
最新刊期
卷 24 , 期 8 , 2019
- 摘要:As a representative technique for deep learning, the deep convolution neural network (DCNN) with strong feature learning and nonlinear mapping ability in the field of digital image processing offers a novel opportunity for image denoising research. DCNN-based denoising models show significant advantages over traditional methods in terms of their denoising effect and execution efficiency. However, most of the existing image denoising models are driven by data. Given their inherent restrictions, the denoising performance of these models can be further improved. To promote the development of existing image denoising technologies, some key challenges that restrict their further improvement must be analyzed and addressed. We first summarize the core ideas of traditional image denoising algorithms based on three types of prior knowledge of the natural image, namely, non-local self-similarity, sparsity, and low rank, and then analyze the advantages and disadvantages of these algorithms. Image denoising algorithms modeled with prior knowledge can flexibly deal with distorted images under different noise levels. Unfortunately, they demonstrate the following limitations:1) the limited hand-crafted image priors are not enough to describe all changes in the image structure, thereby limiting the denoising ability of these algorithms; 2) most of the traditional image denoising algorithms iteratively solve their objective functions, thereby resulting in a high computational complexity; and 3) the optimal solution of the objective function needs to adjust several parameters manually according to the actual situation. Based on the above problems, we point out that the technical advantage of the DCNN-based denoising model lies in its strong nonlinear approximation supported by a graphics processing unit. The inherent characteristics of the DCNN-based denoising model are then analyzed, the bottleneck problems that restrict their future development are presented, and the possible solutions (research directions) to these problems are discussed in detail. A thorough analysis reveals many bottleneck problems in data-driven DCNN-based denoising models that need to be solved, including:1) the small receptive field of the DCNN network that limits the range of image feature representation and the ability to fully utilize the priors contained in natural images; 2) the strong dependence of DCNN-based model parameters on the training dataset, that is, the optimal denoising effect can only be obtained if the distortion level of the observed image is close to that of the training images; and 3) the training set cannot be easily constructed and the denoising model cannot be easily trained to denoise an image if both the noise type and level of noisy image are unknown. To solve these problems, we expand the receptive field of the convolution kernel, weaken the dependency between the network parameters and the training set, or fully utilize the modeling ability of the DCNN network. Therefore, the bottlenecks of the existing DCNN denoising models can be addressed, and research on image denoising algorithms can move to a higher level. In this paper, the technical advantages and development bottlenecks of DCNN in the field of image denoising are summarized, and some future research directions for the image denoising method are proposed. This paper should be of interest to readers in the area of image denoising.关键词:review;image denoising;deep convolutional neural network(DCNN);bottleneck problem;receptive field;data dependencies;parameter space101|63|4更新时间:2024-05-07
Scholar View

-
 摘要:ObjectiveAs an important part of human biometrics, age information has extensive application prospects in the fields of security monitoring, human-computer interaction, and video retrieval. As an emerging biometric recognition technology, age estimation technology based on face image is an important research subject in the fields of computer vision and face analysis. With the fast development of deep learning, the face age estimation method based on deep convolutional neural network has become a research hotspot in these fields.MethodReal and apparent age estimation methods based on deep learning are reviewed based on extensive research and the latest achievements of relevant literature. The basic ideas and characteristics of various methods are analyzed. The research status, key technologies, and limitations based on various age estimation methods are summarized. The performance of various methods on common age estimation datasets is compared. Finally, existing major research problems are summarized and discussed, and potential future research directions are presented.ResultFace age estimation can be divided into real and apparent age estimation according to the subjectivity and objectivity of age labeling, and it can be divided into age group estimation and age value estimation according to the accuracy of age labeling. With the deep convolutional neural network (DCNN) becoming a hotspot in the field of computer vision, from 5-conv 3-fc's AlexNet 33 to 16-conv 3-fc's VGG-19 network and from 21-conv 1-fc's GoogleNet to thousands of layers of ResNets, the learning ability and the depth of the network have improved considerably. An increasing number of face age estimation researchers are focusing on face age estimation based on DCNN with powerful feature extraction and learning capabilities. According to different views, face age estimation methods based on deep learning can be roughly divided into three categories:regression model, multi-class classification, and rank model. Regression model uses regression analysis to achieve age estimation by establishing a functional model that characterizes the age variation of faces. Regression-based age estimation methods may be affected by overfitting due to the randomness in the aging process and the fuzzy mapping between the appearance of the face and its actual age. The age of a person can be easily divided into several age groups. Age group estimation under unconstrained conditions has become a current research topic, and the multi-classification model is the main means of achieving age group estimation because the regression-based age estimation model has difficulty achieving convergence. Moreover, age group classification can meet the needs of most practical applications. The age estimation model based on the rank model regards the age label as a data sequence and converts the age estimation problem into a problem in which the age to be estimated is greater or less than a certain age, thereby transforming the age estimation problem into a series of binary classification problems. Other technologies in the field of computer vision are applied in face age estimation. Although various deep learning-based face age estimation methods have achieved considerable progress, the performance of age estimation fails to meet the practical needs of unconstrained age estimation because current face age estimation research continues to face the following difficulties and challenges:1) insufficient prior knowledge introduced to face age estimation methods; 2) lack of face age estimation feature representation that considers global and local details; 3) the limitations of existing face age estimation datasets; and 4) multi-scale face age estimation problems in practical application environments.ConclusionDeep learning-based face age estimation methods have achieved considerable progress, but they perform poorly due to the complexity of actual application scenarios. A comprehensive review of the current deep learning-based face age estimation techniques is needed to help researchers solve existing problems. Age estimation techniques based on face images are expected to play an important role in the future with the continued efforts of researchers and the in-depth development of related technologies.关键词:face age estimation;deep learning;deep convolutional neural networks(DCNNs);real age;apparent age23|47|10更新时间:2024-05-07
摘要:ObjectiveAs an important part of human biometrics, age information has extensive application prospects in the fields of security monitoring, human-computer interaction, and video retrieval. As an emerging biometric recognition technology, age estimation technology based on face image is an important research subject in the fields of computer vision and face analysis. With the fast development of deep learning, the face age estimation method based on deep convolutional neural network has become a research hotspot in these fields.MethodReal and apparent age estimation methods based on deep learning are reviewed based on extensive research and the latest achievements of relevant literature. The basic ideas and characteristics of various methods are analyzed. The research status, key technologies, and limitations based on various age estimation methods are summarized. The performance of various methods on common age estimation datasets is compared. Finally, existing major research problems are summarized and discussed, and potential future research directions are presented.ResultFace age estimation can be divided into real and apparent age estimation according to the subjectivity and objectivity of age labeling, and it can be divided into age group estimation and age value estimation according to the accuracy of age labeling. With the deep convolutional neural network (DCNN) becoming a hotspot in the field of computer vision, from 5-conv 3-fc's AlexNet 33 to 16-conv 3-fc's VGG-19 network and from 21-conv 1-fc's GoogleNet to thousands of layers of ResNets, the learning ability and the depth of the network have improved considerably. An increasing number of face age estimation researchers are focusing on face age estimation based on DCNN with powerful feature extraction and learning capabilities. According to different views, face age estimation methods based on deep learning can be roughly divided into three categories:regression model, multi-class classification, and rank model. Regression model uses regression analysis to achieve age estimation by establishing a functional model that characterizes the age variation of faces. Regression-based age estimation methods may be affected by overfitting due to the randomness in the aging process and the fuzzy mapping between the appearance of the face and its actual age. The age of a person can be easily divided into several age groups. Age group estimation under unconstrained conditions has become a current research topic, and the multi-classification model is the main means of achieving age group estimation because the regression-based age estimation model has difficulty achieving convergence. Moreover, age group classification can meet the needs of most practical applications. The age estimation model based on the rank model regards the age label as a data sequence and converts the age estimation problem into a problem in which the age to be estimated is greater or less than a certain age, thereby transforming the age estimation problem into a series of binary classification problems. Other technologies in the field of computer vision are applied in face age estimation. Although various deep learning-based face age estimation methods have achieved considerable progress, the performance of age estimation fails to meet the practical needs of unconstrained age estimation because current face age estimation research continues to face the following difficulties and challenges:1) insufficient prior knowledge introduced to face age estimation methods; 2) lack of face age estimation feature representation that considers global and local details; 3) the limitations of existing face age estimation datasets; and 4) multi-scale face age estimation problems in practical application environments.ConclusionDeep learning-based face age estimation methods have achieved considerable progress, but they perform poorly due to the complexity of actual application scenarios. A comprehensive review of the current deep learning-based face age estimation techniques is needed to help researchers solve existing problems. Age estimation techniques based on face images are expected to play an important role in the future with the continued efforts of researchers and the in-depth development of related technologies.关键词:face age estimation;deep learning;deep convolutional neural networks(DCNNs);real age;apparent age23|47|10更新时间:2024-05-07 -
 摘要:ObjectiveIn recent years, as an emerging biometrics technology, low-resolution palmprint recognition has attracted attention due to its potential for civilian applications. Many effective palmprint recognition methods have been proposed. These traditional methods can be roughly divided into categories, such as texture-based, line-based, subspace learning-based, correlation filter-based, local descriptor-based, and orientation coding-based. In the past decade, deep learning was the most important technique in the field of artificial intelligence, introducing performance breakthroughs in many fields such as speech recognition, natural language processing, computer vision, image and video analysis, and multimedia. In the field of biometrics, especially in face recognition, deep learning has become the most mainstream technology. However, research on deep learning-based palmprint recognition remains at the preliminary stage. Research on deep learning-based palmprint recognition is relatively rare, and in-depth analysis and discussion on deep learning-based palmprint recognition is scarce. In addition, most existing work on deep learning-based palmprint recognition exploited simple networks only. In palmprint databases, the palmprint images were usually captured in two different sessions. In traditional palmprint recognition work, the images captured in the first session were usually treated as the training data, and the images captured in the second session were typically used as the test data. However, in existing work on deep learning-based palmprint recognition, the images captured in the first and second sessions are exploited as the training data, which leads to a high recognition accuracy. In this study, we evaluate the performance of various convolutional neural networks (CNNs) in palmprint recognition to thoroughly investigate the problem of deep learning-based palmprint recognition.MethodWe systematically review the classic CNNs in recent years and analyze the structure of various networks and their underlying connections. Then, we perform a large-scale performance evaluation for palmprint recognition. First, we select eight typical CNN networks, namely, AlexNet, VGG, Inception_v3, ResNet, Inception_v4, Inception_ResNet_v2, DenseNet, and Xception, and evaluate these networks on five palmprint databases to determine the best network. We choose the pretrained model in ImageNet Large Scale Visual Recognition Challenge for training because training the CNN model in the case of insufficient data (the scale of the dataset is small) is time consuming and may lead to poor results. Second, we conduct evaluations by using six learning rates from large to small to analyze the impact on performance and obtain the suitable learning rate. Third, we compare the performance of VGG-16 and VGG-19 and ResNet18, ResNet34, and ResNet50 in the evaluation on different layer numbers of the network. Fourth, starting from a single training data, we gradually increase the data amount until the training data contains all the data of the first session to analyze the influence of different training data quantities on performance. Finally, the performance of CNNs is compared with that of several traditional methods, such as competitive code, ordinal code, RLOC, and LLDP.ResultExperimental results on eight CNNs with different structures show that ResNet18 outperforms other networks and can achieve 100% recognition rate on the PolyU M_B database. The performance of DenseNet121 is similar to that of ResNe18, and the performance of AlexNet is poor. To evaluate the learning rate, results show that 5×10-5 is suitable for the palmprint dataset used in this study. If the learning rate is too large, then the performance of these CNNs will be poor. In addition, the appropriate learning rate of the VGG network is 10-5. The performance evaluation of different numbers of network layers indicated that the recognition rate of VGG-16 and VGG-19 is similar. As the layer number of ResNet increases from 18 to 34 and to 50, the recognition rate gradually decreases. Generally speaking, more data involved in network training results in improved performance. In the early stage of the increase in the amount of data, the performance is significantly improved. A comparison of the performance of CNNs with that of traditional non-deep learning methods shows that the performance of CNNs is equivalent to that of non-deep learning methods on the PolyU M_B database. On other databases, the performance of CNNs is worse than that of traditional non-deep learning methods.ConclusionThis paper reviews the CNNs proposed in the literature and conducts a large-scale performance evaluation of palmprint recognition on five different palmprint databases under different network structures, learning rates, network layers, and training data amounts. Results show that ResNet is suitable for palmprint recognition and that 5×10-5 is an appropriate learning rate, which can help researchers engaged in deep learning and palmprint recognition. We also compared the performance of CNNs with that of four traditional methods. The overall performance of CNN is slightly worse than that of traditional methods, but we can still see the great potential of deep learning methods.关键词:biometrics;palmprint recognition;deep learning(DL);convolutional neural network(CNN);palmprint dataset;performance evaluation43|352|2更新时间:2024-05-07
摘要:ObjectiveIn recent years, as an emerging biometrics technology, low-resolution palmprint recognition has attracted attention due to its potential for civilian applications. Many effective palmprint recognition methods have been proposed. These traditional methods can be roughly divided into categories, such as texture-based, line-based, subspace learning-based, correlation filter-based, local descriptor-based, and orientation coding-based. In the past decade, deep learning was the most important technique in the field of artificial intelligence, introducing performance breakthroughs in many fields such as speech recognition, natural language processing, computer vision, image and video analysis, and multimedia. In the field of biometrics, especially in face recognition, deep learning has become the most mainstream technology. However, research on deep learning-based palmprint recognition remains at the preliminary stage. Research on deep learning-based palmprint recognition is relatively rare, and in-depth analysis and discussion on deep learning-based palmprint recognition is scarce. In addition, most existing work on deep learning-based palmprint recognition exploited simple networks only. In palmprint databases, the palmprint images were usually captured in two different sessions. In traditional palmprint recognition work, the images captured in the first session were usually treated as the training data, and the images captured in the second session were typically used as the test data. However, in existing work on deep learning-based palmprint recognition, the images captured in the first and second sessions are exploited as the training data, which leads to a high recognition accuracy. In this study, we evaluate the performance of various convolutional neural networks (CNNs) in palmprint recognition to thoroughly investigate the problem of deep learning-based palmprint recognition.MethodWe systematically review the classic CNNs in recent years and analyze the structure of various networks and their underlying connections. Then, we perform a large-scale performance evaluation for palmprint recognition. First, we select eight typical CNN networks, namely, AlexNet, VGG, Inception_v3, ResNet, Inception_v4, Inception_ResNet_v2, DenseNet, and Xception, and evaluate these networks on five palmprint databases to determine the best network. We choose the pretrained model in ImageNet Large Scale Visual Recognition Challenge for training because training the CNN model in the case of insufficient data (the scale of the dataset is small) is time consuming and may lead to poor results. Second, we conduct evaluations by using six learning rates from large to small to analyze the impact on performance and obtain the suitable learning rate. Third, we compare the performance of VGG-16 and VGG-19 and ResNet18, ResNet34, and ResNet50 in the evaluation on different layer numbers of the network. Fourth, starting from a single training data, we gradually increase the data amount until the training data contains all the data of the first session to analyze the influence of different training data quantities on performance. Finally, the performance of CNNs is compared with that of several traditional methods, such as competitive code, ordinal code, RLOC, and LLDP.ResultExperimental results on eight CNNs with different structures show that ResNet18 outperforms other networks and can achieve 100% recognition rate on the PolyU M_B database. The performance of DenseNet121 is similar to that of ResNe18, and the performance of AlexNet is poor. To evaluate the learning rate, results show that 5×10-5 is suitable for the palmprint dataset used in this study. If the learning rate is too large, then the performance of these CNNs will be poor. In addition, the appropriate learning rate of the VGG network is 10-5. The performance evaluation of different numbers of network layers indicated that the recognition rate of VGG-16 and VGG-19 is similar. As the layer number of ResNet increases from 18 to 34 and to 50, the recognition rate gradually decreases. Generally speaking, more data involved in network training results in improved performance. In the early stage of the increase in the amount of data, the performance is significantly improved. A comparison of the performance of CNNs with that of traditional non-deep learning methods shows that the performance of CNNs is equivalent to that of non-deep learning methods on the PolyU M_B database. On other databases, the performance of CNNs is worse than that of traditional non-deep learning methods.ConclusionThis paper reviews the CNNs proposed in the literature and conducts a large-scale performance evaluation of palmprint recognition on five different palmprint databases under different network structures, learning rates, network layers, and training data amounts. Results show that ResNet is suitable for palmprint recognition and that 5×10-5 is an appropriate learning rate, which can help researchers engaged in deep learning and palmprint recognition. We also compared the performance of CNNs with that of four traditional methods. The overall performance of CNN is slightly worse than that of traditional methods, but we can still see the great potential of deep learning methods.关键词:biometrics;palmprint recognition;deep learning(DL);convolutional neural network(CNN);palmprint dataset;performance evaluation43|352|2更新时间:2024-05-07
Review
-
 摘要:ObjectiveImage colorization is the process of assigning color information to grayscale images and retains grayscale image texture information. The aim of colorization is to increase the visual appeal of an image. This technology is widely used in many areas, such as medical image illustrations, remote sensing images, and old black-and-white photos. Colorization methods have to main categories, namely, user-assisted and automatic colorization methods. User-assisted colorization methods require users to manually define a layer mask or mark color scribbles on a grayscale image. This method is time-consuming and cannot provide sufficient and desirable color scribbles. Automatic colorization methods can reduce user effort and transfer color from a sample color image. The color image is called the reference/source image, and the grayscale image to be colorized is called the target image. The primary difficulty of these automatic colorization methods is to accurately transfer colors and satisfy spatial consistency. Most of these approaches achieve spatial coherency by using weighted filter or global optimization algorithms during colorizing. However, these methods may result in oversmoothed colorization or blur color in edge regions.MethodWe use a grayscale image colorization approach based on a local adaptive weighted average filter. This proposed method considers local neighborhood pixel information and automatically adjusts the domain pixel weights to ensure correct color migration and clear boundary results. A reference image with similar contents as the target image is provided to achieve color transfer. The method includes the following steps:First, the class probability distribution and classification are obtained. Support vector machine (SVM) is adopted to calculate class probability based on feature descriptors, mean luminance, entropy, variance, and local binary pattern (LBP) and Gabor features. The probability results and classification are post-processed to enhance the spatial coherency combined with superpixels that are extracted based on improved simple linear iterative clustering (ISLIC). Second, the color candidate in the reference image is determined based on matching low-level features in the corresponding class. Thereafter, each pixel with high-confidence class probability is assigned a color from the candidate pixel by using an adaptive weight filter. The adaptive weight, which is defined by the class probability of small neighborhood pixels around the corresponding pixel, can improve local spatial consistency and avoid confusion colorization in the boundary region. Finally, the optimization-based colorization algorithm is used on the remaining unassigned pixels with low-confidence class probability.ResultThis paper analyzes single pixel-based, weighted average, and adaptive weighted average methods. Results demonstrate that the adaptive weighted average method is better than the other strategies. The colorized images illustrate that our method takes advantage of the other strategies and that it not only has high spatial consistence but also ensures the boundary detail information with high color discrimination. Compared with previous colorization methods, our method works well in colorization. Colorized images achieved by Gupta's method and Irony's method have obvious erroneous colors due to inaccurate matching or corresponding pixels. Charpiat's method produce oversmoothed color on the boundary regions. Images colorized by using Zhang's method are extracted by training more than a million color images and diversities of colors based on CNN. However, some unreliable and undistinguished colors appear on the boundary contours. The colorization results obtained by using a local adaptive weighted average filter ensures the correctness of color transfer and spatial consistence and avoids oversmoothing simultaneously in the edge areas. Thus, our proposed method performs better than the existing methods. The evaluation scores for experimental images using our method are higher than 3.5, especially in local areas, and the evaluation results are close to or higher than 4.0, which is greater than the results of those using the existing colorization method.ConclusionA new colorization approach using color reference images is presented in this paper. The proposed method combines SVM and ISLIC to determine the class probabilities and classifications with high spatial coherence for images. The corresponding pixels are matched based on the space features according to the same class label between the reference and the target images. A local adaptive weighted average filter is defined to transfer the chrominance from the source image to the grayscale image with high-confidence pixels to facilitate spatially coherent colorization and avoid oversmoothing. The colorized pixels are considered automatic scribbles to be spread across all pixels by using global optimization to obtain the final colorization result. Experimental results demonstrate that our proposed method can achieve satisfactory results and is competitive with the existing methods. However, several limitations are observed. First, this method is not fully automated, requiring some human intervention to provide class samples during the process of calculating class probability. Second, the selected space features are not optimal for all images, especially for images with complex textures and rich colors. We will focus on fully automatic operation and general features in our future work.关键词:colorization;color transfer;local spatial coherency;consistency;smooth16|31|4更新时间:2024-05-07
摘要:ObjectiveImage colorization is the process of assigning color information to grayscale images and retains grayscale image texture information. The aim of colorization is to increase the visual appeal of an image. This technology is widely used in many areas, such as medical image illustrations, remote sensing images, and old black-and-white photos. Colorization methods have to main categories, namely, user-assisted and automatic colorization methods. User-assisted colorization methods require users to manually define a layer mask or mark color scribbles on a grayscale image. This method is time-consuming and cannot provide sufficient and desirable color scribbles. Automatic colorization methods can reduce user effort and transfer color from a sample color image. The color image is called the reference/source image, and the grayscale image to be colorized is called the target image. The primary difficulty of these automatic colorization methods is to accurately transfer colors and satisfy spatial consistency. Most of these approaches achieve spatial coherency by using weighted filter or global optimization algorithms during colorizing. However, these methods may result in oversmoothed colorization or blur color in edge regions.MethodWe use a grayscale image colorization approach based on a local adaptive weighted average filter. This proposed method considers local neighborhood pixel information and automatically adjusts the domain pixel weights to ensure correct color migration and clear boundary results. A reference image with similar contents as the target image is provided to achieve color transfer. The method includes the following steps:First, the class probability distribution and classification are obtained. Support vector machine (SVM) is adopted to calculate class probability based on feature descriptors, mean luminance, entropy, variance, and local binary pattern (LBP) and Gabor features. The probability results and classification are post-processed to enhance the spatial coherency combined with superpixels that are extracted based on improved simple linear iterative clustering (ISLIC). Second, the color candidate in the reference image is determined based on matching low-level features in the corresponding class. Thereafter, each pixel with high-confidence class probability is assigned a color from the candidate pixel by using an adaptive weight filter. The adaptive weight, which is defined by the class probability of small neighborhood pixels around the corresponding pixel, can improve local spatial consistency and avoid confusion colorization in the boundary region. Finally, the optimization-based colorization algorithm is used on the remaining unassigned pixels with low-confidence class probability.ResultThis paper analyzes single pixel-based, weighted average, and adaptive weighted average methods. Results demonstrate that the adaptive weighted average method is better than the other strategies. The colorized images illustrate that our method takes advantage of the other strategies and that it not only has high spatial consistence but also ensures the boundary detail information with high color discrimination. Compared with previous colorization methods, our method works well in colorization. Colorized images achieved by Gupta's method and Irony's method have obvious erroneous colors due to inaccurate matching or corresponding pixels. Charpiat's method produce oversmoothed color on the boundary regions. Images colorized by using Zhang's method are extracted by training more than a million color images and diversities of colors based on CNN. However, some unreliable and undistinguished colors appear on the boundary contours. The colorization results obtained by using a local adaptive weighted average filter ensures the correctness of color transfer and spatial consistence and avoids oversmoothing simultaneously in the edge areas. Thus, our proposed method performs better than the existing methods. The evaluation scores for experimental images using our method are higher than 3.5, especially in local areas, and the evaluation results are close to or higher than 4.0, which is greater than the results of those using the existing colorization method.ConclusionA new colorization approach using color reference images is presented in this paper. The proposed method combines SVM and ISLIC to determine the class probabilities and classifications with high spatial coherence for images. The corresponding pixels are matched based on the space features according to the same class label between the reference and the target images. A local adaptive weighted average filter is defined to transfer the chrominance from the source image to the grayscale image with high-confidence pixels to facilitate spatially coherent colorization and avoid oversmoothing. The colorized pixels are considered automatic scribbles to be spread across all pixels by using global optimization to obtain the final colorization result. Experimental results demonstrate that our proposed method can achieve satisfactory results and is competitive with the existing methods. However, several limitations are observed. First, this method is not fully automated, requiring some human intervention to provide class samples during the process of calculating class probability. Second, the selected space features are not optimal for all images, especially for images with complex textures and rich colors. We will focus on fully automatic operation and general features in our future work.关键词:colorization;color transfer;local spatial coherency;consistency;smooth16|31|4更新时间:2024-05-07 -
 摘要:ObjectiveImage super-resolution is an important branch of digital image processing and computer vision. This method has been widely used in video surveillance, medical imaging, and security and surveillance imaging in recent years. Super-resolution aims to reconstruct a high-resolution image from an observed degraded low-resolution one. Early methods include interpolation, neighborhood embedding, and sparse coding. Deep convolutional neural network has recently become a major research topic in the field of single image super-resolution reconstruction. This network can learn the mapping between high-and low-resolution images better than traditional learning-based methods. However, many deep learning-based methods present two evident drawbacks. First, most methods use chained stacking to create the network. Each layer of the network is only related to its previous layer, leading to weak inter-layer relationships. Second, the hierarchical features of the network are partially utilized. These shortcomings can lead to loss of high frequency components. A novel image super-resolution reconstruction method based on multi-staged fusion network is proposed to address these drawbacks. This method is used to improve the quality of image reconstruction.MethodNumerous studies have shown that feature re-usage can improve the capability of the network to extract and express features. Thus, our research is based on the idea of feature re-usage. We implemented this idea through the multipath connection, which includes two forms, namely, global multipath mode and local fusion unit. First, the proposed model uses an interpolated low-resolution image as input. The feature extraction network extracts shallow features as the mixture network's input. Mixture network consists of two parts. The first one is pixel encoding network, which is used to obtain structural feature information of the image. This network presents four weight layers, each consisting of 64 filters with a size of 1×1, which can guarantee that the feature map distribution will be protected. This process is similar to those of encoding and decoding pixels. The other one is multi-path feedforward network, which is used to extract the high-frequency components needed for reconstruction. This network is formed by staged feature fusion units connected by multi-path mode. Each fusion unit is composed of dense connection, residual learning, and feature selection layers. The dense connection layer is composed of four weight layers with 32 filters with a size of 3×3. This layer is used to improve the nonlinear mapping capability of the network and extract substantial high frequency information. The residual learning layer contains a 1×1 weight layer to alleviate the vanishing gradient problem. Feature selection layer uses a 1×1 weight layer to obtain effective features. Then, the multi-path mode is used to connect different units, which could enhance the relationship between the fusion units. This mode extracts substantial effective features and increases the utilization of hierarchical features. Both sub-networks output 64 feature-maps, fusing their output features as input of reconstructed network that includes a 1×1 weight layer. Therefore, the final residual image between low-and high-resolution images can be obtained. Finally, the reconstructed image can be obtained by combining the original low-resolution and residual images. In the training process, we select the rectified linear unit as the activation function to accelerate the training process and avoid gradient vanishing. For a weight layer with a filter size of 3×3, we pad one pixel to ensure that all feature-maps have the same size, which can improve the edge information of the reconstructed image. Furthermore, the initial learning rate is set to 0.1 and then decreased to half every 10 epochs, which can accelerate network convergence. We set mini-batch size of SGD and momentum parameter to 0.9. We use 291 images as the training set. In addition, we used data augmentation (rotation 90°, 180°, 270°, and vertical flip) to augment the training set, which could avoid the overfitting problems and increase sample diversity. The network is trained with multiple scale factors (×2, ×3, and×4) to ensure that it could be used to solve the reconstruction problem of different scale factors.ResultAll experiments are implemented under the PyTorch framework. We use four common benchmark sets (Set5, Set14, B100, and Urban100) to evaluate our model. Moreover, we use peak signal-to-noise ratio as evaluation criteria. The images of RGB space are converted to YCbCr space. The proposed algorithm only reconstructs the luminance channel Y because human vision is highly sensitive to the luminance channel. The Cb and Cr channels are reconstructed by using the interpolation method. Experimental results on four benchmark sets for scaling factor of four are 31.69 dB, 28.24 dB, 27.39 dB, and 25.46 dB, respectively. The proposed method shows better performance and visual effects than Bicubic, A+, SRCNN, VDSR, DRCN, and DRRN. In addition, we have validated the effectiveness of the proposed components, which includes multipath mode, staged fusion unit, and pixel coding network.ConclusionThe proposed network overcomes the shortcoming of the chain structure and extracts substantial high-frequency information by fully utilizing the hierarchical features. Moreover, such network simultaneously uses the structural feature information carried by the low-resolution image to complete the reconstruction together. Furthermore, techniques that include dense connection and residual learning are adopted to accelerate convergence and mitigate gradient problems during training. Extensive experiments show that the proposed method can reconstruct an image with more high-frequency details than other methods with the same preprocessing step. We will consider using the idea of recursive learning and increasing the number of training samples to optimize the model further in the subsequent work.关键词:convolutional neural network (CNN);super-resolution reconstructions;hierarchical features;staged feature fusion;multi-path mode64|118|9更新时间:2024-05-07
摘要:ObjectiveImage super-resolution is an important branch of digital image processing and computer vision. This method has been widely used in video surveillance, medical imaging, and security and surveillance imaging in recent years. Super-resolution aims to reconstruct a high-resolution image from an observed degraded low-resolution one. Early methods include interpolation, neighborhood embedding, and sparse coding. Deep convolutional neural network has recently become a major research topic in the field of single image super-resolution reconstruction. This network can learn the mapping between high-and low-resolution images better than traditional learning-based methods. However, many deep learning-based methods present two evident drawbacks. First, most methods use chained stacking to create the network. Each layer of the network is only related to its previous layer, leading to weak inter-layer relationships. Second, the hierarchical features of the network are partially utilized. These shortcomings can lead to loss of high frequency components. A novel image super-resolution reconstruction method based on multi-staged fusion network is proposed to address these drawbacks. This method is used to improve the quality of image reconstruction.MethodNumerous studies have shown that feature re-usage can improve the capability of the network to extract and express features. Thus, our research is based on the idea of feature re-usage. We implemented this idea through the multipath connection, which includes two forms, namely, global multipath mode and local fusion unit. First, the proposed model uses an interpolated low-resolution image as input. The feature extraction network extracts shallow features as the mixture network's input. Mixture network consists of two parts. The first one is pixel encoding network, which is used to obtain structural feature information of the image. This network presents four weight layers, each consisting of 64 filters with a size of 1×1, which can guarantee that the feature map distribution will be protected. This process is similar to those of encoding and decoding pixels. The other one is multi-path feedforward network, which is used to extract the high-frequency components needed for reconstruction. This network is formed by staged feature fusion units connected by multi-path mode. Each fusion unit is composed of dense connection, residual learning, and feature selection layers. The dense connection layer is composed of four weight layers with 32 filters with a size of 3×3. This layer is used to improve the nonlinear mapping capability of the network and extract substantial high frequency information. The residual learning layer contains a 1×1 weight layer to alleviate the vanishing gradient problem. Feature selection layer uses a 1×1 weight layer to obtain effective features. Then, the multi-path mode is used to connect different units, which could enhance the relationship between the fusion units. This mode extracts substantial effective features and increases the utilization of hierarchical features. Both sub-networks output 64 feature-maps, fusing their output features as input of reconstructed network that includes a 1×1 weight layer. Therefore, the final residual image between low-and high-resolution images can be obtained. Finally, the reconstructed image can be obtained by combining the original low-resolution and residual images. In the training process, we select the rectified linear unit as the activation function to accelerate the training process and avoid gradient vanishing. For a weight layer with a filter size of 3×3, we pad one pixel to ensure that all feature-maps have the same size, which can improve the edge information of the reconstructed image. Furthermore, the initial learning rate is set to 0.1 and then decreased to half every 10 epochs, which can accelerate network convergence. We set mini-batch size of SGD and momentum parameter to 0.9. We use 291 images as the training set. In addition, we used data augmentation (rotation 90°, 180°, 270°, and vertical flip) to augment the training set, which could avoid the overfitting problems and increase sample diversity. The network is trained with multiple scale factors (×2, ×3, and×4) to ensure that it could be used to solve the reconstruction problem of different scale factors.ResultAll experiments are implemented under the PyTorch framework. We use four common benchmark sets (Set5, Set14, B100, and Urban100) to evaluate our model. Moreover, we use peak signal-to-noise ratio as evaluation criteria. The images of RGB space are converted to YCbCr space. The proposed algorithm only reconstructs the luminance channel Y because human vision is highly sensitive to the luminance channel. The Cb and Cr channels are reconstructed by using the interpolation method. Experimental results on four benchmark sets for scaling factor of four are 31.69 dB, 28.24 dB, 27.39 dB, and 25.46 dB, respectively. The proposed method shows better performance and visual effects than Bicubic, A+, SRCNN, VDSR, DRCN, and DRRN. In addition, we have validated the effectiveness of the proposed components, which includes multipath mode, staged fusion unit, and pixel coding network.ConclusionThe proposed network overcomes the shortcoming of the chain structure and extracts substantial high-frequency information by fully utilizing the hierarchical features. Moreover, such network simultaneously uses the structural feature information carried by the low-resolution image to complete the reconstruction together. Furthermore, techniques that include dense connection and residual learning are adopted to accelerate convergence and mitigate gradient problems during training. Extensive experiments show that the proposed method can reconstruct an image with more high-frequency details than other methods with the same preprocessing step. We will consider using the idea of recursive learning and increasing the number of training samples to optimize the model further in the subsequent work.关键词:convolutional neural network (CNN);super-resolution reconstructions;hierarchical features;staged feature fusion;multi-path mode64|118|9更新时间:2024-05-07 -
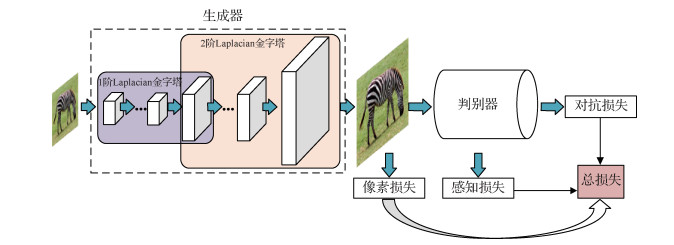 摘要:ObjectiveSingle image super-resolution (SISR) is a research hotspot in computer vision. SISR aims to reconstruct a high-resolution image from its low-resolution counterpart and is widely used in video surveillance, remote sensing image, and medical imaging. In recent years, many researchers have concentrated on convolutional SISR networking to the massive development of deep learning. They constructed shallow convolutional networks, which perform poorly in improving the quality of reconstructed images. However, these methods adopt mean square error as objective function to obtain a high evaluation index. As a result, they are unable to characterize good edge details, thereby failing to sufficiently infer plausible high frequency. To address this problem, we propose a novel generative adversarial network (GAN) for image super-resolution combining perceptual loss to further improve SR performance. This method outperforms state-of-the-art methods by a large margin in terms of peak signal-to-noise ratio and structure similarity, resulting in noticeable improvement of the reconstruction results.MethodSISR is inherently ill-posed because many solutions exist for any given low-resolution pixel. In other words, it is an underdetermined inverse problem that does not have a unique solution. Classical methods constrain the solution space by mitigating the prior information of a natural-scene image, thereby leading to unsatisfactory color analysis and context accuracy results with real high-resolution images. With its strong feature representation ability, CNN outperforms conventional methods. However, these forward CNNs for super-resolution are a single-path model that limits their reconstructive performance because they attempt to optimize the mean square error (MSE) in a pixelwise manner between the super-resolved image and the ground truth. Measuring pixel-wise difference cannot capture perceptual semantic well. Therefore, we propose a novel GAN for image super-resolution that integrates perceptual loss to boost visual performance. Our algorithm model consists of two modules:a generative subnetwork that is mainly composed of Laplacian feature pyramids and a pyramid that contains many dense residual blocks, which serve as the fundamental component. We introduce global residual learning in the identity branch of each residual unit to construct the dense residual block. Therefore, the full usage of all layers not only stabilizes the training process but also effectively preserves information flow through the network. As a result, the generative subnetwork can progressively extract different high-frequency scales of the reconstructed image. The other discriminative subnetwork is a type of forward CNN that introduces stride convolution and global average pooling to enlarge the receptive field and reduce spatial dimensions over a large image region to ensure efficient memory usage and fast inference. The discriminator estimates the probability that a generated high-resolution image came from the ground truth rather than the generative subnetwork by inspecting their feature maps and then feeds back the result to help the generator synthesize more perceptual high-frequency details. Finally, the algorithm model optimizes the objective function to complete the parameter updating.ResultAll experiments are implemented on the PyTorch framework. We train PSGAN (perceptual super-resolution using generative adversarial network) for 100 epochs by using 291 datasets. Following previous experiments, we transform all RGB images into YCbCr format and resolve the Y channel only because the human eye is most sensitive to this channel. We choose two standard datasets (Set5 and Set14) to verify the effectiveness of our proposed network compared with that of other state-of-the-art methods. For subjective visual evaluation, experiment results that the accuracy of all test samples is reasonable given that the perceptual quality difference between the original ground truth and our generated high-resolution image is not significant. Overall, PSGAN achieves superior clarity and barely shows a ripple effect. For objective evaluation, the average peak signal-to-noise ratio achieved by this method is 37.44 dB and 33.14 dB with scale factor 2 and 31.72 dB and 28.34 dB with scale factor 4 on Set5 and Set14, respectively. In the case of structure similarity measurement, the proposed approach obtains 0.961 4/0.892 4 on Set5 and 0.919 3/0.785 6 on Set14, respectively, which indicates PSGAN produces the best index results. In terms of perceptual measures, we calculate the FSIM of each method, and our PSGAN obtains 0.92/0.91 on Set5 and 0.92/0.88 on Set14, respectively. Experiment results demonstrate that our method improves the unsampled image quality by a large margin.ConclusionWe employ a compact and recurrent CNN that mainly consists of dense residual blocks to super-resolve high-resolution image progressively. Comprehensive experiments show that PSGAN achieves considerable improvement in quantitation and visual perception against other state-of-the-art methods. This algorithm provides stronger supervision for brightness consistency and texture recovery and can be applied for photorealistic super-resolution of natural-scene images.关键词:super-resolution reconstruction;deep learning;convolutional neural network(CNN);residual learning;generative adversarial network(GAN);perceptual loss17|4|4更新时间:2024-05-07
摘要:ObjectiveSingle image super-resolution (SISR) is a research hotspot in computer vision. SISR aims to reconstruct a high-resolution image from its low-resolution counterpart and is widely used in video surveillance, remote sensing image, and medical imaging. In recent years, many researchers have concentrated on convolutional SISR networking to the massive development of deep learning. They constructed shallow convolutional networks, which perform poorly in improving the quality of reconstructed images. However, these methods adopt mean square error as objective function to obtain a high evaluation index. As a result, they are unable to characterize good edge details, thereby failing to sufficiently infer plausible high frequency. To address this problem, we propose a novel generative adversarial network (GAN) for image super-resolution combining perceptual loss to further improve SR performance. This method outperforms state-of-the-art methods by a large margin in terms of peak signal-to-noise ratio and structure similarity, resulting in noticeable improvement of the reconstruction results.MethodSISR is inherently ill-posed because many solutions exist for any given low-resolution pixel. In other words, it is an underdetermined inverse problem that does not have a unique solution. Classical methods constrain the solution space by mitigating the prior information of a natural-scene image, thereby leading to unsatisfactory color analysis and context accuracy results with real high-resolution images. With its strong feature representation ability, CNN outperforms conventional methods. However, these forward CNNs for super-resolution are a single-path model that limits their reconstructive performance because they attempt to optimize the mean square error (MSE) in a pixelwise manner between the super-resolved image and the ground truth. Measuring pixel-wise difference cannot capture perceptual semantic well. Therefore, we propose a novel GAN for image super-resolution that integrates perceptual loss to boost visual performance. Our algorithm model consists of two modules:a generative subnetwork that is mainly composed of Laplacian feature pyramids and a pyramid that contains many dense residual blocks, which serve as the fundamental component. We introduce global residual learning in the identity branch of each residual unit to construct the dense residual block. Therefore, the full usage of all layers not only stabilizes the training process but also effectively preserves information flow through the network. As a result, the generative subnetwork can progressively extract different high-frequency scales of the reconstructed image. The other discriminative subnetwork is a type of forward CNN that introduces stride convolution and global average pooling to enlarge the receptive field and reduce spatial dimensions over a large image region to ensure efficient memory usage and fast inference. The discriminator estimates the probability that a generated high-resolution image came from the ground truth rather than the generative subnetwork by inspecting their feature maps and then feeds back the result to help the generator synthesize more perceptual high-frequency details. Finally, the algorithm model optimizes the objective function to complete the parameter updating.ResultAll experiments are implemented on the PyTorch framework. We train PSGAN (perceptual super-resolution using generative adversarial network) for 100 epochs by using 291 datasets. Following previous experiments, we transform all RGB images into YCbCr format and resolve the Y channel only because the human eye is most sensitive to this channel. We choose two standard datasets (Set5 and Set14) to verify the effectiveness of our proposed network compared with that of other state-of-the-art methods. For subjective visual evaluation, experiment results that the accuracy of all test samples is reasonable given that the perceptual quality difference between the original ground truth and our generated high-resolution image is not significant. Overall, PSGAN achieves superior clarity and barely shows a ripple effect. For objective evaluation, the average peak signal-to-noise ratio achieved by this method is 37.44 dB and 33.14 dB with scale factor 2 and 31.72 dB and 28.34 dB with scale factor 4 on Set5 and Set14, respectively. In the case of structure similarity measurement, the proposed approach obtains 0.961 4/0.892 4 on Set5 and 0.919 3/0.785 6 on Set14, respectively, which indicates PSGAN produces the best index results. In terms of perceptual measures, we calculate the FSIM of each method, and our PSGAN obtains 0.92/0.91 on Set5 and 0.92/0.88 on Set14, respectively. Experiment results demonstrate that our method improves the unsampled image quality by a large margin.ConclusionWe employ a compact and recurrent CNN that mainly consists of dense residual blocks to super-resolve high-resolution image progressively. Comprehensive experiments show that PSGAN achieves considerable improvement in quantitation and visual perception against other state-of-the-art methods. This algorithm provides stronger supervision for brightness consistency and texture recovery and can be applied for photorealistic super-resolution of natural-scene images.关键词:super-resolution reconstruction;deep learning;convolutional neural network(CNN);residual learning;generative adversarial network(GAN);perceptual loss17|4|4更新时间:2024-05-07 -
 摘要:ObjectiveGatys et al. successfully used convolutional neural networks (CNNs) to render a content image in different styles in a process referred to as neural style transfer (NST). Their work was the first time deep learning demonstrated its ability in the field of style transfer. In the past, most related problems in style transfer were manually modeled, which was a time consuming and laborious process. The goal of traditional NST is to learn the mapping between two different styles of paired images. Cycle-consistent adversarial networks (CycleGAN) is the first method to apply the generative adversarial network (GAN) to image style transfer. This method has a good performance on unpaired training data but does not work well when the test image is different from the training images. Thus, instance style transfer was developed to address this problem. Instance style transfer is built on image segmentation and should be applied only on the object of interest. The main challenge is the transition between the object and a non-stylized background. Most studies on instance style transfer have focused on the CNN. In this paper, some of these methods are extended to CycleGAN, and some steps are improved based on actual conditions. We propose a method to achieve instance style transfer by combining fully convolutional network (FCN) with CycleGAN. A dataset is used to verify that training data are not the reason CycleGAN cannot work well on instance style transfer.MethodThis study is divided into two parts:The first part is to improve the performance of CycleGAN to make it work efficiently in instance style transfer. The second part is to verify the conjecture in the reference. In the first part, the FCN is utilized to obtain the semantic segmentation of input image
摘要:ObjectiveGatys et al. successfully used convolutional neural networks (CNNs) to render a content image in different styles in a process referred to as neural style transfer (NST). Their work was the first time deep learning demonstrated its ability in the field of style transfer. In the past, most related problems in style transfer were manually modeled, which was a time consuming and laborious process. The goal of traditional NST is to learn the mapping between two different styles of paired images. Cycle-consistent adversarial networks (CycleGAN) is the first method to apply the generative adversarial network (GAN) to image style transfer. This method has a good performance on unpaired training data but does not work well when the test image is different from the training images. Thus, instance style transfer was developed to address this problem. Instance style transfer is built on image segmentation and should be applied only on the object of interest. The main challenge is the transition between the object and a non-stylized background. Most studies on instance style transfer have focused on the CNN. In this paper, some of these methods are extended to CycleGAN, and some steps are improved based on actual conditions. We propose a method to achieve instance style transfer by combining fully convolutional network (FCN) with CycleGAN. A dataset is used to verify that training data are not the reason CycleGAN cannot work well on instance style transfer.MethodThis study is divided into two parts:The first part is to improve the performance of CycleGAN to make it work efficiently in instance style transfer. The second part is to verify the conjecture in the reference. In the first part, the FCN is utilized to obtain the semantic segmentation of input image$\mathit{\boldsymbol{X}}$ $\mathit{\boldsymbol{Y}}$ $\mathit{\boldsymbol{Z}}$ $\mathit{\boldsymbol{Z}}$ $\mathit{\boldsymbol{Y}}$ $\mathit{\boldsymbol{Y}}$ $\mathit{\boldsymbol{R}}$ $\mathit{\boldsymbol{Y}}$ $ \circ $ $\mathit{\boldsymbol{Z}}$ $\mathit{\boldsymbol{Z}}$ $\mathit{\boldsymbol{R}}$ $\mathit{\boldsymbol{X}}$ 关键词:deep learning;style transfer;cycle-consistent generative adversarial network (CycleGAN);semantic segmentation;fully convolutional network(FCN)21|4|9更新时间:2024-05-07 -
 摘要:ObjectiveWith the rapid development of 3D scanner and growing requirements for 3D models in various applications, interest in developing high-quality 3D models is increasing. The unavoidable noise not only damages the quality of 3D models but also affects their appearance. The earliest mesh denoising algorithm is implemented by adjusting the positions of vertices; this process is called the one-step denoising method. Then, the two-step denoising framework that first filters the normal vector of the patch and then updates the vertex position according to the patch normal vector is proposed to improve the denoising effects. Both methods have their own advantages. More algorithms are being proposed as the denoising process matures. However, removing noise while preserving the structural features of the model remains a challenging problem that needs to be solved. Feature preserving methods for mesh denoising have recently become a hot topic in this research field. This paper proposes a three-step denoising framework to retain the feature information of 3D models in the process of denoising, which adds a preprocessing operation to better preserve the features of the mesh and maintain the mesh topology.MethodThe proposed method adds a preprocessing stage before the traditional denoising method and introduces the variational shape approximation (VSA) segmentation algorithm to extract the feature information of the model. On the basis of the combined filters, different features can be processed separately for mesh denoising. The VSA method is a mesh segmentation solution for 3D models, which can extract sharp features from the given meshes. This method performs better in extracting the structural features from the meshes with different noise. The VSA segmentation result also enables the mesh to reduce noise, and it can perform a noise-reducing operation on the entire model without losing the feature information. Specifically, each of the divided regions is locally reduced in noise and finally combined into a grid to obtain an initial low-level noise mesh input. The proposed method uses three major steps to denoise a given mesh. First, the VSA method is used to divide the mesh into several segments. For each segment, local Laplacian smoothing is introduced for the preprocessing of the mesh. Second, on the basis of the difference between the normal of two adjacent surfaces, a predefined feature pattern is used to match the boundaries of the partitions, and the feature boundaries are expanded to divide the model into feature and non-feature regions. In the non-feature region, the center plane normal is filtered by the weighted average neighborhood inner normal vector. For the feature region, the weighted one neighborhood uniform surface normal vector is used to filter the central plane normal. Third, on the basis of the filtered surface normal, the position of the vertex is updated in a non-iterative manner.ResultThe proposed method uses extracted information from noisy meshes to classify different feature segments. The feature information is extracted from the segmentation results based on the VSA method, which gives better results than other existing methods. In the case of moderate Gaussian noise, the results of our method are superior to the results of other methods in the models with sharp features. This method can maintain the characteristics of the model effectively, and the introduced noise reduction preprocessing has a good effect on the preservation of the topology of the nonuniform mesh. This method also has a good effect on other kinds of models, generating good denoising results in the experiment. Consistent with experimental observations obtained by calculating the average angle error of the original and the denoising models, the proposed method has a better denoising effect in visual and numerical aspects than the other method. In the experimental test, the denoising effect is improved by more than 15% compared with the other method.ConclusionThe proposed method can better maintain the characteristics of the model with sharp features than the other methods and has advantages in producing an overall denoising effect. For non-uniformly sampled meshes, this method has a better denoising effect while maintaining the original topology of the mesh. The proposed method obtains robust results for meshes with middle-level noise and can preserve the original feature information of the given meshes.关键词:geometric modeling;three-dimensional mesh denoising;variational shape approximation(VSA);geometric feature extraction;feature-preserving13|4|2更新时间:2024-05-07
摘要:ObjectiveWith the rapid development of 3D scanner and growing requirements for 3D models in various applications, interest in developing high-quality 3D models is increasing. The unavoidable noise not only damages the quality of 3D models but also affects their appearance. The earliest mesh denoising algorithm is implemented by adjusting the positions of vertices; this process is called the one-step denoising method. Then, the two-step denoising framework that first filters the normal vector of the patch and then updates the vertex position according to the patch normal vector is proposed to improve the denoising effects. Both methods have their own advantages. More algorithms are being proposed as the denoising process matures. However, removing noise while preserving the structural features of the model remains a challenging problem that needs to be solved. Feature preserving methods for mesh denoising have recently become a hot topic in this research field. This paper proposes a three-step denoising framework to retain the feature information of 3D models in the process of denoising, which adds a preprocessing operation to better preserve the features of the mesh and maintain the mesh topology.MethodThe proposed method adds a preprocessing stage before the traditional denoising method and introduces the variational shape approximation (VSA) segmentation algorithm to extract the feature information of the model. On the basis of the combined filters, different features can be processed separately for mesh denoising. The VSA method is a mesh segmentation solution for 3D models, which can extract sharp features from the given meshes. This method performs better in extracting the structural features from the meshes with different noise. The VSA segmentation result also enables the mesh to reduce noise, and it can perform a noise-reducing operation on the entire model without losing the feature information. Specifically, each of the divided regions is locally reduced in noise and finally combined into a grid to obtain an initial low-level noise mesh input. The proposed method uses three major steps to denoise a given mesh. First, the VSA method is used to divide the mesh into several segments. For each segment, local Laplacian smoothing is introduced for the preprocessing of the mesh. Second, on the basis of the difference between the normal of two adjacent surfaces, a predefined feature pattern is used to match the boundaries of the partitions, and the feature boundaries are expanded to divide the model into feature and non-feature regions. In the non-feature region, the center plane normal is filtered by the weighted average neighborhood inner normal vector. For the feature region, the weighted one neighborhood uniform surface normal vector is used to filter the central plane normal. Third, on the basis of the filtered surface normal, the position of the vertex is updated in a non-iterative manner.ResultThe proposed method uses extracted information from noisy meshes to classify different feature segments. The feature information is extracted from the segmentation results based on the VSA method, which gives better results than other existing methods. In the case of moderate Gaussian noise, the results of our method are superior to the results of other methods in the models with sharp features. This method can maintain the characteristics of the model effectively, and the introduced noise reduction preprocessing has a good effect on the preservation of the topology of the nonuniform mesh. This method also has a good effect on other kinds of models, generating good denoising results in the experiment. Consistent with experimental observations obtained by calculating the average angle error of the original and the denoising models, the proposed method has a better denoising effect in visual and numerical aspects than the other method. In the experimental test, the denoising effect is improved by more than 15% compared with the other method.ConclusionThe proposed method can better maintain the characteristics of the model with sharp features than the other methods and has advantages in producing an overall denoising effect. For non-uniformly sampled meshes, this method has a better denoising effect while maintaining the original topology of the mesh. The proposed method obtains robust results for meshes with middle-level noise and can preserve the original feature information of the given meshes.关键词:geometric modeling;three-dimensional mesh denoising;variational shape approximation(VSA);geometric feature extraction;feature-preserving13|4|2更新时间:2024-05-07
Image Processing and Coding
-
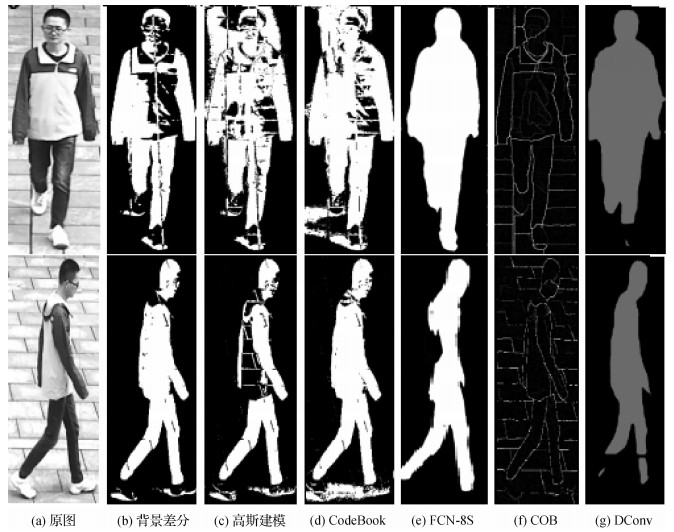 摘要:ObjectiveGait recognition has many advantages over DNA, fingerprint, iris, and 2D and 3D face recognition methods. For example, the observer does not need to cooperate in this method. In addition, the method can be performed at a relatively long distance and at a relatively lower image quality. Moreover, a person's gait is difficult to camouflage and hide. Therefore, gait recognition has become a research hotspot in recent years, and it is widely used in security, anti-terrorism, and medical applications, such as personal identification, treatment, and rehabilitation of abnormal leg and foot diseases. This paper proposes a novel gait human semantic segmentation method based on RPGNet (Region of Interest + Parts of Body Semantics + GaitNet) network to solve the problems of contour loss, human shadow, and long computing time caused by lighting, camera angles, and obstructions when gait recognition is performed by using a surveillance video in the field of anti-terrorism and security.MethodThis method is divided into the R (region of interest), P (parts of body semantics), and GNet (GaitNet) modules according to function. The R module obtains the area of interest of the gait body, which could improve computing efficiency and reduce image noise. First, the original image is processed by using the background subtraction method and translated into a binary image. Then, the image is operated by morphological processing methods, such as expansion, corrosion, and filtering. Second, we search the connected region of the human body in the graph and frame that area with a rectangular frame. Finally, we enlarge the length and width of the rectangular frame by a quarter and clip the image. Therefore, we obtain the connected regions of interest. The main function of the P module is to annotate gait body parts semantically by using LabelMe, an open-source image annotation tool. We train the human body according to its position. The semantics of the human body is defined as six parts:head, trunk, upper arm, lower arm, thigh, and lower leg. We map the semantics of the human body parts to six RGB information one by one. Then, we use LabelMe to annotate the image semantics captured by the camera, which generates the structure file of the image semantics annotation in XML format. Finally, the XML file and the original RGB image are imported into MATLAB to generate a human body part semantic annotation map. The GNet module designs a detailed semantic segmentation network model of the gait body. In the light of existing ResNet and RefineNet network models, we use ResNet model for reference to extract the high-level and the low-level semantics of the gait human body. The RefineNet network model is used to integrate low-level semantics with high-level semantics. Multi-resolution images generate fine low-level semantic feature maps and rough high-level semantic feature maps through residual network convolution units. Then, the feature maps are input into the fusion unit of multi-resolution feature map to generate the fused feature maps. Afterwards, the chained residual pools the fused feature maps to generate the fused pooled feature maps. Furthermore, the pooled feature maps of multi-resolution fusion are processed by output convolution. Thus, we obtain the semantically segmented feature maps. Finally, we use the softmax classifier to output the final gait semantics segmentation image by using bilinear interpolation. Through many experiments, we find that when the resolution is 1/8, 1/16, 1/32, and 1/64 of the original image, the semantics segmentation effect of the gait human body is better than that in other situations.ResultA test conducted on 1 380 images from the gait database shows that the proposed RPGNet method has a higher segmentation accuracy in local and global information processing compared with six human contour segmentation methods, especially at viewing angles of 0°, 45°, and 90°. In this study, we define the formula of segmentation accuracy
摘要:ObjectiveGait recognition has many advantages over DNA, fingerprint, iris, and 2D and 3D face recognition methods. For example, the observer does not need to cooperate in this method. In addition, the method can be performed at a relatively long distance and at a relatively lower image quality. Moreover, a person's gait is difficult to camouflage and hide. Therefore, gait recognition has become a research hotspot in recent years, and it is widely used in security, anti-terrorism, and medical applications, such as personal identification, treatment, and rehabilitation of abnormal leg and foot diseases. This paper proposes a novel gait human semantic segmentation method based on RPGNet (Region of Interest + Parts of Body Semantics + GaitNet) network to solve the problems of contour loss, human shadow, and long computing time caused by lighting, camera angles, and obstructions when gait recognition is performed by using a surveillance video in the field of anti-terrorism and security.MethodThis method is divided into the R (region of interest), P (parts of body semantics), and GNet (GaitNet) modules according to function. The R module obtains the area of interest of the gait body, which could improve computing efficiency and reduce image noise. First, the original image is processed by using the background subtraction method and translated into a binary image. Then, the image is operated by morphological processing methods, such as expansion, corrosion, and filtering. Second, we search the connected region of the human body in the graph and frame that area with a rectangular frame. Finally, we enlarge the length and width of the rectangular frame by a quarter and clip the image. Therefore, we obtain the connected regions of interest. The main function of the P module is to annotate gait body parts semantically by using LabelMe, an open-source image annotation tool. We train the human body according to its position. The semantics of the human body is defined as six parts:head, trunk, upper arm, lower arm, thigh, and lower leg. We map the semantics of the human body parts to six RGB information one by one. Then, we use LabelMe to annotate the image semantics captured by the camera, which generates the structure file of the image semantics annotation in XML format. Finally, the XML file and the original RGB image are imported into MATLAB to generate a human body part semantic annotation map. The GNet module designs a detailed semantic segmentation network model of the gait body. In the light of existing ResNet and RefineNet network models, we use ResNet model for reference to extract the high-level and the low-level semantics of the gait human body. The RefineNet network model is used to integrate low-level semantics with high-level semantics. Multi-resolution images generate fine low-level semantic feature maps and rough high-level semantic feature maps through residual network convolution units. Then, the feature maps are input into the fusion unit of multi-resolution feature map to generate the fused feature maps. Afterwards, the chained residual pools the fused feature maps to generate the fused pooled feature maps. Furthermore, the pooled feature maps of multi-resolution fusion are processed by output convolution. Thus, we obtain the semantically segmented feature maps. Finally, we use the softmax classifier to output the final gait semantics segmentation image by using bilinear interpolation. Through many experiments, we find that when the resolution is 1/8, 1/16, 1/32, and 1/64 of the original image, the semantics segmentation effect of the gait human body is better than that in other situations.ResultA test conducted on 1 380 images from the gait database shows that the proposed RPGNet method has a higher segmentation accuracy in local and global information processing compared with six human contour segmentation methods, especially at viewing angles of 0°, 45°, and 90°. In this study, we define the formula of segmentation accuracy$ρ$ $ρ$ 关键词:gait recognition;semantic segmentation;convolutional neural network(CNN);multi-covariate;human contour segmentation24|110|3更新时间:2024-05-07 -
 摘要:ObjectiveObject tracking is an important research subject in the computer vision area. It has a wide range of applications in surveillance and human-computer interaction. Recently, trackers based on the correlation filter have shown excellent performance because of their great robustness and high efficiency. According to correlation filter theory, an increasing number of trackers improve performance through feature fusion, such as introducing color features to strengthen the trackers' recognition ability. However, color features in some scenes with the problems of similar color objects or background clutter existing are not robust, and they can be used to evaluate the confidence of color models. In addition, traditional methods based on the correlation filter usually update the model every frame without confidence evaluation, which can lead to model drift when the target is occluded or the trackers predict an incorrect position in the last frame. Many trackers solve the above problems by conducting more reliable samples or adopting stronger classifiers, which sacrifices tracking speed. Our work focuses on incorrect samples by applying confidence evaluation because we do not need to take note of their internal details and feature structures. However, defining a comprehensive and robust evaluation index that satisfies the requirement of high speed is difficult. Therefore, a real-time object tracking method based on high-confidence complementary learning strategy is proposed.MethodOur method divides the confidence problem into computing confidence independently and complementary reliability judging in the scenes with specific attributes easily leading to unreliable learning and sensitive to confidence evaluation in the sub-model. First, the average peak-to-correlation energy (APCE) for the correlation filter model is computed in Staple, which constitutes the confidence evaluation criteria with the maximum of the model response map. The result is considered high confidence only if the two criteria of the current frame are greater than their historical average values with certain ratios. Then, the correlation filter model is updated, including the translation filter and the scale filter. Next, the output of the color probability model, called the pixel-wise color probability graph in Staple, is transformed into a binary image by using the classic threshold processing method Otus, and the connected components are extracted from the binary image open operation in advance. We regard the connected component that contains the most pixels as the main connected component of the binary image. With an overall consideration of the PCCP properties, including the area of the main connected component, the amount of all connected components, and the rectangularity about the main connected component, the result is considered high-confidence. The color probability model is then updated when most of the property values take on the forms that stand for high confidence. Otherwise, the result is considered low confidence. Thus, the fusion weight is reduced, and updates to the model are terminated.ResultAs shown in the experiment results for the dataset OTB-2015, the distance precision of the HCCL(High confidence complementary learning)-Staple adopted high-confidence complementary learning strategy increased by 3.2%, and the success rate increased by 2.7% in comparison with the primary algorithm Staple. These improvements were achieved at a high speed of 32.849 frames per second. In the particular scenes where color features are weak to some attributes such as poor illumination condition, similar objects, background clutter, and in complex scenes where occlusion or out-of-view occurs frequently, HCCL-Staple can avoid the problem of model drift efficiently. Moreover, HCCL-Staple outperforms sophisticated trackers according to the OTB benchmark.ConclusionHCCL-Staple, which adopts the high-confidence complementary learning strategy, is an efficient scheme for addressing the problem of model drift under the traditional learning strategy in challenging scenes with occlusion and interference of similar objects. The method is enhanced by translating the tracker's learning need for reliable samples to reduce or suppress correct samples. The experimental data show that confidence computing methods and the condition for high-confidence judging work well in the correlation filter model and the color probability model and have good applicability for confidence evaluations whose model outputs the same-form result. HCCL-Staple pays less attention to feature details of the target appearance under illumination change, scale change, or deformation and focuses on confidence evaluation. Thus, HCCL-Staple achieves the same tracking effect as tracking algorithms that use complex deep features or machine learning methods and outperforms some state-of-the-art tracking algorithms even without using any sophisticated formulas and optimistic models.关键词:model drift;confidence;complementary learning;real-time object tracking;image morphology15|96|2更新时间:2024-05-07
摘要:ObjectiveObject tracking is an important research subject in the computer vision area. It has a wide range of applications in surveillance and human-computer interaction. Recently, trackers based on the correlation filter have shown excellent performance because of their great robustness and high efficiency. According to correlation filter theory, an increasing number of trackers improve performance through feature fusion, such as introducing color features to strengthen the trackers' recognition ability. However, color features in some scenes with the problems of similar color objects or background clutter existing are not robust, and they can be used to evaluate the confidence of color models. In addition, traditional methods based on the correlation filter usually update the model every frame without confidence evaluation, which can lead to model drift when the target is occluded or the trackers predict an incorrect position in the last frame. Many trackers solve the above problems by conducting more reliable samples or adopting stronger classifiers, which sacrifices tracking speed. Our work focuses on incorrect samples by applying confidence evaluation because we do not need to take note of their internal details and feature structures. However, defining a comprehensive and robust evaluation index that satisfies the requirement of high speed is difficult. Therefore, a real-time object tracking method based on high-confidence complementary learning strategy is proposed.MethodOur method divides the confidence problem into computing confidence independently and complementary reliability judging in the scenes with specific attributes easily leading to unreliable learning and sensitive to confidence evaluation in the sub-model. First, the average peak-to-correlation energy (APCE) for the correlation filter model is computed in Staple, which constitutes the confidence evaluation criteria with the maximum of the model response map. The result is considered high confidence only if the two criteria of the current frame are greater than their historical average values with certain ratios. Then, the correlation filter model is updated, including the translation filter and the scale filter. Next, the output of the color probability model, called the pixel-wise color probability graph in Staple, is transformed into a binary image by using the classic threshold processing method Otus, and the connected components are extracted from the binary image open operation in advance. We regard the connected component that contains the most pixels as the main connected component of the binary image. With an overall consideration of the PCCP properties, including the area of the main connected component, the amount of all connected components, and the rectangularity about the main connected component, the result is considered high-confidence. The color probability model is then updated when most of the property values take on the forms that stand for high confidence. Otherwise, the result is considered low confidence. Thus, the fusion weight is reduced, and updates to the model are terminated.ResultAs shown in the experiment results for the dataset OTB-2015, the distance precision of the HCCL(High confidence complementary learning)-Staple adopted high-confidence complementary learning strategy increased by 3.2%, and the success rate increased by 2.7% in comparison with the primary algorithm Staple. These improvements were achieved at a high speed of 32.849 frames per second. In the particular scenes where color features are weak to some attributes such as poor illumination condition, similar objects, background clutter, and in complex scenes where occlusion or out-of-view occurs frequently, HCCL-Staple can avoid the problem of model drift efficiently. Moreover, HCCL-Staple outperforms sophisticated trackers according to the OTB benchmark.ConclusionHCCL-Staple, which adopts the high-confidence complementary learning strategy, is an efficient scheme for addressing the problem of model drift under the traditional learning strategy in challenging scenes with occlusion and interference of similar objects. The method is enhanced by translating the tracker's learning need for reliable samples to reduce or suppress correct samples. The experimental data show that confidence computing methods and the condition for high-confidence judging work well in the correlation filter model and the color probability model and have good applicability for confidence evaluations whose model outputs the same-form result. HCCL-Staple pays less attention to feature details of the target appearance under illumination change, scale change, or deformation and focuses on confidence evaluation. Thus, HCCL-Staple achieves the same tracking effect as tracking algorithms that use complex deep features or machine learning methods and outperforms some state-of-the-art tracking algorithms even without using any sophisticated formulas and optimistic models.关键词:model drift;confidence;complementary learning;real-time object tracking;image morphology15|96|2更新时间:2024-05-07 -
 摘要:ObjectiveFace recognition has become one of the most popular biometric recognition methods because of rich facial information and wide application prospects. However, the quality of images taken by the equipment is often affected in the real environment. Various facial expressions, gestures, and illumination conditions will affect the quality of face images, resulting in occlusion, translation, and scale errors in normalized face images, thereby reducing the robustness and recognition accuracy of face recognition algorithms. Among many known algorithms, the sparse representation-based classification (SRC) algorithm has achieved good face recognition performance. The algorithm is robust to noise and partial occlusion. However, face recognition in cases of facial expression change, posture change, and small sample size remains a challenge. On the one hand, the SRC can be used successfully in face recognition when the training samples are sufficient, where a testing sample can be represented by a linear combination of the images of the same person in the database. On the other hand, the SRC will divide samples into the wrong classes due to misleading coefficients on the under-sampled database. Therefore, studying how to obtain better recognition results under polluted and small samples remains important. On the basis of this situation, this work aims to study a face recognition algorithm with SRC on an uncontrolled and under-sampled database.MethodThis study proposes a superposition linear sparse representation face recognition algorithm based on discriminant non-convex low-rank matrix decomposition considering the sparsity of the SRC method and the low-rank matrix decomposition because the low-rank matrix decomposition has a good effect on removing sample noise. A dictionary that can eliminate interclass correlation is obtained by decomposing the training samples twice. This dictionary is used to classify and recognize by reconstructing the sparse residual model. The proposed algorithm efficiently eliminates the errors caused by occlusion and other unavoidable factors. We utilize non-convex rank approximation (norm) to replace nuclear norm due to two major limitations of robust principal component analysis (RPCA):the lack of structural incoherence and the tendency to shrink all the singular values equally. Non-convex rank approximation overcomes the problem of the singular value of the matrix being scaled to the same multiple when solving the kernel norm by using traditional RPCA method, which may lead to errors in the recognition results. We add to the theory of structural irrelevance in low-rank decomposition to minimize the Frobenius norm among all kinds of low-rank dictionaries and the between-class scatter. In addition, this method increases the incoherence among the low-rank dictionaries, thus improving the discrimination ability of low-rank matrices. After obtaining the low-rank matrix, the classification is completed by superposed linear sparse representation classification (SLRC). We divide the low-rank matrix into the prototype dictionary and the variation dictionary according to SLRC. Then, the two dictionaries are combined into a training dictionary in SRC. The homotopy method is used to obtain the sparse coefficients of
摘要:ObjectiveFace recognition has become one of the most popular biometric recognition methods because of rich facial information and wide application prospects. However, the quality of images taken by the equipment is often affected in the real environment. Various facial expressions, gestures, and illumination conditions will affect the quality of face images, resulting in occlusion, translation, and scale errors in normalized face images, thereby reducing the robustness and recognition accuracy of face recognition algorithms. Among many known algorithms, the sparse representation-based classification (SRC) algorithm has achieved good face recognition performance. The algorithm is robust to noise and partial occlusion. However, face recognition in cases of facial expression change, posture change, and small sample size remains a challenge. On the one hand, the SRC can be used successfully in face recognition when the training samples are sufficient, where a testing sample can be represented by a linear combination of the images of the same person in the database. On the other hand, the SRC will divide samples into the wrong classes due to misleading coefficients on the under-sampled database. Therefore, studying how to obtain better recognition results under polluted and small samples remains important. On the basis of this situation, this work aims to study a face recognition algorithm with SRC on an uncontrolled and under-sampled database.MethodThis study proposes a superposition linear sparse representation face recognition algorithm based on discriminant non-convex low-rank matrix decomposition considering the sparsity of the SRC method and the low-rank matrix decomposition because the low-rank matrix decomposition has a good effect on removing sample noise. A dictionary that can eliminate interclass correlation is obtained by decomposing the training samples twice. This dictionary is used to classify and recognize by reconstructing the sparse residual model. The proposed algorithm efficiently eliminates the errors caused by occlusion and other unavoidable factors. We utilize non-convex rank approximation (norm) to replace nuclear norm due to two major limitations of robust principal component analysis (RPCA):the lack of structural incoherence and the tendency to shrink all the singular values equally. Non-convex rank approximation overcomes the problem of the singular value of the matrix being scaled to the same multiple when solving the kernel norm by using traditional RPCA method, which may lead to errors in the recognition results. We add to the theory of structural irrelevance in low-rank decomposition to minimize the Frobenius norm among all kinds of low-rank dictionaries and the between-class scatter. In addition, this method increases the incoherence among the low-rank dictionaries, thus improving the discrimination ability of low-rank matrices. After obtaining the low-rank matrix, the classification is completed by superposed linear sparse representation classification (SLRC). We divide the low-rank matrix into the prototype dictionary and the variation dictionary according to SLRC. Then, the two dictionaries are combined into a training dictionary in SRC. The homotopy method is used to obtain the sparse coefficients of$l_{1}$ $l_{1}$ 关键词:face recognition;nonconvex low-rank decomposition;structural incoherence;superposed linearsparse representation (SLRC);dictionary learning;principal component analysis (PCA)14|4|4更新时间:2024-05-07 -
 摘要:ObjectiveIn real-world applications, datasets naturally comprise multiple views. For instance, in computer vision, images can be described by different features, such as color, edge, and texture; a web page can be described by the words appearing on the web page itself and the hyperlinks pointing to them; and a person can be recognized by their face, fingerprint, iris, and signature. Clustering aims to explore meaningful patterns in an unsupervised manner. In the era of big data, with the rapid increase of multi-view data, obtaining better clustering performance than any single view by using complementary information from different views is a valuable and challenging task. Popular multi-view clustering methods can be roughly divided into two categories:spectral clustering based and nonnegative matrix factorization (NMF) based. Multi-view spectral clustering methods can have superior performance in nonlinear separate data partitioning. However, the high computational complexity due to the feature decomposition of Laplacian matrix limits their applications in large-scale data clustering. Conversely, the classical
摘要:ObjectiveIn real-world applications, datasets naturally comprise multiple views. For instance, in computer vision, images can be described by different features, such as color, edge, and texture; a web page can be described by the words appearing on the web page itself and the hyperlinks pointing to them; and a person can be recognized by their face, fingerprint, iris, and signature. Clustering aims to explore meaningful patterns in an unsupervised manner. In the era of big data, with the rapid increase of multi-view data, obtaining better clustering performance than any single view by using complementary information from different views is a valuable and challenging task. Popular multi-view clustering methods can be roughly divided into two categories:spectral clustering based and nonnegative matrix factorization (NMF) based. Multi-view spectral clustering methods can have superior performance in nonlinear separate data partitioning. However, the high computational complexity due to the feature decomposition of Laplacian matrix limits their applications in large-scale data clustering. Conversely, the classical$K$ $K$ $K$ $\mathrm{L}_{2, 1}$ $\mathrm{L}_{2}$ $\mathrm{L}_{2, 1}$ $\mathrm{L}_{1}$ $\mathrm{L}_{2}$ $\mathrm{L}_{1}$ $\mathrm{L}_{2, 1}$ $\mathrm{L}_{2, 1}$ $\mathrm{L}_{2, 1}$ $\mathrm{L}_{2, 1}$ $K$ 关键词:multi-view learning;clustering;self-paced learning;robust;diversity15|5|3更新时间:2024-05-07 -
 摘要:ObjectiveVideo object segmentation aims to separate a target object from the background and other instances on the pixel level. Segmenting objects in videos is a fundamental task in computer vision because of its wide applications, such as video surveillance, video editing, and autonomous driving. Video object segmentation suffers from the challenging factors of occlusion, fast motion, motion blur, and significant appearance variation over time. In this paper, we leverage modulators to learn the limited visual and spatial information of a given target object to adapt the general segmentation network to the appearance of a specific object instance. Existing video object segmentation algorithms lack appropriate strategies to use feature information of different scales due to the multi-scale segmentation objects. Therefore, we design a feature attention pyramid module for video object segmentation.MethodTo adapt the generic segmentation network to the appearance of a specific object instance in one single feed-forward pass, we employ two modulators, namely, visual modulator and spatial modulator, to learn to adjust the intermediate layers of the generic segmentation network given an arbitrary target object instance. The modulator produces a list of parameters by extracting information from the image of the annotated object and the spatial prior of the object, which are injected into the segmentation model for layer-wise feature manipulation. The visual modulator network is a convolutional neural network (CNN) that takes the annotated visual object image as input and produces a vector of scale parameters for all modulation layers. The visual modulator is used to adapt the segmentation network to focus on a specific object instance, which is the annotated object in the first frame. The visual modulator implicitly learns an embedding of different types of objects. It should produce similar parameters to adjust the segmentation network for similar objects, whereas it should produce different parameters for different objects. The spatial modulator network is an efficient network that produces bias parameters based on the spatial prior input. Given that objects move continuously in a video, we set the prior as the predicted location of the object mask in the previous frame. Specifically, we encode the location information as a heatmap with a 2D Gaussian distribution on the image plane. The center and standard deviations of the Gaussian distribution are computed from the predicted mask of the previous frame. The spatial modulator downsamples the heatmap into different scales to match the resolution of different feature maps in the segmentation network and then applies a scale-and-shift operation on each downsampled heatmap to generate the bias parameters of the corresponding modulation layer. The scale problem of the segmentation network can be solved by multi-scale pooling of the feature map. The feature fusion of different scales is used to achieve context information fusion of different receptive fields and the fusion of the overall contour and the texture details; thus, large-scale and small-scale object segmentation can be effectively combined with the context information to reduce the loss of detail information as possible, achieving high-quality pixel-level video object segmentation. PSPNet or DeepLab system performs spatial pyramid pooling at different grid scales or dilate rates (called atrous spatial pyramid pooling (ASPP)) to solve this problem. In the ASPP module, dilated convolution is a sparse calculation that may cause grid artifacts. On the one hand, the pyramid pooling module proposed in PSPNet may lose pixel-level localization information. These kinds of structure lack global context prior attention to select the features in a channel-wise manner as in SENet and EncNet. On the other hand, using channel-wise attention vector is not enough to extract multi-scale features effectively, and pixel-wise information is lacking. Inspired by SENet and ParseNet, we attempt to extract precise pixel-level attention for high-level features extracted from CNNs. Our proposed feature attention pyramid (FAP) module is capable of increasing the respective fields and classifying small and big objects effectively, thus solving the problem of multi-scale segmentation. Specifically, the FAP module combines the attention mechanism and the spatial pyramid and achieves context information fusion of different receptive fields by combining the features of different scales and simultaneously by means of the global context prior. We use the 30×30, 15×15, 10×10, and 5×5 pools in the pyramid structure, respectively, to better extract context from different pyramid scales. Then, the pyramid structure concatenates the information of different scales, which can incorporate context features precisely. Furthermore, the origin features from CNNs is multiplied in a pixel-wise manner by the pyramid attention features after passing through a 1×1 convolution. We also introduce the global pooling branch concatenated with output features. The feature map produces improved channel-wise attention to learn good feature representations so that context information can be effectively combined between segmentation of large-and small-scale objects. Benefiting from the spatial pyramid structure, the FAP module can fuse different scale context information and produce improved pixel-level attention for high-level feature maps in the meantime.ResultWe validate the effectiveness and robustness of the proposed method on the challenging DAVIS 2016 and DAVIS 2017 datasets. The proposed methoddemonstrates more competitive results on DAVIS 2016 compared with the state-of-art methods that use online fine-tuning, and it outperforms these methods on DAVIS 2017.ConclusionIn this study, we first use two modulator networks to learn the visual and spatial information of the segmentation object mask. The visual modulator produces channel-wise scale parameters to adjust the weights of different channels in the feature maps, while the spatial modulator generates element-wise bias parameters to inject the spatial prior into the modulated features. We use the modulators as a prior guidance to enable the segmentation model to adapt to the appearance of specific objects. In addition to segmentation of objects of interest, the mask for objects of different scales can effectively combine context information to reduce the loss of details, thereby achieving high-quality pixel-level video object segmentation.关键词:video object segmentation;full convolution network;modulator;spatial pyramid;attention mechanism13|4|2更新时间:2024-05-07
摘要:ObjectiveVideo object segmentation aims to separate a target object from the background and other instances on the pixel level. Segmenting objects in videos is a fundamental task in computer vision because of its wide applications, such as video surveillance, video editing, and autonomous driving. Video object segmentation suffers from the challenging factors of occlusion, fast motion, motion blur, and significant appearance variation over time. In this paper, we leverage modulators to learn the limited visual and spatial information of a given target object to adapt the general segmentation network to the appearance of a specific object instance. Existing video object segmentation algorithms lack appropriate strategies to use feature information of different scales due to the multi-scale segmentation objects. Therefore, we design a feature attention pyramid module for video object segmentation.MethodTo adapt the generic segmentation network to the appearance of a specific object instance in one single feed-forward pass, we employ two modulators, namely, visual modulator and spatial modulator, to learn to adjust the intermediate layers of the generic segmentation network given an arbitrary target object instance. The modulator produces a list of parameters by extracting information from the image of the annotated object and the spatial prior of the object, which are injected into the segmentation model for layer-wise feature manipulation. The visual modulator network is a convolutional neural network (CNN) that takes the annotated visual object image as input and produces a vector of scale parameters for all modulation layers. The visual modulator is used to adapt the segmentation network to focus on a specific object instance, which is the annotated object in the first frame. The visual modulator implicitly learns an embedding of different types of objects. It should produce similar parameters to adjust the segmentation network for similar objects, whereas it should produce different parameters for different objects. The spatial modulator network is an efficient network that produces bias parameters based on the spatial prior input. Given that objects move continuously in a video, we set the prior as the predicted location of the object mask in the previous frame. Specifically, we encode the location information as a heatmap with a 2D Gaussian distribution on the image plane. The center and standard deviations of the Gaussian distribution are computed from the predicted mask of the previous frame. The spatial modulator downsamples the heatmap into different scales to match the resolution of different feature maps in the segmentation network and then applies a scale-and-shift operation on each downsampled heatmap to generate the bias parameters of the corresponding modulation layer. The scale problem of the segmentation network can be solved by multi-scale pooling of the feature map. The feature fusion of different scales is used to achieve context information fusion of different receptive fields and the fusion of the overall contour and the texture details; thus, large-scale and small-scale object segmentation can be effectively combined with the context information to reduce the loss of detail information as possible, achieving high-quality pixel-level video object segmentation. PSPNet or DeepLab system performs spatial pyramid pooling at different grid scales or dilate rates (called atrous spatial pyramid pooling (ASPP)) to solve this problem. In the ASPP module, dilated convolution is a sparse calculation that may cause grid artifacts. On the one hand, the pyramid pooling module proposed in PSPNet may lose pixel-level localization information. These kinds of structure lack global context prior attention to select the features in a channel-wise manner as in SENet and EncNet. On the other hand, using channel-wise attention vector is not enough to extract multi-scale features effectively, and pixel-wise information is lacking. Inspired by SENet and ParseNet, we attempt to extract precise pixel-level attention for high-level features extracted from CNNs. Our proposed feature attention pyramid (FAP) module is capable of increasing the respective fields and classifying small and big objects effectively, thus solving the problem of multi-scale segmentation. Specifically, the FAP module combines the attention mechanism and the spatial pyramid and achieves context information fusion of different receptive fields by combining the features of different scales and simultaneously by means of the global context prior. We use the 30×30, 15×15, 10×10, and 5×5 pools in the pyramid structure, respectively, to better extract context from different pyramid scales. Then, the pyramid structure concatenates the information of different scales, which can incorporate context features precisely. Furthermore, the origin features from CNNs is multiplied in a pixel-wise manner by the pyramid attention features after passing through a 1×1 convolution. We also introduce the global pooling branch concatenated with output features. The feature map produces improved channel-wise attention to learn good feature representations so that context information can be effectively combined between segmentation of large-and small-scale objects. Benefiting from the spatial pyramid structure, the FAP module can fuse different scale context information and produce improved pixel-level attention for high-level feature maps in the meantime.ResultWe validate the effectiveness and robustness of the proposed method on the challenging DAVIS 2016 and DAVIS 2017 datasets. The proposed methoddemonstrates more competitive results on DAVIS 2016 compared with the state-of-art methods that use online fine-tuning, and it outperforms these methods on DAVIS 2017.ConclusionIn this study, we first use two modulator networks to learn the visual and spatial information of the segmentation object mask. The visual modulator produces channel-wise scale parameters to adjust the weights of different channels in the feature maps, while the spatial modulator generates element-wise bias parameters to inject the spatial prior into the modulated features. We use the modulators as a prior guidance to enable the segmentation model to adapt to the appearance of specific objects. In addition to segmentation of objects of interest, the mask for objects of different scales can effectively combine context information to reduce the loss of details, thereby achieving high-quality pixel-level video object segmentation.关键词:video object segmentation;full convolution network;modulator;spatial pyramid;attention mechanism13|4|2更新时间:2024-05-07 -
 摘要:Objective Home service robots have attracted widespread attention in recent years due to their close relationship with the daily lives of humans. Sweeping robots are the first home service robots that have entered the consumer market and are available extensively. At present, the intelligent sweeping robots on the market have only basic functions such as automatic path planning, automatic charging, and automatic obstacle avoidance, thereby greatly reducing the workload of housework, which is an important reason it is widely accepted by the market. Despite this situation, the current level of intelligence of sweeping robots remains low, and the main shortcomings are reflected in two aspects:First, high-level perception and discriminating ability toward the environment are lacking. For example, the behavior pattern adopted in the cleaning process is usually a random walk mode, and some higher intelligence sweeping robots may support simple path planning functions, such as taking a "Z" path. However, this function is generally classified under the "blind" mode, because the robot will perform cleaning activities whether or not garbage is present in its working path. Therefore, the work efficiency is low, and the energy consumption is greatly increased. Second, the current sweeping robots generally do not have the ability to distinguish the category of garbage. If garbage can be handled according to their correct category, then it will not only facilitate the sorting of garbage but also meet environmental protection requirements. Sweeping robots are equipped with visual sensors to achieve visual perception to improve their autonomy and intelligentization. A study of the effective classification model and algorithm of garbage detection can develop the process of location and garbage recognition, and a sweeping robot can be guided to automatically recognize and deal with different types of garbage, thereby improving the purpose and efficiency of its work. Moreover, the sweeping robot can avoid being in the blind state and reduce unnecessary energy consumption.Method The proposed garbage detection and classification method based on machine vision technology aims to improve the autonomous ability of the sweeping robot. This method selects the YOLOv2 network as the main network, which has a fast detection speed in the regression method. The YOLOv2 network is combined with the dense convolutional network (DenseNet) to make full use of the high-resolution features of detection objects. The shallow and deep features of object detection can be reused and fused by embedding deep dense modules to reduce the loss of feature information. Finally, a garbage detection and classification model is built by using a multiscale strategy to train the detection network. The self-built sample dataset is used in the training and testing process. To expand the sample size, the experiment uses the image data enhancement tool ImageDataGenerator provided by Keras to perform horizontal mirror flip, random rotation, cutting, zooming, and other types of processing. The training process of the YOLOv2-dense network is as follows:First, the original image is obtained through data enhancement, and the dataset obtained by the original image and the data enhancement is manually marked. Then, YOLOv2-dense training is performed with the dataset, and the training model is obtained. To adapt large dynamic changes in the scale of the object during the movement of the mobile robot, a multiscale training strategy is adopted for network training, and the detection model is obtained. The mobile robot experiment platform uses the omnidirectional motion of the Anycbot four-wheel-drive robot chassis, the AVR motion controller, and the NVIDIA Jetson TX2 of the 256-core GPU as the visual processor.Result The detection network model is trained and tested with our self-built dataset. Test results show that the improved network structure can retain more original picture information and enhance the extraction ability of target features, and this method can effectively identify the common types of garbage, including different forms of liquid and solid, and quickly and accurately mark out the location of the garbage. Real-time detection with different angles and distances presents good results. The accuracy of YOLOv2 detection is only 82.3%, and the speed is 27 frames per second. By contrast, the accuracy of the proposed improved network YOLOv2-dense reaches 84.98%, which is 2.62% higher than that of YOLOv2, and a speed of 26 frames per second can be achieved, which satisfies real-time detection.Conclusion The experimental results show that the YOLOv2-dense network model built in this study has the speed of real-time detection. It shows strong adaptability and recognition performance when dealing with pictures with different backgrounds, illuminations, visual angles, and resolutions. For the same object, the detection effect is greatly changed at different angles and scales, and the detection performance of long-distance objects is poor. Moreover, for 3D objects, different viewing angles have a greater impact on detection. The result of the object detection is dynamically changed during the movement of the robot. The proposed method can ensure that the type of garbage is accurately identified most of the time or within a certain distance and angle of view. Moreover, the proposed method can guarantee the identification of garbage types with higher accuracy, and its overall performance is better than that of the original YOLOv2 model.关键词:YOLOv2 network;sweeping robot;dense connectivity pattern;neural networks;deep learning14|4|7更新时间:2024-05-07
摘要:Objective Home service robots have attracted widespread attention in recent years due to their close relationship with the daily lives of humans. Sweeping robots are the first home service robots that have entered the consumer market and are available extensively. At present, the intelligent sweeping robots on the market have only basic functions such as automatic path planning, automatic charging, and automatic obstacle avoidance, thereby greatly reducing the workload of housework, which is an important reason it is widely accepted by the market. Despite this situation, the current level of intelligence of sweeping robots remains low, and the main shortcomings are reflected in two aspects:First, high-level perception and discriminating ability toward the environment are lacking. For example, the behavior pattern adopted in the cleaning process is usually a random walk mode, and some higher intelligence sweeping robots may support simple path planning functions, such as taking a "Z" path. However, this function is generally classified under the "blind" mode, because the robot will perform cleaning activities whether or not garbage is present in its working path. Therefore, the work efficiency is low, and the energy consumption is greatly increased. Second, the current sweeping robots generally do not have the ability to distinguish the category of garbage. If garbage can be handled according to their correct category, then it will not only facilitate the sorting of garbage but also meet environmental protection requirements. Sweeping robots are equipped with visual sensors to achieve visual perception to improve their autonomy and intelligentization. A study of the effective classification model and algorithm of garbage detection can develop the process of location and garbage recognition, and a sweeping robot can be guided to automatically recognize and deal with different types of garbage, thereby improving the purpose and efficiency of its work. Moreover, the sweeping robot can avoid being in the blind state and reduce unnecessary energy consumption.Method The proposed garbage detection and classification method based on machine vision technology aims to improve the autonomous ability of the sweeping robot. This method selects the YOLOv2 network as the main network, which has a fast detection speed in the regression method. The YOLOv2 network is combined with the dense convolutional network (DenseNet) to make full use of the high-resolution features of detection objects. The shallow and deep features of object detection can be reused and fused by embedding deep dense modules to reduce the loss of feature information. Finally, a garbage detection and classification model is built by using a multiscale strategy to train the detection network. The self-built sample dataset is used in the training and testing process. To expand the sample size, the experiment uses the image data enhancement tool ImageDataGenerator provided by Keras to perform horizontal mirror flip, random rotation, cutting, zooming, and other types of processing. The training process of the YOLOv2-dense network is as follows:First, the original image is obtained through data enhancement, and the dataset obtained by the original image and the data enhancement is manually marked. Then, YOLOv2-dense training is performed with the dataset, and the training model is obtained. To adapt large dynamic changes in the scale of the object during the movement of the mobile robot, a multiscale training strategy is adopted for network training, and the detection model is obtained. The mobile robot experiment platform uses the omnidirectional motion of the Anycbot four-wheel-drive robot chassis, the AVR motion controller, and the NVIDIA Jetson TX2 of the 256-core GPU as the visual processor.Result The detection network model is trained and tested with our self-built dataset. Test results show that the improved network structure can retain more original picture information and enhance the extraction ability of target features, and this method can effectively identify the common types of garbage, including different forms of liquid and solid, and quickly and accurately mark out the location of the garbage. Real-time detection with different angles and distances presents good results. The accuracy of YOLOv2 detection is only 82.3%, and the speed is 27 frames per second. By contrast, the accuracy of the proposed improved network YOLOv2-dense reaches 84.98%, which is 2.62% higher than that of YOLOv2, and a speed of 26 frames per second can be achieved, which satisfies real-time detection.Conclusion The experimental results show that the YOLOv2-dense network model built in this study has the speed of real-time detection. It shows strong adaptability and recognition performance when dealing with pictures with different backgrounds, illuminations, visual angles, and resolutions. For the same object, the detection effect is greatly changed at different angles and scales, and the detection performance of long-distance objects is poor. Moreover, for 3D objects, different viewing angles have a greater impact on detection. The result of the object detection is dynamically changed during the movement of the robot. The proposed method can ensure that the type of garbage is accurately identified most of the time or within a certain distance and angle of view. Moreover, the proposed method can guarantee the identification of garbage types with higher accuracy, and its overall performance is better than that of the original YOLOv2 model.关键词:YOLOv2 network;sweeping robot;dense connectivity pattern;neural networks;deep learning14|4|7更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveGaze estimation can be divided into 2D and 3D gaze estimation. The 2D gaze estimation based on polynomial mapping uses only single-eye pupil center cornea reflection (PCCR) vector information to calculate the 2D (x, y) point of regard (POG) in a plane. The 3D gaze estimation based on binocular lines of sight intersection needs to use the PCCR vector information of both eyes and the 3D coordinate of the left and right eyeball optical centers (the point at which eye sight is emitted) to calculate 3D (x, y, z) POG in a 3D space. In the process of 3D gaze estimation, the measurement error exists as a result of manual measurement of the 3D coordinates of the eyeball optical center and the large deviation of the 3D gaze estimation results in the direction of depth. On the basis of the traditional binocular lines of the sight intersection method for 3D gaze estimation, we propose two primary improvements. We use a calibration method to obtain the 3D coordinates of the eyeball optical center to replace manual measurement. Then, we use data filtering in-depth direction and Z-plane intercepting correction method to correct the 3D gaze estimation results.Method First, the subject gazes at nine marked points on a calibration plane, which is at the first distance away from human eyes, and an infrared camera in front of the subject is used to capture eye images. The image processing algorithm can obtain the PCCR vector information of both eyes. The mapping functions of both eyes on the first plane can be solved according to the second-order polynomial mapping principle between the PCCR vector and the plane marked points. Second, with the calibration plane moved to a second distance, the subject gazes at the nine marked points again. With the use of the mapping functions of both eyes, the 2D POG of both eyes at the first calibrated distance can be calculated, and the nine marked points at the second distance to the left and right 2D POG at the first calibrated distance can be connected. Multiple lines will intersect at two points, and calculating these two equivalent intersection points obtains the calibration result of the 3D coordinates of the eyeball optical center. Third, 3D gaze estimation can be performed. With the left and right planar 2D POG combined with the 3D coordinates of the eyeball optical center and with the establishment of an appropriate space coordinate system (taking the calibration plane as the X and Y plane and taking the depth of the distance as the Z axis), the lines of sight of both eyes can be calculated. According to the principle of human binocular vision, both eyes' lines of sight will intersect at one point in space, and calculating the intersection point can obtain the rough 3D POG. The binocular vision lines are generally disjoint due to calculation and measurement errors. Thus, the midpoint of the common perpendicular should be chosen as the intersection. Finally, for the larger jitter of the resultant in-depth direction, the proposed data filtering in-depth direction and Z-plane intercepting correction method is used to correct the rough result. In this method, the data sequence of depth distance direction (Z coordinate) is first filtered. Using the filtered distance result generates a plane that is perpendicular to the Z axis. Then, the plane intercepts the left and right lines of sight to obtain two points, and the midpoint of two points is chosen as the correction result of the other two directions (X and Y). After this filtering and correction process, a more accurate 3D POG can be obtained.Result We use two different sizes of workspaces to test the proposed method, and the experiment result shows that in the small workspace (24×18×20 cm3), the work distance in-depth direction is 3050 cm, the angular average error is 0.7°, and the Euclidean distance average error is 17.8 mm. By contrast, in the large workspace (60×36×80 cm3), the work distance in-depth direction is 50130 cm, the angular average error is 1.0°, and the Euclidean distance average error is 117.4 mm. Compared with other traditional 3D gaze estimation methods, the proposed method considerably reduces the angle and distance deviation under the same distance testing condition.Conclusion The proposed calibration method for the eyeball optical center can obtain the 3D coordinates of the eyeball optical center conveniently and accurately. The method can avoid the eyeball optical center measurement error introduced by manual measurement and reduce the angle deviation of 3D POG significantly. The proposed data filtering in-depth direction and Z-plane intercepting correction method can reduce the jitter of the 3D POG result in-depth direction and can reduce the distance deviation of 3D POG significantly. This method is of great significance for the practical application of 3D gaze.关键词:binocular lines of sight;2D gaze;3D gaze;eyeball optical center;3D coordinates calibration;data filter;distance correction23|7|3更新时间:2024-05-07
摘要:ObjectiveGaze estimation can be divided into 2D and 3D gaze estimation. The 2D gaze estimation based on polynomial mapping uses only single-eye pupil center cornea reflection (PCCR) vector information to calculate the 2D (x, y) point of regard (POG) in a plane. The 3D gaze estimation based on binocular lines of sight intersection needs to use the PCCR vector information of both eyes and the 3D coordinate of the left and right eyeball optical centers (the point at which eye sight is emitted) to calculate 3D (x, y, z) POG in a 3D space. In the process of 3D gaze estimation, the measurement error exists as a result of manual measurement of the 3D coordinates of the eyeball optical center and the large deviation of the 3D gaze estimation results in the direction of depth. On the basis of the traditional binocular lines of the sight intersection method for 3D gaze estimation, we propose two primary improvements. We use a calibration method to obtain the 3D coordinates of the eyeball optical center to replace manual measurement. Then, we use data filtering in-depth direction and Z-plane intercepting correction method to correct the 3D gaze estimation results.Method First, the subject gazes at nine marked points on a calibration plane, which is at the first distance away from human eyes, and an infrared camera in front of the subject is used to capture eye images. The image processing algorithm can obtain the PCCR vector information of both eyes. The mapping functions of both eyes on the first plane can be solved according to the second-order polynomial mapping principle between the PCCR vector and the plane marked points. Second, with the calibration plane moved to a second distance, the subject gazes at the nine marked points again. With the use of the mapping functions of both eyes, the 2D POG of both eyes at the first calibrated distance can be calculated, and the nine marked points at the second distance to the left and right 2D POG at the first calibrated distance can be connected. Multiple lines will intersect at two points, and calculating these two equivalent intersection points obtains the calibration result of the 3D coordinates of the eyeball optical center. Third, 3D gaze estimation can be performed. With the left and right planar 2D POG combined with the 3D coordinates of the eyeball optical center and with the establishment of an appropriate space coordinate system (taking the calibration plane as the X and Y plane and taking the depth of the distance as the Z axis), the lines of sight of both eyes can be calculated. According to the principle of human binocular vision, both eyes' lines of sight will intersect at one point in space, and calculating the intersection point can obtain the rough 3D POG. The binocular vision lines are generally disjoint due to calculation and measurement errors. Thus, the midpoint of the common perpendicular should be chosen as the intersection. Finally, for the larger jitter of the resultant in-depth direction, the proposed data filtering in-depth direction and Z-plane intercepting correction method is used to correct the rough result. In this method, the data sequence of depth distance direction (Z coordinate) is first filtered. Using the filtered distance result generates a plane that is perpendicular to the Z axis. Then, the plane intercepts the left and right lines of sight to obtain two points, and the midpoint of two points is chosen as the correction result of the other two directions (X and Y). After this filtering and correction process, a more accurate 3D POG can be obtained.Result We use two different sizes of workspaces to test the proposed method, and the experiment result shows that in the small workspace (24×18×20 cm3), the work distance in-depth direction is 3050 cm, the angular average error is 0.7°, and the Euclidean distance average error is 17.8 mm. By contrast, in the large workspace (60×36×80 cm3), the work distance in-depth direction is 50130 cm, the angular average error is 1.0°, and the Euclidean distance average error is 117.4 mm. Compared with other traditional 3D gaze estimation methods, the proposed method considerably reduces the angle and distance deviation under the same distance testing condition.Conclusion The proposed calibration method for the eyeball optical center can obtain the 3D coordinates of the eyeball optical center conveniently and accurately. The method can avoid the eyeball optical center measurement error introduced by manual measurement and reduce the angle deviation of 3D POG significantly. The proposed data filtering in-depth direction and Z-plane intercepting correction method can reduce the jitter of the 3D POG result in-depth direction and can reduce the distance deviation of 3D POG significantly. This method is of great significance for the practical application of 3D gaze.关键词:binocular lines of sight;2D gaze;3D gaze;eyeball optical center;3D coordinates calibration;data filter;distance correction23|7|3更新时间:2024-05-07 -
 摘要:Objective Stereovision is the current research focus in the field of computer vision, and its main research content is to reconstruct a 3D scene through two or more 2D images of the same scene. Stereovision has been widely used in the fields of military, aerospace, and unmanned aerial vehicle, which require 3D reconstruction and speed measurement. The stereovision system generally consists of four basic processes:image acquisition, camera calibration, stereo matching, and 3D reconstruction. Research on the stereo matching algorithm can be considered the key point of stereovision research because the matching accuracy and speed of the stereo algorithm directly affect the result of 3D reconstruction. Therefore, research on stereo matching algorithm has great practical value and theoretical significance. However, the traditional stereo matching algorithm suffers from problems of weak matching in regions with weak textures, deep discontinuities, and non-occlusion. Therefore, we select the semi-global stereo matching algorithm, which has strong robustness and some advantages of global and local matching algorithms. Furthermore, we propose an improved method that combines adaptive window and semi-global stereo matching algorithms.Method Our algorithm improvement is based on the adaptive window and semi-global stereo matching algorithms, and it uses the absolute difference (AD) algorithm to calculate the matching cost. First, we changed the original AD algorithm to the sum of absolute differences (SAD) algorithm to obtain the matching cost, which provides the possibility of implementing the adaptive window. Thereafter, we analyzed the necessity and rationality of assuming an adaptive window by studying the effect of window size on the performance of the SAD and semi-global stereo matching algorithms. Furthermore, we added the adaptive window algorithm to the SAD and semi-global stereo matching algorithms to study the effects of the adaptive window on the performance of the SAD and semi-global stereo matching algorithms. In this part, we proposed a new parameter adaptive window judgment threshold. We tested the influences of this judgment threshold on the matching algorithm. Next, we evaluated the performance of the algorithms and compared them in terms of the optimal matching precision and matching speed by using the standard test image pairs provided by the test platform. Finally, we used a binocular camera to obtain left and right views in a real indoor scene. We further compared the performance of the above stereo matching algorithms by using a disparity map and by analyzing the algorithms' runtime.Result The experimental results show that the selection of the size of the matching window can affect the performance of the matching algorithm and improve the applicable range of the algorithm. The addition of the adaptive window could improve the matching accuracy of the algorithm, especially in the depth discontinuous region, and effectively reduce the runtime of the algorithm. After adding the adaptive window algorithm, a large preset maximum window corresponds to more evident optimization of the algorithm runtime. However, the change in matching accuracy is uncertain, which may be improved or decreased. As for the effects of window size judgment threshold, the optimal number of judgment thresholds varies in different standard test image pairs, and the judgment thresholds have different effects on the SAD and the semi-global stereo matching algorithms. The window size judgment threshold has minimal influence on the performance of the semi-global stereo matching algorithm. Thus, the choice of the number of window size judgment threshold is more flexible. The optimal window size of the semi-global stereo matching algorithm is small due to the influence of other parameters (penalty coefficient and threshold) on the performance of the algorithm, and the adaptive window performs limited optimization of the runtime of the algorithm. For the test image pair cones, the improved semi-global stereo matching algorithm mismatch rate is reduced by 2.29% on average in three test areas, and for all test image pairs, the runtime of the algorithm is reduced by 28.5%.Conclusion In this paper, we present an improved algorithm that combines the adaptive window and semi-global stereo matching algorithms. This improved algorithm was evaluated on standard image pairs, and its performance of our algorithm was compared with that of conventional algorithms. The improved algorithm showed competitive processing time results and accuracy in cones and teddy image pairs, which have a rich texture and a large disparity range. Such approach could optimize the matching accuracy and runtime despite being evaluated on image pairs with a weak texture and small disparity range. This paper contains detailed experimental results of the mismatch rate and runtime of different matching algorithms in four standard test image pairs and three image test areas. We conclude that our algorithm has the advantages of improving matching accuracy in depth discontinuity regions, effectively reducing the runtime, and adjusting the matching accuracy and speed according to the application scene.关键词:computer vision;image processing;stereo matching;adaptive window;semi-global stereo matching algorithm;sum of absolute differences (SAD) algorithm15|4|10更新时间:2024-05-07
摘要:Objective Stereovision is the current research focus in the field of computer vision, and its main research content is to reconstruct a 3D scene through two or more 2D images of the same scene. Stereovision has been widely used in the fields of military, aerospace, and unmanned aerial vehicle, which require 3D reconstruction and speed measurement. The stereovision system generally consists of four basic processes:image acquisition, camera calibration, stereo matching, and 3D reconstruction. Research on the stereo matching algorithm can be considered the key point of stereovision research because the matching accuracy and speed of the stereo algorithm directly affect the result of 3D reconstruction. Therefore, research on stereo matching algorithm has great practical value and theoretical significance. However, the traditional stereo matching algorithm suffers from problems of weak matching in regions with weak textures, deep discontinuities, and non-occlusion. Therefore, we select the semi-global stereo matching algorithm, which has strong robustness and some advantages of global and local matching algorithms. Furthermore, we propose an improved method that combines adaptive window and semi-global stereo matching algorithms.Method Our algorithm improvement is based on the adaptive window and semi-global stereo matching algorithms, and it uses the absolute difference (AD) algorithm to calculate the matching cost. First, we changed the original AD algorithm to the sum of absolute differences (SAD) algorithm to obtain the matching cost, which provides the possibility of implementing the adaptive window. Thereafter, we analyzed the necessity and rationality of assuming an adaptive window by studying the effect of window size on the performance of the SAD and semi-global stereo matching algorithms. Furthermore, we added the adaptive window algorithm to the SAD and semi-global stereo matching algorithms to study the effects of the adaptive window on the performance of the SAD and semi-global stereo matching algorithms. In this part, we proposed a new parameter adaptive window judgment threshold. We tested the influences of this judgment threshold on the matching algorithm. Next, we evaluated the performance of the algorithms and compared them in terms of the optimal matching precision and matching speed by using the standard test image pairs provided by the test platform. Finally, we used a binocular camera to obtain left and right views in a real indoor scene. We further compared the performance of the above stereo matching algorithms by using a disparity map and by analyzing the algorithms' runtime.Result The experimental results show that the selection of the size of the matching window can affect the performance of the matching algorithm and improve the applicable range of the algorithm. The addition of the adaptive window could improve the matching accuracy of the algorithm, especially in the depth discontinuous region, and effectively reduce the runtime of the algorithm. After adding the adaptive window algorithm, a large preset maximum window corresponds to more evident optimization of the algorithm runtime. However, the change in matching accuracy is uncertain, which may be improved or decreased. As for the effects of window size judgment threshold, the optimal number of judgment thresholds varies in different standard test image pairs, and the judgment thresholds have different effects on the SAD and the semi-global stereo matching algorithms. The window size judgment threshold has minimal influence on the performance of the semi-global stereo matching algorithm. Thus, the choice of the number of window size judgment threshold is more flexible. The optimal window size of the semi-global stereo matching algorithm is small due to the influence of other parameters (penalty coefficient and threshold) on the performance of the algorithm, and the adaptive window performs limited optimization of the runtime of the algorithm. For the test image pair cones, the improved semi-global stereo matching algorithm mismatch rate is reduced by 2.29% on average in three test areas, and for all test image pairs, the runtime of the algorithm is reduced by 28.5%.Conclusion In this paper, we present an improved algorithm that combines the adaptive window and semi-global stereo matching algorithms. This improved algorithm was evaluated on standard image pairs, and its performance of our algorithm was compared with that of conventional algorithms. The improved algorithm showed competitive processing time results and accuracy in cones and teddy image pairs, which have a rich texture and a large disparity range. Such approach could optimize the matching accuracy and runtime despite being evaluated on image pairs with a weak texture and small disparity range. This paper contains detailed experimental results of the mismatch rate and runtime of different matching algorithms in four standard test image pairs and three image test areas. We conclude that our algorithm has the advantages of improving matching accuracy in depth discontinuity regions, effectively reducing the runtime, and adjusting the matching accuracy and speed according to the application scene.关键词:computer vision;image processing;stereo matching;adaptive window;semi-global stereo matching algorithm;sum of absolute differences (SAD) algorithm15|4|10更新时间:2024-05-07 -
 摘要:Objective In the field of image processing, camera calibration is used to determine the relationship between the 3D geometric position of a point in space and the corresponding point in an image. Camera calibration mainly aims to obtain the camera's intrinsic, extrinsic, and distortion parameters. The intrinsic and extrinsic parameters of the camera can be used to calculate vehicle speed and spatial location, and detect and recognize traffic events, among others. Recently, pan-tilt-zoom (PTZ) cameras have been playing an important role in highway monitoring systems due to their wide field of view and high flexibility. The image obtained by the PTZ camera is changed as the focal length and angles of the PTZ camera change with demand, which makes obtaining the camera parameters difficult. Therefore, research on the autocalibration method of the PTZ camera has an important application value in the highway intelligent monitoring system. The calibration of the PTZ camera is mainly based on vanishing points. A set of parallel lines in space intersect on a point in the image through the perspective transformation of the camera. The intersection point is the vanishing point. Three vanishing points that are orthogonal to each other can be formed in the 3D space. According to the number of vanishing points, the calibration method is divided into two categories:based on double (VVH, VVW, VVL) and single vanishing point (VWH, VLH, VWL). V denotes a vanishing point, W denotes the distance between the two-lane lines on the road, L denotes the length of the lane line on the road, and H denotes the height of the camera.Method The PTZ camera has two characteristics:the roll angle is zero, and the principal point is at the center of the image. Therefore, the camera model can be reasonably simplified based on the above characteristics. Determining the focal length, the pan angle, the tilt angle, and the height of the camera is necessary to obtain the intrinsic and extrinsic parameters of the camera. In an actual highway scene, the height of the camera is known. This study proposes a PTZ camera autocalibration method based on two vanishing point constraints and lane line model constraint, which belongs to the VVH method. First, the SSD algorithm is used to detect the vehicle objects, and the optical flow method is used to track the vehicle objects to obtain the object trajectory set. Given that the road is partially curved, each trajectory needs to be processed to obtain a trajectory set that conforms to the linear features. The linear trajectories in the trajectory set are voted in the cascaded Hough transform space to obtain a longitudinal vanishing point. Second, in the actual highway scene, the vehicle object is relatively small in the image because of the high camera height. Therefore, the general method of obtaining a second vanishing point by detecting the edge of the vehicle is not applicable in the scene. No other parallel lines can be used in the scene to directly obtain the second vanishing point. Therefore, taking the physical metric of the lane line model as the constraint, the enumeration strategy is used to obtain the estimated value of the horizontal vanishing point. Finally, an accurate calculation of the calibration parameters of the PTZ camera is achieved under the condition of known camera height.Result The proposed autocalibration of the PTZ camera is performed in different scenes of multiple highways in Zhejiang Province. Videos corresponding to these scenes have standard and high definitions. The height of the PTZ camera in all scenes is 13.0 m. This study used the differences between the actual physical distance of the lane line in the scene and its test distance as the measure of the calibration error. The average errors at different distances were 4.80%, 4.55%, 4.78%, and 4.99%. The proposed method cannot be compared with the existing autocalibration because of different error measures. However, this study uses the same scene for manual calibration to prove that the proposed algorithm is reasonable and has certain practical values. The average error of manual calibration is about 2%. The autocalibration results are not as good as the manual calibration results because no artificial intervention exists. However, the average errors of autocalibration are less than 5%.Conclusion The proposed method has the following advantages:1) It makes full use of the characteristics of the PTZ camera to simplify the camera model and calibration process. 2) It optimizes the vehicle's motion trajectory set and uses the cascaded Hough transform to obtain the longitudinal vanishing point stably and accurately. 3) It makes full use of various kinds of markers in the scene and proposes a method of enumerating tentative acquisition to obtain horizontal vanishing points. Experimental results show that the algorithm could meet application requirements. The obtained camera parameters can also be used in other scenes, such as traffic parameter calculation and vehicle classification. The method of extracting lane lines by Hough transform is susceptible to light. Therefore, we can change the method of extracting lane lines to improve calibration accuracy.关键词:lane line model;vanishing point;auto-calibration;highway;pan-tilt-zoom (PTZ) camera12|5|2更新时间:2024-05-07
摘要:Objective In the field of image processing, camera calibration is used to determine the relationship between the 3D geometric position of a point in space and the corresponding point in an image. Camera calibration mainly aims to obtain the camera's intrinsic, extrinsic, and distortion parameters. The intrinsic and extrinsic parameters of the camera can be used to calculate vehicle speed and spatial location, and detect and recognize traffic events, among others. Recently, pan-tilt-zoom (PTZ) cameras have been playing an important role in highway monitoring systems due to their wide field of view and high flexibility. The image obtained by the PTZ camera is changed as the focal length and angles of the PTZ camera change with demand, which makes obtaining the camera parameters difficult. Therefore, research on the autocalibration method of the PTZ camera has an important application value in the highway intelligent monitoring system. The calibration of the PTZ camera is mainly based on vanishing points. A set of parallel lines in space intersect on a point in the image through the perspective transformation of the camera. The intersection point is the vanishing point. Three vanishing points that are orthogonal to each other can be formed in the 3D space. According to the number of vanishing points, the calibration method is divided into two categories:based on double (VVH, VVW, VVL) and single vanishing point (VWH, VLH, VWL). V denotes a vanishing point, W denotes the distance between the two-lane lines on the road, L denotes the length of the lane line on the road, and H denotes the height of the camera.Method The PTZ camera has two characteristics:the roll angle is zero, and the principal point is at the center of the image. Therefore, the camera model can be reasonably simplified based on the above characteristics. Determining the focal length, the pan angle, the tilt angle, and the height of the camera is necessary to obtain the intrinsic and extrinsic parameters of the camera. In an actual highway scene, the height of the camera is known. This study proposes a PTZ camera autocalibration method based on two vanishing point constraints and lane line model constraint, which belongs to the VVH method. First, the SSD algorithm is used to detect the vehicle objects, and the optical flow method is used to track the vehicle objects to obtain the object trajectory set. Given that the road is partially curved, each trajectory needs to be processed to obtain a trajectory set that conforms to the linear features. The linear trajectories in the trajectory set are voted in the cascaded Hough transform space to obtain a longitudinal vanishing point. Second, in the actual highway scene, the vehicle object is relatively small in the image because of the high camera height. Therefore, the general method of obtaining a second vanishing point by detecting the edge of the vehicle is not applicable in the scene. No other parallel lines can be used in the scene to directly obtain the second vanishing point. Therefore, taking the physical metric of the lane line model as the constraint, the enumeration strategy is used to obtain the estimated value of the horizontal vanishing point. Finally, an accurate calculation of the calibration parameters of the PTZ camera is achieved under the condition of known camera height.Result The proposed autocalibration of the PTZ camera is performed in different scenes of multiple highways in Zhejiang Province. Videos corresponding to these scenes have standard and high definitions. The height of the PTZ camera in all scenes is 13.0 m. This study used the differences between the actual physical distance of the lane line in the scene and its test distance as the measure of the calibration error. The average errors at different distances were 4.80%, 4.55%, 4.78%, and 4.99%. The proposed method cannot be compared with the existing autocalibration because of different error measures. However, this study uses the same scene for manual calibration to prove that the proposed algorithm is reasonable and has certain practical values. The average error of manual calibration is about 2%. The autocalibration results are not as good as the manual calibration results because no artificial intervention exists. However, the average errors of autocalibration are less than 5%.Conclusion The proposed method has the following advantages:1) It makes full use of the characteristics of the PTZ camera to simplify the camera model and calibration process. 2) It optimizes the vehicle's motion trajectory set and uses the cascaded Hough transform to obtain the longitudinal vanishing point stably and accurately. 3) It makes full use of various kinds of markers in the scene and proposes a method of enumerating tentative acquisition to obtain horizontal vanishing points. Experimental results show that the algorithm could meet application requirements. The obtained camera parameters can also be used in other scenes, such as traffic parameter calculation and vehicle classification. The method of extracting lane lines by Hough transform is susceptible to light. Therefore, we can change the method of extracting lane lines to improve calibration accuracy.关键词:lane line model;vanishing point;auto-calibration;highway;pan-tilt-zoom (PTZ) camera12|5|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:Objective Remote sensing image object detection aims to locate and identify the object of interest in remote sensing images, and it is one of the core issues in remote sensing image processing. Object detection in optical remote sensing images is a fundamental and challenging problem in the field of aerial and satellite image analysis and is an important part of automated extraction of remote sensing information. Object detection in remote sensing images plays an important role in a wide range of applications, having a broad application value in the fields of national defense security, urban construction planning, and disaster monitoring. In recent years, it has received great attention. The application range of remote sensing images is expanding day by day, thereby giving fast and effective remote sensing object detection methods a broad application prospect. With the rapid development of platform and sensor technology, the spatial resolution of remote sensing images continues to increase, and the visual difference from natural images is decreasing. An increasing number of computer vision methods can be applied to high-spatial-resolution remote sensing image object recognition, but problems of low detection accuracy and low efficiency still exist and need to be addressed.Method In this paper, an improved convolutional neural network (CNN) detection method for attention mechanism is proposed and tested on the NWPU_VHR-10 dataset. The dataset is a 10-level geospatial object detection dataset. Some of the images have low resolution, which affects the experimental results. Therefore, some low-quality images in the dataset were reconstructed with enhanced depth super-resolution (EDSR) network in super-resolution to provide a high-quality dataset for training CNNs. This paper studies how to use the Faster-RCNN model for multi-class object recognition to adapt to some characteristics of remote sensing images that are different from natural images. The original Faster-RCNN network was improved as follows:An attention mechanism was added to the feature extraction network module. Then, an attention CNN was obtained for more information. The object is focused by inhibiting other useless information from adapting to the background of the large range of remote sensing image vision, which leads to the complex problem of small targets. Weak non-maximal suppression is used to adapt to the target rotation of the remote sensing image. To improve detector performance, the cross-correlation between target distributions is used to further screen redundant candidate frames and reduce false alarm rate.ResultTwo sets of comparative experiments were conducted to prove the validity of the method. The first set of comparative experiments is the ablation experiment between the four modules mentioned in this paper:attention mechanism module, non-maximal suppression, cross-correlation filtering mechanism, and image super-resolution processing for low-quality images. Experimental results show that the improved attentional CNN has higher detection accuracy than the original Faster-RCNN in 10 categories. The average detection accuracy improved by 12.2%. All the modules mentioned in this paper effectively improved the object detection of aerial remote sensing images. Moreover, the added attention module is a lightweight module that hardly increases the computational cost of the network model. Thus, it does not reduce the efficiency of the network. The second set of comparative experiments is the comparison and analysis of the improved attentional CNN and other existing traditional methods and deep learning methods on the open dataset NWPU_VHR-10. The average detection accuracy of this algorithm is 79.1%, which is higher than that of other algorithms.Conclusion CNN has great application potential in remote sensing image object detection and is a research hotspot at present and in the future. How to better apply CNN to object detection of aerial remote sensing images has important theoretical significance. In this study, the enhanced depth super resolution network is used to super-resolve some low-resolution images in the dataset. The attentional mechanism was proposed to improve the gross-RCNN to enable the algorithm to focus on the target region of interest in the image, that is, the extracted features that are more valuable for the current detection task. It improves the adaptability of the algorithm to the complex background, small objects caused by a wide field of view, and object rotation caused by the angle of view used in aerial photography for aerial remote sensing image object detection. Experimental results show the improved average detection accuracy of the proposed algorithm.关键词:remote sensing images;object detection;attention mechanism;convolutional neural networks (CNN);image super-resolution53|8|18更新时间:2024-05-07
摘要:Objective Remote sensing image object detection aims to locate and identify the object of interest in remote sensing images, and it is one of the core issues in remote sensing image processing. Object detection in optical remote sensing images is a fundamental and challenging problem in the field of aerial and satellite image analysis and is an important part of automated extraction of remote sensing information. Object detection in remote sensing images plays an important role in a wide range of applications, having a broad application value in the fields of national defense security, urban construction planning, and disaster monitoring. In recent years, it has received great attention. The application range of remote sensing images is expanding day by day, thereby giving fast and effective remote sensing object detection methods a broad application prospect. With the rapid development of platform and sensor technology, the spatial resolution of remote sensing images continues to increase, and the visual difference from natural images is decreasing. An increasing number of computer vision methods can be applied to high-spatial-resolution remote sensing image object recognition, but problems of low detection accuracy and low efficiency still exist and need to be addressed.Method In this paper, an improved convolutional neural network (CNN) detection method for attention mechanism is proposed and tested on the NWPU_VHR-10 dataset. The dataset is a 10-level geospatial object detection dataset. Some of the images have low resolution, which affects the experimental results. Therefore, some low-quality images in the dataset were reconstructed with enhanced depth super-resolution (EDSR) network in super-resolution to provide a high-quality dataset for training CNNs. This paper studies how to use the Faster-RCNN model for multi-class object recognition to adapt to some characteristics of remote sensing images that are different from natural images. The original Faster-RCNN network was improved as follows:An attention mechanism was added to the feature extraction network module. Then, an attention CNN was obtained for more information. The object is focused by inhibiting other useless information from adapting to the background of the large range of remote sensing image vision, which leads to the complex problem of small targets. Weak non-maximal suppression is used to adapt to the target rotation of the remote sensing image. To improve detector performance, the cross-correlation between target distributions is used to further screen redundant candidate frames and reduce false alarm rate.ResultTwo sets of comparative experiments were conducted to prove the validity of the method. The first set of comparative experiments is the ablation experiment between the four modules mentioned in this paper:attention mechanism module, non-maximal suppression, cross-correlation filtering mechanism, and image super-resolution processing for low-quality images. Experimental results show that the improved attentional CNN has higher detection accuracy than the original Faster-RCNN in 10 categories. The average detection accuracy improved by 12.2%. All the modules mentioned in this paper effectively improved the object detection of aerial remote sensing images. Moreover, the added attention module is a lightweight module that hardly increases the computational cost of the network model. Thus, it does not reduce the efficiency of the network. The second set of comparative experiments is the comparison and analysis of the improved attentional CNN and other existing traditional methods and deep learning methods on the open dataset NWPU_VHR-10. The average detection accuracy of this algorithm is 79.1%, which is higher than that of other algorithms.Conclusion CNN has great application potential in remote sensing image object detection and is a research hotspot at present and in the future. How to better apply CNN to object detection of aerial remote sensing images has important theoretical significance. In this study, the enhanced depth super resolution network is used to super-resolve some low-resolution images in the dataset. The attentional mechanism was proposed to improve the gross-RCNN to enable the algorithm to focus on the target region of interest in the image, that is, the extracted features that are more valuable for the current detection task. It improves the adaptability of the algorithm to the complex background, small objects caused by a wide field of view, and object rotation caused by the angle of view used in aerial photography for aerial remote sensing image object detection. Experimental results show the improved average detection accuracy of the proposed algorithm.关键词:remote sensing images;object detection;attention mechanism;convolutional neural networks (CNN);image super-resolution53|8|18更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0