize the position of key points detetected in the first branch. Thus, valid features may be filtered out when the detected landmarks are with a large deviation. This problem can be alleviated by adjusting the variance of Gaussian distribution in the small offset, but it does not work while the predicted landmarks deviate from the ground truth greatly. Intermediate supervision is introduced to facial landmark localization to solve such a problem by adding the facial expression recognition task with a small weight. The final loss consists of three parts:intermediate supervision loss, facial landmark localization loss in the first branch, and facial expression recognition loss in the second branch.ResultTo validate the effectiveness of proposed method, ablation studies are conducted on three popular databases:CK+ (Cohn-Kanade dataset), Oulu (Oulu-CASIA NIR & VIS facial expression database), and MMI (MMI facial expression database). We also investigate the performance of the multitask network and single-task network to evaluate the importance of introducing the landmark localization to facial expression recognition. The experimental results demonstrate that the proposed multitask network outperforms the traditional convolution networks, and the recognition accuracy on three databases improves by 0.93%, 1.71%, and 2.92%, respectively. Experimental results also prove that generated location attention map is effective, and recognition accuracy improves by 0.14%, 2.43%, and 1.82%, respectively, on three databases. Finally, the performance on three databases reaches peak while adding intermediate supervision. Recognition accuracy on Oulu and MMI databases increases by 0.14% and 0.54%, respectively. Intermediate supervision has minimal effect on CK+ database because samples on this database are simple and predicted landmarks do not have significant deviation.ConclusionA multitask network is designed to recognize the facial expression and localize the facial landmark simultaneously, and the experimental results demonstrated that the relationship information between the task of facial expression recognition and landmark localization is useful for facial expression recognition. The proposed location attention map improved the recognition accuracy and revealed that features distributed among facial organs are powerful for facial expression recognition. Meanwhile, introduced intermediate supervision helps improve the performance of facial landmark localization so that generated location attention map can filter out noise accurately.关键词:facial expression recognition(FER);facial landmark detection;multi-task;attention model;intermediate supervision13|4|4更新时间:2024-05-07
Column of ChinaMM 2020
-
 摘要:ObjectiveImage segmentation is to divide images into homogeneous parts. The level set model is an important method for image segmentation. In theory, this type of models is characterized by the implicit representation of curve evolution, which transforms the image segmentation task into the issue of the mathematical minimization by curve evolution. In recent years, the level set model has been widely used for image segmentation due to its satisfying performance for handling complicated topological changes and has shown good results on ground-based image segmentation. Recently, a variety of feature fusion strategies are introduced into the model framework to stretch the foreground-background contrast to improve the performance on many complicated conditions, such as high noises and several textures. However, different from the ground-based image segmentation, the underwater environment is characterized by the high scattering and strong attenuation factors. As a result, the existing image features and level set models are difficult to be applied in underwater image segmentation. In view of this fact, a region-edge level set model suitable for underwater image segmentation is proposed.MethodThe representation of the underwater image is often characterized by low contrast and strong noise. The factor of the low contrast makes the objects difficult to be distinguished, which likely causes the weakness among edges. Thus, the region-based and edge-based level set segmentation method degenerated under water. Moreover, the strong underwater noises make the level set model difficult to converge on the object region. To solve the problems mentioned above, our proposed method comprehensively utilizes the region features and edge features of the image to identify the object region in underwater images. First, for the region features, the proposed method introduces the underwater image saliency features into the level set model, and estimates the spatial frequency of the image to identify the object region. For the edge features, this study proposes a novel edge feature extraction method based on depth information, and then extracts the depth deviation from the image to distinguish the object and background, which helps formulate the edge constraint. In the level set function, the edge constraint term is embedded as a weight function to adaptively adjust the weight of the level set constraint to make the model stable. The edge term and the region term cooperate to construct an external energy constraint of the level set model. By fusing the region and edge features, the distance regulation term is introduced to formulate the internal energy term of the level set model, which accelerates the evolution of the level set function and standardizes the level set function to enhance the stability of the level set model. The external energy term and the internal energy term are combined to formulate the final level set function.ResultTo prove the performance of the proposed method for underwater image segmentation, the proposed method is applied to segment underwater images with low contrast, uneven grayscale or strong background noise, and compare our method with several advanced level set models. At the same time, our methods are compared with several saliency detection methods. The experimental results demonstrate that the underwater object edge is accurately segmented by our method. The proposed method can effectively solve the problems caused by low contrast. In addition, the proposed method is applied to underwater images with strong background noise. Results show that the underwater object and the background are successfully distinguished. Thus, the robustness of the proposed method against underwater strong background noises is proved. Based on the underwater images selected from Youtube and Bubblevision websites, the proposed method outperform several comparison methods in underwater image segmentation. Finally, this study evaluates various methods by using quantitative experiments. Results show that in contrast to the level set segmentation method local pre-fitting(LPF), the segmentation accuracy of the proposed method is improved by at least 11.5%. At the same time, the segmentation accuracy of the proposed method is improved by approximately 6.7% compared with the saliency detection method hierarchical co-salient detection via color names(HCN). Based on the qualitative and quantitative analysis, the proposed method cannot only obtain satisfying results on segmenting underwater images with high scattering and strong attenuation, but also has good robustness against strong background noises.ConclusionIn this study, a region-edge based level set model is proposed for underwater image segmentation. The region and edge features of the image are utilized comprehensively and applied to segment underwater images with high scattering and strong noise. For region features, saliency detection is used to stretch the object-background contrast and identify the object region. For the edge features, a novel method is proposed to extract the object edge information, which can solve the weak edge problem caused by the underwater environment. In addition, the regularization term makes the evolution of the level set function stable and robust. Experimental results show that the proposed level set model based on the region-edge feature fusion can well overcome several difficulties for underwater image segmentation. The proposed method can accurately segment the underwater object region and identify the object contour. In contrast to the existing methods, good segmentation results can be obtained by our method.关键词:underwater image segmentation;level set;depth information;edge features;image saliency24|4|2更新时间:2024-05-07
摘要:ObjectiveImage segmentation is to divide images into homogeneous parts. The level set model is an important method for image segmentation. In theory, this type of models is characterized by the implicit representation of curve evolution, which transforms the image segmentation task into the issue of the mathematical minimization by curve evolution. In recent years, the level set model has been widely used for image segmentation due to its satisfying performance for handling complicated topological changes and has shown good results on ground-based image segmentation. Recently, a variety of feature fusion strategies are introduced into the model framework to stretch the foreground-background contrast to improve the performance on many complicated conditions, such as high noises and several textures. However, different from the ground-based image segmentation, the underwater environment is characterized by the high scattering and strong attenuation factors. As a result, the existing image features and level set models are difficult to be applied in underwater image segmentation. In view of this fact, a region-edge level set model suitable for underwater image segmentation is proposed.MethodThe representation of the underwater image is often characterized by low contrast and strong noise. The factor of the low contrast makes the objects difficult to be distinguished, which likely causes the weakness among edges. Thus, the region-based and edge-based level set segmentation method degenerated under water. Moreover, the strong underwater noises make the level set model difficult to converge on the object region. To solve the problems mentioned above, our proposed method comprehensively utilizes the region features and edge features of the image to identify the object region in underwater images. First, for the region features, the proposed method introduces the underwater image saliency features into the level set model, and estimates the spatial frequency of the image to identify the object region. For the edge features, this study proposes a novel edge feature extraction method based on depth information, and then extracts the depth deviation from the image to distinguish the object and background, which helps formulate the edge constraint. In the level set function, the edge constraint term is embedded as a weight function to adaptively adjust the weight of the level set constraint to make the model stable. The edge term and the region term cooperate to construct an external energy constraint of the level set model. By fusing the region and edge features, the distance regulation term is introduced to formulate the internal energy term of the level set model, which accelerates the evolution of the level set function and standardizes the level set function to enhance the stability of the level set model. The external energy term and the internal energy term are combined to formulate the final level set function.ResultTo prove the performance of the proposed method for underwater image segmentation, the proposed method is applied to segment underwater images with low contrast, uneven grayscale or strong background noise, and compare our method with several advanced level set models. At the same time, our methods are compared with several saliency detection methods. The experimental results demonstrate that the underwater object edge is accurately segmented by our method. The proposed method can effectively solve the problems caused by low contrast. In addition, the proposed method is applied to underwater images with strong background noise. Results show that the underwater object and the background are successfully distinguished. Thus, the robustness of the proposed method against underwater strong background noises is proved. Based on the underwater images selected from Youtube and Bubblevision websites, the proposed method outperform several comparison methods in underwater image segmentation. Finally, this study evaluates various methods by using quantitative experiments. Results show that in contrast to the level set segmentation method local pre-fitting(LPF), the segmentation accuracy of the proposed method is improved by at least 11.5%. At the same time, the segmentation accuracy of the proposed method is improved by approximately 6.7% compared with the saliency detection method hierarchical co-salient detection via color names(HCN). Based on the qualitative and quantitative analysis, the proposed method cannot only obtain satisfying results on segmenting underwater images with high scattering and strong attenuation, but also has good robustness against strong background noises.ConclusionIn this study, a region-edge based level set model is proposed for underwater image segmentation. The region and edge features of the image are utilized comprehensively and applied to segment underwater images with high scattering and strong noise. For region features, saliency detection is used to stretch the object-background contrast and identify the object region. For the edge features, a novel method is proposed to extract the object edge information, which can solve the weak edge problem caused by the underwater environment. In addition, the regularization term makes the evolution of the level set function stable and robust. Experimental results show that the proposed level set model based on the region-edge feature fusion can well overcome several difficulties for underwater image segmentation. The proposed method can accurately segment the underwater object region and identify the object contour. In contrast to the existing methods, good segmentation results can be obtained by our method.关键词:underwater image segmentation;level set;depth information;edge features;image saliency24|4|2更新时间:2024-05-07
Column of ChinaMM 2021
-
 摘要:ObjectiveAction recognition is a research hotspot in machine vision and artificial intelligence. Action recognition has been applied to human-computer interaction, biometrics, health monitoring, video surveillance systems, somatosensory game, robotics, and other fields. Early studies about action recognition are mainly performed on color video sequences acquired by RGB cameras. However, color video sequences are insensitive to illumination changes. With the development of imaging technology, especially with the launching of deep cameras, researchers begin to conduct human action recognition studies on depth map sequences obtained by deep cameras. However, numerous problems still exist in studies, such as excessive redundant information in the depth map sequences and missing temporal information in the generated feature map. These problems decrease the computational efficiency of human action recognition algorithms and reduce the final accuracy of human action recognition. Aiming at the problem of excessive redundant information in the depth map sequence, this study proposes a key frame algorithm. This algorithm decreases the redundant frames from the depth map sequence. The key frame algorithm improves the computational efficiency of human action recognition algorithms. At the same time, the feature map is accurate in representing human action with the key frame algorithm processing. Aiming at the problem of missing temporal information in the feature map generated by the depth map sequence, this study presents a new representation, namely, depth spatial-temporal energy map (DSTEM). This algorithm completely preserves the temporal information of the depth map sequence. DSTEM improves the accuracy of human action recognition when performing on the database with temporal information.MethodThe key frame algorithm first performs image difference operation between the two adjacent frames of the depth map sequence to produce a differential image sequence. Next, redundancy coefficients of each frame are achieved in the differential image sequence. Then, the redundant frame is placed and deleted by the maximum redundancy coefficient in the depth map sequence. Finally, the above steps are repeated a plurality of times to obtain a key frame sequence to express human action. This algorithm removes redundant information in the depth map sequence by removing redundant frames of the depth map sequence. The DSTEM algorithm first builds the energy field of the human body to obtain the energy information of the human action according to the shape and motion characteristics of the body. Next, the human energy information is projected onto three orthogonal cartesian planes to generate 2D projection maps of three angles. Subsequently, two 2D projection maps are selected and projected on three orthogonal axes to generate 1D energy distribution list. Finally, the 1D energy distribution lists are spliced in temporal to form DSTEM of three orthogonal axes. DSTEM reflects the temporal information of human action through the projection of energy information of human action on three orthogonal axes. Compared with the previous feature map algorithm, DSTEM not only preserves the spatial contour of human action, but also uses the projection of energy information of human action on three orthogonal axes to completely record the temporal information of human action.ResultIn this study, the public dataset MSR_Action3D is used to evaluate the effectiveness of the proposed methods. The experimental results show that the key frame algorithm removes the redundant information of the depth map sequence. The computational efficiency of each feature graph algorithm is improved after the key frame algorithm is processed. Particularly, the DSTEM algorithm improves the computational efficiency by nearly 30% after key frame processing because DSTEM is sensitive to redundant frames in the depth map sequence. After the key frame algorithm is processed, the accuracy of action recognition on each algorithm is improved. Especially, the recognition accuracy of DSTEM in each test is obviously improved, and the accuracy of recognition increases nearly by 5%. The experimental results also show that DSTEM-HOG(histogram of oriented gradient) receives the highest accuracy of human action recognition in all tests or it is consistent with the highest accuracy of human action recognition. DSTEM-HOG has an accuracy of 95.54% on the database with only positive actions. The accuracy is higher than the recognition accuracy of other algorithms. This result indicates that DSTEM completely preserves the spatial information of the depth map sequence. Moreover, DSTEM-HOG maintains an accuracy of 82.14% on the database with both positive and reverse actions. The recognition accuracy is nearly 40% higher than the other algorithms. The recognition rate of DSTEM-HOG is 34% higher than that of MHI(motion history image)-HOG, which retains part of the temporal information. The recognition rate of DSTEM-HOG is 50% higher than that of MHI-HOG and DMM(depth motion map)-HOG, which do not retain temporal information. Result indicates that DSTEM completely describes the temporal information of the depth map sequence.ConclusionThe experimental results show that the proposed methods are effective. The key frame algorithm reduces the redundant frames in the depth map sequence and improves the computational efficiency of the human action recognition algorithms. After the key frame algorithm is processed, the accuracy of human action recognition is obviously improved on human action recognition algorithms. DSTEM not only retains the spatial information of actions, which is highlighted by the energy field but also completely records the temporal information of actions. In addition, DSTEM maintains the highest recognition accuracy when performing human action recognition on conventional databases. It also maintains superior recognition accuracy when performing human action recognition on the databases with temporal information. Results prove that DSTEM completely retains the spatial information and temporal information of human action. DSTEM also has the ability to distinguish between positive and reverse human action.关键词:action recognition;depth map sequence;temporal information;depth spatial-temporal energy map (DSTEM);key frame22|8|2更新时间:2024-05-07
摘要:ObjectiveAction recognition is a research hotspot in machine vision and artificial intelligence. Action recognition has been applied to human-computer interaction, biometrics, health monitoring, video surveillance systems, somatosensory game, robotics, and other fields. Early studies about action recognition are mainly performed on color video sequences acquired by RGB cameras. However, color video sequences are insensitive to illumination changes. With the development of imaging technology, especially with the launching of deep cameras, researchers begin to conduct human action recognition studies on depth map sequences obtained by deep cameras. However, numerous problems still exist in studies, such as excessive redundant information in the depth map sequences and missing temporal information in the generated feature map. These problems decrease the computational efficiency of human action recognition algorithms and reduce the final accuracy of human action recognition. Aiming at the problem of excessive redundant information in the depth map sequence, this study proposes a key frame algorithm. This algorithm decreases the redundant frames from the depth map sequence. The key frame algorithm improves the computational efficiency of human action recognition algorithms. At the same time, the feature map is accurate in representing human action with the key frame algorithm processing. Aiming at the problem of missing temporal information in the feature map generated by the depth map sequence, this study presents a new representation, namely, depth spatial-temporal energy map (DSTEM). This algorithm completely preserves the temporal information of the depth map sequence. DSTEM improves the accuracy of human action recognition when performing on the database with temporal information.MethodThe key frame algorithm first performs image difference operation between the two adjacent frames of the depth map sequence to produce a differential image sequence. Next, redundancy coefficients of each frame are achieved in the differential image sequence. Then, the redundant frame is placed and deleted by the maximum redundancy coefficient in the depth map sequence. Finally, the above steps are repeated a plurality of times to obtain a key frame sequence to express human action. This algorithm removes redundant information in the depth map sequence by removing redundant frames of the depth map sequence. The DSTEM algorithm first builds the energy field of the human body to obtain the energy information of the human action according to the shape and motion characteristics of the body. Next, the human energy information is projected onto three orthogonal cartesian planes to generate 2D projection maps of three angles. Subsequently, two 2D projection maps are selected and projected on three orthogonal axes to generate 1D energy distribution list. Finally, the 1D energy distribution lists are spliced in temporal to form DSTEM of three orthogonal axes. DSTEM reflects the temporal information of human action through the projection of energy information of human action on three orthogonal axes. Compared with the previous feature map algorithm, DSTEM not only preserves the spatial contour of human action, but also uses the projection of energy information of human action on three orthogonal axes to completely record the temporal information of human action.ResultIn this study, the public dataset MSR_Action3D is used to evaluate the effectiveness of the proposed methods. The experimental results show that the key frame algorithm removes the redundant information of the depth map sequence. The computational efficiency of each feature graph algorithm is improved after the key frame algorithm is processed. Particularly, the DSTEM algorithm improves the computational efficiency by nearly 30% after key frame processing because DSTEM is sensitive to redundant frames in the depth map sequence. After the key frame algorithm is processed, the accuracy of action recognition on each algorithm is improved. Especially, the recognition accuracy of DSTEM in each test is obviously improved, and the accuracy of recognition increases nearly by 5%. The experimental results also show that DSTEM-HOG(histogram of oriented gradient) receives the highest accuracy of human action recognition in all tests or it is consistent with the highest accuracy of human action recognition. DSTEM-HOG has an accuracy of 95.54% on the database with only positive actions. The accuracy is higher than the recognition accuracy of other algorithms. This result indicates that DSTEM completely preserves the spatial information of the depth map sequence. Moreover, DSTEM-HOG maintains an accuracy of 82.14% on the database with both positive and reverse actions. The recognition accuracy is nearly 40% higher than the other algorithms. The recognition rate of DSTEM-HOG is 34% higher than that of MHI(motion history image)-HOG, which retains part of the temporal information. The recognition rate of DSTEM-HOG is 50% higher than that of MHI-HOG and DMM(depth motion map)-HOG, which do not retain temporal information. Result indicates that DSTEM completely describes the temporal information of the depth map sequence.ConclusionThe experimental results show that the proposed methods are effective. The key frame algorithm reduces the redundant frames in the depth map sequence and improves the computational efficiency of the human action recognition algorithms. After the key frame algorithm is processed, the accuracy of human action recognition is obviously improved on human action recognition algorithms. DSTEM not only retains the spatial information of actions, which is highlighted by the energy field but also completely records the temporal information of actions. In addition, DSTEM maintains the highest recognition accuracy when performing human action recognition on conventional databases. It also maintains superior recognition accuracy when performing human action recognition on the databases with temporal information. Results prove that DSTEM completely retains the spatial information and temporal information of human action. DSTEM also has the ability to distinguish between positive and reverse human action.关键词:action recognition;depth map sequence;temporal information;depth spatial-temporal energy map (DSTEM);key frame22|8|2更新时间:2024-05-07
Column of ChinaMM 2022
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0