
最新刊期
卷 25 , 期 1 , 2020
- 摘要:Deep learning models have been widely used in multimedia signal processing. They considerably improve the performance of signal processing tasks by introducing nonlinearities but lack analytical formulation of optimum and optimality conditions due to their black-box architectures. In recent years, analyzing the optimal formulation and approximating the deep learning models based on classical signal processing theory have been popular for multimedia, that is, transform/basis projection-based models. This paper presents and analyzes the mathematical models and their theoretical bounds for high-dimensional nonlinear and irregular structured methods based on the fundamental theories of signal processing. The main content includes structured sparse representation, frame-based deep networks, multilayer convolutional sparse coding, and graph signal processing. We begin with sparse representation models based on group and hierarchical sparsities with their optimization methods and subsequently analyze the deep/multilayer networks developed using semi-discrete frames and convolutional sparse coding. We also present graph signal processing models by extending classical signal processing to the non-Euclidean geometry. Recent advances in these topics achieved by domestic and foreign researchers are compared and discussed. Structured sparse representation introduces the mixed norms to formulate a group Lasso problem for structural information, which can be solved using proximal method or network flow optimization. Considering that structured sparse representation is still based on the linear projection onto dictionary atoms, frame-based deep networks are developed to extend the semi-discrete frames in multiscale geometric analysis. They inherit the scale and directional decomposition led by frame theory and introduce nonlinearities to guarantee deformation stability. Inspired by scattering networks, multilayer convolutional sparse coding introduces combined regularization into sparse representation to fit max pooling operation. Sparse representation of irregular multiscale structures can be achieved with the trained overcomplete dictionary in a recursive manner. Graph signal processing extends conventional signal processing into non-Euclidean spaces. When integrated with convolutional neural networks, graph neural networks learn complex relational networks and are desirable for data-driven large-scale high-dimensional irregular signal processing. This paper forecasts the future work of mathematical theories and models for multimedia signal processing. This research is useful for developing a generalized graph signal processing model for large-scale irregular multimedia signals by analyzing the mathematical properties and linkages of conventional signal processing and graph spectral model.关键词:structured sparse representation;frame-based deep convolutional network;multi-layer convolutional sparse coding;graph signal processing;multimedia signal processing25|33|1更新时间:2024-05-07
- 摘要:Traditional visual sensing is based on RGB optical and video imaging data and has achieved great success with the development of computer vision. However, traditional RGB optical imaging has limitations in spectral characterization, sampling effectiveness, measurement accuracy, and operating conditions. The new mechanism of visual sensing and new data processing technology have been developed rapidly recently, bringing considerable opportunities for improving sensing and cognitive capability. The developments are also endowed with important theoretical merits and offer a great chance for major application requirements. This report describes the development status and trends on visual sensing, including laser scanning, sonar, new dynamic imaging system, computational imaging, pose sensing, and other related fields. Researches on laser scanning are increasingly being conducted. In terms of algorithm developments for point cloud data processing, many domestic organizations and teams have reached international synchronization or leading level. Moreover, the application of point cloud data is more extensively shown by Chinese teams. However, at present, several foreign countries still show considerable advantages in hardware equipment, data acquisition, and pre-processing. In terms of event-based (i.e., dynamic vision sensor, DVS) imaging, domestic teams have focused on target classification, target recognition and tracking, stereo matching, and super resolution, achieving progress and breakthroughs. Hardware design and production technology of DVS are concentrated in foreign research institutes, and almost all these institutes have a research history of about 10 years. Few domestic institutions can independently produce DVS. Generally, although domestic DVS research started relatively late, the development in recent years has been very rapid. Moving target detection and underwater acoustic imaging for small static targets have always been the focus in the field of underwater information technology. Underwater acoustic imaging has the characteristics of military and civil applications. Domestically, high-tech research is mainly supported by civil sectors. For example, synthetic aperture sonar was developed under sustained national support. Substantial breakthroughs, such as in common mechanism, key technologies, and demonstration applications, are difficult to achieve in a short time. Therefore, sustained and stable support guarantees technological breakthroughs and industrialization. Learning-based visual positioning and 3D information processing have made remarkable progress, but many problems remain. In non-cooperative target pose imaging perception, many countries and organizations with advanced technology for space have carried out numerous investigations, and results from some of these endeavors have been successfully applied to space operations in practice. By contrast, visual measurement of non-cooperative targets started late in China. Related programs are under way, such as for rendezvous and docking of space non-cooperative targets and on-orbit service of space robots. However, most of the related investigations remain in the stage of theoretical research and ground experiment verification, and no mature engineering application is available. According to the literature survey, at present, in the field of visual sensing, domestic institutions and teams have made substantial progress in data processing and application. However, lags are observable, especially in the development of related hardware. Laser scanning imaging has a large amount of data and abundant information but lacks semantic information. Research has emerged in the frontiers of unmanned driving, virtual reality, and augmented reality. Wide applications are expected in the future, such as in the minimal description of massive 3D point cloud data and cross-dimensional structure description. DVS has a research history of over 10 years and has progressed in SLAM, tracking, reconfiguration, and other fields. The most evident advantages of DVS are in capturing high-speed moving objects and in high-efficiency and low-cost processing. Moreover, the real-time background filtering function of DVS has great prospects in unmanned driving and trajectory analysis, which will attract much attention for wide applications. The development of small-target detection technology in deep-sea area can be used in deep-sea resource development, protection of marine rights, search and rescue, and military applications. However, inadequacy in the sonar equipment for deep-sea small-target detection seriously restricts applications. Two new system imaging sonars, namely, high-speed imaging sonar based on frequency division multiple-input multiple-output and multi-static imaging sonar, are expected to improve the detection rate and recognition rate for underwater small targets. Robustness is critical for visual positioning and 3D information processing. Intelligent methods can solve the problems of visual positioning and 3D information processing. At present, the pose perception algorithm still shows low efficiency, is imperfect, and requires further investigation. Space operations have prerequisites, including relative pose of space non-cooperative target, reconstruction of 3D structure of target, and recognition of feature parts of target. The model information of the target itself can be totally or partly known. Thus, making full use of the priori information of the target model can greatly help solve the target position. Pose tracking based on 3D model to obtain the initial pose of a target is expected to be a future hotspot. In addition, in the tide of artificial intelligence, how to combine it with pose perception is worthy of exploration. Object position and attitude perception based on vision system are crucial for promoting the development of future space operation, including space close-range operation scenarios (e.g., target perception, docking, and capture), small autonomous aircraft, ground intelligent vehicles, and mobile robots. The prospects are given in this paper, which may provide a reference for researchers of related fields.关键词:visual sensing;laser scanning;synthetic aperture sonar;new dynamic imaging system;computational imaging;pose sensing61|54|2更新时间:2024-05-07
Review

-
 摘要:ObjectiveImage compression, which aims to remove redundant information in an image, is a popular issue in image processing and computer vision. In recent years, image compression based on deep learning has attracted much attention of scholars in the field of image processing. Image compression using convolutional neural networks (CNNs) can be roughly divided into two categories. One is the image compression method based on the end-to-end convolutional network. The other category is CNNs combined with the traditional image compression method, which uses CNNs to deeply perceive the image content and obtains salient regions. High-quality coding is then applied to the salient regions, and lower-quality coding is used for non-significant regions to improve the visual quality of the compressed reconstructed images. However, in the latter method, the quality of the reconstructed image is often considerably affected because there is no effective perception of the image content information. In view of the effectiveness of image content perception, the influence of scale on image content detection is disregarded in several conventionally proposed salient region detection methods. Furthermore, the difference in size between the input image and the output saliency map is not considered, which limits the model's perception domain to the image. Consequently, several salient objects in the original image cannot be effectively perceived, which affects the reconstructed image's quality in the subsequent compression. A novel image compression method based on multi-scale depth feature salient region (MS-DFSR) detection is proposed in the current study to deal with this problem.MethodImproved CNNs are used to detect the depth features of multi-scale images. For multi-scale images, with the help of the scale space concept, a plurality of saliency maps is generated by inputting an image into the MS-DFSR model using a pyramid structure to complete the detection of multi-scale saliency regions. Scale selection, in the presence of an extremely large scale, causes the resulting salient area to become too divergent and loses salient meaning. Therefore, two scales are used in this work. The first one is the standard output scale of the network, and the second scale is the larger scale adopted in this work. The latter scale is used to effectively detect multiple salient objects in an image and perceive the image content effectively. For depth features' salient region detection, we replace the fully connected layer and the fourth max pooling layer with a global average pooling layer and an avg pooling layer in order to retain spatial location information on multiple salient objects in an image as much as possible. Then, the salient areas of different scales that are detected by MS-DFSR are obtained. To increase the perceived domain of an image and the perceived image content effectively, the size of the salient region map is adaptively adjusted according to the size of the input image by considering the difference between the input and output salient image sizes. Meanwhile, a Gaussian function is introduced to filter the salient region, retain the original image content information, and obtain a multi-scale fusion saliency region map. Finally, we complete image compression and reconstruction by combining the obtained multi-scale saliency region map with image coding methods. To protect the image's salient content and improve the reconstructed image's quality, the salient regions of an image are compressed using near-lossless and lossy compression methods, such as joint photographic experts' group (JPEG) and set partitioning in hierarchical trees (SPIHT), on the non-salient regions.ResultWe compare our model with three traditional compression methods, namely, JPEG, SPIHT, and run-length encoding (RLE) compression techniques. The experimental datasets include two public datasets, namely, Kodak PhotoCD and Pascal Voc. The quantitative evaluation metrics (higher is better) include the peak signal-to-noise ratio (PSNR), the structural similarity index measure (SSIM), and a modified PSNR metric based on HVS (PSNR-HVS). Experiment results show that our model outperforms all the other traditional methods on the Kodak PhotoCD and Pascal Voc datasets. The saliency map shows that our model can produce results that cover multiple salient objects and improve the effective perception of image content. We compare the image compression method based on MS-DFSR detection with the image compression method based on single-scale depth feature salient region (SS-DFSR) detection, and the validity of the MS-DFSR detection model is verified. Comparative experiments demonstrate that the proposed compression method improves image compression quality. The quality of the image reconstructed using the proposed compression method is higher than that using the JPEG image compression method. When the code rate is approximately 0.39 bpp on the Kodak PhotoCD dataset, PSNR is improved by 2.23 dB, SSIM by 0.024, and PSNR-HVS by 2.07. On the Pascal Voc dataset, PSNR, SSIM, and PSNR-HVS increase by 1.63 dB, 0.039, and 1.57, respectively. At the same time, when MS-DFSR is combined with SPIHT and RLE compression technology on the Kodak PhotoCD dataset, PSNR is increased by 1.85 dB and 1.98 dB, respectively. SSIM is improved by 0.006 and 0.023, respectively, and PSNR-HVS is increaseal by 1.90 and 1.88, respectively.ConclusionThe proposed image compression method using multi-scale depth features exhibits better performance than traditional image compression methods because the proposed method effectively reduces image content loss by improving the effectiveness of image content perception during the image compression process. Consequently, the quality of the reconstructed image can be improved significantly.关键词:image compression;multi-scale depth features;saliency region detection;convolutional neural networks (CNNs);peak signal to noise ratio (PSNR);structural similarity (SSIM)19|21|2更新时间:2024-05-07
摘要:ObjectiveImage compression, which aims to remove redundant information in an image, is a popular issue in image processing and computer vision. In recent years, image compression based on deep learning has attracted much attention of scholars in the field of image processing. Image compression using convolutional neural networks (CNNs) can be roughly divided into two categories. One is the image compression method based on the end-to-end convolutional network. The other category is CNNs combined with the traditional image compression method, which uses CNNs to deeply perceive the image content and obtains salient regions. High-quality coding is then applied to the salient regions, and lower-quality coding is used for non-significant regions to improve the visual quality of the compressed reconstructed images. However, in the latter method, the quality of the reconstructed image is often considerably affected because there is no effective perception of the image content information. In view of the effectiveness of image content perception, the influence of scale on image content detection is disregarded in several conventionally proposed salient region detection methods. Furthermore, the difference in size between the input image and the output saliency map is not considered, which limits the model's perception domain to the image. Consequently, several salient objects in the original image cannot be effectively perceived, which affects the reconstructed image's quality in the subsequent compression. A novel image compression method based on multi-scale depth feature salient region (MS-DFSR) detection is proposed in the current study to deal with this problem.MethodImproved CNNs are used to detect the depth features of multi-scale images. For multi-scale images, with the help of the scale space concept, a plurality of saliency maps is generated by inputting an image into the MS-DFSR model using a pyramid structure to complete the detection of multi-scale saliency regions. Scale selection, in the presence of an extremely large scale, causes the resulting salient area to become too divergent and loses salient meaning. Therefore, two scales are used in this work. The first one is the standard output scale of the network, and the second scale is the larger scale adopted in this work. The latter scale is used to effectively detect multiple salient objects in an image and perceive the image content effectively. For depth features' salient region detection, we replace the fully connected layer and the fourth max pooling layer with a global average pooling layer and an avg pooling layer in order to retain spatial location information on multiple salient objects in an image as much as possible. Then, the salient areas of different scales that are detected by MS-DFSR are obtained. To increase the perceived domain of an image and the perceived image content effectively, the size of the salient region map is adaptively adjusted according to the size of the input image by considering the difference between the input and output salient image sizes. Meanwhile, a Gaussian function is introduced to filter the salient region, retain the original image content information, and obtain a multi-scale fusion saliency region map. Finally, we complete image compression and reconstruction by combining the obtained multi-scale saliency region map with image coding methods. To protect the image's salient content and improve the reconstructed image's quality, the salient regions of an image are compressed using near-lossless and lossy compression methods, such as joint photographic experts' group (JPEG) and set partitioning in hierarchical trees (SPIHT), on the non-salient regions.ResultWe compare our model with three traditional compression methods, namely, JPEG, SPIHT, and run-length encoding (RLE) compression techniques. The experimental datasets include two public datasets, namely, Kodak PhotoCD and Pascal Voc. The quantitative evaluation metrics (higher is better) include the peak signal-to-noise ratio (PSNR), the structural similarity index measure (SSIM), and a modified PSNR metric based on HVS (PSNR-HVS). Experiment results show that our model outperforms all the other traditional methods on the Kodak PhotoCD and Pascal Voc datasets. The saliency map shows that our model can produce results that cover multiple salient objects and improve the effective perception of image content. We compare the image compression method based on MS-DFSR detection with the image compression method based on single-scale depth feature salient region (SS-DFSR) detection, and the validity of the MS-DFSR detection model is verified. Comparative experiments demonstrate that the proposed compression method improves image compression quality. The quality of the image reconstructed using the proposed compression method is higher than that using the JPEG image compression method. When the code rate is approximately 0.39 bpp on the Kodak PhotoCD dataset, PSNR is improved by 2.23 dB, SSIM by 0.024, and PSNR-HVS by 2.07. On the Pascal Voc dataset, PSNR, SSIM, and PSNR-HVS increase by 1.63 dB, 0.039, and 1.57, respectively. At the same time, when MS-DFSR is combined with SPIHT and RLE compression technology on the Kodak PhotoCD dataset, PSNR is increased by 1.85 dB and 1.98 dB, respectively. SSIM is improved by 0.006 and 0.023, respectively, and PSNR-HVS is increaseal by 1.90 and 1.88, respectively.ConclusionThe proposed image compression method using multi-scale depth features exhibits better performance than traditional image compression methods because the proposed method effectively reduces image content loss by improving the effectiveness of image content perception during the image compression process. Consequently, the quality of the reconstructed image can be improved significantly.关键词:image compression;multi-scale depth features;saliency region detection;convolutional neural networks (CNNs);peak signal to noise ratio (PSNR);structural similarity (SSIM)19|21|2更新时间:2024-05-07 -
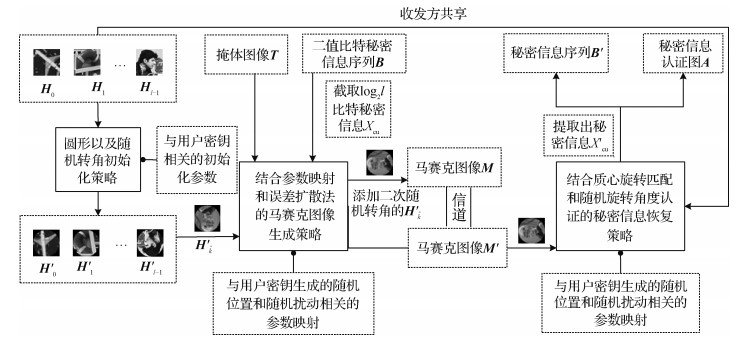 摘要:ObjectiveTraditional search-based coverless information hiding usually searches natural and unmodified carriers that contain appropriate secret vectors to transmit secret information. However, for natural images and texts, the ability to express irrelevant secret information is low. Thus, the hidden capacity is low. Search-based coverless information hiding cannot avoid the dense transmission of massive carriers that attract attacks easily and results in distorted secret information. Texture-based coverless information hiding usually divides sample texture image into several blocks, creating the mapping relationship between texture blocks and secret segments. Although such methods generated stego texture images by sample texture synthesis, they can only generate simple unnatural texture images. Mosaic-based information hiding can generate meaningful stego images, but in essence, such methods are modification-based information hiding, and they inevitably leave modification traces in carriers and have no authentication strategy. Therefore, verifying the authenticity of recovered secret information is impossible. Moreover, mosaic-based information hiding typically uses the LSB(least significant bit)-based modification embedding strategy for a large embedding capacity to embed the transformation parameters. The LSB-based embedding strategy is sensitive to attacks, and the embedded information is easily lost when suffering attacks. To address these problems, this study proposed a generative camouflage method combined with block rotation and photo mosaic.MethodIn the embedding, the proposed method transformed grayscale images into circle images with pseudo-random angles by user keys to construct photo mosaics and then generated random integer coordinate sequence to determine the hidden positions of secret bit strings. For each hidden position, a circle image related to user key and position was placed to express secret bits, and then the random angle related to user key and position was added for authentication. For each non-hidden position, a circle image similar to cover image pixel was set to conceal the secret image, and the added random perturbation angle precluded distinguishing hidden and non-hidden positions. The deviation caused by the placement of the circle image was scattered around unprocessed pixels by the error diffusion method to form the stego photo mosaic image. In the extraction, coordinates for all secret bits in the stego photo mosaic image were obtained by user key, and circle images expressing secret bits were fetched. The centroid of each circle image that expresses secret bits was normalized into the right half-axis and then identified by the strategy of centroid rotation matching. Each circle image index was found to extract the hidden secret bits by the minimum quadratic difference distance. To authenticate the correctness of each circle image fetched secret bits, the factual and theory angles were compared, where the minimum quadratic difference distance of the factual angle, and the theory angle was computed by the user key, and the fetched secret bits. If the factual angle equals the theory angle, then the extracted secret bits are correctly recovered.ResultThe proposed method regards each circle image as a hidden unit and only involves the rotation of circle images without any modification. The added random rotation angles also provide the security assurance for the specific user to extract secret information and conduct angle authentication. Only the user with the correct user key can eliminate the influence of random rotation angles and extract the correct secret information with its corresponding authentication information. Moreover, the proposed method uses photo mosaic to hide secret information. The method is robust in anti-attacks and has good authentication accuracy. At the same time, the proposed strategy relies entirely on the user's key and has high security. The experiments show that secret information can be completely recovered only by the correct key. Whether one or more user key parameters are changed, the changed user key parameters lead to the inaccurate extraction of secret information. In addition, in case of JPEG compression attacks with a quality factor of 50~80 and random rotation angle attacks, the embedded secret information can be completely recovered. Even with salt-and-pepper noise attacks of 8%~20%, the error rate(ER) of extracted information remains approximately 5%. The authentication success rates of the restored information are all above 80%.ConclusionThe proposed method uses randomly placed circle images to express secret information without any modification. The method can use photo mosaic to generate meaningful hidden carrier images and avoid the high cost of database creation and searching of the search-based coverless information hiding. The proposed method combines the parameter mapping and error diffusion mosaic image generation strategy to place stego circle images in their corresponding positions and then generate the stego mosaic image, avoiding the dense transmission of massive carriers in search-based coverless information hiding. Compared with the texture-based coverless information hiding, the proposed method can generate meaningful stego photo mosaic images, avoiding the generation of meaningless texture images in texture-based coverless information hiding. Even during attacks, each circle image expressed secret bits and its placement angle are not easily lost. The proposed method can extract secret information by centroid rotation matching and random rotation angle strategy based on user keys and improve the accuracy of secret information recognition.关键词:photo mosaic;coverless;generative hiding;centroid rotation matching;error diffusion;random angular authentication118|49|2更新时间:2024-05-07
摘要:ObjectiveTraditional search-based coverless information hiding usually searches natural and unmodified carriers that contain appropriate secret vectors to transmit secret information. However, for natural images and texts, the ability to express irrelevant secret information is low. Thus, the hidden capacity is low. Search-based coverless information hiding cannot avoid the dense transmission of massive carriers that attract attacks easily and results in distorted secret information. Texture-based coverless information hiding usually divides sample texture image into several blocks, creating the mapping relationship between texture blocks and secret segments. Although such methods generated stego texture images by sample texture synthesis, they can only generate simple unnatural texture images. Mosaic-based information hiding can generate meaningful stego images, but in essence, such methods are modification-based information hiding, and they inevitably leave modification traces in carriers and have no authentication strategy. Therefore, verifying the authenticity of recovered secret information is impossible. Moreover, mosaic-based information hiding typically uses the LSB(least significant bit)-based modification embedding strategy for a large embedding capacity to embed the transformation parameters. The LSB-based embedding strategy is sensitive to attacks, and the embedded information is easily lost when suffering attacks. To address these problems, this study proposed a generative camouflage method combined with block rotation and photo mosaic.MethodIn the embedding, the proposed method transformed grayscale images into circle images with pseudo-random angles by user keys to construct photo mosaics and then generated random integer coordinate sequence to determine the hidden positions of secret bit strings. For each hidden position, a circle image related to user key and position was placed to express secret bits, and then the random angle related to user key and position was added for authentication. For each non-hidden position, a circle image similar to cover image pixel was set to conceal the secret image, and the added random perturbation angle precluded distinguishing hidden and non-hidden positions. The deviation caused by the placement of the circle image was scattered around unprocessed pixels by the error diffusion method to form the stego photo mosaic image. In the extraction, coordinates for all secret bits in the stego photo mosaic image were obtained by user key, and circle images expressing secret bits were fetched. The centroid of each circle image that expresses secret bits was normalized into the right half-axis and then identified by the strategy of centroid rotation matching. Each circle image index was found to extract the hidden secret bits by the minimum quadratic difference distance. To authenticate the correctness of each circle image fetched secret bits, the factual and theory angles were compared, where the minimum quadratic difference distance of the factual angle, and the theory angle was computed by the user key, and the fetched secret bits. If the factual angle equals the theory angle, then the extracted secret bits are correctly recovered.ResultThe proposed method regards each circle image as a hidden unit and only involves the rotation of circle images without any modification. The added random rotation angles also provide the security assurance for the specific user to extract secret information and conduct angle authentication. Only the user with the correct user key can eliminate the influence of random rotation angles and extract the correct secret information with its corresponding authentication information. Moreover, the proposed method uses photo mosaic to hide secret information. The method is robust in anti-attacks and has good authentication accuracy. At the same time, the proposed strategy relies entirely on the user's key and has high security. The experiments show that secret information can be completely recovered only by the correct key. Whether one or more user key parameters are changed, the changed user key parameters lead to the inaccurate extraction of secret information. In addition, in case of JPEG compression attacks with a quality factor of 50~80 and random rotation angle attacks, the embedded secret information can be completely recovered. Even with salt-and-pepper noise attacks of 8%~20%, the error rate(ER) of extracted information remains approximately 5%. The authentication success rates of the restored information are all above 80%.ConclusionThe proposed method uses randomly placed circle images to express secret information without any modification. The method can use photo mosaic to generate meaningful hidden carrier images and avoid the high cost of database creation and searching of the search-based coverless information hiding. The proposed method combines the parameter mapping and error diffusion mosaic image generation strategy to place stego circle images in their corresponding positions and then generate the stego mosaic image, avoiding the dense transmission of massive carriers in search-based coverless information hiding. Compared with the texture-based coverless information hiding, the proposed method can generate meaningful stego photo mosaic images, avoiding the generation of meaningless texture images in texture-based coverless information hiding. Even during attacks, each circle image expressed secret bits and its placement angle are not easily lost. The proposed method can extract secret information by centroid rotation matching and random rotation angle strategy based on user keys and improve the accuracy of secret information recognition.关键词:photo mosaic;coverless;generative hiding;centroid rotation matching;error diffusion;random angular authentication118|49|2更新时间:2024-05-07 -
 摘要:ObjectiveIn modern times, individuals and communities have devoted increasing attention to privacy problems. With the development of multidirectional technologies, the digital secret key exposes its insufficient in vulnerable to loss, easy to be stolen and difficult to remember. Although biometrics exhibits great advantages in identity recognition technology due to their uniqueness and stability, they also characterized by inaccuracy due to feature instability. Moreover, the security problem of the biometric template should be urgently addressed. Therefore, the biometric key generation and protection technology, which is a branch of biometric encryption technology, has emerged. This technology combines biometrics and cryptography and retains the properties of the biometrics and the secret key while ensuring the security of the biological data. Although the secret key is the most important factor in any cryptosystem, the security of the biometric data is as critical as the management of the keys for the biometric key. To construct a bio-key that can be used in data transmission and can keep a good balance between the ambiguity of the biometrics and accuracy of the cryptography, this study proposes a data encryption and decryption scheme using fingerprint bio-key combing with time stamp.MethodFirst, all minutiae from the fingerprint of the communication sender are extracted. The fingerprint feature-line set of the communication sender is then generated based on the relative information among the minutiae. A 2D coordinate model is generated and segmented by two segmentation metrics (horizontal and vertical). The size of the segmentation metrics can be adjusted through practical application. The feature lines in the set are individually mapped into the given 2D coordinate model to generate a 2D 0-1 matrix called fingerprint feature-line set matrix. The elements in this matrix are multiplied with a confidential random matrix stored by the sender to obtain a fingerprint bio-key matrix. The fingerprint bio-key is the bit string transformed from the fingerprint bio-key matrix, which is a connection of the individual lines in the matrix. The bit string is also protected by this random matrix in the proposed scheme. Then, a preset number, which is predefined by the two communicators, and time stamp are utilized to generate a 256-bit long SHA256 hash value. The hash value is processed to obtain an auxiliary bit-string, which is as long as the fingerprint bio-key, and do the xor(enclusive OR) operation with the fingerprint bio-key to obtain the auxiliary data, which is transmitted to the receiver and used for the fingerprint bio-key recovery. Finally, the fingerprint bio-key of the communication sender is used to encrypt the plain communication data. The encrypted cipher and auxiliary data, along with the SHA256 hash value of the confidential random matrix, are transmitted to the communication receiver in the final step of the encryption stage. At the decryption stage, the communication receiver should use the same preset number and the time stamp to generate the same auxiliary data to obtain the fingerprint bio-key of the communication sender so that the communication receiver can decrypt the cipher date and obtain the original plain data with the help of the sender's fingerprint bio-key. In addition, the authentication of the communication sender is illustrated. When the receiver requests the identity authentication of the sender, the communication sender should provide the regenerated fingerprint bio-key through the same key generation method and calculate the similarity value between the original and regenerated one. The authentication of the communication sender is successful only if the similarity value is not less than the predefined threshold. Moreover, the receiver should check the SHA256 hash value of the received bio-key, as well as the one provided by the sender, which means that only the two hash values are equal, the identity authentication of the sender is complete.ResultWe simulated the data encryption and decryption interfaces for the proposed scheme. Then, to prove the identity authentication function of the generated fingerprint bio-key, we tested the genuine acceptance rate (GAR) and the FAR (false acceptance rate) of the regenerated fingerprint bio-key for the genuine and impostors based on our fingerprint database. The test data proved that the fingerprint bio-key, which also served as a digital identity, was available and verifiable. In addition, the GAR of the regenerated fingerprint bio-key of the genuine reached 99.8%, whereas that of the impostor is close to 0.2%. Moreover, the proposed scheme can be applied in many different scenarios, such as instant communication and symmetric encryption algorithms (e.g., aclvanced encryption standard (AES) and SM4). The length of the fingerprint bio-key can be adjusted using different segmentation metrics.ConclusionThe proposed scheme utilizes a fingerprint key generation method to generate the unique fingerprint bio-key of the communication sender. In addition, the scheme determines the uniqueness and undeniability of every communication event and implements the vital conception "one secret key, one event" of the fingerprint bio-key recovery using time stamp. The revocability of the fingerprint bio-key was realized with the help of the confidential random matrix, which effectively ensures the security of the fingerprint data. Then, a detailed analysis of the availability and security of the proposed scheme is conducted. The innovations and advantages are also identified. However, these experiments are mainly based on the laboratory fingerprint database, so the influence of different feature extraction methods on our scheme is not investigated. Thus, further research is imminent.关键词:fingerprint bio-key;time stamp;preset number;hash value;random matrix;segmentation metric20|22|0更新时间:2024-05-07
摘要:ObjectiveIn modern times, individuals and communities have devoted increasing attention to privacy problems. With the development of multidirectional technologies, the digital secret key exposes its insufficient in vulnerable to loss, easy to be stolen and difficult to remember. Although biometrics exhibits great advantages in identity recognition technology due to their uniqueness and stability, they also characterized by inaccuracy due to feature instability. Moreover, the security problem of the biometric template should be urgently addressed. Therefore, the biometric key generation and protection technology, which is a branch of biometric encryption technology, has emerged. This technology combines biometrics and cryptography and retains the properties of the biometrics and the secret key while ensuring the security of the biological data. Although the secret key is the most important factor in any cryptosystem, the security of the biometric data is as critical as the management of the keys for the biometric key. To construct a bio-key that can be used in data transmission and can keep a good balance between the ambiguity of the biometrics and accuracy of the cryptography, this study proposes a data encryption and decryption scheme using fingerprint bio-key combing with time stamp.MethodFirst, all minutiae from the fingerprint of the communication sender are extracted. The fingerprint feature-line set of the communication sender is then generated based on the relative information among the minutiae. A 2D coordinate model is generated and segmented by two segmentation metrics (horizontal and vertical). The size of the segmentation metrics can be adjusted through practical application. The feature lines in the set are individually mapped into the given 2D coordinate model to generate a 2D 0-1 matrix called fingerprint feature-line set matrix. The elements in this matrix are multiplied with a confidential random matrix stored by the sender to obtain a fingerprint bio-key matrix. The fingerprint bio-key is the bit string transformed from the fingerprint bio-key matrix, which is a connection of the individual lines in the matrix. The bit string is also protected by this random matrix in the proposed scheme. Then, a preset number, which is predefined by the two communicators, and time stamp are utilized to generate a 256-bit long SHA256 hash value. The hash value is processed to obtain an auxiliary bit-string, which is as long as the fingerprint bio-key, and do the xor(enclusive OR) operation with the fingerprint bio-key to obtain the auxiliary data, which is transmitted to the receiver and used for the fingerprint bio-key recovery. Finally, the fingerprint bio-key of the communication sender is used to encrypt the plain communication data. The encrypted cipher and auxiliary data, along with the SHA256 hash value of the confidential random matrix, are transmitted to the communication receiver in the final step of the encryption stage. At the decryption stage, the communication receiver should use the same preset number and the time stamp to generate the same auxiliary data to obtain the fingerprint bio-key of the communication sender so that the communication receiver can decrypt the cipher date and obtain the original plain data with the help of the sender's fingerprint bio-key. In addition, the authentication of the communication sender is illustrated. When the receiver requests the identity authentication of the sender, the communication sender should provide the regenerated fingerprint bio-key through the same key generation method and calculate the similarity value between the original and regenerated one. The authentication of the communication sender is successful only if the similarity value is not less than the predefined threshold. Moreover, the receiver should check the SHA256 hash value of the received bio-key, as well as the one provided by the sender, which means that only the two hash values are equal, the identity authentication of the sender is complete.ResultWe simulated the data encryption and decryption interfaces for the proposed scheme. Then, to prove the identity authentication function of the generated fingerprint bio-key, we tested the genuine acceptance rate (GAR) and the FAR (false acceptance rate) of the regenerated fingerprint bio-key for the genuine and impostors based on our fingerprint database. The test data proved that the fingerprint bio-key, which also served as a digital identity, was available and verifiable. In addition, the GAR of the regenerated fingerprint bio-key of the genuine reached 99.8%, whereas that of the impostor is close to 0.2%. Moreover, the proposed scheme can be applied in many different scenarios, such as instant communication and symmetric encryption algorithms (e.g., aclvanced encryption standard (AES) and SM4). The length of the fingerprint bio-key can be adjusted using different segmentation metrics.ConclusionThe proposed scheme utilizes a fingerprint key generation method to generate the unique fingerprint bio-key of the communication sender. In addition, the scheme determines the uniqueness and undeniability of every communication event and implements the vital conception "one secret key, one event" of the fingerprint bio-key recovery using time stamp. The revocability of the fingerprint bio-key was realized with the help of the confidential random matrix, which effectively ensures the security of the fingerprint data. Then, a detailed analysis of the availability and security of the proposed scheme is conducted. The innovations and advantages are also identified. However, these experiments are mainly based on the laboratory fingerprint database, so the influence of different feature extraction methods on our scheme is not investigated. Thus, further research is imminent.关键词:fingerprint bio-key;time stamp;preset number;hash value;random matrix;segmentation metric20|22|0更新时间:2024-05-07 -
 摘要:ObjectiveAs a powerful image compression method, set partition coding (SPC) method effectively uses the correlation between the wavelet coefficients to obtain a higher data compression ratio, and it has been widely used for all types of image compression. The SPC method uses the idea of successive quantization approximation of the wavelet coefficient set, such as set partition coding system (SPACS), which partitions the coefficient set step-by-step to find significant coefficients and code them. A significance map was used to decide whether a set is significant, based on which set will be partitioned. If a set is significant, then SPC will output a location bit "1" and the set will be partitioned into 4 subsets; otherwise, the set is prepared for the next set coding operation. If set partition operations are conformable to the distribution of the insignificant coefficients, then location bits and unnecessary bits will be decreased. When the coefficient set is sparse, the SPC method can use fewer bits to encode the image. However, with the decrease of the bit plane, the sparseness of the coefficient set decreases, and the SPC method will waste many location and unnecessary bits, especially for lossless compression. To increase the lossless encoding performance of the set SPC method, we construct a set partition coding method that embeds a generalized tree classifier named SPACS_C.MethodThe previous SPC methods process all coordinate sets with "test before partition, " thereby increasing the number of location and unnecessary bits when the correlation between data decreases. SPACS_C calculates the bit costs of two different coding ways called "test before partition" and "partition before test" for each coordinate set. Then, it chooses the one with lower bit cost to process the set. The process method used in SPACS_C takes advantage of the data characteristics in which the sparseness of bottom bit-planes decrease rapidly in wavelet transformed images. SPACS_C performs the coding process in the domain of the wavelet transform of the image. Daubechies (4, 4) integer wavelet transform is used in this study. The level of wavelet transform is determined by the image size. For instance, a level of 5 is recommended for an image with a spatial size of 512×512. Similar to SPACS, a general tree (GT) is used to simultaneously represent the tree and square sets in the wavelet domain. The processing flow of SPACS_C is as follows:1)Initialization. Let the threshold n be most significant digit of the maximum of the wavelet coefficient and the list of significant points (LSP) be an empty list. Add all GTs into the list of insignificant points (LIP), where all GTs that have descendants are added into the list of insignificant sets (LIS). 2)Sorting pass. Perform the significant test for every entry (
摘要:ObjectiveAs a powerful image compression method, set partition coding (SPC) method effectively uses the correlation between the wavelet coefficients to obtain a higher data compression ratio, and it has been widely used for all types of image compression. The SPC method uses the idea of successive quantization approximation of the wavelet coefficient set, such as set partition coding system (SPACS), which partitions the coefficient set step-by-step to find significant coefficients and code them. A significance map was used to decide whether a set is significant, based on which set will be partitioned. If a set is significant, then SPC will output a location bit "1" and the set will be partitioned into 4 subsets; otherwise, the set is prepared for the next set coding operation. If set partition operations are conformable to the distribution of the insignificant coefficients, then location bits and unnecessary bits will be decreased. When the coefficient set is sparse, the SPC method can use fewer bits to encode the image. However, with the decrease of the bit plane, the sparseness of the coefficient set decreases, and the SPC method will waste many location and unnecessary bits, especially for lossless compression. To increase the lossless encoding performance of the set SPC method, we construct a set partition coding method that embeds a generalized tree classifier named SPACS_C.MethodThe previous SPC methods process all coordinate sets with "test before partition, " thereby increasing the number of location and unnecessary bits when the correlation between data decreases. SPACS_C calculates the bit costs of two different coding ways called "test before partition" and "partition before test" for each coordinate set. Then, it chooses the one with lower bit cost to process the set. The process method used in SPACS_C takes advantage of the data characteristics in which the sparseness of bottom bit-planes decrease rapidly in wavelet transformed images. SPACS_C performs the coding process in the domain of the wavelet transform of the image. Daubechies (4, 4) integer wavelet transform is used in this study. The level of wavelet transform is determined by the image size. For instance, a level of 5 is recommended for an image with a spatial size of 512×512. Similar to SPACS, a general tree (GT) is used to simultaneously represent the tree and square sets in the wavelet domain. The processing flow of SPACS_C is as follows:1)Initialization. Let the threshold n be most significant digit of the maximum of the wavelet coefficient and the list of significant points (LSP) be an empty list. Add all GTs into the list of insignificant points (LIP), where all GTs that have descendants are added into the list of insignificant sets (LIS). 2)Sorting pass. Perform the significant test for every entry ($i,j$ $i,j$ $i,j$ $n$ $n$ $n$ $c$ $\mathit{\boldsymbol{c}}$ $c$ ${2^n}$ $c$ ${2^{n + 1}}$ $c$ ${2^n}$ 关键词:set partition coding(SPC);classifier;lossless encoding;location bit;unnecessary bit45|59|0更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveSteel plates are important raw materials in industry. In its manufacturing process, a variety of surface defects inevitably arise. These surface defects have a negative effect on the appearance and performance of the product; thus, detecting and controlling them in time is necessary. At present, an increasing number of iron and steel manufacturing enterprises use the machine vision method to detect and identify steel-plate surface defects automatically. The defect detection of the steel-plate surface based on machine vision collects the image of the steel-plate surface by using a charge-coupled device camera. By image denoising and enhancement, the defect image is segmented, the defect features are extracted, and the defect classification is conducted. In image acquisition, being disturbed by the on-site environment of the production line is unavoidable, as are the reflection of the steel plate, the illumination environment or the instability of the optical elements, often resulting in the non-uniform illumination of the image. If the image is not enhanced, great interference in the detection and recognition of small surface defects of the steel plate would occur. The common characteristics of small defects on the steel plate surface are non-uniform gray scale, low contrast between defects and background, obscure edge, diverse and small shape, and a small proportion of a defective area in the entire image, which is even mixed with noise. The contrast between the surface defect of the steel plate and its background is low. To conduct subsequent image analysis and defect recognition effectively, we need to conduct image enhancement processing to emphasize the surface defect information. The purpose of image enhancement is to make the original image clear or emphasize interesting features, thereby improving the overall contrast of the image and enhancing the local details of the image, which has good visual effect and rich information features. On this basis, the surface defect target is segmented from the background by image segmentation; thus, the feature of the defect can be extracted and recognized in the future.MethodLow-contrast image enhancement methods often include histogram equalization (HE), Retinex model, homomorphic filtering, and gray transform. The HE algorithm is widely used because of its simple principle and easy implementation, but it cannot adapt to the local contrast of the image of small defects on the surface of the steel plate. The Retinex model algorithm is also a common method for low-contrast image enhancement. Based on this model, single-scale Retinex (SSR) and multi-scale Retinex (MSR) algorithms have emerged. These series of algorithms have achieved good results, but the computational complexity is high. Homomorphic filtering can also enhance low-contrast images. This method avoids the distortion of image directly processed by Fourier transform (FFT), but it also has problems, such as over-enhancement and poor enhancement effect in high-light regions. In low-contrast image enhancement, if the local contrast of the image is enhanced in the spatial domain and the detailed information is enhanced by high-pass processing in frequency domain; the spatial and frequency characteristics of the image are considered at the same time. Compared with Fourier transform, wavelet transform (WT) is a localized analysis of space and frequency. It refines the signal step-by-step by scaling and translation operations, and it finally achieves time subdivision at high frequency and frequency subdivision at low frequency, focusing on arbitrary details of the signal. The wavelet-homomorphic filtering algorithm is used in image enhancement to eliminate non-uniform illumination. First, the image is decomposed by wavelet transform, and then the low-frequency coefficients of wavelet are modified by homomorphic filtering, while the high-pass filtering is applied to the high-frequency coefficients. Then, the low-frequency coefficients and high-frequency coefficients of the processed wavelet are reconstructed to obtain the enhanced image to eliminate non-uniform illumination. After image enhancement with wavelet transform and homomorphic filtering, the surface defect target is segmented to obtain the surface defect area of the steel plate. Many methods are used in image segmentation. The common classical methods are threshold segmentation based on gray histogram and edge detection. Given the low contrast of small defects on the surface of the steel plate, the distribution of gray histogram of the image does not have obvious peaks and valleys; thus, obtaining satisfactory results for image segmentation by using threshold method alone is difficult. The edge detection methods of Roberts, Sobel, and Prewitt operators are also poor for this type of small defects with low contrast, and canny edge detection operator remains widely studied and applied, but the segmentation effect is greatly affected by the threshold. On this basis, this study uses the Otsu-Canny algorithm in defect edge detection. In other words, the method of maximum inter-class variance (Otsu method) is used to determine the adaptive threshold for the Canny operator to perform edge detection.ResultIn this study, the algorithm is used to study the multiple types of low-contrast surface small defects on the strip surface, thereby effectively eliminating the non-uniform illumination. The Otsu algorithm or Canny operator cannot easily detect these defects effectively, and the correct detection rate of the Otsu-Canny algorithm in this study is 96%.ConclusionAfter image enhancement with wavelet-homomorphic filtering, the Otsu-Canny algorithm is used to detect the edges of small defects with multiple types and low contrast on the surface of the steel plate, and good results are obtained. Image enhancement and image segmentation should focus not only on the effect of processing but also on the real-time performance of the algorithm. In steel-plate surface defect detection based on machine vision, a real-time algorithm can be used for conventional surface defects. This algorithm is suitable for small surface defects with low contrast. To improve the processing speed, the parallel algorithm of a high-performance processor graphic processing unit can greatly improve the speed of image processing, thereby satisfying the effectiveness and real-time performance of the algorithm.关键词:machine vision;surface defects;low contrast;wavelet transform (WT);homomorphic filtering44|50|7更新时间:2024-05-07
摘要:ObjectiveSteel plates are important raw materials in industry. In its manufacturing process, a variety of surface defects inevitably arise. These surface defects have a negative effect on the appearance and performance of the product; thus, detecting and controlling them in time is necessary. At present, an increasing number of iron and steel manufacturing enterprises use the machine vision method to detect and identify steel-plate surface defects automatically. The defect detection of the steel-plate surface based on machine vision collects the image of the steel-plate surface by using a charge-coupled device camera. By image denoising and enhancement, the defect image is segmented, the defect features are extracted, and the defect classification is conducted. In image acquisition, being disturbed by the on-site environment of the production line is unavoidable, as are the reflection of the steel plate, the illumination environment or the instability of the optical elements, often resulting in the non-uniform illumination of the image. If the image is not enhanced, great interference in the detection and recognition of small surface defects of the steel plate would occur. The common characteristics of small defects on the steel plate surface are non-uniform gray scale, low contrast between defects and background, obscure edge, diverse and small shape, and a small proportion of a defective area in the entire image, which is even mixed with noise. The contrast between the surface defect of the steel plate and its background is low. To conduct subsequent image analysis and defect recognition effectively, we need to conduct image enhancement processing to emphasize the surface defect information. The purpose of image enhancement is to make the original image clear or emphasize interesting features, thereby improving the overall contrast of the image and enhancing the local details of the image, which has good visual effect and rich information features. On this basis, the surface defect target is segmented from the background by image segmentation; thus, the feature of the defect can be extracted and recognized in the future.MethodLow-contrast image enhancement methods often include histogram equalization (HE), Retinex model, homomorphic filtering, and gray transform. The HE algorithm is widely used because of its simple principle and easy implementation, but it cannot adapt to the local contrast of the image of small defects on the surface of the steel plate. The Retinex model algorithm is also a common method for low-contrast image enhancement. Based on this model, single-scale Retinex (SSR) and multi-scale Retinex (MSR) algorithms have emerged. These series of algorithms have achieved good results, but the computational complexity is high. Homomorphic filtering can also enhance low-contrast images. This method avoids the distortion of image directly processed by Fourier transform (FFT), but it also has problems, such as over-enhancement and poor enhancement effect in high-light regions. In low-contrast image enhancement, if the local contrast of the image is enhanced in the spatial domain and the detailed information is enhanced by high-pass processing in frequency domain; the spatial and frequency characteristics of the image are considered at the same time. Compared with Fourier transform, wavelet transform (WT) is a localized analysis of space and frequency. It refines the signal step-by-step by scaling and translation operations, and it finally achieves time subdivision at high frequency and frequency subdivision at low frequency, focusing on arbitrary details of the signal. The wavelet-homomorphic filtering algorithm is used in image enhancement to eliminate non-uniform illumination. First, the image is decomposed by wavelet transform, and then the low-frequency coefficients of wavelet are modified by homomorphic filtering, while the high-pass filtering is applied to the high-frequency coefficients. Then, the low-frequency coefficients and high-frequency coefficients of the processed wavelet are reconstructed to obtain the enhanced image to eliminate non-uniform illumination. After image enhancement with wavelet transform and homomorphic filtering, the surface defect target is segmented to obtain the surface defect area of the steel plate. Many methods are used in image segmentation. The common classical methods are threshold segmentation based on gray histogram and edge detection. Given the low contrast of small defects on the surface of the steel plate, the distribution of gray histogram of the image does not have obvious peaks and valleys; thus, obtaining satisfactory results for image segmentation by using threshold method alone is difficult. The edge detection methods of Roberts, Sobel, and Prewitt operators are also poor for this type of small defects with low contrast, and canny edge detection operator remains widely studied and applied, but the segmentation effect is greatly affected by the threshold. On this basis, this study uses the Otsu-Canny algorithm in defect edge detection. In other words, the method of maximum inter-class variance (Otsu method) is used to determine the adaptive threshold for the Canny operator to perform edge detection.ResultIn this study, the algorithm is used to study the multiple types of low-contrast surface small defects on the strip surface, thereby effectively eliminating the non-uniform illumination. The Otsu algorithm or Canny operator cannot easily detect these defects effectively, and the correct detection rate of the Otsu-Canny algorithm in this study is 96%.ConclusionAfter image enhancement with wavelet-homomorphic filtering, the Otsu-Canny algorithm is used to detect the edges of small defects with multiple types and low contrast on the surface of the steel plate, and good results are obtained. Image enhancement and image segmentation should focus not only on the effect of processing but also on the real-time performance of the algorithm. In steel-plate surface defect detection based on machine vision, a real-time algorithm can be used for conventional surface defects. This algorithm is suitable for small surface defects with low contrast. To improve the processing speed, the parallel algorithm of a high-performance processor graphic processing unit can greatly improve the speed of image processing, thereby satisfying the effectiveness and real-time performance of the algorithm.关键词:machine vision;surface defects;low contrast;wavelet transform (WT);homomorphic filtering44|50|7更新时间:2024-05-07 -
 摘要:ObjectiveChinese ancient murals, as a type of painting on the wall, have a long history of 4000 years and are an indispensable part of Chinese ancient paintings. With the increasing abundance of digital mural images, classifying mural resources is becoming increasingly urgent. The core of mural image classification is how to construct the feature description of an object. In addition to expressing the object adequately, this description should be able to distinguish among different types of objects. However, ancient mural images have certain pluralism and subjectivity due to artificial drawing. Considering the subjective singularity and objective insufficiency of traditional mural image feature extraction, we propose a convolutional neural network based on classical AlexNet network model and feature fusion idea for the automatic classification of ancient mural images.MethodFirst, we define the optimizer as Adam with a learning rate of 0.001 through experiments. We then extract each convolution layer feature of AlexNet for classification. Through the comparison of running time and accuracy, we select the convolution layer to express mural features further. Second, we combine the idea of feature fusion and exchange the two convolution kernels to form channels 1 and 2. The convolution kernels of channel 1 are 11, 5, and 3, and those of channel 2 are 11, 3, and 5. The combination of this method constitutes a two-channel convolution feature extraction layer, which enables the model to utilize multilocal features fully. The overfitting phenomenon caused by numerous full-connection layers is considered. On the basis of the two-channel convolution feature extraction layer, we continue to compare the features of different full-connection layers and select further appropriate full-connection layer features to express mural images. Finally, a mural image classification model with a two-channel convolution layer and optimal full connection layer is presented. The proposed mural image classification model can be divided into three processes. 1) Mural image preprocessing. Given the lack of large mural datasets, we use image enhancement operations, such as zooming, brightness transformation, noise addition, and flipping, to enlarge the mural samples. An ancient mural image dataset, including Buddha, Bodhisattva, Buddhist disciples, secular figures, animals, plants, buildings, and auspicious cloud, is constructed. 2) Training stage of mural image classification model. The module has three stages. In the first stage, the model extracts the low-level features, such as the edge information of the trainset images. In the second stage, the two-channel network with different structures is used to abstract the features of the first stage. The features of the two channels are then obtained. In the last stage, the loss function training network model is constructed by fusing the features of the two channels. Feature fusion improves the robustness of the model and the capability of feature expression. 3) Training stage of mural image classification model. We use the network model with trained parameters to predict the classification results of test set samples. The classification accuracy, recall, and f1-score are obtained.ResultThrough the comparison of running time and accuracy, the comparative experimental results of different convolution layers show that in the AlexNet model, the third convolution layer is the most suitable network layer for this dataset. In addition, the accuracy rate will decrease if the number of layers is higher or lower than the number of layers in the paper. Similarly, the comparative experimental results of different full-connection layers show that the features of the three-layer full-connection layer are further stable and sufficient based on the two-channel convolution extraction layer. Therefore, a six-layer convolution neural network model, including a three-layer dual channel and three-layer full connection layer, is presented with five convolution layers in the two-channel model. The model achieves 85.39% accuracy on the constructed mural image dataset. Experimental results show that the accuracy of the model in most classes is the highest, and each evaluation index of the model is improved by approximately 5%, compared with the AlexNet model and several improved convolution neural network models. Compared with the classical model without pretraining, this model encounters increased difficulty in producing overfitting. Compared with the model with pretraining, the accuracy of the model is improved by approximately 1%~5%, and the cost is reduced in terms of hardware conditions, network structure, and memory consumption. These experimental data verify the validity of the model for the automatic classification of mural images.ConclusionConsidering the influence of network width and depth, ancient mural classification model with AlexNet model using feature fusion can fully express the rich details of mural images. This model has certain advantages and application value and can be further integrated into the mural classification-related model. However, this method is a shallow convolution neural network based on AlexNet, which fails to mine the high-level features of mural images fully. As a result, some images with similar low-level features, such as color and texture, cannot be classified correctly. Moreover, the running time of mural classification in this model is measured by hour, which consumes considerable resources and is inefficient. Therefore, we will combine deep models to express the high-level features of mural images in future work. We will also improve the efficiency of model training to make mural classification further effective and fast.关键词:mural classification;feature fusion;AlexNet model;convolution neural network (CNN);mural dataset73|0|3更新时间:2024-05-07
摘要:ObjectiveChinese ancient murals, as a type of painting on the wall, have a long history of 4000 years and are an indispensable part of Chinese ancient paintings. With the increasing abundance of digital mural images, classifying mural resources is becoming increasingly urgent. The core of mural image classification is how to construct the feature description of an object. In addition to expressing the object adequately, this description should be able to distinguish among different types of objects. However, ancient mural images have certain pluralism and subjectivity due to artificial drawing. Considering the subjective singularity and objective insufficiency of traditional mural image feature extraction, we propose a convolutional neural network based on classical AlexNet network model and feature fusion idea for the automatic classification of ancient mural images.MethodFirst, we define the optimizer as Adam with a learning rate of 0.001 through experiments. We then extract each convolution layer feature of AlexNet for classification. Through the comparison of running time and accuracy, we select the convolution layer to express mural features further. Second, we combine the idea of feature fusion and exchange the two convolution kernels to form channels 1 and 2. The convolution kernels of channel 1 are 11, 5, and 3, and those of channel 2 are 11, 3, and 5. The combination of this method constitutes a two-channel convolution feature extraction layer, which enables the model to utilize multilocal features fully. The overfitting phenomenon caused by numerous full-connection layers is considered. On the basis of the two-channel convolution feature extraction layer, we continue to compare the features of different full-connection layers and select further appropriate full-connection layer features to express mural images. Finally, a mural image classification model with a two-channel convolution layer and optimal full connection layer is presented. The proposed mural image classification model can be divided into three processes. 1) Mural image preprocessing. Given the lack of large mural datasets, we use image enhancement operations, such as zooming, brightness transformation, noise addition, and flipping, to enlarge the mural samples. An ancient mural image dataset, including Buddha, Bodhisattva, Buddhist disciples, secular figures, animals, plants, buildings, and auspicious cloud, is constructed. 2) Training stage of mural image classification model. The module has three stages. In the first stage, the model extracts the low-level features, such as the edge information of the trainset images. In the second stage, the two-channel network with different structures is used to abstract the features of the first stage. The features of the two channels are then obtained. In the last stage, the loss function training network model is constructed by fusing the features of the two channels. Feature fusion improves the robustness of the model and the capability of feature expression. 3) Training stage of mural image classification model. We use the network model with trained parameters to predict the classification results of test set samples. The classification accuracy, recall, and f1-score are obtained.ResultThrough the comparison of running time and accuracy, the comparative experimental results of different convolution layers show that in the AlexNet model, the third convolution layer is the most suitable network layer for this dataset. In addition, the accuracy rate will decrease if the number of layers is higher or lower than the number of layers in the paper. Similarly, the comparative experimental results of different full-connection layers show that the features of the three-layer full-connection layer are further stable and sufficient based on the two-channel convolution extraction layer. Therefore, a six-layer convolution neural network model, including a three-layer dual channel and three-layer full connection layer, is presented with five convolution layers in the two-channel model. The model achieves 85.39% accuracy on the constructed mural image dataset. Experimental results show that the accuracy of the model in most classes is the highest, and each evaluation index of the model is improved by approximately 5%, compared with the AlexNet model and several improved convolution neural network models. Compared with the classical model without pretraining, this model encounters increased difficulty in producing overfitting. Compared with the model with pretraining, the accuracy of the model is improved by approximately 1%~5%, and the cost is reduced in terms of hardware conditions, network structure, and memory consumption. These experimental data verify the validity of the model for the automatic classification of mural images.ConclusionConsidering the influence of network width and depth, ancient mural classification model with AlexNet model using feature fusion can fully express the rich details of mural images. This model has certain advantages and application value and can be further integrated into the mural classification-related model. However, this method is a shallow convolution neural network based on AlexNet, which fails to mine the high-level features of mural images fully. As a result, some images with similar low-level features, such as color and texture, cannot be classified correctly. Moreover, the running time of mural classification in this model is measured by hour, which consumes considerable resources and is inefficient. Therefore, we will combine deep models to express the high-level features of mural images in future work. We will also improve the efficiency of model training to make mural classification further effective and fast.关键词:mural classification;feature fusion;AlexNet model;convolution neural network (CNN);mural dataset73|0|3更新时间:2024-05-07 -
 摘要:ObjectiveObject detection is a fundamental topic in computer vision. Deep learning-based object detection networks consist of two basic parts:feature extraction and object detection modules. Convolution neural networks (CNNs) are used to extract image features. On the one hand, deep feature maps are rich in object semantic information; sensitive to category information; lacking in detailed information; insensitive to position, translation, and rotation information; and widely used in classification tasks. On the other hand, shallow feature maps are rich in detailed information; sensitive to location, translation, and rotation information; lacking in semantic information; and insensitive to category information. The two main subtasks of object detection are classification and location. The former classifies the candidate regions and requires the semantic information of the object, whereas the latter locates the candidate regions and requires detailed information (e.g., location). In the anchor mechanism of faster region-based CNN (R-CNN), each anchor point of the predicted feature map corresponds to nine anchors with different sizes and ratios. A 1×1 convolution filter is used to predict the positions and confidence scores (i.e., the probability that the object contained in the anchor box belongs to a certain category) of multiple anchors with different sizes. Therefore, for the anchors with different sizes that correspond to the anchor points, the same feature region on the feature map is used for prediction. This condition results in the mismatch between the feature region used in prediction and the corresponding anchor. To utilize the advantages of feature maps with different depths and overcome the mismatch problem in the anchor mechanism to accurately solve the problem of multi-scale object detection, we present a single-stage object detection model using convolution filter pyramid and atrous convolution.MethodFeature information is fused in a variety of ways. First, multiple convolutional layers are added to the feature extraction network. The feature information in these layers is fused layer by layer (from the deep layers to the shallow ones) through pixel-by-pixel addition, thereby forming feature maps with rich semantic information and detailed information. Second, to further enhance the fusion of feature information, feature maps with different stages are concatenated for the fusion feature maps obtained in the previous step. To address the mismatch between the feature region and the corresponding anchor used for prediction, this study introduces a convolution filter pyramid structure into the anchor mechanism to detect objects with different sizes. Consequently, the sizes of the convolution filter corresponding to the anchors with different sizes is distinct and those corresponding to anchors with equal sizes but different ratios are the same. This condition alleviates the mismatch problem. In addition, the model uses the atrous convolution mechanism to design a convolution filter with different receptive fields because the large-scale convolution filter increases the number of parameters and the time complexity should be reduced. Under the action of convolution filters with different sizes, the prediction tensors (i.e., feature maps) of different resolutions are generated on the feature maps with rich semantic and detailed information. The model determines the number of anchors according to the generated prediction tensors. The number of small anchors corresponding to small objects is large, whereas those corresponding to large objects is small, thereby reducing the number of anchors.ResultThe proposed method was tested and evaluated on PASCAL visual object classes (VOC) and UCAS-AOD remote sensing datasets, respectively. The code was implemented on the Caffe deep learning framework, where some components of the Caffe open-source library of single-shot multibox detector (SSD) and deconvolutional single-shot detector (DSSD) were utilized. All experiments were performed on an HP workstation with a Titan X GPU. SSD was used as the pre-training model of the proposed method. The model was fine-tuned on PASCAL VOC and UCAS-AOD and the performance was evaluated using the mean average precision (mAP) on VOC2007 and UCAS-AOD test sets. The proposed method was then compared with other advanced deep learning object detection methods in terms of mAP results and detection speed. Experimental results show that on the PASCAL VOC2007 test set, the proposed model can achieve 79.3% mAP for an input size of 300×300, which is higher than SSD and DSSD by 1.8% and 0.9%, respectively. On the UCAS-AOD remote sensing dataset, the proposed model obtained a 91.0% mAP, which is 2.8% and 1.9% higher than SSD and DSSD, respectively. The testing speed of the model is 21 frame per second on Titan X GPU, which is much faster than DSSD.ConclusionIn this study, a single-stage object detection model using convolution filter pyramid and atrous convolution is proposed. First, feature information is merged through pixel-by-pixel addition and channel concatenation to form a feature map with rich semantic and detailed information. The obtained information was used as a prediction feature map to provide rich feature information in predicting boundary box categories and locations. Then, the convolution filter pyramid structure is introduced into the anchor mechanism to overcome the mismatch between the feature region and corresponding anchor, as well as to accurately detect multiscale objects. At the same time, the atrous convolution is introduced to increase the receptive field of the convolution filter without increasing the number of parameters.The number of anchors is determined according to the generated prediction tensor to reduce the time complexity. The proposed model exhibited a faster detection speed and higher detection accuracy than the current advanced methods, especially in solving the problems of small objects and detecting overlapped objects, due to the effective information fusion and introduction of a convolution filter pyramid structure in the anchor mechanism. Although the proposed method demonstrated a good result in terms of detection speed and accuracy, the detection accuracy of the algorithm can still be further improved compared with the two-stage algorithm because the research on the former is limited in the feature fusion part. In the future, further research will be conducted in the feature fusion part to improve the detection accuracy of the algorithm.关键词:single-stage object detection;feature fusion;convolution filter pyramid;anchor box;atrous convolution90|32|5更新时间:2024-05-07
摘要:ObjectiveObject detection is a fundamental topic in computer vision. Deep learning-based object detection networks consist of two basic parts:feature extraction and object detection modules. Convolution neural networks (CNNs) are used to extract image features. On the one hand, deep feature maps are rich in object semantic information; sensitive to category information; lacking in detailed information; insensitive to position, translation, and rotation information; and widely used in classification tasks. On the other hand, shallow feature maps are rich in detailed information; sensitive to location, translation, and rotation information; lacking in semantic information; and insensitive to category information. The two main subtasks of object detection are classification and location. The former classifies the candidate regions and requires the semantic information of the object, whereas the latter locates the candidate regions and requires detailed information (e.g., location). In the anchor mechanism of faster region-based CNN (R-CNN), each anchor point of the predicted feature map corresponds to nine anchors with different sizes and ratios. A 1×1 convolution filter is used to predict the positions and confidence scores (i.e., the probability that the object contained in the anchor box belongs to a certain category) of multiple anchors with different sizes. Therefore, for the anchors with different sizes that correspond to the anchor points, the same feature region on the feature map is used for prediction. This condition results in the mismatch between the feature region used in prediction and the corresponding anchor. To utilize the advantages of feature maps with different depths and overcome the mismatch problem in the anchor mechanism to accurately solve the problem of multi-scale object detection, we present a single-stage object detection model using convolution filter pyramid and atrous convolution.MethodFeature information is fused in a variety of ways. First, multiple convolutional layers are added to the feature extraction network. The feature information in these layers is fused layer by layer (from the deep layers to the shallow ones) through pixel-by-pixel addition, thereby forming feature maps with rich semantic information and detailed information. Second, to further enhance the fusion of feature information, feature maps with different stages are concatenated for the fusion feature maps obtained in the previous step. To address the mismatch between the feature region and the corresponding anchor used for prediction, this study introduces a convolution filter pyramid structure into the anchor mechanism to detect objects with different sizes. Consequently, the sizes of the convolution filter corresponding to the anchors with different sizes is distinct and those corresponding to anchors with equal sizes but different ratios are the same. This condition alleviates the mismatch problem. In addition, the model uses the atrous convolution mechanism to design a convolution filter with different receptive fields because the large-scale convolution filter increases the number of parameters and the time complexity should be reduced. Under the action of convolution filters with different sizes, the prediction tensors (i.e., feature maps) of different resolutions are generated on the feature maps with rich semantic and detailed information. The model determines the number of anchors according to the generated prediction tensors. The number of small anchors corresponding to small objects is large, whereas those corresponding to large objects is small, thereby reducing the number of anchors.ResultThe proposed method was tested and evaluated on PASCAL visual object classes (VOC) and UCAS-AOD remote sensing datasets, respectively. The code was implemented on the Caffe deep learning framework, where some components of the Caffe open-source library of single-shot multibox detector (SSD) and deconvolutional single-shot detector (DSSD) were utilized. All experiments were performed on an HP workstation with a Titan X GPU. SSD was used as the pre-training model of the proposed method. The model was fine-tuned on PASCAL VOC and UCAS-AOD and the performance was evaluated using the mean average precision (mAP) on VOC2007 and UCAS-AOD test sets. The proposed method was then compared with other advanced deep learning object detection methods in terms of mAP results and detection speed. Experimental results show that on the PASCAL VOC2007 test set, the proposed model can achieve 79.3% mAP for an input size of 300×300, which is higher than SSD and DSSD by 1.8% and 0.9%, respectively. On the UCAS-AOD remote sensing dataset, the proposed model obtained a 91.0% mAP, which is 2.8% and 1.9% higher than SSD and DSSD, respectively. The testing speed of the model is 21 frame per second on Titan X GPU, which is much faster than DSSD.ConclusionIn this study, a single-stage object detection model using convolution filter pyramid and atrous convolution is proposed. First, feature information is merged through pixel-by-pixel addition and channel concatenation to form a feature map with rich semantic and detailed information. The obtained information was used as a prediction feature map to provide rich feature information in predicting boundary box categories and locations. Then, the convolution filter pyramid structure is introduced into the anchor mechanism to overcome the mismatch between the feature region and corresponding anchor, as well as to accurately detect multiscale objects. At the same time, the atrous convolution is introduced to increase the receptive field of the convolution filter without increasing the number of parameters.The number of anchors is determined according to the generated prediction tensor to reduce the time complexity. The proposed model exhibited a faster detection speed and higher detection accuracy than the current advanced methods, especially in solving the problems of small objects and detecting overlapped objects, due to the effective information fusion and introduction of a convolution filter pyramid structure in the anchor mechanism. Although the proposed method demonstrated a good result in terms of detection speed and accuracy, the detection accuracy of the algorithm can still be further improved compared with the two-stage algorithm because the research on the former is limited in the feature fusion part. In the future, further research will be conducted in the feature fusion part to improve the detection accuracy of the algorithm.关键词:single-stage object detection;feature fusion;convolution filter pyramid;anchor box;atrous convolution90|32|5更新时间:2024-05-07 -
 摘要:ObjectiveMoving target detection is an important branch of image processing and computer vision, and it is also a core part of intelligent monitoring systems. Its main content is to observe the entire scene in the video sequences and find the moving targets. Therefore, the main purpose of moving target detection is to extract the moving target from the video sequences effectively and obtain the feature information of the moving target, such as color, shape, and contour. Extracting moving targets is the process of target and background classification. The process finds the difference by successive sequences of images and extracts the differences owing to the motion of the object to obtain the desired target. Moving target detection requires fast acquisition of moving targets in the video image and, as much as possible, to ensure the integrity of the acquired moving targets. Thus, speed and integrity are two key indicators of moving target detection algorithms. In terms of rapidity, algorithms are required to have lower complexity and can detect moving targets in real time. The existing algorithms that satisfy speed are easily affected by illumination, have weak adaptability to the dynamic environment, and the acquired target information is incomplete, thereby resulting in a hole problem. The internal integrity of the target and the integrity of the target contour are required, thereby indicating that the internal information of the moving target can be fully obtained, and the phenomenon of missed detection caused by the misidentification of the foreground area as the background in the detection is eliminated. At the same time, the target edges are as continuous and smooth as possible. However, the algorithm with improved integrity has high complexity, slow operation speed, and poor real-time performance. Therefore, achieving the balance between speed and integrity has become a key issue in moving target detection, causing the algorithm to have high extraction efficiency while fully extracting the internal information and contour of the target.MethodThis study proposes a three-frame difference algorithm based on adaptive Gaussian mixture modeling. To ensure the real-time performance of the algorithm, this study relies on the three-frame difference operation, which is simple, extensible, and has good anti-interference ability to extract the target contour of the video image. The operation can improve the detection efficiency of the algorithm. For the problem that the three-frame difference operation leads to incomplete extraction of the internal information of the target, the Gaussian mixture background difference adaptively adjusted by the learning rate is used. The difference achieves an adaptive update of the background model by setting the frame number threshold and adopting different learning rates before and after the threshold. At the beginning of the model creation, the rate of iteration of the background model is increased by the faster update rate of the model, and the "ghosting" caused by the motion of the object is eliminated. After the interference information in the background model is eliminated, the learning rate is adjusted based on the difference between the target pixel and adjacent eight pixels in the current frame and the background model, thereby implementing adaptive correction of the background model and solving the problem of misjudgment and loss of targets generated during the model update process. The approach can increase the integrity of the target image. At the same time, to speed up the Gaussian mixture modeling, the model redundancy decision strategy is adopted to determine the weight and priority of the Gaussian distributions, and the redundant Gaussian distributions are deleted to avoid the time consumption caused by the redundancy models in the matching. Ultimately, the balance between algorithm integrity and algorithm real-time are achieved. To further ensure the integrity and continuity of the target edge, we use the edge contrast difference algorithm, which is based on the target edge detected by the Canny operator. The number of frames participating in the edge contrast operation is adaptively selected based on the target motion speed, thereby decreasing the false positive rate of the background point and making the edge information as continuous and complete as possible.ResultSubjective and objective evaluation methods are combined on the experimental results. Subjectively, the background difference based on Gaussian mixture modeling (BD-GMM), the three-frame difference based on edge contrast (TFD-EC), and the proposed algorithm are used to detect single-target and multi-target video in different backgrounds. The results show that the target information obtained by the algorithm are complete and the edges are smooth. Objectively, the proposed algorithm improves the detection rate while ensuring a high accuracy rate of 95.23%, and the integrity of the target is improved by 28.95%. These values are significantly higher than those of other algorithms. In terms of speed, the time consumption is reduced by 29.18% compared with that of the traditional Gaussian mixture algorithm, thereby meeting the real-time requirements. Compared with the BD-GMM and TFD-EC algorithms, both subjective and objective, the proposed algorithm is superior to the two algorithms.ConclusionThe experimental results show that because the algorithm adopts Gaussian mixture background modeling based on adaptive learning rate, it can effectively suppress the interference of a dynamic environment and decrease the complexity of the algorithm. The three-frame difference algorithm based on edge comparison ensures the timeliness of the algorithm and integrity of the target edge. Therefore, the proposed algorithm ensures real-time performance, has good integrity, and can be widely used in fields such as intelligent video surveillance, military applications, industrial inspection, and aerospace.关键词:moving target detection;three-frame difference;edge contrast difference;background model;Gaussian mixture modeling(GMM);adaptive learning rate13|5|8更新时间:2024-05-07
摘要:ObjectiveMoving target detection is an important branch of image processing and computer vision, and it is also a core part of intelligent monitoring systems. Its main content is to observe the entire scene in the video sequences and find the moving targets. Therefore, the main purpose of moving target detection is to extract the moving target from the video sequences effectively and obtain the feature information of the moving target, such as color, shape, and contour. Extracting moving targets is the process of target and background classification. The process finds the difference by successive sequences of images and extracts the differences owing to the motion of the object to obtain the desired target. Moving target detection requires fast acquisition of moving targets in the video image and, as much as possible, to ensure the integrity of the acquired moving targets. Thus, speed and integrity are two key indicators of moving target detection algorithms. In terms of rapidity, algorithms are required to have lower complexity and can detect moving targets in real time. The existing algorithms that satisfy speed are easily affected by illumination, have weak adaptability to the dynamic environment, and the acquired target information is incomplete, thereby resulting in a hole problem. The internal integrity of the target and the integrity of the target contour are required, thereby indicating that the internal information of the moving target can be fully obtained, and the phenomenon of missed detection caused by the misidentification of the foreground area as the background in the detection is eliminated. At the same time, the target edges are as continuous and smooth as possible. However, the algorithm with improved integrity has high complexity, slow operation speed, and poor real-time performance. Therefore, achieving the balance between speed and integrity has become a key issue in moving target detection, causing the algorithm to have high extraction efficiency while fully extracting the internal information and contour of the target.MethodThis study proposes a three-frame difference algorithm based on adaptive Gaussian mixture modeling. To ensure the real-time performance of the algorithm, this study relies on the three-frame difference operation, which is simple, extensible, and has good anti-interference ability to extract the target contour of the video image. The operation can improve the detection efficiency of the algorithm. For the problem that the three-frame difference operation leads to incomplete extraction of the internal information of the target, the Gaussian mixture background difference adaptively adjusted by the learning rate is used. The difference achieves an adaptive update of the background model by setting the frame number threshold and adopting different learning rates before and after the threshold. At the beginning of the model creation, the rate of iteration of the background model is increased by the faster update rate of the model, and the "ghosting" caused by the motion of the object is eliminated. After the interference information in the background model is eliminated, the learning rate is adjusted based on the difference between the target pixel and adjacent eight pixels in the current frame and the background model, thereby implementing adaptive correction of the background model and solving the problem of misjudgment and loss of targets generated during the model update process. The approach can increase the integrity of the target image. At the same time, to speed up the Gaussian mixture modeling, the model redundancy decision strategy is adopted to determine the weight and priority of the Gaussian distributions, and the redundant Gaussian distributions are deleted to avoid the time consumption caused by the redundancy models in the matching. Ultimately, the balance between algorithm integrity and algorithm real-time are achieved. To further ensure the integrity and continuity of the target edge, we use the edge contrast difference algorithm, which is based on the target edge detected by the Canny operator. The number of frames participating in the edge contrast operation is adaptively selected based on the target motion speed, thereby decreasing the false positive rate of the background point and making the edge information as continuous and complete as possible.ResultSubjective and objective evaluation methods are combined on the experimental results. Subjectively, the background difference based on Gaussian mixture modeling (BD-GMM), the three-frame difference based on edge contrast (TFD-EC), and the proposed algorithm are used to detect single-target and multi-target video in different backgrounds. The results show that the target information obtained by the algorithm are complete and the edges are smooth. Objectively, the proposed algorithm improves the detection rate while ensuring a high accuracy rate of 95.23%, and the integrity of the target is improved by 28.95%. These values are significantly higher than those of other algorithms. In terms of speed, the time consumption is reduced by 29.18% compared with that of the traditional Gaussian mixture algorithm, thereby meeting the real-time requirements. Compared with the BD-GMM and TFD-EC algorithms, both subjective and objective, the proposed algorithm is superior to the two algorithms.ConclusionThe experimental results show that because the algorithm adopts Gaussian mixture background modeling based on adaptive learning rate, it can effectively suppress the interference of a dynamic environment and decrease the complexity of the algorithm. The three-frame difference algorithm based on edge comparison ensures the timeliness of the algorithm and integrity of the target edge. Therefore, the proposed algorithm ensures real-time performance, has good integrity, and can be widely used in fields such as intelligent video surveillance, military applications, industrial inspection, and aerospace.关键词:moving target detection;three-frame difference;edge contrast difference;background model;Gaussian mixture modeling(GMM);adaptive learning rate13|5|8更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveNatural scene images contain numerous textual details with semantic information, which is the key to describe and understand the content of natural scene images. The correct detection of textual information is an important pre-step for computer visual tasks, such as image retrieval, image understanding, and intelligent navigation. However, the complexity of environments, flexible image acquisition styles, and variation of text contents pose many challenges for text detection in natural scene images. The natural scene background embodies disturbing factors, such as lighting, distortion, and stains. In addition, scene text can be expressed in different colors, fonts, sizes, orientations, and shapes, which makes text detection difficult. Moreover, the aspect ratios and layouts of scene text might exhibit variations that can block text detection. Prior to deep learning, most text detection methods adopt connected components analysis-or sliding window-based classifications. These methods extract low-or mid-level hand-crafted image features, which require demanding and repetitive pre-and post-processing steps. Owing to the limitation of hand-crafted features and the complexity of pipelines, those methods can hardly handle intricate circumstances that have a lower precision rate. Recently, text detection based on convolutional neural network (CNN) has become the mainstream method for natural scene text detection. However, existing CNN-based methods hardly detect small-scale texts and produce unsatisfactory results. Given the association between text and other objects, this study proposes a method based on cascaded CNN for the text detection of natural scene images, especially small-scale text detection. A strong association between the text and other objects in natural scene images is identified after observing the texts in natural image scenes. Texts are usually attached to man-made objects (e.g., books, computers, and signboards) but not to natural objects (e.g., water, sky, tree, and grass).MethodWe propose a cascaded CNN-based method for text detection based on RefineDet algorithm to consider the association between texts and other objects. First, the candidate bounding boxes of texts and objects containing texts are detected. Small-scale texts usually exist in these objects; thus, detecting the candidate bounding boxes first can improve the recall rate of text detection. Then, the candidate bounding boxes is enlarged by 10% of the width at each side, cropped as new images, and inputted to the CNN detector to accurately detect the candidate bounding boxes of the texts. Given that candidate bounding boxes cannot completely frame some objects, direct clipping will result in partial text loss and affect the performance of text detection in the next step. Therefore, we expand the boundaries of the candidate bounding boxes on each side by 10% of their width. Finally, the non-maximum suppression algorithm is used to fuse the previous two-step candidate bounding boxes of the texts to obtain the final detection results. The alteration of the intersection over union (IOU) of the candidate bounding boxes in non-maximum suppression algorithm affects text detection; the highest F-score is obtained when the IOU is 20%. We also collected a new available dataset of objects containing texts for training the object detector. This dataset contains 350 and 229 images from the street view text (SVT) and ICDAR-2013 training sets, respectively. Furthermore, all images are manually labeled with ground-truth tight object region bounding boxes.ResultThe results showed that the proposed method can effectively detect small-scale text and is computationally efficient at a rate of 0.33 s/image. The recall rate, precision rate, and F-score for the ICDAR-2013 dataset are 0.817, 0.880, and 0.847, respectively. Compared with RefineDet, Which is our baseline, the proposed method improves the recall rate by 5.5% and F-score by 2.7%. Compared with state of the art methods, the proposed method increased the recall rate and F-score from 0.780 to 0.817 and from 0.830 to 0.847, respectively. In terms of computational efficiency, the proposed method increased the speed from 2 s/image to 0.33 s/image. Compared with Fast TextBoxes, which has the best computational efficiency, the efficiency of the proposed method is lower but the F-score is higher. In summary, our approach is superior to others.ConclusionThis study proposes a text detection method based on cascaded CNN. The proposed method has two advantages. First, this method can obtain texts from real objects. Second, a cascaded CNN model based on RefineDet is established to complete the task of text detection. According to the strong association between texts and other objects containing texts in natural scene images, the proposed method improves the recall rate of text detection. In addition, the use of RefineDet strengthened the association for higher text detection precision rate. In conclusion, the proposed cascaded CNN-based method can effectively detect small-scale texts in natural scene images.关键词:natural scene;text detection;small-scale text;target association;cascaded convolutional neural network (CNN)23|5|6更新时间:2024-05-07
摘要:ObjectiveNatural scene images contain numerous textual details with semantic information, which is the key to describe and understand the content of natural scene images. The correct detection of textual information is an important pre-step for computer visual tasks, such as image retrieval, image understanding, and intelligent navigation. However, the complexity of environments, flexible image acquisition styles, and variation of text contents pose many challenges for text detection in natural scene images. The natural scene background embodies disturbing factors, such as lighting, distortion, and stains. In addition, scene text can be expressed in different colors, fonts, sizes, orientations, and shapes, which makes text detection difficult. Moreover, the aspect ratios and layouts of scene text might exhibit variations that can block text detection. Prior to deep learning, most text detection methods adopt connected components analysis-or sliding window-based classifications. These methods extract low-or mid-level hand-crafted image features, which require demanding and repetitive pre-and post-processing steps. Owing to the limitation of hand-crafted features and the complexity of pipelines, those methods can hardly handle intricate circumstances that have a lower precision rate. Recently, text detection based on convolutional neural network (CNN) has become the mainstream method for natural scene text detection. However, existing CNN-based methods hardly detect small-scale texts and produce unsatisfactory results. Given the association between text and other objects, this study proposes a method based on cascaded CNN for the text detection of natural scene images, especially small-scale text detection. A strong association between the text and other objects in natural scene images is identified after observing the texts in natural image scenes. Texts are usually attached to man-made objects (e.g., books, computers, and signboards) but not to natural objects (e.g., water, sky, tree, and grass).MethodWe propose a cascaded CNN-based method for text detection based on RefineDet algorithm to consider the association between texts and other objects. First, the candidate bounding boxes of texts and objects containing texts are detected. Small-scale texts usually exist in these objects; thus, detecting the candidate bounding boxes first can improve the recall rate of text detection. Then, the candidate bounding boxes is enlarged by 10% of the width at each side, cropped as new images, and inputted to the CNN detector to accurately detect the candidate bounding boxes of the texts. Given that candidate bounding boxes cannot completely frame some objects, direct clipping will result in partial text loss and affect the performance of text detection in the next step. Therefore, we expand the boundaries of the candidate bounding boxes on each side by 10% of their width. Finally, the non-maximum suppression algorithm is used to fuse the previous two-step candidate bounding boxes of the texts to obtain the final detection results. The alteration of the intersection over union (IOU) of the candidate bounding boxes in non-maximum suppression algorithm affects text detection; the highest F-score is obtained when the IOU is 20%. We also collected a new available dataset of objects containing texts for training the object detector. This dataset contains 350 and 229 images from the street view text (SVT) and ICDAR-2013 training sets, respectively. Furthermore, all images are manually labeled with ground-truth tight object region bounding boxes.ResultThe results showed that the proposed method can effectively detect small-scale text and is computationally efficient at a rate of 0.33 s/image. The recall rate, precision rate, and F-score for the ICDAR-2013 dataset are 0.817, 0.880, and 0.847, respectively. Compared with RefineDet, Which is our baseline, the proposed method improves the recall rate by 5.5% and F-score by 2.7%. Compared with state of the art methods, the proposed method increased the recall rate and F-score from 0.780 to 0.817 and from 0.830 to 0.847, respectively. In terms of computational efficiency, the proposed method increased the speed from 2 s/image to 0.33 s/image. Compared with Fast TextBoxes, which has the best computational efficiency, the efficiency of the proposed method is lower but the F-score is higher. In summary, our approach is superior to others.ConclusionThis study proposes a text detection method based on cascaded CNN. The proposed method has two advantages. First, this method can obtain texts from real objects. Second, a cascaded CNN model based on RefineDet is established to complete the task of text detection. According to the strong association between texts and other objects containing texts in natural scene images, the proposed method improves the recall rate of text detection. In addition, the use of RefineDet strengthened the association for higher text detection precision rate. In conclusion, the proposed cascaded CNN-based method can effectively detect small-scale texts in natural scene images.关键词:natural scene;text detection;small-scale text;target association;cascaded convolutional neural network (CNN)23|5|6更新时间:2024-05-07 -
 摘要:ObjectiveSalient object detection, also called saliency detection, aims to localize and segment the most conspicuous and eye-attracting objects or regions in an image. Several applications have benefited from saliency detection, such as image and video compression, context-aware image retargeting, scene parsing, image resizing, object detection, and segmentation. The detection process includes feature extraction and mapping to the saliency value. Most of the state-of-art salient object detection models use extracted features from pre-trained classification convolution network. Related works have shown that models based on fully convolutional networks (FCNs) can encode semantic-rich features, thereby improving the robustness and accuracy of saliency detection. An intuitive opinion states that a large complex network performs better than a small and simple one. Many of the current methods lack efficiency and require numerous storage resources. In the past few years, attention mechanism has been employed to boost and aid many visual tasks in reducing the decoding difficulty and producing lightweight networks. To be more specific, attention mechanism utilizes pre-estimated attention mask and provides useful prior knowledge to the decoding progress. This mechanism eases the mapping from features to the saliency value to eliminate the need to design a large and complex decoding network. However, the wildly used strong attention applies a multiplicative operation between attention mask and features. When the attention mask is normalized, scilicet values range from 0 to 1, where a value of 0 irreversibly wipes out the distribution of certain features. Thus, using strong attention may cause overfitting risks. On the contrary, weak attention applies an additive operation and is less risky and less efficient. Weak attention shifts the features in the feature space and does not destroy the distribution. However, the previously added information can be smoothed by the convolutional operations. The longer the sequence of convolutional layers are, the less effect the attention mask will exert on the decoding features. This work contributes in three aspects:1) We infer about the visual attention mechanism by dividing it into strong and weak attentions before qualitatively explaining how the attention mechanism improves the decoding efficiency. 2) We discuss the principles of the two types of attention mechanism. Finally, 3) we propose a dense weak attention module that can improve the efficiency of utilizing the features compared with the existing methods.MethodInstead of applying the weak attention only at the beginning of the first convolutional layer, we performed the application tautologically and consequently (i.e., applying weak attention before all decoding convolutional layers). The proposed method is called dense weak attention module (DWAM), which introduces an ideal end-to-end detection model called dense weak attention network. The proposed method inherits an FCN-like architecture, which consists of a sequence of convolutional, pooling, and different activation layers. To fine-tune the VGG-16 network, we divide the decoding network into two parts:global saliency detection and edge optimization using DWAM. A rough saliency map is predicted in the deepest branch of the network. Then, the saliency map is treated as an attention mask and concatenated to shallow features to predict a saliency map with increased resolution. To output side saliency maps, we add cross entropy layers after each side output, a process known as deep supervision, to optimize the network. We discover that weak attention plays an important role in the optimization of the detection result by providing effective prior information. With few additional parameters, we have achieved an improved detection result and detection speed. To achieve a more robust prediction than before, the atrous spatial pyramid pooling is used to enhance the ability of detecting multiscale targets.ResultWe compared the proposed method with seven FCN-based state-of-the-art techniques on five widely accepted benchmarks, and set three indicators as evaluation criteria:mean absolute error (MAE), F measure, and precision-recall curve. Under the same condition, the proposed model demonstrated more competitive results compared with the other state-of-art methods. The MAE of the proposed method is generally better than that of other methods, which means that DWAM produces more pixel-level accuracy results than the other techniques. DWAM's F measure is higher by approximately 2%6% than most of the state-of-art methods. In addition, the precision-recall curve shows that DWAM has a slight advantage and better balance between precision and recall metrics than the other techniques. Meanwhile, the model size of the proposed method is only 69.5 MB and the real-time detection speed reaches 32 frame per second.ConclusionIn this study, we proposed an efficient and fully convolutional salient object detection model to improve the efficiency of feature decoding and enhance the generalization ability through weak attention mechanism and deep supervision training than other state-of-the-art methods. Compared with the existing methods, the results of the proposed method is more competitive and the detection speed is faster even if the model remained small.关键词:salient object detection (SOD);visual attention mechanism;encoder-decoder;fully convolutional networks (FCNs);real-time detection19|46|4更新时间:2024-05-07
摘要:ObjectiveSalient object detection, also called saliency detection, aims to localize and segment the most conspicuous and eye-attracting objects or regions in an image. Several applications have benefited from saliency detection, such as image and video compression, context-aware image retargeting, scene parsing, image resizing, object detection, and segmentation. The detection process includes feature extraction and mapping to the saliency value. Most of the state-of-art salient object detection models use extracted features from pre-trained classification convolution network. Related works have shown that models based on fully convolutional networks (FCNs) can encode semantic-rich features, thereby improving the robustness and accuracy of saliency detection. An intuitive opinion states that a large complex network performs better than a small and simple one. Many of the current methods lack efficiency and require numerous storage resources. In the past few years, attention mechanism has been employed to boost and aid many visual tasks in reducing the decoding difficulty and producing lightweight networks. To be more specific, attention mechanism utilizes pre-estimated attention mask and provides useful prior knowledge to the decoding progress. This mechanism eases the mapping from features to the saliency value to eliminate the need to design a large and complex decoding network. However, the wildly used strong attention applies a multiplicative operation between attention mask and features. When the attention mask is normalized, scilicet values range from 0 to 1, where a value of 0 irreversibly wipes out the distribution of certain features. Thus, using strong attention may cause overfitting risks. On the contrary, weak attention applies an additive operation and is less risky and less efficient. Weak attention shifts the features in the feature space and does not destroy the distribution. However, the previously added information can be smoothed by the convolutional operations. The longer the sequence of convolutional layers are, the less effect the attention mask will exert on the decoding features. This work contributes in three aspects:1) We infer about the visual attention mechanism by dividing it into strong and weak attentions before qualitatively explaining how the attention mechanism improves the decoding efficiency. 2) We discuss the principles of the two types of attention mechanism. Finally, 3) we propose a dense weak attention module that can improve the efficiency of utilizing the features compared with the existing methods.MethodInstead of applying the weak attention only at the beginning of the first convolutional layer, we performed the application tautologically and consequently (i.e., applying weak attention before all decoding convolutional layers). The proposed method is called dense weak attention module (DWAM), which introduces an ideal end-to-end detection model called dense weak attention network. The proposed method inherits an FCN-like architecture, which consists of a sequence of convolutional, pooling, and different activation layers. To fine-tune the VGG-16 network, we divide the decoding network into two parts:global saliency detection and edge optimization using DWAM. A rough saliency map is predicted in the deepest branch of the network. Then, the saliency map is treated as an attention mask and concatenated to shallow features to predict a saliency map with increased resolution. To output side saliency maps, we add cross entropy layers after each side output, a process known as deep supervision, to optimize the network. We discover that weak attention plays an important role in the optimization of the detection result by providing effective prior information. With few additional parameters, we have achieved an improved detection result and detection speed. To achieve a more robust prediction than before, the atrous spatial pyramid pooling is used to enhance the ability of detecting multiscale targets.ResultWe compared the proposed method with seven FCN-based state-of-the-art techniques on five widely accepted benchmarks, and set three indicators as evaluation criteria:mean absolute error (MAE), F measure, and precision-recall curve. Under the same condition, the proposed model demonstrated more competitive results compared with the other state-of-art methods. The MAE of the proposed method is generally better than that of other methods, which means that DWAM produces more pixel-level accuracy results than the other techniques. DWAM's F measure is higher by approximately 2%6% than most of the state-of-art methods. In addition, the precision-recall curve shows that DWAM has a slight advantage and better balance between precision and recall metrics than the other techniques. Meanwhile, the model size of the proposed method is only 69.5 MB and the real-time detection speed reaches 32 frame per second.ConclusionIn this study, we proposed an efficient and fully convolutional salient object detection model to improve the efficiency of feature decoding and enhance the generalization ability through weak attention mechanism and deep supervision training than other state-of-the-art methods. Compared with the existing methods, the results of the proposed method is more competitive and the detection speed is faster even if the model remained small.关键词:salient object detection (SOD);visual attention mechanism;encoder-decoder;fully convolutional networks (FCNs);real-time detection19|46|4更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveThe progressive-iterative approximation (PIA) method is a widely used data interpolation method in computer-aided design. The algorithm is simple and flexible, and it has an intuitive geometric meaning. The approximation curve can be obtained by continuously iterating and adjusting the control vertices of the curve. Compared with the classical PIA method, the recently given least-squares progressive iterative approximation (LSPIA) method not only inherits the relevant advantages of the original algorithm but also flexibly fits large-scale data points. The method mostly determines the initial control point in the form of uniform parameterization or chord length parameterization. Although good results are obtained, when processing complex curves, the iterative speed is relatively slow and the error precision does not necessarily reach the expected set value. To improve the fitting precision, we present the LSPIA method of gradually increasing the node, and obtain the smaller fitting error by continuously subdividing the nodes. Even if the new fitting procedure can start from the last fitting result, a large number of calculations are still needed. By reasonable selection of the initial control points, the quality of the convergence curve can be improved. To decrease the number of control points and accelerate the convergence, this study proposes a least-squares asymptotic iterative approximation method based on the key points. Specifically, the key points include two categories:local curvature maximum point and extreme curvature point. Considering the curvature information of the data point set to select the initial control vertex, and combining with the uniform selection control point, we retain the flexibility of selecting the number of control points.MethodFirst, the data points are parameterized, the discrete curvatures of all the data points are calculated based on the discrete curvature calculation formula, and the maximum point of the local curvature is selected. Then, the mean average (avg) of the discrete curvatures of all the data points are found, a suitable initial lower limit of curvature c is set, and the point where the curvature value is greater than c by avg; that is, the extreme curvature point is found. However, in the practice process, the effect of fitting with key points is not good. Careful analysis indicates that for the place where the curve changes drastically, the key points are concentrated and the fitting effect is good. For the smooth part, because extremely few control points are used (certain places have no control points at all), these parts have larger errors. Therefore, we combine two types of control points (uniform control points and key points). Then, because the drawing of the splines is sequential (that is, based on the order in which the control points are arranged), the two sets of control points are often selected separately, resulting in the ordering within the two control point groups, but. However, the merged groups are disordered, and based on the sorting algorithm, the key points and uniformly selected control points are sequentially ordered based on the parameters. Finally, the two types of control points are used as the initial control points of the iteration, and the data points are fitted by the LSPIA method. If the error does not satisfy the previously set value, then the iteration is continued. When the iteration does not satisfy the given precision after reaching a certain number of repetitions, we can increase the initial control points by decreasing the interval of the uniform control points or reducing the lower limit of the key point curvature to improve the fitting accuracy. This method can further decrease the selection of control points, and also compensate for the defects of insufficient fitting of uniform points. For the LSPIA method of gradually increasing the nodes, we continuously refine the nodes based on the error distribution, and we add new nodes and control points by using the incremental algorithm. The results of the previous iteration continue to be iterated using the LSPIA method until the predetermined error accuracy is reached or the number of control points set in advance is reached.ResultWe apply our method to the fitting of complex image contours, including deer, bauhinia, cock, and lotus. The LSPIA and key point-based LSPIA methods are used to fit the same set of data points; the method in this study achieves better error precision and improves the convergence speed several times before iteration. Under the same number of control points and compared with the LSPIA algorithm, the proposed method and the step-by-step increase of the LSPIA of the node all improve the error precision to a certain extent, but the method of this study has a smaller calculation amount. Finally, we fit the method to the data point set of ancient paintings. For graphs with many details and high data volume, our method has achieved a good fitting effect.ConclusionIn this study, the key point selection idea is introduced into the LSPIA method, and a least-squares asymptotic iterative approximation method based on key point selection is proposed, thereby improving the selection of initial control vertices and the iterative efficiency. This method is suitable for more complex curves; based on the selection of key points of curvature distribution, the geometric information of the curve can be reflected effectively. Numerical examples show that the LSPIA algorithm combined with the key point screening strategy improves the computational efficiency and achieves an improved fitting effect. This method can be adopted in the case in which the iterative efficiency requirement is relatively high in real life.关键词:curvature;key point;least squares;progressive iterative approximation (PIA);incremental algorithm13|4|2更新时间:2024-05-07
摘要:ObjectiveThe progressive-iterative approximation (PIA) method is a widely used data interpolation method in computer-aided design. The algorithm is simple and flexible, and it has an intuitive geometric meaning. The approximation curve can be obtained by continuously iterating and adjusting the control vertices of the curve. Compared with the classical PIA method, the recently given least-squares progressive iterative approximation (LSPIA) method not only inherits the relevant advantages of the original algorithm but also flexibly fits large-scale data points. The method mostly determines the initial control point in the form of uniform parameterization or chord length parameterization. Although good results are obtained, when processing complex curves, the iterative speed is relatively slow and the error precision does not necessarily reach the expected set value. To improve the fitting precision, we present the LSPIA method of gradually increasing the node, and obtain the smaller fitting error by continuously subdividing the nodes. Even if the new fitting procedure can start from the last fitting result, a large number of calculations are still needed. By reasonable selection of the initial control points, the quality of the convergence curve can be improved. To decrease the number of control points and accelerate the convergence, this study proposes a least-squares asymptotic iterative approximation method based on the key points. Specifically, the key points include two categories:local curvature maximum point and extreme curvature point. Considering the curvature information of the data point set to select the initial control vertex, and combining with the uniform selection control point, we retain the flexibility of selecting the number of control points.MethodFirst, the data points are parameterized, the discrete curvatures of all the data points are calculated based on the discrete curvature calculation formula, and the maximum point of the local curvature is selected. Then, the mean average (avg) of the discrete curvatures of all the data points are found, a suitable initial lower limit of curvature c is set, and the point where the curvature value is greater than c by avg; that is, the extreme curvature point is found. However, in the practice process, the effect of fitting with key points is not good. Careful analysis indicates that for the place where the curve changes drastically, the key points are concentrated and the fitting effect is good. For the smooth part, because extremely few control points are used (certain places have no control points at all), these parts have larger errors. Therefore, we combine two types of control points (uniform control points and key points). Then, because the drawing of the splines is sequential (that is, based on the order in which the control points are arranged), the two sets of control points are often selected separately, resulting in the ordering within the two control point groups, but. However, the merged groups are disordered, and based on the sorting algorithm, the key points and uniformly selected control points are sequentially ordered based on the parameters. Finally, the two types of control points are used as the initial control points of the iteration, and the data points are fitted by the LSPIA method. If the error does not satisfy the previously set value, then the iteration is continued. When the iteration does not satisfy the given precision after reaching a certain number of repetitions, we can increase the initial control points by decreasing the interval of the uniform control points or reducing the lower limit of the key point curvature to improve the fitting accuracy. This method can further decrease the selection of control points, and also compensate for the defects of insufficient fitting of uniform points. For the LSPIA method of gradually increasing the nodes, we continuously refine the nodes based on the error distribution, and we add new nodes and control points by using the incremental algorithm. The results of the previous iteration continue to be iterated using the LSPIA method until the predetermined error accuracy is reached or the number of control points set in advance is reached.ResultWe apply our method to the fitting of complex image contours, including deer, bauhinia, cock, and lotus. The LSPIA and key point-based LSPIA methods are used to fit the same set of data points; the method in this study achieves better error precision and improves the convergence speed several times before iteration. Under the same number of control points and compared with the LSPIA algorithm, the proposed method and the step-by-step increase of the LSPIA of the node all improve the error precision to a certain extent, but the method of this study has a smaller calculation amount. Finally, we fit the method to the data point set of ancient paintings. For graphs with many details and high data volume, our method has achieved a good fitting effect.ConclusionIn this study, the key point selection idea is introduced into the LSPIA method, and a least-squares asymptotic iterative approximation method based on key point selection is proposed, thereby improving the selection of initial control vertices and the iterative efficiency. This method is suitable for more complex curves; based on the selection of key points of curvature distribution, the geometric information of the curve can be reflected effectively. Numerical examples show that the LSPIA algorithm combined with the key point screening strategy improves the computational efficiency and achieves an improved fitting effect. This method can be adopted in the case in which the iterative efficiency requirement is relatively high in real life.关键词:curvature;key point;least squares;progressive iterative approximation (PIA);incremental algorithm13|4|2更新时间:2024-05-07
Computer Graphics
-
 摘要:Objective Simultaneous localization and mapping (SLAM) has been an important research topic in the last two decades in the computer vision and robotics communities. SLAM aims to build a map of an unknown environment and localize the sensor in the map with real-time operation. Among the existing research results, many state-of-the-art monocular visual SLAM schemes are used. In most existing traditional approaches, the system would set the initial frame instead of the absolute position as the reference frame when it begins running, and it could not acquire the pose in a fixed coordinate system, resulting in the failure of re-using the existing mapping information. Additionally, the present monocular visual SLAM schemes are prone to tracking failure in case of complicated scenes such as cluttered background, motion blur, and defocus, and the existing schemes process it by place recognition, which is a key module of a SLAM system to close loops and relocalize the camera. However, the main drawback of the solution is that it requires the current frame to be highly similar to the existing key frame to ensure the success of relocalization, generally causing inconvenience in certain real application scenarios. For example, an advanced mobile robot is required to return to the place where the location information is lost after tracking failure so that the system could continue tracking and mapping. However, the map information could not be recovered from the failure of system tracking to the success of relocalization, thereby resulting in considerable map information loss. Therefore, to address the limitations, such as loss of map information and requirement for high similarity between a current frame and an existing frame while relocalizing, we propose a prior-information-based visual SLAM system with the capacity of re-initialization, map re-using, and map recovery in complex scenes.Method In this study, the first step is loading the prior map, matching the current frame with the key frame of the prior map in the SLAM system by applying ORB features to obtain matched frames, and finishing the initialization of SLAM system in combination of relocalization, which is conducive to ensuring the consistency of the SLAM coordinate system. Second, a map-saving mechanism is built to save the map of successful tracking before tracing failure occurs to avoid losing the map information. The traditional SLAM always conducts relocalization after tracking failure, and the map could not be generated before the relocalization succeeds accordingly, further resulting in the loss of map information. Considering the aforementioned issues, we address tracking failure by re-initializing rather than relocalizing to establish a new map called the recovery map. To improve the probability of successful initialization and the ability to recover map information, we investigate a self-adaptation fast re-initialization algorithm with the introduction of vanishing point detection. Initially, the scene vanishing points are detected by M-estimator sample consensus (MSAC) method. If vanishing points are present, the fast initialization method would be used. Otherwise, a simple initialization method would be applied; in other words, the proposed algorithm reduces the initialization requirements of the traditional SLAM system. The optimal re-initialization strategy could be selected automatically to ensure that the SLAM system continues tracking and mapping. Finally, for the successful tracking map and the recovery map, the improved loop method is used to obtain the transformation relationship between them. Once the overlapping maps are detected, the relative position and pose relationships between overlapping maps is calculated. Furthermore, the recovery map is transformed into a coordinate system that is consistent with the coordinate system of the matched map in memory. Second, scale information is used to fuse overlapping map points, and a map recovery method is proposed to reduce the errors caused by different scales between the successful tracking map and the recovered map, thereby solving the discrepancy between two maps caused by different scales to obtain accurate global consistency.Result We have compared the proposed system with the state-of-the-art system ORB-SLAM2 on two public datasets, namely, KITTI and EuroC, and a dataset is recorded in complex scenarios. The evaluation metrics contain the number of key frames, integrity rate of key frames, and recovery rate of key frames; moreover, we provide several point cloud maps and trajectory maps of the two systems for comparison. The experimental results show that the proposed system not only performs comparably in accuracy with ORB-SLAM2, but also significantly outperforms state-of-the-art existing methods in various real-world settings in tracking and mapping robustness. The comparative experiment consists of three parts, and the final experiment results are used to verify the effectiveness of the proposed system. In the first part, the KITTI dataset is added with noise, causing the traditional SLAM system to fail in tracking. The map restoration ability of the proposed system on KITTI00, KITTI02, and KITTI05 increased by 39.25%, 47.75%, and 32.46%, respectively. The experimental results show that the advantages of the proposed system are used to address tracking failure effectively and build a complete map, and the proposed systems are better than the state-of-the-art system ORB-SLAM2. In the second part, compared with the results in EuRoC, the proposed system has the same mapping accuracy on V1_01_easy dataset and V1_02_medium dataset as that of ORB-SLAM2. ORB-SLAM2 could not run steadily on the V1_03_difficult dataset, whereas the proposed system could, thereby also indicating that tracking stability has been significantly improved. The third part is the test in the real application scenario. The running dataset is obtained during walking more than one closed track in the underground garage with a camera. The underground garage has a small unlit room. The experimental results show that the proposed system still performs well in real application scenarios with environmental and motion complexity, and they are more complete than the map obtained by ORB-SLAM2.Conclusion Experimental results indicate that the proposed system can effectively recover maps in case of tracking failure. Furthermore, the proposed system can efficiently reuse the existing mapping results of the SLAM system, fix the map coordinate system, and significantly improve the robustness of the system.关键词:visual simultaneous localization and mapping (V-SLAM);map fusion;map reuse;map enhancement;map recovery;self-adaptation fast reinitialization algorithm49|53|1更新时间:2024-05-07
摘要:Objective Simultaneous localization and mapping (SLAM) has been an important research topic in the last two decades in the computer vision and robotics communities. SLAM aims to build a map of an unknown environment and localize the sensor in the map with real-time operation. Among the existing research results, many state-of-the-art monocular visual SLAM schemes are used. In most existing traditional approaches, the system would set the initial frame instead of the absolute position as the reference frame when it begins running, and it could not acquire the pose in a fixed coordinate system, resulting in the failure of re-using the existing mapping information. Additionally, the present monocular visual SLAM schemes are prone to tracking failure in case of complicated scenes such as cluttered background, motion blur, and defocus, and the existing schemes process it by place recognition, which is a key module of a SLAM system to close loops and relocalize the camera. However, the main drawback of the solution is that it requires the current frame to be highly similar to the existing key frame to ensure the success of relocalization, generally causing inconvenience in certain real application scenarios. For example, an advanced mobile robot is required to return to the place where the location information is lost after tracking failure so that the system could continue tracking and mapping. However, the map information could not be recovered from the failure of system tracking to the success of relocalization, thereby resulting in considerable map information loss. Therefore, to address the limitations, such as loss of map information and requirement for high similarity between a current frame and an existing frame while relocalizing, we propose a prior-information-based visual SLAM system with the capacity of re-initialization, map re-using, and map recovery in complex scenes.Method In this study, the first step is loading the prior map, matching the current frame with the key frame of the prior map in the SLAM system by applying ORB features to obtain matched frames, and finishing the initialization of SLAM system in combination of relocalization, which is conducive to ensuring the consistency of the SLAM coordinate system. Second, a map-saving mechanism is built to save the map of successful tracking before tracing failure occurs to avoid losing the map information. The traditional SLAM always conducts relocalization after tracking failure, and the map could not be generated before the relocalization succeeds accordingly, further resulting in the loss of map information. Considering the aforementioned issues, we address tracking failure by re-initializing rather than relocalizing to establish a new map called the recovery map. To improve the probability of successful initialization and the ability to recover map information, we investigate a self-adaptation fast re-initialization algorithm with the introduction of vanishing point detection. Initially, the scene vanishing points are detected by M-estimator sample consensus (MSAC) method. If vanishing points are present, the fast initialization method would be used. Otherwise, a simple initialization method would be applied; in other words, the proposed algorithm reduces the initialization requirements of the traditional SLAM system. The optimal re-initialization strategy could be selected automatically to ensure that the SLAM system continues tracking and mapping. Finally, for the successful tracking map and the recovery map, the improved loop method is used to obtain the transformation relationship between them. Once the overlapping maps are detected, the relative position and pose relationships between overlapping maps is calculated. Furthermore, the recovery map is transformed into a coordinate system that is consistent with the coordinate system of the matched map in memory. Second, scale information is used to fuse overlapping map points, and a map recovery method is proposed to reduce the errors caused by different scales between the successful tracking map and the recovered map, thereby solving the discrepancy between two maps caused by different scales to obtain accurate global consistency.Result We have compared the proposed system with the state-of-the-art system ORB-SLAM2 on two public datasets, namely, KITTI and EuroC, and a dataset is recorded in complex scenarios. The evaluation metrics contain the number of key frames, integrity rate of key frames, and recovery rate of key frames; moreover, we provide several point cloud maps and trajectory maps of the two systems for comparison. The experimental results show that the proposed system not only performs comparably in accuracy with ORB-SLAM2, but also significantly outperforms state-of-the-art existing methods in various real-world settings in tracking and mapping robustness. The comparative experiment consists of three parts, and the final experiment results are used to verify the effectiveness of the proposed system. In the first part, the KITTI dataset is added with noise, causing the traditional SLAM system to fail in tracking. The map restoration ability of the proposed system on KITTI00, KITTI02, and KITTI05 increased by 39.25%, 47.75%, and 32.46%, respectively. The experimental results show that the advantages of the proposed system are used to address tracking failure effectively and build a complete map, and the proposed systems are better than the state-of-the-art system ORB-SLAM2. In the second part, compared with the results in EuRoC, the proposed system has the same mapping accuracy on V1_01_easy dataset and V1_02_medium dataset as that of ORB-SLAM2. ORB-SLAM2 could not run steadily on the V1_03_difficult dataset, whereas the proposed system could, thereby also indicating that tracking stability has been significantly improved. The third part is the test in the real application scenario. The running dataset is obtained during walking more than one closed track in the underground garage with a camera. The underground garage has a small unlit room. The experimental results show that the proposed system still performs well in real application scenarios with environmental and motion complexity, and they are more complete than the map obtained by ORB-SLAM2.Conclusion Experimental results indicate that the proposed system can effectively recover maps in case of tracking failure. Furthermore, the proposed system can efficiently reuse the existing mapping results of the SLAM system, fix the map coordinate system, and significantly improve the robustness of the system.关键词:visual simultaneous localization and mapping (V-SLAM);map fusion;map reuse;map enhancement;map recovery;self-adaptation fast reinitialization algorithm49|53|1更新时间:2024-05-07
Virtual Reality and Augmented Reality
-
 摘要:Objective Positron emission tomography (PET) is a crucial technique established for patient administration in neurology, oncology, and cardiology. Particularly in clinical oncology, fluorodeoxy glucose PET is usually applied in therapy monitoring, radiotherapy planning, staging, diagnosis, and follow-up. Adaptive radiation therapy assists in radiation treatment with the hope that specific therapies aimed at individual patients and target tumors can be developed to re-optimize the treatment plan as early as possible. The use of PET greatly benefits adaptive radiation therapy. Manual delineation is time-consuming and highly dependent on observers. Previous studies have shown that automatic computer-generated segmentations are more reproducible than manual delineations, especially for radiomic analysis. Therefore, automatic and accurate tumor delineation is highly demanded for subsequent determination of therapeutic options and achievement of an improved prognosis. Over the past decade, dozens of methods have been used, which rely on multiple image segmentation approaches or composed methods from broad categories, including thresholding, region-based, contour-based, and graph-based methods as well as clustering, statistical techniques, and machine learning. However, those methods depend on hand-crafted features and possess a limited capability to represent features. For medical image segmentation, convolutional neural networks (CNNs) have demonstrated competitive performance. Nevertheless, these methods show the image classification based on region, in which the integral input image is split up and turns into small regions. Then, whether the small region belongs to the target (foreground) or not can be predicted by the CNN model of each small region. Therefore, each region merely stands for a partial area of the image; thus, this algorithm merely involves limited contextual knowledge that belongs to the small region. A U-Net, which is considered an optimal segmentation network for medical imaging, is trained end to end. It includes a contractive path and an expensive path produced by a combination of convolutional, up-sampling, and pooling layers. This architecture certified itself to be highly effective in using limited amounts of data for segmentation problems. Affected by recent achievements in deep learning, we exploit an automatic tumor segmentation method by deep convolutional U-Net with a pre-trained encoder.Method In this paper, we present a fully automatic method for tumor segmentation by using a 14-layer U-Net model with two blocks of a VGG19 encoder pre-trained with ImageNet. The pre-trained VGG19 encoder contains 260 160 trainable parameters. The rest of our network consists of 14 layers with 1 605 961 trainable parameters. We fix the stride at 2. We propose three-step strategies to ensure effective and efficient learning with limited training data. First, we use the first two blocks of VGG19 as the contracting path and introduce rectified linear units (ReLUs) to each convolutional layer as the activation function. For the symmetrically expanding path, we arrange ReLUs and batch normalization after each convolutional layer. The loss of boundary pixels in each convolution layer necessitates cropping. For the last layer, we use a 1×1 convolution to map each 64-channel feature vector, and each component expresses the chance that the corresponding input pixel is within a target tumor. Second, a tumor holds a small portion within an entire PET image. Therefore, the pixel-wise classification tends to be biased to the outside of targets, leading to a high probability to partially segment or miss tumors. A loss function based on Jaccard distance is applied to eliminate the need for sample re-weighting, which is a typical procedure when using cross-entropy as the loss function for image segmentation due to a strong imbalance between the number of foreground and background pixels. Third, we import the DropBlock technique to replace the normal regularization dropout method because the former can help the U-Net efficiently avoid overfitting. This approach is a structured shape of dropout in which units in a successive region of a feature map are dropped together. In addition to the convolution layers, applying DropBlock in skip connections increases the accuracy.Result A database that contains 1 309 PET images is applied to train and test the proposed segmentation model. We split the database into a before-radiotherapy (BR) sub-database and an after-radiotherapy (AR) sub-database. We use the mask, contour, and smoothed contour of a tumor, which are provided by an expert radiologist, as truths for teaching the proposed model. Experimental results on the BR sub-database show that our method presented a relatively high performance of tumor segmentation in PET images. The Dice coefficient (DI), Hausdorff distance, Jaccard index, sensitivity, and positive predicted value (PPV) are 0.862, 1.735, 0.769, 0.894, and 0.899, respectively. In the test stage, the total processing time of the testing dataset of the BR sub-database needs an average of 1.39 s, which can meet clinical real-time requirements. Then, we fine-tune the weights of the model that we have selected on the BR sub-database by training the network further with the AR sub-database. Experimental results indicate a good segmentation performance with a DI of 0.852, SE of 0.840, and PPV of 0.893. Compared with the traditional U-Net, our method increased by 5.9%, 15.1%, 1.9%, respectively. Finally, the volume of the segmented tumors in the PET images is presented, enabling the accurate automated identification and serial measurement of tumor volumes in PET images.Conclusion This study uses a 14-layer U-Net architecture with a VGG19 pre-trained encoder for tumor segmentation in PET images. We demonstrate how to improve the performance of the U-Net by using a technique called fine-tuning in an encoder of network for initializing weights. Although fine-tuning has been widely applied in image classification tasks, it has not been applied to the like-U-Net-type architectures for medical image segmentation tasks. We use the Jaccard distance as the loss function to improve the segmentation performance. Overall results show that our approach is suitable for various tumors with minimum post-processing and without pre-processing. We believe that this method could be generalized effectively to other medical image segmentation tasks.关键词:deep learning;positron emission tomography(PET);segmentation;tumor;U-Net14|5|4更新时间:2024-05-07
摘要:Objective Positron emission tomography (PET) is a crucial technique established for patient administration in neurology, oncology, and cardiology. Particularly in clinical oncology, fluorodeoxy glucose PET is usually applied in therapy monitoring, radiotherapy planning, staging, diagnosis, and follow-up. Adaptive radiation therapy assists in radiation treatment with the hope that specific therapies aimed at individual patients and target tumors can be developed to re-optimize the treatment plan as early as possible. The use of PET greatly benefits adaptive radiation therapy. Manual delineation is time-consuming and highly dependent on observers. Previous studies have shown that automatic computer-generated segmentations are more reproducible than manual delineations, especially for radiomic analysis. Therefore, automatic and accurate tumor delineation is highly demanded for subsequent determination of therapeutic options and achievement of an improved prognosis. Over the past decade, dozens of methods have been used, which rely on multiple image segmentation approaches or composed methods from broad categories, including thresholding, region-based, contour-based, and graph-based methods as well as clustering, statistical techniques, and machine learning. However, those methods depend on hand-crafted features and possess a limited capability to represent features. For medical image segmentation, convolutional neural networks (CNNs) have demonstrated competitive performance. Nevertheless, these methods show the image classification based on region, in which the integral input image is split up and turns into small regions. Then, whether the small region belongs to the target (foreground) or not can be predicted by the CNN model of each small region. Therefore, each region merely stands for a partial area of the image; thus, this algorithm merely involves limited contextual knowledge that belongs to the small region. A U-Net, which is considered an optimal segmentation network for medical imaging, is trained end to end. It includes a contractive path and an expensive path produced by a combination of convolutional, up-sampling, and pooling layers. This architecture certified itself to be highly effective in using limited amounts of data for segmentation problems. Affected by recent achievements in deep learning, we exploit an automatic tumor segmentation method by deep convolutional U-Net with a pre-trained encoder.Method In this paper, we present a fully automatic method for tumor segmentation by using a 14-layer U-Net model with two blocks of a VGG19 encoder pre-trained with ImageNet. The pre-trained VGG19 encoder contains 260 160 trainable parameters. The rest of our network consists of 14 layers with 1 605 961 trainable parameters. We fix the stride at 2. We propose three-step strategies to ensure effective and efficient learning with limited training data. First, we use the first two blocks of VGG19 as the contracting path and introduce rectified linear units (ReLUs) to each convolutional layer as the activation function. For the symmetrically expanding path, we arrange ReLUs and batch normalization after each convolutional layer. The loss of boundary pixels in each convolution layer necessitates cropping. For the last layer, we use a 1×1 convolution to map each 64-channel feature vector, and each component expresses the chance that the corresponding input pixel is within a target tumor. Second, a tumor holds a small portion within an entire PET image. Therefore, the pixel-wise classification tends to be biased to the outside of targets, leading to a high probability to partially segment or miss tumors. A loss function based on Jaccard distance is applied to eliminate the need for sample re-weighting, which is a typical procedure when using cross-entropy as the loss function for image segmentation due to a strong imbalance between the number of foreground and background pixels. Third, we import the DropBlock technique to replace the normal regularization dropout method because the former can help the U-Net efficiently avoid overfitting. This approach is a structured shape of dropout in which units in a successive region of a feature map are dropped together. In addition to the convolution layers, applying DropBlock in skip connections increases the accuracy.Result A database that contains 1 309 PET images is applied to train and test the proposed segmentation model. We split the database into a before-radiotherapy (BR) sub-database and an after-radiotherapy (AR) sub-database. We use the mask, contour, and smoothed contour of a tumor, which are provided by an expert radiologist, as truths for teaching the proposed model. Experimental results on the BR sub-database show that our method presented a relatively high performance of tumor segmentation in PET images. The Dice coefficient (DI), Hausdorff distance, Jaccard index, sensitivity, and positive predicted value (PPV) are 0.862, 1.735, 0.769, 0.894, and 0.899, respectively. In the test stage, the total processing time of the testing dataset of the BR sub-database needs an average of 1.39 s, which can meet clinical real-time requirements. Then, we fine-tune the weights of the model that we have selected on the BR sub-database by training the network further with the AR sub-database. Experimental results indicate a good segmentation performance with a DI of 0.852, SE of 0.840, and PPV of 0.893. Compared with the traditional U-Net, our method increased by 5.9%, 15.1%, 1.9%, respectively. Finally, the volume of the segmented tumors in the PET images is presented, enabling the accurate automated identification and serial measurement of tumor volumes in PET images.Conclusion This study uses a 14-layer U-Net architecture with a VGG19 pre-trained encoder for tumor segmentation in PET images. We demonstrate how to improve the performance of the U-Net by using a technique called fine-tuning in an encoder of network for initializing weights. Although fine-tuning has been widely applied in image classification tasks, it has not been applied to the like-U-Net-type architectures for medical image segmentation tasks. We use the Jaccard distance as the loss function to improve the segmentation performance. Overall results show that our approach is suitable for various tumors with minimum post-processing and without pre-processing. We believe that this method could be generalized effectively to other medical image segmentation tasks.关键词:deep learning;positron emission tomography(PET);segmentation;tumor;U-Net14|5|4更新时间:2024-05-07
Medical Image Processing
-
 摘要:Objective The traditional remote sensing image segmentation method requires the selection of manyartificial participation featuresandparameters. The shallow machine learning algorithm cannot achieve high-precision segmentation accuracy. The convolutional neural network can automatically learn the characteristics of features and draws on its excellent network structure for performing natural image semantic segmentation. A novel method based on the fully convolutional neural network for remote sensing image segmentation is proposed based on the characteristics of the remote sensing dataset. It studies the fusion between multi-spectral image data bands, increases the learnable features, and improves segmentation accuracy. On the basis of the characteristics of the remote sensing image size, the prediction results of integrated learning and the conditional random field processing model are investigated to mitigate the phenomenon of misclassification, restore the boundary of features, and further improve segmentation accuracy. This study realizes the extraction of features on multi-spectral remote sensing images, which can be applied to subsequent change detection tasks, thus promoting the analysis of changes in surface cover types by automation.Method Aiming at the characteristics of compact targets and the large size range of remote sensing images, a fully convolutional neural network based on pyramid pooling and the dense upsamplingconvolution (DUC) structure is proposed. The proposed network can automatically interpret remote sensing images. The network structure uses improved DenseNet as the underlying network to extract image features, the spatial pyramid pooling structure to obtain context information, and the DUC structure to upsampleand recover detailed information. In the data processing stage, in combination with remote sensing knowledge, the bands are combined to generate multi-source data, and vegetation and normalized water indexes are generated to increase the characteristics. A sliding step prediction method based on integrated learning is proposed to address the problem of remote sensing images being large and the appearance of splicing trace by an ordinary prediction method. Each pixel is predicted 1 to 4 times, and each predicted pixel is located in different image blocks. Different locations vote on the results of multiple predictions. After prediction, the prediction results are post-processed using fully connected conditional random fields (CRFs) to refine the boundary of the features and optimize the segmentation results.Result To verify the validity of the proposed network model and post-processing method, the U-Net model, the fully convolutional neural network FCN-8s model, and the Hdc-DUC model are compared through experiments using a self-built dataset. The accuracy of using the multi-source data from the training model is higher than that obtained by using the original data. The multi-source data training model improves the mIoU evaluation standard by 3.19%, which confirms the validity of the multi-source data generated by band fusion combined with geo-remote sensing knowledge. In terms of effectiveness, when the sliding step prediction method based on integrated learning is used, the segmentation accuracy is improved by 1.44%, and the effect of the characteristics of the remote sensing image on the prediction phase of the model is verified. Although fully connected CRFs may smoothen small-sized features, the use of CRFs to post-process the prediction results effectively improves the segmentation accuracy by 1.03%. The main reason is the image resolution of the self-built dataset. The rate is low, the dataset is relatively fuzzy, the features are highly complicated, and the labeling is inaccurate. The distribution of data is difficult to learn through the fully convolutional neural network, and the accuracy of the prediction results is low. Therefore, fully connected CRFs can improve the segmentation results to a large extent. Experimental results verify the effectiveness of the proposed network model and post-processing method.Conclusion This study mainly investigates the semantic segmentation of remote sensing images. The research belongs to computer vision and pattern recognition. The purpose is to let a computer identify the category of each pixel in the remote sensing image, namely, remote sensing image interpretation. Remote sensing image interpretation is a basic problem in remote sensing.It is an important means to obtain remote sensing image information, and the ground object information obtained from it can provide an important reference for various tasks, such as change detection and disaster relief. Improving the segmentation accuracy of remote sensing images has always been a popular topic. This study proposes a new network structure based on fully convolutional neural network for the characteristics of remote sensing images. On this basis, a sliding step prediction method based on integrated learning is proposed and used. Fully connected conditions are adopted for the post-processing of images to optimize the segmentation results and achieve a high-precision semantic segmentation of remote sensing images.关键词:remote sensing image;semantic segmentation;fully convolutional neural network;dense upsampling convolution(DUC) structure;spatial pyramid pooling;contextual information;multi-scale features14|4|8更新时间:2024-05-07
摘要:Objective The traditional remote sensing image segmentation method requires the selection of manyartificial participation featuresandparameters. The shallow machine learning algorithm cannot achieve high-precision segmentation accuracy. The convolutional neural network can automatically learn the characteristics of features and draws on its excellent network structure for performing natural image semantic segmentation. A novel method based on the fully convolutional neural network for remote sensing image segmentation is proposed based on the characteristics of the remote sensing dataset. It studies the fusion between multi-spectral image data bands, increases the learnable features, and improves segmentation accuracy. On the basis of the characteristics of the remote sensing image size, the prediction results of integrated learning and the conditional random field processing model are investigated to mitigate the phenomenon of misclassification, restore the boundary of features, and further improve segmentation accuracy. This study realizes the extraction of features on multi-spectral remote sensing images, which can be applied to subsequent change detection tasks, thus promoting the analysis of changes in surface cover types by automation.Method Aiming at the characteristics of compact targets and the large size range of remote sensing images, a fully convolutional neural network based on pyramid pooling and the dense upsamplingconvolution (DUC) structure is proposed. The proposed network can automatically interpret remote sensing images. The network structure uses improved DenseNet as the underlying network to extract image features, the spatial pyramid pooling structure to obtain context information, and the DUC structure to upsampleand recover detailed information. In the data processing stage, in combination with remote sensing knowledge, the bands are combined to generate multi-source data, and vegetation and normalized water indexes are generated to increase the characteristics. A sliding step prediction method based on integrated learning is proposed to address the problem of remote sensing images being large and the appearance of splicing trace by an ordinary prediction method. Each pixel is predicted 1 to 4 times, and each predicted pixel is located in different image blocks. Different locations vote on the results of multiple predictions. After prediction, the prediction results are post-processed using fully connected conditional random fields (CRFs) to refine the boundary of the features and optimize the segmentation results.Result To verify the validity of the proposed network model and post-processing method, the U-Net model, the fully convolutional neural network FCN-8s model, and the Hdc-DUC model are compared through experiments using a self-built dataset. The accuracy of using the multi-source data from the training model is higher than that obtained by using the original data. The multi-source data training model improves the mIoU evaluation standard by 3.19%, which confirms the validity of the multi-source data generated by band fusion combined with geo-remote sensing knowledge. In terms of effectiveness, when the sliding step prediction method based on integrated learning is used, the segmentation accuracy is improved by 1.44%, and the effect of the characteristics of the remote sensing image on the prediction phase of the model is verified. Although fully connected CRFs may smoothen small-sized features, the use of CRFs to post-process the prediction results effectively improves the segmentation accuracy by 1.03%. The main reason is the image resolution of the self-built dataset. The rate is low, the dataset is relatively fuzzy, the features are highly complicated, and the labeling is inaccurate. The distribution of data is difficult to learn through the fully convolutional neural network, and the accuracy of the prediction results is low. Therefore, fully connected CRFs can improve the segmentation results to a large extent. Experimental results verify the effectiveness of the proposed network model and post-processing method.Conclusion This study mainly investigates the semantic segmentation of remote sensing images. The research belongs to computer vision and pattern recognition. The purpose is to let a computer identify the category of each pixel in the remote sensing image, namely, remote sensing image interpretation. Remote sensing image interpretation is a basic problem in remote sensing.It is an important means to obtain remote sensing image information, and the ground object information obtained from it can provide an important reference for various tasks, such as change detection and disaster relief. Improving the segmentation accuracy of remote sensing images has always been a popular topic. This study proposes a new network structure based on fully convolutional neural network for the characteristics of remote sensing images. On this basis, a sliding step prediction method based on integrated learning is proposed and used. Fully connected conditions are adopted for the post-processing of images to optimize the segmentation results and achieve a high-precision semantic segmentation of remote sensing images.关键词:remote sensing image;semantic segmentation;fully convolutional neural network;dense upsampling convolution(DUC) structure;spatial pyramid pooling;contextual information;multi-scale features14|4|8更新时间:2024-05-07 -
 摘要:Objective Hyperspectral remote sensing, which is also called imaging spectral remote sensing, is a combined imaging and spectroscopy of multi-dimensional information retrieval technology. It carries abundant spectral information and is widely used in earth observation. A hyperspectral image is a kind of nonlinear structured data with a high dimension, and it poses a great challenge to the clustering task. If direct processing of the spectral information of hyperspectral images requires a large amount of computation, then appropriate dimensionality reduction methods for the nonlinear structure of hyperspectral data must be adopted. Although many clustering methods have been proposed, these traditional methods involve shallow linear models, the efficiency of the similarity measure is low, and the clustering effect is often poor for high-dimensional or hyperspectral data with a nonlinear structure. Traditional clustering algorithms encounter difficulties when clustering high-dimensional data. The concept of subspace clustering has been proposed to solve the problem of high-dimensional data clustering. Subspace clustering can solve the clustering problem of high-dimensional data. However, existing subspace clustering algorithms typically employ shallow models to estimate the underlying subspaces of unlabeled data points and cluster them into corresponding clusters. They have several limitations. First, the clustering effect of these subspace clustering methods depends on the quality of the affinity matrix. Second, due to the linear assumption of the data, these methods cannot deal with data with a nonlinear structure. Several nuclear methods have been proposed to overcome these shortcomings. These methods map the data to a predefined kernel space where they perform subspace clustering. A disadvantage of these nuclear space clustering methods is that their performance depends heavily on the kernel functions used. Existing data transformation methods include linear transformation, such as principal component analysis (PCA), and nonlinear transformation, such as the kernel method. However, data with a highly complex potential structure is still a huge challenge to the effectiveness of existing clustering methods, and most clustering algorithms, such as shallow models, can only extract shallow features. Owing to the limited representation capacity of the employed shallow models, the algorithms may fail in handling realistic data with high-dimensional nonlinear structures. Moreover, most learning approaches treat feature extraction and clustering separately, train the feature extraction model well, and only use the clustering algorithm once in the feature representation of data to obtain clustering results.Method To solve these problems, the use of spectral information is maximized, and a new subspace clustering algorithm, that is, embedded deep neural network fuzzy c-means clustering (EDFCC), is proposed in this study. The EDFCC algorithm can effectively extract the spectral information of hyperspectral images and be used for hyperspectral image clustering. The fuzzy c-means clustering algorithm is embedded into the deep autoencoder network, and the joint learning deep autoencoder network and fuzzy c-means clustering algorithm are used. Optimizing the two tasks jointly can substantially improve the performance of both. First, the feature extraction process of data is assumed to be an unknown transformation, which may be a nonlinear function. To preserve the local structure, the representation of each data point is learned by minimizing the reconstruction error, that is, the feature extraction process is completed by learning the deep autoencoder network. Data should be clustered in an effective manner to learn the representation of the potential features of data suitable for clustering. The fuzzy c-means clustering algorithm is used to constrain the feature extraction process and make the generated features suitable for clustering. The motivation for designing the EDFCC algorithm is to maintain the advantage of the joint optimization of the two tasks while using the capability of the deep autoencoder network to approximate any nonlinear function, gradually map the input data points to the potential nonlinear space, and adjust the clustering indicator matrix dynamically with the model training.Result Two hyperspectral data sets, namely, Indian Pines and Pavia University, are used to test the validity of the EDFCC algorithm. The quantitative evaluation metrics include accuracy and normalized mutual information. The Indian Pines dataset contains data acquired by the airborne visible infrared imaging spectrometer with a spectral range of 0.41~2.45 m, spatial resolution of 25 m, spectral resolution of 10 nm, and a total of 145×145 sample points. A total of 220 original bands are available, but the water vapor absorption band and bands with a low signal-to-noise ratio are excluded. The remaining 200 bands are used as research objects. The Indian Pines dataset has 16 different feature categories. Indian Pines shows that the overall clustering accuracy of the EDFCC algorithm is 42.95%, which is 3% higher than that of the best LRSC algorithm. The Pavia University dataset was obtained by the airborne reflector optical spectral imager in Germany. Its spectral range is 0.43~0.86 m, and its spatial resolution is 1.3 m. The dataset contains 610×340 sample points. A total of 115 original bands exist, but the noise bands are removed. The 103 remaining bands are used as research objects. The Pavia University dataset has nine types of ground objects. The dataset shows that the overall clustering accuracy of the EDFCC algorithm is 60.59%, which is 4% higher than that of the best LRSC algorithm. When compared with the AEKM algorithm for deep clustering, the AEKM algorithm is improved by 2% and 3%.Conclusion The EDFCC algorithm is proposed in this study. The algorithm is first applied in hyperspectral image clustering as a joint learning framework. The indicator matrix can be dynamically adjusted because of joint learning, and no additional training process is required, which greatly improves the training efficiency. Experimentalresults show that the EDFCC algorithm can extract many effective deep features from the high-dimensional spectral information of hyperspectral images and improve clustering accuracy.关键词:embedded learning;deep neural network;adaptive feature mapping;clustering;hyperspectral image14|5|1更新时间:2024-05-07
摘要:Objective Hyperspectral remote sensing, which is also called imaging spectral remote sensing, is a combined imaging and spectroscopy of multi-dimensional information retrieval technology. It carries abundant spectral information and is widely used in earth observation. A hyperspectral image is a kind of nonlinear structured data with a high dimension, and it poses a great challenge to the clustering task. If direct processing of the spectral information of hyperspectral images requires a large amount of computation, then appropriate dimensionality reduction methods for the nonlinear structure of hyperspectral data must be adopted. Although many clustering methods have been proposed, these traditional methods involve shallow linear models, the efficiency of the similarity measure is low, and the clustering effect is often poor for high-dimensional or hyperspectral data with a nonlinear structure. Traditional clustering algorithms encounter difficulties when clustering high-dimensional data. The concept of subspace clustering has been proposed to solve the problem of high-dimensional data clustering. Subspace clustering can solve the clustering problem of high-dimensional data. However, existing subspace clustering algorithms typically employ shallow models to estimate the underlying subspaces of unlabeled data points and cluster them into corresponding clusters. They have several limitations. First, the clustering effect of these subspace clustering methods depends on the quality of the affinity matrix. Second, due to the linear assumption of the data, these methods cannot deal with data with a nonlinear structure. Several nuclear methods have been proposed to overcome these shortcomings. These methods map the data to a predefined kernel space where they perform subspace clustering. A disadvantage of these nuclear space clustering methods is that their performance depends heavily on the kernel functions used. Existing data transformation methods include linear transformation, such as principal component analysis (PCA), and nonlinear transformation, such as the kernel method. However, data with a highly complex potential structure is still a huge challenge to the effectiveness of existing clustering methods, and most clustering algorithms, such as shallow models, can only extract shallow features. Owing to the limited representation capacity of the employed shallow models, the algorithms may fail in handling realistic data with high-dimensional nonlinear structures. Moreover, most learning approaches treat feature extraction and clustering separately, train the feature extraction model well, and only use the clustering algorithm once in the feature representation of data to obtain clustering results.Method To solve these problems, the use of spectral information is maximized, and a new subspace clustering algorithm, that is, embedded deep neural network fuzzy c-means clustering (EDFCC), is proposed in this study. The EDFCC algorithm can effectively extract the spectral information of hyperspectral images and be used for hyperspectral image clustering. The fuzzy c-means clustering algorithm is embedded into the deep autoencoder network, and the joint learning deep autoencoder network and fuzzy c-means clustering algorithm are used. Optimizing the two tasks jointly can substantially improve the performance of both. First, the feature extraction process of data is assumed to be an unknown transformation, which may be a nonlinear function. To preserve the local structure, the representation of each data point is learned by minimizing the reconstruction error, that is, the feature extraction process is completed by learning the deep autoencoder network. Data should be clustered in an effective manner to learn the representation of the potential features of data suitable for clustering. The fuzzy c-means clustering algorithm is used to constrain the feature extraction process and make the generated features suitable for clustering. The motivation for designing the EDFCC algorithm is to maintain the advantage of the joint optimization of the two tasks while using the capability of the deep autoencoder network to approximate any nonlinear function, gradually map the input data points to the potential nonlinear space, and adjust the clustering indicator matrix dynamically with the model training.Result Two hyperspectral data sets, namely, Indian Pines and Pavia University, are used to test the validity of the EDFCC algorithm. The quantitative evaluation metrics include accuracy and normalized mutual information. The Indian Pines dataset contains data acquired by the airborne visible infrared imaging spectrometer with a spectral range of 0.41~2.45 m, spatial resolution of 25 m, spectral resolution of 10 nm, and a total of 145×145 sample points. A total of 220 original bands are available, but the water vapor absorption band and bands with a low signal-to-noise ratio are excluded. The remaining 200 bands are used as research objects. The Indian Pines dataset has 16 different feature categories. Indian Pines shows that the overall clustering accuracy of the EDFCC algorithm is 42.95%, which is 3% higher than that of the best LRSC algorithm. The Pavia University dataset was obtained by the airborne reflector optical spectral imager in Germany. Its spectral range is 0.43~0.86 m, and its spatial resolution is 1.3 m. The dataset contains 610×340 sample points. A total of 115 original bands exist, but the noise bands are removed. The 103 remaining bands are used as research objects. The Pavia University dataset has nine types of ground objects. The dataset shows that the overall clustering accuracy of the EDFCC algorithm is 60.59%, which is 4% higher than that of the best LRSC algorithm. When compared with the AEKM algorithm for deep clustering, the AEKM algorithm is improved by 2% and 3%.Conclusion The EDFCC algorithm is proposed in this study. The algorithm is first applied in hyperspectral image clustering as a joint learning framework. The indicator matrix can be dynamically adjusted because of joint learning, and no additional training process is required, which greatly improves the training efficiency. Experimentalresults show that the EDFCC algorithm can extract many effective deep features from the high-dimensional spectral information of hyperspectral images and improve clustering accuracy.关键词:embedded learning;deep neural network;adaptive feature mapping;clustering;hyperspectral image14|5|1更新时间:2024-05-07 -
 摘要:Objective Among synthetic aperture radar (SAR) image applications, automatic ship detection in SAR images is an active research field and plays a crucial role in various related military and civil applications, such as ocean traffic surveillance, protection against illegal fisheries, and ship rescuing. Many algorithms have been developed for ship detection in SAR images. Among them, constant false alarm rate (CFAR) algorithms, which have minimal operational complexity and a regular structure, are the most commonly used for ship detection in SAR imagery. CFAR-based methods are simple and effective, and the corresponding adaptive threshold preserves a constant false alarm probability. However, due to the non-homogeneity of sea clutter in the intensity domain, which is caused by the complexity of microwave scattering on the ocean surface, traditional CFAR-based detection methods cannot easily adapt to the variability and complexity of the sea clutter environment, and they cannot realize a robust detection of targets within sea clutter. Another approach to detect targets in a sea clutter background is to extract the features of targets in SAR images. The detection strategy relies on the feature description and analysis of targets in high-resolution SAR images. However, each feature representation for targets has its strengths and weaknesses and should be evaluated according to practical application scenarios. Additionally, the resolution of most SAR images is often not sufficiently high to extract effective detailed target information. In view of these situations, a high-performance ship detector based on information geometry is proposed in this study.Method Information geometry originated from the study of the intrinsic properties of manifolds of probability distributions. This theory is a combination of mathematical statistic models and geometrical methods. The development of geometrical theory and numerical techniques has extended the applicability of information geometry to the field of signal/image analysis. The purpose of this research is to obtain an improved understanding and analysis of the statistical manifold and its geometric structure in parameter space. This work explores the application of information geometry theory in ship detection from SAR images and analyzes detection problems from a new perspective. The manifold model is a good representation of the structural information of the pixel distribution controlled by a set of parameter. On this basis, an effective ship detection approach in SAR images is developed in this study. First, the Weibull distribution is used to model clutter, and the maximum likelihood estimation method is adopted to estimate the distribution parameters of the local neighborhood pixels of the SAR image. Second, the statistical distribution under different parameters is regarded as the difference point in the Weibull manifold. Third, a novel Riemannian metric is constructed to realize distance measurement between probability distributions in manifold space. Finally, the targets are extracted using an automatic threshold selection method.Result According to the theory of modern geometry, two points that are similar in Euclidean space may be far apart in non-Euclidean space. A significant statistical difference exists between ship targets and sea clutter because of the complex backscattering feature of ships. The proposed method based on information geometry utilizes this feature and geometrical methods to implement non-Euclidean metrics between classes (ship targets and background clutter to achieve saliency representation and detection of targets). Detection experiments are conducted on real SAR imagery. The results of the conventional Weibull-based CFAR detector is also provided for comparison to validate the effectiveness of the proposed method in real data. Conventional CFAR detection methods fail to yield satisfactory results due to low signal-to-clutter ratio and varying local clutter. Compared with conventional CFAR approaches, the proposed method can enhance targets and measure the local dissimilarity between a target and its neighborhood by using the information geometrical structure. Experimental results also show that the proposed method based on information geometry is effective in discriminating between ships and sea clutter and has good performance in ship detection in SAR images.Conclusion Information geometry began as the application of differential geometry to statistical theory. It has been applied to study the geometrical structure of a manifold of probability distributions. Information geometry has developed and continues to develop with the types of geometric statement used and in its application areas. In reality, no geometric statement is true or false by nature. Sometimes, it is merely a question of choice. Given the discovery of the geometric meaning of Fisher information, which contributes to the development of information geometry in a concise and intuitive manner, the geometric structure of a set of positive densities in a given statistical manifold space has elicited the interest of many researchers. Moreover, the Riemannian metric is not unique. Many important families of probability distributions possess a series of metric structures. Each metric corresponds to a different geometric structure. For these reasons, extensive research has focused on identifying new geometrical structures of parametric statistical models. It provides statistical science with a highly efficient method for constructing abstract models that maximize the use of space in signal/image processing. The aim of this study is to show the benefits of statistical manifolds suitable for ship detection in SAR imagery and based on information geometry theory. The principal tool in this work is the metric construction by means of building new metrics from old ones. Theoretical analysis and experimental results show that information geometry provides detection problems with a new perspective to view the structure of the investigated statistical manifold.关键词:SAR image;target detection;information geometry;statistical manifold;Riemannian metric25|7|2更新时间:2024-05-07
摘要:Objective Among synthetic aperture radar (SAR) image applications, automatic ship detection in SAR images is an active research field and plays a crucial role in various related military and civil applications, such as ocean traffic surveillance, protection against illegal fisheries, and ship rescuing. Many algorithms have been developed for ship detection in SAR images. Among them, constant false alarm rate (CFAR) algorithms, which have minimal operational complexity and a regular structure, are the most commonly used for ship detection in SAR imagery. CFAR-based methods are simple and effective, and the corresponding adaptive threshold preserves a constant false alarm probability. However, due to the non-homogeneity of sea clutter in the intensity domain, which is caused by the complexity of microwave scattering on the ocean surface, traditional CFAR-based detection methods cannot easily adapt to the variability and complexity of the sea clutter environment, and they cannot realize a robust detection of targets within sea clutter. Another approach to detect targets in a sea clutter background is to extract the features of targets in SAR images. The detection strategy relies on the feature description and analysis of targets in high-resolution SAR images. However, each feature representation for targets has its strengths and weaknesses and should be evaluated according to practical application scenarios. Additionally, the resolution of most SAR images is often not sufficiently high to extract effective detailed target information. In view of these situations, a high-performance ship detector based on information geometry is proposed in this study.Method Information geometry originated from the study of the intrinsic properties of manifolds of probability distributions. This theory is a combination of mathematical statistic models and geometrical methods. The development of geometrical theory and numerical techniques has extended the applicability of information geometry to the field of signal/image analysis. The purpose of this research is to obtain an improved understanding and analysis of the statistical manifold and its geometric structure in parameter space. This work explores the application of information geometry theory in ship detection from SAR images and analyzes detection problems from a new perspective. The manifold model is a good representation of the structural information of the pixel distribution controlled by a set of parameter. On this basis, an effective ship detection approach in SAR images is developed in this study. First, the Weibull distribution is used to model clutter, and the maximum likelihood estimation method is adopted to estimate the distribution parameters of the local neighborhood pixels of the SAR image. Second, the statistical distribution under different parameters is regarded as the difference point in the Weibull manifold. Third, a novel Riemannian metric is constructed to realize distance measurement between probability distributions in manifold space. Finally, the targets are extracted using an automatic threshold selection method.Result According to the theory of modern geometry, two points that are similar in Euclidean space may be far apart in non-Euclidean space. A significant statistical difference exists between ship targets and sea clutter because of the complex backscattering feature of ships. The proposed method based on information geometry utilizes this feature and geometrical methods to implement non-Euclidean metrics between classes (ship targets and background clutter to achieve saliency representation and detection of targets). Detection experiments are conducted on real SAR imagery. The results of the conventional Weibull-based CFAR detector is also provided for comparison to validate the effectiveness of the proposed method in real data. Conventional CFAR detection methods fail to yield satisfactory results due to low signal-to-clutter ratio and varying local clutter. Compared with conventional CFAR approaches, the proposed method can enhance targets and measure the local dissimilarity between a target and its neighborhood by using the information geometrical structure. Experimental results also show that the proposed method based on information geometry is effective in discriminating between ships and sea clutter and has good performance in ship detection in SAR images.Conclusion Information geometry began as the application of differential geometry to statistical theory. It has been applied to study the geometrical structure of a manifold of probability distributions. Information geometry has developed and continues to develop with the types of geometric statement used and in its application areas. In reality, no geometric statement is true or false by nature. Sometimes, it is merely a question of choice. Given the discovery of the geometric meaning of Fisher information, which contributes to the development of information geometry in a concise and intuitive manner, the geometric structure of a set of positive densities in a given statistical manifold space has elicited the interest of many researchers. Moreover, the Riemannian metric is not unique. Many important families of probability distributions possess a series of metric structures. Each metric corresponds to a different geometric structure. For these reasons, extensive research has focused on identifying new geometrical structures of parametric statistical models. It provides statistical science with a highly efficient method for constructing abstract models that maximize the use of space in signal/image processing. The aim of this study is to show the benefits of statistical manifolds suitable for ship detection in SAR imagery and based on information geometry theory. The principal tool in this work is the metric construction by means of building new metrics from old ones. Theoretical analysis and experimental results show that information geometry provides detection problems with a new perspective to view the structure of the investigated statistical manifold.关键词:SAR image;target detection;information geometry;statistical manifold;Riemannian metric25|7|2更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0