
最新刊期
卷 24 , 期 9 , 2019
- 摘要:UVRSM (urban video real-scene map) has important significance for construction of urban monitoring system, the development of Internet map products, and the implementation of future "real-scene China construction" strategy given the ability of unified information expression in three-dimensional space and time dimension. This paper presents a preliminary exploration on the construction of UVRSM for the convenience of researchers in related fields. From the point of view of augmented virtual environment (AVE) technology, this work proposes to construct the UVRSM by integrating panoramic video and geographic three-dimensional models. To this end, the technologies and methods involved in panoramic camera calibration, panoramic video geo-registration, automatic video texture mapping, and real-time rendering are comprehensively discussed. Some valuable research ideas and schemes are given. The theory and method of camera calibration and image geo-registration suitable for traditional pinhole model need to be expanded according to the spherical projection model of panoramic camera. The LOD (level of detail) technology and strategy for large-scale 3D scene rendering suitable for static texture need to be innovated to obtain the characteristics of video transmission bandwidth limitation and high frame rate. The construction of UVRSM is a new topic and will strongly promote the development of Internet and AI (artificial intelliqence) frontier technology. This field is expected to bring trillions of market opportunities to UVRSM-related domains or industries.关键词:video real-scene map;3D map;virtual reality;panoramic camera calibration;video geo-registration;video texture mapping;real-time rendering63|64|4更新时间:2024-05-07
Scholar View

-
 摘要:Optical remote sensing images are often affected by clouds or haze, and in most cases, auxiliary data are not available for removing haze from the original satellite images. Therefore, the single image-based haze removal method has become the necessary preprocessing technology. A variety of algorithms have been developed by different researchers, but systematic summary and comparative analysis are rare. This paper aims to systematically summarize the research progress of a single image-based haze removal algorithm and provide the basic theory, advantages, and disadvantages and applicable scenarios of typical algorithms. This paper first classifies and summarizes the current haze removal algorithms from three aspects (haze attenuation model, basic theory, and evaluation method), then analyzes the application scope and problems of current algorithms combined with specific application scenarios, and finally presents feasible solutions with respect to special problems. The imaging models used in the haze removal process are the additive, haze degradation, and illumination-reflection models. The additive model, which is simplified from radiation transfer equations, considers that the at-satellite radiance under haze or cloud conditions is the sum of different radiation components, including the constant path radiance, the surface reflected radiance, and spatially varying haze contribution. This model is adopted by the classical dark object subtraction (DOS) method and its various improved versions. The haze degradation model divides the observed light intensity into two components:direct attenuation describing the scene radiance and its decay in the atmosphere and airlight resulting from scattered light. Both components are correlated to the medium transmission that describes the portion of the light that is not scattered and reaches the sensor. Haze removal methods that rely on the dark channel prior (DCP) usually estimate the medium transmission through the haze degradation model. The illumination-reflection model abstracts the observed image as a product of the illumination component of the light source and the reflection component of the object. In the frequency domain, the haze or the cloud signal is mainly concentrated in the low-frequency region and can be suppressed through high-pass filtering. The widely used methods based on the illumination-reflection model include homomorphic filtering and wavelet decomposition. A haze removal procedure generally consists of two consecutive stages:haze detection and haze correction. Haze detection involves obtaining the precise spatial intensity of haze or thin clouds in an image, and haze correction is the process of removing haze influence depending on the estimated haze intensity. The distributions of haze usually vary dramatically in the spatial and temporal domains; as a result, the collection of detailed in situ measurements of haze conditions during the time of image acquisition is almost impossible in practical applications. Thus, single image-based haze removal methods have attracted increasing interest over the past decades. Existing methods retrieved in the literature fall into four common categories:DOS, frequency filtering, DCP, and image transformation-based approaches. DOS-based methods have evolved from the stage where they are suitable for homogeneous haze conditions only to the stage where they are able to compensate for spatially varying haze contaminations. The typical algorithms belong to the dense dark vegetation (DDV) technique and haze thickness map (HTM) method. The DDV technique depends on the empirical correlation between the reflectance of visible bands (usually blue and/or red) and that of a haze-transparent band (e.g., band 7 in the case of Landsat data) for DDV pixels. A DDV-based method would fail to work if a scene does not contain sufficient and evenly distributed vegetated pixels or the correlation of the DDV pixels is significantly different from the standard one. The HTM algorithm estimates haze intensity by searching dark targets within local neighboring blocks instead of searching in an entire scene. The HTM algorithm is feasible for satellite images with high spatial resolutions because pure dark pixels without mixing with bright targets are required in a small local region, but it is unable to handle scenes that have large areas of relatively bright surfaces. Frequency filtering-based approaches operate in the spatial frequency domain assuming that haze contamination is in a relatively low frequency compared with the changeable reflectance of surface covers and can thus be removed by applying a filtering process. Wavelet decomposition and homomorphic filtering are two representative approaches. The major obstacle in applying these methods is determining a cut-off frequency or choosing the wavelet basis. Current solutions rely on empirical criteria and are usually suitable for some special issues. DCP-based methods combine the haze degradation model and DCP, which originates from the statistics of outdoor haze-free images (i.e., in most non-sky patches of haze-free images, at least one color channel has very low intensity at some pixels). When applying DCP-based methods for haze removal in remote sensing images, improvements are required due to the different characteristics between natural scenes and satellite images. Image transformation-based haze removals are initially developed based on the tasseled cap transformation (TCT) because haze contamination seems to be the major contributor to the fourth component of TCT. Haze-optimized transformation (HOT) might be the most widely used transformation-based haze removal method, which supposes that digital numbers of red and blue bands are highly correlated for pixels within the clearest portions of a scene and that this relationship holds for all surface classes. Given that the algorithm relies on only two visible bands, which means that no haze-transparent band is needed, it can be applied to a broad range of satellite images (e.g., Landsat, MODIS, Sentinel-2, QuikBird, and IKONOS). Nevertheless, serious spurious HOT responses exist over non-vegetated areas (e.g., water bodies, snow cover, bare soil, and urban targets), leading to under-correction or overcorrection of these targets. A usual solution is to exclude sensitive land cover types from original HOT and then estimate HOT values for the excluded pixels through spatial inference. Another suggested strategy for addressing this issue is to fill the sinks and flatten the peaks in a HOT image. Other haze removal methods are also involved in band combination, mixed pixel decomposition, or machine learning techniques. For example, multi-scale residual convolutional neural network (MRCNN) is designed for haze removal of Landsat 8 OLI images. MRCNN is able to predict haze intensity by feeding into specific hazy image blocks after it automatically learns the mapping relations between hazy images and their associated haze transmission from sufficient training samples. As for algorithm analysis and evaluation, researchers are inclined to adopt subjective analysis or choose reference images to evaluate spectral consistency before and after haze removal. Recently, image quality indices have been utilized more frequently to evaluate the contrast, brightness, structural consistency, and fidelity of dehazed images. The existing algorithms are not suitable for all scenarios or images, and they face some problems. For instance, parameters are difficult to adjust adaptively, the model is sensitive to special land cover types, and outputted results are seriously distorted. The evaluation of different algorithms is mainly based on subjective comparative analysis, and building objective indicators according to application requirements has become the current research direction.关键词:remote sensing dehazing;dark object subtraction;dark channel prior;haze degradation model;image quality evaluation;haze optimized transformation;wavelet decomposition95|120|1更新时间:2024-05-07
摘要:Optical remote sensing images are often affected by clouds or haze, and in most cases, auxiliary data are not available for removing haze from the original satellite images. Therefore, the single image-based haze removal method has become the necessary preprocessing technology. A variety of algorithms have been developed by different researchers, but systematic summary and comparative analysis are rare. This paper aims to systematically summarize the research progress of a single image-based haze removal algorithm and provide the basic theory, advantages, and disadvantages and applicable scenarios of typical algorithms. This paper first classifies and summarizes the current haze removal algorithms from three aspects (haze attenuation model, basic theory, and evaluation method), then analyzes the application scope and problems of current algorithms combined with specific application scenarios, and finally presents feasible solutions with respect to special problems. The imaging models used in the haze removal process are the additive, haze degradation, and illumination-reflection models. The additive model, which is simplified from radiation transfer equations, considers that the at-satellite radiance under haze or cloud conditions is the sum of different radiation components, including the constant path radiance, the surface reflected radiance, and spatially varying haze contribution. This model is adopted by the classical dark object subtraction (DOS) method and its various improved versions. The haze degradation model divides the observed light intensity into two components:direct attenuation describing the scene radiance and its decay in the atmosphere and airlight resulting from scattered light. Both components are correlated to the medium transmission that describes the portion of the light that is not scattered and reaches the sensor. Haze removal methods that rely on the dark channel prior (DCP) usually estimate the medium transmission through the haze degradation model. The illumination-reflection model abstracts the observed image as a product of the illumination component of the light source and the reflection component of the object. In the frequency domain, the haze or the cloud signal is mainly concentrated in the low-frequency region and can be suppressed through high-pass filtering. The widely used methods based on the illumination-reflection model include homomorphic filtering and wavelet decomposition. A haze removal procedure generally consists of two consecutive stages:haze detection and haze correction. Haze detection involves obtaining the precise spatial intensity of haze or thin clouds in an image, and haze correction is the process of removing haze influence depending on the estimated haze intensity. The distributions of haze usually vary dramatically in the spatial and temporal domains; as a result, the collection of detailed in situ measurements of haze conditions during the time of image acquisition is almost impossible in practical applications. Thus, single image-based haze removal methods have attracted increasing interest over the past decades. Existing methods retrieved in the literature fall into four common categories:DOS, frequency filtering, DCP, and image transformation-based approaches. DOS-based methods have evolved from the stage where they are suitable for homogeneous haze conditions only to the stage where they are able to compensate for spatially varying haze contaminations. The typical algorithms belong to the dense dark vegetation (DDV) technique and haze thickness map (HTM) method. The DDV technique depends on the empirical correlation between the reflectance of visible bands (usually blue and/or red) and that of a haze-transparent band (e.g., band 7 in the case of Landsat data) for DDV pixels. A DDV-based method would fail to work if a scene does not contain sufficient and evenly distributed vegetated pixels or the correlation of the DDV pixels is significantly different from the standard one. The HTM algorithm estimates haze intensity by searching dark targets within local neighboring blocks instead of searching in an entire scene. The HTM algorithm is feasible for satellite images with high spatial resolutions because pure dark pixels without mixing with bright targets are required in a small local region, but it is unable to handle scenes that have large areas of relatively bright surfaces. Frequency filtering-based approaches operate in the spatial frequency domain assuming that haze contamination is in a relatively low frequency compared with the changeable reflectance of surface covers and can thus be removed by applying a filtering process. Wavelet decomposition and homomorphic filtering are two representative approaches. The major obstacle in applying these methods is determining a cut-off frequency or choosing the wavelet basis. Current solutions rely on empirical criteria and are usually suitable for some special issues. DCP-based methods combine the haze degradation model and DCP, which originates from the statistics of outdoor haze-free images (i.e., in most non-sky patches of haze-free images, at least one color channel has very low intensity at some pixels). When applying DCP-based methods for haze removal in remote sensing images, improvements are required due to the different characteristics between natural scenes and satellite images. Image transformation-based haze removals are initially developed based on the tasseled cap transformation (TCT) because haze contamination seems to be the major contributor to the fourth component of TCT. Haze-optimized transformation (HOT) might be the most widely used transformation-based haze removal method, which supposes that digital numbers of red and blue bands are highly correlated for pixels within the clearest portions of a scene and that this relationship holds for all surface classes. Given that the algorithm relies on only two visible bands, which means that no haze-transparent band is needed, it can be applied to a broad range of satellite images (e.g., Landsat, MODIS, Sentinel-2, QuikBird, and IKONOS). Nevertheless, serious spurious HOT responses exist over non-vegetated areas (e.g., water bodies, snow cover, bare soil, and urban targets), leading to under-correction or overcorrection of these targets. A usual solution is to exclude sensitive land cover types from original HOT and then estimate HOT values for the excluded pixels through spatial inference. Another suggested strategy for addressing this issue is to fill the sinks and flatten the peaks in a HOT image. Other haze removal methods are also involved in band combination, mixed pixel decomposition, or machine learning techniques. For example, multi-scale residual convolutional neural network (MRCNN) is designed for haze removal of Landsat 8 OLI images. MRCNN is able to predict haze intensity by feeding into specific hazy image blocks after it automatically learns the mapping relations between hazy images and their associated haze transmission from sufficient training samples. As for algorithm analysis and evaluation, researchers are inclined to adopt subjective analysis or choose reference images to evaluate spectral consistency before and after haze removal. Recently, image quality indices have been utilized more frequently to evaluate the contrast, brightness, structural consistency, and fidelity of dehazed images. The existing algorithms are not suitable for all scenarios or images, and they face some problems. For instance, parameters are difficult to adjust adaptively, the model is sensitive to special land cover types, and outputted results are seriously distorted. The evaluation of different algorithms is mainly based on subjective comparative analysis, and building objective indicators according to application requirements has become the current research direction.关键词:remote sensing dehazing;dark object subtraction;dark channel prior;haze degradation model;image quality evaluation;haze optimized transformation;wavelet decomposition95|120|1更新时间:2024-05-07
Review
-
 摘要:ObjectiveDiffusion weight imaging (DWI), as a new medical imaging technique, transforms the diffusion motion of water molecules in tissues into grayscale or other parameter information of an image by applying multi-directional diffusion magnetic sensitive gradients under each diffusion sensitive gradient. This technique can be used for the auxiliary diagnosis of living heart myocardial fiber modeling, brain fiber, lesions of the central nervous system, liver fibrosis, and other diseases. With the popularization of telemedicine diagnostic technology, an increasing amount of DWI data are being used for remote diagnosis and scientific research. DWI images, which are originally stored and used on a single machine in a hospital, must be transmitted and used over the network. Many scholars have proposed many watermarking algorithms for protecting medical images, such as the reversible watermarking algorithm, robust reversible watermarking algorithm, and zero-watermarking algorithm. The advantage of the reversible algorithm is that it can be completely used for nondestructive image recovery. The robustness of the reversible watermarking algorithm is too weak to guarantee the existence of the reversible watermark when embedded images are attacked intentionally or unintentionally. Therefore, some researchers propose the robust reversible watermarking algorithm. The robust reversible watermarking algorithm could restore an original picture when no attack occurs and could draw embedded watermarking. It ensures that its robust reversible performance should carry additional information. Thus, it must consume a large amount of transmission bandwidth. Some robust reversible watermarks are constructed by dual watermarking, and they depend on one another's information to extract the watermarks. To protect medical images by other methods, some researchers use the zero-watermarking algorithm, which is different from the traditional method that embeds information into images. The zero-watermarking algorithm can retrieve internal features from data to build binary watermarking and then save it in a third-party application. When the image is used by other people without the license, we could use zero-watermarking to prove copyright. Thus, the zero-watermarking algorithm, as a non-embedded algorithm, cannot actively complete the protection of property information. The robust watermarking algorithm plays an irreplaceable role in ensuring that the medical image watermarking information has certain robustness. To prevent unauthorized DWI images from being used or tampered with, this study proposes a robust watermarking algorithm based on DWI images.MethodThe algorithm initially obtains specified slips by the maximum inter-class variance segmentation algorithm and area control threshold to ensure that the selected slice has a sufficient embedding area because the tip and the bottom of the heart are unsuitable for embedding. The foreground region with a diffusion gradient direction image is prepared for embedding. We obtain the low-frequency sub-band coefficient by using integer wavelet transform in the default region. Then, we count the low frequency and analyze the low sub-frequency coefficient by using the fixed step length; the low sub-frequency coefficient follows the characteristics of the coefficient of DWI images. The ratio relation of adjacent clusters in the histogram subject area is adjusted for watermark embedding. Finally, we propose to design the quantitative reversible relationship between apparent DWI coefficients, with diffusion tensor imaging (DTI) as the key. We use this key to encrypt a DWI image after embedding the watermark to effectively protect the copyright information of the DWI image.ResultThe algorithm can maintain its robustness and reduce the change in the DTI parameters in the experiment on robustness and changes in the parameters of DTI after embedding. The proposed algorithm also has excellent robustness in attack experiments, such as those involving Gaussian noise, contrast expansion, and small angle rotation. In the experiment on parameter change measurement before and after embedding, the algorithm is greatly reduced the volume of change in isotropic and fiber main direction of the myocardial fiber. In our proposed method, the main direction of the fiber is reduced by more than 100, and the average change of the mean diffusivity is reduced by more than 30 in the same database. In the visual quality of the algorithm, the peak signal-to-noise ratio is approximately 8 dB higher than that specified in the comparative literature.ConclusionAn embedded selection feedback mechanism is proposed to carry out the selection of watermark embedding according to actual embedding demands. Then, the statistical histogram of the sub-band coefficient is constructed by specifying the fixed step length according to the characteristics of the wavelet transform coefficient of the DWI image. Finally, the reversible key algorithm based on the quantitative relationship between DWI and DTI is constructed. Experiments show that this algorithm can be applied to the watermark embedding of dispersion weighted imaging and can satisfy fiber direction as little as possible.关键词:diffusion weight imaging (DWI);histogram;stable step;ration relationship;robust watermark24|46|6更新时间:2024-05-07
摘要:ObjectiveDiffusion weight imaging (DWI), as a new medical imaging technique, transforms the diffusion motion of water molecules in tissues into grayscale or other parameter information of an image by applying multi-directional diffusion magnetic sensitive gradients under each diffusion sensitive gradient. This technique can be used for the auxiliary diagnosis of living heart myocardial fiber modeling, brain fiber, lesions of the central nervous system, liver fibrosis, and other diseases. With the popularization of telemedicine diagnostic technology, an increasing amount of DWI data are being used for remote diagnosis and scientific research. DWI images, which are originally stored and used on a single machine in a hospital, must be transmitted and used over the network. Many scholars have proposed many watermarking algorithms for protecting medical images, such as the reversible watermarking algorithm, robust reversible watermarking algorithm, and zero-watermarking algorithm. The advantage of the reversible algorithm is that it can be completely used for nondestructive image recovery. The robustness of the reversible watermarking algorithm is too weak to guarantee the existence of the reversible watermark when embedded images are attacked intentionally or unintentionally. Therefore, some researchers propose the robust reversible watermarking algorithm. The robust reversible watermarking algorithm could restore an original picture when no attack occurs and could draw embedded watermarking. It ensures that its robust reversible performance should carry additional information. Thus, it must consume a large amount of transmission bandwidth. Some robust reversible watermarks are constructed by dual watermarking, and they depend on one another's information to extract the watermarks. To protect medical images by other methods, some researchers use the zero-watermarking algorithm, which is different from the traditional method that embeds information into images. The zero-watermarking algorithm can retrieve internal features from data to build binary watermarking and then save it in a third-party application. When the image is used by other people without the license, we could use zero-watermarking to prove copyright. Thus, the zero-watermarking algorithm, as a non-embedded algorithm, cannot actively complete the protection of property information. The robust watermarking algorithm plays an irreplaceable role in ensuring that the medical image watermarking information has certain robustness. To prevent unauthorized DWI images from being used or tampered with, this study proposes a robust watermarking algorithm based on DWI images.MethodThe algorithm initially obtains specified slips by the maximum inter-class variance segmentation algorithm and area control threshold to ensure that the selected slice has a sufficient embedding area because the tip and the bottom of the heart are unsuitable for embedding. The foreground region with a diffusion gradient direction image is prepared for embedding. We obtain the low-frequency sub-band coefficient by using integer wavelet transform in the default region. Then, we count the low frequency and analyze the low sub-frequency coefficient by using the fixed step length; the low sub-frequency coefficient follows the characteristics of the coefficient of DWI images. The ratio relation of adjacent clusters in the histogram subject area is adjusted for watermark embedding. Finally, we propose to design the quantitative reversible relationship between apparent DWI coefficients, with diffusion tensor imaging (DTI) as the key. We use this key to encrypt a DWI image after embedding the watermark to effectively protect the copyright information of the DWI image.ResultThe algorithm can maintain its robustness and reduce the change in the DTI parameters in the experiment on robustness and changes in the parameters of DTI after embedding. The proposed algorithm also has excellent robustness in attack experiments, such as those involving Gaussian noise, contrast expansion, and small angle rotation. In the experiment on parameter change measurement before and after embedding, the algorithm is greatly reduced the volume of change in isotropic and fiber main direction of the myocardial fiber. In our proposed method, the main direction of the fiber is reduced by more than 100, and the average change of the mean diffusivity is reduced by more than 30 in the same database. In the visual quality of the algorithm, the peak signal-to-noise ratio is approximately 8 dB higher than that specified in the comparative literature.ConclusionAn embedded selection feedback mechanism is proposed to carry out the selection of watermark embedding according to actual embedding demands. Then, the statistical histogram of the sub-band coefficient is constructed by specifying the fixed step length according to the characteristics of the wavelet transform coefficient of the DWI image. Finally, the reversible key algorithm based on the quantitative relationship between DWI and DTI is constructed. Experiments show that this algorithm can be applied to the watermark embedding of dispersion weighted imaging and can satisfy fiber direction as little as possible.关键词:diffusion weight imaging (DWI);histogram;stable step;ration relationship;robust watermark24|46|6更新时间:2024-05-07
Image Processing and Coding
-
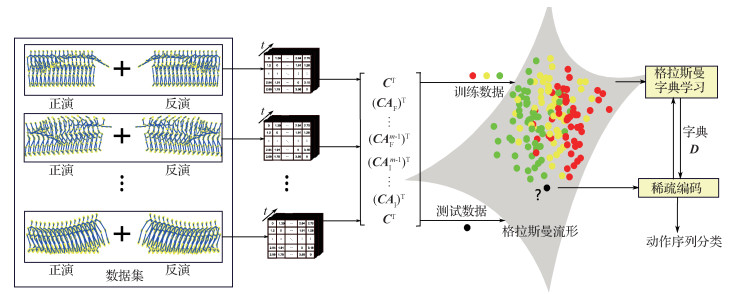 摘要:ObjectiveHuman action recognition has a very wide application prospect in fields such as video surveillance, human-computer interface, environment-assisted life, human-computer interaction, and intelligent driving. In image or video analysis, most of these tasks use color and texture cues in 2D images for recognition. However, due to occlusion, shadows, illumination changes, perspective changes, scale changes, intra-class variations, and similarities between classes, the recognition rate of human behavior is not ideal. In recent years, with the release of 3D depth cameras, such as Microsoft Kinect, 3D depth data can provide pictures of scene changes, thereby improving the recognition rates for the first three challenges of human recognition. In addition, 3D depth cameras provide powerful human motion capture technology, which can output the human skeleton of a 3D joint point position. Therefore, much attention has been paid to skeleton-based action recognition. The linear dynamical system (LDS) is the most common method for encoding spatio-temporal time-series data in various disciplines due to its simplicity and efficiency. A new method is proposed to obtain the parameters of a tensor-based LDS with forward and inverse action sequences to construct a complete observation matrix. The linear subspace of the observation matrix, which maps to a point on Grassmann manifold for human action recognition, is obtained. In this manner, an action can be expressed as a subspace spanned by columns of the matrix corresponding to a point on the Grassmann manifold. On the basis of such action, classification can be performed using dictionary learning and sparse coding.MethodConsidering the dynamics and persistence of human behavior, we do not vectorize the time series according to the general method but retain its own tensor characteristics, that is, we transform the high-dimensional vector into a low-dimensional subspace to analyze the factors affecting actions from various angles (modules). In this method, human skeletons are modeled using human joint points, which are initially extracted from a depth camera recording. To preserve the original spatio-temporal information of an action video and enhance the accuracy of human action recognition, we develop a time series of skeleton motions on the basis of the data in a three-order tensor and convert the skeleton into a two-order tensor. With this action representation, Tucker tensor decomposition methods are applied to obtain dimensionality reduction. Using the tensor-based LDS model with forward and inverse action sequence, we learn a parameter tuple (AF, AI, C), in which C represents the spatial appearance of skeleton information, AF describes the dynamics of the forward time series, and AI describes the dynamics of the inversion time series. We consider using an m-order observable matrix to approximate the extended observable matrix because human behavior has a limited duration and does not extend indefinitely in time. When
摘要:ObjectiveHuman action recognition has a very wide application prospect in fields such as video surveillance, human-computer interface, environment-assisted life, human-computer interaction, and intelligent driving. In image or video analysis, most of these tasks use color and texture cues in 2D images for recognition. However, due to occlusion, shadows, illumination changes, perspective changes, scale changes, intra-class variations, and similarities between classes, the recognition rate of human behavior is not ideal. In recent years, with the release of 3D depth cameras, such as Microsoft Kinect, 3D depth data can provide pictures of scene changes, thereby improving the recognition rates for the first three challenges of human recognition. In addition, 3D depth cameras provide powerful human motion capture technology, which can output the human skeleton of a 3D joint point position. Therefore, much attention has been paid to skeleton-based action recognition. The linear dynamical system (LDS) is the most common method for encoding spatio-temporal time-series data in various disciplines due to its simplicity and efficiency. A new method is proposed to obtain the parameters of a tensor-based LDS with forward and inverse action sequences to construct a complete observation matrix. The linear subspace of the observation matrix, which maps to a point on Grassmann manifold for human action recognition, is obtained. In this manner, an action can be expressed as a subspace spanned by columns of the matrix corresponding to a point on the Grassmann manifold. On the basis of such action, classification can be performed using dictionary learning and sparse coding.MethodConsidering the dynamics and persistence of human behavior, we do not vectorize the time series according to the general method but retain its own tensor characteristics, that is, we transform the high-dimensional vector into a low-dimensional subspace to analyze the factors affecting actions from various angles (modules). In this method, human skeletons are modeled using human joint points, which are initially extracted from a depth camera recording. To preserve the original spatio-temporal information of an action video and enhance the accuracy of human action recognition, we develop a time series of skeleton motions on the basis of the data in a three-order tensor and convert the skeleton into a two-order tensor. With this action representation, Tucker tensor decomposition methods are applied to obtain dimensionality reduction. Using the tensor-based LDS model with forward and inverse action sequence, we learn a parameter tuple (AF, AI, C), in which C represents the spatial appearance of skeleton information, AF describes the dynamics of the forward time series, and AI describes the dynamics of the inversion time series. We consider using an m-order observable matrix to approximate the extended observable matrix because human behavior has a limited duration and does not extend indefinitely in time. When$m$ $m$ 关键词:time series forward inversion;human behavior recognition;human skeleton;linear dynamic system(LDS);Grassmann manifold29|46|0更新时间:2024-05-07 -
 摘要:ObjectiveThe comprehensive perception of traffic management through computer vision technology is particularly important in intelligent transportation systems (ITSs). As the core element of ITSs, vehicles are important objects of perception. Vehicle logos carry important information that benefits vehicle information collection, vehicle identification, and illegal vehicle tracking. As logos are distinctive features of any vehicle, their classification and recognition can also greatly narrow the scope of vehicle model recognition. However, traditional feature descriptor-based vehicle logo recognition methods have the following disadvantages. On the one hand, the number of features extracted is limited; thus, the characteristics of vehicle logos cannot be fully described. On the other hand, the extracted features are extremely complicated and highly dimensional. These traditional methods thus entail substantial computation time and are difficult to apply to actual vehicle identification-related systems. A vehicle logo recognition method based on local quantization of enhanced edge gradient features is proposed in this work to extract abundant vehicle logo image features while effectively reducing feature dimensions to improve recognition efficiency.MethodFirst, the characteristics of vehicle logo images are considered, and the edge gradient is used to represent vehicle logos. The gradient information of the vehicle logo images is extracted by calculating the gradient information of each pixel in each vehicle logo image and dividing the gradient information according to the gradient direction. The sum of the gradient magnitudes corresponding to different gradient directions in the neighborhood of each pixel is calculated to generate a gradient magnitude matrix of different directions. Then, the LTP (local tarnary patterns) descriptor is used to re-extract features from the gradient magnitude matrix. The LTP descriptor has stronger anti-noise capability than LBP (local binary patterns) and can generate features with greater robustness. The extracted features belonging to different direction gradients are concatenated, and the results serve as the final feature for each vehicle logo. Second, the
摘要:ObjectiveThe comprehensive perception of traffic management through computer vision technology is particularly important in intelligent transportation systems (ITSs). As the core element of ITSs, vehicles are important objects of perception. Vehicle logos carry important information that benefits vehicle information collection, vehicle identification, and illegal vehicle tracking. As logos are distinctive features of any vehicle, their classification and recognition can also greatly narrow the scope of vehicle model recognition. However, traditional feature descriptor-based vehicle logo recognition methods have the following disadvantages. On the one hand, the number of features extracted is limited; thus, the characteristics of vehicle logos cannot be fully described. On the other hand, the extracted features are extremely complicated and highly dimensional. These traditional methods thus entail substantial computation time and are difficult to apply to actual vehicle identification-related systems. A vehicle logo recognition method based on local quantization of enhanced edge gradient features is proposed in this work to extract abundant vehicle logo image features while effectively reducing feature dimensions to improve recognition efficiency.MethodFirst, the characteristics of vehicle logo images are considered, and the edge gradient is used to represent vehicle logos. The gradient information of the vehicle logo images is extracted by calculating the gradient information of each pixel in each vehicle logo image and dividing the gradient information according to the gradient direction. The sum of the gradient magnitudes corresponding to different gradient directions in the neighborhood of each pixel is calculated to generate a gradient magnitude matrix of different directions. Then, the LTP (local tarnary patterns) descriptor is used to re-extract features from the gradient magnitude matrix. The LTP descriptor has stronger anti-noise capability than LBP (local binary patterns) and can generate features with greater robustness. The extracted features belonging to different direction gradients are concatenated, and the results serve as the final feature for each vehicle logo. Second, the$K$ 关键词:vehicle logo recognition;gradient feature;multiple gradient direction;enhanced edge gradient feature;local quantization45|195|1更新时间:2024-05-07 -
 摘要:ObjectiveIn the circulation process, the appearance quality of coins decreases due to wear. Thus, recycling coins with worn out appearance is necessary. Generally, the need for coins to be recycled is determined by evaluating the quality of their appearance. The year of coins is an important information to judge their appearance quality. Accurately identifying Euro coins in circulation requires detecting and identifying the year they were issued. However, due to the uncertainty of the position and posture of the Euro coin number, the non-normalization of size, the interference of other characters, and the diversity of number arrangement, one cannot easily realize the automatic detection, recognition, and interpretation of Euro coin year by using computer vision algorithms.MethodThe method of detecting and recognizing Euro coin year consists of two steps. First, we use Faster-RCNN (faster-region convolutional neural network) to detect the number. The model algorithm is mainly completed in the following four steps:the first step is to send the entire image to be detected into the convolution neural network to obtain the convolution feature map; the second step is to input the feature map into the RPN (region proposal network) to obtain multiple candidate regions of the target; the third step is to use the ROI (region of interest) pooling layer to extract the features of the candidate regions; the fourth step is to use the multi-task classifier to carry out position regression to obtain the precise position coordinates of the target. A self-built experimental platform is used to collect five large coins from 12 EU (European Union) countries. The five currencies are 2 Euros, 1 Euro, 50 Euro cents, 20 Euro cents, and 10 Euro cents. In the collection process, the coins are rotated at small angles continuously and then captured at various angles as far as possible. A total of 4 429 pictures are collected from different angles. The ranking order of the number of coin years can be interpreted using four methods. For a given coin image, the method to be used to interpret the year must be determined first. According to observation, the year arrangement of a certain currency value in a country is fixed. If we can predetermine the currency value and country of a coin, then the corresponding year interpretation rules can be determined. This problem can be solved because the image sizes of coins with different values vary significantly and the coin patterns of different countries are different. Second, the obtained digital candidate boxes are grouped into four categories by using $K$-means clustering algorithm, and the most confident candidate boxes are selected in each category. Finally, according to the predetermined year arrangement pattern of coins from different countries, the accurate year information can be obtained by an appropriate sorting algorithm.ResultOn a self-built experimental platform, 4 429 pictures are collected from five types of coins with large currency values from 12 EU countries. The training and test samples are divided at a 1:1 ratio. Experimental results show that the detection accuracy of the method is 89.62% and that the calculation time is approximately 215 ms; these values satisfy the accuracy and real-time requirements.ConclusionThe proposed algorithm offers good real-time performance, robustness, and precision and carries high practical application value. Although the detection accuracy of existing algorithms is close to 90%, they can still be improved from two aspects to solve existing error situations. One aspect is to improve the clustering algorithm to achieve compact clustering or clustering in accordance with the law of the year number distribution; doing so can prevent the misdetection of characters or symbols to a certain extent. The other aspect is to further improve the Faster-RCNN network model and the simplified processing algorithm of candidate boxes to improve the detection accuracy of closely arranged digital boxes.关键词:object detection;digital detection;year sorting;Euro coin;Faster-RCNN;$K$-means clustering12|4|0更新时间:2024-05-07
摘要:ObjectiveIn the circulation process, the appearance quality of coins decreases due to wear. Thus, recycling coins with worn out appearance is necessary. Generally, the need for coins to be recycled is determined by evaluating the quality of their appearance. The year of coins is an important information to judge their appearance quality. Accurately identifying Euro coins in circulation requires detecting and identifying the year they were issued. However, due to the uncertainty of the position and posture of the Euro coin number, the non-normalization of size, the interference of other characters, and the diversity of number arrangement, one cannot easily realize the automatic detection, recognition, and interpretation of Euro coin year by using computer vision algorithms.MethodThe method of detecting and recognizing Euro coin year consists of two steps. First, we use Faster-RCNN (faster-region convolutional neural network) to detect the number. The model algorithm is mainly completed in the following four steps:the first step is to send the entire image to be detected into the convolution neural network to obtain the convolution feature map; the second step is to input the feature map into the RPN (region proposal network) to obtain multiple candidate regions of the target; the third step is to use the ROI (region of interest) pooling layer to extract the features of the candidate regions; the fourth step is to use the multi-task classifier to carry out position regression to obtain the precise position coordinates of the target. A self-built experimental platform is used to collect five large coins from 12 EU (European Union) countries. The five currencies are 2 Euros, 1 Euro, 50 Euro cents, 20 Euro cents, and 10 Euro cents. In the collection process, the coins are rotated at small angles continuously and then captured at various angles as far as possible. A total of 4 429 pictures are collected from different angles. The ranking order of the number of coin years can be interpreted using four methods. For a given coin image, the method to be used to interpret the year must be determined first. According to observation, the year arrangement of a certain currency value in a country is fixed. If we can predetermine the currency value and country of a coin, then the corresponding year interpretation rules can be determined. This problem can be solved because the image sizes of coins with different values vary significantly and the coin patterns of different countries are different. Second, the obtained digital candidate boxes are grouped into four categories by using $K$-means clustering algorithm, and the most confident candidate boxes are selected in each category. Finally, according to the predetermined year arrangement pattern of coins from different countries, the accurate year information can be obtained by an appropriate sorting algorithm.ResultOn a self-built experimental platform, 4 429 pictures are collected from five types of coins with large currency values from 12 EU countries. The training and test samples are divided at a 1:1 ratio. Experimental results show that the detection accuracy of the method is 89.62% and that the calculation time is approximately 215 ms; these values satisfy the accuracy and real-time requirements.ConclusionThe proposed algorithm offers good real-time performance, robustness, and precision and carries high practical application value. Although the detection accuracy of existing algorithms is close to 90%, they can still be improved from two aspects to solve existing error situations. One aspect is to improve the clustering algorithm to achieve compact clustering or clustering in accordance with the law of the year number distribution; doing so can prevent the misdetection of characters or symbols to a certain extent. The other aspect is to further improve the Faster-RCNN network model and the simplified processing algorithm of candidate boxes to improve the detection accuracy of closely arranged digital boxes.关键词:object detection;digital detection;year sorting;Euro coin;Faster-RCNN;$K$-means clustering12|4|0更新时间:2024-05-07 -
 摘要:ObjectivePedestrian detection is an important research topic in computer vision and plays a crucial role in all parts of life. The deformable part model (DPM) algorithm is a graphical model (Markov random field) that uses a series of parts and the spatial positional relationship of parts to represent an object. The DPM algorithm achieves superior detection accuracy in the field of pedestrian detection. However, because the DPM algorithm uses a sliding window strategy to search for objects in images, it handles a large number of candidate areas with low recall rates before constructing the feature pyramid. This property restricts the detection efficiency of the DPM algorithm. In view of this problem, this study proposes a novel model to improve the process of selecting candidate detection regions and puts forward the DPM algorithm integrated with a clustering algorithm with grid density and a selective search algorithm. Compared with the sliding window search method, the proposed model can provide fewer proposal windows and thus reduces computational complexity. Therefore, this study focuses on the advantages of the proposed model and the DPM algorithm to improve detection efficiency and accuracy.MethodThe proposed model contains three modules:the collection module of the coordinate points of moving targets, the generation module of frequently moving regions of targets, and the generation module of candidate detection windows. The modules are executed in series. Three frame difference methods and Gauss mixture models are used to detect moving targets in the first module. The centroid coordinates of each effective target are calculated by the obtained object contour, and a certain number of moving object coordinate points are collected and stored in the queue. In the second module, a G-cluster clustering algorithm based on grid structure and DBSCAN (density-based spatial clustering of applications with noise) clustering is proposed. The greatest advantage of the DBSCAN clustering algorithm is that it can find clusters of different sizes and shapes. However, this algorithm requires traversing every data point in the dataset, thereby leading to a high running time cost. Therefore, we draw lessons from the idea of the grid clustering algorithm based on the DBSCAN clustering algorithm. We develop a grid coordinate model and use the sliding window search method with an adaptive step size instead of neighborhood search to improve the method. This method can greatly reduce the number of data point searches and accelerate the speed of clustering. The specific experimental steps are as follows. The data points in the queue (QUE) are read, and the grid coordinate model is constructed. Frequently moving regions of targets are found by the sliding window strategy with an adaptive step size. Each region is dynamically adjusted with the aid of the moving object detection algorithm, and then the non-frequently moving regions are processed by masking to improve the effects of the candidate window generation module following the generation of frequently moving regions. Finally, the processed images are entered into the next module. In the third module, an improved selective search algorithm is introduced. As a mature image segmentation algorithm, the selective search algorithm can detect object proposals rapidly and effectively. It can also satisfy the accuracy and real-time requirements of pedestrian detection. Therefore, this thesis uses the selective search algorithm to extract a target from an image, and obtains a series of windows with high probability of complete target extraction. To further exclude the candidate windows with low credibility, we count and adjust the width-height ratio of the pedestrian contours in the INRIA dataset of public pedestrian image datasets. The range of the target width-height ratio is considered the condition for further screening candidate windows. Then, according to the coordinates of the final candidate detection window on the image, the corresponding features are extracted and entered into the classifier of the DPM algorithm. The final pedestrian detection window is obtained by classification.ResultExperiments on the PETS 2009 Bench-mark dataset were conducted to evaluate the performance of the proposed algorithm. Results indicated that compared with the sliding window search strategy, our algorithm effectively reduced some redundant windows. Moreover, the detection efficiency of the DPM algorithm showed improvement. The average precision of the proposed method increased by 1.71%, the LAMR (log-average miss rate) decreased by 2.2%, and speed increased by more than threefold.ConclusionTo deal with the problems of high computational complexity and high LAMR of the classical DPM algorithm, this study proposes a candidate field generation algorithm for pedestrian detection based on grid density clustering to improve the DPM model. This algorithm can realize effective candidate detection with a high recall rate, effectively improve the detection accuracy of the model, reduce the LAMR, and accelerate the detection speed. Furthermore, the proposed algorithm can effectively improve the pedestrian detection performance of the DPM model. However, the processing speed of the three-frame difference method and the Gauss model for background migration still requires improvement in the detection process, and further research is required for background migration processing.关键词:deformable part model;grid density;selective search;pedestrian detection;candidate window15|4|0更新时间:2024-05-07
摘要:ObjectivePedestrian detection is an important research topic in computer vision and plays a crucial role in all parts of life. The deformable part model (DPM) algorithm is a graphical model (Markov random field) that uses a series of parts and the spatial positional relationship of parts to represent an object. The DPM algorithm achieves superior detection accuracy in the field of pedestrian detection. However, because the DPM algorithm uses a sliding window strategy to search for objects in images, it handles a large number of candidate areas with low recall rates before constructing the feature pyramid. This property restricts the detection efficiency of the DPM algorithm. In view of this problem, this study proposes a novel model to improve the process of selecting candidate detection regions and puts forward the DPM algorithm integrated with a clustering algorithm with grid density and a selective search algorithm. Compared with the sliding window search method, the proposed model can provide fewer proposal windows and thus reduces computational complexity. Therefore, this study focuses on the advantages of the proposed model and the DPM algorithm to improve detection efficiency and accuracy.MethodThe proposed model contains three modules:the collection module of the coordinate points of moving targets, the generation module of frequently moving regions of targets, and the generation module of candidate detection windows. The modules are executed in series. Three frame difference methods and Gauss mixture models are used to detect moving targets in the first module. The centroid coordinates of each effective target are calculated by the obtained object contour, and a certain number of moving object coordinate points are collected and stored in the queue. In the second module, a G-cluster clustering algorithm based on grid structure and DBSCAN (density-based spatial clustering of applications with noise) clustering is proposed. The greatest advantage of the DBSCAN clustering algorithm is that it can find clusters of different sizes and shapes. However, this algorithm requires traversing every data point in the dataset, thereby leading to a high running time cost. Therefore, we draw lessons from the idea of the grid clustering algorithm based on the DBSCAN clustering algorithm. We develop a grid coordinate model and use the sliding window search method with an adaptive step size instead of neighborhood search to improve the method. This method can greatly reduce the number of data point searches and accelerate the speed of clustering. The specific experimental steps are as follows. The data points in the queue (QUE) are read, and the grid coordinate model is constructed. Frequently moving regions of targets are found by the sliding window strategy with an adaptive step size. Each region is dynamically adjusted with the aid of the moving object detection algorithm, and then the non-frequently moving regions are processed by masking to improve the effects of the candidate window generation module following the generation of frequently moving regions. Finally, the processed images are entered into the next module. In the third module, an improved selective search algorithm is introduced. As a mature image segmentation algorithm, the selective search algorithm can detect object proposals rapidly and effectively. It can also satisfy the accuracy and real-time requirements of pedestrian detection. Therefore, this thesis uses the selective search algorithm to extract a target from an image, and obtains a series of windows with high probability of complete target extraction. To further exclude the candidate windows with low credibility, we count and adjust the width-height ratio of the pedestrian contours in the INRIA dataset of public pedestrian image datasets. The range of the target width-height ratio is considered the condition for further screening candidate windows. Then, according to the coordinates of the final candidate detection window on the image, the corresponding features are extracted and entered into the classifier of the DPM algorithm. The final pedestrian detection window is obtained by classification.ResultExperiments on the PETS 2009 Bench-mark dataset were conducted to evaluate the performance of the proposed algorithm. Results indicated that compared with the sliding window search strategy, our algorithm effectively reduced some redundant windows. Moreover, the detection efficiency of the DPM algorithm showed improvement. The average precision of the proposed method increased by 1.71%, the LAMR (log-average miss rate) decreased by 2.2%, and speed increased by more than threefold.ConclusionTo deal with the problems of high computational complexity and high LAMR of the classical DPM algorithm, this study proposes a candidate field generation algorithm for pedestrian detection based on grid density clustering to improve the DPM model. This algorithm can realize effective candidate detection with a high recall rate, effectively improve the detection accuracy of the model, reduce the LAMR, and accelerate the detection speed. Furthermore, the proposed algorithm can effectively improve the pedestrian detection performance of the DPM model. However, the processing speed of the three-frame difference method and the Gauss model for background migration still requires improvement in the detection process, and further research is required for background migration processing.关键词:deformable part model;grid density;selective search;pedestrian detection;candidate window15|4|0更新时间:2024-05-07 -
 摘要:ObjectiveSaliency detection, as a preprocessing component of computer vision, has received increasing attention in the areas of object relocation, scene classification, semantic segmentation, and visual tracking. Although object detection has been greatly developed, it remains challenging because of a series of realistic factors, such as background complexity and attention mechanism. In the past, many significant target detection methods have been developed. These methods are mainly divided into traditional methods and new methods based on deep learning. The traditional approach is to find significant targets through low-level manual features, such as contrast, color, and texture. These general techniques are proven effective in maintaining image structure and reducing computational effort. However, these low-level features cause difficulty in capturing high-level semantic knowledge about objects and their surroundings. Therefore, these low-level feature-based methods do not achieve excellent results when salient objects are stripped from the stacked background. The saliency detection method based on deep learning mainly seeks significant targets by automatically extracting advanced features. However, most of these advanced models focus on the nonlinear combination of advanced features extracted from the final convolutional layer. The boundaries of salient objects are often extremely blurry due to the lack of low-level visual information such as edges. In these jobs, convolutional neural network (CNN) features are applied directly to the model without any processing. The features extracted from the CNN are generally high in dimension and contain a large amount of noise, thereby reducing the utilization efficiency of CNN features and revealing an opposite effect. Sparse methods can effectively aggregate the salient objects in a feature map and eliminate some of the noise interference. Sparse self-encoding is a sparse method. A traditional saliency recognition method based on sparse self-encoding and image fusion, combined with background prior and contrast analysis and VGG (visual geometry group) saliency calculation, is proposed to solve these problems.MethodThe proposed algorithm is mainly composed of the following:traditional saliency map extraction, VGG feature extraction, sparse self-encoding, and saliency result optimization. The traditional method to be improved is selected, and the corresponding saliency map is calculated. In this experiment, we select four traditional methods with excellent results, namely, discriminative regional feature integration (DRFI), high-dimensional color transform (HDCT), regularized random walks ranking (RRWR), and contour-guided visual search (CGVS). Then, the VGG network is used to extract feature maps. The feature maps obtained by each pooled layer are sparsely self-encoded to obtain 25 sparse saliency feature maps. When a feature map is selected, excessive edge information and texture information are retained because the features extracted by the first three pooling layers are mainly low-level features, indicating duplicate effects with feature maps obtained by the conventional method; thus, the feature maps from low-level are not used. The comparison between the fourth and fifth feature maps shows that the feature information of the fifth pooling layer is excessively lost. After experimental verification, the fifth layer characteristic map exerts an interference effect. Thus, we use the feature map extracted from the fourth pooling layer. Then, these feature maps are placed into the sparse self-encoder to perform the sparse operation to obtain five feature maps. Each feature map is integrated with the corresponding saliency map obtained in the previous volume. Finally, the neural network performs the operation and calculates the final saliency map.ResultOur experiments involved four open datasets:DUT-OMRON, ECSSD, HKU-IS, and MSRA. Then, we obtained half of the images from the four datasets used in the experiment to form a training set and the remaining four test sets. The results obtained can be extremely credible. The following conclusions are drawn from the experiment. 1) The proposed model greatly improves the F value in the four datasets of the four methods, including an increase of 24.53% in the HKU-IS dataset of the DRFI method. 2) The MAE (mean absolute error) value has also been greatly reduced, the least of which is reduced by 12.78% for the ECSSD dataset of the CGVS method and the highest of which is reduced by nearly 50%. 3) The proposed model network has few layers, few parameters, and short calculation time. The training time is approximately 2 h, and the average test time of the image is approximately 0.2 s. On the contrary, Liu chooses an image saliency optimization scheme using adaptive fusion. The training time is approximately 47 h, and the average test time of the image is 56.95 s. The proposed model greatly improves the computational efficiency. 4) The proposed model achieves a significant improvement for the four datasets, especially the HKU-IS and MSRA datasets. These datasets contain difficult images, thereby confirming the effectiveness of the proposed method.ConclusionA low-level feature map based on traditional models, such as a texture and high-level feature map of a sparsely self-encoded VGG network, is proposed to optimize saliency results and greatly improve saliency target recognition. The traditional methods based on DRFI, HDCT, RRWR, and CGVS are tested in the publicly significant object detection datasets DUT-OMRON, ECSSD, HKU-IS, and MSRA, respectively. The obtained F value and MAE value are significantly improved, thereby confirming the effectiveness of the proposed method. Moreover, the method steps and network structure are simple and easy to understand, the training takes little time, and popular promotion can be easily obtained. The limitation of the study is that some of the extracted feature maps are missing. In practice, only the fourth layer of VGG maps is selected, and not all useful information is fully utilized.关键词:significant detection;visual geometry group (VGG);sparse self-encoding;image fusion;convolutional neural network (CNN)13|4|0更新时间:2024-05-07
摘要:ObjectiveSaliency detection, as a preprocessing component of computer vision, has received increasing attention in the areas of object relocation, scene classification, semantic segmentation, and visual tracking. Although object detection has been greatly developed, it remains challenging because of a series of realistic factors, such as background complexity and attention mechanism. In the past, many significant target detection methods have been developed. These methods are mainly divided into traditional methods and new methods based on deep learning. The traditional approach is to find significant targets through low-level manual features, such as contrast, color, and texture. These general techniques are proven effective in maintaining image structure and reducing computational effort. However, these low-level features cause difficulty in capturing high-level semantic knowledge about objects and their surroundings. Therefore, these low-level feature-based methods do not achieve excellent results when salient objects are stripped from the stacked background. The saliency detection method based on deep learning mainly seeks significant targets by automatically extracting advanced features. However, most of these advanced models focus on the nonlinear combination of advanced features extracted from the final convolutional layer. The boundaries of salient objects are often extremely blurry due to the lack of low-level visual information such as edges. In these jobs, convolutional neural network (CNN) features are applied directly to the model without any processing. The features extracted from the CNN are generally high in dimension and contain a large amount of noise, thereby reducing the utilization efficiency of CNN features and revealing an opposite effect. Sparse methods can effectively aggregate the salient objects in a feature map and eliminate some of the noise interference. Sparse self-encoding is a sparse method. A traditional saliency recognition method based on sparse self-encoding and image fusion, combined with background prior and contrast analysis and VGG (visual geometry group) saliency calculation, is proposed to solve these problems.MethodThe proposed algorithm is mainly composed of the following:traditional saliency map extraction, VGG feature extraction, sparse self-encoding, and saliency result optimization. The traditional method to be improved is selected, and the corresponding saliency map is calculated. In this experiment, we select four traditional methods with excellent results, namely, discriminative regional feature integration (DRFI), high-dimensional color transform (HDCT), regularized random walks ranking (RRWR), and contour-guided visual search (CGVS). Then, the VGG network is used to extract feature maps. The feature maps obtained by each pooled layer are sparsely self-encoded to obtain 25 sparse saliency feature maps. When a feature map is selected, excessive edge information and texture information are retained because the features extracted by the first three pooling layers are mainly low-level features, indicating duplicate effects with feature maps obtained by the conventional method; thus, the feature maps from low-level are not used. The comparison between the fourth and fifth feature maps shows that the feature information of the fifth pooling layer is excessively lost. After experimental verification, the fifth layer characteristic map exerts an interference effect. Thus, we use the feature map extracted from the fourth pooling layer. Then, these feature maps are placed into the sparse self-encoder to perform the sparse operation to obtain five feature maps. Each feature map is integrated with the corresponding saliency map obtained in the previous volume. Finally, the neural network performs the operation and calculates the final saliency map.ResultOur experiments involved four open datasets:DUT-OMRON, ECSSD, HKU-IS, and MSRA. Then, we obtained half of the images from the four datasets used in the experiment to form a training set and the remaining four test sets. The results obtained can be extremely credible. The following conclusions are drawn from the experiment. 1) The proposed model greatly improves the F value in the four datasets of the four methods, including an increase of 24.53% in the HKU-IS dataset of the DRFI method. 2) The MAE (mean absolute error) value has also been greatly reduced, the least of which is reduced by 12.78% for the ECSSD dataset of the CGVS method and the highest of which is reduced by nearly 50%. 3) The proposed model network has few layers, few parameters, and short calculation time. The training time is approximately 2 h, and the average test time of the image is approximately 0.2 s. On the contrary, Liu chooses an image saliency optimization scheme using adaptive fusion. The training time is approximately 47 h, and the average test time of the image is 56.95 s. The proposed model greatly improves the computational efficiency. 4) The proposed model achieves a significant improvement for the four datasets, especially the HKU-IS and MSRA datasets. These datasets contain difficult images, thereby confirming the effectiveness of the proposed method.ConclusionA low-level feature map based on traditional models, such as a texture and high-level feature map of a sparsely self-encoded VGG network, is proposed to optimize saliency results and greatly improve saliency target recognition. The traditional methods based on DRFI, HDCT, RRWR, and CGVS are tested in the publicly significant object detection datasets DUT-OMRON, ECSSD, HKU-IS, and MSRA, respectively. The obtained F value and MAE value are significantly improved, thereby confirming the effectiveness of the proposed method. Moreover, the method steps and network structure are simple and easy to understand, the training takes little time, and popular promotion can be easily obtained. The limitation of the study is that some of the extracted feature maps are missing. In practice, only the fourth layer of VGG maps is selected, and not all useful information is fully utilized.关键词:significant detection;visual geometry group (VGG);sparse self-encoding;image fusion;convolutional neural network (CNN)13|4|0更新时间:2024-05-07 -
 摘要:ObjectiveThe leakage monitoring technology of high fill channels is key to the safe monitoring of the South-to-North Water Transfer Project. Aimed at addressing the current problem of leakage detection for high fill channels being easily affected by the environment and resulting in inaccurate judgment results, a model based on Gabor-support vector machine (SVM) is designed for damage monitoring in the cement slope of the high fill channel in the middle route of the South-to-North Water Transfer Project. The high fill channel is widely distributed in the middle route of the South-to-North Water Transfer Project. As a result of the high filling height, wide distribution range, and complex engineering geological conditions of the middle route of the South-to-North Water Transfer Project, the lining panel is cracked, the canal slope surface is damaged, and seepage occurs. Although the effect of leakage is small, the long channel still leads to a large leakage. Therefore, monitoring the seepage of the high fill channel is necessary to ensure its safe operation.MethodThe image of the high fill channel cement is preprocessed. In general, because the acquired image is affected by various noises, it needs to be preprocessed before extracting its features. These processing methods include image enhancement, median filtering, and grayscale processing. Then, Gabor wavelet is used to extract the texture features of the image, as well as the image convolution, commonly used amplitude, and phase to represent the texture features. The amplitude information reflects the energy spectrum of the image and is relatively stable. Therefore, amplitude information is selected as the extracted characteristic data. After analyzing the mean and variance eigenvalues of the amplitude, the image features of the variance are linearly separable. Therefore, the variance characteristic data of amplitude are considered as the characteristic data for classification and recognition. Under the scale and direction of different Gabor wavelets, the image characteristics of the extracted cement slope are analyzed to find the optimal scale and direction parameter group. The scale range is 17, and the direction range is 113. Different Gabor filters are obtained according to different directions and scales. Different Gabor filters are used to filter the high fill cement slope and thereby obtain different image features. Finally, according to the well-trained sample features, SVM is used to classify the damage degrees of cement slope, and the recognition results are refined with the following labels:normal, crack, fracture, and hole. At the same time, various feature extraction methods are studied to objectively reflect the recognition effects of Gabor-SVM. These methods include histogram-SVM, grayscale symbiosis matrix-SVM, and Canny edge detection algorithm-SVM.ResultExperimental results show that the damage recognition model of the cement surface based on Gabor-SVM tends to have a stable value when the small wave has the 6th scales and the 12th directions. The recognition rate of the normal slope image is generally good and stable, mostly distributed between 0.8 and 1.0. The recognition rate of the slope image under the crack category presents stable growth from low to high, but the overall recognition rate is low, with most values being in the range of 0.500.65. The recognition rate of the slope image of the hole type fluctuates greatly, and its recognition rate has a significant relationship with scale changes. For example, when the scale value is 1 or 2, the recognition rate is low. When the scale value is 3, 4, or 5, the recognition rate increases gradually. When the scale value is 6 or 7, the recognition rate decreases. The recognition rate is mostly distributed between 0.78 and 0.88. A certain relationship exists between the size of the slope image recognition rate of the fracture category and the scale. It has the characteristic of fluctuating growth from low to high and then to low, and the recognition rate is generally between 0.80 and 0.95. The normal, crack, hole, and fracture recognition rates are 0.98, 0.63, 0.88, and 0.90, respectively. The average recognition rate of the Gabor-SVM method is approximately 0.85. Compared with the average recognition rates of the other methods (approximately 0.50), that of the proposed method has better recognition ability.ConclusionThe damage recognition model based on Gabor-SVM has a slight recognition effect. The recognition effect peaks given 6 scales/12 directions. The average recognition rate of the Gabor-SVM method for the slope of the high fill channel cement is approximately 0.85. Meanwhile, the cement surface recognition effect of the crack category is unsatisfactory at 0.63. Thus, further research is required to provide technical support for finding the hidden dangers of high fill channels in the South-to-North Water Transfer Project.关键词:middle route of South-to-North Water Transfer Project;feature extraction of multiple scales and directions;damage recognition;Gabor wavelet;support vector machine (SVM) classification11|4|0更新时间:2024-05-07
摘要:ObjectiveThe leakage monitoring technology of high fill channels is key to the safe monitoring of the South-to-North Water Transfer Project. Aimed at addressing the current problem of leakage detection for high fill channels being easily affected by the environment and resulting in inaccurate judgment results, a model based on Gabor-support vector machine (SVM) is designed for damage monitoring in the cement slope of the high fill channel in the middle route of the South-to-North Water Transfer Project. The high fill channel is widely distributed in the middle route of the South-to-North Water Transfer Project. As a result of the high filling height, wide distribution range, and complex engineering geological conditions of the middle route of the South-to-North Water Transfer Project, the lining panel is cracked, the canal slope surface is damaged, and seepage occurs. Although the effect of leakage is small, the long channel still leads to a large leakage. Therefore, monitoring the seepage of the high fill channel is necessary to ensure its safe operation.MethodThe image of the high fill channel cement is preprocessed. In general, because the acquired image is affected by various noises, it needs to be preprocessed before extracting its features. These processing methods include image enhancement, median filtering, and grayscale processing. Then, Gabor wavelet is used to extract the texture features of the image, as well as the image convolution, commonly used amplitude, and phase to represent the texture features. The amplitude information reflects the energy spectrum of the image and is relatively stable. Therefore, amplitude information is selected as the extracted characteristic data. After analyzing the mean and variance eigenvalues of the amplitude, the image features of the variance are linearly separable. Therefore, the variance characteristic data of amplitude are considered as the characteristic data for classification and recognition. Under the scale and direction of different Gabor wavelets, the image characteristics of the extracted cement slope are analyzed to find the optimal scale and direction parameter group. The scale range is 17, and the direction range is 113. Different Gabor filters are obtained according to different directions and scales. Different Gabor filters are used to filter the high fill cement slope and thereby obtain different image features. Finally, according to the well-trained sample features, SVM is used to classify the damage degrees of cement slope, and the recognition results are refined with the following labels:normal, crack, fracture, and hole. At the same time, various feature extraction methods are studied to objectively reflect the recognition effects of Gabor-SVM. These methods include histogram-SVM, grayscale symbiosis matrix-SVM, and Canny edge detection algorithm-SVM.ResultExperimental results show that the damage recognition model of the cement surface based on Gabor-SVM tends to have a stable value when the small wave has the 6th scales and the 12th directions. The recognition rate of the normal slope image is generally good and stable, mostly distributed between 0.8 and 1.0. The recognition rate of the slope image under the crack category presents stable growth from low to high, but the overall recognition rate is low, with most values being in the range of 0.500.65. The recognition rate of the slope image of the hole type fluctuates greatly, and its recognition rate has a significant relationship with scale changes. For example, when the scale value is 1 or 2, the recognition rate is low. When the scale value is 3, 4, or 5, the recognition rate increases gradually. When the scale value is 6 or 7, the recognition rate decreases. The recognition rate is mostly distributed between 0.78 and 0.88. A certain relationship exists between the size of the slope image recognition rate of the fracture category and the scale. It has the characteristic of fluctuating growth from low to high and then to low, and the recognition rate is generally between 0.80 and 0.95. The normal, crack, hole, and fracture recognition rates are 0.98, 0.63, 0.88, and 0.90, respectively. The average recognition rate of the Gabor-SVM method is approximately 0.85. Compared with the average recognition rates of the other methods (approximately 0.50), that of the proposed method has better recognition ability.ConclusionThe damage recognition model based on Gabor-SVM has a slight recognition effect. The recognition effect peaks given 6 scales/12 directions. The average recognition rate of the Gabor-SVM method for the slope of the high fill channel cement is approximately 0.85. Meanwhile, the cement surface recognition effect of the crack category is unsatisfactory at 0.63. Thus, further research is required to provide technical support for finding the hidden dangers of high fill channels in the South-to-North Water Transfer Project.关键词:middle route of South-to-North Water Transfer Project;feature extraction of multiple scales and directions;damage recognition;Gabor wavelet;support vector machine (SVM) classification11|4|0更新时间:2024-05-07 -
 摘要:ObjectiveFew-shot learning aims to build a classifier that recognizes new unseen classes given only a few samples. The solutions are mainly in the following categories:data augmentation, meta-learning, and metric learning. Data augmentation can be used to reduce certain over-fitting given a limited data regime in a new class. The corresponding solution is to augment data in the feature domain as hallucinating features. These methods exert a certain effect on few-shot classification. However, due to the extremely small data space, the transformation mode is considerably limited and cannot solve over-fitting problems. The meta-learning method is suitable for few-shot learning because it is based on the high-level strategy of learning similar tasks. Some methods learn good initial values, some learn task-level update strategies, and others construct external memory storages to remember past information for comparison during testing. The few-shot classification results of these methods are superior, but the network structure is increasingly complicated due to the use of RNNs(recurrent neural networks). The efficiency is also low. The metric learning method is simple and efficient. It first maps a sample to the embedding space and then computes the distance to obtain the similarity metric to predict the category. Some approaches improve the representation of features in the embedding space, some use learnable distance metrics to compute distance for loss, and others combine meta-learning methods to improve accuracy. However, this type of method fails to summarize representative features from multiple support vectors in a class to effectively represent the class concept. This drawback limits the further improvement of the accuracy of small sample classification. To address this problem, this study proposes a representative feature network.MethodThe representative feature network is a metric learning strategy based on class representative features. It uses the representative features learned from a support vector set in a class to express the class concept effectively. It also uses mixture loss to reduce the misclassification of similar classes and thus achieve excellent classification results. Specifically, the representative feature network includes two modules. The embedded vector of a high abstraction level is extracted by the embedded module, and then the representative feature per class is obtained by the representative feature module by inputting stacked support vector sets. The class representative feature fully considers the influence of the embedded vector of the support samples on the basis of the target that may or may not be obvious. The use of network learning to assign different weights to each embedded support vector can effectively avoid misclassification caused by the bias effects of representative features for unobvious target samples. Then, the distances from the embedded query vectors to each class representative feature are calculated to predict the class. In addition, the mixture loss function is proposed for the misclassification of similar classes in the embedded space. The cross-entropy loss combined with the relative error loss function is used to increase the inter-class distances and reduce the similar class error rate.ResultAfter extensive experiments, the Omniglot, miniImageNet, and Cifar100 datasets verify that the model achieves state-of-the-art results. For the simple Omniglot dataset, the five-way, five-shot classification accuracy is 99.7%, which is 1% higher than that of the original matching network. For the complex miniImageNet dataset, the five-way, five-shot classification accuracy is 75.83%, which is approximately 18% higher than that of the original matching network. Representative features provide approximately 8% improvement, indicating that it can effectively express the prototype by distinguishing the contribution of different support vectors, the target of which may or may not be obvious. Mixture loss provides approximately 1% improvement, indicating that it can reduce some misclassification of similar classes in the testing set. However, the improvement is unremarkable because similar samples are uncommon in the dataset. The last 9% improvement is due to the fine-tuning on the test set, indicating that the advantage of the skip connection method benefits loss propagation relative to the original connection between the network module methods. For the Cifar100 dataset, the five-way, five-shot classification accuracy is 87.99%, which is 20% higher than that of the original matching network. Moreover, the high training efficiency is maintained while the performance is significantly improved.ConclusionTo address the problem of extremely simple original embedding networks for extracting high-level features of samples, the improved embedding networks in a representative feature network use a skip connection structure so as to deepen the network and extract advanced features. To address the problem of the noise support vector that disturbs the classification accuracy of a testing sample, the representative feature network can effectively summarize the representative features from multiple support vectors in a class for classifying query samples. Compared with the performance when support vectors are used directly, the classification performance when representative features are used is more robust, and the classification accuracy under few-shot samples is further improved. In addition, the mixture loss function proposed for the classification problem of similar classes is used to enlarge the distance between categories in the embedded space and reduce the misclassification of similar classes. Detailed experiments are carried out to verify that these improved methods achieve great performance in few-shot learning tasks for the Omniglot, miniImageNet, and Cifar100 datasets. At the same time, the representative feature network presents improvement. For embedding networks, advanced structures, such as dense connections or se modules, must be included in future work to further improve the results.关键词:few-shot learning;metric learning;representative feature network;mixture loss function;fine-tuning25|243|2更新时间:2024-05-07
摘要:ObjectiveFew-shot learning aims to build a classifier that recognizes new unseen classes given only a few samples. The solutions are mainly in the following categories:data augmentation, meta-learning, and metric learning. Data augmentation can be used to reduce certain over-fitting given a limited data regime in a new class. The corresponding solution is to augment data in the feature domain as hallucinating features. These methods exert a certain effect on few-shot classification. However, due to the extremely small data space, the transformation mode is considerably limited and cannot solve over-fitting problems. The meta-learning method is suitable for few-shot learning because it is based on the high-level strategy of learning similar tasks. Some methods learn good initial values, some learn task-level update strategies, and others construct external memory storages to remember past information for comparison during testing. The few-shot classification results of these methods are superior, but the network structure is increasingly complicated due to the use of RNNs(recurrent neural networks). The efficiency is also low. The metric learning method is simple and efficient. It first maps a sample to the embedding space and then computes the distance to obtain the similarity metric to predict the category. Some approaches improve the representation of features in the embedding space, some use learnable distance metrics to compute distance for loss, and others combine meta-learning methods to improve accuracy. However, this type of method fails to summarize representative features from multiple support vectors in a class to effectively represent the class concept. This drawback limits the further improvement of the accuracy of small sample classification. To address this problem, this study proposes a representative feature network.MethodThe representative feature network is a metric learning strategy based on class representative features. It uses the representative features learned from a support vector set in a class to express the class concept effectively. It also uses mixture loss to reduce the misclassification of similar classes and thus achieve excellent classification results. Specifically, the representative feature network includes two modules. The embedded vector of a high abstraction level is extracted by the embedded module, and then the representative feature per class is obtained by the representative feature module by inputting stacked support vector sets. The class representative feature fully considers the influence of the embedded vector of the support samples on the basis of the target that may or may not be obvious. The use of network learning to assign different weights to each embedded support vector can effectively avoid misclassification caused by the bias effects of representative features for unobvious target samples. Then, the distances from the embedded query vectors to each class representative feature are calculated to predict the class. In addition, the mixture loss function is proposed for the misclassification of similar classes in the embedded space. The cross-entropy loss combined with the relative error loss function is used to increase the inter-class distances and reduce the similar class error rate.ResultAfter extensive experiments, the Omniglot, miniImageNet, and Cifar100 datasets verify that the model achieves state-of-the-art results. For the simple Omniglot dataset, the five-way, five-shot classification accuracy is 99.7%, which is 1% higher than that of the original matching network. For the complex miniImageNet dataset, the five-way, five-shot classification accuracy is 75.83%, which is approximately 18% higher than that of the original matching network. Representative features provide approximately 8% improvement, indicating that it can effectively express the prototype by distinguishing the contribution of different support vectors, the target of which may or may not be obvious. Mixture loss provides approximately 1% improvement, indicating that it can reduce some misclassification of similar classes in the testing set. However, the improvement is unremarkable because similar samples are uncommon in the dataset. The last 9% improvement is due to the fine-tuning on the test set, indicating that the advantage of the skip connection method benefits loss propagation relative to the original connection between the network module methods. For the Cifar100 dataset, the five-way, five-shot classification accuracy is 87.99%, which is 20% higher than that of the original matching network. Moreover, the high training efficiency is maintained while the performance is significantly improved.ConclusionTo address the problem of extremely simple original embedding networks for extracting high-level features of samples, the improved embedding networks in a representative feature network use a skip connection structure so as to deepen the network and extract advanced features. To address the problem of the noise support vector that disturbs the classification accuracy of a testing sample, the representative feature network can effectively summarize the representative features from multiple support vectors in a class for classifying query samples. Compared with the performance when support vectors are used directly, the classification performance when representative features are used is more robust, and the classification accuracy under few-shot samples is further improved. In addition, the mixture loss function proposed for the classification problem of similar classes is used to enlarge the distance between categories in the embedded space and reduce the misclassification of similar classes. Detailed experiments are carried out to verify that these improved methods achieve great performance in few-shot learning tasks for the Omniglot, miniImageNet, and Cifar100 datasets. At the same time, the representative feature network presents improvement. For embedding networks, advanced structures, such as dense connections or se modules, must be included in future work to further improve the results.关键词:few-shot learning;metric learning;representative feature network;mixture loss function;fine-tuning25|243|2更新时间:2024-05-07 -
 摘要:ObjectiveWith the continuous development of computer technology in recent years, image recognition technology has become one of the most active research topics in the field of computer vision. The image recognition method generates a robust classification model by using existing training samples. Compared with traditional methods, deep learning algorithms have shown superior learning and classification performance by forming abstract and high-level representation through the combination of low-level features. Traditional deep networks assume that training data and test data follow the same distribution, but the same is not true in real-world applications. At the same time, collecting and annotating data sets for each new task or new domain is an expensive and time-consuming process, and the data available for training are limited. If the distributions of training data and test data greatly differ, then the performance of the classifiers trained by traditional machine learning algorithms diminishes considerably, and the advantages of deep network architectures relying on large tag data sets could no longer be maximized. Solving these problems requires cross-domain learning. Cross-domain learning refers to the transfer and learning of knowledge under different data distribution conditions by using the link between existing knowledge and experience to promote the learning of new tasks and ultimately reduce the impact of differences in the sample distributions between domains. The domain adaptive algorithm is used to solve the problem in which the performance of a classifier is degraded due to differences in the distributions of training samples and test samples. Such algorithm has become an effective approach to deal with domain migration problems in image recognition due to the relaxation of the same distribution requirements between fields in traditional machine learning. Its goal is to overcome the differences between training sample and test sample distributions, improve the performance of the training model by using the commonality between fields, achieve classifier migration, and ultimately improve classification accuracy.MethodAn unsupervised domain adaptive method based on multi-layer correction is proposed. A five-layer neural network structure is established by modifying and optimizing the ResNet-18 network. The correction is used to amend the internal representation of the target data to simulate the source data. For the residual layer of the target data, the data classifier of the source domain must adapt to the target domain by additive correction, and additive superposition is employed to perfectly align the data representations of the source and target domains. If the prior distribution of the class is not considered, then the weight deviation of the class can be easily ignored, thereby decreasing domain adaptation performance. Hence, we introduce the auxiliary weight of a specific class to override the set source sample. In this way, the re-weighted source data share the same category weight as the target data. On the basis of the results, we use multiple weight MMD (maximum mean discrepancy) to modify the fully connected layer and increase the representation capability of the network. Finally, the domain invariant features obtained by the learning process are extracted and classified to obtain the final recognition effect of the target image.ResultTest experiments on digital datasets, such as Office-31 image dataset and MNIST, are carried out to confirm the validity of the proposed method. We compare the performances of different algorithms by measuring their classification accuracies in image and digital recognition. For the image dataset, we test two traditional transfer learning methods, three depth domain adaptive methods, and two mainstream deep neural network models. Test results show that our method has higher recognition ability than existing methods and is superior to other methods by 9.5%, on the average, in terms of classification accuracy. For the digital dataset, we test the convolutional neural network classic model LeNet, the subspace alignment method for domain adaptation (SA), and the deep adaptive network model (DAN). Test results show that the proposed method has an average increase of 9.5% in classification accuracy and the best classification performance. In response to disturbances, such as illumination changes, complex backgrounds, and poor image quality, the proposed method can obtain better classification results and show stronger robustness than other methods.ConclusionDeep neural networks have good application prospects in image recognition. The domain adaptive method is also an effective method to deal with domain migration problems in image recognition. With the continuous deepening of network structure and expansion of data samples, the cost and time loss of daily training are also increasing. The unsupervised domain adaptive method has become an important processing method in image recognition because it does not require target sample tags. The application of the domain adaptive method to image recognition and other tasks carries theoretical significance. A multi-layer corrected network structure, which is a new method for unsupervised domain adaptation, is proposed. The additional layer increases the capacity of the neural network because of its excellent generalization performance. The experimental results on the domain adaptive correlation datasets show that the proposed method can learn the complete domain invariant representation for domain adaptive problems, achieves high classification performance, and is superior to other existing unsupervised domain adaptive methods.关键词:domain adaptation;domain invariant feature;multi-layer correction;image recognition;transfer learning50|5|0更新时间:2024-05-07
摘要:ObjectiveWith the continuous development of computer technology in recent years, image recognition technology has become one of the most active research topics in the field of computer vision. The image recognition method generates a robust classification model by using existing training samples. Compared with traditional methods, deep learning algorithms have shown superior learning and classification performance by forming abstract and high-level representation through the combination of low-level features. Traditional deep networks assume that training data and test data follow the same distribution, but the same is not true in real-world applications. At the same time, collecting and annotating data sets for each new task or new domain is an expensive and time-consuming process, and the data available for training are limited. If the distributions of training data and test data greatly differ, then the performance of the classifiers trained by traditional machine learning algorithms diminishes considerably, and the advantages of deep network architectures relying on large tag data sets could no longer be maximized. Solving these problems requires cross-domain learning. Cross-domain learning refers to the transfer and learning of knowledge under different data distribution conditions by using the link between existing knowledge and experience to promote the learning of new tasks and ultimately reduce the impact of differences in the sample distributions between domains. The domain adaptive algorithm is used to solve the problem in which the performance of a classifier is degraded due to differences in the distributions of training samples and test samples. Such algorithm has become an effective approach to deal with domain migration problems in image recognition due to the relaxation of the same distribution requirements between fields in traditional machine learning. Its goal is to overcome the differences between training sample and test sample distributions, improve the performance of the training model by using the commonality between fields, achieve classifier migration, and ultimately improve classification accuracy.MethodAn unsupervised domain adaptive method based on multi-layer correction is proposed. A five-layer neural network structure is established by modifying and optimizing the ResNet-18 network. The correction is used to amend the internal representation of the target data to simulate the source data. For the residual layer of the target data, the data classifier of the source domain must adapt to the target domain by additive correction, and additive superposition is employed to perfectly align the data representations of the source and target domains. If the prior distribution of the class is not considered, then the weight deviation of the class can be easily ignored, thereby decreasing domain adaptation performance. Hence, we introduce the auxiliary weight of a specific class to override the set source sample. In this way, the re-weighted source data share the same category weight as the target data. On the basis of the results, we use multiple weight MMD (maximum mean discrepancy) to modify the fully connected layer and increase the representation capability of the network. Finally, the domain invariant features obtained by the learning process are extracted and classified to obtain the final recognition effect of the target image.ResultTest experiments on digital datasets, such as Office-31 image dataset and MNIST, are carried out to confirm the validity of the proposed method. We compare the performances of different algorithms by measuring their classification accuracies in image and digital recognition. For the image dataset, we test two traditional transfer learning methods, three depth domain adaptive methods, and two mainstream deep neural network models. Test results show that our method has higher recognition ability than existing methods and is superior to other methods by 9.5%, on the average, in terms of classification accuracy. For the digital dataset, we test the convolutional neural network classic model LeNet, the subspace alignment method for domain adaptation (SA), and the deep adaptive network model (DAN). Test results show that the proposed method has an average increase of 9.5% in classification accuracy and the best classification performance. In response to disturbances, such as illumination changes, complex backgrounds, and poor image quality, the proposed method can obtain better classification results and show stronger robustness than other methods.ConclusionDeep neural networks have good application prospects in image recognition. The domain adaptive method is also an effective method to deal with domain migration problems in image recognition. With the continuous deepening of network structure and expansion of data samples, the cost and time loss of daily training are also increasing. The unsupervised domain adaptive method has become an important processing method in image recognition because it does not require target sample tags. The application of the domain adaptive method to image recognition and other tasks carries theoretical significance. A multi-layer corrected network structure, which is a new method for unsupervised domain adaptation, is proposed. The additional layer increases the capacity of the neural network because of its excellent generalization performance. The experimental results on the domain adaptive correlation datasets show that the proposed method can learn the complete domain invariant representation for domain adaptive problems, achieves high classification performance, and is superior to other existing unsupervised domain adaptive methods.关键词:domain adaptation;domain invariant feature;multi-layer correction;image recognition;transfer learning50|5|0更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:Objective The image-based ranging method is more concealed than traditional ranging methods, such as ultrasonic and radar methods. Ranging based on binocular vision for reconnaissance and obstacle avoidance is an important method for unmanned surface vehicles (USVs). However, visual sensor imaging is easily affected by illumination changes and motion blur. The calculated stereo matching cost based on classical Census transform is considerably high, and the stereo parallax accuracy is poor, thereby affecting the productivity and accuracy of ranging. A fast stereo matching and parallax computation algorithm based on improved Census transform for binocular ranging is proposed in this study to improve ranging accuracy and ensure rapid ranging speed.Method A new bit string generation method used in Census transform is proposed. The method selects three pixels at equal intervals on each edge of the square supporting window of the matching point. Eight pixels are selected on the square supporting window edges around the matching point. An eight-bit string is generated by this eight-pixel pairwise comparison and is used for the matching cost calculation between matching points. Then, the Hamming distance between matching points is obtained with the bit OR arithmetic operation between the eight-bit strings of the two matching points from the left and right fields of view separately. The two pixel points from different views with the smallest Hamming distance can be regarded as a pair of matched points. After the matched points are determined, the parallax between the matched points can be achieved easily. The average parallax of the target area in the reference and target images instead of the parallax of the entire area is calculated and adopted to obtain the target distance to reduce the computational complexity. Fortunately, for the stereo ranging used in USVs, the target images always occupy a certain area in two view fields, and the target area has high similarity. The difference in the contours of the targets is minimal, and the concourse can be used to identify the same target in the two views. When the same target area in the left and right fields of view is determined, the parallaxes of all the pixels in the target area are extracted, and the distance of the target is calculated with the average parallax of the target obtained.Result The computation cost of matching based on classical Census transform increases with the matching window. By contrast, the computation cost of matching based on the improved Census transform is stable. The proposed improved algorithm has evident speed advantage when the matching window is large. In the practical binocular ranging for USVs, a binocular image is initially pre-processed via methods such as de-noising and de-blurring. Then, fast stereo matching and parallax calculation based on the improved Census transform are carried out. Finally, the target distance is obtained according to the stereo parallax and binocular imaging model. The ranging error is less than 5% in the range of 1019 m according to the proposed algorithm. The binocular imaging ranging principle indicates that the error of the rapid stereo matching and parallax calculation based on the improved Census transform is not greater than 5%.Conclusion Experiment results show that the proposed matching algorithm based on the improved Census transform can greatly improve the speed of stereo matching. In the practical binocular ranging for USVs, the target area in the left and right fields of view is determined first, and then the average parallax of the target is calculated to obtain the target distance. The actual ranging results show that the distance error is less than 5% and that the proposed algorithm can satisfy the requirements of target ranging and obstacle avoidance for USVs.关键词:distance measurement;binocular stereo vision;improved Census transform;stereo matching;target parallax extraction15|19|3更新时间:2024-05-07
摘要:Objective The image-based ranging method is more concealed than traditional ranging methods, such as ultrasonic and radar methods. Ranging based on binocular vision for reconnaissance and obstacle avoidance is an important method for unmanned surface vehicles (USVs). However, visual sensor imaging is easily affected by illumination changes and motion blur. The calculated stereo matching cost based on classical Census transform is considerably high, and the stereo parallax accuracy is poor, thereby affecting the productivity and accuracy of ranging. A fast stereo matching and parallax computation algorithm based on improved Census transform for binocular ranging is proposed in this study to improve ranging accuracy and ensure rapid ranging speed.Method A new bit string generation method used in Census transform is proposed. The method selects three pixels at equal intervals on each edge of the square supporting window of the matching point. Eight pixels are selected on the square supporting window edges around the matching point. An eight-bit string is generated by this eight-pixel pairwise comparison and is used for the matching cost calculation between matching points. Then, the Hamming distance between matching points is obtained with the bit OR arithmetic operation between the eight-bit strings of the two matching points from the left and right fields of view separately. The two pixel points from different views with the smallest Hamming distance can be regarded as a pair of matched points. After the matched points are determined, the parallax between the matched points can be achieved easily. The average parallax of the target area in the reference and target images instead of the parallax of the entire area is calculated and adopted to obtain the target distance to reduce the computational complexity. Fortunately, for the stereo ranging used in USVs, the target images always occupy a certain area in two view fields, and the target area has high similarity. The difference in the contours of the targets is minimal, and the concourse can be used to identify the same target in the two views. When the same target area in the left and right fields of view is determined, the parallaxes of all the pixels in the target area are extracted, and the distance of the target is calculated with the average parallax of the target obtained.Result The computation cost of matching based on classical Census transform increases with the matching window. By contrast, the computation cost of matching based on the improved Census transform is stable. The proposed improved algorithm has evident speed advantage when the matching window is large. In the practical binocular ranging for USVs, a binocular image is initially pre-processed via methods such as de-noising and de-blurring. Then, fast stereo matching and parallax calculation based on the improved Census transform are carried out. Finally, the target distance is obtained according to the stereo parallax and binocular imaging model. The ranging error is less than 5% in the range of 1019 m according to the proposed algorithm. The binocular imaging ranging principle indicates that the error of the rapid stereo matching and parallax calculation based on the improved Census transform is not greater than 5%.Conclusion Experiment results show that the proposed matching algorithm based on the improved Census transform can greatly improve the speed of stereo matching. In the practical binocular ranging for USVs, the target area in the left and right fields of view is determined first, and then the average parallax of the target is calculated to obtain the target distance. The actual ranging results show that the distance error is less than 5% and that the proposed algorithm can satisfy the requirements of target ranging and obstacle avoidance for USVs.关键词:distance measurement;binocular stereo vision;improved Census transform;stereo matching;target parallax extraction15|19|3更新时间:2024-05-07 -
 摘要:Objective Neuroscientists have studied the Bayesian brain perception theory, which indicates that the human vision system indirectly processes input signals during the processing of input images. A complete set of intrinsic derivation mechanisms actively predicts and understands input image information and attempts to ignore any uncertainty information in an image. In other words, given an input image, the brain does not fully process the input visual information, but it has an intrinsic derivation mechanism that enables it to actively predict the gross structure of the image, including certain information (structured information). At the same time, uncertain information (unstructured information), such as residual clutter, is ignored to realize the understanding and perception of the image. In considering the role of structured information in just noticeable distortion (JND) estimation on natural images, a sparse representation-based structured/unstructured information separation model is proposed and applied to the JND threshold estimation. The proposed method achieves great consistency with the human visual system in terms of the perceived JND threshold.Method Initially, 90 natural images are selected for dictionary learning. These training images are pre-processed, and each image is divided into 8×8 non-overlapping image blocks. The variance of each image block is calculated, and the image blocks with high variances are selected as training samples. Then, an over-complete dictionary is learned from a set of training samples using the classical K-singular value decomposition algorithm. Then, the input natural image is reconstructed by sparse representation using the previously learned dictionary via the orthogonal matching pursuit (OMP) algorithm. The corresponding structural layer and non-structural layer of the input natural image can be obtained by setting an appropriate iteration number during the implementation of the OMP algorithm. Subsequently, we further design different JND estimation models for structural and non-structural layers. 1) Luminance adaptability and contrast mask-based JND estimation model for structural layers. The JND threshold value of an image is mainly related to the brightness adaptability of the visual system, contrast mask, module mask, and image structure. Thus, the luminance adaptability function and contrast mask equation are derived under the experimental environment of a regular structure. The JND calculation model of the structural layer is derived from the fusion of the two models. 2) Luminance contrast and information uncertainty-based JND estimation model for non-structural layer. The modular mask effect reveals the visibility of stimuli in the visual system because of the interaction or interference among visual stimuli in the visual content of the input scene. When the structure of the visual content is ordered and the background is uniform, the module mask effect is extremely weak, and the spatial object is easily detected. On the contrary, when the visual content is disordered and uncertain, the module mask effect is enhanced, that is, the detection of space objects is suppressed. Therefore, the module mask effect is related not only to brightness contrast but also to information uncertainty. Therefore, we construct an unstructured layer of the JND model on the basis of the module mask combined with information uncertainty and brightness contrast. Finally, given the overlap between the structural layer of JND and the non-structural layer of JND, using a simple linear sum to fuse the two layers is impossible, and the overlapping parts must be removed. A nonlinear additive model describing the masking effect between different components is utilized to fuse the two JND estimation results.Result Three existing JND models are selected for comparison. For a fair comparison, the same noise is injected into the original image through the JND models, and then the visual effects of the polluted image are compared. The subjective experimental results show that the proposed JND model can better guide the distribution of noise and avoid the sensitive region of human vision relative to other JND models when the same noise is injected. The proposed JND model is also consistent with the subjective visual perception of human eyes. To further verify the fairness, we compare the four JND models using the classical peak signal-to-noise ratio (PSNR). The PSNRs of the contaminated Goddess image and contaminated Lena images are compared. The objective experimental results show that the PSNRs of the proposed model are significantly higher than those of the other three JND models. The proposed JND estimation model uses sparse representation to separate the structured and unstructured information of the input natural image. It then calculates the JND threshold according to the characteristics of different components. The process is consistent with the mechanism of human visual perception. Therefore, the proposed JND estimation model can effectively and accurately predict the JND threshold of natural images.Conclusion Compared with the existing relevant models, the proposed JND model can effectively predict the JND threshold of natural images, and it is much more consistent with human visual perception.关键词:just noticeable distortion(JND);sparse representation;human visual system;structural information;unstructural information12|4|1更新时间:2024-05-07
摘要:Objective Neuroscientists have studied the Bayesian brain perception theory, which indicates that the human vision system indirectly processes input signals during the processing of input images. A complete set of intrinsic derivation mechanisms actively predicts and understands input image information and attempts to ignore any uncertainty information in an image. In other words, given an input image, the brain does not fully process the input visual information, but it has an intrinsic derivation mechanism that enables it to actively predict the gross structure of the image, including certain information (structured information). At the same time, uncertain information (unstructured information), such as residual clutter, is ignored to realize the understanding and perception of the image. In considering the role of structured information in just noticeable distortion (JND) estimation on natural images, a sparse representation-based structured/unstructured information separation model is proposed and applied to the JND threshold estimation. The proposed method achieves great consistency with the human visual system in terms of the perceived JND threshold.Method Initially, 90 natural images are selected for dictionary learning. These training images are pre-processed, and each image is divided into 8×8 non-overlapping image blocks. The variance of each image block is calculated, and the image blocks with high variances are selected as training samples. Then, an over-complete dictionary is learned from a set of training samples using the classical K-singular value decomposition algorithm. Then, the input natural image is reconstructed by sparse representation using the previously learned dictionary via the orthogonal matching pursuit (OMP) algorithm. The corresponding structural layer and non-structural layer of the input natural image can be obtained by setting an appropriate iteration number during the implementation of the OMP algorithm. Subsequently, we further design different JND estimation models for structural and non-structural layers. 1) Luminance adaptability and contrast mask-based JND estimation model for structural layers. The JND threshold value of an image is mainly related to the brightness adaptability of the visual system, contrast mask, module mask, and image structure. Thus, the luminance adaptability function and contrast mask equation are derived under the experimental environment of a regular structure. The JND calculation model of the structural layer is derived from the fusion of the two models. 2) Luminance contrast and information uncertainty-based JND estimation model for non-structural layer. The modular mask effect reveals the visibility of stimuli in the visual system because of the interaction or interference among visual stimuli in the visual content of the input scene. When the structure of the visual content is ordered and the background is uniform, the module mask effect is extremely weak, and the spatial object is easily detected. On the contrary, when the visual content is disordered and uncertain, the module mask effect is enhanced, that is, the detection of space objects is suppressed. Therefore, the module mask effect is related not only to brightness contrast but also to information uncertainty. Therefore, we construct an unstructured layer of the JND model on the basis of the module mask combined with information uncertainty and brightness contrast. Finally, given the overlap between the structural layer of JND and the non-structural layer of JND, using a simple linear sum to fuse the two layers is impossible, and the overlapping parts must be removed. A nonlinear additive model describing the masking effect between different components is utilized to fuse the two JND estimation results.Result Three existing JND models are selected for comparison. For a fair comparison, the same noise is injected into the original image through the JND models, and then the visual effects of the polluted image are compared. The subjective experimental results show that the proposed JND model can better guide the distribution of noise and avoid the sensitive region of human vision relative to other JND models when the same noise is injected. The proposed JND model is also consistent with the subjective visual perception of human eyes. To further verify the fairness, we compare the four JND models using the classical peak signal-to-noise ratio (PSNR). The PSNRs of the contaminated Goddess image and contaminated Lena images are compared. The objective experimental results show that the PSNRs of the proposed model are significantly higher than those of the other three JND models. The proposed JND estimation model uses sparse representation to separate the structured and unstructured information of the input natural image. It then calculates the JND threshold according to the characteristics of different components. The process is consistent with the mechanism of human visual perception. Therefore, the proposed JND estimation model can effectively and accurately predict the JND threshold of natural images.Conclusion Compared with the existing relevant models, the proposed JND model can effectively predict the JND threshold of natural images, and it is much more consistent with human visual perception.关键词:just noticeable distortion(JND);sparse representation;human visual system;structural information;unstructural information12|4|1更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveVirtual characters with believable behavior can make serious games more interesting and enhance users' experiences. Although the graphics rendering technology of serious games has become more and more mature, most existing virtual character behavioral models are based on deterministic models, which are difficult to reflect the diversity of virtual characters' behaviors. However, humans' behaviors are generally uncertain. On the one hand, the variables involved in behavior generation are ambiguous; on the other hand, behavioral performance, which is mostly realized through body movements, expressions, and interpersonal interactions, is random. The cloud model, a method proposed by DeyiLi to deal with uncertain information, can be a solution to this problem. The model has been applied in many areas, such as pattern recognition, but its application in serious games has not been reported.Method In the proposed game, the plot is designed according to the needs of social training, and agents are used to describe virtual characters. The proposed framework will generate autonomous behavior includes three layers:sensing layer, decision layer, and action layer. The sensing layer acquires external environment information (including stimuli, events, and other virtual characters in the virtual environment) through visual and auditory channels. Each virtual character has a perceptible area. If an object enters into the perceptible area, it will be perceived by the virtual character. The acquired information will then be stored in the memory of the sensing layer and transferred to the database, which stores a virtual character's identity, personality, initial location information, and animation data. The database information will be updated over time. The decision layer is composed of a motivation module, a behavior module, and an emotion module. The motivation module generates motivation. When the motivation intensity reaches a certain value, it triggers the corresponding behavior and emotional state. Based on Maslow's motivation theory, the motivations of finding food, taking rest, doing communication and keeping safety are used to describe the generation of emotions. The big five (OCEAN) personality model is used to divide the virtual characters into five categories:openness, conscientiousness, extraversion, agreeableness, and neuroticism. The behavior module generates behavior, and the emotion module generates the emotion for the virtual character on the basis of the relevant information transmitted by the sensing layer. The intensity of the emotion is calculated according to the distance from the stimulus and the strength of the current motivation. It determines the intensity of the emotional performance and behavioral performance of the virtual character. The action layer includes a navigation module and an action module, which acquires characters' animation data from the database and renders skeletal animation. The navigation module plans the path according to the final destination selected in the decision layer. It also detects possible collisions that may occur between the virtual character and other virtual characters or obstacles in the environment. The behavioral trees are used to describe virtual characters' behaviors. The normal cloud model is used to deal with the uncertainty of the behavior of virtual characters, and specific design methods are provided for the three typical behaviors during communication, walking direction, social distance, and body orientation.Result In the developed game prototype system, the user experience test is carried out to assess the uncertainty of virtual characters' autonomous behavior and behavioral performance. Five children and eleven adults participants are recruited to test the useful of the proposed behavioral models. The 16 participants are divided equally into two groups:experimental group and control group. Participants in experimental group plays the game with autonomous behavioral model while participants in control group plays the game with script-driven behavioral model. Test results showed that the autonomous behavioral model can reduce the time of exploring the scene, and can promote the user to communicate with the virtual character; To test of the uncertainty of behavior performance, thirteen volunteers are recruited. Game video clips are used to compare the changes in walking direction, social distance, and body orientation. The upper part of the contrasted video is the deterministic model, and the lower part is the uncertainty. Volunteers who are not in turn cannot watch other's operation processes to ensure the authenticity of the experimental results. The naturalness of the three behavior is scored.Conclusion Results showed that the proposed model can generate more natural behavior than the deterministic model and obtain higher recognition from users. The virtual characters under the proposed model are natural and attractive to users, and the method can enhance user experience.关键词:serious game;virtual character;social assistant;cloud model;behavioral performance;uncertainty44|4|1更新时间:2024-05-07
摘要:ObjectiveVirtual characters with believable behavior can make serious games more interesting and enhance users' experiences. Although the graphics rendering technology of serious games has become more and more mature, most existing virtual character behavioral models are based on deterministic models, which are difficult to reflect the diversity of virtual characters' behaviors. However, humans' behaviors are generally uncertain. On the one hand, the variables involved in behavior generation are ambiguous; on the other hand, behavioral performance, which is mostly realized through body movements, expressions, and interpersonal interactions, is random. The cloud model, a method proposed by DeyiLi to deal with uncertain information, can be a solution to this problem. The model has been applied in many areas, such as pattern recognition, but its application in serious games has not been reported.Method In the proposed game, the plot is designed according to the needs of social training, and agents are used to describe virtual characters. The proposed framework will generate autonomous behavior includes three layers:sensing layer, decision layer, and action layer. The sensing layer acquires external environment information (including stimuli, events, and other virtual characters in the virtual environment) through visual and auditory channels. Each virtual character has a perceptible area. If an object enters into the perceptible area, it will be perceived by the virtual character. The acquired information will then be stored in the memory of the sensing layer and transferred to the database, which stores a virtual character's identity, personality, initial location information, and animation data. The database information will be updated over time. The decision layer is composed of a motivation module, a behavior module, and an emotion module. The motivation module generates motivation. When the motivation intensity reaches a certain value, it triggers the corresponding behavior and emotional state. Based on Maslow's motivation theory, the motivations of finding food, taking rest, doing communication and keeping safety are used to describe the generation of emotions. The big five (OCEAN) personality model is used to divide the virtual characters into five categories:openness, conscientiousness, extraversion, agreeableness, and neuroticism. The behavior module generates behavior, and the emotion module generates the emotion for the virtual character on the basis of the relevant information transmitted by the sensing layer. The intensity of the emotion is calculated according to the distance from the stimulus and the strength of the current motivation. It determines the intensity of the emotional performance and behavioral performance of the virtual character. The action layer includes a navigation module and an action module, which acquires characters' animation data from the database and renders skeletal animation. The navigation module plans the path according to the final destination selected in the decision layer. It also detects possible collisions that may occur between the virtual character and other virtual characters or obstacles in the environment. The behavioral trees are used to describe virtual characters' behaviors. The normal cloud model is used to deal with the uncertainty of the behavior of virtual characters, and specific design methods are provided for the three typical behaviors during communication, walking direction, social distance, and body orientation.Result In the developed game prototype system, the user experience test is carried out to assess the uncertainty of virtual characters' autonomous behavior and behavioral performance. Five children and eleven adults participants are recruited to test the useful of the proposed behavioral models. The 16 participants are divided equally into two groups:experimental group and control group. Participants in experimental group plays the game with autonomous behavioral model while participants in control group plays the game with script-driven behavioral model. Test results showed that the autonomous behavioral model can reduce the time of exploring the scene, and can promote the user to communicate with the virtual character; To test of the uncertainty of behavior performance, thirteen volunteers are recruited. Game video clips are used to compare the changes in walking direction, social distance, and body orientation. The upper part of the contrasted video is the deterministic model, and the lower part is the uncertainty. Volunteers who are not in turn cannot watch other's operation processes to ensure the authenticity of the experimental results. The naturalness of the three behavior is scored.Conclusion Results showed that the proposed model can generate more natural behavior than the deterministic model and obtain higher recognition from users. The virtual characters under the proposed model are natural and attractive to users, and the method can enhance user experience.关键词:serious game;virtual character;social assistant;cloud model;behavioral performance;uncertainty44|4|1更新时间:2024-05-07
Virtual Reality and Augmented Reality
-
 摘要:Objective The automatic analysis of retinal vascular health status is a fundamental research topic in the area of fundus image processing. Analysis results can supply significant reference information for ophthalmologists to diagnose rapidly and noninvasively a variety of retinal pathologies, such as diabetes, glaucoma, hypertension, and diseases related to the brain and heart stocks. Although great progress has been achieved in the past decades, accurate automatic retinal vessel extraction remains a challenging problem due to the complex vascular network structure of retina vessels, uneven image background illumination, and random noises introduced by optical apparatuses. The traditional unsupervised retinal vessel segmentation methods generally identify retinal vessels with matched filters, vessel tractors, or templates designed artificially according to the vessel shape or prior information of a retinal image. Conversional supervised learning-based retinal vessel extraction algorithms generally consider artifact features as input and train shallow models, such as support vector machine, K-nearest neighbor classifiers, and traditional artificial neural networks. These models perform effectively in the case of normal retinal images with high-quality illumination and contrast. However, because of the representation limit of artificially designed features, these traditional vessel extraction methods fail when fundus vessels have low contrast with respect to the retinal background or are near nonvascular structures, such as the optic disk and fovea region. Recently, deep learning technology with multifarious convolutional neural networks has been widely applied to medical image processing and has achieved the most state-of-the-art performance due to its efficient and robust self-learned features. A series of new advances in retinal image processing has been achieved with deep learning networks. To help advance the research in this field, we adopt a deep neural network called U-net, which has a symmetrical full convolutional structure, and a dense connection to achieve an accurate end-to-end extraction of retinal vessels.Method A specially modified deep neural network for accurate retinal vessel extraction is proposed based on hierarchically symmetrical structure of the U-net model and the dense connection used in the Dense-net model. The introduction of the hierarchical symmetrical structure empowers the proposed model to perceive the coarse-grained and fine-grained image features through symmetrical down-sampling and up-sampling operations. At the same time, the adoption of a dense connection facilitates multiscale feature combination across different layers, including short connections of consecutive layers and skip connections over non-adjacent layers. This feature combination strategy can utilize comprehensive retina image information and enable the entire network to learn efficient and robust features rapidly. To accelerate the training convergence and enhance the generalization of the proposed neural network, we implement image preprocessing and data augmentation prior to model training. The problem of uneven background illumination is alleviated by the whitening operation, which calculates the average value and standard deviation of each input image channel and subtracts them from each pixel of the corresponding input image channel. Then, data augmentation is achieved by random rotation and gamma correction to generate more images than the raw input dataset scale. Subsequently, each image is divided into a mass of random patches with a certain degree of overlap. This operation can reduce the parameter scale dramatically and alleviate the training of the modified neural network greatly. Finally, these image patches are entered our neural network as a feeding group to be trained iteratively.Result The modified U-net, like the deep neural network model, adopts dense connections to effectively identify and enhance actual retinal vessels at different scales and suppress background simultaneously. To evaluate the proposed model's performance quantitatively, we employ the public dataset called DRIVE, which is one of the most rarely used retina vessel segmentation evaluation datasets. DRIVE comprises 40 images with manual segmentation benchmarks and is divided into a training and a test set, each containing 20 images. In our evaluation, four performance indices are used to assess the proposed method thoroughly:accuracy (ACC), sensitivity (SE), specificity (SP), and area under a curve (AUC), all of which are widely accepted evaluation indices for retina vessel segmentation. The comprehensive experiments show that ACC, SE, SP, and AUC of the proposed algorithm for the DRIVE dataset reach 0.970 7, 0.740 9, 0.992 9, and 0.917 1, respectively. Compared with other state-of-the-art methods, our model presents competitive performance. The accuracy of the proposed model structure can shorten the training time dramatically; it only requires five epochs to converge and approximately one-tenth of time, the same as the initial U-net model. This contribution of the dense connection and batch normalization is used in our modified model.Conclusion A specially designed deep neural network for retinal vessel extraction is proposed to address the problems caused by the low contrast of the retinal vascular structure resulting from their background and uneven illumination. The main contributions of this modified model lie in its symmetrical structure and its dense connection over non-adjacent layers. In addition, the data augmentation with random rotation, which is only available for retina images given that the retina area is a circular-like disk, and the addition of batch normalization in the model contribute to the rapid training convergence and high accuracy of vessel segmentation. Experimental results on a widely used open dataset demonstrate that the proposed modified neural network can deal with these problems and achieve accurate retinal vessel segmentation. Compared with other mainstream deep learning algorithms, the proposed method shows enhanced retinal vessel segmentation accuracy and robustness and presents promising potential in retinal image processing.关键词:retinal vessel segmentation;deep learning;full convolutional neural network;U-Net;Dense-net25|67|6更新时间:2024-05-07
摘要:Objective The automatic analysis of retinal vascular health status is a fundamental research topic in the area of fundus image processing. Analysis results can supply significant reference information for ophthalmologists to diagnose rapidly and noninvasively a variety of retinal pathologies, such as diabetes, glaucoma, hypertension, and diseases related to the brain and heart stocks. Although great progress has been achieved in the past decades, accurate automatic retinal vessel extraction remains a challenging problem due to the complex vascular network structure of retina vessels, uneven image background illumination, and random noises introduced by optical apparatuses. The traditional unsupervised retinal vessel segmentation methods generally identify retinal vessels with matched filters, vessel tractors, or templates designed artificially according to the vessel shape or prior information of a retinal image. Conversional supervised learning-based retinal vessel extraction algorithms generally consider artifact features as input and train shallow models, such as support vector machine, K-nearest neighbor classifiers, and traditional artificial neural networks. These models perform effectively in the case of normal retinal images with high-quality illumination and contrast. However, because of the representation limit of artificially designed features, these traditional vessel extraction methods fail when fundus vessels have low contrast with respect to the retinal background or are near nonvascular structures, such as the optic disk and fovea region. Recently, deep learning technology with multifarious convolutional neural networks has been widely applied to medical image processing and has achieved the most state-of-the-art performance due to its efficient and robust self-learned features. A series of new advances in retinal image processing has been achieved with deep learning networks. To help advance the research in this field, we adopt a deep neural network called U-net, which has a symmetrical full convolutional structure, and a dense connection to achieve an accurate end-to-end extraction of retinal vessels.Method A specially modified deep neural network for accurate retinal vessel extraction is proposed based on hierarchically symmetrical structure of the U-net model and the dense connection used in the Dense-net model. The introduction of the hierarchical symmetrical structure empowers the proposed model to perceive the coarse-grained and fine-grained image features through symmetrical down-sampling and up-sampling operations. At the same time, the adoption of a dense connection facilitates multiscale feature combination across different layers, including short connections of consecutive layers and skip connections over non-adjacent layers. This feature combination strategy can utilize comprehensive retina image information and enable the entire network to learn efficient and robust features rapidly. To accelerate the training convergence and enhance the generalization of the proposed neural network, we implement image preprocessing and data augmentation prior to model training. The problem of uneven background illumination is alleviated by the whitening operation, which calculates the average value and standard deviation of each input image channel and subtracts them from each pixel of the corresponding input image channel. Then, data augmentation is achieved by random rotation and gamma correction to generate more images than the raw input dataset scale. Subsequently, each image is divided into a mass of random patches with a certain degree of overlap. This operation can reduce the parameter scale dramatically and alleviate the training of the modified neural network greatly. Finally, these image patches are entered our neural network as a feeding group to be trained iteratively.Result The modified U-net, like the deep neural network model, adopts dense connections to effectively identify and enhance actual retinal vessels at different scales and suppress background simultaneously. To evaluate the proposed model's performance quantitatively, we employ the public dataset called DRIVE, which is one of the most rarely used retina vessel segmentation evaluation datasets. DRIVE comprises 40 images with manual segmentation benchmarks and is divided into a training and a test set, each containing 20 images. In our evaluation, four performance indices are used to assess the proposed method thoroughly:accuracy (ACC), sensitivity (SE), specificity (SP), and area under a curve (AUC), all of which are widely accepted evaluation indices for retina vessel segmentation. The comprehensive experiments show that ACC, SE, SP, and AUC of the proposed algorithm for the DRIVE dataset reach 0.970 7, 0.740 9, 0.992 9, and 0.917 1, respectively. Compared with other state-of-the-art methods, our model presents competitive performance. The accuracy of the proposed model structure can shorten the training time dramatically; it only requires five epochs to converge and approximately one-tenth of time, the same as the initial U-net model. This contribution of the dense connection and batch normalization is used in our modified model.Conclusion A specially designed deep neural network for retinal vessel extraction is proposed to address the problems caused by the low contrast of the retinal vascular structure resulting from their background and uneven illumination. The main contributions of this modified model lie in its symmetrical structure and its dense connection over non-adjacent layers. In addition, the data augmentation with random rotation, which is only available for retina images given that the retina area is a circular-like disk, and the addition of batch normalization in the model contribute to the rapid training convergence and high accuracy of vessel segmentation. Experimental results on a widely used open dataset demonstrate that the proposed modified neural network can deal with these problems and achieve accurate retinal vessel segmentation. Compared with other mainstream deep learning algorithms, the proposed method shows enhanced retinal vessel segmentation accuracy and robustness and presents promising potential in retinal image processing.关键词:retinal vessel segmentation;deep learning;full convolutional neural network;U-Net;Dense-net25|67|6更新时间:2024-05-07 -
 摘要:Objective Information on the size, shape, and location of the prostate relative to adjacent organs is important in surgical planning for prostatectomy, radiation therapy, and emerging minimally invasive therapies. The images obtained by MRI (magnetic resonance imaging) have the advantages of high resolution and good soft tissue contrast, thereby enabling doctors to obtain the required information accurately. Accurate prostate MRI segmentation is an essential pre-processing task for computer-aided detection and diagnostic algorithms. The segmentation of the prostate in MR is challenging because the prostate shows a wide variety of morphological changes, as well as the contrast of the prostate and adjacent blood vessels, bladder, urethra, rectum, and seminal blood vessels. It also has inherently complex changes in intensity. However, manual segmentation from MR images is time consuming and subjective to limited reproducibility. It heavily depends on experience and has large inter- and intra-observer variations. Consequently, an automated or semi-automated prostate segmentation algorithm that provides robust and high-quality results for a wide variety of clinical applications is required. Therefore, an MRI-conditional generative adversarial network with multi-scale discriminators is proposed to automatically segment prostate MRI to satisfy the requirements of clinical practice.Method The proposed segmentation method is based on a conditional generative adversarial network, which consists of a generator and a discriminator. The generator inputs MRI and noise and performs downsampling after a series of two-stride convolution operations. It then performs upsampling after a series of half-stride deconvolution operation resizing to input size. The purpose of the generator composed of the convolutional neural network similar to U-Net is to model a mapping function from the MRI to the prostate region. We propose a multi-scale discriminator with the same structure but different input sizes. The discriminator with the smallest input size has the largest receptive field, which has a global view of the image and can guide the generator to generate a global continuous prostate region. The discriminator with a large input size guides the generator to generate fin details, such as prostate boundary. The structure of the discriminators inherits the patchGAN in pix2pix, which is mapped from an input to an N×N array of outputs, where each element indicates whether the corresponding patch in the image is true or false. In addition, to obtain a stable training, the proposed method uses feature matching loss, which extracts the feature map of the actual image and the generative image from the convolutional network to define the loss function. The network is trained by minimizing the feature loss function, and the difference between the generative image and the actual image is learned. Thus, the generative image and the actual image are more similar in feature. The adversarial training mechanism is used in the training process of the network to iteratively optimize the generator and the discriminator until they converge simultaneously. The generator can be considered as a prostate segmentation network after training.Result The experimental data are obtained from PROMISE12 prostate segmentation challenge and the First Affiliated Hospital of Anhui Medical University. Some of the images are used as training, and some images are used as test. The Dice similarity coefficient and Hausdorff distance are used as evaluation indicators. The Dice similarity coefficient is 88.9%, and Hausdorff distance is 5.3 mm. Our results show that the proposed algorithm is more accurate and robust than U-Net, DSCNN(deeply-supervised convolutional neured network), and other methods. We also compare the segmentation time. During the test phase, each picture is obtained at less than one second to complete the segmentation beyond the speed of the specialist doctor.Conclusion A conditional generative adversarial network with multi-scale discriminators is proposed to segment prostate MRI. The qualitative and quantitative experiments show the effectiveness of the proposed algorithm. This method can effectively improve the robustness of prostate segmentation. More importantly, it satisfies real-time segmentation requirements and can provide a basis for clinical diagnosis and treatment. Therefore, the proposed model is highly appropriate for the clinical segmentation of prostate MRI.关键词:magnetic resonance imaging (MRI);prostate segmentation;generative adversarial networks (GANs);generator;discriminator25|27|1更新时间:2024-05-07
摘要:Objective Information on the size, shape, and location of the prostate relative to adjacent organs is important in surgical planning for prostatectomy, radiation therapy, and emerging minimally invasive therapies. The images obtained by MRI (magnetic resonance imaging) have the advantages of high resolution and good soft tissue contrast, thereby enabling doctors to obtain the required information accurately. Accurate prostate MRI segmentation is an essential pre-processing task for computer-aided detection and diagnostic algorithms. The segmentation of the prostate in MR is challenging because the prostate shows a wide variety of morphological changes, as well as the contrast of the prostate and adjacent blood vessels, bladder, urethra, rectum, and seminal blood vessels. It also has inherently complex changes in intensity. However, manual segmentation from MR images is time consuming and subjective to limited reproducibility. It heavily depends on experience and has large inter- and intra-observer variations. Consequently, an automated or semi-automated prostate segmentation algorithm that provides robust and high-quality results for a wide variety of clinical applications is required. Therefore, an MRI-conditional generative adversarial network with multi-scale discriminators is proposed to automatically segment prostate MRI to satisfy the requirements of clinical practice.Method The proposed segmentation method is based on a conditional generative adversarial network, which consists of a generator and a discriminator. The generator inputs MRI and noise and performs downsampling after a series of two-stride convolution operations. It then performs upsampling after a series of half-stride deconvolution operation resizing to input size. The purpose of the generator composed of the convolutional neural network similar to U-Net is to model a mapping function from the MRI to the prostate region. We propose a multi-scale discriminator with the same structure but different input sizes. The discriminator with the smallest input size has the largest receptive field, which has a global view of the image and can guide the generator to generate a global continuous prostate region. The discriminator with a large input size guides the generator to generate fin details, such as prostate boundary. The structure of the discriminators inherits the patchGAN in pix2pix, which is mapped from an input to an N×N array of outputs, where each element indicates whether the corresponding patch in the image is true or false. In addition, to obtain a stable training, the proposed method uses feature matching loss, which extracts the feature map of the actual image and the generative image from the convolutional network to define the loss function. The network is trained by minimizing the feature loss function, and the difference between the generative image and the actual image is learned. Thus, the generative image and the actual image are more similar in feature. The adversarial training mechanism is used in the training process of the network to iteratively optimize the generator and the discriminator until they converge simultaneously. The generator can be considered as a prostate segmentation network after training.Result The experimental data are obtained from PROMISE12 prostate segmentation challenge and the First Affiliated Hospital of Anhui Medical University. Some of the images are used as training, and some images are used as test. The Dice similarity coefficient and Hausdorff distance are used as evaluation indicators. The Dice similarity coefficient is 88.9%, and Hausdorff distance is 5.3 mm. Our results show that the proposed algorithm is more accurate and robust than U-Net, DSCNN(deeply-supervised convolutional neured network), and other methods. We also compare the segmentation time. During the test phase, each picture is obtained at less than one second to complete the segmentation beyond the speed of the specialist doctor.Conclusion A conditional generative adversarial network with multi-scale discriminators is proposed to segment prostate MRI. The qualitative and quantitative experiments show the effectiveness of the proposed algorithm. This method can effectively improve the robustness of prostate segmentation. More importantly, it satisfies real-time segmentation requirements and can provide a basis for clinical diagnosis and treatment. Therefore, the proposed model is highly appropriate for the clinical segmentation of prostate MRI.关键词:magnetic resonance imaging (MRI);prostate segmentation;generative adversarial networks (GANs);generator;discriminator25|27|1更新时间:2024-05-07 -
 摘要:ObjectiveThe fusion of multimodal medical images is an important medical imaging method that integrates complementary information from multimodal images to produce new composite images. Sparse representation has achieved great success in medical image fusion in the past few years. However, given that the sparse representation method is based on sliding window technology, the ability to preserve the details of the fused image is insufficient. Therefore, a multimodal medical image fusion method based on convolution sparse representation double dictionary learning and adaptive PCNN(pulse couple neural network) is proposed.MethodAccording to the low-rank and sparsity characteristics of the image, the method decomposes the source image into two parts and constructs a double dictionary based on convolution sparse representation. The sparse component contains a large amount of detail textures, and the low-rank component contains basic information such as contour brightness. First, the low-rank feature and sparse feature are extracted from the training image to form two basic dictionaries to represent the test image. The dictionary learning model is improved by adding low-rank and sparse constraints to the low-rank component and the sparse component, respectively, to enhance the discriminability of the double dictionary. In the process of dictionary learning, the method of alternating iterative updating is divided into three parts:auxiliary variable update, sparse coding, and dictionary updates. A convolutional sparse and convoluted low-rank sub-dictionary for the training image is obtained by a three-part cyclic update. Then, the total variation regularization is incorporated into the image decomposition model, and the Fourier domain-based alternating direction multiplier method is used to obtain the representation coefficients of the source image sparse component and the low-rank component in the respective sub-dictionaries. The process is alternately divided into two parts iteratively, namely, convolution sparse coefficient update and convolution low-rank coefficient update. Second, the sparse component of the source image is obtained by convolving the convolutional sparse coefficient with the corresponding sub-dictionary. Similarly, the convolution low-rank coefficient is convolved with the corresponding sub-dictionary to obtain the low-rank component of the source image. The novel sum-modified spatial frequency of the sparse component is calculated as the external excitation of the pulse-coupled neural network to preserve the details of the image, and the link strength is adaptively determined by the regional average gradient to obtain a firing map of the sparse component. The novel sum-modified Laplacian of the low-rank component is calculated as the external excitation of the pulse coupled neural network, and the link strength is adaptively determined by the regional average gradient to obtain the firing map. The fused sparse components are obtained by comparing the number of firings of different sparse components. Similarly, the low-rank components of different source images are fused through the firing map. Finally, the fused image is obtained by combining convolution sparse and convolution low-rank components, thereby further improving the quality of the fused image.ResultThree sets of brain multimodal medical images (namely, CT/MR, MR/PET, and MR/SPECT) were simulated and compared with those processed by other fusion methods. Experimental results show that the proposed fusion method is significantly superior to the six methods according to objective evaluation and visual quality comparison and has the best performance in four indicators. Compared with the six multi-mode image fusion methods, the mean standard deviation of the three groups of experiments increased by 7%, 10%, and 5.2%, respectively. The average mutual information increased by 33.4%, 10.9%, and 11.3%, respectively. The average spatial frequency increased by 8.2%, 9.6%, and 5.6%, respectively. The average marginal evaluation factors increased by 16.9%, 20.7%, and 21.6%, respectively.ConclusionCompared with other sparse representation methods, the proposed algorithm effectively improves the quality of multimodal medical image fusion, better preserves the detailed information of the source image, enriches the information of the fused image, and conforms to the visual characteristics of the human eye, thereby effectively assisting doctors in diagnosing diseases.关键词:medical image fusion;double dictionary learning;convolution sparse;convolution low rank;pulse coupled neural network(PCNN)14|8|4更新时间:2024-05-07
摘要:ObjectiveThe fusion of multimodal medical images is an important medical imaging method that integrates complementary information from multimodal images to produce new composite images. Sparse representation has achieved great success in medical image fusion in the past few years. However, given that the sparse representation method is based on sliding window technology, the ability to preserve the details of the fused image is insufficient. Therefore, a multimodal medical image fusion method based on convolution sparse representation double dictionary learning and adaptive PCNN(pulse couple neural network) is proposed.MethodAccording to the low-rank and sparsity characteristics of the image, the method decomposes the source image into two parts and constructs a double dictionary based on convolution sparse representation. The sparse component contains a large amount of detail textures, and the low-rank component contains basic information such as contour brightness. First, the low-rank feature and sparse feature are extracted from the training image to form two basic dictionaries to represent the test image. The dictionary learning model is improved by adding low-rank and sparse constraints to the low-rank component and the sparse component, respectively, to enhance the discriminability of the double dictionary. In the process of dictionary learning, the method of alternating iterative updating is divided into three parts:auxiliary variable update, sparse coding, and dictionary updates. A convolutional sparse and convoluted low-rank sub-dictionary for the training image is obtained by a three-part cyclic update. Then, the total variation regularization is incorporated into the image decomposition model, and the Fourier domain-based alternating direction multiplier method is used to obtain the representation coefficients of the source image sparse component and the low-rank component in the respective sub-dictionaries. The process is alternately divided into two parts iteratively, namely, convolution sparse coefficient update and convolution low-rank coefficient update. Second, the sparse component of the source image is obtained by convolving the convolutional sparse coefficient with the corresponding sub-dictionary. Similarly, the convolution low-rank coefficient is convolved with the corresponding sub-dictionary to obtain the low-rank component of the source image. The novel sum-modified spatial frequency of the sparse component is calculated as the external excitation of the pulse-coupled neural network to preserve the details of the image, and the link strength is adaptively determined by the regional average gradient to obtain a firing map of the sparse component. The novel sum-modified Laplacian of the low-rank component is calculated as the external excitation of the pulse coupled neural network, and the link strength is adaptively determined by the regional average gradient to obtain the firing map. The fused sparse components are obtained by comparing the number of firings of different sparse components. Similarly, the low-rank components of different source images are fused through the firing map. Finally, the fused image is obtained by combining convolution sparse and convolution low-rank components, thereby further improving the quality of the fused image.ResultThree sets of brain multimodal medical images (namely, CT/MR, MR/PET, and MR/SPECT) were simulated and compared with those processed by other fusion methods. Experimental results show that the proposed fusion method is significantly superior to the six methods according to objective evaluation and visual quality comparison and has the best performance in four indicators. Compared with the six multi-mode image fusion methods, the mean standard deviation of the three groups of experiments increased by 7%, 10%, and 5.2%, respectively. The average mutual information increased by 33.4%, 10.9%, and 11.3%, respectively. The average spatial frequency increased by 8.2%, 9.6%, and 5.6%, respectively. The average marginal evaluation factors increased by 16.9%, 20.7%, and 21.6%, respectively.ConclusionCompared with other sparse representation methods, the proposed algorithm effectively improves the quality of multimodal medical image fusion, better preserves the detailed information of the source image, enriches the information of the fused image, and conforms to the visual characteristics of the human eye, thereby effectively assisting doctors in diagnosing diseases.关键词:medical image fusion;double dictionary learning;convolution sparse;convolution low rank;pulse coupled neural network(PCNN)14|8|4更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveHyperspectral image classification is a challenging task because of the large number of spectral channels, small-sized labeled training samples, and large spatial variability. Most existing hyperspectral image classification models only consider spectral feature information and neglect the important role of spatial information in classification. Spatial features have become increasingly important in hyperspectral image classification because adjacent pixels are likely to belong to the same category, and the spectral-spatial classification method has the best classification accuracy. Compared with other remote sensing image data, hyperspectral remote sensing image data comprise 2D spatial plane images and increase spectral dimensions that contain the spectral information of objects. Hence, hyperspectral remote sensing image data are able to form 3D data cubes containing rich image information and spectral information. However, the number of bands increases with an increase in the dimension of a hyperspectral image. The information correlation between bands is high, and the hidden features are rich. The problem with high-dimensional small-sized labeled samples is that the number of labeled samples in a dataset is much smaller than the dimension of the sample features. The high data dimensions of hyperspectral images lead to low classification accuracy, excessive dependence on training samples, extended iteration training time, and low efficiency. First, the scale of corresponding feature space increases rapidly with an increase in feature dimensions, thereby leading to dimension issues. Second, the presence of many irrelevant or noise features means that the learning samples are few, resulting in overfitting. Therefore, a small training error still leads to the poor generalization ability of classifiers, which directly reduces the prediction capability of classification models. Multi-spectral image processing algorithms cannot be directly applied to hyperspectral image processing, which involves high-dimensional information and features that are complex, diverse, and massive. A dimensionality-varied convolutional neural network is proposed in this work to solve the problems of low classification accuracy, complex model structure, and large computational complexity of the algorithm on the basis of a convolution neural network for small-sized labeled samples of hyperspectral images.MethodThe dimensionality-varied convolutional neural network is an improved model that is based on convolution neural networks. Optimizing the structure of 3D convolution and 2D convolution in a network is the key to a successful classification. In a dimensionality-varied convolutional neural network, the main component of the convolution layer is a convolution core. The convolution core of the 3D feature extraction process is a 3D filter composed of a set of learning parameters. The application of the 3D convolution core to hyperspectral image classification simplifies the network structure and improves the accuracy of feature extraction. The convolution core of the 2D feature extraction process is a 2D filter composed of a set of learning parameters. If the number of convolution kernels is sufficient, then we can extract all feature types of an image synthetically and obtain an effective and rich extraction of the convolution layer. The basic function of the pooling layer is to gradually reduce the size of the feature expression space so as to reduce the network parameters and computational load and thereby control the fitting. The dimensionality-varied convolutional neural network mainly uses a max pooling operation, which is a non-linear operation, and improves the computational speed and robustness of feature extraction. The classification accuracy is higher when the classification model has many layers and convolution kernels. However, as the complexity of the model increases, the computational complexity increases as well. The dimensionality-varied convolutional neural network can be divided into spectral-spatial information fusion, dimension reduction, mixed feature extraction, and spectral-spatial classification according to the changes in the dimensions of internal feature maps. The process can ensure that the network can extract small-sized labeled sample features in a certain depth. In the feature extraction process of the dimensionality-varied convolutional neural network, the dimension of the internal feature map is changed instead of retaining the 3D structure, thereby reducing the required computation and storage space. This dimensionality-varied structure simplifies the network structure and reduces computational complexity by changing the dimension of feature mapping. The accuracy of the convolutional neural network for hyperspectral image classification of small-sized labeled samples is improved by fully extracting the spectral-spatial information.ResultThe experiment is divided into performance analysis and classification performance comparison of the dimensionality-varied convolutional neural network. The datasets used are the Indian Pines and Pavia University Scene datasets. Experiment results show that the dimensionality-varied convolutional neural network can achieve high classification accuracy for hyperspectral images with small-sized labeled samples. The selection of parameters in the dimensionality-varied convolutional neural network greatly influences classification accuracy. Experiments on batch size, threshold, dropout, and kernel number show that a reasonable parameter selection has an important impact on the classification performance of the algorithm. For the Indian Pines and Pavia University Scene datasets, the optimal classification performance is achieved when the batch sizes are set to 40 and 150, the thresholds are both set to 1×10-15, the dropout values are both set to 0.8, and the kernel numbers are set to 8 and 5, respectively. The overall classification accuracies for the Indian Pines and Pavia University Scene datasets are 87.87% and 98.18%, respectively. Compared with other classification algorithms, the proposed algorithm has evident performance advantages. The combination of the two optimization methods, namely, spectral-spatial information and dimensionality reduction for feature maps, can effectively improve the classification of hyperspectral images with small-sized labeled samples.ConclusionExperimental results show that by changing the dimensions of feature maps in feature extraction, high-precision spectral-spatial feature extraction is realized, and the complexity of the model is reduced. Compared with other classification algorithms, the dimensionality-varied convolutional neural network can effectively improve the classification of small-sized labeled samples and greatly reduce the complexity of the model. Reasonable parameter optimization can effectively improve the classification accuracy of the dimensionality-varied convolutional neural network. This dimensionality-varied model can greatly improve the classification performance of small-sized labeled samples in hyperspectral images and can be further extended to other deep learning classification models related to hyperspectral images.关键词:convolutional neural network (CNN);hyperspectral image(HSI);small-sized samples;dimensionality-varied feature extraction;spectral-spatial classification12|4|2更新时间:2024-05-07
摘要:ObjectiveHyperspectral image classification is a challenging task because of the large number of spectral channels, small-sized labeled training samples, and large spatial variability. Most existing hyperspectral image classification models only consider spectral feature information and neglect the important role of spatial information in classification. Spatial features have become increasingly important in hyperspectral image classification because adjacent pixels are likely to belong to the same category, and the spectral-spatial classification method has the best classification accuracy. Compared with other remote sensing image data, hyperspectral remote sensing image data comprise 2D spatial plane images and increase spectral dimensions that contain the spectral information of objects. Hence, hyperspectral remote sensing image data are able to form 3D data cubes containing rich image information and spectral information. However, the number of bands increases with an increase in the dimension of a hyperspectral image. The information correlation between bands is high, and the hidden features are rich. The problem with high-dimensional small-sized labeled samples is that the number of labeled samples in a dataset is much smaller than the dimension of the sample features. The high data dimensions of hyperspectral images lead to low classification accuracy, excessive dependence on training samples, extended iteration training time, and low efficiency. First, the scale of corresponding feature space increases rapidly with an increase in feature dimensions, thereby leading to dimension issues. Second, the presence of many irrelevant or noise features means that the learning samples are few, resulting in overfitting. Therefore, a small training error still leads to the poor generalization ability of classifiers, which directly reduces the prediction capability of classification models. Multi-spectral image processing algorithms cannot be directly applied to hyperspectral image processing, which involves high-dimensional information and features that are complex, diverse, and massive. A dimensionality-varied convolutional neural network is proposed in this work to solve the problems of low classification accuracy, complex model structure, and large computational complexity of the algorithm on the basis of a convolution neural network for small-sized labeled samples of hyperspectral images.MethodThe dimensionality-varied convolutional neural network is an improved model that is based on convolution neural networks. Optimizing the structure of 3D convolution and 2D convolution in a network is the key to a successful classification. In a dimensionality-varied convolutional neural network, the main component of the convolution layer is a convolution core. The convolution core of the 3D feature extraction process is a 3D filter composed of a set of learning parameters. The application of the 3D convolution core to hyperspectral image classification simplifies the network structure and improves the accuracy of feature extraction. The convolution core of the 2D feature extraction process is a 2D filter composed of a set of learning parameters. If the number of convolution kernels is sufficient, then we can extract all feature types of an image synthetically and obtain an effective and rich extraction of the convolution layer. The basic function of the pooling layer is to gradually reduce the size of the feature expression space so as to reduce the network parameters and computational load and thereby control the fitting. The dimensionality-varied convolutional neural network mainly uses a max pooling operation, which is a non-linear operation, and improves the computational speed and robustness of feature extraction. The classification accuracy is higher when the classification model has many layers and convolution kernels. However, as the complexity of the model increases, the computational complexity increases as well. The dimensionality-varied convolutional neural network can be divided into spectral-spatial information fusion, dimension reduction, mixed feature extraction, and spectral-spatial classification according to the changes in the dimensions of internal feature maps. The process can ensure that the network can extract small-sized labeled sample features in a certain depth. In the feature extraction process of the dimensionality-varied convolutional neural network, the dimension of the internal feature map is changed instead of retaining the 3D structure, thereby reducing the required computation and storage space. This dimensionality-varied structure simplifies the network structure and reduces computational complexity by changing the dimension of feature mapping. The accuracy of the convolutional neural network for hyperspectral image classification of small-sized labeled samples is improved by fully extracting the spectral-spatial information.ResultThe experiment is divided into performance analysis and classification performance comparison of the dimensionality-varied convolutional neural network. The datasets used are the Indian Pines and Pavia University Scene datasets. Experiment results show that the dimensionality-varied convolutional neural network can achieve high classification accuracy for hyperspectral images with small-sized labeled samples. The selection of parameters in the dimensionality-varied convolutional neural network greatly influences classification accuracy. Experiments on batch size, threshold, dropout, and kernel number show that a reasonable parameter selection has an important impact on the classification performance of the algorithm. For the Indian Pines and Pavia University Scene datasets, the optimal classification performance is achieved when the batch sizes are set to 40 and 150, the thresholds are both set to 1×10-15, the dropout values are both set to 0.8, and the kernel numbers are set to 8 and 5, respectively. The overall classification accuracies for the Indian Pines and Pavia University Scene datasets are 87.87% and 98.18%, respectively. Compared with other classification algorithms, the proposed algorithm has evident performance advantages. The combination of the two optimization methods, namely, spectral-spatial information and dimensionality reduction for feature maps, can effectively improve the classification of hyperspectral images with small-sized labeled samples.ConclusionExperimental results show that by changing the dimensions of feature maps in feature extraction, high-precision spectral-spatial feature extraction is realized, and the complexity of the model is reduced. Compared with other classification algorithms, the dimensionality-varied convolutional neural network can effectively improve the classification of small-sized labeled samples and greatly reduce the complexity of the model. Reasonable parameter optimization can effectively improve the classification accuracy of the dimensionality-varied convolutional neural network. This dimensionality-varied model can greatly improve the classification performance of small-sized labeled samples in hyperspectral images and can be further extended to other deep learning classification models related to hyperspectral images.关键词:convolutional neural network (CNN);hyperspectral image(HSI);small-sized samples;dimensionality-varied feature extraction;spectral-spatial classification12|4|2更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0