
最新刊期
卷 25 , 期 12 , 2020
-
 摘要:Saliency detection is an important task in the computer vision community, especially in visual tracking, image compression, and object recognition tasks. However, the extant saliency detection methods based on RGB or RGB depth (RGB-D) often suffer from problems related to complex backgrounds, illumination, occlusion, and other factors, thereby leading to their inferior detection performance. In this case, a solution for improving the robustness of saliency detection results is warranted. In recent years, commercial and industrial light field cameras based on micro-lens arrays inserted between the main lens and the photosensor have introduced a new method for solving the saliency detection problem. The light field not only records spatial information but also the directions of all incoming light rays. The spatial and angular information inherent in a light field implicitly contains the geometry and reflection characteristics of the observed scene, which can provide reliable prior information for saliency detection, such as background clues and depth information. For example, the digital refocus technique can divide the light field into focal slices that focus at different depths. The background clues can be obtained from the focused areas. The light field contains effective saliency object occlusion information. Depth information also be obtained from the light field in various ways. Therefore, using light fields offers many advantages in dealing with problems related to saliency detection. Although saliency detection based on light fields has received much attention in recent years, a deep understanding of this method is yet to be achieved. In this paper, we review the research progress on light field saliency detection to build a foundation for future studies on this topic. First, we briefly discuss light field imaging theory, light field cameras, and the existing light field datasets used for saliency detection and then point out the differences among various datasets. Second, we systematically review the extant algorithms and the latest progress in light filed saliency detection from the aspects of hand-crafted features, sparse coding, and deep learning. Saliency detection algorithms based on light field hand-crafted features are generally based on the idea of contrast. These algorithms detect salient regions by calculating the feature difference between each pixel and super pixel as well as between other pixels and other super pixels. Saliency detection based on sparse coding and deep learning follow the same idea of feature learning, that is, they use image feature coding or the outstanding feature representation abilities of convolution network to determine the salient regions. By analyzing the experimental data on four publicly available light field saliency detection datasets, we summarize the advantages and disadvantages of the existing light field saliency detection methods, summarize the recent progress in light-field-based saliency detection and point out the limitations in this field. Only a few light field datasets are presently available for saliency detection, and these datasets are all generated by light field cameras based on micro-lens array, which has a narrow baseline. Therefore, the effective utilization of various information present in a light field remains a challenge. While saliency detection algorithms based on light fields have been proposed in previous studies, saliency detection based on light fields warrant further study due to the complexity of real scenes.关键词:saliency detection;light field cameras;light field features;sparse coding;deep learning74|83|4更新时间:2024-05-07
摘要:Saliency detection is an important task in the computer vision community, especially in visual tracking, image compression, and object recognition tasks. However, the extant saliency detection methods based on RGB or RGB depth (RGB-D) often suffer from problems related to complex backgrounds, illumination, occlusion, and other factors, thereby leading to their inferior detection performance. In this case, a solution for improving the robustness of saliency detection results is warranted. In recent years, commercial and industrial light field cameras based on micro-lens arrays inserted between the main lens and the photosensor have introduced a new method for solving the saliency detection problem. The light field not only records spatial information but also the directions of all incoming light rays. The spatial and angular information inherent in a light field implicitly contains the geometry and reflection characteristics of the observed scene, which can provide reliable prior information for saliency detection, such as background clues and depth information. For example, the digital refocus technique can divide the light field into focal slices that focus at different depths. The background clues can be obtained from the focused areas. The light field contains effective saliency object occlusion information. Depth information also be obtained from the light field in various ways. Therefore, using light fields offers many advantages in dealing with problems related to saliency detection. Although saliency detection based on light fields has received much attention in recent years, a deep understanding of this method is yet to be achieved. In this paper, we review the research progress on light field saliency detection to build a foundation for future studies on this topic. First, we briefly discuss light field imaging theory, light field cameras, and the existing light field datasets used for saliency detection and then point out the differences among various datasets. Second, we systematically review the extant algorithms and the latest progress in light filed saliency detection from the aspects of hand-crafted features, sparse coding, and deep learning. Saliency detection algorithms based on light field hand-crafted features are generally based on the idea of contrast. These algorithms detect salient regions by calculating the feature difference between each pixel and super pixel as well as between other pixels and other super pixels. Saliency detection based on sparse coding and deep learning follow the same idea of feature learning, that is, they use image feature coding or the outstanding feature representation abilities of convolution network to determine the salient regions. By analyzing the experimental data on four publicly available light field saliency detection datasets, we summarize the advantages and disadvantages of the existing light field saliency detection methods, summarize the recent progress in light-field-based saliency detection and point out the limitations in this field. Only a few light field datasets are presently available for saliency detection, and these datasets are all generated by light field cameras based on micro-lens array, which has a narrow baseline. Therefore, the effective utilization of various information present in a light field remains a challenge. While saliency detection algorithms based on light fields have been proposed in previous studies, saliency detection based on light fields warrant further study due to the complexity of real scenes.关键词:saliency detection;light field cameras;light field features;sparse coding;deep learning74|83|4更新时间:2024-05-07
Review

-
 摘要:ObjectiveRain lines adversely affect the visual quality of images collected from outdoors. Severe weather conditions, such as rain, fog, and haze, can affect the quality of these images and make them unusable. These degraded images may also drastically affect the performance of man's vision system. Given that rain is a common meteorological phenomenon, an algorithm that can remove rain from single image is of practical significance. Given that video-based de-raining methods obtain pixel information of the same location at different periods, removing rain from an individual image is more challenging because of less available information. Traditional de-raining methods mainly focus on rain map modeling and use mathematical optimization to detect and remove rain streaks, but the performance of such approach requires further improvement.MethodTo address the above problems, this paper establishes a convolution neural network for single image rain removal that is trained on a synthetic dataset. The contributions of this work are as follows. 1) To expand the neural receptive field of a convolution neural network that learns abstract feature representation of rain streaks and the ground truth, this work establishes a selective kernel network based on multi-scale convolution with different kernel for feature learning. To accomplish useful information fusion and selection, an external non-linear weight learning mechanism is developed to redistribute the weight for the corresponding channel's feature information from different convolution kernels. This mechanism enables the network to select the feature information of different receptive fields adaptively and enhance its expression ability and rain removal capability. 2) The existing rain map model shows some limitations at the training stage. Completing this model by adding a learnable refine factor that modifies each pixel in a rain streak image, can enhance the accuracy of the result and prevent background misjudgment. The range of the refining factor is also limited to reduce the mapping range of the network training process. 3) At the training stage the existing single image rain removal networks need to learn various types of image content, including rain streaks removal and background restoration, which will undoubtedly increase their burden. By using the novel idea of residual learning the proposed network can directly learn the rain streak map by using the input rain map. In this way, the mapping interval of the network learning process is reduced, the background of the original graph can be preserved, and loss of details can be prevented. The validity of the above arguments is tested by designing a comparison network with different modules. Specifically, based on general convolution, different modules are combined step by step, including the SK net, residual learning mechanism, and refine factor learning net. Single image rain removal network based on selective kernel convolution using residual refine factor (SKRF) is eventually designed. The residual learning mechanism is used to reduce the mapping interval, and the refined factor is used to enhance the rain streak map to improve the rain removal performance.ResultAn SKRF network, including the three subnets of SK net, refine factor net, and residual net, is designed in a rain removal experiment and tested on the open Rain12 test set. This network achieves a higher accuracy, peak signal to noise ratio(PSNR) (34.62), and structural similarity(SSIM) (0.970 6) compared with the existing methods. The SKRF network shows obvious advantages in removing rain from single image.ConclusionWe construct a convolution neural network based on SKRF to remove rain streaks from single image. A selective kernel convolution network is established to improve the expression ability of the proposed network via the adaptive adjustment mechanism of the size of the receptive field by the internal neurons. A rain map with different characteristics can be well learned, and the effect of rain removal can be improved. The residual learning mechanism can reduce the mapping interval of the network learning process and retain more details of the original image. In the modified rain map model, an additional refine factor is provided for the rain streak map, which can further reduce the mapping interval and reduce background misjudgment. This network not only removes the majority of the visible rain streaks but also retains the ground truth. In our feature work, we plan to extend this network to a wider range of image restoration tasks.关键词:single image rain removal;deep learning;selective kernel network(SK Net);refine factor (RF);residual learning40|23|4更新时间:2024-05-07
摘要:ObjectiveRain lines adversely affect the visual quality of images collected from outdoors. Severe weather conditions, such as rain, fog, and haze, can affect the quality of these images and make them unusable. These degraded images may also drastically affect the performance of man's vision system. Given that rain is a common meteorological phenomenon, an algorithm that can remove rain from single image is of practical significance. Given that video-based de-raining methods obtain pixel information of the same location at different periods, removing rain from an individual image is more challenging because of less available information. Traditional de-raining methods mainly focus on rain map modeling and use mathematical optimization to detect and remove rain streaks, but the performance of such approach requires further improvement.MethodTo address the above problems, this paper establishes a convolution neural network for single image rain removal that is trained on a synthetic dataset. The contributions of this work are as follows. 1) To expand the neural receptive field of a convolution neural network that learns abstract feature representation of rain streaks and the ground truth, this work establishes a selective kernel network based on multi-scale convolution with different kernel for feature learning. To accomplish useful information fusion and selection, an external non-linear weight learning mechanism is developed to redistribute the weight for the corresponding channel's feature information from different convolution kernels. This mechanism enables the network to select the feature information of different receptive fields adaptively and enhance its expression ability and rain removal capability. 2) The existing rain map model shows some limitations at the training stage. Completing this model by adding a learnable refine factor that modifies each pixel in a rain streak image, can enhance the accuracy of the result and prevent background misjudgment. The range of the refining factor is also limited to reduce the mapping range of the network training process. 3) At the training stage the existing single image rain removal networks need to learn various types of image content, including rain streaks removal and background restoration, which will undoubtedly increase their burden. By using the novel idea of residual learning the proposed network can directly learn the rain streak map by using the input rain map. In this way, the mapping interval of the network learning process is reduced, the background of the original graph can be preserved, and loss of details can be prevented. The validity of the above arguments is tested by designing a comparison network with different modules. Specifically, based on general convolution, different modules are combined step by step, including the SK net, residual learning mechanism, and refine factor learning net. Single image rain removal network based on selective kernel convolution using residual refine factor (SKRF) is eventually designed. The residual learning mechanism is used to reduce the mapping interval, and the refined factor is used to enhance the rain streak map to improve the rain removal performance.ResultAn SKRF network, including the three subnets of SK net, refine factor net, and residual net, is designed in a rain removal experiment and tested on the open Rain12 test set. This network achieves a higher accuracy, peak signal to noise ratio(PSNR) (34.62), and structural similarity(SSIM) (0.970 6) compared with the existing methods. The SKRF network shows obvious advantages in removing rain from single image.ConclusionWe construct a convolution neural network based on SKRF to remove rain streaks from single image. A selective kernel convolution network is established to improve the expression ability of the proposed network via the adaptive adjustment mechanism of the size of the receptive field by the internal neurons. A rain map with different characteristics can be well learned, and the effect of rain removal can be improved. The residual learning mechanism can reduce the mapping interval of the network learning process and retain more details of the original image. In the modified rain map model, an additional refine factor is provided for the rain streak map, which can further reduce the mapping interval and reduce background misjudgment. This network not only removes the majority of the visible rain streaks but also retains the ground truth. In our feature work, we plan to extend this network to a wider range of image restoration tasks.关键词:single image rain removal;deep learning;selective kernel network(SK Net);refine factor (RF);residual learning40|23|4更新时间:2024-05-07 -
 摘要:ObjectiveRandom-valued impulse noise (RVIN) is a common cause of image degradation that is frequently observed in images captured by digital camera sensors. In addition to degrading image quality, this type of noise also leads to pixel failure and inaccurate storage location or transmission. The presence of impulse noise may also introduce difficulties in feature extraction, target tracking, image classification, and subsequent image processing and analysis works. For RVIN, the noise value of a corrupted pixels uniformly distributed between 0 and 255. In this case, detecting the RVIN is very difficult. The available local image statistics for RVIN detection, which are used to determine whether the center pixel of an image patch is corrupted by RVIN noise or not, have are latively weak description ability, thereby restricting their accuracy to some extent and affecting the restoration performance of subsequent switching RVIN denoising modules.MethodNine local image statistics, including eight neighbor rank-ordered logarithmic difference (ROLD) statistics and one min-imum orientation logarithmic difference (MOLD) statistics, were used to construct a highly sensitive RVIN noise-aware feature vector that can describe the RVIN likeness of the center pixel of a given patch. Based on this vector, RVIN noise-aware feature vectors extracted from numerous noisy patches, their corresponding noise labels were formed as a set of training pairs for a multi-layer perception (MLP) network, and the MLP-based RVIN detector was trained.ResultComparative experiments were performed to test the estimation accuracy and denoising effect of the proposed RVIN detector. The proposed detector was compared with several state-of-the-art image denoising methods, including progressive switching median filter(PSMF), ROLD-edge preserving regularization(ROLD-EPR), adaptive switching median(ASWM), robust outlyingness ratio nonlocal means(ROR-NLM), MLP-edge preserving regularization(MLP-EPR), convolutional neural network based(CNN-based), blind convolutional neural network(BCNN), and MLP neural network classifier(MLPNNC), to demonstrate its estimation accuracy. Two image sets were used in the experiments. One image set included the "Lena", "House", "Peppers", "Couple", "Hill", "Barbara", "Boat", "Man", "Cameraman", and "Monarch" images, whereas the other set contained 50 textured images that were randomly selected from the BSD database(unlike the noise detection model training set). For a fair comparison, all competing algorithms were implemented in the MATLAB 2017b environment on the same hardware platform. To verify the estimation accuracy of the proposed RVIN detector, we applied different RVIN noise ratios to images taken from commonly used image sets, applied the proposed detector to count the instances of error, false, and missed detections for a noisy image, and compared its performance with that of existing classical RVIN noise reduction algorithms. Usually, a higher rate of error detection indicates that more noise has been left undetected in an image, and a false detection can reduce the noise of normal non-distorted pixels during the noise reduction stage, which can lead to blurry images. The total number of errors represents the number of missed and false detections, whereas a smaller number of these detections corresponds to a lower algorithm detection error rate and a better image quality after noise reduction. Experimental results show that the proposed algorithm has a relatively balanced number of missed and false detections and ranks second among all compared algorithms in this respect, thereby offering a solid foundation for the subsequent noise reduction module. In the second image set, we combined the proposed RVIN detector with the generic iteratively reweighted annihilating filter(GIRAF) algorithm to form a RVIN noise reduction algorithm. To verify the effectiveness of the proposed detector, we applied different ratios of RVIN noise (i.e., 10%, 20%, 30%, 40%, 50%, and 60%) to 50 textured images and recorded the average peak signal-to-noise ratio (PSNR) of these images under each noise ratio. Experimental results show that the images restored by the proposed-GIRAF algorithm achieve the optimal PSNR under each noise ratio and that this algorithm greatly outperforms the Xu, Chen-GIRAF, and MLPNNC-GIRAF algorithms. The proposed-GIRAF algorithm also outperforms the second-best algorithm by 0.47 dB to 1.96 dB in terms of the average PSNR of its 50 images, thereby suggesting that the actual detection results of the proposed noise detector are the most effective for the subsequent noise reduction module. Experimental results also show that the proposed RVIN detector outperforms most of the existing detectors in terms of detection accuracy. As such, a switching RVIN removal method with an improved denoising performance can be obtained by combining the proposed RVIN detector with any inpainting algorithm.ConclusionExtensive experiments show that the estimation accuracy of the proposed MLP-based noise detector is robust across a wide range of noise ratios. When combined with the GIRAF algorithm, this detector significantly outperforms the traditional RVIN denoising algorithm in terms of denoising effect.关键词:image denoising;random-valued impulse noise (RVIN);local spatial structure;eight neighbor rank-ordered logarithmic difference (EN-ROLD);minimum orientation logarithmic difference (MOLD);multi-layer perception (MLP);detection accuracy29|22|0更新时间:2024-05-07
摘要:ObjectiveRandom-valued impulse noise (RVIN) is a common cause of image degradation that is frequently observed in images captured by digital camera sensors. In addition to degrading image quality, this type of noise also leads to pixel failure and inaccurate storage location or transmission. The presence of impulse noise may also introduce difficulties in feature extraction, target tracking, image classification, and subsequent image processing and analysis works. For RVIN, the noise value of a corrupted pixels uniformly distributed between 0 and 255. In this case, detecting the RVIN is very difficult. The available local image statistics for RVIN detection, which are used to determine whether the center pixel of an image patch is corrupted by RVIN noise or not, have are latively weak description ability, thereby restricting their accuracy to some extent and affecting the restoration performance of subsequent switching RVIN denoising modules.MethodNine local image statistics, including eight neighbor rank-ordered logarithmic difference (ROLD) statistics and one min-imum orientation logarithmic difference (MOLD) statistics, were used to construct a highly sensitive RVIN noise-aware feature vector that can describe the RVIN likeness of the center pixel of a given patch. Based on this vector, RVIN noise-aware feature vectors extracted from numerous noisy patches, their corresponding noise labels were formed as a set of training pairs for a multi-layer perception (MLP) network, and the MLP-based RVIN detector was trained.ResultComparative experiments were performed to test the estimation accuracy and denoising effect of the proposed RVIN detector. The proposed detector was compared with several state-of-the-art image denoising methods, including progressive switching median filter(PSMF), ROLD-edge preserving regularization(ROLD-EPR), adaptive switching median(ASWM), robust outlyingness ratio nonlocal means(ROR-NLM), MLP-edge preserving regularization(MLP-EPR), convolutional neural network based(CNN-based), blind convolutional neural network(BCNN), and MLP neural network classifier(MLPNNC), to demonstrate its estimation accuracy. Two image sets were used in the experiments. One image set included the "Lena", "House", "Peppers", "Couple", "Hill", "Barbara", "Boat", "Man", "Cameraman", and "Monarch" images, whereas the other set contained 50 textured images that were randomly selected from the BSD database(unlike the noise detection model training set). For a fair comparison, all competing algorithms were implemented in the MATLAB 2017b environment on the same hardware platform. To verify the estimation accuracy of the proposed RVIN detector, we applied different RVIN noise ratios to images taken from commonly used image sets, applied the proposed detector to count the instances of error, false, and missed detections for a noisy image, and compared its performance with that of existing classical RVIN noise reduction algorithms. Usually, a higher rate of error detection indicates that more noise has been left undetected in an image, and a false detection can reduce the noise of normal non-distorted pixels during the noise reduction stage, which can lead to blurry images. The total number of errors represents the number of missed and false detections, whereas a smaller number of these detections corresponds to a lower algorithm detection error rate and a better image quality after noise reduction. Experimental results show that the proposed algorithm has a relatively balanced number of missed and false detections and ranks second among all compared algorithms in this respect, thereby offering a solid foundation for the subsequent noise reduction module. In the second image set, we combined the proposed RVIN detector with the generic iteratively reweighted annihilating filter(GIRAF) algorithm to form a RVIN noise reduction algorithm. To verify the effectiveness of the proposed detector, we applied different ratios of RVIN noise (i.e., 10%, 20%, 30%, 40%, 50%, and 60%) to 50 textured images and recorded the average peak signal-to-noise ratio (PSNR) of these images under each noise ratio. Experimental results show that the images restored by the proposed-GIRAF algorithm achieve the optimal PSNR under each noise ratio and that this algorithm greatly outperforms the Xu, Chen-GIRAF, and MLPNNC-GIRAF algorithms. The proposed-GIRAF algorithm also outperforms the second-best algorithm by 0.47 dB to 1.96 dB in terms of the average PSNR of its 50 images, thereby suggesting that the actual detection results of the proposed noise detector are the most effective for the subsequent noise reduction module. Experimental results also show that the proposed RVIN detector outperforms most of the existing detectors in terms of detection accuracy. As such, a switching RVIN removal method with an improved denoising performance can be obtained by combining the proposed RVIN detector with any inpainting algorithm.ConclusionExtensive experiments show that the estimation accuracy of the proposed MLP-based noise detector is robust across a wide range of noise ratios. When combined with the GIRAF algorithm, this detector significantly outperforms the traditional RVIN denoising algorithm in terms of denoising effect.关键词:image denoising;random-valued impulse noise (RVIN);local spatial structure;eight neighbor rank-ordered logarithmic difference (EN-ROLD);minimum orientation logarithmic difference (MOLD);multi-layer perception (MLP);detection accuracy29|22|0更新时间:2024-05-07 -
 摘要:ObjectiveImage inpainting is a hot research topic in computer vision. In recent years, this task has been considered a conditional pattern generation problem in deep learning that has received much attention from researchers. Compared with traditional algorithms, deep-learning-based image inpainting methods can be used in more extensive scenarios with better inpainting effects. Nevertheless, these methods have limitations. For instance, their image inpainting results need to be improved in terms of semantic rationality, structural coherence, and detail accuracy when processing the close association among global and local attributed images, especially when dealing with images involving a large defect area. This paper proposes a novel image inpainting model based on the fully convolutional neural network and the idea of generative adversarial network to solve the above problems. This model optimizes the network structure, loss constraints, and training strategies to obtain improved image inpainting effects.MethodFirst, this paper proposes a novel image inpainting network as a generator to repair defective images by using effective methods in the field of image processing. A network framework based on a fully convolutional neural network is then built in the form of an encoder-decoder. For instance, we replace part of convolutional layers in the network decoding stage with dilated convolution. We also apply dilated convolution superposition with multiple dilation rates to obtain a larger input image area compared with ordinary convolution in small-size feature graphs and then effectively increase the receptive field of the convolution kernel without increasing the calculation amount to develop a better understanding of images. We also set long-skip connections in the corresponding stage of encoding-decoding. This connection strengthens the structural information by transmitting low-level features to the decoding stage. The setting enhances the correlation among deep features and reduces the difficulties in network training. Second, we introduce structural similarity (SSIM) as the reconstruction loss of image inpainting. This image quality evaluation index is built from the perspective of the human visual perception system and differs from the common mean square error (MSE) loss per pixel. This index comprehensively evaluates via an experiment the similarity between two images in their brightness, contrast, and structure. Structural similarity, as the reconstruction loss of an image, can effectively improve the visual effects of image inpainting results. We use the improved global and local context discriminator as a two-way discriminator to determine the authenticity of the inpainting results. The global context discriminator guarantees the consistency of attributes between the image inpainting area and the entire image, whereas the local context discriminator improves the detailed performance of the image inpainting area. Combined with adversarial loss, this paper proposes a joint loss to improve the performance of the model and reduce the difficulties in its training. By drawing lessons from the training mode of generative adversarial networks, we presents a novel method to alternately train image inpainting network and image discriminative network, which obtains an ideal result. In practical applications, we only use image inpainting network to repair defective images.ResultTo verify the effectiveness of the proposed image inpainting model, we compare the image inpainting effect of this model with that of mainstream image inpainting algorithms on the CelebA-HQ dataset by using subjective perception and objective indicators. To achieve the best inpainting effect in controlled experiments, we use official versions of codes and examples. The image inpainting result is taken from loading pre-training files or online demos. We place the specific defect mask onto 50 randomly selected images as test cases and then apply different image inpainting algorithms to repair and collect statistics for the comparison. The CelebA-HQ dataset is a cropped and super-resolution reconstructed version of the CelebA dataset, which contains 30 000 high-resolution face images. The human face represents a special image that not only contains specific features but also an infinite amount of details. Therefore, face images can fully test the expressiveness of the image inpainting method. Considering the algorithm consistent attribute of the global and local images in the controlled experiment, experiment results show that the image inpainting model demonstrates some improvements in its semantic rationality, structural coherence, and detail performance compared with other algorithms. Subjectively, this model has a natural edge transition and a very detailed image inpainting area. Objectively, this model has a peak signal-to-noise ratio(PSNR), and SSIM of 31.30 dB and 90.58% on average, respective, both of which exceed those of mainstream deep learning-based image inpainting algorithms. To verify its generality, we test the image inpainting model on the Places2 dataset.ConclusionThis paper proposes a novel image inpainting model that shows improvements in terms of network structure, cost, training strategy, and image inpainting results. This model also provides a better understanding of the high-level semantics of images. Given its highly accurate context and details, the proposed model obtains better image inpainting results from human visual perception. We will continue to improve the effect of image inpainting and explore the conditional image inpainting task in the future. Our plan is to improve and optimize this model in terms of network structure and loss constraint to reduce losses in an image during the feature extraction process under a controllable network training setup. We shall also try to make the defect mask do more work with channel domain attention mechanism to further improve the quality of image inpainting. We also plan to analyze the relationship between image boundary structure and feature reconstruction. We aim to improve the convergence speed of network training and the quality of image inpainting by using an accurate and effective loss function. Furthermore, we would use human-computer interaction or presupposed condition to affect the results of image inpainting, which explores more practical values of the model.关键词:image inpainting;fully convolutional neural network;dilated convolution;skip connection;adversarial loss94|146|4更新时间:2024-05-07
摘要:ObjectiveImage inpainting is a hot research topic in computer vision. In recent years, this task has been considered a conditional pattern generation problem in deep learning that has received much attention from researchers. Compared with traditional algorithms, deep-learning-based image inpainting methods can be used in more extensive scenarios with better inpainting effects. Nevertheless, these methods have limitations. For instance, their image inpainting results need to be improved in terms of semantic rationality, structural coherence, and detail accuracy when processing the close association among global and local attributed images, especially when dealing with images involving a large defect area. This paper proposes a novel image inpainting model based on the fully convolutional neural network and the idea of generative adversarial network to solve the above problems. This model optimizes the network structure, loss constraints, and training strategies to obtain improved image inpainting effects.MethodFirst, this paper proposes a novel image inpainting network as a generator to repair defective images by using effective methods in the field of image processing. A network framework based on a fully convolutional neural network is then built in the form of an encoder-decoder. For instance, we replace part of convolutional layers in the network decoding stage with dilated convolution. We also apply dilated convolution superposition with multiple dilation rates to obtain a larger input image area compared with ordinary convolution in small-size feature graphs and then effectively increase the receptive field of the convolution kernel without increasing the calculation amount to develop a better understanding of images. We also set long-skip connections in the corresponding stage of encoding-decoding. This connection strengthens the structural information by transmitting low-level features to the decoding stage. The setting enhances the correlation among deep features and reduces the difficulties in network training. Second, we introduce structural similarity (SSIM) as the reconstruction loss of image inpainting. This image quality evaluation index is built from the perspective of the human visual perception system and differs from the common mean square error (MSE) loss per pixel. This index comprehensively evaluates via an experiment the similarity between two images in their brightness, contrast, and structure. Structural similarity, as the reconstruction loss of an image, can effectively improve the visual effects of image inpainting results. We use the improved global and local context discriminator as a two-way discriminator to determine the authenticity of the inpainting results. The global context discriminator guarantees the consistency of attributes between the image inpainting area and the entire image, whereas the local context discriminator improves the detailed performance of the image inpainting area. Combined with adversarial loss, this paper proposes a joint loss to improve the performance of the model and reduce the difficulties in its training. By drawing lessons from the training mode of generative adversarial networks, we presents a novel method to alternately train image inpainting network and image discriminative network, which obtains an ideal result. In practical applications, we only use image inpainting network to repair defective images.ResultTo verify the effectiveness of the proposed image inpainting model, we compare the image inpainting effect of this model with that of mainstream image inpainting algorithms on the CelebA-HQ dataset by using subjective perception and objective indicators. To achieve the best inpainting effect in controlled experiments, we use official versions of codes and examples. The image inpainting result is taken from loading pre-training files or online demos. We place the specific defect mask onto 50 randomly selected images as test cases and then apply different image inpainting algorithms to repair and collect statistics for the comparison. The CelebA-HQ dataset is a cropped and super-resolution reconstructed version of the CelebA dataset, which contains 30 000 high-resolution face images. The human face represents a special image that not only contains specific features but also an infinite amount of details. Therefore, face images can fully test the expressiveness of the image inpainting method. Considering the algorithm consistent attribute of the global and local images in the controlled experiment, experiment results show that the image inpainting model demonstrates some improvements in its semantic rationality, structural coherence, and detail performance compared with other algorithms. Subjectively, this model has a natural edge transition and a very detailed image inpainting area. Objectively, this model has a peak signal-to-noise ratio(PSNR), and SSIM of 31.30 dB and 90.58% on average, respective, both of which exceed those of mainstream deep learning-based image inpainting algorithms. To verify its generality, we test the image inpainting model on the Places2 dataset.ConclusionThis paper proposes a novel image inpainting model that shows improvements in terms of network structure, cost, training strategy, and image inpainting results. This model also provides a better understanding of the high-level semantics of images. Given its highly accurate context and details, the proposed model obtains better image inpainting results from human visual perception. We will continue to improve the effect of image inpainting and explore the conditional image inpainting task in the future. Our plan is to improve and optimize this model in terms of network structure and loss constraint to reduce losses in an image during the feature extraction process under a controllable network training setup. We shall also try to make the defect mask do more work with channel domain attention mechanism to further improve the quality of image inpainting. We also plan to analyze the relationship between image boundary structure and feature reconstruction. We aim to improve the convergence speed of network training and the quality of image inpainting by using an accurate and effective loss function. Furthermore, we would use human-computer interaction or presupposed condition to affect the results of image inpainting, which explores more practical values of the model.关键词:image inpainting;fully convolutional neural network;dilated convolution;skip connection;adversarial loss94|146|4更新时间:2024-05-07 -
 摘要:ObjectiveHuman action recognition in videos aims to identify action categories by analyzing human action-related information and utilizing spatial and temporal cues. Research on human action recognition are crucial in the development of intelligent security, pedestrian monitoring, and clinical nursing; hence, this topic has become increasingly popular among researchers. The key point of improving the accuracy of human action recognition lies on how to construct distinctive features to describe human action categories effectively. Existing human action recognition methods fall into three categories:extracting visual features using deep learning networks, manually constructing image visual descriptors, and combining manual construction with deep learning networks. The methods that use deep learning networks normally operate convolution and pooling on small neighbor regions, thereby ignoring the connection among regions. By contrast, manual construction methods often have strong pertinence and poor adaptability to specific human actions, and its application scenarios are limited. Therefore, some researchers combine the idea of handmade features with deep learning computation. However, the existing methods still have problems in the effective utilization of the spatial and temporal information of human action, and the accuracy of human action recognition still needs to be improved. Considering the above problems, we research on how to design and construct distinguishable human action features and propose a new human action recognition method in which the key semantic information in the spatial domain of human action is extracted using a deep learning network and then connected and analyzed in the time domain.MethodHuman action videos usually record more than 24 frames per second; however, human poses do not change at this speed. In the computation of human action characteristics in videos, changes between consecutive video frames are usually minimal, and most human action information contained in the video is similar or repeated. To avoid redundant computations, we calculate the key frames of videos in accordance with the amplitude variation of the image content of interframes. Frames with repetitive content or slight changes are eliminated to avoid redundant calculation in the subsequent semantic information analysis and extraction. The calculated key frames contain evident changes of human body and human-related background and thus reveal sufficient human action information in videos for recognition. Then, to analyze and describe the spatial information of human action effectively, we design and construct a deep learning network to analyze the semantic information of images and extract the key semantic regions that can express important semantic information. The constructed network is denoted as Net1, which is trained by transfer learning and can use continuous convolutional layers to mine the semantic information of images. The output data of Net1 provides image regions, which contain various kinds of foreground semantic information and region scores, which represent the probability of containing foreground information. In addition, a nonmaximal suppression algorithm is used to eliminate areas that have too much overlap. Afterward, the key semantic regions are classified into person and nonperson regions, and then the position and proportion of person regions are used to distinguish the main person and the secondary persons. Moreover, object regions that have no relationship with the main person are eliminated, and only foreground regions that reveal human action-related semantic information are reserved. Afterward, a Siamese network is constructed to calculate the correlation of key semantic regions among frames and concatenate key semantic regions in the temporal domain. The proposed Siamese network is denoted as Net2, which has two inputs and one output; Net2 can be used to mine deeply and measure the similarity between two input image regions, and the output values are used to express the similarity. The constructed Net2 can concatenate the key semantic regions into a semantic region chain to ensure the time consistency of semantic information, and express human action change information in time domain more effectively. Moreover, we tailor the feature map of Net1 using the interpolation and scaling method, in order to obtain feature submaps of uniform size. That is, each semantic region chain corresponds to a feature matrix chain. Given that the length of each feature matrix chain is different, the maximum fusion method is used to fuse the feature matrix chain and obtain a single fused matrix, which reveals one kind of video semantic information. We stack the fused matrix from all feature matrix chains together and then design and train a classifier, which consists of two fully connected layers and a support vector machine. The output of the classifier is the final human action recognition result for videos.ResultThe UCF(University of Central Florida)50 dataset, a publicly available challenging human action recognition dataset, is used to verify the performance of our proposed human action recognition method. In this dataset, the average human action recognition accuracy of the proposed method is 94.3%, which is higher than that of state-of-the-are methods, such as that based on optical flow motion expression (76.9%), that based on a two-stream convolutional neural network (88.0%), and that based on SURF(speeded up robust features) descriptors and Fisher encoding (91.7%). In addition, the proposed crucial algorithms of the semantic region chain computation and the key semantic region correlation calculation are verified through a control experiment. Results reveal that the two crucial algorithms effectively improve the accuracy of human action recognition.ConclusionThe proposed human action recognition method, which uses semantic region extraction and concatenation, can effectively improve the accuracy of human action recognition in videos.关键词:human-machine interaction;deep learning network;key semantic information of human action;human action recognition;video key frame33|26|1更新时间:2024-05-07
摘要:ObjectiveHuman action recognition in videos aims to identify action categories by analyzing human action-related information and utilizing spatial and temporal cues. Research on human action recognition are crucial in the development of intelligent security, pedestrian monitoring, and clinical nursing; hence, this topic has become increasingly popular among researchers. The key point of improving the accuracy of human action recognition lies on how to construct distinctive features to describe human action categories effectively. Existing human action recognition methods fall into three categories:extracting visual features using deep learning networks, manually constructing image visual descriptors, and combining manual construction with deep learning networks. The methods that use deep learning networks normally operate convolution and pooling on small neighbor regions, thereby ignoring the connection among regions. By contrast, manual construction methods often have strong pertinence and poor adaptability to specific human actions, and its application scenarios are limited. Therefore, some researchers combine the idea of handmade features with deep learning computation. However, the existing methods still have problems in the effective utilization of the spatial and temporal information of human action, and the accuracy of human action recognition still needs to be improved. Considering the above problems, we research on how to design and construct distinguishable human action features and propose a new human action recognition method in which the key semantic information in the spatial domain of human action is extracted using a deep learning network and then connected and analyzed in the time domain.MethodHuman action videos usually record more than 24 frames per second; however, human poses do not change at this speed. In the computation of human action characteristics in videos, changes between consecutive video frames are usually minimal, and most human action information contained in the video is similar or repeated. To avoid redundant computations, we calculate the key frames of videos in accordance with the amplitude variation of the image content of interframes. Frames with repetitive content or slight changes are eliminated to avoid redundant calculation in the subsequent semantic information analysis and extraction. The calculated key frames contain evident changes of human body and human-related background and thus reveal sufficient human action information in videos for recognition. Then, to analyze and describe the spatial information of human action effectively, we design and construct a deep learning network to analyze the semantic information of images and extract the key semantic regions that can express important semantic information. The constructed network is denoted as Net1, which is trained by transfer learning and can use continuous convolutional layers to mine the semantic information of images. The output data of Net1 provides image regions, which contain various kinds of foreground semantic information and region scores, which represent the probability of containing foreground information. In addition, a nonmaximal suppression algorithm is used to eliminate areas that have too much overlap. Afterward, the key semantic regions are classified into person and nonperson regions, and then the position and proportion of person regions are used to distinguish the main person and the secondary persons. Moreover, object regions that have no relationship with the main person are eliminated, and only foreground regions that reveal human action-related semantic information are reserved. Afterward, a Siamese network is constructed to calculate the correlation of key semantic regions among frames and concatenate key semantic regions in the temporal domain. The proposed Siamese network is denoted as Net2, which has two inputs and one output; Net2 can be used to mine deeply and measure the similarity between two input image regions, and the output values are used to express the similarity. The constructed Net2 can concatenate the key semantic regions into a semantic region chain to ensure the time consistency of semantic information, and express human action change information in time domain more effectively. Moreover, we tailor the feature map of Net1 using the interpolation and scaling method, in order to obtain feature submaps of uniform size. That is, each semantic region chain corresponds to a feature matrix chain. Given that the length of each feature matrix chain is different, the maximum fusion method is used to fuse the feature matrix chain and obtain a single fused matrix, which reveals one kind of video semantic information. We stack the fused matrix from all feature matrix chains together and then design and train a classifier, which consists of two fully connected layers and a support vector machine. The output of the classifier is the final human action recognition result for videos.ResultThe UCF(University of Central Florida)50 dataset, a publicly available challenging human action recognition dataset, is used to verify the performance of our proposed human action recognition method. In this dataset, the average human action recognition accuracy of the proposed method is 94.3%, which is higher than that of state-of-the-are methods, such as that based on optical flow motion expression (76.9%), that based on a two-stream convolutional neural network (88.0%), and that based on SURF(speeded up robust features) descriptors and Fisher encoding (91.7%). In addition, the proposed crucial algorithms of the semantic region chain computation and the key semantic region correlation calculation are verified through a control experiment. Results reveal that the two crucial algorithms effectively improve the accuracy of human action recognition.ConclusionThe proposed human action recognition method, which uses semantic region extraction and concatenation, can effectively improve the accuracy of human action recognition in videos.关键词:human-machine interaction;deep learning network;key semantic information of human action;human action recognition;video key frame33|26|1更新时间:2024-05-07 -
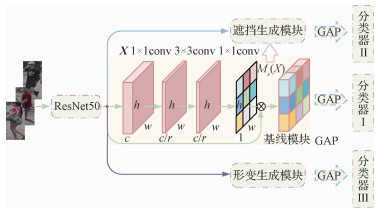 摘要:ObjectivePerson re-identification (re-ID) identifies a target person from a collection of images and shows great value in person retrieval and tracking from a collection of images captured by network cameras. Due to its important applications in public security and surveillance, person re-ID has attracted the attention of academic and industrial practitioner sat home and abroad. Although most existing re-ID methods have achieved significant progress, person re-ID continues to face two challenges resulting from the change of view in different surveillance cameras. First, pedestrians have a wide range of pose variations. Second, some people in public spaces are often occluded by various obstructions, such as bicycles or other people. These problems result in significant appearance changes and may introduce some distracting information. As a result, the same pedestrian captured by different cameras may look drastically different from each other and may prevent re-ID. One simple, effective method for addressing this problem is to obtain additional pedestrian samples. Using abundant practical scene images can help generate more post-variant and occluded samples, thereby helping re-ID systems achieve excellent robustness in complex situations. Some researchers have considered the representations of both the image and the key point-based pose as inputs to generate target poses and views via the generative adversarial networks (GAN) approach. However, GAN usually suffers from a convergence problem, and the generated target images usually have poor texture. In random erasing, a rectangle region is randomly selected from an image or feature map, and the original pixel value is discarded afterward to generate occluded examples. However, this approach only creates hard examples by spatially blocking the original image and (similar to the methods mentioned above) is very time consuming. To address these problems, we propose a person re-ID algorithm that generates hard deformation and occlusion samples.MethodWe use a deformable convolution module to simulate variations in pedestrian posture. The 2D offsets of regular grid sampling locations on the last feature map of the ResNet50 network are calculated by other branches that contain a multiple convolutional layer structure. These 2D offsets include the horizontal and vertical values X and Y. Afterward, these offsets are reapplied to the feature maps to produce new feature maps and deformable features via resampling. In this way, the network can change the posture of pedestrians in both horizontal and vertical directions and subsequently generate deformable features, thereby improving the ability of the network in dealing with deformed images. To address the occlusion problem, we generate spatial attention maps by using the spatial attention mechanism. We also apply other convolutional operations on the last feature map of the ResNet50 backbone to produce a spatial attention map that highlights the important spatial locations. Afterward, we mask out the most discriminative regions in the spatial attention map and retain only the low responses by using a fixed threshold value. The processed spatial attention map is then multiplied by the original features to produce the occluded features. In this way, we simulate the occluded pedestrian samples and further improve the ability of the network to adapt to other occluded samples. In the testing, we cascade two features with the original features as our final descriptors. We implement and train our network by using Pytorch and an NVIDIA TITAN GPU device, respectively. We set the batch size to 32 and rescaled all images to a fixed size of 256×128 pixels during the training and testing procedures. We also adopt a stochastic gradient descent (SGD) with a momentum of 0.9 and weight decay coefficient of 0.000 5 to update our network parameters. The initial learning rate is set to 0.04, which is further divided by 10 after 40 epochs (the training process has 60 epochs). We fix the reduction ratio and erasing threshold to 16 and 0.7 in all datasets, respectively. We adopt random flip as our data augmentation technique, and we use ResNet50 as our backbone model that contains parameters that are pre-trained on the ImageNet dataset. This model is also trained end-to-end. We adopt cumulative match characteristic (CMC) and mean average precision (mAP) to compare the re-ID performance of the proposed method with that of existing methods.ResultThe performance of our proposed method is evaluated on public large-scale datasets Market-1501, DukeMTMC-reID, and CUHK03. We use a uniform random seed to ensure the repeatability of the equity comparison and the results. In the Market-1501, DukeMTMC-reID, and CUHK03 (detected and labeled) datasets, the proposed method has obtained Rank-1 (represents the proportion of the queried people) values of 89.52%, 81.96%, 48.79%, and 50.29%, respectively, while its mAP values in these datasets reach 73.98%, 64.45%, 43.77%, and 45.57%, respectively. In the detected and labeled CUHK03 datasets, the proposed method shows 9.43%/8.74% and 8.72%/8.0% improvements in its Rank-1 and mAP values, respectively. These experimental results validate the competitive performance of this method for small and large datasets.ConclusionThe proposed person re-ID system based on the deformation and occlusion mechanisms can construct a highly recognizable model for extracting robust pedestrian features. This system maintains high recognition accuracy in complex application scenarios where occlusion and wide variations in pedestrian posture are observed. The proposed method can also effectively mitigate model overfitting in small-scale datasets (e.g., CUHK03 dataset), thereby improving its recognition rate.关键词:person re-identification;deformation;occlusion;spatial attention mechanism;robustness117|121|7更新时间:2024-05-07
摘要:ObjectivePerson re-identification (re-ID) identifies a target person from a collection of images and shows great value in person retrieval and tracking from a collection of images captured by network cameras. Due to its important applications in public security and surveillance, person re-ID has attracted the attention of academic and industrial practitioner sat home and abroad. Although most existing re-ID methods have achieved significant progress, person re-ID continues to face two challenges resulting from the change of view in different surveillance cameras. First, pedestrians have a wide range of pose variations. Second, some people in public spaces are often occluded by various obstructions, such as bicycles or other people. These problems result in significant appearance changes and may introduce some distracting information. As a result, the same pedestrian captured by different cameras may look drastically different from each other and may prevent re-ID. One simple, effective method for addressing this problem is to obtain additional pedestrian samples. Using abundant practical scene images can help generate more post-variant and occluded samples, thereby helping re-ID systems achieve excellent robustness in complex situations. Some researchers have considered the representations of both the image and the key point-based pose as inputs to generate target poses and views via the generative adversarial networks (GAN) approach. However, GAN usually suffers from a convergence problem, and the generated target images usually have poor texture. In random erasing, a rectangle region is randomly selected from an image or feature map, and the original pixel value is discarded afterward to generate occluded examples. However, this approach only creates hard examples by spatially blocking the original image and (similar to the methods mentioned above) is very time consuming. To address these problems, we propose a person re-ID algorithm that generates hard deformation and occlusion samples.MethodWe use a deformable convolution module to simulate variations in pedestrian posture. The 2D offsets of regular grid sampling locations on the last feature map of the ResNet50 network are calculated by other branches that contain a multiple convolutional layer structure. These 2D offsets include the horizontal and vertical values X and Y. Afterward, these offsets are reapplied to the feature maps to produce new feature maps and deformable features via resampling. In this way, the network can change the posture of pedestrians in both horizontal and vertical directions and subsequently generate deformable features, thereby improving the ability of the network in dealing with deformed images. To address the occlusion problem, we generate spatial attention maps by using the spatial attention mechanism. We also apply other convolutional operations on the last feature map of the ResNet50 backbone to produce a spatial attention map that highlights the important spatial locations. Afterward, we mask out the most discriminative regions in the spatial attention map and retain only the low responses by using a fixed threshold value. The processed spatial attention map is then multiplied by the original features to produce the occluded features. In this way, we simulate the occluded pedestrian samples and further improve the ability of the network to adapt to other occluded samples. In the testing, we cascade two features with the original features as our final descriptors. We implement and train our network by using Pytorch and an NVIDIA TITAN GPU device, respectively. We set the batch size to 32 and rescaled all images to a fixed size of 256×128 pixels during the training and testing procedures. We also adopt a stochastic gradient descent (SGD) with a momentum of 0.9 and weight decay coefficient of 0.000 5 to update our network parameters. The initial learning rate is set to 0.04, which is further divided by 10 after 40 epochs (the training process has 60 epochs). We fix the reduction ratio and erasing threshold to 16 and 0.7 in all datasets, respectively. We adopt random flip as our data augmentation technique, and we use ResNet50 as our backbone model that contains parameters that are pre-trained on the ImageNet dataset. This model is also trained end-to-end. We adopt cumulative match characteristic (CMC) and mean average precision (mAP) to compare the re-ID performance of the proposed method with that of existing methods.ResultThe performance of our proposed method is evaluated on public large-scale datasets Market-1501, DukeMTMC-reID, and CUHK03. We use a uniform random seed to ensure the repeatability of the equity comparison and the results. In the Market-1501, DukeMTMC-reID, and CUHK03 (detected and labeled) datasets, the proposed method has obtained Rank-1 (represents the proportion of the queried people) values of 89.52%, 81.96%, 48.79%, and 50.29%, respectively, while its mAP values in these datasets reach 73.98%, 64.45%, 43.77%, and 45.57%, respectively. In the detected and labeled CUHK03 datasets, the proposed method shows 9.43%/8.74% and 8.72%/8.0% improvements in its Rank-1 and mAP values, respectively. These experimental results validate the competitive performance of this method for small and large datasets.ConclusionThe proposed person re-ID system based on the deformation and occlusion mechanisms can construct a highly recognizable model for extracting robust pedestrian features. This system maintains high recognition accuracy in complex application scenarios where occlusion and wide variations in pedestrian posture are observed. The proposed method can also effectively mitigate model overfitting in small-scale datasets (e.g., CUHK03 dataset), thereby improving its recognition rate.关键词:person re-identification;deformation;occlusion;spatial attention mechanism;robustness117|121|7更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveWith the rapid development of internet technology and the increasing popularity of video shooting equipment (e.g., digital cameras and smart phones), online video services have shown an explosive growth. Short videos have become indispensable sources of information for people in their daily production and life. Therefore, identifying how these people understand these videos is critical. Videos contain rich amounts of hidden information as these media can store more information compared with traditional ones, such as images and texts. Videos also show complexity in their space-time structure, content, temporal relevance, and event integrity. Given such complexities, behavior recognition research is presently facing challenges in extracting the time domain representation and features of videos. To address these difficulties, this study proposes a behavior recognition model based on multi-feature fusion.MethodThe proposed model is mainly composed of three parts, namely, the time domain fusion, two-way feature extraction, and feature modeling modules. The two- and three-frame fusion algorithms are initially adopted to compress the original data by extracting high- and low-frequency information from videos. This approach not only retains most information contained in these videos but also enhances the original dataset to facilitate the expression of original behavior information. Second, based on the design of a two-way feature extraction network, detailed features are extracted from videos through the positive input of the fused data to the network, whereas overall features are extracted through the reserve input of these data. A weighted fusion of these features is then achieved by using the common video descriptor, 3D ConvNets (3D convolutional neural networks) structure. Afterward, BiConvLSTM (bidirectional convolutional long short-term memory network) is used to further extract the local information of the fused features and to establish a model on the time axis to address the relatively long behavior intervals in some video sequences. Softmax is then applied to maximize the likelihood function and to classify the behavioral actions.ResultTo verify its effectiveness, the proposed algorithm was tested and analyzed on public datasets UCF101 and HMDB51. Results of a five-fold cross-validation show that this algorithm has average accuracies of 96.47% and 80.03%for these datasets, respectively. Comparative statistics for each type of behavior show that the classification accuracy of the proposed algorithm is approximately equal in almost all categories.ConclusionCompared with the available mainstream behavior recognition models, the proposed multi-feature model achieves higher recognition accuracy and is more universal, compact, simple, and efficient. The accuracy of this model is mainly improved via two- and three-frame fusions in the time domain to facilitate video information analysis and behavior information expression. The network is extracted by a two-way feature to efficiently determine the spatio-temporal features of videos. The BiConvLSTM network is then applied to further extract the features and establish a timing relationship.关键词:behavior recognition;two-way feature extraction network;3D convolutional neural networks (3D ConvNets);bidirectional convolutional long short-term memory network (BiConvLSTM);weighted fusion;high-frequency feature;low-frequency feature55|50|5更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of internet technology and the increasing popularity of video shooting equipment (e.g., digital cameras and smart phones), online video services have shown an explosive growth. Short videos have become indispensable sources of information for people in their daily production and life. Therefore, identifying how these people understand these videos is critical. Videos contain rich amounts of hidden information as these media can store more information compared with traditional ones, such as images and texts. Videos also show complexity in their space-time structure, content, temporal relevance, and event integrity. Given such complexities, behavior recognition research is presently facing challenges in extracting the time domain representation and features of videos. To address these difficulties, this study proposes a behavior recognition model based on multi-feature fusion.MethodThe proposed model is mainly composed of three parts, namely, the time domain fusion, two-way feature extraction, and feature modeling modules. The two- and three-frame fusion algorithms are initially adopted to compress the original data by extracting high- and low-frequency information from videos. This approach not only retains most information contained in these videos but also enhances the original dataset to facilitate the expression of original behavior information. Second, based on the design of a two-way feature extraction network, detailed features are extracted from videos through the positive input of the fused data to the network, whereas overall features are extracted through the reserve input of these data. A weighted fusion of these features is then achieved by using the common video descriptor, 3D ConvNets (3D convolutional neural networks) structure. Afterward, BiConvLSTM (bidirectional convolutional long short-term memory network) is used to further extract the local information of the fused features and to establish a model on the time axis to address the relatively long behavior intervals in some video sequences. Softmax is then applied to maximize the likelihood function and to classify the behavioral actions.ResultTo verify its effectiveness, the proposed algorithm was tested and analyzed on public datasets UCF101 and HMDB51. Results of a five-fold cross-validation show that this algorithm has average accuracies of 96.47% and 80.03%for these datasets, respectively. Comparative statistics for each type of behavior show that the classification accuracy of the proposed algorithm is approximately equal in almost all categories.ConclusionCompared with the available mainstream behavior recognition models, the proposed multi-feature model achieves higher recognition accuracy and is more universal, compact, simple, and efficient. The accuracy of this model is mainly improved via two- and three-frame fusions in the time domain to facilitate video information analysis and behavior information expression. The network is extracted by a two-way feature to efficiently determine the spatio-temporal features of videos. The BiConvLSTM network is then applied to further extract the features and establish a timing relationship.关键词:behavior recognition;two-way feature extraction network;3D convolutional neural networks (3D ConvNets);bidirectional convolutional long short-term memory network (BiConvLSTM);weighted fusion;high-frequency feature;low-frequency feature55|50|5更新时间:2024-05-07 -
 摘要:ObjectiveAlong with the wide usage of various digital image processing hardware and software and the continuous advancements in the field of computer vision, biometric recognition has been introduced to solve identification problems in people's daily lives and has been applied in the fields of finance, education, healthcare, and social security, among others. Compared with iris, palm print, and other biometric recognition technologies, face recognition has received the most attention due to its special characteristics (e.g., on-contact, imperceptible, and easy to promote). Given the wide usage of mobile Internet, cloud face recognition can achieve high recognition accuracy requires a large amount of face data to be uploaded to a third-party server. On the one hand, face images may reflect one's private information, such as gender, age, and health status. On the other hand, given that each person has unique facial features, hacking into face image databases may expose people to threats, including template and fake attacks. Therefore, how to boost the privacy and security of face images has become a core issue in the field of biometric recognition. Among the available biometric template protection methods, the transform-based method can simultaneously satisfy multiple criteria of biometric template protection and is presently considered the most typical cancelable biometric algorithm. The protected biometric template is obtained via anon-invertible transformation of the original biometric that is saved in a database. When this biometric template is attacked or threatened, a new feature template can be reissued to replace the previous template by modifying the external factors. To guarantee the security of the face recognition system and improve its recognition rate, this paper investigates a cancelable face recognition algorithm that integrates the structural features of the human face.MethodFirst, structural features are extracted from the original face image by using its gradient, local binary pattern, and local variance. By taking the original face images as real components and the extracted structural features as imaginary components, a complex matrix is built to represent the face image. To render the original face images and contour of their structural features invisible, the complex matrix is permuted by multiplying it by a random binary matrix. Afterward, complex 2D principal component analysis (C2DPCA) is performed to project a random permuted complex matrix into a new feature space. The 2DPCA result for the scrambled complex face matrix is theoretically deduced and verified to be the result of original complex face matrix 2DPCA multiplied by a random binary matrix. The resulting value does not change after scrambling given that only the row of the original 2DPCA is scrambled in the process. The nearest neighbor classifier based on Manhattan distance is then employed to calculate the recognition rate, that is, the distance between the tested face images and all training samples, and the training sample category that corresponds to the minimum distance is taken as the category.ResultThe experimental results obtained for the four face databases reveal that after scrambling the original face and structural feature images by using a random binary matrix, the human eye cannot detect useful information, and the scrambled results can be regenerated. Therefore, scrambling the random binary matrix can ensure the security of the proposed algorithm. Compared with three other algorithms, the fusion of a structural feature can effectively improve the recognition rate. Among the three structural features considered in this work, the variance feature obtains the highest recognition rate, which has increased by 4.9% on the Georgia Tech(GT) database, 2.25% on the Near Infrared(NIR) database, 2.25% on the Visible Light(VIS) database, and 1.98% on the YouTube MakeupYMU database. The employed random binary matrix does not affect the recognition rate, that is, the recognition rates of each database are the same before and after random scrambling. Given that the introduced random matrix is binary, the values do not change after random scrambling. The average testing time for the four face databases is within 1 millisecond.ConclusionA combination of the original face image with the structural features of the human face enriches the representation ability of face image information and helps improve facial recognition rate. A random permutation operation can also protect the privacy of the original face image. When the biometric template is leaked, resetting position 1 in the random binary matrix will re-scramble the complex face matrix and generate a new biometric template. The proposed algorithm also shows an excellent real-time performance and can meet the demands of practical application scenarios.关键词:cancelable face recognition;random binary matrix;two-dimensional principal component analysis(2DPCA);face structural feature;complex matrix18|19|1更新时间:2024-05-07
摘要:ObjectiveAlong with the wide usage of various digital image processing hardware and software and the continuous advancements in the field of computer vision, biometric recognition has been introduced to solve identification problems in people's daily lives and has been applied in the fields of finance, education, healthcare, and social security, among others. Compared with iris, palm print, and other biometric recognition technologies, face recognition has received the most attention due to its special characteristics (e.g., on-contact, imperceptible, and easy to promote). Given the wide usage of mobile Internet, cloud face recognition can achieve high recognition accuracy requires a large amount of face data to be uploaded to a third-party server. On the one hand, face images may reflect one's private information, such as gender, age, and health status. On the other hand, given that each person has unique facial features, hacking into face image databases may expose people to threats, including template and fake attacks. Therefore, how to boost the privacy and security of face images has become a core issue in the field of biometric recognition. Among the available biometric template protection methods, the transform-based method can simultaneously satisfy multiple criteria of biometric template protection and is presently considered the most typical cancelable biometric algorithm. The protected biometric template is obtained via anon-invertible transformation of the original biometric that is saved in a database. When this biometric template is attacked or threatened, a new feature template can be reissued to replace the previous template by modifying the external factors. To guarantee the security of the face recognition system and improve its recognition rate, this paper investigates a cancelable face recognition algorithm that integrates the structural features of the human face.MethodFirst, structural features are extracted from the original face image by using its gradient, local binary pattern, and local variance. By taking the original face images as real components and the extracted structural features as imaginary components, a complex matrix is built to represent the face image. To render the original face images and contour of their structural features invisible, the complex matrix is permuted by multiplying it by a random binary matrix. Afterward, complex 2D principal component analysis (C2DPCA) is performed to project a random permuted complex matrix into a new feature space. The 2DPCA result for the scrambled complex face matrix is theoretically deduced and verified to be the result of original complex face matrix 2DPCA multiplied by a random binary matrix. The resulting value does not change after scrambling given that only the row of the original 2DPCA is scrambled in the process. The nearest neighbor classifier based on Manhattan distance is then employed to calculate the recognition rate, that is, the distance between the tested face images and all training samples, and the training sample category that corresponds to the minimum distance is taken as the category.ResultThe experimental results obtained for the four face databases reveal that after scrambling the original face and structural feature images by using a random binary matrix, the human eye cannot detect useful information, and the scrambled results can be regenerated. Therefore, scrambling the random binary matrix can ensure the security of the proposed algorithm. Compared with three other algorithms, the fusion of a structural feature can effectively improve the recognition rate. Among the three structural features considered in this work, the variance feature obtains the highest recognition rate, which has increased by 4.9% on the Georgia Tech(GT) database, 2.25% on the Near Infrared(NIR) database, 2.25% on the Visible Light(VIS) database, and 1.98% on the YouTube MakeupYMU database. The employed random binary matrix does not affect the recognition rate, that is, the recognition rates of each database are the same before and after random scrambling. Given that the introduced random matrix is binary, the values do not change after random scrambling. The average testing time for the four face databases is within 1 millisecond.ConclusionA combination of the original face image with the structural features of the human face enriches the representation ability of face image information and helps improve facial recognition rate. A random permutation operation can also protect the privacy of the original face image. When the biometric template is leaked, resetting position 1 in the random binary matrix will re-scramble the complex face matrix and generate a new biometric template. The proposed algorithm also shows an excellent real-time performance and can meet the demands of practical application scenarios.关键词:cancelable face recognition;random binary matrix;two-dimensional principal component analysis(2DPCA);face structural feature;complex matrix18|19|1更新时间:2024-05-07 -
 摘要:ObjectiveImage co-segmentation refers to segmenting common objects from image groups that contain the same or similar objects (foregrounds). Deep neural networks are widely used in this task given their excellent segmentation results. The end-to-end Siamese network is one of the most effective networks for image co-segmentation. However, this network has huge computational costs, which greatly limit its applications. Therefore, network compression is required. Although various network compression methods have been presented in the literature, they are mainly designed for single-branch networks and do not consider the characteristics of a Siamese network. To this end, we propose a novel network compression method specifically for Siamese networks.MethodThe proposed method transfers the important knowledge of a large network to a compressed small network. This method involves three steps. First, we acquire the important knowledge of the large network. To fulfill such task, we develop a binary attention mechanism that is applied to each stage of the encode module of the Siamese network. This mechanism maintains the features of common objects and eliminates the features of non-common objects in two images. As a result, the response of each stage of the Siamese network is represented as a matrix with sparse channels. We map this sparse response matrix to a dense matrix with smaller channel dimensions through a 1×1 kernel size convolution layer. This dense matrix represents the important knowledge of the large network. Second, we build a small network structure. As described in the first step, the number of channels used to represent the knowledge in each stage of a large network can be reduced. Accordingly, the number of channels in each convolution and normalization layers included in each stage can also be reduced. Therefore, we reconstruct each stage of the large network according to the channel dimensions of the dense matrix obtained in the first step to determine the final small network structure. Third, we transfer the knowledge from the large network to the compressed small network. We propose a two-step knowledge distillation method to implement this step. First, the output of each stage/deconvolutional layer of the large network is used as the supervision information. We calculate the Euclidean distance between the middle-layer outputs of the large and small networks as our loss function to guide the training of the small network. This loss function is designed to make sure that the middle-layer outputs of the small and large networks are as similar as possible at the end of the first training stage. Second, we compute the dice loss between the network output and the real label to guide the final refining of the small network and to further improve the segmentation accuracy.ResultWe perform two groups of experiments on three datasets, namely MLMR-COS, Internet, and iCoseg. MLMR-COS has a large scale of images with pixel-wise ground truth. An ablation study is performed on this dataset to verify the rationality of the proposed method. Meanwhile, although Internet and iCoseg are commonly used datasets for co-segmentation, they are too small to be used as training sets for methods based on deep learning. Therefore, we train our network on a training set generated by Pascal VOC 2012 and MSRC before testing it on the Internet and iCoseg to verify its effectiveness. Experimental results show that the proposed method can reduce the size of the original Siamese network by 3.3 times thereby significantly reducing the required amount of computation. Moreover, compared with the existing co-segmentation methods based on deep learning, the proposed method can significantly reduce the amount of computation required in a compressed network. The segmentation accuracy of this compressed network on three datasets is close to the stat of the art. On the MLMR-COS dataset, this compressed small network obtains an average Jaccard index that is 0.07% higher than that of the original large network. Meanwhile, on the Internet and iCoseg datasets, we compare the compressed network with 12 traditional supervised/unsupervised image co-segmentation methods and 3 co-segmentation methods based on deep learning. On the Internet dataset, the compressed network has a Jaccard index that is 5% than the those of traditional image segmentation methods and existing co-segmentation methods based on deep learning. On the iCoseg dataset with relatively complex images, the segmentation accuracy of the compressed small network is slightly lower than those of the other methods.ConclusionWe propose a network compression method by combining binary attention mechanism and knowledge distillation and apply it to a Siamese network for image co-segmentation. This network significantly reduces the amount of calculation and parameters in Siamese networks and is similar to the state-of-the-art methods in terms of co-segmentation performance.关键词:siamese network;network compression;knowledge distillation;attention mechanism;image co-segmentation47|29|2更新时间:2024-05-07
摘要:ObjectiveImage co-segmentation refers to segmenting common objects from image groups that contain the same or similar objects (foregrounds). Deep neural networks are widely used in this task given their excellent segmentation results. The end-to-end Siamese network is one of the most effective networks for image co-segmentation. However, this network has huge computational costs, which greatly limit its applications. Therefore, network compression is required. Although various network compression methods have been presented in the literature, they are mainly designed for single-branch networks and do not consider the characteristics of a Siamese network. To this end, we propose a novel network compression method specifically for Siamese networks.MethodThe proposed method transfers the important knowledge of a large network to a compressed small network. This method involves three steps. First, we acquire the important knowledge of the large network. To fulfill such task, we develop a binary attention mechanism that is applied to each stage of the encode module of the Siamese network. This mechanism maintains the features of common objects and eliminates the features of non-common objects in two images. As a result, the response of each stage of the Siamese network is represented as a matrix with sparse channels. We map this sparse response matrix to a dense matrix with smaller channel dimensions through a 1×1 kernel size convolution layer. This dense matrix represents the important knowledge of the large network. Second, we build a small network structure. As described in the first step, the number of channels used to represent the knowledge in each stage of a large network can be reduced. Accordingly, the number of channels in each convolution and normalization layers included in each stage can also be reduced. Therefore, we reconstruct each stage of the large network according to the channel dimensions of the dense matrix obtained in the first step to determine the final small network structure. Third, we transfer the knowledge from the large network to the compressed small network. We propose a two-step knowledge distillation method to implement this step. First, the output of each stage/deconvolutional layer of the large network is used as the supervision information. We calculate the Euclidean distance between the middle-layer outputs of the large and small networks as our loss function to guide the training of the small network. This loss function is designed to make sure that the middle-layer outputs of the small and large networks are as similar as possible at the end of the first training stage. Second, we compute the dice loss between the network output and the real label to guide the final refining of the small network and to further improve the segmentation accuracy.ResultWe perform two groups of experiments on three datasets, namely MLMR-COS, Internet, and iCoseg. MLMR-COS has a large scale of images with pixel-wise ground truth. An ablation study is performed on this dataset to verify the rationality of the proposed method. Meanwhile, although Internet and iCoseg are commonly used datasets for co-segmentation, they are too small to be used as training sets for methods based on deep learning. Therefore, we train our network on a training set generated by Pascal VOC 2012 and MSRC before testing it on the Internet and iCoseg to verify its effectiveness. Experimental results show that the proposed method can reduce the size of the original Siamese network by 3.3 times thereby significantly reducing the required amount of computation. Moreover, compared with the existing co-segmentation methods based on deep learning, the proposed method can significantly reduce the amount of computation required in a compressed network. The segmentation accuracy of this compressed network on three datasets is close to the stat of the art. On the MLMR-COS dataset, this compressed small network obtains an average Jaccard index that is 0.07% higher than that of the original large network. Meanwhile, on the Internet and iCoseg datasets, we compare the compressed network with 12 traditional supervised/unsupervised image co-segmentation methods and 3 co-segmentation methods based on deep learning. On the Internet dataset, the compressed network has a Jaccard index that is 5% than the those of traditional image segmentation methods and existing co-segmentation methods based on deep learning. On the iCoseg dataset with relatively complex images, the segmentation accuracy of the compressed small network is slightly lower than those of the other methods.ConclusionWe propose a network compression method by combining binary attention mechanism and knowledge distillation and apply it to a Siamese network for image co-segmentation. This network significantly reduces the amount of calculation and parameters in Siamese networks and is similar to the state-of-the-art methods in terms of co-segmentation performance.关键词:siamese network;network compression;knowledge distillation;attention mechanism;image co-segmentation47|29|2更新时间:2024-05-07 -
 摘要:ObjectiveSaliency detection, which has extensive applications in computer vision, aims to locate pixels or regions in a scene that attract the visual attention of humans the most. An accurate and reliable salient region detection can benefit numerous vision and graphics tasks, such as scene analysis, object tracking, and target recognition. Traditional 2D images focus on low features, including color, texture, and focus cues, to detect salient objects from the background. Although state-of-the-art 2D saliency detection methods have shown promising results, they may encounter failure in complex scenes where the foreground and background have a similar appearance or where the background is cluttered.3D images provide in-depth information that benefits saliency detection to some extent. However, most of 3D saliency detection results greatly depend on the quality of depth maps; in this way, an inaccurate depth map can greatly affect the final saliency detection result. Moreover, 3D saliency detection methods may produce inaccurate detection when the salient object cannot be distinguished at the depth level. The human visual system can distinguish regions at different depth levels by adjusting the focus of eyes. Similarly, light field has a focusing capability where a stack of images that emphasize different depth levels can be stacked. The focus cue supplied by a focal stack helps determine the background and foreground slice candidates or those conditions with certain complexities (i.e., the foreground and background having similar color/textures). Therefore, focus can improve the precision of saliency detection in challenging scenarios. The extant light field saliency detection methods verify the effectiveness of integrating light field cues, including focus, location, and color contrast cues. From the above discussion, an important aim of saliency detection for a light field is to explore the interactions and complementarities among light field cues.MethodThis paper builds a foreground/background probability model that can highlight salient objects and suppress the background by using location and focus cues. A propagation mechanism is also proposed to enhance the spatial consistency of the saliency results and to refine the saliency map. The focal stack and the all-focus image are taken as light field input images that are segmented into a set of non-overlapping super-pixels via simple linear iterative clustering (SLIC). First, we detect the in-focus regions of each image in the focal stack by applying the harmonic variance measure in the frequency domain to define our focus measure. Second, to determine the foreground image set and background image, we scale the focus of the focal stack by using a Gaussian filter. Saliency detection follows a common assumption that salient objects are more likely to lie at the central area and are often photographed in focus. Therefore, we analyze the distribution of in-focus objects with respect to their prior location by using a 1D band-pass Gaussian filter and then compute the foreground likelihood score of each focal slice. We choose the slice with the lowest foreground likelihood score as our background slice and the slice whose likelihood score is 0.9 times higher than the highest reported foreground likelihood score as our foreground slice. Afterward, we construct a foreground/background probability function by combing the focus of the background slice with the spatial location. We then compute the foreground cue from the foreground slice candidates and the color cue on the all-focus image. To enhance contrast, we use the foreground/background probability function to guide the foreground and color cues, which we use in turn to obtain the foreground and color saliency maps, respectively. From these maps, we find that the low saliency value of a salient object can be improved and that the high saliency value of the background area in complex scenarios (e.g., where the foreground and background are the same) can be restrained. We combine the foreground and color saliency maps by using a Bayesian fusion strategy to generate a new saliency map. We then apply a K-NN enhanced graph-based saliency propagation method that considers the neighboring relationships in both spatial and feature spaces to further optimize this saliency map. Optimizing the spatial consistency of adjacent super-pixels can uniformly highlight the saliency of objects. We eventually obtain a high-level saliency map.ResultWe compare the performance of our model with that of five state-of-the-art saliency models, including traditional approaches and deep learning methods, on a leading light field saliency dataset(LFSD). Our proposed model effectively suppresses the background and evenly highlights the entire saliency object, thereby obtaining sharp edges for the saliency map. We also evaluate the similarity between the predicted saliency maps and the ground truth by using three quantitative evaluation metrics, namely, canonical precision-recall curve (PRC), F-measure, and mean absolute error (MAE). Experiment results show that our proposed method outperforms all the other methods in terms of accuracy (85.16%). F-measure (72.79%), and MAE (13.49%).ConclusionWe propose a light field saliency detection model that combs the focus and propagation mechanisms. Experiment results prove that our saliency detection scheme can efficiently work in challenging scenarios, such as scenes with similar foregrounds and backgrounds or complex background textures, and out performs the state-of-the-art traditional approaches in terms of precision rates in PRC and false positive rates in MAE.关键词:saliency detection;light field image;focus;probability function of foreground/background;propagation mechanism;spatial consistency26|24|5更新时间:2024-05-07
摘要:ObjectiveSaliency detection, which has extensive applications in computer vision, aims to locate pixels or regions in a scene that attract the visual attention of humans the most. An accurate and reliable salient region detection can benefit numerous vision and graphics tasks, such as scene analysis, object tracking, and target recognition. Traditional 2D images focus on low features, including color, texture, and focus cues, to detect salient objects from the background. Although state-of-the-art 2D saliency detection methods have shown promising results, they may encounter failure in complex scenes where the foreground and background have a similar appearance or where the background is cluttered.3D images provide in-depth information that benefits saliency detection to some extent. However, most of 3D saliency detection results greatly depend on the quality of depth maps; in this way, an inaccurate depth map can greatly affect the final saliency detection result. Moreover, 3D saliency detection methods may produce inaccurate detection when the salient object cannot be distinguished at the depth level. The human visual system can distinguish regions at different depth levels by adjusting the focus of eyes. Similarly, light field has a focusing capability where a stack of images that emphasize different depth levels can be stacked. The focus cue supplied by a focal stack helps determine the background and foreground slice candidates or those conditions with certain complexities (i.e., the foreground and background having similar color/textures). Therefore, focus can improve the precision of saliency detection in challenging scenarios. The extant light field saliency detection methods verify the effectiveness of integrating light field cues, including focus, location, and color contrast cues. From the above discussion, an important aim of saliency detection for a light field is to explore the interactions and complementarities among light field cues.MethodThis paper builds a foreground/background probability model that can highlight salient objects and suppress the background by using location and focus cues. A propagation mechanism is also proposed to enhance the spatial consistency of the saliency results and to refine the saliency map. The focal stack and the all-focus image are taken as light field input images that are segmented into a set of non-overlapping super-pixels via simple linear iterative clustering (SLIC). First, we detect the in-focus regions of each image in the focal stack by applying the harmonic variance measure in the frequency domain to define our focus measure. Second, to determine the foreground image set and background image, we scale the focus of the focal stack by using a Gaussian filter. Saliency detection follows a common assumption that salient objects are more likely to lie at the central area and are often photographed in focus. Therefore, we analyze the distribution of in-focus objects with respect to their prior location by using a 1D band-pass Gaussian filter and then compute the foreground likelihood score of each focal slice. We choose the slice with the lowest foreground likelihood score as our background slice and the slice whose likelihood score is 0.9 times higher than the highest reported foreground likelihood score as our foreground slice. Afterward, we construct a foreground/background probability function by combing the focus of the background slice with the spatial location. We then compute the foreground cue from the foreground slice candidates and the color cue on the all-focus image. To enhance contrast, we use the foreground/background probability function to guide the foreground and color cues, which we use in turn to obtain the foreground and color saliency maps, respectively. From these maps, we find that the low saliency value of a salient object can be improved and that the high saliency value of the background area in complex scenarios (e.g., where the foreground and background are the same) can be restrained. We combine the foreground and color saliency maps by using a Bayesian fusion strategy to generate a new saliency map. We then apply a K-NN enhanced graph-based saliency propagation method that considers the neighboring relationships in both spatial and feature spaces to further optimize this saliency map. Optimizing the spatial consistency of adjacent super-pixels can uniformly highlight the saliency of objects. We eventually obtain a high-level saliency map.ResultWe compare the performance of our model with that of five state-of-the-art saliency models, including traditional approaches and deep learning methods, on a leading light field saliency dataset(LFSD). Our proposed model effectively suppresses the background and evenly highlights the entire saliency object, thereby obtaining sharp edges for the saliency map. We also evaluate the similarity between the predicted saliency maps and the ground truth by using three quantitative evaluation metrics, namely, canonical precision-recall curve (PRC), F-measure, and mean absolute error (MAE). Experiment results show that our proposed method outperforms all the other methods in terms of accuracy (85.16%). F-measure (72.79%), and MAE (13.49%).ConclusionWe propose a light field saliency detection model that combs the focus and propagation mechanisms. Experiment results prove that our saliency detection scheme can efficiently work in challenging scenarios, such as scenes with similar foregrounds and backgrounds or complex background textures, and out performs the state-of-the-art traditional approaches in terms of precision rates in PRC and false positive rates in MAE.关键词:saliency detection;light field image;focus;probability function of foreground/background;propagation mechanism;spatial consistency26|24|5更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveUnderstanding the shape and structure of objects is extremely important in object recognition. The most commonly utilized pattern recognition method is machine learning, which often requires a large number of training data. However, this object-oriented learning method lacks a priori knowledge, uses a large amount of training data and complex computations, and is unable to extract explicit knowledge after learning (i.e., "knowing how without knowing why"). Great uncertainties are encountered in object recognition tasks due to changes in size, color, illumination, position, and environmental background. To deal with such uncertainties, a large number of samples should be trained and powerful machine learning algorithms should be used to generate a classifier. Despite achieving a favorable recognition accuracy in some standard datasets, these models lack explainability, and recent studies have shown that these purely data-driven models are vulnerable. These models also often ignore knowledge representation and even consider this aspect redundant. However, cognitive and experimental psychology research suggests that humans do not adopt such mechanism. Similar symbolic artificial intelligence methods, such as representation, induction, reasoning, interpretation, and constraint propagation have also been used to deal with the uncertainties in object recognition. In vision tasks, improving explainability is considered more important than improving accuracy. Such is the goal of interpretable artificial intelligence. Accordingly, this paper aims to provide an interpretable way of thinking from the traditional symbolic computing idea and adopts the skeleton topology representation.MethodPsychological research reveals that humans show strong topological and geometric preferences when engaged in visual tasks. To explicitly characterize geometric and topological features, the proposed method adopts skeleton descriptors with excellent topological geometric characteristics. First, an object was decomposed into several connected components based on a skeleton graph, and each component was represented by a skeleton branch. Second, the statistical parameter of these skeleton branches were obtained, including their area ratio, path length, and skeletal mass ratio distribution. Third, the skeleton radius path was used to describe the contour of the object. Fourth, to form a robust spatial topology constraint, the spine-like axis (SPA) was used to describe the spatial distribution of shape components. Finally, a skeleton tree was used to represent the topological structure (RTS) of objects. A similarity measure based on RTS was also proposed, and the optimal subsequence bijection (OSB) was used for the elastic matching of object shapes. A multi-level generalization framework was then built to extract knowledge from a small number of similar representations and to subsequently form a generalized explicit representation (GRTS) of the object categories. The uncertainty reasoning and explainability were verified based on certainty factor theory.ResultThe proposed model illustrates the process of generating GRTS on the Kimia99 and Tari56 datasets and presents the physical meanings of most general representations obtained from homogeneous objects. The skeletal path of an object of the same category was used for reconstruction to clearly describe the object meaning of each part of GRTS. In the explainability verification experiment, the GRTS of several categories obtained from the Tari56 dataset was used to apply the topological character to a sample of Kimia99's closest category to discover the specific differences of the new test sample relative to the GRTS. Results show that the representation has good explainability. Meanwhile, in the shape complementing experiments, RTS was initially extracted from incomplete shapes to gather evidence, and the uncertainty reasoning was validated with the rule set (Tari56) that was established according to GRTS. The proposed model only provided are cognition conclusion and showed specific judgment basis, thereby further verifying the explainability of the representation.ConclusionA skeleton tree was used as the basic means for generating a formal representation of the topological and geometric features of an object. Based on the generalization framework, the knowledge extracted from a small number of similar representations was used to form a generalized explicit representation of the knowledge about an object category. The knowledge representation results were then used to conduct uncertainty reasoning experiments. This work presents a new perspective toward explainability and helps build trust-based relationships between models and people. Experiment results show that the generalized formal representation can cope with uncertainties in size, color, and shape. This representation also has strong robustness and universality, can prevent uncertainties arising from texture features, and is suitable for any primitive-based representation. The proposed approach significantly outperforms the mainstream machine learning methods in terms of explainability and computational cost.关键词:vision task;skeleton;uncertainty;topological knowledge representation;explainability41|22|0更新时间:2024-05-07
摘要:ObjectiveUnderstanding the shape and structure of objects is extremely important in object recognition. The most commonly utilized pattern recognition method is machine learning, which often requires a large number of training data. However, this object-oriented learning method lacks a priori knowledge, uses a large amount of training data and complex computations, and is unable to extract explicit knowledge after learning (i.e., "knowing how without knowing why"). Great uncertainties are encountered in object recognition tasks due to changes in size, color, illumination, position, and environmental background. To deal with such uncertainties, a large number of samples should be trained and powerful machine learning algorithms should be used to generate a classifier. Despite achieving a favorable recognition accuracy in some standard datasets, these models lack explainability, and recent studies have shown that these purely data-driven models are vulnerable. These models also often ignore knowledge representation and even consider this aspect redundant. However, cognitive and experimental psychology research suggests that humans do not adopt such mechanism. Similar symbolic artificial intelligence methods, such as representation, induction, reasoning, interpretation, and constraint propagation have also been used to deal with the uncertainties in object recognition. In vision tasks, improving explainability is considered more important than improving accuracy. Such is the goal of interpretable artificial intelligence. Accordingly, this paper aims to provide an interpretable way of thinking from the traditional symbolic computing idea and adopts the skeleton topology representation.MethodPsychological research reveals that humans show strong topological and geometric preferences when engaged in visual tasks. To explicitly characterize geometric and topological features, the proposed method adopts skeleton descriptors with excellent topological geometric characteristics. First, an object was decomposed into several connected components based on a skeleton graph, and each component was represented by a skeleton branch. Second, the statistical parameter of these skeleton branches were obtained, including their area ratio, path length, and skeletal mass ratio distribution. Third, the skeleton radius path was used to describe the contour of the object. Fourth, to form a robust spatial topology constraint, the spine-like axis (SPA) was used to describe the spatial distribution of shape components. Finally, a skeleton tree was used to represent the topological structure (RTS) of objects. A similarity measure based on RTS was also proposed, and the optimal subsequence bijection (OSB) was used for the elastic matching of object shapes. A multi-level generalization framework was then built to extract knowledge from a small number of similar representations and to subsequently form a generalized explicit representation (GRTS) of the object categories. The uncertainty reasoning and explainability were verified based on certainty factor theory.ResultThe proposed model illustrates the process of generating GRTS on the Kimia99 and Tari56 datasets and presents the physical meanings of most general representations obtained from homogeneous objects. The skeletal path of an object of the same category was used for reconstruction to clearly describe the object meaning of each part of GRTS. In the explainability verification experiment, the GRTS of several categories obtained from the Tari56 dataset was used to apply the topological character to a sample of Kimia99's closest category to discover the specific differences of the new test sample relative to the GRTS. Results show that the representation has good explainability. Meanwhile, in the shape complementing experiments, RTS was initially extracted from incomplete shapes to gather evidence, and the uncertainty reasoning was validated with the rule set (Tari56) that was established according to GRTS. The proposed model only provided are cognition conclusion and showed specific judgment basis, thereby further verifying the explainability of the representation.ConclusionA skeleton tree was used as the basic means for generating a formal representation of the topological and geometric features of an object. Based on the generalization framework, the knowledge extracted from a small number of similar representations was used to form a generalized explicit representation of the knowledge about an object category. The knowledge representation results were then used to conduct uncertainty reasoning experiments. This work presents a new perspective toward explainability and helps build trust-based relationships between models and people. Experiment results show that the generalized formal representation can cope with uncertainties in size, color, and shape. This representation also has strong robustness and universality, can prevent uncertainties arising from texture features, and is suitable for any primitive-based representation. The proposed approach significantly outperforms the mainstream machine learning methods in terms of explainability and computational cost.关键词:vision task;skeleton;uncertainty;topological knowledge representation;explainability41|22|0更新时间:2024-05-07 -
 摘要:ObjectiveCalculating 3D shapes correspondence is a central problem in the field of geometry processing that plays an important role in shapes reconstruction, object recognition and classification, and other tasks. Therefore, finding a meaningful and accurate correspondence among shapes has important research significance and application value. In recent years, deep-learning-based calculation of the correspondence among 3D shapes has attracted the attention of many scholars in the field of geometry processing. Using neural networks to learn the feature descriptors on the surfaces of 3D shapes can help us obtain accurate and comprehensive feature information and provides a solid foundation for building accurate correspondences among 3D shapes. Deep-learning-based methods for calculating the correspondences can be roughly divided into 1) methods based on the end-to-end depth functional maps network, and 2) methods based on other neural networks. The first method uses deep functional map networks to learn the feature descriptors of 3D shapes and then use these descriptors to analyze the spatial structure characteristics of shapes. Afterward, theory of functional maps is applied to solve the shape matching problem, find out the functional maps matrix among shapes, and determine the correspondence among shapes. Meanwhile, the second method uses neural networks to learn the feature descriptors of shapes, takes the calculation of correspondences as part of the learning process, uses the learned shape spatial geometric structure features for shape matching, and obtains the ideal correspondence among shapes. The feature descriptors and the network of learning descriptors of shapes play a crucial role in calculating 3D shapes correspondence calculation methods ignore the important influence of feature descriptors on the representation of 3D shapes, and the calculated shape descriptors contain relatively few information that cannot solve the problems related to shape symmetry and shape boundary descriptor distortion. Moreover, in the subsequent correspondence calculation process, these methods are unable to generate an accurate functional map of the symmetrical part of shapes, thereby leading to inaccurate correspondence calculations. The existing 3D shape correspondence calculation methods based on deep learning all adopt a supervision mechanism, which limits the universality of these methods to a large extent. To address these problems, this paper proposes a self-supervised deep residual functional maps network (SSDRFMN) to calculate 3D shapes correspondence.MethodThe proposed method involves two steps. First, we calculate the feature descriptor of the 3D shape by combining the local coordinate system with a histogram, which is a signature of the histograms of orientations (SHOT) descriptor. We initially establish a local coordinate on the surface of shapes and then enhance the recognition ability of our descriptor by introducing the geometric information of the feature points. Afterward, we calculate the local histogram at a given point and use the calculated geometric information to form a histogram and a signature. Compared with traditional feature descriptors, hybrid feature descriptors can better represent the spatial structure and surface feature information of 3D shapes and provide high-quality inputs for network learning. Second, we use end-to-end SSDRFMN to calculate the correspondence among shapes. The SHOT descriptors of the source and target shapes are inputted into SSDRFMN, and the feature descriptor iteratively trains the neural network. The deep functional maps (DFM) layer is then used to calculate the function mapping matrix between two shapes. The corresponding relationship problem is transformed into solving the function mapping matrix problem, and the functional map relationship is converted into a point-to-point correspondence relationship through a fuzzy correspondence layer. The self-supervised loss function is then used to calculate the geodesic distance error between shapes and to evaluate the corresponding relationship. The loss function minimizes the geodesic distance error between shapes via network training and replaces the real correspondence between the manually labeled models with geometric constraints to achieve a self-supervised learning of the network.ResultExperimental results show that compared with the supervised deep functional maps (SDFM) and spectral upsampling (SU) algorithms, the proposed algorithm reduces the geodesic error of correspondences between the human model and the MPI-FAUST dataset by 1.45% and 1.67%, respectively. Meanwhile, in the TOSCA dataset, the proposed algorithm reduces the geodesic errors of the correspondences of dog, cat, and wolf models by 3.13% (2.81%), 0.98% (2.22%), and 1.89% (1.11%) compared with SDFM (SU), respectively. Therefore, apart from its applicability to different datasets and its high scalability, this algorithm effectively overcomes the shortcomings of extant depth functional maps methods that require the true correspondence among shapes to supervise.ConclusionExperimental results show that the proposed method outperforms the existing methods for calculating the correspondence among 3D shapes. On the one hand, our proposed method trains the neural network through the SHOT descriptor of shapes, there by effectively solving the symmetry and boundary distortion of the model and producing a better representation of the surface features of 3D shapes. On the other hand, the proposed method uses a self-supervised deep neural network to learn the features of descriptors and to accurately calculate the correspondences among shapes. This method also shows excellent universality and accuracy, thereby highlighting its value in shapes matching, model recognition, segmentation, and retrieval.关键词:non-rigid 3D shapes;shape correspondences;deep functional maps (DFM);soft correspondence;self-supervised loss function;geodesic error33|18|0更新时间:2024-05-07
摘要:ObjectiveCalculating 3D shapes correspondence is a central problem in the field of geometry processing that plays an important role in shapes reconstruction, object recognition and classification, and other tasks. Therefore, finding a meaningful and accurate correspondence among shapes has important research significance and application value. In recent years, deep-learning-based calculation of the correspondence among 3D shapes has attracted the attention of many scholars in the field of geometry processing. Using neural networks to learn the feature descriptors on the surfaces of 3D shapes can help us obtain accurate and comprehensive feature information and provides a solid foundation for building accurate correspondences among 3D shapes. Deep-learning-based methods for calculating the correspondences can be roughly divided into 1) methods based on the end-to-end depth functional maps network, and 2) methods based on other neural networks. The first method uses deep functional map networks to learn the feature descriptors of 3D shapes and then use these descriptors to analyze the spatial structure characteristics of shapes. Afterward, theory of functional maps is applied to solve the shape matching problem, find out the functional maps matrix among shapes, and determine the correspondence among shapes. Meanwhile, the second method uses neural networks to learn the feature descriptors of shapes, takes the calculation of correspondences as part of the learning process, uses the learned shape spatial geometric structure features for shape matching, and obtains the ideal correspondence among shapes. The feature descriptors and the network of learning descriptors of shapes play a crucial role in calculating 3D shapes correspondence calculation methods ignore the important influence of feature descriptors on the representation of 3D shapes, and the calculated shape descriptors contain relatively few information that cannot solve the problems related to shape symmetry and shape boundary descriptor distortion. Moreover, in the subsequent correspondence calculation process, these methods are unable to generate an accurate functional map of the symmetrical part of shapes, thereby leading to inaccurate correspondence calculations. The existing 3D shape correspondence calculation methods based on deep learning all adopt a supervision mechanism, which limits the universality of these methods to a large extent. To address these problems, this paper proposes a self-supervised deep residual functional maps network (SSDRFMN) to calculate 3D shapes correspondence.MethodThe proposed method involves two steps. First, we calculate the feature descriptor of the 3D shape by combining the local coordinate system with a histogram, which is a signature of the histograms of orientations (SHOT) descriptor. We initially establish a local coordinate on the surface of shapes and then enhance the recognition ability of our descriptor by introducing the geometric information of the feature points. Afterward, we calculate the local histogram at a given point and use the calculated geometric information to form a histogram and a signature. Compared with traditional feature descriptors, hybrid feature descriptors can better represent the spatial structure and surface feature information of 3D shapes and provide high-quality inputs for network learning. Second, we use end-to-end SSDRFMN to calculate the correspondence among shapes. The SHOT descriptors of the source and target shapes are inputted into SSDRFMN, and the feature descriptor iteratively trains the neural network. The deep functional maps (DFM) layer is then used to calculate the function mapping matrix between two shapes. The corresponding relationship problem is transformed into solving the function mapping matrix problem, and the functional map relationship is converted into a point-to-point correspondence relationship through a fuzzy correspondence layer. The self-supervised loss function is then used to calculate the geodesic distance error between shapes and to evaluate the corresponding relationship. The loss function minimizes the geodesic distance error between shapes via network training and replaces the real correspondence between the manually labeled models with geometric constraints to achieve a self-supervised learning of the network.ResultExperimental results show that compared with the supervised deep functional maps (SDFM) and spectral upsampling (SU) algorithms, the proposed algorithm reduces the geodesic error of correspondences between the human model and the MPI-FAUST dataset by 1.45% and 1.67%, respectively. Meanwhile, in the TOSCA dataset, the proposed algorithm reduces the geodesic errors of the correspondences of dog, cat, and wolf models by 3.13% (2.81%), 0.98% (2.22%), and 1.89% (1.11%) compared with SDFM (SU), respectively. Therefore, apart from its applicability to different datasets and its high scalability, this algorithm effectively overcomes the shortcomings of extant depth functional maps methods that require the true correspondence among shapes to supervise.ConclusionExperimental results show that the proposed method outperforms the existing methods for calculating the correspondence among 3D shapes. On the one hand, our proposed method trains the neural network through the SHOT descriptor of shapes, there by effectively solving the symmetry and boundary distortion of the model and producing a better representation of the surface features of 3D shapes. On the other hand, the proposed method uses a self-supervised deep neural network to learn the features of descriptors and to accurately calculate the correspondences among shapes. This method also shows excellent universality and accuracy, thereby highlighting its value in shapes matching, model recognition, segmentation, and retrieval.关键词:non-rigid 3D shapes;shape correspondences;deep functional maps (DFM);soft correspondence;self-supervised loss function;geodesic error33|18|0更新时间:2024-05-07 -
 摘要:ObjectiveWith the recent improvements in people's living standards and quality and the rapid development of digital information technology, all sectors of society have paid increasing attention to the application of science and technology in the field of public safety. To maintain a safe public environment, video surveillance equipment has been increasingly installed in streets, schools, communities, subways, and other public places. However, traditional video surveillance systems gradually become unable to process the ever-increasing size of video data. Therefore, the development of intelligent surveillance systems with automatic detection, identification, and alarm functions has broad and far-reaching significance for maintaining public safety and developing artificial intelligence. Anomaly detection is an important part of intelligent monitoring systems that plays a key role in maintaining public safety. As such, anomaly detection has become a hot research topic for both academic and industrial practitioners. In the past, video anomalies are manually detected, which requires much human labor. Therefore, the introduction of an efficient and automated anomaly detection system has significantly reduced the labor costs for such undertaking. Video anomaly detection technologies play an important role in automated and intelligent modern production and manufacturing, video anomaly detection remains a challenging task in complex factory environments given the anomalous events and interference of unrelated contexts in such scenarios. Many methods use hand-designed low-level features to extract features from the local areas of a video. However, these features cannot represent both motion and appearance. To address this problem, we propose a novel detection method based on deep spatial-temporal features.MethodFirst, given that abnormalities are mainly observed in the motion areas of videos, this article extracts the surveillance video motion area via a Gaussian mixture model (GMM). Specifically, this model is used to extract a fixed-size spatial-temporal region of interest from a video. Second, to facilitate the detection of subsequent abnormal events, high-level features are extracted from the region of interest (ROI) via a 3Dconvolutional neural network. Third, to enhance anomaly detection efficiency, the extracted features are used to train a denoising auto-encoder and to detect anomalous events based on reconstruction errors. Finally, given that the self-encoding reconstruction errors of some tested abnormal samples tend to be very small, a model that uses only self-encoding reconstruction errors for anomaly detection can miss many abnormal events. To further rule out anomalies, a one-class support vector machine (SVM) is trained on low-dimensional featuresResultSeveral experiments are performed in an actual manufacturing environment operated by robots. Two common indicators are used for evaluation, namely, area under ROC (AUC) and equal error rate (EER).The receiver operating characteristic (ROC) curve is drawn by using the results obtained from various classification standards and can be used to evaluate classifier performance. Meanwhile, the AUC represents the coverage area under the ROC curve, whereas the EER can be represented by the point where the ROC curve intersects with a 45° straight line. A smaller EER indicates a better detection effect. When the appropriate error threshold is set(approximately 0.15), the AUC under the ROC curve reaches 91.7%, whereas the EER is 13.8%.The performance of the proposed model is also evaluated and compared with that of other models on public data feature sets University of California, San Diego (USCD) Ped1 and Ped2. In the USCD Ped1 dataset, the proposed model demonstrates 2.6% and 22.3% improvements in its AUC at the frame and pixel levels, respectively. In the same dataset, compared with the second-best method, the proposed model has a 5.7% higher AUC at the frame level, thereby verifying its effectiveness and accuracy.ConclusionThe proposed video abnormal event detection model combines traditional and deep learning models to increase the accuracy of video abnormal event detection results. A 3D convolutional neural network (C3D) was used to extract the spatiotemporal features. A video anomaly event detection method based on deep spatiotemporal features was also developed by combining the stacked denoising autoencoder with a one-class SVM model. In extracting deep spatiotemporal features through a pre-trained C3D network, those features that were extracted from the last convolutional layer of the network were treated as the features of the spatiotemporal interest block. These features consider both the appearance and motion modes. A denoising auto-encoder was also trained to reduce the dimensions of C3D-extracted features, and the reconstruction error of an auto-encoder was used to facilitate the detection of abnormal events. Experimental results show that the proposed model can still detect anomalies when such events appear in partially occluded situations. Therefore, this model can be used for anomalous event detection in dense scenes. Future studies may consider examining other network architectures, integrating multiple input data (e.g., RGB or optical flow frames), and introducing trajectory tracking methods to track obstructed objects and improve abnormality detection accuracy. The proposed framework is suitable for highly complex scenarios.关键词:video anomaly event detection;region of interest (ROI);3D convolutional neural network (C3D);denoising autoencoder;one-class support vector machine (SVM)40|51|6更新时间:2024-05-07
摘要:ObjectiveWith the recent improvements in people's living standards and quality and the rapid development of digital information technology, all sectors of society have paid increasing attention to the application of science and technology in the field of public safety. To maintain a safe public environment, video surveillance equipment has been increasingly installed in streets, schools, communities, subways, and other public places. However, traditional video surveillance systems gradually become unable to process the ever-increasing size of video data. Therefore, the development of intelligent surveillance systems with automatic detection, identification, and alarm functions has broad and far-reaching significance for maintaining public safety and developing artificial intelligence. Anomaly detection is an important part of intelligent monitoring systems that plays a key role in maintaining public safety. As such, anomaly detection has become a hot research topic for both academic and industrial practitioners. In the past, video anomalies are manually detected, which requires much human labor. Therefore, the introduction of an efficient and automated anomaly detection system has significantly reduced the labor costs for such undertaking. Video anomaly detection technologies play an important role in automated and intelligent modern production and manufacturing, video anomaly detection remains a challenging task in complex factory environments given the anomalous events and interference of unrelated contexts in such scenarios. Many methods use hand-designed low-level features to extract features from the local areas of a video. However, these features cannot represent both motion and appearance. To address this problem, we propose a novel detection method based on deep spatial-temporal features.MethodFirst, given that abnormalities are mainly observed in the motion areas of videos, this article extracts the surveillance video motion area via a Gaussian mixture model (GMM). Specifically, this model is used to extract a fixed-size spatial-temporal region of interest from a video. Second, to facilitate the detection of subsequent abnormal events, high-level features are extracted from the region of interest (ROI) via a 3Dconvolutional neural network. Third, to enhance anomaly detection efficiency, the extracted features are used to train a denoising auto-encoder and to detect anomalous events based on reconstruction errors. Finally, given that the self-encoding reconstruction errors of some tested abnormal samples tend to be very small, a model that uses only self-encoding reconstruction errors for anomaly detection can miss many abnormal events. To further rule out anomalies, a one-class support vector machine (SVM) is trained on low-dimensional featuresResultSeveral experiments are performed in an actual manufacturing environment operated by robots. Two common indicators are used for evaluation, namely, area under ROC (AUC) and equal error rate (EER).The receiver operating characteristic (ROC) curve is drawn by using the results obtained from various classification standards and can be used to evaluate classifier performance. Meanwhile, the AUC represents the coverage area under the ROC curve, whereas the EER can be represented by the point where the ROC curve intersects with a 45° straight line. A smaller EER indicates a better detection effect. When the appropriate error threshold is set(approximately 0.15), the AUC under the ROC curve reaches 91.7%, whereas the EER is 13.8%.The performance of the proposed model is also evaluated and compared with that of other models on public data feature sets University of California, San Diego (USCD) Ped1 and Ped2. In the USCD Ped1 dataset, the proposed model demonstrates 2.6% and 22.3% improvements in its AUC at the frame and pixel levels, respectively. In the same dataset, compared with the second-best method, the proposed model has a 5.7% higher AUC at the frame level, thereby verifying its effectiveness and accuracy.ConclusionThe proposed video abnormal event detection model combines traditional and deep learning models to increase the accuracy of video abnormal event detection results. A 3D convolutional neural network (C3D) was used to extract the spatiotemporal features. A video anomaly event detection method based on deep spatiotemporal features was also developed by combining the stacked denoising autoencoder with a one-class SVM model. In extracting deep spatiotemporal features through a pre-trained C3D network, those features that were extracted from the last convolutional layer of the network were treated as the features of the spatiotemporal interest block. These features consider both the appearance and motion modes. A denoising auto-encoder was also trained to reduce the dimensions of C3D-extracted features, and the reconstruction error of an auto-encoder was used to facilitate the detection of abnormal events. Experimental results show that the proposed model can still detect anomalies when such events appear in partially occluded situations. Therefore, this model can be used for anomalous event detection in dense scenes. Future studies may consider examining other network architectures, integrating multiple input data (e.g., RGB or optical flow frames), and introducing trajectory tracking methods to track obstructed objects and improve abnormality detection accuracy. The proposed framework is suitable for highly complex scenarios.关键词:video anomaly event detection;region of interest (ROI);3D convolutional neural network (C3D);denoising autoencoder;one-class support vector machine (SVM)40|51|6更新时间:2024-05-07 -
 摘要:ObjectiveImage depth, which refers to the distance from a point in a scene to the center plane of a camera, reflects the 3D geometric information of a scene. Reliable depth information is important in many visual tasks, including image segmentation, target detection, and 3D surface reconstruction. Depth estimation has become one of the most important research topics in the field of computer vision. With the development of sensor technology, light field cameras, as new multi-angle image acquisition devices, have increased the convenience of acquiring optical field data. These cameras can simultaneously acquire the spatial and angular information of a scene and show unique advantages in depth estimation. At present, most of the available methods for light field depth estimation can obtain highly accurate depth information in many scenes. However, these methods implicitly assume that objects are on a Lambertian surface or a uniform reflection coefficient surface. When specular reflection or non-Lambertian surfaces appear in a scene, depth information cannot be accurately obtained. Specular reflection is commonly observed in real-world scenes when light strikes the surface of an object, such as metals, plastics, ceramics, and glass. Specular reflection tends to change the color of an object and obscure its texture, thereby leading to local area information loss. Previous studies have shown that the specular region changes along with angle of view. Furthermore, we can speculate on the location of the specular area based on the context information of its surroundings. Inspired by these principles, we propose an anti-specular depth estimation method based on the context information of the light field image. In this way, this method can improve the reliability of the algorithm in handling problems associated with specular reflection.MethodBased on the changes in the change of an image with the angle of view, we design our network by considering the light field geometry, select the horizontal, vertical, left diagonal, and right diagonal dimensions, and create four independent yet identical sub-aperture image processing branches. In this configuration, the network generates four directional independent depth feature representations that are combined at a later stage. We also use a fixed light direction, due to the obstruction of the front object or the incident angle of the light, smooth surface at the same depth level, not all areas will appear as highlights. In addition, the degree of reflection of specular on the smooth surface is different, indirectly showing the geometric characteristics. Therefore, we process each sub-aperture image branch via dilated convolution, which expands the network receptive field. Our constructed network obtains a wide range of image context information and then restores the specular region depth information. To improve the depth estimation accuracy in the specular area, we apply a novel multi-scale feature fusion method where the multi-rate dilated convolution feature is connected to a multi-kernel common convolution feature to obtain the fusion features. To enhance the robustness of our depth estimation, we use a series of residual modules to reintroduce part of the feature information that is lost by the previous layer convolution in the network, learn the relationship among the fusion features, and encode such relationship into higher-dimension features. We use Tensorflow as our training backend, the Ker as programming language to build our network, Rmsprop as our optimizer, and set the batch size to 16. We initialize our model parameters by using the Glorot uniform distribution initialization and set our initial learning rate to 1E-4, which decreases to 1E-6 along with the number of iterations. We use the mean absolute error (MAE) as our loss function given its robustness to outliers. We use an Intel i7-5820K@3.30 GHz processor with GeForce GTX 1080Ti as our experimental machine. Our network trains 200 epochs for approximately 2 to 3 days.Result4D light field benchmark synthetic scene dataset was used for quantitative experiments, and the computer vision and image analysis (CVIA) Konstanz specular synthetic scene dataset and real scene dataset captured by Lytro Illum were used for the qualitative experiments. We used three evaluation criteria in our quantitative experiment, namely, mean square error (MSE), bad pixel (BP), and peak signal-to-noise ratio (PSNR). Experiment results show that our proposed method has an improved depth estimation. Our quantitative analysis on 4D light field benchmark synthetic dataset shows that our proposed method reduces the MSE value by 20.24%, has a BP value (0.07) that is 2.62% lower than that of the second-best model, and a 4.96% PSNR value. Meanwhile, in our qualitative analysis of the CVIA Konstanz specular synthetic dataset and the real scene dataset captured by Lytro Illum, our proposed algorithm achieves ideal depth estimation results, thereby verifying its effectiveness in recovering depth information in the specular highlight region. We also perform an ablation experiment of the network receptive field expansion and residual feature coding modules, and we find that the multi-scale feature fusion method improves the effect of depth estimation in the highlight areas and greatly improves the residual structure.ConclusionOur model can effectively estimate image depth information. This model achieves a high recovery accuracy in recovering highlight region depth information, has a smooth object edge region, and can efficiently preserve image detail information.关键词:depth estimation;light field (LF);anti-specular;context information;convolutional neural network (CNN)56|19|2更新时间:2024-05-07
摘要:ObjectiveImage depth, which refers to the distance from a point in a scene to the center plane of a camera, reflects the 3D geometric information of a scene. Reliable depth information is important in many visual tasks, including image segmentation, target detection, and 3D surface reconstruction. Depth estimation has become one of the most important research topics in the field of computer vision. With the development of sensor technology, light field cameras, as new multi-angle image acquisition devices, have increased the convenience of acquiring optical field data. These cameras can simultaneously acquire the spatial and angular information of a scene and show unique advantages in depth estimation. At present, most of the available methods for light field depth estimation can obtain highly accurate depth information in many scenes. However, these methods implicitly assume that objects are on a Lambertian surface or a uniform reflection coefficient surface. When specular reflection or non-Lambertian surfaces appear in a scene, depth information cannot be accurately obtained. Specular reflection is commonly observed in real-world scenes when light strikes the surface of an object, such as metals, plastics, ceramics, and glass. Specular reflection tends to change the color of an object and obscure its texture, thereby leading to local area information loss. Previous studies have shown that the specular region changes along with angle of view. Furthermore, we can speculate on the location of the specular area based on the context information of its surroundings. Inspired by these principles, we propose an anti-specular depth estimation method based on the context information of the light field image. In this way, this method can improve the reliability of the algorithm in handling problems associated with specular reflection.MethodBased on the changes in the change of an image with the angle of view, we design our network by considering the light field geometry, select the horizontal, vertical, left diagonal, and right diagonal dimensions, and create four independent yet identical sub-aperture image processing branches. In this configuration, the network generates four directional independent depth feature representations that are combined at a later stage. We also use a fixed light direction, due to the obstruction of the front object or the incident angle of the light, smooth surface at the same depth level, not all areas will appear as highlights. In addition, the degree of reflection of specular on the smooth surface is different, indirectly showing the geometric characteristics. Therefore, we process each sub-aperture image branch via dilated convolution, which expands the network receptive field. Our constructed network obtains a wide range of image context information and then restores the specular region depth information. To improve the depth estimation accuracy in the specular area, we apply a novel multi-scale feature fusion method where the multi-rate dilated convolution feature is connected to a multi-kernel common convolution feature to obtain the fusion features. To enhance the robustness of our depth estimation, we use a series of residual modules to reintroduce part of the feature information that is lost by the previous layer convolution in the network, learn the relationship among the fusion features, and encode such relationship into higher-dimension features. We use Tensorflow as our training backend, the Ker as programming language to build our network, Rmsprop as our optimizer, and set the batch size to 16. We initialize our model parameters by using the Glorot uniform distribution initialization and set our initial learning rate to 1E-4, which decreases to 1E-6 along with the number of iterations. We use the mean absolute error (MAE) as our loss function given its robustness to outliers. We use an Intel i7-5820K@3.30 GHz processor with GeForce GTX 1080Ti as our experimental machine. Our network trains 200 epochs for approximately 2 to 3 days.Result4D light field benchmark synthetic scene dataset was used for quantitative experiments, and the computer vision and image analysis (CVIA) Konstanz specular synthetic scene dataset and real scene dataset captured by Lytro Illum were used for the qualitative experiments. We used three evaluation criteria in our quantitative experiment, namely, mean square error (MSE), bad pixel (BP), and peak signal-to-noise ratio (PSNR). Experiment results show that our proposed method has an improved depth estimation. Our quantitative analysis on 4D light field benchmark synthetic dataset shows that our proposed method reduces the MSE value by 20.24%, has a BP value (0.07) that is 2.62% lower than that of the second-best model, and a 4.96% PSNR value. Meanwhile, in our qualitative analysis of the CVIA Konstanz specular synthetic dataset and the real scene dataset captured by Lytro Illum, our proposed algorithm achieves ideal depth estimation results, thereby verifying its effectiveness in recovering depth information in the specular highlight region. We also perform an ablation experiment of the network receptive field expansion and residual feature coding modules, and we find that the multi-scale feature fusion method improves the effect of depth estimation in the highlight areas and greatly improves the residual structure.ConclusionOur model can effectively estimate image depth information. This model achieves a high recovery accuracy in recovering highlight region depth information, has a smooth object edge region, and can efficiently preserve image detail information.关键词:depth estimation;light field (LF);anti-specular;context information;convolutional neural network (CNN)56|19|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveDigital bas-relief is a special model that is either raised or lowered and is usually attached to a planar background. The spatial structure of a digital bas-relief lies between a 3D shape and a flat shape. Despite taking up limited space, a bas-relief contains a rich amount of details. Given its unique spatial structure and visual effects, a bas-relief can be applied across various fields. Various bas-relief models have been applied in designing ceramic vessels, wooden carvings, and coin badges, among others. Given its effective space utilization and excellent visual presentation, the bas-relief has been increasingly applied in decoration. However, with the continuous development of digital technology and 3D printing, the demand for and the requirements of bas-relief generation have become increasingly diverse. To enhance the diversity of digital bas-relief design and realize its stylized application, generating a bas-relief model based on height maps has been examined in the literature. Designing and adjusting the height map of relief works can help obtain highly efficient and intuitive embossed decorated models.MethodBy introducing masks and integrating image processing technology, a height map is generated to control the relief effect, and the existing bas-relief model generation method is adopted to generate bas-relief models with different styles. Masks have an important application value in the field of image processing. A mask is used to control the height of the local area and different areas of the relief to obtain different height information. Through this mask, a normal map with different height information can be obtained and used as input for the bas-relief model generation algorithm. This algorithm normalizes the vectors of different height information. Normal information processing offers two key advantages. On the one hand, transforming normal information can directly reflect surface variation characteristics, which play important roles in the later stages of geometric reconstruction. On the other hand, the depth value discontinuity caused by occlusion does not pose a problem because normal information ignores the differences in distance. In this paper, a Gaussian mixture model based rolling guidance normal filtering (GRNF) is applied in a normal decomposition operation. This model involves two steps. First, by using the rolling guide normal filtering algorithm, a rough structural side layer is decomposed from the original normal layer, and then the original normal layer and rough structure are subtracted to obtain a rough detail layer. Second, by using the expectation-maximization algorithm to solve the final parameter estimated by the Gaussian mixture model, the remaining detail and structural layers that contained tailed information can be separated in the coarse detail layer. After passing the filter based on the rolling guide, a structural layer with the overall contour feature of the relief model and a detail layer that retains the detailed feature information can be obtained. Finally, the surface of the decomposed detail and structural layers is reconstructed. Surface construction based on surface-from-gradients (SfG) local adjustment and global reconstruction is applied to transform the continuous surface reconstruction into a discrete space, and the surface reconstruction problem is effectively solved via least squares optimization. After obtaining the geometric model via surface reconstruction, some noise or interference can influence the visual effect of the bas-relief model. Laplacian smoothing and bilateral filters are then used for smoothing and denoising to obtain the final bas-relief model.ResultMask processing is used to control the height of the relief model and ensure the diversity of relief model generation. A model that references the existing bas-relief model generation algorithm shows a better generation effect. By setting the detail parameters of the adjustment model, the structural and flatness parameters of the overall relief are effectively controlled, and the bas-relief model can be used for diversification. A bas-relief model with different visual effects is eventually obtained. The experiment lists some elements, including pillows and tables, in the home decoration industry. The bas-relief models generated by masking also have unique characteristics and can be applied in decorating vases and walls. By adjusting their detail and structural features, bas-relief models can meet diverse needs, have clear outlines, and rich amounts of detail.ConclusionHeight-map-based bas-relief model generation method can benefit the design of bas-relief model sand help meet the demands in home decoration. Results of this study can be combined with the existing 3D printing technology and applied in the production and processing of embossed products.关键词:bas-relief;normal decomposition;geometric reconstruction;height map;mask theory32|18|1更新时间:2024-05-07
摘要:ObjectiveDigital bas-relief is a special model that is either raised or lowered and is usually attached to a planar background. The spatial structure of a digital bas-relief lies between a 3D shape and a flat shape. Despite taking up limited space, a bas-relief contains a rich amount of details. Given its unique spatial structure and visual effects, a bas-relief can be applied across various fields. Various bas-relief models have been applied in designing ceramic vessels, wooden carvings, and coin badges, among others. Given its effective space utilization and excellent visual presentation, the bas-relief has been increasingly applied in decoration. However, with the continuous development of digital technology and 3D printing, the demand for and the requirements of bas-relief generation have become increasingly diverse. To enhance the diversity of digital bas-relief design and realize its stylized application, generating a bas-relief model based on height maps has been examined in the literature. Designing and adjusting the height map of relief works can help obtain highly efficient and intuitive embossed decorated models.MethodBy introducing masks and integrating image processing technology, a height map is generated to control the relief effect, and the existing bas-relief model generation method is adopted to generate bas-relief models with different styles. Masks have an important application value in the field of image processing. A mask is used to control the height of the local area and different areas of the relief to obtain different height information. Through this mask, a normal map with different height information can be obtained and used as input for the bas-relief model generation algorithm. This algorithm normalizes the vectors of different height information. Normal information processing offers two key advantages. On the one hand, transforming normal information can directly reflect surface variation characteristics, which play important roles in the later stages of geometric reconstruction. On the other hand, the depth value discontinuity caused by occlusion does not pose a problem because normal information ignores the differences in distance. In this paper, a Gaussian mixture model based rolling guidance normal filtering (GRNF) is applied in a normal decomposition operation. This model involves two steps. First, by using the rolling guide normal filtering algorithm, a rough structural side layer is decomposed from the original normal layer, and then the original normal layer and rough structure are subtracted to obtain a rough detail layer. Second, by using the expectation-maximization algorithm to solve the final parameter estimated by the Gaussian mixture model, the remaining detail and structural layers that contained tailed information can be separated in the coarse detail layer. After passing the filter based on the rolling guide, a structural layer with the overall contour feature of the relief model and a detail layer that retains the detailed feature information can be obtained. Finally, the surface of the decomposed detail and structural layers is reconstructed. Surface construction based on surface-from-gradients (SfG) local adjustment and global reconstruction is applied to transform the continuous surface reconstruction into a discrete space, and the surface reconstruction problem is effectively solved via least squares optimization. After obtaining the geometric model via surface reconstruction, some noise or interference can influence the visual effect of the bas-relief model. Laplacian smoothing and bilateral filters are then used for smoothing and denoising to obtain the final bas-relief model.ResultMask processing is used to control the height of the relief model and ensure the diversity of relief model generation. A model that references the existing bas-relief model generation algorithm shows a better generation effect. By setting the detail parameters of the adjustment model, the structural and flatness parameters of the overall relief are effectively controlled, and the bas-relief model can be used for diversification. A bas-relief model with different visual effects is eventually obtained. The experiment lists some elements, including pillows and tables, in the home decoration industry. The bas-relief models generated by masking also have unique characteristics and can be applied in decorating vases and walls. By adjusting their detail and structural features, bas-relief models can meet diverse needs, have clear outlines, and rich amounts of detail.ConclusionHeight-map-based bas-relief model generation method can benefit the design of bas-relief model sand help meet the demands in home decoration. Results of this study can be combined with the existing 3D printing technology and applied in the production and processing of embossed products.关键词:bas-relief;normal decomposition;geometric reconstruction;height map;mask theory32|18|1更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveRemote sensing image semantic segmentation, in which each pixel in an image is classified according to the land cover type, presents an important research direction in the field of remote sensing image processing. However, accurately segmenting and extracting features from remote sensing images is difficult due to the wide coverage of these images and the large-scale difference and complex boundaries among these features. Meanwhile, the traditional remote sensing image processing methods are inefficient, inaccurate, and require much expertise. Convolutional neural networks are deep learning networks that are suitable for processing data with grid structures, such as 1D data with time series features (e.g., speech) and image data with 2D pixel matrix grids. Given its multi-layer structure, a convolutional neural network can automatically learn features at different levels. This network also has two features that facilitate image processing. First, a convolutional neural network uses the 2D characteristics of an image in feature extraction. Given the high correlation among adjacent pixels in an image, the neuron nodes in the network do not need to connect all pixels; only a local connection is required to extract features. Second, convolution kernel parameters are shared when the convolutional neural network performs convolution operations, and features at different positions of an image use the same convolution kernel to calculate their values, there by greatly reducing the model parameters. In this paper, a full convolutional neural network based on a residual dense spatial pyramid is applied in urban remote sensing image segmentation to achieve an accurate semantic segmentation of high-resolution remote sensing images.MethodTo improve the semantic segmentation precision of high-resolution urban remote sensing images, we first take a 101-layer residual convolutional network as our backbone in extracting remote sensing image feature maps. When extracting features by using classic convolutional neural networks, the repeated concatenation of max-pooling and striding at consecutive layers significantly reduces the spatial resolution of the feature maps, typically by a factor of 32 across each direction in general deep convolutional neural networks(DCNNs), thereby leading to spatial information loss. Semantic segmentation is a pixel-to-pixel mapping task whose class intensity reaches the pixel level. Reducing the spatial resolution of feature maps can lead to spatial information loss, which is not conducive to the semantic segmentation of remote sensing images. To avoid such loss, the proposed model introduces atrous convolution into the residual convolutional neural network. Compared with ordinary convolution, atrous convolution uses the parameter r to control the receptive field of the convolution kernel during the calculation. The convolutional neural network with atrous convolution can expand the receptive field of the feature map while keeping the feature map size unchanged, thereby significantly improving the remote sensing image semantic segmentation performance of the proposed model. Objects in remote sensing images often demonstrate large-scale variations and complex texture features, both of which challenge the accurate encoding of multi-scale advanced features. To accurately extract multi-scale features in these images, the proposed model cascades each branch of aspatial pyramid structure based on a dense connection mechanism, which allows each branch to output highly dense receptive field information. In these mantic segmentation of remote sensing images, not only the high-level semantic features extracted by the convolutional neural network are required to correctly determine the category of each pixel; low-level texture features are also required to determine the edges of the target. Low-level texture features can benefit the reconstruction of object edges during semantic segmentation. Our proposed model uses a simple encoder to effectively use high-level semantic features and low-level texture features in a network. A decoder also uses skip connection to fuse cross-layer network information and to combine high-level semantic features with the underlying texture features. After fusing high- and low-level information, we use two 3×3 convolutions to integrate the information among channels and to recover spatial information. We eventually input the extracted feature map to a softmax classifier for pixel-level classification and obtain the remote sensing image semantic segmentation results.ResultFull experiments are performed by using the ISPRS(International Society for Phtogrammetry and Remote Sensing) remote sensing dataset of the Vaihingen area. WE use intersection over union (IoU) and F1 as our indicators for evaluating the segmentation performance of the proposed model. We also build and train our models based on the NVIDIA Tesla P100 platform and the Tensorflow deep learning framework. The complexity of tasks in the experiment increases at each stage. Experimental results show that the proposed model obtains mean IoU (MIoU) and F1values of 69.88% and 81.39% over six types of surface features, respectively, thereby demonstrating vast improvements compared with a residual convolutional network without atrous convolution. Our proposed method also outperforms SegNet, Res-shuffling-Net and SDFCN (symmetrical dense-shortcut fully convolutional network) in terms of mathematics and outperforms pix2pix in terms of visual effects, thereby cementing its validity. We then apply this model on the remote sensing image data of Potsdam area and obtain MIoU and F1 values of 74.02% and 83.86%, respectively, thereby proving the robustness of our model.ConclusionWe build an end-to-end deep learning model for the semantic segmentation of remote sensing images of high-resolution urban areas. By applying an improved spatial pyramid pooling network based on atrous convolution and dense connections, our proposed model effectively extracts multi-scale features from remote sensing images and fuse high-level semantic information and low-level texture information of the network, which in turn can improve the accuracy of the model in the remote sensing image segmentation of urban areas. Experimental results prove that the proposed model achieves an excellent performance in terms of mathematical and visual effects and has high application value in the semantic segmentation of high-resolution remote sensing images.关键词:semantic segmentation;remote sensing images;multiscale;residual convolutional network;dense connection41|44|2更新时间:2024-05-07
摘要:ObjectiveRemote sensing image semantic segmentation, in which each pixel in an image is classified according to the land cover type, presents an important research direction in the field of remote sensing image processing. However, accurately segmenting and extracting features from remote sensing images is difficult due to the wide coverage of these images and the large-scale difference and complex boundaries among these features. Meanwhile, the traditional remote sensing image processing methods are inefficient, inaccurate, and require much expertise. Convolutional neural networks are deep learning networks that are suitable for processing data with grid structures, such as 1D data with time series features (e.g., speech) and image data with 2D pixel matrix grids. Given its multi-layer structure, a convolutional neural network can automatically learn features at different levels. This network also has two features that facilitate image processing. First, a convolutional neural network uses the 2D characteristics of an image in feature extraction. Given the high correlation among adjacent pixels in an image, the neuron nodes in the network do not need to connect all pixels; only a local connection is required to extract features. Second, convolution kernel parameters are shared when the convolutional neural network performs convolution operations, and features at different positions of an image use the same convolution kernel to calculate their values, there by greatly reducing the model parameters. In this paper, a full convolutional neural network based on a residual dense spatial pyramid is applied in urban remote sensing image segmentation to achieve an accurate semantic segmentation of high-resolution remote sensing images.MethodTo improve the semantic segmentation precision of high-resolution urban remote sensing images, we first take a 101-layer residual convolutional network as our backbone in extracting remote sensing image feature maps. When extracting features by using classic convolutional neural networks, the repeated concatenation of max-pooling and striding at consecutive layers significantly reduces the spatial resolution of the feature maps, typically by a factor of 32 across each direction in general deep convolutional neural networks(DCNNs), thereby leading to spatial information loss. Semantic segmentation is a pixel-to-pixel mapping task whose class intensity reaches the pixel level. Reducing the spatial resolution of feature maps can lead to spatial information loss, which is not conducive to the semantic segmentation of remote sensing images. To avoid such loss, the proposed model introduces atrous convolution into the residual convolutional neural network. Compared with ordinary convolution, atrous convolution uses the parameter r to control the receptive field of the convolution kernel during the calculation. The convolutional neural network with atrous convolution can expand the receptive field of the feature map while keeping the feature map size unchanged, thereby significantly improving the remote sensing image semantic segmentation performance of the proposed model. Objects in remote sensing images often demonstrate large-scale variations and complex texture features, both of which challenge the accurate encoding of multi-scale advanced features. To accurately extract multi-scale features in these images, the proposed model cascades each branch of aspatial pyramid structure based on a dense connection mechanism, which allows each branch to output highly dense receptive field information. In these mantic segmentation of remote sensing images, not only the high-level semantic features extracted by the convolutional neural network are required to correctly determine the category of each pixel; low-level texture features are also required to determine the edges of the target. Low-level texture features can benefit the reconstruction of object edges during semantic segmentation. Our proposed model uses a simple encoder to effectively use high-level semantic features and low-level texture features in a network. A decoder also uses skip connection to fuse cross-layer network information and to combine high-level semantic features with the underlying texture features. After fusing high- and low-level information, we use two 3×3 convolutions to integrate the information among channels and to recover spatial information. We eventually input the extracted feature map to a softmax classifier for pixel-level classification and obtain the remote sensing image semantic segmentation results.ResultFull experiments are performed by using the ISPRS(International Society for Phtogrammetry and Remote Sensing) remote sensing dataset of the Vaihingen area. WE use intersection over union (IoU) and F1 as our indicators for evaluating the segmentation performance of the proposed model. We also build and train our models based on the NVIDIA Tesla P100 platform and the Tensorflow deep learning framework. The complexity of tasks in the experiment increases at each stage. Experimental results show that the proposed model obtains mean IoU (MIoU) and F1values of 69.88% and 81.39% over six types of surface features, respectively, thereby demonstrating vast improvements compared with a residual convolutional network without atrous convolution. Our proposed method also outperforms SegNet, Res-shuffling-Net and SDFCN (symmetrical dense-shortcut fully convolutional network) in terms of mathematics and outperforms pix2pix in terms of visual effects, thereby cementing its validity. We then apply this model on the remote sensing image data of Potsdam area and obtain MIoU and F1 values of 74.02% and 83.86%, respectively, thereby proving the robustness of our model.ConclusionWe build an end-to-end deep learning model for the semantic segmentation of remote sensing images of high-resolution urban areas. By applying an improved spatial pyramid pooling network based on atrous convolution and dense connections, our proposed model effectively extracts multi-scale features from remote sensing images and fuse high-level semantic information and low-level texture information of the network, which in turn can improve the accuracy of the model in the remote sensing image segmentation of urban areas. Experimental results prove that the proposed model achieves an excellent performance in terms of mathematical and visual effects and has high application value in the semantic segmentation of high-resolution remote sensing images.关键词:semantic segmentation;remote sensing images;multiscale;residual convolutional network;dense connection41|44|2更新时间:2024-05-07 -
 摘要:ObjectiveWith the rapid development of remote sensing technology, numerous high-resolution remote sensing images have become available. As a result, the effective retrieval of remote sensing images has become a challenging research topic. Feature extraction is key to determining the retrieval performance of high-resolution remote sensing image retrieval tasks. Traditional feature extraction methods are mainly based on handcrafted features, whereas such shallow features are easily affected by artificial intervention. Convolutional neural networks (CNNs) can learn feature representations automatically, and thus are suitable to deal with high-resolution remote sensing images with complex content. However, the parameters of CNNs are difficult to train fully due to the small scale of currently available public remote sensing datasets. In this case, the transfer learning of CNNs has attracted much attention. CNNs pretrained on large-scale datasets have good generalization ability, and parameters can be transferred to small-scale data effectively. Therefore, extracting CNN features on the basis of transfer learning has become an effective method in the field of remote sensing image retrieval. Given the abundant and complex visual content of high-resolution remote sensing images, it is difficult to accurately express the content of remote sensing images using a single feature. Thus, feature fusion is a useful method to improve the feature representation of remote sensing images. To maximize the learning parameters of different CNNs to represent the content of remote sensing images, a method based on discriminant correlation analysis (DCA) is proposed to fuse the high-level features of different CNNs.MethodFirst, CNN parameters from VGGM(visual geometry group medium), VGG(visual geometry group)16, GoogLeNet, and ResNet50 are transferred for high-resolution remote sensing images, and the high-level features are adopted as special convolutional features. To preserve the original spatial information of the image, the high-level features are extracted under the original input image size, and the output form of three-dimensional tensor is retained. Then, max pooling is adopted on the high-level features to extract salient features. Second, DCA is adopted to enhance the feature representation. The DCA is the first to incorporate the class structure into the feature level fusion and has low computational complexity. To maximize the correlation of corresponding features across the two feature sets and in the same time decorrelates features that belong to different classes within each feature set, the between-class scatter matrices of the two sets of high-level features are calculated, and matrix diagonalization and singular value decomposition are adopted to transform the features. The transformed matrix contains the important eigenvectors of the between-class scatter matrix, and the dimension of the transformed matrix is reduced accordingly. Thus, the transformed feature vectors have strong discriminative power and low dimension. Lastly, two methods of concatenation and summation are selected to perform the fusion of transformed feature vectors, and the fused features are normalized via Gaussian normalization. The similarities between the query and dataset features are calculated using the Euclidean distance method, and the retrieval results are returned in accordance with the sort of similarities.ResultExperiment results on the UC-Merced, RSSCN7, and WHU-RS19 datasets show that the retrieval accuracy and retrieval time of most fusion features are effectively improved in comparison with a single high-level feature; the mean average precision (mAP) of the fusion feature is improved by 10.4%14.1%, 5.7%9.9%, and 5.9%17.6%, respectively. The retrieval results of the fused features using the concatenation method are better than that using the summation method. Multifeature fusion experiments show that the best result on the UC-Merced dataset is obtained from the fusion of four features, whereas the best results on the RSSCN7 and WHU-RS19 datasets are obtained from the fusion of three features. This finding indicates that a larger number of fused features does not translate into better performance; selecting the appropriate features is crucial for feature fusion. Especially, when the different features have good representation and similar retrieval capabilities, the fusion of these features can achieve good retrieval performance. Compared with other state-of-the-art approaches, the average normalized modified retrieval rank(ANMRR) and mAP of the proposed fused feature on the UC-Merced dataset reach 0.132 1 and 84.06%, respectively. Experimental results demonstrate that our method outperforms state-of-the-art approaches.ConclusionThe feature fusion method based on discriminant correlation analysis combines the salient information of different high-level features. This method reduces feature redundancy while improving feature discrimination. Features with equivalent retrieval capabilities can be fused by the proposed method well, thus effectively improving the retrieval performance of high-resolution remote sensing images.关键词:remote sensing image retrieval;convolutional neural network (CNN);high-level feature fusion;discriminant correlation analysis(DCA);max pooling55|108|4更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of remote sensing technology, numerous high-resolution remote sensing images have become available. As a result, the effective retrieval of remote sensing images has become a challenging research topic. Feature extraction is key to determining the retrieval performance of high-resolution remote sensing image retrieval tasks. Traditional feature extraction methods are mainly based on handcrafted features, whereas such shallow features are easily affected by artificial intervention. Convolutional neural networks (CNNs) can learn feature representations automatically, and thus are suitable to deal with high-resolution remote sensing images with complex content. However, the parameters of CNNs are difficult to train fully due to the small scale of currently available public remote sensing datasets. In this case, the transfer learning of CNNs has attracted much attention. CNNs pretrained on large-scale datasets have good generalization ability, and parameters can be transferred to small-scale data effectively. Therefore, extracting CNN features on the basis of transfer learning has become an effective method in the field of remote sensing image retrieval. Given the abundant and complex visual content of high-resolution remote sensing images, it is difficult to accurately express the content of remote sensing images using a single feature. Thus, feature fusion is a useful method to improve the feature representation of remote sensing images. To maximize the learning parameters of different CNNs to represent the content of remote sensing images, a method based on discriminant correlation analysis (DCA) is proposed to fuse the high-level features of different CNNs.MethodFirst, CNN parameters from VGGM(visual geometry group medium), VGG(visual geometry group)16, GoogLeNet, and ResNet50 are transferred for high-resolution remote sensing images, and the high-level features are adopted as special convolutional features. To preserve the original spatial information of the image, the high-level features are extracted under the original input image size, and the output form of three-dimensional tensor is retained. Then, max pooling is adopted on the high-level features to extract salient features. Second, DCA is adopted to enhance the feature representation. The DCA is the first to incorporate the class structure into the feature level fusion and has low computational complexity. To maximize the correlation of corresponding features across the two feature sets and in the same time decorrelates features that belong to different classes within each feature set, the between-class scatter matrices of the two sets of high-level features are calculated, and matrix diagonalization and singular value decomposition are adopted to transform the features. The transformed matrix contains the important eigenvectors of the between-class scatter matrix, and the dimension of the transformed matrix is reduced accordingly. Thus, the transformed feature vectors have strong discriminative power and low dimension. Lastly, two methods of concatenation and summation are selected to perform the fusion of transformed feature vectors, and the fused features are normalized via Gaussian normalization. The similarities between the query and dataset features are calculated using the Euclidean distance method, and the retrieval results are returned in accordance with the sort of similarities.ResultExperiment results on the UC-Merced, RSSCN7, and WHU-RS19 datasets show that the retrieval accuracy and retrieval time of most fusion features are effectively improved in comparison with a single high-level feature; the mean average precision (mAP) of the fusion feature is improved by 10.4%14.1%, 5.7%9.9%, and 5.9%17.6%, respectively. The retrieval results of the fused features using the concatenation method are better than that using the summation method. Multifeature fusion experiments show that the best result on the UC-Merced dataset is obtained from the fusion of four features, whereas the best results on the RSSCN7 and WHU-RS19 datasets are obtained from the fusion of three features. This finding indicates that a larger number of fused features does not translate into better performance; selecting the appropriate features is crucial for feature fusion. Especially, when the different features have good representation and similar retrieval capabilities, the fusion of these features can achieve good retrieval performance. Compared with other state-of-the-art approaches, the average normalized modified retrieval rank(ANMRR) and mAP of the proposed fused feature on the UC-Merced dataset reach 0.132 1 and 84.06%, respectively. Experimental results demonstrate that our method outperforms state-of-the-art approaches.ConclusionThe feature fusion method based on discriminant correlation analysis combines the salient information of different high-level features. This method reduces feature redundancy while improving feature discrimination. Features with equivalent retrieval capabilities can be fused by the proposed method well, thus effectively improving the retrieval performance of high-resolution remote sensing images.关键词:remote sensing image retrieval;convolutional neural network (CNN);high-level feature fusion;discriminant correlation analysis(DCA);max pooling55|108|4更新时间:2024-05-07 -
 摘要:ObjectiveThe urban built-up area is an important source of basic information for urban research and serves as a prerequisite for the regional planning and implementation of the spatial layout of urban functions. Given the recent developments in Earth observational technologies and improvements in the resolution of remote sensing images, accurately and efficiently extracting information on urban built-up areas has become possible. However, due to the complex environment of urban built-up areas in high-resolution remote sensing images and the variations in their locations and development scales, various forms of remote sensing image representations increase the difficulty of using traditional information extraction methods for urban built-up areas. Recent studies show that deep learning algorithms have significant advantages in processing of large-scale images. This paper then examines these deep learning algorithms and reviews previous research that apply deep convolutional neural network methods, which have been widely used in computer vision to extract information on urban built-up areas from high-resolution satellite images. This article also improves the application of computer image processing technology in the field of remote sensing.MethodSemantic image segmentation is crucial in image processing and computer vision. This process recognizes an image at the pixel level and then labels the object category to which each pixel in the image belongs. Based on the deep convolutional neural network oriented to semantic image segmentation, this paper uses the refinement module for the feature map and the attention module of the channel domain to improve the original DeepLab v3 network. The feature refinement module accurately obtains relevant information between pixels and reduces the grid effect. Afterward, the network model processes the feature map through atrous spatial pyramid pooling. The decoding part of the network extracts the attention information of the channel domain and then weighs the low-level features to achieve a better representation and to restore the detailed information. Afterward, the urban built-up area is extracted via the sliding window prediction and full connection conditional random fields methods, both of which can be applied to extract urban built-up areas with better accuracy. However, the use of deep learning algorithms is prone to overfitting and poor robustness. Accordingly, data augmentation and extension are used to enhance the capabilities of the model. Specifically, we use rotation and filter operations while cutting the original training and verification data into 256×256 samples.ResultExtracting information from remote sensing images involves an effective mining and category judgment of such information. The experimental data are taken from Gaofen-2 remote sensing images of Sanya and Haikou cities in Hainan Province, China. These images are specifically taken at the Qiongshan District of Haikou City and at the Tianya District, Jiyang District, and the sea surrounding the Jiaotouding Island of Sanya City. Given their weak sample processing ability, traditional classification algorithms have achieved an accuracy rate of no higher than 85% in the experiments. Meanwhile, deep learning methods, such as SegNet and DeepLab v3, have relatively high accuracy and better performance in extracting urban built-up area information from remote sensing satellite images. By using the refinement module for the feature map and the attention module of the channel domain, this paper improves the accuracy rate of the original DeepLab v3 network by 1.95%. Meanwhile, the proposed method has an accuracy rate of above 93%, a Kappa coefficient of greater than 0.837, a missed detection rate of less than 4.9%, and a false alarm rate of below 2.1%. This method can effectively extract urban built-up areas from large-scale high spatial resolution remote sensing images, and its extraction results are the closest to the actual situation.ConclusionThe comparative experiment shows that the proposed method outperforms others in extracting urban built-up area information from high-resolution remote sensing satellite imagers with diverse spectral information and complex texture structure. Two processing methods are also proposed to significantly improve the accuracy of the model. Both the sliding window method and conditional random fields processing demonstrate an excellent performance in extracting information from high-resolution remote sensing images and show high application value for large-scale remote sensing images.关键词:convolutional neural network (CNN);attention mechanism;remote sensing image;urban built-up area;information extraction41|20|3更新时间:2024-05-07
摘要:ObjectiveThe urban built-up area is an important source of basic information for urban research and serves as a prerequisite for the regional planning and implementation of the spatial layout of urban functions. Given the recent developments in Earth observational technologies and improvements in the resolution of remote sensing images, accurately and efficiently extracting information on urban built-up areas has become possible. However, due to the complex environment of urban built-up areas in high-resolution remote sensing images and the variations in their locations and development scales, various forms of remote sensing image representations increase the difficulty of using traditional information extraction methods for urban built-up areas. Recent studies show that deep learning algorithms have significant advantages in processing of large-scale images. This paper then examines these deep learning algorithms and reviews previous research that apply deep convolutional neural network methods, which have been widely used in computer vision to extract information on urban built-up areas from high-resolution satellite images. This article also improves the application of computer image processing technology in the field of remote sensing.MethodSemantic image segmentation is crucial in image processing and computer vision. This process recognizes an image at the pixel level and then labels the object category to which each pixel in the image belongs. Based on the deep convolutional neural network oriented to semantic image segmentation, this paper uses the refinement module for the feature map and the attention module of the channel domain to improve the original DeepLab v3 network. The feature refinement module accurately obtains relevant information between pixels and reduces the grid effect. Afterward, the network model processes the feature map through atrous spatial pyramid pooling. The decoding part of the network extracts the attention information of the channel domain and then weighs the low-level features to achieve a better representation and to restore the detailed information. Afterward, the urban built-up area is extracted via the sliding window prediction and full connection conditional random fields methods, both of which can be applied to extract urban built-up areas with better accuracy. However, the use of deep learning algorithms is prone to overfitting and poor robustness. Accordingly, data augmentation and extension are used to enhance the capabilities of the model. Specifically, we use rotation and filter operations while cutting the original training and verification data into 256×256 samples.ResultExtracting information from remote sensing images involves an effective mining and category judgment of such information. The experimental data are taken from Gaofen-2 remote sensing images of Sanya and Haikou cities in Hainan Province, China. These images are specifically taken at the Qiongshan District of Haikou City and at the Tianya District, Jiyang District, and the sea surrounding the Jiaotouding Island of Sanya City. Given their weak sample processing ability, traditional classification algorithms have achieved an accuracy rate of no higher than 85% in the experiments. Meanwhile, deep learning methods, such as SegNet and DeepLab v3, have relatively high accuracy and better performance in extracting urban built-up area information from remote sensing satellite images. By using the refinement module for the feature map and the attention module of the channel domain, this paper improves the accuracy rate of the original DeepLab v3 network by 1.95%. Meanwhile, the proposed method has an accuracy rate of above 93%, a Kappa coefficient of greater than 0.837, a missed detection rate of less than 4.9%, and a false alarm rate of below 2.1%. This method can effectively extract urban built-up areas from large-scale high spatial resolution remote sensing images, and its extraction results are the closest to the actual situation.ConclusionThe comparative experiment shows that the proposed method outperforms others in extracting urban built-up area information from high-resolution remote sensing satellite imagers with diverse spectral information and complex texture structure. Two processing methods are also proposed to significantly improve the accuracy of the model. Both the sliding window method and conditional random fields processing demonstrate an excellent performance in extracting information from high-resolution remote sensing images and show high application value for large-scale remote sensing images.关键词:convolutional neural network (CNN);attention mechanism;remote sensing image;urban built-up area;information extraction41|20|3更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0