
最新刊期
卷 24 , 期 6 , 2019
-
 摘要:Objective Image deblurring has been an active research area over the last decade. Image blurring may bring serious problems in our daily life. For example, almost all cities have installed electronic monitoring and controlling systems to capture various things on robbery, accident, or other useful information. When people and vehicles are moving fast, the captured images become blurry. Moreover, a camera that is out of focus causes image blurring. With the wide use of electrical camera equipment, blurring caused by movement and out of focus has become widespread. Thus, deblurring in traffic monitoring, astronomical remote sensing, and public security investigation has a great value.Method Although the topic of image blur analysis has attracted considerable attention in recent years, most previous works focus on solving the deblurring problem. On the contrary, general blur detection is seldom explored and remains far from practical application. In terms of blurring kernel, image deblurring algorithms can be divided into two categories:blind image deconvolution (BID) and non-blind image deconvolution (NBID). BID recovers the focused image with unknown blurring kernel. By contrast, the NBID deblurs image with known blurring kernel. In practice, the blurring kernel is often difficult to determine beforehand. Therefore, BID is more widely used than NBID. However, the blind deconvolution algorithm still has challenges:1) The first is how to estimate the blurring kernel accurately. The reason is that the blurring kernel is susceptible to noise, which might result in kernel misestimation. 2) The ringing artifacts may occur around prominent edges of the image. In this paper, we discuss these two challenges. We focus on a deblurring algorithm based on conspicuous edge detection. We propose a novel fused edge detection method based on the modified edge operators and morphological edge detection to improve the deblurring effect. The proposed algorithm accurately extracts the conspicuous edges. Then, we use conspicuous edges to estimate the blur kernel and deconvolve the image. Moreover, we obtain the gap mask and subtract it to retain the necessary gaps. The pixels are protected from being missing because abundant edge pixels are avoided. Results show that our scheme significantly enhances the deconvolution results especially for reducing the ringing artifacts.Result We compare our algorithm with Chan's, Krishnan's, and Hu's algorithms to evaluate its performance. First, the algorithms are tested on basic graphic elements, such as straight line, broken line, and curve. For the three elements, Chan's method causes several ringing artifacts. For the straight line, the edges remain blurred when processed using Krishnan's and Hu's methods. The blurred line processed by our method is sharp in the edge without ringing artifacts. For the broken line, Krishnan's method spreads the black points to the white region and crosses colors between each other. Hu's method shows no ringing artifacts and cross-color, but the vertex is round and not sharp enough. The element processed by our method has slight ringing artifacts in the border but remains sharp. For the curve, Krishnan's method also has drawbacks on cross-color between the black and white regions. In addition, the curve has become less smooth. Our method and Hu's method have achieved good results but with slight ringing artifacts under the curve. These comparisons show that our algorithm and Hu's algorithm obtain the best results for maintaining the sharpness and reducing the ringing artifacts. Second, we test these algorithms by using natural images. Results indicate that Chan's method has excellent details, but it has the most evident ringing artifacts. Krishnan's method has good deblurring results but most of them are too sharpened. Hu's method performs well on low-light images, but details are missing in the results. Our method has the least ringing artifacts at the edges and detailed region of the image. Experimental results demonstrate that our edge-aware deblurring algorithm can recover better image details and better suppress the ringing effect than conventional deblurring algorithms. In comparison with Chan's, Krishnan's, and Hu's methods, our proposed algorithm achieves the best accuracy in terms of
摘要:Objective Image deblurring has been an active research area over the last decade. Image blurring may bring serious problems in our daily life. For example, almost all cities have installed electronic monitoring and controlling systems to capture various things on robbery, accident, or other useful information. When people and vehicles are moving fast, the captured images become blurry. Moreover, a camera that is out of focus causes image blurring. With the wide use of electrical camera equipment, blurring caused by movement and out of focus has become widespread. Thus, deblurring in traffic monitoring, astronomical remote sensing, and public security investigation has a great value.Method Although the topic of image blur analysis has attracted considerable attention in recent years, most previous works focus on solving the deblurring problem. On the contrary, general blur detection is seldom explored and remains far from practical application. In terms of blurring kernel, image deblurring algorithms can be divided into two categories:blind image deconvolution (BID) and non-blind image deconvolution (NBID). BID recovers the focused image with unknown blurring kernel. By contrast, the NBID deblurs image with known blurring kernel. In practice, the blurring kernel is often difficult to determine beforehand. Therefore, BID is more widely used than NBID. However, the blind deconvolution algorithm still has challenges:1) The first is how to estimate the blurring kernel accurately. The reason is that the blurring kernel is susceptible to noise, which might result in kernel misestimation. 2) The ringing artifacts may occur around prominent edges of the image. In this paper, we discuss these two challenges. We focus on a deblurring algorithm based on conspicuous edge detection. We propose a novel fused edge detection method based on the modified edge operators and morphological edge detection to improve the deblurring effect. The proposed algorithm accurately extracts the conspicuous edges. Then, we use conspicuous edges to estimate the blur kernel and deconvolve the image. Moreover, we obtain the gap mask and subtract it to retain the necessary gaps. The pixels are protected from being missing because abundant edge pixels are avoided. Results show that our scheme significantly enhances the deconvolution results especially for reducing the ringing artifacts.Result We compare our algorithm with Chan's, Krishnan's, and Hu's algorithms to evaluate its performance. First, the algorithms are tested on basic graphic elements, such as straight line, broken line, and curve. For the three elements, Chan's method causes several ringing artifacts. For the straight line, the edges remain blurred when processed using Krishnan's and Hu's methods. The blurred line processed by our method is sharp in the edge without ringing artifacts. For the broken line, Krishnan's method spreads the black points to the white region and crosses colors between each other. Hu's method shows no ringing artifacts and cross-color, but the vertex is round and not sharp enough. The element processed by our method has slight ringing artifacts in the border but remains sharp. For the curve, Krishnan's method also has drawbacks on cross-color between the black and white regions. In addition, the curve has become less smooth. Our method and Hu's method have achieved good results but with slight ringing artifacts under the curve. These comparisons show that our algorithm and Hu's algorithm obtain the best results for maintaining the sharpness and reducing the ringing artifacts. Second, we test these algorithms by using natural images. Results indicate that Chan's method has excellent details, but it has the most evident ringing artifacts. Krishnan's method has good deblurring results but most of them are too sharpened. Hu's method performs well on low-light images, but details are missing in the results. Our method has the least ringing artifacts at the edges and detailed region of the image. Experimental results demonstrate that our edge-aware deblurring algorithm can recover better image details and better suppress the ringing effect than conventional deblurring algorithms. In comparison with Chan's, Krishnan's, and Hu's methods, our proposed algorithm achieves the best accuracy in terms of$ {\mathrm{PSNR}}$ ${\mathrm{SSIM}} $ $ {\mathrm{PSNR}}$ ${\mathrm{SSIM}} $ $ {\mathrm{PSNR}}$ ${\mathrm{SSIM}} $ 关键词:image deblurring;blurring kernel estimation;ringing artifacts;fused edge detection;weighted blind deconvolution72|256|2更新时间:2024-05-07
Image Processing and Coding

-
 摘要:Objective Steel plate is an indispensable raw material in machinery manufacturing, automobile production, aerospace, and shipyard manufacturing. Its surface quality directly affects the performance and quality of final products. In an actual steel plate production line, various defects often occur on the surface of the steel sheet due to various processing factors, such as imperfect processing technology and aging of equipment components. Owing to the variety of surface defects and the complex gray structure, if the existing image segmentation technology is applied to a steel plate defect image with a complex gray structure and blurred target edge, then low recognition efficiency, obvious over-segmentation, and other issues will arise. In this study, we analyze the spatial characteristics of the gray matrix of a steel plate defect image and find that transforming a two-dimensional image gray matrix into 3D space can help us identify the defect position of the steel plate surface. Therefore, we propose a steel surface defect recognition algorithm based on the 3D gray matrix.Method First, the 2D gray image of the steel plate's surface defect image is obtained and transformed into a 3D gray matrix using the matrix transformation algorithm. The transformed matrix is drawn in a 3D space, and the local concave and convex portions are identified, that is, the position of the defect corresponding to the surface of the steel sheet. Second, the kriging space interpolation algorithm is used to process the transformed 3D matrix. The kriging algorithm is derived from geostatistics; therefore, to make the method suitable for processing image data, this study introduces semi-class variance to improve the Kriging interpolation algorithm. A contour map of the 3D gray matrix is thus drawn. Third, after obtaining the contours corresponding to the 3D matrix, we use the position principle between the points and curves to construct a topological relationship tree of the contours and determine the inclusion relationship between the contours. Finally, according to the combination of customized global and local search strategies, the local concave and convex areas are searched to locate the defect area and achieve the purpose of dividing the surface defects of the steel plate.Result Our method can effectively identify the surface defect area of the steel plate, is not sensitive to illumination change, and improves the effective division rate under the premise of ensuring a low error rate. Fisher's threshold segmentation method (FT), classical CV model (CV), HTB model (HTB), and improved background difference method (ABDM) are compared. For the FT algorithm based on edge information and the Fisher criterion, a fixed single threshold is selected, which can effectively segment an image with a large defect area and obvious difference with background grayscale. However, distinguishing the surface defect of the steel plate effectively is difficult when the target is similar to the grayscale of the background. For the CV model, image segmentation with a complex structure is inaccurate, and the number of iterations is large. The method of processing the four types of defect images has over-segmentation. This method cannot cope with the image segmentation task under boundary blur conditions. The HTB model solves the problem that the CV model cannot, that is, to adapt to the grayscale uneven image segmentation problem. However, regardless of the good segmentation effect on the knotted defect image, the algorithm has a poor segmentation effect on the other three types of defects. The ABDM algorithm, which aims to improve the background difference, requires that the constructed background model be as suitable as possible for the foreground image; therefore, the segmentation effect of the steel plate defect image that has a large defect target region is poor. In this study, the 3D gray matrix of the image is used to realize localization and segmentation of the defect region. The proposed algorithm can obtain accurate segmentation results for defect target extraction of the four types of defect images. Compared with Otsu, 1DMFE, and MFEE in terms of segmentation of the hole and roll image, our method improves the effective information rate by 1.6% and 2.1%, respectively, under the premise of ensuring that the mis-segmentation rate is kept below 2.0%. For the inclusion image, our method has an effective information rate of more than 85% under the premise of 3.4% mis-segmentation rate.Conclusion By transforming a 2D grayscale image into a 3D gray matrix, we analyze the characteristics of the grayscale image in 3D space and find that the defect area on the surface of the steel plate image corresponds to the local unevenness of the 3D space. Thus, a method based on an image segmentation algorithm for steel plate surface defects in a 3D gray matrix is proposed. First, a 3D gray matrix is generated from the original gray image. Second, a gray contour map is drawn. Third, the relationship between contours is determined, and a contour topological relationship tree is constructed. Finally, the contour is traversed according to a search strategy, the local concave and convex regions are identified, and the target position is determined to achieve segmentation. Experimental results show that the proposed algorithm can effectively segment common steel plate defects with uneven grayscale. From qualitative and quantitative perspectives, the algorithm can quickly and effectively extract defect regions in a steel plate image. In summary, the proposed steel plate defect image recognition algorithm based on a 3D gray matrix can effectively identify many types of steel plate defects, even in image recognition with a complex defect structure.关键词:steel surface defect identification;three-dimensional gray matrix;Kriging interpolation algorithm;gray contour;topological relationship tree16|9|3更新时间:2024-05-07
摘要:Objective Steel plate is an indispensable raw material in machinery manufacturing, automobile production, aerospace, and shipyard manufacturing. Its surface quality directly affects the performance and quality of final products. In an actual steel plate production line, various defects often occur on the surface of the steel sheet due to various processing factors, such as imperfect processing technology and aging of equipment components. Owing to the variety of surface defects and the complex gray structure, if the existing image segmentation technology is applied to a steel plate defect image with a complex gray structure and blurred target edge, then low recognition efficiency, obvious over-segmentation, and other issues will arise. In this study, we analyze the spatial characteristics of the gray matrix of a steel plate defect image and find that transforming a two-dimensional image gray matrix into 3D space can help us identify the defect position of the steel plate surface. Therefore, we propose a steel surface defect recognition algorithm based on the 3D gray matrix.Method First, the 2D gray image of the steel plate's surface defect image is obtained and transformed into a 3D gray matrix using the matrix transformation algorithm. The transformed matrix is drawn in a 3D space, and the local concave and convex portions are identified, that is, the position of the defect corresponding to the surface of the steel sheet. Second, the kriging space interpolation algorithm is used to process the transformed 3D matrix. The kriging algorithm is derived from geostatistics; therefore, to make the method suitable for processing image data, this study introduces semi-class variance to improve the Kriging interpolation algorithm. A contour map of the 3D gray matrix is thus drawn. Third, after obtaining the contours corresponding to the 3D matrix, we use the position principle between the points and curves to construct a topological relationship tree of the contours and determine the inclusion relationship between the contours. Finally, according to the combination of customized global and local search strategies, the local concave and convex areas are searched to locate the defect area and achieve the purpose of dividing the surface defects of the steel plate.Result Our method can effectively identify the surface defect area of the steel plate, is not sensitive to illumination change, and improves the effective division rate under the premise of ensuring a low error rate. Fisher's threshold segmentation method (FT), classical CV model (CV), HTB model (HTB), and improved background difference method (ABDM) are compared. For the FT algorithm based on edge information and the Fisher criterion, a fixed single threshold is selected, which can effectively segment an image with a large defect area and obvious difference with background grayscale. However, distinguishing the surface defect of the steel plate effectively is difficult when the target is similar to the grayscale of the background. For the CV model, image segmentation with a complex structure is inaccurate, and the number of iterations is large. The method of processing the four types of defect images has over-segmentation. This method cannot cope with the image segmentation task under boundary blur conditions. The HTB model solves the problem that the CV model cannot, that is, to adapt to the grayscale uneven image segmentation problem. However, regardless of the good segmentation effect on the knotted defect image, the algorithm has a poor segmentation effect on the other three types of defects. The ABDM algorithm, which aims to improve the background difference, requires that the constructed background model be as suitable as possible for the foreground image; therefore, the segmentation effect of the steel plate defect image that has a large defect target region is poor. In this study, the 3D gray matrix of the image is used to realize localization and segmentation of the defect region. The proposed algorithm can obtain accurate segmentation results for defect target extraction of the four types of defect images. Compared with Otsu, 1DMFE, and MFEE in terms of segmentation of the hole and roll image, our method improves the effective information rate by 1.6% and 2.1%, respectively, under the premise of ensuring that the mis-segmentation rate is kept below 2.0%. For the inclusion image, our method has an effective information rate of more than 85% under the premise of 3.4% mis-segmentation rate.Conclusion By transforming a 2D grayscale image into a 3D gray matrix, we analyze the characteristics of the grayscale image in 3D space and find that the defect area on the surface of the steel plate image corresponds to the local unevenness of the 3D space. Thus, a method based on an image segmentation algorithm for steel plate surface defects in a 3D gray matrix is proposed. First, a 3D gray matrix is generated from the original gray image. Second, a gray contour map is drawn. Third, the relationship between contours is determined, and a contour topological relationship tree is constructed. Finally, the contour is traversed according to a search strategy, the local concave and convex regions are identified, and the target position is determined to achieve segmentation. Experimental results show that the proposed algorithm can effectively segment common steel plate defects with uneven grayscale. From qualitative and quantitative perspectives, the algorithm can quickly and effectively extract defect regions in a steel plate image. In summary, the proposed steel plate defect image recognition algorithm based on a 3D gray matrix can effectively identify many types of steel plate defects, even in image recognition with a complex defect structure.关键词:steel surface defect identification;three-dimensional gray matrix;Kriging interpolation algorithm;gray contour;topological relationship tree16|9|3更新时间:2024-05-07 -
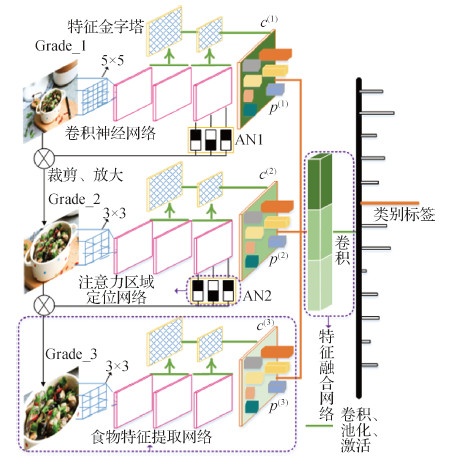 摘要:Objective Food images have special characteristics, uncertainties in food appearances, complex backgrounds, inter-class similarities, and intra-class differences. Hence, these images are more difficult to identify than ordinary fine-grained pictures. Traditional food image recognition mainly uses manual design features, including color, histogram of oriented gradient (HOG), and local binary pattern (LBP), then utilizes a classifier (e.g., support vector machine (SVM)) to deal with features. However, manual design features cannot establish the connection between various features. Several integrated feature methods only superimpose numerous features; thus, the recognition accuracy on each food image data set is up to 70% only. Compared with the weak expression capability of manual design features, deep learning has a stronger feature representation capability. They both use large-scale, labeled food images to train multi-level convolutional neural network models for food image recognition to improve recognition accuracy. However, in the current method of using the sonorous convolutional neural network for food image classification, the food image is directly inputted into the convolutional neural network to extract features. The food image has a relatively complicated background information, which critically influences the recognition result. We developed a model called multi-level convolution feature pyramid for fine-grained food image recognition to improve the accuracy of food image recognition and take full advantage of the local details.Method We extracted features from the whole to local, which not only avoids the shortcomings of baseline methods but also retains the global information and local details. We extracted features only from the target areas of the food image and discarded the background information with large interference. The multi-level convolution feature pyramid model consists of three main parts, namely, food feature extraction, attention localization, and feature fusion networks. The single-level feature extraction network cannot obtain the global and local features of the food image simultaneously. We developed a three-level food feature extraction network by cascading, which can transfer features from global to local. Moreover, a feature pyramid network was constructed between the feature maps of each food feature extraction network to deal with the large variation of food image scale. To automatically locate the network to the fine-grained area, an attention area localization network was designed between the levels of the feature extraction network, and the feature extraction range was reduced from global to local. Then, the fine-grained area of the original picture was cropped, enlarged, and inputted to the next-level feature extraction network. The features extracted by each level of the feature extraction network were subsequently sent to the feature fusion network. The merged features included the global features of the food image and the detailed features of the food target. For our model, two loss functions were used to optimize the feature extraction, feature fusion, and attention localization networks. For the feature extraction and feature fusion networks, the SoftMax loss function, which is referred to as the classification loss function, was used. The inter-stage loss function was utilized for the attention area positioning network.Result We adopted step-by-step and alternating training methods to train the feature extraction and attention localization networks and the cascade model separately. We conducted experiments on current mainstream datasets of food images. Our model obtained the top accuracy rates with 91.4%, 82.8%, and 90.3% on Food-101, ChineseFoodNet, and Food-172 datasets, respectively. The implemented framework showed the best performance compared with baselines for food picture recognition, with 1%8% improvement in recognition accuracy. Moreover, we trained the model in the Food-202 dataset, which we constructed ourselves, to verify the performance of our model fully. Food-202 is a food image dataset of 202 classes, and the number of food images in each class is more than 1 000; it includes Chinese and Western food. Results show that the accuracy of the model with the feature pyramid network increased by 2.4%.Conclusion We built a fine-grained food image recognition model with a multi-level feature pyramid convolutional neural network. The model can automatically locate areas with large discrimination of food images and integrate the global and local features of food images to achieve fine-grained recognition. It can effectively enhance the accuracy of food recognition and the robustness of the target size. Experimental results show that the proposed model demonstrated better performance than the baseline models in current mainstream food image datasets.关键词:food picture recognition;convolutional neural network;attention network;fine-grained recognition;feature pyramid46|37|3更新时间:2024-05-07
摘要:Objective Food images have special characteristics, uncertainties in food appearances, complex backgrounds, inter-class similarities, and intra-class differences. Hence, these images are more difficult to identify than ordinary fine-grained pictures. Traditional food image recognition mainly uses manual design features, including color, histogram of oriented gradient (HOG), and local binary pattern (LBP), then utilizes a classifier (e.g., support vector machine (SVM)) to deal with features. However, manual design features cannot establish the connection between various features. Several integrated feature methods only superimpose numerous features; thus, the recognition accuracy on each food image data set is up to 70% only. Compared with the weak expression capability of manual design features, deep learning has a stronger feature representation capability. They both use large-scale, labeled food images to train multi-level convolutional neural network models for food image recognition to improve recognition accuracy. However, in the current method of using the sonorous convolutional neural network for food image classification, the food image is directly inputted into the convolutional neural network to extract features. The food image has a relatively complicated background information, which critically influences the recognition result. We developed a model called multi-level convolution feature pyramid for fine-grained food image recognition to improve the accuracy of food image recognition and take full advantage of the local details.Method We extracted features from the whole to local, which not only avoids the shortcomings of baseline methods but also retains the global information and local details. We extracted features only from the target areas of the food image and discarded the background information with large interference. The multi-level convolution feature pyramid model consists of three main parts, namely, food feature extraction, attention localization, and feature fusion networks. The single-level feature extraction network cannot obtain the global and local features of the food image simultaneously. We developed a three-level food feature extraction network by cascading, which can transfer features from global to local. Moreover, a feature pyramid network was constructed between the feature maps of each food feature extraction network to deal with the large variation of food image scale. To automatically locate the network to the fine-grained area, an attention area localization network was designed between the levels of the feature extraction network, and the feature extraction range was reduced from global to local. Then, the fine-grained area of the original picture was cropped, enlarged, and inputted to the next-level feature extraction network. The features extracted by each level of the feature extraction network were subsequently sent to the feature fusion network. The merged features included the global features of the food image and the detailed features of the food target. For our model, two loss functions were used to optimize the feature extraction, feature fusion, and attention localization networks. For the feature extraction and feature fusion networks, the SoftMax loss function, which is referred to as the classification loss function, was used. The inter-stage loss function was utilized for the attention area positioning network.Result We adopted step-by-step and alternating training methods to train the feature extraction and attention localization networks and the cascade model separately. We conducted experiments on current mainstream datasets of food images. Our model obtained the top accuracy rates with 91.4%, 82.8%, and 90.3% on Food-101, ChineseFoodNet, and Food-172 datasets, respectively. The implemented framework showed the best performance compared with baselines for food picture recognition, with 1%8% improvement in recognition accuracy. Moreover, we trained the model in the Food-202 dataset, which we constructed ourselves, to verify the performance of our model fully. Food-202 is a food image dataset of 202 classes, and the number of food images in each class is more than 1 000; it includes Chinese and Western food. Results show that the accuracy of the model with the feature pyramid network increased by 2.4%.Conclusion We built a fine-grained food image recognition model with a multi-level feature pyramid convolutional neural network. The model can automatically locate areas with large discrimination of food images and integrate the global and local features of food images to achieve fine-grained recognition. It can effectively enhance the accuracy of food recognition and the robustness of the target size. Experimental results show that the proposed model demonstrated better performance than the baseline models in current mainstream food image datasets.关键词:food picture recognition;convolutional neural network;attention network;fine-grained recognition;feature pyramid46|37|3更新时间:2024-05-07 -
 摘要:Objective Synthetic aperture radar (SAR) systems are widely applied in many areas, such as civil and mili-tary fields, because they can operate day and night under various weather conditions. As a key and basic section of target recognition and interpretation for SAR images, SAR image segmentation has received much attention in recent years. However, SAR images suffer from strong speckle noise due to the influence of coherent illumination, which makes target segmentation in images difficult. Considering the importance of SAR image segmentation, this study proposes to segment the targets of a SAR image automatically. Many algorithms can solve SAR image target segmentation, and one of these is the GrabCut algorithm. The GrabCut algorithm, which is based on graph theory, achieves optimal segmentation and transforms the image segmentation problem into a problem of computing the maximum flow in the flow network. After this transformation, the problem can be solved with the min-cut or max-flow method. Nevertheless, the GrabCut algorithm has crucial deficiencies; for example, it not only requires artificial interaction but also merely utilizes one of the following:information, texture, or boundary information in the images. To improve such deficiencies, this study uses two kinds of information, namely, texture and boundary, for utilization in SAR images and for achieving automatic target segmentation.Method The proposed algorithm involves several steps. First, the proposed algorithm transforms a colored or gray SAR image into a 24-bit bitmap that contains substantial SAR image information. Second, with the aid of the 24-bit bitmap, a SAR image model is built according to graph theory. The model is a Gaussian mixed model that assigns each pixel in SAR images into three types of chroma spaces. Under the model framework, the energy function of the minimized description diagram is generated. Third, to segment the target region in the SAR image, the max-flow method is applied to determine the smallest cut set of the energy function in the description diagram. Coherent noise has a serious impact on image segmentation; thus, the proposed algorithm utilizes the median filter method to reduce noise in the target region and achieve precise SAR image target segmentation. Lastly, one of main problems in segmentation is that the interference of SAR image spots and small objects leads to incorrect targets during target segmentation. The neighborhood growth method, which removes specks in the SAR image target region and filters out small targets, is applied to tackle this problem and connect the target boundary. Through these steps, SAR image target segmentation can be performed automatically.Result Several state-of-the-start image segmentation algorithms, including mean-shift and Otsu segmentation algorithms, are compared with the proposed algorithm to validate its superiority. All experiments are performed in the processing platform of MATLAB R2014 in a 64-bit Windows 7 environment. In the first experiment, four different SAR images involving buildings, garages, trees, and cars are tested for image target segmentation. Results show that the proposed algorithm can segment many useful characteristics in the targets and can effectively remove background clutter, target shadows, and small interfering targets in the tested SAR images. This capability demonstrates that the proposed algorithm performs well in SAR image segmentation. A second experiment is conducted to illustrate the performance of the proposed algorithm. Here, mean-shift and Otsu segmentation algorithms and the proposed algorithm are simultaneously tested using four SAR images. As shown in the figures and tables, the proposed algorithm exhibits the best performance in SAR image target segmentation among all of the tested algorithms. The mean-shift algorithm can segment SAR image targets, but the contour boundary of the targets is fuzzy, and the computational efficiency is low. The Otsu segmentation algorithm can hardly segment targets correctly. Meanwhile, the proposed algorithm can split image targets accurately and reduce the computation time.Conclusion One of the most common methods of SAR image target segmentation is the GrabCut algorithm. However, GrabCut's precision of target segmentation is considerably affected by image background clutter and coherent noise. Meanwhile, targets in SAR images are often shielded, resulting in inaccurate image segmentation results. To address these problems, the proposed algorithm builds a Gaussian mixed model then transforms the target segmentation problem into a problem of minimizing the energy function of the description diagram. The max-flow method is used to determine the smallest cut set. The proposed algorithm can segment SAR image targets accurately through multiple iterations of the max-flow method in the SAR image color space domain and by using a median filter to remove specks in the SAR image target region and filter out small targets. However, the model in the proposed algorithm is not adaptive and thus cannot perform well in target segmentation of various SAR images. Moreover, the proposed algorithm applies the max-flow method to compute the max flow in the description diagram, thus spending considerable time in searching. In the future, we will further improve the precision of target segmentation by using an adaptive Gaussian mixed model and several useful approaches for computing the max flow to improve the performance of SAR image target segmentation.关键词:SAR image;target segmentation;Maxflow algorithm;median filtering;neighbor-rhood growth algorithm28|149|4更新时间:2024-05-07
摘要:Objective Synthetic aperture radar (SAR) systems are widely applied in many areas, such as civil and mili-tary fields, because they can operate day and night under various weather conditions. As a key and basic section of target recognition and interpretation for SAR images, SAR image segmentation has received much attention in recent years. However, SAR images suffer from strong speckle noise due to the influence of coherent illumination, which makes target segmentation in images difficult. Considering the importance of SAR image segmentation, this study proposes to segment the targets of a SAR image automatically. Many algorithms can solve SAR image target segmentation, and one of these is the GrabCut algorithm. The GrabCut algorithm, which is based on graph theory, achieves optimal segmentation and transforms the image segmentation problem into a problem of computing the maximum flow in the flow network. After this transformation, the problem can be solved with the min-cut or max-flow method. Nevertheless, the GrabCut algorithm has crucial deficiencies; for example, it not only requires artificial interaction but also merely utilizes one of the following:information, texture, or boundary information in the images. To improve such deficiencies, this study uses two kinds of information, namely, texture and boundary, for utilization in SAR images and for achieving automatic target segmentation.Method The proposed algorithm involves several steps. First, the proposed algorithm transforms a colored or gray SAR image into a 24-bit bitmap that contains substantial SAR image information. Second, with the aid of the 24-bit bitmap, a SAR image model is built according to graph theory. The model is a Gaussian mixed model that assigns each pixel in SAR images into three types of chroma spaces. Under the model framework, the energy function of the minimized description diagram is generated. Third, to segment the target region in the SAR image, the max-flow method is applied to determine the smallest cut set of the energy function in the description diagram. Coherent noise has a serious impact on image segmentation; thus, the proposed algorithm utilizes the median filter method to reduce noise in the target region and achieve precise SAR image target segmentation. Lastly, one of main problems in segmentation is that the interference of SAR image spots and small objects leads to incorrect targets during target segmentation. The neighborhood growth method, which removes specks in the SAR image target region and filters out small targets, is applied to tackle this problem and connect the target boundary. Through these steps, SAR image target segmentation can be performed automatically.Result Several state-of-the-start image segmentation algorithms, including mean-shift and Otsu segmentation algorithms, are compared with the proposed algorithm to validate its superiority. All experiments are performed in the processing platform of MATLAB R2014 in a 64-bit Windows 7 environment. In the first experiment, four different SAR images involving buildings, garages, trees, and cars are tested for image target segmentation. Results show that the proposed algorithm can segment many useful characteristics in the targets and can effectively remove background clutter, target shadows, and small interfering targets in the tested SAR images. This capability demonstrates that the proposed algorithm performs well in SAR image segmentation. A second experiment is conducted to illustrate the performance of the proposed algorithm. Here, mean-shift and Otsu segmentation algorithms and the proposed algorithm are simultaneously tested using four SAR images. As shown in the figures and tables, the proposed algorithm exhibits the best performance in SAR image target segmentation among all of the tested algorithms. The mean-shift algorithm can segment SAR image targets, but the contour boundary of the targets is fuzzy, and the computational efficiency is low. The Otsu segmentation algorithm can hardly segment targets correctly. Meanwhile, the proposed algorithm can split image targets accurately and reduce the computation time.Conclusion One of the most common methods of SAR image target segmentation is the GrabCut algorithm. However, GrabCut's precision of target segmentation is considerably affected by image background clutter and coherent noise. Meanwhile, targets in SAR images are often shielded, resulting in inaccurate image segmentation results. To address these problems, the proposed algorithm builds a Gaussian mixed model then transforms the target segmentation problem into a problem of minimizing the energy function of the description diagram. The max-flow method is used to determine the smallest cut set. The proposed algorithm can segment SAR image targets accurately through multiple iterations of the max-flow method in the SAR image color space domain and by using a median filter to remove specks in the SAR image target region and filter out small targets. However, the model in the proposed algorithm is not adaptive and thus cannot perform well in target segmentation of various SAR images. Moreover, the proposed algorithm applies the max-flow method to compute the max flow in the description diagram, thus spending considerable time in searching. In the future, we will further improve the precision of target segmentation by using an adaptive Gaussian mixed model and several useful approaches for computing the max flow to improve the performance of SAR image target segmentation.关键词:SAR image;target segmentation;Maxflow algorithm;median filtering;neighbor-rhood growth algorithm28|149|4更新时间:2024-05-07 -
 摘要:ObjectiveObject segmentation from multiple images involves locating the positions and ranges of common target objects in a scene, as presented in a sequence image set or multi-view images. This process is applied to various computer vision tasks and beyond, such as object detection and tracking, scene understanding, and 3D reconstruction. Early approaches consider object segmentation as a histogram matching of color values, and they are only applied to pair-wise images with the same or similar objects. Later on, object co-segmentation methods are introduced. Most of these methods take the MRF model as the basic framework and establish the cost function that consists of the energy within the image itself and the energy between images by using the feature calculation based on the gray or color values of pixels. The cost function is minimized to obtain consistent segmentation. However, when the foreground and background colors in these images are similar, co-segmentation cannot easily realize object segmentation with consistent regions. In recent years, with the development of deep learning, methods based on various deep learning models have been proposed. Some methods, such as the full convolutional network, adopt convolutional neural networks to extract the high-level semantic features of images to attain end-to-end image classification with pixel level. These algorithms can obtain better precision than traditional methods could. Compared with these traditional methods, deep learning methods can learn appropriate features automatically for individual classes without manual selection and adjustment of features. Exactly segmenting a single image must combine multi-level spatial domain information. Hence, multi-image segmentation not only demands fine grit accuracy in local regions and single image segmentation but also requires the balance of local and global information among multiple images. When ambiguous regions around the foreground and background are involved or when sufficient priori information is not given about objects, most deep learning methods tend to generate errors and achieve inconsistent segmentation from sequential image sets or multi-view images.MethodIn this study, we propose a multi-image segmentation method on the basis of depth feature exaction. The method is similar to the neural network model of PSPNet-50, in which a residual network is used to exact the features of the first 50 layers of the network. These extracted features are integrated into the pyramid pooling module by using pooling layers with differently sized pooling filters. Then, the features of different levels are fused. After applying a convolutional layer and up-convolutional layer, the initial end-to-end outputs are attained. To make the model learn the detail features from the multi-view images of complex scenes comprehensively, we join the first and fifth parts of the output network features. Thus, the PSPNet-50 network model is improved by integrating the high-resolution details of the shallow layer network, which also is used to reduce the effects of spatial information loss on the segmentation edge details as the network deepens. In the training phase, the improved network model is first pre-trained using the ADE20k dataset. Thus, the model, after considerable data training, achieves strong robustness and generalization. Afterward, one or two prior segmentations of the object are gained by using the interactive segmentation approach. These small priori segmentation integrations are fused into the new model. The network is then re-trained to solve the ambiguity segmentation problem between the foreground and the background and the inconsistent segmentation problem among multi-image. We analyze the relationship between the number of re-training iterations and the segmentation accuracy by employing a large number of experimental results to determine the optimal number of iterations. Finally, by constructing a fully connected conditional random field, the recognition ability of the deep convolutional neural network and the accurate locating ability of the fully connected condition random field are coupled together. The object region is effectively located, and the object edge is clearly detected.ResultWe evaluate our method on multi-image from various public data sets showing outdoor buildings and indoor objects. We also compare our results with those of other deep learning methods, such as fully convolutional networks (FCNs) and pyramid scene parsing network (PSPNet). Experiments in the multi-view dataset of "Valbonne" and "Box" show that our algorithm can exactly segment the region of the object in re-training classes while effectively avoiding the ambiguous region segmentation for those untraining object classes. To evaluate our algorithm quantitatively, we compute the commonly used accuracy evaluation, average values of pixel accuracy (PA), and intersection over union (IOU) and then evaluate the segmentation accuracy of the object.Resultsshow that our algorithm attains satisfactory scores not only in complex scene image sets with similar foreground and background contexts but also in simple image sets with obvious differences between the foreground and background contexts. For example, in the "Valbonne" set, the PA and IOU values of our result are 0.968 3 and 0.946 9, respectively; whereas the values of FCN are 0.702 7 and 0.694 2, respectively. The values of PSPNet are 0.850 9 and 0.824 0. Our method achieves 10% higher scores than FCN does and 20% higher scores than PSPNet does. In the "Box" set, our method achieves the PA values of 0.994 6 and IOU values of 0.957 7. However, FCN and PSPNet cannot find the real region of the object because the "Box" class is not contained in their re-training classes. The same improvements are found in other data sets. The average scores of PA and IOU of our method are more than 0.95.ConclusionExperimental results demonstrate that our algorithm has strong robustness in various scenes and can achieve consistent segmentation in multi-view images. A small amount of priori integration can help to accurately predict object pixel-level region and make the model effectively distinguish object regions from the background. The proposed approach consistently outperforms competing methods for contained and un-contained object classes.关键词:multi-image;object segmentation;deep learning;convolutional neural networks(CNN);segmentation prior;conditional random field(CRF)51|437|6更新时间:2024-05-07
摘要:ObjectiveObject segmentation from multiple images involves locating the positions and ranges of common target objects in a scene, as presented in a sequence image set or multi-view images. This process is applied to various computer vision tasks and beyond, such as object detection and tracking, scene understanding, and 3D reconstruction. Early approaches consider object segmentation as a histogram matching of color values, and they are only applied to pair-wise images with the same or similar objects. Later on, object co-segmentation methods are introduced. Most of these methods take the MRF model as the basic framework and establish the cost function that consists of the energy within the image itself and the energy between images by using the feature calculation based on the gray or color values of pixels. The cost function is minimized to obtain consistent segmentation. However, when the foreground and background colors in these images are similar, co-segmentation cannot easily realize object segmentation with consistent regions. In recent years, with the development of deep learning, methods based on various deep learning models have been proposed. Some methods, such as the full convolutional network, adopt convolutional neural networks to extract the high-level semantic features of images to attain end-to-end image classification with pixel level. These algorithms can obtain better precision than traditional methods could. Compared with these traditional methods, deep learning methods can learn appropriate features automatically for individual classes without manual selection and adjustment of features. Exactly segmenting a single image must combine multi-level spatial domain information. Hence, multi-image segmentation not only demands fine grit accuracy in local regions and single image segmentation but also requires the balance of local and global information among multiple images. When ambiguous regions around the foreground and background are involved or when sufficient priori information is not given about objects, most deep learning methods tend to generate errors and achieve inconsistent segmentation from sequential image sets or multi-view images.MethodIn this study, we propose a multi-image segmentation method on the basis of depth feature exaction. The method is similar to the neural network model of PSPNet-50, in which a residual network is used to exact the features of the first 50 layers of the network. These extracted features are integrated into the pyramid pooling module by using pooling layers with differently sized pooling filters. Then, the features of different levels are fused. After applying a convolutional layer and up-convolutional layer, the initial end-to-end outputs are attained. To make the model learn the detail features from the multi-view images of complex scenes comprehensively, we join the first and fifth parts of the output network features. Thus, the PSPNet-50 network model is improved by integrating the high-resolution details of the shallow layer network, which also is used to reduce the effects of spatial information loss on the segmentation edge details as the network deepens. In the training phase, the improved network model is first pre-trained using the ADE20k dataset. Thus, the model, after considerable data training, achieves strong robustness and generalization. Afterward, one or two prior segmentations of the object are gained by using the interactive segmentation approach. These small priori segmentation integrations are fused into the new model. The network is then re-trained to solve the ambiguity segmentation problem between the foreground and the background and the inconsistent segmentation problem among multi-image. We analyze the relationship between the number of re-training iterations and the segmentation accuracy by employing a large number of experimental results to determine the optimal number of iterations. Finally, by constructing a fully connected conditional random field, the recognition ability of the deep convolutional neural network and the accurate locating ability of the fully connected condition random field are coupled together. The object region is effectively located, and the object edge is clearly detected.ResultWe evaluate our method on multi-image from various public data sets showing outdoor buildings and indoor objects. We also compare our results with those of other deep learning methods, such as fully convolutional networks (FCNs) and pyramid scene parsing network (PSPNet). Experiments in the multi-view dataset of "Valbonne" and "Box" show that our algorithm can exactly segment the region of the object in re-training classes while effectively avoiding the ambiguous region segmentation for those untraining object classes. To evaluate our algorithm quantitatively, we compute the commonly used accuracy evaluation, average values of pixel accuracy (PA), and intersection over union (IOU) and then evaluate the segmentation accuracy of the object.Resultsshow that our algorithm attains satisfactory scores not only in complex scene image sets with similar foreground and background contexts but also in simple image sets with obvious differences between the foreground and background contexts. For example, in the "Valbonne" set, the PA and IOU values of our result are 0.968 3 and 0.946 9, respectively; whereas the values of FCN are 0.702 7 and 0.694 2, respectively. The values of PSPNet are 0.850 9 and 0.824 0. Our method achieves 10% higher scores than FCN does and 20% higher scores than PSPNet does. In the "Box" set, our method achieves the PA values of 0.994 6 and IOU values of 0.957 7. However, FCN and PSPNet cannot find the real region of the object because the "Box" class is not contained in their re-training classes. The same improvements are found in other data sets. The average scores of PA and IOU of our method are more than 0.95.ConclusionExperimental results demonstrate that our algorithm has strong robustness in various scenes and can achieve consistent segmentation in multi-view images. A small amount of priori integration can help to accurately predict object pixel-level region and make the model effectively distinguish object regions from the background. The proposed approach consistently outperforms competing methods for contained and un-contained object classes.关键词:multi-image;object segmentation;deep learning;convolutional neural networks(CNN);segmentation prior;conditional random field(CRF)51|437|6更新时间:2024-05-07 -
 摘要:ObjectiveFinger vein recognition, an emerging biometric identification technology, has attracted the attention of numerous researchers. However, the quality of several collected finger vein images is not ideal due to individual differences, changes in the collection environment, and differences in the performance of acquisition equipment. In a finger vein recognition system, low-quality images seriously affect feature extraction and matching, resulting in poor identification performance of the system. In an application scene that requires the establishment of a standard template library of personal finger vein information in real life, registered low-quality images seriously influence the use of the finger vein standard template library. Therefore, correct quality assessment after collecting finger vein images is necessary to filter low-quality images and select high-quality ones to be inputted to a finger vein recognition system or to register a finger vein standard template library. To address the problems of considerable computation complexity, weak robustness, and unsatisfactory expression and the issue that the hand-crafted finger vein quality characteristic is sensitive to various factors, we develop a finger vein quality assessment method. These problems are addressed via multi-feature fusion, which is primarily based on the cascaded fine-tuning convolutional neural network (CNN).MethodFinger vein image quality assessment methods based on deep learning require many labeled finger vein images. However, existing finger vein image public databases only provide finger vein images and do not mark them for quality. Thus, the first step should be labeling. In this study, the public finger vein database MMCBNU_6000 is labeled for quality representation in a semi-automated manner. This manner is based on the calculation of the number of veins in a finger vein image, followed by manual correction. Such an annotation method is more accurate, time saving, and cost effective than a pure manual annotation method. However, the collected low-quality finger vein images are fewer than the high-quality finger vein images in the actual scene; hence, the R-SMOTE algorithm is employed to balance all categories. The excellent capabilities of deep neural networks have been proven in the fields of image and speech. However, with regard to finger vein quality assessment, most existing methods are based on hand-crafted features, and only a few methods gain quality features via self-learning. In this study, the CNN structure in deep learning is applied to finger vein quality assessment, and the depth of the CNN framework is investigated for its contribution to quality representation. Deeper networks may not be good at representing the quality characteristics of finger vein images. The best network depth is confirmed after an experiment and used as the basis for subsequent research. Meanwhile, inspired by the combination of binary and grayscale images in traditional quality evaluation, two models, namely, multi-column CNN (MC-CNN) and cascaded fine-tuning CNN (CF-CNN), are designed to merge the quality features of grayscale and binary images. When MC-CNN is trained and tested, binary and grayscale images must be inputted together to the model. As for CF-CNN, binary and grayscale images are inputted to the model in stages during training, and only the grayscale image is inputted during testing. Notably, we input the binary finger vein image to the network and verify that the quality characteristics of the binary finger vein help distinguish high-and low-quality finger vein images. After verification, we obtain a basis to believe that the combination of binary and grayscale images through CNN produces remarkable results.ResultSeveral experimental results for testing are set on the MMCBNU_6000 database. The classification accuracy rates of the CNN-K (K=3, 4, 5) designed in this study are 93.31%, 93.94%, and 85.63%, respectively; the classification accuracy rates of CNN-4 with grayscale and binary images as the input are 93.94% and 91.92%, and the classification accuracy rates of MC-CNN and CF-CNN are 91.44% and 94.62%, respectively. The experimental results of the simple CNN structure show that CNN-3 has the highest classification accuracy rate for high-quality images, CNN-5 has the highest classification accuracy rate for low-quality images, and CNN-4 has the highest classification accuracy rate for the entire test set. The experimental results of CNN-4 show that the grayscale vein form performs better than the binary vein form. Meanwhile, the experimental results of the complex CNN structure show that CF-CNN performs better than MC-CNN. Compared with other existing algorithms, CF-CNN has the highest classification accuracy rate for high-quality, low-quality, and overall test images on the MMCBNU_6000 database.ConclusionFirst, three simple CNN structures are designed and used for finger vein quality assessment. The comprehensive performance of CNN-4 is found to be better than that of CNN-3 and CNN-5, indicating that the network is not as deep as possible, and the structure of the network should be adjusted to suit the research questions. Second, the performance difference when gray and binary images are used for the same network is compared. Results show that both images characterize the vein quality to varying degrees. Finally, to fuse the quality features of grayscale and binary images, two fusion models (MC-CNN and CF-CNN) are proposed. CF-CNN, an end-to-end quality evaluation model of finger veins, is better than MC-CNN and has a simpler structure. In summary, our method demonstrates state-of-the-art performance and obtains better features than those from existing manual and single vein forms.关键词:finger vein quality assessment;CNN(convolutional neural network);feature fusion;MC-CNN (multi-column CNN);CF-CNN(cascaded fine-tuning CNN)17|7|3更新时间:2024-05-07
摘要:ObjectiveFinger vein recognition, an emerging biometric identification technology, has attracted the attention of numerous researchers. However, the quality of several collected finger vein images is not ideal due to individual differences, changes in the collection environment, and differences in the performance of acquisition equipment. In a finger vein recognition system, low-quality images seriously affect feature extraction and matching, resulting in poor identification performance of the system. In an application scene that requires the establishment of a standard template library of personal finger vein information in real life, registered low-quality images seriously influence the use of the finger vein standard template library. Therefore, correct quality assessment after collecting finger vein images is necessary to filter low-quality images and select high-quality ones to be inputted to a finger vein recognition system or to register a finger vein standard template library. To address the problems of considerable computation complexity, weak robustness, and unsatisfactory expression and the issue that the hand-crafted finger vein quality characteristic is sensitive to various factors, we develop a finger vein quality assessment method. These problems are addressed via multi-feature fusion, which is primarily based on the cascaded fine-tuning convolutional neural network (CNN).MethodFinger vein image quality assessment methods based on deep learning require many labeled finger vein images. However, existing finger vein image public databases only provide finger vein images and do not mark them for quality. Thus, the first step should be labeling. In this study, the public finger vein database MMCBNU_6000 is labeled for quality representation in a semi-automated manner. This manner is based on the calculation of the number of veins in a finger vein image, followed by manual correction. Such an annotation method is more accurate, time saving, and cost effective than a pure manual annotation method. However, the collected low-quality finger vein images are fewer than the high-quality finger vein images in the actual scene; hence, the R-SMOTE algorithm is employed to balance all categories. The excellent capabilities of deep neural networks have been proven in the fields of image and speech. However, with regard to finger vein quality assessment, most existing methods are based on hand-crafted features, and only a few methods gain quality features via self-learning. In this study, the CNN structure in deep learning is applied to finger vein quality assessment, and the depth of the CNN framework is investigated for its contribution to quality representation. Deeper networks may not be good at representing the quality characteristics of finger vein images. The best network depth is confirmed after an experiment and used as the basis for subsequent research. Meanwhile, inspired by the combination of binary and grayscale images in traditional quality evaluation, two models, namely, multi-column CNN (MC-CNN) and cascaded fine-tuning CNN (CF-CNN), are designed to merge the quality features of grayscale and binary images. When MC-CNN is trained and tested, binary and grayscale images must be inputted together to the model. As for CF-CNN, binary and grayscale images are inputted to the model in stages during training, and only the grayscale image is inputted during testing. Notably, we input the binary finger vein image to the network and verify that the quality characteristics of the binary finger vein help distinguish high-and low-quality finger vein images. After verification, we obtain a basis to believe that the combination of binary and grayscale images through CNN produces remarkable results.ResultSeveral experimental results for testing are set on the MMCBNU_6000 database. The classification accuracy rates of the CNN-K (K=3, 4, 5) designed in this study are 93.31%, 93.94%, and 85.63%, respectively; the classification accuracy rates of CNN-4 with grayscale and binary images as the input are 93.94% and 91.92%, and the classification accuracy rates of MC-CNN and CF-CNN are 91.44% and 94.62%, respectively. The experimental results of the simple CNN structure show that CNN-3 has the highest classification accuracy rate for high-quality images, CNN-5 has the highest classification accuracy rate for low-quality images, and CNN-4 has the highest classification accuracy rate for the entire test set. The experimental results of CNN-4 show that the grayscale vein form performs better than the binary vein form. Meanwhile, the experimental results of the complex CNN structure show that CF-CNN performs better than MC-CNN. Compared with other existing algorithms, CF-CNN has the highest classification accuracy rate for high-quality, low-quality, and overall test images on the MMCBNU_6000 database.ConclusionFirst, three simple CNN structures are designed and used for finger vein quality assessment. The comprehensive performance of CNN-4 is found to be better than that of CNN-3 and CNN-5, indicating that the network is not as deep as possible, and the structure of the network should be adjusted to suit the research questions. Second, the performance difference when gray and binary images are used for the same network is compared. Results show that both images characterize the vein quality to varying degrees. Finally, to fuse the quality features of grayscale and binary images, two fusion models (MC-CNN and CF-CNN) are proposed. CF-CNN, an end-to-end quality evaluation model of finger veins, is better than MC-CNN and has a simpler structure. In summary, our method demonstrates state-of-the-art performance and obtains better features than those from existing manual and single vein forms.关键词:finger vein quality assessment;CNN(convolutional neural network);feature fusion;MC-CNN (multi-column CNN);CF-CNN(cascaded fine-tuning CNN)17|7|3更新时间:2024-05-07 -
 摘要:ObjectiveEye gaze is an input mode that has a potential to serve as an efficient computer interface. Eye movement has consistently been a research hotspot. Knowledge on gaze tracking can provide valuable information on a person's point of attention. The methods used at present are mainly model and regression based. The model-based method extracts facial features and calculates the 3D gaze direction through the geometric relationship between facial features. However, to obtain good accuracy, this method requires individual calibration, which is difficult and reduces user experience. Meanwhile, the regression-based method utilizes powerful computer learning technology to perform mapping from eye appearance characteristics to the gaze direction. Compared with the model-based method, the regression-based method avoids the modeling of the complicated eyeball structure and only needs to collect a large amount of data. Regression-based approaches can be further divided into feature-and appearance-based methods. The feature-based regression method learns the mapping function from an eye feature to the gaze direction, whereas appearance-based regression learns the mapping function of gaze direction from eye appearance. Learning algorithms use traditional support vector regression, random forest, and the latest in-depth learning technology. However, this method requires one or more data sets, thus making the model complicated. Meanwhile, regression-based methods commonly use additional data to compensate for head movements. In addition, substantial data are needed to learn a good mapping function. To improve line-of-sight tracking accuracy in a 2D environment, a new method based on the geometric features of the human eyes is proposed to solve the problem of high error rate and large time consumption of traditional iris location methods.MethodFirst, the position of the face is located by a face location algorithm. The location of the eye angle point is determined by the feature point of the feature point detection, and the eye area is calculated by the angle point. A traditional iris location method may take a long time to locate the iris center. To increase the speed of iris center location, an iris template is established by an iris image and used to detect the location of the iris region. Subsequently, the iris center position is roughly located. Second, the iris center position is located by an iris center precise location algorithm. Through facial feature point localization and iris center localization, the corners of the eye and the iris center are obtained and used as basic information to describe eye movement vectors. The extracted eye motion vector comprises only the information on eye corners and iris center points; thus, the angle is introduced based on the position relation of the points, and the distance from the departure information is adopted as the final eye motion vector. In this study, the neural network model is used to judge the point of sight, and the eye movement vector is utilized as the input feature of the neural network model. Then, the mapping relation of the gaze point is established to realize line-of-sight tracking.ResultA camera is used to record videos as the neural network training dataset. In the feature extraction stage, the original data are preprocessed to enhance image quality, thus making the iris center extraction accurate. Training results are obtained via feature extraction, training, and testing. Results show that in an ordinary experimental light environment, the recognition rate reaches 98.9% when the head pose is fixed, and the average recognition rate reaches 95.74%. When the head posture changes, the recognition rate of the algorithm changes to some extent, but the recognition rate can remain stable if stable eye movement features are extracted. When the restricted area of head posture changes, the recognition rate is still high, and the average recognition rate exceeds 90%. Experimental results show that the proposed method has good robustness to restricted area of head variation.ConclusionIn this study, a neural network is used to map eye images and the gaze point. Hence, the system does not need to use multiple cameras and infrared light sources, nor does it need camera calibration. A single camera system with no light source is utilized to locate the iris center through a combination of template matching and iris precision positioning. Compared with other methods, this system has a simpler structure, which is realized by using only a single webcam without an auxiliary light source and camera calibration. The neural network is adopted to map the line-of-sight landing point and calculate the line-of-sight landing area. Relatively stable features are extracted in an ordinary light source environment. Experiments show that the method performs well when the camera detects a complete head image in a certain range of head posture changes.关键词:geometric feature;iris template;iris center;eye movement vector feature;area of injection22|108|0更新时间:2024-05-07
摘要:ObjectiveEye gaze is an input mode that has a potential to serve as an efficient computer interface. Eye movement has consistently been a research hotspot. Knowledge on gaze tracking can provide valuable information on a person's point of attention. The methods used at present are mainly model and regression based. The model-based method extracts facial features and calculates the 3D gaze direction through the geometric relationship between facial features. However, to obtain good accuracy, this method requires individual calibration, which is difficult and reduces user experience. Meanwhile, the regression-based method utilizes powerful computer learning technology to perform mapping from eye appearance characteristics to the gaze direction. Compared with the model-based method, the regression-based method avoids the modeling of the complicated eyeball structure and only needs to collect a large amount of data. Regression-based approaches can be further divided into feature-and appearance-based methods. The feature-based regression method learns the mapping function from an eye feature to the gaze direction, whereas appearance-based regression learns the mapping function of gaze direction from eye appearance. Learning algorithms use traditional support vector regression, random forest, and the latest in-depth learning technology. However, this method requires one or more data sets, thus making the model complicated. Meanwhile, regression-based methods commonly use additional data to compensate for head movements. In addition, substantial data are needed to learn a good mapping function. To improve line-of-sight tracking accuracy in a 2D environment, a new method based on the geometric features of the human eyes is proposed to solve the problem of high error rate and large time consumption of traditional iris location methods.MethodFirst, the position of the face is located by a face location algorithm. The location of the eye angle point is determined by the feature point of the feature point detection, and the eye area is calculated by the angle point. A traditional iris location method may take a long time to locate the iris center. To increase the speed of iris center location, an iris template is established by an iris image and used to detect the location of the iris region. Subsequently, the iris center position is roughly located. Second, the iris center position is located by an iris center precise location algorithm. Through facial feature point localization and iris center localization, the corners of the eye and the iris center are obtained and used as basic information to describe eye movement vectors. The extracted eye motion vector comprises only the information on eye corners and iris center points; thus, the angle is introduced based on the position relation of the points, and the distance from the departure information is adopted as the final eye motion vector. In this study, the neural network model is used to judge the point of sight, and the eye movement vector is utilized as the input feature of the neural network model. Then, the mapping relation of the gaze point is established to realize line-of-sight tracking.ResultA camera is used to record videos as the neural network training dataset. In the feature extraction stage, the original data are preprocessed to enhance image quality, thus making the iris center extraction accurate. Training results are obtained via feature extraction, training, and testing. Results show that in an ordinary experimental light environment, the recognition rate reaches 98.9% when the head pose is fixed, and the average recognition rate reaches 95.74%. When the head posture changes, the recognition rate of the algorithm changes to some extent, but the recognition rate can remain stable if stable eye movement features are extracted. When the restricted area of head posture changes, the recognition rate is still high, and the average recognition rate exceeds 90%. Experimental results show that the proposed method has good robustness to restricted area of head variation.ConclusionIn this study, a neural network is used to map eye images and the gaze point. Hence, the system does not need to use multiple cameras and infrared light sources, nor does it need camera calibration. A single camera system with no light source is utilized to locate the iris center through a combination of template matching and iris precision positioning. Compared with other methods, this system has a simpler structure, which is realized by using only a single webcam without an auxiliary light source and camera calibration. The neural network is adopted to map the line-of-sight landing point and calculate the line-of-sight landing area. Relatively stable features are extracted in an ordinary light source environment. Experiments show that the method performs well when the camera detects a complete head image in a certain range of head posture changes.关键词:geometric feature;iris template;iris center;eye movement vector feature;area of injection22|108|0更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveDense matching between images is the basis of 3D reconstruction, SLAM (simultaneous localization and mapping), and other advanced image processing methods. However, the problems of excessive baseline, repeated texture, non-rigid deformation, and time-space efficiency largely affect the practicability of such methods. To solve such problems, this study proposes an efficient dense matching method for repeated textures and non-rigid deformation.MethodFirst, the source and target images are scaled
摘要:ObjectiveDense matching between images is the basis of 3D reconstruction, SLAM (simultaneous localization and mapping), and other advanced image processing methods. However, the problems of excessive baseline, repeated texture, non-rigid deformation, and time-space efficiency largely affect the practicability of such methods. To solve such problems, this study proposes an efficient dense matching method for repeated textures and non-rigid deformation.MethodFirst, the source and target images are scaled$ \alpha $ $ \alpha $ $ \alpha $ $ \alpha $ $ \alpha $ 关键词:dense matching;non-rigid;repeated texture;wide baseline;histogram of oriented gradient17|9|0更新时间:2024-05-07 -
 摘要:ObjectiveIn industrial production, we often encounter 2D cutting problems, such as the cutting process of metal sheet, glass, and plywood. A good cutting pattern can effectively simplify the cutting process, improve the utilization rate of metal sheets, reduce resource consumption, and reduce the production costs of enterprises. The 2D cutting problem can be categorized into rectangular and other shape cutting problems according to the geometric shape of the workpiece. According to whether the workpiece can rotate, the same problem can be classified as rotatable and non-rotatable. According to the number of times each workpiece can appear in the sheet, it can be divided into constrained and unconstrained cutting problems. According to whether the cutting process of blanking meets the requirement of guillotine cuts, it can be categorized into guillotine and non-guillotine cutting problems. This study focuses on the unconstrained 2D guillotine cutting problem of rectangular pieces (UTGCR), which refers to cutting a sheet into several rectangular pieces of different sizes and values, and the number of occurrences of each rectangular piece in the sheet is unconstrained. The optimization goal of this problem is to maximize the total value of rectangular pieces cut out of the sheet. The cutting stock algorithm iteratively calls the cutting algorithm to generate the cutting pattern of rectangular pieces on a sheet. After a new cutting pattern is generated, the number of times of using the new cutting pattern is determined by the residual demand of rectangular pieces. The value of the rectangle is corrected by the number of the rectangular pieces included in the new cutting pattern to make the subsequent cutting pattern reasonable. A good cutting algorithm can improve the material utilization of the sheet, reduce resource consumption, reduce production costs and improve the competitiveness of enterprises. From the viewpoint of computational complexity, UTGCR is a complex combinatorial optimization problem with NP complexity. The exact algorithm takes too long to solve large-scale problems and cannot meet practical application requirements because the solution space of the feasible cutting pattern is large. In practice, heuristic algorithms are generally used to solve UTGCR problems, which can be divided into two categories according to the construction idea of the algorithms. The first is the intelligent optimization algorithm, which is widely used in rectangular nonguillotine cutting problems and relatively less used in UTGCR problems. Guaranteeing the quality of the solution is difficult because of the unknown convergence of the algorithm. In addition, the structure of the cutting pattern is complex, which is not conducive to the sheet cutting process. The second is to reduce the solution space and computational complexity of the algorithm by restricting the cutting pattern to satisfy a certain geometric characteristic. Although this kind of algorithm is not guaranteed to obtain the optimal solution, it is widely used because of its minimal calculation time and simple layout structure, which is conducive to the sheet cutting process. A simple block corner-occupying pattern that can simplify the sheet-cutting process is presented, and a dynamic programming algorithm for generating this pattern is constructed.MethodThe dynamic programming principle is used to construct a simple block corner-occupying pattern with different sizes of sub sheets one by one from small to large. The pattern information of sub sheets with small sizes can be directly used when constructing the sub sheet with current sizes. A simple block corner-occupying pattern is obtained when the simple block corner-occupying pattern of the sub sheet L×W is obtained. With this pattern, several rows and columns of identical pieces are packed at the lower left corner of the sheet according to a simple block mode. The remaining part of the sheet is divided into two sub sheets. Recursive packing and partitioning of the sub sheet are continued according to the above method until the sub sheets are fully filled with rectangular pieces. A dynamic programming algorithm is used to determine the optimal piece type, the optimal number of rows and columns of pieces, and the optimal partitioning of the remaining part of the all possible sheet sizes. The normal size is used to exclude unnecessary calculations.ResultFive groups of instances in literature are used. The first, second, and fourth groups are international benchmark instances, which can be found at http://www.laria.u-picardie.fr/hifi/OR-Benchmark. The third group comprises random instances, and the fifth group consists of actual production instances. After comparing the algorithm in this study with the algorithms in common literature, experimental results show that the algorithm in this study has more reasonable calculation time and higher pattern value. In the first set of 41 benchmark instances, the algorithm in this study has found the exact solution to all instances, whereas the homogeneous block T-shape, homogeneous block two-segment, and compound strip two-segment algorithms have not found the exact solution of seven, five, and four instances, respectively. In the second set of 20 benchmark instances, only one has not been solved accurately by the algorithm in this study. A total of 18, 15, 15, and 20 instances have not been solved accurately by the common three-stage, homogeneous block T-type, homogeneous block two-stage, and homogeneous strip three-block algorithms, respectively. In the third set of 50 random instances, the sheet utilization rates of the algorithm in this study, the ordinary two-stage algorithm, and the homogeneous block two-stage algorithm are 99.913 7%, 99.862 3%, and 99.796 1%, respectively. In the fourth set of 31 benchmark instances, the exact solutions of all instances are solved by the algorithm in this study, and the exact solutions of two instances are not solved by the common corner-occupying algorithm.ConclusionThe computation time of the algorithm in this study is much less than that of the exact cutting algorithms, and its optimization effect is close to that of the exact cutting algorithms. The computation time of the algorithm in this study is close to that of many heuristic cutting algorithms, and its optimization effect is better than that of many heuristic cutting algorithms. As a cutting pattern generation algorithm, this algorithm can be combined with linear programming, integer programming, and sequential heuristic algorithm to solve the 2D guillotine cutting stock problem of rectangular pieces.关键词:unconstrained two-dimensional guillotine cutting problem;packing algorithm;corner-occupying pattern;dynamic programming;normal size20|8|2更新时间:2024-05-07
摘要:ObjectiveIn industrial production, we often encounter 2D cutting problems, such as the cutting process of metal sheet, glass, and plywood. A good cutting pattern can effectively simplify the cutting process, improve the utilization rate of metal sheets, reduce resource consumption, and reduce the production costs of enterprises. The 2D cutting problem can be categorized into rectangular and other shape cutting problems according to the geometric shape of the workpiece. According to whether the workpiece can rotate, the same problem can be classified as rotatable and non-rotatable. According to the number of times each workpiece can appear in the sheet, it can be divided into constrained and unconstrained cutting problems. According to whether the cutting process of blanking meets the requirement of guillotine cuts, it can be categorized into guillotine and non-guillotine cutting problems. This study focuses on the unconstrained 2D guillotine cutting problem of rectangular pieces (UTGCR), which refers to cutting a sheet into several rectangular pieces of different sizes and values, and the number of occurrences of each rectangular piece in the sheet is unconstrained. The optimization goal of this problem is to maximize the total value of rectangular pieces cut out of the sheet. The cutting stock algorithm iteratively calls the cutting algorithm to generate the cutting pattern of rectangular pieces on a sheet. After a new cutting pattern is generated, the number of times of using the new cutting pattern is determined by the residual demand of rectangular pieces. The value of the rectangle is corrected by the number of the rectangular pieces included in the new cutting pattern to make the subsequent cutting pattern reasonable. A good cutting algorithm can improve the material utilization of the sheet, reduce resource consumption, reduce production costs and improve the competitiveness of enterprises. From the viewpoint of computational complexity, UTGCR is a complex combinatorial optimization problem with NP complexity. The exact algorithm takes too long to solve large-scale problems and cannot meet practical application requirements because the solution space of the feasible cutting pattern is large. In practice, heuristic algorithms are generally used to solve UTGCR problems, which can be divided into two categories according to the construction idea of the algorithms. The first is the intelligent optimization algorithm, which is widely used in rectangular nonguillotine cutting problems and relatively less used in UTGCR problems. Guaranteeing the quality of the solution is difficult because of the unknown convergence of the algorithm. In addition, the structure of the cutting pattern is complex, which is not conducive to the sheet cutting process. The second is to reduce the solution space and computational complexity of the algorithm by restricting the cutting pattern to satisfy a certain geometric characteristic. Although this kind of algorithm is not guaranteed to obtain the optimal solution, it is widely used because of its minimal calculation time and simple layout structure, which is conducive to the sheet cutting process. A simple block corner-occupying pattern that can simplify the sheet-cutting process is presented, and a dynamic programming algorithm for generating this pattern is constructed.MethodThe dynamic programming principle is used to construct a simple block corner-occupying pattern with different sizes of sub sheets one by one from small to large. The pattern information of sub sheets with small sizes can be directly used when constructing the sub sheet with current sizes. A simple block corner-occupying pattern is obtained when the simple block corner-occupying pattern of the sub sheet L×W is obtained. With this pattern, several rows and columns of identical pieces are packed at the lower left corner of the sheet according to a simple block mode. The remaining part of the sheet is divided into two sub sheets. Recursive packing and partitioning of the sub sheet are continued according to the above method until the sub sheets are fully filled with rectangular pieces. A dynamic programming algorithm is used to determine the optimal piece type, the optimal number of rows and columns of pieces, and the optimal partitioning of the remaining part of the all possible sheet sizes. The normal size is used to exclude unnecessary calculations.ResultFive groups of instances in literature are used. The first, second, and fourth groups are international benchmark instances, which can be found at http://www.laria.u-picardie.fr/hifi/OR-Benchmark. The third group comprises random instances, and the fifth group consists of actual production instances. After comparing the algorithm in this study with the algorithms in common literature, experimental results show that the algorithm in this study has more reasonable calculation time and higher pattern value. In the first set of 41 benchmark instances, the algorithm in this study has found the exact solution to all instances, whereas the homogeneous block T-shape, homogeneous block two-segment, and compound strip two-segment algorithms have not found the exact solution of seven, five, and four instances, respectively. In the second set of 20 benchmark instances, only one has not been solved accurately by the algorithm in this study. A total of 18, 15, 15, and 20 instances have not been solved accurately by the common three-stage, homogeneous block T-type, homogeneous block two-stage, and homogeneous strip three-block algorithms, respectively. In the third set of 50 random instances, the sheet utilization rates of the algorithm in this study, the ordinary two-stage algorithm, and the homogeneous block two-stage algorithm are 99.913 7%, 99.862 3%, and 99.796 1%, respectively. In the fourth set of 31 benchmark instances, the exact solutions of all instances are solved by the algorithm in this study, and the exact solutions of two instances are not solved by the common corner-occupying algorithm.ConclusionThe computation time of the algorithm in this study is much less than that of the exact cutting algorithms, and its optimization effect is close to that of the exact cutting algorithms. The computation time of the algorithm in this study is close to that of many heuristic cutting algorithms, and its optimization effect is better than that of many heuristic cutting algorithms. As a cutting pattern generation algorithm, this algorithm can be combined with linear programming, integer programming, and sequential heuristic algorithm to solve the 2D guillotine cutting stock problem of rectangular pieces.关键词:unconstrained two-dimensional guillotine cutting problem;packing algorithm;corner-occupying pattern;dynamic programming;normal size20|8|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveContent-based image retrieval or text-based retrieval has played a major role in practical computer vision applications. In several scenarios, however, retrieval becomes a problem when sample queries are unavailable or describing them with a keyword is difficult. However, compared with text, sketches can intrinsically capture object appearance and structure. Sketches are incredibly intuitive to humans and descriptive in nature. They provide a convenient and intuitive means to specify object appearance and structure. As a query modality, they offer a degree of precision and flexibility that is missing in traditional text-based image retrieval. Closely correlated with the proliferation of touch-screen devices, sketch-based image retrieval has become an increasingly prominent research topic in recent years. Conventional sketch-based image retrieval (SBIR) principally focuses on retrieving images of the same category and disregards the fine-grained feature of sketches. However, SBIR is challenging because humans draw free-hand sketches without any reference but only focus on the salient object structures. Hence, the shapes and scales in sketches are usually distorted compared with those in natural images. To deal with this problem, studies have developed methods to bridge the domain gap between sketches and natural images for SBIR. These approaches can be roughly divided into hand-crafted and cross-domain deep learning-based methods. SBIR generates approximate sketches by extracting edge or contour maps from natural images. Afterward, hand-crafted features are extracted for sketches and edge maps of natural images, which are then fed into "bag-of-words" methods to generate representations for SBIR. The major limitation of hand-crafted methods is that the domain gap between sketches and natural images cannot be well remedied because matching edge maps to non-aligned sketches with large variations and ambiguity is difficult. For this problem, we propose a novel sketch-based image retrieval method based on fine-grained feature and deep convolutional neural network. This fine-grained SBIR (FG-SBIR) approach focuses not only on coarse holistic matching via a deep cross-domain but also on explicit accounting for fine-grained detail matching. The proposed deep convolutional neural network is designed for sketch-based image retrieval.MethodMost existing SBIR studies have focused on category-level sketch-to-photo retrieval. A bag-of-words representation combined with a form of edge detection from photo images is often employed to bridge the domain gap. Previous work that attempted to address the fine-grained SBIR problem is based on a deformable part-based model and graph matching. However, the definition of fine-grained in previous work is different from ours-a sketch is considered to be a match to a photo if the objects depicted look similar. In addition, these hand-crafted feature-based approaches are inadequate in capturing the subtle intra-category and inter-instance differences, as demonstrated in our experiments. Our methods are demonstrated as follows:First, we construct a multiple branch of confusing deep convolutional neural network to perform a different deal with sketch and natural image; Three different branches are used:one sketch branch and two nature image branches. The sketch branch has four convolutional and two pooling layers, whereas the natural image branch has five and two, respectively. By adding a convolutional layer to obtain abstractive natural image features, the problem of abstraction level inconsistency is solved. Different branch designs can reduce domain differences. Second, we extract detail information by adding the attention model in the neural network. Most attention models learn an attention mask, which assigns different weights to different regions of an image. Soft attention is the most commonly used model because it is differentiable and can thus be learned end-to-end with the rest of the network. Our attention model is specifically designed for FG-SBIR in that it is robust against spatial misalignment through the shortcut connection architecture. Third, we combine coarse and fine semantic information to achieve retrieval. By combining the information, we obtain robust features. Finally, we use deep triplet loss to obtain good results. The loss is defined using the max-margin framework.ResultThe experiment on different benchmark datasets comprises shoe and chair datasets. We use two traditional hand-crafted feature-based models, namely, scale-invariant feature transform (SIFT) and histogram of oriented gradient (HOG), apart from three other baseline models, namely, deep SaN, deep 3D, and deep TSN, which use the deep features designed for the sketch. We utilize the ratio of correctly predicting the true match at Top1 and Top10 as the evaluation metrics. We compare the performance of our full model and the five baselines. Results prove that the proposed method obtains higher retrieval precision than the traditional methods. Our model performs the best overall in each metric and in both datasets. The improvement is particularly clear at Top1, with an approximately 12% increase. In the chair dataset, we obtain an approximately 11% increase. Moreover, we obtain an approximately 3% increase at Top10. In other words, we can acquire the right result on the first image. In the proposed method, we wish to achieve instance-level retrieval. Thus, the proposed model obtains good results in the FG-SBIR task.ConclusionThe proposed sketch-based image retrieval provides a new means of thinking for the cross-domain retrieval of sketch and natural images. This sketch convolutional neural network obtains good results in sketch-based image retrieval. This task is more challenging than the well-studied category-level SBIR task, but it is also more useful for commercial SBIR adoption. Achieving fine-grained retrieval across the sketch/image gap requires a deep network learned with triplet annotation requirements. We demonstrate how to sidestep these requirements in order to achieve good performance in this new and challenging task. By introducing attention modeling and the sketch convolutional neural network, the model can concentrate on the subtle differences between local regions of a sketch and photo images and compute deep features containing fine-grained and high-level semantics. The proposed sketch neural network is suitable for FG-SIBR.关键词:sketch-based image retrieval (SBIR);convolutional neural network;attention model;fine-grained feature;feature fusion16|7|0更新时间:2024-05-07
摘要:ObjectiveContent-based image retrieval or text-based retrieval has played a major role in practical computer vision applications. In several scenarios, however, retrieval becomes a problem when sample queries are unavailable or describing them with a keyword is difficult. However, compared with text, sketches can intrinsically capture object appearance and structure. Sketches are incredibly intuitive to humans and descriptive in nature. They provide a convenient and intuitive means to specify object appearance and structure. As a query modality, they offer a degree of precision and flexibility that is missing in traditional text-based image retrieval. Closely correlated with the proliferation of touch-screen devices, sketch-based image retrieval has become an increasingly prominent research topic in recent years. Conventional sketch-based image retrieval (SBIR) principally focuses on retrieving images of the same category and disregards the fine-grained feature of sketches. However, SBIR is challenging because humans draw free-hand sketches without any reference but only focus on the salient object structures. Hence, the shapes and scales in sketches are usually distorted compared with those in natural images. To deal with this problem, studies have developed methods to bridge the domain gap between sketches and natural images for SBIR. These approaches can be roughly divided into hand-crafted and cross-domain deep learning-based methods. SBIR generates approximate sketches by extracting edge or contour maps from natural images. Afterward, hand-crafted features are extracted for sketches and edge maps of natural images, which are then fed into "bag-of-words" methods to generate representations for SBIR. The major limitation of hand-crafted methods is that the domain gap between sketches and natural images cannot be well remedied because matching edge maps to non-aligned sketches with large variations and ambiguity is difficult. For this problem, we propose a novel sketch-based image retrieval method based on fine-grained feature and deep convolutional neural network. This fine-grained SBIR (FG-SBIR) approach focuses not only on coarse holistic matching via a deep cross-domain but also on explicit accounting for fine-grained detail matching. The proposed deep convolutional neural network is designed for sketch-based image retrieval.MethodMost existing SBIR studies have focused on category-level sketch-to-photo retrieval. A bag-of-words representation combined with a form of edge detection from photo images is often employed to bridge the domain gap. Previous work that attempted to address the fine-grained SBIR problem is based on a deformable part-based model and graph matching. However, the definition of fine-grained in previous work is different from ours-a sketch is considered to be a match to a photo if the objects depicted look similar. In addition, these hand-crafted feature-based approaches are inadequate in capturing the subtle intra-category and inter-instance differences, as demonstrated in our experiments. Our methods are demonstrated as follows:First, we construct a multiple branch of confusing deep convolutional neural network to perform a different deal with sketch and natural image; Three different branches are used:one sketch branch and two nature image branches. The sketch branch has four convolutional and two pooling layers, whereas the natural image branch has five and two, respectively. By adding a convolutional layer to obtain abstractive natural image features, the problem of abstraction level inconsistency is solved. Different branch designs can reduce domain differences. Second, we extract detail information by adding the attention model in the neural network. Most attention models learn an attention mask, which assigns different weights to different regions of an image. Soft attention is the most commonly used model because it is differentiable and can thus be learned end-to-end with the rest of the network. Our attention model is specifically designed for FG-SBIR in that it is robust against spatial misalignment through the shortcut connection architecture. Third, we combine coarse and fine semantic information to achieve retrieval. By combining the information, we obtain robust features. Finally, we use deep triplet loss to obtain good results. The loss is defined using the max-margin framework.ResultThe experiment on different benchmark datasets comprises shoe and chair datasets. We use two traditional hand-crafted feature-based models, namely, scale-invariant feature transform (SIFT) and histogram of oriented gradient (HOG), apart from three other baseline models, namely, deep SaN, deep 3D, and deep TSN, which use the deep features designed for the sketch. We utilize the ratio of correctly predicting the true match at Top1 and Top10 as the evaluation metrics. We compare the performance of our full model and the five baselines. Results prove that the proposed method obtains higher retrieval precision than the traditional methods. Our model performs the best overall in each metric and in both datasets. The improvement is particularly clear at Top1, with an approximately 12% increase. In the chair dataset, we obtain an approximately 11% increase. Moreover, we obtain an approximately 3% increase at Top10. In other words, we can acquire the right result on the first image. In the proposed method, we wish to achieve instance-level retrieval. Thus, the proposed model obtains good results in the FG-SBIR task.ConclusionThe proposed sketch-based image retrieval provides a new means of thinking for the cross-domain retrieval of sketch and natural images. This sketch convolutional neural network obtains good results in sketch-based image retrieval. This task is more challenging than the well-studied category-level SBIR task, but it is also more useful for commercial SBIR adoption. Achieving fine-grained retrieval across the sketch/image gap requires a deep network learned with triplet annotation requirements. We demonstrate how to sidestep these requirements in order to achieve good performance in this new and challenging task. By introducing attention modeling and the sketch convolutional neural network, the model can concentrate on the subtle differences between local regions of a sketch and photo images and compute deep features containing fine-grained and high-level semantics. The proposed sketch neural network is suitable for FG-SIBR.关键词:sketch-based image retrieval (SBIR);convolutional neural network;attention model;fine-grained feature;feature fusion16|7|0更新时间:2024-05-07 -
 摘要:ObjectiveGeospatial multi-dimensional data are mainly composed of spatial location and attribute information, which can effectively record and describe events and phenomena, such as social and economic development, natural environment changes, and human social activities. As a commonly used method for multi-dimensional data visualization, parallel coordinates do not work well for the visual exploration of geospatial multi-dimensional data because of the lack of spatial information and uncertainty of spatial correlation. Therefore, analysis and understanding of geospatial multidimensional data are highly important in establishing an effective association between spatial locations and multiple attributes.MethodIn this study, we propose a novel geospatial multi-dimensional data visualization method that uses geographical maps to display spatial locations, visualizes multi-dimensional attributes via parallel coordinates, and associates map and parallel coordinates through data lines. We design a corresponding visual analysis system that allows users to explore and analyze the spatial distribution of geospatial multi-dimensional data and its associated feature patterns interactively on the basis of the initial geospatial multidimensional data, including different spatial locations and their corresponding multi-dimensional attribute information. Spatial areas are classified into different clusters according to multi-dimensional attributes and spatial distance, and Voronoi diagrams and color mappings are designed to represent different clusters visually. The attribute information of the geospatial multi-dimensional data is represented by parallel coordinates, and the data on different attribute axes are clustered and analyzed. Mutual information is used to calculate the correlation between the geospatial clustering and attribute categories dynamically, and the ordering of the parallel coordinate plot is adaptively determined. Then, the map is embedded into the parallel coordinates on the basis of the axis alignment results, and the map view and parallel coordinate systems are effectively correlated through data lines. Furthermore, the binding position of the data line between the attribute axis and the map is dynamically calculated according to the geospatial clustering, and the layout of the data line is optimized to reduce the disorder of the data line distribution between the map and parallel coordinate system. We design and implement a geospatial multi-dimensional data visualization analysis system that integrates the above visual designs and data analysis methods. To demonstrate the validity and practicability of the proposed visual analysis system, a convenient user interaction mode is provided, and two case studies are conducted based on the datasets with multi-dimensional geospatial attributes. GDP data containing 11 attributes and 32 spatial locations are visualized using our visual analysis system.ResultComparison of the geospatial clustering and actual urban development in the map view proves that the proposed geospatial clustering algorithm that comprehensively considers data attribute and spatial location information is useful. By observing the arrangement of parallel axes, we confirm that the dynamic arrangement of parallel axes based on mutual information exhibits a certain rationality. In the second case based on geospatial multi-dimensional data, we explore the spatial distribution of attribute information in a certain spatial cluster. When a user clicks on a geospatial clustering of interest, the system rearranges the parallel coordinate axes.ConclusionBy comparing the distributions of attributes of the same geospatial clustering at different times, we find that the proposed method is highly sensitive to data. When the data change slightly, the order of the parallel axis changes, making the map embedded in parallel coordinates match the spatial distribution of multi-dimensional attribute information well. We invite experts from different fields, such as geography and economics, to use and evaluate the system. The validity and practicability of the geospatial multidimensional data visual analysis system are further verified through one-on-one interviews. A set of case studies and expert feedback shows that the visual analysis methods and tools proposed in this study can help users quickly analyze the spatial distribution characteristics and associated patterns of geospatial multi-dimensional attributes and provide domain experts with an effective means of exploring geospatial multi-dimensional data.关键词:visual analysis;geographic space;multi-dimensional data;parallel coordinates;mutual information16|8|2更新时间:2024-05-07
摘要:ObjectiveGeospatial multi-dimensional data are mainly composed of spatial location and attribute information, which can effectively record and describe events and phenomena, such as social and economic development, natural environment changes, and human social activities. As a commonly used method for multi-dimensional data visualization, parallel coordinates do not work well for the visual exploration of geospatial multi-dimensional data because of the lack of spatial information and uncertainty of spatial correlation. Therefore, analysis and understanding of geospatial multidimensional data are highly important in establishing an effective association between spatial locations and multiple attributes.MethodIn this study, we propose a novel geospatial multi-dimensional data visualization method that uses geographical maps to display spatial locations, visualizes multi-dimensional attributes via parallel coordinates, and associates map and parallel coordinates through data lines. We design a corresponding visual analysis system that allows users to explore and analyze the spatial distribution of geospatial multi-dimensional data and its associated feature patterns interactively on the basis of the initial geospatial multidimensional data, including different spatial locations and their corresponding multi-dimensional attribute information. Spatial areas are classified into different clusters according to multi-dimensional attributes and spatial distance, and Voronoi diagrams and color mappings are designed to represent different clusters visually. The attribute information of the geospatial multi-dimensional data is represented by parallel coordinates, and the data on different attribute axes are clustered and analyzed. Mutual information is used to calculate the correlation between the geospatial clustering and attribute categories dynamically, and the ordering of the parallel coordinate plot is adaptively determined. Then, the map is embedded into the parallel coordinates on the basis of the axis alignment results, and the map view and parallel coordinate systems are effectively correlated through data lines. Furthermore, the binding position of the data line between the attribute axis and the map is dynamically calculated according to the geospatial clustering, and the layout of the data line is optimized to reduce the disorder of the data line distribution between the map and parallel coordinate system. We design and implement a geospatial multi-dimensional data visualization analysis system that integrates the above visual designs and data analysis methods. To demonstrate the validity and practicability of the proposed visual analysis system, a convenient user interaction mode is provided, and two case studies are conducted based on the datasets with multi-dimensional geospatial attributes. GDP data containing 11 attributes and 32 spatial locations are visualized using our visual analysis system.ResultComparison of the geospatial clustering and actual urban development in the map view proves that the proposed geospatial clustering algorithm that comprehensively considers data attribute and spatial location information is useful. By observing the arrangement of parallel axes, we confirm that the dynamic arrangement of parallel axes based on mutual information exhibits a certain rationality. In the second case based on geospatial multi-dimensional data, we explore the spatial distribution of attribute information in a certain spatial cluster. When a user clicks on a geospatial clustering of interest, the system rearranges the parallel coordinate axes.ConclusionBy comparing the distributions of attributes of the same geospatial clustering at different times, we find that the proposed method is highly sensitive to data. When the data change slightly, the order of the parallel axis changes, making the map embedded in parallel coordinates match the spatial distribution of multi-dimensional attribute information well. We invite experts from different fields, such as geography and economics, to use and evaluate the system. The validity and practicability of the geospatial multidimensional data visual analysis system are further verified through one-on-one interviews. A set of case studies and expert feedback shows that the visual analysis methods and tools proposed in this study can help users quickly analyze the spatial distribution characteristics and associated patterns of geospatial multi-dimensional attributes and provide domain experts with an effective means of exploring geospatial multi-dimensional data.关键词:visual analysis;geographic space;multi-dimensional data;parallel coordinates;mutual information16|8|2更新时间:2024-05-07 -
 摘要:ObjectiveThis study proposes a detail-aware texture removal algorithm based on existing studies. When removing image textures, the proposed method maintains the fine structural information of the image, particularly the special details (e.g., slender structure and corner information) that are easily obscured in other methods. With the continuous development of computer technology, the application of image processing technology has become increasingly widespread in pattern recognition, security monitoring, smart driving, computer photography, and other areas. However, the image quality obtained directly from the image acquisition card is not satisfactory. Therefore, image preprocessing is necessary. Texture filtering is an important step in image preprocessing. The image edge in a texture image is the main component of the image structure. Traditional image filter processing techniques, such as median and Gaussian filtering, can filter noise to a certain extent, but the structure context is also filtered. Therefore, this study investigates how to remove texture and maintain the slender structure context simultaneously.MethodThe main idea of the proposed algorithm is to compute the optimal filter scale by leveraging a novel slender structure recognition technique and an improved structure angle relative total variation based on multiple directions and obtain the filtering result through a guided filter. The method consists of four steps. First, to address the deficiency of existing algorithms, this study proposes a method that can identify and enhance slender structures to avoid smoothing them in the subsequent texture filtering process. Second, to estimate the optimal filtering kernel scale of each pixel, the original relative total variation model is improved by searching the minimum relative total variation in multiple directions so that it can distinguish textures and boundaries effectively, and corner information is effectively distinguished from texture. Then, the detected elongated structure is normalized to the improved metric of relative total variation, and the filtered kernel scale is estimated to generate a guided filtered image. Thus, large-scale filtering kernels are used in flat or textured regions, and the filtering kernels are reduced near the edges and corners of the structure. Finally, a texture-removed image is obtained by combining the joint bilateral filters.ResultWe evaluate our method on different types of pictures, including mosaics and paintings. Experiments are conducted on a Windows 8.1 operating system, and the proposed method is implemented in MATLAB language. No reasonable quantitative objective evaluation metrics exist in the research field of texture filtering; thus, subjective evaluation by human eyes is commonly used. In the experiments, we compare five existing methods of texture filtering, namely, bilateral texture filtering, rotation guided filtering, relative total variation, scale-sensitive structural protection filtering, and interval gradient operator. Compared with these methods, the proposed algorithm needs a slightly longer computing time. Specifically, for an image with 394×304 pixels, the proposed method consumes 3.37 s, whereas bilateral texture filtering, rotation guided filtering, relative total variation, scale-sensitive structural protection filtering, and interval gradient operator consume 2.23, 0.07, 0.23, 1.01, and 3.29 s, respectively. Our method outperforms these methods in terms of texture removal while maintaining slender structures and corner details. We also analyze the iteration number and parameter value standard deviation (σ) of the proposed algorithm. The comparative experiments demonstrate that with one iteration used to remove texture, the result of our algorithm is better than those of relative total variation and interval gradient operator methods. A large σ is selected when the optimal filter scale is large, and a small σ is equipped when the optimal filter scale is small.ConclusionThe texture filter designed in this study performs well in maintaining features, such as elongated structures and sharp corners in an image after texture removal, thus providing a powerful image preprocessing method for image subsequent processing, including image detail enhancement, edge detection, image abstraction, and image segmentation. For the problem of sharp reduction in the filter kernel scale encountered in the experiment, this study provides a reasonable explanation and solution. The proposed algorithm is limited by its long computing time. In general, the proposed algorithm obtains better results compared with others despite its slightly lower computing time efficiency.关键词:texture filtering;long structure;structure detection;edge preservation;bilateral filtering16|8|1更新时间:2024-05-07
摘要:ObjectiveThis study proposes a detail-aware texture removal algorithm based on existing studies. When removing image textures, the proposed method maintains the fine structural information of the image, particularly the special details (e.g., slender structure and corner information) that are easily obscured in other methods. With the continuous development of computer technology, the application of image processing technology has become increasingly widespread in pattern recognition, security monitoring, smart driving, computer photography, and other areas. However, the image quality obtained directly from the image acquisition card is not satisfactory. Therefore, image preprocessing is necessary. Texture filtering is an important step in image preprocessing. The image edge in a texture image is the main component of the image structure. Traditional image filter processing techniques, such as median and Gaussian filtering, can filter noise to a certain extent, but the structure context is also filtered. Therefore, this study investigates how to remove texture and maintain the slender structure context simultaneously.MethodThe main idea of the proposed algorithm is to compute the optimal filter scale by leveraging a novel slender structure recognition technique and an improved structure angle relative total variation based on multiple directions and obtain the filtering result through a guided filter. The method consists of four steps. First, to address the deficiency of existing algorithms, this study proposes a method that can identify and enhance slender structures to avoid smoothing them in the subsequent texture filtering process. Second, to estimate the optimal filtering kernel scale of each pixel, the original relative total variation model is improved by searching the minimum relative total variation in multiple directions so that it can distinguish textures and boundaries effectively, and corner information is effectively distinguished from texture. Then, the detected elongated structure is normalized to the improved metric of relative total variation, and the filtered kernel scale is estimated to generate a guided filtered image. Thus, large-scale filtering kernels are used in flat or textured regions, and the filtering kernels are reduced near the edges and corners of the structure. Finally, a texture-removed image is obtained by combining the joint bilateral filters.ResultWe evaluate our method on different types of pictures, including mosaics and paintings. Experiments are conducted on a Windows 8.1 operating system, and the proposed method is implemented in MATLAB language. No reasonable quantitative objective evaluation metrics exist in the research field of texture filtering; thus, subjective evaluation by human eyes is commonly used. In the experiments, we compare five existing methods of texture filtering, namely, bilateral texture filtering, rotation guided filtering, relative total variation, scale-sensitive structural protection filtering, and interval gradient operator. Compared with these methods, the proposed algorithm needs a slightly longer computing time. Specifically, for an image with 394×304 pixels, the proposed method consumes 3.37 s, whereas bilateral texture filtering, rotation guided filtering, relative total variation, scale-sensitive structural protection filtering, and interval gradient operator consume 2.23, 0.07, 0.23, 1.01, and 3.29 s, respectively. Our method outperforms these methods in terms of texture removal while maintaining slender structures and corner details. We also analyze the iteration number and parameter value standard deviation (σ) of the proposed algorithm. The comparative experiments demonstrate that with one iteration used to remove texture, the result of our algorithm is better than those of relative total variation and interval gradient operator methods. A large σ is selected when the optimal filter scale is large, and a small σ is equipped when the optimal filter scale is small.ConclusionThe texture filter designed in this study performs well in maintaining features, such as elongated structures and sharp corners in an image after texture removal, thus providing a powerful image preprocessing method for image subsequent processing, including image detail enhancement, edge detection, image abstraction, and image segmentation. For the problem of sharp reduction in the filter kernel scale encountered in the experiment, this study provides a reasonable explanation and solution. The proposed algorithm is limited by its long computing time. In general, the proposed algorithm obtains better results compared with others despite its slightly lower computing time efficiency.关键词:texture filtering;long structure;structure detection;edge preservation;bilateral filtering16|8|1更新时间:2024-05-07 -
 摘要:ObjectiveWith the development of artificial intelligence and online shopping, clothing matching based on clothing images is crucial in helping merchants promote sales. An increasing number of young consumers are inclined to buy clothing online, but existing research mainly focuses on clothing search, clothing recommendations, and fashion trends. Quickly, accurately, and effectively matching the right clothing to the clothing that the user has already purchased remains a challenging task. With the development of the economy and the improvement of material level, the clothing style and number are increasing. Therefore, clothing matching among a large number of garments is vital. Aiming at the problem that the existing clothing matching framework is used in fashion clothing matching and the depth feature of clothing image extraction requires a large time overhead, this study proposes a new FMatchNet network for extracting hash features for a fast clothing matching.MethodDeep learning is an important development in the field of machine learning and artificial intelligence. At present, deep convolutional neural networks have become one of the most effective means of extracting image features. The early extraction feature method is based on artificial extraction features, such as scale-invariant feature transform, speeded-up robust features, and histogram of oriented gradient. The features extracted by deep neural networks are more accurate than traditional features. By contrast, the use of binary Hashing codes for image features is an effective approach for reducing overhead and increasing computational speed. The core of the clothing mix is the description of the clothing image content. To match the clothing efficiently, the content of the clothing image must be described, and the basic idea is to express the clothing image as a feature vector. In general, the more closely matched the clothing images, the smaller the distance between their feature vectors. Recent studies in many image fields have begun to explore methods for generating Hashing codes on the basis of features extracted by deep networks. This research also applies this idea to study the clothing image representation method combined with deep learning and Hashing code. This study proposes a fast, accurate, and effective clothing matching network, namely, FMatchNet. The faster regional convolutional neural network (Faster-RCNN) method is adopted to detect the clothing area in the image. The clothing area can be used to maximize the original clothing information and eliminate the interference of image background information. Then, the image of the clothing area extracts the depth feature of the garment and the Hashing code of the garment through a two-way deep convolutional neural network. Finally, clothing matching is completed by using the query expansion method. The model applies the Siamese network training method to extract the depth features of the clothing image and the Hashing code extracted by this method, which can preserve the semantic information of the clothing image as much as possible. The Hashing code is used to select the candidate set of clothing matching, and then depth feature is used to rank the clothing matching in the selected clothing matching candidate set. In addition, given the lack of large-scale fashion clothing database in the world, a fine-grained fashion apparel database has been expanded in this paper. The expanded FClothes clothing dataset and dataset images mainly come from the Weibo website, which contains a large number of popular people and high-resolution clothing pictures that meet fashion demands. Finally, the algorithm is experimentally verified on the expanded fine-grained fashion clothing database.ResultThe method used in this study was verified on the expanded FClothes database and compared with current popular methods. This study compares the 8 bits, 16 bits, and 32 bits Hashing codes, and experimental results show that as the length of the Hashing code increases, the precision of the clothing mix increases. However, the time consumption also increases. When the lengths of the Hashing code are 16 and 32 bits, the matching accuracy of the upper and lower garments is higher than that of the baseline. When the length of the Hashing code is 16 bits, the matching accuracy of the method used in this paper is 50.81% in the upper and lower clothing, and the matching speed is nearly three times higher than that of the basic alignment algorithm. The basic accuracy of the comparison comes from the "Learning visual clothing style with heterogeneous dyadic co-occurrences" of the International Conference on Computer Vision 2015. From this point of view, the accuracy and time of the upper and lower clothing combinations of the algorithm are better than those of the current cutting-edge methods.ConclusionIn view of the problem of large-scale clothing matching, this study proposes a new FMatchNet network extraction feature, which improves the precision and speed of clothing matching and is suitable for daily clothing matching.关键词:clothing matching;Siamese network;Hashing;query extension(QE);Faster-RCNN23|9|1更新时间:2024-05-07
摘要:ObjectiveWith the development of artificial intelligence and online shopping, clothing matching based on clothing images is crucial in helping merchants promote sales. An increasing number of young consumers are inclined to buy clothing online, but existing research mainly focuses on clothing search, clothing recommendations, and fashion trends. Quickly, accurately, and effectively matching the right clothing to the clothing that the user has already purchased remains a challenging task. With the development of the economy and the improvement of material level, the clothing style and number are increasing. Therefore, clothing matching among a large number of garments is vital. Aiming at the problem that the existing clothing matching framework is used in fashion clothing matching and the depth feature of clothing image extraction requires a large time overhead, this study proposes a new FMatchNet network for extracting hash features for a fast clothing matching.MethodDeep learning is an important development in the field of machine learning and artificial intelligence. At present, deep convolutional neural networks have become one of the most effective means of extracting image features. The early extraction feature method is based on artificial extraction features, such as scale-invariant feature transform, speeded-up robust features, and histogram of oriented gradient. The features extracted by deep neural networks are more accurate than traditional features. By contrast, the use of binary Hashing codes for image features is an effective approach for reducing overhead and increasing computational speed. The core of the clothing mix is the description of the clothing image content. To match the clothing efficiently, the content of the clothing image must be described, and the basic idea is to express the clothing image as a feature vector. In general, the more closely matched the clothing images, the smaller the distance between their feature vectors. Recent studies in many image fields have begun to explore methods for generating Hashing codes on the basis of features extracted by deep networks. This research also applies this idea to study the clothing image representation method combined with deep learning and Hashing code. This study proposes a fast, accurate, and effective clothing matching network, namely, FMatchNet. The faster regional convolutional neural network (Faster-RCNN) method is adopted to detect the clothing area in the image. The clothing area can be used to maximize the original clothing information and eliminate the interference of image background information. Then, the image of the clothing area extracts the depth feature of the garment and the Hashing code of the garment through a two-way deep convolutional neural network. Finally, clothing matching is completed by using the query expansion method. The model applies the Siamese network training method to extract the depth features of the clothing image and the Hashing code extracted by this method, which can preserve the semantic information of the clothing image as much as possible. The Hashing code is used to select the candidate set of clothing matching, and then depth feature is used to rank the clothing matching in the selected clothing matching candidate set. In addition, given the lack of large-scale fashion clothing database in the world, a fine-grained fashion apparel database has been expanded in this paper. The expanded FClothes clothing dataset and dataset images mainly come from the Weibo website, which contains a large number of popular people and high-resolution clothing pictures that meet fashion demands. Finally, the algorithm is experimentally verified on the expanded fine-grained fashion clothing database.ResultThe method used in this study was verified on the expanded FClothes database and compared with current popular methods. This study compares the 8 bits, 16 bits, and 32 bits Hashing codes, and experimental results show that as the length of the Hashing code increases, the precision of the clothing mix increases. However, the time consumption also increases. When the lengths of the Hashing code are 16 and 32 bits, the matching accuracy of the upper and lower garments is higher than that of the baseline. When the length of the Hashing code is 16 bits, the matching accuracy of the method used in this paper is 50.81% in the upper and lower clothing, and the matching speed is nearly three times higher than that of the basic alignment algorithm. The basic accuracy of the comparison comes from the "Learning visual clothing style with heterogeneous dyadic co-occurrences" of the International Conference on Computer Vision 2015. From this point of view, the accuracy and time of the upper and lower clothing combinations of the algorithm are better than those of the current cutting-edge methods.ConclusionIn view of the problem of large-scale clothing matching, this study proposes a new FMatchNet network extraction feature, which improves the precision and speed of clothing matching and is suitable for daily clothing matching.关键词:clothing matching;Siamese network;Hashing;query extension(QE);Faster-RCNN23|9|1更新时间:2024-05-07 -
 摘要:ObjectiveInfrared and visible image fusion is an important problem in the field of image fusion which has been applied widely in military, security, and surveillance areas. Infrared imaging is based on the thermal radiation of scene, and it is not susceptible to weather and illumination. But infrared images are rather vague as a whole, and the spatial resolution and image contrast of infrared images are low. In contrast, visible imaging is based on the reflection of visible light. The spatial resolution of visible images is higher, and they have clear texture information and abundant details. However, they are vulnerable to the interference of illumination and climatic conditions. Therefore, infrared and visible images of the same scene exhibit a large difference and complementary information. Because of the redundancy and complementary, image fusion can accurately describe the object by effectively combining the target characteristics in infrared image and the details of the scene in visible image. Multi-scale techniques, including wavelet transform and multi-scale geometric decomposition, are widely used in image fusion. Empirical mode decomposition (EMD) and W-transform are two such tools. EMD is a fully data-driven time-frequency analysis method that adaptively decomposes signals into intrinsic mode functions (IMFs) and has shown considerable prowess in the analysis of non-stationary data. W-transform is a new orthogonal transform that has a strong decomposability and reconstruction capability for continuous and discontinuous information and can characterize the local variation of images effectively. In view of the deficiency of traditional multi-scale transform-based image fusion algorithms, this study proposes a new infrared and visible image fusion method based on W-transform and bidimensional empirical mode decomposition (BEMD).MethodThe proposed method is applied on registered infrared and visible images with the same spatial resolution. To eliminate the modal aliasing phenomenon in EMD, a new decomposition method called W-BEMD, which is based on BEMD and W-transform, is proposed. The main idea of the W-BEMD method is performing W-transform on the low-frequency components of each level in the BEMD decomposition process and superimposing the obtained high-frequency component into the corresponding IMFs of the same decomposition level. W-BEMD is an improved BEMD method that can effectively extract high-frequency information and suppress the frequency aliasing effect in BEMD. W-BEMD is further applied on infrared and visible image fusion to achieve satisfactory fused results. First, the registered infrared and visible captures of the same scene are decomposed into the high-frequency component WIMFs and the residual component WR through W-BEMD. Second, the corresponding WIMFs of the same decomposition level of the source images are fused using the weighted average fusion rule on the basis of the local area variance to obtain fused WIMF images, whereas the weighted average strategy based on area energy is adopted for the fusion of the residual component WR. Finally, the fused image is generated by adding the fused WIMF images and fused residual component.ResultDecomposition experiments are conducted to evaluate the effect of W-BEMD, and they show that the high-frequency part under W-BEMD contains more complete edge information compared with the one under BEMD. Simulation experiments on four groups of infrared and visible images are conducted to verify the superiority and validity of the proposed fusion method. Three objective evaluation indices, including mean gradient, spatial frequency, and mutual information, are also employed to evaluate the fusion results quantitatively. The fusion experiment results show that the proposed method outperforms the other five methods in terms of objective assessment and subjective visual quality. Visually, the proposed method not only preserves the rich scene information of the visible light image but also effectively highlights the hot target information in the infrared image. The fused results of the proposed method have high contrast, rich edge details, and remarkable target information, and they are obviously better than the results generated by the other five methods. Objectively, the proposed algorithm achieves the best average gradient and space frequency and is almost superior to the other compared algorithms in the index of mutual information.ConclusionA new fusion method for infrared and visible images based on BEMD and W-transform is proposed. According to the characteristic of the W-BEMD of the source images, we design different fusion rules for different frequency bands. Four groups of infrared and visible images are employed for the performance evaluation of the proposed method. Analysis shows that the proposed algorithm is more effective in preserving details in the visible images and highlighting target information in the infrared images compared with the other algorithms.关键词:infrared image;visible image;W-transform;bidimensional empirical mode decomposition(BEMD);W-BEMD multi-scale decomposition method;image fusion21|12|6更新时间:2024-05-07
摘要:ObjectiveInfrared and visible image fusion is an important problem in the field of image fusion which has been applied widely in military, security, and surveillance areas. Infrared imaging is based on the thermal radiation of scene, and it is not susceptible to weather and illumination. But infrared images are rather vague as a whole, and the spatial resolution and image contrast of infrared images are low. In contrast, visible imaging is based on the reflection of visible light. The spatial resolution of visible images is higher, and they have clear texture information and abundant details. However, they are vulnerable to the interference of illumination and climatic conditions. Therefore, infrared and visible images of the same scene exhibit a large difference and complementary information. Because of the redundancy and complementary, image fusion can accurately describe the object by effectively combining the target characteristics in infrared image and the details of the scene in visible image. Multi-scale techniques, including wavelet transform and multi-scale geometric decomposition, are widely used in image fusion. Empirical mode decomposition (EMD) and W-transform are two such tools. EMD is a fully data-driven time-frequency analysis method that adaptively decomposes signals into intrinsic mode functions (IMFs) and has shown considerable prowess in the analysis of non-stationary data. W-transform is a new orthogonal transform that has a strong decomposability and reconstruction capability for continuous and discontinuous information and can characterize the local variation of images effectively. In view of the deficiency of traditional multi-scale transform-based image fusion algorithms, this study proposes a new infrared and visible image fusion method based on W-transform and bidimensional empirical mode decomposition (BEMD).MethodThe proposed method is applied on registered infrared and visible images with the same spatial resolution. To eliminate the modal aliasing phenomenon in EMD, a new decomposition method called W-BEMD, which is based on BEMD and W-transform, is proposed. The main idea of the W-BEMD method is performing W-transform on the low-frequency components of each level in the BEMD decomposition process and superimposing the obtained high-frequency component into the corresponding IMFs of the same decomposition level. W-BEMD is an improved BEMD method that can effectively extract high-frequency information and suppress the frequency aliasing effect in BEMD. W-BEMD is further applied on infrared and visible image fusion to achieve satisfactory fused results. First, the registered infrared and visible captures of the same scene are decomposed into the high-frequency component WIMFs and the residual component WR through W-BEMD. Second, the corresponding WIMFs of the same decomposition level of the source images are fused using the weighted average fusion rule on the basis of the local area variance to obtain fused WIMF images, whereas the weighted average strategy based on area energy is adopted for the fusion of the residual component WR. Finally, the fused image is generated by adding the fused WIMF images and fused residual component.ResultDecomposition experiments are conducted to evaluate the effect of W-BEMD, and they show that the high-frequency part under W-BEMD contains more complete edge information compared with the one under BEMD. Simulation experiments on four groups of infrared and visible images are conducted to verify the superiority and validity of the proposed fusion method. Three objective evaluation indices, including mean gradient, spatial frequency, and mutual information, are also employed to evaluate the fusion results quantitatively. The fusion experiment results show that the proposed method outperforms the other five methods in terms of objective assessment and subjective visual quality. Visually, the proposed method not only preserves the rich scene information of the visible light image but also effectively highlights the hot target information in the infrared image. The fused results of the proposed method have high contrast, rich edge details, and remarkable target information, and they are obviously better than the results generated by the other five methods. Objectively, the proposed algorithm achieves the best average gradient and space frequency and is almost superior to the other compared algorithms in the index of mutual information.ConclusionA new fusion method for infrared and visible images based on BEMD and W-transform is proposed. According to the characteristic of the W-BEMD of the source images, we design different fusion rules for different frequency bands. Four groups of infrared and visible images are employed for the performance evaluation of the proposed method. Analysis shows that the proposed algorithm is more effective in preserving details in the visible images and highlighting target information in the infrared images compared with the other algorithms.关键词:infrared image;visible image;W-transform;bidimensional empirical mode decomposition(BEMD);W-BEMD multi-scale decomposition method;image fusion21|12|6更新时间:2024-05-07 -
 摘要:ObjectiveSealing strips play an important role in the automotive industry. However, accurate results in the measurement of sealing strips are difficult to obtain due to the large deformation of their complex contour. This study proposes a novel automatic vision-based deviation measurement method for cross sections of flexible sealing strips. With this method, the matching relationship between the local contour of the captured image and the reference contour of the design drawing is computed using a two-stage image contour registration algorithm. Then, the deviation calculation is performed to evaluate the quality of sealing strips.MethodThe method involves three steps:global registration of the contours of the captured image and reference drawing, local registration of the contours of the captured image and reference drawing, and calculation of deviations. Global registration includes three sub-steps:corner extraction, initial registration, and fine-tuning. First, corners of the contours of the sealing strips for computer vision-based measurement are extracted using a multi-resolution-based contour corner extraction algorithm. Second, on the basis of the idea of minimizing the mean square error, an exhaustive search method is applied on the corner sets of the contours of the captured image and reference drawing to obtain the matched corner pairs and affine transformation matrix. Finally, to improve the accuracy of the initial registration, the corner pairs with larger position deviation than the average position deviation are removed from the matched corner sets, and the remaining matched corners are fed into the linear regression equation to fine-tune the affine transformation matrix. On the basis of global registration, local registration aims to determine the corresponding relationships between the local contours of the captured image and reference drawing. The shape descriptors extracted from the two global contours include shape representation and restrictions of the local contours, and the similarity of shape descriptors is used to obtain the optimal result of local registration. After the global and local registrations, the positional deviations of the sealing strips are measured on the basis of the corresponding predefined instances of positional tolerances. Here, the instances of positional tolerances are defined on the reference drawing and are used in the calculation of corresponding deviations. For all deviations, if the measured value is within the corresponding tolerance, then the quality check passes. This study concentrates on the distance and angular deviations, such as point offsetting, point distance limitation, and angular positional deviations. Point offsetting deviation refers to the offsetting distance from the original point defined on the contour of the reference drawing to the corresponding point on the contour of the captured image. The corresponding point is obtained by the similarity between two shape descriptors calculated in the previous local registration. Point distance limitation deviation refers to the maximum distance from the point on the corresponding line segment of the measurement segment to the corresponding datum line on the contour of the captured image. Point distance limitation tolerance indicates the tolerable distance from the original point to the datum line defined in the reference drawing. For angular positional deviation, the intersection of the two perpendicular bisectors of the two tolerance lines defined in the standard contour is computed as the rotation center of the angular positional deviation. In the measurement, the angular positional deviation is quantified as the value of the angle between the line segments from the barycenter of the measured local contour of the captured image to the rotation center of the angular positional deviation and from the barycenter of the standard local contour of the reference drawing to the rotation center of the angular positional deviation. Finally, the product quality can be assessed automatically on the basis of the tolerances and deviations of the sealing strips.ResultIn this study, the sealing strips are registered using a two-stage registration algorithm, and various deviations are measured between the local contours of the captured image and reference drawing. The proposed method has been tested in the actual production process. Several types of sealing strips have been tested during the experiments, whereas all captured images of the actual products have been rotated to increase the number of testing images. Finally, experimental results show that the method achieves good stability and reliability and is invariant to the rotation of the position of the sealing strips. These results are consistent with the manual testing results. Therefore, the system can effectively promote the development of automated testing for sealing strips.ConclusionThis study proposes a novel vision-based deviation measurement method for flexible sealing strips. The proposed method achieves good stability and reliability in the actual production process, as well as effectively performs the deviation measurement and quality inspection of flexible products. The proposed method can accelerate the development of automated quality inspection because it can automatically measure the deviation of sealing strips.关键词:vision-based measurement;sealing strip;image registration;deviation;corner detection14|7|0更新时间:2024-05-07
摘要:ObjectiveSealing strips play an important role in the automotive industry. However, accurate results in the measurement of sealing strips are difficult to obtain due to the large deformation of their complex contour. This study proposes a novel automatic vision-based deviation measurement method for cross sections of flexible sealing strips. With this method, the matching relationship between the local contour of the captured image and the reference contour of the design drawing is computed using a two-stage image contour registration algorithm. Then, the deviation calculation is performed to evaluate the quality of sealing strips.MethodThe method involves three steps:global registration of the contours of the captured image and reference drawing, local registration of the contours of the captured image and reference drawing, and calculation of deviations. Global registration includes three sub-steps:corner extraction, initial registration, and fine-tuning. First, corners of the contours of the sealing strips for computer vision-based measurement are extracted using a multi-resolution-based contour corner extraction algorithm. Second, on the basis of the idea of minimizing the mean square error, an exhaustive search method is applied on the corner sets of the contours of the captured image and reference drawing to obtain the matched corner pairs and affine transformation matrix. Finally, to improve the accuracy of the initial registration, the corner pairs with larger position deviation than the average position deviation are removed from the matched corner sets, and the remaining matched corners are fed into the linear regression equation to fine-tune the affine transformation matrix. On the basis of global registration, local registration aims to determine the corresponding relationships between the local contours of the captured image and reference drawing. The shape descriptors extracted from the two global contours include shape representation and restrictions of the local contours, and the similarity of shape descriptors is used to obtain the optimal result of local registration. After the global and local registrations, the positional deviations of the sealing strips are measured on the basis of the corresponding predefined instances of positional tolerances. Here, the instances of positional tolerances are defined on the reference drawing and are used in the calculation of corresponding deviations. For all deviations, if the measured value is within the corresponding tolerance, then the quality check passes. This study concentrates on the distance and angular deviations, such as point offsetting, point distance limitation, and angular positional deviations. Point offsetting deviation refers to the offsetting distance from the original point defined on the contour of the reference drawing to the corresponding point on the contour of the captured image. The corresponding point is obtained by the similarity between two shape descriptors calculated in the previous local registration. Point distance limitation deviation refers to the maximum distance from the point on the corresponding line segment of the measurement segment to the corresponding datum line on the contour of the captured image. Point distance limitation tolerance indicates the tolerable distance from the original point to the datum line defined in the reference drawing. For angular positional deviation, the intersection of the two perpendicular bisectors of the two tolerance lines defined in the standard contour is computed as the rotation center of the angular positional deviation. In the measurement, the angular positional deviation is quantified as the value of the angle between the line segments from the barycenter of the measured local contour of the captured image to the rotation center of the angular positional deviation and from the barycenter of the standard local contour of the reference drawing to the rotation center of the angular positional deviation. Finally, the product quality can be assessed automatically on the basis of the tolerances and deviations of the sealing strips.ResultIn this study, the sealing strips are registered using a two-stage registration algorithm, and various deviations are measured between the local contours of the captured image and reference drawing. The proposed method has been tested in the actual production process. Several types of sealing strips have been tested during the experiments, whereas all captured images of the actual products have been rotated to increase the number of testing images. Finally, experimental results show that the method achieves good stability and reliability and is invariant to the rotation of the position of the sealing strips. These results are consistent with the manual testing results. Therefore, the system can effectively promote the development of automated testing for sealing strips.ConclusionThis study proposes a novel vision-based deviation measurement method for flexible sealing strips. The proposed method achieves good stability and reliability in the actual production process, as well as effectively performs the deviation measurement and quality inspection of flexible products. The proposed method can accelerate the development of automated quality inspection because it can automatically measure the deviation of sealing strips.关键词:vision-based measurement;sealing strip;image registration;deviation;corner detection14|7|0更新时间:2024-05-07
Chinagraph 2018
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0