
最新刊期
卷 25 , 期 2 , 2020
-
 摘要:Brain tumors,abnormal cells growing in the human brain,are common neurological diseases that are extremely harmful to human health. Malignant brain tumors can lead to high mortality. Magnetic resonance imaging (MRI),a typical noninvasive imaging technology,can produce high-quality brain images without damage and skull artifacts,as well as provide comprehensive information to facilitate the diagnosis and treatment of brain tumors. Additionally,the segmentation of MRI brain tumors utilizes computer technology to segment and label tumors (necrosis,edema,and nonenhanced and enhanced tumors) and normal tissues automatically on multimodal brain images,which assists in their diagnosis and treatment. However,given the complexity of brain tissue structure,the diversity of spatial location,the shape and size of brain tumors,and various influence factors,such as field offset effect,volume effect,and equipment noise,during the processing of MRI brain images,automatically achieving accurate tumor segmentation results from MRI brain images has been challenging. With the continuous breakthroughs of deep learning technology in computer vision and medical image analysis,MRI brain tumor segmentation methods based on deep learning have also attracted wide attention in recent years. A series of important research results have been reported,illuminating the promising potential of deep learning methods for MRI brain tumor segmentation task. Therefore,this work aims to review deep learning-based MRI brain tumor segmentation methods,i.e.,the current mainstream of MRI brain tumor segmentation. Through an extensive study of the literature on MRI brain tumor segmentation problem,we comprehensively summarize and analyze the existing deep learning methods for MRI brain tumor segmentation. To provide a further understanding of this task,we first introduce a family of authoritative brain tumor segmentation databases,i.e.,BraTS (2012-2018) Databases,which run in conjunction with the Medical Image Computing and Computer Assisted Intervention (MICCAI) 2012-2018 Conferences. Several important evaluation metrics,including dice similarity coefficient,predictive positivity value,and sensitivity,are also briefly described. On the basis of the basic network architecture for brain tumor segmentation,we classify the existing deep learning-based MRI brain tumor segmentation methods into three categories,namely,convolutional neural network-,fully convolutional network-,and generative adversarial network-based MRI brain tumor segmentation methods. Convolutional neural network-based methods can be further divided into three sub-categories:single network-based,multinetwork-based,and traditional-method-combination-based approaches. On the basis of the three categories,we comprehensively describe and analyze the basic ideas,network architecture,and typical improvement schemes for each type of method. In addition,we compare the performance results of the representative methods achieved on the BraTS series datasets and summarize the comparative analysis results as well as the advantages and disadvantages of the representative methods. Finally,we discuss three possible future research directions.By reviewing the main work in this field,the existing deep learning methods for MRI brain tumor segmentation are examined well,and our threefold conclusion follows:1) Embedding advanced network architecture or introducing prior information of brain tumors into the deep segmentation network will achieve superior accuracy performance for each type of method. 2) Fully convolutional network-based MRI brain tumor segmentation methods can obtain improved balance between accuracy and efficiency. 3) Generative adversarial network-based MRI brain tumor segmentation methods,a novel and powerful semi-supervised method,has shown good potential for the extremely challenging construction of a large-scale MRI brain tumor segmentation dataset with fine labels. Three possible future research directions are recommended,namely,embedding numerous powerful feature representation modules (e.g.,squeeze-and-excitation block,matrix power normalization unit),constructing semi-supervised networks with prior medical knowledge (e.g.,constraint information,location,and size and shape information of brain tumors),and transferring networks from other image tasks (e.g.,promising detection networks of faster and masker region-based convolutional neural networks). MRI brain tumor segmentation is an important step in the diagnosis and treatment of brain tumors. This process can quickly obtain further accurate MRI brain tumor segmentation results through computer technology,which can effectively assist doctors in computing the location and size of tumors and formulating numerous reasonable treatment and rehabilitation strategies for patients with brain tumors. As a new development direction in recent years,deep learning-based MRI brain tumor segmentation has achieved significant performance improvement over traditional methods. As the mainstream in this field,this method will further promote the clinical diagnosis and treatment level of computer-aided MRI brain tumor segmentation technology.关键词:magnetic resonance imaging(MRI);brain tumor;artificial neural networks;deep learning;segmentation114|274|18更新时间:2024-05-07
摘要:Brain tumors,abnormal cells growing in the human brain,are common neurological diseases that are extremely harmful to human health. Malignant brain tumors can lead to high mortality. Magnetic resonance imaging (MRI),a typical noninvasive imaging technology,can produce high-quality brain images without damage and skull artifacts,as well as provide comprehensive information to facilitate the diagnosis and treatment of brain tumors. Additionally,the segmentation of MRI brain tumors utilizes computer technology to segment and label tumors (necrosis,edema,and nonenhanced and enhanced tumors) and normal tissues automatically on multimodal brain images,which assists in their diagnosis and treatment. However,given the complexity of brain tissue structure,the diversity of spatial location,the shape and size of brain tumors,and various influence factors,such as field offset effect,volume effect,and equipment noise,during the processing of MRI brain images,automatically achieving accurate tumor segmentation results from MRI brain images has been challenging. With the continuous breakthroughs of deep learning technology in computer vision and medical image analysis,MRI brain tumor segmentation methods based on deep learning have also attracted wide attention in recent years. A series of important research results have been reported,illuminating the promising potential of deep learning methods for MRI brain tumor segmentation task. Therefore,this work aims to review deep learning-based MRI brain tumor segmentation methods,i.e.,the current mainstream of MRI brain tumor segmentation. Through an extensive study of the literature on MRI brain tumor segmentation problem,we comprehensively summarize and analyze the existing deep learning methods for MRI brain tumor segmentation. To provide a further understanding of this task,we first introduce a family of authoritative brain tumor segmentation databases,i.e.,BraTS (2012-2018) Databases,which run in conjunction with the Medical Image Computing and Computer Assisted Intervention (MICCAI) 2012-2018 Conferences. Several important evaluation metrics,including dice similarity coefficient,predictive positivity value,and sensitivity,are also briefly described. On the basis of the basic network architecture for brain tumor segmentation,we classify the existing deep learning-based MRI brain tumor segmentation methods into three categories,namely,convolutional neural network-,fully convolutional network-,and generative adversarial network-based MRI brain tumor segmentation methods. Convolutional neural network-based methods can be further divided into three sub-categories:single network-based,multinetwork-based,and traditional-method-combination-based approaches. On the basis of the three categories,we comprehensively describe and analyze the basic ideas,network architecture,and typical improvement schemes for each type of method. In addition,we compare the performance results of the representative methods achieved on the BraTS series datasets and summarize the comparative analysis results as well as the advantages and disadvantages of the representative methods. Finally,we discuss three possible future research directions.By reviewing the main work in this field,the existing deep learning methods for MRI brain tumor segmentation are examined well,and our threefold conclusion follows:1) Embedding advanced network architecture or introducing prior information of brain tumors into the deep segmentation network will achieve superior accuracy performance for each type of method. 2) Fully convolutional network-based MRI brain tumor segmentation methods can obtain improved balance between accuracy and efficiency. 3) Generative adversarial network-based MRI brain tumor segmentation methods,a novel and powerful semi-supervised method,has shown good potential for the extremely challenging construction of a large-scale MRI brain tumor segmentation dataset with fine labels. Three possible future research directions are recommended,namely,embedding numerous powerful feature representation modules (e.g.,squeeze-and-excitation block,matrix power normalization unit),constructing semi-supervised networks with prior medical knowledge (e.g.,constraint information,location,and size and shape information of brain tumors),and transferring networks from other image tasks (e.g.,promising detection networks of faster and masker region-based convolutional neural networks). MRI brain tumor segmentation is an important step in the diagnosis and treatment of brain tumors. This process can quickly obtain further accurate MRI brain tumor segmentation results through computer technology,which can effectively assist doctors in computing the location and size of tumors and formulating numerous reasonable treatment and rehabilitation strategies for patients with brain tumors. As a new development direction in recent years,deep learning-based MRI brain tumor segmentation has achieved significant performance improvement over traditional methods. As the mainstream in this field,this method will further promote the clinical diagnosis and treatment level of computer-aided MRI brain tumor segmentation technology.关键词:magnetic resonance imaging(MRI);brain tumor;artificial neural networks;deep learning;segmentation114|274|18更新时间:2024-05-07
Review

-
 摘要:ObjectiveThe image captured by the monitor will be affected by the ambiguity of the atmosphere and motion transformation of the target, resulting in the low resolution of the captured face image, which cannot be recognized by human or machine. Therefore, the clarity of face images must be urgently improved. The method of enhancing the resolution of face image by using super-resolution (SR) restoration technology has become an important means for solving this problem. Face SR reconstruction is the process of predicting high-resolution (HR) face images from one or more observed low-resolution (LR) face images, which is a typical pathological problem. As a domain-specific super-resolution task, we can use facial priori knowledge to improve the effect of super-resolution. We propose a deep end-to-end face SR reconstruction algorithm based on multitask joint learning method. Multitask learning algorithm is an inductive transfer mechanism, which can improve the generalization performance of backbone models by utilizing specific domain information hidden in training signals. Existing SR methods use different methods to fuse face priori information, which substantially improves the performance of face super-resolution algorithm. However, these networks generally use the method of the direct fusion of facial geometry information and image features to integrate the priori feature information, but they do not fully utilize the semantic information, such as facial landmark, gender, and facial expression. Moreover, at a large magnification, the priori features obtained by these methods are rough to reconstruct detailed facial edges and texture details. To solve this problem, we propose a face SR reconstruction algorithm based on multitask joint learning. MTFSR combines face SR with assistant tasks, such as facial feature point detection, gender classification, and facial expression recognition, by using multitask learning method to obtain the shared representation of facial features among related tasks, acquire rich facial prior knowledge, and optimize the performance of face SR algorithm.MethodFirst, a face SR reconstruction algorithm based on multitask joint learning is proposed. The model uses residual learning and symmetrical cross-layer connection to extract multilevel features. Local residual mapping improves the expressive capability of the network to enhance performance, solves gradient dissipation in network training, and reduces the number of convolution cores in the model through feature reuse. To reduce the parameters of the convolution kernel, the dimension transformation of the input of the residual block is performed by using the convolution kernel with 1×1 scale, which initially reduces and then increases the dimension. The network adopts the encoder-decoder structure. In the encoder structure, the dimension of feature space is gradually reduced, and the redundant information in the input image is discarded. The feature expression of the face image at the high-dimensional visual level is obtained. The visual feature is sent to the decoder through the cross-layer connection structure. The decoder cascades and fuses all levels of visual features in the unit to achieve accurate filtering of effective information. The deconvolution layer is used to restore the spatial dimension gradually and repair the details and texture features of the face. We design a joint training method for face multiattribute learning tasks:setting loss weights and loss thresholds on the basis of the learning difficulty of different tasks and avoiding the influence of subtasks on the learning of head tasks after fitting the training set to obtain considerable abundant face prior knowledge information. The perceptual loss function is used to measure the semantic gap between HR and SR images, and the output feature map of perceptual loss network is visually processed to demonstrate the effectiveness of perceptual loss in improving the reconstruction effect of facial semantic information. Finally, we enhance the dataset of face attributes and filter the data that are missing relevant attribute labels. The key point detection algorithm is used to re-extract the attributes of feature points. On this basis, joint multitask learning is conducted to obtain numerous realistic SR results of visual perception.ResultIn this experiment, a total of 35 000 face images are selected, and two sets of LR/HR face image data pairs with different resolution magnifications are produced via double cubic interpolation downsampling using×4 and×8 scales. The sizes of each pair of images are 322/1282 and 162/1282. The first 30 000 face images are used as training set, and the last 5 000 face images are used as test set. Six models are trained for each of the three cases:×4 and×8 resolution amplifications, whether to use multitask joint learning, and whether to use perceptual loss function. The single task face SR network using pixel-by-pixel loss is defined as STFSR-MSE, and the face SR network using pixel-by-pixel loss is defined as MTFSR-MSE. Face SR network based on multitask joint learning with sense perception loss is defined as MTFSR-Perce. Two objective evaluation criteria, namely, peak signal-to-noise ratio and structural similarity index, are used to test the experimental results. The effect of this algorithm is improved by 2.15 dB at the scale of×8 magnification, compared with the general SR MemNet algorithm, and approximately 1.2 dB at the scale of×8 magnification, compared with the face SR FSRNet algorithm. A joint training method for the multiattribute learning task of the face is designed. On the basis of the learning difficulty of different tasks, loss weights and loss thresholds are set to avoid the influence of subtasks on the learning of head services after the training set has been fitted and to obtain abundant face prior knowledge information.ConclusionExperimental data and results show that the proposed algorithm can further utilize the face prior knowledge and create further realistic and clear facial edges and texture details in visual perception.关键词:multi-task joint learning;image restoration;deep learning;super resolution;perception loss58|99|4更新时间:2024-05-07
摘要:ObjectiveThe image captured by the monitor will be affected by the ambiguity of the atmosphere and motion transformation of the target, resulting in the low resolution of the captured face image, which cannot be recognized by human or machine. Therefore, the clarity of face images must be urgently improved. The method of enhancing the resolution of face image by using super-resolution (SR) restoration technology has become an important means for solving this problem. Face SR reconstruction is the process of predicting high-resolution (HR) face images from one or more observed low-resolution (LR) face images, which is a typical pathological problem. As a domain-specific super-resolution task, we can use facial priori knowledge to improve the effect of super-resolution. We propose a deep end-to-end face SR reconstruction algorithm based on multitask joint learning method. Multitask learning algorithm is an inductive transfer mechanism, which can improve the generalization performance of backbone models by utilizing specific domain information hidden in training signals. Existing SR methods use different methods to fuse face priori information, which substantially improves the performance of face super-resolution algorithm. However, these networks generally use the method of the direct fusion of facial geometry information and image features to integrate the priori feature information, but they do not fully utilize the semantic information, such as facial landmark, gender, and facial expression. Moreover, at a large magnification, the priori features obtained by these methods are rough to reconstruct detailed facial edges and texture details. To solve this problem, we propose a face SR reconstruction algorithm based on multitask joint learning. MTFSR combines face SR with assistant tasks, such as facial feature point detection, gender classification, and facial expression recognition, by using multitask learning method to obtain the shared representation of facial features among related tasks, acquire rich facial prior knowledge, and optimize the performance of face SR algorithm.MethodFirst, a face SR reconstruction algorithm based on multitask joint learning is proposed. The model uses residual learning and symmetrical cross-layer connection to extract multilevel features. Local residual mapping improves the expressive capability of the network to enhance performance, solves gradient dissipation in network training, and reduces the number of convolution cores in the model through feature reuse. To reduce the parameters of the convolution kernel, the dimension transformation of the input of the residual block is performed by using the convolution kernel with 1×1 scale, which initially reduces and then increases the dimension. The network adopts the encoder-decoder structure. In the encoder structure, the dimension of feature space is gradually reduced, and the redundant information in the input image is discarded. The feature expression of the face image at the high-dimensional visual level is obtained. The visual feature is sent to the decoder through the cross-layer connection structure. The decoder cascades and fuses all levels of visual features in the unit to achieve accurate filtering of effective information. The deconvolution layer is used to restore the spatial dimension gradually and repair the details and texture features of the face. We design a joint training method for face multiattribute learning tasks:setting loss weights and loss thresholds on the basis of the learning difficulty of different tasks and avoiding the influence of subtasks on the learning of head tasks after fitting the training set to obtain considerable abundant face prior knowledge information. The perceptual loss function is used to measure the semantic gap between HR and SR images, and the output feature map of perceptual loss network is visually processed to demonstrate the effectiveness of perceptual loss in improving the reconstruction effect of facial semantic information. Finally, we enhance the dataset of face attributes and filter the data that are missing relevant attribute labels. The key point detection algorithm is used to re-extract the attributes of feature points. On this basis, joint multitask learning is conducted to obtain numerous realistic SR results of visual perception.ResultIn this experiment, a total of 35 000 face images are selected, and two sets of LR/HR face image data pairs with different resolution magnifications are produced via double cubic interpolation downsampling using×4 and×8 scales. The sizes of each pair of images are 322/1282 and 162/1282. The first 30 000 face images are used as training set, and the last 5 000 face images are used as test set. Six models are trained for each of the three cases:×4 and×8 resolution amplifications, whether to use multitask joint learning, and whether to use perceptual loss function. The single task face SR network using pixel-by-pixel loss is defined as STFSR-MSE, and the face SR network using pixel-by-pixel loss is defined as MTFSR-MSE. Face SR network based on multitask joint learning with sense perception loss is defined as MTFSR-Perce. Two objective evaluation criteria, namely, peak signal-to-noise ratio and structural similarity index, are used to test the experimental results. The effect of this algorithm is improved by 2.15 dB at the scale of×8 magnification, compared with the general SR MemNet algorithm, and approximately 1.2 dB at the scale of×8 magnification, compared with the face SR FSRNet algorithm. A joint training method for the multiattribute learning task of the face is designed. On the basis of the learning difficulty of different tasks, loss weights and loss thresholds are set to avoid the influence of subtasks on the learning of head services after the training set has been fitted and to obtain abundant face prior knowledge information.ConclusionExperimental data and results show that the proposed algorithm can further utilize the face prior knowledge and create further realistic and clear facial edges and texture details in visual perception.关键词:multi-task joint learning;image restoration;deep learning;super resolution;perception loss58|99|4更新时间:2024-05-07 -
 摘要:ObjectiveThe style transfer of images has been a research hotspot in computer vision and image processing in recent years. The image style transfer technology can transfer the style of the style image to the content image, and the obtained result image contains the main content structure information of the content image and the style information of the style image, thereby satisfying people's artistic requirements for the image. The development of image style transfer can be divided into two phases. In the first phase, people often use non-photorealistic rendering methods to add artistic style to the design works. These methods only use the low-level features of the image for style transfer, and most of them have problems, such as poor visual effects and low operational efficiency. In the second phase, researchers have performed considerable meaningful work by introducing the achievements of deep learning to style transfer. In the framework of convolutional neural networks, Researchers proposed a classical image style transfer method, which uses convolutional neural networks to extract advanced features of style and content images, and obtained the stylized result image by minimizing the loss function. Compared with the traditional non-photorealistic rendering method, the convolutional neural network-based method does not require user intervention in the style transfer process, is applicable to any type of style image, and has good universality. However, the resulting image has uneven texture expression and increased noise, and the method is more complex than other traditional methods. To address these problems, we propose a new model of total variational style transfer based on correlation alignment from a detailed analysis of the traditional style transfer method.MethodIn this study, we design a style texture extraction method based on correlation alignment to make the style information evenly distributed on the resulting image. In addition, the total variational regularity is introduced to suppress the noise generated during the style transfer effectively, and a more efficient result image convolution layer selection strategy is adopted to improve the overall efficiency of the new model. We build a new model consisting of three VGG-19 networks. Only the cov4_3 convolutional layer of the VGG(visual geometry group)-style network is used to provide style information. Only the cov4_2 convolutional layer of the VGG content network is used to provide content information. For a given content image
摘要:ObjectiveThe style transfer of images has been a research hotspot in computer vision and image processing in recent years. The image style transfer technology can transfer the style of the style image to the content image, and the obtained result image contains the main content structure information of the content image and the style information of the style image, thereby satisfying people's artistic requirements for the image. The development of image style transfer can be divided into two phases. In the first phase, people often use non-photorealistic rendering methods to add artistic style to the design works. These methods only use the low-level features of the image for style transfer, and most of them have problems, such as poor visual effects and low operational efficiency. In the second phase, researchers have performed considerable meaningful work by introducing the achievements of deep learning to style transfer. In the framework of convolutional neural networks, Researchers proposed a classical image style transfer method, which uses convolutional neural networks to extract advanced features of style and content images, and obtained the stylized result image by minimizing the loss function. Compared with the traditional non-photorealistic rendering method, the convolutional neural network-based method does not require user intervention in the style transfer process, is applicable to any type of style image, and has good universality. However, the resulting image has uneven texture expression and increased noise, and the method is more complex than other traditional methods. To address these problems, we propose a new model of total variational style transfer based on correlation alignment from a detailed analysis of the traditional style transfer method.MethodIn this study, we design a style texture extraction method based on correlation alignment to make the style information evenly distributed on the resulting image. In addition, the total variational regularity is introduced to suppress the noise generated during the style transfer effectively, and a more efficient result image convolution layer selection strategy is adopted to improve the overall efficiency of the new model. We build a new model consisting of three VGG-19 networks. Only the cov4_3 convolutional layer of the VGG(visual geometry group)-style network is used to provide style information. Only the cov4_2 convolutional layer of the VGG content network is used to provide content information. For a given content image$\mathit{\boldsymbol{c}}$ $\mathit{\boldsymbol{s}}$ $\mathit{\boldsymbol{x}}$ $\mathit{\boldsymbol{c}}$ $\mathit{\boldsymbol{x}}$ 关键词:correlation alignment;total variation;style transfer;machine vision;convolutional neural network (CNN)31|33|7更新时间:2024-05-07 -
 摘要:ObjectiveSemantic segmentation, a challenging task in computer vision, aims to assign corresponding semantic class labels to every pixel in an image. This process is widely applied into many fields, such as autonomous driving, obstacle detection, medical image analysis, 3D geometry, environment modeling, reconstruction of indoor environment, and 3D semantic segmentation. Despite the many achievements in semantic segmentation task, two challenges remain:1) the lack of rich multiscale information and 2) the loss of spatial information. Starting from capturing rich multiscale information and extracting affluent spatial information, a new semantic segmentation model is proposed, which can greatly improve the segmentation results.MethodThe new module is built on an encoder-decoder structure, which can effectively promote the fusion of high-level semantic information and low-level spatial information. The details of the entire architecture are elaborated as follows:First, in the encoder part, the ResNet-101 network is used as our backbone to capture feature maps. In ResNet-101 network, the last two blocks utilize atrous convolutions with rate=2 and rate=4, which can reduce the spatial resolution loss. A multiscale information fusion module is designed in the encoder part to capture feature maps with rich multiscale and discriminative information in the deep stage of the network. In this module, by applying expansion and stacking principle, Kronecker convolutions are arranged in parallel structure to expand the receptive field for extracting multiscale information. A global attention module is applied to highlight discriminative information selectively in the feature maps captured by Kronecker convolutions. Subsequently, a spatial information capturing module is introduced as a decoder part in the shallow stage of the network. The spatial information capturing module aims to supplement the affluent spatial information, which can compensate for the spatial resolution loss caused by the repeated combination of max-pooling and striding at consecutive layers in ResNet-101. Moreover, the spatial information-capturing module plays an important role in effectively enhancing the relationships between the widely separated spatial regions. The feature maps with rich multiscale and discriminative information captured by the multiscale information fusion module in the deep stage and the feature maps with affluent spatial information captured by the spatial information-capturing module will be fused to obtain a new feature map set, which is full of effective information. Afterward, a multikernel convolution block is utilized to refine these feature maps. In the multikernel convolution block, two convolutions are in parallel. The sizes of the two convolution kernels are 3×3 and 5×5. The feature maps refined by the multikernel convolution block will be fed to a Data-dependent Upsampling (DUpsampling) operator to obtain the final prediction feature maps. The reason for replacing the upsample operators with bilinear interpolation with DUpsampling is that DUpsampling not only can utilize the redundancy in the segmentation label space but also can effectively recover the pixel-wise prediction. We can safely downsample arbitrary low-level feature maps to the resolution of the lowest resolution of feature maps and then fuse these features to produce the final prediction.ResultTo prove the effectiveness of the proposals, extensive experiments are conducted on two public datasets:PASCAL VOC 2012 and Cityscapes. We first conduct several ablation studies on the PASCAL VOC 2012 dataset to evaluate the effectiveness of each module and then perform several contrast experiments on the PASCAL VOC 2012 and Cityscapes datasets with existing approaches, such as FCN (fully convolutional network), FRRN(full-resolution residual networks), DeepLabv2, CRF-RNN(conditional random fields as recurrent neural networks), DeconvNet, GCRF (Gaussion conditional random field network), DeepLabv2-CRF, Piecewise, Dilation10, DPN (deep parsing network), LRR (Laplacian reconstruction and refinement), and RefineNet models, to verify the effectiveness of the entire architecture. On the Cityscapes dataset, our model achieves 0.52%, 3.72%, and 4.42% mIoU improvement in performance compared with the RefineNet, DeepLabv2-CRF, and LRR models, respectively. On the PASCAL VOC 2012 dataset, our model achieves 6.23%, 7.43%, and 8.33% mIoU improvement in performance compared with the Piecewise, DPN, and GCRF models, respectively. Several examples of visualization results from our model experimented on the Cityscapes and PASCAL VOC 2012 datasets demonstrate the superiority of the proposals.ConclusionExperimental results show that our model outperforms several state-of-the-art saliency approaches and can dramatically improve the results of semantic segmentation. This model has great application value in many fields, such as medical image analysis, automatic driving, and unmanned aerial vehicle.关键词:semantic segmentation;Kronecker convolution;multiscale information;spatial information;attention mechanism;encoder-decoder structure;Cityscapes dataset;PASCAL VOC 2012 dataset53|73|5更新时间:2024-05-07
摘要:ObjectiveSemantic segmentation, a challenging task in computer vision, aims to assign corresponding semantic class labels to every pixel in an image. This process is widely applied into many fields, such as autonomous driving, obstacle detection, medical image analysis, 3D geometry, environment modeling, reconstruction of indoor environment, and 3D semantic segmentation. Despite the many achievements in semantic segmentation task, two challenges remain:1) the lack of rich multiscale information and 2) the loss of spatial information. Starting from capturing rich multiscale information and extracting affluent spatial information, a new semantic segmentation model is proposed, which can greatly improve the segmentation results.MethodThe new module is built on an encoder-decoder structure, which can effectively promote the fusion of high-level semantic information and low-level spatial information. The details of the entire architecture are elaborated as follows:First, in the encoder part, the ResNet-101 network is used as our backbone to capture feature maps. In ResNet-101 network, the last two blocks utilize atrous convolutions with rate=2 and rate=4, which can reduce the spatial resolution loss. A multiscale information fusion module is designed in the encoder part to capture feature maps with rich multiscale and discriminative information in the deep stage of the network. In this module, by applying expansion and stacking principle, Kronecker convolutions are arranged in parallel structure to expand the receptive field for extracting multiscale information. A global attention module is applied to highlight discriminative information selectively in the feature maps captured by Kronecker convolutions. Subsequently, a spatial information capturing module is introduced as a decoder part in the shallow stage of the network. The spatial information capturing module aims to supplement the affluent spatial information, which can compensate for the spatial resolution loss caused by the repeated combination of max-pooling and striding at consecutive layers in ResNet-101. Moreover, the spatial information-capturing module plays an important role in effectively enhancing the relationships between the widely separated spatial regions. The feature maps with rich multiscale and discriminative information captured by the multiscale information fusion module in the deep stage and the feature maps with affluent spatial information captured by the spatial information-capturing module will be fused to obtain a new feature map set, which is full of effective information. Afterward, a multikernel convolution block is utilized to refine these feature maps. In the multikernel convolution block, two convolutions are in parallel. The sizes of the two convolution kernels are 3×3 and 5×5. The feature maps refined by the multikernel convolution block will be fed to a Data-dependent Upsampling (DUpsampling) operator to obtain the final prediction feature maps. The reason for replacing the upsample operators with bilinear interpolation with DUpsampling is that DUpsampling not only can utilize the redundancy in the segmentation label space but also can effectively recover the pixel-wise prediction. We can safely downsample arbitrary low-level feature maps to the resolution of the lowest resolution of feature maps and then fuse these features to produce the final prediction.ResultTo prove the effectiveness of the proposals, extensive experiments are conducted on two public datasets:PASCAL VOC 2012 and Cityscapes. We first conduct several ablation studies on the PASCAL VOC 2012 dataset to evaluate the effectiveness of each module and then perform several contrast experiments on the PASCAL VOC 2012 and Cityscapes datasets with existing approaches, such as FCN (fully convolutional network), FRRN(full-resolution residual networks), DeepLabv2, CRF-RNN(conditional random fields as recurrent neural networks), DeconvNet, GCRF (Gaussion conditional random field network), DeepLabv2-CRF, Piecewise, Dilation10, DPN (deep parsing network), LRR (Laplacian reconstruction and refinement), and RefineNet models, to verify the effectiveness of the entire architecture. On the Cityscapes dataset, our model achieves 0.52%, 3.72%, and 4.42% mIoU improvement in performance compared with the RefineNet, DeepLabv2-CRF, and LRR models, respectively. On the PASCAL VOC 2012 dataset, our model achieves 6.23%, 7.43%, and 8.33% mIoU improvement in performance compared with the Piecewise, DPN, and GCRF models, respectively. Several examples of visualization results from our model experimented on the Cityscapes and PASCAL VOC 2012 datasets demonstrate the superiority of the proposals.ConclusionExperimental results show that our model outperforms several state-of-the-art saliency approaches and can dramatically improve the results of semantic segmentation. This model has great application value in many fields, such as medical image analysis, automatic driving, and unmanned aerial vehicle.关键词:semantic segmentation;Kronecker convolution;multiscale information;spatial information;attention mechanism;encoder-decoder structure;Cityscapes dataset;PASCAL VOC 2012 dataset53|73|5更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveThe task of salient object detection is to detect the most salient and attention-attracting regions in an image. It can be divided depending on its usage into two different types:predicting human fixations and detecting salient objects. Unlike detecting large-size objects from images with simple backgrounds and high center bias, the detection of small targets under complex backgrounds remains challenging. The main characteristics are the diverse resolution of input images, complicated backgrounds, and scenes with multiple small targets. Moreover, the location of objects under this scenario lacks prior information. To cope with these challenges, the salient object detection models must be able to detect salient objects quickly and accurately in an image without losing the information of the original image and the target and must be able to maintain stable performance when processing images with different sizes. In recent years, superpixel-based salient object detection methods have performed well on several public benchmark datasets. However, the number and size of superpixel can hardly self-adapt to the variation of image resolution and target size when transferred to realistic applications, resulting in reduced performance. Excessive segmentation of superpixels also results in high time consumption. Therefore, superpixel-based methods are unsuitable for salient object detection under complex backgrounds. Despite its shortcomings in suppressing cluttered backgrounds, methods based on global color contrast can uniformly highlight salient objects in an image. In addition, this type of method is computationally efficient compared with most superpixel-based methods. A newly proposed Boolean map-based saliency method has been known for its simplicity, high performance, and high computational efficiency. This method utilizes the Gestalt principle of foreground-background segregation to compute saliency maps from Boolean maps. The advantage of this method is that the calculation of the saliency map is independent of the size of the image or the target; thus, it can maintain stable performance on input images with different resolutions. However, the results remain less than ideal when dealing with images with a complex background, especially those with multiple small targets. Considering these problems, this paper proposes a novel bottom-up salient object detection method that combines the advantages of Boolean map and grayscale rarity.MethodFirst, the input RGB image is converted into a grayscale image. Second, a set of Boolean maps is obtained by binarizing the grayscale image with equally spaced thresholds. The salient surrounded regions are extracted from the Boolean map. The saliency value of each salient region is assigned on the basis of its area. Third, the grayscale image is quantized at different levels, and its histogram is calculated. Afterward, the less frequent grayscale value in the histogram will be assigned a high saliency value to suppress several typical backgrounds, such as smog, cloud, and light vignetting. Finally, Boolean map and grayscale rarity saliencies are merged to obtain a final saliency map with full resolution, highlighted salient object, and clear contour. In the second step, instead of directly using the area of the salient region as the saliency value, the logarithmic value of the area is used to expand the difference between cluttered backgrounds and real salient objects. This strategy can efficiently suppress cluttered backgrounds, such as grass, car trail, and rock on the ground, and it can highlight the large salient object without excessively suppressing the small one. In the third step, when assigning saliency value to an individual pixel, not only the grayscale rarity but also the quantization coefficient is considered. The more the grayscale image is compressed, the greater the weight of the saliency value of its corresponding quantization level. In the final step, a simple linear multiplication strategy is used to fuse two different saliency maps.ResultThe experiment is divided into two parts:qualitative analysis and quantitative evaluation. In the first part, the stability and time consumption of our method and other classic methods are analyzed through computation on five images with multiple targets. These five images are downsampled from the same image; thus, they vary in resolution but are identical in content. We verify that most superpixel-based methods can hardly maintain stability when handling images with different resolutions. Several methods are good in large images, whereas others specialize in small images. In addition to instability, the time consumption of several methods on large-size images is unacceptable. Combined with time consumption and stability, the models that can maintain stability and have fast run speed are mainly pixel-based models, including Itti, LC (local contrast), HC(histogram-based contrasty), and our method. In the second part, all methods are quantitatively evaluated on three different datasets:the complex-background images, which are annotated by ourselves, the SED2 dataset, and the small-object images, which are from DUT-OMRON, ECSSD, ImgSal, and MSRA10K. First, our method obtains the highest F-measure value and smallest MAE (mean absolute error) score over the complex-background images and is only slightly lower than the DRFI (discriminative regional feature integration) and ASNet (attentive saliency network) method in terms of AUC (area under ROC curve) value. The AUC, F-measure, and MAE scores of our method are 0.910 2, 0.700 2, and 0.045 8, respectively. Second, our method outperforms six traditional methods in the SED2 dataset. Furthermore, on the small-object images from public datasets, the performance of our algorithm is second only to the ASNet method and has the highest F-measure value. On the basis of the visual comparison of different saliency maps, 1) superpixel-based methods tend to ignore the small objects, even though these objects have the same feature as the large objects; 2) methods based on color contrast can detect large and small objects in the image, but they also highlight the background; 3) our method can efficiently suppress the background and detect almost all objects, and the saliency map is the closest to the ground truth map.ConclusionIn this study, we propose a full-resolution salient object detection method that combines Boolean map and grayscale rarity. This method is robust to the size variation of salient objects and the diverse resolution of input images and can efficiently cope with the detection of small targets in complex backgrounds. Experimental results demonstrate that our method has the best comprehensive performance on our dataset and outperforms six traditional saliency models on the SED2 dataset. In addition, our method is computationally efficient on images with various sizes.关键词:salient object detection;Boolean map;grayscale rarity;small target;complex background44|15|3更新时间:2024-05-07
摘要:ObjectiveThe task of salient object detection is to detect the most salient and attention-attracting regions in an image. It can be divided depending on its usage into two different types:predicting human fixations and detecting salient objects. Unlike detecting large-size objects from images with simple backgrounds and high center bias, the detection of small targets under complex backgrounds remains challenging. The main characteristics are the diverse resolution of input images, complicated backgrounds, and scenes with multiple small targets. Moreover, the location of objects under this scenario lacks prior information. To cope with these challenges, the salient object detection models must be able to detect salient objects quickly and accurately in an image without losing the information of the original image and the target and must be able to maintain stable performance when processing images with different sizes. In recent years, superpixel-based salient object detection methods have performed well on several public benchmark datasets. However, the number and size of superpixel can hardly self-adapt to the variation of image resolution and target size when transferred to realistic applications, resulting in reduced performance. Excessive segmentation of superpixels also results in high time consumption. Therefore, superpixel-based methods are unsuitable for salient object detection under complex backgrounds. Despite its shortcomings in suppressing cluttered backgrounds, methods based on global color contrast can uniformly highlight salient objects in an image. In addition, this type of method is computationally efficient compared with most superpixel-based methods. A newly proposed Boolean map-based saliency method has been known for its simplicity, high performance, and high computational efficiency. This method utilizes the Gestalt principle of foreground-background segregation to compute saliency maps from Boolean maps. The advantage of this method is that the calculation of the saliency map is independent of the size of the image or the target; thus, it can maintain stable performance on input images with different resolutions. However, the results remain less than ideal when dealing with images with a complex background, especially those with multiple small targets. Considering these problems, this paper proposes a novel bottom-up salient object detection method that combines the advantages of Boolean map and grayscale rarity.MethodFirst, the input RGB image is converted into a grayscale image. Second, a set of Boolean maps is obtained by binarizing the grayscale image with equally spaced thresholds. The salient surrounded regions are extracted from the Boolean map. The saliency value of each salient region is assigned on the basis of its area. Third, the grayscale image is quantized at different levels, and its histogram is calculated. Afterward, the less frequent grayscale value in the histogram will be assigned a high saliency value to suppress several typical backgrounds, such as smog, cloud, and light vignetting. Finally, Boolean map and grayscale rarity saliencies are merged to obtain a final saliency map with full resolution, highlighted salient object, and clear contour. In the second step, instead of directly using the area of the salient region as the saliency value, the logarithmic value of the area is used to expand the difference between cluttered backgrounds and real salient objects. This strategy can efficiently suppress cluttered backgrounds, such as grass, car trail, and rock on the ground, and it can highlight the large salient object without excessively suppressing the small one. In the third step, when assigning saliency value to an individual pixel, not only the grayscale rarity but also the quantization coefficient is considered. The more the grayscale image is compressed, the greater the weight of the saliency value of its corresponding quantization level. In the final step, a simple linear multiplication strategy is used to fuse two different saliency maps.ResultThe experiment is divided into two parts:qualitative analysis and quantitative evaluation. In the first part, the stability and time consumption of our method and other classic methods are analyzed through computation on five images with multiple targets. These five images are downsampled from the same image; thus, they vary in resolution but are identical in content. We verify that most superpixel-based methods can hardly maintain stability when handling images with different resolutions. Several methods are good in large images, whereas others specialize in small images. In addition to instability, the time consumption of several methods on large-size images is unacceptable. Combined with time consumption and stability, the models that can maintain stability and have fast run speed are mainly pixel-based models, including Itti, LC (local contrast), HC(histogram-based contrasty), and our method. In the second part, all methods are quantitatively evaluated on three different datasets:the complex-background images, which are annotated by ourselves, the SED2 dataset, and the small-object images, which are from DUT-OMRON, ECSSD, ImgSal, and MSRA10K. First, our method obtains the highest F-measure value and smallest MAE (mean absolute error) score over the complex-background images and is only slightly lower than the DRFI (discriminative regional feature integration) and ASNet (attentive saliency network) method in terms of AUC (area under ROC curve) value. The AUC, F-measure, and MAE scores of our method are 0.910 2, 0.700 2, and 0.045 8, respectively. Second, our method outperforms six traditional methods in the SED2 dataset. Furthermore, on the small-object images from public datasets, the performance of our algorithm is second only to the ASNet method and has the highest F-measure value. On the basis of the visual comparison of different saliency maps, 1) superpixel-based methods tend to ignore the small objects, even though these objects have the same feature as the large objects; 2) methods based on color contrast can detect large and small objects in the image, but they also highlight the background; 3) our method can efficiently suppress the background and detect almost all objects, and the saliency map is the closest to the ground truth map.ConclusionIn this study, we propose a full-resolution salient object detection method that combines Boolean map and grayscale rarity. This method is robust to the size variation of salient objects and the diverse resolution of input images and can efficiently cope with the detection of small targets in complex backgrounds. Experimental results demonstrate that our method has the best comprehensive performance on our dataset and outperforms six traditional saliency models on the SED2 dataset. In addition, our method is computationally efficient on images with various sizes.关键词:salient object detection;Boolean map;grayscale rarity;small target;complex background44|15|3更新时间:2024-05-07 -
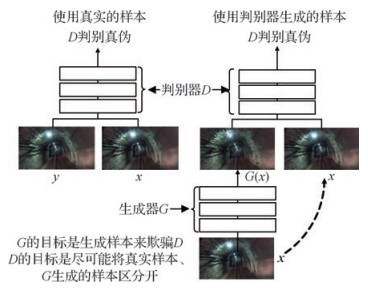 摘要:ObjectiveIn recent years, the frequent occurrence of large-scale mine accidents has led to many casualties and property losses. The mines' production and transportation should be promoted in the way of intelligence. When moving under the mine, the controller of a locomotive needs track information to detect the presence of pedestrians or obstacles in front of it. Then, the locomotive slows down or stops as soon as an emergency condition appears. Track detection, which uses image processing technology to identify the track area in a video or image and displays the specific position of the track, is a key technology for computer vision to achieve automatic driving downhole. Track detection algorithms based on traditional image processing can be classified into two categories. The first is a feature-based approach, which uses the difference between the edge and surrounding environment to extract the track region and obtains the specific track location in the image. However, this method relies heavily on the underlying features of the image and is easily interfered by the surrounding environment, which brings great challenges to the subsequent work and affects the final detection effect of the track. The second is a model-based strategy, which converts the track detection into a problem of solving the track model parameters and achieves the fitting of the track based on its shape in the local range. The track model often cannot adapt to multiple scenarios, and the approach lacks robustness and flexibility. Track detection results based on the convolutional neural network algorithm lack a detailed, unique characterization of the object and rely heavily on visual post-processing techniques. Therefore, we propose conditional generative adversarial net, a track detection algorithm combining multiscale information.MethodFirst, the multigranularity structure is used to decompose it into global and local parts in the generator network. The global part is responsible for low-resolution image generation, and the local part will combine with the global part to generate high-resolution images. Second, the multiscale shared convolution structure is adopted in the discriminator network. The primary features of the real and synthesized samples are extracted by sharing the convolution layer, the corresponding feature map is obtained, and different samples are sent to the multiscale discriminator to supervise the training of the generator further. Finally, the Monte Carlo search technique is introduced to search the intermediate state of the generator, and the result is sent to the discriminator for comparison.ResultThe proposed algorithm achieves an average pixel accuracy of 82.43% and a mean intersection over-union of 0.621 8. Moreover, the accuracy of detecting the track can reach 95.01%. For many different underground scenes, the track test results show good performance and superiority compared with the existing semantic segmentation algorithms.ConclusionThe proposed algorithm can be effectively applied to the complex underground environment and resolves the dilemma of algorithms existing in traditional image processing and convolutional neural network, thus effectively serving underground automatic driving. The algorithm has the following virtues. First, it generates high-resolution images by generative adversarial nets and addresses unstable training in generating edge features of high-resolution images. Second, the multitask learning mechanism is further conducive to discriminator identification, thereby effectively monitoring the results generated by the generator. Finally, the Monte Carlo search strategy is used to search the intermediate state of the generator, which is then feed it into the discriminator, thereby strengthening the constraints of the generator and enhancing the quality of the generated image. Experimental results show that our algorithm can achieve satisfactory results. In the future, we will focus on overcoming the issue of track line prediction under occlusion, expanding the datasets, and strengthening the speed, robustness, and practicality of the algorithm.关键词:track detection;conditional generative adversarial nets(CGAN);multi-scale information;Monte Carlo search;automatic driving downhole19|18|2更新时间:2024-05-07
摘要:ObjectiveIn recent years, the frequent occurrence of large-scale mine accidents has led to many casualties and property losses. The mines' production and transportation should be promoted in the way of intelligence. When moving under the mine, the controller of a locomotive needs track information to detect the presence of pedestrians or obstacles in front of it. Then, the locomotive slows down or stops as soon as an emergency condition appears. Track detection, which uses image processing technology to identify the track area in a video or image and displays the specific position of the track, is a key technology for computer vision to achieve automatic driving downhole. Track detection algorithms based on traditional image processing can be classified into two categories. The first is a feature-based approach, which uses the difference between the edge and surrounding environment to extract the track region and obtains the specific track location in the image. However, this method relies heavily on the underlying features of the image and is easily interfered by the surrounding environment, which brings great challenges to the subsequent work and affects the final detection effect of the track. The second is a model-based strategy, which converts the track detection into a problem of solving the track model parameters and achieves the fitting of the track based on its shape in the local range. The track model often cannot adapt to multiple scenarios, and the approach lacks robustness and flexibility. Track detection results based on the convolutional neural network algorithm lack a detailed, unique characterization of the object and rely heavily on visual post-processing techniques. Therefore, we propose conditional generative adversarial net, a track detection algorithm combining multiscale information.MethodFirst, the multigranularity structure is used to decompose it into global and local parts in the generator network. The global part is responsible for low-resolution image generation, and the local part will combine with the global part to generate high-resolution images. Second, the multiscale shared convolution structure is adopted in the discriminator network. The primary features of the real and synthesized samples are extracted by sharing the convolution layer, the corresponding feature map is obtained, and different samples are sent to the multiscale discriminator to supervise the training of the generator further. Finally, the Monte Carlo search technique is introduced to search the intermediate state of the generator, and the result is sent to the discriminator for comparison.ResultThe proposed algorithm achieves an average pixel accuracy of 82.43% and a mean intersection over-union of 0.621 8. Moreover, the accuracy of detecting the track can reach 95.01%. For many different underground scenes, the track test results show good performance and superiority compared with the existing semantic segmentation algorithms.ConclusionThe proposed algorithm can be effectively applied to the complex underground environment and resolves the dilemma of algorithms existing in traditional image processing and convolutional neural network, thus effectively serving underground automatic driving. The algorithm has the following virtues. First, it generates high-resolution images by generative adversarial nets and addresses unstable training in generating edge features of high-resolution images. Second, the multitask learning mechanism is further conducive to discriminator identification, thereby effectively monitoring the results generated by the generator. Finally, the Monte Carlo search strategy is used to search the intermediate state of the generator, which is then feed it into the discriminator, thereby strengthening the constraints of the generator and enhancing the quality of the generated image. Experimental results show that our algorithm can achieve satisfactory results. In the future, we will focus on overcoming the issue of track line prediction under occlusion, expanding the datasets, and strengthening the speed, robustness, and practicality of the algorithm.关键词:track detection;conditional generative adversarial nets(CGAN);multi-scale information;Monte Carlo search;automatic driving downhole19|18|2更新时间:2024-05-07 -
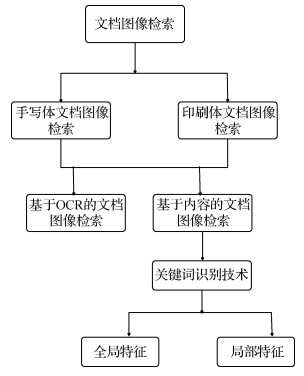 摘要:ObjectiveIn the 21st century, the rapid development of Internet information provides great convenience for people's lifestyles, but people also must face information redundancy when they go online because most information is now in text. The existence of forms emphasizes the importance of accurately and efficiently obtaining the information that users need. Moreover, with the acceleration of informationization, the number of electronic documents has risen sharply, making the efficient and fast retrieval of document images further urgent. In document image retrieval, traditional optical character recognition (OCR) technology has difficulty in achieving effective retrieval due to the quality of document images and fonts. As an alternative to OCR technology, word recognition technology does not require cumbersome OCR recognition and can directly search for keywords to achieve good results. In keyword extraction, local feature extraction has a more detailed and accurate description than global feature extraction. In terms of corner detection, this paper focuses on the serious clustering and slow computing speed of Harris algorithm.MethodIn the framework of word-spotting technology, an improved Harris image matching algorithm is proposed, which is used for document image retrieval for the first time. First, the original Harris algorithm uses the Gaussian function to smooth the window in the feature point extraction process of the image. When calculating the corner response value R, the differential operator is used as the directional derivative to calculate the number of multiplication operations, resulting in many computational algorithms, slow operation, and other issues. Given the deficiencies of the original Harris algorithm, FAST algorithm is used in the detection of corner points. 1) The gray values of the center pixel and surrounding 16 pixels are compared using the formula in the radius 3 field. 2) To improve the detection speed, the 0th and 8th pixel points on the circumference are first detected, and the two points on the other diameters are sequentially detected. 3) A difference between the gray values of 12 consecutive points and the p-point exceeding the threshold indicates a corner point. 4) After obtaining the primary corner, the Harris algorithm is used to remove the pseudo corner. Second, the original Harris algorithm sorts and compares the local maximum of the corner response function, establishes the response and coordinate matrices, records the local maximum and response coordinates, and compares the global maximum. At this point, all corner points have been recorded, but a case wherein multiple corner points coexist in the domain of a corner point, namely, "clustering" phenomenon, is likely. To address the serious clustering problem of the Harris algorithm, a nonmaximum value suppression method is adopted, which essentially searches for the local maximum and suppresses nonmaximum elements. When detecting the diagonal points, the local maximum is sorted from large to small, the suppression radius is set, a new response function matrix is established, and the corner points are extracted by continuously reducing the radius, thereby effectively avoiding Harris corner clustering. 1) The value of the corner response function of all pixels in the graph is calculated, the local maximum is searched for, and the pixel of the local maximum is recorded. 2) The local maximum ordering matrix and corresponding coordinate matrix are established, and the local maxima are sorted from large to small. 3) The suppression radius is set to the local maximum, a new matrix of response functions is established, and the corner points are extracted by continuously reducing the radius. 4) Whether the local maximum value is the maximum value within the suppression radius, that is, the desired corner point, is judged; if the condition is satisfied, then the local maximum value is added to the response function matrix. 5) The radius reduction is continued to extract the corner points. If the number of corner points is preset, then the process ends. Otherwise, step 4) is repeated.ResultExperimental results show that the accuracy rate is 98% and the recall rate is 87.5% without noise. Good experimental results are obtained under the condition of constant mean and continuous improvement of variance of Gaussian noise. Compared with the SIFT algorithm, the time is considerably improved, and the accuracy is increased.ConclusionStarting from the document image of the printed matter, FAST+Harris is used to search for keywords under the framework of keyword recognition technology. On the one hand, this method saves retrieval time and improves the real-time performance of the algorithm. On the other hand, it improves the aggregation of Harris. The cluster phenomenon improves the accuracy of corner detection. Compared with the SIFT algorithm, time is greatly improved, and good experimental results are achieved under the influence of different degrees of noise.关键词:Fast+Harris;feature extraction;brute force;corner detection;word spotting;print document image21|23|1更新时间:2024-05-07
摘要:ObjectiveIn the 21st century, the rapid development of Internet information provides great convenience for people's lifestyles, but people also must face information redundancy when they go online because most information is now in text. The existence of forms emphasizes the importance of accurately and efficiently obtaining the information that users need. Moreover, with the acceleration of informationization, the number of electronic documents has risen sharply, making the efficient and fast retrieval of document images further urgent. In document image retrieval, traditional optical character recognition (OCR) technology has difficulty in achieving effective retrieval due to the quality of document images and fonts. As an alternative to OCR technology, word recognition technology does not require cumbersome OCR recognition and can directly search for keywords to achieve good results. In keyword extraction, local feature extraction has a more detailed and accurate description than global feature extraction. In terms of corner detection, this paper focuses on the serious clustering and slow computing speed of Harris algorithm.MethodIn the framework of word-spotting technology, an improved Harris image matching algorithm is proposed, which is used for document image retrieval for the first time. First, the original Harris algorithm uses the Gaussian function to smooth the window in the feature point extraction process of the image. When calculating the corner response value R, the differential operator is used as the directional derivative to calculate the number of multiplication operations, resulting in many computational algorithms, slow operation, and other issues. Given the deficiencies of the original Harris algorithm, FAST algorithm is used in the detection of corner points. 1) The gray values of the center pixel and surrounding 16 pixels are compared using the formula in the radius 3 field. 2) To improve the detection speed, the 0th and 8th pixel points on the circumference are first detected, and the two points on the other diameters are sequentially detected. 3) A difference between the gray values of 12 consecutive points and the p-point exceeding the threshold indicates a corner point. 4) After obtaining the primary corner, the Harris algorithm is used to remove the pseudo corner. Second, the original Harris algorithm sorts and compares the local maximum of the corner response function, establishes the response and coordinate matrices, records the local maximum and response coordinates, and compares the global maximum. At this point, all corner points have been recorded, but a case wherein multiple corner points coexist in the domain of a corner point, namely, "clustering" phenomenon, is likely. To address the serious clustering problem of the Harris algorithm, a nonmaximum value suppression method is adopted, which essentially searches for the local maximum and suppresses nonmaximum elements. When detecting the diagonal points, the local maximum is sorted from large to small, the suppression radius is set, a new response function matrix is established, and the corner points are extracted by continuously reducing the radius, thereby effectively avoiding Harris corner clustering. 1) The value of the corner response function of all pixels in the graph is calculated, the local maximum is searched for, and the pixel of the local maximum is recorded. 2) The local maximum ordering matrix and corresponding coordinate matrix are established, and the local maxima are sorted from large to small. 3) The suppression radius is set to the local maximum, a new matrix of response functions is established, and the corner points are extracted by continuously reducing the radius. 4) Whether the local maximum value is the maximum value within the suppression radius, that is, the desired corner point, is judged; if the condition is satisfied, then the local maximum value is added to the response function matrix. 5) The radius reduction is continued to extract the corner points. If the number of corner points is preset, then the process ends. Otherwise, step 4) is repeated.ResultExperimental results show that the accuracy rate is 98% and the recall rate is 87.5% without noise. Good experimental results are obtained under the condition of constant mean and continuous improvement of variance of Gaussian noise. Compared with the SIFT algorithm, the time is considerably improved, and the accuracy is increased.ConclusionStarting from the document image of the printed matter, FAST+Harris is used to search for keywords under the framework of keyword recognition technology. On the one hand, this method saves retrieval time and improves the real-time performance of the algorithm. On the other hand, it improves the aggregation of Harris. The cluster phenomenon improves the accuracy of corner detection. Compared with the SIFT algorithm, time is greatly improved, and good experimental results are achieved under the influence of different degrees of noise.关键词:Fast+Harris;feature extraction;brute force;corner detection;word spotting;print document image21|23|1更新时间:2024-05-07 -
 摘要:ObjectiveImage segmentation is based on the grayscale information of the image, and the homogenous regions with different properties of the image are divided using different methods without overlapping each other. When image segmentation is performed to obtain the region of interest, the image will inevitably have a certain degree of noise due to various factors, the noise will cause the image edge to be weakened, the false edge will be generated during segmentation, the segmentation curve will fall into the local minimum, and the evolution will stop. The situation, in turn, affects the accuracy of the edge recognition of the target to be segmented during image segmentation, and the segmentation result encounters difficulty in achieving the desired effect. The level set method based on active set is widely used in image segmentation, but it is still affected by noise. Thus, a new method is proposed to solve the noise problem.MethodSince given that the anisotropic diffusion model is applied to image segmentation, including denoising and maintaining the edge of the target to be segmented, a new model is proposed to fuse the anisotropic diffusion divergence field information into the DRLSE model to improve the efficiency and accuracy of the existing segmentation algorithm of the noise image based on the distance regularization level set (DRLSE) evolution model.The model can overcome the problems of the distance regularized level set model, such as slow convergence speed, easy to fall into the false boundary and leak from the weak edge. The improved model can accelerate the initial contour evolution to the edge of the target to be segmented when segmenting the noise image. The main improvement is to change the constant coefficient α of the control area term in the DRLSE evolution model to the variable weight coefficient α(
摘要:ObjectiveImage segmentation is based on the grayscale information of the image, and the homogenous regions with different properties of the image are divided using different methods without overlapping each other. When image segmentation is performed to obtain the region of interest, the image will inevitably have a certain degree of noise due to various factors, the noise will cause the image edge to be weakened, the false edge will be generated during segmentation, the segmentation curve will fall into the local minimum, and the evolution will stop. The situation, in turn, affects the accuracy of the edge recognition of the target to be segmented during image segmentation, and the segmentation result encounters difficulty in achieving the desired effect. The level set method based on active set is widely used in image segmentation, but it is still affected by noise. Thus, a new method is proposed to solve the noise problem.MethodSince given that the anisotropic diffusion model is applied to image segmentation, including denoising and maintaining the edge of the target to be segmented, a new model is proposed to fuse the anisotropic diffusion divergence field information into the DRLSE model to improve the efficiency and accuracy of the existing segmentation algorithm of the noise image based on the distance regularization level set (DRLSE) evolution model.The model can overcome the problems of the distance regularized level set model, such as slow convergence speed, easy to fall into the false boundary and leak from the weak edge. The improved model can accelerate the initial contour evolution to the edge of the target to be segmented when segmenting the noise image. The main improvement is to change the constant coefficient α of the control area term in the DRLSE evolution model to the variable weight coefficient α($I$ 关键词:image segmentation;noise;edge recognition;level set;anisotropic diffusion40|53|0更新时间:2024-05-07 -
 摘要:ObjectiveDocument image layout analysis aims to segment different regions on the basis of the content of the page and to identify the different regions quickly. Different strategies must be developed for diverse layout objects owing to varied handling for each type of area. Therefore, document image layout must be first analyzed to facilitate subsequent processing. The traditional method of document image layout analysis is generally based on complex rules. The method of first positioning and post-classification cannot simultaneously achieve the regional positioning and classification of document layout, and different document images need their own specific strategies, thereby limiting versatility. Compared with the feature representation of traditional method, the deep learning model has powerful representation and modeling capabilities and is further adaptable to complex target detection tasks. Proposal-based networks, such as Faster region-convolutional neural networks (Faster R-CNN) and region based fully convolutional network (R-FCN), and proposal-free networks, such as single shot multbox detecter (SSD), you only look once (YOLO), and other representative object-level object detection networks, have been proposed. The application of pixel-level object detection networks, such as fully convolutional networks and a series of DeepLab networks, enables deep learning technology to make breakthroughs in target detection tasks. In deep learning, object detection techniques at the object or pixel level have been applied in document layout analysis. However, most methods based on deep learning currently require complex preprocessing processes, such as color coding, image binarization, and simple rules, making the model structure complex. Moreover, the document image will lose considerable information due to the complicated preprocessing process, which affects the recognition accuracy. In addition, common deep learning models are difficult to apply to small datasets. To address these problems, this paper proposes a deep learning method for multi-feature fusion convolutional neural networks.Methodirst, feature extraction is performed on the input image by convolution layers composed of convolution kernels with different sizes. The convolutional layer of the parallel extraction feature has three layers. The numbers of three convolution kernels are 3, 4, and 3. The first layer uses a large-scale convolution kernel with sizes of 11×11, 9×9, and 7×7 to increase the receptive field and retain additional feature information. The number of convolution kernels in the second layer is 4, and the sizes of the convolution kernel are 7×7, 5×5, 3×3, and 1×1 to increase the feature extraction while ensuring coarse extraction. The third layer is composed of three different scale convolution kernels of 5×5, 3×3, and 1×1 to extract detailed information further. The feature fusion module consists of a convolutional layer and a 1×1 size convolution kernel. The fusion module then adds the convolutional layer to extract the features again. The atrous spatial pyramid pooling (ASPP) strategy in DeepLabV3 is selected. ASPP consists of four convolution kernels with different sizes, which are the standard 1×1 convolution kernel and 3×3atrous convolution kernel with expansion ratios of 6, 12, and 18. When the size of the sampled convolution kernel is close to the size of the feature map, the 3×3atrous convolution kernel loses the capability to capture full image information and degenerates into a 1×1 convolution kernel; thus, image-level features are added. The role of ASPP is to expand the receptive field of the convolution kernel without losing the resolution and to retain the information of the feature map to the utmost extent. Finally, the image is restored by bilinear interpolation, and the document layout target is completed as the positioning and identification of figures, tables, and formulas. During training, the experimental environment is Ubuntu 18.04 system, which is trained with TensorFlow framework and NVDIA 1080 GPU with 16 GB memory. The data use the ICDAR 2017 POD document layout target detection dataset with 1 600 training images and 812 test images. The input data pixels are uniformly reduced to 513×513 during training to reduce the model training parameters.ResultMean intersection over union (IOU) and pixel accuracy (PA) are used as evaluation criteria. The experiments on the ICDAR 2017 POD document layout object detection dataset show that the proposed algorithm achieves 87.26% and 98.10% mIOU and PA, respectively. Compared with fully convolutional networks, the proposed algorithm improves mIOU and PA by 14.66% and 2.22%, respectively, and the proposed feature fusion module improves mIOU and PA by 1.45% and 0.22%, respectively.ConclusionThis paper proposes the positioning and recognition of multiple targets in the document layout under a network framework. It does not need complex preprocessing on the image, and it simplifies the model structure. The experimental data prove that the algorithm can further efficiently identify the background, illustrations, tables, and formulas and achieve improved recognition results with less training data.关键词:document image processing;layout analysis;object detection;deep learning;semantic segmentation54|36|5更新时间:2024-05-07
摘要:ObjectiveDocument image layout analysis aims to segment different regions on the basis of the content of the page and to identify the different regions quickly. Different strategies must be developed for diverse layout objects owing to varied handling for each type of area. Therefore, document image layout must be first analyzed to facilitate subsequent processing. The traditional method of document image layout analysis is generally based on complex rules. The method of first positioning and post-classification cannot simultaneously achieve the regional positioning and classification of document layout, and different document images need their own specific strategies, thereby limiting versatility. Compared with the feature representation of traditional method, the deep learning model has powerful representation and modeling capabilities and is further adaptable to complex target detection tasks. Proposal-based networks, such as Faster region-convolutional neural networks (Faster R-CNN) and region based fully convolutional network (R-FCN), and proposal-free networks, such as single shot multbox detecter (SSD), you only look once (YOLO), and other representative object-level object detection networks, have been proposed. The application of pixel-level object detection networks, such as fully convolutional networks and a series of DeepLab networks, enables deep learning technology to make breakthroughs in target detection tasks. In deep learning, object detection techniques at the object or pixel level have been applied in document layout analysis. However, most methods based on deep learning currently require complex preprocessing processes, such as color coding, image binarization, and simple rules, making the model structure complex. Moreover, the document image will lose considerable information due to the complicated preprocessing process, which affects the recognition accuracy. In addition, common deep learning models are difficult to apply to small datasets. To address these problems, this paper proposes a deep learning method for multi-feature fusion convolutional neural networks.Methodirst, feature extraction is performed on the input image by convolution layers composed of convolution kernels with different sizes. The convolutional layer of the parallel extraction feature has three layers. The numbers of three convolution kernels are 3, 4, and 3. The first layer uses a large-scale convolution kernel with sizes of 11×11, 9×9, and 7×7 to increase the receptive field and retain additional feature information. The number of convolution kernels in the second layer is 4, and the sizes of the convolution kernel are 7×7, 5×5, 3×3, and 1×1 to increase the feature extraction while ensuring coarse extraction. The third layer is composed of three different scale convolution kernels of 5×5, 3×3, and 1×1 to extract detailed information further. The feature fusion module consists of a convolutional layer and a 1×1 size convolution kernel. The fusion module then adds the convolutional layer to extract the features again. The atrous spatial pyramid pooling (ASPP) strategy in DeepLabV3 is selected. ASPP consists of four convolution kernels with different sizes, which are the standard 1×1 convolution kernel and 3×3atrous convolution kernel with expansion ratios of 6, 12, and 18. When the size of the sampled convolution kernel is close to the size of the feature map, the 3×3atrous convolution kernel loses the capability to capture full image information and degenerates into a 1×1 convolution kernel; thus, image-level features are added. The role of ASPP is to expand the receptive field of the convolution kernel without losing the resolution and to retain the information of the feature map to the utmost extent. Finally, the image is restored by bilinear interpolation, and the document layout target is completed as the positioning and identification of figures, tables, and formulas. During training, the experimental environment is Ubuntu 18.04 system, which is trained with TensorFlow framework and NVDIA 1080 GPU with 16 GB memory. The data use the ICDAR 2017 POD document layout target detection dataset with 1 600 training images and 812 test images. The input data pixels are uniformly reduced to 513×513 during training to reduce the model training parameters.ResultMean intersection over union (IOU) and pixel accuracy (PA) are used as evaluation criteria. The experiments on the ICDAR 2017 POD document layout object detection dataset show that the proposed algorithm achieves 87.26% and 98.10% mIOU and PA, respectively. Compared with fully convolutional networks, the proposed algorithm improves mIOU and PA by 14.66% and 2.22%, respectively, and the proposed feature fusion module improves mIOU and PA by 1.45% and 0.22%, respectively.ConclusionThis paper proposes the positioning and recognition of multiple targets in the document layout under a network framework. It does not need complex preprocessing on the image, and it simplifies the model structure. The experimental data prove that the algorithm can further efficiently identify the background, illustrations, tables, and formulas and achieve improved recognition results with less training data.关键词:document image processing;layout analysis;object detection;deep learning;semantic segmentation54|36|5更新时间:2024-05-07 -
 摘要:ObjectiveSaliency object detection has been widely used in many fields, such as image matching. Although the current saliency object detection algorithm has achieved good results, the following problems still exist:the texture detail is not obvious and the edge contours are incomplete. In addition, the saliency detection results of images are influenced by many factors, such as contrast and texture, and the reliability of the saliency detection results based on a single saliency factor is low. Hence, to solve these problems, a method of saliency object detection based on multiple features and prior information is proposed, this method can obtain final saliency images with prominent saliency areas, high brightness contrast, clear levels, distinct texture details, and complete edge contours.MethodFirst, the convex hulls of the image are extracted, the points near the boundary in the convex hulls are removed, and the set of points of interest (i.e., the hull) is preserved. Meanwhile, the superpixel segmentation method is used to obtain compact image blocks with a uniform size, calculate the contrast and spatial distribution of each image block, the contrast and spatial distribution are fused linearly to obtain the global contrast map, calculate the prior probability and likelihood probability based on the hull and global contrast map. The Bayesian algorithm is utilized to obtain the contrast feature map. Under multi-scale conditions, the color histogram of the image is calculated and used to obtain the color spatial map. In accordance with information entropy theory, the information entropy of each color spatial map is calculated, the minimum information entropy is obtained, and the image is used with this scale as the color feature map. The unsharp mask method is adopted to improve the sharpness of the original image, enhance the edge of the image, and highlight other details. The local binary pattern operator is employed to obtain the texture feature map of the image, and the popular graph regularized and manifold ranking algorithms are used to obtain the center prior map and edge prior map. Finally, the primary saliency map is obtained by using the cellular automation fusion contrast feature map, color feature map, texture feature map, center prior map and edge prior maps. The primary saliency map is optimized with a fast guided filter to obtain the final saliency map.ResultTo confirm the availability and accuracy of the proposed algorithm, its performance is tested on two open datasets, namely, MSRA10K and ECSSD (extended complex scence saliency datay base). The MSRA10K dataset is one of the most frequently used datasets for comparing saliency test results. It contains 10 000 images and their corresponding ground truth images. The images in the datasets are surrounded by the bounding box of the artificial marker, and the background is simple. The ECSSD dataset contains 1 000 images and their corresponding ground truth images. The images in this dataset contain multiple targets, which are close to natural images and have an extremely complex background. Under the same experiment environment, 200 images are randomly selected from each dataset and compared with 12 saliency object detection methods with an open-source code based on multi-information fusion. Experimental results show that the proposed saliency object detection method based on multiple features and prior information is significantly improved in terms of PR (precision-recall) curves, ROC (receiver operating characteristic) curves, F-measure, MAE (mean absolute error), and S-measure. Its overall performance is better than that of the compared algorithms, and it can solve the above mentioned problems well. On the MSRA10K and ECSSD datasets, the PR curves of the proposed algorithm are the closest to the upper right, and the DCL (diffusion-based compactness and local wntrast) algorithm is close to our algorithm, both of which are higher than the other compared algorithms. The ROC curves of the BSCA (background-based map optimized via single-lager cellular automata) and DCL algorithms are closer to the upper left than our algorithm on the MSRA10K dataset. Our algorithm is close to the ROC curves of the DCL algorithm, and they are better than the other compared methods on the ECSSD dataset. The F-measure values of our algorithm are the highest and reach 0.944 49 and 0.855 73. The values for the popular SACS (self-adaptively weighted co-saliency detection via rank constraint), BSCA, DCL, and WMR (weighted manifold ranking) algorithms are slightly lower than that of the proposed algorithm, which indicates that our algorithm has an optimal overall performance. The MAE values of our algorithm are the smallest and reach 0.070 8 and 0.125 71, indicating that our algorithm has the best detection effect. The S-measure values of our algorithm are the highest and reach 0.913 26 and 0.818 88, indicating that the salient image of our algorithm is the more similar to the structure of the ground truth image, and the detection effect is perfect.ConclusionIn this study, a saliency object detection method based on multiple features and prior information is proposed. This method fully combines the advantages of contrast features, color features, texture features, center prior information, and edge prior information. It comprehensively extracts the salient region and preserves the texture and detail information of the image well. Thus, the edge contour is more complete. The proposed method also satisfies the hierarchical and detail requirements of the human eye and has a certain applicability. However, the method is not perfect when dealing with the no-salient region of complex images. Optimization will be considered in future research.关键词:saliency object detection;multiple features;prior information;cellular automaton;fast guided filter22|12|3更新时间:2024-05-07
摘要:ObjectiveSaliency object detection has been widely used in many fields, such as image matching. Although the current saliency object detection algorithm has achieved good results, the following problems still exist:the texture detail is not obvious and the edge contours are incomplete. In addition, the saliency detection results of images are influenced by many factors, such as contrast and texture, and the reliability of the saliency detection results based on a single saliency factor is low. Hence, to solve these problems, a method of saliency object detection based on multiple features and prior information is proposed, this method can obtain final saliency images with prominent saliency areas, high brightness contrast, clear levels, distinct texture details, and complete edge contours.MethodFirst, the convex hulls of the image are extracted, the points near the boundary in the convex hulls are removed, and the set of points of interest (i.e., the hull) is preserved. Meanwhile, the superpixel segmentation method is used to obtain compact image blocks with a uniform size, calculate the contrast and spatial distribution of each image block, the contrast and spatial distribution are fused linearly to obtain the global contrast map, calculate the prior probability and likelihood probability based on the hull and global contrast map. The Bayesian algorithm is utilized to obtain the contrast feature map. Under multi-scale conditions, the color histogram of the image is calculated and used to obtain the color spatial map. In accordance with information entropy theory, the information entropy of each color spatial map is calculated, the minimum information entropy is obtained, and the image is used with this scale as the color feature map. The unsharp mask method is adopted to improve the sharpness of the original image, enhance the edge of the image, and highlight other details. The local binary pattern operator is employed to obtain the texture feature map of the image, and the popular graph regularized and manifold ranking algorithms are used to obtain the center prior map and edge prior map. Finally, the primary saliency map is obtained by using the cellular automation fusion contrast feature map, color feature map, texture feature map, center prior map and edge prior maps. The primary saliency map is optimized with a fast guided filter to obtain the final saliency map.ResultTo confirm the availability and accuracy of the proposed algorithm, its performance is tested on two open datasets, namely, MSRA10K and ECSSD (extended complex scence saliency datay base). The MSRA10K dataset is one of the most frequently used datasets for comparing saliency test results. It contains 10 000 images and their corresponding ground truth images. The images in the datasets are surrounded by the bounding box of the artificial marker, and the background is simple. The ECSSD dataset contains 1 000 images and their corresponding ground truth images. The images in this dataset contain multiple targets, which are close to natural images and have an extremely complex background. Under the same experiment environment, 200 images are randomly selected from each dataset and compared with 12 saliency object detection methods with an open-source code based on multi-information fusion. Experimental results show that the proposed saliency object detection method based on multiple features and prior information is significantly improved in terms of PR (precision-recall) curves, ROC (receiver operating characteristic) curves, F-measure, MAE (mean absolute error), and S-measure. Its overall performance is better than that of the compared algorithms, and it can solve the above mentioned problems well. On the MSRA10K and ECSSD datasets, the PR curves of the proposed algorithm are the closest to the upper right, and the DCL (diffusion-based compactness and local wntrast) algorithm is close to our algorithm, both of which are higher than the other compared algorithms. The ROC curves of the BSCA (background-based map optimized via single-lager cellular automata) and DCL algorithms are closer to the upper left than our algorithm on the MSRA10K dataset. Our algorithm is close to the ROC curves of the DCL algorithm, and they are better than the other compared methods on the ECSSD dataset. The F-measure values of our algorithm are the highest and reach 0.944 49 and 0.855 73. The values for the popular SACS (self-adaptively weighted co-saliency detection via rank constraint), BSCA, DCL, and WMR (weighted manifold ranking) algorithms are slightly lower than that of the proposed algorithm, which indicates that our algorithm has an optimal overall performance. The MAE values of our algorithm are the smallest and reach 0.070 8 and 0.125 71, indicating that our algorithm has the best detection effect. The S-measure values of our algorithm are the highest and reach 0.913 26 and 0.818 88, indicating that the salient image of our algorithm is the more similar to the structure of the ground truth image, and the detection effect is perfect.ConclusionIn this study, a saliency object detection method based on multiple features and prior information is proposed. This method fully combines the advantages of contrast features, color features, texture features, center prior information, and edge prior information. It comprehensively extracts the salient region and preserves the texture and detail information of the image well. Thus, the edge contour is more complete. The proposed method also satisfies the hierarchical and detail requirements of the human eye and has a certain applicability. However, the method is not perfect when dealing with the no-salient region of complex images. Optimization will be considered in future research.关键词:saliency object detection;multiple features;prior information;cellular automaton;fast guided filter22|12|3更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveImage description, a popular research field in computer vision and natural language processing, focuses on generating sentences that accurately describe the image content. Image description has a wide application in infant education, film production, and road navigation. In previous methods, generating image description based on deep learning achieved great success. On the basis of encoder-decoder framework, convolutional neural network is used as the feature extractor, and recurrent neural network is used as the caption generator. Cross entropy is applied to calculate the generation loss. However, the descriptions produced by these methods are often overly disorderly and inaccurate. Some researchers have exposed regularization method based on the encoder-decoder framework to strengthen the relationship between the image and generated description. However, incoherent problems remain with the generated descriptions caused by missing local information and high-level semantic concepts. Therefore, we propose a novel fusion training method based on encoder-decoder framework and generative adversarial networks, which enables global and local information to be calculated by a generator and inhibitor. This method encourages high linguistic coherence to human level while closing semantic concepts between image and description.MethodThe model is composed of an image feature extractor, inhibitor, generator, and discriminator. First, ResNet-152 is used as the image feature extractor. In ResNet-152, a key module named bottleneck is made up of a 1×1 convolution layer in 64 dimensions, a 3×3 convolution layer in 64 dimensions, a 1×1 convolution layer in 256 dimensions, and a shortcut connection. To suppress the time complexity per layer, an important principle is that the number of filters will be doubled if the dimension of convolutions is halved. The shortcut connection is introduced to address vanishing gradient. The last layer in ResNet-152 is replaced by a fully connected layer to align the dimension between the image feature and word after embedding. For the input of an image, the output of the extractor is an image feature vector with 512 dimensions. Second, the inhibitor is composed of a long short-term memory (LSTM). The input of the first moment is an image feature from the extractor. Every moment after that, the input is a word vector after embedding from ground truth. The results of inhibitor and "ground truth" are used to calculate the local score. The local score represents the coherence of the generated sentences. Third, the structure of the generator is the same as that of the inhibitor. Despite parameter sharing between the inhibitor and generator, the input of the generator is different from that of the inhibitor. In the generator, the output of the previous moment is used as the input of the current moment. The generator result is the image description and is used as part of the discriminator input. Fourth, the discriminator similarly consists of LSTM. Each word in the description generated by the generator corresponds to the input of the discriminator at each moment. The discriminator output at the last moment is combined with the image features obtained by the feature extractor to calculate the global score. The global score measures the semantic similarity between the generated description and image. Finally, the fusion loss consists of local and global scores. By controlling the weight of the local and global scores in fusion loss, coherence and accuracy are given different degrees of attention, and different descriptions may be generated for the same image. On the basis of the fusion loss, the model optimizes the parameter by backpropagation. In the experiment, the feature extractor is pretrained on the basis of the ImageNet dataset, and the parameters of the last layer are fine-tuned in formal training. As the training number increases, the generated sentences will perform increasingly well in terms of coherence and accuracy.ResultModel performance is evaluated using three datasets, namely, MSCOCO-2014, Oxford-102, and CUB-200-2011. In the CUB-200-2011 dataset, our method shows improvement compared with that using the maximum likelihood estimate as the optimization function (CIDEr +1.6%, BLEU-3 +0.2%, BLEU-2 +0.8%, BLEU-1 +0.7%, and ROUGE-L +0.5%). The model performance declines when the inhibitor is removed from the model (BLEU-4 -0.8%, BLEU-3 -1.2%, BLEU-2 -1.6%, BLEU-1 -0.9%, ROUGE-L -1.8%, and METEOR -1.0%). In the Oxford-102 dataset, our method gains additional improvements compared with that using MLE as the optimization function (CIDEr +3.6%, BLEU-4 +0.7%, BLEU-3 +0.6%, BLEU-2 +0.4%, BLEU-1 +0.2%, ROUGE-L +0.6%, and METEOR +0.7%). The model performance declines substantially after removing the inhibitor (CIDEr -3.8%, BLEU-4 -1.5%, BLEU-3 -1.7%, BLEU-2 -1.4%, BLEU-1 -1.5%, ROUGE-L -0.5%, and METEOR -0.1%). In the MSCOCO-2014 dataset, our method achieves a leading position in several evaluation metrics compared with several proposed methods (BLEU-3 +0.4%, BLEU-2 +0.4%, BLEU-1 +0.4%, and ROUGE-L +0.3%).ConclusionThe new optimization function and fusion training method are considered in the dependency relationships between words and the semantic relativity between the generated description and image. The method in this study obtains better scores in multiple evaluation metrics than that using MLE as the optimization function. Experiment results indicate that the inhibitor has a positive effect on the model performance in terms of evaluation metrics while optimizing the coherence of generated descriptions. The method increases the coherency of generated captions on the premise of the captions generated by the generator and image matching in the content.关键词:image description generation;inhibiting learning;reinforcement learning;generative adversarial networks(GAN);fusion training22|20|2更新时间:2024-05-07
摘要:ObjectiveImage description, a popular research field in computer vision and natural language processing, focuses on generating sentences that accurately describe the image content. Image description has a wide application in infant education, film production, and road navigation. In previous methods, generating image description based on deep learning achieved great success. On the basis of encoder-decoder framework, convolutional neural network is used as the feature extractor, and recurrent neural network is used as the caption generator. Cross entropy is applied to calculate the generation loss. However, the descriptions produced by these methods are often overly disorderly and inaccurate. Some researchers have exposed regularization method based on the encoder-decoder framework to strengthen the relationship between the image and generated description. However, incoherent problems remain with the generated descriptions caused by missing local information and high-level semantic concepts. Therefore, we propose a novel fusion training method based on encoder-decoder framework and generative adversarial networks, which enables global and local information to be calculated by a generator and inhibitor. This method encourages high linguistic coherence to human level while closing semantic concepts between image and description.MethodThe model is composed of an image feature extractor, inhibitor, generator, and discriminator. First, ResNet-152 is used as the image feature extractor. In ResNet-152, a key module named bottleneck is made up of a 1×1 convolution layer in 64 dimensions, a 3×3 convolution layer in 64 dimensions, a 1×1 convolution layer in 256 dimensions, and a shortcut connection. To suppress the time complexity per layer, an important principle is that the number of filters will be doubled if the dimension of convolutions is halved. The shortcut connection is introduced to address vanishing gradient. The last layer in ResNet-152 is replaced by a fully connected layer to align the dimension between the image feature and word after embedding. For the input of an image, the output of the extractor is an image feature vector with 512 dimensions. Second, the inhibitor is composed of a long short-term memory (LSTM). The input of the first moment is an image feature from the extractor. Every moment after that, the input is a word vector after embedding from ground truth. The results of inhibitor and "ground truth" are used to calculate the local score. The local score represents the coherence of the generated sentences. Third, the structure of the generator is the same as that of the inhibitor. Despite parameter sharing between the inhibitor and generator, the input of the generator is different from that of the inhibitor. In the generator, the output of the previous moment is used as the input of the current moment. The generator result is the image description and is used as part of the discriminator input. Fourth, the discriminator similarly consists of LSTM. Each word in the description generated by the generator corresponds to the input of the discriminator at each moment. The discriminator output at the last moment is combined with the image features obtained by the feature extractor to calculate the global score. The global score measures the semantic similarity between the generated description and image. Finally, the fusion loss consists of local and global scores. By controlling the weight of the local and global scores in fusion loss, coherence and accuracy are given different degrees of attention, and different descriptions may be generated for the same image. On the basis of the fusion loss, the model optimizes the parameter by backpropagation. In the experiment, the feature extractor is pretrained on the basis of the ImageNet dataset, and the parameters of the last layer are fine-tuned in formal training. As the training number increases, the generated sentences will perform increasingly well in terms of coherence and accuracy.ResultModel performance is evaluated using three datasets, namely, MSCOCO-2014, Oxford-102, and CUB-200-2011. In the CUB-200-2011 dataset, our method shows improvement compared with that using the maximum likelihood estimate as the optimization function (CIDEr +1.6%, BLEU-3 +0.2%, BLEU-2 +0.8%, BLEU-1 +0.7%, and ROUGE-L +0.5%). The model performance declines when the inhibitor is removed from the model (BLEU-4 -0.8%, BLEU-3 -1.2%, BLEU-2 -1.6%, BLEU-1 -0.9%, ROUGE-L -1.8%, and METEOR -1.0%). In the Oxford-102 dataset, our method gains additional improvements compared with that using MLE as the optimization function (CIDEr +3.6%, BLEU-4 +0.7%, BLEU-3 +0.6%, BLEU-2 +0.4%, BLEU-1 +0.2%, ROUGE-L +0.6%, and METEOR +0.7%). The model performance declines substantially after removing the inhibitor (CIDEr -3.8%, BLEU-4 -1.5%, BLEU-3 -1.7%, BLEU-2 -1.4%, BLEU-1 -1.5%, ROUGE-L -0.5%, and METEOR -0.1%). In the MSCOCO-2014 dataset, our method achieves a leading position in several evaluation metrics compared with several proposed methods (BLEU-3 +0.4%, BLEU-2 +0.4%, BLEU-1 +0.4%, and ROUGE-L +0.3%).ConclusionThe new optimization function and fusion training method are considered in the dependency relationships between words and the semantic relativity between the generated description and image. The method in this study obtains better scores in multiple evaluation metrics than that using MLE as the optimization function. Experiment results indicate that the inhibitor has a positive effect on the model performance in terms of evaluation metrics while optimizing the coherence of generated descriptions. The method increases the coherency of generated captions on the premise of the captions generated by the generator and image matching in the content.关键词:image description generation;inhibiting learning;reinforcement learning;generative adversarial networks(GAN);fusion training22|20|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveEmbroidery, a unique handicraft technology in China, has high artistic and commodity value. The production of realistic embroidery works of art requires considerable time and strict manual skills. With the development of modern science and technology, the use of computer algorithms to simulate the generation of embroidery art style images is crucial for the protection and inheritance of embroidery culture. Traditional embroidery simulation algorithm has limitations and requires the designer to understand embroidery stitching. Convolutional neural network can learn the characteristics of embroidery artistic style to simulate the generation of embroidery artistic style on different images. Therefore, to address the problem that the existing embroidery art style simulation algorithm produces nonevident needle characteristics and single needle direction, this paper proposes an embroidery simulation algorithm based on multi-scale two-channel convolution neural network.MethodMulti-scale two-channel convolution neural network, VGG19 network, VGG16 network, and Laplacian module are used to learn and extract texture features of embroidery art style images, and the learned texture features are simulated and generated in content images. The content image becomes the image with the characteristics of embroidery art. First, the overall structure of the convolution neural network is determined by using deep convolutional generative adversarial network. A multi-scale two-channel convolution neural network is constructed as the generating network. The concrete structure of the network consists of multi-scale input, dual-channel convolution blocks propagating simultaneously in the RGB and gray channels, and integrated convolution blocks. VGG19 network, VGG16 network, and Laplacian module are used as loss networks. The real image of embroidery works is selected as the style image of embroidery art, and the MSCOCO image dataset is used as the training data. The training data are input into the network, and the VGG network and Laplacian loss values are obtained by calculating the loss network. The total loss value is returned to the multi-scale two-channel convolution neural network, and the gradient descent method is used to update the convolution neural network. Parameters are repeated until a specified number of network training iterations complete the training of the multi-scale two-channel convolution neural network; a target image is selected as the content image input to the multi-scale two-channel convolution neural network that has been trained, such that the content image becomes an image with embroidery artistic characteristics. At this time, the embroidery art style simulation of the content image is preliminarily completed. Finally, the mask image of the content image is used to fuse the generated image with the background image. The content image part that needs to be simulated as the foreground image is retained, whereas the other part of the image is displayed as the background image to complete the simulation of the embroidery art style of the content image.ResultThe embroidery simulation result image obtained by the algorithm in this paper is compared with the embroidery simulation result image obtained by some existing convolutional neural networks. Result images obtained by the existing convolutional neural networks do not show fine needle-line characteristics and the style is further inclined to artistic painting style. Even if the obtained embroidery simulation result images show clear embroidery texture, but the needle-line direction is evidently single and the gap between the textures is large, the comparison with the real embroidery texture is insufficiently natural. The simulated image of embroidery artistic style obtained by the multi-scale and dual-channel convolution neural network presented in this paper has evident needle-line characteristics and multi-direction needle-line trajectory. This method solves the existing problems in generating the effect image of embroidery artistic style by using the existing simulation algorithm and efficiently displays the artistic characteristics of embroidery.ConclusionIn this paper, the target image is forward-propagated through a multi-scale two-channel convolutional neural network, and VGG19 network, VGG16 network, and Laplacian module are used as the loss networks to simulate the embroidery art style. Experimental results show that in comparison with the results of the existing convolutional neural network for the style simulation, the proposed multi-scale two-channel convolutional neural network can learn the detailed stitching features in the embroidery style art image, and the final result image is displayed. With a clear sense of stitching and multi-directional stitching, the overall artistic style is close to real embroidery art. In future work, we will focus on embroidery texture connection and transition generation in different areas of the existing generated result image to make the final embroidery art style simulation image close to the actual embroidery art work.关键词:embroidery simulation;convolutional neural network (CNN);multi-scale two-channel;VGGNet loss;Laplacian loss13|4|1更新时间:2024-05-07
摘要:ObjectiveEmbroidery, a unique handicraft technology in China, has high artistic and commodity value. The production of realistic embroidery works of art requires considerable time and strict manual skills. With the development of modern science and technology, the use of computer algorithms to simulate the generation of embroidery art style images is crucial for the protection and inheritance of embroidery culture. Traditional embroidery simulation algorithm has limitations and requires the designer to understand embroidery stitching. Convolutional neural network can learn the characteristics of embroidery artistic style to simulate the generation of embroidery artistic style on different images. Therefore, to address the problem that the existing embroidery art style simulation algorithm produces nonevident needle characteristics and single needle direction, this paper proposes an embroidery simulation algorithm based on multi-scale two-channel convolution neural network.MethodMulti-scale two-channel convolution neural network, VGG19 network, VGG16 network, and Laplacian module are used to learn and extract texture features of embroidery art style images, and the learned texture features are simulated and generated in content images. The content image becomes the image with the characteristics of embroidery art. First, the overall structure of the convolution neural network is determined by using deep convolutional generative adversarial network. A multi-scale two-channel convolution neural network is constructed as the generating network. The concrete structure of the network consists of multi-scale input, dual-channel convolution blocks propagating simultaneously in the RGB and gray channels, and integrated convolution blocks. VGG19 network, VGG16 network, and Laplacian module are used as loss networks. The real image of embroidery works is selected as the style image of embroidery art, and the MSCOCO image dataset is used as the training data. The training data are input into the network, and the VGG network and Laplacian loss values are obtained by calculating the loss network. The total loss value is returned to the multi-scale two-channel convolution neural network, and the gradient descent method is used to update the convolution neural network. Parameters are repeated until a specified number of network training iterations complete the training of the multi-scale two-channel convolution neural network; a target image is selected as the content image input to the multi-scale two-channel convolution neural network that has been trained, such that the content image becomes an image with embroidery artistic characteristics. At this time, the embroidery art style simulation of the content image is preliminarily completed. Finally, the mask image of the content image is used to fuse the generated image with the background image. The content image part that needs to be simulated as the foreground image is retained, whereas the other part of the image is displayed as the background image to complete the simulation of the embroidery art style of the content image.ResultThe embroidery simulation result image obtained by the algorithm in this paper is compared with the embroidery simulation result image obtained by some existing convolutional neural networks. Result images obtained by the existing convolutional neural networks do not show fine needle-line characteristics and the style is further inclined to artistic painting style. Even if the obtained embroidery simulation result images show clear embroidery texture, but the needle-line direction is evidently single and the gap between the textures is large, the comparison with the real embroidery texture is insufficiently natural. The simulated image of embroidery artistic style obtained by the multi-scale and dual-channel convolution neural network presented in this paper has evident needle-line characteristics and multi-direction needle-line trajectory. This method solves the existing problems in generating the effect image of embroidery artistic style by using the existing simulation algorithm and efficiently displays the artistic characteristics of embroidery.ConclusionIn this paper, the target image is forward-propagated through a multi-scale two-channel convolutional neural network, and VGG19 network, VGG16 network, and Laplacian module are used as the loss networks to simulate the embroidery art style. Experimental results show that in comparison with the results of the existing convolutional neural network for the style simulation, the proposed multi-scale two-channel convolutional neural network can learn the detailed stitching features in the embroidery style art image, and the final result image is displayed. With a clear sense of stitching and multi-directional stitching, the overall artistic style is close to real embroidery art. In future work, we will focus on embroidery texture connection and transition generation in different areas of the existing generated result image to make the final embroidery art style simulation image close to the actual embroidery art work.关键词:embroidery simulation;convolutional neural network (CNN);multi-scale two-channel;VGGNet loss;Laplacian loss13|4|1更新时间:2024-05-07
Computer Graphics
-
Generic approach to obtain contours of fascicular groups from MicroCT images of the peripheral nerve
 摘要:ObjectivePeripheral nerve injury can result in severe paralysis and dysfunction. For a long time, repairing and regenerating injured peripheral nerves have been urgent goals. Detailed intraneural spatial information can be provided by the 3D visualization of fascicular groups in the peripheral nerve. Suitable surgical methods must be selected to repair clinical peripheral nerve defects. The contour information of peripheral nerve MicroCT image is the basis of peripheral nerve 3D reconstruction and visualization. Obtaining the contour information of the fascicular groups is a key step during 3D nerve visualization. In the previous research, the MicroCT images of peripheral nerve were obtained. The foreground and background of these images were relatively different when the images came from samples stained by different methods, such as dyed or not dyed with calcium chloride. If previous segmentation approaches were used to extract the contours of fascicular groups, then various labor-intensive feature extracting and recognition methods had to be applied, and the results were inconsistent. An assistance methodology using image processing can improve the accuracy of obtaining the contour information of fascicular groups. Thus, this study analyzes graph cut theory and algorithm and proposes a generic framework to obtain numerous consistent results easily. The proposed algorithm can be used to assist in neurosurgery diagnosis and has great clinical application value. In the generic framework, the MicroCT images from different dyed samples are processed by the same algorithm, which results in consistent and accurate extracted contours of fascicular groups.MethodThis method is based on deep learning. The method can automatically extract instinct features from image data and instantly analyze images, can effectively improve detection efficiency, and can be applied to complex images. Mask region convolution neural network (mask R-CNN) is used to extract the contour information from peripheral nerve MicroCT images. Given the impressive achievement of Mask R-CNN for object segmentation, the accuracy of recognition and classification at the pixel level is greatly improved. First, the structure of the generic framework is designed, and the image datasets are constructed. Several key preparations are performed, such as image annotation and grouping. The dataset of images is divided into two groups at a ratio of 3:1, namely, training and test sets. On the basis of the dyed method of the MicroCT images from peripheral nerve, the training and test datasets have three subsets, namely, calcium chloride-dyed image dataset (subset 1), nondyed image dataset (subset 2), and mixed image dataset (subset 3). Second, the principle of mask R-CNN is analyzed, and the generic frameworks of image classification and segmentation are designed, combining mask R-CNN with transfer learning. Even though mask R-CNN is efficient in common segmentation task, it has several limitations. In normal task, mask R-CNN often needs many images to train. However, the datasets of the MicroCT images of peripheral nerves do not have sufficient number of images to train mask R-CNN. Thus, mask R-CNN cannot be used to extract the contour of fascicular groups directly from the MicroCT images of peripheral nerves. Therefore, the transfer learning strategy is combined with mask R-CNN to solve the problem. The training parameters of neural network structure are adjusted manually. mask R-CNN is pretrained by the COCO dataset. mask R-CNN is transferred to the dataset of peripheral nerves for further learning to improve the extracting accuracy of the contour of the fascicular groups. Finally, the target segmentation model based on the contour information of peripheral nerve MicroCT image tasks is constructed. Third, the generic framework is trained and testified by image datasets from different groups. This finding indicates that a highly effective segmentation effect can be achieved.ResultAll experiments are accomplished in the GTX1070-8G environment. The experimental data are derived from a 5 cm peripheral nerve segment. The peripheral nerve sample is transected into 3 mm segments at -20℃. These segments are used for calcium chloride-dyed and nondyed methods to facilitate the discrimination of different fascicular groups in MicroCT images. The scan sequence from the calcium chloride-dyed method includes 228 images. The scan sequence from the nondyed method includes 523 images. The training dataset in each dataset is used to train the parameters of the neural network structure, and the test dataset is used to test the actual segmentation results. The model execution took 15 000 iterations for the training process. Experiment results show that the pixel average precision of all types of datasets exceeds 95%, and the segmentation accuracy is high, which is highly consistent with the results of artificial segmentation. The intersection over union exceeds 86%, and the mean time to detect is less than 0.06 s, which satisfies the real-time requirements. In comparison with the original mask R-CNN, the proposed framework achieved improved performance, increased average precision by approximately 5.5%-9.8%, and increased intersection over union by approximately 2.4%3.2%.ConclusionTheoretical analysis and experiment results justify the feasibility of the proposed framework. On the basis of the experimental dataset, our training set is relatively limited, but the experiments show that the proposed approach can accurately, rapidly, and automatically extract the contours of fascicular groups. Furthermore, the accuracy, segmentation effect, and robustness are improved greatly when mask R-CNN is combined with transfer learning. The framework can be widely used to segment various MicroCT images, which come from different dyed samples. The auto-mated segmentation of the MicroCT images of peripheral nerves has substantial clinical values. Finally, we discuss the challenges in this generic framework and several unsolved problems.关键词:peripheral nerves;fascicular groups;acquisition contours;transfer learning;mask region convolution neural network (mask R-CNN);MicroCT images12|4|1更新时间:2024-05-07
摘要:ObjectivePeripheral nerve injury can result in severe paralysis and dysfunction. For a long time, repairing and regenerating injured peripheral nerves have been urgent goals. Detailed intraneural spatial information can be provided by the 3D visualization of fascicular groups in the peripheral nerve. Suitable surgical methods must be selected to repair clinical peripheral nerve defects. The contour information of peripheral nerve MicroCT image is the basis of peripheral nerve 3D reconstruction and visualization. Obtaining the contour information of the fascicular groups is a key step during 3D nerve visualization. In the previous research, the MicroCT images of peripheral nerve were obtained. The foreground and background of these images were relatively different when the images came from samples stained by different methods, such as dyed or not dyed with calcium chloride. If previous segmentation approaches were used to extract the contours of fascicular groups, then various labor-intensive feature extracting and recognition methods had to be applied, and the results were inconsistent. An assistance methodology using image processing can improve the accuracy of obtaining the contour information of fascicular groups. Thus, this study analyzes graph cut theory and algorithm and proposes a generic framework to obtain numerous consistent results easily. The proposed algorithm can be used to assist in neurosurgery diagnosis and has great clinical application value. In the generic framework, the MicroCT images from different dyed samples are processed by the same algorithm, which results in consistent and accurate extracted contours of fascicular groups.MethodThis method is based on deep learning. The method can automatically extract instinct features from image data and instantly analyze images, can effectively improve detection efficiency, and can be applied to complex images. Mask region convolution neural network (mask R-CNN) is used to extract the contour information from peripheral nerve MicroCT images. Given the impressive achievement of Mask R-CNN for object segmentation, the accuracy of recognition and classification at the pixel level is greatly improved. First, the structure of the generic framework is designed, and the image datasets are constructed. Several key preparations are performed, such as image annotation and grouping. The dataset of images is divided into two groups at a ratio of 3:1, namely, training and test sets. On the basis of the dyed method of the MicroCT images from peripheral nerve, the training and test datasets have three subsets, namely, calcium chloride-dyed image dataset (subset 1), nondyed image dataset (subset 2), and mixed image dataset (subset 3). Second, the principle of mask R-CNN is analyzed, and the generic frameworks of image classification and segmentation are designed, combining mask R-CNN with transfer learning. Even though mask R-CNN is efficient in common segmentation task, it has several limitations. In normal task, mask R-CNN often needs many images to train. However, the datasets of the MicroCT images of peripheral nerves do not have sufficient number of images to train mask R-CNN. Thus, mask R-CNN cannot be used to extract the contour of fascicular groups directly from the MicroCT images of peripheral nerves. Therefore, the transfer learning strategy is combined with mask R-CNN to solve the problem. The training parameters of neural network structure are adjusted manually. mask R-CNN is pretrained by the COCO dataset. mask R-CNN is transferred to the dataset of peripheral nerves for further learning to improve the extracting accuracy of the contour of the fascicular groups. Finally, the target segmentation model based on the contour information of peripheral nerve MicroCT image tasks is constructed. Third, the generic framework is trained and testified by image datasets from different groups. This finding indicates that a highly effective segmentation effect can be achieved.ResultAll experiments are accomplished in the GTX1070-8G environment. The experimental data are derived from a 5 cm peripheral nerve segment. The peripheral nerve sample is transected into 3 mm segments at -20℃. These segments are used for calcium chloride-dyed and nondyed methods to facilitate the discrimination of different fascicular groups in MicroCT images. The scan sequence from the calcium chloride-dyed method includes 228 images. The scan sequence from the nondyed method includes 523 images. The training dataset in each dataset is used to train the parameters of the neural network structure, and the test dataset is used to test the actual segmentation results. The model execution took 15 000 iterations for the training process. Experiment results show that the pixel average precision of all types of datasets exceeds 95%, and the segmentation accuracy is high, which is highly consistent with the results of artificial segmentation. The intersection over union exceeds 86%, and the mean time to detect is less than 0.06 s, which satisfies the real-time requirements. In comparison with the original mask R-CNN, the proposed framework achieved improved performance, increased average precision by approximately 5.5%-9.8%, and increased intersection over union by approximately 2.4%3.2%.ConclusionTheoretical analysis and experiment results justify the feasibility of the proposed framework. On the basis of the experimental dataset, our training set is relatively limited, but the experiments show that the proposed approach can accurately, rapidly, and automatically extract the contours of fascicular groups. Furthermore, the accuracy, segmentation effect, and robustness are improved greatly when mask R-CNN is combined with transfer learning. The framework can be widely used to segment various MicroCT images, which come from different dyed samples. The auto-mated segmentation of the MicroCT images of peripheral nerves has substantial clinical values. Finally, we discuss the challenges in this generic framework and several unsolved problems.关键词:peripheral nerves;fascicular groups;acquisition contours;transfer learning;mask region convolution neural network (mask R-CNN);MicroCT images12|4|1更新时间:2024-05-07 -
 摘要:ObjectiveUltrasound fetal head circumference measurement is crucial for monitoring fetus growth and estimating the gestational age. Computer-aided measurement of fetal head circumference is valuable for sonographers who are short of experiments in ultrasound examinations. Through computer-aided measurement, they can further accurately detect fetal head edge and quickly finish an examination. Fetal head edge detection is necessary for the automatic measurement of fetal head circumference. Ultrasound fetal head image boundary is fuzzy, and the gray scale of fetal head is similar to the mother's abdominal tissue, especially in the first trimester. Ultrasound shadow leads to the loss of head edge and incomplete fetal head in the image, which brings certain difficulties in detecting the complete fetal head edge and fit head ellipse. The structures of the amniotic fluid and uterine wall are similar to the head texture and gray scale, often leading to misclassification of this part as fetal head. All these factors result in challenges to ultrasound fetal head edge detection. Therefore, we propose a method for detecting the ultrasound fetal head edge by using convolutional neural network to segment the fetal head region end-to-end.MethodThe model proposed in this paper is based on UNet++. In deep supervised UNet++, every output is different and can provide a predicted result of the region of interest, but only the best predicted result will be used to predict the region of fetal head. Generally, the output results increase in accuracy from left to right. Four feature blocks exist before four outputs of UNet++. The left feature contains location information, and the right one contains sematic information. To utilize the feature map before outputs fully, we fuse them by concatenation and further extract fused features. The improved model is named Fusion UNet++. To prevent overfitting, we introduce spatial dropout after each convolutional layer instead of standard dropout, which extends the dropout value across the entire feature map. The idea of fetal head circumference measurement is as follows:first, we use Fusion UNet++ to learn the features of 2D ultrasound fetal head image and obtain the semantic segmentation result of the fetal head by using fetal head probability map. Second, on the basis of the image segmentation result, we extract the fetal head edge by using an edge detection algorithm and use the direct least square ellipse fitting method to fit the head contour. Finally, the fetal head circumference can be calculated using the ellipse circumference formula.ResultThe open dataset of the automated measurement of fetal head circumference of the 2D ultrasound image named HC18 on Grand Challenges contains the first, second, and third trimester images of fetal heads. All fetal head images are the standard plane of measuring fetal head circumference. In the HC18 dataset, 999 2D ultrasound images have annotations of fetal head circumference in the train set, and 335 2D ultrasound fetal head images have no annotations in the test set. We use the train set to train the convolutional neural network and submit the predicted results of the test set to participate in the model evaluation on HC18, Grand Challenges. We use the Dice coefficient, Hausdorff distance (HD), and absolute difference (AD) as assessment indexes to evaluate the proposed method quantitatively. With the proposed method, for the dataset of fetal head images for all three trimesters, the Dice coefficient of the fetal head segmentation is 98.06%, the HD is 1.21±0.69 mm, and the AD of the fetal head circumference measurement is 1.84±1.73 mm. The skull in the second trimester is visible and appears as a bright structure; it is invisible in the first trimester and visible but incomplete in the third trimester. Seeing the complete skull is difficult in the first and third trimesters; thus, the measurement result of the fetal head circumference in the second trimester is the best among all trimesters. Most algorithms measure the fetal head circumference only in the second trimester or in the second and third trimester fetal head ultrasound images. For the second trimester, the Dice coefficient of the fetal head segmentation is 98.24%, the HD is 1.15±0.59 mm, and the AD of the fetal head circumference measurement is 1.76±1.55 mm. On the basis of the results presented in the open test set, our Dice ranked the 3rd, HD is the 2nd, and AD is the 10th.ConclusionIn comparison with the traditional and machine learning methods, the proposed method can effectively overcome the interference of fuzzy boundary and lack of edge and can accurately segment the fetal head region. In comparison with existing neural network methods, the proposed method surpasses the other methods in the second trimester of pregnancy in fetal head segmentation and head circumference measurement. The proposed method achieves the state-of-the-art results of fetal head segmentation.关键词:medical image segmentation;UNet++;fetal head edge detection;fetal head circumference measurement;deep learning;ultrasound image19|8|5更新时间:2024-05-07
摘要:ObjectiveUltrasound fetal head circumference measurement is crucial for monitoring fetus growth and estimating the gestational age. Computer-aided measurement of fetal head circumference is valuable for sonographers who are short of experiments in ultrasound examinations. Through computer-aided measurement, they can further accurately detect fetal head edge and quickly finish an examination. Fetal head edge detection is necessary for the automatic measurement of fetal head circumference. Ultrasound fetal head image boundary is fuzzy, and the gray scale of fetal head is similar to the mother's abdominal tissue, especially in the first trimester. Ultrasound shadow leads to the loss of head edge and incomplete fetal head in the image, which brings certain difficulties in detecting the complete fetal head edge and fit head ellipse. The structures of the amniotic fluid and uterine wall are similar to the head texture and gray scale, often leading to misclassification of this part as fetal head. All these factors result in challenges to ultrasound fetal head edge detection. Therefore, we propose a method for detecting the ultrasound fetal head edge by using convolutional neural network to segment the fetal head region end-to-end.MethodThe model proposed in this paper is based on UNet++. In deep supervised UNet++, every output is different and can provide a predicted result of the region of interest, but only the best predicted result will be used to predict the region of fetal head. Generally, the output results increase in accuracy from left to right. Four feature blocks exist before four outputs of UNet++. The left feature contains location information, and the right one contains sematic information. To utilize the feature map before outputs fully, we fuse them by concatenation and further extract fused features. The improved model is named Fusion UNet++. To prevent overfitting, we introduce spatial dropout after each convolutional layer instead of standard dropout, which extends the dropout value across the entire feature map. The idea of fetal head circumference measurement is as follows:first, we use Fusion UNet++ to learn the features of 2D ultrasound fetal head image and obtain the semantic segmentation result of the fetal head by using fetal head probability map. Second, on the basis of the image segmentation result, we extract the fetal head edge by using an edge detection algorithm and use the direct least square ellipse fitting method to fit the head contour. Finally, the fetal head circumference can be calculated using the ellipse circumference formula.ResultThe open dataset of the automated measurement of fetal head circumference of the 2D ultrasound image named HC18 on Grand Challenges contains the first, second, and third trimester images of fetal heads. All fetal head images are the standard plane of measuring fetal head circumference. In the HC18 dataset, 999 2D ultrasound images have annotations of fetal head circumference in the train set, and 335 2D ultrasound fetal head images have no annotations in the test set. We use the train set to train the convolutional neural network and submit the predicted results of the test set to participate in the model evaluation on HC18, Grand Challenges. We use the Dice coefficient, Hausdorff distance (HD), and absolute difference (AD) as assessment indexes to evaluate the proposed method quantitatively. With the proposed method, for the dataset of fetal head images for all three trimesters, the Dice coefficient of the fetal head segmentation is 98.06%, the HD is 1.21±0.69 mm, and the AD of the fetal head circumference measurement is 1.84±1.73 mm. The skull in the second trimester is visible and appears as a bright structure; it is invisible in the first trimester and visible but incomplete in the third trimester. Seeing the complete skull is difficult in the first and third trimesters; thus, the measurement result of the fetal head circumference in the second trimester is the best among all trimesters. Most algorithms measure the fetal head circumference only in the second trimester or in the second and third trimester fetal head ultrasound images. For the second trimester, the Dice coefficient of the fetal head segmentation is 98.24%, the HD is 1.15±0.59 mm, and the AD of the fetal head circumference measurement is 1.76±1.55 mm. On the basis of the results presented in the open test set, our Dice ranked the 3rd, HD is the 2nd, and AD is the 10th.ConclusionIn comparison with the traditional and machine learning methods, the proposed method can effectively overcome the interference of fuzzy boundary and lack of edge and can accurately segment the fetal head region. In comparison with existing neural network methods, the proposed method surpasses the other methods in the second trimester of pregnancy in fetal head segmentation and head circumference measurement. The proposed method achieves the state-of-the-art results of fetal head segmentation.关键词:medical image segmentation;UNet++;fetal head edge detection;fetal head circumference measurement;deep learning;ultrasound image19|8|5更新时间:2024-05-07 -
 摘要:ObjectiveIntravascular ultrasound (IVUS) image segmentation of arterial wall boundaries are essential not only for the quantitative analysis of the characteristics of vascular walls and plaques but also for the qualitative analysis of vascular elasticity and the reconstruction of the 3D model of arteries. The importance lies in the following:1)IVUS image segmentation is the basis for follow-up work, such as plaque extraction and recognition, vessel wall elasticity analysis, and image registration. 2) Doctors must evaluate the morphological characteristics of blood vessels and plaques, such as the maximum or minimum diameter of the lumen, cross-sectional area, and plaque area. IVUS provides a reliable data support for doctors to diagnose patients objectively.3) IVUS can locate the region of interest to determine the position and shape of the anatomical structure for interventional surgery and the diagnosis and treatment targets for radiotherapy, chemotherapy, and surgery. However, given the different environments in which the intima and adventitia are located, traditional segmentation methods, which belong to serial extraction methods, need to design the segmentation algorithms for intima and adventitia separately. Moreover, extremely complex models affect the speed of segmentation. To address these problems, this paper proposes a segmentation method based on the extreme region detection of IVUS images.MethodThe problem of edge detection is broadened to the problem of extreme region detection, and the proposed method consists of three parts:extreme region detection, extreme region screening, and contour fitting. First, edge points are extracted from the IVUS image, and a global vector is created by using the edge points and threshold images by each gray level to obtain the gray thresholds. The obtained thresholds make the change of threshold images most stable.Next, the final threshold images are obtained on the basis of the filtered gray thresholds. The morphological closing operation is used to fill in the small holes of the threshold images, and the connected component labeling algorithm is used to mark the connected regions in the threshold images to obtain the final extreme regions. In addition, extreme regions contains regions with unstable states and large or small areas that cannot represent the lumen and media because the extracted extreme regions contain many sub-regions. Therefore, the area of the extreme regions must be screened for preliminary filtering.By using local binary mode feature, gray difference, and edge circumference, a filter vector based on region stability is designed to extract two extreme regions representing the lumen and media. Finally, the contours of the lumen and media regions are fitted by ellipse to complete the segmentation.ResultQualitative and quantitative analyses are used to evaluate the accuracy of the proposed method.The extreme region and final contours are initially qualitatively displayed on a standard published dataset containing 32 620 MHz IVUS B-mode images. The extracted final contours are qualitatively compared with the results drawn manually by clinical experts.The artifacts are also classified on the basis of their types. For images without artifacts and with different types of artifacts, the robust performance and generalization performance of the proposed algorithm are verified by calculating the DC coefficient, JI index, PAD index, and HD distance. On the basis of the DC coefficient, JI index, PAD index, and HD distance, the inner border index values are 0.94±0.02, 0.90±0.04, 0.05±0.05, and 0.28±0.14 mm, respectively; the outer border index values are 0.91±0.07, 0.87±0.11, 0.11±0.11, and 0.41±0.31 mm, respectively.In addition, the values of DC coefficient, JI index, PAD index, and HD distance of the IVUS image segmentation algorithms in the relevant literature in the last few years are compared with those of the proposed method.The quantitative comparison with the relevant literature in the last few years shows the improved performance of the inner and outer borders extracted by the proposed method. In addition, the test results of the proposed method on the clinical dataset are very good.ConclusionThe method proposed is suitable for the extraction of not only the inner border but also the outer border; it is a parallel extraction algorithm. Experiment results show that in addition to high extraction accuracy, the proposed method has strong robustness and outperforms several state-of-the-art segmentation approaches.关键词:intravascular ultrasound (IVUS) images;inner and outer borders segmentation;edge detection;extreme region;contour fitting24|4|1更新时间:2024-05-07
摘要:ObjectiveIntravascular ultrasound (IVUS) image segmentation of arterial wall boundaries are essential not only for the quantitative analysis of the characteristics of vascular walls and plaques but also for the qualitative analysis of vascular elasticity and the reconstruction of the 3D model of arteries. The importance lies in the following:1)IVUS image segmentation is the basis for follow-up work, such as plaque extraction and recognition, vessel wall elasticity analysis, and image registration. 2) Doctors must evaluate the morphological characteristics of blood vessels and plaques, such as the maximum or minimum diameter of the lumen, cross-sectional area, and plaque area. IVUS provides a reliable data support for doctors to diagnose patients objectively.3) IVUS can locate the region of interest to determine the position and shape of the anatomical structure for interventional surgery and the diagnosis and treatment targets for radiotherapy, chemotherapy, and surgery. However, given the different environments in which the intima and adventitia are located, traditional segmentation methods, which belong to serial extraction methods, need to design the segmentation algorithms for intima and adventitia separately. Moreover, extremely complex models affect the speed of segmentation. To address these problems, this paper proposes a segmentation method based on the extreme region detection of IVUS images.MethodThe problem of edge detection is broadened to the problem of extreme region detection, and the proposed method consists of three parts:extreme region detection, extreme region screening, and contour fitting. First, edge points are extracted from the IVUS image, and a global vector is created by using the edge points and threshold images by each gray level to obtain the gray thresholds. The obtained thresholds make the change of threshold images most stable.Next, the final threshold images are obtained on the basis of the filtered gray thresholds. The morphological closing operation is used to fill in the small holes of the threshold images, and the connected component labeling algorithm is used to mark the connected regions in the threshold images to obtain the final extreme regions. In addition, extreme regions contains regions with unstable states and large or small areas that cannot represent the lumen and media because the extracted extreme regions contain many sub-regions. Therefore, the area of the extreme regions must be screened for preliminary filtering.By using local binary mode feature, gray difference, and edge circumference, a filter vector based on region stability is designed to extract two extreme regions representing the lumen and media. Finally, the contours of the lumen and media regions are fitted by ellipse to complete the segmentation.ResultQualitative and quantitative analyses are used to evaluate the accuracy of the proposed method.The extreme region and final contours are initially qualitatively displayed on a standard published dataset containing 32 620 MHz IVUS B-mode images. The extracted final contours are qualitatively compared with the results drawn manually by clinical experts.The artifacts are also classified on the basis of their types. For images without artifacts and with different types of artifacts, the robust performance and generalization performance of the proposed algorithm are verified by calculating the DC coefficient, JI index, PAD index, and HD distance. On the basis of the DC coefficient, JI index, PAD index, and HD distance, the inner border index values are 0.94±0.02, 0.90±0.04, 0.05±0.05, and 0.28±0.14 mm, respectively; the outer border index values are 0.91±0.07, 0.87±0.11, 0.11±0.11, and 0.41±0.31 mm, respectively.In addition, the values of DC coefficient, JI index, PAD index, and HD distance of the IVUS image segmentation algorithms in the relevant literature in the last few years are compared with those of the proposed method.The quantitative comparison with the relevant literature in the last few years shows the improved performance of the inner and outer borders extracted by the proposed method. In addition, the test results of the proposed method on the clinical dataset are very good.ConclusionThe method proposed is suitable for the extraction of not only the inner border but also the outer border; it is a parallel extraction algorithm. Experiment results show that in addition to high extraction accuracy, the proposed method has strong robustness and outperforms several state-of-the-art segmentation approaches.关键词:intravascular ultrasound (IVUS) images;inner and outer borders segmentation;edge detection;extreme region;contour fitting24|4|1更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveThe Northwest Pacific Ocean is an important operational area for the large-scale commercial fishing of offshore fishing vessels of China and an active area of mesoscale eddies. Mesoscale eddies are important marine phenomena in the upper oceans. They play indispensable roles in ocean circulation, heat and mass transport, entrainment of marine nutrients, and marine life. However, traditional eddy extraction methods have shortcomings. First, they have difficulties in extracting the multicore of the eddy. Second, the ocean eddy is affected not only by other eddies in the process of movement but also by the strong flow, such as the Kuroshio extension in the Pacific Ocean. The eddy could be dragged and detached. Therefore, the shape of the ocean eddy is generally not a standard circle on the horizontal direction. However, most traditional research methods rely on the standard circle to fit the shape of the ocean eddy.The extraction result of traditional research methods is different from the irregularity and complexity of the shape and structure of the actual ocean eddy. In the end, raster data are always applied to display the ocean eddy in the traditional research. Vector data are more accurate than raster data. Thus, the present study improves the extraction method of eddy.MethodGiven the eddy constraints in previous studies, the threshold-free closed contour method (TFCCM) fully considered the ocean eddy shape diversity and the advantages of the vector data structure. This method was used to determine the eddy boundary and core on the basis of the sea surface height anomaly (SSHA) data. The TFCCM did not need to provide a new value to judge the existence of the eddy and extract its core and boundary. This method used the extreme point in the local range of the eddy as the core and the outermost contour containing its core as the boundary. In case of missing data points in the study area, the invalid values of the SSHA data were interpolated by the inverse distance weighting method. After generating the SSHA data contour, the topological relationship between the contours was determined. The eddy boundary was the outermost contour and should satisfy the limiting condition of the amplitude and spatial scale. Considering the deformation rate in the latitude and longitude direction of the earth ellipsoid, the spatial scale of the eddy was calculated as the spherical distance on the earth ellipsoid. On the basis of the SSHA difference between the core and boundary of the eddy, the extracted eddy was judged whether it was cyclonic or anticyclonic. In addition, when extracting the eddy boundary, several unreasonable burrs may appear in the extraction result, and the eddy boundary had to be smoothed.ResultThe original SSHA raster data map was close to the shape and location where the eddy actually exists in the ocean. The extraction of eddies in this paper were compared with the original SSHA data raster map and the standard circular eddy extraction results of the traditional research method in the same study area. Results of the eddy extraction by TFCCM were compared with raster eddies on June 1, 1997, 2000, 2003, 2006, 2009, and 2015. Comparison results showed that the eddy boundary in the raster data graph mode was generally blurred. After continuing to enlarge, the image in the raster format exhibited a mosaic phenomenon. Thus, accurately determining the shape and position of the eddy was difficult. TFCCM results were close to the actual shape and position of the eddy in the ocean. They can maintain the smoothness when scaling to analysis. For quantitative analysis, the extraction result on June 1, 1994, was used as an example to amplify the eddy at the same position with the same ratio. The overlap ratio was calculated by the results in further analysis. The maximum overlap rate was 89%. The minimum value was 22%. The average overlap rate was 65%. These advantages may bring convenience in the further vector data analysis, such as topology analysis and buffer overlay, in studying the relationship between eddy and fishery.ConclusionThe TFCCM was applied to achieve the extraction of the irregular vector eddy based on the SSHA data in the Northwest Pacific Ocean. Unlike previous studies, only the SSHA data were used in the eddy extraction without any other data resources. The deformation of the ellipsoidal of the Earth was considered. The TFCCM did not need to rely on the threshold of the SSHA data. Thus, the TFCCM could reduce the variable and noise source to simplify calculation. The format of the eddy extraction results belonged to the irregular vector data structure. These results displayed a clear multicore structure. Without considering the interaction between eddies, the eddy extraction results were compared with the original SSHA raster data maps and then overlaid on the traditional standard circular eddy extraction. Finally, comparison results were analyzed and discussed. The overlap rate was calculated, showing that the extraction results by the TFCCM did not deviate much from the actual shape and position of the eddy in the ocean. The extraction method achieved improved fitting degree and accuracy. It is suitable for the practical application. In the future work, the irregular vector results of eddies can be performed in fishery field analysis to improve the accuracy in judging the fishery area, which is affected by the eddy. On the basis of the analysis and discussion, the TFCCM can obtain marine environmental characteristic information that is close to the actual situation and achieve high reliability when combined with fishery data for subsequent research. This finding provides reference for the subsequent study of the relationships between eddies and fishery distribution.关键词:ocean eddy;ocean satellite altimeter;irregular vector;vector data structure12|4|0更新时间:2024-05-07
摘要:ObjectiveThe Northwest Pacific Ocean is an important operational area for the large-scale commercial fishing of offshore fishing vessels of China and an active area of mesoscale eddies. Mesoscale eddies are important marine phenomena in the upper oceans. They play indispensable roles in ocean circulation, heat and mass transport, entrainment of marine nutrients, and marine life. However, traditional eddy extraction methods have shortcomings. First, they have difficulties in extracting the multicore of the eddy. Second, the ocean eddy is affected not only by other eddies in the process of movement but also by the strong flow, such as the Kuroshio extension in the Pacific Ocean. The eddy could be dragged and detached. Therefore, the shape of the ocean eddy is generally not a standard circle on the horizontal direction. However, most traditional research methods rely on the standard circle to fit the shape of the ocean eddy.The extraction result of traditional research methods is different from the irregularity and complexity of the shape and structure of the actual ocean eddy. In the end, raster data are always applied to display the ocean eddy in the traditional research. Vector data are more accurate than raster data. Thus, the present study improves the extraction method of eddy.MethodGiven the eddy constraints in previous studies, the threshold-free closed contour method (TFCCM) fully considered the ocean eddy shape diversity and the advantages of the vector data structure. This method was used to determine the eddy boundary and core on the basis of the sea surface height anomaly (SSHA) data. The TFCCM did not need to provide a new value to judge the existence of the eddy and extract its core and boundary. This method used the extreme point in the local range of the eddy as the core and the outermost contour containing its core as the boundary. In case of missing data points in the study area, the invalid values of the SSHA data were interpolated by the inverse distance weighting method. After generating the SSHA data contour, the topological relationship between the contours was determined. The eddy boundary was the outermost contour and should satisfy the limiting condition of the amplitude and spatial scale. Considering the deformation rate in the latitude and longitude direction of the earth ellipsoid, the spatial scale of the eddy was calculated as the spherical distance on the earth ellipsoid. On the basis of the SSHA difference between the core and boundary of the eddy, the extracted eddy was judged whether it was cyclonic or anticyclonic. In addition, when extracting the eddy boundary, several unreasonable burrs may appear in the extraction result, and the eddy boundary had to be smoothed.ResultThe original SSHA raster data map was close to the shape and location where the eddy actually exists in the ocean. The extraction of eddies in this paper were compared with the original SSHA data raster map and the standard circular eddy extraction results of the traditional research method in the same study area. Results of the eddy extraction by TFCCM were compared with raster eddies on June 1, 1997, 2000, 2003, 2006, 2009, and 2015. Comparison results showed that the eddy boundary in the raster data graph mode was generally blurred. After continuing to enlarge, the image in the raster format exhibited a mosaic phenomenon. Thus, accurately determining the shape and position of the eddy was difficult. TFCCM results were close to the actual shape and position of the eddy in the ocean. They can maintain the smoothness when scaling to analysis. For quantitative analysis, the extraction result on June 1, 1994, was used as an example to amplify the eddy at the same position with the same ratio. The overlap ratio was calculated by the results in further analysis. The maximum overlap rate was 89%. The minimum value was 22%. The average overlap rate was 65%. These advantages may bring convenience in the further vector data analysis, such as topology analysis and buffer overlay, in studying the relationship between eddy and fishery.ConclusionThe TFCCM was applied to achieve the extraction of the irregular vector eddy based on the SSHA data in the Northwest Pacific Ocean. Unlike previous studies, only the SSHA data were used in the eddy extraction without any other data resources. The deformation of the ellipsoidal of the Earth was considered. The TFCCM did not need to rely on the threshold of the SSHA data. Thus, the TFCCM could reduce the variable and noise source to simplify calculation. The format of the eddy extraction results belonged to the irregular vector data structure. These results displayed a clear multicore structure. Without considering the interaction between eddies, the eddy extraction results were compared with the original SSHA raster data maps and then overlaid on the traditional standard circular eddy extraction. Finally, comparison results were analyzed and discussed. The overlap rate was calculated, showing that the extraction results by the TFCCM did not deviate much from the actual shape and position of the eddy in the ocean. The extraction method achieved improved fitting degree and accuracy. It is suitable for the practical application. In the future work, the irregular vector results of eddies can be performed in fishery field analysis to improve the accuracy in judging the fishery area, which is affected by the eddy. On the basis of the analysis and discussion, the TFCCM can obtain marine environmental characteristic information that is close to the actual situation and achieve high reliability when combined with fishery data for subsequent research. This finding provides reference for the subsequent study of the relationships between eddies and fishery distribution.关键词:ocean eddy;ocean satellite altimeter;irregular vector;vector data structure12|4|0更新时间:2024-05-07 -
 摘要:ObjectiveThe development of synthetic aperture radar (SAR) technology has resulted in the generation of high-resolution SAR images under all weather conditions and time periods. SAR images are widely used in many fields, such as disaster monitoring and ocean science. SAR image segmentation is a crucial step in image processing. The statistical model-based SAR segmentation algorithm is popular for its statistical distribution of homogeneous regions in SAR images with specific regularity. However, the statistical distribution of pixel intensities in high-resolution SAR images can be asymmetric, heavy-tailed, or multi-modal. Traditional mixture models use the weighted sum of components to model the statistical distribution of pixel intensities in SAR image segmentation. The components of mixture models are defined by probability density functions to mainly model the statistical distribution of homogeneous regions. The components can be Gaussian, student's, or Gamma distribution in the Gaussian mixture model (GMM), student's mixture model, and gamma mixture model (GaMM), respectively. However, these components fail to model the complicated distribution of pixel intensities in SAR images. To address the problem, this study proposes a SAR image segmentation algorithm that is based on a hierarchically weighted Gamma mixture model (HWGaMM) with spatial constraint.MethodA mixture model is defined by the weighted sum of its components to model the statistical distribution of pixel intensities. Its components are usually defined by the probability distribution, which results in the difficulty of modeling the complicated distribution of homogeneous regions in SAR images. To accurately model the asymmetric, heavy-tailed, or multi-modal distribution of pixel intensities, the proposed algorithm uses the HWGaMM to model the statistical distribution of pixel intensities in SAR images. The component of the HWGaMM is defined by the weighted sum of Gamma distributions, which represent the element used to model the statistical distribution of local homogeneous regions. As a result of the differences in pixel intensities in the same region and the similarities of pixel intensities in different regions for high-resolution SAR images, the HWGaMM is defined by the weighted sum of the components. The hierarchy of the HWGaMM can be expressed as follows. The basic layer is the element, i.e., Gamma distribution, which is used to model the statistical distribution of local homogeneous regions. The second layer is the component, which is the weighted sum of elements to mainly model the statistical distribution of homogeneous regions. The top layer is the HWGaMM, which is the weighted sum of components to model the statistical distribution of SAR images. The spatial relation of pixels is modeled by a Markov random field to reduce the influence of image noise. The spatial relation of pixels is introduced to the HWGaMM by defining the weight of components by the posterior probabilities of the pixels and neighboring pixels. Such introduction can improve the robustness of the proposed algorithm and prevent the increase in the complexity of model parameter estimation. In this work, SAR image segmentation is realized by estimating the model parameters through the combination of the Metropolis-Hastings (M-H) algorithm and expectation maximization (EM) algorithm. The traditional M-H algorithm usually suffers from poor efficiency because of its sampling for every model parameter in each iteration. The EM algorithm cannot easily estimate the shape parameter of a Gamma distribution because the shape parameter is included in the gamma function. To address such problem, the proposed algorithm uses the M-H algorithm in simulating the posterior distribution of the shape parameter and the EM algorithm in estimating the scale parameter and element weight. The method of parameter estimation overcomes the drawback of the EM algorithm and achieves higher efficiency than the M-H algorithm.ResultSegmentation experiments are carried out on simulated and real SAR images, and the results are analyzed qualitatively and quantitatively to verify the feasibility and effectiveness of the proposed algorithm. The proposed algorithm is compared with the GMM-based, Gamma distribution-based, and GaMM-based segmentation algorithms to highlight its advantages. The results of the fitting histograms reveal that the HWGaMM can accurately model the complicated distribution of pixel intensities. The segmentation accuracy can be calculated from the confusion matrix to quantitatively evaluate the proposed algorithm. The segmentation accuracies of the proposed algorithm are 33%, 29%, and 9% higher than those of the GMM-based, Gamma distribution-based, and GaMM-based segmentation algorithms, respectively. The segmentation time of the proposed algorithm is 64 s faster than that of GMM-based segmentation algorithm but is 600 s and 420 s slower than that of the gamma distribution-and GaMM-based segmentation algorithms, respectively.ConclusionThis work proposes an SAR image segmentation algorithm that is based on a spatially constrained HWGaMM. The proposed HWGaMM can model the complicated distribution of pixel intensities. The proposed segmentation algorithm also has higher accuracy than other relevant methods. Although the efficiency of the proposed algorithm is lower than that of the EM-based segmentation algorithm, it is much higher than that of the M-H-based segmentation algorithm.关键词:synthetic aperture radar (SAR) image segmentation;hierarchically weighted Gamma mixture model (HWGaMM);Markov random field (MRF);expectation maximization (EM);Metropolis-Hastings (M-H) algorithm13|5|1更新时间:2024-05-07
摘要:ObjectiveThe development of synthetic aperture radar (SAR) technology has resulted in the generation of high-resolution SAR images under all weather conditions and time periods. SAR images are widely used in many fields, such as disaster monitoring and ocean science. SAR image segmentation is a crucial step in image processing. The statistical model-based SAR segmentation algorithm is popular for its statistical distribution of homogeneous regions in SAR images with specific regularity. However, the statistical distribution of pixel intensities in high-resolution SAR images can be asymmetric, heavy-tailed, or multi-modal. Traditional mixture models use the weighted sum of components to model the statistical distribution of pixel intensities in SAR image segmentation. The components of mixture models are defined by probability density functions to mainly model the statistical distribution of homogeneous regions. The components can be Gaussian, student's, or Gamma distribution in the Gaussian mixture model (GMM), student's mixture model, and gamma mixture model (GaMM), respectively. However, these components fail to model the complicated distribution of pixel intensities in SAR images. To address the problem, this study proposes a SAR image segmentation algorithm that is based on a hierarchically weighted Gamma mixture model (HWGaMM) with spatial constraint.MethodA mixture model is defined by the weighted sum of its components to model the statistical distribution of pixel intensities. Its components are usually defined by the probability distribution, which results in the difficulty of modeling the complicated distribution of homogeneous regions in SAR images. To accurately model the asymmetric, heavy-tailed, or multi-modal distribution of pixel intensities, the proposed algorithm uses the HWGaMM to model the statistical distribution of pixel intensities in SAR images. The component of the HWGaMM is defined by the weighted sum of Gamma distributions, which represent the element used to model the statistical distribution of local homogeneous regions. As a result of the differences in pixel intensities in the same region and the similarities of pixel intensities in different regions for high-resolution SAR images, the HWGaMM is defined by the weighted sum of the components. The hierarchy of the HWGaMM can be expressed as follows. The basic layer is the element, i.e., Gamma distribution, which is used to model the statistical distribution of local homogeneous regions. The second layer is the component, which is the weighted sum of elements to mainly model the statistical distribution of homogeneous regions. The top layer is the HWGaMM, which is the weighted sum of components to model the statistical distribution of SAR images. The spatial relation of pixels is modeled by a Markov random field to reduce the influence of image noise. The spatial relation of pixels is introduced to the HWGaMM by defining the weight of components by the posterior probabilities of the pixels and neighboring pixels. Such introduction can improve the robustness of the proposed algorithm and prevent the increase in the complexity of model parameter estimation. In this work, SAR image segmentation is realized by estimating the model parameters through the combination of the Metropolis-Hastings (M-H) algorithm and expectation maximization (EM) algorithm. The traditional M-H algorithm usually suffers from poor efficiency because of its sampling for every model parameter in each iteration. The EM algorithm cannot easily estimate the shape parameter of a Gamma distribution because the shape parameter is included in the gamma function. To address such problem, the proposed algorithm uses the M-H algorithm in simulating the posterior distribution of the shape parameter and the EM algorithm in estimating the scale parameter and element weight. The method of parameter estimation overcomes the drawback of the EM algorithm and achieves higher efficiency than the M-H algorithm.ResultSegmentation experiments are carried out on simulated and real SAR images, and the results are analyzed qualitatively and quantitatively to verify the feasibility and effectiveness of the proposed algorithm. The proposed algorithm is compared with the GMM-based, Gamma distribution-based, and GaMM-based segmentation algorithms to highlight its advantages. The results of the fitting histograms reveal that the HWGaMM can accurately model the complicated distribution of pixel intensities. The segmentation accuracy can be calculated from the confusion matrix to quantitatively evaluate the proposed algorithm. The segmentation accuracies of the proposed algorithm are 33%, 29%, and 9% higher than those of the GMM-based, Gamma distribution-based, and GaMM-based segmentation algorithms, respectively. The segmentation time of the proposed algorithm is 64 s faster than that of GMM-based segmentation algorithm but is 600 s and 420 s slower than that of the gamma distribution-and GaMM-based segmentation algorithms, respectively.ConclusionThis work proposes an SAR image segmentation algorithm that is based on a spatially constrained HWGaMM. The proposed HWGaMM can model the complicated distribution of pixel intensities. The proposed segmentation algorithm also has higher accuracy than other relevant methods. Although the efficiency of the proposed algorithm is lower than that of the EM-based segmentation algorithm, it is much higher than that of the M-H-based segmentation algorithm.关键词:synthetic aperture radar (SAR) image segmentation;hierarchically weighted Gamma mixture model (HWGaMM);Markov random field (MRF);expectation maximization (EM);Metropolis-Hastings (M-H) algorithm13|5|1更新时间:2024-05-07
Remote Sensing Image Processing
-
 摘要:ObjectiveWith the continuous improvement of people's living standards and the advancement of urbanization, the number of private cars has been increasing, leading to the growing problem of road congestion. Road congestion will increase social costs, such as fuel consumption, waste of resources, travel time, emissions, and environmental pollution. If these problems are not resolved in time, then immeasurable harm will come to the future city development. The main reason for the traffic congestion is that the existing traffic structure system cannot meet the growing travel needs of people. To improve the traffic structure system, areas where traffic congestion is common must be identified. The establishment of an effective road congestion visualization system plays an important role in the construction of smart cities. In this paper, a road congestion based on density-based spatial clustering of applications with noise plus (DBSCAN+) is proposed to deal with single mode and low credibility. This algorithm is based on vehicle density analysis, vehicle speed determination, and driving time judgment methods.MethodDBSCAN+ first introduces block parallel computing. In comparison with the traditional density algorithm, DBSCAN+ can adapt to large-scale trajectory data and has fast parallel dimensionality reduction clustering. This algorithm solves the time-consuming problem of the traditional density-based clustering algorithm (DBSCAN), which scans all data points for each sample point with large-scale data. DBSCAN+ performs block-wise parallel calculation of the data and iterates the results again until reaching the iteration termination condition. Then, the algorithm discriminates the start and end points of the link segment from the slow-running class cluster in the result. For each trajectory data point in the slow-moving area cluster, the surface distance between the data points is calculated and marked by latitude and longitude data. The marked data points are no longer repeated in the comparison. The two points farthest from each other are selected. Finally, through curve fitting and topological network rectification algorithm, the road segments represented by the trajectory sample points in the cluster are matched to the electronic map via the map matching algorithm. The average driving speed of the floating vehicles in each cluster is used to determine the degree of road congestion. The degree of congestion is visualized by the color depth.ResultExperiments show that the DBSCAN+ algorithm has advantages over the existing improved DBSCAN algorithm in terms of time complexity from exponential to linear, adapting to massive trajectory points. In comparison with the mainstream map products, the urban taxi congestion OBD (on board diagnostics) data are used to identify the urban road congestion. The total detection length of the nonsmooth path segment is 28.9% higher than that of the optimal product. The experiment simultaneously conducted hit rate detection on the mainstream map products. The tested products included Baidu map, Gaode map, and Tencent map. The experimental results were compared, showing that the method has an advantage in detecting the hit rate of urban congestion events. The hit rate of congestion identification reaches 91%, which is 15% higher than the average detection hit rate of mainstream products.ConclusionOn the basis of DBSCAN+ density clustering and slow moving average moving speed, the multicharacterized road congestion identification algorithm is more representative of the congestion identification rate and commute degree in the urban road network than the mainstream map products. The algorithm provides real-time protection for urban traffic congestion identification. In this study, the taxi GPS (global positioning system) trajectory data of Huai'an City are used to utilize DBSCAN+, average commute speed, and other multifeature methods comprehensively for clustering the GPS trajectory of the taxis in the urban commuting area. The visualization method and system of road congestion identification can be well adapted to the GPS trajectory data of the large-scale urban taxi OBD terminal, which is convenient for identifying the urban road congestion situation and distinguishing the congestion degree in real time. In comparison with traditional map manufacturers, the number of urban taxis' GPS data is large and widely distributed, which can further effectively analyze the commute status of urban roads. The innovative parallel multithread clustering algorithm can efficiently fit the calculation demands. On the basis of the topological road network matching correction algorithm and congestion identification model, urban taxi distribution can be used to visualize the actual congestion situation. Furthermore, it can provide scientific decision-making for passenger travel and scheduling of public transport.关键词:parallel clustering;congestion identification;trajectory big data;smart city;visualization13|5|2更新时间:2024-05-07
摘要:ObjectiveWith the continuous improvement of people's living standards and the advancement of urbanization, the number of private cars has been increasing, leading to the growing problem of road congestion. Road congestion will increase social costs, such as fuel consumption, waste of resources, travel time, emissions, and environmental pollution. If these problems are not resolved in time, then immeasurable harm will come to the future city development. The main reason for the traffic congestion is that the existing traffic structure system cannot meet the growing travel needs of people. To improve the traffic structure system, areas where traffic congestion is common must be identified. The establishment of an effective road congestion visualization system plays an important role in the construction of smart cities. In this paper, a road congestion based on density-based spatial clustering of applications with noise plus (DBSCAN+) is proposed to deal with single mode and low credibility. This algorithm is based on vehicle density analysis, vehicle speed determination, and driving time judgment methods.MethodDBSCAN+ first introduces block parallel computing. In comparison with the traditional density algorithm, DBSCAN+ can adapt to large-scale trajectory data and has fast parallel dimensionality reduction clustering. This algorithm solves the time-consuming problem of the traditional density-based clustering algorithm (DBSCAN), which scans all data points for each sample point with large-scale data. DBSCAN+ performs block-wise parallel calculation of the data and iterates the results again until reaching the iteration termination condition. Then, the algorithm discriminates the start and end points of the link segment from the slow-running class cluster in the result. For each trajectory data point in the slow-moving area cluster, the surface distance between the data points is calculated and marked by latitude and longitude data. The marked data points are no longer repeated in the comparison. The two points farthest from each other are selected. Finally, through curve fitting and topological network rectification algorithm, the road segments represented by the trajectory sample points in the cluster are matched to the electronic map via the map matching algorithm. The average driving speed of the floating vehicles in each cluster is used to determine the degree of road congestion. The degree of congestion is visualized by the color depth.ResultExperiments show that the DBSCAN+ algorithm has advantages over the existing improved DBSCAN algorithm in terms of time complexity from exponential to linear, adapting to massive trajectory points. In comparison with the mainstream map products, the urban taxi congestion OBD (on board diagnostics) data are used to identify the urban road congestion. The total detection length of the nonsmooth path segment is 28.9% higher than that of the optimal product. The experiment simultaneously conducted hit rate detection on the mainstream map products. The tested products included Baidu map, Gaode map, and Tencent map. The experimental results were compared, showing that the method has an advantage in detecting the hit rate of urban congestion events. The hit rate of congestion identification reaches 91%, which is 15% higher than the average detection hit rate of mainstream products.ConclusionOn the basis of DBSCAN+ density clustering and slow moving average moving speed, the multicharacterized road congestion identification algorithm is more representative of the congestion identification rate and commute degree in the urban road network than the mainstream map products. The algorithm provides real-time protection for urban traffic congestion identification. In this study, the taxi GPS (global positioning system) trajectory data of Huai'an City are used to utilize DBSCAN+, average commute speed, and other multifeature methods comprehensively for clustering the GPS trajectory of the taxis in the urban commuting area. The visualization method and system of road congestion identification can be well adapted to the GPS trajectory data of the large-scale urban taxi OBD terminal, which is convenient for identifying the urban road congestion situation and distinguishing the congestion degree in real time. In comparison with traditional map manufacturers, the number of urban taxis' GPS data is large and widely distributed, which can further effectively analyze the commute status of urban roads. The innovative parallel multithread clustering algorithm can efficiently fit the calculation demands. On the basis of the topological road network matching correction algorithm and congestion identification model, urban taxi distribution can be used to visualize the actual congestion situation. Furthermore, it can provide scientific decision-making for passenger travel and scheduling of public transport.关键词:parallel clustering;congestion identification;trajectory big data;smart city;visualization13|5|2更新时间:2024-05-07
Geoinformatics
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0